00:17 Введение
03:35 Порядки величин
06:55 Этапы оптимизации цепей поставок
12:17 S-образные кривые аппаратного обеспечения
15:52 История на данный момент
17:34 Вспомогательные науки
20:25 Современные компьютеры
20:57 Задержка 1/2
27:15 Задержка 2/2
30:37 Вычисления, тактовая частота
36:36 Вычисления, конвейеризация, 1/3
39:11 Вычисления, конвейеризация, 2/3
40:27 Вычисления, конвейеризация, 3/3
46:36 Вычисления, суперскалярность 1/2
49:55 Вычисления, суперскалярность 2/2
56:45 Память 1/3
01:00:42 Память 2/3
01:06:43 Память 3/3
01:11:13 Хранение данных 1/2
01:14:06 Хранение данных 2/2
01:18:36 Полоса пропускания
01:23:20 Заключение
01:27:33 Следующая лекция и вопросы аудитории
Описание
Современные цепи поставок требуют вычислительных ресурсов для работы, как моторизованные конвейерные ленты требуют электричества. Однако медленные системы цепей поставок остаются повсеместными, в то время как вычислительная мощность компьютеров увеличилась более чем в 10,000 раз с 1990 года. Непонимание основных характеристик современных вычислительных ресурсов — даже среди IT или наука о данных кругов — во многом объясняет это положение дел. Конструкция программного обеспечения, лежащая в основе числовых рецептов, не должна конфликтовать с фундаментом вычислительной техники.
Полная стенограмма

Добро пожаловать в эту серию лекций о цепях поставок. Я — Йоаннес Верморель, и сегодня я представлю «Современные компьютеры для цепей поставок». Цепи поставок на Западе были оцифрованы давно, иногда до трёх десятилетий назад. Компьютерное принятие решений происходит повсеместно, и соответствующие числовые рецепты носят различные названия, такие как точки повторного заказа, минимум-максимум запасов и резервные запасы, с различной степенью человеческого контроля.
Тем не менее, если мы посмотрим на крупные компании, сегодня управляющие аналогично масштабными цепями поставок, мы увидим миллионы решений, которые по сути управляются компьютерами и определяют эффективность цепей поставок. Таким образом, когда речь заходит об улучшении эффективности цепей поставок, всё сводится к совершенствованию числовых рецептов, управляющих цепью поставок. При этом неизбежно, когда мы начинаем рассматривать превосходящие числовые рецепты любого рода, в которых нам нужны более лучшие модели и более точные прогнозы, эти улучшенные рецепты в итоге требуют гораздо больше вычислительных ресурсов.
Вычислительные ресурсы всегда были проблемой для цепей поставок, так как они стоят больших денег, и всегда наступает следующий этап эволюции для новой модели или следующей системы прогнозирования, которая требует в десять раз больше вычислительных ресурсов, чем предыдущая. Да, это может повысить эффективность цепи поставок, но сопровождается увеличением затрат на вычисления. За последние несколько десятилетий аппаратное обеспечение кардинально прогрессировало, но, как мы увидим сегодня, этот прогресс, несмотря на то, что он продолжается, часто противодействует корпоративному программному обеспечению. В результате программное обеспечение не становится быстрее на более современном оборудовании; наоборот, оно зачастую может работать медленнее.
Цель этой лекции — привить аудитории определённое понимание «механической симпатии», чтобы вы могли оценить, использует ли корпоративное программное обеспечение, которое должно реализовывать числовые рецепты для обеспечения превосходной эффективности цепей поставок, имеющееся вычислительное оборудование, как оно существует сейчас и как будет через десятилетие, или же оно конфликтует с ним, в результате чего не использует в полной мере вычислительный потенциал сегодняшнего оборудования.

Один из самых загадочных аспектов современных компьютеров — это диапазон порядков величины, с которым приходится иметь дело. С точки зрения управления цепями поставок, у нас обычно имеется около пяти порядков величины, и это уже предел; зачастую даже меньше. Пять порядков величины означают, что мы можем перейти от одной единицы к 100 000 единицам. Помните, что я упоминал в предыдущих лекциях закон малых чисел. Если у вас много единиц, вы не будете обрабатывать их по одной; вы будете упаковывать их в коробки, таким образом остаётся гораздо меньше коробок. Аналогичным образом, если у вас много коробок, вы будете собирать их в поддоны и так далее, поэтому итоговое число поддонов будет значительно меньше. Экономия на масштабе способствует прогнозированию количеств, и с точки зрения цепей поставок, когда речь идёт о потоках физических товаров, неэффективность в 10% уже является довольно значительной.
В области вычислений всё совершенно иначе; мы имеем дело с 15 порядками величины, что является абсолютно гигантским масштабом. Чтобы перейти от одной единицы к одному миллиону миллиардов единиц, число настолько велико, что его трудно себе представить. Мы переходим от одного байта, который составляет всего восемь бит и может представлять букву или цифру, к петабайту, который равен миллиону гигабайт. Петабайт соответствует порядку величины объёма данных, которыми в настоящее время управляет Lokad, и крупные компании, управляющие масштабными цепями поставок, также используют наборы данных порядка одного петабайта.
Мы переходим от одного FLOP (операция с плавающей точкой в секунду) к одному петаFLOP, что составляет миллион гигаFLOPS. Эти порядки величины поистине гигантские и обманчивые. В результате, в области цепей поставок, где 10% считаются неэффективностью, в мире вычислений обычно речь идёт не о неэффективности в 10%, а о неэффективности в 10 раз, а иногда и на несколько порядков величины. Таким образом, если вы допустите ошибку с точки зрения производительности в вычислительной сфере, ваше наказание составит не 10%; ваша система будет в 10 раз медленнее, чем должна быть, или в 100 раз, а порой даже в 1000 раз медленнее. Именно в этом и заключается суть вопроса: достижение истинного соответствия, которое требует определённой механической симпатии между корпоративным программным обеспечением и базовым вычислительным оборудованием.
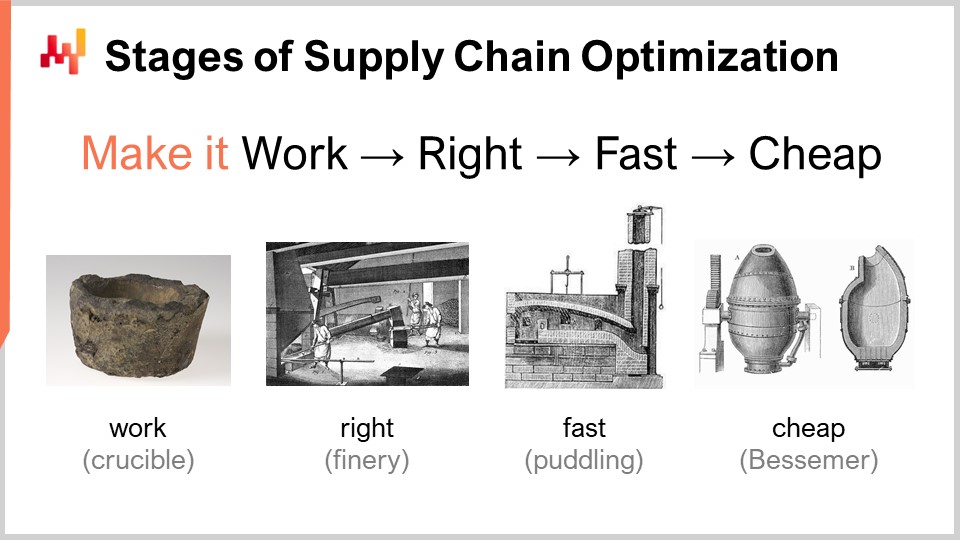
При рассмотрении числового рецепта, который должен обеспечить превосходную эффективность цепей поставок, существует набор этапов зрелости, представляющих концептуальный интерес. Конечно, на практике всё может отличаться, но, как правило, это те этапы, которые мы определили в Lokad. Эти этапы можно свести к следующим: заставить работать, сделать правильно, сделать быстро и сделать дешево.
«Заставить работать» означает оценить, действительно ли прототип числового рецепта обеспечивает ожидаемые результаты, такие как более высокий уровень сервиса, меньше нераспроданных товаров, лучшее использование активов или любую иную цель, значимую с точки зрения цепей поставок. Цель на этом этапе — убедиться, что новый числовой рецепт действительно работает.
Затем необходимо «сделать правильно». С точки зрения цепей поставок это означает трансформировать, по сути, уникальный прототип в продукт, пригодный для промышленного производства. Обычно это включает в себя обеспечение числового рецепта определённой корректностью по замыслу. Цепи поставок — это огромные, сложные и, что ещё важнее, очень запутанные системы. Если у вас есть числовой рецепт, который является очень хрупким, даже если числовой метод хорош, его легко можно испортить, и в итоге вы создадите гораздо больше проблем, чем ожидаемых выгод. Это не выигрышное решение. Сделать правильно означает обеспечить наличие чего-то, что можно развернуть в масштабе с минимальными трудностями. Затем вы хотите сделать этот числовой рецепт быстрым, и когда я говорю «быстрым», я имею в виду скорость выполнения в реальном времени. Когда вы запускаете расчёт, вы должны получить результаты в течение нескольких минут или максимум часа-двух, но не дольше. Цепи поставок запутаны, и наступит момент в истории вашей компании, когда возникнут сбои, такие как грузовые суда, застрявшие посреди Суэцкого канала, пандемия или склад, подвергшийся затоплению. Когда это случается, вам нужно быстро реагировать. Я не говорю о реакции в течение нескольких миллисекунд, но если у вас числовые рецепты, выполнение которых занимает дни, это создаёт огромное операционное трение. Вам нужны решения, которые могут функционировать в короткие сроки, то есть они должны быть быстрыми.
Помните, современное корпоративное программное обеспечение работает в облаке, и вы всегда можете заплатить за дополнительные вычислительные ресурсы на облачных платформах. Таким образом, ваше программное обеспечение может быть быстрым просто потому, что вы арендуете большое количество вычислительной мощности. Дело не в том, что само программное обеспечение должно быть должным образом разработано для использования всей вычислительной мощности, которую может предоставить облако, а в том, что оно может быть быстрым и очень неэффективным, просто потому, что вы арендуете столько вычислительной мощности у вашего поставщика облачных услуг.
Следующий этап — сделать метод дешевым, то есть он не должен потреблять слишком много облачных вычислительных ресурсов. Если вы не достигнете этого последнего этапа, это означает, что вы никогда не сможете усовершенствовать свой метод. Если у вас есть метод, который работает, сделан правильно и быстро, но потребляет много ресурсов, то когда вы захотите перейти к следующему этапу числового рецепта, который неизбежно будет требовать ещё больше вычислительных ресурсов, чем вы используете сейчас, вы окажетесь в тупике. Вам нужно сделать существующий метод максимально эффективным, чтобы начать экспериментировать с числовыми рецептами, менее требовательными к ресурсам, чем текущий.
Именно на этом последнем этапе вам действительно нужно использовать базовое оборудование, доступное в современных компьютерах. Вы можете обходиться первыми тремя этапами без особой привязанности, но последний является ключевым. Помните, если вы не достигнете этапа «сделать дешево», вы не сможете проводить итерации, и окажетесь в тупике. Именно поэтому, даже если это последний этап, это итеративный процесс, и необходимо пройти все этапы, если вы хотите повторно совершенствовать метод.
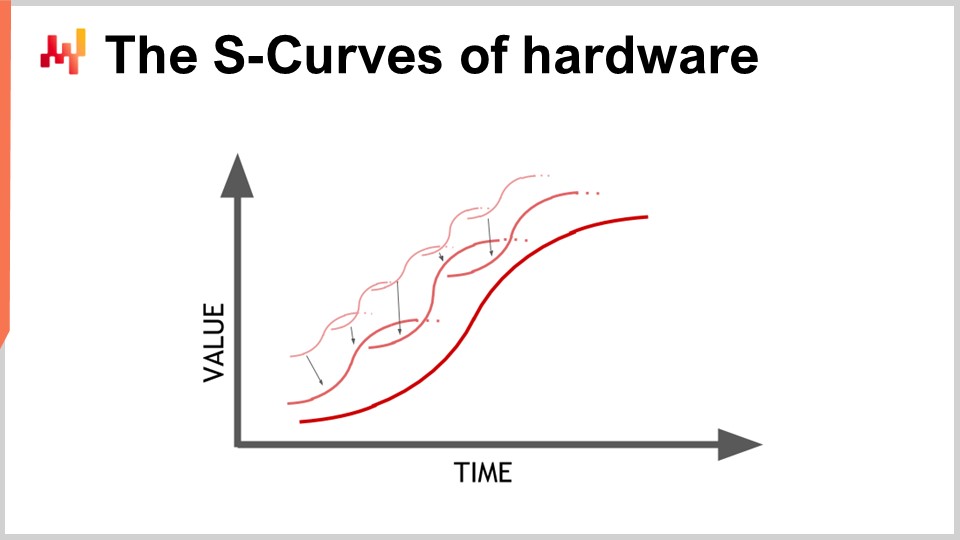
Прогресс в области аппаратного обеспечения идёт, и он выглядит экспоненциальным, но на самом деле этот экспоненциальный рост вычислительного оборудования состоит из тысяч S-образных кривых. S-образная кривая — это график, на котором вы вводите новый дизайн, процесс, материал или архитектуру, и изначально он не лучше того, что было раньше. Затем вступает в силу эффект запланированного нововведения, происходит ускоренный рост, за которым следует плато после исчерпания всех преимуществ новшества. Плато на S-кривых характерно для прогресса в компьютерном оборудовании, состоящем из тысяч таких кривых. Для неспециалиста это выглядит как экспоненциальный рост. Однако эксперты видят, как отдельные S-кривые достигают плато, что может вести к пессимистичному взгляду. Даже эксперты не всегда предвидят появление новых S-кривых, которые удивляют всех и продолжают экспоненциальный рост прогресса.
Хотя компьютерное оборудование всё ещё прогрессирует, темпы этого прогресса далеки от тех, что были в 1980-х или 1990-х годах. Сейчас они гораздо медленнее и довольно предсказуемы, главным образом из-за огромных инвестиций, необходимых для строительства новых фабрик по производству вычислительного оборудования. Эти инвестиции часто составляют сотни миллионов долларов, обеспечивая предсказуемость на пять-десять лет вперёд. Хотя прогресс замедлился, у нас всё ещё есть достаточно точное представление о том, что произойдёт в области развития вычислительного оборудования в течение следующего десятилетия.
Урок для корпоративного программного обеспечения, реализующего числовые рецепты, заключается в том, что нельзя пассивно ожидать, что будущее оборудование само по себе решит все ваши проблемы. Аппаратное обеспечение всё ещё прогрессирует, но использование этого прогресса требует усилий с программной стороны. Вы сможете достичь большего с оборудованием, которое будет доступно через десятилетие, но только при условии, что архитектура в основе вашего корпоративного программного обеспечения использует базовую вычислительную технику. В противном случае вы можете оказаться в худшем положении, чем сегодня, что вовсе не так неразумно, как может показаться.
Эта лекция является первой в четвертой главе данной серии лекций о цепях поставок. Я не закончил третью главу о персонажах цепей поставок. В последующих лекциях я, вероятно, буду чередовать между настоящей главой, в которой я рассматриваю вспомогательные науки цепей поставок, и третьей главой о персонажах цепей поставок.
В самой первой главе пролога я изложил свои взгляды на цепи поставок как на область изучения и практику. Мы увидели, что цепи поставок по сути представляют собой совокупность сложнейших проблем, а не простых задач, омрачённых враждебным поведением и конкурентными играми. Поэтому нам следует уделять большое внимание методологии, поскольку наивные прямые методики показывают плохие результаты в этой области. Именно поэтому вторая глава была посвящена методологии, необходимой для изучения цепей поставок и выработки практик их постоянного улучшения.
Третья глава, персонажи цепочки поставок, была посвящена характеристике самих проблем цепочки поставок, с девизом «влюбляйтесь в проблему, а не в решение». Четвертая глава, которую мы сегодня открываем, посвящена вспомогательным наукам в области цепочек поставок.

Вспомогательные науки – это дисциплины, поддерживающие изучение другой дисциплины. Здесь нет оценки значимости; речь не о том, что одна дисциплина превосходит другую. Например, медицина не превосходит биологию, но биология является вспомогательной наукой для медицины. Подход вспомогательных наук хорошо устоялся и широко применяется во многих областях исследований, таких как медицинские науки и история.
В медицинских науках вспомогательными являются биология, химия, физика и социология, среди прочих. Современного врача нельзя считать компетентным, если он не обладает знаниями по физике. Например, понимание основ физики необходимо для интерпретации рентгеновского снимка. То же самое касается и истории, которая имеет длинную традицию использования вспомогательных наук.
Когда речь заходит о цепочках поставок, одним из моих главных замечаний к типичным материалам, курсам, книгам и статьям по этой теме является то, что они рассматривают её, не углубляясь во вспомогательные науки. Они трактуют цепочку поставок как изолированный, самостоятельный объект знаний. Однако я считаю, что современная практика в области цепочек поставок может быть достигнута только при полном использовании вспомогательных наук цепочек поставок. Одной из таких вспомогательных наук, и именно на ней сосредоточена сегодняшняя лекция, является вычислительное оборудование.
Эта лекция не является строго лекцией по цепочкам поставок, а скорее посвящена вычислительному оборудованию с учетом его применения в цепочках поставок. Я считаю, что это является основополагающим для современной практики в области цепочек поставок, в отличие от методов, применявшихся сто лет назад.

Давайте взглянем на современные компьютеры. В этой лекции мы рассмотрим, что они могут сделать для цепочек поставок, особенно сосредотачиваясь на аспектах, которые имеют огромное значение для производительности корпоративного программного обеспечения. Мы обсудим задержки, вычислительную мощность, память, хранение данных и пропускную способность.

Скорость света составляет около 30 сантиметров за наносекунду, что относительно медленно. Если учитывать характерное расстояние для современного процессора, работающего на 5 гигагерцах (5 миллиардов операций в секунду), расстояние, которое свет проходит за 0,2 наносекунды, составляет всего 3 сантиметра. Это означает, что из-за ограничения скорости света взаимодействия не могут происходить на расстоянии более 3 сантиметров. Это жесткое ограничение, наложенное законами физики, и неизвестно, сможем ли мы когда-либо его преодолеть.
Задержка – чрезвычайно жесткий ограничительный фактор. С точки зрения цепочек поставок, вовлечены как минимум два типа распределенного вычислительного оборудования. Под распределенным вычислительным оборудованием я подразумеваю устройства, которые не могут располагаться в одном физическом пространстве, поскольку каждое из них имеет свои габариты. Однако первая причина, по которой нам нужно распределенное вычислительное оборудование, связана с тем, что цепочки поставок распределены географически. По своей сути цепочки поставок охватывают различные регионы, и, соответственно, вычислительное оборудование также распределено по этим регионам. С точки зрения скорости света, даже если устройства находятся всего в трех метрах друг от друга, это уже достаточно медленно, поскольку требуется 100 тактовых циклов на обратный путь. Три метра — довольно большое расстояние с учетом скорости света и тактовой частоты современных процессоров.
Другой тип распределения – это горизонтальное масштабирование. Современный способ получения большей вычислительной мощности не заключается в том, чтобы иметь устройство, в 10 или миллион раз мощнее; так не конструируется техника. Если вам нужно больше вычислительных ресурсов, требуются дополнительные вычислительные устройства, больше процессоров, чипов памяти и жестких дисков. Именно путем накопления аппаратного обеспечения можно получить больше вычислительной мощности. Однако все эти устройства занимают место, и поэтому вы в итоге распределяете свое вычислительное оборудование, поскольку невозможно централизовать его в устройстве шириной в сантиметр.
Что касается задержек, если рассматривать те задержки, которые наблюдаются в профессиональном интернете (те, что в дата-центрах, а не по домашнему Wi-Fi), мы уже работаем на уровне около 30% от скорости света. Например, задержка между дата-центром возле Парижа (Франция) и Нью-Йорком (США) составляет примерно 30% от скорости света. Это невероятное достижение для человечества; информация перемещается по интернету почти со скоростью света. Да, еще есть возможности для улучшения, но мы уже близки к жестким ограничениям, установленным физикой.
В результате существуют компании, которые планируют провести кабель через морское дно Арктики, чтобы соединить Лондон с Токио кабелем, проходящим под Северным полюсом, лишь для того, чтобы снизить задержку на несколько миллисекунд в финансовых транзакциях. По сути, задержка и скорость света – это серьезные проблемы, и наш интернет, по сути, так хорош, как только может быть, если не произойдут прорывы в физике. Однако в ближайшее десятилетие ничего подобного не предвидится.
Из-за того, что задержка является чрезвычайно сложной проблемой, последствия для корпоративного программного обеспечения огромны. Обмен информацией в виде обратных циклов является критическим, и производительность вашего корпоративного программного обеспечения в значительной степени будет зависеть от количества таких циклов между различными подсистемами. Количество обратных циклов характеризует ту неизбежную задержку, с которой вы сталкиваетесь. Минимизация количества циклов и улучшение задержек является, для большинства корпоративного программного обеспечения, включая то, что предназначено для предиктивной оптимизации цепочек поставок, главной задачей. Снижение задержек часто означает повышение производительности.

Интересный прием, хотя и не то, что каждый из присутствующих в зале будет применять в продакшен-среде, заключается в устранении осложнений, вызванных задержками. Само понятие времени становится неуловимым и расплывчатым, когда вы переходите в область наносекундных вычислений. Точные часы найти сложно в распределенных вычислениях, и их отсутствие вносит дополнительные сложности в распределенное корпоративное программное обеспечение. Для синхронизации различных частей системы требуются многочисленные обратные циклы. Из-за отсутствия точных часов приходится прибегать к алгоритмическим альтернативам, таким как векторные часы или многочастные временные метки, которые представляют собой структуры данных, отражающие частичный порядок работы часов устройств в системе. Эти дополнительные циклы могут негативно сказаться на производительности.
Один из хитрых приемов, примененный Google более десяти лет назад, заключался в использовании атомных часов на чипе. Разрешающая способность этих атомных часов значительно превосходит тактовые кварцевые часы, встречающиеся в электронных часах или компьютерах. NIST продемонстрировал новую установку атомных часов на чипе с еще более точным ежедневным дрейфом. Google использовал внутренние атомные часы для синхронизации различных компонентов своей глобально распределенной SQL-базы данных Google Spanner, чтобы сократить количество обратных циклов и повысить производительность на глобальном уровне. Это способ обойти задержки за счет очень точных измерений времени.
Если взглянуть на десятилетнюю перспективу, Google, вероятно, не будет единственной компанией, использующей подобный хитрый прием, и они относительно доступны по цене — атомные часы на чипе стоят около 1500 долларов за штуку.

Теперь давайте рассмотрим вычислительную мощность, то есть совершение вычислений с помощью компьютера. Тактовая частота была волшебным ингредиентом улучшения в 80-х и 90-х годах. Действительно, если бы вы могли во всех аспектах удвоить тактовую частоту вашего компьютера, вы бы фактически удвоили его производительность, независимо от типа используемого программного обеспечения. Всё программное обеспечение становилось бы линейно быстрее в зависимости от тактовой частоты. Увеличение тактовой частоты чрезвычайно интересно, и оно все еще совершенствуется, хотя темпы роста со временем снизились. Почти 20 лет назад тактовая частота составляла около 2 ГГц, а сегодня – 5 ГГц.
Основная причина стагнации улучшения – энергетический барьер. Проблема в том, что при увеличении тактовой частоты на чипе вы, как правило, приблизительно удваиваете энергопотребление, которое затем необходимо рассеять. Проблема заключается в тепловом рассеянии, поскольку если энергию не рассеивают, устройство нагревается до такой степени, что может быть повреждено. В наши дни полупроводниковая индустрия перешла от увеличения количества операций в секунду к увеличению количества операций на ватт.
Это правило, при котором увеличение тактовой частоты на 30% удваивает энергопотребление, имеет двоякое значение. Если вас устраивает жертвовать четвертью вычислительной мощности за единицу времени на ЦП, вы можете фактически сократить энергопотребление вдвое. Это особенно актуально для смартфонов, где экономия энергии имеет решающее значение, а также для облачных вычислений, где одним из основных факторов затрат является сама энергия. Для экономически эффективной облачной вычислительной мощности важно не иметь супербыстрые ЦП, а иметь тактовые частоты, которые могут быть снижены до 1 ГГц, поскольку они обеспечивают больше операций в секунду на каждую затраченную единицу энергии.
Энергетическая проблема настолько остра, что современные архитектуры процессоров используют всевозможные хитрые приемы для ее смягчения. Например, современные процессоры могут регулировать свою тактовую частоту, временно увеличивая ее на секунду или около того, а затем снижая для рассеивания тепла. Они также могут использовать так называемый «темный кремний». Идея в том, что, если процессор может чередовать горячие участки на чипе, энергия рассеивается легче, чем если бы один и тот же участок был активен в каждом тактовом цикле. Это крайне важный элемент современного дизайна. С точки зрения корпоративного программного обеспечения это означает, что вам действительно необходимо уметь масштабироваться горизонтально. Вы должны уметь выполнять больше задач с использованием в несколько раз большего количества процессоров, хотя по отдельности их эффективность будет ниже, чем у предыдущих моделей. Речь не о том, чтобы получать лучшее оборудование в целом; важно иметь процессоры, обеспечивающие больше операций на ватт, и эта тенденция будет сохраняться.
Может быть, через десятилетие мы с трудом достигнем семи, а возможно, и восьми гигагерц, но я даже не уверен, что нам удастся это сделать. Когда я смотрю на тактовую частоту у большинства облачных провайдеров в 2021 году, она обычно составляет около 2 ГГц, то есть мы вернулись к тактовой частоте, которая была 20 лет назад, и это самое экономичное решение.
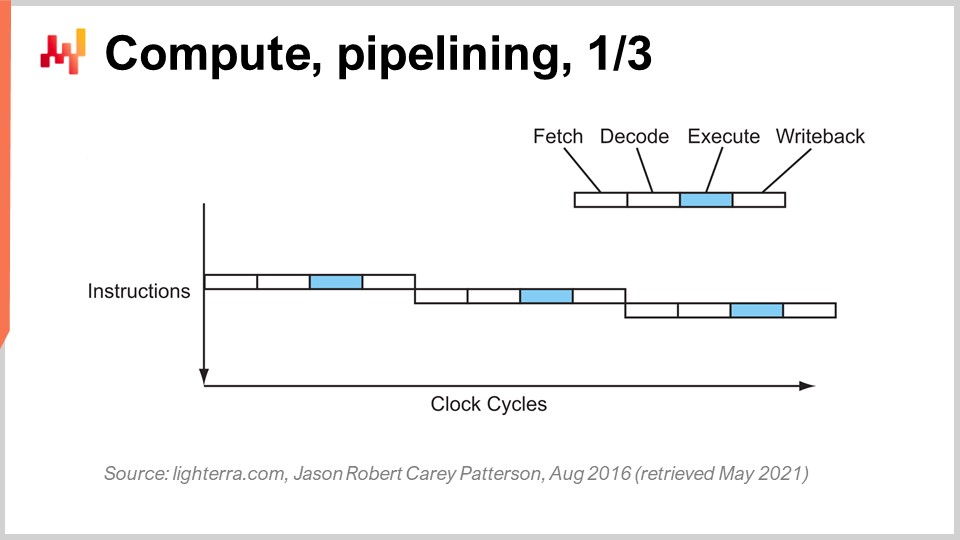
Достижение нынешней производительности процессоров потребовало серии ключевых инноваций. Я собираюсь представить несколько из них, особенно те, которые оказывают наибольшее влияние на проектирование корпоративного программного обеспечения. На этом экране вы видите поток инструкций последовательного процессора, каким они создавались до начала 80-х годов. Система представляет собой серию инструкций, выполняемых сверху вниз, что отражает течение времени. Каждая инструкция проходит через несколько этапов: выборку, декодирование, выполнение и запись результата.
На этапе выборки извлекается инструкция, регистрируется, захватывается следующая инструкция, увеличивается счетчик инструкций и подготавливается процессор. На этапе декодирования инструкция декодируется, и генерируется внутренний микрокод, который процессор исполняет. На этапе выполнения происходит получение необходимых входных данных из регистров и само вычисление, а этап записи результата заключается в том, чтобы взять только что вычисленный результат и записать его в один из регистров. В этом последовательном процессоре каждый этап занимает один тактовый цикл, поэтому на выполнение одной инструкции требуется четыре тактовых цикла. Как мы видели, увеличить частоту тактовых циклов весьма сложно из-за множества осложнений.
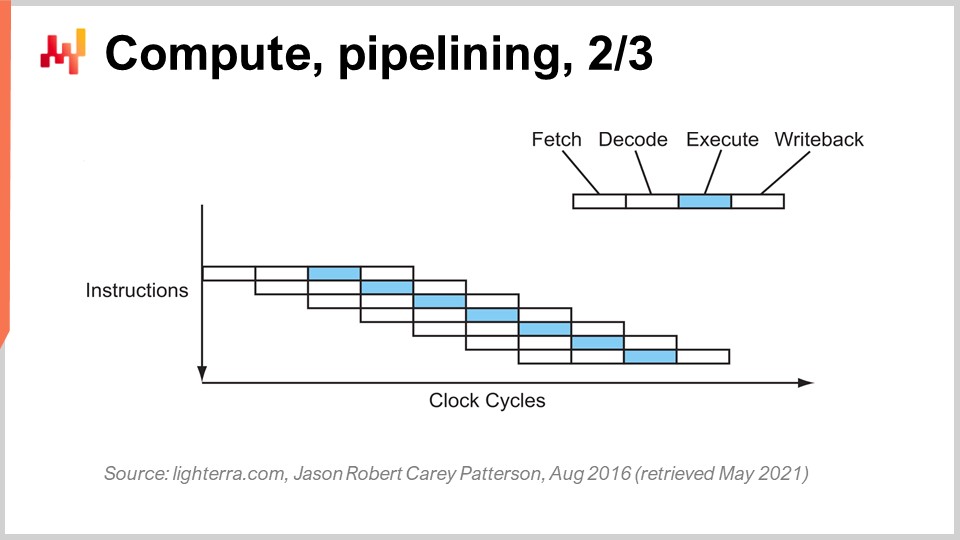
Ключевой прием, применяемый с начала 80-х годов, известен как конвейеризация. Конвейеризация может существенно ускорить вычисления процессора. Идея заключается в том, что, поскольку каждая инструкция проходит несколько этапов, мы можем накладывать эти этапы друг на друга, и таким образом процессор будет иметь целый конвейер инструкций. На этой диаграмме вы видите процессор с конвейером глубиной четыре, где одновременно выполняются четыре инструкции, однако каждая из них находится на своем этапе: одна на выборке, одна на декодировании, одна на выполнении и одна на записи результата. С помощью этого простого приема, реализованного в виде конвейерного процессора, мы увеличили эффективную производительность процессора в четыре раза, просто применив конвейеризацию операций. Все современные процессоры используют конвейеризацию.
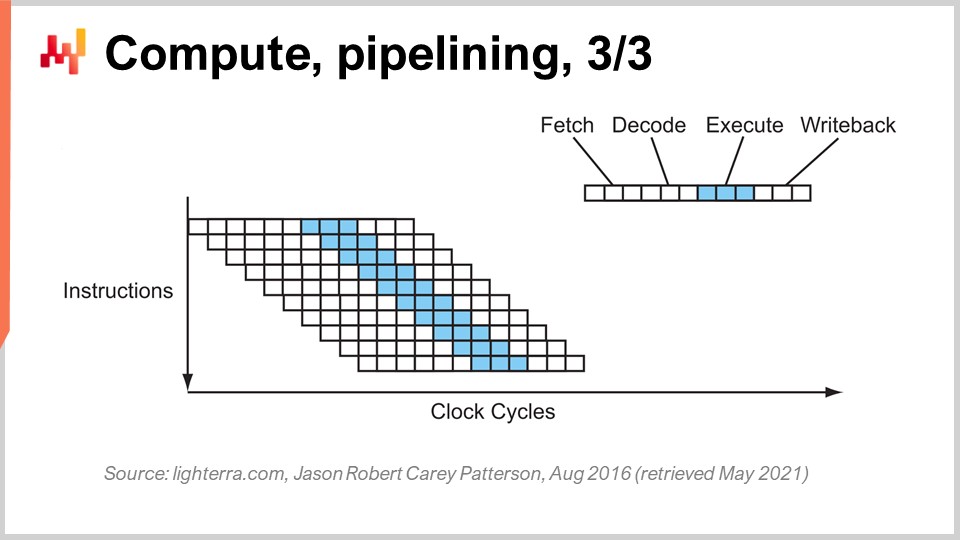
Следующий этап совершенствования называется суперконвейеризацией. Современные процессоры значительно превосходят простую конвейеризацию. На самом деле количество этапов в современном процессоре составляет примерно 30. На схеме в качестве примера приведен процессор с 12 этапами, но на практике их будет около 30. Благодаря такому более глубокому конвейеру одновременно могут выполняться 12 операций, что значительно улучшает производительность при сохранении той же тактовой частоты.
Однако появляется новая проблема: следующая инструкция начинается до завершения предыдущей. Это означает, что если у вас есть зависимые операции, возникает проблема, так как вычисление входных данных для следующей инструкции еще не завершено, и приходится ждать. Мы хотим использовать весь доступный конвейер для максимальной вычислительной мощности. Поэтому современные процессоры извлекают не одну инструкцию за раз, а около 500 инструкций за раз. Они заглядывают далеко вперед в список предстоящих инструкций и переставляют их, чтобы смягчить зависимости, чередуя потоки выполнения для использования полной глубины конвейера.
Существует множество факторов, усложняющих эту операцию, особенно ветвления. Ветвление — это просто условие в программировании, такое как оператор “if”. Результат условия может быть истинным или ложным, и в зависимости от результата программа выполнит один блок логики или другой. Это усложняет управление зависимостями, поскольку процессору приходится угадывать, куда пойдёт следующее ветвление. Современные процессоры используют предсказание ветвлений, применяя простые эвристики, и обладают очень высокой точностью прогнозирования. Они могут предсказывать направление ветвлений с точностью свыше 99%, что лучше, чем мы можем предсказать в реальном контексте цепочки поставок. Такая точность необходима для использования сверхглубоких конвейеров.
Чтобы дать представление о том, какие эвристики применяются для предсказания ветвлений, можно привести простой пример: предположить, что ветвление пойдёт в том же направлении, что и в предыдущий раз. Эта простая эвристика обеспечивает точность порядка 90%, что довольно хорошо. Если добавить уточнение к этой эвристике, а именно, что ветвление пойдёт в том же направлении, что и в прошлый раз, но при этом нужно учитывать исходную точку (то есть, что это то же самое ветвление, происходящее из того же места), то точность возрастёт до примерно 95%. Современные процессоры фактически используют достаточно сложные персептроны — технику машинного обучения для предсказания направления ветвлений.
При правильных условиях можно достаточно точно предсказывать ветвления и таким образом максимально использовать конвейер, чтобы извлечь максимум из современного процессора. Однако с точки зрения разработки программного обеспечения необходимо учитывать особенности работы процессора, особенно предсказание ветвлений. Если не соблюдать эти принципы, предсказание ветвлений может ошибиться, и когда это случится, процессор предскажет направление ветвления, организует конвейер и начнёт выполнять вычисления заранее. Когда ветвление фактически встретится, а вычисления будут готовы, процессор поймёт, что предсказание было неверным. Неверное предсказание ветвления не приводит к ошибочному результату, оно приводит к потере производительности. Процессору не остаётся ничего другого, как очистить весь конвейер или его значительную часть, подождать выполнения оставшихся вычислений и затем перезапустить процесс. Потеря производительности может быть очень значительной, и вы легко можете потерять один или два порядка величины из-за бизнес-логики, не учитывающей особенности предсказания ветвлений процессора.
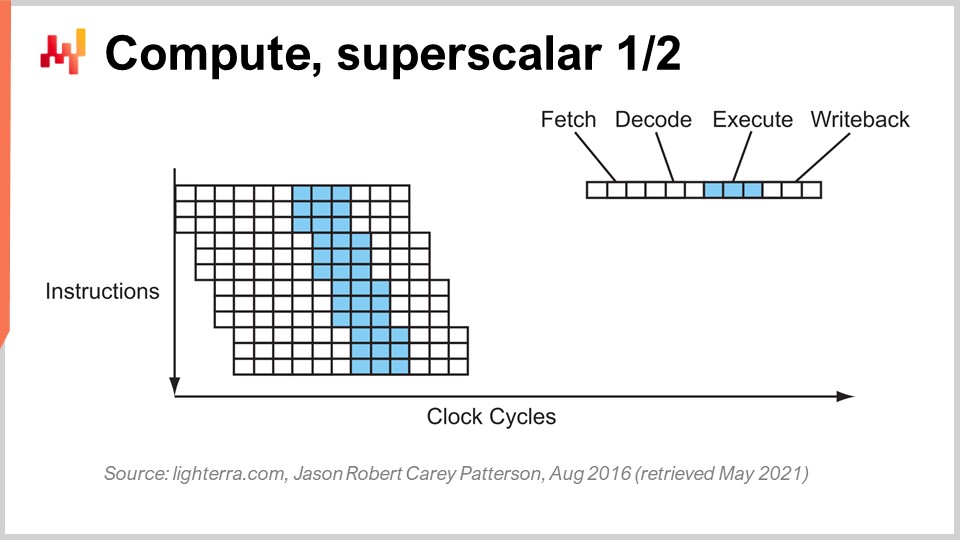
Другой заметный приём, помимо конвейерной обработки, — суперскалярные инструкции. Обычно процессоры обрабатывают скаляры или пары скаляров за раз — например, два числа с 32-битной точностью с плавающей запятой. Они выполняют скалярные операции, по сути обрабатывая одно число за раз. Однако современные процессоры за последнее десятилетие практически все оснащены суперскалярными инструкциями, которые способны одновременно обрабатывать несколько векторов чисел и выполнять векторные операции напрямую. Это означает, что процессор может взять вектор, состоящий, скажем, из восьми чисел с плавающей запятой, и второй вектор также из восьми чисел, выполнить их сложение и получить вектор с результатами сложения. Всё это происходит за один такт.
Например, специализированные наборы инструкций, такие как AVX2, позволяют выполнять операции с 32-битной точностью, обрабатывая наборы по восемь чисел, в то время как AVX512 позволяет работать с наборами по 16 чисел. Если вы умеете использовать эти инструкции, это значит, что вы буквально можете получить прирост в один порядок в скорости обработки, поскольку одна инструкция, один такт, выполняет намного больше вычислений, чем последовательная обработка чисел по одному. Этот процесс известен как SIMD (одна инструкция, несколько данных) и обладает огромной мощностью. Он определяет основное направление прогресса вычислительной мощности за последнее десятилетие, и современные процессоры всё больше основаны на векторных операциях и суперскалярности. Однако с точки зрения корпоративного программного обеспечения всё это довольно сложно. При конвейерной обработке ваше ПО должно работать в унисон с архитектурой процессора, и возможно, это происходит случайно вместе с предсказанием ветвлений. Но когда дело доходит до суперскалярных инструкций, ничего не происходит случайно. Вашему ПО обычно требуется явно реализовать определённые подходы для использования этой дополнительной вычислительной мощности. Это не даётся само собой; нужно осознанно применять этот подход, зачастую организовывая сами данные таким образом, чтобы обеспечить параллелизм и соответствие требованиям инструкций SIMD. Это не высшая математика, но такое поведение не возникает само по себе и даёт огромный прирост вычислительной мощности.

Теперь современные процессоры могут иметь множество ядер, и каждое ядро обеспечивает отдельный поток инструкций. В самых современных многоядерных процессорах обычно используется до 64 ядер, то есть 64 независимых параллельных потока выполнения. Вы фактически можете достичь примерно одного терафлопа, что является верхним пределом пропускной способности, доступной от современного процессора. Однако, если вы хотите пойти дальше, можно обратить внимание на GPU (графические процессоры). Несмотря на то, что можно подумать иначе, эти устройства можно использовать и для задач, не связанных с графикой.
GPU, такой как от NVIDIA, является суперскалярным процессором. Вместо того чтобы иметь до 64 ядер, как у высокопроизводительных CPU, GPU могут содержать более 10 000 ядер. Эти ядра гораздо проще и не так мощны или быстры, как обычные ядра CPU, но их в несколько раз больше. Они выводят SIMD на новый уровень, позволяя обрабатывать не только наборы по 8 или 16 чисел за раз, но буквально тысячи чисел одновременно для выполнения векторных инструкций. С помощью GPU вы можете достичь более 30 терафлопс на одном устройстве, что является огромным показателем. Лучшие CPU на рынке могут обеспечить один терафлоп, тогда как лучшие GPU дают свыше 30 терафлопс. Это разница более чем в один порядок, что чрезвычайно важно.
Если пойти ещё дальше, для специализированных вычислений, таких как линейная алгебра (кстати, такие вещи, как машинное обучение и глубокое обучение, по сути, представляют собой всюду матричную линейную алгебру), можно использовать процессоры, такие как TPU (тензорные процессорные установки). Google решил назвать их “тензорами” из-за TensorFlow, но на самом деле TPU следовало бы назвать процессорами для матричного умножения. Интересно то, что при матричном умножении задействовано не только огромное количество параллелизма данных, но и большое число повторений, поскольку операции крайне повторяемы. Организовав TPU в виде систолической решётки, по сути двумерной сетки с вычислительными узлами, можно преодолеть барьер петалафлопов — достичь свыше 1000 терафлопс на одном устройстве. Однако есть оговорка: Google использует 16-битные числа с плавающей запятой вместо обычных 32-битных. С точки зрения цепочки поставок, 16 бит точности — неплохо; это означает, что точность операций составляет примерно 0.1%, и для многих задач машинного обучения или статистического анализа такая точность более чем достаточна, если всё сделано правильно и без накопления смещения.
Мы видим, что путь прогресса в вычислительной технике, если смотреть только на производительность, заключается в использовании более специализированных и жёстких устройств. Переход на суперскалярные инструкции даёт прирост в один порядок; использование видеокарты — прирост на один или два порядка; а применение чистой линейной алгебры даёт, по сути, прирост в два порядка. Это чрезвычайно важно.
Кстати, все эти аппаратные конструкции являются двумерными. Современные чипы и вычислительные структуры чрезвычайно плоские. Современный процессор не состоит более чем из 20 слоёв, и поскольку эти слои имеют толщину всего несколько микрон, CPU, GPU или TPU по сути являются плоскими структурами. Вы можете подумать: “А что насчёт третьего измерения?” Оказывается, из-за проблемы энергопотребления, связанной с рассеивающей способностью, мы не можем перейти в третье измерение, потому что не знаем, как отвести всю энергию, подаваемую в устройство.
То, что мы можем предсказать на следующее десятилетие, так это то, что эти устройства останутся, по сути, двумерными. С точки зрения корпоративного ПО самый главный урок заключается в том, что необходимо заложить параллелизм данных прямо в основе вашего программного обеспечения. Если этого не сделать, вы не сможете использовать все достижения в области вычислительной мощности. Это не должно быть сделано в последнюю очередь; это должно стать ядром архитектуры, на уровне организации всех данных, которые должны обрабатываться в вашей системе. Если этого не сделать, вы застрянете на уровне процессоров, которые использовались два десятилетия назад.
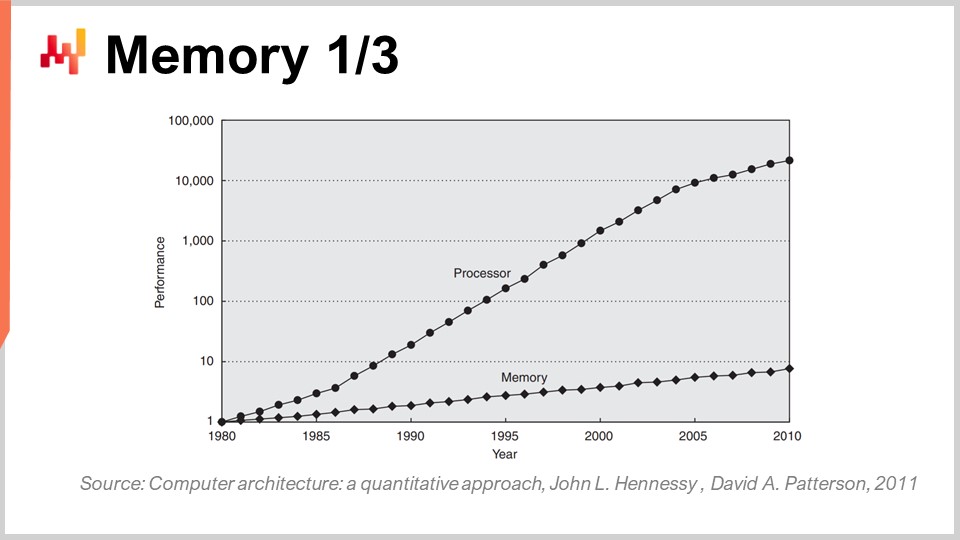
Теперь о памяти: в начале 80-х годов память работала с такой же скоростью, как и процессоры, то есть один такт был равен одному такту для памяти и одному для ЦП. Однако сейчас дело обстоит иначе. С тех пор, как появились 80-е, соотношение между скоростью памяти и задержками доступа к данным, уже находящимся в регистрах процессора, только увеличивалось. Мы начинали с соотношения один к одному, а теперь оно обычно превышает тысячу. Эта проблема известна как “стена памяти” и только усиливается на протяжении последних четырех десятилетий. Она продолжает расти, пусть и очень медленно, в первую очередь потому, что тактовая частота процессоров растет крайне медленно. Поскольку процессоры почти не прогрессируют в плане тактовой частоты, проблема стены памяти больше не усугубляется. Однако текущее соотношение таково, что доступ к памяти по сути в три порядка медленнее, чем доступ к данным, которые уже удобно находятся внутри процессора.
Эта картина полностью отменяет все классические алгоритмы, которые до сих пор преподаются в большинстве университетов. Классический алгоритмический подход предполагает, что время доступа к памяти одинаково для всех ячеек, то есть любой бит памяти доступен за единичное время. Но в современных системах это абсолютно не так. Время, необходимое для доступа к определенной части памяти, сильно зависит от того, где физически находятся эти данные в системе.
С точки зрения корпоративного программного обеспечения оказывается, что, к сожалению, большинство архитектур, разработанных в 80-х и 90-х годах, полностью игнорировали эту проблему, поскольку в первые десятилетия она была незначительной. Проблема действительно разрослась за последние два десятилетия, и как результат, большинство шаблонов, встречающихся в современных корпоративных приложениях, полностью игнорируют эту особенность, поскольку исходит из предположения, что доступ к памяти происходит за постоянное время.
Кстати, если задуматься о языках программирования, таких как Python (первый релиз 1989 года) или Java (в 1995 году), использующих объектно-ориентированное программирование, то это идёт вразрез с тем, как работает память в современных компьютерах. Когда у вас есть объекты, и особенно если используется позднее связывание, как в Python, для выполнения любой операции вам придётся перемещаться по указателям и совершать случайные прыжки по памяти. Если один из таких прыжков окажется неудачным, потому что соответствующий участок памяти не находится в кэше, это может работать в тысячу раз медленнее. Это очень значительная проблема.

Чтобы лучше понять масштаб стены памяти, интересно взглянуть на типичные задержки в современном компьютере. Если перевести эти задержки в человеческие масштабы, предположим, что процессор работает с тактом, равным одной секунде. При таком допущении типичная задержка ЦП составила бы одну секунду. Однако, если обратиться к данным в памяти, это может занять до шести минут. Таким образом, в то время как вы можете выполнять одну операцию в секунду, доступ к данным в памяти потребует шести минут ожидания. А если обращаться к данным на диске, это может занять до месяца или даже целого года. Это невероятно долго, и именно такие порядки разницы в производительности я упоминал в начале этой лекции. Когда вы имеете дело с разницей в 15 порядков, легко не осознать тот огромный удар по производительности, когда приходится ждать, эквивалентно человеческим месяцам, если данные находятся не в нужном месте. Это по-настоящему гигантская проблема.
Кстати, инженеры корпоративного ПО не единственные, кто сталкивается с этой эволюцией современного вычислительного оборудования. Если взглянуть на задержки, наблюдаемые при использовании сверхбыстрых SSD-накопителей, таких как серия Intel Optane, можно увидеть, что половина задержки при доступе к памяти этого устройства обусловлена накладными расходами самого ядра, в данном случае ядра Linux. Именно операционная система генерирует половину задержки. Что это означает? Это значит, что даже разработчикам Linux предстоит ещё много работы, чтобы догнать современные технологии. Тем не менее, это серьёзная проблема для всех.
Однако это особенно заметно в корпоративном ПО, особенно когда речь идёт об оптимизации цепочки поставок, поскольку приходится обрабатывать огромное количество данных. Это уже само по себе довольно сложная задача. С точки зрения enterprise-разработки, вам действительно необходимо принять архитектуру, которая эффективно использует кэш, поскольку в нём хранятся локальные копии данных, доступ к которым осуществляется гораздо быстрее и они находятся ближе к процессору.
Суть в том, что когда вы обращаетесь к одному байту основной памяти, доступ к одному байту в современной системе невозможен. Когда вы запрашиваете даже один байт в оперативной памяти, аппаратное обеспечение фактически копирует 4 килобайта, то есть всю страницу размером 4 килобайта. Основное предположение заключается в том, что когда вы начинаете считывать один байт, следующий байт, скорее всего, будет тем, что находится рядом. Это принцип локальности, который означает, что если вы соблюдаете правило и организуете доступ так, чтобы сохранялась локальность, память будет работать почти так же быстро, как процессор.
Однако для этого требуется согласование между обращениями к памяти и локальностью данных. В частности, существует много языков программирования, таких как Python, которые не предоставляют подобные возможности нативно. Напротив, они создают огромные трудности в обеспечении локальности. Это огромная борьба, и в конечном итоге это битва, где язык программирования разработан по шаблонам, которые полностью противоречат имеющемуся у нас оборудованию. Эта проблема не изменится в предстоящем десятилетии; она только станет хуже.
Таким образом, с точки зрения корпоративного программного обеспечения, вы хотите обеспечить локальность данных, а также минимизацию их объёма. Если вы сможете уменьшить большие данные до малого размера, они будут работать быстрее. Это не интуитивно понятно, но если вы можете уменьшить объём данных, обычно за счёт устранения избыточности, вы ускорите вашу программу, так как будете гораздо лучше использовать кэш. Вы разместите больше релевантных данных в нижних уровнях кэша, которые имеют гораздо меньшую задержку, как показано на этом дисплее.

Наконец, давайте обсудим конкретно случай DRAM. DRAM – это буквально физический компонент, из которого формируется оперативная память, используемая в вашем настольном компьютере или сервере в облаке. DRAM также называют основной памятью, которая строится из DRAM-чипов. За последнее десятилетие цены на DRAM едва снизились. Мы перешли от $5 за гигабайт к $3 за гигабайт за десятилетие. Цена оперативной памяти продолжает снижаться, хотя и не очень быстро. Она стагнирует в течение нескольких следующих лет, и учитывая, что на этом рынке есть всего три основных игрока, способных производить DRAM в промышленных масштабах, надежды на какие-либо неожиданные изменения в этом сегменте в ближайшее десятилетие практически нет.
Но это ещё не весь комплекс проблем. Существует также вопрос энергопотребления на гигабайт. Если посмотреть на энергопотребление, оказывается, что современная оперативная память потребляет немногим больше энергии на гигабайт, чем десять лет назад. Причина в том, что сегодняшняя память работает быстрее, и действует то же правило «энергетической стены»: если вы увеличиваете тактовую частоту, вы значительно увеличиваете энергопотребление. Кстати, оперативная память потребляет довольно много энергии, потому что DRAM по своей сути является активным компонентом. Вам нужно постоянно обновлять данные в памяти из-за утечки электричества, так что, если вы отключите питание, вы потеряете все данные. Ячейки нужно обновлять постоянно.
Таким образом, вывод для корпоративного программного обеспечения таков: DRAM – это тот компонент, который больше не развивается. Есть масса вещей, которые всё ещё развиваются очень быстро, например, вычислительная мощность; однако для DRAM ситуация иная – её развитие крайне замедлено. Если учесть энергопотребление, которое также составляет значительную часть затрат на облачные вычисления, прогресс в области оперативной памяти едва заметен. Поэтому, если вы выбираете архитектуру, чрезмерно опирающуюся на основную память, как это обычно бывает, когда поставщик заявляет: “О, у нас есть дизайн программного обеспечения, основанный на использовании памяти”, помните об этих ключевых моментах.
Каждый раз, когда вы слышите от поставщика, что у него есть дизайн, основанный на использовании памяти, он сообщает вам – и это не самое убедительное предложение – что их архитектура полностью зависит от будущей эволюции DRAM, о которой мы уже знаем, что цены не будут снижаться. Так что, если учесть, что через 10 лет ваша цепочка поставок, вероятно, будет обрабатывать примерно в 10 раз больше данных, просто потому, что компании всё лучше собирают данные в своих цепочках поставок и сотрудничают, собирая данные от клиентов и поставщиков, не будет нелогично ожидать, что через десятилетие любая крупная компания, управляющая обширной цепочкой поставок, будет собирать в 10 раз больше данных, чем сейчас. Однако цена за гигабайт оперативной памяти останется прежней. Так что, если произвести расчёты, у вас могут оказаться расходы на облачные вычисления или ИТ, которые фактически будут почти на порядок дороже, просто чтобы выполнить примерно ту же работу, поскольку вы вынуждены справляться с постоянно растущим объемом данных, который сложно разместить в памяти. Ключевой вывод здесь в том, что вам действительно следует избегать всех видов архитектур, основанных на использовании памяти. Такие архитектуры устарели, и далее мы рассмотрим, какие альтернативы у нас есть.

Теперь давайте взглянем на хранение данных, то есть на постоянное хранение данных. По сути, существует два класса широко распространённых систем хранения данных. Первый – это жёсткие диски (HDD) или вращающиеся диски. Второй – твердотельные накопители (SSD). Интересно то, что задержка при использовании вращающихся дисков ужасна, и, если вы посмотрите на это изображение, вы легко поймёте почему. Эти диски буквально вращаются, и когда вы хотите получить доступ к произвольной точке данных на диске, в среднем вам приходится ждать половину оборота диска. Учитывая, что самые высокопроизводительные диски вращаются примерно со скоростью 10 000 оборотов в минуту, это означает, что у вас есть встроенная задержка в три миллисекунды, которую нельзя уменьшить. Это буквально время, необходимое для того, чтобы диск сделал один оборот и позволил считать нужную точку. Это механическое ограничение, которое не изменится.
Жёсткие диски ужасны в плане задержки, но у них есть и другая проблема – энергопотребление. Как правило, жёсткий диск и SSD оба потребляют около трёх ватт в час на устройство. Это примерно текущий статус-кво. Однако, когда жёсткий диск работает, даже если вы не читаете с него активно, он потребляет три ватта просто для того, чтобы поддерживать вращение диска. Достижение 10 000 оборотов в минуту занимает много времени, так что диск должен вращаться постоянно, даже если вы используете его очень редко.
С другой стороны, когда речь идёт о твердотельных накопителях, они потребляют три ватта, когда к ним обращаются, но когда данные не запрашиваются, они почти не потребляют энергии. У них есть остаточное энергопотребление, но оно чрезвычайно мало – порядка милливатт. Это очень интересно, поскольку можно использовать огромное количество SSD; если вы их не используете, вы не оплачиваете энергию, которую они потребляют. За последнее десятилетие вся индустрия постепенно перешла от HDD к SSD.
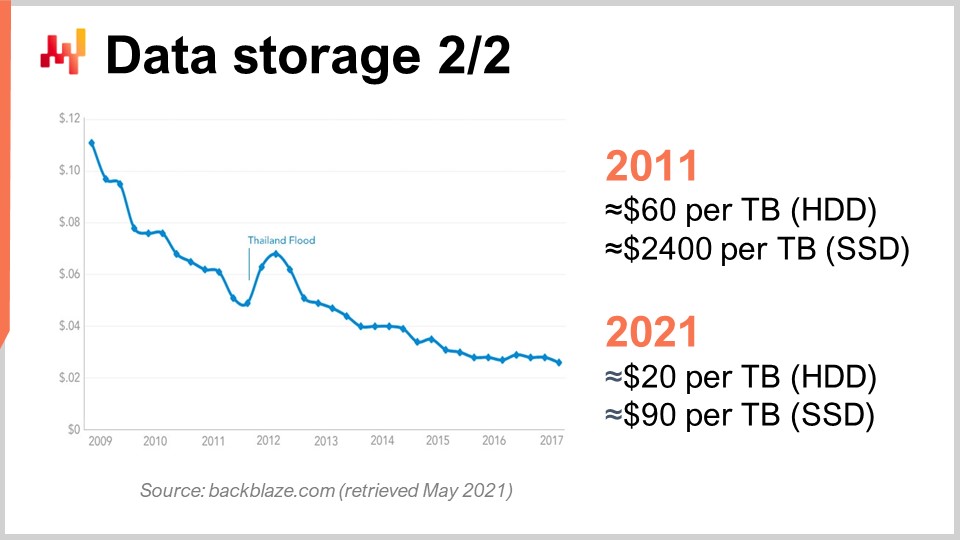
Чтобы это понять, можно взглянуть на эту кривую. Мы видим, что цена за гигабайт как для HDD, так и для SSD снижается за последние несколько лет. Однако сейчас цена стабилизируется. Данные немного устарели, но за последние несколько лет значительных изменений не наблюдалось. Десятилетие назад SSD стоили чрезвычайно дорого – $2400 за терабайт, в то время как жёсткие диски стоили всего $60 за терабайт. Однако в настоящее время цена на жёсткие диски сократилась втрое, примерно до $20 за терабайт. Цена на SSD снизилась более чем в 25 раз, и тенденция к снижению цен на SSD не останавливается. В данный момент, и, вероятно, в течение ближайшего десятилетия, SSD являются компонентом, который развивается быстрее всего, и это очень интересно.
Кстати, я говорил, что дизайн современных вычислительных устройств (CPU, GPU, TPU) по существу двухмерный, с максимум 20 слоями. Однако когда речь заходит об SSD, их архитектура становится всё более трёхмерной. Самые современные SSD имеют порядка 176 слоев. Мы приближаемся, по сути, к 200 слоям. Учитывая, что эти слои невероятно тонкие, не будет нелогично ожидать, что в будущем устройства смогут содержать тысячи слоев и, возможно, обладать в несколько раз большей ёмкостью хранения. Очевидно, что проблема в том, что вы не сможете постоянно обращаться ко всем этим данным из-за ограничений, связанных с «тёмным кремнием» и рассеиванием энергии.
Оказывается, если всё сделать правильно, многие данные запрашиваются чрезвычайно редко. SSD подразумевают очень специфичный аппаратный дизайн, который имеет массу особенностей, таких как тот факт, что вы можете включать биты, но не можете их выключать. По сути, представьте, что изначально у вас все нули; вы можете превратить ноль в единицу, однако локально вы не можете превратить эту единицу обратно в ноль. Если вы хотите это сделать, вам придётся сбросить весь блок, который может достигать восьми мегабайт, что означает, что при записи вы можете перевести биты из нуля в единицу, но не наоборот. Чтобы перевести биты из единицы в ноль, необходимо очистить весь блок и перезаписать его, что приводит ко множеству проблем, известных как усиление записи.
За последнее десятилетие SSD-накопители внутренне содержат компонент под названием Flash Translation Layer, который способен смягчать все эти проблемы. Эти слои постоянно совершенствуются с течением времени. Однако остаётся множество возможностей для дальнейшего улучшения, и с точки зрения корпоративного программного обеспечения это означает, что вам действительно следует оптимизировать ваш дизайн, чтобы максимально использовать возможности SSD. SSD уже являются намного более выгодным решением по сравнению с DRAM для хранения данных, и если действовать разумно, можно ожидать, что через десятилетие аппаратная индустрия принесёт прирост производительности в несколько порядков, чего нельзя сказать о DRAM.
Наконец, давайте поговорим о пропускной способности. Пропускная способность, вероятно, является самой решённой проблемой с точки зрения технологий. Однако, даже если её можно обеспечить, мы уже достигаем потрясающих значений пропускной способности на сегодняшний день. Коммерчески телекоммуникационная индустрия крайне сложна, и существует масса проблем, поэтому конечные потребители на самом деле не видят всех преимуществ прогресса в области оптических коммуникаций.
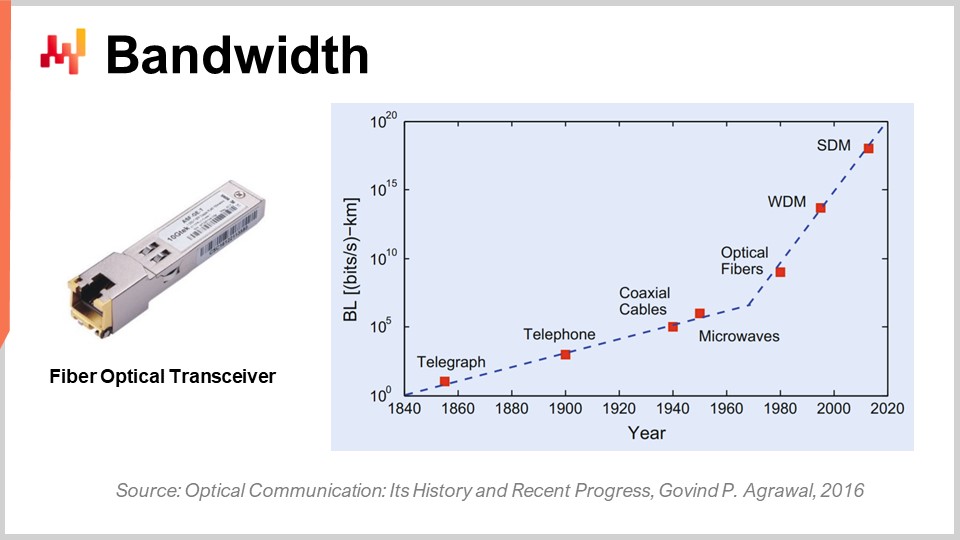
Что касается оптической связи с использованием волоконно-оптических трансиверов, прогресс здесь поистине ошеломляющий. Это, наверное, одна из тех вещей, которая развивается так стремительно, как процессоры в 80-х или 90-х годах. Чтобы дать представление, с использованием мультиплексирования по длине волны (WDM) или пространственного мультиплексирования (SDM) теперь можно достигать буквально десятой терабайта передаваемых данных в секунду по одному оптоволоконному кабелю. Это абсолютно огромно. Мы приближаемся к тому, что один кабель способен передавать достаточно данных, чтобы обеспечить работу целого дата-центра. Что ещё более впечатляет, так это то, что телекоммуникационная индустрия смогла разработать новые трансиверы, которые способны обеспечить эти невероятные характеристики, используя старые кабели. Вам даже не нужно прокладывать новое волокно на улицах; можно взять оптоволокно, проложенное десятилетие назад, установить новый трансивер и получить увеличение пропускной способности в несколько порядков на том же самом кабеле.
Интересно, что существует общий закон оптических коммуникаций: каждое десятилетие расстояние, при котором становится выгодно заменять электрическую связь оптической, сокращается. Если оглянуться несколько десятилетий назад, двадцать лет назад требовалось примерно 100 метров, чтобы оптическая связь превзошла электрическую. Так что если расстояние меньше 100 метров, вы выбираете медь; если больше – волокно. Однако в наши дни с последним поколением технологий оптика побеждает даже на расстоянии всего трех метров. Если заглянуть в будущее на десятилетие, меня не удивит, если мы увидим случаи, когда оптическая связь будет выигрывать даже на расстоянии полуметра. Это означает, что в какой-то момент меня не удивит, если в самих компьютерах появятся оптические коммуникационные пути, просто потому что они эффективнее электрических.
С точки зрения корпоративного программного обеспечения это также очень интересно, поскольку означает, что если вы заглядываете в будущее, стоимость пропускной способности резко снизится. Это существенно субсидируется такими компаниями, как Netflix, которые расходуют огромные суммы на пропускную способность. Это означает, что чтобы снизить задержки, вы можете, например, заблаговременно загружать огромное количество данных для пользователя, а затем позволять пользователю взаимодействовать с данными, которые были перенесены ближе к нему и имеют гораздо меньшую задержку. Даже если вы загружаете данные, которые не требуются, проблема заключается не в объёме данных, а в задержках. Лучше сказать: “У меня есть сомнения, какие данные понадобятся; я могу загрузить в тысячу раз больше данных, чем действительно нужно, просто переместив их ближе к конечному пользователю, дать пользователю или программе с ними работать и минимизировать время отклика, – и я выиграю в производительности.” Это, вновь, оказывает глубокое влияние на архитектурные решения, принимаемые сегодня, поскольку они определяют, сможете ли вы извлечь выгоду из прогресса в этой категории аппаратного обеспечения через десятилетие.

В заключение, задержка является главной проблемой нашего времени в области разработки программного обеспечения. Это действительно определяет всю производительность, которой мы обладаем и которая будет иметься. Производительность – абсолютно ключевой фактор, поскольку она влияет не только на ИТ-расходы, но и на продуктивность людей, работающих в вашей цепочке поставок. В конечном итоге это также влияет на производительность самой цепочки поставок, ведь без достаточной производительности вы не сможете даже реализовать такой алгоритм, который действительно был бы умным и позволил бы проводить продвинутую оптимизацию и предиктивную оптимизацию, чего мы и стремимся достичь. Однако, в целом, эта битва за повышение производительности пока не выигрывается, по крайней мере, в сфере корпоративного программного обеспечения. Новые системы могут быть, и часто оказываются, медленнее старых. Это острая проблема. Замедление работы программного обеспечения порождает поразительные затраты для компаний, которые поддаются этому.
Просто приведу вам пример: не стоит считать само собой разумеющимся, что лучшее вычислительное оборудование обеспечивает более высокую производительность. Некоторые люди в интернете решили измерить задержку ввода, или input lag, то есть время, которое проходит между нажатием клавиши и появлением соответствующей буквы на экране. На Apple II в 1983 году, с процессором 1 МГц, это время составляло 30 миллисекунд. В 2016 году, с Lenovo X1, оснащённым процессором 2.6 ГГц, очень хорошим ноутбуком, задержка оказалась 110 миллисекунд. Таким образом, у нас есть вычислительное оборудование, которое в несколько тысяч раз лучше, но задержка оказывается почти в четыре раза медленнее. Это характерно для того, когда отсутствует механическая симпатия и не уделяется должное внимание тому, какое вычислительное оборудование имеется. Если вы агрессивно относитесь к оборудованию, оно воздаст вам плохой производительностью.
Проблема очень реальна. Мой совет таков: когда вы начинаете рассматривать любое корпоративное программное обеспечение для вашей компании, будь то с открытым исходным кодом или нет, помните о принципах механической симпатии, о которых мы сегодня говорили. Посмотрите на это программное обеспечение и тщательно обдумайте, учитывает ли оно глубокие тенденции в развитии вычислительного оборудования или полностью их игнорирует. Если оно их игнорирует, это означает, что производительность не только не будет улучшаться со временем, но, скорее всего, ухудшится. В наши дни большинство улучшений достигается за счёт специализации, а не повышения тактовой частоты. Если вы пропустите эту автомагистраль, вы пойдёте по пути, который со временем будет становиться всё медленнее. Избегайте этих решений, потому что они обычно являются результатом ранних ключевых проектных решений, которые невозможно отменить. Вы останетесь с ними навсегда, и ситуация будет только ухудшаться из года в год. Думайте на десятилетие вперёд, когда начинаете рассматривать эти аспекты.

Теперь давайте рассмотрим вопросы. Лекция была довольно длинной, но тема весьма сложная.
Question: Каково ваше мнение о квантовых компьютерах и их полезности для решения сложных задач оптимизации цепочки поставок?
Очень интересный вопрос. Я зарегистрировался в бета-версии квантового компьютера IBM 18 месяцев назад, когда они открыли доступ к своему квантовому компьютеру в облаке. Мне кажется, что это захватывающе, так как эксперты видят, как все S-образные кривые выравниваются, но не замечают, как появляются новые. Квантовые вычисления — одна из тех областей. Однако, я считаю, что квантовые компьютеры представляют собой очень трудную задачу с точки зрения цепочки поставок. Во-первых, как я уже сказал, в сегодняшнем корпоративном программном обеспечении главным вопросом является задержка, а квантовые компьютеры в этом плане не помогают. Они могут дать ускорение до, возможно, 10 порядков для сверхточных вычислительных задач. Таким образом, квантовые компьютеры стали бы следующим этапом после TPU, где вы можете выполнять сверхточные операции невероятно быстро.
Это очень интересно, но, если быть честным, на данный момент, насколько мне известно, существует очень мало компаний, которые даже пытаются задействовать суперскалярные инструкции в своем корпоративном программном обеспечении. Это означает, что весь рынок упускает ускорение от 10 до 28 раз, которое могла бы предоставить суперскалярная GPU. Очень немногие специалисты в области цепочки поставок этим занимаются; возможно, Lokad — может и нет. Что касается TPU, то, насколько я знаю, буквально никто их не использует. Google применяет их повсеместно, но мне не известно ни одного случая использования TPU для задач, связанных с цепочкой поставок. Квантовые процессоры стали бы этапом после TPU.
Я, безусловно, внимательно слежу за развитием квантовых компьютеров, но считаю, что это не то узкое место, с которым мы сталкиваемся. Это захватывающе, потому что мы возвращаемся к архитектуре фон Неймана, установленной примерно 70 лет назад, но это не та проблема, с которой мы или цепочка поставок будем сталкиваться в ближайшее десятилетие. Дальше — кому как. Да, это может потенциально всё изменить, а может — и нет.
Question: Облачные и SaaS-сервисы позволяют организациям использовать и преобразовывать фиксированные затраты. Разрабатывают ли компании, предлагающие такие услуги, также стратегии по сокращению своих фиксированных затрат и связанных с ними рисков?
Ну, это зависит от ситуации. Если я являюсь облачной вычислительной платформой и продаю вам вычислительную мощность, действительно ли в моих интересах сделать ваше корпоративное программное обеспечение максимально эффективным? Не совсем. Я продаю вам виртуальные машины, гигабайты пропускной способности и хранилище, так что, по сути, наоборот. Мой интерес заключается в том, чтобы ваше программное обеспечение было как можно менее эффективным, чтобы вы потребляли и платили за огромные объёмы ресурсов по модели pay-as-you-go.
Внутри крупные технологические компании, такие как Microsoft, Amazon и Google, чрезвычайно агрессивны в оптимизации своих вычислительных ресурсов. Но они также агрессивны, когда приходят к оплате счета за аренду виртуальной машины для клиента. Если клиент арендует виртуальную машину, которая в 10 раз больше, чем требуется, просто потому что используемое им корпоративное программное обеспечение крайне неэффективно, им невыгодно вмешиваться в ошибку клиента. Для них это нормально; это выгодный бизнес. Когда вы думаете о том, что системные интеграторы и облачные вычислительные платформы, как правило, работают в тесном партнерстве, становится ясно, что эти категории людей не всегда думают в ваших интересах. Теперь, когда речь идет о SaaS, ситуация немного иная. Действительно, если вы в итоге платите поставщику SaaS за каждого пользователя, то это в интересах компании, как, например, в случае с Lokad. Мы не взимаем плату за вычислительные ресурсы, которые потребляем; обычно мы берем с клиентов фиксированную ежемесячную плату. Таким образом, поставщики SaaS, как правило, очень агрессивно расходуют собственные вычислительные ресурсы.
Однако, будьте осторожны, тут есть один нюанс: если вы SaaS-компания, вы можете быть довольно неохотно делать то, что могло бы быть гораздо лучше для ваших клиентов, но гораздо дороже для вас с точки зрения аппаратного обеспечения. Всё не так однозначно. Существует определённый конфликт интересов, который затрагивает всех поставщиков SaaS, работающих в области цепочки поставок. Например, они могли бы инвестировать в реинжиниринг всех своих систем для обеспечения лучшей задержки и более быстрых веб-страниц, но дело в том, что это требует ресурсов, и их клиенты, естественно, не станут платить им больше, если они это сделают.
Проблема усугубляется, когда речь идёт о корпоративном программном обеспечении. Почему? Потому что человек, который покупает программное обеспечение, обычно не является тем, кто им пользуется. Вот почему так много корпоративных систем чрезвычайно медленные. Тот, кто покупает программное обеспечение, не страдает так сильно, как бедный планировщик спроса или менеджер по запасам, которому приходится каждый день иметь дело с супермедленной системой. Таким образом, существует ещё один аспект, специфичный для корпоративного программного обеспечения. Вам действительно нужно проанализировать ситуацию, учитывая все действующие стимулы, а в корпоративном программном обеспечении обычно много противоречивых стимулов.
Question: Сколько раз Lokad приходилось пересматривать свой подход с учётом прогресса в аппаратном обеспечении? Можете ли вы привести пример, чтобы поставить этот вопрос в контекст решённых реальных проблем?
Я считаю, что Lokad многократно, примерно полудюжины раз, полностью реконструировала нашу технологическую основу. Однако Lokad была основана в 2008 году, и мы провели около полудюжины масштабных переписываний всей архитектуры. Это произошло не потому, что программное обеспечение сделало огромный скачок; оно, конечно, развивалось, но основным двигателем большинства наших переписываний было не столько обновление аппаратного обеспечения, сколько наше понимание его принципов работы. Всё, что я сегодня представил, уже в основном было известно тем, кто обращал внимание еще десять лет назад. Так что, видите ли, оборудование развивается, но очень медленно, и большинство тенденций можно предсказать даже за десятилетие вперёд. Это игра в долгую.
Lokad пришлось пройти через масштабные переписывания, но это больше отражало то, что мы постепенно становились менее некомпетентными. Мы набирались опыта, и поэтому у нас появилось лучшее понимание того, как использовать возможности оборудования, а не просто реагировать на его изменения. Конечно, были конкретные моменты, которые действительно изменили правила игры для нас. Самым заметным из них стали SSD. Мы перешли с HDD на SSD, и это коренным образом изменило нашу производительность, оказав огромное влияние на нашу архитектуру. В качестве конкретного примера можно привести дизайн Envision — специализированного языка программирования, который предоставляет Lokad, основанного на знаниях, полученных на уровне аппарата. Это не единичное достижение; это возможность делать всё, что только можно ускорить.
Хотите обработать таблицу с миллиардом строк и 100 столбцами и сделать это в 100 раз быстрее, используя те же вычислительные ресурсы? Да, можно. Хотите выполнять объединения между очень большими таблицами с минимальными вычислительными ресурсами? Да, снова. Можете ли вы создать суперсложные dashboards с буквально сотней таблиц, отображаемых конечному пользователю, менее чем за 500 миллисекунд? Да, мы этого достигли. Это банальные достижения, но именно благодаря им мы смогли внедрить довольно изысканные рецепты предиктивной оптимизации в продакшене. Нам нужно удостовериться, что все этапы, приведшие нас к этому, выполнены с очень высокой производительностью.
Самая большая проблема, когда вы хотите сделать что-то действительно изысканное для цепочки поставок с использованием числовых методов, заключается не в стадии «заставить это работать». Вы можете взять студентов колледжа, и они за несколько недель разработают серию прототипов, которые обеспечат некоторое улучшение производительности цепочки поставок. Вы просто берете Python и какую-нибудь случайную библиотеку машинного обучения с открытым исходным кодом, и эти студенты, если они умны и мотивированы, смогут создать рабочий прототип за несколько недель. Однако вы никогда не сможете внедрить его в продакшн в масштабах. Вот в чем проблема. Речь идёт о том, как пройти через все стадии зрелости: «сделать правильно», «сделать быстро» и «сделать дешево». Именно здесь проявляется истинное значение приверженности аппаратному обеспечению и ваши возможности к итерациям.
Нет одного единственного достижения. Однако всё, что мы делаем, например, когда говорим, что Lokad занимается probabilistic forecasting, не требует такой уж огромной вычислительной мощности. То, что действительно требует ресурсов, — это использование очень обширных распределений вероятностей и рассмотрение всех возможных будущих сценариев с последующим их сочетанием со всеми возможными решениями, которые вы можете принять. Таким образом, вы выбираете лучшие варианты, используя финансовую оптимизацию, которая становится очень затратной. Если у вас нет чего-то крайне оптимизированного, вы застрянете. Сам факт того, что Lokad может использовать вероятностное прогнозирование в продакшене, является свидетельством того, что мы выполнили масштабную оптимизацию на уровне аппаратуры на всех этапах рабочих конвейеров для всех наших клиентов. Сегодня мы обслуживаем около 100 компаний.
Question: Лучше ли иметь собственный сервер для корпоративного ПО (ERP, WMS), чем использовать облачные сервисы, чтобы избежать задержек?
Я бы сказал, что в наши дни это не имеет значения, поскольку большая часть задержек, с которыми вы сталкиваетесь, возникает внутри системы. Это не проблема задержки между вашим пользователем и ERP. Да, если у вас очень низкая задержка, может добавляться около 50 миллисекунд. Очевидно, что если у вас есть ERP, вы не захотите, чтобы она находилась в Мельбурне, когда вы работаете, скажем, в Париже. Вы хотите, чтобы центр обработки данных был как можно ближе к месту ваших операций. Однако современные облачные вычислительные платформы имеют десятки дата-центров, поэтому разницы в задержке между внутренним хостингом и облачными сервисами практически нет.
Как правило, внутренний хостинг не означает размещение ERP прямо на полу в середине завода или склада. Это значит, что ваша ERP размещается в дата-центре, где вы арендуете вычислительное оборудование. Я считаю, что с точки зрения современных облачных вычислительных платформ с дата-центрами по всему миру, практической разницы между внутренним хостингом и облачными сервисами нет.
Что действительно имеет значение, так это то, насколько ваша ERP минимизирует количество обратных запросов. Например, то, что обычно замедляет работу ERP, — это взаимодействие между бизнес-логикой и реляционной базой данных. Если для отображения веб-страницы приходится выполнять сотни обменов информацией, ваша ERP будет ужасно медленной. Поэтому вам нужно рассмотреть варианты корпоративного программного обеспечения, которые не предполагают огромное количество таких запросов. Это внутренняя особенность того ПО, которое вы рассматриваете, и она не зависит от того, где оно размещено.
Question: Считаете ли вы, что нам нужны новые языки программирования, которые с самого начала учитывали бы особенности нового аппаратного дизайна, используя его возможности в полной мере?
Да, и да. Но, раскрывая всю правду, у меня здесь конфликт интересов. Именно это Lokad сделала с Envision. Envision родился из наблюдения, что использовать всю вычислительную мощность современных компьютеров — дело непростое, но не должно быть таким, если разработать сам язык программирования с ориентацией на производительность. Вы можете сделать его сверхъестественным, и именно поэтому в лекции 1.4 о программных парадигмах для цепочки поставок я сказал, что если вы выберете правильные парадигмы, такие как программирование массивов или работа с датафреймами, и построите язык программирования, учитывающий эти принципы, вы получите производительность почти бесплатно.
Цена, которую вы платите, заключается в том, что язык будет не таким выразительным, как, например, Python или C++, но если вы готовы пожертвовать частью выразительности, охватывая при этом все случаи использования, актуальные для цепочки поставок, то да, вы можете добиться масштабного прироста производительности. Это мое убеждение, и именно поэтому я также утверждал, что, например, объектно-ориентированное программирование с точки зрения оптимизации цепочки поставок не приносит пользы.
Наоборот, это своего рода парадигма, которая лишь противодействует базовому вычислительному оборудованию. Я не говорю, что объектно-ориентированное программирование — это полностью плохо; я не утверждаю этого. Я лишь говорю, что есть области в программной инженерии, где оно имеет смысл, но в контексте предиктивной оптимизации цепочки поставок оно неуместно. Так что, да, нам действительно нужны языки программирования, которые в полной мере используют потенциал нового аппаратного дизайна.
Я знаю, что я склонен повторяться, но Python был создан в конце 80-х, и они как будто упустили всё, что нужно знать о современных компьютерах. У него есть особенность, что по замыслу он не может использовать многопоточность. У него есть этот глобальный замок, поэтому он не может использовать несколько ядер. Он не может использовать локальность. У него позднее связывание, что действительно усложняет доступ к памяти. Они очень переменчивы, поэтому потребляют много памяти, что негативно сказывается на кэше и т.д.
Это те самые проблемы, при использовании Python, что означает, что вам предстоят упорные битвы в течение следующих десятилетий, и борьба будет только усугубляться со временем. Они не станут лучше.
Следующая лекция состоится через три недели, в тот же день недели, в то же время. Она начнётся в 15:00 по парижскому времени, 9 июня. Мы обсудим современные алгоритмы для управления цепочками поставок, что является своего рода аналогом современных компьютеров для цепочек поставок. До встречи.


