00:19 Introduction
04:33 Two definitions for ‘algorithm’
08:09 Big-O
13:10 The story so far
15:11 Auxiliary sciences (recap)
17:26 Modern algorithms
19:36 Outperforming “optimality”
22:23 Data structures - 1/4 - List
25:50 Data structures - 2/4 - Tree
27:39 Data structures - 3/4 - Graph
29:55 Data structures - 4/4 - Hash table
31:30 Magic recipes - 1/2
37:06 Magic recipes - 2/2
39:17 Tensor comprehensions - 1/3 - The ‘Einstein’ notation
42:53 Tensor comprehensions - 2/3 - Facebook’s team’s breakthrough
46:52 Tensor comprehensions - 3/3 - Supply chain perspective
52:20 Meta techniques - 1/3 - Compression
56:11 Meta techniques - 2/3 - Memoization
58:44 Meta techniques - 3/3 - immutability
01:03:46 Conclusion
01:06:41 Upcoming lecture and audience questions
Descrizione
L’ottimizzazione delle supply chains si basa sulla risoluzione di numerosi problemi numerici. Gli algoritmi sono ricette numeriche altamente codificate intese a risolvere problemi computazionali precisi. Algoritmi superiori significano che è possibile ottenere risultati superiori con meno risorse di calcolo. Concentrandosi sulle specificità di supply chain, le prestazioni algoritmiche possono essere notevolmente migliorate, a volte di ordini di grandezza. Gli algoritmi “supply chain” devono anche abbracciare il design dei computer moderni, che si è evoluto significativamente negli ultimi decenni.
Trascrizione completa

Benvenuti a questa serie di lezioni su supply chain. Sono Joannes Vermorel, e oggi presenterò “Algoritmi moderni per supply chain.” Capacità computazionali superiori sono fondamentali per ottenere una performance supply chain. Previsioni più accurate, un’ottimizzazione più dettagliata e un’ottimizzazione più frequente sono tutti elementi auspicabili per raggiungere una performance supply chain superiore. C’è sempre un metodo numerico superiore, leggermente al di là delle risorse di calcolo che puoi permetterti.
Per semplificare, gli algoritmi fanno andare i computer più velocemente. Gli algoritmi sono un ramo della matematica e rappresentano un campo di ricerca molto attivo. I progressi in questo campo spesso superano quelli dell’hardware di calcolo stesso. L’obiettivo di questa lezione è capire di cosa trattano gli algoritmi moderni e, più nello specifico da una prospettiva supply chain, come affrontare i problemi in modo da sfruttare al meglio questi algoritmi moderni per la tua supply chain.

Per quanto riguarda gli algoritmi, c’è un libro che è un punto di riferimento assoluto: Introduction to Algorithms, pubblicato per la prima volta nel 1990. È un libro da leggere assolutamente. La qualità della presentazione e della scrittura è semplicemente eccezionale. Questo libro ha venduto oltre mezzo milione di copie nei suoi primi 20 anni e ha ispirato un’intera generazione di autori accademici. Infatti, la maggior parte dei libri recenti su supply chain che trattano la teoria della supply chain pubblicati nell’ultimo decennio sono stati spesso fortemente ispirati dallo stile e dalla presentazione presenti in questo libro.
Personalmente, ho letto questo libro nel 1997, e si trattava in realtà di una traduzione francese della primissima edizione. Ha avuto un’influenza profonda sull’intera mia carriera. Dopo aver letto questo libro, non ho più visto il software allo stesso modo. Un avvertimento, tuttavia: questo libro adotta una prospettiva sull’hardware di calcolo che era prevalente alla fine degli anni ‘80 e all’inizio degli anni ‘90. Come abbiamo visto nelle lezioni precedenti di questa serie, l’hardware di calcolo ha progredito in modo piuttosto drammatico negli ultimi decenni, e quindi alcune delle ipotesi fatte in questo libro sembrano relativamente datate. Ad esempio, il libro presume che gli accessi alla memoria avvengano in tempo costante, indipendentemente dalla quantità di memoria che desideri indirizzare. Questo non è più il funzionamento dei computer moderni.
Tuttavia, credo che ci siano certe situazioni in cui essere semplicistici è una proposta ragionevole se ciò che si guadagna in cambio è un grado molto più elevato di chiarezza e semplicità nell’esposizione. Questo libro eccelle in questo aspetto. Pur consigliando di tenere presente che alcune delle ipotesi chiave fatte nel libro sono datate, rimane comunque un punto di riferimento assoluto che consiglierei a tutto il pubblico.

Chiarifichiamo il termine “algoritmo” per il pubblico che potrebbe non essere così familiare con il concetto. Esiste la definizione classica, in cui è definito come una sequenza finita di istruzioni informatiche ben definite. Questo è il tipo di definizione che troverai nei libri di testo o su Wikipedia. Sebbene la definizione classica di un algoritmo abbia i suoi meriti, credo che sia deludente, in quanto non chiarisce l’intento associato agli algoritmi. Non si tratta di una qualsiasi sequenza di istruzioni; è una sequenza molto specifica di istruzioni informatiche. Propongo quindi una definizione personale del termine algoritmo: un algoritmo è fondamentalmente un metodo software orientato alle prestazioni, fine-grained e risolutivo dei problemi.
Analizziamo questa definizione, d’accordo? Innanzitutto, la parte che riguarda la risoluzione dei problemi: un algoritmo è completamente caratterizzato dal problema che cerca di risolvere. Su questo schermo, quello che vedi è il pseudocodice dell’algoritmo Quicksort, che è un algoritmo popolare e ben noto. Quicksort cerca di risolvere il problema dell’ordinamento, che è il seguente: hai un array che contiene voci di dati e desideri un algoritmo che restituisca lo stesso array, ma con tutte le voci ordinate in ordine crescente. Gli algoritmi sono focalizzati interamente su un problema specifico e ben definito.
Il secondo aspetto riguarda come stabilisci di avere un algoritmo migliore. Un algoritmo migliore è qualcosa che ti permette di risolvere lo stesso problema con meno risorse di calcolo, il che in pratica significa più velocità. Infine, c’è la parte fine-grained. Quando parliamo di “algoritmi”, intendiamo che vogliamo esaminare problemi molto elementari, modulari e che possono essere composti all’infinito per risolvere problemi molto più complicati. È proprio questo il fulcro degli algoritmi.
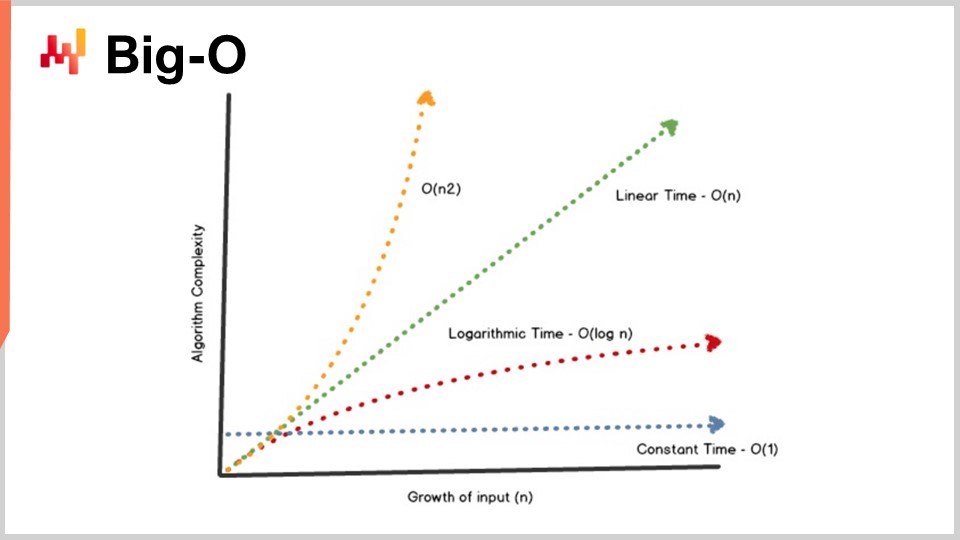
Uno dei risultati chiave della teoria degli algoritmi è fornire una caratterizzazione delle prestazioni degli algoritmi in maniera abbastanza astratta. Oggi non avrò il tempo di entrare nei dettagli di questa caratterizzazione e del relativo quadro matematico. L’idea è che, per caratterizzare l’algoritmo, vogliamo esaminare il comportamento asintotico. Abbiamo un problema che dipende da una o più dimensioni critiche che ne caratterizzano il collo di bottiglia. Ad esempio, nel problema dell’ordinamento presentato in precedenza, la dimensione caratteristica è solitamente il numero di elementi da ordinare. La domanda è: cosa succede quando l’array degli elementi da ordinare diventa molto grande? Mi riferirò a questa dimensione caratteristica con il numero “n” per convenzione.
Ora, ho questa notazione, la notazione Big O, che potreste aver visto quando si ha a che fare con gli algoritmi. Riassumerò alcuni elementi per darvi un’intuizione di cosa stia succedendo. Per esempio, supponiamo di avere un dataset e di voler estrarre un semplice indicatore statistico come una media. Se dico di avere un algoritmo Big O di 1, significa che sono in grado di restituire una soluzione a questo problema (calcolare la media) in tempo costante, indipendentemente dal fatto che il dataset sia piccolo o grande. Il tempo costante, o Big O di 1, è un requisito fondamentale ogni volta che si vuole fare qualcosa in tempo reale nel senso di comunicazione macchina a macchina.
Tipicamente, un altro aspetto chiave delle prestazioni è il Big O di N. Big O di N significa che la complessità dell’algoritmo è strettamente lineare rispetto alla dimensione del dataset di interesse. Questo è ciò che si ottiene quando si ha un’implementazione efficiente in grado di risolvere il problema leggendo i dati una sola volta o un numero fisso di volte. La complessità Big O di N è tipicamente compatibile solo con l’esecuzione batch. Se desideri qualcosa di online e in tempo reale, non puoi avere un algoritmo che attraversa l’intero dataset, a meno che tu non sappia che il dataset ha una dimensione fissa.
Oltre la linearità, abbiamo il Big O di N quadrato. Il Big O di N quadrato è un caso molto interessante perché rappresenta il punto critico dell’esplosione produttiva. Significa che la complessità cresce in modo quadratico rispetto alla dimensione del dataset, il che implica che se hai 10 volte più dati, le prestazioni peggioreranno di 100 volte. Questo è tipicamente il tipo di prestazione in cui non si verificheranno problemi nel prototipo perché si lavora con dataset piccoli. Non vedrai alcun problema durante la fase di test perché, ancora una volta, si utilizzano dataset piccoli. Non appena si passa alla produzione, il software diventa completamente lento. Molto spesso, nel mondo del enterprise software, specialmente in quello del software enterprise per supply chain, la maggior parte dei problemi di prestazioni abissali che si possono osservare sul campo sono causati da algoritmi quadratici non identificati. Di conseguenza, si osserva un comportamento quadratico che è semplicemente super lento. Questo problema non è stato individuato in una fase iniziale perché i computer moderni sono abbastanza veloci, e N quadrato non è poi così male finché N è abbastanza piccolo. Tuttavia, non appena si ha a che fare con un dataset di produzione su larga scala, il danno è notevole.
Questa lezione è in realtà la seconda lezione del mio quarto capitolo in questa serie di lezioni su supply chain. Nel primo capitolo, il prologo, ho presentato le mie opinioni su supply chain sia come campo di studio che come pratica. Ciò che abbiamo visto è che supply chain è una vasta raccolta di problemi complessi, a differenza dei problemi banali. I problemi complessi non possono essere affrontati con metodologie naïve poiché vi sono comportamenti avversativi ovunque, e quindi è necessario dedicare molta attenzione alla metodologia stessa. La maggior parte dei metodi naïve fallisce in modo piuttosto spettacolare. È esattamente ciò che ho fatto nel secondo capitolo, interamente dedicato alle metodologie adatte a studiare supply chain e a migliorare la pratica del supply chain management. Il terzo capitolo, che non è ancora completo, è sostanzialmente un approfondimento su ciò che chiamo “personale supply chain”, una metodologia molto specifica in cui ci concentriamo sui problemi stessi anziché sulle soluzioni che possiamo pensare per affrontarli. In futuro, alternerò tra il capitolo numero tre e il capitolo presente, che riguarda le scienze ausiliarie di supply chain.
Nell’ultima lezione, abbiamo visto che possiamo ottenere maggiori capacità di calcolo per la nostra supply chain attraverso hardware di calcolo migliore e più moderno. Oggi, guardiamo al problema da un’altra angolazione – cerchiamo maggiori capacità di calcolo perché abbiamo software migliore. È di questo che parlano gli algoritmi.

Un breve riassunto: le scienze ausiliarie rappresentano sostanzialmente una prospettiva sulla supply chain stessa. La lezione di oggi non riguarda strettamente supply chain; parla di algoritmi. Tuttavia, credo che sia di importanza fondamentale per supply chain. Supply chain non è un’isola; il progresso che si può ottenere in supply chain dipende in larga misura dai progressi già raggiunti in altri campi adiacenti. Mi riferisco a questi campi come le scienze ausiliarie di supply chain.
Credo che la situazione sia abbastanza simile al rapporto tra le scienze mediche e la chimica nel corso del XIX secolo. All’inizio del XIX secolo, le scienze mediche non si curavano affatto della chimica. La chimica era ancora il nuovo arrivato e non era considerata una proposta valida per un paziente reale. Avanzando nel XXI secolo, l’idea che si possa essere un eccellente medico senza sapere nulla di chimica sarebbe vista come del tutto assurda. È convenuto che essere un eccellente chimico non ti rende un eccellente medico, ma si concorda generalmente sul fatto che, se non sai nulla della chimica corporea, non puoi assolutamente essere competente quanto alle scienze mediche moderne. La mia visione per il futuro è che nel corso del XXI secolo, il settore supply chain inizierà a considerare il campo degli algoritmi quasi nello stesso modo in cui le scienze mediche iniziarono a guardare alla chimica nel XIX secolo.

Gli algoritmi rappresentano un vasto campo di ricerca, un ramo della matematica, e oggi ne graffieremo solo la superficie. In particolare, questo campo di ricerca ha accumulato risultati straordinari decennio dopo decennio. Può essere un campo di ricerca alquanto teorico, ma ciò non significa che si tratti solo di teoria. In realtà, è un campo di ricerca piuttosto teorico, ma ci sono state innumerevoli scoperte che hanno fatto il loro ingresso nella produzione.
Di fatto, qualsiasi tipo di smartphone o computer che stai usando oggi utilizza letteralmente decine di migliaia di algoritmi che sono stati originariamente pubblicati da qualche parte. Questo curriculum è in realtà molto più impressionante rispetto alla teoria generale degli algoritmi, soprattutto considerando che la maggior parte delle supply chain non funziona ancora basandosi sui risultati della teoria della supply chain. Quando si tratta di computer moderni e algoritmi moderni, praticamente tutto ciò che è correlato al software è completamente guidato da decenni di ricerche algoritmiche. Questo è al cuore praticamente di ogni computer che usiamo oggi.
Per la lezione di oggi, ho selezionato una lista di argomenti che ritengo piuttosto illustrativi di ciò che dovresti sapere per affrontare il tema degli algoritmi moderni. Per prima cosa, discuteremo di come sia possibile superare algoritmi presumibilmente ottimali, specialmente per supply chain. Successivamente, daremo una rapida occhiata alle strutture dati, seguita da ricette magiche, compressione tensoriale e infine, meta-tecniche.
Innanzitutto, vorrei chiarire che quando dico “algoritmi per supply chain”, non intendo algoritmi destinati a risolvere problemi specifici della supply chain. La prospettiva corretta è guardare agli algoritmi classici per problemi classici e rivalutare quei problemi classici da una prospettiva supply chain per vedere se possiamo effettivamente fare qualcosa di meglio. La risposta è sì, possiamo.
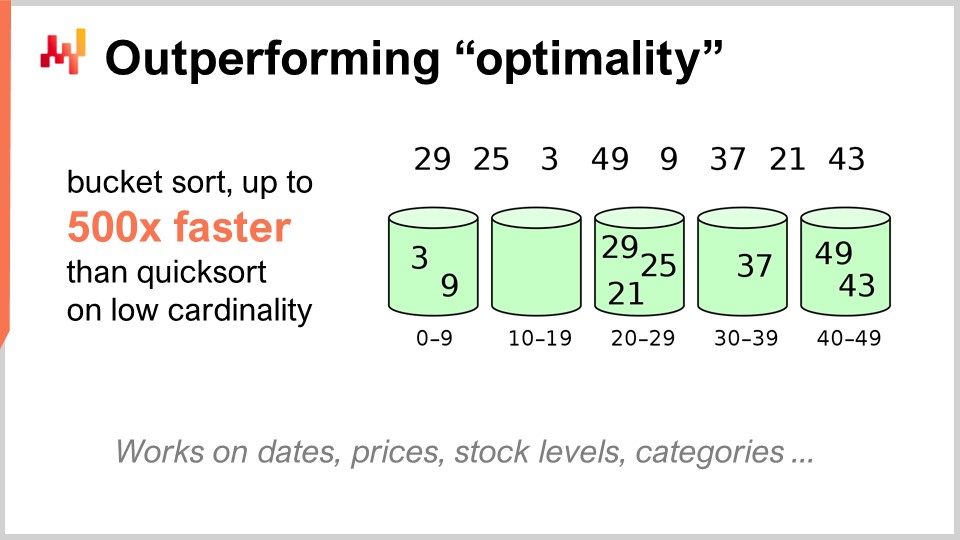
Ad esempio, l’algoritmo quicksort, secondo la teoria generale degli algoritmi, è ottimale nel senso che non è possibile introdurre un algoritmo arbitrariamente migliore di quicksort. Pertanto, in questo contesto, quicksort è il migliore che si possa ottenere. Tuttavia, se ci concentriamo specificamente sulla supply chain, è possibile ottenere accelerazioni sorprendenti. In particolare, se osserviamo i problemi di ordinamento in cui la cardinalità dei dataset di interesse è bassa, come date, prezzi, stock levels, o categorie, tutti questi sono dataset a bassa cardinalità. Quindi, se hai ulteriori ipotesi, come trovarsi in una situazione di bassa cardinalità, allora puoi utilizzare il bucket sort. In produzione, ci sono numerose situazioni in cui puoi ottenere accelerazioni monumentali, fino a 500 volte più veloce di quicksort. Puoi quindi essere di ordini di grandezza più veloce di quanto fosse presumibilmente ottimale, semplicemente perché non sei nel caso generale ma nel caso della supply chain. Questo è molto importante, e credo che qui risieda il fulcro dei risultati stupefacenti che possiamo ottenere sfruttando algoritmi per supply chain.
Ritengo che questa visione sia errata per almeno due ragioni. In primo luogo, come abbiamo visto, non è necessariamente l’algoritmo standard a essere di interesse. Abbiamo osservato che esiste un algoritmo presumibilmente ottimale come quicksort, ma se prendi lo stesso problema da un punto di vista della supply chain, puoi ottenere accelerazioni massicce. Quindi, è di primaria importanza familiarizzare con gli algoritmi, anche solo per poter rivedere i classici e ottenere accelerazioni massicce semplicemente perché non sei nel caso generale ma nel caso della supply chain.
La seconda ragione per cui ritengo che questa visione sia errata è che gli algoritmi riguardano fortemente le strutture dati. Le strutture dati sono modi per organizzare i dati in modo da poterli utilizzare in maniera più efficiente. La cosa interessante è che tutte queste strutture formano una sorta di vocabolario, e avere accesso a questo vocabolario è essenziale per poter descrivere situazioni di supply chain in modi che si prestano a una facile traduzione in software. Se inizi con una descrizione in termini semplici, di solito finisci per ottenere cose estremamente difficili da tradurre in software. Se ti aspetti che un ingegnere del software, che non conosce nulla della supply chain, implementi questa traduzione per te, potrebbe essere una ricetta per i guai. In realtà, è molto più semplice se conosci questo vocabolario, così puoi parlare direttamente i termini che facilitano la traduzione delle idee in software.
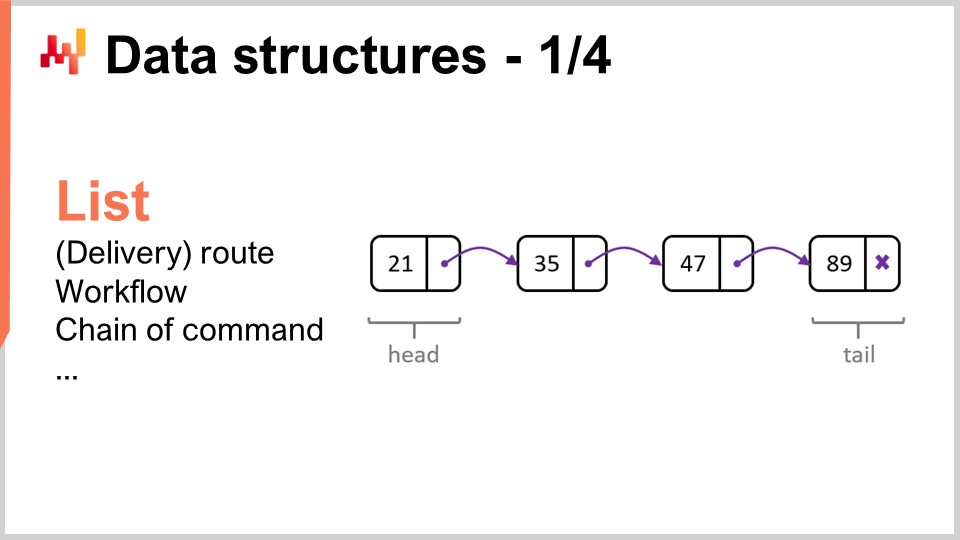
Esaminiamo le strutture dati più popolari e semplici. La prima è la lista. La lista può essere usata, per esempio, per rappresentare un percorso di consegna, che è la sequenza delle consegne da effettuare, con una voce per ogni consegna. Puoi enumerare il percorso man mano che lo percorri. Una lista può anche rappresentare un workflow, che è una sequenza di operazioni necessarie per fabbricare un certo pezzo di equipaggiamento, o una catena di comando, che determina chi deve prendere certe decisioni.
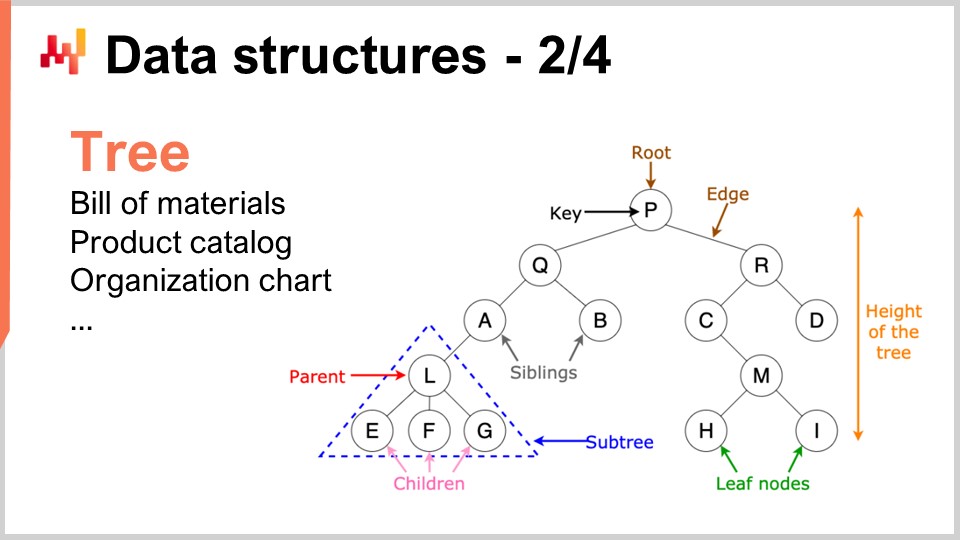
Analogamente, gli alberi sono un’altra struttura dati onnipresente. A proposito, gli alberi algoritmici sono capovolti, con la radice in alto e i rami in basso. Gli alberi ti permettono di descrivere ogni tipo di gerarchia, e le supply chain hanno gerarchie ovunque. Per esempio, una distinta base è un albero; hai un pezzo di equipaggiamento che vuoi fabbricare, e questo pezzo è composto da assiemi. Ogni insieme è composto da sottoassiemi, e ogni sottoassieme è composto da parti. Se espandi completamente la distinta base, ottieni un albero. Analogamente, un catalogo prodotti, in cui hai famiglie di prodotti, categorie, prodotti, sottocategorie, ecc., ha molto spesso un’architettura ad albero associata. Un organigramma, con l’amministratore delegato in cima, i dirigenti di livello C al di sotto, e così via, è anch’esso rappresentato da un albero. La teoria algoritmica ti fornisce una moltitudine di strumenti e metodi per elaborare gli alberi ed eseguire operazioni in modo efficiente su di essi. Ogni volta che puoi rappresentare i dati come un albero, hai a disposizione un intero arsenale di metodi matematici per lavorare in modo efficace con quegli alberi. Ecco perché questo è di grande interesse.
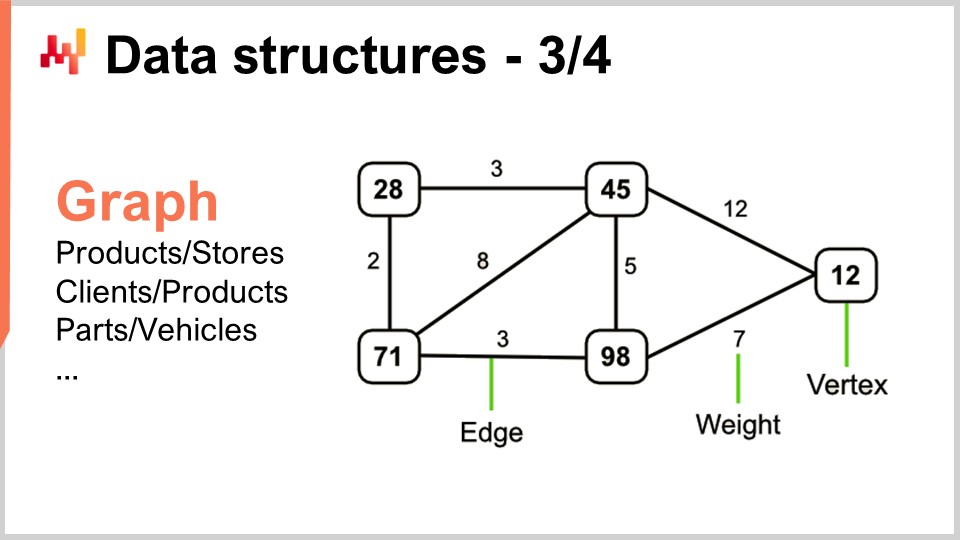
Ora, i grafi ti permettono di descrivere ogni sorta di rete. A proposito, un grafo, nel senso matematico, è un insieme di vertici e un insieme di spigoli, con gli spigoli che collegano due vertici tra loro. Il termine “grafo” potrebbe essere leggermente fuorviante perché non ha nulla a che fare con la grafica. Un grafo è semplicemente un oggetto matematico, non un disegno o qualcosa di grafico. Quando impari a identificarli, vedrai che le supply chain sono disseminate di grafi ovunque.
Alcuni esempi: un assortimento in una rete di vendita al dettaglio, che è fondamentalmente un grafo bipartito, connette prodotti e negozi. Se hai un programma di loyalty in cui registri quale cliente ha acquistato quale prodotto nel corso del tempo, hai un altro grafo bipartito che collega clienti e prodotti. Nel mercato aftermarket automobilistico, dove ci sono riparazioni da eseguire, solitamente devi utilizzare una matrice di compatibilità che indica l’elenco delle parti compatibili meccanicamente con il veicolo di interesse. Questa matrice di compatibilità è essenzialmente un grafo. Esiste una quantità enorme di letteratura su diversi algoritmi che ti permettono di lavorare con i grafi, quindi è molto interessante quando puoi caratterizzare un problema come supportato da una struttura a grafo, in quanto tutti i metodi noti in letteratura diventano facilmente disponibili.
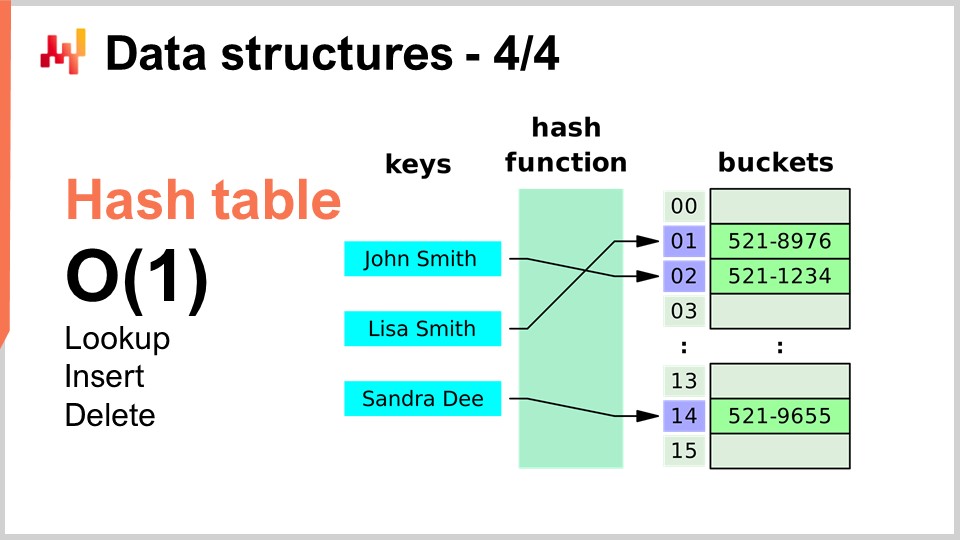
Infine, l’ultima struttura dati che tratterò oggi è la hash table. La hash table è essenzialmente il coltellino svizzero degli algoritmi. Non è nuova; nessuna delle strutture dati che ho presentato è recente secondo alcun criterio. La hash table è probabilmente la più recente del gruppo, risalente agli anni ‘50, quindi non è recente. Tuttavia, la hash table è una struttura dati incredibilmente utile. È un contenitore che accoglie coppie di chiavi e valori. L’idea è che con questo contenitore puoi memorizzare molti dati, e offre prestazioni in O(1) per le operazioni di ricerca, inserimento e cancellazione. Hai un contenitore in cui puoi, in tempo costante, aggiungere dati, verificare se i dati sono presenti (osservando la chiave) e potenzialmente rimuoverli. Questo è molto interessante e utile. Le hash table sono letteralmente ovunque e sono ampiamente usate in altri algoritmi.
Una cosa che sottolineerò, e riprenderemo in seguito, è che le prestazioni di una hash table dipendono fortemente dall’efficienza della funzione hash che utilizzi.

Adesso, diamo un’occhiata alle ricette magiche, e cambieremo completamente prospettiva. I numeri magici sono fondamentalmente un anti-pattern. Nella lezione precedente, quella sulla conoscenza negativa per supply chain, abbiamo discusso di come gli anti-pattern solitamente inizino con una buona intenzione ma finiscano per avere conseguenze non intenzionali che annullano i benefici presunti della soluzione. I numeri magici sono un noto anti-pattern di programmazione. Questo anti-pattern consiste nello scrivere codice disseminato di costanti che sembrano completamente fuori contesto, rendendo il software molto difficile da manutenere. Quando hai un sacco di costanti, non è chiaro perché esistano quei vincoli e come siano stati scelti.
Di solito, quando vedi numeri magici in un programma, è meglio isolare tutte quelle costanti in un luogo dove siano più gestibili. Tuttavia, ci sono situazioni in cui una scelta accurata delle costanti produce risultati completamente inaspettati, e ottieni benefici quasi magici, del tutto non intenzionali, dall’utilizzo di numeri che sembrano caduti dal cielo. Questo è esattamente ciò di cui tratta il brevissimo algoritmo che sto presentando qui.
Nella supply chain, molto frequentemente, vogliamo essere in grado di simulare certi processi. Le simulazioni o i processi Monte Carlo sono uno dei trucchi base che puoi utilizzare in una miriade di situazioni nella supply chain. Tuttavia, le prestazioni della tua simulazione dipendono fortemente dalla tua capacità di generare numeri casuali. Per generare simulazioni, solitamente è coinvolto un certo grado di casualità generata, e quindi hai bisogno di un algoritmo per generare questa casualità. Per i computer, si tratta tipicamente di pseudocasualità – non è vera casualità; è solo qualcosa che assomiglia a numeri casuali e possiede le caratteristiche statistiche dei numeri casuali, ma in realtà non lo è.
La domanda diventa: quanto efficientemente puoi generare numeri casuali? Si scopre che esiste un algoritmo chiamato “Shift,” pubblicato nel 2003 da George Marsaglia, che è davvero impressionante. Questo algoritmo genera numeri casuali di altissima qualità, creando una permutazione completa di 2 alla potenza di 64 meno 1 bit. Esso attraversa tutte le combinazioni a 64 bit, meno una, con lo zero come punto fisso. Lo fa essenzialmente con sei operazioni: tre shift binari e tre operazioni XOR (exclusive or), che sono operazioni bitwise. Gli shift sono anch’essi operazioni bitwise.
Quello che osserviamo è che ci sono tre numeri magici in mezzo: 13, 7 e 17. A proposito, tutti questi numeri sono primi; non è un caso. Si scopre che se scegli quegli specifici costanti, ottieni un generatore di numeri casuali eccellente che risulta essere super veloce. Quando dico super veloce, intendo dire che puoi letteralmente generare 10 megabyte al secondo di numeri casuali. Questo è assolutamente enorme. Se torniamo alla lezione precedente, possiamo capire perché questo algoritmo è così efficiente. Non solo utilizza soltanto sei istruzioni che corrispondono direttamente a quelle supportate nativamente dall’hardware sottostante, come il processore, ma inoltre non presenta alcun branching. Non c’è nessun test, e ciò significa che questo algoritmo, una volta eseguito, sfrutterà al massimo la capacità di pipelining del processore perché non c’è branching. Possiamo letteralmente sfruttare al massimo la profonda capacità di pipelining di un processore moderno. Questo è molto interessante.
La domanda è: potremmo scegliere altri numeri per far funzionare questo algoritmo? La risposta è no. Esistono solo qualche dozzina o forse circa un centinaio di combinazioni di numeri che funzionerebbero davvero, e tutte le altre ti daranno un generatore di numeri di qualità molto bassa. Ed è qui che diventa magico. Vedi, questa è una tendenza recente nello sviluppo algoritmico, quella di trovare qualcosa di completamente inaspettato, in cui si scopre una costante semi-magica che offre benefici completamente non intenzionali mescolando operazioni binarie molto inaspettate. La generazione di numeri casuali è di importanza critica per supply chain.

Ma, come dicevo, le hash table sono dappertutto, ed è anche di grande interesse avere una funzione hash generica ad altissime prestazioni. Esiste? Sì. Esistono intere classi di funzioni hash disponibili da decenni, ma nel 2019 è stato pubblicato un altro algoritmo che ha prestazioni da record. Questo è quello che puoi vedere sullo schermo, “WyHash” di Wang Yi. Essenzialmente, puoi notare che la struttura è molto simile all’algoritmo XORShift. È un algoritmo senza branch, come XORShift, e utilizza anche l’operazione XOR. L’algoritmo usa sei istruzioni: quattro operazioni XOR e due operazioni Multiply-No-Flags.
Multiply-No-Flags è semplicemente la moltiplicazione base tra due interi a 64 bit, e di conseguenza ottieni i 64 bit più significativi e i 64 bit meno significativi. Questa è una vera istruzione disponibile nei processori moderni, implementata a livello hardware, quindi conta come una sola istruzione. Ne abbiamo due. Ancora, abbiamo tre numeri magici, scritti in forma esadecimale. A proposito, questi sono numeri primi, ancora una volta, completamente semi-magici. Se applichi questo algoritmo, otterrai una funzione hash non crittografica assolutamente eccellente che opera quasi alla velocità di memcpy. È molto veloce e di primaria importanza.

Ora, cambiamo nuovamente argomento in maniera completamente diversa. Il successo del deep learning e di molti altri metodi moderni di machine learning risiede in alcuni insight algoritmici chiave sui problemi che possono essere massivamente accelerati da hardware di calcolo dedicato. È questo che ho discusso nella mia lezione precedente quando parlavo di processori con istruzioni superscalari e, se volete di più, di GPU e persino TPU. Rivisitiamo questo insight per vedere come tutto ciò sia emerso in modo piuttosto caotico. Tuttavia, credo che gli insight rilevanti si siano cristallizzati negli ultimi anni. Per comprendere dove siamo oggi, dobbiamo tornare alla notazione di Einstein, che fu introdotta poco più di un secolo fa da Albert Einstein in uno dei suoi articoli. L’intuizione è semplice: hai un’espressione y che è una somma da i uguale a 1 a i uguale a 3 di c_y per x_y. Abbiamo espressioni scritte in questo modo, e l’intuizione della notazione di Einstein è dire, in questo tipo di situazione, che dovremmo scriverla omettendo completamente la sommatoria. In termini di software, la sommatoria sarebbe un ciclo for. L’idea è di omettere completamente la sommatoria e dire che, per convenzione, eseguiamo la somma su tutti gli indici per la variabile i che hanno senso.
Questa semplice intuizione produce due risultati molto sorprendenti ma positivi. Il primo è la correttezza per progettazione. Quando scriviamo esplicitamente la sommatoria, rischiamo di non avere gli indici corretti, il che può portare a errori di indice fuori dai limiti nel software. Rimuovendo la sommatoria esplicita e affermando che, per definizione, prenderemo tutte le posizioni di indice valide, abbiamo un approccio corretto per progettazione. Questo da solo è di interesse primario ed è correlato all’array programming, un paradigma di programmazione di cui ho accennato brevemente in una delle mie lezioni precedenti.
Il secondo insight, che è più recente e di grande interesse al giorno d’oggi, è che se riesci a scrivere il tuo problema nella forma in cui si applica la notazione di Einstein, il tuo problema può beneficiare, in pratica, di un’accelerazione hardware massiccia. Questo è un elemento che cambia le regole del gioco.

Per capire il perché, c’è un articolo molto interessante intitolato “Tensor Comprehensions” pubblicato nel 2018 dal team di ricerca di Facebook. Hanno introdotto la nozione di tensor comprehensions. Prima, permettetemi di definire le due parole. Nel campo dell’informatica, un tensor è essenzialmente una matrice multidimensionale (in fisica, i tensori sono completamente diversi). Un valore scalare è un tensor di dimensione zero, un vettore è un tensor di dimensione uno, una matrice è un tensor di dimensione due, e puoi avere tensori con dimensioni ancora maggiori. I tensori sono oggetti a cui sono collegate proprietà simili a quelle degli array.
La comprehension è qualcosa di simile ad un’algebra con le quattro operazioni basilari – somma, sottrazione, moltiplicazione e divisione – oltre ad altre operazioni. È più estesa dell’algebra aritmetica regolare; ecco perché hanno una tensor comprehension invece di una tensor algebra. È più comprensiva ma non espressiva come un linguaggio di programmazione completo. Quando hai una comprehension, è più restrittiva rispetto a un linguaggio di programmazione completo in cui puoi fare tutto ciò che vuoi.
L’idea è che se guardi la funzione MV (def MV), essa è fondamentalmente una funzione, e MV sta per matrix-vector. In questo caso, si tratta di una moltiplicazione matrice-vettore, e questa funzione esegue essenzialmente una moltiplicazione tra la matrice A e il vettore X. Vediamo in questa definizione che è in gioco la notazione di Einstein: scriviamo C_i = A_ik * X_k. Quali valori dovremmo scegliere per i e k? La risposta è tutti gli accoppiamenti validi per quelle variabili che sono indici. Prendiamo tutti i valori di indice validi, facciamo la somma, e in pratica, questo ci dà una moltiplicazione matrice-vettore.
In fondo allo schermo, puoi vedere lo stesso metodo MV riscritto con cicli for, specificando esplicitamente gli intervalli di valori. Il risultato chiave del team di ricerca di Facebook è che ogni volta che puoi scrivere un programma con questa sintassi di tensor comprehension, hanno sviluppato un compilatore che ti permette di beneficiare ampiamente dell’accelerazione hardware tramite GPU. Fondamentalmente, ti consentono di accelerare qualsiasi programma che riesci a scrivere con questa sintassi di tensor comprehension. Ogni volta che riesci a scrivere un programma in questa forma, beneficerai di un’accelerazione hardware massiccia, e stiamo parlando di qualcosa che sarà due ordini di grandezza più veloce di un processore normale. Questo è un risultato sorprendente in sé.

Ora diamo un’occhiata a cosa possiamo fare da una prospettiva supply chain con questo approccio. Un aspetto chiave per la pratica moderna della supply chain è il previsione probabilistica. Il previsione probabilistica, di cui ho parlato in una lezione precedente, è l’idea che non avrai una previsione puntuale, ma piuttosto prevederai tutte le varie probabilità per una variabile di interesse. Consideriamo, per esempio, una previsione del tempo di consegna. Vuoi prevedere il tuo tempo di consegna e avere una previsione probabilistica del tempo di consegna.
Ora, supponiamo che il tuo tempo di consegna possa essere scomposto nel tempo di consegna di produzione e nel tempo di consegna del trasporto. In realtà, molto probabilmente hai una previsione probabilistica per il tempo di consegna di produzione, che sarà una variabile casuale discreta che ti fornirà la probabilità di osservare un tempo di un giorno, due giorni, tre giorni, quattro giorni, ecc. Puoi considerarlo come un grande istogramma che ti dà le probabilità di osservare questa durata per il tempo di consegna di produzione. Poi avrai un processo simile per il tempo di consegna del trasporto, con un’altra variabile casuale discreta che fornisce una previsione probabilistica.
Ora vuoi calcolare il tempo di consegna totale. Se i tempo di consegna previsti fossero numeri, faresti semplicemente un’addizione. Tuttavia, i due tempo di consegna previsti non sono numeri; sono distribuzioni di probabilità. Quindi, dobbiamo combinare queste due distribuzioni di probabilità per ottenere una terza distribuzione, che è la distribuzione di probabilità per il tempo di consegna totale. Risulta che se assumiamo che i due tempo di consegna, il tempo di consegna di produzione e il tempo di consegna del trasporto, siano indipendenti, l’operazione che possiamo fare per eseguire questa somma di variabili casuali è semplicemente una convoluzione monodimensionale. Può sembrare complesso, ma in realtà non lo è così tanto. Quello che ho implementato, e quello che puoi vedere sullo schermo, è l’implementazione di una convoluzione monodimensionale tra un vettore che rappresenta l’istogramma delle probabilità per il tempo di consegna di produzione (A) e l’istogramma associato alle probabilità per il tempo di consegna del trasporto (B). Il risultato è il tempo totale, che è la somma di quei tempo di consegna probabilistici. Se usi la notazione di tensor comprehension, questo può essere scritto in un algoritmo molto compatto, in una sola riga.
Ora, se torniamo alla notazione Big O che ho introdotto all’inizio di questa lezione, vediamo che fondamentalmente abbiamo un algoritmo quadratico. È Big O di N^2, con N che rappresenta la dimensione caratteristica degli array per A e B. Come ho detto, le prestazioni quadratiche sono un punto dolce nei problemi di previsione. Quindi, cosa possiamo fare per affrontare questo problema? Innanzitutto, dobbiamo considerare che questo è un problema di supply chain, e abbiamo la legge dei piccoli numeri che possiamo sfruttare a nostro vantaggio. Come abbiamo discusso nella lezione precedente, le supply chain riguardano prevalentemente i piccoli numeri. Se stiamo considerando i tempo di consegna, possiamo ragionevolmente presumere che quei tempo di consegna saranno inferiori, diciamo, a 400 giorni. E questo è già un periodo abbastanza lungo per questo istogramma di probabilità.
Quindi, quello che ci resta è un Big O di N^2, ma con N inferiore a 400. 400 può essere piuttosto grande, dato che 400 per 400 è 160.000. È un numero significativo, e ricorda che aggiungere a questa distribuzione di probabilità è un’operazione molto basilare. Non appena iniziamo a fare previsione probabilistica, vorremo combinare le nostre previsioni in vari modi, e molto probabilmente finiremo per fare milioni di queste convoluzioni, semplicemente perché, fondamentalmente, queste convoluzioni non sono altro che un’addizione glorificata proiettata nel regno delle variabili casuali. Pertanto, anche se abbiamo vincolato N a meno di 400, è di grande interesse introdurre l’accelerazione hardware, ed è esattamente ciò che possiamo ottenere con la tensor comprehension.
La cosa fondamentale da ricordare è che non appena riesci a scrivere quell’algoritmo, devi sfruttare ciò che conosci sui concetti della supply chain per chiarire le assunzioni applicabili e poi utilizzare gli strumenti a tua disposizione per ottenere l’accelerazione hardware.

Ora, parliamo delle meta tecniche. Le meta tecniche sono di grande interesse perché possono essere sovrapposte agli algoritmi esistenti e, quindi, se hai un algoritmo, c’è la possibilità di utilizzare una di queste meta tecniche per migliorarne le prestazioni. Il primo insight chiave è la compressione, semplicemente perché dati più piccoli significano un’elaborazione più veloce. Come abbiamo visto nella lezione precedente, non abbiamo un accesso uniforme alla memoria. Se vuoi accedere a più dati, devi accedere a diversi tipi di memoria fisica e, man mano che la memoria cresce, accedi a tipi di memoria molto meno efficienti. La cache L1 all’interno del processore è molto piccola, circa 64 kilobyte, ma è molto veloce. La RAM, o memoria principale, è diverse centinaia di volte più lenta di questa piccola cache, ma puoi avere letteralmente un terabyte di RAM. Pertanto, è di grande interesse assicurarsi che i tuoi dati siano il più piccoli possibile, in quanto questo quasi invariabilmente farà sì che i tuoi algoritmi girino più velocemente. Esiste una serie di trucchi che puoi usare a questo proposito.
Innanzitutto, puoi pulire e sistemare i tuoi dati. Questo è il campo del software aziendale. Quando hai un algoritmo che opera sui dati, spesso c’è una grande quantità di dati inutilizzati che non contribuiscono alla soluzione d’interesse. È essenziale assicurarsi di non finire con i dati d’interesse intercalati con dati che, per caso, vengono ignorati.
La seconda idea è il bit packing. Ci sono molte situazioni in cui puoi comprimere alcuni flag all’interno di altri elementi, come i puntatori. Potresti avere un puntatore a 64 bit, ma è molto raro che tu abbia effettivamente bisogno di un intervallo di indirizzi a 64 bit nella sua interezza. Puoi sacrificare alcuni bit del tuo puntatore per iniettare alcuni flag, il che ti permette di minimizzare i tuoi dati con quasi nessuna perdita di prestazioni.
Inoltre, puoi ottimizzare la tua precisione. Hai bisogno di 64 bit di precisione in virgola mobile in supply chain? È molto raro che tu abbia effettivamente bisogno di questa precisione. Di solito, 32 bit di precisione sono sufficienti, e ci sono anche molte situazioni in cui 16 bit di precisione bastano. Potresti pensare che ridurre la precisione non sia significativo, ma frequentemente, quando puoi dividere la dimensione dei dati per un fattore di due, non acceleri semplicemente il tuo algoritmo di un fattore 2; lo acceleri letteralmente di un fattore 10. Il packing dei dati produce benefici completamente non lineari in termini di velocità di esecuzione.
Infine, hai l’entropy coding, che è essenzialmente la compressione. Tuttavia, non vuoi necessariamente utilizzare algoritmi che comprimono in modo efficiente, come per esempio l’algoritmo utilizzato per un archivio ZIP. Vuoi qualcosa che possa essere un po’ meno efficiente in termini di compressione ma molto più veloce in esecuzione.
La compressione ruota fondamentalmente attorno all’idea che puoi scambiare un po’ di utilizzo extra della CPU per diminuire il carico sulla memoria, e in quasi tutte le situazioni, questo è il trucco di interesse.
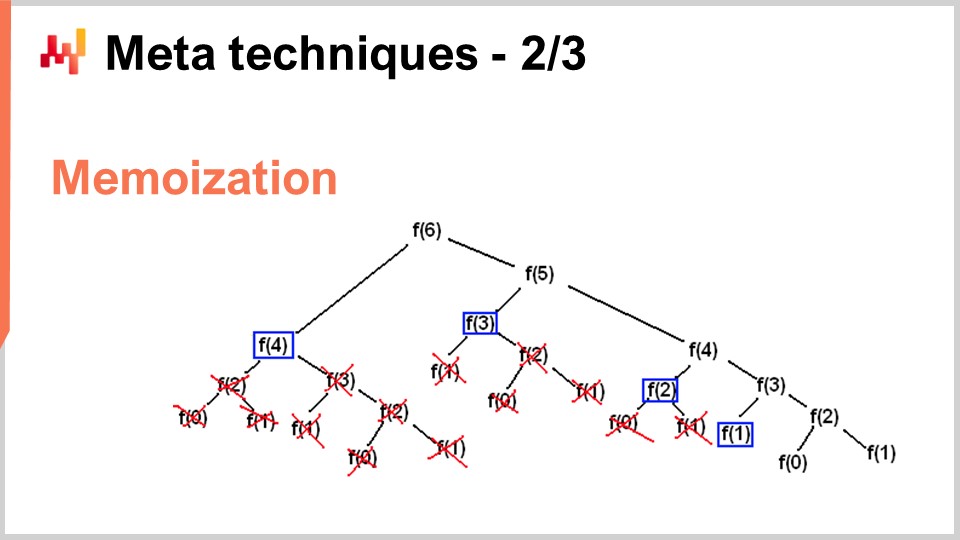
Tuttavia, ci sono situazioni in cui vuoi fare l’esatto opposto – scambiare memoria per ridurre drasticamente il consumo di CPU. Questo è esattamente ciò che fai con il trucco della memoization. La memoization è fondamentalmente l’idea che se una funzione viene chiamata molte volte durante l’esecuzione della tua soluzione, e la stessa funzione viene chiamata con gli stessi input, non hai bisogno di ricalcolare la funzione. Puoi registrare il risultato, metterlo da parte (ad esempio, in una tabella hash), e quando rivedi la stessa funzione, sarai in grado di controllare se la tabella hash contiene già una chiave associata all’input o se la tabella hash contiene già il risultato perché è stato precomputato. Se la funzione che stai memoizzando è molto costosa, puoi ottenere un’accelerazione massiccia. Dove diventa molto interessante è quando inizi a utilizzare la memoization non con la memoria principale, dato che, come abbiamo visto nella lezione precedente, la DRAM è molto costosa. Diventa molto interessante quando inizi a mettere i tuoi risultati su disco o SSD, che sono economici e abbondanti. L’idea è che puoi scambiare gli SSD in cambio di una riduzione della pressione sulla CPU, il che è, in un certo senso, l’esatto opposto della compressione che ho appena descritto.
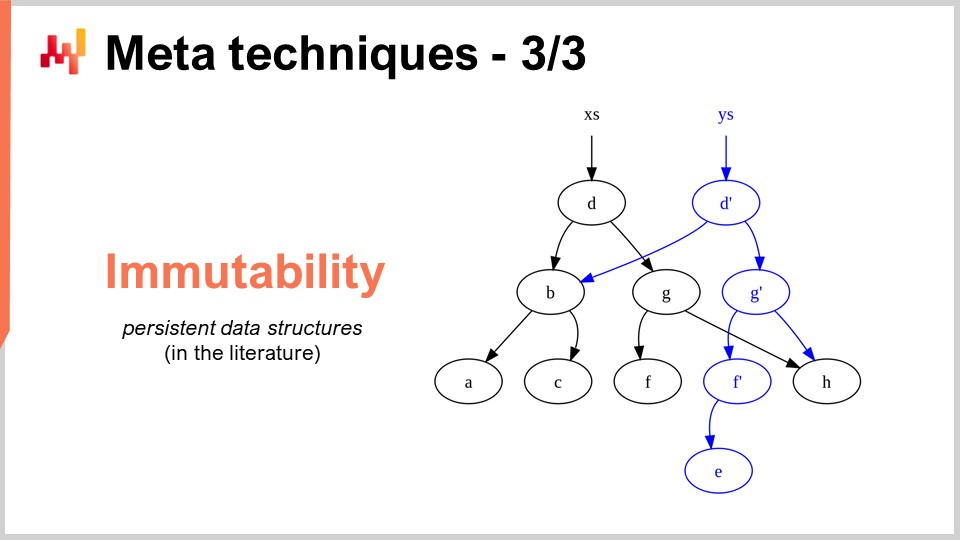
L’ultima meta-tecnica è l’immutabilità. Le strutture dati immutabili sono fondamentalmente strutture dati che non vengono mai modificate. L’idea è che le modifiche si stratificano sopra. Per esempio, con una tabella hash immutabile, quando aggiungi un elemento, quello che ritorni è una nuova tabella hash che contiene tutto ciò che c’era nella vecchia tabella hash più il nuovo elemento. Il modo più ingenuo per farlo è copiare interamente la struttura dati e restituire l’intera copia; tuttavia, questo è molto inefficiente. L’insight chiave con le strutture dati immutabili è che quando modifichi la struttura dati, restituisci una nuova struttura dati che implementa solo la modifica, ma questa nuova struttura dati ricicla tutte le parti della vecchia struttura dati che non sono state toccate.
Quasi tutte le strutture dati classiche, come liste, alberi, grafi e tabelle hash, hanno le loro controparti immutabili. In molte situazioni, è di grande interesse utilizzarle. A proposito, esistono linguaggi di programmazione moderni che hanno abbracciato completamente l’immutabilità, come Clojure, ad esempio, per chi di voi potrebbe essere familiare con questo linguaggio di programmazione.
Perché è di grande interesse? In primo luogo, perché semplifica enormemente la parallelizzazione degli algoritmi. Come abbiamo visto nella lezione precedente, non è possibile trovare un processore che funzioni a 100 GHz nei normali processori per desktop. Ciò che puoi trovare, tuttavia, è una macchina con 50 core, ognuno dei quali funziona a 2 GHz. Se vuoi sfruttare tutti quei core, devi parallelizzare l’esecuzione, e così la tua parallelizzazione è a rischio di errori molto incasinati chiamati race conditions. Diventa molto difficile capire se l’algoritmo che hai scritto è corretto o no, perché potresti avere vari processori che, simultaneamente, cercano di scrivere nello stesso pezzo di memoria del computer.
Tuttavia, se hai strutture dati immutabili, questo non accade mai per design, semplicemente perché una volta presentata una struttura dati, essa non cambierà mai—apparirà solo una nuova struttura dati. Così, puoi ottenere un notevole incremento in termini di prestazioni seguendo la via immutabile, proprio perché puoi implementare più facilmente versioni parallele dei tuoi algoritmi. Tieni presente che, di solito, il collo di bottiglia per implementare un’accelerazione algoritmica è il tempo necessario per implementare effettivamente gli algoritmi. Se hai qualcosa che, per design, ti permette di applicare una sorta di principio di concorrenza senza timori, puoi in realtà ottenere accelerazioni algoritmiche molto più rapidamente, con meno risorse in termini di numero di programmatori coinvolti. Un altro beneficio importante delle strutture dati immutabili è che facilitano notevolmente il debugging. Quando modifichi in modo distruttivo una struttura dati e incontri un errore, potrebbe essere molto difficile capire come ci sei arrivato. Con un debugger, individuare il problema può diventare un’esperienza davvero spiacevole. La particolarità delle strutture dati immutabili è che le modifiche non sono distruttive, così puoi vedere la versione precedente della tua struttura dati e comprendere più facilmente come sei giunto al punto in cui si manifesta un comportamento errato.

Per concludere, algoritmi migliori possono sembrare dei superpoteri. Con algoritmi migliori ottieni di più dallo stesso hardware di calcolo, e quei benefici sono indefiniti. È uno sforzo una tantum, e poi hai un potenziale illimitato perché hai accesso a capacità di calcolo superiori, considerando la stessa quantità di risorse computazionali dedicate a un determinato problema di supply chain di interesse. Credo che questa prospettiva offra opportunità per miglioramenti massicci nella gestione della supply chain.
Se osserviamo un campo completamente diverso, come i videogiochi, questi hanno stabilito le proprie tradizioni e scoperte algoritmiche dedicate all’esperienza ludica. Le grafiche sbalorditive che sperimenti con i videogiochi moderni sono il prodotto di una comunità che ha trascorso decenni a ripensare l’intero stack algoritmico per massimizzare la qualità dell’esperienza di gioco. La prospettiva nel gaming non è avere un modello 3D che sia corretto da un punto di vista fisico o scientifico, ma massimizzare la qualità percepita in termini di esperienza grafica per il giocatore, e hanno ottimizzato gli algoritmi per ottenere risultati straordinari.
Credo che questo tipo di lavoro sia appena iniziato per le supply chain. Il software aziendale per la supply chain è bloccato e, secondo la mia percezione, non stiamo utilizzando nemmeno l'1% di ciò che l’hardware di calcolo moderno può fare per noi. La maggior parte delle opportunità è ancora davanti a noi e può essere colta attraverso gli algoritmi, non solo algoritmi di supply chain come quelli per il vehicle routing, ma ripensando agli algoritmi classici da una prospettiva di supply chain per ottenere accelerazioni massicce lungo il percorso.

Ora darò un’occhiata alle domande.
Domanda: Hai parlato delle specificità della supply chain, come i numeri piccoli. Quando sappiamo in anticipo che abbiamo numeri ridotti nelle nostre decisioni potenziali, che tipo di semplificazione comporta questo? Ad esempio, quando sappiamo che possiamo ordinare al massimo uno o due container, riesci a pensare a esempi concreti di come ciò influenzerebbe il livello di granularità delle previsioni olistiche che saranno utilizzate per calcolare la funzione di ricompensa degli stock?
Innanzitutto, tutto ciò che ho presentato oggi è in produzione presso Lokad. Tutti questi insight, in un modo o nell’altro, sono pienamente applicabili alla supply chain perché sono in produzione da Lokad. Devi renderti conto che quello che ottieni dal software moderno è qualcosa che non è stato ottimizzato per sfruttare al massimo l’hardware di calcolo. Basta pensare che, come ho mostrato nella mia ultima lezione, oggi abbiamo computer che sono mille volte più capaci rispetto a quelli di qualche decennio fa. Funzionano mille volte più veloci? No. Riescono ad affrontare problemi fantastici, molto più complicati rispetto a quelli di qualche decennio fa? No. Quindi non sottovalutare il fatto che esistono enormi potenzialità di miglioramento.
Il bucket sort che ho presentato in questa lezione è un esempio semplice. Le operazioni di ordinamento sono ovunque nella supply chain, e per quanto ne so, è molto raro trovare un software aziendale che sfrutti algoritmi specializzati perfettamente adatti alle situazioni della supply chain. Ora, quando sappiamo di avere uno o due container, ne approfittiamo presso Lokad? Sì, lo facciamo sempre, e ci sono un sacco di trucchi che possono essere implementati a quel livello.
I trucchi operano solitamente a un livello inferiore, e i benefici si rifletteranno sulla soluzione complessiva. Devi pensare di scomporre i problemi di riempimento dei container in tutte le loro sottoparti. Puoi ottenere benefici applicando le idee e i trucchi che ho presentato oggi a quel livello.
Ad esempio, quale tipo di precisione numerica ti serve se parliamo di container? Forse numeri a 16 bit, con solo 16 bit di precisione, potrebbero bastare. Questo rende i dati più piccoli. Quanti prodotti distinti stiamo ordinando? Forse stiamo ordinando solo qualche migliaio di prodotti distinti, così possiamo utilizzare il bucket sort. La distribuzione di probabilità è un numero minore, quindi in teoria abbiamo istogrammi che possono andare da zero unità, a una unità, tre unità, fino all’infinito, ma si arriva all’infinito? No, non lo facciamo. Forse possiamo fare alcune assunzioni intelligenti sul fatto che è molto raro imbattersi in un istogramma in cui superiamo le 1.000 unità. Quando ciò accade, possiamo approssimare. Non abbiamo necessariamente bisogno di una precisione di 2 unità se stiamo trattando con un container che contiene 1.000 unità. Possiamo approssimare e avere un istogramma con bucket più grandi e cose del genere. Non si tratta tanto, direi, di introdurre principi algoritmici come il tensor comprehension, che sono incredibili perché semplificano tutto in modo fantastico. Tuttavia, la maggior parte degli acceleramenti algoritmici si traduce alla fine in un algoritmo più veloce ma leggermente più complicato. Non è necessariamente più semplice, perché di solito l’algoritmo più semplice è anche in qualche modo inefficiente. Un algoritmo più appropriato per un determinato caso potrebbe essere un po’ più lungo da scrivere e più complesso, ma alla fine girerà più velocemente. Questo non è sempre il caso, come abbiamo visto con le ricette magiche, ma ciò che volevo mostrare è che dobbiamo ripensare i fondamenti di ciò che stiamo facendo per costruire davvero software aziendale.
Domanda: Quanto ampiamente sono implementati questi insight nei fornitori di ERP , APS e nei best of breeds come GTA?
La cosa interessante è che questi insight sono fondamentalmente, per la maggior parte, completamente incompatibili con il software transazionale. La maggior parte del software aziendale è costruita attorno a un nucleo che è un database transazionale, e tutto viene canalizzato attraverso il database. Questo database non è un database specifico per la supply chain; è un database generico che dovrebbe essere in grado di gestire tutte le possibili situazioni a cui tu possa pensare, dalla finanza al calcolo scientifico, alle cartelle cliniche e altro ancora.
Il problema è che se il software che stai osservando ha un database transazionale al suo interno, allora gli insight che ho proposto non possono essere implementati per design. È praticamente game over. Se guardi ai videogiochi, quanti videogiochi sono costruiti sopra un database transazionale? La risposta è zero. Perché? Perché non puoi ottenere buone prestazioni grafiche implementate su un database transazionale. Non si può fare grafica computerizzata in un database transazionale.
Un database transazionale è molto utile; ti offre la transazionalità, ma ti rinchiude in un mondo in cui quasi tutti gli acceleramenti algoritmici che potresti immaginare non possono essere applicati. Credo che quando iniziamo a pensare agli APS, tali sistemi non presentino nulla di avanzato. Sono rimasti bloccati nel passato da decenni, e lo sono perché al centro del loro design sono completamente basati su un database transazionale che impedisce l’applicazione di qualsiasi insight emerso nel campo degli algoritmi negli ultimi, probabilmente, quattro decenni.
Ecco il nocciolo del problema nel campo del software aziendale. Le decisioni progettuali che prendi nel primo mese di sviluppo del tuo prodotto ti perseguiteranno per decenni, essenzialmente fino alla fine dei tempi. Non puoi fare aggiornamenti una volta che hai definito un design specifico per il tuo prodotto; sei bloccato con esso. Proprio come non puoi semplicemente riconvertire un’auto in un’auto elettrica, se vuoi avere una buona auto elettrica dovrai riprogettare completamente l’auto attorno all’idea che il motore di propulsione sarà elettrico. Non si tratta semplicemente di cambiare il motore e dire: “Ecco un’auto elettrica”. Non funziona così. Questo è uno di quei principi fondamentali di design in cui, una volta deciso di produrre un’auto elettrica, devi ripensare tutto intorno al motore affinché sia adeguato. Sfortunatamente, gli ERP e gli APS, che sono fortemente centrati sul database, temo, non possono utilizzare nessuno di questi insight. È sempre possibile avere una bolla isolata in cui beneficiare di questi trucchi, ma sarà un componente aggiuntivo applicato in maniera forzata; non arriverà mai al nucleo.
Per quanto riguarda le impressionanti capacità di Blue Yonder, vi prego di avere pazienza, poiché Lokad è un concorrente diretto di Blue Yonder, e per me è difficile essere completamente imparziale. Nel mercato del software aziendale bisogna fare affermazioni ridicolmente audaci per restare competitivi. Non sono convinto che ci sia sostanza in tali affermazioni. Metto in discussione l’idea che qualcuno in questo mercato abbia qualcosa che potrebbe essere definito impressionante.
Se vuoi vedere qualcosa di straordinario e ultra-impressionante, guarda l’ultima demo dell’Unreal Engine o gli algoritmi specializzati per i videogiochi. Considera la grafica computerizzata sull’hardware di prossima generazione della PlayStation 5; è assolutamente sbalorditiva. Abbiamo qualcosa di paragonabile in termini di traguardi tecnologici nel campo del software aziendale? Per quanto riguarda Lokad, ho un’opinione fortemente di parte, ma osservando il mercato in generale vedo un oceano di persone che da decenni cercano di massimizzare le performance dei database relazionali. A volte vengono proposti altri tipi di database, come i graph databases, ma questo perde completamente di vista il punto degli insight che ho presentato. Non fornisce nulla di sostanziale per offrire valore al mondo della supply chain.
Il messaggio chiave qui per il pubblico è che si tratta di una questione di design. Dobbiamo assicurarci che le decisioni iniziali che hanno guidato il design del tuo software aziendale non siano quel tipo di scelte che, per design, impediscono l’uso di queste classi di tecniche fin dall’inizio.
La prossima lezione si terrà tra tre settimane, mercoledì alle 15:00 orario di Parigi. Sarà il 13 giugno e ripasseremo il terzo capitolo, che riguarda il personale della supply chain, tratti di personalità sorprendenti e aziende fittizie. La prossima volta parleremo di formaggio. A presto!


