00:12 Introduction
02:23 Falsifiabilité
08:25 L’histoire jusqu’à présent
09:38 Approches de modélisation : Optimisation mathématique (MO)
11:25 Vue d’ensemble de l’optimisation mathématique
14:04 Théorie dominante de la supply chain (récapitulatif)
19:56 Étendue de la perspective de l’optimisation mathématique
23:29 Heuristiques de rejet
30:54 Le lendemain
32:43 Qualités rédemptrices ?
36:13 Approches de modélisation : Optimisation expérimentale (EO)
38:39 Vue d’ensemble de l’optimisation expérimentale
42:54 Les causes profondes de l’insanité
51:28 Identifier les décisions insensées
58:51 Améliorer l’instrumentation
01:01:13 Améliorer et recommencer
01:04:40 La pratique de l’optimisation expérimentale
01:11:16 Récapitulatif
01:14:14 Conclusion
01:16:39 Prochaine leçon et questions du public
Description
Loin de la perspective cartésienne naïve où l’optimisation consisterait simplement à déployer un optimiseur pour une fonction d’évaluation donnée, la supply chain exige un processus beaucoup plus itératif. Chaque itération sert à identifier des décisions « insensées » devant être examinées. La cause première est fréquemment liée à des leviers économiques, qui doivent être réévalués quant à leurs conséquences imprévues. Les itérations s’arrêtent lorsque les recettes numériques ne produisent plus de résultats insensés.
Transcription intégrale

Bonjour à tous, bienvenue dans cette série de conférences supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter « Optimisation expérimentale », qu’il faut comprendre comme l’optimisation des supply chains via une série d’expériences. Pour ceux d’entre vous qui regardent la conférence en direct, vous pouvez poser des questions à tout moment via le chat YouTube. Cependant, je ne consulterai pas le chat pendant la conférence ; je m’y rendrai à la toute fin de la conférence pour répondre aux questions qui y seront posées.
L’objectif pour nous aujourd’hui est l’amélioration quantitative des supply chains, et nous voulons y parvenir de manière contrôlée, fiable et mesurable. Nous avons besoin de quelque chose s’apparentant à une méthode scientifique, et l’une des caractéristiques clés de la science moderne est qu’elle est profondément ancrée dans la réalité ou, plus précisément, dans l’expérience. Dans une conférence précédente, j’ai brièvement abordé l’idée des expériences supply chain et mentionné qu’à première vue, elles semblent longues et coûteuses. La durée et le coût pourraient même contrecarrer le but même de ces expériences, au point qu’elles ne vaudraient peut-être même pas la peine. Mais le défi est que nous avons besoin d’une meilleure manière d’aborder l’expérimentation, et c’est exactement ce dont il s’agit en optimisation expérimentale.
L’optimisation expérimentale est fondamentalement une pratique qui a émergé chez Lokad il y a environ une décennie. Elle offre une manière de réaliser des expériences supply chain de façon réellement efficace, pratique et rentable, et c’est le sujet spécifique de la conférence d’aujourd’hui.

Mais d’abord, revenons un instant sur cette notion même de la nature de la science et sa relation avec la réalité.
Il existe un livre, “The Logic of Scientific Discovery,” publié en 1934 et dont l’auteur est Karl Popper, qui est considéré comme un jalon absolu dans l’histoire de la science. Il proposait une idée complètement renversante, celle de la falsifiabilité. Pour comprendre comment cette idée de falsifiabilité est née et en quoi elle consiste, il est très intéressant de revenir sur le parcours de Karl Popper lui-même.
Vous voyez, dans sa jeunesse, Popper était proche de plusieurs cercles d’intellectuels. Parmi ces cercles, deux étaient d’un intérêt majeur : l’un était un cercle d’économistes sociaux, généralement partisans de la théorie marxiste de l’époque, et l’autre était un cercle de physiciens, dans lequel se trouvait notamment Albert Einstein. Popper a constaté que les économistes sociaux défendaient une théorie visant à élaborer une théorie scientifique capable d’expliquer l’évolution de la société et de son économie. Cette théorie marxiste formulait en fait des prédictions sur ce qui allait se passer. La théorie avançait qu’il y aurait une révolution, et que celle-ci se produirait dans le pays le plus industrialisé, où se trouvait le plus grand nombre d’ouvriers d’usine.
Il s’est avéré que la révolution a bien eu lieu en 1917 ; cependant, elle s’est produite en Russie, qui était le pays le moins industrialisé d’Europe et, par conséquent, était en totale opposition aux prédictions de la théorie. Du point de vue de Popper, il y avait une théorie scientifique qui formulait des prédictions, puis des événements sont survenus qui contredisaient cette théorie. Ce qu’il attendait, c’était que la théorie soit réfutée, et que l’on passe à autre chose. Au lieu de cela, ce qu’il a observé était tout autre. Les partisans de la théorie marxiste ont modifié la théorie pour l’adapter aux événements tels qu’ils se déroulaient. Ce faisant, ils ont progressivement rendu la théorie insensible à la réalité. Ce qui avait commencé comme une théorie scientifique a été graduellement transformé en quelque chose de complètement immunisé, au point que rien ne pouvait désormais contredire la théorie dans le monde réel.
Cela contrastait fortement avec ce qui se passait dans les cercles des physiciens, où Popper a vu des personnes comme Albert Einstein créer des théories puis déployer de grands efforts pour concevoir des expériences susceptibles de réfuter leurs propres théories. Les physiciens ne consacraient pas toute leur énergie à prouver les théories, mais plutôt à les réfuter. Popper s’est interrogé sur l’approche la plus propice à la production scientifique et a développé le concept de falsifiabilité.
Popper a proposé que la falsifiabilité soit un critère permettant de déterminer si une théorie peut être considérée comme scientifique. Il a affirmé qu’une théorie est scientifique si elle satisfait deux critères. Le premier est que la théorie doit prendre des risques par rapport à la réalité. La théorie doit être formulée de manière à ce qu’il soit possible que la réalité contredise ce qui est énoncé. Si une théorie ne peut être contredite, ce n’est pas une question de vrai ou de faux ; cela dépasse le cadre, du moins du point de vue scientifique. Ainsi, pour qu’une théorie soit considérée comme scientifique, elle doit prendre un certain degré de risque face à la réalité.
Le second critère est que le niveau de crédibilité ou de confiance que nous pouvons accorder à une théorie devrait être, dans une certaine mesure (et je simplifie ici), proportionnel à l’effort investi par les scientifiques pour tenter de réfuter la théorie. La caractéristique scientifique d’une théorie réside dans le fait qu’elle prend de grands risques, et de nombreuses personnes essaient d’exploiter ses faiblesses pour la réfuter. Si elles échouent à plusieurs reprises, alors nous pouvons accorder un certain crédit à la théorie.
Cette perspective montre qu’il existe une asymétrie profonde entre ce qui est vrai et ce qui est faux. Les théories scientifiques modernes ne devraient jamais être considérées comme vraies ou prouvées, mais simplement comme en attente. Le fait que de nombreuses personnes aient tenté de les réfuter sans succès renforce la crédibilité que nous pouvons leur accorder. Cette observation revêt une importance capitale pour le monde de la supply chain, et en particulier, cette notion de falsifiabilité a alimenté bon nombre des évolutions les plus remarquables de la science, notamment en physique moderne.
Jusqu’ici, il s’agit de la troisième conférence du deuxième chapitre de cette série sur la supply chain. Dans le premier chapitre du prologue, j’ai présenté mes vues sur la supply chain, autant comme domaine d’étude que comme pratique. L’une des idées clés était que la supply chain englobe un ensemble de problèmes épineux, contrairement à des problèmes simples. Ces problèmes ne se prêtent pas, par conception, à une solution évidente. Par conséquent, nous devons accorder une grande attention à la méthodologie que nous devons à la fois utiliser pour étudier et pratiquer la supply chain. Ce deuxième chapitre porte sur ces méthodologies.
Dans la première conférence du deuxième chapitre, j’ai proposé une méthode qualitative pour apporter des connaissances et, par la suite, des améliorations à la supply chain grâce à la notion de personae de la supply chain. Ici, dans cette troisième conférence, je propose une méthode quantitative : l’optimisation expérimentale.

Pour apporter une amélioration quantitative aux supply chains, nous avons besoin d’un modèle quantitatif, d’un modèle numérique. Il existe au moins deux approches : la méthode grand public, l’optimisation mathématique, et une autre perspective, l’optimisation expérimentale.
L’approche grand public pour apporter des améliorations quantitatives à la supply chain est l’optimisation mathématique. Cette méthode consiste essentiellement à construire un long catalogue d’associations problème-solution. Cependant, je pense que cette méthode n’est pas très efficace, et nous avons besoin d’une autre perspective, qui est précisément l’objet de l’optimisation expérimentale. Cela doit être compris comme l’optimisation des supply chains via une série d’expériences.
L’optimisation expérimentale n’a pas été inventée par Lokad. Elle est d’abord apparue chez Lokad comme une pratique, puis a été conceptualisée en tant que telle des années plus tard. Ce que je présente aujourd’hui n’est pas la manière dont elle a progressivement émergé chez Lokad. Ce fut un processus bien plus progressif et brouillard. J’ai revisité cette pratique émergente des années plus tard pour la formaliser sous la forme d’une théorie que je peux présenter sous le titre d’optimisation expérimentale.

Tout d’abord, nous devons clarifier le terme optimisation mathématique. Il y a deux choses distinctes qu’il nous faut différencier : l’optimisation mathématique en tant que domaine de recherche indépendant et l’optimisation mathématique en tant que perspective d’amélioration quantitative de la supply chain, qui est le sujet d’intérêt aujourd’hui. Mettons de côté la seconde perspective un instant et clarifions de quoi il s’agit dans l’optimisation mathématique en tant que domaine autonome de recherche.
C’est un domaine de recherche qui s’intéresse à une classe de problèmes mathématiques qui se présentent comme décrits à l’écran. Essentiellement, on part d’une fonction qui va d’un ensemble arbitraire (noté A) à un nombre réel. Cette fonction, souvent appelée la fonction de perte, est notée f. Nous recherchons la solution optimale, qui sera un point x appartenant à A, l’ensemble, et qui ne peut pas être amélioré. Naturellement, il s’agit d’un domaine de recherche très vaste comportant de nombreuses subtilités techniques. Certaines fonctions peuvent ne présenter aucun minimum, tandis que d’autres peuvent avoir plusieurs minima distincts. En tant que domaine de recherche, l’optimisation mathématique a été prolifique et couronnée de succès. De nombreuses techniques ont été élaborées et des concepts introduits, qui ont été utilisés avec grand succès dans de nombreux autres domaines. Cependant, je ne traiterai pas de tout cela aujourd’hui, car ce n’est pas le but de cette conférence.
Le point que je souhaite souligner est que l’optimisation mathématique, en tant que science auxiliaire pour la supply chain, a rencontré un succès considérable par elle-même. En retour, cela a profondément façonné l’étude quantitative des supply chains, ce dont traite l’optimisation mathématique du supply chain perspective.

Revenons sur deux livres que j’ai présentés dans ma toute première conférence supply chain. Je pense que ces deux ouvrages représentent la théorie quantitative dominante de la supply chain, incarnant les cinq dernières décennies de publications scientifiques et de production logicielle. Il ne s’agit pas seulement des articles publiés, mais aussi des logiciels qui ont été mis sur le marché. En ce qui concerne l’optimisation quantitative des supply chains, tout est fait et est fait depuis longtemps via des instruments logiciels.
Si l’on regarde ces livres, chaque chapitre peut être considéré comme une application de la perspective de l’optimisation mathématique. Tout se réduit à une énonciation de problème avec divers ensembles d’hypothèses, suivie de la présentation d’une solution. La justesse et parfois l’optimalité de la solution sont ensuite démontrées par rapport à l’énoncé du problème. Ces livres sont essentiellement des catalogues de paires problème-solution, se présentant comme des problèmes d’optimisation mathématique.
Par exemple, la prévision peut être considérée comme un problème dans lequel vous disposez d’une fonction de perte, qui représentera votre erreur de prévision, et d’un modèle avec des paramètres que vous souhaitez ajuster. Vous cherchez alors à maîtriser le processus d’optimisation, d’un point de vue numérique, qui vous fournit les paramètres optimaux. La même approche s’applique à une politique de stocks, où vous pouvez formuler des hypothèses sur la demande, puis démontrer que vous disposez d’une solution qui s’avère être optimale par rapport aux hypothèses que vous venez d’énoncer.
Comme je l’ai déjà évoqué dans la toute première conférence, je nourris de grandes inquiétudes à l’égard de cette théorie dominante de la supply chain. Les livres que j’ai mentionnés ne sont pas des sélections aléatoires ; je pense qu’ils reflètent fidèlement les dernières décennies de recherche sur la supply chain. À présent, en examinant les idées de falsifiabilité telles qu’introduites par Karl Popper, nous pouvons mieux comprendre le problème : aucun de ces livres n’est véritablement scientifique, car la réalité ne peut réfuter ce qui y est présenté. Ces ouvrages sont essentiellement complètement immunisés face aux supply chains du monde réel. Lorsqu’un livre se présente essentiellement comme une collection de paires problème-solution, il n’y a rien à réfuter. Il s’agit d’une construction purement mathématique. Le fait qu’une supply chain fasse ceci ou cela n’a aucune incidence sur la preuve ou la réfutation de ce qui est présenté dans ces livres. C’est sans doute ma plus grande inquiétude concernant ces théories.
Ce n’est pas seulement une question de recherche dont il est question ici. Si vous regardez ce qui existe en termes de logiciels d’entreprise pour servir les supply chains, le logiciel qui existe aujourd’hui sur le marché est très majoritairement le reflet de ces publications scientifiques. Ce logiciel n’a pas été inventé indépendamment de ces publications scientifiques ; généralement, ils vont de pair. La plupart des logiciels d’entreprise que l’on trouve sur le marché pour répondre aux problèmes d’optimization de la supply chain sont le reflet d’une certaine série d’articles ou de livres, parfois rédigés par les mêmes personnes qui ont produit le logiciel et les livres.
Le fait que la réalité n’ait aucune incidence sur les théories présentées ici est, je pense, une explication très plausible du fait que si peu des théories exposées dans ces livres soient réellement utiles dans les supply chains du monde réel. C’est une affirmation assez subjective de ma part, mais au cours de ma carrière, j’ai eu l’occasion de discuter avec plusieurs centaines de directeurs de supply chain. Ils connaissent ces théories et, s’ils n’en maîtrisent pas tous les aspects, ils ont dans leurs équipes des personnes qui les connaissent. Très souvent, le logiciel utilisé par l’entreprise implémente déjà une série de solutions telles que présentées dans ces livres, et pourtant elles ne sont pas utilisées. Pour diverses raisons, les gens retombent sur leurs propres tableurs Excel.
Ce n’est donc pas de l’ignorance. Nous avons ce problème très réel, et je crois que la cause fondamentale est tout simplement que ce n’est pas de la science. Vous ne pouvez pas infirmer ce qui est présenté. Ce n’est pas que ces théories soient incorrectes – elles sont mathématiquement correctes – mais elles ne sont pas scientifiques dans le sens où elles ne remplissent même pas les conditions pour être considérées comme telles.

Maintenant, la question se poserait : quelle est l’ampleur du problème ? Car j’ai en réalité choisi deux livres, mais quelle est l’ampleur réelle de cette perspective d’optimization mathématique dans la supply chain ? Je dirais que l’étendue de cette perspective est absolument massive. À titre d’anecdote pour le démontrer, j’ai récemment utilisé Google Scholar, un moteur de recherche spécialisé proposé par Google qui ne fournit des résultats que pour des publications scientifiques. Si vous recherchez “optimal stocks” uniquement pour l’année 2020, vous obtiendrez plus de 30 000 résultats.
Ce chiffre doit être pris avec des pincettes. Évidemment, il y a probablement de nombreux doublons dans cette liste, et il y aura très probablement des faux positifs – des articles où apparaissent à la fois les mots “inventory” et “optimal” dans le titre et le résumé, alors que l’article ne traite pas du tout de supply chain. C’est purement accidentel. Néanmoins, un examen superficiel des résultats laisse fortement entendre que nous parlons de plusieurs milliers d’articles publiés par an dans ce domaine. Pour mettre cela en perspective, ce nombre est très élevé, même comparé à des domaines absolument massifs, comme deep learning. Deep learning est probablement l’une des théories en informatique qui connaît le plus grand succès depuis deux ou trois décennies. Ainsi, le fait que seule la requête “optimal stocks” renvoie un résultat de l’ordre d’un cinquième de celui obtenu pour deep learning est en réalité très stupéfiant. Optimal stocks n’est évidemment qu’une fraction de ce dont traitent les études de supply chain quantitative.
Cette requête simple montre que la perspective d’optimization mathématique est vraiment massive, et j’affirmerais, bien que cela soit peut-être quelque peu subjectif, qu’en ce qui concerne les études quantitatives de supply chain, elle domine réellement. Si nous avons plusieurs milliers d’articles qui fournissent des politiques de stocks optimaux et des modèles d’inventory management pour gérer des entreprises, produits sur une base annuelle, il est certain que la majorité des grandes entreprises devrait fonctionner sur la base de ces méthodes. Nous ne parlons pas de quelques articles seulement ; nous parlons d’une quantité absolument massive de publications.
D’après mon expérience, avec quelques centaines de cas de supply chain dont je suis au courant, ce n’est vraiment pas le cas. Ces méthodes sont pratiquement introuvables. Nous constatons un décalage absolument saisissant entre l’état du domaine en ce qui concerne les articles publiés – et, d’ailleurs, les logiciels, car ces derniers reflètent essentiellement ce qui est publié sous forme d’articles scientifiques – et la manière dont les supply chains fonctionnent réellement.

La question que je me posais était : avec des milliers d’articles, y a-t-il quelque chose de bon à trouver ? J’ai eu le plaisir de parcourir des centaines d’articles de supply chain quantitative, et je peux vous proposer une série d’heuristiques qui vous garantiront presque à 100 % qu’un article n’apporte aucune valeur ajoutée réelle. Ces heuristiques ne sont pas absolument vraies, mais elles sont très précises, avec une exactitude supérieure à 99 %. Ce n’est pas parfaitement exact, mais c’est presque parfait.
Alors, comment détecter les articles qui apportent une valeur réelle, ou inversement, comment rejeter ceux qui n’apportent aucune valeur ? J’ai dressé une courte série d’heuristiques. La première est que, si l’article avance une quelconque affirmation d’optimalité, alors vous pouvez être sûr qu’il n’apporte aucune valeur aux supply chains du monde réel. D’une part, cela reflète le fait que les auteurs ne comprennent même pas, ou n’ont pas la moindre compréhension du fait que les supply chains sont essentiellement un problème complexe. Affirmer que vous avez une solution optimale pour la supply chain revient un peu à dire qu’il existe une limite stricte à l’ingéniosité humaine. Je n’y crois pas un seul instant. Je pense que c’est une proposition complètement déraisonnable. Nous constatons qu’il y a un très gros problème dans l’approche de la supply chain.
Un autre problème est que, dès qu’il y a une affirmation d’optimalité, il s’ensuit invariablement une solution qui repose fortement sur certaines hypothèses. Vous pouvez avoir une solution dont l’optimalité est prouvée selon un certain ensemble d’hypothèses, mais qu’adviendra-t-il si ces hypothèses sont violées ? La solution restera-t-elle valable ? Au contraire, je crois que si vous avez une solution dont vous pouvez prouver l’optimalité, c’est une solution incroyablement dépendante de la validité, même approximative, des hypothèses formulées. Si vous violez ces hypothèses, la solution qui en résulte est fort probablement absolument terrible, car elle n’a jamais été conçue pour être robuste face à quoi que ce soit. Les affirmations d’optimalité peuvent être pratiquement écartées d’emblée.
Le second point concerne les distributions normales. Chaque fois que vous voyez un article ou un logiciel d’entreprise qui affirme utiliser des distributions normales, vous pouvez être sûr que ce qui est proposé ne fonctionne pas dans les supply chains réelles. Dans un cours précédent, où je présentais les principes quantitatifs pour la supply chain, j’ai démontré que toutes les populations d’intérêt dans les supply chains suivent une loi de Zipf, et non une distribution normale. Les distributions normales sont introuvables dans les supply chains, et je suis absolument convaincu que ce résultat est connu depuis des décennies. Si vous trouvez des articles ou des logiciels qui reposent sur cette hypothèse, il est quasi certain que vous obtenez une solution conçue par commodité, afin qu’il soit plus facile d’écrire la démonstration mathématique ou le logiciel, et non par désir de performance concrète. La présence de distributions normales n’est que de la pure paresse ou, au mieux, le signe d’une incompréhension profonde de ce qu’est la supply chain. Cela peut servir à rejeter ces articles.
Ensuite, la stationnarité – cela n’existe pas. C’est une hypothèse qui semble acceptable : les choses sont stationnaires, toujours les mêmes. Mais ce n’est pas le cas ; c’est une hypothèse très forte. Elle implique essentiellement que vous avez un processus qui a commencé au début des temps et qui se poursuivra jusqu’à la fin des temps. C’est une perspective très déraisonnable pour des supply chains réelles. Dans les supply chains réelles, tout produit est introduit à un moment donné, et tout produit sera retiré du marché à un moment donné. Même si l’on considère des produits à durée de vie relativement longue, comme dans l’industrie automobile, ces processus ne sont pas stationnaires. Ils ne dureront peut-être qu’une décennie au mieux. La durée d’intérêt, l’intervalle de temps considéré, est fini, donc la perspective stationnaire est tout simplement erronée.
Un autre élément pour identifier une étude quantitative vouée à l’échec est l’absence même de la notion de substitution. Dans les supply chains réelles, les substitutions sont omniprésentes. Si l’on revient à l’exemple de supply chain que j’ai présenté il y a deux semaines lors d’un cours précédent, vous pouviez observer au moins une demi-douzaine de situations où des substitutions interviennent – du côté de l’offre, de la transformation et de la demande. Si vous avez un modèle où, conceptuellement, la substitution n’existe même pas, alors vous avez quelque chose qui est franchement en décalage avec les supply chains réelles.
De même, l’absence de globalité ou d’une perspective holistique sur la supply chain est également un signe révélateur que quelque chose ne va pas. Si je reviens au cours précédent où j’ai présenté les principes quantitatifs pour la supply chain, j’ai déclaré que si vous avez quelque chose qui ressemble à un processus d’optimisation local, vous n’optimiserez rien ; vous vous contenterez de déplacer les problèmes au sein de votre supply chain. La supply chain est un système, un réseau, et vous ne pouvez donc pas appliquer une optimisation locale en espérant qu’elle soit véritablement bénéfique pour l’ensemble de la supply chain. Ce n’est tout simplement pas le cas.
Avec ces heuristiques, je pense que vous pouvez presque éliminer la majeure partie de la littérature sur la supply chain quantitative, ce qui est en soi assez stupéfiant.

Le fait est que si je devais convaincre chaque comité de rédaction de chaque conférence et revue sur la supply chain qu’ils devraient utiliser ces heuristiques pour filtrer les contributions de faible qualité, cela ne fonctionnerait pas. Les auteurs s’adapteraient et contourneraient le processus, même si nous ajoutions ces directives pour la publication dans les revues de supply chain. Si les analystes de marché ajoutaient cela à leur checklist, ce qui se produirait, c’est que les auteurs, qu’ils rédigent des articles ou développent des logiciels, s’adapteraient tout simplement. Ils obscurciraient le problème en formulant des hypothèses plus compliquées, de sorte qu’on ne puisse plus voir qu’il s’agit en réalité d’une distribution normale ou d’une hypothèse de stationnarité. C’est juste que c’est formulé de manière très opaque.
Ces heuristiques sont utiles pour identifier les contributions de faible qualité, tant pour les articles que pour les logiciels, mais nous ne pouvons pas les utiliser pour filtrer ce qui est bon. Nous avons besoin d’un changement plus profond ; nous devons revoir tout le paradigme. À ce stade, il nous manque toujours la falsifiabilité. La réalité n’a aucun moyen de riposter et de réfuter ce qui est présenté.

Comme dernier élément pour clore cette partie du cours sur la perspective d’optimization mathématique, y a-t-il une qualité rédemptrice à trouver dans cette production énorme d’articles et de logiciels ? Ma réponse, très subjective, à cette question est absolument non. Ces articles – et j’en ai lu un très grand nombre sur la supply chain quantitative – ne sont pas intéressants. Au contraire, ils sont extrêmement ennuyeux, même les meilleurs. Lorsqu’on observe les sciences auxiliaires, il n’y a rien de vraiment intéressant à y découvrir. Vous pouvez examiner tous ces articles, et j’en ai recensé des milliers. Du point de vue mathématique, c’est très terne. Il n’y a pas de grandes idées mathématiques présentées. Du point de vue algorithmique, il s’agit simplement d’une application directe de ce qui est connu depuis longtemps dans le domaine des algorithmes. Il en va de même pour la modélisation statistique et la méthodologie, qui sont extrêmement médiocres. En termes de méthodologie, tout se résume à la perspective d’optimization mathématique, où vous présentez un modèle, optimisez quelque chose, fournissez la solution, et prouvez que cette solution possède certaines caractéristiques mathématiques par rapport à l’énoncé du problème.
Nous devons vraiment changer plus qu’en surface. Je ne critique pas l’approche. Il existe des précédents historiques à cela. Il peut sembler complètement stupéfiant que j’affirme que nous avons des dizaines de milliers d’articles complètement stériles, mais cela s’est produit historiquement. Si vous regardez la vie d’Isaac Newton, l’un des pères de la physique moderne, vous verrez qu’il a passé environ la moitié de son temps à travailler sur la physique, laissant un héritage considérable, et l’autre moitié à travailler sur l’alchimie. Il était un physicien brillant et un alchimiste très médiocre. Les archives historiques tendent à montrer qu’Isaac Newton était aussi brillant, dévoué et sérieux dans son travail sur l’alchimie que dans celui sur la physique. Du fait que la perspective alchimique était tout simplement mal cadrée, tout le travail et toute l’intelligence que Newton y a investis se sont révélés complètement stériles, sans aucun héritage notable. Ma critique n’est pas que nous ayons des milliers de personnes publiant des choses idiotes. La plupart de ces auteurs sont très intelligents. Le problème est que le cadre lui-même est stérile. C’est le point que je voulais souligner.

Passons maintenant à la deuxième approche de modélisation que je souhaite présenter aujourd’hui. Dans les premières années, la méthodologie de Lokad était profondément enracinée dans la perspective d’optimization mathématique. Nous étions très mainstream à cet égard, et cela fonctionnait très mal pour nous. Une chose qui était très spécifique chez Lokad, et qui était presque accidentelle, c’est qu’à un moment donné, j’ai décidé que Lokad ne vendrait pas de logiciels d’entreprise, mais vendrait directement des décisions de supply chain end-game. J’entends par là les quantités exactes qu’une entreprise doit acheter, les quantités qu’elle doit produire, et le nombre d’unités à déplacer du point A au point B – que le prix unique doive baisser ou non – Lokad était dans le métier de vendre des décisions de supply chain end-game. En raison de cette décision semi-accidentelle de ma part, nous avons été brutalement confrontés à nos propres insuffisances. Nous avons été mis à l’épreuve, et la réalité nous a rattrapés de la manière la plus brutale. Si nous produisions des décisions de supply chain qui s’avéraient mauvaises, les clients se ruaient immédiatement sur moi, hurlant leur ras-le-bol, parce que Lokad ne fournissait pas quelque chose de satisfaisant.
D’une certaine manière, l’optimisation expérimentale a émergé chez Lokad. Elle n’a pas été inventée chez Lokad ; c’était une pratique émergente qui était simplement une réponse au fait que nous étions soumis à une immense pression de la part de notre clientèle pour faire quelque chose contre ces défauts qui pullulaient au début. Nous avons dû trouver une sorte de mécanisme de survie, et nous avons essayé bien des choses, parfois presque au hasard. Ce qui a émergé, c’est ce que l’on appelle l’optimisation expérimentale.

L’optimisation expérimentale est une méthode très simple. Le but est de produire des décisions de supply chain en rédigeant une recette pilotée par logiciel, qui génère des décisions de supply chain. La méthode commence ainsi : étape zéro, vous écrivez simplement des recettes qui génèrent des décisions. Il y a énormément de savoir-faire, de technologies et d’outils qui nous intéressent ici. Ce n’est pas le sujet de cette conférence ; cela sera traité en détail dans de futures conférences. Donc, étape un, vous rédigez simplement une recette et, très probablement, elle ne sera pas très bonne.
Ensuite, vous entrez dans une pratique d’itération indéfinie, où d’abord vous allez exécuter la recette. Par “exécuter”, je veux dire que la recette doit pouvoir s’exécuter dans un environnement de production de qualité. Il ne s’agit pas simplement d’avoir un algorithme dans le data science lab que vous pouvez lancer. Il s’agit d’avoir une recette qui possède toutes les qualités, de sorte que si vous décidez que ces décisions sont assez bonnes pour être mises en production, vous pouvez le faire en un seul clic. L’ensemble de l’environnement doit être de qualité production ; c’est de cela qu’il s’agit quand on parle d’exécuter la recette.
La prochaine étape consiste à identifier les décisions insensées, sujet qui a été abordé dans une de mes conférences précédentes sur la livraison orientée produit pour la supply chain. Pour ceux d’entre vous qui n’ont pas assisté à cette conférence, en résumé, nous voulons que les investissements en supply chain soient capitalistes et accroissants, et pour y parvenir, nous devons nous assurer que les personnes qui travaillent dans cette division de supply chain ne se contentent pas d’éteindre des incendies. La situation par défaut dans la grande majorité des entreprises actuellement est que les décisions de supply chain sont générées par des logiciels – la plupart des entreprises modernes utilisent déjà de manière intensive des logiciels d’entreprise pour gérer leur supply chain, et toutes les décisions sont déjà générées via ces logiciels. Cependant, une très grande partie de ces décisions est tout simplement complètement insensée. Ce que font la plupart des équipes de supply chain, c’est de revisiter manuellement toutes ces décisions insensées et de s’engager dans une lutte constante contre les incendies pour les éliminer. Ainsi, tous les efforts finissent par être absorbés par le fonctionnement de l’entreprise. Vous nettoyez toutes vos exceptions un jour, puis vous revenez le lendemain avec un tout nouveau lot d’exceptions à traiter, et le cycle se répète. Vous ne pouvez pas capitaliser ; vous consommez simplement le temps de vos experts en supply chain. L’idée chez Lokad est donc que nous devons traiter ces décisions insensées comme des défauts logiciels et les éliminer entièrement, afin de pouvoir instaurer un processus et une pratique de supply chain capitalistes.
Une fois cela établi, nous devons améliorer l’instrumentation et, par conséquent, améliorer la recette numérique elle-même. Tout ce travail est réalisé par le Supply Chain Scientist, une notion que j’ai introduite dans ma deuxième conférence du premier chapitre, “La Supply Chain Quantitative,” telle que perçue par Lokad. L’instrumentation revêt une importance capitale, car c’est grâce à une instrumentation améliorée que vous pouvez mieux comprendre ce qui se passe dans votre supply chain, dans votre recette, et comment vous pouvez l’améliorer pour remédier à ces décisions insensées qui continuent de surgir.

Approfondissons un instant les causes profondes de l’absurdité qui expliquent ces décisions insensées. Fréquemment, lorsque je demande aux directeurs de supply chain pourquoi ils pensent que leurs systèmes logiciels d’entreprise qui gèrent leurs opérations de supply chain continuent de produire ces décisions insensées, une réponse très courante mais erronée que j’obtiens est : “Oh, c’est simplement parce que nous avons de mauvaises prévisions.” Je pense que cette réponse est erronée sur au moins deux points. Premièrement, si vous passez de la précision que vous pouvez obtenir avec un modèle de moyenne mobile très simpliste à un modèle de deep learning à la pointe de la technologie, il y a peut-être un gain de 20 % en précision. Donc oui, c’est significatif, mais cela ne peut pas faire la différence entre une décision qui est excellente et une décision qui est complètement insensée. Deuxièmement, le plus gros problème avec les prévisions est qu’elles ne prennent pas en compte toutes les alternatives ; elles ne sont pas probabilistes. Mais je m’égare ; ce serait un sujet pour une autre conférence.
Si nous revenons à la cause première de cette absurdité, je pense que, bien que les erreurs de prévision soient préoccupantes, elles ne constituent absolument pas le problème principal. Fort d’une décennie d’expérience chez Lokad, je peux affirmer qu’il s’agit, au mieux, d’une préoccupation secondaire. La préoccupation principale, le plus gros problème qui engendre des décisions insensées, est la sémantique des données. Rappelez-vous que vous ne pouvez pas observer une supply chain directement ; ce n’est pas possible. Vous ne pouvez observer une supply chain qu’en tant que reflet via les enregistrements électroniques que vous recueillez grâce à des morceaux de logiciels d’entreprise. L’observation que vous faites de votre supply chain est un processus très indirect, à travers le prisme du logiciel.
Ici, il est question de centaines de tables relationnelles et de milliers de champs, et la sémantique de chacun de ces champs est vraiment importante. Mais comment savoir que vous avez la bonne compréhension et le bon état d’esprit ? La seule façon de s’en assurer est de mettre cette compréhension à l’épreuve de l’expérimentation. Dans l’optimisation expérimentale, le test expérimental consiste en la génération de décisions. Vous supposez qu’une colonne signifie quelque chose ; c’est, en quelque sorte, votre théorie scientifique. Ensuite, vous générez une décision basée sur cette compréhension, et si la décision est bonne, alors votre compréhension est correcte. Fondamentalement, la seule chose que vous pouvez observer, c’est si votre compréhension conduit ou non à des décisions insensées. C’est ici que la réalité vous rattrape.
Ce n’est pas un petit problème ; c’est un problème très important. Les logiciels d’entreprise sont complexes, c’est le moins qu’on puisse dire, et ils comportent des bugs. Le problème avec la perspective de l’optimisation mathématique, c’est qu’elle aborde le problème comme s’il s’agissait d’une simple série d’hypothèses, puis vous pouvez déployer une solution relativement simple et mathématiquement élégante. Mais la réalité est que nous avons des couches de logiciels d’entreprise superposées et que des problèmes peuvent survenir partout. Certains de ces problèmes sont très banals, comme une copie incorrecte, une liaison erronée entre des variables, ou des systèmes qui devraient être synchronisés se désynchronisant. Il peut y avoir des mises à niveau de version des logiciels qui créent des bugs, et ainsi de suite. Ces bugs sont omniprésents, et la seule façon de savoir si vous en avez ou non est, encore une fois, d’examiner les décisions. Si les décisions se révèlent correctes, alors soit il n’y a pas de bugs, soit les bugs présents sont insignifiants et nous n’en tenons pas compte.
Concernant les moteurs économiques, une autre approche erronée surgit fréquemment lors des discussions avec des directeurs de supply chain. Ils me demandent souvent de prouver qu’il y aura un certain retour économique pour leur entreprise. Ma réponse est que nous ne connaissons même pas encore les moteurs économiques. Mon expérience chez Lokad m’a appris que la seule façon de déterminer avec certitude quels sont les moteurs économiques – et ces moteurs servent à construire la fonction de perte qui, à son tour, est utilisée pour réaliser l’optimisation dans la recette numérique elle-même – est de les mettre véritablement à l’épreuve, encore une fois, par l’expérience de génération de décisions et en observant si ces décisions sont insensées ou non. Ces moteurs économiques doivent être découverts et validés sur la base de l’expérience. Au mieux, vous pouvez avoir une intuition de ce qui est correct, mais seule l’expérience et les expérimentations peuvent vous dire si votre compréhension est réellement juste.
Ensuite, il y a toutes les impraticabilités. Vous avez une recette numérique qui génère des décisions, et ces décisions semblent conformes à toutes les règles que vous avez établies. Par exemple, s’il existe des quantités minimales de commande (MOQ), vous générez des bons de commande conformes à vos MOQ. Mais que se passe-t-il si un fournisseur revient et vous dit que la MOQ est autre chose ? À travers ce processus, vous pourriez découvrir de nombreuses impraticabilités et des décisions apparemment réalisables qui, lorsqu’on tente de les mettre à l’épreuve du monde réel, s’avèrent irréalisables. Vous découvrez toutes sortes de cas limites et de restrictions, parfois même ceux auxquels vous n’aviez pas pensé, où le monde vous rattrape et où vous devez également apporter des corrections.
Ensuite, il y a même votre stratégie. Vous pouvez penser que vous avez une stratégie globale et de haut niveau pour votre supply chain, mais est-elle correcte ? Pour vous donner une idée, prenons l’exemple d’Amazon. Vous pouvez dire que vous souhaitez être orienté client. Par exemple, si des clients achètent quelque chose en ligne et que cela ne leur plaît pas, ils devraient pouvoir le retourner très facilement. Vous voulez être très généreux en matière de retours. Mais alors, que se passe-t-il si vous avez des adversaires ou de mauvais clients qui abusent du système ? Ils pourraient commander en ligne un smartphone coûteux à 500 $, le recevoir, remplacer le véritable smartphone par une contrefaçon valant seulement 50 $, puis le retourner. Amazon se retrouve alors avec des contrefaçons dans ses stocks sans même s’en rendre compte. C’est un problème bien réel qui a été maintes fois abordé en ligne.
Vous pourriez avoir une stratégie qui dit que vous voulez être orienté client, mais peut-être que votre stratégie devrait être de l’être uniquement pour les clients honnêtes. Ainsi, il ne s’agit pas de tous les clients ; c’est un sous-ensemble de clients. Même si votre stratégie est approximativement correcte, le diable se cache dans les détails. Encore une fois, la seule façon de vérifier si les subtilités de votre stratégie sont justes est de recourir à l’expérimentation, afin d’en examiner les détails.

Maintenant, discutons de la manière dont nous identifions les décisions insensées. Comment faire la différence entre des décisions saines et insensées ? Par “décision insensée”, j’entends une décision qui n’est pas raisonnable pour votre entreprise. C’est un type de problème qui requiert véritablement une intelligence humaine générale. Il n’y a aucun espoir que vous puissiez résoudre ce problème par le biais d’un algorithme. Cela peut paraître paradoxal, mais c’est exactement le genre de problème qui nécessite une intelligence au niveau humain, sans pour autant exiger un humain particulièrement brillant.
Il existe de nombreux autres problèmes de ce type dans le monde réel. Par exemple, une analogie serait celle des erreurs dans les films. Si vous demandiez aux studios hollywoodiens un algorithme capable d’identifier toutes les erreurs de n’importe quel film, ils diraient probablement qu’ils n’ont aucune idée de comment concevoir un tel algorithme, car cela semble être une tâche nécessitant une intelligence humaine. Cependant, si vous transformez le problème en celui de disposer simplement de personnes pouvant être formées pour être très compétentes dans l’identification des erreurs dans les films, la tâche devient bien plus simple. Il est tout à fait envisageable de consolider un manuel regroupant toutes les astuces pour repérer les erreurs dans les films. Il n’est pas nécessaire de recruter des personnes exceptionnellement intelligentes pour ce travail ; il suffit de personnes raisonnablement intelligentes et dévouées. C’est exactement de cela qu’il s’agit.
Alors, à quoi ressemble la situation du point de vue de la supply chain ? Si nous voulons examiner concrètement le problème, fondamentalement, nous allons rechercher des valeurs aberrantes. Il suffit de commencer sous un certain angle. Prenons, par exemple, le persona de Paris que j’ai présenté il y a deux semaines. Il s’agit d’une entreprise de mode qui exploite un grand réseau de magasins de mode. Prenons, par exemple, le fait que nous nous préoccupions de la qualité de service.
Commençons par les ruptures de stock. Si nous exécutons simplement une requête sur tous les produits et tous les magasins, nous constaterons que nous avons des milliers de ruptures de stock sur l’ensemble du réseau. Cela n’aide donc pas vraiment ; nous en avons des milliers, et la réponse est “et alors ?” Peut-être qu’il ne s’agit pas seulement des ruptures de stock ; ce qui est vraiment intéressant, ce sont les ruptures de stock dans les magasins phares, les magasins qui réalisent beaucoup de ventes. C’est là que ça compte, et non pas les ruptures de stock concernant n’importe quels produits, mais celles des best-sellers. Réduisons notre recherche aux ruptures de stock qui se produisent dans les magasins phares pour les best-sellers.
Ensuite, nous pouvons examiner un SKU où le stock est à zéro. Mais en y regardant de plus près, nous verrons que, peut-être, au début de la journée, le stock était en réalité de trois unités, et que la dernière unité a été vendue seulement 30 minutes avant la fermeture du magasin. Si nous y prêtons une attention particulière, nous constaterons que trois unités seront réapprovisionnées le lendemain. Ici, nous avons donc une situation où l’on observe une rupture de stock, mais est-ce vraiment important ? Eh bien, il s’avère que non, car la dernière unité a été vendue juste avant la fermeture du magasin le soir, et la quantité doit être réapprovisionnée. De plus, si nous regardons plus loin, nous verrons qu’il n’y a peut-être pas assez de place dans le magasin pour stocker plus de trois unités, ce qui nous impose une contrainte.
Donc, ce n’est pas exactement une préoccupation majeure. Peut-être devrions-nous restreindre la recherche aux ruptures de stock où nous avions la possibilité de réapprovisionner – magasin phare, produit phare – mais nous ne l’avons pas fait. Nous trouvons un exemple pour un SKU donné, puis nous constatons qu’il n’y a plus de stocks dans le centre de distribution. Alors, dans ce cas, est-ce vraiment un problème ? On pourrait dire non, mais attendez une minute. Nous n’avons plus de stocks dans le centre de distribution, mais pour le même produit, examinons le réseau dans son ensemble. Avons-nous encore des stocks quelque part ?
Disons que, pour ce produit – produit phare, magasin phare – nous avons de nombreux magasins faibles qui disposent encore de beaucoup de stocks pour ce même produit, mais qui ne font tout simplement pas tourner ces stocks. Ici, nous constatons qu’il y a bel et bien un problème. Le souci n’était pas qu’il n’y avait pas assez de stocks alloués au magasin phare ; le problème est qu’il y avait trop de stocks alloués, probablement lors de l’allocation initiale vers les magasins pour la nouvelle collection, dans des magasins très faibles. Nous procédons donc étape par étape pour identifier la cause première du problème. Nous pouvons la remonter à une question de qualité de service causée non pas par l’envoi insuffisant de stocks, mais au contraire par un envoi excessif, qui finit par avoir un impact au niveau du système sur la qualité de service de ces magasins phares.
Ce que j’ai fait ici est tout à fait l’opposé de la statistique, et c’est quelque chose d’important lorsque nous recherchons des décisions “insensées”. Vous ne voulez pas agréger les données ; au contraire, vous voulez travailler sur des données complètement désagrégées afin que tous les problèmes se manifestent. Dès que vous commencez à agréger les données, en général, ces comportements subtils disparaissent. L’astuce consiste généralement à démarrer au niveau le plus désagrégé et à parcourir le réseau pour comprendre exactement ce qui se passe, non pas au niveau statistique, mais à un niveau très basique et élémentaire qui vous permet de comprendre.
Cette méthode se prête également très bien à la perspective que j’ai introduite dans la Supply Chain Quantitative, où je dis qu’il faut avoir des moteurs économiques. C’est possible futures, toutes les décisions possibles, puis vous attribuez un score à toutes les décisions en fonction de ces moteurs économiques. Il s’avère que ces moteurs économiques sont très utiles pour trier tous ces SKU, décisions et événements qui se produisent dans la supply chain. Vous pouvez les classer par ordre décroissant d’impact en dollars, et c’est un mécanisme très puissant, même si les moteurs économiques sont partiellement incorrects ou incomplets. Cela s’avère être une méthode très efficace pour enquêter et diagnostiquer avec une grande productivité ce qui se passe dans une supply chain donnée.
Au fur et à mesure que vous examinez des décisions “insensées” au cours des initiatives où vous déployez cette méthode d’optimisation expérimentale, il y a un glissement progressif des décisions véritablement insensées et dysfonctionnelles vers des décisions tout simplement mauvaises. Elles ne vont pas faire exploser votre entreprise, mais elles sont tout simplement médiocres.

C’est ici que nous avons une divergence profonde par rapport à la perspective d’optimisation mathématique pour la supply chain.
Avec l’optimisation expérimentale, la fonction de perte elle-même, parce que l’optimisation expérimentale utilise en interne des outils d’optimisation mathématique, généralement au cœur des recettes numériques qui génèrent la décision, comporte une composante d’optimisation mathématique. Mais ce n’est qu’un moyen, et non une fin, qui soutient votre processus. Au lieu de suivre la perspective d’optimisation mathématique où vous énoncez votre problème puis optimisez, ici vous remettez sans cesse en question ce que vous comprenez du problème lui-même et modifiez la fonction de perte en conséquence.
Pour améliorer votre compréhension, vous devez instrumenter à peu près tout. Vous devez instrumenter votre processus d’optimisation lui-même, votre recette numérique, et toutes sortes de caractéristiques relatives aux données avec lesquelles vous travaillez. C’est très intéressant car, d’un point de vue historique, lorsque vous observez nombre des plus grands développements scientifiques qui ont permis des découvertes significatives, généralement quelques décennies avant que ces découvertes ne soient faites, il y a eu une percée en matière d’instrumentation. Lorsqu’il s’agit de découvrir des connaissances, on découvre souvent d’abord une nouvelle manière d’observer l’univers, on réalise une avancée au niveau de l’instrumentation, puis on peut effectuer la découverte de ce qui intéresse réellement le monde. C’est vraiment ce qui se passe ici. D’ailleurs, Galilée a réalisé la plupart de ses découvertes parce qu’il fut le premier à disposer d’un télescope fait maison, et c’est ainsi qu’il découvrit les lunes de Jupiter, par exemple. Toutes ces métriques sont les instruments qui font réellement avancer votre progression.

Maintenant, le défi est que, comme je l’ai dit, l’optimisation expérimentale est un processus itératif. La question très importante ici est de savoir si nous ne faisons pas l’échange d’une bureaucratie contre une autre. L’une de mes plus grandes critiques concernant la gestion de la supply chain traditionnelle est que nous finissons par avoir une bureaucratie de personnes qui ne font que gérer des crises, pataugeant dans toutes ces exceptions au quotidien, et leur travail n’est pas capitaliste. J’ai présenté la perspective contrastée du Supply Chain Scientist, où leur travail est censé être capitaliste et accréditif. Cependant, tout se résume à quel niveau de productivité peut être atteint par les Supply Chain Scientists, et ces personnes doivent être très productives.
Ici, je vous présente une courte liste d’indicateurs clés de performance relatifs à cette productivité. Tout d’abord, vous devez être capable de parcourir les pipelines de données de bout en bout en moins d’une heure. Comme je l’ai dit, l’une des causes profondes de l’insanité réside dans la sémantique des données. Lorsque vous vous rendez compte que vous avez un problème au niveau sémantique, vous voulez le tester, et vous devez relancer l’ensemble du pipeline de données. Votre équipe supply chain ou votre Supply Chain Scientist doit être capable de faire cela plusieurs fois par jour.
En ce qui concerne la recette numérique qui réalise elle-même l’optimisation, à ce stade, les données sont déjà préparées et consolidées, de sorte qu’il s’agit d’un sous-ensemble de l’ensemble du pipeline de données. Vous aurez besoin d’un très grand nombre d’itérations, donc vous devez être capable d’effectuer des dizaines d’itérations chaque jour. Le temps réel serait fantastique, mais la réalité est que l’optimisation locale dans la supply chain ne fait que déplacer les problèmes. Vous devez adopter une perspective holistique, et le problème avec les modèles naïfs ou triviaux sur votre supply chain est qu’ils ne seront pas très efficaces pour saisir toutes les complexités présentes dans les supply chains. Vous faites face à un compromis entre l’expressivité et la capacité de la recette numérique et le temps nécessaire pour la rafraîchir. En général, l’équilibre est bon tant que vous maintenez le calcul dans quelques minutes.
Enfin, et ce point a également été abordé dans la conférence sur la livraison de logiciels orientés produit pour la supply chain, vous devez vraiment être capable de mettre en production une nouvelle recette chaque jour. Ce n’est pas tant que je recommande de le faire, mais plutôt que vous devez pouvoir le faire parce que des événements inattendus se produiront. Il peut s’agir d’une pandémie, ou parfois ce n’est pas aussi extravagant. Il y a toujours la possibilité qu’un warehouse soit inondé, que vous ayez un incident de production, ou que vous receviez une grande surprise promotion d’un concurrent. Toutes sortes de choses peuvent arriver et perturber votre opération, donc vous devez être capable d’appliquer des mesures correctives très rapidement. Cela signifie que vous devez disposer d’un environnement où il est possible de mettre en production une nouvelle itération de votre recette supply chain chaque jour.

La pratique de l’optimisation expérimentale est intéressante. L’approche de Lokad était une pratique émergente, et elle s’est progressivement intégrée dans la pratique quotidienne depuis une décennie. Pendant les premières années, nous avions mis en place quelque chose comme un processus proto-d’optimisation expérimentale. La principale différence était que nous itérions encore, mais en utilisant des modèles mathématiques de supply chain issus de la littérature sur la supply chain. Il s’est avéré que ces modèles sont généralement monolithiques et ne se prêtent pas au processus itératif dont je parle dans l’optimisation expérimentale. En conséquence, nous itérions, mais nous étions loin de pouvoir mettre en production une nouvelle recette chaque jour. C’était plutôt comme s’il fallait plusieurs mois pour concevoir une nouvelle recette. Si vous regardez le site web de Lokad retraçant notre parcours, les itérations successives sur notre moteur de prévision étaient le reflet de cette approche. Il fallait en gros 18 mois pour passer d’un moteur de prévision à la génération suivante de moteurs de prévision, avec une courte série d’une grande itération par trimestre ou quelque chose du genre.
C’était ce qui venait avant, et le tournant décisif est survenu avec l’introduction des paradigmes de programmation. Il existe une conférence précédente dans mon prologue où j’ai présenté les paradigmes de programmation pour la supply chain. Maintenant, avec cette conférence, il devrait devenir plus clair pourquoi nous accordons tant d’importance à ces paradigmes de programmation. Ce sont eux qui alimentent cette méthode d’optimisation expérimentale. Ce sont les paradigmes dont vous avez besoin pour construire une recette numérique, où vous pouvez itérer efficacement chaque jour afin de vous débarrasser de toutes ces décisions insensées et vous orienter vers quelque chose qui crée réellement beaucoup de valeur pour la supply chain.
Maintenant, l’optimisation expérimentale en situation réelle, eh bien, je suis convaincu que c’est quelque chose qui a émergé. Elle n’a pas vraiment été inventée chez Lokad ; c’est plutôt qu’elle y est apparue parce que nous étions sans cesse confrontés à nos propres insuffisances en matière de décisions réelles dans la supply chain. Je soupçonne fortement que d’autres entreprises, soumises aux mêmes forces, ont mis au point leurs propres processus d’optimisation expérimentale, qui ne sont qu’une variante de ce que je vous ai présenté aujourd’hui.
Ici, si vous regardez des géants de la tech comme les GAFA, j’ai des contacts là-bas qui, sans dévoiler aucun secret commercial, laissent entendre que ce genre de pratique porte différents noms mais est déjà très présent chez ces géants de la tech. Vous pouvez même le constater en tant qu’observateur externe par le fait que bon nombre des outils open-source qu’ils publient sont des outils qui prennent tout leur sens lorsque vous commencez à réfléchir aux types d’outils que vous aimeriez avoir si vous deviez mener des initiatives suivant cette méthode d’optimisation expérimentale. Par exemple, PyTorch n’est pas un modèle ; c’est une méta-solution, un paradigme de programmation pour faire du deep learning, donc cela s’inscrit parfaitement dans ce cadre.
Ensuite, vous pourriez vous demander pourquoi, si c’est si réussi, ce n’est pas davantage reconnu comme tel. Lorsqu’il s’agit de reconnaître l’optimisation expérimentale en situation réelle, c’est délicat. Si vous prenez un instantané d’une entreprise à un moment donné, cela ressemble exactement à la perspective d’optimisation mathématique. Par exemple, si Lokad prend un instantané de l’une des entreprises que nous servons, nous avons à ce moment-là une problématique et une solution que nous proposons. Ainsi, à cet instant, la situation ressemble exactement à la perspective d’optimisation mathématique. Cependant, ce n’est que la perspective statique. Dès que vous commencez à considérer la dimension temporelle et la dynamique, c’est radicalement différent.
Par ailleurs, il est important de noter que, bien qu’il s’agisse d’un processus itératif, ce n’est pas un processus convergent. Cela peut être quelque peu perturbant. L’idée que vous puissiez avoir un processus itératif qui converge vers quelque chose d’optimal revient à dire qu’il existe une limite stricte à l’ingéniosité humaine. Je crois que c’est une proposition extravagante. Les problèmes de supply chain sont épineux, il n’y a donc pas de convergence, simplement parce qu’il y a toujours des éléments capables de changer radicalement la donne. Ce n’est pas un problème défini de manière étroite où l’on pourrait espérer trouver la solution optimale. De plus, un autre facteur pour lequel il n’y a pas de convergence en pratique est que le monde ne cesse de changer. Votre supply chain ne fonctionne pas dans le vide ; vos fournisseurs, clients et l’environnement évoluent. Quelle que soit la recette numérique que vous aviez à un moment donné peut commencer à produire des décisions insensées simplement parce que les conditions du marché ont changé, et ce qui était raisonnable dans le passé ne l’est plus. Vous devez vous réajuster pour correspondre à la situation actuelle. Il suffit de regarder ce qui s’est passé en 2020 avec la pandémie ; évidemment, il y a eu tellement de changements que quelque chose de sensé avant la pandémie n’a pas pu rester valable pendant celle-ci. La même chose se reproduira.
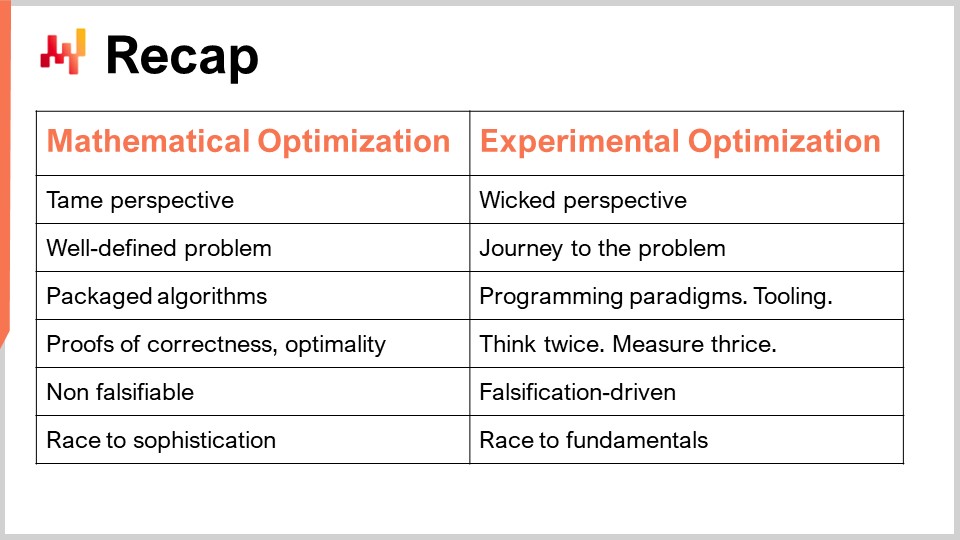
Pour résumer, nous avons deux perspectives différentes : la perspective d’optimisation mathématique, où nous traitons des problèmes bien définis, et la perspective d’optimisation expérimentale, où le problème est épineux. Vous ne pouvez même pas définir le problème ; vous ne pouvez qu’avancer vers lui. En conséquence, dans la perspective d’optimisation mathématique, ayant un problème bien défini, vous pouvez disposer d’un algorithme clair comme solution et l’emballer dans un logiciel, prouvant ainsi sa justesse et son optimalité. Dans le monde de l’optimisation expérimentale, cependant, vous ne pouvez pas tout empaqueter car c’est bien trop complexe. Ce que vous pouvez avoir, ce sont des paradigmes de programmation, des outils, une infrastructure, et ensuite tout se réduit continuellement à l’intelligence humaine. Il s’agit de réfléchir à deux fois, de mesurer trois fois et de faire un pas en avant. Rien de tout cela ne peut être automatisé ; tout se résume à l’intelligence humaine du Supply Chain Scientist.
En termes de falsifiabilité, ma principale proposition est que la perspective d’optimisation mathématique n’est pas de la science car vous ne pouvez falsifier rien de ce qu’elle produit. Ainsi, au final, vous vous retrouvez dans une course vers la sophistication – vous voulez des modèles toujours plus complexes, mais ce n’est pas parce qu’ils sont plus sophistiqués qu’ils sont plus scientifiques ou qu’ils créent plus de valeur pour l’entreprise. En net contraste, l’optimisation expérimentale est orientée falsification. Toutes les itérations sont motivées par le fait que vous mettez vos recettes numériques à l’épreuve du monde réel, en générant des décisions et en identifiant les bonnes décisions. Ce test expérimental peut être réalisé plusieurs fois par jour pour mettre au défi votre théorie et la prouver fausse à maintes reprises, en itérant à partir de là et, espérons-le, en apportant beaucoup de valeur dans le processus.
C’est intéressant car, en fin de compte, l’optimisation expérimentale n’est pas une course vers la sophistication ; c’est une course vers les fondamentaux. Il s’agit de comprendre ce qui fait fonctionner votre supply chain, les éléments fondamentaux qui régissent la supply chain, et exactement comment vous devez appréhender ce qui se passe dans vos recettes numériques afin qu’elles ne continuent pas à produire ces décisions insensées qui nuisent à votre supply chain. En fin de compte, vous voulez produire quelque chose de très bon pour votre supply chain.

Cela a été une longue conférence, mais le message à retenir devrait être que l’optimisation mathématique est une illusion. C’est une illusion séduisante, sophistiquée et attrayante, mais une illusion néanmoins. L’optimisation expérimentale, quant à moi, représente le monde réel. Nous l’utilisons depuis près d’une décennie pour soutenir le processus pour de vraies entreprises. Lokad n’est qu’un point de données, mais de mon point de vue, c’est un point de données très convaincant. Il s’agit vraiment de se familiariser avec le monde réel. D’ailleurs, cette approche est extrêmement difficile pour vous, car lorsque vous vous confrontez au monde réel, la réalité vous rattrape. Vous aviez de belles théories sur le type de recette numérique qui devrait fonctionner pour gouverner et optimiser la supply chain, et puis la réalité revient frapper. Cela peut être, par moments, incroyablement frustrant, car la réalité trouve toujours des moyens d’annuler toutes les idées ingénieuses que vous pouviez imaginer. Ce processus est bien plus frustrant, mais je crois que c’est la dose de réalité dont nous avons besoin pour obtenir de réels retours profitables pour vos supply chains. Selon moi, à l’avenir, il y aura un moment où l’optimisation expérimentale, ou peut-être un descendant de cette méthode, supplantera entièrement la perspective de l’optimisation mathématique en ce qui concerne les études et pratiques de supply chain.

Dans les prochaines conférences, nous passerons en revue les méthodes réelles, les méthodes numériques et les outils numériques que nous pouvons utiliser pour soutenir cette pratique. La conférence d’aujourd’hui traitait uniquement de la méthode ; plus tard, nous aborderons le savoir-faire et les tactiques nécessaires pour la faire fonctionner. La prochaine conférence aura lieu dans deux semaines, le même jour et à la même heure, et portera sur la connaissance négative en supply chain.
Maintenant, examinons les questions.
Question: Si les articles sur la supply chain n’ont aucune chance d’être reliés à la réalité, même de près, et que tout cas réel serait soumis à un accord de confidentialité, que suggéreriez-vous à ceux qui souhaitent réaliser des études sur la supply chain et publier leurs résultats ?
Ma suggestion est que vous devez remettre en question la méthode. Les méthodes que nous avons ne sont pas adaptées à l’étude de la supply chain. J’ai présenté deux approches dans cette série de conférences : le personnel de supply chain et l’optimisation expérimentale. Il reste beaucoup à faire en nous appuyant sur ces méthodologies. Ce ne sont là que deux méthodologies ; je suis assez certain qu’il en existe bien d’autres qui n’ont pas encore été découvertes ou inventées. Mon conseil serait de remettre en cause, au cœur même, ce qui fait d’une discipline une véritable science.
Question: Si l’optimisation mathématique n’est pas la meilleure représentation de la manière dont la supply chain devrait fonctionner dans le monde réel, pourquoi la méthode de deep learning serait-elle meilleure ? Le deep learning ne prend-il pas des décisions en se basant sur des décisions optimales antérieures ?
Dans cette conférence, j’ai clairement distingué l’optimisation mathématique en tant que domaine de recherche indépendant et le deep learning en tant que domaine de recherche indépendant, ainsi que l’optimisation mathématique en tant que perspective appliquée à la supply chain. Je ne dis pas que l’optimisation mathématique en tant que domaine de recherche est invalide ; bien au contraire. Dans cette méthode d’optimisation expérimentale dont je parle, au cœur de la recette numérique, vous trouverez généralement un algorithme d’optimisation mathématique d’une certaine sorte. L’enjeu, c’est l’optimisation mathématique en tant que perspective ; c’est ce que je remets en question ici. Je sais que c’est subtil, mais c’est une différence cruciale. Le deep learning est une science auxiliaire. Le deep learning est un domaine de recherche à part, tout comme l’optimisation mathématique l’est. Ce sont deux domaines de recherche formidables, mais ils sont complètement indépendants et distincts des études sur la supply chain. Ce qui nous préoccupe vraiment aujourd’hui, c’est l’amélioration quantitative des supply chains. Voilà de quoi il s’agit – des méthodes pour obtenir des améliorations quantitatives dans la supply chain de manière contrôlée, fiable et mesurable. C’est là tout l’enjeu.
Question: Le reinforcement learning peut-il être la bonne approche pour la gestion de la supply chain ?
Tout d’abord, je dirais que c’est probablement la bonne approche pour l’optimisation de la supply chain. C’est une distinction que j’ai faite dans l’une de mes conférences précédentes – d’un point de vue logiciel, vous avez le côté gestion avec l’Enterprise Resource Management, puis vous avez le côté optimisation. Le reinforcement learning est un autre domaine de recherche qui peut également tirer parti d’éléments issus du deep learning et de l’optimisation mathématique. C’est ce genre d’ingrédient que vous pouvez utiliser dans cette méthode d’optimisation expérimentale. Le point critique sera de savoir si vous disposez des paradigmes de programmation capables d’intégrer ces techniques de reinforcement learning de manière fluide et itérative. C’est un grand défi. Vous devez être capable d’itérer, et si vous avez un modèle de reinforcement learning complexe et monolithique, alors vous aurez des difficultés, tout comme Lokad a eu dans ses premières années lorsque nous tentions d’utiliser ce type de modèles monolithiques où nos itérations étaient très lentes. Une série d’avancées techniques a été nécessaire pour rendre le processus itératif beaucoup plus fluide.
Question: L’optimisation mathématique est-elle un élément intégral du reinforcement learning ?
Oui, le reinforcement learning est un sous-domaine du machine learning, et le machine learning peut être considéré, en quelque sorte, comme un sous-domaine de l’optimisation mathématique. Cependant, il se trouve que lorsque l’on fait cela, tout s’imbrique, et ce qui différencie vraiment tous ces domaines, c’est qu’ils n’adoptent pas la même perspective sur le problème. Tous ces domaines sont connectés, mais généralement, ce qui les distingue réellement, c’est l’intention que vous avez.
Question: Comment définissez-vous une décision insensée dans le contexte des méthodes de deep learning qui anticipent souvent de nombreuses décisions ?
Une décision insensée dépend des décisions futures. C’est exactement ce que j’ai démontré dans l’exemple lorsque j’ai dit, « Est-ce qu’une rupture de stock est un problème ? » Eh bien, ce n’est pas un problème si vous constatez que la prochaine décision à être prise est un réapprovisionnement. Ainsi, le fait que je qualifiais cette situation d’insensée ou non dépendait en réalité d’une décision imminente. Cela complique l’investigation, mais c’est précisément de cela qu’il s’agit quand je dis que vous devez disposer d’une instrumentation de très grande qualité. Par exemple, cela signifie que lorsque vous examinez une situation de rupture de stock, vous devez être capable de projeter les décisions futures que vous êtes sur le point de prendre, afin de pouvoir voir non seulement les données dont vous disposez, mais aussi les décisions que vous prévoyez de prendre selon votre recette numérique actuelle. Vous voyez, il s’agit de disposer d’une instrumentation appropriée, et encore une fois, ce n’est pas une tâche facile. Cela requiert une intelligence de niveau humain ; vous ne pouvez pas simplement l’automatiser.
Question: Comment l’optimisation expérimentale, l’identification de l’insanité et la recherche de solutions fonctionnent-elles en pratique ? Je ne peux pas attendre que l’insanité se produise dans la réalité, n’est-ce pas ?
Absolument correct. Si je reviens au début de cette conférence, j’ai mentionné deux groupes de personnes : les physiciens modernes et les marxistes. Le groupe de physiciens, lorsque j’ai dit qu’ils faisaient de la vraie science, n’était pas passif en attendant que leurs théories soient falsifiées. Ils allaient même jusqu’à concevoir des expériences incroyablement ingénieuses qui auraient une chance d’infirmer leurs théories. C’était un mécanisme très proactif.
Si vous regardez ce que Albert Einstein a fait pendant la majeure partie de sa vie, c’était de trouver des moyens ingénieux de mettre à l’épreuve, au moins en partie, les théories de la physique qu’il avait inventées par le biais d’expériences. Alors oui, vous n’attendez pas que la décision insensée se produise. C’est pourquoi vous devez être capable de faire tourner votre recette encore et encore et d’investir du temps à rechercher la décision insensée. Évidemment, il existe certaines décisions, comme celles présentant des impraticabilités, pour lesquelles il n’y a aucun espoir — vous devez les mettre en production, et alors le monde vous ripostera. Mais pour la grande majorité, les décisions insensées peuvent être identifiées simplement en réalisant des expériences jour après jour. Mais il vous faut des données, et il vous faut disposer du véritable processus qui génère les décisions réelles pouvant être mises en production.
Question: Si une recette pouvait être brisée à cause d’une méthode et/ou d’une perspective mathématique, et si vous ne connaissez pas cette autre perspective, comment pouvez-vous découvrir que vous avez un problème de perspective, et non de méthode, et vous pousser à découvrir une autre perspective mieux adaptée au problème ?
C’est un très gros problème. Comment pouvez-vous voir quelque chose qui n’est pas là ? Si je reviens à l’exemple des personnels de supply chain de Paris, une entreprise de mode exploitant des magasins de détail, imaginons un instant que vous ayez oublié de penser à l’effet à long terme que vous auriez sur les habitudes de vos clients en offrant des remises de fin de saison. Vous ne réalisez pas que vous créez une habitude au sein de votre clientèle. Comment pourriez-vous jamais vous en apercevoir ? C’est un problème d’intelligence générale. Il n’existe pas de solution magique.
Vous devez faire preuve de brainstorming ; d’ailleurs, la réponse très concrète de Lokad est que l’entreprise est basée à Paris. Nous servons des clients dans une vingtaine de pays lointains, y compris l’Australie, la Russie, les États-Unis et le Canada. Pourquoi ai-je regroupé toutes mes équipes de Supply Chain Scientist à Paris, bien qu’avec la pandémie ce soit un peu plus compliqué, avec beaucoup de télétravail ? Mais pourquoi ai-je rassemblé tous ces Supply Chain Scientist en un seul endroit plutôt que de les externaliser partout ? La réponse était que j’avais besoin que ces personnes soient réunies afin de pouvoir discuter, faire du brainstorming et proposer de nouvelles idées. Encore une fois, c’est une solution très low-tech, mais je ne peux vraiment pas promettre mieux. Lorsqu’il y a quelque chose que vous ne pouvez pas voir, comme, par exemple, la nécessité de penser aux implications à long terme, et que vous l’avez tout simplement oublié ou n’y avez jamais pensé, ce problème peut être très évident tout en demeurant ignoré. Dans l’une de mes conférences précédentes, j’ai donné l’exemple de la valise. Il a fallu 5 000 ans pour parvenir à l’idée qu’il serait judicieux de mettre des roues sur les valises. Les roues ont été inventées il y a des milliers d’années, et la meilleure version de la valise a été inventée des décennies après avoir envoyé des hommes sur la lune. C’est ce genre de chose où il peut y avoir quelque chose d’évident que vous ne voyez pas. Il n’y a pas de recette pour cela ; c’est simplement l’intelligence humaine. Vous faites simplement avec ce que vous avez.
Question: Des conditions en constante évolution rendront la solution optimale pour votre supply chain constamment obsolète, n’est-ce pas ?
Oui et non. Du point de vue de l’optimisation expérimentale, il n’existe pas de solution optimale. Vous disposez de solutions optimisées, mais cette distinction fait toute la différence. Les solutions optimisées sont loin d’être optimales. Optimal, c’est comme dire, et je me répète, qu’il existe une limite stricte à l’ingéniosité humaine. Ainsi, il n’y a rien d’optimal ; c’est simplement optimisé. Et oui, à mesure que chaque jour passe, le marché diverge de toutes les expériences que vous avez menées jusqu’à présent. La simple évolution du monde dégrade l’optimisation que vous avez produite. C’est ainsi que va le monde. Il y a certains jours, par exemple, où une pandémie se produit, et où la divergence s’accélère considérablement. Encore une fois, c’est ainsi que va le monde. Le monde change, et ainsi votre recette numérique doit évoluer avec lui. Il s’agit d’une force externe, donc oui, il n’y a pas d’échappatoire ; la solution devra être réexaminée constamment.
C’est l’une des raisons pour lesquelles Lokad vend un abonnement, et nous disons à nos clients : “Non, nous ne pouvons pas vous vendre un Supply Chain Scientist uniquement pour la phase de mise en œuvre. Cela n’a aucun sens. Le monde continuera de changer ; ce Supply Chain Scientist qui a élaboré la recette numérique devra être présent jusqu’à la fin des temps ou jusqu’à ce que vous en ayez assez de nous.” Ainsi, cette personne sera capable d’adapter la recette numérique. Il n’y a pas d’échappatoire ; c’est simplement le monde externe qui ne cesse de changer.
Question: Le cheminement vers le problème, bien que correct, rend les cadres supérieurs fous. Ils ne comprennent tout simplement pas cela ; ils se disent : “Comment peut-on revisiter le problème plusieurs fois au cours d’un projet ?” Quelles analogies de la vie réelle suggéreriez-vous pour alimenter ces discussions et prouver qu’il s’agit d’un problème largement répandu ?
Tout d’abord, c’est exactement ce que j’ai dit dans la dernière diapositive où j’ai affiché la capture d’écran de The Matrix. À un moment donné, vous devez décider si vous voulez vivre dans un fantasme ou dans le monde réel. La direction, espérons-le, si vos cadres supérieurs dans votre entreprise sont simplement une bande d’idiots, ma seule suggestion est que vous feriez mieux d’aller dans une autre entreprise, car je ne suis pas sûr que celle-ci va durer longtemps. Mais la réalité, c’est que je pense que les managers ne sont pas dupes. Ils ne veulent pas s’occuper de problèmes inventés. Si vous êtes manager dans une grande entreprise, des personnes viennent vous voir dix fois par jour avec un “problème majeur”, qui n’est pas un véritable problème. La réaction de la direction, qui est une réaction correcte, est : “Il n’y a aucun problème, continuez simplement à faire ce que vous avez fait. Désolé, je n’ai pas le temps de refaire le monde avec vous. Ce n’est tout simplement pas la bonne manière d’aborder le problème.” Ils ont raison de le faire, car, grâce à des décennies d’expérience, ils ont de meilleures heuristiques que ceux des échelons inférieurs.
Mais parfois, il y a un souci très réel. Par exemple, votre question est la suivante : comment convaincre la direction d’il y a deux décennies que le e-commerce va être une force dominante à prendre en compte dans deux décennies ? À un moment donné, il faut choisir ses batailles judicieusement. Si vos cadres supérieurs ne sont pas dupes et que vous arrivez à une réunion bien préparé, en disant : “Eh patron, j’ai ce problème. Ce n’est pas une plaisanterie. C’est une préoccupation très importante avec des millions de dollars en jeu. Je ne plaisante pas. C’est une énorme somme d’argent que nous laissons sur la table. Pire encore, je soupçonne que la plupart de nos concurrents vont nous piquer notre déjeuner si nous ne faisons rien. Ce n’est pas un point mineur, c’est un problème très réel. J’ai besoin que vous me consacriez 20 minutes de votre attention.” Encore une fois, il est rare dans les grandes entreprises que la direction soit complètement idiote. Ils peuvent être occupés, mais ils ne sont pas des idiots.
Question: Quel serait le paysage approprié des outils pour les entreprises manufacturières : l’optimisation expérimentale comme chez Lokad, plus ERP, plus la visualisation ? Qu’en est-il du rôle des systèmes de planification simultanée en ligne ?
La grande majorité de nos concurrents adhère à la perspective d’optimisation mathématique de la supply chain. Ils ont défini le problème et mis en œuvre des logiciels pour le résoudre. Ce que je veux dire, c’est que lorsqu’ils mettent le logiciel à l’épreuve et qu’il finit invariablement par produire des tonnes de décisions insensées, ils disent, “Oh, c’est parce que vous n’avez pas correctement configuré le logiciel.” Cela rend le produit logiciel à l’abri du test de la réalité. Ils trouvent des moyens de détourner la critique plutôt que de l’aborder.
Chez Lokad, cette méthode n’a émergé que parce que nous étions très différents de nos concurrents. Nous n’avions pas le luxe de pouvoir chercher une excuse. Comme le dit le proverbe, “On peut soit avoir des excuses, soit des résultats, mais on ne peut pas avoir les deux.” Chez Lokad, nous n’avions pas l’option de chercher des excuses. Nous prenions des décisions, et il n’y avait rien à configurer ou à ajuster du côté client. Lokad faisait face frontalement à ses propres insuffisances. À ma connaissance, tous nos concurrents sont fermement ancrés dans la perspective d’optimisation mathématique, et ils souffrent du problème d’être quelque peu à l’abri de la réalité. Pour être honnête, ils ne sont pas complètement à l’abri de la réalité, mais ils finissent par avoir un rythme d’itération très lent, comme celui que j’ai décrit pour Lokad durant ses premières années. Ils ne sont pas complètement à l’abri de la réalité, mais leur processus d’amélioration est d’une lenteur glaciaire, et le monde continue de changer.
Ce qui se passe invariablement, c’est que les logiciels d’entreprise ne changent pas assez rapidement pour suivre l’évolution du monde en général, si bien que l’on se retrouve avec des logiciels qui ne font que vieillir. Ils ne s’améliorent pas vraiment car, chaque année qui passe, le logiciel évolue, mais le monde devient plus étrange et différent. Les logiciels d’entreprise prennent de plus en plus de retard sur un monde qui est de plus en plus déconnecté de ses origines.
Question: Quel serait le paysage adéquat des outils pour les entreprises manufacturières ?
Le paysage adéquat repose sur des outils de gestion des ressources d’entreprise capables de gérer tous les aspects transactionnels. Par-dessus tout, ce qui importe vraiment, c’est de disposer d’une solution très intégrée en ce qui concerne votre recette numérique. Vous ne voulez pas avoir une pile technologique pour la visualisation, une autre pour l’optimisation, une autre pour l’investigation et encore une autre pour la préparation des données. Si vous vous retrouvez avec une demi-douzaine de piles technologiques pour toutes ces différentes tâches, il vous faudra une armée d’ingénieurs logiciels pour tout brancher ensemble, et vous obtiendrez quelque chose qui sera l’opposé de l’agile.
Il faut tellement de compétences en ingénierie logicielle qu’il ne reste plus de place pour de réelles compétences en supply chain. Rappelez-vous, c’était le point de ma troisième conférence sur la livraison de logiciels orientée produit. Il vous faut quelque chose qu’un spécialiste de la supply chain, et non un ingénieur logiciel, puisse exploiter.
C’est tout. Rendez-vous dans deux semaines, même jour et à la même heure, pour “Negative Knowledge in Supply Chain.”
References
- La Logique de la découverte scientifique, Karl Popper, 1934


