Esplorazione dati in tempo reale con slices
Due mesi fa, abbiamo lanciato una nuova funzionalità importante per Lokad: il nostro primo sistema di esplorazione dati in tempo reale. Questa funzionalità ha in codice il nome dashboard slicing, e ci ha richiesto una completa revisione del back-end per l’elaborazione dati a basso livello che alimenta Envision per realizzarla. Con i dashboard slices, ogni dashboard diventa un intero dizionario di viste del dashboard, che possono essere esplorate in tempo reale tramite una barra di ricerca.
Per esempio, utilizzando il metodo slicing su un dashboard concepito come product inspector, che raccoglie in un unico luogo tutte le informazioni relative a un prodotto - comprese le previsioni probabilistiche di domanda e lead time - è ora possibile passare in tempo reale da un prodotto all’altro.
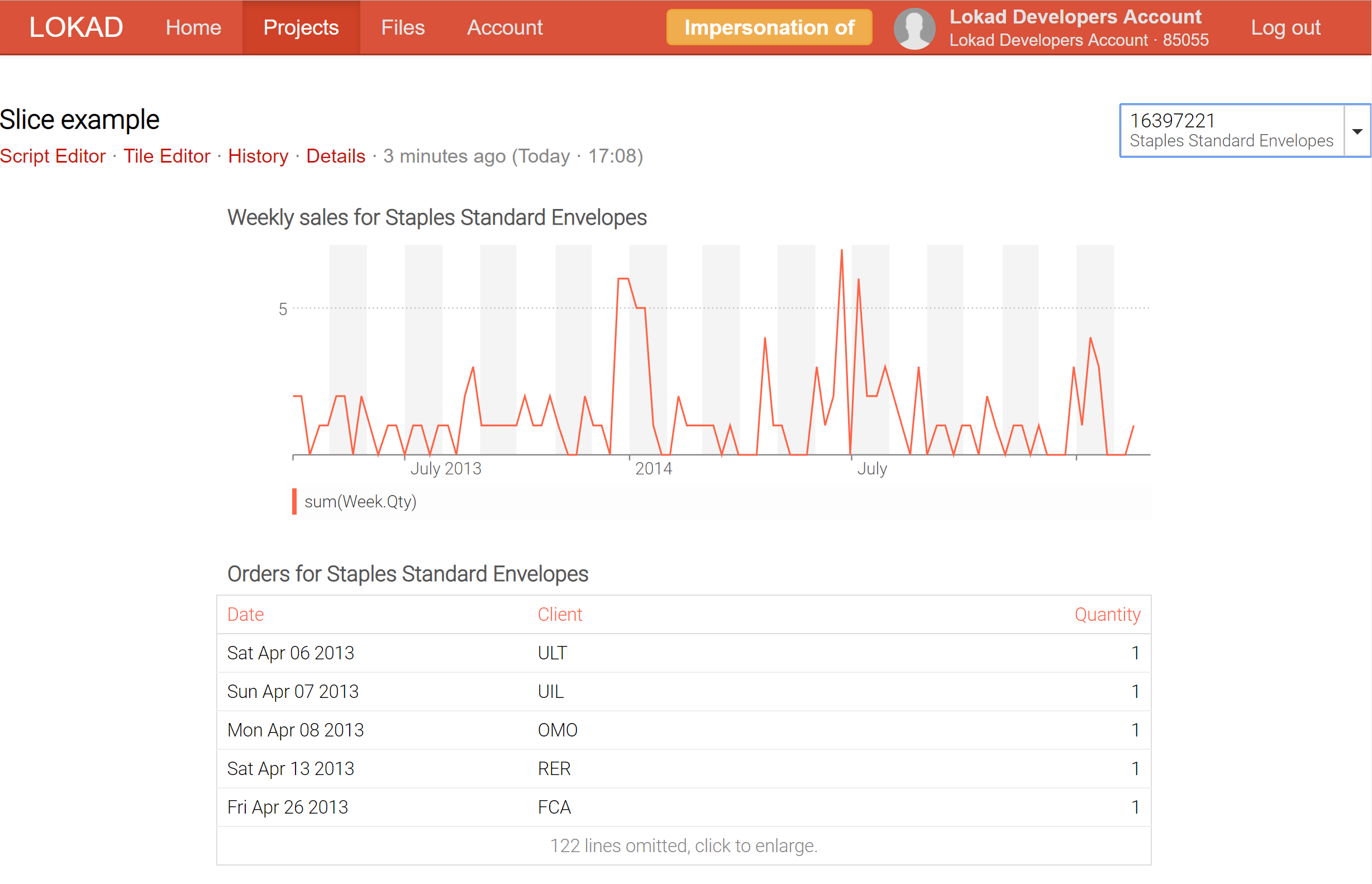
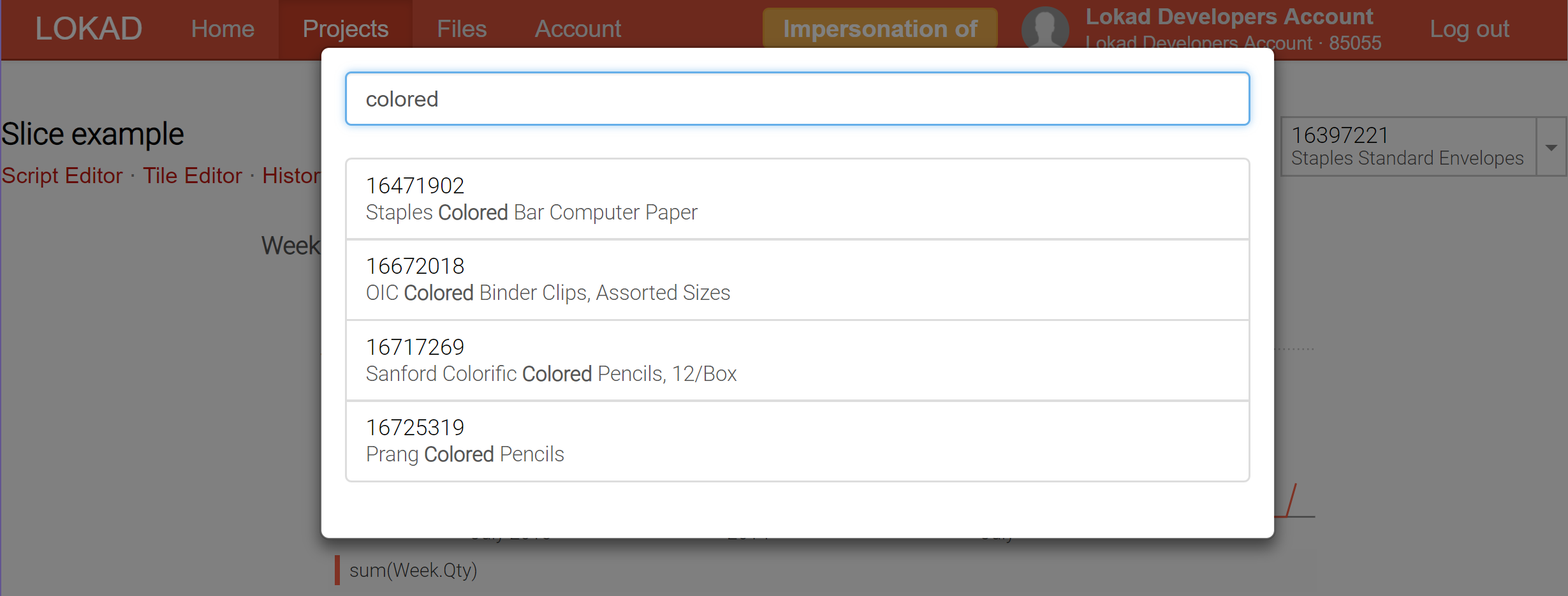
Attualmente, Lokad supporta fino a 200,000 slices (ovvero, viste del dashboard) che possono essere prodotte per un singolo dashboard; e tali slices possono essere visualizzate in tempo reale tramite il selettore, che dispone di una funzione di ricerca in tempo reale per facilitare l’esplorazione dei dati. A differenza degli strumenti di business intelligence (BI), queste slices possono contenere calcoli estremamente complessi, non semplicemente operazioni di slice-and-dice su un cubo OLAP.
Quando si tratta di elaborazione dei dati e reporting, esistono tipicamente due scuole di pensiero: l’elaborazione online e quella batch. L’elaborazione online prende in input un flusso di dati, e generalmente ci si aspetta che tutto ciò che viene visualizzato dal sistema sia sempre aggiornato: il sistema non deve essere in ritardo più di pochi minuti, a volte non più di pochi secondi rispetto alla realtà. I cubi OLAP, e la maggior parte degli strumenti definiti business intelligence rientrano in questa categoria. Pur essendo altamente desiderabili le analisi in tempo reale 1, non solo da una prospettiva aziendale (dati freschi sono migliori di dati obsoleti), ma anche dal punto di vista dell’utente finale (performance è una caratteristica), esse presentano anche limitazioni stringenti. In parole povere, è estremamente difficile fornire analisi intelligenti2 in tempo reale. Di conseguenza, tutti i sistemi analitici online presentano severe limitazioni per quanto riguarda il tipo di analisi che il sistema può effettuare.
D’altra parte, l’elaborazione batch viene tipicamente eseguita secondo una programmazione definita (ad es. esecuzioni giornaliere), mentre vengono immessi tutti i dati storici (o una parte consistente di essi). L’aggiornamento dei risultati è limitato dalla frequenza della programmazione: un batch giornaliero fornisce sempre risultati che riflettono la situazione di ieri, non quella di oggi. Poiché tutti i dati sono disponibili fin dall’inizio, l’elaborazione batch è ideale per eseguire ogni sorta di ottimizzazione computazionale che può aumentare enormemente le prestazioni complessive del processo. Di conseguenza, attraverso l’elaborazione batch è possibile eseguire intere classi di calcoli complessi che rimangono fuori portata se si considera l’elaborazione online. Inoltre, da una prospettiva IT, l’elaborazione batch tende ad essere molto più semplice sia da implementare che da gestire 3. L’aspetto negativo principale dell’elaborazione batch è il ritardo intrinseco alla natura raggruppata del processo.
In quanto piattaforma software, Lokad rientra decisamente nella categoria dell’elaborazione batch. Infatti, mentre l’ottimizzazione Quantitative Supply Chain richiede un alto grado di reattività, ci sono molte decisioni che non necessitano di una reattività istantanea, ad esempio decidere se produrre un pallet extra di prodotti, o decidere se è il momento di abbassare il prezzo per liquidare un stock. Per queste decisioni, la preoccupazione principale è prendere la migliore decisione possibile, e se questa può essere migliorata in modo misurabile dedicando un’ora di calcolo in più al caso, allora è quasi garantito che questa ora extra di calcolo sarà un buon investimento 4.
Pertanto, Envision è progettato con una prospettiva di elaborazione batch. Abbiamo più di qualche trucco alla mano per rendere Envision molto veloce anche quando si tratta di terabytes di dati; ma a questa scala parliamo di ottenere risultati in pochi minuti, non in meno di un secondo. In realtà, a causa della natura altamente distribuita del modello di calcolo di Envision, è difficile per Lokad completare l’esecuzione di qualsiasi script Envision in meno di 5 secondi - anche quando sono coinvolti solo pochi megabyte di dati. Più un sistema è distribuito, maggiore è l’inerzia interna nel sincronizzare tutte le parti. Maggiore scalabilità è il nemico di una latenza ridotta.
Qualche anno fa, abbiamo introdotto il concetto di entry forms in Envision: una funzionalità che ti permette di aggiungere un modulo configurabile sul dashboard, il quale diventa un input accessibile dallo script di Envision. Per esempio, grazie a questa funzionalità, era semplice progettare un dashboard inteso come un product inspector che visualizzasse tutte le informazioni rilevanti relative ai prodotti specificati. Purtroppo, per allineare il dashboard al nuovo valore inserito nel modulo, lo script di Envision doveva essere rieseguito, causando un ritardo di alcuni secondi per ottenere i risultati aggiornati; una durata inaccettabilmente lunga per l’esplorazione dei dati.
Le dashboard slices (consulta la nostra documentazione tecnica) rappresentano il nostro tentativo di ottenere il meglio di entrambi i mondi: elaborazione online e batch. Il trucco è che Lokad può ora calcolare in batch un vasto numero di slices (ogni slice può rappresentare un prodotto, una località, uno scenario, o una combinazione di tutte queste cose) e permetterti di passare da uno slice all’altro in tempo reale, il che è possibile perché tutto è stato precomputato. Naturalmente, precomputare un gran numero di slices è più costoso dal punto di vista computazionale, ma non tanto quanto si potrebbe pensare. Di solito, per Lokad è più conveniente calcolare 10,000 slices in una volta, piuttosto che eseguire 100 esecuzioni indipendenti, ciascuna dedicata a un singolo slice.
Attraverso le slices, Lokad sta acquisendo capacità di business intelligence su steroidi: non solo è possibile esplorare molteplici viste (ad es. prodotti, località, periodi di tempo) in tempo reale, ma lo si può fare senza alcuna delle consuete restrizioni delle architetture di elaborazione online.
-
In un sistema distribuito, non esiste il concetto di “tempo reale”. La velocità della luce stessa impone limiti rigidi al grado di sincronizzazione di un sistema che si estende su più continenti. Pertanto, questa terminologia risulta un po’ abusiva. Tuttavia, se la latenza complessiva è inferiore a un secondo circa, è generalmente accettabile definire un’applicazione di elaborazione dati come “in tempo reale”. ↩︎
-
Anche i sistemi avanzati di elaborazione dati in tempo reale, come quelli utilizzati per la guida autonoma, evitano attentamente qualsiasi operazione di apprendimento quando operano in tempo reale. Tutti i modelli di machine learning sono precomputati e statici. ↩︎
-
L’implementazione tipica di un processo batch consiste nello spostare file flat, una funzionalità di base supportata praticamente da ogni sistema al giorno d’oggi. Inoltre, da una prospettiva operativa, se un componente del processo batch subisce un’interruzione temporanea, una semplice politica di ritentativo solitamente risolve il problema. Al contrario, i sistemi online tendono a comportarsi male quando un componente va in crash. ↩︎
-
Ad oggi, un’ora di calcolo su una CPU moderna costa tipicamente meno di $0.02 quando si utilizza il modello pay-as-you-go sulle principali piattaforme di cloud computing. Pertanto, finché i benefici generati da una singola decisione migliore per la supply chain valgano molto più di $0.02, ha senso investire quest’ora di calcolo. ↩︎

