00:19 Einführung
04:33 Zwei Definitionen für ‘Algorithmus’
08:09 Big-O
13:10 Der bisherige Verlauf
15:11 Hilfswissenschaften (Zusammenfassung)
17:26 Moderne Algorithmen
19:36 Übertreffen der “Optimalität”
22:23 Datenstrukturen - 1/4 - Liste
25:50 Datenstrukturen - 2/4 - Baum
27:39 Datenstrukturen - 3/4 - Graph
29:55 Datenstrukturen - 4/4 - Hash-Tabelle
31:30 Magische Rezepte - 1/2
37:06 Magische Rezepte - 2/2
39:17 Tensor-Komprehensionen - 1/3 - Die ‘Einstein’-Notation
42:53 Tensor-Komprehensionen - 2/3 - Durchbruch des Facebook-Teams
46:52 Tensor-Komprehensionen - 3/3 - Supply Chain-Perspektive
52:20 Metatechniken - 1/3 - Kompression
56:11 Metatechniken - 2/3 - Memoisierung
58:44 Metatechniken - 3/3 - Unveränderlichkeit
01:03:46 Fazit
01:06:41 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Die Optimierung von Supply Chains beruht auf der Lösung zahlreicher numerischer Probleme. Algorithmen sind hochgradig codierte numerische Rezepte, die dazu dienen, präzise Berechnungsprobleme zu lösen. Überlegene Algorithmen bedeuten, dass überlegene Ergebnisse mit weniger Rechenressourcen erzielt werden können. Durch die Fokussierung auf die Besonderheiten der Supply Chain kann die algorithmische Leistungsfähigkeit erheblich verbessert werden, manchmal um Größenordnungen. “Supply Chain”-Algorithmen müssen auch das Design moderner Computer berücksichtigen, das sich in den letzten Jahrzehnten erheblich weiterentwickelt hat.
Vollständiges Transkript

Willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich “Moderne Algorithmen für die Supply Chain” präsentieren. Überlegene Rechenleistung ist entscheidend für eine überlegene Leistung der Supply Chain. Genauere Prognosen, feinere Optimierung und häufigere Optimierung sind alle wünschenswert, um eine überlegene Leistung der Supply Chain zu erreichen. Es gibt immer eine überlegene numerische Methode, die nur geringfügig über den verfügbaren Rechenressourcen liegt.
Algorithmen machen es, um es einfach auszudrücken, Computern schneller. Algorithmen sind ein Teilgebiet der Mathematik und dies ist ein sehr aktives Forschungsfeld. Der Fortschritt in diesem Forschungsbereich übertrifft häufig den Fortschritt der Computertechnologie selbst. Das Ziel dieser Vorlesung ist es zu verstehen, worum es bei modernen Algorithmen geht und wie man Probleme, insbesondere aus einer Supply Chain-Perspektive, angehen kann, um tatsächlich das Beste aus diesen modernen Algorithmen für Ihre Supply Chain zu machen.

In Bezug auf Algorithmen gibt es ein Buch, das ein absolutes Referenzwerk ist: “Introduction to Algorithms”, das erstmals 1990 veröffentlicht wurde. Es ist ein Muss. Die Qualität der Darstellung und des Schreibens ist einfach überragend. Dieses Buch verkaufte sich in den ersten 20 Jahren seines Bestehens über eine halbe Million Mal und inspirierte eine ganze Generation von akademischen Autoren. Tatsächlich wurden die meisten kürzlich veröffentlichten Supply Chain-Bücher, die sich mit Supply Chain-Theorie befassen, in den letzten zehn Jahren häufig stark von Stil und Darstellung in diesem Buch inspiriert.
Persönlich habe ich dieses Buch 1997 gelesen, und es handelte sich tatsächlich um eine französische Übersetzung der allerersten Ausgabe. Es hatte einen tiefgreifenden Einfluss auf meine gesamte Karriere. Nachdem ich dieses Buch gelesen hatte, habe ich Software nie mehr auf die gleiche Weise gesehen. Ein Wort der Vorsicht ist jedoch, dass dieses Buch eine Perspektive über die Computertechnologie annimmt, die Ende der 80er und Anfang der 90er Jahre vorherrschend war. Wie wir in den vorherigen Vorlesungen dieser Reihe gesehen haben, hat sich die Computertechnologie in den letzten Jahrzehnten dramatisch weiterentwickelt, und daher wirken einige der Annahmen in diesem Buch relativ veraltet. Zum Beispiel geht das Buch davon aus, dass der Zugriff auf den Speicher eine konstante Zeit hat, unabhängig davon, wie viel Speicher Sie adressieren möchten. So funktionieren moderne Computer nicht mehr.
Dennoch glaube ich, dass es bestimmte Situationen gibt, in denen es vernünftig ist, vereinfachend vorzugehen, wenn man im Gegenzug einen viel höheren Grad an Klarheit und Einfachheit der Darstellung gewinnt. Dieses Buch leistet in dieser Hinsicht eine erstaunliche Arbeit. Obwohl ich darauf hinweisen möchte, dass einige der grundlegenden Annahmen, die im gesamten Buch gemacht werden, veraltet sind, bleibt es dennoch ein absolutes Referenzwerk, das ich dem gesamten Publikum empfehlen würde.

Klären wir den Begriff “Algorithmus” für das Publikum, das möglicherweise nicht so vertraut mit dem Begriff ist. Es gibt die klassische Definition, bei der es sich um eine endliche Folge wohldefinierter Computeranweisungen handelt. Dies ist die Art von Definition, die Sie in Lehrbüchern oder auf Wikipedia finden. Obwohl die klassische Definition eines Algorithmus ihre Vorzüge hat, finde ich sie enttäuschend, da sie die mit Algorithmen verbundene Absicht nicht klärt. Es handelt sich nicht um irgendeine Art von Anweisungsfolge, die interessant ist; es handelt sich um eine sehr spezifische Sequenz von Computeranweisungen. Daher schlage ich eine persönliche Definition des Begriffs Algorithmus vor: Ein Algorithmus ist im Wesentlichen eine leistungsorientierte, feingranulare, problemorientierte Softwaremethode.
Lassen Sie uns diese Definition genauer betrachten. Erstens der Teil des Problemlösens: Ein Algorithmus wird vollständig durch das Problem charakterisiert, das er zu lösen versucht. Auf diesem Bildschirm sehen Sie den Pseudocode für den Quicksort-Algorithmus, der ein beliebter und bekannter Algorithmus ist. Quicksort versucht das Sortierproblem zu lösen, das wie folgt aussieht: Sie haben ein Array, das Dateneinträge enthält, und Sie möchten einen Algorithmus, der dasselbe Array zurückgibt, aber mit allen Einträgen in aufsteigender Reihenfolge sortiert. Algorithmen konzentrieren sich vollständig auf ein spezifisches und klar definiertes Problem.
Der zweite Aspekt ist, wie Sie feststellen, dass Sie einen besseren Algorithmus haben. Ein besserer Algorithmus ist etwas, das es Ihnen ermöglicht, dasselbe Problem mit weniger Rechenressourcen zu lösen, was in der Praxis schneller bedeutet. Schließlich gibt es den feingranularen Teil. Wenn wir den Begriff “Algorithmen” verwenden, geht es darum, sehr elementare Probleme zu betrachten, die modular sind und endlos zusammengesetzt werden können, um viel komplexere Probleme zu lösen. Darum geht es bei Algorithmen wirklich.
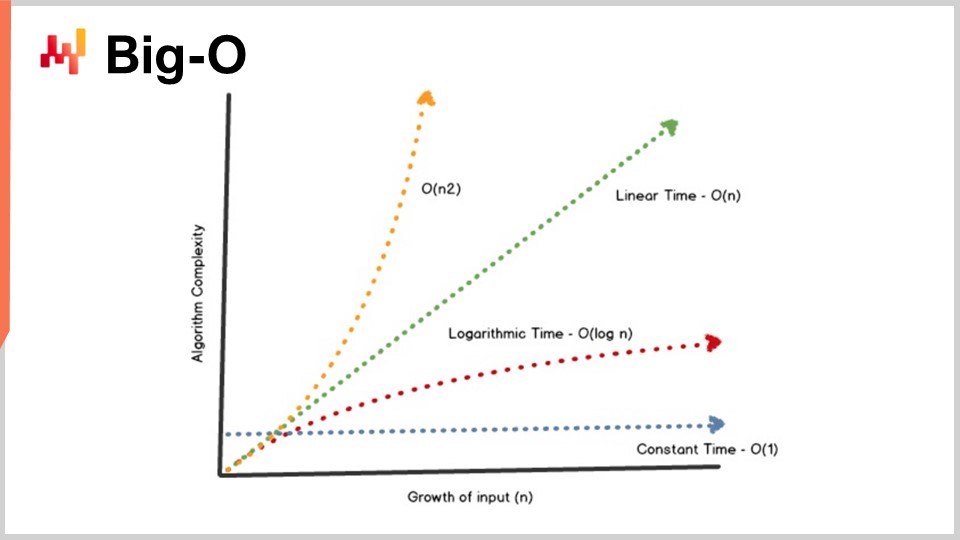
Eine wichtige Errungenschaft der Algorithmus-Theorie besteht darin, eine Charakterisierung der Leistung von Algorithmen auf recht abstrakte Weise zu liefern. Ich werde heute nicht die Zeit haben, mich mit den Details dieser Charakterisierung und des mathematischen Rahmens zu befassen. Die Idee ist, dass wir zur Charakterisierung des Algorithmus das asymptotische Verhalten betrachten wollen. Wir haben ein Problem, das von einer oder mehreren Schlüsselabmessungen abhängt, die das Problem charakterisieren. Zum Beispiel ist bei dem zuvor vorgestellten Sortierproblem die charakteristische Dimension in der Regel die Anzahl der zu sortierenden Elemente. Die Frage ist, was passiert, wenn das Array der zu sortierenden Elemente sehr groß wird? Ich werde diese charakteristische Dimension mit der Zahl “n” als Konvention bezeichnen.
Nun habe ich diese Notation, die sogenannte Big-O-Notation, die Sie vielleicht schon bei der Arbeit mit Algorithmen gesehen haben. Ich werde nur einige Elemente skizzieren, um Ihnen eine Vorstellung davon zu geben, was passiert. Zunächst einmal nehmen wir an, wir haben einen Datensatz und möchten einen einfachen statistischen Indikator wie einen Durchschnitt berechnen. Wenn ich sage, dass ich einen Big-O-1-Algorithmus habe, bedeutet das, dass ich in konstanter Zeit eine Lösung für dieses Problem (Berechnung des Durchschnitts) liefern kann, unabhängig davon, ob der Datensatz klein oder groß ist. Konstante Zeit oder Big O von 1 ist eine absolute Voraussetzung, wenn Sie etwas in Echtzeit im Sinne der Kommunikation zwischen Maschinen tun möchten. Wenn Sie nichts haben, das in konstanter Zeit abläuft, ist es sehr schwierig, manchmal sogar unmöglich, eine Echtzeit-Leistung zu erreichen.
Typischerweise ist ein weiterer wichtiger Leistungsaspekt Big O von N. Big O von N bedeutet, dass die Komplexität des Algorithmus linear zur Größe des interessierenden Datensatzes ist. Dies ist das Ergebnis einer effizienten Implementierung, die das Problem durch einmaliges Lesen der Daten oder eine feste Anzahl von Lesevorgängen lösen kann. Eine Komplexität von Big O von N ist in der Regel nur mit Stapelausführung kompatibel. Wenn Sie etwas haben möchten, das online und in Echtzeit ist, können Sie nichts haben, das den gesamten Datensatz durchläuft, es sei denn, Sie wissen, dass Ihr Datensatz eine feste Größe hat.
Über die Linearität hinaus haben Sie Big O von N Quadrat. Big O von N Quadrat ist ein sehr interessanter Fall, weil es der Punkt ist, an dem die Produktionsausweitung explodiert. Das bedeutet, dass die Komplexität quadratisch mit der Größe des Datensatzes wächst, was bedeutet, dass Ihre Leistung 100-mal schlechter wird, wenn Sie 10-mal mehr Daten haben. Dies ist in der Regel die Art von Leistung, bei der Sie kein Problem im Prototyp sehen, weil Sie mit kleinen Datensätzen arbeiten. Sie werden auch kein Problem in der Testphase sehen, weil Sie wiederum mit kleinen Datensätzen arbeiten. Sobald Sie jedoch in die Produktion gehen, haben Sie eine Software, die völlig träge ist. Sehr häufig in der Welt der Unternehmenssoftware, insbesondere in der Welt der Unternehmenssoftware für die Lieferkette, werden die meisten katastrophalen Leistungsprobleme, die Sie im Feld beobachten können, tatsächlich durch quadratische Algorithmen verursacht, die nicht identifiziert wurden. Als Ergebnis sehen Sie das quadratische Verhalten, das einfach super langsam ist. Dieses Problem wurde nicht frühzeitig erkannt, weil moderne Computer ziemlich schnell sind und N Quadrat nicht so schlimm ist, solange N ziemlich klein ist. Sobald Sie es jedoch mit einem großen Produktionsdatensatz zu tun haben, tut es sehr weh.
Diese Vorlesung ist tatsächlich die zweite Vorlesung meines vierten Kapitels in dieser Reihe von Supply Chain-Vorlesungen. Im ersten Kapitel, dem Prolog, habe ich meine Ansichten zur Supply Chain als Studiengebiet und Praxis vorgestellt. Was wir gesehen haben, ist, dass die Supply Chain eine große Sammlung von komplexen Problemen ist, im Gegensatz zu einfachen Problemen. Komplexe Probleme können nicht mit naiven Methoden angegangen werden, da es überall adversäre Verhaltensweisen gibt, und daher müssen Sie der Methodik selbst große Aufmerksamkeit schenken. Die meisten naiven Methoden scheitern auf spektakuläre Weise. Genau das habe ich im zweiten Kapitel gemacht, das sich vollständig den Methoden widmet, die für die Untersuchung von Supply Chains und die Verbesserung der Praxis des Supply Chain Managements geeignet sind. Das dritte Kapitel, das noch nicht abgeschlossen ist, ist im Wesentlichen eine Betrachtung dessen, was ich “Supply Chain-Personal” nenne, eine sehr spezifische Methodik, bei der wir uns auf die Probleme selbst konzentrieren, anstatt auf die Lösungen, die wir zur Lösung des Problems denken können. In Zukunft werde ich zwischen Kapitel Nummer drei und dem aktuellen Kapitel wechseln, das sich mit den Hilfswissenschaften der Supply Chain befasst.
In der letzten Vorlesung haben wir gesehen, dass wir durch bessere, modernere Hardware für unsere Supply Chain mehr Rechenleistung erhalten können. Heute betrachten wir das Problem aus einem anderen Blickwinkel - wir suchen nach mehr Rechenleistung, weil wir bessere Software haben. Darum geht es bei Algorithmen.

Eine kurze Zusammenfassung: Die Hilfswissenschaften sind im Wesentlichen eine Perspektive auf die Supply Chain selbst. Die heutige Vorlesung handelt nicht streng genommen von der Supply Chain; sie handelt von Algorithmen. Ich glaube jedoch, dass dies von grundlegender Bedeutung für die Supply Chain ist. Die Supply Chain ist keine Insel; der Fortschritt, der in der Supply Chain erzielt werden kann, hängt sehr stark vom Fortschritt ab, der bereits in anderen angrenzenden Bereichen erzielt wurde. Ich beziehe mich auf diese Bereiche als die Hilfswissenschaften der Supply Chain.
Ich glaube, dass die Situation der Beziehung zwischen den medizinischen Wissenschaften und der Chemie im 19. Jahrhundert ziemlich ähnlich ist. Zu Beginn des 19. Jahrhunderts kümmerten sich die medizinischen Wissenschaften überhaupt nicht um Chemie. Die Chemie war immer noch der Neuling und wurde nicht als gültige Vorschlag für einen tatsächlichen Patienten angesehen. Springen wir ins 21. Jahrhundert, würde der Vorschlag, ein ausgezeichneter Arzt zu sein, während man nichts über Chemie weiß, als völlig absurd angesehen. Es wird allgemein anerkannt, dass man kein ausgezeichneter Chemiker sein muss, um ein ausgezeichneter Arzt zu sein, aber es wird allgemein anerkannt, dass man, wenn man nichts über Körperchemie weiß, in Bezug auf moderne medizinische Wissenschaften nicht kompetent sein kann. Meine Vorstellung für die Zukunft ist, dass das Supply Chain-Feld im 21. Jahrhundert das Feld der Algorithmen ziemlich genau so betrachten wird, wie das Feld der medizinischen Wissenschaften im 19. Jahrhundert die Chemie betrachtet hat.

Algorithmen sind ein großes Forschungsgebiet, ein Teilgebiet der Mathematik, und wir werden heute nur an der Oberfläche dieses Forschungsgebiets kratzen. Insbesondere hat sich dieses Forschungsgebiet seit Jahrzehnten mit beeindruckenden Ergebnissen überschlagen. Es mag ein ziemlich theoretisches Forschungsgebiet sein, aber das bedeutet nicht, dass es nur Theorie ist. Tatsächlich ist es ein Forschungsgebiet, das ziemlich theoretisch ist, aber es gab viele Erkenntnisse, die ihren Weg in die Produktion gefunden haben.
Tatsächlich verwendet jedes Smartphone oder jeder Computer, den Sie heute verwenden, buchstäblich Zehntausende von Algorithmen, die ursprünglich irgendwo veröffentlicht wurden. Diese Erfolgsbilanz ist tatsächlich im Vergleich zur Supply Chain-Theorie viel beeindruckender, bei der die große Mehrheit der Supply Chains noch nicht auf den Erkenntnissen der Supply Chain-Theorie basiert. Wenn es um moderne Computer und moderne Algorithmen geht, wird praktisch alles, was mit Software zu tun hat, vollständig von all diesen Jahrzehnten der algorithmischen Forschung vorangetrieben. Dies ist der Kern praktisch jedes einzelnen Computers, den wir heute verwenden.
Für die heutige Vorlesung habe ich eine Liste von Themen zusammengestellt, von denen ich glaube, dass sie recht anschaulich sind und die Sie kennen sollten, um das Thema moderne Algorithmen anzugehen. Zuerst werden wir besprechen, wie wir angeblich optimale Algorithmen tatsächlich übertreffen können, insbesondere für die Supply Chain. Dann werfen wir einen kurzen Blick auf Datenstrukturen, gefolgt von magischen Rezepten, Tensor-Kompression und schließlich Meta-Techniken.
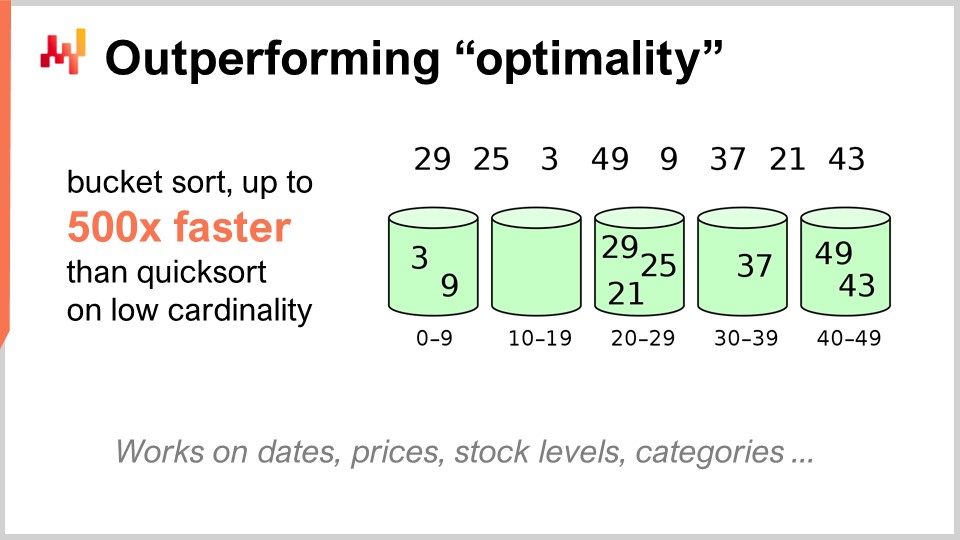
Zunächst möchte ich klarstellen, dass ich mit “Algorithmen für die Supply Chain” nicht Algorithmen meine, die dazu bestimmt sind, spezifische Probleme der Supply Chain zu lösen. Die richtige Perspektive besteht darin, sich klassische Algorithmen für klassische Probleme anzusehen und diese klassischen Probleme aus der Perspektive der Supply Chain zu betrachten, um zu sehen, ob wir tatsächlich etwas Besseres tun können. Die Antwort ist ja, das können wir.
Zum Beispiel ist der Quicksort-Algorithmus nach der allgemeinen Theorie der Algorithmen optimal in dem Sinne, dass Sie keinen Algorithmus einführen können, der beliebig besser ist als Quicksort. In dieser Hinsicht ist Quicksort so gut, wie es jemals sein kann. Wenn wir uns jedoch speziell auf die Supply Chain konzentrieren, ist es möglich, beeindruckende Geschwindigkeitssteigerungen zu erzielen. Insbesondere bei Sortierproblemen, bei denen die Kardinalität der interessierenden Datensätze gering ist, wie z.B. Daten, Preise, Bestandswerte oder Kategorien, handelt es sich um Datensätze mit geringer Kardinalität. Wenn Sie also zusätzliche Annahmen haben, wie z.B. in einer Situation mit geringer Kardinalität zu sein, können Sie den Bucket-Sort verwenden. In der Produktion gibt es viele Situationen, in denen Sie absolut monumentale Geschwindigkeitssteigerungen erzielen können, z.B. 500-mal schneller als Quicksort. Sie können also um Größenordnungen schneller sein als das, was angeblich optimal war, nur weil Sie nicht im allgemeinen Fall, sondern im Fall der Supply Chain sind. Das ist etwas sehr Wichtiges, und ich glaube, hier liegt der Kern der beeindruckenden Ergebnisse, die wir erzielen können, indem wir Algorithmen für die Supply Chain nutzen.
Ich glaube, dass diese Perspektive aus mindestens zwei Gründen falsch ist. Erstens ist es, wie wir gesehen haben, nicht unbedingt der Standardalgorithmus, der von Interesse ist. Wir haben gesehen, dass es einen angeblich optimalen Algorithmus wie Quicksort gibt, aber wenn Sie dasselbe Problem aus der Perspektive der Supply Chain betrachten, können Sie tatsächlich massive Geschwindigkeitssteigerungen erzielen. Es ist also von vorrangigem Interesse, mit Algorithmen vertraut zu sein, um die Klassiker überdenken und massive Geschwindigkeitssteigerungen erzielen zu können, nur weil Sie nicht im allgemeinen Fall, sondern im Fall der Supply Chain sind.
Der zweite Grund, warum ich glaube, dass diese Perspektive falsch ist, besteht darin, dass Algorithmen sehr stark von Datenstrukturen abhängen. Datenstrukturen sind Möglichkeiten, Daten so zu organisieren, dass Sie effizienter mit den Daten arbeiten können. Das Interessante ist, dass all diese Datenstrukturen eine Art Vokabular bilden, und der Zugang zu diesem Vokabular ist entscheidend, um Supply Chain-Situationen in einer Weise zu beschreiben, die sich leicht in Software übersetzen lässt. Wenn Sie mit einer Beschreibung in Laienbegriffen beginnen, enden Sie in der Regel mit Dingen, die äußerst schwer in Software zu übersetzen sind. Wenn Sie von einem Softwareingenieur erwarten, der nichts über die Supply Chain weiß, dass er diese Übersetzung für Sie implementiert, kann das zu Problemen führen. Es ist tatsächlich viel einfacher, wenn Sie dieses Vokabular kennen, damit Sie direkt die Begriffe verwenden können, die sich leicht in die Übersetzung der Ideen, die Sie haben, in Software übertragen lassen.
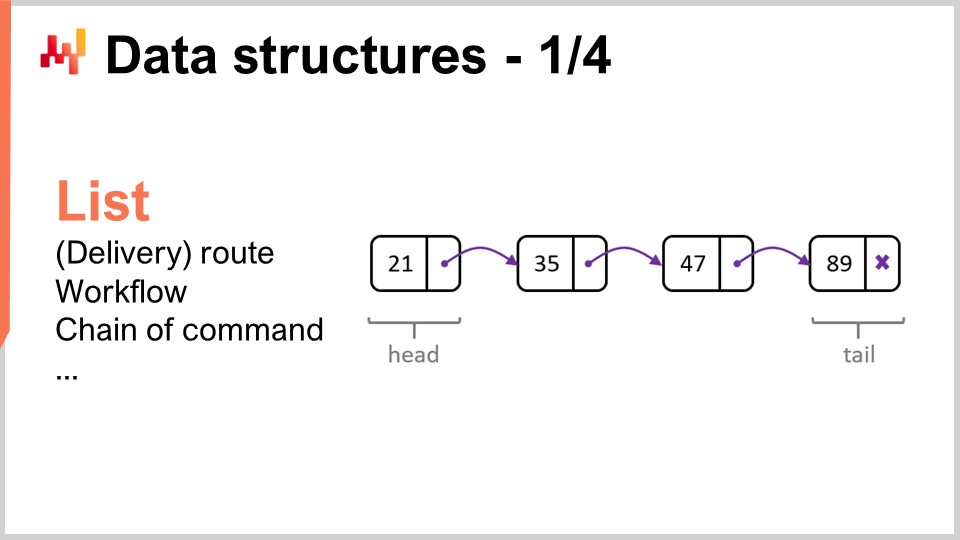
Lassen Sie uns die beliebtesten und einfachsten Datenstrukturen überprüfen. Die erste wäre die Liste. Die Liste kann beispielsweise eine Lieferstrecke darstellen, die die Reihenfolge der zu machenden Lieferungen mit einem Eintrag pro Lieferung angibt. Sie können die Lieferstrecke beim Fortschreiten durch sie aufzählen. Eine Liste kann auch einen Workflow darstellen, der eine Sequenz von Operationen darstellt, die zur Herstellung eines bestimmten Geräts erforderlich sind, oder eine Befehlskette, die festlegt, wer bestimmte Entscheidungen treffen soll.
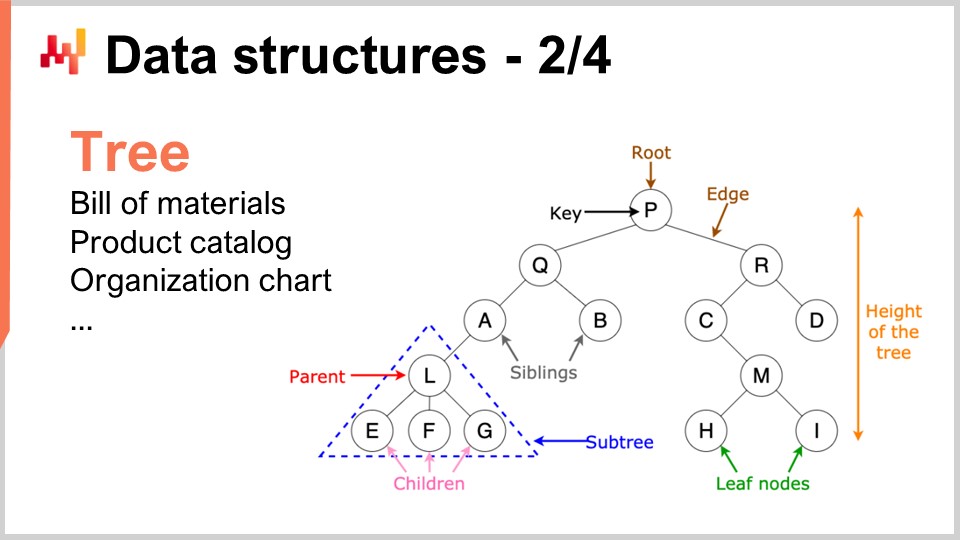
Ebenso sind Bäume eine weitere allgegenwärtige Datenstruktur. Übrigens sind algorithmische Bäume umgekehrt, mit der Wurzel oben und den Zweigen unten. Bäume ermöglichen es Ihnen, alle Arten von Hierarchien zu beschreiben, und in Supply Chains gibt es überall Hierarchien. Zum Beispiel ist eine Stückliste ein Baum; Sie haben ein Gerät, das Sie herstellen möchten, und dieses Gerät besteht aus Baugruppen. Jede Baugruppe besteht aus Unterbaugruppen, und jede Unterbaugruppe besteht aus Teilen. Wenn Sie die Stückliste vollständig erweitern, erhalten Sie einen Baum. Ebenso hat ein Produktkatalog, in dem Sie Produktfamilien, Produktkategorien, Produkte, Unterkategorien usw. haben, sehr häufig eine baumartige Architektur. Eine Organigramm, mit dem CEO oben, den C-Level-Executives darunter usw., wird ebenfalls durch einen Baum dargestellt. Die algorithmische Theorie bietet Ihnen eine Vielzahl von Werkzeugen und Methoden, um Bäume zu verarbeiten und Operationen effizient über Bäume durchzuführen. Immer wenn Sie Daten als Baum darstellen können, haben Sie ein ganzes Arsenal an mathematischen Methoden, um effizient mit diesen Bäumen zu arbeiten. Deshalb ist dies von großem Interesse.
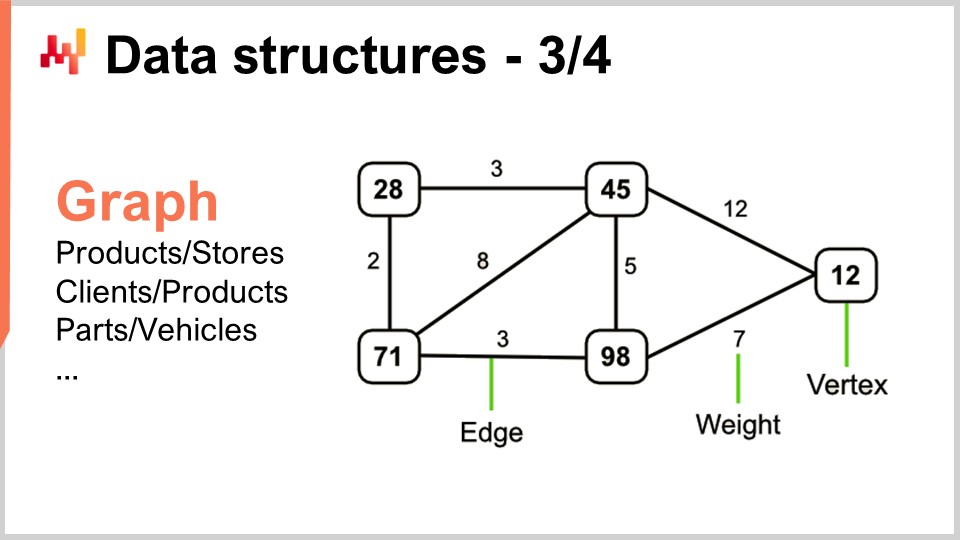
Nun, Graphen ermöglichen es Ihnen, alle Arten von Netzwerken zu beschreiben. Übrigens ist ein Graph im mathematischen Sinne eine Menge von Knoten und eine Menge von Kanten, wobei Kanten zwei Knoten miteinander verbinden. Der Begriff “Graph” könnte ein kleines bisschen irreführend sein, weil er nichts mit Grafiken zu tun hat. Ein Graph ist nur ein mathematisches Objekt, keine Zeichnung oder irgendetwas Grafisches. Wenn Sie wissen, wie Sie nach Graphen suchen müssen, werden Sie feststellen, dass in Supply Chains überall Graphen vorhanden sind.
Ein paar Beispiele: Eine Sortimentsliste in einem Einzelhandelsnetzwerk, das im Wesentlichen ein bipartiter Graph ist, verbindet Produkte und Geschäfte. Wenn Sie ein Treueprogramm haben, in dem Sie aufzeichnen, welcher Kunde welches Produkt im Laufe der Zeit gekauft hat, haben Sie einen weiteren bipartiten Graphen, der Kunden und Produkte verbindet. Im Automobil-Ersatzteilmarkt, wo Sie Reparaturen durchführen müssen, müssen Sie in der Regel eine Kompatibilitätsmatrix verwenden, die Ihnen die Liste der Teile angibt, die eine mechanische Kompatibilität mit dem interessierenden Fahrzeug haben. Diese Kompatibilitätsmatrix ist im Wesentlichen ein Graph. Es gibt eine enorme Menge an Literatur über alle Arten von Algorithmen, mit denen Sie mit Graphen arbeiten können, daher ist es sehr interessant, wenn Sie ein Problem als von einer Graphenstruktur unterstützt charakterisieren können, da alle in der Literatur bekannten Methoden sofort verfügbar werden.
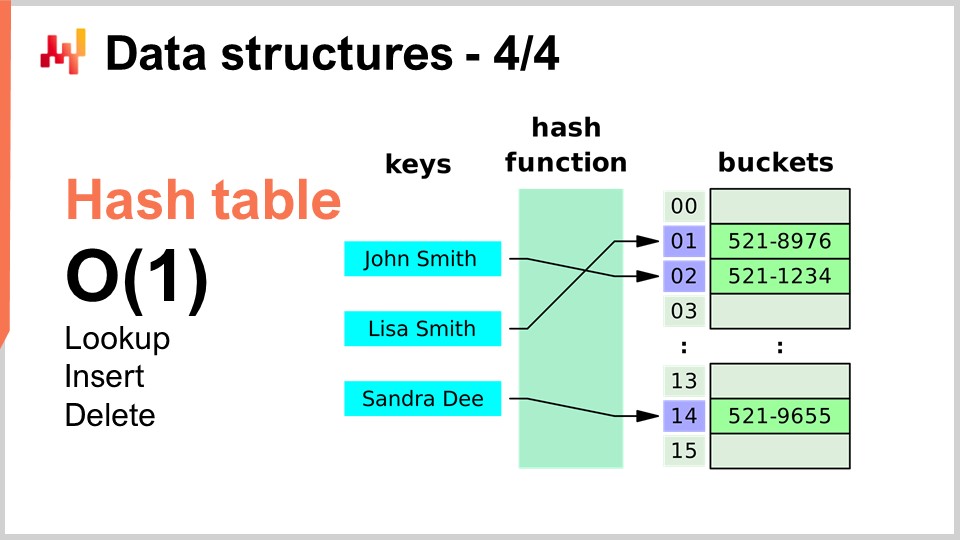
Schließlich ist die letzte Datenstruktur, über die ich heute sprechen werde, die Hashtabelle. Die Hashtabelle ist im Wesentlichen das Schweizer Taschenmesser der Algorithmen. Sie ist nicht neu; keine der von mir vorgestellten Datenstrukturen ist neu nach heutigen Maßstäben. Die Hashtabelle ist wahrscheinlich die neueste von allen und stammt aus den 1950er Jahren, also ist sie nicht neu. Dennoch ist die Hashtabelle eine unglaublich nützliche Datenstruktur. Es ist ein Container, der Schlüssel-Wert-Paare enthält. Die Idee ist, dass Sie mit diesem Container eine große Menge an Daten speichern können und eine Leistung von O(1) für Suche, Einfügen und Löschen erhalten. Sie haben einen Container, in dem Sie in konstanter Zeit Daten hinzufügen können, überprüfen können, ob Daten vorhanden sind oder nicht (indem Sie den Schlüssel betrachten) und potenziell Daten entfernen können. Dies ist sehr interessant und nützlich. Hashtabellen sind buchstäblich überall und werden in anderen Algorithmen umfangreich verwendet.
Eines möchte ich betonen, und wir werden später darauf zurückkommen, ist, dass die Leistung einer Hashtabelle sehr stark von der Leistung der Hashfunktion abhängt, die Sie haben.

Nun werfen wir einen Blick auf magische Rezepte und wechseln komplett die Perspektive. Magische Zahlen sind grundsätzlich ein Anti-Pattern. In der vorherigen Vorlesung, derjenigen über negatives Wissen für die Supply Chain, haben wir besprochen, wie Anti-Patterns in der Regel mit einer guten Absicht beginnen, aber ungewollte Konsequenzen haben, die die vermeintlichen Vorteile der Lösung zunichte machen. Magische Zahlen sind ein bekanntes Programmier-Anti-Pattern. Dieses Programmier-Anti-Pattern besteht darin, Code mit Konstanten zu schreiben, die völlig aus dem Nichts zu kommen scheinen und Ihre Software sehr schwer wartbar machen. Wenn Sie Tonnen von Konstanten haben, ist unklar, warum Sie diese Einschränkungen haben und wie sie ausgewählt wurden.
Normalerweise ist es besser, wenn Sie magische Zahlen in einem Programm isolieren, an einem Ort, an dem sie besser verwaltet werden können. Es gibt jedoch Situationen, in denen eine sorgfältige Auswahl von Konstanten etwas völlig Unerwartetes bewirkt und Sie nahezu magische, völlig ungewollte Vorteile durch die Verwendung von Zahlen haben, die scheinbar vom Himmel gefallen sind. Genau darum geht es bei dem sehr kurzen Algorithmus, den ich hier vorstelle.
In der Supply Chain möchten wir sehr häufig eine Art Simulation erreichen. Simulationen oder Monte-Carlo-Prozesse sind einer der grundlegenden Tricks, die Sie in einer Vielzahl von Supply-Chain-Situationen anwenden können. Die Leistung Ihrer Simulation hängt jedoch sehr stark von Ihrer Fähigkeit ab, Zufallszahlen zu generieren. Bei der Generierung von Simulationen ist in der Regel eine gewisse Menge an generierter Zufälligkeit beteiligt, und daher benötigen Sie einen Algorithmus zur Generierung dieser Zufälligkeit. Soweit Computer betroffen sind, handelt es sich in der Regel um Pseudorandomness - es handelt sich nicht um echte Zufälligkeit; es ist nur etwas, das wie Zufallszahlen aussieht und die statistischen Eigenschaften von Zufallszahlen aufweist, aber tatsächlich nicht zufällig ist.
Die Frage lautet, wie effizient können Sie Zufallszahlen generieren? Es gibt einen Algorithmus namens “Shift”, der 2003 von George Marsaglia veröffentlicht wurde und ziemlich beeindruckend ist. Dieser Algorithmus generiert sehr hochwertige Zufallszahlen und erzeugt eine vollständige Permutation von 2 hoch 64 minus 1 Bits. Er wird alle 64-Bit-Kombinationen, minus eins, mit Null als festem Punkt durchlaufen. Dies geschieht im Wesentlichen mit sechs Operationen: drei binäre Verschiebungen und drei XOR (exklusives Oder)-Operationen, die bitweise Operationen sind. Die Verschiebungen sind ebenfalls bitweise Operationen.
Was wir sehen, ist, dass es drei magische Zahlen in der Mitte gibt: 13, 7 und 17. Übrigens sind alle diese Zahlen Primzahlen; das ist kein Zufall. Es stellt sich heraus, dass Sie mit diesen spezifischen Konstanten einen ausgezeichneten Zufallszahlengenerator erhalten, der auch noch super schnell ist. Wenn ich von super schnell spreche, meine ich, dass Sie buchstäblich 10 Megabyte pro Sekunde an Zufallszahlen generieren können. Das ist absolut enorm. Wenn wir zur vorherigen Vorlesung zurückgehen, können wir sehen, warum dieser Algorithmus auch so effizient ist. Wir haben nicht nur sechs Anweisungen, die direkt auf Anweisungen abgebildet werden, die von der zugrunde liegenden Hardware, wie dem Prozessor, nativ unterstützt werden, sondern es gibt auch keine Verzweigung. Es gibt keinen Test und das bedeutet, dass dieser Algorithmus, sobald er ausgeführt wird, die Pipelining-Kapazität des Prozessors voll auslastet, weil es keine Verzweigung gibt. Wir können buchstäblich die tiefe Pipelining-Kapazität, die wir in einem modernen Prozessor haben, voll auslasten. Das ist sehr interessant.
Die Frage ist, könnten wir andere Zahlen wählen, um diesen Algorithmus zum Laufen zu bringen? Die Antwort ist nein. Es gibt nur einige Dutzend oder vielleicht etwa hundert verschiedene Kombinationen von Zahlen, die tatsächlich funktionieren würden, und alle anderen würden Ihnen einen Zufallsgenerator von sehr geringer Qualität geben. Das ist das Magische daran. Sie sehen, das ist ein aktueller Trend in der algorithmischen Entwicklung, etwas völlig Unerwartetes zu finden, wo Sie eine halb-magische Konstante finden, die Ihnen völlig unbeabsichtigte Vorteile durch die Vermischung sehr unerwarteter binärer Operationen einer Art gibt. Die Zufallsgenerierung ist von entscheidender Bedeutung für die Supply Chain.

Aber wie gesagt, Hash-Tabellen sind überall zu finden und es ist auch von großem Interesse, eine super leistungsstarke generische Hash-Funktion zu haben. Gibt es so etwas? Ja. Es gibt seit Jahrzehnten ganze Klassen von Hash-Funktionen, aber 2019 wurde ein weiterer Algorithmus veröffentlicht, der eine Rekordleistung erzielt. Dies ist der, den Sie auf dem Bildschirm sehen können, “WyHash” von Wang Yi. Im Wesentlichen können Sie sehen, dass die Struktur sehr ähnlich dem XORShift-Algorithmus ist. Es ist ein Algorithmus, der keine Verzweigung hat, wie XORShift, und er verwendet auch die XOR-Operation. Der Algorithmus verwendet sechs Anweisungen: vier XOR-Operationen und zwei Multiply-No-Flags-Operationen.
Multiply-No-Flags ist einfach die Standardmultiplikation zwischen zwei 64-Bit-Integer und als Ergebnis sammeln Sie die oberen 64 Bits und die unteren 64 Bits. Dies ist eine tatsächliche Anweisung, die in modernen Prozessoren verfügbar ist und auf Hardware-Ebene implementiert ist, daher zählt sie als nur eine Computeranweisung. Wir haben zwei davon. Wieder haben wir drei magische Zahlen, die in hexadezimaler Form geschrieben sind. Übrigens sind das wieder Primzahlen, komplett halb-magisch. Wenn Sie diesen Algorithmus anwenden, haben Sie eine absolut ausgezeichnete nicht-kryptografische Hash-Funktion, die fast mit der Geschwindigkeit von memcpy arbeitet. Sie ist sehr schnell und von großem Interesse.

Nun wechseln wir wieder zu etwas völlig anderem. Der Erfolg des Deep Learning und vieler anderer moderner maschineller Lernmethoden beruht auf einigen wichtigen algorithmischen Erkenntnissen zu Problemen, die durch dedizierte Rechenhardware massiv beschleunigt werden können. Das habe ich in meiner vorherigen Vorlesung besprochen, als ich über Prozessoren mit superskalaren Anweisungen und, wenn Sie mehr wollen, über GPUs und sogar TPUs gesprochen habe. Lassen Sie uns diese Erkenntnis noch einmal betrachten, um zu sehen, wie das Ganze eher chaotisch entstanden ist. Ich glaube jedoch, dass sich die relevanten Erkenntnisse in den letzten Jahren kristallisiert haben. Um zu verstehen, wo wir heute stehen, müssen wir zur Einstein-Notation zurückkehren, die vor etwas mehr als einem Jahrhundert von Albert Einstein in einem seiner Artikel eingeführt wurde. Die Intuition ist einfach: Sie haben einen Ausdruck y, der eine Summe von i gleich 1 bis i gleich 3 von c_y mal x_y ist. Wir haben Ausdrücke, die so geschrieben sind, und die Intuition der Einstein-Notation besagt, dass wir in dieser Art von Situation die Summe vollständig weglassen sollten. In Software-Begriffen wäre die Summe eine Schleife. Die Idee ist, die Summe vollständig wegzulassen und zu sagen, dass wir aus Konvention die Summe über alle Indizes für die Variable i machen.
Diese einfache Intuition führt zu zwei sehr überraschenden, aber positiven Ergebnissen. Das erste ist die Korrektheit des Designs. Wenn wir die Summe explizit schreiben, riskieren wir, nicht die richtigen Indizes zu haben, was zu Index-Out-of-Bounds-Fehlern in der Software führen kann. Indem wir die explizite Summe entfernen und festlegen, dass wir per Definition alle gültigen Indexpositionen verwenden, haben wir einen korrekten Ansatz von Design her. Das allein ist von größtem Interesse und steht im Zusammenhang mit der Array-Programmierung, einem Programmierparadigma, das ich in einer meiner vorherigen Vorlesungen kurz angesprochen habe.
Die zweite Erkenntnis, die heutzutage von großem Interesse ist, ist, dass Ihr Problem von massiver Hardwarebeschleunigung profitieren kann, wenn Sie es in der Form schreiben können, in der die Einstein-Notation gilt. Das ist ein elementarer Wendepunkt.

Um zu verstehen, warum, gibt es ein sehr interessantes Paper namens “Tensor Comprehensions”, das 2018 vom Facebook-Forschungsteam veröffentlicht wurde. Sie führten den Begriff der Tensor Comprehensions ein. Zuerst möchte ich die beiden Wörter definieren. Im Bereich der Informatik ist ein Tensor im Wesentlichen eine mehrdimensionale Matrix (in der Physik sind Tensoren völlig anders). Ein skalierter Wert ist ein Tensor der Dimension Null, ein Vektor ist ein Tensor der Dimension Eins, eine Matrix ist ein Tensor der Dimension Zwei und Sie können Tensoren mit noch höheren Dimensionen haben. Tensoren sind Objekte mit array-ähnlichen Eigenschaften.
Comprehension ist etwas Ähnliches wie eine Algebra mit den vier Grundoperationen - Plus, Minus, Multiplikation und Division - sowie anderen Operationen. Es ist umfangreicher als die reguläre arithmetische Algebra; deshalb haben sie eine Tensor Comprehension anstelle einer Tensor Algebra. Sie ist umfassender, aber nicht so ausdrucksstark wie eine vollwertige Programmiersprache. Wenn Sie eine Comprehension haben, ist sie restriktiver als eine vollständige Programmiersprache, in der Sie alles tun können, was Sie wollen.
Die Idee ist, dass wenn Sie sich die MV-Funktion (def MV) ansehen, handelt es sich im Grunde um eine Funktion, und MV steht für Matrix-Vektor. In diesem Fall handelt es sich um eine Matrix-Vektor-Multiplikation, und diese Funktion führt im Wesentlichen eine Multiplikation zwischen der Matrix A und dem Vektor X durch. Wir sehen in dieser Definition, dass die Einstein-Notation im Spiel ist: Wir schreiben C_i = A_ik * X_k. Welche Werte sollten wir für i und k wählen? Die Antwort lautet alle gültigen Kombinationen für diese Variablen, die Indizes sind. Wir nehmen alle gültigen Indexwerte, machen die Summe, und in der Praxis erhalten wir eine Matrix-Vektor-Multiplikation.
Am unteren Rand des Bildschirms sehen Sie dieselbe Methode MV, die mit for-Schleifen umgeschrieben wurde und explizit die Wertebereiche angibt. Die Hauptleistung des Facebook-Forschungsteams besteht darin, dass sie immer dann, wenn Sie ein Programm mit dieser Syntax der Tensor Comprehension schreiben können, einen Compiler entwickelt haben, der es Ihnen ermöglicht, umfangreich von Hardwarebeschleunigung mit GPUs zu profitieren. Im Grunde genommen ermöglichen sie es Ihnen, jedes Programm zu beschleunigen, das Sie mit dieser Tensor Comprehension-Syntax schreiben können. Immer wenn Sie ein Programm in dieser Form schreiben können, profitieren Sie von massiver Hardwarebeschleunigung, und wir sprechen hier von etwas, das zwei Größenordnungen schneller ist als ein regulärer Prozessor. Dies ist ein beeindruckendes Ergebnis für sich.

Schauen wir uns nun an, was wir aus der Perspektive der Supply Chain mit diesem Ansatz tun können. Ein zentrales Interesse für die moderne Supply Chain-Praxis ist die probabilistische Vorhersage. Probabilistische Vorhersage, die ich in einem früheren Vortrag behandelt habe, ist die Idee, dass Sie keine Punktprognose haben werden, sondern dass Sie alle verschiedenen Wahrscheinlichkeiten für eine interessierende Variable prognostizieren werden. Betrachten wir zum Beispiel eine Durchlaufzeit-Prognose. Sie möchten Ihre Durchlaufzeit prognostizieren und eine probabilistische Durchlaufzeitprognose haben.
Angenommen, Ihre Durchlaufzeit kann in die Fertigungsdurchlaufzeit und die Transportdurchlaufzeit zerlegt werden. In der Realität haben Sie höchstwahrscheinlich eine probabilistische Prognose für die Fertigungsdurchlaufzeit, die eine diskrete Zufallsvariable ist und Ihnen die Wahrscheinlichkeit gibt, eine Zeit von einem Tag, zwei Tagen, drei Tagen, vier Tagen usw. zu beobachten. Sie können es sich als ein großes Histogramm vorstellen, das Ihnen die Wahrscheinlichkeiten gibt, diese Dauer für die Fertigungsdurchlaufzeit zu beobachten. Dann werden Sie einen ähnlichen Prozess für die Transportdurchlaufzeit haben, mit einer anderen diskreten Zufallsvariable, die eine probabilistische Prognose liefert.
Nun möchten Sie die Gesamtdurchlaufzeit berechnen. Wenn die prognostizierten Durchlaufzeiten Zahlen wären, würden Sie einfach eine einfache Addition durchführen. Die beiden prognostizierten Durchlaufzeiten sind jedoch keine Zahlen; es handelt sich um Wahrscheinlichkeitsverteilungen. Daher müssen wir diese beiden Wahrscheinlichkeitsverteilungen kombinieren, um eine dritte Wahrscheinlichkeitsverteilung zu erhalten, die die Wahrscheinlichkeitsverteilung für die Gesamtdurchlaufzeit ist. Es stellt sich heraus, dass, wenn wir die Annahme machen, dass die beiden Durchlaufzeiten, Fertigungsdurchlaufzeit und Transportdurchlaufzeit, unabhängig voneinander sind, die Operation, die wir durchführen können, um diese Addition von Zufallsvariablen durchzuführen, eine eindimensionale Faltung ist. Es mag komplex klingen, ist aber eigentlich nicht so komplex. Was ich implementiert habe und was Sie auf dem Bildschirm sehen können, ist die Implementierung einer eindimensionalen Faltung zwischen einem Vektor, der das Histogramm für die Wahrscheinlichkeiten der Fertigungsdurchlaufzeit (A) darstellt, und dem Histogramm, das mit den Wahrscheinlichkeiten der Transportdurchlaufzeit (B) verbunden ist. Das Ergebnis ist die Gesamtzeit, die die Summe dieser probabilistischen Durchlaufzeiten ist. Wenn Sie die Tensor Comprehension-Notation verwenden, kann dies in einem sehr kompakten, einzeiligen Algorithmus geschrieben werden.
Nun, wenn wir zur Big-O-Notation zurückkehren, die ich zu Beginn dieses Vortrags eingeführt habe, sehen wir, dass wir grundsätzlich einen quadratischen Algorithmus haben. Es ist Big O von N^2, wobei N die charakteristische Größe der Arrays für A und B ist. Wie ich bereits erwähnt habe, ist eine quadratische Leistung ein optimaler Punkt für Vorhersageprobleme. Also, was können wir tun, um dieses Problem anzugehen? Zunächst müssen wir berücksichtigen, dass dies ein Supply-Chain-Problem ist und wir das Gesetz der kleinen Zahlen zu unserem Vorteil nutzen können. Wie wir in dem vorherigen Vortrag besprochen haben, geht es bei Supply Chains hauptsächlich um kleine Zahlen. Wenn wir uns Lieferzeiten ansehen, können wir vernünftigerweise davon ausgehen, dass diese Lieferzeiten kleiner sein werden als zum Beispiel 400 Tage. Das ist bereits eine ziemlich lange Zeit für dieses Histogramm der Wahrscheinlichkeit.
Also, was bleibt uns übrig ist ein Big O von N^2, aber mit N kleiner als 400. 400 kann ziemlich groß sein, da 400 mal 400 160.000 ergibt. Das ist eine signifikante Zahl, und denken Sie daran, dass das Hinzufügen zu dieser Wahrscheinlichkeitsverteilung eine sehr grundlegende Operation ist. Sobald wir mit probabilistischer Prognose beginnen, möchten wir unsere Prognosen auf verschiedene Weise kombinieren, und höchstwahrscheinlich werden wir Millionen dieser Faltungen durchführen, einfach weil diese Faltungen letztendlich nichts anderes als glorifizierte Additionen im Bereich der Zufallsvariablen sind. Daher ist es auch dann, wenn wir N auf kleiner als 400 begrenzt haben, von großem Interesse, Hardwarebeschleunigung einzusetzen, und genau das können wir mit Tensorverständnis erreichen.
Das Wichtigste, woran man sich erinnern sollte, ist, dass Sie, sobald Sie diesen Algorithmus schreiben können, das Wissen über die Konzepte der Supply Chain nutzen möchten, um die anwendbaren Annahmen zu klären, und dann die Werkzeuge nutzen möchten, die Sie haben, um Hardwarebeschleunigung zu erreichen.

Nun wollen wir Meta-Techniken besprechen. Meta-Techniken sind von großem Interesse, weil sie auf bestehende Algorithmen aufgesetzt werden können, und daher besteht die Möglichkeit, dass Sie eine dieser Meta-Techniken verwenden können, um die Leistung zu verbessern. Der erste Schlüsselerkenntnis ist die Kompression, einfach weil kleinere Daten eine schnellere Verarbeitung bedeuten. Wie wir in dem vorherigen Vortrag gesehen haben, haben wir keinen gleichmäßigen Speicherzugriff. Wenn Sie auf mehr Daten zugreifen möchten, müssen Sie auf verschiedene Arten von physischem Speicher zugreifen, und je größer der Speicher wird, desto ineffizienter wird er. Der L1-Cache im Prozessor ist sehr klein, etwa 64 Kilobyte, aber er ist sehr schnell. Der RAM oder der Hauptspeicher ist mehrere hundert Mal langsamer als dieser kleine Cache, aber Sie können buchstäblich ein Terabyte RAM haben. Daher ist es von großem Interesse sicherzustellen, dass Ihre Daten so klein wie möglich sind, da dies Ihre Algorithmen fast immer schneller ausführen lässt. Es gibt eine Reihe von Tricks, die Sie in diesem Zusammenhang verwenden können.
Zunächst können Sie Ihre Daten aufräumen und ordnen. Dies ist der Bereich der Unternehmenssoftware. Wenn Sie einen Algorithmus haben, der gegen Daten läuft, gibt es oft viele ungenutzte Daten, die nicht zur Lösung des Interesses beitragen. Es ist wichtig sicherzustellen, dass Sie nicht mit Daten enden, die von Interesse sind und mit Daten vermischt sind, die ignoriert werden.
Die zweite Idee ist die Bit-Packing. Es gibt viele Situationen, in denen Sie einige Flags in andere Elemente, wie zum Beispiel Zeiger, packen können. Sie könnten einen 64-Bit-Zeiger haben, aber es ist sehr selten, dass Sie tatsächlich einen 64-Bit-Adressbereich in vollem Umfang benötigen. Sie können ein paar Bits Ihres Zeigers opfern, um einige Flags einzufügen, was es Ihnen ermöglicht, Ihre Daten mit fast keiner Einbuße an Leistung zu minimieren.
Außerdem können Sie Ihre Genauigkeit anpassen. Benötigen Sie in der Supply Chain 64 Bit Fließkommagenauigkeit? Es ist sehr selten, dass Sie diese Genauigkeit tatsächlich benötigen. In der Regel reichen 32 Bit Genauigkeit aus, und es gibt sogar viele Situationen, in denen 16 Bit Genauigkeit ausreicht. Sie könnten denken, dass die Reduzierung der Genauigkeit nicht signifikant ist, aber häufig, wenn Sie die Größe der Daten um den Faktor zwei teilen können, beschleunigen Sie Ihren Algorithmus nicht nur um den Faktor 2, sondern tatsächlich um den Faktor 10. Das Verpacken der Daten führt zu völlig nichtlinearen Vorteilen in Bezug auf die Ausführungsgeschwindigkeit.
Schließlich haben Sie die Entropie-Codierung, die im Wesentlichen Kompression ist. Sie möchten jedoch nicht unbedingt Algorithmen verwenden, die so effizient komprimieren wie beispielsweise der Algorithmus, der für ein ZIP-Archiv verwendet wird. Sie möchten etwas, das möglicherweise etwas weniger effizient in Bezug auf die Kompression ist, aber viel schneller in der Ausführung.
L8 Die Kompression dreht sich im Wesentlichen um die Idee, dass Sie etwas zusätzliche CPU-Nutzung gegen den Druck auf den Speicher eintauschen können, und in fast allen Situationen ist dies der interessante Trick.
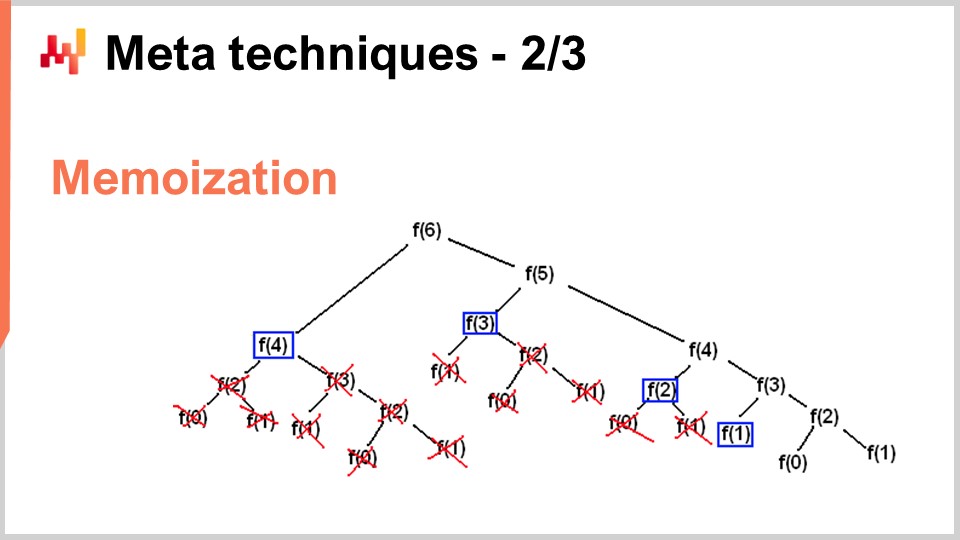
Es gibt jedoch Situationen, in denen Sie das genaue Gegenteil tun möchten - Speicher gegen eine erhebliche Reduzierung des CPU-Verbrauchs eintauschen. Genau das machen Sie mit dem Memoization-Trick. Memoization ist im Wesentlichen die Idee, dass, wenn eine Funktion während der Ausführung Ihrer Lösung häufig aufgerufen wird und dieselbe Funktion mit denselben Eingaben aufgerufen wird, Sie die Funktion nicht erneut berechnen müssen. Sie können das Ergebnis aufzeichnen, beiseite legen (zum Beispiel in einer Hashtabelle) und wenn Sie dieselbe Funktion erneut aufrufen, können Sie überprüfen, ob die Hashtabelle bereits einen Schlüssel mit dem Eingabeobjekt enthält oder ob die Hashtabelle bereits das Ergebnis enthält, weil es vorberechnet wurde. Wenn die Funktion, die Sie memoisieren, sehr teuer ist, können Sie eine massive Geschwindigkeitssteigerung erzielen. Wo es sehr interessant wird, ist, wenn Sie Memoization nicht mit dem Hauptspeicher verwenden, wie wir in der vorherigen Vorlesung gesehen haben, DRAM ist sehr teuer. Es wird sehr interessant, wenn Sie Ihre Ergebnisse auf Festplatte oder SSDs ablegen, die billig und reichlich vorhanden sind. Die Idee besteht darin, SSDs gegen eine Reduzierung des CPU-Drucks einzutauschen, was in gewisser Weise das genaue Gegenteil der gerade beschriebenen Kompression ist.
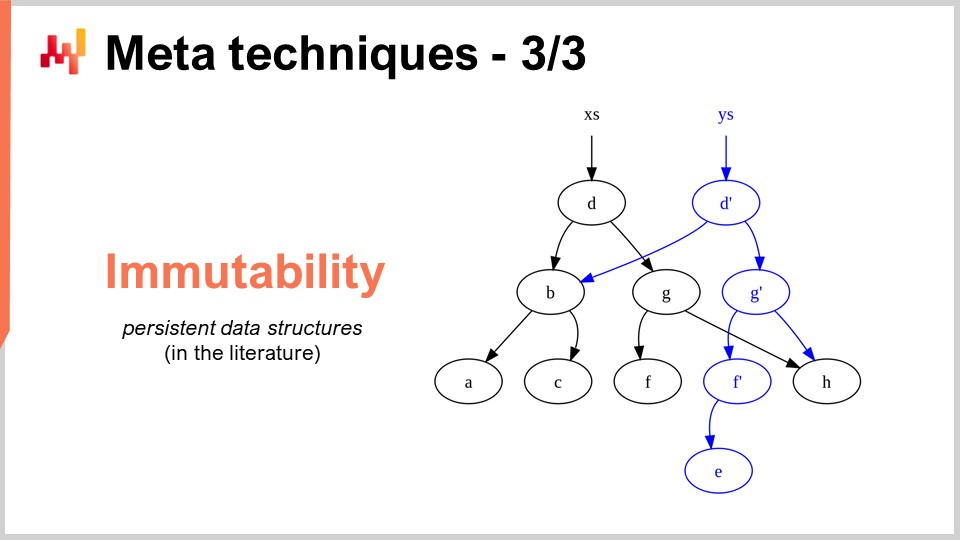
Die letzte Meta-Technik ist Unveränderlichkeit. Unveränderliche Datenstrukturen sind im Wesentlichen Datenstrukturen, die niemals geändert werden. Die Idee besteht darin, Änderungen oben aufzuschichten. Zum Beispiel, mit einer unveränderlichen Hashtabelle, wenn Sie ein Element hinzufügen, was Sie zurückgeben werden, ist eine neue Hashtabelle, die alles in der alten Hashtabelle plus das neue Element enthält. Der sehr naive Weg, dies zu tun, besteht darin, eine vollständige Kopie der Datenstruktur zu erstellen und die gesamte Kopie zurückzugeben; dies ist jedoch sehr ineffizient. Der Schlüsselgedanke bei unveränderlichen Datenstrukturen ist, dass Sie beim Ändern der Datenstruktur eine neue Datenstruktur zurückgeben, die nur die Änderung implementiert, aber diese neue Datenstruktur alle Teile der alten Datenstruktur wiederverwendet, die nicht berührt wurden.
Fast alle klassischen Datenstrukturen wie Listen, Bäume, Graphen und Hashtabellen haben ihre unveränderlichen Gegenstücke. In vielen Situationen ist es sehr interessant, diese zu verwenden. Übrigens gibt es moderne Programmiersprachen, die vollständig auf Unveränderlichkeit setzen, wie zum Beispiel Clojure, für diejenigen von Ihnen, die mit dieser Programmiersprache vertraut sein könnten.
Warum ist das so interessant? Erstens vereinfacht es die Parallelisierung von Algorithmen massiv. Wie wir in der vorherigen Vorlesung gesehen haben, ist es nicht möglich, einen Prozessor zu finden, der mit 100 GHz für allgemeine Desktop-Computerprozessoren läuft. Was Sie jedoch finden können, ist eine Maschine mit 50 Kernen, von denen jeder mit 2 GHz läuft. Wenn Sie von diesen vielen Kernen profitieren möchten, müssen Sie Ihre Ausführung parallelisieren, und dann besteht Ihr Parallelisierungsrisiko aus sehr unangenehmen Fehlern, die Rennbedingungen genannt werden. Es wird sehr schwierig zu verstehen, ob der von Ihnen geschriebene Algorithmus korrekt ist oder nicht, weil Sie verschiedene Prozessoren haben können, die gleichzeitig versuchen, auf dasselbe Speicherstück im Computer zu schreiben.
Wenn Sie jedoch unveränderliche Datenstrukturen haben, passiert dies aus Designgründen nie, einfach weil, sobald eine Datenstruktur präsentiert wird, sie sich nie ändern wird - es wird nur eine neue Datenstruktur entstehen. Auf diese Weise können Sie mit dem unveränderlichen Ansatz eine massive Leistungssteigerung erzielen, einfach weil Sie parallele Versionen Ihrer Algorithmen leichter implementieren können. Denken Sie daran, dass in der Regel der Engpass für die Implementierung von algorithmischen Geschwindigkeitssteigerungen die Zeit ist, die benötigt wird, um die Algorithmen tatsächlich zu implementieren. Wenn Sie etwas haben, das es Ihnen ermöglicht, eine Art furchtloses Nebenläufigkeitsprinzip anzuwenden, können Sie tatsächlich viel schneller algorithmische Geschwindigkeitssteigerungen einführen, mit weniger Ressourcen in Bezug auf die Anzahl der beteiligten Programmierer. Ein weiterer wichtiger Vorteil unveränderlicher Datenstrukturen besteht darin, dass sie das Debuggen erheblich erleichtern. Wenn Sie eine Datenstruktur destruktiv ändern und auf einen Fehler stoßen, kann es sehr schwierig sein, herauszufinden, wie Sie dorthin gelangt sind. Mit einem Debugger kann es eine ziemlich unangenehme Erfahrung sein, das Problem zu lokalisieren. Das Interessante an unveränderlichen Datenstrukturen ist, dass Änderungen nicht destruktiv sind, sodass Sie die vorherige Version Ihrer Datenstruktur sehen können und leichter erfassen können, wie Sie zu dem Punkt gelangt sind, an dem Sie auf ein falsches Verhalten stoßen.

Abschließend können bessere Algorithmen sich wie Superkräfte anfühlen. Mit besseren Algorithmen erhalten Sie mehr von derselben Rechenhardware, und diese Vorteile sind unbegrenzt. Es ist eine einmalige Anstrengung, und dann haben Sie einen unbegrenzten Vorteil, weil Sie Zugang zu überlegenen Rechenfähigkeiten haben, wenn Sie dieselbe Menge an Rechenressourcen für ein bestimmtes interessantes Supply-Chain-Problem verwenden. Ich glaube, dass diese Perspektive Möglichkeiten für massive Verbesserungen im Supply-Chain-Management bietet.
Wenn wir uns ein völlig anderes Gebiet wie Videospiele ansehen, haben sie ihre eigenen algorithmischen Traditionen und Erkenntnisse etabliert, die dem Spielerlebnis gewidmet sind. Die atemberaubende Grafik, die Sie bei modernen Videospielen erleben, ist das Ergebnis einer Community, die Jahrzehnte damit verbracht hat, den gesamten Algorithmus-Stack neu zu überdenken, um die Qualität des Spielerlebnisses zu maximieren. Die Perspektive im Gaming besteht nicht darin, ein 3D-Modell zu haben, das aus physikalischer oder wissenschaftlicher Sicht korrekt ist, sondern die wahrgenommene Qualität in Bezug auf das grafische Erlebnis für den Spieler zu maximieren, und sie haben Algorithmen feinabgestimmt, um atemberaubende Ergebnisse zu erzielen.
Ich glaube, dass diese Art von Arbeit für Supply Chains kaum begonnen hat. Enterprise Supply Chain Software ist festgefahren, und meiner eigenen Wahrnehmung nach nutzen wir noch nicht einmal 1% dessen, was moderne Rechenhardware für uns tun kann. Die meisten Möglichkeiten liegen noch vor uns und können durch Algorithmen erfasst werden, nicht nur durch Supply-Chain-Algorithmen wie Fahrzeugrouten-Algorithmen, sondern auch durch die Überarbeitung klassischer Algorithmen aus einer Supply-Chain-Perspektive, um massive Geschwindigkeitssteigerungen auf dem Weg zu erreichen.

Nun werde ich mir die Fragen ansehen.
Frage: Sie haben über die spezifischen Merkmale der Supply Chain gesprochen, wie kleine Zahlen. Wenn wir im Voraus wissen, dass wir nur kleine Zahlen für unsere potenziellen Entscheidungen haben, welche Art von Vereinfachung bringt dies mit sich? Zum Beispiel, wenn wir wissen, dass wir höchstens einen oder zwei Container bestellen können, können Sie sich konkrete Beispiele dafür vorstellen, wie dies das Granularitätsniveau der ganzheitlichen Prognosen beeinflussen würde, die zur Berechnung der Lagerprämienfunktion verwendet werden?
Zunächst einmal ist alles, was ich heute präsentiert habe, bei Lokad in Produktion. All diese Erkenntnisse sind auf die Supply Chain anwendbar, weil sie bei Lokad in Produktion sind. Sie müssen sich darüber im Klaren sein, dass das, was Sie von moderner Software erhalten, nicht darauf abgestimmt ist, das Beste aus der Rechenhardware herauszuholen. Denken Sie nur daran, dass wir heutzutage Computer haben, die tausendmal leistungsfähiger sind als Computer vor einigen Jahrzehnten. Laufen sie tausendmal schneller? Nein. Können sie Probleme lösen, die fantastisch komplizierter sind als vor einigen Jahrzehnten? Nein. Unterschätzen Sie also nicht die Tatsache, dass es sehr große Verbesserungspotenziale gibt.
Das Bucket-Sortierverfahren, das ich in diesem Vortrag vorgestellt habe, ist ein einfaches Beispiel. In der Supply Chain gibt es überall Sortiervorgänge, und meines Wissens gibt es sehr selten Unternehmenssoftware, die spezialisierte Algorithmen nutzt, die gut zu Supply-Chain-Situationen passen. Nun, wenn wir wissen, dass wir einen oder zwei Container haben, nutzen wir diese Elemente bei Lokad? Ja, wir tun dies die ganze Zeit, und es gibt viele Tricks, die auf dieser Ebene umgesetzt werden können.
Die Tricks befinden sich normalerweise auf einer niedrigeren Ebene, und die Vorteile werden sich auf die Gesamtlösung auswirken. Sie müssen darüber nachdenken, Containerfüllprobleme in all ihre Teile zu zerlegen. Sie können Vorteile erzielen, indem Sie die Ideen und Tricks anwenden, die ich heute vorgestellt habe, auf einer niedrigeren Ebene.
Zum Beispiel, welche Art von numerischer Genauigkeit benötigen Sie, wenn es um Container geht? Vielleicht reichen 16-Bit-Zahlen mit nur 16 Bits Genauigkeit aus. Das macht die Daten kleiner. Wie viele verschiedene Produkte bestellen wir? Vielleicht bestellen wir nur ein paar tausend verschiedene Produkte, sodass wir den Bucket-Sortieralgorithmus verwenden können. Die Wahrscheinlichkeitsverteilung ist eine niedrigere, kleinere Zahl, sodass wir theoretisch Histogramme haben können, die von null Einheiten, einer Einheit, drei Einheiten bis unendlich reichen, aber gehen wir bis unendlich? Nein, das tun wir nicht. Vielleicht können wir einige kluge Annahmen darüber treffen, dass es sehr selten vorkommt, dass wir ein Histogramm haben, bei dem wir 1.000 Einheiten überschreiten. Wenn wir das haben, können wir approximieren. Wir müssen nicht unbedingt eine Genauigkeit von 2 Einheiten haben, wenn wir es mit einem Container zu tun haben, der 1.000 Einheiten enthält. Wir können approximieren und ein Histogramm mit größeren Buckets und solchen Dingen haben. Es geht nicht so sehr darum, algorithmische Prinzipien wie Tensor-Komprehension einzuführen, die unglaublich sind, weil sie alles auf eine sehr coole Weise vereinfachen. Die meisten algorithmischen Geschwindigkeitssteigerungen führen am Ende zu einem schnelleren, aber etwas komplizierteren Algorithmus. Es ist nicht unbedingt einfacher, weil der einfachste Algorithmus in der Regel auch ineffizient ist. Ein geeigneterer Algorithmus für einen Fall könnte etwas länger zu schreiben und komplexer sein, aber am Ende wird er schneller ausgeführt. Dies ist nicht immer der Fall, wie wir bei den magischen Rezepten gesehen haben, aber ich wollte zeigen, dass wir die grundlegenden Bausteine dessen, was wir tun, überdenken müssen, um tatsächlich Unternehmenssoftware zu entwickeln.
Frage: Wie weit sind diese Erkenntnisse in ERP-Anbietern, APS und Best-of-Breeds wie GTA implementiert?
Das Interessante ist, dass diese Erkenntnisse grundlegend, die meisten von ihnen, mit transaktionaler Software unvereinbar sind. Die meisten Unternehmenssoftwarelösungen basieren auf einer Kernkomponente, die eine transaktionale Datenbank ist, und alles wird durch die Datenbank geleitet. Diese Datenbank ist keine spezifische Supply-Chain-Datenbank; es handelt sich um eine generische Datenbank, die in der Lage sein soll, mit allen möglichen Situationen umzugehen, von Finanzen über wissenschaftliches Rechnen bis hin zu medizinischen Aufzeichnungen und mehr.
Das Problem besteht darin, dass die vorgeschlagene Software, die Sie sich ansehen, einen transaktionalen Datenbankkern hat, dann können die von mir vorgeschlagenen Erkenntnisse aus Designgründen nicht implementiert werden. Es ist sozusagen Game Over. Wie viele Videospiele basieren auf einer transaktionalen Datenbank? Die Antwort lautet null. Warum? Weil Sie keine gute Grafikleistung auf einer transaktionalen Datenbank implementieren können. Sie können keine Computergrafik in einer transaktionalen Datenbank machen.
Eine transaktionale Datenbank ist sehr schön; sie gibt Ihnen Transaktionalität, aber sie sperrt Sie in eine Welt ein, in der nahezu alle algorithmischen Geschwindigkeitssteigerungen, die Sie sich vorstellen können, nicht angewendet werden können. Ich glaube, wenn wir über APS nachdenken, gibt es nichts Fortgeschrittenes an diesen Systemen. Sie sind seit Jahrzehnten in der Vergangenheit stecken geblieben, und sie sind stecken geblieben, weil sie im Kern ihres Designs komplett um eine transaktionale Datenbank herum konzipiert sind, die sie daran hindert, irgendwelche der Erkenntnisse anzuwenden, die in den letzten wahrscheinlich vier Jahrzehnten aus dem Bereich der Algorithmen hervorgegangen sind.
Das ist der Kern des Problems im Bereich der Unternehmenssoftware. Die Designentscheidungen, die Sie im ersten Monat der Gestaltung Ihres Produkts treffen, werden Sie im Grunde genommen für Jahrzehnte verfolgen, bis zum Ende der Zeit. Sie können nicht aktualisieren, sobald Sie sich für ein bestimmtes Design für Ihr Produkt entschieden haben; Sie stecken fest. Genauso wie Sie ein Auto nicht einfach zu einem Elektroauto umgestalten können, wenn Sie ein sehr gutes Elektroauto haben möchten, werden Sie das Auto komplett um die Idee herum umgestalten, dass der Antriebsmotor elektrisch sein wird. Es geht nicht nur darum, den Motor auszutauschen und zu sagen: “Hier ist ein Elektroauto.” Es funktioniert nicht so. Dies ist einer dieser grundlegenden Designprinzipien, bei dem Sie, sobald Sie sich dazu verpflichtet haben, ein Elektroauto herzustellen, alles um den Motor herum überdenken müssen, damit es gut passt. Leider können ERPs und APS, die sehr datenbankzentriert sind, keine dieser Erkenntnisse nutzen, fürchte ich. Es ist immer möglich, eine isolierte Blase zu haben, in der Sie von diesen Tricks profitieren, aber es wird ein aufgesetztes Add-On sein; es wird nie zum Kern vordringen.
In Bezug auf die beeindruckenden Fähigkeiten von Blue Yonder bitte ich um Verständnis, da Lokad ein direkter Konkurrent von Blue Yonder ist, und es ist für mich schwierig, völlig unvoreingenommen zu sein. Auf dem Markt für Unternehmenssoftware müssen Sie lächerlich kühne Behauptungen aufstellen, um wettbewerbsfähig zu bleiben. Ich bin nicht überzeugt, dass irgendeine dieser Behauptungen Substanz hat. Ich hinterfrage die Annahme, dass irgendjemand in diesem Markt irgendetwas hat, das als beeindruckend qualifizieren würde.
Wenn Sie etwas Beeindruckendes und Ultra-Beeindruckendes sehen wollen, schauen Sie sich die neueste Demo für die Unreal Engine oder spezialisierte Videospielalgorithmen an. Betrachten Sie die Computergrafik auf der Hardware der nächsten Generation der PlayStation 5; sie ist absolut beeindruckend. Haben wir etwas in derselben Größenordnung an technologischer Leistung im Bereich der Unternehmenssoftware? Was Lokad betrifft, habe ich eine super voreingenommene Meinung, aber wenn ich den Markt allgemeiner betrachte, sehe ich ein Meer von Menschen, die seit Jahrzehnten versuchen, relationale Datenbanken maximal auszureizen. Manchmal bringen sie andere Arten von Datenbanken, wie Graphdatenbanken, aber das verfehlt völlig den Kern der von mir präsentierten Erkenntnisse. Es liefert nichts Substanzielles, um Wert für die Welt der Supply Chain zu liefern.
Die Kernbotschaft hier für das Publikum ist, dass es eine Frage des Designs ist. Wir müssen sicherstellen, dass die anfänglichen Entscheidungen, die in das Design Ihrer Unternehmenssoftware eingeflossen sind, nicht die Art von Dingen sind, die diese Technikenklassen von vornherein verhindern würden.
Die nächste Vorlesung findet in drei Wochen statt, am Mittwoch um 15 Uhr Pariser Zeit. Es wird der 13. Juni sein, und wir werden das dritte Kapitel noch einmal besprechen, das sich mit Supply-Chain-Personal, überraschenden Persönlichkeitsmerkmalen und fiktiven Unternehmen befasst. Nächstes Mal werden wir über Käse sprechen. Bis dann!


