00:19 Введение
04:33 Два определения ‘алгоритма’
08:09 Big-O
13:10 История до настоящего момента
15:11 Вспомогательные науки (резюме)
17:26 Современные алгоритмы
19:36 Превосходство над “оптимальностью”
22:23 Структуры данных - 1/4 - Список
25:50 Структуры данных - 2/4 - Дерево
27:39 Структуры данных - 3/4 - Граф
29:55 Структуры данных - 4/4 - Хеш-таблица
31:30 Волшебные рецепты - 1/2
37:06 Волшебные рецепты - 2/2
39:17 Понимание тензоров - 1/3 - Нотация «Эйнштейна»
42:53 Понимание тензоров - 2/3 - Прорыв команды Facebook
46:52 Понимание тензоров - 3/3 - С точки зрения цепочки поставок
52:20 Мета-техники - 1/3 - Сжатие
56:11 Мета-техники - 2/3 - Мемоизация
58:44 Мета-техники - 3/3 - неизменяемость
01:03:46 Заключение
01:06:41 Предстоящая лекция и вопросы аудитории
Описание
Оптимизация цепочек поставок зависит от решения многочисленных числовых задач. Алгоритмы — это строго кодифицированные числовые рецепты, предназначенные для решения конкретных вычислительных проблем. Превосходные алгоритмы означают, что можно добиться выдающихся результатов с использованием меньших вычислительных ресурсов. Сосредоточившись на особенностях цепочки поставок, эффективность алгоритмов может быть значительно улучшена, иногда в разы. Алгоритмы «цепочки поставок» также должны учитывать конструкцию современных компьютеров, которая значительно эволюционировала за последние несколько десятилетий.
Полная стенограмма

Добро пожаловать в эту серию лекций о цепочках поставок. Я — Жоаннес Верморель, и сегодня я представлю «Современные алгоритмы для цепочки поставок». Выдающиеся вычислительные возможности играют ключевую роль в достижении превосходной эффективности цепочек поставок. Более точные прогнозы, более детальная оптимизация и более частая оптимизация — всё это необходимо для достижения превосходной эффективности цепочки поставок. Всегда существует превосходный числовой метод, чуть превосходящий те вычислительные ресурсы, которые вы можете себе позволить.
Проще говоря, алгоритмы ускоряют работу компьютеров. Алгоритмы — это отрасль математики, и данная область исследований развивается очень активно. Прорыв в этой области часто опережает развитие самой вычислительной техники. Цель этой лекции — понять суть современных алгоритмов и, особенно с точки зрения цепочки поставок, как подходить к решению задач, чтобы максимально эффективно использовать современные алгоритмы для вашей цепочки поставок.

Что касается алгоритмов, существует одна книга, являющаяся абсолютным авторитетом: “Introduction to Algorithms”, впервые изданная в 1990 году. Это must-read книга. Качество изложения и стиля написания просто на высшем уровне. За первые 20 лет жизни книга была продана тиражом более полумиллиона экземпляров и вдохновила целое поколение академических авторов. Более того, большинство современных книг по теории цепочек поставок, опубликованных за последнее десятилетие, часто были сильно вдохновлены стилем и подачей, найденными в этой книге.
Лично я прочитал эту книгу еще в 1997 году, и это был, собственно, французский перевод первого издания. Она оказала глубокое влияние на всю мою карьеру. После прочтения этой книги я уже больше не воспринимал программное обеспечение так, как раньше. Однако предупреждаю: эта книга принимает точку зрения на вычислительную технику, которая была распространена в конце 80-х и начале 90-х годов. Как мы видели в предыдущих лекциях этой серии, вычислительная техника прогрессировала довольно драматично за последние несколько десятилетий, и поэтому некоторые предположения, сделанные в этой книге, кажутся относительно устаревшими. Например, в книге предполагается, что доступ к памяти занимает постоянное время, независимо от объема адресуемой памяти. Это уже не соответствует работе современных компьютеров.
Тем не менее, я считаю, что существуют ситуации, в которых упрощенность является разумным выбором, если в обмен вы получаете гораздо большую ясность и простоту изложения. Эта книга справляется с этим очень хорошо. Хотя я советую помнить, что некоторые из ключевых предположений, сделанных в книге, устарели, она по-прежнему остается абсолютным авторитетом, который я рекомендовал бы всей аудитории.

Давайте проясним термин «алгоритм» для аудитории, которая может быть не совсем знакома с этим понятием. Существует классическое определение, согласно которому алгоритм — это конечная последовательность четко определенных команд для компьютера. Такое определение вы найдете в учебниках или на Википедии. Хотя классическое определение алгоритма имеет свои достоинства, я считаю его недостаточным, поскольку оно не раскрывает намерения, связанного с алгоритмами. Интерес представляют не любые последовательности команд, а очень конкретные последовательности компьютерных инструкций. Таким образом, я предлагаю собственное определение термина алгоритм: алгоритм — это, по сути, ориентированный на производительность, мелкозернистый метод программного решения проблемы.
Давайте разберем это определение подробнее, не так ли? Во-первых, часть, касающаяся решения проблемы: алгоритм полностью определяется проблемой, которую он пытается решить. На этом слайде вы видите псевдокод алгоритма быстрой сортировки (Quicksort), который является популярным и широко известным алгоритмом. Quicksort пытается решить задачу сортировки, которая заключается в следующем: у вас есть массив с данными, и вам нужен алгоритм, который вернет тот же массив, но с элементами, отсортированными по возрастанию. Алгоритмы фокусируются исключительно на конкретной и четко определенной проблеме.
Второй аспект — это критерий, по которому можно судить, что алгоритм лучше. Лучший алгоритм позволяет решать ту же задачу, используя меньше вычислительных ресурсов, что на практике означает большую скорость. Наконец, имеется в виду детализированность. Когда мы говорим об «алгоритмах», подразумевается, что мы хотим рассматривать элементарные задачи, которые являются модульными и могут быть бесконечно комбинируемыми для решения гораздо более сложных проблем. Именно этим и являются алгоритмы.
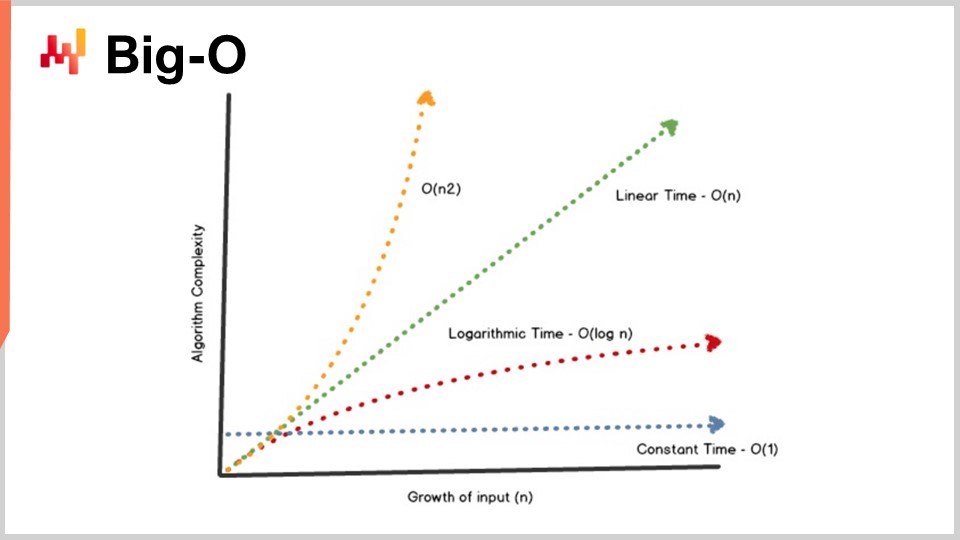
Одним из ключевых достижений теории алгоритмов является предоставление характеристики их производительности в довольно абстрактной форме. Сегодня у меня не будет времени вдаваться в подробности этого определения и математической основы. Идея в том, что для характеристики алгоритма мы рассматриваем его асимптотическое поведение. Задача зависит от одной или нескольких ключевых ограничивающих сложностей, характеризующих проблему. Например, в задаче сортировки, которую я представил ранее, ключевым параметром обычно является число элементов, которые нужно отсортировать. Вопрос в том, что происходит, когда массив элементов для сортировки становится очень большим? Я буду обозначать этот параметр буквой “n” по договоренности.
Итак, у меня есть такое обозначение — нотация Big O, с которым вы, возможно, сталкивались при работе с алгоритмами. Я просто кратко опишу несколько моментов, чтобы дать вам интуицию того, как это работает. Во-первых, допустим, у нас есть набор данных, и мы хотим извлечь простой статистический индикатор, например, среднее значение. Если я говорю, что у меня есть алгоритм с Big O(1), это означает, что я могу получить решение этой задачи (вычисление среднего) за постоянное время, независимо от того, мал набор данных или велик. Постоянное время, или Big O(1), является абсолютным требованием, когда вы хотите осуществлять задачи в режиме реального времени в смысле машинной связи. Если у вас нет алгоритма с постоянным временем, очень сложно, а иногда и невозможно добиться производительности в реальном времени.
Обычно еще одним важным показателем производительности является Big O(N). Big O(N) означает, что сложность алгоритма растет строго линейно в зависимости от размера набора данных. Это достигается при эффективной реализации, при которой проблему можно решить, просто один или несколько раз пройдясь по данным. Сложность Big O(N) обычно совместима только с пакетной обработкой. Если вам необходимо работать в режиме онлайн и в реальном времени, вы не можете допускать, чтобы алгоритм проходил через весь набор данных, если только вы не знаете, что размер набора данных фиксирован.
Помимо линейной сложности, существует Big O(N²). Big O(N²) — очень интересный случай, поскольку это область, где возникает проблемный взрыв в производстве. Это означает, что сложность растет квадратично в зависимости от размера набора данных, то есть если данных в 10 раз больше, производительность ухудшится в 100 раз. Такая производительность, как правило, не вызывает проблем на стадии прототипа, поскольку вы работаете с небольшими наборами данных. Проблемы могут не проявляться и на этапе тестирования, так как, опять же, вы работаете с малыми наборами данных. Однако как только вы переходите в продакшн, программное обеспечение становится крайне медленным. Очень часто в мире корпоративного ПО, особенно в секторе корпоративного программного обеспечения для цепочек поставок, большинство критически плохих проблем с производительностью, наблюдаемых в реальных условиях, на самом деле вызваны квадратичными алгоритмами, которые не были выявлены. В результате вы наблюдаете квадратичное поведение, которое просто невероятно медленное. Эта проблема не была обнаружена на ранней стадии, так как современные компьютеры достаточно быстры, и N² не так уж плохо, пока N довольно мало. Однако, когда вы работаете с большим набором данных производственного масштаба, это становится огромной проблемой.
Эта лекция на самом деле является второй лекцией моего четвертого раздела в этой серии лекций о цепочках поставок. В первом разделе, прологе, я представил свои взгляды на цепочку поставок как на область изучения, так и на практику. Мы увидели, что цепочка поставок — это большое собрание сложнейших проблем, а не простых задач. Сложные проблемы невозможно решить наивными методами, поскольку встречаются конфликтующие ситуации повсюду, и поэтому необходимо уделять большое внимание самой методологии. Большинство наивных методов терпят неудачу весьма эффектно. Именно это я и сделал во втором разделе, полностью посвященном методологиям, подходящим для изучения цепочек поставок и совершенствования практики управления ими. Третий раздел, который еще не завершен, по сути представляет собой детальный обзор того, что я называю “персоналом цепочки поставок” — очень специфической методологии, где мы сосредотачиваемся на проблемах, а не на решениях, которые можно предложить. В будущем я буду чередовать третий раздел с настоящим, который касается вспомогательных наук цепочки поставок.
На прошлой лекции мы увидели, что для нашей цепочки поставок можно получить больше вычислительных возможностей благодаря лучшему, более современному компьютерному оборудованию. Сегодня мы рассматриваем проблему под другим углом — мы ищем дополнительные вычислительные возможности благодаря лучшему программному обеспечению. Именно об этом и идут алгоритмы.

Краткое резюме: Вспомогательные науки — это, по сути, взгляд на саму цепочку поставок. Сегодняшняя лекция не столько о цепочке поставок, сколько об алгоритмах. Однако я считаю, что это имеет фундаментальное значение для цепочки поставок. Цепочка поставок не является изолированной; прогресс, которого можно добиться в этой области, во многом зависит от достижений, уже достигнутых в смежных областях. Я называю эти области вспомогательными науками цепочки поставок.
Я считаю, что ситуация довольно похожа на взаимоотношения между медицинскими науками и химией в 19-м веке. В самом начале 19-го века медицина вовсе не интересовалась химией. Химия была еще новичком и не считалась значимым для лечения пациентов. Перенесемся в 21-й век, и предположение, что можно быть отличным врачом, не зная ничего о химии, будет воспринято как совершенно абсурдное. Все согласны с тем, что быть отличным химиком не делает вас отличным врачом, но при этом общепризнано, что если вы ничего не знаете о химии организма, то вы никак не сможете быть компетентным с точки зрения современных медицинских наук. По моему мнению, в 21-м веке область цепочек поставок начнет воспринимать сферу алгоритмов примерно так же, как в 19-м веке медицина стала смотреть на химию.

Алгоритмы — это огромная область исследований, отрасль математики, и сегодня мы затронем только верхушку этого айсберга. В частности, за десятилетия в этой области накопилось множество поразительных результатов. Это может быть довольно теоретическая область исследований, но это не значит, что это всего лишь теория. На самом деле, это область, хотя и достаточно теоретическая, но в ней накоплено множество открытий, которые нашли применение в производстве.
Фактически, любой смартфон или компьютер, которые вы используете сегодня, буквально применяют десятки тысяч алгоритмов, первоначально опубликованных где-то. Этот послужной список на самом деле гораздо впечатляет по сравнению с теорией цепей поставок, где подавляющее большинство цепей поставок до сих пор не работают на основе выводов этой теории. Когда речь идёт о современных компьютерах и алгоритмах, практически всё, что связано с программным обеспечением, полностью определяется десятилетиями исследований в области алгоритмов. Это составляет суть практически каждого компьютера, которым мы пользуемся сегодня.
Для сегодняшней лекции я отобрал перечень тем, которые, по моему мнению, наглядно демонстрируют, что вам следует знать для освоения современных алгоритмов. Сначала мы обсудим, как можно превзойти якобы оптимальные алгоритмы, особенно для цепей поставок. Затем мы кратко рассмотрим структуры данных, после чего перейдём к волшебным рецептам, сжатию тензоров и, наконец, к метаподходам.
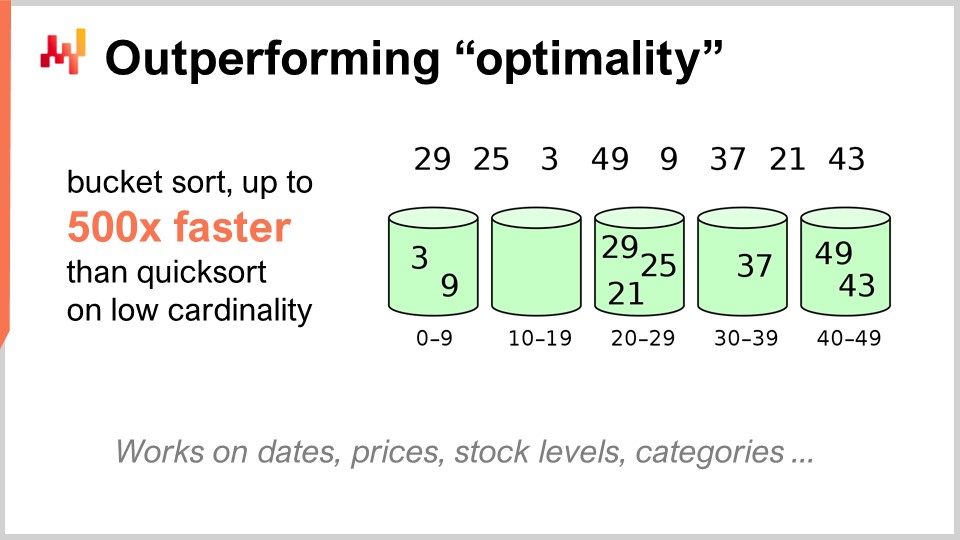
Прежде всего, я хотел бы пояснить, что когда я говорю «алгоритмы для цепей поставок», я не имею в виду алгоритмы, предназначенные для решения специфических задач цепей поставок. Правильный подход заключается в том, чтобы рассматривать классические алгоритмы для классических задач и переосмысливать эти задачи с позиции цепей поставок, чтобы понять, можем ли мы сделать что-то лучше. Ответ таков: да, можем.
Например, алгоритм быстрой сортировки, согласно общей теории алгоритмов, оптимален в том смысле, что нельзя предложить алгоритм, который бы имел произвольно лучшую производительность, чем быстрая сортировка. Таким образом, с этой точки зрения быстрая сортировка настолько хороша, насколько только возможно. Однако если мы сосредоточимся непосредственно на цепях поставок, можно добиться поразительного ускорения. В частности, если рассмотреть задачи сортировки, где кардинальность интересующих наборов данных невысока, например, даты, цены, уровни запасов или категории, то все они обладают низкой кардинальностью. Таким образом, если у вас есть дополнительные предположения, например, работа с данными низкой кардинальности, вы можете использовать сортировку по корзинам. В производственной практике существует множество ситуаций, где можно добиться поистине колоссального ускорения — вплоть до 500 раз быстрее, чем быстрая сортировка. Таким образом, вы можете работать на порядки величины быстрее того, что предположительно оптимально, просто потому что вы не в общем случае, а в случае цепей поставок. Это чрезвычайно важно, и, как мне кажется, именно здесь заключается суть ключевых поразительных результатов, которых мы можем достичь, используя алгоритмы для цепей поставок.
Я считаю, что эта точка зрения ошибочна, по крайней мере, по двум причинам. Во-первых, как мы видели, не обязательно стандартный алгоритм является тем, что представляет интерес. Мы увидели, что существует якобы оптимальный алгоритм, как быстрая сортировка, но если рассматривать ту же задачу с точки зрения цепей поставок, можно добиться колоссального ускорения. Поэтому знание алгоритмов имеет первостепенное значение, хотя бы для того, чтобы вернуться к классике и добиться значительного ускорения именно в случае цепей поставок, а не в общем случае.
Вторая причина, по которой я считаю данную точку зрения ошибочной, заключается в том, что алгоритмы во многом зависят от структур данных. Структуры данных представляют собой способы организации информации, позволяющие работать с ней более эффективно. Примечательно, что все эти структуры данных образуют своего рода словарь, доступ к которому необходим для описания ситуаций в цепях поставок таким образом, чтобы их можно было легко перевести в программное обеспечение. Если вы начинаете с описания на обыденном языке, то обычно получаются конструкции, которые чрезвычайно трудно реализовать в коде. Если вы рассчитываете, что программист, ничего не знающий о цепях поставок, сможет выполнить этот перевод, то это может обернуться проблемами. На самом деле гораздо проще, если вы знаете этот словарь, чтобы напрямую использовать термины, облегчающие перевод ваших идей в программное обеспечение.
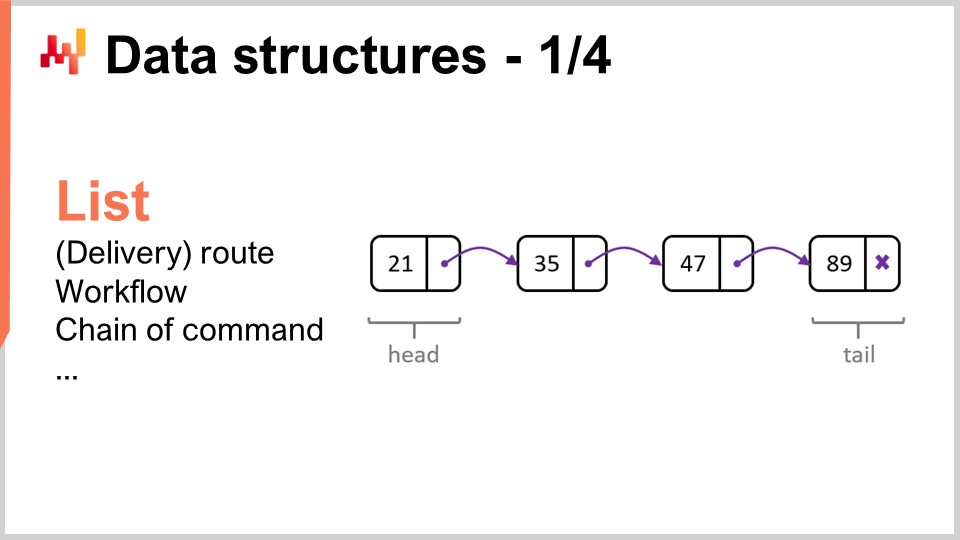
Давайте рассмотрим самые популярные и простейшие структуры данных. Первая — это список. Список можно использовать, например, для представления маршрута доставки, который представляет собой последовательность доставок, где каждая доставка занимает одну запись. Вы можете последовательно перебрать маршрут по мере его выполнения. Список также может представлять рабочий процесс, который является последовательностью операций, необходимых для изготовления определённого оборудования, или цепочку командования, определяющую, кто должен принимать те или иные решения.
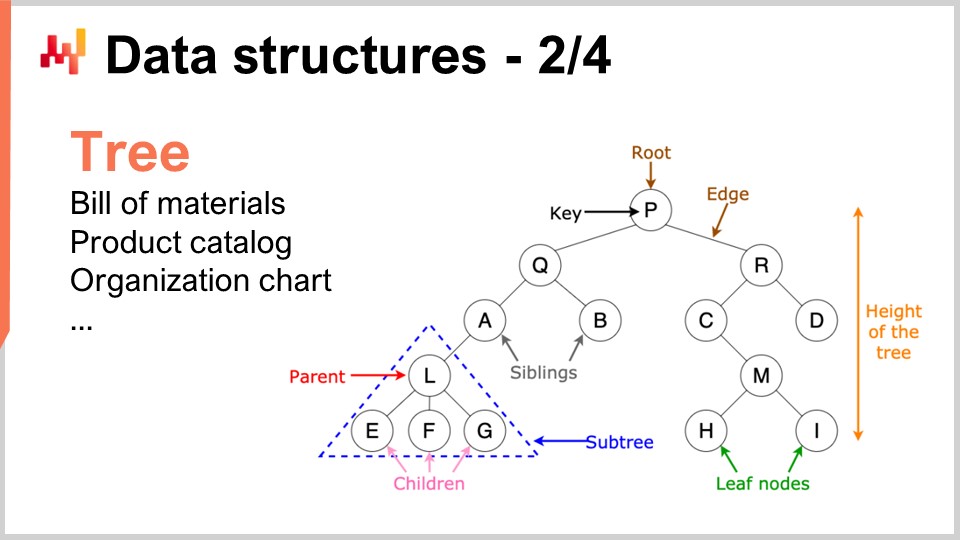
Аналогично, деревья — это ещё одна повсеместная структура данных. Кстати, алгоритмические деревья перевёрнуты: корень находится вверху, а ветви — внизу. Деревья позволяют описывать всевозможные иерархии, а цепи поставок изобилуют иерархиями. Например, спецификация материалов представляет собой дерево: имеется оборудование, которое вы хотите произвести, и это оборудование состоит из сборочных единиц. Каждая сборочная единица состоит из подсборок, а каждая подсборка — из деталей. Если полностью развернуть спецификацию материалов, получится дерево. Аналогичным образом, каталог продукции, где есть продуктовые семейства, категории, товары, подкатегории и т.д., очень часто обладает древовидной архитектурой. Организационная структура с гендиректором наверху, топ-менеджерами ниже и так далее, также представлена в виде дерева. Алгоритмическая теория предоставляет множество инструментов и методов для обработки деревьев и эффективного выполнения операций над ними. Когда вы можете представить данные в виде дерева, у вас появляется целый арсенал математических методов для работы с ними. Вот почему это имеет большое значение.
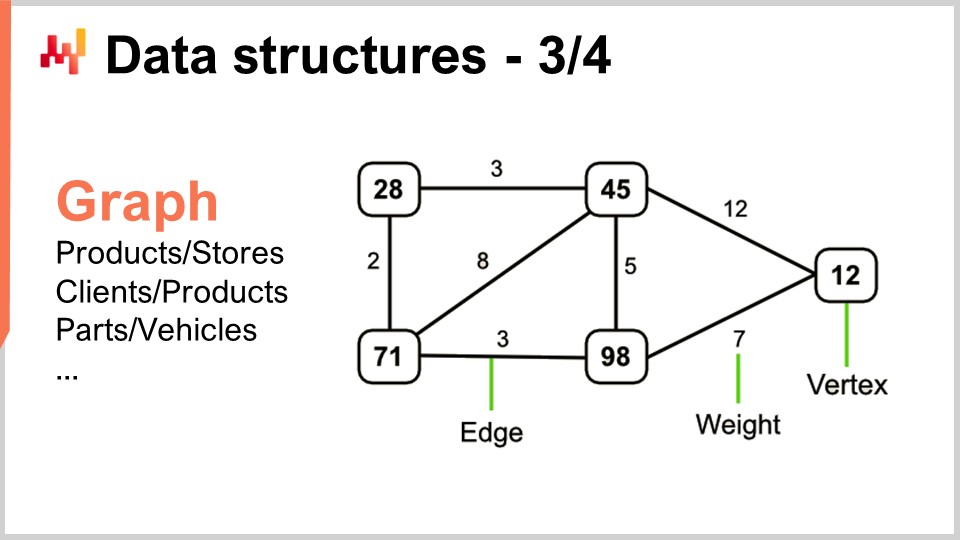
Теперь графы позволяют описывать всевозможные сети. Кстати, граф в математическом смысле — это множество вершин и множество рёбер, соединяющих две вершины. Термин «граф» может показаться несколько вводящим в заблуждение, так как он не имеет ничего общего с графикой. Граф — это просто математический объект, а не рисунок или нечто графическое. Когда вы научитесь распознавать графы, вы увидите, что цепи поставок изобилуют ими.
Несколько примеров: ассортимент в розничной сети, который по сути является двудольным графом, соединяет товары и магазины. Если у вас есть программа лояльности, в которой фиксируется, какой клиент покупал какой товар с течением времени, вы получаете ещё один двудольный граф, соединяющий клиентов и товары. В автомобильном послепродажном обслуживании, когда необходимо провести ремонт, обычно применяется матрица совместимости, которая указывает перечень деталей, имеющих механическую совместимость с конкретным транспортным средством. Эта матрица по сути является графом. Существует огромное количество литературы по алгоритмам для работы с графами, поэтому очень интересно, когда проблему можно охарактеризовать как поддерживаемую графовой структурой, поскольку все известные методы из литературы становятся сразу доступными.
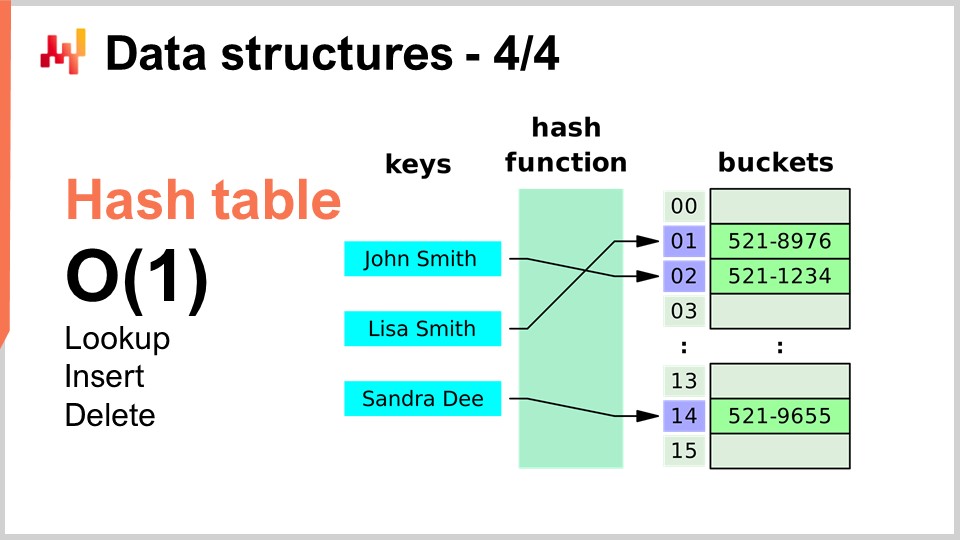
Наконец, последняя структура данных, которую я рассмотрю сегодня, — это хеш-таблица. Хеш-таблица по сути является швейцарским ножом алгоритмов. Это не новинка; ни одна из структур данных, которые я упоминал, не является новой по современным меркам. Хеш-таблица, пожалуй, самая современная из представленных, датируется 1950-ми годами, так что она не является недавней разработкой. Тем не менее, хеш-таблица — невероятно полезная структура данных. Это контейнер, содержащий пары ключ-значение. Идея заключается в том, что с этим контейнером можно хранить огромное количество данных, и он обеспечивает выполнение операций поиска, вставки и удаления за время O(1). У вас есть контейнер, в котором можно за константное время добавить данные, проверить их наличие (по ключу) и, при необходимости, удалить их. Это очень интересно и полезно. Хеш-таблицы буквально встречаются повсюду и широко используются в других алгоритмах.
Одно, на что я хотел бы обратить внимание, и к чему мы вернёмся позже, — это то, что производительность хеш-таблицы сильно зависит от эффективности используемой хеш-функции.

Теперь давайте обратим внимание на волшебные рецепты, и мы полностью перейдём к другой точке зрения. Волшебные числа по своей сути являются антипаттерном. На предыдущей лекции, посвящённой негативным аспектам цепей поставок, мы обсуждали, как антипаттерны обычно начинаются с благих намерений, но в итоге приводят к непредвиденным последствиям, сворачивающим предполагаемые преимущества решения. Волшебные числа — это хорошо известный антипаттерн программирования. Он заключается в том, что код изобилует константами, которые кажутся совершенно случайными, что значительно осложняет сопровождение программного обеспечения. Когда у вас много констант, непонятно, зачем существуют эти ограничения и как они были выбраны.
Обычно, когда вы встречаете волшебные числа в программе, лучше изолировать все эти константы в одном месте, где ими легче управлять. Однако бывают ситуации, когда тщательный выбор констант приводит к совершенно неожиданным результатам, и вы получаете почти магические, абсолютно непредвиденные преимущества от использования чисел, которые, как кажется, упали с неба. Именно об этом и идёт речь в представленном мной коротком алгоритме.
В цепях поставок очень часто требуется моделирование определённого рода процессов. Симуляции или методы Монте-Карло — один из базовых приёмов, которые можно использовать во множестве ситуаций в цепях поставок. Однако производительность вашей симуляции во многом зависит от вашей способности генерировать случайные числа. Для проведения симуляций обычно необходим определённый уровень случайности, и, следовательно, вам нужен алгоритм для её генерации. Что касается компьютеров, то это, как правило, псевдослучайность — не настоящая случайность, а лишь нечто, что выглядит как случайные числа и обладает их статистическими характеристиками, но на самом деле не является таковой.
Вопрос заключается в том, насколько эффективно можно генерировать случайные числа. Оказывается, существует алгоритм под названием “Shift”, опубликованный в 2003 году Джорджем Марсaglia, который весьма впечатляет. Этот алгоритм генерирует случайные числа очень высокого качества, создавая полную перестановку из 2 в степени 64 минус 1 бита. Он проходит через все 64-битные комбинации, за исключением одной, где ноль остаётся фиксированной точкой. Он выполняет это с помощью, по сути, шести операций: трёх бинарных сдвигов и трёх операций XOR (исключающее или), которые являются побитовыми операциями. Сдвиги также являются побитовыми операциями.
Мы видим, что в его основе лежат три волшебных числа: 13, 7 и 17. Кстати, все эти числа являются простыми; это не случайность. Оказывается, если выбрать именно эти конкретные константы, вы получите превосходный генератор случайных чисел, который, кроме того, работает супербыстро. Когда я говорю «супербыстро», я имею в виду, что вы буквально можете генерировать 10 мегабайт случайных чисел в секунду. Это поистине огромно. Если вернуться к предыдущей лекции, можно понять, почему этот алгоритм так эффективен. У нас не только всего шесть инструкций, которые напрямую соответствуют командам, поддерживаемым на уровне аппаратного обеспечения, например процессором, но и отсутствуют любые условные переходы. Нет проверок, что означает, что после запуска алгоритм максимально задействует возможности глубокой конвейеризации современного процессора. Это действительно впечатляет.
Вопрос в том, можем ли мы выбрать другие числа, чтобы алгоритм работал? Ответ — нет. Существует всего несколько десятков, а может быть, около ста различных комбинаций чисел, которые действительно будут работать, а все остальные дадут генератор чисел низкого качества. Вот в чём его магия. Видите ли, это современная тенденция в разработке алгоритмов — находить нечто совершенно неожиданное, когда обнаруживается полумагическая константа, дающая совершенно непредвиденные преимущества при сочетании весьма неожиданных побитовых операций. Генерация случайных чисел имеет критическое значение для цепей поставок.

Но, как я уже говорил, хеш-таблицы встречаются повсюду, и также крайне важно иметь универсальную хеш-функцию с супер высокой производительностью. Существует ли такая? Да. Существуют целые классы хеш-функций, доступных уже десятилетиями, но в 2019 году был опубликован ещё один алгоритм, демонстрирующий рекордную производительность. Это тот, который вы видите на экране, “WyHash” от Ван Яя. По сути, видно, что его структура очень похожа на алгоритм XORShift. Это алгоритм без ветвлений, как и XORShift, и он также использует операцию XOR. Алгоритм использует шесть инструкций: четыре операции XOR и две операции Multiply-No-Flags.
Операция Multiply-No-Flags — это просто обычное умножение двух 64-битных целых чисел, в результате которого вы получаете старшие 64 бита и младшие 64 бита. Это реальная инструкция, доступная в современных процессорах и реализованная на уровне железа, поэтому считается одной машинной инструкцией. У нас их две. И снова, мы имеем три волшебных числа, записанных в шестнадцатеричном виде. Кстати, они — простые числа, снова, полностью полумагические. Если вы примените этот алгоритм, у вас получится абсолютно отличная некриптографическая хеш-функция, работающая почти со скоростью memcpy. Она очень быстрая и имеет первостепенное значение.

Итак, давайте снова переключимся на совершенно другую тему. Успех глубокого обучения и многих других современных методов машинного обучения заключается в нескольких ключевых алгоритмических идеях, которые могут быть массово ускорены с помощью специализированного аппаратного обеспечения. Именно об этом я говорил в предыдущей лекции, когда обсуждал процессоры с суперскалярными инструкциями и, если хотите больше, GPU и даже TPU. Давайте еще раз рассмотрим эту идею, чтобы понять, как всё возникло довольно хаотично. Однако я считаю, что соответствующие идеи кристаллизовались за последние несколько лет. Чтобы понять, где мы находимся сегодня, нам нужно вернуться к обозначению Эйнштейна, которое было введено чуть более века назад Альбертом Эйнштейном в одной из его работ. Интуиция проста: у вас есть выражение y, которое представляет собой сумму от i = 1 до i = 3, где суммируется c_y, умноженное на x_y. Мы записываем выражения подобным образом, и суть обозначения Эйнштейна заключается в том, чтобы в таких случаях записывать выражение, полностью опуская знак суммирования. В терминах программирования суммирование означало бы цикл for. Идея состоит в том, чтобы полностью опустить сумму и, по соглашению, считать, что суммирование происходит по всем индексам переменной i, где это имеет смысл.
Эта простая интуиция приводит к двум весьма неожиданным, но положительным результатам. Первый из них — корректность конструкции. Когда мы явно записываем сумму, существует риск выбрать неправильные индексы, что может привести к ошибкам выхода за границы массива в программном обеспечении. Убирая явное суммирование и утверждая, что по определению мы суммируем по всем допустимым позициям индексов, мы получаем подход, корректный по своей конструкции. Это само по себе имеет первостепенное значение и связано с программированием массивов, парадигмой программирования, о которой я кратко упоминал в одной из предыдущих лекций.
Второй вывод, который является более современным и представляет большой интерес в наши дни, заключается в том, что если вы можете записать задачу в форме, где применяется обозначение Эйнштейна, ваша задача может на практике получить выгоду от массового аппаратного ускорения. Это принципиально меняет правила игры.

Чтобы понять, почему, существует очень интересная статья под названием “Tensor Comprehensions”, опубликованная в 2018 году исследовательской группой Facebook. Они ввели понятие тензорных исчислений. Сначала позвольте определить оба термина. В области информатики тензор по сути является многомерной матрицей (в физике тензоры совершенно иные). Скаляром является тензор нулевого измерения, вектор — тензор первого измерения, матрица — тензор второго измерения, а тензоры могут иметь и более высокие измерения. Тензоры — это объекты, обладающие свойствами, подобными массивам.
Тензорное исчисление — это нечто похожее на алгебру с четырьмя базовыми операциями — сложением, вычитанием, умножением и делением — а также с другими операциями. Оно более обширно, чем обычная арифметическая алгебра; именно поэтому используется тензорное исчисление вместо тензорной алгебры. Оно всеобъемлющее, но не такое выразительное, как полноценный язык программирования. Когда у вас есть исчисление, оно оказывается более ограниченным, чем полноценный язык программирования, где можно делать что угодно.
Идея заключается в том, что если вы посмотрите на функцию MV (def MV), то по сути это функция, и MV означает “матрица-вектор”. В данном случае это умножение матрицы на вектор, и эта функция по сути выполняет умножение матрицы A на вектор X. Мы видим в этом определении, что используется обозначение Эйнштейна: мы записываем C_i = A_ik * X_k. Какие значения следует выбрать для i и k? Ответ: все допустимые комбинации этих переменных, являющихся индексами. Мы берем все допустимые значения индексов, выполняем суммирование, и на практике это дает нам умножение матрицы на вектор.
В нижней части экрана вы можете увидеть ту же функцию MV, переписанную с использованием циклов for с явным указанием диапазонов значений. Главное достижение исследовательской группы Facebook заключается в том, что если вы можете написать программу с использованием этого синтаксиса тензорного исчисления, они разработали компилятор, который позволяет значительно воспользоваться аппаратным ускорением с использованием GPU. По сути, они позволяют ускорить любую программу, которую можно написать с этим синтаксисом тензорного исчисления. Если вы пишете программу в такой форме, вы получите выгоду от массового аппаратного ускорения, и это будет в два порядка быстрее, чем обычный процессор. Это поразительный результат сам по себе.

Теперь давайте рассмотрим, что мы можем сделать с этой точки зрения в области цепочек поставок. Одним из ключевых направлений современной практики управления цепочками поставок является вероятностное прогнозирование. Вероятностное прогнозирование, о котором я говорил в предыдущей лекции, подразумевает, что у вас не будет единственной точечной прогноза, а будет предсказание различных вероятностей для интересующей переменной. Рассмотрим, например, прогноз срока поставки. Вы хотите спрогнозировать срок поставки и получить вероятностный прогноз этого срока.
Предположим, что ваш срок поставки можно разложить на производственный срок и транспортный срок. На практике, скорее всего, у вас имеется вероятностный прогноз производственного срока, который представляет собой дискретную случайную величину, дающую вероятность наблюдения времени в один день, два дня, три дня, четыре дня и так далее. Можно представить это как большую гистограмму, которая показывает вероятности наблюдения данной длительности производственного срока. Затем для транспортного срока вы получите аналогичный процесс, где другая дискретная случайная величина предоставляет вероятностный прогноз.
Теперь вы хотите вычислить общий срок поставки. Если бы прогнозируемые сроки были числами, вы просто бы их сложили. Однако два прогнозируемых срока не являются числами; они представляют собой распределения вероятностей. Таким образом, нам необходимо объединить эти два распределения, чтобы получить третье распределение — распределение вероятностей для общего срока поставки. Оказывается, если предположить, что оба срока, производственный и транспортный, независимы, операция, позволяющая суммировать случайные величины, представляет собой одномерную свертку. Это может звучать сложно, но на самом деле не так уж сложно. То, что я реализовал, и что вы видите на экране, — это реализация одномерной свертки между вектором, представляющим гистограмму вероятностей производственного срока (A), и гистограммой, связанной с вероятностями транспортного срока (B). Результатом является общее время, то есть сумма этих вероятностных сроков. Если использовать обозначение тензорного исчисления, это можно записать в очень компактном, однострочном алгоритме.
Теперь, если мы вернемся к нотации Big O, которую я представил ранее в этой лекции, то увидим, что у нас по существу квадратичный алгоритм. Это Big O от N^2, где N — характерный размер массивов для A и B. Как я уже упоминал, квадратичная производительность является “сладкой точкой” для проблем прогнозирования. Так что же мы можем сделать для решения этой проблемы? Прежде всего, нужно учитывать, что это задача цепочки поставок, и здесь действует закон малых чисел, который мы можем использовать в своих интересах. Как обсуждалось в предыдущей лекции, цепочки поставок в основном связаны с малыми числами. Если речь идет о сроках поставки, можно разумно предположить, что они будут меньше, скажем, 400 дней. И это уже довольно длительный период для такой гистограммы вероятностей.
Таким образом, у нас остается алгоритм с Big O от N^2, но при этом N меньше 400. 400 может быть довольно большим числом, ведь 400, умноженное на 400, дает 160 000. Это значительное число, и не забывайте, что операция сложения в этом распределении вероятностей является очень базовой. Как только мы начинаем работать с вероятностным прогнозированием, нам нужно комбинировать наши прогнозы различными способами, и, скорее всего, мы будем выполнять миллионы таких сверток, потому что по сути эти свертки представляют собой ничто иное, как возвышенное сложение в контексте случайных величин. Таким образом, даже если мы ограничиваем N значением менее 400, крайне важно использовать аппаратное ускорение, и именно это можно достичь с помощью тензорного исчисления.
Главное, что нужно помнить, заключается в том, что как только вы сможете записать этот алгоритм, вы захотите использовать свои знания о концепциях цепочки поставок для уточнения применимых предположений, а затем задействовать доступные инструментарии для получения аппаратного ускорения.

Теперь давайте обсудим мета-техники. Мета-техники представляют большой интерес, потому что их можно накладывать поверх существующих алгоритмов, и, если у вас есть алгоритм, есть шанс, что вы сможете использовать одну из этих мета-техник для повышения его производительности. Первое ключевое соображение — сжатие, просто потому что меньший объем данных означает более быструю обработку. Как мы видели в предыдущей лекции, у нас нет равномерного доступа к памяти. Если вы хотите работать с большим объемом данных, вам нужно обращаться к разным типам физической памяти, и по мере роста объема памяти вы сталкиваетесь с типами, которые гораздо менее эффективны. Кэш L1 внутри процессора очень маленький, около 64 килобайт, но он чрезвычайно быстр. Оперативная память (RAM) в несколько сотен раз медленнее этого небольшого кэша, но ее объем может достигать буквально терабайта. Поэтому крайне важно убедиться, что ваши данные максимально малы, так как это почти неизбежно ускорит работу ваших алгоритмов. Существует ряд приемов, которые можно применить в этом отношении.
Во-первых, вы можете очистить и упорядочить ваши данные. Это область корпоративного программного обеспечения. Когда у вас есть алгоритм, работающий с данными, часто присутствует большое количество неиспользуемых данных, которые не способствуют решению задачи. Важно убедиться, что интересующие вас данные не перемешаны с данными, которые планируется игнорировать.
Вторая идея — упаковка битов. Существует множество ситуаций, когда можно вложить некоторые флаги внутрь других элементов, например указателей. Возможно, у вас есть 64-битный указатель, но крайне редко вам действительно нужен весь 64-битный диапазон адресации. Вы можете пожертвовать несколькими битами указателя, чтобы включить некоторые флаги, что позволяет сократить объем данных почти без какой-либо потери производительности.
Также, вы можете настроить точность. Нужна ли вам 64-битная точность чисел с плавающей запятой в цепочке поставок? Очень редко требуется такая точность. Обычно 32-битной точности достаточно, и существует множество случаев, когда достаточно и 16 бит точности. Вы можете подумать, что снижение точности не существенно, но часто, если вы можете уменьшить размер данных вдвое, алгоритм ускоряется не в 2 раза, а буквально в 10 раз. Упаковка данных дает совершенно нелинейные преимущества с точки зрения скорости выполнения.
Наконец, имеется энтропийное кодирование, которое по сути представляет собой сжатие. Однако вам не обязательно использовать алгоритмы, которые так же эффективно сжимают данные, как, скажем, алгоритм, применяемый для ZIP-архива. Вы хотите что-то, что может быть немного менее эффективным с точки зрения сжатия, но значительно быстрее в выполнении.
Сжатие в основе своей сводится к идее, что можно обменять немного дополнительных затрат процессора на снижение нагрузки на память, и практически во всех случаях этот прием оказывается эффективным.
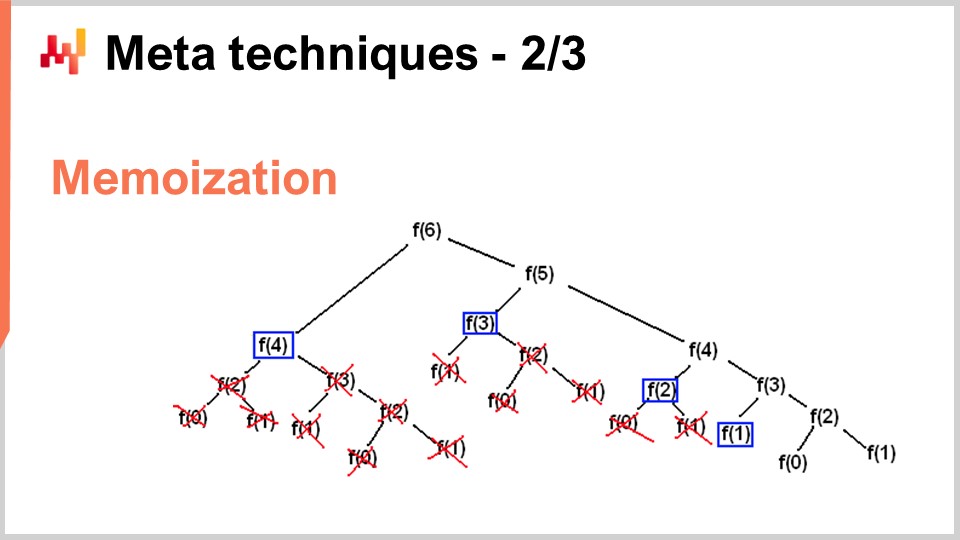
Однако существуют ситуации, когда вы хотите сделать прямо противоположное — обменять память на существенное снижение нагрузки на процессор. Именно это вы и делаете с помощью приема мемоизации. Мемоизация — это, по сути, идея о том, что если функция вызывается много раз в ходе выполнения вашего решения, и эта же функция вызывается с одними и теми же входными данными, то нет необходимости пересчитывать её каждый раз. Вы можете сохранить результат, отложить его (например, в хэш-таблице), и при повторном вызове функции проверить, содержится ли уже в хэш-таблице результат для данных входных параметров. Если функция, которую вы мемоизируете, требует значительных вычислительных ресурсов, вы можете добиться огромного ускорения. Особенно интересно становится, когда вы начинаете использовать мемоизацию не с основной памятью, ведь, как мы видели в предыдущей лекции, DRAM очень дорогая. Интерес появляется, когда вы начинаете сохранять результаты на дисках или SSD, которые дешевы и доступны в изобилии. Суть в том, что вы можете обменять SSD на снижение нагрузки на процессор, что, в некотором смысле, является полной противоположностью описанному ранее сжатию.
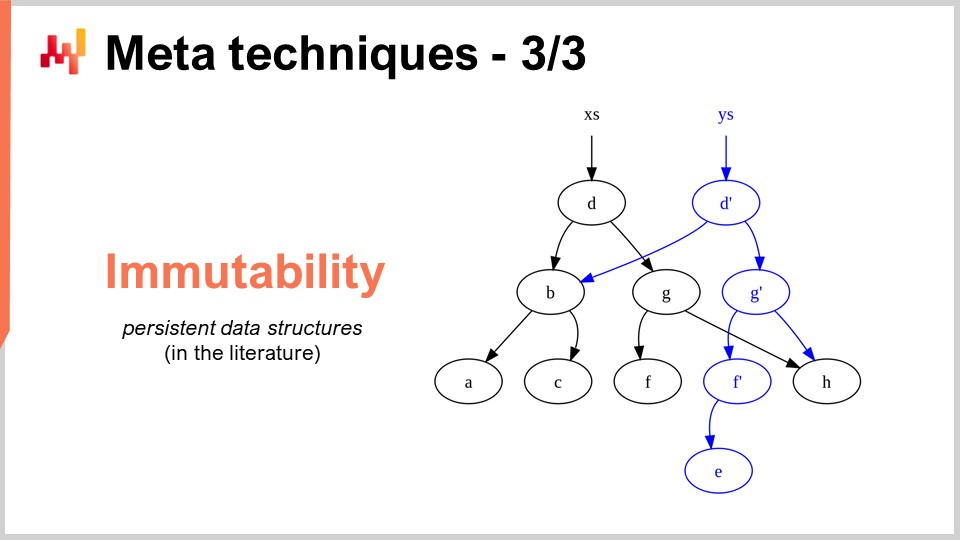
Последняя мета-техника — неизменяемость. Неизменяемые структуры данных — это структуры, которые никогда не изменяются. Идея состоит в том, что изменения накладываются сверху. Например, в случае неизменяемой хэш-таблицы при добавлении элемента возвращается новая хэш-таблица, содержащая всё, что было в старой таблице, плюс новый элемент. Самый наивный способ сделать это — скопировать всю структуру данных и вернуть копию, однако это крайне неэффективно. Ключевой момент неизменяемых структур данных заключается в том, что при модификации структуры возвращается новая структура, которая реализует только внесенные изменения, при этом повторно используя те части старой структуры, которые не были затронуты.
Почти все классические структуры данных, такие как списки, деревья, графы и хэш-таблицы, имеют свои неизменяемые аналоги. Во многих случаях их использование представляет большой интерес. Кстати, существуют современные языки программирования, которые полностью перешли на неизменяемость, например, Clojure, для тех, кто знаком с этим языком.
Почему это представляет большой интерес? Во-первых, потому что это существенно упрощает параллелизацию алгоритмов. Как мы видели в предыдущей лекции, невозможно найти процессор, работающий на 100 ГГц для обычных настольных компьютеров. Однако можно найти машину с 50 ядрами, каждое из которых работает на 2 ГГц. Если вы хотите воспользоваться преимуществами множества ядер, вам нужно распараллелить выполнение, и тогда ваша параллелизация может столкнуться с весьма неприятными ошибками, называемыми гонками. Стать очень трудно понять, корректен ли написанный вами алгоритм, поскольку различные процессоры могут одновременно пытаться записать в один и тот же участок памяти компьютера.
Однако, если у вас есть неизменяемые структуры данных, этого никогда не происходит по замыслу, поскольку как только структура данных создана, она никогда не изменится — появится только новая структура данных. Таким образом, вы можете добиться огромного прироста производительности с неизменяемым подходом, потому что вы можете легче реализовать параллельные версии ваших алгоритмов. Имейте в виду, что обычно узким местом при реализации ускорения алгоритмов является время, необходимое для их фактической реализации. Если у вас есть нечто, что по замыслу позволяет применять принципы бесстрашной параллелизации, вы сможете значительно быстрее реализовать алгоритмическое ускорение с меньшими затратами в смысле числа программистов. Еще одно важное преимущество неизменяемых структур данных заключается в том, что они значительно облегчают отладку. Когда вы изменяете структуру данных деструктивно и сталкиваетесь с ошибкой, может оказаться очень трудно понять, как вы туда попали. Использование отладчика может превратиться в очень неприятный опыт при поиске проблемы. Интересная вещь в неизменяемых структурах данных заключается в том, что изменения не разрушают предыдущую версию, так что вы можете увидеть прежнюю версию вашей структуры данных и легче понять, как произошёл переход к тому состоянию, с которым вы столкнулись.

В заключение, лучшие алгоритмы могут казаться сверхспособностями. С лучшими алгоритмами вы получаете больше от того же самого вычислительного оборудования, и эти преимущества неограниченны. Это разовое усилие, после которого у вас появляется неограниченный потенциал, поскольку вы получаете доступ к улучшенным вычислительным возможностям, используя те же ресурсы, выделенные для решения конкретной проблемы в управлении цепочками поставок. Я считаю, что эта перспектива представляет возможности для значительных улучшений в управлении цепями поставок.
Если мы посмотрим на совершенно другую область, такую как видеоигры, они выработали свои собственные алгоритмические традиции и результаты, направленные на улучшение игрового опыта. Поразительная графика, которую вы наблюдаете в современных видеоиграх, является результатом работы сообщества, десятилетиями переосмысливающего весь алгоритмический стек для максимального повышения качества игрового опыта. В играх цель состоит не в том, чтобы 3D-модель была корректной с физической или научной точки зрения, а в том, чтобы максимизировать воспринимаемое качество графического опыта для игрока, и они отточили алгоритмы для достижения потрясающих результатов.
Я считаю, что подобная работа для цепей поставок только началась. Программное обеспечение для управления цепями поставок на предприятиях застряло, и, по моему мнению, мы не используем даже 1% того, на что способно современное вычислительное оборудование. Большинство возможностей ещё впереди и могут быть реализованы с помощью алгоритмов, не только таких, как алгоритмы маршрутизации транспортных средств для цепей поставок, но и при пересмотре классических алгоритмов с точки зрения цепей поставок для достижения значительного ускорения.

Теперь я перейду к вопросам.
Вопрос: Вы говорили о специфике цепей поставок, например, о небольших числах. Когда мы заранее знаем, что в наших возможных решениях задействованы небольшие числа, какое упрощение это вносит? Например, когда мы знаем, что можем заказать максимум один или два контейнера, можете ли вы привести конкретные примеры того, как это повлияет на уровень детализации целостных прогнозов, которые будут использоваться для вычисления функции вознаграждения за запас?
Во-первых, всё, что я представил сегодня, уже используется в производстве в Lokad. Все эти идеи, так или иначе, вполне применимы к цепям поставок, поскольку они внедрены в Lokad. Вы должны понять, что современное программное обеспечение не оптимизировано для максимально эффективного использования вычислительного оборудования. Просто подумайте: как я упоминал в последней лекции, сегодня у нас есть компьютеры, которые в тысячу раз мощнее тех, что были несколько десятилетий назад. Работают ли они в тысячу раз быстрее? Нет. Могут ли они решать задачи, фантастически более сложные, чем те, что были несколько десятилетий назад? Нет. Так что не стоит недооценивать огромный потенциал для улучшений.
Блочная сортировка, которую я представил в этой лекции, является простым примером. Операции сортировки присутствуют повсеместно в цепях поставок, и, насколько мне известно, очень редко встречается корпоративное программное обеспечение, которое использует специализированные алгоритмы, идеально подходящие для ситуаций в цепях поставок. А теперь, когда мы знаем, что у нас один или два контейнера, мы используем эти элементы в Lokad? Да, мы используем постоянно, и существует масса трюков, которые можно реализовать на этом уровне.
Эти трюки обычно реализуются на более низком уровне, и их преимущества в итоге проявляются в общем решении. Нужно думать о декомпозиции задач заполнения контейнеров на все их составляющие. Вы можете получить выгоду, применяя идеи и ходы, которые я представил сегодня, на нижнем уровне.
Например, какая числовая точность вам нужна, если речь идет о контейнерах? Возможно, 16-битные числа с точностью всего 16 бит будут достаточны. Это делает данные меньше. Сколько различных продуктов мы заказываем? Возможно, мы заказываем всего несколько тысяч различных продуктов, так что мы можем использовать блочную сортировку. Вероятностное распределение — это меньшее число, так что, теоретически, у нас есть гистограммы, которые могут охватывать от нуля единиц, одной единицы, трёх единиц до бесконечности, но мы не идем до бесконечности, правда? Может быть, мы можем сделать разумные предположения о том, что очень редко столкнёмся с гистограммой, где количество превысит 1000 единиц. Когда это происходит, мы можем аппроксимировать. Нам не обязательно иметь точность в 2 единицы, если мы имеем дело с контейнером, содержащим 1000 единиц. Мы можем аппроксимировать и сделать гистограмму с большими корзинами и тому подобное. Я бы сказал, что это не столько введение алгоритмических принципов, таких как понимание тензоров, которые невероятны, потому что они упрощают всё очень крутым способом. Однако большинство алгоритмических ускорений в конечном итоге приводят к более быстрому, но немного более сложному алгоритму. Он не обязательно проще, так как обычно самый простой алгоритм также является неэффективным. Более подходящий алгоритм для конкретного случая может быть немного длиннее в написании и более сложным, но в итоге он будет работать быстрее. Это не всегда так, как мы видели на примере волшебных рецептов, но я хотел показать, что нам нужно пересмотреть фундаментальные строительные блоки того, что мы делаем, чтобы действительно создавать корпоративное программное обеспечение.
Вопрос: Насколько широко реализованы эти идеи у поставщиков ERP, APS и лучших в своем классе, таких как GTA?
Интересно, что эти идеи в своей сути, в основном, полностью несовместимы с транзакционным программным обеспечением. Большинство корпоративного ПО построено вокруг ядра, представляющего собой транзакционную базу данных, и всё проходит через базу данных. Эта база данных не является специфической для цепей поставок; это универсальная база данных, которая должна справляться со всеми возможными ситуациями, которые можно представить, от финансов до научных вычислений, от медицинских записей и многого другого.
Проблема в том, что если рассматриваемое программное обеспечение имеет транзакционную базу данных в основе, то предложенные мною идеи не могут быть реализованы по замыслу. Это своего рода конец игры. Если посмотреть на видеоигры, сколько из них построено поверх транзакционной базы данных? Ответ — ноль. Почему? Потому что нельзя добиться хорошей производительности графики, используя транзакционную базу данных. Невозможно реализовать компьютерную графику в транзакционной базе данных.
Транзакционная база данных, безусловно, хороша; она обеспечивает транзакционность, но она запирает вас в мир, где почти все алгоритмические ускорения, о которых можно подумать, просто не применимы. Я считаю, что если задуматься об APS, то в этих системах нет ничего продвинутого. Они застряли в прошлом уже десятилетиями, и это потому, что в основе их дизайна лежит транзакционная база данных, которая препятствует применению любых идей, возникших в области алгоритмов за последние, возможно, четыре десятилетия.
Вот суть проблемы в области корпоративного программного обеспечения. Дизайнерские решения, принятые в первый месяц разработки вашего продукта, будут преследовать вас десятилетиями, по сути, до конца времен. Нельзя обновить продукт, как только вы выбрали конкретный дизайн; вы запертированы в нем. Так же, как вы не можете просто переделать автомобиль в электромобиль, если вы хотите получить действительно хороший электромобиль, вам придется полностью перестроить автомобиль, исходя из идеи, что двигатель будет электрическим. Речь идёт не просто о замене двигателя и утверждении: “Вот электромобиль.” Это не так работает. Это один из ключевых принципов дизайна: как только вы определились с производством электромобиля, вам нужно переосмыслить всё вокруг двигателя, чтобы всё подходило. К сожалению, ERP и APS, сильно завязанные на базе данных, просто не могут использовать эти идеи, боюсь. Всегда возможно создать изолированное решение, где вы получите выгоду от этих трюков, но это будет навесное дополнение; оно никогда не станет основным.
Что касается впечатляющих возможностей Blue Yonder, прошу отнестись с пониманием, так как Lokad является прямым конкурентом Blue Yonder, и мне сложно быть полностью объективным. На рынке корпоративного программного обеспечения приходится делать невероятно смелые заявления, чтобы оставаться конкурентоспособным. Я не убеждён, что в этих заявлениях есть какая-либо суть. Я ставлю под сомнение предпосылку, что кто-либо на этом рынке обладает чем-то, что можно было бы квалифицировать как впечатляющее.
Если вы хотите увидеть что-то потрясающее и ультра-впечатляющее, взгляните на последнюю демонстрацию Unreal Engine или специализированных алгоритмов для видеоигр. Обратите внимание на компьютерную графику на аппаратуре следующего поколения PlayStation 5; она просто поразительна. Есть ли у нас в области корпоративного программного обеспечения что-то сопоставимое по уровню технологических достижений? Что касается Lokad, у меня крайне предвзятое мнение, но если смотреть на рынок в целом, я вижу океан людей, которые десятилетиями пытались выжать максимум из реляционных баз данных. Иногда они применяют и другие типы баз данных, такие как графовые базы, но это полностью упускает с виду суть представленных мною идей. Это не даёт ничего существенного для создания ценности в мире цепей поставок.
Основной посыл для аудитории заключается в том, что всё сводится к дизайну. Мы должны убедиться, что первоначальные решения, принятые при создании корпоративного программного обеспечения, не являются такими, которые по замыслу предотвратили бы возможность использования этих техник с самого начала.
Следующая лекция состоится через три недели, в среду, в 15:00 по парижскому времени. Это будет 13 июня, и мы вновь рассмотрим третью главу, которая посвящена персоналу цепей поставок, удивительным особенностям личностей и вымышленным компаниям. В следующий раз мы поговорим о сыре. До встречи!


