00:28 Introduzione
00:43 Robert A. Heinlein
03:03 La storia finora
06:52 Una selezione di paradigmi
08:20 Analisi statica
18:26 Programmazione con array
28:08 Miscibilità hardware
35:38 Programmazione probabilistica
40:53 Programmazione differenziabile
55:12 Versionamento di codice+dati
01:00:01 Programmazione sicura
01:05:37 In conclusione, anche per la supply chain gli strumenti contano
01:06:40 Prossima lezione e domande dal pubblico
Descrizione
Mentre la teoria della supply chain mainstream fatica a prevalere nelle aziende in generale, uno strumento, vale a dire Microsoft Excel, ha goduto di un notevole successo operativo. Re-implementare le ricette numeriche della teoria della supply chain mainstream tramite fogli di calcolo è banale, tuttavia, questo non è accaduto nella pratica nonostante la conoscenza della teoria. Dimostriamo che i fogli di calcolo hanno prevalso adottando paradigmi di programmazione che si sono dimostrati superiori nel fornire risultati per la supply chain.
Trascrizione completa

Ciao a tutti, benvenuti a questa serie di lezioni sulla supply chain. Io sono Joannes Vermorel, e oggi presenterò la mia quarta lezione: Paradigmi di programmazione per la supply chain.

Quindi quando mi viene chiesto, “Signor Vermorel, quali ritiene siano le aree di maggior interesse in termini di conoscenza della supply chain?” una delle mie risposte principali è solitamente i paradigmi di programmazione. E poi, non troppo frequentemente, ma abbastanza da essere notato, la reazione della persona con cui parlo è, “Paradigmi di programmazione, Signor Vermorel? Di che diavolo sta parlando? In che modo è anche minimamente rilevante per il compito a portata di mano?” E quelle reazioni, ovviamente, non sono così frequenti, ma quando accadono, mi ricordano invariabilmente questa citazione completamente incredibile di Robert A. Heinlein, considerato come il decano degli scrittori di fantascienza.
Heinlein ha una citazione fantastica sull’uomo competente, che evidenzia l’importanza della competenza in vari campi, soprattutto nella supply chain, dove abbiamo problemi complessi nelle nostre mani. Questi problemi sono quasi impegnativi quanto la vita stessa, e credo che valga davvero la pena esplorare l’idea dei paradigmi di programmazione, poiché potrebbe portare molto valore alla supply chain.
Finora, nella prima lezione, abbiamo visto che i problemi della supply chain sono complessi. Chiunque parli di soluzioni ottimali non colpisce nel segno; non c’è nulla neanche remotamente vicino all’ottimalità. Nella seconda lezione, ho presentato il Quantitative Supply Chain, una visione con cinque requisiti chiave per la grandezza nella gestione della supply chain. Questi requisiti non sono sufficienti da soli, ma non possono essere trascurati se si vuole raggiungere l’eccellenza.
Nella terza lezione, ho discusso della consegna di prodotti software nel contesto dell’ottimizzazione della supply chain. Ho sostenuto la tesi secondo cui l’ottimizzazione della supply chain richiede che un prodotto software venga affrontato in maniera capitalistica adeguata, ma non è possibile trovare tale prodotto sugli scaffali. C’è troppa diversità, e le sfide affrontate sono ben oltre le tecnologie di cui disponiamo attualmente. Quindi, per necessità, sarà qualcosa di completamente su misura. Pertanto, se si tratta di un prodotto software che deve essere fatto su misura per l’azienda o per la supply chain in questione, sorge la domanda su quali siano gli strumenti appropriati per fornire effettivamente questo prodotto. Questo mi porta all’argomento di oggi: lo strumento giusto inizia con i giusti paradigmi di programmazione, perché dovremo programmare questo prodotto in un modo o nell’altro.

Finora, abbiamo bisogno di capacità programmatiche per affrontare il lato dell’ottimizzazione del problema, non confondendolo con il lato gestionale. Quello che abbiamo visto, che è stato l’argomento della mia lezione precedente, è che Microsoft Excel è stato il vincitore finora. Dalle aziende molto piccole a quelle molto grandi, è onnipresente, viene utilizzato ovunque. Anche in aziende che hanno investito milioni di dollari in sistemi super-intelligenti, Excel domina ancora, e perché? Perché possiede le proprietà di programmazione adeguate. È molto espressivo, agile, accessibile e manutenibile. Tuttavia, Excel non è il traguardo finale. Credo fermamente che possiamo fare molto di più, ma abbiamo bisogno degli strumenti giusti, della mentalità giusta, delle intuizioni giuste e dei paradigmi di programmazione.

I paradigmi di programmazione potrebbero sembrare eccessivamente oscuri per il pubblico, ma in realtà rappresentano un campo di studio che è stato intensamente studiato negli ultimi cinque decenni. È stato svolto un immenso lavoro in questo campo. Non è ampiamente conosciuto da un pubblico più vasto, ma esistono intere librerie piene di lavori di alta qualità realizzati da molte persone. Quindi oggi, introdurrò una serie di sette paradigmi adottati da Lokad. Non abbiamo inventato nessuna di queste idee; le abbiamo prese da chi le aveva inventate prima di noi. Tutti questi paradigmi sono stati implementati nel prodotto software di Lokad, e dopo quasi un decennio di Lokad in produzione, sfruttando questi paradigmi, credo che siano stati assolutamente fondamentali per il nostro successo operativo finora.

Procediamo con questo elenco partendo dall’analisi statica. Il problema qui è la complessità. Come affronti la complessità nella supply chain? Ti troverai di fronte a sistemi aziendali che hanno centinaia di tabelle, ciascuna con decine di campi. Se consideri un problema semplice come il riapprovvigionamento di un magazzino, ci sono così tante cose da tenere in considerazione. Puoi avere MOQ, sconti sui prezzi, previsioni di domanda, previsioni dei tempi di consegna, e ogni tipo di reso. Puoi avere limitazioni dello spazio sugli scaffali, limiti alla capacità di ricezione e date di scadenza che rendono obsoleti alcuni dei tuoi lotti. Quindi, ti ritrovi con una miriade di elementi da considerare. Nella supply chain, l’idea di “muoviti velocemente e rompi le cose” non è la mentalità giusta. Se per sbaglio ordini merci per un valore di un milione di dollari che non ti servono affatto, questo è un errore molto costoso. Non puoi avere un piece of software che guida la tua supply chain, prendendo decisioni routinarie, e quando c’è un bug, costa milioni. Abbiamo bisogno di qualcosa con un grado molto elevato di correttezza per progettazione. Non vogliamo scoprire gli errori in produzione. Questo è molto diverso dal software medio in cui un crash non è un problema.
Per quanto riguarda l’ottimizzazione della supply chain, questo non è il tuo problema abituale. Se hai appena passato un ordine massiccio e incorretto a un fornitore, non puoi semplicemente chiamarlo una settimana dopo per dire: “Oh, è stato un errore, no, dimentica, non abbiamo mai ordinato nulla del genere.” Quegli errori costeranno molti soldi. L’analisi statica viene chiamata così perché riguarda l’analisi di un programma senza eseguirlo. L’idea è che hai un programma scritto con istruzioni, parole chiave e tutto il resto, e senza nemmeno eseguirlo, puoi già dire se il programma presenta problemi che quasi certamente impatterebbero negativamente la tua produzione, specialmente quella della supply chain. La risposta è sì. Queste tecniche esistono, sono implementate e sono estremamente preziose.
Solo per fare un esempio, puoi vedere uno screenshot di Envision sullo schermo. Envision è un linguaggio di programmazione domain-specific che è stato progettato per quasi un decennio da Lokad ed è dedicato all’ottimizzazione predittiva della supply chain. Quello che vedi è uno screenshot dell’editor di codice di Envision, una web app che puoi utilizzare online per modificare il codice. La sintassi è fortemente influenzata da Python. In questo piccolo screenshot, con appena quattro linee, sto illustrando l’idea che se stai scrivendo un ampio pezzo di logica per il riapprovvigionamento di un magazzino, e introduci alcune variabili economiche, come sconti sui prezzi, attraverso un’analisi logica del programma, puoi vedere che tali sconti sui prezzi non hanno alcuna relazione con i risultati finali restituiti dal programma, che sono le quantità da riapprovvigionare. Qui, hai un problema ovvio. Hai introdotto una variabile importante, gli sconti sui prezzi, e tali sconti logicamente non influenzano in alcun modo i risultati finali. Quindi qui, abbiamo un problema che può essere rilevato tramite analisi statica. È un problema evidente, perché se introduciamo variabili nel codice che non hanno alcun impatto sull’output del programma, allora non servono a nessun fine. In questo caso, ci troviamo di fronte a due opzioni: o quelle variabili sono effettivamente codice morto, e il programma non dovrebbe compilare (bisognerebbe semplicemente eliminare questo codice morto per ridurre la complessità e non accumulare complessità accidentale), oppure è stato un errore genuino e c’è una variabile economica importante che avrebbe dovuto essere integrata nel tuo calcolo, ma hai lasciato perdere a causa di distrazione o per qualche altro motivo.
L’analisi statica è assolutamente fondamentale per ottenere un qualsiasi grado di correttezza per progettazione. Si tratta di correggere le cose in fase di compilazione quando scrivi il codice, anche prima di toccare i dati. Se sorgono problemi quando li esegui, è probabile che si verifichino durante la notte, quando il batch notturno gestisce il riapprovvigionamento del magazzino. Il programma probabilmente verrà eseguito in orari dispari, quando nessuno lo sta monitorando, quindi non vuoi che qualcosa si blocchi mentre non c’è nessuno davanti al programma. Dovrebbe bloccarsi nel momento in cui le persone stanno effettivamente scrivendo il codice.
L’analisi statica ha molti scopi. Per esempio, in Lokad, utilizziamo l’analisi statica per l’edizione WYSIWYG dei dashboard. WYSIWYG sta per “what you see is what you get.” Immagina di costruire un dashboard per il reporting, con grafici a linee, grafici a barre, tabelle, colori e vari effetti di stile. Vuoi poterlo fare in modo visivo, non modificare lo stile del tuo dashboard tramite il codice, poiché è molto macchinoso. Tutte le impostazioni che hai implementato verranno reiniettate nel codice stesso, e ciò avviene tramite l’analisi statica.
Un altro aspetto in Lokad, che potrebbe non essere di così grande importanza per la supply chain in generale ma che è certamente critico per intraprendere il progetto, era affrontare un linguaggio di programmazione chiamato Envision che stiamo progettando. Sapevamo fin dal primo giorno, quasi un decennio fa, che sarebbero stati commessi errori. Non avevamo una sfera di cristallo per avere una visione perfetta fin dal primo giorno. La domanda era, come possiamo assicurarci di poter correggere quegli errori di progettazione nel linguaggio di programmazione stesso nel modo più comodo possibile? Qui, Python è stato un monito per me.
Python, che non è un linguaggio nuovo, è stato rilasciato per la prima volta nel 1991, quasi 30 anni fa. La migrazione da Python 2 a Python 3 ha richiesto all’intera comunità quasi un decennio, ed è stato un processo da incubo, molto doloroso per le aziende coinvolte in questa migrazione. La mia percezione era che il linguaggio stesso non avesse sufficienti costrutti. Non è stato progettato in modo che si potessero migrare i programmi da una versione del linguaggio a un’altra. Era effettivamente estremamente difficile farlo in maniera completamente automatizzata, ed è perché Python non è stato ingegnerizzato tenendo in conto l’analisi statica. Quando hai un linguaggio di programmazione per la supply chain, desideri davvero uno che abbia un’eccellente qualità in termini di analisi statica, perché i tuoi programmi dureranno a lungo. Le supply chain non hanno il lusso di dire, “Aspetta per tre mesi; stiamo semplicemente riscrivendo il codice. Aspettateci; sta arrivando la cavalleria. Non funzionerà per un paio di mesi.” È letteralmente come riparare un treno mentre il treno sta correndo sui binari a tutta velocità, e vuoi riparare il motore mentre il treno è in funzione. È così che si sembra riparare le cose della supply chain che sono effettivamente in produzione. Non hai il lusso di mettere in pausa il sistema; non si ferma mai.

Il secondo paradigma è la programmazione con array. Vogliamo tenere sotto controllo la complessità, dato che è un tema ricorrente nelle supply chain. Vogliamo avere una logica in cui non si presentino determinate classi di errori di programmazione. Per esempio, ogni volta che hai loop o rami scritti esplicitamente dai programmatori, ti espone a intere classi di problemi molto difficili. Diventa estremamente complicato quando le persone possono semplicemente scrivere loop arbitrari per avere garanzie sulla durata del calcolo. Sebbene possa sembrare un problema di nicchia, non è del tutto così nell’ottimizzazione della supply chain.
Nella pratica, supponiamo che tu abbia una catena di retail. A mezzanotte, consolideranno completamente tutte le vendite dell’intera rete, e i dati verranno consolidati e passati a un qualche tipo di sistema per l’ottimizzazione. Questo sistema avrà esattamente una finestra di 60 minuti per fare le previsioni, l’ottimizzazione degli inventari e le decisioni di riallocazione per ogni singolo negozio della rete. Una volta terminato, i risultati verranno passati al sistema di gestione del magazzino affinché possano iniziare a preparare tutte le spedizioni. I camion verranno caricati, magari alle 5:00, e alle 9:00 i negozi apriranno con la merce già ricevuta e esposta sugli scaffali.
Tuttavia, avete tempi molto rigidi, e se il vostro calcolo supera questa finestra di 60 minuti, mettete a rischio l’intera supply chain execution. Non volete scoprire in produzione quanto tempo impiegano le cose. Se avete cicli in cui le persone possono decidere quante iterazioni eseguire, è molto difficile avere qualsiasi prova della durata del vostro calcolo. Tenete presente che stiamo parlando di ottimizzazione della supply chain. Non avete il lusso di fare revisione tra pari e ricontrollare tutto. A volte, a causa della pandemia, alcuni paesi si chiudono mentre altri riaprono in modo piuttosto irregolare, solitamente con un preavviso di 24 ore. Dovete reagire rapidamente.
Quindi, la programmazione degli array è l’idea secondo cui si può operare direttamente sugli array. Se osserviamo il frammento di codice che abbiamo qui, questo è codice Envision, il DSL di Lokad. Per capire cosa sta succedendo, bisogna comprendere che quando scrivo “orders.amounts”, quello che segue è una variabile e “orders” è in realtà una tabella nel senso di una tabella relazionale, come in una tabella del tuo database. Ad esempio, qui nella prima riga, “amounts” sarebbe una colonna della tabella. Nella prima riga, sto praticamente dicendo che per ogni singola riga della tabella orders, prenderò semplicemente la “quantity”, che è una colonna, e la moltiplicherò per “price”, ottenendo così una terza colonna che viene generata dinamicamente, cioè “amount”.
Inoltre, il termine moderno per la programmazione degli array al giorno d’oggi è noto anche come programmazione con data frame. Il campo di studio è abbastanza antico; risale a tre o quattro decenni, forse anche quattro o cinque. È stato conosciuto come programmazione degli array anche se oggi la gente è solitamente più familiare con l’idea dei data frame. Nella seconda riga, quello che stiamo facendo è un filtro, proprio come in SQL. Stiamo filtrando le date, e capita che la tabella orders contenga una data. Verrà filtrata, e dico “date that is greater than today minus 365”, quindi in giorni. Manteniamo i dati dell’anno scorso, e poi scriviamo “products.soldLastYear = SUM(orders.amount)”.
Adesso, la cosa interessante è che abbiamo quello che chiamiamo un natural join tra products e orders. Perché? Perché ogni riga d’ordine è associata a un solo prodotto, e un prodotto è associato a zero o più righe d’ordine. In questa configurazione, puoi dichiarare direttamente: “Voglio calcolare qualcosa a livello di prodotto che sia semplicemente la somma di ciò che accade a livello di orders,” ed è esattamente ciò che viene fatto alla riga nove. Potresti notare che la sintassi è molto essenziale; non ci sono molti dettagli o tecnicismi. Sostengo che questo codice è quasi interamente privo di particolarità quando si tratta di programmazione con data frame. Poi, nelle righe 10, 11 e 12, stiamo semplicemente mostrando una tabella sul nostro dashboard, cosa che può essere fatta in modo molto conveniente: “LIST(PRODUCTS)”, e poi “TO(products)”.
Ci sono molti vantaggi della programmazione degli array per le supply chain. Innanzitutto, elimina intere classi di problemi. Non avrai bug di indice off-by-one nei tuoi array. Sarà molto più facile parallelizzare e persino distribuire il calcolo. Questo è molto interessante perché significa che puoi scrivere un programma ed eseguirlo non su una singola macchina locale, ma direttamente su una flotta di macchine che risiedono nel cloud, e a proposito, questo è esattamente ciò che viene fatto in Lokad. Questa parallelizzazione automatica è di altissimo interesse.
Vedete, il funzionamento è che quando si fa ottimizzazione della supply chain, i vostri tipici modelli di consumo in termini di hardware di calcolo sono estremamente intermittenti. Se torno all’esempio che stavo facendo riguardo alla finestra di 60 minuti per le reti retail durante il rifornimento dei negozi, ciò significa che c’è un’ora al giorno in cui avete bisogno di potenza di calcolo per eseguire tutti i vostri calcoli, ma per il resto del tempo, le altre 23 ore, non ne avete bisogno. Quindi, ciò che desiderate è un programma che, quando siete pronti ad eseguirlo, si distribuisce su molte macchine e poi, una volta completato, libera tutte quelle macchine affinché possano avere luogo altri calcoli. L’alternativa sarebbe avere molte macchine che noleggiate e per le quali paghiate tutto il giorno, ma che usate solo per il 5% del tempo, il che è molto inefficiente.
Questa idea che si possa distribuire il carico su molte macchine in modo rapido e prevedibile, per poi cedere la potenza di calcolo, richiede il cloud in un ambiente multi-tenant e una serie di altre cose che Lokad sta implementando. Ma prima di tutto, necessita della collaborazione stessa del linguaggio di programmazione. È qualcosa che semplicemente non è fattibile con un linguaggio di programmazione generico come Python, perché il linguaggio stesso non si presta a questo tipo di approccio intelligente e pertinente. Questo va oltre i semplici trucchi; si tratta letteralmente di dividere i costi dell’hardware IT per 20, accelerare enormemente l’esecuzione ed eliminare intere classi di potenziali bug nella vostra supply chain. Questo cambia le regole del gioco.
La programmazione degli array esiste già in molti aspetti, come ad esempio in NumPy e pandas in Python, che sono così popolari per il segmento degli data scientist dell’audience. Ma la domanda che vi pongo è: se è così importante e utile, perché queste cose non sono cittadini di prima classe del linguaggio stesso? Se tutto ciò che fate è canalizzare tramite NumPy, allora NumPy dovrebbe essere un cittadino di prima classe. Direi che si può andare persino oltre NumPy. NumPy si occupa solo della programmazione degli array su una macchina, ma perché non fare programmazione degli array su una flotta di macchine? È molto più potente e molto più adeguato quando si dispone di un cloud con capacità hardware accessibile.
Quindi, qual è il collo di bottiglia nell’ottimizzazione della supply chain? C’è un detto di Goldratt che afferma: “Qualsiasi miglioramento portato al di là del collo di bottiglia in una supply chain è un’illusione,” e sono pienamente d’accordo con questa affermazione. Realisticamente, quando vogliamo fare ottimizzazione della supply chain, il collo di bottiglia saranno le persone, e più specificamente, i Supply Chain Scientist che, sfortunatamente per Lokad e i miei clienti, non crescono sugli alberi.
Il collo di bottiglia sono i Supply Chain Scientist, le persone che sanno creare le ricette numeriche che tengono conto di tutte le strategie dell’azienda, dei comportamenti avversari dei concorrenti, e che trasformano tutta questa intelligenza in qualcosa di meccanico che può essere eseguito su larga scala. La tragedia del modo ingenuo di fare data science, quando ho iniziato il mio dottorato, che comunque non ho mai portato a termine, era che vedevo tutti in laboratorio letteralmente fare data science. La maggior parte delle persone scriveva codice per qualche tipo di modello avanzato di machine learning, premevano invio e poi iniziavano ad aspettare. Se hai un dataset di grandi dimensioni, diciamo 5-10 gigabyte, non sarà in tempo reale. Così, l’intero laboratorio era pieno di persone che scrivevano poche righe, premevano invio, e poi andavano a prendere una tazza di caffè o a leggere qualcosa online. Di conseguenza, la produttività era estremamente bassa.
Quando ho fondato la mia azienda, avevo ben chiaro in mente che non volevo finire per pagare un esercito di persone super intelligenti che trascorrono la maggior parte della giornata a sorseggiare caffè, aspettando che i loro programmi finissero per ottenere risultati e andare avanti. In teoria, potrebbero parallelizzare molte cose contemporaneamente ed eseguire esperimenti, ma in pratica, non ho mai veramente visto ciò. Intellettualmente, quando sei impegnato nella ricerca di una soluzione per un problema, vuoi testare la tua ipotesi e hai bisogno del risultato per proseguire. È molto difficile fare multitasking su argomenti altamente tecnici e inseguire più percorsi intellettuali allo stesso tempo.
Tuttavia, c’era un lato positivo. I data scientist, e ora i Supply Chain Scientist in Lokad, non finiscono per scrivere mille righe di codice e poi dire “per favore esegui”. Di solito aggiungono due righe a uno script che è lungo mille righe, e poi chiedono che lo script venga eseguito. Questo script viene eseguito contro esattamente gli stessi dati che hanno appena elaborato pochi minuti prima. È quasi esattamente la stessa logica, tranne quelle due righe. Quindi, come si possono elaborare terabyte di dati in secondi invece che in diversi minuti? La risposta è che, se per l’esecuzione precedente dello script avete registrato tutti i passaggi intermedi del calcolo e li avete memorizzati (tipicamente su unità a stato solido o SSD), che sono molto economici, veloci e convenienti.
La prossima volta che eseguirai il tuo programma, il sistema noterà che lo script è quasi identico. Verrà eseguita una comparazione, e si renderà conto che in termini di grafo dei calcoli è quasi identico, tranne per alcuni dettagli. In termini di dati, è solitamente identico al 100%. A volte ci sono alcune variazioni, ma quasi null’altro. Il sistema diagnosticherà automaticamente che ci sono solo poche cose da calcolare, così da fornire i risultati in pochi secondi. Questo può aumentare drasticamente la produttività dei vostri Supply Chain Scientist. Si passa da persone che premono invio e attendono 20 minuti per il risultato a qualcosa in cui premono invio e 5 o 10 secondi dopo hanno il risultato e possono andare avanti.
Sto parlando di qualcosa che può sembrare super oscuro, ma in pratica, stiamo parlando di qualcosa che ha un impatto 10 volte maggiore sulla produttività. Questo è enorme. Quindi, ciò che stiamo facendo qui è usare un trucco astuto che Lokad non ha inventato. Stiamo sostituendo una risorsa grezza, ovvero la capacità di calcolo, con un’altra, ossia la memoria e lo storage. Abbiamo le risorse computazionali fondamentali: capacità di calcolo, memoria (sia volatile che persistente) e banda. Queste sono le risorse fondamentali per cui si paga quando si acquistano risorse su una piattaforma di cloud computing. In realtà, è possibile sostituire una risorsa con un’altra, e l’obiettivo è ottenere il massimo rendimento per il vostro investimento.
Quando le persone dicono che dovreste utilizzare il calcolo in-memory, direi che è una sciocchezza. Se si parla di calcolo in-memory, significa che si sta ponendo l’accento sulla progettazione di una risorsa a scapito di tutte le altre. Ma no, ci sono dei compromessi, e la cosa interessante è che si può avere un linguaggio di programmazione e un ambiente che rendono questi compromessi e queste prospettive più facili da implementare. In un normale linguaggio di programmazione a uso generale, è possibile farlo, ma bisogna farlo manualmente. Questo significa che la persona che lo fa deve essere un ingegnere software professionista. Un Supply Chain Scientist non eseguirà queste operazioni a basso livello con le risorse computazionali fondamentali della vostra piattaforma. Questo deve essere progettato a livello del linguaggio di programmazione stesso.
Ora, parliamo di programmazione probabilistica. Nella seconda lezione in cui ho presentato la visione per la quantitative supply chain, il mio primo requisito era che dobbiamo considerare tutti i possibili futuri. La risposta tecnica a questo requisito è previsione probabilistica. Vuoi affrontare futuri in cui sono presenti delle probabilità. Tutti i futuri sono possibili, ma non sono tutti egualmente probabili. È necessario disporre di un’algebra che consenta di eseguire calcoli con l’incertezza. Una delle mie grandi critiche a Excel è che è estremamente difficile rappresentare l’incertezza in un foglio di calcolo, indipendentemente dal fatto che si tratti di Excel o di una variante moderna basata sul cloud. In un foglio di calcolo, è molto difficile rappresentare l’incertezza perché serve qualcosa di migliore dei semplici numeri.
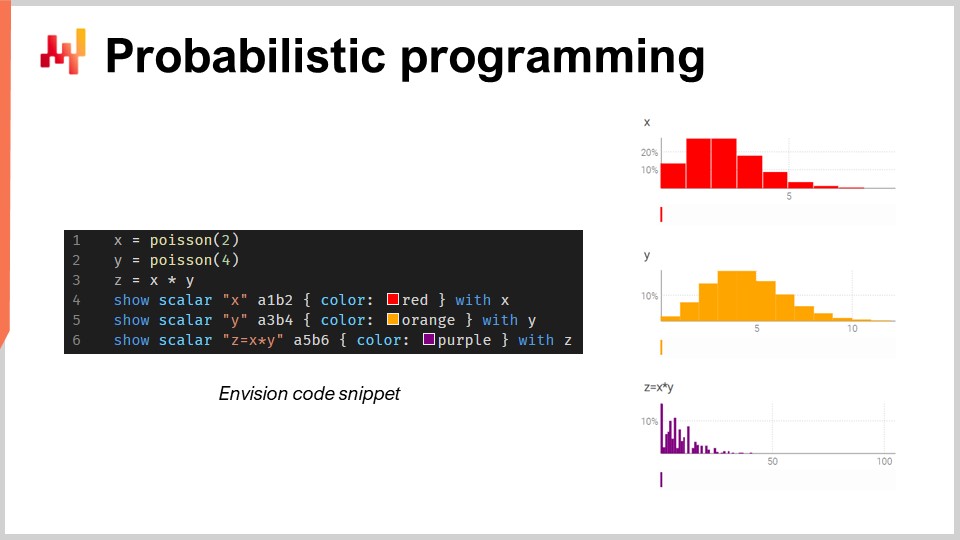
In questo piccolo frammento, sto illustrando l’algebra delle variabili casuali, che è una caratteristica nativa di Envision. Nella prima riga, genero una distribuzione di Poisson, discreta, con una media di 2, e la assegno alla variabile X. Poi, faccio lo stesso per un’altra distribuzione di Poisson, Y. Successivamente, calcolo Z come il prodotto di X per Y. Questa operazione, la moltiplicazione di variabili casuali, può sembrare molto bizzarra. Perché avreste bisogno di una cosa del genere da una prospettiva di supply chain?
Supponiamo che tu sia nel mercato aftermarket automobilistico e che stia vendendo pastiglie dei freni. Le persone non acquistano le pastiglie dei freni unitariamente; ne comprano due o quattro. Quindi, la domanda è: se vuoi fare una previsione, potresti voler prevedere le probabilità che i clienti si presentino effettivamente per acquistare un certo tipo di pastiglie dei freni. Questa sarà la tua prima variabile casuale, che ti darà la probabilità di osservare zero unità di domanda, una unità di domanda, due, tre, quattro, ecc. per le pastiglie dei freni. Poi avrai un’altra distribuzione di probabilità che rappresenta se le persone acquisteranno due o quattro pastiglie dei freni. Forse sarà 50-50, o forse sarà il 10 percento che acquista due e il 90 percento che acquista quattro. La questione è che hai questi due aspetti, e se vuoi conoscere il consumo totale effettivo delle pastiglie dei freni, devi moltiplicare la probabilità che un cliente si presenti per queste pastiglie per la distribuzione di probabilità relativa all’acquisto di due o quattro. Così, è necessario effettuare questa moltiplicazione di queste due quantità incerte.
Qui, sto assumendo che le due variabili casuali siano indipendenti. A proposito, questa moltiplicazione di variabili casuali è nota in matematica come convoluzione discreta. Puoi vedere nello screenshot il dashboard generato da Envision. Nelle prime tre righe, sto eseguendo questo calcolo dell’algebra casuale, e poi nelle righe quattro, cinque e sei, sto mostrando questi risultati sulla pagina web, nel dashboard generato dallo script. Sto tracciando, ad esempio, A1, B2, proprio come in una griglia di Excel. I dashboard di Lokad sono organizzati in modo simile alle griglie di Excel, con posizioni aventi colonne B, C, ecc., e righe 1, 2, 3, 4, 5.
Puoi notare che la convoluzione discreta, Z, presenta un pattern molto bizzarro ed estremamente spigoloso che si riscontra comunemente nelle supply chain quando le persone possono acquistare confezioni, lotti o multipli. In questo tipo di situazione, solitamente è meglio scomporre le fonti degli eventi moltiplicativi associati al lotto o alla confezione. Hai bisogno di un linguaggio di programmazione che metta a disposizione queste capacità a portata di mano, come cittadini di prima classe. Questo è esattamente ciò di cui tratta la programmazione probabilistica, ed è così che l’abbiamo implementata in Envision.

Ora, discutiamo di differentiable programming. Devo fare un’avvertenza qui: non mi aspetto che il pubblico capisca davvero cosa stia succedendo, e me ne scuso. Non è che la vostra intelligenza manchi; è solo che questo argomento merita un’intera serie di lezioni. Infatti, se guardate il programma delle prossime lezioni, c’è un’intera serie dedicata alla differentiable programming. Andrò super veloce, e sarà abbastanza criptico, quindi mi scuso in anticipo.
Procediamo con il problema della supply chain di interesse qui, che riguarda la cannibalizzazione e la sostituzione. Questi problemi sono molto interessanti, e sono probabilmente il punto in cui le previsioni time series — che sono onnipresenti — falliscono in maniera brutale. Perché? Perché spesso abbiamo clienti o potenziali clienti che vengono da me e chiedono se possiamo fare, ad esempio, previsioni a 13 settimane in avanti per alcuni articoli come gli zaini. Direi di sì, possiamo, ma ovviamente, se prendiamo uno zaino e vogliamo prevedere la domanda per questo prodotto, dipende massicciamente da cosa fate con gli altri zaini. Se avete un solo zaino, allora forse concentrerete tutta la domanda per gli zaini su questo unico prodotto. Se ne introducete 10 varianti diverse, ovviamente ci sarà molta cannibalizzazione. Non moltiplicherete l’ammontare totale delle vendite per un fattore di 10 solo perché avete moltiplicato il numero di referenze per 10. Quindi, ovviamente, si verifica cannibalizzazione e sostituzione. Questi fenomeni sono prevalenti nelle supply chain.
Come si analizza la cannibalizzazione o la sostituzione? Il modo in cui lo facciamo a Lokad, e non pretendo che sia l’unico metodo, ma è sicuramente un approccio che funziona, è tipicamente osservare il grafo che connette i clienti e i prodotti. Perché? Perché la cannibalizzazione si verifica quando i prodotti competono tra loro per gli stessi clienti. La cannibalizzazione è letteralmente il riflesso del fatto che un cliente ha un bisogno, ma possiede delle preferenze e sceglierà un solo prodotto tra l’insieme di prodotti che rispecchiano la sua affinità. Questa è l’essenza della cannibalizzazione.
Se vuoi analizzare questo aspetto, non devi esaminare le serie temporali delle vendite, perché quelle informazioni non vengono catturate in primo luogo. Vuoi analizzare il grafo che connette le transazioni storiche tra clienti e prodotti. Si scopre, infatti, che nella maggior parte delle imprese questi dati sono facilmente disponibili. Per l’e-commerce, è scontato. Per ogni unità venduta, conosci il cliente. Nel B2B è la stessa cosa. Anche nel B2C nel retail, la maggior parte delle volte le catene di vendita al dettaglio al giorno d’oggi hanno programmi di loyalty in cui conoscono una percentuale a doppia cifra dei clienti che si presentano con le loro tessere, così sai chi compra cosa. Non per il 100% del traffico, ma non serve. Se hai il 10% o più delle transazioni storiche in cui conosci la coppia cliente-prodotto, è sufficiente per questo tipo di analisi.
In questo frammento relativamente breve, andrò a dettagliare un’analisi di affinità tra clienti e prodotti. Questo è letteralmente il passaggio fondamentale da compiere per realizzare qualsiasi tipo di analisi di cannibalizzazione. Diamo un’occhiata a ciò che sta accadendo in questo codice.
Dalle righe una a cinque, è tutto molto banale; sto semplicemente leggendo un file flat che contiene una cronologia delle transazioni. Sto leggendo un file CSV che ha quattro colonne: data, prodotto, cliente e quantità. Qualcosa di molto basilare. Non sto nemmeno usando tutte quelle colonne, ma è solo per rendere l’esempio un po’ più concreto. Nella cronologia delle transazioni, presumo che i clienti siano noti per tutte quelle transazioni. Quindi, è molto banale; sto semplicemente leggendo dati da una tabella.
Poi, alle righe sette e otto, sto semplicemente creando la tabella per i prodotti e la tabella per i clienti. In un vero ambiente di produzione, di solito non creerei queste tabelle; le leggerei da altri file flat altrove. Volevo mantenere l’esempio super semplice, quindi sto semplicemente estraendo una tabella di prodotti dai prodotti che ho osservato nella cronologia delle transazioni, e faccio lo stesso per i clienti. Vedi, è solo un trucco per mantenerlo super semplice.
Ora, le righe 10, 11 e 12 riguardano gli spazi latini, e questo diventerà un po’ più oscuro. Prima di tutto, alla riga 10, sto creando una tabella con 64 righe. La tabella non contiene nulla; è definita soltanto dal fatto che ha 64 righe, e basta. Quindi è come un segnaposto, una tabella banale con molte righe e nessuna colonna. Non è molto utile così com’è. Poi, “P” è fondamentalmente un prodotto cartesiano, un’operazione matematica che genera tutte le coppie. È una tabella in cui hai una riga per ogni riga dei prodotti e per ogni riga della tabella “L”. Quindi, questa tabella “P” ha 64 righe in più rispetto alla tabella dei prodotti, e sto facendo la stessa cosa per i clienti. Sto semplicemente gonfiando quelle tabelle attraverso questa dimensione extra, che è proprio questa tabella “L”.
Questo costituirà il mio supporto per gli spazi latini, che è esattamente ciò che imparerò. Quello che voglio apprendere è che, per ogni prodotto, esista uno spazio latino rappresentato da un vettore di 64 valori, e per ogni cliente, uno spazio latino di 64 valori. Se voglio conoscere l’affinità tra un cliente e un prodotto, desidero semplicemente poter eseguire il dot product tra i due. Il dot product è semplicemente la moltiplicazione punto per punto di tutti i termini di quei due vettori, seguita da una somma. Può sembrare molto tecnico, ma è solo moltiplicazione punto per punto più somma – questo è il dot product.
Questi spazi latini sono solo un gergo sofisticato per creare uno spazio con parametri un po’ inventati, che voglio semplicemente apprendere. Tutta la magia della differentiable programming avviene in sole cinque righe, dalla riga 14 alla 18. Ho una parola chiave, “autodiff”, e “transactions”, che indica che questa è una tabella di interesse, una tabella di osservazioni. Elaborerò questa tabella riga per riga per eseguire il mio processo di apprendimento. In questo blocco, sto dichiarando un insieme di parametri. I parametri sono le cose che vuoi apprendere, come dei numeri, ma non conosci ancora i loro valori. Queste cose saranno semplicemente inizializzate a caso, con numeri casuali.
Introduco “X”, “X*” e “Y”. Non entrerò nei dettagli su cosa faccia esattamente “X*”; forse nelle domande. Sto restituendo un’espressione che rappresenta la mia funzione di perdita, ed essa è la somma. L’idea del collaborative filtering o della decomposizione matriciale è semplicemente che vuoi apprendere spazi latini che si adattino a tutti i collegamenti nel tuo grafo bipartito. So che è un po’ tecnico, ma quello che stiamo facendo è letteralmente molto semplice, in termini di supply chain. Stiamo apprendendo l’affinità tra prodotti e clienti.
So che può sembrare probabilmente super opaco, ma restate con me, e ci saranno altre lezioni in cui vi darò un’introduzione più approfondita a questo tema. L’intera operazione è fatta in cinque righe, ed è completamente notevole. Quando dico cinque righe, non sto imbrogliando dicendo: “Guardate, sono solo cinque righe, ma in realtà sto chiamando una libreria di terze parti di complessità gigantesca in cui nascondo tutta l’intelligenza.” No, no, no. Qui, in questo esempio, non c’è letteralmente alcuna magia del machine learning oltre le due parole chiave “autodiff” e “params”. “Autodiff” viene usato per definire un blocco in cui si svolgerà la differentiable programming, e, a proposito, questo è un blocco in cui posso programmare qualsiasi cosa, quindi letteralmente posso iniettare il nostro programma. Poi, ho “params” per dichiarare i miei problemi, ed ecco qua. Quindi, vedete, non c’è alcuna magia opaca in corso; non c’è una libreria da un milione di righe in background che fa tutto il lavoro per voi. Tutto ciò che dovete sapere è letteralmente presente su questo schermo, e questa è la differenza tra un paradigma di programmazione e una libreria. Il paradigma di programmazione vi offre accesso a capacità apparentemente incredibilmente sofisticate, come svolgere un’analisi di cannibalizzazione con solo poche righe di codice, senza ricorrere a massicce librerie di terze parti che nascondono la complessità. Esso trascende il problema, rendendolo molto più semplice, così potete avere qualcosa che sembra super complicato risolto in poche righe.
Adesso, alcune parole su come funziona la differentiable programming. Ci sono due intuizioni. Una è la automatic differentiation. Per chi di voi ha avuto il privilegio di una formazione ingegneristica, ha visto due modi per calcolare le derivate. C’è la derivata simbolica, per esempio, se hai x al quadrato, calcoli la derivata rispetto a x, e ti dà 2x. Quella è una derivata simbolica. Poi c’è la derivata numerica, quindi se hai una funzione f(x) che vuoi differenziare, essa sarà f’(x) ≈ (f(x + ε) - f(x))/ε. Questa è la derivazione numerica. Entrambe non sono adatte a ciò che stiamo cercando di fare qui. La derivazione simbolica presenta problemi di complessità, dato che la tua derivata potrebbe essere un programma molto più complesso del programma originale. La derivazione numerica, invece, è numericamente instabile, quindi avrai molti problemi in termini di stabilità numerica.
La automatic differentiation è un’idea fantastica che risale agli anni ‘70 ed è stata riscoperta dal mondo intero nell’ultimo decennio. È l’idea che puoi calcolare la derivata di un programma arbitrario, il che è a dir poco sbalorditivo. Ancora più sorprendente, il programma che rappresenta la derivata ha la stessa complessità computazionale del programma originale, il che è stupefacente. La differentiable programming è semplicemente una combinazione di automatic differentiation e dei parametri che si vuole apprendere.
Quindi, come si impara? Quando hai la derivata, significa che puoi propagare all’indietro i gradienti, e con lo stochastic gradient descent puoi apportare piccoli aggiustamenti ai valori dei parametri. Modificando questi parametri, convergerai in maniera incrementale, attraverso numerose iterazioni dello stochastic gradient descent, a parametri che abbiano senso e raggiungano ciò che vuoi apprendere o ottimizzare.
La differentiable programming può essere usata per problemi di apprendimento, come quello che sto illustrando, in cui voglio apprendere l’affinità tra i miei clienti e i miei prodotti. Può anche essere impiegata per problemi di ottimizzazione numerica, come ottimizzare elementi sotto vincoli, ed è un paradigma molto scalabile. Come si può vedere, questo aspetto è stato elevato a cittadino di prima classe in Envision. A proposito, ci sono ancora alcune cose in corso in termini di sintassi di Envision, quindi non aspettatevi esattamente quelle funzionalità ancora; stiamo ancora affinando alcuni aspetti. Ma l’essenza è lì. Non entrerò nei dettagli minuti delle poche cose che sono ancora in evoluzione.

Passiamo ora a un altro problema rilevante per la prontezza produttiva del tuo ambiente. Tipicamente, nell’ottimizzazione della supply chain, ci si imbatte in Heisenbug. Cos’è un Heisenbug? È un tipo di bug frustrante in cui si esegue un’ottimizzazione che produce risultati spazzatura. Ad esempio, hai eseguito un calcolo batch per il rifornimento dell’inventario durante la notte, e al mattino scopri che alcuni di quei risultati erano insensati, causando errori costosi. Non vuoi che il problema si ripresenti, quindi riesegui il processo. Tuttavia, quando lo riesegui, il problema è sparito. Non riesci a riprodurre l’errore, e l’Heisenbug non si manifesta.
Può sembrare un caso limite strano, ma nei primi anni di Lokad abbiamo affrontato questi problemi ripetutamente. Ho visto molte iniziative nella supply chain, specialmente nel campo della data science, fallire a causa di Heisenbug irrisolti. I bug si verificavano in produzione, si cercava di riprodurre i problemi in locale ma senza successo, e quindi i problemi non venivano mai risolti. Dopo un paio di mesi in modalità panico, l’intero progetto veniva solitamente chiuso silenziosamente, e le persone tornavano a usare fogli di calcolo Excel.
Se vuoi ottenere una replicabilità completa della tua logica, devi versionare sia il codice che i dati. La maggior parte delle persone in sala, che sono ingegneri del software o data scientist, potrebbero essere familiari con l’idea di versionare il codice. Tuttavia, vuoi anche versionare tutti i dati, così che quando il tuo programma viene eseguito tu sappia esattamente quale versione di codice e di dati viene utilizzata. Potresti non essere in grado di replicare il problema il giorno successivo perché i dati sono cambiati a causa di nuove transazioni o altri fattori, così le condizioni che hanno innescato il bug in origine non sono più presenti.
Vuoi assicurarti che il tuo ambiente di programmazione possa replicare esattamente la logica e i dati così come erano in produzione in un determinato momento. Ciò richiede il versioning completo di tutto. Ancora una volta, il linguaggio di programmazione e lo stack devono cooperare per rendere ciò possibile. È realizzabile senza che il paradigma di programmazione sia un cittadino di prima classe del tuo stack, ma in tal caso il Supply Chain Scientist deve essere estremamente cauto riguardo a tutto ciò che fa e al modo in cui programma. Altrimenti, non sarà in grado di replicare i propri risultati. Questo esercita un’enorme pressione sulle spalle dei Supply Chain Scientists, che sono già sotto notevole pressione dalla supply chain stessa. Non vuoi che questi professionisti debbano affrontare una complessità accidentale, come il non riuscire a replicare i propri risultati. Da Lokad, chiamiamo questo “time machine”, dove puoi replicare tutto in qualsiasi punto del passato.
Attenzione, non si tratta solo di replicare ciò che è successo la scorsa notte. A volte, scopri un errore molto tempo dopo. Ad esempio, se effettui un ordine di acquisto a un fornitore che ha un tempo di consegna di tre mesi, potresti scoprire, tre mesi dopo, che l’ordine era insensato. Devi tornare indietro nel tempo di tre mesi, al punto in cui hai generato questo finto ordine di acquisto, per capire qual era il problema. Non si tratta solo di versionare le ultime poche ore di lavoro; si tratta letteralmente di avere una cronologia completa dell’ultimo anno di esecuzione.

Un’altra preoccupazione è l’aumento dei ransomware e degli attacchi informatici nelle supply chain. Questi attacchi sono estremamente dirompenti e possono essere molto costosi. Quando si implementano soluzioni basate sul software, è necessario considerare se si sta rendendo la propria azienda e la supply chain più vulnerabili agli attacchi informatici e ai rischi. Da questo punto di vista, Excel e Python non sono ideali. Questi componenti sono programmabili, il che significa che possono comportare numerose vulnerabilità di sicurezza.
Se hai un team di data scientists o Supply Chain Scientist che si occupa di problemi della supply chain, non possono permettersi il processo attento e iterativo di revisione paritaria del codice, comune nell’industria del software. Se una tariffa cambia da un giorno all’altro o un magazzino viene allagato, hai bisogno di una risposta rapida. Non puoi passare settimane a produrre specifiche del codice, revisioni e così via. Il problema è che stai dando capacità di programmazione a persone che, di default, hanno il potenziale di arrecare danni all’azienda in modo accidentale. La situazione può peggiorare se c’è un dipendente malintenzionato, ma anche escludendo questo aspetto, rimane il rischio che qualcuno esponga accidentalmente una parte interna dei sistemi IT. Ricorda, i sistemi di ottimizzazione della supply chain, per definizione, hanno accesso a una grande quantità di dati in tutta l’azienda. Questi dati non sono solo un asset, ma anche una liability.
Quello che desideri è un paradigma di programmazione che promuova una programmazione sicura. Vuoi un linguaggio di programmazione in cui intere classi di operazioni non siano permesse. Per esempio, perché dovresti avere un linguaggio di programmazione in grado di eseguire system calls per scopi di ottimizzazione della supply chain? Python può fare system calls, così come Excel. Ma perché vorresti avere un sistema programmabile con tali capacità in primo luogo? È come comprarsi una pistola per spararsi al piede.
Vuoi qualcosa in cui intere classi o funzionalità siano assenti perché non sono necessarie per l’ottimizzazione della supply chain. Se queste funzionalità sono presenti, diventano una liability enorme. Se introduci capacità programmabili senza gli strumenti che impongono per design una programmazione sicura, aumenti il rischio di attacchi informatici e ransomware, peggiorando la situazione.
Certo, è sempre possibile compensare raddoppiando il team di cybersecurity, ma ciò è molto costoso e non ideale quando si affrontano situazioni urgenti nella supply chain. Devi agire rapidamente e in sicurezza, senza il tempo per i consueti processi, revisioni e approvazioni. Vuoi anche una programmazione sicura che elimini problemi banali come eccezioni di riferimento nullo, errori di memoria esaurita, loop off-by-one ed effetti collaterali.

In conclusione, gli strumenti contano. C’è un detto: “Non portare una spada a uno scontro a fuoco.” Hai bisogno degli strumenti e dei paradigmi di programmazione adeguati, non solo di quelli che hai imparato all’università. Hai bisogno di qualcosa di professionale e di livello produttivo per soddisfare le esigenze della tua supply chain. Anche se potresti ottenere alcuni risultati con strumenti scadenti, non saranno eccellenti. Un musicista fantastico può fare musica anche con un cucchiaio, ma con uno strumento adeguato può fare molto di più.

Ora, passiamo alle domande. Tieni presente che c’è un ritardo di circa 20 secondi, quindi c’è una latenza nello stream tra il video che stai vedendo e il momento in cui leggo le tue domande.
Domanda: Che dire della programmazione dinamica in termini di ricerca operativa?
La programmazione dinamica, nonostante il nome, non è un paradigma di programmazione. È piuttosto una tecnica algoritmica. L’idea è che, se vuoi eseguire un compito algoritmico o risolvere un determinato problema, ripeterai molto frequentemente la stessa sotto-operazione. La programmazione dinamica è un caso specifico del compromesso spazio-tempo di cui ho parlato prima, in cui investi un po’ di più in memoria per risparmiare tempo di calcolo. Fu una delle prime tecniche algoritmiche, risalente agli anni ‘60 e ‘70. È una buona tecnica, ma il nome è un po’ sfortunato perché non c’è nulla di veramente dinamico in essa, e non riguarda veramente la programmazione. Quindi, per me, nonostante il nome, non si qualifica come paradigma di programmazione; è più una tecnica algoritmica specifica.
Domanda: Johannes, potresti gentilmente indicarci alcuni libri di riferimento che ogni buon ingegnere della supply chain dovrebbe avere? Purtroppo sono nuovo nel campo e il mio attuale focus è sulla scienza dei dati e l’ingegneria dei sistemi.
Ho un’opinione molto mista sulla letteratura esistente. Nella mia prima lezione, ho presentato due libri che ritengo siano il culmine degli studi accademici relativi alla supply chain. Se vuoi leggere due libri, puoi farlo. Tuttavia, ho costantemente avuto problemi con i libri che ho letto finora. Fondamentalmente, ci sono persone che presentano raccolte di ricette numeriche giocattolo per supply chain idealizzate, e credo che questi libri non affrontino la supply chain dal giusto punto di vista, mancando completamente il fatto che si tratta di un problema complesso. Esiste un vasto corpus di letteratura molto tecnica, con equazioni, algoritmi, teoremi e dimostrazioni, ma a mio avviso perde completamente il nocciolo della questione.
Poi, ci sono libri di supply chain management di un altro stile, più incentrati sul consulente. Puoi riconoscere facilmente questi libri perché usano analogie sportive ogni due pagine. Questi testi contengono ogni sorta di diagrammi semplicistici, come varianti 2x2 dei diagrammi SWOT (Strengths, Weaknesses, Opportunities, Threats), che considero metodi di ragionamento di bassa qualità. Il problema con questi libri è che tendono a comprendere meglio che la supply chain è un’impresa complessa. Capiscono molto meglio che si tratta di un gioco giocato da persone, in cui possono accadere cose bizzarre, e che puoi essere astuto nei metodi adottati. Gli do credito per questo. Il problema con quei libri, tipicamente scritti da consulenti o professori di scuole di management, è che non sono molto applicabili. Il messaggio si riduce a “diventa un leader migliore”, “sii più intelligente”, “abbi più energia”, e per me questo non è applicabile. Non ti fornisce elementi che puoi trasformare in qualcosa di altamente prezioso, come può fare il software.
Quindi, torno alla prima lezione: leggete i due libri se volete, ma non sono sicuro che ne varrà il tempo. È utile sapere cosa hanno scritto gli altri. Dal lato dei consulenti nella letteratura, il mio preferito è probabilmente il lavoro di Katana, che non ho elencato nella prima lezione. Non è tutto negativo; alcune persone hanno più talento, anche se seguono uno stile più da consulente. Potete dare un’occhiata al lavoro di Katana; ha un libro sulle supply chain dinamiche. Elencherò il libro nelle referenze.
Domanda: Come si usa la parallelizzazione quando si affrontano decisioni di cannibalizzazione o assortimento, dove il problema non è facilmente parallelizzabile?
Perché non è facilmente parallelizzabile? Il gradient descent stocastico è abbastanza banale da parallelizzare. Abbiamo passi di gradient descent stocastici che possono essere eseguiti in ordine casuale, e puoi avere più passi contemporaneamente. Quindi, credo che qualsiasi procedimento guidato dal gradient descent stocastico sia piuttosto banale da parallelizzare.
Nel trattare la cannibalizzazione, la parte più difficile è affrontare un altro tipo di parallelizzazione, ovvero l’ordine di introduzione. Se introduco prima questo prodotto e faccio una previsione, poi prendo un altro prodotto, l’insieme cambia. La risposta è che devi avere un modo per affrontare frontalmente l’intero panorama. Non si dice: “Prima introduco questo prodotto e faccio la previsione; poi introduco un altro prodotto e rifaccio la previsione, modificando la prima.” Lo fai frontalmente, tutti insieme, contemporaneamente. Hai bisogno di ulteriori paradigmi di programmazione. I paradigmi di programmazione che ho introdotto oggi possono contribuire notevolmente in tal senso.
Per quanto riguarda le decisioni sull’assortimento, questo tipo di problemi non presenta grandi difficoltà per la parallelizzazione. Lo stesso vale se hai una rete retail mondiale e vuoi ottimizzare l’assortimento per tutti i tuoi negozi. Puoi effettuare calcoli per tutti i negozi in parallelo. Non vuoi farlo in sequenza, ottimizzando l’assortimento di un negozio per poi passare al successivo. Questo è il modo sbagliato di procedere, ma puoi ottimizzare la rete in parallelo, propagare tutte le informazioni e poi ripetere. Esistono diverse tecniche, e gli strumenti possono aiutarti notevolmente a farlo in maniera molto più semplice.
Domanda: State utilizzando un approccio basato su database a grafo?
No, non nel senso tecnico e canonico. Esistono molti database a grafo sul mercato che sono di grande interesse. Quello che usiamo internamente in Lokad è un’integrazione verticale completa tramite uno stack unificato e monolitico di compilatori, che elimina completamente tutti gli elementi tradizionali che troveresti in uno stack classico. È così che otteniamo prestazioni molto elevate, in termini di potenza di calcolo, molto vicine al metallo. Non perché siamo programmatori straordinariamente intelligenti, ma semplicemente perché abbiamo eliminato praticamente tutti gli strati che tradizionalmente esistono. Lokad non utilizza letteralmente alcun database. Abbiamo un compilatore che si occupa di tutto, fino all’organizzazione delle strutture dati per la persistenza. È un po’ strano, ma è molto più efficiente farlo in questo modo, e così puoi sfruttare al meglio il fatto di compilare uno script per una flotta di macchine sul cloud. La tua piattaforma di destinazione, in termini di hardware, non è una singola macchina; è una flotta di macchine.
Domanda: Qual è la tua opinione su Power BI, che esegue anche codici Python e algoritmi correlati come gradient descent, greedy, ecc.?
Il problema che ho con tutto ciò che riguarda la business intelligence, Power BI in primis, è che adotta un paradigma che ritengo inadeguato per la supply chain. Vedi tutti i problemi come un ipercubo, in cui hai dimensioni che vengono solo sezionate e analizzate. Al centro c’è un problema di espressività, che risulta molto limitato. Quando finisci per usare Power BI con Python nel mezzo, hai bisogno di Python perché l’espressività offerta dall’ipercubo è molto scarsa. Per ripristinare l’espressività, aggiungi Python nel mezzo. Tuttavia, ricorda quanto ho detto nella domanda precedente riguardo a quegli strati: la maledizione del moderno enterprise software è che ci sono troppi livelli. Ogni singolo strato che aggiungi introdurrà inefficienze e bug. Se usi Power BI insieme a Python, avrai troppi livelli. Quindi, hai Power BI che si appoggia su altri sistemi, il che significa che hai già più sistemi prima di Power BI. Poi c’è Power BI sopra, e sopra Power BI c’è Python. Ma Python agisce da solo? No, è probabile che utilizzi librerie Python, come Pandas o NumPy. Quindi, si accumulano livelli in Python, finendo per avere decine di strati. Puoi avere bug in uno qualsiasi di questi strati, per cui la situazione diventerà davvero un incubo.
Non sono un sostenitore di quelle soluzioni in cui finisci per avere un numero massiccio di stack. C’è questa battuta che in C++ puoi sempre risolvere qualsiasi problema aggiungendo un ulteriore strato di indirezione, compreso il problema di avere troppi livelli di indirezione. Ovviamente, questa affermazione è un po’ insensata, ma sono profondamente in disaccordo con l’approccio in cui le persone creano un prodotto con un design di base inadeguato e, invece di affrontare il problema frontalmente, finiscono per sovraccaricare tutto sopra, mentre le fondamenta sono fragili. Questo non è il modo giusto di procedere, e porterà a una produttività scarsa, continue battaglie con bug che non risolverai mai e, in termini di manutenibilità, è semplicemente una ricetta per un incubo.
Domanda: Come possono essere integrati i risultati di un’analisi di collaborative filtering nell’algoritmo di previsione della domanda per ciascun prodotto, ad esempio per gli zaini?
Mi dispiace, ma tratterò questo argomento nella prossima lezione. La risposta breve è che non vuoi integrarlo in un algoritmo di previsione esistente. Vuoi qualcosa di molto più nativamente integrato. Non lo fai e poi torni ai vecchi metodi di previsione; invece, abbandoni il vecchio approccio e adotti qualcosa di radicalmente diverso che ne sfrutti il potenziale. Ma ne parlerò in una lezione successiva. Sarebbe troppo per oggi.
Credo che sia tutto per questa lezione. Grazie mille a tutti per aver partecipato. La prossima lezione si terrà mercoledì 6 gennaio, alla stessa ora e nello stesso giorno della settimana. Mi prenderò qualche vacanza di Natale, quindi auguro a tutti un felice Natale e un felice anno nuovo. Continueremo la nostra serie di lezioni l’anno prossimo. Grazie mille.


