00:01 Einführung
02:18 Die moderne Prognose
06:37 Probabilistisch werden
11:58 Die Geschichte bisher
15:10 Wahrscheinlicher Plan für heute
17:18 Bestiarium der Vorhersagen
28:10 Metriken - CRPS - 1/2
33:21 Metriken - CRPS - 2/2
37:20 Metriken - Monge-Kantorovich
42:07 Metriken - Wahrscheinlichkeit - 1/3
47:23 Metriken - Wahrscheinlichkeit - 2/3
51:45 Metriken - Wahrscheinlichkeit - 3/3
55:03 1D-Verteilungen - 1/4
01:01:13 1D-Verteilungen - 2/4
01:06:43 1D-Verteilungen - 3/4
01:15:39 1D-Verteilungen - 4/4
01:18:24 Generatoren - 1/3
01:24:00 Generatoren - 2/3
01:29:23 Generatoren - 3/3
01:37:56 Bitte warten Sie, während wir Sie ignorieren
01:40:39 Fazit
01:43:50 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Eine Prognose gilt als probabilistisch, anstatt deterministisch, wenn sie eine Reihe von Wahrscheinlichkeiten enthält, die mit allen möglichen zukünftigen Ergebnissen verbunden sind, anstatt ein bestimmtes Ergebnis als “die” Prognose zu bestimmen. Probabilistische Prognosen sind immer dann wichtig, wenn Unsicherheit unvermeidbar ist, was fast immer der Fall ist, wenn komplexe Systeme betroffen sind. Für Supply Chains sind probabilistische Prognosen unerlässlich, um robuste Entscheidungen gegenüber unsicheren zukünftigen Bedingungen zu treffen.
Vollständiges Transkript

Willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich “Probabilistische Prognose für die Supply Chain” präsentieren. Probabilistische Prognose ist eine der wichtigsten, wenn nicht sogar die wichtigste Paradigmenverschiebung in über einem Jahrhundert statistischer Prognosewissenschaft. Auf technischer Ebene handelt es sich jedoch größtenteils um dasselbe. Ob wir uns probabilistische Prognosemodelle oder ihre nicht-probabilistischen Alternativen ansehen, es handelt sich um dieselbe Statistik, dieselben Wahrscheinlichkeiten. Probabilistische Prognose spiegelt eine Veränderung in der Art und Weise wider, wie wir über Prognosen selbst denken sollten. Die größte Veränderung, die die probabilistische Prognose für die Supply Chain mit sich bringt, findet sich nicht in der Prognosewissenschaft. Die größte Veränderung findet sich in der Art und Weise, wie Supply Chains im Hinblick auf Vorhersagemodelle betrieben und optimiert werden.
Das Ziel der heutigen Vorlesung ist eine sanfte technische Einführung in die probabilistische Prognose. Am Ende dieser Vorlesung sollten Sie verstehen, worum es bei der probabilistischen Prognose geht, wie man probabilistische Prognosen von nicht-probabilistischen Prognosen unterscheidet, wie man die Qualität einer probabilistischen Prognose bewertet und sogar in der Lage sein, Ihr eigenes Einsteigermodell für probabilistische Prognosen zu entwickeln. Heute werde ich nicht auf die Nutzung von probabilistischen Prognosen für Entscheidungsfindungszwecke im Kontext von Supply Chains eingehen. Der Schwerpunkt liegt ausschließlich auf der Darlegung der Grundlagen der probabilistischen Prognose. Die Verbesserung der Entscheidungsprozesse in der Supply Chain durch probabilistische Prognosen wird in der nächsten Vorlesung behandelt.

Um die Bedeutung von probabilistischen Prognosen zu verstehen, ist ein wenig historischer Kontext erforderlich. Die moderne Form der Prognose, die statistische Prognose, im Gegensatz zur Wahrsagerei, entstand zu Beginn des 20. Jahrhunderts. Die Prognose entstand in einem breiteren wissenschaftlichen Kontext, in dem Naturwissenschaften, einige sehr erfolgreiche Disziplinen wie Kinematik, Elektromagnetismus und Chemie, scheinbar beliebig genaue Ergebnisse erzielen konnten. Diese Ergebnisse wurden im Wesentlichen durch einen mehrere Jahrhunderte dauernden Aufwand erzielt, der beispielsweise auf Galileo Galilei zurückgeführt werden kann und zur Entwicklung überlegener Technologien führte, die überlegene Messmethoden ermöglichten. Präzisere Messungen wiederum würden die wissenschaftliche Entwicklung weiter vorantreiben, indem sie Wissenschaftlern ermöglichen, ihre Theorien und Vorhersagen auf noch präzisere Weise zu testen und herauszufordern.
In diesem breiteren Kontext, in dem einige Wissenschaften unglaublich erfolgreich waren, übernahm das aufstrebende Prognosefeld zu Beginn des 20. Jahrhunderts im Grunde genommen das, was diese Naturwissenschaften im Bereich der Wirtschaft erreicht hatten. Wenn wir uns zum Beispiel Pioniere wie Roger Babson ansehen, einen der Väter der modernen wirtschaftlichen Prognose, gründete er zu Beginn des 20. Jahrhunderts ein erfolgreiches Unternehmen für wirtschaftliche Prognosen in den Vereinigten Staaten. Das Motto des Unternehmens lautete wörtlich: “Für jede Aktion gibt es eine gleichwertige und entgegengesetzte Reaktion.” Babsons Vision bestand darin, den Erfolg der newtonschen Physik auf die Wirtschaft zu übertragen und letztendlich ebenso präzise Ergebnisse zu erzielen.
Nach mehr als einem Jahrhundert statistischer akademischer Prognosen, in denen Supply Chains operieren, bleibt die Idee, beliebig genaue Ergebnisse zu erzielen, die sich in prognostischen Begriffen in beliebig genauen Prognosen niederschlagen, genauso schwer fassbar wie vor mehr als einem Jahrhundert. Seit einigen Jahrzehnten gibt es Stimmen in der breiteren Supply Chain-Welt, die Bedenken geäußert haben, dass diese Prognosen niemals genau genug werden. Es gab Bewegungen wie Lean Manufacturing, die unter anderem starke Befürworter dafür waren, die Abhängigkeit von Supply Chains von diesen unzuverlässigen Prognosen weitgehend zu verringern. Darum geht es beim Just-in-Time: Wenn Sie alles, was der Markt benötigt, rechtzeitig herstellen und liefern können, dann benötigen Sie plötzlich keine zuverlässige, genaue Prognose mehr.
In diesem Kontext ist die probabilistische Prognose eine Rehabilitierung der Prognose, jedoch mit wesentlich bescheideneren Ambitionen. Die probabilistische Prognose beginnt mit der Idee, dass es eine unvermeidliche Unsicherheit über die Zukunft gibt. Alle Zukünfte sind möglich, sie sind nur nicht alle gleich wahrscheinlich, und das Ziel der probabilistischen Prognose besteht darin, die jeweilige Wahrscheinlichkeit all dieser alternativen Zukünfte vergleichend zu bewerten, nicht alle möglichen Zukünfte auf nur eine Zukunft zu reduzieren.

Die newtonische Perspektive auf statistische wirtschaftliche Prognosen ist im Wesentlichen gescheitert. Die Meinung in unserer Gemeinschaft, dass beliebig genaue Prognosen jemals erreicht werden können, ist weitgehend verschwunden. Doch seltsamerweise basieren fast alle Lieferkettensoftware und eine große Menge an gängigen Lieferkettenpraktiken tatsächlich auf der Annahme, dass solche Prognosen letztendlich verfügbar sein werden.
Zum Beispiel basiert die Vertriebs- und Betriebsplanung (S&OP) auf der Idee, dass eine vereinheitlichte, quantifizierte Vision für das Unternehmen erreicht werden kann, wenn alle Beteiligten zusammenkommen und gemeinsam eine Prognose erstellen. Ebenso ist die Open-to-Buy-Methode im Wesentlichen eine Methode, die auf der Idee basiert, dass ein Top-Down-Budgetierungsprozess möglich ist, der auf der Annahme beruht, dass es möglich ist, beliebig präzise Top-Down-Prognosen zu erstellen. Darüber hinaus sind selbst bei vielen Werkzeugen, die bei der Prognose und Planung im Bereich der Lieferketten sehr verbreitet sind, wie Business Intelligence und Tabellenkalkulationen, diese Werkzeuge weitgehend auf eine Punkt-Zeitreihen-Prognose ausgerichtet. Im Wesentlichen geht es darum, dass Sie Ihre historischen Daten in die Zukunft verlängern können, wobei ein Punkt pro interessantem Zeitraum vorhanden ist. Diese Werkzeuge haben von ihrer Konzeption her eine enorme Menge an Reibung, wenn es darum geht, die Art von Berechnungen zu verstehen, die bei einer probabilistischen Prognose involviert sind, bei der es nicht nur eine Zukunft, sondern alle möglichen Zukünfte gibt.
Tatsächlich geht es bei der probabilistischen Prognose nicht darum, eine klassische Prognose mit einer Art Unsicherheit zu versehen. Die probabilistische Prognose besteht auch nicht darin, eine Liste von Szenarien zu erstellen, wobei jedes Szenario eine eigenständige klassische Prognose ist. Gängige Lieferkettenmethoden arbeiten in der Regel nicht mit probabilistischen Prognosen, weil sie implizit oder explizit auf der Idee basieren, dass es eine Art Referenzprognose gibt und dass sich alles um diese Referenzprognose dreht. Im Gegensatz dazu ist die probabilistische Prognose die frontale numerische Bewertung aller möglichen Zukünfte.
Natürlich sind wir durch die Menge an Rechenressourcen, die wir haben, begrenzt. Wenn ich also von “allen möglichen Zukünften” spreche, betrachten wir in der Praxis nur eine endliche Anzahl von Zukünften. Angesichts der Art von moderner Rechenleistung, die wir haben, können wir tatsächlich Millionen von Zukünften in Betracht ziehen. Hierbei stoßen Business Intelligence und Tabellenkalkulationen an ihre Grenzen. Sie sind nicht auf die Art von Berechnungen ausgelegt, die bei der Arbeit mit probabilistischen Prognosen erforderlich sind. Dies ist ein Problem des Software-Designs. Sie sehen, eine Tabellenkalkulation hat Zugriff auf die gleichen Computer und die gleiche Rechenleistung, aber wenn die Software nicht über das richtige Design verfügt, können bestimmte Aufgaben unglaublich schwierig zu erreichen sein, selbst wenn Sie über eine große Menge an Rechenleistung verfügen.
Daher besteht die größte Herausforderung aus Sicht der Lieferkette darin, sich von Jahrzehnten von Werkzeugen und Praktiken zu lösen, die auf einem sehr ehrgeizigen, aber meiner Meinung nach fehlgeleiteten Ziel basieren, nämlich dass beliebig genaue Prognosen möglich sind. Ich möchte sofort darauf hinweisen, dass es äußerst fehlgeleitet wäre, die probabilistische Prognose als Möglichkeit zu betrachten, genauere Prognosen zu erstellen. Das ist nicht der Fall. Probabilistische Prognosen sind nicht genauer und können nicht als Ersatz für klassische, gängige Prognosen verwendet werden. Die Überlegenheit probabilistischer Prognosen liegt in der Art und Weise, wie diese Prognosen für Zwecke der Lieferkette, insbesondere für Entscheidungsfindungszwecke im Kontext von Lieferketten, genutzt werden können. Unser Ziel heute ist es jedoch nur zu verstehen, worum es bei diesen probabilistischen Prognosen geht, und die Nutzung dieser probabilistischen Prognosen wird in der nächsten Vorlesung behandelt.

Diese Vorlesung ist Teil einer Reihe von Vorlesungen zur Lieferkette. Ich versuche, diese Vorlesungen weitgehend unabhängig voneinander zu halten. Wir erreichen jedoch einen Punkt, an dem es dem Publikum wirklich helfen wird, wenn diese Vorlesungen in der richtigen Reihenfolge angesehen werden, da ich häufig auf das Bezug nehme, was in früheren Vorlesungen präsentiert wurde.
Diese Vorlesung ist also die dritte des fünften Kapitels, das sich dem prädiktiven Modellieren widmet. Im ersten Kapitel dieser Reihe habe ich meine Ansichten über Lieferketten als Forschungsgebiet und Praxis vorgestellt. Im zweiten Kapitel habe ich Methoden vorgestellt. Tatsächlich sind die meisten Situationen in der Lieferkette von adversarialer Natur, und diese Situationen tendieren dazu, naive Methoden zu besiegen. Wenn wir in der Welt der Lieferketten einen gewissen Erfolg erzielen wollen, müssen wir angemessene Methoden haben.
Das dritte Kapitel war dem parsimonischen Ansatz in der Lieferkette gewidmet und konzentrierte sich ausschließlich auf das Problem und die Natur der Herausforderung, mit der wir in verschiedenen Situationen konfrontiert sind, die von Lieferketten abgedeckt werden. Die Idee hinter der parsimonischen Lieferkette besteht darin, alle Aspekte auf der Lösungsseite vollständig zu ignorieren, da wir uns ausschließlich auf das Problem konzentrieren möchten, bevor wir die Lösung auswählen, die wir zur Bewältigung verwenden möchten.
Im vierten Kapitel habe ich eine Vielzahl von Hilfswissenschaften untersucht. Diese Wissenschaften sind nicht direkt Teil der Lieferkette; es handelt sich um andere Forschungsbereiche, die angrenzend oder unterstützend sind. Ich bin jedoch der Meinung, dass ein grundlegendes Verständnis dieser Hilfswissenschaften eine Voraussetzung für die moderne Praxis der Lieferketten ist.
Schließlich gehen wir im fünften Kapitel auf die Techniken ein, mit denen wir die Zukunft quantifizieren und bewerten können, insbesondere um Aussagen über die Zukunft zu treffen. Tatsächlich spiegelt alles, was wir in der Lieferkette tun, in gewisser Weise eine gewisse Vorwegnahme der Zukunft wider. Wenn wir die Zukunft besser antizipieren können, werden wir bessere Entscheidungen treffen können. Darum geht es in diesem fünften Kapitel: quantitativ bessere Einblicke in die Zukunft zu bekommen. In diesem Kapitel stellen probabilistische Prognosen einen entscheidenden Ansatz dar, um die Zukunft anzugehen.
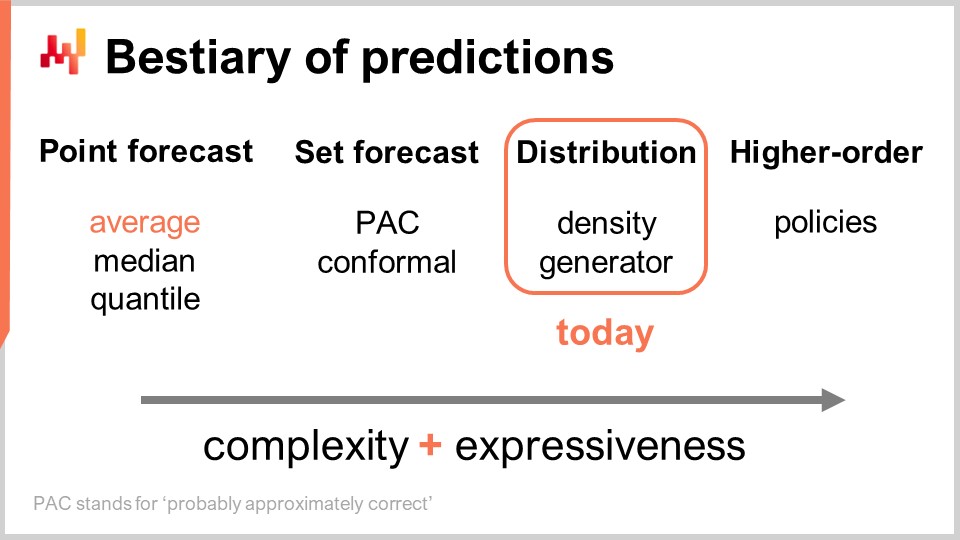
Der Rest dieser Vorlesung ist in vier Abschnitte unterschiedlicher Länge unterteilt. Zunächst werden wir die gängigsten Arten von Prognosen über die klassische Prognose hinaus überprüfen. Ich werde gleich klären, was ich mit klassischer Prognose meine. Tatsächlich ist vielen Menschen in Lieferkettenkreisen nicht bewusst, dass es viele Optionen gibt. Die probabilistische Prognose selbst sollte als Oberbegriff für eine ziemlich vielfältige Reihe von Werkzeugen und Techniken verstanden werden.
Zweitens werden wir Metriken einführen, um die Qualität probabilistischer Prognosen zu bewerten. Egal was passiert, eine gut gestaltete probabilistische Prognose wird Ihnen immer sagen: “Nun, es gab eine Wahrscheinlichkeit, dass dies passiert.” Die Frage ist also: Wie sortieren Sie aus, was tatsächlich eine gute probabilistische Prognose von einer schlechten ist? Hier kommen diese Metriken ins Spiel. Es gibt spezialisierte Metriken, die sich vollständig der Situation der probabilistischen Prognose widmen.
Drittens werden wir eine eingehende Untersuchung eindimensionaler Verteilungen durchführen. Sie sind die einfachste Art von Verteilung, und obwohl sie offensichtliche Einschränkungen haben, sind sie auch der einfachste Einstiegspunkt in die Welt der probabilistischen Prognosen.
Viertens werden wir kurz auf Generatoren eingehen, die häufig als Monte-Carlo-Methoden bezeichnet werden. Tatsächlich besteht eine Dualität zwischen Generatoren und Wahrscheinlichkeitsdichteschätzern, und diese Monte-Carlo-Methoden werden uns einen Weg bieten, höherdimensionale Probleme und Formen der probabilistischen Prognose anzugehen.

Es gibt mehrere Arten von Prognosen, und dieser Aspekt sollte nicht mit der Tatsache verwechselt werden, dass es mehrere Arten von Prognosemodellen gibt. Wenn Modelle nicht zur gleichen Art oder Klasse von Prognosen gehören, lösen sie nicht einmal die gleichen Probleme. Die häufigste Art von Prognose ist die Punktprognose. Wenn ich zum Beispiel sage, dass morgen der Gesamtumsatz in einem Geschäft in Euro 10.000 Euro für die Gesamtumsatzsumme des Tages betragen wird, mache ich eine Punktprognose darüber, was in diesem Geschäft morgen passieren wird. Wenn ich diese Übung wiederhole und eine Zeitreihenprognose erstelle, indem ich eine Aussage für den Tag von morgen mache und dann eine weitere Aussage für den Tag übermorgen mache, habe ich mehrere Datenpunkte. Allerdings bleibt das immer noch eine Punktprognose, weil wir im Wesentlichen unseren Kampf wählen, indem wir eine bestimmte Aggregationsebene wählen und auf dieser Aggregationsebene unsere Prognosen uns eine einzige Zahl liefern, die die Antwort sein soll.
Innerhalb der Art der Punktprognose gibt es mehrere Untertypen von Prognosen, je nachdem, welche Metrik optimiert wird. Die am häufigsten verwendete Metrik ist wahrscheinlich der quadratische Fehler, also haben wir einen mittleren quadratischen Fehler, der Ihnen die durchschnittliche Prognose liefert. Übrigens neigt dies dazu, die am häufigsten verwendete Prognose zu sein, weil es die einzige Prognose ist, die zumindest einigermaßen additiv ist. Keine Prognose ist jemals vollständig additiv; sie kommt immer mit vielen Einschränkungen. Einige Prognosen sind jedoch additiver als andere, und offensichtlich neigen Durchschnittsprognosen dazu, die additivsten zu sein. Wenn Sie eine Durchschnittsprognose haben möchten, haben Sie im Wesentlichen eine Punktprognose, die gegen den mittleren quadratischen Fehler optimiert ist. Wenn Sie eine andere Metrik verwenden, wie zum Beispiel den absoluten Fehler, und dagegen optimieren, erhalten Sie eine Medianprognose. Wenn Sie die Pinball Loss-Funktion verwenden, die wir in der allerersten Vorlesung dieses fünften Kapitels dieser Reihe von Supply-Chain-Vorlesungen eingeführt haben, erhalten Sie eine Quantilprognose. Übrigens klassifiziere ich Quantilprognosen heute als nur eine weitere Art von Punktprognose. Tatsächlich erhalten Sie mit der Quantilprognose im Wesentlichen eine einzelne Schätzung. Diese Schätzung kann eine Verzerrung aufweisen, die beabsichtigt ist. Darum geht es bei Quantilen, aber meiner Meinung nach qualifiziert sie sich vollständig als Punktprognose, weil die Form der Prognose nur ein einzelner Punkt ist.
Nun gibt es die Mengenprognose, die anstelle eines einzelnen Punktes eine Menge von Punkten zurückgibt. Es gibt eine Variation, abhängig davon, wie Sie die Menge aufbauen. Wenn wir uns eine PAC-Prognose ansehen, steht PAC für Probably Approximately Correct. Dies ist im Wesentlichen ein Rahmen, der vor etwa zwei Jahrzehnten von Valiant eingeführt wurde, und er besagt, dass die Menge, die Ihre Vorhersage ist, eine bestimmte Wahrscheinlichkeit hat, so dass ein Ergebnis innerhalb Ihrer Vorhersage mit einer bestimmten Wahrscheinlichkeit beobachtet wird. Die Menge, die Sie produzieren, sind tatsächlich alle Punkte, die innerhalb einer Region liegen, die durch einen maximalen Abstand zu einem Referenzpunkt charakterisiert ist. In gewisser Weise ist die PAC-Perspektive auf Prognosen bereits eine Mengenprognose, weil die Ausgabe nicht mehr ein Punkt ist. Was wir jedoch haben, ist immer noch ein Referenzpunkt, ein zentrales Ergebnis, und was wir haben, ist ein maximaler Abstand zu diesem zentralen Punkt. Wir sagen nur, dass es eine bestimmte angegebene Wahrscheinlichkeit gibt, dass das Ergebnis letztendlich innerhalb unserer Vorhersagemenge beobachtet wird.
Der PAC-Ansatz kann durch den konformalen Ansatz verallgemeinert werden. Die konformale Vorhersage besagt: “Hier ist eine Menge, und ich sage Ihnen, dass es diese gegebene Wahrscheinlichkeit gibt, dass das Ergebnis innerhalb dieser Menge liegt.” Der konformale Ansatz verallgemeinert den PAC-Ansatz dahingehend, dass konformale Vorhersagen nicht mehr an einen Referenzpunkt und den Abstand zum Referenzpunkt gebunden sind. Sie können diese Menge beliebig formen und sind dennoch Teil des Mengenprognose-Paradigmas.
Die Zukunft kann noch granularer und komplexer dargestellt werden: die Verteilungsprognose. Die Verteilungsprognose liefert eine Funktion, die alle möglichen Ergebnisse auf ihre jeweiligen lokalen Wahrscheinlichkeitsdichten abbildet. In gewisser Weise beginnen wir mit der Punktprognose, bei der die Prognose nur ein Punkt ist. Dann gehen wir zur Mengenprognose über, bei der die Prognose eine Menge von Punkten ist. Schließlich ist die Verteilungsprognose technisch gesehen eine Funktion oder etwas, das eine Funktion verallgemeinert. Übrigens, wenn ich in diesem Vortrag den Begriff “Verteilung” verwende, bezieht er sich immer implizit auf eine Verteilung von Wahrscheinlichkeiten. Verteilungsprognosen stellen etwas noch Reichhaltigeres und Komplexeres als eine Menge dar, und das wird heute unser Schwerpunkt sein.
Es gibt zwei gängige Ansätze zur Behandlung von Verteilungen: der Dichtean nährungsansatz und der Generatoransatz. Wenn ich von “Dichte” spreche, bezieht sich dies im Wesentlichen auf die lokale Schätzung von Wahrscheinlichkeitsdichten. Der Generatoransatz umfasst einen Monte-Carlo-generativen Prozess, der Ergebnisse generiert, die als Abweichungen bezeichnet werden und angeblich dieselbe lokale Wahrscheinlichkeitsdichte widerspiegeln. Dies sind die beiden Hauptansätze zur Bewältigung von Verteilungsprognosen.
Über die Verteilung hinaus haben wir höherstufige Konstrukte. Dies mag etwas kompliziert zu verstehen sein, aber mein Punkt hier, obwohl wir heute nicht höherstufige Konstrukte behandeln werden, ist nur, um zu verdeutlichen, dass probabilistische Prognosen, wenn sie sich darauf konzentrieren, Verteilungen zu erzeugen, nicht das Endziel sind; es ist nur ein Schritt, und es gibt mehr. Höherstufige Konstrukte sind wichtig, wenn wir jemals befriedigende Antworten auf einfache Situationen erhalten wollen.
Um zu verstehen, worum es bei höherstufigen Konstrukten geht, betrachten wir einen einfachen Einzelhandelsladen mit einer Rabattpolitik für Produkte, die sich dem Ablaufdatum nähern. Offensichtlich möchte der Laden keine unverkäufliche Ware auf Lager haben, daher wird automatisch ein Rabatt gewährt, wenn die Produkte kurz vor ihrem Ablaufdatum stehen. Die Nachfrage, die dieser Laden generieren würde, hängt stark von dieser Politik ab. Die Prognose, die wir haben möchten, die eine Verteilung darstellen kann, die die Wahrscheinlichkeiten für alle möglichen Ergebnisse darstellt, sollte von dieser Politik abhängig sein. Diese Politik ist jedoch ein mathematisches Objekt; es ist eine Funktion. Was wir haben möchten, ist keine probabilistische Prognose, sondern etwas Metamäßigeres - ein höherstufiges Konstrukt, das anhand einer Politik die resultierende Verteilung generieren kann.
Aus Sicht der Lieferkette gewinnen wir beim Übergang von einer Art von Prognose zur nächsten viele Informationen. Dies darf nicht mit einer genaueren Prognose verwechselt werden; es geht darum, Zugang zu einer ganz anderen Art von Informationen zu erhalten, wie wenn man die Welt in Schwarzweiß sieht und plötzlich die Fähigkeit hat, Farben zu sehen, anstatt nur eine höhere Auflösung zu erhalten. In Bezug auf die Werkzeuge sind Tabellenkalkulationen und Business-Intelligence-Tools für den Umgang mit Punktprognosen recht angemessen. Je nach Art der betrachteten Mengenprognose können sie angemessen sein, aber Sie dehnen bereits ihre Designfähigkeiten aus. Sie sind nicht wirklich darauf ausgelegt, mit irgendeiner Art von ausgefallener Mengenprognose umzugehen, die über die offensichtliche hinausgeht, bei der Sie nur einen Bereich mit Mindest- und Höchstwerten im Bereich der erwarteten Werte definieren. Wir werden sehen, dass wir im Grunde genommen, wenn wir eine Chance haben wollen, mit Verteilungsprognosen oder sogar höherstufigen Konstrukten zu arbeiten, eine völlig andere Art von Werkzeugen benötigen, obwohl dies in einem Moment klarer werden sollte.
Um mit probabilistischen Prognosen zu beginnen, versuchen wir zu charakterisieren, was eine gute probabilistische Prognose ausmacht. Egal was passiert, eine probabilistische Prognose wird Ihnen sagen, dass es eine Wahrscheinlichkeit für dieses Ereignis gab, egal welche Art von Ergebnis Sie beobachten. Unter diesen Bedingungen, wie unterscheidet man eine gute probabilistische Prognose von einer schlechten? Es ist sicherlich nicht so, dass plötzlich alle Prognosemodelle gut sind, nur weil sie probabilistisch sind.
Genau darum geht es bei den Metriken, die der probabilistischen Prognose gewidmet sind, und der Continuous Ranked Probability Score (CRPS) ist die Verallgemeinerung des absoluten Fehlers für eindimensionale probabilistische Prognosen. Es tut mir wirklich leid für diesen schrecklichen Namen - den CRPS. Ich habe mir diese Terminologie nicht ausgedacht; sie wurde mir übergeben. Die CRPS-Formel wird auf dem Bildschirm angezeigt. Im Wesentlichen ist die Funktion F die kumulative Verteilungsfunktion; sie ist die probabilistische Prognose, die gemacht wird. Der Punkt x ist die tatsächliche Beobachtung und der CRPS-Wert ist etwas, das Sie zwischen Ihrer probabilistischen Prognose und der gerade gemachten Beobachtung berechnen.
Wir können sehen, dass der Punkt im Wesentlichen in eine quasi-probabilistische Prognose umgewandelt wird, indem die Heaviside-Sprungfunktion verwendet wird. Die Einführung der Heaviside-Sprungfunktion entspricht einfach der Umwandlung des gerade beobachteten Punktes in eine Dirac-Wahrscheinlichkeitsverteilung, die eine Verteilung ist, die die gesamte Wahrscheinlichkeitsmasse auf ein einzelnes Ergebnis konzentriert. Dann haben wir ein Integral und im Wesentlichen führt der CRPS eine Art Formanpassung durch. Wir gleichen die Form der kumulativen Verteilungsfunktion (CDF) mit der Form einer anderen CDF ab, nämlich derjenigen, die der Dirac entspricht, die den Punkt, den wir beobachtet haben, abbildet.
Aus Sicht einer Punktprognose ist der CRPS nicht nur wegen der komplizierten Formel verwirrend, sondern auch, weil diese Metrik zwei Argumente hat, die nicht denselben Typ haben. Eines dieser Argumente ist eine Verteilung und das andere ist nur ein einzelner Datenpunkt. Wir haben also eine Asymmetrie, die bei den meisten anderen Punktprognosemetriken wie dem absoluten Fehler und dem mittleren quadratischen Fehler nicht existiert. Beim CRPS vergleichen wir im Wesentlichen einen Punkt mit einer Verteilung.
Wenn wir mehr darüber verstehen wollen, was wir mit dem CRPS berechnen, ist eine interessante Beobachtung, dass der CRPS dieselbe Einheit wie die Beobachtung hat. Wenn zum Beispiel x in Euro ausgedrückt wird und der CRPS-Wert zwischen F und x auch in Bezug auf die Einheiten homogen zu Euro ist, deshalb sage ich, dass der CRPS eine Verallgemeinerung des absoluten Fehlers ist. Übrigens, wenn Sie Ihre probabilistische Prognose in eine Dirac-Funktion zusammenfallen lassen, gibt Ihnen der CRPS einen Wert, der genau dem absoluten Fehler entspricht.

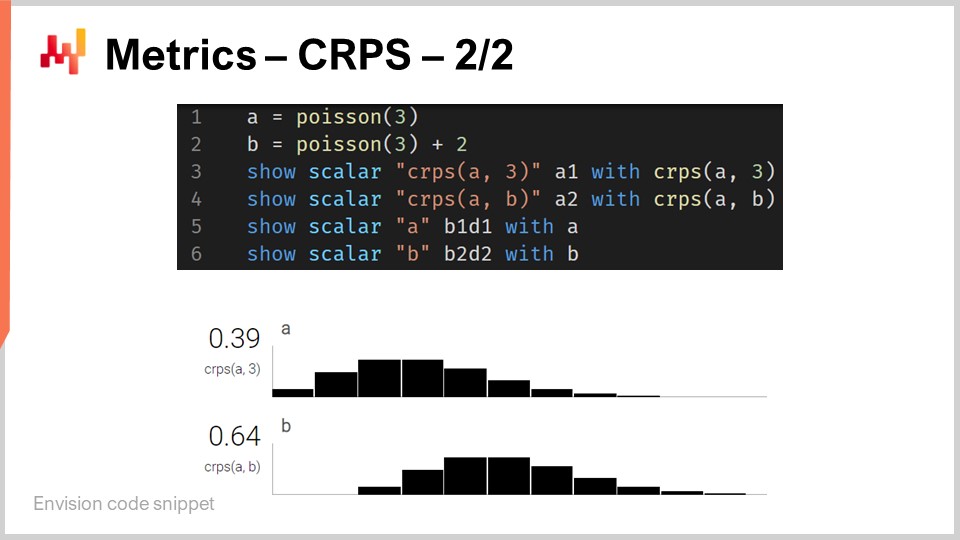
Während der CRPS möglicherweise recht einschüchternd und kompliziert erscheint, ist die Implementierung tatsächlich recht einfach. Auf dem Bildschirm sehen Sie ein kleines Envision-Skript, das veranschaulicht, wie der CRPS aus einer programmiersprachlichen Perspektive verwendet werden kann. Envision ist eine domänenspezifische Programmiersprache, die sich der prädiktiven Optimierung von Lieferketten widmet und von Lokad entwickelt wurde. In diesen Vorlesungen verwende ich Envision der Klarheit und Kürze halber. Bitte beachten Sie jedoch, dass an Envision nichts Einzigartiges ist; die gleichen Ergebnisse könnten in jeder anderen Programmiersprache wie Python, Java, JavaScript, C#, F# oder einer anderen erzielt werden. Mein Punkt ist, dass es nur mehr Codezeilen erfordern würde, daher bleibe ich bei Envision. Alle hier in dieser Vorlesung gegebenen Codeausschnitte und übrigens auch in den vorherigen sind eigenständig und vollständig. Sie könnten diesen Code technisch gesehen kopieren und einfügen, und er würde funktionieren. Es sind keine Module beteiligt, kein versteckter Code und keine Umgebung einzurichten.
Also zurück zum Codeausschnitt. In den Zeilen eins und zwei definieren wir eindimensionale Verteilungen. Ich werde noch darauf eingehen, wie diese eindimensionalen Verteilungen tatsächlich in Envision funktionieren, aber wir haben hier zwei Verteilungen: eine ist eine Poisson-Verteilung, die eine eindimensionale diskrete Verteilung ist, und die zweite in Zeile zwei ist dieselbe Poisson-Verteilung, aber um zwei Einheiten nach rechts verschoben. Das ist wofür das “+2” steht. In Zeile drei berechnen wir den CRPS-Abstand zwischen einer Verteilung und dem Wert 3, der eine Zahl ist. Hier finden wir also diese Asymmetrie in Bezug auf Datentypen, von der ich gesprochen habe. Die Ergebnisse werden unten angezeigt, wie Sie unten auf dem Bildschirm sehen können.
In Zeile vier berechnen wir den CRPS zwischen Verteilung A und Verteilung B. Obwohl die klassische Definition des CRPS zwischen einer Verteilung und einem einzelnen Punkt liegt, ist es völlig unkompliziert, diese Definition auf ein Paar von Verteilungen zu verallgemeinern. Alles, was Sie tun müssen, ist, die gleiche Formel für den CRPS zu verwenden und die Heaviside-Sprungfunktion durch die kumulative Verteilungsfunktion der zweiten Verteilung zu ersetzen. Die “show”-Anweisungen von Zeile drei bis sechs führen zur Anzeige, die Sie unten auf dem Bildschirm sehen können, was buchstäblich ein Screenshot ist.
Wir sehen also, dass die Verwendung von CRPS nicht schwieriger oder komplizierter ist als die Verwendung einer speziellen Funktion wie der Kosinusfunktion. Natürlich ist es etwas umständlich, wenn Sie den Kosinus selbst neu implementieren müssen, aber alles in allem ist CRPS nichts Besonderes Kompliziertes. Nun, gehen wir weiter.

Das Monge-Kantorovich-Problem gibt uns Einblick, wie man den Formanpassungsprozess, der beim CRPS im Spiel ist, mit höheren Dimensionen angehen kann. Denken Sie daran, dass der CRPS tatsächlich auf Dimension eins beschränkt ist. Die Formanpassung ist konzeptionell etwas, das auf jede Anzahl von Dimensionen verallgemeinert werden könnte, und das Monge-Kantorovich-Problem ist sehr interessant, umso mehr, weil es im Kern tatsächlich ein Lieferkettenproblem ist.
Das Monge-Kantorovich-Problem, das ursprünglich nichts mit probabilistischer Prognose zu tun hatte, wurde vom französischen Wissenschaftler Gaspard Monge in einer 1781 veröffentlichten Abhandlung mit dem Titel “Mémoire sur la théorie des déblais et des remblais” eingeführt, was in etwa übersetzt “Abhandlung über die Theorie des Bewegens von Erde” bedeutet. Eine Möglichkeit, das Monge-Kantorovich-Problem zu verstehen, besteht darin, sich eine Situation vorzustellen, in der wir eine Liste von Minen haben, die als M auf dem Bildschirm gekennzeichnet sind, und eine Liste von Fabriken, die als F gekennzeichnet sind. Die Minen produzieren Erz und die Fabriken verbrauchen Erz. Was wir wollen, ist einen Transportplan T zu erstellen, der das gesamte von den Minen produzierte Erz mit dem von den Fabriken benötigten Verbrauch verbindet.
Monge definierte das Kapital C als die Kosten, um das gesamte Erz von den Minen zu den Fabriken zu transportieren. Die Kosten sind die Summe, um das Erz von jeder Mine zu jeder Fabrik zu transportieren, aber es gibt offensichtlich sehr ineffiziente Möglichkeiten, das Erz zu transportieren. Wenn wir also sagen, dass wir bestimmte Kosten haben, meinen wir, dass die Kosten den optimalen Transportplan widerspiegeln. Dieses Kapital C repräsentiert die besten erreichbaren Kosten, wenn der optimale Transportplan berücksichtigt wird.
Dies ist im Wesentlichen ein Lieferkettenproblem, das im Laufe der Jahrhunderte umfassend untersucht wurde. In der vollständigen Problemformulierung gibt es Einschränkungen für T. Um der Kürze willen habe ich nicht alle Einschränkungen auf dem Bildschirm angegeben. Es gibt zum Beispiel eine Einschränkung, dass der Transportplan die Produktionskapazität jeder Mine nicht überschreiten sollte und jede Fabrik vollständig zufrieden sein sollte, indem sie eine Zuweisung erhält, die ihren Anforderungen entspricht. Es gibt viele Einschränkungen, aber sie sind recht umfangreich, daher habe ich sie nicht auf dem Bildschirm aufgeführt.
Nun, während das Transportproblem an sich interessant ist, haben wir, wenn wir die Liste der Minen und die Liste der Fabriken als zwei Wahrscheinlichkeitsverteilungen interpretieren, eine Möglichkeit, eine punktweise Metrik in eine verteilungsbasierte Metrik umzuwandeln. Dies ist eine wichtige Erkenntnis über die Formanpassung in höheren Dimensionen aus der Sicht des Monge-Kantorovich. Eine andere Bezeichnung für diese Perspektive ist die Wasserstein-Metrik, obwohl sie sich hauptsächlich auf den nicht-diskreten Fall bezieht, der für uns von geringerem Interesse ist.
Die Monge-Kantorovich-Perspektive ermöglicht es uns, eine punktweise Metrik, die den Unterschied zwischen zwei Zahlen oder zwei Vektoren von Zahlen berechnen kann, in eine Metrik umzuwandeln, die auf Wahrscheinlichkeitsverteilungen über demselben Raum angewendet wird. Dies ist ein sehr leistungsfähiger Mechanismus. Das Monge-Kantorovich-Problem ist jedoch schwierig zu lösen und erfordert erhebliche Rechenleistung. Für den Rest des Vortrags werde ich mich auf Techniken konzentrieren, die einfacher zu implementieren und auszuführen sind.

Die bayesianische Perspektive besteht darin, eine Reihe von Beobachtungen aus der Sicht einer vorherigen Überzeugung zu betrachten. Die bayesianische Perspektive wird in der Regel im Gegensatz zur frequentistischen Perspektive verstanden, die die Häufigkeit von Ergebnissen auf der Grundlage tatsächlicher Beobachtungen schätzt. Die Idee ist, dass die frequentistische Perspektive keine vorherigen Überzeugungen mit sich bringt. Daher gibt uns die bayesianische Perspektive ein Werkzeug namens Likelihood, um den Grad der Überraschung bei Betrachtung der Beobachtungen und eines gegebenen Modells zu bewerten. Das Modell, das im Wesentlichen ein probabilistisches Prognosemodell ist, ist die Formalisierung unserer vorherigen Überzeugungen. Die bayesianische Perspektive gibt uns eine Möglichkeit, einen Datensatz im Hinblick auf ein probabilistisches Prognosemodell zu bewerten. Um zu verstehen, wie dies geschieht, sollten wir mit der Likelihood für einen einzelnen Datenpunkt beginnen. Die Likelihood, wenn wir eine Beobachtung x haben, ist die Wahrscheinlichkeit, x gemäß dem Modell zu beobachten. Hier wird angenommen, dass das Modell eine gewisse parametrische Form hat und theta der vollständige Vektor aller Modellparameter ist.
Wenn wir von Theta sprechen, nehmen wir implizit an, dass wir eine vollständige Charakterisierung des probabilistischen Modells haben, das uns eine lokale Wahrscheinlichkeitsdichte für alle Punkte gibt. Daher ist die Likelihood die Wahrscheinlichkeit, diesen einen Datenpunkt zu beobachten. Wenn wir die Likelihood für das Modell Theta haben, handelt es sich um die gemeinsame Wahrscheinlichkeit, alle Datenpunkte im Datensatz zu beobachten. Wir nehmen an, dass diese Punkte unabhängig voneinander sind, daher ist die Likelihood ein Produkt von Wahrscheinlichkeiten.
Wenn wir Tausende von Beobachtungen haben, ist die Likelihood als Produkt von Tausenden von Werten kleiner als eins wahrscheinlich numerisch verschwindend klein. Ein verschwindend kleiner Wert ist in der Regel schwierig darzustellen, da Gleitkommazahlen in Computern dargestellt werden. Anstatt direkt mit der Likelihood zu arbeiten, die eine verschwindend kleine Zahl ist, neigen wir dazu, mit der Log-Likelihood zu arbeiten. Die Log-Likelihood ist einfach der Logarithmus der Likelihood und hat die unglaubliche Eigenschaft, die Multiplikation in Addition umzuwandeln.
Die Log-Likelihood des Modells Theta ist die Summe des Logarithmus aller einzelnen Likelihoods für alle Datenpunkte, wie in der letzten Gleichung auf dem Bildschirm gezeigt. Die Likelihood ist eine Metrik, die uns eine Anpassungsgüte für eine gegebene probabilistische Prognose gibt. Sie sagt uns, wie wahrscheinlich es ist, dass das Modell den beobachteten Datensatz generiert hat. Wenn wir zwei konkurrierende probabilistische Prognosen haben und alle anderen Anpassungsprobleme vorerst beiseite lassen, sollten wir das Modell wählen, das uns die höchste Likelihood oder die höchste Log-Likelihood gibt, denn je höher, desto besser.
Die Likelihood ist sehr interessant, weil sie in hohen Dimensionen ohne Komplikationen arbeiten kann, im Gegensatz zur Monge-Kantorovich-Methode. Solange wir ein Modell haben, das uns eine lokale Wahrscheinlichkeitsdichte gibt, können wir die Likelihood oder realistischerweise die Log-Likelihood als Metrik verwenden.

Darüber hinaus, sobald wir eine Metrik haben, die die Anpassungsgüte darstellen kann, bedeutet dies, dass wir gegen diese Metrik optimieren können. Alles, was wir brauchen, ist ein Modell mit mindestens einem Freiheitsgrad, was im Grunde mindestens einen Parameter bedeutet. Wenn wir dieses Modell gegen die Likelihood optimieren, unsere Metrik für die Anpassungsgüte, werden wir hoffentlich ein trainiertes Modell erhalten, bei dem wir gelernt haben, zumindest eine anständige probabilistische Prognose zu erstellen. Genau das wird hier auf dem Bildschirm gemacht.
In den Zeilen eins und zwei generieren wir einen simulierten Datensatz. Wir erstellen eine Tabelle mit 2.000 Zeilen und generieren dann in Zeile zwei 2.000 Abweichungen, unsere Beobachtungen aus einer Poisson-Verteilung mit einem Mittelwert von zwei. Also haben wir unsere 2.000 Beobachtungen. In Zeile drei starten wir einen Autodiff-Block, der Teil des differenzierbaren Programmierparadigmas ist. Dieser Block führt einen stochastischen Gradientenabstieg aus und iteriert viele Male über alle Beobachtungen in der Beobachtungstabelle. Hier ist die Beobachtungstabelle T.
In Zeile vier deklarieren wir den einen Parameter des Modells, der Lambda genannt wird. Wir geben an, dass dieser Parameter ausschließlich positiv sein sollte. Diesen Parameter werden wir durch den stochastischen Gradientenabstieg wiederentdecken. In Zeile fünf definieren wir die Verlustfunktion, die einfach minus die Log-Likelihood ist. Wir möchten die Likelihood maximieren, aber der Autodiff-Block versucht, den Verlust zu minimieren. Daher müssen wir vor der Log-Likelihood dieses Minuszeichen hinzufügen, was genau das ist, was wir getan haben.
Der erlernte Lambda-Parameter wird in Zeile sechs angezeigt. Nicht überraschend ist der gefundene Wert sehr nahe am Wert zwei, da wir mit einer Poisson-Verteilung mit einem Mittelwert von zwei gestartet sind. Wir haben ein probabilistisches Prognosemodell erstellt, das auch parametrisch ist und die gleiche Form hat, nämlich eine Poisson-Verteilung. Wir wollten den einen Parameter der Poisson-Verteilung wiederentdecken, und das ist genau das, was wir bekommen haben. Wir erhalten ein Modell, das etwa ein Prozent von der ursprünglichen Schätzung abweicht.
Wir haben gerade unser erstes probabilistisches Prognosemodell gelernt, und alles, was es brauchte, waren im Grunde genommen drei Zeilen Code. Dies ist offensichtlich ein sehr einfaches Modell; trotzdem zeigt es, dass probabilistische Prognosen nichts intrinsisch Kompliziertes haben. Es handelt sich nicht um eine gewöhnliche quadratische Mittelprognose, aber abgesehen davon ist es mit den richtigen Werkzeugen wie differenzierbarer Programmierung nicht komplizierter als eine klassische Punktprognose.
Die zuvor verwendete Funktion log_likelihood.poisson ist Teil der Standardbibliothek von Envision. Es gibt jedoch keine Magie dabei. Schauen wir uns an, wie diese Funktion tatsächlich unter der Haube implementiert ist. Die ersten beiden Zeilen oben geben uns die Implementierung der Log-Likelihood der Poisson-Verteilung. Eine Poisson-Verteilung wird vollständig durch ihren einen Parameter Lambda charakterisiert, und die Log-Likelihood-Funktion nimmt nur zwei Argumente an: den einen Parameter, der die Poisson-Verteilung vollständig charakterisiert, und die tatsächliche Beobachtung. Die von mir geschriebene Formel ist buchstäblich Lehrmaterial. Es ist das, was man bekommt, wenn man die Formel aus dem Lehrbuch implementiert, die die Poisson-Verteilung charakterisiert. Hier ist nichts Besonderes.
Beachten Sie, dass diese Funktion mit dem Autodiff-Schlüsselwort markiert ist. Wie wir in der vorherigen Vorlesung gesehen haben, stellt das Autodiff-Schlüsselwort sicher, dass die automatische Differentiation korrekt durch diese Funktion fließen kann. Die Log-Likelihood der Poisson-Verteilung verwendet auch eine andere spezielle Funktion, log_gamma. Die log_gamma-Funktion ist der Logarithmus der Gamma-Funktion, die die Verallgemeinerung der Fakultätsfunktion auf komplexe Zahlen ist. Hier benötigen wir nur die Verallgemeinerung der Fakultätsfunktion auf reelle positive Zahlen.
Die Implementierung der log_gamma-Funktion ist etwas umfangreich, aber auch hier handelt es sich um Lehrmaterial. Es verwendet eine kontinuierliche Bruchapproximation für die log_gamma-Funktion. Das Schöne daran ist, dass wir die automatische Differentiation die ganze Zeit über für uns arbeiten lassen. Wir beginnen mit dem Autodiff-Block, rufen die Funktion log_likelihood.poisson auf, die als Autodiff-Funktion implementiert ist. Diese Funktion ruft wiederum die log_gamma-Funktion auf, die ebenfalls mit dem Autodiff-Marker implementiert ist. Im Wesentlichen sind wir in der Lage, unsere probabilistischen Prognosemethoden in drei Zeilen Code zu erstellen, weil wir eine gut entwickelte Standardbibliothek haben, die unter Berücksichtigung der automatischen Differentiation implementiert wurde.
Nun wollen wir uns dem speziellen Fall der eindimensionalen diskreten Verteilungen zuwenden. Diese Verteilungen sind in der gesamten Supply Chain weit verbreitet und stellen unseren Einstieg in die probabilistische Prognose dar. Wenn wir zum Beispiel Durchlaufzeiten mit täglicher Granularität prognostizieren möchten, können wir sagen, dass es eine bestimmte Wahrscheinlichkeit für eine Durchlaufzeit von einem Tag gibt, eine andere Wahrscheinlichkeit für eine Durchlaufzeit von zwei Tagen, drei Tagen und so weiter. All das summiert sich zu einem Histogramm von Wahrscheinlichkeiten für Durchlaufzeiten. Ähnlich können wir, wenn wir uns die Nachfrage nach einem bestimmten SKU an einem bestimmten Tag ansehen, sagen, dass es eine Wahrscheinlichkeit gibt, null Einheiten Nachfrage zu beobachten, eine Einheit Nachfrage, zwei Einheiten Nachfrage und so weiter.
Wenn wir all diese Wahrscheinlichkeiten zusammenpacken, erhalten wir ein Histogramm, das sie repräsentiert. Ebenso können wir, wenn wir über den Lagerbestand eines SKUs nachdenken, interessiert sein, wie viel Bestand am Ende der Saison für dieses bestimmte SKU übrig bleibt. Wir können eine probabilistische Prognose verwenden, um die Wahrscheinlichkeit zu bestimmen, dass am Ende der Saison kein Bestand mehr vorhanden ist, ein Bestand von einer Einheit vorhanden ist, zwei Einheiten vorhanden sind und so weiter. All diese Situationen passen zum Muster, dass sie durch ein Histogramm mit Buckets repräsentiert werden, die jedem diskreten Ergebnis des interessierenden Phänomens zugeordnet sind.
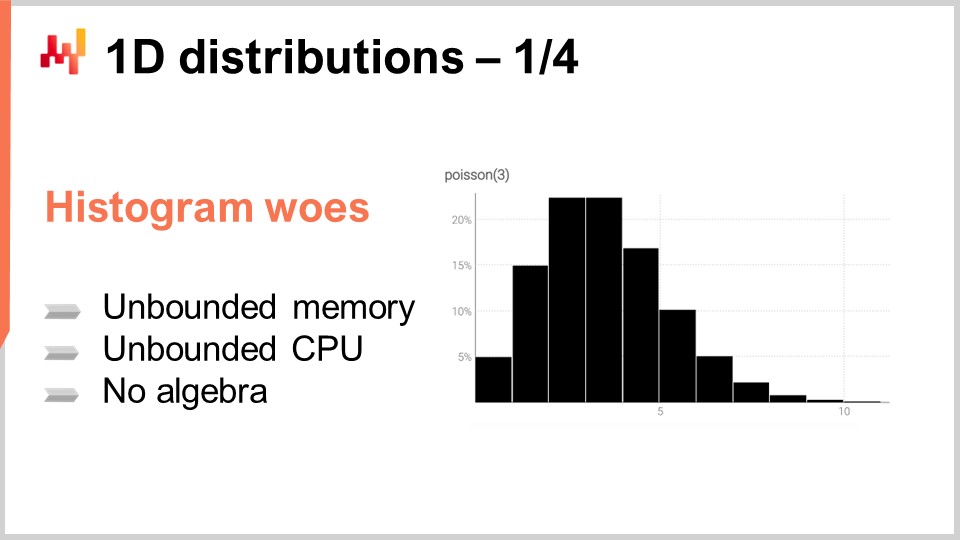
Das Histogramm ist die kanonische Art und Weise, eine eindimensionale diskrete Verteilung darzustellen. Jeder Bucket ist mit der Wahrscheinlichkeitsmasse für das diskrete Ergebnis verbunden. Abgesehen von der Verwendung zur Datenvisualisierung sind Histogramme jedoch etwas enttäuschend. Tatsächlich ist die Arbeit mit Histogrammen etwas umständlich, wenn wir etwas anderes als die Visualisierung dieser Wahrscheinlichkeitsverteilungen tun möchten. Es gibt im Wesentlichen zwei Kategorien von Problemen mit Histogrammen: Das erste Problem betrifft die Rechenressourcen, und die zweite Kategorie von Problemen betrifft die Programmierausdruckskraft von Histogrammen.
In Bezug auf die Rechenressourcen sollten wir bedenken, dass der Speicherbedarf eines Histogramms grundsätzlich unbegrenzt ist. Man kann sich ein Histogramm als ein Array vorstellen, das so groß wird, wie es benötigt wird. Wenn man es mit einem einzelnen Histogramm zu tun hat, selbst mit einem aus Supply-Chain-Sicht außergewöhnlich großen Histogramm, ist der Speicherbedarf für einen modernen Computer kein Problem. Das Problem entsteht, wenn man nicht nur ein Histogramm hat, sondern Millionen von Histogrammen für Millionen von SKUs in einem Supply-Chain-Kontext. Wenn jedes Histogramm ziemlich groß werden kann, kann das Verwalten dieser Histogramme zu einer Herausforderung werden, insbesondere wenn man bedenkt, dass moderne Computer tendenziell einen nicht einheitlichen Speicherzugriff bieten.
Umgekehrt ist auch die benötigte CPU-Leistung zur Verarbeitung dieser Histogramme unbegrenzt. Während die Operationen auf Histogrammen größtenteils linear sind, nimmt die Verarbeitungszeit mit zunehmendem Speicherbedarf aufgrund des nicht einheitlichen Speicherzugriffs zu. Daher besteht ein erhebliches Interesse daran, klare Grenzen für den Speicher- und CPU-Bedarf festzulegen.
Das zweite Problem mit Histogrammen ist das Fehlen einer angehängten Algebra. Während man bei der Betrachtung von zwei Histogrammen eine Addition oder Multiplikation der Werte pro Bucket durchführen kann, ergibt dies keine sinnvolle Darstellung einer Zufallsvariablen, wenn man das Histogramm interpretiert. Wenn man zum Beispiel zwei Histogramme nimmt und eine punktweise Multiplikation durchführt, erhält man ein Histogramm, das nicht einmal eine Wahrscheinlichkeitsmasse von eins hat. Dies ist keine gültige Operation aus der Perspektive einer Algebra von Zufallsvariablen. Man kann Histogramme nicht wirklich addieren oder multiplizieren, daher ist man in dem, was man mit ihnen tun kann, eingeschränkt.
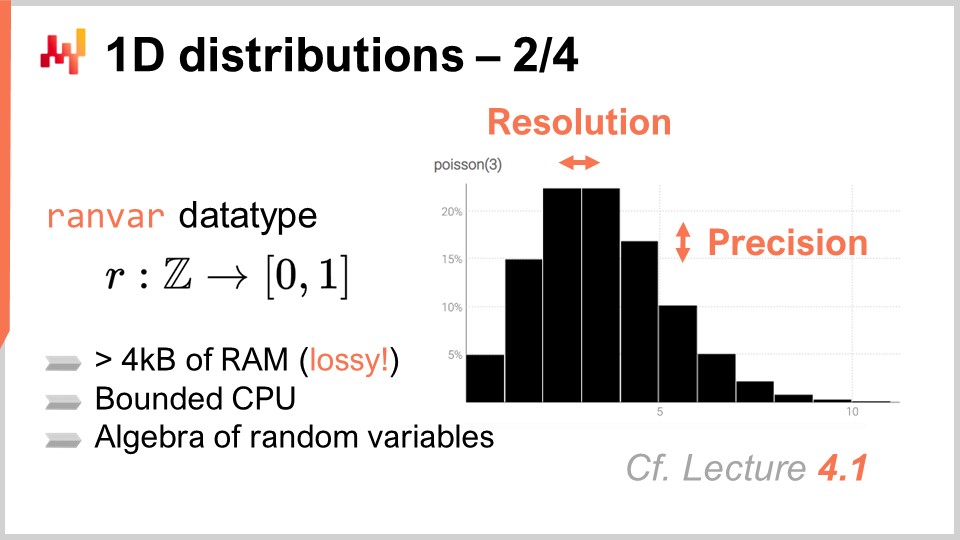
Bei Lokad haben wir den Ansatz gefunden, mit diesen allgegenwärtigen diskreten eindimensionalen Verteilungen umzugehen, indem wir einen dedizierten Datentyp einführen. Das Publikum ist wahrscheinlich mit gängigen Datentypen vertraut, die in den meisten Programmiersprachen existieren, wie Ganzzahlen, Gleitkommazahlen und Zeichenketten. Dies sind die typischen primitiven Datentypen, die überall zu finden sind. Es hindert Sie jedoch nichts daran, spezialisiertere Datentypen einzuführen, die besonders gut zu unseren Anforderungen aus Sicht der Supply Chain passen. Genau das hat Lokad mit dem Datentyp “ranvar” gemacht.
Der Datentyp “ranvar” ist für eindimensionale diskrete Verteilungen vorgesehen, und der Name ist eine Abkürzung für Zufallsvariable. Technisch gesehen ist der “ranvar” eine Funktion von Z (die Menge aller ganzen Zahlen, positiv und negativ) zu Wahrscheinlichkeiten, die Zahlen zwischen null und eins sind. Die Gesamtmasse von Z ist immer gleich eins, da es Wahrscheinlichkeitsverteilungen darstellt.
Aus rein mathematischer Sicht könnte man argumentieren, dass die Menge an Informationen, die in eine solche Funktion gepackt werden können, beliebig groß werden kann. Das ist wahr; jedoch gibt es aus Sicht der Supply Chain eine sehr klare Grenze dafür, wie viele relevante Informationen in einer einzigen “ranvar” enthalten sein können. Es ist theoretisch möglich, eine Wahrscheinlichkeitsverteilung zu erstellen, die Megabytes benötigt, um dargestellt zu werden, aber es gibt keine solche Verteilung, die für Supply Chain-Zwecke relevant ist.
Es ist möglich, eine Obergrenze von 4 Kilobyte für den Datentyp “ranvar” zu definieren. Durch eine Begrenzung des Speichers, den dieser “ranvar” einnehmen kann, erhalten wir auch eine Obergrenze für die CPU-Leistung für alle Operationen, was sehr wichtig ist. Anstatt die Buckets einfach auf 1.000 zu begrenzen, führt Lokad eine Komprimierung mit dem “ranvar”-Datentyp ein. Diese Komprimierung ist im Wesentlichen eine verlustbehaftete Darstellung der Originaldaten, bei der Auflösung und Genauigkeit verloren gehen. Die Idee besteht jedoch darin, eine Komprimierung zu entwickeln, die eine ausreichend genaue Darstellung der Histogramme liefert, sodass der Grad der Approximation aus Sicht der Supply Chain vernachlässigbar ist.
Die Details des Komprimierungsalgorithmus, der mit dem “ranvar”-Datentyp verbunden ist, liegen außerhalb des Rahmens dieser Vorlesung. Es handelt sich jedoch um einen sehr einfachen Komprimierungsalgorithmus, der um Größenordnungen einfacher ist als die Komprimierungsalgorithmen, die für Bilder auf Ihrem Computer verwendet werden. Als Nebeneffekt der Begrenzung des Speichers, den dieser “ranvar” einnehmen kann, erhalten wir auch eine Obergrenze für die CPU-Leistung für alle Operationen, was sehr wichtig ist. Schließlich erhalten wir mit dem “ranvar”-Datentyp den wichtigsten Punkt, nämlich eine Algebra von Variablen, die es uns ermöglicht, tatsächlich mit diesen Datentypen zu arbeiten und alle Arten von Operationen durchzuführen, die wir mit primitiven Datentypen tun möchten, nämlich sie auf verschiedene Arten zu kombinieren, die unseren Anforderungen entsprechen.
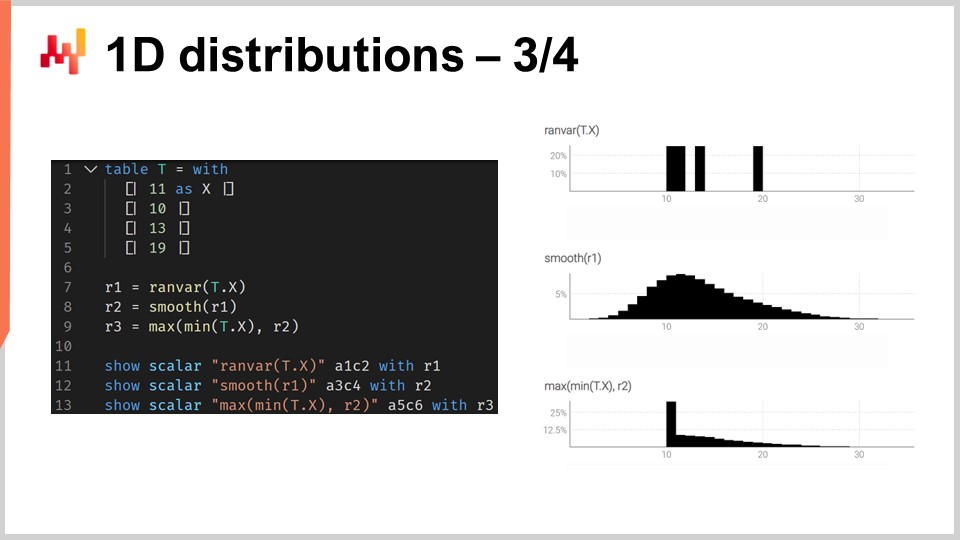
Um zu veranschaulichen, was es bedeutet, mit “ranvars” zu arbeiten, betrachten wir eine Situation der Vorhersage der Lieferzeit, genauer gesagt eine probabilistische Vorhersage der Lieferzeit. Auf dem Bildschirm ist ein kurzes Envision-Skript zu sehen, das zeigt, wie eine solche probabilistische Vorhersage erstellt wird. In den Zeilen 1-5 führen wir die Tabelle T ein, die die vier Lieferzeiten mit Werten von 11 Tagen, 10 Tagen, 13 Tagen und 90 Tagen enthält. Vier Beobachtungen sind zwar sehr wenige, aber es ist leider sehr häufig, dass nur sehr wenige Datenpunkte in Bezug auf Lieferzeiten vorliegen. Wenn wir zum Beispiel einen Überseelieferanten betrachten, der zwei Bestellungen pro Jahr erhält, dauert es zwei Jahre, um diese vier Datenpunkte zu sammeln. Daher ist es wichtig, Techniken zu haben, die auch mit einem äußerst begrenzten Satz von Beobachtungen arbeiten können.
In Zeile 7 erstellen wir ein “ranvar”, indem wir die vier Beobachtungen direkt aggregieren. Hier ist der Begriff “ranvar”, der in Zeile 7 erscheint, tatsächlich ein Aggregator, der eine Reihe von Zahlen als Eingabe nimmt und einen einzigen Wert des “ranvar”-Datentyps zurückgibt. Das Ergebnis wird oben rechts auf dem Bildschirm angezeigt und ist ein empirischer “ranvar”.
Dieser empirische “ranvar” ist jedoch keine realistische Darstellung der tatsächlichen Verteilung. Zum Beispiel können wir eine Lieferzeit von 11 Tagen und eine Lieferzeit von 13 Tagen beobachten, es fühlt sich jedoch unrealistisch an, keine Lieferzeit von 12 Tagen beobachten zu können. Wenn wir diesen “ranvar” als probabilistische Vorhersage interpretieren würden, würde er besagen, dass die Wahrscheinlichkeit, jemals eine Lieferzeit von 12 Tagen zu beobachten, null ist, was nicht korrekt erscheint. Dies ist offensichtlich ein Overfitting-Problem.
Um diese Situation zu beheben, glätten wir den ursprünglichen “ranvar” in Zeile 8, indem wir die Funktion “smooth” aufrufen. Die Funktion “smooth” ersetzt im Wesentlichen den ursprünglichen “ranvar” durch eine Mischung von Verteilungen. Für jeden Eimer der ursprünglichen Verteilung ersetzen wir den Eimer durch eine Poisson-Verteilung mit einem Mittelwert, der auf dem Eimer zentriert ist und entsprechend der jeweiligen Wahrscheinlichkeit der Eimer gewichtet ist. Durch die glatte Verteilung erhalten wir das Histogramm, das in der Mitte rechts auf dem Bildschirm angezeigt wird. Das sieht schon viel besser aus; wir haben keine seltsamen Lücken mehr und in der Mitte haben wir keine Nullwahrscheinlichkeit mehr. Wenn wir die Wahrscheinlichkeit betrachten, eine Lieferzeit von 12 Tagen zu beobachten, gibt uns dieses Modell eine nicht-null Wahrscheinlichkeit, was viel vernünftiger klingt. Es gibt uns auch eine nicht-null Wahrscheinlichkeit, über 20 Tage hinauszugehen, und wenn wir bedenken, dass wir vier Datenpunkte hatten und bereits eine Lieferzeit von 19 Tagen beobachtet haben, erscheint die Idee, dass eine Lieferzeit von bis zu 20 Tagen möglich ist, sehr vernünftig. Mit dieser probabilistischen Vorhersage haben wir also eine schöne Verteilung, die eine nicht-null Wahrscheinlichkeit für diese Ereignisse darstellt, was sehr gut ist.
Auf der linken Seite haben wir jedoch etwas Seltsames. Während es in Ordnung ist, dass sich diese Wahrscheinlichkeitsverteilung nach rechts erstreckt, kann dasselbe nicht über die linke Seite gesagt werden. Wenn wir berücksichtigen, dass die beobachteten Lieferzeiten das Ergebnis von Transportzeiten waren, aufgrund der Tatsache, dass es neun Tage dauert, bis der LKW ankommt, erscheint es unwahrscheinlich, dass wir jemals eine Lieferzeit von drei Tagen beobachten würden. In dieser Hinsicht ist das Modell ziemlich unrealistisch.
Daher führen wir in Zeile 9 einen bedingt angepassten “ranvar” ein, indem wir sagen, dass er größer sein muss als die kleinste jemals beobachtete Lieferzeit. Wir haben “min_of(T, x)”, das den kleinsten Wert unter den Zahlen der Tabelle T nimmt, und dann verwenden wir “max”, um das Maximum zwischen einer Verteilung und einer Zahl zu berechnen. Das Ergebnis muss größer sein als dieser Wert. Der angepasste “ranvar” wird unten rechts angezeigt, und hier sehen wir unsere endgültige Vorhersage der Lieferzeit. Die letzte fühlt sich wie eine sehr vernünftige probabilistische Vorhersage der Lieferzeit an, wenn man bedenkt, dass wir nur einen äußerst begrenzten Datensatz mit nur vier Datenpunkten haben. Wir können nicht sagen, dass es eine großartige probabilistische Vorhersage ist, aber ich würde behaupten, dass dies eine Produktionsvorhersage ist und diese Art von Techniken in der Produktion gut funktionieren würden, im Gegensatz zu einer durchschnittlichen Punktprognose, die das Risiko von variablen Lieferzeiten stark unterschätzen würde.
Das Schöne an probabilistischen Vorhersagen ist, dass sie, obwohl sie sehr roh sein können, bereits ein gewisses Maß an Minderungspotenzial für schlecht informierte Entscheidungen bieten, die aus der naiven Anwendung einer Durchschnittsprognose basierend auf den beobachteten Daten resultieren würden.
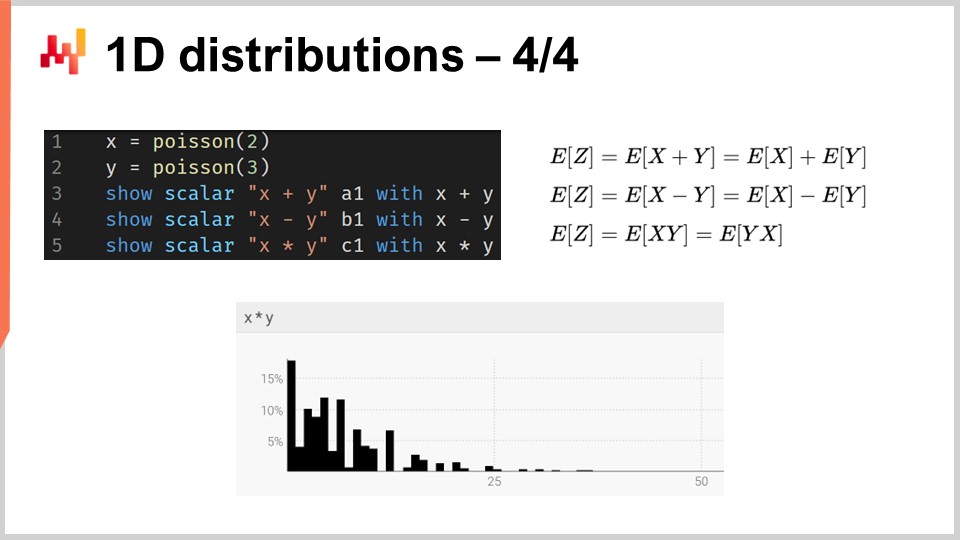
Allgemeiner unterstützen Zufallsvariablen eine ganze Reihe von Operationen: Es ist möglich, Zufallsvariablen zu addieren, zu subtrahieren und zu multiplizieren, genau wie es möglich ist, ganze Zahlen zu addieren, zu subtrahieren und zu multiplizieren. Im Hintergrund werden all diese Operationen als Faltungen implementiert, da wir es semantisch mit diskreten Zufallsvariablen zu tun haben. Auf dem Bildschirm wird das Histogramm, das unten angezeigt wird, durch die Multiplikation von zwei Poisson-Verteilungen erhalten, jeweils mit einem Mittelwert von zwei und drei. In der Supply Chain wird die Multiplikation von Zufallsvariablen als direkte Faltung bezeichnet. Im Kontext der Supply Chain macht es Sinn, die Multiplikation von zwei Zufallsvariablen darzustellen, um zum Beispiel die Ergebnisse darzustellen, die Sie erhalten können, wenn Kunden nach denselben Produkten suchen, aber mit unterschiedlichen Multiplikatoren. Angenommen, wir haben eine Buchhandlung, die zwei Kundengruppen bedient. Auf der einen Seite haben wir die erste Gruppe, bestehend aus Studenten, die beim Betreten des Ladens eine Einheit kaufen. In dieser anschaulichen Buchhandlung haben wir eine zweite Gruppe von Professoren, die beim Betreten des Ladens 20 Bücher kaufen.
Aus modelltechnischer Sicht könnten wir eine probabilistische Vorhersage haben, die die Ankunftsrate in der Buchhandlung entweder von Studenten oder von Professoren repräsentiert. Dies würde uns die Wahrscheinlichkeit geben, an einem Tag null Kunden, einen Kunden, zwei Kunden usw. zu beobachten und die Wahrscheinlichkeitsverteilung zu enthüllen, eine bestimmte Anzahl von Kunden an einem beliebigen Tag zu beobachten. Die zweite Variable würde Ihnen die jeweiligen Wahrscheinlichkeiten geben, eine (Studenten) versus 20 (Professoren) zu kaufen. Um eine Darstellung der Nachfrage zu haben, würden wir einfach diese beiden Zufallsvariablen multiplizieren, was zu einem scheinbar willkürlichen Histogramm führt, das die Multiplikatoren widerspiegelt, die in den Konsumgewohnheiten Ihrer Gruppen vorhanden sind.

Monte Carlo-Generatoren oder einfach Generatoren stellen einen alternativen Ansatz zur probabilistischen Vorhersage dar. Anstatt eine Verteilung zu zeigen, die uns die lokale Wahrscheinlichkeitsdichte gibt, können wir einen Generator zeigen, der, wie der Name schon sagt, Ergebnisse generiert, die implizit den gleichen lokalen Wahrscheinlichkeitsverteilungen folgen sollen. Es gibt eine Dualität zwischen Generatoren und Wahrscheinlichkeitsdichten, was bedeutet, dass die beiden im Wesentlichen zwei Facetten derselben Perspektive sind.
Wenn Sie einen Generator haben, ist es immer möglich, die Ergebnisse, die aus diesem Generator erhalten wurden, zu mitteln, um Schätzungen der lokalen Wahrscheinlichkeitsdichten zu rekonstruieren. Umgekehrt ist es immer möglich, Abweichungen gemäß dieser Verteilung zu ziehen, wenn Sie lokale Wahrscheinlichkeitsdichten haben. Grundsätzlich sind diese beiden Ansätze nur verschiedene Möglichkeiten, die probabilistische oder stochastische Natur des Phänomens, das wir modellieren möchten, zu betrachten.
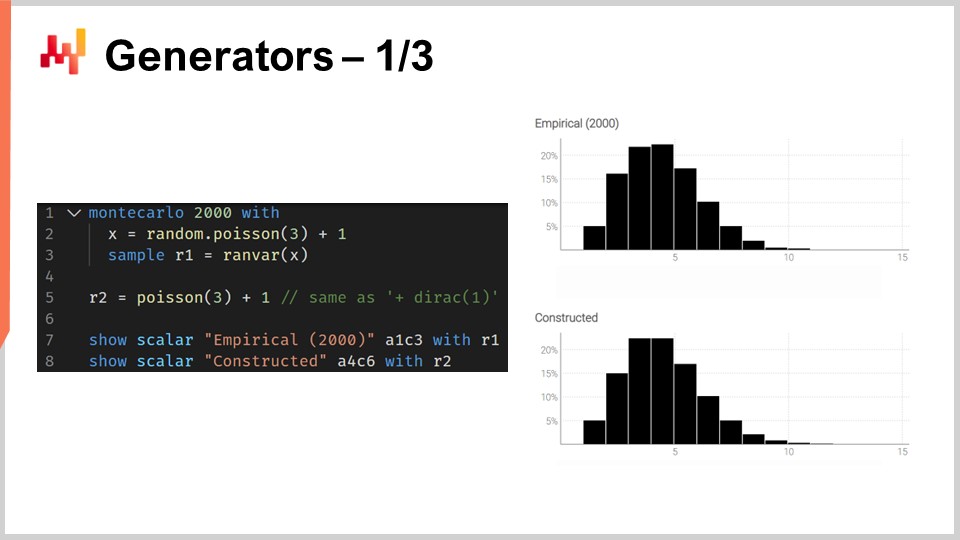
Das Skript auf dem Bildschirm veranschaulicht diese Dualität. In Zeile eins führen wir einen Monte Carlo-Block ein, der vom System durchlaufen wird, ähnlich wie die Auto-Differentiationsblöcke viele Schritte des stochastischen Gradientenabstiegs durchlaufen. Der Monte Carlo-Block wird 2.000 Mal ausgeführt, und aus diesem Block werden 2.000 Abweichungen gesammelt.
In Zeile zwei ziehen wir eine Abweichung aus einer Poisson-Verteilung mit einem Mittelwert von drei und fügen dann eins hinzu. Im Wesentlichen erhalten wir eine Zufallszahl aus dieser Poisson-Verteilung und fügen dann eins hinzu. In Zeile drei sammeln wir diese Abweichung in L1, das als Akkumulator für den Aggregator ranvar fungiert. Dies ist genau der gleiche Aggregator wie der, den wir zuvor für unser Beispiel zur Vorlaufzeit eingeführt haben. Hier sammeln wir all diese Beobachtungen in L1, was uns eine eindimensionale Verteilung liefert, die durch einen Monte Carlo-Prozess erhalten wird. In Zeile fünf konstruieren wir dieselbe eindimensionale diskrete Verteilung, diesmal jedoch mit der Algebra der Zufallsvariablen. Wir verwenden also Poisson minus drei und fügen eins hinzu. In Zeile fünf läuft kein Monte Carlo-Prozess ab; es handelt sich um eine reine Angelegenheit diskreter Wahrscheinlichkeiten und Faltungen.
Wenn wir die beiden Verteilungen visuell in den Zeilen sieben und acht vergleichen, sehen wir, dass sie fast identisch sind. Ich sage “fast”, weil wir 2.000 Iterationen verwenden, was viel ist, aber nicht unendlich. Die Abweichungen zwischen den genauen Wahrscheinlichkeiten, die Sie mit ranvar erhalten, und den ungefähren Wahrscheinlichkeiten, die Sie mit dem Monte Carlo-Prozess erhalten, sind immer noch erkennbar, wenn auch nicht groß.
Generatoren werden manchmal Simulatoren genannt, aber lassen Sie sich nicht täuschen, sie sind dasselbe. Immer wenn Sie einen Simulator haben, haben Sie einen generativen Prozess, der implizit einem probabilistischen Prognoseprozess zugrunde liegt. Immer wenn ein Simulator oder Generator beteiligt ist, sollte die Frage, die Ihnen durch den Kopf geht, lauten: Wie genau ist diese Simulation? Sie ist nicht genau durch Design, genauso wie es sehr gut möglich ist, völlig ungenaue Prognosen, probabilistisch oder nicht, zu haben. Sie können sehr leicht eine völlig ungenaue Simulation erhalten.
Mit Generatoren sehen wir, dass Simulationen nur eine Möglichkeit sind, die probabilistische Perspektive der Prognose zu betrachten, aber das ist eher ein technisches Detail. Es ändert nichts daran, dass Sie am Ende etwas haben möchten, das eine genaue Darstellung des Systems ist, das Sie mit Ihrer Prognose charakterisieren möchten, probabilistisch oder nicht.
Der generative Ansatz ist nicht nur sehr nützlich, wie wir gleich an einem konkreten Beispiel sehen werden, sondern er ist auch konzeptionell einfacher zu erfassen, zumindest etwas einfacher im Vergleich zum Ansatz mit Wahrscheinlichkeitsdichten. Allerdings ist der Monte Carlo-Ansatz auch nicht ohne technische Details. Es gibt ein paar Dinge, die notwendig sind, wenn Sie diesen Ansatz in einem Produktionskontext für eine tatsächliche Supply Chain einsetzen möchten.
Erstens müssen Generatoren schnell sein. Monte Carlo ist immer ein Kompromiss zwischen der Anzahl der gewünschten Iterationen und der Anzahl der Iterationen, die Sie sich leisten können, unter Berücksichtigung der verfügbaren Rechenressourcen. Ja, moderne Computer haben viel Rechenleistung, aber Monte Carlo-Prozesse können unglaublich ressourcenintensiv sein. Sie möchten etwas, das standardmäßig super schnell ist. Wenn wir zu den in der zweiten Vorlesung des vierten Kapitels vorgestellten Bestandteilen zurückkehren, haben wir sehr schnelle Funktionen wie ExhaustShift oder WhiteHash, die für den Aufbau der Primitiven unerlässlich sind, mit denen Sie elementare Zufallsgeneratoren generieren können, die super schnell sind. Sie brauchen das, sonst werden Sie Schwierigkeiten haben. Zweitens müssen Sie Ihre Ausführung verteilen. Die naive Implementierung eines Monte Carlo-Programms besteht einfach darin, eine Schleife zu haben, die sequentiell iteriert. Wenn Sie jedoch nur eine CPU verwenden, um Ihre Monte Carlo-Anforderungen zu bewältigen, erhalten Sie im Wesentlichen die Rechenleistung, die Computer vor zwei Jahrzehnten gekennzeichnet hat. Dieser Punkt wurde in der allerersten Vorlesung des vierten Kapitels angesprochen. In den letzten zwei Jahrzehnten sind Computer leistungsfähiger geworden, aber hauptsächlich durch Hinzufügen von CPUs und Parallelisierungsgraden. Sie müssen also eine verteilte Perspektive für Ihre Generatoren haben.
Schließlich muss die Ausführung deterministisch sein. Was bedeutet das? Es bedeutet, dass bei zweimaligem Ausführen des gleichen Codes die exakt gleichen Ergebnisse erzielt werden sollten. Das mag kontraintuitiv erscheinen, da wir es mit randomisierten Methoden zu tun haben. Dennoch entstand das Bedürfnis nach Determinismus sehr schnell. Es wurde in den 90er Jahren auf schmerzhafte Weise entdeckt, als die Finanzwelt begann, Monte Carlo-Generatoren für ihre Preisgestaltung zu verwenden. Die Finanzwelt hat sich vor langer Zeit auf den Weg der probabilistischen Prognose gemacht und umfangreichen Gebrauch von Monte Carlo-Generatoren gemacht. Eine der Dinge, die sie gelernt haben, war, dass es nahezu unmöglich ist, die Bedingungen zu replizieren, die einen Fehler oder einen Absturz verursacht haben, wenn Sie keinen Determinismus haben. Aus Sicht der Supply Chain können Fehler bei der Berechnung von Bestellaufträgen unglaublich teuer sein.
Wenn Sie eine gewisse Produktionsbereitschaft für die Software erreichen möchten, die Ihre Supply Chain steuert, müssen Sie diese deterministische Eigenschaft haben, wenn Sie es mit Monte Carlo zu tun haben. Beachten Sie, dass viele Open-Source-Lösungen aus der akademischen Welt stammen und sich überhaupt nicht um Produktionsbereitschaft kümmern. Stellen Sie sicher, dass Ihr Prozess, wenn Sie es mit Monte Carlo zu tun haben, von Design aus super schnell ist, von Design aus verteilt ist und deterministisch ist, damit Sie eine Chance haben, die Fehler zu diagnostizieren, die im Laufe der Zeit zwangsläufig in Ihrer Produktionsumgebung auftreten werden.
Wir haben eine Situation gesehen, in der ein Generator eingeführt wurde, um das zu replizieren, was sonst mit einem ranvar gemacht wurde. Als Faustregel gilt: Immer wenn Sie nur mit Wahrscheinlichkeitsdichten und Zufallsvariablen ohne Einsatz von Monte Carlo auskommen können, ist es besser. Sie erhalten genauere Ergebnisse und müssen sich nicht um die numerische Stabilität kümmern, die bei Monte Carlo immer etwas heikel ist. Die Ausdruckskraft der Algebra der Zufallsvariablen ist jedoch begrenzt, und genau hier glänzt Monte Carlo. Diese Generatoren sind ausdrucksstärker, weil sie es Ihnen ermöglichen, Situationen zu erfassen, die nur mit einer Algebra der Zufallsvariablen nicht bewältigt werden können.
Lassen Sie uns dies anhand einer Supply-Chain-Situation veranschaulichen. Betrachten Sie eine einzelne SKU mit einem anfänglichen Lagerbestand, einer probabilistischen Prognose für die Nachfrage und einem Zeitraum von drei Monaten, wobei eine eingehende Lieferung in der Mitte des Zeitraums erfolgt. Wir nehmen an, dass die Nachfrage entweder sofort aus dem vorhandenen Lagerbestand bedient wird oder für immer verloren geht. Wir möchten den erwarteten Lagerbestand am Ende des Zeitraums für die SKU wissen, da uns dies dabei hilft, das Risiko eines toten Lagerbestands abzuschätzen.
Die Situation ist tückisch, weil sie so konstruiert wurde, dass es eine dritte Chance für einen Fehlbestand gibt, der genau in der Mitte des Zeitraums auftreten kann. Der naive Ansatz wäre es, den anfänglichen Lagerbestand, die Verteilung der Nachfrage für den gesamten Zeitraum zu nehmen und die Nachfrage vom Lagerbestand abzuziehen, was zu dem verbleibenden Lagerbestand führt. Dies berücksichtigt jedoch nicht die Tatsache, dass wir einen erheblichen Teil der Nachfrage verlieren könnten, wenn wir einen Fehlbestand haben, während die eingehende Auffüllung noch aussteht. Wenn wir es auf naive Weise tun würden, würde dies die Menge des Lagerbestands unterschätzen, die wir am Ende des Zeitraums haben werden, und die Menge der Nachfrage überschätzen, die bedient wird.
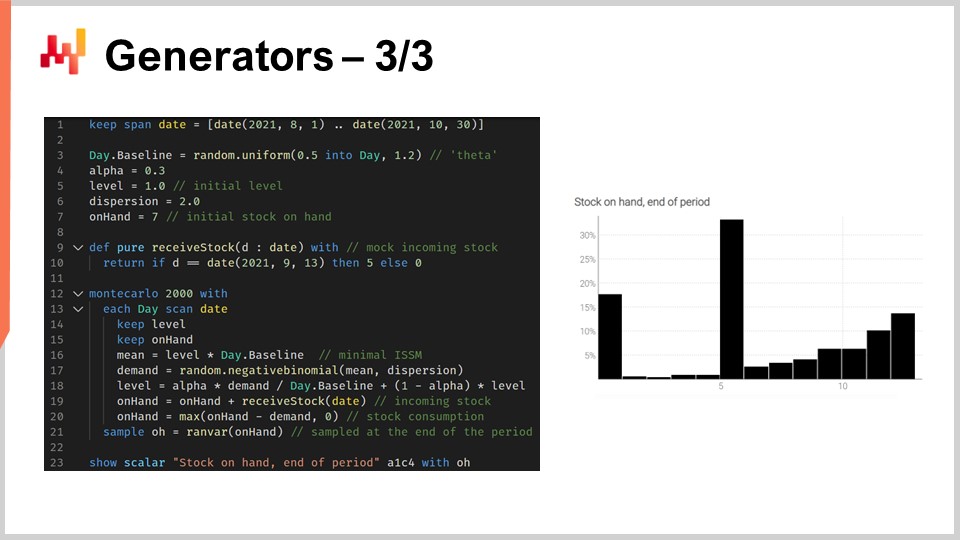
Das angezeigte Skript modelliert das Auftreten von Fehlbeständen, damit wir einen korrekten Schätzer für den Lagerbestand für diese SKU am Ende des Zeitraums haben können. Von Zeile 1 bis 10 definieren wir die Mock-Daten, die unser Modell charakterisieren. In den Zeilen 3 bis 6 befinden sich die Parameter für das ISSM-Modell. Wir haben das ICSM-Modell bereits in der allerersten Vorlesung dieses fünften Kapitels gesehen. Dieses Modell generiert im Wesentlichen eine Nachfrage-Trajektorie mit einem Datenpunkt pro Tag. Der Interessenszeitraum ist in der Tabelle “day” definiert, und wir haben die Parameter für diese Trajektorie ganz am Anfang.
In den vorherigen Vorlesungen haben wir das AICSM-Modell und die benötigten Methoden zur differenzierbaren Programmierung eingeführt, um diese Parameter zu erlernen. Heute verwenden wir das Modell und nehmen an, dass wir alles gelernt haben, was wir lernen müssen. In Zeile 7 definieren wir den anfänglichen Lagerbestand, der normalerweise aus dem ERP oder WMS stammt. In den Zeilen 9 und 10 definieren wir die Menge und das Datum für die Auffüllung. Diese Datenpunkte würden normalerweise als geschätzte Ankunftszeit vom Lieferanten erhalten und im ERP gespeichert werden. Wir nehmen an, dass das Lieferdatum perfekt bekannt ist. Es wäre jedoch einfach, dieses einzelne Datum durch eine probabilistische Prognose der Vorlaufzeit zu ersetzen.
Von Zeile 12 bis 21 haben wir das ISSM-Modell, das die Nachfrage-Trajektorie generiert. Wir befinden uns in einer Monte-Carlo-Schleife, und für jede Monte-Carlo-Iteration iterieren wir über jeden einzelnen Tag des Interessenszeitraums. Die Iteration der Tage beginnt in Zeile 13. Es gibt den ESSM-Mechanismus, aber in den Zeilen 19 und 20 aktualisieren wir die Variable “on-hand”. Die Variable “on-hand” ist kein Bestandteil des ISSM-Modells; dies ist etwas Zusätzliches. In Zeile 19 sagen wir, dass der Lagerbestand von gestern plus der eingehenden Lieferung ist, die für die meisten Tage null und für den 13. September fünf Einheiten beträgt. Dann aktualisieren wir in Zeile 20 den Lagerbestand, indem wir sagen, dass eine bestimmte Anzahl von Einheiten durch die Nachfrage des Tages verbraucht wird, und wir haben dieses “max 0”, um zu sagen, dass der Lagerbestand nicht ins Negative gehen kann.
Schließlich sammeln wir den endgültigen Lagerbestand in Zeile 21 und in Zeile 23 wird dieser endgültige Lagerbestand angezeigt. Dies ist das Histogramm, das Sie rechts auf dem Bildschirm sehen. Hier sehen wir eine Verteilung mit einer sehr unregelmäßigen Form. Diese Form kann nicht durch die Algebra der Zufallsvariablen erhalten werden. Generatoren sind unglaublich ausdrucksstark, aber Sie sollten die Ausdruckskraft dieser Generatoren nicht mit Genauigkeit verwechseln. Während Generatoren unglaublich ausdrucksstark sind, ist es nicht trivial, die Genauigkeit solcher Generatoren zu bewerten. Machen Sie keinen Fehler, jedes Mal, wenn Sie einen Generator oder Simulator verwenden, haben Sie eine Wahrscheinlichkeitsprognose im Spiel, und Simulationen können genauso ungenau sein wie jede andere Prognose, sei sie probabilistisch oder nicht.

Es war bereits eine lange Vorlesung, und doch habe ich heute viele Themen noch nicht einmal angesprochen. Entscheidungsfindung zum Beispiel, wenn alle Zukünfte möglich sind, wie treffen wir dann überhaupt Entscheidungen? Ich habe diese Frage noch nicht beantwortet, aber sie wird in der nächsten Vorlesung behandelt.
Auch höhere Dimensionen sind wichtig zu berücksichtigen. Eine eindimensionale Verteilung ist ein Ausgangspunkt, aber eine Supply Chain benötigt mehr. Wenn wir zum Beispiel einen Lagerbestandsausfall für eine bestimmte SKU haben, kann es zu Kannibalisierung kommen, bei der Kunden natürlich auf einen Ersatz zurückgreifen. Wir möchten dies modellieren, auch wenn es auf grobe Weise geschieht.
Auch höhere Ordnungskonstrukte spielen eine Rolle. Wie gesagt, die Vorhersage der Nachfrage ist nicht wie die Vorhersage der Bewegungen von Planeten. Wir haben überall selbstprophetische Effekte. Irgendwann möchten wir unsere Preispolitik und Bestandsergänzungspolitik berücksichtigen und einbeziehen. Dazu benötigen wir höhere Ordnungskonstrukte, was bedeutet, dass Sie bei einer Richtlinie eine probabilistische Prognose des Ergebnisses erhalten, aber die Richtlinie in die höheren Ordnungskonstrukte einfügen müssen.
Darüber hinaus erfordert die Beherrschung probabilistischer Prognosen zahlreiche numerische Rezepte und Fachkenntnisse, um zu wissen, welche Verteilungen in bestimmten Situationen am wahrscheinlichsten passen. In dieser Reihe von Vorlesungen werden wir später weitere Beispiele vorstellen.
Schließlich gibt es die Herausforderung des Wandels. Probabilistische Prognosen sind ein radikaler Bruch mit den gängigen Praktiken in der Supply Chain. Häufig sind die technischen Aspekte, die mit probabilistischen Prognosen verbunden sind, nur ein kleiner Teil der Herausforderung. Die schwierige Aufgabe besteht darin, die Organisation selbst neu zu erfinden, damit sie anstelle von Punktprognosen, die im Wesentlichen Wunschdenken sind, diese probabilistischen Prognosen verwenden kann. All diese Elemente werden in späteren Vorlesungen behandelt, aber es wird Zeit brauchen, da wir viel zu behandeln haben.

Zusammenfassend stellen probabilistische Prognosen einen radikalen Bruch mit der Perspektive der Punktprognose dar, bei der wir eine Art Konsens über die eine Zukunft erwarten, die eintreten soll. Probabilistische Prognosen basieren auf der Beobachtung, dass die Unsicherheit der Zukunft irreduzibel ist. Ein Jahrhundert der Prognosewissenschaft hat gezeigt, dass alle Versuche, etwas zu erreichen, das auch nur annähernd genaue Prognosen liefern würde, gescheitert sind. Daher sind wir mit vielen unbestimmten Zukünften konfrontiert. Probabilistische Prognosen geben uns jedoch Techniken und Werkzeuge an die Hand, um diese Zukünfte zu quantifizieren und zu bewerten. Probabilistische Prognosen sind eine bedeutende Leistung. Es hat fast ein Jahrhundert gedauert, um sich mit der Idee anzufreunden, dass die wirtschaftliche Prognose nicht wie die Astronomie ist. Während wir die genaue Position eines Planeten in einem Jahrhundert mit großer Genauigkeit vorhersagen können, haben wir keine Hoffnung, etwas Vergleichbares im Bereich der Supply Chains zu erreichen. Die Idee, eine Prognose zu haben, die alles beherrscht, kehrt einfach nicht zurück. Dennoch klammern sich viele Unternehmen immer noch an die Hoffnung, dass irgendwann die eine wahre genaue Prognose erreicht wird. Nach einem Jahrhundert der Versuche ist dies im Wesentlichen Wunschdenken.
Mit modernen Computern ist diese Ein-Zukunft-Perspektive nicht die einzige Perspektive in der Stadt. Wir haben Alternativen. Probabilistische Prognosen gibt es seit den 90er Jahren, also vor drei Jahrzehnten. Bei Lokad verwenden wir probabilistische Prognosen seit über einem Jahrzehnt, um Supply Chains in der Produktion zu steuern. Es ist vielleicht noch nicht weit verbreitet, aber es ist weit entfernt von Science-Fiction. Es ist seit drei Jahrzehnten eine Realität für viele Unternehmen in der Finanzbranche und seit einem Jahrzehnt in der Welt der Supply Chains.
Obwohl probabilistische Prognosen einschüchternd und hochtechnisch erscheinen mögen, sind es mit den richtigen Werkzeugen nur wenige Zeilen Code. Es gibt nichts Besonderes Schwieriges oder Herausforderndes an probabilistischen Prognosen, zumindest im Vergleich zu anderen Arten von Prognosen. Die größte Herausforderung bei probabilistischen Prognosen besteht darin, sich von dem Komfort zu lösen, der mit der Illusion verbunden ist, dass die Zukunft perfekt unter Kontrolle ist. Die Zukunft ist nicht perfekt unter Kontrolle und wird es auch nie sein, und alles in allem ist es wahrscheinlich das Beste.

Damit endet der Vortrag für heute. Nächste Woche, am 6. April, werde ich die Entscheidungsfindung bei der Bestandsverteilung im Einzelhandel vorstellen und zeigen, wie die heute vorgestellten probabilistischen Prognosen zur Steuerung einer grundlegenden Supply Chain-Entscheidung, nämlich der Bestandsauffüllung in einem Einzelhandelsnetzwerk, genutzt werden können. Der Vortrag findet am gleichen Wochentag, Mittwoch, zur gleichen Tageszeit, 15 Uhr, statt und es ist der erste Mittwoch im April.
Frage: Können wir die Auflösung der Präzision gegenüber dem RAM-Volumen für Envision optimieren?
Ja, absolut, allerdings nicht in Envision selbst. Das ist eine Entscheidung, die wir bei der Gestaltung von Envision getroffen haben. Mein Ansatz, wenn es um Supply Chain Scientists geht, besteht darin, sie von technischen Details auf niedriger Ebene zu befreien. Envisions 4 Kilobyte bieten viel Platz für eine genaue Darstellung Ihrer Supply Chain-Situation. Die Genauigkeit, die Sie in Bezug auf Auflösung und Präzision verlieren, ist vernachlässigbar.
Natürlich gibt es bei der Gestaltung Ihres Komprimierungsalgorithmus viele Abwägungen zu berücksichtigen. Zum Beispiel müssen Eimer, die sehr nahe bei Null liegen, eine perfekte Auflösung haben. Wenn Sie die Wahrscheinlichkeit beobachten möchten, dass null Einheiten Nachfrage auftreten, möchten Sie nicht, dass Ihre Approximation die Eimer für null Nachfrage, eine Einheit und zwei Einheiten zusammenfasst. Wenn Sie jedoch Eimer für die Wahrscheinlichkeit beobachten, 1.000 Einheiten Nachfrage zu beobachten, ist es wahrscheinlich in Ordnung, 1.000 und 1.001 Einheiten Nachfrage zusammenzufassen. Es gibt also viele Tricks, um einen Komprimierungsalgorithmus zu entwickeln, der den Anforderungen der Supply Chain wirklich entspricht. Dies ist im Vergleich zur Bildkompression um Größenordnungen einfacher. Meiner Meinung nach würde eine korrekt gestaltete Werkzeugunterstützung das Problem für Supply Chain Scientists im Wesentlichen abstrahieren. Dies ist zu niedrig, und Sie müssen in den meisten Fällen nicht mikrooptimieren. Wenn Sie Walmart sind und nicht nur 1 Million SKUs, sondern mehrere hundert Millionen SKUs haben, kann es sinnvoll sein, mikrooptimieren. Es sei denn, Sie sprechen von außergewöhnlich großen Supply Chains, glaube ich, dass Sie etwas haben können, das gut genug ist, so dass der Leistungseinbruch durch fehlende vollständige Optimierung größtenteils vernachlässigbar ist.
Frage: Welche praktischen Überlegungen sind aus Sicht der Supply Chain zu berücksichtigen, während diese Parameter optimiert werden?
Wenn es um probabilistische Prognosen in der Supply Chain geht, ist eine Präzision von mehr als eins von 100.000 in der Regel vernachlässigbar, einfach weil Sie nie genug Daten haben, um eine Genauigkeit in Bezug auf die Schätzung Ihrer Wahrscheinlichkeiten zu haben, die granularer ist als ein Teil von 100.000.
Frage: Welche Branche profitiert am meisten von dem probabilistischen Prognoseansatz?
Die kurze Antwort lautet: Je unregelmäßiger und unregelmäßiger Ihre Muster sind, desto größer sind die Vorteile. Wenn Sie eine intermittierende Nachfrage haben, haben Sie große Vorteile; wenn Sie eine unregelmäßige Nachfrage haben, haben Sie große Vorteile; wenn Sie stark schwankende Vorlaufzeiten und unregelmäßige Störungen in Ihren Lieferketten haben, profitieren Sie am meisten. Am anderen Ende des Spektrums, nehmen wir zum Beispiel die Lieferkette der Wasserverteilung, der Wasserverbrauch ist äußerst gleichmäßig und hat fast nie große Störungen - höchstens Mikrostörungen. Dies ist die Art von Problem, die nicht vom probabilistischen Ansatz profitiert. Die Idee ist, dass es einige Situationen gibt, in denen klassische Punktprognosen sehr genaue Prognosen liefern. Wenn Sie sich in einer Situation befinden, in der Ihre Prognosen für alle Ihre Produkte einen Fehler von weniger als fünf Prozent haben, dann benötigen Sie keine probabilistischen Prognosen; Sie befinden sich in einer Situation, in der eine wirklich genaue Prognose tatsächlich funktioniert. Wenn Sie jedoch wie viele Unternehmen in Situationen sind, in denen die Genauigkeit Ihrer Prognose sehr gering ist, mit einer Abweichung von 30% oder mehr, dann profitieren Sie stark von der probabilistischen Prognose. Übrigens, wenn ich von einer Prognosefehler von 30% spreche, beziehe ich mich immer auf die sehr disaggregierte Prognose. Viele Unternehmen werden Ihnen sagen, dass ihre Prognosen zu 5% genau sind, aber wenn Sie alles aggregieren, kann dies eine sehr irreführende Wahrnehmung Ihrer Prognosegenauigkeit sein. Ihre Prognosegenauigkeit spielt nur auf der disaggregiertesten Ebene eine Rolle, in der Regel auf der SKU-Ebene und der täglichen Ebene, weil Ihre Entscheidungen auf der SKU-Ebene und der täglichen Ebene getroffen werden. Wenn Sie auf der SKU-Ebene und der täglichen Ebene Ihre disaggregiertesten Prognosen mit einer Genauigkeit von 5% erhalten können, dann benötigen Sie keine probabilistischen Prognosen. Wenn Sie jedoch zweistellige Ungenauigkeiten in Bezug auf Prozentsätze feststellen, dann profitieren Sie stark von der probabilistischen Prognose.
Frage: Können sich Vorlaufzeiten saisonal ändern? Würden Sie Vorhersagen für Vorlaufzeiten in mehrere Vorhersagen aufteilen, jeweils eine für jede einzelne Saison, um keine multimodale Verteilung zu betrachten?
Das ist eine gute Frage. Die Idee hier ist, dass Sie typischerweise ein parametrisches Modell für Ihre Vorlaufzeiten erstellen würden, das ein Saisonalitäts-Profil enthält. Der Umgang mit Saisonalität bei Vorlaufzeiten unterscheidet sich grundsätzlich nicht wesentlich von der Bewältigung jeder anderen Zyklik, wie wir es in der vorherigen Vorlesung für die Nachfrage getan haben. Der typische Weg besteht nicht darin, mehrere Modelle zu erstellen, denn wie Sie richtig bemerkt haben, wenn Sie mehrere Modelle haben, werden Sie alle möglichen seltsamen Sprünge beobachten, wenn Sie von einer Modalität zur nächsten wechseln. Es ist in der Regel besser, nur ein Modell mit einem Saisonalitätsprofil in der Mitte des Modells zu haben. Es wäre wie eine parametrische Zerlegung, bei der Sie einen Vektor haben, der Ihnen den wöchentlichen Effekt gibt, der die Vorlaufzeit in einer bestimmten Woche des Jahres beeinflusst. Vielleicht haben wir in einer späteren Vorlesung Zeit, ein ausführlicheres Beispiel dafür zu geben.
Frage: Ist die probabilistische Prognose ein guter Ansatz, wenn Sie eine intermittierende Nachfrage prognostizieren möchten?
Absolut. Tatsächlich glaube ich, dass bei intermittierender Nachfrage die probabilistische Prognose nicht nur eine gute Methode ist, sondern die klassische Punktprognose völlig unsinnig ist. Mit der klassischen Prognose würden Sie typischerweise Schwierigkeiten haben, mit all diesen Nullen umzugehen. Was machen Sie mit all diesen Nullen? Sie enden mit einem Wert, der sehr niedrig und gebrochen ist, was nicht wirklich sinnvoll ist. Bei intermittierender Nachfrage ist die Frage, die Sie wirklich beantworten möchten: Ist mein Lager groß genug, um diese Nachfrageausschläge zu bedienen, die gelegentlich auftreten? Wenn Sie eine Durchschnittsprognose verwenden, werden Sie das nie wissen.
Um zum Beispiel des Buchladens zurückzukehren: Wenn Sie sagen, dass Sie in einer bestimmten Woche durchschnittlich eine Einheit Nachfrage pro Tag beobachten, wie viele Bücher müssen Sie in Ihrem Buchladen aufbewahren, um eine hohe Servicequalität zu haben? Nehmen wir an, der Buchladen wird jeden Tag aufgefüllt. Wenn Sie nur Studenten bedienen, dann führt eine durchschnittliche Nachfrage von einer Einheit pro Tag dazu, dass drei Bücher im Lager eine sehr hohe Servicequalität ergeben. Wenn jedoch gelegentlich ein Professor hereinkommt und nach 20 Büchern auf einmal sucht, dann wird Ihre Servicequalität, wenn Sie nur drei Bücher im Laden haben, miserabel sein, weil Sie keinen der Professoren bedienen können. Das ist typischerweise bei intermittierender Nachfrage der Fall - es geht nicht nur darum, dass die Nachfrage intermittierend ist, sondern auch darum, dass einige Nachfrageausschläge in Bezug auf ihre Größe erheblich variieren können. Hier kommt die probabilistische Prognose wirklich zum Tragen, da sie die Feinstruktur der Nachfrage erfassen kann, anstatt alles in Durchschnittswerte zusammenzufassen, bei denen diese Feinstruktur verloren geht.
Frage: Wenn wir die Vorlaufzeit durch eine Verteilung ersetzen, wird der Ausschlag durch eine glatte Glockenkurve auf der ersten Folie für den Generator dargestellt?
In gewissem Maße, wenn Sie mehr zufällig machen, neigen die Dinge dazu, sich zu verteilen. Auf der ersten Folie über den Generator müssten wir das Experiment mit verschiedenen Einstellungen durchführen, um zu sehen, was wir bekommen. Die Idee ist, dass wir die Vorlaufzeit durch eine Verteilung ersetzen möchten, weil wir ein Verständnis für das Problem haben, das uns sagt, dass die Vorlaufzeit variiert. Wenn wir unserem Lieferanten absolut vertrauen und er unglaublich zuverlässig war, dann ist es völlig in Ordnung zu sagen, dass die ETA (geschätzte Ankunftszeit) das ist, was sie ist und eine nahezu perfekte Schätzung des Realen ist. Wenn wir jedoch gesehen haben, dass Lieferanten in der Vergangenheit manchmal unzuverlässig waren oder das Ziel verfehlt haben, ist es besser, die Vorlaufzeit durch eine Verteilung zu ersetzen.
Die Einführung einer Verteilung zur Ersetzung der Vorlaufzeit glättet nicht zwangsläufig die Ergebnisse, die Sie am Ende erhalten; es hängt davon ab, worauf Sie schauen. Wenn Sie zum Beispiel den extremsten Fall von Überbestand betrachten, kann eine variable Vorlaufzeit sogar das Risiko erhöhen, dass Sie tote Bestände haben. Warum ist das so? Wenn Sie ein sehr saisonales Produkt und eine variable Vorlaufzeit haben und das Produkt nach dem Ende der Saison ankommt, haben Sie ein Produkt, das außerhalb der Saison ist, was das Risiko erhöht, am Ende der Saison tote Bestände zu haben. Es ist also knifflig. Die Tatsache, dass Sie eine Variable durch ihren probabilistischen Ersatz ersetzen, glättet nicht automatisch das, was Sie beobachten werden; manchmal kann es die Verteilung sogar schärfer machen. Die Antwort lautet also: Es kommt darauf an.
Ausgezeichnet, das war es für heute. Bis zum nächsten Mal.


