00:00 Einführung
02:52 Hintergrund und Haftungsausschluss
07:39 Naiver Rationalismus
13:14 Die Geschichte bisher
16:37 Wissenschaftler, wir brauchen euch!
18:25 Mensch + Maschine (das Problem 1/4)
23:16 Die Einrichtung (das Problem 2/4)
26:44 Die Wartung (das Problem 3/4)
30:02 Der IT-Rückstand (das Problem 4/4)
32:56 Die Mission (die Aufgabe des Wissenschaftlers 1/6)
35:58 Terminologie (die Aufgabe des Wissenschaftlers 2/6)
37:54 Liefergegenstände (die Aufgabe des Wissenschaftlers 3/6)
41:11 Der Umfang (die Aufgabe des Wissenschaftlers 4/6)
44:59 Tägliche Routine (die Aufgabe des Wissenschaftlers 5/6)
46:58 Verantwortung (die Aufgabe des Wissenschaftlers 6/6)
49:25 Eine Position in der Lieferkette (HR 1/6)
51:13 Einstellung eines Wissenschaftlers (HR 2/6)
53:58 Schulung des Wissenschaftlers (HR 3/6)
55:43 Überprüfung des Wissenschaftlers (HR 4/6)
57:24 Bindung des Wissenschaftlers (HR 5/6)
59:37 Vom einen Wissenschaftler zum nächsten (HR 6/6)
01:01:17 Über IT (Unternehmensdynamik 1/3)
01:03:50 Über Finanzen (Unternehmensdynamik 2/3)
01:05:42 Über Führung (Unternehmensdynamik 3/3)
01:09:18 Alte Schule Planung (Modernisierung 1/5)
01:11:56 Ende von S&OP (Modernisierung 2/5)
01:13:31 Alte Schule BI (Modernisierung 3/5)
01:15:24 Ausstieg aus der Datenwissenschaft (Modernisierung 4/5)
01:17:28 Ein neuer Deal für IT (Modernisierung 5/5)
01:19:28 Fazit
01:22:05 7.3 Der Quantitative Supply Chain - Fragen?
Beschreibung
Im Kern einer quantitativen Supply Chain-Initiative steht der Supply Chain Scientist (SCS), der die Datenvorbereitung, die wirtschaftliche Modellierung und das KPI-Reporting durchführt. Die intelligente Automatisierung der Supply Chain-Entscheidungen ist das Endprodukt der Arbeit des SCS. Der SCS übernimmt die Verantwortung für die generierten Entscheidungen. Der SCS liefert menschliche Intelligenz, die durch maschinelles Verarbeitungsvermögen verstärkt wird.
Vollständiges Transkript

Herzlich willkommen zu dieser Reihe von Vorlesungen über die Lieferkette. Ich bin Joannes Vermorel und heute werde ich den Supply Chain Scientist aus der Perspektive der quantifizierten Lieferkette vorstellen. Der Supply Chain Scientist ist die Person oder möglicherweise die kleine Gruppe von Personen, die für die Leitung der Lieferketteninitiative verantwortlich sind. Diese Person überwacht die Entwicklung und spätere Aufrechterhaltung der numerischen Rezepte, die die interessanten Entscheidungen generieren. Diese Person ist auch dafür verantwortlich, alle notwendigen Beweise für den Rest des Unternehmens zu liefern, um zu beweisen, dass die generierten Entscheidungen fundiert sind.
Das Motto der quantifizierten Lieferkette lautet, das Beste aus dem herauszuholen, was moderne Hardware und moderne Software für Lieferketten zu bieten haben. Die verkörperte Ausprägung dieser Perspektive ist jedoch naiv. Menschliche Intelligenz ist nach wie vor ein Eckpfeiler des gesamten Unternehmens und kann aus verschiedenen Gründen noch nicht so schön verpackt werden, wie es eine Lieferkette erfordert. Das Ziel dieser Vorlesung ist es zu verstehen, warum und wie die Rolle des Supply Chain Scientist in den letzten zehn Jahren zu einer bewährten Lösung geworden ist, um das Beste aus moderner Software für Lieferkettenzwecke zu machen.
Um dieses Ziel zu erreichen, müssen zunächst die großen Engpässe verstanden werden, mit denen moderne Software immer noch konfrontiert ist, wenn sie versucht, Lieferkettenentscheidungen zu automatisieren. Basierend auf diesem neuen Verständnis werden wir die Rolle des Supply Chain Scientist einführen, die im Wesentlichen eine Antwort auf diese Engpässe darstellt. Schließlich werden wir sehen, wie diese Rolle das Unternehmen als Ganzes in kleineren und größeren Maßstäben neu gestaltet. Tatsächlich kann der Supply Chain Scientist nicht als Silo innerhalb des Unternehmens agieren. Genauso wie der Wissenschaftler mit dem Rest des Unternehmens zusammenarbeiten muss, um etwas zu erreichen, muss auch der Rest des Unternehmens mit dem Wissenschaftler zusammenarbeiten, damit dies geschehen kann.

Bevor wir weitermachen, möchte ich noch einmal auf einen Haftungsausschluss hinweisen, den ich in der allerersten Vorlesung dieser Reihe gemacht habe. Die vorliegende Vorlesung basiert fast ausschließlich auf einem einzigartigen, über ein Jahrzehnt durchgeführten Experiment bei Lokad, einem Enterprise-Software-Anbieter, der auf Supply Chain-Optimierung spezialisiert ist. Alle diese Vorlesungen wurden durch die Reise von Lokad geprägt, aber wenn es um die Rolle des Supply Chain Scientist geht, ist die Verbindung noch stärker. In großem Maße kann die Reise von Lokad selbst durch die Linse unserer allmählichen Entdeckung der Rolle des Supply Chain Scientist gelesen werden.
Dieser Prozess ist noch im Gange. Zum Beispiel haben wir vor etwa fünf Jahren die gängige Perspektive eines Data Scientists mit der Einführung von Programmierparadigmen für Lern- und Optimierungszwecke aufgegeben. Lokad beschäftigt derzeit drei Dutzend Supply Chain Scientists. Unsere fähigsten Wissenschaftler haben durch ihre Erfolgsbilanzen das Vertrauen erlangt, auf großer Skala Entscheidungen zu treffen. Einige von ihnen sind individuell für Parameter verantwortlich, die den Wert von einer halben Milliarde Dollar überschreiten. Dieses Vertrauen erstreckt sich auf eine Vielzahl von Entscheidungen, wie zum Beispiel Bestellmengen, Produktionsaufträge, Bestandszuweisungs-Aufträge oder Preisgestaltung.
Wie Sie sich vorstellen können, musste dieses Vertrauen erarbeitet werden. Tatsächlich würden nur sehr wenige Unternehmen ihren eigenen Mitarbeitern solche Befugnisse anvertrauen, geschweige denn einem Drittanbieter wie Lokad. Das Erlangen dieses Vertrauensgrades ist ein Prozess, der in der Regel Jahre dauert, unabhängig von den technologischen Möglichkeiten. Doch ein Jahrzehnt später wächst Lokad schneller als je zuvor in seinen Anfangsjahren, und ein beträchtlicher Teil dieses Wachstums kommt von unseren bestehenden Kunden, die den Umfang der Entscheidungen erweitern, die Lokad vertraut werden.
Das bringt mich zu meinem Ausgangspunkt: Diese Vorlesung ist mit Sicherheit mit allerlei Vorurteilen behaftet. Ich habe versucht, diese Perspektive durch ähnliche Erfahrungen außerhalb von Lokad zu erweitern; jedoch gibt es dazu nicht viel zu erzählen. Nach meinem Kenntnisstand gibt es einige Technologieriesen, genauer gesagt einige riesige E-Commerce-Unternehmen, die einen Grad an Entscheidungsautomatisierung erreichen, der mit dem von Lokad vergleichbar ist.
Diese Giganten investieren in der Regel zwei Größenordnungen mehr Ressourcen als normale große Unternehmen, mit Hunderten von Ingenieuren. Die Machbarkeit dieser Ansätze ist mir jedoch unklar, da sie möglicherweise nur in äußerst profitablen Unternehmen funktionieren. Andernfalls könnten die enormen Personalkosten die Vorteile einer besseren Supply-Chain-Ausführung übersteigen.
Darüber hinaus wird es zur Herausforderung, auf solch einer Skala Ingenieurtalente anzuziehen. Die Einstellung eines talentierten Softwareingenieurs ist schon schwierig genug; die Einstellung von 100 von ihnen erfordert eine bemerkenswerte Arbeitgebermarke. Glücklicherweise ist die heute präsentierte Perspektive viel schlanker. Viele Supply-Chain-Initiativen von Lokad werden von einem einzigen Supply Chain Scientist durchgeführt, wobei ein zweiter als Ersatz fungiert. Neben den Einsparungen bei den Personalkosten zeigen unsere Erfahrungen, dass mit einer kleineren Mitarbeiterzahl erhebliche Vorteile in der Supply Chain verbunden sind.

Die gängige Perspektive der Supply Chain nimmt die Haltung der angewandten Mathematik ein. Methoden und Algorithmen werden in einer Weise präsentiert, die den menschlichen Operator vollständig aus dem Bild entfernt. Zum Beispiel werden die Formel für den Sicherheitsbestand und die Formel für die optimale Bestellmenge als reine Angelegenheit der angewandten Mathematik präsentiert. Die Identität der Person, die diese Formeln verwendet, ihre Fähigkeiten oder ihr Hintergrund, ist nicht nur unwichtig, sondern wird auch nicht Teil der Präsentation.
Allgemeiner betrachtet wird diese Haltung in Supply-Chain-Lehrbüchern und folglich in Supply-Chain-Software weitgehend übernommen. Es fühlt sich sicherlich objektiver an, den menschlichen Faktor aus dem Bild zu entfernen. Schließlich hängt die Gültigkeit eines Theorems nicht von der Person ab, die den Beweis formuliert, und ebenso hängt die Leistung eines Algorithmus nicht von der Person ab, die den letzten Tastendruck bei seiner Implementierung ausführt. Dieser Ansatz zielt darauf ab, eine überlegene Form der Rationalität zu erreichen.
Ich argumentiere jedoch, dass diese Haltung naiv ist und eine weitere Form des naiven Rationalismus darstellt. Mein Vorschlag ist subtil, aber wichtig: Ich behaupte nicht, dass das Ergebnis eines numerischen Rezepts von der Person abhängt, die es letztendlich ausführt, noch dass der Charakter eines Mathematikers etwas mit der Gültigkeit seiner Theoreme zu tun hat. Stattdessen behaupte ich, dass die intellektuelle Haltung, die mit dieser Perspektive verbunden ist, für die Herangehensweise an Supply Chains unangemessen ist.
Ein Rezept für eine Supply Chain in der realen Welt ist ein komplexes Handwerk, und der Autor des Rezepts ist bei weitem nicht so neutral oder irrelevant, wie es scheinen mag. Lassen Sie uns diesen Punkt verdeutlichen, indem wir zwei identische numerische Rezepte betrachten, die sich nur in der Benennung ihrer Variablen unterscheiden. Auf numerischer Ebene liefern die beiden Rezepte identische Ergebnisse. Das erste Rezept hat jedoch gut gewählte, sinnvolle Variablennamen, während das zweite Rezept kryptische, inkonsistente Namen hat. In der Produktion ist das zweite Rezept (das mit den kryptischen, inkonsistenten Variablennamen) eine Katastrophe, die nur darauf wartet, zu passieren. Jede Weiterentwicklung oder Fehlerbehebung, die auf das zweite Rezept angewendet wird, erfordert im Vergleich zur gleichen Aufgabe beim ersten Rezept einen um Größenordnungen höheren Aufwand. Tatsächlich sind Probleme mit der Variablenbenennung so häufig und schwerwiegend, dass viele Lehrbücher für Softwaretechnik ein ganzes Kapitel dieser einzigen Frage widmen.
Weder Mathematik, Algorithmik noch Statistik sagen etwas über die Angemessenheit von Variablennamen aus. Die Angemessenheit dieser Namen liegt offensichtlich im Auge des Betrachters. Obwohl wir zwei numerisch identische Rezepte haben, wird eines aus scheinbar subjektiven Gründen als weit überlegen angesehen. Die These, die ich hier verteidige, ist, dass in diesen subjektiven Bedenken ebenfalls Rationalität zu finden ist. Diese Bedenken sollten nicht einfach abgetan werden, weil sie von einem Subjekt oder einer Person abhängig sind. Im Gegenteil, die Erfahrung von Lokad zeigt, dass bestimmte Supply Chain-Wissenschaftler mit den gleichen Softwaretools, mathematischen Instrumenten und Algorithmenbibliotheken überlegene Ergebnisse erzielen. Tatsächlich ist die Identität des verantwortlichen Wissenschaftlers einer der besten Vorhersagefaktoren für den Erfolg der Initiative.
Unter der Annahme, dass angeborenes Talent die Unterschiede im Erfolg der Supply Chain nicht vollständig erklären kann, sollten wir die Elemente, die zu erfolgreichen Initiativen beitragen, ob objektiv oder subjektiv, annehmen. Aus diesem Grund haben wir bei Lokad in den letzten Jahrzehnten viel Aufwand betrieben, um unseren Ansatz für die Rolle des Supply Chain-Wissenschaftlers zu verfeinern, was genau das Thema dieses Vortrags ist. Die Nuancen, die mit der Position eines Supply Chain-Wissenschaftlers verbunden sind, sollten nicht unterschätzt werden. Die Größenordnung der Verbesserungen, die durch diese subjektiven Elemente erreicht werden, ist vergleichbar mit unseren bemerkenswertesten technologischen Errungenschaften.
Diese Vortragsreihe ist als Schulungsmaterial für die Supply Chain-Wissenschaftler von Lokad gedacht. Ich hoffe jedoch auch, dass diese Vorträge für ein breiteres Publikum von Supply Chain-Praktikern oder sogar Supply Chain-Studenten von Interesse sein können. Es ist am besten, diese Vorträge in der Reihenfolge anzusehen, um ein gründliches Verständnis dafür zu bekommen, mit welchen Herausforderungen Supply Chain-Wissenschaftler konfrontiert sind.
Im ersten Kapitel haben wir gesehen, warum Supply Chains programmatisch werden müssen und warum es äußerst wünschenswert ist, ein numerisches Rezept in die Produktion bringen zu können. Die zunehmende Komplexität von Supply Chains macht Automatisierung dringender denn je. Darüber hinaus besteht ein finanzieller Zwang, Supply Chain-Praktiken kapitalistisch zu gestalten.
Das zweite Kapitel ist den Methoden gewidmet. Supply Chains sind wettbewerbsfähige Systeme, und diese Kombination macht naive Methoden zunichte. Die Rolle der Wissenschaftler kann als Gegenmittel zur naiven angewandten mathematischen Methodik betrachtet werden.
Das dritte Kapitel untersucht die Probleme, mit denen das Supply Chain-Personal konfrontiert ist. Dieses Kapitel versucht, die Klassen von Entscheidungsproblemen zu charakterisieren, die angegangen werden müssen. Es zeigt, dass vereinfachte Perspektiven wie die Auswahl der richtigen Lagerbestandsmenge für jede SKU nicht zu realen Situationen passen; es gibt immer Tiefe in Form von Entscheidungsfindung.
Das vierte Kapitel untersucht die Elemente, die erforderlich sind, um eine moderne Praxis der Supply Chain zu erfassen, in der Softwareelemente allgegenwärtig sind. Diese Elemente sind grundlegend, um den breiteren Kontext zu verstehen, in dem die digitale Supply Chain tätig ist.
Die Kapitel 5 und 6 sind jeweils der Vorhersagemodellierung und der Entscheidungsfindung gewidmet. Diese Kapitel behandeln die “intelligenten” Bestandteile des numerischen Rezepts und umfassen maschinelles Lernen und mathematische Optimierung. Insbesondere sammeln diese Kapitel Techniken, die sich in den Händen von Supply Chain-Wissenschaftlern bewährt haben.
Schließlich ist das siebte und aktuelle Kapitel der Durchführung einer quantitativen Supply Chain-Initiative gewidmet. Wir haben gesehen, was erforderlich ist, um eine Initiative zu starten und die richtigen Grundlagen zu legen. Wir haben gesehen, wie man die Ziellinie überquert und das numerische Rezept in die Produktion bringt.

Heute werden wir sehen, welche Art von Person erforderlich ist, um das Ganze zum Laufen zu bringen.
Die Rolle des Wissenschaftlers zielt darauf ab, Probleme zu lösen, die in der akademischen Literatur zu finden sind. Wir werden die Aufgabe des Supply Chain-Wissenschaftlers überprüfen, einschließlich ihrer Mission, ihres Umfangs, ihres täglichen Ablaufs und ihrer Interessensgebiete. Diese Stellenbeschreibung spiegelt die heutige Praxis bei Lokad wider.
Eine neue Position im Unternehmen wirft eine Reihe von Bedenken auf, daher müssen Wissenschaftler eingestellt, geschult, überprüft und gehalten werden. Wir werden diese Bedenken aus der Perspektive des Personalwesens angehen. Von den Wissenschaftlern wird erwartet, dass sie mit anderen Abteilungen im Unternehmen zusammenarbeiten, über ihre Supply Chain-Abteilung hinaus. Wir werden sehen, welche Art von Interaktionen zwischen den Wissenschaftlern und der IT, der Finanzabteilung und sogar der Unternehmensführung erwartet werden.
Der Wissenschaftler bietet auch eine Möglichkeit für das Unternehmen, sein Personal und seine Abläufe zu modernisieren. Diese Modernisierung ist der schwierigste Teil der Reise, da es weitaus herausfordernder ist, eine Position zu entfernen, die nicht mehr relevant ist, als eine neue einzuführen.
Die Herausforderung, die wir uns in dieser Vortragsreihe gestellt haben, besteht darin, Supply Chains systematisch durch quantitative Methoden zu verbessern. Der allgemeine Ansatz besteht darin, das Beste aus dem zu machen, was moderne Computer und Software für Supply Chains zu bieten haben. Es muss jedoch geklärt werden, was noch zum Bereich der menschlichen Intelligenz gehört und was erfolgreich automatisiert werden kann.
Die Grenze zwischen menschlicher Intelligenz und Automatisierung hängt immer noch stark von der Technologie ab. Es wird erwartet, dass überlegene Technologie ein breiteres Spektrum an Entscheidungen mechanisiert und bessere Ergebnisse liefert. Aus Sicht der Supply Chain bedeutet dies, dass vielfältigere Entscheidungen getroffen werden, wie z.B. Preisentscheidungen zusätzlich zu Entscheidungen über die Bestandsauffüllung, und dass bessere Entscheidungen getroffen werden, die die Rentabilität des Unternehmens weiter verbessern.
Die Rolle des Wissenschaftlers verkörpert diese Grenze zwischen menschlicher Intelligenz und Automatisierung. Während routinemäßige Ankündigungen über künstliche Intelligenz den Eindruck erwecken können, dass die menschliche Intelligenz kurz davor steht, automatisiert zu werden, zeigt mein Verständnis des aktuellen Standes der Technik, dass die allgemeine künstliche Intelligenz noch weit entfernt ist. Tatsächlich sind menschliche Erkenntnisse immer noch sehr gefragt, wenn es darum geht, quantitative Methoden von Supply Chain-Relevanz zu entwerfen. Die Entwicklung einer grundlegenden Supply Chain-Strategie liegt größtenteils außerhalb dessen, was Software liefern kann.
Allgemeiner gesagt haben wir noch keine Technologien, die in der Lage sind, schlecht gestellte oder nicht identifizierte Probleme anzugehen, die in der Supply Chain weit verbreitet sind. Sobald jedoch ein eng umrissenes, gut spezifiziertes Problem isoliert wurde, ist es denkbar, dass ein automatisierter Prozess seine Lösung erlernt und diese Lösung sogar mit wenig oder keiner menschlichen Überwachung automatisiert.
Diese Perspektive ist nicht neu. Zum Beispiel sind Anti-Spam-Filter weit verbreitet. Diese Filter erfüllen eine anspruchsvolle Aufgabe: die Trennung des Relevanten vom Irrelevanten. Die Gestaltung der nächsten Generation von Filtern obliegt jedoch größtenteils den Menschen, auch wenn neuere Daten zur Aktualisierung dieser Filter verwendet werden können. Tatsächlich erfinden Spammer, die Anti-Spam-Filter umgehen wollen, immer wieder neue Methoden, die einfache datengesteuerte Aktualisierungen dieser Filter überwinden.
Daher sind menschliche Erkenntnisse immer noch erforderlich, um die Automatisierung zu entwickeln. Es ist jedoch nicht klar, warum ein Softwareanbieter wie Lokad zum Beispiel keine umfassende Supply Chain-Engine entwickeln könnte, die all diese Herausforderungen bewältigt. Sicherlich sprechen die wirtschaftlichen Aspekte von Software sehr dafür, eine solche umfassende Supply Chain-Engine zu entwickeln. Selbst wenn die anfängliche Investition hoch ist, da Software zu vernachlässigbaren Kosten repliziert werden kann, wird der Anbieter ein Vermögen mit Lizenzgebühren verdienen, indem er diese grandiose Engine an eine große Anzahl von Unternehmen verkauft.
Lokad hat sich bereits 2008 auf eine solche Reise begeben, um eine grandiose Engine zu schaffen, die als verpacktes Softwareprodukt eingesetzt werden könnte. Genauer gesagt konzentrierte sich Lokad zu dieser Zeit auf eine grandiose Prognose-Engine anstelle einer grandiosen Supply Chain-Engine. Trotz dieser vergleichsweise bescheideneren Ambitionen ist Lokad jedoch daran gescheitert, eine solche grandiose Prognose-Engine zu schaffen. Die quantitative Perspektive der Supply Chain, die in dieser Vortragsreihe präsentiert wird, ist aus den Trümmern dieser grandiosen Engine-Ambition entstanden.
In Bezug auf die Supply Chain stellte sich heraus, dass es drei große Engpässe gibt, die angegangen werden müssen. Wir werden sehen, warum diese grandiose Engine von Anfang an zum Scheitern verurteilt war und warum wir wahrscheinlich noch Jahrzehnte von einer solchen technischen Leistung entfernt sind.
Die Anwendungslandschaft der typischen Supply Chain ist ein Dschungel, der in den letzten zwei oder drei Jahrzehnten wild gewachsen ist. Diese Landschaft ist kein französischer formaler Garten mit ordentlichen geometrischen Linien und gut geschnittenen Büschen; es ist ein Dschungel, lebendig, aber auch voller Dornen und feindlicher Fauna. Noch ernster ist, dass Supply Chains das Produkt ihrer digitalen Geschichte sind. Es kann mehrere halb redundante ERPs geben, halbfertige hausgemachte Anpassungen, Stapelintegrationen, insbesondere mit Systemen, die von übernommenen Unternehmen stammen, und überlappende Softwareplattformen, die um die gleichen Funktionsbereiche konkurrieren.
Die Vorstellung, dass eine grandiose Engine einfach eingesteckt werden kann, ist angesichts des gegenwärtigen Standes der Softwaretechnologie illusorisch. Das Zusammenführen aller Systeme, die die Supply Chain betreiben, ist eine umfangreiche Aufgabe, die vollständig von menschlichen Ingenieursleistungen abhängt.
Die Analyse der gemeinsamen Ausgaben zeigt, dass die Datenbereinigung mindestens drei Viertel des gesamten technischen Aufwands im Zusammenhang mit einer Supply Chain-Initiative ausmacht. Im Gegensatz dazu machen die intelligenten Aspekte des numerischen Rezepts, wie Prognosen und Optimierung, nicht mehr als wenige Prozent des Gesamtaufwands aus. Daher ist die Verfügbarkeit einer verpackten, grandiosen Engine in Bezug auf Kosten oder Verzögerungen weitgehend unerheblich. Damit diese Engine in die oft willkürliche IT-Landschaft, die in Supply Chains häufig anzutreffen ist, automatisch integriert werden kann, müsste sie über eine menschenähnliche Intelligenz verfügen.
Darüber hinaus wird diese Aufgabe durch die Existenz einer grandiosen Engine noch herausfordernder. Anstatt mit einem komplexen System, der Anwendungslandschaft, umzugehen, haben wir jetzt zwei komplexe Systeme: die Anwendungslandschaft und die grandiose Engine. Die Komplexität der Integration dieser beiden Systeme ist nicht die Summe ihrer jeweiligen Komplexitäten, sondern das Produkt dieser Komplexitäten.
Die Auswirkungen dieser Komplexität auf die Entwicklungskosten sind stark nichtlinear, wie bereits im ersten Kapitel dieser Vortragsreihe festgestellt wurde. Der erste große Engpass für die Optimierung der Supply Chain ist die Einrichtung des numerischen Rezepts, die einen dedizierten Engineering-Aufwand erfordert. Dieser Engpass eliminiert weitgehend die Vorteile, die mit einer Art verpackter grandioser Supply Chain-Engine verbunden sein könnten.

Während die Einrichtung einen erheblichen Engineering-Aufwand erfordert, könnte es sich um eine einmalige Investition handeln, vergleichbar mit dem Kauf eines Eintrittstickets. Leider sind Supply Chains lebendige Einheiten, die sich ständig weiterentwickeln. Der Tag, an dem sich eine Supply Chain nicht mehr verändert, ist der Tag, an dem das Unternehmen bankrott geht. Die Veränderungen sind sowohl intern als auch extern.
Intern ist die Anwendungslandschaft ständigen Veränderungen unterworfen. Unternehmen können ihre Anwendungslandschaft nicht einfrieren, selbst wenn sie wollten, da viele Upgrades von Unternehmenssoftware-Anbietern vorgeschrieben sind. Das Ignorieren dieser Vorgaben würde die Anbieter von ihren vertraglichen Verpflichtungen entbinden, was nicht akzeptabel ist. Neben rein technischen Updates wird jede größere Supply Chain zwangsläufig Softwarekomponenten einführen und ausphasen, während sich das Unternehmen selbst verändert.
Extern ändern sich auch die Märkte ständig. Es tauchen ständig neue Wettbewerber, Vertriebskanäle und potenzielle Lieferanten auf, während einige verschwinden. Die Vorschriften ändern sich ständig. Während Algorithmen einige der offensichtlichen Veränderungen automatisch erfassen können, wie z.B. die Nachfragesteigerung für eine Produktklasse, haben wir noch keine Algorithmen, um mit Marktveränderungen in Art und nicht nur in Größenordnung umzugehen. Die Probleme, die die Optimierung der Supply Chain zu lösen versucht, verändern sich selbst.
Wenn die Software, die für die Optimierung der Supply Chain verantwortlich ist, mit diesen Veränderungen nicht umgehen kann, greifen die Mitarbeiter auf Tabellenkalkulationen zurück. Tabellenkalkulationen mögen primitiv sein, aber zumindest können die Mitarbeiter sie auf die anstehende Aufgabe abstimmen. Laut einer Anekdote arbeiten die allermeisten Supply Chains auf Entscheidungsebene immer noch mit Tabellenkalkulationen und nicht auf Transaktionsebene. Dies ist der lebende Beweis dafür, dass die Wartung der Software gescheitert ist.
Seit den 1980er Jahren liefern Anbieter von Unternehmenssoftware Softwareprodukte zur Automatisierung von Supply Chain-Entscheidungen. Die meisten Unternehmen mit großen Supply Chains haben in den letzten Jahrzehnten bereits mehrere dieser Lösungen implementiert. Mitarbeiter greifen jedoch immer wieder auf ihre Tabellenkalkulationen zurück, was beweist, dass selbst wenn die Einrichtung ursprünglich als Erfolg angesehen wurde, bei der Wartung etwas schiefgelaufen ist.
Die Wartung ist der zweite große Engpass der Optimierung der Supply Chain. Das Rezept erfordert eine aktive Wartung, auch wenn die Ausführung weitgehend unbeaufsichtigt bleiben kann.

Zu diesem Zeitpunkt haben wir gezeigt, dass die Optimierung der Supply Chain nicht nur anfängliche Software-Engineering-Ressourcen erfordert, sondern auch fortlaufende Software-Engineering-Ressourcen. Wie bereits in dieser Vortragsreihe festgestellt wurde, können nur programmatische Fähigkeiten die Vielfalt der Probleme bewältigen, mit denen reale Supply Chains konfrontiert sind. Tabellenkalkulationen zählen als programmierbare Werkzeuge, und ihre Ausdrucksstärke im Gegensatz zu Schaltflächen und Menüs macht sie für Supply Chain-Experten so attraktiv.
Da Software-Engineering-Ressourcen in den meisten Unternehmen gesichert werden müssen, liegt es nahe, die IT-Abteilung anzurufen. Leider ist die Supply Chain nicht die einzige Abteilung, die so denkt. Jede einzelne Abteilung, einschließlich Vertrieb, Marketing und Finanzen, erkennt letztendlich, dass die Automatisierung ihrer jeweiligen Entscheidungsprozesse Software-Engineering-Ressourcen erfordert. Darüber hinaus müssen sie sich auch mit der Transaktionsebene und ihrer zugrunde liegenden Infrastruktur befassen.
Als Ergebnis haben die meisten Unternehmen mit großen Supply Chains ihre IT-Abteilungen mit jahrelangen Rückständen belastet. Daher verschlimmert es die Situation nur noch, von der IT-Abteilung weitere fortlaufende Ressourcen für die Supply Chain zu fordern. Die Möglichkeit, mehr Ressourcen der IT-Abteilung zuzuweisen, wurde bereits untersucht und ist in der Regel nicht mehr machbar. Diese Unternehmen stehen bereits vor erheblichen Skalennachteilen in Bezug auf die IT-Abteilung. Der IT-Rückstand stellt den dritten großen Engpass für die Optimierung der Supply Chain dar.
Fortlaufende Engineering-Ressourcen sind erforderlich, aber der Großteil dieser Ressourcen kann nicht von der IT-Abteilung kommen. Eine gewisse Unterstützung von der IT-Abteilung kann zwar vorgesehen werden, aber es muss eine unauffällige Angelegenheit sein.
Diese drei großen Engpässe definieren, warum eine spezifische Rolle benötigt wird: Der Supply Chain Scientist ist der Name, den wir den fortlaufenden Software-Engineering-Ressourcen geben, die benötigt werden, um die banalen Entscheidungen der Supply Chain und anspruchsvolle Entscheidungsprozesse zu automatisieren.

Fahren wir mit einer präziseren Definition basierend auf der Praxis von Lokad fort. Die Aufgabe des Supply Chain Scientists besteht darin, numerische Rezepte zu entwickeln, die die banalen Entscheidungen generieren, die täglich für den Betrieb der Supply Chain benötigt werden. Die Arbeit des Wissenschaftlers beginnt mit den aus der gesamten Anwendungslandschaft gesammelten Datenbankextrakten. Der Wissenschaftler soll das Rezept programmieren, das diese Datenbankextrakte verarbeitet und diese Rezepte in die Produktion bringt. Der Wissenschaftler trägt die volle Verantwortung für die Qualität der durch das Rezept generierten Entscheidungen. Die Entscheidungen werden nicht von irgendeinem Umgebungssystem generiert; sie sind der direkte Ausdruck der Erkenntnisse des Wissenschaftlers, die durch ein Rezept vermittelt werden.
Dieser eine Aspekt ist ein entscheidender Unterschied zu dem, was normalerweise als Rolle eines Data Scientists verstanden wird. Die Aufgabe endet jedoch nicht dort. Von einem Supply Chain Scientist wird erwartet, dass er Beweise vorlegen kann, die jede einzelne Entscheidung, die durch das Rezept generiert wurde, unterstützen. Es handelt sich nicht um ein undurchsichtiges System, das für die Entscheidungen verantwortlich ist; es ist die Person, der Wissenschaftler. Der Wissenschaftler sollte in der Lage sein, sich mit dem Leiter der Supply Chain oder sogar mit dem CEO zu treffen und eine überzeugende Begründung für jede Entscheidung zu liefern, die durch das Rezept generiert wurde.
Wenn der Wissenschaftler nicht in der Lage ist, potenziell großen Schaden für das Unternehmen anzurichten, dann stimmt etwas nicht. Ich plädiere nicht dafür, irgendjemandem, und schon gar nicht dem Wissenschaftler, große Befugnisse ohne Aufsicht oder Rechenschaftspflicht zu gewähren. Ich weise lediglich auf das Offensichtliche hin: Wenn Sie nicht die Macht haben, Ihrem Unternehmen negativ zu schaden, egal wie schlecht Sie abschneiden, haben Sie auch nicht die Macht, Ihrem Unternehmen positiv zu helfen, egal wie gut Sie abschneiden.
Große Unternehmen sind leider von Natur aus risikoscheu. Daher ist es sehr verlockend, den Wissenschaftler durch einen Analysten zu ersetzen. Im Gegensatz zum Wissenschaftler, der für die Entscheidungen selbst verantwortlich ist, ist der Analyst nur dafür verantwortlich, hier und da etwas Licht ins Dunkel zu bringen. Der Analyst ist größtenteils harmlos und kann nicht viel mehr tun, als seine eigene Zeit und einige Rechenressourcen zu verschwenden. Es geht jedoch nicht darum, harmlos zu sein, sondern um die Rolle des Supply Chain Scientists.

Lassen Sie uns für einen Moment über den Begriff “Supply Chain Scientist” sprechen. Diese Terminologie ist leider unvollkommen. Ich habe diesen Ausdruck vor etwa einem Jahrzehnt als Variation von “Data Scientist” geprägt, mit der Idee, diese Rolle als Variation von Data Scientist, aber mit einer starken Spezialisierung auf Supply Chain, zu brandmarken. Die Erkenntnis über die Spezialisierung war richtig, aber die Erkenntnis über Data Science war es nicht. Ich werde diesen Punkt am Ende der Vorlesung noch einmal aufgreifen.
Ein “Supply Chain Engineer” wäre vielleicht eine bessere Bezeichnung gewesen, da dies den Wunsch betont, das Fachgebiet zu beherrschen und zu kontrollieren, im Gegensatz zu reinem Verständnis. Ingenieure werden jedoch im allgemeinen Verständnis nicht erwartet, an vorderster Front tätig zu sein. Der richtige Begriff wäre wahrscheinlich Supply Chain Quant, als quantitative Supply Chain-Praktiker.
Im Finanzbereich ist ein Quant oder quantitativer Trader ein Spezialist, der Algorithmen und quantitative Methoden nutzt, um Handelsentscheidungen zu treffen. Quants können eine Bank enorm profitabel oder umgekehrt enorm unprofitabel machen. Die menschliche Intelligenz wird durch Maschinen verstärkt, sowohl das Gute als auch das Schlechte.
In jedem Fall liegt es in der Verantwortung der gesamten Community, über die richtige Terminologie zu entscheiden: Analyst, Wissenschaftler, Ingenieur, Operativ oder Quant. Um der Konsistenz willen werde ich den Begriff Wissenschaftler in der restlichen Vorlesung beibehalten.

Das Hauptergebnis für den Wissenschaftler ist ein Softwarestück, genauer gesagt das numerische Rezept, das für die Generierung der täglichen Supply Chain-Entscheidungen von Interesse verantwortlich ist. Dieses Rezept ist eine Sammlung aller beteiligten Skripte von den frühesten Stadien der Datenvorbereitung bis zu den endgültigen Stadien der unternehmensweiten Validierung der Entscheidungen selbst. Dieses Rezept muss produktionsfähig sein, das heißt, es kann unbeaufsichtigt ausgeführt werden und die generierten Entscheidungen werden standardmäßig vertraut. Natürlich musste dieses Vertrauen zunächst verdient werden, und eine fortlaufende Überwachung muss sicherstellen, dass dieses Vertrauensniveau im Laufe der Zeit gerechtfertigt bleibt.
Die Bereitstellung eines produktionsfähigen Rezepts ist entscheidend, um die Supply Chain-Praxis in ein produktives Asset umzuwandeln. Dieser Aspekt wurde bereits in der vorherigen Vorlesung zur produktorientierten Lieferung diskutiert.
Neben diesem Rezept gibt es zahlreiche sekundäre Ergebnisse. Einige von ihnen sind ebenfalls Software, auch wenn sie nicht direkt zur Generierung der Entscheidungen beitragen. Dazu gehören beispielsweise alle Instrumente, die der Wissenschaftler einführen muss, um das Rezept selbst zu erstellen und später zu warten. Einige andere Elemente sind für Kollegen im Unternehmen bestimmt, einschließlich aller Dokumentationen der Initiative selbst und des Rezepts.
Der Quellcode des Rezepts beantwortet das “wie” – wie wird es gemacht? Der Quellcode beantwortet jedoch nicht das “warum” – warum wird es gemacht? Das “warum” muss dokumentiert werden. Häufig hängt die Richtigkeit des Rezepts von einem subtilen Verständnis der Absicht ab. Die gelieferte Dokumentation muss den reibungslosen Übergang von einem Wissenschaftler zum nächsten so weit wie möglich erleichtern, auch wenn der ehemalige Wissenschaftler nicht verfügbar ist, um den Prozess zu unterstützen.
Bei Lokad besteht unser Standardverfahren darin, ein umfassendes Handbuch der Initiative zu erstellen und zu pflegen, das als Joint Procedure Manual (JPM) bezeichnet wird. Dieses Handbuch ist nicht nur ein vollständiges Betriebshandbuch des Rezepts, sondern auch eine Sammlung aller strategischen Erkenntnisse, die den Modellierungswahlen der Wissenschaftler zugrunde liegen.
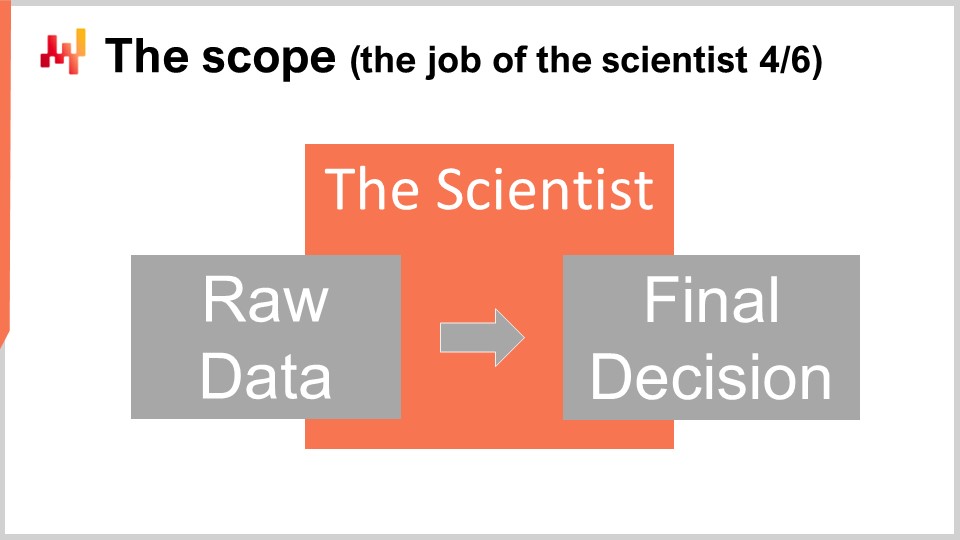
Auf technischer Ebene beginnt die Arbeit des Wissenschaftlers mit der Extraktion der Rohdaten und endet mit der Generierung der finalisierten Supply Chain-Entscheidungen. Der Wissenschaftler muss mit Rohdaten arbeiten, wie sie aus den bestehenden Geschäftssystemen extrahiert werden. Da jedes Geschäftssystem seine eigene technologische Basis haben kann, ist die Extraktion selbst in der Regel am besten IT-Spezialisten vorbehalten. Es ist nicht vernünftig zu erwarten, dass der Wissenschaftler halbes Dutzend SQL-Dialekte oder halbes Dutzend API-Technologien beherrscht, nur um Zugang zu den Geschäftsdaten zu erhalten. Auf der anderen Seite sollte von IT-Spezialisten nichts erwartet werden, außer Rohdatenextrakten, weder Datenverarbeitung noch Datenbereitstellung. Die dem Wissenschaftler zugänglich gemachten extrahierten Daten müssen so nah wie möglich an den Daten liegen, wie sie sich in den Geschäftssystemen präsentieren.
Am anderen Ende der Pipeline muss das vom Wissenschaftler erstellte Rezept die finalisierten Entscheidungen generieren. Die Elemente, die mit der Umsetzung der Entscheidungen verbunden sind, fallen nicht in den Zuständigkeitsbereich des Wissenschaftlers. Sie sind wichtig, aber auch weitgehend unabhängig von der Entscheidung selbst. Wenn beispielsweise Bestellungen berücksichtigt werden, fällt die Festlegung der endgültigen Mengen in den Zuständigkeitsbereich des Wissenschaftlers, aber die Generierung der PDF-Datei – des Bestelldokuments, das vom Lieferanten erwartet wird – nicht. Trotz dieser Grenzen ist der Umfang etwas groß. Daher ist es verlockend, aber falsch, den Umfang in eine Reihe von Teilen aufzuteilen. In größeren Unternehmen wird diese Versuchung sehr stark und muss widerstanden werden. Die Aufteilung des Umfangs ist der sicherste Weg, um zahlreiche Probleme zu schaffen.
Im Upstream-Bereich führt der Versuch, den Wissenschaftlern durch Manipulation der Eingabe zu helfen, unweigerlich zu Problemen wie “Müll rein, Müll raus”. Geschäftssysteme sind bereits komplex genug; die Vorverarbeitung der Daten trägt nur eine zusätzliche zufällige Schicht von Komplexität bei. Im Midstream-Bereich führt der Versuch, den Wissenschaftlern zu helfen, indem man sich um einen anspruchsvollen Teil des Rezepts kümmert, wie z.B. die Prognose, dazu, dass die Wissenschaftler einer Blackbox in der Mitte ihres eigenen Rezepts gegenüberstehen. Eine solche Blackbox untergräbt die Bemühungen der Wissenschaftler um Transparenz. Und im Downstream-Bereich führt der Versuch, den Wissenschaftlern durch eine weitere Optimierung der Entscheidungen zu helfen, unweigerlich zu Verwirrung, und die zweischichtige Optimierungslogik kann sogar gegensätzliche Ziele verfolgen.
Das bedeutet nicht, dass der Wissenschaftler alleine arbeiten muss. Es kann ein Team von Wissenschaftlern gebildet werden, aber der Umfang bleibt bestehen. Wenn ein Team gebildet wird, muss es eine gemeinsame Verantwortung für das Rezept geben. Das bedeutet zum Beispiel, dass jedes Mitglied des Teams in der Lage sein sollte, einen Fehler im Rezept zu erkennen und zu beheben.

Die Erfahrung von Lokad zeigt, dass eine gesunde Mischung für einen Supply Chain Scientist darin besteht, 40% seiner Zeit für das Codieren, 30% für den Dialog mit dem Rest des Unternehmens und 30% für das Verfassen von Dokumenten, Schulungsmaterialien und den Austausch mit anderen Supply Chain-Praktikern oder -Wissenschaftlern aufzuwenden.
Das Codieren ist natürlich notwendig, um das Rezept selbst zu implementieren. Sobald das Rezept jedoch in Produktion ist, richten sich die meisten Codierungsanstrengungen nicht mehr auf das Rezept selbst, sondern auf dessen Instrumentierung. Um das Rezept zu verbessern, benötigt der Wissenschaftler weitere Erkenntnisse, und diese Erkenntnisse erfordern wiederum eine dedizierte Instrumentierung, die implementiert werden muss.
Der Dialog mit dem Rest des Unternehmens ist grundlegend. Anders als bei der S&OP geht es bei diesen Diskussionen nicht darum, die Prognose nach oben oder unten zu lenken. Es geht darum sicherzustellen, dass die in das Rezept eingebetteten Modellierungswahlen sowohl die Unternehmensstrategie als auch alle operativen Einschränkungen des Unternehmens widerspiegeln.
Schließlich ist es entscheidend, das institutionelle Wissen, das das Unternehmen über die Optimierung der Supply Chain hat, entweder durch direktes Training der Wissenschaftler selbst oder durch die Erstellung von Dokumenten für Kollegen zu pflegen. Die Leistung des Rezepts ist zu einem großen Teil ein Spiegelbild der Kompetenz des Wissenschaftlers. Der Zugang zu Kollegen und die Suche nach Feedback sind erwartungsgemäß eine der effizientesten Möglichkeiten, die Kompetenz der Wissenschaftler zu verbessern.

Der größte Unterschied zwischen einem Supply Chain Scientist, wie ihn sich Lokad vorstellt, und einem Mainstream-Datenwissenschaftler ist das persönliche Engagement für realweltliche Ergebnisse. Es mag wie eine kleine, unbedeutende Sache erscheinen, aber die Erfahrung zeigt etwas anderes. Vor einem Jahrzehnt hat Lokad auf die harte Tour gelernt, dass das Engagement für die Lieferung eines produktionsreifen Rezepts nicht selbstverständlich ist. Im Gegenteil, die Standardhaltung von Personen, die als Datenwissenschaftler ausgebildet sind, scheint darin zu bestehen, die Produktion als sekundäre Angelegenheit zu betrachten. Der Mainstream-Datenwissenschaftler erwartet, sich um die intelligenten Teile wie maschinelles Lernen und mathematische Optimierung zu kümmern, während sich mit all dem zufälligen Beiwerk, das mit der realen Supply Chain einhergeht, zu oft als unter seiner Würde erweist.
Dennoch impliziert das Engagement für ein produktionsreifes Rezept, sich mit den unterschiedlichsten Dingen auseinanderzusetzen. Zum Beispiel wurden im Juli 2021 viele europäische Länder von katastrophalen Überschwemmungen heimgesucht. Ein Kunde von Lokad mit Sitz in Deutschland hatte die Hälfte seiner Lagerhäuser überflutet. Der für dieses Konto zuständige Supply Chain Scientist musste das Rezept quasi über Nacht neu konzipieren, um das Beste aus dieser stark beeinträchtigten Situation zu machen. Die Lösung war keine Art von großem maschinellen Lernalgorithmus, sondern eine Reihe von dekodierten Heuristiken. Wenn der Supply Chain Scientist jedoch nicht die Entscheidungsgewalt hat, kann diese Person kein produktionsreifes Rezept erstellen. Es ist eine Frage der Psychologie. Die Lieferung eines produktionsreifen Rezepts erfordert immense intellektuelle Anstrengungen, und die Einsätze müssen real sein, um das erforderliche Maß an Konzentration von einem Mitarbeiter zu erreichen.
Nachdem wir die Aufgabe eines Supply Chain Scientists geklärt haben, wollen wir besprechen, wie es aus Sicht des Personalwesens funktioniert. Zunächst muss der Wissenschaftler in der Hierarchie des Unternehmens dem Leiter der Supply Chain oder zumindest jemandem, der als leitende Führungskraft der Supply Chain qualifiziert ist, Bericht erstatten. Es spielt keine Rolle, ob der Wissenschaftler intern oder extern ist, wie es bei Lokad oft der Fall ist. Der Punkt bleibt, dass der Wissenschaftler der direkten Aufsicht einer Person unterstellt sein muss, die die Macht eines Supply Chain Executives hat.
Ein häufiger Fehler besteht darin, dass der Wissenschaftler dem Leiter der IT oder dem Leiter der Datenanalyse unterstellt ist. Da das Erstellen eines Rezepts eine Programmieraufgabe ist, fühlt sich die Supply Chain-Führung möglicherweise nicht vollständig wohl dabei, eine solche Aufgabe zu überwachen. Dies ist jedoch falsch. Der Wissenschaftler benötigt eine Aufsicht von jemandem, der genehmigen kann, ob die generierten Entscheidungen akzeptabel sind oder nicht, oder der zumindest diese Genehmigung ermöglichen kann. Den Wissenschaftler nicht direkt der Aufsicht der Supply Chain-Führung zu unterstellen, führt dazu, dass endlos mit Prototypen gearbeitet wird, die niemals in die Produktion gelangen. In dieser Situation wird die Rolle zwangsläufig zu der eines Analysten, und die ursprünglichen Ambitionen der quantitativen Supply Chain-Initiative werden aufgegeben.

Die allerbesten Supply Chain Scientists erzielen im Vergleich zu durchschnittlichen Wissenschaftlern überdurchschnittliche Ergebnisse. Dies ist die Erfahrung von Lokad und spiegelt das vor Jahrzehnten in der Softwarebranche identifizierte Muster wider. Softwareunternehmen haben schon lange beobachtet, dass die allerbesten Softwareingenieure mindestens 10-mal produktiver sind als durchschnittliche Ingenieure, und mittelmäßige Ingenieure können sogar eine negative Produktivität haben, wodurch die Software bei jeder Stunde, die im Codebase verbracht wird, schlechter wird.
Im Fall von Supply Chain Scientists verbessert überlegene Kompetenz nicht nur die Produktivität, sondern vor allem die Leistung der Lieferkette am Ende. Bei gleichen Softwaretools und mathematischen Instrumenten erzielen zwei Wissenschaftler nicht dasselbe Ergebnis. Daher ist es von größter Bedeutung, jemanden einzustellen, der das Potenzial hat, einer der besten Wissenschaftler zu werden.
Die Erfahrung von Lokad, basierend auf der Einstellung von mehr als 50 Wissenschaftlern, zeigt, dass unspezialisierte Ingenieursprofile in der Regel ziemlich gut sind. Obwohl es kontraintuitiv ist, sind Personen mit formaler Ausbildung in Datenwissenschaft, Statistik oder Informatik in der Regel nicht die beste Wahl für Positionen als Supply Chain Scientists. Diese Personen komplizieren das Rezept zu oft unnötig und schenken den banalen, aber entscheidenden Aspekten der Supply Chain nicht genügend Aufmerksamkeit. Die Fähigkeit, auf eine Vielzahl von Details zu achten, und die Fähigkeit, endlos nach Randnummernartefakten zu suchen, scheinen die führenden Qualitäten der besten Wissenschaftler zu sein.
Anekdotisch gesehen hat Lokad gute Erfahrungen mit jungen Ingenieuren gemacht, die einige Jahre als Wirtschaftsprüfer tätig waren. Neben der Vertrautheit mit der Unternehmensfinanzierung scheint es, dass talentierte Wirtschaftsprüfer die Fähigkeit entwickeln, sich durch eine Flut von Unternehmensunterlagen zu kämpfen, was mit der täglichen Realität eines Supply Chain Scientists übereinstimmt.

Während der Einstellung stellt Lokad sicher, dass die neuen Mitarbeiter das richtige Potenzial haben, aber der nächste Schritt besteht darin, sicherzustellen, dass sie ordnungsgemäß geschult werden. Die Standardposition von Lokad ist, dass sie nicht erwarten, dass die Mitarbeiter bereits etwas über die Supply Chain wissen. Kenntnisse über die Supply Chain sind ein Pluspunkt, aber die akademische Ausbildung ist in dieser Hinsicht noch etwas mangelhaft. Die meisten Supply Chain-Studiengänge konzentrieren sich auf Management und Führung, aber für junge Absolventen ist es wichtig, ein solides Grundwissen in Themen zu haben, die in den zweiten, dritten oder vierten Kapiteln dieser Vortragsreihe behandelt werden. Leider ist dies oft nicht der Fall, und die quantitativen Teile dieser Studiengänge können enttäuschend sein. Daher müssen Supply Chain Scientists von ihren Arbeitgebern geschult werden. Diese Vortragsreihe spiegelt die Art von Schulungsmaterialien wider, die bei Lokad verwendet werden.

Leistungsbeurteilungen für Supply Chain Scientists sind aus verschiedenen Gründen wichtig, wie z.B. sicherzustellen, dass das Geld des Unternehmens gut investiert ist und Beförderungen zu bestimmen. Die üblichen Kriterien gelten: Einstellung, Fleiß, Fachkenntnisse usw. Es gibt jedoch einen kontraintuitiven Aspekt: Die besten Wissenschaftler erzielen Ergebnisse, die Supply Chain-Herausforderungen fast unsichtbar erscheinen lassen, mit minimalem Drama.

Die Schulung eines Wissenschaftlers, um bestehende Rezepte beizubehalten und gleichzeitig das bisherige Leistungsniveau der Supply Chain aufrechtzuerhalten, dauert etwa sechs Monate, während die Schulung eines Wissenschaftlers, um ein Rezept für Vorhersagen von Grund auf zu implementieren, etwa zwei Jahre dauert. Die Bindung von Talenten ist entscheidend, insbesondere da die Einstellung erfahrener Supply Chain Scientists noch keine Option ist.
In vielen Ländern ist die durchschnittliche Beschäftigungsdauer für Ingenieure unter 30 Jahren in der Software- und angrenzenden Branchen recht niedrig. Lokad erreicht eine höhere durchschnittliche Beschäftigungsdauer, indem es sich auf das Wohlbefinden der Mitarbeiter konzentriert. Unternehmen können ihren Mitarbeitern kein Glück bringen, aber sie können vermeiden, dass ihre Mitarbeiter durch unsinnige Prozesse unglücklich werden. Vernunft trägt wesentlich zur Mitarbeiterbindung bei.

Von einem kompetenten, erfahrenen Supply Chain Scientist kann nicht erwartet werden, dass er schnell ein bestehendes Rezept übernimmt, da das Rezept die einzigartige Strategie des Unternehmens und die Eigenheiten der Supply Chain widerspiegelt. Der Übergang von einer Supply Chain zur anderen kann unter den besten Bedingungen etwa einen Monat dauern. Es ist nicht vernünftig, dass ein großes Unternehmen von einem einzigen Wissenschaftler abhängt; Lokad stellt sicher, dass zwei Wissenschaftler jederzeit mit jedem in der Produktion verwendeten Rezept vertraut sind. Kontinuität ist entscheidend, und eine Möglichkeit, dies zu erreichen, besteht darin, ein gemeinsam mit den Kunden erstelltes Handbuch zu verwenden, das ungeplante Übergänge zwischen Wissenschaftlern erleichtern kann.

Die Rolle des Supply Chain Scientists erfordert ein ungewöhnliches Maß an Zusammenarbeit mit mehreren Abteilungen, insbesondere der IT. Die ordnungsgemäße Ausführung des Rezepts hängt von der Datenextraktionspipeline ab, die in der Verantwortung der IT liegt.
Es gibt eine relativ intensive Phase der Interaktion zwischen IT und dem Wissenschaftler zu Beginn der ersten quantitativen Supply Chain-Initiative, die etwa zwei bis drei Monate dauert. Danach, wenn die Datenextraktionspipeline eingerichtet ist, wird die Interaktion weniger häufig. Dieser Dialog stellt sicher, dass der Wissenschaftler über die IT-Roadmap und etwaige Software-Upgrades oder Änderungen informiert bleibt, die sich auf die Supply Chain auswirken können.
In der Anfangsphase einer quantitativen Supply Chain-Initiative gibt es eine relativ intensive Interaktion zwischen IT und den Wissenschaftlern. Während der ersten zwei oder drei Monate muss der Wissenschaftler mehrmals pro Woche mit der IT interagieren. Danach, wenn die Datenextraktionspipeline eingerichtet ist, wird die Interaktion viel seltener, etwa einmal im Monat oder seltener. Neben der Behebung gelegentlicher Probleme in der Pipeline stellt dieser Dialog sicher, dass der Wissenschaftler über die IT-Roadmap informiert bleibt. Ein Software-Upgrade oder -Ersatz kann für den Wissenschaftler Tage oder sogar Wochen Arbeit erfordern. Um Ausfallzeiten zu vermeiden, muss das Rezept an Änderungen in der Anwendungslandschaft angepasst werden.

Das Rezept, wie es vom Wissenschaftler umgesetzt wird, optimiert den Gewinn in Dollar oder Euro. Wir haben diesen Aspekt bereits in den ersten Vorlesungen dieser Serie behandelt. Es sollte jedoch nicht erwartet werden, dass der Wissenschaftler entscheidet, wie Kosten und Gewinne modelliert werden sollen. Obwohl sie Modelle vorschlagen sollten, um die wirtschaftlichen Treiber widerzuspiegeln, liegt es letztendlich in der Verantwortung der Finanzabteilung zu entscheiden, ob diese Treiber als korrekt erachtet werden oder nicht. Viele Supply Chain-Praktiken umgehen das Problem, indem sie sich auf Prozentsätze wie Service Levels und Prognosegenauigkeiten konzentrieren. Diese Prozentsätze haben jedoch fast keine Korrelation mit der finanziellen Gesundheit des Unternehmens. Daher muss der Wissenschaftler regelmäßig mit der Finanzabteilung zusammenarbeiten und sie dazu bringen, die Modellierungswahlen und Annahmen, die in dem numerischen Rezept getroffen wurden, in Frage zu stellen.
Finanzielle Modellierungswahlen sind vorübergehend, da sie die sich ändernde Strategie des Unternehmens widerspiegeln. Es wird auch erwartet, dass der Wissenschaftler einige Instrumente für die Finanzabteilung entwickelt, wie z.B. die maximal projizierte Menge an Umlaufvermögen, die mit dem Lagerbestand für das kommende Jahr verbunden ist. Für ein mittelgroßes oder großes Unternehmen ist es vernünftig, dass ein Finanzvorstand das vom Supply Chain Scientist geleistete Arbeit vierteljährlich überprüft.

Eine der größten Bedrohungen für die Gültigkeit des Rezepts besteht darin, die strategische Absicht des Unternehmens versehentlich zu verraten. Zu viele Supply Chain-Praktiken umgehen die Strategie, indem sie sich hinter Prozentsätzen verstecken, die als Leistungsindikatoren verwendet werden. Das Aufblähen oder Absenken der Prognose durch Verkaufs- und Betriebsplanung (S&OP) ersetzt nicht die Klärung der strategischen Absicht. Der Wissenschaftler ist nicht für die Unternehmensstrategie verantwortlich, aber das Rezept wird falsch sein, wenn er sie nicht versteht. Die Ausrichtung des Rezepts auf die Strategie muss geplant werden.
Der direkteste Weg, um festzustellen, ob der Wissenschaftler die Strategie versteht, besteht darin, ihn darum zu bitten, sie der Unternehmensleitung erneut zu erklären. Dadurch können Missverständnisse leichter erkannt werden. In der Theorie ist dieses Verständnis bereits vom Wissenschaftler im Initiativhandbuch dokumentiert. Erfahrungen zeigen jedoch, dass Führungskräfte selten die Zeit haben, operative Dokumentationen im Detail zu überprüfen. Ein einfaches Gespräch beschleunigt den Prozess für beide Seiten.
Dieses Treffen dient nicht dazu, dass der Wissenschaftler alles über Supply Chain-Modelle oder finanzielle Ergebnisse erklärt. Der einzige Zweck besteht darin, sicherzustellen, dass die Person, die den digitalen Stift hält, die Strategie richtig versteht. Selbst in einem großen Unternehmen ist es vernünftig, dass der Wissenschaftler mindestens einmal im Jahr mit dem CEO oder der relevanten Führungskraft zusammentrifft. Die Vorteile eines Rezepts, das besser auf die Führungsabsicht abgestimmt ist, sind enorm und werden oft unterschätzt.

Supply Chain-Verbesserungen sind Teil der laufenden digitalen Modernisierung. Dies erfordert eine gewisse Umstrukturierung des Unternehmens selbst. Obwohl die Änderungen nicht drastisch sein müssen, ist es ein mühsamer Kampf, veraltete Praktiken auszumerzen. Wenn sie richtig umgesetzt werden, ist die Produktivität eines Supply Chain Scientists signifikant höher als die eines traditionellen Planers. Es ist nicht ungewöhnlich, dass ein einziger Wissenschaftler für mehr als eine halbe Milliarde Dollar oder Euro an Inventar verantwortlich ist.
Eine drastische Reduzierung der Anzahl der Mitarbeiter in der Supply Chain ist möglich. Einige Kundenunternehmen von Lokad, die historisch unter immensem Wettbewerbsdruck standen, haben diesen Ansatz gewählt und konnten teilweise aufgrund dieser Einsparungen überleben. Die meisten unserer Kunden entscheiden sich jedoch für eine schrittweise Reduzierung der Mitarbeiterzahl, da Planer natürlich zu anderen Positionen wechseln.
Die verbleibenden Planer richten ihre Bemühungen auf Kunden und Lieferanten aus. Das von ihnen gesammelte Feedback ist für die Supply Chain Scientists sehr nützlich. Tatsächlich ist die Arbeit des Wissenschaftlers von Natur aus nach innen gerichtet. Sie arbeiten mit den Daten des Unternehmens und es ist schwierig zu erkennen, was einfach fehlt.
Viele Geschäftsstimmen haben sich schon lange dafür ausgesprochen, stärkere Bindungen zu Kunden und Lieferanten aufzubauen. Es ist jedoch leichter gesagt als getan, insbesondere wenn Bemühungen aufgrund laufender Brandbekämpfung, Beruhigung der Kunden und Druck auf Lieferanten routinemäßig neutralisiert werden. Die Supply Chain Scientists können auf beiden Seiten dringend benötigte Erleichterung bieten.

S&OP (Sales and Operations Planning) ist eine weit verbreitete Praxis, die eine unternehmensweite Ausrichtung durch eine gemeinsame Nachfrageprognose fördern soll. Unabhängig von den ursprünglichen Ambitionen waren die S&OP-Prozesse, die ich je erlebt habe, am besten durch eine endlose Reihe unproduktiver Meetings gekennzeichnet. Abgesehen von ERP-Implementierungen und Compliance fällt mir keine Unternehmenspraxis ein, die so seelenzerstörend ist wie S&OP. Die Sowjetunion mag verschwunden sein, aber der Geist des Gosplan lebt durch S&OP weiter.
Eine eingehende Kritik an S&OP würde einen eigenen Vortrag verdienen. Doch um es kurz zu machen, kann ich nur sagen, dass ein Supply Chain Scientist in jeder relevanten Dimension eine überlegene Alternative zu S&OP ist. Im Gegensatz zu S&OP basiert der Supply Chain Scientist auf realen Entscheidungen. Das Einzige, was einen Wissenschaftler davon abhält, ein weiterer Agent einer aufgeblähten Unternehmensbürokratie zu sein, ist nicht sein Charakter oder seine Kompetenz, sondern die Beteiligung an diesen realen Entscheidungen.
Planer, Bestandsmanager und Produktionsmanager sind häufig große Verbraucher aller Arten von Geschäftsberichten. Diese Berichte werden in der Regel von Unternehmenssoftwareprodukten erstellt, die allgemein als Business Intelligence-Tools bezeichnet werden. Die typische Supply Chain-Praxis besteht darin, eine Reihe von Berichten in Tabellenkalkulationen zu exportieren und dann eine Sammlung von Tabellenkalkulationsformeln zu verwenden, um all diese Informationen zu mischen und halbautomatisch die interessierenden Entscheidungen zu generieren. Wie wir gesehen haben, ersetzt das Rezept des Wissenschaftlers diese Kombination aus Business Intelligence und Tabellenkalkulationen.
Darüber hinaus eignen sich weder Business Intelligence noch Tabellenkalkulationen zur Unterstützung der Implementierung eines Rezepts. Business Intelligence fehlt es an Ausdruckskraft, da die relevanten Berechnungen nicht mit dieser Art von Tools ausgedrückt werden können. Tabellenkalkulationen fehlen an Wartbarkeit und manchmal auch an Skalierbarkeit, aber vor allem an Wartbarkeit. Das Design von Tabellenkalkulationen ist weitgehend unvereinbar mit jeder Art von Korrektheit durch Design, die für Supply Chain-Zwecke dringend benötigt wird.
In der Praxis umfasst die Instrumentierung eines Rezepts, wie es vom Wissenschaftler implementiert wird, zahlreiche Geschäftsberichte. Diese Berichte ersetzen diejenigen, die bisher durch Business Intelligence generiert wurden. Diese Entwicklung bedeutet nicht zwangsläufig das Ende von Business Intelligence, da andere Abteilungen weiterhin von dieser Art von Tools profitieren können. Was die Supply Chain betrifft, läutet die Einführung des Supply Chain Scientists jedoch das Ende der Ära der Business Intelligence ein.

Wenn wir einige Tech-Giganten beiseite lassen, die es sich leisten können, Hunderte, wenn nicht Tausende von Ingenieuren für jedes Softwareproblem einzusetzen, ist das typische Ergebnis von Data-Science-Teams in regulären Unternehmen ernüchternd. In der Regel wird von diesen Teams nichts Substanzielles erreicht. Data Science als Unternehmenspraxis ist jedoch nur die neueste Iteration einer Reihe von Unternehmensmoden.
In den 1970er Jahren war Operationsforschung der letzte Schrei. In den 1980er Jahren waren Regelmaschinen und Wissensexperten beliebt. An der Jahrtausendwende waren Data Mining und Data Miner gefragt. Seit den 2010er Jahren gelten Data Science und Data Scientists als das nächste große Ding. All diese Unternehmens-Trends folgen dem gleichen Muster: Eine echte Software-Innovation findet statt, die Menschen werden übermäßig begeistert davon, und sie beschließen, diese Innovation durch die Schaffung einer neuen dedizierten Abteilung gewaltsam in das Unternehmen zu integrieren. Das liegt daran, dass es immer viel einfacher ist, Abteilungen zu einer Organisation hinzuzufügen, anstatt bestehende zu ändern oder zu entfernen.
Data Science als Unternehmenspraxis scheitert jedoch, weil es nicht fest in der Handlung verankert ist. Das macht den Unterschied zwischen einem Supply Chain Scientist, der von Anfang an dafür verantwortlich ist, realitätsnahe Entscheidungen zu treffen, und der IT-Abteilung aus.

Wenn wir Egos und Herrschaftsbereiche beiseite legen können, stellt der Supply Chain Scientist eine viel bessere Lösung als der frühere Status quo dar. Die typische IT-Abteilung ist von jahrelangen Rückständen überlastet, und die Suche nach mehr Ressourcen ist kein vernünftiger Vorschlag, da dies zu überhöhten Erwartungen anderer Abteilungen und einer weiteren Zunahme des Rückstands führt.
Im Gegensatz dazu ebnet der Supply Chain Scientist den Weg für eine Verringerung der Erwartungen. Der Wissenschaftler erwartet nur, dass Rohdatenextrakte zur Verfügung gestellt werden, und ihre Auswertungskämpfe sind ihre Verantwortung. Sie erwarten in dieser Hinsicht nichts von der IT-Abteilung. Der Supply Chain Scientist sollte nicht als eine von der Unternehmensleitung sanktionierte Version des Schatten-IT angesehen werden. Es geht darum, die Supply Chain-Abteilung für ihre eigene Kernkompetenz verantwortlich und rechenschaftspflichtig zu machen. Die IT-Abteilung verwaltet die Low-Level-Infrastruktur und die Transaktionsebene, während die Supply Chain-Entscheidungsebene vollständig in der Verantwortung der Supply Chain-Abteilung liegen sollte.
Die IT-Abteilung muss ein Enabler sein, kein Entscheidungsträger, außer für die wirklich IT-zentrischen Teile des Unternehmens. Viele IT-Abteilungen sind sich ihres Rückstands bewusst und begrüßen dieses neue Modell. Wenn jedoch der Instinkt, das als ihr Territorium wahrgenommene zu schützen, zu stark ist, können sie sich weigern, die Supply Chain-Entscheidungsebene loszulassen. Solche Situationen sind schmerzhaft und können nur durch das direkte Eingreifen des CEO gelöst werden.

Aus der Ferne betrachtet könnte man zu dem Schluss kommen, dass die Rolle des Supply Chain Scientists als eine spezialisiertere Variation des Data Scientists angesehen werden kann. Historisch gesehen war dies der Ansatz, den Lokad verfolgte, um Probleme im Zusammenhang mit der Unternehmenspraxis der Data Science zu beheben. Vor einem Jahrzehnt haben wir jedoch erkannt, dass dies nicht ausreicht. Es hat Jahre gedauert, um nach und nach alle Elemente aufzudecken, die heute präsentiert wurden.
Der Supply Chain Scientist ist keine Ergänzung zur Supply Chain des Unternehmens; es handelt sich um eine Klarstellung zur Zuständigkeit der alltäglichen Supply Chain-Entscheidungen. Um das Beste aus diesem Ansatz herauszuholen, muss die Supply Chain, oder zumindest ihr Planungskomponente, umgestaltet werden. Angrenzende Abteilungen wie Finanzen und Betrieb müssen ebenfalls einige Veränderungen akzeptieren, wenn auch in viel geringerem Maße.
Die Entwicklung eines Teams von Supply Chain Scientists ist eine bedeutende Verpflichtung für ein Unternehmen, aber wenn es richtig gemacht wird, ist die Produktivität hoch. In der Praxis ersetzt jeder Wissenschaftler 10 bis 100 Planer, Prognostiker oder Lagerverwalter und erzielt enorme Personalkosteneinsparungen, selbst wenn die Wissenschaftler höhere Gehälter beziehen. Der Supply Chain Scientist verdeutlicht einen neuen Umgang mit der IT, indem er sie als Ermöglicher statt als Lösungsanbieter positioniert und viele, wenn nicht die meisten, mit der IT verbundenen Engpässe beseitigt.
Im Allgemeinen kann dieser Ansatz auch in allen anderen nicht-IT-Abteilungen des Unternehmens, wie Marketing, Vertrieb und Finanzen, gespiegelt werden. Jede Abteilung hat ihre eigenen alltäglichen Entscheidungen zu treffen, die ebenfalls stark von derselben Art der Automatisierung profitieren würden. Doch genauso wie der Supply Chain Scientist in erster Linie ein Experte für die Supply Chain ist,
Doch genauso wie ein Supply Chain Scientist in erster Linie ein Experte für die Supply Chain ist, sollte ein Marketing Scientist oder Marketing Quant ein Experte für Marketing sein. Die Perspektive des Wissenschaftlers ebnet den Weg, um das Beste aus der Kombination von maschineller und menschlicher Intelligenz in diesem frühen 21. Jahrhundert zu machen.
Die nächste Vorlesung findet am 10. Mai, einem Mittwoch, zur gleichen Tageszeit um 15 Uhr Pariser Zeit statt. Die heutige Vorlesung war nicht technisch, aber die nächste wird größtenteils technisch sein. Ich werde Techniken zur Preisoptimierung vorstellen. In gängigen Supply Chain-Lehrbüchern wird der Preis in der Regel nicht als Bestandteil der Supply Chain behandelt. Der Preis trägt jedoch wesentlich zum Gleichgewicht von Angebot und Nachfrage bei. Außerdem ist der Preis oft stark domänenspezifisch, da es sehr einfach ist, die Herausforderung insgesamt falsch anzugehen, wenn man in abstrakten Begriffen denkt. Daher werden wir unsere Untersuchungen auf den Automobil-Ersatzteilmarkt beschränken. Dies wird die Gelegenheit sein, die mit Stuttgart vorgestellten Elemente zu überdenken, einer der Supply Chain Personas, die ich im dritten Kapitel dieser Vorlesungsreihe eingeführt habe.

Und jetzt werde ich mit den Fragen fortfahren.
Frage: Es hat fast ein Jahrzehnt gedauert, bis die Wissenschaft erkannt hat, dass das Feld der Data Science entstanden ist und dass sie es an Schulen unterrichten sollten. Sehen Sie bereits dasselbe in den Kreisen der Supply Chain-Akademie, die die Perspektive der Supply Chain Sciences übernehmen?
Zunächst einmal weiß ich nicht, dass Data Science in Frankreich an Schulen unterrichtet wird. In der High School wird kaum etwas gelehrt, was mit Computern zu tun hat, geschweige denn Data Science. Ich bin mir nicht einmal sicher, wo sie die Professoren oder Lehrer dafür finden würden. Aber ich kann verstehen, dass Sie möchten, dass Schüler in der High School über digitale Kompetenz verfügen. Ich glaube, dass es sehr gut ist, sich mit Programmierung vertraut zu machen, und man kann es sogar schon früher tun, aus eigener Erfahrung, ab dem Alter von sieben oder acht Jahren, je nach Reife des Kindes. Man kann es sogar in der Grundschule tun, aber wir sprechen hier nur von grundlegenden Programmierkonzepten: Variablen, Listen von Anweisungen und solche Dinge. Ich glaube, dass Data Science weit über das hinausgeht, was in der High School gelehrt werden sollte, es sei denn, Sie haben Wunderkinder oder so etwas. Für mich ist es klar etwas, das für Menschen auf Universitätsniveau gedacht ist, entweder im Bachelor- oder Masterstudium.
In der Tat hat es die akademische Welt ein Jahrzehnt gedauert, um Data Science voranzubringen, aber lassen Sie uns einen Moment innehalten. Ich habe Data Science als eine unternehmerische Praxis beschrieben, die im Wesentlichen die Spiegelversion dessen ist, was die akademische Welt tut, wenn sie Data Science unterrichtet. Wir müssen also über das Problem nachdenken, und hier denke ich, dass eines der Probleme darin besteht, dass es unglaublich schwierig ist, etwas zu lehren, das man nicht praktiziert. Zumindest auf Universitätsniveau, wenn nicht darunter. Was ich sehe, ist, dass wir bereits ein Problem mit Data Science haben, da diejenigen, die Data Science unterrichten, nicht diejenigen sind, die tatsächlich Data Science in wichtigen Unternehmen wie Microsoft, Google, Facebook, OpenAI und dergleichen betreiben.
Bei der Supply Chain haben wir ein ähnliches Problem, und es ist äußerst schwierig, Zugang zu Personen mit der richtigen Erfahrung zu haben. Ich hoffe, und das ist eine unverfrorene Eigenwerbung meinerseits, dass Lokad in den kommenden Wochen damit beginnen wird, Materialien für Supply Chain-Studiengänge bereitzustellen. Wir werden einige Materialien herausbringen, die so aufbereitet sind, dass sie für Professoren in der akademischen Welt geeignet sind, damit sie diese Erkenntnisse vermitteln können. Natürlich müssen sie ihr eigenes Urteilsvermögen verwenden, um zu beurteilen, ob die von Lokad bereitgestellten Materialien tatsächlich für den Unterricht an Studenten geeignet sind.
Frage: Wird die domänenspezifische Sprache von Lokad nicht anderswo verwendet? Wie motivieren Sie potenzielle neue Mitarbeiter, etwas zu lernen, das sie wahrscheinlich nie wieder in ihrem nächsten Job verwenden werden?
Das ist genau der Punkt, den ich bezüglich des Problems mit Data Scientists gemacht habe. Die Leute haben sich buchstäblich beworben und gesagt: “Ich möchte TensorFlow machen, ich bin ein TensorFlow-Typ” oder “Ich bin ein PyTorch-Typ”. Das ist nicht die richtige Einstellung. Wenn Sie Ihre Identität mit einer Reihe von technischen Werkzeugen verwechseln, verstehen Sie den Kern nicht. Die Herausforderung besteht darin, Supply Chain-Probleme zu verstehen und zu quantitativ zu lösen, um produktionsreife Entscheidungen zu generieren.
In diesem Vortrag habe ich erwähnt, dass es sechs Monate dauert, bis ein Supply Chain Scientist die Fähigkeiten erlangt, ein Rezept zu warten, und zwei Jahre, um ein Rezept von Grund auf zu entwickeln. Wie viel Zeit benötigt man, um Envision, unsere proprietäre Programmiersprache, vollständig zu beherrschen? Unsere Erfahrung zeigt, dass es drei Wochen dauert. Envision ist im Vergleich zur Gesamtherausforderung ein kleines Detail, aber ein wichtiges. Wenn Ihre Werkzeuge schlecht sind, werden Sie immense zufällige Probleme haben. Aber seien wir realistisch: Es ist nur ein kleines Stück des Gesamtpuzzles.
Diejenigen, die Zeit bei Lokad verbringen, lernen unglaublich viel über Supply Chain-Probleme. Die Programmiersprache könnte in anderen Sprachen neu geschrieben werden, aber es könnte mehr Codezeilen erfordern. Was die Leute, insbesondere junge Ingenieure, oft nicht erkennen, ist, wie vergänglich viele Technologien sind. Sie halten nicht lange, normalerweise nur ein paar Jahre, bevor sie durch etwas anderes ersetzt werden.
Wir haben eine endlose Reihe von Technologien kommen und gehen sehen. Wenn ein Bewerber sagt: “Mir sind die technischen Details wirklich wichtig”, ist er wahrscheinlich kein guter Bewerber. Das war mein Problem mit Data Scientists - sie wollten die neuesten, modernsten Sachen. Supply Chains sind unglaublich komplexe Systeme, und wenn Sie einen Fehler machen, kann es Millionen kosten. Sie benötigen Werkzeuge auf Produktionsniveau, nicht das neueste, ungetestete Paket.
Die besten Bewerber haben ein echtes Interesse daran, Supply Chain-Experten zu werden. Der wichtige Teil ist die Supply Chain, nicht die Details der Programmiersprache.
Frage: Ich strebe einen Bachelor-Abschluss in Supply Chain, Transport und Logistikmanagement an. Wie kann ich ein Supply Chain Scientist werden?
Zunächst ermutige ich Sie, sich bei Lokad zu bewerben. Wir haben ständig offene Stellen. Aber im Ernst, der Schlüssel dazu, ein Supply Chain Scientist zu werden, besteht darin, die Möglichkeit bei einem Unternehmen zu haben, das bereit ist, seine Supply Chain-Entscheidungen zu automatisieren. Der wichtigste Aspekt ist die Übernahme der Entscheidungen. Wenn Sie ein Unternehmen finden können, das dies ausprobieren möchte, wird Ihnen dies sehr dabei helfen, ein Wissenschaftler zu werden.
Wenn Sie sich den Herausforderungen der Entscheidungsfindung auf Produktionsniveau stellen, werden Sie die Bedeutung der Themen erkennen, über die ich in dieser Vortragsreihe spreche. Wenn Sie es mit Vorhersagen zu tun haben, die Millionen von Dollar an Inventar, Bestellungen und Lagerbewegungen steuern werden, werden Sie die immense Verantwortung und die Notwendigkeit der Korrektheit durch Design verstehen. Ich bin ziemlich sicher, dass andere Unternehmen wachsen und viele weitere Möglichkeiten erwerben werden. Aber selbst in meinen wildesten Träumen glaube ich nicht, dass ich hoffen kann, dass jedes einzelne Unternehmen auf der Erde Lokad nutzen wird. Es wird viele Unternehmen geben, die sich immer dafür entscheiden werden, es auf ihre eigene Weise zu tun, und sie werden damit gut zurechtkommen.
Frage: Da 40% des täglichen Arbeitsablaufs eines Supply Chain Scientists aus Codierung besteht, welche Programmiersprache würden Sie Studenten im Grundstudium empfehlen, insbesondere solchen, die Management studieren?
Ich würde sagen, nehmen Sie, was immer verfügbar ist. Python ist ein guter Anfang. Mein Vorschlag ist, tatsächlich mehrere Programmiersprachen auszuprobieren. Was Sie von einem Supply Chain-Ingenieur erwarten, ist im Grunde das Gegenteil von dem, was Sie von Software-Ingenieuren erwarten. Für Software-Ingenieure ist mein Standardrat, eine Sprache auszuwählen und sich sehr intensiv damit zu beschäftigen, alle Feinheiten wirklich zu verstehen. Aber für Menschen, die letztendlich Generalisten sind, würde ich sagen, tun Sie das Gegenteil. Probieren Sie ein wenig SQL, ein wenig Python, ein wenig R aus. Achten Sie auf die Syntax von Excel und werfen Sie vielleicht einen Blick auf Sprachen wie Rust, um zu sehen, wie sie aussehen. Also nehmen Sie, was immer Sie zur Verfügung haben. Übrigens plant Lokad, Envision für Studenten kostenlos zugänglich zu machen, also bleiben Sie dran.
Frage: Sehen Sie eine signifikante Auswirkung von Graphdatenbanken auf die Vorhersagen der Supply Chain?
Absolut nicht. Graphdatenbanken gibt es seit mehr als zwei Jahrzehnten, und obwohl sie interessant sind, sind sie nicht so leistungsfähig wie relationale Datenbanken wie PostgreSQL und MariaDB. Für Vorhersagen der Supply Chain reichen graphenähnliche Operatoren nicht aus. In Prognosewettbewerben haben keine der Top 100 Teilnehmer eine Graphdatenbank verwendet. Es gibt jedoch Dinge, die mit Deep Learning angewendet auf Graphen gemacht werden können, was ich in meinem nächsten Vortrag über Preisgestaltung veranschaulichen werde.
In Bezug auf die Frage, ob Supply Chain Scientists an der Zieldefinition bei Kundenprojekten im Bereich Data Science beteiligt sein sollten, glaube ich, dass es ein Problem mit der zugrunde liegenden Annahme gibt, sich auf Data Science zu konzentrieren, bevor wir das Problem verstehen, das wir lösen wollen. Wenn man die Frage jedoch umformuliert, sollten Supply Chain Scientists an der Zieldefinition der Supply Chain-Optimierung beteiligt sein? Ja, absolut. Es ist schwierig, dass der Wissenschaftler herausfindet, was wir wirklich wollen, und es erfordert eine enge Zusammenarbeit mit den Stakeholdern, um sicherzustellen, dass die richtigen Ziele verfolgt werden. Also sollten die Wissenschaftler dafür an Bord sein? Absolut, es ist entscheidend.
Allerdings sollten wir klären, dass es sich hierbei nicht um eine Data-Science-Initiative handelt; es handelt sich um eine Supply-Chain-Initiative, die zufällig Daten als geeignete Zutat verwenden kann. Wir müssen wirklich bei den Problemen und Ambitionen der Supply Chain anfangen und dann, da wir das Beste aus moderner Software machen wollen, diese Wissenschaftler benötigen. Sie werden Ihnen helfen, Ihr Verständnis des Problems weiter zu verfeinern, da die Abgrenzung zwischen dem, was in der Software machbar ist und was streng genommen dem Bereich der menschlichen Intelligenz vorbehalten bleibt, etwas unscharf ist. Sie benötigen die Wissenschaftler, um diese Abgrenzung zu navigieren.
Ich hoffe, wir sehen uns in zwei Monaten, am 10. Mai, zur nächsten Vorlesung, in der wir über Preisgestaltung sprechen werden. Bis dann.