00:17 Introduction
03:35 Orders of Magnitude
06:55 Stages of Supply Chain Optimization
12:17 The S-Curves of hardware
15:52 The story so far
17:34 Auxiliary sciences
20:25 Modern computers
20:57 Latency 1/2
27:15 Latency 2/2
30:37 Compute, clock speed
36:36 Compute, pipelining, 1/3
39:11 Compute, pipelining, 2/3
40:27 Compute, pipelining, 3/3
46:36 Compute, superscalar 1/2
49:55 Compute, superscalar 2/2
56:45 Memory 1/3
01:00:42 Memory 2/3
01:06:43 Memory 3/3
01:11:13 Data storage 1/2
01:14:06 Data storage 2/2
01:18:36 Bandwidth
01:23:20 Conclusion
01:27:33 Upcoming lecture and audience questions
Description
Les supply chains modernes requièrent des ressources informatiques pour fonctionner tout comme les convoyeurs motorisés nécessitent de l’électricité. Pourtant, des systèmes de supply chain lents restent omniprésents, tandis que la puissance de calcul des ordinateurs a augmenté d’un facteur supérieur à 10 000 depuis 1990. Un manque de compréhension des caractéristiques fondamentales des ressources informatiques modernes – même parmi les cercles IT ou data science – contribue largement à expliquer cet état de choses. La conception logicielle sous-jacente aux recettes numériques ne devrait pas antagoniser le substrat informatique sous-jacent.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter “Ordinateurs modernes pour supply chain”. Les supply chains occidentales ont été digitalisées depuis longtemps, parfois il y a jusqu’à trois décennies. Les décisions basées sur l’informatique sont partout, et les recettes numériques associées se déclinent sous divers noms tels que points de réapprovisionnement, min-max stocks, et safety stocks, avec divers degrés de supervision humaine.
Néanmoins, si nous observons les grandes entreprises d’aujourd’hui qui opèrent des supply chains tout aussi vastes, nous constatons des millions de décisions essentiellement pilotées par l’informatique, qui déterminent la performance de la supply chain. Ainsi, lorsqu’il s’agit d’améliorer la performance de la supply chain, cela se résume rapidement à l’amélioration des recettes numériques qui la pilotent. Ici, invariablement, dès que nous commençons à envisager des recettes numériques supérieures de quelque nature que ce soit, où nous souhaitons de meilleurs modèles et des prévisions plus précises, ces recettes supérieures finissent par coûter beaucoup plus de ressources informatiques.
Les ressources informatiques ont toujours été un défi pour la supply chain car elles coûtent très cher, et il y a toujours la prochaine étape d’évolution pour le modèle suivant ou le système de prévision suivant qui nécessite dix fois plus de ressources informatiques que le précédent. Oui, cela pourrait apporter une performance supply chain supplémentaire, mais cela s’accompagne d’un coût informatique accru. Au cours des dernières décennies, le matériel informatique a progressé de manière spectaculaire, mais comme nous le verrons aujourd’hui, cette progression, bien qu’encore en cours, est fréquemment antagonisée par les enterprise software. En conséquence, les logiciels ne deviennent pas plus rapides avec du matériel plus moderne ; au contraire, ils peuvent très souvent devenir plus lents.
L’objectif de cette conférence est d’inculquer au public une certaine sympathie mécanique, pour que vous puissiez évaluer si un logiciel d’entreprise censé mettre en œuvre des recettes numériques destinées à offrir une performance supply chain supérieure exploite le matériel informatique tel qu’il existe déjà et tel qu’il existera dans une décennie, ou s’il l’antagonise et, par conséquent, n’exploite pas pleinement le matériel informatique dont nous disposons aujourd’hui.

L’un des aspects les plus déconcertants des ordinateurs modernes est l’éventail des ordres de grandeur impliqués. Du point de vue de la supply chain, nous avons généralement environ cinq ordres de grandeur, et cela est déjà considérable ; généralement, ce n’est même pas le cas. Cinq ordres de grandeur signifient que nous pouvons passer d’une unité à 100 000 unités. Rappelez-vous que j’ai évoqué dans des conférences précédentes la loi des petits nombres en jeu. Si vous avez un grand nombre d’unités, vous ne les traiterez pas individuellement ; vous allez les regrouper dans des boîtes, et vous vous retrouverez ainsi avec un nombre bien plus réduit de boîtes. De même, si vous avez de nombreuses boîtes, vous les emballerez sur des palettes, etc., de sorte à avoir un nombre bien plus réduit de palettes. Les économies d’échelle induisent des prévisions de quantités et, du point de vue de la supply chain, lorsque nous traitons le flux de biens physiques, une inefficacité de 10 % tend déjà à être assez significative.
Dans le domaine de l’informatique, c’est très différent ; nous traitons avec 15 ordres de grandeur, ce qui est absolument gigantesque. Passer d’une unité à un million de milliards d’unités, le nombre est si grand qu’il est en fait très difficile à visualiser. Nous passons d’un octet, qui n’est que huit bits et peut être utilisé pour représenter une lettre ou un chiffre, à un petaoctet, soit un million de gigaoctets. Un petaoctet correspond approximativement à l’ordre de grandeur de la quantité de données que Lokad gère actuellement, et les grandes entreprises exploitant d’importantes supply chains gèrent également des ensembles de données de l’ordre d’un petaoctet.
Nous passons d’un FLOP (opération en virgule flottante par seconde) à un petaFLOP, soit un million de gigaFLOPS. Ces ordres de grandeur sont absolument gigantesques et très trompeurs. En conséquence, dans le domaine de la supply chain, où 10 % est considéré comme inefficace, ce qui se produit typiquement dans le domaine de l’informatique, ce n’est pas tant une inefficacité de 10 %, mais plutôt une inefficacité par un facteur de 10, et parfois de plusieurs ordres de grandeur. Ainsi, si vous faites une erreur en termes de performance dans le domaine de l’informatique, votre pénalité ne sera pas de 10 % ; au contraire, votre système sera 10 fois plus lent qu’il ne le devrait, ou 100 fois, et parfois même 1000 fois plus lent qu’il ne l’aurait dû être. C’est vraiment ce qui est en jeu : avoir un véritable alignement, qui requiert une certaine sympathie mécanique entre le logiciel d’entreprise et le matériel informatique sous-jacent.
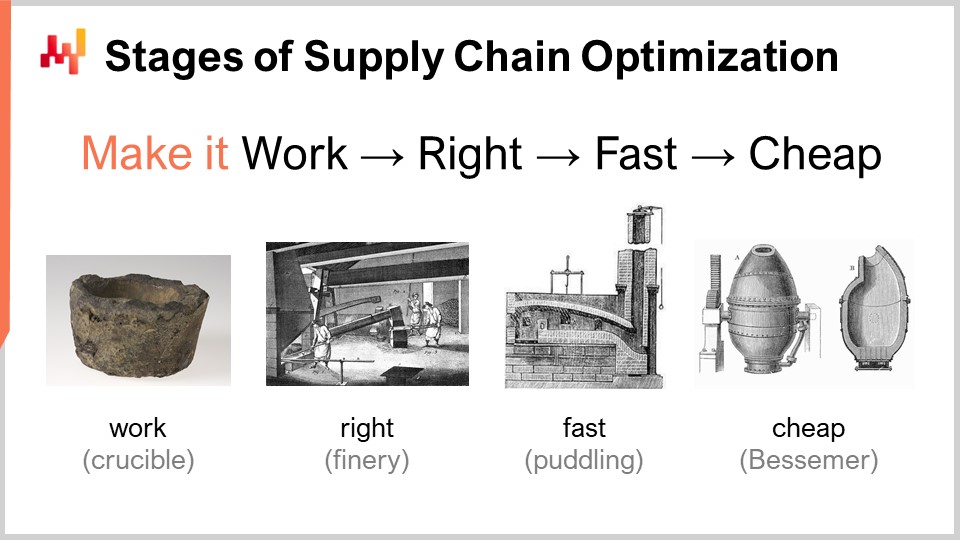
Lorsqu’on considère une recette numérique censée offrir une performance supply chain supérieure, il existe un certain nombre d’étapes de maturité qui présentent, conceptuellement, un intérêt. Bien entendu, les résultats peuvent varier en pratique, mais c’est typiquement ce que nous avons identifié chez Lokad. Ces étapes peuvent être résumées ainsi : la faire fonctionner, la rendre correcte, la rendre rapide, et la rendre économique.
« La faire fonctionner » consiste à évaluer si un prototype de recette numérique fournit réellement les résultats escomptés, tels que des taux de service plus élevés, moins de stocks morts, une meilleure utilisation des actifs, ou tout autre objectif pertinent du point de vue de la supply chain. Le but est d’abord de s’assurer que la nouvelle recette numérique fonctionne réellement au premier stade de maturité.
Ensuite, vous devez « la rendre correcte ». Du point de vue de la supply chain, cela signifie transformer ce qui était essentiellement un prototype unique en quelque chose de qualité industrielle. Cela implique généralement d’incorporer à la recette numérique un certain degré de rigueur par conception. Les supply chains sont vastes, complexes, et surtout, très désordonnées. Si vous avez une recette numérique très fragile, même si la méthode numérique est bonne, il est très facile de se tromper, et vous finirez par créer bien plus de problèmes que les bénéfices escomptés initialement. Ce n’est pas une proposition gagnante. La rendre correcte consiste à s’assurer que vous disposez de quelque chose pouvant être déployé à grande échelle avec un minimum de friction. Ensuite, vous voulez rendre cette recette numérique rapide, et quand je dis rapide, j’entends rapide en termes de temps d’exécution. Lorsque vous lancez le calcul, vous devriez obtenir les résultats en quelques minutes, ou peut-être une heure ou deux au maximum, mais pas plus longtemps. Les supply chains sont chaotiques, et il arrivera un moment dans l’histoire de votre entreprise où il y aura des disruptions, telles que des porte-conteneurs coincés au milieu du canal de Suez, une pandémie, ou un entrepôt inondé. Lorsque cela se produit, vous devez être capable de réagir rapidement. Je ne dis pas réagir dans les millisecondes qui suivent, mais si vous avez des recettes numériques qui prennent des jours à s’exécuter, cela crée une friction opérationnelle massive. Il vous faut des solutions pouvant être exploitées dans un délai humain court, donc elles doivent être rapides.
Rappelez-vous, les logiciels d’entreprise modernes fonctionnent sur cloud computing, et vous pouvez toujours payer pour obtenir plus de ressources informatiques sur ces plateformes. Ainsi, votre logiciel peut être rapide simplement parce que vous louez beaucoup de puissance de traitement. Ce n’est pas que le logiciel lui-même doive être correctement conçu pour tirer parti de toute la puissance de traitement que le cloud peut fournir, mais il peut être rapide et très inefficace simplement parce que vous louez autant de puissance de traitement auprès de votre fournisseur de cloud computing.
L’étape suivante est de rendre la méthode économique, c’est-à-dire qu’elle n’utilise pas trop de ressources cloud computing. Si vous n’atteignez pas cette étape finale, cela signifie que vous ne pourrez jamais améliorer votre méthode. Si vous avez une méthode qui fonctionne, est correcte et est rapide mais consomme beaucoup de ressources, lorsque vous voudrez passer à l’étape suivante de la recette numérique, qui impliquera invariablement quelque chose qui coûte encore plus de ressources informatiques que ce que vous utilisez actuellement, vous serez bloqué. Il vous faut rendre la méthode que vous avez très efficiente afin de pouvoir commencer à expérimenter des recettes numériques moins performantes que celle que vous avez actuellement.
Cette dernière étape est celle où vous devez vraiment exploiter le matériel sous-jacent disponible dans les ordinateurs modernes. Vous pouvez vous en sortir avec les trois premières étapes sans trop d’affinité, mais la dernière est essentielle. Rappelez-vous, si vous n’atteignez pas l’étape « la rendre économique », vous ne pourrez pas itérer, et donc vous serez bloqué. C’est pourquoi, même s’il s’agit de la dernière étape, c’est un jeu itératif, et il est essentiel de passer par toutes les étapes si vous souhaitez itérer de manière répétée.
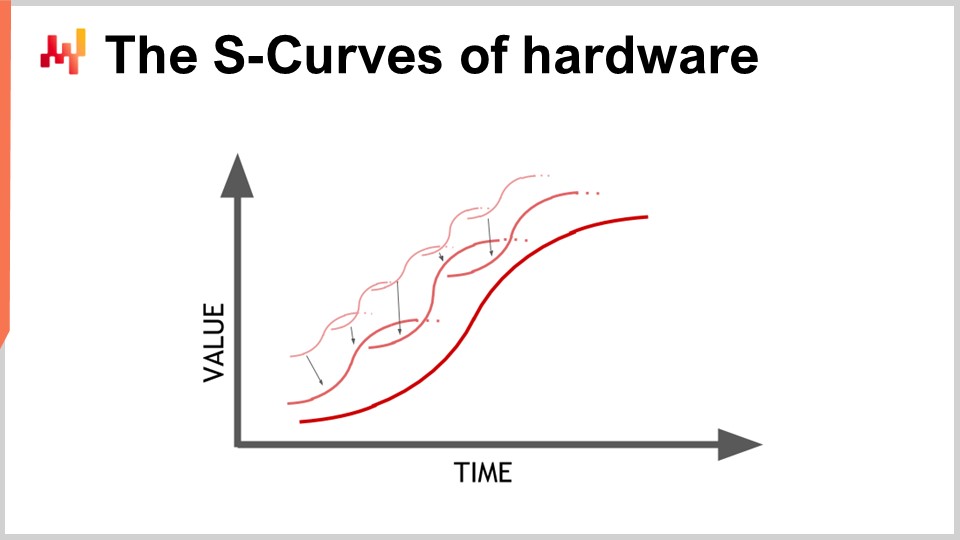
Le matériel progresse, et cela ressemble à une progression exponentielle, mais en réalité, cette progression exponentielle du matériel informatique est en fait composée de milliers de courbes en S. Une courbe en S est une courbe où vous introduisez un nouveau design, procédé, matériau ou architecture, et, initialement, ce n’est pas vraiment supérieur à ce que vous aviez auparavant. Ensuite, l’effet de l’innovation prévue entre en jeu, et vous avez une montée en puissance, suivie d’un plateau après avoir épuisé tous les bénéfices de l’innovation. Les courbes en S en plateau sont caractéristiques des progrès du matériel informatique, qui sont constitués de milliers de ces courbes. Pour un profane, cela apparaît comme une croissance exponentielle. Cependant, les experts voient les courbes en S individuelles se stabiliser, ce qui peut conduire à une vue pessimiste. Même les experts ne voient pas toujours l’émergence de nouvelles courbes en S qui surprennent tout le monde et poursuivent la croissance exponentielle du progrès.
Bien que le matériel informatique progresse encore, le taux de progression n’est pas du tout comparable à ce que nous avons connu dans les années 1980 ou 1990. Le rythme est désormais bien plus lent et assez prévisible, en grande partie en raison des investissements massifs requis pour construire de nouvelles usines de production de matériel informatique. Ces investissements s’élèvent souvent à plusieurs centaines de millions de dollars, offrant une visibilité de cinq à dix ans à l’avance. Bien que la progression se soit ralentie, nous avons encore une vision relativement précise de ce qui se passera en termes de progrès du matériel informatique pour la prochaine décennie.
La leçon pour les logiciels d’entreprise mettant en œuvre des recettes numériques est que vous ne pouvez pas vous attendre passivement à ce que le matériel futur améliore tout pour vous. Le matériel progresse encore, mais capter cette progression nécessite un effort du côté logiciel. Vous serez capable de faire plus avec le matériel qui existera dans une décennie, mais seulement si l’architecture au cœur de votre logiciel d’entreprise exploite le matériel informatique sous-jacent. Sinon, vous pourriez en réalité faire pire que ce que vous faites aujourd’hui, une proposition qui n’est pas aussi déraisonnable qu’il n’y paraît.
Cette conférence est la première du quatrième chapitre de cette série de conférences sur la supply chain. Je n’ai pas terminé le troisième chapitre concernant les personae de la supply chain. Dans les conférences suivantes, j’alternerai probablement entre le présent chapitre, où je traite des sciences auxiliaires de la supply chain, et le troisième chapitre sur les personae de la supply chain.
Dans le tout premier chapitre du prologue, j’ai présenté mes points de vue sur la supply chain en tant que domaine d’étude et en tant que pratique. Nous avons vu que la supply chain est essentiellement un ensemble de problèmes épineux, par opposition à des problèmes simples, entachés d’un comportement antagoniste et de jeux compétitifs. Par conséquent, nous devons accorder une grande attention à la méthodologie car les méthodes directes naïves performent mal dans ce domaine. C’est pourquoi le deuxième chapitre a été consacré à la méthodologie nécessaire pour étudier les supply chains et établir des pratiques visant à les améliorer au fil du temps.
Le troisième chapitre, Supply Chain Personae, s’est concentré sur la caractérisation des problèmes supply chain eux-mêmes, avec la devise “tombez amoureux du problème, pas de la solution.” Le quatrième chapitre que nous ouvrons aujourd’hui traite des sciences auxiliaires des supply chains.

Les sciences auxiliaires sont des disciplines qui soutiennent l’étude d’une autre discipline. Il ne s’agit pas d’un jugement de valeur ; ce n’est pas qu’une discipline est supérieure à une autre. Par exemple, la médecine n’est pas supérieure à la biologie, mais la biologie est une science auxiliaire pour la médecine. La perspective des sciences auxiliaires est bien établie et présente dans de nombreux domaines de recherche, tels que les sciences médicales et l’histoire.
Dans les sciences médicales, les sciences auxiliaires incluent la biologie, la chimie, la physique et la sociologie, entre autres. Un médecin moderne ne serait pas considéré comme compétent s’il n’avait aucune connaissance en physique. Par exemple, comprendre les bases de la physique est nécessaire pour interpréter une image radiographique. Il en va de même pour l’histoire, qui bénéficie d’une longue série de sciences auxiliaires.
En ce qui concerne la supply chain, l’une de mes plus grandes critiques vis-à-vis des supports, cours, livres et articles typiques sur la supply chain est qu’ils abordent le sujet sans approfondir aucune science auxiliaire. Ils traitent la supply chain comme si c’était une branche de connaissance isolée et autonome. Cependant, je crois que la pratique moderne de la supply chain ne peut être réalisée qu’en exploitant pleinement les sciences auxiliaires des supply chains. L’une de ces sciences auxiliaires, et le point focal de la conférence d’aujourd’hui, est le hardware informatique.
Cette conférence n’est pas strictement une conférence supply chain, mais plutôt sur le hardware informatique en ayant à l’esprit des applications supply chain. Je crois qu’il est fondamental de pratiquer la supply chain de manière moderne, contrairement à ce qui se faisait il y a un siècle.

Examinons les ordinateurs modernes. Dans cette conférence, nous passerons en revue ce qu’ils peuvent faire pour la supply chain, en nous concentrant particulièrement sur les aspects ayant un impact massif sur la performance des logiciels d’entreprise. Nous examinerons la latence, la capacité de calcul, la mémoire, le stockage de données et la bande passante.

La vitesse de la lumière est d’environ 30 centimètres par nanoseconde, ce qui est relativement lent. Si l’on considère la distance caractéristique d’intérêt pour un CPU moderne qui fonctionne à 5 gigahertz (5 milliards d’opérations par seconde), la distance aller-retour que la lumière peut parcourir en 0,2 nanoseconde n’est que de 3 centimètres. Cela signifie que, en raison de la limitation de la vitesse de la lumière, les interactions ne peuvent pas avoir lieu au-delà de 3 centimètres. Ceci est une limite stricte imposée par les lois de la physique, et il n’est pas clair que nous puissions jamais la dépasser.
La latence est une contrainte extrêmement difficile. D’un point de vue supply chain, nous avons au moins deux modes de distribution du hardware informatique impliqués. Quand je parle de hardware informatique distribué, je veux dire du hardware informatique qui implique de nombreux appareils ne pouvant pas occuper le même espace physique. Évidemment, il faut les séparer simplement parce qu’ils occupent chacun un certain volume. Cependant, la première raison pour laquelle nous avons besoin de hardware informatique distribué est la nature des supply chains, qui sont géographiquement réparties. Par conception, les supply chains sont dispersées sur plusieurs zones géographiques, et ainsi, il y aura également du hardware informatique réparti dans ces territoires. D’un point de vue vitesse de la lumière, même si vous avez des appareils seulement à trois mètres les uns des autres, c’est déjà très lent car il faut 100 cycles d’horloge pour effectuer l’aller-retour. Trois mètres constituent une distance considérable compte tenu de la vitesse de la lumière et de la fréquence d’horloge des CPU modernes.
Un autre type de distribution est l’échelle horizontale. La manière moderne d’obtenir plus de puissance de traitement n’est pas d’avoir un appareil de computing qui soit 10 fois ou un million de fois plus puissant ; ce n’est pas ainsi que cela est conçu. Si vous voulez plus de ressources de traitement, vous avez besoin d’appareils informatiques supplémentaires, de processeurs supplémentaires, de puces mémoire supplémentaires et de disques durs supplémentaires. C’est en empilant le hardware informatique que vous pouvez disposer de plus de ressources de calcul. Cependant, tous ces appareils prennent de la place, et donc, vous finissez par distribuer votre hardware informatique simplement parce que vous ne pouvez pas le centraliser dans un ordinateur de largeur d’un centimètre.
En ce qui concerne les latences, en regardant le type de latences que nous avons sur l’internet professionnel (les latences que vous pouvez obtenir dans un data center, et non sur votre Wi-Fi à la maison), nous sommes déjà à environ 30 % de la vitesse de la lumière. Par exemple, la latence entre un data center près de Paris, France, et New York, États-Unis, n’atteint qu’environ 30 % de la vitesse de la lumière. C’est une réalisation incroyable pour l’humanité ; l’information circule sur internet à une vitesse proche de celle de la lumière. Certes, il reste encore une marge d’amélioration, mais nous sommes déjà proches des limites strictes imposées par la physique.
En conséquence, il existe désormais même des entreprises qui souhaitent poser un câble sur le plancher marin de l’Arctique pour connecter Londres à Tokyo avec un câble passant sous le pôle Nord, juste pour gagner quelques millisecondes de latence lors de transactions financières. Fondamentalement, la latence et la vitesse de la lumière sont des préoccupations très réelles, et l’internet que nous avons est essentiellement aussi performant qu’il ne le sera jamais à moins qu’il n’y ait des percées en physique. Cependant, nous n’anticipons rien de tel dans la décennie à venir.
Du fait que la latence est un problème extrêmement difficile, les implications pour les logiciels d’entreprise sont significatives. Les allers-retours en termes de flux d’information sont fatals, et la performance de vos logiciels d’entreprise dépendra en grande partie du nombre d’allers-retours entre les divers sous-systèmes existants dans votre logiciel. Le nombre d’allers-retours caractérisera la latence incompressible que vous subissez. Minimiser ces allers-retours et améliorer les latences est, pour la plupart des logiciels d’entreprise, y compris ceux dédiés à l’optimisation prédictive des supply chains, le problème numéro un. Réduire les latences équivaut souvent à offrir de meilleures performances.

Une astuce intéressante, bien que pas nécessairement quelque chose que tout le monde dans cet auditoire mettra en production, consiste à aborder les complications introduites par la latence. Le temps lui-même devient insaisissable et flou lorsque vous entrez dans le domaine des calculs en nanosecondes. Des horloges précises font défaut dans le computing distribué, et leur absence complique les logiciels d’entreprise distribués. De nombreux allers-retours sont nécessaires pour synchroniser les différentes parties du système. En raison du manque d’une horloge précise, vous finissez par recourir à des alternatives algorithmiques telles que les horloges vectorielles ou les timestamps multipartites, qui sont des structures de données reflétant un ordre partiel des horloges des appareils dans votre système. Ces allers-retours supplémentaires peuvent nuire à la performance.
Une conception astucieuse adoptée par Google il y a plus d’une décennie fut l’utilisation d’horloges atomiques à l’échelle de puce. La résolution de ces horloges atomiques est nettement supérieure à celle des horloges à quartz que l’on trouve dans les montres électroniques ou les ordinateurs. Le NIST a démontré une nouvelle configuration d’horloge atomique à l’échelle de puce avec une dérive quotidienne encore plus précise. Google a utilisé des horloges atomiques internes pour synchroniser les différentes parties de leur base de données SQL distribuée à l’échelle mondiale, Google Spanner, afin d’économiser des allers-retours et d’améliorer les performances à l’échelle globale. C’est une manière de contourner la latence grâce à des mesures temporelles très précises.
En regardant une décennie en avant, il est probable que Google ne sera pas la dernière entreprise à utiliser ce genre d’astuce ingénieuse, et elles sont relativement abordables, les horloges atomiques à l’échelle de puce coûtant environ 1 500 $ chacune.

Passons maintenant au calcul, c’est-à-dire effectuer des opérations avec un ordinateur. La fréquence d’horloge était l’ingrédient magique d’amélioration dans les années 80 et 90. En effet, si vous pouviez doubler la fréquence d’horloge de votre ordinateur dans son ensemble, vous doubleriez effectivement la performance de celui-ci, quel que soit le type de logiciel impliqué. Tous les logiciels seraient linéairement plus rapides en fonction de la fréquence d’horloge. Il est extrêmement intéressant d’augmenter la fréquence d’horloge, et elle continue de s’améliorer, même si cette amélioration s’est stabilisée avec le temps. Il y a presque 20 ans, la fréquence d’horloge était d’environ 2 GHz, et de nos jours, elle est de 5 GHz.
La raison principale de cette amélioration stabilisée est le mur de puissance. Le problème est que lorsque vous augmentez la fréquence d’horloge sur une puce, vous avez tendance à doubler approximativement la consommation d’énergie, et ensuite, vous devez dissiper cette énergie. Le problème est la dissipation thermique car, si vous ne pouvez pas dissiper l’énergie, votre appareil accumule de la chaleur au point de l’endommager. De nos jours, l’industrie des semi-conducteurs est passée d’une augmentation du nombre d’opérations par seconde à une augmentation du nombre d’opérations par watt.
Cette règle d’une augmentation de 30 % pour doubler la consommation d’énergie est une arme à double tranchant. Si vous êtes d’accord pour renoncer à un quart de votre puissance de traitement par unité de temps sur le CPU, vous pouvez en réalité diviser la consommation d’énergie par deux. Ceci est particulièrement intéressant pour les smartphones, où les économies d’énergie sont cruciales, et également pour le cloud computing, où l’un des moteurs clés du coût est l’énergie elle-même. Pour disposer d’une puissance de traitement cloud computing rentable, il ne s’agit pas d’avoir des CPU ultra-rapides, mais plutôt d’avoir des CPU sous-cadencés qui peuvent être aussi lents que 1 GHz, car ils offrent plus d’opérations par seconde pour votre investissement en énergie.
Le mur de puissance est un problème tel que les architectures des CPU modernes utilisent toutes sortes d’astuces ingénieuses pour le contourner. Par exemple, les CPU modernes peuvent réguler leur fréquence d’horloge, la boostant temporairement pendant une seconde ou deux avant de la réduire pour dissiper la chaleur. Ils peuvent également tirer parti de ce que l’on appelle le dark silicon. L’idée est que si le CPU peut alterner les zones chaudes sur la puce, il est plus facile de dissiper l’énergie, contrairement à toujours avoir la même zone active cycle après cycle. C’est un ingrédient clé de la conception moderne. Du point de vue des logiciels d’entreprise, cela signifie que vous voulez vraiment pouvoir étendre horizontalement. Vous voulez être capable de faire plus avec un nombre de CPU plusieurs fois supérieur, mais individuellement, ces processeurs seront plus faibles que ceux que vous aviez auparavant. Il ne s’agit pas d’obtenir de meilleurs processeurs dans le sens où tout serait meilleur globalement ; il s’agit d’avoir des processeurs qui vous fournissent plus d’opérations par watt, et cette tendance va se poursuivre.
Peut-être qu’une décennie à partir de maintenant, nous atteindrons, avec difficulté, sept ou peut-être huit gigahertz, mais je ne suis même pas sûr que nous y parviendrons. Lorsque je regarde la fréquence d’horloge en 2021 chez la plupart des fournisseurs de cloud computing, elle est plus alignée avec typiquement 2 GHz, donc nous sommes revenus à la fréquence d’horloge que nous avions il y a 20 ans, et c’est la solution la plus rentable.
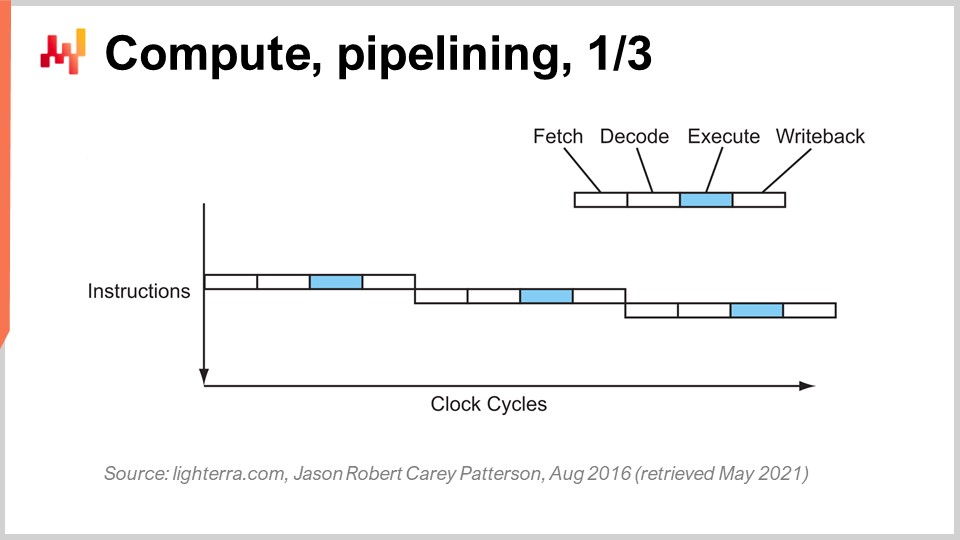
Pour atteindre la performance actuelle des CPU, une série d’innovations clés a été nécessaire. Je vais en présenter quelques-unes, en particulier celles qui ont le plus d’impact sur la conception des logiciels d’entreprise. Sur cet écran, ce que vous voyez est le flux d’instructions d’un processeur séquentiel, tel qu’ils étaient fabriqués essentiellement jusqu’au début des années 80. Vous avez une série d’instructions qui s’exécutent du haut vers le bas du graphique, représentant le temps. Chaque instruction traverse une série d’étapes : récupération, décodage, exécution et écriture du résultat.
Lors de l’étape de récupération, vous récupérez l’instruction, l’enregistrez, saisissez l’instruction suivante, incrémentez le compteur d’instructions et préparez le CPU. Lors de l’étape de décodage, vous décodez l’instruction et générez le microcode interne, qui est ce que le CPU exécute en interne. L’étape d’exécution consiste à récupérer les entrées pertinentes depuis les registres et à effectuer le calcul effectif, et l’étape d’écriture consiste à prendre le résultat que vous venez de calculer et à le placer quelque part dans l’un des registres. Dans ce processeur séquentiel, chaque étape requiert un cycle d’horloge, donc il faut quatre cycles d’horloge pour exécuter une instruction. Comme nous l’avons vu, il est très difficile d’augmenter la fréquence des cycles eux-mêmes en raison de nombreuses complications.
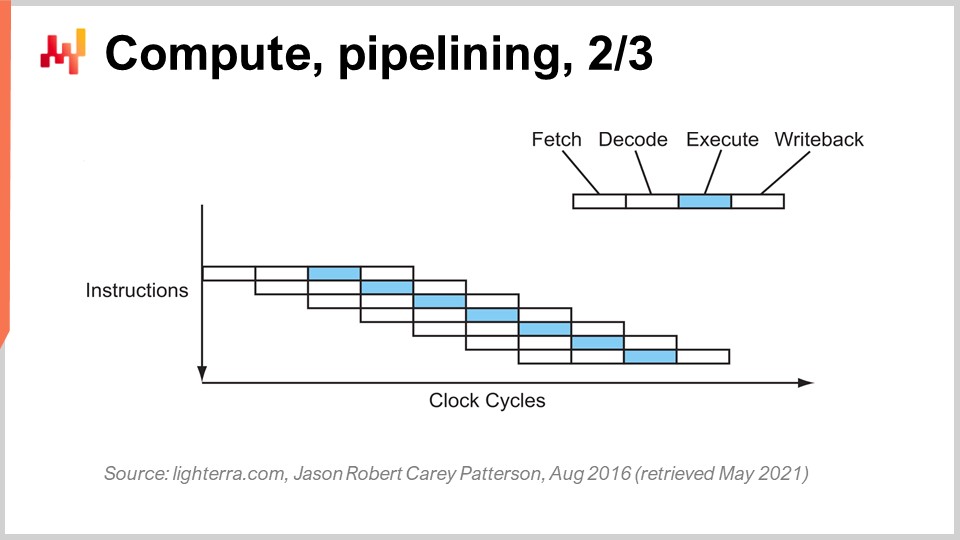
L’astuce clé en place depuis le début des années 80 est connue sous le nom de pipelining. Le pipelining peut accélérer considérablement le calcul de votre processeur. L’idée est que, du fait que chaque instruction passe par une série d’étapes, nous allons chevaucher ces étapes, et ainsi le CPU lui-même disposera d’un pipeline complet d’instructions. Sur ce schéma, vous voyez un CPU avec un pipeline de profondeur quatre, où il y a toujours quatre instructions s’exécutant simultanément. Cependant, elles ne sont pas à la même étape : une instruction est en récupération, une en décodage, une en exécution et une en écriture du résultat. Avec cette astuce simple, représentée ici par un processeur en pipeline, nous avons multiplié par quatre la performance effective du processeur en appliquant simplement le pipelining des opérations. Tous les CPU modernes utilisent le pipelining.
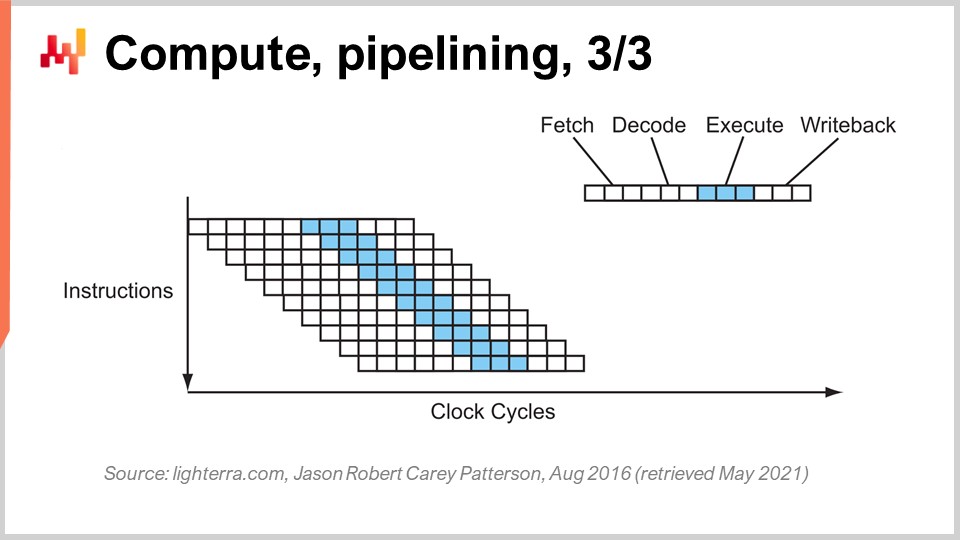
L’étape suivante de cette amélioration est appelée super pipelining. Les CPU modernes vont bien au-delà du simple pipelining. En réalité, le nombre d’étapes impliquées dans un CPU moderne réel est plus proche de 30 étapes. Sur le graphique, vous pouvez voir un exemple de CPU avec 12 étapes, mais en réalité, il y en aurait plutôt environ 30. Avec ce pipeline plus profond, 12 opérations peuvent s’exécuter simultanément, ce qui est très bénéfique pour la performance tout en utilisant le même cycle d’horloge.
Cependant, un nouveau problème émerge : la prochaine instruction commence avant que la précédente ne soit terminée. Cela signifie que si vous avez des opérations dépendantes, vous rencontrez un problème car le calcul des entrées pour la prochaine instruction n’est pas encore prêt, et vous devez attendre. Nous voulons exploiter pleinement le pipeline à notre disposition pour maximiser la puissance de traitement. Ainsi, les CPU modernes récupèrent non pas une, mais environ 500 instructions à la fois. Ils regardent bien en amont dans la liste des instructions à venir et les réarrangent pour atténuer les dépendances, en entrelaçant les flux d’exécution pour tirer parti de la pleine profondeur du pipeline.
Il y a plein de choses qui compliquent cette opération, notamment les branches. Une branche est simplement une condition en programmation, par exemple lorsque vous écrivez une instruction “if”. Le résultat de la condition peut être vrai ou faux, et selon le résultat, votre programme exécutera une logique ou une autre. Cela complique la gestion des dépendances car le CPU doit deviner la direction que prendront les branches à venir. Les CPU modernes utilisent la prédiction de branches, qui implique des heuristiques simples et offre une très grande précision en prévision. Ils peuvent prédire la direction des branches avec une précision de plus de 99 %, ce qui est mieux que ce que la plupart d’entre nous peuvent faire dans un contexte réel de supply chain. Cette précision est nécessaire pour tirer parti de pipelines super profonds.
Pour vous donner une idée du type d’heuristiques utilisées pour la prédiction de branches, une heuristique très simple consiste à dire que la branche ira dans la même direction qu’elle a prise la dernière fois. Cette heuristique simple vous donne environ 90 % de précision, ce qui est assez bon. Si vous ajoutez une nuance à cette heuristique, en précisant que la branche ira dans la même direction que la dernière fois, mais qu’il faut tenir compte de l’origine, c’est-à-dire qu’il s’agit de la même branche provenant de la même origine, alors vous obtiendrez environ 95 % de précision. Les CPU modernes utilisent en réalité des perceptrons assez complexes, qui sont une technique de machine learning, pour prédire la direction des branches.
Dans les bonnes conditions, vous pouvez prédire les branches assez précisément et ainsi tirer pleinement profit du pipeline pour exploiter au maximum un processeur moderne. Cependant, du point de vue de l’ingénierie logicielle, vous devez bien jouer avec votre processeur, surtout en ce qui concerne la prédiction des branches. Si vous ne jouez pas le jeu, cela signifie que le prédicteur de branches se trompera, et lorsque cela se produit, le CPU prédira la direction de la branche, organisera le pipeline et commencera à effectuer des calculs en avance. Lorsque la branche est réellement rencontrée et que le calcul est effectivement terminé, le CPU se rend compte que la prédiction de branche était fausse. Une prédiction de branche incorrecte ne se traduit pas par un résultat erroné ; elle entraîne une perte de performance. Le CPU n’aura d’autre choix que de vider l’intégralité du pipeline, ou une grande partie de celui-ci, d’attendre que d’autres calculs soient effectués, puis de redémarrer le calcul. L’impact sur les performances peut être très significatif, et vous pouvez très facilement perdre une ou deux ordres de grandeur en performance en raison d’une logique logicielle d’entreprise qui ne joue pas bien avec la logique de prédiction des branches de votre CPU.
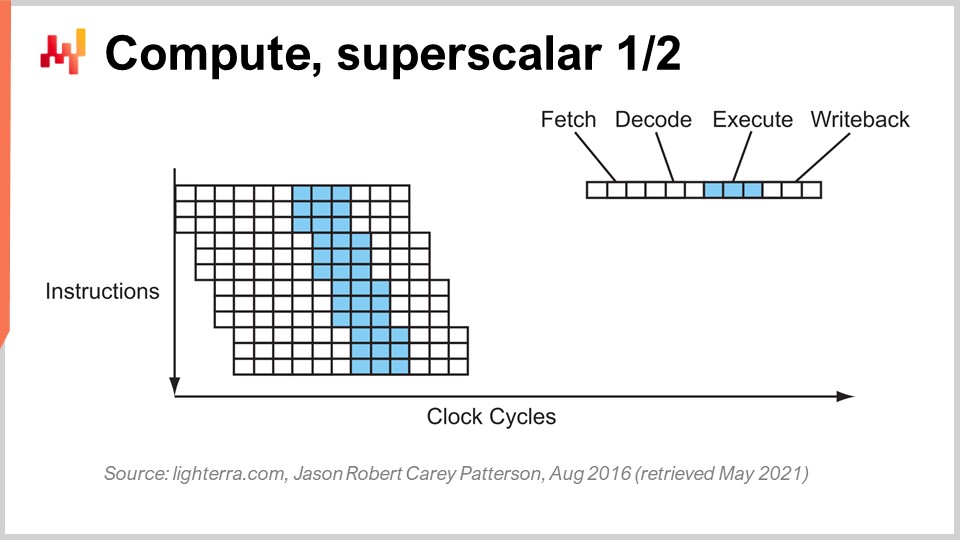
Une autre astuce notable au-delà du pipelining est l’instruction superscalaire. Les CPU traitent généralement des scalaires, ou des paires de scalaires, à la fois – par exemple, deux nombres avec une précision en virgule flottante de 32 bits. Ils effectuent des opérations scalaires, traitant essentiellement un nombre à la fois. Cependant, les CPU modernes de la dernière décennie ont pratiquement tous intégré l’instruction superscalaire, qui peut en réalité traiter plusieurs vecteurs de nombres et effectuer directement des opérations vectorielles. Cela signifie qu’un CPU peut prendre un vecteur, disons, de huit nombres en virgule flottante et un second vecteur de huit nombres en virgule flottante, effectuer une addition, et obtenir un vecteur de nombres en virgule flottante représentant les résultats de cette addition. Tout cela se fait en un seul cycle.
Par exemple, des ensembles d’instructions spécialisés comme AVX2 vous permettent d’effectuer des opérations en considérant 32 bits de précision avec des paquets de huit nombres, tandis que AVX512 vous permet de faire cela avec des paquets de 16 nombres. Si vous êtes capable de tirer parti de ces instructions, cela signifie que vous pouvez littéralement gagner un ordre de grandeur en termes de vitesse de traitement, car une instruction, un cycle d’horloge, effectue beaucoup plus de calculs que le traitement des nombres un par un. Ce processus est connu sous le nom de SIMD (Single Instruction, Multiple Data), et il est très puissant. Il a été le moteur principal du progrès au cours de la dernière décennie en termes de puissance de calcul, et les processeurs modernes sont de plus en plus basés sur les vecteurs et superscalaire. Cependant, du point de vue des logiciels d’entreprise, c’est relativement compliqué. Avec le pipelining, votre logiciel doit bien jouer, et peut-être qu’il joue bien avec la prédiction de branches par accident. Cependant, quand il s’agit d’instructions superscalaires, rien n’est accidentel. Votre logiciel doit vraiment faire certaines choses de manière explicite, la plupart du temps, pour tirer parti de cette puissance de traitement supplémentaire. Ce n’est pas gratuit ; vous devez adopter cette approche, et généralement, vous devez organiser les données elles-mêmes de manière à disposer d’un parallélisme de données, et les données doivent être organisées d’une façon adaptée aux instructions SIMD. Ce n’est pas de la science-fusée, mais cela ne se produit pas par accident, et cela vous offre un énorme gain en termes de puissance de traitement.

Maintenant, les CPU modernes peuvent avoir de nombreux cœurs, et un cœur de CPU peut vous offrir un flux distinct d’instructions. Avec des CPU très modernes qui possèdent de nombreux cœurs, typiquement, les CPU actuels peuvent atteindre jusqu’à 64 cœurs, soit 64 flux d’exécution indépendants et simultanés. Vous pouvez atteindre environ un téraflop, qui est la limite supérieure du débit de traitement que vous pouvez obtenir d’un processeur très moderne. Cependant, si vous voulez aller au-delà, vous pouvez vous tourner vers les GPUs (Graphical Processing Units). Malgré ce que vous pourriez penser, ces dispositifs peuvent être utilisés pour des tâches qui n’ont rien à voir avec les graphismes.
Un GPU, comme celui de NVIDIA, est un processeur superscalaire. Au lieu d’avoir jusqu’à 64 cœurs comme les CPU haut de gamme, les GPUs peuvent en avoir plus de 10 000. Ces cœurs sont beaucoup plus simples et ne sont pas aussi puissants ou rapides que les cœurs de CPU réguliers, mais ils sont en bien plus grand nombre. Ils élèvent le SIMD à un nouveau niveau, où vous pouvez traiter non seulement des paquets de 8 ou 16 nombres à la fois, mais littéralement des milliers de nombres simultanément pour exécuter des instructions vectorielles. Avec les GPUs, vous pouvez atteindre une plage de plus de 30 téraflops sur un seul appareil, ce qui est énorme. Les meilleurs CPU du marché peuvent fournir un téraflop, tandis que les meilleurs GPUs en fournissent plus de 30. Cela représente plus d’un ordre de grandeur de différence, ce qui est très significatif.
Si vous allez encore plus loin, pour des types de calculs spécialisés tels que l’algèbre linéaire (soit dit en passant, des choses comme le machine learning et deep learning sont essentiellement de l’algèbre linéaire impliquant des matrices partout), vous pouvez avoir des processeurs comme les TPUs (Tensor Processing Units). Google a décidé de les nommer Tensors en raison de TensorFlow, mais en réalité, les TPUs seraient mieux appelés Matrix Multiplication Processing Units. L’aspect intéressant de la multiplication de matrices est qu’il n’y a pas seulement une tonne de parallélisme de données impliquée, mais également une quantité énorme de répétition, car les opérations sont hautement répétitives. En organisant un TPU sous forme de réseau systolique, qui est essentiellement une grille bidimensionnelle avec des unités de calcul sur la grille, vous pouvez franchir la barrière du petaflop – atteindre plus de 1000 téraflops sur un seul appareil. Cependant, un bémol : Google le fait avec des nombres à virgule flottante de 16 bits au lieu des 32 bits habituels. Du point de vue de la supply chain, 16 bits de précision n’est pas mal ; cela signifie que vous avez environ 0,1 % de précision dans vos opérations, et pour de nombreuses opérations de machine learning ou statistiques, 0,1 % de précision est tout à fait acceptable si c’est bien fait et sans accumulation de biais.
Ce que nous voyons, c’est que la voie du progrès en matière de matériel informatique, en se concentrant uniquement sur le calcul, a été de se tourner vers des dispositifs plus spécialisés et plus rigides. Grâce à cette spécialisation, vous pouvez réaliser des gains énormes en puissance de traitement. Si vous passez à une instruction superscalaire, vous gagnez un ordre de grandeur ; si vous optez pour une carte graphique, vous gagnez un ou deux ordres de grandeur ; et si vous choisissez l’algèbre linéaire pure, vous gagnez essentiellement deux ordres de grandeur. C’est très significatif.
Au fait, tous ces designs de matériel sont bidimensionnels. Les puces modernes et les structures de traitement sont très plates. Un CPU moderne ne comporte pas plus de 20 couches, et comme ces couches ne mesurent que quelques microns d’épaisseur, les CPU, GPUs ou TPUs sont essentiellement des structures plates. Vous pourriez penser : “Qu’en est-il de la troisième dimension ?” Eh bien, il s’avère qu’en raison du mur de puissance, qui est le problème de dissipation de l’énergie, nous ne pouvons pas vraiment passer à la troisième dimension car nous ne savons pas comment évacuer toute l’énergie injectée dans le dispositif.
Ce que nous pouvons prévoir pour la prochaine décennie, c’est que ces dispositifs resteront essentiellement bidimensionnels. Du point de vue des logiciels d’entreprise, la plus grande leçon est que vous devez intégrer le parallélisme des données au cœur de votre logiciel. Si vous ne faites pas cela, alors vous ne serez pas en mesure de capter tout le progrès qui se fait en termes de puissance de calcul brute. Cependant, cela ne peut pas être une réflexion après coup. Cela doit se faire au niveau même de l’architecture, au niveau auquel vous organisez toutes les données qui doivent être traitées dans vos systèmes. Sinon, vous resterez bloqué avec le genre de processeurs que nous avions il y a deux décennies.
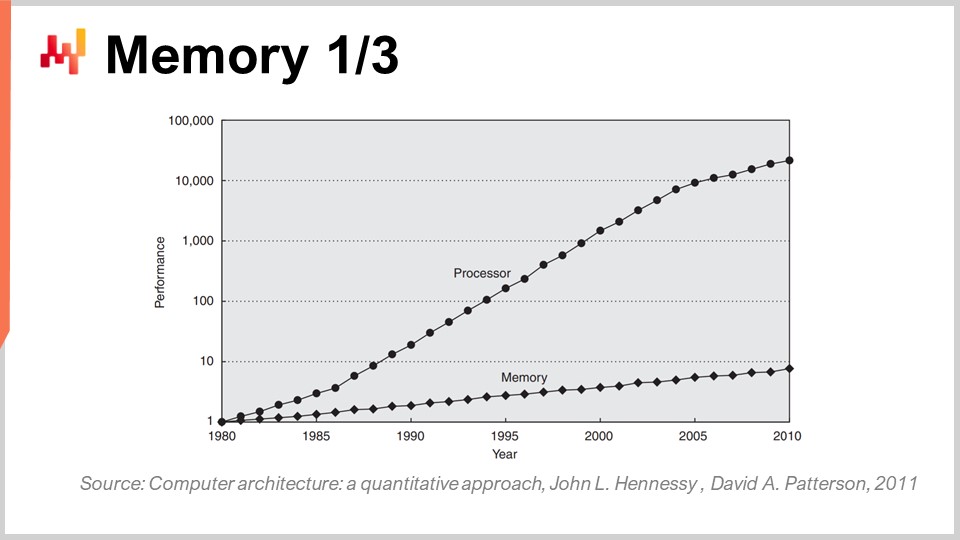
À l’époque des années 80, la mémoire était aussi rapide que les processeurs, ce qui signifie qu’un cycle d’horloge était identique pour la mémoire et pour le CPU. Cependant, ce n’est plus le cas. Au fil du temps, depuis les années 80, le rapport entre la vitesse de la mémoire et les latences d’accès aux données déjà présentes dans les registres du processeur n’a fait qu’augmenter. Nous avons commencé avec un rapport de un, et nous avons maintenant un rapport typiquement supérieur à mille. Ce problème est connu sous le nom de mur de mémoire, et il n’a fait qu’augmenter au cours des quatre dernières décennies. Il continue d’augmenter de nos jours, bien que très lentement, principalement parce que la vitesse d’horloge des processeurs augmente très lentement. Du fait que les processeurs ne progressent pas beaucoup en termes de vitesse d’horloge, ce problème du mur de mémoire n’augmente plus davantage. Cependant, la situation actuelle est incroyablement déséquilibrée, l’accès à la mémoire étant essentiellement trois ordres de grandeur plus lent que l’accès aux données qui se trouvent déjà commodément à l’intérieur du processeur.
Cette perspective contredit complètement toutes les algorithmiques classiques telles qu’elles sont encore enseignées de nos jours dans la plupart des universités. Le point de vue algorithmique classique part du principe que vous disposez d’un temps uniforme pour accéder à la mémoire, signifiant que l’accès à n’importe quel octet de mémoire prend le même temps. Mais dans les systèmes modernes, ce n’est absolument pas le cas. Le temps nécessaire pour accéder à une certaine partie de la mémoire dépend énormément de l’emplacement physique des données dans votre système informatique.
Du point de vue des logiciels d’entreprise, il s’avère qu’hélas, la plupart des conceptions logicielles établies au cours des années 80 et 90 ont complètement ignoré ce problème car il était très mineur durant la première décennie. Il ne s’est vraiment amplifié que ces deux dernières décennies, et par conséquent, la plupart des schémas observés dans les logiciels d’entreprise actuels vont complètement à l’encontre de cette conception, car ils partent du principe que l’accès à toute la mémoire se fait en temps constant.
Au fait, si vous pensez aux langages de programmation comme Python (première version en 1989) ou Java (en 1995) qui proposent la programmation orientée objet, cela va à l’encontre du fonctionnement de la mémoire dans les ordinateurs modernes. Chaque fois que vous avez des objets, et c’est encore pire si vous avez des liaisons tardives comme en Python, cela signifie que pour faire quoi que ce soit, vous devrez suivre des pointeurs et effectuer des sauts aléatoires dans la mémoire. Si l’un de ces sauts se trouve être malchanceux parce qu’il s’agit d’une portion qui n’est pas déjà présente dans le processeur, cela peut être mille fois plus lent. C’est un très gros problème.

Pour mieux comprendre l’étendue du mur de mémoire, il est intéressant de regarder les latences typiques dans un ordinateur moderne. Si nous recontextualisons ces latences en termes humains, supposons qu’un processeur fonctionnait à un cycle d’horloge par seconde. Dans cette hypothèse, la latence typique du CPU serait d’une seconde. Cependant, si nous voulons accéder à des données en mémoire, cela pourrait prendre jusqu’à six minutes. Ainsi, alors que vous pouvez effectuer une opération par seconde, si vous voulez accéder à quelque chose en mémoire, vous devez attendre six minutes. Et si vous voulez accéder à quelque chose sur disque, cela peut prendre jusqu’à un mois voire une année entière. C’est incroyablement long, et c’est de cela qu’il s’agit quand on parle de ces ordres de grandeur de performance que j’ai mentionnés au tout début de cette conférence. Lorsqu’on traite avec 15 ordres de grandeur, cela est très trompeur ; vous ne réalisez pas nécessairement l’énorme impact sur les performances que cela peut avoir, où littéralement vous pouvez vous retrouver à attendre l’équivalent humain de mois si vous ne placez pas les informations au bon endroit. C’est absolument gigantesque.
Au fait, les ingénieurs en logiciels d’entreprise ne sont pas les seuls à lutter contre cette évolution du matériel informatique moderne. Si nous examinons les latences que nous obtenons avec des cartes SSD ultra-rapides, telles que la série Intel Optane, vous pouvez constater que la moitié de la latence pour accéder à la mémoire de cet appareil est en réalité causée par le surcoût du noyau lui-même, dans ce cas, le noyau Linux. C’est le système d’exploitation lui-même qui génère la moitié de la latence. Qu’est-ce que cela signifie ? Eh bien, cela signifie que même les personnes qui développent Linux ont encore du travail à faire pour rattraper le matériel moderne. Néanmoins, c’est un grand défi pour tout le monde.
Cependant, cela nuit vraiment aux logiciels d’entreprise, surtout lorsqu’on pense à l’optimization de la supply chain, en raison du fait que nous avons une tonne de données à traiter. C’est déjà une entreprise assez complexe dès le départ. Du point de vue des logiciels d’entreprise, vous devez vraiment adopter une conception qui fonctionne bien avec le cache, car le cache contient des copies locales qui sont plus rapides d’accès et plus proches du CPU.
Le fonctionnement est le suivant : lorsque vous accédez à un octet dans votre mémoire principale, vous ne pouvez pas accéder à un seul octet dans les logiciels modernes. Lorsque vous souhaitez accéder à un octet dans votre RAM, le matériel va en fait copier 4 kilo-octets, essentiellement toute la page qui fait 4 kilo-octets de large. Le postulat de base est que lorsque vous commencez à lire un octet, le prochain octet que vous allez demander sera celui qui le suit. C’est le principe de localité, ce qui signifie que si vous respectez cette règle et appliquez un accès qui préserve la localité, alors vous pouvez avoir une mémoire qui semble fonctionner presque aussi vite que votre processeur.
Cependant, cela requiert un alignement entre les accès à la mémoire et la localité des données. En particulier, il existe de nombreux langages de programmation, comme Python, qui ne fournissent pas ce genre de fonctionnalités nativement. Au contraire, ils représentent un défi colossal pour instaurer un quelconque degré de localité. C’est une lutte immense, et en fin de compte, c’est une bataille où vous avez un langage de programmation conçu autour de schémas qui s’opposent complètement au matériel dont nous disposons. Ce problème ne va pas changer dans la prochaine décennie ; il ne fera qu’empirer.
Ainsi, du point de vue du logiciel d’entreprise, vous souhaitez imposer la localité des données mais aussi réduire leur taille. Si vous parvenez à transformer vos big data en données plus petites, cela sera plus rapide. Ce n’est pas très intuitif, mais si vous réduisez la taille des données, généralement en éliminant une certaine redondance, vous améliorerez les performances de votre programme car vous serez beaucoup plus efficace avec le cache. Vous pourrez faire tenir davantage de données pertinentes dans les niveaux de cache inférieurs qui offrent des latences bien plus faibles, comme le montre cet affichage.

Enfin, abordons spécifiquement le cas de la DRAM. La DRAM est littéralement le composant physique qui constitue la RAM que vous utilisez pour votre poste de travail de bureau ou votre serveur dans le cloud computing. La DRAM est également appelée mémoire principale, construite à partir de puces DRAM. Au cours de la dernière décennie, en termes de prix, la DRAM a à peine diminué. Nous sommes passés de 5 dollars par gigaoctet à 3 dollars par gigaoctet dix ans plus tard. Le prix de la RAM baisse encore, bien que pas très rapidement. Il stagne depuis quelques années et, du fait qu’il n’existe que trois acteurs majeurs capables de produire de la DRAM à grande échelle, il y a très peu d’espoir de voir quelque chose d’inattendu sur ce marché dans la décennie à venir.
Mais ce n’est même pas le pire du problème. Il y a également la consommation d’énergie par gigaoctet. En examinant cette consommation, on se rend compte que la RAM moderne consomme un peu plus d’énergie par gigaoctet qu’elle ne le faisait il y a une décennie. La raison en est essentiellement que la RAM actuelle est plus rapide, et la même règle du power wall s’applique : augmenter la fréquence d’horloge accroît significativement la consommation d’énergie. D’ailleurs, la RAM consomme beaucoup d’énergie car la DRAM est fondamentalement un composant actif. Il faut rafraîchir la RAM en permanence à cause des fuites électriques ; ainsi, si vous éteignez votre RAM, vous perdez toutes vos données. Il faut rafraîchir les cellules constamment.
Ainsi, la conclusion pour le logiciel d’entreprise est que la DRAM est le seul composant qui ne progresse plus. De nombreuses choses, comme la puissance de traitement, continuent d’évoluer très rapidement ; cependant, ce n’est pas le cas de la DRAM – elle stagne nettement. Si l’on tient compte de la consommation d’énergie, qui représente également une part importante des coûts de cloud computing, la RAM progresse à peine. Par conséquent, si vous adoptez une conception qui suraccentue la mémoire principale – ce qui est typiquement le cas lorsqu’un fournisseur annonce : “Oh, nous avons une conception in-memory pour le logiciel” – souvenez-vous bien de ces mots-clés.
Chaque fois que vous entendez un fournisseur vous affirmer qu’il dispose d’une conception in-memory, ce qu’il vous dit – et ce n’est pas une proposition très convaincante – c’est que sa conception repose entièrement sur l’évolution future de la DRAM, alors que nous savons déjà que les coûts ne vont pas diminuer. Ainsi, si l’on considère qu’à l’horizon 10 ans, votre supply chain aura probablement environ 10 fois plus de données à traiter, simplement parce que les entreprises s’améliorent continuellement dans la collecte de données au sein de leur supply chain et dans la collaboration pour recueillir davantage d’informations auprès de leurs clients et fournisseurs, il n’est pas déraisonnable de s’attendre à ce que, dans une décennie, toute grande entreprise opérant une large supply chain collecte 10 fois plus de données qu’elle n’en a actuellement. Cependant, le prix par gigaoctet de RAM restera le même. Donc, si vous faites le calcul, vous pourriez vous retrouver avec des coûts de cloud computing ou des coûts informatiques essentiellement presque un ordre de grandeur plus élevés, juste pour faire à peu près la même chose, parce que vous devez gérer une masse de données sans cesse croissante qui ne tient pas facilement en mémoire. L’idéal est d’éviter toutes sortes de conceptions in-memory. Ces conceptions sont très dépassées, et nous verrons dans la suite quelles alternatives s’offrent à nous.

Examinons maintenant le stockage des données, qui concerne le stockage persistant. Essentiellement, il existe deux classes de stockage de données répandu. La première concerne les disques durs (HDD) ou disques rotatifs. La seconde concerne les disques à état solide (SSD). Fait intéressant, la latence des disques rotatifs est terrible, et en regardant cette image, on comprend facilement pourquoi. Ces disques tournent littéralement, et lorsque vous souhaitez accéder à un point quelconque sur le disque, en moyenne, vous devez attendre la moitié d’une rotation. Étant donné que les disques haut de gamme tournent à environ 10 000 rotations par minute, cela signifie qu’il y a une latence inhérente de trois millisecondes qui ne peut être réduite. C’est littéralement le temps nécessaire pour que le disque tourne et permette de lire précisément le point d’intérêt. C’est mécanique et cela n’évoluera pas davantage.
Les HDD sont terribles en termes de latence, mais ils présentent également un autre problème, celui de la consommation d’énergie. En règle générale, un HDD et un SSD consomment chacun environ trois watts par heure et par appareil. C’est généralement l’ordre de grandeur actuel. Cependant, lorsque le disque dur est en fonctionnement, même si vous n’accédez pas activement aux données, vous consommez trois watts simplement parce que vous devez maintenir le disque en rotation. Atteindre 10 000 rotations par minute demande beaucoup de temps, il faut donc garder le disque en rotation en permanence, même si son utilisation est très rare.
D’autre part, pour les disques à état solide, ils consomment trois watts lors de l’accès, mais lorsqu’on n’accède pas aux données, leur consommation est quasi nulle. Ils présentent une consommation résiduelle, mais elle est extrêmement faible, de l’ordre de quelques milliwatts. C’est très intéressant car vous pouvez disposer de nombreux SSD ; si vous ne les utilisez pas, vous ne payez pas pour l’énergie qu’ils consomment. L’ensemble de l’industrie est passé progressivement des HDD aux SSD au cours de la dernière décennie.
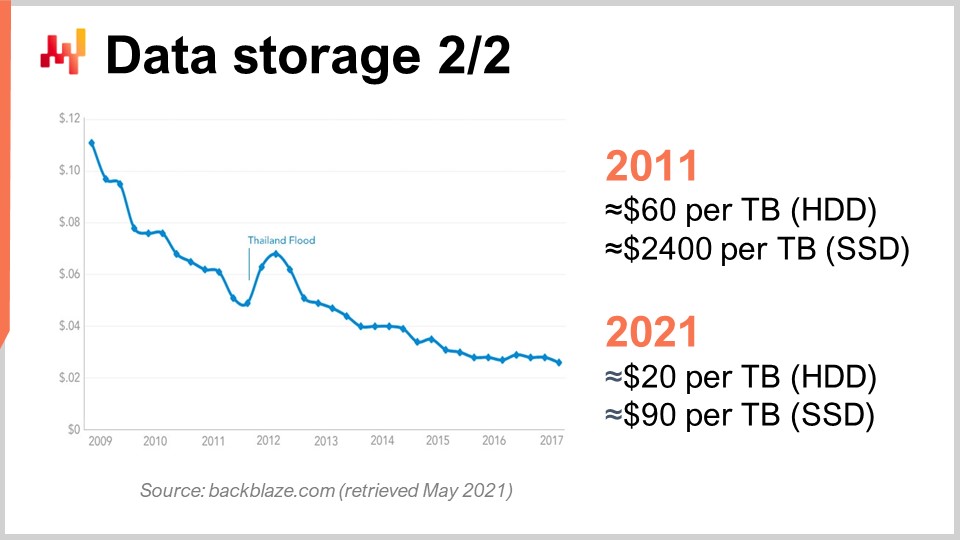
Pour comprendre cela, nous pouvons observer cette courbe. Ce que nous voyons, c’est que le prix par gigaoctet, tant pour les HDD que pour les SSD, a baissé au cours des dernières années. Cependant, le prix atteint désormais un palier. Les données sont un peu anciennes, mais elles n’ont pas beaucoup varié ces dernières années. Il y a dix ans, les SSD étaient extrêmement chers, à 2 400 dollars par téraoctet, tandis que les disques durs coûtaient seulement 60 dollars par téraoctet. Aujourd’hui, le prix des disques durs a été divisé par trois, se situant à environ 20 dollars par téraoctet. Le prix des SSD a été réduit de plus de 25 fois, et la tendance à la baisse des prix des SSD ne s’arrête pas. Les SSD représentent actuellement, et probablement pour la décennie à venir, le composant qui progresse le plus, ce qui est très intéressant.
Au fait, je vous avais dit que la conception des dispositifs de calcul modernes (CPU, GPU, TPU) était essentiellement bidimensionnelle, avec au maximum 20 couches. Cependant, en ce qui concerne les SSD, la conception devient de plus en plus tridimensionnelle. Les SSD les plus récents disposent d’environ 176 couches. Nous approchons, en termes d’ordre, de 200 couches. Du fait que ces couches sont incroyablement fines, il n’est pas déraisonnable de s’attendre à ce qu’à l’avenir, nous disposions de dispositifs comportant des milliers de couches et potentiellement d’ordres de grandeur supérieurs en termes de capacités de stockage. Évidemment, le hic sera que vous ne pourrez pas accéder à toutes ces données en permanence, encore une fois, en raison du dark silicon et de la dissipation de puissance.
Il s’avère que, si vous vous y prenez bien, de nombreuses données sont accédées très rarement. Les SSD impliquent une conception matérielle très spécifique qui présente de nombreuses particularités, comme le fait que vous pouvez uniquement passer des bits de 0 à 1 et non l’inverse. Imaginez, par exemple, que vous partez d’un état composé uniquement de zéros ; vous pouvez transformer un zéro en un, cependant, vous ne pouvez pas localement transformer ce un en zéro. Pour ce faire, vous devez réinitialiser l’intégralité du bloc, qui peut atteindre huit mégaoctets, ce qui signifie que lors de l’écriture, vous pouvez passer des bits de 0 à 1, mais pas de 1 à 0. Pour transformer des bits de 1 en 0, il faut vider le bloc entier et le réécrire, ce qui engendre toutes sortes de problèmes connus sous le nom d’amplification d’écriture.
Au cours de la dernière décennie, les disques SSD disposent en interne d’une couche appelée flash translation layer qui peut atténuer tous ces problèmes. Ces couches de traduction s’améliorent continuellement. Cependant, il existe encore de grandes marges de progression et, en termes de logiciel d’entreprise, cela signifie que vous devez optimiser votre conception pour tirer le meilleur parti des SSD. Les SSD représentent déjà une bien meilleure solution que la DRAM pour le stockage des données, et si vous y jouez intelligemment, vous pouvez vous attendre, dans une décennie, à des gains d’ordres de grandeur rendus possibles par les progrès de l’industrie du matériel, ce qui n’est pas le cas de la DRAM.
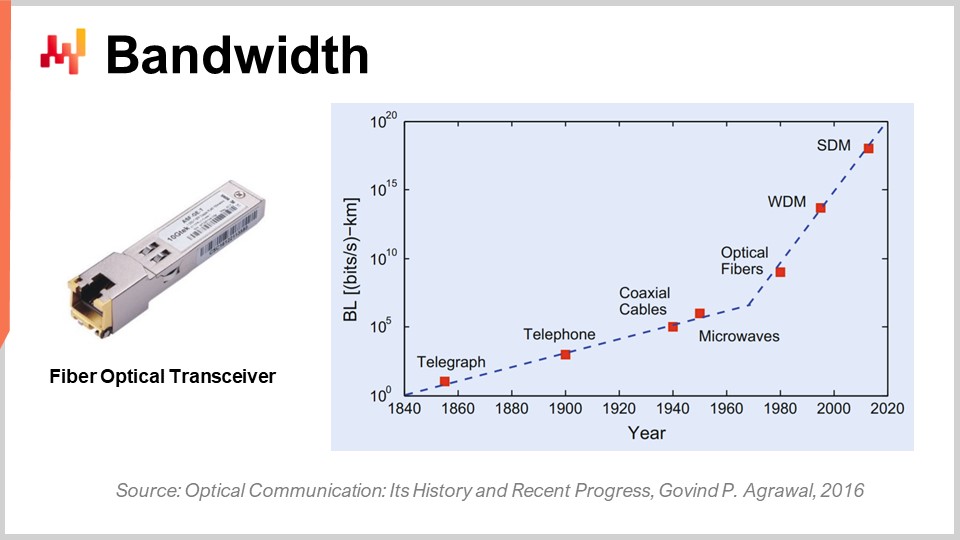
Enfin, parlons de la bande passante. La bande passante est probablement le problème le mieux résolu en termes de technologie. Cependant, même si la bande passante peut être atteinte, nous pouvons obtenir des débits absolument incroyables de nos jours. Commercialement, l’industrie des télécoms est très complexe et regorge de problèmes, de sorte que les consommateurs finaux ne perçoivent pas réellement tous les bénéfices des progrès réalisés en matière de communications optiques.
En ce qui concerne la communication optique avec des émetteurs-récepteurs en fibre optique, les progrès sont absolument hallucinants. C’est probablement l’une des domaines qui progressent comme les CPU progressaient dans les années 80 ou 90. Pour vous donner une idée, avec le multiplexage en longueur d’onde (WDM) ou le multiplexage en espace (SDM), nous pouvons désormais atteindre littéralement un dixième de téraoctet de données transférées par seconde sur un seul câble de fibre optique. C’est absolument énorme. Nous approchons du point où un seul câble peut acheminer suffisamment de données pour alimenter un data center entier. Ce qui est encore plus impressionnant, c’est que l’industrie des télécoms a su développer de nouveaux émetteurs-récepteurs capables de fournir ces performances extraordinaires en se basant sur d’anciens câbles. Il n’est même pas nécessaire de déployer de nouvelles fibres dans les rues ou physiquement ; vous pouvez littéralement reprendre la fibre déployée il y a une décennie, installer le nouvel émetteur-récepteur, et obtenir plusieurs ordres de grandeur de bande passante supplémentaires sur le même câble.
Le point intéressant est qu’il existe une loi générale des communications optiques : à chaque décennie, la distance à partir de laquelle il devient intéressant de remplacer la communication électrique par la communication optique diminue. Si l’on remonte de quelques décennies, il y a vingt ans, il fallait environ 100 mètres pour que la communication optique dépasse la communication électrique. Ainsi, pour des distances inférieures à 100 mètres, on privilégiait le cuivre ; pour plus de 100 mètres, la fibre était de rigueur. Cependant, de nos jours, avec la dernière génération, nous pouvons avoir des distances où l’optique l’emporte, même pour seulement trois mètres. Si l’on envisage la décennie à venir, je ne serais pas étonné de voir des situations où la communication optique l’emporte même pour des distances aussi courtes que 0,5 mètre. Cela signifie qu’à terme, je ne serais pas surpris que les ordinateurs eux-mêmes disposent de voies optiques en interne, tout simplement parce que ces voies sont plus performantes que les voies électriques.
D’un point de vue du logiciel d’entreprise, cela est également très intéressant, car cela signifie que, si vous anticipez l’avenir, le coût de la bande passante va diminuer de manière spectaculaire. Cela est largement subventionné par des entreprises comme Netflix, qui consomment une quantité dramatique de bande passante. Cela signifie que, pour compenser la latence, vous pourriez par exemple précharger une masse de données vers l’utilisateur, puis laisser ce dernier interagir avec des données rapprochées de lui, avec une latence bien moindre. Même si vous apportez des données non nécessaires, ce qui vous pénalise, c’est la latence, et non la bande passante. Il vaut mieux dire : « J’ai des doutes sur le type de données qui sera nécessaire ; je peux prendre mille fois plus de données que nécessaire, les rapprocher de l’utilisateur final, laisser l’utilisateur ou le programme interagir avec ces données, et minimiser le temps de trajet, ainsi je gagnerai en performance. » Cela a de nouveau un impact profond sur le type de décisions architecturales prises aujourd’hui, car elles détermineront si vous pourrez gagner en performance grâce aux progrès de ce type de matériel dans une décennie.

En conclusion, la latence est la grande bataille de notre époque en matière d’ingénierie logicielle. Elle conditionne véritablement toutes les formes de performance que nous avons et que nous aurons. La performance est absolument cruciale, car elle ne détermine pas seulement le coût informatique, mais aussi la productivité des personnes qui œuvrent dans votre supply chain. En définitive, cela impactera également la performance de la supply chain elle-même, car sans cette performance, vous ne pouvez même pas mettre en œuvre une sorte de recette numérique vraiment intelligente qui offrirait une optimisation avancée et prédictive – ce que nous recherchons. Cependant, dans l’ensemble, cette bataille pour une meilleure performance n’est pas remportée, du moins pas dans le domaine du logiciel d’entreprise. Les nouveaux systèmes peuvent être, et le sont fréquemment, plus lents que les anciens. C’est un problème aigu. Des performances logicielles plus lentes génèrent des coûts vertigineux pour les entreprises qui s’y laissent prendre.
Pour vous donner un exemple, il ne faut pas considérer comme acquis que du matériel informatique meilleur vous offre de meilleures performances. Certaines personnes sur Internet ont décidé de mesurer la latence d’entrée, c’est-à-dire le délai entre l’appui sur une touche et l’affichage de la lettre correspondante à l’écran. Avec un Apple II en 1983, qui disposait d’un processeur de 1 MHz, ce délai était de 30 millisecondes. En 2016, avec un Lenovo X1, équipé d’un processeur de 2,6 GHz, un très joli ordinateur portable, la latence s’est avérée être de 110 millisecondes. Nous disposons donc d’un matériel informatique plusieurs milliers de fois meilleur, et pourtant nous nous retrouvons avec une latence presque quatre fois plus lente. C’est caractéristique de ce qui se passe lorsque l’on ne fait pas preuve de mechanical sympathy et que l’on ne prête pas attention au matériel informatique dont on dispose. Si vous antagonisez le matériel informatique, il vous le rend par de mauvaises performances.
Le problème est bien réel. Ma suggestion est que, lorsque vous commencez à examiner un logiciel d’entreprise pour votre société, qu’il soit open-source ou non, vous vous souveniez des éléments de mechanical sympathy que vous avez appris aujourd’hui. Analysez le logiciel et réfléchissez sérieusement pour savoir s’il intègre les grandes tendances du matériel informatique ou s’il les ignore complètement. S’il les ignore, cela signifie non seulement que les performances ne s’amélioreront pas avec le temps, mais qu’elles se dégraderont probablement. La plupart des améliorations de nos jours sont obtenues grâce à la spécialisation plutôt qu’à l’augmentation de la fréquence d’horloge. Si vous ratez cette autoroute, vous empruntez un chemin qui deviendra de plus en plus lent avec le temps. Évitez ces solutions, car elles résultent généralement de décisions clés de conception prises trop tôt et qui ne peuvent être annulées. Vous y serez condamné pour toujours, et cela ne fera qu’empirer année après année. Pensez à la décennie à venir lorsque vous examinez ces aspects.

Regardons maintenant les questions. C’était un cours assez long, mais le sujet est complexe.
Question: Quel est votre avis sur les ordinateurs quantiques et leur utilité pour aborder les problèmes complexes d’optimisation de la supply chain ?
Une question très intéressante. Je me suis inscrit à la bêta de l’ordinateur quantique d’IBM il y a 18 mois, lorsque l’accès à leur ordinateur quantique dans le cloud a été ouvert. Mon impression est que c’est passionnant, car les experts peuvent voir toutes les courbes en S se stabiliser, sans voir de nouvelles courbes surgir de nulle part. Le cloud computing quantique en fait partie. Cependant, je crois que les ordinateurs quantiques posent des défis très coriaces en ce qui concerne les supply chains. Tout d’abord, comme je l’ai dit, le combat actuel dans le domaine des logiciels d’entreprise concerne la latence, et les ordinateurs quantiques n’y apportent rien. Les ordinateurs quantiques peuvent vous offrir, potentiellement, jusqu’à 10 ordres de grandeur d’accélération pour des problèmes de calcul extrêmement serrés. Ainsi, les ordinateurs quantiques représenteraient la prochaine étape après les TPU, où des opérations ultra serrées peuvent être effectuées incroyablement rapidement.
C’est très intéressant, mais pour être honnête, à ma connaissance, il y a actuellement très peu d’entreprises qui parviennent même à exploiter les instructions superscalaires dans leurs logiciels d’entreprise. Cela signifie que l’ensemble du marché laisse sur la table une accélération de 10 à 28 fois grâce aux GPUs superscalaires. Il y a très peu de personnes dans le domaine de la supply chain qui le font ; peut-être Lokad, peut-être pas. Quant aux TPU, je pense qu’il n’y a littéralement personne. Google s’en sert de manière intensive, mais je ne connais personne qui ait jamais utilisé des TPU pour quelque chose lié à la supply chain. Les processeurs quantiques représenteraient l’étape au-delà des TPU.
Je suis définitivement très attentif à ce qui se passe avec les ordinateurs quantiques, mais je crois que ce n’est pas le goulot d’étranglement auquel nous sommes confrontés. C’est passionnant car nous revisitons la conception von Neumann établie il y a environ 70 ans, mais ce n’est pas le goulot d’étranglement que nous ou la supply chain affronterons durant la prochaine décennie. Au-delà, votre supposition vaut la mienne. Oui, cela pourrait potentiellement tout changer, ou pas.
Question: Les offres de cloud computing et de SaaS permettent aux organisations de tirer parti et de transformer les coûts fixes. Est-ce que les entreprises proposant de tels services travaillent également à réduire leurs coûts fixes et les risques associés ?
Eh bien, cela dépend. Si je suis une plateforme de cloud computing et que je vous vends de la puissance de traitement, est-ce vraiment dans mon intérêt de rendre votre logiciel d’entreprise aussi efficace que possible ? Pas vraiment. Je vous vends des machines virtuelles, des gigaoctets de bande passante et du stockage, donc en réalité, tout le contraire. Mon intérêt est de m’assurer que vous disposez d’un logiciel aussi inefficace que possible, afin que vous consommiez et payiez à l’usage pour une quantité exorbitante de ressources.
En interne, les grandes entreprises technologiques comme Microsoft, Amazon et Google sont incroyablement agressives en matière d’optimisation de leurs ressources informatiques. Mais elles le sont aussi lorsqu’il s’agit de régler l’addition en facturant à un client la location d’une machine virtuelle. Si le client loue une machine virtuelle dix fois plus grande qu’elle ne devrait l’être simplement parce que le logiciel d’entreprise qu’il utilise est extrêmement inefficace, il n’est pas dans leur intérêt d’interrompre l’erreur du client. Tout va bien pour eux ; c’est une bonne affaire. Quand on pense que les intégrateurs de systèmes et les plateformes de cloud computing travaillent main dans la main en tant que partenaires, on se rend compte que ces catégories de personnes n’ont pas nécessairement votre intérêt à cœur. Maintenant, en ce qui concerne le SaaS, c’est un peu différent. En effet, si vous finissez par payer un fournisseur SaaS par utilisateur, alors c’est dans l’intérêt de l’entreprise, comme c’est le cas chez Lokad, par exemple. Nous ne facturons pas en fonction des ressources informatiques que nous consommons ; nous facturons généralement nos clients selon des forfaits mensuels fixes. Ainsi, les fournisseurs de SaaS ont tendance à être très agressifs en matière de consommation de leurs propres ressources de calcul.
Cependant, attention, il existe un biais : si vous êtes une entreprise de SaaS, vous pouvez être assez réticent à faire quelque chose qui serait bien meilleur pour vos clients, mais bien plus coûteux en termes de matériel pour vous. Tout n’est pas rose. Il existe une sorte de conflit d’intérêts qui affecte tous les fournisseurs de SaaS opérant dans le domaine de la supply chain. Par exemple, ils pourraient investir dans la réingénierie de tous leurs systèmes pour offrir une meilleure latence et des pages web plus rapides, mais le fait est que cela coûte des ressources, et leurs clients ne vont naturellement pas payer plus s’ils le font.
Le problème tend à être amplifié lorsqu’il s’agit de logiciels d’entreprise. Pourquoi ? Parce que la personne qui achète le logiciel n’est généralement pas celle qui l’utilise. C’est pourquoi une grande partie du système d’entreprise est incroyablement lente. La personne qui achète le logiciel ne souffre pas autant qu’un planificateur de la demande ou un responsable des stocks qui doit faire face à un système extrêmement lent chaque jour de l’année. Il y a donc un autre angle spécifique au domaine des logiciels d’entreprise. Vous devez vraiment analyser la situation en tenant compte de tous les incitatifs en jeu, et avec les logiciels d’entreprise, il y a généralement de nombreux incitatifs conflictuels.
Question: Combien de fois Lokad a-t-il dû revoir son approche, étant donné les progrès observés dans le matériel informatique ? Pouvez-vous citer un exemple, si possible, pour replacer ce contenu dans le contexte de problèmes réels résolus ?
Chez Lokad, je crois que nous avons entièrement réingénieré notre pile technologique environ une demi-douzaine de fois. Cependant, Lokad a été fondé en 2008, et nous avons effectué une demi-douzaine de réécritures majeures de l’architecture globale. Ce n’est pas parce que le logiciel avait beaucoup progressé — le logiciel avait progressé, certes — mais ce qui a motivé la plupart de nos réécritures n’était pas le fait que le matériel ait beaucoup évolué. C’était plutôt parce que nous avions acquis une meilleure compréhension du matériel. Tout ce que j’ai présenté aujourd’hui était essentiellement connu des personnes qui y prêtaient attention il y a une décennie. Vous voyez, le matériel évolue, certes, mais très lentement, et la plupart des tendances sont très prévisibles, même une décennie à l’avance. C’est un jeu sur le long terme.
Lokad a dû subir d’importantes réécritures, mais cela reflétait plutôt le fait que nous devenions progressivement moins incompétents. Nous gagnions en compétence, et ainsi nous avions une meilleure compréhension de la manière d’exploiter le matériel, plutôt que de nous en remettre aux changements du matériel. Ce n’était pas toujours le cas ; il y a eu des éléments spécifiques qui ont vraiment tout changé pour nous. Le plus remarquable a été les SSD. Nous sommes passés des HDD aux SSD, et cela a radicalement transformé nos performances, avec des impacts massifs sur notre architecture. En termes d’exemples très concrets, l’ensemble de la conception d’Envision, le langage de programmation spécifique au domaine que Lokad propose, repose sur les enseignements que nous avons tirés du niveau matériel. Ce n’est pas une réussite isolée ; il s’agit de faire tout ce à quoi vous pouvez penser, mais simplement plus rapidement.
Vous voulez traiter une table contenant un milliard de lignes et 100 colonnes, et vous souhaitez le faire 100 fois plus vite avec les mêmes ressources informatiques ? Oui, c’est possible. Vous voulez pouvoir réaliser des jointures entre des tables très volumineuses avec un minimum de ressources ? Oui, encore. Pouvez-vous disposer de dashboards super complexes avec littéralement une centaine de tables affichées à l’utilisateur final en moins de 500 millisecondes ? Oui, nous l’avons réalisé. Ce sont des réussites ordinaires, mais c’est grâce à cela que nous pouvons mettre en production des recettes d’optimisation prédictive assez sophistiquées. Nous devons nous assurer que toutes les étapes qui nous y ont conduits sont réalisées avec une très grande productivité.
Le plus grand défi lorsque vous souhaitez réaliser quelque chose de très sophistiqué pour la supply chain, en termes de recettes numériques, n’est pas l’étape du « faire fonctionner ». Vous pouvez prendre des étudiants et concevoir une série de prototypes qui apporteront une amélioration des performances de la supply chain en quelques semaines. Il suffit de prendre Python et n’importe quelle bibliothèque de machine learning open-source du moment, et ces étudiants, s’ils sont intelligents et motivés, produiront un prototype fonctionnel en quelques semaines. Cependant, vous n’arriverez jamais à mettre cela en production à grande échelle. Voilà le problème. Il s’agit de franchir toutes ces étapes de maturité du « faire bien », du « faire vite » et du « faire économique ». C’est là que l’affinité avec le matériel brille vraiment et que votre capacité à itérer se révèle.
Il n’y a pas une réussite unique. Cependant, tout ce que nous faisons, par exemple lorsque nous disons que Lokad utilise la prévision probabiliste, ne nécessite pas autant de puissance de traitement. Ce qui demande vraiment de la puissance, c’est d’exploiter des distributions de probabilités très étendues et d’envisager tous ces futurs possibles afin de les combiner avec toutes les décisions que vous pouvez prendre. De cette manière, vous pouvez en sélectionner les meilleures grâce à une optimisation financière, ce qui devient très coûteux. Si vous ne disposez pas de quelque chose de très optimisé, vous êtes coincé. Le simple fait que Lokad puisse utiliser la prévision probabiliste en production témoigne de l’optimisation poussée au niveau matériel que nous avons réalisée sur l’ensemble de nos chaînes de traitement pour tous nos clients. Nous desservons environ 100 entreprises de nos jours.
Question: Est-il préférable de disposer d’un serveur interne pour les logiciels d’entreprise (ERP, WMS) plutôt que d’utiliser des services cloud afin d’éviter la latence ?
Je dirais qu’aujourd’hui, cela n’a pas d’importance car la plupart des latences que vous rencontrez se situent à l’intérieur du système. Ce n’est pas la latence entre votre utilisateur et l’ERP. Oui, si vous avez une très mauvaise latence, cela peut ajouter environ 50 millisecondes de délai. Évidemment, si vous avez un ERP, vous ne voulez pas qu’il soit installé à Melbourne alors que vous opérez, par exemple, à Paris. Vous souhaitez que le data center soit proche de votre zone d’activité. Cependant, les plateformes modernes de cloud computing disposent de dizaines de centres de données, de sorte qu’il n’y a pas une grande différence de latence entre l’hébergement interne et les services cloud.
Typiquement, l’hébergement interne ne signifie pas placer l’ERP sur le sol, en plein milieu de l’usine ou de l’entrepôt. Il s’agit plutôt d’installer votre ERP dans un data center où vous louez du matériel informatique. Je crois qu’il n’y a pas de différence pratique entre l’hébergement interne et les plateformes de cloud computing, vu que ces dernières possèdent des centres de données partout dans le monde.
Ce qui fait vraiment la différence, c’est de savoir si vous disposez d’un ERP qui minimise en interne tous les allers-retours. Par exemple, ce qui nuit généralement aux performances d’un ERP, c’est l’interaction entre la logique métier et la base de données relationnelle. Si vous avez des centaines d’interactions aller-retour pour afficher une page web, votre ERP sera terriblement lent. Ainsi, vous devez envisager des conceptions de logiciels d’entreprise qui n’impliquent pas un nombre massif d’allers-retours. Cela relève d’une propriété intrinsèque du logiciel d’entreprise examiné, et cela ne dépend pas vraiment de l’endroit où il est hébergé.
Question: Pensez-vous que nous avons besoin de nouveaux langages de programmation qui adopteraient la nouvelle conception matérielle au niveau fondamental, en utilisant pleinement les fonctionnalités de l’architecture du matériel ?
Oui, et oui. Mais pour être totalement transparent, j’ai ici un conflit d’intérêts. C’est précisément ce que Lokad a réalisé avec Envision. Envision est né de l’observation qu’il est délicat d’exploiter toute la puissance de traitement disponible dans les ordinateurs modernes, alors que cela ne devrait pas être le cas si vous concevez le langage de programmation lui-même en tenant compte de la performance. Vous pouvez le rendre surnaturel, et c’est pourquoi, lors du cours 1.4 sur les paradigmes de programmation pour la supply chain, j’ai dit que si vous choisissez les bons paradigmes de programmation, tels que la programmation par tableaux ou la programmation par data frames, et que vous concevez un langage de programmation qui adopte ces concepts, vous obtenez des performances quasiment gratuites.
Le prix à payer est que vous n’êtes pas aussi expressif qu’un langage de programmation comme Python ou C++, mais si vous êtes prêt à accepter une expressivité réduite tout en couvrant tous les cas d’utilisation pertinents pour la supply chain, alors oui, vous pouvez obtenir des améliorations de performances massives. C’est ce que je crois, et c’est pourquoi j’ai également affirmé que, par exemple, la programmation orientée objet du point de vue de l’optimisation de la supply chain n’apporte rien de plus.
Au contraire, c’est un type de paradigme qui ne fait qu’antagoniser le matériel informatique sous-jacent. Je ne dis pas que la programmation orientée objet est entièrement mauvaise ; ce n’est pas ce que je dis. Je dis qu’il existe des domaines du génie logiciel où elle a parfaitement du sens, mais qu’elle n’a pas de sens en ce qui concerne l’optimisation prédictive de la supply chain. Alors oui, absolument, nous avons besoin de langages de programmation qui adoptent réellement cela.
Je sais que j’ai tendance à répéter cela, mais Python a été essentiellement conçu à la fin des années 80, et ils ont en quelque sorte raté tout ce qu’il y avait à voir sur les ordinateurs modernes. Ils ont quelque chose qui, par conception, les empêche de tirer parti du multi-threading. Ils possèdent ce verrou global, de sorte qu’ils ne peuvent pas tirer parti de plusieurs cœurs. Ils ne peuvent pas tirer parti de la localité. Ils ont du late binding qui complique vraiment les accès mémoire. Ils sont très variables, donc ils consomment beaucoup de mémoire, ce qui signifie que cela jouera contre le cache, etc.
Ce sont le genre de problèmes où, si vous utilisez Python, cela signifie que vous allez faire face à des batailles difficiles pour les décennies à venir, et que la situation ne fera qu’empirer avec le temps. Ça ne s’améliorera pas.
La prochaine conférence aura lieu dans trois semaines, le même jour de la semaine, à la même heure. Elle se tiendra à 15h, heure de Paris, le 9 juin. Nous allons discuter des algorithmes modernes pour supply chain, qui est en quelque sorte l’équivalent des ordinateurs modernes pour supply chain. À la prochaine fois.


