幅と深さ、営業予測を90度回転させる
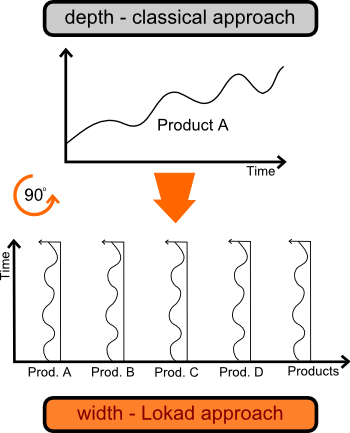
これまでに、Lokad が予測する際に中華料理ではなくスポーツバー向けの飲料にあまり重きを置かなかった理由について議論してきました。私たちの技術を考える別の方法は、営業予測を90度回転させることにあります。
平均して、消費財は3年間のライフサイクルを持つことが観察されています。これは、平均して 各製品について約18か月分のデータが利用可能であることを意味します。月次集計による販売履歴を見ると、18か月分のデータは18ポイントに相当します。
18ポイントのデータしかない場合、どんなに優れた先進的な予測理論であっても、堅牢な統計分析を行うためのデータが全く不足しているため、あまり有用な結果は得られません。18ポイントでは、パターンすら、完全な季節の観測が2回分も得られないため、季節性を観察するのが困難になるのです。
業界によって状況は異なるかもしれませんが、製品が数十年にわたって市場に留まらない限り、この問題に直面する可能性が高いです.
その直接的な結果として、古典的な予測ツールキットは、わずか18ポイントの入力データで堅牢に適合させることができる_非自明な_統計モデルが存在しないため、各製品ごとに予測モデルを_微調整_するために統計学者を必要とします。
しかし、Lokad は統計学者を全く必要としないのです。その魔法は90度の回転にあります。私たちのモデルは、単一の時系列ごとにデータを反復処理するのではなく、すべての時系列に対して一度に処理を行います。したがって、はるかに多くの入力データが利用可能となり、結果として高度なモデルで成功を収めることができるのです。
このアプローチはまさに常識です。もし新しいチョコレートバーの季節性を予測したいのであれば、他のチョコレートバーの季節性が有力な候補となるでしょう。なぜ各チョコレートバーを他と完全に隔離して扱う必要があるのでしょうか?
しかし、計算機的な観点から見ると、この問題は一層困難になっています。もし10,000のSKUがある場合、2つのSKU間の関連数は約1億に達します(なお、10,000のSKUは決して_大きな_数ではありません)。まさにここでクラウドの登場となるのです。たとえあなたのアルゴリズムが厳密な二次計算量を回避するように設計されていたとしても、依然として_大量_の処理能力が必要となります。クラウドはこの処理能力を非常に低価格でオンデマンドで提供してくれるのです。
クラウドがなければ、この種の技術を提供することは単に不可能です。


