00:12 Introduction
02:23 Falsifiability
08:25 The story so far
09:38 Modelling approaches : Mathematical Optimization (MO)
11:25 Overview of Mathematical Optimization
14:04 Mainstream supply chain theory (recap)
19:56 Extent of the Mathematical Optimization Perspective
23:29 Rejection heuristics
30:54 The day after
32:43 Redeeming qualities?
36:13 Modelling approaches : Experimental Optimization (EO)
38:39 Overview of Experimental Optimization
42:54 Root causes of insanity
51:28 Identify insane decisions
58:51 Improve the instrumentation
01:01:13 Improve and repeat
01:04:40 The practice of EO
01:11:16 Recap
01:14:14 Conclusion
01:16:39 Upcoming lecture and audience questions
Description
Far from the naïve Cartesian perspective where optimization would just be about rolling-out an optimizer for a given score function, supply chain requires a much more iterative process. Each iteration is used to identify “insane” decisions that are to be investigated. The root cause is frequently improper economic drivers, which need to be re-assessed in regards to their unintended consequences. The iterations stop when the numerical recipes no longer produce insane results.
Full transcript

Hi everyone, welcome to this series of supply chain lectures. I am Joannes Vermorel, and today I will be presenting “Experimental Optimization,” which should be understood as the optimization of supply chains via a series of experiments. For those of you who are watching the lecture live, you can ask questions at any point in time via the YouTube chat. However, I will not be reading the chat during the lecture; I will be getting back to the chat at the very end of the lecture to answer the questions found there.
The goal for us today is the quantitative improvement of supply chains, and we want to be able to achieve that in ways that are controlled, reliable, and measurable. We need something akin to a scientific method of a kind, and one of the key characteristics of modern science is that it’s deeply rooted in reality or, more precisely, in the experiment. In a previous lecture, I briefly discussed the idea of supply chain experiments and mentioned that, at first glance, they seem lengthy and costly. The length and cost could even defeat the very purpose of why we are doing those experiments, to the point where it might not even be worth it. But the challenge is that we need a better way of approaching experimentation, and that’s exactly what experimental optimization is about.
Experimental optimization is fundamentally a practice that emerged at Lokad about a decade ago. It provides a way to do supply chain experiments in ways that actually work, that can be done conveniently and profitably, and that will be the specific topic of the lecture today.

But first, let’s go back for a second on this very notion of the nature of science and its relationship with regard to reality.
There is one book, “The Logic of Scientific Discovery,” which was published in 1934 with Karl Popper as its author, that is considered an absolute landmark in the history of science. It proposed a completely stunning idea, which is falsifiability. To understand how this idea of falsifiability came to be and what it’s about, it’s very interesting to revisit the journey of Karl Popper himself.
You see, in his youth, Popper was close to several circles of intellectuals. Among those circles, there were two of key interest: one was a circle of social economists, typically proponents of the Marxist theory at the time, and the other was a circle of physicists, which included most notably Albert Einstein. Popper witnessed that the social economists had a theory with the intent of having a scientific theory that could explain the evolution of society and its economy. This Marxist theory was actually making predictions about what would happen. The theory pointed out that there would be a revolution, and that the revolution would happen in the country that was most industrialized and where the greatest number of factory workers were to be found.
It turned out that the revolution did happen in 1917; however, it did happen in Russia, which was the least industrialized country in Europe and thus was completely against what the theory was predicting. From Popper’s perspective, there was a scientific theory making predictions, and then events happened which contradicted the theory. What he expected was for the theory to be disproven, and for people to move on to something else. Instead, what he saw was something very different. The proponents of the Marxist theory modified the theory to fit the events as they unfolded. By doing so, they gradually made the theory immune to reality. What started as a scientific theory was gradually modified to become something completely immune, and nothing that could happen in the real world would go against the theory anymore.
This was in stark contrast to what was happening in the circles of physicists, where Popper witnessed people like Albert Einstein creating theories and then going to great lengths to think of experiments that could disprove their own theories. The physicists were not spending all their energy on proving the theories but rather on disproving them. Popper considered which approach was the better way to do science and developed the concept of falsifiability.
Popper proposed that falsifiability is a criterion to establish whether a theory can be considered scientific. He said that a theory is scientific if it satisfies two criteria. The first one is that the theory should be at risk with regard to reality. The theory needs to be expressed in a way that it’s possible for reality to contradict what is being said. If a theory cannot be contradicted, it’s not that it’s true or false; it’s beyond the point, at least from a scientific perspective. So, for a theory to be considered scientific, it should take a certain degree of risk with regard to reality.
The second criterion is that the amount of credence or trust that we can put in a theory should be, to some extent (and I’m simplifying here), proportional to the amount of work that has been invested by scientists themselves in trying to disprove the theory. The scientific characteristic of a theory is that it takes a great deal of risk, and many people try to exploit those weaknesses to disprove the theory. If they have failed over and over, then we can lend some credibility to the theory.
This perspective shows that there is a profound asymmetry between what is true and what is false. Modern scientific theories should never be considered as true or proven, but just as pending. The fact that many people have tried to disprove them without success enhances the credibility that we can give them. This insight is of critical importance for the world of supply chain, and in particular, this notion of falsifiability has fueled many of the most stunning developments in science, especially when it came to modern physics.
So far, this is the third lecture of the second chapter of this series on supply chain. In the first chapter of the prologue, I presented my views on supply chain both as a field of study and as a practice. One of the key insights was that supply chain covers a set of wicked problems, as opposed to tame problems. These problems don’t lend themselves, by design, to any straightforward solution. Therefore, we need to pay a great deal of attention to the methodology that we have both to study and practice supply chain. This second chapter is about those methodologies.
In the first lecture of the second chapter, I proposed a qualitative method to bring knowledge and later on improvement to supply chain via the notion of supply chain personas. Here, in this third lecture, I’m proposing a quantitative method: experimental optimization.

When it comes to bringing quantitative improvement to supply chains, we need a quantitative model, a numerical model. There are at least two ways to approach this: the mainstream way, mathematical optimization, and another perspective, experimental optimization.
The mainstream approach to delivering quantitative improvements in supply chain is mathematical optimization. This approach is essentially constructing a long catalog of problem-solution pairs. However, I believe that this method is not very good, and we need another perspective, which is what experimental optimization is about. It should be understood as the optimization of supply chains via a series of experiments.
Experimental optimization was not invented by Lokad. It emerged at Lokad as a practice first and was conceptualized as such years later. What I’m presenting today is not the way it gradually emerged at Lokad. It was a much more gradual and muddy process. I revisited this emergent practice years later to solidify it under the form of a theory that I can present under the title of experimental optimization.

First, we need to clarify the term mathematical optimization. We have two different things that we need to differentiate: mathematical optimization as an independent field of research and mathematical optimization as a perspective for the quantitative improvement of supply chain, which is the topic of interest today. Let’s put the second perspective aside for a second and clarify what mathematical optimization is about as a standalone field of research.
It’s a field of research interested in the class of mathematical problems that present themselves as described on the screen. Essentially, you start with a function that goes from an arbitrary set (capital A) to a real number. This function, frequently referred to as the loss function, is denoted by f. We are looking for the optimal solution, which is going to be a point x that belongs to capital A, the set, and cannot be improved upon. Obviously, this is a very broad field of research with tons of technicalities involved. Some functions may not have any minimum, while others might have many distinct minima. As a field of research, mathematical optimization has been prolific and successful. There are numerous techniques that have been devised and concepts introduced, which have been used with great success in many other fields. However, I won’t be discussing all of that today, as it is not the point of this lecture.
The point I would like to make is that mathematical optimization, as an auxiliary science concerning supply chain, has enjoyed a considerable degree of success on its own. In turn, this has profoundly shaped the quantitative study of supply chains, which is what the mathematical optimization of supply chain perspective is about.

Let’s go back to two books that I introduced in my very first supply chain lecture. These two books represent, I believe, the mainstream quantitative supply chain theory, embodying the last five decades of both scientific publications and software production. It’s not just the published papers, but also the software that has been pushed into the market. As far as the quantitative optimization of supply chains is concerned, everything is done and has been done for a long time via software instruments.
If you look at these books, every single chapter can be seen as an application of the mathematical optimization perspective. It always boils down to a problem statement with various sets of assumptions, followed by the presentation of a solution. The correctness and sometimes the optimality of the solution are then proven with regard to the problem statement. These books are essentially catalogs of problem-solution pairs, presenting themselves as mathematical optimization problems.
For example, forecasting can be seen as a problem where you have a loss function, which is going to be your forecasting error, and a model with parameters that you want to tune. You then want to learn the optimization process, numerically speaking, that gives you the optimal parameters. The same approach applies to an inventory policy, where you can make hypotheses about the demand and then go about proving that you have a solution that turns out to be optimal with regard to the assumptions you’ve just made.
As I’ve already covered in the very first lecture, I have great concerns about this mainstream supply chain theory. The books I mentioned are not random selections; I believe they accurately reflect the last couple of decades of supply chain research. Now, looking at the ideas about falsifiability as introduced by Karl Popper, we can see more clearly what the problem is: neither of these books are actually science, as reality cannot disprove what is presented. Those books are essentially completely immune to real-world supply chains. When you have a book that is essentially a collection of problem-solution pairs, there is nothing to disprove. This is a purely mathematical construct. The fact that a supply chain is doing this or that has no bearing on either proving or disproving anything about what is presented in those books. That’s probably my biggest concern with these theories.
This is not just a matter of research being discussed here. If you look at what exists in terms of enterprise software to serve supply chains, the software that exists today in the market is very dominantly a reflection of these scientific publications. This software wasn’t invented separately from those scientific publications; usually, they go hand in hand. Most of the pieces of enterprise software that are found on the market to address supply chain optimization problems are reflections of a certain series of papers or books, sometimes authored by the same people who produced the software and the books.
The fact that reality has no bearing on the theories presented here is, I think, a very plausible explanation for why there is so little of the theories presented in these books that are actually of any use in real-world supply chains. This is a fairly subjective statement that I’m making, but in my career, I’ve had the chance to discuss with several hundred supply chain directors. They are aware of these theories, and if they are not very knowledgeable about them, they have people on their team who are. Very frequently, the software being used by the company already implements a series of solutions as presented in these books, and yet they are not used. People fall back for various reasons to their own Excel spreadsheets.
So, this is not ignorance. We have this very real problem, and I believe that the root cause is literally that it’s not science. You can’t falsify any of the things that are presented. It’s not that these theories are incorrect – they are mathematically correct – but they are not scientific in the sense that they don’t even qualify to be science.

Now, the question would be: what is the extent of the problem? Because I actually picked two books, but what is the actual extent of this mathematical optimization perspective in supply chain? I would say the extent of this perspective is absolutely massive. As a piece of anecdotal evidence to demonstrate that, I recently used Google Scholar, a specialized search engine provided by Google that only provides results for scientific publications. If you look for “optimal inventory” just for the year 2020 alone, you will get 30,000+ results.
This number should be taken with a grain of salt. Obviously, there are probably numerous duplicates in this list, and there are most likely going to be false positives – papers where both the words “inventory” and “optimal” appear in the title and abstract, but the paper is not about supply chain at all. It’s just accidental. Nonetheless, a cursory inspection of the results hints very strongly that we are talking about several thousand papers published per year in this area. As a baseline, this number is very large, even compared to fields that are absolutely massive, like deep learning. Deep learning is probably one of the computer science theories that enjoys the greatest degree of success over the last two or three decades. So, the fact that just the query “optimal inventory” returns something that is of the order of one-fifth of what you get for deep learning is actually very stunning. Optimal inventory is obviously only a fraction of what quantitative supply chain studies are about.
This simple query shows that the mathematical optimization perspective is really massive, and I would argue, although it’s maybe a bit subjective, that as far as quantitative studies of supply chain go, it really dominates. If we have several thousand papers that provide optimal inventory policies and optimal inventory management models to run companies, produced on a yearly basis, surely the majority of large companies should be running based on these methods. We are not talking about just a few papers; we are talking about an absolutely massive amount of publications.
In my experience, with a few hundred data points of supply chain that I know about, this is really not the case. These methods are almost nowhere to be seen. We have an absolutely stunning disconnect between the state of the field when it comes to the papers that are being published – and, by the way, the software, because again, the software is pretty much a reflection of what is published as scientific papers – and the way supply chains actually operate.

The question I had is: with thousands of papers, is there anything good to be found? I had the pleasure of going through hundreds of quantitative supply chain papers, and I can give you a series of heuristics that will give you near certainty that the paper presents no real-world added value whatsoever. These heuristics are not absolutely true, but they are very accurate, something that would be 99%+ accurate. It’s not perfectly accurate, but it’s almost perfectly accurate.
So, how do we detect papers that add real-world value, or conversely, how do we reject papers that don’t bring any value whatsoever? I’ve listed a short series of heuristics. The first one is just if the paper makes any claim about any kind of optimality, then you can rest assured that the paper brings no value whatsoever to real-world supply chains. First, because it reflects the fact that the authors don’t even understand, or have the slightest understanding about the fact that supply chains are essentially a wicked problem. The fact that you would say that you have an optimal solution – so, let’s go back to the definition of an optimal solution: a solution that is optimal if it cannot be improved upon. Saying that you have an optimal supply chain solution is very much like saying there is a hard limit on human ingenuity. I don’t believe that for a moment. I believe that is a completely unreasonable proposition. We see that there is a very big problem with the way supply chain is approached.
Another problem is that whenever there is a claim of optimality, what follows is that you invariably have a solution that relies very strongly on assumptions. You may have a solution that is proven to be optimal according to a certain set of assumptions, but what if those assumptions are violated? Will the solution remain any good? On the contrary, I believe that if you have a solution that you can prove the optimality of, you have a solution that is incredibly dependent on the assumptions being made to be even remotely correct. If you violate the assumptions, the resulting solution is very likely to be absolutely terrible, because it was never engineered to be robust against anything. Optimality claims can pretty much be discarded right off the bat.
The second thing is normal distributions. Whenever you see a paper or a piece of software that claims to use normal distributions, you can rest assured that what is proposed does not work in real supply chains. In a previous lecture, where I presented quantitative principles for supply chain, I showed that all the populations of interest in supply chains are Zipf distributed, not normally distributed. Normal distributions are nowhere to be found in supply chains, and I’m absolutely convinced that this result has been known for decades. If you find papers or pieces of software that rely on this assumption, it’s a near certainty that you have a solution that was engineered out of convenience, so that it would be easier to write the mathematical proof or the software, not because there was any desire to have real-world performance. The presence of normal distributions is just pure laziness or, at best, a sign of profound incomprehension of what supply chains are about. This can be used to reject those papers.
Then, stationarity – there is no such thing. It’s an assumption that looks like it’s okay: things are stationary, more of the same. But it’s not; it’s a very strong assumption. It basically says that you have some kind of process that started at the beginning of time and will continue until the end of time. This is a very unreasonable perspective for real-world supply chains. In real supply chains, any product was introduced at a point in time, and any product will be phased out of the market at a point in time. Even if you’re looking at reasonably long-lived products as they are found, let’s say, in the automotive industry, these processes are not stationary. They’re going to last maybe a decade at best. The lifetime of interest, the timespan of interest, is finite, so the stationary perspective is just widely incorrect.
Another element to identify a quantitative study that’s not going to work is if the very notion of substitution is absent. In real-world supply chains, substitutions are all over the place. If we go back to the supply chain example I introduced two weeks ago in a previous lecture, you could see at least half a dozen situations where there were substitutions at play – on the supply side, the transformation side, and the demand side. If you have a model where conceptually substitution does not even exist, then you have something that is really at odds with real-world supply chains.
Similarly, the lack of globality or the lack of a holistic perspective on supply chain is also a telltale sign that something is not right. If I go back to the previous lecture where I introduced the quantitative principles for supply chain, I stated that if you have something that is akin to a local optimization process, you will not optimize anything; you will merely displace the problems within your supply chain. The supply chain is a system, a network, and so you can’t apply some kind of local optimization and hope that it will actually be for the greater good of the supply chain as a whole. This is just not the case.
With these heuristics, I think you can almost eliminate the bulk of the quantitative supply chain literature, which is kind of stunning in itself.

The thing is that if I were to convince every single editorial board for every supply chain conference and journal that they ought to use these heuristics to filter out low-quality contributions, it would not work. Authors would just adapt and circumvent the process, even if we were adding those guidelines for publication in supply chain journals. If market analysts were adding those to their checklist, what would happen is that authors, both of papers and software, would just adapt. They would obfuscate the problem, making more complicated assumptions where you can’t see anymore that it boils down to a normal distribution or a stationary assumption. It’s just that it’s phrased in ways that are very opaque.
These heuristics are nice to identify low-quality contributions, both papers and software, but we can’t use them to just filter out what is good. We need a more profound change; we need to revisit the whole paradigm. At this point, we are still lacking falsifiability. Reality has nowhere to strike back and somehow disprove what is being presented.

As the last element to close this part of the lecture on the mathematical optimization perspective, is there any redeeming quality to be found in this enormous production of papers and software? My very subjective answer to this question is absolutely no. These papers, and I’ve read a great many of quantitative supply chain papers, are not interesting. On the contrary, they are exceedingly dull, even the best of them. When we look at the auxiliary sciences, there are no nuggets of really interesting things to be found. You can look at all those papers, and I’ve listed thousands of them. From a mathematical perspective, it’s very dull. There are no grand mathematical ideas being presented. From an algorithmic perspective, it’s just a direct application of what has been known for a long time in the field of algorithms. The same can be said about statistics modeling and methodology, which is exceedingly poor. In terms of methodology, it all boils down to the mathematical optimization perspective, where you present a model, optimize something, provide the solution, and prove that this solution has some mathematical characteristics with regard to the problem statement.
We really need to change more than superficially. I’m not criticizing the approach. There are historical precedents for this. It may sound completely stunning that I’m claiming that we have tens of thousands of papers that are completely sterile, but it did happen historically. If you look at the life of Isaac Newton, one of the fathers of modern physics, you will see that he spent about half of his time working on physics, with a massive legacy, and the other half working on alchemy. He was a brilliant physicist and a very poor alchemist. Historical records tend to show that Isaac Newton was as brilliant, dedicated, and serious in his work on alchemy as he was in his work on physics. Due to the fact that the alchemic perspective was just badly framed, all the work and intelligence that Newton injected into this area proved to be completely sterile, with no legacy whatsoever to speak of. My criticism is not that we have thousands of people publishing idiotic things. Most of those authors are very intelligent. The problem is that the framework itself is sterile. That’s the point I want to make.

Now, let’s move on to the second modeling approach I want to present today. In the early years, Lokad’s methodology was deeply rooted in the mathematical optimization perspective. We were very mainstream in this regard, and it was working very poorly for us. One thing that was very specific about Lokad, which was almost accidental, is that at some point, I decided that Lokad would not be selling enterprise software but would be selling directly end-game supply chain decisions. I really mean the exact quantities that a certain company needs to buy, the quantities that a company needs to produce, and how many units need to be moved from place A to place B – whether any single price should be moving down – Lokad was in the business of selling end-game supply chain decisions. Due to this semi-accidental decision of mine, we were brutally confronted with our own inadequacies. We were put to the test, and there was a reality check that was very brutal. If we were producing supply chain decisions that turned out to be bad, clients were immediately on me, screaming bloody murder because Lokad was not delivering something that was satisfying.
In a way, experimental optimization emerged at Lokad. It was not invented at Lokad; it was an emergent practice that was just a response to the fact that we were under immense pressure from our customer base to do something about those defects that were all over the place at the beginning. We had to come up with some kind of survival mechanism, and we tried many things, sometimes pretty much at random. What emerged was what is being referred to as experimental optimization.

Experimental optimization is a very simple method. The goal is to produce supply chain decisions by writing a recipe, software-driven, that generates supply chain decisions. The method starts as follows: step zero, you just write recipes that generate decisions. There is a great deal of know-how, technologies, and tools that are of interest here. This is not the topic of this lecture; this will be covered in great detail in later lectures. So, step one, you just write a recipe, and most likely, it’s not going to be very good.
Then you enter an indefinite iteration practice, where first you’re going to run the recipe. By “run,” I mean that the recipe should be able to run in a production-grade environment. It’s not just about having an algorithm in the data science lab that you can run. It’s about having a recipe that has all the qualities, so that if you decide those decisions are good enough to be put into production, you can do so in a single click. The whole environment has to be production-grade; that’s what running the recipe is about.
The next thing is that you need to identify the insane decisions, which has been covered in one of my previous lectures on product-oriented delivery for supply chain. For those of you who did not attend this lecture, in a nutshell, we want investments in supply chain to be capitalistic, accretive, and in order to achieve that, we have to make sure that the people who work in this supply chain division are not firefighting. The default situation in the vast majority of companies at present time is that supply chain decisions are generated by software – most modern companies are already extensively using pieces of enterprise software to run their supply chain, and all decisions are already generated through software. However, a very large portion of those decisions are just completely insane. What most of the supply chain teams are about is to manually revisit all of those insane decisions and engage in ongoing firefighting efforts to eliminate them. Thus, all the efforts end up being consumed by the operation of the company. You clean up all your exceptions one day, and then you come back the next day with a whole new set of exceptions to attend to, and the cycle repeats. You can’t capitalize; you just consume the time of your supply chain experts. So the idea of Lokad is that we need to treat those insane decisions as software defects and eliminate them entirely, so that we can have a capitalistic process and practice of the supply chain itself.
Once we have that, we need to improve the instrumentation and, in turn, improve the numerical recipe itself. All of this work is conducted by the supply chain scientist, a notion I introduced in my second lecture of the first chapter, “The Quantitative Supply Chain Perspective,” as seen by Lokad. The instrumentation is of key interest because it’s through better instrumentation that you can better understand what is going on in your supply chain, what is going on in your recipe, and how you can further improve it to address those insane decisions that keep popping up.

Let’s delve for a moment into the root causes of insanity that explain those insane decisions. Frequently, when I ask supply chain directors why they think their enterprise software systems that govern their supply chain operations keep producing those insane decisions, a very common but misguided answer I get is, “Oh, it’s just because we have bad forecasts.” I believe this answer is misguided on at least two fronts. First, if you go from the accuracy you can gain from a very simplistic moving average model to a state-of-the-art machine learning model, there is maybe a 20% accuracy to be gained. So yes, it’s significant, but it cannot make the difference between a decision that is very good and a decision that is completely insane. Second, the biggest problem with forecasts is that they don’t see all the alternatives; they are not probabilistic. But I digress; this would be a subject for another lecture.
If we go back to the root cause of insanity, I believe that, although forecasting errors are a concern, they are absolutely not a top concern. From a decade of experience at Lokad, I can say that this is a secondary concern at best. The primary concern, the biggest issue that generates insane decisions, is data semantics. Remember that you cannot observe a supply chain directly; it’s not possible. You can only observe a supply chain as a reflection via the electronic records that you gather through pieces of enterprise software. The observation that you’re making about your supply chain is a very indirect process through the prism of software.
Here, we are talking about hundreds of relational tables and thousands of fields, and the semantics of every single one of those fields really matter. But how do you know that you have the correct understanding and mindset? The only way to know for sure that you truly understand what a specific column means is to put it to the test of the experiment. In experimental optimization, the experimental test is the generation of decisions. You assume that this column means something; that’s your scientific theory in a way. Then you generate a decision based on this understanding, and if the decision is good, then your understanding is correct. Fundamentally, the only thing you can observe is whether your understanding leads to insane decisions or not. This is where reality strikes back.
This is not a small problem; it is a very big one. Enterprise software is complex, to say the least, and there are bugs. The problem with the mathematical optimization perspective is that it looks at the problem as if it were a simple series of assumptions, and then you can roll out a relatively simple, mathematically elegant solution. But the reality is that we have layers of enterprise software on top of layers, and problems can occur all over the place. Some of these problems are very mundane, like incorrect copying, incorrect binding between variables, or systems that should be in sync getting out of sync. There may be version upgrades for software that create bugs, and so on. These bugs are all over the place, and the only way to know whether you have bugs or not is, again, to look at decisions. If the decisions come out correct, then there are either no bugs or the bugs that are present are inconsequential and we don’t care.
Regarding economic drivers, another incorrect approach frequently arises when discussing with supply chain directors. They often ask me to prove that there will be some amount of economic return for their company. My answer to that is that we don’t even know the economic drivers yet. My experience at Lokad has taught me that the only way to know for sure what the economic drivers are – and these drivers are used to build the loss function that, in turn, is used to perform the actual optimization in the numerical recipe itself – is to actually put them to the test, again, through the experience of generating decisions and observing whether those decisions are insane or not. These economic drivers need to be discovered and validated according to experience. At best, you can just have an intuition of what is correct, but only experience and experiments can tell you if your understanding is actually correct.
Then, there are also all the impracticalities. You have a numerical recipe that generates decisions, and those decisions appear to be compliant with all the rules that you have stated. For example, if there are minimum order quantities (MOQs), you generate purchase orders that are compliant with your MOQs. But what if a supplier comes back and tells you that the MOQ is something else? Through this process, you might discover many impracticalities and seemingly feasible decisions that, when you try to put them to the test of the real world, turn out to be unfeasible. You discover all sorts of edge cases and limitations, sometimes ones you didn’t even think about, where the world strikes back and you need to fix that as well.
Then there is even your strategy. You may think you have an overall, high-level strategy for your supply chain, but is it correct? Just to give you an idea, let’s take Amazon as an example. You may say you want to be customer-first. So, for instance, if clients buy something online and they don’t like it, they should be able to return it very easily. You want to be very generous when it comes to returns. But then, what happens if you have adversaries or bad customers who game the system? They may order an expensive $500 smartphone online, receive it, replace the genuine smartphone with a counterfeit one worth only $50, and then return it. Amazon ends up with counterfeits in their inventory without even realizing it. This is a very real problem that has been discussed online many times.
You might have a strategy that says you want to be customer-first, but maybe your strategy should be to be customer-first for honest customers only. So, it’s not just all customers; it’s a subsection of customers. Even if your strategy is approximately correct, the devil is in the details. Again, the only way to see if the fine print of your strategy is correct is through experimentation, where you can look at the details.

Now, let’s discuss how we identify insane decisions. How do we tell the difference between sane and insane decisions? By “insane decision,” I mean a decision that is not sane for your company. This is a type of problem that really requires general human intelligence. There is no hope whatsoever that you can solve this problem through an algorithm. It might be a paradox, but this is the kind of problem that requires human-level intelligence, but not necessarily a very smart human.
There are plenty of other problems like this in the real world. For example, an analogy is movie mistakes. If you were to ask Hollywood studios for an algorithm that can identify all the mistakes in any movie, they would probably say they have no idea how to conceive such an algorithm, as it seems to be a task that requires human intelligence. However, if you transform the problem into one where you just want to have people that can be trained to be very good at identifying movie mistakes, the task becomes much more straightforward. It’s very straightforward to conceive that you can consolidate a handbook of all the tricks for identifying movie mistakes. You don’t need to have people that are exceptionally intelligent to do this work; you just need people who are reasonably intelligent and dedicated. That’s exactly what it’s about.
So, what does the situation look like from a supply chain perspective? If we want to concretely examine the problem, fundamentally, we are going to look for outliers. We just need to start with an angle. Let’s say, for example, we go back to the Paris persona that I introduced two weeks ago. This is a fashion company that operates a large retail network of fashion stores. Let’s say, for example, that we are concerned with quality of service.
Let’s start with stockouts. If we just do a query over all the products and all the stores, we will see that we have thousands of stockouts across the network. So, it doesn’t really help; we have thousands of them, and the answer is “so what?” Maybe it’s not just the stockouts; what is really of interest is the stockouts in the power stores, the stores that sell a lot. That’s where it matters, and not the stockouts for any products but for the top sellers. Let’s narrow down our search for the stockouts that happen in the power stores for the top sellers.
Then, we can examine one SKU where the stock happens to be at zero. But on closer inspection, we’ll see that maybe at the beginning of the day, the stock was actually three units, and the last unit was sold only 30 minutes before the closure of the store. If we pay closer attention, we’ll see that three units will be replenished the next day. So here, we have a situation where we see that we have a stockout, but is it really important? Well, it turns out, not really, because the last unit was sold just before closing down the store in the evening, and the quantity is to be replenished. Furthermore, if we look further, we’ll see that maybe there is not enough room in the store to put more than three units, so we are constrained here.
So, this is not exactly a significant concern. Maybe we should narrow down the search to stockouts where we had the opportunity to replenish - top store, top product - but we didn’t. We find an example of such a given SKU, and then we see that there is no stock left in the distribution center. So, in this case, is it really a problem? We could say no, but wait a minute. We have no stock in the distribution center, but for the same product, let’s have a look at the network at large. Do we still have stock somewhere?
Let’s say that, for this product - top product, top store - we have plenty of weak stores that still have plenty of inventory left for the same product, but they just don’t rotate. Here, we see that we have indeed a problem. The issue was not that there is not enough stock allocated to the top store; the problem is that there was too much stock allocated, probably during the initial allocation towards the stores for the new collection, for very weak stores. So, we go step by step to identify the root cause of the problem. We can trace it back to a quality of service issue caused not by sending too little stock but, on the contrary, by sending too much, which ends up having a system-level impact on the quality of service for those power stores.
What I’ve done here is very much the opposite of statistics, and that’s something important when we are looking for “insane” decisions. You do not want to aggregate the data; on the contrary, you want to work on data that is completely disaggregated so that all the problems manifest themselves. As soon as you start aggregating the data, usually, those subtle behaviors disappear. The trick is usually to start at the most disaggregated level and go through the network to figure out exactly what is going on, not at a statistical level but at a very basic, elementary level where you can understand.
This method also lends itself very well to the perspective that I introduced in the quantitative supply chain, where I say you need to have economic drivers. It’s all possible futures, all possible decisions, and then you score all the decisions according to the economic drivers. It turns out that those economic drivers are very useful when it comes to sorting out all those SKUs, decisions, and events that happen in the supply chain. You can sort them by decreasing dollars of impact, and that’s a very powerful mechanism, even if the economic drivers are partially incorrect or incomplete. It turns out to be a very effective method to investigate and diagnose with high productivity what is happening in a given supply chain.
As you investigate “insane” decisions through the course of the initiatives where you roll out this experimental optimization method, there is a gradual shift from truly insane, dysfunctional decisions to just decisions that are plain bad. They are not going to blow up your company, but they are just not very good.

This is where we have a profound divergence from the mathematical optimization perspective for supply chain.
With experimental optimization, the loss function itself, because the experimental optimization is using internally mathematical optimization tools, usually at the core of the numerical recipes that generate the decision, has a mathematical optimization component. But it’s just a means, not an end, that supports your process. Instead of going through the mathematical optimization perspective where you state your problem and then optimize, here you are repeatedly challenging what you even understand about the problem itself and modifying the loss function itself.
In order to gain in terms of understanding, you need to instrument pretty much everything. You need to instrument your optimization process itself, your numerical recipe itself, and all sorts of characteristics that you have about the data that you’re playing with. It’s very interesting because, from a historical perspective, when you look at many of the biggest scientific developments where there were significant discoveries to be made, usually a few decades before those discoveries were made, there was a breakthrough in terms of instrumentation. When it comes to discovering knowledge, usually you first discover a new way to observe the universe, make a breakthrough at the instrumentation level, and then you can actually make your breakthrough in what is of interest in the world. This is really what is going on here. By the way, Galileo made most of his discoveries because he was the first person to have a telescope of his own making available to him, and that’s how he discovered the moons of Jupiter, for example. All those metrics are the instruments that really drive your journey forward.

Now, the challenge is that, as I said, experimental optimization is an iterative process. The question that is very important here is whether we are trading one bureaucracy for another. One of my biggest criticisms of mainstream supply chain management is that we end up with a bureaucracy of people who are just firefighting, wading through all those exceptions on a daily basis, and their work is not capitalistic. I presented the contrasting perspective of the supply chain scientist, where their work is supposed to be capitalistically accretive. However, it really boils down to what sort of productivity can be achieved with supply chain scientists, and these people need to be very productive.
Here, I’m giving you a short list of KPIs for what this productivity entails. First, you really want to be able to go through the data pipelines in less than an hour, end to end. As I said, one of the root causes for insanity is data semantics. When you realize that you have a problem at the semantic level, you want to put it to the test, and you need to rerun the entire data pipeline. Your supply chain team or supply chain scientist needs to be able to do that multiple times a day.
When it comes to the numerical recipe that does the optimization itself, at this point, data is already prepared and consolidated, so it’s a subset of the whole data pipeline. You will need a very large number of iterations, so you want to be able to do dozens of iterations every single day. Real-time would be fantastic, but the reality is that local optimization in supply chain only displaces problems. You need to have a holistic perspective, and the problem with naive or trivial models about your supply chain is that they are not going to be very good in terms of their capacity to embrace all the complexities found in supply chains. You have a trade-off between the expressiveness and capacity of the numerical recipe and the time it takes to refresh it. Typically, the balance is good as long as you keep the calculation within a few minutes.
Lastly, and this point was also covered in the lecture about product-oriented software delivery for supply chain, you really need to be able to put one new recipe into production every single day. It’s not exactly that I recommend doing that, but rather, you need to be able to do that because unexpected events will happen. It may be a pandemic, or sometimes it’s not as extravagant as that. There is always the possibility that a warehouse can get flooded, you might have a production incident, or you might have a big surprise promotion from a competitor. All sorts of things can happen and disrupt your operation, so you need to be able to apply corrective measures very swiftly. That means you need to have an environment where it’s possible to go live with a new iteration of your supply chain recipe every single day.

Now, the practice of experimental optimization is interesting. Lokad’s approach was an emergent practice, and it has been gradually phasing into the daily practice for a decade now. During the early years, we had something like a proto-experimental optimization process in place. The main difference was that we were still iterating, but we were using mathematical supply chain models obtained from the supply chain literature. It turned out that those models are usually monolithic and don’t lend themselves to the very iterative process that I’m describing with experimental optimization. As a result, we were iterating, but we were far from being able to put one new recipe in production every single day. It was more like it was taking several months to come up with a new recipe. If you look at Lokad’s website on the journey we took, the successive iterations we had on our forecasting engine were a reflection of this approach. It was basically taking 18 months to go from one forecasting engine to the next generation of forecasting engines, with a short series of maybe one big iteration per quarter or something.
That was what came before, and where the game really changed was with the introduction of programming paradigms. There is a previous lecture in my prologue where I introduced programming paradigms for supply chain. Now, with this lecture, it should become clearer why we care so much about those programming paradigms. They are what fuel this experimental optimization method. They are the paradigms that you need to build a numerical recipe, where you can efficiently iterate every single day to get rid of all those insane decisions and steer towards something that really creates a lot of value for the supply chain.
Now, experimental optimization in the wild, well, my belief is that it’s something that emerged. It wasn’t really invented at Lokad; it’s more like it emerged there, just because we were confronted again and again with our own inadequacies when it came to actual supply chain decisions. I strongly suspect that other companies, subject to the same sort of forces, came up with their own experimental optimization processes that are just some kind of variant of what I’ve presented to you today.
Here, if you look at the tech giants like GAFA, I have contacts there who, without disclosing any trade secrets, seem to hint that this sort of practice goes by different names but is already very present in those tech giants. You can even see that as an external observer by the fact that many of the open-source tools they publish are tools that really make sense when you start thinking about the sort of tools you would like to have if you were to conduct initiatives following this experimental optimization method. For example, PyTorch is not a model; it’s a meta-solution, a programming paradigm to do machine learning, so it fits within this framework.
Then, you might wonder why, if it’s so successful, it’s not more recognized as such. When it comes to recognizing experimental optimization in the wild, it’s tricky. If you take a snapshot of a company at a given point in time, it looks exactly like the mathematical optimization perspective. For example, if Lokad takes a snapshot of any of the companies we serve, we have a problem statement at that point in time and a solution we put forth. So, at that point in time, the situation looks exactly like the mathematical optimization perspective. However, this is only the static perspective. As soon as you start to look at the time dimension and the dynamics, it’s radically different.
Also, it’s important to note that although it’s an iterative process, it’s not a convergent one. This can be a bit disturbing. The idea that you can have an iterative process that converges to something optimal is like saying there’s a hard limit on human ingenuity. I believe this is an extravagant proposition. Supply chain problems are wicked, so there is no convergence just because there are always things that can radically change the game. It’s not a narrowly defined problem where you can have any hope to find the optimal solution. Additionally, another factor why you don’t have convergence in practice is that the world keeps changing. Your supply chain doesn’t operate in a vacuum; your suppliers, clients, and landscape are changing. Whatever numerical recipe you had at a point in time can start producing insane decisions just because the market conditions have changed, and what was reasonable in the past is not reasonable anymore. You need to readjust to fit the present situation. Just look at what happened in 2020 with the pandemic; obviously, there was so much change that something sane before the pandemic could not remain sane during it. The same thing will happen again.
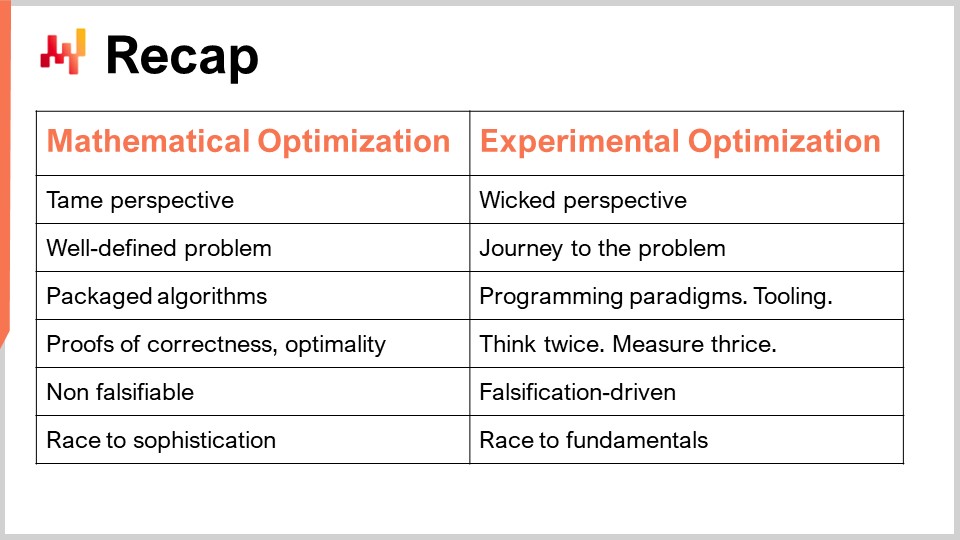
To recap, we have two different perspectives: the mathematical optimization perspective, where we are dealing with well-defined problems, and the experimental optimization perspective, where the problem is wicked. You can’t even define the problem; you can only journey toward the problem. As a consequence of having a well-defined problem within the mathematical optimization perspective, you can have a clear algorithm as the solution you provide, and you can package it in a piece of software, proving its correctness and optimality. In the world of experimental optimization, however, you can’t package it all since it’s way too complex. What you can have is programming paradigms, tooling, infrastructure, and then it’s a matter of human intelligence all the time. It’s about thinking twice, measuring thrice, and taking a step forward. There is nothing that can be automated about it; it all boils down to the human intelligence of the supply chain scientist.
In terms of falsifiability, my main proposition is that the mathematical optimization perspective is not science because you can’t falsify anything it produces. Thus, at the end game, you end up with a race towards sophistication – you want models that are always more complex, but it’s not because they are more sophisticated that they are more scientific or create more value for the company. In sharp contrast, experimental optimization is falsification-driven. All the iterations are driven by the fact that you’re putting your numerical recipes to the test of the real world, generating decisions, and identifying the right decisions. This experimental test can be done multiple times a day to challenge your theory and prove it wrong over and over, iterating from there, and hopefully delivering a lot of value in the process.
It’s interesting because, in terms of endgame, experimental optimization is not a race towards sophistication; it’s a race toward fundamentals. It’s about understanding what makes your supply chain tick, the fundamental elements that govern supply chain, and exactly how you should understand what is going on within your numerical recipes so that they don’t keep producing those insane decisions that hurt your supply chain. Ultimately, you want to produce something very good for your supply chain.

This has been a long lecture, but the takeaway should be that mathematical optimization is an illusion. It’s a seductive, sophisticated, and attractive illusion, but an illusion nonetheless. Experimental optimization, as far as I’m concerned, is the real world. We have been using it for almost a decade to support the process for real companies. Lokad is just one data point, but from my vantage point, it’s a very convincing data point. It’s really a matter of getting a taste of the real world. By the way, this approach is brutally tough on you because when you go out there in the real world, reality strikes back. You had your nice theories about what sort of numerical recipe should work to govern and optimize the supply chain, and then reality strikes back. It can be, at times, incredibly frustrating because reality always finds ways to undo all the clever things you could think of. This process is much more frustrating, but I believe this is the dose of reality that we need to actually deliver real, profitable returns for your supply chains. My take is that, in the future, there will be a point where experimental optimization, or maybe a descendant of this method, supersedes entirely the mathematical optimization perspective when it comes to supply chain studies and practices.

In the coming lectures, we will be reviewing the actual methods, numerical methods, and numerical tools that we can use to support this practice. Today’s lecture was only dealing with the method; later on, we will be dealing with the know-how and the tactics needed to make it work. The next lecture will be two weeks from now, same day and time, and will be about negative knowledge in supply chain.
Now, let me have a look at the questions.
Question: If supply chain papers have no chance to be connected to reality, even remotely, and any real case would be under NDA, what would you suggest to those willing to make supply chain studies and publish their findings?
My suggestion is you need to challenge the method. The methods that we have are not suitable to study supply chain. I have presented two ways in this series of lectures: the supply chain personnel and the experimental optimization. There is a great deal to be done based on those methodologies. Those are just two methodologies; I’m fairly certain there are many more that are yet to be discovered or invented. My suggestion would be to challenge at the core what makes a discipline an actual science.
Question: If mathematical optimization isn’t the best reflection of how supply chain should operate in the real world, why would the deep learning method be better? Isn’t deep learning making decisions based on prior optimal decisions?
In this lecture, I made a clear distinction between mathematical optimization as an independent field of research and deep learning as an independent field of research, and mathematical optimization as a perspective applied to supply chain. I’m not criticizing that mathematical optimization as a field of research is invalid; quite on the contrary. In this experimental optimization method that I’m discussing, at the core of the numerical recipe, you will usually have a mathematical optimization algorithm of some kind. The point is mathematical optimization as a perspective; this is what I’m challenging here. I know it’s subtle, but this is a critical difference that I’m making. Deep learning is an auxiliary science. Deep learning is a separate field of research, just like mathematical optimization is a separate field of research. They are both great fields of research, but they are completely independent and distinct from supply chain studies. What really concerns us today is the quantitative improvement of supply chains. That’s what I’m about – methods to deliver quantitative improvements in supply chain in ways that are controlled, reliable, and measurable. That’s what is at stake here.
Question: Can reinforcement learning be the right approach to supply chain management?
First, I would say it’s the right approach probably for supply chain optimization. It’s a distinction that I made in one of my earlier lectures – from a software perspective, you have the management side with Enterprise Resource Management, and then you have the optimization side. Reinforcement learning is another field of research that can also leverage elements from deep learning and mathematical optimization. It is the sort of ingredient that you can use in this experimental optimization method. The critical part will be whether you have the programming paradigms that can import those reinforcement learning techniques in ways where you can operate very fluently and iteratively. That’s a big challenge. You want to be able to iterate, and if you have something that is a complex, monolithic reinforcement learning model, then you will struggle, just like Lokad did in the early years when we were trying to use these kinds of monolithic models where our iterations were very slow. A series of technical breakthroughs were needed to make the iteration a much more fluid process.
Question: Is mathematical optimization an integral element of reinforcement learning?
Yes, reinforcement learning is a subdomain of machine learning, and machine learning can be seen as, in a way, a subdomain of mathematical optimization. However, the thing is that when you do that, everything is within everything, and what really differentiates all those fields is that they don’t adopt the same perspective on the problem. All those fields are connected, but usually, what really differentiates them is the intent that you have.
Question: How do you define an insane decision in the context of deep learning methods that often think many decisions ahead?
An insane decision is dependent on future decisions. That’s exactly what I demonstrated in the example when I said, “Is having a stockout a problem?” Well, it’s not a problem if you see that the next decision that is about to be made is a replenishment. So, whether I was qualifying this situation as insane or not was actually dependent on a decision that was about to be made. This complicates the investigation, but this is exactly what it’s about when I say you need to have very good instrumentation. For example, it means that when you investigate an out-of-stock situation, you need to be able to project the future decisions that you’re about to make, so that you can see not only the data that you have but also the decisions that you project to be taken according to your present numerical recipe. You see, it’s a matter of having suitable instrumentation, and again, this is no easy task. It does require human-level intelligence; you can’t just automate that away.
Question: How does the experimental optimization, identifying insanity, and finding solutions work in practice? I cannot wait for the insanity to occur in reality, correct?
Absolutely correct. If I go back to the beginning of this lecture, I mentioned two groups of people: modern physicists and Marxists. The group of physicists, when I said they were doing proper science, were not passive, waiting for their theories to be falsified. They were going out of their way to design incredibly clever experiments that would have a chance to disprove their theories. It was a very proactive mechanism.
If you look at what Albert Einstein did during most of his life, it was to find clever ways to put the theories of physics that he had invented, at least in part, to the test of experiments. So yes, you don’t wait for the insane decision to happen. That’s why you need to be able to run your recipe again and again and invest time looking for the insane decision. Obviously, there are some decisions, such as the one with impracticalities, where there is no hope—you have to do it in production, and then the world will strike back. But for the vast majority, insane decisions can be identified by just doing experiments day in and day out. But you need data, and you need to have the real process that generates the real decisions that could be put into production.
Question: If a recipe could be broken because of a mathematical method and/or perspective, and if you don’t know this other perspective, how can you discover that you have a perspective issue, not a method issue, and drive yourself to discover another perspective that is better to fit the problem?
That’s a very big problem. How can you see something that is not there? If I go back to the example of the supply chain personnel of Paris, a fashion company operating retail stores, let’s imagine for a second that you forgot to think about the long-term effect you had on your customer habits by giving away end-of-season discounts. You don’t realize that you’re creating a habit out of your customer base. How can you ever realize that? This is a problem of general intelligence. There is no magic solution.
You need to brainstorm, and by the way, the very concrete answer of Lokad is that the company is based in Paris. We serve clients in 20-something distant countries, including Australia, Russia, the US, and Canada. Why did I put all my teams of supply chain scientists together in Paris, although with the pandemic, it’s a bit more complicated, there is a lot of remote work. But why did I put all those supply chain scientists in one place rather than outsourcing them all over the place? The answer was because I needed those people to be in one place so that they can talk, brainstorm, and come up with new ideas. Again, this is a very low-tech solution, but I can’t really promise any better. When there is something that you cannot see, such as, for example, the need to think of the long-term implications, and you just forgot about it or never thought about it, this problem can be very obvious and missing. In one of my previous lectures, I gave the example of the suitcase. It took 5,000 years to come up with the invention that it would be a good idea to put wheels on suitcases. The wheels were invented thousands of years ago, and the better version of the suitcase was invented decades after putting people on the moon. That’s the sort of thing where there might be something obvious that you do not see. There is no recipe for that; it’s just human intelligence. You just do what you have.
Question: Constantly changing conditions will make the optimal solution for your supply chain constantly obsolete, right?
Yes and no. From the experimental optimization perspective, there is no such thing as an optimal solution. You have optimized solutions, but the distinction makes all the difference. Optimized solutions are nowhere near optimal. Optimal is like saying, and I’m repeating myself, that there is a hard limit on human ingenuity. So, there is nothing optimal; it’s just optimized. And yes, as every single day passes, the market diverges from all the experiments you’ve done so far. The sheer evolution of the world just degrades the optimization you’ve produced. That’s just the way the world is. There are some days, for example, when a pandemic happens, and the divergence vastly accelerates. Again, that’s just the way the world is. The world is changing, and so your numerical recipe needs to change along with it. This is an external force, so yes, there is no escape; the solution will have to be revisited all the time.
That’s one of the reasons why Lokad is selling a subscription, and we tell our clients, “No, we cannot sell you a supply chain scientist just for the implementation phase. This is nonsense. The world will keep changing; this supply chain scientist who came up with the numerical recipe will need to be there until the end of time or until you’re fed up with us.” So, this person will be able to adapt the numerical recipe. There is no escape; this is just the external world that keeps changing.
Question: The journey to the problem, while correct, drives senior managers crazy. They just can’t understand this; they think, ‘How can you revisit the problem multiple times in the project life?’ What known analogies from life would you suggest to bring on those conversations to prove that it’s a broadly existent issue?
First, that’s exactly what I said in the last slide where I put the screenshot of The Matrix. At some point, you have to decide whether you want to live in a fantasy or in the real world. Management, hopefully, if your upper management in your company is just a bunch of idiots, my only suggestion is you better go to another company because I’m not sure that this company will be around for long. But the reality is, I think managers are no fools. They don’t want to deal with made-up problems. If you’re a manager in a large company, you have people coming to you ten times a day with a “major problem,” which is not a real problem. The response of the management, which is a correct reaction, is “There is no problem whatsoever, just keep doing what you’ve done. Sorry, I don’t have time to redo the world with you. This is just not the proper way to look at the problem.” They are right to do that because, through decades of experience, they can sort it out. They have better heuristics than those lower down the hierarchy.
But sometimes there is a very real concern. For example, your question is, how do you convince upper management two decades ago that e-commerce is going to be a dominant force to reckon with two decades from now? At some point, you just have to pick your battles wisely. If your upper management is no fool and you come to a meeting well-prepared, saying, “Hey boss, I have this problem. It’s not a joke. It’s a very key concern with millions of dollars at stake. I’m not joking. This is tons of money that we’re leaving on the table. Worse, I suspect that most of our competitors are going to eat our lunch if we do nothing. This is not a minor point; this is a very real problem. I need you to pay 20 minutes of your attention.” Again, it’s rare in large companies for upper management to be a bunch of complete idiots. They may be busy, but they are not idiots.
Question: What would be the proper landscape of tools for manufacturing companies: experimental optimization like Lokad, plus ERP, plus visualization? What about the role of concurrent planning systems online?
The vast majority of our competitors align with the mathematical optimization perspective on supply chains. They have defined the problem and implemented software to solve the problem. What I’m saying is that when they put the software to the test and it invariably ends up producing tons of insane decisions, they say, “Oh, it’s because you did not configure the software correctly.” This makes the software product immune to the test of reality. They find ways to deflect the criticism rather than addressing it.
At Lokad, this method only emerged because we were very different from our competitors. We didn’t have the luxury of having an excuse. As the saying goes, “You can either have excuses or results, but you can’t have both.” At Lokad, we didn’t have the option of making excuses. We were delivering decisions, and there was nothing to configure or tweak from the client side. Lokad was frontally facing its own inadequacies. As far as I know, all our competitors are firmly anchored in the mathematical optimization perspective, and they suffer from problems of being somewhat immune to reality. To be honest, they are not completely immune to reality, but they end up having a very slow pace of iteration, like the one I described for Lokad during the early years. They are not completely immune to reality, but their improvement process is glacially slow, and the world keeps changing.
What invariably happens is that the enterprise software doesn’t change nearly as fast to keep up with the world at large, so you end up with software that is just aging. It’s not really getting better because, every year that passes, the software improves, but the world is getting stranger and more different. The enterprise software is only getting further and further behind a world that is more and more disconnected from where it originated.
Question: What would be the proper landscape of tools for manufacturing companies?
The proper landscape is enterprise resource management tools that can manage all the transactional aspects. On top of that, what’s really important is having a solution that is very integrated when it comes to your numerical recipe. You don’t want to have a tech stack for visualization, another for optimization, another for investigation, and yet another for data preparation. If you end up with half a dozen technological stacks for all those different things, you’ll need an army of software engineers to plug them all together, and you’ll end up with something that is the opposite of agile.
There’s so much software engineering competency required that there’s no room left for actual supply chain competency. Remember, that was the point of my third lecture about product-oriented software delivery. You need something that a supply chain specialist, not a software engineer, can operate.
That’s everything. Let’s see you two weeks from now, same day and same hour, for “Negative Knowledge in Supply Chain.”
References
- The Logic of Scientific Discovery, Karl Popper, 1934


