00:28 Einführung
00:43 Robert A. Heinlein
03:03 Der bisherige Verlauf
06:52 Eine Auswahl an Paradigmen
08:20 Statische Analyse
18:26 Array-Programmierung
28:08 Hardware-Kompatibilität
35:38 Probabilistische Programmierung
40:53 Differenzierbare Programmierung
55:12 Versionierung von Code+Daten
01:00:01 Sichere Programmierung
01:05:37 Zusammenfassend: Auch bei Supply Chain ist die Werkzeugauswahl wichtig
01:06:40 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Während die Mainstream-Supply-Chain-Theorie in Unternehmen nach wie vor Schwierigkeiten hat, hat ein Tool, nämlich Microsoft Excel, beträchtlichen operativen Erfolg erzielt. Die Neuumsetzung der numerischen Rezepte der Mainstream-Supply-Chain-Theorie über Tabellenkalkulationen ist trivial, aber in der Praxis ist dies trotz des Bewusstseins für die Theorie nicht geschehen. Wir zeigen, dass Tabellenkalkulationen durch die Übernahme von Programmierparadigmen, die sich als überlegen erwiesen haben, Supply-Chain-Ergebnisse liefern konnten.
Vollständiges Transkript

Hallo zusammen, herzlich willkommen zu dieser Reihe von Supply-Chain-Vorlesungen. Ich bin Joannes Vermorel und heute werde ich meine vierte Vorlesung präsentieren: Programmierparadigmen für die Supply Chain.

Wenn man mich fragt: “Herr Vermorel, was sind Ihrer Meinung nach die interessantesten Bereiche im Bereich Supply Chain-Wissen?”, ist eine meiner Top-Antworten in der Regel Programmierparadigmen. Und dann, nicht allzu häufig, aber doch häufig genug, ist die Reaktion der Person, mit der ich spreche, oft: “Programmierparadigmen, Herr Vermorel? Wovon zum Teufel reden Sie überhaupt? Wie ist das auch nur ansatzweise relevant für die anstehende Aufgabe?” Und diese Art von Reaktionen erinnern mich immer wieder an dieses unglaubliche Zitat von Robert A. Heinlein, der als der Dekan der Science-Fiction-Autoren gilt.
Heinlein hat ein fantastisches Zitat über den kompetenten Menschen, das die Bedeutung von Kompetenz in verschiedenen Bereichen hervorhebt, insbesondere in der Supply Chain, wo wir es mit kniffligen Problemen zu tun haben. Diese Probleme sind fast genauso herausfordernd wie das Leben selbst, und ich glaube, dass es wirklich lohnenswert ist, sich mit dem Konzept der Programmierparadigmen zu beschäftigen, da es Ihrer Supply Chain einen großen Mehrwert bringen könnte.
Bisher haben wir in der ersten Vorlesung gesehen, dass Supply-Chain-Probleme knifflig sind. Jeder, der von optimalen Lösungen spricht, verfehlt den Punkt; es gibt nichts, was auch nur annähernd an Optimalität heranreicht. In der zweiten Vorlesung habe ich das Quantitative Supply Chain vorgestellt, eine Vision mit fünf Schlüsselanforderungen für Großartigkeit im Supply Chain Management. Diese Anforderungen sind allein nicht ausreichend, aber sie können nicht umgangen werden, wenn man Großartigkeit erreichen möchte.
In der dritten Vorlesung habe ich die Lieferung von Softwareprodukten im Kontext der Optimierung der Supply Chain diskutiert. Ich habe die These verteidigt, dass die Optimierung der Supply Chain ein Softwareprodukt erfordert, das auf kapitalistische Weise angegangen werden muss, aber ein solches Produkt nicht von der Stange zu finden ist. Es gibt zu viel Vielfalt und die Herausforderungen sind weit über die Technologien hinaus, die wir derzeit haben. Es wird also zwangsläufig etwas komplett maßgeschneidertes sein. Wenn es sich also um ein Softwareprodukt handelt, das maßgeschneidert für das Unternehmen oder die interessierte Supply Chain sein soll, stellt sich die Frage, welche geeigneten Werkzeuge es gibt, um dieses Produkt tatsächlich zu liefern. Das bringt mich zum heutigen Thema: Das richtige Werkzeug beginnt mit den richtigen Programmierparadigmen, denn wir werden dieses Produkt auf die eine oder andere Weise programmieren müssen.

Bisher benötigen wir programmatische Fähigkeiten, um uns mit der Optimierungsseite des Problems auseinanderzusetzen, nicht zu verwechseln mit der Managementseite. Was wir bisher gesehen haben, was das Thema meiner vorherigen Vorlesung war, ist, dass Microsoft Excel bisher der Gewinner war. Von sehr kleinen Unternehmen bis hin zu sehr großen Unternehmen ist es allgegenwärtig, es wird überall verwendet. Selbst in Unternehmen, die Millionen von Dollar in superintelligente Systeme investiert haben, regiert Excel immer noch, und warum? Weil es die richtigen Programmierungseigenschaften hat. Es ist sehr ausdrucksstark, agil, zugänglich und wartbar. Excel ist jedoch nicht das Endziel. Ich bin fest davon überzeugt, dass wir noch viel mehr tun können, aber wir brauchen die richtigen Werkzeuge, Denkweisen, Erkenntnisse und Programmierparadigmen.

Programmierparadigmen mögen für das Publikum übermäßig obskur erscheinen, aber es handelt sich tatsächlich um ein Forschungsgebiet, das in den letzten fünf Jahrzehnten intensiv untersucht wurde. Es wurde eine immense Menge an Arbeit in diesem Forschungsgebiet geleistet. Es ist einer breiteren Öffentlichkeit nicht weit bekannt, aber es gibt ganze Bibliotheken, die mit qualitativ hochwertiger Arbeit gefüllt sind, die von vielen Menschen geleistet wurde. Heute werde ich eine Reihe von sieben Paradigmen vorstellen, die Lokad übernommen hat. Wir haben keine dieser Ideen erfunden; wir haben sie von Menschen übernommen, die sie vor uns erfunden haben. Alle diese Paradigmen wurden in Lokads Softwareprodukt implementiert, und nach fast einem Jahrzehnt des Betriebs von Lokad unter Verwendung dieser Paradigmen glaube ich, dass sie bisher absolut entscheidend für unseren operativen Erfolg waren.

Lassen Sie uns diese Liste mit statischer Analyse durchgehen. Das Problem hier ist die Komplexität. Wie gehen Sie mit Komplexität in der Supply Chain um? Sie werden es mit Unternehmenssystemen zu tun haben, die Hunderte von Tabellen haben, von denen jede Dutzende von Feldern hat. Wenn Sie ein Problem so einfach wie die Lagerauffüllung in einem Lager betrachten, haben Sie so viele Dinge zu berücksichtigen. Sie können Mindestbestellmengen, Preisstaffeln, Nachfrageprognosen, Durchlaufzeiten und alle Arten von Rücksendungen haben. Sie können Platzbeschränkungen im Regal, Kapazitätsbeschränkungen bei der Annahme und Verfallsdaten haben, die einige Ihrer Chargen überflüssig machen. Sie haben also tonnenweise Dinge zu berücksichtigen. In der Supply Chain ist die Idee “schnell vorankommen und Dinge kaputt machen” einfach nicht die richtige Denkweise. Wenn Sie versehentlich Waren im Wert von einer Million Dollar bestellen, die Sie überhaupt nicht benötigen, ist dies ein sehr teurer Fehler. Sie können keine Software haben, die Ihre Supply Chain steuert, routinemäßige Entscheidungen trifft und bei einem Fehler Millionen kostet. Wir müssen etwas haben, das von Anfang an sehr korrekt ist. Wir möchten die Fehler nicht erst in der Produktion entdecken. Das ist sehr unterschiedlich zu Ihrer durchschnittlichen Software, bei der ein Absturz keine große Sache ist.
Wenn es um die Optimierung der Supply Chain geht, handelt es sich nicht um ein gewöhnliches Problem. Wenn Sie einem Lieferanten gerade eine massive, falsche Bestellung übermittelt haben, können Sie nicht einfach eine Woche später anrufen und sagen: “Oh, mein Fehler, vergessen Sie das, wir haben das nie bestellt.” Diese Fehler werden viel Geld kosten. Statische Analyse wird so genannt, weil es darum geht, ein Programm zu analysieren, ohne es auszuführen. Die Idee ist, dass Sie ein Programm haben, das mit Anweisungen, Schlüsselwörtern und allem geschrieben ist, und ohne dieses Programm überhaupt auszuführen, können Sie bereits feststellen, ob das Programm Probleme aufweist, die Ihre Produktion, insbesondere Ihre Supply Chain-Produktion, fast sicher negativ beeinflussen würden. Die Antwort ist ja. Diese Techniken existieren und sind implementiert und äußerst wertvoll.
Nur um ein Beispiel zu geben, sehen Sie einen Envision-Screenshot auf dem Bildschirm. Envision ist eine domänenspezifische Programmiersprache, die von Lokad seit fast einem Jahrzehnt entwickelt wurde und der prädiktiven Optimierung der Supply Chain gewidmet ist. Was Sie sehen, ist ein Screenshot des Code-Editors von Envision, einer Webanwendung, mit der Sie online Code bearbeiten können. Die Syntax ist stark von Python beeinflusst. In diesem winzigen Screenshot illustriere ich die Idee, dass Sie, wenn Sie eine große Logik für die Lagerauffüllung in einem Lager schreiben und einige wirtschaftliche Variablen einführen, wie Preisstaffeln, durch eine logische Analyse des Programms sehen können, dass diese Preisstaffeln keinerlei Beziehung zu den vom Programm zurückgegebenen Endergebnissen haben, nämlich den aufzufüllenden Mengen. Hier haben Sie ein offensichtliches Problem. Sie haben eine wichtige Variable, Preisstaffeln, eingeführt, und diese Preisstaffeln haben logischerweise keinen Einfluss auf die Endergebnisse. Hier haben wir ein Problem, das durch statische Analyse erkannt werden kann. Es ist ein offensichtliches Problem, denn wenn wir Variablen in den Code einführen, die keinen Einfluss auf die Ausgabe des Programms haben, dann haben sie überhaupt keinen Zweck. In diesem Fall stehen wir vor zwei Möglichkeiten: Entweder sind diese Variablen tatsächlich toter Code, und das Programm sollte nicht kompiliert werden (Sie sollten diesen toten Code einfach loswerden, um die Komplexität zu reduzieren und nicht versehentliche Komplexität anzuhäufen), oder es war ein echter Fehler und es gibt eine wichtige wirtschaftliche Variable, die in Ihre Berechnung hätte eingefügt werden sollen, aber Sie haben den Ball aufgrund von Ablenkung oder aus einem anderen Grund fallen lassen.
Statische Analyse ist absolut grundlegend, um einen beliebigen Grad an Korrektheit durch Design zu erreichen. Es geht darum, Dinge zur Kompilierzeit zu beheben, wenn Sie den Code schreiben, noch bevor Sie die Daten berühren. Wenn Probleme auftreten, wenn Sie sie ausführen, besteht die Wahrscheinlichkeit, dass Ihre Probleme nur nachts auftreten, wenn Sie die nächtliche Stapelverarbeitung für die Warenhausauffüllung haben. Das Programm wird wahrscheinlich zu ungewöhnlichen Zeiten ausgeführt, wenn niemand davor sitzt, sodass Sie nicht möchten, dass etwas abstürzt, wenn niemand vor dem Programm ist. Es sollte abstürzen, wenn die Leute tatsächlich den Code schreiben.
Statische Analyse hat viele Zwecke. Bei Lokad verwenden wir beispielsweise die statische Analyse für die WYSIWYG-Bearbeitung von Dashboards. WYSIWYG steht für “what you see is what you get”. Stellen Sie sich vor, Sie erstellen ein Dashboard für Berichterstattung mit Liniendiagrammen, Balkendiagrammen, Tabellen, Farben und verschiedenen Stileffekten. Sie möchten dies visuell tun und nicht den Stil Ihres Dashboards über den Code anpassen, da dies sehr umständlich ist. Alle von Ihnen implementierten Einstellungen werden in den Code selbst zurückgespeist, und dies erfolgt durch statische Analyse.
Ein weiterer Aspekt bei Lokad, der für die gesamte Supply Chain möglicherweise nicht von so großer Bedeutung ist, aber für die Durchführung des Projekts sicherlich kritisch war, bestand darin, mit einer Programmiersprache namens Envision umzugehen, die wir entwickeln. Wir wussten von Anfang an, vor fast einem Jahrzehnt, dass Fehler gemacht werden würden. Wir hatten keine Kristallkugel, um von Anfang an die perfekte Vision zu haben. Die Frage war, wie können wir sicherstellen, dass wir diese Designfehler in der Programmiersprache selbst so bequem wie möglich beheben können? Hier war Python eine Warnung für mich.
Python, das keine neue Sprache ist, wurde erstmals 1991, vor fast 30 Jahren, veröffentlicht. Die Migration von Python 2 zu Python 3 dauerte fast ein Jahrzehnt und war ein Albtraumprozess, sehr schmerzhaft für die beteiligten Unternehmen. Meine Wahrnehmung war, dass die Sprache selbst nicht genügend Konstrukte hatte. Sie wurde nicht so konzipiert, dass Programme von einer Version der Programmiersprache auf eine andere Version migriert werden können. Es war tatsächlich äußerst schwierig, dies auf vollständig automatisierte Weise zu tun, und das liegt daran, dass Python nicht mit statischer Analyse im Hinterkopf entwickelt wurde. Wenn Sie eine Programmiersprache für die Supply Chain haben, möchten Sie wirklich eine Sprache, die hervorragende Qualität in Bezug auf statische Analyse aufweist, da Ihre Programme eine lange Lebensdauer haben werden. Supply Chains haben nicht die Möglichkeit zu sagen: “Warten Sie drei Monate; wir schreiben gerade den Code neu. Warten Sie auf uns; die Kavallerie kommt. Es wird nur ein paar Monate lang nicht funktionieren.” Es ist buchstäblich so, als würde man einen Zug reparieren, während der Zug mit voller Geschwindigkeit auf den Gleisen fährt, und Sie möchten den Motor reparieren, während der Zug funktioniert. So sieht es aus, wenn man Supply Chain-Dinge repariert, die tatsächlich in Produktion sind. Sie haben nicht die Möglichkeit, das System einfach anzuhalten; es pausiert nie.

Das zweite Paradigma ist die Array-Programmierung. Wir möchten die Komplexität unter Kontrolle haben, da dies ein häufiges Thema in Supply Chains ist. Wir möchten Logik haben, bei der wir bestimmte Klassen von Programmierfehlern nicht haben. Wenn Sie beispielsweise Schleifen oder Verzweigungen haben, die explizit von Programmierern geschrieben werden, setzen Sie sich einem ganzen Satz sehr schwieriger Probleme aus. Es wird äußerst schwierig, wenn Personen einfach beliebige Schleifen schreiben können, um Garantien für die Dauer der Berechnung zu haben. Obwohl es wie ein Nischenproblem erscheinen mag, ist dies im Bereich der Supply Chain-Optimierung nicht ganz der Fall.
In der Praxis nehmen wir an, Sie haben eine Einzelhandelskette. Um Mitternacht werden alle Verkäufe im gesamten Netzwerk vollständig konsolidiert, und die Daten werden konsolidiert und an irgendein System zur Optimierung weitergegeben. Dieses System hat genau ein 60-minütiges Zeitfenster, um die Prognose, Bestandsoptimierung und Umverteilungsentscheidungen für jeden einzelnen Laden im Netzwerk durchzuführen. Sobald dies erledigt ist, werden die Ergebnisse an das Lagerverwaltungssystem übergeben, damit sie mit der Vorbereitung aller Sendungen beginnen können. Die Lastwagen werden vielleicht um 5:00 Uhr morgens beladen, und um 9:00 Uhr morgens öffnen die Geschäfte bereits mit der bereits erhaltenen Ware, die auf den Regalen steht.
Sie haben jedoch eine sehr strenge Zeitvorgabe, und wenn Ihre Berechnung über dieses 60-minütige Zeitfenster hinausgeht, setzen Sie die gesamte Ausführung der Supply Chain aufs Spiel. Sie möchten nicht erst in der Produktion feststellen, wie viel Zeit die Dinge in Anspruch nehmen. Wenn Sie Schleifen haben, in denen die Anzahl der Iterationen festgelegt werden kann, ist es sehr schwierig, einen Nachweis über die Dauer Ihrer Berechnung zu erbringen. Bedenken Sie, dass es sich hier um die Optimierung der Supply Chain handelt. Sie haben nicht die Möglichkeit, eine Peer-Review durchzuführen und alles doppelt zu überprüfen. Manchmal werden aufgrund der Pandemie einige Länder unregelmäßig geschlossen, während andere mit einer Vorankündigung von 24 Stunden wiedereröffnet werden. Sie müssen schnell reagieren.
Array-Programmierung ist die Idee, dass Sie direkt auf Arrays arbeiten können. Wenn wir uns den Codeausschnitt hier ansehen, handelt es sich um Envision-Code, die DSL von Lokad. Um zu verstehen, was hier vor sich geht, müssen Sie verstehen, dass, wenn ich “orders.amounts” schreibe, eine Variable kommt und “orders” tatsächlich eine Tabelle im Sinne einer relationalen Tabelle ist, wie eine Tabelle in Ihrer Datenbank. Hier in der ersten Zeile wäre “amounts” eine Spalte in der Tabelle. In der ersten Zeile sage ich buchstäblich für jede einzelne Zeile der Auftragsliste, dass ich einfach die “Menge”, die eine Spalte ist, nehme und mit dem “Preis” multipliziere, und dann erhalte ich eine dritte Spalte, die dynamisch generiert wird, nämlich “Betrag”.
Übrigens ist der moderne Begriff für Array-Programmierung heutzutage auch als Dataframe-Programmierung bekannt. Das Studiengebiet ist ziemlich alt; es geht drei oder vier Jahrzehnte zurück, vielleicht sogar vier oder fünf. Es wurde auch als Array-Programmierung bezeichnet, auch wenn die Leute heutzutage normalerweise mit der Idee von Dataframes vertrauter sind. In der zweiten Zeile machen wir eine Filterung, ähnlich wie bei SQL. Wir filtern die Daten und es stellt sich heraus, dass die Auftragsliste ein Datum hat. Es wird gefiltert, und ich sage “Datum, das größer ist als heute minus 365”, also Tage. Wir behalten die Daten vom letzten Jahr und dann schreiben wir “products.soldLastYear = SUM(orders.amount)”.
Jetzt kommt das Interessante: Wir haben, was wir als natürlichen Join zwischen Produkten und Aufträgen bezeichnen. Warum? Weil jede Auftragszeile mit einem Produkt und nur einem Produkt verbunden ist und ein Produkt mit null oder mehr Auftragszeilen verbunden ist. In dieser Konfiguration können Sie direkt sagen: “Ich möchte etwas auf Produktebene berechnen, das nur eine Summe dessen ist, was auf Auftragsebene passiert”, und das ist genau das, was in Zeile neun gemacht wird. Ihnen mag auffallen, dass die Syntax sehr schlicht ist; es gibt nicht viele Zufälligkeiten oder technische Details. Ich würde behaupten, dass dieser Code fast vollständig frei von Zufälligkeiten ist, wenn es um die Dataframe-Programmierung geht. Dann setzen wir in den Zeilen 10, 11 und 12 einfach eine Tabelle auf unserem Dashboard, was sehr bequem möglich ist: “LIST(PRODUCTS)”, und dann “TO(products)”.
Es gibt viele Vorteile der Array-Programmierung für Supply Chains. Erstens eliminiert sie ganze Klassen von Problemen. Sie werden keine Off-by-One-Fehler in Ihren Arrays haben. Es wird viel einfacher sein, die Berechnung zu parallelisieren und sogar zu verteilen. Das ist sehr interessant, denn das bedeutet, dass Sie ein Programm schreiben können und das Programm nicht auf einer lokalen Maschine, sondern direkt auf einer Flotte von Maschinen, die in der Cloud leben, ausgeführt wird. Und übrigens ist das genau das, was bei Lokad gemacht wird. Diese automatische Parallelisierung ist von höchstem Interesse.
Sie sehen, wie es funktioniert, ist, dass wenn Sie Supply Chain-Optimierung durchführen, Ihre typischen Verbrauchsmuster in Bezug auf die Rechenhardware super intermittierend sind. Wenn ich zum Beispiel auf das Beispiel zurückkomme, das ich über das 60-minütige Fenster für die Einzelhandelsnetzwerke während der Warenbestandsauffüllung gegeben habe, bedeutet das, dass es eine Stunde pro Tag gibt, in der Sie Rechenleistung benötigen, um alle Ihre Berechnungen durchzuführen, aber den Rest der Zeit, die anderen 23 Stunden, benötigen Sie das nicht. Also möchten Sie ein Programm, das sich beim Ausführen auf viele Maschinen verteilt und dann, sobald es fertig ist, all diese Maschinen freigibt, damit andere Berechnungen stattfinden können. Die Alternative wäre, viele Maschinen zu haben, die Sie den ganzen Tag lang mieten und bezahlen, aber nur 5% der Zeit nutzen, was sehr ineffizient ist.
Diese Idee, dass Sie sich schnell und vorhersehbar auf viele Maschinen verteilen und dann die Rechenleistung aufgeben können, erfordert die Cloud in einem Multi-Tenant-Setup und eine Reihe anderer Dinge, die Lokad tut. Aber in erster Linie benötigt es die Zusammenarbeit der Programmiersprache selbst. Es ist etwas, das mit einer generischen Programmiersprache wie Python einfach nicht machbar ist, weil sich die Sprache selbst nicht für diese Art von sehr intelligentem und relevantem Ansatz eignet. Das geht über einfache Tricks hinaus; es geht buchstäblich darum, Ihre IT-Hardwarekosten um das 20-fache zu senken, die Ausführung massiv zu beschleunigen und ganze Klassen potenzieller Fehler in Ihrer Supply Chain zu eliminieren. Das ist bahnbrechend.
Die Array-Programmierung existiert bereits in vielen Aspekten, wie zum Beispiel in NumPy und pandas in Python, die für das Segment der Supply Chain Scientist so beliebt sind. Aber die Frage, die ich Ihnen stelle, ist: Wenn es so wichtig und nützlich ist, warum sind diese Dinge nicht selbstverständlicher Bestandteil der Sprache? Wenn Sie nur über NumPy gehen, sollte NumPy ein erstklassiger Bürger sein. Ich würde sagen, Sie können sogar besser als NumPy gehen. NumPy geht nur um die Array-Programmierung auf einer Maschine, aber warum nicht die Array-Programmierung auf einer Flotte von Maschinen machen? Es ist viel leistungsstärker und viel angemessener, wenn Sie eine Cloud mit zugänglicher Hardware-Kapazität haben.
Also, was wird der Engpass in der Supply Chain-Optimierung sein? Es gibt dieses Sprichwort von Goldratt, das besagt: “Jede Verbesserung, die neben dem Engpass in einer Supply Chain vorgenommen wird, ist eine Illusion”, und ich stimme dieser Aussage sehr zu. Realistisch betrachtet wird der Engpass bei der Supply Chain-Optimierung die Menschen sein, und genauer gesagt die Supply Chain Scientists, die leider für Lokad und meine Kunden nicht auf Bäumen wachsen.
Der Engpass sind die Supply Chain Scientists, die Menschen, die die numerischen Rezepte erstellen können, die alle Strategien des Unternehmens, das feindliche Verhalten der Konkurrenten berücksichtigen und diese Intelligenz in etwas Mechanisches umwandeln können, das im großen Maßstab ausgeführt werden kann. Die Tragödie der naiven Art, Data Science zu betreiben, als ich mein Promotionsstudium begann, das ich übrigens nie abgeschlossen habe, war, dass ich sehen konnte, dass jeder im Labor buchstäblich Data Science betrieb. Die meisten Leute haben Code für irgendein fortgeschrittenes maschinelles Lernmodell geschrieben, sie haben Enter gedrückt und dann angefangen zu warten. Wenn Sie einen großen Datensatz haben, sagen wir 5-10 Gigabyte, wird es nicht in Echtzeit sein. Das gesamte Labor war also mit Leuten gefüllt, die ein paar Zeilen Code geschrieben, Enter gedrückt und dann eine Tasse Kaffee geholt oder etwas online gelesen haben. Die Produktivität war daher außerordentlich gering.
Als ich mein eigenes Unternehmen gründete, hatte ich im Kopf, dass ich nicht eine Armee von super klugen Leuten bezahlen wollte, die den Großteil ihres Tages Kaffee trinken und darauf warten, dass ihre Programme abgeschlossen sind, damit sie Ergebnisse haben und weitermachen können. Theoretisch könnten sie viele Dinge gleichzeitig parallelisieren und Experimente durchführen, aber in der Praxis habe ich das nie wirklich gesehen. Intellektuell gesehen, wenn Sie damit beschäftigt sind, eine Lösung für ein Problem zu finden, möchten Sie Ihre Hypothese testen und das Ergebnis benötigen, um weiterzumachen. Es ist sehr schwer, bei hochtechnischen Dingen mehrere Aufgaben gleichzeitig zu erledigen und mehreren intellektuellen Spuren gleichzeitig nachzugehen.
Allerdings gab es einen Silberstreifen am Horizont. Datenwissenschaftler und jetzt auch Supply Chain Scientists bei Lokad schreiben nicht tausend Zeilen Code und sagen dann “bitte ausführen”. Sie fügen normalerweise zwei Zeilen zu einem tausend Zeilen langen Skript hinzu und bitten dann darum, das Skript auszuführen. Dieses Skript wird gegen dieselben Daten ausgeführt, die sie gerade wenige Minuten zuvor ausgeführt haben. Es ist fast genau dieselbe Logik, abgesehen von diesen zwei Zeilen. Wie können Sie also Terabytes an Daten in Sekunden statt mehreren Minuten verarbeiten? Die Antwort lautet: Wenn Sie für die vorherige Ausführung des Skripts alle Zwischenschritte der Berechnung aufgezeichnet und auf Speichermedien abgelegt haben (typischerweise Solid-State-Laufwerke oder SSDs), die sehr günstig, schnell und praktisch sind.
Das nächste Mal, wenn Sie Ihr Programm ausführen, wird das System feststellen, dass es sich um dasselbe Skript handelt. Es wird einen Unterschied feststellen und sehen, dass es in Bezug auf den Berechnungsgraphen fast identisch ist, abgesehen von einigen Bits. In Bezug auf die Daten ist es normalerweise zu 100% identisch. Manchmal gibt es ein paar Änderungen, aber fast nichts. Das System wird automatisch diagnostizieren, dass Sie nur wenige Dinge berechnen müssen, sodass Sie die Ergebnisse in Sekunden haben können. Dies kann die Produktivität Ihres Supply Chain Scientists erheblich steigern. Sie können von Personen, die die Eingabetaste drücken und 20 Minuten auf das Ergebnis warten, zu Personen werden, die die Eingabetaste drücken und 5 oder 10 Sekunden später das Ergebnis haben und weitermachen können.
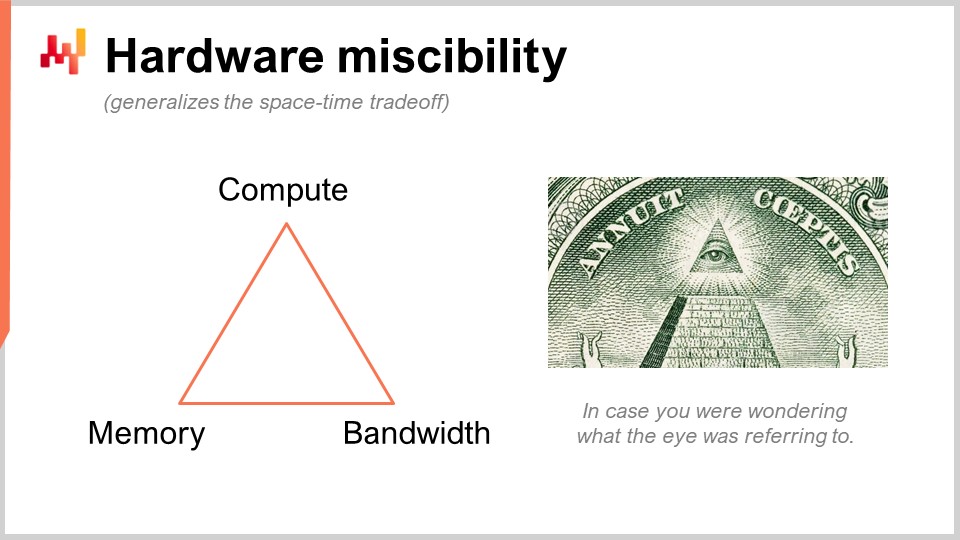
Ich spreche von etwas, das vielleicht sehr obskur erscheinen mag, aber in der Praxis sprechen wir von etwas, das eine 10-fache Auswirkung auf die Produktivität hat. Das ist enorm. Also das, was wir hier tun, ist ein cleverer Trick, den Lokad nicht erfunden hat. Wir ersetzen eine rohe Rechenressource, nämlich die Berechnung, durch eine andere, nämlich den Speicher und die Speicherung. Wir haben die grundlegenden Rechenressourcen: Berechnung, Speicher (entweder flüchtig oder persistent) und Bandbreite. Dies sind die grundlegenden Ressourcen, für die Sie bezahlen, wenn Sie Ressourcen auf einer Cloud-Computing-Plattform kaufen. Sie können tatsächlich eine Ressource durch eine andere ersetzen, und das Ziel ist es, den größten Nutzen für Ihr Geld zu erzielen.
Wenn Leute sagen, dass Sie In-Memory Computing verwenden sollten, würde ich sagen, dass das Unsinn ist. Wenn Sie In-Memory Computing sagen, bedeutet das, dass Sie einen Design-Schwerpunkt auf eine Ressource im Vergleich zu allen anderen legen. Aber nein, es gibt Kompromisse, und das Interessante ist, dass Sie eine Programmiersprache und eine Umgebung haben können, die diese Kompromisse und Perspektiven leichter umsetzen. In einer regulären allgemeinen Programmiersprache ist es möglich, das zu tun, aber Sie müssen es manuell tun. Das bedeutet, dass die Person, die es tut, ein professioneller Softwareingenieur sein muss. Ein Supply Chain Scientist wird diese Low-Level-Operationen mit den grundlegenden Rechenressourcen Ihrer Plattform nicht durchführen. Dies muss auf der Ebene der Programmiersprache selbst entwickelt werden.
Nun sprechen wir über probabilistisches Programmieren. In der zweiten Vorlesung, in der ich die Vision für die quantitative Supply Chain vorgestellt habe, war meine erste Anforderung, dass wir uns alle möglichen Zukunftsszenarien ansehen müssen. Die technische Antwort auf diese Anforderung ist die probabilistische Prognose. Sie möchten mit Zukunftsszenarien umgehen, bei denen Sie Wahrscheinlichkeiten haben. Alle Zukunftsszenarien sind möglich, aber sie sind nicht alle gleich wahrscheinlich. Sie benötigen eine Algebra, mit der Sie Berechnungen mit Unsicherheit durchführen können. Eine meiner großen Kritikpunkte an Excel ist, dass es äußerst schwierig ist, Unsicherheit in einer Tabelle darzustellen, unabhängig davon, ob es sich um Excel oder eine modernere Cloud-basierte Variante handelt. In einer Tabelle ist es sehr schwierig, Unsicherheit darzustellen, weil Sie etwas Besseres als Zahlen benötigen.
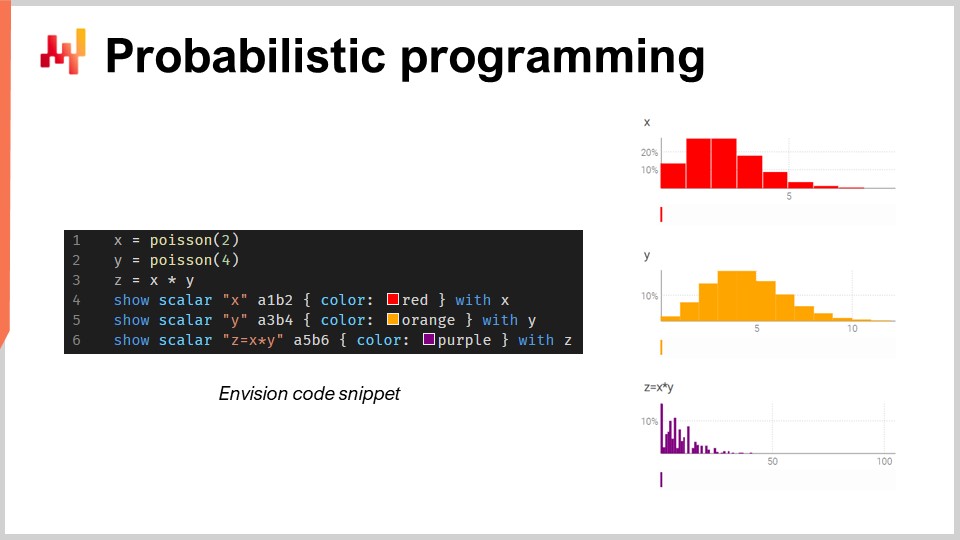
In diesem kleinen Ausschnitt illustriere ich die Algebra der Zufallsvariablen, die eine natürliche Funktion von Envision ist. In Zeile eins erzeuge ich eine diskrete Poisson-Verteilung mit einem Mittelwert von 2 und speichere sie in der Variablen X. Dann mache ich dasselbe für eine andere Poisson-Verteilung, Y. Anschließend berechne ich Z als das Produkt von X mal Y. Diese Operation, die Multiplikation von Zufallsvariablen, mag sehr seltsam erscheinen. Warum brauchen Sie so etwas überhaupt aus Sicht der Supply Chain? Lassen Sie mich ein Beispiel geben.
Angenommen, Sie sind im Bereich der Automobil-Nachrüstung und verkaufen Bremsbeläge. Die Leute kaufen keine Bremsbeläge einzeln; sie kaufen entweder zwei oder vier. Die Frage ist, wenn Sie eine Prognose erstellen möchten, möchten Sie die Wahrscheinlichkeiten prognostizieren, dass Kunden tatsächlich bestimmte Arten von Bremsbelägen kaufen. Das wird Ihre erste Zufallsvariable sein, die Ihnen die Wahrscheinlichkeit gibt, null Einheiten Nachfrage, eine Einheit Nachfrage, zwei, drei, vier usw. für die Bremsbeläge zu beobachten. Dann haben Sie eine andere Wahrscheinlichkeitsverteilung, die repräsentiert, ob die Leute zwei oder vier Bremsbeläge kaufen werden. Vielleicht wird es 50-50 sein, oder vielleicht werden 10 Prozent zwei kaufen und 90 Prozent vier kaufen. Das Problem ist, dass Sie diese beiden Aspekte haben, und wenn Sie den tatsächlichen Gesamtverbrauch von Bremsbelägen wissen möchten, möchten Sie die Wahrscheinlichkeit multiplizieren, dass ein Kunde für diesen Bremsbelag auftaucht, und dann die Wahrscheinlichkeitsverteilung, entweder zwei oder vier zu kaufen. Daher müssen Sie diese Multiplikation dieser beiden unsicheren Größen haben.
Hier gehe ich davon aus, dass die beiden Zufallsvariablen unabhängig sind. Übrigens ist diese Multiplikation von Zufallsvariablen in der Mathematik als diskrete Faltung bekannt. Sie können auf dem Screenshot das von Envision generierte Dashboard sehen. In den ersten drei Zeilen führe ich diese Berechnung der Zufallsalgebra durch, und dann in den Zeilen vier, fünf und sechs zeige ich diese Dinge auf der Webseite an, im Dashboard, das vom Skript generiert wird. Ich zeichne zum Beispiel A1, B2, ähnlich wie in einem Excel-Raster. Die Lokad-Dashboards sind ähnlich wie Excel-Raster organisiert, mit Positionen in den Spalten B, C usw. und den Zeilen 1, 2, 3, 4, 5.
Sie können sehen, dass die diskrete Faltung, Z, dieses sehr seltsame, stark gezackte Muster hat, das in Supply Chains sehr häufig vorkommt, wenn Menschen Pakete, Mengen oder Vielfache kaufen können. In solchen Situationen ist es in der Regel besser, die Quellen der multiplikativen Ereignisse, die mit dem Paket oder der Menge verbunden sind, zu zerlegen. Sie benötigen eine Programmiersprache, die diese Fähigkeiten zur Verfügung hat, als Bürger erster Klasse. Genau darum geht es beim probabilistischen Programmieren, und so haben wir es in Envision implementiert.

Nun wollen wir über differenzierbares Programmieren sprechen. Hier muss ich eine Einschränkung machen: Ich erwarte nicht, dass das Publikum wirklich versteht, was hier vor sich geht, und dafür entschuldige ich mich. Es liegt nicht daran, dass Ihnen Intelligenz fehlt; es ist nur so, dass dieses Thema eine ganze Reihe von Vorlesungen verdient. Tatsächlich gibt es im Plan für die kommenden Vorlesungen eine ganze Serie, die dem differenzierbaren Programmieren gewidmet ist. Ich werde sehr schnell sein, und es wird ziemlich kryptisch sein, also entschuldige ich mich im Voraus.
Fahren wir fort mit dem hier interessierenden Problem der Supply Chain, nämlich Kannibalisierung und Substitution. Diese Probleme sind sehr interessant und wahrscheinlich der Bereich, in dem die Zeitreihen-Prognose, die allgegenwärtig ist, am brutalsten versagt. Warum? Weil wir häufig Kunden oder Interessenten haben, die zu mir kommen und fragen, ob wir zum Beispiel 13-wöchige Prognosen für bestimmte Artikel wie Rucksäcke erstellen können. Ich würde sagen, ja, das können wir, aber offensichtlich hängt die Nachfrageprognose für dieses Produkt in hohem Maße davon ab, was Sie mit Ihren anderen Rucksäcken machen. Wenn Sie nur einen Rucksack haben, konzentrieren Sie möglicherweise die gesamte Nachfrage nach Rucksäcken auf dieses eine Produkt. Wenn Sie 10 verschiedene Varianten einführen, gibt es offensichtlich eine Menge Kannibalisierung. Sie multiplizieren den Gesamtumsatz nicht einfach mit einem Faktor von 10, nur weil Sie die Anzahl der Referenzen um 10 multipliziert haben. Es findet also offensichtlich Kannibalisierung und Substitution statt. Diese Phänomene sind in Supply Chains weit verbreitet.
Wie analysiert man Kannibalisierung oder Substitution? Die Art und Weise, wie wir es bei Lokad machen - und ich behaupte nicht, dass es der einzige Weg ist, aber es ist sicherlich ein funktionierender Weg - besteht darin, sich typischerweise den Graphen anzusehen, der Kunden und Produkte verbindet. Warum das? Weil Kannibalisierung stattfindet, wenn Produkte miteinander um die gleichen Kunden konkurrieren. Kannibalisierung ist buchstäblich der Ausdruck dafür, dass Sie einen Kunden mit einem Bedarf haben, aber er Präferenzen hat und ein Produkt aus der Menge der Produkte auswählt, die seiner Affinität entsprechen, und nur eines auswählt. Das ist das Wesen der Kannibalisierung.
Wenn Sie das analysieren möchten, müssen Sie nicht die Zeitreihen der Verkäufe analysieren, weil Sie diese Informationen zunächst nicht erfassen. Sie möchten den Graphen analysieren, der die historischen Transaktionen zwischen Kunden und Produkten verbindet. Es stellt sich heraus, dass diese Daten in den meisten Unternehmen leicht verfügbar sind. Im E-Commerce ist das eine Selbstverständlichkeit. Jede Einheit, die Sie verkaufen, kennen Sie den Kunden. Im B2B ist es dasselbe. Selbst im B2C-Einzelhandel haben die meisten Einzelhandelsketten heutzutage Treue-Programme, bei denen sie einen zweistelligen Prozentsatz der Kunden kennen, die mit ihren Karten auftauchen, sodass Sie wissen, wer was kauft. Nicht für 100% des Verkehrs, aber das brauchen Sie nicht. Wenn Sie 10% und mehr Ihrer historischen Transaktionen haben, bei denen Sie das Paar aus Kunden und Produkten kennen, reicht das für diese Art von Analyse aus.
In diesem relativ kleinen Ausschnitt werde ich eine Affinitätsanalyse zwischen Kunden und Produkten detaillieren. Das ist buchstäblich der grundlegende Schritt, den Sie unternehmen müssen, um eine Kannibalisierungsanalyse durchzuführen. Schauen wir uns an, was in diesem Code passiert.
Von Zeile eins bis fünf ist das sehr banal; ich lese nur eine Flachdatei ein, die eine Historie von Transaktionen enthält. Ich lese nur eine CSV-Datei ein, die vier Spalten enthält: Datum, Produkt, Kunde und Menge. Etwas sehr Grundlegendes. Ich verwende nicht einmal alle diese Spalten, aber nur um das Beispiel etwas konkreter zu machen. In der Transaktionshistorie gehe ich davon aus, dass die Kunden für all diese Transaktionen bekannt sind. Also, es ist sehr banal; ich lese nur Daten aus einer Tabelle ein.
Dann, in den Zeilen sieben und acht, erstelle ich lediglich die Tabelle für Produkte und die Tabelle für Kunden. In einer echten Produktionsumgebung würde ich diese Tabellen normalerweise nicht erstellen; ich würde diese Tabellen aus anderen Flachdateien anderswo lesen. Ich wollte das Beispiel super einfach halten, also extrahiere ich nur eine Produkt-Tabelle aus den Produkten, die ich in der Transaktionshistorie beobachtet habe, und ich mache dasselbe für Kunden. Sie sehen, es ist nur ein Trick, um es super einfach zu halten.
Jetzt werden die Zeilen 10, 11 und 12 etwas obskurer, da es um lateinische Räume geht. Zuerst, in Zeile 10, erstelle ich eine Tabelle mit 64 Zeilen. Die Tabelle enthält nichts; sie wird nur durch die Tatsache definiert, dass sie 64 Zeilen hat, und das ist es. Es ist also wie ein Platzhalter, eine triviale Tabelle mit vielen Zeilen und ohne Spalten. So ist es nicht besonders nützlich. Dann ist “P” im Grunde genommen ein kartesisches Produkt, eine mathematische Operation mit allen Paaren. Es ist eine Tabelle, in der Sie eine Zeile für jede Zeile in den Produkten und jede Zeile in der Tabelle “L” haben. Diese Tabelle “P” hat 64 Zeilen mehr als die Produkttabelle, und ich mache dasselbe für Kunden. Ich blase diese Tabellen nur durch diese zusätzliche Dimension, die diese Tabelle “L” ist, auf.
Dies wird meine Grundlage für meine lateinischen Räume sein, die genau das ist, was ich lernen werde. Was ich lernen möchte, ist für jedes Produkt ein lateinischer Raum, der ein Vektor von 64 Werten sein wird, und für jeden Kunden ebenfalls ein lateinischer Raum von 64 Werten. Wenn ich die Affinität zwischen einem Kunden und einem Produkt wissen möchte, möchte ich einfach das Skalarprodukt zwischen den beiden berechnen können. Das Skalarprodukt ist einfach die elementweise Multiplikation aller Terme dieser beiden Vektoren, und dann machen Sie die Summe. Es mag sehr technisch klingen, aber es ist nur elementweise Multiplikation plus Summe - das ist das Skalarprodukt.
Diese lateinischen Räume sind nur schicke Fachbegriffe für die Erstellung eines Raums mit Parametern, die ein wenig erfunden sind, wo ich einfach lernen möchte. Die ganze Magie des differenzierbaren Programmierens passiert in nur fünf Zeilen, von Zeile 14 bis 18. Ich habe ein Schlüsselwort, “autodiff”, und “transactions”, was besagt, dass dies eine interessante Tabelle ist, eine Tabelle mit Beobachtungen. Ich werde diese Tabelle Zeile für Zeile verarbeiten, um meinen Lernprozess durchzuführen. In diesem Block deklariere ich eine Reihe von Parametern. Die Parameter sind die Dinge, die Sie lernen möchten, wie Zahlen, aber Sie kennen die Werte noch nicht. Diese Dinge werden einfach zufällig initialisiert, mit Zufallszahlen.
Ich führe “X”, “X*” und “Y” ein. Ich werde nicht genau darauf eingehen, was “X*” genau macht; vielleicht in den Fragen. Ich gebe einen Ausdruck zurück, der meine Verlustfunktion ist, und das ist die Summe. Die Idee der kollaborativen Filterung oder der Matrixzerlegung besteht einfach darin, lateinische Räume zu lernen, die alle Ihre Kanten in Ihrem bipartiten Graphen abdecken. Ich weiß, dass es ein wenig technisch ist, aber was wir tun, ist buchstäblich sehr einfach, was die Lieferkette betrifft. Wir lernen die Affinität zwischen Produkten und Kunden.
Ich weiß, dass es wahrscheinlich sehr undurchsichtig erscheint, aber bleiben Sie bei mir, und es wird noch mehr Vorlesungen geben, in denen ich Ihnen eine durchdachtere Einführung dazu gebe. Das Ganze wird in fünf Zeilen erledigt, und das ist völlig bemerkenswert. Wenn ich von fünf Zeilen spreche, betrüge ich nicht, indem ich sage: “Schauen Sie, es sind nur fünf Zeilen, aber ich rufe tatsächlich eine Drittanbieterbibliothek von gigantischer Komplexität auf, in der ich alle Intelligenz verstecke.” Nein, nein, nein. Hier, in diesem Beispiel, gibt es buchstäblich keine maschinelle Lernmagie außer den beiden Schlüsselwörtern “autodiff” und “params”. “Autodiff” wird verwendet, um einen Block zu definieren, in dem differenzierbare Programmierung stattfindet, und übrigens handelt es sich um einen Block, in dem ich alles programmieren kann, also buchstäblich kann ich unser Programm einspritzen. Dann habe ich “params”, um meine Probleme zu deklarieren, und das war’s. Also sehen Sie, es passiert keine undurchsichtige Magie; es gibt keine einmillionen Zeilen Bibliothek im Hintergrund, die die ganze Arbeit für Sie erledigt. Alles, was Sie wissen müssen, befindet sich buchstäblich auf diesem Bildschirm, und das ist der Unterschied zwischen einem Programmierparadigma und einer Bibliothek. Das Programmierparadigma gibt Ihnen Zugang zu scheinbar unglaublich anspruchsvollen Fähigkeiten, wie zum Beispiel die Kannibalisierungsanalyse mit nur wenigen Zeilen Code durchzuführen, ohne auf massive Drittanbieterbibliotheken zurückgreifen zu müssen, die die Komplexität umschließen. Es überwindet das Problem und macht es viel einfacher, sodass Sie etwas, das super kompliziert erscheint, in nur wenigen Zeilen lösen können.
Nun, ein paar Worte dazu, wie differenzierbare Programmierung funktioniert. Es gibt zwei Erkenntnisse. Eine ist die automatische Differentiation. Für diejenigen von Ihnen, die das Glück hatten, eine Ingenieurausbildung zu absolvieren, haben Sie zwei Möglichkeiten gesehen, Ableitungen zu berechnen. Es gibt eine symbolische Ableitung, zum Beispiel, wenn Sie x quadratisch haben, machen Sie die Ableitung nach x, und es gibt Ihnen 2x. Das ist eine symbolische Ableitung. Dann haben Sie die numerische Ableitung, also wenn Sie eine Funktion f(x) haben, die Sie ableiten möchten, wird es f’(x) ≈ (f(x + ε) - f(x))/ε sein. Das ist die numerische Ableitung. Beide sind für das, was wir hier tun wollen, nicht geeignet. Die symbolische Ableitung hat Probleme mit der Komplexität, da Ihre Ableitung ein Programm sein kann, das viel komplexer ist als das ursprüngliche Programm. Die numerische Ableitung ist numerisch instabil, sodass Sie viele Probleme mit numerischer Stabilität haben werden.
Automatische Differentiation ist eine fantastische Idee aus den 70er Jahren, die in den letzten Jahrzehnten von der Welt wiederentdeckt wurde. Es ist die Idee, dass Sie die Ableitung eines beliebigen Computerprogramms berechnen können, was atemberaubend ist. Noch atemberaubender ist, dass das Programm, das die Ableitung ist, die gleiche Rechenkomplexität wie das ursprüngliche Programm hat, was beeindruckend ist. Differenzierbare Programmierung ist nur eine Kombination aus automatischer Differentiation und Parametern, die Sie lernen möchten.
Wie lernen Sie also? Wenn Sie die Ableitung haben, bedeutet das, dass Sie Gradienten nach oben blubbern können, und mit stochastischem Gradientenabstieg können Sie kleine Anpassungen an den Werten der Parameter vornehmen. Durch Anpassung dieser Parameter werden Sie inkrementell, durch viele Iterationen des stochastischen Gradientenabstiegs, zu Parametern konvergieren, die sinnvoll sind und das erreichen, was Sie lernen oder optimieren möchten.
Differenzierbare Programmierung kann für Lernprobleme verwendet werden, wie das, was ich illustriere, wo ich die Affinität zwischen meinen Kunden und meinen Produkten lernen möchte. Es kann auch für numerische Optimierungsprobleme verwendet werden, wie das Optimieren von Dingen unter Einschränkungen, und es ist als Paradigma sehr skalierbar. Wie Sie sehen können, wurde dieser Aspekt in Envision zu einem Bürger erster Klasse gemacht. Übrigens gibt es noch ein paar Dinge, die in Bezug auf die Envision-Syntax in Bearbeitung sind, also erwarten Sie noch nicht genau diese Dinge; wir verfeinern noch ein paar Aspekte. Aber die Essenz ist da. Ich werde nicht auf die Feinheiten der wenigen Dinge eingehen, die sich noch entwickeln.

Lassen Sie uns nun zu einem anderen Problem kommen, das für die Produktionsbereitschaft Ihrer Einrichtung relevant ist. Typischerweise treten in der Supply Chain-Optimierung Heisenbugs auf. Was ist ein Heisenbug? Es handelt sich um einen frustrierenden Bug-Typ, bei dem eine Optimierung durchgeführt wird und Müllergebnisse erzeugt. Zum Beispiel hatten Sie eine Stapelberechnung für die Bestandsauffüllung während der Nacht, und am Morgen stellen Sie fest, dass einige dieser Ergebnisse unsinnig waren und teure Fehler verursacht haben. Sie möchten nicht, dass das Problem erneut auftritt, also führen Sie Ihren Prozess erneut aus. Wenn Sie den Prozess jedoch erneut ausführen, ist das Problem verschwunden. Sie können das Problem nicht reproduzieren, und der Heisenbug manifestiert sich nicht.
Es mag wie ein seltsamer Randfall klingen, aber in den ersten Jahren von Lokad hatten wir immer wieder mit diesen Problemen zu kämpfen. Ich habe viele Supply Chain-Initiativen gesehen, insbesondere solche im Bereich der Datenwissenschaft, die aufgrund ungelöster Heisenbugs gescheitert sind. Es traten Fehler in der Produktion auf, es wurde versucht, die Probleme lokal zu reproduzieren, aber es gelang nicht, sodass die Probleme nie behoben wurden. Nach ein paar Monaten im Panikmodus wurde das gesamte Projekt normalerweise stillschweigend eingestellt, und die Leute kehrten zu Excel-Tabellen zurück.
Wenn Sie eine vollständige Reproduzierbarkeit Ihrer Logik erreichen möchten, müssen Sie den Code und die Daten versionieren. Die meisten Personen im Publikum, die Softwareingenieure oder Datenwissenschaftler sind, sind möglicherweise mit der Idee der Versionsverwaltung des Codes vertraut. Sie möchten jedoch auch alle Daten versionieren, damit Sie bei der Ausführung Ihres Programms genau wissen, welche Version des Codes und der Daten verwendet wird. Möglicherweise können Sie das Problem am nächsten Tag nicht replizieren, da sich die Daten aufgrund neuer Transaktionen oder anderer Faktoren geändert haben, sodass die Bedingungen, die den Fehler in erster Linie ausgelöst haben, nicht mehr vorhanden sind.
Sie möchten sicherstellen, dass Ihre Programmierumgebung die Logik und Daten genau so replizieren kann, wie sie zum Zeitpunkt der Produktion waren. Dies erfordert eine vollständige Versionierung von allem. Auch hier müssen die Programmiersprache und der Programmierstapel zusammenarbeiten, um dies möglich zu machen. Es ist möglich, ohne dass das Programmierparadigma ein Bürger erster Klasse Ihres Stacks ist, aber dann muss der Supply Chain Scientist äußerst vorsichtig sein, was er tut und wie er programmiert. Andernfalls kann er seine Ergebnisse nicht replizieren. Dies setzt immense Belastungen auf die Schultern von Supply Chain Scientists, die bereits unter erheblichem Druck von der Supply Chain selbst stehen. Sie möchten nicht, dass diese Fachleute mit zufälliger Komplexität umgehen müssen, wie zum Beispiel der Unfähigkeit, ihre eigenen Ergebnisse zu replizieren. Bei Lokad nennen wir dies eine “Zeitmaschine”, mit der Sie alles zu jedem Zeitpunkt in der Vergangenheit replizieren können.
Vorsicht, es geht nicht nur darum, zu replizieren, was gestern Abend passiert ist. Manchmal entdecken Sie lange nach dem Ereignis einen Fehler. Wenn Sie zum Beispiel eine Bestellung bei einem Lieferanten aufgeben, der eine Vorlaufzeit von drei Monaten hat, können Sie drei Monate später feststellen, dass die Bestellung unsinnig war. Sie müssen drei Monate in die Vergangenheit zurückgehen, um den Zeitpunkt zu erreichen, an dem Sie diese fehlerhafte Bestellung generiert haben, um herauszufinden, was das Problem war. Es geht nicht nur darum, die letzten Stunden der Arbeit zu versionieren; es geht buchstäblich darum, eine vollständige Geschichte des letzten Jahres der Ausführung zu haben.

Ein weiteres Anliegen ist der Anstieg von Ransomware und Cyberangriffen auf Supply Chains. Diese Angriffe sind massiv störend und können sehr kostspielig sein. Bei der Implementierung von softwaregesteuerten Lösungen müssen Sie berücksichtigen, ob Sie Ihr Unternehmen und Ihre Supply Chain anfälliger für Cyberangriffe und Risiken machen. Aus dieser Perspektive sind Excel und Python nicht ideal. Diese Komponenten sind programmierbar, was bedeutet, dass sie zahlreiche Sicherheitslücken aufweisen können.
Wenn Sie ein Team von Datenwissenschaftlern oder Supply Chain-Wissenschaftlern haben, die sich mit Supply Chain-Problemen befassen, können sie sich den sorgfältigen, iterativen Peer-Review-Prozess von Code, der in der Softwarebranche üblich ist, nicht leisten. Wenn sich beispielsweise über Nacht ein Tarif ändert oder ein Lagerhaus überflutet wird, benötigen Sie eine schnelle Reaktion. Sie können keine Wochen damit verbringen, Code-Spezifikationen, Reviews usw. zu erstellen. Das Problem besteht darin, dass Sie Programmierfähigkeiten an Personen weitergeben, die standardmäßig das Potenzial haben, dem Unternehmen versehentlich Schaden zuzufügen. Es kann sogar noch schlimmer sein, wenn es einen absichtlichen Mitarbeiter gibt, aber selbst wenn man das beiseite lässt, hat man immer noch das Problem, dass jemand versehentlich einen inneren Teil der IT-Systeme freilegt. Denken Sie daran, dass Supply Chain-Optimierungssysteme per Definition Zugriff auf eine große Menge an Daten im gesamten Unternehmen haben. Diese Daten sind nicht nur ein Vermögenswert, sondern auch eine Haftung.
Was Sie wollen, ist ein Programmierparadigma, das sichere Programmierung fördert. Sie möchten eine Programmiersprache, in der es ganze Klassen von Dingen gibt, die Sie nicht tun können. Warum sollte man beispielsweise eine Programmiersprache haben, die Systemaufrufe für Zwecke der Supply Chain-Optimierung durchführen kann? Python kann Systemaufrufe durchführen, und das kann auch Excel. Aber warum möchten Sie ein programmierbares System mit solchen Fähigkeiten überhaupt haben? Es ist, als würde man eine Waffe kaufen, um sich selbst in den Fuß zu schießen.
Sie möchten etwas, bei dem ganze Klassen oder Funktionen fehlen, weil Sie sie für die Optimierung der Supply Chain nicht benötigen. Wenn diese Funktionen vorhanden sind, werden sie zu einer massiven Haftung. Wenn Sie programmierbare Fähigkeiten einführen, ohne die Werkzeuge, die sichere Programmierung durch Design durchsetzen, erhöhen Sie das Risiko von Cyberangriffen und Ransomware und verschlimmern die Dinge.
Natürlich ist es immer möglich, durch Verdoppelung der Größe des Cybersicherheitsteams auszugleichen, aber das ist sehr kostspielig und nicht ideal, wenn man es mit dringenden Supply Chain-Situationen zu tun hat. Sie müssen schnell und sicher handeln, ohne Zeit für die üblichen Prozesse, Reviews und Genehmigungen zu haben. Sie möchten auch eine sichere Programmierung, die banale Probleme wie Nullreferenzausnahmen, Out-of-Memory-Fehler, Off-by-One-Schleifen und Nebeneffekte beseitigt.

Zusammenfassend lässt sich sagen, dass Werkzeuge wichtig sind. Es gibt ein Sprichwort: “Nimm kein Schwert mit zu einem Schusswechsel.” Sie benötigen die richtigen Werkzeuge und Programmierparadigmen, nicht nur diejenigen, die Sie an der Universität gelernt haben. Sie benötigen etwas Professionelles und Produktionsreifes, um den Anforderungen Ihrer Supply Chain gerecht zu werden. Mit minderwertigen Werkzeugen können Sie möglicherweise einige Ergebnisse erzielen, aber es wird nicht großartig sein. Ein fantastischer Musiker kann Musik mit einem Löffel machen, aber mit einem richtigen Instrument kann er so viel besser sein.

Nun gehen wir zu den Fragen über. Bitte beachten Sie, dass es eine Verzögerung von etwa 20 Sekunden gibt, sodass zwischen dem Video, das Sie sehen, und dem Lesen Ihrer Fragen eine gewisse Latenz besteht.
Frage: Was ist mit dynamischer Programmierung im Hinblick auf Operationsforschung?
Dynamische Programmierung ist trotz des Namens kein Programmierparadigma. Es handelt sich eher um eine algorithmische Technik. Die Idee ist, dass Sie bei der Durchführung einer algorithmischen Aufgabe oder der Lösung eines bestimmten Problems dieselbe Teiloperation sehr häufig wiederholen. Dynamische Programmierung ist ein spezieller Fall des von mir zuvor erwähnten Raum-Zeit-Trade-offs, bei dem Sie etwas mehr in den Speicher investieren, um Zeit auf der Berechnungsseite zu sparen. Es war eine der frühesten algorithmischen Techniken und stammt aus den 60er und 70er Jahren. Es ist eine gute Technik, aber der Name ist etwas unglücklich, denn es gibt nichts wirklich Dynamisches daran, und es geht nicht wirklich um Programmierung. Es geht eher um die Konzeption von Algorithmen. Für mich qualifiziert es sich trotz des Namens nicht als Programmierparadigma; es handelt sich eher um eine spezifische algorithmische Technik.
Frage: Johannes, könnten Sie bitte einige Referenzbücher nennen, die jeder gute Supply Chain-Ingenieur haben sollte? Leider bin ich neu auf diesem Gebiet, und mein derzeitiger Schwerpunkt liegt auf Data Science und System Engineering.
Ich habe eine sehr gemischte Meinung über die vorhandene Literatur. In meinem ersten Vortrag habe ich zwei Bücher vorgestellt, die meiner Meinung nach den Höhepunkt der akademischen Studien zum Thema Supply Chain darstellen. Wenn Sie zwei Bücher lesen möchten, können Sie diese Bücher lesen. Allerdings habe ich ein ständiges Problem mit den Büchern, die ich bisher gelesen habe. Im Grunde genommen haben Sie Autoren, die Sammlungen von Spielzeugnumerik für idealisierte Supply Chains präsentieren, und ich glaube, dass diese Bücher die Supply Chain nicht aus dem richtigen Blickwinkel betrachten und völlig verfehlen, dass es sich um ein böses Problem handelt. Es gibt eine umfangreiche Literatur, die sehr technisch ist, mit Gleichungen, Algorithmen, Theoremen und Beweisen, aber ich glaube, dass sie völlig am Ziel vorbeigeht.
Dann haben Sie einen anderen Stil von Supply Chain Management-Büchern, die eher beratungsorientiert sind. Sie können diese Bücher leicht erkennen, weil sie alle zwei Seiten Sportanalogien verwenden. Diese Bücher enthalten allerlei vereinfachte Diagramme, wie z.B. 2x2-Varianten von SWOT (Stärken, Schwächen, Chancen, Bedrohungen)-Diagrammen, die ich als minderwertige Denkweisen betrachte. Das Problem bei diesen Büchern ist, dass sie tendenziell besser darin sind zu verstehen, dass die Supply Chain ein böses Unterfangen ist. Sie verstehen viel besser, dass es ein Spiel ist, das von Menschen gespielt wird, bei dem allerlei bizarre Dinge passieren können und bei dem man auf intelligente Weise vorgehen kann. Dafür gebe ich ihnen Anerkennung. Das Problem bei diesen Büchern, die in der Regel von Beratern oder Professoren von Management-Schulen geschrieben werden, ist, dass sie nicht sehr handlungsorientiert sind. Die Botschaft läuft darauf hinaus, “ein besserer Anführer zu sein”, “klüger zu sein”, “mehr Energie zu haben”, und für mich ist das nicht handlungsorientiert. Es gibt Ihnen keine Elemente, die Sie in etwas Hochwertiges umwandeln können, wie es Software kann.
Also, ich komme zurück zum ersten Vortrag: Lesen Sie die beiden Bücher, wenn Sie möchten, aber ich bin mir nicht sicher, ob es gut investierte Zeit sein wird. Es ist gut zu wissen, was andere geschrieben haben. Auf der Beraterseite der Literatur ist mein Favorit wahrscheinlich die Arbeit von Katana, die ich im ersten Vortrag nicht aufgelistet habe. Nicht alles ist schlecht; manche Leute haben mehr Talent, auch wenn sie mehr beratungsorientiert sind. Sie können die Arbeit von Katana überprüfen; er hat ein Buch über dynamische Supply Chains. Ich werde das Buch in den Referenzen auflisten.
Frage: Wie nutzen Sie Parallelisierung bei der Bewältigung von Kannibalisierung oder Sortimentsentscheidungen, bei denen das Problem nicht leicht parallelisiert werden kann?
Warum lässt es sich nicht leicht parallelisieren? Stochastischer Gradientenabstieg ist ziemlich trivial zu parallelisieren. Sie haben stochastische Gradientenschritte, die in zufälliger Reihenfolge durchgeführt werden können, und Sie können mehrere Schritte gleichzeitig durchführen. Also glaube ich, dass alles, was durch stochastischen Gradientenabstieg gesteuert wird, ziemlich trivial zu parallelisieren ist.
Bei der Bewältigung von Kannibalisierung ist es schwieriger, mit einer anderen Art von Parallelisierung umzugehen, nämlich mit dem, was zuerst kommt. Wenn ich dieses Produkt zuerst einführe, mache ich eine Prognose, aber dann nehme ich ein anderes Produkt, das die Situation verändert. Die Antwort ist, dass Sie eine Möglichkeit haben möchten, die gesamte Situation frontal anzugehen. Sie sagen nicht: “Zuerst führe ich dieses Produkt ein und mache die Prognose; ich führe ein weiteres Produkt ein und mache dann die Prognose, wodurch das erste Produkt verändert wird.” Sie machen es einfach frontal, all diese Dinge auf einmal, zur gleichen Zeit. Sie benötigen mehr Programmierparadigmen. Die Programmierparadigmen, die ich heute vorgestellt habe, können Ihnen dabei sehr helfen.
Bei Sortimentsentscheidungen stellen diese Art von Problemen keine großen Schwierigkeiten für die Parallelisierung dar. Das Gleiche gilt, wenn Sie ein weltweites Einzelhandelsnetzwerk haben und das Sortiment für alle Ihre Geschäfte optimieren möchten. Sie können Berechnungen durchführen, die für alle Geschäfte parallel ablaufen. Sie möchten es nicht sequenziell machen, bei dem Sie das Sortiment für ein Geschäft optimieren und dann zum nächsten Geschäft übergehen. Das ist der falsche Weg, es zu tun, aber Sie können das Netzwerk parallel optimieren, alle Informationen propagieren und dann wiederholen. Es gibt allerlei Techniken, und die Werkzeuge können Ihnen dabei sehr helfen, das auf viel einfachere Weise zu tun.
Frage: Verwenden Sie einen Graphdatenbankansatz?
Nein, nicht im technischen, kanonischen Sinne. Es gibt viele Graphdatenbanken auf dem Markt, die von großem Interesse sind. Was wir bei Lokad intern verwenden, ist jedoch eine vollständige vertikale Integration durch einen vereinheitlichten, monolithischen Compiler-Stack, um vollständig alle traditionellen Elemente zu entfernen, die Sie in einem klassischen Stack finden würden. So erreichen wir eine sehr gute Leistung, in Bezug auf die Rechenleistung, die sehr nahe am Metall liegt. Nicht, weil wir fantastisch kluge Programmierer sind, sondern einfach, weil wir praktisch alle Schichten, die traditionell existieren, eliminiert haben. Lokad verwendet buchstäblich keine Datenbank. Wir haben einen Compiler, der sich um alles kümmert, bis hin zur Organisation der Datenstrukturen für die Persistenz. Es ist etwas seltsam, aber es ist viel effizienter, es auf diese Weise zu tun, und auf diese Weise spielen Sie viel besser mit der Tatsache, dass Sie ein Skript zu einer Flotte von Maschinen in der Cloud kompilieren. Ihre Zielplattform in Bezug auf die Hardware ist nicht eine Maschine, sondern eine Flotte von Maschinen.
Frage: Was ist Ihre Meinung zu Power BI, das auch Python-Code und verwandte Algorithmen wie Gradientenabstieg, Gierig usw. ausführt?
Das Problem, das ich mit allem im Zusammenhang mit Business Intelligence habe, Power BI ist eines davon, ist, dass es ein Paradigma hat, das ich für die Supply Chain für unzureichend halte. Sie sehen alle Probleme als Hypercube, bei dem Sie Dimensionen haben, die Sie nur schneiden und würfeln. Im Kern haben Sie ein Problem der Ausdrucksfähigkeit, das sehr begrenzt ist. Wenn Sie Power BI mit Python in der Mitte verwenden, benötigen Sie Python, weil die Ausdrucksfähigkeit in Bezug auf den Hypercube sehr gering ist. Um die Ausdrucksfähigkeit zurückzugewinnen, fügen Sie Python in der Mitte hinzu. Denken Sie jedoch daran, was ich in der vorherigen Frage zu diesen Schichten gesagt habe: Der Fluch moderner Unternehmenssoftware besteht darin, dass Sie zu viele Schichten haben. Jede einzelne Schicht, die Sie hinzufügen, führt zu Ineffizienzen und Fehlern. Wenn Sie Power BI plus Python verwenden, haben Sie viel zu viele Schichten. Sie haben also Power BI, das auf anderen Systemen sitzt, was bedeutet, dass Sie bereits mehrere Systeme vor Power BI haben. Dann haben Sie Power BI oben drauf, und auf Power BI haben Sie Python. Aber handelt Python für sich allein? Nein, wahrscheinlich werden Sie Python-Bibliotheken wie Pandas oder NumPy verwenden. Sie haben also Schichten in Python, die sich aufstapeln, und Sie enden mit Dutzenden von Schichten. Sie können Fehler in einer dieser Schichten haben, daher wird die Situation ziemlich albtraumhaft sein.
Ich glaube nicht an Lösungen, bei denen Sie am Ende eine massive Anzahl von Stapeln haben. Es gibt diesen Witz, dass Sie in C++ jedes Problem lösen können, indem Sie eine weitere Schicht der Indirektion hinzufügen, einschließlich des Problems, zu viele Schichten der Indirektion zu haben. Offensichtlich ist dies als Aussage etwas unsinnig, aber ich bin zutiefst anderer Meinung als der Ansatz, bei dem Menschen ein Produkt mit einem unzureichenden Kernentwurf haben und anstatt das Problem frontal anzugehen, sie Dinge oben drauf setzen, während die Grundlagen wackelig sind. Das ist nicht der richtige Weg, es zu tun, und Sie werden eine geringe Produktivität haben, fortlaufende Kämpfe mit Fehlern, die Sie nie lösen werden, und dann, was die Wartbarkeit betrifft, ist es einfach ein Rezept für einen Albtraum.
Frage: Wie können die Ergebnisse einer kollaborativen Filteranalyse in den Nachfrageprognosealgorithmus für jedes Produkt, wie z.B. Rucksäcke, eingebunden werden?
Es tut mir leid, aber ich werde dieses Thema in der nächsten Vorlesung behandeln. Die kurze Antwort ist, dass Sie das nicht in einen vorhandenen Prognosealgorithmus einbinden möchten. Sie möchten etwas haben, das viel natürlicher integriert ist. Sie tun das nicht und kehren dann zu Ihren alten Methoden der Prognoseerstellung zurück; stattdessen verwerfen Sie einfach die alte Methode der Prognoseerstellung und tun etwas radikal anderes, das darauf aufbaut. Aber ich werde dies in einer späteren Vorlesung besprechen. Es wäre zu viel für heute.
Ich denke, das war es für diese Vorlesung. Vielen Dank an alle, die teilgenommen haben. Die nächste Vorlesung findet am Mittwoch, dem 6. Januar, zur gleichen Zeit und am gleichen Wochentag statt. Ich werde einige Weihnachtsferien machen, daher wünsche ich allen frohe Weihnachten und ein glückliches neues Jahr. Wir werden unsere Vorlesungsreihe im nächsten Jahr fortsetzen. Vielen Dank.


