00:17 Einführung
03:35 Größenordnungen
06:55 Stufen der Supply Chain-Optimierung
12:17 Die S-Kurven der Hardware
15:52 Der bisherige Verlauf
17:34 Hilfswissenschaften
20:25 Moderne Computer
20:57 Latenz 1/2
27:15 Latenz 2/2
30:37 Rechenleistung, Taktgeschwindigkeit
36:36 Rechenleistung, Pipelining, 1/3
39:11 Rechenleistung, Pipelining, 2/3
40:27 Rechenleistung, Pipelining, 3/3
46:36 Rechenleistung, superskalar 1/2
49:55 Rechenleistung, superskalar 2/2
56:45 Speicher 1/3
01:00:42 Speicher 2/3
01:06:43 Speicher 3/3
01:11:13 Datenspeicherung 1/2
01:14:06 Datenspeicherung 2/2
01:18:36 Bandbreite
01:23:20 Fazit
01:27:33 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Moderne Supply Chains benötigen Rechenressourcen, um genauso zu funktionieren wie motorisierte Förderbänder Strom benötigen. Dennoch sind träge Supply Chain-Systeme allgegenwärtig, während die Rechenleistung von Computern seit 1990 um das über 10.000-fache gestiegen ist. Ein mangelndes Verständnis der grundlegenden Eigenschaften moderner Rechenressourcen - selbst unter IT- oder Data Science-Kreisen - trägt maßgeblich zu diesem Zustand bei. Das Software-Design, das den numerischen Rezepten zugrunde liegt, sollte den zugrunde liegenden Rechenuntergrund nicht antagonisieren.
Vollständiges Transkript

Willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich “Moderne Computer für die Supply Chain präsentieren”. Westliche Supply Chains wurden schon vor langer Zeit digitalisiert, manchmal sogar vor drei Jahrzehnten. Computerbasierte Entscheidungen sind überall präsent und die damit verbundenen numerischen Rezepte tragen verschiedene Namen wie Nachbestellpunkte, Min-Max Lagerbestand und Sicherheitsbestände, mit unterschiedlichem Grad an menschlicher Überwachung.
Nichtsdestotrotz sehen wir heute bei großen Unternehmen, die ähnlich große Supply Chains betreiben, Millionen von Entscheidungen, die im Wesentlichen von Computern gesteuert werden und die Leistung der Supply Chain beeinflussen. Daher reduziert sich die Verbesserung der Leistung der Supply Chain schnell auf die Verbesserung der numerischen Rezepte, die die Supply Chain antreiben. Hierbei kostet die Verwendung überlegener numerischer Rezepte in der Regel deutlich mehr Rechenressourcen, da wir bessere Modelle und genauere Prognosen möchten.
Rechenressourcen waren für die Supply Chain schon immer eine Herausforderung, da sie viel Geld kosten und es immer die nächste Entwicklungsstufe für das nächste Modell oder das nächste Prognosesystem gibt, das zehnmal mehr Rechenressourcen als das vorherige erfordert. Ja, dies könnte eine bessere Leistung der Supply Chain bringen, aber es geht mit erhöhten Rechenkosten einher. In den letzten Jahrzehnten hat sich die Rechenhardware enorm weiterentwickelt, aber wie wir heute sehen werden, wird dieser Fortschritt, obwohl er noch anhält, häufig durch Unternehmenssoftware behindert. Als Ergebnis wird die Software mit modernerer Hardware nicht schneller, sondern kann sogar häufig langsamer werden.
Das Ziel dieser Vorlesung ist es, beim Publikum ein gewisses Maß an mechanischem Verständnis zu wecken, damit Sie beurteilen können, ob eine Unternehmenssoftware, die numerische Rezepte implementieren soll, um eine überlegene Leistung der Supply Chain zu erzielen, die vorhandene Rechenhardware bereits nutzt und dies auch in zehn Jahren tun wird, oder ob sie sich dagegenstellt und somit die vorhandene Rechenhardware nicht optimal nutzt.

Eines der verwirrendsten Aspekte moderner Computer ist die Bandbreite der beteiligten Größenordnungen. Aus der Perspektive der Supply Chain haben wir in der Regel etwa fünf Größenordnungen, und das ist schon eine Dehnung; normalerweise ist es nicht einmal so viel. Fünf Größenordnungen bedeuten, dass wir von einer Einheit auf 100.000 Einheiten gehen können. Denken Sie daran, dass ich in früheren Vorlesungen das Gesetz der kleinen Zahlen erwähnt habe. Wenn Sie eine große Anzahl von Einheiten haben, werden Sie diese Einheiten nicht einzeln verarbeiten; Sie werden sie in Boxen verpacken und somit eine viel kleinere Anzahl von Boxen haben. Ähnlich verhält es sich, wenn Sie viele Boxen haben, werden Sie sie in Paletten verpacken usw., sodass Sie eine viel kleinere Anzahl von Paletten haben. Skaleneffekte führen zu Vorhersagen von Mengen und aus der Perspektive der Supply Chain ist bereits eine 10%ige Ineffizienz bei der physischen Warenbewegung recht signifikant.
Im Bereich der Computer ist es jedoch ganz anders; wir haben es mit 15 Größenordnungen zu tun, was absolut gigantisch ist. Wir gehen von einer Einheit auf eine Million Milliarden Einheiten. Die Zahl ist so groß, dass es tatsächlich sehr schwierig ist, sie sich vorzustellen. Wir gehen von einem Byte aus, das nur acht Bits umfasst und einen Buchstaben oder eine Ziffer darstellen kann, bis hin zu einem Petabyte, das eine Million Gigabyte entspricht. Ein Petabyte entspricht etwa der Größenordnung der von Lokad derzeit verwalteten Datenmenge, und große Unternehmen, die große Supply Chains betreiben, verwalten ebenfalls Datensätze in der Größenordnung von einem Petabyte.
Wir gehen von einer FLOP (Floating Point Operation pro Sekunde) auf eine PetaFLOP, was einer Million GigaFLOPS entspricht. Diese Größenordnungen sind absolut gigantisch und sehr irreführend. Als Ergebnis dessen, was im Bereich der Supply Chain als ineffizient angesehen wird, nämlich 10%, ist es im Bereich der Computer nicht so, dass man um 10% ineffizient ist, sondern eher um den Faktor 10 oder manchmal sogar um mehrere Größenordnungen ineffizient. Wenn also etwas in Bezug auf die Leistung im Bereich der Computer falsch gemacht wird, beträgt die Strafe nicht 10%, sondern das System wird 10-mal langsamer sein als es sein sollte, oder 100-mal oder manchmal sogar tausendmal langsamer als es hätte sein sollen. Das ist wirklich das, worum es geht: eine wahre Ausrichtung zu haben, die eine Art mechanisches Verständnis zwischen der Unternehmenssoftware und der zugrunde liegenden Rechenhardware erfordert.
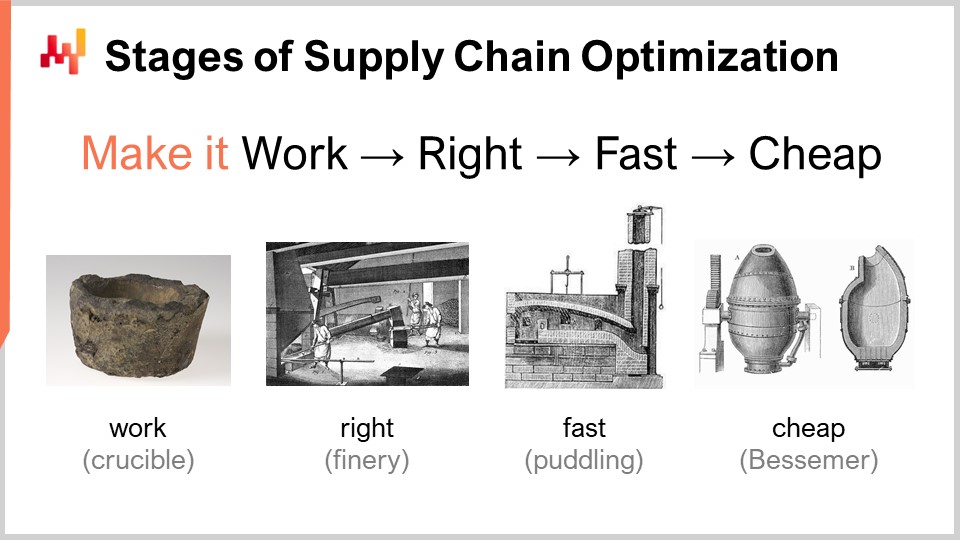
Bei der Betrachtung eines numerischen Rezepts, das eine überlegene Leistung in der Supply Chain liefern soll, gibt es eine Reihe von Reifegraden, die konzeptionell interessant sind. In der Praxis kann das natürlich variieren, aber das ist typischerweise das, was wir bei Lokad identifiziert haben. Diese Stufen können wie folgt zusammengefasst werden: Mach es funktionieren, mach es richtig, mach es schnell und mach es billig.
“Mach es funktionieren” bedeutet, zu bewerten, ob ein prototypisches numerisches Rezept tatsächlich die beabsichtigten Ergebnisse liefert, wie z.B. höhere Service Levels, weniger Tote Lagerbestände, bessere Auslastung von Vermögenswerten oder jedes andere Ziel, das aus Sicht der Supply Chain erstrebenswert ist. Das Ziel besteht zunächst darin, sicherzustellen, dass das neue numerische Rezept in der ersten Reifegradstufe tatsächlich funktioniert.
Dann müssen Sie “es richtig machen”. Aus Sicht der Supply Chain bedeutet dies, was im Wesentlichen ein einzigartiger Prototyp war, in etwas mit produktionsreifer Qualität zu verwandeln. Dies beinhaltet in der Regel, dem numerischen Rezept einen gewissen Grad an Korrektheit durch Design beizufügen. Supply Chains sind umfangreich, komplex und vor allem sehr unordentlich. Wenn Sie ein numerisches Rezept haben, das sehr fragil ist, selbst wenn die numerische Methode gut ist, ist es sehr einfach, es falsch zu machen, und dann schaffen Sie viele Probleme im Vergleich zu den beabsichtigten Vorteilen, die Sie ursprünglich bringen wollten. Das ist kein gewinnbringender Vorschlag. Es richtig zu machen bedeutet sicherzustellen, dass Sie etwas haben, das mit minimalem Aufwand im großen Maßstab implementiert werden kann. Dann möchten Sie dieses numerische Rezept schnell machen, und wenn ich schnell sage, meine ich schnell in Bezug auf die Wanduhrzeit. Wenn Sie die Berechnung starten, sollten Sie die Ergebnisse innerhalb von Minuten oder vielleicht höchstens einer Stunde oder zwei erhalten, aber nicht länger. Supply Chains sind unordentlich und es wird einen Zeitpunkt in der Geschichte Ihres Unternehmens geben, an dem es Störungen geben wird, wie z.B. Container, die im Suezkanal stecken bleiben, eine Pandemie oder ein überflutetes Lagerhaus. Wenn dies geschieht, müssen Sie in der Lage sein, schnell zu reagieren. Ich sage nicht, dass Sie in den nächsten Millisekunden reagieren müssen, aber wenn Sie numerische Rezepte haben, die Tage dauern, um abgeschlossen zu werden, entsteht ein massiver operativer Reibungswiderstand. Sie benötigen Dinge, die innerhalb eines kurzen menschlichen Zeitrahmens betrieben werden können, also muss es schnell sein.
Denken Sie daran, moderne Unternehmenssoftware läuft in der Cloud, und Sie können immer für mehr Rechenressourcen auf Cloud-Computing-Plattformen bezahlen. Daher kann Ihre Software tatsächlich schnell sein, nur weil Sie viel Rechenleistung mieten. Es geht nicht darum, dass die Software selbst ordnungsgemäß entwickelt werden muss, um die gesamte Rechenleistung nutzen zu können, die eine Cloud bereitstellen kann, aber sie kann schnell und sehr ineffizient sein, nur weil Sie so viel Rechenleistung von Ihrem Cloud-Computing-Anbieter mieten.
Die nächste Stufe besteht darin, die Methode kostengünstig zu machen, was bedeutet, dass sie nicht zu viele Cloud-Computing-Ressourcen verwendet. Wenn Sie nicht in diese letzte Stufe gehen, bedeutet das, dass Sie Ihre Methode niemals verbessern können. Wenn Sie eine Methode haben, die funktioniert, richtig ist und schnell ist, aber viele Ressourcen verbraucht, wenn Sie zur nächsten Stufe des numerischen Rezepts übergehen möchten, die zwangsläufig etwas beinhaltet, das noch mehr Rechenressourcen kostet als das, was Sie derzeit verwenden, werden Sie stecken bleiben. Sie müssen die Methode, die Sie haben, super schlank machen, damit Sie mit numerischen Rezepten experimentieren können, die weniger effizient sind als das, was Sie derzeit haben.
Diese letzte Stufe ist der Punkt, an dem Sie die zugrunde liegende Hardware, die in modernen Computern verfügbar ist, wirklich nutzen müssen. Sie können die ersten drei Stufen ohne zu viel Affinität bewältigen, aber die letzte ist entscheidend. Denken Sie daran, wenn Sie nicht zur “machen Sie es kostengünstig” Stufe gelangen, können Sie nicht iterieren und bleiben stecken. Deshalb ist dies, auch wenn es die letzte Stufe ist, ein iteratives Spiel, und es ist unerlässlich, alle Stufen durchzugehen, wenn Sie wiederholt iterieren möchten.
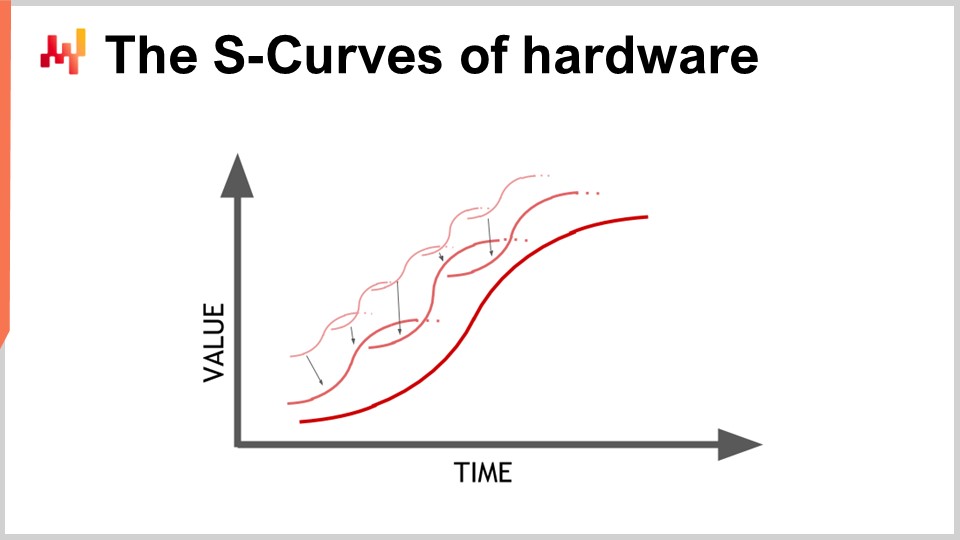
Die Hardware entwickelt sich weiter, und es sieht aus wie eine exponentielle Entwicklung, aber die Realität ist, dass diese exponentielle Entwicklung der Rechenhardware tatsächlich aus Tausenden von S-Kurven besteht. Eine S-Kurve ist eine Kurve, bei der Sie ein neues Design, einen Prozess, ein Material oder eine Architektur einführen und anfangs nicht wirklich besser ist als das, was Sie zuvor hatten. Dann tritt der Effekt der beabsichtigten Innovation ein, und Sie haben einen Anstieg, gefolgt von einem Plateau, nachdem Sie alle Vorteile der Innovation genutzt haben. Plateauende S-Kurven sind charakteristisch für den Fortschritt in der Computerhardware, der aus Tausenden dieser Kurven besteht. Aus der Sicht eines Laien erscheint dies als exponentielles Wachstum. Experten sehen jedoch die einzelnen S-Kurven, die sich auf einem Plateau befinden, was zu einer pessimistischen Sicht führen kann. Selbst die Experten sehen nicht immer das Auftauchen neuer S-Kurven, die alle überraschen und das exponentielle Wachstum des Fortschritts fortsetzen.
Obwohl sich die Rechenhardware immer noch weiterentwickelt, ist das Fortschrittstempo bei weitem nicht mit dem vergleichbar, was wir in den 1980er und 1990er Jahren erlebt haben. Das Tempo ist jetzt viel langsamer und ziemlich vorhersehbar, hauptsächlich aufgrund der massiven Investitionen, die für den Bau neuer Fabriken zur Produktion von Rechenhardware erforderlich sind. Diese Investitionen belaufen sich oft auf Hunderte von Millionen Dollar und bieten eine Sicht fünf bis zehn Jahre voraus. Obwohl der Fortschritt verlangsamt hat, haben wir immer noch eine ziemlich genaue Vorstellung davon, was in Bezug auf den Fortschritt der Rechenhardware in den nächsten zehn Jahren passieren wird.
Die Lehre für Unternehmenssoftware, die numerische Rezepte implementiert, ist, dass Sie nicht passiv erwarten können, dass zukünftige Hardware alles für Sie verbessert. Die Hardware entwickelt sich zwar weiter, aber um diesen Fortschritt zu nutzen, ist Anstrengung von der Softwareseite erforderlich. Sie werden in der Lage sein, mehr mit der Hardware zu tun, die in einem Jahrzehnt existiert, aber nur wenn die Architektur Ihrer Unternehmenssoftware die zugrunde liegende Rechenhardware umfasst. Andernfalls könnten Sie tatsächlich schlechter abschneiden als das, was Sie heute tun, eine Annahme, die nicht so unvernünftig ist, wie es klingt.
Diese Vorlesung ist die erste des vierten Kapitels in dieser Reihe von Lieferkettenvorlesungen. Ich habe das dritte Kapitel über Lieferketten Personae noch nicht abgeschlossen. In den folgenden Vorlesungen werde ich wahrscheinlich zwischen dem aktuellen Kapitel, in dem ich die Hilfswissenschaften der Lieferkette behandele, und dem dritten Kapitel über Lieferketten-Personae wechseln.
Im allerersten Kapitel des Prologs habe ich meine Ansichten über die Lieferkette als Studiengebiet und Praxis vorgestellt. Wir haben gesehen, dass die Lieferkette im Wesentlichen eine Sammlung von komplexen Problemen ist, im Gegensatz zu einfachen Problemen, die von antagonistischem Verhalten und Wettbewerbsspielen geplagt sind. Daher müssen wir der Methodik große Aufmerksamkeit schenken, da naive direkte Methoden in diesem Bereich schlecht abschneiden. Deshalb war das zweite Kapitel der Methodik gewidmet, die benötigt wird, um Lieferketten zu untersuchen und Praktiken zur Verbesserung im Laufe der Zeit zu etablieren.
Das dritte Kapitel, Lieferketten-Personae, konzentrierte sich darauf, die Lieferkettenprobleme selbst zu charakterisieren, mit dem Motto “Verliebe dich in das Problem, nicht in die Lösung”. Das vierte Kapitel, das wir heute eröffnen, handelt von den Hilfswissenschaften der Lieferketten.

Hilfswissenschaften sind Disziplinen, die das Studium einer anderen Disziplin unterstützen. Es gibt kein Werturteil; es geht nicht darum, dass eine Disziplin der anderen überlegen ist. Zum Beispiel ist die Medizin nicht überlegen gegenüber der Biologie, aber die Biologie ist eine Hilfswissenschaft für die Medizin. Die Perspektive der Hilfswissenschaften ist in vielen Forschungsbereichen gut etabliert und verbreitet, wie zum Beispiel in den medizinischen Wissenschaften und der Geschichte.
In den medizinischen Wissenschaften gehören zu den Hilfswissenschaften Biologie, Chemie, Physik und Soziologie, unter anderem. Ein moderner Arzt würde nicht als kompetent angesehen werden, wenn er keine Kenntnisse in Physik hätte. Zum Beispiel ist das Verständnis der Grundlagen der Physik notwendig, um ein Röntgenbild zu interpretieren. Das Gleiche gilt für die Geschichte, die eine lange Reihe von Hilfswissenschaften hat.
Wenn es um die Lieferkette geht, ist eine meiner größten Kritiken an typischen Lieferkettenmaterialien, Kursen, Büchern und Artikeln, dass sie das Thema behandeln, ohne auf Hilfswissenschaften einzugehen. Sie behandeln die Lieferkette, als ob sie ein isoliertes, eigenständiges Wissen wäre. Ich glaube jedoch, dass moderne Lieferkettenpraxis nur durch vollständige Nutzung der Hilfswissenschaften der Lieferketten erreicht werden kann. Eine dieser Hilfswissenschaften und der Schwerpunkt der heutigen Vorlesung ist die Hardware für die Berechnung.
Diese Vorlesung ist nicht streng genommen eine Lieferkettenvorlesung, sondern eine Vorlesung über Hardware für die Berechnung mit Anwendungen in der Lieferkette. Ich glaube, dass dies fundamental ist, um die Lieferkette auf moderne Weise zu praktizieren, im Gegensatz dazu, wie es vor einem Jahrhundert gemacht wurde.

Werfen wir einen Blick auf moderne Computer. In dieser Vorlesung werden wir untersuchen, was sie für die Lieferkette tun können, wobei wir uns insbesondere auf Aspekte konzentrieren, die einen massiven Einfluss auf die Leistung von Unternehmenssoftware haben. Wir werden Latenz, Berechnung, Speicher, Datenspeicherung und Bandbreite überprüfen.

Die Geschwindigkeit des Lichts beträgt etwa 30 Zentimeter pro Nanosekunde, was relativ langsam ist. Wenn man die charakteristische Entfernung von Interesse für eine moderne CPU betrachtet, die mit 5 Gigahertz (5 Milliarden Operationen pro Sekunde) arbeitet, beträgt die Hin- und Rückwegstrecke, die das Licht in 0,2 Nanosekunden zurücklegen kann, nur 3 Zentimeter. Das bedeutet, dass aufgrund der Begrenzung der Lichtgeschwindigkeit Interaktionen nicht über 3 Zentimeter hinaus stattfinden können. Dies ist eine harte Begrenzung, die durch die Gesetze der Physik auferlegt wird, und es ist unklar, ob wir sie jemals überwinden können.
Latenz ist eine äußerst harte Einschränkung. Aus Sicht der Lieferkette sind mindestens zwei Verteilungen von Rechenhardware beteiligt. Wenn ich von verteilter Rechenhardware spreche, meine ich Rechenhardware, die viele Geräte umfasst, die nicht denselben physischen Raum einnehmen können. Natürlich müssen Sie sie voneinander trennen, nur weil sie eigene Abmessungen haben. Der erste Grund, warum wir verteilte Berechnungen benötigen, ist jedoch die Natur der Lieferketten, die geografisch verteilt sind. Lieferketten sind von Natur aus über geografische Gebiete verteilt, und daher wird sich auch die Rechenhardware über diese Gebiete verteilen. Aus Sicht der Lichtgeschwindigkeit ist es selbst dann, wenn Sie Geräte haben, die nur drei Meter voneinander entfernt sind, bereits sehr langsam, da es 100 Taktzyklen dauert, um den Hin- und Rückweg zu machen. Drei Meter sind aus Sicht der Lichtgeschwindigkeit und der Taktrate moderner CPUs eine ziemliche Entfernung.
Eine andere Art der Verteilung ist das horizontale Skalieren. Die moderne Art, über mehr Rechenleistung zu verfügen, besteht nicht darin, ein Rechengerät zu haben, das 10-mal oder eine Million Mal leistungsstärker ist; so ist es nicht konstruiert. Wenn Sie mehr Rechenressourcen möchten, benötigen Sie zusätzliche Rechengeräte, mehr Prozessoren, mehr Speicherchips und mehr Festplatten. Indem Sie die Hardware stapeln, können Sie über mehr Rechenressourcen verfügen. Allerdings nimmt all diese Geräte Platz ein, und daher verteilen Sie Ihre Rechenhardware, einfach weil Sie sie nicht in einen Zentimeter breiten Computer zentralisieren können.
Wenn es um Latenzen geht und wir uns die Art von Latenzen ansehen, die wir im professionellen Internet haben (die Latenzen, die Sie in einem Rechenzentrum erhalten, nicht über Ihr WLAN zu Hause), sind wir bereits zu 30% der Lichtgeschwindigkeit. Zum Beispiel liegt die Latenz zwischen einem Rechenzentrum in der Nähe von Paris, Frankreich, und New York, USA, nur innerhalb von 30% der Lichtgeschwindigkeit. Dies ist eine unglaubliche Leistung für die Menschheit; Informationen fließen über das Internet nahezu mit Lichtgeschwindigkeit. Ja, es gibt immer noch Raum für Verbesserungen, aber wir sind bereits nahe an den physikalischen Grenzen.
Als Ergebnis gibt es sogar Unternehmen, die jetzt ein Kabel durch den arktischen Meeresboden legen möchten, um London mit Tokio zu verbinden, wobei das Kabel unter dem Nordpol verlaufen würde, nur um einige Millisekunden Latenz für Finanztransaktionen einzusparen. Latenz und die Lichtgeschwindigkeit sind grundlegende Anliegen, und das Internet, das wir haben, ist im Wesentlichen so gut, wie es jemals sein wird, es sei denn, es gibt Durchbrüche in der Physik. Aber für das nächste Jahrzehnt haben wir nichts dergleichen in Aussicht.
Aufgrund der Tatsache, dass Latenz ein sehr schwieriges Problem ist, haben Unternehmenssoftware erhebliche Auswirkungen. Rundreisen in Bezug auf den Informationsfluss sind tödlich, und die Leistung Ihrer Unternehmenssoftware hängt weitgehend von der Anzahl der Rundreisen zwischen den verschiedenen Teilsystemen ab, die in Ihrer Software vorhanden sind. Die Anzahl der Rundreisen bestimmt die unkomprimierbare Latenz, unter der Sie leiden. Die Minimierung von Rundreisen und die Verbesserung von Latenzen ist für die meisten Unternehmenssoftware, einschließlich derjenigen, die der vorhersagenden Optimierung von Lieferketten gewidmet sind, das Hauptproblem. Die Reduzierung von Latenzen führt oft zu einer besseren Leistung.

Ein interessanter Trick, obwohl nicht jeder in diesem Publikum dies in der Produktion einsetzen wird, besteht darin, die durch Latenz eingeführten Komplikationen anzugehen. Die Zeit selbst wird flüchtig und unscharf, wenn Sie in den Bereich der Nanosekundenberechnungen eintreten. Genau Uhren sind in der verteilten Rechenhardware schwer zu finden, und ihr Fehlen führt zu Komplikationen in der verteilten Unternehmenssoftware. Zahlreiche Rundreisen sind erforderlich, um die verschiedenen Teile des Systems zu synchronisieren. Aufgrund des Mangels an einer genauen Uhr enden Sie mit algorithmischen Alternativen wie Vektoruhren oder mehrteiligen Zeitstempeln, die Datenstrukturen sind, die eine teilweise Ordnung der Geräteuhren in Ihrem System widerspiegeln. Diese zusätzlichen Rundreisen können die Leistung beeinträchtigen.
Ein cleveres Design, das Google vor über einem Jahrzehnt übernommen hat, war die Verwendung von atomaren Chip-Uhren. Die Auflösung dieser atomaren Uhren ist deutlich besser als die von quarzbasierten Uhren in elektronischen Uhren oder Computern. NIST hat eine neue Einrichtung einer atomaren Chip-Uhr mit einer noch präziseren täglichen Drift demonstriert. Google verwendete interne atomare Uhren, um die verschiedenen Teile ihrer global verteilten SQL-Datenbank, Google Spanner, zu synchronisieren, um Rundreisen zu sparen und die Leistung im globalen Maßstab zu verbessern. Dies ist eine Möglichkeit, Latenz durch sehr präzise Zeitmessungen zu umgehen.
Wenn wir ein Jahrzehnt vorausschauen, wird Google wahrscheinlich nicht das letzte Unternehmen sein, das diese Art von cleverem Trick verwendet, und sie sind relativ erschwinglich, wobei atomare Chip-Uhren etwa 1.500 US-Dollar pro Stück kosten.

Nun werfen wir einen Blick auf die Berechnung, bei der es darum geht, Berechnungen mit einem Computer durchzuführen. Die Taktgeschwindigkeit war der magische Bestandteil der Verbesserung in den 80er und 90er Jahren. Tatsächlich würde sich die Leistung Ihres Computers verdoppeln, wenn Sie die Taktgeschwindigkeit über das gesamte Board hinweg verdoppeln könnten, unabhängig von der Art der Software. Alle Software wäre gemäß der Taktgeschwindigkeit linear schneller. Es ist äußerst interessant, die Taktgeschwindigkeit zu erhöhen, und sie verbessert sich immer noch, obwohl die Verbesserung im Laufe der Zeit abgeflacht ist. Vor fast 20 Jahren betrug die Taktgeschwindigkeit etwa 2 GHz, und heute beträgt sie 5 GHz.
Der Hauptgrund für diese abgeflachte Verbesserung ist die Leistungsgrenze. Das Problem besteht darin, dass beim Erhöhen der Taktgeschwindigkeit auf einem Chip der Energieverbrauch in etwa verdoppelt wird und diese Energie dann abgeführt werden muss. Das Problem ist die thermische Abführung, denn wenn Sie die Energie nicht abführen können, erhitzt sich Ihr Gerät so stark, dass es das Gerät selbst beschädigt. Die Halbleiterindustrie hat sich heute von mehr Operationen pro Sekunde zu mehr Operationen pro Watt entwickelt.
Diese Regel, dass eine 30%ige Erhöhung den Energieverbrauch verdoppelt, ist ein zweischneidiges Schwert. Wenn Sie damit einverstanden sind, ein Viertel Ihrer Rechenleistung pro Zeiteinheit auf der CPU aufzugeben, können Sie den Stromverbrauch tatsächlich halbieren. Dies ist besonders interessant für Smartphones, bei denen Energieeinsparungen entscheidend sind, und auch für Cloud Computing, bei dem einer der Hauptkostentreiber die Energie selbst ist. Um kosteneffiziente Cloud-Computing-Rechenleistung zu haben, geht es nicht darum, superschnelle CPUs zu haben, sondern eher um untertaktete CPUs, die so langsam wie 1 GHz sein können, da sie mehr Operationen pro Sekunde für Ihre Energieinvestition bieten.
Die Leistungsgrenze ist ein so großes Problem, dass moderne CPU-Architekturen alle möglichen cleveren Tricks verwenden, um sie zu mildern. Moderne CPUs können beispielsweise ihre Taktgeschwindigkeit regulieren, indem sie sie vorübergehend für eine Sekunde oder so erhöhen, bevor sie sie reduzieren, um die Wärme abzuführen. Sie können auch das sogenannte “dunkle Silizium” nutzen. Die Idee dabei ist, dass es einfacher ist, die Energie abzuführen, wenn die CPU die heißen Bereiche auf dem Chip abwechseln kann, anstatt immer den gleichen Bereich aktiv zu haben, Taktzyklus für Taktzyklus. Dies ist eine sehr wichtige Komponente modernen Designs. Aus der Perspektive von Unternehmenssoftware bedeutet dies, dass Sie wirklich in der Lage sein möchten, horizontal zu skalieren. Sie möchten in der Lage sein, mit vielen CPUs mehr zu tun, aber einzeln betrachtet werden diese Prozessoren schwächer sein als die vorherigen, die Sie hatten. Es geht nicht darum, bessere Prozessoren im Sinne von “alles ist besser in jeder Hinsicht” zu bekommen; es geht darum, Prozessoren zu haben, die Ihnen mehr Operationen pro Watt bieten, und dieser Trend wird sich fortsetzen.
Vielleicht werden wir in einem Jahrzehnt mit Schwierigkeiten sieben oder vielleicht sogar acht Gigahertz erreichen, aber ich bin mir nicht einmal sicher, ob wir dorthin gelangen werden. Wenn ich mir die Taktgeschwindigkeit im Jahr 2021 bei den meisten Cloud-Computing-Anbietern anschaue, liegt sie eher bei typischerweise 2 GHz, sodass wir wieder bei der Taktgeschwindigkeit sind, die wir vor 20 Jahren hatten, und das ist die kostengünstigste Lösung.
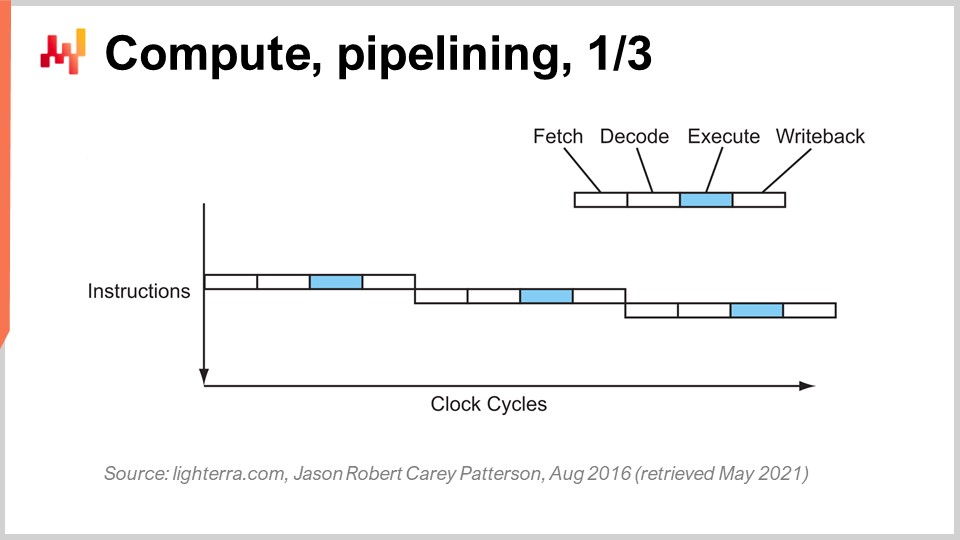
Um die aktuelle CPU-Leistung zu erreichen, waren eine Reihe von Schlüsselinnovationen erforderlich. Ich werde einige von ihnen vorstellen, insbesondere diejenigen, die den größten Einfluss auf das Design von Unternehmenssoftware haben. Auf diesem Bildschirm sehen Sie den Anweisungsfluss eines sequentiellen Prozessors, wie er bis in die frühen 80er Jahre hinein hergestellt wurde. Sie haben eine Reihe von Anweisungen, die von oben nach unten, repräsentativ für die Zeit, ausgeführt werden. Jede Anweisung durchläuft eine Reihe von Phasen: Fetch, Decode, Execute und Write Back.
Während der Fetch-Phase holen Sie die Anweisung, registrieren, greifen die nächste Anweisung ab, erhöhen den Anweisungszähler und bereiten die CPU vor. Während der Decode-Phase decodieren Sie die Anweisung und geben den internen Mikrocode aus, den die CPU intern ausführt. Die Ausführungsphase umfasst das Abrufen der relevanten Eingaben aus den Registern und die Durchführung der tatsächlichen Berechnung, und die Write-Back-Phase umfasst das Speichern des gerade berechneten Ergebnisses an einer Stelle in einem der Register. In diesem sequentiellen Prozessor erfordert jede einzelne Phase einen Taktzyklus, sodass es vier Taktzyklen dauert, um eine Anweisung auszuführen. Wie wir gesehen haben, ist es aufgrund vieler Komplikationen sehr schwierig, die Frequenz der Taktzyklen selbst zu erhöhen.
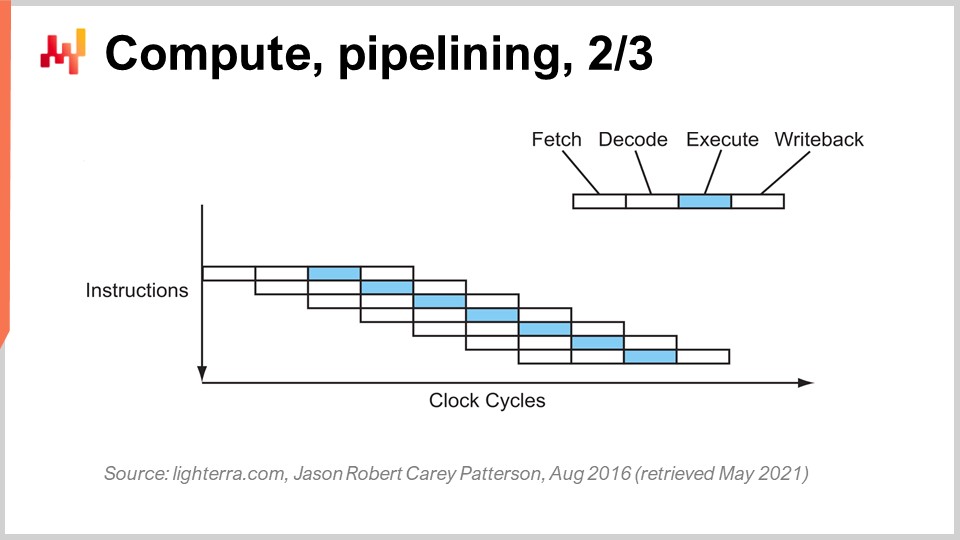
Der entscheidende Trick, der seit den frühen 80er Jahren und darüber hinaus verwendet wird, wird als Pipelining bezeichnet. Pipelining kann die Berechnung Ihres Prozessors enorm beschleunigen. Die Idee besteht darin, dass aufgrund der Tatsache, dass jede einzelne Anweisung eine Reihe von Phasen durchläuft, wir die Phasen überlappen und die CPU selbst eine ganze Pipeline von Anweisungen haben wird. Auf diesem Diagramm sehen Sie eine CPU mit einer Pipeline von vier Stufen, in der immer vier Anweisungen gleichzeitig ausgeführt werden. Sie befinden sich jedoch nicht in derselben Phase: Eine Anweisung befindet sich in der Fetch-Phase, eine in der Decode-Phase, eine in der Execute-Phase und eine in der Write-Back-Phase. Mit diesem einfachen Trick, der hier als Pipeline-Prozessor dargestellt ist, haben wir die effektive Leistung des Prozessors durch das Pipelining der Operationen um das Vierfache multipliziert. Alle modernen CPUs verwenden Pipelining.
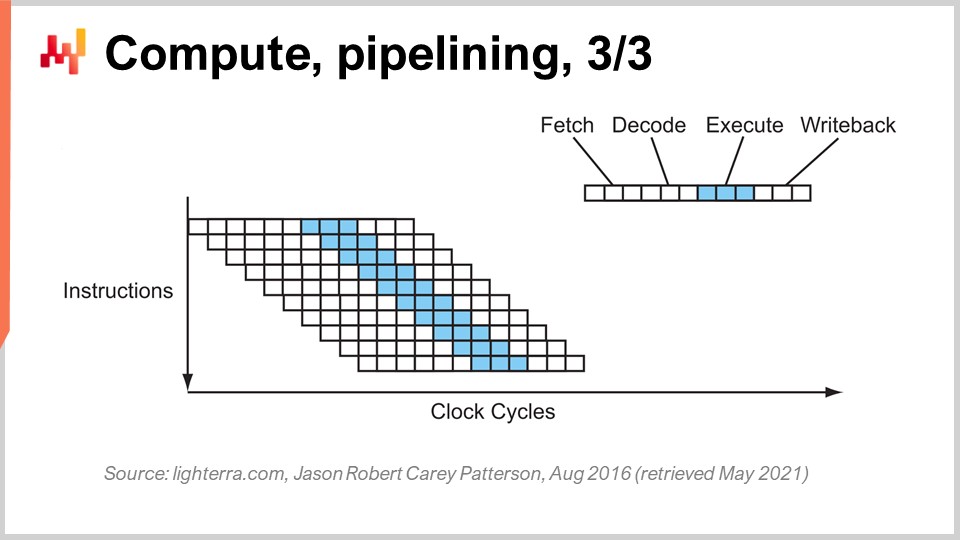
Die nächste Stufe dieser Verbesserung wird als Super-Pipelining bezeichnet. Moderne CPUs gehen weit über einfaches Pipelining hinaus. In Wirklichkeit umfasst die Anzahl der Phasen, die in einer echten modernen CPU enthalten sind, eher 30 Phasen. Auf dem Diagramm sehen Sie eine CPU mit 12 Phasen als Beispiel, aber in Wirklichkeit wären es eher 30 Phasen. Mit dieser tieferen Pipeline können 12 Operationen gleichzeitig ausgeführt werden, was sehr gut für die Leistung ist und dabei den gleichen Taktzyklus verwendet.
Es gibt jedoch ein neues Problem: Die nächste Anweisung beginnt, bevor die vorherige abgeschlossen ist. Das bedeutet, dass Sie bei abhängigen Operationen ein Problem haben, da die Berechnung der Eingaben für die nächste Anweisung noch nicht bereit ist und Sie warten müssen. Wir möchten die gesamte Pipeline nutzen, die uns zur Verfügung steht, um die Verarbeitungsleistung zu maximieren. Daher holen moderne CPUs nicht nur eine Anweisung pro Mal, sondern etwa 500 Anweisungen pro Mal. Sie schauen weit voraus in der Liste der anstehenden Anweisungen und ordnen sie um, um Abhängigkeiten zu minimieren, indem sie die Ausführungsflüsse abwechseln, um die volle Tiefe der Pipeline zu nutzen.
Es gibt viele Dinge, die diesen Vorgang komplizieren, insbesondere Verzweigungen. Eine Verzweigung ist nur eine Bedingung in der Programmierung, wie zum Beispiel wenn Sie eine “if”-Anweisung schreiben. Das Ergebnis der Bedingung kann wahr oder falsch sein, und je nach Ergebnis wird Ihr Programm eine bestimmte Logik ausführen oder eine andere. Dies erschwert das Management von Abhängigkeiten, da die CPU die Richtung der kommenden Verzweigungen erraten muss. Moderne CPUs verwenden Vorhersagen von Verzweigungen, die einfache Heuristiken beinhalten und eine sehr hohe Vorhersagegenauigkeit aufweisen. Sie können die Richtung von Verzweigungen mit einer Genauigkeit von über 99% vorhersagen, was besser ist als das, was die meisten von uns in einem realen Supply-Chain-Kontext tun können. Diese Präzision ist erforderlich, um super tiefe Pipelines zu nutzen.
Um Ihnen eine Vorstellung von den verwendeten Heuristiken für die Vorhersage von Verzweigungen zu geben, ist eine sehr einfache Heuristik zu sagen, dass die Verzweigung den gleichen Weg in die gleiche Richtung geht wie beim letzten Mal. Diese einfache Heuristik liefert eine Genauigkeit von etwa 90%, was ziemlich gut ist. Wenn Sie dieser Heuristik eine Wendung hinzufügen, nämlich dass die Verzweigung in die gleiche Richtung wie beim letzten Mal geht, aber Sie den Ursprung berücksichtigen müssen, also die gleiche Verzweigung vom gleichen Ursprung kommt, dann erhalten Sie eine Genauigkeit von etwa 95%. Moderne CPUs verwenden tatsächlich ziemlich komplexe Perzeptronen, eine maschinelles Lernverfahren, um die Richtung der Verzweigungen vorherzusagen.
Unter den richtigen Bedingungen können Verzweigungen ziemlich genau vorhergesagt werden und somit die volle Pipeline nutzen, um das Beste aus einem modernen Prozessor herauszuholen. Aus Sicht der Softwareentwicklung müssen Sie jedoch mit Ihrem Prozessor zusammenarbeiten, insbesondere mit der Vorhersage von Verzweigungen. Wenn Sie nicht kooperieren, bedeutet das, dass der Verzweigungsvorhersager falsch liegt, und wenn das passiert, wird die CPU die Richtung der Verzweigung vorhersagen, die Pipeline organisieren und mit den Berechnungen im Voraus beginnen. Wenn die Verzweigung tatsächlich auftritt und die Berechnung effektiv abgeschlossen ist, wird die CPU feststellen, dass die Vorhersage der Verzweigung falsch war. Eine falsche Vorhersage der Verzweigung führt nicht zu einem falschen Ergebnis, sondern zu einem Leistungsverlust. Die CPU hat keine andere Wahl, als die gesamte Pipeline oder einen großen Teil davon zu leeren, auf andere Berechnungen zu warten und dann die Berechnung neu zu starten. Der Leistungsverlust kann sehr signifikant sein, und aufgrund von Unternehmenssoftwarelogik, die nicht gut mit der Verzweigungsvorhersagelogik Ihrer CPU zusammenarbeitet, können Sie sehr leicht eine oder zwei Größenordnungen an Leistung verlieren.
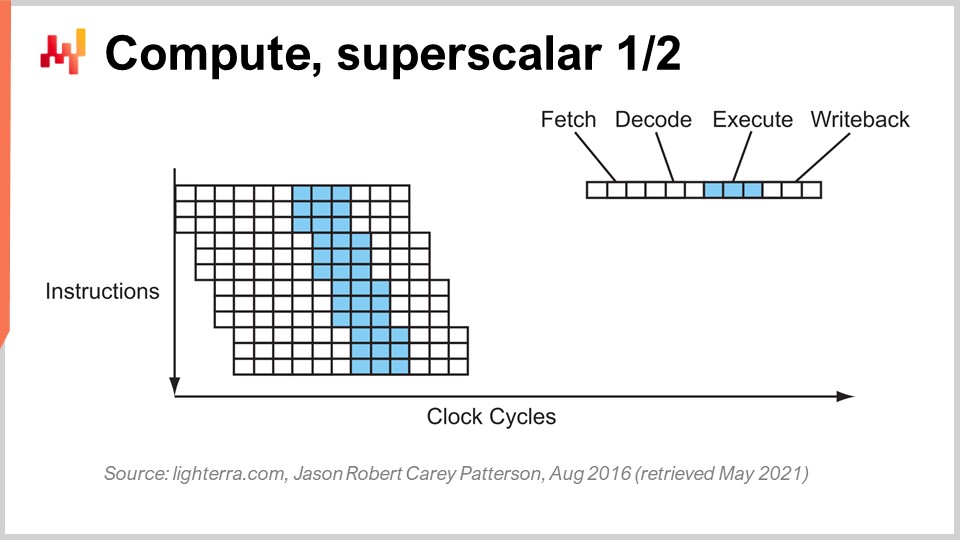
Ein weiterer bemerkenswerter Trick neben der Pipeline ist die superskalare Anweisung. CPUs verarbeiten in der Regel Skalare oder Paare von Skalaren gleichzeitig - zum Beispiel zwei Zahlen mit 32-Bit-Gleitkommagenauigkeit. Sie führen skalare Operationen durch, bei denen im Wesentlichen eine Zahl nach der anderen verarbeitet wird. Moderne CPUs der letzten zehn Jahre verfügen jedoch praktisch alle über superskalare Anweisungen, mit denen tatsächlich mehrere Vektoren von Zahlen verarbeitet und Vektoroperationen direkt durchgeführt werden können. Das bedeutet, dass eine CPU einen Vektor von zum Beispiel acht Gleitkommazahlen und einen zweiten Vektor von acht Gleitkommazahlen nehmen kann, eine Addition durchführen und einen Vektor von Gleitkommazahlen erhalten kann, der die Ergebnisse dieser Addition darstellt. All das geschieht in einem Zyklus.
Spezialisierte Befehlssätze wie AVX2 ermöglichen es Ihnen zum Beispiel, Operationen mit 32-Bit-Genauigkeit mit Paketen von acht Zahlen durchzuführen, während AVX512 dies mit Paketen von 16 Zahlen ermöglicht. Wenn Sie in der Lage sind, diese Anweisungen zu nutzen, bedeutet das, dass Sie buchstäblich eine Größenordnung an Verarbeitungsgeschwindigkeit gewinnen können, weil eine Anweisung, ein Taktzyklus, viel mehr Berechnungen durchführt als die Verarbeitung von Zahlen einzeln. Dieser Prozess wird als SIMD (Single Instruction, Multiple Data) bezeichnet und ist sehr leistungsstark. Er hat den Großteil des Fortschritts in Bezug auf Rechenleistung in den letzten zehn Jahren vorangetrieben, und moderne Prozessoren sind zunehmend vektorbasiert und superskalar. Aus Sicht der Unternehmenssoftware ist es jedoch relativ knifflig. Bei der Pipeline muss Ihre Software kooperieren, und vielleicht kooperiert sie zufällig mit der Verzweigungsvorhersage. Wenn es jedoch um superskalare Anweisungen geht, gibt es nichts Zufälliges. Ihre Software muss wirklich explizit einige Dinge tun, um diese zusätzliche Verarbeitungsleistung zu nutzen. Sie bekommen sie nicht umsonst; Sie müssen diesen Ansatz übernehmen, und in der Regel müssen Sie die Daten selbst so organisieren, dass Sie Datenparallelität haben und die Daten in einer für SIMD-Anweisungen geeigneten Weise organisiert sind. Es ist keine Raketenwissenschaft, aber es passiert nicht zufällig, und es gibt Ihnen einen massiven Schub in Bezug auf die Verarbeitungsleistung.

Jetzt können moderne CPUs viele Kerne haben, und ein CPU-Kern kann Ihnen einen eigenen Fluss von Anweisungen geben. Mit sehr modernen CPUs, die viele Kerne haben können, können heutige CPUs in der Regel bis zu 64 Kerne haben, also 64 unabhängige gleichzeitige Ausführungsströme. Sie können praktisch etwa ein Teraflop erreichen, was das obere Limit der Verarbeitungsleistung ist, das Sie von einem sehr modernen Prozessor erhalten können. Wenn Sie jedoch darüber hinausgehen möchten, können Sie sich GPUs (Graphical Processing Units) ansehen. Trotz dessen, was Sie vielleicht denken, können diese Geräte für Aufgaben verwendet werden, die nichts mit Grafik zu tun haben.
Eine GPU, wie die von NVIDIA, ist ein superskalarer Prozessor. Anstatt bis zu 64 Kerne wie High-End-CPUs zu haben, können GPUs mehr als 10.000 Kerne haben. Diese Kerne sind viel einfacher und nicht so leistungsstark oder schnell wie reguläre CPU-Kerne, aber es gibt viele Male mehr von ihnen. Sie bringen SIMD auf ein neues Niveau, bei dem Sie nicht nur Pakete von 8 oder 16 Zahlen auf einmal verarbeiten können, sondern buchstäblich Tausende von Zahlen auf einmal, um Vektoranweisungen auszuführen. Mit GPUs können Sie auf nur einem Gerät einen Bereich von mehr als 30 Teraflops erreichen, was enorm ist. Die besten CPUs auf dem Markt können Ihnen ein Teraflop geben, während Ihnen die besten GPUs mehr als 30 Teraflops geben. Das ist mehr als eine Größenordnung Unterschied, was sehr signifikant ist.
Wenn Sie noch weiter gehen, für spezialisierte Arten von Berechnungen wie lineare Algebra (übrigens sind Dinge wie maschinelles Lernen und Deep Learning im Wesentlichen matrixbasierte lineare Algebra überall involviert), können Sie Prozessoren wie TPUs (Tensor Processing Units) haben. Google hat sich entschieden, sie Tensoren zu nennen, wegen TensorFlow, aber die Realität ist, dass TPUs besser als Matrix-Multiplikations-Verarbeitungseinheiten bezeichnet werden könnten. Das Interessante an der Matrixmultiplikation ist, dass nicht nur eine Menge Datenparallelität involviert ist, sondern auch eine enorme Menge an Wiederholung, weil die Operationen stark repetitiv sind. Durch die Organisation eines TPUs als systolisches Array, das im Wesentlichen ein zweidimensionales Gitter mit Berechnungseinheiten auf dem Gitter ist, können Sie die Petaflop-Barriere durchbrechen und auf nur einem einzigen Gerät mehr als 1000 Teraflops erreichen. Es gibt jedoch einen Haken: Google macht es mit 16-Bit-Gleitkommazahlen anstelle der üblichen 32-Bit. Aus Sicht der Supply Chain ist eine Genauigkeit von 16 Bit nicht schlecht; das bedeutet, dass Sie etwa 0,1% Genauigkeit in Ihren Operationen haben, und für viele maschinelle Lern- oder statistische Operationen ist eine Genauigkeit von 0,1% durchaus in Ordnung, wenn sie richtig und ohne Ansammlung von Verzerrungen durchgeführt wird.
Was wir sehen, ist, dass der Fortschritt im Bereich der Hardware für Computer, wenn man sich nur die Rechenleistung ansieht, darin besteht, sich für spezialisiertere und starrere Geräte zu entscheiden. Dank dieser Spezialisierung können enorme Gewinne bei der Verarbeitungsleistung erzielt werden. Wenn Sie von superskalaren Anweisungen ausgehen, gewinnen Sie eine Größenordnung; wenn Sie sich für eine Grafikkarte entscheiden, gewinnen Sie eine oder zwei Größenordnungen; und wenn Sie sich für reine lineare Algebra entscheiden, gewinnen Sie im Wesentlichen zwei Größenordnungen. Das ist sehr signifikant.
Übrigens sind all diese Hardware-Designs zweidimensional. Moderne Chips und Verarbeitungsstrukturen sind sehr flach. Eine moderne CPU umfasst nicht mehr als 20 Schichten, und da diese Schichten nur wenige Mikrometer dick sind, sind CPUs, GPUs oder TPUs im Wesentlichen flache Strukturen. Sie könnten denken: “Was ist mit der dritten Dimension?” Nun, es stellt sich heraus, dass wir aufgrund der Leistungsgrenze, dem Problem der Energieabfuhr, nicht wirklich in die dritte Dimension gehen können, weil wir nicht wissen, wie wir all die Energie abführen können, die in das Gerät eingespeist wird.
Was wir für das nächste Jahrzehnt vorhersagen können, ist, dass diese Geräte im Wesentlichen zweidimensional bleiben werden. Aus der Perspektive der Unternehmenssoftware ist die wichtigste Erkenntnis, dass Sie die Datenparallelität direkt im Kern Ihrer Software entwickeln müssen. Wenn Sie das nicht tun, werden Sie nicht in der Lage sein, den Fortschritt in Bezug auf die Rohrechenleistung vollständig zu nutzen. Es kann jedoch kein Nachgedanke sein. Es muss auf der Ebene geschehen, auf der Sie alle Daten organisieren, die in Ihren Systemen verarbeitet werden müssen. Wenn Sie das nicht tun, bleiben Sie bei den Prozessoren stecken, die wir vor zwei Jahrzehnten hatten.
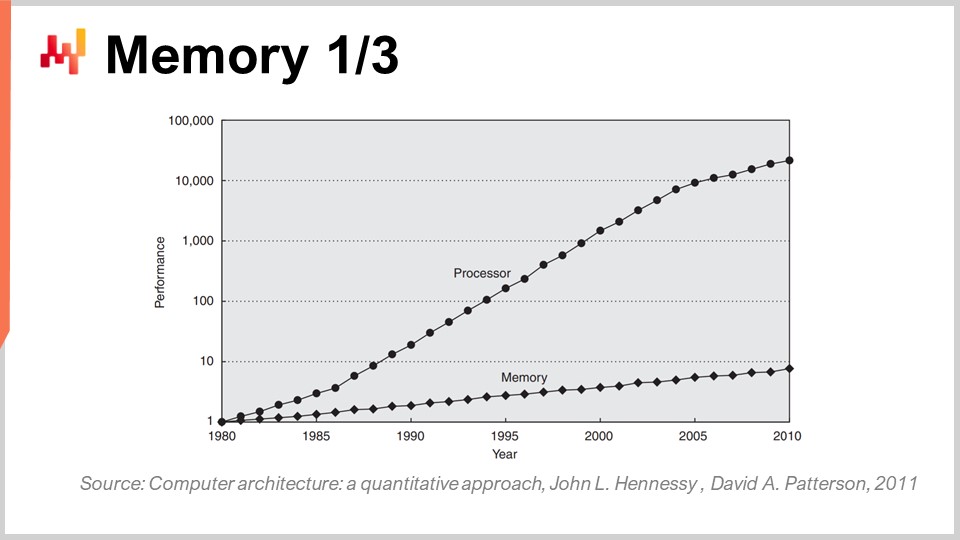
Jetzt war der Speicher Anfang der 80er Jahre genauso schnell wie die Prozessoren, was bedeutet, dass ein Taktzyklus für den Speicher und einer für die CPU gleich war. Das ist jedoch nicht mehr der Fall. Im Laufe der Zeit, seit den 80er Jahren, hat sich das Verhältnis zwischen der Geschwindigkeit des Speichers und den Latenzen zum Zugriff auf Daten, die bereits in den Registern des Prozessors vorhanden sind, nur erhöht. Wir begannen mit einem Verhältnis von eins und haben jetzt in der Regel ein Verhältnis von mehr als tausend. Dieses Problem wird als Speicherwand bezeichnet und hat sich in den letzten vier Jahrzehnten nur noch verschlimmert. Es nimmt immer noch zu, wenn auch sehr langsam, hauptsächlich weil die Taktfrequenz der Prozessoren nur sehr langsam zunimmt. Da sich die Prozessoren in Bezug auf die Taktfrequenz nicht viel weiterentwickeln, nimmt dieses Problem der Speicherwand nicht weiter zu. Der Ort, an dem wir uns im Moment befinden, ist jedoch unglaublich unausgewogen, da der Zugriff auf den Speicher im Wesentlichen um drei Größenordnungen langsamer ist als der Zugriff auf Daten, die bereits bequem im Prozessor sitzen.
Diese Perspektive widerspricht völlig der klassischen Algorithmik, wie sie heutzutage noch an den meisten Universitäten gelehrt wird. Der klassische algorithmische Standpunkt geht davon aus, dass Sie eine gleichmäßige Zeit haben, um auf den Speicher zuzugreifen, was bedeutet, dass der Zugriff auf jedes Bit des Speichers die gleiche Zeit dauert. Aber in modernen Systemen ist das absolut nicht der Fall. Die Zeit, die benötigt wird, um auf einen bestimmten Teil des Speichers zuzugreifen, hängt sehr stark davon ab, wo sich die tatsächlichen Daten physisch in Ihrem Computersystem befinden.
Aus der Perspektive der Unternehmenssoftware stellt sich heraus, dass leider die meisten Softwareentwürfe, die in den 80er und 90er Jahren etabliert wurden, das Problem völlig ignoriert haben, weil es während des ersten Jahrzehnts sehr gering war. Es hat sich erst in den letzten beiden Jahrzehnten wirklich aufgebläht, aber als Ergebnis widersprechen die meisten Muster, die in heutiger Unternehmenssoftware zu sehen sind, diesem Design, weil sie davon ausgehen, dass Sie für alle Speicherzugriffe eine konstante Zeit haben.
Übrigens, wenn Sie an Programmiersprachen wie Python (erstmals veröffentlicht 1989) oder Java (1995) denken, die objektorientierte Programmierung unterstützen, steht dies in starkem Widerspruch zur Funktionsweise des Speichers in modernen Computern. Wenn Sie Objekte haben und es noch schlimmer ist, wenn Sie späte Bindungen wie in Python haben, bedeutet das, dass Sie zum Ausführen von Aufgaben Zeigern folgen und zufällige Sprünge in den Speicher machen müssen. Wenn einer dieser Sprünge unglücklich ist, weil es sich um einen Bereich handelt, der sich noch nicht im Prozessor befindet, kann er tausendmal langsamer sein. Das ist ein sehr großes Problem.

Um das Ausmaß der Speicherwand besser zu erfassen, ist es interessant, sich die typischen Latenzen in einem modernen Computer anzusehen. Wenn wir diese Latenzen in menschlichen Begriffen umrechnen, nehmen wir an, dass ein Prozessor mit einer Taktzyklus pro Sekunde arbeitet. Unter dieser Annahme beträgt die typische Latenz der CPU eine Sekunde. Wenn wir jedoch auf Daten im Speicher zugreifen möchten, kann es bis zu sechs Minuten dauern. Wenn Sie also eine Operation pro Sekunde ausführen können, müssen Sie sechs Minuten warten, um auf etwas im Speicher zuzugreifen. Und wenn Sie auf etwas auf der Festplatte zugreifen möchten, kann es bis zu einem Monat oder sogar einem ganzen Jahr dauern. Das ist unglaublich lang, und darum geht es bei den Leistungsunterschieden, von denen ich am Anfang dieses Vortrags gesprochen habe. Wenn Sie es mit 15 Größenordnungen zu tun haben, ist das sehr irreführend; Sie erkennen nicht unbedingt den massiven Leistungsverlust, den Sie haben können, wo Sie buchstäblich Monate warten müssen, wenn Sie die Informationen nicht an der richtigen Stelle platzieren. Das ist absolut gigantisch.
Übrigens haben nicht nur Softwareingenieure für Unternehmenssoftware mit dieser Entwicklung der modernen Hardware zu kämpfen. Wenn wir uns die Latenzen ansehen, die wir mit superschnellen SSD-Karten wie der Intel Optane-Serie erhalten, sehen wir, dass die Hälfte der Latenzzeit für den Zugriff auf den Speicher auf diesem Gerät tatsächlich durch den Overhead des Kernels verursacht wird, in diesem Fall der Linux-Kernel. Es ist das Betriebssystem selbst, das die Hälfte der Latenz verursacht. Was bedeutet das? Nun, das bedeutet, dass selbst diejenigen, die Linux entwickeln, noch weitere Arbeit leisten müssen, um mit moderner Hardware Schritt zu halten. Nichtsdestotrotz ist es eine große Herausforderung für alle.
Es schmerzt jedoch wirklich die Unternehmenssoftware, insbesondere wenn es um die Optimierung der Lieferkette geht, aufgrund der Tatsache, dass wir tonnenweise Daten verarbeiten müssen. Es ist von Anfang an schon eine ziemlich komplexe Aufgabe. Aus der Perspektive der Unternehmenssoftware müssen Sie wirklich ein Design übernehmen, das gut mit dem Cache zusammenarbeitet, da der Cache lokale Kopien enthält, die schneller zugänglich und näher an der CPU sind.
Die Funktionsweise besteht darin, dass wenn Sie ein Byte in Ihrem Hauptspeicher abrufen, Sie in moderner Software nicht nur ein Byte abrufen können. Wenn Sie auch nur ein Byte in Ihrem RAM abrufen möchten, kopiert die Hardware tatsächlich 4 Kilobyte, also die gesamte Seite, die 4 Kilobyte groß ist. Die zugrunde liegende Annahme ist, dass wenn Sie ein Byte lesen, das nächste Byte, das Sie anfordern werden, das folgende sein wird. Das ist das Lokalitätsprinzip, was bedeutet, dass wenn Sie nach dieser Regel spielen und den Zugriff erzwingen, der die Lokalität erhält, dann können Sie einen Speicher haben, der fast so schnell wie Ihr Prozessor funktioniert.
Das erfordert jedoch eine Ausrichtung zwischen Speicherzugriffen und der Lokalität der Daten. Insbesondere gibt es viele Programmiersprachen wie Python, die solche Dinge nicht nativ liefern. Im Gegenteil, sie stellen eine enorme Herausforderung dar, um irgendeinen Grad an Lokalität zu erreichen. Das ist ein immenser Kampf, und letztendlich ist es ein Kampf, bei dem Sie eine Programmiersprache haben, die um Muster herum entwickelt wurde, die der Hardware, die uns zur Verfügung steht, völlig entgegenwirken. Dieses Problem wird sich in den nächsten zehn Jahren nicht ändern, es wird nur schlimmer.
Daher möchten Sie aus der Perspektive der Unternehmenssoftware die Lokalität der Daten erzwingen, aber auch die Minimierung. Wenn Sie Ihre Big Data klein machen können, wird sie schneller. Das ist etwas, das nicht sehr intuitiv ist, aber wenn Sie die Größe der Daten reduzieren können, indem Sie redundante Informationen eliminieren, können Sie Ihr Programm schneller machen, weil Sie viel freundlicher mit dem Cache umgehen. Sie passen mehr relevante Daten in die niedrigeren Cache-Ebenen, die viel niedrigere Latenzen haben, wie auf dieser Anzeige gezeigt.

Schließlich wollen wir speziell den Fall von DRAM diskutieren. DRAM ist buchstäblich die physische Komponente, die den RAM aufbaut, den Sie für Ihren Desktop-Arbeitsplatz oder Ihren Server in der Cloud verwenden. DRAM wird auch als Hauptspeicher bezeichnet, der aus DRAM-Chips besteht. In den letzten zehn Jahren ist der Preis für DRAM kaum gesunken. Wir sind von 5 US-Dollar pro Gigabyte auf 3 US-Dollar pro Gigabyte ein Jahrzehnt später gegangen. Der Preis für RAM sinkt immer noch, wenn auch nicht sehr schnell. In den nächsten Jahren wird er stagnieren, und aufgrund der Tatsache, dass es nur drei große Akteure auf diesem Markt gibt, die die Kapazität haben, DRAM in großem Maßstab herzustellen, gibt es sehr wenig Hoffnung, dass es in diesem Markt in den nächsten zehn Jahren etwas Unerwartetes geben wird.
Aber das ist noch nicht das Schlimmste an dem Problem. Es gibt auch den Stromverbrauch pro Gigabyte. Wenn Sie sich den Stromverbrauch ansehen, stellt sich heraus, dass der moderne RAM pro Gigabyte etwas mehr Strom verbraucht als vor einem Jahrzehnt. Der Grund dafür ist im Wesentlichen, dass der RAM, den wir heute haben, schneller ist, und die gleiche Regel der Leistungsgrenze gilt: Wenn Sie die Taktfrequenz erhöhen, erhöhen Sie den Stromverbrauch erheblich. Übrigens verbraucht RAM ziemlich viel Strom, weil DRAM grundsätzlich eine aktive Komponente ist. Sie müssen den RAM ständig aktualisieren, aufgrund von elektrischer Leckage, also wenn Sie Ihren RAM ausschalten, verlieren Sie alle Ihre Daten. Sie müssen die Zellen ständig aktualisieren.
Daher ist das Fazit für Unternehmenssoftware, dass DRAM die eine Komponente ist, die nicht mehr vorankommt. Es gibt viele Dinge, die sich immer noch sehr schnell entwickeln, wie die Rechenleistung; dies ist jedoch nicht der Fall für DRAM - es stagniert sehr stark. Wenn wir den Stromverbrauch berücksichtigen, der auch einen erheblichen Teil der Kosten für Cloud Computing ausmacht, macht RAM kaum Fortschritte. Wenn Sie also ein Design übernehmen, das den Hauptspeicher überbetont, und das ist normalerweise das, was Sie bekommen, wenn Sie einen Anbieter haben, der sagt: “Oh, wir haben ein In-Memory-Design für Software”, denken Sie an diese Stichworte.
Wenn Sie also von einem Anbieter hören, dass er ein In-Memory-Design hat, sagt Ihnen der Anbieter - und dies ist kein sehr überzeugendes Angebot - dass sein Design vollständig von der zukünftigen Entwicklung von DRAM abhängt, bei dem wir bereits wissen, dass die Kosten nicht sinken werden. Wenn wir also berücksichtigen, dass Ihr Lieferkettenmanagement in 10 Jahren wahrscheinlich etwa 10-mal mehr Daten verarbeiten wird, nur weil Unternehmen immer besser darin werden, mehr Daten in ihren Lieferketten zu sammeln und zusammenzuarbeiten, um mehr Daten von ihren Kunden und Lieferanten zu sammeln, ist es nicht unvernünftig zu erwarten, dass ein großes Unternehmen, das eine große Lieferkette betreibt, 10-mal mehr Daten sammeln wird als bisher. Der Preis pro Gigabyte RAM wird jedoch gleich bleiben. Wenn Sie also die Mathematik machen, könnten Sie am Ende Cloud Computing-Kosten oder IT-Kosten haben, die im Wesentlichen fast eine Größenordnung teurer sind, nur um im Grunde genommen dasselbe zu tun, nur weil Sie mit einer ständig wachsenden Datenmenge umgehen müssen, die nicht einfach in den Speicher passt. Der Schlüsselgedanke ist, dass Sie alle Arten von In-Memory-Designs vermeiden möchten. Diese Designs sind sehr veraltet, und wir werden im Folgenden sehen, welche Art von Alternativen wir haben.

Werfen wir nun einen Blick auf die Datenspeicherung, die die persistente Datenspeicherung betrifft. Im Wesentlichen gibt es zwei Arten von weit verbreiteter Datenspeicherung. Die erste sind Festplattenlaufwerke (HDD) oder Rotationsdisks. Die zweite sind Solid-State-Laufwerke (SSD). Das Interessante ist, dass die Latenz bei Rotationsdisks schrecklich ist, und wenn Sie sich dieses Bild ansehen, können Sie leicht verstehen, warum. Diese Disks drehen sich buchstäblich, und wenn Sie auf einen beliebigen zufälligen Datenpunkt auf der Disk zugreifen möchten, müssen Sie im Durchschnitt auf eine halbe Umdrehung der Disk warten. Angenommen, die Spitzenlaufwerke drehen sich mit etwa 10.000 Umdrehungen pro Minute, bedeutet dies, dass Sie eine eingebaute Latenz von drei Millisekunden haben, die nicht komprimiert werden kann. Es ist buchstäblich die Zeit, die benötigt wird, damit sich die Disk dreht und um den genauen interessierenden Punkt auf der Disk lesen zu können. Es ist mechanisch und wird sich nicht weiter verbessern.
HDDs sind in Bezug auf die Latenz schrecklich, aber sie haben auch ein weiteres Problem, nämlich den Stromverbrauch. Als Faustregel verbrauchen sowohl eine HDD als auch eine SSD etwa drei Watt pro Stunde pro Gerät. Das ist typischerweise der Status quo im Moment. Wenn jedoch die Festplatte läuft, auch wenn Sie nichts Aktives von der Festplatte lesen, verbrauchen Sie drei Watt, nur weil Sie die Disk am Laufen halten müssen. Das Erreichen von 10.000 Umdrehungen pro Minute dauert viel Zeit, daher müssen Sie die Disk die ganze Zeit am Laufen halten, auch wenn Sie die Disk sehr selten verwenden.
Auf der anderen Seite verbrauchen Solid-State-Laufwerke, wenn Sie auf sie zugreifen, drei Watt, aber wenn Sie nicht auf die Daten zugreifen, verbrauchen sie fast keine Leistung. Sie haben einen Reststromverbrauch, aber er ist äußerst gering, in der Größenordnung von Milliwatt. Das ist sehr interessant, denn Sie können Tonnen von SSDs haben; wenn Sie sie nicht verwenden, zahlen Sie nicht für die Leistung, die sie verbrauchen. Die gesamte Branche hat sich in den letzten zehn Jahren allmählich von HDDs zu SSDs gewandelt.
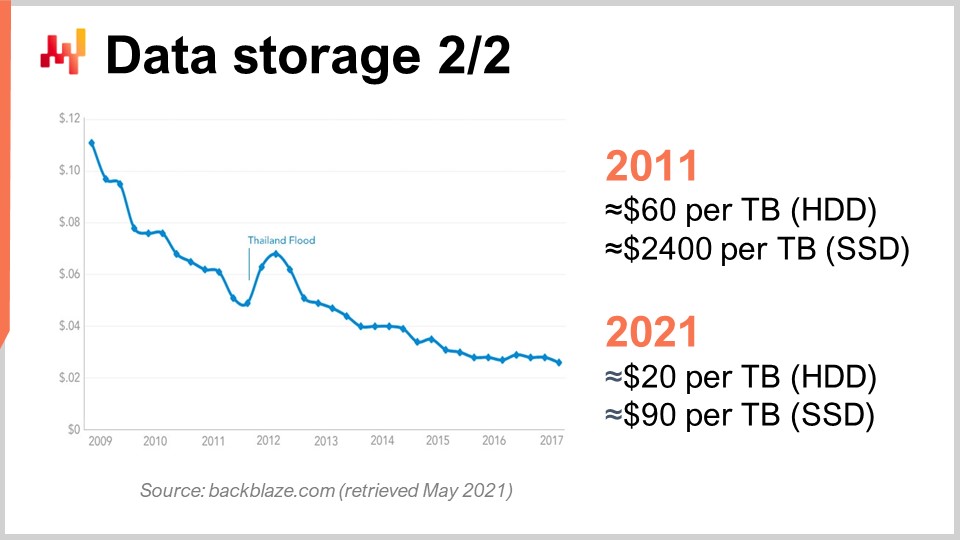
Um dies zu verstehen, können wir uns diese Kurve ansehen. Was wir sehen, ist, dass der Preis pro Gigabyte sowohl für HDDs als auch für SSDs in den letzten Jahren gesunken ist. Der Preis hat sich jetzt jedoch stabilisiert. Die Daten sind ein kleines bisschen alt, aber sie haben sich in den letzten Jahren nicht so sehr verändert. In den letzten 10 Jahren sehen wir, dass vor einem Jahrzehnt SSDs extrem teuer waren, nämlich 2.400 US-Dollar pro Terabyte, während Festplatten nur 60 US-Dollar pro Terabyte kosteten. Heutzutage hat sich der Preis von Festplatten um das Dreifache geteilt, also auf etwa 20 US-Dollar pro Terabyte. Der Preis von SSDs hat sich um mehr als 25 geteilt, und der Trend sinkender SSD-Preise hält an. SSDs sind im Moment und wahrscheinlich für das nächste Jahrzehnt die Komponente, die sich am meisten entwickelt, und das ist sehr interessant.
Übrigens habe ich Ihnen gesagt, dass das Design moderner Rechengeräte (CPU, GPU, TPU) im Wesentlichen zweidimensional ist und höchstens 20 Schichten hat. Wenn es jedoch um SSDs geht, wird das Design zunehmend dreidimensional. Die neuesten SSDs haben etwa 176 Schichten. Wir erreichen in Bezug auf die Reihenfolge 200 Schichten. Aufgrund der Tatsache, dass diese Schichten unglaublich dünn sind, ist es nicht unrealistisch zu erwarten, dass wir in Zukunft Geräte mit Tausenden von Schichten und potenziell um Größenordnungen mehr Speicherkapazität haben werden. Natürlich wird der Trick darin bestehen, dass Sie nicht in der Lage sein werden, jederzeit auf all diese Daten zuzugreifen, wiederum aufgrund von Dark Silicon und Leistungsverlust.
Es stellt sich heraus, dass bei einer ordentlichen Nutzung sehr viele Daten nur sehr selten abgerufen werden. SSDs erfordern ein sehr spezifisches Hardware-Design, das mit vielen Eigenheiten einhergeht, wie zum Beispiel der Tatsache, dass Sie Bits nur einschalten, aber nicht ausschalten können. Stellen Sie sich im Grunde vor, dass Sie anfangs nur Nullen haben; Sie können eine Null in eine Eins umwandeln, aber Sie können diese Eins nicht lokal in eine Null umwandeln. Wenn Sie das tun möchten, müssen Sie den gesamten Block zurücksetzen, der so groß sein kann wie acht Megabyte, was bedeutet, dass Sie beim Schreiben Bits von Null auf Eins umwandeln können, aber nicht von Eins auf Null. Um Bits von Eins auf Null umzuwandeln, müssen Sie den gesamten Block löschen und neu schreiben, was zu allerlei Problemen führt, die als Schreibverstärkung bekannt sind.
In den letzten zehn Jahren haben SSD-Laufwerke intern eine Schicht namens Flash Translation Layer, die all diese Probleme für Sie mildern kann. Diese Flash Translation Layers werden im Laufe der Zeit immer besser. Es gibt jedoch große Möglichkeiten zur weiteren Verbesserung, und in Bezug auf Unternehmenssoftware bedeutet dies, dass Sie Ihr Design wirklich optimieren möchten, um das Beste aus SSDs herauszuholen. SSDs sind bereits ein viel besseres Angebot als DRAM, wenn es um die Speicherung von Daten geht, und wenn Sie klug vorgehen, können Sie in einem Jahrzehnt eine Größenordnung an Gewinn erwarten, der durch den Fortschritt der Hardware-Industrie erzielt wird, was im Falle von DRAM nicht der Fall ist.
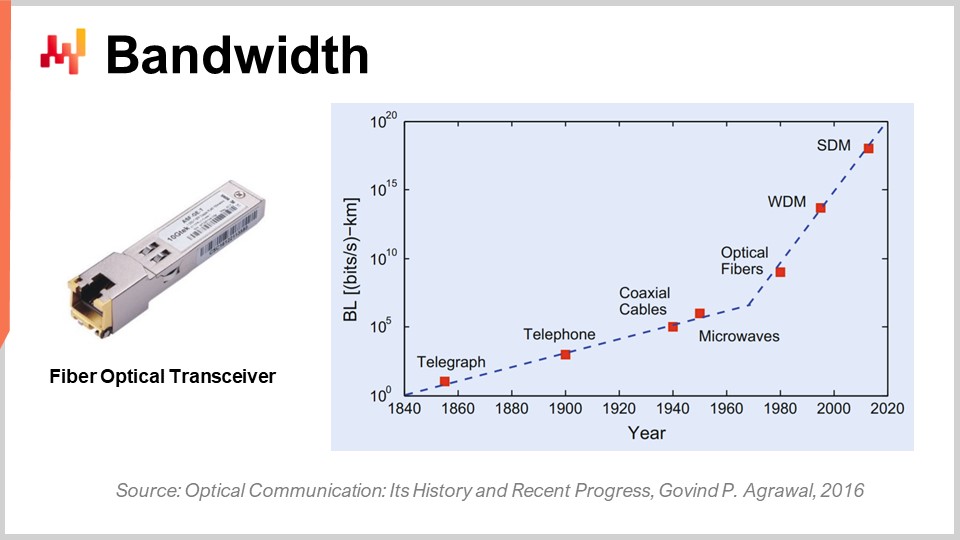
Schließlich wollen wir über Bandbreite sprechen. Bandbreite ist wahrscheinlich das am besten gelöste Problem in Bezug auf Technologie. Selbst wenn Bandbreite erreicht werden kann, können wir die Art von Bandbreiten erreichen, die absolut verrückt sind. Kommerziell gesehen ist die Telekommunikationsbranche sehr komplex, und es gibt viele Probleme, so dass Endverbraucher nicht alle Vorteile des Fortschritts sehen, der in Bezug auf optische Kommunikation gemacht wurde.
In Bezug auf die optische Kommunikation mit Glasfaser-Transceivern ist der Fortschritt absolut verrückt. Es ist wahrscheinlich eine dieser Dinge, die sich so entwickeln wie CPUs in den 80er oder 90er Jahren. Nur um Ihnen eine Vorstellung zu geben, mit Wellenlängen-Multiplexing (WDM) oder Raum-Multiplexing (SDM) können wir jetzt buchstäblich ein Zehntel Terabyte an Daten pro Sekunde auf einem einzigen Kabel aus optischer Faser übertragen. Das ist absolut enorm. Wir erreichen den Punkt, an dem ein einziges Kabel genügend Daten tragen kann, um im Grunde ein ganzes Rechenzentrum zu versorgen. Noch beeindruckender ist, dass die Telekommunikationsbranche in der Lage war, neue Transceiver zu entwickeln, die diese absolut verrückten Leistungen auf der Grundlage alter Kabel liefern können. Sie müssen nicht einmal neue Fasern in den Straßen oder physisch verlegen; Sie können buchstäblich die Faser nehmen, die vor einem Jahrzehnt verlegt wurde, den neuen Transceiver einsetzen und auf demselben Kabel mehrere Größenordnungen mehr Bandbreite haben.
Das Interessante ist, dass es ein allgemeines Gesetz der optischen Kommunikation gibt: Jedes Jahrzehnt schrumpft die Entfernung, bei der es interessant wird, elektrische Kommunikation durch optische Kommunikation zu ersetzen. Wenn wir einige Jahrzehnte zurückgehen, vor zwei Jahrzehnten, dauerte es etwa 100 Meter, bis die optische Kommunikation die elektrische Kommunikation übertraf. Wenn Sie also Entfernungen von weniger als 100 Metern hatten, entschieden Sie sich für Kupfer; wenn Sie mehr als 100 Meter hatten, entschieden Sie sich für Glasfaser. Heutzutage können wir jedoch mit der neuesten Generation eine Entfernung haben, bei der Optik sogar schon bei drei Metern gewinnt. Wenn wir ein Jahrzehnt vorausschauen, würde es mich nicht überraschen, wenn wir Situationen sehen, in denen optische Kommunikation auch dann gewinnt, wenn wir Entfernungen von nur einem halben Meter betrachten. Das bedeutet, dass ich mich nicht wundern würde, wenn Computer selbst irgendwann optische Verbindungen haben, einfach weil sie leistungsfähiger sind als elektrische Verbindungen.
Aus der Perspektive von Unternehmenssoftware ist dies auch sehr interessant, denn es bedeutet, dass die Bandbreite in Bezug auf die Kosten massiv abnehmen wird. Dies wird maßgeblich von Unternehmen wie Netflix subventioniert, die einen enormen Bandbreitenverbrauch haben. Das bedeutet, dass Sie, um die Latenz zu umgehen, Dinge tun könnten wie das vorzeitige Abrufen von Tonnen von Daten in Richtung des Benutzers und dann dem Benutzer ermöglichen, mit Daten zu interagieren, die mit viel kürzerer Latenz näher an ihn herangebracht wurden. Selbst wenn Sie Daten mitbringen, die nicht benötigt werden, ist das, was Sie tötet, die Latenz, nicht die Bandbreite. Es ist besser zu sagen: “Ich habe Zweifel, welche Art von Daten benötigt wird; Ich kann tausendmal mehr Daten mitbringen, als ich wirklich brauche, bringe sie näher an den Endbenutzer, lasse den Benutzer oder das Programm mit diesen Daten interagieren und minimiere den Roundtrip, und ich werde in Bezug auf die Leistung gewinnen.” Dies hat wiederum einen tiefgreifenden Einfluss auf die Art der architektonischen Entscheidungen, die heute getroffen werden, da sie darüber entscheiden werden, ob Sie mit dem Fortschritt dieser Art von Hardware in einem Jahrzehnt Leistung gewinnen können.

Zusammenfassend ist die Latenz die große Herausforderung unserer Zeit im Bereich der Softwareentwicklung. Dies beeinflusst alle Arten von Leistung, die wir haben und haben werden. Leistung ist absolut entscheidend, denn sie treibt nicht nur die IT-Kosten an, sondern auch die Produktivität der Menschen, die in Ihrer Supply Chain tätig sind. Letztendlich beeinflusst dies auch die Leistung der Supply Chain selbst, denn ohne diese Leistung können Sie nicht einmal eine Art numerisches Rezept implementieren, das wirklich intelligent ist und fortschrittliche Optimierung und vorhersagende Optimierung ermöglicht. Doch in diesem Kampf um bessere Leistung wird nicht überall gewonnen, zumindest nicht im Bereich der Unternehmenssoftware. Neue Systeme können langsamer sein als die alten. Dies ist ein akutes Problem. Eine langsamere Softwareleistung verursacht erhebliche Kosten für Unternehmen, die darauf hereinfallen.
Nur um Ihnen ein Beispiel zu geben, sollte nicht als gegeben angesehen werden, dass bessere Hardware eine bessere Leistung bringt. Einige Leute im Internet haben beschlossen, die Eingangslatenz oder Eingangsverzögerung zu messen, also die Zeit, die nach dem Drücken einer Taste vergeht, bis der entsprechende Buchstabe auf dem Bildschirm angezeigt wird. Mit einem Apple II aus dem Jahr 1983, der einen 1-MHz-Prozessor hatte, dauerte es 30 Millisekunden. Im Jahr 2016, mit einem Lenovo X1, ausgestattet mit einem 2,6-GHz-Prozessor, einem sehr schönen Notebook, betrug die Latenz 110 Millisekunden. Wir haben also eine Rechenhardware, die mehrere tausendmal besser ist, und dennoch haben wir eine Latenz, die fast viermal langsamer ist. Dies ist charakteristisch für das, was passiert, wenn Sie keine mechanische Sympathie haben und keine Aufmerksamkeit auf die Rechenhardware richten, die Sie haben. Wenn Sie die Rechenhardware antagonisieren, wird sie Ihnen mit schlechter Leistung antworten.
Das Problem ist sehr real. Mein Vorschlag ist, dass Sie, wenn Sie sich jede Art von Unternehmenssoftware für Ihr Unternehmen ansehen, egal ob Open Source oder nicht, sich an die heute gelernten Elemente der mechanischen Sympathie erinnern. Betrachten Sie die Software und überlegen Sie genau, ob sie den tiefen Trends der Rechenhardware gerecht wird oder ob sie sie völlig ignoriert. Wenn sie sie ignoriert, bedeutet das nicht nur, dass die Leistung im Laufe der Zeit nicht verbessert wird, sondern höchstwahrscheinlich wird sie schlechter. Die meisten Verbesserungen werden heutzutage durch Spezialisierung und nicht durch Taktfrequenz erreicht. Wenn Sie diese Autobahn verpassen, wählen Sie einen Weg, der im Laufe der Zeit immer langsamer wird. Vermeiden Sie diese Lösungen, denn sie resultieren in der Regel aus frühen Schlüssel-Designentscheidungen, die nicht rückgängig gemacht werden können. Sie sind für immer damit festgelegt, und es wird von Jahr zu Jahr nur schlimmer. Denken Sie zehn Jahre voraus, wenn Sie sich diese Aspekte ansehen.

Werfen wir nun einen Blick auf die Fragen. Das war eine ziemlich lange Vorlesung, aber es ist ein anspruchsvolles Thema.
Frage: Was ist Ihre Meinung zu Quantencomputern und ihrer Nützlichkeit bei der Bewältigung komplexer Optimierungsprobleme in der Supply Chain?
Eine sehr interessante Frage. Ich habe mich vor 18 Monaten für die Beta-Version des Quantencomputers von IBM registriert, als sie den Zugang zu ihrem Quantencomputer in der Cloud eröffneten. Meiner Meinung nach ist das faszinierend, da Experten alle S-Kurven abflachen sehen, aber keine neuen Kurven aus dem Nichts auftauchen sehen. Quantencomputing ist eines davon. Allerdings glaube ich, dass Quantencomputer in Bezug auf Supply Chains sehr schwierige Herausforderungen darstellen. Erstens, wie gesagt, ist die Latenz die große Herausforderung unserer Zeit im Bereich der Unternehmenssoftware, und Quantencomputer ändern daran nichts. Quantencomputer bieten Ihnen potenziell eine 10-fache Geschwindigkeitssteigerung für extrem enge Berechnungsprobleme. Also wären Quantencomputer die nächste Stufe nach TPUs, wo Sie extrem enge Operationen unglaublich schnell durchführen können.
Das ist sehr interessant, aber um ehrlich zu sein, gibt es derzeit sehr wenige Unternehmen, soweit ich weiß, die es schaffen, superskalare Anweisungen in ihrer Unternehmenssoftware zu nutzen. Das bedeutet, dass der gesamte Markt eine 10- bis 28-fache Geschwindigkeitssteigerung auf dem Tisch liegen lässt, die superskalare GPUs sind. Es gibt sehr wenige Menschen in der Supply-Chain-Welt, die es tun; vielleicht Lokad, vielleicht auch nicht. TPUs, ich glaube, da gibt es buchstäblich niemanden. Google nutzt sie umfangreich, aber ich kenne niemanden, der TPUs jemals für etwas mit Bezug zur Supply Chain verwendet hat. Quantenprozessoren wären die Stufe über TPUs.
Ich bin definitiv sehr aufmerksam, was mit Quantencomputern passiert, aber ich glaube, dass dies nicht das Engpass ist, dem wir gegenüberstehen. Es ist faszinierend, weil wir das von Neumann-Design, das vor etwa 70 Jahren etabliert wurde, überdenken, aber dies ist nicht der Engpass, dem wir oder die Supply Chain in den nächsten zehn Jahren gegenüberstehen werden. Danach ist Ihre Vermutung so gut wie meine. Ja, es könnte potenziell alles ändern oder auch nicht.
Frage: Cloud- und SaaS-Angebote ermöglichen es Unternehmen, fixe Kosten zu nutzen und umzuwandeln. Arbeiten die Unternehmen, die solche Dienste anbieten, auch daran, ihre fixen Kosten und das damit verbundene Risiko zu reduzieren?
Nun, das kommt darauf an. Wenn ich eine Cloud-Computing-Plattform bin und Ihnen Rechenleistung verkaufe, ist es dann wirklich in meinem Interesse, Ihre Unternehmenssoftware so effizient wie möglich zu machen? Nicht wirklich. Ich verkaufe Ihnen virtuelle Maschinen, Gigabyte an Bandbreite und Speicherplatz, also eigentlich genau das Gegenteil. Mein Interesse besteht darin, sicherzustellen, dass Sie Software haben, die so ineffizient wie möglich ist, damit Sie eine enorme Menge an Ressourcen verbrauchen und dafür bezahlen.
Intern arbeiten große Technologieunternehmen wie Microsoft, Amazon und Google äußerst aggressiv an der Optimierung ihrer Rechenressourcen. Aber sie sind auch aggressiv, wenn es darum geht, die Rechnung zu bezahlen, wenn sie einem Kunden eine virtuelle Maschine vermieten. Wenn der Kunde eine virtuelle Maschine mietet, die 10-mal größer ist als sie sein sollte, nur weil das Stück Unternehmenssoftware, das er verwendet, äußerst ineffizient ist, ist es nicht in ihrem Interesse, den Fehler des Kunden zu korrigieren. Für sie ist das in Ordnung; das ist gutes Geschäft. Wenn man bedenkt, dass Systemintegratoren und Cloud-Computing-Plattformen tendenziell partnerschaftlich zusammenarbeiten, wird deutlich, dass diese Personengruppen nicht unbedingt Ihr bestes Interesse im Blick haben. Bei SaaS ist das jedoch etwas anders. Tatsächlich ist es im Interesse des Unternehmens, wenn Sie einen SaaS-Anbieter pro Benutzer bezahlen, und das ist zum Beispiel bei Lokad der Fall. Wir berechnen nicht die von uns verbrauchten Rechenressourcen; wir berechnen unseren Kunden in der Regel monatliche Pauschalgebühren. Daher sind SaaS-Anbieter tendenziell sehr aggressiv, wenn es um ihren eigenen Verbrauch von Rechenressourcen geht.
Allerdings gibt es hier einen Bias: Wenn Sie ein SaaS-Unternehmen sind, können Sie ziemlich zögerlich sein, etwas zu tun, das für Ihre Kunden viel angenehmer wäre, aber für Sie selbst in Bezug auf Hardware viel kostspieliger wäre. Es ist nicht alles gut und rosig. Es gibt eine Art Interessenkonflikt, der alle SaaS-Anbieter betrifft, die im Bereich der Supply Chain tätig sind. Sie könnten beispielsweise in die Neugestaltung all ihrer Systeme investieren, um eine bessere Latenz und schnellere Webseiten bereitzustellen, aber das Problem ist, dass dies Ressourcen kostet und ihre Kunden ihnen nicht automatisch mehr bezahlen werden, wenn sie das tun.
Das Problem wird verstärkt, wenn es um Unternehmenssoftware geht. Warum ist das so? Weil die Person, die die Software kauft, in der Regel nicht die Person ist, die sie verwendet. Das ist der Grund, warum so viel von dem Unternehmenssystem unglaublich langsam ist. Die Person, die die Software kauft, leidet nicht so sehr wie ein armer Bedarfsplaner oder Bestandsmanager, der jeden Tag des Jahres mit einem super langsamen System zurechtkommen muss. Es gibt also einen weiteren Aspekt, der spezifisch für den Bereich der Unternehmenssoftware ist. Sie müssen die Situation wirklich analysieren und alle Anreize betrachten, die im Spiel sind, und bei der Arbeit mit Unternehmenssoftware gibt es in der Regel viele widersprüchliche Anreize.
Frage: Wie oft musste Lokad seine Vorgehensweise angesichts des beobachteten Fortschritts in der Hardware überdenken? Können Sie, wenn möglich, ein Beispiel nennen, um diesen Inhalt in den Kontext realer gelöster Probleme zu stellen?
Lokad hat meiner Meinung nach unsere Technologie-Stack etwa ein halbes Dutzend Mal umfassend umgestaltet. Lokad wurde jedoch 2008 gegründet, und wir haben etwa ein halbes Dutzend große Neuschreibungen der gesamten Architektur durchgeführt. Es lag nicht daran, dass die Software so weit fortgeschritten war; die Software hatte sich ja verbessert, aber das meiste, was uns zu den Neuschreibungen veranlasst hat, war nicht die Tatsache, dass die Hardware so weit fortgeschritten war. Es war eher so, dass wir ein besseres Verständnis für die Hardware gewonnen hatten. Alles, was ich heute präsentiert habe, war im Grunde denjenigen bekannt, die bereits vor einem Jahrzehnt aufmerksam waren. Sie sehen also, ja, die Hardware entwickelt sich weiter, aber das geschieht sehr langsam, und die meisten Trends sind sogar ein Jahrzehnt im Voraus sehr vorhersehbar. Hier wird ein langes Spiel gespielt.
Lokad musste massive Neuschreibungen durchlaufen, aber es war eher ein Spiegelbild davon, dass wir allmählich weniger inkompetent wurden. Wir haben Kompetenz gewonnen, und so hatten wir ein besseres Verständnis dafür, wie man die Hardware nutzen kann, anstatt dass die Hardware die Aufgabe verändert hat. Das war nicht immer wahr; es gab spezifische Elemente, die wirklich bahnbrechend für uns waren. Das bemerkenswerteste war SSDs. Wir sind von HDD auf SSD umgestiegen, und das hat unser Leistungsniveau komplett verändert und massive Auswirkungen auf unsere Architektur gehabt. In Bezug auf sehr konkrete Beispiele basiert das gesamte Design von Envision, der domänenspezifischen Programmiersprache, die Lokad bereitstellt, auf den Erkenntnissen, die wir auf Hardwareebene gesammelt haben. Es ist nicht nur eine Leistung; es geht darum, alles, was Sie sich vorstellen können, einfach schneller zu machen.
Sie möchten eine Tabelle mit einer Milliarde Zeilen und 100 Spalten verarbeiten und dies mit den gleichen Rechenressourcen 100-mal schneller tun? Ja, das ist möglich. Sie möchten Joins zwischen sehr großen Tabellen mit minimalen Rechenressourcen durchführen? Ja, auch das ist möglich. Können Sie super komplexe Dashboards mit buchstäblich hundert Tabellen anzeigen, die dem Endbenutzer in weniger als 500 Millisekunden angezeigt werden? Ja, das haben wir erreicht. Das sind alltägliche Leistungen, aber genau deshalb können wir recht ausgefallene vorhersagende Optimierungsrezepte in die Produktion bringen. Wir müssen sicherstellen, dass alle Schritte, die uns dorthin gebracht haben, mit sehr hoher Produktivität durchgeführt werden.
Die größte Herausforderung, wenn Sie etwas sehr Ausgefallenes für die Supply Chain in Bezug auf numerische Rezepte tun möchten, ist nicht die Phase “es zum Laufen bringen”. Sie können College-Studenten nehmen und eine Reihe von Prototypen erstellen, die in wenigen Wochen eine Art Verbesserung der Supply Chain-Leistung liefern werden. Sie nehmen einfach Python und irgendeine zufällige Open-Source-Machine-Learning-Bibliothek des Tages, und diese Studenten werden, wenn sie klug und willens sind, in wenigen Wochen einen funktionierenden Prototyp erstellen. Sie werden ihn jedoch niemals in großem Maßstab in die Produktion bringen. Das ist das Problem. Es geht darum, wie Sie all diese Reifungsstufen von “machen Sie es richtig”, “machen Sie es schnell” und “machen Sie es billig” durchlaufen. Hier kommt die Hardware-Affinität wirklich zum Tragen und Ihre Fähigkeit zur Iteration.
Es gibt keine einzelne Leistung. Alles, was wir tun, erfordert zum Beispiel, wenn wir sagen, dass Lokad probabilistische Prognosen erstellt, nicht so viel Rechenleistung. Was wirklich Rechenleistung erfordert, ist die Nutzung sehr umfangreicher Wahrscheinlichkeitsverteilungen und die Betrachtung all dieser möglichen Zukunftsszenarien in Kombination mit allen möglichen Entscheidungen, die Sie treffen können. Auf diese Weise können Sie die besten mit finanzieller Optimierung auswählen, was sehr kostspielig ist. Wenn Sie nichts haben, das sehr optimiert ist, sind Sie festgefahren. Die Tatsache, dass Lokad probabilistische Prognosen in der Produktion verwenden kann, ist ein Zeugnis dafür, dass wir auf Hardwareebene umfangreiche Optimierungen in allen unseren Pipelines für alle unsere Kunden vorgenommen haben. Wir bedienen derzeit etwa 100 Unternehmen.
Frage: Ist es besser, für Unternehmenssoftware (ERP, WMS) einen firmeneigenen Server zu haben, anstatt Cloud-Dienste zu nutzen, um Latenz zu vermeiden?
Ich würde sagen, heutzutage spielt es keine Rolle mehr, da die meisten Latenzen, die Sie erleben, innerhalb des Systems liegen. Dies ist nicht das Problem der Latenz zwischen Ihrem Benutzer und dem ERP. Ja, wenn Sie eine sehr schlechte Latenz haben, können Sie etwa 50 Millisekunden Latenz hinzufügen. Natürlich möchten Sie, wenn Sie ein ERP haben, nicht, dass es in Melbourne sitzt, während Sie zum Beispiel in Paris arbeiten. Sie möchten das Rechenzentrum in der Nähe Ihres Betriebs halten. Moderne Cloud-Computing-Plattformen verfügen jedoch über Dutzende von Rechenzentren, sodass es in Bezug auf die Latenz keinen großen Unterschied zwischen firmeneigener Hosting und Cloud-Diensten gibt.
In der Regel bedeutet firmeneigenes Hosting nicht, das ERP auf dem Boden in der Mitte der Fabrik oder des Lagers zu platzieren. Stattdessen bedeutet es, Ihr ERP in ein Rechenzentrum zu stellen, in dem Sie Computing-Hardware mieten. Ich glaube, dass es aus der Perspektive moderner Cloud-Computing-Plattformen mit Rechenzentren auf der ganzen Welt keinen praktischen Unterschied zwischen firmeneigenem Hosting und Cloud-Computing-Plattformen gibt.
Was wirklich einen Unterschied macht, ist, ob Sie ein ERP haben, das alle Rundreisen intern minimiert. Zum Beispiel ist das, was die Leistung eines ERPs in der Regel beeinträchtigt, die Interaktion zwischen der Geschäftslogik und der relationalen Datenbank. Wenn Sie Hunderte von Hin- und Her-Interaktionen haben, um eine Webseite anzuzeigen, wird Ihr ERP sehr langsam sein. Sie müssen also Unternehmenssoftware-Designs in Betracht ziehen, die nicht mit einer großen Anzahl von Rundreisen einhergehen. Dies ist eine innere Eigenschaft der von Ihnen betrachteten Unternehmenssoftware und hängt nicht stark davon ab, wo Sie die Software platzieren.
Frage: Glauben Sie, dass wir neue Programmiersprachen benötigen, die das neue Hardware-Design auf Kernebene nutzen und die Hardwarearchitekturmerkmale in vollem Umfang nutzen?
Ja, und ja. Aber um vollständig zu sein, ich habe hier einen Interessenkonflikt. Genau das hat Lokad mit Envision gemacht. Envision entstand aus der Beobachtung, dass es schwierig ist, die gesamte verfügbare Rechenleistung moderner Computer zu nutzen, aber es sollte nicht schwierig sein, wenn Sie die Programmiersprache selbst mit Leistung im Hinterkopf entwerfen. Sie können es übernatürlich machen, und deshalb habe ich in der Vorlesung 1.4 über Programmierparadigmen für die Supply Chain gesagt, dass Sie bei der Auswahl der richtigen Programmierparadigmen, wie z.B. Array-Programmierung oder Dataframe-Programmierung, und der Konstruktion einer Programmiersprache, die diese Konzepte umfasst, nahezu kostenlos Leistung erhalten.
Der Preis, den Sie zahlen, ist, dass Sie nicht so ausdrucksstark sind wie eine Programmiersprache wie Python oder C++, aber wenn Sie bereit sind, eine reduzierte Ausdrucksstärke zu akzeptieren und alle relevanten Anwendungsfälle für die Supply Chain abzudecken, dann ja, können Sie massive Leistungsverbesserungen erzielen. Das ist meine Überzeugung, und deshalb habe ich auch gesagt, dass objektorientierte Programmierung aus der Perspektive der Optimierung der Supply Chain nichts bringt.
Im Gegenteil, dies ist eine Art Paradigma, das die zugrunde liegende Rechenhardware nur antagonisiert. Ich sage nicht, dass objektorientierte Programmierung völlig schlecht ist; das ist nicht das, was ich sage. Ich sage, dass es Bereiche der Softwareentwicklung gibt, in denen es vollkommen sinnvoll ist, aber was die vorhersagende Optimierung der Supply Chain betrifft, macht es keinen Sinn. Ja, wir brauchen wirklich Programmiersprachen, die das wirklich umfassen.
Ich weiß, dass ich dazu neige, dies zu wiederholen, aber Python wurde im Wesentlichen in den späten 80er Jahren entwickelt, und sie haben irgendwie alles verpasst, was es über moderne Computer zu sehen gab. Sie haben etwas, wo sie aufgrund ihres Designs kein Multithreading nutzen können. Sie haben dieses globale Schloss, sodass sie keine mehreren Kerne nutzen können. Sie können keine Lokalität nutzen. Sie haben eine späte Bindung, die den Zugriff auf den Speicher wirklich kompliziert. Sie sind sehr variabel, sodass sie viel Speicher verbrauchen, was bedeutet, dass es gegen den Cache spielt, usw.
Dies sind die Arten von Problemen, bei denen, wenn Sie Python verwenden, bedeutet, dass Sie in den kommenden Jahrzehnten mit bergauf kämpfen werden, und der Kampf wird im Laufe der Zeit nur schlimmer werden. Sie werden nicht besser.
Die nächste Vorlesung findet in drei Wochen statt, am gleichen Wochentag zur gleichen Zeit. Sie wird um 15 Uhr Pariser Zeit am 9. Juni stattfinden. Wir werden moderne Algorithmen für die Supply Chain diskutieren, die sozusagen das Gegenstück zu modernen Computern für die Supply Chain sind. Bis zum nächsten Mal.


