00:00 Introduction
03:39 Automation has always been the goal
06:28 Exception management and alerts
10:27 The story so far
14:33 Our production rollout today
15:59 Recap: deliverable, scope and roles
19:01 Uncovering the form of the decision
23:00 Legacy-driven response
27:20 Iterating to zero percent insanity
32:30 Aspirational metrics
36:27 Dual run: manual + mechanical
39:19 Analysis paralysis
43:21 Gradual automation take-over
46:08 Process sedimentation
48:57 From planner to network manager
52:46 The KPI tourist
54:58 Leadership: from coach to product owner
58:46 The analogic supply chain boss
01:02:25 Conclusion
01:04:44 7.2 Bringing automated decisions to production - Questions ?
Description
We seek a numerical recipe to drive an entire class of mundane decisions, such as stock replenishments. Automation is essential to make supply chain a capitalistic endeavor. However, it carries substantial risks of doing damage at scale if the numerical recipe is defective. Fail fast and break things is not the proper mindset to green-light a numerical recipe for production. However, many alternatives, such as the waterfall model, are even worse as they usually give an illusion of rationality and control. A highly iterative process is the key to design the numerical recipe that proves to be production grade.
Full transcript

Welcome to this series of supply chain lectures. I’m Johannes Vermorel and today I will be presenting “Bringing Automated Supply Chain Decisions to Production”. During the last two centuries, our economies underwent a massive transformation through mechanization. Companies that achieved a superior degree of mechanization compared to their competitors almost always systematically pushed those competitors to bankruptcy. Mechanization allows us to do more, better, and faster while reducing the cost. This is true for physical tasks like moving goods with a forklift instead of hand-carrying boxes, but it is also true for intellectual tasks like computing how much money you have left in the bank.
However, our capacity to mechanize a task is dependent on technology. There are still many physical tasks that cannot yet be mechanized, for example doing a haircut or changing bedsheets. Conversely, there are still many intellectual tasks that cannot yet be mechanized such as hiring the right person or figuring out what the customer wants. There is no reason to believe that those tasks, either intellectual or mechanical, can’t ever be mechanized. However, the technology isn’t quite there yet.
Most of the mundane routine supply chain decisions can now be automated. This is a relatively recent development. A decade ago, the scope of supply chain decisions that could be successfully automated was only a fraction of the whole spectrum of supply chain decisions. Nowadays, the situation is reversed and with the right technology, repetitive supply chain decisions that cannot be successfully automated are few and far between. By successful automation, I refer to a process where the automated decisions are superior to those obtained with a manual process, not to the capacity to generate decisions with a computer which is trivial as long as you don’t care about the quality of the generated decisions.
Our focus today isn’t on the numerical recipe - that is, the piece of software that makes such automation possible in the first place. In the context of supply chain decision-making processes, the ingredients to craft such a numerical recipe have been covered in previous chapters of this series of lectures. Our focus today is on the parts of the supply chain initiative that are needed to bring such a numerical recipe to production. The goal of this lecture is to outline what it takes to transition a company from manual supply chain decisions to automated ones. By the end of this lecture, you should have insights about the do’s and don’ts when transitioning towards automation. Indeed, the sheer technical difficulty associated with the numerical recipe itself tends to overshadow the organizational aspects that are nevertheless equally critical for the initiative to succeed.

When present-day supply chain practitioners are presented with the idea of decision-making automation, their immediate reaction tends to be ‘This is such a futuristic idea. We are not nearly there yet.’ However, complete automation of mundane and repetitive supply chain decisions has literally been the goal from the very start of the digital age of supply chains more than four decades ago.
As soon as computers became readily available to companies, people realized that most supply chain decisions were obvious candidates for complete automation. On the screen, I cherry-picked a list of publications that illustrate this ambition. Back in the 1970s and 1980s, this field was not even called supply chain yet. The term would only become popular in the 1990s. However, the intent was already clear. Those computer systems appeared immediately suitable to automate the most repetitive supply chain decisions such as inventory replenishments.
The most puzzling thing to me is that this community seems to be somewhat oblivious to its former ambitions. Nowadays, in order to sound futuristic, the term “autonomous supply chain” is sometimes used by consultancy firms or IT companies to convey this perspective of mechanization of mundane supply chain decisions. However, the term “autonomous” feels inappropriate to me. We don’t use the term “autonomous logistics” to refer to a conveyor belt featuring a sorting system. The conveyor belt is mechanized, not autonomous. The conveyor belt still requires technical supervision but this innovation represents only a tiny fraction of the manpower that would otherwise be needed by the company to convey the goods without the conveyor belt. As far as supply chain decisions are concerned, the goal is not to remove humans altogether from the organization, hence achieving some truly autonomous technology. The goal is to merely remove humans from the most time-consuming and crudest part of the process. This is exactly the perspective that has been adopted in those papers published four decades ago and this is the perspective that I am adopting in this lecture as well.

During the 1990s, it seems that software vendors, both ERP vendors and inventory optimization specialists, largely gave up on the idea of achieving automated supply chain decisions. In hindsight, the simplistic models of the 1970s which largely ignored many important factors such as uncertainty were the obvious root cause to explain why automation didn’t succeed at the time. However, fixing this root cause proved to be beyond what technology could deliver in this period. Instead, software vendors defaulted to exception management systems. Those systems are expected to produce inventory alerts based on rules set up by the client company itself. The line of reasoning was: let’s have the automation take care of the majority of lines that can be processed automatically to keep human intervention centered on the difficult lines, the lines that are beyond the capability of the machine.
Let’s immediately point out that selling an exception management system is a very good deal for the software vendor but much less so for the client company. First, the exception management shifts the burden of supply chain performance from the vendor to the client. Once the exception management is in place, if results are bad, it is the fault of the client. They should have been configuring better alerts to prevent damaging situations from happening in the first place.
Second, creating a system to manage parameterized inventory alerts is easy for the software vendor as long as a vendor does not have to deliver any parameter value that governs source alerts. Indeed, from an analytical perspective, being able to produce a good inventory alert means that you can engineer a rule that can reliably identify bad inventory decisions. If you can engineer a rule that can reliably identify bad inventory decisions, then by definition the same rule can also be used to reliably produce good inventory decisions. Indeed, the rule just has to be used as a filter to prevent bad decisions from being taken.
Third, exception management is a somewhat cunning strategy for the software vendor to exploit human psychology. Indeed, those alerts exploit a mechanism known as “commitment and consistency” by empirical psychologists. This mechanism creates a strong but largely accidental addiction to the software product. In short, once employees start tweaking inventory numbers, it’s not arbitrary numbers anymore. It is their numbers, their work and thus employees get emotionally attached to the system no matter whether the system actually delivers superior supply chain performance or not.
Overall, exception management is a technological dead-end because in the general case engineering reliable exceptions and engineering reliable alerts is exactly as difficult as engineering a reliable automation for the decisions. If you can’t trust your alerts and if you can’t trust your exceptions to be reliable, then you have to manually review everything anyway which brings you back to the starting point. The decision-making process remains strictly manual.

This series of supply chain lectures includes two dozen episodes. At this point, in a way, all the elements that we have introduced so far have been done with the explicit purpose of getting to the point where we stand today: on the verge of getting this quantitative supply chain initiative in production. More specifically, it’s the numerical recipe that we want to put in prediction and this undertaking is the focus of today’s lecture.
In those lectures, I’m using the term “numerical recipe” to refer to the sequence of calculations that takes raw historical data as input and outputs the final decisions. This terminology is intentionally vague because it reflects a lot of different concepts, methods and techniques which have been precisely covered through the lectures of the previous chapters. In the first chapter, we have seen why supply chain must become programmatic and why it is highly desirable to be able to put such a numerical recipe in production. The ever-increasing complexity of the supply chains themselves makes automation more pressing than ever. There is also an imperative to make the supply chain practice a capitalistic undertaking.
The second chapter is dedicated to methodologies. Indeed, supply chains are competitive systems. This combination defeats naive methodologies. Among the methodologies that we have introduced, supply chain personae and experimental optimization are of prime relevance for the topic of today. Supply chain personae are the key to adopt the right form of decisions. We will revisit this point in a few minutes. Experimental optimization is essential to deliver something that actually works. Again, we will be revisiting this point also in a few minutes.
The third chapter surveys the problem, putting aside the solution through supply chain personae. This chapter attempts to characterize the classes of decision-making problems that must be addressed. This chapter shows that simplistic perspectives like just having to pick the right quantity for every SKU don’t really fit real-world situations. There is almost invariably a deepness in the form of decisions.
The fourth chapter surveys the elements that are required to apprehend a modern practice of supply chain where software elements are ubiquitous. Those elements are fundamental to understand the broader context in which the numerical recipe and actually most of the supply chain processes operate. Indeed, many supply chain textbooks implicitly assume that their techniques and formulas operate in some sort of vacuum. This is not the case. The applicative landscape matters.
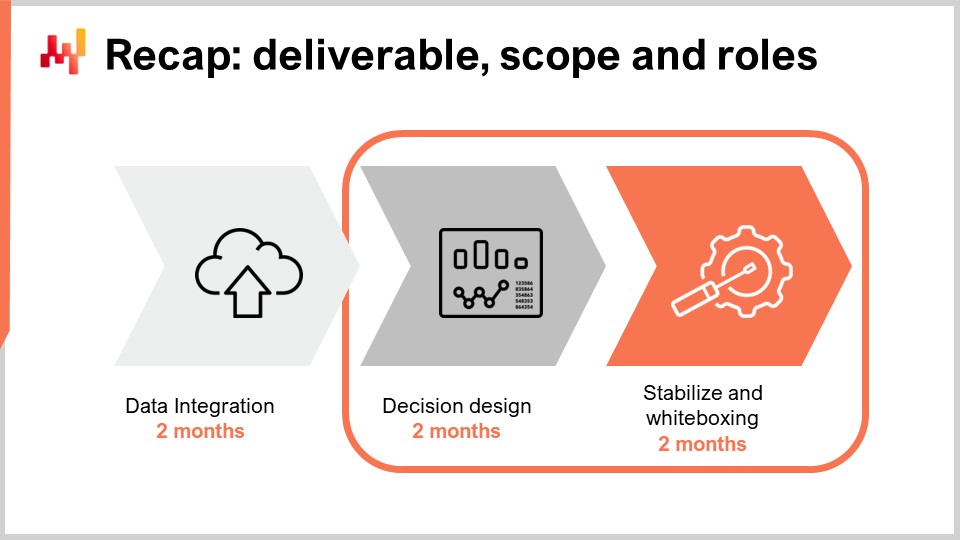
Chapters 5 and 6 are dedicated to predictive modeling and decision-making respectively. Those chapters cover the smart bits of the numerical recipe featuring machine learning techniques and mathematical optimization techniques. Finally, the seventh and present chapter is dedicated to the execution of a quantitative supply chain initiative whose purpose is precisely to put a numerical recipe in production and maintain it afterward. In the previous lecture, we have covered what it takes to kick off the initiative while laying out the proper foundations at the technical level. It means the setup of a proper data pipeline. Today, we want to cross the finish line and put this numerical recipe into action.

We will start with a short recap of the previous lecture and then proceed with three important aspects of the later stages of the initiative. The first aspect is about the design of the numerical recipe. However, I won’t be talking about the design of the numerical bits of the recipe, but about the design of the engineering process itself, which surrounds the numerical recipe. We will see how to approach the challenge in order to give the initiative a chance of letting a satisfying solution emerge.
The second aspect is about the proper rollout of the numerical recipe. Indeed, the company starts with a manual process and shall end with an automated one. An adequate rollout can largely mitigate the risk associated with this transition or rather mitigate the risk associated with a numerical recipe that would prove defective, at least initially.
The third aspect is about the change that needs to happen in the company once the automation is deployed. We will see that the roles and the missions of the people in the supply chain division should undergo a substantial amount of change.
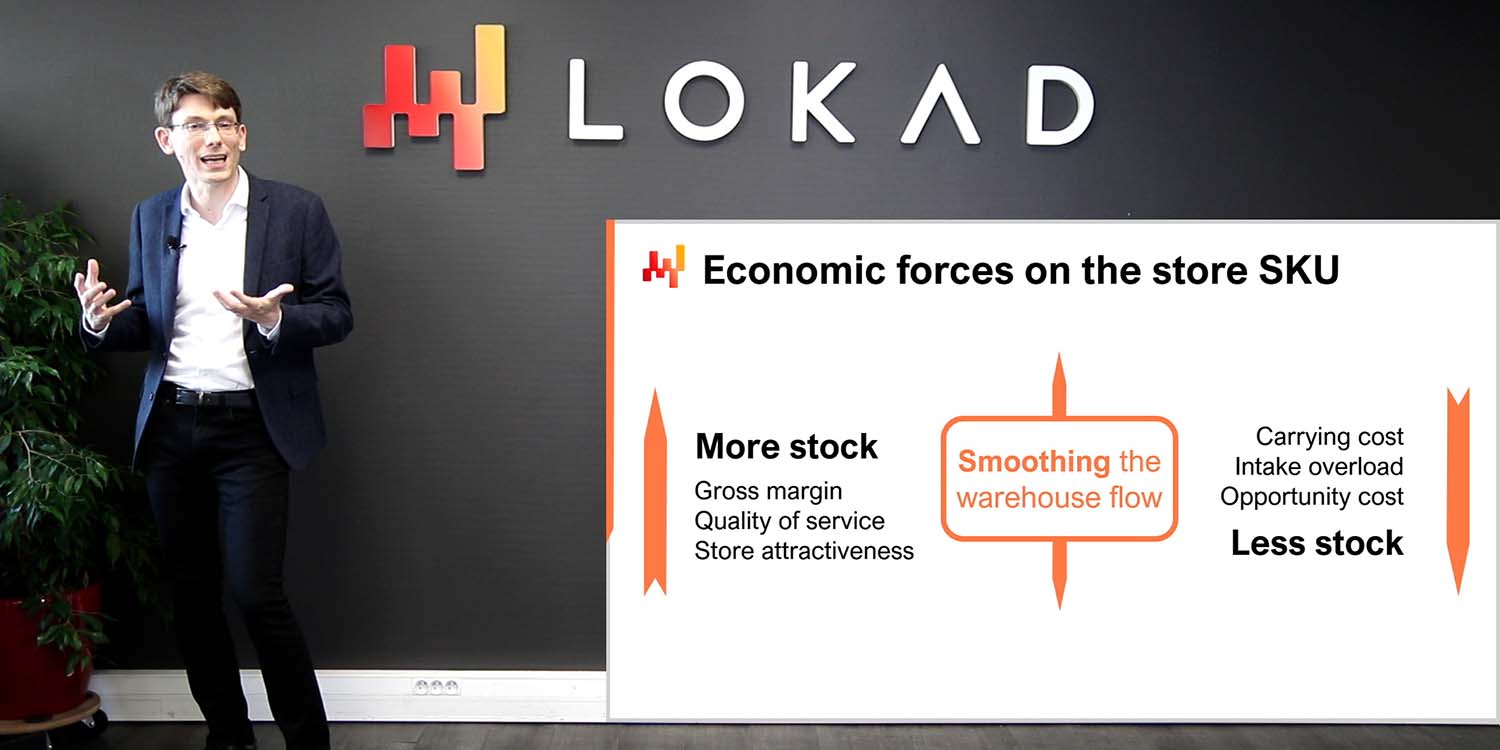
In the previous lecture, we have seen how to get a quantitative supply chain initiative started. Let’s revisit the most important aspects. The deliverable is an operational numerical recipe, which is a piece of software that drives a class of supply chain decisions, for example, inventory replenishment. This numerical recipe, once it is put into production, will deliver the automation we are looking for. Decisions should not be confused with numerical artifacts like demand forecasts, which are merely intermediate results that may contribute to the calculation of the decisions themselves.
The scope of the initiative must be aligned with both the supply chain, understood as a system, and its underlying applicative landscape. Paying attention to the system properties of the supply chain is critical in order to avoid displacing problems rather than solving them. For example, if the inventory optimization of a store in a retail chain is performed to the detriment of the other stores, then this optimization is meaningless. Also, paying attention to the applicative landscape is important because we have to minimize the initial amount of data plumbing efforts. IT resources are almost always a bottleneck, and we must be careful not to exacerbate this limitation.
Finally, we have identified four roles for this initiative, namely the supply chain executive, the data officer, the supply chain scientist, and the supply chain practitioner. The supply chain executive owns the strategy, the conduct of change, and arbitrates the modeling choices. The data officer is responsible for the setup of the data pipeline, which makes the relevant transactional data available to the analytical layer. In this lecture, we assume that the data pipeline has already been set up. The supply chain scientist is in charge of the implementation of the numerical recipe, which includes a lot of instrumentation, not just the smart algorithmic bits. Lastly, the supply chain practitioner is a person involved in the manual decision-making process. This person typically has a supply and demand planner role, although the terminology varies. At the start of the initiative, they are expected to transition toward the role of network manager by the end of the initiative. We will revisit this point later in the lecture.

Supply chains are quite favorable when it comes to the automation of decision-making processes. There are numerous mundane, highly repetitive decisions that are quantitative in nature. Unfortunately, the modeling perspective offered in most supply chain textbooks is usually overly simplistic. I’m not saying that the textbook techniques are overly simple or simplistic. However, I am merely saying that the sort of problems presented in those textbooks tend to be simplistic. Let’s consider, for example, an inventory replenishment situation. The textbook perspective seeks the optimal inventory policy to compute how many units should be reordered. This is fine but this is frequently a rather incomplete answer.
For example, we may have to decide whether the goods are going to be shipped by air or by sea with the two modes of transportation representing a trade-off between lead time and transportation cost. We may have to pick one supplier among multiple eligible suppliers. We may have to decide the exact shipment plan with several shipping dates if the quantity is large enough to warrant several shipments.
The third chapter of this series, a chapter dedicated to supply chain personae, presented detailed views of real-world supply chain situations in which we see that there are almost always subtleties beyond picking a single quantity for a given SKU. Thus, the supply chain scientist, with the help of the supply chain practitioner and the supply chain executive, must start by uncovering the complete form of the decision. The complete form of the decision must include all the elements that contribute to shaping the actual supply chain operation. Uncovering the complete form of the decision is difficult.
First, the division of labor as implemented in most companies operating a large supply chain usually fragments the various aspects of the decision across several employees and sometimes across several departments. For example, one person picks the quantity to be reordered while another person decides which supplier gets the purchase order.
Second, the more subtle aspects of the decision such as requesting the supplier to expedite the order when there has been a surge of demand tend to be overlooked because practitioners don’t realize that those aspects can and should be automated as well. I suggest having the description of this complete form of decision written down, not as a series of slides but as an actual piece of text. In particular, the text must clarify the “why”. What is exactly at stake with each aspect of the decision? Indeed, while some aspects of the decision might be relatively obvious such as the quantity in a reorder, some other aspects might be overlooked or forgotten. For example, a supplier might offer for a price the option to return the goods within six months if the packages remain untouched. Exercising or not this option should be part of the decision but it can be easily forgotten.

Failing at identifying the complete form of the supply chain decision or worse mischaracterizing the decision altogether is one of the surest ways to fail the initiative. In particular, the legacy-driven response is one of the most frequent mistakes that happens in large companies. The essence of the legacy-driven response is to adopt a form of decision that does not actually make sense for the company and its supply chain but that is adopted nonetheless because the form fits an existing transactional software or fits an existing process within the organization.
For example, it can be decided that inventory replenishment should be controlled through the computation of safety stock levels instead of directly computing the actual quantities to be reordered. Computing safety stocks may feel easier because those safety stocks already exist within the ERP. Thus, if safety stock values were to be recomputed, those values could be easily injected into the ERP, overriding whatever formula was actually used in DRP.
However, safety stocks have substantial shortcomings. Even something as basic as a minimal order quantity (MOQ) doesn’t fit a safety stock perspective. At the very least, this implementation is favored not because of a piece of software but because of pre-existing processes within the organization.
For example, a retail network may have two planning teams: one team dedicated to the replenishment of the stores and one team dedicated to the staffing levels of the distribution centers. However, those two problems are fundamentally one and the same. Once the reorder quantities have been picked for the stores, there is no more leeway to decide how much staff is needed for the distribution centers. Thus, the two teams have fundamentally overlapping missions. This division of labor works as long as humans are in the loop. Humans are good at dealing with ambiguous requirements. However, this ambiguity represents a massive hurdle for any attempt at automating either replenishment or staffing requirements.
This anti-pattern, the legacy-driven response, is very tempting because it minimizes the amount of change to be implemented. However, the automation of the decision changes the way the decision should even be approached. Frequently, if the legacy design is maintained then the quantitative supply chain initiative is going to fail.
First, it complicates further the design of the numerical recipe which is already a fairly complex undertaking. Indeed, the patterns that were suitable for a division of labor among human employees are not the ones that are suitable for a piece of software which is just mechanical.
Second, the legacy-driven response also negates many of the potential benefits associated with automation. Indeed, in supply chain many inefficiencies are to be found at the boundaries that exist within the company. Automation removes the need for most of those boundaries which were just introduced due to a specific way to organize the division of labor which doesn’t make sense if you have one computer that takes care of the whole thing. Do not let decisions which were taken two or three decades ago dictate the future of your supply chain.
Once the form of the decision has been properly characterized, the supply chain scientist starts crafting the numerical recipe itself, leveraging historical transactional data. In this series of lectures, there are two chapters dedicated to the fine print of the algorithmic techniques that can be used to learn and optimize. I will not be revisiting those elements today. Let’s just say that the supply chain scientist makes a series of judgment calls in order to craft an initial numerical recipe based on his knowledge and experience and also the tools that are available to supply chain scientists.
With the proper tools and techniques, this initial draft can and should be implemented in a matter of days, a few weeks at most. Indeed, we are not talking about advanced research trying to uncover some kind of novel technique but merely to craft an adaptation of known techniques that embrace the specificities of the supply chain of interest. Indeed, the numerical recipe must very strictly embrace the fine print of the decision as they have been identified in their complete form.
Even considering a very competent supply chain scientist leveraging the very best tools that money can buy, it is pointless to expect that the numerical recipe will be correct on the first attempt. Indeed, supply chains are too complex and obscure, especially their digital representations, to get a numerical recipe right the first time. Inward-looking numerical methods like having metrics and benchmarks cannot detect a misunderstanding by the supply chain scientist of a piece of data.
For every column in every table obtained from the transaction system that operates the company, there are usually several possible ways to interpret that data. Considering that we are talking of dozens of columns to be integrated into the numerical recipe, mistakes are guaranteed to happen. The only way to assess the correctness of the numerical recipe is to put it to the test and to obtain some real-world feedback. This was discussed in the second chapter of this series in the lecture titled “Experimental Optimization”.
Thus, the supply chain scientist must collaborate with the supply chain practitioner in order to identify situations where the numerical recipe in its current form still returns insane results. Broadly speaking, the supply chain scientist implements a dashboard that consolidates the decision as it would be taken today by the numerical recipe and the supply chain practitioner attempts to identify lines that appear insane.
Based on this feedback, the scientists further instrument the numerical recipe. The instrumentation takes the form of indicators that attempt to answer the question: why was this seemingly insane decision taken in this context? Based on this instrumentation, it becomes possible to decide whether the numerical recipe needs fixing, for example, because an economic driver is improperly modeled, or if the seemingly insane decision is actually correct, just unlike the way things were done in the company so far.
Experimental optimization is a highly iterative process. As a rule of thumb, with the right tooling, a single full-time supply chain scientist must be able to present a new iteration of the numerical recipe every single day to the supply chain practitioner. If the numerical recipe is properly instrumented, as the initiative progresses, the practitioner should not need more than two hours a day to provide feedback about the latest iteration of the numerical recipe.
The iteration stops when the numerical recipe does not generate insane results anymore, that is, when the practitioner cannot identify decisions that are demonstrably harmful to the company anymore. The absence of insane decisions may seem like a low bar compared to our overall objective of generating superior decisions compared to the manual process. However, let’s keep in mind that the numerical recipe has been engineered from the start to explicitly perform a mathematical optimization of the long-term economic interest of the company. If the results are sensible, then the optimization is working, and more importantly, it also proves that the optimization criterion itself is somewhat correct.

While the highly iterative engineering process of the numerical recipe can fix numerous issues that are present in the initial implementation, iterations alone aren’t sufficient if the very perspective that goes into the optimization is incorrect. In this series of lectures, I’ve already said that the optimization must be performed according to a financial metric, that is, a metric expressed in euros or dollars. However, let me clarify this statement: not using a financial metric is a mistake that endangers the whole initiative.
Unfortunately, large organizations usually shy away from financial metrics. Instead, they prefer aspirational metrics, which come as a percentage and represent some sort of perfection that would be achieved if either zero percent or 100 percent, depending on the case, were to be reached. Naturally, perfection is not of this world, and this limit situation won’t ever be reached. Service levels are, for example, the archetype of the aspirational metric. The 100% service level is impossible to reach, as it would take an unreasonable amount of stock.
Some managers in large companies love these aspirational metrics. Teams will routinely meet to discuss what can be done to further improve those metrics. As those metrics invariably depend on factors that are outside the control of the company, they can be endlessly revisited. For example, service levels depend on the volume of demand expressed by customers and the lead times offered by suppliers. Neither demand nor lead times are under the full control of the company.
Those aspirational metrics somewhat work as corporate targets when humans remain in the decision-making loop because humans don’t pay too much attention to those metrics in the first place. For example, even if everybody agrees that the service level should be increased, planners will still maintain a lot of undocumented exceptions. The service level will be systematically increased, except if the inventory risk is too high, if the minimum order quantity is too high, if the product is about to be phased out, or if there is no budget left for the product, etc.
Unfortunately, those aspirational metrics become poison when rolling out an automated process. Indeed, those metrics are incomplete and do not reflect what is actually desirable for the company. For example, achieving a 100% service level is not desirable because it would create massive overstocks for the company. It is possible - not unwise but possible - to try to re-implement all those constraints, all those exceptions on top of the aspirational metrics. I mean to have the numerical recipe shooting for the aspirational metrics with plenty of constraints mimicking what may be happening in the head of a planner. For example, we could define the rule that says that service level should be increased as long as we keep the inventory under four months’ worth of stock. However, this strategy for the design and actual implementation of the numerical recipe is exceedingly brittle. Direct financial optimization is a vastly safer, superior path.

In order to achieve an efficient collaboration between the supply chain practitioner - or more likely practitioners, plural - and the supply chain scientist, I recommend adopting early on a dual-run strategy. The numerical recipe should be run daily alongside the pre-existing manual process. With the dual run, the company is effectively generating the decision twice through two competing processes. However, despite the friction, a dual run offers substantial benefits. First, the supply chain practitioner needs freshly generated decisions that match the present-day situation to make his assessment. Otherwise, the practitioner can’t even make sense of the automated decision, can’t even identify the parts that are insane. Indeed, from the practitioner’s perspective, decisions reflecting the situation of the supply chain three weeks ago are ancient history. There is little to be gained in spending hours revisiting past stock levels.
On the contrary, if the automated decisions are fresh and reflect the present-day situation, then those automated decisions compete with the decisions that the practitioner is about to make manually. Those automated decisions can be seen as suggestions for the time being.
Second, the daily run of the numerical recipe ensures that the whole data pipeline gets a full functional test every day. Indeed, the numerical recipe does not only need to return sane results; it must also operate flawlessly from an IT infrastructure perspective. Indeed, supply chains are chaotic enough; the numerical recipe must not add its own layer of chaos on top. Putting the recipe in what amounts to be production conditions as early as possible ensures that infrequent problems will manifest themselves early and thus that the data officer and the supply chain scientists may get the chance to fix those problems early. As a rule of thumb, by the end of the first third - so by the end of the third month after starting a quantity supply initiative - the dual run should be in place, even if the numerical recipe isn’t ready yet to be put into production.
Also, by the end of the first month of the dual run, if the scientist does a proper job, then the practitioner should start observing patterns in the list of automated decisions that would have been missed otherwise, even if there are still some insane lines that still require further improvement of the numerical recipe.

Once the dual run is in place, the supply chain practitioner is expected to spend some time - one or two hours a day - to survey the decisions generated by the numerical recipe and he is expected to attempt identifying the bits that are still not quite sane. However, sometimes the situation will simply be unclear. A decision is surprising - maybe the numerical recipe is slow, maybe it isn’t. The practitioner feels uncertain and in this case he should ask the scientist to add some more instrumentation to shed light on the case. This process is exactly what is being referred to in this series of lectures as white-boxing the numerical recipe. White-boxing is a process in which the numerical recipe is made as transparent as possible to shareholders. White-boxing is a good thing - essential even - to build trust about the numerical recipe.
Assuming that the automated decisions are gathered in a table in the dashboard, the most typical form of instrumentation will be extra columns next to the decision columns. For example, if we are considering re-order quantities, then there are obvious instrumentation columns that can be considered such as the stock-on-hand quantity, the expected average lead time, the expected average demand over daily time, etc. This instrumentation is critical for the practitioner to make rapid assessments about the sanity of the automated decisions. However, we must be mindful about the amount of instrumentation that is being piled up on top of the numerical recipe. Every single indicator that gets introduced to decorate the automated decision as part of the white boxing process clutters a little bit more the view one can have of the decisions themselves. Too much of a good thing can become a bad thing. If after two months of a run, the practitioner keeps routinely requesting more instrumentation while the data pipeline has already been stabilized, then we may have a problem.
The root cause of the problem can be associated with smart bits of the numerical recipe. In chapters 5 and 6 of this series, we have seen that all techniques and models are not born equal in terms of interpretability. Many models are very opaque by design, even for data scientists who wield them. I’m not going to revisit today the classes of models that fit the bill as far as interpretability is concerned. For the sake of this discussion, I will just assume that the models that have been embedded into the numerical recipe are properly interpretable from a supply chain perspective. In this context, when the initiative appears to be stalling due to an endless stream of requests for more instrumentation, the most likely root cause is analysis paralysis. The supply chain practitioner is overthinking their assessment about the numerical recipe. This is the essence of analysis paralysis. The practitioner is holding the numerical recipe to a degree of scrutiny that exceeds what is being done for the manual process. It is the role of the supply chain executive to make sure that the initiative doesn’t get stuck in analysis paralysis. And if it happens still, and it may, it is also the role of the supply chain executive to gently remind the team that human-driven decisions are imperfect too. We are seeking an improvement over the manual process, not perfection.

Once the numerical recipe does not generate insane decisions anymore and once the decisions themselves come with what feels to be an appropriate level of instrumentation, it’s time for a gradual takeover of the automated process replacing the manual process. As a rule of thumb, this point should be reached within two to four months after the kickoff of the dual run. From day one of the dual run, the numerical recipe should have been operating over the entire scope of the initiative. Thus, in theory, the transition from manual decisions to automated ones could happen effectively overnight.
However, practice frequently disagrees with theory. If we are talking about a sizeable company, it is important to transition all decisions overnight from one process to another. Supply chains are very complex and we should expect the unexpected. Thus it is wiser to start with a small operating scope like a single product category and expand from there. For the earliest stages of the takeover, it is appropriate to take one week or maybe two weeks for each iteration. Both the supply chain practitioner and the supply chain scientists need to carefully inspect how the automated decisions get played out. And if nothing unexpected happens over this small operating scope, indeed even if the numerical recipe does not generate any more seemingly insane decisions at this point, there might still be issues in the way the automated decisions get integrated into the transactional systems. Once the numerical recipe has been driving production for a few weeks, even if the scope was relatively small, it is appropriate to accelerate the iterations.
The takeover can get more substantial increases at each iteration and the duration of the iterations themselves can be compressed as well, possibly up to two iterations per week. Indeed, the entire time frame of the transition toward the automated process should be kept reasonably short. Otherwise, the takeover delay itself introduces other classes of risk. The supply chain keeps changing as well as its applicative landscape. As a rule of thumb, the takeover should not exceed two to four months depending on the scale and complexity of the company.

As the supply chain transitions from a manual process to an automated one, a series of changes within the organization need to happen as well. Large organizations are notoriously difficult to change, but there are two distinct directions for change. The organization can add a process or the organization can remove a process.
Removing a process is much harder than adding one. Adding a process means hiring people and the only opposition to this is going to come from the very top of the company because it’s an extra budget line. Removing a process means firing people or at the very least firing their jobs while retaining and retraining the employees. When removing a process, the situation is reversed. One can expect opposition from the entire organization except from its very top.
The easiest way to bring a numerical recipe to production involves maintaining a dual run indefinitely. The existing manual process is preserved, and it now leverages the automated decisions as simple suggestions. This approach feels safe and may even provide marginal gains, as the automatic suggestions offer some benefits by helping practitioners identify some of the worst mistakes associated with the manual process. However, preserving the dual run indefinitely results in process sedimentation, where the organization fails to remove something.
For supply chain practices to become a capitalistic undertaking – a productive asset – the organization must let go of the manual process. The manual process is a dead end; it will not improve further over time. The organization must redirect all the time and energy spent on the manual process into the ongoing improvement of the automated one. Keeping the manual process around only hinders the capacity to make the most of the automation and what it has to offer. In particular, as long as manual overrides keep happening, nothing is truly reproducible due to manual interventions, and thus, nothing can be truly optimized, as optimization requires reproducibility.

The automation of decisions, even considering mundane and repetitive ones, represents a paradigm shift in the way supply chains are managed. The change is so significant that it is tempting to dismiss it altogether. However, change is coming. Two centuries of progressive mechanization of our economy have made it abundantly clear: once something can be automated, it gets automated. After a while, there is no going back to the former state of affairs. Lokad operates about 100 supply chains in highly automated setups, providing living proof that supply chain automation is already here; it’s just not widespread yet.
One of the biggest changes to be implemented by our clients concerns the role of the supply and demand planner. The mainstream form of these roles, which goes by various names in the industry – such as inventory managers, category managers, or supply managers – involves an employee owning a shortlist of SKUs, which can vary from 50 to 5,000 SKUs depending on the flow volume. The planner is responsible for the ongoing availability of the SKUs in the shortlist, either by triggering inventory replenishment or production batches, or both. The division of labor is straightforward: as the number of SKUs increases, the number of planners increases as well.
The focus of the planner is inward. This person spends a lot of time reviewing numbers, either consolidated in a spreadsheet or displayed on dashboards. Planners might be leveraging enterprise software tools, but they almost invariably finalize their decisions within spreadsheets that they personally maintain. The purpose of the spreadsheet is to provide an accessible and fully customizable numerical context to support the decisions made by the planner. The routine of the planner consists of revisiting the entire shortlist of SKUs every week, possibly every day.
However, once the numerical recipe is in production, there is no point in maintaining this schedule of manual review of the shortlist of SKUs by the planner. The planner should transition into the role of a network manager. Largely freed from data-related routines, the network manager can invest their time in communicating with the network, both upstream with suppliers and downstream with clients, and revisiting the assumptions supporting the design of the numerical recipe. The primary danger threatening the numerical recipe isn’t losing its accuracy; it’s losing its relevance. The network manager tries to identify what cannot be seen through the data lenses, at least not yet. It’s not about micromanaging the numerical recipe or making numerical adjustments to the decisions themselves; it’s about identifying factors that remain ignored or misunderstood by the numerical recipe.
The network manager consolidates insights intended for both the supply chain scientists and the supply chain executives. Based on these insights, the scientists can adjust or refactor the numerical recipe to reflect a renewed understanding of the situation.

Unfortunately, opposing the rollout of the numerical recipe isn’t the only way for the planner to maintain the status quo. Another strategy consists of continuing the same job routine: keep reviewing the shortlist of SKUs but, instead of overriding the decisions, simply report all findings, if any, to the supply chain scientist. People love their habits, and employees of large companies even more so.
The problem with this approach is that, once the automation is in place, the supply chain scientists can directly observe the outcomes of the automated process, both the good and the bad. The planner and the scientists have access to the same data; however, the scientist, by definition, has access to more powerful analytical tools compared to the planner. Thus, once the automation is rolled out, the added value of the planner’s feedback rapidly diminishes when it comes to the continuous improvement of the numerical recipe.
As the planner now has more time to analyze, they are likely to request more indicators and dashboards to be crafted by the scientist. This leads to “KPI tourism”: increasing the number of indicators to be reviewed until merely examining them becomes a full-time job. This workload also becomes a distraction for the scientists. At this stage, post-deployment, improving the numerical recipe requires a fairly good grasp of the weaknesses of the actual implementation. The scientist is ideally positioned to do this work, whereas the planner is much less suited. To be of help, the planner should become a network manager and, as pointed out earlier, start looking outward. Otherwise, the planner’s position devolves into KPI tourism.

The job of the supply chain executive is largely defined by the organization and its processes. As long as mundane decisions remain the result of a manual process, there is no alternative for the organization but to adopt a division of labor where each planner operates over their own shortlist of SKUs. Thus, the supply chain executive is first and foremost the manager of a team of planners. If the company is large enough to warrant a layer of middle management, then the executive might only be indirectly managing planners. Still, the supply chain division remains the same: a pyramid with planners at the bottom. By necessity, being a good supply chain executive means being a good coach for those planners. The executive isn’t driving the supply chain decisions; it’s the planners who are making those decisions. Improving the decisions is primarily a matter of having better work done by the planners.
Supply chain software vendors argue that their tools can make a difference. However, as we’ve already pointed out, spreadsheets are almost always used to make those decisions, no matter how much tooling has been put in place within the company. Hence, ultimately, it boils down to what the planners are doing with their own spreadsheets.
Once a class of supply chain decision has been automated, the job of the supply chain executive changes quite substantially. The job is no longer about coaching a large team of planners who are all doing variations of the same job. The job is now for the supply chain executive to do whatever it takes so that the company makes the most of its supply chain automation. The executive must become the owner of the software product that effectively drives the supply chain decisions.
Indeed, the focus and contribution of the supply chain scientists are inward-looking, just like the former contributions of the planners. The scientists can only improve the numerical recipe from the inside. They cannot be expected to refactor the applicative landscape or the broader company processes. It’s the job of the supply chain executive to make this happen. In particular, the executive becomes responsible for establishing a roadmap for the ongoing improvement of the automation.
As long as decisions were driven by planners, the roadmap was largely self-evident. Planners would continue doing what they do, and the mission for the next quarter would be largely similar to the mission they had during the previous quarter. However, once automation is in place, improving the numerical recipe almost always involves doing something that has never been done before. When crafting software, if you’re doing it right, you don’t repeat yourself – you move on. Once an insight has been acquired, a new kind of insight must be sought. The mission of the people working under a software product owner is continuously changing by design.
The new directions and objectives don’t fall from the sky. It is the responsibility of the supply chain executive to steer the development of the supply chain software product in favorable directions.

The majority of the day-to-day problems faced by supply chains are software problems. This has been the case for more than a decade already in developed countries, even in companies where all decisions are manually derived from spreadsheets. This situation is a direct consequence of supply chains being at the crossroads of many systems: the ERP, CRM, WMS, OMS, PIM, and dozens of three-letter acronyms loved by enterprise software vendors describing the various pieces of enterprise software that contain all the data of interest for supply chain purposes. Supply chains call for an end-to-end perspective of the business, and as a result, they end up connecting most of the applicative landscape of the company. However, most companies seem to still be picking supply chain leaders who know very little about software. Even worse, some of those leaders have no intention of ever learning anything about software. This situation is the “analytics supply chain bus” anti-pattern. When I say software, it should be understood as the sort of subject that I covered in the fourth chapter of this series of lectures, with topics ranging from computing hardware to software engineering.
Nowadays, software illiteracy in the top management of the supply chain spells massive trouble for the company. Either the management believes that they can do just fine without software expertise, or the management believes that they can do just fine with external software expertise. Either way, the consequences are not good.
If the top management believes that they can do just fine without software expertise, then the company is going to lose ground on all electronic channels, both on the selling side and on the buying side. Yet, as many employees do realize that those electronic channels matter, whether the top management likes it or not, shadow IT will be rampant. Furthermore, rest assured that for the next major software transition within the company, this transition is going to be vastly mismanaged, resulting in extensive periods of low quality of service due to software-related problems that should have been avoided entirely in the first place.
If the management believes that they can do just fine with third-party software expertise, it is marginally better than the previous case, but not by much. Relying on third-party experts is fine if you have a narrow, self-contained problem, like ensuring your hiring process is compliant with a piece of regulation. However, supply chain challenges are not self-contained; they spread across the entire company and very frequently even beyond the company. The most frequent pitfall associated with thinking that expertise can be outsourced consists of pushing unreasonable amounts of money to large software vendors, hoping that they will solve the problems for you. Surprise—they will not. The only cure for these problems is a modicum of software literacy from the top management.
Today, we have outlined how to bring automated supply chain decisions to production. The process is a mix of design, engineering, and conduct of change. It’s a difficult journey, with numerous seemingly easy or reassuring paths leading straight to the failure of the initiative. To be successful, the initiative requires a substantial evolution of the roles and missions of both the top management of the supply chain and its employees.
For companies that are profoundly entrenched in their manual processes, carrying out such an initiative may seem insurmountable, and thus maintaining the status quo may seem like the only option. However, I disagree with this conclusion on two fronts. First, while the journey is arduous, it is cheap, at least compared to most business investments. By reinvesting the yearly cost of five demand planners, the company can automate the workload of 50 demand planners. Naturally, large enterprise software vendors can be trusted to claim that it takes tens of millions of dollars to even get started, but there are much leaner alternatives. Second, the journey might be arduous, but it isn’t really optional either. Companies that employ armies of clerks to take their mundane, repetitive supply chain decisions also suffer from long, self-imposed lead times caused by their own internal processes. Those companies won’t remain competitive against companies that have automated their routine decision-making processes. The competitive edge to be gained from automation is always modest at the beginning; however, as the automation can be improved over time while a manual process cannot, the competitive edge becomes exponentially stronger over time. At this point in time, automated supply chain decisions may still be perceived as futuristic, but two decades from now, the opposite will be true. Manual processes will be the ones perceived as antiquated remnants of a past era.

This concludes the lecture for today. We will proceed in a minute with the questions. The next lecture will be the first week of November, on Wednesday, at 3 p.m., Paris time, as usual. We will go back to the third chapter with a supply chain persona. It will be about a fictitious company named Stuttgart, which is an automotive aftermarket company. We’ll see that automotive is the industry of the industries, and it presents quite a series of fairly specific challenges that are, once again, not properly reflected in supply chain textbooks.
Let’s have a look at the questions.
Question: Does quantitative supply chain require its own ideal way of division of labor?
Yes, it can be a gradual transition, but the idea is that the division of labor that you had with a manual process was defined by the fact that a planner can only manage so many SKUs. More SKUs, more planners. This is a very simplistic division of labor. When you have a large company and you want to have an automated process, the idea is that you are going to have people that specialize. For example, a network manager may become a specialist in the quality of service as perceived by the client. Perception matters; it’s not the abstract quality of service, like service levels. Maybe the clients have their own perspective on that, so someone may specialize in that. Another network manager may specialize in a specific angle where tighter coordination and integration with some suppliers could, for example, shorten lead times and bring new options to the table. Suddenly, the division of labor becomes more focused on the many angles that must be studied, revisited, and re-analyzed from an analytics perspective. You can have several people working on that. But again, it’s not about having something as clear-cut as a list of SKUs. It is also the essence of improving something. Maybe people would just need to be several people so that they can brainstorm together and try to identify the better ideas and sort them out. Once you go down the path of a quantitative supply chain initiative, your division of labor becomes much more akin to an ongoing engineering process, with people having deeper knowledge in specific areas and trying to come together to let a superior product emerge.
Question: Using percentages instead of financial metrics helps to hide the inefficiencies of the legacy process. When it is the case, how likely is it that the initiative can succeed?
That’s a very loaded question. One of the reasons why large companies, and so many managers within them, love those aspirational metrics is that there is no blame attached to them. Once you have an indicator expressed as a percentage, nobody realizes that it represents millions of dollars that have been lost due to a specific mistake made by a particular division led by a certain person for the last quarter alone. These percentages are incredibly opaque, and it’s a real challenge to make those initiatives succeed because, very frequently, once you put things in dollars or euros, you will uncover the true extent of the inefficiencies, which can be absolutely massive.
In the Lokad experience, for public companies that were disclosing all the numbers to the public markets with more than 200 auditors certifying the value of the inventory, we found that the inventory values were off by 20% in favor of the company. We are talking about a company with over a million euros worth of inventory in their books. The insane thing was that the inventory had been audited by more than 200 people for literally decades, and everything had been digitalized for decades as well.
When you uncover these sorts of things, it is difficult, but I believe that the way to approach it is to be tough on problems and soft on people. Companies have to learn to be soft on the people and really tough on the problems, instead of ignoring the problem and firing the people.
Question: Large companies use way more KPIs than they need. When you roll out the initiative, how do you challenge all KPIs?
Very good question. All those KPIs are a large distraction to support the work done manually by planners. Once you have a numerical recipe, why do you even care about all those KPIs? Everything that you optimize should be embedded into your financial criteria. You should have a metric that tells you for every potential decision how much money there is at stake, how much you will win or lose depending on the outcome of the decision. Instead of piling up an endless series of indicators, if you want to refine your financial metric, you can add a factor. But it doesn’t mean that you add an extra column in the report; it just means that you adjust a little bit by attributing an extra factor that additively adds or subtracts a few euros or dollars to the values that you assign to a given decision.
Fundamentally, everything that is outside these financial targets is ignored by the numerical recipe. The numerical recipe is performing a mathematical optimization process that strictly optimizes a financial target. This is it. All those other indicators are ignored. An automated setup makes it much more obvious that those indicators are pointless. They are not factored into the recipe, they are not considered by the numerical recipe, and they are not even part of the decision-making process. It also clarifies that aspirational metrics, like service levels, are adverse. You can’t just bring your quality of service to a 100% service level because it is not a desirable outcome for the company. When done correctly, automation clarifies what is actually needed in terms of indicators, and you realize that there aren’t that many indicators needed. Also, because you have fewer people involved in the process, there is less pressure to keep adding indicators. Another aspect of having large teams of planners is that every single person tends to have their one or two pet indicators. If you have 200 people and every single person wants one indicator to be added for their personal convenience, you end up with 200 indicators, which is way too many. But if you only have a tenth of that staff, the amount of pressure to pile up the indicators is much lower.
Question: How do demand planning software vendors understand their prospective clients’ ecosystems, such as safety stock requirements, while doing customization before deployment at the client? I mean, once deployment happens, there are no pitfalls in terms of forecasting error.
The classic perspective, which I believe failed to bring automation to supply chain decisions in the 1970s, was based on the assumption that a packaged software solution could address the problems of companies. I firmly believe that this is not the case. A packaged piece of software cannot fit any non-trivial supply chain. What happens is that an enterprise software vendor with some kind of inventory optimization and forecasting module tries to sell the product to a company, and as features are missing, they keep adding them. Over 10 years or more, they end up with a monstrous, bloated software product with hundreds of screens and thousands of parameter values.
The problem is that the more complex the software product, the more specific your expectations are in terms of data and what the company should have. The more complex the software product, the more difficult it becomes to plug it into the client company because you have a complex supply chain with plenty of systems already in place and a super complex supply chain optimization product. There are gaps and mismatches all over the place.
The reality is that most large companies I’ve spoken to have been operating digital supply chains in developed countries for two to three decades, and they have already deployed half a dozen demand planning, inventory optimization, supply chain design software solutions over the last two or three decades. So, they have already been there and done that, not just once, but half a dozen times. Usually, people have not been in the company long enough to realize that these processes have been happening over and over for the last two or three decades. And yet, the processes are still completely manual and often rely on tools like Excel. The problem is not forecasting error; I believe that is a misdiagnosis of the problem because the idea that you could have a perfect forecast with one system or another is ludicrous. It’s not possible to generate a perfect forecast, and humans driving a supply chain manually do not have access to perfect information either. It’s not because you’re a human demand planner that you can perfectly forecast demand.
Demand planners are capable of doing their job with less-than-perfect forecasts. These people are not magicians or super-advanced scientists. They may not be bad when it comes to forecasting, but there is no reason to expect that, on average, demand planners in this industry, which employs hundreds of thousands of people worldwide, are all super talented and capable of incredibly accurate demand forecasts. What makes the system work is that these people have their heuristics and ways of manually handling the supply chain that survive despite having poor forecasts at their disposal.
The goal in your automated setup is to have a system that works just fine even if the forecasts are not that great in the first place. This is the essence of the probabilistic forecasting approach; it’s not about refining accuracy but acknowledging and embracing the fact that the forecast is not that good. If we go back to those vendors, I believe that the industry has collectively failed to bring any satisfying degree of automation for the last four decades, and the crux of the problem was the packaged perspective, where companies were expected to just plug in a module and be done with it. This doesn’t work. Supply chains are way too diverse, versatile, and ever-changing for such a mechanical approach to be successful.
Question: With the presented perspective, how do you approach the problem of reconciling the different forecasts of the company, such as sales, inventory, and others?
My question is, why are you even doing forecasts in the first place? Forecasts are just numerical artifacts; they don’t matter. Your company is not going to be more profitable because there is a better forecast. Forecasts are exactly what I called in the previous chapters of this series of lectures, a numerical artifact. It’s an abstraction that may or may not prove to be useful for deriving certain classes of decisions. It turns out that depending on the decision you consider, the type of forecast you need may be very different.
I challenge the idea that you can have a forecast at the top and then orchestrate the entire supply chain based on those forecasts. I strongly disagree with this approach, as it has not been my experience, and I believe it does not work that well. I’ve seen tons of companies where there is a senior planning process that produces forecasts on the sales side, which is a massive exercise in sandbagging. Salespeople often vastly undershoot their projections because that way, if they exceed those numbers, they can more easily exceed expectations later on. People in factories or warehouses see these numbers coming their way and may think they can’t possibly be right, so they discard the number and do something completely different. In my opinion, the forecasting exercises carried out by the vast majority of companies are just pointless bureaucratic efforts. There is no added value in that.
From a quantitative supply chain perspective, it’s essential to focus on the decisions that matter, rather than the forecasts, which may only be technicalities. Some classes of decisions may not even need a forecast to be made, or if they do, they might require a type of forecast that is very different from what companies are currently considering. When we talk about forecasting, most people mean time series forecasts. However, if you go back to the third chapter of this series of lectures, which is dedicated to supply chain personas and real-world situations, you’ll find that time series forecasts are often not the answer. The very form of the forecast is inadequate to capture the patterns that we want to identify in the business.
To conclude, I would suggest not even trying to reconcile those forecasts. Instead, ignore them and focus on the decisions themselves. See what it takes to engineer recipes that generate good decisions, and chances are that all those forecasts can be entirely ignored.
In response to the comment about comparing financials with percentage KPI results, it’s true that you can draw comparisons by trying to correlate service levels or fill rates with your financial metrics. However, does this actually create a return on investment for the company? Taking better inventory decisions can create value for the company, but spending time correlating KPIs does not. Many companies are addicted to these KPIs expressed as percentages, but they are often meaningless bureaucratic distractions.
Enterprise software vendors love these indicators because they can sell them to client companies, resulting in many vendors pushing for more indicators. In reality, for a class of supply chain decisions, having ten numbers worth looking at every day is already quite a lot. It’s usually difficult to even identify ten numbers that are worth being looked at daily by a human. Often, it’s even less than that, and that’s fine. The classes of problems in supply chains tend to be very specific to the company and the supply chain of interest, but they are not impossibly complicated. I am not saying that supply chain situations require thousands of economic drivers. Instead, I am saying that supply chains vary a lot, and you have to make sure you solve the right problem that fits the subtleties of the supply chain of interest. For one supply chain of interest, you might have three or four basic drivers like cost of stock, gross margin, and other factors that you’ll find pretty much across the board. Then you might have four or five indicators, again financial metrics, that are very specific to one business of interest. Altogether, we are still below ten numbers.
In response to the question about balancing the trade-off between financial KPIs and supply chain KPIs, I would say yes and no. If you believe that financial KPIs are not the ones you should be optimizing, then there is a problem in the very definition of your financial KPIs. In the first chapter of this series of lectures, I mentioned that there are typically two circles of drivers to consider when establishing a financial metric. The first circle involves factors that finance can directly read in the books, such as gross margin, value of stock, and purchasing costs. The second circle includes drivers such as client goodwill and the implicit penalty when there is low quality of service. All of this needs to be integrated.
The financial perspective is not about having KPIs where there’s a trade-off. Instead, it’s about consolidating everything into one score in dollars or euros for your performance and decision-making. It’s not about reconciling supply chain KPIs with financial KPIs. Rather, it’s about having a governance in place in the company so that people can agree on the actual cost of stock, the actual cost of stockouts, and whether a reorder decision is the best option or not.
From this new perspective of owning the software product that drives the supply chain, the supply chain executive’s job is to facilitate consensus within the company. Instead of driving a mindless S&OP process where people try to revisit the numbers every month and agree on meaningless sales figures, it’s about implementing an S&OP 2.0 led by the supply chain director. Contrary to what S&OP vendors say, the CEO doesn’t have to own the S&OP process, as this might be more of a distraction for them. There’s no need to involve the CEO in every single battle.
The supply chain director’s mission is to work with the head of finance, head of marketing, and head of sales to agree on how to measure the financial impact of factors such as the quality of service. This is their job. There is no need for reconciliation of various metrics, as they are already pre-unified thanks to the work that has been carried out under the leadership of the head of the supply chain or supply chain director, depending on the title in place within the company.
That concludes today’s lecture. We will see you next time during the first week of November.