00:00 Introduction
02:01 Solving the Byzantine consensus
09:35 Hard requirements of a free blockchain
20:31 The story so far
22:44 Getting rich quick today
24:03 Mini Bitcoin 1/3 - Hashing and Signing
29:23 Mini Bitcoin 2/3 - Transactions
34:44 Mini Bitcoin 3/3 - Blocks and Proof of Work
44:47 Scaling the blockchain 1/2 - Applicative landscape
49:07 Scaling the blockchain 2/2 - Bigger blocks
57:11 Speeding the blockchain 1/2
59:30 Speeding the blockchain 2/2
01:06:54 Empowering the blockchain
01:14:51 Use case: payments
01:19:25 Use case: passive traceability
01:25:33 Use case: active traceability
01:32:47 Use case: incentivized recycling
01:35:40 Use case: incentivized security
01:41:30 Softening the requirements
01:44:53 Conclusion
01:49:35 4.21 Blockchains for supply chain - Questions?
Description
Cryptocurrencies have attracted a lot of attention. Fortunes were made. Fortunes were lost. Pyramid schemes were rampant. From a corporate perspective, the “blockchain” is the polite euphemism used to introduce similar ideas and technologies while establishing a distanciation with those cryptocurrencies. Supply chain use cases exist for the blockchain but challenges abound as well.
Full transcript

Welcome to this series of supply chain lectures. I’m Joannes Vermorel, and today I will be presenting “Blockchains for Supply Chain.” Cryptocurrencies captured the public imagination, fortunes were made and lost, some villains have been caught and jailed, and more will follow. Amidst all this agitation, the term cryptocurrency became a bit too loaded for average large companies that tend to be quite conservative. Thus, the term blockchain was adopted as a way to distance the innovation from all the craziness happening in the crypto world. However, fundamentally, blockchains and cryptocurrencies are one and the same thing.
The goal of this lecture is to gain a technical understanding, in-depth technical understanding, of what is going on with blockchains. If you happen to have some programming skills, by the end of this lecture, you should be able to re-implement your own toy blockchain if you wish to. Based on this newfound technical understanding of the blockchain, we will start reviewing supply chain use cases and assess their viability as technologies to solve problems and their added value in terms of what they can do for supply chains. Let’s get started.

The origin of Bitcoin is just weird. In 2008, under a pseudonym, Satoshi Nakamoto, which is probably a team effort, a white paper was published called “Bitcoin: A Peer-to-Peer Electronic Cash System.” This paper presents a system and approach for a new kind of electronic currency. It’s a relatively short paper with a few mathematical parts, and even the mathematical parts are partly incorrect.
The original paper states that the system is supposed to be safe if at least half of the hash power is on the good side. However, it was later demonstrated in a subsequent paper published in 2013, “Majority is Not Enough: Bitcoin Mining is Vulnerable,” that to keep the network secure, you don’t need half of the hash power to be honest; you need actually two-thirds plus of the hash power.
Nevertheless, there is a white paper and a piece of software. The software is open source, and it’s a very low-quality implementation. The Satoshi client is of very low quality, and during the first year after the publication of the software, open source contributors were hastily fixing tons of bugs and issues. Some of these issues were hard to fix due to the original design and had a lasting effect on the whole community. Many of the cryptocurrencies that exist today are forks of the original Satoshi client and, to some extent, still carry many of the problems that could not have been fixed over the years.
Thus, this is a very puzzling situation where you have a paper that is not of the greatest quality and a piece of software which is arguably very low quality, and yet the Satoshi Nakamoto team had done a stunning discovery. Fundamentally, the problem was known as the Byzantine consensus problem. It’s a problem of distributed computing. Imagine you have participants, and all those participants can see what is supposed to be the state of the system, which in the digital world can be thought of as a long series of zeros and ones, a data payload. Participants can update the state of the system, flip some bits, add a bit, remove a bit, and they can do all of that at the same time. Participants can communicate with each other, and the problem of the Byzantine consensus is to have all the honest participants agreeing at a specific point in time on what the state of the system is, down to the last bit.
The problem is very difficult if you have Byzantine participants who are acting as adversaries, trying to confuse all the other participants. The stunning discovery of Bitcoin is that if we go back to 2008 and ask experts, they would likely have said that it doesn’t seem possible to solve the Byzantine consensus problem in a fully decentralized manner without a central authority. However, Satoshi Nakamoto’s discovery, the Nakamoto consensus, is that they figured out a way to solve this problem.
The solution is very surprising. It seems like an algorithmic problem, but the essence of the solution behind Bitcoin is that Satoshi Nakamoto solved this problem by adding monetary incentives, a financial incentive. It’s not just an algorithmic solution; it is literally an algorithm that only works because, inside the system, monetary incentives are entangled, giving participants incentives to act in a certain way.
If we want to have those incentives in place, we need an electronic currency of a kind, so we can engineer those incentives in the first place. That’s exactly what is being done in Bitcoin. If you want to have an electronic currency, you have at least two very difficult problems. The first problem is double spending. If you have a certain amount of digital money represented by some bits of information, what prevents you from making a copy of this digital money and spending the money once to pay for something and then re-spending the same money with your copy to pay for something else? This problem is known as double spending, and it’s one very difficult problem addressed by Bitcoin.
The second problem is coin emission. Where does this money come from? The interesting thing is that typically, when you have a very difficult problem that you want to approach, you adopt a divide-and-conquer approach, subdividing your big problem into sub-problems that are simpler and can be solved separately. Then, the total problem can be solved. The interesting thing with Bitcoin is that there are two distinct and very difficult problems: double spending and coin emission. Instead of using a divide-and-conquer approach, Bitcoin employs a unify-and-entangle approach, which was novel at the time, to solve both problems simultaneously. The solution, as we will see later in this lecture, is surprisingly simple.

This lecture is not primarily about what makes a digital currency a good currency, as that would deserve a talk of its own. Nevertheless, blockchains do not operate without the financial incentives engineered via the digital currencies that support the blockchain itself. When we say cryptocurrency and blockchains are very much the same, the idea is that if you want to have a blockchain, you will broadcast messages, and those messages will be transactions with a flow of money involved. The cryptocurrency perspective is that the primary focus is on the monetary aspect, while the blockchain perspective is more interested in the metadata that is overlaid on top of the transactions.
Remember that the whole security model of these blockchain/cryptocurrency systems relies on the economic incentives engineered on top of the system. You cannot completely separate the economic and the cryptocurrency goals from the blockchain. It’s just a matter of perspective.
Now, let’s have a quick look at the requirements that come with a blockchain/cryptocurrency system, and how we can potentially relax those requirements. The first one is non-deniability. Non-deniability means that as a participant, nobody can prevent you from broadcasting a transaction. Nobody can prevent a valid transaction from happening. This is very important, as if there is a participant capable of doing that, then essentially you have a central authority. Conversely, no participant can prevent a valid transaction from happening, but also there is no participant that can deny you the possibility to conduct a transaction because they can consume your own coin or make an invalid transaction succeed. That’s the first requirement.
The second requirement is anonymity. Technically, Bitcoin is a pseudo-anonymous network, but fundamentally, when I say the anonymous requirement, it means that there is no list of participants. In a true blockchain, participants may appear or leave the system at any point in time, with no gatekeeper. As participants may join or exit freely, there is nobody tracking their identity. It doesn’t mean that it has to be anonymous; it just means that if you have a true canonical blockchain, the anonymity requirement, where participants can join and leave as they wish, needs to be met.
Then, I’m listing mass scalability as a requirement, which is particularly hard for blockchains because, as we will see, these types of distributed systems are not intrinsically easy to scale. On the contrary, scaling a blockchain is remarkably difficult. Fundamentally, there is a conflict: if you let any participant broadcast an arbitrary large number of messages, transactions, or updates to the system, one participant can flood the entire network and essentially spam the entire network. Thus, all blockchains have to deal with this scalability problem, which is solved by engineering financial incentives.
The idea is to keep the cost of a transaction, which is the elementary message broadcasted on the blockchain, at something like a tenth of a cent. This is very cheap – imagine that you had to pay one-tenth of a cent to send an email. It’s not free, but it is still very low cost. So, if you have regular usage and you want to have a transaction associated with, for example, the movement of a product in a warehouse, it’s okay; the cost is still very low. However, by having the cost at 0.1 cent, you make those transactions too expensive for an attacker who would like to flood the network with billions of transactions, which are very easy to do if you don’t have fees. Each transaction has to pay a fee for its existence and to support its broadcast; otherwise, an attacker could flood the distributed system with no obstacles.
So, the transaction fees are another angle in terms of economic engineering to keep the blockchain viable. You want to be able to maintain this 0.1 cent fee at any scale because another problem of denying mass scalability is that if we have millions of transactions, the cost of transactions will skyrocket. This is a big problem we do not want. We don’t want to have a situation where we have a bus with 100 people who want to take it at a certain time, but there are only 50 seats. If this happens, then there will be some kind of auction mechanism taking place, and the price for the tickets is going to skyrocket. In blockchain terms, this means that the cost for transactions will skyrocket. By the way, these sorts of problems are happening with multiple blockchains at the present time. For example, on the Bitcoin Core network, it is very frequent that the cost of a transaction exceeds ten dollars, and this is a very big problem.
Now, we also want to have fairly low latency. What Satoshi Nakamoto uncovered in 2008, the Nakamoto consensus, works very nicely, but fundamentally, it’s a very slow process. When I say very slow, it means that for participants to converge on the state of the system, it takes roughly one hour. It’s not dramatically slow, but it’s not very fast either. If we want to do anything supply chain-related, where we want to make payments or trace the movement of goods, it would be much nicer if we can keep the latency of the system at something like three seconds and below – the same sort of latencies you would expect from a fast credit card payment.
Finally, one of the last requirements is the infrastructure. When I say the software infrastructure that supports the blockchain or cryptocurrency, it must be a public good that is funded with some kind of agreed social contract. That’s something I believe Satoshi Nakamoto did not foresee in 2008. If you want to operate a very complex worldwide distributed system, there is a ton of software infrastructure to be put in place and maintained. The problem is that if you don’t have some kind of socially accepted way to fund all those efforts, adversaries emerge, not just as Byzantine adversaries in the network that try to confuse other participants about the state of the network, but they also emerge as adversaries who will take over the codebase itself and do things with the software infrastructure that antagonize the interests of the broader community. It has happened in the history of cryptocurrencies to have hostile takeovers from one team to another, with the new teams having interests that are completely misaligned with the interests of the broader community. This is a class of attacks, more of a social engineering kind, that were not clearly seen by Satoshi Nakamoto back in 2008. However, after a decade of operation, these types of attacks are now much clearer to observers of the crypto world.
Now, the story so far: this is a series of lectures on supply chain. We are part of the fourth chapter. In the first chapter, I presented my views on supply chain as a field of study and as a practice, and we have seen that it requires very specific methodologies. The entire second chapter is devoted to supply chain methodologies that are suitable to operate in this space. Most naive methodologies do not survive the contact with reality, especially when there are conflicts of interest in place. By the way, many of the aspects in the second chapter, where I deal with conflicts of interest, are very much relevant for the lecture of today, so I invite the audience, if you have not already seen the lectures from the second chapter, to have a look at that. The third chapter is devoted to supply chain problems, which is literally lectures where I focus exclusively on supply chain problems, not solutions. The idea is to really understand the problem before starting to conjure solutions.
The fourth chapter is essentially a collection of auxiliary sciences. Blockchain is a fringe topic that I’m adding at the end of this chapter, but fundamentally, auxiliary sciences are disciplines that really support modern supply chain practices. Just as you would expect a modern physician to have some knowledge about chemistry, you don’t have to be a brilliant chemist to be a brilliant physician. The general agreement would be that, from a modern perspective on medical science, if you know nothing about chemistry, you can’t possibly be a good physician by modern standards. The same is true for supply chain, in my perspective. There is a series of auxiliary sciences where you need to have some background on those subjects if you want to have a reasonably modern supply chain practice.

Now, for the present lecture, I will be presenting first Mini Bitcoin, which is a toy blockchain implementation. It should shed light on how cryptocurrencies work and what the key insight discovered by Satoshi Nakamoto was back in 2008. It should also clarify the three very big challenges that we face when designing blockchains, which are namely scalability, latency, and expressiveness. These three challenges have a significant impact on the sort of supply chain use cases that we can have based on blockchain. It’s essential to understand the limitations that come with blockchains because they essentially limit what we can do supply chain-wise and the sort of value that we can create. Finally, as a second part of the lecture, I will review a series of supply chain use cases where, to varying degrees, supply chain has something to add to the table.

The goal of Mini Bitcoin is to build a toy blockchain, a simplistic version of Bitcoin from scratch. We won’t be paying too much attention to all the technicalities involved because, in real life, engineering a blockchain is very much a work of paying attention to tons of details. Here, I just want to lay out the overall structure to keep it dramatically simplified compared to the real thing so that we can grasp in a few slides what is going on, how it’s being engineered, and how it works.
In this very simple example, we are going to engineer a currency where every single coin is worth exactly one bitcoin. You have a set of coins, each coin is worth exactly one bitcoin, and the only thing that you can do is essentially transfer one coin from one participant. If a participant possesses many coins, they can transfer all the coins, but we are only looking at a very simple currency where we don’t have fractional quantities and other elements.
In order to build this Mini Bitcoin, we only need three special functions: a hash function, a signature function, and a verification function. These functions were already standard back in 2008, so when Bitcoin was invented, all the cryptographic building blocks were already in place. Satoshi Nakamoto did not invent any of these tools. These special cryptographic functions, also known as trapdoor functions, were well-known, standard, and widely used back in 2008. The key innovation by Satoshi Nakamoto was to use these functions in a very special way, which we will see.
We have these three functions: the hashing function, which I won’t go into detail about here, but I have discussed in a previous lecture. This is a cryptographic version of the hashing function, which can take any message, a series of bits of arbitrary length, and create a digest of 256 bits. The function cannot be, in practice, inverted. If you have a digest, the only way to identify a message that produces the digest is to know the message beforehand.
The signature function can take a message, a private key, and produce a signature, which is again 256 bits. The signature function works in pair with a verification function. For those who might not be familiar with asymmetric cryptography, the idea is that you can have mechanisms where you have pairs of public and private keys. With the private key, you can produce a signature and publish a message without disclosing your private key. Any participant can use the verification function to take the message, your signature, and your public key to verify that the message has been signed by the private key associated with this public key.
These trapdoor functions cannot be inverted, so if you don’t know the original message, you cannot go back from the hash function, from the digest to the original message. The same thing applies if you don’t have the private key; you can’t produce a signature on your own if you have a new message.
These three special functions are readily available in essentially all modern programming environments, whether it’s C++, Python, Java, C#, or others. It is part of the standard environment to have access to these classes of cryptographic functions.

Now, let’s look at a situation where I am supposed to be the owner of coin number one. What does that mean? It means that as part of this Byzantine consensus, there is a shared agreement among all the participants for this mini Bitcoin network that, as part of the UTXO (Unspent Transaction Outputs), this coin is actually present. When I say this coin, I mean a message that includes public key number one and signature zero. I just assume that this is part of a set of coins and all the participants agree that this coin actually exists and is ready to be spent. Now, as the owner of this coin number one, how do I actually spend this coin to transfer the ownership of this coin to somebody else?
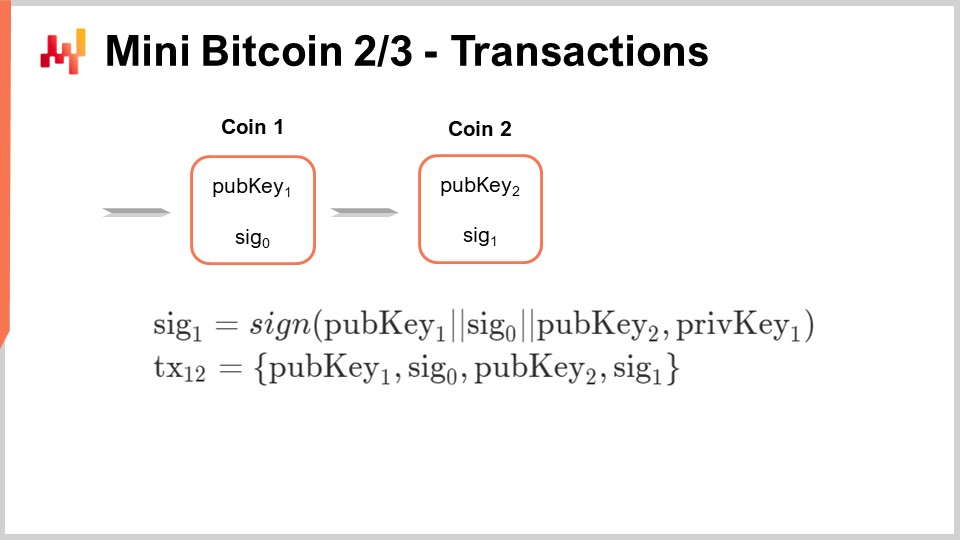
The way I do that is by producing a signature. The signature is constructed as follows: I’m using the special “sign” function and I’m going to sign a message. This message is just going to be public key number one, signature zero, and then public key number two. The public key number two is literally the address to which I’m sending the money. Whoever owns the private key associated with this public key number two is going to be the recipient of my transaction. So, I sign this transaction, and in order to sign it, I am using private key number one. The only participant who can actually produce this signature number one is the person who has the secret, the private key number one, associated with public key number one.
If I want to let the entire network know that this transaction has been made, I need to broadcast a transaction. The transaction is just going to be a message that lists public key number one, signature zero, public key number two, and signature one that I’ve just produced. It’s just a list of the elements that contribute to the transaction. When I publish this transaction from one to two, essentially, coin number one is exiting the pool of coins, and coin number two enters the pool of coins as part of the system. That’s why it’s crucial to have this Byzantine consensus at play. We need this Byzantine consensus because, potentially, you would like to be able to spend money that you don’t own and confuse the network about the ownership of some coins. However, if you can solve the Byzantine consensus problem, there is a firm agreement on the coins that actually belong to the system. Once a coin is spent, the owner number two now has a coin. A coin can exit the network, and a new coin gets created and enters the state of the system.

The mechanism can be repeated; coin number two can be sent to coin number three using the same system: produce a signature, broadcast a transaction, and so on.
By the way, whenever I said that the “sign” function is being used, implicitly, it means that all the observers can use the “verify” function to verify that the signature is correct. Fundamentally, when the participants are going to observe the transactions, the first thing they will do is use the “verify” function that I introduced previously to check that the transaction is indeed correct. There are two checks involved: each participant has to verify that the coin being transferred was already part of the state of the system, ensuring it is a valid coin, and that the transaction is valid according to the signature. What I have not addressed here is the double-spend problem. How do we prevent two conflicting transactions from being made at the same time, and how do we prevent the network from being confused if an adversary tries to broadcast two conflicting transactions simultaneously, sending the same money to two distinct participants?
I also have not clarified where these coins come from. How are they introduced into the system in the first place? The crux of the discovery of Satoshi Nakamoto and his Nakamoto Consensus is solving these two problems at once.

Satoshi Nakamoto’s proposition is to introduce a special class of participants into the network, nowadays nicknamed “miners.”
Miners essentially listen to the network and collect all the transactions that have been broadcast. They collect these broadcast transactions and put them into a container called a “block.” A block is just a collection of transactions broadcast by anybody in the peer-to-peer network.
The very first transaction of a block is going to be a special transaction called a “coinbase.” A coinbase is a unique transaction that creates one new coin in this mini Bitcoin setup out of thin air. The first transaction is the coinbase, creating one new coin out of thin air, and then in the block follows the list of transactions that have been broadcast, as perceived by the miner. The miner may not be able to capture all the transactions of the Bitcoin network, but they try to do so.
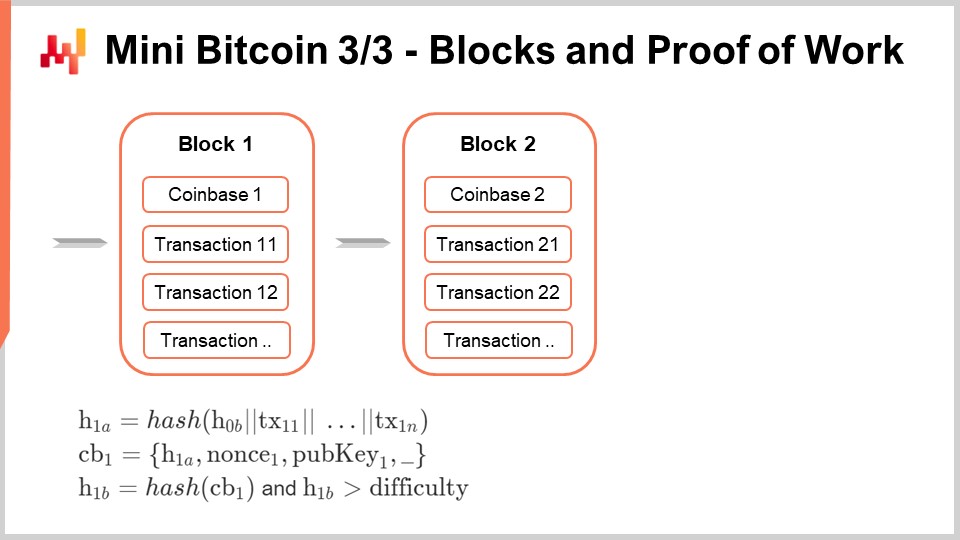
The coinbase is special, and I will explain how to build this coinbase because it is a unique transaction. First, we are going to produce a hash of the block, a partial hash (H1a). This hash is essentially a hash of a message, and this message starts with a hash of the previous block (H0b), concatenated with all the transactions present in the block.
The coinbase is then a tuple that includes the hash H1a, followed by a nonce. A nonce is a random number chosen randomly by the miner and has its importance. The coinbase also contains the public key of the miner. The coinbase includes a hash of all the content of the block. The coinbase contains a random number and the public key of the miner. This public key will be used by the miner later on to claim the coinbase as a regular coin. In this mini Bitcoin setup, coins are emitted at a rate of one Bitcoin per block. In reality, on the Bitcoin Core network or Bitcoin Cash, the process is more complicated, but most of the complexity can be simplified for the sake of clarity.
The idea is that for the block to be considered valid, we need to produce a coinbase. However, if we stop at this point, all miners could claim that they have a block whenever they want, and all miners would have an interest in saying, “I can produce a package, a digest of all those transactions. I can produce a coinbase. Please give me this extra Bitcoin.” How do we sort out all miners competing to have their version of the block selected by the network and considered the one true block?
Satoshi Nakamoto introduced the concept of proof of work. The hash of the coinbase, which is a large 256-bit number, has to be above a difficulty threshold. This process is like solving a puzzle, and the only way to solve this puzzle is to figure out a coinbase that has a hash meeting this difficulty target. The miner can try many random numbers for the nonce in hopes of being the first to reach the difficulty and claim the block for themselves.
In Bitcoin, the difficulty is adaptive, and the network uses a glorified moving average algorithm to keep the difficulty around 10 minutes per block. If blocks are found on average at a pace faster than 10 minutes, the difficulty will rise until blocks are found every 10 minutes on average. If blocks start being found every 11 minutes, the difficulty will drop to maintain the average time to find a block at 10 minutes.
Satoshi Nakamoto’s proposal is that miners always follow the longest valid chain. A chain of blocks must meet the difficulty target to be valid. When constructing a block, you always build it on top of a pre-existing block, except for the genesis block, which is the default starting point. The rule is not just about having the longest chain, but the longest valid chain. Other miners will check that all the transactions listed in a block are indeed valid, ensuring that the signatures are matching and the coins being spent are eligible to be spent. They maintain this state, and that’s exactly how Bitcoin can solve both the double-spend problem and the coin emission problem. We have everything needed to build a blockchain.
In reality, if you want to build a real production-grade blockchain, there are tons of extra things to consider. First, you would like to have fractional quantities. You probably don’t want to be able to have just one Bitcoin at a time; you want something where you can transfer multiple or fractional quantities of Bitcoins.
In terms of coins, you would like to have transactions that can consume many coins as inputs at once and then produce many coins at once. It’s not going to be one-to-one transactions that connect one coin to one coin; it’s going to be many-to-many transactions, with many input coins connecting to many output coins. By the way, this is how various Bitcoin networks operate nowadays.
You also have the transaction fees that I mentioned. If you let people broadcast transactions endlessly, they could send money back and forth between the same addresses and flood the market. The idea is that a fee is fundamentally the notion that a certain portion of the transaction is redirected to the miner. The way it’s typically done in most Bitcoin variants is to say that the total input should be, in terms of monetary value, slightly greater than the total output. The missing fraction of value, the gap, is the reward paid to the miner.
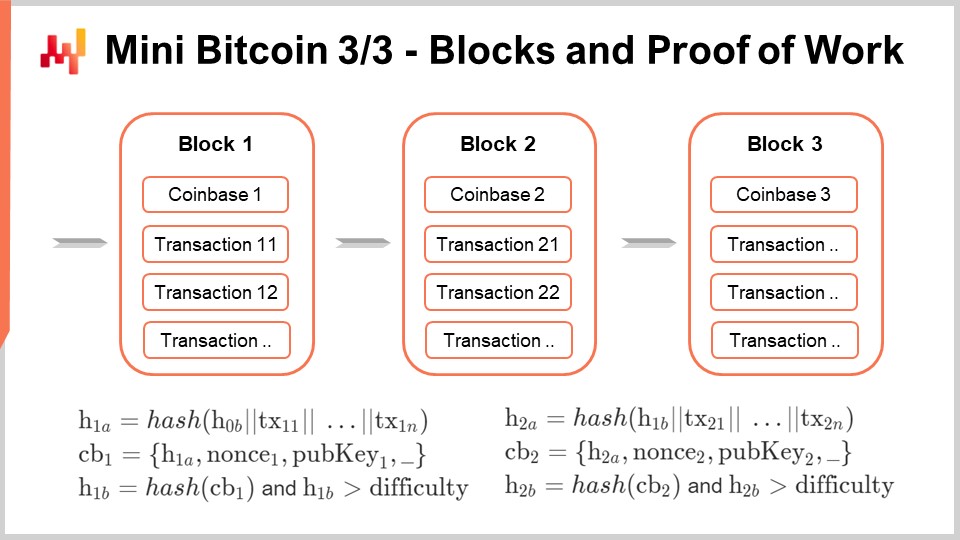
Now we have completed our mini Bitcoin. If you know how to program, you have all the elements you need to implement your own blockchain. By the way, you can also repeat blocks, and that’s what I’m doing here. What you’ve just done for one block, you can repeat the exact same formulas for another block, with a second codebase. This is just like transactions; the same mechanism is repeated over and over.
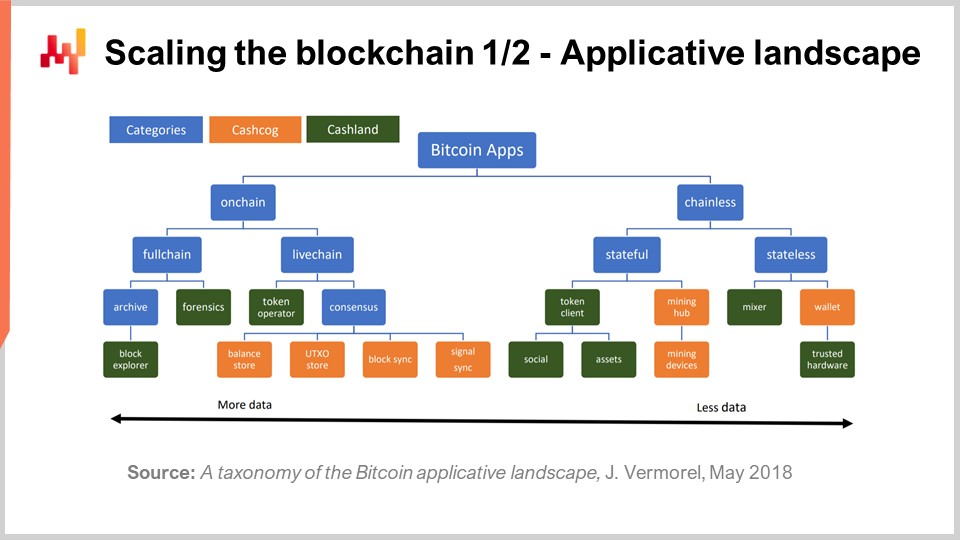
Scaling the blockchain is very challenging. In a short white paper from 2018, I published an applicative landscape of Bitcoin. The idea is that, depending on the amount of data your blockchains are involved in, the amount of data that you have to process and move around varies greatly depending on what you’re doing with the blockchain. Essentially, it ranges from roughly 100 bytes to move around (the order of magnitude of a private key) up to 10 orders of magnitude if you have to deal with the entire blockchain.
It’s hard to wrap your head around the fact that, depending on what you’re doing, the amount of computing resources you will have to inject to get the job done varies by 10 orders of magnitude. One order of magnitude means that you multiply the amount of resources by a factor of 10, and when you have 10 orders of magnitude, you can go from one to 10 billion. This is staggering and enormous. In this applicative landscape, you will see that there are two main distinctions: on-chain and off-chain applications. Off-chain apps are those that deal only with the data generated by you or your close partners. If you are a large company, you may have to deal with millions of transactions, but these are only your own transactions. In terms of data, it can be large, but it is manageable since it directly relates to your own business.
On the other hand, on-chain apps deal with all transactions broadcasted over the network. This can be vastly larger, especially if you are a small player and need to handle all transactions on a large network, which can be millions of times more than the transactions you care about.
Additionally, we need to distinguish between components that are “cash cogs” and “cash lands.” Cash cogs are fundamental components that contribute to the resolution of the consensus problem. If you remove them, the blockchain stops working because you no longer have consensus. Cash lands, on the other hand, are optional components that can be built on top of the blockchain infrastructure. These are not strictly required for the blockchain to operate.
Typically, when we think about supply chain use cases, we position ourselves with metadata in the cash lands realm. What we are doing is not strictly required for the blockchain to continue operating; it can keep functioning without our specific use case.
In terms of scaling the blockchain for real supply chain use cases, you have to consider that the blockchain should be able to handle millions of transactions. Large companies deal with millions of weekly transactions, which is not exceptional in the supply chain world. However, blockchains are poorly scalable, as evidenced by the fact that miners have to deal with all transactions from everybody.
To address this issue, some innovations have been introduced, such as the solutions discussed earlier in the lecture. The main goal is to make blockchain technology more scalable and suitable for handling the massive transaction volume typically seen in supply chain applications. If you want a blockchain to be used for supply chain purposes, it must be able to handle not just the transactions of a single company but also all the companies participating in the blockchain initiative. That can become exceedingly large, or actually very large, maybe exceedingly so. That’s what we have to see, and here, to the rescue, there has been essentially two notable papers. When Satoshi Nakamoto published his paper, he said that with the progress of hardware, this problem would be solved, and we would scale as much as it takes. This would happen. However, it turned out to be difficult, and for more than a decade now, pretty much all the players in this blockchain and cryptocurrency space have been struggling when it comes to scalability.
The first notable paper is ECMH, Elliptic Curve Multiset Hash. It’s a fairly technical paper, but the key takeaway is the idea that you do not have to keep all the transactions around; you only have to keep the coins that are ready to spend. This collection of coins that can be spent is technically known in the Bitcoin ecosystem as the UTXO. Just as an order of magnitude, the UTXO of the Bitcoin Core network is currently slightly below five gigabytes. This is the size of the UTXO dataset, but if you look at the blockchain of Bitcoin Core, the blockchain size is slightly below 350 gigabytes, and the blockchain is growing much faster than the UTXO.
What the ECMH paper gives you is a hash function that has an affinity to multisets. Essentially, it’s a hash function where you can update your hash if you add or remove elements to your collection. You don’t preserve the set or the multiset itself, but you just preserve the hash, and you can add or remove elements. This set-like property means you can do those additions or deletions in any order and still get to the same hash. What you can get through ECMH is a way to have a UTXO commitment, which allows the community to move away from the full blockchain. Most of the community does not have to deal with the full blockchain but can only deal with UTXO. I repeat, the Bitcoin Core network’s size of the UTXO is five gigabytes, and the size of the blockchain is 350 gigabytes, so you are basically gaining two orders of magnitude. This is very significant. Essentially, with ECMH, you gain two orders of magnitude on persistent data storage, which is a massive win.
The second paper is Graphene, a new protocol for block propagation using set reconciliation. Graphene lets you gain essentially two orders of magnitude on peak bandwidth requirements. In this mini Bitcoin setup that I just described, you have miners and transactions broadcasted peer-to-peer style all the time for the network. Bandwidth is probably the most solved problem of Bitcoin, but nonetheless, you have a problem when it comes to bandwidth at the moment when a block is found. The miner, in order to claim the block, has to propagate the coinbase, where he says, “Look, I have a coinbase that meets my difficulty target.” Then, all the other miners have to download the entire block, and if it’s done naively, they have to validate that the block is indeed valid, not just that the coinbase meets the difficulty target.
Every time a block is found, there is a peak requirement because you want to keep the amount of time it takes to transfer an entire block, if you’re doing it naively, well below the 10-minute interval. In Bitcoin, the puzzle is tuned in terms of difficulty in such a way that the average time between two consecutive blocks is on average at 10 minutes. Thus, you want the block transfer to be only a fraction, let’s say less than 30 seconds, if you want to keep the network very stable. However, that means that the block has to be transferred within 30 seconds, which puts a limit on your peak bandwidth. The speed at which you’re going to transfer your block is going to be limited by your bandwidth.
The idea is that with Graphene, a technique based on compression, you will not need to transfer the entire block because most of what the block contains are actually the transactions that have already been broadcast through the network. The only thing that you want to broadcast is a reconciliation set, just to give information to your peers (other miners) about which transactions have been included or not in your block, in a way that is perfectly reliable. If you do that, you can shave again two orders of magnitude on the peak bandwidth, which is very significant.
This is of great interest, for example, Graphene would work on Bitcoin Cash networks or the more recent eCash networks, due to complete technical accidents. It would not work on the Bitcoin Core network. This was part of the things that were not really anticipated by Satoshi Nakamoto.
The last requirement that I mentioned in my list of requirements is that maintaining the software means that you need to have a social contract in place, so that you have teams that can do the maintenance and embed later discoveries into your blockchain. Otherwise, you remain stuck with the sort of performance and stability that you had a decade ago or at the time of inception of the blockchain.
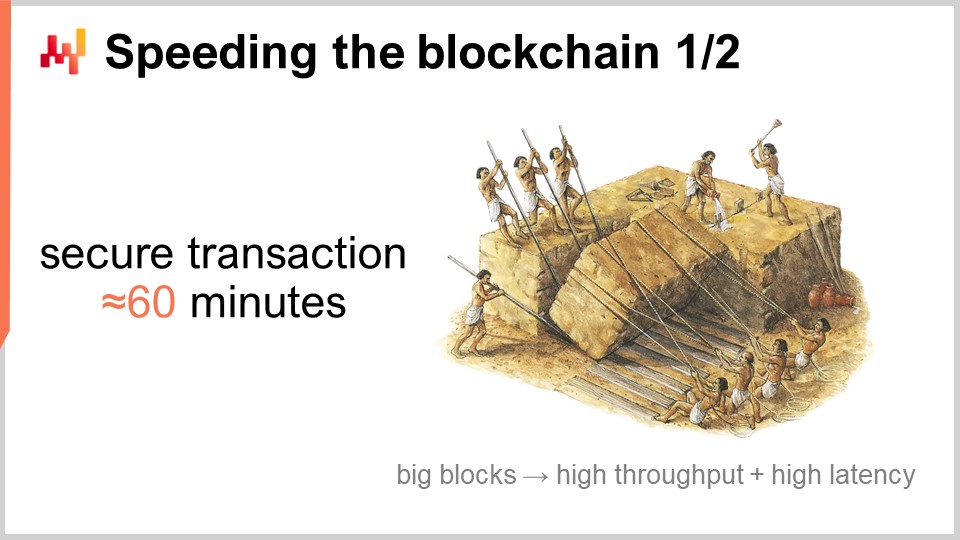
Now we have another problem: speeding up the blockchain. The classic Bitcoin network has an average time between blocks of 10 minutes, and if you want to have true confidence in the state of the consensus, you need to wait for multiple blocks. As a rule of thumb, people usually estimate that if you want to have absolute confidence, you need to wait for six confirmations, which gives you a time frame of one hour. The idea is that we could make this time between blocks shorter. However, the problem is that the smaller the amount of time, the smaller the blocks have to be, which undermines scalability. Infrequent blocks mean that you can have very large blocks, which is a good thing; it helps your network cope with the mass of transactions.
Considering the delays that you have on the global network, this 10-minute target is not optimal, but it is within the ballpark of what is efficient to operate this sort of distributed consensus with very large blocks, blocks that can be up to one terabyte in size. That sounds very large, but actually, if you look at the use case at a mankind scale, that’s what it takes. You need to keep the blocks far apart in terms of timing if you want to preserve your scalability. However, then you have the problem that the network is slow. One hour to confirm a transaction might be okay for an e-commerce use case, where it’s fine if you start doing nothing after payment for 60 minutes since the delivery will not take place before tomorrow anyway. But if you want to have anything that would happen inside a warehouse or at the point of sale, this is way too slow. It’s like a credit card that would take one hour for the payment to be cleared, which is very slow.

What we want is typically a target of something that would be three seconds and below. This is because, from a human user experience perspective, something that takes three seconds to clear will be perceived as reasonably fast. Think of it as a credit card payment; if you count one-two-three when doing a payment, that’s fine, it’s reasonably fast. If you can be completely secure within this timeframe, you can get a very decent user experience for most use cases. It’s still too slow for machine-to-machine, low-latency communication, but it is sufficient for most use cases that involve human perception.
For nearly a decade, numerous solutions were presented to address this latency issue. The vast majority of those solutions were not very good. They all had various limitations that undermined Bitcoin or its scalability, or they were naive solutions that emerged rapidly once Bitcoin was published. Most of these solutions relied on electing a leader, and this leader would act as a temporary central authority for a point of time, providing low-latency services. However, the problem with electing a leader is that when you transition from one leader to another, the process can be very messy, and you can have a situation where, in terms of quality of service, most of the time it’s a few seconds and then sometimes it’s actually one hour. That would be perceived by everybody as a downtime of the network.
It took a decade for a solution that was, in my opinion, good enough, to be published. This solution is a brilliant piece of work by an anonymous team called Team Rocket, published in May 2018: Snowflake to Avalanche, another metastable consensus protocol family for cryptocurrencies. This paper presents a series of three algorithms: Snowflake, Snowball, and Avalanche. Each algorithm is built on top of the previous one, and by the way, the real magic is located in the Snowball algorithm, which is precisely the one that does not appear in the title of the paper.
Fundamentally, what they engineered is metastability, and that’s very interesting. Remember, when you have conflicting transactions, it doesn’t really matter which is chosen because improving latency is about preventing double spending or actually reducing the timeframe at which you can have ambiguity about double-spending. The idea of having something that is meta-stable is that you would like to have a protocol where participants chat with each other constantly. The goal is that if there are two conflicting transactions, the network will reach a metastable equilibrium. The network will rapidly converge towards one interpretation of the truth; it doesn’t matter which one, it just has to be one. So if there are conflicting objects, the network will discuss and resolve the conflict.
Snowflake provides a slow converging process, while Snowball, in this paper, offers a trick that allows for an exponential speedup, resulting in a much faster convergence. Avalanche contributes some graph properties related to the graph of transactions. However, my personal understanding is that the contribution of Avalanche is much weaker; it’s really Snowball that is doing the magic. You may want to implement Avalanche, but just Snowball will give you about 99% of the metastability you seek.
There is one drawback to this approach. With Satoshi Nakamoto’s proof of work and blocks, any observer can step in and witness what has happened, reproducing the entire process and checking everything. The security does not depend on the observer being online. The observer can be online or offline, and it does not matter. This is a great security model that does not rely on a live connection to the network.
Avalanche, on the other hand, requires the observer to constantly monitor the network’s chats to generate security. It is not possible for a late observer to join and reassess the security of past transactions. However, we don’t really care about this issue because if you’re live on the network, you assess the security of the transactions happening at that moment. For things that happened in the past when you were not there, proof of work and blocks still provide a way to validate the transactions.
Avalanche is not in opposition to Bitcoin; it is complementary. One of the weak aspects of the Snowflake to Avalanche solution is that it doesn’t provide a clean solution to the coin emission problem. To get the best of both worlds, it would be ideal to maintain a Bitcoin-like design with proof of work and large blocks, while overlaying this with low-latency security.
In order to avoid certain classes of Sybil attacks that might confuse Avalanche, proof of stake could be employed. This introduces layers of economic entanglement, which is a very Bitcoin-esque way of thinking. To achieve the desired security, a web of economic entanglements should be created to ensure everyone stays honest. There are ways to engineer solutions to achieve better latency.

Now, still on the topic of expressiveness, we’re looking for more than just financial transactions, as this is about supply chain and using a blockchain for supply chain purposes. Financial transactions are necessary in the background, but we want to be able to do more. The question is, how do we incorporate this extra logic?
In the cryptocurrency circles, many cryptocurrencies have introduced the notion of smart contracts. A smart contract is fundamentally a program that is operated by the miners themselves on the blockchain. Miners check the validity of the transactions, but if you can include programming language or assembly code as part of your transaction, miners could run the programs and check that the programs verify certain properties. This is what is typically done on Ethereum, and it’s referred to as a smart contract. There is this motto that “code is law,” meaning we trust the execution of the program because it is certified as correct by the miners themselves.
However, I believe this approach to be deeply misguided on two very different fronts. The first issue is that you are making the scalability problem much worse. Scaling a blockchain is already very difficult, as you have to channel all those transactions towards the miners. Miners don’t have to do much with these transactions; they just have to check the signature. A miner can potentially process a massive amount of transactions because the amount of checks to perform for each transaction is minimal. Now, imagine if a miner not only has to validate transactions but also run arbitrary programs from all the companies. It becomes very difficult, and this is exactly what has been happening for a long time on the Ethereum network and other cryptocurrencies geared towards complex contracts.
Although later cryptocurrencies like Ethereum benefited from better engineering, they still face a massively more difficult problem in terms of scalability. Once they reach some level of notoriety and activity on the network, they all face massive scalability issues. It all boils down to the fact that you have to execute all those programs.
The second major problem with smart contracts is that they are fundamentally immutable programs. When you put programs on the blockchain, the idea is that you trust those programs because they operate autonomously. By “autonomously,” it means that there are miners with financial incentives to run those programs for the community, and the whole process is transparent and verifiable. However, the big problem with immutable programs is that if there is a bug, you cannot fix it.
The history of smart contracts has been an endless series of breaches resulting in massive losses for those operating the contracts. Even Ethereum itself had to undergo a massive fork, leading to Ethereum and Ethereum Classic, because a breached contract was so significant that the operators decided it was better to roll back the problems and undermine the immutable property that the blockchain is supposed to offer. There is no workaround, and if you do something non-trivial in a smart contract, you are exposing yourself to breaches.
In 2018, I published another approach called Tokida that shows how you can have arbitrary programs running alongside the blockchain. With Tokida, the program is open-source and operates on a “trust but verify” model. All the people who are interested in the outcome of the contract can verify if they want to, and performance-wise, it’s more flexible because the rest of the community doesn’t have to run your program. If you want to patch your software, you can still do it at any time without the rest of the community being unaware of what you’ve done.
If there’s a breach, it’s not a significant problem because you can patch it, and the community can assess that the patch was done in good faith. The insight is that most of what you need in terms of a security model for supply chain purposes is just trust but verify. You just need to ensure that if someone cheats, all the other people will notice, and that will be sufficient. For the currency itself, you want to prevent people from cheating in the first place. But for smart contracts, you don’t need the same degree of security as with currency itself. Being able to detect fraud after the fact is sufficient. If someone starts to defraud your business, you’re simply not going to do business with that partner again, and that would be the end of the story. You don’t need to have something that prevents fraud from happening in the first place. Trust is essential in business, and if you’re working with a partner, you have a certain degree of trust with them.

Now, we are entering the second part of the lecture, which covers use cases. I believe that the primary use case for blockchains remains payments. Paying suppliers, especially those overseas, can still be a challenge. Clearing a wire transfer can be slow, taking up to two weeks in some cases. The banking system’s payment workflows are far from being up to date with the 21st century, which can lead to mistakes like double payments for large invoices.
I believe that there are plenty of use cases for payments, especially when it comes to implementing complex mechanisms such as delayed payments, conditional payments, or penalties for products that do not meet quality requirements or deadlines. With programmatic money, you can implement all these schemes in ways that would have seemed like science fiction.
However, there are two caveats to this use case. First, cryptocurrencies are still incredibly volatile in value, which means that their worth can fluctuate dramatically over time. This volatility is an ongoing problem, but over the last decade, it has been decreasing. Volatility was even higher ten years ago, and it has been gradually decreasing since then, but it still remains beyond the comfort zone of most large companies. Observing daily fluctuations of 10% in value for these cryptocurrencies is still the norm. A decade ago, it was around 50%. The second problem for payments is the existence of thousands of cryptocurrencies, which creates the issue of choosing one and agreeing with your partner. However, there are classes of robotized foreign exchange systems that can convert any cryptocurrency into another, taking very low fees like 0.1%, which helps mitigate this issue.

Another use case is passive traceability. Traceability is essential in many industries like aerospace, pharmaceuticals, and automotive, as it can be a matter of life and death. Counterfeit car parts, for example, can lead to fatal accidents if they fail under stress. Non-fungible tokens (NFTs) can be used to bring traceability to a new level. An NFT is like a transferable serial number. With secure transactions, only the owner of this number, with their private keys, has the power to transfer the number to another participant. Using NFTs can prevent forgeries, even from the original emitters.
To implement NFT-based traceability, you only need QR codes and a smartphone, making it primarily a software-based solution. Blockchain technology offers a way to maintain transparent traceability from production to consumer. However, there are challenges. First, everyone must agree on one format and one blockchain. The blockchain carries binary payloads, so if you want to use it for traceability purposes, the format must be agreed upon. This becomes a complex issue since many industries and companies have their own unique formats and standards.
What people don’t necessarily realize is how flexible supply chains tend to be in the real world. For example, even in aerospace where traceability is absolutely excellent, you will notice that at point A, the document following a part is a PDF. For the next stage, it’s the same PDF but scanned, and maybe for the next stage, it’s the same scan but annotated and rescanned. Fundamentally, you assume that a human can step in and decipher the documents. However, if you want to operate on a blockchain, you can’t have such a loose process. You need to completely specify the binary format for all the data that you want to expose over the blockchain; otherwise, you lose the programmatic angle where you can work with programmatic tools.
Unifying all the standards is difficult, and you have to pick one blockchain because, for traceability to work, you need to pick one blockchain that is shared across all the participants, at least for a vertical and a region. The problem is that when it comes to picking one blockchain, you have massive conflicts of interest. Since a blockchain can never be completely disentangled from its underlying cryptocurrency, if you invest in a cryptocurrency, you become conflicted in the sense that you have a vested interest in making sure the company chooses the blockchain associated with the cryptocurrency you own.
These conflicts of interest are pervasive and difficult to assess since blockchains are typically anonymous. If you want to test the waters and get feedback on which blockchain to choose, you must consider the potential conflicts of interest that may arise among your staff. Companies that operate large supply chains typically have many people involved, and these problems are magnified.

Now, let’s consider a more adversarial example. Imagine pharmaceutical companies operating in very poor countries, like some African countries, where they face significant problems with counterfeit drugs. The problem is that in these poor countries, all the intermediaries are corrupt to some extent. Corrupt intermediaries may take a real box with real products, swap the real drugs out of the box, put counterfeit drugs in their place, and then sell the box to the market. People who buy counterfeit drugs may have a life-threatening condition and really need the drug. This is a very serious problem in poor countries, and reproducing the packaging for counterfeit drugs is trivial. One potential solution is using blockchains and tokens for active traceability, which is reminiscent of how the value-added tax (VAT) works in Europe. VAT is a difficult tax to defraud because it creates a social engineering scheme where companies are entangled with their honest suppliers.
The idea is to take the same concept and apply it to the blockchain. For example, let’s say you’re a pharmaceutical company producing a drug. You sell a pack of the drug to an intermediary or wholesaler at a higher price, such as $15 instead of the actual price of $10. The transfer of ownership of the token occurs, and the wholesaler can redeem $1 on the value, bringing their cost down to $14. The wholesaler then sells the pack of drugs to the distributor, and again, there is a transfer of ownership of the token. Once the distributor claims the token, they can redeem $1 of the value they just purchased, and so on, up to the end consumer.
When the end consumer receives the box of drugs, they pay $11, and by scanning the QR code with a smartphone, they can redeem $1, which flows back to them. The app does two things: first, it allows the end consumer to get back their extra dollar, and most importantly, it checks the entire traceability and displays it to the client. The end consumer is informed that they have just recovered the extra dollar, and the serial number is now declared as consumed.
In the end, the end consumer cannot transfer the token to anybody else, and the person who has just received the box can see on their mobile app that the entire traceability chain has been checked, and this is a real box. The idea is that with these financial incentives, it becomes very difficult to cheat, as distributing the drugs without the associated serial number becomes impossible. At the end of the chain, people might be poor, but they still want to make sure they can check if the drug is legitimate, especially if it’s for a life-threatening condition. This is what I would call active traceability, where you have a non-fungible token (NFT) with an overlaid financial mechanism that gives incentives to all players to perform certain actions.
In the case of the drug example, every single end consumer has a financial incentive to claim the serial number. Without this incentive, people might not declare the box as consumed, and counterfeit drugs could be reintroduced into the network. By marking the serial number as consumed, it cannot be reused by anybody. However, this approach requires alignment and participation from all participants, and all intermediaries will have to play this financial game. While this is a valid use case, it requires significant coordination among many parties.

Another potential application is incentivizing recycling through deposit refund systems. These systems have been around for a long time and are more or less prevalent depending on the country. The original manufacturer is usually the best-positioned participant in the network to reuse, recycle, or repair the equipment pushed down the supply chain. However, there is friction in getting these systems in place, and the challenge is to lower the friction further. Blockchain and cryptocurrencies offer a way to lower the amount of friction for micropayments and potentially reduce the infrastructure needed to ensure that operations are not gamed.
For example, if you were to give 20 cents back whenever people bring back a glass bottle, adversaries could potentially gamify the system by producing counterfeit bottles and cashing in on the margin they make by selling the recovered parts. Blockchains can provide a simple way to mitigate some of these shenanigans, but it is fundamentally something of an incremental nature. I’m not claiming that deposit refund systems are new; they have been around for a long time. It’s just about lowering the friction a little bit so that there can be more use cases.

Another use case of interest is security, as supply chains are vulnerable to cyberattacks. Supply chains are distributed geographically by design, meaning that IT systems and devices are spread all over the place. By design, the attack surface area is large, and it is difficult to do otherwise. A supply chain must be connected to clients, suppliers, partners, and third-party logistics providers, creating a vast attack surface area. While system integration, like EDI, can be valuable for ordering from suppliers and improving response times, tighter integration also brings more security problems.
An example of this vulnerability is the Colonial Pipeline incident, where a seemingly minor service related to billing was hacked, preventing the entire pipeline from operating for a week and endangering critical infrastructure in the US. How can blockchain help in this context? One approach would be to have a small amount of Bitcoin, worth around $100, in every single system and device, even IoT devices. By publicizing that all systems and devices have this stash, you create an incentive for hackers to try to penetrate your systems and steal the money.
However, this is not theft; it’s considered a bounty for hackers to breach your system. If a hacker manages to breach, let’s say, an IoT device, they can claim the amount of money inside. Additionally, if they come back to you and tell you how they did it and how to fix the problem, you could pay a second part of the bounty, worth around $300 in Bitcoin. By creating an incentive, you fund the work of ethical hackers who test your security. If only the bad actors have an incentive to attack your systems, you will be discovering a breach with a bad actor, which can be very nasty, as it happened with the Colonial Pipeline. However, if you give an incentive to honest, ethical hackers to get into your system, then most likely the people who will get into your system will be honest individuals who will then tell you how to fix your system to prevent problems from happening. The interesting thing is that these stashes are public, so if you put that into your network, you can transparently monitor whether you’ve been breached or not. You can also externally monitor all the devices, even if the IoT device is not connected to the internet. If you see the coins that were inside this device move, then it means that somehow this device was breached one way or another, and that is critical to know.
Remember that in those high-profile breaches that get publicized, usually what happens is that the actors were in the systems for months before they finally decided to claim their ransom. By using this blockchain-based security system, you create an early warning mechanism. Even if unethical hackers get into the system, they might just grab the money and run, without going through the messy ransom process.
This is a different way to think about security and probably not the use case you were thinking of for the blockchain in your supply chain. But as you can see, the interesting use cases for the supply chain always include some kind of monetary incentive, which is very Bitcoin-esque in terms of thinking about how to approach blockchain with regard to supply chain use cases.

Now, as I mentioned, blockchains are very difficult to engineer compared to pretty much any alternative solution. You can expect it to be at least two orders of magnitude more difficult to engineer a blockchain solution. So, whenever you think you could address a problem by spending one week of a software engineer’s time, multiply that number by 100, and that will give you the sort of effort it takes to do the same thing with the blockchain. There are situations where it makes sense; it’s not because it’s expensive that it can’t be profitable, but it is fundamentally difficult, and you have to keep that in consideration. The costs are also much higher when it comes to computing resources. Typically, the blockchain is very difficult to scale, and compared to a non-blockchain setup, you end up spending 100 times more computing resources for whatever you want to do with the blockchain. In some situations, you might not care, but in many other situations, a 100 times increase in your computing hardware cost is significant.
The question is, how do we try alternatives? In almost every situation where a blockchain is involved, there is a non-blockchain alternative. Typically, this is achieved by softening the requirements. In terms of added value, if you’re willing to give up the non-deniability property that I described at the beginning of this lecture, you can appoint a consortium of some kind. This consortium will use a checkpoint database, publish logs that can be verified by any third parties from within the consortium or potentially from companies or entities that are outside the consortium. One of the critical points will be to have very clearly specified binary formats so that it’s possible for parties to operate programmatically. With that in place, you will get most of the value that you would otherwise get from a blockchain.
One great supply chain example of this would be GS1 for barcodes. GS1 is an entity that allocates barcodes, and they have been doing that for decades. This organization was created as a separate entity, so at the time it wasn’t IBM directly that managed the barcodes. GS1 delivers the added value of a blockchain without actually using a blockchain. However, this approach requires a central authority or a consortium that you can trust. In many industries that are very concentrated, like pharma, establishing a consortium where there is already a significant market share may not be too difficult.

To conclude, the Satoshi Nakamoto consensus is a stunning discovery. Back in 2008, if you had asked experts in distributed systems if it was possible to solve the Byzantine consensus problem without resorting to any central authority, most of them would have said no, as it didn’t seem possible. The idea was so outside the realm of what people thought to be possible that they were not even looking in that direction. In that respect, it was a stunning discovery. As I presented with the mini Bitcoin, it is a very simple idea that has uses beyond money, with money being the primary use case.
What we have to keep in mind is that for every blockchain use case, there is typically a non-blockchain alternative that is vastly simpler to operate. We really have to assess whether the extra overhead associated with a blockchain is worth all the hassle that you will get. As a concluding thought, never forget that a blockchain is fundamentally entangled with its underlying currency, and this generates the mother of all conflicts of interest.
In one of my previous lectures about adversarial market research, I presented my views on how to pick enterprise vendors and discussed the issues surrounding reviews. Many intuitive ways to approach these problems are undermined due to conflicts of interest. With blockchains and cryptocurrencies, the problem is a thousand times worse. Everyone has massive incentives if they own Bitcoin, Bitcoin Cash, eCash, or any other cryptocurrencies. They will have a significant bias due to their investments, and if your company takes a direction that is favorable to a specific blockchain, it may be favorable for their investments as well.
I don’t have a good solution to this problem, but I advise being aware and prepared. Most of the information found online about cryptocurrencies is unreliable, as many people have a conflict of interest in promoting their preferred currency. Trust nobody, except for colleagues you would trust with your life. Rely on your own judgment or the judgment of colleagues who understand what’s going on. The conflicts of interest with blockchains lead to unexpected behaviors, especially in supply chain, where long-lived relationships and a high degree of trust are typically present.
Organizations operating large supply chains may be unprepared for the level of distrust found in the cryptocurrency space. This concludes the lecture. Let’s have a look at the questions.

Question: Blockchain and Bitcoin are not the same; one is unique while the other is a basic technology.
Yes, semantics and terminology are important. I knew when I was doing this lecture that there would be people pointing out that they are not exactly the same thing. However, if you want to examine a pure blockchain in the technical sense, then a Git repository, like GitHub, is a blockchain. Git repositories have been around for about 15 years, and they have not driven the world crazy. There are not billions of euros and dollars flowing in and out of these Git repositories.
The point is that the blockchain only works in terms of the added value it creates. What differentiates Bitcoin from Git, despite both being blockchains, is that Bitcoin has built-in financial incentives that unlock certain aspects of the technology. That’s the trick. If you remove all the monetary aspects and incentives that are engineered, then you have something that is just a technical data structure, but it has no interest whatsoever. Yes, it is a nice data structure – Git is a nice data structure – but it didn’t drive the entire market crazy, and certainly people would not go crazy and say, “Oh, this Git repository is worth billions.” There is something different. Nitpicking on the terminology aside, I believe that the primary reason many businesses went for the blockchain terminology was to introduce some distinction in the discourse from those cryptocurrencies that were seen like the complete wild west.
Question: Blockchain is the technology that allows decentralized consensus but with a cost – delay, scalability, etc., and pollution.
Absolutely. By the way, I can also address the pollution use case. The thing is that whenever you have a money emission process, no matter how the money is emitted – whether it’s the central bank for the euro, the Fed for the dollar, or whatever – if economic actors can invest to benefit from this money emission, they will invest up to the marginal cost. So, if the central bank prints 100 and I can invest 90 to get back those 100, I will do it.
No matter how you have a money emission process, people are going to spend up to the marginal cost to match the utility. It turned out that because Bitcoin Core has been inflating in value, people are willing to pay a lot in terms of electricity to acquire those newly minted Bitcoins. However, the process is exponentially decreasing, which means that a few decades from now, the amount of newly minted Bitcoins will dwindle to almost nothing, and thus the amount that people will be willing to pay for proof of work will be almost nothing. This is a transient problem, and right now, it is mostly unused spare electricity capacity that is being used.
I agree with your takeaway; it gives you decentralized consensus in the Byzantine consensus perspective, and yes, there are massive overheads associated. Absolutely, this is the correct takeaway.
Question: Why use it in the supply chain industry? What does the decentralized paradigm solve? What problem does it bring?
I provided various use cases in my lecture. Having decentralization relieves you from the need to engineer a consortium. The problem is that if you have a central authority that you trust and this central authority is honest, then good – you don’t need a blockchain. The trick is, what do you do when you don’t have that?
Even areas that had central authorities, like for example wire transfers for payments, are under the control of central authorities – there are gatekeepers that are the banks and then the central banks. We are not, I would say, in a shortage of central authorities, but nonetheless, in 2021, clearing a payment with my overseas clients still takes two weeks. This is the 21st century; I can send an email, and it is received within seconds by those clients, but sending a wire transfer takes weeks. So obviously, there are some problems that are sometimes very hard to solve because maybe the problem is not that you have no central authorities, but that you have too many central authorities, or you have complex problems where you can’t get people together to come up with a solution.
I’ve described some use cases, for example, active traceability, where you operate in a poor country where all the intermediaries are corrupt. This is another problem where you cannot trust anybody. When you have epidemic corruption, these problems are very difficult to address. That’s a situation where the decentralized blockchain can give you a way to engineer the honesty of the participants. That’s the trick: the participants are not expected to be honest; they are engineered to remain honest while they operate the supply chain. If everybody is already very honest and central authorities are enforced, then there is very little added value.
Question: How do you deal with the existence of ASICs (Application-Specific Integrated Circuits) hardware specialized in mining and farms to ensure no one can easily have 51% of the power of the networks?
Historically, ASICs have been a positive force for the security of the Bitcoin Core network. Why is that? Because there is another problem in the modern landscape: botnets. Botnets are vast fleets of compromised computers controlled by criminal organizations that literally take control of millions of everyday devices such as computers, printers, and security cameras. These organizations don’t want to prevent you from using your device, as that would lead to repairs and the removal of the malware.
In terms of security, the landscape we are at is that criminal organizations have at their disposal literally tens of millions of computers for free. These organizations that operate botnets, if you look at the security updates from Microsoft, you will see that a couple of times per year, Microsoft has wiped out absolutely massive botnets in the past. They would communicate, say, “We did pass this Windows update, and by the way, we did just eliminate, wipe out this 50 million machine botnet.” That is impressive. So, ASICs mean that there is no point in playing this game with regular hardware like the one in your regular computers. Thus, criminals who operate botnets cannot use those botnets to mine cryptocurrency, which removes one angle to monetize those botnets. It forces miners to be committed to the currency.
You see, ASICs are not a problem; they are, on the contrary, the sort of solution that makes sure that this extra processing power doesn’t wreak havoc or leverage the sort of processing power that is available through botnets. Botnets are already a massive problem for everybody, and we don’t want to further empower those botnets.
Question: What are your thoughts on the Telegram Open Network that couldn’t see the light due to U.S courts? What are your thoughts in general on cryptocurrencies issued by messengers? Does it bring anything new?
Well, I believe the situation is very predictable for Telegram and the same thing for Facebook, and any company that wants to operate as a public company. There are general regulations that say that if you’re a company, there are KYC (Know Your Customer) requirements, and I’m not going to go too much into the details. Basically, if you’re a large company, you can expect that in many jurisdictions, there will be KYC requirements. I’m not here to discuss whether the regulations are adequate or not; I’m just saying that KYC regulations are prevalent in many countries.
If you go back to what makes a blockchain a blockchain, as I described in the list of requirements, point number two is that participants are anonymous. Thus, here goes the KYC requirements. If you want to operate a blockchain, you have to be okay preserving some kind of pseudo-anonymity of whoever is participating in this network, which means that in terms of KYC requirements, you’re completely off.
I was not too sure what those companies were thinking, but I cannot see a company that wants to be both public and answer to authorities like the SEC in the US or the AMF in France, while being able to engage in a scheme that obviously goes completely against the sort of KYC regulations that are very prevalent for large companies. My take is that fundamentally, they were probably testing the waters to see if maybe the regulators would relax regulations just for them, just because they were big. It might not have gone their way, and thus they are pulling back on that. Fundamentally, other than that, I believe that, for example, Telegram or Facebook, if they accept that they would just promote a cryptocurrency but not operate it, they could actually give a massive boost to this cryptocurrency. However, the problem is that because they would just be promoting, not operating, they would have little to gain for themselves, except if they have engineered a conflict of interest where they benefit from the growth of the currency. By the way, Elon Musk, I am looking at you when you start tweeting about Bitcoin and the fact that your company has a position on that. This is literally the game that can be played: you first acquire a stake in a cryptocurrency and then you literally pump this cryptocurrency by just making very visible statements about it. Let the valuation rise and then, once it’s higher, sell it. By the way, this process is called pump and dump. Probably Telegram and Facebook realized that the only way they could actually profit from just promoting a currency but not operating it was pump and dumps, and they didn’t want their reputation to be damaged by doing this sort of shenanigans.
Question: Seven years ago, I saw many startups bringing blockchain technology to supply chain-related fields. None of them succeeded, at least at scale. Do you know any that succeeded and proved to work at scale?
Good question. I mean, first, I don’t think that anybody has, on the planet, a blockchain that is provably scalable and actually working at scale. If we look at the Bitcoin Core experiment, it’s not going well. The network is completely saturated; it has been now saturated for four years. This is really the opposite of scalability. If you look at Bitcoin Cash, that’s another blockchain. They made some headway, but they never really had time; they had some internal dissent, and thus they never did all the final bits in terms of engineering to get it working. There is another, as I was mentioning, newly created fork called eCash that is basically a fork of Bitcoin Cash, where they are again trying to do all the things that were not done in the original Satoshi client because most of the scalability problems can be traced back to the original Satoshi client. There is some hope that they can achieve massive scalability, but again, this is more of a theoretical perspective. This is not proven in the sense that there is something that, at present day, works at hyperscale, although we have reason to believe that it is, to some degree, possible. I have published on that, by the way, if you want to look at my publication about terabyte size blocks for Bitcoin.
Now, there is nobody that has succeeded in bringing those sorts of things to scale. It is very difficult. Scaling the base layer is the first challenge, and then obviously, startups wanting to do it for supply chain want to do something that is even more advanced. They need to have the base layer that can scale, and then they want to do something that is supply chain at scale as well. I believe that none of them succeeded because, as I was describing, yes, there are use cases for supply chain, and yes, there is some room for added value, but first, you have to resolve those very hard problems of scalability and latency. It might not have gone their way, and you can see the papers that I did quote are not that old. I mean, the papers on Avalanche are literally only a few years old. There have been some breakthroughs that are still fairly recent, and it will still take a lot of time. In order to scale, you have to make breakthroughs at the level of theoretical algorithmics, which is very difficult to move forward.
The algorithms I described, like Avalanche, are nightmarishly difficult to implement correctly. There are plenty of details that you can get wrong, and in terms of blockchain, if you get anything wrong, it will mean that you will be breached, assaulted, and money will be lost. The severity of having bugs and problems when you operate in the blockchain world is very severe. This is not like your run-of-the-mill enterprise software where if it crashes, you can restart, correct manually the bits of data that have been affected, and just take it from there. With blockchains, once you have massive corruption, the damage might be permanent, and that’s a very tough spot to operate in.
I believe that many of the startups that went into this space were absolutely unprepared in terms of the engineering mindset required to face the challenges of operating in the blockchain realm. Good engineering is not enough; you need really great engineering to succeed.
This concludes the Q&A section for this lecture. The next lecture will be on mathematical optimization for supply chain and will be held on Wednesday, August 25th. I will be taking some vacation time off. By the way, mathematical optimization, contrary to blockchain, is used daily in many supply chains. The applications are enormous, and the use cases are very down-to-earth. We are not talking about niche use cases; the applications are massive.
Mathematical optimization is very much related to statistical learning and taking the best supply chain decisions. See you next time.


