00:28 Введение
00:43 Robert A. Heinlein
03:03 История до настоящего момента
06:52 Подборка парадигм
08:20 Статический анализ
18:26 Массивное программирование
28:08 Аппаратная совместимость
35:38 Вероятностное программирование
40:53 Дифференцируемое программирование
55:12 Версионирование кода и данных
01:00:01 Безопасное программирование
01:05:37 В заключении, инструменты также важны в цепочках поставок
01:06:40 Предстоящая лекция и вопросы аудитории
Описание
Хотя доминирующая теория управления цепями поставок с трудом находит применение в крупных компаниях, один инструмент, а именно Microsoft Excel, добился значительного операционного успеха. Реализация числовых рецептов доминирующей теории цепочек поставок через электронные таблицы тривиальна, однако на практике, несмотря на осведомленность о теории, это не произошло. Мы демонстрируем, что электронные таблицы победили благодаря использованию программных парадигм, которые оказались более эффективными для достижения результатов в цепочках поставок.
Полная расшифровка

Всем привет, добро пожаловать на серию лекций по цепям поставок. Меня зовут Жоаннес Верморель, и сегодня я представлю мою четвертую лекцию: Программные парадигмы для цепей поставок.

Когда меня спрашивают: “Господин Верморель, какие области знаний о цепях поставок вам наиболее интересны?” — один из моих главных ответов обычно: программные парадигмы. И затем, не слишком часто, но достаточно часто, реакция собеседника звучит так: “Программные парадигмы, господин Верморель? О чем вы, черт возьми, вообще говорите? Как это может иметь хоть какое-то отношение к текущей задаче?” Такие реакции, очевидно, случаются не так часто, но когда они происходят, они неизменно напоминают мне об этом совершенно удивительном высказывании Роберта А. Хайнлайна, которого считают деканом писателей научной фантастики.
У Хайнлайна есть потрясающая цитата о компетентном человеке, которая подчеркивает важность компетентности в различных областях, особенно в цепях поставок, где мы сталкиваемся с очень сложными задачами. Эти проблемы практически так же сложны, как сама жизнь, и я считаю, что вам действительно стоит изучить идею программных парадигм, так как они могут принести большую ценность вашей цепочке поставок.
До сих пор, на первой лекции, мы увидели, что проблемы цепей поставок являются крайне сложными. Любой, кто говорит об оптимальных решениях, упускает суть; нет ничего, что даже отдаленно можно было бы назвать оптимальным. На второй лекции я представил Количественную цепочку поставок, видение с пятью ключевыми требованиями для достижения великолепия в управлении цепями поставок. Эти требования сами по себе недостаточны, но их нельзя обойти, если вы хотите достичь совершенства.
На третьей лекции я обсуждал доставку программного продукта в контексте оптимизации цепей поставок. Я отстаивал точку зрения, что для оптимизации цепей поставок необходимо решать вопрос программного продукта в капиталистическом ключе, однако такого продукта не найти на полке. Существует слишком большое разнообразие, и стоящие перед нами задачи выходят далеко за рамки современных технологий. Таким образом, по необходимости это будет нечто совершенно уникальное. Следовательно, если программный продукт будет уникальным для компании или конкретной цепочки поставок, возникает вопрос: какие же правильные инструменты использовать для его создания. Это подводит меня к теме сегодняшнего занятия: правильный инструмент начинается с правильных программных парадигм, потому что нам всё равно придется программировать этот продукт.

На данный момент нам необходимы программные возможности для решения задачи оптимизации, не путать с управленческой стороной. Как мы видели на моей предыдущей лекции, победителем пока оказался Microsoft Excel. От очень маленьких до очень больших компаний, он повсеместен, его используют везде. Даже в компаниях, инвестировавших миллионы долларов в суперумные системы, Excel по-прежнему правит бал, и почему? Потому что он обладает правильными программными характеристиками. Он весьма выразителен, гибок, доступен и прост в обслуживании. Однако Excel — это не конечная цель. Я твердо убежден, что мы можем сделать гораздо больше, но для этого нам нужны правильные инструменты, образ мышления, понимание и программные парадигмы.

Программные парадигмы могут показаться аудитории слишком абстрактными, но на самом деле это область, которая интенсивно изучалась в течение последних пяти десятилетий. Было сделано огромное количество работы в этой сфере. Это не широко известно широкой публике, но существуют целые библиотеки, наполненные высококачественными разработками, выполненными множеством специалистов. Итак, сегодня я представлю серию из семи парадигм, которые были приняты в Lokad. Мы не изобретали эти идеи; мы заимствовали их у тех, кто разработал их до нас. Все эти парадигмы были реализованы в программном продукте Lokad, и после почти десятилетия использования Lokad в производственной среде с применением этих парадигм, я убежден, что они были абсолютно критичны для нашего операционного успеха до сих пор.

Давайте перейдем к этому списку с помощью статического анализа. Проблема здесь — сложность. Как справиться со сложностью в цепях поставок? Вы столкнетесь с корпоративными системами, в которых сотни таблиц, каждая из которых содержит десятки полей. Если вы рассматриваете такую задачу, как, например, пополнение запасов на складе, вам придется учитывать множество факторов. Могут быть минимальные объемы заказа, скидки по ценам, прогнозы спроса, прогнозы сроков поставки и всевозможные возвраты. Могут быть ограничения по площади для хранения, ограничения по пропускной способности приемки и сроки годности, из-за которых некоторые партии становятся непригодными. Так что в итоге остается учитывать тонны факторов. В цепях поставок идея “быстро двигаться и ломать все” просто не соответствует нужному подходу. Если вы случайно закажете товаров на сумму в один миллион долларов, которые вам совсем не нужны, это обойдется очень дорого. Нельзя допустить, чтобы программа управляла вашей цепью поставок, принимая рутинные решения, и при обнаружении ошибки это стоило бы миллионов. Нам нужно иметь что-то с очень высокой степенью корректности по замыслу. Мы не хотим обнаруживать ошибки уже в продакшене. Это принципиально отличается от обычного программного обеспечения, где сбой не представляет большой проблемы.
Когда речь идет об оптимизации цепей поставок, это не обычная задача. Если вы просто передали поставщику огромный, неверный заказ, вы не можете позвонить им неделю спустя и сказать: «О, моя ошибка, забудьте, мы и не заказывали этого». Такие ошибки обойдутся в большие деньги. Статический анализ так называется, потому что он заключается в анализе программы без её выполнения. Идея в том, что у вас есть программа с написанными операторами, ключевыми словами и прочим, и, даже не запуская эту программу, вы можете определить, имеет ли она проблемы, которые почти наверняка негативно повлияют на вашу продукцию, особенно на производство цепей поставок. Ответ — да. Эти техники существуют, они внедрены и чрезвычайно ценны.
Чтобы привести пример, на экране вы видите снимок Envision. Envision — это предметно-ориентированный язык программирования, разработанный Lokad почти десятилетие и предназначенный для предиктивной оптимизации цепей поставок. То, что вы видите, — это скриншот редактора кода Envision, веб-приложения, которое можно использовать онлайн для редактирования кода. Синтаксис в значительной степени заимствован из Python. В этом маленьком скриншоте, состоящем всего из четырех строк, я иллюстрирую идею: если вы пишете большой объем логики для пополнения запасов на складе и вводите некоторые экономические переменные, такие как скидки по ценам, посредством логического анализа программы, вы видите, что эти скидки никак не связаны с конечными результатами, которые возвращает программа, а именно с количеством, которое надо пополнить. Здесь возникает очевидная проблема. Вы ввели важную переменную — скидки по ценам, но логически они не влияют на итоговые результаты. Таким образом, мы сталкиваемся с проблемой, которую можно обнаружить с помощью статического анализа. Это очевидная проблема, поскольку если в коде присутствуют переменные, не влияющие на вывод программы, то они не имеют никакого смысла. В этом случае у нас есть два варианта: либо эти переменные фактически являются неиспользуемым кодом, и программа не должна компилироваться (вы должны просто избавиться от этого неиспользуемого кода, чтобы снизить сложность и не накапливать случайную сложность), либо это была настоящая ошибка, и важная экономическая переменная должна была быть включена в ваш расчет, но вы упустили её по невнимательности или по другой причине.
Статический анализ абсолютно фундаментален для достижения любой степени корректности по замыслу. Речь идет о том, чтобы исправлять ошибки на этапе компиляции, еще до того, как вы приступите к данным. Если проблемы проявляются во время запуска, велика вероятность, что они возникнут ночью, когда ночной пакет управляет пополнением запасов на складе. Программа, скорее всего, будет работать в неурочное время, когда никто не следит за её работой, поэтому вы не хотите, чтобы что-то давало сбой, пока никого нет рядом с программой. Сбой должен происходить именно в тот момент, когда люди пишут код.
Статический анализ имеет множество целей. Например, в Lokad мы используем статический анализ для визуального редактирования панелей управления. WYSIWYG означает “то, что видишь, то и получаешь”. Представьте, что вы создаете панель для отчетности, с линейными графиками, гистограммами, таблицами, цветами и различными эффектами оформления. Вы хотите иметь возможность сделать это визуально, а не настраивать стиль панели через код, так как это очень неудобно. Все настройки, которые вы внедрили, будут вновь интегрированы в сам код, и это достигается с помощью статического анализа.
Еще один аспект в Lokad, который, возможно, не имеет такого большого значения для цепей поставок в целом, но, безусловно, является критически важным для выполнения проекта, — это работа с языком программирования под названием Envision, который мы разрабатываем. С первого дня, почти десять лет назад, мы знали, что ошибки будут допускаться. У нас не было хрустального шара, чтобы с самого начала иметь идеальное видение. Вопрос заключался в том, как мы можем гарантировать, что сможем исправлять эти ошибки дизайна в самом языке программирования как можно удобнее? В этом случае Python стал для меня предупреждением.
Python, который не является новым языком, был впервые выпущен в 1991 году, почти 30 лет назад. Миграция от Python 2 к Python 3 заняла у всего сообщества почти десятилетие, и этот процесс был кошмарным, чрезвычайно болезненным для компаний, участвовавших в этой миграции. По моему мнению, сам язык не имел достаточного количества конструкций. Он не был разработан таким образом, чтобы можно было мигрировать программы с одной версии языка программирования на другую. На самом деле, сделать это полностью автоматически оказалось чрезвычайно сложно, и всё потому, что Python не был создан с учетом статического анализа. Когда у вас есть язык программирования для цепей поставок, вы действительно хотите, чтобы он обладал высоким качеством в плане статического анализа, потому что ваши программы будут иметь долгий жизненный цикл. Цепочки поставок не могут позволить себе говорить: “Подождите три месяца, мы просто переписываем код. Подождите нас; уже приближается кавалерия. Это просто не будет работать пару месяцев.” Это буквально как починка поезда, когда он едет по рельсам на полной скорости, и вы хотите починить двигатель, пока поезд работает. Вот как выглядит исправление вопросов цепей поставок, которые находятся в производстве. У вас нет возможности просто остановить систему; она никогда не останавливается.

Вторая парадигма — массивное программирование. Мы хотим держать сложность под контролем, так как это является одной из ключевых повторяющихся тем в цепях поставок. Мы стремимся к логике, где отсутствуют определенные классы программных ошибок. Например, когда вы пишете циклы или ветвления явно, разработчик подвергается риску столкнуться с целыми классами весьма сложных проблем. Ситуация становится чрезвычайно трудной, когда люди могут просто написать произвольные циклы, чтобы гарантировать определенную длительность вычислений. Хотя это может показаться нишевой проблемой, в оптимизации цепей поставок это не так.
На практике, допустим, у вас есть розничная сеть. В полночь все продажи из всей сети будут полностью консолидацированы, и данные будут переданы в систему для оптимизации. Эта система будет иметь ровно 60-минутное окно для проведения прогнозирования, оптимизации запасов и принятия решений по перераспределению для каждого магазина сети. После завершения работы результаты будут переданы в систему управления складом, чтобы начать подготовку всех поставок. Грузовики будут загружаться, возможно, в 5:00 утра, а к 9:00 утра магазины откроются, и товары уже будут получены и размещены на полках.
Однако у вас очень строгие временные рамки, и если ваши вычисления выйдут за пределы этого 60-минутного интервала, вы подвергаете риску выполнение всей цепочки поставок. Вы не хотите оказаться в ситуации, когда в производстве узнаёте, сколько времени что-то занимает. Если у вас есть циклы, в которых люди могут решать, сколько итераций выполнить, очень трудно доказать длительность ваших вычислений. Учтите, что речь идёт об оптимизации цепочки поставок. У вас нет роскоши проводить проверку коллег и двойную проверку всего.
Итак, программирование массивов — это концепция, согласно которой вы можете работать напрямую с массивами. Если мы посмотрим на этот фрагмент кода, то увидим, что это код Envision, DSL от Lokad. Чтобы понять, что происходит, нужно осознать, что когда я пишу “orders.amounts”, это переменная, а “orders” на самом деле является таблицей в смысле реляционной таблицы, как в базе данных. Например, здесь, в первой строке, “amounts” будет столбцом таблицы. На первой строке я буквально говорю, что для каждой строки таблицы orders я возьму значение столбца “quantity”, умножу его на “price”, и затем получу третий столбец, который генерируется динамически, под названием “amount”.
Кстати, современный термин для программирования массивов сегодня также известен как программирование с использованием датафреймов. Эта область изучения довольно древняя; она насчитывает три-четыре десятилетия, а может быть, даже четыре-пять. Её называли программированием массивов, даже если сейчас люди обычно больше знакомы с понятием датафреймов. Во второй строке мы выполняем фильтрацию, как в SQL. Мы фильтруем даты, и оказывается, что таблица orders содержит дату. Она будет отфильтрована, и я пишу “date, который больше, чем сегодня минус 365”, то есть дни. Мы сохраняем данные за прошлый год, а затем записываем “products.soldLastYear = SUM(orders.amount)”.
Теперь интересный момент в том, что у нас имеется то, что называется естественным соединением между таблицами products и orders. Почему? Потому что каждая строка заказа связана ровно с одним продуктом, и один продукт может быть связан с нулём или более строками заказа. В такой конфигурации вы можете прямо сказать: “Я хочу вычислить нечто на уровне продукта, что является просто суммой того, что происходит на уровне заказов”, и именно это делается в строке девять. Возможно, вы заметите, что синтаксис весьма минимален; здесь нет множества случайных элементов или технических сложностей. Я считаю, что этот код почти полностью лишён случайностей, когда речь идёт о программировании с датафреймами. Затем, в строках 10, 11 и 12, мы просто выводим таблицу на нашу панель управления, что делается очень удобно: “LIST(PRODUCTS)”, а затем “TO(products)”.
Существует множество преимуществ программирования массивов для цепочек поставок. Во-первых, оно устраняет целые классы проблем. В ваших массивах не возникнут ошибки off-by-one. Параллелизацию и даже распределение вычислений осуществлять гораздо проще. Это очень интересно, поскольку означает, что вы можете написать программу, которая будет выполняться не на одном локальном компьютере, а сразу на ряде машин в облаке, и, кстати, именно это и делается в Lokad. Эта автоматическая параллелизация имеет чрезвычайно высокую значимость.
Видите ли, когда вы занимаетесь оптимизацией цепочки поставок, типичное потребление вычислительных ресурсов весьма прерывисто. Если вернуться к примеру с 60-минутным интервалом для розничных сетей при пополнении запасов в магазине, это означает, что у вас есть один час в сутки, когда требуется вычислительная мощность для всех расчётов, а остальные 23 часа — нет. Так что вам нужна программа, которая, когда вы решите её запустить, распределится на множестве машин, а затем, как только работа завершится, освободит все эти машины для других вычислений. Альтернативой было бы наличие множества машин, которые вы арендуете и за которые платите весь день, но используете их лишь на 5% времени, что крайне неэффективно.
Эта идея, что можно быстро и предсказуемо распределять вычисления между множеством машин, а затем возвращать вычислительные мощности, требует облачной инфраструктуры в многопользовательском режиме и ряда других элементов, которые реализует Lokad. Но прежде всего, это требует поддержки со стороны самого языка программирования. Речь идёт не просто о какой-то хитрости; это буквально возможность уменьшить затраты на IT-оборудование в 20 раз, значительно ускорить выполнение вычислений и устранить целые классы потенциальных ошибок в вашей цепочке поставок. Это изменение правил игры.
Программирование массивов уже применяется во многих аспектах, например, в NumPy и pandas в Python, которые так популярны в сегменте data scientist. Но вопрос, который я вам задаю: если это так важно и полезно, почему эти инструменты не являются первоклассными элементами самого языка? Если всё, что вы делаете, — это работа через NumPy, то NumPy должен стать первоклассным гражданином. Я бы сказал, что можно добиться даже большего, чем NumPy. NumPy предназначен для программирования массивов на одной машине, но почему бы не реализовать программирование массивов на флоте машин? Это гораздо мощнее и гораздо адекватнее, когда у вас есть облако с доступными вычислительными ресурсами.
Итак, что станет узким местом в оптимизации цепочки поставок? Существует поговорка Голдратта: “Любое улучшение вне узкого места в цепочке поставок — иллюзия”, и я полностью согласен с этим утверждением. Реально, когда речь идёт об оптимизации цепочки поставок, узким местом будут люди, а точнее, специалисты по цепочке поставок, которые, к сожалению для Lokad и моих клиентов, не растут на деревьях.
Узким местом являются сами специалисты по цепочке поставок — те, кто способен создать числовые рецепты, учитывающие все стратегии компании, поведение конкурентов и превращающие всю эту информацию в нечто механическое, что можно выполнить в масштабе. Трагедия наивного подхода к data science, когда я начинал свою кандидатскую (которую, кстати, так и не закончил), заключалась в том, что я видел, как все в лаборатории буквально занимались data science. Большинство людей писали код для какого-либо продвинутого алгоритма машинного обучения, нажимали Enter и затем ждали. Если у вас большой набор данных, скажем, 5–10 гигабайт, это не будет происходить в режиме реального времени. Поэтому лаборатория была заполнена людьми, которые писали несколько строк, нажимали Enter, а потом уходили пить кофе или читать что-то в интернете. В итоге продуктивность была крайне низкой.
Когда я основал свою компанию, я твердо решил, что не хочу в итоге нанимать армию сверхумных людей, которые большую часть дня проводят, попивая кофе и ожидая завершения своих программ, чтобы получить результаты и двигаться дальше. Теоретически они могли бы параллельно запускать множество экспериментов, но на практике я никогда этого не видел. Интеллектуально, когда вы ищете решение проблемы, вы хотите проверить свою гипотезу и получить результат, чтобы двигаться дальше. Очень сложно заниматься многозадачностью в высокотехнологичной сфере и одновременно следовать нескольким интеллектуальным направлениям.
Однако была и положительная сторона. Data scientists, а теперь и специалисты по цепочке поставок в Lokad, не пишут тысячу строк кода, а затем говорят: “Пожалуйста, запустите”. Обычно они добавляют две строки в скрипт, насчитывающий тысячу строк, и просят его запустить. Этот скрипт выполняется на тех же данных, которые они только что запускали несколько минут назад. Логика почти абсолютно идентична, за исключением этих двух строк. Так как же можно обрабатывать терабайты данных за секунды, а не за несколько минут? Ответ в том, что если при предыдущем запуске скрипта вы записали все промежуточные этапы вычислений и сохранили их на накопителе (обычно это твердотельные накопители или SSD), которые являются очень дешевыми, быстрыми и удобными.
В следующий раз, когда вы запустите свою программу, система заметит, что скрипт практически идентичен предыдущему. Она выполнит сравнение и увидит, что вычислительный граф почти не изменился, за исключением нескольких деталей. Что касается данных, они обычно совпадают на 100%. Иногда вносятся незначительные изменения, но почти ничего не меняется. Система автоматически определит, что вам нужно вычислить всего несколько вещей, так что результат можно получить за секунды. Это может значительно повысить продуктивность вашего специалиста по цепочке поставок. Можно перейти от ситуации, когда человек нажимает Enter и ждёт 20 минут результатов, к ситуации, когда он нажимает Enter, и через 5–10 секунд получает результат и продолжает работу.
Я говорю о том, что может показаться чем-то совершенно незначительным, но на практике это оказывает 10-кратное влияние на продуктивность. Это огромный скачок. То, что мы здесь делаем, — это использование хитрого приема, который Lokad не изобрёл. Мы заменяем один исчерпывающий вычислительный ресурс — процессорное время, — другим, а именно памятью и хранением. У нас есть базовые вычислительные ресурсы: вычисления, память (как оперативная, так и постоянная) и пропускная способность. Это те ресурсы, за которые вы платите, когда арендуете вычислительную мощность в облаке. Фактически, вы можете заменить один ресурс другим, и цель заключается в том, чтобы получить максимальную отдачу от вложенных средств.
Когда говорят, что следует использовать вычисления в памяти, я считаю, что это бессмыслица. Если вы говорите о вычислениях в памяти, это означает, что вы делаете упор на один ресурс в ущерб другим. Но нет, здесь существуют компромиссы, и что интересно, можно иметь язык программирования и окружающую среду, которые упрощают реализацию таких компромиссов и подходов. В обычном языке программирования общего назначения это возможно, но вы вынуждены делать это вручную. Это означает, что человек, занимающийся этим, должен быть профессиональным разработчиком. Специалист по цепочке поставок не будет выполнять такие низкоуровневые операции с основными вычислительными ресурсами вашей платформы. Это должно быть заложено на уровне самого языка программирования.
Теперь давайте поговорим о вероятностном программировании. Во второй лекции, в которой я представил видение количественной цепочки поставок, моим первым требованием было рассмотреть все возможные будущие сценарии. Технический ответ на это требование — вероятностное прогнозирование. Вы хотите работать с будущим, где заданы вероятности. Все варианты будущего возможны, но они не все равновероятны. Вам нужна алгебра, позволяющая проводить вычисления с учетом неопределенности. Одну из моих больших претензий к Excel состоит в том, что в электронной таблице чрезвычайно сложно адекватно представить неопределенность, независимо от того, используете ли вы Excel или его какую-либо более современную облачную версию. В таблице очень трудно учесть неопределённость, потому что нужно нечто большее, чем просто числа.
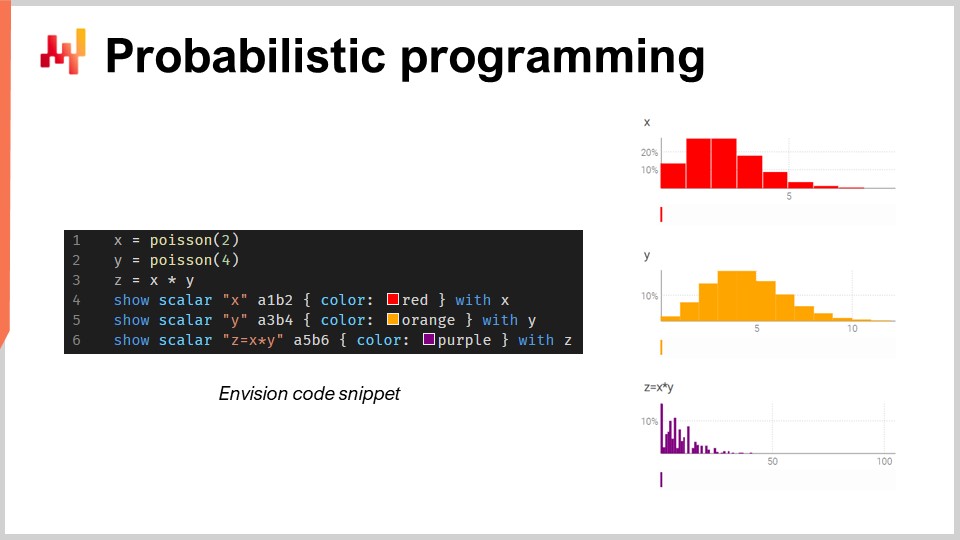
В этом небольшом фрагменте я иллюстрирую алгебру случайных величин, которая является встроенной функцией Envision. В первой строке я генерирую дискретное распределение Пуассона со средним значением 2 и помещаю его в переменную X. Затем я поступаю аналогичным образом для другого распределения Пуассона, Y. После этого я вычисляю Z как произведение X на Y. Эта операция, умножение случайных величин, может показаться весьма странной. Зачем вам вообще понадобится такой прием для решения задач цепочки поставок? Позвольте привести пример.
Предположим, вы работаете на рынке послепродажного обслуживания автомобилей и продаёте тормозные колодки. Люди не покупают тормозные колодки поштучно; они покупают либо две, либо четыре. Таким образом, если вы хотите выполнить прогноз, вам, возможно, придётся определить вероятности того, что клиенты придут и купят определённый тип тормозных колодок. Это станет вашей первой случайной величиной, задающей вероятность наблюдения нуля, одной, двух, трёх, четырёх и так далее единиц спроса на тормозные колодки. Затем у вас будет другое распределение, которое задаёт, будут ли люди покупать две или четыре колодки. Может быть, это будет 50–50, а может, 10 процентов купят две и 90 процентов — четыре. Суть в том, что у вас есть два аспекта, и если вы хотите узнать реальное общее потребление тормозных колодок, вам нужно умножить вероятность того, что клиент придёт за колодками, на распределение вероятностей покупки двух или четырёх. Таким образом, вам необходимо перемножить эти две неопределённые величины.
Здесь я предполагаю, что две случайные величины независимы. Кстати, это умножение случайных величин в математике известно как дискретная свертка. Вы можете увидеть на скриншоте панель управления, сгенерированную Envision. В первых трёх строках я выполняю этот расчет с использованием случайной алгебры, а затем в строках четыре, пять и шесть вывожу эти данные на веб-страницу — на панель управления, созданную скриптом. Я располагаю значения A1, B2, например, как в Excel-сетке. Панели Lokad организованы аналогично Excel-сеткам, где позиции соответствуют столбцам B, C и т.д., а ряды — 1, 2, 3, 4, 5.
Вы видите, что дискретная свертка Z имеет весьма странный, очень резкий узор, который на самом деле очень часто встречается в цепочках поставок, когда люди могут покупать упаковки, лоты или сразу несколько штук. В подобной ситуации обычно лучше декомпозировать источники мультипликативных событий, связанных с лотом или упаковкой. Вам нужен язык программирования, предоставляющий эти возможности непосредственно, как первоклассные объекты. Именно об этом и говорит вероятностное программирование, и именно так мы реализовали его в Envision.

Теперь давайте обсудим дифференцируемое программирование. Я должен сделать оговорку: я не ожидаю, что аудитория действительно поймет, что происходит, и прошу прощения за это. Дело не в том, что вам не хватает интеллекта; просто эта тема заслуживает целой серии лекций. На самом деле, если вы посмотрите на план предстоящих лекций, там есть целая серия, посвященная дифференцируемому программированию. Я собираюсь идти очень быстро, и это будет довольно криптично, так что заранее прошу прощения.
Давайте перейдем к проблеме цепочки поставок, представляющей здесь интерес, а именно к каннибализации и замещению. Эти проблемы очень интересны, и, вероятно, именно здесь прогнозирование временных рядов (повсеместное) терпит самые жестокие неудачи. Почему? Потому что часто ко мне обращаются клиенты или потенциальные заказчики и спрашивают, можем ли мы сделать, например, 13-недельный прогноз для определенных товаров, таких как рюкзаки. Я бы сказал: да, можем, но, очевидно, если мы берем один рюкзак и хотим спрогнозировать спрос на этот продукт, он крайне зависит от того, что вы делаете с другими рюкзаками. Если у вас всего один рюкзак, то, возможно, вы сосредоточите весь спрос на нем. Если же вы вводите 10 различных вариантов, очевидно, что произойдет масса каннибализации. Вы не умножите общий объем продаж в 10 раз просто потому, что увеличили количество товарных позиций в 10 раз. Таким образом, происходит каннибализация и замещение. Эти явления распространены в цепочках поставок.
Как анализировать каннибализацию или замещение? Способ, которым мы поступаем в Lokad, и я не претендую на то, что это единственный способ, но это, безусловно, рабочий подход, обычно заключается в анализе графа, который соединяет клиентов и продукты. Почему так? Потому что каннибализация происходит, когда продукты конкурируют сами с собой за одного и того же клиента. Каннибализация – это буквально отражение того, что у клиента есть потребность, но у него есть предпочтения, и он выбирает один продукт из набора удовлетворяющих его склонности товаров, выбирая только один. Вот суть каннибализации.
Если вы хотите это анализировать, вам нужно анализировать не временные ряды продаж, потому что вы изначально не захватываете эту информацию. Вы хотите анализировать граф, который соединяет исторические транзакции между клиентами и продуктами. Оказывается, что в большинстве бизнесов эти данные доступны. Для электронной коммерции это само собой разумеется. Каждую проданную единицу можно отнести к конкретному клиенту. В B2B ситуация та же. Даже в рознице B2C, в большинстве случаев, современные розничные сети имеют программы лояльности, при которых известно значительное число клиентов, приходящих с их картами, так что вы знаете, кто что покупает. Не для 100% трафика, но этого не требуется. Если у вас есть 10% и более исторических транзакций, где известна пара клиент-продукт, этого достаточно для такого анализа.
В этом сравнительно небольшом фрагменте я подробно опишу анализ аффинности между клиентами и продуктами. Это буквально базовый шаг, который нужно предпринять для проведения любого анализа каннибализации. Давайте посмотрим, что происходит в этом коде.
Со строк с первой по пятую всё предельно банально: я просто читаю плоский файл, содержащий историю транзакций. Я читаю CSV-файл, который содержит четыре столбца: дата, продукт, клиент и количество. Что-то очень простое. Я даже не использую все эти столбцы, но делаю пример более конкретным. В истории транзакций я предполагаю, что клиенты известны для всех этих транзакций. Так что всё очень банально — я просто читаю данные из таблицы.
Затем, в строках семь и восемь, я просто создаю таблицу для продуктов и таблицу для клиентов. В реальной производственной среде я, как правило, не создавал бы эти таблицы; я бы считал их из других плоских файлов. Я хотел сохранить пример предельно простым, поэтому просто извлекаю таблицу продуктов из наблюдаемых в истории транзакций, и делаю то же самое для клиентов. Видите, это просто трюк, чтобы всё было максимально просто.
Теперь, строки 10, 11 и 12 касаются латинских пространств, и это станет немного более запутанным. Во-первых, в строке 10 я создаю таблицу с 64 строками. Таблица не содержит ничего; она определяется лишь фактом наличия 64 строк, и всё. Это как заполнитель, тривиальная таблица с множеством строк и без столбцов. Она не так полезна сама по себе. Затем «P» представляет собой по сути декартово произведение, математическую операцию со всеми парами. Это таблица, в которой есть одна строка для каждой строки из таблицы продуктов и для каждой строки из таблицы «L». Таким образом, эта таблица «P» имеет на 64 строки больше, чем таблица продуктов, и я делаю то же самое для клиентов. Я просто раздуваю эти таблицы через это дополнительное измерение, которым является таблица «L».
Это будет моей опорой для латинских пространств, то, чему я собираюсь научиться. Я хочу изучить, чтобы для каждого продукта латинское пространство представляло собой вектор из 64 значений, а для каждого клиента – аналогично вектор из 64 значений. Если я хочу узнать аффинность между клиентом и продуктом, мне нужно просто уметь вычислять скалярное произведение между ними. Скалярное произведение – это просто покомпонентное умножение всех членов этих двух векторов с последующим суммированием. Это может звучать очень технически, но по сути это просто покомпонентное умножение плюс сумма – вот что такое скалярное произведение.
Эти латинские пространства – это просто модное выражение для создания пространства с параметрами, которые несколько выдуманы, для того, чему я хочу научиться. Вся магия дифференцируемого программирования происходит всего за пять строк, со строки 14 по 18. У меня есть ключевое слово “autodiff” и “transactions”, которое указывает, что это таблица интереса, таблица наблюдений. Я собираюсь обрабатывать эту таблицу построчно для проведения моего процесса обучения. В этом блоке я объявляю набор параметров. Параметры – это то, чему вы хотите научиться, как числа, но вы еще не знаете их значения. Эти значения будут инициализированы случайно, случайными числами.
Я вводя “X”, “X*” и “Y”. Я не собираюсь вдаваться в детали того, что именно делает “X*”; возможно, в вопросах. Я возвращаю выражение, которое является моей функцией потерь, а именно сумму. Идея коллаборативной фильтрации или разложения матрицы заключается в том, что вы хотите обучить латинские пространства, соответствующие всем вашим связям в двудольном графе. Я знаю, что это немного технически, но то, что мы делаем, в терминах цепочки поставок, на самом деле очень просто. Мы изучаем аффинность между продуктами и клиентами.
Я знаю, что это может показаться совершенно непонятным, но оставайтесь со мной, и будет еще множество лекций, где я дам более вдумчивое введение в эту тему. Всё делается за пять строк, и это поистине замечательно. Когда я говорю “пять строк”, я не обманываю, заявляя: “Смотрите, это всего пять строк, но на самом деле я вызываю стороннюю библиотеку гигантской сложности, где скрываю весь интеллект.” Нет, нет, нет. Здесь, в этом примере, буквально нет никакой магии машинного обучения, кроме двух ключевых слов “autodiff” и “params”. “Autodiff” используется для определения блока, в котором происходит дифференцируемое программирование, и, кстати, это блок, в котором я могу программировать что угодно, так что буквально я могу внедрить нашу программу. Затем я использую “params” для объявления своих задач, и всё. Видите, никакой темной магии здесь нет; нет миллионы строк кода в библиотеке, выполняющей всю работу за вас. Всё, что вам нужно знать, буквально находится на этом экране, и вот в чем разница между парадигмой программирования и библиотекой. Парадигма программирования дает вам доступ к, казалось бы, невероятно сложным возможностям, таким как анализ каннибализации за несколько строк кода, без привлечения массивных сторонних библиотек, оборачивающих всю сложность. Это упрощает проблему, делая ее намного проще, так что вы можете решить то, что кажется супер сложным, всего за несколько строк.
Теперь несколько слов о том, как работает дифференцируемое программирование. Существует два принципа. Один из них — автоматическое дифференцирование. Для тех из вас, кто имел удовольствие получить инженерное образование, существуют два способа вычисления производных. Существует символьная производная, например, если у вас есть x в квадрате, вы берете производную по x, и получаете 2x. Это символьная производная. Затем есть численная производная, то есть если у вас есть функция f(x), которую нужно дифференцировать, то f’(x) ≈ (f(x + ε) - f(x))/ε. Это численное вычисление производной. Оба метода не подходят для того, что мы пытаемся сделать здесь. Символьное дифференцирование имеет проблемы со сложностью, поскольку ваша производная может оказаться программой гораздо более сложной, чем исходная программа. Численное дифференцирование численно нестабильно, поэтому у вас возникнет множество проблем с численной стабильностью.
Автоматическое дифференцирование — это фантастическая идея, возникшая в 70-х годах и заново открытая миром в последнее десятилетие. Это идея о том, что можно вычислить производную произвольной компьютерной программы, что поразительно. Еще более поразительно то, что программа, являющаяся производной, имеет ту же вычислительную сложность, что и исходная программа, что потрясающе. Дифференцируемое программирование — это просто сочетание автоматического дифференцирования и параметров, которым вы хотите обучиться.
Так как же происходит обучение? Когда у вас есть производная, это означает, что вы можете передавать градиенты назад, и с помощью стохастического градиентного спуска вы можете вносить небольшие корректировки в значения параметров. Настраивая эти параметры, вы постепенно, через множество итераций стохастического градиентного спуска, придете к значениям, которые имеют смысл и достигают того, чему вы хотите научиться или что оптимизировать.
Дифференцируемое программирование может использоваться для задач обучения, подобных той, которую я демонстрирую, где я хочу изучить аффинность между моими клиентами и моими продуктами. Оно также может использоваться для задач численной оптимизации, таких как оптимизация при наличии ограничений, и как парадигма оно весьма масштабируемо. Как видите, этот аспект стал первоклассным в Envision. Кстати, все еще есть несколько моментов, находящихся в разработке с точки зрения синтаксиса Envision, так что пока не ожидайте именно их; мы все еще уточняем некоторые аспекты. Но суть остается. Я не буду вдаваться в мелкие подробности тех аспектов, которые еще развиваются.

Теперь перейдем к другой проблеме, связанной с готовностью вашего производства. Обычно при оптимизации цепочек поставок вы сталкиваетесь с Heisenbug’ами. Что такое Heisenbug? Это разочаровывающий вид ошибки, когда оптимизация проводится, и получается мусорный результат. Например, у вас был пакетный расчет для пополнения запасов ночью, а утром вы обнаруживаете, что некоторые из этих результатов были абсурдными, что привело к дорогостоящим ошибкам. Вы не хотите, чтобы проблема повторялась, поэтому запускаете процесс заново. Однако при повторном запуске проблема исчезает. Вы не можете воспроизвести ошибку, и Heisenbug не проявляется.
Это может звучать как странный крайний случай, но в первые годы работы Lokad мы регулярно сталкивались с этими проблемами. Я видел, как многие инициативы в области цепочек поставок, особенно в сфере Data Science, проваливались из-за неустраненных Heisenbug’ов. Ошибки возникали в продакшене, пытались воспроизвести их локально, но не удавалось, поэтому проблемы так и не решались. Через пару месяцев в режиме паники весь проект обычно тихо закрывался, и люди возвращались к использованию Excel-таблиц.
Если вы хотите достичь полной воспроизводимости вашей логики, вам необходимо версионировать и код, и данные. Большинство из вас, кто является инженерами-программистами или специалистами по данным, возможно, знакомы с идеей версионирования кода. Однако вы также хотите версионировать все данные, чтобы при выполнении вашей программы точно знать, какая версия кода и данных используется. Возможно, вам не удастся воспроизвести проблему на следующий день, потому что данные изменились из-за новых транзакций или других факторов, так что условия, приводящие к возникновению ошибки изначально, больше не присутствуют.
Вы хотите быть уверены, что ваша программная среда может точно воспроизвести логику и данные такими, какие они были в продакшене в определенный момент времени. Это требует полного версионирования всего. Опять же, язык программирования и программный стек должны сотрудничать, чтобы это стало возможным. Это достижимо и без того, чтобы парадигма программирования была первоклассным элементом вашего стека, но тогда специалист по цепочке поставок должен быть чрезвычайно осторожен в своих действиях и способе программирования. Иначе он не сможет воспроизвести свои результаты. Это возлагает огромную нагрузку на плечи специалистов по цепочкам поставок, которые и так уже испытывают значительное давление со стороны самой цепочки поставок. Вы не хотите, чтобы этим профессионалам приходилось иметь дело со случайной сложностью, например, с невозможностью воспроизвести собственные результаты. В Lokad мы называем это “машиной времени”, где можно воспроизвести всё в любой точке прошлого.
Будьте осторожны, речь идет не только о воспроизведении того, что произошло прошлой ночью. Иногда вы обнаруживаете ошибку гораздо позже. Например, если вы размещаете заказ на покупку у поставщика с трехмесячным сроком поставки, вы можете через три месяца выяснить, что заказ был бессмысленным. Вам нужно вернуться на три месяца назад к тому моменту, когда вы сгенерировали этот фиктивный заказ, чтобы понять, в чем была проблема. Речь идет не только о версионировании последних нескольких часов работы; речь идет буквально о наличии полной истории за последний год работы.

Еще одна проблема — рост числа программ-вымогателей и кибератак на цепочки поставок. Эти атаки оказывают огромное разрушительное воздействие и могут стать очень дорогостоящими. При внедрении программных решений необходимо учитывать, не делаете ли вы свою компанию и цепочку поставок более уязвимыми для кибератак и рисков. С этой точки зрения, Excel и Python не являются идеальными. Эти компоненты программируемы, что означает, что они могут содержать многочисленные уязвимости в сфере безопасности.
Если у вас есть команда специалистов по данным или специалистов по цепочкам поставок, занимающихся вопросами оптимизации цепочек, они не могут позволить себе тщательный, пошаговый процесс проверки кода, характерный для индустрии программного обеспечения. Если тариф изменится за одну ночь или склад затопит, нужна быстрая реакция. Нельзя тратить недели на разработку спецификаций кода, его ревью и тому подобное. Проблема в том, что вы наделяете людей возможностями программирования, которые по своей природе могут случайно нанести вред компании. И ситуация может ухудшиться, если имеется преднамеренно вредоносный сотрудник, но даже если забыть об этом, проблема всё равно остаётся: кто-то может случайно раскрыть внутреннюю часть ИТ-систем. Помните, что системы оптимизации цепочек поставок по определению имеют доступ к огромному объёму данных по всей компании. Эти данные являются не только активом, но и обременением.
Вам нужна парадигма программирования, способствующая безопасному программированию. Вам нужен язык программирования, в котором отсутствуют целые классы операций, которые вы не сможете выполнить. Например, зачем нужен язык программирования, способный выполнять системные вызовы для целей оптимизации цепочек поставок? Python может выполнять системные вызовы, как и Excel. Но зачем вообще нужна программируемая система с такими возможностями? Это всё равно, что купить оружие, чтобы выстрелить себе в ногу.
Вам нужно решение, в котором отсутствуют целые классы или функции, так как они не нужны для оптимизации цепочек поставок. Если такие функции присутствуют, они становятся огромным риском. Если вы внедряете возможности программирования без инструментов, которые по своей природе обеспечивают безопасное программирование, вы увеличиваете риск кибератак и программ-вымогателей, что усугубляет ситуацию.
Конечно, всегда можно компенсировать это удвоением численности отдела кибербезопасности, но это очень дорого и далеко не оптимально в условиях неотложных поставок. Вам нужно действовать быстро и безопасно, без времени на обычные процессы, проверки и согласования. Вам также необходимо безопасное программирование, которое устраняет банальные проблемы, такие как исключения из-за обращения к null-ссылкам, ошибки нехватки памяти, ошибки в циклах типа off-by-one и побочные эффекты.

В заключение, инструменты имеют значение. Существует поговорка: “Не ходи на войну с мечом, если противник вооружён автоматом.” Вам нужны надлежащие инструменты и парадигмы программирования, а не те, которые вы изучали в университете. Вам нужно что-то профессиональное и промышленного уровня, чтобы удовлетворить потребности вашей цепочки поставок. Хотя с посредственными инструментами можно добиться некоторых результатов, это никогда не будет идеально. Фантастический музыкант может создать музыку, играя ложкой, но с правильным инструментом он способен на гораздо большее.

Теперь перейдём к вопросам. Обратите внимание, что задержка составляет около 20 секунд, поэтому между моментом, когда вы видите видео, и тем, когда я читаю ваши вопросы, существует небольшая латентность.
Вопрос: А как насчёт динамического программирования с точки зрения операционных исследований?
Динамическое программирование, несмотря на своё название, не является парадигмой программирования. Это скорее алгоритмическая техника. Суть в том, что если вы хотите выполнить алгоритмическую задачу или решить определённую проблему, вам придётся многократно повторять одни и те же подоперации. Динамическое программирование — это конкретный случай компромисса между временем и пространством, о котором я упоминал ранее, когда вы вкладываете немного больше в память, чтобы сэкономить время на вычислениях. Эта техника относится к числу самых ранних алгоритмических подходов, появившихся в 60-х и 70-х годах. Она хороша, но название несколько неудачно, ведь в ней нет ничего по-настоящему динамичного, и она вовсе не о программировании, а больше об осмыслении алгоритмов. Поэтому, на мой взгляд, несмотря на название, она не может считаться парадигмой программирования, а лишь специфическим алгоритмическим приёмом.
Вопрос: Йоханнес, не могли бы вы порекомендовать несколько справочных книг, которые должен иметь каждый хороший инженер по цепочке поставок? К сожалению, я новичок в этой области, а мой нынешний фокус — науке о данных и системной инженерии.
У меня сложное мнение относительно существующей литературы. На моей первой лекции я представил две книги, которые, по моему мнению, являются вершиной академических исследований в области цепочек поставок. Если хотите, можете прочитать именно эти две книги. Однако у меня постоянно возникают проблемы с книгами, которые я читал до сих пор. По сути, некоторые авторы представляют собой сборники игрушечных числовых рецептов для идеализированных цепочек поставок, и я считаю, что эти книги не рассматривают цепочку поставок с правильной точки зрения и полностью упускают из виду тот факт, что это действительно «злая» проблема. Существует обширная техническая литература с уравнениями, алгоритмами, теоремами и доказательствами, но, на мой взгляд, она совершенно не передаёт суть проблемы.
Затем существуют книги по управлению цепочками поставок другого стиля, более ориентированные на консалтинг. Эти книги легко узнать по тому, что каждые две страницы наполнены спортивными аналогиями. В них встречаются всевозможные упрощённые диаграммы, такие как 2x2 варианты SWOT-анализа (сильные стороны, слабости, возможности, угрозы), что я считаю низкокачественными способами рассуждения. Проблема этих книг в том, что они, как правило, лучше понимают, что управление цепочками поставок — это сложная задача, понимающая, что это игра, в которой участвуют люди и где могут происходить самые неожиданные вещи, требующие смекалки. За это я им и отдаю должное. Но с другой стороны, эти книги, как правило, написанные консультантами или профессорами школ менеджмента, не дают конкретных рекомендаций. Суть сводится к фразам “будь лучшим лидером”, “будь умнее”, “имей больше энергии”, что для меня не даёт практической пользы. Это не даёт вам элементов, которые можно превратить во что-то действительно ценное, как это способно сделать программное обеспечение.
Таким образом, я возвращаюсь к первой лекции: читайте те две книги, если хотите, но я не уверен, что это время будет потрачено с умом. Хорошо знать, что писали другие. Что касается консалтинговой литературы, мой любимый, пожалуй, труд Катаны, которого я не упоминал на первой лекции. Не всё так плохо; некоторые авторы обладают большим талантом, даже если их подход более консалтинговый. Вы можете ознакомиться с творчеством Катаны, у него есть книга о динамических цепочках поставок. Я укажу эту книгу в списке литературы.
Вопрос: Как вы используете параллелизацию при решении вопросов каннибализации или ассортимента, когда проблему не так просто распараллелить?
Почему это не так просто распараллелить? Стохастический градиентный спуск достаточно тривиально распараллеливается. Вы можете выполнять шаги стохастического градиентного спуска в случайном порядке, и их можно проводить одновременно. Поэтому, я считаю, что всё, что основано на стохастическом градиентном спуске, можно достаточно легко распараллелить.
При решении вопросов каннибализации сложнее справиться с другим видом параллелизации — с определением порядка действий. Если я запускаю этот продукт первым, затем делаю прогноз, а потом добавляю другой продукт, это меняет общую картину. Решение заключается в том, чтобы решать всю задачу одновременно, целиком. Вы не говорите: “Сначала запускаю этот продукт, делаю прогноз, потом запускаю другой и пересчитываю прогноз, корректируя первый.” Вы делаете всё сразу, одновременно. Для этого вам нужны другие парадигмы программирования. Парадигмы программирования, о которых я сегодня говорил, могут в этом помочь.
Что касается вопросов ассортимента, подобные проблемы не представляют серьёзных трудностей для параллелизации. То же самое применимо, если у вас есть международная сеть розничной торговли и вы хотите оптимизировать ассортимент для всех магазинов. Вы можете выполнять расчёты для всех магазинов параллельно. Вы не хотите делать это последовательно, оптимизируя ассортимент одного магазина за другим. Это неверный подход, но вы можете оптимизировать всю сеть параллельно, распространяя всю информацию и затем повторяя процесс. Существует множество техник, и инструменты могут значительно облегчить это.
Вопрос: Используете ли вы подход с графовыми базами данных?
Нет, не в техническом, каноническом смысле. На рынке существует множество графовых баз данных, представляющих большой интерес. Внутри Lokad мы используем полную вертикальную интеграцию с помощью единого монолитного компиляторского стека, чтобы полностью устранить все традиционные элементы, которые можно было бы найти в классическом стеке. Именно так мы достигаем очень высокой вычислительной производительности, практически работая максимально близко к “железу”. Не потому, что мы исключительно умные программисты, а потому что мы устранили практически все традиционные уровни. Lokad буквально не использует базу данных. У нас есть компилятор, который заботится обо всём — вплоть до организации структур данных для постоянного хранения. Это немного странно, но гораздо эффективнее, и таким образом вы лучше учитываете тот факт, что компилируете скрипт для группы машин в облаке. Ваша целевая платформа по аппаратным средствам — это не одна машина, а целый кластер.
Вопрос: Каково ваше мнение о Power BI, который также выполняет коды на Python и связанные с этим алгоритмы, такие как градиентный спуск, жадный алгоритм и т.д.?
Проблема, которую я вижу во всём, что связано с бизнес-аналитикой — в числе которых и Power BI — заключается в том, что у него присутствует парадигма, которую я считаю неадекватной для цепочек поставок. Вы смотрите на все проблемы как на гиперкуб, где есть измерения, которые вы лишь разбиваете на части. По сути, проблема заключается в ограниченной выразительности. Когда вы начинаете использовать Power BI с Python посредине, вам нужен Python, поскольку выразительность, связанная с гиперкубом, очень слаба. Чтобы вернуть выразительность, вы добавляете Python как промежуточный слой. Однако помните, что я говорил в предыдущем вопросе о слоях: проклятие современной enterprise software заключается в том, что добавление каждого нового слоя приводит к неэффективности и ошибкам. Если вы используете Power BI с Python, у вас окажется слишком много уровней. Таким образом, Power BI располагается поверх других систем, то есть до него уже существует несколько уровней систем. Затем сверху идёт сам Power BI, а поверх него — Python. Но действует ли Python самостоятельно? Скорее всего, вы будете использовать библиотеки Python, такие как Pandas или NumPy. В итоге слои в Python накапливаются, и их может оказаться десятки. В любом из этих слоёв могут быть баги, поэтому ситуация обещает быть настоящим кошмаром.
Я не верю в решения, где в итоге оказывается огромное количество слоёв. Существует шутка, что в C++ любую проблему можно решить, добавив ещё один уровень косвенности, включая проблему чрезмерного числа уровней. Конечно, это несколько абсурдное утверждение, но я решительно не согласен с подходом, при котором у продукта неадекватное базовое проектирование, и вместо того чтобы решать проблему напрямую, люди накидывают дополнительные слои на нестабильный фундамент. Это не путь к успеху, и вы столкнётесь с низкой продуктивностью, постоянными проблемами с багами, которые никогда не удастся устранить, а с точки зрения поддерживаемости — это просто рецепт кошмара.
Вопрос: Как результаты анализа коллаборативной фильтрации можно интегрировать в алгоритм прогнозирования спроса для каждого продукта, например, рюкзаков?
Прошу прощения, но я затрону эту тему на следующей лекции. Краткий ответ таков: не стоит встраивать это в существующий алгоритм прогнозирования. Вам нужно нечто, что будет гораздо более нативно интегрировано. Вы не делаете это, а затем не возвращаетесь к старым методам прогнозирования; вместо этого вы полностью отказываетесь от традиционного подхода и создаёте нечто радикально иное, что использует эти данные. Но я обсудю это на следующих лекциях. На сегодня этого достаточно.
Полагаю, на сегодня лекция подошла к концу. Большое спасибо всем за участие. Следующая лекция состоится в среду, 6 января, в то же время и в тот же день недели. Я планирую взять рождественские каникулы, поэтому желаю всем счастливого Рождества и Нового года. Мы продолжим серию лекций в следующем году. Большое спасибо.


