00:01 Introduzione
01:56 La sfida dell’incertezza M5 - Dati (1/3)
04:52 La sfida dell’incertezza M5 - Regole (2/3)
08:30 La sfida dell’incertezza M5 - Risultati (3/3)
11:59 La storia finora
14:56 Cosa sta per accadere (probabilmente)
15:43 Pinball loss - Fondamenti 1/3
20:45 Binomiale negativa - Fondamenti 2/3
24:04 Modello di stato dello spazio di innovazione (ISSM) - Fondamenti 3/3
31:36 Struttura delle vendite - Il modello REMT 1/3
37:02 Mettendo insieme - Il modello REMT 2/3
39:10 Livelli aggregati - Il modello REMT 3/3
43:11 Apprendimento a singolo stadio - Discussione 1/4
45:37 Pattern completi - Discussione 2/4
49:05 Pattern mancanti - Discussione 3/4
53:20 Limiti del M5 - Discussione 4/4
56:46 Conclusioni
59:27 Prossima lezione e domande del pubblico
Descrizione
Nel 2020, un team di Lokad ha raggiunto il quinto posto su 909 squadre concorrenti nella competizione di previsione M5, una competizione di previsione globale. Tuttavia, a livello di aggregazione SKU, quelle previsioni si sono classificate al primo posto. La previsione della domanda è di primaria importanza per la supply chain. L’approccio adottato in questa competizione si è rivelato atipico e diverso dagli altri metodi adottati dagli altri 50 migliori concorrenti. Ci sono molte lezioni da imparare da questo risultato come preludio per affrontare ulteriori sfide predictive per la supply chain.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Numero uno al livello SKU nella competizione di previsione M5”. Una previsione accurata della domanda è considerata uno dei pilastri dell’ottimizzazione della supply chain. Infatti, ogni singola decisione della supply chain riflette una certa anticipazione del futuro. Se possiamo ottenere informazioni superiori sul futuro, allora possiamo prendere decisioni quantitativamente superiori per i nostri scopi di supply chain. Pertanto, identificare modelli che offrano una previsione accurata all’avanguardia è di primaria importanza e interesse per l’ottimizzazione della supply chain.
Oggi presenterò un semplice modello di previsione delle vendite che, nonostante la sua semplicità, si è classificato al primo posto al livello SKU in una competizione di previsione globale nota come M5, basata su un set di dati fornito da Walmart. Ci saranno due obiettivi per questa lezione. Il primo obiettivo sarà capire cosa serve per ottenere una previsione delle vendite all’avanguardia. Questa comprensione sarà di interesse fondamentale per gli sforzi successivi nella modellazione predittiva. Il secondo obiettivo sarà impostare la giusta prospettiva quando si tratta di modellazione predittiva per scopi di supply chain. Questa prospettiva sarà anche utilizzata per guidare la nostra progressione successiva in questa area di modellazione predittiva per la supply chain.

Il M5 è stata una competizione di previsione che si è svolta nel 2020. Questa competizione prende il nome da Spyros Makridakis, un noto ricercatore nel campo delle previsioni. Questa è stata la quinta edizione di questa competizione. Queste competizioni si svolgono ogni paio di anni e tendono a variare in termini di focus a seconda del tipo di set di dati utilizzato. Il M5 era una sfida legata alla supply chain, poiché il set di dati utilizzato era costituito dai dati dei negozi al dettaglio forniti da Walmart. La sfida M6, che deve ancora avvenire, si concentrerà sulla previsione finanziaria.
Il set di dati utilizzato per il M5 era e rimane un set di dati pubblico. Si trattava di dati aggregati dei negozi al dettaglio Walmart a livello giornaliero. Questo set di dati includeva circa 30.000 SKU, che, dal punto di vista del settore al dettaglio, è un set di dati piuttosto piccolo. Infatti, come regola generale, un singolo supermercato di solito ha circa 20.000 SKU e Walmart gestisce oltre 10.000 negozi. Pertanto, nel complesso, questo set di dati - il set di dati M5 - rappresentava meno dello 0,1% del set di dati su scala mondiale di Walmart che sarebbe rilevante dal punto di vista della supply chain.
Inoltre, come vedremo in seguito, c’erano intere classi di dati mancanti dal set di dati M5. Di conseguenza, la mia stima approssimativa è che questo set di dati sia effettivamente più vicino allo 0,01% della scala di ciò che sarebbe necessario a livello di Walmart. Tuttavia, questo set di dati è più che sufficiente per fare un benchmark molto solido dei modelli di previsione in un contesto reale. In un contesto reale, dovremmo prestare molta attenzione alle questioni di scalabilità. Tuttavia, dal punto di vista di una competizione di previsione, è lecito rendere il set di dati sufficientemente piccolo in modo che la maggior parte dei metodi, anche i metodi ampiamente inefficienti, possano essere utilizzati nella competizione di previsione. Inoltre, ciò garantisce che i concorrenti non siano limitati dalla quantità di risorse di calcolo che possono effettivamente utilizzare in questa competizione di previsione.
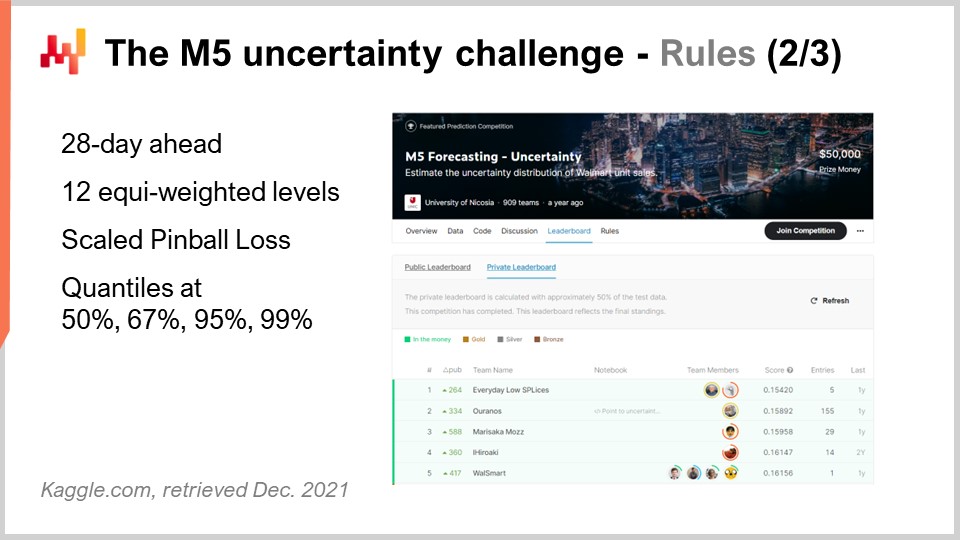
La competizione M5 includeva due sfide distinte note come Accuracy e Uncertainty. Le regole erano semplici: c’era un set di dati pubblico a cui ogni partecipante poteva accedere e, per partecipare a una o entrambe queste sfide, ogni partecipante doveva produrre un proprio set di dati, che era il suo set di dati di previsione, e inviarlo alla piattaforma Kaggle. La sfida Accuracy consisteva nel fornire una previsione media delle serie temporali, che è il tipo più classico di previsione formale. In questa situazione specifica, si trattava di fornire una previsione media giornaliera per circa 40.000 serie temporali. La sfida Uncertainty consisteva nel fornire previsioni quantili. I quantili sono previsioni con un bias; tuttavia, il bias è intenzionale. Questo è il punto principale dei quantili. Questa lezione si concentra esclusivamente sulla sfida Uncertainty e il motivo è che nella supply chain, è la domanda inaspettatamente alta che crea stockout, mentre è la domanda inaspettatamente bassa che crea scritture di inventario. I costi nelle supply chain sono concentrati agli estremi. Non è la media che ci interessa.
Infatti, se guardiamo a cosa significa anche la media nella situazione di Walmart, si scopre che per la maggior parte dei prodotti, nella maggior parte dei negozi, per la maggior parte dei giorni, le vendite medie che verranno osservate sono zero. Pertanto, la maggior parte dei prodotti ha una previsione media frazionaria. Tali previsioni medie sono molto deludenti per quanto riguarda la supply chain. Se le tue opzioni sono o conservare zero o rifornire una unità, le previsioni medie sono di scarsa rilevanza. Il settore al dettaglio non si trova in una posizione unica qui; è praticamente la stessa situazione che stiamo discutendo, che si tratti di FMCG, aviation, manifatturiero o lusso - praticamente ogni altro settore verticale.
Tornando alla sfida dell’incertezza M5, c’erano quattro quantili da produrre, rispettivamente al 50%, 67%, 95% e 99%. Puoi pensare a quei target di quantili come obiettivi di livello di servizio. L’accuratezza di quelle previsioni di quantili è stata valutata rispetto a una metrica nota come funzione di perdita pinball pinball loss function. Tornerò su questa metrica di errore più avanti in questa lezione.

In questa sfida dell’incertezza, c’erano 909 squadre che competevano in tutto il mondo. Una squadra di Lokad si è classificata al quinto posto in generale, ma al primo posto a livello di SKU. Infatti, mentre gli SKU rappresentavano circa tre quarti delle serie temporali in questa sfida, c’erano vari livelli di aggregazione che spaziavano dallo stato (come negli Stati Uniti - Texas, California, ecc.) all’SKU, e tutti i livelli di aggregazione avevano lo stesso peso nel punteggio finale di questa competizione. Pertanto, anche se gli SKU rappresentavano circa tre quarti delle serie temporali, rappresentavano solo circa l'8% del peso totale nel punteggio finale della competizione.
Il metodo utilizzato da questa squadra di Lokad è stato pubblicato in un articolo intitolato “A White Box ISSM Approach to Estimate Uncertainty Distribution of Walmart’s Sales”. Metterò un link a questo articolo nella descrizione di questo video dopo che questa lezione sarà completa. Troverai tutti gli elementi in maggior dettaglio. Per chiarezza e concisione, farò riferimento al modello presentato in questo articolo come modello BRAMPT, semplicemente chiamato così dalle iniziali dei quattro coautori.
Sullo schermo ho elencato i primi cinque risultati per l’M5, ottenuti da un articolo che fornisce informazioni generali sul risultato di questa competizione di previsione. I dettagli del ranking dipendono molto dalla metrica scelta. Questo non è sorprendente. La sfida dell’incertezza ha utilizzato una variante scalata della funzione di perdita pinball. Torneremo su questa metrica di errore tra un minuto. Sebbene la sfida dell’incertezza M5 abbia dimostrato che non abbiamo i mezzi per eliminare l’incertezza con i metodi di previsione che abbiamo, nemmeno lontanamente, non è affatto un risultato sorprendente. Considerando che le vendite dei negozi al dettaglio tendono ad essere erratiche e intermittenti, si sottolinea l’importanza di abbracciare l’incertezza anziché semplicemente respingerla completamente. Tuttavia, è notevole notare che i fornitori di software per la supply chain erano tutti assenti tra i primi 50 posti di questa competizione di previsione, il che è ancora più intrigante considerando che quei fornitori vantano una tecnologia di previsione all’avanguardia presumibilmente superiore.
Ora, questa lezione fa parte di una serie di lezioni sulla supply chain. Questa lezione attuale è la prima di quello che sarà il mio quinto capitolo in questa serie. Questo quinto capitolo sarà dedicato alla modellazione predittiva. Infatti, raccogliere informazioni quantitative è necessario per ottimizzare una supply chain. Ogni volta che viene presa una decisione sulla supply chain - che si tratti di decidere di acquistare materiali, produrre un certo prodotto, spostare scorte da un luogo all’altro o aumentare o diminuire il prezzo di qualcosa che vendi - questa decisione comporta una certa anticipazione della domanda futura. Marginalmente, ogni singola decisione sulla supply chain comporta un’aspettativa incorporata sul futuro. Questa aspettativa può essere implicita e nascosta. Tuttavia, se vogliamo migliorare la qualità della nostra aspettativa sul futuro, dobbiamo rendere concreta questa aspettativa, che di solito viene fatta attraverso una previsione, anche se non necessariamente deve essere una previsione di serie temporali.
Il quinto e presente capitolo si intitola “Modellazione predittiva” anziché “Previsione” per due motivi. Primo, la previsione è quasi sempre associata alla previsione delle serie temporali. Tuttavia, come vedremo in questo capitolo, ci sono molte situazioni della supply chain che non si prestano davvero alla prospettiva della previsione delle serie temporali. Pertanto, sotto questo aspetto, la modellazione predittiva è un termine più neutro. Secondo, è la modellazione che detiene la vera intuizione, non i modelli. Stiamo cercando tecniche di modellazione e è attraverso queste tecniche che possiamo aspettarci di essere in grado di affrontare la pura diversità di situazioni incontrate nelle supply chain del mondo reale.
La presente lezione serve come prologo per il nostro capitolo sulla modellazione predittiva per stabilire che la modellazione predittiva non è una sorta di pensiero utopico sulla previsione, ma che si qualifica come una tecnica di previsione all’avanguardia. Questo si aggiunge a tutti gli altri vantaggi che diventeranno gradualmente chiari man mano che procedo in questo capitolo.
Il resto di questa lezione sarà organizzato in tre parti. Prima, esamineremo una serie di ingredienti matematici, che sono essenzialmente i mattoni del modello BRAMPT. Secondo, assembleremo questi ingredienti per costruire il modello BRAMPT, proprio come è stato durante la competizione M5. Terzo, discuteremo cosa può essere fatto per migliorare il modello BRAMPT e anche per vedere cosa potrebbe essere fatto per migliorare la sfida della previsione stessa, come è stata presentata nella competizione M5.

La sfida dell’incertezza del M5 mira a calcolare stime dei quantili delle vendite future. Un quantile è un punto in una distribuzione unidimensionale e, per definizione, un quantile del 90 percento è il punto in cui c’è una probabilità del 90 percento di essere al di sotto di questo valore di quantità e una probabilità del 10 percento di essere al di sopra di esso. La mediana è, per definizione, il quantile del 50 percento.
La funzione di perdita pinball è una funzione con una profonda affinità per i quantili. Fondamentalmente, per qualsiasi valore di tau compreso tra zero e uno, tau può essere interpretato, da una prospettiva della supply chain, come un obiettivo di livello di servizio. Per qualsiasi valore di tau, il quantile associato a tau si rivela essere il valore all’interno della distribuzione di probabilità che minimizza la funzione di perdita pinball. Sullo schermo, vediamo una semplice implementazione della funzione di perdita pinball, scritta in Envision, il linguaggio di programmazione specifico del dominio di Lokad dedicato agli scopi di ottimizzazione della supply chain. La sintassi è abbastanza simile a Python e dovrebbe essere relativamente trasparente per il pubblico.
Se cerchiamo di scomporre questo codice, abbiamo y, che è il valore reale, y-hat, che è la nostra stima, e tau, che è il nostro obiettivo di quantile. Di nuovo, l’obiettivo di quantile è fondamentalmente l’obiettivo di livello di servizio in termini di supply chain. Vediamo che la sotto-previsione ha un peso pari a tau, mentre la sovrapprezzazione ha un peso pari a uno meno tau. La funzione di perdita pinball è una generalizzazione dell’errore assoluto. Se torniamo a tau uguale a 0,5, possiamo vedere che la funzione di perdita pinball è proprio l’errore assoluto. Se abbiamo una stima che minimizza l’errore assoluto, otteniamo una stima della mediana.
Sullo schermo, puoi vedere un grafico della funzione di perdita pinball. Questa funzione di perdita è asimmetrica e attraverso una funzione di perdita asimmetrica, possiamo ottenere non la previsione media o mediana, ma una previsione con un bias controllato, che è esattamente ciò che vogliamo avere per una stima di quantile. La bellezza della funzione di perdita pinball è la sua semplicità. Se hai una stima che minimizza la funzione di perdita pinball, allora hai una previsione di quantile per costruzione. Pertanto, se hai un modello che ha parametri e guidi l’ottimizzazione dei parametri attraverso la lente della funzione di perdita pinball, ciò che otterrai dal tuo modello è essenzialmente un modello di previsione di quantile.
La sfida dell’incertezza M5 ha presentato una serie di quattro obiettivi di quantile al 50, 67, 95 e 99. Di solito mi riferisco a una serie di obiettivi di quantile come una griglia di quantili. Una griglia di quantili, o previsioni a griglia quantizzata, non sono previsioni probabilistiche complete; è vicino, ma non ancora lì. Con una griglia di quantili, stiamo ancora scegliendo i nostri obiettivi. Ad esempio, se diciamo che vogliamo produrre una previsione di quantile per il 95 percento, la domanda diventa, perché 95, perché non 94 o 96? Questa domanda rimane senza risposta. Ne parleremo più approfonditamente in seguito in questo capitolo, ma non in questa lezione. Diciamo semplicemente che il principale vantaggio che abbiamo con le previsioni probabilistiche è quello di eliminare completamente questo aspetto di scelta arbitraria delle griglie di quantili.
La maggior parte del pubblico è probabilmente familiare con la distribuzione normale, la curva a campana gaussiana che si verifica molto frequentemente nei fenomeni naturali. Una distribuzione di conteggio è una distribuzione di probabilità su ogni intero. A differenza delle distribuzioni reali continue come la distribuzione normale che ti dà una probabilità per ogni singolo intero reale, le distribuzioni di conteggio si preoccupano solo di interi non negativi. Ci sono molte classi di distribuzioni di conteggio; tuttavia, oggi il nostro interesse si concentra sulla distribuzione binomiale negativa, che è utilizzata dal modello REM.
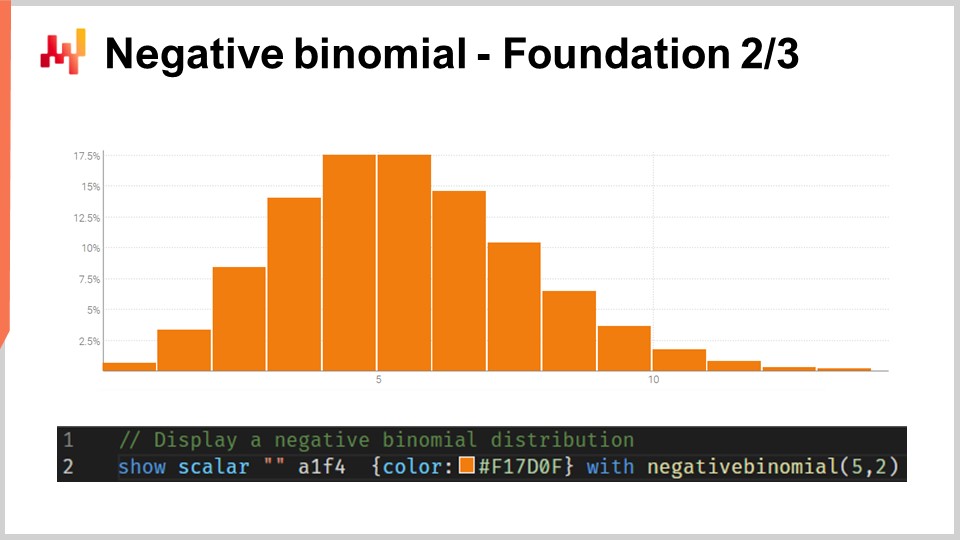
La distribuzione binomiale negativa ha due parametri, proprio come la distribuzione normale, che controllano efficacemente la media e la varianza della distribuzione. Se scegliamo la media e la varianza per una distribuzione binomiale negativa in modo che la maggior parte della massa della distribuzione di probabilità sia lontana da zero, abbiamo un comportamento per la distribuzione binomiale negativa che converge asintoticamente a un comportamento di distribuzione normale se dovessimo far collassare tutti i valori di probabilità verso gli interi più vicini. Tuttavia, se guardiamo a distribuzioni in cui la media è piccola, soprattutto rispetto alla varianza, vedremo che la distribuzione binomiale negativa inizia a divergere significativamente in termini di comportamento rispetto a una distribuzione normale. In particolare, se guardiamo a distribuzioni binomiali negative con medie basse, vedremo che queste distribuzioni diventano altamente asimmetriche, a differenza della distribuzione normale, che rimane completamente simmetrica indipendentemente dalla media e dalla varianza scelta.
Sullo schermo è tracciata una distribuzione binomiale negativa attraverso Envision. La riga di codice utilizzata per produrre questo grafico è visualizzata di seguito. La funzione richiede due argomenti, il che è previsto poiché questa distribuzione ha due parametri, e il risultato è solo una variabile casuale che viene visualizzata come un istogramma. Non entrerò nei dettagli della distribuzione binomiale negativa qui in questa lezione. Questa è teoria delle probabilità semplice. Abbiamo formule analitiche esplicite a forma chiusa per la moda, la mediana, la funzione di distribuzione cumulativa, la skewness, la kurtosi, ecc. La pagina di Wikipedia ti fornisce un riassunto abbastanza decente di tutte queste formule, quindi invito il pubblico a dare un’occhiata se vogliono saperne di più su questo particolare tipo di distribuzione di conteggio.
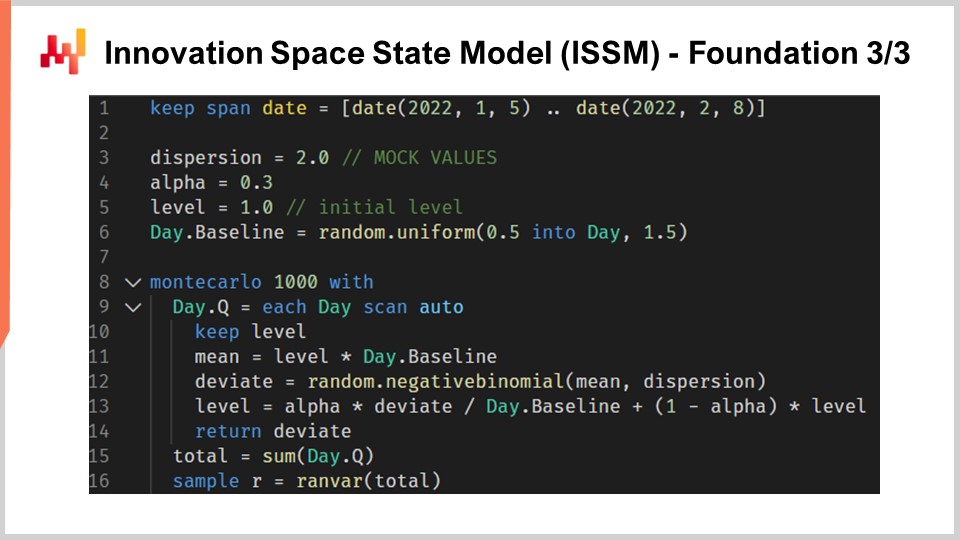
Passiamo al Modello di Stato dello Spazio dell’Innovazione, o ISSM. Il modello di stato dello spazio dell’innovazione è un nome lungo e impressionante per fare qualcosa di piuttosto semplice. Infatti, l’ISSM è un modello che trasforma una serie temporale in un random walk. Con l’ISSM, puoi trasformare una semplice previsione di serie temporale “vanilla”, e quando dico media, intendo una previsione in cui per ogni periodo avrai un valore impostato alla media, in una previsione probabilistica, e non solo una previsione quantile ma direttamente una previsione probabilistica. Sullo schermo, puoi vedere un’implementazione completa dell’ISSM scritta ancora una volta in Envision. Possiamo vedere che sono solo una dozzina di righe di codice, e in realtà, la maggior parte di quelle righe di codice non sta nemmeno facendo molto. L’ISSM è letteralmente molto semplice, e sarebbe molto semplice reimplementare questo pezzo di codice in qualsiasi altro linguaggio, come Python.
Diamo un’occhiata più da vicino ai dettagli di quelle righe di codice. Nella riga uno, sto specificando l’intervallo dei periodi in cui avverrà il random walk. Dal punto di vista del M5, vogliamo un random walk per un periodo di 28 giorni, quindi abbiamo 28 punti, un punto al giorno. Alle righe tre, quattro e cinque, introduciamo una serie di parametri che controlleranno il random walk stesso. Il primo parametro è la dispersione, che verrà utilizzata come argomento per controllare la forma delle binomiali negative che si verificano all’interno del processo ISSM. Poi abbiamo alpha, che è essenzialmente il fattore che controlla il processo di smoothing esponenziale che avviene anche all’interno dell’ISSM. Alla riga cinque, abbiamo il livello, che è solo lo stato iniziale del random walk. Infine, alla riga sei, abbiamo una serie di fattori che sono tipicamente intesi per catturare tutti i modelli del calendario che vogliamo incorporare nel nostro modello di previsione.
Ora, i valori dalle righe tre alla sei vengono forniti solo con un’inizializzazione fittizia. Per motivi di concisione, spiegherò come quei valori vengono effettivamente ottimizzati tra un minuto, ma qui tutte le inizializzazioni che vedi sono solo valori fittizi. Sto persino disegnando valori casuali per la linea di base. Arriveremo a come, in realtà, se vuoi usare questo modello, dovrai inizializzare correttamente quei valori, cosa che faremo più avanti in questa lezione.
Ora diamo un’occhiata al cuore del processo ISSM. Il cuore inizia alla riga otto e inizia con un ciclo di 1000 iterazioni. Ho appena detto che il processo ISSM è un processo per generare random walk, quindi qui stiamo facendo 1000 iterazioni, o faremo 1000 random walk. Potremmo averne di più, potremmo averne di meno; è un processo di Monte Carlo semplice. Poi alla riga nove, facciamo un secondo ciclo. Questo è il ciclo che itera un giorno alla volta per il periodo di interesse. Quindi abbiamo il ciclo esterno, che è essenzialmente un’iterazione per random walk, e poi abbiamo il ciclo interno, che è un’iterazione, passando semplicemente da un giorno all’altro all’interno del random walk stesso.
Alla riga 10, abbiamo un livello di mantenimento. Per mantenere il livello, diciamo semplicemente che questo parametro viene mutato all’interno del ciclo interno, non all’interno del ciclo esterno. Quindi significa che il livello è qualcosa che varia quando passiamo da un giorno all’altro, ma quando passiamo da un random walk all’altro attraverso il ciclo di Monte Carlo, questo livello verrà ripristinato al suo valore iniziale dichiarato sopra. Alla riga 11, calcoliamo la media. La media è il secondo parametro che usiamo per controllare la distribuzione binomiale negativa. Quindi abbiamo la media, abbiamo la dispersione e abbiamo una distribuzione binomiale negativa. Alla riga 12, estraiamo un deviato in base alla distribuzione binomiale normale. Estrarre un deviato significa semplicemente prendere un campione casuale estratto da questa distribuzione di conteggio. Poi alla riga 13, aggiorniamo questo livello in base al deviato che abbiamo visto, e il processo di aggiornamento è solo un processo di smoothing esponenziale molto semplice, guidato dal parametro alfa. Se prendiamo alfa molto grande, uguale a uno, significa che mettiamo tutto il peso sull’ultima osservazione. Al contrario, se dovessimo mettere alfa uguale a zero, significherebbe che avremmo una deriva zero; rimarremmo fedeli alla serie temporale originale come definita nella linea di base.
A proposito, in Envision, quando è scritto “.baseline,” quello che vediamo qui è che c’è una tabella, quindi è una tabella che ha, diciamo, NDM5; che avrebbe 28 valori, e la linea di base è solo un vettore che appartiene a questa tabella. Alla riga 15, raccogliamo tutti i deviati e li sommiamo attraverso “someday.q.” Li inviamo in una variabile chiamata “total,” quindi all’interno di un random walk, abbiamo il totale dei deviati che sono stati raccolti per ogni singolo giorno. Quindi abbiamo il totale delle vendite per 28 giorni. Infine, alla riga 16, stiamo essenzialmente raccogliendo e raccogliendo quei campioni in un “render.” Un render è un oggetto specifico in Envision, che è essenzialmente una distribuzione di probabilità di interi relativi, positivi e negativi.
In sintesi, quello che abbiamo è l’ISSM come generatore casuale di random walk unidimensionali. Nel contesto delle previsioni delle vendite, puoi pensare a quei random walk come possibili osservazioni future per le vendite stesse. È interessante perché non pensiamo alla previsione come alla media o alla mediana; letteralmente pensiamo alla nostra previsione come una possibile istanza di un futuro.

A questo punto, abbiamo raccolto tutto ciò di cui abbiamo bisogno per iniziare a assemblare il modello REMT, che faremo ora.
Il modello REMT adotta una struttura moltiplicativa, che ricorda il modello di previsione di Holt-Winters. Ogni giorno ottiene una linea di base, che è un singolo valore che si rivela essere il prodotto di cinque effetti del calendario. Abbiamo, cioè, il mese dell’anno, il giorno della settimana, il giorno del mese, gli effetti di Natale e Halloween. Questa logica è implementata come uno script Envision conciso.
Envision ha un’algebra relazionale che offre relazioni di broadcast tra tabelle, che sono molto pratiche per questa situazione. Le cinque tabelle che abbiamo costruito, una tabella per ogni pattern del calendario, sono costruite come tabelle di raggruppamento. Quindi, abbiamo la tabella delle date, e la tabella delle date ha una chiave primaria chiamata “date.” Quando scriviamo che dichiariamo una nuova tabella con una aggregazione “by” e poi abbiamo la data, stiamo costruendo una tabella che ha una relazione di broadcast diretta con la tabella delle date.
Se guardiamo specificamente la tabella del giorno della settimana alla riga quattro, stiamo costruendo una tabella che avrà esattamente sette righe. Ogni riga della tabella sarà associata a una sola riga del giorno della settimana. Pertanto, se inseriamo valori in questa tabella del giorno della settimana, possiamo trasmettere quei valori in modo naturale perché ogni riga sul lato del destinatario, sul lato della data, avrà una riga da abbinare in questa tabella del giorno della settimana.
Alla riga nove, con il vettore “de.dot.baseline,” viene calcolato come la moltiplicazione semplice dei cinque fattori sul lato destro dell’assegnazione. Tutti questi fattori vengono prima trasmessi alla tabella delle date, e poi procediamo con una moltiplicazione semplice riga per riga per ogni singola riga nella tabella delle date.
Ora, abbiamo un modello che ha alcune dozzine di parametri. Possiamo contare quei parametri: abbiamo 12 parametri per il mese dell’anno, da 1 a 12; abbiamo sette parametri per il giorno della settimana; e abbiamo 31 parametri per il giorno del mese. Tuttavia, nel caso di NDM5, non stiamo per imparare un valore di parametro distinto per tutti quei valori per ogni singolo SKU, poiché finiremmo con un numero massiccio di parametri che molto probabilmente sovradimensionerebbero l’insieme di dati di Walmart. Invece, a NDM5, è stato fatto leva su un trucco noto come condivisione dei parametri.
La condivisione dei parametri significa che anziché imparare parametri distinti per ogni singolo SKU, stiamo per stabilire sottogruppi e quindi imparare quei parametri a livello di sottogruppo. Quindi, utilizziamo gli stessi valori all’interno di quei gruppi per quei parametri. La condivisione dei parametri è una tecnica molto classica che viene ampiamente utilizzata nel deep learning, anche se precede il deep learning stesso. Durante il M5, il mese dell’anno e il giorno della settimana sono stati appresi a livello di aggregazione del reparto del negozio. Tornerò sui vari livelli di aggregazione del M5 tra un attimo. Il valore del giorno del mese era in realtà un fattore codificato che era impostato a livello di stato, e quando dico stato, mi riferisco agli Stati Uniti, come California, Texas, ecc. Durante il M5, tutti quei parametri del calendario sono stati semplicemente appresi come medie dirette sui loro ambiti correlati. È un modo molto diretto per impostare quei parametri: basta prendere tutti gli SKU che appartengono allo stesso ambito, fare la media di tutto, normalizzare, e hai il tuo parametro.

Ora, a questo punto, abbiamo raccolto tutto per assemblare il modello REMT. Abbiamo visto come costruire la linea di base giornaliera, che incorpora tutti i pattern del calendario. I pattern del calendario sono stati appresi attraverso medie dirette di un certo ambito, che è un meccanismo di apprendimento rudimentale ma efficace. Abbiamo anche visto che l’ISSM trasforma una serie temporale in una random walk. Ci resta solo da stabilire i valori appropriati per i parametri ISSM, ovvero alpha, il parametro utilizzato per il processo di smoothing esponenziale che si è verificato all’interno dell’SSM; la dispersione, che è un parametro utilizzato per controllare la distribuzione binomiale negativa; e il valore iniziale per il livello, che viene utilizzato per inizializzare la nostra random walk.
Durante la competizione M5, il team di Lokad ha utilizzato un’ottimizzazione di ricerca a griglia semplice per apprendere questi tre parametri rimanenti. La ricerca a griglia significa essenzialmente che si iterano tutte le possibili combinazioni di quei valori, passando attraverso piccoli incrementi alla volta. La ricerca a griglia è stata guidata utilizzando la funzione di perdita pinball, che ho descritto in precedenza, per orientare l’ottimizzazione di quei tre parametri. Per ogni SKU, la ricerca a griglia è probabilmente una delle forme più inefficienti di ottimizzazione matematica. Tuttavia, considerando che abbiamo solo tre parametri e che dobbiamo eseguire un’ottimizzazione per ogni serie temporale, e che il dataset M5 stesso è abbastanza piccolo, era adatto per la competizione M5.
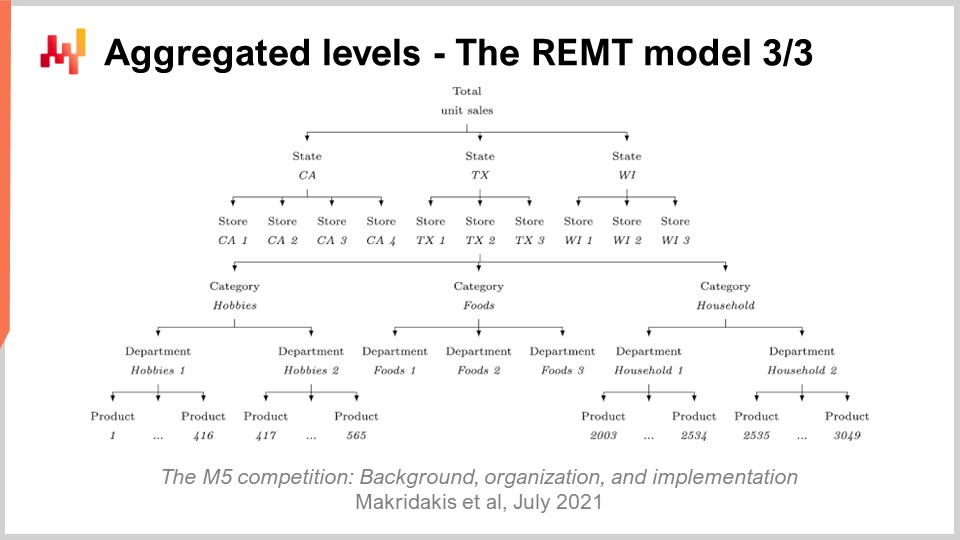
Finora, abbiamo presentato come il modello REMT opera a livello di SKU. Tuttavia, nel M5, c’erano 12 diversi livelli di aggregazione. Il livello di SKU, essendo il livello di disaggregazione più elevato, era il più importante. Un SKU, o unità di conservazione delle scorte, è letteralmente un prodotto in una posizione. Se hai lo stesso prodotto in 10 posizioni, allora hai 10 SKU. Sebbene l’SKU sia probabilmente il livello di aggregazione più rilevante per una supply chain, quasi tutte le decisioni relative all’inventario, come il riapprovvigionamento e l’assortimento, avvengono a livello di SKU. Il M5 era principalmente una competizione di previsione, e quindi c’era molta enfasi sugli altri livelli di aggregazione.
Sullo schermo, questi livelli riassumono i livelli di aggregazione presenti nel dataset M5. Puoi vedere che abbiamo gli stati, come California e Texas. Per gestire i livelli di aggregazione più elevati, il team di Lokad ha utilizzato due tecniche: sommare le random walk, ovvero eseguire le random walk a un livello di aggregazione inferiore, sommarle e quindi ottenere random walk a un livello di aggregazione superiore; o riavviare completamente il processo di apprendimento, passando direttamente al livello di aggregazione superiore. Nella sfida di incertezza M5, il modello REMT era il migliore a livello di SKU, ma non era il migliore negli altri livelli di aggregazione, anche se si è comportato bene complessivamente.
La mia ipotesi di lavoro su perché il modello REMT non era il migliore a tutti i livelli è la seguente (nota che questa è un’ipotesi e non l’abbiamo effettivamente testata): la distribuzione binomiale negativa offre due gradi di libertà attraverso i suoi due parametri. Quando si osservano dati abbastanza sparsi, come quelli trovati a livello di SKU, due gradi di libertà trovano il giusto equilibrio tra underfitting e overfitting. Tuttavia, man mano che ci spostiamo verso livelli di aggregazione più elevati, i dati diventano più densi e ricchi, quindi il compromesso probabilmente si sposta verso qualcosa di più adatto a catturare in modo più preciso la forma della distribuzione. Avremmo bisogno di alcuni gradi di libertà extra - probabilmente solo uno o due parametri extra - per raggiungere questo obiettivo.
Sospetto che aumentare il grado di parametrizzazione della distribuzione dei conteggi utilizzata al centro del modello REMT avrebbe permesso di ottenere qualcosa di molto vicino, se non direttamente all’avanguardia, per i livelli di aggregazione più elevati. Tuttavia, non abbiamo avuto il tempo di farlo, e potremmo riesaminare il caso in futuro. Questo conclude ciò che è stato fatto dal team di Lokad durante la competizione M5.

Discutiamo cosa avrebbe potuto essere fatto in modo diverso o migliore. Anche se il modello REMT è un modello parametrico a bassa dimensionalità con una struttura moltiplicativa semplice, il processo utilizzato per ottenere i valori dei parametri durante la competizione M5 è stato in qualche modo complicato in modo accidentale. È stato un processo a più fasi, con ciascun pattern del calendario che aveva il suo trattamento speciale ad hoc, che si concludeva con una ricerca su griglia personalizzata per completare il modello REMT. L’intero processo richiedeva molto tempo per i data scientist, e sospetto che sarebbe stato abbastanza poco affidabile in ambienti di produzione a causa della grande quantità di codice ad hoc coinvolto.
In particolare, penso che possiamo e dovremmo unificare il processo di apprendimento di tutti i parametri come un processo a singola fase o, almeno, unificare il processo di apprendimento in modo che venga utilizzato lo stesso metodo ripetutamente. Al giorno d’oggi, Lokad sta utilizzando la programmazione differenziabile per fare esattamente questo. La programmazione differenziabile elimina la necessità di aggregazioni ad hoc per quanto riguarda i pattern del calendario. Rimuove anche il problema di ordinare precisamente l’estrazione dei pattern del calendario estraendo tutti i pattern in una sola volta. Infine, poiché la programmazione differenziabile è un processo di ottimizzazione a sé stante, sostituisce la ricerca su griglia con una logica di ottimizzazione molto più efficiente. Esamineremo in dettaglio come la programmazione differenziabile può essere utilizzata per la modellazione predittiva nel contesto degli scopi della supply chain in lezioni successive di questo capitolo.
Ora, uno dei risultati più sorprendenti della competizione M5 è che nessun pattern statistico è rimasto senza nome. Avevamo letteralmente quattro pattern: semplicità, stato, dispersione e deriva, che erano tutto ciò che serviva per ottenere una precisione di previsione all’avanguardia nella competizione M5.
Le semplicità sono tutte basate sul calendario e nessuna di esse è anche lontanamente sorprendente. Lo stato può essere rappresentato come un singolo numero che rappresenta il livello raggiunto dal SKU in un determinato momento. La dispersione può essere rappresentata con un singolo numero che è la dispersione utilizzata per parametrizzare la distribuzione binomiale negativa, e la deriva può essere rappresentata con un singolo numero associato al processo di smoothing esponenziale che si è verificato all’interno del SSM. Non abbiamo nemmeno dovuto includere la tendenza, che era troppo debole per un orizzonte di 28 giorni.
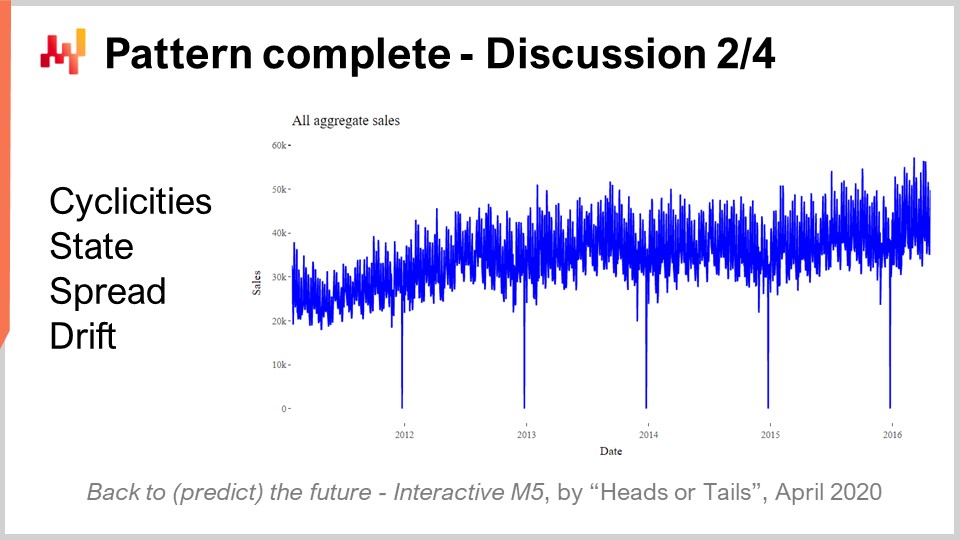
Mentre osserviamo le vendite aggregate totali dei cinque anni per la competizione M5 visualizzate sullo schermo, l’aggregazione mostra chiaramente una modesta tendenza al rialzo. Tuttavia, il modello REMT funziona senza di essa e non ha avuto alcuna conseguenza in termini di precisione. Le prestazioni del modello REMT pongono la domanda: c’è qualche altro pattern da catturare e abbiamo perso qualche pattern?
Almeno, le prestazioni del modello REMT mostrano che nessuno dei modelli più sofisticati coinvolti in questa competizione, come gli alberi di boosting del gradiente o i metodi di deep learning, ha catturato qualcosa al di là di quei quattro pattern. Infatti, se uno di quei modelli fosse riuscito a catturare in modo sostanziale qualcosa, avrebbe nettamente superato il modello REMT a livello di SKU, cosa che non ha fatto. Lo stesso si può dire di tutti i metodi statistici più sofisticati come ARIMA. Anche questi modelli non sono riusciti a catturare nulla al di là di ciò che questo modello parametrico moltiplicativo molto semplice ha catturato.
Il principio della navaja di Occam ci dice che, a meno che non possiamo trovare una buona ragione per pensare che un pattern ci sfugga o una buona ragione per qualche proprietà molto interessante che superi la semplicità di questo modello, non abbiamo motivo di utilizzare altro che un modello che sia almeno semplice come il modello REMT.

Tuttavia, una serie di pattern erano assenti dalla competizione M5 a causa del design stesso del dataset M5. Questi pattern sono importanti e, nella pratica, qualsiasi modello che li ignora funzionerà male in un vero ambiente di vendita al dettaglio. Baso questa affermazione sulla mia esperienza personale.
Innanzitutto, abbiamo i lanci di prodotto. La competizione M5 includeva solo prodotti che avevano almeno cinque anni di storia delle vendite. Questa è un’assunzione irragionevole per quanto riguarda la supply chain. Infatti, i prodotti FMCG hanno tipicamente una durata di vita di soli un paio di anni e quindi in un negozio reale c’è sempre una parte significativa dell’assortimento che ha meno di un anno di storia delle vendite. Inoltre, quando si considerano i prodotti con tempi di approvvigionamento lunghi, devono essere prese numerose decisioni sulla supply chain anche prima che il prodotto abbia la possibilità di essere venduto anche una sola volta in qualsiasi negozio. Pertanto, abbiamo bisogno di modelli di previsione che possano funzionare anche con una storia delle vendite pari a zero per un determinato prodotto.
Il secondo pattern di importanza critica sono le mancanze di magazzino. Le mancanze di magazzino si verificano nel settore del retail e il dataset della competizione M5 le ha completamente ignorate. Tuttavia, le mancanze di magazzino limitano le vendite. Se un prodotto è esaurito nel negozio, non verrà venduto quel giorno e quindi le mancanze di magazzino introducono un significativo bias nelle vendite che osserviamo. Il problema nel caso di Walmart e dei negozi di articoli vari è ancora più complicato perché i registri elettronici che registrano i valori di stock-on-hand non possono essere completamente affidabili. Ci sono numerose inesattezze dell’inventario e anche questo deve essere preso in considerazione.
Terzo, abbiamo le promozioni. La competizione M5 includeva dati storici sui prezzi; tuttavia, i dati sui prezzi non sono stati forniti per il periodo da prevedere. Di conseguenza, sembra che nessun concorrente in questa competizione sia riuscito a sfruttare le informazioni sui prezzi per migliorare l’accuratezza delle previsioni. Il modello REMT non utilizza affatto le informazioni sui prezzi. Oltre al fatto che ci mancavano le informazioni sui prezzi per il periodo di previsione, le promozioni non riguardano solo i prezzi. Un prodotto può essere promosso essendo esposto in modo prominente in un negozio, il che può aumentare significativamente la domanda, indipendentemente dal fatto che il prezzo sia stato abbassato. Inoltre, con le promozioni, dobbiamo considerare gli effetti di cannibalizzazione e sostituzione.
Nel complesso, il dataset M5, dal punto di vista della supply chain, può essere considerato un dataset giocattolo. Sebbene rimanga probabilmente il miglior dataset pubblico esistente per effettuare benchmark sulla supply chain, non è ancora nulla di simile a un vero ambiente di produzione anche in una catena di vendita al dettaglio di dimensioni modeste.

Tuttavia, le limitazioni della competizione M5 non sono solo dovute al dataset. Dal punto di vista della supply chain, ci sono problemi fondamentali con le regole utilizzate per condurre la competizione M5.
Il primo problema fondamentale è non confondere le vendite con la domanda. Abbiamo già affrontato questo problema con le mancanze di magazzino. Dal punto di vista della supply chain, il vero interesse risiede nell’anticipare la domanda, non nelle vendite. Tuttavia, il problema va oltre. La corretta stima della domanda è fondamentalmente un problema di apprendimento non supervisionato. Non è perché sono state prese scelte arbitrarie sull’assortimento applicabile in un negozio che la domanda di un prodotto non dovrebbe essere stimata. Dobbiamo stimare la domanda dei prodotti, indipendentemente dal fatto che facciano parte dell’assortimento in un determinato negozio.
Il secondo aspetto è che le previsioni dei quantili sono meno utili delle previsioni probabilistiche. Scegliere i livelli di servizio a caso lascia delle lacune nell’immagine e le previsioni dei quantili sono relativamente deboli in termini di utilizzo nella supply chain. Una previsione probabilistica fornisce una visione molto più completa perché fornisce l’intera distribuzione di probabilità, eliminando questa classe di problemi. L’unico svantaggio chiave delle previsioni probabilistiche è che richiedono più strumenti, specialmente quando si tratta di fare effettivamente qualcosa con la previsione a valle dopo che la previsione è stata prodotta. A proposito, il modello REMT in realtà fornisce qualcosa che si qualifica come una previsione probabilistica perché, attraverso il processo di Monte Carlo, è possibile generare un’intera distribuzione di probabilità. Basta regolare il numero di iterazioni di Monte Carlo.
Nel settore della vendita al dettaglio, ai clienti non interessa realmente la prospettiva SKU o il livello di servizio che può essere raggiunto su un determinato SKU. La percezione dei clienti in un negozio di articoli vari come Walmart è guidata dal carrello della spesa. Tipicamente, i clienti entrano in un negozio Walmart con una lista della spesa completa in mente, non solo un prodotto. Inoltre, ci sono tonnellate di sostituti disponibili nel negozio. Il problema di utilizzare una singola metrica SKU per valutare la qualità del servizio è che si perde completamente ciò che i clienti percepiscono come qualità del servizio nel negozio.
In conclusione, come punto di riferimento per le previsioni delle serie temporali, la competizione M5 è solida in termini di dataset e metodologia. Tuttavia, la prospettiva delle serie temporali stesse è carente per quanto riguarda la supply chain. Le serie temporali non riflettono i dati come si trovano nelle supply chain, né riflettono i problemi come si presentano nelle supply chain. Durante la competizione M5, c’erano molti metodi molto più sofisticati tra i primi posti. Tuttavia, secondo me, quei modelli sono effettivamente strade senza uscita. Sono già troppo complicati per l’uso in produzione e abbracciano così tanto la prospettiva delle serie temporali che non hanno spazio operativo per svilupparsi nella sorta di prospettiva fresca necessaria per adattare quei modelli alle nostre esigenze di supply chain.
Al contrario, come punto di partenza, il modello REMT è il migliore che si possa ottenere. È una combinazione molto semplice di ingredienti che sono, di per sé, molto semplici. Inoltre, non ci vuole molta immaginazione per vedere che ci sono molte modalità di utilizzo e combinazione di questi elementi al di là della combinazione specifica messa insieme per la competizione M5. Il posizionamento ottenuto dal modello REMT nella competizione M5 dimostra che, fino a prova contraria, dovremmo attenerci a un modello molto semplice, poiché non abbiamo alcun motivo convincente per optare per modelli molto complicati che sono quasi garantiti di essere più difficili da debuggare, più difficili da utilizzare in produzione e che consumeranno risorse di calcolo molto più ampie.
Nelle prossime lezioni di questo quinto capitolo, vedremo come possiamo utilizzare gli ingredienti che facevano parte del modello REMT, così come molti altri ingredienti, per affrontare l’ampia varietà di sfide predictive come si trovano nelle supply chain. La cosa fondamentale da ricordare è che il modello non è importante; è la modellazione che conta.

Domanda: Perché le distribuzioni binomiali negative? Qual è stata la ragione quando le hai selezionate?
È una domanda molto valida. Beh, si scopre che se esiste un bestiario mondiale di distribuzioni di conteggio, probabilmente ci sono una ventina di distribuzioni di conteggio molto conosciute. Da Lokad, ne abbiamo testate una dozzina per le nostre esigenze interne. Si scopre che la distribuzione di Poisson, che è una distribuzione di conteggio molto semplicistica con un solo parametro, funziona abbastanza bene quando i dati sono molto sparsi. Quindi Poisson è abbastanza buona, ma in realtà, il dataset M5 era un po’ più ricco. Nel caso del dataset di Walmart, abbiamo provato distribuzioni di conteggio che avevano qualche parametro in più, e sembrava funzionare. Non abbiamo la prova che sia effettivamente la migliore; ci sono probabilmente opzioni migliori. La distribuzione binomiale negativa ha alcuni vantaggi chiave: l’implementazione è molto semplice ed è una distribuzione di conteggio ampiamente studiata. Quindi, hai un algoritmo molto noto, non solo per calcolare le probabilità, ma anche per campionare un deviato, ottenere la media o la distribuzione cumulativa. Tutti gli strumenti che ci si può aspettare in termini di distribuzione di conteggio sono presenti, il che non è il caso per tutte le distribuzioni di conteggio.
C’è un grado di pragmatismo che è entrato in questa scelta, ma anche un po’ di logica. Con Poisson, hai un grado di libertà; la distribuzione binomiale negativa ne ha due. Poi puoi usare trucchi come la distribuzione binomiale negativa con inflazione di zeri, che ti dà una sorta di due gradi e mezzo di libertà, ecc. Non direi che ci sia un valore specifico definitivo per questa distribuzione di conteggio.
Domanda: C’erano altri fornitori di software di ottimizzazione della supply chain nel M5, ma nessuno utilizzava modelli live che si scalavano bene in produzione. Cosa utilizza la maggior parte, modelli di machine learning pesanti?
Innanzitutto, vorrei dire che dobbiamo distinguere e chiarire che il M5 è stato fatto su Kaggle, una piattaforma per la scienza dei dati. Su Kaggle, hai un incentivo enorme a utilizzare la macchina più complicata possibile. Il dataset è piccolo, hai molto tempo e per essere il primo classificato, devi essere solo dello 0,1% più preciso dell’altro ragazzo. Questo è tutto ciò che conta. Quindi, praticamente in ogni competizione di Kaggle, vedresti che i primi posti sono occupati da persone che hanno fatto cose molto complicate solo per ottenere una precisione aggiuntiva dello 0,1%. Quindi, la stessa natura di una competizione di previsione ti dà un forte incentivo a provare di tutto, compresi i modelli più pesanti che puoi trovare.
Se chiediamo se le persone stanno effettivamente utilizzando questi modelli di machine learning pesanti in produzione, la mia osservazione occasionale personale è assolutamente no. È effettivamente estremamente raro. Come CEO di Lokad, un fornitore di software per la supply chain, ho parlato con centinaia di direttori della supply chain. Letteralmente, più del 90% delle grandi supply chain viene gestito tramite Excel. Non ho mai visto alcuna supply chain su larga scala gestita con alberi potenziati dal gradiente o reti di deep learning. Se mettiamo da parte Amazon, Amazon è probabilmente un caso a parte. Ci sono forse mezza dozzina di aziende, come Amazon, Alibaba, JD.com e altre poche - i supergiganti del commercio elettronico molto grandi - che stanno effettivamente utilizzando questo tipo di tecnologia. Ma sono eccezionali in questo senso. Le grandi aziende FMCG o le grandi aziende di vendita al dettaglio fisico mainstream non utilizzano queste cose in produzione.
Domanda: È strano che tu menzioni molti termini matematici e statistici, ma ignori la natura delle vendite al dettaglio e i principali fattori influenti.
Direi che sì, questo è più un commento, ma la mia domanda per te sarebbe: cosa porti sul tavolo? Questo è quello che stavo dicendo quando i fornitori di supply chain vantavano una tecnologia di previsione superiore e poi erano assenti quando c’era un benchmark pubblico. L’altra spiegazione è che le persone stanno bluffando.
Riguardo alla natura delle vendite al dettaglio e ai molti fattori influenti, ho elencato i modelli che sono stati utilizzati e utilizzando quei quattro modelli, il modello REMT si è classificato al primo posto a livello di SKU in termini di precisione. Se prendiamo in considerazione la proposta che ci sono molti altri modelli importanti là fuori, il peso della prova è su di te. La mia personale supposizione è che se tra oltre 900 squadre quei modelli non sono stati osservati, probabilmente non erano lì, o catturare questi modelli è così al di fuori del campo di ciò che possiamo fare con il tipo di tecnologia che abbiamo che, per ora, è come se quei modelli non esistessero da un punto di vista pratico.
Domanda: Quali idee hanno applicato i concorrenti nel M5 che, pur non battendo Lokad, sarebbero preziose da incorporare, specialmente per applicazioni generiche? Menzione d’onore?
Ho prestato molta attenzione ai miei concorrenti e sono abbastanza sicuro che anche loro stiano prestando attenzione a Lokad. Non ho visto nulla del genere. Il modello REMT era davvero unico nel suo genere, completamente diverso da ciò che è stato fatto da praticamente tutti gli altri primi 50 concorrenti per entrambi i compiti. Gli altri partecipanti stavano utilizzando cose molto più classiche nei circoli di machine learning.
Durante la competizione sono stati dimostrati alcuni trucchi molto intelligenti di data science. Ad esempio, alcune persone hanno utilizzato trucchi molto intelligenti e fantasiosi per fare l’aumento dei dati sul dataset di Walmart per renderlo molto più grande di quanto fosse per ottenere qualche punto percentuale in più di precisione. Questo è stato fatto dal concorrente che si è classificato al primo posto nella sfida dell’incertezza. L’aumento dei dati, non l’inflazione dei dati, è il termine corretto. L’aumento dei dati è comunemente utilizzato nelle tecniche di deep learning, ma qui è stato utilizzato con alberi potenziati dal gradiente in modi piuttosto insoliti. Durante questa competizione sono stati dimostrati trucchi di data science molto intelligenti e fantasiosi. Non sono sicuro se quei trucchi si generalizzino bene alla supply chain, ma probabilmente ne menzionerò un paio durante il resto di questo capitolo se si presenterà l’opportunità.
Domanda: Hai stimato livelli più alti aggregando i tuoi livelli SKU o calcolando freschi i livelli intermedi per i livelli superiori? Se entrambi, come si sono confrontati?
Il problema con le griglie di quantili è che tendi ad ottimizzare i modelli separatamente per ogni livello di destinazione. Ciò che può accadere con le griglie di quantili è che si possono ottenere incroci di quantili, il che significa che, solo per instabilità numeriche, il tuo 99° quantile finisce per essere inferiore al tuo 97° quantile. Questo è insignificante; di solito, basta riordinare i valori. Fondamentalmente, questo è il tipo di problema a cui mi riferivo in termini di griglie di quantili che non sono previsioni probabilistiche. Hai un sacco di dettagli minuziosi da risolvere, ma la realtà è che sono insignificanti nel grande schema delle cose. Quando passi a previsioni probabilistiche, quei problemi non esistono nemmeno più.
Domanda: Se stessi progettando un’altra competizione per fornitori di software, com’è che sarebbe?
Onestamente, non lo so, ed è una domanda molto difficile. Credo che, nonostante tutte le mie pesanti critiche, per quanto riguarda i benchmark di previsione, M5 sia il migliore che abbiamo. Ora, per quanto riguarda i benchmark della supply chain, il problema è che non sono nemmeno completamente convinto che sia possibile. Quando ho accennato che alcuni dei problemi richiedono effettivamente l’apprendimento non supervisionato, questo è complicato. Quando entri nel campo dell’apprendimento non supervisionato, devi rinunciare ad avere metriche, e l’intero campo dell’apprendimento automatico avanzato sta ancora lottando come comunità per capire cosa significhi operare con strumenti di apprendimento superiori e automatizzati in un campo in cui sei non supervisionato. Come si possono persino valutare tali cose?
Per il pubblico che non era presente alla mia lezione sull’apprendimento automatico, in contesti supervisionati, stai essenzialmente cercando di portare a termine un compito in cui hai input-output e una metrica per valutare la qualità dei tuoi output. Quando sei non supervisionato, significa che non hai etichette, non hai nulla con cui confrontare, e le cose diventano molto più difficili. Inoltre, vorrei sottolineare che nella supply chain ci sono molte cose in cui non puoi nemmeno fare il back-test. Oltre all’aspetto non supervisionato, c’è anche la prospettiva del back-testing che non è completamente soddisfacente. Ad esempio, prevedere la domanda genererà determinati tipi di decisioni, come decisioni di prezzo. Se decidi di regolare il prezzo al rialzo o al ribasso, è una decisione che hai preso e influenzerà per sempre il futuro. Quindi, non puoi tornare indietro nel tempo per dire: “Okay, farò una previsione di domanda diversa e prenderò una decisione di prezzo diversa, e poi lascio che la storia si ripeta, tranne che questa volta ho un prezzo diverso.” Ci sono molti aspetti in cui l’idea del back-testing non funziona nemmeno. Ecco perché credo che una competizione sia qualcosa di molto interessante dal punto di vista della previsione. È utile come punto di partenza per scopi di supply chain, ma dobbiamo fare meglio e in modo diverso se vogliamo ottenere qualcosa che sia veramente soddisfacente per scopi di supply chain. In questo capitolo sulla modellazione predittiva, mostrerò perché la modellazione merita una tale attenzione.
Domanda: Questa metodologia può essere utilizzata in situazioni in cui si hanno pochi punti dati?
Direi assolutamente di sì. Questo tipo di modellazione strutturata, come dimostrato qui con il modello REMT, brilla intensamente in situazioni in cui si dispone di dati molto scarsi. Il motivo è semplice: è possibile incorporare molte conoscenze umane nella stessa struttura del modello. La struttura del modello non è qualcosa che è stato tirato fuori dal nulla; è letteralmente la conseguenza della comprensione del problema da parte del team di Lokad. Ad esempio, quando osserviamo i modelli del calendario come il giorno della settimana, il mese dell’anno, ecc., non abbiamo cercato di scoprire quei modelli; il team di Lokad sapeva fin dall’inizio che quei modelli erano già presenti. L’unica incertezza riguardava la prevalenza rispettiva del modello del giorno del mese, che tende ad essere debole in molte situazioni. Nel caso dell’impostazione di Walmart, è dovuto al fatto che negli Stati Uniti esiste un programma di timbri che rende il modello del giorno del mese così forte come lo è.
Se si dispone di pochi dati, questo tipo di approccio funziona estremamente bene perché qualsiasi meccanismo di apprendimento che si sta cercando di utilizzare, sfrutterà ampiamente la struttura che si è imposto. Quindi sì, sorge la domanda: e se la struttura è sbagliata? Ma è per questo che il pensiero e la comprensione della supply chain sono davvero importanti, in modo da poter prendere le decisioni corrette. Alla fine, si hanno modi per valutare se le decisioni arbitrarie sono state buone o cattive, ma fondamentalmente, questo avviene molto tardi nel processo. Più avanti in questo capitolo sulla modellazione predittiva, illustreremo come la modellazione strutturata può essere utilizzata in modo efficace su set di dati estremamente scarsi, come quelli dell’aviazione, del lusso e delle smeraldi di ogni tipo. In queste situazioni, i modelli strutturati brillano davvero.
La prossima lezione si terrà il 2 febbraio, che è un mercoledì, alla stessa ora, alle 15:00 ora di Parigi. Ci vediamo allora!
Riferimenti
- Un approccio ISSM a scatola bianca per stimare le distribuzioni di incertezza delle vendite di Walmart, Rafael de Rezende, Katharina Egert, Ignacio Marin, Guilherme Thompson, dicembre 2021 (link)
- La competizione di incertezza M5: Risultati, conclusioni e scoperte, Spyros Makridakis, Evangelos Spiliotis, Vassilis Assimakopoulos, Zhi Chen, novembre 2020 (link)


