00:18 Einführung
02:18 Hintergrund
12:08 Warum optimieren? 1/2 Prognose mit Holt-Winters
17:32 Warum optimieren? 2/2 - Fahrzeugroutenproblem
20:49 Der bisherige Verlauf
22:21 Hilfswissenschaften (Zusammenfassung)
23:45 Probleme und Lösungen (Zusammenfassung)
27:12 Mathematische Optimierung
28:09 Konvexität
34:42 Stochastizität
42:10 Mehrziel
46:01 Solver-Design
50:46 Tiefgreifende (Lern-)Lektionen
01:10:35 Mathematische Optimierung
01:10:58 “Wahres” Programmieren
01:12:40 Lokale Suche
01:19:10 Stochastischer Gradientenabstieg
01:26:09 Automatische Differentiation
01:31:54 Differentielles Programmieren (ca. 2018)
01:35:36 Fazit
01:37:44 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Mathematische Optimierung ist der Prozess der Minimierung einer mathematischen Funktion. Nahezu alle modernen statistischen Lernverfahren - d.h. Prognosen, wenn wir eine Supply-Chain-Perspektive einnehmen - basieren im Kern auf mathematischer Optimierung. Darüber hinaus beruht die Identifizierung der profitabelsten Entscheidungen, sobald die Prognosen erstellt sind, ebenfalls im Kern auf mathematischer Optimierung. Supply-Chain-Probleme beinhalten häufig viele Variablen. Sie sind auch in der Regel stochastischer Natur. Mathematische Optimierung ist ein Eckpfeiler einer modernen Supply-Chain-Praxis.
Vollständiges Transkript

Willkommen zu dieser Reihe von Supply-Chain-Vorlesungen. Ich bin Joannes Vermorel und heute werde ich “Mathematische Optimierung für die Supply Chain” präsentieren. Mathematische Optimierung ist die klar definierte, formalisierte, algorithmisch handhabbare Methode zur Identifizierung der besten Lösung für ein gegebenes Problem. Alle Prognoseprobleme können als mathematische Optimierungsprobleme betrachtet werden. Alle Entscheidungssituationen in der Supply Chain und außerhalb der Supply Chains können ebenfalls als mathematische Optimierungsprobleme betrachtet werden. Tatsächlich ist die Perspektive der mathematischen Optimierung so fest in unserer modernen Sichtweise der Welt verankert, dass es sehr schwierig geworden ist, das Verb “optimieren” außerhalb des sehr kleinen Rahmens zu definieren, den uns das Paradigma der mathematischen Optimierung gibt.
Die wissenschaftliche Literatur zur mathematischen Optimierung ist umfangreich, ebenso wie das Software-Ökosystem, das Tools für mathematische Optimierung bereitstellt. Leider ist der Großteil davon im Hinblick auf die Supply Chain von sehr geringem Nutzen und Relevanz. Das Ziel dieser Vorlesung ist zweifach: Erstens möchten wir verstehen, wie man überhaupt mathematische Optimierung angehen kann, um etwas Wertvolles und Praktisches aus einer Supply-Chain-Perspektive zu erhalten. Das zweite Element besteht darin, in dieser umfangreichen Landschaft einige der wertvollsten Elemente zu identifizieren, die zu finden sind.

Die formale Definition der mathematischen Optimierung ist einfach: Man denkt an eine Funktion, die in der Regel als Verlustfunktion bezeichnet wird, und diese Funktion liefert reelle Zahlen. Das Ziel besteht darin, den Eingabewert (X0) zu identifizieren, der den besten Wert liefert, der die Verlustfunktion minimiert. Dies ist in der Regel das mathematische Optimierungsparadigma und es ist trügerisch einfach. Wir werden sehen, dass es viele Dinge gibt, die über diese allgemeine Perspektive gesagt werden können.
Dieses Feld wurde meiner Meinung nach, wenn wir in Bezug auf angewandte mathematische Optimierung denken, hauptsächlich unter dem Namen Operationsforschung entwickelt, die wir spezifischer als die klassische Operationsforschung definieren, die von den 1940er bis in die späten 1970er Jahre im 20. Jahrhundert reichte. Die Idee ist, dass sich die klassische Operationsforschung im Vergleich zur mathematischen Optimierung wirklich um Geschäftsprobleme gekümmert hat. Die mathematische Optimierung kümmert sich um die allgemeine Form des Optimierungsproblems, viel weniger darum, ob das Problem irgendeine Art von geschäftlicher Bedeutung hat. Im Gegenteil, die klassische Operationsforschung hat im Wesentlichen Optimierung betrieben, aber nicht bei Problemen - sondern bei Problemen, die als wichtig für Unternehmen identifiziert wurden.
Interessanterweise sind wir von der Operationsforschung zur mathematischen Optimierung sozusagen auf die gleiche Weise gewechselt, wie wir vom Forecasting gewechselt sind, das zu Beginn des 20. Jahrhunderts als ein Bereich entstand, der sich mit der allgemeinen Vorhersage zukünftiger wirtschaftlicher Aktivitätsniveaus befasste, typischerweise im Zusammenhang mit Zeitreihenprognosen. Dieses Gebiet wurde im Wesentlichen durch maschinelles Lernen abgelöst, das sich breiter mit der Vorhersage auf einem viel breiteren Spektrum von Problemen befasste. Man könnte sagen, dass wir in etwa den gleichen Übergang von der Operationsforschung zur mathematischen Optimierung hatten wie von der Prognose zum maschinellen Lernen. Als ich sagte, dass die klassische Ära der Operationsforschung bis in die späten 70er Jahre ging, hatte ich ein ganz bestimmtes Datum im Sinn. Im Februar 1979 veröffentlichte Russell Ackoff einen beeindruckenden Artikel mit dem Titel “The Future of Operational Research is Past”. Um diesen Artikel zu verstehen, der meiner Meinung nach wirklich ein Meilenstein in der Geschichte der Optimierungswissenschaft ist, muss man verstehen, dass Russell Ackoff im Wesentlichen einer der Gründungsväter der Operationsforschung ist.
Als er diesen Artikel veröffentlichte, war er kein junger Mann mehr; er war 60 Jahre alt. Ackoff wurde 1919 geboren und hatte praktisch seine gesamte Karriere lang an Operationsforschung gearbeitet. Als er seinen Artikel veröffentlichte, stellte er im Grunde genommen fest, dass die Operationsforschung gescheitert war. Sie lieferte nicht nur keine Ergebnisse, sondern das Interesse an der Branche nahm ab, sodass das Interesse am Ende der 90er Jahre geringer war als vor 20 Jahren.
Das Interessante daran zu verstehen ist, dass die Ursache absolut nicht darin liegt, dass die Computer damals viel schwächer waren als diejenigen, die wir heute haben. Das Problem hat nichts mit der Begrenzung der Rechenleistung zu tun. Wir befinden uns am Ende der 70er Jahre; Computer sind im Vergleich zu dem, was wir heute haben, sehr bescheiden, aber sie können immer noch Millionen von arithmetischen Operationen in angemessener Zeit durchführen. Das Problem hängt nicht mit der Begrenzung der Rechenleistung zusammen, insbesondere zu einer Zeit, in der die Rechenleistung unglaublich schnell voranschreitet.
Übrigens ist dieser Artikel eine fantastische Lektüre. Ich empfehle dem Publikum wirklich, einen Blick darauf zu werfen; Sie können ihn leicht mit Ihrer bevorzugten Suchmaschine finden. Dieser Artikel ist sehr zugänglich und gut geschrieben. Obwohl die Art von Problemen, auf die Ackoff in diesem Artikel hinweist, auch vier Jahrzehnte später noch sehr stark mitschwingt, ist der Artikel in vielerlei Hinsicht sehr vorausschauend für viele der Probleme, die die heutigen Supply Chains immer noch plagen.
Also, was ist dann das Problem? Das Problem besteht darin, dass dieses Paradigma, bei dem man eine Funktion nimmt und sie optimiert, beweisen kann, dass der Optimierungsprozess eine gute oder vielleicht optimale Lösung identifiziert. Wie beweisen Sie jedoch, dass die Verlustfunktion, die Sie tatsächlich optimieren, für das Geschäft von Interesse ist? Das Problem ist, dass, wenn ich sage, dass wir ein bestimmtes Problem oder eine bestimmte Funktion optimieren können, was ist, wenn das, was Sie optimieren, tatsächlich eine Fantasie ist? Was ist, wenn diese Sache nichts mit der Realität des Geschäfts zu tun hat, das Sie optimieren möchten?
Hier liegt der Kern des Problems, und hier liegt der Grund, warum diese frühen Versuche im Grunde alle gescheitert sind. Es stellte sich heraus, dass, wenn man eine Art mathematischen Ausdruck erschafft, der das Interesse des Unternehmens darstellen soll, man eine mathematische Fantasie erhält. Das ist wörtlich das, worauf Russell Ackoff in diesem Artikel hinweist, und er ist an einem Punkt seiner Karriere angelangt, an dem er dieses Spiel schon sehr lange spielt und erkennt, dass es im Grunde nirgendwohin führt. In seinem Artikel teilt er die Ansicht, dass das Feld gescheitert ist, und er stellt seine Diagnose, hat aber nicht viel Lösung anzubieten. Es ist sehr interessant, weil einer der Gründungsväter, ein sehr angesehener und anerkannter Forscher, sagt, dass dieses gesamte Forschungsfeld eine Sackgasse ist. Er wird den Rest seines Lebens, das noch ziemlich lang ist, vollständig von einer quantitativen Perspektive auf die Optimierung von Geschäftsprozessen zu einer qualitativen Perspektive übergehen. Er wird die letzten drei Jahrzehnte seines Lebens qualitative Methoden anwenden und nach diesem Wendepunkt noch sehr interessante Arbeiten produzieren.
Nun, was machen wir in Bezug auf diese Vortragsreihe, denn die Punkte, die Russell Ackoff über Operationsforschung anspricht, sind auch heute noch sehr relevant? Tatsächlich habe ich bereits begonnen, die größten Probleme anzugehen, auf die Ackoff hingewiesen hat, und damals hatten er und seine Kollegen keine Lösungen anzubieten. Sie konnten das Problem diagnostizieren, aber sie hatten keine Lösung. In dieser Vortragsreihe sind die Lösungen, die ich vorschlage, methodischer Natur, genau wie die Tatsache, dass Ackoff darauf hinweist, dass es ein tiefgreifendes methodisches Problem mit dieser Perspektive der Operationsforschung gibt.
Die von mir vorgeschlagenen Methoden sind im Wesentlichen zweifach: auf der einen Seite das Supply Chain-Personal und auf der anderen Seite die Methode mit dem Titel experimentelle Optimierung, die sich als wirklich ergänzend zur mathematischen Optimierung erweist. Außerdem positioniere ich mich anders als die Operationsforschung, die behauptet, von geschäftlichem Interesse oder geschäftlicher Relevanz zu sein. Die Art und Weise, wie ich das Problem heute angehe, erfolgt nicht durch den Blickwinkel oder die Perspektive der Operationsforschung. Ich gehe das Problem durch die Brille der mathematischen Optimierung an, die ich als reine Hilfswissenschaft für die Supply Chain positioniere. Ich sage, dass mathematische Optimierung für die Supply Chain nichts Intrinsisch Fundamentales hat; sie ist nur von grundlegender Bedeutung. Sie ist nur ein Mittel, kein Zweck. Das ist der Unterschied. Der Punkt mag sehr einfach sein, aber er hat große Bedeutung, wenn es darum geht, tatsächlich vorhersagefähige Ergebnisse mit dem Ganzen zu erzielen.

Warum wollen wir überhaupt optimieren? Die meisten Prognosealgorithmen haben ein mathematisches Optimierungsproblem als Kern. Auf diesem Bildschirm sehen Sie den sehr klassischen multiplikativen Holt-Winters-Zeitreihenprognosealgorithmus. Dieser Algorithmus ist hauptsächlich von historischem Interesse; Ich würde keinem heutigen Supply Chain empfehlen, diesen spezifischen Algorithmus tatsächlich zu nutzen. Aber der Einfachheit halber handelt es sich um eine sehr einfache parametrische Methode, und sie ist so prägnant, dass Sie sie tatsächlich vollständig auf einem Bildschirm anzeigen können. Sie ist nicht einmal besonders ausführlich.
Alle Variablen, die Sie auf dem Bildschirm sehen können, sind einfach nur Zahlen; es sind keine Vektoren beteiligt. Im Wesentlichen ist Y(t) Ihre Schätzung; dies ist Ihre Zeitreihenprognose. Hier auf dem Bildschirm wird es H Perioden im Voraus prognostizieren, also ist H so etwas wie der Horizont. Und Sie können denken, dass Sie tatsächlich an Y(t) arbeiten, was im Wesentlichen Ihre Zeitreihe ist. Sie können an wöchentlich aggregierte Verkaufsdaten oder monatlich aggregierte Verkaufsdaten denken. Dieses Modell hat im Wesentlichen drei Komponenten: es hat Lt, was das Niveau ist (Sie haben ein Niveau pro Periode), Bt, was der Trend ist, und St, was eine saisonale Komponente ist. Wenn Sie sagen, dass Sie das Holt-Winters-Modell lernen möchten, haben Sie drei Parameter: Alpha, Beta und Gamma. Diese drei Parameter sind im Wesentlichen nur Zahlen zwischen null und eins. Also haben Sie drei Parameter, alle Zahlen zwischen null und eins, und wenn Sie sagen, dass Sie den Holt-Winters-Algorithmus anwenden möchten, bedeutet das nur, dass Sie die richtigen Werte für diese drei Parameter identifizieren werden, und das ist es. Die Idee ist, dass diese Parameter, Alpha, Beta und Gamma, am besten sind, wenn sie den von Ihnen für Ihre Prognose angegebenen Fehler minimieren. Auf diesem Bildschirm sehen Sie einen mittleren quadratischen Fehler, der sehr klassisch ist.
Der Punkt bei der mathematischen Optimierung besteht darin, eine Methode zu entwickeln, um diese Identifizierung der richtigen Parameterwerte für Alpha, Beta und Gamma durchzuführen. Was können wir tun? Nun, die einfachste und einfachste Methode ist so etwas wie eine Gittersuche. Die Gittersuche würde besagen, dass wir alle Werte erkunden werden. Da es sich um Bruchzahlen handelt, gibt es eine unendliche Anzahl von Werten, also werden wir tatsächlich eine Auflösung wählen, sagen wir Schritte von 0,1, und wir werden in Schritten von 0,1 vorangehen. Da wir drei Variablen zwischen 0 und 1 haben, gehen wir in Schritten von 0,1; das sind etwa 1.000 Iterationen, um durchzugehen und den besten Wert unter Berücksichtigung dieser Auflösung zu identifizieren.
Diese Auflösung ist jedoch ziemlich schwach. 0,1 gibt Ihnen eine Auflösung von etwa 10% auf der Art von Skala, die Sie für Ihre Parameter haben. Vielleicht möchten Sie also 0,01 verwenden, was viel besser ist; das ist eine Auflösung von 1%. Wenn Sie das jedoch tun, explodiert die Anzahl der Kombinationen wirklich. Sie gehen von 1.000 Kombinationen auf eine Million Kombinationen, und Sie sehen, das ist das Problem bei der Gittersuche: Sehr schnell stoßen Sie auf eine kombinatorische Grenze und haben eine enorme Anzahl von Optionen.
Mathematische Optimierung besteht darin, Algorithmen zu entwickeln, die Ihnen mehr Nutzen für Ihre investierten Ressourcen bieten, die Sie für das Problem einsetzen möchten. Können Sie eine viel bessere Lösung als nur eine Brute-Force-Suche erhalten? Die Antwort ist ja, absolut.
Was können wir in diesem Fall tun, um mit weniger Rechenressourcen eine bessere Lösung zu erhalten? Zunächst könnten wir eine Art Gradienten verwenden. Der gesamte Ausdruck für Holt-Winters ist vollständig differenzierbar, mit Ausnahme einer einzigen Division, die ein kleiner Randfall ist und relativ einfach zu behandeln ist. Dieser gesamte Ausdruck, einschließlich der Verlustfunktion, ist vollständig differenzierbar. Wir könnten einen Gradienten verwenden, um unsere Suche zu führen; das wäre ein Ansatz.
Ein anderer Ansatz würde besagen, dass Sie in der Praxis in der Supply Chain möglicherweise Tonnen von Zeitreihen haben. Anstatt also jede einzelne Zeitreihe unabhängig zu behandeln, möchten Sie vielleicht eine Gittersuche für die ersten 1.000 Zeitreihen durchführen und investieren, und dann möchten Sie Kombinationen für Alpha, Beta und Gamma identifizieren, die gut sind. Dann wählen Sie für alle anderen Zeitreihen einfach aus dieser Shortlist von Kandidaten die beste Lösung aus.
Sie sehen, es gibt viele einfache Ideen, wie Sie tatsächlich viel besser abschneiden können als nur mit einem reinen Gittersuchansatz, und das Wesen der mathematischen Optimierung und dann aller Arten von Entscheidungsproblemen kann auch typischerweise als mathematisches Optimierungsproblem betrachtet werden.
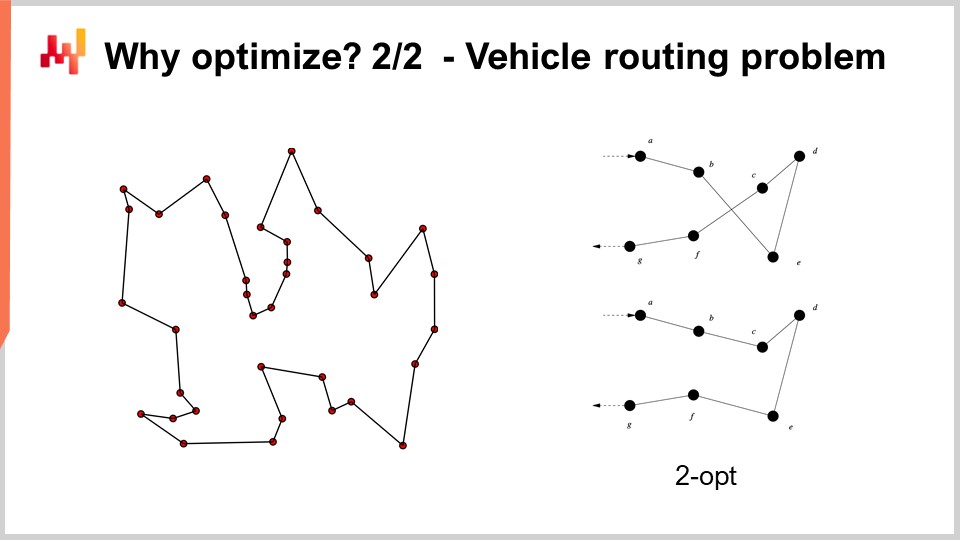
Zum Beispiel kann das auf dem Bildschirm angezeigte Fahrzeugroutenproblem als mathematisches Optimierungsproblem betrachtet werden. Es geht darum, die Liste der Punkte auszuwählen. Ich habe die formale Version des Problems nicht aufgeschrieben, weil sie relativ variabel ist und nicht viel Einblick bietet. Aber wenn Sie darüber nachdenken möchten, können Sie einfach denken: “Ich habe Punkte, ich kann jedem einzelnen Punkt eine Art Pseudorang zuweisen, der nur eine Punktzahl ist, und dann habe ich einen Algorithmus, der alle Punkte nach Pseudorängen in aufsteigender Reihenfolge sortiert, und das ist meine Route.” Das Ziel des Algorithmus besteht darin, die Werte für diese Pseudoränge zu identifizieren, die Ihnen die besten Routen geben.
Nun sehen wir bei diesem Problem, dass Gittersuche plötzlich überhaupt keine Option mehr ist. Wir haben Dutzende von Punkten, und wenn wir alle Kombinationen ausprobieren würden, wäre das viel zu groß. Auch der Gradient wird uns nicht helfen, zumindest ist nicht offensichtlich, wie er uns helfen wird, denn das Problem ist sehr diskret in seiner Natur, und es gibt nichts, was wie ein offensichtlicher Gradientenabstieg für diese Art von Problem ist.
Es stellt sich jedoch heraus, dass es für diese Art von Problem sehr leistungsstarke Heuristiken gibt, die in der Literatur identifiziert wurden. Zum Beispiel gibt Ihnen die von Croes im Jahr 1958 veröffentlichte Two-Opt-Heuristik eine sehr einfache Heuristik. Sie beginnen mit einer zufälligen Route, und in dieser Route wenden Sie immer dann eine Permutation an, um den Überkreuzungspunkt zu entfernen, wenn die Route sich selbst kreuzt. Sie beginnen also mit einer zufälligen Route, und die erste Überkreuzung, die Sie beobachten, führen Sie die Permutation durch, um die Überkreuzung zu entfernen, und dann wiederholen Sie den Vorgang. Sie wiederholen den Prozess mit der Heuristik, bis keine Überkreuzungen mehr vorhanden sind. Was Sie aus dieser sehr einfachen Heuristik erhalten, ist tatsächlich eine sehr gute Lösung. Es ist möglicherweise nicht optimal im eigentlichen mathematischen Sinne, also nicht unbedingt die perfekte Lösung; es ist jedoch eine sehr gute Lösung, und Sie können das mit relativ geringem Aufwand an Rechenressourcen erreichen.
Das Problem bei der Two-Opt-Heuristik ist, dass sie eine sehr feine Heuristik ist, aber sie ist unglaublich spezifisch für dieses eine Problem. Was für die mathematische Optimierung wirklich interessant ist, ist die Identifizierung von Methoden, die auf großen Klassen von Problemen funktionieren, anstatt eine Heuristik zu haben, die nur für eine bestimmte Version eines Problems funktioniert. Wir möchten also sehr allgemeine Methoden haben.
Bisher in dieser Vortragsreihe: Dieser Vortrag ist Teil einer Reihe von Vorträgen, und dieses Kapitel ist den Hilfswissenschaften der Supply Chain gewidmet. Im ersten Kapitel habe ich meine Ansichten zur Supply Chain sowohl als Forschungsfeld als auch als Praxis vorgestellt. Das zweite Kapitel war der Methodik gewidmet, und insbesondere haben wir eine Methodik eingeführt, die für den vorliegenden Vortrag von größter Relevanz ist, nämlich die experimentelle Optimierung. Das ist der Schlüssel zur Lösung des von Russell Ackoff vor Jahrzehnten identifizierten sehr gültigen Problems. Das dritte Kapitel ist ausschließlich dem Supply Chain-Personal gewidmet. In diesem Vortrag konzentrieren wir uns darauf, das Problem zu identifizieren, das wir lösen wollen, anstatt die Lösung und das Problem zusammenzuführen. In diesem vierten Kapitel untersuchen wir alle Hilfswissenschaften der Supply Chain. Es gibt eine Fortschreitung vom niedrigsten Hardware-Level über den Algorithmus-Level bis hin zur mathematischen Optimierung. Wir machen Fortschritte in Bezug auf die Abstraktionsebenen in dieser Reihe.

Nur eine kurze Zusammenfassung der Hilfswissenschaften: Sie bieten eine Perspektive auf die Supply Chain selbst. Der vorliegende Vortrag handelt nicht von der Supply Chain an sich, sondern von einer der Hilfswissenschaften der Supply Chain. Diese Perspektive macht einen signifikanten Unterschied zur klassischen Perspektive der Operationsforschung, die ein Endpunkt sein sollte, im Gegensatz zur mathematischen Optimierung, die ein Mittel zum Zweck ist, aber kein Selbstzweck, zumindest was die Supply Chain betrifft. Mathematische Optimierung kümmert sich nicht um geschäftsspezifische Details, und die Beziehung zwischen mathematischer Optimierung und Supply Chain ist ähnlich wie die Beziehung zwischen Chemie und Medizin. Aus moderner Sicht muss man kein brillanter Chemiker sein, um ein brillanter Arzt zu sein; jedoch würde ein Arzt, der behauptet, nichts über Chemie zu wissen, verdächtig erscheinen.

Mathematische Optimierung geht davon aus, dass das Problem bekannt ist. Es kümmert sich nicht um die Gültigkeit des Problems, sondern konzentriert sich darauf, das Beste aus einem gegebenen Problem in Bezug auf Optimierung herauszuholen. In gewisser Weise ist es wie ein Mikroskop - sehr leistungsstark, aber mit einem unglaublich engen Fokus. Die Gefahr, wenn wir zur Diskussion über die Zukunft der Operationsforschung zurückkehren, besteht darin, dass Sie, wenn Sie Ihr Mikroskop an die falsche Stelle richten, von interessanten, aber letztendlich irrelevanten intellektuellen Herausforderungen abgelenkt werden könnten.
Deshalb muss mathematische Optimierung in Verbindung mit experimenteller Optimierung verwendet werden. Experimentelle Optimierung, die wir im vorherigen Vortrag behandelt haben, ist der Prozess, bei dem Sie mit Rückmeldungen aus der realen Welt iterieren, um bessere Versionen des Problems selbst zu erhalten. Experimentelle Optimierung ist ein Prozess, um nicht die Lösung, sondern das Problem zu verändern, damit Sie iterativ zu einem guten Problem konvergieren können. Das ist der Kern der Sache und das, worauf Russell Ackoff und seine Kollegen damals keine Lösung hatten. Sie hatten die Werkzeuge, um ein gegebenes Problem zu optimieren, aber nicht die Werkzeuge, um das Problem zu verändern, bis das Problem gut war. Wenn Sie ein mathematisches Problem so nehmen, wie Sie es in Ihrem Elfenbeinturm schreiben können, ohne Rückmeldungen aus der realen Welt, dann bekommen Sie eine Fantasie. Ihr Ausgangspunkt, wenn Sie einen experimentellen Optimierungsprozess beginnen, ist nur eine Fantasie. Es braucht das Feedback der realen Welt, um es zum Funktionieren zu bringen. Die Idee ist, zwischen mathematischer Optimierung und experimenteller Optimierung hin und her zu wechseln. In jeder Phase Ihres experimentellen Optimierungsprozesses werden Sie mathematische Optimierungswerkzeuge verwenden. Das Ziel ist es, sowohl die Rechenressourcen als auch die Engineering-Bemühungen zu minimieren und den Prozess zu ermöglichen, sich zur nächsten Version des Problems zu entwickeln.

In diesem Vortrag werden wir zuerst unser Verständnis der mathematischen Optimierungsperspektive verfeinern. Die formale Definition ist trügerisch einfach, aber es gibt Komplexitäten, die wir beachten müssen, um eine praktische Relevanz für Supply Chain-Zwecke zu erreichen. Anschließend werden wir zwei große Klassen von Solvern erkunden, die den Stand der Technik in der mathematischen Optimierung aus Sicht der Supply Chain darstellen.
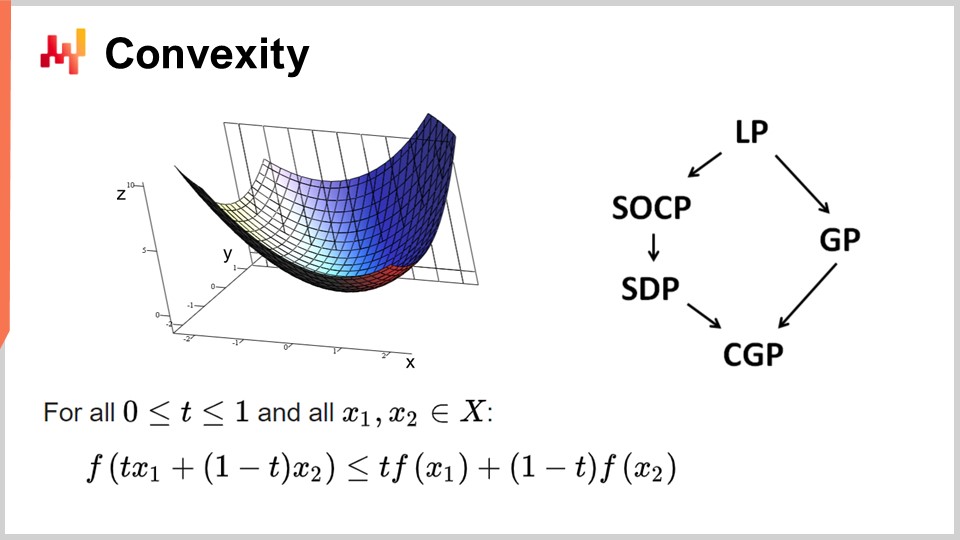
Zuerst wollen wir über Konvexität und frühe Arbeiten in der mathematischen Optimierung sprechen. Die Operationsforschung konzentrierte sich zunächst auf konvexe Verlustfunktionen. Eine Funktion gilt als konvex, wenn sie bestimmte Eigenschaften erfüllt. Intuitiv ist eine Funktion konvex, wenn die Gerade, die zwei Punkte auf der von der Funktion definierten Mannigfaltigkeit verbindet, immer über den Werten liegt, die die Funktion zwischen diesen Punkten annimmt.
Konvexität ist der Schlüssel, um echte mathematische Optimierung zu ermöglichen, bei der man Ergebnisse beweisen kann. Intuitiv bedeutet dies, dass bei einer konvexen Funktion für jeden Punkt der Funktion (jede Kandidatenlösung) immer eine Richtung gefunden werden kann, in der man absteigen kann. Egal wo man anfängt, man kann immer absteigen, und das Absteigen ist immer ein guter Schritt. Der einzige Punkt, an dem man nicht weiter absteigen kann, ist im Wesentlichen der optimale Punkt. Ich vereinfache hier; es gibt Randfälle, bei denen es nicht eindeutige Lösungen oder überhaupt keine Lösungen gibt. Aber abgesehen von einigen Randfällen ist der optimale Punkt der einzige Punkt, an dem man mit einer konvexen Funktion nicht weiter optimieren kann. Ansonsten kann man immer absteigen, und das Absteigen ist ein guter Schritt.
Es wurde eine enorme Menge an Forschung zu konvexen Funktionen betrieben, und im Laufe der Jahre sind verschiedene Programmierparadigmen entstanden. LP steht für lineare Programmierung, und andere Paradigmen umfassen konische Programmierung zweiter Ordnung, geometrische Programmierung (die sich mit Polynomen befasst), semidefinite Programmierung (die Matrizen mit positiven Eigenwerten umfasst) und geometrische konische Programmierung. Diese Frameworks haben alle gemeinsam, dass sie sich mit strukturierten konvexen Problemen befassen. Sie sind sowohl in ihrer Verlustfunktion als auch in den Einschränkungen, die zulässige Lösungen beschränken, konvex.
Diese Frameworks waren von sehr großem Interesse und haben eine intensive wissenschaftliche Literatur hervorgebracht. Trotz ihrer beeindruckend klingenden Namen haben diese Paradigmen jedoch nur sehr wenig Ausdruckskraft. Selbst einfache Probleme überschreiten die Fähigkeiten dieser Frameworks. Zum Beispiel übersteigt die Optimierung der Holt-Winters-Parameter, ein grundlegendes Prognosemodell aus den 1960er Jahren, bereits das, was eines dieser Frameworks leisten kann. Ebenso überschreiten das Fahrzeugroutenproblem und das Problem des Handlungsreisenden, die beide einfache Probleme sind, die Fähigkeiten dieser Frameworks.
Deshalb habe ich am Anfang gesagt, dass es eine enorme Menge an Literatur gibt, aber sehr wenig Nutzen. Der einzige Punkt, an dem man nicht weiter absteigen kann, ist im Wesentlichen der optimale Punkt. Ich vereinfache hier; es gibt Randfälle, bei denen es nicht eindeutige Lösungen oder überhaupt keine Lösungen gibt. Aber abgesehen von einigen Randfällen ist der optimale Punkt der einzige Punkt, an dem man mit einer konvexen Funktion nicht weiter optimieren kann. Ansonsten kann man immer absteigen, und das Absteigen ist ein guter Schritt.
Es wurde eine enorme Menge an Forschung zu konvexen Funktionen betrieben, und im Laufe der Jahre sind verschiedene Programmierparadigmen entstanden. LP steht für lineare Programmierung, und andere Paradigmen umfassen konische Programmierung zweiter Ordnung, geometrische Programmierung (die sich mit Polynomen befasst), semidefinite Programmierung (die Matrizen mit positiven Eigenwerten umfasst) und geometrische konische Programmierung. Diese Frameworks haben alle gemeinsam, dass sie sich mit strukturierten konvexen Problemen befassen. Sie sind sowohl in ihrer Verlustfunktion als auch in den Einschränkungen, die zulässige Lösungen beschränken, konvex.
Diese Frameworks waren von sehr großem Interesse und haben eine intensive wissenschaftliche Literatur hervorgebracht. Trotz ihrer beeindruckend klingenden Namen haben diese Paradigmen jedoch nur sehr wenig Ausdruckskraft. Selbst einfache Probleme überschreiten die Fähigkeiten dieser Frameworks. Zum Beispiel übersteigt die Optimierung der Holt-Winters-Parameter, ein grundlegendes Prognosemodell aus den 1960er Jahren, bereits das, was eines dieser Frameworks leisten kann. Ebenso überschreiten das Fahrzeugroutenproblem und das Problem des Handlungsreisenden, die beide einfache Probleme sind, die Fähigkeiten dieser Frameworks.
Deshalb habe ich am Anfang gesagt, dass es eine enorme Menge an Literatur gibt, aber sehr wenig Nutzen. Ein Teil des Problems lag in einem fehlgeleiteten Fokus auf den rein mathematischen Optimierungslösern. Diese Löser sind aus mathematischer Sicht sehr interessant, weil man mathematische Beweise liefern kann, aber sie können nur mit buchstäblich Spielzeugproblemen oder völlig erfundenen Problemen verwendet werden. Sobald man in der realen Welt ist, versagen sie, und in den letzten Jahrzehnten hat es in diesen Bereichen sehr wenig Fortschritt gegeben. Was die Supply Chain betrifft, haben diese Löser bis auf wenige Nischen kaum Relevanz.

Ein weiterer Aspekt, der während der klassischen Ära der Operationsforschung vollständig missachtet und ignoriert wurde, ist die Zufälligkeit. Zufälligkeit oder Stochastizität ist in zwei radikal unterschiedlichen Weisen von entscheidender Bedeutung. Der erste Weg, dem wir uns der Zufälligkeit nähern müssen, liegt im Löser selbst. Heutzutage nutzen alle modernen Löser umfangreich stochastische Prozesse intern. Dies ist sehr interessant im Gegensatz zu einem vollständig deterministischen Prozess. Ich spreche von den inneren Arbeitsweisen des Löser, dem Softwarestück, das die mathematischen Optimierungstechniken implementiert.
Der Grund, warum alle modernen Löser umfangreich stochastische Prozesse nutzen, hat mit der Art und Weise zu tun, wie moderne Computerhardware existiert. Die Alternative zur Zufälligkeit bei der Erkundung von Lösungen besteht darin, sich daran zu erinnern, was man in der Vergangenheit getan hat, um nicht in der gleichen Schleife stecken zu bleiben. Wenn man sich erinnern muss, wird man Speicher verbrauchen. Das Problem liegt darin, dass wir viele Speicherzugriffe durchführen müssen. Eine Möglichkeit, Zufälligkeit einzuführen, ist in der Regel eine Möglichkeit, den Bedarf an zufälligem Speicherzugriff weitgehend zu verringern.
Indem man den Prozess stochastisch gestaltet, kann man vermeiden, die eigene Datenbank zu sondieren, was man unter den möglichen Lösungen für das zu optimierende Problem getestet oder nicht getestet hat. Man macht es ein wenig zufällig, aber nicht vollständig. Dies hat in praktisch allen modernen Lösern eine entscheidende Bedeutung. Einer der etwas gegenintuitiven Aspekte eines stochastischen Prozesses besteht darin, dass obwohl man einen stochastischen Löser haben kann, das Ergebnis dennoch ziemlich deterministisch sein kann. Um dies zu verstehen, betrachten Sie die Analogie eines Siebes. Ein Sieb ist grundsätzlich ein physischer stochastischer Prozess, bei dem man zufällige Bewegungen anwendet und der Siebprozess stattfindet. Obwohl der Prozess völlig zufällig ist, ist das Ergebnis völlig deterministisch. Am Ende erhält man ein vollständig vorhersehbares Ergebnis aus dem Siebprozess, obwohl der Prozess grundsätzlich zufällig war. Genau das passiert mit gut konstruierten stochastischen Lösern. Dies ist eine der Schlüsselkomponenten moderner Löser.
Ein weiterer Aspekt, der orthogonal zur Zufälligkeit ist, ist die stochastische Natur der Probleme selbst. Dies war in der klassischen Ära der Operationsforschung weitgehend abwesend - die Idee, dass Ihre Verlustfunktion rauschig ist und dass jede Messung, die Sie davon erhalten, einen gewissen Grad an Rauschen aufweisen wird. Dies ist fast immer der Fall in der Supply Chain. Warum? Die Realität ist, dass in der Supply Chain, immer wenn Sie eine Entscheidung treffen, dies geschieht, weil Sie mit zukünftigen Ereignissen rechnen. Wenn Sie sich entscheiden, etwas zu kaufen, geschieht dies, weil Sie erwarten, dass es später in der Zukunft Bedarf dafür geben wird. Die Zukunft ist nicht festgelegt, also können Sie einige Einblicke in die Zukunft haben, aber der Einblick ist nie perfekt. Wenn Sie sich entscheiden, ein Produkt jetzt herzustellen, geschieht dies, weil Sie erwarten, dass es später in der Zukunft eine Nachfrage nach diesem Produkt geben wird. Die Qualität Ihrer Entscheidung, die heute getroffen wird, hängt von zukünftigen unsicheren Bedingungen ab, und daher wird jede Entscheidung, die Sie in der Supply Chain treffen, eine Verlustfunktion haben, die je nach diesen zukünftigen Bedingungen, die nicht kontrolliert werden können, variiert. Die Art der Zufälligkeit, die mit zukünftigen Ereignissen einhergeht, ist irreduzibel, und das ist von großem Interesse, weil es bedeutet, dass wir es grundsätzlich mit stochastischen Problemen zu tun haben.
Wenn wir jedoch zu den klassischen mathematischen Lösern zurückkehren, sehen wir, dass dieser Aspekt völlig abwesend ist, was ein großes Problem darstellt. Das bedeutet, dass wir Klassen von Lösern haben, die die Art von Problemen, mit denen wir konfrontiert werden, nicht einmal erfassen können, weil die Probleme, an denen wir interessiert sind und auf die wir mathematische Optimierung anwenden möchten, eine stochastische Natur haben werden. Ich spreche von dem Rauschen in der Verlustfunktion.
Es gibt einen Einwand, dass man ein stochastisches Problem immer in ein deterministisches Problem zurückverwandeln kann, indem man Stichproben nimmt. Wenn man die rauschige Verlustfunktion 10.000 Mal auswertet, kann man eine annähernd deterministische Verlustfunktion haben. Dieser Ansatz ist jedoch unglaublich ineffizient, da er einen 10.000-fachen Overhead für den Optimierungsprozess einführt. Die mathematische Optimierungsperspektive besteht darin, die besten Ergebnisse für Ihre begrenzten Rechenressourcen zu erzielen. Es geht nicht darum, eine unendlich große Menge an Rechenressourcen zu investieren, um das Problem zu lösen. Wir müssen mit einer begrenzten Menge an Rechenressourcen umgehen, auch wenn diese Menge recht groß ist. Daher müssen wir bei der Betrachtung von Lösern später im Hinterkopf behalten, dass es von vorrangigem Interesse ist, Löser zu haben, die stochastische Probleme von Natur aus erfassen können, anstatt auf den deterministischen Ansatz zurückzugreifen.
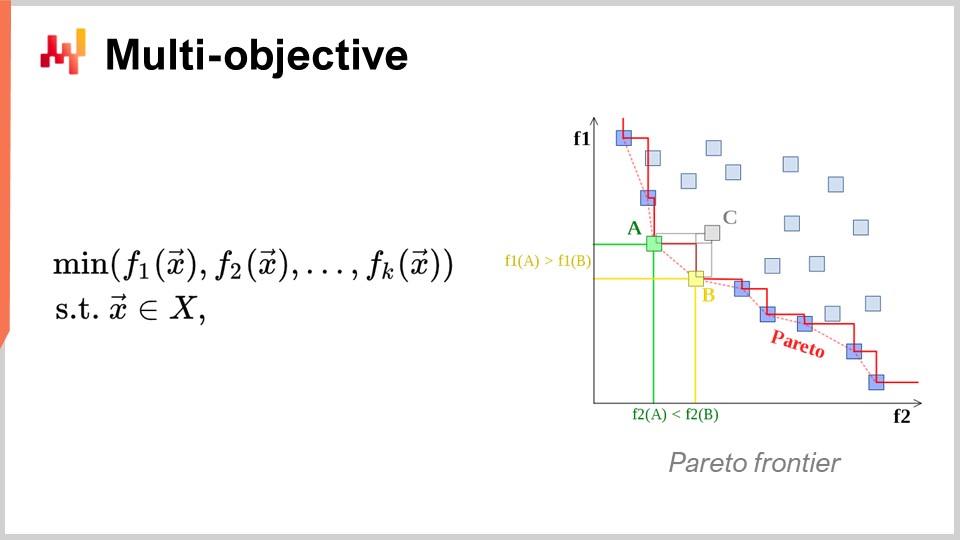
Ein weiterer Aspekt, der ebenfalls von vorrangigem Interesse ist, ist die Mehrzieloptimierung. In der naiven Formulierung des mathematischen Optimierungsproblems habe ich gesagt, dass die Verlustfunktion im Wesentlichen einwertig war, also hatten wir einen Wert, den wir minimieren wollten. Aber was ist, wenn wir einen Vektor von Werten haben und was wir tun wollen, ist die Lösung zu finden, die den niedrigsten Punkt gemäß der lexikographischen Ordnung aller Vektoren gibt, wie f1, f2, f3, usw.?
Warum ist dies überhaupt aus Sicht der Supply Chain interessant? Die Realität ist, dass Sie, wenn Sie diese mehrzielige Perspektive übernehmen, alle Ihre Einschränkungen als nur eine dedizierte Verlustfunktion ausdrücken können. Sie können zuerst eine Funktion haben, die Ihre Einschränkungsverletzung zählt. Warum haben Sie Einschränkungen in der Supply Chain? Nun, Sie haben überall Einschränkungen. Wenn Sie zum Beispiel eine Bestellung aufgeben, müssen Sie sicherstellen, dass Sie genügend Platz in Ihrem Lager haben, um die Waren bei ihrer Ankunft zu lagern. Sie haben also Einschränkungen hinsichtlich des Lagerplatzes, der Produktionskapazität und mehr. Die Idee ist, anstatt einen Solver zu haben, bei dem Sie die Einschränkungen speziell behandeln müssen, ist es interessanter, einen Solver zu haben, der mit mehrzieliger Optimierung umgehen kann und bei dem Sie die Einschränkungen als eines der Ziele ausdrücken können. Sie zählen einfach die Anzahl der Verletzungen der Einschränkungen und möchten diese minimieren, um diese Anzahl von Verletzungen auf null zu bringen.
Der Grund, warum diese Denkweise für die Supply Chain sehr relevant ist, liegt darin, dass die Optimierungsprobleme, mit denen Supply Chains konfrontiert sind, keine kryptografischen Rätsel sind. Dies sind nicht die super engen kombinatorischen Probleme, bei denen entweder Sie eine Lösung haben und sie gut ist, oder Sie sind nur ein Bit von der Lösung entfernt und haben nichts. In der Supply Chain ist es in der Regel völlig trivial, eine sogenannte machbare Lösung zu erhalten - eine Lösung, die alle Einschränkungen erfüllt. Eine Lösung zu identifizieren, die die Einschränkungen erfüllt, ist keine große Aufgabe. Was sehr schwierig ist, ist es, unter allen Lösungen, die die Einschränkungen erfüllen, diejenige zu identifizieren, die für das Unternehmen am profitabelsten ist. Hier wird es sehr schwierig. Eine Lösung zu finden, die die Einschränkungen nicht verletzt, ist sehr einfach. Dies ist nicht der Fall in anderen Bereichen, zum Beispiel in der mathematischen Optimierung für industrielles Design, wo Sie die Komponentenplatzierung in einem Mobiltelefon durchführen möchten. Dies ist ein unglaublich enges Problem und Sie können nicht betrügen, indem Sie auf eine Einschränkung verzichten und eine kleine Beule auf Ihrem Mobiltelefon haben. Es handelt sich um ein Problem, das unglaublich eng und kombinatorisch ist und bei dem Sie Einschränkungen wirklich als Bürger erster Klasse behandeln müssen. Dies ist meiner Meinung nach für die große Mehrheit der Supply Chain-Probleme nicht notwendig. Daher ist es wieder von sehr großem Interesse, Techniken zu haben, die nativ mit mehrzieliger Optimierung umgehen können.
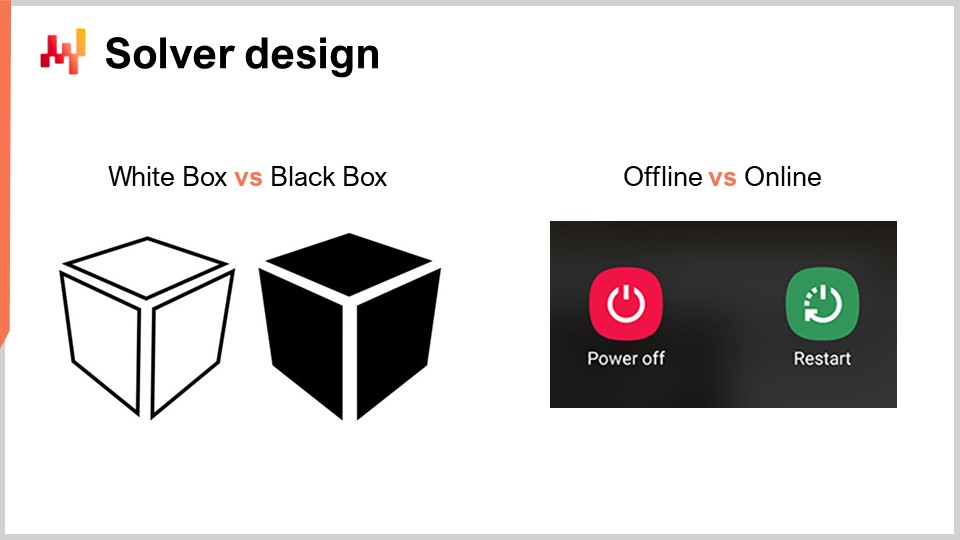
Nun wollen wir etwas genauer über das Design des Solvers diskutieren. Aus einer sehr allgemeinen Perspektive, wie wir eine Software entwickeln möchten, die Lösungen für eine sehr breite Klasse von Problemen liefert, gibt es zwei sehr bemerkenswerte Designaspekte, die ich hervorheben möchte. Der erste Aspekt, den wir berücksichtigen sollten, ist, ob wir aus einer White-Box- oder Black-Box-Perspektive arbeiten möchten. Die Idee einer Black-Box-Perspektive besteht darin, dass wir jedes beliebige Programm verarbeiten können, sodass die Verlustfunktion jedes beliebige Programm sein kann. Es ist uns egal; wir behandeln das als eine vollständige Black Box. Das Einzige, was wir wollen, ist ein Programm, mit dem wir das Programm bewerten und den Wert einer vorläufigen Lösung erhalten können. Im Gegensatz dazu betont ein White-Box-Ansatz die Tatsache, dass die Verlustfunktion selbst eine Struktur hat, die wir inspizieren und nutzen können. Wir können in die Verlustfunktion hineinschauen. Übrigens, als ich ein paar Folien zuvor über Konvexität gesprochen habe, waren all diese Modelle und rein mathematischen Solver wirklich White-Box-Ansätze. Sie sind der Extremfall von White-Box-Ansätzen, bei denen Sie nicht nur in das Problem hineinschauen können, sondern das Problem eine sehr starre Struktur hat, wie zum Beispiel semidefinite Programmierung, bei der die Form sehr eng ist. Ohne jedoch etwas so starres wie ein mathematisches Framework zu verwenden, können Sie zum Beispiel sagen, dass Sie als Teil der White-Box etwas wie den Gradienten haben, der Ihnen hilft. Ein Gradient der Verlustfunktion ist von entscheidendem Interesse, denn plötzlich können Sie wissen, in welche Richtung Sie absteigen möchten, auch wenn Sie kein konvexes Problem haben, bei dem der einfache Gradientenabstieg ein gutes Ergebnis garantiert. Als Faustregel gilt: Wenn Sie Ihren Solver als White-Box gestalten können, haben Sie einen Solver, der im Vergleich zu einem Black-Box-Solver um Größenordnungen leistungsfähiger ist.
Nun, als zweiter Aspekt haben wir Offline- gegenüber Online-Lösern. Der Offline-Löser arbeitet in der Regel im Batch-Modus, d.h. ein Offline-Löser nimmt einfach das Problem, führt es aus und Sie müssen warten, bis es abgeschlossen ist. Zu diesem Zeitpunkt, wenn der Löser fertig ist, gibt er Ihnen die beste Lösung oder etwas, das als beste identifizierte Lösung gilt. Im Gegensatz dazu arbeitet ein Online-Löser viel mehr mit einem Best-Effort-Ansatz. Er wird eine Lösung identifizieren, die akzeptabel ist, und dann rechnerische Ressourcen investieren, um sich im Laufe der Zeit und mit zunehmender Investition von rechnerischen Ressourcen zu besseren Lösungen zu entwickeln. Was wirklich von großem Interesse ist, ist, dass wenn Sie ein Problem mit einem Online-Löser angehen, bedeutet dies, dass Sie den Prozess im Grunde genommen jederzeit anhalten und eine frühe Kandidatenlösung erhalten können. Sie können den Prozess sogar fortsetzen. Wenn wir zu den mathematischen Lösern zurückkehren, handelt es sich in der Regel um Batch-Löser, bei denen Sie bis zum Ende des Prozesses warten müssen.
Leider kann die Arbeit in der Supply Chain-Welt sehr holprig sein, wie in einer der vorherigen Vorlesungen dieser Serie behandelt wurde. Es wird Situationen geben, in denen Sie normalerweise drei Stunden Zeit haben, um diesen mathematischen Optimierungsprozess auszuführen. Aber manchmal können IT-Probleme, reale Probleme oder ein Notfall in Ihrer Supply Chain auftreten. In solchen Fällen ist es ein Lebensretter, wenn das, was normalerweise drei Stunden dauert, nach fünf Minuten unterbrochen werden kann und eine Antwort liefert, auch wenn sie schlecht ist, anstatt überhaupt keine Antwort zu haben. Es gibt ein Sprichwort in der Armee, dass der schlechteste Plan kein Plan ist, also ist es besser, einen sehr groben Plan zu haben, als überhaupt nichts. Genau das bietet Ihnen ein Online-Löser. Dies sind die wichtigsten Designelemente, die wir in der folgenden Diskussion im Hinterkopf behalten werden.
Abschließend wollen wir uns in diesem ersten Teil der Vorlesung über den Umgang mit mathematischer Optimierung die Deep Learning-Lektionen ansehen. Deep Learning hat eine vollständige Revolution für das Gebiet des maschinellen Lernens bedeutet. Aber im Kern hat auch Deep Learning ein mathematisches Optimierungsproblem. Ich glaube, dass Deep Learning eine Revolution innerhalb der mathematischen Optimierung selbst ausgelöst hat und die Art und Weise, wie wir Optimierungsprobleme betrachten, vollständig verändert hat. Deep Learning hat neu definiert, was wir als den Stand der Technik der mathematischen Optimierung betrachten.
Heutzutage beschäftigen sich die größten Deep Learning-Modelle mit mehr als einer Billion Parametern, was tausend Milliarden entspricht. Nur um das in Perspektive zu setzen: Die meisten mathematischen Löser haben Schwierigkeiten, selbst mit 1.000 Variablen umzugehen, und brechen in der Regel bereits bei einigen Zehntausend Variablen zusammen, egal wie viel Rechenhardware Sie einsetzen. Im Gegensatz dazu hat Deep Learning, wenn auch möglicherweise unter Verwendung einer großen Menge an Rechenressourcen, Erfolg. Es gibt Deep Learning-Modelle in der Produktion, die über eine Billion Parameter verfügen, und all diese Parameter werden optimiert, was bedeutet, dass wir mathematische Optimierungsprozesse haben, die auf eine Billion Parameter skalieren können. Das ist absolut beeindruckend und radikal anders als die Leistung, die wir mit klassischen Optimierungsperspektiven gesehen haben.
Das Interessante ist, dass selbst Probleme, die völlig deterministisch sind, wie das Spielen von Go oder Schach, die nicht statistisch, diskret und kombinatorisch sind, am erfolgreichsten mit Methoden gelöst wurden, die völlig stochastisch und statistisch sind. Das ist verwirrend, denn das Spielen von Go oder Schach kann als diskretes Optimierungsproblem betrachtet werden, aber heutzutage werden sie am effizientesten mit Methoden gelöst, die völlig stochastisch und statistisch sind. Das widerspricht der Intuition, die die wissenschaftliche Gemeinschaft vor zwei Jahrzehnten über diese Probleme hatte.
Lassen Sie uns das Verständnis, das durch Deep Learning in Bezug auf mathematische Optimierung freigesetzt wurde, noch einmal überdenken. Das Erste ist, den Fluch der Dimensionalität vollständig zu überdenken. Ich glaube, dass dieses Konzept größtenteils fehlerhaft ist, und Deep Learning beweist, dass man so nicht einmal über die Schwierigkeit eines Optimierungsproblems nachdenken sollte. Es stellt sich heraus, dass, wenn man Klassen von mathematischen Problemen betrachtet, man mathematisch beweisen kann, dass bestimmte Probleme extrem schwer perfekt zu lösen sind. Wenn Sie zum Beispiel schon einmal von NP-schweren Problemen gehört haben, wissen Sie, dass es mit zunehmender Dimension des Problems exponentiell schwieriger wird, es zu lösen. Jede zusätzliche Dimension macht das Problem schwieriger, und es gibt eine kumulative Barriere. Sie können beweisen, dass kein Algorithmus jemals hoffen kann, das Problem perfekt mit einer begrenzten Menge an Rechenressourcen zu lösen. Deep Learning hat jedoch gezeigt, dass diese Perspektive größtenteils fehlerhaft war.
Zunächst müssen wir zwischen der repräsentativen Komplexität des Problems und der inhärenten Komplexität des Problems unterscheiden. Lassen Sie mich diese beiden Begriffe anhand eines Beispiels verdeutlichen. Werfen wir einen Blick auf das Beispiel der Zeitreihenprognose, das zu Beginn gegeben wurde. Angenommen, wir haben eine Verkaufshistorie, die über drei Jahre täglich aggregiert wurde, also haben wir einen Zeitvektor, der über etwa 1.000 Tage aggregiert ist. Dies ist die Darstellung des Problems.
Nun, was ist, wenn ich zu einer Zeitreihendarstellung nach Sekunden wechsle? Dies ist dieselbe Verkaufshistorie, aber anstatt meine Verkaufsdaten in täglichen Aggregaten darzustellen, werde ich diese Zeitreihe, dieselbe Zeitreihe, in Sekundenaggregaten darstellen. Das bedeutet, dass es in jedem einzelnen Tag 86.400 Sekunden gibt, also werde ich die Größe und Dimension meiner Darstellung des Problems um 86.000 aufblähen.
Aber wenn wir über die inhärente Dimension nachdenken, dann erhöhe ich die Komplexität oder die dimensionale Komplexität des Problems nicht um 1.000, nur weil ich eine Verkaufshistorie habe und nicht, weil ich von einer täglichen Aggregation zu einer sekundengenauen Aggregation wechsle. Wahrscheinlich wird die Zeitreihe, wenn ich sie pro Sekunde aggregiere, unglaublich dünn besetzt sein, also werden praktisch alle Buckets größtenteils Nullen sein. Ich erhöhe die interessante Dimensionalität des Problems nicht um den Faktor 100.000. Deep Learning verdeutlicht, dass es nicht darum geht, dass man eine Problemstellung mit vielen Dimensionen hat, dass das Problem grundsätzlich schwierig ist.
Ein weiterer Aspekt, der mit der Dimensionalität zusammenhängt, ist, dass man zwar beweisen kann, dass bestimmte Probleme NP-vollständig sind, zum Beispiel das Problem des Handlungsreisenden (eine vereinfachte Version des zu Beginn dieser Vorlesung vorgestellten Fahrzeugroutenproblems), der Handlungsreisende ist technisch gesehen jedoch ein NP-schweres Problem. Das bedeutet, dass es ein Problem ist, bei dem es exponentiell teuer wird, die beste Lösung im Allgemeinen zu finden, wenn man Punkte zu seiner Karte hinzufügt. Aber die Realität ist, dass diese Probleme sehr einfach zu lösen sind, wie am Beispiel der Two-Opt-Heuristik gezeigt wird; man kann ausgezeichnete Lösungen mit einer minimalen Menge an Rechenressourcen erhalten. Seien Sie also vorsichtig, mathematische Beweise, die zeigen, dass einige Probleme sehr schwer sind, können irreführend sein. Sie sagen Ihnen nicht, dass Sie, wenn Sie mit einer ungefähren Lösung zufrieden sind, eine ausgezeichnete Approximation erhalten können und manchmal sogar eine optimale Lösung. Es ist nur so, dass Sie nicht beweisen können, dass es optimal ist. Das sagt nichts darüber aus, ob Sie das Problem approximieren können, und sehr oft sind diese Probleme, die angeblich von der Fluch der Dimensionalität geplagt sind, einfach zu lösen, weil ihre interessanten Dimensionen nicht so hoch sind. Deep Learning hat erfolgreich gezeigt, dass viele Probleme, die als unglaublich schwierig angesehen wurden, es im Grunde genommen gar nicht sind.
Die zweite Schlüsselerkenntnis waren lokale Minima. Die Mehrheit der Forscher, die an mathematischer Optimierung und Operationsforschung arbeiten, entschied sich für konvexe Funktionen, weil es keine lokalen Minima gab. Eine lange Zeit lang dachten diejenigen, die nicht mit konvexen Funktionen arbeiteten, darüber nach, wie sie es vermeiden könnten, in einem lokalen Minimum stecken zu bleiben. Die meisten Anstrengungen wurden darauf verwendet, an Dingen wie Metaheuristiken zu arbeiten. Deep Learning hat ein neues Verständnis vermittelt: Es ist uns egal, ob es lokale Minima gibt. Dieses Verständnis stammt aus jüngsten Arbeiten aus der Deep Learning Community.
Wenn Sie eine sehr hohe Dimension haben, können Sie zeigen, dass lokale Minima verschwinden, wenn die Dimension des Problems zunimmt. Lokale Minima treten sehr häufig in niedrigdimensionalen Problemen auf, aber wenn Sie die Dimension der Probleme auf Hunderte oder Tausende erhöhen, werden lokale Minima statistisch gesehen unglaublich unwahrscheinlich. So sehr, dass sie bei sehr großen Dimensionen wie Millionen vollständig verschwinden.
Anstatt zu denken, dass eine höhere Dimension Ihr Feind ist, wie es mit dem Fluch der Dimensionalität assoziiert wurde, was wäre, wenn Sie das genaue Gegenteil tun könnten und die Dimension des Problems so weit aufblähen könnten, dass es trivial wird, einen sauberen Abstieg ohne lokale Minima zu haben? Es stellt sich heraus, dass genau das in der Deep Learning Community und mit Modellen, die eine Billion Parameter haben, gemacht wird. Dieser Ansatz bietet Ihnen einen sehr sauberen Weg, um voranzukommen.
Im Wesentlichen hat die Deep Learning Community gezeigt, dass es unwichtig ist, einen Beweis über die Qualität des Abstiegs oder die ultimative Konvergenz zu haben. Es kommt darauf an, wie schnell der Abstieg ist. Sie möchten schnell iterieren und sehr schnell zu einer sehr guten Lösung absteigen. Wenn Sie einen Prozess haben können, der schneller absteigt, werden Sie letztendlich in Bezug auf die Optimierung weiter kommen. Diese Erkenntnisse widersprechen dem allgemeinen Verständnis der mathematischen Optimierung oder dem, was vor zwei Jahrzehnten das vorherrschende Verständnis war.
Es gibt noch andere Lektionen aus dem Deep Learning, da es ein sehr reiches Gebiet ist. Eine davon ist die Hardware-Sympathie. Das Problem bei mathematischen Solvern wie konischen oder geometrischen Programmen ist, dass sie sich zunächst auf mathematische Intuition konzentrieren und nicht auf die Rechenhardware. Wenn Sie einen Solver entwerfen, der Ihre Rechenhardware grundsätzlich bekämpft, egal wie klug Ihre Mathematik sein mag, besteht die Chance, dass Sie aufgrund einer schlechten Nutzung der Rechenhardware verzweifelt ineffizient sind.
Eine der wichtigsten Erkenntnisse der Deep Learning Community ist, dass Sie sich gut mit der Rechenhardware verstehen und einen Solver entwerfen müssen, der sie unterstützt. Deshalb habe ich diese Reihe von Vorlesungen über Hilfswissenschaften für die Supply Chain mit modernen Computern für die Supply Chain begonnen. Es ist wichtig, die Hardware, die Sie haben, zu verstehen und bestmöglich zu nutzen. Diese Hardware-Sympathie ist der Grund, warum Sie Modelle mit einer Billion Parametern erreichen können, vorausgesetzt, Sie benötigen einen großen Cluster von Computern oder einen Supercomputer.
Eine weitere Lektion aus dem Deep Learning ist die Verwendung von Surrogatfunktionen. Traditionell versuchten mathematische Solver, das Problem so zu optimieren, wie es war, ohne davon abzuweichen. Deep Learning hat jedoch gezeigt, dass es manchmal besser ist, Surrogatfunktionen zu verwenden. Zum Beispiel verwenden Deep Learning-Modelle für Vorhersagen sehr häufig Kreuzentropie als Fehlermetrik anstelle des mittleren Quadrats. In der realen Welt interessiert sich praktisch niemand für Kreuzentropie als Metrik, da sie ziemlich bizarr ist.
Warum verwenden die Leute also Kreuzentropie? Sie liefert unglaublich steile Gradienten, und wie Deep Learning gezeigt hat, geht es nur um die Geschwindigkeit des Abstiegs. Wenn Sie sehr steile Gradienten haben, können Sie sehr schnell absteigen. Man könnte einwenden und sagen: “Wenn ich das mittlere Quadrat optimieren möchte, warum sollte ich Kreuzentropie verwenden? Es ist nicht einmal dasselbe Ziel.” Die Realität ist, dass Sie, wenn Sie Kreuzentropie optimieren, sehr steile Gradienten haben werden und am Ende, wenn Sie Ihre Lösung gegen das mittlere Quadrat bewerten, gemäß dem mittleren Quadratkriterium eine bessere Lösung erhalten werden, sehr häufig, wenn nicht immer. Ich vereinfache das nur für diese Erklärung. Die Idee der Surrogatfunktionen besteht darin, dass das eigentliche Problem nicht absolut ist; es ist nur etwas, das Sie zur Kontrolle verwenden, um die endgültige Gültigkeit Ihrer Lösung zu bewerten. Es ist nicht unbedingt etwas, das Sie während des Fortschritts des Solvers verwenden werden. Dies widerspricht völlig den Ideen, die mit den mathematischen Solvern verbunden waren, die in den letzten Jahrzehnten beliebt waren.
Schließlich gibt es die Bedeutung des Arbeitens in Paradigmen. Bei der mathematischen Optimierung gibt es implizit eine Arbeitsteilung bei der Organisation Ihrer Ingenieurteams. Die implizite Arbeitsteilung, die mit mathematischen Solvern verbunden ist, besteht darin, dass Sie auf der einen Seite mathematische Ingenieure haben, die für die Entwicklung des Solvers verantwortlich sind, und auf der anderen Seite Problem-Ingenieure, deren Aufgabe es ist, das Problem in einer für die mathematischen Solver geeigneten Form auszudrücken. Diese Arbeitsteilung war weit verbreitet, und die Idee war, es für den Problem-Ingenieur so einfach wie möglich zu machen, damit er das Problem in der minimalistischsten und reinsten Form ausdrücken kann und der Solver die Arbeit erledigt.
Deep Learning hat gezeigt, dass diese Perspektive zutiefst ineffizient war. Diese willkürliche Arbeitsteilung war überhaupt nicht der beste Weg, das Problem anzugehen. Wenn Sie das tun, landen Sie in Situationen, die unmöglich schwierig sind und den Stand der Technik für die mathematischen Ingenieure, die an dem Optimierungsproblem arbeiten, bei weitem überschreiten. Ein viel besserer Weg besteht darin, dass die Problem-Ingenieure sich etwas mehr Mühe geben, die Probleme so umzurahmen, dass sie für die Optimierung durch den mathematischen Optimierer viel besser geeignet sind.
Das Deep Learning besteht aus einer Reihe von Rezepten, mit denen Sie das Problem auf Ihrem Solver formulieren können, um das Beste aus Ihrem Optimierer herauszuholen. Die meisten Entwicklungen in der Deep Learning-Community konzentrieren sich darauf, diese Rezepte zu entwickeln, die sehr gut darin sind, zu lernen und gleichzeitig gut innerhalb des Paradigmas der verwendeten Solver (z. B. TensorFlow, PyTorch, MXNet) zu funktionieren. Die Schlussfolgerung ist, dass Sie wirklich mit dem Problem-Ingenieur zusammenarbeiten möchten, oder in der Sprache der Supply Chain, dem Supply Chain Scientist.

Kommen wir nun zum zweiten und letzten Abschnitt dieses Vortrags über die wertvollsten Elemente der Literatur. Wir werden uns zwei große Klassen von Solvern ansehen: Local Search und Differentiable Programming.

Zuerst möchte ich noch einmal auf den Begriff “Programming” eingehen. Dieses Wort ist von entscheidender Bedeutung, denn aus Sicht der Supply Chain möchten wir wirklich in der Lage sein, das Problem, mit dem wir konfrontiert sind oder das wir zu haben glauben, auszudrücken. Wir möchten keine Art von super niedrig aufgelöster Version des Problems haben, die zufällig zu einer halb absurden mathematischen Hypothese passt, wie zum Beispiel die Notwendigkeit, Ihr Problem in einem Kegel auszudrücken oder so etwas. Was uns wirklich interessiert, ist der Zugang zu einem echten Programmierparadigma.
Denken Sie daran, dass diese mathematischen Solver wie lineare Programmierung, konvexe Programmierung zweiter Ordnung und geometrische Programmierung alle mit einem Programmier-Keyword geliefert wurden. In den letzten Jahrzehnten hat sich jedoch unsere Erwartung an ein Programmierparadigma dramatisch verändert. Heutzutage möchten wir etwas, das es Ihnen ermöglicht, mit nahezu beliebigen Programmen umzugehen, Programmen, in denen Sie Schleifen, Verzweigungen und möglicherweise Speicherzuweisungen usw. haben. Sie möchten wirklich etwas haben, das so nah wie möglich an einem beliebigen Programm ist, nicht irgendeine Art von super begrenzter Spielzeugversion, die interessante mathematische Eigenschaften hat. In der Supply Chain ist es besser, ungefähr richtig zu sein, als genau falsch.

Um die generische Optimierung zu behandeln, beginnen wir mit der Local Search. Die Local Search ist eine trügerisch einfache mathematische Optimierungstechnik. Der Pseudocode sieht vor, dass Sie mit einer zufälligen Lösung beginnen, die Sie als Bit-Packung darstellen. Sie initialisieren dann Ihre Lösung zufällig und beginnen damit, Bits zufällig umzukehren, um die Nachbarschaft der Lösung zu erkunden. Wenn Sie durch diese zufällige Erkundung eine Lösung finden, die besser ist, wird dies Ihre neue Referenzlösung.
Dieser überraschend leistungsstarke Ansatz kann mit praktisch jedem Programm arbeiten, indem es es als Black Box behandelt, und kann auch von jeder bekannten Lösung aus neu gestartet werden. Es gibt viele Möglichkeiten, diesen Ansatz zu verbessern. Eine Möglichkeit ist die differentielle Berechnung, nicht zu verwechseln mit der differentiellen Berechnung. Die differentielle Berechnung besagt, dass Sie, wenn Sie Ihr Programm auf einer gegebenen Lösung ausführen und dann ein Bit umkehren, das gleiche Programm mit einer differentiellen Ausführung erneut ausführen können, ohne das gesamte Programm erneut ausführen zu müssen. Natürlich kann das Ergebnis variieren und hängt sehr von der Struktur des Problems ab. Eine Möglichkeit, den Prozess zu beschleunigen, besteht darin, nicht zusätzliche Informationen über das Black Box-Programm zu nutzen, mit dem wir arbeiten, sondern das Programm selbst zu beschleunigen, indem es größtenteils als Black Box behandelt wird, da Sie das gesamte Programm nicht jedes Mal erneut ausführen.
Es gibt andere Ansätze, um die Local Search zu verbessern. Sie können die Art der Bewegungen verbessern, die Sie machen. Die einfachste Strategie ist die sogenannten k-Flips, bei der Sie eine bestimmte Anzahl k von Bits umkehren, wobei k eine sehr kleine Zahl ist, etwas zwischen ein paar und einem Dutzend. Anstatt nur Bits umzukehren, können Sie den Problem-Ingenieur bitten, die Art der Mutationen anzugeben, die auf die Lösung angewendet werden sollen. Zum Beispiel können Sie angeben, dass Sie eine Art Permutation in Ihrem Problem anwenden möchten. Die Idee ist, dass diese intelligenten Bewegungen oft die Erfüllung einiger Einschränkungen in Ihrem Problem bewahren, was den Konvergenzprozess der Local Search beschleunigen kann.
Eine weitere Möglichkeit, die Local Search zu verbessern, besteht darin, den Raum nicht vollständig zufällig zu erkunden. Anstatt Bits zufällig umzukehren, können Sie versuchen, die richtigen Richtungen zu erlernen und die vielversprechendsten Bereiche für Umkehrungen zu identifizieren. Einige aktuelle Studien haben gezeigt, dass Sie ein winziges Deep Learning-Modul oben auf der Local Search einsetzen können, das als Generator fungiert. Diese Herangehensweise kann jedoch in Bezug auf die Ingenieursarbeit knifflig sein, da Sie sicherstellen müssen, dass der Overhead, der durch den Machine Learning-Prozess eingeführt wird, einen positiven Nutzen in Bezug auf die Rechenressourcen bringt.
Es gibt noch andere bekannte Heuristiken, und wenn Sie einen sehr guten synthetischen Überblick darüber haben möchten, was es braucht, um eine moderne Local Search Engine zu implementieren, können Sie den Artikel “LocalSolver: A Black-Box Local-Search Solver for 0-1 Programs” lesen. Das Unternehmen, das LocalSolver betreibt, hat auch ein Produkt mit demselben Namen. In diesem Artikel geben sie einen Einblick in die Ingenieursarbeit, die hinter ihrem produktionsreifen Solver steckt. Sie verwenden Multi-Start und Simulated Annealing für bessere Ergebnisse.
Ein Vorbehalt, den ich bei der Local Search hinzufügen würde, ist, dass sie nicht sehr gut oder nativ mit stochastischen Problemen umgeht. Bei stochastischen Problemen ist es nicht so einfach zu sagen “Ich habe eine bessere Lösung” und sofort zu entscheiden, dass sie die beste Lösung wird. Es ist komplizierter als das, und Sie müssen etwas mehr Aufwand betreiben, bevor Sie zur als neue beste bewerteten Lösung springen.

Nun wollen wir uns der zweiten Klasse von Solvern zuwenden, über die wir heute sprechen werden, nämlich dem differentiable programming. Aber zuerst müssen wir das stochastische Gradientenabstiegsverfahren verstehen, um differentiable programming zu begreifen. Der stochastische Gradientenabstieg ist eine iterative, gradientenbasierte Optimierungstechnik. Er entstand als eine Reihe von Techniken, die in den frühen 1950er Jahren entwickelt wurden und somit fast 70 Jahre alt sind. Er blieb fast sechs Jahrzehnte lang relativ spezialisiert, und wir mussten auf den Fortschritt des Deep Learnings warten, um das wahre Potenzial und die Kraft des stochastischen Gradientenabstiegs zu erkennen.
Der stochastische Gradientenabstieg geht davon aus, dass die Verlustfunktion additiv in eine Reihe von Komponenten zerlegt werden kann. In der Gleichung stellt Q(W) die Verlustfunktion dar, die in eine Reihe von Teilfunktionen, Qi, zerlegt wird. Dies ist relevant, da die meisten Lernprobleme als das Erlernen einer Vorhersage basierend auf einer Reihe von Beispielen betrachtet werden können. Die Idee ist, dass Sie Ihre Verlustfunktion als den durchschnittlichen Fehler über den gesamten Datensatz zerlegen können, mit einem lokalen Fehler für jeden Datenpunkt. Viele Supply Chain-Probleme können auch auf diese Weise additiv zerlegt werden. Sie können zum Beispiel Ihr Supply Chain-Netzwerk in eine Reihe von Leistungen für jede einzelne SKU zerlegen, wobei jeder SKU eine Verlustfunktion zugeordnet ist. Die wahre Verlustfunktion, die Sie optimieren möchten, ist die Gesamtverlustfunktion.
Wenn Sie diese Zerlegung haben, die für Lernprobleme sehr natürlich ist, können Sie mit dem stochastischen Gradientenabstiegsverfahren (SGD) iterieren. Der Parametervektor W kann eine sehr große Serie sein, da die größten Deep Learning-Modelle eine Billion Parameter haben. Die Idee ist, dass Sie in jedem Schritt des Prozesses Ihre Parameter aktualisieren, indem Sie eine kleine Menge an Gradienten anwenden. Eta ist die Lernrate, eine kleine Zahl typischerweise zwischen 0 und 1, oft um 0,01. Nabla von Q ist der Gradient für eine Teilverlustfunktion Qi. Überraschenderweise funktioniert dieser Prozess gut.
SGD wird als stochastisch bezeichnet, weil Sie Ihr nächstes i-Element zufällig auswählen, durch Ihren Datensatz springen und bei jedem Schritt eine winzige Menge an Gradienten auf Ihre Parameter anwenden. Das ist das Wesen des stochastischen Gradientenabstiegs.
Es blieb fast sechs Jahrzehnte lang relativ spezialisiert und wurde von der Community weitgehend ignoriert, weil es ziemlich überraschend ist, dass der stochastische Gradientenabstieg überhaupt funktioniert. Er funktioniert, weil er einen ausgezeichneten Kompromiss zwischen dem Rauschen in der Verlustfunktion und den Rechenkosten für den Zugriff auf die Verlustfunktion selbst bietet. Anstatt eine Verlustfunktion zu haben, die gegen den gesamten Datensatz bewertet werden muss, können wir mit dem stochastischen Gradientenabstieg einen Datenpunkt nach dem anderen nehmen und trotzdem einen kleinen Gradienten anwenden. Diese Messung wird sehr bruchstückhaft und rauschig sein, aber dieses Rauschen ist tatsächlich in Ordnung, weil es sehr schnell ist. Sie können Größenordnungen mehr winzige, rauschige Optimierungen durchführen im Vergleich zur Verarbeitung des gesamten Datensatzes.
Überraschenderweise hilft das eingeführte Rauschen dem Gradientenabstieg. Eines der Probleme in hochdimensionalen Räumen besteht darin, dass lokale Minima relativ inexistent werden. Sie können jedoch immer noch große Bereiche von Plateaus haben, in denen der Gradient sehr klein ist und der Gradientenabstieg keine Richtung zum Abstieg hat. Das Rauschen liefert steilere, rauschigere Gradienten, die beim Abstieg helfen.
Was auch interessant am Gradientenabstieg ist, ist, dass es sich um einen stochastischen Prozess handelt, der jedoch kostenlos mit stochastischen Problemen umgehen kann. Wenn Qi eine stochastische Funktion mit Rauschen ist und jedes Mal, wenn Sie sie auswerten, ein zufälliges Ergebnis liefert, müssen Sie nicht einmal eine einzige Zeile des Algorithmus ändern. Der stochastische Gradientenabstieg ist von großem Interesse, weil er Ihnen etwas gibt, das vollständig mit dem Paradigma übereinstimmt, das für Supply-Chain-Zwecke relevant ist.

Die zweite Frage lautet: Woher kommt der Gradient? Wir haben ein Programm und nehmen einfach den Gradienten der Teilverlustfunktion, aber woher kommt dieser Gradient? Wie bekommt man einen Gradienten für ein beliebiges Programm? Es stellt sich heraus, dass es eine sehr elegante, minimalistische Technik gibt, die vor langer Zeit entdeckt wurde und als automatische Differentiation bezeichnet wird.
Die automatische Differentiation entstand in den 1960er Jahren und wurde im Laufe der Zeit verfeinert. Es gibt zwei Arten: den Vorwärtsmodus, der 1964 entdeckt wurde, und den Rückwärtsmodus, der 1980 entdeckt wurde. Die automatische Differentiation kann als Kompilierungstrick betrachtet werden. Die Idee ist, dass Sie ein Programm zum Kompilieren haben und mit automatischer Differentiation haben Sie Ihr Programm, das die Verlustfunktion darstellt. Sie können dieses Programm neu kompilieren, um ein zweites Programm zu erhalten, und die Ausgabe des zweiten Programms ist nicht die Verlustfunktion, sondern die Gradienten aller an der Berechnung der Verlustfunktion beteiligten Parameter.
Darüber hinaus liefert die automatische Differentiation ein zweites Programm mit einer Berechnungskomplexität, die im Wesentlichen identisch mit der Ihres ursprünglichen Programms ist. Das bedeutet, dass Sie nicht nur eine Möglichkeit haben, ein zweites Programm zu erstellen, das die Gradienten berechnet, sondern auch das zweite Programm hat die gleichen Berechnungsmerkmale in Bezug auf die Leistung wie das erste Programm. Es handelt sich um eine konstante Faktor-Inflation in Bezug auf die Berechnungskosten. Die Realität ist jedoch, dass das erhaltene zweite Programm nicht genau die gleichen Speichermerkmale wie das ursprüngliche Programm aufweist. Obwohl die Feinheiten den Rahmen dieses Vortrags überschreiten, können wir das während der Fragen diskutieren. Im Wesentlichen erfordert das zweite Programm, das als Rückwärtsprogramm bezeichnet wird, mehr Speicher und kann in einigen pathologischen Situationen viel mehr Speicher als das ursprüngliche Programm erfordern. Denken Sie daran, dass mehr Speicher Probleme mit der Berechnungsleistung verursacht, da Sie keinen gleichmäßigen Speicherzugriff annehmen können.
Um ein wenig zu veranschaulichen, wie die automatische Differentiation aussieht, gibt es wie erwähnt zwei Modi: Vorwärts- und Rückwärtsmodus. Aus Lern- oder Supply-Chain-Optimierungssicht ist der einzige für uns interessante Modus der Rückwärtsmodus. Was Sie auf dem Bildschirm sehen können, ist eine völlig erfundene Verlustfunktion F. Sie können die Vorwärtsverfolgung sehen, eine Sequenz von arithmetischen oder elementaren Operationen, die stattfinden, um Ihre Funktion für zwei gegebene Eingabewerte X1 und X2 zu berechnen. Dies gibt Ihnen alle elementaren Schritte, die zur Berechnung des endgültigen Werts durchgeführt werden.
Die Idee ist, dass für jeden elementaren Schritt, und die meisten von ihnen sind nur grundlegende arithmetische Operationen wie Multiplikation oder Addition, der Rückwärtsmodus ein Programm ist, das dieselben Schritte in umgekehrter Reihenfolge ausführt. Anstelle der Vorwärtswerte haben Sie die Adjunkten. Für jede arithmetische Operation haben Sie ihren Rückwärtsgegenpart. Der Übergang von der Vorwärtsoperation zum Gegenpart ist sehr einfach.
Auch wenn es kompliziert aussieht, haben Sie eine Vorwärtsausführung und eine Rückwärtsausführung, wobei Ihre Rückwärtsausführung nichts anderes als eine elementare Transformation ist, die auf jede einzelne Operation angewendet wird. Am Ende der Rückwärtsausführung erhalten Sie die Gradienten. Automatische Differentiation mag kompliziert aussehen, ist es aber nicht. Der erste Prototyp, den wir implementiert haben, bestand aus weniger als 100 Zeilen Code, daher ist es sehr einfach und im Wesentlichen ein günstiger Transpilations-Trick.
Nun, das ist interessant, weil wir stochastischen Gradientenabstieg haben, der ein fantastisch leistungsfähiger Optimierungsmechanismus ist. Er ist unglaublich skalierbar, online, Whiteboard und funktioniert nativ mit stochastischen Problemen. Das einzige Problem, das übrig blieb, war, wie man den Gradienten erhält, und mit automatischer Differentiation haben wir den Gradienten für einen festen Overhead oder einen konstanten Faktor für praktisch jedes beliebige Programm. Am Ende erhalten wir differenzierbare Programmierung.
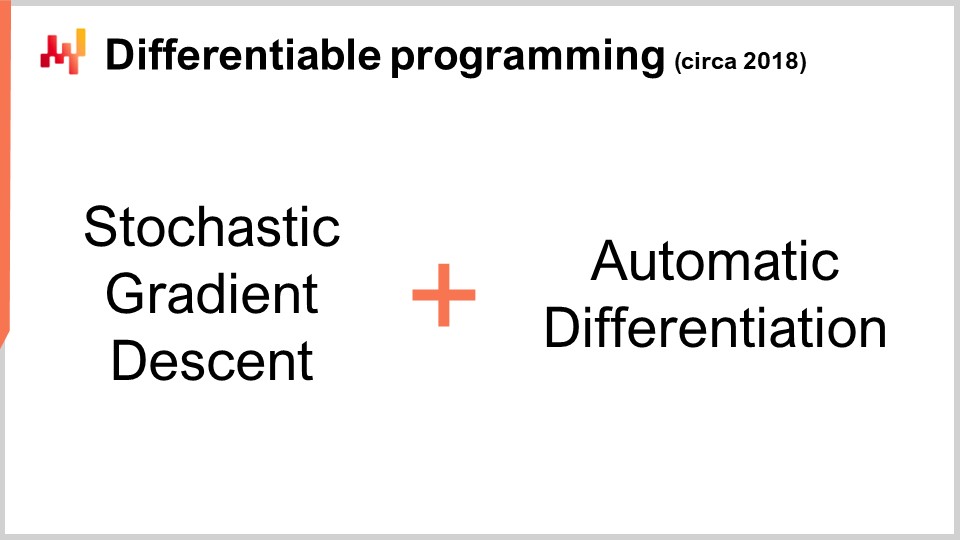
Interessanterweise ist die differenzierbare Programmierung eine Kombination aus stochastischem Gradientenabstieg und automatischer Differentiation. Obwohl diese beiden Techniken, stochastischer Gradientenabstieg und automatische Differentiation, seit Jahrzehnten existieren, wurde die differenzierbare Programmierung erst Anfang 2018 bekannt, als Yann LeCun, der Leiter der KI bei Facebook, begann, über dieses Konzept zu kommunizieren. LeCun hat dieses Konzept nicht erfunden, aber er hat dazu beigetragen, es populär zu machen.
Zum Beispiel hat die Deep-Learning-Community anfangs Backpropagation anstelle von automatischer Differentiation verwendet. Für diejenigen, die mit neuronalen Netzwerken vertraut sind, ist Backpropagation ein komplexer Prozess, der um Größenordnungen komplizierter zu implementieren ist als automatische Differentiation. Automatische Differentiation ist in allen Aspekten überlegen. Mit dieser Erkenntnis hat die Deep-Learning-Community ihre Vorstellung davon, was beim Lernen im Deep Learning zählt, verfeinert. Deep Learning kombiniert mathematische Optimierung mit verschiedenen Lerntechniken, und differenzierbare Programmierung hat sich als ein sauberes Konzept herauskristallisiert, das die nicht-lernenden Teile des Deep Learning isoliert.
Moderne Deep-Learning-Techniken wie das Transformer-Modell gehen davon aus, dass eine differenzierbare Programmierumgebung darunter arbeitet. Dies ermöglicht es Forschern, sich auf die Lernaspekte zu konzentrieren, die darauf aufbauen. Differenzierbare Programmierung ist zwar grundlegend für Deep Learning, aber auch für die Optimierung der Supply Chain und die Unterstützung von Lernprozessen in der Supply Chain, wie statistische Prognosen, von hoher Relevanz.
Ähnlich wie beim Deep Learning gibt es zwei Teile des Problems: differenzierbare Programmierung als Basisschicht und Optimierungs- oder Lerntechniken darauf aufbauend. Die Deep-Learning-Community zielt darauf ab, Architekturen zu identifizieren, die gut mit differenzierbarer Programmierung funktionieren, wie zum Beispiel Transformer. Ebenso muss man die Architekturen identifizieren, die gut für Optimierungszwecke funktionieren. Dies wurde getan, um zu lernen, wie man Go oder Schach in hoch kombinatorischen Umgebungen spielt. In späteren Vorlesungen werden wir Techniken diskutieren, die gut für die optimale Gestaltung der Supply Chain geeignet sind.

Aber jetzt ist es Zeit, abzuschließen. Ein beträchtlicher Teil der Literatur zur Supply Chain und sogar die meisten Softwareimplementierungen sind ziemlich verwirrt, wenn es um mathematische Optimierung geht. Dieser Aspekt wird in der Regel nicht einmal richtig identifiziert, und als Ergebnis mischen sich Praktiker, Forscher und sogar Softwareingenieure, die für Unternehmen arbeiten, oft recht willkürlich in ihre numerischen Rezepte ein, wenn es um mathematische Optimierung geht. Sie haben ein großes Problem, da eine Komponente nicht als mathematische Optimierung erkannt wurde und weil die Menschen nicht einmal wissen, was in der Literatur verfügbar ist, greifen sie oft auf grobe Gittersuchen oder hastige Heuristiken zurück, die zu unregelmäßiger und inkonsistenter Leistung führen. Als Schlussfolgerung dieser Vorlesung sollten Sie sich ab sofort immer fragen, was in Bezug auf mathematische Optimierung geschieht, wenn Sie auf eine numerische Methode oder eine Software zur Supply Chain stoßen, die behauptet, irgendeine Art von analytischer Funktion zu bieten. Wenn Sie feststellen, dass die Anbieter keine kristallklare Sichtweise zu diesem Aspekt bieten, stehen die Chancen gut, dass Sie sich auf der linken Seite der Abbildung befinden, und das ist nicht der Ort, an dem Sie sein möchten.
Nun werfen wir einen Blick auf die Fragen.

Frage: Ist der Übergang zu computergestützten Methoden eine Voraussetzung für Fähigkeiten im Bereich Operations, und werden operative Rollen überflüssig oder umgekehrt?
Zunächst möchte ich einiges klarstellen. Ich glaube, es ist ein Fehler, diese Art von Bedenken an den CIO zu richten. Die Leute erwarten viel zu viel von ihren CIOs. Als Chief Information Officer müssen Sie sich bereits mit der Basisschicht Ihrer Softwareinfrastruktur befassen, wie z.B. Rechenressourcen, transaktionale Systeme auf niedriger Ebene, Netzwerkintegrität und Cybersicherheit. Vom CIO sollte nicht erwartet werden, dass er versteht, was erforderlich ist, um tatsächlich etwas Wertvolles für Ihre Supply Chain zu tun.
Das Problem ist, dass in vielen Unternehmen die Menschen so verzweifelt unwissend sind, was Computerangelegenheiten betrifft, dass der CIO zur Anlaufstelle für alles wird. Die Realität ist, dass sich der CIO mit der Basisschicht der Infrastruktur befassen sollte und dann jeder Spezialist seine spezifischen Anforderungen mit den verfügbaren Rechenressourcen und Softwaretools erfüllen sollte.
Was die Überflüssigkeit operativer Rollen betrifft, so ist es sehr wahrscheinlich, dass Ihre Rolle überflüssig wird, wenn Sie den ganzen Tag lang manuell Excel-Tabellen durchgehen müssen. Dies ist seit 1979 bekannt, als Russell Ackoff seinen Artikel veröffentlichte. Das Problem ist, dass die Leute wussten, dass diese Methode der Entscheidungsfindung nicht die Zukunft war, aber sie blieb lange Zeit der Status quo. Der Kern des Problems ist, dass Unternehmen den experimentellen Prozess verstehen müssen. Ich glaube, es wird einen Übergang geben, bei dem Unternehmen diese Fähigkeiten wiedererlangen. Viele große nordamerikanische Unternehmen hatten nach dem Zweiten Weltkrieg Kenntnisse über Operations Research unter ihren Führungskräften. Es war ein heißes neues Thema, und die Vorstände großer Unternehmen wussten Dinge über Operations Research. Wie Russell Ackoff feststellt, wurden diese Ideen aufgrund des Mangels an Ergebnissen in der Hierarchie des Unternehmens nach unten gedrückt, bis sie sogar vollständig ausgelagert wurden, da sie größtenteils irrelevant waren und keine greifbaren Ergebnisse lieferten. Ich glaube, dass Operations Research nur zurückkehren wird, wenn die Menschen aus den Fehlern der klassischen Ära des Operations Research lernen. Der CIO wird nur einen bescheidenen Beitrag zu diesem Vorhaben leisten; es geht hauptsächlich darum, den Mehrwert der Menschen im Unternehmen neu zu überdenken.
Sie möchten einen kapitalistischen Beitrag leisten, und das geht auf eine meiner früheren Vorlesungen über produktorientierte Lieferung im Sinne von Softwareprodukten für Supply Chains zurück. Der Kernpunkt ist: Welche Art von kapitalistischem Mehrwert liefern Sie Ihrem Unternehmen? Wenn die Antwort keine ist, dann sind Sie möglicherweise nicht Teil dessen, was Ihr Unternehmen werden sollte und in Zukunft sein wird.
Frage: Was ist mit der Verwendung des Excel-Solvers zur Minimierung des MRMSC-Werts und zur Ermittlung des optimalen Werts für Alpha, Beta und Gamma?
Ich glaube, diese Frage ist relevant für den Holt-Winters-Fall, wo Sie tatsächlich eine Lösung mit Gittersuche finden können. Was passiert jedoch in diesem Excel-Solver? Handelt es sich um einen Gradientenabstieg oder etwas anderes? Wenn Sie sich auf den linearen Solver von Excel beziehen, handelt es sich nicht um ein lineares Problem, daher kann Excel in diesem Fall nichts für Sie tun. Wenn Sie andere Solver in Excel oder Add-Ins haben, können sie ja funktionieren, aber dies ist eine sehr veraltete Perspektive. Es umfasst keine stochastischere Sichtweise; die Art der Prognose, die Sie erhalten, ist eine nicht-probabilistische Prognose, was ein veraltetes Konzept ist.
Ich sage nicht, dass Excel nicht verwendet werden kann, aber die Frage ist, welche Art von Programmierfähigkeiten in Excel freigeschaltet werden. Können Sie stochastischen Gradientenabstieg in Excel durchführen? Wahrscheinlich, wenn Sie ein dediziertes Add-In hinzufügen. Excel ermöglicht es Ihnen, jedes beliebige Programm darauf zu installieren. Könnten Sie potenziell differenzierbare Programmierung in Excel durchführen? Ja. Ist es eine gute Idee, es in Excel zu tun? Nein. Um zu verstehen, warum, müssen Sie zum Konzept der produktorientierten Softwarelieferung zurückkehren, das beschreibt, was mit Excel schief läuft. Es kommt auf das Programmiermodell an und ob Sie tatsächlich Ihre Arbeit im Laufe der Zeit mit einem Teamaufwand aufrechterhalten können.
Frage: Optimierungsprobleme sind in der Regel auf die Fahrzeugroutenplanung oder Prognose ausgerichtet. Warum nicht auch die gesamte Supply Chain optimieren? Würde das nicht im Vergleich zur Betrachtung isolierter Bereiche die Kosten senken?
Ich stimme vollkommen zu. Der Fluch der Supply Chain-Optimierung besteht darin, dass wenn Sie eine lokale Optimierung für ein Teilproblem durchführen, Sie das Problem höchstwahrscheinlich verlagern und nicht für die gesamte Supply Chain lösen. Ich stimme vollkommen zu, und sobald Sie sich mit einem komplexeren Problem befassen, haben Sie es mit einem hybriden Problem zu tun - zum Beispiel einem Fahrzeugroutenproblem in Kombination mit einer Auffüllungsstrategie. Das Problem besteht darin, dass Sie einen sehr generischen Solver benötigen, um dies anzugehen, da Sie nicht eingeschränkt sein möchten. Wenn Sie einen sehr generischen Solver haben, benötigen Sie sehr generische Mechanismen anstelle von intelligenten Heuristiken wie dem Two-Opt, der nur für die Fahrzeugroutenplanung gut funktioniert und nicht für etwas, das gleichzeitig eine Kombination aus Auffüllung und Fahrzeugroutenplanung ist.
Um zu dieser ganzheitlichen Perspektive überzugehen, dürfen Sie sich nicht vor dem Fluch der Dimensionalität fürchten. Vor zwanzig Jahren sagten die Leute, dass diese Probleme bereits extrem schwierig und NP-vollständig seien, wie das Problem des Handlungsreisenden, und Sie möchten ein noch schwierigeres Problem lösen, indem Sie es mit einem anderen Problem verflechten. Die Antwort lautet ja; Sie möchten dazu in der Lage sein, und deshalb ist es wichtig, einen Solver zu haben, der es Ihnen ermöglicht, beliebige Programme zu behandeln, da Ihre Lösung die Konsolidierung vieler verflochtener und ineinandergreifender Probleme sein kann.
Tatsächlich ist die Idee, diese Probleme isoliert zu lösen, im Vergleich zur Lösung aller Probleme viel schwächer. Es ist besser, annähernd richtig zu sein als genau falsch. Es ist viel besser, einen sehr schwachen Solver zu haben, der die gesamte Supply Chain als System, als Block, angeht, anstatt fortschrittliche lokale Optimierungen zu haben, die nur Probleme an anderen Stellen schaffen, während Sie lokal mikrooptimieren. Die wahre Optimierung des Systems ist nicht unbedingt die beste Optimierung für jeden Teil, daher ist es natürlich, dass Sie bei der Optimierung für das Interesse des gesamten Unternehmens und seiner gesamten Supply Chain nicht lokal optimal sind, da Sie die anderen Aspekte des Unternehmens und seiner Supply Chain berücksichtigen.
Frage: Nach Durchführung einer Optimierungsübung, wann sollten wir das Szenario überdenken, da jederzeit neue Einschränkungen auftreten können? Die Antwort ist, dass Sie die Optimierung häufig überprüfen sollten. Dies ist die Aufgabe des Supply Chain Scientists, den ich in der zweiten Vorlesung dieser Serie vorgestellt habe. Der Supply Chain Scientist wird die Optimierung so oft wie nötig überprüfen. Wenn eine neue Einschränkung auftritt, wie zum Beispiel ein riesiges Schiff, das den Suezkanal blockiert, war dies unerwartet, aber Sie müssen sich mit dieser Störung in Ihrer Supply Chain befassen. Sie haben keine andere Wahl, als sich mit diesen Problemen auseinanderzusetzen, da das von Ihnen implementierte System unsinnige Ergebnisse erzeugen wird, da es unter falschen Bedingungen arbeiten wird. Selbst wenn Sie keine Notfallsituation haben, möchten Sie trotzdem Ihre Zeit investieren, um über den wahrscheinlichsten Ansatz nachzudenken, der das größte Ergebnis für das Unternehmen generieren kann. Dies ist im Wesentlichen Forschung und Entwicklung. Sie haben das System implementiert, es funktioniert und Sie versuchen nur, Bereiche zu identifizieren, in denen Sie das System verbessern können. Es wird zu einem angewandten Forschungsprozess, der sehr kapitalistisch und unberechenbar ist. Als Supply Chain Scientist verbringen Sie an manchen Tagen den ganzen Tag damit, numerische Methoden zu testen, von denen keine besseren Ergebnisse liefern als das, was Sie bereits haben. An manchen Tagen machen Sie eine kleine Änderung und haben sehr viel Glück, wodurch das Unternehmen Millionen spart. Es ist ein unberechenbarer Prozess, aber im Durchschnitt kann das Ergebnis massiv sein.
Frage: Welche Anwendungsfälle gibt es für Optimierungsprobleme außer linearem Programmieren, ganzzahligem Programmieren, gemischtem Programmieren und im Fall von Weber und Warenkosten?
Ich würde die Frage umkehren: Wo sehen Sie, dass lineares Programmieren für ein Supply Chain-Problem relevant ist? Es gibt praktisch kein Supply Chain-Problem, das linear ist. Mein Einwand ist, dass diese Frameworks sehr vereinfacht sind und nicht einmal Spielprobleme lösen können. Wie gesagt, diese mathematischen Frameworks wie lineares Programmieren können nicht einmal ein Spielproblem wie die Optimierung für einen alten, niedrigdimensionalen parametrischen Prognosemodell im harten Winter angehen. Sie können nicht einmal das Problem des Handlungsreisenden oder so ziemlich irgendetwas anderes lösen.
Ganzzahliges Programmieren oder gemischtes ganzzahliges Programmieren ist nur ein generischer Begriff dafür, dass einige der Variablen ganzzahlig sein werden, aber das ändert nichts daran, dass diese Programmierframeworks nur Spielmathematikframeworks sind, die bei weitem nicht die Ausdrucksstärke haben, um Supply Chain-Probleme anzugehen.
Wenn Sie nach den Anwendungsfällen von Optimierungsproblemen fragen, lade ich Sie ein, sich alle meine Vorlesungen über Supply Chain Personas anzusehen. Wir haben bereits eine Reihe von Supply Chain-Personas und ich liste buchstäblich Tonnen von Problemen auf, die mit mathematischer Optimierung angegangen werden können. In den Vorlesungen über die Supply Chain-Personas haben wir Paris, Miami, Amsterdam und eine Weltserie, und es kommen noch mehr. Wir haben viele Probleme, die angegangen werden müssen und die es verdienen, mit einer angemessenen mathematischen Optimierungsperspektive angegangen zu werden. Sie werden jedoch feststellen, dass Sie für jedes einzelne dieser Probleme nicht in der Lage sein werden, sie innerhalb der super engen und meist seltsamen Einschränkungen zu formulieren, die aus diesen mathematischen Frameworks entstehen. Nochmals, diese mathematischen Frameworks handeln hauptsächlich von Konvexität, und dies ist nicht die richtige Perspektive für die Supply Chain. Die meisten Punkte, mit denen wir uns befassen, sind nicht konvex. Aber das ist in Ordnung; es ist nicht so, dass sie deshalb unmöglich schwer sind. Sehen Sie, es ist nur so, dass Sie am Ende des Tages keinen mathematischen Beweis haben werden. Aber Ihr Chef oder Ihr Unternehmen interessieren sich für Gewinn, nicht dafür, ob Sie einen mathematischen Beweis haben, der die Entscheidung unterstützt. Es geht darum, dass Sie die richtige Entscheidung in Bezug auf Produktion, Auffüllung, Preise, Sortimente und dergleichen treffen können, nicht darum, dass Sie einen mathematischen Beweis für diese Entscheidungen haben.
Frage: Wie lange sollten die Daten des Lernalgorithmus gespeichert werden, um beim Lernen zu helfen?
Nun, ich würde sagen, angesichts der Tatsache, dass die Datenspeicherung heutzutage unglaublich günstig ist, warum sie nicht für immer aufbewahren? Die Datenspeicherung ist so kostengünstig; zum Beispiel gehen Sie einfach in einen Supermarkt und Sie können den Preis für eine Festplatte mit einem Terabyte sehen, der bei etwa 60 liegt oder so. Es ist also unglaublich günstig.
Nun, offensichtlich gibt es eine separate Sorge, dass die Daten, die Sie aufbewahren, zu einer Haftung werden, wenn Sie personenbezogene Daten in Ihren Daten haben. Aber aus Sicht der Supply Chain, wenn wir davon ausgehen, dass Sie zuerst alle personenbezogenen Daten gelöscht haben, weil Sie normalerweise keine personenbezogenen Daten benötigen. Sie müssen keine Kreditkartennummern aufbewahren oder die Namen Ihrer Kunden. Sie müssen nur Kundenidentifikatoren und dergleichen haben. Wenn Sie also alle personenbezogenen Daten aus Ihren Daten löschen, würde ich sagen, wie lange? Nun, behalten Sie sie für immer.
Einer der Punkte in der Supply Chain ist, dass Sie begrenzte Daten haben. Es ist nicht wie bei Deep-Learning-Problemen wie der Bilderkennung, bei denen Sie alle Bilder im Web verarbeiten und auf nahezu unendliche Datenbanken zugreifen können. In der Supply Chain sind Ihre Daten immer begrenzt. Tatsächlich gibt es nur sehr wenige Branchen, in denen es statistisch relevant ist, über ein Jahrzehnt in die Vergangenheit zu schauen, um die Nachfrage für das nächste Quartal vorherzusagen. Aber trotzdem würde ich sagen, es ist immer einfacher, die Daten abzuschneiden, wenn Sie sie benötigen, anstatt festzustellen, dass Sie Daten verworfen haben und sie jetzt fehlen. Also mein Vorschlag ist, alles aufzubewahren, personenbezogene Daten zu löschen und am Ende Ihrer Datenpipeline zu sehen, ob es besser ist, die sehr alten Daten herauszufiltern. Es könnte sein oder auch nicht; es hängt von der Branche ab, in der Sie tätig sind. Zum Beispiel ist es in der Luft- und Raumfahrt relevant, wenn Sie Teile und Flugzeuge mit einer Betriebsdauer von vier Jahrzehnten haben, Daten in Ihrem System für die letzten vier Jahrzehnte zu haben.
Frage: Ist die Mehrzielprogrammierung eine Funktion von zwei oder mehr Zielen, wie die Summe oder Minimierung mehrerer Funktionen in einem Ziel?
Es gibt mehrere Varianten, wie Sie die Mehrziele angehen können. Es geht nicht darum, eine Funktion zu haben, die eine Summe ist, denn wenn Sie die Summe haben, dann geht es nur um die Zerlegung und Struktur der Verlustfunktion. Nein, es geht wirklich darum, einen Vektor zu haben. Und tatsächlich gibt es im Wesentlichen mehrere Arten von Mehrzielprogrammierung. Die interessanteste Variante ist diejenige, bei der Sie eine lexikografische Ordnung anstreben möchten. Soweit die Supply Chain betrifft, kann die Minimierung, wenn Sie den Durchschnitt oder das Maximum der vielen Funktionen nehmen möchten, von Interesse sein, aber ich bin mir nicht sicher. Ich glaube, dass der Mehrzielansatz, bei dem Sie tatsächlich Einschränkungen einbringen und die Einschränkungen als Teil Ihrer regulären Optimierung behandeln können, für die Supply Chain sehr interessant ist. Die anderen Varianten könnten auch interessant sein, aber ich bin mir nicht so sicher. Ich sage nicht, dass sie es nicht sind; ich sage nur, dass ich mir nicht sicher bin.
Frage: Wie würden Sie entscheiden, wann Sie eine Näherungslösung gegen die optimierte Lösung verwenden sollten?
Ich meine, ich bin mir nicht sicher, ob ich die Frage verstehe. Die Idee ist, dass es, wenn es eine Lektion aus dem Deep Learning gibt, zu lernen gibt, dass es keine optimale Lösung gibt. Alles ist eine gewisse Art von Näherung. Selbst wenn Sie sagen, dass Sie Zahlen haben, kommen Zahlen in Computern nicht mit unendlicher Genauigkeit; sie kommen mit endlicher Genauigkeit. Und diese endliche Genauigkeit kann unter bestimmten Umständen auf Sie zurückkommen und Sie beißen. Also die Antwort ist, es ist immer eine Näherung. Ich würde sagen, die größte Lektion ist, dass es eine Illusion ist zu denken, dass es überhaupt eine perfekte Lösung gibt. Es gibt keine perfekte, optimale Lösung. Alle Lösungen, die Sie haben, sind Näherungen, und einige von ihnen sind, würde ich sagen, etwas weniger oder mehr genau. Also, ich bin mir nicht sicher über den Sinn Ihrer Frage, aber aus der mathematischen Optimierungsperspektive bedeutet es, dass Sie eine Verlustfunktion haben, um die Qualität zu bewerten, und am Ende des Tages, wenn Sie zwei konkurrierende Lösungen haben, haben Sie Ihre Verlustfunktion, um festzustellen, welche die beste ist. So funktioniert es.
Frage: Warum wurde die Zeitreihe in Bezug auf historische Daten überhaupt durch 86.400 geteilt?
Das war nicht der Fall. Es war nur ein Beispiel. Ich wollte nur die Situation verdeutlichen und auf einen absurden Zustand hinweisen, bei dem man sieht, dass man bei einer Zeitreihe einen klassischen Zeitreihenprognosealgorithmus verwendet, der als gleichmäßig verteilte Zeitreihe bekannt ist. Es gibt viele Möglichkeiten, Zeitreihen darzustellen, und die typischste Art, Zeitreihen darzustellen, ist die gleichmäßig verteilte Variante von Zeitreihen, bei der man eine Aggregation in gleich langen Buckets durchführt. Das ist typischerweise das Ergebnis einer täglichen oder wöchentlichen Aggregation. Sie haben Buckets, die die gleiche Länge haben, und Ihre Reihe hat eine schöne vektorähnliche Struktur.
Aber was ich betonen möchte, ist, dass dies in hohem Maße willkürlich ist. Sie können sich dafür entscheiden, Daten als tägliche Daten darzustellen, aber Sie könnten sich auch dafür entscheiden, Daten nach Sekunden zu repräsentieren. Würde es jemals Sinn machen, Daten nach Sekunden zu repräsentieren? Die Antwort ist ja, es hängt von der Art der Probleme ab. Wenn Sie zum Beispiel ein Stromversorger sind und ein Netzwerk verwalten möchten, müssen Sie die Leistung in jeder Sekunde verwalten, damit Sie genau das Gleichgewicht zwischen der Stromversorgung in Ihrem Netzwerk und dem Stromverbrauch haben. Und dieses Gleichgewicht wird tatsächlich sekundengenau abgestimmt. Es kann also Situationen geben, in denen es sinnvoll ist, Daten nach Sekunden zu repräsentieren. Für den Verkauf in Ihrem örtlichen Geschäft ergibt es möglicherweise keinen Sinn. Was ich übrigens mit diesen 86.400 sagen wollte, ist einfach 24 Stunden mal 60 Minuten mal 60 Sekunden, und ich wollte verdeutlichen, dass Sie immer eine Repräsentation Ihrer Daten haben und die Repräsentation Ihrer Daten, die mit einer bestimmten Dimensionalität einhergeht, nicht mit der intrinsischen Dimension Ihrer Daten verwechseln sollten, die eine völlig andere Dimension haben kann. Die Repräsentation ist zu einem großen Teil völlig willkürlich und erfunden. Sie gibt Ihnen einen numerischen Indikator, wie zum Beispiel drei Jahre an Daten, sodass Sie einen Vektor der Dimension tausend haben. Aber diese tausend ist etwas, das weitgehend erfunden ist, weil es auf der Entscheidung beruht, Daten täglich zu aggregieren. Wenn Sie sich für einen anderen Zeitraum entscheiden würden, würden Sie eine andere Dimension erhalten. Das ist der Punkt, den ich machen wollte, und das ist es, was Deep Learning wirklich richtig gemacht hat: andere Dinge zu haben, bei denen Sie nicht durch willkürliche Entscheidungen bei der Repräsentation der Daten verwirrt werden. Sie möchten sozusagen repräsentationsunabhängig sein.
Frage: Durch die Einführung der probabilistischen Prognose wechseln wir zu einer Kostenfunktion und Einschränkungen, die probabilistisch sind. Welche Auswirkungen hat dies auf den Prozess der Lösungsfindung?
Nun, es gibt eine sehr grundlegende und fundamentale Einschränkung. Wenn Sie einen Solver haben, der Probleme nicht verarbeiten kann, und denken Sie daran, dass Sie immer von einem stochastischen Problem zu einem deterministischen Problem zurückkehren können, indem Sie das Ergebnis über eine sehr große Anzahl von Stichproben mitteln, dann haben Sie in Bezug auf die Rechenkosten sozusagen ein Problem. Das bedeutet, dass Sie etwa 10.000 Mal mehr Rechenleistung aufwenden müssen, um zu einer zufriedenstellenden Lösung zu gelangen, verglichen mit einer alternativen Lösung. Die Auswirkung besteht darin, dass Sie sicherstellen möchten, dass Ihre mathematische Optimierungswerkzeug, die Infrastruktur, die Sie haben, nativ in der Lage ist, mit stochastischen Problemen umzugehen. Genau das erhalten Sie mit differenzierbarer Programmierung, nicht so sehr mit lokaler Suche, aber Sie können die lokale Suche verbessern oder überarbeiten, damit sie auch in solchen Situationen reibungsloser funktioniert.
Grundsätzlich stellt die probabilistische Prognose nicht nur die Art und Weise, wie Sie in die Zukunft schauen, in Frage, sondern auch die Art von Werkzeugen und Instrumenten, mit denen Sie mit diesen Prognosen arbeiten müssen. Genau das sind die Art von Werkzeugen, die Lokad in den letzten zehn Jahren entwickelt hat. Der Grund dafür ist, dass wir Werkzeuge benötigen, die gut mit den Art von stochastischen Problemen zusammenarbeiten können, die in der Supply Chain unweigerlich auftreten, da praktisch alle Probleme in der Supply Chain eine Komponente der Unsicherheit haben und somit alle in gewissem Maße mit einem stochastischen Problem umgehen.
Ausgezeichnet. Die nächste Vorlesung findet am gleichen Wochentag statt, nämlich am Mittwoch. Es wird einige Ferien dazwischen geben. Die nächste Vorlesung findet am 22. September statt und ich hoffe, euch alle dort zu sehen. Dieses Mal werden wir über maschinelles Lernen für die Supply Chain diskutieren. Bis dann.
Referenzen
- The Future of Operational Research Is Past, Russell L. Ackoff, Februar 1979
- LocalSolver 1.x: A black-box local-search solver for 0-1 programming, Thierry Benoist, Bertrand Estellon, Frédéric Gardi, Romain Megel, Karim Nouioua , September 2011
- Automatic differentiation in machine learning: a survey, Atilim Gunes Baydin, Barak A. Pearlmutter, Alexey Andreyevich Radul, Jeffrey Mark Siskind, zuletzt überarbeitet im Februar 2018


