00:01 Введение
01:56 Проблема неопределенности M5 - Данные (1/3)
04:52 Проблема неопределенности M5 - Правила (2/3)
08:30 Проблема неопределенности M5 - Результаты (3/3)
11:59 История до настоящего момента
14:56 Что, вероятно, вот-вот произойдет
15:43 Пинбольные потери - Основа 1/3
20:45 Негативное биномиальное распределение - Основа 2/3
24:04 Модель состояния пространства инноваций (ISSM) - Основа 3/3
31:36 Структура продаж - Модель REMT 1/3
37:02 Объединение - Модель REMT 2/3
39:10 Уровни агрегации - Модель REMT 3/3
43:11 Одноступенчатое обучение - Обсуждение 1/4
45:37 Полный шаблон - Обсуждение 2/4
49:05 Отсутствующие шаблоны - Обсуждение 3/4
53:20 Ограничения M5 - Обсуждение 4/4
56:46 Заключение
59:27 Предстоящая лекция и вопросы аудитории
Описание
В 2020 году команда Lokad заняла 5-е место среди 909 команд-участников на конкурсе прогнозирования M5, мировом конкурсе прогнозирования. Однако на уровне агрегации SKU эти прогнозы заняли первое место. Прогнозирование спроса имеет первостепенное значение для цепочки поставок. Подход, применённый в этом конкурсе, оказался нетрадиционным и отличался от методов, применённых среди остальных 50 лучших участников. Из этого достижения можно извлечь множество уроков в преддверии решения дальнейших задач прогнозирования для цепочки поставок.
Полная расшифровка

Добро пожаловать в этот цикл лекций по цепочке поставок. Меня зовут Joannes Vermorel, и сегодня я представлю «№1 на уровне SKU в конкурсе прогнозирования M5». Точный прогноз спроса считается одним из краеугольных камней оптимизации цепей поставок. Действительно, каждое решение в цепочке поставок отражает определённое предвидение будущего. Если мы сможем получить превосходное представление о будущем, то сможем принимать решения, количественно оптимальные для наших целей в цепочке поставок. Таким образом, выявление моделей, обеспечивающих передовую предиктивную точность, имеет первостепенное значение и интерес для оптимизации цепей поставок.
Сегодня я представлю простую модель прогнозирования продаж, которая, несмотря на свою простоту, заняла первое место на уровне SKU в мировом конкурсе прогнозирования под названием M5, основанном на наборе данных, предоставленном Walmart. В этой лекции будет две цели. Первая цель — понять, что требуется для достижения передовой точности прогнозирования продаж. Это понимание будет иметь основополагающее значение для последующих усилий в области предиктивного моделирования. Вторая цель — установить правильную перспективу в вопросах предиктивного моделирования для цепочки поставок. Эта перспектива также будет использована для руководства нашим дальнейшим продвижением в этой области предиктивного моделирования для цепочки поставок.

Конкурс M5 был мероприятием по прогнозированию, которое состоялось в 2020 году. Этот конкурс носит имя Спироса Макридэкиса, известного исследователя в области прогнозирования. Это было пятое издание конкурса. Эти соревнования проводятся каждые несколько лет и, как правило, различаются по тематике в зависимости от типа используемого набора данных. M5 был задачей, связанной с цепочкой поставок, поскольку использовался агрегированный по дням набор данных розничных магазинов Walmart. Задача M6, которая еще предстоит, будет сосредоточена на финансовом прогнозировании.
Набор данных, использованный для M5, был и остается общедоступным. Это были данные розничных магазинов Walmart, агрегированные на ежедневной основе. Набор включал около 30 000 SKU, что, с точки зрения розничной торговли, является довольно небольшим набором данных. Действительно, по правилу, один супермаркет обычно имеет около 20 000 SKU, а Walmart управляет более чем 10 000 магазинов. Таким образом, в целом этот набор данных – набор данных M5 – составлял менее 0.1% от мирового набора данных масштаба Walmart, который был бы релевантен с точки зрения цепочки поставок.
Более того, как мы увидим далее, в наборе данных M5 отсутствовали целые классы данных. В результате моя приблизительная оценка такова, что этот набор данных на самом деле ближе к 0.01% масштаба того, что потребовалось бы на уровне Walmart. Тем не менее, этого набора данных достаточно для проведения очень солидного бенчмарка моделей прогнозирования в реальных условиях. В реальной обстановке нам пришлось бы уделять пристальное внимание вопросам масштабируемости. Однако с точки зрения конкурса прогнозирования, допустимо сделать набор данных достаточно малым, чтобы большинство методов, даже широко неэффективных, могли быть использованы в конкурсе прогнозирования. Кроме того, это обеспечивает, что участники не ограничены количеством вычислительных ресурсов, которые они могут задействовать в этом конкурсе.
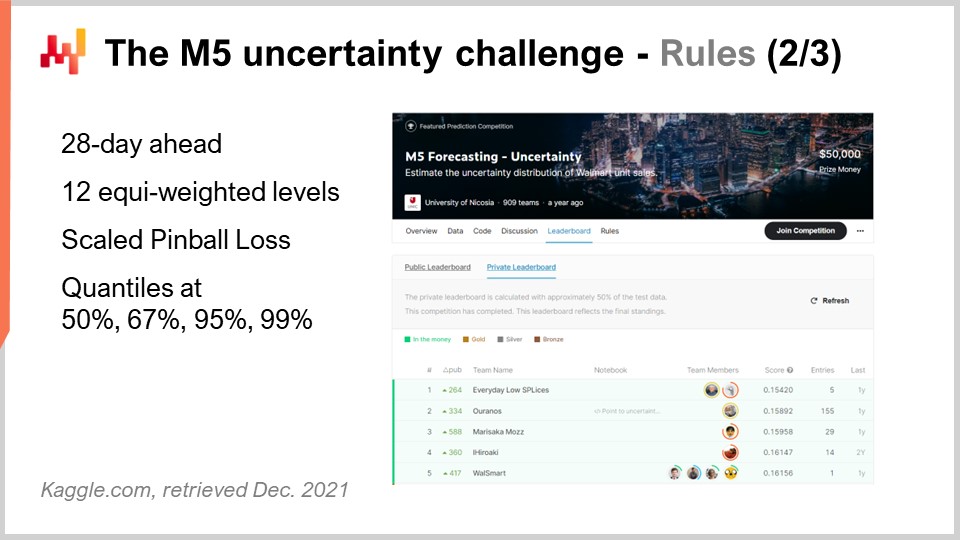
Конкурс M5 включал два различных испытания, известных как Точность и Неопределенность. Правила были простыми: существовал общедоступный набор данных, к которому мог получить доступ каждый участник, и для участия в одном или обоих испытаниях от каждого участника требовалось создать собственный набор данных – свой прогноз – и загрузить его на платформу Kaggle. Испытание Точности заключалось в предоставлении среднего прогноза временных рядов, что является самым классическим видом формального прогноза. В данной конкретной ситуации речь шла о предоставлении ежедневного среднего прогноза для около 40 000 временных рядов. Испытание Неопределенности заключалось в представлении квантильных прогнозов. Квантили – это прогнозы с уклоном; однако уклон является преднамеренным. Именно в этом и состоит суть квантилей. Эта лекция полностью посвящена испытанию Неопределенности, и причина в том, что в цепочке поставок неожиданно высокий спрос приводит к дефициту товаров, а неожиданно низкий спрос — к списанию запасов. Затраты в цепочках поставок концентрируются на крайних значениях. Нас не интересует среднее значение.
Действительно, если обратить внимание на то, что означает среднее даже в контексте Walmart, оказывается, что для большинства товаров, в большинстве магазинов и в большинство дней наблюдаемые продажи в среднем равны нулю. Таким образом, для большинства товаров средний прогноз является скудным. Если ваш выбор заключается между хранением нуля или пополнением одной единицы, средние прогнозы имеют мало значения. Розничная торговля не находится в уникальном положении: ситуация примерно аналогична в секторах FMCG, авиации, производства или роскоши – практически в каждом другом секторе.
Возвращаясь к испытанию Неопределенности M5, необходимо было построить четыре квантиля – 50%, 67%, 95% и 99%. Вы можете рассматривать эти квантильные цели как целевые уровни сервиса. Точность этих квантильных прогнозов оценивалась по метрике, известной как пинбольная функция потерь функция потерь. В этой лекции я ещё вернусь к этой метрике.

В конкурсе принимали участие 909 команд со всего мира в испытании Неопределенности. Команда из Lokad заняла в общем пятерку, но на уровне SKU – первое место. Действительно, хотя SKU составляли около трех четвертей временных рядов в этом испытании, существовали различные уровни агрегации, от штата (например, в Соединенных Штатах – Техас, Калифорния и т.д.) до SKU, и все уровни агрегации имели равный вес в итоговом счете конкурса. Таким образом, даже если SKU составляли примерно три четверти временных рядов, они были лишь около 8% общего веса итогового счета конкурса.
Метод, использованный этой командой из Lokad, был опубликован в статье под названием “A White Box ISSM Approach to Estimate Uncertainty Distribution of Walmart’s Sales”. Я оставлю ссылку на эту статью в описании видео по завершении этой лекции. Вы найдете все элементы в более подробном изложении. Для ясности и краткости я буду называть модель, представленную в этой статье, моделью BRAMPT, просто по инициалам четырех соавторов.
На экране я привел топ-5 результатов конкурса M5, полученных из статьи, дающей общее представление о результатах этого конкурса прогнозирования. Точные показатели ранжирования довольно зависимы от выбранной метрики. Это не так уж удивительно. Испытание Неопределенности использовало модифицированную версию пинбольной функции потерь. Мы ещё вернемся к этой метрике ошибки через минуту. Хотя испытание Неопределенности M5 показало, что у нас нет возможности устранить неопределенность с помощью методов прогнозирования с формулами в Excel, даже близко, это вовсе не является неожиданным результатом. Учитывая, что продажи в розничных магазинах, как правило, являются непредсказуемыми и прерывистыми, это подчеркивает важность признания неопределенности, а не полного её игнорирования. Однако примечательно, что поставщики программного обеспечения для цепочек поставок отсутствовали в топ-50 результатов этого конкурса прогнозирования, что еще более интригующе, учитывая, что эти поставщики могут похвастаться якобы передовыми технологиями прогнозирования.
Теперь эта лекция является частью серии лекций по цепочке поставок. Настоящая лекция — первая из моих пяти глав в этой серии. Пятая глава будет посвящена предиктивному моделированию. Действительно, получение количественных данных необходимо для оптимизации цепочки поставок. Каждый раз, когда принимается решение в цепочке поставок — будь то покупка материалов, производство определенного изделия, перемещение товара с одного места на другое или изменение цены на то, что вы продаете — это решение сопровождается определенным предвидением будущего спроса. Косвенно каждое решение в цепочке поставок включает заложенное ожидание будущего. Это ожидание может быть неявным и скрытым. Однако, если мы хотим повысить качество наших ожиданий относительно будущего, нам нужно сделать их явными, что обычно достигается с помощью прогноза, хотя это не обязательно должен быть прогноз временных рядов.
Пятая, нынешняя глава названа “Предиктивное моделирование”, а не “Прогнозирование” по двум причинам. Во-первых, прогнозирование почти всегда ассоциируется с временными рядами. Однако, как мы увидим в этой главе, существует множество ситуаций в цепочке поставок, которые не подходят для классической парадигмы временных рядов. Таким образом, в этом контексте термин “предиктивное моделирование” является более нейтральным. Во-вторых, именно моделирование приносит настоящие инсайты, а не сами модели. Мы ищем методы моделирования, и именно с их помощью можно справиться с огромным разнообразием ситуаций, встречающихся в реальных цепочках поставок.
Настоящая лекция служит прологом к нашей главе о предиктивном моделировании, чтобы показать, что предиктивное моделирование — это не просто мечтательное размышление о прогнозировании, а техника прогнозирования, соответствующая передовому уровню. Это наряду со всеми другими преимуществами, которые постепенно станут очевидными по мере прохождения этой главы.
Оставшаяся часть этой лекции будет организована в три части. Сначала мы рассмотрим ряд математических компонентов, которые являются фундаментальными элементами модели BRAMPT. Затем мы соберем эти компоненты для построения модели BRAMPT, точно так, как это было сделано в конкурсе M5. И, наконец, обсудим, что можно сделать для улучшения модели BRAMPT, а также что можно сделать для совершенствования самого конкурса прогнозирования, каким он был представлен в конкурсе M5.

Испытание Неопределенности M5 направлено на вычисление квантильных оценок будущих продаж. Квантиль — это точка в одномерном распределении, и по определению 90-процентный квантиль — это такая точка, ниже которой вероятность составляет 90%, а выше — 10%. Медиана, по определению, является 50-процентным квантилем.
Функция пинбольных потерь — это функция, глубоко связанная с квантилями. По сути, для любого значения tau от нуля до единицы, tau можно интерпретировать с точки зрения цепочки поставок как целевой уровень сервиса. Для любого значения tau соответствующий квантиль оказывается таким значением в распределении вероятностей, которое минимизирует функцию пинбольных потерь. На экране мы видим прямолинейную реализацию функции пинбольных потерь, написанную на Envision — предметно-ориентированном языке программирования Lokad, предназначенном для оптимизации цепочек поставок. Синтаксис довольно похож на Python и должен быть понятен аудитории.
Если попытаться разобрать этот код, то y — это реальное значение, y-hat — наша оценка, а tau — это наша квантильная цель. Снова, квантильная цель по сути является целевым уровнем сервиса в терминах цепочки поставок. Мы видим, что недооценка имеет вес, равный tau, в то время как переоценка имеет вес, равный единице минус tau. Функция пинбольных потерь является обобщением абсолютной ошибки. Если мы вернемся к tau, равному 0.5, можно заметить, что функция пинбольных потерь представляет собой просто абсолютную ошибку. Если у нас есть оценка, минимизирующая абсолютную ошибку, то мы получаем оценку медианы.
На экране вы можете увидеть график функции потерь pinball. Эта функция потерь является асимметричной, и благодаря ей мы можем получить не просто прогноз среднего или медианы, а прогноз с контролируемым уклоном, что как раз нужно для оценки квантиля. Прелесть функции потерь pinball заключается в её простоте. Если у вас есть оценка, минимизирующая функцию потерь pinball, то по определению вы получаете квантильный прогноз. Таким образом, если у вас есть модель с параметрами, и вы управляете оптимизацией параметров через призму функции потерь pinball, то фактически вы получаете модель прогнозирования квантилей.
Задача M5 Uncertainty представила ряд из четырех квантильных целей: 50, 67, 95 и 99. Я обычно называю такую серию квантильных целей квантильной сеткой. Квантильная сетка, или прогнозы по квантильной сетке, не являются в точности вероятностными прогнозами; они близки к этому, но еще не дотянуты. При использовании квантильной сетки мы все равно выбираем конкретные цели. Например, если мы говорим, что хотим получить квантильный прогноз для 95%, встает вопрос: почему 95, а не 94 или 96? Этот вопрос остается без ответа. Мы рассмотрим это подробнее позже в данной главе, но не в этой лекции. Скажем так, главное преимущество вероятностных прогнозов заключается в полном устранении этой выборочности квантильных сеток.
Большинство слушателей, вероятно, знакомы с нормальным распределением, гауссовой колоколообразной кривой, которая очень часто встречается в природных явлениях. Распределение счётных величин — это распределение вероятностей для каждого целого числа. В отличие от непрерывных распределений, таких как нормальное, которое дает вероятность для каждого отдельного числа, распределения счётных величин касаются только неотрицательных целых чисел. Существует множество классов таких распределений; однако сегодня нас интересует отрицательное биномиальное распределение, которое используется в модели REM.
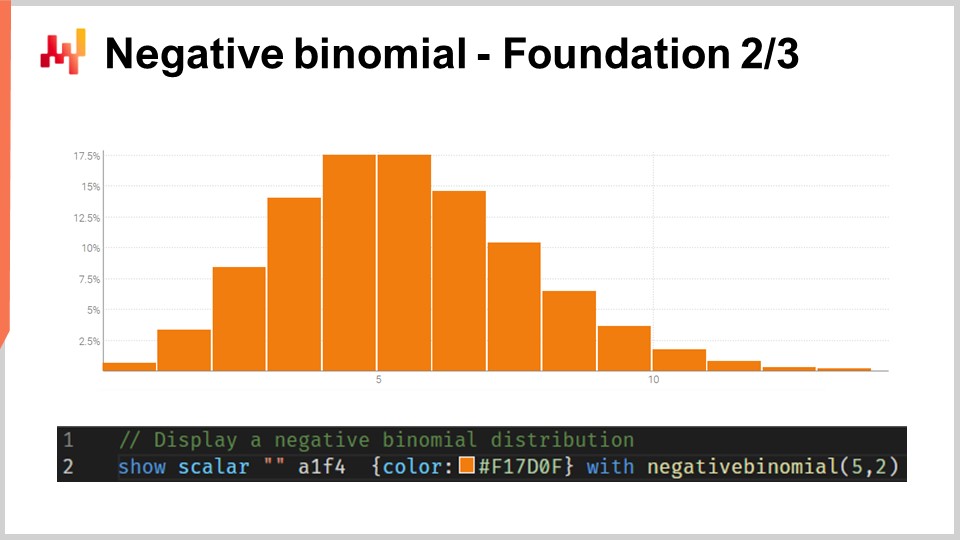
Отрицательное биномиальное распределение имеет два параметра, как и нормальное распределение, которые эффективно управляют средним значением и дисперсией распределения. Если мы подберем среднее и дисперсию так, чтобы основная масса вероятности была далеко от нуля, поведение отрицательного биномиального распределения асимптотически будет приближаться к поведению нормального распределения, если все вероятностные значения сжать к ближайшим целым числам. Однако если рассматривать распределения с малым средним, особенно по сравнению с дисперсией, то отрицательное биномиальное распределение будет существенно отличаться по поведению от нормального. В частности, при малом среднем отрицательное биномиальное распределение становится крайне асимметричным, в отличие от нормального распределения, которое остается полностью симметричным независимо от выбранных среднего и дисперсии.
На экране с помощью Envision построено отрицательное биномиальное распределение. Строка кода, использованная для получения этого графика, приведена ниже. Функция принимает два аргумента, как и ожидалось для распределения с двумя параметрами, а результат представляет собой случайную величину, отображаемую в виде гистограммы. Я не буду вдаваться в подробности отрицательного биномиального распределения в этой лекции. Это элементарная теория вероятностей. У нас есть явные аналитические формулы в замкнутом виде для моды, медианы, функции накопления вероятности, асимметрии, эксцесса и т.д. Страница Википедии дает достаточно подробное резюме всех этих формул, поэтому я приглашаю слушателей ознакомиться с ней, если они хотят узнать больше об этом конкретном виде распределения счётных величин.
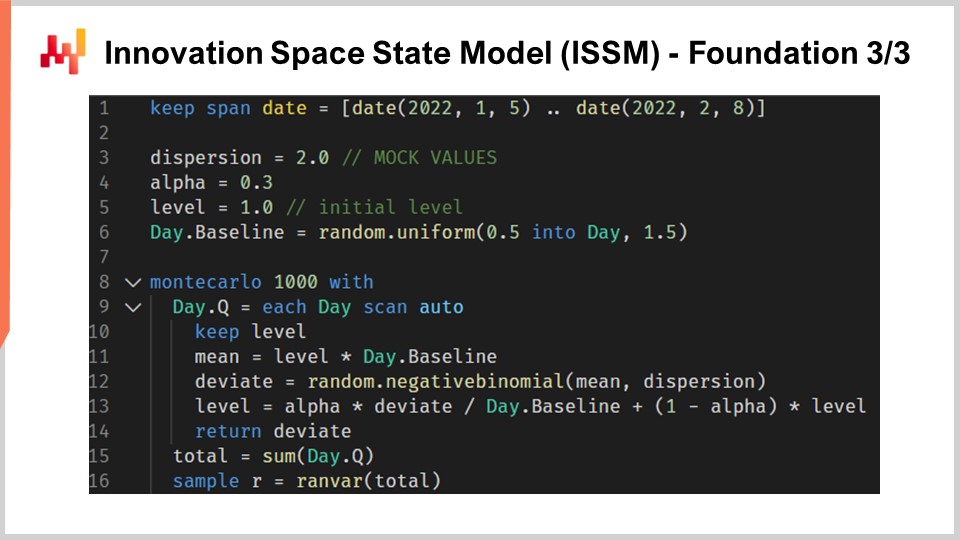
Перейдем к модели состояния инновационного пространства, или ISSM. Название модели состояния инновационного пространства звучит длинно и впечатляюще, хотя на деле она решает достаточно простую задачу. Фактически, ISSM — это модель, которая преобразует временной ряд в случайное блуждание. С помощью ISSM можно превратить обычный прогноз временного ряда, и когда я говорю «обычный», я имею в виду прогноз, где для каждого периода задано одно значение, равное среднему, — в вероятностный прогноз, и не просто квантильный, а непосредственно вероятностный. На экране вы видите полную реализацию ISSM, снова написанную в Envision. Видно, что это всего лишь около дюжины строк кода, и на самом деле большинство этих строк не содержат ничего сложного. ISSM действительно очень прямолинейна, и её можно легко переписать на любом другом языке, например, на Python.
Давайте внимательнее рассмотрим детали этих строк кода. В строке один я задаю диапазон периодов, в течение которых будет происходить случайное блуждание. С точки зрения M5, нам необходимо случайное блуждание на 28 дней, то есть у нас 28 точек, по одной на каждый день. В строках три, четыре и пять мы вводим ряд параметров, которые будут управлять самим случайным блужданием. Первый параметр — дисперсия, используемая для контроля формы отрицательных биномиальных распределений, возникающих в процессе ISSM. Затем идет альфа, который по сути является коэффициентом, контролирующим процесс экспоненциального сглаживания, происходящий также внутри ISSM. В строке пять задается уровень, который является исходным состоянием случайного блуждания. И наконец, в строке шесть у нас ряд факторов, предназначенных для захвата всех календарных закономерностей, которые мы хотим встроить в нашу модель прогнозирования.
Теперь значения в строках три-шесть являются всего лишь фиктивной инициализацией. Ради краткости, я позже поясню, как эти значения на самом деле оптимизируются, но здесь вся инициализация представлена фиктивными значениями. Я даже случайно выбираю значения для базового уровня. Мы поговорим о том, как на самом деле, если вы захотите использовать эту модель, нужно правильно инициализировать эти значения, что мы сделаем позже в этой лекции.
Теперь давайте рассмотрим основную часть процесса ISSM. Она начинается в строке восемь и представляет собой цикл из 1000 итераций. Как я уже сказал, процесс ISSM генерирует случайные блуждания, поэтому здесь мы выполняем 1000 итераций, то есть создаем 1000 случайных блужданий. Может быть, мы сделаем больше или меньше; это стандартный метод Монте-Карло. Затем в строке девять мы запускаем второй цикл. Этот цикл проходит по одному дню за раз в течение интересующего нас периода. Таким образом, у нас есть внешний цикл — по сути, одна итерация на случайное блуждание, — и внутренний цикл, который проходит по одному дню за раз внутри самого блуждания.
В строке 10 мы сохраняем уровень. Сохранение уровня означает, что этот параметр будет изменяться внутри внутреннего цикла, а не внешнего. То есть уровень изменяется при переходе от одного дня к следующему, а при переходе от одного случайного блуждания к следующему в цикле Монте-Карло этот уровень сбрасывается к начальному значению, указанному выше. В строке 11 вычисляем среднее значение. Среднее — это второй параметр, который мы используем для управления отрицательным биномиальным распределением. Таким образом, у нас есть и среднее, и дисперсия, и отрицательное биномиальное распределение. В строке 12 мы выбираем отклонение по нормальному биномиальному распределению. Выбор отклонения означает, что мы берем случайную выборку из этого распределения счётных величин. Затем, в строке 13, мы обновляем уровень на основе полученного отклонения, а процесс обновления представляет собой простейшее экспоненциальное сглаживание, управляемое параметром альфа. Если взять альфа равным единице, это означает, что весь вес приходится на последнее наблюдение. Напротив, если установить альфа равным нулю, это означает отсутствие сдвига, то есть мы будем придерживаться исходного временного ряда, заданного в базовом уровне.
Кстати, в Envision, когда пишется “.baseline”, это означает, что имеется таблица, скажем, NDM5, содержащая 28 значений, и baseline — это вектор, принадлежащий этой таблице. В строке 15 мы собираем все отклонения и суммируем их с помощью “someday.q”. Мы сохраняем их в переменную с именем “total”, так что в рамках одного случайного блуждания эта переменная содержит сумму отклонений, собранных за каждый день. Таким образом, это суммарные продажи за 28 дней. Наконец, в строке 16 мы, по сути, собираем эти образцы в объект “render”. Render — это специфический объект в Envision, представляющий собой распределение вероятностей относительных целых чисел, как положительных, так и отрицательных.
В итоге, ISSM выступает в роли генератора одномерных случайных блужданий. В контексте прогнозирования продаж эти блуждания можно рассматривать как возможные будущие наблюдения самих продаж. Примечательно, что мы не рассматриваем прогноз как среднее или медиану; мы буквально воспринимаем наш прогноз как один из возможных вариантов будущего.

На данном этапе мы собрали всё необходимое для сборки модели REMT, которую мы приступим собирать прямо сейчас.
Модель REMT использует мультипликативную структуру, напоминающую модель Холта-Винтерса. Каждый день получает базовый уровень — единственное значение, которое является произведением пяти календарных эффектов. А именно, это эффекты месяца, дня недели, дня месяца, Рождества и Хэллоуина. Эта логика реализована в виде краткого скрипта на Envision.
Envision обладает реляционной алгеброй, предлагающей отношения вещания между таблицами, что очень удобно в данной ситуации. Пять таблиц, которые мы построили — по одной на каждый календарный паттерн — созданы как группировочные таблицы. Таким образом, у нас есть таблица дат, в которой первичный ключ называется “date”. Когда мы объявляем новую таблицу с агрегацией “by” и указываем дату, мы создаем таблицу, имеющую прямое отношение вещания с таблицей дат.
Если мы конкретно посмотрим на таблицу дней недели в строке четыре, то увидим, что создается таблица, содержащая ровно семь строк. Каждая строка таблицы будет связана с одной единственной строкой таблицы дней недели. Таким образом, если мы зададим значения в этой таблице, мы сможем естественно передавать эти значения, так как каждая строка в таблице дат найдет соответствующую строку в таблице дней недели.
В строке девять, с вектором “de.dot.baseline”, вычисление происходит посредством простого умножения пяти факторов, расположенных справа от знака присваивания. Все эти факторы сначала транслируются в таблицу дат, а затем для каждой строки в таблице дат выполняется простое покстрочное умножение.
Теперь у нас есть модель с несколькими десятками параметров. Посчитаем их: 12 параметров для месяца (от 1 до 12); 7 параметров для дня недели; и 31 параметр для дня месяца. Однако в случае NDM5 мы не будем обучать отдельное значение параметра для каждого SKU, так как это приведет к колоссальному количеству параметров, что, скорее всего, приведет к переобучению набора данных Walmart. Вместо этого в NDM5 был использован прием, известный как разделение параметров.
Разделение параметров означает, что вместо обучения уникальных параметров для каждого SKU мы создаем подгруппы и обучаем параметры на уровне этих подгрупп. Далее мы используем одинаковые значения параметров в рамках каждой группы. Разделение параметров — это классическая техника, широко используемая в deep learning, хотя она появилась еще до возникновения глубокого обучения. Во время конкурса M5 параметры для месяца и дня недели обучались на уровне агрегирования по отделам магазинов. Я вернусь к различным уровням агрегирования в M5 чуть позже. Значения для дня месяца представляли собой жестко заданные факторы, установленные на уровне штатов, подразумевая, например, Калифорнию, Техас и т.д. Во время конкурса M5 все эти календарные параметры просто обучались как прямые средние значения по соответствующим областям. Это очень прямой способ задания параметров: вы берете все SKU, принадлежащие к одной области, рассчитываете среднее, нормализуете, и таким образом получаете нужный параметр.

Теперь, на данном этапе, мы собрали всё необходимое для сборки модели REMT. Мы увидели, как построить ежедневный базовый уровень, включающий все календарные паттерны. Календарные паттерны были определены с помощью прямых средних значений для определенной области, что является грубым, но эффективным методом обучения. Мы также увидели, что ISSM преобразует временной ряд в случайное блуждание. Осталось лишь установить правильные значения параметров ISSM, а именно: альфа — параметр, используемый для экспоненциального сглаживания внутри SSM; дисперсия — параметр, контролирующий отрицательное биномиальное распределение; и начальное значение уровня, которое используется для инициализации случайного блуждания.
Во время конкурса M5 команда из Lokad использовала простую оптимизацию по перебору в сетке для обучения этих трех оставшихся параметров. По сути, grid search означает, что вы перебираете все возможные комбинации этих значений, изменяя их малыми шагами. Поиск по сетке осуществлялся с использованием функции потерь pinball, о которой я уже говорил, для управления оптимизацией этих трех параметров. Для каждого SKU grid search, вероятно, является одним из самых неэффективных методов математической оптимизации. Однако, учитывая, что у нас всего три параметра, что оптимизацию нужно проводить для каждого временного ряда, и что сам набор данных M5 довольно мал, этот метод оказался подходящим для конкурса.
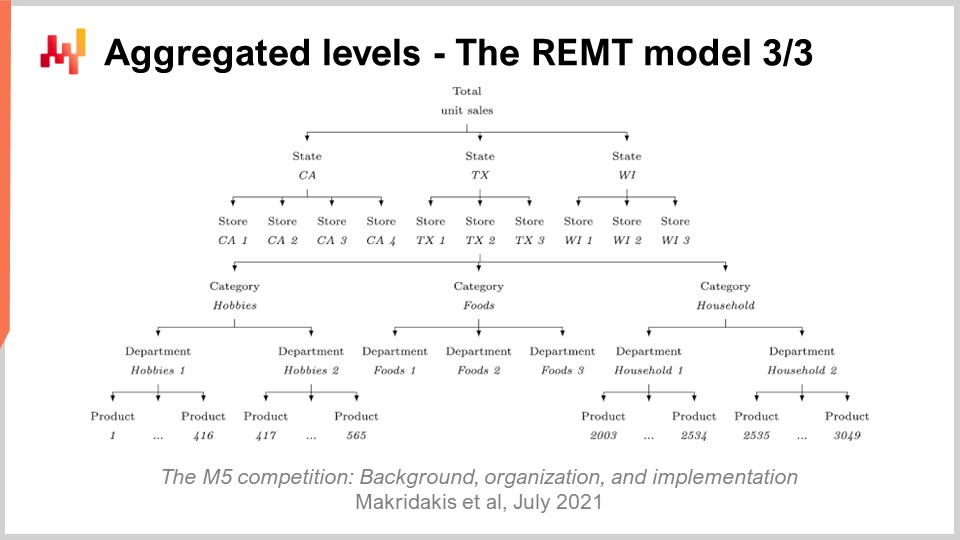
До сих пор мы объясняли, как работает модель REMT на уровне SKU. Однако в M5 было 12 различных уровней агрегации. Уровень SKU, являясь самым детализированным, был самым важным. SKU, или единица складского учёта, буквально означает один продукт в одном месте. Если у вас один и тот же продукт в 10 местах, то у вас 10 SKU. Хотя уровень SKU, пожалуй, является наиболее релевантным для цепочки поставок, почти все решения, связанные с запасами, такие как пополнение запасов и ассортимент, принимаются именно на уровне SKU. M5 в первую очередь был конкурсом прогнозирования, и поэтому основное внимание уделялось и другим уровням агрегации.
На экране эти уровни обобщают уровни агрегации, присутствовавшие в наборе данных M5. Вы можете видеть, что у нас есть штаты, такие как Калифорния и Техас. Для работы с более высокими уровнями агрегации команда из Lokad использовала две техники: либо суммировать случайные блуждания, то есть выполнять случайные блуждания на более низком уровне агрегации, суммировать их, а затем получать случайные блуждания на более высоком уровне; либо полностью перезапускать процесс обучения, переходя напрямую к более высокому уровню агрегации. В конкурсе M5 по неопределенности модель REMT оказалась лучшей на уровне SKU, но не была так хороша на остальных уровнях агрегации, хотя в целом показывала хорошие результаты.
Моя собственная рабочая гипотеза относительно того, почему модель REMT оказалась не лучшей на всех уровнях, выглядит следующим образом (обратите внимание, что это гипотеза, и мы её фактически не проверяли): распределение отрицательного бинома предлагает две степени свободы благодаря своим двум параметрам. Когда речь идёт о довольно разреженных данных, как на уровне SKU, две степени свободы создают нужный баланс между недообучением и переобучением. Однако по мере перехода к более высоким уровням агрегации данные становятся плотнее и богаче, поэтому компромисс вероятно смещается в сторону чего-то, что способно точнее отражать форму распределения. Для этого понадобится несколько дополнительных степеней свободы – вероятно, всего один или два дополнительных параметра.
Я подозреваю, что увеличение степени параметризации распределения счёта, используемого в основе модели REMT, значительно приблизило бы нас к результатам, очень близким к современному уровню, если не даже полностью ему соответствующим, на более высоких уровнях агрегации. Тем не менее, у нас не было времени на это, и мы, возможно, вернёмся к этому вопросу в будущем. Это завершает описание того, что было сделано командой из Lokad во время конкурса M5.

Давайте обсудим, что можно было сделать иначе или лучше. Несмотря на то, что модель REMT является низкоразмерной параметрической моделью с простой мультипликативной структурой, процесс получения значений параметров в ходе M5 оказался несколько случайно усложнённым. Это был многоступенчатый процесс, при котором каждый календарный паттерн обрабатывался особым способом, в итоге завершаясь индивидуальным поиском по сетке для доработки модели REMT. Весь процесс требовал довольно много времени от специалистов по цепям поставок, и я подозреваю, что он оказался бы довольно ненадёжным в производственной среде из-за огромного количества специального кода.
В частности, я считаю, что мы можем и должны объединить процесс обучения всех параметров в единый этап или, как минимум, унифицировать процесс обучения так, чтобы использовался один и тот же метод многократно. На сегодняшний день Lokad использует дифференцируемое программирование именно для этой цели. Дифференцируемое программирование устраняет необходимость в специальных агрегациях, касающихся календарных паттернов. Оно также решает проблему точного порядка извлечения календарных паттернов, позволяя извлечь их сразу все. Наконец, поскольку дифференцируемое программирование является собственным процессом оптимизации, оно заменяет поиск по сетке гораздо более эффективной логикой оптимизации. Позже в лекциях этой главы мы подробнее рассмотрим, как дифференцируемое программирование может применяться для прогнозного моделирования в контексте цепей поставок.
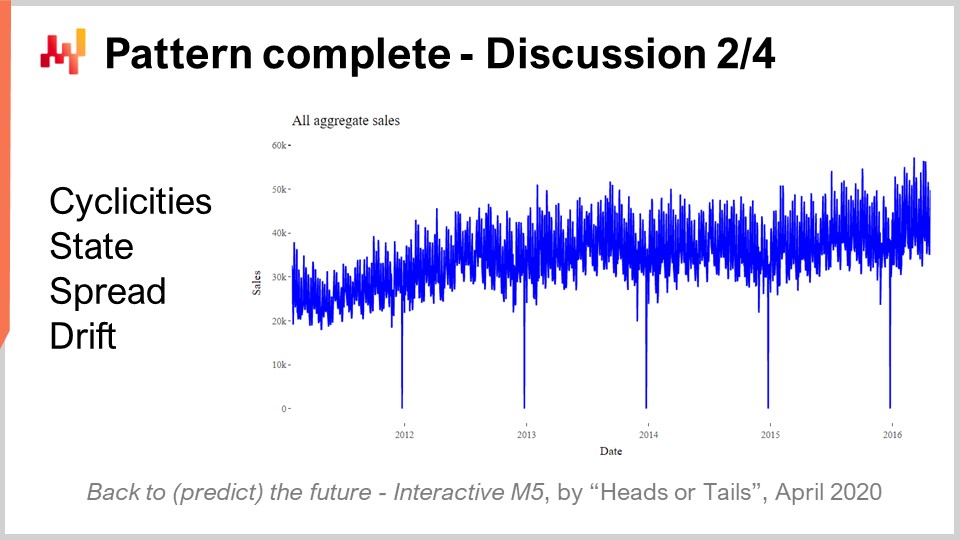
Теперь один из самых удивительных результатов конкурса M5 заключался в том, что ни один статистический паттерн не остался без названия. У нас было буквально четыре паттерна: простота, состояние, разброс и дрейф, и этого оказалось достаточно, чтобы достичь прогностической точности на уровне современных стандартов конкурса M5.
Простые паттерны основываются исключительно на календаре, и ни один из них даже отдалённо не является неожиданным. Состояние можно представить как одно число, которое отражает уровень, достигнутый SKU в определённый момент времени. Разброс можно представить одним числом, являющимся показателем дисперсии, используемой для параметризации отрицательного бинома, а дрейф — одним числом, связанным с процессом экспоненциального сглаживания, происходящим внутри SSM. Нам даже не пришлось включать тренд, который был слишком слаб для 28-дневного горизонта.
Хотя мы рассматриваем суммарные продажи за пять лет для M5, как показано на экране, агрегация явно демонстрирует умеренный восходящий тренд. Тем не менее, модель REMT работает без учёта этого тренда, и это не сказалось на точности. Результаты модели REMT заставляют задуматься: существует ли ещё какой-либо паттерн, который можно уловить, и не упустили ли мы какие-нибудь паттерны?
По крайней мере, результаты модели REMT показывают, что ни одна из более сложных моделей, участвовавших в этом конкурсе, таких как градиентный бустинг или методы глубокого обучения, не смогла уловить ничего сверх этих четырёх паттернов. Действительно, если бы какая-либо из этих моделей смогла существенно что-либо уловить, она значительно превосходила бы модель REMT на уровне SKU, а этого не произошло. То же самое можно сказать и о более сложных статистических методах, таких как ARIMA. Эти модели также не смогли уловить ничего сверх того, что удалось зафиксировать этой весьма простой мультипликативной параметрической модели.
Принцип Бритвы Оккама подсказывает, что, если у нас нет веских оснований полагать, что какой-либо паттерн ускользнул от нашего внимания или что существует какая-то интересная особенность, перевешивающая простоту этой модели, то у нас нет причин использовать что-либо, кроме модели, которая по крайней мере так же проста, как модель REMT.

Однако ряд паттернов отсутствовал в конкурсе M5 из-за самой структуры набора данных M5. Эти паттерны важны, и на практике любая модель, их игнорирующая, будет работать плохо в реальной розничной среде. Я основываю это утверждение на собственном опыте.
Во-первых, имеются запуски продуктов. Конкурс M5 включал только те продукты, у которых была история продаж не менее пяти лет. Это неразумное предположение с точки зрения цепочки поставок. Действительно, товары FMCG обычно имеют жизненный цикл всего несколько лет, и, следовательно, в реальном магазине значительная часть ассортимента имеет историю продаж менее года. Кроме того, если рассматривать товары с долгими сроками поставки, многие решения по цепочке поставок приходится принимать ещё до того, как продукт успевает быть продан хотя бы один раз. Таким образом, нам нужны прогнозные модели, способные работать даже без истории продаж для конкретного продукта.
Второй критически важный паттерн — это отсутствие запасов (stockouts). Отсутствие запасов имеет место в розничной торговле, и набор данных конкурса M5 полностью их игнорировал. Однако отсутствие запасов ограничивает продажи. Если продукт отсутствует в магазине, он не будет продан в этот день, и поэтому отсутствие запасов вносит существенное искажение в наблюдаемые продажи. Проблема в случае Walmart и универмагов ещё более усложняется тем, что электронные записи, фиксирующие запасы на складе, не всегда вызывают доверие. Существует множество неточностей в данных о запасах, и это также следует учитывать.
Третьим важным паттерном являются промоакции. В конкурсе M5 была представлена историческая ценовая информация; однако данные о ценах не были предоставлены для периода прогнозирования. В результате, похоже, ни один участник конкурса не смог использовать ценовую информацию для улучшения точности прогнозов. Модель REMT вообще не использует ценовую информацию. Помимо того, что нам не хватало информации о ценах для периода прогнозирования, промоакции — это не только вопрос цен. Продукт может продвигаться посредством его заметного размещения в магазине, что может значительно повысить спрос, независимо от сниженной ли цена. Кроме того, при промоакциях необходимо учитывать эффекты каннибализации и замещения.
В целом, набор данных M5 с точки зрения цепочки поставок можно рассматривать как игрушечный набор данных. Хотя он, вероятно, остаётся лучшим публичным набором данных для проведения бенчмаркинга в цепочках поставок, он всё же далёк от того, чтобы быть по-настоящему эквивалентным реальной производственной среде даже в относительно небольшой розничной сети.

Однако ограничения конкурса M5 связаны не только с набором данных. С точки зрения цепочки поставок существуют фундаментальные проблемы с правилами, по которым проводился конкурс M5.
Первая фундаментальная проблема заключается в том, чтобы не путать продажи со спросом. Мы уже поднимали этот вопрос, когда говорили об отсутствии запасов. С точки зрения цепочки поставок настоящий интерес заключается в прогнозировании спроса, а не продаж. Однако проблема глубже. Правильная оценка спроса по сути является задачей обучения без учителя. То, что для определения ассортимента в магазине были сделаны произвольные выборы, не означает, что спрос на продукт нельзя оценивать. Мы должны оценивать спрос на товары, независимо от того, входят ли они в ассортимент конкретного магазина.
Второй аспект заключается в том, что квантильные прогнозы менее полезны, чем вероятностные. Выбор отдельных уровней сервиса оставляет пробелы в общей картине, а квантильные прогнозы относительно слабы с точки зрения применения в цепочках поставок. Вероятностный прогноз даёт гораздо более полное видение, поскольку предоставляет полное распределение вероятностей, устраняя данный класс проблем. Единственный ключевой недостаток вероятностных прогнозов заключается в том, что они требуют более развитых инструментов, особенно когда дело доходит до практического использования прогноза на последующих этапах. Кстати, модель REMT на самом деле выдаёт нечто, что можно назвать вероятностным прогнозом, поскольку с помощью процесса Монте-Карло можно сгенерировать целое распределение вероятностей. Нужно лишь настроить число итераций Монте-Карло.
В розничной торговле покупателям на самом деле безразличен вопрос о SKU или уровне обслуживания, который может быть обеспечен для отдельного SKU. Восприятие качества обслуживания в универсальном магазине, таком как Walmart, определяется состоянием всей корзины покупок. Обычно покупатели заходят в магазин Walmart с готовым списком покупок, а не с намерением приобрести один единственный продукт. Кроме того, в магазине имеется множество заменителей. Проблема использования единой метрики SKU для оценки качества обслуживания заключается в том, что она полностью упускает из виду то, что покупатели воспринимают как качество обслуживания в магазине.
В заключение, как эталон для прогнозирования временных рядов конкурс M5 силён как с точки зрения набора данных, так и методологии. Однако сама перспектива временных рядов уступает с точки зрения цепочки поставок. Временные ряды не отражают данные так, как они встречаются в цепочках поставок, и не передают проблемы, с которыми сталкиваются цепочки поставок. Во время конкурса M5 среди лидирующих методов было много гораздо более сложных подходов. Однако, на мой взгляд, эти модели фактически являются тупиковыми. Они уже слишком сложны для применения в производственной среде, и они настолько погружены в перспективу временных рядов, что у них отсутствует оперативное пространство для развития в сторону свежего подхода, который позволил бы адаптировать эти модели для наших собственных потребностей в цепочках поставок.
Наоборот, в качестве отправной точки модель REMT является настолько хороша, насколько это возможно. Это очень простое сочетание компонентов, которые сами по себе крайне просты. Более того, не требуется много фантазии, чтобы увидеть, что существует множество способов использования и комбинирования этих элементов, помимо того конкретного набора, который был собран для конкурса M5. Рейтинг модели REMT в конкурсе M5 демонстрирует, что, если не будет доказано иное, мы должны придерживаться очень простой модели, поскольку у нас нет убедительной причины переходить на очень сложные модели, которые почти гарантированно будут сложнее при отладке, труднее эксплуатироваться в производственной среде и потребуют существенно больших вычислительных ресурсов.
В последующих лекциях этой пятой главы мы увидим, как можно использовать компоненты, присутствующие в модели REMT, а также множество других элементов для решения широкого спектра прогнозных задач, встречающихся в цепочках поставок. Главное, что нужно помнить: модель не имеет значения; важно моделирование.

Вопрос: Почему отрицательные биномиальные распределения? Какова была логика их выбора?
Это очень хороший вопрос. Оказывается, если существует целый «зверинец» распределений для счёта, то, вероятно, существует около двадцати широко известных распределений для счёта. В Lokad мы тестировали дюжину для наших собственных внутренних нужд. Оказалось, что распределение Пуассона, которое является очень простым распределением для счёта с всего одним параметром, работает довольно хорошо, когда данные очень разрежены. Таким образом, распределение Пуассона довольно эффективно, но, собственно, набор данных M5 был немного богаче. В случае набора данных Walmart мы пробовали распределения для счёта с несколькими дополнительными параметрами, и они показали себя вполне работоспособными. У нас нет доказательств, что именно это распределение является лучшим; вероятно, существуют и лучшие варианты. Отрицательное биномиальное распределение имеет несколько ключевых преимуществ: его реализация очень проста, и оно широко изучалось. Таким образом, у вас есть хорошо известный алгоритм не только для вычисления вероятностей, но и для генерации случайного отклонения, получения среднего значения или кумулятивного распределения. Все инструменты, которые можно ожидать для работы с распределениями счёта, доступны, чего нельзя сказать обо всех распределениях.
При выборе использован определённый прагматизм, но и логика сыграла свою роль. У распределения Пуассона есть одна степень свободы; у отрицательного биномиального распределения — две. Затем можно использовать такие уловки, как отрицательное биномиальное распределение с избытком нулей, которое даёт вам, можно сказать, две с половиной степени свободы и т.д. Я не стал бы утверждать, что для этого распределения счётов существует какое-то конкретное окончательное значение.
Вопрос: Были и другие поставщики программного обеспечения для оптимизации цепочек поставок в M5, но никто не использовал живые модели, которые хорошо масштабируются в производстве. Что использует большинство: тяжёлые модели машинного обучения?
Во-первых, я бы сказал, что необходимо различать и уточнять: M5 проводился на платформе Kaggle для науки о данных. На Kaggle существует огромный стимул использовать самую сложную технику. Набор данных небольшой, у вас много времени, и чтобы занять первое место, вам нужно быть всего на 0,1% точнее конкурентов. Это всё, что имеет значение. Таким образом, практически в каждом соревновании на Kaggle вы увидите, что первые места занимают люди, которые применяли очень сложные методы лишь для получения дополнительного 0,1% точности. По сути, природа конкуренции в прогнозировании даёт вам сильный стимул пробовать всё, включая самые тяжёлые модели, которые можно найти.
Если спрашивать, используют ли люди на практике эти тяжеловесные модели машинного обучения, моё обычное наблюдение однозначно — нет. Это действительно чрезвычайно редко. Будучи CEO компании Lokad, поставщика программного обеспечения для цепочек поставок, я разговаривал со сотнями руководителей цепочек поставок. Буквально более 90% крупных цепочек поставок управляются при помощи Excel. Я никогда не видел, чтобы какая-либо крупномасштабная цепочка поставок управлялась с помощью градиентного бустинга или нейронных сетей глубокого обучения. Если не считать Amazon — Amazon, вероятно, уникален. Существует, может быть, полдюжины компаний, таких как Amazon, Alibaba, JD.com и ещё несколько — крупных гигантов электронной коммерции — которые на практике используют такого рода технологии. Но они являются исключениями в этом отношении. Ваши мейнстримовые крупные FMCG-компании или крупные традиционные ритейлеры не используют подобные технологии в производстве.
Вопрос: Странно, что вы упоминаете множество математических и статистических терминов, но игнорируете природу розничных продаж и основные влияющие факторы.
Я бы сказал, да, это больше похоже на комментарий, но мой вопрос к вам: что вы вносите в общее дело? Вот что я и имел в виду, когда поставщики для цепочек поставок, хвастающиеся превосходными технологиями прогнозирования, отсутствовали. Почему, если у вас есть абсолютно превосходная технология прогнозирования, вы как бы не появляются, когда проводится что-то вроде публичного бенчмарка? Другое объяснение состоит в том, что люди блефуют.
Что касается природы розничных продаж и множества влияющих факторов, я перечислил использованные шаблоны, и, используя эти четыре шаблона, модель REMT оказалась первой по точности на уровне SKU. Если вы утверждаете, что существует гораздо больше важных шаблонов, бремя доказательства лежит на вас. Моё собственное подозрение таково, что если среди более чем 900 команд эти шаблоны не были замечены, то, вероятно, их и не существовало, или их выявление выходит за рамки возможностей технологий, которые мы имеем на данный момент, так что практически их можно считать несуществующими с практической точки зрения.
Вопрос: Применяли ли какие-либо конкуренты в M5 идеи, которые, хотя и не обгоняли Lokad, были бы полезны для внедрения, особенно для универсальных приложений? Заслуживающее упоминания?
Я внимательно следил за своими конкурентами и почти уверен, что они тоже прислушиваются к Lokad. Я этого не видел. Модель REMT была действительно уникальной, совершенно не похожей на то, что делали практически все остальные из топ-50 участников для любой задачи. Остальные участники использовали методы, гораздо более классические для машинного обучения.
Во время конкурса были продемонстрированы весьма умные приёмы в области науки о данных. Например, некоторые участники использовали хитрые, изысканные методы аугментации данных в наборе данных Walmart, чтобы сделать его намного больше и получить дополнительный процент точности. Это сделал участник, занявший первое место в категории неопределенности. Правильный термин — аугментация данных, а не инфляция данных. Аугментация данных обычно используется в техниках глубокого обучения, но здесь её применяли с градиентными бустинг-деревьями довольно нестандартными способами. На этом конкурсе были показаны изощрённые и очень умные приёмы работы с данными. Я не уверен, насколько эти методы хорошо обобщаются на цепочки поставок, но, возможно, упомяну пару из них позже в этой главе, если представится возможность.
Вопрос: Оценивали ли вы более высокие уровни, агрегируя уровни SKU, или с помощью нового расчёта методом «middle-out» для более высоких уровней? Если и то, и другое, как они соотносятся?
Проблема квантильных сеток заключается в том, что вы склонны оптимизировать модели отдельно для каждого целевого уровня. В результате может происходить пересечение квантилей, что означает, что из-за числовых нестабильностей ваш 99-й квантиль оказывается ниже 97-го квантиля. Это не имеет особого значения; обычно вы просто упорядочиваете значения заново. В сущности, это именно та проблема, о которой я говорил, утверждая, что квантильные сетки не являются по-настоящему вероятностными прогнозами. У вас множество мелких деталей, которые нужно решить, но на общем уровне они несущественны. Когда вы переходите к вероятностным прогнозам, этих проблем уже вовсе не существует.
Вопрос: Если бы вы разрабатывали ещё одно соревнование для поставщиков программного обеспечения, как бы оно выглядело?
Честно говоря, я не знаю, и это очень сложный вопрос. Я считаю, что, несмотря на всю мою серьёзную критику, если говорить о бенчмарках прогнозирования, M5 — лучший из имеющихся. Что касается бенчмарков для цепочек поставок, проблема в том, что я даже не полностью убеждён, что это вообще возможно. Когда я намекал, что некоторые проблемы требуют, по сути, неконтролируемого обучения, ситуация становится сложной. Когда вы вступаете в область неконтролируемого обучения, вам приходится отказываться от метрик, и всё сообщество продвинутого машинного обучения всё ещё пытается разобраться, что вообще означает использование превосходных, автоматизированных инструментов обучения в условиях отсутствия контроля. Как, собственно, вообще можно оценить эффективность такого рода систем?
Для аудитории, которой не посчастливилось побывать на моей лекции о машинном обучении, в условиях контролируемого обучения вы фактически решаете задачу, где есть входы, выходы и метрика для оценки качества ваших результатов. Когда же вы работаете в условиях неконтролируемого обучения, у вас нет меток, с чем можно сравнить результаты, и всё становится гораздо сложнее. Кроме того, я хотел бы отметить, что в цепочках поставок существует множество аспектов, где даже обратное тестирование невозможно. Помимо аспекта неконтролируемого обучения, идея обратного тестирования тоже не всегда работает удовлетворительно. Например, прогнозирование спроса порождает определённые виды решений, такие как ценовые решения. Если вы решаете повысить или понизить цену, это ваше решение, которое навсегда повлияет на будущее. Таким образом, вы не можете вернуться назад и сказать: “Хорошо, я сделаю другой прогноз спроса, а затем приму иное ценовое решение, и позволю истории повториться, только на этот раз с другой ценой.” Существует множество аспектов, где даже сама идея обратного тестирования не работает. Именно поэтому я считаю, что соревнование — это нечто очень интересное с точки зрения прогнозирования. Оно полезно как отправная точка для целей цепочек поставок, но нам нужно действовать лучше и по-новому, если мы хотим получить действительно удовлетворительные результаты для цепочек поставок. В этой главе о предиктивном моделировании я покажу, почему моделирование заслуживает такого внимания.
Вопрос: Можно ли использовать эту методологию в ситуациях, когда данных мало?
Я бы сказал, безусловно. Такой структурированный подход к моделированию, как продемонстрировано здесь на примере модели REMT, особенно хорошо проявляет себя в условиях скудных данных. Причина проста: в структуру модели можно встроить огромное количество человеческих знаний. Структура модели — это не нечто, вытащенное из ниоткуда; это буквально результат того, что команда Lokad поняла проблему. Например, рассматривая календарные шаблоны, такие как день недели, месяц года и т.д., мы не пытались «открыть» эти паттерны; команда Lokad с самого начала знала, что они уже существуют. Единственная неопределённость заключалась в относительной значимости шаблона «день месяца», который зачастую выражен слабо. В случае с настройками Walmart это было вызвано наличием в США программы штампов, поэтому шаблон дня месяца проявляется настолько ярко.
Если данных мало, такой подход работает чрезвычайно хорошо, поскольку какой бы механизм обучения вы ни использовали, он будет максимально задействован на основе наложенной вами структуры. Так что да, возникает вопрос: что если структура неверна? Но именно поэтому понимание принципов цепочек поставок так важно, чтобы принимать правильные решения. В конечном итоге, существуют способы оценить, были ли ваши произвольные решения хорошими или плохими, но, по сути, это происходит очень поздно в процессе. Позже в этой главе о предиктивном моделировании мы покажем, как структурированное моделирование может эффективно использоваться на наборах данных, которые невероятно скудны, таких как данные в авиации, сегменте предметов роскоши и в эмальдах всех видов. В этих случаях структурированные модели действительно блистают.
Следующая лекция состоится 2 февраля, в среду, в то же время, в 15:00 по парижскому времени. До встречи!
Литература
- Метод белого ящика ISSM для оценки распределений неопределенности продаж Walmart, Рафаэль де Резенде, Катарины Эгерт, Игнасио Марин, Гильерме Томпсон, декабрь 2021 (link)
- Конкурс неопределенности M5: результаты, выводы и заключения, Спирос Макридакис, Эвангелос Спилиотис, Василис Ассимакопулос, Чжи Чен, ноябрь 2020 (link)


