Aprendizaje a gran escala: una contribución a algoritmos de clustering distribuidos asincrónicos
El primer gran avance de Lokad fue el uso de tipos de previsión altamente atípicos para fines de supply chain, específicamente pronósticos cuantílicos. En Lokad, los pronósticos cuantílicos fueron los precursores de las previsiones probabilísticas. Los cuantiles marcaron la primera desviación significativa de Lokad respecto a lo que aún se considera la teoría ‘mainstream’ de la supply chain theory. Este avance se asoció al trabajo del primer empleado de Lokad, Benoit Patra. (Como CEO y fundador, no me incorporé a la nómina de mi propia empresa hasta mucho después.)
Quince años después, para mi horror, me di cuenta de que los manuscritos de los múltiples doctorados realizados en Lokad nunca habían sido publicados en nuestro sitio web. ¡Así que, más vale tarde que nunca, republicamos este manuscrito!
Autor: Benoit Patra
Fecha: marzo 2012

Resumen:
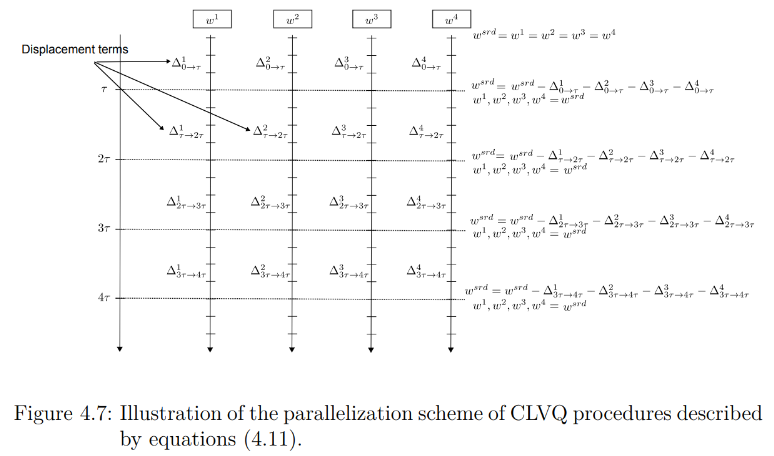
Los temas abordados en este manuscrito de tesis están inspirados en problemas de investigación encontrados por la empresa Lokad, los cuales se resumen en el primer capítulo. El Capítulo 2 trata de un método no paramétrico para la previsión de cuantiles de una serie temporal. En particular, establecemos un resultado de consistencia para esta técnica bajo supuestos mínimos. El resto de la disertación se dedica al análisis de algoritmos de clustering asincrónicos distribuidos (DALVQ). El Capítulo 3 propone primero una descripción matemática de los modelos y luego ofrece un análisis teórico, donde se demuestra la existencia de un consenso asintótico y la convergencia casi segura hacia puntos críticos de la distorsión. En el capítulo siguiente, proponemos una discusión exhaustiva, así como algunos experimentos sobre esquemas de paralelización para ser implementados en un despliegue práctico de algoritmos DALVQ. Finalmente, el Capítulo 5 contiene una implementación efectiva de DALVQ en la plataforma computación en la nube Microsoft Windows Azure. Estudiamos, entre otros temas, las aceleraciones logradas por el algoritmo con más recursos de computación paralela, y comparamos este algoritmo con el llamado método de Lloyd, que también es distribuido y se despliega en Windows Azure.
Dato curioso: El resumen menciona ‘Windows Azure’, que fue efectivamente el nombre comercial de Microsoft Azure en sus primeros años.
Jurado:



