00:12 イントロダクション
02:23 反証可能性
08:25 これまでの経緯
09:38 モデリング手法:数理最適化 (MO)
11:25 数理最適化の概要
14:04 メインストリームサプライチェーン理論(再確認)
19:56 数理最適化の視点の範囲
23:29 排除ヒューリスティクス
30:54 翌日の状況
32:43 挽回要素は?
36:13 モデリング手法:実験的最適化 (EO)
38:39 実験的最適化の概要
42:54 狂気の根本原因
51:28 非常識な意思決定の特定
58:51 計測装置の改善
01:01:13 改善し、繰り返す
01:04:40 実験的最適化の実践
01:11:16 まとめ
01:14:14 結論
01:16:39 次回の講義と聴衆からの質問
説明
原始的なデカルト的視点では、最適化とは単に与えられたスコア関数に対してオプティマイザを展開することにすぎないが、サプライチェーンでははるかに反復的なプロセスが求められる。各反復は、調査対象となる「非常識な」意思決定を特定するために用いられる。その根本原因はしばしば不適切な economic drivers にあり、意図しない結果に照らして再評価される必要がある。反復は、numerical recipes がもはや非常識な結果を生み出さなくなったときに終了する。
完全な文字起こし

皆さん、こんにちは。今回のサプライチェーン講義シリーズへようこそ。私はジョアネス・ヴェルモレルです。本日は「実験的最適化」についてご講義します。これは、一連の実験を通じてサプライチェーンを最適化する手法として理解されるべきものです。ライブで講義をご覧の方は、いつでもYouTubeのチャットを通じて質問が可能です。ただし、講義中はチャットを閲覧しませんので、講義の最後にチャットに寄せられた質問に回答いたします。
本日の目標は、サプライチェーンの定量的な改善を実現することであり、それを制御された、信頼性が高く、測定可能な方法で達成したいと考えています。私たちは、いわば科学的方法に類似したものを必要としており、現代科学の重要な特徴の一つは、それが現実、つまり実験に深く根ざしている点にあります。前回の講義では、サプライチェーン実験という考え方について簡単に触れ、一見するとそれが長期かつ高コストに見えると述べました。その長さとコストが、実験を行う目的自体を打ち消しかねない状況にさえなる可能性があります。しかし、問題は、実験に取り組むためのより良い方法が必要であるという点にあり、これこそが実験的最適化の核心なのです。
実験的最適化は、本質的には約10年前にLokadで生まれた実践手法です。これは、実際に機能し、手軽かつ利益を生む方法でサプライチェーン実験を行う手段を提供するものであり、本日の講義の具体的なテーマとなるものです。

しかしまず、科学の本質と現実との関係という概念について、少し振り返ってみましょう。
1934年に出版されたカール・ポパー著「科学的発見の論理」という一冊の本がありますが、これは科学史における絶対的なランドマークとされています。この本は、非常に驚くべきアイデア、すなわち「反証可能性」を提唱しました。この反証可能性という概念がどのように生まれ、何を意味するのかを理解するためには、カール・ポパー自身の歩みを振り返ることが非常に興味深いでしょう。
ご存じのように、若き日のポパーは、いくつかの知識人の集まりに親しく関わっていました。その中で特に重要な二つの集まりがあり、一つは、当時マルクス主義理論を支持する傾向にあった社会経済学者のサークルであり、もう一つは、特にアルバート・アインシュタインをはじめとする物理学者のサークルでした。ポパーは、社会経済学者たちが、社会と経済の進化を説明する科学的な理論を持とうとする試みを行っているのを目の当たりにしました。このマルクス主義理論は、実際に将来起こる出来事について予測を行っていたのです。理論は、革命が起こるだろうと示唆し、その革命は最も工業化が進み、工場労働者が最も多く存在する国で起こると予想していました。
結果として、革命は1917年に起こりました。しかし、それが起こったのは工業化が進んでいないヨーロッパで最も産業が未発達なロシアであり、理論が予測したものとは全く反対の結果となりました。ポパーの視点では、科学的な理論が予測を行い、その後に理論と矛盾する出来事が起こったのです。彼は、その理論が反証され、人々が他の何かに目を向けることを期待していました。しかし、彼が目の当たりにしたのは、まったく異なるものでした。マルクス主義理論の支持者たちは、出来事に合わせて理論を修正し、次第に理論を現実に対して免疫性のあるものにしていったのです。科学的理論として始まったものが、次第に完全に免疫力を持つものへと変わっていき、現実世界で起こり得る何事も理論に反することがなくなってしまいました。
これは、物理学者たちが所属する集団で起こっていたこととは対照的でした。そこでポパーは、アルバート・アインシュタインのような人物が理論を構築し、自らの理論を反証するための実験を考案するために多大な努力を払っているのを目撃しました。物理学者たちは、理論を証明するために全エネルギーを注ぐのではなく、むしろそれを反証するために努力していたのです。ポパーは、どちらのアプローチが科学を行う上でより良い方法なのかを考察し、「反証可能性」という概念を発展させました。
ポパーは、反証可能性を、理論が科学的であるとみなされるための基準として提唱しました。彼は、理論が科学的であるためには二つの条件を満たす必要があると述べています。一つ目は、理論が現実に対してリスクを伴っている必要があるということです。理論は、現実がそれに反証できる形で表現されなければなりません。もし理論が反証不可能であれば、それは真でも偽でもなく、少なくとも科学的観点からは問題外となります。したがって、理論が科学的であると認められるためには、現実に対して一定のリスクを負うべきなのです。
二つ目の条件は、理論に対して持つ信頼度、または信用が、ある程度(簡略化すると)その理論を反証しようとする科学者たち自身が投じた努力の量に比例すべきだということです。科学的な理論の特徴は、多大なリスクを伴い、その弱点を反証しようと多くの人々が試みる点にあります。もし彼らが何度も反証に失敗したならば、その理論には一定の信頼性を与えることができるのです。
この視点は、真と偽の間に深い非対称性が存在することを示しています。現代の科学理論は決して真または証明されたものとみなされるべきではなく、あくまで未確定のものと考えられるべきです。多数の人々がそれらを反証しようと試み、成功しなかったという事実が、理論に対する信頼性を高めるのです。この洞察は、サプライチェーンの世界にとって極めて重要であり、特に反証可能性の概念は、現代物理学における非常に驚異的な進展を促す原動力となってきました。
ここまでで、サプライチェーンに関するこのシリーズの第2章の第3講義となります。プロローグの第1章では、サプライチェーンを学問分野として、また実践として捉える私の考え方を提示しました。そこでの重要な洞察の一つは、サプライチェーンが手に負えない(wicked)問題群、いわゆる手ごわい問題を包含しているという点です。これらの問題は、設計上、単純な解決策にはなり得ません。したがって、サプライチェーンを学び実践するための方法論に、私たちは非常に注意を払う必要があるのです。本第2章は、その方法論について論じるものです。
第2章の第1講義では、サプライチェーンに知見、そして後の改善をもたらすために、サプライチェーン ペルソナー の概念を用いた定性的手法を提案しました。ここ、第3講義では、定量的手法、すなわち実験的最適化を提案します。

サプライチェーンに定量的な改善をもたらすには、定量的なモデル、すなわち数値モデルが必要です。これにアプローチする方法は少なくとも二通りあり、主流の方法である 数理最適化 と、もう一つの視点である実験的最適化があります。
サプライチェーンにおいて定量的改善をもたらす主流のアプローチは、数理最適化です。この方法は本質的に、問題と解のペアの長いカタログを作成することに他なりません。しかし、私はこの方法があまり有効ではないと考えており、別の視点が必要であると考えています。これが実験的最適化の狙いであり、一連の実験を通じたサプライチェーンの最適化として理解されるべきものです。
実験的最適化はLokadによって発明されたわけではありません。まず実践としてLokadで現れ、その数年後に理論として体系化されたのです。今日ご紹介するものは、Lokadで徐々に現れたプロセスそのものではありません。はるかに漸進的で曖昧なプロセスでした。私はその発展的な実践に数年後に再び取り組み、実験的最適化というタイトルで発表できる理論として固めました。

まずは、「数理最適化」という用語を明確にする必要があります。ここで区別すべき二つの側面があります。一つ目は、独立した研究分野としての数理最適化、二つ目は、サプライチェーンの定量的改善のための視点としての数理最適化、これが今日のテーマです。まずは後者の視点を脇に置き、数理最適化が独立した研究分野として何を意味するのかを明らかにしましょう。
これは、画面に示されるような数学的問題のクラスに関心を持つ研究分野です。基本的には、任意の集合(大文字のA)から実数へと写る関数、しばしば loss function と呼ばれる、fという関数から始まります。ここで求めるのは最適解、つまり集合Aに属する改善不可能な点xです。もちろん、これは膨大な技術的要素を含む非常に広範な研究分野です。中には極小値を持たない関数もあれば、複数の異なる極小値を持つものもあります。研究分野としての数理最適化は、数多くの手法が考案され、概念が導入され、他分野でも大いに成功を収めてきました。しかし、これらすべてについては、本講義の趣旨とは異なるため、今日は触れません。
ここで述べたいのは、サプライチェーンに関する補助科学としての数理最適化が、それ自体でかなりの成功を収めてきたという点です。そして、それがサプライチェーンの定量的研究に大きな影響を与え、供給チェーン-管理-定義における数理最適化の視点を形成してきたのです。

最初のサプライチェーン講義で紹介した二冊の本に立ち返ってみましょう。これら二冊の本は、過去50年にわたる科学的出版物とソフトウェア開発を体現する、主流の定量的サプライチェーン理論を表していると私は考えています。ここで取り上げるのは、発表された論文だけでなく、市場に投入されたソフトウェアも含まれます。サプライチェーンの定量的最適化に関しては、すべてが長い間ソフトウェアによって実施されてきたのです。
これらの本を見ると、どの章も数理最適化の視点の応用例として捉えることができます。常に、様々な仮定のもとでの問題の提示と、その後に解の提示へと収束しています。そして、その解の正しさや時には最適性が、問題の設定に照らして証明されるのです。これらの本は、本質的に問題と解のペアを羅列したカタログとして構成されており、数理最適化問題として提示されています。
例えば、予測は、損失関数(ここでは予測誤差となる)と、調整すべきパラメータを持つモデル上の問題と捉えることができます。そして、数値的手法を用いて最適なパラメータを導く最適化プロセスを学習するのです。同じアプローチは、在庫ポリシーにも適用され、需要について仮説を立て、その仮定に基づいて最適な解が得られることを実証していくのです。
既に最初の講義で触れた通り、私はこの主流のサプライチェーン理論に大きな懸念を抱いています。ここで紹介した本は、ランダムな選択ではなく、過去数十年にわたるサプライチェーン研究を正確に反映していると信じています。カール・ポパーが提唱した反証可能性の概念に目を向けると、問題がより明確になります。すなわち、これらの本は実際には科学ではなく、提示されている内容が現実によって反証されることがないためです。これらの本は、実際のサプライチェーンに対して完全に免疫性があるのです。問題と解のペアの集大成である本には、反証すべきものが存在しません。これは純粋な数学的構造に過ぎません。サプライチェーンが何かを行っているという事実は、提示された内容の証明や反証には全く影響を及ぼさないのです。これが、私がこれらの理論に対して抱く最大の懸念点です。
これは単にここで議論されている研究の問題だけでなく、サプライチェーンを支援するためのエンタープライズソフトウェアに存在するものを見ると、今日市場に存在するソフトウェアのほとんどがこれらの科学的出版物の反映であるということを意味します。このソフトウェアは、これらの科学的出版物から独立して発明されたのではなく、通常は一緒に進化しているのです。サプライチェーン最適化問題に対処するために市場で見られるエンタープライズソフトウェアの大部分は、ある一連の論文や書籍の反映であり、時にはソフトウェアと書籍の両方を生み出した同じ人物によって書かれています。
ここで提示されている理論と現実が無関係であるという事実は、私が考えるに、これらの書籍で紹介されている理論のうち、実際のサプライチェーンで実用的なものがほとんど見当たらない理由として非常にもっともらしい説明です。これは私自身のかなり主観的な意見ですが、私のキャリアでは数百人ものサプライチェーンディレクターと議論する機会がありました。彼らはこれらの理論を認識しており、もし自分自身がそれらについて深い知識を持っていなくても、チーム内に知識のある人物がいます。非常に頻繁に、企業で使用されているソフトウェアはすでにこれらの書籍で提示された一連のソリューションを実装していますが、それらは実際には使われていません。人々はさまざまな理由で自分自身のExcel スプレッドシートに頼っているのです。
つまり、これは無知というわけではありません。私たちはこの非常に現実的な問題を抱えており、その根本原因は文字通りそれが科学ではないという点にあると私は考えています。提示された事柄のいずれも反証できないのです。これらの理論が間違っているのではなく、数学的には正しいのですが、科学と呼ぶほどの資格すら持っていないのです。

さて、問題はどの程度のものでしょうか? 実際、私は2冊の書籍を取り上げましたが、サプライチェーンにおけるこの数学的最適化の視点の実際の範囲はどれほどでしょうか? 私は、この視点の適用範囲は絶対に巨大だと言えます。その証拠として、最近私が使用したのは、Googleが提供する科学的出版物のみを対象とした専門の検索エンジンであるGoogle Scholarです。2020年だけで「最適在庫」を検索すると、30,000件以上の結果が得られます。
この数字には注意が必要です。明らかに、このリストには多数の重複が含まれている可能性があり、またタイトルや抄録に「在庫」と「最適」という両方の単語が現れるものの、全くサプライチェーンについての論文でない偽陽性が存在する可能性も高いです。それは単なる偶然です。それにもかかわらず、結果をざっと見れば、この分野では毎年数千本の論文が発表されていることを強く示唆しています。基準として、この数字は、ディープラーニングのような絶対に巨大な分野と比べても非常に大きいのです。ディープラーニングは、過去二、三十年で最も成功を収めたコンピュータサイエンス理論の一つと言えるでしょう。ですから、「最適在庫」というクエリだけで、ディープラーニングの検索結果の約5分の1の件数が得られるという事実は、実に驚くべきものです。最適在庫は、定量的サプライチェーン研究全体のほんの一部に過ぎません。
この単純なクエリは、数学的最適化の視点がいかに巨大であるかを示しており、たとえ多少主観的ではあっても、定量的サプライチェーン研究においてはこの視点が圧倒的に支配していると言えるでしょう。もし毎年、最適在庫ポリシーや最適な在庫管理モデルを提供する数千本の論文が発表されているなら、ほとんどの大企業はこれらの手法をもとに運営されるはずです。ここで議論しているのは、単に数本の論文のことではなく、絶対に膨大な量の出版物のことなのです。
私の経験では、私が知っている数百件のサプライチェーンに関するデータでは、実際にはこのような状況は見受けられません。これらの手法はほとんど見かけることがなく、発表される論文―ちなみにソフトウェアもですが、ソフトウェアは科学的論文のほぼ写しです―と実際のサプライチェーンの運用との間には、驚くべき乖離が存在しています。

私が抱いた疑問は、数千本の論文の中に、本当に価値のあるものは何か見つけられるのか、ということです。私自身、数百本の定量的サプライチェーン論文を精査する機会に恵まれ、その論文が実際に現実に何の付加価値ももたらさないことを、ほぼ確実に示す一連のヒューリスティック(経験則)を示すことができます。これらのヒューリスティックが絶対に正しいわけではありませんが、非常に高い精度、99%以上の精度で判断できるものです。完全ではありませんが、ほぼ完全に正確と言えるでしょう。
では、どのようにして実際の価値を付加する論文を見分け、逆に全く価値をもたらさない論文を排除するのでしょうか? 私は短い一連のヒューリスティックを挙げています。最初のものは、論文がいかなる種類の最適性についても主張しているなら、その論文が現実のサプライチェーンに対して全く価値をもたらさないことは確実だということです。まず、これは著者たちがサプライチェーンが本質的に解決困難な問題であるという事実を、全く、あるいはほんのわずかしか理解していないことを反映しているからです。最適解を持っていると言うということは、最適解の定義に戻ると、改良できる余地のない解という意味です。最適なサプライチェーン解決策を持っていると主張することは、人間の創意工夫に硬い限界があるとでも言っているようなものです。私はそれを一瞬たりとも信じません。それは全く不合理な命題だと考えているのです。我々は、サプライチェーンへのアプローチ方法に非常に大きな問題があることを認識しています。
もう一つの問題は、最適性が主張されるたびに、必ず仮定に大きく依存した解決策が提示されるということです。ある一定の仮定の下で最適であると証明された解決策があったとしても、その仮定が崩れたらどうなるでしょうか? 解決策は依然として有効でしょうか?逆に、もし最適性を証明できる解決策があるならば、それは仮定がわずかでも正しいということに非常に依存している解決策であると考えます。仮定が崩れれば、結果として得られる解決策はおそらく全く酷いものになってしまうでしょう。なぜなら、それは何に対しても頑強性を持つように設計されていなかったからです。最適性の主張は、ほぼ一蹴できるのです。
次に問題なのは正規分布です。正規分布を使用していると主張する論文やソフトウェアを見るたびに、提案されているものが実際のサプライチェーンでは機能しないことは明白です。以前の講義でサプライチェーンの定量原則を提示した際、サプライチェーンにおける対象の全母集団が正規分布ではなくZipf分布に従っていることを示しました。サプライチェーンには正規分布は存在せず、この結果が数十年前から知られていることに私は絶対の確信を持っています。この仮定に依存する論文やソフトウェアを見つけた場合、数学的証明やソフトウェアの記述を容易にするために便宜的に作られた解決策である可能性が非常に高く、実際の性能を求める意図からではないに違いありません。正規分布の存在は、単なる怠慢か、せいぜいサプライチェーンの本質を深く理解していない兆候にすぎません。これを根拠に、そうした論文は排除できるのです。
次に、定常性―それは存在しません―という点です。一見、物事が定常している、つまり同じ状態が続くという仮定は妥当に見えるかもしれませんが、実際にはそうではなく、非常に強い仮定です。これは、時間の始まりから終わりまで続く何らかのプロセスが存在するということを基本的に意味しています。これは実際のサプライチェーンにとって非常に不合理な視点です。実際のサプライチェーンでは、いかなる製品もある時点で導入され、またある時点で市場から姿を消します。たとえ自動車業界のような比較的長寿命の製品を見たとしても、これらのプロセスは定常的ではなく、せいぜい十年程度しか続かないでしょう。関心のある寿命や期間は有限であるため、定常性の視点は全体として誤っているのです。
定量的な研究が機能しないことを見抜くもう一つの要素は、置換の概念が全く存在しない場合です。実際のサプライチェーンでは、置換はあらゆる所に存在します。2週間前の講義で紹介したサプライチェーンの例に戻れば、供給側、変換側、需要側と、置換が働いている状況が少なくとも6件は見受けられたはずです。もし、概念上で置換自体が存在しないモデルであれば、それは実際のサプライチェーンと大きく乖離していると言えるのです。
同様に、サプライチェーンに対するグローバルな視点や全体論的なアプローチが欠如していることも、何かがおかしいという決定的なサインです。前回の講義で定量的サプライチェーンの原則を紹介した際、局所的な最適化プロセスに類似するものでは全体を最適化できず、単にサプライチェーン内の問題を別の場所に移動させるだけだと述べました。サプライチェーンはシステムでありネットワークであるため、局所的な最適化だけでサプライチェーン全体にとって有益な結果が得られるはずはありません。実際はそうではないのです。
これらのヒューリスティックを用いれば、定量的サプライチェーン文献の大部分をほぼ排除できると思います。それ自体、非常に驚くべきことです。

問題は、もし私がすべてのサプライチェーン会議やジャーナルの編集委員会を説得して、低品質な寄稿を除外するためにこれらのヒューリスティックを使用すべきだと主張したとしても、それはうまくいかないということです。たとえサプライチェーンジャーナルの投稿ガイドラインにそれらを加えたとしても、著者は単に適応してそのプロセスを回避するでしょう。市場アナリストがチェックリストにそれらを加えた場合、論文もソフトウェアも著者は単に適応し、問題を曖昧にして、正規分布や定常性という根本的な仮定に帰結していることが分からなくなるほど、より複雑な仮定を設けるようになるのです。それは単に非常に不透明な表現に過ぎません。
これらのヒューリスティックは、論文やソフトウェアといった低品質な寄稿を識別するには有効ですが、良いものを単に選別するためには使えません。もっと根本的な変革が必要であり、全体のパラダイムを見直す必要があります。現時点では、我々はまだ反証可能性を欠いており、提示されているものに対して現実が反論する手立てを持っていないのです。

この数学的最適化の視点に関する講義の部分を締めくくる最後の要素として、この膨大な量の論文とソフトウェアの生産物に、何か価値あるものが見出せるでしょうか? この質問に対する私の非常に主観的な答えは、絶対に「いや」というものです。これらの論文、そして私が読んできた多くの定量的サプライチェーン論文は、決して面白いものではありません。むしろ、最高のものですら極めて退屈です。補助科学を見渡しても、本当に興味深い要素は見つかりません。何千もの論文を挙げても、その数学的内容は非常に退屈で、偉大な数学的アイデアは提示されていないのです。アルゴリズムの視点から見ても、これは長年アルゴリズム分野で知られているものの直接的な応用に過ぎません。統計モデリングと方法論についても同様で、その質は非常に低いのです。方法論においては、結局のところ数学的最適化の視点に帰着し、モデルを提示し、何かを最適化し、解を提供し、その解が問題文に対してある数学的特性を有することを証明するという流れに終始してしまいます。
私たちは表面的な変化以上の、より根本的な変革が本当に必要です。私はこのアプローチ自体を批判しているのではありません。歴史的な前例もあります。何万本もの論文が全く実りのないものであると主張するのは驚くべきことに聞こえるかもしれませんが、実際に歴史上そのようなことは起こりました。近代物理学の父の一人であるアイザック・ニュートンの生涯を見れば、彼は物理学に関しては膨大な遺産を残すほどの半分の時間を費やし、残りの半分は錬金術に費やしました。彼は卓越した物理学者である一方、錬金術師としては非常に下手でした。歴史的記録は、ニュートンが錬金術においても物理学においても、同じくらい優秀で献身的かつ真剣であったことを示しています。しかし、錬金術の枠組み自体が不適切であったために、ニュートンがこの分野に注ぎ込んだ全ての労力と知性は全く実を結ばず、語るに足る遺産を残すことができなかったのです。私の批判は、何千人もの人々が愚かなことを発表しているということではありません。ほとんどの著者は非常に知的です。問題は、枠組み自体が実りのないものであるという点にあるのです。それが私の訴えたいポイントです。

さて、今日紹介したい第二のモデリングアプローチに移りましょう。初期の頃、Lokadの方法論は数学的最適化の視点に深く根ざしていました。この点では非常に主流のものでしたが、私たちにとってはうまく機能していなかったのです。Lokadに特有で、ほとんど偶然とも言える一点は、ある時点で私が、Lokadはエンタープライズソフトウェアを販売するのではなく、直接、最終的なサプライチェーンの意思決定、つまり、ある企業が購入すべき正確な数量、生産すべき数量、そして場所Aから場所Bに移動すべき単位数―さらにはどの価格が下がるべきかという決定―を販売するものになると決定したことです。この半ば偶然の私の決断により、私たちは自らの不十分さと容赦なく向き合うことになりました。試練にさらされ、非常に厳しい現実のチェックを受けたのです。もし私たちが作り出したサプライチェーンの意思決定が悪い結果を招けば、クライアントは即座に私のもとに集まり、Lokadが満足のいくものを提供していないとして激しく非難したでしょう。
ある意味で、実験的最適化はLokadで生まれました。それはLokadで発明されたものではなく、初期に各所に散在していた欠陥に対処するために、顧客からの莫大なプレッシャーに応える形で自然発生的に実践されたものです。私たちは何らかの生存メカニズムを考案する必要があり、時にはほぼランダムに、多くの試みを行いました。そして、その結果として「実験的最適化」と呼ばれるものが生まれたのです.

実験的最適化は非常にシンプルな手法です。目標は、ソフトウェアによって駆動されるレシピを作成し、それによってサプライチェーンの意思決定を生み出すことにあります。この手法は次のように始まります。ゼロステップとして、まず意思決定を生成するレシピを書くのです。ここには多くのノウハウ、技術、ツールが関係しますが、これは本講義のテーマではなく、後の講義で詳細に扱います。ですから、ステップ1として、レシピを書くだけであり、ほとんどの場合、それはあまり良いものにはならないでしょう.
次に、無期限の反復作業に入ります。まずレシピを"実行"します。ここでの「実行」とは、そのレシピが本番レベルの環境で動作できる状態であるべきだということです。単にデータサイエンスラボ内で動かせるアルゴリズムを持つというだけではなく、本番環境に投入するに足るすべての品質を備えたレシピが必要なのです。もしその意思決定が本番投入に十分だと判断できるなら、ワンクリックで実行できるように、環境全体が本番レベルでなければなりません。これがレシピを実行するということの意味です.
次に必要なのは、常軌を逸した意思決定を特定することです。これは、サプライチェーンのプロダクト志向のデリバリーに関する以前の講義で取り上げました。この講義に参加されなかった方々のために要約すると、サプライチェーンへの投資を資本主義的かつ増分的にするためには、このサプライチェーン部門で働く人々が火消し作業に追われないようにしなければなりません。現在の大多数の企業では、サプライチェーンの意思決定がソフトウェアによって生成されています―ほとんどの現代企業は既にエンタープライズソフトウェアを用いてサプライチェーンを運用しており、すべての意思決定がソフトウェアによって生み出されています。しかし、その決定のごく大部分が全く常軌を逸しているのです。多くのサプライチェーンチームは、これらの常軌を逸した決定を手動で見直し、継続的な火消し作業に従事して除去しようと努めています。その結果、すべての努力が企業運営に消費され、例外を一日で解消しても、翌日にはまた新たな例外が発生し、サイクルが繰り返されるのです。資本化はできず、サプライチェーンの専門家の時間をただ消費してしまうのです。したがって、Lokadの考えは、これらの常軌を逸した意思決定をソフトウェアの欠陥として扱い、完全に排除することで、サプライチェーンそのものの資本主義的プロセスと実践を実現しようというものです.
これが整ったら、次に計測手法を改善し、その結果として数値レシピ自体を改良する必要があります。これらすべての作業はサプライチェーンサイエンティストによって遂行されます。この「サプライチェーンサイエンティスト」という概念は、最初の章『定量的サプライチェーンパースペクティブ』の第2講義で紹介しました。計測手法は非常に重要な要素であり、より優れた計測により、サプライチェーン上で何が起こっているのか、レシピ上で何が生じているのか、そして常に現れる常軌を逸した決定にどう対処すべきかをより深く理解することができるのです.

ここで、常軌を逸した意思決定をもたらす根本原因について少し掘り下げてみましょう。サプライチェーンディレクターに、自社のサプライチェーン運用を管理するエンタープライズソフトウェアがなぜ常軌を逸した決定を出し続けるのか尋ねると、非常に一般的かつ誤った回答として「単に予測が悪いからだ」というものが返ってくるのです。私はこの回答が少なくとも二つの点で誤っていると考えます。まず第一に、非常に単純な移動平均モデルから最先端の機械学習モデルに切り替えた場合、得られる精度の向上はおよそ20%程度です。確かにこれは重要ですが、それだけで非常に良い決定と全く常軌を逸した決定との差をつけることはできません。第二に、予測の最大の問題は、すべての選択肢を見渡せず、確率的でない点にあります。しかし、これはまた別の講義のテーマになるでしょう.
常軌を逸した原因に立ち返ると、予測誤差は確かに問題ですが、決して最優先の問題ではありません。Lokadでの10年の経験から、これはせいぜい二次的な懸念にすぎないと言えます。主要な問題、つまり常軌を逸した意思決定を生み出す最大の要因は、データ意味論にあります。サプライチェーンを直接観察することはできない―それは不可能なのです。観察できるのは、エンタープライズソフトウェアを通じて収集された電子記録を介した、サプライチェーンの反映像に過ぎません。あなたがサプライチェーンについて行っている観察は、ソフトウェアというプリズムを通した非常に間接的なプロセスなのです.
ここでは、何百ものリレーショナルテーブルと数千のフィールドが存在し、それぞれのフィールドの意味が非常に重要になります。しかし、どのようにして自分の理解や考えが正しいと確信できるのでしょうか。特定のカラムが何を意味するかを真に理解しているかどうかを確認する唯一の方法は、実際に実験で試すことです。実験的最適化において、その実験とは意思決定の生成を意味します。あなたはそのカラムが何かを示すと仮定し、それが一種の科学的理論となります。そして、その理解に基づいて意思決定を生成し、その決定が良好であれば、あなたの理解は正しいということになります。根本的に観察できるのは、あなたの理解が常軌を逸した意思決定につながるかどうかだけなのです。ここで現実が逆襲してくるのです.
これは些細な問題ではなく、非常に大きな問題です。エンタープライズソフトウェアは言うまでもなく複雑であり、バグが存在します。数学的最適化の視点の問題は、問題を単純な一連の仮定として捉え、比較的シンプルで数学的に洗練された解決策を展開できるかのように見せかける点にあります。しかし実際には、何層にも重なったエンタープライズソフトウェアが存在し、問題は各所で発生し得るのです。これらの問題の中には、誤ったコピー、変数間の不適切な結びつき、または同期しているべきシステムが同期を失うといった非常に平凡なものもあります。ソフトウェアのバージョンアップによってバグが生じることもあり、など々。これらのバグは至る所に存在し、バグの有無を確かめる唯一の方法は、再び意思決定を観察することに他なりません。もし意思決定が正しく出ているなら、バグは存在しないか、存在するバグが影響の小さいもので気にする必要がないということです.
経済的推進要因に関しては、サプライチェーンディレクターとの議論の中でまた別の誤ったアプローチが頻繁に現れます。彼らはしばしば、自社に経済的リターンがもたらされることを証明してほしいと要求します。私の答えは、経済的推進要因さえも我々はまだ把握していない、というものです。Lokadでの経験から、経済的推進要因―これらは数値レシピ自体の実際の最適化を行う際に用いられる損失関数を構築するために使われる―を確実に知る唯一の方法は、再び意思決定を生成し、その決定が常軌を逸しているか否かを観察するという実験を通して実際に検証することにほかならないと学びました。これらの経済的推進要因は、経験に基づいて発見され、検証される必要があるのです。せいぜい、何が正しいのかを直感的に掴むことはできるかもしれませんが、実際に理解が正しいかどうかを判断できるのは、経験と実験だけなのです.
さらに、多くの実用性に欠ける点も存在します。あなたは意思決定を生成する数値レシピを持っており、その決定はあなたが定めたすべてのルールに準拠しているように見えます。例えば、最小発注数量(MOQs)がある場合、あなたはMOQに適合する購買注文を生成します。しかし、もしサプライヤーが戻ってきて、MOQが別のものであると言ってきたらどうでしょうか。このプロセスを通じて、多くの非現実的な点や、一見実行可能に見えるが実際のテストでは実現不可能である意思決定が明らかになるかもしれません。あなたは様々なエッジケースや制限事項―時には全く考慮していなかったものも―を発見し、現実が逆襲してくるため、それらも修正しなければならなくなるのです.
さらに、あなたの戦略さえも問題となることがあります。サプライチェーン全体に対して包括的な高次戦略を持っていると思っていても、それが正しいかどうかは疑問です。例えばAmazonを例に挙げてみましょう。あなたは顧客優先を掲げたいかもしれません。例えば、顧客がオンラインで何かを購入し、気に入らなかった場合、非常に容易に返品できるようにすべきです。返品に対して非常に寛大でありたいのです。しかし、システムを悪用する敵対者や悪質な顧客が現れた場合はどうでしょうか?彼らは、高価な500ドルのスマートフォンをオンラインで注文し、受け取った後、本物のスマートフォンと50ドル相当の偽物とをすり替え、返品するかもしれません。結果として、Amazonは気づくことなく在庫に偽物を抱えることになるのです。これはオンライン上で何度も議論されてきた非常に現実的な問題です.
あなたは顧客優先の戦略を掲げているかもしれませんが、実際には正直な顧客だけを対象とした顧客優先であるべきかもしれません。つまり、全ての顧客ではなく、特定の顧客層に限定するということです。たとえ戦略がおおむね正しかったとしても、細部に問題が潜んでいる可能性は否めません。再び、戦略の細かい部分が正しいかどうかを判断する唯一の方法は、実験を通じて細部を検証することにあるのです.

さて、常軌を逸した意思決定をどのように特定するのかを議論してみましょう。健全な意思決定と常軌を逸した意思決定の違いをどのように見分ければよいのでしょうか?ここでいう「常軌を逸した意思決定」とは、あなたの会社にとって健全ではない決定を意味します。この種の問題は、真に一般的な人間の知能を必要とする問題です。アルゴリズムによってこの問題が解決できる見込みは全くありません。一見パラドックスのようですが、これは人間レベルの知能を要求するものであり、必ずしも非常に賢い人間である必要はないのです.
実世界にはこのような問題は他にもたくさん存在します。例えば、映画のミスを例に挙げましょう。もしハリウッドのスタジオに、どの映画におけるすべてのミスを特定できるアルゴリズムを求めたら、人間の知能が必要なタスクであるため、そのようなアルゴリズムの構想すらできないだろうと言われるでしょう。しかし、問題を「映画のミスを非常に上手に特定できる人材を育成する」という方向に変えれば、そのタスクははるかに単純になります。映画のミスを見抜くためのあらゆるコツをまとめたハンドブックを作成できるという考えは非常に分かりやすいものです。この作業を行うのに、例外的に優秀な人材である必要はなく、十分に知的で献身的な人々さえいればよいのです。これがまさに本質なのです.
では、サプライチェーンの視点から状況はどのように見えるのでしょうか?問題を具体的に検証するためには、基本的に外れ値を探すことになります。ある一側面からアプローチすればよいのです。例えば、2週間前に紹介したパリのペルソナに戻ってみましょう。これは、大規模なファッションストアの小売ネットワークを運営するファッション企業です。例えば、我々がサービスの品質に懸念を抱いているとしましょう.
まずはstockoutsから始めましょう。すべての製品とすべての店舗に対してクエリを実行すれば、ネットワーク全体で何千もの在庫切れがあることが分かります。しかし、それでは実際の助けにはならず、何千も在庫切れがあるというだけで「それがどうした?」という状態です。おそらく重要なのは単なる在庫切れではなく、売上の多いパワーストア、つまりトップセラーの商品における在庫切れなのです。そこで、パワーストアにおけるトップセラー商品の在庫切れに絞って調査してみましょう.
次に、在庫がゼロとなっている一つのSKUを調べます。しかし、よく見ると、その日初めには実際に3単位の在庫があり、最後の1単位は店舗閉店の30分前に販売されたことが分かります。さらに注意深く見ると、翌日には3単位が補充されることも確認できます。つまり、ここでは在庫切れの状況が見られますが、本当に重要な問題なのでしょうか?実際、そうでもありません。なぜなら、最後の1単位は夕方の閉店直前に販売されたものであり、その数量は補充されるからです。さらに、店舗内に3単位以上を配置できるスペースがない可能性もあり、そこに制約があるのです.
したがって、これは必ずしも重大な懸念事項ではありません。もしかすると、補充の機会があったはずなのに補充されなかった在庫切れ―つまり、トップ店舗かつトップ商品の在庫切れに絞って調査すべきかもしれません。そのような[SKU]の一例を見つけ、流通センターに在庫が全く残っていないことを確認したとしましょう。この場合、本当に問題なのでしょうか?一見、問題ないように思えるかもしれませんが、少し考えてみてください。流通センターに在庫がないとしても、同じ製品についてネットワーク全体を見れば、どこかに在庫が残っている可能性はありませんか?
例えば、この製品―トップ商品、トップ店舗―については、弱い店舗が十分な在庫を持っているものの、在庫回転が行われていない場合があります。ここで、実際に問題が存在することが明らかになります。問題は、トップ店舗に十分な在庫が割り当てられていないのではなく、おそらく新コレクションの初期配分時に非常に弱い店舗へ過剰な在庫が割り当てられたことにあるのです。こうして、問題の根本原因を段階的に特定していくことになります。それは、在庫が少なすぎることではなく、むしろ多すぎることによって引き起こされるサービス品質の問題であり、その結果、パワーストアにおけるサービス品質にシステムレベルの影響を及ぼしてしまっているのです.
ここで行ったことは統計学のアプローチとは全く逆のものであり、「常軌を逸した」意思決定を探る際に重要な意味を持ちます。データを集約してはいけません。むしろ、すべての問題が明るみに出るように、完全に分解されたデータで作業する必要があります。データを集約し始めると、通常、微妙な挙動は消えてしまいます。コツは、最も細分化されたレベルからスタートし、何が起こっているのかを統計レベルではなく、非常に基本的なレベルで理解するためにネットワーク全体を見渡すことです。
この手法は、定量的サプライチェーンで紹介した経済的ドライバーの視点にも非常に適用できます。すなわち、possible futuresというあらゆる可能性、あらゆる意思決定が存在し、それらの意思決定を経済的ドライバーに基づいてスコア付けするのです。結果として、これらの経済的ドライバーは、サプライチェーンにおけるSKU、意思決定、イベントの整理に非常に役立つことが分かりました。影響度の高い順に並べることができ、経済的ドライバーが部分的に不正確または不完全であっても、非常に強力な仕組みになります。これにより、特定のサプライチェーンで何が起こっているのかを高い生産性で調査・診断する、非常に効果的な手法となるのです。
実験的最適化手法を展開する取り組みを進める中で、「常軌を逸した」意思決定が、本当に常軌を逸した(機能不全な)決定から、単に悪い決定へと徐々に変化していくことが分かります。それらは会社を破綻させるほどのものではありませんが、決して良いものではありません。

こここそが、サプライチェーンの数学的最適化の視点から大きく逸脱する点です。
実験的最適化では、内部で数学的最適化ツール、つまり意思決定を生成する数値レシピの中核を利用しているため、損失関数自体に数学的最適化の要素が含まれています。しかし、それは目的そのものではなく、あくまでプロセスをサポートする手段に過ぎません。問題を定義して最適化するという数学的最適化のアプローチをとるのではなく、ここでは問題に対する自身の理解を繰り返し問い直し、損失関数自体を修正していくのです。
理解を深めるためには、ほぼすべてのものに計測装置を取り付ける必要があります。最適化プロセスそのもの、数値レシピそのもの、そして扱っているデータに関するあらゆる特徴に対して計測を行う必要があるのです。興味深いことに、歴史的な視点で見ると、重要な発見があった多くの大きな科学的進展では、その発見の数十年前に計測装置の画期的な進歩がありました。知識を発見するということは、通常、まず宇宙を観察する新たな方法、つまり計測装置の革新を果たし、その後で興味の対象においてブレークスルーを果たすということなのです。ここで実際に起こっているのはまさにそのことです。ちなみに、ガリレオは自作の望遠鏡を初めて使用したことで、例えば木星の衛星を発見するなど、ほとんどの発見を成し遂げたのです。これらの指標こそが、あなたの旅路を前進させる計器なのです。

さて、問題は、先に述べたように実験的最適化が反復的なプロセスであるという点です。ここで非常に重要なのは、我々が一つの官僚制を別の官僚制と交換しているのかどうかという疑問です。私が主流のサプライチェーン管理に対して最も批判している点の一つは、日々の例外対応に追われる官僚制の人々の集団ができてしまい、その仕事が資本主義的ではなくなってしまうことです。対照的に、サプライチェーン科学者の視点を提示しましたが、彼らの仕事は資本主義的に価値を積み上げるものであるべきです。しかし、最終的には、サプライチェーン科学者がどれだけの生産性を発揮できるかに帰着し、彼らは非常に生産的でなければならないのです。
ここでは、この生産性が何を意味するのかについての短いKPIリストを示します。まず、データパイプラインをエンドツーエンドで1時間以内に通過できることが求められます。先にも述べたように、常軌を逸する原因の一つはデータの意味論にあります。意味論的な問題に気づいたとき、それを検証するためにパイプライン全体を再実行する必要があります。サプライチェーンチームやサプライチェーン科学者は、これを1日に何度も実行できなければなりません。
最適化そのものを行う数値レシピに関しては、この時点でデータはすでに準備・統合されているため、全体のデータパイプラインの一部となります。非常に多くの反復が必要となるので、毎日何十回も反復できる環境が必要です。リアルタイムでの実行が理想的ですが、現実にはサプライチェーンの局所的な最適化は問題を先送りにするだけです。全体的な視点が必要であり、単純またはありふれたモデルではサプライチェーンに存在する複雑な要素を十分に捉えることはできません。通常、数値レシピの表現力とそのリフレッシュ時間との間にはトレードオフがあり、計算が数分以内に収まればバランスは良好と言えます。
最後に、この点はサプライチェーン向けのプロダクト指向ソフトウェアデリバリーに関する講義でも触れましたが、新しい数値レシピを毎日1つでも本番環境に投入できなければなりません。これは必ずしも推奨するというより、予期せぬ事態が発生するために必要な条件なのです。パンデミックであったり、それほど大規模でなくても、warehouseが浸水したり、生産現場で事故が起こったり、競合他社から大規模なサプライズpromotionが展開されたり、様々な事態が発生して事業が混乱する可能性が常にあります。したがって、非常に迅速に対策を講じることができる環境、すなわち毎日新たなサプライチェーンレシピの反復をライブ環境に適用できる環境が必要なのです。

さて、実験的最適化の実践は非常に興味深いものです。Lokadのアプローチは現場で自然に発現してきた実践であり、ここ10年で徐々に日常的な手法へと浸透していきました。初期の頃には、いわばプロトタイプ的な実験的最適化プロセスが存在していました。主な違いは、当時はまだ反復を行っていたものの、サプライチェーン文献から得た数学的モデルを使用していた点にあります。結果として、これらのモデルは通常、モノリシックであり、ここで説明している非常に反復的なプロセスには適用できなかったため、反復はしていたものの、毎日新しいレシピを本番環境に投入するほどの状態には至りませんでした。むしろ、新しいレシピの開発には数ヶ月を要していたのです。Lokadのウェブサイトで私たちの旅路を見ると、予測エンジンの連続した反復がこのアプローチの反映となっており、1つの予測エンジンから次の世代へ移行するのに概ね18ヶ月を要し、四半期ごとに大きな反復が1回程度行われていたのが実情です。
これが以前の状況であり、ゲームチェンジが起こったのはプログラミングパラダイムの導入です。私のプロローグでサプライチェーン向けのプログラミングパラダイムを紹介しましたが、この講義を通して、なぜそれらが重要なのかがより明確になるはずです。これらこそが、数値レシピを構築し、毎日効率的に反復するための燃料であり、サプライチェーンにおける常軌を逸した意思決定を排除し、大きな価値を生み出すために不可欠なパラダイムなのです。
さて、現実の実験的最適化ですが、私の見解では、それはLokadで発明されたのではなく、むしろそこで何度も自社のサプライチェーンにおける不十分な意思決定に直面した結果、自然発生的に現れたものです。同様の圧力を受ける他の企業も、本日ご紹介したものの変種ともいえる実験的最適化プロセスを独自に構築しているのではないかと強く感じています。
例えば、GAFAのようなテックジャイアントに目を向けると、秘密情報を開示しない範囲で内部関係者がほのめかしているように、これらの手法は異なる名称で呼ばれているものの、すでにそれらの企業で広く実践されています。外部から見ても、彼らが公開している多くのオープンソースツールは、まさにこの実験的最適化手法に沿ったイニシアチブを進めるために必要なツール群であることが分かります。例えば、PyTorchは一つのモデルではなく、機械学習を行うためのプログラミングパラダイムというメタソリューションであり、この枠組みにぴったり合致します。
では、なぜこれほど成功しているにもかかわらず、あまり認知されていないのかと疑問に感じるかもしれません。野生の実験的最適化を認識するのは容易ではありません。ある時点で企業のスナップショットを取れば、それはまるで数学的最適化の視点と同じに見えるからです。例えば、Lokadが支援する企業のスナップショットを取ると、その時点では問題の定義と解決策が提示されており、数学的最適化と全く同様です。しかし、それは静的な視点に過ぎず、時間軸やダイナミクスを考慮すると、状況は全く異なるのです。
また、反復的なプロセスであっても収束するものではない点にも注意が必要です。最適解に収束する反復プロセスが存在するというのは、人間の創意工夫に厳しい限界があると言うようなもので、私はこれは贅沢な命題だと考えています。サプライチェーンの問題は非常に複雑で、最適解が定まる狭い問題設定ではなく、常に状況が変化するため、収束はありえません。さらに、現実に収束が見られないもう一つの理由は、世界が常に変化しているからです。サプライチェーンは孤立して運営されているのではなく、供給業者、顧客、環境が絶えず変動しているため、ある時点で有効だった数値レシピも、市場状況の変化により突然常軌を逸した意思決定を生み出してしまう可能性があるのです。2020年のパンデミック時に見られたように、パンデミック前に正当とされたものが、パンデミック中にはもはや正当ではなくなるということは容易に想像でき、今後も同様の事態は繰り返されるでしょう。
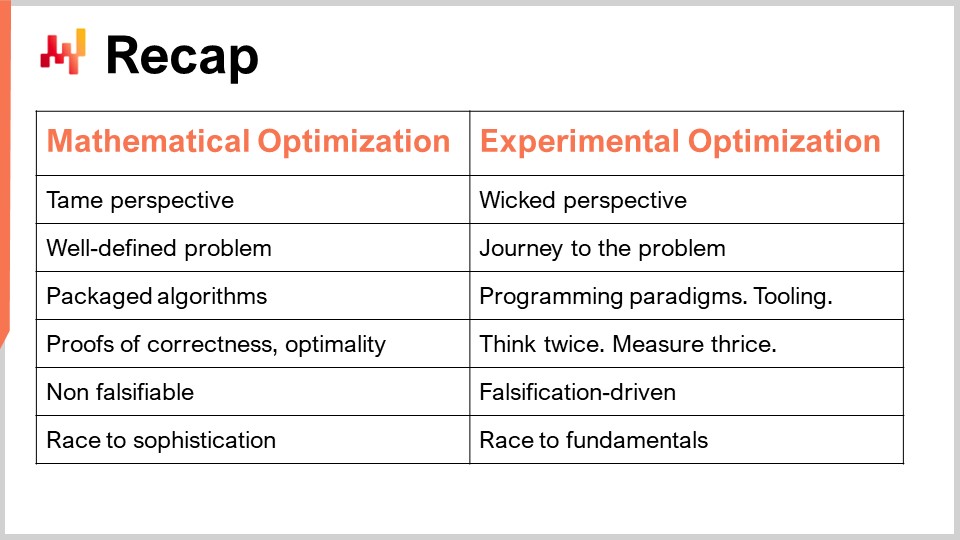
まとめると、我々には2つの異なる視点があります。一つは、明確に定義された問題に取り組む数学的最適化の視点、もう一つは問題自体すら定義しがたい複雑なサプライチェーンに取り組む実験的最適化の視点です。数学的最適化の視点では、明確な問題定義があれば、明確なアルゴリズム解を提供でき、それをソフトウェアに組み込みその正確性と最適性を証明することが可能です。しかし、実験的最適化の世界では、すべてをパッケージ化することは不可能です。代わりに、プログラミングパラダイム、ツール、インフラストラクチャを駆使し、最終的には常に人間の知性に依存するのです。すなわち、二度考え、三度測り、一歩前進するということに集約され、自動化できるものはなく、すべてはサプライチェーン科学者の知性にかかっているのです。
反証可能性の観点から言えば、私の主張は、数学的最適化の視点は、生成されるものを何一つ反証できないため科学と呼べないというものです。結果、最終的には常により複雑なモデルを求める競争に陥りますが、複雑であることが科学的であるとか、企業にもたらす価値が高いというわけではありません。対照的に、実験的最適化は反証主導型です。すべての反復は、数値レシピを実世界のテストに晒し、意思決定を生成し、正しい意思決定を見極めるという事実に基づいています。この実験的テストは1日に何度も繰り返され、理論に挑戦し、何度もその誤りが証明され、そこから反復を重ね、最終的に大きな価値を創出するのです。
興味深いのは、最終的な成果という点で、実験的最適化は複雑さを追求する競争ではなく、基礎に立ち返る競争であるということです。つまり、サプライチェーンを駆動する根本的な要素、サプライチェーンを規定する基本的な要素を理解し、数値レシピが常軌を逸した意思決定を出し続けないように、何が起こっているのかを正確に把握することに尽きます。最終的には、サプライチェーンにとって非常に有益なものを生み出すことを目指すのです。

これは長い講義でしたが、結論として、数学的最適化は幻想に過ぎないということを理解していただければと思います。それは誘惑的で洗練され魅力的な幻想ですが、それでも幻想に過ぎません。私にとって実験的最適化こそが現実の世界です。我々は実際の企業プロセスを支援するために、ほぼ10年間これを活用してきました。Lokadは単なるデータポイントに過ぎませんが、私の視点では非常に説得力のあるデータと言えます。つまり、現実の世界を体験することが肝要なのです。ところで、このアプローチは非常に過酷です。なぜなら、現実の世界に出れば、現実が容赦なく反撃してくるからです。あなたはサプライチェーンを管理・最適化するための適切な数値的レシピについて素晴らしい理論を立てましたが、そして現実が反撃します。それは時に非常に苛立たしいものです。現実は常に、あなたが考えた巧妙な手法を無効にする方法を見つけ出すからです。このプロセスは非常に悩ましいですが、私はこれがサプライチェーンに実際の、かつ利益をもたらす改善を実現するために必要な現実の一撃だと信じています。私の見解では、将来的には実験的最適化、あるいはその派生手法が、サプライチェーンの研究や実践において数学的最適化の視点に完全に取って代わる時が来るでしょう。

今後の講義では、この実践を支えるために使用できる具体的な手法、数値的手法、および数値ツールをレビューしていきます。今日の講義では手法のみを扱いましたが、後ほどそれを機能させるためのノウハウや戦術も取り上げます。次回の講義は2週間後の同じ曜日・同じ時間に行われ、サプライチェーンにおけるネガティブナレッジについて講義します。
それでは、質問を見てみましょう。
質問: もしサプライチェーンに関する論文が現実と全く結びつく可能性がなく、いかなる実例もNDAの下にある場合、サプライチェーンの研究を行い、その成果を発表しようとする人々には何を提案しますか?
私の提案は、手法に挑戦すべきだということです。現状の手法はサプライチェーンの研究には適していません。この一連の講義で、サプライチェーン担当者によるアプローチと実験的最適化の2つの方法を提示しました。これらの方法論に基づいて行うべきことはまだ多くあります。これはほんの2つの方法論にすぎず、まだ発見または発明されるべき多くの方法論が存在すると私は確信しています。私の提案は、学問を真の科学たらしめる根幹に挑戦することです。
質問: もし数学的最適化が現実のサプライチェーンの運営を最もよく反映していないのであれば、なぜディープラーニング手法の方が優れているのでしょうか?ディープラーニングは過去の最適な決定に基づいて意思決定を行っているのではないですか?
この講義では、数学的最適化を独立した研究分野として捉えることと、ディープラーニングを独立した研究分野として捉えること、そしてサプライチェーンに応用する数学的最適化という視点との違いを明確に区別しました。数学的最適化そのものが無効だと批判しているのではなく、正反対です。私が議論している実験的最適化手法の数値レシピの中核には、通常、何らかの数学的最適化アルゴリズムが組み込まれています。問題は、あくまで数学的最適化という視点にあり、これこそが私の挑戦点です。微妙なほどの差異ですが、これは非常に重要な違いです。ディープラーニングは補助的な科学であり、数学的最適化が独立した研究分野であるのと同様に、独立した研究分野です。どちらも優れた研究分野ですが、サプライチェーン研究とは全く異なり、独立しています。本当に我々が関心を抱くのはサプライチェーンの定量的な改善です。つまり、制御可能で信頼性が高く、測定可能な方法でサプライチェーンを改善する手法を追求することなのです。これが、今回の焦点です。
質問: 強化学習はサプライチェーン管理への適切なアプローチになり得るのでしょうか?
まず、サプライチェーン最適化の文脈では、強化学習は適切なアプローチであると言えます。これは以前の講義で区別した点ですが、ソフトウェアの視点からは、エンタープライズリソースマネジメントによる管理側と、最適化側という区分があります。強化学習は、ディープラーニングや数学的最適化の要素をも活用できる別の研究分野です。これは実験的最適化手法で利用できる要素のひとつです。重要なのは、これらの強化学習技術を非常に流暢かつ反復的に取り込むことができるプログラミングパラダイムが存在するかどうかです。これが大きな挑戦です。反復が可能でなければ、複雑で一枚岩な強化学習モデルに頼ることになり、まさにLokadが初期にこれらの一枚岩モデルを使っていた頃のように、反復が極めて遅くなってしまいます。一連の技術的ブレークスルーが、反復プロセスをより流動的なものにしたのです。
質問: 数学的最適化は強化学習の不可欠な要素なのでしょうか?
はい、強化学習は機械学習の一分野であり、機械学習はある意味で数学的最適化の一部門とも捉えられます。しかし、そうすることで全てが包含し合う状態となり、実際にこれらの分野を区別するのは、問題に対するアプローチの違いなのです。これらの分野は互いに連関していますが、通常、それらを真に区別するのはあなたが持つ意図です。
質問: 多くの先の決定を考慮するディープラーニング手法の文脈で、どのように「非常識な決定」を定義しますか?
非常識な決定とは、将来の決定に依存するものです。まさに、「品切れは問題か?」という例で示した通りです。次に行われる決定が補充であると予測されるなら、品切れ自体は問題ではありません。したがって、この状況を非常識と判断するか否かは、実際にこれから下される決定に依存しているのです。これにより調査は複雑になりますが、これこそが、優れた計測手段が必要であるという理由です。例えば、品切れの状況を調査する場合、現状のデータだけでなく、現在の数値レシピに基づいて採られると予測される将来の決定も予測できなければなりません。適切な計測装置が必要なのです。そして、これを自動化することはできず、人間レベルの知能が求められるのです。
質問: 実験的最適化、非常識な決定の識別、そして解決策の発見は実際にはどのように機能するのでしょうか?現実で非常識な決定が起こるのを待つわけにはいかない、ということでしょうか?
全くその通りです。この講義の冒頭で、私は現代物理学者とマルクス主義者という2つのグループに言及しました。物理学者のグループは、適切な科学を実践しているという点で、理論が反証されるのを受動的に待っていたのではなく、むしろ自ら進んで、自分たちの理論を反証する可能性のある非常に巧妙な実験を設計していました。非常に積極的なアプローチだったのです。
アルバート・アインシュタインが生涯の大半で行っていたのは、自ら発明した(少なくとも部分的には)物理理論を実験で検証するための巧妙な方法を見出すことでした。つまり、非常識な決定が起こるのを待つのではなく、何度も数値レシピを実行し、非常識な決定を探し出すために時間を投資する必要があるのです。当然、実用性に欠けるような決定もあり、そういった場合は生産現場で実施せざるを得ず、その時は世界が反撃するでしょう。しかし、大多数の場合、日々実験を繰り返すことで非常識な決定は識別できます。ただし、データが必要であり、実際に生産可能な決定を生み出す実際のプロセスが必須です。
質問: もし数値レシピが数学的手法や視点のために破綻し、なおかつ他の視点が分からない場合、どのようにしてそれが手法の問題ではなく視点の問題であると発見し、より問題に適した別の視点を見出すべきだと自らを駆り立てるのでしょうか?
これは非常に大きな問題です。存在しないものをどうやって見つけ出すのでしょうか?例えば、パリに拠点を置く小売業を営むファッション企業のサプライチェーン担当者の例に戻りましょう。もし、シーズン終了時の割引を行った結果、顧客の購買習慣へ長期的な影響を与えていることをしばしば考慮し忘れてしまったとしたら、あなたは自分が顧客に習慣を植え付けているという事実に気づかないでしょう。どうしてそれに気づけるというのでしょうか?これは一般的な知能の問題であり、魔法のような解決策は存在しません。
ブレインストーミングが必要です。ちなみに、Lokadの非常に具体的な答えは、同社がパリに拠点を置いているということです。私たちは、オーストラリア、ロシア、米国、カナダなど20か国以上の遠隔地にある顧客にサービスを提供しています。なぜ、パンデミックによりリモートワークが増えているにもかかわらず、すべてのサプライチェーン・サイエンティストのチームをパリに集めたのでしょうか?それは、彼らが一箇所に集まり、自由に対話し、ブレインストーミングを行い、新たなアイデアを生み出す必要があったからです。これも非常に低技術的な解決策ですが、これ以上のものを約束することはできません。たとえば、長期的な影響を考慮すべき必要性のように、見えない何かがあって、それを単に忘れてしまったり、考えもしなかった場合、その問題は非常に明白かつ見落とされがちになります。以前の講義で、スーツケースの例を挙げました。スーツケースに車輪を付けるという発明に5000年もの歳月がかかったのです。車輪は何千年も前に発明されましたが、人が月に到達してから数十年後に、より優れたスーツケースが発明されました。こうした例は、明白なものが見過ごされる可能性があるということを示しています。そんなレシピは存在せず、結局は人間の知性に委ねられるのです。あるがままに活用するしかありません。
質問: 変化し続ける状況が、あなたのサプライチェーンの最適解を常に陳腐化させるということでしょうか?
はい、そうでもあり、そうでもありません。実験的最適化の視点からは、最適解というものは存在しません。最適化された解はあるものの、それは決して最適な状態ではありません。最適というのは、人間の創意工夫に厳しい限界があると言うのと同じことです。つまり、最適というものは存在せず、ただ最適化された解があるだけです。そして、毎日市場はこれまでに行った実験から徐々に乖離していきます。世界の進化そのものが、あなたが得た最適化を劣化させるのです。これが現実の世界のあり方です。たとえば、パンデミックのような日には、その乖離は急激に加速します。つまり、世界は変化し続けるため、あなたの数値レシピもそれに合わせて変化しなければならないのです。これは外部からの圧力であり、逃れることはできず、解決策は常に見直されなければならないのです。
これが、Lokadがサブスクリプション形式でサービスを提供している理由のひとつです。そして、私たちはクライアントにこう伝えています。「いいえ、実装フェーズのためだけにサプライチェーン・サイエンティストを提供することはできません。そんなのはナンセンスです。世界は絶えず変化し続けます。この数値レシピを考案したサプライチェーン・サイエンティストは、時間の終わりまで、もしくはあなたが我々に飽きるまで必要とされるのです。」つまり、この担当者は数値レシピを適応させることができるのです。逃れることはできません。これは単に外部の世界が変化し続ける現実なのです。
質問: 問題へのアプローチは正しいとしても、上級管理職はこれに悩まされます。彼らは『どうしてプロジェクト全体で問題を何度も見直すことができるのか?』と理解できません。この問題が普遍的に存在する問題であることを示すために、どのような生活上のアナロジーを提案しますか?
まず、これはまさに前回のスライドで『マトリックス』のスクリーンショットを示した時に述べたことです。ある時点で、あなたは幻想の世界に生きるか、現実の世界に生きるかを決断しなければなりません。もしあなたの会社の上層部が完全な愚か者ばかりであれば、他社に移ったほうが良いでしょう。なぜなら、そのような会社は長続きしないかもしれないからです。しかし、現実には、マネージャーは愚か者ではないと思います。彼らは作り話の問題に付き合いたくはありません。大企業のマネージャーであれば、1日に10回も「重大な問題」を持ち込まれることがありますが、それは実際の問題ではありません。管理部門として適切な対応は、「問題は全くありません。今まで通りに進めてください。申し訳ありませんが、あなたと共に世界をやり直す時間はありません。これが問題を見る正しい方法ではありません。」というものです。彼らは何十年にもわたる経験を通じて、それを解決できるだけの洞察力を持っているのです。
しかし、時には非常に現実的な懸念も存在します。例えば、20年前の上層部をどのように説得して、20年後に電子商取引が支配的な力になると納得させるか、という問題です。ある時点では、戦いを賢明に選ぶ必要があるのです。もし上層部が愚か者でなければ、十分に準備を整えて会議に臨み、「社長、この問題があります。冗談ではありません。数百万ドルがかかる非常に重要な懸念事項です。冗談ではなく、莫大な金額を置き去りにしている状況です。さらに、何もしなければ競合他社が我々に追い打ちをかけると疑っています。これは軽視できる問題ではなく、非常に深刻な問題です。20分ほどご注目いただきたいのです。」と訴えるべきです。大企業において、上層部が完全な愚か者であることは稀です。たとえ多忙であっても、彼らは決して愚かではありません。
質問: 製造企業にとって適切なツールの構成は何でしょうか。例えば、Lokadのような実験的最適化に加え、ERPや可視化ツールなどでしょうか?さらに、オンラインの同時計画システムの役割はどうでしょうか?
The vast majority of our competitors align with the mathematical optimization perspective on supply chains. They have defined the problem and implemented software to solve the problem. What I’m saying is that when they put the software to the test and it invariably ends up producing tons of insane decisions, they say, “Oh, it’s because you did not configure the software correctly.” This makes the software product immune to the test of reality. They find ways to deflect the criticism rather than addressing it.
Lokadでは、この手法が生まれたのは、我々が競合他社とは大きく異なっていたからです。言い訳をする余裕はなかったのです。ことわざにもあるように、「言い訳か結果のどちらかであって、両方は得られない」。Lokadでは言い訳をする選択肢はありませんでした。我々は意思決定を提供しており、クライアント側で設定や微調整を行う余地は一切なかったのです。Lokadは自らの不十分さに正面から向き合っていました。私の知る限り、すべての競合他社は数学的最適化の視点に固執しており、そのため、現実に対してある程度免疫があるという問題に苦しんでいます。正直なところ、彼らが完全に現実に免疫があるわけではありませんが、Lokadの初期の頃に私が説明したような非常に遅いイテレーションのペースになってしまいます。彼らは完全に現実に免疫があるわけではありませんが、改善プロセスは氷河のように遅く、世界は常に変化し続けています。
常に起こることは、エンタープライズソフトウェアが大局の世界の変化に追いつくほど速く変化しないため、単に時代遅れになっていくということです。毎年ソフトウェアは改善されても、世界はますます奇妙で異なるものになっていくため、本当に良くなっているとは言えません。エンタープライズソフトウェアは、その起源からどんどん乖離した世界に対して、ただ後れをとっているだけです。
Question: 製造業向けの適切なツールの構成は何でしょうか?
適切な構成とは、すべての取引面を管理できるエンタープライズリソース管理ツールです。その上で、本当に重要なのは、数値レシピに関して非常に統合されたソリューションを持つことです。視覚化用のテックスタック、最適化用の、調査用の、さらにデータ準備用のと、用途ごとに技術スタックを分けたくはありません。もしそれら異なる用途のために半ダースもの技術スタックが出来上がってしまえば、それらを全て接続するためのソフトウェアエンジニアの軍団が必要となり、結果的にアジャイルとは正反対の状態になってしまいます。
求められるソフトウェアエンジニアリングの能力があまりにも多いため、実際のサプライチェーンの専門知識に割く余地がなくなってしまいます。覚えておいてください、これが製品志向のソフトウェア提供に関する私の第3回講義の主旨でした。必要なのは、ソフトウェアエンジニアではなく、サプライチェーンの専門家が操作できるものです。
以上です。では、2週間後の同じ曜日、同じ時間に「サプライチェーンにおけるネガティブナレッジ」でお会いしましょう。
References
- The Logic of Scientific Discovery, Karl Popper, 1934


