00:00 イントロダクション
02:52 背景と免責事項
07:39 単純合理主義
13:14 これまでの経緯
16:37 科学者の皆さん、あなたたちが必要です!
18:25 ヒューマン+マシン(問題 1/4)
23:16 セットアップ(問題 2/4)
26:44 メンテナンス(問題 3/4)
30:02 ITバックログ(問題 4/4)
32:56 ミッション(科学者の役割 1/6)
35:58 用語集(科学者の役割 2/6)
37:54 成果物(科学者の役割 3/6)
41:11 スコープ(科学者の役割 4/6)
44:59 日常業務(科学者の役割 5/6)
46:58 オーナーシップ(科学者の役割 6/6)
49:25 サプライチェーンの職位(人事 1/6)
51:13 科学者の採用(人事 2/6)
53:58 科学者のトレーニング(人事 3/6)
55:43 科学者の評価(人事 4/6)
57:24 科学者の定着(人事 5/6)
59:37 一人の科学者から次の科学者へ(人事 6/6)
01:01:17 ITについて(企業ダイナミクス 1/3)
01:03:50 財務について(企業ダイナミクス 2/3)
01:05:42 リーダーシップについて(企業ダイナミクス 3/3)
01:09:18 旧来の計画(近代化 1/5)
01:11:56 S&OPの終わり(近代化 2/5)
01:13:31 旧来のBI(近代化 3/5)
01:15:24 データサイエンスからの脱却(近代化 4/5)
01:17:28 ITとの新たな取引(近代化 5/5)
01:19:28 結論
01:22:05 7.3 サプライチェーンサイエンティスト - 質問
説明
定量的サプライチェーンの取り組みの中核には、定量的サプライチェーン・マニフェストの考え方があり、サプライチェーンサイエンティスト(SCS)がデータ抽出パイプライン、経済モデリング、KPI レポートを担います。決定駆動最適化によるサプライチェーンの意思決定の自動化こそが、SCS の成果物です。SCS は生成された意思決定のオーナーシップを担い、機械処理能力によって拡張された人間の知性を発揮します。
全文記録

この一連のサプライチェーン講義へようこそ。私は Joannes Vermorel です。本日は、定量的サプライチェーンの視点からサプライチェーンサイエンティストについて解説します。サプライチェーンサイエンティストとは、サプライチェーンの取り組みを牽引する責任を持つ人物、もしくは少数精鋭のチームのことです。この役割は、対象となる意思決定を生み出す数値レシピの作成と、その後の保守を監督します。また、生成された意思決定が妥当であることを会社全体に示すために必要な証拠の提示も担います。
定量的サプライチェーンのモットーは、最新のハードウェアとソフトウェアがサプライチェーンにもたらす恩恵を最大限に活用することにあります。しかし、この視点をそれだけで説明するのは単純化しすぎです。人間の知性は依然として取り組み全体の基盤であり、いくつもの理由からサプライチェーンでは簡単にパッケージ化できません。本講義の目的は、なぜ、そしてどのようにして、この10年間でサプライチェーンサイエンティストという役割が、最新ソフトウェアをサプライチェーンに最大限活用するための実証済みの解決策になったのかを理解することです。
この目標に到達するには、まず最新ソフトウェアがサプライチェーンの意思決定自動化に挑む際の大きなボトルネックを理解しなければなりません。そこから、それらへの答えとしてサプライチェーンサイエンティストの役割を紹介し、さらにこの役割が企業全体を小規模にも大規模にも再編成していく様子を見ていきます。実際、サプライチェーンサイエンティストは企業内でサイロとして機能することはできません。科学者が成果を上げるには会社全体との協力が必要であり、会社全体もまた、それを実現するために科学者と協力する必要があります。

さらに先に進む前に、このシリーズ最初の講義で述べた免責事項を改めて申し上げます。本講義は、Lokad で行われた、やや特異な 10 年以上にわたる実験にほぼ全面的に基づいています。Lokad はエンタープライズソフトウェアを提供し、サプライチェーン最適化を専門とするベンダーです。これらすべての講義は Lokad の歩みによって形作られていますが、サプライチェーンサイエンティストという役割に関しては、その結び付きがさらに強くなっています。Lokad 自身の歩みは、サプライチェーンサイエンティストという役割を段階的に発見していく過程として読むこともできます。
このプロセスはまだ進行中です。たとえば約 5 年前、Lokad は学術的なデータサイエンティストの視点を捨て、学習と最適化のためにプログラミングのパラダイムを導入しました。現在、Lokad には約 36 名のサプライチェーンサイエンティストが在籍しており、最も能力の高い人材は、その実績ゆえに大規模な意思決定を任されています。なかには、個人で 5 億ドル超の在庫を管理するパラメータを担当する者もいます。この信頼は、発注、製造指示、在庫配分、価格設定など、さまざまな意思決定にまで及んでいます。
想像に難くないように、この信頼は獲得されなければなりませんでした。実際、非常に少数の企業でさえ、自社従業員にこれほどの権限を委ねることを躊躇します。ましてや Lokad のような第三者ベンダーに任せるとなればなおさらです。この程度の信頼を築くには、技術的手段に依存せずとも、通常、何年もかかるプロセスが必要です。それでも10年後、Lokad は初期の頃以上の速さで成長しており、この成長の大部分は、Lokadに委ねられる意思決定の範囲が拡大している既存顧客からもたらされています。
ここで最初のポイントに戻ります。本講義には、ほぼ確実に様々なバイアスが含まれています。Lokad外での類似体験を通じて視点を広げようと試みましたが、その点について語れることはあまりありません。私の知る限り、数社のテック大手、より具体的には巨大なeコマース企業が、Lokad と同等の意思決定自動化を実現しています。
しかし、これらの巨大企業は通常、一般の大企業が確保できる資源の約2桁多いリソースを配分し、エンジニアリング人員は数百人にも上ります。これらのアプローチの実現可能性は、非常に高い利益率を持つ企業でなければ成り立たないのでは、と私は疑問視しています。さもなければ、莫大な人件費が、より良いサプライチェーン実行によってもたらされる利益を上回ってしまうかもしれません。
さらに、この規模でエンジニアリング人材を惹きつけること自体が大きな課題です。優秀なソフトウェアエンジニアを 1 人採用するだけでも難しいのに、100 人ともなれば極めて強い採用ブランドが必要です。幸い、ここで提示する視点はもっとスリムです。Lokad による多くのサプライチェーンの取り組みは、基本的に 1 人のサプライチェーンサイエンティストが主担当となり、もう 1 人が補佐役として機能しています。人件費の節約だけでなく、私たちの経験では、少人数であること自体がサプライチェーンに大きな利益をもたらします。

主流のサプライチェーンの視点は、応用数学の立場をとります。手法やアルゴリズムは、人間のオペレーターを完全に排除するかのように提示されます。たとえば、安全在庫の公式や経済発注量 (EOQ)の公式は、純粋な応用数学の問題として示され、その公式を操る人物やその能力、背景は、一切の説明から省かれています。
より一般的に、この立場はサプライチェーンの教科書や、それに連なるソフトウェアで広く採用されています。人間要素を排除することで客観性が増すように感じられるのは確かです。結局、定理の正しさはそれを述べる人物に依存せず、また、アルゴリズムの性能は最後のキー入力を行った人物に依存するものではありません。このアプローチは、一段と優れた合理性を追求するものです。
しかし、私はこの立場が単純合理主義のまた一例であると主張します。私がここで提案しているのは、数値レシピの成果が実行者に依存すると主張するのではなく、むしろ、その背後にある知的立場がサプライチェーンに取り組むには適切でないということです。
実際のサプライチェーンのレシピは、複雑な職人技の産物であり、その作成者は決して中立的または些細な存在ではありません。たとえば、変数名のみが異なる2つの同一の数値レシピを考えてみましょう。数値上は同一の出力を生みますが、1つ目は意味のある適切な変数名が用いられているのに対し、2つ目は暗号的で一貫性のない名前となっています。実運用では、2つ目のレシピ(暗号的で一貫性のない変数名を用いたもの)は、災害の温床となる可能性があります。2つ目のレシピに対する変更やバグ修正は、1つ目のレシピで同様の作業を行う場合と比較して、桁違いの労力がかかることでしょう。実際、多くのソフトウェアエンジニアリングの教科書は、この問題そのものに丸ごと1章を割いて論じています。
数学、アルゴリズム、統計学はいずれも、変数名の適切さについては何も教えてくれません。その適切さは、当然ながら受け手の主観に委ねられています。たとえ数値上は同一のレシピでも、一方が主観的理由からはるかに優れていると評価されるのです。ここで私が主張したいのは、そうした主観的な懸念にも合理性が宿っているということです。これらの懸念は、単に主観や個人に依存しているという理由だけで退けるべきではありません。Lokad の経験は、同じソフトウェアツールや数学的手法、アルゴリズムライブラリを与えられても、特定のサプライチェーンサイエンティストがより優れた成果を上げることを示しています。実際、担当する人材の質はイニシアティブの成功を予測する最良の指標の一つです。
先天的な才能だけでサプライチェーンの成功の差異が完全に説明できないのなら、客観的要因も主観的要因も、成功するイニシアティブに寄与する要素として受け入れるべきです。これが、Lokad が過去数十年にわたりサプライチェーンサイエンティストという役割へのアプローチを洗練してきた理由です。サプライチェーンサイエンティストの職務に関する微妙なニュアンスは、決して過小評価されるべきではありません。こうした主観的要素による改善の大きさは、私たちの最も顕著な技術的成果にも匹敵します。
この一連の講義は、Lokad のサプライチェーンサイエンティスト向けの訓練資料として企画されています。しかし、より広範なサプライチェーンの実務家や学生にも関心を持っていただけるはずです。サプライチェーンサイエンティストが直面している事象を十分に理解するには、これらの講義を順を追って視聴するのが最適です。
第1章では、なぜサプライチェーンはプログラム的である必要があり、また数値レシピを実運用に移すことが極めて望ましいのかを見てきました。サプライチェーンの複雑性が増すにつれて自動化の必要性はかつてないほど高まっており、さらにサプライチェーンの実践を資本主義的に進める財務上の必然性も存在します。
第2章は方法論に捧げられています。サプライチェーンは競争システムであり、その特性は単純な方法論を打破します。科学者の役割は、単純な応用数学的手法に対する解毒剤とも見なせます。
第3章では、サプライチェーン担当者が直面する問題を概観しています。この章は、対処すべき意思決定上の課題の分類を試みています。SKUごとの在庫数量を単に選定するという単純な視点では、実務上の状況に対応できないこと、すなわち、意思決定には必ず奥行きが存在することを示しています。
第4章では、ソフトウェア要素が遍在する現代のサプライチェーン実践を理解するために必要な要素を概観しています。これらの要素は、デジタルサプライチェーンが機能する広範な文脈を把握するための基礎となります。
第5章と第6章は、それぞれ予測モデリングと意思決定に捧げられています。これらの章では、機械学習と数理最適化を活用した、数値レシピの「スマートな」部分に焦点を当てています。特に、これらの章では、サプライチェーンサイエンティストが実際に成果を上げる手法が数多く紹介されています。
最後に、第7章、すなわち本講義は、定量的サプライチェーンの取り組みの実行に焦点を当てています。イニシアティブを立ち上げ、適切な基盤を整え、そしてフィニッシュラインを突破して数値レシピを実運用に移すまでの過程を見てきました。

本日は、この全体を実現するためにどのような人物が必要であるかを見ていきます。
科学者の役割は、学術文献に見られる問題を解決するためのものです。ここでは、サプライチェーンサイエンティストの使命、スコープ、日常業務、そして注目すべき事項について概観します。この職務記述は、現代の Lokad における実践を反映しています。
会社内の新しい役職は、一連の懸念事項を生み出すため、科学者を採用し、教育し、評価し、維持する必要がある。これらの懸念事項には人事の視点から取り組む。科学者はサプライチェーン部門を超えて、他の部門、例えばIT、財務、さらには経営陣と協力することが期待される。
科学者はまた、会社が従業員とオペレーションを近代化するための機会をも表している。この近代化は、もはや重要性が失われた役職を廃止することが、新しい役職を導入するよりもはるかに困難であるため、旅路の中で最も難しい部分である。
本講義シリーズで私たちが自らに課した挑戦は、定量的手法によってサプライチェーンを体系的に改善することである。このアプローチの基本的な考え方は、現代のコンピューティングとソフトウェアがサプライチェーンにもたらす恩恵を最大限に活かすことにある。しかし、依然として何が人間の知性の領域に属し、何が自動化可能であるのかを明らかにする必要がある。
人間の知性と自動化との境界線は、依然として技術に大きく依存している。優れた技術は、より広範な意思決定の機械化と、より良い成果の提供を期待される。サプライチェーンの観点からは、在庫補充の意思決定に加えて、価格設定など、より多様な意思決定を行い、会社の収益性をさらに向上させるより良い意思決定を生み出すことを意味する。
科学者の役割は、人間の知性と自動化の境界線を体現するものである。人工知能に関する日常的な発表が、人間の知性が自動化に淘汰されようとしている印象を与えるかもしれないが、私の最先端技術に関する理解では、汎用人工知能はまだ遠い存在である。実際、定量的なサプライチェーン手法の設計には、依然として人間の洞察が非常に必要とされる。基本的なサプライチェーン戦略の策定すら、ソフトウェアが提供できる範囲を大きく超えている。
より一般的に言えば、サプライチェーンにおいては、枠組みが不十分な問題や未定義の問題に対処できる技術はまだ存在しない。しかし、狭く明確に定義された問題が特定されれば、その解決策を自動プロセスが学習し、ほとんど、あるいは全く人間の監督なしに自動化することは十分に考えられる。
この視点自体は新しいものではない。たとえば、スパムフィルタは広く採用されている。これらのフィルタは、関連するものと無関係なものを仕分けるという困難な課題を達成している。しかし、最新のデータを用いてこれらのフィルタを更新できたとしても、次世代のフィルタの設計は依然として主に人間に委ねられている。実際、スパマーはスパムフィルタを回避するために、単純なデータ駆動型の更新では打破できない新たな手法を次々と考案している。
したがって、自動化の構築には依然として人間の洞察が必要であるにもかかわらず、例えばLokadのようなソフトウェアベンダーが、これらすべての課題に対処する壮大なサプライチェーンエンジンを設計できない理由は明確ではない。確かに、ソフトウェアの経済性はそのような壮大なサプライチェーンエンジンの構築に非常に有利である。初期投資が高額であっても、ソフトウェアはほとんど無視できるコストで複製可能なため、そのエンジンを多数の企業に再販することで、ライセンス料による莫大な利益が得られるだろう。
2008年に、Lokadはパッケージソフトウェア製品として展開可能な壮大なエンジンの構築という旅に乗り出した。より正確には、当時のLokadは壮大なサプライチェーンエンジンではなく、壮大な予測エンジンに注力していた。しかし、予測はグローバルなサプライチェーン課題のごく一部に過ぎないため、これら比較的控えめな野望にもかかわらず、Lokadは壮大な予測エンジンの構築に失敗した。本講義シリーズで提示される定量的サプライチェーンの視点は、この壮大なエンジンへの野望の灰燼から生まれた。
サプライチェーンの観点からは、対処すべき三つの大きなボトルネックが存在することが明らかになった。我々は、この壮大なエンジンが初日から失敗に定められていた理由と、我々がそのような工学的偉業から依然として数十年先の未来である理由を見ていくことになる。
典型的なサプライチェーンのアプリケーションランドスケープは、ここ二、三十年で無秩序に成長したジャングルである。このランドスケープは、整然とした幾何学的な線や手入れの行き届いた低木が並ぶフレンチフォーマルガーデンではなく、活気に満ちる一方で、茨と攻撃的な動物が混在するジャングルである。さらに重要なことに、サプライチェーンはそのデジタルヒストリーの産物である。複数の半ば冗長なERP、未完成の自社カスタマイズ、バッチ統合、特に買収企業由来のシステムとの統合、さらには同じ機能領域を巡って競合する重複するソフトウェアプラットフォームが存在する可能性がある。
現代のソフトウェア技術の状況を考えると、どんな壮大なエンジンも単に接続すればすぐに機能するという考えは幻想に過ぎない。サプライチェーンを運用するすべてのシステムを統合することは、完全に人間の工学的努力に依存する大規模な試みである。
総経費の分析によれば、データ整備作業はサプライチェーンプロジェクトに関連する技術的労力の少なくとも4分の3を占める。一方、予測や最適化といった数値レシピのスマートな側面の構築は、全体の数パーセントにすぎない。したがって、パッケージ化された壮大なエンジンの存在は、コストや遅延の面ではほとんど意味をなさない。このエンジンが、サプライチェーンで一般的に見られる無秩序なITランドスケープに自動的に統合されるためには、人間レベルの知能が内蔵されていなければならない。
さらに、どんな壮大なエンジンであっても、その存在自体がこの試みをさらに困難なものにする。複雑なアプリケーションランドスケープという一つのシステムを扱うのではなく、今やアプリケーションランドスケープと壮大なエンジンという二つの複雑なシステムを統合しなければならない。この二つのシステムの統合の複雑さは、それぞれの複雑さの和ではなく、その積である。
この複雑さがエンジニアリングコストに与える影響は極めて非線形であり、この点は本講義シリーズの第1章でも既に述べられている。サプライチェーン最適化における最初の大きなボトルネックは、専用のエンジニアリング努力を必要とする数値レシピのセットアップである。このボトルネックは、いかなるパッケージ化された壮大なサプライチェーンエンジンからも得られるはずの利益を大きく打ち消す。

セットアップには多大なエンジニアリング努力が必要であるものの、それは入場券の支払いのような一度限りの投資かもしれない。しかし、サプライチェーンは常に進化し続ける生きた存在である。サプライチェーンが変化を止めるその日、会社は破綻する。変化は内部的なものと外部的なものの両方で起こる。
内部的には、アプリケーションランドスケープは絶えず変化している。多くのアップグレードがエンタープライズソフトウェアベンダーによって義務付けられているため、企業は望んでも自社のアプリケーションランドスケープを凍結することはできない。これらの義務を無視すれば、ベンダーは契約上の義務を免れることになり、これは容認し得ない結果となる。純粋な技術的アップデートを超えて、企業自体が変わるにつれて、どんな大規模なサプライチェーンでもソフトウェアの一部が段階的に導入されたり撤退したりするのは避けられない。
外部的には、市場も絶えず変化している。新たな競合他社、販売チャネル、潜在的なサプライヤーが次々と現れる一方で、いくつかは姿を消していく。規制も変動し続ける。アルゴリズムが、ある製品群の需要増加のような単純な変化を自動的に捉えることができたとしても、市場の性質そのものの変化に対応できるアルゴリズムはまだ存在しない。サプライチェーン最適化が解決しようとする問題そのものが、常に変化しているのだ。
もしサプライチェーンの最適化を担うソフトウェアがこれらの変化に対処できなければ、従業員はスプレッドシートに戻ることになる。スプレッドシートは粗雑かもしれないが、少なくとも従業員はそれを現在のタスクに合わせて運用できる。逸話的には、ほとんどのサプライチェーンが取引レベルではなく意思決定レベルで依然としてスプレッドシートを使用している。これは、ソフトウェアメンテナンスが失敗している生きた証拠である。
1980年代以降、エンタープライズソフトウェアベンダーはサプライチェーンの意思決定を自動化するソフトウェア製品を提供してきた。大規模なサプライチェーンを運営するほとんどの企業は、過去数十年でこれらのソリューションをいくつか導入している。しかし、従業員は常にスプレッドシートに戻るため、初期のセットアップが成功と見なされたとしても、メンテナンスに何か問題があったことを示している。
メンテナンスはサプライチェーン最適化における第二の大きなボトルネックである。実行が大部分放置可能であっても、レシピは積極的なメンテナンスを必要とする。

ここまでで、サプライチェーン最適化には初期のソフトウェアエンジニアリングリソースだけでなく、継続的なソフトウェアエンジニアリングリソースも必要であることが示された。本講義シリーズで以前に述べたように、プログラム可能な能力がなければ、現実のサプライチェーンが直面する多様な問題に現実的に対応することはできない。スプレッドシートは確かにプログラム可能なツールであり、ボタンやメニューとは対照的なその表現力が、サプライチェーンの実務者にとって非常に魅力的である。
ほとんどの企業でソフトウェアエンジニアリングリソースを確保する必要があるため、自然とIT部門に頼ることになる。残念ながら、サプライチェーンだけがこの考え方を持っているわけではない。営業、マーケティング、財務を含むすべての部門が、それぞれの意思決定プロセスの自動化にはソフトウェアエンジニアリングリソースが必要であると気づかざるを得ず、さらに取引層とその基盤となるインフラにも対処しなければならない。
その結果、現在大規模なサプライチェーンを運営する多くの企業では、IT部門が長年の未処理案件に埋もれている。したがって、IT部門にさらなる継続的リソースをサプライチェーンに割り当てることを期待しても、未処理案件がさらに悪化するだけである。IT部門への追加リソースの割当という選択肢は既に検討されたが、通常はもはや現実的ではない。これらの企業は、IT部門に関してはすでに深刻な不経済に直面しており、ITのバックログはサプライチェーン最適化における第三の大きなボトルネックを示している。
継続的なエンジニアリングリソースは必要とされるが、その大部分はIT部門からは得られない。ITからの支援が想定されるとしても、それは控えめなものでなければならない。
これら三つの大きなボトルネックが、サプライチェーンの凡庸な意思決定や要求の厳しい意思決定プロセスを自動化するために必要な継続的なソフトウェアエンジニアリングリソースという特定の役割、すなわち「サプライチェーンサイエンティスト」が必要である理由を定義している。

ここでは、Lokadの実践に基づいたより正確な定義を進めよう。サプライチェーンサイエンティストの使命は、サプライチェーンを日々運営するために必要な凡庸な意思決定を生み出す数値レシピを作成することである。科学者の作業は、アプリケーションランドスケープ全体から収集されたデータベースの抽出物から始まる。科学者は、これらのデータベース抽出物を処理するレシピをコーディングし、そのレシピを実運用へと移行することが期待される。なお、レシピによって生成される意思決定の品質については、科学者が全責任を負う。意思決定は、何かしらの環境システムによって生み出されるのではなく、科学者の洞察がレシピを通じて直接表現された結果である。
この一点は、通常データサイエンティストの役割として理解されているものからの大きな逸脱である。しかし、使命はそれだけに留まらない。サプライチェーンサイエンティストは、レシピによって生成されたあらゆる意思決定を裏付ける証拠を提示できなければならない。意思決定の責任を持つのは、何らかの不透明なシステムではなく、すなわち科学者である。科学者はサプライチェーンの責任者やCEOと面会し、レシピによって生成されたどんな意思決定に対しても説得力のある根拠を示すことができる必要がある。
もし科学者が会社に大きな損害を与える可能性すら持っていなければ、何かがおかしい。私は、誰に対しても、ましてや科学者に対して、監督や説明責任なしに大きな権限を与えることを推奨しているわけではない。ただ、明白な事実を指摘しているだけである。すなわち、自分のパフォーマンスがどれほど低くても会社に悪影響を与える力がなければ、どれほど高いパフォーマンスを発揮しても会社に良い影響を与えることはできない、ということである。
大企業は残念ながら本質的にリスク回避的である。そのため、科学者をアナリストに置き換える誘惑は非常に強い。意思決定自体を担当する科学者とは異なり、アナリストはあくまで部分的に情報を提供する役割に留まる。アナリストは基本的に無害であり、自分の時間や一部のコンピュータ資源を浪費する以上のことはできない。しかし、無害であることはサプライチェーンサイエンティストの役割ではない。

ここで「サプライチェーンサイエンティスト」という用語について少し議論しよう。この用語は残念ながら完璧ではない。私は約10年前に、「データサイエンティスト」を変形させた形で、この役割をサプライチェーンに特化させたバリエーションとしてブランディングする意図でこの表現を作り出した。専門性に関する洞察は正しかったが、データサイエンスに関する部分はそうではなかった。この点については講義の最後で再考する予定である。
「サプライチェーンエンジニア」という用語の方が、単なる理解に留まらず、領域を習熟し管理しようとする意欲を強調できるため、より適切であったかもしれない。しかし、一般的にエンジニアは最前線で活躍することが期待されない。適切な呼称は、おそらくサプライチェーンクオンツ、つまり定量的サプライチェーン実務者であっただろう。
金融分野では、クオンツまたは定量トレーダーは、アルゴリズムと定量的手法を駆使して取引の意思決定を行う専門家である。クオンツは、銀行を非常に利益の出るものにすることもあれば、逆に莫大な損失をもたらすこともある。人間の知性は、機械によって、その良い面も悪い面も拡大される。
いずれにせよ、どの用語が適切かはコミュニティ全体で決められるべきです:アナリスト、サイエンティスト、エンジニア、オペラティブ、またはクオンツ。その一貫性のため、今後の講義では「サイエンティスト」という用語を使い続けます。

サイエンティストにとって主要な成果物はソフトウェア、より正確には、関心のある日々のサプライチェーン意思決定を生み出す数値レシピです。このレシピは、データ準備の初期段階から意思決定そのものの企業による最終検証に至るまで関わるすべてのスクリプトの集合体です。このレシピはプロダクショングレードでなければならず、無人で動作でき、生成される意思決定がデフォルトで信頼されるものでなければなりません。当然ながら、この信頼は最初に獲得され、継続的な監視によりその信頼性が時間の経過とともに保証される必要があります。
プロダクショングレードのレシピを提供することは、サプライチェーンの実践を生産的な資産へと転換するために不可欠です。この観点はすでに以前のプロダクト指向のデリバリーに関する講義で論じられています。
このレシピ以外にも、数多くの二次的成果物があります。その中には、意思決定の生成に直接貢献しなくてもソフトウェアであるものも含まれます。たとえば、サイエンティストがレシピを構築し、後に維持するために導入しなければならないすべての計測ツールがこれにあたります。また、社内の同僚向けのイニシアティブやレシピ自体の全ドキュメントなど、他の項目も存在します。
レシピのソースコードは「どのように」実現されるかについては答えますが、「なぜ」実現されるのかについては答えません。「なぜ」については文書化されなければなりません。しばしば、レシピの正確性は意図の微妙な理解に依存しています。提供されるドキュメントは、前任のサイエンティストがサポートできなくても、次のサイエンティストへの円滑な引き継ぎを可能な限り促進しなければなりません。
Lokadでは、標準手順としてJoint Procedure Manual(JPM)と呼ばれるイニシアティブの大全を作成し維持しています。このマニュアルは、レシピの完全な運用マニュアルであると同時に、サイエンティストが行うモデリングの選択の根底にあるすべての戦略的洞察の集大成でもあります。
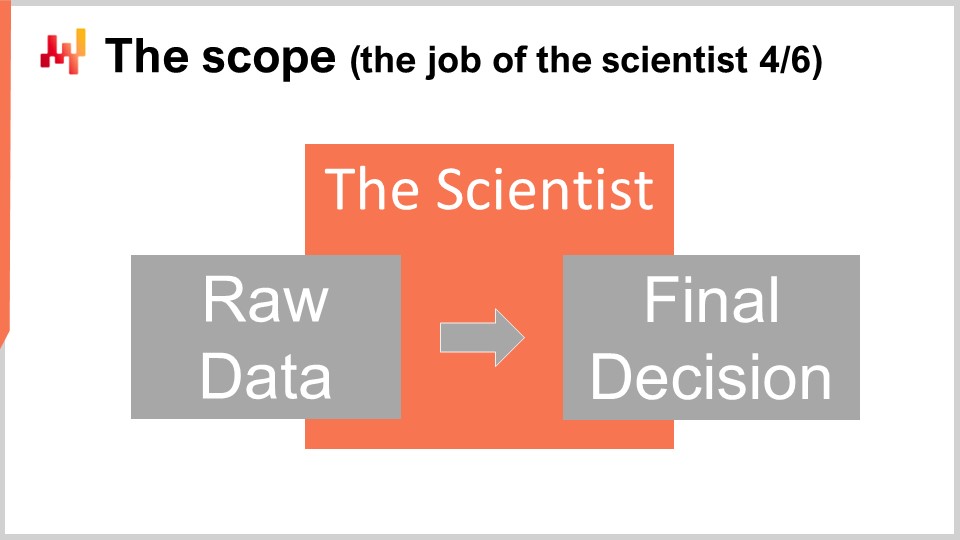
技術的なレベルでは、サイエンティストの作業は、生データの抽出から始まり、最終的なサプライチェーン意思決定の生成で終わります。サイエンティストは、既存のビジネスシステムから抽出された生データをもとに作業しなければなりません。各ビジネスシステムが独自の技術スタックを持っているため、抽出自体は通常、IT専門家に任せるのが最適です。サイエンティストがビジネスデータにアクセスするためだけに、せいぜい6種類程度のSQL方言や6種類程度のAPI技術に習熟することを期待するのは非現実的です。一方、IT専門家には生データの抽出以外、データ変換やデータ準備などは期待されるべきではありません。サイエンティストに提供される抽出データは、ビジネスシステム内に現れるデータそれ自体にできるだけ近いものでなければなりません。
パイプラインの反対側では、サイエンティストが作成したレシピが最終的な意思決定を生み出さなければなりません。意思決定の展開に関する要素はサイエンティストの管轄外です。これらは重要ですが、意思決定そのものとは大部分が独立しています。たとえば、購買注文の場合、最終数量の確定はサイエンティストの業務範囲ですが、供給業者が求める注文書となるPDFファイルの生成は含まれません。これらの制約があるにもかかわらず、業務範囲は依然として大きいため、範囲を一連のサブスコープに分割する誘惑に駆られがちですが、これは誤った考えです。大企業ではこの誘惑が非常に強くなるため、断片化は避けるべきです。範囲の断片化は、多くの問題を生み出す最も確実な方法です。
上流工程で、誰かが入力データの調整によってサイエンティストを支援しようとすると、その試みは必ず「ゴミが入ればゴミが出る」という結果になります。ビジネスシステムは十分に複雑であり、事前にデータを変換することは、偶発的な余分な複雑さを加えるにすぎません。中流工程では、誰かが予測などの困難な部分を担当してサイエンティストを助けようとすると、サイエンティストは自らのレシピの中にブラックボックスを抱え込むことになり、そのブラックボックスはサイエンティストのホワイトボックス化の試みを損ないます。そして下流工程では、誰かがさらに意思決定を再最適化しようとすると、その試みは必然的に混乱を招き、二重の最適化ロジックが互いに矛盾する可能性さえあります。
これは、サイエンティストが一人で作業しなければならないという意味ではありません。サイエンティストのチームを編成することは可能ですが、業務範囲は変わりません。チームを組む場合、レシピに対する集団的な所有が求められます。つまり、レシピに欠陥が見つかった場合、チームのどのメンバーでも介入して修正できるようにする必要があります。

Lokadの経験から、サプライチェーンサイエンティストの理想的なワークバランスは、作業時間の40%をコーディングに、30%を社内との対話に、残り30%をドキュメント作成やトレーニング資料の作成、同僚のサプライチェーン実務者やサイエンティストとの交流に費やすことであると示されています。
コーディングは当然、レシピ自体を実装するために必要です。しかし、一度レシピが稼働すると、ほとんどのコーディング作業はレシピそのものではなく、その計測ツールの実装に向けられます。レシピを改善するためには更なる洞察が必要であり、その洞察を得るためには専用の計測ツールが実装されなければなりません。
社内との対話は基本的に不可欠です。S&OPとは異なり、これらの議論の目的は予測を上方または下方に操作することではなく、レシピに組み込まれたモデリングの選択が、企業の戦略とすべての運用上の制約を忠実に反映しているかどうかを確認することにあります。
最後に、サプライチェーン最適化に関する企業の組織的知識を、サイエンティスト自身の直接の訓練や、同僚向けのドキュメント作成を通じて育むことは極めて重要です。レシピの性能は大部分、サイエンティストの能力の反映であり、仲間との交流やフィードバックの取得は、サイエンティストの能力向上において最も効果的な手段の一つです。

Lokadが描くサプライチェーンサイエンティストと主流のデータサイエンティストとの最大の違いは、現実世界での成果に対する個人的なコミットメントにあります。一見すると些細なことのように思えますが、経験はそれが非常に重要であると示しています。10年前、Lokadはプロダクショングレードのレシピの提供へのコミットメントが当然のものではないことを痛感しました。むしろ、データサイエンティストとして訓練を受けた人々のデフォルトの姿勢は、プロダクションを二次的な関心事とみなすことにあるのです。主流のデータサイエンティストは、機械学習や数理最適化といったスマートな部分を管理する一方で、実世界のサプライチェーンに伴うランダムな雑事を扱うことを、自分たちの領域外だと考えがちです。
しかし、プロダクショングレードのレシピへのコミットメントは、非常にランダムな事象に対処することを意味します。たとえば、2021年7月に多くのヨーロッパ諸国が壊滅的な洪水に見舞われた際、ドイツに拠点を置くLokadのクライアントでは、倉庫の半数が浸水しました。このアカウントを担当するサプライチェーンサイエンティストは、悪化した状況を打開するため、ほぼ一晩でレシピを再設計せざるを得なかったのです。なお、その修正は壮大な機械学習アルゴリズムによるものではなく、一連の解読されたヒューリスティックスによるものでした。逆に、サプライチェーンサイエンティストが意思決定を所有していなければ、プロダクショングレードのレシピを作成することはできません。これは心理的な問題であり、プロダクショングレードのレシピを提供するためには膨大な知的努力が必要で、従業員が必要な集中力を発揮するためには、リスクが現実的でなければなりません。
サプライチェーンサイエンティストの職務が明確になったところで、人事面からこの役割がどのように機能するかを考えましょう。まず、企業の重要事項として、サイエンティストはサプライチェーン部門の責任者、または上級サプライチェーンリーダーに報告しなければなりません。Lokadのように、サイエンティストが内部か外部かは問題ではなく、重要なのは、サイエンティストがサプライチェーン経営者の直接の監督下に置かれていることであるという点です。
よくある誤りとして、サイエンティストをIT部門の責任者やデータ分析部門の責任者に報告させるケースがあります。レシピ作成がコーディング作業であるため、サプライチェーンリーダーシップはそのような取り組みを完全に管理できないと感じるかもしれません。しかし、これは誤りです。サイエンティストは、生成された意思決定が受け入れ可能かどうかを承認できる、もしくはその承認を実現できる人物の監督が必要です。サイエンティストをサプライチェーンリーダーシップの直接の監督下以外に置くことは、プロトタイプが永遠に生産に至らない状態で運用され続けるレシピとなり、その結果、サイエンティストの役割は必然的にアナリストに変わり、定量的サプライチェーンイニシアティブの最初の野望が放棄されることになります。

最も優れたサプライチェーンサイエンティストは、平均的なサイエンティストに比べ、はるかに大きな成果を上げます。これはLokadの経験でもあり、数十年前にソフトウェア業界で認識されたパターンを反映しています。ソフトウェア企業は、最高のソフトウェアエンジニアが平均の10倍以上の生産性を持ち、平凡なエンジニアは場合によっては生産性がマイナスであり、コードベースに費やす時間ごとにソフトウェアを悪化させることさえあると長らく観察してきました。
サプライチェーンサイエンティストの場合、優れた能力は生産性を向上させるだけでなく、最終的なsupply chain performanceの改善にも寄与します。同じソフトウェアツールや数学的手法が与えられても、二人のサイエンティストが同じ結果を出すとは限らないのです。したがって、最も優れたサイエンティストになり得る可能性を持つ人材の採用が極めて重要です。
50人以上のサイエンティストを採用してきたLokadの経験では、専門特化していないエンジニアリングプロファイルも通常は非常に優れていることが示されています。直感に反するかもしれませんが、データサイエンス、統計学、またはコンピュータサイエンスの正式な訓練を受けた人々は、サプライチェーンサイエンティストのポジションに最適とは言えない場合が多いです。彼らはしばしばレシピを過度に複雑化し、重要ではあるが平凡なサプライチェーンの側面に十分な注意を払わない傾向があります。多くの細部に注意を払い、些細な数値的アーティファクトを追い続ける忍耐力こそが、最高のサイエンティストに求められる資質のようです。
逸話的な事実として、Lokadでは監査人として数年間働いた若手エンジニアが優れた成果を上げてきた実績があります。企業財務に精通している点に加え、才能ある監査人は膨大な企業記録の中を切り抜ける能力を身につけるようで、これはサプライチェーンサイエンティストの日常業務と合致しています。

採用によって候補者が適切な潜在能力を持っていることは保証されますが、その次のステップは、彼らが適切に訓練されることを確実にすることです。Lokadの基本方針は、あらかじめサプライチェーンについて何も知っていることを期待しないというものです。サプライチェーンに詳しいことはプラスですが、学界はこの点においてやや不足しています。多くのサプライチェーン学位はマネジメントやリーダーシップに焦点を当てていますが、若い卒業生にとっては、この講義シリーズの第2章、第3章、第4章で扱われるような基礎知識を持つことが不可欠です。残念ながら、そうでない場合が多く、これらの学位の定量的部分は期待外れなことがあります。その結果、サプライチェーンサイエンティストは雇用主によって訓練されなければなりません。この講義シリーズは、Lokadで使用されるトレーニング資料の一例を反映しています。

サプライチェーンサイエンティストの業績評価は、企業のお金が有効に使われているかどうかを確認したり、昇進を決定したりするなど、さまざまな理由で重要です。態度、勤勉さ、熟練度など、通常の基準が適用されますが、意外な点として、最高のサイエンティストはサプライチェーンの課題をほぼ見えなくさせる成果を上げ、劇的な問題をほとんど引き起こしません。

既存のレシピを維持しながら従来のサプライチェーンパフォーマンスを保つためのサイエンティストの訓練には約6ヶ月、ゼロから予測グレードのレシピを実装するための訓練には約2年かかります。経験豊富なサプライチェーンサイエンティストの採用がまだ選択肢にないため、人材の定着は極めて重要です。
多くの国では、30歳未満のエンジニアのソフトウェアおよび関連分野での平均在職期間は非常に短いですが、Lokadは従業員の幸福に注力することで、より長い平均在職期間を実現しています。企業は従業員に幸福をもたらすことはできなくとも、不毛なプロセスによって従業員を不幸にすることは回避できます。健全な職場環境は従業員の定着に大きく寄与します。

有能で経験豊富なサプライチェーンサイエンティストであっても、既存のレシピを迅速に引き継ぐことは期待できません。なぜなら、レシピは企業固有の戦略とサプライチェーンの特性を反映しているからです。一つのサプライチェーンから別のものへ移行するには、最良の条件下でも約1ヶ月かかります。大企業が一人のサイエンティストに依存するのは現実的でないため、Lokadでは常に2人のサイエンティストが現場で使用されるどのレシピにも精通するようにしています。継続性は不可欠であり、その実現の一つの方法として、クライアントと共同で作成するマニュアルがあり、これによりサイエンティスト間の予期せぬ交代が円滑に進むのです。

サプライチェーンサイエンティストの役割は、特にITを含む複数の部門との並外れた協力を必要とします。レシピの適切な実行は、ITが責任を持つデータ抽出パイプラインに依存しています。
最初の定量的サプライチェーンイニシアチブの開始時には、ITと科学者との間に比較的激しい相互作用のフェーズがあり、約2~3ヶ月続きます。その後、データ抽出パイプラインが確立されると、相互作用の頻度は低くなります。この対話は、科学者がITロードマップやサプライチェーンに影響を与える可能性のあるソフトウェアのアップグレードや変更について認識し続けることを保証します。
定量的サプライチェーンイニシアチブの初期段階では、ITと科学者の間に比較的激しい相互作用があります。最初の2~3ヶ月の間、科学者は週に何度もITとやり取りする必要があります。その後、データ抽出パイプラインが確立されると、相互作用は月に1回またはそれ以下になります。たまたま発生するパイプラインの不具合を解消することに加え、この対話は、科学者がITロードマップを常に把握していることを保証します。あらゆるソフトウェアのアップグレードや交換は、科学者にとって数日、あるいは数週間の作業を要する可能性があります。ダウンタイムを避けるために、レシピはアプリケーション環境の変化に対応するように修正されなければなりません。

科学者によって実装されたレシピは、ドルまたはユーロ単位のリターンを最適化します。この点は、本シリーズの初回講義で取り上げました。しかし、科学者がコストや利益のモデリング方法を決定することは期待されるべきではありません。彼らは経済的要因を反映するモデルの提案を行うべきですが、それらが正しいと判断するのは最終的に財務部門の役割です。多くのサプライチェーン手法は、サービスレベルや予測精度などのパーセンテージに注目することで問題を回避します。しかし、これらのパーセンテージは、企業の財務状態とほとんど相関していません。したがって、科学者は定期的に財務部門と連携し、数値レシピで採用されたモデリングの選択肢や仮定に対して検証を受ける必要があります。
財務モデリングの選択は一時的なものであり、企業戦略の変化を反映します。科学者はまた、次年度の在庫に伴う最大の運転資本額など、財務部門向けのレシピに付随するいくつかの指標を作成することが期待されています。中規模または大企業では、サプライチェーンサイエンティストが行った業務を四半期ごとに財務幹部がレビューするのは合理的です。

レシピの有効性に対する最大の脅威の一つは、偶然にも企業の戦略的意図を裏切ってしまうことです。多くのサプライチェーン手法は、パフォーマンスの指標として用いられるパーセンテージに隠れて戦略を回避します。営業およびオペレーション計画(S&OP)を通じて予測を誇張または縮小することは、戦略的意図を明確にする代替手段にはなりません。科学者は企業戦略の責任者ではありませんが、戦略を理解していなければレシピは誤ったものになります。レシピと戦略の整合性は、意図的に設計される必要があります。
科学者が戦略を理解しているかどうかを評価する最も直接的な方法は、彼らに改めて経営陣に説明させることです。これにより、誤解を容易に発見することができます。本来、この理解は科学者がイニシアチブマニュアルに既に文書化しているはずです。しかし、経験上、経営幹部が詳細な運用文書を確認する時間はほとんどありません。単純な会話が、双方にとってプロセスを迅速化します。
この会議は、科学者がサプライチェーンモデルや財務結果のすべてを説明するためのものではありません。唯一の目的は、デジタルペンを握る人物の正しい理解を確実にすることです。大企業であっても、科学者がCEOや関連するエグゼクティブと年に少なくとも一度会うのは合理的です。リーダーシップの意図に沿ったレシピの恩恵は計り知れず、しばしば過小評価されがちです。

サプライチェーンの改善は、継続的なデジタル近代化の一部です。これは、企業自体の再編成を必要とします。変化は劇的ではないかもしれませんが、時代遅れの手法を排除するのは困難な戦いです。適切に実行された場合、サプライチェーンサイエンティストの生産性は、従来のプランナーよりも大幅に高くなります。1人のサイエンティストが、5億ドルまたはユーロ以上の在庫を担当していることも珍しくありません。
サプライチェーン部門の人員を大幅に削減することは可能です。歴史的に激しい競争圧力にさらされてきたLokadのクライアント企業の中には、このアプローチを採用し、その節約分のおかげで生き残った例もあります。しかし、ほとんどのクライアントは、プランナーが自然と他の職へ移行していくため、人員削減をより段階的に進めています。
残ったプランナーは、顧客やサプライヤーに向けた取り組みへと努力を再調整します。彼らが収集するフィードバックは、サプライチェーンサイエンティストにとって非常に有用です。実際、科学者の仕事は本質的に内向きであり、企業のデータを取り扱うため、何が単に欠如しているのかを見抜くのは困難です。
多くのビジネス界の声は、長い間、顧客やサプライヤーとの結びつきを強化すべきだと唱えてきました。しかし、継続的な火消し作業、顧客の安心、サプライヤーへの圧力などによって、これらの努力が日常的に中和されるため、実行は容易ではありません。サプライチェーンサイエンティストは、これら双方の面において必要な緩和策を提供することができます。

S&OP(営業およびオペレーション計画)は、共有需要予測を通じて企業全体の整合性を促進するための広く普及した手法です。しかし、元々の意図が何であれ、私がこれまで目にしたS&OPプロセスは、生産性の低い会議が果てしなく続くものとして最も適切に表現されます。ERP実装やコンプライアンスを除けば、S&OPほど企業精神にダメージを与える実践は思い当たりません。ソ連は消滅しましたが、Gosplanの精神はS&OPを通じて今も息づいています。
S&OPの詳細な批評は、それ自体で1回の講義に値するでしょう。しかし、簡潔に言えば、サプライチェーンサイエンティストは、重要な点においてあらゆる面でS&OPよりも優れた代替手段です。S&OPとは異なり、サプライチェーンサイエンティストは現実の意思決定に根ざしており、現実の意思決定に対して初日から責任を持つ限り、単なる官僚的組織の一員にはなりません。
プランナー、在庫管理者、生産管理者は、あらゆる種類のビジネスレポートの主要な利用者です。これらのレポートは、通常、ビジネスインテリジェンスツールと呼ばれるエンタープライズソフトウェア製品によって生成されます。典型的なサプライチェーンの手法は、一連のレポートをスプレッドシートにエクスポートし、そして複数のスプレッドシートの数式を使ってこれらの情報を組み合わせ、半自動的に重要な意思決定を生成するというものです。しかし、先に述べたように、科学者のレシピは、ビジネスインテリジェンスとスプレッドシートのこの組み合わせに取って代わります。
さらに、ビジネスインテリジェンスもスプレッドシートも、レシピの実装をサポートするには適していません。ビジネスインテリジェンスは表現力に欠け、関連する計算をこの種のツールで表現することができません。スプレッドシートは保守性、時には拡張性にも欠けますが、主に保守性に問題があります。スプレッドシートの設計は、サプライチェーンで非常に必要とされる「設計による正確性」とは大きく相容れません。
実際、科学者が実装するレシピの指標には、多数のビジネスレポートが含まれています。これらのレポートは、これまでビジネスインテリジェンスを通じて生成されていたものに取って代わります。この進化は必ずしもビジネスインテリジェンスの終焉を意味するものではなく、他の部門は依然としてこの種のツールから利益を得るでしょう。しかし、サプライチェーンに関しては、サプライチェーンサイエンティストの導入はビジネスインテリジェンス時代の終わりを告げるものです。

数百、場合によっては数千人のエンジニアをあらゆるソフトウェア問題に投入できるテックジャイアンツを除けば、一般企業におけるデータサイエンスチームの成果は惨憺たるものです。通常、これらのチームは実質的な成果を上げることがほとんどありません。しかし、企業としてのデータサイエンスは、企業流行の最新の反復に過ぎません。
1970年代にはオペレーショナルリサーチが大流行し、1980年代にはルールエンジンやナレッジエキスパートが人気を博しました。世紀の変わり目にはデータマイニングとデータマイナーが注目され、2010年代以降、データサイエンスとデータサイエンティストが次の大物と見なされるようになりました。これらすべての企業トレンドは同じパターンに従います。すなわち、実際に画期的なソフトウェアイノベーションが起こり、人々が過度に熱狂し、そのイノベーションを新たな専任部門の創設を通じて企業に強制的に組み込む、というものです。なぜなら、既存の部門を変更または撤廃するよりも、新しい部門を追加する方が常に遥かに容易だからです。
しかし、企業としてのデータサイエンスは、実際の行動に十分に根ざしていないために失敗します。これが、初日から現実の意思決定を生み出す責務を負うサプライチェーンサイエンティストと、単なるIT部門との大きな違いです。

エゴや領域意識を脇に置くことができれば、サプライチェーンサイエンティストは従来の現状よりもはるかに有利な存在となります。典型的なIT部門は、何年にも及ぶ未処理案件に埋もれており、更なるリソースの投入は、他部門の期待を膨らませ、さらに未処理案件を増やすため、合理的な提案ではありません。
これに対して、サプライチェーンサイエンティストは期待値を下げる道を切り開きます。科学者は、必要なものは生データの抽出だけでよく、その解析は自らの責任で行うと考えます。彼らはIT部門に対して何も要求しません。サプライチェーンサイエンティストは、企業公認のシャドウITと見なされるべきではありません。むしろ、サプライチェーン部門が自らの中核的能力に対して責任と説明責任を持つという新たな取り決めを示すものです。IT部門は低レベルのインフラとトランザクション層を管理し、サプライチェーンの意思決定層は完全にサプライチェーン部門に委ねられるべきです。
IT部門は、真にIT中心の業務を除けば、意思決定者ではなく支援者でなければなりません。多くのIT部門は、未処理案件の山を認識しており、この新たな取り決めを受け入れています。しかし、自らの領域を守ろうとする本能が強すぎる場合、彼らはサプライチェーンの意思決定層を手放すことを拒むかもしれません。こうした状況は痛みを伴い、CEOの直接介入によってのみ解決可能です。

遠くから見ると、サプライチェーンサイエンティストの役割は、データサイエンティストのより専門化されたバリエーションと捉えることができます。これは、歴史的にLokadが企業としてのデータサイエンスに伴う問題を解決しようと試みた方法でもありました。しかし、私たちは10年前にこれでは不十分であると気付いたのです。今日提示されたすべての要素を徐々に明らかにするまでに、何年も要しました。
サプライチェーンサイエンティストは、企業のサプライチェーンに対する単なる追加要素ではなく、日常のサプライチェーン意思決定の所有権を明確にするものです。このアプローチを最大限に活用するためには、サプライチェーン、もしくは少なくともその計画部門は再構築されなければなりません。財務やオペレーションなどの隣接部門も、多少の変更に対応する必要がありますが、その程度ははるかに小さいです。
サプライチェーンサイエンティストのチームを育成することは、企業にとって大きなコミットメントですが、適切に行われれば生産性は非常に高くなります。実際、各科学者は10~100人のプランナー、予測担当者、または在庫管理者の役割を置き換え、たとえ科学者の給与が高くとも大幅な人件費削減を実現しています。サプライチェーンサイエンティストは、ITとの新たな取り決めを示し、ITを解決策提供者ではなく支援者に再配置することで、多くの、あるいはほとんどのIT関連のボトルネックを除去しています。
より一般的には、このアプローチは、マーケティング、営業、財務など、企業の他のIT以外の部門にも応用可能です。各部門には、それぞれ日常の意思決定が存在し、同様の自動化によって大いに恩恵を受けることができるのです。しかし、サプライチェーンサイエンティストが何よりもまずサプライチェーンの専門家であるのと同様に、
しかし、サプライチェーンサイエンティストが何よりもまずサプライチェーンの専門家であるのと同様に、マーケティング科学者またはマーケティングクォントもマーケティングの専門家であるべきです。科学者の視点は、21世紀初頭において機械と人間の知能の組み合わせから最大限の成果を引き出す道を切り開きます。
次回の講義は、5月10日(水)午後3時(パリ時間)に行われます。本日の講義は技術的な内容ではありませんでしたが、次回は主に技術的内容となります。私は価格最適化の手法を紹介する予定です。主流のサプライチェーン教科書では、通常、価格設定はサプライチェーンの要素として扱われませんが、実際には価格設定が需給のバランスに大きく寄与します。また、価格設定は非常にドメイン固有であり、抽象的に考えると全く誤ったアプローチをとりがちです。したがって、調査は自動車アフターマーケットに絞られます。これは、本講義シリーズ第3章で私が紹介したサプライチェーンのペルソナーの一例であるシュトゥットガルトで提示された要素を再検証する機会となるでしょう。

そして、質疑応答に進みます。
質問: 学界がデータサイエンスという分野の出現に気付き、高校で教えるべきだと判断するまでにほぼ10年を要したのと同様に、サプライチェーン学界においても、サプライチェーンサイエンスの視点を取り入れる動きが既に見られると思いますか?
まず最初に申し上げますが、フランスの高校でデータサイエンスが教えられているという認識はありません。高校ではコンピュータ関連のことさえほとんど教えられておらず、ましてやデータサイエンスなどという科目は到底存在しません。どのようにしてその分野の教師や教授を確保するのかも疑問です。しかし、高校生にある程度のデジタルリテラシーを身につけさせたいという考えは理解できます。プログラミングに慣れることは非常に良いことであり、私自身の経験から言えば、子供の成熟度にもよりますが、7歳や8歳から始めることも可能です。小学校でも基本的なプログラミング概念、つまり変数や命令のリストといった基本的な内容は学べますが、データサイエンスは高校で教えるべき範囲を大幅に超えていると考えています。特別な才能を持つ子でない限り、これは明らかに大学、もしくは大学院レベルの内容です。
実際、学界がデータサイエンスを前面に押し出すまでには10年近くかかりましたが、ここで一旦立ち止まって考えましょう。私はデータサイエンスを企業での実践として捉えていますが、これは学界がデータサイエンスを教えるやり方の鏡像とも言えます。つまり、問題は「実践していないことを教えるのは非常に難しい」という点にあります。少なくとも大学レベルではそうで、それ以下の教育機関においても同様の課題があるように感じます。現状、データサイエンスを教えている人々は、実際にマイクロソフト、グーグル、フェイスブック、OpenAIなどの重要な現場でデータサイエンスを実践している人たちではないのが問題です。
サプライチェーンにおいても同じ問題が存在し、適切な経験を持つ人材を確保するのは非常に困難です。ここで、わたし自身の宣伝にもなってしまいますが、Lokadは今後数週間以内にサプライチェーン専攻向けの資料提供を開始する予定です。学界の教授陣が活用できるような形でパッケージ化された資料を展開していくつもりですが、当然ながら、Lokadが提供するそれらの資料が実際に学生に教えるに値するかどうかは、各教授の判断に委ねられることになります。
質問: Lokad のドメイン特化言語は他では使われていないのでしょうか。Lokad の外では次の仕事で使う可能性が低いものを、新しい候補者にどうやって学ぶ気にさせるのですか。
まさにこれが、私がデータサイエンティストに対して抱いていた問題点です。人々は実際に「僕はTensorFlowのやつだ、TensorFlow派だ」とか「僕はPyTorch派だ」と名乗っていました。しかし、これは正しい態度ではありません。自分のアイデンティティを特定の技術ツールと混同してしまうと、本質を見失ってしまうのです。課題は、サプライチェーンの問題を理解し、それに定量的に対応して生産現場レベルの意思決定を導き出すことにあります。
この講義では、サプライチェーンサイエンティストが既存のレシピを管理するために習熟するのに6ヶ月、ゼロからレシピを設計するには2年かかると述べました。では、当社独自のプログラミング言語であるEnvisionを完全に習得するにはどのくらいの時間が必要でしょうか?私たちの経験では、3週間で十分です。Envision自体は全体の課題に比べれば小さな部分ですが、極めて重要です。ツールが不十分だと、予期せぬ大きな問題に直面することになります。しかし、現実的に言えば、これは全体というパズルの中のごく一部にすぎません。
Lokadで働く人々は、サプライチェーンの問題について飛躍的に学ぶことができます。プログラミング言語自体は他の言語に書き換えることもできるのですが、その場合、コードの量が増えてしまう可能性があります。特に若いエンジニアたちは、多くの技術が一時的なものであるという事実に気付いていないのです。ほとんどの場合、それらは数年で新たな技術に取って代わられてしまいます。
技術は尽きることなく入れ替わっていきます。もし候補者が「技術的な細部にこだわる」と言うなら、その人はおそらく適任ではないでしょう。これこそが、私がデータサイエンティストに抱いていた問題であり、彼らはいつも最先端の派手な技術を求めたのです。サプライチェーンは極めて複雑なシステムであり、一度のミスが数百万の損失を招く可能性があります。最新の、検証されていないツールではなく、生産現場レベルの確かなツールが必要です。
最も優秀な候補者は、本当にサプライチェーンのプロフェッショナルになりたいと意欲を持っている人たちです。重要なのは、プログラミング言語の細部ではなくサプライチェーンそのものなのです。
質問: 私はサプライチェーン、輸送、物流管理の学士課程にいます。どうすればサプライチェーンサイエンティストになれますか。
まず、私はあなたにLokadへの応募を強くお勧めします。常に募集ポジションはあります。しかし、より真剣な話として、サプライチェーンサイエンティストになる鍵は、サプライチェーンの意思決定を自動化する意欲を持つ企業での機会を得ることにあります。最も重要なのは、そうした意思決定のオーナーシップを持つことです。もしそのようなチャレンジを試みる企業を見つけることができれば、それがサイエンティストへの道を大いに開くでしょう。
生産現場レベルの意思決定に直面する中で、この一連の講義で取り上げるトピックの重要性に気づくはずです。何百万ドル相当の在庫、受注、在庫移動を左右する予測を扱うとき、その莫大な責任とゼロから正確さを保証する必要性が理解できるでしょう。他の企業も成長し、さらに多くの機会を手に入れるに違いありません。しかし、私のどんな夢想においても、地球上の全ての企業がLokadを活用するとは思いません。各社が自分たちのやり方を貫いても十分に成功するのです。
質問: サプライチェーンサイエンティストの日常業務の 40% がコーディングであるなら、特に経営系の学部生は最初にどのプログラミング言語を学ぶべきでしょうか。
私は、手軽に利用できるものであれば何でも良いと考えます。Pythonは良いスタート地点でしょう。私の提案は、実際にいくつかのプログラミング言語を試してみることです。サプライチェーンエンジニアに求められるものは、ソフトウェアエンジニアに求められるものとはまったく逆です。ソフトウェアエンジニアには、一つの言語を選び、その言語のあらゆるニュアンスを徹底的に掘り下げることをお勧めします。しかし、最終的にジェネラリストとなる人々には逆のアプローチ、すなわち、SQLを少し、Pythonを少し、Rを少し試してみることを勧めます。Excelの文法にも注意を払い、Rustのような言語がどのようなものかも見てみると良いでしょう。つまり、手元にある利用可能な言語で構わないのです。ちなみに、Lokadは学生向けにEnvisionを無料で利用できるようにする計画も進めていますので、今後の発表にご注目ください。
質問: グラフデータベースはサプライチェーン予測に大きな影響を与えると思いますか。
全く影響はないと思います。グラフデータベースは20年以上前から存在していますが、興味深いものではあるものの、PostgreSQLやMariaDBのようなリレーショナルデータベースほどの強力さはありません。サプライチェーンの予測において必要なのは、グラフライクな演算子があることではないのです。予測コンペティションでは、上位100名の参加者の中にグラフデータベースを使用している者は一人もいませんでした。しかし、ディープラーニングをグラフに応用することで可能なこともあり、その点については次回の価格設定に関する講義で解説します。
サプライチェーンサイエンティストが顧客データサイエンスプロジェクトの目標定義に関わるべきかという問いに関しては、まず、解決すべき問題を理解する前にデータサイエンスに焦点を当てるという根本的な前提に問題があると考えます。しかし、言い換えれば、サプライチェーン最適化の目標定義にサプライチェーンサイエンティストが関与すべきかということですが、答えは「はい」、絶対に参加すべきです。真に何を求めているのかをサイエンティストが見出すのは容易ではなく、利害関係者と密に協力し、正しい目標を追求する必要があるからです。つまり、サイエンティストがそのプロジェクトに加わることは極めて重要なのです。
ただし、ここで明確にしておきたいのは、これはデータサイエンスの取り組みではなく、サプライチェーンの取り組みであり、データはあくまで適切な要素として利用されるに過ぎないということです。本当に必要なのは、サプライチェーンの問題と野望から出発し、最新のソフトウェアの利点を最大限に活用することです。そのために、これらのサイエンティストが必須となるのです。彼らは、人間の知性とソフトウェアで実現可能な範囲との境界が曖昧な中で、問題の理解をさらに深める手助けをしてくれます。この境界線を乗り越えるためにも、サイエンティストの存在が重要なのです。
次回の講義は価格設定についてです。2か月後の5月10日にお会いしましょう。