00:12 Einführung
02:23 Falsifizierbarkeit
08:25 Die Geschichte bisher
09:38 Modellierungsansätze: Mathematische Optimierung (MO)
11:25 Überblick über die mathematische Optimierung
14:04 Mainstream-Supply-Chain-Theorie (Zusammenfassung)
19:56 Ausmaß der Perspektive der mathematischen Optimierung
23:29 Ablehnungsheuristiken
30:54 Der Tag danach
32:43 Wiedergutmachende Eigenschaften?
36:13 Modellierungsansätze: Experimentelle Optimierung (EO)
38:39 Überblick über die experimentelle Optimierung
42:54 Ursachen für Verrücktheit
51:28 Identifizieren verrückter Entscheidungen
58:51 Verbesserung der Instrumentierung
01:01:13 Verbessern und wiederholen
01:04:40 Die Praxis der EO
01:11:16 Zusammenfassung
01:14:14 Fazit
01:16:39 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Weit entfernt von der naiven kartesischen Perspektive, bei der Optimierung lediglich darum geht, einen Optimierer für eine gegebene Score-Funktion auszurollen, erfordert die Supply Chain einen viel iterativeren Prozess. Jede Iteration wird genutzt, um “verrückte” Entscheidungen zu identifizieren, die untersucht werden sollen. Die Ursache liegt häufig in unangemessenen wirtschaftlichen Anreizen, die in Bezug auf ihre unbeabsichtigten Folgen neu bewertet werden müssen. Die Iterationen enden, wenn die numerischen Rezepte keine verrückten Ergebnisse mehr produzieren.
Vollständiges Transkript

Hallo zusammen, willkommen zu dieser Reihe von Supply-Chain-Vorlesungen. Ich bin Joannes Vermorel und heute werde ich “Experimentelle Optimierung” präsentieren, was als Optimierung von Supply Chains über eine Reihe von Experimenten verstanden werden sollte. Für diejenigen von Ihnen, die die Vorlesung live verfolgen, können Sie jederzeit über den YouTube-Chat Fragen stellen. Während der Vorlesung werde ich den Chat jedoch nicht lesen; ich werde am Ende der Vorlesung auf den Chat zurückkommen, um die dort gefundenen Fragen zu beantworten.
Unser Ziel heute ist die quantitative Verbesserung von Supply Chains, und wir möchten das auf kontrollierte, zuverlässige und messbare Weise erreichen. Wir brauchen so etwas wie eine wissenschaftliche Methode, und eine der wichtigsten Eigenschaften der modernen Wissenschaft ist, dass sie tief in der Realität oder genauer gesagt im Experiment verwurzelt ist. In einer früheren Vorlesung habe ich kurz die Idee von Supply-Chain-Experimenten diskutiert und erwähnt, dass sie auf den ersten Blick langwierig und kostspielig erscheinen. Die Länge und die Kosten könnten sogar den eigentlichen Zweck der Experimente zunichte machen, bis zu dem Punkt, an dem es möglicherweise nicht einmal lohnenswert ist. Aber die Herausforderung besteht darin, dass wir eine bessere Art und Weise brauchen, Experimente anzugehen, und genau darum geht es bei der experimentellen Optimierung.
Experimentelle Optimierung ist im Wesentlichen eine Praxis, die vor etwa einem Jahrzehnt bei Lokad entstanden ist. Es bietet eine Möglichkeit, Supply-Chain-Experimente auf eine Art und Weise durchzuführen, die tatsächlich funktioniert, die bequem und profitabel durchgeführt werden kann, und das wird das spezifische Thema der heutigen Vorlesung sein.

Aber zuerst wollen wir für einen Moment auf diese sehr Vorstellung von der Natur der Wissenschaft und ihrer Beziehung zur Realität zurückkommen.
Es gibt ein Buch, “Die Logik der Forschung”, das 1934 mit Karl Popper als Autor veröffentlicht wurde und als absoluter Meilenstein in der Geschichte der Wissenschaft gilt. Es schlug eine völlig erstaunliche Idee vor, nämlich die Falsifizierbarkeit. Um zu verstehen, wie diese Idee der Falsifizierbarkeit entstanden ist und worum es geht, ist es sehr interessant, die Reise von Karl Popper selbst zu betrachten.
Sie sehen, in seiner Jugend stand Popper mehreren Kreisen von Intellektuellen nahe. Unter diesen Kreisen gab es zwei von besonderem Interesse: einen Kreis von Sozialökonomen, die in der Regel Anhänger der marxistischen Theorie waren, und einen Kreis von Physikern, zu denen vor allem Albert Einstein gehörte. Popper beobachtete, dass die Sozialökonomen eine Theorie mit der Absicht hatten, eine wissenschaftliche Theorie zu haben, die die Entwicklung der Gesellschaft und ihrer Wirtschaft erklären konnte. Diese marxistische Theorie machte tatsächlich Vorhersagen darüber, was passieren würde. Die Theorie wies darauf hin, dass es eine Revolution geben würde und dass die Revolution im Land stattfinden würde, das am meisten industrialisiert war und wo die größte Anzahl von Fabrikarbeitern zu finden war.
Es stellte sich heraus, dass die Revolution tatsächlich 1917 in Russland stattfand, dem am wenigsten industrialisierten Land Europas, was vollkommen gegen das war, was die Theorie vorhersagte. Aus Poppers Perspektive gab es eine wissenschaftliche Theorie, die Vorhersagen machte, und dann geschahen Ereignisse, die der Theorie widersprachen. Was er erwartet hatte, war, dass die Theorie widerlegt würde und die Menschen zu etwas anderem übergehen würden. Stattdessen sah er etwas ganz anderes. Die Befürworter der marxistischen Theorie modifizierten die Theorie, um sie an die Ereignisse anzupassen, wie sie sich entwickelten. Dadurch machten sie die Theorie allmählich immun gegen die Realität. Was als wissenschaftliche Theorie begann, wurde allmählich zu etwas völlig Immunem und nichts, was in der realen Welt passieren könnte, würde mehr gegen die Theorie sprechen.
Dies stand im krassen Gegensatz zu dem, was in den Kreisen der Physiker geschah, wo Popper beobachtete, wie Menschen wie Albert Einstein Theorien entwickelten und dann große Anstrengungen unternahmen, um Experimente zu denken, die ihre eigenen Theorien widerlegen könnten. Die Physiker gaben nicht all ihre Energie darauf aus, die Theorien zu beweisen, sondern darauf, sie zu widerlegen. Popper überlegte, welcher Ansatz der bessere Weg sei, Wissenschaft zu betreiben, und entwickelte das Konzept der Falsifizierbarkeit.
Popper schlug vor, dass Falsifizierbarkeit ein Kriterium ist, um festzustellen, ob eine Theorie als wissenschaftlich angesehen werden kann. Er sagte, dass eine Theorie wissenschaftlich ist, wenn sie zwei Kriterien erfüllt. Das erste ist, dass die Theorie mit Bezug auf die Realität einem Risiko ausgesetzt sein sollte. Die Theorie muss so ausgedrückt werden, dass es möglich ist, dass die Realität dem widerspricht, was gesagt wird. Wenn eine Theorie nicht widersprochen werden kann, ist es nicht so, dass sie wahr oder falsch ist; es ist jenseits des Punktes, zumindest aus wissenschaftlicher Sicht. Um als wissenschaftlich angesehen zu werden, sollte eine Theorie ein gewisses Risiko in Bezug auf die Realität eingehen.
Das zweite Kriterium ist, dass der Grad des Vertrauens, das wir in eine Theorie setzen können, bis zu einem gewissen Grad (und ich vereinfache hier), proportional zur Menge der Arbeit sein sollte, die von den Wissenschaftlern selbst investiert wurde, um die Theorie zu widerlegen. Die wissenschaftliche Eigenschaft einer Theorie besteht darin, dass sie ein großes Risiko eingeht und viele Menschen versuchen, diese Schwächen auszunutzen, um die Theorie zu widerlegen. Wenn sie immer wieder gescheitert sind, können wir der Theorie etwas Glaubwürdigkeit verleihen.
Diese Perspektive zeigt, dass es eine tiefe Asymmetrie zwischen dem gibt, was wahr und was falsch ist. Moderne wissenschaftliche Theorien sollten niemals als wahr oder bewiesen angesehen werden, sondern nur als ausstehend. Die Tatsache, dass viele Menschen versucht haben, sie zu widerlegen, ohne Erfolg zu haben, erhöht die Glaubwürdigkeit, die wir ihnen geben können. Diese Erkenntnis ist von entscheidender Bedeutung für die Welt der Supply Chain und insbesondere hat diese Vorstellung der Falsifizierbarkeit viele der erstaunlichsten Entwicklungen in der Wissenschaft vorangetrieben, insbesondere wenn es um die moderne Physik ging.
Bisher ist dies die dritte Vorlesung des zweiten Kapitels dieser Serie über Supply Chain. Im ersten Kapitel des Prologs habe ich meine Ansichten über Supply Chain sowohl als Studienfach als auch als Praxis vorgestellt. Eine der wichtigsten Erkenntnisse war, dass Supply Chain eine Reihe von bösen Problemen umfasst, im Gegensatz zu zahmen Problemen. Diese Probleme lassen sich aus Gründen des Designs nicht einfach lösen. Daher müssen wir der Methodik, die wir sowohl zum Studium als auch zur Praxis von Supply Chain haben, große Aufmerksamkeit schenken. Dieses zweite Kapitel handelt von diesen Methoden.
In der ersten Vorlesung des zweiten Kapitels habe ich eine qualitative Methode vorgeschlagen, um Wissen und später Verbesserungen in der Supply Chain über die Vorstellung von Supply Chain Personas zu bringen. Hier, in dieser dritten Vorlesung, schlage ich eine quantitative Methode vor: experimentelle Optimierung.

Wenn es darum geht, quantitative Verbesserungen in der Supply Chain zu bringen, benötigen wir ein quantitatives Modell, ein numerisches Modell. Es gibt mindestens zwei Möglichkeiten, dies anzugehen: den Mainstream-Weg, die mathematische Optimierung, und eine andere Perspektive, die experimentelle Optimierung.
Der Mainstream-Ansatz zur Bereitstellung quantitativer Verbesserungen in der Supply Chain ist die mathematische Optimierung. Dieser Ansatz besteht im Wesentlichen darin, einen langen Katalog von Problem-Lösungs-Paaren zu erstellen. Ich glaube jedoch, dass diese Methode nicht sehr gut ist und wir eine andere Perspektive benötigen, die das ist, worum es bei der experimentellen Optimierung geht. Es sollte als die Optimierung von Supply Chains über eine Reihe von Experimenten verstanden werden.
Die experimentelle Optimierung wurde nicht von Lokad erfunden. Es entstand bei Lokad zuerst als Praxis und wurde Jahre später als solche konzeptualisiert. Was ich heute präsentiere, ist nicht der Weg, auf dem es allmählich bei Lokad entstanden ist. Es war ein viel graduellerer und schlammigerer Prozess. Ich habe diese emergente Praxis Jahre später überarbeitet, um sie unter der Form einer Theorie zu festigen, die ich unter dem Titel experimentelle Optimierung präsentieren kann.

Zunächst müssen wir den Begriff der mathematischen Optimierung klären. Wir haben zwei verschiedene Dinge, die wir unterscheiden müssen: die mathematische Optimierung als eigenständiges Forschungsfeld und die mathematische Optimierung als Perspektive für die quantitative Verbesserung der Supply Chain, die heute von Interesse ist. Lassen Sie uns die zweite Perspektive für einen Moment beiseite legen und klären, worum es bei der mathematischen Optimierung als eigenständigem Forschungsfeld geht.
Es ist ein Forschungsfeld, das sich für die Klasse mathematischer Probleme interessiert, die sich wie auf dem Bildschirm beschrieben darstellen. Im Wesentlichen beginnen Sie mit einer Funktion, die von einer beliebigen Menge (Großbuchstabe A) zu einer reellen Zahl geht. Diese Funktion, häufig als Verlustfunktion bezeichnet, wird mit f bezeichnet. Wir suchen die optimale Lösung, die ein Punkt x ist, der zu Großbuchstabe A, der Menge, gehört und nicht verbessert werden kann. Offensichtlich handelt es sich hierbei um ein sehr breites Forschungsfeld mit vielen technischen Details. Einige Funktionen haben möglicherweise kein Minimum, während andere viele verschiedene Minima haben können. Als Forschungsfeld war die mathematische Optimierung fruchtbar und erfolgreich. Es wurden zahlreiche Techniken entwickelt und Konzepte eingeführt, die in vielen anderen Bereichen mit großem Erfolg eingesetzt wurden. Ich werde jedoch heute nicht alles diskutieren, da dies nicht der Zweck dieser Vorlesung ist.
Der Punkt, den ich machen möchte, ist, dass die mathematische Optimierung als Hilfswissenschaft für die Supply Chain auf eigene Faust einen erheblichen Erfolg hatte. Dies hat wiederum das quantitative Studium von Supply Chains tiefgreifend geprägt, worum es bei der mathematischen Optimierung der Supply Chain-Perspektive geht.

Gehen wir zurück zu zwei Büchern, die ich in meiner allerersten Supply Chain-Vorlesung vorgestellt habe. Diese beiden Bücher repräsentieren meiner Meinung nach die Mainstream-quantitative Supply Chain-Theorie und verkörpern die letzten fünf Jahrzehnte sowohl wissenschaftlicher Veröffentlichungen als auch Software-Produktion. Es sind nicht nur die veröffentlichten Papiere, sondern auch die Software, die auf den Markt gebracht wurde. Was die quantitative Optimierung von Supply Chains betrifft, wird alles über Software-Instrumente erledigt und wurde schon lange Zeit so gemacht.
Wenn Sie sich diese Bücher ansehen, kann jedes Kapitel als Anwendung der mathematischen Optimierungsperspektive betrachtet werden. Es läuft immer auf eine Problemstellung mit verschiedenen Annahmen hinaus, gefolgt von der Vorstellung einer Lösung. Die Richtigkeit und manchmal auch die Optimalität der Lösung werden dann im Hinblick auf die Problemstellung nachgewiesen. Diese Bücher sind im Wesentlichen Kataloge von Problem-Lösungs-Paaren, die sich als mathematische Optimierungsprobleme präsentieren.
Zum Beispiel kann die Prognose als ein Problem betrachtet werden, bei dem Sie eine Verlustfunktion haben, die Ihr Prognosefehler sein wird, und ein Modell mit Parametern, die Sie abstimmen möchten. Sie möchten dann den Optimierungsprozess numerisch lernen, der Ihnen die optimalen Parameter liefert. Der gleiche Ansatz gilt für eine Bestandspolitik, bei der Sie Hypothesen über die Nachfrage aufstellen und dann nachweisen können, dass Sie eine Lösung haben, die sich als optimal im Hinblick auf die Annahmen erweist, die Sie gerade gemacht haben.
Wie ich bereits in der allerersten Vorlesung behandelt habe, habe ich große Bedenken hinsichtlich dieser Mainstream-Supply-Chain-Theorie. Die von mir genannten Bücher sind keine zufälligen Auswahlmöglichkeiten; Ich glaube, sie spiegeln die letzten Jahrzehnte der Supply-Chain-Forschung genau wider. Wenn wir uns die Ideen zur Falsifizierbarkeit ansehen, die von Karl Popper eingeführt wurden, können wir klarer erkennen, worin das Problem besteht: Keines dieser Bücher ist tatsächlich Wissenschaft, da die Realität nicht widerlegen kann, was präsentiert wird. Diese Bücher sind im Wesentlichen vollständig immun gegen reale Supply Chains. Wenn Sie ein Buch haben, das im Wesentlichen eine Sammlung von Problem-Lösungs-Paaren ist, gibt es nichts zu widerlegen. Dies ist ein rein mathematisches Konstrukt. Die Tatsache, dass eine Supply Chain dies oder das tut, hat keinen Einfluss darauf, ob etwas von dem, was in diesen Büchern präsentiert wird, bewiesen oder widerlegt wird. Das ist wahrscheinlich mein größtes Anliegen bei diesen Theorien.
Hier geht es nicht nur um die diskutierte Forschung. Wenn Sie sich ansehen, was in Bezug auf Unternehmenssoftware zur Unterstützung von Supply Chains existiert, ist die Software, die heute auf dem Markt existiert, sehr dominant eine Reflexion dieser wissenschaftlichen Veröffentlichungen. Diese Software wurde nicht separat von diesen wissenschaftlichen Veröffentlichungen erfunden; Normalerweise gehen sie Hand in Hand. Die meisten Stücke von Unternehmenssoftware, die auf dem Markt gefunden werden, um Supply-Chain-Optimierungsprobleme zu lösen, sind Reflexionen einer bestimmten Reihe von Papieren oder Büchern, die manchmal von denselben Personen verfasst wurden, die die Software und die Bücher produziert haben.
Die Tatsache, dass die Realität keinen Einfluss auf die hier präsentierten Theorien hat, ist meiner Meinung nach eine sehr plausible Erklärung dafür, warum so wenig von den in diesen Büchern präsentierten Theorien tatsächlich in realen Supply Chains von Nutzen sind. Dies ist eine ziemlich subjektive Aussage, die ich mache, aber in meiner Karriere hatte ich die Chance, mit mehreren hundert Supply-Chain-Direktoren zu diskutieren. Sie kennen diese Theorien, und wenn sie nicht sehr sachkundig sind, haben sie Leute in ihrem Team, die es sind. Sehr häufig implementiert die von dem Unternehmen verwendete Software bereits eine Reihe von Lösungen, wie sie in diesen Büchern präsentiert werden, und dennoch werden sie nicht verwendet. Die Menschen greifen aus verschiedenen Gründen oft auf ihre eigenen Excel-Tabellen zurück.
Also, das ist keine Unwissenheit. Wir haben dieses sehr reale Problem, und ich glaube, dass die eigentliche Ursache buchstäblich darin besteht, dass es keine Wissenschaft ist. Sie können nichts von dem widerlegen, was präsentiert wird. Es geht nicht darum, dass diese Theorien falsch sind - sie sind mathematisch korrekt -, aber sie sind nicht wissenschaftlich im Sinne von Wissenschaft.

Nun stellt sich die Frage: Wie groß ist das Problem? Denn ich habe tatsächlich zwei Bücher ausgewählt, aber wie groß ist der tatsächliche Umfang dieser mathematischen Optimierungsperspektive in der Supply Chain? Ich würde sagen, dass der Umfang dieser Perspektive absolut massiv ist. Als ein Stück anekdotischer Beweise, um das zu demonstrieren, habe ich kürzlich Google Scholar verwendet, eine spezialisierte Suchmaschine von Google, die nur Ergebnisse für wissenschaftliche Veröffentlichungen liefert. Wenn Sie nur für das Jahr 2020 nach “optimaler Bestand” suchen, erhalten Sie über 30.000 Ergebnisse.
Diese Zahl sollte mit Vorsicht betrachtet werden. Offensichtlich gibt es wahrscheinlich zahlreiche Duplikate in dieser Liste, und es wird höchstwahrscheinlich falsche positive Ergebnisse geben - Papiere, in denen sowohl die Wörter “Bestand” als auch “optimal” im Titel und Abstract erscheinen, aber das Papier hat nichts mit der Supply Chain zu tun. Es ist nur zufällig. Trotzdem deutet eine oberflächliche Inspektion der Ergebnisse sehr stark darauf hin, dass wir über mehrere tausend pro Jahr in diesem Bereich veröffentlichte Papiere sprechen. Als Basis ist diese Zahl sehr groß, selbst im Vergleich zu Feldern, die absolut massiv sind, wie zum Beispiel Deep Learning. Deep Learning ist wahrscheinlich eine der Informatiktheorien, die in den letzten zwei oder drei Jahrzehnten den größten Erfolg genießt. Die Tatsache, dass allein die Abfrage “optimaler Bestand” etwas zurückgibt, das etwa ein Fünftel dessen ist, was Sie für Deep Learning erhalten, ist tatsächlich sehr beeindruckend. Optimaler Bestand ist offensichtlich nur ein Bruchteil dessen, worum es bei quantitativen Supply-Chain-Studien geht.
Diese einfache Abfrage zeigt, dass die mathematische Optimierungsperspektive wirklich massiv ist, und ich würde argumentieren, obwohl es vielleicht etwas subjektiv ist, dass sie, soweit es um quantitative Studien der Supply Chain geht, wirklich dominiert. Wenn wir mehrere tausend Papiere haben, die optimale Bestandsrichtlinien und optimale Bestandsmanagementmodelle zur Führung von Unternehmen bereitstellen, die jährlich produziert werden, sollten die meisten großen Unternehmen sicherlich auf der Grundlage dieser Methoden arbeiten. Wir sprechen nicht nur von ein paar Papieren; wir sprechen von einer absolut massiven Menge an Veröffentlichungen.
Meiner Erfahrung nach ist das bei ein paar hundert Datenpunkten der Supply Chain, die ich kenne, wirklich nicht der Fall. Diese Methoden sind fast nirgendwo zu sehen. Wir haben eine absolut atemberaubende Diskrepanz zwischen dem Stand der Forschung, wenn es um die veröffentlichten Papiere geht - und übrigens auch der Software, denn die Software spiegelt im Wesentlichen das wider, was als wissenschaftliche Papiere veröffentlicht wird - und der Art und Weise, wie Supply Chains tatsächlich betrieben werden.

Die Frage, die ich hatte, war: Mit Tausenden von Papieren gibt es etwas Gutes zu finden? Ich hatte das Vergnügen, Hunderte von quantitativen Supply-Chain-Papieren durchzugehen, und ich kann Ihnen eine Reihe von Heuristiken geben, die Ihnen nahezu sicherstellen, dass das Papier keinen realen Mehrwert für die reale Welt bietet. Diese Heuristiken sind nicht absolut wahr, aber sie sind sehr genau, etwas, das zu 99%+ genau ist. Es ist nicht perfekt genau, aber es ist fast perfekt genau.
Wie erkennen wir also Papiere, die einen realen Mehrwert bieten, oder umgekehrt, wie lehnen wir Papiere ab, die überhaupt keinen Wert bringen? Ich habe eine kurze Reihe von Heuristiken aufgelistet. Die erste ist einfach, wenn das Papier irgendeine Behauptung über irgendeine Art von Optimalität aufstellt, dann können Sie sicher sein, dass das Papier keinen realen Mehrwert für die Supply Chain bietet. Erstens, weil es reflektiert, dass die Autoren nicht einmal verstehen oder das geringste Verständnis dafür haben, dass Supply Chains im Wesentlichen ein böses Problem sind. Die Tatsache, dass Sie sagen würden, dass Sie eine optimale Lösung haben - also lassen Sie uns zur Definition einer optimalen Lösung zurückkehren: Eine Lösung ist optimal, wenn sie nicht verbessert werden kann. Zu sagen, dass Sie eine optimale Supply-Chain-Lösung haben, ist sehr ähnlich wie zu sagen, dass es eine harte Grenze für menschliche Einfallsreichtum gibt. Das glaube ich kein bisschen. Ich glaube, dass das eine völlig unvernünftige Proposition ist. Wir sehen, dass es ein sehr großes Problem mit der Art und Weise gibt, wie die Supply Chain angegangen wird.
Ein weiteres Problem ist, dass immer dann, wenn eine Behauptung der Optimalität vorliegt, darauf in der Regel eine Lösung folgt, die sehr stark auf Annahmen beruht. Sie können eine Lösung haben, die gemäß einer bestimmten Reihe von Annahmen als optimal nachgewiesen wurde, aber was ist, wenn diese Annahmen verletzt werden? Wird die Lösung noch gut sein? Im Gegenteil, ich glaube, dass Sie, wenn Sie eine Lösung haben, deren Optimalität Sie beweisen können, eine Lösung haben, die unglaublich von den getroffenen Annahmen abhängt, um auch nur annähernd korrekt zu sein. Wenn Sie die Annahmen verletzen, ist die resultierende Lösung sehr wahrscheinlich absolut schrecklich, weil sie nie darauf ausgelegt war, gegen irgendetwas robust zu sein. Optimalitätsansprüche können praktisch von vornherein verworfen werden.
Das zweite ist die Normalverteilung. Wenn Sie also ein Papier oder eine Software sehen, die behauptet, Normalverteilungen zu verwenden, können Sie sicher sein, dass das vorgeschlagene Verfahren in realen Supply Chains nicht funktioniert. In einem früheren Vortrag, in dem ich quantitative Prinzipien für die Supply Chain vorgestellt habe, habe ich gezeigt, dass alle interessanten Populationen in Supply Chains Zipf-verteilt sind, nicht normalverteilt. Normalverteilungen sind in Supply Chains nirgendwo zu finden, und ich bin absolut überzeugt, dass dieses Ergebnis seit Jahrzehnten bekannt ist. Wenn Sie also Papiere oder Software finden, die auf dieser Annahme beruhen, ist es nahezu sicher, dass Sie eine Lösung haben, die aus Bequemlichkeit entwickelt wurde, damit es einfacher ist, den mathematischen Beweis oder die Software zu schreiben, nicht weil es einen Wunsch nach realer Leistung gab. Das Vorhandensein von Normalverteilungen ist nur reine Faulheit oder bestenfalls ein Zeichen für tiefgreifendes Unverständnis dessen, worum es in Supply Chains geht. Dies kann verwendet werden, um diese Papiere abzulehnen.
Dann die Stationarität - so etwas gibt es nicht. Es ist eine Annahme, die aussieht, als ob sie in Ordnung ist: Dinge sind stationär, mehr vom Gleichen. Aber das stimmt nicht; es ist eine sehr starke Annahme. Es besagt im Grunde, dass Sie einen Prozess haben, der am Anfang der Zeit begann und bis zum Ende der Zeit fortgesetzt wird. Dies ist eine sehr unvernünftige Perspektive für reale Supply Chains. In realen Supply Chains wurde jedes Produkt zu einem bestimmten Zeitpunkt eingeführt und wird zu einem bestimmten Zeitpunkt vom Markt genommen. Selbst wenn Sie sich Produkte ansehen, die relativ lange leben, wie sie beispielsweise in der Automobilindustrie zu finden sind, sind diese Prozesse nicht stationär. Sie werden höchstens ein Jahrzehnt dauern. Der interessierende Lebenszeitraum, der interessierende Zeitraum, ist endlich, daher ist die stationäre Perspektive einfach falsch.
Ein weiteres Element, um eine quantitative Studie zu identifizieren, die nicht funktionieren wird, ist, wenn die Vorstellung von Substitution vollständig fehlt. In realen Supply Chains gibt es überall Substitutionen. Wenn wir zum Beispiel zum Supply-Chain-Beispiel zurückkehren, das ich vor zwei Wochen in einem früheren Vortrag vorgestellt habe, konnten Sie mindestens ein halbes Dutzend Situationen sehen, in denen Substitutionen im Spiel waren - auf der Lieferseite, der Transformationsseite und der Nachfrageseite. Wenn Sie ein Modell haben, in dem das Konzept der Substitution konzeptionell nicht einmal existiert, haben Sie also etwas, das wirklich im Widerspruch zu realen Supply Chains steht.
Ebenso ist das Fehlen von Globalität oder einer holistischen Perspektive auf die Supply Chain auch ein sicheres Zeichen dafür, dass etwas nicht stimmt. Wenn ich zum vorherigen Vortrag zurückkehre, in dem ich die quantitativen Prinzipien für die Supply Chain vorgestellt habe, habe ich festgestellt, dass Sie, wenn Sie etwas haben, das einer lokalen Optimierungsprozess ähnelt, nichts optimieren werden; Sie werden nur die Probleme innerhalb Ihrer Supply Chain verlagern. Die Supply Chain ist ein System, ein Netzwerk, und so können Sie keine Art von lokaler Optimierung anwenden und hoffen, dass es tatsächlich zum Wohle der Supply Chain als Ganzes sein wird. Das ist einfach nicht der Fall.
Mit diesen Heuristiken denke ich, dass Sie fast die gesamte quantitative Supply-Chain-Literatur eliminieren können, was an sich schon erstaunlich ist.

Das Problem ist, dass es nicht funktionieren würde, wenn ich jeden einzelnen Redaktionsausschuss für jede Supply-Chain-Konferenz und jedes Journal davon überzeugen würde, dass sie diese Heuristiken verwenden sollten, um minderwertige Beiträge herauszufiltern. Autoren würden sich einfach anpassen und den Prozess umgehen, selbst wenn wir diese Richtlinien für die Veröffentlichung in Supply-Chain-Journalen hinzufügen würden. Wenn Marktforschungsanalysten diese in ihre Checkliste aufnehmen würden, würden Autoren von Papieren und Software sich einfach anpassen. Sie würden das Problem verschleiern, kompliziertere Annahmen machen, bei denen man nicht mehr sehen kann, dass es auf eine Normalverteilung oder eine stationäre Annahme zurückzuführen ist. Es ist nur so, dass es in sehr undurchsichtiger Weise formuliert ist.
Diese Heuristiken sind schön, um minderwertige Beiträge, sowohl Papier als auch Software, zu identifizieren, aber wir können sie nicht verwenden, um herauszufiltern, was gut ist. Wir brauchen eine tiefgreifendere Veränderung; wir müssen das ganze Paradigma überdenken. An diesem Punkt fehlt uns immer noch die Falsifizierbarkeit. Die Realität hat nirgendwohin zurückzuschlagen und irgendwie zu widerlegen, was präsentiert wird.

Als letztes Element, um diesen Teil des Vortrags über die mathematische Optimierungsperspektive abzuschließen, gibt es irgendeine erlösende Qualität in dieser enormen Produktion von Papieren und Software zu finden? Meine sehr subjektive Antwort auf diese Frage ist absolut nein. Diese Papiere, und ich habe viele quantitative Supply-Chain-Papiere gelesen, sind nicht interessant. Im Gegenteil, sie sind sogar sehr langweilig, selbst die besten von ihnen. Wenn wir uns die Hilfswissenschaften ansehen, gibt es keine Nuggets von wirklich interessanten Dingen zu finden. Sie können sich all diese Papiere ansehen, und ich habe Tausende von ihnen aufgelistet. Aus mathematischer Sicht ist es sehr langweilig. Es werden keine großen mathematischen Ideen präsentiert. Aus algorithmischer Sicht handelt es sich lediglich um eine direkte Anwendung dessen, was in der Algorithmusforschung schon lange bekannt ist. Das Gleiche gilt für die Statistikmodellierung und -methodik, die äußerst schlecht ist. In Bezug auf die Methodik reduziert sich alles auf die mathematische Optimierungsperspektive, bei der Sie ein Modell präsentieren, etwas optimieren, die Lösung bereitstellen und nachweisen, dass diese Lösung einige mathematische Merkmale in Bezug auf die Problemstellung aufweist.
Wir müssen wirklich mehr als oberflächlich ändern. Ich kritisiere den Ansatz nicht. Es gibt historische Präzedenzfälle dafür. Es mag völlig erstaunlich klingen, dass ich behaupte, dass wir Zehntausende von Papieren haben, die völlig steril sind, aber historisch gesehen ist dies passiert. Wenn Sie sich das Leben von Isaac Newton ansehen, einem der Väter der modernen Physik, werden Sie feststellen, dass er etwa die Hälfte seiner Zeit mit Physik verbracht hat, mit einem riesigen Erbe, und die andere Hälfte mit Alchemie. Er war ein brillanter Physiker und ein sehr schlechter Alchemist. Historische Aufzeichnungen zeigen tendenziell, dass Isaac Newton genauso brillant, engagiert und ernsthaft in seiner Arbeit an der Alchemie war wie in seiner Arbeit an der Physik. Aufgrund der Tatsache, dass die alchemistische Perspektive einfach schlecht gerahmt war, erwies sich die gesamte Arbeit und Intelligenz, die Newton in diesen Bereich einbrachte, als völlig steril, ohne jegliches Erbe, von dem man sprechen könnte. Meine Kritik ist nicht, dass wir Tausende von Menschen haben, die idiotische Dinge veröffentlichen. Die meisten dieser Autoren sind sehr intelligent. Das Problem ist, dass der Rahmen selbst steril ist. Das ist der Punkt, den ich machen möchte.

Lassen Sie uns nun zum zweiten Modellierungsansatz übergehen, den ich heute vorstellen möchte. In den frühen Jahren war die Methodik von Lokad tief in der mathematischen Optimierungsperspektive verwurzelt. In dieser Hinsicht waren wir sehr mainstream und es funktionierte sehr schlecht für uns. Etwas, das bei Lokad sehr spezifisch war und fast zufällig war, ist, dass ich irgendwann beschlossen habe, dass Lokad keine Unternehmenssoftware verkaufen würde, sondern direkt End-to-End-Supply-Chain-Entscheidungen verkaufen würde. Ich meine wirklich die genauen Mengen, die ein bestimmtes Unternehmen kaufen muss, die Mengen, die ein Unternehmen produzieren muss, und wie viele Einheiten von Ort A nach Ort B bewegt werden müssen - ob ein einzelner Preis sinken sollte oder nicht - Lokad war im Geschäft, um End-to-End-Supply-Chain-Entscheidungen zu verkaufen. Aufgrund dieser halb zufälligen Entscheidung von mir wurden wir brutal mit unseren eigenen Unzulänglichkeiten konfrontiert. Wir wurden auf die Probe gestellt und es gab eine sehr brutale Realitätsprüfung. Wenn wir Supply-Chain-Entscheidungen produzierten, die sich als schlecht herausstellten, waren die Kunden sofort bei mir und schrien Blut und Mord, weil Lokad nichts zufriedenstellendes lieferte.
Experimentaloptimierung entstand auf gewisse Weise bei Lokad. Es wurde nicht bei Lokad erfunden; es war eine emergente Praxis, die nur eine Reaktion auf die Tatsache war, dass wir unter immensem Druck von unserer Kundenbasis standen, etwas gegen diese Defekte zu unternehmen, die am Anfang überall waren. Wir mussten eine Art Überlebensmechanismus entwickeln und haben viele Dinge ausprobiert, manchmal ziemlich zufällig. Was entstand, wird als Experimentaloptimierung bezeichnet.

Experimentaloptimierung ist eine sehr einfache Methode. Das Ziel besteht darin, Supply-Chain-Entscheidungen zu produzieren, indem man ein Rezept schreibt, das softwaregesteuert ist und Supply-Chain-Entscheidungen generiert. Die Methode beginnt wie folgt: Schritt null, Sie schreiben einfach Rezepte, die Entscheidungen generieren. Hier sind eine Menge Know-how, Technologien und Werkzeuge von Interesse. Dies ist nicht das Thema dieser Vorlesung; dies wird in späteren Vorlesungen ausführlich behandelt. Also, Schritt eins, Sie schreiben einfach ein Rezept, und höchstwahrscheinlich wird es nicht sehr gut sein.
Dann betreten Sie eine unbestimmte Iterationspraxis, bei der Sie zuerst das Rezept ausführen werden. Mit “ausführen” meine ich, dass das Rezept in einer produktionsfähigen Umgebung ausgeführt werden sollte. Es geht nicht nur darum, einen Algorithmus im Data-Science-Labor auszuführen. Es geht darum, ein Rezept zu haben, das alle Qualitäten hat, damit Sie, wenn Sie entscheiden, dass diese Entscheidungen gut genug sind, um in die Produktion zu gehen, dies mit einem einzigen Klick tun können. Die gesamte Umgebung muss produktionsfähig sein; darum geht es beim Ausführen des Rezepts.
Als nächstes müssen Sie die verrückten Entscheidungen identifizieren, die in einem meiner vorherigen Vorträge über produktorientierte Lieferung für die Supply Chain behandelt wurden. Für diejenigen von Ihnen, die diesen Vortrag nicht besucht haben, wollen wir Investitionen in die Supply Chain kapitalistisch, akkretiv machen, und um das zu erreichen, müssen wir sicherstellen, dass die Menschen, die in dieser Supply-Chain-Division arbeiten, nicht Feuerwehr spielen. Die Standard-Situation in der überwiegenden Mehrheit der Unternehmen ist derzeit so, dass Supply-Chain-Entscheidungen von Software generiert werden - die meisten modernen Unternehmen nutzen bereits umfangreich Stücke von Unternehmenssoftware, um ihre Supply-Chain zu betreiben, und alle Entscheidungen werden bereits durch Software generiert. Ein sehr großer Teil dieser Entscheidungen ist jedoch völlig verrückt. Bei den meisten Supply-Chain-Teams geht es darum, alle diese verrückten Entscheidungen manuell zu überprüfen und sich in fortlaufenden Feuerwehraktionen zu engagieren, um sie zu beseitigen. So werden alle Anstrengungen von der Betriebsführung des Unternehmens aufgezehrt. Sie bereinigen alle Ihre Ausnahmen an einem Tag und kommen dann am nächsten Tag mit einem ganz neuen Satz von Ausnahmen zurück, und der Zyklus wiederholt sich. Sie können nicht kapitalisieren; Sie verbrauchen nur die Zeit Ihrer Supply-Chain-Experten. Die Idee von Lokad ist daher, dass wir diese verrückten Entscheidungen als Softwarefehler behandeln müssen und sie vollständig eliminieren müssen, damit wir einen kapitalistischen Prozess und eine Praxis der Supply Chain selbst haben können.
Sobald wir das haben, müssen wir die Instrumentierung verbessern und damit das numerische Rezept selbst verbessern. All diese Arbeit wird vom Supply-Chain-Scientist durchgeführt, ein Begriff, den ich in meinem zweiten Vortrag des ersten Kapitels “Die quantitative Supply-Chain-Perspektive”, wie von Lokad gesehen, eingeführt habe. Die Instrumentierung ist von entscheidender Bedeutung, denn durch eine bessere Instrumentierung können Sie besser verstehen, was in Ihrer Supply Chain vor sich geht, was in Ihrem Rezept vor sich geht und wie Sie es weiter verbessern können, um diese verrückten Entscheidungen zu bewältigen, die immer wieder auftauchen.

Lassen Sie uns für einen Moment in die Ursachen von Wahnsinn eintauchen, die diese verrückten Entscheidungen erklären. Häufig, wenn ich Supply-Chain-Direktoren frage, warum sie denken, dass ihre Unternehmenssoftware-Systeme, die ihre Supply-Chain-Operationen regeln, diese verrückten Entscheidungen produzieren, bekomme ich eine sehr häufige, aber fehlgeleitete Antwort: “Oh, es liegt nur daran, dass wir schlechte Prognosen haben.” Ich glaube, dass diese Antwort auf mindestens zwei Ebenen fehlgeleitet ist. Erstens, wenn Sie von der Genauigkeit ausgehen, die Sie von einem sehr simplen gleitenden Durchschnittsmodell bis hin zu einem modernen Machine-Learning-Modell erzielen können, gibt es vielleicht eine Genauigkeit von 20%, die erzielt werden kann. Ja, das ist signifikant, aber es kann nicht den Unterschied zwischen einer Entscheidung ausmachen, die sehr gut ist, und einer Entscheidung, die völlig verrückt ist. Zweitens ist das größte Problem bei Prognosen, dass sie nicht alle Alternativen sehen; sie sind nicht probabilistisch. Aber ich schweife ab; das wäre ein Thema für einen anderen Vortrag.
Wenn wir zur Ursache des Wahnsinns zurückkehren, glaube ich, dass, obwohl Prognosefehler ein Anliegen sind, sie absolut nicht das wichtigste Anliegen sind. Aus einem Jahrzehnt Erfahrung bei Lokad kann ich sagen, dass dies höchstens ein sekundäres Anliegen ist. Das Hauptanliegen, das größte Problem, das verrückte Entscheidungen generiert, sind Daten-Semantiken. Denken Sie daran, dass Sie eine Supply Chain nicht direkt beobachten können; das ist nicht möglich. Sie können eine Supply Chain nur als Reflexion über die elektronischen Aufzeichnungen beobachten, die Sie durch Stücke von Unternehmenssoftware sammeln. Die Beobachtung, die Sie über Ihre Supply Chain machen, ist ein sehr indirekter Prozess durch das Prisma der Software.
Hier geht es um Hunderte von relationalen Tabellen und Tausende von Feldern, und die Semantik jedes einzelnen dieser Felder ist wirklich wichtig. Aber wie wissen Sie, dass Sie das richtige Verständnis und die richtige Denkweise haben? Der einzige Weg, um sicher zu wissen, dass Sie wirklich verstehen, was eine bestimmte Spalte bedeutet, besteht darin, sie dem Experiment zu unterziehen. Bei der experimentellen Optimierung ist der experimentelle Test die Generierung von Entscheidungen. Sie nehmen an, dass diese Spalte etwas bedeutet; das ist Ihre wissenschaftliche Theorie in gewisser Weise. Dann generieren Sie eine Entscheidung auf der Grundlage dieses Verständnisses, und wenn die Entscheidung gut ist, dann ist Ihr Verständnis korrekt. Grundsätzlich ist das Einzige, was Sie beobachten können, ob Ihr Verständnis zu verrückten Entscheidungen führt oder nicht. Hier schlägt die Realität zurück.
Dies ist kein kleines Problem; es ist ein sehr großes. Unternehmenssoftware ist, gelinde gesagt, komplex, und es gibt Fehler. Das Problem mit der mathematischen Optimierungsperspektive ist, dass es das Problem so betrachtet, als ob es eine einfache Reihe von Annahmen wäre, und dann können Sie eine relativ einfache, mathematisch elegante Lösung ausrollen. Aber die Realität ist, dass wir Schichten von Unternehmenssoftware auf Schichten haben, und Probleme können überall auftreten. Einige dieser Probleme sind sehr banal, wie z.B. falsches Kopieren, falsche Bindung zwischen Variablen oder Systeme, die synchronisiert sein sollten, die aus der Synchronisation geraten. Es kann Version-Upgrades für Software geben, die Fehler erzeugen, und so weiter. Diese Fehler sind überall, und der einzige Weg zu wissen, ob Sie Fehler haben oder nicht, ist wiederum, Entscheidungen zu betrachten. Wenn die Entscheidungen korrekt sind, dann gibt es entweder keine Fehler oder die vorhandenen Fehler sind unbedeutend und wir kümmern uns nicht darum.
In Bezug auf wirtschaftliche Treiber entsteht häufig ein weiterer falscher Ansatz, wenn man mit Supply-Chain-Direktoren diskutiert. Sie fragen mich oft, ob ich beweisen kann, dass ihr Unternehmen einen wirtschaftlichen Nutzen haben wird. Meine Antwort darauf ist, dass wir die wirtschaftlichen Treiber noch nicht einmal kennen. Meine Erfahrung bei Lokad hat mich gelehrt, dass der einzige Weg, um sicher zu wissen, was die wirtschaftlichen Treiber sind - und diese Treiber werden verwendet, um die Verlustfunktion aufzubauen, die wiederum zur Durchführung der eigentlichen Optimierung im numerischen Rezept selbst verwendet wird - ist, sie tatsächlich durch die Erfahrung der Generierung von Entscheidungen zu testen und zu validieren, und zu beobachten, ob diese Entscheidungen verrückt sind oder nicht. Diese wirtschaftlichen Treiber müssen nach Erfahrung entdeckt und validiert werden. Im besten Fall können Sie nur eine Intuition haben, was richtig ist, aber nur Erfahrung und Experimente können Ihnen sagen, ob Ihr Verständnis tatsächlich korrekt ist.
Dann gibt es auch noch alle Unpraktikabilitäten. Sie haben ein numerisches Rezept, das Entscheidungen generiert, und diese Entscheidungen scheinen mit allen Regeln, die Sie festgelegt haben, konform zu sein. Wenn es zum Beispiel Mindestbestellmengen (MOQs) gibt, generieren Sie Bestellungen, die mit Ihren MOQs konform sind. Aber was ist, wenn ein Lieferant zurückkommt und Ihnen sagt, dass die MOQ etwas anderes ist? Durch diesen Prozess können Sie viele Unpraktikabilitäten und scheinbar machbare Entscheidungen entdecken, die sich als undurchführbar herausstellen, wenn Sie versuchen, sie dem Test der realen Welt zu unterziehen. Sie entdecken alle Arten von Randfällen und Einschränkungen, manchmal solche, an die Sie nicht einmal gedacht haben, wo die Welt zurückschlägt und Sie das auch beheben müssen.
Dann gibt es sogar Ihre Strategie. Sie denken vielleicht, dass Sie eine Gesamtstrategie für Ihre Lieferkette haben, aber ist sie korrekt? Um Ihnen eine Vorstellung zu geben, nehmen wir Amazon als Beispiel. Sie könnten sagen, dass Sie kundenorientiert sein wollen. Wenn Kunden zum Beispiel etwas online kaufen und es ihnen nicht gefällt, sollten sie es sehr einfach zurücksenden können. Sie möchten sehr großzügig sein, wenn es um Rücksendungen geht. Aber was passiert, wenn Sie Gegner oder schlechte Kunden haben, die das System manipulieren? Sie können ein teures $500 Smartphone online bestellen, es erhalten, das echte Smartphone durch ein gefälschtes im Wert von nur $50 ersetzen und es dann zurücksenden. Amazon hat gefälschte Produkte in ihrem Inventar, ohne es überhaupt zu bemerken. Dies ist ein sehr reales Problem, das online oft diskutiert wurde.
Sie könnten eine Strategie haben, die besagt, dass Sie kundenorientiert sein wollen, aber vielleicht sollte Ihre Strategie darin bestehen, nur für ehrliche Kunden kundenorientiert zu sein. Es sind also nicht nur alle Kunden; es ist ein Teil der Kunden. Selbst wenn Ihre Strategie ungefähr korrekt ist, steckt der Teufel im Detail. Auch hier ist der einzige Weg, um zu sehen, ob der Feinschliff Ihrer Strategie korrekt ist, die Experimentation, bei der Sie sich die Details ansehen können.

Nun wollen wir besprechen, wie wir verrückte Entscheidungen identifizieren. Wie unterscheiden wir zwischen vernünftigen und verrückten Entscheidungen? Mit “verrückter Entscheidung” meine ich eine Entscheidung, die für Ihr Unternehmen nicht vernünftig ist. Dies ist eine Art Problem, das wirklich menschliche Intelligenz erfordert. Es gibt absolut keine Hoffnung, dass Sie dieses Problem durch einen Algorithmus lösen können. Es mag paradox klingen, aber dies ist die Art von Problem, die menschliche Intelligenz auf allgemeinem Niveau erfordert, aber nicht unbedingt von einem sehr intelligenten Menschen.
Es gibt viele andere Probleme wie dieses in der realen Welt. Ein Analogon sind Filmfehler. Wenn Sie Hollywood-Studios nach einem Algorithmus fragen würden, der alle Fehler in jedem Film identifizieren kann, würden sie wahrscheinlich sagen, dass sie keine Ahnung haben, wie man einen solchen Algorithmus konzipieren kann, da es eine Aufgabe zu sein scheint, die menschliche Intelligenz erfordert. Wenn Sie das Problem jedoch in eines transformieren, bei dem Sie nur Menschen haben möchten, die darauf trainiert werden können, sehr gut darin zu sein, Filmfehler zu identifizieren, wird die Aufgabe viel einfacher. Es ist sehr einfach vorstellbar, dass Sie ein Handbuch aller Tricks zur Identifizierung von Filmfehlern konsolidieren können. Sie müssen keine Menschen haben, die außergewöhnlich intelligent sind, um diese Arbeit zu leisten; Sie brauchen nur Menschen, die vernünftig intelligent und engagiert sind. Darum geht es genau.
Wie sieht die Situation also aus einer Supply-Chain-Perspektive aus? Wenn wir das Problem konkret untersuchen wollen, werden wir grundsätzlich nach Ausreißern suchen. Wir müssen nur mit einem Winkel beginnen. Nehmen wir zum Beispiel die Paris-Persona, die ich vor zwei Wochen vorgestellt habe. Dies ist ein Modeunternehmen, das ein großes Einzelhandelsnetzwerk von Modegeschäften betreibt. Nehmen wir zum Beispiel an, dass wir uns um die Servicequalität kümmern.
Beginnen wir mit Stockouts. Wenn wir nur eine Abfrage über alle Produkte und alle Geschäfte machen, werden wir sehen, dass wir Tausende von Stockouts im Netzwerk haben. Es hilft also nicht wirklich; wir haben Tausende von ihnen, und die Antwort lautet “und was dann?” Vielleicht geht es nicht nur um die Stockouts; was wirklich interessant ist, sind die Stockouts in den Power-Stores, den Geschäften, die viel verkaufen. Dort ist es wichtig, und nicht die Stockouts für irgendwelche Produkte, sondern für die Top-Seller. Lassen Sie uns unsere Suche nach den Stockouts, die in den Power-Stores für die Top-Seller auftreten, eingrenzen.
Dann können wir uns ein SKU ansehen, bei dem der Bestand zufällig null beträgt. Aber bei genauerer Betrachtung werden wir sehen, dass der Bestand vielleicht am Anfang des Tages tatsächlich drei Einheiten betrug und die letzte Einheit nur 30 Minuten vor Schließung des Geschäfts verkauft wurde. Wenn wir genauer hinschauen, werden wir sehen, dass drei Einheiten am nächsten Tag aufgefüllt werden. Hier haben wir also eine Situation, in der wir einen Stockout sehen, aber ist es wirklich wichtig? Nun, es stellt sich heraus, dass es nicht wirklich wichtig ist, weil die letzte Einheit kurz vor Schließung des Geschäfts am Abend verkauft wurde und die Menge aufgefüllt werden soll. Darüber hinaus werden wir, wenn wir weiter suchen, sehen, dass vielleicht nicht genug Platz im Geschäft ist, um mehr als drei Einheiten unterzubringen, also sind wir hier eingeschränkt.
Also ist das nicht wirklich ein signifikantes Problem. Vielleicht sollten wir die Suche auf Stockouts eingrenzen, bei denen wir die Möglichkeit hatten, aufzufüllen - Top-Store, Top-Produkt -, aber wir haben es nicht getan. Wir finden ein Beispiel für ein solches gegebenes SKU, und dann sehen wir, dass im Distributionszentrum kein Bestand mehr vorhanden ist. Ist es also in diesem Fall wirklich ein Problem? Wir könnten sagen nein, aber Moment mal. Wir haben keinen Bestand im Distributionszentrum, aber für dasselbe Produkt werfen wir einen Blick auf das Netzwerk im Allgemeinen. Haben wir noch irgendwo Bestand?
Angenommen, für dieses Produkt - Top-Produkt, Top-Store - haben wir viele schwache Geschäfte, die noch viel Inventar für dasselbe Produkt haben, aber sie drehen sich einfach nicht. Hier sehen wir, dass wir tatsächlich ein Problem haben. Das Problem war nicht, dass dem Top-Store nicht genügend Bestand zugewiesen wurde; das Problem war, dass zu viel Bestand zugewiesen wurde, wahrscheinlich während der anfänglichen Zuweisung an die Geschäfte für die neue Kollektion, für sehr schwache Geschäfte. So gehen wir Schritt für Schritt vor, um die Ursache des Problems zu identifizieren. Wir können es bis zu einem Qualitätsproblem zurückverfolgen, das nicht durch das Senden von zu wenig Bestand, sondern im Gegenteil durch das Senden von zu viel verursacht wird, was sich auf die Qualität des Service auf Systemebene für diese Power-Stores auswirkt.
Was ich hier gemacht habe, ist genau das Gegenteil von Statistik, und das ist etwas Wichtiges, wenn wir nach “verrückten” Entscheidungen suchen. Sie möchten die Daten nicht aggregieren; im Gegenteil, Sie möchten an Daten arbeiten, die vollständig disaggregiert sind, damit sich alle Probleme manifestieren. Sobald Sie anfangen, die Daten zu aggregieren, verschwinden diese subtilen Verhaltensweisen normalerweise. Der Trick besteht normalerweise darin, auf der am stärksten disaggregierten Ebene zu beginnen und das Netzwerk durchzugehen, um genau herauszufinden, was los ist, nicht auf statistischer Ebene, sondern auf einer sehr grundlegenden, elementaren Ebene, auf der Sie verstehen können.
Diese Methode eignet sich auch sehr gut für die Perspektive, die ich in der quantitativen Supply Chain eingeführt habe, wo ich sage, dass Sie wirtschaftliche Treiber haben müssen. Es sind alle möglichen Zukünfte, alle möglichen Entscheidungen, und dann bewerten Sie alle Entscheidungen nach den wirtschaftlichen Treibern. Es stellt sich heraus, dass diese wirtschaftlichen Treiber sehr nützlich sind, wenn es darum geht, all diese SKUs, Entscheidungen und Ereignisse zu sortieren, die in der Supply Chain auftreten. Sie können sie nach abnehmenden Dollar-Auswirkungen sortieren, und das ist ein sehr leistungsfähiger Mechanismus, auch wenn die wirtschaftlichen Treiber teilweise falsch oder unvollständig sind. Es stellt sich als sehr effektive Methode heraus, um mit hoher Produktivität zu untersuchen und zu diagnostizieren, was in einer bestimmten Supply Chain passiert.
Wenn Sie im Laufe der Initiativen, bei denen Sie diese experimentelle Optimierungsmethode einführen, “verrückte” Entscheidungen untersuchen, gibt es einen allmählichen Übergang von wirklich verrückten, dysfunktionalen Entscheidungen zu Entscheidungen, die einfach schlecht sind. Sie werden Ihr Unternehmen nicht sprengen, aber sie sind einfach nicht sehr gut.

Hier haben wir eine tiefgreifende Abweichung von der mathematischen Optimierungsperspektive für die Supply Chain.
Bei der experimentellen Optimierung hat die Verlustfunktion selbst, weil die experimentelle Optimierung intern mathematische Optimierungswerkzeuge verwendet, in der Regel einen mathematischen Optimierungskomponenten. Aber es ist nur ein Mittel, kein Ziel, das Ihren Prozess unterstützt. Anstatt die mathematische Optimierungsperspektive zu durchlaufen, bei der Sie Ihr Problem angeben und dann optimieren, fordern Sie hier wiederholt heraus, was Sie über das Problem selbst verstehen, und modifizieren die Verlustfunktion selbst.
Um an Verständnis zu gewinnen, müssen Sie praktisch alles instrumentieren. Sie müssen Ihren Optimierungsprozess selbst, Ihr numerisches Rezept selbst und alle Arten von Merkmalen instrumentieren, die Sie über die Daten haben, mit denen Sie spielen. Es ist sehr interessant, denn aus historischer Sicht, wenn Sie sich viele der größten wissenschaftlichen Entwicklungen ansehen, bei denen bedeutende Entdeckungen gemacht wurden, gab es in der Regel einige Jahrzehnte vor diesen Entdeckungen einen Durchbruch in Bezug auf die Instrumentierung. Wenn es darum geht, Wissen zu entdecken, entdecken Sie in der Regel zuerst eine neue Möglichkeit, das Universum zu beobachten, machen einen Durchbruch auf der Instrumentierungsebene und können dann tatsächlich Ihren Durchbruch in dem machen, was in der Welt von Interesse ist. Das ist wirklich das, was hier vor sich geht. Übrigens hat Galileo die meisten seiner Entdeckungen gemacht, weil er der erste Mensch war, der ein Teleskop seiner eigenen Herstellung zur Verfügung hatte, und so hat er zum Beispiel die Monde des Jupiter entdeckt. All diese Metriken sind die Instrumente, die Ihre Reise wirklich vorantreiben.

Die Herausforderung besteht nun darin, dass die experimentelle Optimierung ein iterativer Prozess ist. Die Frage, die hier sehr wichtig ist, ist, ob wir eine Bürokratie gegen eine andere tauschen. Eine meiner größten Kritiken an der Mainstream-Supply-Chain-Management ist, dass wir eine Bürokratie von Menschen haben, die nur Feuerwehr spielen, sich täglich durch all diese Ausnahmen kämpfen und ihre Arbeit nicht kapitalistisch ist. Ich habe die kontrastierende Perspektive des Supply Chain Scientist vorgestellt, bei der ihre Arbeit kapitalistisch akkretiv sein soll. Es kommt jedoch wirklich darauf an, welche Produktivität mit Supply Chain Scientists erreicht werden kann, und diese Menschen müssen sehr produktiv sein.
Hier gebe ich Ihnen eine kurze Liste von KPIs für das, was diese Produktivität beinhaltet. Zunächst möchten Sie wirklich in der Lage sein, die Datenpipelines in weniger als einer Stunde von Anfang bis Ende zu durchlaufen. Wie ich sagte, ist eine der Hauptursachen für Wahnsinn die Semantik der Daten. Wenn Sie erkennen, dass Sie ein Problem auf der semantischen Ebene haben, möchten Sie es auf die Probe stellen, und Sie müssen die gesamte Datenpipeline mehrmals am Tag neu ausführen. Ihr Supply-Chain-Team oder Supply-Chain-Scientist muss dazu in der Lage sein.
Wenn es um das numerische Rezept geht, das die Optimierung selbst durchführt, ist zu diesem Zeitpunkt die Daten bereits vorbereitet und konsolidiert, sodass es sich um einen Teil der gesamten Datenpipeline handelt. Sie benötigen eine sehr große Anzahl von Iterationen, sodass Sie jeden Tag Dutzende von Iterationen durchführen möchten. Echtzeit wäre fantastisch, aber die Realität ist, dass die lokale Optimierung in der Supply Chain nur Probleme verdrängt. Sie benötigen eine ganzheitliche Perspektive, und das Problem bei naiven oder trivialen Modellen Ihrer Supply Chain besteht darin, dass sie nicht sehr gut in Bezug auf ihre Fähigkeit sind, alle Komplexitäten in Supply Chains zu erfassen. Sie haben einen Kompromiss zwischen der Ausdrucksfähigkeit und Kapazität des numerischen Rezepts und der Zeit, die für die Aktualisierung benötigt wird. In der Regel ist das Gleichgewicht gut, solange Sie die Berechnung innerhalb weniger Minuten durchführen.
Schließlich, und dieser Punkt wurde auch in der Vorlesung über produktorientierte Softwarelieferung für die Supply Chain behandelt, müssen Sie wirklich in der Lage sein, jeden Tag ein neues Rezept in die Produktion zu bringen. Es geht nicht unbedingt darum, das zu empfehlen, sondern vielmehr darum, dass Sie in der Lage sein müssen, das zu tun, weil unerwartete Ereignisse eintreten werden. Es kann eine Pandemie sein, oder manchmal ist es nicht so extravagant. Es besteht immer die Möglichkeit, dass ein Lagerhaus überflutet wird, Sie einen Produktionsvorfall haben oder eine große Überraschungsförderung von einem Konkurrenten erhalten. Es können alle möglichen Dinge passieren und Ihren Betrieb stören, daher müssen Sie in der Lage sein, sehr schnell Korrekturmaßnahmen anzuwenden. Das bedeutet, dass Sie eine Umgebung benötigen, in der es möglich ist, jeden Tag eine neue Iteration Ihres Supply-Chain-Rezepts live zu schalten.

Die Praxis der experimentellen Optimierung ist interessant. Der Ansatz von Lokad war eine aufkommende Praxis und hat sich in den letzten zehn Jahren allmählich in die tägliche Praxis eingefügt. In den frühen Jahren hatten wir so etwas wie einen proto-experimentellen Optimierungsprozess. Der Hauptunterschied bestand darin, dass wir immer noch iterierten, aber mathematische Supply-Chain-Modelle aus der Supply-Chain-Literatur verwendeten. Es stellte sich heraus, dass diese Modelle in der Regel monolithisch sind und sich nicht für den sehr iterativen Prozess eignen, den ich mit experimenteller Optimierung beschreibe. Als Ergebnis haben wir iteriert, aber wir waren weit davon entfernt, jeden Tag ein neues Rezept in die Produktion zu bringen. Es dauerte eher mehrere Monate, um ein neues Rezept zu erstellen. Wenn Sie sich die Reise auf der Lokad-Website ansehen, die wir unternommen haben, sind die aufeinanderfolgenden Iterationen, die wir auf unserem Prognose-Engine hatten, eine Reflexion dieses Ansatzes. Es dauerte im Grunde 18 Monate, um von einer Prognose-Engine zur nächsten Generation von Prognose-Engines zu gelangen, mit einer kurzen Serie von vielleicht einer großen Iteration pro Quartal oder so.
Das war das, was vorher kam, und wo das Spiel wirklich geändert wurde, war mit der Einführung von Programmierparadigmen. Es gibt eine frühere Vorlesung in meinem Prolog, in der ich Programmierparadigmen für die Supply Chain eingeführt habe. Jetzt sollte es mit dieser Vorlesung klarer werden, warum uns diese Programmierparadigmen so wichtig sind. Sie sind es, die diese experimentelle Optimierungsmethode antreiben. Es sind die Paradigmen, die Sie benötigen, um ein numerisches Rezept zu erstellen, bei dem Sie effizient jeden Tag iterieren können, um all diese verrückten Entscheidungen loszuwerden und auf etwas zuzusteuern, das wirklich einen großen Wert für die Supply Chain schafft.
Nun, experimentelle Optimierung in freier Wildbahn, nun, meine Überzeugung ist, dass es etwas ist, das entstanden ist. Es wurde nicht wirklich bei Lokad erfunden; es ist eher dort entstanden, weil wir immer wieder mit unseren eigenen Unzulänglichkeiten bei tatsächlichen Supply-Chain-Entscheidungen konfrontiert wurden. Ich vermute stark, dass andere Unternehmen, die denselben Kräften ausgesetzt sind, ihre eigenen experimentellen Optimierungsprozesse entwickelt haben, die nur eine Art Variante dessen sind, was ich Ihnen heute vorgestellt habe.
Hier, wenn Sie sich die Tech-Giganten wie GAFA ansehen, habe ich Kontakte dort, die, ohne Geschäftsgeheimnisse preiszugeben, darauf hinweisen, dass diese Art von Praxis unter verschiedenen Namen existiert, aber bereits sehr präsent in diesen Tech-Giganten ist. Sie können das sogar als externer Beobachter sehen, indem Sie feststellen, dass viele der von ihnen veröffentlichten Open-Source-Tools Tools sind, die wirklich Sinn ergeben, wenn Sie darüber nachdenken, welche Art von Tools Sie haben möchten, wenn Sie Initiativen im Rahmen dieser experimentellen Optimierungsmethode durchführen möchten. PyTorch ist zum Beispiel kein Modell; es ist eine Metalösung, ein Programmierparadigma zur Durchführung von maschinellem Lernen, das also in dieses Framework passt.
Dann fragen Sie sich vielleicht, warum es, wenn es so erfolgreich ist, nicht mehr als solches anerkannt wird. Wenn es darum geht, experimentelle Optimierung in freier Wildbahn zu erkennen, ist es schwierig. Wenn Sie einen Momentaufnahme eines Unternehmens zu einem bestimmten Zeitpunkt machen, sieht es genau wie die mathematische Optimierungsperspektive aus. Wenn Lokad zum Beispiel eine Momentaufnahme eines der von uns bedienten Unternehmen macht, haben wir zu diesem Zeitpunkt eine Problemstellung und eine von uns vorgeschlagene Lösung. Zu diesem Zeitpunkt sieht die Situation also genau wie die mathematische Optimierungsperspektive aus. Dies ist jedoch nur die statische Perspektive. Sobald Sie jedoch die Zeitdimension und die Dynamik betrachten, ist es radikal anders.
Außerdem ist es wichtig zu beachten, dass es sich zwar um einen iterativen Prozess handelt, aber nicht um einen konvergenten Prozess. Das kann ein wenig beunruhigend sein. Die Idee, dass Sie einen iterativen Prozess haben können, der zu etwas Optimalen konvergiert, ist so, als würde man sagen, dass es eine harte Grenze für menschliche Einfallsreichtum gibt. Ich glaube, dass dies eine extravagante Behauptung ist. Supply-Chain-Probleme sind böse, daher gibt es keine Konvergenz, nur weil es immer Dinge gibt, die das Spiel radikal verändern können. Es handelt sich nicht um ein eng definiertes Problem, bei dem Sie irgendeine Hoffnung haben können, die optimale Lösung zu finden. Ein weiterer Faktor, warum es in der Praxis keine Konvergenz gibt, ist, dass sich die Welt ständig verändert. Ihre Lieferkette arbeitet nicht in einem Vakuum; Ihre Lieferanten, Kunden und Landschaft ändern sich. Was auch immer numerische Rezepte Sie zu einem bestimmten Zeitpunkt hatten, kann anfangen, verrückte Entscheidungen zu treffen, nur weil sich die Marktbedingungen geändert haben, und was in der Vergangenheit vernünftig war, ist es nicht mehr. Sie müssen sich an die aktuelle Situation anpassen. Schauen Sie sich nur an, was 2020 mit der Pandemie passiert ist; offensichtlich gab es so viele Veränderungen, dass etwas Vernünftiges vor der Pandemie währenddessen nicht mehr vernünftig bleiben konnte. Das Gleiche wird wieder passieren.
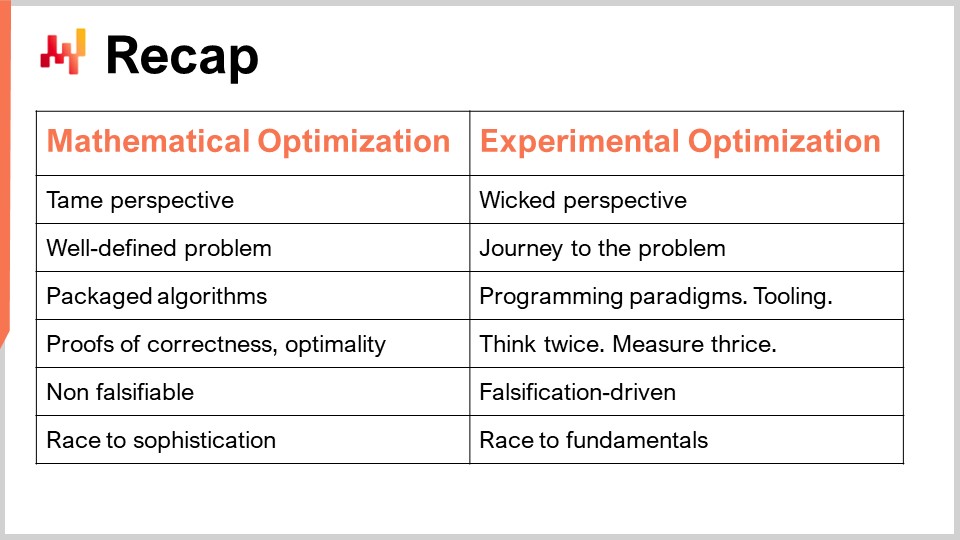
Zusammenfassend haben wir zwei verschiedene Perspektiven: die mathematische Optimierungsperspektive, bei der wir es mit wohldefinierten Problemen zu tun haben, und die experimentelle Optimierungsperspektive, bei der das Problem böse ist. Sie können das Problem nicht einmal definieren; Sie können nur auf das Problem zugehen. Als Folge davon, dass Sie ein wohldefiniertes Problem innerhalb der mathematischen Optimierungsperspektive haben, können Sie einen klaren Algorithmus als die von Ihnen bereitgestellte Lösung haben und ihn in einem Stück Software verpacken, um dessen Korrektheit und Optimalität zu beweisen. In der Welt der experimentellen Optimierung können Sie jedoch nicht alles verpacken, da es viel zu komplex ist. Was Sie haben können, sind Programmierparadigmen, Tools, Infrastruktur, und dann geht es immer um menschliche Intelligenz. Es geht darum, zweimal nachzudenken, dreimal zu messen und einen Schritt nach vorne zu machen. Es gibt nichts, was automatisiert werden kann; es kommt alles auf die menschliche Intelligenz des Supply-Chain-Wissenschaftlers an.
In Bezug auf Falsifizierbarkeit ist meine Hauptthese, dass die mathematische Optimierungsperspektive keine Wissenschaft ist, weil Sie nichts falsifizieren können, was sie produziert. Am Ende haben Sie also ein Rennen um die Raffinesse - Sie wollen Modelle, die immer komplexer sind, aber es ist nicht so, dass sie aufgrund ihrer Raffinesse wissenschaftlicher sind oder mehr Wert für das Unternehmen schaffen. Im scharfen Gegensatz dazu ist die experimentelle Optimierung falsifikationsgetrieben. Alle Iterationen werden durch die Tatsache angetrieben, dass Sie Ihre numerischen Rezepte dem Test der realen Welt unterziehen, Entscheidungen generieren und die richtigen Entscheidungen identifizieren. Dieser experimentelle Test kann mehrmals täglich durchgeführt werden, um Ihre Theorie herauszufordern und sie immer wieder falsch zu beweisen, von dort aus zu iterieren und hoffentlich dabei viel Wert zu liefern.
Es ist interessant, weil es in Bezug auf das Endspiel bei der experimentellen Optimierung kein Rennen um die Raffinesse ist; es ist ein Rennen um die Grundlagen. Es geht darum zu verstehen, was Ihre Lieferkette antreibt, die grundlegenden Elemente, die die Lieferkette regieren, und genau zu verstehen, wie Sie verstehen sollten, was in Ihren numerischen Rezepten vor sich geht, damit sie nicht weiterhin diese verrückten Entscheidungen treffen, die Ihrer Lieferkette schaden. Letztendlich möchten Sie etwas sehr Gutes für Ihre Lieferkette produzieren.

Dies war eine lange Vorlesung, aber die Quintessenz sollte sein, dass mathematische Optimierung eine Illusion ist. Es ist eine verführerische, anspruchsvolle und attraktive Illusion, aber dennoch eine Illusion. Experimentelle Optimierung ist meiner Meinung nach die reale Welt. Wir verwenden sie seit fast einem Jahrzehnt, um den Prozess für echte Unternehmen zu unterstützen. Lokad ist nur ein Datenpunkt, aber aus meiner Sicht ist es ein sehr überzeugender Datenpunkt. Es geht wirklich darum, einen Vorgeschmack auf die reale Welt zu bekommen. Übrigens ist dieser Ansatz brutal hart für Sie, denn wenn Sie in die reale Welt gehen, schlägt die Realität zurück. Sie hatten Ihre schönen Theorien darüber, welche Art von numerischem Rezept zur Steuerung und Optimierung der Lieferkette funktionieren sollte, und dann schlägt die Realität zurück. Es kann zuweilen unglaublich frustrierend sein, weil die Realität immer Wege findet, alle cleveren Dinge rückgängig zu machen, an die Sie denken könnten. Dieser Prozess ist viel frustrierender, aber ich glaube, dass dies die Dosis an Realität ist, die wir brauchen, um tatsächlich echte, profitable Renditen für Ihre Lieferketten zu liefern. Meine Meinung ist, dass es in Zukunft einen Punkt geben wird, an dem die experimentelle Optimierung oder vielleicht ein Nachkomme dieser Methode die mathematische Optimierungsperspektive bei der Untersuchung und Praxis von Lieferketten vollständig übertrifft.

In den kommenden Vorlesungen werden wir die tatsächlichen Methoden, numerischen Methoden und numerischen Werkzeuge überprüfen, die wir verwenden können, um diese Praxis zu unterstützen. Die heutige Vorlesung befasste sich nur mit der Methode; später werden wir uns mit dem Know-how und den Taktiken befassen, die erforderlich sind, um sie zum Funktionieren zu bringen. Die nächste Vorlesung wird in zwei Wochen stattfinden, am selben Tag und zur gleichen Zeit, und wird sich mit negativem Wissen in der Lieferkette befassen.
Nun lasst uns einen Blick auf die Fragen werfen.
Frage: Wenn Lieferkettenpapiere keine Chance haben, auch nur entfernt mit der Realität verbunden zu werden, und jeder reale Fall unter NDA stehen würde, was würden Sie denen vorschlagen, die Lieferkettenstudien durchführen und ihre Ergebnisse veröffentlichen möchten?
Meine Empfehlung ist, dass Sie die Methode herausfordern müssen. Die Methoden, die wir haben, sind nicht geeignet, um Lieferketten zu studieren. Ich habe in dieser Vorlesungsreihe zwei Möglichkeiten vorgestellt: das Lieferkettenpersonal und die experimentelle Optimierung. Es gibt noch viel zu tun, basierend auf diesen Methoden. Das sind nur zwei Methoden; Ich bin ziemlich sicher, dass es noch viele weitere gibt, die noch entdeckt oder erfunden werden müssen. Meine Empfehlung wäre, herauszufordern, was eine Disziplin zu einer tatsächlichen Wissenschaft macht.
Frage: Wenn mathematische Optimierung nicht die beste Reflexion dessen ist, wie die Lieferkette in der realen Welt funktionieren sollte, warum wäre die Deep-Learning-Methode besser? Entscheidet Deep Learning nicht auf der Grundlage früherer optimaler Entscheidungen?
In dieser Vorlesung habe ich einen klaren Unterschied zwischen mathematischer Optimierung als eigenständigem Forschungsfeld und Deep Learning als eigenständigem Forschungsfeld und mathematischer Optimierung als Perspektive angewendet auf die Lieferkette gemacht. Ich kritisiere nicht, dass mathematische Optimierung als Forschungsfeld ungültig ist; ganz im Gegenteil. In dieser experimentellen Optimierungsmethode, über die ich spreche, haben Sie im Kern des numerischen Rezepts in der Regel einen mathematischen Optimierungsalgorithmus. Der Punkt ist die mathematische Optimierung als Perspektive; das ist es, was ich hier herausfordere. Ich weiß, es ist subtil, aber das ist ein entscheidender Unterschied, den ich mache. Deep Learning ist eine Hilfswissenschaft. Deep Learning ist ein eigenständiges Forschungsfeld, genauso wie mathematische Optimierung ein eigenständiges Forschungsfeld ist. Sie sind beide großartige Forschungsfelder, aber sie sind völlig unabhängig und unterscheiden sich von Lieferkettenstudien. Was uns heute wirklich betrifft, ist die quantitative Verbesserung von Lieferketten. Darum geht es mir - Methoden zur quantitativen Verbesserung von Lieferketten auf kontrollierte, zuverlässige und messbare Weise. Das steht hier auf dem Spiel.
Frage: Kann das Verstärkungslernen der richtige Ansatz für das Lieferkettenmanagement sein?
Zunächst würde ich sagen, dass es wahrscheinlich der richtige Ansatz für die Optimierung der Lieferkette ist. Das ist eine Unterscheidung, die ich in einer meiner früheren Vorlesungen gemacht habe - aus der Sicht der Software haben Sie die Managementseite mit Enterprise Resource Management und dann haben Sie die Optimierungsseite. Verstärkungslernen ist ein weiteres Forschungsfeld, das auch Elemente des Deep Learning und der mathematischen Optimierung nutzen kann. Es ist die Art von Zutat, die Sie in dieser experimentellen Optimierungsmethode verwenden können. Der entscheidende Teil wird sein, ob Sie die Programmierparadigmen haben, die diese Verstärkungslern-Techniken auf eine Weise importieren können, in der Sie sehr fließend und iterativ arbeiten können. Das ist eine große Herausforderung. Sie möchten in der Lage sein, zu iterieren, und wenn Sie etwas haben, das ein komplexes, monolithisches Verstärkungslernmodell ist, werden Sie kämpfen, genau wie Lokad in den frühen Jahren, als wir versuchten, diese Art von monolithischen Modellen zu verwenden, bei denen unsere Iterationen sehr langsam waren. Eine Reihe von technischen Durchbrüchen war erforderlich, um die Iteration zu einem viel flüssigeren Prozess zu machen.
Frage: Ist die mathematische Optimierung ein integraler Bestandteil des Verstärkungslernens?
Ja, Verstärkungslernen ist ein Teilbereich des maschinellen Lernens, und maschinelles Lernen kann in gewisser Weise als Teilbereich der mathematischen Optimierung betrachtet werden. Der Punkt ist jedoch, dass, wenn Sie das tun, alles innerhalb von allem ist, und was diese Felder wirklich voneinander unterscheidet, ist, dass sie nicht dieselbe Perspektive auf das Problem annehmen. Alle diese Felder sind miteinander verbunden, aber in der Regel ist das, was sie wirklich voneinander unterscheidet, die Absicht, die Sie haben.
Frage: Wie definieren Sie eine wahnsinnige Entscheidung im Kontext von Deep-Learning-Methoden, die oft viele Entscheidungen vorausdenken?
Eine wahnsinnige Entscheidung hängt von zukünftigen Entscheidungen ab. Das ist genau das, was ich in dem Beispiel demonstriert habe, als ich sagte: “Ist ein Lagerbestandsausfall ein Problem?” Nun, es ist kein Problem, wenn Sie sehen, dass die nächste Entscheidung, die getroffen wird, eine Auffüllung ist. Also, ob ich diese Situation als wahnsinnig qualifiziert habe oder nicht, hing tatsächlich von einer Entscheidung ab, die getroffen werden sollte. Das erschwert die Untersuchung, aber genau darum geht es, wenn ich sage, dass Sie sehr gute Instrumentierung haben müssen. Zum Beispiel bedeutet dies, dass Sie bei der Untersuchung einer Out-of-Stock-Situation in der Lage sein müssen, die zukünftigen Entscheidungen zu projizieren, die Sie treffen werden, damit Sie nicht nur die Daten haben, die Sie haben, sondern auch die Entscheidungen, die Sie nach Ihrer gegenwärtigen numerischen Rezeptur treffen werden. Es geht also darum, geeignete Instrumentierung zu haben, und auch das ist keine leichte Aufgabe. Es erfordert menschenähnliche Intelligenz; Sie können das nicht einfach automatisieren.
Frage: Wie funktionieren experimentelle Optimierung, Identifizierung von Wahnsinn und Lösungsfindung in der Praxis? Ich kann nicht darauf warten, dass der Wahnsinn in der Realität auftritt, oder?
Absolut richtig. Wenn ich zum Anfang dieser Vorlesung zurückkehre, habe ich zwei Gruppen von Menschen erwähnt: moderne Physiker und Marxisten. Die Gruppe der Physiker, als ich sagte, dass sie richtige Wissenschaft betreiben, waren nicht passiv und warteten darauf, dass ihre Theorien widerlegt wurden. Sie haben sich alle Mühe gegeben, unglaublich clevere Experimente zu entwerfen, die eine Chance hatten, ihre Theorien zu widerlegen. Es war ein sehr proaktiver Mechanismus.
Wenn Sie sich ansehen, was Albert Einstein während eines Großteils seines Lebens getan hat, war es, clevere Wege zu finden, um die Theorien der Physik, die er zumindest teilweise erfunden hatte, auf die Probe von Experimenten zu stellen. Also ja, Sie warten nicht darauf, dass die wahnsinnige Entscheidung passiert. Deshalb müssen Sie in der Lage sein, Ihr Rezept immer wieder auszuführen und Zeit investieren, um nach der wahnsinnigen Entscheidung zu suchen. Natürlich gibt es Entscheidungen, wie die mit Unpraktikabilitäten, bei denen es keine Hoffnung gibt - Sie müssen es in der Produktion tun, und dann wird die Welt zurückschlagen. Aber für die große Mehrheit können wahnsinnige Entscheidungen identifiziert werden, indem man Tag für Tag Experimente durchführt. Aber Sie brauchen Daten, und Sie müssen den realen Prozess haben, der die realen Entscheidungen generiert, die in die Produktion übernommen werden könnten.
Frage: Wenn ein Rezept aufgrund einer mathematischen Methode und/oder Perspektive gebrochen werden könnte und Sie diese andere Perspektive nicht kennen, wie können Sie entdecken, dass Sie ein Perspektivenproblem und kein Methodenproblem haben, und sich selbst dazu bringen, eine andere Perspektive zu entdecken, die besser zum Problem passt?
Das ist ein sehr großes Problem. Wie können Sie etwas sehen, das nicht da ist? Wenn ich zum Beispiel auf das Personal der Supply Chain von Paris zurückkomme, ein Modeunternehmen, das Einzelhandelsgeschäfte betreibt, stellen wir uns für einen Moment vor, dass Sie vergessen haben, über den langfristigen Effekt nachzudenken, den Sie auf die Gewohnheiten Ihrer Kunden haben, indem Sie End-of-Season-Rabatte geben. Sie erkennen nicht, dass Sie eine Gewohnheit aus Ihrer Kundenbasis schaffen. Wie können Sie jemals darauf kommen? Dies ist ein Problem der allgemeinen Intelligenz. Es gibt keine magische Lösung.
Sie müssen brainstormen, und übrigens ist die sehr konkrete Antwort von Lokad, dass das Unternehmen in Paris ansässig ist. Wir bedienen Kunden in 20-something entfernten Ländern, darunter Australien, Russland, die USA und Kanada. Warum habe ich all meine Teams von Supply Chain Scientists an einem Ort in Paris zusammengeführt, obwohl es mit der Pandemie etwas komplizierter ist und es viel Remote-Arbeit gibt? Aber warum habe ich all diese Supply Chain Scientists an einem Ort zusammengebracht, anstatt sie überall auszulagern? Die Antwort war, dass ich diese Leute an einem Ort brauchte, damit sie sprechen, brainstormen und neue Ideen entwickeln können. Auch das ist eine sehr low-tech Lösung, aber ich kann wirklich keine bessere versprechen. Wenn es etwas gibt, das Sie nicht sehen können, wie zum Beispiel die Notwendigkeit, über die langfristigen Auswirkungen nachzudenken, und Sie haben es einfach vergessen oder nie daran gedacht, kann dieses Problem sehr offensichtlich und vermisst sein. In einem meiner früheren Vorträge gab ich das Beispiel des Koffers. Es dauerte 5000 Jahre, um die Erfindung zu machen, dass es eine gute Idee wäre, Räder an Koffern anzubringen. Die Räder wurden vor Tausenden von Jahren erfunden, und die bessere Version des Koffers wurde Jahrzehnte nach der Landung von Menschen auf dem Mond erfunden. Das ist die Art von Dingen, bei denen es etwas Offensichtliches geben könnte, das Sie nicht sehen. Es gibt kein Rezept dafür; es ist einfach menschliche Intelligenz. Sie tun einfach, was Sie haben.
Frage: Werden sich ständig ändernde Bedingungen dazu führen, dass die optimale Lösung für Ihre Supply Chain ständig veraltet ist, oder?
Ja und nein. Aus der Perspektive der experimentellen Optimierung gibt es keine optimale Lösung. Sie haben optimierte Lösungen, aber der Unterschied macht alles aus. Optimierte Lösungen sind bei weitem nicht optimal. Optimal zu sein, ist wie zu sagen, und ich wiederhole mich, dass es eine harte Grenze für menschliche Einfallsreichtum gibt. Also gibt es nichts Optimales; es ist nur optimiert. Und ja, mit jedem einzelnen Tag entfernt sich der Markt von all den Experimenten, die Sie bisher durchgeführt haben. Die reine Evolution der Welt degradiert einfach die von Ihnen produzierte Optimierung. Das ist einfach die Art und Weise, wie die Welt ist. Es gibt Tage, an denen eine Pandemie passiert, und die Abweichung beschleunigt sich enorm. Auch das ist einfach die Art und Weise, wie die Welt ist. Die Welt verändert sich, und so muss sich Ihre numerische Rezeptur damit ändern. Dies ist eine externe Kraft, also ja, es gibt kein Entkommen; die Lösung muss ständig überarbeitet werden.
Das ist einer der Gründe, warum Lokad ein Abonnement verkauft und unseren Kunden sagt: “Nein, wir können Ihnen keinen Supply Chain Scientist nur für die Implementierungsphase verkaufen. Das ist Unsinn. Die Welt wird sich weiter verändern; dieser Supply Chain Scientist, der die numerische Rezeptur entwickelt hat, muss bis ans Ende der Zeit oder bis Sie genug von uns haben, da sein.” Diese Person wird in der Lage sein, die numerische Rezeptur anzupassen. Es gibt kein Entkommen; dies ist einfach die sich ständig verändernde externe Welt.
Frage: Die Reise zum Problem, während korrekt, treibt Senior Manager verrückt. Sie können es einfach nicht verstehen; sie denken: “Wie können Sie das Problem mehrmals im Projektleben überprüfen?” Welche bekannten Analogien aus dem Leben würden Sie vorschlagen, um diese Gespräche zu führen und zu beweisen, dass es ein breit existierendes Problem ist?
Zunächst einmal habe ich genau das in der letzten Folie gesagt, wo ich den Screenshot von The Matrix gezeigt habe. Irgendwann müssen Sie sich entscheiden, ob Sie in einer Fantasiewelt oder in der realen Welt leben möchten. Das Management, hoffentlich, wenn Ihr oberes Management in Ihrem Unternehmen nur aus Idioten besteht, ist mein einziger Vorschlag, dass Sie besser zu einem anderen Unternehmen gehen sollten, weil ich nicht sicher bin, dass dieses Unternehmen lange existieren wird. Aber die Realität ist, dass ich denke, dass Manager keine Narren sind. Sie wollen sich nicht mit erfundenen Problemen befassen. Wenn Sie Manager in einem großen Unternehmen sind, haben Sie zehnmal am Tag Leute, die mit einem “großen Problem” zu Ihnen kommen, das kein echtes Problem ist. Die Reaktion des Managements, die eine richtige Reaktion ist, lautet: “Es gibt überhaupt kein Problem, machen Sie einfach weiter, was Sie getan haben. Entschuldigung, ich habe keine Zeit, um mit Ihnen die Welt neu zu gestalten. Das ist einfach nicht die richtige Art, das Problem anzugehen.” Sie haben Recht, das zu tun, weil sie es durch jahrzehntelange Erfahrung sortieren können. Sie haben bessere Heuristiken als diejenigen weiter unten in der Hierarchie.
Aber manchmal gibt es eine sehr reale Sorge. Zum Beispiel ist Ihre Frage, wie Sie das obere Management vor zwei Jahrzehnten davon überzeugen können, dass E-Commerce in zwei Jahrzehnten eine dominierende Kraft sein wird, mit der man rechnen muss? Irgendwann müssen Sie einfach klug Ihre Kämpfe auswählen. Wenn Ihr oberes Management kein Narr ist und Sie gut vorbereitet zu einem Meeting kommen und sagen: “Hey Chef, ich habe dieses Problem. Es ist kein Witz. Es ist ein sehr wichtiges Anliegen mit Millionen von Dollar im Spiel. Ich mache keinen Witz. Das sind Tonnen von Geld, die wir auf dem Tisch liegen lassen. Schlimmer noch, ich vermute, dass die meisten unserer Konkurrenten uns das Wasser abgraben werden, wenn wir nichts tun. Das ist kein kleiner Punkt; das ist ein sehr reales Problem. Ich brauche 20 Minuten Ihrer Aufmerksamkeit.” Wiederum ist es in großen Unternehmen selten, dass das obere Management eine Gruppe von vollständigen Idioten ist. Sie sind vielleicht beschäftigt, aber sie sind keine Idioten.
Frage: Was wäre die richtige Landschaft von Tools für Fertigungsunternehmen: experimentelle Optimierung wie Lokad, plus ERP, plus Visualisierung? Was ist mit der Rolle von gleichzeitigen Planungssystemen online?
Die große Mehrheit unserer Konkurrenten stimmt mit der mathematischen Optimierungsperspektive in Bezug auf Supply Chains überein. Sie haben das Problem definiert und Software implementiert, um das Problem zu lösen. Was ich sage, ist, dass wenn sie die Software auf die Probe stellen und sie unweigerlich Tonnen von verrückten Entscheidungen produziert, sagen sie: “Oh, es liegt daran, dass Sie die Software nicht richtig konfiguriert haben.” Dadurch wird das Softwareprodukt immun gegen den Test der Realität. Sie finden Wege, um die Kritik abzulenken, anstatt sie anzugehen.
Bei Lokad ist diese Methode nur entstanden, weil wir sehr unterschiedlich von unseren Konkurrenten waren. Wir hatten nicht den Luxus, eine Ausrede zu haben. Wie es so schön heißt: “Sie können Entschuldigungen oder Ergebnisse haben, aber Sie können beides nicht haben.” Bei Lokad hatten wir nicht die Möglichkeit, Ausreden zu machen. Wir haben Entscheidungen getroffen, und es gab nichts zu konfigurieren oder von der Client-Seite aus zu optimieren. Lokad stand seinen eigenen Unzulänglichkeiten frontal gegenüber. Soweit ich weiß, sind alle unsere Konkurrenten fest in der mathematischen Optimierungsperspektive verankert, und sie leiden unter Problemen, die etwas immun gegen die Realität sind. Um ehrlich zu sein, sie sind nicht völlig immun gegen die Realität, aber sie haben einen sehr langsamen Iterationsprozess, wie den, den ich für Lokad in den frühen Jahren beschrieben habe. Sie sind nicht völlig immun gegen die Realität, aber ihr Verbesserungsprozess ist glazial langsam, und die Welt verändert sich ständig.
Was unweigerlich passiert, ist, dass die Unternehmenssoftware nicht annähernd so schnell verändert wird, um mit der Welt im Allgemeinen Schritt zu halten, so dass Sie am Ende mit Software enden, die einfach altert. Es wird nicht wirklich besser, weil jedes Jahr, das vergeht, die Software besser wird, aber die Welt wird immer seltsamer und anders. Die Unternehmenssoftware hinkt einer Welt, die immer mehr von ihrem Ursprung entfernt ist, immer weiter hinterher.
Frage: Was wäre die richtige Landschaft von Werkzeugen für Fertigungsunternehmen?
Die richtige Landschaft sind Enterprise Resource Management-Tools, die alle transaktionalen Aspekte verwalten können. Darüber hinaus ist es sehr wichtig, eine Lösung zu haben, die bei Ihrer numerischen Rezeptur sehr integriert ist. Sie möchten keinen Tech-Stack für Visualisierung, einen anderen für Optimierung, einen weiteren für Untersuchungen und noch einen anderen für die Datenvorbereitung haben. Wenn Sie mit einem halben Dutzend technologischer Stacks für all diese verschiedenen Dinge enden, benötigen Sie eine Armee von Software-Ingenieuren, um sie alle zusammenzustecken, und Sie werden etwas haben, das das Gegenteil von agil ist.
Es wird so viel Software-Engineering-Kompetenz benötigt, dass kein Platz mehr für tatsächliche Supply-Chain-Kompetenz bleibt. Denken Sie daran, das war der Punkt meiner dritten Vorlesung über produktorientierte Softwarelieferung. Sie benötigen etwas, das ein Supply-Chain-Spezialist, kein Software-Ingenieur, betreiben kann.
Das ist alles. Wir sehen uns in zwei Wochen, am selben Tag und zur selben Stunde, für “Negative Knowledge in Supply Chain”.
Referenzen
- Die Logik der Forschung, Karl Popper, 1934


