Exploración de datos en tiempo real con slices
Hace dos meses, lanzamos una gran nueva característica para Lokad: nuestro primer ejemplo de exploración de datos en tiempo real. Esta característica tiene el nombre en código dashboard slicing, y nos requirió una revisión completa del back-end de procesamiento de datos de bajo nivel que impulsa Envision para lograrlo. Con dashboard slices, cada dashboard se convierte en un diccionario completo de vistas de dashboard, que pueden explorarse en tiempo real con una barra de búsqueda.
Por ejemplo, al dividir un dashboard destinado a ser un inspector de producto, que reúne en un solo lugar toda la información sobre un producto -incluyendo forecast probabilístico de demanda y lead time forecast, por ejemplo- ahora es posible cambiar en tiempo real de un producto a otro.
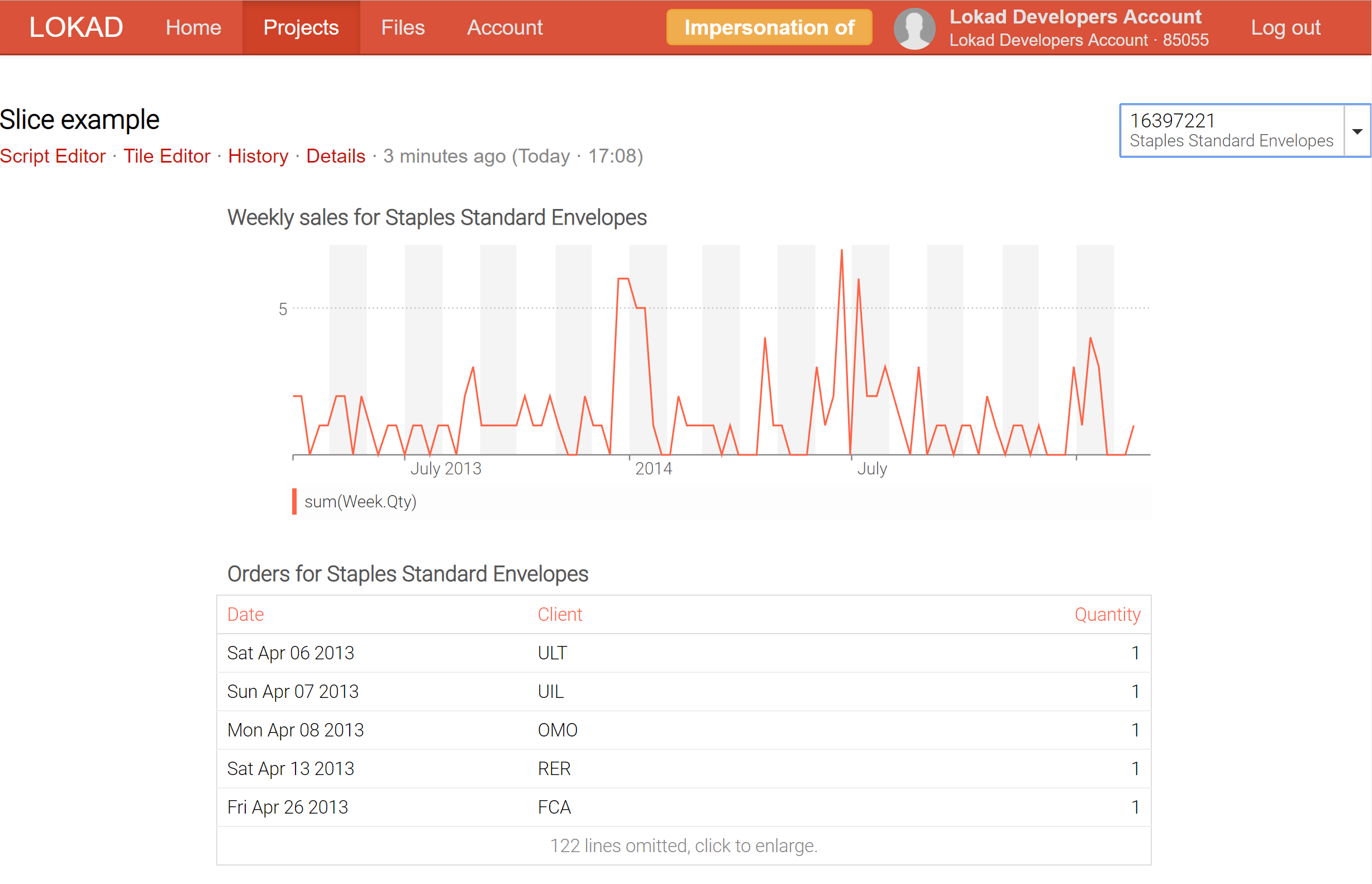
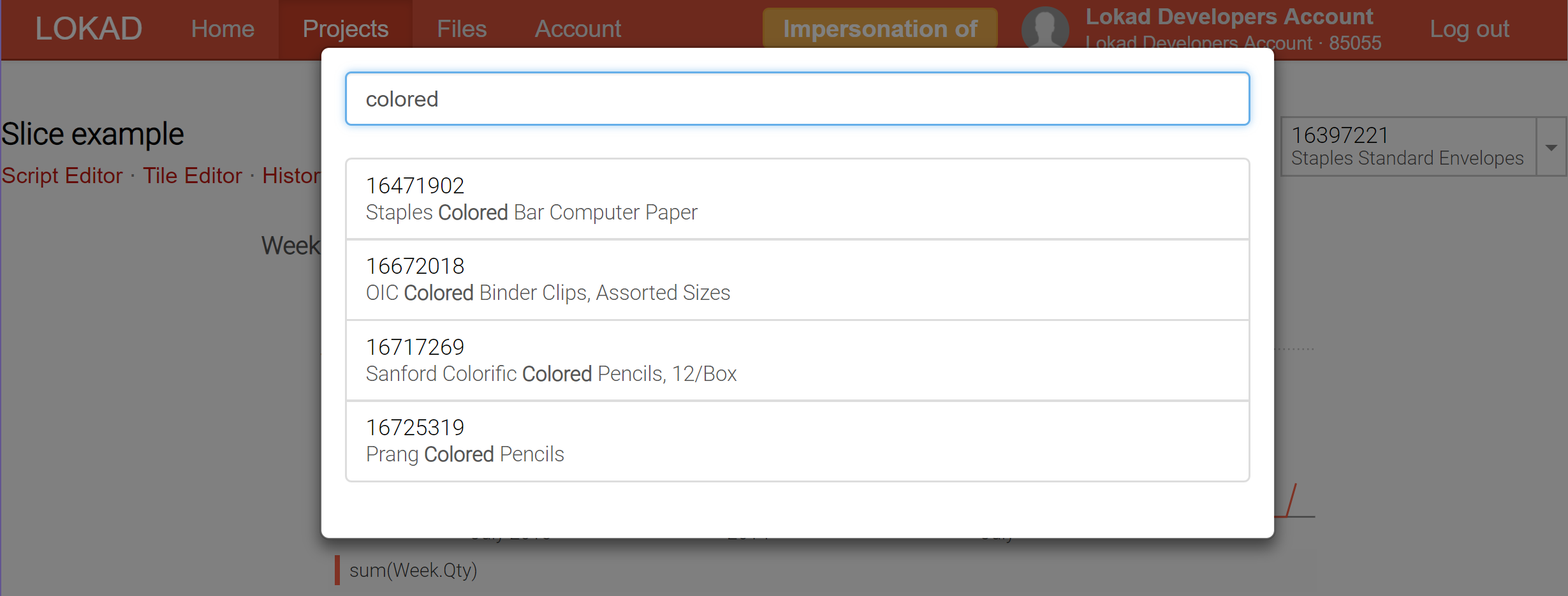
Actualmente, Lokad soporta hasta 200,000 slices (también conocidas como vistas de dashboard) para ser producidas para un solo dashboard; y esas slices se pueden mostrar en tiempo real a través del selector, que incluye una función de búsqueda en tiempo real para facilitar la exploración de los datos. A diferencia de las herramientas de business intelligence (BI), esas slices pueden contener cálculos altamente complejos, no meramente slice-and-dice sobre un cubo OLAP.
En lo que respecta al procesamiento de datos y la elaboración de informes, típicamente existen dos enfoques: el procesamiento en línea y el procesamiento por lotes. El procesamiento en línea toma un flujo de datos, y se espera que todo lo que muestra el sistema esté siempre actualizado: el sistema no se retrasa más de unos pocos minutos, a veces ni más de unos pocos segundos respecto a la realidad. Los cubos OLAP y la mayoría de las herramientas referidas como business intelligence entran en esta categoría. Aunque el analytics en tiempo real 1 es muy deseable, no solo desde una perspectiva empresarial (los datos frescos son mejores que los datos estancados), sino también desde la perspectiva del usuario final (performance is a feature), también vienen acompañados de limitaciones estrictas. Dicho de forma sencilla, es extremadamente difícil ofrecer analítica inteligente2 en tiempo real. Como resultado, todos los sistemas analíticos en línea presentan severas limitaciones en cuanto al tipo de análisis que el sistema puede llevar a cabo.
Por otro lado, el procesamiento por lotes se ejecuta típicamente de manera programada (por ejemplo, ejecuciones diarias) mientras se ingresan todos los datos históricos (o una porción considerable de ellos). La frescura de los resultados está limitada por la frecuencia del cronograma: un lote diario siempre te da resultados que reflejan la situación de ayer, no la situación de hoy. Dado que todos los datos están disponibles desde el inicio, el procesamiento por lotes es ideal para realizar todo tipo de optimizaciones computacionales que pueden incrementar en gran medida el rendimiento global del proceso. Como resultado, mediante el procesamiento por lotes es posible ejecutar clases enteras de cálculos complejos que quedan fuera del alcance cuando se considera el procesamiento en línea. Además, desde una perspectiva informática, el procesamiento por lotes tiende a ser mucho más sencillo tanto de implementar como de operar 3. La principal desventaja del procesamiento por lotes es el retraso inherente que impone la naturaleza agrupada del proceso.
Como plataforma de software, Lokad se sitúa definitivamente en el campamento del processing por lotes. De hecho, aunque la optimización de Supply Chain Quantitativa requiere un alto grado de reactividad, existen muchas decisiones que no exigen una reactividad instantánea, por ejemplo, decidir si se debe producir un pallet extra de productos o determinar si es momento de bajar el precio para liquidar un stock. Para estas decisiones, la preocupación principal es tomar la mejor decisión posible, y si esta decisión puede mejorarse mensurablemente dedicando una hora más de cómputo al caso, entonces es casi seguro que esa hora extra de cómputo será una buena inversión 4.
Así, Envision está diseñado desde una perspectiva de procesamiento por lotes. Tenemos varios trucos bajo la manga para hacer que Envision sea muy rápido incluso al manejar terabytes de datos; pero a esta escala hablamos de obtener resultados en cuestión de minutos, no en menos de un segundo. De hecho, debido a la naturaleza altamente distribuida del modelo de cómputo de Envision, es un desafío para Lokad completar la ejecución de cualquier script de Envision en menos de 5 segundos, incluso cuando solo se involucran unos pocos megabytes de datos. Cuanto más distribuido es un sistema, mayor es la inercia interna para sincronizar todas sus partes. Más escalabilidad es enemiga de una latencia menor.
Hace unos años, introdujimos la noción de entry forms en Envision: una característica que te permite añadir un formulario configurable en el dashboard, el cual se convierte en una entrada accesible desde el script de Envision. Por ejemplo, gracias a esta característica, fue sencillo diseñar un dashboard destinado a ser un inspector de producto, que mostraba toda la información relevante correspondiente a los productos especificados. Desafortunadamente, para alinear el dashboard con el valor recién ingresado en el formulario, el script de Envision tenía que ser reejecutado, lo que ocasionaba un retraso de varios segundos para obtener los resultados actualizados; una duración inaceptablemente larga para la exploración de datos.
Las slices de dashboard (consulta nuestra documentación técnica) representan nuestro intento de obtener lo mejor de ambos mundos: procesamiento en línea y por lotes. La clave es que Lokad ahora puede calcular por lotes una gran cantidad de slices (cada slice puede reflejar un producto, una ubicación, un scenario, o una combinación de todas esas cosas) y permitirte cambiar de un slice a otro en tiempo real, lo cual es posible porque todo ha sido precomputado. Naturalmente, precomputar una gran cantidad de slices es más costoso computacionalmente, pero no tanto como se podría pensar. Generalmente, es más barato para Lokad calcular 10,000 slices de una vez, en lugar de realizar 100 ejecuciones independientes, cada una dedicada a un único slice.
Con las slices, Lokad está ganando capacidades de business-intelligence-on-steroid: no solo es posible explorar muchas vistas diferentes (por ejemplo, productos, ubicaciones, periodos de tiempo) en tiempo real, sino que además se eliminan las restricciones habituales de las arquitecturas de procesamiento en línea.
-
En un sistema distribuido, no existe algo como el “tiempo real”. La velocidad de la luz misma impone límites estrictos al grado de sincronización de un sistema que se extiende por varios continentes. Por lo tanto, esta terminología es algo abusiva. Sin embargo, si la latencia global es inferior a un segundo, por lo general es aceptable calificar una aplicación de procesamiento de datos como “en tiempo real”. ↩︎
-
Incluso sistemas avanzados de procesamiento de datos en tiempo real, como los que se utilizan para la conducción autónoma, evitan cuidadosamente cualquier operación de learning cuando funcionan en tiempo real. Todos los modelos de machine learning se precomputan y son estáticos. ↩︎
-
La implementación típica de un proceso por lotes consiste en mover archivos planos, lo cual es una característica básica soportada por prácticamente todos los sistemas en la actualidad. Luego, desde una perspectiva operativa, si un componente del proceso por lotes sufre una caída transitoria, una política de reintento simple suele resolver el problema. En contraste, los sistemas en línea tienden a comportarse mal cuando un componente falla. ↩︎
-
A día de hoy, una hora de cómputo en una CPU moderna típicamente cuesta menos de $0.02 cuando se utiliza el modelo pay-as-you-go a través de las principales plataformas de computación en la nube. Por lo tanto, mientras que los beneficios generados por una única mejor decisión de supply chain valgan mucho más de $0.02, tiene sentido invertir esa una hora de cómputo. ↩︎

