00:01 Introduzione
02:18 La previsione moderna
06:37 Andare probabilistico
11:58 La storia finora
15:10 Piano probabile per oggi
17:18 Bestiario delle previsioni
28:10 Metriche - CRPS - 1/2
33:21 Metriche - CRPS - 2/2
37:20 Metriche - Monge-Kantorovich
42:07 Metriche - likelihood - 1/3
47:23 Metriche - likelihood - 2/3
51:45 Metriche - likelihood - 3/3
55:03 Distribuzioni 1D - 1/4
01:01:13 Distribuzioni 1D - 2/4
01:06:43 Distribuzioni 1D - 3/4
01:15:39 Distribuzioni 1D - 4/4
01:18:24 Generatori - 1/3
01:24:00 Generatori - 2/3
01:29:23 Generatori - 3/3
01:37:56 Per favore, aspetta mentre ti ignoriamo
01:40:39 Conclusioni
01:43:50 Prossima lezione e domande del pubblico
Descrizione
Una previsione è definita probabilistica, invece che deterministica, se contiene un insieme di probabilità associate a tutti i possibili risultati futuri, invece di individuare un singolo risultato come “la” previsione. Le previsioni probabilistiche sono importanti ogni volta che l’incertezza è irriducibile, il che è quasi sempre il caso quando si tratta di sistemi complessi. Per le supply chain, le previsioni probabilistiche sono essenziali per prendere decisioni robuste in condizioni future incerte.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Previsione Probabilistica per la Supply Chain”. La previsione probabilistica è uno dei cambiamenti di paradigma più importanti, se non il più importante, nella scienza delle previsioni statistiche degli ultimi cento anni. Tuttavia, a livello tecnico, è per lo più più dello stesso. Se stiamo guardando modelli di previsione probabilistica o le loro alternative non probabilistiche, si tratta delle stesse statistiche, delle stesse probabilità. La previsione probabilistica riflette un cambiamento nel modo in cui dovremmo pensare alla previsione stessa. Il cambiamento più grande portato dalla previsione probabilistica alla supply chain non si trova nella scienza delle previsioni. Il cambiamento più grande si trova nel modo in cui le supply chain vengono gestite e ottimizzate in presenza di modelli predittivi.
L’obiettivo della lezione di oggi è fornire un’introduzione tecnica alla previsione probabilistica. Alla fine di questa lezione, dovreste essere in grado di capire di cosa si tratta la previsione probabilistica, come differenziare le previsioni probabilistiche da quelle non probabilistiche, come valutare la qualità di una previsione probabilistica e persino di creare il vostro modello di previsione probabilistica di base. Oggi non parlerò dell’utilizzo delle previsioni probabilistiche per scopi decisionali nel contesto delle supply chain. L’attenzione sarà esclusivamente rivolta a stabilire le basi della previsione probabilistica. Il miglioramento dei processi decisionali nella supply chain tramite previsioni probabilistiche sarà trattato nella prossima lezione.

Per comprendere l’importanza delle previsioni probabilistiche, è necessario un po’ di contesto storico. La forma moderna di previsione, la previsione statistica, rispetto alla divinazione, è emersa all’inizio del XX secolo. La previsione è emersa in un contesto scientifico più ampio in cui le scienze esatte, poche discipline di grande successo come la cinematica, l’elettromagnetismo e la chimica, sono state in grado di ottenere risultati apparentemente arbitrariamente precisi. Questi risultati sono stati ottenuti attraverso essenzialmente quello che potrebbe essere considerato uno sforzo plurisecolare, che potrebbe essere fatto risalire, ad esempio, a Galileo Galilei, nello sviluppo di tecnologie superiori che avrebbero permesso forme superiori di misurazione. Misure più precise, a loro volta, avrebbero alimentato ulteriori sviluppi scientifici, consentendo agli scienziati di testare e mettere alla prova le loro teorie e previsioni in modi ancora più precisi.
In questo contesto più ampio in cui alcune scienze hanno avuto un successo incredibile, il campo emergente della previsione all’inizio del XX secolo si è assunto l’incarico di replicare essenzialmente ciò che quelle scienze esatte avevano realizzato nel campo dell’economia. Ad esempio, se guardiamo ai pionieri come Roger Babson, uno dei padri della moderna previsione economica, ha fondato un’azienda di previsione economica di successo negli Stati Uniti all’inizio del XX secolo. Il motto dell’azienda era letteralmente: “Per ogni azione, c’è una reazione uguale e opposta”. La visione di Babson era quella di trasporre il successo della fisica newtoniana nel campo dell’economia e, in definitiva, di ottenere risultati altrettanto precisi.
Tuttavia, dopo più di un secolo di previsioni accademiche statistiche, in cui le supply chain operano, l’idea di ottenere risultati arbitrariamente precisi, che si traducono in termini di previsioni accurate, rimane tanto elusiva quanto lo era più di un secolo fa. Da un paio di decenni, nel mondo più ampio delle supply chain, ci sono state voci che hanno sollevato preoccupazioni sul fatto che queste previsioni non diventeranno mai abbastanza accurate. Ci sono stati movimenti, come la produzione snella, che tra gli altri sono stati forti sostenitori della riduzione della dipendenza delle supply chain da queste previsioni non affidabili. Di questo si tratta il just-in-time: se puoi produrre e servire proprio in tempo tutto ciò di cui il mercato ha bisogno, allora improvvisamente non hai più bisogno di una previsione affidabile e precisa.
In questo contesto, la previsione probabilistica è una riabilitazione della previsione, ma con ambizioni molto più modeste. La previsione probabilistica parte dall’idea che ci sia un’incertezza irriducibile sul futuro. Tutti i futuri sono possibili, semplicemente non sono tutti altrettanto possibili, e l’obiettivo della previsione probabilistica è valutare comparativamente la probabilità rispettiva di tutti quei futuri alternativi, non ridurre tutti i futuri possibili a un solo futuro.

La prospettiva newtoniana sulle previsioni economiche statistiche è essenzialmente fallita. L’opinione nella nostra comunità che previsioni arbitrariamente accurate possano mai essere raggiunte è in gran parte scomparsa. Eppure, stranamente, quasi tutto il software di supply chain e una grande quantità di pratiche di supply chain mainstream sono effettivamente radicate nel presupposto che tali previsioni saranno alla fine disponibili.
Ad esempio, la Sales and Operations Planning (S&OP) si basa sull’idea che una visione unificata e quantificata per l’azienda possa essere raggiunta se tutti gli stakeholder si mettono insieme e collaborano nella costruzione di una previsione. Allo stesso modo, l’open-to-buy è essenzialmente un metodo basato sull’idea che un processo di budgeting top-down, basato sull’idea che sia possibile costruire previsioni top-down arbitrariamente precise. Inoltre, anche quando guardiamo a molti strumenti che sono molto comuni quando si tratta di previsioni e pianificazione nel campo delle supply chain, come business intelligence e fogli di calcolo, questi strumenti sono ampiamente orientati verso una previsione di serie temporali. Fondamentalmente, l’idea è che si possano estendere i dati storici nel futuro, avendo un punto per ogni periodo di interesse. Questi strumenti, per loro natura, presentano un’enorme quantità di attrito quando si tratta di comprendere anche il tipo di calcoli che sono coinvolti in una previsione probabilistica, in cui non c’è un solo futuro ma tutti i futuri possibili.
Infatti, la previsione probabilistica non consiste nel decorare una previsione classica con qualche tipo di incertezza. La previsione probabilistica non consiste nemmeno nell’individuare una lista ristretta di scenari, con ciascuno scenario che è una previsione classica a sé stante. I metodi di supply chain mainstream di solito non funzionano con previsioni probabilistiche perché, nel loro nucleo, si basano implicitamente o esplicitamente sull’idea che esista una sorta di previsione di riferimento, e che tutto ruoterà attorno a questa previsione di riferimento. Al contrario, la previsione probabilistica è la valutazione numerica frontale di tutti i futuri possibili.
Naturalmente, siamo limitati dalla quantità di risorse di calcolo che abbiamo, quindi quando dico “tutti i futuri possibili”, nella pratica, guarderemo solo un numero finito di futuri. Tuttavia, considerando il tipo di potenza di elaborazione moderna che abbiamo, il numero di futuri che possiamo effettivamente considerare varia in milioni. Ecco dove business intelligence e fogli di calcolo faticano. Non sono orientati al tipo di calcoli che sono coinvolti quando si tratta di previsioni probabilistiche. Questo è un problema di progettazione del software. Vedete, un foglio di calcolo ha accesso agli stessi computer e alla stessa potenza di elaborazione, ma se il software non è dotato del giusto tipo di progettazione, alcune attività possono essere incredibilmente difficili da realizzare, anche se si dispone di una vasta quantità di potenza di elaborazione.
Pertanto, dal punto di vista della supply chain, la sfida più grande per adottare la previsione probabilistica è lasciare andare decenni di strumenti e pratiche che si basano su un obiettivo molto ambizioso, ma a mio avviso fuorviante, ovvero che sia possibile ottenere previsioni arbitrariamente accurate. Vorrei subito sottolineare che sarebbe incredibilmente fuorviante pensare alla previsione probabilistica come un modo per ottenere previsioni più accurate. Questo non è il caso. Le previsioni probabilistiche non sono più accurate e non possono essere utilizzate come sostituto diretto delle previsioni classiche e mainstream. La superiorità delle previsioni probabilistiche risiede nei modi in cui queste previsioni possono essere sfruttate per scopi di supply chain, in particolare per scopi decisionali nel contesto delle supply chain. Tuttavia, il nostro obiettivo oggi è solo quello di capire di cosa si tratta queste previsioni probabilistiche, e lo sfruttamento di queste previsioni probabilistiche verrà trattato nella prossima lezione.

Questa lezione fa parte di una serie di lezioni sulla supply chain. Sto cercando di mantenere queste lezioni abbastanza indipendenti l’una dall’altra. Tuttavia, stiamo raggiungendo un punto in cui sarà davvero utile per il pubblico seguire queste lezioni in sequenza, poiché farò frequenti riferimenti a ciò che è stato presentato nelle lezioni precedenti.
Quindi, questa lezione è la terza del quinto capitolo, che è dedicato alla modellazione predittiva. Nel primo capitolo di questa serie, ho presentato il mio punto di vista sulle supply chain come campo di studio e pratica. Nel secondo capitolo, ho presentato le metodologie. Infatti, la maggior parte delle situazioni di supply chain sono di natura avversaria e queste situazioni tendono a sconfiggere le metodologie naive. Abbiamo bisogno di avere metodologie adeguate se vogliamo ottenere un certo grado di successo nel campo delle supply chain.
Il terzo capitolo è stato dedicato alla parsimonia della supply chain, con un focus esclusivo sul problema e sulla natura stessa della sfida che stiamo affrontando nelle varie situazioni che le supply chain coprono. L’idea alla base della parsimonia della supply chain è di ignorare completamente tutti gli aspetti che riguardano la soluzione, poiché vogliamo solo essere in grado di guardare esclusivamente al problema prima di scegliere la soluzione che vogliamo utilizzare per affrontarlo.
Nel quarto capitolo, ho esaminato una vasta gamma di scienze ausiliarie. Queste scienze non sono propriamente supply chain; sono altri campi di ricerca adiacenti o di supporto. Tuttavia, ritengo che un comando di base di queste scienze ausiliarie sia un requisito per la pratica moderna delle supply chain.
Infine, nel quinto capitolo, approfondiamo le tecniche che ci permettono di quantificare e valutare il futuro, in particolare per produrre affermazioni sul futuro. Infatti, tutto ciò che facciamo nella supply chain riflette in qualche misura una certa anticipazione del futuro. Se possiamo anticipare il futuro in modo migliore, saremo in grado di prendere decisioni migliori. Di questo si tratta il quinto capitolo: ottenere una comprensione quantitativamente migliore del futuro. In questo capitolo, le previsioni probabilistiche rappresentano un modo fondamentale nel nostro approccio per affrontare il futuro.
Il resto di questa lezione è diviso in quattro sezioni di lunghezza disuguale. Prima di tutto, faremo una revisione dei tipi di previsioni più comuni, oltre a quella classica. Spiegherò cosa intendo con previsione classica tra un momento. Infatti, troppo poche persone nei circoli della supply chain si rendono conto che ci sono molte opzioni disponibili. La previsione probabilistica stessa dovrebbe essere intesa come un’ombrello che copre un insieme piuttosto diversificato di strumenti e tecniche.
In secondo luogo, introdurremo metriche per valutare la qualità delle previsioni probabilistiche. Qualunque cosa accada, una previsione probabilistica ben progettata ti dirà sempre: “Beh, c’era una probabilità che accadesse questo.” Quindi la domanda diventa: come distinguere una previsione probabilistica buona da una cattiva? Ecco dove entrano in gioco queste metriche. Ci sono metriche specializzate che sono interamente dedicate alla situazione delle previsioni probabilistiche.
In terzo luogo, faremo un esame approfondito delle distribuzioni unidimensionali. Sono il tipo più semplice di distribuzione e, sebbene abbiano limitazioni ovvie, sono anche il punto di ingresso più facile nel campo delle previsioni probabilistiche.
Infine, toccheremo brevemente i generatori, che vengono spesso chiamati metodi Monte Carlo. Infatti, c’è una dualità tra i generatori e gli stimatori di densità di probabilità, e questi metodi Monte Carlo ci daranno un percorso per affrontare problemi di dimensioni superiori e forme di previsione probabilistica.

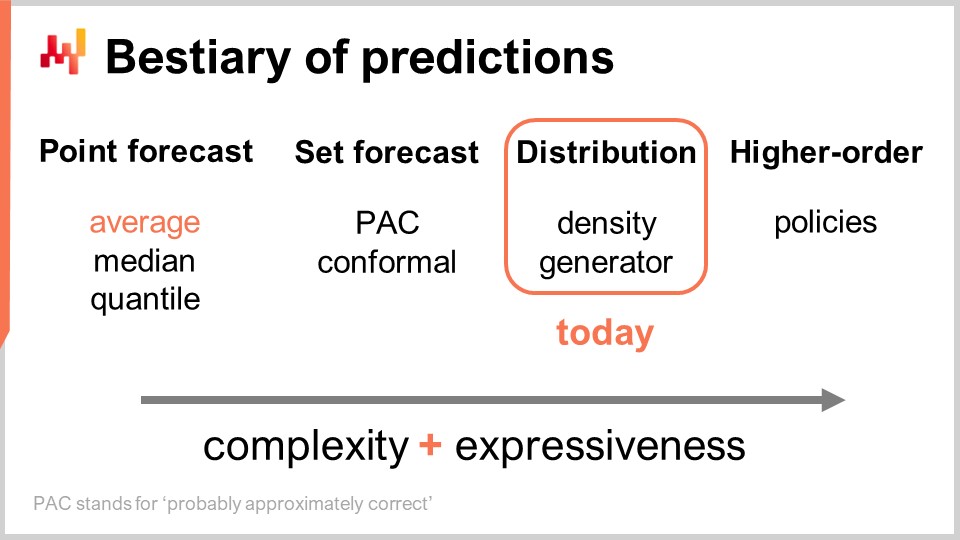
Ci sono diversi tipi di previsioni, e questo aspetto non dovrebbe essere confuso con il fatto che ci sono diversi tipi di modelli di previsione. Quando i modelli non appartengono allo stesso tipo o classe di previsione, non stanno nemmeno risolvendo gli stessi problemi. Il tipo più comune di previsione è la previsione puntata. Ad esempio, se dico che domani le vendite totali in euro in un negozio saranno di 10.000 euro per l’aggregato delle vendite totali della giornata, sto facendo una previsione puntata su ciò che accadrà in questo negozio domani. Se ripeto questo esercizio e inizio a costruire una previsione di serie temporale facendo una dichiarazione per il giorno di domani, poi un’altra dichiarazione per il giorno dopo domani, avrò più punti dati. Tuttavia, tutto ciò rimane comunque una previsione puntata perché, fondamentalmente, stiamo scegliendo la nostra battaglia scegliendo un certo livello di aggregazione e, a quel livello di aggregazione, le nostre previsioni ci danno un solo numero, che si suppone sia la risposta.
Ora, all’interno del tipo di previsione puntata, ci sono diversi sottotipi di previsioni a seconda della metrica che viene ottimizzata. La metrica più comunemente utilizzata è probabilmente l’errore quadratico medio, quindi abbiamo un errore quadratico medio, che ti dà la previsione media. A proposito, questa tende ad essere la previsione più comunemente utilizzata perché è l’unica previsione che è almeno in parte additiva. Nessuna previsione è mai completamente additiva; arriva sempre con tonnellate di avvertenze. Tuttavia, alcune previsioni sono più additive di altre e chiaramente le previsioni medie tendono ad essere le più additive del gruppo. Se vuoi avere una previsione media, ciò che hai è essenzialmente una previsione puntata che viene ottimizzata rispetto all’errore quadratico medio. Se usi un’altra metrica, come l’errore assoluto, e ottimizzi rispetto a quella, otterrai una previsione mediana. Se usi la funzione di perdita pinball che abbiamo introdotto nella prima lezione di questo quinto capitolo di questa serie di lezioni sulla supply chain, otterrai una previsione quantile. A proposito, come possiamo vedere oggi, sto classificando le previsioni quantili come un altro tipo di previsione puntata. Infatti, con la previsione quantile, ottieni essenzialmente una singola stima. Questa stima potrebbe avere un bias, che è intenzionale. Di questo si tratta il concetto di quantili, ma comunque, secondo me, si qualifica pienamente come una previsione puntata perché la forma della previsione è solo un singolo punto.
Ora, c’è la previsione a insieme, che restituisce un insieme di punti invece di un singolo punto. C’è una variazione a seconda di come costruisci l’insieme. Se guardiamo a una previsione PAC, PAC sta per Probably Approximately Correct. Questo è essenzialmente un framework introdotto da Valiant circa due decenni fa, e afferma che l’insieme, che è la tua previsione, ha una certa probabilità affinché un risultato venga osservato all’interno del tuo insieme che stai prevedendo con una certa probabilità. L’insieme che produci è effettivamente tutti i punti che cadono all’interno di una regione caratterizzata da una distanza massima da un punto di riferimento. In un certo senso, la prospettiva PAC sulla previsione è già una previsione a insieme perché l’output non è più un punto. Tuttavia, quello che abbiamo è ancora un punto di riferimento, un risultato centrale, e quello che abbiamo è una distanza massima da questo punto centrale. Stiamo solo dicendo che c’è una certa probabilità specificata che il risultato sarà alla fine osservato all’interno del nostro insieme di previsione.
L’approccio PAC può essere generalizzato attraverso l’approccio conforme. La previsione conforme afferma: “Ecco un insieme, e ti dico che c’è questa data probabilità che il risultato sarà all’interno di questo insieme”. Dove la previsione conforme generalizza l’approccio PAC è che le previsioni conformi non sono più legate a un punto di riferimento e alla distanza dal punto di riferimento. Puoi modellare questo insieme nel modo che desideri, e sarai comunque parte del paradigma di previsione a insieme.
Il futuro può essere rappresentato in modo ancora più dettagliato e complesso: la previsione di distribuzione. La previsione di distribuzione ti fornisce una funzione che mappa tutti i possibili risultati alle rispettive densità di probabilità locali. In un certo senso, partiamo dalla previsione di un punto, dove la previsione è solo un punto. Poi passiamo alla previsione a insieme, dove la previsione è un insieme di punti. Infine, la previsione di distribuzione è tecnicamente una funzione o qualcosa che generalizza una funzione. A proposito, quando uso il termine “distribuzione” in questa lezione, si riferirà sempre implicitamente a una distribuzione di probabilità. Le previsioni di distribuzione rappresentano qualcosa di ancora più ricco e complesso di un insieme, e questo sarà il nostro focus oggi.
Ci sono due modi comuni per affrontare le distribuzioni: l’approccio della densità e l’approccio del generatore. Quando dico “densità”, si riferisce essenzialmente alla stima locale delle densità di probabilità. L’approccio del generatore coinvolge un processo generativo di Monte Carlo che genera risultati, chiamati deviates, che dovrebbero riflettere la stessa densità di probabilità locale. Questi sono i due modi principali per affrontare le previsioni di distribuzione.
Oltre alla distribuzione, abbiamo costrutti di ordine superiore. Questo potrebbe essere un po’ complicato da capire, ma il mio punto qui, anche se non affronteremo i costrutti di ordine superiore oggi, è solo quello di delineare che la previsione probabilistica, quando si concentra sulla generazione di distribuzioni, non è il fine ultimo; è solo un passo, e c’è di più. I costrutti di ordine superiore sono importanti se vogliamo mai essere in grado di ottenere risposte soddisfacenti a situazioni semplici.
Per capire di cosa si tratta i costrutti di ordine superiore, consideriamo un semplice negozio al dettaglio con una politica di sconto in vigore per i prodotti che si avvicinano alla loro data di scadenza. Ovviamente, il negozio non vuole avere inventario invenduto tra le mani, quindi viene applicato automaticamente uno sconto quando i prodotti sono molto vicini alla loro data di scadenza. La domanda che questo negozio genererebbe dipende molto da questa politica. Pertanto, la previsione che vorremmo avere, che può essere una distribuzione che rappresenta le probabilità per tutti i possibili risultati, dovrebbe dipendere da questa politica. Tuttavia, questa politica è un oggetto matematico; è una funzione. Quello che vorremmo avere non è una previsione probabilistica ma qualcosa di più meta - un costrutto di ordine superiore che, data una politica, può generare la distribuzione risultante.
Da una prospettiva di supply chain, quando passiamo da un tipo di previsione all’altro, otteniamo molte più informazioni. Questo non deve essere confuso con rendere la previsione più accurata; si tratta di ottenere accesso a un tipo completamente diverso di informazioni, come vedere il mondo in bianco e nero e improvvisamente acquisire la capacità di vedere i colori invece di ottenere solo una maggiore risoluzione. In termini di strumenti, i fogli di calcolo e gli strumenti di business intelligence sono abbastanza adeguati per gestire le previsioni puntuali. A seconda del tipo di previsione a insieme che stai considerando, potrebbero essere adeguati, ma stai già spingendo al limite le loro capacità di progettazione. Non sono davvero progettati per gestire alcun tipo di previsione a insieme fantasiosa oltre a quella ovvia, in cui stai solo definendo un intervallo con valori minimi e massimi nell’intervallo dei valori attesi. Vedremo che, fondamentalmente, se vogliamo avere qualche possibilità di lavorare con previsioni di distribuzione o addirittura costrutti di ordine superiore, abbiamo bisogno di un tipo di strumentazione completamente diversa, anche se questo dovrebbe diventare più chiaro tra un momento.
Per iniziare con le previsioni probabilistiche, cerchiamo di caratterizzare cosa rende una buona previsione probabilistica. Infatti, non importa cosa accada, una previsione probabilistica ti dirà che, indipendentemente dal tipo di risultato che osservi, c’era una probabilità che accadesse. Quindi, in queste condizioni, come si differenzia una buona previsione probabilistica da una cattiva? Certamente non è perché è probabilistica che improvvisamente tutti i modelli di previsione sono buoni.
Questo è esattamente ciò di cui si occupano le metriche dedicate alle previsioni probabilistiche, e il Continuous Ranked Probability Score (CRPS) è la generalizzazione dell’errore assoluto per le previsioni probabilistiche unidimensionali. Mi scuso sinceramente per questo nome orrendo - il CRPS. Non sono stato io a coniare questa terminologia; mi è stata passata. La formula del CRPS è riportata sullo schermo. Fondamentalmente, la funzione F è la funzione di distribuzione cumulativa; è la previsione probabilistica che viene fatta. Il punto x è l’osservazione effettiva e il valore del CRPS è qualcosa che si calcola tra la previsione probabilistica e l’osservazione appena effettuata.
Possiamo vedere che, fondamentalmente, il punto viene trasformato in una previsione quasi probabilistica attraverso la funzione gradino di Heaviside. Introdurre la funzione gradino di Heaviside è semplicemente l’equivalente di trasformare il punto che abbiamo appena osservato in una distribuzione di probabilità di Dirac, che è una distribuzione che concentra tutta la massa di probabilità su un singolo risultato. Poi abbiamo un integrale e fondamentalmente il CRPS sta facendo una sorta di confronto di forma. Stiamo confrontando la forma della CDF (funzione di distribuzione cumulativa) con la forma di un’altra CDF, quella associata alla Dirac che corrisponde al punto che abbiamo osservato.
Da una prospettiva di previsione puntiforme, il CRPS è sorprendente non solo a causa della formula complicata, ma anche perché questa metrica prende due argomenti che non hanno lo stesso tipo. Uno di questi argomenti è una distribuzione e l’altro è solo un singolo punto dati. Quindi, abbiamo un’asimmetria qui che non esiste con la maggior parte delle altre metriche di previsione puntiforme, come l’errore assoluto e l’errore quadratico medio. Nel CRPS, stiamo essenzialmente confrontando un punto con una distribuzione.
Se vogliamo capire di più su cosa calcoliamo con il CRPS, una osservazione interessante è che il CRPS ha la stessa unità dell’osservazione. Ad esempio, se x è espresso in euro e il valore del CRPS tra F e x è anche omogeneo in termini di unità in euro, è per questo che dico che il CRPS è una generalizzazione dell’errore assoluto. A proposito, se riduci la tua previsione probabilistica a una Dirac, il CRPS ti restituisce un valore che è esattamente l’errore assoluto.

Mentre il CRPS può sembrare piuttosto intimidatorio e complicato, l’implementazione è in realtà abbastanza semplice. Sullo schermo c’è uno script Envision che illustra come il CRPS può essere utilizzato da una prospettiva di linguaggio di programmazione. Envision è un linguaggio di programmazione specifico del dominio dedicato all’ottimizzazione predittiva delle supply chain, sviluppato da Lokad. In queste lezioni, sto usando Envision per una questione di chiarezza e concisione. Tuttavia, si noti che non c’è nulla di unico in Envision; gli stessi risultati potrebbero essere ottenuti in qualsiasi linguaggio di programmazione, che sia Python, Java, JavaScript, C#, F# o altro. Il mio punto è che richiederebbe solo più righe di codice, quindi sto usando Envision. Tutti gli snippet di codice presenti in questa lezione e, a proposito, anche nelle precedenti, sono autonomi e completi. Potresti tecnicamente copiare e incollare questo codice e funzionerebbe. Non ci sono moduli coinvolti, nessun codice nascosto e nessun ambiente da configurare.
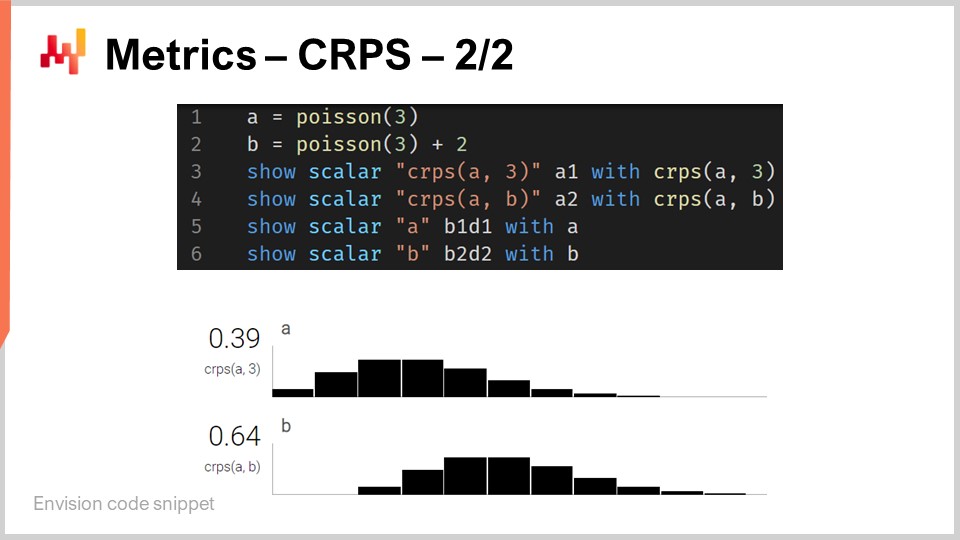
Quindi, tornando allo snippet di codice. Alle righe uno e due, definiamo distribuzioni unidimensionali. Tornerò su come funzionano effettivamente queste distribuzioni unidimensionali in Envision, ma abbiamo due distribuzioni qui: una è una distribuzione di Poisson, che è una distribuzione discreta unidimensionale, e la seconda alla riga due è la stessa distribuzione di Poisson ma spostata di due unità verso destra. Ecco cosa significa “+2”. Alla riga tre, calcoliamo la distanza CRPS tra una distribuzione e il valore 3, che è un numero. Quindi qui, stiamo trovando questa asimmetria in termini di tipi di dati di cui parlavo. I risultati vengono visualizzati in basso, come puoi vedere in fondo allo schermo.
Alla riga quattro, calcoliamo il CRPS tra la distribuzione A e la distribuzione B. Sebbene la definizione classica del CRPS sia tra una distribuzione e un singolo punto, è completamente semplice generalizzare questa definizione a una coppia di distribuzioni. Tutto ciò che devi fare è prendere la stessa identica formula per il CRPS e sostituire la funzione gradino di Heaviside con la funzione di distribuzione cumulativa della seconda distribuzione. Le istruzioni “show” dalle righe tre alla sei risultano nella visualizzazione che puoi vedere in fondo allo schermo, che è letteralmente uno screenshot.
Quindi, vediamo che utilizzare il CRPS non è più difficile o complicato che utilizzare una qualsiasi funzione speciale, come la funzione coseno. Ovviamente, è un po’ fastidioso se devi reimplementare il coseno tu stesso, ma tutto considerato, non c’è nulla di particolarmente complicato nel CRPS. Ora, passiamo avanti.

Il problema di Monge-Kantorovich ci fornisce un’idea su come affrontare il processo di corrispondenza di forma in gioco nel CRPS ma con dimensioni superiori. Ricorda, il CRPS è effettivamente bloccato con la dimensione uno. La corrispondenza di forma è concettualmente qualcosa che potrebbe essere generalizzata a qualsiasi numero di dimensioni, e il problema di Monge-Kantorovich è molto interessante, doppiamente interessante perché, nel suo nucleo, è effettivamente un problema di supply chain.
Il problema di Monge-Kantorovich, originariamente non correlato alla previsione probabilistica, è stato introdotto dallo scienziato francese Gaspard Monge in un memoria del 1781 intitolata “Mémoire sur la théorie des déblais et des remblais,” che potrebbe essere tradotto approssimativamente come “Memoria sulla teoria dello spostamento della terra.” Un modo per comprendere il problema di Monge-Kantorovich è pensare a una situazione in cui abbiamo un elenco di miniere, indicate come M sullo schermo, e un elenco di fabbriche indicate come F. Le miniere producono minerale e le fabbriche consumano minerale. Quello che vogliamo fare è costruire un piano di trasporto, T, che mappa tutto il minerale prodotto dalle miniere al consumo richiesto dalle fabbriche.
Monge ha definito la lettera C come il costo per spostare tutto il minerale dalle miniere alle fabbriche. Il costo è la somma per trasportare tutto il minerale da ogni miniera a ogni fabbrica, ma ovviamente ci sono modi molto inefficienti per trasportare il minerale. Quindi, quando diciamo che abbiamo un costo specifico, intendiamo che il costo riflette il piano di trasporto ottimale. Questa lettera C rappresenta il miglior costo ottenibile considerando il piano di trasporto ottimale.
Questo è essenzialmente un problema di supply chain che è stato ampiamente studiato nei secoli. Nella formulazione completa del problema, ci sono vincoli su T. Per motivi di concisione, non ho inserito tutti i vincoli sullo schermo. Ad esempio, c’è un vincolo che il piano di trasporto non dovrebbe superare la capacità produttiva di ogni miniera e ogni fabbrica dovrebbe essere completamente soddisfatta, avendo un’allocazione che corrisponde alle sue esigenze. Ci sono molti vincoli, ma sono abbastanza verbosi, quindi non li ho inclusi sullo schermo.
Ora, mentre il problema del trasporto è interessante di per sé, se iniziamo a interpretare l’elenco delle miniere e l’elenco delle fabbriche come due distribuzioni di probabilità, abbiamo un modo per trasformare una metrica punto per punto in una metrica basata sulla distribuzione. Questa è una chiave di lettura fondamentale sulla corrispondenza di forma in dimensioni superiori attraverso la prospettiva di Monge-Kantorovich. Un altro termine per questa prospettiva è la metrica di Wasserstein, anche se riguarda principalmente il caso non discreto, che è di minore interesse per noi.
La prospettiva di Monge-Kantorovich ci consente di trasformare una metrica punto per punto, che può calcolare la differenza tra due numeri o due vettori di numeri, in una metrica che si applica a distribuzioni di probabilità che operano sullo stesso spazio. Questo è un meccanismo molto potente. Tuttavia, il problema di Monge-Kantorovich è difficile da risolvere e richiede una notevole potenza di elaborazione. Per il resto della lezione, mi attengo a tecniche più semplici da implementare ed eseguire.

La prospettiva bayesiana consiste nel guardare una serie di osservazioni dal punto di vista di una convinzione precedente. La prospettiva bayesiana è generalmente intesa in opposizione alla prospettiva frequentista, che stima la frequenza degli esiti basandosi sulle osservazioni effettive. L’idea è che la prospettiva frequentista non venga fornita con convinzioni precedenti. Pertanto, la prospettiva bayesiana ci fornisce uno strumento noto come verosimiglianza per valutare il grado di sorpresa quando si considerano le osservazioni e un determinato modello. Il modello, che è essenzialmente un modello di previsione probabilistica, è la formalizzazione delle nostre convinzioni precedenti. La prospettiva bayesiana ci offre un modo per valutare un set di dati rispetto a un modello di previsione probabilistica. Per capire come ciò viene fatto, dovremmo iniziare con la verosimiglianza per un singolo punto dati. La verosimiglianza, quando abbiamo un’osservazione x, è la probabilità di osservare x secondo il modello. Qui, si assume che il modello sia completamente caratterizzato da theta, i parametri del modello. La prospettiva bayesiana assume tipicamente che il modello abbia una qualche forma parametrica e theta sia il vettore completo di tutti i parametri del modello.
Quando diciamo theta, implicitamente assumiamo di avere una caratterizzazione completa del modello probabilistico, che ci fornisce una densità di probabilità locale per tutti i punti. Pertanto, la verosimiglianza è la probabilità di osservare questo singolo punto dati. Quando abbiamo la verosimiglianza per il modello theta, essa rappresenta la probabilità congiunta di osservare tutti i punti dati nel set di dati. Assumiamo che questi punti siano indipendenti, quindi la verosimiglianza è un prodotto di probabilità.
Se abbiamo migliaia di osservazioni, la verosimiglianza, come prodotto di migliaia di valori inferiori a uno, è probabilmente molto piccola numericamente. Un valore molto piccolo è tipicamente difficile da rappresentare con il modo in cui i numeri in virgola mobile sono rappresentati nei computer. Invece di lavorare direttamente con la verosimiglianza, che è un numero molto piccolo, tendiamo a lavorare con il logaritmo della verosimiglianza. Il logaritmo della verosimiglianza è semplicemente il logaritmo della verosimiglianza, che ha la proprietà incredibile di trasformare la moltiplicazione in addizione.
Il logaritmo della verosimiglianza del modello theta è la somma del logaritmo di tutte le verosimiglianze individuali per tutti i punti dati, come mostrato nell’ultima riga dell’equazione sullo schermo. La verosimiglianza è una metrica che ci fornisce una bontà di adattamento per una determinata previsione probabilistica. Ci dice quanto è probabile che il modello abbia generato il set di dati che osserviamo. Se abbiamo due previsioni probabilistiche in competizione e se mettiamo da parte tutti gli altri problemi di adattamento per un momento, dovremmo scegliere il modello che ci dà la verosimiglianza più alta o il logaritmo della verosimiglianza più alta, perché più alta è meglio.
La verosimiglianza è molto interessante perché può operare in dimensioni elevate senza complicazioni, a differenza del metodo di Monge-Kantorovich. Finché abbiamo un modello che ci fornisce una densità di probabilità locale, possiamo usare la verosimiglianza, o più realisticamente il logaritmo della verosimiglianza, come metrica.

Inoltre, non appena abbiamo una metrica che può rappresentare la bontà di adattamento, significa che possiamo ottimizzare rispetto a questa stessa metrica. Tutto ciò che serve è un modello con almeno un grado di libertà, che significa essenzialmente almeno un parametro. Se ottimizziamo questo modello rispetto alla verosimiglianza, la nostra metrica per la bontà di adattamento, speriamo di ottenere un modello addestrato in cui abbiamo imparato a produrre almeno una previsione probabilistica decente. Questo è esattamente ciò che viene fatto qui sullo schermo.
Alle righe uno e due, generiamo un set di dati fittizi. Creiamo una tabella con 2.000 righe e poi alla riga due generiamo 2.000 deviazioni, le nostre osservazioni da una distribuzione di Poisson con una media di due. Quindi, abbiamo le nostre 2.000 osservazioni. Alla riga tre, iniziamo un blocco di autodiff, che fa parte del paradigma della programmazione differenziabile. Questo blocco eseguirà una discesa del gradiente stocastica e itererà molte volte su tutte le osservazioni nella tabella delle osservazioni. Qui, la tabella delle osservazioni è la tabella T.
Alla riga quattro, dichiariamo il parametro del modello, chiamato lambda. Specifichiamo che questo parametro dovrebbe essere esclusivamente positivo. Questo parametro è ciò che cercheremo di riscoprire attraverso la discesa del gradiente stocastica. Alla riga cinque, definiamo la funzione di perdita, che è semplicemente il meno del logaritmo della verosimiglianza. Vogliamo massimizzare la verosimiglianza, ma il blocco di autodiff sta cercando di minimizzare la perdita. Pertanto, se vogliamo massimizzare il logaritmo della verosimiglianza, dobbiamo aggiungere questo segno meno davanti al logaritmo della verosimiglianza, ed è esattamente ciò che abbiamo fatto.
Il parametro lambda appreso viene visualizzato alla riga sei. Non sorprendentemente, il valore trovato è molto vicino al valore due, perché abbiamo iniziato con una distribuzione di Poisson con una media di due. Abbiamo creato un modello di previsione probabilistico che è anche parametrico e della stessa forma, una distribuzione di Poisson. Volevamo riscoprire il parametro unico della distribuzione di Poisson, ed è esattamente ciò che otteniamo. Otteniamo un modello che è entro circa l’uno percento della stima originale.
Abbiamo appena imparato il nostro primo modello di previsione probabilistico, e tutto ciò che ci è voluto sono essenzialmente tre righe di codice. Questo è ovviamente un modello molto semplice; tuttavia, mostra che non c’è nulla di intrinsecamente complicato nella previsione probabilistica. Non è la solita previsione del quadrato medio, ma a parte questo, con gli strumenti appropriati come la programmazione differenziabile, non è più complicato di una previsione classica a punto.
La funzione log_likelihood.poisson che abbiamo usato in precedenza fa parte della libreria standard di Envision. Tuttavia, non c’è magia coinvolta. Diamo un’occhiata a come questa funzione è effettivamente implementata sotto il cofano. Le prime due righe in alto ci danno l’implementazione del logaritmo della verosimiglianza della distribuzione di Poisson. Una distribuzione di Poisson è completamente caratterizzata dal suo parametro unico, lambda, e la funzione di logaritmo della verosimiglianza richiede solo due argomenti: il parametro unico che caratterizza completamente la distribuzione di Poisson e l’osservazione effettiva. La formula effettiva che ho scritto è letteralmente materiale di testo. È ciò che ottieni quando implementi la formula di testo che caratterizza la distribuzione di Poisson. Non c’è nulla di straordinario qui.
Presta attenzione al fatto che questa funzione è contrassegnata con la parola chiave autodiff. Come abbiamo visto nella lezione precedente, la parola chiave autodiff garantisce che la differenziazione automatica possa fluire correttamente attraverso questa funzione. Il logaritmo della verosimiglianza della distribuzione di Poisson utilizza anche un’altra funzione speciale, log_gamma. La funzione log_gamma è il logaritmo della funzione gamma, che è la generalizzazione della funzione fattoriale ai numeri complessi. Qui, abbiamo solo bisogno della generalizzazione della funzione fattoriale ai numeri reali positivi.
L’implementazione della funzione log_gamma è leggermente verbosa, ma è ancora materiale di testo. Utilizza un’approssimazione di frazione continua per la funzione log_gamma. La bellezza qui è che abbiamo la differenziazione automatica che funziona per noi fino in fondo. Iniziamo con il blocco di autodiff, chiamando la funzione log_likelihood.poisson, che è implementata come una funzione autodiff. Questa funzione, a sua volta, chiama la funzione log_gamma, implementata anche con il marcatore autodiff. Fondamentalmente, siamo in grado di produrre i nostri metodi di previsione probabilistica in tre righe di codice perché abbiamo una libreria standard ben progettata che è stata implementata, prestando attenzione alla differenziazione automatica.
Ora passiamo al caso speciale delle distribuzioni discrete unidimensionali. Queste distribuzioni sono ovunque in una supply chain e rappresentano il nostro punto di ingresso nella previsione probabilistica. Ad esempio, se vogliamo prevedere i tempi di consegna con una granularità giornaliera, possiamo dire che c’è una certa probabilità di avere un tempo di consegna di un giorno, un’altra probabilità di avere un tempo di consegna di due giorni, tre giorni, e così via. Tutto ciò si accumula in un istogramma di probabilità per i tempi di consegna. Allo stesso modo, se stiamo guardando la domanda di un determinato SKU in un determinato giorno, possiamo dire che c’è una probabilità di osservare zero unità di domanda, una unità di domanda, due unità di domanda, e così via.
Se mettiamo insieme tutte queste probabilità, otteniamo un istogramma che le rappresenta. Allo stesso modo, se stiamo pensando al livello di stock di un SKU, potremmo essere interessati a valutare quante scorte rimarranno per questo dato SKU alla fine della stagione. Possiamo utilizzare una previsione probabilistica per determinare la probabilità che non ci siano unità rimaste in stock alla fine della stagione, una unità rimasta in stock, due unità, e così via. Tutte queste situazioni si adattano al modello di essere rappresentate attraverso un istogramma con bucket associati a ogni singolo risultato discreto del fenomeno di interesse.
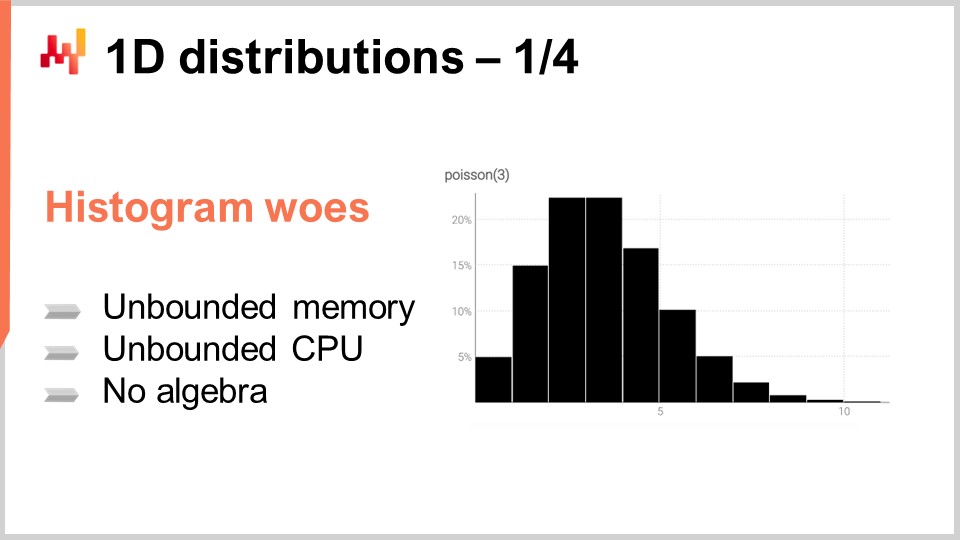
L’istogramma è il modo canonico per rappresentare una distribuzione discreta unidimensionale. Ogni bucket è associato alla massa di probabilità per il risultato discreto. Tuttavia, tralasciando l’uso della visualizzazione dei dati, gli istogrammi sono un po’ deludenti. Infatti, lavorare sugli istogrammi è un po’ difficile se vogliamo fare qualcosa oltre alla visualizzazione di quelle distribuzioni di probabilità. Abbiamo essenzialmente due classi di problemi con gli istogrammi: la prima difficoltà è legata alle risorse di calcolo, e la seconda classe di difficoltà è legata all’espressività di programmazione degli istogrammi.
Per quanto riguarda le risorse di calcolo, dovremmo considerare che la quantità di memoria necessaria per un istogramma è fondamentalmente illimitata. Puoi pensare a un istogramma come a un array che cresce quanto necessario. Quando si tratta di un singolo istogramma, anche uno straordinariamente grande dal punto di vista della supply chain, la quantità di memoria necessaria non è un problema per un computer moderno. Il problema sorge quando non hai solo un istogramma, ma milioni di istogrammi per milioni di SKU in un contesto di supply chain. Se ogni istogramma può diventare abbastanza grande, gestire questi istogrammi può diventare una sfida, soprattutto considerando che i computer moderni tendono a offrire un accesso alla memoria non uniforme.
Al contrario, la quantità di CPU necessaria per elaborare questi istogrammi è anche illimitata. Sebbene le operazioni sugli istogrammi siano per lo più lineari, il tempo di elaborazione aumenta all’aumentare della quantità di memoria a causa dell’accesso non uniforme alla memoria. Di conseguenza, c’è un interesse significativo nel porre limiti rigorosi alla quantità di memoria e CPU richiesta.
La seconda difficoltà con gli istogrammi è la mancanza di un’algebra associata. Sebbene sia possibile eseguire l’addizione o la moltiplicazione dei valori bucket per bucket quando si considerano due istogrammi, farlo non darà un risultato che ha senso quando si interpreta l’istogramma come rappresentazione di una variabile casuale. Ad esempio, se si prendono due istogrammi e si esegue la moltiplicazione punto per punto, si ottiene un istogramma che non ha nemmeno una massa di uno. Questa non è un’operazione valida dal punto di vista di un’algebra delle variabili casuali. Non è possibile sommare o moltiplicare istogrammi, quindi si è limitati in ciò che si può fare con essi.
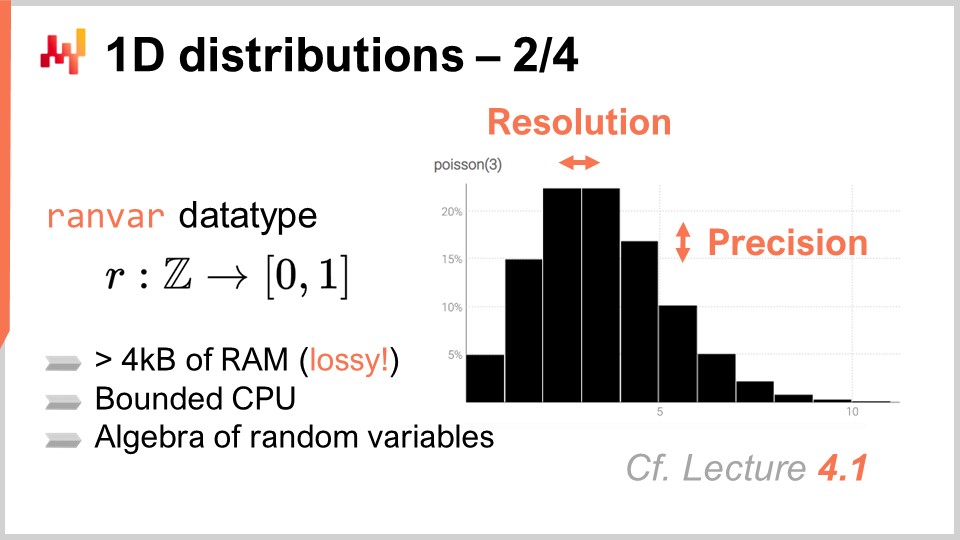
Presso Lokad, l’approccio che abbiamo trovato più pratico per gestire queste distribuzioni discrete unidimensionali ubiquitarie è quello di introdurre un tipo di dato dedicato. Il pubblico è probabilmente familiare con i tipi di dati comuni che esistono nella maggior parte dei linguaggi di programmazione, come interi, numeri in virgola mobile e stringhe. Questi sono i tipici tipi di dati primitivi che si trovano ovunque. Tuttavia, nulla impedisce di introdurre tipi di dati più specializzati che si adattano particolarmente alle nostre esigenze dal punto di vista della supply chain. Questo è esattamente ciò che Lokad ha fatto con il tipo di dato ranvar.
Il tipo di dato ranvar è dedicato alle distribuzioni discrete unidimensionali e il nome è un’abbreviazione di variabile casuale. Tecnicamente, da un punto di vista formale, il ranvar è una funzione da Z (l’insieme di tutti gli interi, positivi e negativi) alle probabilità, che sono numeri compresi tra zero e uno. La massa totale di Z è sempre uguale a uno, in quanto rappresenta distribuzioni di probabilità.
Da un punto di vista puramente matematico, qualcuno potrebbe sostenere che la quantità di informazioni che possono essere inserite in una tale funzione può diventare arbitrariamente grande. Questo è vero; tuttavia, la realtà è che, dal punto di vista della supply chain, esiste un limite molto chiaro a quante informazioni rilevanti possono essere contenute all’interno di un singolo ranvar. Sebbene sia teoricamente possibile creare una distribuzione di probabilità che richiederebbe megabyte per essere rappresentata, non esistono distribuzioni di questo tipo che siano rilevanti per scopi legati alla supply chain.
È possibile progettare un limite superiore di 4 kilobyte per il tipo di dato ranvar. Avendo un limite sulla memoria che questo ranvar può occupare, otteniamo anche un limite superiore per tutte le operazioni in termini di CPU, il che è molto importante. Invece di avere un limite ingenuo che limita i bucket a 1.000, Lokad introduce uno schema di compressione con il tipo di dato ranvar. Questa compressione è essenzialmente una rappresentazione con perdita dei dati originali, perdendo risoluzione e precisione. Tuttavia, l’idea è progettare uno schema di compressione che fornisca una rappresentazione sufficientemente precisa degli istogrammi, in modo che il grado di approssimazione introdotto sia trascurabile dal punto di vista della supply chain.
I dettagli dell’algoritmo di compressione associato al tipo di dato ranvar esulano dallo scopo di questa lezione. Tuttavia, si tratta di un algoritmo di compressione molto semplice che è ordini di grandezza più semplice rispetto ai tipi di algoritmi di compressione utilizzati per le immagini sul tuo computer. Come beneficio collaterale di avere un limite sulla memoria che questo ranvar può occupare, otteniamo anche un limite superiore per tutte le operazioni in termini di CPU, il che è molto importante. Infine, con il tipo di dato ranvar, il punto più importante è che otteniamo un’algebra di variabili che ci offre un modo per operare effettivamente su questi tipi di dati e fare tutte le cose che vogliamo fare con i tipi di dati primitivi, ovvero avere tutti i tipi di primitive per combinarli in modi che si adattano alle nostre esigenze.
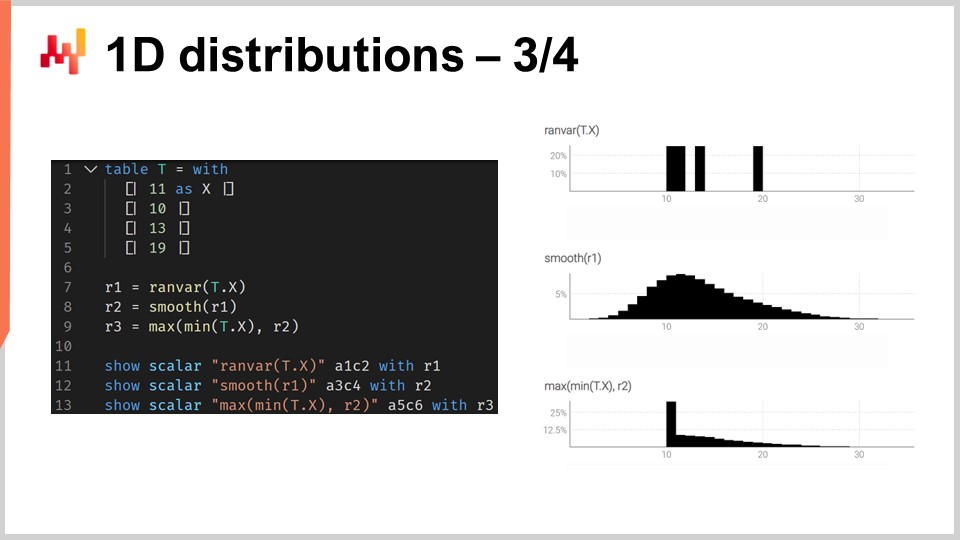
Per illustrare cosa significa lavorare con ranvars, consideriamo una situazione di previsione dei tempi di consegna, più specificamente, una previsione probabilistica di un tempo di consegna. Sullo schermo è presente uno script Envision breve che mostra come costruire una previsione probabilistica del genere. Alle righe 1-5, introduciamo la tabella T che contiene i quattro tempi di consegna di variazione, con valori di 11 giorni, 10 giorni, 13 giorni e 90 giorni. Sebbene quattro osservazioni siano molto poche, purtroppo è molto comune avere un numero molto limitato di punti dati per quanto riguarda le osservazioni dei tempi di consegna. Infatti, se stiamo considerando un fornitore d’oltremare che riceve due ordini di acquisto all’anno, allora ci vogliono due anni per raccogliere quei quattro punti dati. Pertanto, è importante avere tecniche che possano funzionare anche con un insieme di osservazioni estremamente limitato.
Alla riga 7, creiamo un ranvar aggregando direttamente le quattro osservazioni. Qui, il termine “ranvar” che appare alla riga 7 è in realtà un aggregatore che prende una serie di numeri in input e restituisce un singolo valore del tipo di dati ranvar. Il risultato viene visualizzato in alto a destra dello schermo, che è un ranvar empirico.
Tuttavia, questo ranvar empirico non è una rappresentazione realistica della distribuzione effettiva. Ad esempio, mentre possiamo osservare un tempo di consegna di 11 giorni e un tempo di consegna di 13 giorni, sembra irrealistico non essere in grado di osservare un tempo di consegna di 12 giorni. Se interpretiamo questo ranvar come una previsione probabilistica, direbbe che la probabilità di osservare mai un tempo di consegna di 12 giorni è zero, il che sembra incorretto. Questo è ovviamente un problema di sovradattamento.
Per rimediare a questa situazione, alla riga 8, levighiamo il ranvar originale chiamando la funzione “smooth”. La funzione smooth sostituisce essenzialmente il ranvar originale con una miscela di distribuzioni. Per ogni intervallo della distribuzione originale, sostituiamo l’intervallo con una distribuzione di Poisson di una media centrata sull’intervallo, ponderata in base alla probabilità rispettiva degli intervalli. Attraverso la distribuzione levigata, otteniamo l’istogramma che viene visualizzato al centro a destra dello schermo. Questo già sembra molto meglio; non abbiamo più strani vuoti e non abbiamo una probabilità zero al centro. Inoltre, guardando la probabilità di osservare un tempo di consegna di 12 giorni, questo modello ci dà una probabilità diversa da zero, il che sembra molto più ragionevole. Ci dà anche una probabilità diversa da zero di superare i 20 giorni, e considerando che avevamo quattro punti dati e abbiamo già osservato un tempo di consegna di 19 giorni, l’idea che un tempo di consegna fino a 20 giorni sia possibile sembra molto ragionevole. Quindi, con questa previsione probabilistica, abbiamo una buona distribuzione che rappresenta una probabilità diversa da zero per quegli eventi, il che è molto buono.
Tuttavia, a sinistra, abbiamo qualcosa di un po’ strano. Mentre è accettabile che questa distribuzione di probabilità si estenda verso destra, lo stesso non può essere detto per la sinistra. Se consideriamo che i tempi di consegna che abbiamo osservato sono il risultato dei tempi di trasporto, a causa del fatto che ci vogliono nove giorni per il camion per arrivare, sembra improbabile che osserveremmo mai un tempo di consegna di tre giorni. A questo proposito, il modello è piuttosto irrealistico.
Pertanto, alla riga 9, introduciamo un ranvar condizionalmente adattato dicendo che deve essere maggiore del tempo di consegna minimo mai osservato. Abbiamo “min_of(T, x)” che prende il valore più piccolo tra i numeri della tabella T, e poi usiamo “max” per fare il massimo tra una distribuzione e un numero. Il risultato deve essere maggiore di questo valore. Il ranvar adattato viene visualizzato a destra in fondo, e qui vediamo la nostra previsione finale del tempo di consegna. L’ultima sembra una previsione probabilistica molto ragionevole del tempo di consegna, considerando che abbiamo un insieme di dati estremamente limitato con solo quattro punti dati. Non possiamo dire che sia una grande previsione probabilistica; tuttavia, sostenerei che questa sia una previsione di produzione, e queste sorta di tecniche funzionerebbero bene in produzione, a differenza di una previsione di punto medio che sottostimerebbe notevolmente il rischio di tempi di consegna variabili.
La bellezza delle previsioni probabilistiche è che, sebbene possano essere molto rudimentali, già ti danno una certa estensione del potenziale di mitigazione per decisioni poco informate che deriverebbero dall’applicazione ingenua di una previsione media basata sui dati osservati.
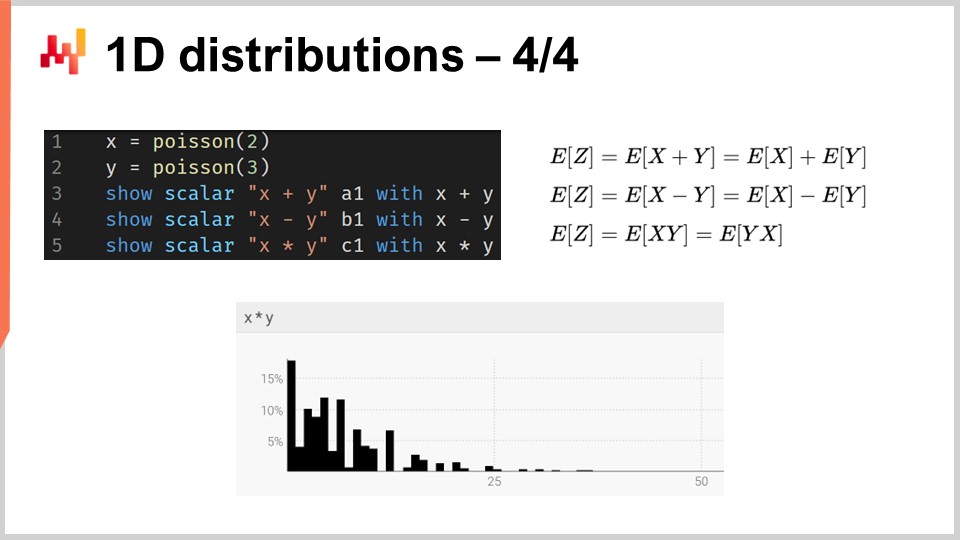
Più in generale, le ranvars supportano una vasta gamma di operazioni: è possibile aggiungere, sottrarre e moltiplicare ranvars, proprio come è possibile aggiungere, sottrarre e moltiplicare numeri interi. Sotto il cofano, poiché stiamo trattando variabili casuali discrete in termini di semantica, tutte queste operazioni sono implementate come convoluzioni. Sullo schermo, l’istogramma visualizzato in basso viene ottenuto tramite la moltiplicazione di due distribuzioni di Poisson, rispettivamente di media due e tre. Nella supply chain, la moltiplicazione di variabili casuali viene chiamata convoluzione diretta. Nel contesto della supply chain, la moltiplicazione di due variabili casuali ha senso per rappresentare, ad esempio, i risultati che si possono ottenere quando i clienti cercano gli stessi prodotti ma con moltiplicatori variabili. Supponiamo di avere una libreria che serve due gruppi di clienti. Da un lato, abbiamo il primo gruppo composto da studenti, che acquistano una unità quando entrano nel negozio. In questa libreria illustrativa, abbiamo un secondo gruppo composto da professori, che acquistano 20 libri quando entrano nel negozio.
Dal punto di vista della modellazione, potremmo avere una previsione probabilistica che rappresenta i tassi di arrivo nella libreria sia degli studenti che dei professori. Ciò ci darebbe la probabilità di osservare zero clienti per il giorno, un cliente, due clienti, ecc., rivelando la distribuzione di probabilità di osservare un certo numero di clienti per qualsiasi giorno dato. La seconda variabile ti darebbe le rispettive probabilità di acquistare uno (studenti) rispetto all’acquisto di 20 (professori). Per avere una rappresentazione della domanda, basta moltiplicare queste due variabili casuali insieme, ottenendo un istogramma apparentemente erratico che riflette i moltiplicatori presenti nei modelli di consumo dei tuoi gruppi.

I generatori di Monte Carlo, o semplicemente generatori, rappresentano un approccio alternativo alle previsioni probabilistiche. Invece di mostrare una distribuzione che ci fornisce la densità di probabilità locale, possiamo mostrare un generatore che, come suggerisce il nome, genera risultati che si prevede seguire implicitamente le stesse distribuzioni di probabilità locali. C’è una dualità tra generatori e densità di probabilità, il che significa che i due sono essenzialmente due facce della stessa prospettiva.
Se hai un generatore, è sempre possibile mediare i risultati ottenuti da questo generatore per ricostruire stime delle densità di probabilità locali. Al contrario, se hai densità di probabilità locali, è sempre possibile estrarre deviate secondo questa distribuzione. Fondamentalmente, questi due approcci sono solo modi diversi di guardare la stessa natura probabilistica o stocastica del fenomeno che stiamo cercando di modellare.
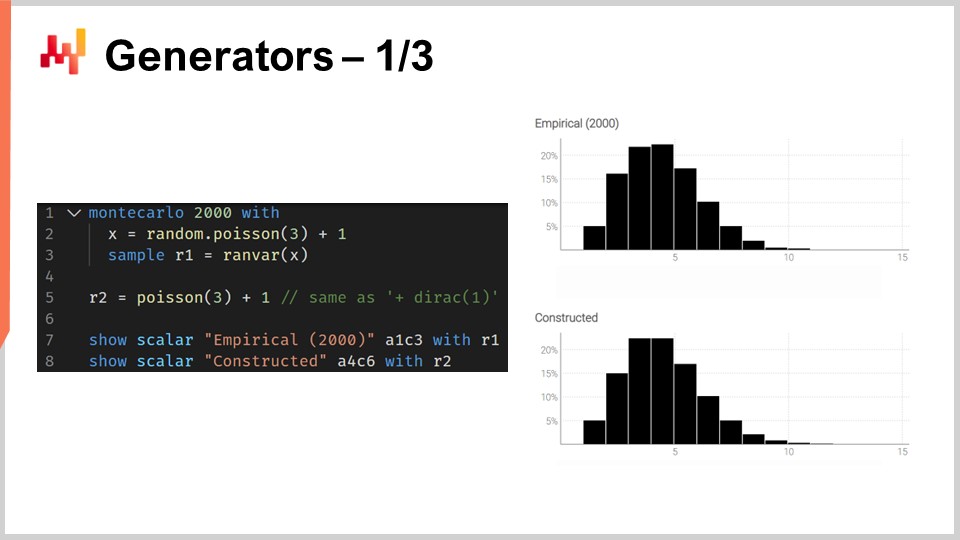
Lo script sullo schermo illustra questa dualità. Alla riga uno, introduciamo un blocco di Monte Carlo, che verrà iterato dal sistema, proprio come i blocchi di auto-differenziazione vengono iterati attraverso molte fasi di discesa del gradiente stocastico. Il blocco di Monte Carlo verrà eseguito 2.000 volte e da questo blocco raccoglieremo 2.000 deviate.
Alla riga due, estraiamo una deviata da una distribuzione di Poisson di media tre e poi aggiungiamo uno alla deviata. Fondamentalmente, otteniamo un numero casuale da questa distribuzione di Poisson e poi aggiungiamo uno. Alla riga tre, raccogliamo questa deviata in L1, che agisce come un accumulatore per il ranvar aggregatore. Questo è lo stesso aggregatore che abbiamo introdotto in precedenza per il nostro esempio di tempo di attesa. Qui, stiamo raccogliendo tutte quelle osservazioni in L1, che ci dà una distribuzione unidimensionale ottenuta attraverso un processo di Monte Carlo. Alla riga cinque, costruiamo la stessa distribuzione discreta unidimensionale, ma questa volta lo facciamo con l’algebra delle variabili casuali. Quindi, usiamo semplicemente Poisson meno tre e aggiungiamo uno. Alla riga cinque, non c’è alcun processo di Monte Carlo in corso; è una questione pura di probabilità discrete e convoluzioni.
Quando confrontiamo le due distribuzioni visivamente alle righe sette e otto, vediamo che sono quasi identiche. Dico “quasi” perché, sebbene stiamo usando 2.000 iterazioni, che è molto, non è infinito. Le deviazioni tra le probabilità esatte che si ottengono con ranvar e le probabilità approssimate che si ottengono con il processo di Monte Carlo sono ancora evidenti, sebbene non siano grandi.
I generatori vengono talvolta chiamati simulatori, ma non sbagliate, sono la stessa cosa. Ogni volta che si ha un simulatore, si ha un processo generativo che sottende implicitamente un processo di previsione probabilistica. Ogni volta che si ha un simulatore o un generatore coinvolto, la domanda che dovrebbe venire in mente è: qual è l’accuratezza di questa simulazione? Non è accurata per design, proprio come è molto possibile avere previsioni completamente inaccurate, probabilistiche o meno. È molto facile ottenere una simulazione completamente inaccurata.
Con i generatori, vediamo che le simulazioni sono solo un modo per guardare prospetticamente la previsione probabilistica, ma questo è più un dettaglio tecnico. Non cambia nulla sul fatto che, alla fine, si desidera avere qualcosa che sia una rappresentazione accurata del sistema che si sta cercando di caratterizzare con la propria previsione, probabilistica o meno.
L’approccio generativo non è solo molto utile, come vedremo con un esempio specifico tra un minuto, ma è anche concettualmente più facile da comprendere, almeno leggermente, rispetto all’approccio con le densità di probabilità. Tuttavia, l’approccio di Monte Carlo non è privo di tecnicità. Ci sono alcune cose che sono necessarie se si vuole rendere questo approccio fattibile in un contesto di produzione per una catena di approvvigionamento reale nel mondo reale.
Prima di tutto, i generatori devono essere veloci. Monte Carlo è sempre un trade-off tra il numero di iterazioni che si vorrebbe avere e il numero di iterazioni che si può permettere, considerando le risorse di calcolo disponibili. Sì, i computer moderni hanno molta potenza di elaborazione, ma i processi di Monte Carlo possono richiedere risorse incredibili. Si desidera qualcosa che sia, per impostazione predefinita, super veloce. Se torniamo agli ingredienti introdotti nella seconda lezione del quarto capitolo, abbiamo funzioni molto veloci come ExhaustShift o WhiteHash che sono essenziali per la costruzione delle primitive che consentono di generare generatori casuali elementari che sono super veloci. Ne hai bisogno, altrimenti avrai problemi. In secondo luogo, è necessario distribuire l’esecuzione. L’implementazione ingenua di un programma di Monte Carlo è semplicemente avere un ciclo che itera in modo sequenziale. Tuttavia, se si utilizza solo una singola CPU per affrontare le proprie esigenze di Monte Carlo, essenzialmente si sta tornando alla potenza di calcolo che caratterizzava i computer due decenni fa. Questo punto è stato affrontato nella prima lezione del quarto capitolo. Negli ultimi due decenni, i computer sono diventati più potenti, ma è stato principalmente aggiungendo CPU e gradi di parallelizzazione. Quindi, è necessario avere una prospettiva distribuita per i propri generatori.
Infine, l’esecuzione deve essere deterministica. Cosa significa? Significa che se si esegue lo stesso codice due volte, dovrebbe restituire gli stessi risultati esatti. Questo potrebbe sembrare controintuitivo perché stiamo trattando metodi casuali. Tuttavia, la necessità di determinismo è emersa molto rapidamente. È stato scoperto in modo doloroso negli anni ‘90 quando la finanza ha iniziato a utilizzare generatori di Monte Carlo per la loro valutazione dei prezzi. La finanza ha intrapreso la strada delle previsioni probabilistiche molto tempo fa e ha fatto un ampio uso dei generatori di Monte Carlo. Una delle cose che hanno imparato è che se non si ha determinismo, diventa quasi impossibile replicare le condizioni che hanno generato un bug o un crash. Dal punto di vista della catena di approvvigionamento, gli errori nei calcoli degli ordini di acquisto possono essere incredibilmente costosi.
Se si desidera raggiungere un certo grado di prontezza alla produzione per il software che governa la propria catena di approvvigionamento, è necessario avere questa proprietà deterministica ogni volta che si tratta di Monte Carlo. Fate attenzione che molte soluzioni open-source provengono dall’accademia e non si preoccupano affatto della prontezza alla produzione. Assicurarsi che quando si tratta di Monte Carlo, il proprio processo sia super veloce per design, distribuito per design e deterministico, in modo da avere la possibilità di diagnosticare i bug che inevitabilmente si presenteranno nel tempo nella propria configurazione di produzione.
Abbiamo visto una situazione in cui è stato introdotto un generatore per replicare ciò che altrimenti veniva fatto con un ranvar. Come regola generale, quando si può fare a meno solo di densità di probabilità con variabili casuali senza coinvolgere Monte Carlo, è meglio. Si ottengono risultati più precisi e non si deve preoccupare della stabilità numerica che è sempre un po’ complicata con Monte Carlo. Tuttavia, l’espressività dell’algebra delle variabili casuali è limitata, ed è qui che Monte Carlo brilla davvero. Questi generatori sono più espressivi perché ti permettono di affrontare situazioni che non possono essere affrontate solo con un’algebra di variabili casuali.
Rappresentiamo questo con una situazione di catena di approvvigionamento. Consideriamo un singolo SKU con un livello di stock iniziale, una previsione probabilistica della domanda e un periodo di interesse che si estende su tre mesi, con una spedizione in arrivo a metà del periodo. Assumiamo che la domanda venga soddisfatta immediatamente dallo stock disponibile o che venga persa per sempre. Vogliamo conoscere il livello di stock previsto alla fine del periodo per lo SKU, poiché sapere questo ci aiuterà a decidere quanto rischio abbiamo in termini di inventario invenduto.
La situazione è insidiosa perché è stata progettata in modo tale che ci sia una terza possibilità che si verifichi una rottura di stock proprio nel mezzo del periodo. L’approccio ingenuo sarebbe prendere il livello di stock iniziale, la distribuzione della domanda per l’intero periodo e sottrarre la domanda dal livello di stock, ottenendo così il livello di stock rimanente. Tuttavia, questo non tiene conto del fatto che potremmo perdere una parte consistente della domanda se abbiamo una rottura di stock mentre il riapprovvigionamento è ancora in sospeso. Fare in modo ingenuo sottostimerebbe la quantità di stock che avremo alla fine del periodo e sovrastimerebbe la quantità di domanda che verrà soddisfatta.
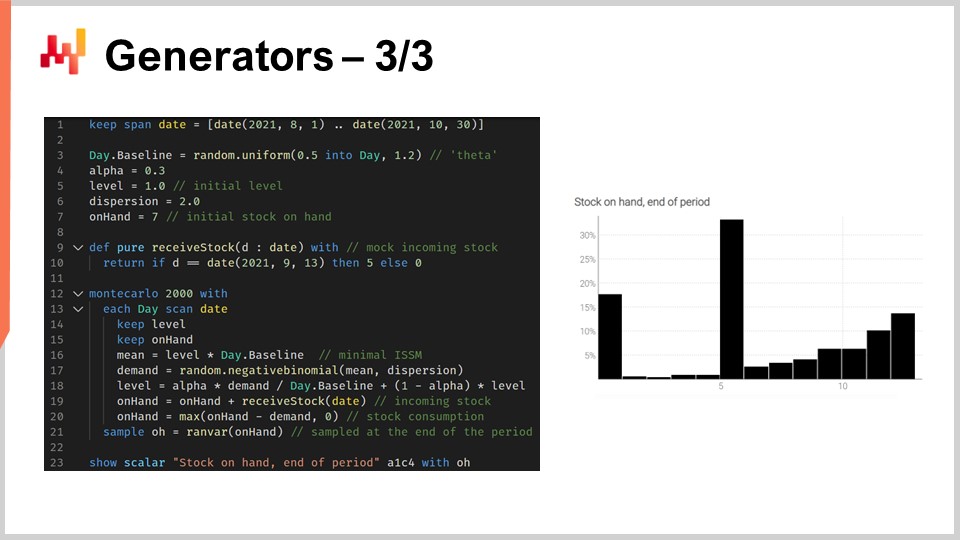
Lo script in mostra modella l’occorrenza di rotture di stock in modo da poter avere un corretto stimatore per il livello di stock per questo SKU alla fine del periodo. Dalla riga 1 alla riga 10, stiamo definendo i dati di prova che caratterizzano il nostro modello. Dalla riga 3 alla riga 6 sono presenti i parametri per il modello ISSM. Abbiamo già visto il modello ICSM nella prima lezione di questo quinto capitolo. Fondamentalmente, questo modello genera una traiettoria della domanda con un punto dati al giorno. Il periodo di interesse è definito nella tabella dei giorni e abbiamo i parametri per questa traiettoria all’inizio.
Nelle lezioni precedenti, abbiamo introdotto il modello AICSM e i metodi necessari attraverso la programmazione differenziabile per apprendere questi parametri. Oggi, stiamo utilizzando il modello, assumendo che abbiamo imparato tutto ciò che dobbiamo imparare. Alla riga 7, definiamo lo stock iniziale disponibile, che tipicamente sarebbe ottenuto dall’ERP o dal WMS. Alle righe 9 e 10, definiamo la quantità e la data per il riapprovvigionamento. Questi punti dati tipicamente sarebbero ottenuti come un tempo stimato di arrivo fornito dal fornitore e memorizzato nell’ERP. Assumiamo che la data di consegna sia perfettamente nota; tuttavia, sarebbe semplice sostituire questa singola data con una previsione probabilistica del tempo di consegna.
Dalla riga 12 alla riga 21, abbiamo il modello ISSM che genera la traiettoria della domanda. Siamo all’interno di un ciclo Monte Carlo e per ogni iterazione Monte Carlo, iteriamo su ogni singolo giorno del periodo di interesse. L’iterazione dei giorni inizia alla riga 13. Abbiamo in corso la meccanica ESSM, ma alle righe 19 e 20, aggiorniamo la variabile in mano. La variabile in mano non fa parte del modello ISSM; questo è qualcosa in più. Alla riga 19, diciamo che lo stock in mano è lo stock in mano di ieri più la spedizione in arrivo, che sarà zero per la maggior parte dei giorni e cinque unità per il 13 settembre. Quindi, alla riga 20, aggiorniamo lo stock in mano dicendo che un certo numero di unità viene consumato dalla domanda del giorno e abbiamo questo max 0 per dire che il livello di stock non può diventare negativo.
Infine, raccogliamo lo stock finale in mano alla riga 21 e alla riga 23, questo stock finale in mano viene visualizzato. Questo è l’istogramma che vedi a destra dello schermo. Qui vediamo una distribuzione con una forma molto irregolare. Questa forma non può essere ottenuta attraverso l’algebra delle variabili casuali. I generatori sono incredibilmente espressivi; tuttavia, non dovresti confondere l’espressività di questi generatori con l’accuratezza. Mentre i generatori sono incredibilmente espressivi, è non banale valutare l’accuratezza di tali generatori. Non sbagliarti, ogni volta che hai un generatore o un simulatore in gioco, hai una previsione di probabilità in gioco e le simulazioni possono essere drasticamente inaccurate, proprio come qualsiasi previsione, probabilistica o meno.

È stata già una lunga lezione eppure ci sono molti argomenti di cui non ho nemmeno parlato oggi. La presa di decisioni, ad esempio, se tutti i futuri sono possibili, come possiamo decidere qualcosa? Non ho risposto a questa domanda, ma verrà affrontata nella prossima lezione.
Le dimensioni superiori sono anche importanti da considerare. Una distribuzione unidimensionale è un punto di partenza, ma una supply chain ha bisogno di altro. Ad esempio, se esauriamo le scorte per un determinato SKU, potremmo sperimentare la cannibalizzazione, dove i clienti naturalmente si rivolgono a un sostituto. Vorremmo modellare questo, anche se in modo approssimativo.
Anche le costruzioni di ordine superiore svolgono un ruolo. Come ho detto, prevedere la domanda non è come prevedere i movimenti dei pianeti. Abbiamo effetti auto-profezionali ovunque. A un certo punto, vogliamo considerare e inserire le nostre politiche di prezzo e le politiche di rifornimento delle scorte. Per fare ciò, abbiamo bisogno di costruzioni di ordine superiore, il che significa che dato una politica, ottieni una previsione probabilistica dell’esito, ma devi inserire la politica all’interno delle costruzioni di ordine superiore.
Inoltre, padroneggiare le previsioni probabilistiche comporta numerose ricette numeriche e competenze specifiche per sapere quali distribuzioni sono più adatte a determinate situazioni. In questa serie di lezioni, introdurremo ulteriori esempi in seguito.
Infine, c’è la sfida del cambiamento. Le previsioni probabilistiche rappresentano una deviazione radicale dalle pratiche tradizionali della supply chain. Spesso, le questioni tecniche legate alle previsioni probabilistiche sono solo una piccola parte della sfida. La parte difficile è reinventare l’organizzazione stessa, in modo che possa iniziare a utilizzare queste previsioni probabilistiche invece di fare affidamento su previsioni puntuali, che sono essenzialmente pensieri desiderosi. Tutti questi elementi saranno trattati in lezioni successive, ma ci vorrà tempo perché abbiamo molto da coprire.

In conclusione, le previsioni probabilistiche rappresentano una deviazione radicale dalla prospettiva delle previsioni puntuali, in cui ci aspettiamo una sorta di consenso sull’unico futuro che si suppone debba avverarsi. Le previsioni probabilistiche si basano sull’osservazione che l’incertezza del futuro è irriducibile. Un secolo di scienza delle previsioni ha dimostrato che tutti i tentativi di ottenere previsioni anche solo approssimativamente accurate sono falliti. Pertanto, siamo bloccati con molti futuri indefiniti. Tuttavia, le previsioni probabilistiche ci forniscono tecniche e strumenti per quantificare e valutare questi futuri. Le previsioni probabilistiche sono un risultato significativo. Ci sono voluti quasi un secolo per accettare l’idea che le previsioni economiche non fossero come l’astronomia. Mentre possiamo prevedere con grande precisione la posizione esatta di un pianeta tra un secolo, non abbiamo alcuna speranza di ottenere qualcosa di remotamente equivalente nel campo delle supply chain. L’idea di avere una previsione per governarle tutte non tornerà mai. Eppure, molte aziende si aggrappano ancora alla speranza che ad un certo punto, la previsione accurata unica e vera sarà mai raggiunta. Dopo un secolo di tentativi, questo è essenzialmente pensiero desideroso.
Con i computer moderni, questa prospettiva di un unico futuro non è l’unica prospettiva in città. Abbiamo delle alternative. Le previsioni probabilistiche esistono dagli anni ‘90, quindi tre decenni fa. Da Lokad, utilizziamo le previsioni probabilistiche per guidare le supply chain in produzione da oltre un decennio. Potrebbe non essere ancora diffuso, ma è molto lontano dalla fantascienza. È stata una realtà per molte aziende nel settore finanziario per tre decenni e nel mondo delle supply chain per un decennio.
Sebbene le previsioni probabilistiche possano sembrare intimidatorie e altamente tecniche, con gli strumenti giusti, sono solo poche righe di codice. Non c’è nulla di particolarmente difficile o impegnativo nelle previsioni probabilistiche, almeno non rispetto ad altri tipi di previsioni. La sfida più grande quando si tratta di previsioni probabilistiche è rinunciare al comfort associato all’illusione che il futuro sia perfettamente sotto controllo. Il futuro non è perfettamente sotto controllo e non lo sarà mai, e tutto considerato, è probabilmente meglio così.

Questo conclude la lezione di oggi. La prossima volta, il 6 aprile, presenterò la presa di decisioni nella gestione degli inventari nel settore del commercio al dettaglio, e vedremo come le previsioni probabilistiche che sono state presentate oggi possono essere utilizzate per guidare una decisione di base sulla supply chain, ovvero il rifornimento di inventario in una rete di vendita al dettaglio. La lezione si svolgerà lo stesso giorno della settimana, mercoledì, alla stessa ora, alle 15:00, ed sarà il primo mercoledì di aprile.
Domanda: Possiamo ottimizzare la risoluzione sulla precisione rispetto al volume di RAM per Envision?
Sì, assolutamente, anche se non in Envision stesso. Questa è una scelta che abbiamo fatto nella progettazione di Envision. Il mio approccio quando si tratta di supply chain scientist è quello di liberarli dalle tecniche di basso livello. I 4 kilobyte di Envision sono molti spazio, consentendo una rappresentazione accurata della situazione della tua supply chain. Quindi, l’approssimazione che perdi in termini di risoluzione e precisione è insignificante.
Certamente, quando si tratta della progettazione del tuo algoritmo di compressione, ci sono molti compromessi da considerare. Ad esempio, i bucket che sono molto vicini allo zero devono avere una risoluzione perfetta. Se vuoi avere la probabilità di osservare zero unità di domanda, non vuoi che la tua approssimazione raggruppi insieme i bucket per la domanda zero, una unità e due unità. Tuttavia, se stai guardando i bucket per la probabilità di osservare 1.000 unità di domanda, raggruppare insieme 1.000 e 1.001 unità di domanda va bene. Quindi, ci sono molti trucchi per sviluppare un algoritmo di compressione che si adatti davvero alle esigenze della supply chain. Questo è molto più semplice rispetto a ciò che accade per la compressione delle immagini. La mia opinione è che uno strumento progettato correttamente dovrebbe essenzialmente astrarre il problema per i supply chain scientist. Questo è troppo dettagliato e non è necessario micro-ottimizzare nella maggior parte dei casi. Se sei Walmart e hai non solo 1 milione di SKU ma diversi centinaia di milioni di SKU, allora potrebbe avere senso micro-ottimizzare. Tuttavia, a meno che non si stia parlando di supply chain estremamente grandi, credo che si possa avere qualcosa di sufficientemente buono in modo che l’impatto sulle prestazioni dovuto alla mancanza di ottimizzazione completa sia per lo più insignificante.
Domanda: Quali sono le considerazioni pratiche da prendere in considerazione dal punto di vista della supply chain durante l’ottimizzazione di questi parametri?
Quando si tratta di previsioni probabilistiche nella supply chain, avere una precisione superiore a una su 100.000 è tipicamente insignificante, semplicemente perché non si dispone mai di dati sufficienti per avere un’accuratezza nella stima delle probabilità più granulare di una parte su 100.000.
Domanda: Quali settori traggono maggior beneficio dall’approccio delle previsioni probabilistiche?
La risposta breve è che maggiore è l’irregolarità dei tuoi modelli, maggiori sono i benefici. Se hai una domanda intermittente, hai grandi benefici; se hai una domanda irregolare, hai grandi benefici; se hai tempi di consegna ampiamente variabili e scosse erratiche nelle tue supply chain, trai il massimo beneficio. All’estremo opposto dello spettro, ad esempio, se stessimo analizzando la supply chain della distribuzione dell’acqua, il consumo di acqua è estremamente regolare e quasi mai presenta grandi scosse, solo micro scosse al massimo. Questo è il tipo di problema che non trae beneficio dall’approccio probabilistico. L’idea è che ci sono alcune situazioni in cui le previsioni puntuali classiche forniscono previsioni molto accurate. Se ti trovi in una situazione in cui le previsioni per tutti i tuoi prodotti hanno un errore inferiore al cinque percento guardando avanti, allora non hai bisogno di previsioni probabilistiche; ti trovi in una situazione in cui avere una previsione davvero accurata funziona effettivamente. Tuttavia, se sei come molte aziende in situazioni in cui l’accuratezza delle tue previsioni è molto bassa, con una divergenza del 30% o più, allora trai grandi benefici dalle previsioni probabilistiche. A proposito, quando parlo di errore di previsione del 30%, mi riferisco sempre alla previsione molto disaggregata. Molte aziende ti diranno che le loro previsioni sono accurate al 5%, ma se aggregi tutto, questa può essere una percezione molto fuorviante della tua accuratezza di previsione. La tua accuratezza di previsione conta solo al livello più disaggregato, tipicamente al livello SKU e al livello giornaliero, perché le tue decisioni vengono prese al livello SKU e al livello giornaliero. Se al livello SKU e al livello giornaliero riesci a ottenere le tue previsioni più disaggregate con un’accuratezza del 5%, allora non hai bisogno di previsioni probabilistiche. Tuttavia, se osservi inesattezze a due cifre in termini di percentuali, allora trarrai grandi benefici dalle previsioni probabilistiche.
Domanda: Poiché i tempi di consegna possono essere stagionali, decomporresti le previsioni dei tempi di consegna in più previsioni, ognuna per ogni stagione distinta, per evitare di osservare una distribuzione multimodale?
Questa è una buona domanda. L’idea qui è che tipicamente costruirai un modello parametrico per i tuoi tempi di consegna che includa un profilo di stagionalità. Affrontare la stagionalità per i tempi di consegna non è fondamentalmente molto diverso dall’affrontare qualsiasi altra ciclicità, come abbiamo fatto nella precedente lezione per la domanda. Il modo tipico non è quello di costruire modelli multipli, perché come hai giustamente osservato, se hai modelli multipli, osserverai tutti i tipi di salti bizzarri quando passi da una modalità all’altra. È tipicamente meglio avere un solo modello con un profilo di stagionalità nel mezzo del modello. Sarebbe come una decomposizione parametrica in cui hai un vettore che ti fornisce l’effetto settimanale che influenza il tempo di consegna in una determinata settimana dell’anno. Forse avremo tempo in una lezione successiva per dare un esempio più esteso di ciò.
Domanda: Le previsioni probabilistiche sono un buon approccio quando si desidera prevedere una domanda intermittente?
Assolutamente. In effetti, credo che quando hai una domanda intermittente, le previsioni probabilistiche non siano solo un buon metodo, ma la previsione puntuale classica sia completamente insensata. Con la previsione classica, tipicamente avresti difficoltà a gestire tutti quei zeri. Cosa fai di quei zeri? Alla fine ti ritrovi con un valore molto basso e frazionario, che non ha molto senso. Con la domanda intermittente, la domanda a cui vuoi davvero rispondere è: il mio stock è abbastanza grande da soddisfare quei picchi di domanda che tendono a sorgere di tanto in tanto? Se usi una previsione media, non lo saprai mai.
Solo per tornare all’esempio della libreria, se diciamo che in una settimana osservi in media una unità di domanda al giorno, quante copie di un libro devi tenere in libreria per avere un alto livello di servizio? Supponiamo che la libreria venga rifornita ogni giorno. Se le uniche persone che serviamo sono gli studenti, allora se hai in media una unità di domanda ogni giorno, avere tre libri in magazzino garantirà un livello di servizio molto elevato. Tuttavia, se ogni tanto arriva un professore che cerca 20 libri in una volta sola, allora il tuo livello di servizio, se hai solo tre libri in negozio, sarà pessimo perché non sarai mai in grado di soddisfare nessuno dei professori. Questo è tipicamente il caso della domanda intermittente: non è solo il fatto che la domanda sia intermittente, ma anche che alcuni picchi di domanda possano variare significativamente in termini di entità. Ed è qui che le previsioni probabilistiche brillano davvero, perché possono catturare la struttura fine della domanda anziché raggrupparla tutta insieme in medie in cui tutta questa struttura fine viene persa.
Domanda: Se sostituiamo il tempo di consegna con una distribuzione, la punta rappresentata da una curva a campana liscia sulla prima diapositiva per il generatore?
In qualche misura, se randomizzi di più, tendi a distribuire le cose. Sulla prima diapositiva riguardante il generatore, dovremmo eseguire l’esperimento con diverse impostazioni per vedere cosa otteniamo. L’idea è che quando vogliamo sostituire il tempo di consegna con una distribuzione, lo facciamo perché abbiamo una comprensione del problema che ci dice che il tempo di consegna varia. Se fidiamo assolutamente del nostro fornitore e sono stati incredibilmente affidabili, allora va benissimo dire che l’ETA (tempo stimato di arrivo) è quello che è ed è una stima quasi perfetta della realtà. Tuttavia, se abbiamo visto che in passato i fornitori erano a volte erratici o non raggiungevano l’obiettivo, allora è meglio sostituire il tempo di consegna con una distribuzione.
Introdurre una distribuzione al posto del tempo di consegna non necessariamente rende più regolari i risultati che si ottengono alla fine; dipende da cosa stai guardando. Ad esempio, se stai considerando il caso più estremo di sovrastoccaggio, un tempo di consegna variabile potrebbe addirittura aumentare il rischio di avere un inventario morto. Perché succede questo? Se hai un prodotto molto stagionale e un tempo di consegna variabile, e il prodotto arriva dopo la fine della stagione, ti ritrovi con un prodotto fuori stagione, il che amplifica il rischio di avere un inventario morto alla fine della stagione. Quindi, è complicato. Il fatto di trasformare una variabile nel suo sostituto probabilistico non renderà naturalmente più regolare ciò che osserverai; a volte, può rendere la distribuzione ancora più nitida. Quindi, la risposta è: dipende.
Eccellente, penso che sia tutto per oggi. Ci vediamo la prossima volta.


