
1.1 The foundations of supply chain
Supply chain is the quantitative yet street-smart mastery of optionality when facing variability and constraints related to the flow of physical goods.
Watch lectureThis lecture series presents the foundations of supply chain management: the challenges, the methodology, and the technologies. The perspective developed by Joannes Vermorel diverges from mainstream supply chain theory and is referred to as the Quantitative Supply Chain.
The series progresses from definitions and methodological principles to a set of fictional supply chain personae, then to the auxiliary sciences, forecasting, decision-making, and execution practices that support this perspective. It is intended to be read as a structured body of work, not as isolated talks.

Supply chain is the quantitative yet street-smart mastery of optionality when facing variability and constraints related to the flow of physical goods.
Watch lecture
A concise manifesto of the quantitative supply chain and the principles that set it apart from mainstream supply chain theory.
Watch lecture
Why a quantitative supply chain initiative should be treated as a product-engineering effort rather than a spreadsheet-heavy operational patchwork.
Watch lecture
A review of the programming paradigms and software design choices that make predictive optimization workable in real supply chains.
Watch lecture
A survey of the major long-term trends that have reshaped supply chains, from complexity and competition to the growing role of software.
Watch lecture
A look at the general observational and optimization principles that recur across most real-world supply chains.
Watch lecture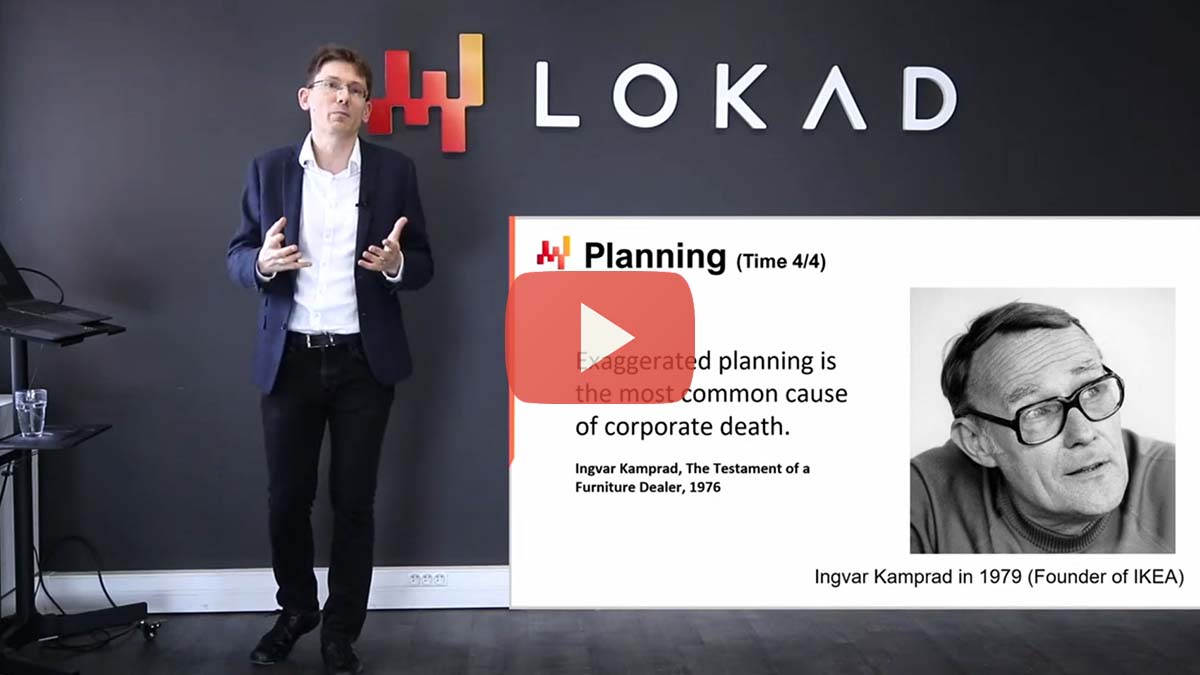
An exploration of how economics, systems thinking, and the passage of time shape sound supply chain decisions.
Watch lecture
Why fictitious companies can be better teaching tools than biased real-world case studies when exploring supply chain problems.
Watch lecture
An iterative approach to optimization focused on investigating insane decisions and correcting the economic drivers behind them.
Watch lecture
How antipatterns and other forms of negative knowledge help practitioners remember what repeatedly fails in practice.
Watch lecture
Why software vendor evaluation needs to account for conflicts of interest, biased analysts, and marketing distortion.
Watch lecture
Why written documentation is indispensable for scalable supply chain work and for long-term continuity across teams.
Watch lecture
A fashion persona centered on novelty, collections, pricing, store allocation, and the operational consequences of rapid assortment turnover.
Watch lecture
A persona built around aviation maintenance, repair, and overhaul, where uptime and AOG avoidance dominate decision-making.
Watch lecture
A dairy FMCG persona used to explore freshness, waste, promotions, and the competing constraints of branded food supply chains.
Watch lecture
A homeware ecommerce persona illustrating marketplace competition, service quality, and the complexity of online retail operations.
Watch lecture
An automotive aftermarket persona spanning branches, ecommerce, and used vehicles in a highly competitive spare-parts landscape.
Watch lecture
Why computing hardware characteristics matter directly to the performance of supply chain systems and numerical recipes.
Watch lecture
How algorithmic design shapes computational efficiency and why supply chain problems benefit from algorithmic specialization.
Watch lecture
Why mathematical optimization sits at the core of both forecasting systems and decision-making systems in modern supply chains.
Watch lecture
An overview of modern learning methods and the paradoxes practitioners must understand to make data-driven anticipation work.
Watch lecture
Why programmatic expressiveness, not just enterprise software feature lists, determines what supply chain teams can actually achieve.
Watch lecture
A software-engineering perspective on why complexity, reliability, and maintainability make or break supply chain initiatives.
Watch lecture
How cyber risk intersects with distributed operations, numerical recipes, and the broader software stack used by supply chain teams.
Watch lecture
A critical look at blockchain use cases for supply chain, separating the few real opportunities from the broader hype.
Watch lecture
Lessons from Lokad's M5 competition performance and what the result reveals about practical forecasting for supply chain.
Watch lecture
An introduction to differentiable programming and why structured modeling supersedes much of the classic forecasting literature.
Watch lecture
Why probabilistic forecasts outperform point forecasts when uncertainty is irreducible and supply chain decisions carry financial risk.
Watch lecture
How lead times can be forecast probabilistically and then combined with demand forecasts for stronger supply chain modeling.
Watch lecture
A practical illustration of risk-adjusted stock allocation in a retail network where stores compete for the same inventory.
Watch lecture
A pricing case study showing why optimizing the right objective matters more than polishing the mathematics around the wrong one.
Watch lecture
A review of the early mistakes that derail supply chain initiatives and the principles needed to avoid them.
Watch lecture
How to turn numerical recipes into production-grade decision systems without relying on brittle waterfall-style delivery.
Watch lecture
An explanation of the supply chain scientist role and its responsibility for data, economics, KPIs, and automated decisions.
Watch lecture