00:17 Introduction
03:35 Orders of Magnitude
06:55 Stages of Supply Chain Optimization
12:17 The S-Curves of hardware
15:52 The story so far
17:34 Auxiliary sciences
20:25 Modern computers
20:57 Latency 1/2
27:15 Latency 2/2
30:37 Compute, clock speed
36:36 Compute, pipelining, 1/3
39:11 Compute, pipelining, 2/3
40:27 Compute, pipelining, 3/3
46:36 Compute, superscalar 1/2
49:55 Compute, superscalar 2/2
56:45 Memory 1/3
01:00:42 Memory 2/3
01:06:43 Memory 3/3
01:11:13 Data storage 1/2
01:14:06 Data storage 2/2
01:18:36 Bandwidth
01:23:20 Conclusion
01:27:33 Upcoming lecture and audience questions
Descripción
Modern supply chains requieren recursos de computación para operar, al igual que las cintas transportadoras motorizadas requieren electricidad. Sin embargo, los sistemas de supply chain lentos siguen siendo ubicuos, mientras que la potencia de procesamiento de las computadoras ha aumentado por un factor mayor a 10,000x desde 1990. Una falta de comprensión de las características fundamentales de los recursos modernos de computación -incluso entre círculos de IT o de data science - explica en gran medida este estado de cosas. El diseño de software subyacente a las recetas numéricas no debería antagonizar el sustrato informático subyacente.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy estaré “Presentando Computadoras Modernas para supply chain.” Las supply chains occidentales se digitalizaron hace ya bastante tiempo, a veces hasta hace tres décadas. Las decisiones basadas en computadoras están en todas partes, y las recetas numéricas asociadas reciben diversos nombres como reorder points, inventario min-max, y safety stocks, con distintos grados de supervisión humana.
No obstante, si observamos a las grandes empresas actuales que operan supply chains igualmente grandes, vemos millones de decisiones que son esencialmente impulsadas por computadoras y que determinan el rendimiento de la supply chain. Así, cuando se trata de mejorar el supply chain performance, rápidamente se reduce a la mejora de las recetas numéricas que impulsan la supply chain. Aquí, de manera invariable, cuando comenzamos a considerar recetas numéricas superiores de cualquier tipo, donde deseamos modelos mejores y más accurate previsiones, esas recetas numéricas superiores terminan costando muchos más recursos de computación.
Los recursos de computación han sido un desafío para la supply chain, ya que cuestan mucho dinero, y siempre hay una siguiente etapa de evolución para el próximo modelo o el próximo sistema de previsión que requiere diez veces más recursos de computación que el anterior. Sí, podría aportar un rendimiento extra a la supply chain, pero viene acompañado de un mayor costo de computación. En las últimas décadas, el hardware de computación ha progresado tremendamente, pero como veremos hoy, este progreso, aunque aún continúa, frecuentemente es antagonizado por el enterprise software. Como resultado, el software no se acelera con hardware más moderno; por el contrario, muy a menudo se vuelve más lento.
El objetivo de esta conferencia es inculcar en la audiencia cierto grado de simpatía mecánica, para que puedan evaluar si un trozo de enterprise software que se supone implementa recetas numéricas destinadas a aportar un superior supply chain performance, aprovecha el hardware de computación tal como existe y como existirá dentro de una década, o si lo antagoniza y, por ende, esencialmente no saca el máximo provecho del hardware de computación que tenemos hoy en día.

Uno de los aspectos más desconcertantes de las computadoras modernas es el rango de órdenes de magnitud involucradas. Desde la supply chain perspective, normalmente tenemos alrededor de cinco órdenes de magnitud, lo cual ya es mucho; usualmente, ni siquiera es tanto. Cinco órdenes de magnitud significa que podemos ir de una unidad a 100,000 unidades. Recuerda que algo que discutí en conferencias anteriores es la ley de los números pequeños en acción. Si tienes un gran número de unidades, no las procesarás individualmente; las agruparás en cajas, y así te quedarás con un número mucho menor de cajas. De manera similar, si tienes muchas cajas, las empacarás en pallets, etcétera, de modo que tendrás un número mucho menor de pallets. Economías de escala inducen predicciones de cantidades, y desde la perspective de supply chain, cuando se trata del flujo de bienes físicos, una ineficiencia del 10% tiende a ser ya bastante significativa.
En el ámbito de las computadoras, es muy diferente; tratamos con 15 órdenes de magnitud, lo cual es absolutamente gigantesco. Pasar de una unidad a un millón de billones de unidades, el número es tan grande que resulta realmente difícil de visualizar. Pasamos de un byte, que son solo ocho bits y pueden usarse para representar una letra o dígito, a un petabyte, que equivale a un millón de gigabytes. Un petabyte está en el mismo orden de magnitud que la cantidad de datos que Lokad gestiona actualmente, y las grandes empresas que operan supply chains grandes también manejan conjuntos de datos del orden de magnitud de un petabyte.
Pasamos de un FLOP (operación de punto flotante por segundo) a un petaFLOP, que es un millón de gigaFLOPS. Estas órdenes de magnitud son absolutamente gigantescas y muy engañosas. Como resultado, en el ámbito de la supply chain, donde se considera que un 10% es ineficiente, lo que típicamente ocurre en el ámbito de las computadoras es que no se trata de ser ineficiente en un 10%, sino más bien en ser ineficiente por un factor de 10, y a veces varias órdenes de magnitud. Por lo tanto, si haces algo mal en términos de rendimiento en el ámbito de las computadoras, tu penalización no será del 10%; en cambio, tu sistema será 10 veces más lento de lo que debería, o 100 veces, y a veces incluso mil veces más lento de lo que debería haber sido. Eso es realmente lo que está en juego: tener una verdadera alineación, que requiere algún tipo de simpatía mecánica entre el enterprise software y el hardware de computación subyacente.
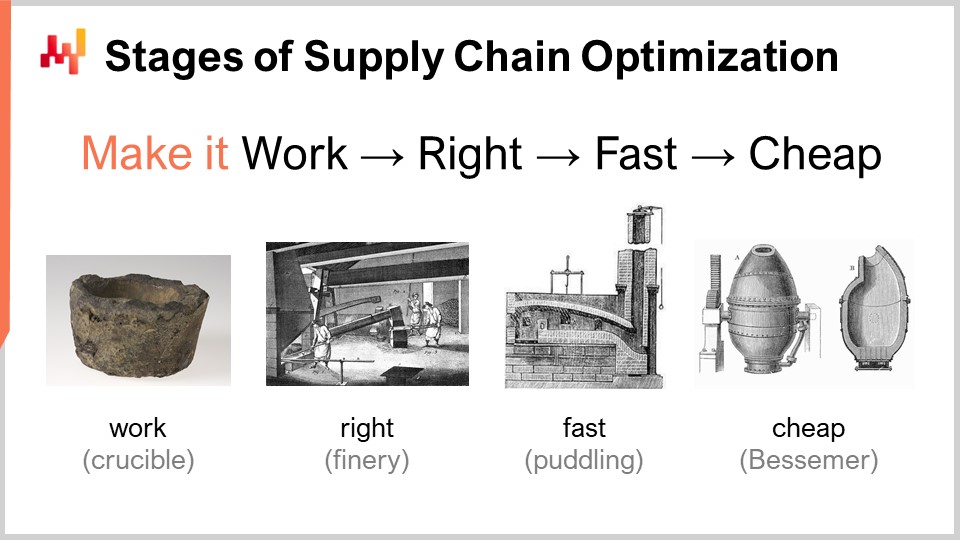
Al considerar una receta numérica que se supone brinda algún tipo de superior supply chain performance, existe un conjunto de etapas de madurez que son de interés conceptualmente. Obviamente, los resultados pueden variar en la práctica, pero típicamente eso es lo que hemos identificado en Lokad. Estas etapas se pueden resumir en: hacerlo funcionar, hacerlo bien, hacerlo rápido y hacerlo barato.
“Hacerlo funcionar” se trata de evaluar si un prototipo de receta numérica realmente está entregando los resultados previstos, tales como mayores niveles de servicio, menos dead stock, mejor utilización de los activos, o cualquier otro objetivo que tenga relevancia desde la perspective de supply chain. El objetivo es primero asegurarse de que la nueva receta numérica realmente funcione en la primera etapa de madurez.
Luego, tienes que “hacerlo bien.” Desde la perspective de supply chain, esto significa transformar lo que era esencialmente un prototipo único en algo con calidad de producción. Esto típicamente implica dotar a la receta numérica de cierto grado de corrección por diseño. Las supply chains son vastas, complejas y, lo que es más importante, muy desordenadas. Si tienes una receta numérica que es muy frágil, incluso si el método numérico es bueno, es muy fácil equivocarse, y entonces terminas creando muchas veces más problemas en comparación con los beneficios que pretendías aportar en primer lugar. Esta no es una propuesta ganadora. Hacerlo bien significa asegurarse de tener algo que pueda desplegarse a escala con mínima fricción. Luego, se quiere hacer que esta receta numérica sea rápida, y cuando digo rápida, me refiero a rápida en términos de tiempo real. Cuando inicies el cálculo, deberías obtener los resultados en cuestión de minutos, o tal vez una o dos horas como máximo, pero no más. Las supply chains son desordenadas, y llegará un momento en la historia de tu empresa en que habrán disruptions, tales como barcos portacontenedores atascados en medio del Canal de Suez, una pandemia, o un warehouse inundado. Cuando esto ocurra, necesitas poder reaccionar rápidamente. No digo reaccionar en los siguientes milisegundos, pero si tienes recetas numéricas que tardan días en completarse, se crea una fricción operativa masiva. Necesitas cosas que puedan operarse en un corto plazo humano, por lo que deben ser rápidas.
Recuerda, el modern enterprise software se ejecuta en clouds, y siempre puedes pagar por más recursos de computación en plataformas de computación en la nube. Así, tu software puede ser rápido simplemente porque estás alquilando mucha potencia de procesamiento. No es que el software en sí tenga que estar diseñado adecuadamente para aprovechar toda la potencia de procesamiento que un cloud puede proporcionar, sino que puede ser rápido y muy ineficiente simplemente porque estás alquilando tanta potencia de procesamiento de tu proveedor de computación en la nube.
La siguiente etapa es hacer que el método sea barato, lo que significa que no utiliza demasiados recursos de computación en la nube. Si no alcanzas esta etapa final, significa que nunca podrás mejorar tu método. Si tienes un método que funciona, es correcto y es rápido, pero consume muchos recursos, cuando quieras pasar a la siguiente etapa de receta numérica, que invariablemente involucrará algo que cuesta aún más recursos de computación de los que estás usando actualmente, te quedarás estancado. Necesitas hacer que el método que tienes sea súper lean para que puedas comenzar a experimentar con recetas numéricas que sean menos eficientes que las que tienes actualmente.
Esta última etapa es donde realmente necesitas abrazar el hardware subyacente que está disponible en las computadoras modernas. Puedes manejar las primeras tres etapas sin demasiada afinidad, pero la última es clave. Recuerda, si no alcanzas la etapa de “hacerlo barato”, no podrás iterar, y por lo tanto te quedarás estancado. Por eso, aunque sea la última etapa, este es un juego iterativo, y es esencial pasar por todas las etapas si deseas iterar de forma repetida.
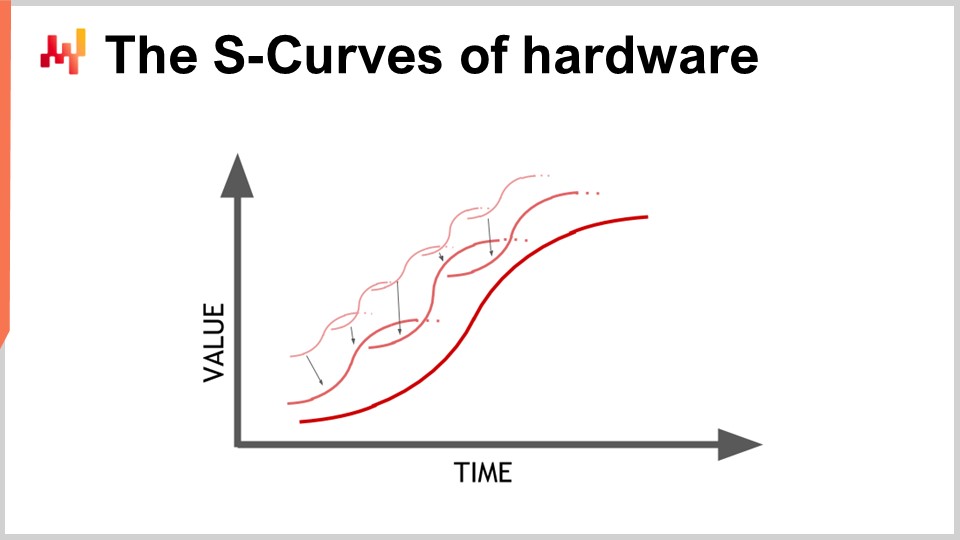
El hardware está progresando, y parece una progresión exponencial, pero la realidad es que esta progresión exponencial del hardware de computación en realidad está compuesta por miles de curvas en S. Una curva en S es una curva donde se introduce un nuevo diseño, proceso, material o arquitectura, y al principio no es realmente mejor que lo que tenías antes. Luego, el efecto de la innovación prevista se activa, y se produce un aumento, seguido de una meseta una vez que se consumen todos los beneficios de la innovación. Las curvas en S que se estancan son características del progreso en el hardware de computación, que está conformado por miles de estas curvas. Desde la perspectiva de un profano, esto aparece como crecimiento exponencial. Sin embargo, los expertos ven cómo se estancan las curvas en S individuales, lo que puede llevar a una visión pesimista. Incluso los expertos no siempre ven la emergencia de nuevas curvas en S que sorprenden a todos y continúan el crecimiento exponencial del progreso.
Aunque el hardware de computación aún progresa, la tasa de progreso está muy por debajo de lo que experimentamos en los años 80 o 90. El ritmo ahora es mucho más lento y bastante predecible, en gran parte debido a las enormes inversiones requeridas para construir nuevas fábricas de producción de hardware de computación. Estas inversiones a menudo ascienden a cientos de millones de dólares, proporcionando visibilidad a cinco o diez años vista. Aunque el progreso se ha desacelerado, todavía tenemos una visión bastante precisa de lo que ocurrirá en términos del progreso del hardware de computación para la próxima década.
La lección para el enterprise software que implementa recetas numéricas es que no puedes esperar pasivamente que el hardware futuro lo haga todo mejor para ti. El hardware aún progresa, pero capturar este progreso requiere esfuerzo desde el lado del software. Podrás hacer más con el hardware que exista dentro de una década, pero solo si la arquitectura en el núcleo de tu enterprise software abraza el hardware de computación subyacente. De lo contrario, en realidad podrías obtener peores resultados de lo que obtienes hoy, una proposición que no es tan descabellada como parece.
Esta conferencia es la primera del cuarto capítulo en esta serie de conferencias de supply chain. No he terminado el tercer capítulo sobre personae de supply chain. En las siguientes conferencias, probablemente alternaré entre el capítulo presente, donde estoy cubriendo las ciencias auxiliares de supply chain, y el tercer capítulo sobre personae de supply chain.
En el primer capítulo del prólogo, presenté mis puntos de vista sobre supply chain tanto como campo de estudio como práctica. Hemos visto que supply chain es esencialmente una colección de problemas intratables, en contraposición a problemas manejables, plagados de comportamientos adversariales y juegos competitivos. Por lo tanto, necesitamos prestar mucha atención a la metodología porque las metodologías directas ingenuas tienen un desempeño deficiente en este campo. Por eso, el segundo capítulo se dedicó a la metodología necesaria para estudiar supply chains y establecer prácticas para mejorarlas a lo largo del tiempo.
El tercer capítulo, Supply Chain Personae, se centró en caracterizar los problemas de supply chain en sí mismos, con el lema “enamórate del problema, no de la solución.” El cuarto capítulo que abrimos hoy trata sobre las ciencias auxiliares de supply chains.

Las ciencias auxiliares son disciplinas que apoyan el estudio de otra disciplina. No hay juicio de valor; no se trata de que una disciplina sea superior a otra. Por ejemplo, la medicina no es superior a la biología, pero la biología es una ciencia auxiliar para la medicina. La perspectiva de las ciencias auxiliares está bien establecida y es prevalente en muchos campos de investigación, como las ciencias médicas y la historia.
En las ciencias médicas, las ciencias auxiliares incluyen la biología, la química, la física y la sociología, entre otras. Un médico moderno no se consideraría competente si no tuviera conocimientos de física. Por ejemplo, entender los fundamentos de la física es necesario para interpretar una imagen de rayos X. Lo mismo ocurre con la historia, que cuenta con una larga serie de ciencias auxiliares.
Cuando se trata de supply chain, una de mis mayores críticas a los materiales típicos de supply chain, cursos, libros y artículos es que tratan el tema sin profundizar en ninguna ciencia auxiliar. Tratan la supply chain como si fuera un conocimiento aislado e independiente. Sin embargo, creo que la práctica moderna de supply chain solo se puede lograr aprovechando al máximo las ciencias auxiliares de supply chains. Una de estas ciencias auxiliares, y el foco de la conferencia de hoy, es el hardware de computación.
Esta conferencia no es estrictamente una conferencia de supply chain, sino más bien de hardware de computación con aplicaciones en supply chain en mente. Creo que es fundamental para practicar supply chain de manera moderna, a diferencia de cómo se hacía hace un siglo.

Echemos un vistazo a las computadoras modernas. En esta conferencia, revisaremos lo que pueden hacer por supply chain, centrándonos en particular en aspectos que tienen un impacto masivo en el rendimiento del software empresarial. Revisaremos la latencia, la computación, la memoria, el almacenamiento de datos y el ancho de banda.

La velocidad de la luz es de aproximadamente 30 centímetros por nanosegundo, lo cual es relativamente lento. Si consideras la distancia característica de interés para una CPU moderna que opera a 5 gigahertz (5 mil millones de operaciones por segundo), la distancia de ida y vuelta que la luz puede recorrer en 0.2 nanosegundos es de solo 3 centímetros. Esto significa que, debido a la limitación de la velocidad de la luz, las interacciones no pueden ocurrir más allá de 3 centímetros. Esta es una limitación estricta impuesta por las leyes de la física, y es incierto si alguna vez podremos superarla.
La latencia es una restricción sumamente difícil. Desde la perspectiva de supply chain, al menos tenemos dos distribuciones de hardware de computación involucradas. Cuando hablo de hardware de computación distribuido, me refiero a hardware de computación que involucra muchos dispositivos que no pueden ocupar el mismo espacio físico. Obviamente, necesitas mantenerlos separados simplemente porque tienen dimensiones propias. Sin embargo, la primera razón por la que necesitamos la computación distribuida es la naturaleza de supply chains, las cuales están distribuidas geográficamente. Por diseño, supply chains se extienden a través de geografías, y por ende, habrá hardware de computación distribuido también en esas geografías. Desde la perspectiva de la velocidad de la luz, incluso si tienes dispositivos que están a solo tres metros de distancia, ya es muy lento porque se requieren 100 ciclos de reloj para hacer el viaje de ida y vuelta. Tres metros es una distancia considerable desde la perspectiva de la velocidad de la luz y la tasa de reloj de las CPUs modernas.
Otro tipo de distribución es la escalabilidad horizontal. La forma moderna de disponer de más potencia de procesamiento no es tener un dispositivo de computación que sea 10 veces o un millón de veces más potente; así no se diseña. Si deseas más recursos de procesamiento, necesitas dispositivos de computación adicionales, más procesadores, más chips de memoria y más discos duros. Es apilando el hardware como se pueden disponer de más recursos computacionales. Sin embargo, todos esos dispositivos ocupan espacio, y por ello, terminas distribuyendo tu hardware de computación simplemente porque no puedes centralizarlo en una computadora de un centímetro de ancho.
Cuando se trata de latencias, observando las latencias que tenemos en el internet profesional (las latencias que puedes obtener en un centro de datos, no a través de tu Wi-Fi en casa), ya estamos dentro del 30% de la velocidad de la luz. Por ejemplo, la latencia entre un centro de datos cerca de París, Francia, y Nueva York, Estados Unidos, está solo dentro del 30% de la velocidad de la luz. Esto es un logro increíble para la humanidad; la información fluye a través de internet casi a la velocidad de la luz. Sí, todavía hay margen de mejora, pero ya estamos cerca de los límites estrictos impuestos por la física.
Como resultado, hay incluso compañías ahora que quieren tender cable a través del lecho marino del Ártico para conectar Londres con Tokio con un cable que pasaría por debajo del Polo Norte, solo para recortar unos pocos milisegundos de latencia en las transacciones financieras. Fundamentalmente, la latencia y la velocidad de la luz son preocupaciones muy reales, y el internet que tenemos es esencialmente tan bueno como jamás será, a menos que haya avances revolucionarios en la física. Sin embargo, no tenemos nada parecido en el horizonte para la próxima década.
Debido a que la latencia es un problema sumamente difícil, las implicaciones para el software empresarial son significativas. Los viajes de ida y vuelta en términos del flujo de información son letales, y el rendimiento de tu software empresarial dependerá en gran medida del número de viajes de ida y vuelta entre los diversos subsistemas que existen dentro de tu software. El número de estos viajes caracterizará la latencia ineludible que sufres. Minimizar los viajes de ida y vuelta y mejorar las latencias es, para la mayoría del software empresarial, incluidos aquellos dedicados a la optimización predictiva de supply chains, el problema número uno. Mitigar las latencias a menudo equivale a ofrecer un mejor rendimiento.

Un truco interesante, aunque no es algo que todos en esta audiencia desplieguen en producción, es abordar las complicaciones introducidas por la latencia. El tiempo mismo se vuelve esquivo y borroso cuando entras en el ámbito de los cálculos en nanosegundos. Es difícil conseguir relojes precisos en la computación distribuida, y su ausencia introduce complicaciones en el software empresarial distribuido. Se necesitan numerosos viajes de ida y vuelta para sincronizar las diversas partes del sistema. Debido a la falta de un reloj preciso, terminas con alternativas algorítmicas como los relojes vectoriales o las marcas de tiempo multipartes, que son estructuras de datos que reflejan un ordenamiento parcial de los relojes de los dispositivos en tu sistema. Estos viajes adicionales pueden afectar el rendimiento.
Un diseño ingenioso adaptado por Google hace más de una década fue utilizar relojes atómicos a escala de chip. La resolución de estos relojes atómicos es significativamente mejor que la de los relojes basados en cuarzo que se encuentran en relojes electrónicos o computadoras. NIST demostró una nueva configuración de reloj atómico a escala de chip con un desplazamiento diario aún más preciso. Google utilizó relojes atómicos internos para sincronizar las diversas partes de su base de datos SQL distribuida globalmente, Google Spanner, para ahorrar viajes de ida y vuelta y mejorar el rendimiento a escala global. Esta es una manera de sortear la latencia mediante mediciones de tiempo muy precisas.
Mirando una década hacia el futuro, es probable que Google no sea la última empresa en utilizar este tipo de truco ingenioso, y son relativamente asequibles, con relojes atómicos a escala de chip que cuestan alrededor de $1,500 cada uno.

Ahora, echemos un vistazo a la computación, que consiste en realizar cálculos con una computadora. La velocidad de reloj fue el ingrediente mágico de la mejora durante los años 80 y 90. De hecho, si pudieras duplicar la velocidad de reloj de tu computadora en general, duplicarías efectivamente el rendimiento de tu computadora, sin importar el tipo de software involucrado. Todo el software sería linealmente más rápido de acuerdo con la velocidad de reloj. Es extremadamente interesante aumentar la velocidad de reloj, y aún sigue mejorando, aunque la mejora se ha aplanado con el tiempo. Hace casi 20 años, la velocidad de reloj era de aproximadamente 2 GHz, y hoy en día es de 5 GHz.
La razón clave de esta mejora aplanada es el power wall. El problema es que cuando aumentas la velocidad de reloj en un chip, tiendes a duplicar aproximadamente el consumo de energía, y luego tienes que disipar esa energía. El problema es la disipación térmica, porque si no puedes disipar la energía, tu dispositivo se calienta hasta el punto de dañar el dispositivo mismo. Hoy en día, la industria de los semiconductores ha pasado de tener más operaciones por segundo a tener más operaciones por vatio.
Esta regla de que un aumento del 30% duplica el consumo de energía es un arma de doble filo. Si estás de acuerdo con renunciar a una cuarta parte de tu potencia de procesamiento por unidad de tiempo en la CPU, en realidad puedes dividir el consumo de energía por dos. Esto resulta especialmente interesante para los smartphones, donde el ahorro de energía es crucial, y también para computación en la nube, donde uno de los factores clave de costo es la misma energía. Para tener una potencia de procesamiento en computación en la nube rentable, no se trata de tener CPUs superrápidas, sino de tener CPUs con bajo reloj que pueden ser tan lentas como 1 GHz, ya que proporcionan más operaciones por segundo para tu inversión energética.
El power wall es un problema tal que las arquitecturas modernas de CPU están utilizando todo tipo de trucos ingeniosos para mitigarla. Por ejemplo, las CPUs modernas pueden regular su velocidad de reloj, aumentándola temporalmente durante un segundo aproximadamente, antes de reducirla para disipar el calor. También pueden aprovechar lo que se conoce como dark silicon. La idea es que si la CPU puede alternar las áreas calientes en el chip, es más fácil disipar la energía, en lugar de tener siempre la misma área activa ciclo tras ciclo. Este es un ingrediente clave del diseño moderno. Desde la perspectiva del software empresarial, significa que realmente deseas poder escalar horizontalmente. Quieres poder hacer más con muchas veces más CPUs, pero individualmente, esos procesadores serán más débiles que los anteriores que tenías. No se trata de obtener mejores procesadores en el sentido de que todo sea mejor en general; se trata de tener procesadores que te brinden más operaciones por vatio, y esta tendencia continuará.
Quizás dentro de una década, con dificultad, alcancemos siete o tal vez ocho gigahertz, pero ni siquiera estoy seguro de que lleguemos allí. Cuando miro la velocidad de reloj en 2021 en la mayoría de los proveedores de computación en la nube, está más alineada típicamente con 2 GHz, por lo que volvemos a la velocidad de reloj que teníamos hace 20 años, y esa es la solución más rentable.
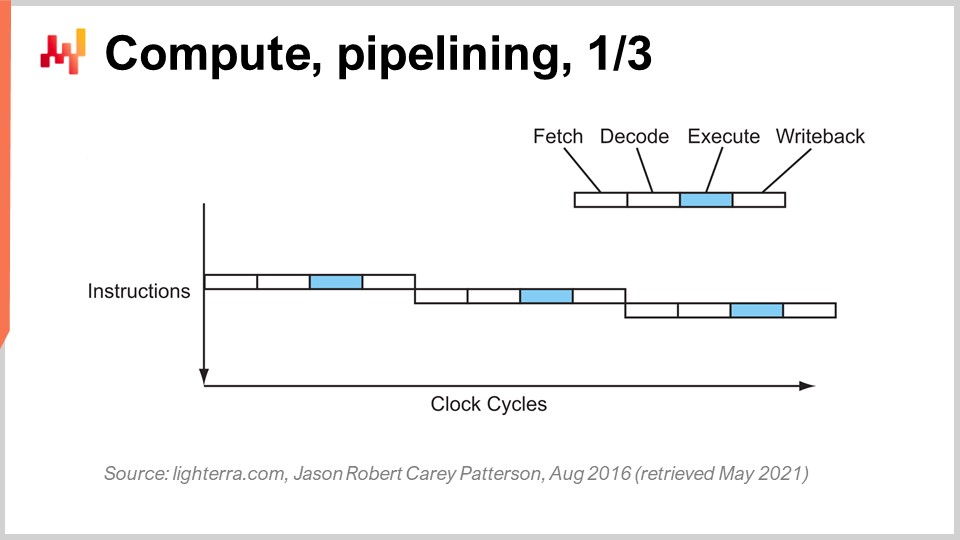
Alcanzar el rendimiento actual de la CPU requirió una serie de innovaciones clave. Voy a presentar algunas de ellas, especialmente las que tienen mayor impacto en el diseño del software empresarial. En esta pantalla, lo que ves es el flujo de instrucciones de un procesador secuencial, como se fabricaban esencialmente hasta principios de los años 80. Tienes una serie de instrucciones que se ejecutan desde la parte superior del gráfico hasta la inferior, representando el tiempo. Cada instrucción pasa por una serie de etapas: obtener, decodificar, ejecutar y escribir de vuelta.
Durante la etapa de obtener, se obtiene la instrucción, se la registra, se toma la siguiente instrucción, se incrementa el contador de instrucciones y se prepara la CPU. Durante la etapa de decodificar, se decodifica la instrucción y se emite el microcódigo interno, que es lo que la CPU está ejecutando internamente. La etapa de ejecución implica tomar las entradas relevantes de los registros y realizar el cálculo real, y la etapa de escribir de vuelta implica obtener el resultado que acabas de calcular y colocarlo en uno de los registros. En este procesador secuencial, cada etapa requiere un ciclo de reloj, por lo que se necesitan cuatro ciclos de reloj para ejecutar una instrucción. Como hemos visto, es muy difícil aumentar la frecuencia de los ciclos de reloj debido a muchas complicaciones.
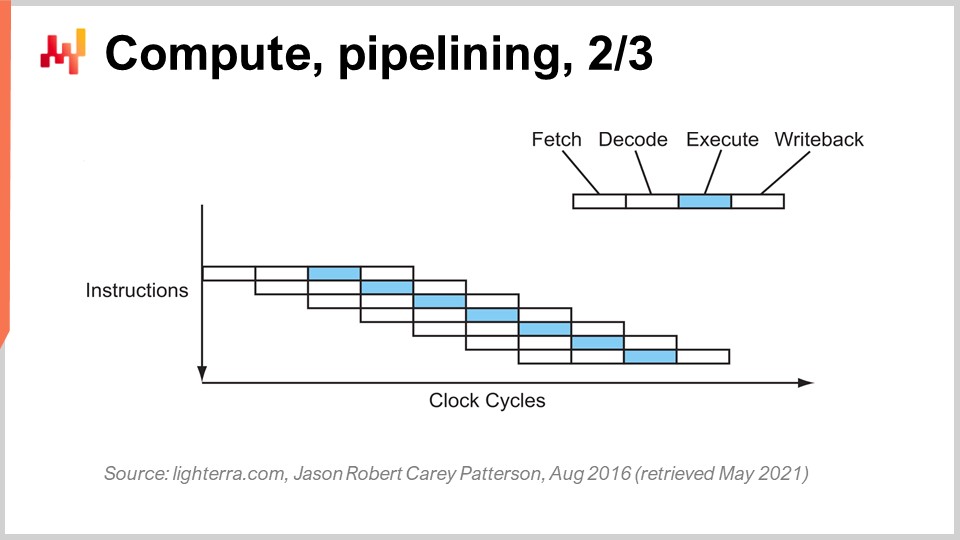
El truco clave que se ha utilizado desde principios de los años 80 en adelante se conoce como pipelining. El pipelining puede acelerar enormemente el cálculo de tu procesador. La idea es que, debido a que cada instrucción pasa por una serie de etapas, vamos a superponer las etapas, de modo que la CPU misma tendrá una tubería completa de instrucciones. En este diagrama, puedes ver una CPU con una profundidad de pipeline de cuatro, donde siempre hay cuatro instrucciones ejecutándose concurrentemente. Sin embargo, no están en la misma etapa: una instrucción está en la etapa de obtener, otra en la de decodificar, otra en la de ejecutar y otra en la de escribir de vuelta. Con este truco simple, representado aquí como un procesador pipeline, hemos multiplicado el rendimiento efectivo del procesador por cuatro simplemente mediante el pipelining de las operaciones. Todas las CPUs modernas utilizan pipelining.
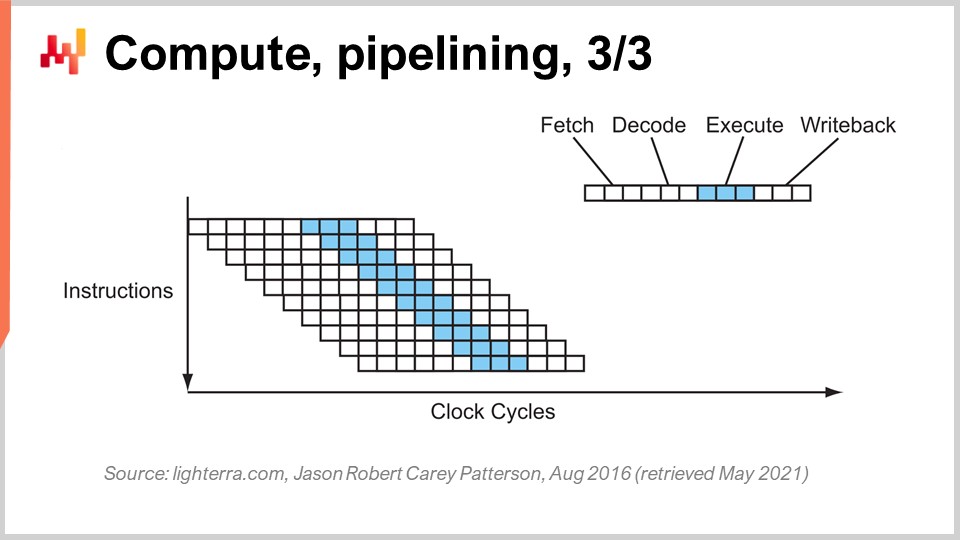
La siguiente etapa de esta mejora se llama super pipelining. Las CPUs modernas van mucho más allá del simple pipelining. En realidad, el número de etapas involucradas en una CPU moderna real es más bien de unas 30 etapas. En el gráfico, puedes ver una CPU con 12 etapas como ejemplo, pero en realidad serían más como 30 etapas. Con este pipeline más profundo, 12 operaciones pueden ejecutarse concurrentemente, lo cual es muy bueno para el rendimiento mientras se usa el mismo ciclo de reloj.
Sin embargo, hay un nuevo problema: la siguiente instrucción comienza antes de que la anterior haya terminado. Esto significa que, si tienes operaciones que dependen unas de otras, tienes un problema porque el cálculo de las entradas para la siguiente instrucción aún no está listo, y debes esperar. Queremos utilizar toda la pipeline a nuestra disposición para maximizar la potencia de procesamiento. Así, las CPUs modernas obtienen no solo una instrucción a la vez, sino algo así como 500 instrucciones a la vez. Miran muy adelante en la lista de instrucciones próximas y las reordenan para mitigar las dependencias, intercalando los flujos de ejecución para aprovechar toda la profundidad del pipeline. Hay muchas cosas que complican esta operación, sobre todo las ramas. Una rama es simplemente una condición en programación, como cuando escribes una sentencia “if”. El resultado de la condición puede ser verdadero o falso, y dependiendo del resultado, tu programa ejecutará una lógica u otra. Esto complica la gestión de dependencias porque la CPU tiene que adivinar la dirección que tomarán las ramas venideras. Las CPUs modernas utilizan la predicción de ramas, que involucra heurísticas simples y tiene una alta precisión de previsión. Pueden predecir la dirección de las ramas con más del 99% de precisión, lo cual es mejor de lo que la mayoría de nosotros puede lograr en un contexto real de supply chain. Esta precisión es necesaria para aprovechar pipelines muy profundos.
Solo para darte una idea del tipo de heurísticas utilizadas para la predicción de ramas, una heurística muy simple es decir que la rama irá de la misma manera, en la misma dirección, que la última vez. Esta heurística simple ofrece aproximadamente un 90% de precisión, lo cual es bastante bueno. Si le añades un giro a esa heurística, que consiste en que la rama irá en la misma dirección que la última vez, pero hay que considerar el origen, es decir, que se trata de la misma rama proveniente del mismo origen, entonces obtendrás algo como un 95% de precisión. Las CPUs modernas están utilizando en realidad perceptrones bastante complejos, que son una técnica de aprendizaje automático, para predecir la dirección de las ramas.
Bajo las condiciones adecuadas, puedes predecir las ramas con bastante precisión y así aprovechar al máximo el pipeline para obtener el mayor rendimiento de un procesador moderno. Sin embargo, desde una perspectiva de ingeniería de software, necesitas llevarte bien con tu procesador, especialmente con la predicción de ramas. Si no lo haces, significa que el predictor de ramas se equivocará, y cuando eso ocurra, la CPU predecirá la dirección de la rama, organizará el pipeline y comenzará a realizar cálculos por adelantado. Cuando finalmente se encuentre la rama y el cálculo se haya efectuado, la CPU se dará cuenta de que la predicción fue incorrecta. Una predicción equivocada de la rama no resulta en un resultado erróneo; resulta en una pérdida de rendimiento. La CPU no tendrá otra alternativa que vaciar todo el pipeline, o una gran parte de él, esperar hasta que se realicen otros cálculos, y luego reiniciar la operación. El impacto en el rendimiento puede ser muy significativo, y puedes perder fácilmente uno o dos órdenes de magnitud en rendimiento debido a la lógica del software empresarial que no se lleva bien con la lógica de predicción de ramas de tu CPU.
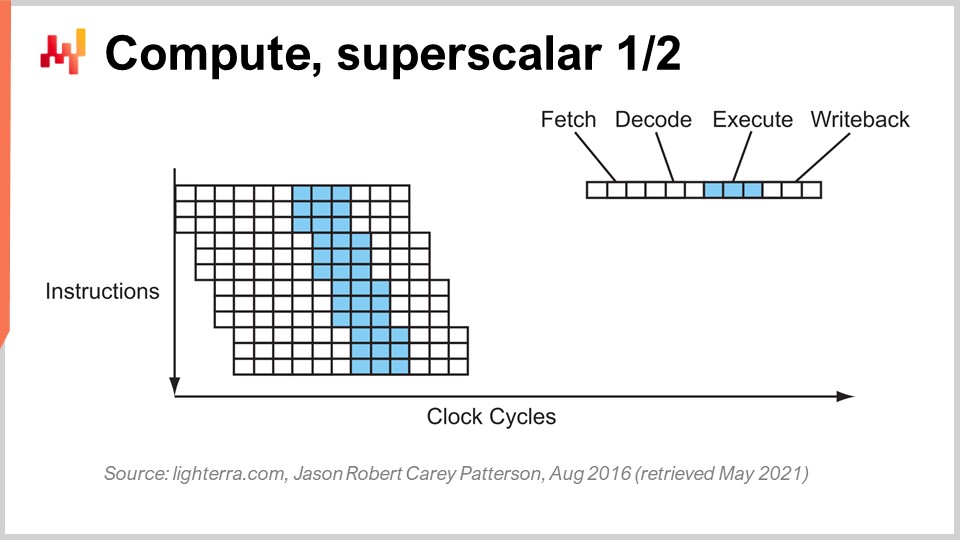
Otro truco notable más allá del pipelining es la instrucción superscalar. Las CPUs típicamente procesan escalares, o pares de escalares, a la vez – por ejemplo, dos números con precisión de punto flotante de 32 bits. Realizan operaciones escalares, esencialmente procesando un número a la vez. Sin embargo, las CPUs modernas de la última década prácticamente han incorporado la instrucción superscalar, la cual puede procesar varios vectores de números y realizar operaciones vectoriales de manera directa. Esto significa que una CPU puede tomar un vector de, digamos, ocho números de punto flotante y un segundo vector de ocho números de punto flotante, realizar una suma y obtener un vector de números de punto flotante que representan los resultados de dicha suma. Todo esto se realiza en un solo ciclo.
Por ejemplo, conjuntos de instrucciones especializadas como AVX2 te permiten realizar operaciones considerando 32 bits de precisión con paquetes de ocho números, mientras que AVX512 te permite hacerlo con paquetes de 16 números. Si eres capaz de aprovechar estas instrucciones, significa que literalmente puedes ganar un orden de magnitud en términos de velocidad de procesamiento, ya que una instrucción, un ciclo de reloj, realiza muchas más operaciones que procesar los números uno por uno. Este proceso se conoce como SIMD (Single Instruction, Multiple Data), y es muy poderoso. Ha impulsado la mayor parte del progreso durante la última década en términos de potencia de procesamiento, y los procesadores modernos son cada vez más basados en vectores y superscalar. Sin embargo, desde una perspectiva de software empresarial, resulta relativamente complicado. Con el pipelining, tu software tiene que llevarse bien, y quizá lo haga accidentalmente con la predicción de ramas. Sin embargo, cuando se trata de la instrucción superscalar, no hay nada accidental. Tu software realmente necesita hacer algunas cosas de manera explícita, la mayoría de las veces, para aprovechar esa potencia de procesamiento extra. No lo obtienes gratis; necesitas adoptar este enfoque y, típicamente, organizar los datos de modo que exista paralelismo de datos, y que éstos estén organizados de forma adecuada para las instrucciones SIMD. No es ciencia de cohetes, pero no sucede por accidente, y te proporciona un impulso masivo en términos de potencia de procesamiento.

Ahora, las CPUs modernas pueden tener muchos núcleos, y un núcleo de CPU puede ofrecerte un flujo distinto de instrucciones. Con CPUs muy modernas que poseen muchos núcleos, típicamente las CPUs actuales pueden llegar hasta 64 núcleos, es decir, 64 flujos independientes de ejecución concurrente. Puedes alcanzar, prácticamente, alrededor de un teraflop, que es el límite superior de rendimiento de procesamiento que puedes obtener de un procesador muy moderno. Sin embargo, si deseas ir más allá, puedes considerar las GPUs (Graphical Processing Units). A pesar de lo que puedas pensar, estos dispositivos se pueden utilizar para tareas que no tienen nada que ver con gráficos.
Una GPU, como la de NVIDIA, es un procesador superscalar. En lugar de tener hasta 64 núcleos como las CPUs de gama alta, las GPUs pueden tener más de 10,000 núcleos. Estos núcleos son mucho más simples y no tan potentes o rápidos como los núcleos de una CPU regular, pero hay muchas más veces la cantidad de ellos. Llevan el SIMD a un nuevo nivel, donde puedes procesar no solo paquetes de 8 o 16 números a la vez, sino literalmente miles de números a la vez para realizar instrucciones vectoriales. Con las GPUs, puedes alcanzar más de 30 teraflops en un solo dispositivo, lo cual es enorme. Las mejores CPUs del mercado pueden ofrecerte un teraflop, mientras que las mejores GPUs te darán más de 30 teraflops. Eso representa más de un orden de magnitud de diferencia, lo cual es muy significativo.
Si vas incluso más allá, para tipos de cálculos especializados como el álgebra lineal (por cierto, cosas como machine learning y deep learning son esencialmente álgebra lineal basada en matrices por doquier), puedes disponer de procesadores como los TPUs (Tensor Processing Units). Google decidió llamarlos Tensors por TensorFlow, pero la realidad es que los TPUs se deberían llamar mejor Matrix Multiplication Processing Units. Lo interesante de la multiplicación de matrices es que no solo implica un montón de paralelismo de datos, sino también una enorme cantidad de repetición, ya que las operaciones son altamente repetitivas. Al organizar un TPU como una matriz sistólica, que es esencialmente una cuadrícula bidimensional con unidades computacionales en ella, puedes romper la barrera del petaflop, alcanzando más de 1000 teraflops en un solo dispositivo. Sin embargo, hay una salvedad: Google lo está haciendo con números de punto flotante de 16 bits en lugar de los habituales 32 bits. Desde una perspectiva de supply chain, 16 bits de precisión no es malo; significa que tienes aproximadamente un 0.1% de precisión en tus operaciones, y para muchas operaciones de machine learning o estadísticas, un 0.1% de precisión es bastante aceptable si se realiza correctamente y sin acumular sesgos.
Lo que observamos es que el camino del progreso en términos de hardware de computación, cuando se trata únicamente de cómputo, ha sido optar por dispositivos más especializados y rígidos. Gracias a esa especialización, se pueden lograr enormes ganancias en potencia de procesamiento. Si pasas de la instrucción superscalar, ganas un orden de magnitud; si optas por una tarjeta gráfica, ganas uno o dos órdenes de magnitud; y si optas por el álgebra lineal pura, ganas esencialmente dos órdenes de magnitud. Esto es muy significativo.
Por cierto, todos estos diseños de hardware son bidimensionales. Los chips modernos y las estructuras de procesamiento son muy planas. Una CPU moderna no involucra más de 20 capas, y dado que estas capas tienen apenas unos pocos micrones de grosor, las CPUs, GPUs o TPUs son esencialmente estructuras planas. Podrías pensar, “¿Qué pasa con la tercera dimensión?” Pues resulta que, debido al power wall, que es el problema de disipar energía, realmente no podemos adentrarnos en la tercera dimensión porque no sabemos cómo evacuar toda la energía que se vierte en el dispositivo.
Lo que podemos predecir para la próxima década es que estos dispositivos permanecerán esencialmente bidimensionales. Desde la perspectiva del software empresarial, la mayor lección es que necesitas diseñar el paralelismo de datos desde el núcleo mismo de tu software. Si no haces esto, no podrás aprovechar todo el progreso que se está logrando en cuanto a potencia de cómputo se refiere. Sin embargo, no puede ser una idea de último momento. Tiene que realizarse en el núcleo mismo de la arquitectura, al nivel en el que organizas todos los datos que deben ser procesados en tus sistemas. Si no lo haces, te quedarás atrapado con el tipo de procesadores que teníamos hace dos décadas.
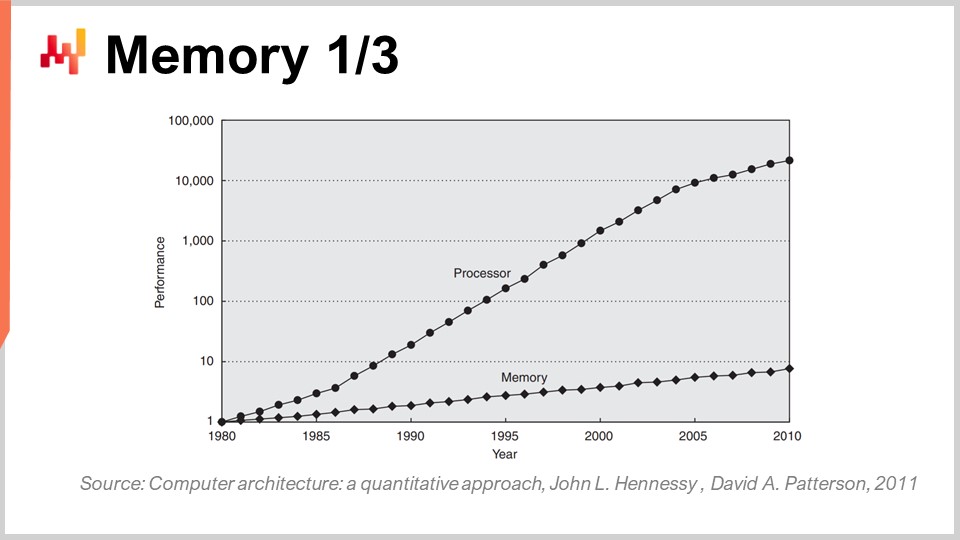
Ahora, en los primeros años de los 80 la memoria era tan rápida como los procesadores, lo que significaba que un ciclo de reloj era igual tanto para la memoria como para la CPU. Sin embargo, ese ya no es el caso. Con el tiempo, desde los años 80, la proporción entre la velocidad de la memoria y las latencias para acceder a los datos que ya se encuentran en los registros del procesador solo ha ido aumentando. Comenzamos con una proporción de uno, y ahora tenemos una proporción típicamente mayor a mil. Este problema se conoce como el memory wall, y solo ha aumentado en las últimas cuatro décadas. Todavía sigue aumentando, aunque muy lentamente, principalmente porque la velocidad de reloj de los procesadores está incrementándose muy despacio. Debido a que los procesadores no están avanzando mucho en términos de velocidad de reloj, este problema del memory wall no se incrementa más. Sin embargo, la situación actual es increíblemente desequilibrada, donde acceder a la memoria es esencialmente tres órdenes de magnitud más lento que acceder a los datos que ya se encuentran convenientemente dentro del procesador.
Esta perspectiva derrota por completo toda la algorítmica clásica tal como se enseña en la mayoría de las universidades hoy en día. La visión clásica de los algoritmos asume que el tiempo para acceder a la memoria es uniforme, lo que significa que acceder a cualquier porción de la memoria toma la misma cantidad de tiempo. Pero en los sistemas modernos, esto no es en absoluto así. El tiempo que se tarda en acceder a una cierta parte de la memoria depende en gran medida de dónde se encuentren físicamente los datos dentro de tu sistema informático.
Desde una perspectiva de software empresarial, resulta que, desafortunadamente, la mayoría de los diseños de software establecidos durante los años 80 y 90 ignoraron por completo el problema porque era muy menor durante la primera década. Realmente, solo se infló en las últimas dos décadas, y como consecuencia, la mayoría de los patrones presentes en el software empresarial actual antagonizan completamente este diseño, ya que asumen que se tiene un acceso en tiempo constante a toda la memoria.
Por cierto, si empiezas a considerar lenguajes de programación como Python (lanzado por primera vez en 1989) o Java (en 1995), que presentan programación orientada a objetos, vas en contra de la manera en que la memoria funciona en las computadoras modernas. Siempre que tienes objetos, y es aún peor si tienes enlaces tardíos como en Python, significa que para hacer cualquier cosa tendrás que seguir punteros y realizar saltos aleatorios en la memoria. Si alguno de esos saltos resulta ser desafortunado porque se trata de una porción que no está ya en el procesador, puede ser mil veces más lento. Eso es un problema muy grande.

Para comprender mejor la magnitud del memory wall, es interesante observar las latencias típicas en una computadora moderna. Si reescalamos esas latencias en términos humanos, supongamos que un procesador operara a un ciclo de reloj por segundo. Bajo esa suposición, la latencia típica de la CPU sería de un segundo. Sin embargo, si queremos acceder a datos en la memoria, podría tomar hasta seis minutos. Así, mientras puedes realizar una operación por segundo, si deseas acceder a algo en la memoria, tendrás que esperar seis minutos. Y si quieres acceder a algo en disco, puede tomar hasta un mes o incluso un año entero. Esto es increíblemente largo, y de ello se tratan esos órdenes de magnitud en rendimiento que mencioné al inicio de esta conferencia. Cuando se trata de 15 órdenes de magnitud, es muy engañoso; no te das cuenta necesariamente del enorme impacto en el rendimiento que puedes tener, donde literalmente puedes acabar teniendo que esperar el equivalente humano de meses si no ubicas la información en el lugar correcto. Esto es absolutamente gigantesco.
Por cierto, los ingenieros de software empresarial no son los únicos que tienen dificultades con esta evolución del hardware de cómputo moderno. Si observamos las latencias que se obtienen con tarjetas SSD súper rápidas, como la serie Intel Optane, podemos ver que la mitad de la latencia para acceder a la memoria en este dispositivo es, en realidad, causada por la sobrecarga del propio kernel, en este caso, el kernel de Linux. Es el propio sistema operativo el que genera la mitad de la latencia. ¿Qué significa eso? Pues significa que incluso las personas que están desarrollando Linux tienen aún trabajo por hacer para ponerse al día con el hardware moderno. No obstante, es un gran desafío para todos.
Sin embargo, esto afecta realmente al software empresarial, especialmente cuando se piensa en la optimización de supply chain, debido a que tenemos toneladas de datos por procesar. Ya es una tarea bastante compleja desde el inicio. Desde la perspectiva del software empresarial, realmente necesitas adoptar un diseño que se lleve bien con la caché, ya que ésta contiene copias locales que son más rápidas de acceder y están más cerca de la CPU.
La manera en que funciona es que cuando accedes a un byte en tu memoria principal, no puedes acceder a ese único byte en el software moderno. Cuando deseas acceder siquiera a un byte en tu RAM, el hardware en realidad copiará 4 kilobytes, esencialmente toda la página de 4 kilobytes. La suposición subyacente es que, al comenzar a leer un byte, el siguiente byte que vas a solicitar será el que le sigue. Ese es el principio de localidad, lo que significa que, si sigues la regla y haces cumplir un acceso que preserve la localidad, entonces puedes disponer de una memoria que parece funcionar casi tan rápido como tu CPU.
Sin embargo, eso requiere una alineación entre los accesos a la memoria y la localidad de los datos. En particular, hay muchos lenguajes de programación, como Python, que no ofrecen este tipo de funcionalidades de manera nativa. Por el contrario, suponen un desafío enorme para lograr cualquier grado de localidad. Esta es una lucha inmensa y, en última instancia, es una batalla en la que dispones de un lenguaje de programación que ha sido diseñado en torno a patrones que antagonizan por completo al hardware a nuestra disposición. Este problema no va a cambiar en la próxima década; solo va a empeorar.
Así, desde una perspectiva de software empresarial, se desea imponer la localidad de los datos pero también la minificación. Si puedes hacer que tu big data sea pequeño, será más rápido. Eso es algo que no resulta muy intuitivo, pero si logras reducir el tamaño de los datos, típicamente eliminando algo de redundancia, puedes acelerar tu programa porque tratarás la caché de manera mucho más eficiente. Podrás ajustar más datos relevantes en los niveles inferiores de caché, que tienen latencias mucho menores, como se muestra en esta pantalla.

Finalmente, analicemos específicamente el caso de la DRAM. La DRAM es, literalmente, el componente físico que conforma la RAM que usas para tu estación de trabajo de escritorio o para tu servidor en la computación en la nube. La DRAM también se conoce como la memoria principal, la cual se construye a partir de chips DRAM. Durante la última década, en términos de precio, la DRAM apenas ha disminuido. Pasamos de $5 por gigabyte a $3 por gigabyte una década después. El precio de la RAM sigue bajando, aunque no muy rápido. Ha estado estancado durante los últimos años, y debido a que solo existen tres actores principales en este mercado con la capacidad de fabricar DRAM a gran escala, hay muy pocas esperanzas de que ocurra algo inesperado en este mercado durante la próxima década.
Pero eso ni es lo peor del problema. También está el consumo de energía por gigabyte. Si observas el consumo, resulta que la RAM moderna consume un poco más de energía por gigabyte de lo que lo hacía hace una década. La razón es, esencialmente, que la RAM que tenemos actualmente es más rápida, y se aplica la misma regla del power wall: si aumentas la frecuencia del reloj, incrementas significativamente el consumo de energía. Por cierto, la RAM consume bastanta energía porque la DRAM es, fundamentalmente, un componente activo. Necesitas refrescar la RAM todo el tiempo debido a la fuga eléctrica, así que si apagas tu RAM, pierdes todos tus datos. Es necesario refrescar las celdas de manera constante.
Por lo tanto, la conclusión para el software empresarial es que la DRAM es el único componente que ya no progresa. Existen montones de cosas que aún avanzan muy rápidamente, como la potencia de procesamiento; sin embargo, este no es el caso de la DRAM: está completamente estancada. Si consideramos el consumo de energía, que también representa una buena porción de los costos de computación en la nube, la RAM apenas avanza. Por lo tanto, si adoptas un diseño que sobreenfatiza la memoria principal —y eso es típicamente lo que obtendrás cada vez que un proveedor dice, “Oh, tenemos un diseño en memoria para software”— recuerda estas palabras clave.
Cada vez que escuchas a un proveedor que te dice que tiene un diseño en memoria, lo que ese proveedor te está comunicando —y esta no es una propuesta muy convincente— es que su diseño depende enteramente de la evolución futura de la DRAM, donde ya sabemos que los costos no van a disminuir. Así que, si tenemos en cuenta el hecho de que, dentro de 10 años, tu supply chain probablemente tendrá algo así como 10 veces más datos para procesar, simplemente porque las empresas están siendo cada vez mejores en recolectar más datos dentro de sus supply chains y colaborando para obtener más datos de sus clientes y proveedores, no es irracional esperar que, dentro de una década, cualquier gran empresa que opere una gran supply chain esté recolectando 10 veces más datos de los que tiene actualmente. Sin embargo, el precio por gigabyte de la RAM seguirá siendo el mismo. Entonces, si haces los cálculos, podrías terminar con costos de computación en la nube o costos de TI que sean esencialmente casi un orden de magnitud más caros, solo para hacer prácticamente lo mismo, debido a que tienes que lidiar con una masa de datos en constante crecimiento que no cabe fácilmente en la memoria. La idea clave es que realmente quieres evitar todo tipo de diseños en memoria. Estos diseños están muy anticuados, y veremos a continuación qué tipo de alternativa tenemos.

Ahora, echemos un vistazo al almacenamiento de datos, que se refiere al almacenamiento persistente. Esencialmente, cuentas con dos clases de almacenamiento de datos muy difundidas. La primera son los discos duros (HDD) o discos rotativos. La segunda son las unidades de estado sólido (SSD). Lo interesante es que la latencia en los discos rotativos es terrible, y cuando miras esta imagen, puedes entender fácilmente por qué. Estos discos literalmente giran, y cuando deseas acceder a cualquier punto aleatorio de datos en el disco, en promedio, necesitas esperar la mitad de una rotación del disco. Teniendo en cuenta que los discos de alta gama giran a aproximadamente 10,000 revoluciones por minuto, significa que tienes una latencia incorporada de tres milisegundos que no se puede reducir. Es literalmente el tiempo que tarda el disco en girar y en poder leer el punto preciso de interés. Es mecánico y no mejorará más.
Los HDD son terribles en términos de latencia, pero también tienen otro problema, que es el consumo de energía. Como regla general, un HDD y un SSD consumen ambos aproximadamente tres vatios por hora por dispositivo. Ese es, típicamente, el estado actual. Sin embargo, cuando el disco duro está en funcionamiento, incluso si no estás leyendo activamente nada de él, estarás consumiendo tres vatios simplemente porque necesitas mantenerlo girando. Alcanzar 10,000 revoluciones por minuto lleva mucho tiempo, por lo que es necesario mantener el disco girando todo el tiempo, incluso si lo utilizas muy poco.
Por otro lado, en lo que respecta a las unidades de estado sólido, consumen tres vatios cuando se accede a ellas, pero cuando no se accede a los datos, casi no consumen energía. Tienen un consumo residual, pero es sumamente pequeño, del orden de miliwatts. Esto es muy interesante porque puedes tener toneladas de SSD; si no las usas, no pagas por la energía que consumen. Toda la industria ha ido haciendo una transición gradual de HDD a SSD durante la última década.
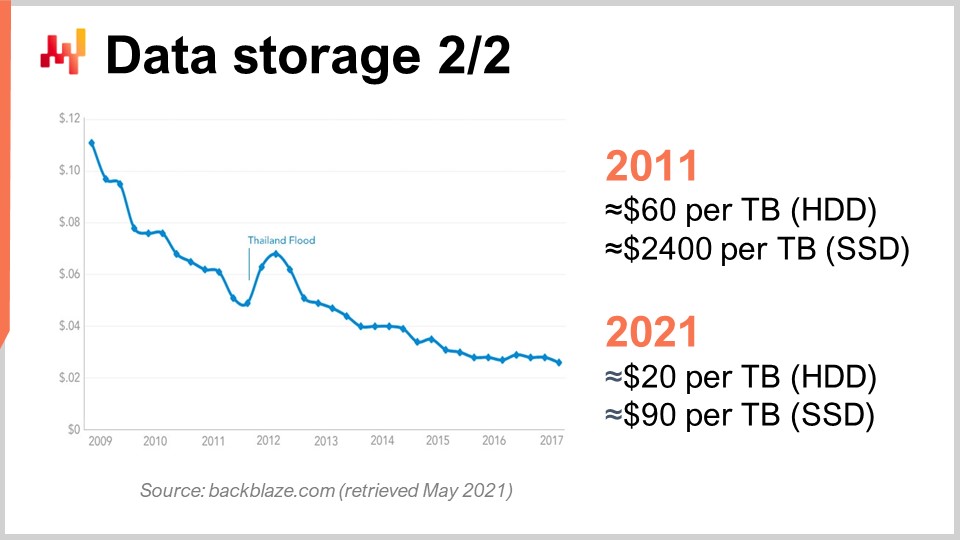
Para entender esto, podemos observar esta curva. Lo que vemos es que el precio por gigabyte de los HDD y los SSD ha ido bajando durante los últimos años. Sin embargo, el precio ahora se ha estabilizado. Los datos son algo antiguos, pero no variaron demasiado en los últimos años. Durante los últimos 10 años, vemos que hace una década los SSD eran extremadamente caros a $2,400 por terabyte, mientras que los discos duros estaban a solo $60 por terabyte. Sin embargo, en la actualidad, el precio de los discos duros se ha dividido por tres, situándose esencialmente en $20 por terabyte. El precio de los SSD se ha dividido por más de 25, y la tendencia a la baja de los precios de los SSD no se detiene. Los SSD son ahora, y probablemente durante la próxima década, el componente que más progresa, y eso es muy interesante.
Por cierto, les comenté que el diseño de los dispositivos de cómputo modernos (CPU, GPU, TPU) era esencialmente bidimensional, con un máximo de 20 capas. Sin embargo, en lo que respecta a los SSD, el diseño es cada vez más tridimensional. Los SSD más recientes cuentan con algo así como 176 capas. Estamos alcanzando, en términos de orden, las 200 capas. Debido a que esas capas son increíblemente delgadas, no es irracional esperar que en el futuro tengamos dispositivos con miles de capas y potencialmente órdenes de magnitud más en capacidades de almacenamiento. Obviamente, el truco será que no podrás acceder a todos estos datos todo el tiempo, nuevamente, debido al dark silicon y a la disipación de energía.
Resulta que, si lo gestionas bien, muchos datos se acceden de forma muy infrecuente. Los SSD implican un diseño de hardware muy específico que viene con un montón de peculiaridades, como el hecho de que solo puedes encender bits, pero no apagarlos. Esencialmente, imagina que inicialmente tienes todos ceros; puedes convertir un cero en uno, sin embargo, no puedes convertir ese uno en cero de forma local. Si deseas hacerlo, tienes que reiniciar todo el bloque, el cual puede ser de hasta ocho megabytes, lo que significa que al escribir, puedes cambiar bits de cero a uno, pero no de uno a cero. Para convertir bits de uno a cero, necesitas vaciar todo el bloque y reescribirlo, lo que conlleva todo tipo de problemas conocidos como amplificación de escritura.
Durante la última década, las unidades SSD cuentan internamente con una capa llamada flash translation layer que puede mitigar todos esos problemas. Estas capas de traducción flash están mejorando cada vez más con el tiempo. Sin embargo, existen grandes oportunidades de mejora, y en términos de software empresarial, significa que realmente quieres optimizar tu diseño para aprovechar al máximo los SSD. Los SSD ya son una opción mucho mejor que la DRAM para almacenar datos, y si actúas de forma inteligente, puedes esperar, dentro de una década, órdenes de magnitud de ganancia que se obtendrán con el progreso de la industria del hardware, lo cual no sucede con la DRAM.
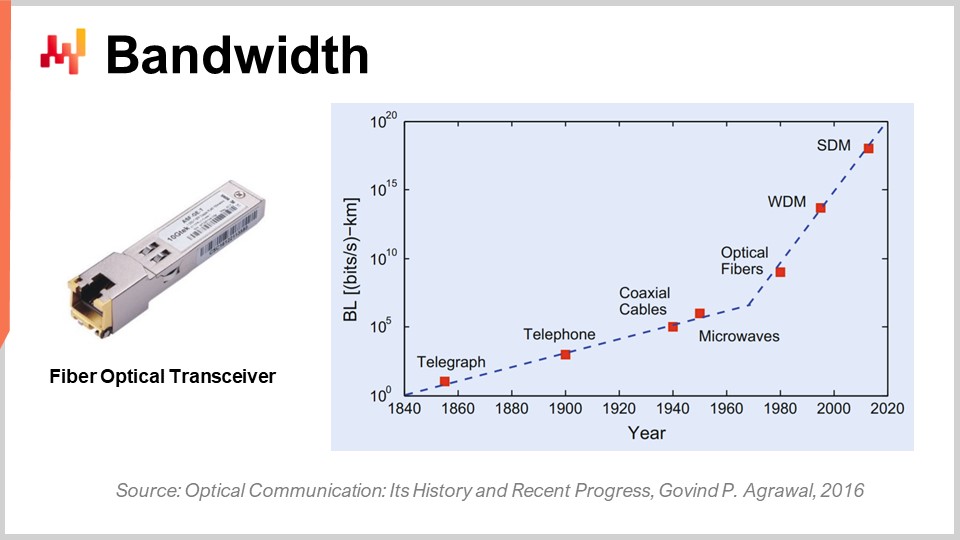
Finalmente, hablemos sobre el ancho de banda. El ancho de banda es probablemente el problema más solucionado en términos de tecnología. Sin embargo, aun pudiendo alcanzarse, podemos lograr niveles de ancho de banda que son absolutamente insanos en la actualidad. Comercialmente, la industria de las telecomunicaciones es muy compleja y existen un montón de problemas, de modo que los consumidores finales no perciben realmente todos los beneficios del progreso que se ha logrado en las comunicaciones ópticas.
En términos de comunicación óptica con transceptores de fibra óptica, el progreso es absolutamente insano. Probablemente es una de esas cosas que están avanzando como lo hacían las CPUs en los años 80 o 90. Solo para darte una idea, con la multiplexación por división de longitud de onda (WDM) o la multiplexación por división espacial (SDM), ahora podemos alcanzar literalmente una décima parte de terabytes de datos transferidos por segundo en un solo cable de fibra óptica. Esto es absolutamente enorme. Estamos llegando al punto en que un solo cable puede transportar suficientes datos como para alimentar esencialmente a un centro de datos completo. Lo que resulta aún más impresionante es que la industria de las telecomunicaciones ha sido capaz de desarrollar nuevos transceptores que pueden ofrecer estas prestaciones absolutamente increíbles basándose en cables antiguos. Ni siquiera tienes que desplegar nueva fibra en las calles o de forma física; literalmente puedes tomar la fibra que se instaló hace una década, instalar el nuevo transceptor y obtener varias órdenes de magnitud más de ancho de banda en el mismo cable.
Lo interesante es que existe una ley general en las comunicaciones ópticas: cada década, la distancia a la que resulta interesante reemplazar la comunicación eléctrica por la óptica se reduce. Si retrocedemos unas décadas, hace dos décadas se necesitaban algo así como 100 metros para que la comunicación óptica superara a la eléctrica. Así que, si las distancias eran inferiores a 100 metros, se optaba por el cobre; si eran mayores a 100 metros, se elegía la fibra. Sin embargo, hoy en día, con la última generación, podemos tener una distancia en la que la óptica gana incluso en tan solo tres metros. Si miramos una década hacia adelante, no me sorprendería ver situaciones en las que las comunicaciones ópticas ganen incluso en distancias de tan solo medio metro. Esto significa que, en algún momento, no me sorprenderá si las mismas computadoras tienen rutas ópticas internas, simplemente porque son más eficientes que las rutas eléctricas.
Desde una perspectiva de software empresarial, esto también es muy interesante porque significa que, de cara al futuro, el ancho de banda va a disminuir masivamente en costo. Esto está sustancialmente subvencionado por compañías como Netflix, que tienen un consumo dramático de ancho de banda. Esto implica que, para mitigar la latencia, podrías hacer cosas como obtener toneladas de datos de forma preventiva hacia el usuario y luego permitir que éste interactúe con datos que han sido acercados a él con una latencia mucho menor. Incluso si traes datos que no son necesarios, lo que te afecta es la latencia, no el ancho de banda. Es mejor decir: “Tengo dudas sobre qué tipo de datos serán necesarios; puedo tomar mil veces más datos de los que realmente preciso, solo acercarlos al usuario final, permitir que el usuario o el programa interactúe con esos datos y minimizar el ida y vuelta, obteniendo así un mayor rendimiento”. Esto, nuevamente, tiene un impacto profundo en el tipo de decisiones arquitectónicas que se toman hoy, ya que condicionarán si puedes ganar en rendimiento con el progreso de esta clase de hardware dentro de una década.

En conclusión, la latencia es la gran batalla de nuestro tiempo en términos de ingeniería de software. Esto está condicionando realmente todo el tipo de rendimiento que tenemos y que tendremos. El rendimiento es absolutamente clave porque no solo impulsará el costo de TI, sino que también influirá en la productividad de las personas que operan en tu supply chain. En última instancia, eso también impulsará el rendimiento de la supply chain en sí, pues si no cuentas con dicho rendimiento, ni siquiera podrás implementar una especie de receta numérica que realmente sea inteligente y ofrezca eventos de optimización avanzada y optimización predictiva, que es lo que buscamos. Sin embargo, en todos los ámbitos, esta batalla por un mejor rendimiento no se está ganando, al menos no en el ámbito del software empresarial. Los sistemas nuevos pueden ser, y frecuentemente son, más lentos que los antiguos. Este es un problema agudo. El menor rendimiento del software genera costos asombrosos para las empresas que caen en ello.
Solo para dar un ejemplo, no se debe considerar algo dado que un mejor hardware de computación te ofrece mejor rendimiento. Algunas personas en internet decidieron medir la latencia de entrada, o input lag, que es el tiempo que transcurre después de presionar una tecla para que la letra correspondiente se muestre en la pantalla. Con un Apple II en 1983, que tenía un procesador de 1 MHz, el tiempo que tardaba era de 30 milisegundos. En 2016, con un Lenovo X1, equipado con un procesador de 2.6 GHz, un notebook muy elegante, la latencia resultó ser de 110 milisegundos. Así que tenemos hardware de computación que es varias miles de veces mejor, sin embargo terminamos con una latencia que es casi cuatro veces más lenta. Esto es característico de lo que sucede cuando no tienes simpatía mecánica y no prestas atención al hardware de computación que posees. Si antagonizas el hardware de computación, te lo paga con bajo rendimiento.
El problema es muy real. Mi sugerencia es que, cuando empieces a mirar cualquier software empresarial para tu empresa, ya sea de código abierto o no, recuerdes los elementos de simpatía mecánica que has aprendido hoy. Observa el software y reflexiona seriamente sobre si abraza las profundas tendencias del hardware de computación o si las ignora por completo. Si las ignora, no solo significa que el rendimiento no mejorará con el tiempo, sino que, lo más probable, empeorará. La mayoría de las mejoras en la actualidad se logran a través de la especialización y no de la velocidad de reloj. Si pierdes esta autopista, estás tomando un camino que se volverá cada vez más lento a lo largo del tiempo. Evita estas soluciones, ya que generalmente resultan de decisiones clave de diseño tomadas en etapas tempranas que no pueden deshacerse. Quedas atrapado con ellas para siempre, y solo empeorará año tras año. Piensa a una década vista cuando empieces a considerar estos aspectos.

Ahora echemos un vistazo a las preguntas. Fue una conferencia bastante larga, pero es un tema desafiante.
Pregunta: ¿Cuál es tu opinión sobre las computadoras cuánticas y su utilidad para abordar problemas complejos de optimización de supply chain?
Una pregunta muy interesante. Me inscribí en la beta de la computadora cuántica de IBM hace 18 meses, cuando abrieron el acceso a su computadora cuántica en la computación en la nube. Mi sensación es que es emocionante, ya que los expertos pueden ver que todas las curvas en S se están aplanando, pero no ven nuevas curvas apareciendo de la nada. La computación cuántica es una de esas. Sin embargo, creo que las computadoras cuánticas presentan desafíos muy duros en lo que respecta a supply chain. Primero, como dije, la batalla de nuestro tiempo en términos de software empresarial es la latencia, y las computadoras cuánticas no hacen nada al respecto. Las computadoras cuánticas te ofrecen, potencialmente, hasta 10 órdenes de magnitud de aumento de velocidad para problemas de cómputo sumamente apretados. Así que, las computadoras cuánticas serían la siguiente etapa más allá de las TPU, donde puedes tener operaciones sumamente apretadas realizadas de forma increíblemente rápida.
Esto es muy interesante, pero para ser honesto, en este momento hay muy pocas empresas, hasta donde yo sé, que logran aprovechar instrucciones superscalar dentro de su software empresarial. Eso significa que todo el mercado está dejando sobre la mesa una aceleración de 10 a 28 veces que ofrecen las GPUs superscalar. Hay muy pocas personas en el mundo de supply chain que lo hacen; tal vez Lokad, tal vez no. En cuanto a las TPU, creo que literalmente no hay nadie. Google lo está haciendo extensamente, pero no conozco a nadie que haya usado TPU para algo relacionado con supply chain. Los procesadores cuánticos serían la etapa siguiente a las TPU.
Definitivamente estoy muy atento a lo que sucede con las computadoras cuánticas, pero creo que este no es el cuello de botella que enfrentamos. Es emocionante porque revisitamos el diseño de von Neumann establecido hace aproximadamente 70 años, pero este no es el cuello de botella al que nosotros o la supply chain nos enfrentaremos durante la próxima década. Más allá de eso, tu conjetura es tan buena como la mía. Sí, podría potencialmente cambiar todo, o no.
Pregunta: ¿Las ofertas de computación en la nube y SaaS están permitiendo a las organizaciones aprovechar y convertir costos fijos? ¿Las empresas que ofrecen tales servicios también están trabajando para reducir sus costos fijos y el riesgo asociado?
Bueno, depende. Si soy una plataforma de computación en la nube y te vendo potencia de procesamiento, ¿realmente es de mi interés que tu software empresarial sea lo más eficiente posible? No realmente. Te estoy vendiendo máquinas virtuales, gigabytes de ancho de banda y almacenamiento, así que, en realidad, es todo lo contrario. Mi interés es asegurarme de que tengas un software que sea lo más ineficiente posible, para que consumas y pagues conforme lo uses una cantidad increíble de recursos.
Internamente, las grandes empresas tecnológicas como Microsoft, Amazon y Google son increíblemente agresivas en lo que respecta a optimizar sus recursos de computación. Pero también son agresivas cuando están en primera línea para pagar la factura al cobrar a un cliente por alquilar una máquina virtual. Si el cliente está alquilando una máquina virtual que es 10 veces mayor de lo que debería ser, solo porque la pieza de software empresarial que utiliza es enormemente ineficiente, no es de su interés interrumpir el error del cliente. Para ellos está bien; es un buen negocio. Cuando piensas que los integradores de sistemas y las plataformas de computación en la nube tienden a trabajar de la mano como socios, te das cuenta de que estas categorías de personas no tienen necesariamente tu mejor interés en mente. Ahora bien, en lo que respecta a SaaS, es algo diferente. De hecho, si terminas pagando a un proveedor de SaaS por usuario, entonces sí está en el interés de la empresa, y ese es el caso de Lokad, por ejemplo. No cobramos según los recursos de computación que consumimos; normalmente cobramos a nuestros clientes con tarifas mensuales planas. Así, los proveedores de SaaS tienden a ser muy agresivos en lo que atañe a su propio consumo de recursos de computación.
Sin embargo, ten en cuenta que existe un sesgo: si eres una empresa SaaS, puedes ser bastante reacio a hacer algo que sería mucho mejor para tus clientes, pero mucho más costoso en términos de hardware para ti. No todo es color de rosas. Existe una especie de conflicto de intereses que afecta a todos los proveedores de SaaS que operan en el ámbito de supply chain. Por ejemplo, podrían invertir en reingenierizar todos sus sistemas para ofrecer mejor latencia y páginas web más rápidas, pero la cuestión es que eso cuesta recursos y sus clientes no necesariamente pagarán más si lo hacen.
El problema tiende a amplificarse cuando se trata de software empresarial. ¿Por qué es eso? Porque la persona que compra el software, típicamente, no es la persona que lo utiliza. Por eso, gran parte del sistema empresarial es increíblemente lento. La persona que compra el software no sufre tanto como un planificador de demanda o un gerente de inventario que tiene que lidiar con un sistema súper lento cada día del año. Así que hay otro ángulo que es específico del ámbito del software empresarial. Realmente necesitas analizar la situación, considerando todos los incentivos que están en juego, y al tratar con software empresarial, por lo general existen numerosos incentivos en conflicto.
Pregunta: ¿Cuántas veces ha tenido Lokad que revisar su enfoque, dado el progreso observado en el hardware? ¿Puedes mencionar un ejemplo, si es posible, para poner este contenido en el contexto de problemas reales resueltos?
Creo que Lokad reingenierizó extensamente nuestra pila tecnológica alrededor de media docena de veces. Sin embargo, Lokad fue fundada en 2008, y tuvimos media docena de reescrituras importantes de toda la arquitectura. No es porque el software hubiera progresado tanto; el software progresó, sí, pero lo que impulsó la mayoría de nuestras reescrituras no fue el hecho de que el hardware hubiera avanzado tanto. Fue más bien que habíamos adquirido un mayor entendimiento del hardware. Todo lo que he presentado hoy ya era esencialmente conocido por quienes prestaban atención hace una década. Así que, ya ves, sí, el hardware evoluciona, pero de forma muy lenta, y la mayoría de las tendencias son muy predecibles, incluso una década adelante. Este es un juego a largo plazo.
Lokad tuvo que someterse a reescrituras masivas, pero fue más un reflejo de que gradualmente nos estábamos volviendo menos incompetentes. Estábamos ganando competencia, y por ello tuvimos una mejor comprensión de cómo aprovechar el hardware, en lugar de que el hardware cambiara la tarea. No siempre fue así; hubo elementos específicos que realmente marcaron un antes y un después para nosotros. El más notable fueron los SSD. Hicimos la transición de HDD a SSD, y fue un cambio radical en nuestro rendimiento, con impactos masivos en nuestra arquitectura. En términos de ejemplos muy concretos, todo el diseño de Envision, el lenguaje de programación específico de dominio que Lokad ofrece, se basa en los conocimientos que recopilamos a nivel de hardware. No es solo un logro; se trata de hacer todo lo que se te ocurra, solo que de manera más rápida.
¿Quieres procesar una tabla con mil millones de líneas y 100 columnas, y hacerlo 100 veces más rápido con los mismos recursos de computación? Sí, se puede hacer. ¿Quieres poder realizar joins entre tablas muy grandes con recursos de computación mínimos? Sí, nuevamente. ¿Puedes tener super complejos paneles de control con literalmente cien tablas mostradas al usuario final en menos de 500 milisegundos? Sí, lo logramos. Estos son logros mundanos, pero es porque alcanzamos todos esos objetivos que nos permiten incorporar recetas de optimización predictiva bastante sofisticadas en producción. Debemos asegurarnos de que todos los pasos que nos llevaron allí se realicen con una productividad muy alta.
El mayor desafío cuando quieres hacer algo muy sofisticado para supply chain en términos de recetas numéricas no es la etapa de “hacer que funcione”. Puedes tomar estudiantes universitarios y lograr una serie de prototipos que ofrecerán alguna mejora en el rendimiento de supply chain en cuestión de semanas. Simplemente usas Python y alguna biblioteca al azar de machine learning de código abierto, y esos estudiantes, si son inteligentes y están dispuestos, producirán un prototipo funcional en cuestión de semanas. Sin embargo, nunca lograrás ponerlo en producción a gran escala. Ese es el problema. Se trata de cómo superar todas esas etapas de madurez de “hacerlo bien”, “hacerlo rápido” y “hacerlo barato”. Ahí es donde la afinidad con el hardware realmente destaca y tu capacidad para iterar.
No existe un único logro. Sin embargo, todo lo que hacemos, por ejemplo, cuando decimos que Lokad está haciendo previsión probabilística, no requiere tanta potencia de procesamiento. Lo que realmente exige potencia de procesamiento es aprovechar distribuciones muy extensas de probabilidades y examinar todos esos futuros posibles, combinándolos con todas las decisiones que puedes tomar. De esa manera, puedes elegir las mejores mediante optimización financiera, lo cual resulta muy costoso. Si no cuentas con algo que esté muy optimizado, quedas atascado. El hecho mismo de que Lokad pueda utilizar previsión probabilística en producción es un testimonio de que tuvimos una optimización a nivel de hardware muy extensa a lo largo de todos los procesos para todos nuestros clientes. Actualmente atendemos a aproximadamente 100 empresas.
Pregunta: ¿Es mejor tener un servidor interno para software empresarial (ERP, WMS) en lugar de usar servicios de computación en la nube para evitar la latencia?
Diría que, en la actualidad, no importa porque la mayoría de las latencias que experimentas se encuentran dentro del sistema. Este no es el problema de latencia entre tu usuario y el ERP. Sí, si tienes una latencia muy pobre, podrías sumar alrededor de 50 milisegundos adicionales. Obviamente, si tienes un ERP, no querrás que esté ubicado en Melbourne mientras operas, por ejemplo, en París. Quieres mantener el centro de datos cerca de donde operas. Sin embargo, las modernas plataformas de computación en la nube tienen docenas de centros de datos, por lo que no hay mucha diferencia en términos de latencia entre el hosting interno y los servicios en la nube.
Típicamente, el hosting interno no significa colocar el ERP en el suelo, en medio de la fábrica o del almacén. En cambio, significa alojar tu ERP en un centro de datos donde rentas hardware de computación. Creo que no existe una diferencia práctica entre el hosting interno y las plataformas de computación en la nube desde la perspectiva de las modernas plataformas con centros de datos repartidos por todo el mundo.
Lo que realmente marca la diferencia es si tienes un ERP que minimiza internamente todas las idas y vueltas. Por ejemplo, lo que típicamente afecta el rendimiento de un ERP es la interacción entre la lógica de negocio y la base de datos relacional. Si tienes cientos de interacciones de ida y vuelta para mostrar una página web, tu ERP resultará terriblemente lento. Por lo tanto, necesitas considerar diseños de software empresarial que no impliquen un número masivo de idas y vueltas. Esto es una propiedad intrínseca del software empresarial que estás evaluando, y no depende mucho de dónde se ubique.
Pregunta: ¿Crees que necesitamos nuevos lenguajes de programación que abracen el nuevo diseño de hardware a nivel de núcleo, aprovechando al máximo las características de la arquitectura del hardware?
Sí, y sí. Pero siendo totalmente franco, tengo un conflicto de intereses aquí. Esto es precisamente lo que Lokad ha hecho con Envision. Envision nació de la observación de que es complicado aprovechar toda la potencia de procesamiento disponible en las computadoras modernas, pero no debería serlo si diseñas el lenguaje de programación con el rendimiento en mente. Puedes hacerlo sobrenatural, y por eso, en la conferencia 1.4 sobre paradigmas de programación para supply chain, dije que si eliges los paradigmas de programación correctos, como la programación en arreglos o la programación con data frames, y construyes un lenguaje de programación que abrace esos conceptos, obtienes rendimiento casi de forma gratuita.
El precio que pagas es que no eres tan expresivo como un lenguaje de programación como Python o C++, pero si estás dispuesto a aceptar una expresividad reducida y cubrir todos los casos de uso relevantes para supply chain, entonces sí, puedes lograr mejoras masivas en el rendimiento. Esa es mi creencia, y por eso también afirmé que, por ejemplo, la programación orientada a objetos desde la perspectiva de la optimización de supply chain no aporta nada.
Por el contrario, este es un tipo de paradigma que solo antagoniza el hardware de computación subyacente. No estoy diciendo que la programación orientada a objetos sea totalmente mala; no es eso lo que digo. Estoy diciendo que hay áreas de la ingeniería de software en las que tiene completo sentido, pero no lo tiene en lo que respecta a la optimización predictiva de supply chain. Así que sí, definitivamente necesitamos lenguajes de programación que realmente abracen eso.
Sé que tiendo a repetir esto, pero Python fue esencialmente diseñado a finales de los años 80, y de alguna manera se perdieron todo lo que había que ver sobre computadoras modernas. Tienen algo en lo que, por diseño, no pueden aprovechar el multi-threading. Tienen este bloqueo global, por lo que no pueden aprovechar múltiples núcleos. No pueden aprovechar la localidad. Tienen late binding que realmente complica los accesos a la memoria. Son muy variables, así que consumen mucha memoria, lo que significa que va a jugar en contra de la caché, etc.
Estos son el tipo de problemas donde, si usas Python, significa que vas a enfrentar batallas cuesta arriba durante las próximas décadas, y la batalla solo empeorará con el tiempo. No mejorarán nunca.
La siguiente clase será dentro de tres semanas, el mismo día de la semana, a la misma hora. Será a las 3 PM, hora de París, el 9 de junio. Vamos a discutir algoritmos modernos para supply chain, que es como el equivalente de las computadoras modernas para supply chain. Nos vemos la próxima vez.


