00:28 Introduzione
00:43 Robert A. Heinlein
03:03 La storia finora
06:52 Una selezione di paradigmi
08:20 Analisi statica
18:26 Programmazione ad array
28:08 Compatibilità hardware
35:38 Programmazione probabilistica
40:53 Programmazione differenziabile
55:12 Versionamento codice+dati
01:00:01 Programmazione sicura
01:05:37 In conclusione, anche gli strumenti contano nella Supply Chain
01:06:40 Prossima lezione e domande del pubblico
Descrizione
Mentre la teoria della supply chain mainstream fatica a imporsi nelle aziende in generale, uno strumento, ovvero Microsoft Excel, ha goduto di un notevole successo operativo. La reimplementazione delle ricette numeriche della teoria della supply chain mainstream tramite fogli di calcolo è banale, tuttavia, questo non è ciò che è accaduto nella pratica nonostante la consapevolezza della teoria. Dimostriamo che i fogli di calcolo hanno vinto adottando paradigmi di programmazione che si sono dimostrati superiori nel fornire risultati di supply chain.
Trascrizione completa

Ciao a tutti, benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò la mia quarta lezione: Paradigmi di programmazione per la supply chain.

Quindi, quando mi viene chiesto: “Signor Vermorel, quali sono le aree di maggior interesse per lei in termini di conoscenza della supply chain?”, una delle mie risposte principali è di solito i paradigmi di programmazione. E poi, non troppo frequentemente, ma abbastanza frequentemente, la reazione della persona con cui sto parlando è: “Paradigmi di programmazione, signor Vermorel? Di cosa stai parlando? Come può essere anche lontanamente rilevante per il compito in questione?” E questo tipo di reazioni, ovviamente, non sono così frequenti, ma quando accadono, mi ricordano invariabilmente questa citazione completamente incredibile di Robert A. Heinlein, considerato il decano degli scrittori di fantascienza.
Heinlein ha una citazione fantastica sull’uomo competente, che sottolinea l’importanza della competenza in vari campi, specialmente nella supply chain dove abbiamo problemi complessi tra le mani. Questi problemi sono quasi altrettanto sfidanti come la vita stessa, e credo che valga davvero la pena dedicare del tempo all’esplorazione dell’idea dei paradigmi di programmazione, in quanto potrebbe portare molto valore alla vostra supply chain.
Finora, nella prima lezione, abbiamo visto che i problemi della supply chain sono complessi. Chiunque parli di soluzioni ottimali non ha capito il punto; non esiste nulla di remotamente vicino all’ottimalità. Nella seconda lezione, ho delineato la Supply Chain Quantitativa, una visione con cinque requisiti chiave per l’eccellenza nella gestione della supply chain. Questi requisiti non sono sufficienti da soli, ma non possono essere bypassati se si vuole raggiungere l’eccellenza.
Nella terza lezione, ho discusso la consegna di prodotti software nel contesto dell’ottimizzazione della supply chain. Ho difeso la proposta che l’ottimizzazione della supply chain richiede un prodotto software che venga affrontato correttamente in modo capitalista, ma non è possibile trovare un tale prodotto sugli scaffali. C’è troppa diversità e le sfide affrontate vanno ben oltre le tecnologie che abbiamo al momento. Quindi, sarà necessariamente qualcosa di completamente personalizzato. Pertanto, se si tratta di un prodotto software che sarà personalizzato per l’azienda o la supply chain di interesse, sorge la questione di quali sono gli strumenti adeguati per consegnare effettivamente questo prodotto. Questo mi porta all’argomento di oggi: lo strumento adeguato inizia con i giusti paradigmi di programmazione, perché dovremo programmare questo prodotto in un modo o nell’altro.

Finora, abbiamo bisogno di capacità programmatiche per affrontare il lato dell’ottimizzazione del problema, da non confondere con il lato gestionale. Quello che abbiamo visto, che è stato l’argomento della mia precedente lezione, è che Microsoft Excel è stato il vincitore finora. Dalle piccole alle grandi aziende, è onnipresente, viene utilizzato ovunque. Anche nelle aziende che hanno investito milioni di dollari in sistemi super intelligenti, Excel è ancora il re, e perché? Perché ha le giuste proprietà di programmazione. È molto espressivo, agile, accessibile e mantenibile. Tuttavia, Excel non è il punto finale. Credo fermamente che possiamo fare molto di più, ma abbiamo bisogno degli strumenti giusti, della mentalità giusta, delle intuizioni e dei paradigmi di programmazione giusti.

I paradigmi di programmazione potrebbero sembrare eccessivamente oscuri per il pubblico, ma in realtà è un campo di studio che è stato intensamente studiato negli ultimi cinque decenni. È stato fatto un immenso lavoro in questo campo di studio. Non è ampiamente conosciuto da un pubblico più vasto, ma ci sono intere biblioteche piene di lavori di alta qualità che sono stati realizzati da molte persone. Quindi oggi, sto per presentare una serie di sette paradigmi che Lokad ha adottato. Non abbiamo inventato nessuna di queste idee; le abbiamo prese da persone che le hanno inventate prima di noi. Tutti questi paradigmi sono stati implementati nel prodotto software di Lokad, e dopo quasi un decennio di esecuzione di Lokad in produzione, sfruttando questi paradigmi, credo che siano stati assolutamente fondamentali per il nostro successo operativo finora.

Procediamo con questa lista con l’analisi statica. Il problema qui è la complessità. Come affronti la complessità nella supply chain? Ti troverai di fronte a sistemi aziendali che hanno centinaia di tabelle, ognuna con decine di campi. Se stai considerando un problema semplice come il riapprovvigionamento di inventario in un magazzino, devi tenere conto di così tante cose. Puoi avere quantitativi minimi d’ordine (MOQ), sconti sul prezzo, previsioni della domanda, previsioni dei tempi di consegna e tutti i tipi di resi. Puoi avere limitazioni di spazio sugli scaffali, limiti di capacità di ricezione e date di scadenza che rendono obsoleti alcuni dei tuoi lotti. Quindi, ti ritrovi con un sacco di cose da considerare. Nella supply chain, l’idea di “muoversi velocemente e rompere le cose” non è proprio la mentalità giusta. Se ordini involontariamente merci del valore di un milione di dollari che non ti servono affatto, questo è un errore molto costoso. Non puoi avere un software che gestisce la tua supply chain, prende decisioni di routine e quando c’è un bug, costa milioni. Abbiamo bisogno di qualcosa con un grado di correttezza molto elevato per design. Non vogliamo scoprire i bug in produzione. Questo è molto diverso dal tuo software medio in cui un crash non è un grosso problema.
Quando si tratta di ottimizzazione della supply chain, questo non è il solito problema. Se hai appena inviato un ordine massiccio e errato a un fornitore, non puoi semplicemente telefonargli una settimana dopo per dire: “Oh, mi scuso, no, dimentica quello, non abbiamo mai ordinato quello”. Quegli errori costeranno molti soldi. L’analisi statica viene chiamata così perché si tratta di analizzare un programma senza eseguirlo. L’idea è che hai un programma scritto con istruzioni, parole chiave e tutto il resto, e senza nemmeno eseguire questo programma, puoi già dire se il programma presenta problemi che quasi certamente avranno un impatto negativo sulla tua produzione, soprattutto sulla produzione della tua supply chain. La risposta è sì. Queste tecniche esistono e sono implementate ed estremamente preziose.
Solo per dare un esempio, puoi vedere uno screenshot di Envision sullo schermo. Envision è un linguaggio di programmazione specifico per un dominio che è stato sviluppato da Lokad per quasi un decennio ed è dedicato all’ottimizzazione predittiva della supply chain. Quello che stai vedendo è uno screenshot dell’editor di codice di Envision, un’app web che puoi usare online per modificare il codice. La sintassi è fortemente influenzata da Python. In questo piccolo screenshot, con solo quattro righe, sto illustrando l’idea che se stai scrivendo una grande logica per il riapprovvigionamento di inventario in un magazzino e introduci alcune variabili economiche, come gli sconti sul prezzo, attraverso un’analisi logica del programma, puoi vedere che quegli sconti sul prezzo non hanno alcuna relazione con i risultati finali restituiti dal programma, che sono le quantità da riapprovvigionare. Qui hai un problema ovvio. Hai introdotto una variabile importante, gli sconti sul prezzo, e quegli sconti sul prezzo logicamente non hanno alcuna influenza sui risultati finali. Quindi qui abbiamo un problema che può essere rilevato tramite analisi statica. È un problema ovvio perché se introduciamo variabili nel codice che non hanno alcun impatto sull’output del programma, allora non servono a nulla. In questo caso, ci troviamo di fronte a due opzioni: o quelle variabili sono effettivamente codice morto e il programma non dovrebbe compilare (dovresti semplicemente eliminare questo codice morto per ridurre la complessità e non accumulare complessità accidentale), o è stato un errore genuino e c’è una variabile economica importante che avrebbe dovuto essere inserita nel tuo calcolo, ma hai fatto cadere la palla a causa di distrazione o qualche altra ragione.
L’analisi statica è assolutamente fondamentale per raggiungere qualsiasi grado di correttezza progettuale. Si tratta di risolvere i problemi a tempo di compilazione quando si scrive il codice, prima ancora di toccare i dati. Se i problemi emergono durante l’esecuzione, è probabile che si verifichino solo durante la notte, quando viene eseguito il batch notturno per il rifornimento del magazzino. Il programma è probabile che venga eseguito in orari insoliti quando non c’è nessuno che lo controlla, quindi non si vuole che si blocchi quando non c’è nessuno davanti al programma. Dovrebbe bloccarsi quando le persone stanno effettivamente scrivendo il codice.
L’analisi statica ha molti scopi. Ad esempio, presso Lokad, utilizziamo l’analisi statica per l’edizione WYSIWYG dei dashboard. WYSIWYG sta per “what you see is what you get”. Immagina di costruire un dashboard per la segnalazione, con grafici a linee, grafici a barre, tabelle, colori e vari effetti di stile. Vuoi essere in grado di farlo in modo visuale, senza dover modificare lo stile del tuo dashboard tramite il codice, poiché è molto complicato. Tutte le impostazioni che hai implementato verranno reiniettate nel codice stesso, e ciò avviene attraverso l’analisi statica.
Un altro aspetto presso Lokad, che potrebbe non essere così importante per l’intera supply chain ma sicuramente critico per il progetto, era affrontare un linguaggio di programmazione chiamato Envision che stiamo sviluppando. Sapevamo fin dal primo giorno, quasi dieci anni fa, che sarebbero stati commessi errori. Non avevamo una sfera di cristallo per avere una visione perfetta fin dal primo giorno. La domanda era: come possiamo assicurarci di poter correggere quegli errori di progettazione nel linguaggio di programmazione stesso nel modo più comodo possibile? Qui, Python è stata una storia di avvertimento per me.
Python, che non è un linguaggio nuovo, è stato rilasciato per la prima volta nel 1991, quasi 30 anni fa. La migrazione da Python 2 a Python 3 ha richiesto all’intera comunità quasi un decennio ed è stato un processo da incubo, molto doloroso per le aziende coinvolte in questa migrazione. La mia percezione era che il linguaggio stesso non avesse abbastanza costrutti. Non è stato progettato in modo tale da consentire la migrazione dei programmi da una versione del linguaggio di programmazione a un’altra versione. Era effettivamente estremamente difficile farlo in modo completamente automatizzato, e questo perché Python non è stato progettato tenendo conto dell’analisi statica. Quando si ha un linguaggio di programmazione per la supply chain, si desidera davvero uno che abbia un’ottima qualità in termini di analisi statica perché i programmi saranno a lunga durata. Le supply chain non hanno il lusso di dire: “Aspettate tre mesi; stiamo solo riscrivendo il codice. Aspettateci; la cavalleria sta arrivando. Non funzionerà solo per un paio di mesi”. È letteralmente come riparare un treno mentre il treno sta viaggiando sui binari a piena velocità e si vuole riparare il motore mentre il treno sta funzionando. È così che sembra riparare le cose della supply chain che sono effettivamente in produzione. Non hai il lusso di mettere in pausa il sistema; non si ferma mai.

Il secondo paradigma è la programmazione ad array. Vogliamo avere la complessità sotto controllo, poiché è un tema ricorrente nelle supply chain. Vogliamo avere una logica in cui non ci siano determinate classi di errori di programmazione. Ad esempio, ogni volta che si hanno cicli o rami scritti esplicitamente dai programmatori, ci si espone a intere classi di problemi molto difficili. Diventa estremamente difficile quando le persone possono scrivere cicli arbitrari per avere garanzie sulla durata del calcolo. Sebbene possa sembrare un problema di nicchia, non è esattamente il caso nell’ottimizzazione della supply chain.
Nella pratica, diciamo che hai una catena di vendita al dettaglio. A mezzanotte, avranno consolidato completamente tutte le vendite di tutta la rete e i dati verranno consolidati e passati a qualche tipo di sistema per l’ottimizzazione. Questo sistema avrà esattamente una finestra di 60 minuti per fare la previsione, l’ottimizzazione delle scorte e le decisioni di riallocazione per ogni singolo negozio della rete. Una volta fatto, i risultati verranno passati al sistema di gestione del magazzino in modo che possano iniziare a preparare tutte le spedizioni. I camion verranno caricati, forse alle 5:00 del mattino, e alle 9:00 del mattino i negozi apriranno con la merce già ricevuta e messa sugli scaffali.
Tuttavia, hai un timing molto rigoroso e se i tuoi calcoli vanno oltre questa finestra di 60 minuti, metti a rischio l’intera esecuzione della supply chain. Non vuoi scoprire in produzione quanto tempo richiedono le cose. Se hai cicli in cui le persone possono decidere quante iterazioni fare, è molto difficile avere una prova della durata del tuo calcolo. Tieni presente che stiamo parlando di ottimizzazione della supply chain. Non hai il lusso di fare una revisione tra pari e controllare tutto due volte. A volte, a causa della pandemia, alcuni paesi si chiudono mentre altri riaprono in modo piuttosto erratico, di solito con un preavviso di 24 ore. Devi reagire rapidamente.
Quindi, la programmazione ad array è l’idea che puoi operare direttamente sugli array. Se guardiamo il frammento di codice che abbiamo qui, questo è il codice Envision, il DSL di Lokad. Per capire cosa sta succedendo, devi capire che quando scrivo “orders.amounts”, quello che viene è una variabile e “orders” è effettivamente una tabella nel senso di una tabella relazionale, come una tabella nel tuo database. Ad esempio, qui nella prima riga, “amounts” sarebbe una colonna nella tabella. Nella riga uno, quello che sto facendo è che sto letteralmente dicendo per ogni singola riga della tabella degli ordini, prenderò solo la “quantità”, che è una colonna, e la moltiplicherò per il “prezzo”, e poi ottengo una terza colonna che viene generata dinamicamente, che è “amount”.
A proposito, il termine moderno per la programmazione ad array oggi è anche conosciuto come programmazione di data frame. Il campo di studio è piuttosto antico; risale a tre o quattro decenni, forse anche a quattro o cinque. È stato chiamato programmazione ad array anche se oggi le persone sono di solito più familiari con l’idea di data frame. Nella riga due, stiamo facendo un filtro, proprio come SQL. Stiamo filtrando le date e si verifica che la tabella degli ordini abbia una data. Verrà filtrata e dico “data che è maggiore di oggi meno 365”, quindi sono giorni. Manteniamo i dati dell’anno scorso e poi scriviamo “products.soldLastYear = SUM(orders.amount)”.
Ora, la cosa interessante è che abbiamo quello che chiamiamo un join naturale tra prodotti e ordini. Perché? Perché ogni riga dell’ordine è associata a un prodotto e un solo prodotto, e un prodotto è associato a zero o più righe dell’ordine. In questa configurazione, puoi dire direttamente, “Voglio calcolare qualcosa a livello di prodotto che è solo una somma di ciò che sta accadendo a livello di ordini,” ed è esattamente quello che viene fatto alla riga nove. Potresti notare che la sintassi è molto essenziale; non ci sono molti accidenti o tecnicismi. Sostengo che questo codice sia quasi completamente privo di qualsiasi accidentale quando si tratta di programmazione di data frame. Quindi, nelle righe 10, 11 e 12, stiamo semplicemente mettendo una tabella in mostra sul nostro dashboard, cosa che può essere fatta molto comodamente: “LIST(PRODUCTS)”, e poi “TO(products)”.
Ci sono molti vantaggi della programmazione ad array per le supply chain. Prima di tutto, elimina intere classi di problemi. Non avrai errori di uno in più nei tuoi array. Sarà molto più facile parallelizzare e persino distribuire il calcolo. Questo è molto interessante perché significa che puoi scrivere un programma e far eseguire il programma non su una sola macchina locale ma direttamente su un insieme di macchine che vivono nel cloud, e a proposito, è esattamente quello che viene fatto in Lokad. Questa parallelizzazione automatica è di grande interesse.
Vedi, il modo in cui funziona è che quando fai ottimizzazione della supply chain, i tuoi tipici modelli di consumo in termini di hardware informatico sono super intermittenti. Se torno all’esempio che stavo dando sulla finestra di 60 minuti per le reti di vendita durante il rifornimento dei negozi, significa che c’è un’ora al giorno in cui hai bisogno di potenza di calcolo per fare tutti i tuoi calcoli, ma il resto del tempo, le altre 23 ore, non ne hai bisogno. Quindi quello che vuoi è un programma che, quando stai per eseguirlo, si distribuisca su molte macchine e poi, una volta fatto, rilasci tutte quelle macchine in modo che possano avvenire altri calcoli. L’alternativa sarebbe avere molte macchine che stai affittando e pagando tutto il giorno ma che usi solo il 5% del tempo, il che è molto inefficiente.
Questa idea che puoi distribuire rapidamente e in modo prevedibile su molte macchine e poi cedere la potenza di elaborazione, ha bisogno del cloud in un ambiente multi-tenant e di una serie di altre cose che Lokad sta facendo. Ma prima di tutto, ha bisogno della cooperazione del linguaggio di programmazione stesso. È qualcosa che semplicemente non è fattibile con un linguaggio di programmazione generico come Python, perché il linguaggio stesso non si presta a questo tipo di approccio molto intelligente e pertinente. Questo va oltre i semplici trucchi; si tratta letteralmente di dividere i costi dell’hardware informatico del tuo reparto IT per 20, accelerando massicciamente l’esecuzione ed eliminando intere classi di potenziali errori nella tua supply chain. Questo cambia il gioco.
La programmazione ad array esiste già in molti aspetti, come NumPy e pandas in Python, che sono così popolari per il segmento degli scienziati della supply chain. Ma la domanda che ti faccio è: se è così importante e utile, perché queste cose non sono cittadini di prima classe del linguaggio stesso? Se tutto ciò che fai è passare attraverso NumPy, allora NumPy dovrebbe essere un cittadino di prima classe. Direi che puoi fare ancora meglio di NumPy. NumPy riguarda solo la programmazione ad array su una macchina, ma perché non fare la programmazione ad array su un insieme di macchine? È molto più potente e molto più adatto quando hai un cloud con capacità hardware accessibile.
Quindi, qual è il collo di bottiglia nell’ottimizzazione della supply chain? C’è questo detto di Goldratt che dice: “Qualsiasi miglioramento apportato accanto al collo di bottiglia in una supply chain è un’illusione”, e sono molto d’accordo con questa affermazione. Realisticamente, quando vogliamo fare ottimizzazione della supply chain, il collo di bottiglia saranno le persone, e più specificamente, gli scienziati della supply chain che, sfortunatamente per Lokad e i miei clienti, non crescono sugli alberi.
Il collo di bottiglia sono gli scienziati della supply chain, le persone che possono creare le ricette numeriche che tengono conto di tutte le strategie dell’azienda, dei comportamenti avversari dei concorrenti e che trasformano tutta questa intelligenza in qualcosa di meccanico che può essere eseguito su larga scala. La tragedia del modo ingenuo di fare data science, quando ho iniziato il mio dottorato, che non ho mai completato tra l’altro, era che potevo vedere che tutti nel laboratorio facevano letteralmente data science. La maggior parte delle persone stava scrivendo codice per qualche tipo di modello avanzato di machine learning, premevano invio e poi iniziavano ad aspettare. Se hai un grande dataset, diciamo 5-10 gigabyte, non sarà in tempo reale. Quindi, l’intero laboratorio era pieno di persone che scrivevano poche righe, premevano invio e poi andavano a prendere un caffè o leggere qualcosa online. Di conseguenza, la produttività era estremamente bassa.
Quando ho creato la mia azienda, avevo in mente che non volevo finire per pagare un esercito di persone super intelligenti che passano la maggior parte della giornata sorseggiando caffè, aspettando che i loro programmi completino in modo da poter avere risultati e andare avanti. In teoria, avrebbero potuto parallelizzare molte cose contemporaneamente e fare esperimenti, ma nella pratica non ho mai visto davvero questo. Intellettualmente, quando sei impegnato a trovare una soluzione per un problema, vuoi testare la tua ipotesi e hai bisogno del risultato per andare avanti. È molto difficile fare multitasking su cose altamente tecniche e seguire contemporaneamente più percorsi intellettuali.
Tuttavia, c’era un lato positivo. Gli scienziati dei dati e ora gli scienziati della supply chain presso Lokad, non finiscono per scrivere mille righe di codice e poi dire “per favore esegui”. Di solito aggiungono solo due righe a uno script lungo mille righe e chiedono di eseguire lo script. Questo script viene eseguito sugli stessi dati che hanno appena eseguito pochi minuti prima. È quasi esattamente la stessa logica, tranne per quelle due righe. Quindi, come puoi elaborare terabyte di dati in pochi secondi invece di diversi minuti? La risposta è che se per l’esecuzione precedente dello script hai registrato tutti i passaggi intermedi del calcolo e li hai messi in archiviazione (tipicamente unità a stato solido o SSD), che sono molto economiche, veloci e convenienti.
La prossima volta che esegui il tuo programma, il sistema noterà che è quasi lo stesso script. Farà una differenza e vedrà che in termini di grafo di calcolo, è quasi identico, tranne per alcuni bit. In termini di dati, di solito è identico al 100%. A volte ci sono alcuni cambiamenti, ma quasi nulla. Il sistema autodiagnosticherà che hai solo alcune cose da calcolare, quindi puoi avere i risultati in pochi secondi. Questo può aumentare notevolmente la produttività del tuo scienziato della supply chain. Puoi passare da persone che premendo Invio aspettano 20 minuti per il risultato a qualcosa in cui premendo Invio e dopo 5 o 10 secondi hanno il risultato e possono andare avanti.
Sto parlando di qualcosa che potrebbe sembrare super oscuro, ma nella pratica stiamo parlando di qualcosa che ha un impatto 10 volte maggiore sulla produttività. Questo è enorme. Quindi quello che stiamo facendo qui è utilizzare un trucco intelligente che Lokad non ha inventato. Stiamo sostituendo una risorsa di calcolo grezzo, che è il calcolo, con un’altra, che è la memoria e l’archiviazione. Abbiamo le risorse di calcolo fondamentali: calcolo, memoria (volatile o persistente) e larghezza di banda. Queste sono le risorse fondamentali che paghi quando acquisti risorse su una piattaforma di cloud computing. In realtà puoi sostituire una risorsa con un’altra e l’obiettivo è ottenere il massimo risultato con il minor costo possibile.
Quando le persone dicono che dovresti utilizzare il calcolo in memoria, direi che è una sciocchezza. Se dici calcolo in memoria, significa che stai mettendo l’accento sul design su una risorsa rispetto a tutte le altre. Ma no, ci sono compromessi e la cosa interessante è che puoi avere un linguaggio di programmazione e un ambiente che rendono più facili da implementare questi compromessi e prospettive. In un linguaggio di programmazione generico, è possibile farlo, ma devi farlo manualmente. Ciò significa che la persona che lo fa deve essere un ingegnere software professionista. Uno scienziato della supply chain non eseguirà queste operazioni a basso livello con le risorse di calcolo fondamentali della tua piattaforma. Questo deve essere progettato a livello del linguaggio di programmazione stesso.
Ora, parliamo di programmazione probabilistica. Nella seconda lezione in cui ho presentato la visione per la supply chain quantitativa, il mio primo requisito era che dovessimo guardare a tutti i futuri possibili. La risposta tecnica a questa esigenza è la previsione probabilistica. Vuoi occuparti di futuri in cui hai probabilità. Tutti i futuri sono possibili, ma non sono tutti ugualmente probabili. Devi avere un’algebra in cui puoi fare calcoli con l’incertezza. Una delle mie grandi critiche a Excel è che è estremamente difficile rappresentare l’incertezza in un foglio di calcolo, indipendentemente che sia Excel o una qualsiasi versione più moderna basata su cloud. In un foglio di calcolo, è molto difficile rappresentare l’incertezza perché hai bisogno di qualcosa di meglio dei numeri.
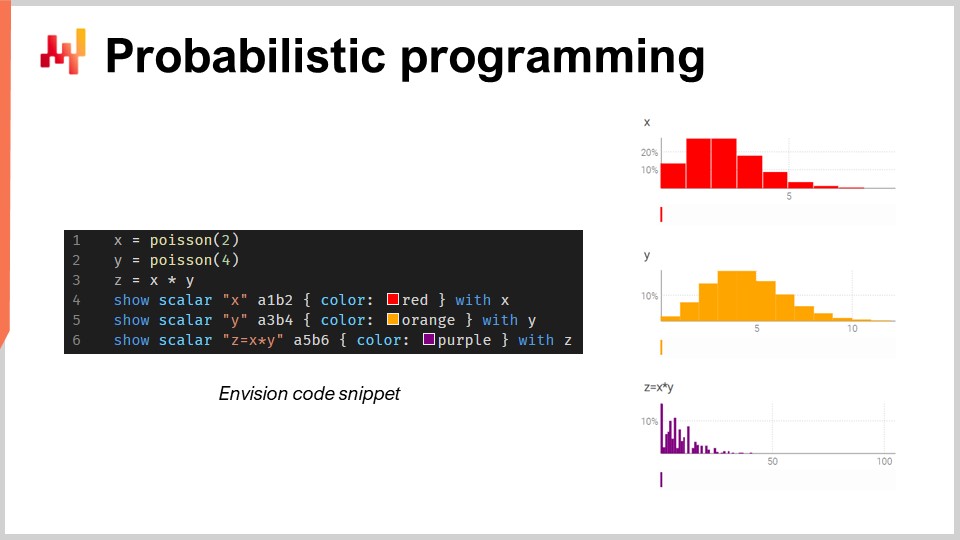
In questo piccolo frammento, sto illustrando l’algebra delle variabili casuali, che è una caratteristica nativa di Envision. Nella prima riga, sto generando una distribuzione di Poisson che è discreta, con una media di 2, e metto tutto nella variabile X. Poi, faccio lo stesso per un’altra distribuzione di Poisson, Y. Poi, calcolo Z come la moltiplicazione di X per Y. Questa operazione, la moltiplicazione di variabili casuali, può sembrare molto strana. Perché hai bisogno di questo tipo di cosa dal punto di vista della supply chain? Lasciami darti un esempio.
Supponiamo che tu sia nel settore dell’aftermarket automobilistico e stai vendendo pastiglie dei freni. Le persone non comprano pastiglie dei freni singolarmente; ne comprano due o quattro. Quindi la domanda è, se vuoi fare una previsione, potresti voler prevedere le probabilità che i clienti si presentino effettivamente per acquistare un certo tipo di pastiglie dei freni. Quella sarà la tua prima variabile casuale che ti dà la probabilità di osservare zero unità di domanda, una unità di domanda, due, tre, quattro, ecc. per le pastiglie dei freni. Poi avrai un’altra distribuzione di probabilità che rappresenta se le persone compreranno due o quattro pastiglie dei freni. Forse sarà 50-50, o forse sarà il 10 percento che compra due e il 90 percento che compra quattro. La cosa è che hai questi due angoli, e se vuoi conoscere il consumo effettivo totale delle pastiglie dei freni, devi moltiplicare la probabilità che un cliente si presenti per questa pastiglia dei freni e poi la distribuzione di probabilità dell’acquisto di due o quattro. Quindi, devi avere questa moltiplicazione di queste due quantità incerte.
Qui, sto assumendo che le due variabili casuali siano indipendenti. A proposito, questa moltiplicazione di variabili casuali è conosciuta in matematica come convoluzione discreta. Puoi vedere nella schermata il cruscotto generato da Envision. Nelle prime tre righe, sto facendo questo calcolo di algebra casuale, e poi nelle righe quattro, cinque e sei, sto mettendo queste cose in mostra nella pagina web, nel cruscotto generato dallo script. Sto tracciando A1, B2, ad esempio, proprio come in una griglia di Excel. I cruscotti di Lokad sono organizzati in modo simile alle griglie di Excel, con le posizioni che hanno colonne B, C, ecc., e righe 1, 2, 3, 4, 5.
Puoi vedere che la convoluzione discreta, Z, ha questo pattern molto strano e molto comune nelle supply chain quando le persone possono comprare pacchetti, lotti o multipli. In questo tipo di situazione, di solito è meglio decomporre le fonti degli eventi moltiplicativi associati al lotto o al pacchetto. Devi avere un linguaggio di programmazione che abbia queste capacità disponibili a portata di mano, come cittadini di prima classe. Ecco esattamente di cosa si tratta la programmazione probabilistica, ed è così che l’abbiamo implementata in Envision.

Ora, parliamo di programmazione differenziabile. Devo mettere una nota qui: non mi aspetto che il pubblico capisca davvero cosa sta succedendo, e mi scuso per questo. Non è che la vostra intelligenza sia carente; è solo che questo argomento merita una serie di lezioni completa. Infatti, se guardi il piano per le prossime lezioni, c’è una serie intera dedicata alla programmazione differenziabile. Andrò molto veloce, e sarà abbastanza criptico, quindi mi scuso in anticipo.
Procediamo con il problema della supply chain di interesse qui, che è la cannibalizzazione e la sostituzione. Questi problemi sono molto interessanti e probabilmente sono dove la previsione delle serie temporali , che è onnipresente, fallisce nel modo più brutale. Perché? Perché spesso abbiamo clienti o potenziali clienti che vengono da me e chiedono se possiamo fare, ad esempio, previsioni a 13 settimane per determinati articoli come zaini. Direi di sì, possiamo farlo, ma ovviamente, se prendiamo uno zaino e vogliamo prevedere la domanda per questo prodotto, dipende enormemente da cosa stai facendo con gli altri zaini. Se hai solo uno zaino, allora forse concentrerai tutta la domanda per gli zaini su questo prodotto. Se introduci 10 varianti diverse, ovviamente ci sarà un sacco di cannibalizzazione. Non moltiplicherai il totale delle vendite per un fattore di 10 solo perché hai moltiplicato il numero di riferimenti per 10. Quindi ovviamente, si verificano cannibalizzazione e sostituzione. Questi fenomeni sono diffusi nelle supply chain.
Come si analizza la cannibalizzazione o la sostituzione? Il modo in cui lo facciamo in Lokad, e non pretendo che sia l’unico modo, ma è sicuramente un modo che funziona, è tipicamente guardando il grafico che collega i clienti e i prodotti. Perché? Perché la cannibalizzazione avviene quando i prodotti sono in competizione tra loro per gli stessi clienti. La cannibalizzazione è letteralmente il riflesso che hai un cliente con un bisogno, ma hanno preferenze e sceglieranno un prodotto tra l’insieme di prodotti che soddisfano la loro affinità, e ne sceglieranno solo uno. Questa è l’essenza della cannibalizzazione.
Se vuoi analizzare questo, devi analizzare non le serie temporali delle vendite, perché in primo luogo non catturi queste informazioni. Vuoi analizzare il grafico che collega le transazioni storiche tra clienti e prodotti. Si scopre che nella maggior parte delle attività commerciali, questi dati sono facilmente disponibili. Per il commercio elettronico, è scontato. Ogni unità che vendi, conosci il cliente. Nel B2B, è la stessa cosa. Anche nel B2C nel settore del commercio al dettaglio, nella maggior parte dei casi, le catene di vendita al dettaglio hanno programmi di fedeltà in cui conoscono una percentuale a due cifre dei clienti che si presentano con le loro carte, quindi sai chi sta comprando cosa. Non per il 100% del traffico, ma non ne hai bisogno. Se hai il 10% e oltre delle tue transazioni storiche in cui conosci la coppia di clienti e prodotti, è abbastanza buono per questo tipo di analisi.
In questo frammento relativamente piccolo, dettaglierò un’analisi di affinità tra clienti e prodotti. Questo è letteralmente il passo fondamentale che devi compiere per fare qualsiasi tipo di analisi di cannibalizzazione. Diamo un’occhiata a cosa sta succedendo in questo codice.
Dalle righe uno a cinque, questo è molto banale; sto solo leggendo un file piatto che contiene un’elenco delle transazioni. Sto solo leggendo un file CSV che ha quattro colonne: data, prodotto, cliente e quantità. Qualcosa di molto basilare. Non sto nemmeno usando tutte quelle colonne, ma solo per rendere l’esempio un po’ più concreto. Nella cronologia delle transazioni, assumo che i clienti siano noti per tutte quelle transazioni. Quindi, è molto banale; sto solo leggendo i dati da una tabella.
Quindi, nelle righe sette e otto, sto semplicemente creando la tabella dei prodotti e la tabella dei clienti. In un ambiente di produzione reale, di solito non creerei quelle tabelle; le leggerei da altri file piatti altrove. Volevo mantenere l’esempio super semplice, quindi sto solo estraendo una tabella dei prodotti dai prodotti che ho osservato nella cronologia delle transazioni, e faccio lo stesso per i clienti. Vedi, è solo un trucco per mantenerlo super semplice.
Ora, le righe 10, 11 e 12 coinvolgono spazi latini, e questo diventerà un po’ più oscuro. Prima, nella riga 10, sto creando una tabella con 64 righe. La tabella non contiene nulla; è definita solo dal fatto stesso che ha 64 righe, e basta. Quindi questo è come un segnaposto, una tabella banale con molte righe e nessuna colonna. Non è così utile così com’è. Poi, “P” è fondamentalmente un prodotto cartesiano, un’operazione matematica con tutte le coppie. È una tabella in cui hai una riga per ogni riga nei prodotti e ogni riga nella tabella “L”. Quindi, questa tabella “P” ha 64 righe in più rispetto alla tabella dei prodotti, e faccio la stessa cosa per i clienti. Sto solo gonfiando quelle tabelle attraverso questa dimensione extra, che è questa tabella “L”.
Questo sarà il mio supporto per i miei spazi latini, che è esattamente ciò che sto per imparare. Quello che voglio imparare è, per ogni prodotto, uno spazio latino che sarà un vettore di 64 valori, e per ogni cliente, uno spazio latino di 64 valori anche. Se voglio conoscere l’affinità tra un cliente e un prodotto, voglio solo essere in grado di fare il prodotto scalare tra i due. Il prodotto scalare è semplicemente la moltiplicazione punto per punto di tutti i termini di quei due vettori, e poi fai la somma. Può sembrare molto tecnico, ma è solo la moltiplicazione punto per punto più la somma - questo è il prodotto scalare.
Questi spazi latini sono solo un gergo fantasioso per creare uno spazio con parametri un po’ inventati, dove voglio solo imparare. Tutta la magia della programmazione differenziabile avviene in soli cinque righe, dalle righe 14 alla 18. Ho una parola chiave, “autodiff”, e “transazioni”, che indica che questa è una tabella di interesse, una tabella di osservazioni. Elaborerò questa tabella riga per riga per fare il mio processo di apprendimento. In questo blocco, sto dichiarando un insieme di parametri. I parametri sono le cose che vuoi imparare, come numeri, ma non conosci ancora i valori. Queste cose verranno semplicemente inizializzate casualmente, con numeri casuali.
Introduco “X”, “X*” e “Y”. Non entrerò nel dettaglio di cosa fa esattamente “X*”, forse nelle domande. Restituisco un’espressione che è la mia funzione di perdita, e questa è la somma. L’idea del filtraggio collaborativo o della decomposizione di matrici è semplicemente che vuoi imparare spazi latini che si adattino a tutti i tuoi collegamenti nel tuo grafo bipartito. So che è un po’ tecnico, ma quello che stiamo facendo è letteralmente molto semplice, dal punto di vista della supply chain. Stiamo imparando l’affinità tra prodotti e clienti.
So che sembra probabilmente super opaco, ma rimani con me e ci saranno altre lezioni in cui ti darò un’introduzione più ponderata su questo argomento. Tutto il processo viene fatto in cinque righe, ed è completamente notevole. Quando dico cinque righe, non sto barando dicendo: “Guarda, sono solo cinque righe, ma in realtà sto facendo una chiamata a una libreria di terze parti di complessità gigantesca in cui sto nascondendo tutta l’intelligenza”. No, no, no. Qui, in questo esempio, non c’è letteralmente nessuna magia dell’apprendimento automatico oltre alle due parole chiave “autodiff” e “params”. “Autodiff” viene utilizzato per definire un blocco in cui avverrà la programmazione differenziabile, e a proposito, questo è un blocco in cui posso programmare qualsiasi cosa, quindi letteralmente posso iniettare il nostro programma. Poi, ho “params” per dichiarare i miei problemi, e questo è tutto. Quindi, vedi, non c’è magia opaca in corso; non c’è una libreria di un milione di righe sullo sfondo che fa tutto il lavoro per te. Tutto ciò che devi sapere è letteralmente su questo schermo, e questa è la differenza tra un paradigma di programmazione e una libreria. Il paradigma di programmazione ti offre accesso a capacità apparentemente incredibilmente sofisticate, come fare analisi di cannibalizzazione con poche righe di codice, senza ricorrere a librerie di terze parti che avvolgono la complessità. Trascende il problema, rendendolo molto più semplice, in modo che tu possa risolvere qualcosa che sembra super complicato in poche righe.
Ora, alcune parole su come funziona la programmazione differenziabile. Ci sono due intuizioni. Una è la differenziazione automatica. Per coloro di voi che hanno avuto il lusso di una formazione ingegneristica, avete visto due modi per calcolare le derivate. C’è una derivata simbolica, ad esempio, se hai x al quadrato, fai la derivata rispetto a x e ottieni 2x. Questa è una derivata simbolica. Poi hai la derivata numerica, quindi se hai una funzione f(x) che vuoi differenziare, sarà f’(x) ≈ (f(x + ε) - f(x))/ε. Questa è la derivazione numerica. Entrambe non sono adatte a quello che stiamo cercando di fare qui. La derivazione simbolica ha problemi di complessità, poiché la tua derivata potrebbe essere un programma molto più complesso del programma originale. La derivazione numerica è numericamente instabile, quindi avrai molti problemi di stabilità numerica.
La differenziazione automatica è un’idea fantastica che risale agli anni ‘70 e riscoperta dal mondo intero nell’ultimo decennio. È l’idea che puoi calcolare la derivata di un programma informatico arbitrario, il che è incredibile. Ancora più incredibile, il programma che è la derivata ha la stessa complessità computazionale del programma originale, il che è stupefacente. La programmazione differenziabile è solo una combinazione di differenziazione automatica e parametri che vuoi imparare.
Quindi come si impara? Quando hai la derivazione, significa che puoi propagare i gradienti e, con la discesa del gradiente stocastico, puoi apportare piccoli aggiustamenti ai valori dei parametri. Modificando quei parametri, incrementerai gradualmente, attraverso molte iterazioni della discesa del gradiente stocastico, per convergere a parametri che hanno senso e raggiungono ciò che vuoi imparare o ottimizzare.
La programmazione differenziabile può essere utilizzata per problemi di apprendimento, come quello che sto illustrando, in cui voglio imparare l’affinità tra i miei clienti e i miei prodotti. Può anche essere utilizzata per problemi di ottimizzazione numerica, come ottimizzare le cose in presenza di vincoli, ed è molto scalabile come paradigma. Come puoi vedere, questo aspetto è stato reso un cittadino di prima classe in Envision. A proposito, ci sono ancora alcune cose in corso in termini di sintassi di Envision, quindi non aspettarti esattamente quelle cose ancora; stiamo ancora perfezionando alcuni aspetti. Ma l’essenza è lì. Non discuterò dei dettagli delle poche cose che stanno ancora evolvendo.

Ora passiamo a un altro problema rilevante per la prontezza alla produzione della tua configurazione. Tipicamente, nell’ottimizzazione della supply chain, ti trovi di fronte a Heisenbug. Cosa è un Heisenbug? È un tipo frustrante di bug in cui si verifica un’ottimizzazione e si producono risultati errati. Ad esempio, hai effettuato un calcolo batch per il rifornimento di inventario durante la notte e al mattino scopri che alcuni di quei risultati erano senza senso, causando costosi errori. Non vuoi che il problema si ripeta, quindi riesegui il tuo processo. Tuttavia, quando riesegui il processo, il problema scompare. Non puoi riprodurre il problema e l’Heisenbug non si manifesta.
Potrebbe sembrare un caso limite strano, ma nei primi anni di Lokad, abbiamo affrontato questi problemi ripetutamente. Ho visto molti progetti di supply chain, specialmente di tipo data science, fallire a causa di Heisenbug irrisolti. Si verificavano bug in produzione, si cercava di riprodurre i problemi localmente ma non si riusciva, quindi i problemi non venivano mai risolti. Dopo un paio di mesi in modalità panico, l’intero progetto veniva di solito silenziosamente chiuso e le persone tornavano a usare fogli di calcolo Excel.
Se vuoi ottenere una replicabilità completa della tua logica, devi versionare il codice e i dati. La maggior parte delle persone in pubblico che sono ingegneri del software o data scientist potrebbe essere familiare con l’idea di versionare il codice. Tuttavia, vuoi anche versionare tutti i dati in modo che quando il tuo programma viene eseguito, sai esattamente quale versione del codice e dei dati viene utilizzata. Potresti non essere in grado di replicare il problema il giorno successivo perché i dati sono cambiati a causa di nuove transazioni o altri fattori, quindi le condizioni che hanno scatenato il bug in primo luogo non sono più presenti.
Vuoi assicurarti che il tuo ambiente di programmazione possa replicare esattamente la logica e i dati come erano in produzione in un determinato momento. Questo richiede una versione completa di tutto. Di nuovo, il linguaggio di programmazione e lo stack di programmazione devono cooperare per rendere ciò possibile. È possibile senza che il paradigma di programmazione sia un cittadino di prima classe del tuo stack, ma allora lo scienziato della supply chain deve essere estremamente attento a tutte le cose che fa e al modo in cui programma. Altrimenti, non sarà in grado di replicare i suoi risultati. Questo mette una pressione immensa sulle spalle degli scienziati della supply chain, che sono già sotto una pressione significativa dalla supply chain stessa. Non vuoi che questi professionisti si occupino di complessità accidentale, come non essere in grado di replicare i propri risultati. Da Lokad, chiamiamo questo una “macchina del tempo” in cui puoi replicare tutto in qualsiasi punto nel passato.
Attenzione, non si tratta solo di replicare ciò che è successo l’ultima notte. A volte, scopri un errore molto tempo dopo il fatto. Ad esempio, se effettui un ordine di acquisto con un fornitore che ha un tempo di consegna di tre mesi, potresti scoprire tre mesi dopo che l’ordine era senza senso. Devi tornare indietro di tre mesi nel tempo al punto in cui hai generato questo falso ordine di acquisto per capire qual era il problema. Non si tratta di versionare solo le ultime poche ore di lavoro; si tratta letteralmente di avere un’intera storia dell’ultimo anno di esecuzione.

Un’altra preoccupazione è l’aumento dei ransomware e degli attacchi informatici alle catene di approvvigionamento. Questi attacchi sono estremamente disruptivi e possono essere molto costosi. Quando si implementano soluzioni basate su software, è necessario considerare se si sta rendendo l’azienda e la catena di approvvigionamento più vulnerabili agli attacchi informatici e ai rischi. Da questo punto di vista, Excel e Python non sono ideali. Questi componenti sono programmabili, il che significa che possono presentare numerose vulnerabilità di sicurezza.
Se hai un team di data scientist o supply chain scientist che si occupa di problemi legati alla catena di approvvigionamento, non possono permettersi il processo di revisione tra pari accurato e iterativo del codice comune nell’industria del software. Se una tariffa cambia da un giorno all’altro o un magazzino viene allagato, hai bisogno di una risposta rapida. Non puoi passare settimane a produrre specifiche di codice, revisioni e così via. Il problema è che stai dando capacità di programmazione a persone che, per impostazione predefinita, hanno il potenziale per arrecare danni all’azienda accidentalmente. Può essere ancora peggio se c’è un dipendente disonesto intenzionale, ma anche mettendo da parte questo, hai comunque il problema che qualcuno può accidentalmente esporre una parte interna dei sistemi IT. Ricorda, i sistemi di ottimizzazione della catena di approvvigionamento, per definizione, hanno accesso a una grande quantità di dati in tutta l’azienda. Questi dati non sono solo un asset, ma anche una responsabilità.
Quello che vuoi è un paradigma di programmazione che promuova la programmazione sicura. Vuoi un linguaggio di programmazione in cui ci siano intere classi di cose che non puoi fare. Ad esempio, perché dovresti avere un linguaggio di programmazione che può fare chiamate di sistema per scopi di ottimizzazione della catena di approvvigionamento? Python può fare chiamate di sistema, così come Excel. Ma perché vorresti un sistema programmabile con tali capacità in primo luogo? È come comprare una pistola per spararti al piede.
Vuoi qualcosa in cui intere classi o funzionalità siano assenti perché non ne hai bisogno per l’ottimizzazione della catena di approvvigionamento. Se queste funzionalità sono presenti, diventano una grande responsabilità. Se introduci capacità programmabili senza gli strumenti che impongono la programmazione sicura per design, aumenti il rischio di attacchi informatici e ransomware, peggiorando le cose.
Naturalmente, è sempre possibile compensare raddoppiando le dimensioni del team di sicurezza informatica, ma questo è molto costoso e non ideale quando si affrontano situazioni urgenti legate alla catena di approvvigionamento. Devi agire rapidamente e in modo sicuro, senza il tempo per i soliti processi, revisioni e approvazioni. Vuoi anche una programmazione sicura che elimini problemi banali come eccezioni di riferimento nullo, errori di memoria esaurita, loop fuori per uno e effetti collaterali.

In conclusione, gli strumenti sono importanti. C’è un detto: “Non portare una spada a una sparatoria”. Hai bisogno degli strumenti adeguati e dei paradigmi di programmazione, non solo di quelli che hai imparato all’università. Hai bisogno di qualcosa di professionale e di qualità produttiva per soddisfare le esigenze della tua catena di approvvigionamento. Sebbene tu possa ottenere alcuni risultati con strumenti scadenti, non sarà eccezionale. Un musicista fantastico può fare musica solo con un cucchiaio, ma con uno strumento adeguato può fare molto meglio.

Ora, procediamo con le domande. Si prega di notare che c’è un ritardo di circa 20 secondi, quindi c’è una certa latenza nello streaming tra il video che stai vedendo e la mia lettura delle tue domande.
Domanda: Cosa ne pensi della programmazione dinamica in termini di ricerca operativa?
La programmazione dinamica, nonostante il nome, non è un paradigma di programmazione. È più una tecnica algoritmica. L’idea è che se vuoi eseguire un compito algoritmico o risolvere un certo problema, ripeterai molto frequentemente la stessa sotto-operazione. La programmazione dinamica è un caso specifico del compromesso spazio-tempo che ho menzionato in precedenza, in cui investi un po’ di più nella memoria per risparmiare tempo sul lato del calcolo. È una delle prime tecniche algoritmiche, risalente agli anni ‘60 e ‘70. È una buona tecnica, ma il nome è un po’ sfortunato perché non c’è nulla di veramente dinamico al riguardo e non riguarda realmente la programmazione. Riguarda piuttosto la concezione degli algoritmi. Quindi, per me, nonostante il nome, non si qualifica come un paradigma di programmazione; è più una tecnica algoritmica specifica.
Domanda: Johannes, potresti gentilmente fornire alcuni libri di riferimento che ogni buon ingegnere della catena di approvvigionamento dovrebbe avere? Sfortunatamente, sono nuovo nel campo e il mio attuale focus è la scienza dei dati e l’ingegneria di sistema.
Ho un’opinione molto mista sulla letteratura esistente. Nella mia prima lezione, ho presentato due libri che ritengo essere il culmine degli studi accademici riguardanti la catena di approvvigionamento. Se vuoi leggere due libri, puoi leggere quei libri. Tuttavia, ho un problema costante con i libri che ho letto finora. Fondamentalmente, ci sono persone che presentano collezioni di ricette numeriche giocattolo per catene di approvvigionamento idealizzate, e ritengo che questi libri non affrontino la catena di approvvigionamento dal giusto punto di vista e che perdano completamente il punto che è un problema complesso. C’è un’ampia letteratura molto tecnica, con equazioni, algoritmi, teoremi e dimostrazioni, ma ritengo che manchi completamente il punto.
Poi, hai un altro stile di libri sulla gestione della catena di approvvigionamento, che sono più di tipo consulenziale. Puoi riconoscere facilmente questi libri perché utilizzano analogie sportive ogni due pagine. Questi libri hanno tutti i tipi di diagrammi semplicistici, come varianti 2x2 dei diagrammi SWOT (Punti di Forza, Punti Deboli, Opportunità, Minacce), che considero modi di ragionamento di bassa qualità. Il problema di questi libri è che tendono a capire meglio che la catena di approvvigionamento è un’impresa complessa. Capiscono molto meglio che è un gioco giocato dalle persone, in cui possono accadere tutte le cose più strane, e puoi essere intelligente in termini di modi. Li apprezzo per questo. Il problema di quei libri, di solito scritti da consulenti o professori di scuole di management, è che non sono molto pratici. Il messaggio si riduce a “essere un leader migliore”, “essere più intelligenti”, “avere più energia”, e per me questo non è pratico. Non ti fornisce elementi che puoi trasformare in qualcosa di altamente prezioso, come può fare il software.
Quindi, torno alla prima lezione: leggi i due libri se vuoi, ma non sono sicuro che sarà tempo ben speso. È bello sapere cosa hanno scritto le persone. Sul lato consulenziale della letteratura, il mio preferito è probabilmente il lavoro di Katana, che non ho elencato nella prima lezione. Non tutto è cattivo; alcune persone hanno più talento, anche se sono più di tipo consulenziale. Puoi controllare il lavoro di Katana; ha un libro sulle catene di approvvigionamento dinamiche. Includerò il libro nei riferimenti.
Domanda: Come si utilizza la parallelizzazione quando si affrontano decisioni di cannibalizzazione o assortimento, dove il problema non è facilmente parallelizzabile?
Perché non è facilmente parallelizzabile? La discesa del gradiente stocastico è piuttosto banale da parallelizzare. Hai passi di discesa del gradiente stocastico che possono essere eseguiti in ordine casuale e puoi avere più passi contemporaneamente. Quindi, credo che tutto ciò che è guidato dalla discesa del gradiente stocastico sia piuttosto banale da parallelizzare.
Quando si affronta la cannibalizzazione, ciò che è più difficile è gestire un altro tipo di parallelizzazione, ovvero ciò che viene prima. Se metto questo prodotto per primo, poi faccio una previsione, ma poi prendo un altro prodotto, modifica il panorama. La risposta è che vuoi avere un modo per affrontare l’intero panorama frontalmente. Non dici, “Prima, introduco questo prodotto e faccio la previsione; introduco un altro prodotto e poi rifaccio la previsione, modificando il primo.” Lo fai semplicemente frontalmente, tutte quelle cose contemporaneamente, allo stesso tempo. Hai bisogno di paradigmi di programmazione più avanzati. I paradigmi di programmazione che ho introdotto oggi possono fare molto per questo.
Per quanto riguarda le decisioni di assortimento, questo tipo di problemi non presenta grandi difficoltà per la parallelizzazione. Lo stesso vale se hai una rete di vendita al dettaglio globale e vuoi ottimizzare l’assortimento per tutti i tuoi negozi. Puoi eseguire calcoli che avvengono per tutti i negozi in parallelo. Non vuoi farlo in sequenza, dove ottimizzi l’assortimento per un negozio e poi passi al negozio successivo. Questo è il modo sbagliato per farlo, ma puoi ottimizzare la rete in parallelo, propagare tutte le informazioni e poi ripetere. Ci sono tutti i tipi di tecniche e gli strumenti possono aiutarti molto a farlo in modo molto più semplice.
Domanda: Stai utilizzando un approccio di database a grafo?
No, non nel senso tecnico, canonico. Ci sono molti database a grafo sul mercato che sono di grande interesse. Quello che stiamo usando internamente presso Lokad è un’integrazione verticale completa attraverso uno stack di compilatori unificato e monolitico per rimuovere completamente tutti gli elementi tradizionali che troveresti in uno stack classico. In questo modo otteniamo ottime prestazioni, in termini di prestazioni di calcolo, molto vicine al metallo. Non perché siamo programmatori fantastici, ma solo perché abbiamo eliminato praticamente tutti gli strati che esistono tradizionalmente. Lokad non utilizza letteralmente alcun database. Abbiamo un compilatore che si occupa di tutto, fino all’organizzazione delle strutture dati per la persistenza. È un po’ strano, ma è molto più efficiente farlo in questo modo e in questo modo si gioca molto meglio con il fatto che si compila uno script verso una flotta di macchine sul cloud. La tua piattaforma di destinazione, in termini di hardware, non è una macchina, ma una flotta di macchine.
Domanda: Qual è la tua opinione su Power BI, che esegue anche codici Python e algoritmi correlati come la discesa del gradiente, l’avidità, ecc.?
Il problema che ho con tutto ciò che riguarda l’intelligence aziendale, Power BI incluso, è che ha un paradigma che ritengo inadeguato per la supply chain. Si vedono tutti i problemi come un ipercubo, in cui si hanno dimensioni che si tagliano e si sminuzzano. Al centro, si ha un problema di espressività, che è molto limitante. Quando si finisce per utilizzare Power BI con Python nel mezzo, si ha bisogno di Python perché l’espressività legata all’ipercubo è molto scarsa. Per riguadagnare espressività, si aggiunge Python nel mezzo. Tuttavia, ricorda ciò che ho detto nella domanda precedente riguardo a quegli strati: la maledizione del software aziendale moderno è che si hanno troppi strati. Ogni singolo strato che si aggiunge introdurrà inefficienze e bug. Se si utilizza Power BI più Python, si avranno troppi strati. Quindi, si ha Power BI che si posiziona sopra altri sistemi, il che significa che si hanno già più sistemi prima di Power BI. Poi si ha Power BI in cima, e sopra Power BI si ha Python. Ma Python agisce da solo? No, è probabile che si utilizzi librerie Python, come Pandas o NumPy. Quindi, si hanno strati in Python che si accumulano, e si finisce con decine di strati. Si possono avere bug in ognuno di quegli strati, quindi la situazione sarà piuttosto da incubo.
Non credo in quelle soluzioni in cui si finisce per avere un numero enorme di stack. C’è questa battuta che in C++ si può sempre risolvere qualsiasi problema aggiungendo un altro livello di indirezione, incluso il problema di avere troppi livelli di indirezione. Ovviamente, questa affermazione è un po’ senza senso, ma sono profondamente in disaccordo con l’approccio in cui le persone hanno un prodotto con un design di base inadeguato e, invece di affrontare il problema frontalmente, finiscono per aggiungere cose sopra mentre le fondamenta sono traballanti. Questo non è il modo di farlo, e si avrà una scarsa produttività, battaglie continue con bug che non si risolveranno mai, e poi, in termini di manutenibilità, è solo una ricetta per un incubo.
Domanda: Come si possono inserire i risultati di un’analisi di filtraggio collaborativo nell’algoritmo di previsione della domanda per ogni prodotto, come ad esempio gli zaini?
Mi dispiace, ma affronterò questo argomento nella prossima lezione. La risposta breve è che non si vuole inserirlo in un algoritmo di previsione esistente. Si vuole avere qualcosa che sia molto più integrato in modo nativo. Non si fa così e poi si torna ai vecchi modi di fare previsioni; invece, si scarta il vecchio modo di fare previsioni e si fa qualcosa di radicalmente diverso che sfrutta quello. Ma ne parlerò in una lezione successiva. Sarebbe troppo per oggi.
Credo che sia tutto per questa lezione. Grazie mille a tutti per la partecipazione. La prossima lezione sarà mercoledì 6 gennaio, alla stessa ora, lo stesso giorno della settimana. Prenderò qualche vacanza di Natale, quindi auguro a tutti un felice Natale e un felice anno nuovo. Continueremo la nostra serie di lezioni l’anno prossimo. Grazie mille.


