00:00 Einführung
03:39 Automatisierung war schon immer das Ziel
06:28 Ausnahmemanagement und Benachrichtigungen
10:27 Der bisherige Verlauf
14:33 Unsere heutige Produktionsimplementierung
15:59 Zusammenfassung: Lieferumfang und Rollen
19:01 Die Form der Entscheidung aufdecken
23:00 Reaktion auf Legacy-Systeme
27:20 Iteration bis zu null Prozent Wahnsinn
32:30 Zielmetriken
36:27 Doppelte Ausführung: manuell + mechanisch
39:19 Analyseparalyse
43:21 Schrittweise Übernahme der Automatisierung
46:08 Prozesssedimentation
48:57 Vom Planer zum Netzwerkmanager
52:46 Der KPI-Tourist
54:58 Führung: vom Coach zum Produktbesitzer
58:46 Der analoge Supply Chain Boss
01:02:25 Fazit
01:04:44 7.2 Automatisierte Entscheidungen in der Produktion - Fragen?
Beschreibung
Wir suchen ein numerisches Rezept, um eine ganze Klasse von banalen Entscheidungen, wie z.B. Lagerauffüllungen, zu steuern. Automatisierung ist entscheidend, um die Supply Chain zu einer kapitalistischen Unternehmung zu machen. Allerdings birgt sie erhebliche Risiken, wenn das numerische Rezept fehlerhaft ist und Schaden in großem Maßstab anrichtet. “Fail fast and break things” ist nicht die richtige Denkweise, um ein numerisches Rezept für die Produktion freizugeben. Viele Alternativen, wie das Wasserfallmodell, sind noch schlimmer, da sie in der Regel eine Illusion von Rationalität und Kontrolle vermitteln. Ein hochiterativer Prozess ist der Schlüssel, um das numerische Rezept zu entwerfen, das sich als produktionsfähig erweist.
Vollständiges Transkript

Willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Johannes Vermorel und heute werde ich “Automatisierte Entscheidungen in der Supply Chain - Vorlesung 7.2” präsentieren. In den letzten beiden Jahrhunderten haben unsere Volkswirtschaften eine massive Transformation durchlaufen, die durch Mechanisierung ermöglicht wurde. Unternehmen, die einen höheren Grad an Mechanisierung im Vergleich zu ihren Konkurrenten erreicht haben, haben diese fast immer systematisch in den Bankrott getrieben. Mechanisierung ermöglicht es uns, mehr, besser und schneller zu arbeiten und gleichzeitig die Kosten zu senken. Dies gilt für physische Aufgaben wie das Bewegen von Waren mit einem Gabelstapler anstelle des manuellen Tragens von Kisten, aber auch für intellektuelle Aufgaben wie die Berechnung des verbleibenden Geldes auf dem Bankkonto.
Allerdings ist unsere Fähigkeit, eine Aufgabe zu mechanisieren, von der Technologie abhängig. Es gibt immer noch viele physische Aufgaben, die noch nicht mechanisiert werden können, wie zum Beispiel das Schneiden von Haaren oder das Wechseln von Bettlaken. Umgekehrt gibt es immer noch viele intellektuelle Aufgaben, die noch nicht mechanisiert werden können, wie z.B. die Einstellung der richtigen Person oder das Herausfinden, was der Kunde möchte. Es gibt keinen Grund zu glauben, dass diese Aufgaben, sei es intellektuell oder mechanisch, nicht irgendwann mechanisiert werden können. Die Technologie ist jedoch noch nicht ganz so weit.
Die meisten der banalen routinemäßigen Entscheidungen in der Lieferkette können jetzt automatisiert werden. Dies ist eine relativ neue Entwicklung. Vor einem Jahrzehnt konnte nur ein Bruchteil des gesamten Spektrums der Entscheidungen in der Lieferkette erfolgreich automatisiert werden. Heutzutage ist die Situation umgekehrt und mit der richtigen Technologie sind nur noch wenige repetitive Entscheidungen in der Lieferkette übrig, die nicht erfolgreich automatisiert werden können. Mit erfolgreicher Automatisierung meine ich einen Prozess, bei dem die automatisierten Entscheidungen besser sind als diejenigen, die mit einem manuellen Prozess erzielt werden, und nicht die Fähigkeit, Entscheidungen mit einem Computer zu generieren, was trivial ist, solange Ihnen die Qualität der generierten Entscheidungen egal ist.
Unser Fokus liegt heute nicht auf dem numerischen Rezept - das heißt, der Software, die eine solche Automatisierung überhaupt erst möglich macht. Im Kontext der Entscheidungsprozesse in der Lieferkette wurden die Zutaten für ein solches numerisches Rezept in früheren Kapiteln dieser Vortragsreihe behandelt. Unser Fokus liegt heute auf den Teilen der Lieferketteninitiative, die erforderlich sind, um ein solches numerisches Rezept in die Produktion zu bringen. Das Ziel dieses Vortrags ist es, zu umreißen, was erforderlich ist, um ein Unternehmen von manuellen Lieferkettenentscheidungen zu automatisierten zu überführen. Am Ende dieses Vortrags sollten Sie Einblicke in die Do’s und Don’ts bei der Umstellung auf Automatisierung haben. Tatsächlich neigt die bloße technische Schwierigkeit, die mit dem numerischen Rezept selbst verbunden ist, dazu, die organisatorischen Aspekte zu überdecken, die dennoch gleichermaßen entscheidend für den Erfolg der Initiative sind.

Wenn heutigen Lieferkettenpraktikern die Idee der Automatisierung von Entscheidungsprozessen vorgestellt wird, ist ihre unmittelbare Reaktion oft: “Das ist so eine futuristische Idee. Wir sind noch lange nicht so weit.” Dabei war die vollständige Automatisierung banaler und repetitiver Entscheidungen in der Lieferkette bereits das Ziel seit Beginn des digitalen Zeitalters der Lieferketten vor mehr als vier Jahrzehnten.
Sobald Computer für Unternehmen verfügbar wurden, wurde klar, dass die meisten Entscheidungen in der Lieferkette offensichtliche Kandidaten für eine vollständige Automatisierung waren. Auf dem Bildschirm habe ich eine Liste von Veröffentlichungen ausgewählt, die diese Ambitionen verdeutlichen. In den 1970er und 1980er Jahren wurde dieses Gebiet noch nicht einmal Lieferkette genannt. Der Begriff wurde erst in den 1990er Jahren populär. Die Absicht war jedoch bereits klar. Diese Computersysteme schienen sofort geeignet, die repetitivsten Entscheidungen in der Lieferkette wie z.B. die Bestandsauffüllung zu automatisieren.
Das Verblüffendste für mich ist, dass diese Gemeinschaft anscheinend etwas ahnungslos gegenüber ihren früheren Ambitionen ist. Heutzutage wird der Begriff “autonome Lieferkette” manchmal von Beratungsfirmen oder IT-Unternehmen verwendet, um diese Perspektive der Mechanisierung banaler Lieferkettenentscheidungen zu vermitteln. Der Begriff “autonom” erscheint mir jedoch unangemessen. Wir verwenden nicht den Begriff “autonome Logistik”, um ein Förderband mit einem Sortiersystem zu bezeichnen. Das Förderband ist mechanisiert, nicht autonom. Das Förderband erfordert immer noch technische Überwachung, aber diese Innovation repräsentiert nur einen winzigen Bruchteil der Arbeitskräfte, die das Unternehmen sonst benötigen würde, um die Waren ohne das Förderband zu befördern. Was die Entscheidungen in der Lieferkette betrifft, geht es nicht darum, Menschen vollständig aus der Organisation zu entfernen und so eine wirklich autonome Technologie zu erreichen. Das Ziel besteht lediglich darin, Menschen aus dem zeitaufwändigsten und grobsten Teil des Prozesses zu entfernen. Dies ist genau die Perspektive, die vor vier Jahrzehnten in diesen Veröffentlichungen eingenommen wurde und die ich auch in diesem Vortrag einnehme.

Während der 1990er Jahre scheint es, dass Softwareanbieter, sowohl ERP-Anbieter als auch Spezialisten für Bestandsoptimierung, weitgehend von der Idee automatisierter Entscheidungen in der Lieferkette abgekommen sind. Im Rückblick waren die simplen Modelle der 1970er Jahre, die viele wichtige Faktoren wie Unsicherheit weitgehend ignorierten, offensichtlich die Hauptursache dafür, warum die Automatisierung damals nicht erfolgreich war. Die Behebung dieser Hauptursache stellte sich jedoch als über das hinaus heraus, was die Technologie in diesem Zeitraum liefern konnte. Stattdessen griffen Softwareanbieter auf Ausnahmemanagementsysteme zurück. Diese Systeme sollen Bestandsalarme auf der Grundlage von Regeln erzeugen, die vom Kundenunternehmen selbst festgelegt wurden. Die Argumentation lautete: Lassen Sie die Automatisierung sich um die Mehrheit der Positionen kümmern, die automatisch verarbeitet werden können, damit sich die menschliche Intervention auf die schwierigen Positionen konzentrieren kann, die außerhalb der Fähigkeiten der Maschine liegen.
Lassen Sie uns sofort darauf hinweisen, dass der Verkauf eines Ausnahmemanagementsystems für den Softwareanbieter ein sehr gutes Geschäft ist, für das Kundenunternehmen jedoch weniger vorteilhaft. Erstens verlagert das Ausnahmemanagement die Verantwortung für die Leistung der Lieferkette vom Anbieter auf den Kunden. Wenn das Ausnahmemanagement erst einmal implementiert ist und die Ergebnisse schlecht sind, liegt es in der Verantwortung des Kunden. Sie hätten bessere Alarme konfigurieren sollen, um schädliche Situationen von vornherein zu verhindern.
Zweitens ist es für den Softwareanbieter einfach, ein System zur Verwaltung von parametrisierten Bestandsalarmen zu erstellen, solange der Anbieter keinen Parameterwert liefern muss, der die Alarme steuert. Tatsächlich bedeutet die Fähigkeit, einen guten Bestandsalarm zu erzeugen, aus analytischer Sicht, dass Sie eine Regel entwickeln können, die schlechte Bestandsentscheidungen zuverlässig identifizieren kann. Wenn Sie eine Regel entwickeln können, die schlechte Bestandsentscheidungen zuverlässig identifizieren kann, dann kann dieselbe Regel auch verwendet werden, um gute Bestandsentscheidungen zuverlässig zu treffen. Die Regel muss einfach als Filter verwendet werden, um zu verhindern, dass schlechte Entscheidungen getroffen werden.
Drittens ist das Ausnahmemanagement eine ziemlich raffinierte Strategie für den Softwareanbieter, um die menschliche Psychologie auszunutzen. Diese Alarme nutzen einen Mechanismus, der als “Verpflichtung und Konsistenz” von empirischen Psychologen bekannt ist. Dieser Mechanismus erzeugt eine starke, aber weitgehend zufällige Abhängigkeit vom Softwareprodukt. Kurz gesagt, wenn Mitarbeiter anfangen, Bestandszahlen anzupassen, handelt es sich nicht mehr um willkürliche Zahlen. Es sind ihre Zahlen, ihre Arbeit, und die Mitarbeiter entwickeln eine emotionale Bindung an das System, unabhängig davon, ob das System tatsächlich eine überlegene Leistung in der Lieferkette erbringt oder nicht.
Insgesamt ist das Ausnahmemanagement eine technologische Sackgasse, denn im Allgemeinen ist es genauso schwierig, zuverlässige Ausnahmen und zuverlässige Alarme zu entwickeln wie eine zuverlässige Automatisierung für die Entscheidungen. Wenn Sie Ihren Alarmen nicht vertrauen können und Ihre Ausnahmen nicht zuverlässig sind, müssen Sie sowieso alles manuell überprüfen, was Sie wieder zum Ausgangspunkt zurückführt. Der Entscheidungsprozess bleibt streng manuell.

Diese Reihe von Lieferkettenvorlesungen umfasst zwei Dutzend Episoden. An diesem Punkt wurden alle bisher eingeführten Elemente mit dem ausdrücklichen Ziel eingeführt, zu dem Punkt zu gelangen, an dem wir heute stehen: kurz davor, diese Initiative zur quantitativen Lieferkette in die Produktion zu bringen. Genauer gesagt geht es um das numerische Rezept, das wir in die Vorhersage einbringen möchten, und dieser Schwerpunkt steht im Mittelpunkt der heutigen Vorlesung.
In diesen Vorlesungen verwende ich den Begriff “numerisches Rezept”, um die Abfolge von Berechnungen zu bezeichnen, die rohe historische Daten als Eingabe nehmen und die endgültigen Entscheidungen ausgeben. Diese Terminologie ist absichtlich vage, weil sie viele verschiedene Konzepte, Methoden und Techniken widerspiegelt, die in den Vorlesungen der vorherigen Kapitel genau behandelt wurden. Im ersten Kapitel haben wir gesehen, warum die Lieferkette programmatisch werden muss und warum es äußerst wünschenswert ist, ein solches numerisches Rezept in die Produktion zu bringen. Die zunehmende Komplexität der Lieferketten selbst macht die Automatisierung dringender denn je. Es besteht auch die Notwendigkeit, die Praxis der Lieferkette zu einem kapitalistischen Unterfangen zu machen.
Das zweite Kapitel ist den Methoden gewidmet. Tatsächlich sind Lieferketten wettbewerbsfähige Systeme. Diese Kombination macht naive Methoden zunichte. Unter den von uns eingeführten Methoden sind Lieferketten-Personae und experimentelle Optimierung von besonderer Relevanz für das heutige Thema. Lieferketten-Personae sind der Schlüssel zur Annahme der richtigen Entscheidungsform. Wir werden diesen Punkt in wenigen Minuten erneut besprechen. Experimentelle Optimierung ist entscheidend, um etwas zu liefern, das tatsächlich funktioniert. Auch diesen Punkt werden wir in wenigen Minuten erneut besprechen.
Das dritte Kapitel untersucht das Problem und lässt die Lösung durch Lieferketten-Personae beiseite. In diesem Kapitel wird versucht, die Klassen von Entscheidungsproblemen zu charakterisieren, die angegangen werden müssen. Dieses Kapitel zeigt, dass vereinfachte Perspektiven wie die Auswahl der richtigen Menge für jede Lagerhaltungseinheit (SKU) nicht wirklich zu realen Situationen passen. Es gibt fast immer eine Tiefe in der Form der Entscheidungen.
Das vierte Kapitel untersucht die Elemente, die erforderlich sind, um eine moderne Praxis der Lieferkette zu erfassen, in der Software-Elemente allgegenwärtig sind. Diese Elemente sind grundlegend, um den breiteren Kontext zu verstehen, in dem das numerische Rezept und tatsächlich die meisten Lieferkettenprozesse arbeiten. Tatsächlich nehmen viele Lieferketten-Lehrbücher implizit an, dass ihre Techniken und Formeln in einer Art Vakuum funktionieren. Das ist nicht der Fall. Die Anwendungslandschaft ist wichtig.
Die Kapitel 5 und 6 sind der Vorhersagemodellierung bzw. der Entscheidungsfindung gewidmet. Diese Kapitel behandeln die intelligenten Bestandteile des numerischen Rezepts mit Techniken des maschinellen Lernens und mathematischen Optimierungstechniken. Schließlich ist das siebte und vorliegende Kapitel der Durchführung einer quantitativen Lieferketteninitiative gewidmet, deren Zweck es ist, ein numerisches Rezept in die Produktion zu bringen und es anschließend zu pflegen. In der vorherigen Vorlesung haben wir besprochen, was erforderlich ist, um die Initiative zu starten und dabei die richtigen Grundlagen auf technischer Ebene zu legen. Das bedeutet die Einrichtung einer ordnungsgemäßen Datenextraktionspipeline. Heute möchten wir die Ziellinie überqueren und dieses numerische Rezept in Aktion setzen.

Wir werden mit einer kurzen Zusammenfassung der vorherigen Vorlesung beginnen und dann mit drei wichtigen Aspekten der späteren Phasen der Initiative fortfahren. Der erste Aspekt betrifft das Design des numerischen Rezepts. Dabei werde ich jedoch nicht über das Design der numerischen Bestandteile des Rezepts sprechen, sondern über das Design des Engineering-Prozesses selbst, das das numerische Rezept umgibt. Wir werden sehen, wie man die Herausforderung angehen kann, um der Initiative eine Chance zu geben, eine zufriedenstellende Lösung hervorzubringen.
Der zweite Aspekt betrifft die ordnungsgemäße Einführung des numerischen Rezepts. Das Unternehmen beginnt tatsächlich mit einem manuellen Prozess und soll am Ende einen automatisierten Prozess haben. Eine angemessene Einführung kann das mit dieser Umstellung verbundene Risiko weitgehend mindern oder zumindest das Risiko mindern, das mit einem numerischen Rezept verbunden wäre, das sich als fehlerhaft erweisen würde, zumindest anfangs.
Der dritte Aspekt betrifft die Veränderungen, die im Unternehmen stattfinden müssen, sobald die Automatisierung implementiert ist. Wir werden sehen, dass die Rollen und Aufgaben der Personen in der Lieferkettenabteilung einer erheblichen Veränderung unterliegen sollten.
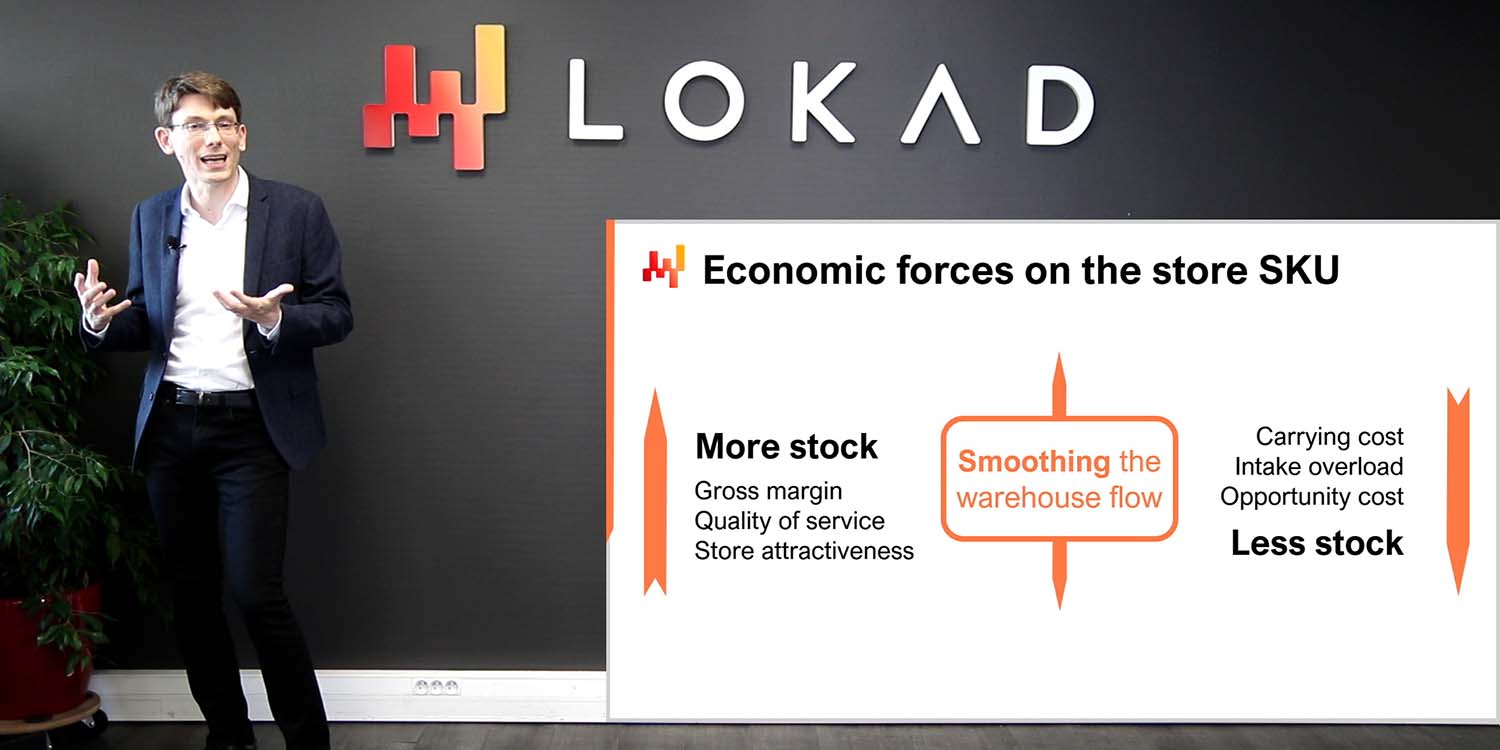
In der vorherigen Vorlesung haben wir gesehen, wie man eine quantitative Lieferketteninitiative startet. Lassen Sie uns die wichtigsten Aspekte noch einmal überprüfen. Das Ergebnis ist ein operatives numerisches Rezept, das ein Stück Software ist, das eine Klasse von Lieferkettenentscheidungen steuert, zum Beispiel die Bestandsauffüllung. Dieses numerische Rezept wird, sobald es in Produktion geht, die von uns angestrebte Automatisierung liefern. Entscheidungen sollten nicht mit numerischen Artefakten wie Nachfrageprognosen verwechselt werden, die lediglich Zwischenergebnisse sind, die zur Berechnung der Entscheidungen selbst beitragen können.
Der Umfang der Initiative muss sowohl mit der Lieferkette als System als auch mit ihrer zugrunde liegenden Anwendungslandschaft abgestimmt sein. Es ist wichtig, auf die Systemeigenschaften der Lieferkette zu achten, um Probleme nicht zu verlagern, sondern zu lösen. Wenn zum Beispiel die Bestandsoptimierung eines Ladens in einer Einzelhandelskette zu Lasten der anderen Läden durchgeführt wird, ist diese Optimierung sinnlos. Auch die Beachtung der Anwendungslandschaft ist wichtig, da wir den anfänglichen Aufwand für die Datenintegration minimieren müssen. IT-Ressourcen sind fast immer ein Engpass, und wir müssen darauf achten, diese Begrenzung nicht zu verschärfen.
Schließlich haben wir vier Rollen für diese Initiative identifiziert, nämlich den Supply Chain Executive, den Data Officer, den Supply Chain Scientist und den Supply Chain Practitioner. Der Supply Chain Executive ist für die Strategie, die Durchführung der Veränderung und die Entscheidung über die Modellierung verantwortlich. Der Data Officer ist für die Einrichtung der Datenpipeline verantwortlich, die die relevanten Transaktionsdaten für die analytische Ebene verfügbar macht. In dieser Vorlesung gehen wir davon aus, dass die Datenpipeline bereits eingerichtet wurde. Der Supply Chain Scientist ist für die Umsetzung des numerischen Rezepts zuständig, was eine Vielzahl von Instrumentierungen umfasst, nicht nur die intelligenten algorithmischen Teile. Schließlich ist der Supply Chain Practitioner eine Person, die am manuellen Entscheidungsprozess beteiligt ist. Diese Person hat in der Regel eine Rolle als Supply and Demand Planner, obwohl die Terminologie variieren kann. Zu Beginn der Initiative wird erwartet, dass sie bis zum Ende der Initiative in die Rolle des Netzwerkmanagers wechseln. Wir werden später in der Vorlesung auf diesen Punkt zurückkommen.

Lieferketten sind sehr geeignet für die Automatisierung von Entscheidungsprozessen. Es gibt zahlreiche banale, stark repetitive Entscheidungen, die quantitativer Natur sind. Leider ist die Modellierungsperspektive, die in den meisten Lehrbüchern zur Lieferkette angeboten wird, in der Regel übermäßig vereinfacht. Ich sage nicht, dass die Techniken in den Lehrbüchern übermäßig einfach oder simplistisch sind. Ich sage jedoch lediglich, dass die in diesen Lehrbüchern präsentierten Probleme tendenziell simplistisch sind. Betrachten wir zum Beispiel eine Situation der Bestandsauffüllung. Die Perspektive des Lehrbuchs sucht die optimale Bestellpolitik, um zu berechnen, wie viele Einheiten nachbestellt werden sollten. Das ist in Ordnung, aber das ist oft eine recht unvollständige Antwort.
Zum Beispiel müssen wir entscheiden, ob die Waren per Luftfracht oder per Seefracht versendet werden sollen, wobei die beiden Transportarten einen Kompromiss zwischen Durchlaufzeit und Transportkosten darstellen. Wir müssen einen Lieferanten aus mehreren geeigneten Lieferanten auswählen. Wir müssen den genauen Versandplan festlegen, wenn die Menge groß genug ist, um mehrere Sendungen zu rechtfertigen.
Das dritte Kapitel dieser Serie, ein Kapitel, das den Lieferkettenpersonen gewidmet ist, präsentierte detaillierte Ansichten von realen Lieferketten-Situationen, in denen wir sehen, dass es fast immer Feinheiten jenseits der Auswahl einer einzigen Menge für eine bestimmte SKU gibt. Daher muss der Supply Chain Scientist mit Hilfe des Supply Chain Practitioners und des Supply Chain Executives beginnen, die vollständige Form der Entscheidung aufzudecken. Die vollständige Form der Entscheidung muss alle Elemente enthalten, die zur Gestaltung des tatsächlichen Lieferkettenbetriebs beitragen. Die vollständige Form der Entscheidung aufzudecken, ist schwierig.
Zunächst fragmentiert die Arbeitsteilung, wie sie in den meisten Unternehmen mit einer großen Lieferkette umgesetzt wird, die verschiedenen Aspekte der Entscheidung auf mehrere Mitarbeiter und manchmal auf mehrere Abteilungen. Zum Beispiel wählt eine Person die Menge aus, die nachbestellt werden soll, während eine andere Person entscheidet, welcher Lieferant den Kaufauftrag erhält.
Zweitens werden die subtileren Aspekte der Entscheidung, wie z.B. die Aufforderung an den Lieferanten, die Bestellung zu beschleunigen, wenn es einen Nachfrageanstieg gegeben hat, oft übersehen, weil die Praktiker nicht erkennen, dass diese Aspekte ebenfalls automatisiert werden können und sollten. Ich schlage vor, die Beschreibung dieser vollständigen Entscheidungsform nicht als Reihe von Folien, sondern als tatsächlichen Text zu verfassen. Insbesondere muss der Text das “Warum” klären. Was steht genau auf dem Spiel bei jedem Aspekt der Entscheidung? Während einige Aspekte der Entscheidung relativ offensichtlich sein können, wie z.B. die Menge bei einer Nachbestellung, können andere Aspekte übersehen oder vergessen werden. Zum Beispiel könnte ein Lieferant für einen Preis die Möglichkeit anbieten, die Ware innerhalb von sechs Monaten zurückzugeben, wenn die Verpackungen unberührt bleiben. Die Ausübung oder Nichtausübung dieser Option sollte Teil der Entscheidung sein, kann aber leicht vergessen werden.

Das Scheitern bei der Identifizierung der vollständigen Form der Lieferkettenentscheidung oder noch schlimmer, die Entscheidung falsch zu charakterisieren, ist einer der sichersten Wege, um das Vorhaben scheitern zu lassen. Insbesondere ist die reaktionäre Antwort, die von der Vergangenheit geprägt ist, einer der häufigsten Fehler, der in großen Unternehmen passiert. Die Essenz der reaktionären Antwort besteht darin, eine Entscheidungsform zu übernehmen, die für das Unternehmen und seine Lieferkette tatsächlich keinen Sinn ergibt, aber dennoch übernommen wird, weil die Form zu einer vorhandenen Transaktionssoftware passt oder zu einem vorhandenen Prozess innerhalb der Organisation passt.
Zum Beispiel kann beschlossen werden, dass die Bestandsauffüllung durch die Berechnung von Sicherheitsbeständen gesteuert werden sollte, anstatt die tatsächlichen Mengen direkt zu berechnen. Die Berechnung von Sicherheitsbeständen mag einfacher erscheinen, weil diese Sicherheitsbestände bereits im ERP vorhanden sind. Wenn also die Sicherheitsbestände neu berechnet werden müssten, könnten diese Werte problemlos in das ERP eingespeist werden und die tatsächlich in DRP verwendete Formel außer Kraft setzen.
Sicherheitsbestände haben jedoch erhebliche Mängel. Selbst etwas so Grundlegendes wie eine minimale Bestellmenge (MOQ) passt nicht in eine Sicherheitsbestandsperspektive. Diese Implementierung wird zumindest deshalb bevorzugt, weil es bereits bestehende Prozesse innerhalb der Organisation gibt, nicht wegen einer Software.
Zum Beispiel kann ein Einzelhandelsnetzwerk zwei Planungsteams haben: ein Team, das sich der Auffüllung der Geschäfte widmet, und ein Team, das sich den Personalbeständen der Verteilungszentren widmet. Diese beiden Probleme sind jedoch grundsätzlich dasselbe. Sobald die Nachbestellmengen für die Geschäfte festgelegt wurden, gibt es keine Möglichkeit mehr zu entscheiden, wie viel Personal für die Verteilungszentren benötigt wird. Daher haben die beiden Teams grundsätzlich überlappende Aufgaben. Diese Arbeitsteilung funktioniert, solange Menschen beteiligt sind. Menschen sind gut darin, mit mehrdeutigen Anforderungen umzugehen. Diese Mehrdeutigkeit stellt jedoch eine massive Hürde für jeden Versuch dar, sowohl die Nachbestellung als auch die Personalanforderungen zu automatisieren.
Dieses Anti-Pattern, die reaktionäre Antwort, ist sehr verlockend, weil es die Menge an Veränderungen minimiert, die umgesetzt werden müssen. Die Automatisierung der Entscheidung verändert jedoch die Art und Weise, wie die Entscheidung überhaupt angegangen werden sollte. Häufig wird das quantitative Supply Chain-Vorhaben scheitern, wenn das Erbe-Design beibehalten wird.
Erstens erschwert es die Gestaltung des numerischen Rezepts, das bereits eine ziemlich komplexe Aufgabe ist, weiter. Die Muster, die für eine Arbeitsteilung unter menschlichen Mitarbeitern geeignet waren, sind nicht diejenigen, die für eine Software geeignet sind, die nur mechanisch ist.
Zweitens negiert die reaktionäre Antwort auch viele der potenziellen Vorteile, die mit der Automatisierung verbunden sind. In der Lieferkette sind tatsächlich viele Ineffizienzen an den Grenzen zu finden, die innerhalb des Unternehmens bestehen. Die Automatisierung beseitigt die Notwendigkeit für die meisten dieser Grenzen, die nur aufgrund einer bestimmten Art der Organisation der Arbeitsteilung eingeführt wurden, die keinen Sinn ergibt, wenn man einen Computer hat, der sich um alles kümmert. Lassen Sie Entscheidungen, die vor zwei oder drei Jahrzehnten getroffen wurden, nicht die Zukunft Ihrer Lieferkette bestimmen.
Sobald die Form der Entscheidung richtig charakterisiert wurde, beginnt der Supply Chain Scientist damit, das numerische Rezept selbst zu erstellen und dabei auf historische Transaktionsdaten zurückzugreifen. In dieser Vortragsreihe gibt es zwei Kapitel, die sich mit den Feinheiten der algorithmischen Techniken befassen, die zum Lernen und Optimieren verwendet werden können. Diese Elemente werde ich heute nicht erneut behandeln. Lassen Sie uns einfach sagen, dass der Supply Chain Scientist eine Reihe von Entscheidungen trifft, um ein anfängliches numerisches Rezept auf der Grundlage seines Wissens, seiner Erfahrung und der verfügbaren Tools für Supply Chain Scientists zu erstellen.
Mit den richtigen Werkzeugen und Techniken kann dieser erste Entwurf in wenigen Tagen, höchstens ein paar Wochen, umgesetzt werden. Tatsächlich handelt es sich nicht um fortgeschrittene Forschung, die versucht, eine neuartige Technik aufzudecken, sondern lediglich um die Anpassung bekannter Techniken, die die Besonderheiten der jeweiligen Lieferkette berücksichtigen. Das numerische Rezept muss die Feinheiten der Entscheidung sehr streng berücksichtigen, wie sie in ihrer vollständigen Form identifiziert wurden.
Selbst wenn ein sehr kompetenter Supply Chain Scientist die besten verfügbaren Tools nutzt, ist es sinnlos zu erwarten, dass das numerische Rezept beim ersten Versuch korrekt ist. Lieferketten sind zu komplex und undurchsichtig, insbesondere ihre digitalen Darstellungen, um ein numerisches Rezept beim ersten Mal richtig zu machen. Numerische Methoden, die nach innen gerichtet sind und Metriken und Benchmarks verwenden, können ein Missverständnis des Supply Chain Scientists über ein Datenstück nicht erkennen.
Für jede Spalte in jeder Tabelle, die aus dem Transaktionssystem des Unternehmens stammt, gibt es in der Regel mehrere mögliche Interpretationen dieser Daten. Angesichts der Tatsache, dass wir von Dutzenden von Spalten sprechen, die in das numerische Rezept integriert werden müssen, sind Fehler garantiert. Die einzige Möglichkeit, die Korrektheit des numerischen Rezepts zu bewerten, besteht darin, es zu testen und ein Feedback aus der realen Welt zu erhalten. Dies wurde im zweiten Kapitel dieser Reihe in der Vorlesung mit dem Titel “Experimentelle Optimierung” diskutiert.
Daher muss der Supply Chain Scientist mit dem Supply Chain Practitioner zusammenarbeiten, um Situationen zu identifizieren, in denen das numerische Rezept in seiner aktuellen Form immer noch unsinnige Ergebnisse liefert. Im Allgemeinen implementiert der Supply Chain Scientist ein Dashboard, das die Entscheidung konsolidiert, wie sie heute vom numerischen Rezept getroffen würde, und der Supply Chain Practitioner versucht, Linien zu identifizieren, die unsinnig erscheinen.
Basierend auf diesem Feedback instrumentieren die Wissenschaftler das numerische Rezept weiter. Die Instrumentierung erfolgt in Form von Indikatoren, die versuchen, die Frage zu beantworten: Warum wurde diese scheinbar unsinnige Entscheidung in diesem Kontext getroffen? Basierend auf dieser Instrumentierung ist es möglich zu entscheiden, ob das numerische Rezept repariert werden muss, zum Beispiel, weil ein wirtschaftlicher Treiber falsch modelliert ist, oder ob die scheinbar unsinnige Entscheidung tatsächlich korrekt ist, nur anders als bisher im Unternehmen gehandhabt.
Die experimentelle Optimierung ist ein hoch iterativer Prozess. Als Faustregel sollte ein einziger Vollzeit-Supply-Chain-Scientist mit den richtigen Werkzeugen in der Lage sein, jeden Tag eine neue Iteration des numerischen Rezepts dem Supply Chain Practitioner vorzustellen. Wenn das numerische Rezept ordnungsgemäß instrumentiert ist, sollte der Practitioner nicht mehr als zwei Stunden pro Tag benötigen, um Feedback zur neuesten Iteration des numerischen Rezepts zu geben.
Die Iteration endet, wenn das numerische Rezept keine unsinnigen Ergebnisse mehr generiert, das heißt, wenn der Practitioner keine Entscheidungen identifizieren kann, die nachweislich schädlich für das Unternehmen sind. Das Fehlen von unsinnigen Entscheidungen mag im Vergleich zu unserem Gesamtziel, über den manuellen Prozess hinaus überlegene Entscheidungen zu generieren, niedrig erscheinen. Es sei jedoch daran erinnert, dass das numerische Rezept von Anfang an darauf ausgelegt wurde, eine mathematische Optimierung des langfristigen wirtschaftlichen Interesses des Unternehmens durchzuführen. Wenn die Ergebnisse sinnvoll sind, funktioniert die Optimierung und noch wichtiger, es beweist auch, dass das Optimierungskriterium selbst zumindest teilweise korrekt ist.

Während der stark iterative Entwicklungsprozess des numerischen Rezepts zahlreiche Probleme beheben kann, die in der ursprünglichen Implementierung vorhanden sind, reichen Iterationen allein nicht aus, wenn die Perspektive, die in die Optimierung einfließt, falsch ist. In dieser Vortragsreihe habe ich bereits gesagt, dass die Optimierung gemäß einer finanziellen Kennzahl durchgeführt werden muss, das heißt einer Kennzahl, die in Euro oder Dollar ausgedrückt wird. Lassen Sie mich jedoch diese Aussage klären: Die Verwendung einer nicht-finanziellen Kennzahl ist ein Fehler, der die gesamte Initiative gefährdet.
Leider scheuen große Organisationen in der Regel finanzielle Kennzahlen. Stattdessen bevorzugen sie ambitionierte Kennzahlen, die als Prozentsatz angegeben werden und eine Art Perfektion repräsentieren, die erreicht werden würde, wenn entweder null Prozent oder 100 Prozent, je nach Fall, erreicht würden. Natürlich gibt es keine Perfektion in dieser Welt, und diese Grenzsituation wird niemals erreicht werden. Service-Level sind zum Beispiel das Archetyp der ambitionierten Kennzahl. Das 100%ige Service-Level ist unmöglich zu erreichen, da es eine unvernünftige Menge an Lagerbestand erfordern würde.
Einige Manager in großen Unternehmen lieben diese ambitionierten Kennzahlen. Teams treffen sich regelmäßig, um zu besprechen, was getan werden kann, um diese Kennzahlen weiter zu verbessern. Da diese Kennzahlen zwangsläufig von Faktoren abhängen, die außerhalb der Kontrolle des Unternehmens liegen, können sie endlos überarbeitet werden. Zum Beispiel hängen Service-Level von der Nachfrage ab, die von Kunden geäußert wird, und von den Lieferzeiten, die von Lieferanten angeboten werden. Weder die Nachfrage noch die Lieferzeiten stehen vollständig unter der Kontrolle des Unternehmens.
Diese ambitionierten Kennzahlen funktionieren in gewisser Weise als Unternehmensziele, solange Menschen in der Entscheidungsfindung involviert bleiben, da Menschen diesen Kennzahlen an erster Stelle nicht allzu viel Aufmerksamkeit schenken. Zum Beispiel, selbst wenn alle zustimmen, dass das Service-Level erhöht werden sollte, werden Planer immer noch viele nicht dokumentierte Ausnahmen beibehalten. Das Service-Level wird systematisch erhöht, es sei denn, das Lagerbestandsrisiko ist zu hoch, die Mindestbestellmenge ist zu hoch, das Produkt wird auslaufen oder es ist kein Budget mehr für das Produkt vorhanden, usw.
Leider werden diese ambitionierten Kennzahlen zu Gift, wenn ein automatisierter Prozess eingeführt wird. Tatsächlich sind diese Kennzahlen unvollständig und spiegeln nicht das wider, was tatsächlich für das Unternehmen wünschenswert ist. Zum Beispiel ist es nicht wünschenswert, ein 100%iges Service-Level zu erreichen, da dies massive Überbestände für das Unternehmen schaffen würde. Es ist möglich - nicht unklug, aber möglich - all diese Einschränkungen, all diese Ausnahmen zusätzlich zu den ambitionierten Kennzahlen wieder zu implementieren. Ich meine, dass das numerische Rezept auf die ambitionierten Kennzahlen zielen sollte, wobei viele Einschränkungen nachgeahmt werden, die das Denken eines Planers widerspiegeln könnten. Zum Beispiel könnten wir die Regel definieren, dass das Service-Level erhöht werden sollte, solange wir den Lagerbestand unter vier Monaten halten. Diese Strategie für das Design und die tatsächliche Implementierung des numerischen Rezepts ist jedoch äußerst brüchig. Eine direkte finanzielle Optimierung ist ein weitaus sichererer und überlegenerer Weg.

Um eine effiziente Zusammenarbeit zwischen dem Supply Chain Practitioner - oder wahrscheinlicher, den Praktikern - und dem Supply Chain Scientist zu erreichen, empfehle ich frühzeitig eine Dual-Run-Strategie zu übernehmen. Das numerische Rezept sollte täglich parallel zum bestehenden manuellen Prozess ausgeführt werden. Mit dem Dual-Run generiert das Unternehmen effektiv die Entscheidung zweimal durch zwei konkurrierende Prozesse. Trotz der Reibung bietet ein Dual-Run erhebliche Vorteile. Erstens benötigt der Supply Chain Practitioner frisch generierte Entscheidungen, die der aktuellen Situation entsprechen, um seine Bewertung vorzunehmen. Andernfalls kann der Practitioner die automatisierte Entscheidung nicht einmal verstehen, kann nicht einmal die Teile identifizieren, die unsinnig sind. Aus Sicht des Practitioners sind Entscheidungen, die die Situation der Supply Chain vor drei Wochen widerspiegeln, längst vergangen. Es gibt wenig zu gewinnen, wenn Stunden damit verbracht werden, vergangene Lagerbestände zu überprüfen.
Im Gegenteil, wenn die automatisierten Entscheidungen frisch sind und die aktuelle Situation widerspiegeln, konkurrieren diese automatisierten Entscheidungen mit den Entscheidungen, die der Practitioner manuell treffen wird. Diese automatisierten Entscheidungen können vorerst als Vorschläge betrachtet werden.
Zweitens stellt der tägliche Ablauf des numerischen Rezepts sicher, dass die gesamte Datenpipeline jeden Tag einem vollständigen Funktionstest unterzogen wird. Das numerische Rezept muss nicht nur vernünftige Ergebnisse liefern, sondern auch aus Sicht der IT-Infrastruktur einwandfrei funktionieren. Tatsächlich sind Lieferketten bereits chaotisch genug; das numerische Rezept darf nicht noch eine zusätzliche Schicht Chaos hinzufügen. Indem das Rezept so früh wie möglich unter Produktionsbedingungen eingesetzt wird, wird sichergestellt, dass seltene Probleme frühzeitig auftreten und dass der Datenbeauftragte und die Supply Chain-Wissenschaftler die Möglichkeit haben, diese Probleme frühzeitig zu beheben. Als Faustregel sollte der Dual Run bis zum Ende des ersten Drittels - also bis zum Ende des dritten Monats nach Beginn einer quantitativen Supply-Initiative - eingerichtet sein, auch wenn das numerische Rezept noch nicht bereit ist, in die Produktion übernommen zu werden.
Außerdem sollte der Praktiker bis zum Ende des ersten Monats des Dual Runs, wenn der Wissenschaftler seine Arbeit ordnungsgemäß erledigt, Muster in der Liste der automatisierten Entscheidungen erkennen, die sonst übersehen worden wären, auch wenn es immer noch einige unsinnige Zeilen gibt, die eine weitere Verbesserung des numerischen Rezepts erfordern.

Sobald der Dual Run eingerichtet ist, wird erwartet, dass der Supply Chain-Praktiker einige Zeit - ein oder zwei Stunden pro Tag - damit verbringt, die Entscheidungen zu überprüfen, die vom numerischen Rezept generiert werden, und dass er versucht, die Teile zu identifizieren, die noch nicht ganz vernünftig sind. Manchmal ist die Situation jedoch einfach unklar. Eine Entscheidung ist überraschend - vielleicht ist das numerische Rezept langsam, vielleicht auch nicht. Der Praktiker fühlt sich unsicher und in diesem Fall sollte er den Wissenschaftler bitten, weitere Instrumente hinzuzufügen, um den Fall zu klären. Dieser Prozess wird in dieser Vortragsreihe als “White-Boxing” des numerischen Rezepts bezeichnet. “White-Boxing” ist ein Prozess, bei dem das numerische Rezept für die Aktionäre so transparent wie möglich gemacht wird. “White-Boxing” ist eine gute Sache - sogar unerlässlich -, um Vertrauen in das numerische Rezept aufzubauen.
Vorausgesetzt, die automatisierten Entscheidungen werden in einer Tabelle im Dashboard gesammelt, wird die häufigste Form der Instrumentierung zusätzliche Spalten neben den Entscheidungsspalten sein. Wenn wir zum Beispiel Nachbestellmengen betrachten, gibt es offensichtliche Instrumentierungsspalten, die in Betracht gezogen werden können, wie die Lagerbestandsmenge, die erwartete durchschnittliche Vorlaufzeit, die erwartete durchschnittliche Nachfrage über die tägliche Zeit usw. Diese Instrumentierung ist für den Praktiker entscheidend, um schnelle Bewertungen über die Vernunft der automatisierten Entscheidungen zu treffen. Wir müssen jedoch darauf achten, wie viel Instrumentierung auf das numerische Rezept aufgetürmt wird. Jeder einzelne Indikator, der im Rahmen des “White-Boxing”-Prozesses eingeführt wird, um die automatisierte Entscheidung zu schmücken, belastet die Sicht auf die Entscheidungen selbst ein wenig mehr. Zu viel des Guten kann zum Schlechten werden. Wenn der Praktiker nach zwei Monaten Laufzeit routinemäßig weitere Instrumentierung anfordert, obwohl die Datenpipeline bereits stabilisiert wurde, dann haben wir möglicherweise ein Problem.
Die Ursache des Problems kann mit intelligenten Teilen des numerischen Rezepts in Verbindung gebracht werden. In den Kapiteln 5 und 6 dieser Reihe haben wir gesehen, dass nicht alle Techniken und Modelle in Bezug auf Interpretierbarkeit gleich sind. Viele Modelle sind von Natur aus sehr undurchsichtig, selbst für Datenwissenschaftler, die sie einsetzen. Ich werde heute nicht erneut auf die Klassen von Modellen eingehen, die hinsichtlich der Interpretierbarkeit geeignet sind. Für diese Diskussion gehe ich einfach davon aus, dass die Modelle, die in das numerische Rezept eingebettet wurden, aus Sicht der Lieferkette angemessen interpretierbar sind. In diesem Zusammenhang, wenn die Initiative aufgrund einer endlosen Anzahl von Anfragen nach weiterer Instrumentierung ins Stocken zu geraten scheint, ist die wahrscheinlichste Ursache eine Analyseparalyse. Der Supply Chain-Praktiker denkt zu viel über seine Bewertung des numerischen Rezepts nach. Das ist das Wesen der Analyseparalyse. Der Praktiker legt das numerische Rezept einem Prüfungsgrad vor, der über das hinausgeht, was für den manuellen Prozess getan wird. Es ist die Aufgabe des Supply Chain-Executives sicherzustellen, dass die Initiative nicht in einer Analyseparalyse stecken bleibt. Und wenn es dennoch passiert, und das kann passieren, ist es auch die Aufgabe des Supply Chain-Executives, das Team sanft daran zu erinnern, dass auch menschliche Entscheidungen unvollkommen sind. Wir streben eine Verbesserung gegenüber dem manuellen Prozess an, nicht die Perfektion.

Sobald das numerische Rezept keine verrückten Entscheidungen mehr generiert und die Entscheidungen selbst mit einem angemessenen Maß an Instrumentierung einhergehen, ist es an der Zeit, den automatisierten Prozess schrittweise einzuführen und den manuellen Prozess zu ersetzen. Als Faustregel sollte dieser Punkt innerhalb von zwei bis vier Monaten nach dem Start des Dual Runs erreicht werden. Ab dem ersten Tag des Dual Runs sollte das numerische Rezept über den gesamten Umfang der Initiative hinweg aktiv sein. Somit könnte theoretisch der Übergang von manuellen zu automatisierten Entscheidungen über Nacht erfolgen.
In der Praxis widerspricht dies jedoch häufig der Theorie. Wenn wir von einem größeren Unternehmen sprechen, ist es wichtig, alle Entscheidungen über Nacht von einem Prozess auf einen anderen umzustellen. Supply Chains sind sehr komplex und wir sollten das Unerwartete erwarten. Daher ist es klüger, mit einem kleinen Anwendungsbereich wie einer einzelnen Produktkategorie zu beginnen und von dort aus zu erweitern. Für die frühen Phasen der Übernahme ist es angemessen, eine Woche oder vielleicht zwei Wochen für jede Iteration einzuplanen. Sowohl der Supply Chain-Praktiker als auch der Supply Chain-Scientist müssen sorgfältig prüfen, wie die automatisierten Entscheidungen umgesetzt werden. Und wenn über diesen kleinen Anwendungsbereich nichts Unerwartetes passiert, selbst wenn das numerische Rezept zu diesem Zeitpunkt keine scheinbar verrückten Entscheidungen mehr generiert, könnte es immer noch Probleme bei der Integration der automatisierten Entscheidungen in die Transaktionssysteme geben. Sobald das numerische Rezept einige Wochen lang die Produktion gesteuert hat, selbst wenn der Anwendungsbereich relativ klein war, ist es angemessen, die Iterationen zu beschleunigen.
Die Übernahme kann bei jeder Iteration deutlich umfangreicher werden und die Dauer der Iterationen selbst kann ebenfalls verkürzt werden, möglicherweise auf bis zu zwei Iterationen pro Woche. Tatsächlich sollte der gesamte Zeitrahmen des Übergangs zum automatisierten Prozess vernünftig kurz gehalten werden. Andernfalls führt die Verzögerung der Übernahme zu anderen Risikoklassen. Die Supply Chain verändert sich ebenso wie ihre Anwendungslandschaft. Als Faustregel sollte die Übernahme je nach Größe und Komplexität des Unternehmens nicht länger als zwei bis vier Monate dauern.

Wenn sich die Supply Chain von einem manuellen Prozess zu einem automatisierten Prozess entwickelt, müssen auch innerhalb der Organisation eine Reihe von Veränderungen stattfinden. Große Organisationen sind berüchtigt schwer zu verändern, aber es gibt zwei verschiedene Richtungen für Veränderungen. Die Organisation kann einen Prozess hinzufügen oder einen Prozess entfernen.
Einen Prozess zu entfernen ist viel schwieriger als einen hinzuzufügen. Das Hinzufügen eines Prozesses bedeutet, Mitarbeiter einzustellen, und der einzige Widerstand dagegen wird von der obersten Führungsebene des Unternehmens kommen, da es eine zusätzliche Budgetposition ist. Das Entfernen eines Prozesses bedeutet, Mitarbeiter zu entlassen oder zumindest ihre Aufgaben zu entlassen und die Mitarbeiter weiterzubeschäftigen und umzuschulen. Bei der Entfernung eines Prozesses ist die Situation umgekehrt. Man kann Widerstand von der gesamten Organisation erwarten, außer von ihrer obersten Führungsebene.
Der einfachste Weg, ein numerisches Rezept in die Produktion zu bringen, besteht darin, einen Dual Run unbegrenzt aufrechtzuerhalten. Der bestehende manuelle Prozess wird beibehalten und nutzt nun die automatisierten Entscheidungen als einfache Vorschläge. Dieser Ansatz fühlt sich sicher an und kann sogar marginale Gewinne bringen, da die automatischen Vorschläge den Praktikern helfen, einige der schlimmsten Fehler im Zusammenhang mit dem manuellen Prozess zu identifizieren. Das dauerhafte Beibehalten des Dual Runs führt jedoch zu Prozesssedimentation, bei der die Organisation etwas nicht entfernt.
Damit Supply Chain-Praktiken zu einer kapitalistischen Unternehmung - einem produktiven Vermögenswert - werden können, muss die Organisation den manuellen Prozess aufgeben. Der manuelle Prozess ist eine Sackgasse; er wird sich im Laufe der Zeit nicht weiter verbessern. Die Organisation muss die gesamte Zeit und Energie, die für den manuellen Prozess aufgewendet wird, in die kontinuierliche Verbesserung des automatisierten Prozesses umleiten. Das Beibehalten des manuellen Prozesses behindert nur die Möglichkeit, das Beste aus der Automatisierung und ihren Vorteilen zu machen. Insbesondere solange manuelle Eingriffe weiterhin stattfinden, ist nichts wirklich reproduzierbar aufgrund manueller Interventionen und somit kann nichts wirklich optimiert werden, da Optimierung Reproduzierbarkeit erfordert.

Die Automatisierung von Entscheidungen, auch bei banalen und wiederholenden Entscheidungen, stellt einen Paradigmenwechsel in der Art und Weise dar, wie Supply Chains verwaltet werden. Die Veränderung ist so signifikant, dass es verlockend ist, sie vollständig abzulehnen. Doch der Wandel kommt. Zwei Jahrhunderte progressive Mechanisierung unserer Wirtschaft haben es deutlich gemacht: Sobald etwas automatisiert werden kann, wird es automatisiert. Nach einer Weile gibt es kein Zurück zum früheren Zustand. Lokad betreibt etwa 100 Supply Chains in hochautomatisierten Setups und liefert den lebenden Beweis, dass die Automatisierung der Supply Chain bereits vorhanden ist; sie ist nur noch nicht weit verbreitet.
Eine der größten Veränderungen, die von unseren Kunden umgesetzt werden sollen, betrifft die Rolle des Supply- und Demand-Planners. Die gängige Form dieser Rollen, die in der Branche unter verschiedenen Namen wie Bestandsmanager, Kategoriemanager oder Lieferantenmanager bekannt ist, umfasst einen Mitarbeiter, der eine Kurzliste von SKUs besitzt, die je nach Flussvolumen von 50 bis 5.000 SKUs variieren kann. Der Planner ist dafür verantwortlich, dass die SKUs auf der Kurzliste kontinuierlich verfügbar sind, entweder durch Auslösen der Bestandsauffüllung oder der Produktionschargen oder beides. Die Arbeitsteilung ist einfach: Mit zunehmender Anzahl von SKUs steigt auch die Anzahl der Planner.
Der Fokus des Planners liegt nach innen. Diese Person verbringt viel Zeit damit, Zahlen zu überprüfen, entweder konsolidiert in einer Tabellenkalkulation oder auf Dashboards angezeigt. Planner nutzen möglicherweise Unternehmenssoftwaretools, aber sie treffen ihre Entscheidungen fast immer in Tabellenkalkulationen, die sie persönlich pflegen. Der Zweck der Tabellenkalkulation besteht darin, einen zugänglichen und vollständig anpassbaren numerischen Kontext bereitzustellen, um die Entscheidungen des Planners zu unterstützen. Die Routine des Planners besteht darin, die gesamte Kurzliste von SKUs jede Woche, möglicherweise jeden Tag, zu überprüfen.
Sobald jedoch das numerische Rezept in Produktion ist, macht es keinen Sinn mehr, diesen Zeitplan der manuellen Überprüfung der Kurzliste von SKUs durch den Planner beizubehalten. Der Planner sollte in die Rolle eines Netzwerkmanagers wechseln. Als Netzwerkmanager, der weitgehend von datenbezogenen Routinen befreit ist, kann er seine Zeit in die Kommunikation mit dem Netzwerk investieren, sowohl stromaufwärts mit Lieferanten als auch stromabwärts mit Kunden, und die Annahmen überprüfen, die das Design des numerischen Rezepts unterstützen. Die größte Gefahr für das numerische Rezept besteht nicht darin, seine Genauigkeit zu verlieren, sondern seine Relevanz. Der Netzwerkmanager versucht zu identifizieren, was durch die Datenbrille nicht gesehen werden kann, zumindest noch nicht. Es geht nicht darum, das numerische Rezept zu mikromanagen oder numerische Anpassungen an den Entscheidungen selbst vorzunehmen, sondern darum, Faktoren zu identifizieren, die vom numerischen Rezept ignoriert oder missverstanden werden.
Der Netzwerkmanager konsolidiert Erkenntnisse, die sowohl für die Supply Chain Scientists als auch für die Supply Chain Executives bestimmt sind. Basierend auf diesen Erkenntnissen können die Scientists das numerische Rezept anpassen oder umstrukturieren, um ein erneuertes Verständnis der Situation widerzuspiegeln.

Leider ist die Ablehnung des Rollouts des numerischen Rezepts nicht der einzige Weg für den Planner, den Status quo aufrechtzuerhalten. Eine andere Strategie besteht darin, dieselbe Arbeitsroutine beizubehalten: weiterhin die Kurzliste von SKUs überprüfen, aber anstatt die Entscheidungen zu überschreiben, einfach alle Ergebnisse, falls vorhanden, an den Supply Chain Scientist zu melden. Menschen lieben ihre Gewohnheiten, und Mitarbeiter großer Unternehmen umso mehr.
Das Problem bei diesem Ansatz ist, dass die Supply Chain Scientists nach der Implementierung der Automatisierung die Ergebnisse des automatisierten Prozesses direkt beobachten können, sowohl die guten als auch die schlechten. Der Planner und die Scientists haben Zugriff auf dieselben Daten; jedoch hat der Scientist per Definition Zugriff auf leistungsstärkere Analysetools im Vergleich zum Planner. Daher nimmt der Mehrwert des Feedbacks des Planners zur kontinuierlichen Verbesserung des numerischen Rezepts schnell ab, sobald die Automatisierung eingeführt ist.
Da der Planner nun mehr Zeit für Analysen hat, ist es wahrscheinlich, dass er vom Scientist mehr Indikatoren und Dashboards anfordert. Dies führt zu “KPI-Tourismus”: Die Anzahl der zu überprüfenden Indikatoren wird erhöht, bis ihre Untersuchung zu einer Vollzeitbeschäftigung wird. Diese Arbeitsbelastung wird auch zu einer Ablenkung für die Scientists. In dieser Phase nach der Implementierung erfordert die Verbesserung des numerischen Rezepts ein ziemlich gutes Verständnis der Schwächen der tatsächlichen Implementierung. Der Scientist ist ideal positioniert, um diese Arbeit zu leisten, während der Planner dafür weniger geeignet ist. Um hilfreich zu sein, sollte der Planner ein Netzwerkmanager werden und, wie bereits erwähnt, nach außen schauen. Andernfalls verkommt die Position des Planners zu KPI-Tourismus.

Die Aufgabe des Supply Chain Executives wird weitgehend durch die Organisation und ihre Prozesse definiert. Solange banale Entscheidungen das Ergebnis eines manuellen Prozesses sind, bleibt der Organisation keine andere Wahl, als eine Arbeitsteilung zu übernehmen, bei der jeder Planner mit seiner eigenen Kurzliste von SKUs arbeitet. Daher ist der Supply Chain Executive in erster Linie der Manager eines Teams von Plannern. Wenn das Unternehmen groß genug ist, um eine Schicht mittleren Managements zu rechtfertigen, könnte der Executive nur indirekt Planner verwalten. Dennoch bleibt die Supply Chain Division dieselbe: eine Pyramide mit Plannern an der Basis. Aus der Notwendigkeit heraus bedeutet ein guter Supply Chain Executive auch ein guter Coach für diese Planner zu sein. Der Executive trifft nicht die Supply Chain Entscheidungen; es sind die Planner, die diese Entscheidungen treffen. Die Verbesserung der Entscheidungen ist in erster Linie eine Frage der besseren Arbeit der Planner.
Supply Chain Softwareanbieter argumentieren, dass ihre Tools einen Unterschied machen können. Wie bereits erwähnt, werden jedoch fast immer Tabellenkalkulationen verwendet, um diese Entscheidungen zu treffen, unabhängig davon, wie viel Werkzeug innerhalb des Unternehmens implementiert wurde. Letztendlich kommt es also darauf an, was die Planner mit ihren eigenen Tabellenkalkulationen machen.
Sobald eine Klasse von Supply Chain Entscheidungen automatisiert wurde, ändert sich die Aufgabe des Supply Chain Executives erheblich. Die Aufgabe besteht nun darin, alles zu tun, damit das Unternehmen das Beste aus seiner Supply Chain Automatisierung macht. Der Executive muss zum Eigentümer des Softwareprodukts werden, das die Supply Chain Entscheidungen effektiv steuert.
Tatsächlich sind der Fokus und der Beitrag der Supply Chain Scientists nach innen gerichtet, genauso wie die früheren Beiträge der Planner. Die Scientists können das numerische Rezept nur von innen verbessern. Es kann nicht erwartet werden, dass sie die Anwendungslandschaft oder die breiteren Unternehmensprozesse umgestalten. Das ist die Aufgabe des Supply Chain Executives. Insbesondere ist der Executive dafür verantwortlich, einen Fahrplan für die kontinuierliche Verbesserung der Automatisierung festzulegen.
Solange die Entscheidungen von Plannern getroffen wurden, war der Fahrplan weitgehend selbstverständlich. Die Planner würden weiterhin das tun, was sie tun, und die Mission für das nächste Quartal wäre weitgehend ähnlich wie die Mission, die sie im vorherigen Quartal hatten. Sobald jedoch eine Automatisierung implementiert ist, erfordert die Verbesserung des numerischen Rezepts fast immer etwas, das noch nie zuvor getan wurde. Wenn Sie Software entwickeln und es richtig machen, wiederholen Sie sich nicht - Sie gehen weiter. Sobald eine Erkenntnis gewonnen wurde, muss eine neue Art von Erkenntnis gesucht werden. Die Mission der Mitarbeiter unter einem Softwareprodukteigentümer ändert sich kontinuierlich durch Design.
Die neuen Richtungen und Ziele fallen nicht vom Himmel. Es ist die Verantwortung des Supply Chain Executives, die Entwicklung des Supply Chain Softwareprodukts in günstige Richtungen zu lenken.

Die meisten Probleme, mit denen Supply Chains im Alltag konfrontiert sind, sind Softwareprobleme. Dies ist bereits seit mehr als einem Jahrzehnt in entwickelten Ländern der Fall, selbst in Unternehmen, in denen alle Entscheidungen manuell aus Tabellenkalkulationen abgeleitet werden. Diese Situation ist eine direkte Folge davon, dass Supply Chains an der Schnittstelle vieler Systeme stehen: dem ERP, CRM, WMS, OMS, PIM und Dutzenden von dreibuchstabigen Akronyme, die von Enterprise-Softwareanbietern geliebt werden und die verschiedenen Teile der Unternehmenssoftware beschreiben, die alle Daten von Interesse für Supply Chain Zwecke enthalten. Supply Chains erfordern eine end-to-end Perspektive des Geschäfts und verbinden daher den größten Teil der Anwendungslandschaft des Unternehmens. Dennoch scheinen die meisten Unternehmen immer noch Supply Chain Führungskräfte auszuwählen, die sehr wenig über Software wissen. Noch schlimmer ist, dass einige dieser Führungskräfte keinerlei Absicht haben, jemals etwas über Software zu lernen. Diese Situation ist das “Analytics Supply Chain Bus” Anti-Pattern. Wenn ich von Software spreche, sollte verstanden werden, dass es sich um das Thema handelt, das ich im vierten Kapitel dieser Vortragsreihe behandelt habe, mit Themen von Computertechnik bis Softwareentwicklung.
Heutzutage bedeutet Software-Unkenntnis in der obersten Führungsebene der Supply Chain massive Probleme für das Unternehmen. Entweder glaubt das Management, dass es auch ohne Software-Experten gut zurechtkommt, oder es glaubt, dass es mit externer Software-Expertise gut zurechtkommt. In beiden Fällen sind die Konsequenzen nicht gut.
Wenn das Top-Management glaubt, dass es auch ohne Software-Experten gut zurechtkommt, wird das Unternehmen auf allen elektronischen Kanälen, sowohl auf der Verkaufsseite als auch auf der Einkaufsseite, an Boden verlieren. Doch da viele Mitarbeiter erkennen, dass diese elektronischen Kanäle wichtig sind, ob es dem Top-Management gefällt oder nicht, wird der Schatten-IT weit verbreitet sein. Darüber hinaus können Sie sich sicher sein, dass bei der nächsten großen Softwareumstellung im Unternehmen diese Umstellung weitgehend schlecht gemanagt wird, was zu langen Zeiträumen mit geringer Servicequalität aufgrund von softwarebezogenen Problemen führt, die von Anfang an vermieden hätten werden können.
Wenn das Management glaubt, dass es mit Software-Expertise von Drittanbietern gut zurechtkommt, ist es etwas besser als im vorherigen Fall, aber nicht viel. Sich auf Drittanbieter-Experten zu verlassen, ist in Ordnung, wenn Sie ein enges, in sich geschlossenes Problem haben, wie zum Beispiel sicherzustellen, dass Ihr Einstellungsprozess mit einer Vorschrift konform ist. Supply Chain Herausforderungen sind jedoch nicht in sich geschlossen; sie erstrecken sich über das gesamte Unternehmen und oft sogar darüber hinaus. Die häufigste Falle beim Denken, dass Expertise ausgelagert werden kann, besteht darin, unvernünftige Geldbeträge an große Softwareanbieter zu zahlen, in der Hoffnung, dass sie die Probleme für Sie lösen werden. Überraschung - das werden sie nicht. Das einzige Heilmittel für diese Probleme ist ein Mindestmaß an Software-Kenntnissen in der obersten Führungsebene.
Heute haben wir erläutert, wie automatisierte Supply Chain Entscheidungen in die Produktion gebracht werden können. Der Prozess ist eine Mischung aus Design, Engineering und Veränderungsmanagement. Es ist eine schwierige Reise, mit zahlreichen scheinbar einfachen oder beruhigenden Wegen, die direkt zum Scheitern der Initiative führen. Um erfolgreich zu sein, erfordert die Initiative eine wesentliche Weiterentwicklung der Rollen und Aufgaben sowohl der obersten Führungsebene der Supply Chain als auch ihrer Mitarbeiter.
Für Unternehmen, die tief in ihren manuellen Prozessen verwurzelt sind, mag die Durchführung einer solchen Initiative unüberwindbar erscheinen, und daher mag die Aufrechterhaltung des Status quo als einzige Option erscheinen. Ich bin jedoch anderer Meinung und widerspreche dieser Schlussfolgerung aus zwei Gründen. Erstens ist die Reise zwar mühsam, aber billig, zumindest im Vergleich zu den meisten Geschäftsinvestitionen. Durch die Wiederverwendung der jährlichen Kosten von fünf Bedarfsplanern kann das Unternehmen die Arbeitsbelastung von 50 Bedarfsplanern automatisieren. Natürlich können großen Enterprise-Softwareanbietern vertrauen, die behaupten, dass es zig Millionen Dollar kostet, überhaupt erst anzufangen, aber es gibt viel schlankere Alternativen. Zweitens mag die Reise mühsam sein, aber sie ist auch nicht wirklich optional. Unternehmen, die Armeen von Angestellten beschäftigen, um ihre banalen, wiederholenden Supply Chain Entscheidungen zu treffen, leiden auch unter langen, selbst auferlegten Vorlaufzeiten, die durch ihre eigenen internen Prozesse verursacht werden. Diese Unternehmen werden im Wettbewerb gegen Unternehmen, die ihre routinemäßigen Entscheidungsprozesse automatisiert haben, nicht wettbewerbsfähig bleiben. Der Wettbewerbsvorteil, der durch Automatisierung gewonnen werden kann, ist zu Beginn immer bescheiden. Im Laufe der Zeit kann die Automatisierung jedoch verbessert werden, während ein manueller Prozess dies nicht kann, wodurch der Wettbewerbsvorteil im Laufe der Zeit exponentiell stärker wird. Zu diesem Zeitpunkt werden automatisierte Supply Chain Entscheidungen vielleicht noch als futuristisch wahrgenommen, aber in zwei Jahrzehnten wird das Gegenteil der Fall sein. Manuelle Prozesse werden als antiquierte Überbleibsel einer vergangenen Ära angesehen werden.

Das schließt den Vortrag für heute ab. In einer Minute werden wir mit den Fragen weitermachen. Der nächste Vortrag findet in der ersten Woche im November statt, am Mittwoch um 15 Uhr, wie üblich. Wir werden zum dritten Kapitel mit einer Supply Chain-Persona zurückkehren. Es wird um ein fiktives Unternehmen namens Stuttgart gehen, das ein Unternehmen für den Automobil-Nachmarkt ist. Wir werden sehen, dass die Automobilindustrie die Industrie der Industrien ist und dass sie eine Reihe von ziemlich spezifischen Herausforderungen darstellt, die wiederum in den Supply Chain-Lehrbüchern nicht angemessen reflektiert werden.
Schauen wir uns die Fragen an.
Frage: Benötigt die quantitative Supply Chain ihre eigene ideale Arbeitsteilung?
Ja, es kann ein schrittweiser Übergang sein, aber die Idee ist, dass die Arbeitsteilung, die Sie mit einem manuellen Prozess hatten, durch die Tatsache definiert wurde, dass ein Planer nur so viele SKUs verwalten kann. Mehr SKUs bedeuten mehr Planer. Dies ist eine sehr vereinfachte Arbeitsteilung. Wenn Sie ein großes Unternehmen haben und einen automatisierten Prozess haben möchten, ist die Idee, dass Sie spezialisierte Mitarbeiter haben werden. Zum Beispiel kann ein Netzwerkmanager sich auf die Qualität des Dienstes spezialisieren, wie sie vom Kunden wahrgenommen wird. Die Wahrnehmung ist wichtig; es geht nicht um die abstrakte Dienstleistungsqualität, wie zum Beispiel Service Levels. Vielleicht haben die Kunden ihre eigene Perspektive darauf, also kann sich jemand darauf spezialisieren. Ein anderer Netzwerkmanager kann sich auf einen bestimmten Bereich spezialisieren, in dem eine engere Koordination und Integration mit einigen Lieferanten beispielsweise die Durchlaufzeiten verkürzen und neue Optionen auf den Tisch bringen könnten. Plötzlich konzentriert sich die Arbeitsteilung mehr auf die vielen Aspekte, die aus einer analytischen Perspektive untersucht, überarbeitet und neu analysiert werden müssen. Sie können mehrere Personen daran arbeiten lassen. Aber es geht nicht darum, etwas so klar definiertes wie eine Liste von SKUs zu haben. Es geht auch darum, etwas zu verbessern. Vielleicht bräuchte man einfach mehrere Personen, damit sie gemeinsam brainstormen und versuchen können, die besseren Ideen zu identifizieren und auszusortieren. Sobald Sie den Weg einer quantitativen Supply Chain-Initiative einschlagen, wird Ihre Arbeitsteilung viel mehr einem fortlaufenden Engineering-Prozess ähneln, bei dem die Mitarbeiter tiefere Kenntnisse in spezifischen Bereichen haben und versuchen, zusammenzuarbeiten, um ein überlegenes Produkt entstehen zu lassen.
Frage: Hilft es, anstelle von finanziellen Kennzahlen Prozentsätze zu verwenden, um die Ineffizienzen des Legacy-Prozesses zu verbergen? Wie wahrscheinlich ist es, dass die Initiative erfolgreich ist, wenn dies der Fall ist?
Das ist eine sehr heikle Frage. Einer der Gründe, warum große Unternehmen und so viele Manager in ihnen diese ambitionierten Kennzahlen lieben, ist, dass ihnen keine Schuld zugeschrieben wird. Sobald Sie einen Indikator als Prozentsatz ausdrücken, merkt niemand, dass dies Millionen von Dollar sind, die allein im letzten Quartal aufgrund eines bestimmten Fehlers gemacht wurden, der von einer bestimmten Abteilung unter der Leitung einer bestimmten Person gemacht wurde. Diese Prozentsätze sind unglaublich undurchsichtig, und es ist eine echte Herausforderung, diese Initiativen erfolgreich zu machen, weil sehr häufig, sobald Sie die Dinge in Dollar oder Euro umrechnen, Sie das wahre Ausmaß der Ineffizienzen aufdecken, die absolut massiv sein können.
In der Erfahrung von Lokad stellten wir fest, dass bei börsennotierten Unternehmen, die alle Zahlen an die öffentlichen Märkte weitergaben und mehr als 200 Wirtschaftsprüfer den Wert des Lagerbestands bestätigten, die Lagerwerte um 20% zugunsten des Unternehmens abwichen. Wir sprechen von einem Unternehmen mit einem Lagerbestand im Wert von über einer Million Euro in ihren Büchern. Das Wahnsinnige war, dass der Lagerbestand seit Jahrzehnten von mehr als 200 Personen geprüft worden war und auch seit Jahrzehnten digitalisiert war.
Wenn Sie solche Dinge aufdecken, ist es schwierig, aber ich glaube, dass der richtige Ansatz darin besteht, hart gegen Probleme und sanft gegen Menschen vorzugehen. Unternehmen müssen lernen, sanft gegenüber den Menschen zu sein und wirklich hart gegenüber den Problemen, anstatt das Problem zu ignorieren und die Menschen zu entlassen.
Frage: Große Unternehmen verwenden viel mehr KPIs als sie benötigen. Wie fordern Sie bei der Einführung der Initiative alle KPIs heraus?
Sehr gute Frage. All diese KPIs sind eine große Ablenkung, um die manuelle Arbeit der Planer zu unterstützen. Wenn Sie einmal ein numerisches Rezept haben, warum kümmern Sie sich dann überhaupt um all diese KPIs? Alles, was Sie optimieren, sollte in Ihre finanziellen Kriterien eingebettet sein. Sie sollten eine Kennzahl haben, die Ihnen für jede potenzielle Entscheidung sagt, wie viel Geld auf dem Spiel steht, wie viel Sie gewinnen oder verlieren, abhängig vom Ergebnis der Entscheidung. Anstatt eine endlose Reihe von Indikatoren anzuhäufen, können Sie, wenn Sie Ihre finanzielle Kennzahl verfeinern möchten, einen Faktor hinzufügen. Aber das bedeutet nicht, dass Sie eine zusätzliche Spalte im Bericht hinzufügen; es bedeutet nur, dass Sie ein wenig anpassen, indem Sie einen zusätzlichen Faktor zuweisen, der additiv ein paar Euro oder Dollar zu den Werten hinzufügt oder abzieht, die Sie einer bestimmten Entscheidung zuweisen.
Grundsätzlich wird alles, was außerhalb dieser finanziellen Ziele liegt, von dem numerischen Rezept ignoriert. Das numerische Rezept führt einen mathematischen Optimierungsprozess durch, der streng ein finanzielles Ziel optimiert. Das ist es. Alle diese anderen Indikatoren werden ignoriert. Eine automatisierte Einrichtung macht es viel offensichtlicher, dass diese Indikatoren sinnlos sind. Sie werden nicht in das Rezept einbezogen, sie werden vom numerischen Rezept nicht berücksichtigt und sie sind nicht einmal Teil des Entscheidungsprozesses. Es klärt auch, dass ambitionierte Kennzahlen wie Servicelevels nachteilig sind. Sie können Ihren Servicequalitätsgrad nicht einfach auf 100% erhöhen, weil dies kein wünschenswertes Ergebnis für das Unternehmen ist. Wenn die Automatisierung korrekt durchgeführt wird, wird deutlich, welche Indikatoren tatsächlich benötigt werden, und man erkennt, dass nicht so viele Indikatoren benötigt werden. Außerdem gibt es aufgrund der geringeren Anzahl von Personen, die am Prozess beteiligt sind, weniger Druck, Indikatoren hinzuzufügen. Ein weiterer Aspekt großer Planungsteams ist, dass jede einzelne Person dazu neigt, ihre ein oder zwei Lieblingsindikatoren zu haben. Wenn Sie 200 Personen haben und jede einzelne Person einen Indikator für ihre persönliche Bequemlichkeit hinzufügen möchte, erhalten Sie 200 Indikatoren, was viel zu viele sind. Aber wenn Sie nur ein Zehntel dieses Personals haben, ist der Druck, Indikatoren anzuhäufen, viel geringer.
Frage: Wie verstehen Anbieter von Bedarfsplanungssoftware die Ökosysteme ihrer potenziellen Kunden, wie zum Beispiel Sicherheitsbestandsanforderungen, während sie die Anpassung vor der Implementierung beim Kunden durchführen? Ich meine, sobald die Implementierung erfolgt ist, gibt es keine Fallstricke in Bezug auf Prognosefehler.
Die klassische Perspektive, die meiner Meinung nach in den 1970er Jahren gescheitert ist, bestand darin, dass eine verpackte Softwarelösung die Probleme von Unternehmen lösen könnte. Ich bin fest davon überzeugt, dass dies nicht der Fall ist. Eine verpackte Software kann nicht in jede nicht-triviale Lieferkette passen. Was passiert ist, dass ein Unternehmenssoftwareanbieter mit einem Bestandsoptimierungs- und Prognosemodul versucht, das Produkt an ein Unternehmen zu verkaufen, und da Funktionen fehlen, fügen sie sie hinzu. Über 10 Jahre oder mehr hinweg entsteht ein monströses, aufgeblähtes Softwareprodukt mit Hunderten von Bildschirmen und Tausenden von Parameterwerten.
Das Problem besteht darin, dass je komplexer das Softwareprodukt ist, desto spezifischer sind Ihre Erwartungen in Bezug auf Daten und das, was das Unternehmen haben sollte. Je komplexer das Softwareprodukt ist, desto schwieriger wird es, es in das Kundunternehmen einzufügen, da Sie eine komplexe Lieferkette mit vielen bereits vorhandenen Systemen und einem superkomplexen Lieferkettenoptimierungsprodukt haben. Es gibt Lücken und Unstimmigkeiten an jeder Ecke.
Die Realität ist, dass die meisten großen Unternehmen, mit denen ich gesprochen habe, seit zwei bis drei Jahrzehnten digitale Lieferketten in entwickelten Ländern betreiben und in den letzten zwei bis drei Jahrzehnten bereits ein halbes Dutzend Lösungen für die Bedarfsplanung, Bestandsoptimierung und Lieferkettenentwicklung implementiert haben. Also, sie waren schon da und haben das schon gemacht, nicht nur einmal, sondern ein halbes Dutzend Mal. Normalerweise sind die Leute nicht lange genug im Unternehmen, um zu realisieren, dass diese Prozesse in den letzten zwei bis drei Jahrzehnten immer wieder stattgefunden haben. Und dennoch sind die Prozesse immer noch vollständig manuell und verlassen sich oft auf Tools wie Excel. Das Problem ist nicht der Prognosefehler; Ich glaube, das ist eine Fehldiagnose des Problems, denn die Vorstellung, dass man mit einem System oder einem anderen eine perfekte Prognose haben könnte, ist lächerlich. Es ist nicht möglich, eine perfekte Prognose zu erstellen, und Menschen, die eine Lieferkette manuell steuern, haben auch keinen Zugang zu perfekten Informationen. Nur weil Sie ein menschlicher Bedarfsplaner sind, können Sie nicht perfekt die Nachfrage prognostizieren.
Bedarfsplaner sind in der Lage, ihre Arbeit mit weniger als perfekten Prognosen zu erledigen. Diese Menschen sind keine Magier oder hochentwickelten Wissenschaftler. Sie mögen nicht schlecht sein, wenn es um Prognosen geht, aber es gibt keinen Grund zu erwarten, dass durchschnittlich alle Bedarfsplaner in dieser Branche, die weltweit Hunderttausende von Menschen beschäftigt, überaus talentiert und in der Lage sind, unglaublich genaue Nachfrageprognosen zu erstellen. Was das System funktionieren lässt, ist, dass diese Menschen ihre Heuristiken und Wege haben, um die Lieferkette manuell zu handhaben, die trotz schlechter Prognosen zur Verfügung stehen.
Das Ziel in Ihrer automatisierten Einrichtung besteht darin, ein System zu haben, das auch dann gut funktioniert, wenn die Prognosen von Anfang an nicht so gut sind. Dies ist das Wesen des probabilistischen Prognoseansatzes; es geht nicht darum, die Genauigkeit zu verbessern, sondern anzuerkennen und zu akzeptieren, dass die Prognose nicht so gut ist. Wenn wir zu diesen Anbietern zurückkehren, glaube ich, dass die Branche in den letzten vier Jahrzehnten kollektiv versagt hat, eine zufriedenstellende Automatisierungsstufe zu erreichen, und der Kern des Problems war die verpackte Perspektive, bei der erwartet wurde, dass Unternehmen einfach ein Modul einstecken und fertig sind. Das funktioniert nicht. Lieferketten sind viel zu vielfältig, vielseitig und ständig im Wandel, um mit einem solchen mechanischen Ansatz erfolgreich zu sein.
Frage: Mit der dargestellten Perspektive, wie gehen Sie das Problem der Abstimmung der verschiedenen Prognosen des Unternehmens, wie Verkauf, Lagerbestand und andere, an?
Meine Frage ist, warum machen Sie überhaupt Prognosen? Prognosen sind nur numerische Artefakte; sie sind unwichtig. Ihr Unternehmen wird nicht profitabler sein, nur weil es eine bessere Prognose gibt. Prognosen sind genau das, was ich in den vorherigen Kapiteln dieser Vortragsreihe als numerisches Artefakt bezeichnet habe. Es ist eine Abstraktion, die sich als nützlich oder auch nicht nützlich erweisen kann, um bestimmte Arten von Entscheidungen abzuleiten. Es stellt sich heraus, dass je nach betrachteter Entscheidung der benötigte Prognosetyp sehr unterschiedlich sein kann.
Ich bezweifle die Idee, dass man eine Prognose an der Spitze haben kann und dann die gesamte Lieferkette basierend auf diesen Prognosen orchestrieren kann. Ich bin mit diesem Ansatz stark anderer Meinung, da dies nicht meine Erfahrung war und ich glaube, dass es nicht so gut funktioniert. Ich habe viele Unternehmen gesehen, bei denen es einen Senior-Planungsprozess gibt, der Prognosen auf der Verkaufsseite erstellt, was eine massive Übung in Zurückhaltung ist. Verkäufer unterschätzen oft ihre Prognosen erheblich, weil sie auf diese Weise, wenn sie diese Zahlen überschreiten, später leichter die Erwartungen übertreffen können. Menschen in Fabriken oder Lagern sehen diese Zahlen auf sich zukommen und denken vielleicht, dass sie unmöglich richtig sein können, also verwerfen sie die Zahl und tun etwas völlig anderes. Meiner Meinung nach sind die von der überwiegenden Mehrheit der Unternehmen durchgeführten Prognoseübungen nur sinnlose bürokratische Anstrengungen. Es gibt keinen Mehrwert darin.
Aus quantitativer Supply-Chain-Sicht ist es wichtig, sich auf die Entscheidungen zu konzentrieren, die wichtig sind, anstatt auf die Prognosen, die möglicherweise nur technische Details sind. Einige Arten von Entscheidungen erfordern möglicherweise nicht einmal eine Prognose oder, wenn doch, benötigen sie möglicherweise eine Art von Prognose, die sehr unterschiedlich ist von dem, was Unternehmen derzeit in Betracht ziehen. Wenn wir über Prognosen sprechen, meinen die meisten Menschen Zeitreihen Prognosen. Wenn Sie jedoch zum dritten Kapitel dieser Vortragsreihe zurückkehren, das den Supply-Chain-Personas und realen Situationen gewidmet ist, werden Sie feststellen, dass Zeitreihenprognosen oft nicht die Antwort sind. Die Form der Prognose ist für die Erfassung der Muster, die wir im Geschäft identifizieren möchten, unzureichend.
Abschließend würde ich vorschlagen, diese Prognosen nicht einmal zu versuchen, abzustimmen. Ignorieren Sie sie stattdessen und konzentrieren Sie sich auf die Entscheidungen selbst. Sehen Sie, was erforderlich ist, um Rezepte zu entwickeln, die gute Entscheidungen generieren, und die Chancen stehen gut, dass all diese Prognosen vollständig ignoriert werden können.
Als Antwort auf den Kommentar zur Vergleichbarkeit von Finanzkennzahlen mit prozentualen KPI-Ergebnissen ist es wahr, dass Sie Vergleiche anstellen können, indem Sie versuchen, Servicelevel oder Füllraten mit Ihren finanziellen Kennzahlen in Beziehung zu setzen. Schafft dies jedoch tatsächlich einen Return on Investment für das Unternehmen? Bessere Bestandsentscheidungen können Wert für das Unternehmen schaffen, aber Zeit damit zu verbringen, KPIs in Beziehung zu setzen, tut dies nicht. Viele Unternehmen sind süchtig nach diesen als Prozentsätze ausgedrückten KPIs, aber sie sind oft bedeutungslose bürokratische Ablenkungen.
Enterprise-Software-Anbieter lieben diese Indikatoren, weil sie sie an Kundenunternehmen verkaufen können, was dazu führt, dass viele Anbieter nach mehr Indikatoren drängen. In Wirklichkeit sind für eine Klasse von Supply-Chain-Entscheidungen bereits zehn Zahlen, die es wert sind, täglich betrachtet zu werden, ziemlich viel. Es ist oft schwierig, überhaupt zehn Zahlen zu identifizieren, die es wert sind, täglich von einem Menschen betrachtet zu werden. Oft sind es sogar weniger, und das ist in Ordnung. Die Probleme in Supply Chains tendieren dazu, sehr spezifisch für das Unternehmen und die betreffende Supply Chain zu sein, aber sie sind nicht unendlich kompliziert. Ich sage nicht, dass Supply-Chain-Situationen Tausende von wirtschaftlichen Treibern erfordern. Stattdessen sage ich, dass Supply Chains sehr unterschiedlich sind und Sie sicherstellen müssen, dass Sie das richtige Problem lösen, das den Feinheiten der betreffenden Supply Chain entspricht. Für eine interessante Supply Chain können Sie beispielsweise drei oder vier grundlegende Treiber wie Lagerkosten, Bruttomarge und andere Faktoren haben, die Sie praktisch überall finden. Dann können Sie vier oder fünf Indikatoren haben, wiederum finanzielle Kennzahlen, die sehr spezifisch für ein interessantes Geschäft sind. Insgesamt sind wir immer noch unter zehn Zahlen.
Als Antwort auf die Frage nach dem Ausgleich zwischen finanziellen KPIs und Supply-Chain-KPIs würde ich sagen, ja und nein. Wenn Sie der Meinung sind, dass finanzielle KPIs nicht diejenigen sind, die Sie optimieren sollten, dann besteht ein Problem in der Definition Ihrer finanziellen KPIs. Im ersten Kapitel dieser Vortragsreihe habe ich erwähnt, dass es in der Regel zwei Kreise von Treibern gibt, die bei der Festlegung einer finanziellen Kennzahl zu berücksichtigen sind. Der erste Kreis umfasst Faktoren, die die Finanzabteilung direkt aus den Büchern ablesen kann, wie Bruttomarge, Lagerwert und Einkaufskosten. Der zweite Kreis umfasst Treiber wie die Kundenzufriedenheit und die implizite Strafe bei geringer Servicequalität. All dies muss integriert werden.
Die finanzielle Perspektive geht nicht darum, KPIs zu haben, bei denen es einen Kompromiss gibt. Stattdessen geht es darum, alles zu einer einzigen Bewertung in Dollar oder Euro für Ihre Leistung und Entscheidungsfindung zusammenzufassen. Es geht nicht darum, Supply-Chain-KPIs mit finanziellen KPIs in Einklang zu bringen. Vielmehr geht es darum, in dem Unternehmen eine Governance zu haben, damit die Menschen sich auf die tatsächlichen Lagerkosten, die tatsächlichen Kosten für Fehlbestände und die Frage, ob eine Nachbestellungsentscheidung die beste Option ist oder nicht, einigen können.
Aus dieser neuen Perspektive, das Softwareprodukt zu besitzen, das die Supply Chain steuert, besteht die Aufgabe des Supply-Chain-Executives darin, einen Konsens im Unternehmen zu fördern. Anstatt einen sinnlosen S&OP-Prozess zu steuern, bei dem die Leute versuchen, die Zahlen jeden Monat zu überarbeiten und sich auf bedeutungslose Verkaufszahlen zu einigen, geht es darum, ein von der Supply-Chain-Leitung geleitetes S&OP 2.0 umzusetzen. Entgegen dem, was S&OP-Anbieter sagen, muss der CEO den S&OP-Prozess nicht besitzen, da dies für sie eher eine Ablenkung sein kann. Es besteht keine Notwendigkeit, den CEO in jede einzelne Schlacht einzubeziehen.
Die Aufgabe des Supply-Chain-Direktors besteht darin, mit dem Leiter der Finanzabteilung, dem Leiter des Marketings und dem Leiter des Vertriebs zusammenzuarbeiten, um sich darauf zu einigen, wie der finanzielle Einfluss von Faktoren wie der Servicequalität gemessen werden kann. Das ist ihre Aufgabe. Es besteht keine Notwendigkeit, verschiedene Kennzahlen abzustimmen, da sie bereits dank der Arbeit, die unter der Leitung des Leiters der Supply Chain oder des Supply-Chain-Direktors durchgeführt wurde, voreinheitlich sind, je nachdem, welcher Titel im Unternehmen verwendet wird.
Damit endet der heutige Vortrag. Wir sehen uns das nächste Mal in der ersten Woche im November.