00:12 Introduzione
02:23 Falsificabilità
08:25 La storia finora
09:38 Approcci di modellizzazione : Ottimizzazione Matematica (OM)
11:25 Panoramica dell’Ottimizzazione Matematica
14:04 Teoria mainstream della supply chain (riassunto)
19:56 Estensione della Prospettiva dell’Ottimizzazione Matematica
23:29 Euristiche di rigetto
30:54 Il giorno dopo
32:43 Qualità redentrici?
36:13 Approcci di modellizzazione : Ottimizzazione Sperimentale (OS)
38:39 Panoramica dell’Ottimizzazione Sperimentale
42:54 Cause profonde della follia
51:28 Identificare decisioni insane
58:51 Migliorare la strumentazione
01:01:13 Migliorare e ripetere
01:04:40 La pratica dell’OS
01:11:16 Riassunto
01:14:14 Conclusione
01:16:39 Prossima lezione e domande dal pubblico
Descrizione
Lontano dalla prospettiva cartesiana ingenua in cui l’ottimizzazione sarebbe semplicemente l’implementazione di un ottimizzatore per una data funzione obiettivo, la supply chain richiede un processo molto più iterativo. Ogni iterazione viene utilizzata per identificare decisioni “insane” che devono essere investigate. La causa principale è frequentemente rappresentata da inadeguati economic drivers, che devono essere rivalutati in relazione alle loro conseguenze non intenzionali. Le iterazioni si interrompono quando le numerical recipes non producono più risultati insani.
Trascrizione completa

Ciao a tutti, benvenuti a questa serie di lezioni sulla supply chain. Io sono Joannes Vermorel, e oggi presenterò “Ottimizzazione Sperimentale”, che andrà intesa come l’ottimizzazione delle supply chain attraverso una serie di esperimenti. Per chi di voi sta seguendo la lezione in diretta, può fare domande in qualsiasi momento tramite la chat di YouTube. Tuttavia, non leggerò la chat durante la lezione; tornerò ad essa alla fine della lezione per rispondere alle domande presenti.
L’obiettivo per noi oggi è il miglioramento quantitativo delle supply chain, e vogliamo essere in grado di raggiungerlo in modi controllati, affidabili e misurabili. Abbiamo bisogno di qualcosa di simile a un metodo scientifico, e una delle caratteristiche chiave della scienza moderna è che è profondamente radicata nella realtà o, più precisamente, nell’esperimento. In una lezione precedente, ho discusso brevemente l’idea degli esperimenti sulla supply chain e ho menzionato che, a prima vista, sembrano lunghi e costosi. La lunghezza e il costo potrebbero persino compromettere lo scopo per cui stiamo svolgendo tali esperimenti, al punto da renderli non convenienti. Ma la sfida è che abbiamo bisogno di un modo migliore per affrontare la sperimentazione, ed è proprio di questo che tratta l’ottimizzazione sperimentale.
L’ottimizzazione sperimentale è fondamentalmente una pratica emersa da Lokad circa un decennio fa. Essa offre un modo per condurre esperimenti sulla supply chain in modalità che funzionano davvero, che possono essere eseguiti in maniera conveniente e redditizia, e che sarà l’argomento specifico della lezione di oggi.

Ma prima, torniamo un attimo su questa nozione della natura della scienza e il suo rapporto con la realtà.
C’è un libro, “La Logica della Scoperta Scientifica,” pubblicato nel 1934 e scritto da Karl Popper, che è considerato una pietra miliare assoluta nella storia della scienza. Esso propose un’idea sorprendente, la falsificabilità. Per comprendere come sia nata questa idea della falsificabilità e di cosa si tratti, è molto interessante rivedere il percorso di Karl Popper stesso.
Vedete, da giovane Popper era vicino a vari circoli intellettuali. Tra questi circoli, ce ne erano due di particolare interesse: uno era un circolo di economisti sociali, tipicamente sostenitori della teoria marxista dell’epoca, e l’altro era un circolo di fisici, che includeva soprattutto Albert Einstein. Popper osservò che gli economisti sociali avevano una teoria con l’intento di formulare una teoria scientifica in grado di spiegare l’evoluzione della società e della sua economia. Questa teoria marxista faceva in effetti delle previsioni su ciò che sarebbe accaduto. La teoria indicava che ci sarebbe stata una rivoluzione, e che la rivoluzione sarebbe avvenuta nel paese più industrializzato e dove si trovava il maggior numero di operai d’industria.
Si è poi scoperto che la rivoluzione avvenne nel 1917; tuttavia, essa si svolse in Russia, il paese meno industrializzato d’Europa, contrariamente a quanto previsto dalla teoria. Dal punto di vista di Popper, esisteva una teoria scientifica che formulava previsioni, e poi accaddero eventi che contraddicevano la teoria. Quello che lui si aspettava era che la teoria venisse smentita e che si passasse ad altro. Invece, ciò che osservò fu qualcosa di molto diverso. I sostenitori della teoria marxista modificarono la teoria per adattarla agli eventi man mano che si svolgevano. In tal modo, resero gradualmente la teoria immune alla realtà. Quello che era iniziato come una teoria scientifica fu modificato progressivamente fino a diventare qualcosa di completamente immune, tanto che nulla che accadesse nel mondo reale potesse più contraddirla.
Questo era in netto contrasto con quanto accadeva nei circoli dei fisici, dove Popper osservò persone come Albert Einstein che creavano teorie e poi si impegnavano a ideare esperimenti capaci di smentire le proprie teorie. I fisici non spendevano tutta la loro energia a dimostrare le teorie, bensì a metterle in discussione. Popper valutò quale approccio fosse il migliore per fare scienza e sviluppò il concetto di falsificabilità.
Popper propose che la falsificabilità sia un criterio per stabilire se una teoria può essere considerata scientifica. Egli affermò che una teoria è scientifica se soddisfa due criteri. Il primo è che la teoria debba essere a rischio rispetto alla realtà. La teoria deve essere espressa in un modo tale che la realtà possa contraddirla. Se una teoria non può essere contraddetta, non è questione di vero o falso; diventa irrilevante, almeno dal punto di vista scientifico. Pertanto, affinché una teoria sia considerata scientifica, essa deve esporsi a un certo grado di rischio nei confronti della realtà.
Il secondo criterio è che il grado di fiducia o credibilità che possiamo attribuire a una teoria dovrebbe essere, in una certa misura (e sto semplificando), proporzionale al lavoro che gli scienziati stessi hanno investito nel tentativo di smentirla. La caratteristica scientifica di una teoria risiede nel fatto che essa assume un grande rischio, e che molti cercano di sfruttare le sue debolezze per smentirla. Se tali tentativi falliscono ripetutamente, allora possiamo attribuirle una certa credibilità.
Questa prospettiva mostra che esiste una profonda asimmetria tra ciò che è vero e ciò che è falso. Le teorie scientifiche moderne non dovrebbero mai essere considerate come vere o provate, ma soltanto come in sospeso. Il fatto che molti abbiano tentato di smentirle senza successo ne accresce la credibilità che possiamo attribuirle. Questa intuizione è di importanza cruciale per il mondo della supply chain, e in particolare, questa nozione di falsificabilità ha alimentato molti degli sviluppi più sorprendenti della scienza, specialmente nel campo della fisica moderna.
Finora, questa è la terza lezione del secondo capitolo di questa serie sulla supply chain. Nel primo capitolo del prologo, ho presentato le mie opinioni sulla supply chain sia come campo di studio sia come pratica. Uno degli spunti chiave è stato che la supply chain copre un insieme di problemi intrattabili, in contrasto con problemi gestibili. Questi problemi non si prestano, per loro natura, a soluzioni semplici. Pertanto, dobbiamo prestare grande attenzione alla metodologia che dobbiamo sia studiare che applicare nella supply chain. Questo secondo capitolo riguarda proprio quelle metodologie.
Nella prima lezione del secondo capitolo, ho proposto un metodo qualitativo per apportare conoscenza e, successivamente, miglioramenti alla supply chain attraverso il concetto di supply chain personas. Qui, in questa terza lezione, propongo un metodo quantitativo: l’ottimizzazione sperimentale.

Quando si tratta di apportare un miglioramento quantitativo alle supply chain, abbiamo bisogno di un modello quantitativo, un modello numerico. Esistono almeno due modi per affrontare questo: il metodo mainstream, mathematical optimization, e un’altra prospettiva, l’ottimizzazione sperimentale.
L’approccio mainstream per ottenere miglioramenti quantitativi nella supply chain è l’ottimizzazione matematica. Questo approccio consiste sostanzialmente nel costruire un lungo catalogo di coppie problema-soluzione. Tuttavia, credo che questo metodo non sia molto efficace, e che sia necessaria un’altra prospettiva, che è di cosa tratta l’ottimizzazione sperimentale. Essa andrà intesa come l’ottimizzazione delle supply chain mediante una serie di esperimenti.
L’ottimizzazione sperimentale non è stata inventata da Lokad. È emersa inizialmente come pratica in Lokad ed è stata concettualizzata come tale anni dopo. Quello che presento oggi non corrisponde al modo in cui essa è gradualmente emersa in Lokad. È stato un processo molto più graduale e confuso. Ho rivisitato questa pratica emergente anni dopo per solidificarla sotto forma di una teoria che posso presentare col titolo di ottimizzazione sperimentale.

Innanzitutto, dobbiamo chiarire il termine ottimizzazione matematica. Esistono due concetti distinti da differenziare: l’ottimizzazione matematica come campo di ricerca autonomo e l’ottimizzazione matematica come prospettiva per il miglioramento quantitativo della supply chain, che è l’argomento di interesse oggi. Mettiamo da parte per un attimo la seconda prospettiva e chiarifichiamo di cosa tratta l’ottimizzazione matematica intesa come campo di ricerca indipendente.
Si tratta di un campo di ricerca interessato alla classe di problemi matematici che si presentano come descritto sullo schermo. In sostanza, si parte da una funzione che mappa un insieme arbitrario (A) in un numero reale. Questa funzione, frequentemente indicata come la loss function, è denotata da f. Cerchiamo la soluzione ottimale, ovvero un punto x che appartiene all’insieme A e che non può essere ulteriormente migliorato. Ovviamente, questo è un campo di ricerca molto ampio, con innumerevoli tecnicalità. Alcune funzioni potrebbero non avere un minimo, mentre altre potrebbero presentare molteplici minimi distinti. Come campo di ricerca, l’ottimizzazione matematica ha riscosso un notevole successo. Sono state ideate numerose tecniche e introdotti concetti che hanno avuto grande successo in molti altri settori. Tuttavia, non discuterò tutto ciò oggi, poiché non è l’obiettivo di questa lezione.
Il punto che vorrei evidenziare è che l’ottimizzazione matematica, in quanto scienza ausiliaria riguardante la supply chain, ha ottenuto un notevole successo in modo autonomo. A sua volta, ciò ha plasmato profondamente lo studio quantitativo delle supply chain, che è di cosa tratta supply chain perspective.

Torniamo a due libri che ho introdotto nella mia primissima lezione sulla supply chain. Questi due libri rappresentano, credo, la teoria quantitativa mainstream della supply chain, incarnando gli ultimi cinque decenni sia di pubblicazioni scientifiche sia di produzione software. Non si tratta solo degli articoli pubblicati, ma anche del software che è stato immesso sul mercato. Per quanto concerne l’ottimizzazione quantitativa delle supply chain, tutto viene fatto – e da tempo – tramite strumenti software.
Se si osservano questi libri, ogni singolo capitolo può essere visto come un’applicazione della prospettiva dell’ottimizzazione matematica. Tutto si riduce a una formulazione del problema con vari insiemi di ipotesi, seguita dalla presentazione di una soluzione. La correttezza e talvolta l’optimalità della soluzione vengono poi dimostrate in relazione al problema enunciato. Questi libri sono essenzialmente cataloghi di coppie problema-soluzione, che si presentano come problemi di ottimizzazione matematica.
Ad esempio, il forecasting può essere visto come un problema in cui si ha una loss function, che rappresenta l’errore di previsione, e un modello con parametri che si desidera regolare. Successivamente, si vuole apprendere il processo di ottimizzazione, in senso numerico, che fornisce i parametri ottimali. Lo stesso approccio si applica a una inventory policy, in cui si possono formulare ipotesi sulla domanda e poi dimostrare di avere una soluzione che risulta essere ottimale in relazione alle ipotesi appena formulate.
Come ho già trattato nella primissima lezione, nutro grandi preoccupazioni riguardo a questa teoria mainstream della supply chain. I libri che ho menzionato non sono selezioni casuali; credo riflettano fedelmente gli ultimi decenni di ricerca sulla supply chain. Osservando le idee sulla falsificabilità introdotte da Karl Popper, si comprende meglio qual è il problema: nessuno di questi libri è realmente scienza, poiché la realtà non può smentire quanto viene presentato. Questi libri sono essenzialmente completamente immuni alle supply chain del mondo reale. Quando si ha un libro che è sostanzialmente una raccolta di coppie problema-soluzione, non c’è nulla da smentire. Si tratta di un costrutto puramente matematico. Il fatto che una supply chain faccia questo o quello non incide in alcun modo sulla dimostrazione o confutazione di quanto presentato in tali libri. Probabilmente questa è la mia più grande preoccupazione riguardo a queste teorie.
Questo non è soltanto una questione di ricerca di cui si parla qui. Se osservi ciò che esiste in termini di enterprise software per servire le supply chain, noterai che il software attualmente sul mercato è in gran parte il riflesso di queste pubblicazioni scientifiche. Questo software non è stato inventato separatamente da quelle pubblicazioni; di solito, vanno di pari passo. La maggior parte degli strumenti di enterprise software trovati sul mercato, destinati a risolvere problemi di ottimizzazione della supply chain, sono il riflesso di una certa serie di articoli o libri, a volte scritti dalle stesse persone che hanno prodotto sia il software che i libri.
Il fatto che la realtà non influenzi le teorie presentate qui è, secondo me, una spiegazione molto plausibile del perché così poche delle teorie esposte in questi libri siano effettivamente utili nelle supply chain reali. Questa è un’affermazione piuttosto soggettiva, ma nella mia carriera ho avuto l’opportunità di parlare con diverse centinaia di direttori di supply chain. Essi sono a conoscenza di queste teorie, e anche se non ne sono molto esperti, hanno nel proprio team persone che lo sono. Molto spesso, il software usato dall’azienda implementa già una serie di soluzioni presentate in questi libri, eppure non vengono utilizzate. Per vari motivi, le persone ricorrono ai propri fogli di calcolo Excel spreadsheets.
Quindi, non si tratta di ignoranza. Abbiamo un problema molto reale, e credo che la causa principale sia proprio il fatto che non si tratta di scienza. Non puoi falsificare nulla di quanto presentato. Non è che queste teorie siano errate – sono matematicamente corrette – ma non sono scientifiche nel senso che non arrivano nemmeno a qualificarsi come scienza.

Ora, la domanda sarebbe: qual è l’entità del problema? Perché in realtà ho scelto due libri, ma qual è l’effettiva portata di questa prospettiva di ottimizzazione matematica nella supply chain? Direi che l’estensione di questa prospettiva è assolutamente massiccia. A titolo aneddotico, per dimostrarlo, ho recentemente utilizzato Google Scholar, un motore di ricerca specializzato fornito da Google che restituisce risultati esclusivamente per pubblicazioni scientifiche. Se cerchi “optimal inventory” soltanto per l’anno 2020, otterrai oltre 30.000 risultati.
Questo numero va preso con le pinze. Ovviamente ci sono probabilmente numerosi duplicati in questo elenco, e quasi sicuramente saranno presenti dei falsi positivi – articoli in cui appaiono sia le parole “inventory” che “optimal” nel titolo e nell’abstract, ma che in realtà non trattano affatto della supply chain. È solo una coincidenza. Tuttavia, una rapida ispezione dei risultati suggerisce fortemente che stiamo parlando di diverse migliaia di articoli pubblicati ogni anno in questo ambito. A titolo di paragone, questo numero è molto elevato, anche rispetto a settori veramente massicci, come il deep learning. Il deep learning è probabilmente una delle teorie dell’informatica che ha riscontrato il maggior successo negli ultimi due o tre decenni. Quindi, il fatto che la sola query “optimal inventory” restituisca qualcosa dell’ordine di un quinto di ciò che si ottiene per il deep learning è davvero sorprendente. L’“optimal inventory” è ovviamente solo una frazione di ciò di cui trattano gli studi quantitativi sulla supply chain.
Questa semplice query dimostra che la prospettiva dell’ottimizzazione matematica è davvero massiccia, e sostengo, sebbene possa sembrare un po’ soggettivo, che per quanto riguarda gli studi quantitativi sulla supply chain, essa domini veramente. Se abbiamo diverse migliaia di articoli che forniscono politiche di inventory ottimale e modelli ottimali di controllo delle scorte per gestire le aziende, prodotti su base annua, sicuramente la maggior parte delle grandi imprese dovrebbe operare secondo questi metodi. Non stiamo parlando di pochi articoli; stiamo parlando di una quantità assolutamente massiccia di pubblicazioni.
Per quanto mi riguarda, con qualche centinaio di dati sulla supply chain di cui sono a conoscenza, la realtà è tutt’altro. Questi metodi sono quasi invisibili. Abbiamo un divario sorprendente tra lo stato dell’arte nel campo degli articoli pubblicati – e, tra l’altro, anche del software, perché anch’esso è praticamente un riflesso di ciò che viene pubblicato come articoli scientifici – e il modo in cui le supply chain operano realmente.

La domanda che mi sono posto è: con migliaia di articoli, c’è qualcosa di buono da trovare? Ho avuto il piacere di esaminare centinaia di articoli quantitativi sulla supply chain e posso darti una serie di euristiche che ti daranno quasi la certezza che l’articolo non aggiunge alcun valore reale. Queste euristiche non sono assolutamente universali, ma sono molto accurate, quasi al 99% di precisione. Non sono perfette, ma sono quasi impeccabili.
Quindi, come rileviamo gli articoli che aggiungono valore reale, o al contrario, come scartiamo quelli che non apportano alcun valore? Ho elencato una breve serie di euristiche. La prima è che, se l’articolo sostiene qualsiasi affermazione riguardo a un tipo di optimalità, puoi stare certo che l’articolo non apporta alcun valore alle supply chain reali. Innanzitutto, perché ciò riflette il fatto che gli autori non comprendono, neppure minimamente, che le supply chain sono fondamentalmente un problema complesso e intrattabile. Il fatto che tu dica di avere una soluzione ottimale – torniamo alla definizione di soluzione ottimale: una soluzione che è ottimale se non può essere migliorata ulteriormente – è molto simile a dire che esiste un limite invalicabile all’ingegno umano. Non ci credo neanche per un momento. Credo che sia una proposizione completamente irragionevole. Vediamo chiaramente che c’è un grandissimo problema nell’approccio alla supply chain.
Un altro problema è che ogni volta che si afferma un’optimalità, ne consegue inevitabilmente una soluzione che si basa fortemente su delle ipotesi. Potresti avere una soluzione dimostrata ottimale sulla base di un certo insieme di ipotesi, ma cosa succede se tali ipotesi vengono violate? La soluzione resterà valida? Al contrario, credo che se hai una soluzione di cui puoi dimostrare l’optimalità, allora hai una soluzione incredibilmente dipendente dall’esattezza delle ipotesi formulate, anche in minima parte. Se violi queste ipotesi, la soluzione risultante è molto probabilmente pessima, perché non è mai stata progettata per essere robusta. Le affermazioni di optimalità possono essere praticamente scartate fin da subito.
Il secondo punto riguarda le distribuzioni normali. Ogni volta che vedi un articolo o un pezzo di software che sostiene di utilizzare distribuzioni normali, puoi essere sicuro che quanto proposto non funziona nelle supply chain reali. In una lezione precedente, in cui ho presentato i principi quantitativi per la supply chain, ho mostrato che tutte le popolazioni di interesse nelle supply chain seguono una distribuzione secondo Zipf, e non una distribuzione normale. Le distribuzioni normali non si trovano nelle supply chain, e sono assolutamente convinto che questo risultato sia noto da decenni. Se trovi articoli o software che si affidano a quest’ipotesi, è quasi certo che avrai una soluzione progettata per comodità, così da facilitare la dimostrazione matematica o la scrittura del software, non perché vi fosse un sincero intento di ottenere performance nel mondo reale. La presenza delle distribuzioni normali è pura pigrizia o, nel migliore dei casi, un segno di profonda incomprensione di ciò di cui trattano le supply chain. Ciò può essere usato per scartare tali articoli.
Poi, c’è la stazionarietà – qualcosa che in realtà non esiste. È un’ipotesi che sembra accettabile: le cose sono stazionarie, sempre le stesse. Ma non lo sono; è un’ipotesi molto forte. Sostanzialmente, afferma che esiste un processo che è iniziato all’inizio dei tempi e continuerà fino alla loro fine. Questa è una prospettiva completamente irragionevole per le supply chain reali. Nelle supply chain, ogni prodotto viene lanciato in un determinato momento e, allo stesso modo, verrà ritirato dal mercato in un certo momento. Anche se si prendono in considerazione prodotti con una vita relativamente lunga, come quelli presenti, ad esempio, nell’industria automobilistica, tali processi non sono stazionari. Reggeranno al massimo per un decennio. La durata di interesse, l’arco temporale considerato, è finito, quindi la prospettiva stazionaria è completamente errata.
Un altro elemento per identificare uno studio quantitativo destinato a non funzionare è l’assenza stessa del concetto di sostituzione. Nelle supply chain reali le sostituzioni sono ovunque. Se torniamo all’esempio di supply chain che ho introdotto due settimane fa in una lezione precedente, avresti modo di vedere almeno una mezza dozzina di situazioni in cui erano in gioco le sostituzioni – dal lato della fornitura, della trasformazione e della domanda. Se hai un modello in cui, per concetto, la sostituzione non esiste nemmeno, allora hai qualcosa che è davvero in contrasto con le supply chain reali.
Allo stesso modo, la mancanza di globalità o di una prospettiva olistica sulla supply chain è anche un segnale inconfondibile che qualcosa non va. Se torno alla lezione precedente in cui ho presentato i principi quantitativi per la supply chain, ho affermato che se hai qualcosa che si avvicina a un processo di ottimizzazione locale, non otterrai un’ottimizzazione reale; sposterai semplicemente i problemi all’interno della tua supply chain. La supply chain è un sistema, una rete, e quindi non puoi applicare un certo tipo di ottimizzazione locale e sperare che ciò porti in realtà al bene dell’intera supply chain. Non è affatto così.
Con queste euristiche, penso che si possa quasi eliminare la maggior parte della letteratura quantitativa sulla supply chain, il che è già di per sé sorprendente.

Il fatto è che se dovessi convincere ogni singola commissione editoriale di ogni conferenza e rivista sulla supply chain a utilizzare queste euristiche per filtrare i contributi di bassa qualità, non funzionerebbe. Gli autori si adatterebbero semplicemente e aggirerebbero il processo, anche se aggiungessimo tali linee guida per la pubblicazione nelle riviste di supply chain. Se gli analisti di mercato le aggiungessero alla loro checklist, succederebbe che gli autori, sia di articoli che di software, si adatterebbero. Occulterebbero il problema, formulando ipotesi più complicate al punto da nascondere il fatto che tutto si riduca a una distribuzione normale o a un’ipotesi di stazionarietà. È solo che viene espresso in termini molto opachi.
Queste euristiche sono utili per identificare contributi di bassa qualità, sia di articoli che di software, ma non possiamo usarle per filtrare ciò che è buono. Abbiamo bisogno di un cambiamento più profondo; dobbiamo ripensare l’intero paradigma. A questo punto, ci manca ancora la falsificabilità. La realtà non ha modo di reagire e confutare ciò che viene presentato.

Come ultimo elemento per concludere questa parte della lezione sulla prospettiva dell’ottimizzazione matematica, c’è qualche qualità riscattabile da trovare in questa enorme produzione di articoli e software? La mia risposta, puramente soggettiva, è assolutamente no. Questi articoli – e ne ho letto moltissimi sulla supply chain quantitativa – non sono interessanti. Al contrario, sono estremamente noiosi, persino i migliori. Quando osserviamo le scienze ausiliarie, non si trovano pepite di cose davvero interessanti. Si può dare un’occhiata a tutti quegli articoli, ne ho elencati migliaia. Da un punto di vista matematico, è tutto molto monotono. Non vengono presentate grandi idee matematiche. Da un punto di vista algoritmico, si tratta solo di un’applicazione diretta di ciò che da tempo è noto nel campo degli algoritmi. Lo stesso può essere detto della modellazione statistica e della metodologia, che sono estremamente carenti. In termini metodologici, tutto si riduce alla prospettiva dell’ottimizzazione matematica, in cui presenti un modello, ottimizzi qualcosa, fornisci la soluzione e dimostri che questa soluzione possiede alcune caratteristiche matematiche rispetto alla formulazione del problema.
Dobbiamo davvero cambiare più in profondità. Non sto criticando l’approccio. Esistono precedenti storici a riguardo. Può sembrare sorprendente affermare che abbiamo decine di migliaia di articoli completamente sterili, ma ciò è effettivamente avvenuto in passato. Se guardi alla vita di Isaac Newton, uno dei padri della fisica moderna, noterai che trascorse circa la metà del suo tempo lavorando sulla fisica, lasciando un’eredità massiccia, e l’altra metà dedicata all’alchimia. Era un fisico brillante e un alchimista molto povero. I documenti storici tendono a mostrare che Isaac Newton era altrettanto brillante, dedito e serio nel suo lavoro alchemico quanto in quello sulla fisica. A causa del fatto che la prospettiva alchemica era semplicemente mal inquadrata, tutto il lavoro e l’ingegno che Newton investì in quell’area si rivelarono completamente sterili, senza alcuna eredità da raccontare. La mia critica non è che migliaia di persone pubblichino cose idiote. La maggior parte di quegli autori è molto intelligente. Il problema è che il quadro stesso è sterile. Questo è il punto che voglio sottolineare.

Passiamo ora al secondo approccio di modellazione che desidero presentare oggi. Nei primi anni, la metodologia di Lokad era profondamente radicata nella prospettiva dell’ottimizzazione matematica. Eravamo molto mainstream in questo ambito, e questo stava funzionando alla pessima. Una cosa molto specifica di Lokad, che fu quasi accidentale, è che a un certo punto ho deciso che Lokad non avrebbe venduto enterprise software, ma avrebbe venduto decisioni definitive per la supply chain. Intendo veramente le quantità esatte che una determinata azienda deve acquistare, le quantità che essa deve produrre, e quante unità devono essere spostate dal punto A al punto B – se un determinato prezzo debba scendere o meno – Lokad era nel business di vendere decisioni definitive per la supply chain. A causa di questa mia decisione semi-accidentale, siamo stati brutalmente confrontati con le nostre stesse inadeguatezze. Siamo stati messi alla prova, e il riscontro con la realtà è stato molto duro. Se producevamo decisioni per la supply chain che si rivelavano errate, i clienti mi incolpavano immediatamente, urlando a gran voce perché Lokad non forniva nulla di soddisfacente.
In un certo senso, l’ottimizzazione sperimentale è emersa in Lokad. Non è stata inventata in Lokad; è stata una pratica emergente, una risposta al fatto che eravamo sotto un’immensa pressione da parte della nostra clientela per fare qualcosa riguardo quei difetti che erano dappertutto all’inizio. Dovevamo inventare una sorta di meccanismo di sopravvivenza, e abbiamo provato molte soluzioni, a volte praticamente a caso. Ciò che è emerso è quello che viene indicato come ottimizzazione sperimentale.

L’ottimizzazione sperimentale è un metodo molto semplice. L’obiettivo è produrre decisioni della supply chain scrivendo una ricetta, supportata da software, che generi decisioni della supply chain. Il metodo inizia così: passo zero, scrivi semplicemente ricette che generano decisioni. Vi è un grande bagaglio di know-how, tecnologie e strumenti che sono di interesse qui. Questo non è l’argomento di questa lezione; verrà trattato in dettaglio nelle lezioni successive. Quindi, passo uno, scrivi una ricetta, e molto probabilmente non sarà molto buona.
Poi entri in una pratica di iterazione indefinita, nella quale innanzitutto esegui la ricetta. Con “eseguire” intendo che la ricetta deve essere in grado di funzionare in un ambiente di produzione. Non si tratta solo di avere un algoritmo nel laboratorio di data science che puoi eseguire. Si tratta di avere una ricetta che possieda tutte le qualità, in modo che se decidi che quelle decisioni sono abbastanza buone da essere messe in produzione, tu possa farlo con un solo click. L’intero ambiente deve essere di grado produzione; questo è ciò che significa eseguire la ricetta.
Il passo successivo è identificare le decisioni assurde, argomento già trattato in una mia lezione precedente sulla consegna orientata al prodotto per la supply chain. Per chi di voi non ha seguito quella lezione, in breve, vogliamo che gli investimenti nella supply chain siano capitalisti, accrescenti, e per ottenere ciò dobbiamo assicurarci che le persone che lavorano in questa divisione della supply chain non siano impegnate a spegnere incendi. La situazione tipica nella stragrande maggioranza delle aziende al giorno d’oggi è che le decisioni della supply chain sono generate dal software – la maggior parte delle aziende moderne utilizza già ampiamente software aziendale per gestire la propria supply chain, e tutte le decisioni sono già generate tramite software. Tuttavia, una gran parte di queste decisioni è completamente assurda. Quello di cui si occupano la maggior parte dei team della supply chain è rivedere manualmente tutte queste decisioni assurde e impegnarsi in sforzi continui di spegnimento incendi per eliminarle. Di conseguenza, tutti gli sforzi finiscono per essere assorbiti dall’operatività dell’azienda. Un giorno risolvi tutte le eccezioni, e il giorno dopo torni con un nuovo insieme di eccezioni da gestire, e il ciclo si ripete. Non puoi capitalizzare; consumi semplicemente il tempo dei tuoi esperti della supply chain. Quindi, l’idea di Lokad è che dobbiamo trattare queste decisioni assurde come difetti del software ed eliminarle completamente, in modo da poter avere un processo e una pratica capitalistica della supply chain stessa.
Una volta fatto ciò, dobbiamo migliorare l’instrumentation e, di conseguenza, migliorare la ricetta numerica stessa. Tutto questo lavoro è condotto dal Supply Chain Scientist, una nozione che ho introdotto nella mia seconda lezione del primo capitolo, “The Quantitative Supply Chain Perspective”, come vista da Lokad. L’instrumentation è di fondamentale interesse perché è attraverso una migliore instrumentation che puoi comprendere meglio cosa sta succedendo nella tua supply chain, cosa sta succedendo nella tua ricetta e come puoi ulteriormente migliorarla per affrontare quelle decisioni assurde che continuano a emergere.

Esaminiamo per un momento le cause radici dell’insanità che spiegano quelle decisioni assurde. Spesso, quando chiedo ai direttori della supply chain perché pensano che i loro sistemi software aziendali, che governano le operazioni della supply chain, continuino a produrre quelle decisioni assurde, una risposta molto comune ma fuorviante che ricevo è: “Oh, è solo perché abbiamo previsioni sbagliate.” Credo che questa risposta sia fuorviante su almeno due fronti. Primo, se passi dall’accuratezza che puoi ottenere con un modello a media mobile molto semplice a un modello di machine learning all’avanguardia, c’è forse un guadagno del 20% in accuratezza. Quindi sì, è significativo, ma non può fare la differenza tra una decisione molto buona e una decisione completamente assurda. Secondo, il problema principale delle previsioni è che non vedono tutte le alternative; non sono probabilistiche. Ma divago; questo sarebbe un argomento per un’altra lezione.
Se torniamo alla causa principale dell’insanità, credo che, sebbene gli errori di previsione siano una preoccupazione, non lo siano assolutamente al massimo livello. Da un decennio di esperienza in Lokad, posso dire che al meglio questo è un problema secondario. La preoccupazione primaria, il problema più grande che genera decisioni assurde, è data semantics. Ricorda che non puoi osservare una supply chain direttamente; non è possibile. Puoi solo osservare una supply chain come riflesso tramite i record elettronici che raccogli attraverso il software aziendale. L’osservazione che fai della tua supply chain è un processo molto indiretto attraverso il prisma del software.
Qui stiamo parlando di centinaia di tabelle relazionali e migliaia di campi, e la semantica di ciascuno di questi campi conta davvero. Ma come fai a sapere se possiedi la giusta comprensione e mentalità? L’unico modo per sapere con certezza se capisci veramente cosa significhi una specifica colonna è metterla alla prova sperimentale. Nell’ottimizzazione sperimentale, la prova sperimentale è la generazione di decisioni. Presumi che questa colonna significhi qualcosa; questa è, in un certo senso, la tua teoria scientifica. Poi generi una decisione basata su questa comprensione, e se la decisione è buona, allora la tua comprensione è corretta. Fondamentalmente, l’unica cosa che puoi osservare è se la tua comprensione porta o meno a decisioni assurde. È qui che la realtà reagisce.
Questo non è un problema minore; è un problema molto grande. Il software aziendale è complesso, per usare un eufemismo, e ci sono dei bug. Il problema della prospettiva dell’ottimizzazione matematica è che considera il problema come se fosse una semplice serie di ipotesi, e poi puoi implementare una soluzione relativamente semplice ed elegantemente matematica. Ma la realtà è che abbiamo strati di software aziendale uno sopra l’altro, e i problemi possono verificarsi ovunque. Alcuni di questi problemi sono molto banali, come copie errate, associazioni scorrette tra variabili o sistemi che dovrebbero essere sincronizzati ma non lo sono. Potrebbero esserci aggiornamenti di versione del software che creano bug, e così via. Questi bug sono dappertutto, e l’unico modo per sapere se ce ne sono o meno è, ancora una volta, osservare le decisioni. Se le decisioni risultano corrette, allora o non ci sono bug oppure i bug presenti sono irrilevanti e non ce ne importano.
Per quanto riguarda i driver economici, un altro approccio errato sorge frequentemente nelle discussioni con i direttori della supply chain. Spesso mi chiedono di provare che ci sarà un certo ritorno economico per la loro azienda. La mia risposta è che non conosciamo ancora i driver economici. La mia esperienza in Lokad mi ha insegnato che l’unico modo per sapere con certezza quali siano i driver economici – e questi driver vengono utilizzati per costruire la funzione di perdita che, a sua volta, viene usata per eseguire l’ottimizzazione effettiva nella ricetta numerica – è metterli effettivamente alla prova, ancora una volta, attraverso l’esperienza di generare decisioni e osservare se quelle decisioni siano assurde o meno. Questi driver economici devono essere scoperti e validati secondo l’esperienza. Al massimo, puoi avere solo un’intuizione di ciò che è corretto, ma solo l’esperienza e gli esperimenti possono dirti se la tua comprensione è effettivamente corretta.
Poi, ci sono anche tutte le inadempienze pratiche. Hai una ricetta numerica che genera decisioni, e quelle decisioni sembrano essere conformi a tutte le regole che hai stabilito. Per esempio, se ci sono quantità minime d’ordine (MOQs), generi ordini di acquisto che rispettano i tuoi MOQs. Ma cosa succede se un fornitore ritorna e ti dice che il MOQ è qualcos’altro? Attraverso questo processo potresti scoprire molte inadempienze pratiche e decisioni apparentemente fattibili che, quando provi a metterle alla prova nel mondo reale, risultano essere inattuabili. Scopri ogni sorta di casi limite e limitazioni, a volte anche aspetti a cui non avevi nemmeno pensato, dove il mondo reagisce e devi intervenire.
Poi c’è anche la tua strategia. Potresti pensare di avere una strategia complessiva e di alto livello per la tua supply chain, ma è corretta? Per farti un’idea, prendiamo ad esempio Amazon. Potresti dire che vuoi mettere il cliente al primo posto. Quindi, per esempio, se i clienti acquistano qualcosa online e non lo gradiscono, dovrebbero poterlo restituire molto facilmente. Vuoi essere molto generoso per quanto riguarda i resi. Ma poi, cosa succede se hai avversari o clienti malintenzionati che sfruttano il sistema? Possono ordinare online uno smartphone costoso da 500$, riceverlo, sostituire lo smartphone genuino con uno contraffatto del valore di soli 50$, e poi restituirlo. Amazon finisce per avere contraffazioni nel suo inventario senza nemmeno rendersene conto. Questo è un problema molto reale che è stato discusso online molte volte.
Potresti avere una strategia che dice di voler mettere il cliente al primo posto, ma forse la tua strategia dovrebbe essere quella di mettere il cliente al primo posto solo per i clienti onesti. Quindi, non tutti i clienti; ma solo una sottosezione di clienti. Anche se la tua strategia è approssimativamente corretta, il diavolo sta nei dettagli. Ancora una volta, l’unico modo per verificare se i dettagli della tua strategia sono corretti è attraverso la sperimentazione, dove puoi esaminare i particolari.

Ora, discutiamo di come identifichiamo le decisioni assurde. Come distinguiamo tra decisioni sensate e decisioni assurde? Con “decisione assurda” intendo una decisione che non è sensata per la tua azienda. Questo è un tipo di problema che richiede davvero un’intelligenza umana generale. Non c’è alcuna speranza che tu possa risolvere questo problema tramite un algoritmo. Potrebbe sembrare un paradosso, ma questo è il tipo di problema che richiede un’intelligenza a livello umano, sebbene non necessariamente un essere umano particolarmente intelligente.
Ci sono molti altri problemi simili nel mondo reale. Per esempio, un’analogia sono gli errori nei film. Se chiedessi agli studi di Hollywood un algoritmo in grado di identificare tutti gli errori in un qualsiasi film, probabilmente direbbero di non avere idea di come concepire un tale algoritmo, dato che sembra un compito che richiede intelligenza umana. Tuttavia, se trasformi il problema in uno in cui vuoi solo avere persone che possano essere addestrate per essere molto brave a identificare gli errori nei film, il compito diventa molto più semplice. È abbastanza facile concepire che si possa consolidare un manuale di tutti i trucchi per identificare gli errori nei film. Non hai bisogno di persone eccezionalmente intelligenti per svolgere questo lavoro; ti servono solo persone ragionevolmente intelligenti e dedicate. È esattamente questo.
Quindi, come appare la situazione da una prospettiva della supply chain? Se vogliamo esaminare concretamente il problema, fondamentalmente cercheremo degli outlier. Dobbiamo solo iniziare con un approccio. Per esempio, torniamo alla persona parigina che ho introdotto due settimane fa. Si tratta di un’azienda di moda che gestisce una vasta rete di negozi di moda. Diciamo, per esempio, che siamo preoccupati per la qualità del servizio.
Iniziamo con gli stockouts. Se eseguiamo una query su tutti i prodotti e su tutti i negozi, vedremo che abbiamo migliaia di stockout in tutta la rete. Quindi, non è davvero utile; ce ne sono migliaia, e la risposta sarebbe “e allora?” Forse non si tratta solo degli stockout; ciò che è veramente di interesse sono gli stockout nei negozi di punta, quei negozi che vendono molto. È lì che conta, e non gli stockout per qualsiasi prodotto, ma per i top seller. Stringiamo la ricerca agli stockout che si verificano nei negozi di punta per i top seller.
Poi, possiamo analizzare un SKU in cui il magazzino risulta a zero. Ma ad un’analisi più attenta, vedremo che forse all’inizio della giornata il magazzino contava in realtà tre unità, e l’ultima unità è stata venduta solo 30 minuti prima della chiusura del negozio. Se ci soffermiamo, vedremo che tre unità saranno rifornite il giorno successivo. Quindi, qui abbiamo una situazione in cui osserviamo uno stockout, ma è davvero importante? Beh, a quanto pare no, perché l’ultima unità è stata venduta proprio prima della chiusura del negozio in serata, e la quantità verrà rifornita. Inoltre, se analizziamo ulteriormente, vedremo che forse non c’è spazio sufficiente nel negozio per tenere più di tre unità, quindi siamo vincolati.
Quindi, questo non è esattamente un problema significativo. Forse dovremmo restringere la ricerca agli stockout in cui abbiamo avuto l’opportunità di rifornire – negozio di punta, prodotto top – ma non l’abbiamo fatto. Troviamo un esempio di un dato SKU, e poi vediamo che non c’è più stock nel centro di distribuzione. Quindi, in questo caso, è davvero un problema? Potremmo dire di no, ma aspetta un attimo. Non abbiamo stock nel centro di distribuzione, ma per lo stesso prodotto, diamo un’occhiata all’intera rete. C’è ancora stock da qualche parte?
Diciamo che, per questo prodotto – top product, top store – abbiamo molti negozi deboli che hanno ancora molto inventario per lo stesso prodotto, ma semplicemente non ruotano. Qui vediamo che c’è effettivamente un problema. Il problema non era che non ci fosse abbastanza stock assegnato al negozio di punta; il problema è che è stato assegnato troppo stock, probabilmente durante l’allocazione iniziale verso i negozi per la nuova collezione, per negozi molto deboli. Quindi, procediamo passo dopo passo per identificarne la causa principale. Possiamo ricondurlo a una questione di qualità del servizio causata non dall’invio di troppo poco stock, ma al contrario, dall’invio di troppo, che finisce per avere un impatto a livello di sistema sulla qualità del servizio per quei negozi di punta.
Quello che ho fatto qui è l’esatto opposto della statistica, ed è qualcosa di importante quando cerchiamo decisioni “insane”. Non vuoi aggregare i dati; al contrario, vuoi lavorare su dati completamente disaggregati in modo che tutti i problemi emergano. Non appena inizi ad aggregare i dati, solitamente quei comportamenti sottili scompaiono. Il trucco è tipicamente partire dal livello più disaggregato ed attraversare la rete per capire esattamente cosa stia succedendo, non a livello statistico ma a un livello molto basilare ed elementare in cui puoi capire.
Questo metodo si presta molto bene anche alla prospettiva che ho introdotto nel quantitative supply chain, dove dico che è necessario avere driver economici. Sono tutti possible futures, tutte decisioni possibili, e poi si valutano tutte le decisioni secondo i driver economici. Si scopre che quei driver economici sono molto utili quando si tratta di smistare tutti quegli SKU, decisioni ed eventi che avvengono nella supply chain. Puoi ordinarli in ordine decrescente in base all’impatto in dollari, e questo è un meccanismo molto potente, anche se i driver economici sono parzialmente errati o incompleti. Si rivela un metodo molto efficace per indagare e diagnosticare con elevata produttività ciò che sta accadendo in una determinata supply chain.
Man mano che indaghi decisioni “insane” nel corso delle iniziative in cui implementi questo metodo sperimentale di ottimizzazione, si verifica uno spostamento graduale dal prendere decisioni veramente insane e disfunzionali al commettere semplicemente decisioni palesemente cattive. Queste non faranno saltare in aria la tua azienda, ma semplicemente non sono molto valide.

Qui abbiamo una profonda divergenza dalla prospettiva dell’ottimizzazione matematica per la supply chain.
Con l’ottimizzazione sperimentale, la funzione di perdita stessa, poiché l’ottimizzazione sperimentale utilizza internamente strumenti di ottimizzazione matematica, di solito alla base delle ricette numeriche che generano la decisione, possiede una componente di ottimizzazione matematica. Ma è solo un mezzo, non un fine, che supporta il tuo processo. Invece di adottare la prospettiva dell’ottimizzazione matematica in cui enunci il problema e poi ottimizzi, qui stai continuamente mettendo in discussione ciò che intendi per problema e modificando la funzione di perdita stessa.
Per ottenere una maggiore comprensione, devi strumentare praticamente tutto. Devi strumentare il tuo processo di ottimizzazione, la tua ricetta numerica, e ogni sorta di caratteristica che possiedi riguardo ai dati con cui stai lavorando. È molto interessante perché, da una prospettiva storica, quando si osservano molte delle più grandi scoperte scientifiche in cui c’erano notevoli innovazioni, solitamente qualche decennio prima di tali scoperte c’era una svolta in termini di strumentazione. Quando si tratta di scoprire conoscenza, di solito prima si scopre un nuovo modo di osservare l’universo, si fa una svolta a livello di strumentazione, e solo poi si riesce a compiere il grande balzo in avanti in ciò che interessa il mondo. Questo è davvero ciò che sta accadendo qui. Tra l’altro, Galileo fece la maggior parte delle sue scoperte perché fu il primo ad avere a disposizione un telescopio da lui costruito, ed è così che scoprì, ad esempio, le lune di Giove. Tutte quelle metriche sono gli strumenti che realmente alimentano il tuo percorso.

Adesso, la sfida è che, come ho detto, l’ottimizzazione sperimentale è un processo iterativo. La domanda molto importante qui è se stiamo scambiando una burocrazia con un’altra. Una delle mie più grandi critiche al management mainstream della supply chain è che finiamo per avere una burocrazia di persone che passano le giornate a spegnere incendi, destreggiandosi tra tutte quelle eccezioni, e il loro lavoro non è capitalisticamente accrescitore. Ho presentato la prospettiva contrapposta del Supply Chain Scientist, dove il loro lavoro dovrebbe essere capitalisticamente accrescitore. Tuttavia, tutto si riduce davvero a quale tipo di produttività si possa ottenere con i Supply Chain Scientist, e queste persone devono essere estremamente produttive.
Qui ti presento una breve lista di KPI che definiscono cosa comporta questa produttività. Innanzitutto, devi essere in grado di percorrere i data pipelines in meno di un’ora, end-to-end. Come ho detto, una delle cause principali dell’insanità è la semantica dei dati. Quando ti rendi conto di avere un problema a livello semantico, vuoi metterlo alla prova, e devi rieseguire l’intero data pipeline. Il tuo team della supply chain o il Supply Chain Scientist deve essere in grado di farlo più volte al giorno.
Quando si tratta della ricetta numerica che esegue l’ottimizzazione stessa, a questo punto i dati sono già preparati e consolidati, quindi rappresentano un sottoinsieme dell’intero data pipeline. Avrai bisogno di un numero molto elevato di iterazioni, per cui vuoi essere in grado di effettuare dozzine di iterazioni ogni singolo giorno. Il real-time sarebbe fantastico, ma la realtà è che l’ottimizzazione locale nella supply chain sposta solo i problemi. Devi avere una visione olistica, e il problema con modelli ingenui o banali della tua supply chain è che non saranno molto efficaci nel saper abbracciare tutte le complessità che si riscontrano nelle supply chains. C’è un compromesso tra l’espressività e la capacità della ricetta numerica e il tempo necessario per aggiornarla. In genere, l’equilibrio è buono finché mantieni il calcolo entro pochi minuti.
Infine, e questo punto è stato trattato anche nella lezione sulla consegna di software orientato al prodotto per la supply chain, devi essere davvero in grado di mettere in produzione una nuova ricetta ogni singolo giorno. Non è esattamente che io raccomandi di farlo, ma piuttosto che devi poterlo fare perché accadranno eventi imprevisti. Potrebbe trattarsi di una pandemia, o a volte non è così stravagante. C’è sempre la possibilità che un warehouse venga allagato, che si verifichi un incidente in produzione, o che arrivi una grande sorpresa, una promotion da un concorrente. Tutte le tipologie di eventi possono accadere e disturbare la tua operazione, quindi devi essere in grado di applicare misure correttive molto rapidamente. Ciò significa che devi avere un ambiente in cui è possibile lanciare in produzione una nuova iterazione della tua supply chain recipe ogni singolo giorno.

La pratica dell’ottimizzazione sperimentale è interessante. L’approccio di Lokad è stato una pratica emergente, che si è gradualmente integrata nella routine quotidiana da ormai un decennio. Nei primi anni, avevamo qualcosa come un processo proto-ottimizzazione sperimentale. La principale differenza era che iteravamo ancora, ma utilizzavamo modelli di supply chain matematica ottenuti dalla letteratura sulla supply chain. Si è scoperto che quei modelli sono solitamente monolitici e non si prestano al processo iterativo che sto descrivendo con l’ottimizzazione sperimentale. Di conseguenza, iteravamo, ma eravamo ben lontani dall’essere in grado di mettere in produzione una nuova ricetta ogni singolo giorno. Era più come se ci volessero diversi mesi per ideare una nuova ricetta. Se guardi il sito di Lokad sul percorso che abbiamo seguito, le successive iterazioni che abbiamo avuto sul nostro motore di previsione riflettevano questo approccio. Fondamentalmente, ci volevano 18 mesi per passare da un motore di previsione alla generazione successiva, con una breve serie di forse un’iterazione importante per trimestre o qualcosa del genere.
Quello che c’era prima, e dove il gioco è veramente cambiato, è stata l’introduzione dei paradigmi di programmazione. C’è una lezione precedente nel mio prologo in cui ho introdotto i paradigmi di programmazione per la supply chain. Ora, con questa lezione, dovrebbe diventare più chiaro perché ci interessano così tanto quei paradigmi. Sono ciò che alimenta questo metodo di ottimizzazione sperimentale. Sono i paradigmi di cui hai bisogno per costruire una ricetta numerica, che ti permetta di iterare in modo efficiente ogni singolo giorno per eliminare tutte quelle decisioni “insane” e orientarti verso qualcosa che crei veramente molto valore per la supply chain.
Ora, l’ottimizzazione sperimentale in situ, beh, credo che sia qualcosa che sia emerso. Non è stata realmente inventata da Lokad; è più come se fosse emersa lì, semplicemente perché ci siamo confrontati ripetutamente con le nostre stesse inadeguatezze quando si trattava di decisioni reali nella supply chain. Sospetto fortemente che altre aziende, soggette alle stesse forze, abbiano ideato i propri processi di ottimizzazione sperimentale che sono in qualche modo una variante di ciò che vi ho presentato oggi.
Qui, se guardi i giganti della tecnologia come GAFA, ho contatti lì che, senza divulgare segreti commerciali, sembrano far intendere che questo tipo di pratica vada sotto nomi differenti, ma sia già molto presente in quei giganti tecnologici. Puoi persino notarlo come osservatore esterno dal fatto che molti degli strumenti open-source che pubblicano sono strumenti che hanno davvero senso quando inizi a pensare al tipo di strumenti che vorresti avere se dovessi condurre iniziative seguendo questo metodo di ottimizzazione sperimentale. Per esempio, PyTorch non è un modello; è una meta-soluzione, un paradigma di programmazione per il machine learning, quindi si inserisce perfettamente in questo quadro.
Potresti quindi chiederti perché, se ha tanto successo, non sia riconosciuto maggiormente come tale. Riconoscere l’ottimizzazione sperimentale in situ è complicato. Se catturi un’istantanea di un’azienda in un dato momento, essa appare esattamente come la prospettiva dell’ottimizzazione matematica. Per esempio, se Lokad cattura un’istantanea di una delle aziende che serviamo, abbiamo una formulazione del problema in quel momento e una soluzione che proponiamo. Quindi, in quel momento, la situazione appare esattamente come quella dell’ottimizzazione matematica. Tuttavia, questa è solo la prospettiva statica. Non appena inizi a considerare la dimensione temporale e le dinamiche, la situazione diventa radicalmente diversa.
Inoltre, è importante notare che, pur essendo un processo iterativo, non è uno che converge. Questo può risultare un po’ inquietante. L’idea che un processo iterativo possa convergere verso qualcosa di ottimale è come dire che esista un limite fisso all’ingegno umano. Io credo che questa sia una proposta stravagante. I problemi della supply chain sono complessi, perciò non si arriva a una convergenza, semplicemente perché ci sono sempre elementi in grado di cambiare radicalmente le regole del gioco. Non si tratta di un problema definito in modo ristretto in cui si possa sperare di trovare la soluzione ottimale. Inoltre, un altro fattore per cui in pratica non si ottiene convergenza è che il mondo è in continuo mutamento. La tua supply chain non opera in un vuoto; i tuoi fornitori, clienti e il contesto cambiano. Qualunque ricetta numerica tu avessi in un dato momento può iniziare a produrre decisioni “insane” semplicemente perché le condizioni di mercato sono mutate, e ciò che era ragionevole in passato non lo è più. Devi ritararti per adattarti alla situazione attuale. Basta guardare ciò che è successo nel 2020 con la pandemia; ovviamente, c’erano così tanti cambiamenti che qualcosa di sensato prima della pandemia non poteva rimanere tale durante essa. La stessa cosa succederà ancora.
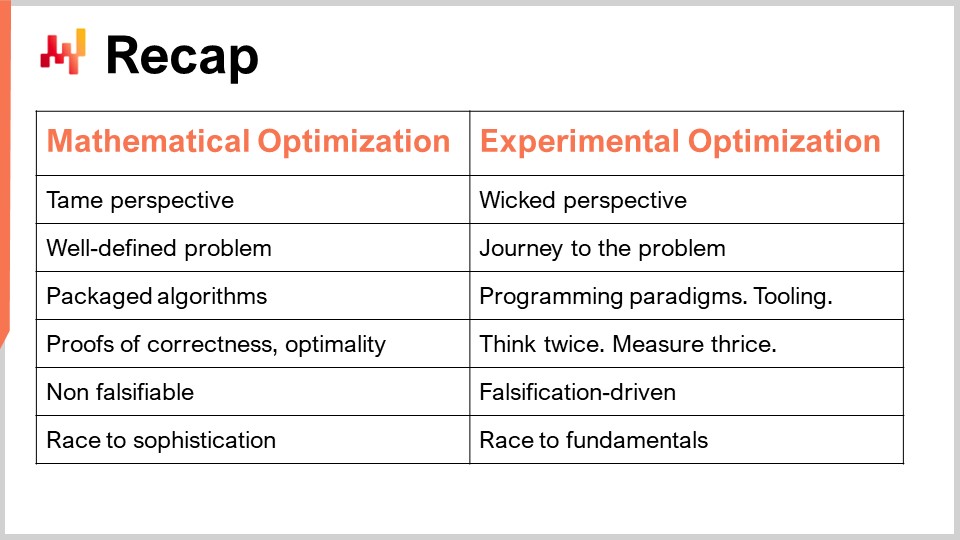
Per riassumere, abbiamo due prospettive differenti: quella dell’ottimizzazione matematica, in cui ci occupiamo di problemi ben definiti, e quella dell’ottimizzazione sperimentale, in cui il problema è complesso. Non puoi nemmeno definirlo; puoi solo intraprendere il percorso verso il problema. Di conseguenza, avendo un problema ben definito nell’ottimizzazione matematica, puoi offrire un algoritmo chiaro come soluzione e confezionarlo in un software, provandone la correttezza e l’optimalità. Nel mondo dell’ottimizzazione sperimentale, tuttavia, non puoi confezionare tutto perché è troppo complesso. Quello che puoi avere sono paradigmi di programmazione, strumenti, infrastruttura, e poi tutto ruota attorno all’intelligenza umana. Si tratta di riflettere due volte, misurare tre volte e fare un passo avanti. Nulla di tutto ciò può essere automatizzato; si riduce tutto all’intelligenza umana del Supply Chain Scientist.
In termini di falsificabilità, la mia principale tesi è che la prospettiva dell’ottimizzazione matematica non è scienza perché non puoi falsificare nulla di ciò che produce. Così, alla fine, ci ritroviamo in una corsa verso la sofisticazione – vuoi modelli sempre più complessi, ma non è perché sono più sofisticati che risultano più scientifici o creano più valore per l’azienda. In netto contrasto, l’ottimizzazione sperimentale è guidata dalla falsificazione. Tutte le iterazioni derivano dal fatto che metti le tue ricette numeriche alla prova nel mondo reale, generando decisioni e identificando quelle giuste. Questo test sperimentale può essere effettuato più volte al giorno per mettere in discussione la tua teoria e confutarla ripetutamente, iterando di conseguenza e sperando di generare molto valore nel processo.
È interessante perché, in termini di risultato finale, l’ottimizzazione sperimentale non è una corsa verso la sofisticazione; è una corsa verso i fondamentali. Si tratta di capire cosa fa “ticchettare” la tua supply chain, gli elementi fondamentali che la governano, e esattamente come dovresti interpretare ciò che accade nelle tue ricette numeriche in modo che non continuino a produrre quelle decisioni “insane” che danneggiano la supply chain. In definitiva, vuoi produrre qualcosa di veramente eccellente per la supply chain.

Questa è stata una lezione lunga, ma il punto da portare a casa dovrebbe essere che l’ottimizzazione matematica è un’illusione. È un’illusione seducente, sofisticata e attraente, ma un’illusione comunque. L’ottimizzazione sperimentale, per quanto mi riguarda, è il mondo reale. La usiamo da quasi un decennio per supportare il processo per aziende reali. Lokad è solo un punto dati, ma dal mio punto di vista è un punto dati molto convincente. Si tratta davvero di farsi un’idea del mondo reale. A proposito, questo approccio è brutalmente duro con te perché quando esci nel mondo reale la realtà risponde con forza. Avevi le tue belle teorie su quale tipo di ricetta numerica dovesse funzionare per governare e ottimizzare la supply chain, e poi la realtà torna a bussare. A volte può essere incredibilmente frustrante perché la realtà trova sempre modi per annullare tutte le idee ingegnose che potresti concepire. Questo processo è molto più frustrante, ma credo che questa sia la dose di realtà di cui abbiamo bisogno per ottenere veri rendimenti profittevoli per le tue supply chains. Il mio punto di vista è che, in futuro, arriverà un momento in cui l’ottimizzazione sperimentale, o forse un suo discendente, soppianterà completamente la prospettiva dell’ottimizzazione matematica quando si tratta di studi e pratiche di supply chain.

Nelle prossime lezioni esamineremo i metodi effettivi, i metodi numerici e gli strumenti numerici che possiamo utilizzare per supportare questa pratica. La lezione di oggi trattava solo del metodo; più avanti affronteremo il know-how e le tattiche necessarie per farlo funzionare. La prossima lezione sarà tra due settimane, nello stesso giorno e alla stessa ora, e tratterà della conoscenza negativa nella supply chain.
Ora, diamo un’occhiata alle domande.
Domanda: Se i paper sulla supply chain non hanno alcuna possibilità di essere collegati alla realtà, neanche lontanamente, e ogni caso reale sarebbe soggetto ad NDA, cosa suggeriresti a chi è intenzionato a fare studi sulla supply chain e a pubblicarne i risultati?
Il mio suggerimento è che bisogna mettere in discussione il metodo. I metodi che abbiamo non sono adatti a studiare la supply chain. Ho presentato due modalità in questa serie di lezioni: il personale della supply chain e l’ottimizzazione sperimentale. C’è molto da fare basato su queste metodologie. Queste sono solo due metodologie; sono abbastanza certo che ce ne siano molte altre ancora da scoprire o inventare. Il mio suggerimento sarebbe di mettere in discussione alla radice ciò che rende una disciplina una vera scienza.
Domanda: Se l’ottimizzazione matematica non riflette al meglio come la supply chain dovrebbe operare nel mondo reale, perché il metodo del deep learning sarebbe migliore? Il deep learning non prende decisioni basandosi su decisioni precedentemente ottimali?
In questa lezione ho tracciato una chiara distinzione tra l’ottimizzazione matematica come campo di ricerca indipendente e il deep learning come campo di ricerca indipendente, e l’ottimizzazione matematica come prospettiva applicata alla supply chain. Non sto dicendo che l’ottimizzazione matematica, in quanto campo di ricerca, sia invalida; anzi, tutto il contrario. In questo metodo di ottimizzazione sperimentale di cui parlo, al centro della ricetta numerica, di solito trovi un qualche algoritmo di ottimizzazione matematica. Il punto riguarda l’ottimizzazione matematica come prospettiva; questo è ciò che sto mettendo in discussione qui. So che è sottile, ma questa è una differenza critica che sto sottolineando. Il deep learning è una scienza ausiliaria. Il deep learning è un campo di ricerca separato, proprio come l’ottimizzazione matematica è un campo di ricerca separato. Entrambi sono grandi campi di ricerca, ma sono completamente indipendenti e distinti dagli studi sulla supply chain. Ciò che ci interessa veramente oggi è il miglioramento quantitativo delle supply chains. Questo è ciò di cui mi occupo: metodi per ottenere miglioramenti quantitativi nella supply chain in modi controllati, affidabili e misurabili. È questo il punto fondamentale.
Domanda: Il reinforcement learning può essere l’approccio giusto per la gestione della supply chain?
Prima di tutto, direi che è probabilmente l’approccio giusto per l’ottimizzazione della supply chain. È una distinzione che ho fatto in una delle mie lezioni precedenti – da una prospettiva software, hai il lato gestionale con l’Enterprise Resource Management, e poi hai il lato dell’ottimizzazione. Il reinforcement learning è un altro campo di ricerca che può anche sfruttare elementi dal deep learning e dall’ottimizzazione matematica. È quel tipo di ingrediente che puoi utilizzare in questo metodo di ottimizzazione sperimentale. La parte critica sarà se hai paradigmi di programmazione che possono integrare quelle tecniche di reinforcement learning in maniera fluida e iterativa. È una grande sfida. Vuoi essere in grado di iterare, e se disponi di qualcosa che è un modello monolitico e complesso di reinforcement learning, allora faticherai, proprio come fece Lokad nei primi anni quando cercavamo di utilizzare questi modelli monolitici in cui le iterazioni erano molto lente. Fu necessaria una serie di progressi tecnici per rendere il processo iterativo molto più fluido.
Domanda: L’ottimizzazione matematica è un elemento integrale del reinforcement learning?
Sì, il reinforcement learning è un sottoinsieme del machine learning, e il machine learning può essere visto, in un certo senso, come un sottoinsieme dell’ottimizzazione matematica. Tuttavia, il fatto è che quando fai ciò, tutto è interconnesso, e ciò che davvero differenzia questi campi è che non adottano la stessa prospettiva sul problema. Tutti questi campi sono collegati, ma di solito ciò che li distingue realmente è l’intento che ci metti.
Domanda: Come definisci una decisione insana nel contesto dei metodi di deep learning che spesso considerano molte decisioni in anticipo?
Una decisione insana dipende dalle decisioni future. È esattamente quanto ho dimostrato nell’esempio in cui ho detto: “Essere in stockout è un problema?” Beh, non è un problema se vedi che la prossima decisione che sta per essere presa è un riapprovvigionamento. Quindi, il fatto che qualificassi questa situazione da insana o meno dipendeva in realtà da una decisione imminente. Questo complica l’indagine, ma è proprio di questo che si tratta quando dico che è necessario disporre di un’ottima strumentazione. Ad esempio, significa che quando esamini una situazione di esaurimento delle scorte, devi essere in grado di proiettare le decisioni future che stai per prendere, in modo da poter vedere non solo i dati in tuo possesso, ma anche le decisioni che prevedi di prendere in base all’attuale ricetta numerica. Vedi, si tratta di disporre di una strumentazione adeguata, e ancora una volta, non è un compito semplice. Richiede un’intelligenza a livello umano; non puoi semplicemente automatizzarlo.
Domanda: Come funzionano nella pratica l’ottimizzazione sperimentale, l’identificazione dell’insanità e il trovare soluzioni? Non vedo l’ora che l’insanità si verifichi nella realtà, giusto?
Assolutamente corretto. Se torno all’inizio di questa lezione, ho menzionato due gruppi di persone: i fisici moderni e i marxisti. Il gruppo dei fisici, quando ho detto che facevano una scienza vera e propria, non era passivo in attesa che le loro teorie venissero falsificate. Si impegnavano attivamente a progettare esperimenti incredibilmente ingegnosi che avessero la possibilità di smentire le loro teorie. Era un meccanismo molto proattivo.
Se osservi ciò che fece Albert Einstein per la maggior parte della sua vita, capirai che cercava modi ingegnosi per mettere alla prova, anche se in parte, le teorie della fisica che aveva inventato mediante esperimenti. Quindi sì, non aspetti l’insana decisione che accada. È per questo che devi essere in grado di eseguire la tua ricetta più e più volte, investendo tempo nella ricerca dell’insana decisione. Ovviamente ci sono alcune decisioni, come quelle impraticabili, per le quali non c’è speranza: devi farle in produzione, e poi il mondo reagirà. Ma per la stragrande maggior parte, le decisioni insane possono essere identificate semplicemente sperimentando giorno dopo giorno. Tuttavia, hai bisogno di dati e di avere il processo reale che genera le vere decisioni che potrebbero essere implementate in produzione.
Domanda: Se una ricetta potesse essere infranta a causa di un metodo e/o di una prospettiva matematica, e se non conosci questa altra prospettiva, come puoi accorgerti di avere un problema di prospettiva e non di metodo, e spingerti a scoprire un’altra prospettiva più adatta al problema?
Questo è un problema molto grande. Come puoi vedere qualcosa che non esiste? Se torno all’esempio del personale della supply chain di Parigi, di una società di moda che gestisce negozi al dettaglio, immaginiamo per un attimo che ti sia dimenticato di considerare l’effetto a lungo termine che avevi sulle abitudini dei tuoi clienti offrendo sconti di fine stagione. Non ti rendi conto che stai creando un’abitudine nella tua base clienti. Come potresti mai accorgertene? Questo è un problema di intelligenza generale. Non esiste una soluzione magica.
Devi fare brainstorming, e a proposito, la risposta concreta di Lokad è che l’azienda ha sede a Parigi. Serviamo clienti in una ventina di paesi lontani, compresi Australia, Russia, Stati Uniti e Canada. Perché ho messo insieme tutti i miei team di Supply Chain Scientist a Parigi, anche se con la pandemia le cose sono un po’ più complicate e il lavoro da remoto è molto diffuso? Perché ho scelto di raggruppare quei Supply Chain Scientist in un unico luogo invece di esternalizzarli ovunque? La risposta è stata perché avevo bisogno che quelle persone fossero nello stesso posto in modo da poter parlare, fare brainstorming e proporre nuove idee. Ancora una volta, questa è una soluzione a bassa tecnologia, ma non posso davvero promettere niente di meglio. Quando c’è qualcosa che non riesci a vedere, come ad esempio la necessità di considerare le implicazioni a lungo termine, e te ne dimentichi o non ci pensi affatto, questo problema può risultare molto evidente e mancante. In una delle mie lezioni precedenti ho fatto l’esempio della valigia. Ci sono voluti 5.000 anni per giungere all’invenzione secondo cui sarebbe stata una buona idea mettere le ruote sulle valigie. Le ruote sono state inventate migliaia di anni fa, e la versione migliore della valigia è stata concepita decenni dopo che l’uomo fu mandato sulla luna. È proprio il tipo di cosa in cui potrebbe esserci qualcosa di ovvio che non noti. Non esiste una ricetta per questo; è semplicemente intelligenza umana. Devi fare semplicemente quello che hai.
Domanda: Le condizioni in continuo mutamento renderanno la soluzione ottimale per la tua supply chain costantemente obsoleta, giusto?
Sì e no. Dal punto di vista dell’ottimizzazione sperimentale non esiste una soluzione ottimale. Esistono soluzioni ottimizzate, ma questa distinzione fa tutta la differenza. Le soluzioni ottimizzate sono ben lontane dall’essere ottimali. Ottimale è come dire – e mi ripeto – che esiste un limite fisso all’ingegnosità umana. Quindi, non esiste niente di ottimale; è solo ottimizzato. E sì, ogni singolo giorno che passa, il mercato si discosta da tutti gli esperimenti che hai condotto fino ad ora. La sola evoluzione del mondo degrada l’ottimizzazione che hai prodotto. È semplicemente così che è il mondo. Ci sono giorni, per esempio, in cui accade una pandemia e la divergenza accelera notevolmente. Ancora una volta, è così che è il mondo. Il mondo sta cambiando, e quindi la tua ricetta numerica deve cambiare insieme ad esso. Questa è una forza esterna, quindi sì, non c’è via di scampo: la soluzione dovrà essere rivisitata costantemente.
Questa è una delle ragioni per cui Lokad vende un abbonamento, e diciamo ai nostri clienti: “No, non possiamo fornirti un Supply Chain Scientist solo per la fase di implementazione. Non ha senso. Il mondo continuerà a cambiare; questo Supply Chain Scientist che ha ideato la ricetta numerica dovrà essere presente fino alla fine dei tempi o finché non ne sarai stufo.” Quindi, questa persona sarà in grado di adattare la ricetta numerica. Non c’è scampo; è semplicemente il mondo esterno che continua a cambiare.
Domanda: Il percorso verso il problema, pur essendo corretto, fa impazzire i dirigenti. Non riescono a capirlo; pensano: “Come puoi rivedere il problema più volte nel corso di un progetto?” Quali analogie della vita suggeriresti per affrontare queste conversazioni e dimostrare che si tratta di un problema ampiamente diffuso?
Innanzitutto, è esattamente ciò che ho detto nell’ultima diapositiva in cui ho mostrato lo screenshot de The Matrix. A un certo punto, devi decidere se vuoi vivere in una fantasia o nel mondo reale. La direzione, sperabilmente se la tua alta direzione fosse solo composta da idioti, il mio unico suggerimento sarebbe di cambiare azienda, perché non sono sicuro che questa resterà a lungo. Ma la realtà è che penso che i manager non siano sciocchi. Non vogliono occuparsi di problemi inventati. Se sei un manager in una grande azienda, hai persone che vengono da te dieci volte al giorno con un “problema importante”, che in realtà non è un problema vero. La reazione del management, che è corretta, è: “Non c’è problema alcuno, continuate a fare quello che avete fatto. Mi dispiace, non ho tempo di rifare il mondo con voi. Questo non è il modo giusto di affrontare il problema.” Hanno ragione a farlo perché, grazie a decenni di esperienza, sanno come risolvere. Hanno euristiche migliori rispetto a chi sta più in basso nella gerarchia.
Ma a volte c’è una preoccupazione davvero reale. Ad esempio, la tua domanda è: come convincere la direzione, vent’anni fa, che l’e-commerce sarebbe diventato una forza dominante da tenere in considerazione tra vent’anni? A un certo punto, devi fare le tue scelte con saggezza. Se la tua alta direzione non è sciocca e ti presenti a una riunione ben preparato, dicendo: “Ehi capo, ho questo problema. Non è uno scherzo. È una questione molto importante con milioni di dollari in gioco. Non sto scherzando. Stiamo lasciando sul tavolo una massa di denaro. Peggio ancora, sospetto che la maggior parte dei nostri concorrenti ci prenderà il pranzo se non facciamo nulla. Non è un fatto secondario; è un problema molto reale. Ho bisogno che mi dedichi 20 minuti della tua attenzione.” Ancora una volta, è raro che in grandi aziende la direzione sia composta da completi idioti. Possono essere impegnati, ma non sono idioti.
Domanda: Quale sarebbe il panorama adeguato di strumenti per le aziende manifatturiere: ottimizzazione sperimentale come Lokad, più ERP, più visualizzazione? Che dire del ruolo dei sistemi di pianificazione concorrente online?
The stragrande maggioranza dei nostri concorrenti aderisce alla prospettiva dell’ottimizzazione matematica sulle supply chain. Hanno definito il problema e implementato software per risolverlo. Quello che sto dicendo è che, quando mettono il software alla prova e questo finisce invariabilmente per produrre una quantità enorme di decisioni insensate, essi dicono, “Oh, è perché non hai configurato correttamente il software.” Questo rende il prodotto software immune alla prova della realtà. Trovano modi per deviazzare le critiche anziché affrontarle.
Presso Lokad, questo metodo è emerso solo perché eravamo molto diversi dai nostri concorrenti. Non avevamo il lusso di poter dare scuse. Come si suol dire, “Puoi avere scuse o risultati, ma non entrambi.” Da Lokad, non avevamo l’opzione di trovare scuse. Stavamo fornendo decisioni, e non c’era nulla da configurare o regolare dal lato del cliente. Lokad si confrontava frontalmente con le proprie inadeguatezze. Per quanto ne so, tutti i nostri concorrenti sono saldamente ancorati alla prospettiva dell’ottimizzazione matematica, e soffrono del problema di essere in qualche modo immuni alla realtà. Ad essere onesti, non sono completamente immuni alla realtà, ma finiscono per avere un iter di miglioramento molto lento, come quello che ho descritto per Lokad nei primi anni. Non sono completamente immuni alla realtà, ma il loro processo di miglioramento è glacialmente lento, e il mondo continua a cambiare.
Ciò che accade invariabilmente è che il software aziendale non cambia quasi abbastanza rapidamente da stare al passo con il mondo in generale, così finisci per avere un software che sta semplicemente invecchiando. In realtà non sta migliorando perché, ogni anno che passa, il software migliora, ma il mondo diventa sempre più strano e diverso. Il software aziendale sta solo rimanendo sempre più indietro rispetto a un mondo che è sempre più disconnesso da dove ha avuto origine.
Domanda: Quale sarebbe il panorama corretto di strumenti per le aziende manifatturiere?
Il panorama corretto consiste in strumenti di gestione delle risorse aziendali in grado di gestire tutti gli aspetti transazionali. Inoltre, ciò che è davvero importante è disporre di una soluzione altamente integrata quando si tratta della tua ricetta numerica. Non vuoi avere un tech stack per la visualizzazione, un altro per l’ottimizzazione, un altro per l’investigazione e ancora un altro per la preparazione dei dati. Se finisci per avere mezza dozzina di stack tecnologici per tutte queste cose diverse, avrai bisogno di un esercito di ingegneri del software per collegarli tutti insieme, e finirai con qualcosa che è l’opposto di agile.
È richiesta tanta competenza in ingegneria del software che non rimane spazio per una vera competenza nelle supply chain. Ricorda, quello era il punto della mia terza lezione sulla consegna di software orientata al prodotto. Hai bisogno di qualcosa che possa essere gestito da uno specialista delle supply chain, non da un ingegnere del software.
Questo è tutto. Ci vediamo tra due settimane, lo stesso giorno e alla stessa ora, per “Negative Knowledge in Supply Chain.”
Riferimenti
- La Logica della scoperta scientifica, Karl Popper, 1934


