00:21 Einführung
01:53 Von Prognosen zum Lernen
05:32 Maschinelles Lernen 101
09:51 Der bisherige Verlauf
11:49 Meine Vorhersagen für heute
13:54 Genauigkeit bei Daten, die wir nicht haben 1/4
16:30 Genauigkeit bei Daten, die wir nicht haben 2/4
20:03 Genauigkeit bei Daten, die wir nicht haben 3/4
25:11 Genauigkeit bei Daten, die wir nicht haben 4/4
31:49 Ruhm dem Vorlagen-Matcher
35:36 Eine Tiefe im Lernen 1/4
39:11 Eine Tiefe im Lernen 2/4
44:27 Eine Tiefe im Lernen 3/4
47:29 Eine Tiefe im Lernen 4/4
51:59 Groß denken oder nach Hause gehen
56:45 Jenseits des Verlusts 1/2
01:00:17 Jenseits des Verlusts 2/2
01:04:22 Jenseits des Labels
01:10:24 Jenseits der Beobachtung
01:14:43 Fazit
01:16:36 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Prognosen sind in der Supply Chain nicht reduzierbar, da jede Entscheidung (Einkauf, Produktion, Lagerung usw.) eine Antizipation zukünftiger Ereignisse darstellt. Statistisches Lernen und maschinelles Lernen haben das klassische Feld der ‘Prognose’ sowohl theoretisch als auch praktisch weitgehend abgelöst. Wir werden versuchen zu verstehen, was eine datengetriebene Antizipation der Zukunft aus einer modernen ‘Lern’-Perspektive überhaupt bedeutet.
Vollständiges Transkript

Willkommen zu der Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich “Maschinelles Lernen für die Supply Chain” präsentieren. Wir können Güter nicht in Echtzeit 3D drucken und wir können sie nicht dorthin teleportieren, wo sie geliefert werden sollen. Tatsächlich müssen fast alle Entscheidungen in der Supply Chain vorausschauend getroffen werden, indem sie zukünftige Nachfrage oder Preisbewegungen antizipieren und implizit oder explizit einige erwartete zukünftige Marktbedingungen auf der Nachfrageseite oder auf der Angebotsseite widerspiegeln. Prognosen sind daher ein integraler und nicht reduzierbarer Bestandteil der Supply Chain. Wir wissen nie sicher, wie die Zukunft aussehen wird; wir können nur mit unterschiedlichem Grad an Sicherheit über die Zukunft spekulieren. Das Ziel dieser Vorlesung ist es zu verstehen, was maschinelles Lernen in Bezug auf die Erfassung der Zukunft beiträgt.

In dieser Vorlesung werden wir sehen, dass die Bereitstellung genauerer Prognosen im großen Ganzen ein relativ sekundäres Anliegen ist. Tatsächlich bedeutet Prognose in der heutigen Supply Chain Zeitreihenprognose. Historisch gesehen wurden Zeitreihenprognosen zu Beginn des 20. Jahrhunderts in den USA populär. Tatsächlich war die USA das erste Land, in dem Millionen von Angestellten der Mittelschicht auch Aktien besaßen. Da die Menschen kluge Investoren sein wollten, wollten sie Einblicke in ihre Investitionen haben, und es stellte sich heraus, dass Zeitreihen und Zeitreihenprognosen eine intuitive und effektive Möglichkeit waren, diese Einblicke zu vermitteln. Sie konnten Zeitreihenprognosen über zukünftige Marktpreise, zukünftige Dividenden und zukünftige Marktanteile haben.
In den 80er und 90er Jahren, als die Supply Chain im Wesentlichen digitalisiert wurde, begannen auch die Supply Chain Unternehmenssoftware von Zeitreihenprognosen zu profitieren. Tatsächlich wurden Zeitreihenprognosen in dieser Art von Unternehmenssoftware allgegenwärtig. Wenn Sie sich jedoch dieses Bild ansehen, können Sie erkennen, dass Zeitreihenprognosen tatsächlich eine sehr vereinfachte und naive Art sind, in die Zukunft zu schauen.
Sie sehen, wenn ich mir nur dieses Bild anschaue, kann ich bereits sagen, was als nächstes passieren wird: höchstwahrscheinlich wird eine Crew auftauchen, sie werden dieses Durcheinander aufräumen und sehr wahrscheinlich werden sie dann die Gabelstapler aus Sicherheitsgründen inspizieren. Sie könnten sogar einige leichte Reparaturen durchführen, und mit einem hohen Maß an Zuversicht kann ich sagen, dass dieser Gabelstapler wahrscheinlich bald wieder in Betrieb genommen wird. Wenn wir uns nur dieses Bild ansehen, können wir auch vorhersagen, welche Art von Bedingungen zu dieser Situation geführt haben. Nichts davon passt zur Perspektive einer Zeitreihenprognose, und dennoch sind all diese Vorhersagen sehr relevant.
Diese Vorhersagen betreffen nicht die Zukunft an sich, da dieses Bild vor einiger Zeit aufgenommen wurde und auch die Ereignisse, die auf die Aufnahme dieses Bildes folgten, jetzt Teil unserer Vergangenheit sind. Aber dennoch sind es Vorhersagen im Sinne von Aussagen über Dinge, von denen wir nicht sicher wissen. Wir haben keine direkte Messung. Das primäre Interesse besteht also darin, wie ich überhaupt in der Lage bin, diese Vorhersagen zu treffen und diese Aussagen zu machen.
Es stellt sich heraus, dass ich als Mensch gelebt habe, Ereignisse erlebt habe und daraus gelernt habe. So kann ich tatsächlich diese Aussagen treffen. Und es stellt sich heraus, dass maschinelles Lernen genau das ist: Es ist der Anspruch, diese Fähigkeit zum Lernen mit Maschinen zu replizieren, wobei die bevorzugte Art von Maschinen heutzutage Computer sind. An diesem Punkt fragen Sie sich vielleicht, wie maschinelles Lernen überhaupt von anderen Begriffen wie künstlicher Intelligenz, kognitiven Technologien oder statistischem Lernen abweicht. Nun, es stellt sich heraus, dass diese Begriffe viel mehr über die Menschen aussagen, die sie verwenden, als über das Problem selbst. In Bezug auf das Problem sind die Grenzen zwischen all diesen Bereichen sehr unscharf.

Nun wollen wir uns mit einer Überprüfung des Archetyps der maschinellen Lernframeworks befassen und eine kurze Reihe zentraler Konzepte des maschinellen Lernens behandeln. Die meisten wissenschaftlichen Arbeiten und Softwareprodukte in diesem Bereich des maschinellen Lernens nutzen dieses Framework in recht großem Umfang. Das Merkmal repräsentiert ein Stück Daten, das zur Durchführung der Vorhersageaufgabe zur Verfügung gestellt wird. Die Idee ist, dass Sie eine Vorhersageaufgabe durchführen möchten und ein Merkmal (oder mehrere Merkmale) repräsentiert, was zur Durchführung dieser Aufgabe zur Verfügung steht. Im Kontext von Zeitreihenprognosen würde das Merkmal den vergangenen Abschnitt der Zeitreihe repräsentieren, und Sie hätten einen Vektor von Merkmalen, der alle vergangenen Datenpunkte repräsentiert.
Das Label repräsentiert die Antwort auf die Vorhersageaufgabe. Im Fall einer Zeitreihenprognose repräsentiert es typischerweise den Teil der Zeitreihe, den Sie nicht kennen, wo die Zukunft liegt. Wenn Sie eine Reihe von Merkmalen und ein Label haben, wird dies als Beobachtung bezeichnet. Das typische maschinelle Lernsetup geht davon aus, dass Sie einen Datensatz haben, der sowohl Merkmale als auch Labels enthält, was Ihren Trainingsdatensatz darstellt.
Das Ziel besteht darin, ein Programm namens Modell zu erstellen, das die Merkmale als Eingabe nimmt und das gewünschte vorhergesagte Label berechnet. Dieses Modell wird in der Regel durch einen Lernprozess entwickelt, der den gesamten Trainingsdatensatz durchläuft und das Modell aufbaut. Das Lernen im maschinellen Lernen ist der Teil, in dem Sie tatsächlich das Programm konstruieren, das die Vorhersagen trifft.
Schließlich gibt es den Verlust. Der Verlust ist im Wesentlichen der Unterschied zwischen dem echten Label und dem vorhergesagten Label. Das Ziel besteht darin, dass der Lernprozess ein Modell generiert, das Vorhersagen erzeugt, die so nah wie möglich an den wahren Labels liegen. Sie möchten ein Modell, das die vorhergesagten Labels so nah wie möglich an den wahren Labels hält.
Maschinelles Lernen kann als eine umfassende Verallgemeinerung der Zeitreihenprognose betrachtet werden. Aus der Sicht des maschinellen Lernens können Merkmale alles sein, nicht nur ein vergangener Abschnitt einer Zeitreihe. Labels können auch alles sein, nicht nur der zukünftige Abschnitt einer Zeitreihe. Das Modell kann alles sein, und sogar der Verlust kann so ziemlich alles sein. Wir haben also ein Framework, das weitaus ausdrucksstärker ist als Zeitreihenprognosen. Wie wir jedoch sehen werden, stammen die meisten Hauptleistungen des maschinellen Lernens als Forschungs- und Praxisfeld aus den Entdeckungen von Elementen, die uns zwingen, die Liste der Konzepte, die ich gerade kurz vorgestellt habe, zu überdenken und in Frage zu stellen.
Diese Vorlesung ist die vierte Vorlesung in der Reihe der Lieferkettenvorlesungen. Hilfswissenschaften repräsentieren Elemente, die nicht direkt die Lieferkette selbst sind, aber etwas von grundlegender Bedeutung für die Lieferkette darstellen. Im ersten Kapitel habe ich meine Ansichten über die Lieferkette sowohl als physische Studie als auch als Praxis vorgestellt. Im zweiten Kapitel haben wir eine Reihe von Methoden überprüft, die erforderlich sind, um sich mit einem Bereich wie der Lieferkette auseinanderzusetzen, der viele gegnerische Verhaltensweisen aufweist und nicht leicht isoliert werden kann. Das dritte Kapitel ist ausschließlich den Lieferketten-Personas gewidmet, was eine Möglichkeit ist, sich auf die Probleme zu konzentrieren, die wir lösen wollen.
In diesem vierten Kapitel bin ich allmählich die Leiter der Abstraktion hinaufgestiegen, angefangen bei Computern, dann Algorithmen und der vorherigen Vorlesung über mathematische Optimierung, die als Basisschicht des modernen maschinellen Lernens angesehen werden kann. Heute wagen wir uns in das maschinelle Lernen, das für die Erfassung der Zukunft unerlässlich ist, die in allen Lieferkettenentscheidungen präsent ist, die wir jeden Tag treffen müssen.

Also, was ist der Plan für diese Vorlesung? Das maschinelle Lernen ist ein enormes Forschungsgebiet, und diese Vorlesung wird von einer kurzen Reihe von Fragen geleitet, die sich auf die Konzepte und Ideen beziehen, die ich zuvor vorgestellt habe. Wir werden sehen, wie die Antworten auf diese Fragen uns zwingen, das eigentliche Konzept des Lernens und den Umgang mit den Daten zu überdenken. Eine der spektakulärsten Errungenschaften des maschinellen Lernens besteht darin, dass es uns gezwungen hat zu erkennen, dass viel mehr im Spiel ist als die großen anfänglichen Ambitionen der Forscher, die dachten, wir könnten menschliche Intelligenz innerhalb eines Jahrzehnts replizieren.
Insbesondere werden wir uns Deep Learning ansehen, das wahrscheinlich der beste Kandidat ist, den wir derzeit haben, um einen höheren Grad an Intelligenz nachzuahmen. Obwohl Deep Learning als eine unglaublich empirische Praxis entstanden ist, werfen der Fortschritt und die Errungenschaften, die durch Deep Learning erzielt wurden, ein neues Licht auf die grundlegende Perspektive des Lernens aus beobachteten Phänomenen.
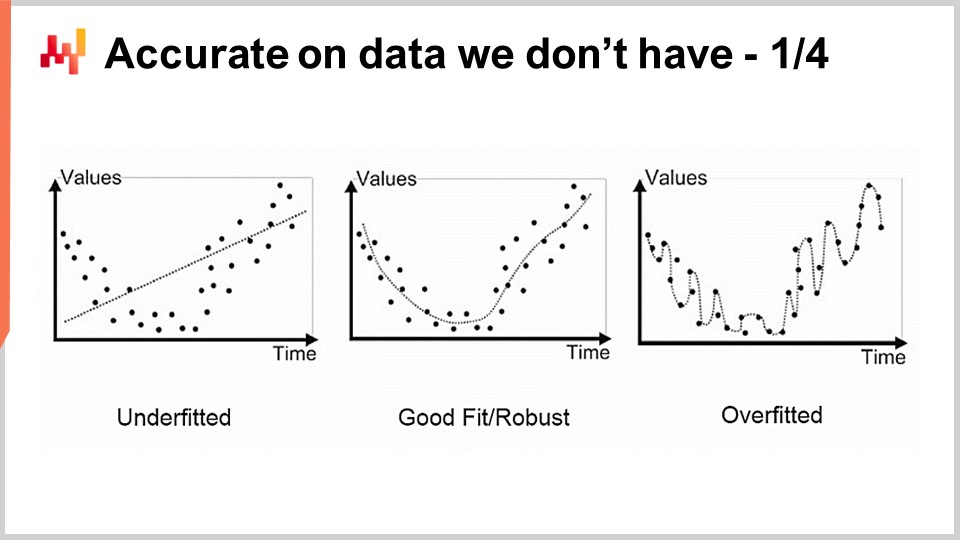
Das erste Problem, das wir mit der Modellierung, statistisch oder anderweitig, haben, ist die Genauigkeit der Daten, die uns fehlen. Aus einer Lieferkettenperspektive ist dies entscheidend, da unser Interesse darin besteht, die Zukunft erfassen zu können. Per Definition stellt die Zukunft eine Menge von Daten dar, die wir noch nicht haben. Es gibt Techniken wie Backtesting oder Kreuzvalidierung, die uns einige empirische Messungen darüber geben können, was wir von der Genauigkeit der Daten erwarten sollten, die wir nicht haben. Warum diese Methoden überhaupt funktionieren, ist jedoch ein relativ faszinierendes und schwieriges Problem. Das Problem besteht nicht darin, ein Modell zu haben, das zu den vorhandenen Daten passt; es ist einfach, ein Modell zu erstellen, das zu den Daten passt, indem man ein Polynom mit ausreichendem Grad verwendet. Dieses Modell ist jedoch nicht sehr zufriedenstellend, da es nicht das erfasst, was wir erfassen möchten.
Der klassische Ansatz für dieses Problem wird als Bias-Varianz-Dilemma bezeichnet. Auf der rechten Seite haben wir ein Modell mit sehr wenigen Parametern, das das Problem unterschätzt und eine hohe Verzerrung aufweist. Auf der linken Seite haben wir ein Modell mit zu vielen Parametern, das überanpasst ist und eine zu hohe Varianz aufweist. In der Mitte haben wir ein Modell, das einen guten Kompromiss zwischen Verzerrung und Varianz darstellt und als gute Anpassung bezeichnet wird. Bis zum Ende des 20. Jahrhunderts war es eher unklar, wie man dieses Problem jenseits des Bias-Varianz-Dilemmas angehen sollte.

Die erste wirkliche Erkenntnis über die Genauigkeit von Daten, die uns fehlen, stammt aus den Theorien der Erlernbarkeit, die Valiant 1984 veröffentlichte. Valiant führte die PAC-Theorie ein - Wahrscheinlich Annähernd Korrekt. In dieser PAC-Theorie bezieht sich der “wahrscheinlich”-Teil auf ein Modell mit einer bestimmten Wahrscheinlichkeit, gute genug Antworten zu liefern. Der “annähernd”-Teil bedeutet, dass die Antwort nicht zu weit von dem entfernt ist, was als gut oder gültig angesehen wird.
Valiant zeigte, dass es in vielen Situationen einfach nicht möglich ist, etwas zu lernen oder genauer gesagt, dass wir eine so übermäßig große Anzahl von Beispielen bräuchten, um zu lernen, dass es nicht praktikabel wäre. Dies war bereits ein sehr interessantes Ergebnis. Die angezeigte Formel stammt aus der PAC-Theorie und ist eine Ungleichung, die besagt, dass Sie eine Anzahl von Beobachtungen, n, haben müssen, die größer als eine bestimmte Menge sein muss, wenn Sie ein Modell produzieren möchten, das wahrscheinlich annähernd korrekt ist. Diese Menge hängt von zwei Faktoren ab: Epsilon, der Fehlerquote (der annähernd korrekte Teil), und Eta, der Wahrscheinlichkeit des Scheiterns (eins minus Eta ist die Wahrscheinlichkeit des Nicht-Scheiterns).
Was wir sehen, ist, dass wir, wenn wir eine geringere Wahrscheinlichkeit des Scheiterns oder ein kleineres Epsilon (einen ausreichend guten Bereich) haben möchten, mehr Beispiele benötigen. Diese Formel hängt auch von der Kardinalität des Hypothesenraums ab. Die Idee ist, dass je zahlreicher die konkurrierenden Hypothesen sind, desto mehr Beobachtungen wir benötigen, um sie zu sortieren. Dies ist sehr interessant, denn im Grunde genommen gibt uns die PAC-Theorie größtenteils negative Ergebnisse, sie sagt uns, was wir nicht tun können, nämlich ein nachweislich wahrscheinlich annähernd korrektes Modell mit weniger Beispielen zu erstellen. Die Theorie sagt uns nicht wirklich, wie wir etwas tun sollen; sie ist nicht sehr vorschreibend in der Art und Weise, wie wir tatsächlich besser darin werden können, jede Art von Vorhersageaufgabe zu lösen. Trotzdem war es ein Meilenstein, weil es die Idee kristallisierte, dass es möglich war, dieses Problem der Genauigkeit und der Daten, die wir nicht hatten, auf robustere Weise anzugehen als nur durch einige sehr empirische Messungen mit Cross-Validation oder Backtesting, zum Beispiel.
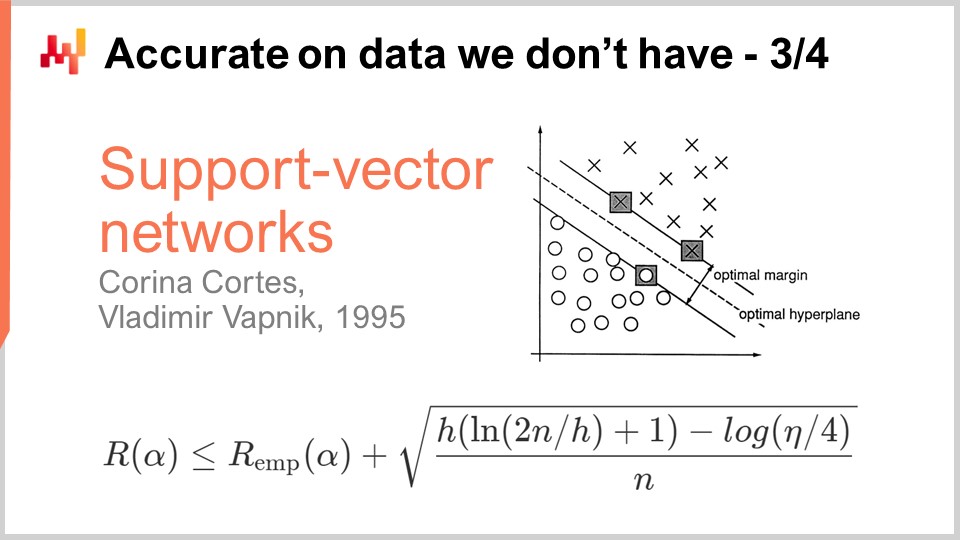
Ein Jahrzehnt später kam der erste operative Durchbruch, als Vapnik und einige andere die heute als Vapnik-Chervonenkis (VC)-Theorie bekannte Theorie aufstellten. Diese Theorie zeigt, dass es möglich ist, den realen Verlust, der als Risiko bezeichnet wird und den Sie auf den Daten beobachten werden, die Sie nicht hatten, zu erfassen. Es war möglich, mathematisch zu beweisen, dass Sie die Fähigkeit haben, etwas über den realen Fehler zu wissen, den Sie per Definition niemals messen können. Dies ist ein sehr verwirrendes Ergebnis.
Im Wesentlichen sagt uns diese Formel, direkt aus der VC-Theorie, dass das reale Risiko durch das empirische Risiko nach oben begrenzt ist, das das Risiko ist, das wir auf den Daten messen können, die wir haben, plus einen weiteren Term, der häufig als strukturelles Risiko bezeichnet wird. Wir haben die Anzahl der Beobachtungen, n, und Eta, das die Wahrscheinlichkeit des Scheiterns ist, genau wie in der PAC-Theorie. Wir haben auch h, das ein Maß für die VC-Dimension des Modells ist. Die VC-Dimension spiegelt die Fähigkeit des Modells wider zu lernen; je größer die Fähigkeit des Modells zu lernen ist, desto größer ist die VC-Dimension.
Mit diesen Ergebnissen sehen wir, dass wir für Modelle, die die Fähigkeit haben, alles zu lernen, nichts über sie sagen können. Das ist sehr verwirrend. Wenn Ihr Modell alles lernen kann, dann können Sie zumindest mathematisch nichts über es sagen.
Der Durchbruch im Jahr 1995 kam von einer Implementierung von Cortes und Vapnik, die später als Support Vector Machines (SVM) bekannt wurde. Diese SVMs sind buchstäblich die direkte Umsetzung dieser mathematischen Theorie. Die Erkenntnis ist, dass wir aufgrund einer Theorie, die uns diese Ungleichung gibt, ein Modell implementieren können, das das Ausmaß des Fehlers, den wir auf den Daten machen (das empirische Risiko), und die VC-Dimension ausbalanciert. Wir können direkt ein mathematisches Modell aufbauen, das diese beiden Faktoren genau ausbalanciert, um die Gleichheit so eng wie möglich und so niedrig wie möglich zu machen. Das ist genau das, worum es bei den Support Vector Machines (SVMs) geht. Diese Ergebnisse waren so beeindruckend, dass sie in der Praxis sehr gute Ergebnisse erzielten und einen bedeutenden Einfluss auf die Machine-Learning-Gemeinschaft hatten. Zum ersten Mal war die Genauigkeit auf den Daten, die wir nicht hatten, kein Nachgedanke mehr; sie wurde direkt durch das mathematische Design der Methode selbst erhalten. Das war so beeindruckend und kraftvoll, dass es die gesamte Machine-Learning-Gemeinschaft für ein Jahrzehnt abgelenkt hat, diesem Weg zu folgen. Wie wir sehen werden, stellte sich heraus, dass dieser Weg größtenteils eine Sackgasse war, aber es gab gute Gründe dafür: Es war ein absolut beeindruckendes Ergebnis.
Operationell gesehen hatten SVMs aufgrund der Tatsache, dass sie größtenteils aus einer mathematischen Theorie hervorgegangen sind, sehr wenig mechanisches Verständnis. Sie passten nicht gut zur Rechenhardware, die wir haben. Genauer gesagt, die naive Implementierung von SVMs geht mit einem quadratischen Kostenfaktor in Bezug auf den Speicherbedarf in Bezug auf die Anzahl der Beobachtungen einher. Das ist viel, und folglich machen SVMs sehr langsam. Es gab später Verbesserungen mit einigen Online-Varianten von SVMs, die die Speicheranforderungen erheblich reduziert haben, aber dennoch wurden SVMs nie wirklich als ein wirklich skalierbarer Ansatz für maschinelles Lernen betrachtet.

SVMs ebneten den Weg für eine andere, bessere Klasse von Modellen, die wahrscheinlich auch nicht überangepasst waren. Überanpassung bedeutet im Grunde genommen, dass man sehr ungenau auf Daten ist, die man nicht hat. Die bekanntesten Beispiele sind wahrscheinlich Random Forests und Gradient Boosted Trees, die ihre fast unmittelbaren Nachkommen sind. Ihr Kernstück ist das Boosting, ein Meta-Algorithmus, der schwache Modelle in stärkere umwandelt. Boosting entstand aus Fragen, die Ende der 80er Jahre zwischen Kearns und Valiant aufkamen, die wir zuvor in diesem Vortrag erwähnt haben.
Um zu verstehen, wie ein Random Forest funktioniert, ist es relativ einfach: Nehmen Sie Ihren Trainingsdatensatz und nehmen Sie dann eine Stichprobe Ihres Datensatzes. Auf dieser Stichprobe bauen Sie einen Entscheidungsbaum. Wiederholen Sie dies, indem Sie eine weitere Stichprobe aus dem ursprünglichen Trainingsdatensatz nehmen und einen weiteren Entscheidungsbaum erstellen. Wiederholen Sie diesen Vorgang, und am Ende haben Sie viele Entscheidungsbäume. Entscheidungsbäume sind relativ schwach in Bezug auf maschinelles Lernen, da sie keine sehr komplexen Muster erfassen können. Wenn Sie jedoch all diese Bäume zusammenfügen und die Ergebnisse durchschnittlich auswerten, erhalten Sie einen Wald, der als Random Forest bezeichnet wird, weil jeder Baum auf einer zufälligen Teilmenge des ursprünglichen Trainingsdatensatzes aufgebaut wurde. Mit einem Random Forest erhalten Sie ein viel stärkeres, besseres maschinelles Lernmodell.
Gradient Boosted Trees sind nur eine geringfügige Variation dieser Erkenntnis. Die Hauptvariation besteht darin, dass anstelle einer zufälligen Stichprobe Ihres Trainingsdatensatzes und dem zufälligen Aufbau eines Baums alle Bäume unabhängig voneinander aufgebaut werden, Gradient Boosted Trees zuerst den Wald aufbauen und dann der nächste Baum anhand der Residuen des bereits vorhandenen Waldes aufgebaut wird. Die Idee ist, dass Sie begonnen haben, ein Modell aus vielen Bäumen aufzubauen, und Vorhersagen machen, die sich von der Realität unterscheiden. Sie haben diese Deltas, die die Unterschiede zwischen den realen und den vorhergesagten Werten sind, die als Residuen bezeichnet werden. Die Idee ist, dass Sie den nächsten Baum nicht gegen den ursprünglichen Datensatz, sondern gegen eine Stichprobe der Residuen trainieren. Gradient Boosted Trees funktionieren sogar noch besser als Random Forests. In der Praxis überpassen Random Forests, aber nur ein wenig. Es gibt einige Beweise, die zeigen, dass Random Forests unter bestimmten Bedingungen nicht überangepasst sein sollen.
Interessanterweise dominieren Gradient Boosted Trees seit anderthalb Jahrzehnten die hohen Punktzahlen in nahezu allen maschinellen Lernwettbewerben. Wenn Sie sich etwa 80-90% der Kaggle-Wettbewerbe ansehen, werden Sie feststellen, dass es im Wesentlichen ein Gradient Boosted Tree ist, der den ersten Platz belegt hat. Trotz dieser unglaublichen Dominanz in maschinellen Lernwettbewerben gab es jedoch sehr wenig Durchbruch bei der Anwendung von Gradient Boosted Trees auf Supply-Chain-Probleme in freier Wildbahn. Der Hauptgrund dafür ist, dass Gradient Boosted Trees sehr wenig mechanisches Verständnis mitbringen; ihr Design ist überhaupt nicht benutzerfreundlich für die Rechenhardware, die wir haben.
Es ist leicht zu verstehen, warum: Sie bauen ein Modell mit einer Reihe von Bäumen, und das Modell wird so groß wie ein Bruchteil Ihres Datensatzes. In vielen Situationen haben Sie am Ende ein Modell, das datenmäßig größer ist als der Datensatz, mit dem Sie begonnen haben. Wenn Ihr Datensatz bereits sehr groß ist, dann ist Ihr Modell riesig, und das ist ein sehr problematisches Problem.
In Bezug auf die Geschichte der Gradient Boosted Trees gab es eine Reihe von Implementierungen, die mit GBM (Gradient Boosted Machines) im Jahr 2007 begannen und diesen Ansatz wirklich in einem R-Paket populär machten. Von Anfang an gab es Probleme mit der Skalierbarkeit. Die Leute begannen schnell, die Ausführung mit PGBRT (Parallel Gradient Boosted Regression Trees) zu parallelisieren, aber es war immer noch sehr langsam. XGBoost war ein Meilenstein, weil es eine Größenordnung in der Skalierbarkeit gewonnen hat. Der Schlüsselgedanke bei XGBoost war es, ein spaltenorientiertes Design in den Daten zu übernehmen, um den Baumkonstruktionsprozess zu beschleunigen. Später hat LightGBM alle Erkenntnisse von XGBoost wiederverwendet, aber die Strategie zum Aufbau der Bäume geändert. XGBoost hat den Baum ebenenweise aufgebaut, während LightGBM beschlossen hat, den Baum blattweise aufzubauen. Das Ergebnis ist, dass LightGBM jetzt unter Berücksichtigung der gleichen Rechenhardware mehrere Größenordnungen schneller ist als GBM jemals war. Aus praktischer Sicht der Supply Chain ist es jedoch in der Regel praktisch unmöglich, Gradient Boosted Trees zu verwenden. Es ist nicht unmöglich, sie zu verwenden; es ist nur so, dass es eine so große Hürde ist, dass es normalerweise nicht lohnt.

Das Verblüffende ist, dass Gradient Boosted Trees stark genug sind, um fast alle maschinellen Lernwettbewerbe zu gewinnen, und dennoch sind diese Modelle meiner bescheidenen Meinung nach eine technologische Sackgasse. Support Vector Machines, Random Forests und Gradient Boosted Trees haben alle gemeinsam, dass sie nichts anderes als Vorlagenübereinstimmungen sind. Es sind sehr gute Vorlagenübereinstimmungen, aber wirklich nichts weiter. Was sie außergewöhnlich gut machen, ist im Wesentlichen die Variablenselektion, und darin sind sie sehr gut, aber es steckt nicht viel dahinter. Insbesondere gibt es keine Ausdruckskraft in ihrer Fähigkeit, die Eingabe in etwas anderes als eine direkte Auswahl oder Filterung der Eingabe zu transformieren.
Wenn wir zum Gabelstaplerbild zurückkehren, das ich am Anfang dieses Vortrags gezeigt habe, besteht keinerlei Hoffnung, dass eines dieser Modelle die gleiche Art von Aussagen machen könnte, egal wie groß der Datensatz der Bilder ist. Sie könnten buchstäblich all diese Modelle mit Millionen von Bildern füttern, die aus Lagern auf der ganzen Welt stammen, und sie wären immer noch nicht in der Lage, Aussagen wie “Oh, ich habe in dieser Situation einen Gabelstapler gesehen; eine Crew wird auftauchen und Reparaturen durchführen.” zu machen. Nicht wirklich.
In der Praxis haben wir festgestellt, dass die Tatsache, dass diese Modelle maschinelle Lernwettbewerbe gewinnen, trügerisch ist, weil es Faktoren gibt, die in solchen Situationen zu ihren Gunsten spielen. Erstens sind reale Datensätze sehr komplex, was sich von maschinellen Lernwettbewerben unterscheidet, bei denen Sie im besten Fall Spielzeugdatensätze haben, die nur einen Bruchteil der Komplexitäten in realen Umgebungen darstellen. Zweitens müssen Sie bei der Verwendung von Modellen wie Gradient Boosted Trees umfangreiche Feature-Engineering betreiben, um einen maschinellen Lernwettbewerb zu gewinnen. Aufgrund der Tatsache, dass diese Modelle glorifizierte Vorlagenübereinstimmungen sind, müssen Sie die richtigen Features haben, damit allein die Auswahl der Variablen das Modell hervorragend funktionieren lässt. Sie müssen eine hohe Dosis menschlicher Intelligenz in die Datenvorbereitung einbringen, damit es funktioniert. Dies ist ein großes Problem, denn in der realen Welt, wenn Sie versuchen, ein Problem für echte Supply Chains zu lösen, ist die Anzahl der Ingenieursstunden, die Sie für das Problem aufwenden können, begrenzt. Sie können keine sechs Monate für ein winziges, zeitlich begrenztes, Spielzeugproblem in Ihrer Supply Chain aufwenden.
Das dritte Problem besteht darin, dass sich in Supply Chains die Datensätze ständig ändern. Es geht nicht nur darum, dass sich die Daten ändern, sondern auch das Problem ändert sich allmählich. Dies verschärft die Probleme, die Sie mit dem Feature-Engineering haben. Grundsätzlich bleiben uns Modelle, die maschinelles Lernen und Prognosewettbewerbe gewinnen, aber wenn wir ein Jahrzehnt vorausschauen, sehen wir, dass diese Modelle nicht die Zukunft des maschinellen Lernens sind; sie sind die Vergangenheit.

Deep Learning war die Antwort auf diese oberflächlichen Vorlagenübereinstimmungen. Deep Learning wird oft als Nachkomme künstlicher neuronaler Netzwerke dargestellt, aber die Realität ist, dass Deep Learning erst Fahrt aufgenommen hat, als Forscher beschlossen haben, biologische Metaphern aufzugeben und sich stattdessen auf mechanisches Verständnis zu konzentrieren. Wieder einmal ist mechanisches Verständnis, was bedeutet, sich gut mit den Computern zu verstehen, die wir haben, entscheidend. Das Problem, das wir mit künstlichen neuronalen Netzwerken hatten, war, dass wir versuchten, die Biologie nachzuahmen, aber die Computer, die wir haben, sind völlig anders als die biologischen Substrate, die unser Gehirn unterstützen. Diese Situation erinnert an die frühe Luftfahrtsgeschichte, in der zahlreiche Erfinder versuchten, Flugmaschinen zu bauen, indem sie Vögel nachahmten. Heutzutage haben wir Flugmaschinen, die viele Male schneller fliegen als die schnellsten Vögel, aber die Art und Weise, wie diese Maschinen fliegen, hat fast nichts mit dem Flugverhalten von Vögeln gemeinsam.
Die erste Erkenntnis über Deep Learning war die Notwendigkeit von etwas Tiefem und Ausdrucksstarkem, das jede Art von Transformation auf die Eingangsdaten anwenden konnte, um intelligentes Vorhersageverhalten aus dem Modell entstehen zu lassen. Es musste jedoch auch gut mit der vorhandenen Hardware zusammenarbeiten. Die Idee war, dass wir mit komplexen Modellen, die sehr gut mit der Hardware zusammenarbeiten, höchstwahrscheinlich Funktionen lernen können, die um mehrere Größenordnungen komplexer sind, wenn alle anderen Dinge gleich sind, im Vergleich zu einer Methode, die nicht den gleichen Grad an mechanischem Verständnis aufweisen würde.
Differenzierbares Programmieren, das in der vorherigen Vorlesung vorgestellt wurde, kann als Basisschicht des Deep Learning betrachtet werden. Ich werde in dieser Vorlesung nicht auf differenzierbares Programmieren zurückkommen, aber ich lade das Publikum ein, die vorherige Vorlesung anzusehen, wenn Sie sie noch nicht gesehen haben. Sie sollten in der Lage sein, zu verstehen, was folgt, auch wenn Sie die vorherige Vorlesung nicht gesehen haben. Die vorherige Vorlesung sollte einige der Details des Lernprozesses selbst klären. Zusammenfassend ist differenzierbares Programmieren nur eine Möglichkeit, wenn wir eine bestimmte Form des Modells wählen, die besten Werte für die Parameter zu identifizieren, die innerhalb dieses Modells existieren.
Während sich differenzierbares Programmieren darauf konzentriert, die besten Parameter zu identifizieren, konzentriert sich maschinelles Lernen darauf, die überlegenen Formen von Modellen zu identifizieren, die die höchste Kapazität haben, aus Daten zu lernen.

Wie erstellen wir also eine Vorlage für eine beliebig komplexe Funktion, die jede beliebig komplexe Transformation der Eingangsdaten widerspiegeln kann? Fangen wir mit einer Schaltung von Gleitkommazahlen an. Warum Gleitkommazahlen? Nun, es ist die Art von Sache, auf die wir Gradient Descent anwenden können, was, wie wir in der vorherigen Vorlesung gesehen haben, sehr skalierbar ist. Also, Gleitkommazahlen sind es. Wir werden eine Sequenz von Gleitkommazahlen haben, was bedeutet, dass Gleitkommazahlen als Eingabe und Gleitkommazahlen als Ausgabe verwendet werden.
Was machen wir jetzt in der Mitte? Lassen Sie uns lineare Algebra machen, genauer gesagt Matrixmultiplikation. Warum das? Die Antwort auf die Frage, warum Matrixmultiplikation verwendet wird, wurde in der allerersten Vorlesung dieses vierten Kapitels gegeben. Es hat mit der Art und Weise zu tun, wie moderne Computer entwickelt sind; im Wesentlichen ist es möglich, eine relativ dramatische Beschleunigung in Bezug auf die Verarbeitungsgeschwindigkeit zu erzielen, wenn man sich nur auf lineare Algebra beschränkt. Also, lineare Algebra ist es. Wenn ich nun meine Eingaben nehme und eine lineare Transformation anwende, die nur eine Matrixmultiplikation mit einer Matrix namens W ist (diese Matrix enthält die Parameter, die wir später lernen möchten), wie können wir es komplexer machen? Wir können eine zweite Matrixmultiplikation hinzufügen. Wenn Sie sich jedoch an Ihre lineare Algebra-Kurse erinnern, wenn Sie eine lineare Funktion mit einer anderen linearen Funktion multiplizieren, erhalten Sie eine lineare Funktion. Wenn wir also nur die Matrixmultiplikation zusammensetzen, haben wir immer noch eine Matrixmultiplikation, und sie ist immer noch vollständig linear.
Was wir tun werden, ist, Nichtlinearitäten zwischen den linearen Operationen zu mischen. Genau das habe ich auf diesem Bildschirm gemacht. Ich habe eine Funktion eingefügt, die in der Deep-Learning-Literatur typischerweise als Rectified Linear Unit (ReLU) bekannt ist. Dieser Name, der im Vergleich zu dem, was er tut, fantastisch kompliziert ist, ist nur eine sehr einfache Funktion, die besagt, dass, wenn ich eine Zahl nehme und diese Zahl positiv ist, ich dieselbe Zahl zurückgebe (also eine Identitätsfunktion), aber wenn die Zahl negativ ist, gebe ich 0 zurück. Sie können es auch als das Maximum Ihres Werts und Null schreiben. Dies ist eine sehr triviale Nichtlinearität.
Wir könnten viel anspruchsvollere nichtlineare Funktionen verwenden. Historisch gesehen wollten die Leute, als sie neuronale Netzwerke erstellten, anspruchsvolle Sigmoid-Funktionen verwenden, weil angenommen wurde, dass dies in unseren Neuronen funktioniert. Aber die Realität ist, warum sollten wir Rechenleistung verschwenden, um Dinge zu berechnen, die irrelevant sind? Der Schlüsselgedanke ist, dass wir etwas Einführen müssen, das nichtlinear ist, und es spielt keine Rolle, welche nichtlineare Funktion wir verwenden. Das Einzige, was zählt, ist, es sehr schnell zu machen. Wir möchten das Ganze so schnell wie möglich halten.
Was ich hier aufbaue, nennt man Dense Layers. Eine Dense Layer ist im Wesentlichen eine Matrixmultiplikation mit einer Nichtlinearität (der Rectified Linear Unit). Wir können sie stapeln. Auf dem Bildschirm sehen Sie ein Netzwerk, das typischerweise als Multi-Layer Perceptron bezeichnet wird, und wir haben drei Schichten. Wir könnten sie weiter stapeln und 20 oder 2.000 davon haben; es spielt keine Rolle. Die Realität ist, dass, so einfach es auch scheinen mag, wenn Sie ein solches Netzwerk mit nur ein paar Schichten nehmen und es in Ihr differenzierbares Programmier-Framework einfügen, das Ihnen die Parameter liefert, wird das differenzierbare Programmieren als Basisschicht in der Lage sein, die Parameter zu trainieren, die anfangs zufällig ausgewählt wurden. Wenn Sie es initialisieren möchten, initialisieren Sie einfach alle Parameter zufällig. Sie erhalten ziemlich gute Ergebnisse für eine sehr große Vielfalt von Problemen.
Das ist sehr interessant, denn an diesem Punkt haben Sie praktisch alle grundlegenden Bestandteile des Deep Learnings. Also, Glückwunsch an das Publikum! Sie können wahrscheinlich “Deep Learning-Spezialist” zu Ihrem Lebenslauf hinzufügen, denn das ist fast alles, was dazu gehört. Nun, nicht wirklich, aber sagen wir, es ist ein guter Ausgangspunkt.

Die Realität ist, dass Deep Learning abgesehen von Tensoralgebra, die im Wesentlichen computerisierte lineare Algebra ist, sehr wenig Theorie beinhaltet. Allerdings beinhaltet Deep Learning eine Vielzahl von Tricks. Zum Beispiel müssen wir die Eingaben normalisieren und die Gradienten stabilisieren. Wenn wir viele solcher Operationen stapeln, können die Gradienten exponentiell anwachsen, wenn wir im Netzwerk rückwärts gehen, und irgendwann wird das die Kapazität zur Darstellung dieser Zahlen übersteigen. Wir haben echte Computer, und sie sind nicht in der Lage, beliebig große Zahlen darzustellen. Irgendwann überschreiten Sie einfach Ihre Kapazität, die Zahl mit einem 32-Bit- oder 16-Bit-Gleitkommawert darzustellen. Es gibt eine Vielzahl von Tricks zur Gradientenstabilisierung. Zum Beispiel ist der Trick in der Regel die Batch-Normalisierung, aber es gibt auch andere Tricks dafür.
Wenn Sie Eingaben haben, die eine geometrische Struktur haben, zum Beispiel eindimensional wie eine Zeitreihe (historischer Umsatz, wie wir es in der Supply Chain sehen), die zweidimensional sein kann (stellen Sie es sich als ein Bild vor), dreidimensional (das könnte ein Film sein) oder vierdimensional usw. Wenn die Eingaben eine geometrische Struktur haben, dann gibt es spezielle Schichten, die diese geometrische Struktur erfassen können. Die bekanntesten sind wahrscheinlich die Faltungs-Schichten.
Dann haben Sie auch Techniken und Tricks, um mit kategorischen Eingaben umzugehen. Im Deep Learning sind alle Eingaben Gleitkommawerte, also wie gehen Sie mit kategorischen Variablen um? Die Antwort sind Embeddings. Sie haben Ersatzverluste, die alternative Verluste sind, die sehr steile Gradienten aufweisen und den Konvergenzprozess erleichtern und letztendlich verstärken, was Sie aus den Daten lernen können. Es gibt eine Vielzahl von Tricks, und all diese Tricks können in das Programm eingefügt werden, das Sie erstellen, weil wir mit differenzierbarer Programmierung als unserer Basisschicht arbeiten.
Deep Learning geht wirklich darum, wie wir ein Programm komponieren, das, sobald es durch den Trainingsprozess der differenzierbaren Programmierung läuft, eine sehr hohe Lernkapazität hat. Die meisten der gerade auf dem Bildschirm aufgelisteten Punkte haben auch einen programmatischen Charakter, was sehr praktisch ist, wenn man bedenkt, dass wir differenzierbare Programmierung, ein Programmierparadigma, haben, das all das unterstützt.
An diesem Punkt sollte klarer werden, warum Deep Learning anders ist als klassisches maschinelles Lernen. Deep Learning dreht sich nicht um Modelle. Tatsächlich enthalten die meisten Open-Source-Deep-Learning-Bibliotheken nicht einmal Modelle. Bei Deep Learning geht es vielmehr um Modellarchitekturen, die Sie als Vorlagen betrachten können, die stark angepasst werden müssen, wenn Sie sie an eine bestimmte Situation anpassen möchten. Wenn Sie jedoch eine geeignete Architektur übernehmen, können Sie davon ausgehen, dass Ihre Anpassungen immer noch die Essenz der Lernfähigkeit Ihres Modells bewahren. Bei Deep Learning verschieben wir das Interesse vom endgültigen Modell, das etwas Uninteressantes wird, zur Architektur, die zur eigentlichen Forschungsfrage wird.
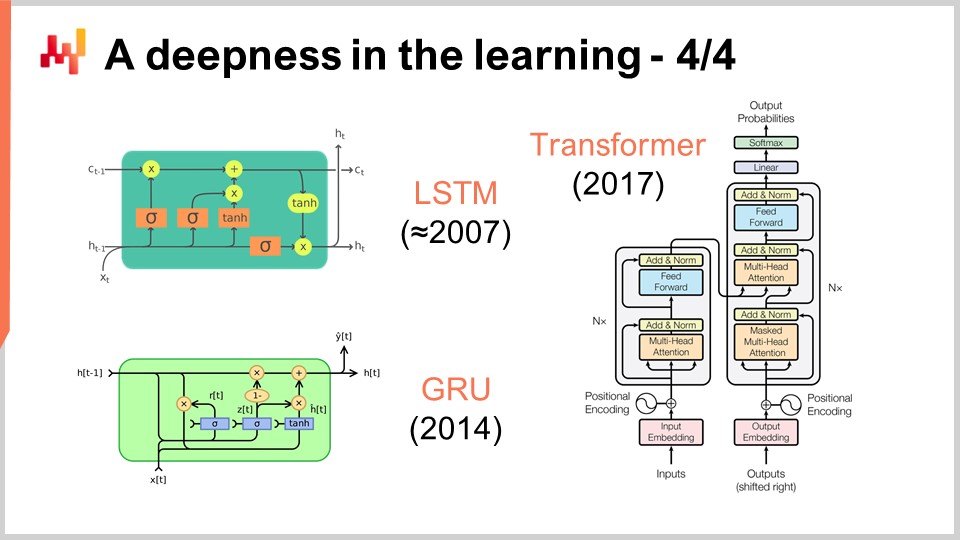
Auf dem Bildschirm sehen Sie eine Reihe bemerkenswerter Architekturbeispiele. Zuerst begann LSTM, was für Long Short-Term Memory steht, 2007 zu funktionieren. Die Veröffentlichungsgeschichte von LSTM ist etwas komplizierter, aber es begann im Wesentlichen 2007 im Stil des Deep Learnings zu funktionieren. Es wurde von Gated Recurrent Units (GRU) abgelöst, die im Wesentlichen dasselbe wie LSTM sind, aber einfacher und schöner. Ein Großteil der LSTM-Komplexität stammt im Wesentlichen von den biologischen Metaphern. Es stellt sich heraus, dass man die biologischen Metaphern weglassen kann und etwas Einfacheres erhält, das im Wesentlichen genauso funktioniert. Das sind die Gated Recurrent Units (GRU). Später kamen Transformers hinzu, die sowohl LSTM als auch GRU praktisch überflüssig machten. Transformers waren ein Durchbruch, da sie viel schneller waren, weniger Rechenressourcen benötigten und eine noch größere Lernkapazität hatten.
Die meisten dieser Architekturen kommen mit Metaphern. LSTM hat eine kognitive Metapher, das Langzeitgedächtnis, während Transformers eine Metapher der Informationssuche haben. Diese Metaphern haben jedoch sehr wenig Vorhersagekraft und könnten tatsächlich mehr Verwirrung und Ablenkung von dem sein, was diese Architekturen wirklich zum Funktionieren bringt, was zu diesem Zeitpunkt noch nicht vollständig verstanden ist.
Transformers sind für die Supply Chain von großem Interesse, da sie eine der vielseitigsten Architekturen sind. Sie werden heutzutage für praktisch alles verwendet, von autonomen Fahrzeugen bis hin zur automatischen Übersetzung und vielen anderen schwierigen Problemen. Dies ist ein Beweis für die Kraft der richtigen Architekturwahl, die dann verwendet werden kann, um eine enorme Vielfalt von Problemen zu lösen. Was die Supply Chain betrifft, so besteht eine der Hauptschwierigkeiten bei der Anwendung von maschinellem Lernen darin, dass wir eine unglaubliche Vielfalt von Problemen bewältigen müssen. Wir können es uns nicht leisten, ein Team zu haben, das fünf Jahre lang Forschungsarbeit für jedes einzelne Unterproblem betreibt. Wir brauchen etwas, mit dem wir schnell vorankommen können, ohne die Hälfte des maschinellen Lernens neu erfinden zu müssen, wenn wir das nächste Problem lösen wollen.
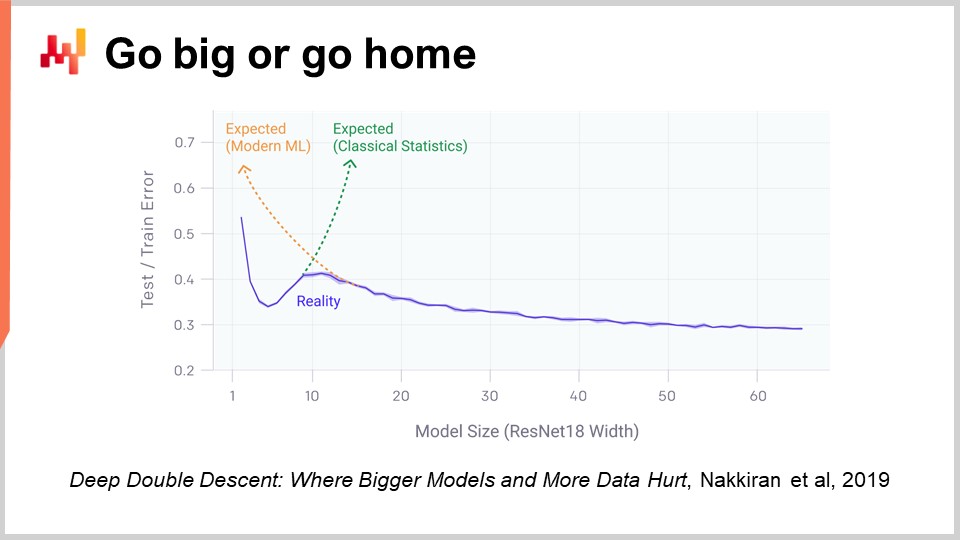
Ein Aspekt des Deep Learning, der wirklich schockierend ist, wenn man darüber nachdenkt, ist die enorme Anzahl von Parametern. Bei dem Multi-Layer Perceptron, das ich vor einigen Minuten vorgestellt habe, mit dichten Schichten, die Matrixmultiplikationen beinhalten, können wir viele Parameter in diesen Matrizen haben. Tatsächlich ist es nicht sehr schwierig, so viele Parameter zu haben wie Datenpunkte oder Beobachtungen in unseren Trainingsdatensätzen. Wie wir am Anfang unserer Vorlesung gesehen haben, sollte ein Modell mit so vielen Parametern dramatisch unter Überanpassung leiden.
Die Realität des Deep Learning ist noch rätselhafter. Es gibt viele Situationen, in denen wir weit mehr Parameter haben als Beobachtungen, und dennoch haben wir keine dramatischen Probleme mit Überanpassung. Noch rätselhafter ist, dass Deep Learning-Modelle dazu neigen, den Trainingsdatensatz vollständig anzupassen, sodass Sie einen nahezu Null-Fehler auf Ihrem Trainingsdatensatz haben, und dennoch behalten sie ihre Vorhersagekraft für Daten, die wir nicht haben.
Vor zwei Jahren hat das von OpenAI veröffentlichte Paper “Deep Double Descent” einige sehr interessante Erkenntnisse zu dieser Situation geliefert. Das Team zeigte, dass wir im Bereich des maschinellen Lernens im Wesentlichen ein unheimliches Tal haben. Die Idee ist, dass wenn Sie ein Modell nehmen und nur wenige Parameter haben, haben Sie eine hohe Verzerrung und die Qualität Ihrer Ergebnisse auf unbekannten Daten ist nicht so gut. Dies entspricht der klassischen Vision des maschinellen Lernens und auch der klassischen statistischen Vision. Wenn Sie die Anzahl der Parameter erhöhen, verbessern Sie die Qualität Ihres Modells, aber irgendwann werden Sie anfangen, Überanpassung zu erleben. Dies ist genau das, was wir bei der früheren Diskussion über Unteranpassung und Überanpassung gesehen haben. Es gibt ein Gleichgewicht zu finden.
Was sie jedoch gezeigt haben, ist, dass wenn Sie die Anzahl der Parameter weiter erhöhen, etwas sehr Seltsames passieren wird: Sie werden immer weniger Überanpassung haben, was dem widerspricht, was die klassische statistische Lerntheorie vorhersagen würde. Dieses Verhalten ist nicht zufällig. Die Autoren zeigten, dass dieses Verhalten sehr robust und weit verbreitet ist. Es passiert so gut wie immer in einer Vielzahl von Situationen. Noch ist nicht sehr gut verstanden, warum, aber was zu diesem Zeitpunkt sehr gut verstanden ist, ist, dass der Deep Double Descent sehr real und weit verbreitet ist.
Dies hilft auch zu verstehen, warum Deep Learning relativ spät zur Party des maschinellen Lernens kam. Um mit Deep Learning erfolgreich zu sein, mussten wir zuerst erfolgreich Modelle entwickeln, die Zehntausende oder sogar Hunderttausende von Parametern verarbeiten konnten, um dieses unheimliche Tal zu überwinden. In den 80er und 90er Jahren wäre es nicht möglich gewesen, einen Durchbruch im Deep Learning zu erzielen, einfach weil die Hardware-Computing-Ressourcen nicht in der Lage waren, dieses unheimliche Tal zu überwinden.
Glücklicherweise ist es mit der heutigen Hardware möglich, Modelle ohne großen Aufwand zu trainieren, die Millionen oder sogar Milliarden von Parametern haben. Wie wir in den vorherigen Vorlesungen festgestellt haben, gibt es jetzt Unternehmen wie Facebook, die Modelle mit über einer Billion Parametern trainieren. Wir können also sehr weit gehen.

Bisher haben wir angenommen, dass die Verlustfunktion bekannt war. Aber warum sollte das der Fall sein? Betrachten wir doch einmal die Situation eines Modegeschäfts aus der Perspektive der Supply Chain. Ein Modegeschäft hat Bestandsniveaus für jede einzelne SKU, und wir möchten die zukünftige Nachfrage projizieren. Wir möchten ein mögliches Szenario projizieren, das für die zukünftige Nachfrage in diesem Geschäft glaubwürdig ist. Was passieren wird, ist, dass, wenn bestimmte SKUs nicht mehr vorrätig sind, wir Kannibalisierung und Substitution beobachten sollten. Wenn eine bestimmte SKU einen Lagerbestandsfehler aufweist, sollte die Nachfrage normalerweise teilweise auf ähnliche Produkte zurückprallen.
Aber wenn wir versuchen, diesen Ansatz mit klassischen Prognosemetriken wie dem Mean Absolute Percentage Error (MAPE), dem Mean Absolute Error (MAE), dem Mean Square Error (MSE) oder anderen Metriken anzugehen, die SKU für SKU, Tag für Tag oder Woche für Woche arbeiten, werden wir keine dieser Verhaltensweisen erfassen. Was wir wirklich wollen, ist eine Metrik, die erfasst, ob wir in der Lage sind, all diese Kannibalisierungs- und Substitutionseffekte gut zu erfassen. Aber wie sollte diese Verlustfunktion aussehen? Das ist sehr unklar und scheint ziemlich anspruchsvolles Verhalten zu erfordern. Einer der wichtigsten Durchbrüche des Deep Learning bestand im Wesentlichen darin, die Erkenntnis zu gewinnen, dass die Verlustfunktion erlernt werden sollte. Genau so wurde das Bild auf dem Bildschirm erzeugt. Dies ist ein vollständig maschinell generiertes Bild; Keine dieser Personen ist real. Sie wurden generiert, und das Problem war: Wie baut man eine Verlustfunktion oder eine Metrik, die Ihnen sagt, ob ein Bild ein gutes, fotorealistisches Porträt eines Menschen ist oder nicht?
Die Realität ist, dass Sie, wenn Sie in Bezug auf den Mean Absolute Percentage Error (MAPE) denken, eine Metrik erhalten, die Pixel für Pixel arbeitet. Das Problem ist, dass eine Metrik, die Pixel für Pixel arbeitet, Ihnen nichts darüber sagt, ob das Bild insgesamt wie ein menschliches Gesicht aussieht. Wir haben das gleiche Problem im Modegeschäft für SKUs und die Prognose der Nachfrage. Es ist sehr einfach, eine Metrik auf SKU-Ebene zu haben, aber das sagt uns nichts über das Gesamtbild des Geschäfts. Aus Sicht der Supply Chain sind wir nicht am Genauigkeitsgrad auf SKU-Ebene interessiert; wir sind am Genauigkeitsgrad auf Geschäftsebene interessiert. Wir möchten wissen, ob die Bestandsniveaus insgesamt für das Geschäft gut sind, nicht ob sie für eine SKU gut sind und dann für eine andere SKU. Wie hat die Deep Learning-Community dieses Problem gelöst?
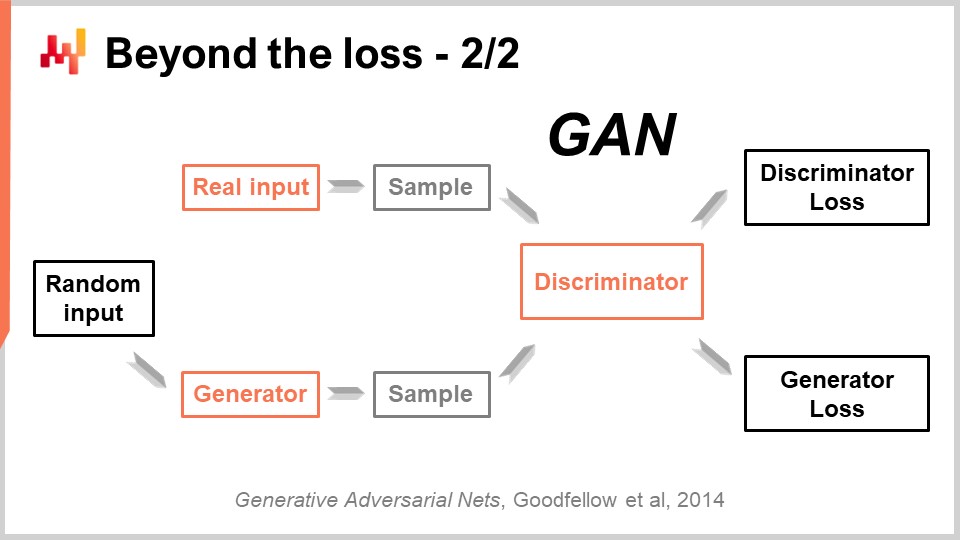
Diese beeindruckende Leistung wurde mit einer wunderschön einfachen Technik namens Generative Adversarial Networks (GANs) erzielt. In der Presse haben Sie vielleicht von diesen Techniken als Deepfakes gehört. Deepfakes sind Bilder, die mit dieser GAN-Technik erzeugt wurden. Wie funktioniert das?
Nun, so funktioniert es: Sie beginnen zunächst mit einem Generator. Der Generator nimmt einige Rauschwerte als Eingabe, die nur zufällige Werte sind, und erzeugt in diesem Fall ein Bild. Wenn wir zum Fall der Supply Chain zurückkehren, würde er Trajektorien für alle beobachteten Nachfragepunkte für jede einzelne SKU für die nächsten drei Monate in diesem Modegeschäft erzeugen. Dieser Generator ist selbst ein Deep Learning-Netzwerk.
Jetzt haben wir einen Diskriminator. Ein Diskriminator ist ebenfalls ein Deep Learning-Netzwerk, und das Ziel des Diskriminators besteht darin, zu lernen, ob das gerade Generierte echt oder synthetisch ist. Der Diskriminator ist ein binärer Klassifizierer, der nur sagen muss, ob es echt oder nicht echt ist. Wenn der Diskriminator in der Lage ist, korrekt vorherzusagen, dass eine Probe gefälscht ist, synthetisch ist, führen wir die Gradienten zurück zum Generator und lassen den Generator daraus lernen.
Was aus dieser Konfiguration passiert, ist, dass der Generator lernt, wie er Proben generiert, die den Diskriminator tatsächlich täuschen und verwirren. Gleichzeitig lernt der Diskriminator, wie er besser zwischen den echten Proben und den synthetischen Proben unterscheiden kann. Wenn Sie diesen Prozess durchlaufen, konvergiert er hoffentlich zu einem Zustand, in dem Sie sowohl einen Generator von sehr hoher Qualität haben, der Proben erzeugt, die unglaublich realistisch sind, als auch einen sehr guten Diskriminator, der Ihnen sagen kann, ob es echt ist oder nicht. Genau das wird mit GANs gemacht, um diese fotorealistischen Bilder zu generieren. Wenn wir zur Supply Chain zurückkehren, werden Sie Experten in Supply Chain-Kreisen finden, die sagen, dass für eine bestimmte Situation die beste Metrik MAPE oder gewichteter MAPE oder was auch immer ist. Sie werden Rezepte entwickeln, die Ihnen sagen, dass Sie in bestimmten Situationen diese Metrik oder jene verwenden müssen. Die Realität ist jedoch, dass das Deep Learning zeigt, dass eine Prognosemetrik ein veraltetes Konzept ist. Wenn Sie eine hochdimensionale Genauigkeit erreichen möchten, nicht nur eine punktweise Genauigkeit, müssen Sie die Metrik lernen. Obwohl ich im Moment vermute, dass es kaum Supply Chains gibt, die diese Techniken nutzen, werden sie irgendwann in der Zukunft genutzt werden. Es wird zur Norm werden, die Prognosemetrik mithilfe von generativen adversarialen Netzwerken oder den Nachfolgern dieser Techniken zu lernen, weil es eine Möglichkeit ist, das subtile, hochdimensionale Verhalten zu erfassen, das wirklich interessant ist, anstatt nur eine punktweise Genauigkeit zu haben.

Nun, bisher kam jede einzelne Beobachtung mit einem Label, und das Label war die Ausgabe, die wir vorhersagen wollen. Es gibt jedoch Situationen, die nicht als Ein- und Ausgabeprobleme formuliert werden können. Labels sind einfach nicht verfügbar. Wenn wir ein Beispiel aus der Supply Chain nehmen wollen, wäre das ein Hypermarkt. In Hypermärkten sind die Lagerbestände nicht perfekt genau. Waren können beschädigt, gestohlen oder abgelaufen sein, und es gibt viele Gründe, warum die elektronischen Aufzeichnungen in Ihrem System nicht wirklich widerspiegeln, was auf dem Regal verfügbar ist, wie es von den Kunden wahrgenommen wird. Die Inventur ist zu teuer, um eine Echtzeit-Datenquelle für genaue Bestandsdaten zu sein. Sie können eine Inventur durchführen, aber Sie können nicht jeden Tag den gesamten Hypermarkt durchlaufen. Am Ende haben Sie eine große Menge leicht ungenauer Lagerbestände. Sie haben Tonnen davon, aber Sie können nicht wirklich sagen, welche genau sind und welche nicht.
Dies ist im Wesentlichen die Art von Situation, in der unüberwachtes Lernen wirklich Sinn macht. Wir möchten etwas lernen; wir haben Daten, aber wir haben die richtigen Antworten nicht zur Verfügung. Wir haben diese Labels nicht. Was wir haben, sind einfach Tonnen von Daten. Unüberwachtes Lernen galt jahrzehntelang als das Nonplusultra in der maschinellen Lerngemeinschaft. Lange Zeit war es die Zukunft, aber eine ferne Zukunft. In letzter Zeit gab es jedoch einige unglaubliche Durchbrüche in diesem Bereich. Einer der Durchbrüche wurde zum Beispiel von einem Facebook-Team mit einem Artikel mit dem Titel “Unsupervised Machine Translation Using Monolingual Corpora Only” erreicht.
Was das Facebook-Team in diesem Artikel getan hat, war, ein Übersetzungssystem aufzubauen, das nur einen Korpus englischen Textes und einen Korpus französischen Textes verwendet. Diese beiden Korpora haben nichts gemeinsam; es handelt sich nicht einmal um denselben Text. Es handelt sich einfach um Text auf Englisch und Text auf Französisch. Dann haben sie ohne tatsächliche Übersetzung dem System beigebracht, von Englisch nach Französisch zu übersetzen. Dies ist ein absolut beeindruckendes Ergebnis. Übrigens wird dies durch eine Technik erreicht, die unglaublich an die generativen gegnerischen Netzwerke erinnert, die ich gerade zuvor vorgestellt habe. Ebenso hat vor zwei Jahren ein Team bei Google BERT (Bidirectional Encoder Representations from Transformers) veröffentlicht. BERT ist ein Modell, das weitgehend unüberwacht trainiert wird. Wir sprechen wieder über Text. Bei BERT wird dies erreicht, indem riesige Textdatenbanken genommen und Wörter zufällig maskiert werden. Dann trainieren Sie das Modell, um diese Wörter vorherzusagen, und wiederholen Sie dies für den gesamten Korpus. Einige Leute bezeichnen diese Technik als selbstüberwacht, aber was bei BERT sehr interessant ist und wo es für die Supply Chain relevant wird, ist, dass plötzlich die Art und Weise, wie Sie Ihre Daten angehen, darin besteht, eine Maschine zu bauen, in der Sie Teile der Daten verbergen können und die Maschine immer noch in der Lage ist, die Daten zu vervollständigen.
Der Grund, warum dies für die Supply Chain von größter Bedeutung ist, besteht darin, dass das, was mit BERT im Zusammenhang mit der natürlichen Sprachverarbeitung getan wird, auf viele andere Bereiche ausgedehnt werden kann. Es ist die ultimative “Was-wäre-wenn”-Antwortmaschine. Was wäre zum Beispiel, wenn ich noch einen Laden hätte? Dieses “Was-wäre-wenn” kann beantwortet werden, weil Sie einfach Ihre Daten ändern, den Laden hinzufügen und das gerade erstellte maschinelle Lernmodell abfragen können. Was wäre, wenn ich ein zusätzliches Produkt hätte? Was wäre, wenn ich einen zusätzlichen Kunden hätte? Was wäre, wenn ich einen anderen Preis für dieses Produkt hätte? Und so weiter. Unüberwachtes Lernen ist von großem Interesse, weil Sie Ihre Daten als Ganzes behandeln und nicht nur als Liste von Paaren. Sie erhalten einen Mechanismus, der völlig allgemein ist und Vorhersagen zu jedem Aspekt treffen kann, der in den Daten irgendwie vorhanden ist. Das ist sehr mächtig.
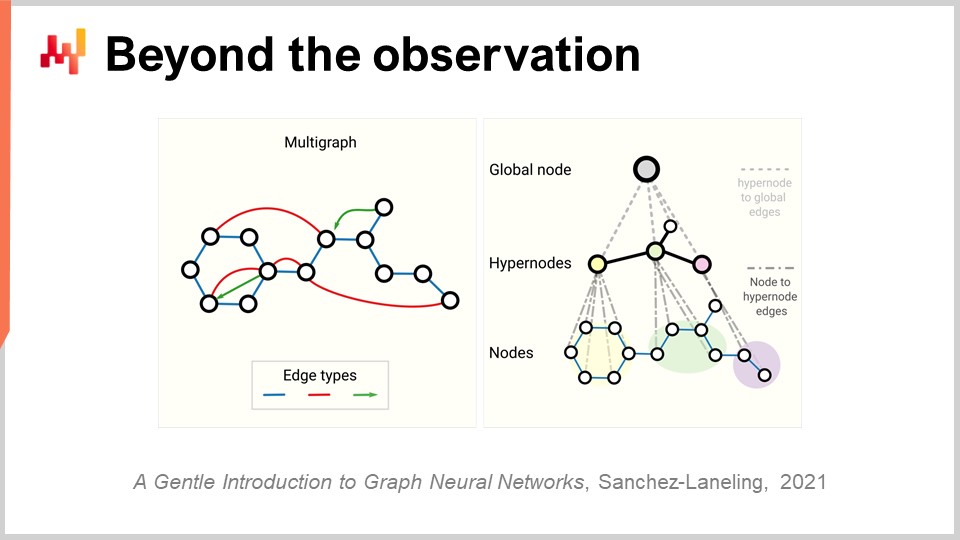
Jetzt müssen wir das Konzept der Beobachtung noch einmal überdenken. Zunächst haben wir gesagt, dass eine Beobachtung ein Paar von Merkmalen plus einem Label ist. Wir haben gesehen, wie wir das Label entfernen können, aber was ist mit den Merkmalen selbst und der Beobachtung? Das Problem bei der Supply Chain ist, dass wir keine wirklichen Beobachtungen haben. Es ist nicht einmal klar, dass wir eine Supply Chain in eine Liste unabhängiger oder homogener Beobachtungen zerlegen können. Wie in einem früheren Vortrag erörtert, was wir zur Beobachtung einer Supply Chain benötigen, ist keine direkte wissenschaftliche Beobachtung der Supply Chain selbst. Was wir haben, sind eine Reihe von Unternehmenssoftware-Stücken, und die einzige Möglichkeit, eine Supply Chain zu beobachten, besteht indirekt durch die in diesen Unternehmenssoftware-Stücken gesammelten Aufzeichnungen. Das kann das ERP sein, das WMS, der Point of Sale usw. Aber die Quintessenz ist, dass alles, was wir haben, im Wesentlichen elektronische Aufzeichnungen sind, die transaktionaler Natur sind, weil all diese Systeme typischerweise auf transaktionalen Datenbanken implementiert sind. Die Beobachtungen sind also nicht unabhängig. Die Aufzeichnungen, die wir haben, sind relational, ganz wörtlich, weil sie in einer relationalen Datenbank existieren. Wenn ich sage, dass sie Beziehungen haben, meine ich, dass ein Kunde mit einer Treue-Karte beispielsweise mit allen Produkten verbunden ist, die er gekauft hat. Jedes einzelne Produkt ist mit allen Geschäften verbunden, in denen das Produkt Teil des Sortiments ist. Jedes einzelne Geschäft ist mit allen Lagern verbunden, die die Kapazität haben, das gewünschte Geschäft zu bedienen. Wir haben also keine unabhängigen Beobachtungen; wir haben Daten mit einer Vielzahl von relationalen Strukturen, die darauf überlagert sind, und keines dieser Elemente ist wirklich unabhängig von den anderen.
Der relevante Durchbruch im Bereich des Deep Learning, um mit solchen vernetzten Daten umzugehen, wird als Graph-Learning bezeichnet. Graph-Learning ist genau das, was Sie benötigen, um Verhaltensweisen wie Substitution und Kannibalisierung in der Mode anzugehen. Der beste Weg, Kannibalisierung zu verstehen, besteht darin, dass alle Produkte um dieselben Kunden konkurrieren, und indem Sie die Daten analysieren, die Kunden und Produkte verbinden, können Sie Kannibalisierung analysieren. Vorsicht, Graph-Learning hat nichts mit Graphdatenbanken zu tun, die etwas völlig anderes sind. Graphdatenbanken sind im Wesentlichen nur Datenbanken, die zum Abfragen von Graphen verwendet werden, ohne dass dabei ein Lernprozess stattfindet. Beim Graph-Learning geht es darum, zusätzliche Eigenschaften der Graphen selbst zu erlernen. Es geht darum, Beziehungen zu erlernen, die beobachtet oder nicht beobachtet werden können, oder um die Art der Beziehung zu dekorieren, die wir mit einer überlagernden handlungsorientierten Kenntnis haben.
Meiner Meinung nach wird Graph-Learning aufgrund der Tatsache, dass die Supply Chain von Natur aus ein System ist, in dem alle Teile miteinander verbunden sind - das ist der Fluch der Supply Chain, bei dem Sie nichts lokal optimieren können, ohne Probleme zu verlagern - immer häufiger als Ansatz zur Bewältigung dieser Probleme in der Supply Chain und im maschinellen Lernen eingesetzt werden. Im Wesentlichen handelt es sich bei Graph-Neuralen Netzwerken um Deep-Learning-Techniken, die für den Umgang mit Graphen entwickelt wurden.
Zusammenfassend lässt sich sagen, dass es naiv ist zu denken, dass maschinelles Lernen darauf abzielt, genauere Prognosen zu liefern. Es ist so, als würde man sagen, dass der Hauptzweck eines Autos darin besteht, schneller Zugang zu einem Pferd zu haben. Ja, es ist wahr, dass wir mit Hilfe des maschinellen Lernens wahrscheinlich genauere Prognosen erstellen können. Dies ist jedoch nur ein kleiner Teil eines sehr großen Bildes, und ein Bild, das immer größer wird, da es Durchbrüche in der maschinellen Lerngemeinschaft gibt. Wir begannen mit maschinellen Lernframeworks, die eine Reihe von Konzepten umfassten: Merkmal, Label, Beobachtung, Modell und Verlust. Dieses kleine, elementare Framework war bereits weitaus allgemeiner als die Perspektive der Zeitreihenprognose. Mit der jüngsten Entwicklung des maschinellen Lernens sehen wir, dass selbst diese Konzepte langsam an Bedeutung verlieren, da wir Wege entdecken, sie zu überwinden. Für die Supply Chain ist dieser Paradigmenwechsel von entscheidender Bedeutung, denn er bedeutet, dass wir diesen Paradigmenwechsel auch bei der Prognose anwenden müssen. Das maschinelle Lernen zwingt uns dazu, völlig neu darüber nachzudenken, wie wir Daten angehen und was wir mit Daten tun können. Das maschinelle Lernen öffnet Türen, die bis vor kurzem fest verschlossen waren.

Werfen wir nun einen Blick auf einige Fragen.
Frage: Verwenden Random Forests nicht Bagging?
Meine Meinung ist, dass sie eine Erweiterung davon sind und mehr als nur Bagging beinhalten. Bagging ist eine interessante Technik, aber immer wenn Sie eine maschinelle Lerntechnik sehen, müssen Sie sich fragen: Wird mich diese Technik dazu befähigen, mich in Richtung meiner Fähigkeit zur Lösung wirklich schwieriger Probleme wie Kannibalisierung oder Substitution weiterzuentwickeln? Und wird diese Art von Technik gut mit der von Ihnen verwendeten Hardware zusammenarbeiten? Dies ist eine der wichtigsten Erkenntnisse, die Sie aus diesem Vortrag mitnehmen sollten.
Frage: Mit dem Drängen der Unternehmen auf vollständige Automatisierung mit Robotern, wie sieht die Zukunft der Logistiklagerarbeiter aus? Werden sie in naher Zukunft von Robotern ersetzt?
Diese Frage hat nicht unbedingt etwas mit maschinellem Lernen zu tun, aber es ist eine sehr gute Frage. Fabriken haben eine massive Transformation in Richtung umfassender Robotisierung durchlaufen, die möglicherweise Roboter verwendet oder auch nicht. Die Produktivität von Fabriken hat zugenommen, und selbst in China sind Fabriken größtenteils stark automatisiert. Lagerhäuser waren spät dran. Was ich jedoch heute sehe, ist die Entwicklung von Lagern, die immer mechanischer und automatisierter werden. Ich würde nicht unbedingt sagen, dass es sich um Roboter handelt; es gibt viele konkurrierende Technologien, um ein Lager zu bauen, das einen höheren Grad an Automatisierung erreicht. Die Quintessenz ist, dass der Trend klar ist. Lagerhäuser und Logistikzentren im Allgemeinen werden die gleiche Art von massiver Produktivitätssteigerung durchlaufen, die wir bereits in der Produktion erlebt haben.
Um Ihre Frage zu beantworten, möchte ich sagen, dass Menschen nicht unbedingt von Robotern ersetzt werden, sondern von Automatisierung. Automatisierung kann manchmal in Form eines Roboters auftreten, aber sie kann auch viele andere Formen annehmen. Einige dieser Formen sind einfach clevere Lösungen, die die Produktivität erheblich verbessern, ohne die Art von Technologie einzubeziehen, die wir intuitiv mit Robotern in Verbindung bringen. Ich glaube jedoch, dass der logistische Teil der Lieferkette insgesamt schrumpfen wird. Das Einzige, was dies derzeit noch steigert, ist die Tatsache, dass wir uns mit dem Aufkommen des E-Commerce um den letzten Kilometer kümmern müssen. Der letzte Kilometer beansprucht zunehmend den Großteil der Arbeitskräfte, die sich mit Logistik befassen müssen. Selbst der letzte Kilometer wird in naher Zukunft automatisiert sein. Autonome Fahrzeuge stehen kurz vor der Tür; sie wurden für dieses Jahrzehnt versprochen, und obwohl sie vielleicht etwas spät kommen, werden sie kommen.
Frage: Glauben Sie, dass es sich lohnt, Zeit zu investieren, um maschinelles Lernen zu erlernen, um in der Lieferkette zu arbeiten?
Absolut. Meiner Meinung nach ist maschinelles Lernen eine Hilfswissenschaft der Lieferkette. Betrachten Sie die Beziehung, die ein Arzt zur Chemie hat. Wenn Sie ein Arzt der heutigen Zeit sind, erwartet niemand von Ihnen, dass Sie ein Chemiker sind. Wenn Sie Ihrem Patienten jedoch sagen, dass Sie absolut nichts über Chemie wissen, würden die Leute denken, dass Sie nicht das Zeug dazu haben, ein moderner Arzt zu sein. Maschinelles Lernen sollte genauso angegangen werden, wie Menschen, die Medizin studieren, sich der Chemie nähern. Es ist kein Ende, sondern ein Mittel. Wenn Sie ernsthafte Arbeit in der Lieferkette leisten möchten, müssen Sie solide Grundlagen im maschinellen Lernen haben.
Frage: Können Sie Beispiele nennen, in denen Sie maschinelles Lernen angewendet haben? Wurde das Tool operational?
Ich spreche hier als Joannes Vermorel, der Unternehmer und CEO von Lokad. Wir haben derzeit über 100 Unternehmen in Produktion, die alle maschinelles Lernen für verschiedene Aufgaben verwenden. Diese Aufgaben umfassen die Vorhersage von Durchlaufzeiten, die Erstellung probabilistischer Nachfrageprognosen, die Vorhersage von Rücksendungen, die Vorhersage von Qualitätsproblemen, die Überarbeitung von Schätzungen der mittleren Zeit zwischen ungeplanten Reparaturen und die Erkennung, ob wettbewerbsfähige Preise korrekt sind oder nicht. Es gibt viele Anwendungen, wie die Neubewertung von Kompatibilitätsmatrizen zwischen Autos und Teilen im Automobil-Ersatzteilmarkt. Mit maschinellem Lernen können Sie einen großen Teil der Datenbankfehler automatisch beheben. Bei Lokad haben wir nicht nur diese 100 Unternehmen in Produktion, sondern das ist seit fast einem Jahrzehnt der Fall. Die Zukunft ist bereits da, sie ist nur nicht gleichmäßig verteilt.
Frage: Was ist der beste Weg, um maschinelles Lernen in Ihrer Freizeit zu lernen? Würden Sie Websites wie Udemy, Coursera oder etwas anderes empfehlen?
Mein Vorschlag wäre eine Kombination aus Wikipedia und dem Lesen von wissenschaftlichen Artikeln. Wie Sie in diesem Vortrag gesehen haben, ist es wichtig, die Grundlagen zu verstehen und über die neuesten Entwicklungen auf dem Laufenden zu bleiben. Wie Sie in diesen Vorträgen gesehen haben, zitiere ich tatsächliche Forschungsarbeiten. Vertrauen Sie nicht auf Informationen aus zweiter Hand, sondern gehen Sie direkt zu dem, was veröffentlicht wurde. All diese Informationen sind direkt online verfügbar. Es gibt wissenschaftliche Arbeiten im Bereich des maschinellen Lernens, die schlecht geschrieben und unverständlich sind, aber es gibt auch Arbeiten, die brillant geschrieben sind und klare Einblicke darüber geben, was vor sich geht. Mein Vorschlag ist, Wikipedia für einen Überblick über ein Fachgebiet zu nutzen, damit Sie das große Ganze verstehen, und dann mit dem Lesen von wissenschaftlichen Artikeln zu beginnen. Anfangs mag es undurchsichtig erscheinen, aber nach einer Weile werden Sie sich daran gewöhnen. Sie können Udemy oder Coursera nutzen, aber persönlich habe ich das nie gemacht. Mein Ziel bei diesen Vorträgen ist es, Ihnen ein paar intuitive Denkanstöße zu geben, damit Sie das große Ganze verstehen. Wenn Sie in die Details gehen möchten, steigen Sie einfach in den tatsächlichen Artikel ein, der vor Jahren oder Jahrzehnten veröffentlicht wurde. Gehen Sie auf Informationen aus erster Hand und vertrauen Sie Ihrer eigenen Intelligenz.
Das Deep Learning ist ein sehr empirisches Forschungsfeld. Die meisten Dinge, die gemacht werden, sind mathematisch gesehen nicht extrem komplex. Es geht in der Regel nicht über das hinaus, was man am Ende der High School lernt, daher ist es ziemlich zugänglich.
Frage: Mit dem Aufkommen von No-Code-Tools wie CodeX und Co-Pilot von OpenAI, glauben Sie, dass Supply-Chain-Experten Modelle irgendwann in einfacher englischer Sprache schreiben werden?
Die kurze Antwort lautet: Nein, überhaupt nicht. Die Idee, dass man das Programmieren umgehen könnte, gibt es schon lange. Zum Beispiel sollte Microsofts Visual Basic ein visuelles Werkzeug sein, damit die Leute nicht mehr programmieren müssen; sie könnten einfach visuell Dinge wie Legos zusammensetzen. Aber heutzutage hat sich dieser Ansatz als unwirksam erwiesen, und der nächste Trend besteht darin, Dinge verbal auszudrücken.
Allerdings verwende ich in diesen Vorträgen mathematische Formeln, weil es viele Situationen gibt, in denen eine mathematische Formel die einzige Möglichkeit ist, klar zu vermitteln, was man sagen möchte. Das Problem mit der englischen Sprache oder jeder natürlichen Sprache ist, dass sie oft ungenau und anfällig für Missinterpretationen ist. Im Gegensatz dazu sind mathematische Formeln präzise und klar. Das Problem mit einfacher Sprache ist, dass sie unglaublich vage ist, und obwohl sie ihre Verwendung hat, verwenden wir Formeln, um eine eindeutige Bedeutung dessen zu liefern, was gesagt wird. Ich versuche, Formeln nur begrenzt einzusetzen, aber wenn ich eine einbeziehe, dann deshalb, weil ich das Gefühl habe, dass es die einzige Möglichkeit ist, die Idee klar zu vermitteln, mit einer Klarheit, die ich verbal nicht erreichen kann.
In Bezug auf Low-Code-Plattformen bin ich sehr skeptisch, da dieser Ansatz in der Vergangenheit bereits viele Male ohne großen Erfolg versucht wurde. Meine persönliche Meinung ist, dass wir das Programmieren besser für das Supply Chain Management machen sollten, indem wir herausfinden, warum das Programmieren schwierig ist, und zufällige Komplexität beseitigen. Was übrig bleibt, ist das richtige Programmieren für die Supply Chain, und das ist es, was Lokad erreichen möchte.
Frage: Macht maschinelles Lernen die Nachfrageprognose für saisonale oder regelmäßige Verkaufshistoriendaten genauer?
Wie ich in diesem Vortrag erwähnt habe, macht maschinelles Lernen das Konzept der Genauigkeit überflüssig. Wenn Sie sich den letzten großen Wettbewerb zur Zeitreihenprognose, den M5-Wettbewerb, ansehen, waren die besten 10 Modelle alle in gewissem Maße maschinelles Lernen. Macht maschinelles Lernen also genauere Prognosen? Tatsächlich ja, basierend auf dem Prognosewettbewerb. Aber es ist nur marginal genauer im Vergleich zu anderen Techniken, und es ist keine bahnbrechende zusätzliche Genauigkeit.
Außerdem sollten Sie nicht in einer eindimensionalen Perspektive über Prognosen nachdenken. Wenn Sie nach Genauigkeit für Saisonalität fragen, betrachten Sie ein Produkt nach dem anderen, aber das ist nicht der richtige Ansatz. Wahre Genauigkeit besteht darin zu bewerten, wie sich die Einführung eines neuen Produkts auf alle anderen Produkte auswirkt, da es eine gewisse Kannibalisierung geben wird. Der Schlüssel besteht darin zu bewerten, ob die Art und Weise, wie Sie diese Kannibalisierung in Ihrem Modell widerspiegeln, korrekt ist oder nicht. Plötzlich wird dies zu einem mehrdimensionalen Problem. Wie ich in der Vorlesung mit generativen Netzwerken dargelegt habe, muss die Metrik dessen, was Genauigkeit tatsächlich bedeutet, erlernt werden; sie kann nicht vorgegeben werden. Mathematische Formeln wie der mittlere absolut Fehler, der mittlere absolute prozentuale Fehler und der mittlere quadratische Fehler sind nur mathematische Kriterien. Sie sind nicht die Art von Metriken, die wir tatsächlich benötigen; sie sind nur sehr naive Metriken.
Frage: Wird die mühsame Arbeit der Prognostiker durch die automatische Prognose ersetzt?
Ich würde sagen, die Zukunft ist bereits da, aber sie ist nicht gleichmäßig verteilt. Bei Lokad prognostizieren wir bereits täglich Millionen von SKU, und ich habe niemanden, der Prognosen bezahlt. Ja, es wird bereits gemacht, aber das ist nur ein kleiner Teil des Bildes. Wenn Sie Leute benötigen, die Prognosen anpassen oder Prognosemodelle optimieren, deutet dies auf einen dysfunktionalen Ansatz hin. Sie sollten die Notwendigkeit, Prognosen anzupassen, als Fehler betrachten und diesen Teil des Prozesses automatisieren.
Aus Lokads Erfahrung werden diese Dinge vollständig eliminiert, weil wir sie bereits erledigt haben. Wir sind nicht die einzigen, die es auf diese Weise tun, also ist es für uns fast schon Geschichte, seit fast einem Jahrzehnt.
Frage: Wie aktiv wird maschinelles Lernen bei der Entscheidungsfindung in der Supply Chain eingesetzt?
Das hängt vom Unternehmen ab. Bei Lokad wird es überall eingesetzt, und wenn ich “bei Lokad” sage, meine ich Unternehmen, die von Lokad bedient werden. Die überwiegende Mehrheit des Marktes verwendet jedoch immer noch Excel, ohne maschinelles Lernen. Lokad verwaltet aktiv Milliarden von Euro oder Dollar an Lagerbeständen, das ist also bereits Realität und das schon seit geraumer Zeit. Aber Lokad ist nicht einmal 0,1% des Marktes, also sind wir immer noch eine Ausnahme. Wir wachsen schnell, genauso wie einige Konkurrenten. Meine Vermutung ist, dass es immer noch eine Randerscheinung im gesamten Supply-Chain-Markt ist, aber es gibt zweistelliges Wachstum. Unterschätzen Sie niemals die Kraft des exponentiellen Wachstums über einen langen Zeitraum. Letztendlich wird es sehr groß werden, hoffentlich mit Lokad, aber das ist eine andere Geschichte.
Frage: Mit vielen Unbekannten in der Supply Chain, welche Strategie kann angenommen werden, um Annahmen für ein Modell zu treffen?
Die Idee ist, dass es zwar viele Unbekannte gibt, aber die Eingaben Ihres Modells sind nicht wirklich wählbar. Es kommt darauf an, was Sie in Ihren Unternehmenssystemen haben, wie zum Beispiel welche Art von Daten in Ihrem ERP vorhanden ist. Wenn Ihr ERP historische Lagerbestände hat, können Sie sie als Teil Ihres maschinellen Lernmodells verwenden. Wenn Ihr ERP nur aktuelle Lagerbestände führt, stehen diese Daten nicht zur Verfügung. Sie können anfangen, Ihre Lagerbestände zu erfassen, wenn Sie sie als zusätzliche Eingaben verwenden möchten, aber die Kernbotschaft ist, dass es sehr wenig Auswahlmöglichkeiten gibt, was Sie als Eingaben verwenden können; es ist buchstäblich das, was in Ihren Systemen vorhanden ist.
Mein üblicher Ansatz ist, dass es langsam und schmerzhaft ist, neue Datenquellen zu erstellen, und das wird wahrscheinlich nicht Ihr Ausgangspunkt für den Einsatz von maschinellem Lernen in der Supply Chain sein. Größere Unternehmen sind seit Jahrzehnten digitalisiert, daher ist das, was Sie in Ihren Transaktionssystemen wie Ihrem ERP und WMS haben, bereits ein ausgezeichneter Ausgangspunkt. Wenn Sie später feststellen, dass Sie mehr haben möchten, wie zum Beispiel Wettbewerbsinformationen, autorisierte Lagerbestände oder von Ihren Lieferanten angegebene voraussichtliche Liefertermine, sind dies lohnenswerte Ergänzungen, die als Eingaben für Ihre Modelle verwendet werden können. Normalerweise verwenden Sie als Eingaben etwas, von dem Sie eine gute Intuition haben, dass es mit dem, was Sie zuerst vorhersagen möchten, korreliert, und eine hochrangige Intuition reicht normalerweise aus. Gesunder Menschenverstand, der schwer zu definieren ist, ist weitgehend ausreichend. Dies ist nicht der Engpass in Bezug auf die Technik.
Frage: Welchen Einfluss haben Preisentscheidungen auf die Schätzung der zukünftigen Nachfrage, auch aus probabilistischer Sicht, und wie geht man damit aus einer maschinellen Lernperspektive um?
Das ist eine sehr gute Frage. Es gab eine Episode auf LokadTV, die genau dieses Problem behandelte. Die Idee ist, dass das, was Sie lernen, zu dem wird, was in der Regel als Richtlinie bekannt ist, ein Objekt, das die Art und Weise steuert, wie Sie auf verschiedene Ereignisse reagieren. Die Art und Weise, wie Sie prognostizieren, besteht darin, eine Art Landschaft im Monte-Carlo-Stil zu erzeugen. Sie werden eine Trajektorie erzeugen, aber Ihre Prognose wird keine statischen Datenpunkte sein. Es wird ein viel generativerer Prozess sein, bei dem Sie in jedem Stadium des Prognoseprozesses die Art von Nachfrage generieren müssen, die Sie beobachten können, die Entscheidungen generieren, die Sie treffen, und die Art von Marktreaktion auf das, was Sie gerade getan haben, erneut generieren.
Es wird sehr kompliziert, die Genauigkeit Ihres Nachfragegenerierungsprozesses zu bewerten, und deshalb müssen Sie Ihre Prognosemetriken tatsächlich erlernen. Das ist sehr knifflig, aber deshalb können Sie Ihre Prognosemetriken, Ihre Genauigkeitsmetriken, nicht als eindimensionales Problem betrachten. Zusammenfassend lässt sich sagen, dass die Nachfrageprognose zu einem Generator wird, sie ist also grundsätzlich dynamisch, nicht statisch. Es ist etwas, das generativ ist. Dieser Generator reagiert auf einen Agenten, einen Agenten, der als Richtlinie implementiert wird. Sowohl der Generator als auch das politische Entscheidungssystem müssen erlernt werden. Sie müssen auch die Verlustfunktion erlernen. Es gibt viel zu lernen, aber zum Glück ist Deep Learning ein sehr modularer und programmatischer Ansatz, der sich gut zur Zusammensetzung all dieser Techniken eignet.
Frage: Ist es schwierig, Daten zu sammeln, insbesondere von KMUs?
Ja, es ist sehr schwierig. Der Grund dafür ist, dass es bei einem Unternehmen mit einem Umsatz von weniger als 10 Millionen keine IT-Abteilung gibt. Es kann ein kleines ERP vorhanden sein, aber selbst wenn die Tools gut, anständig und modern sind, gibt es keine IT-Abteilung im Unternehmen. Wenn Sie nach den Daten fragen, gibt es niemanden im Kundenunternehmen, der die Kompetenz hat, eine SQL-Abfrage auszuführen, um die Daten abzurufen.
Ich bin mir nicht sicher, ob ich Ihre Frage richtig verstehe, aber das Problem besteht nicht darin, die Daten zu sammeln. Das Sammeln der Daten erfolgt natürlich über die Buchhaltungssoftware oder das ERP, das vorhanden ist, und heutzutage gibt es sogar ERPs, die für ziemlich kleine Unternehmen zugänglich sind. Das Problem ist die Extraktion von Daten aus diesen Unternehmenssoftwareteilen. Wenn Sie mit einem Unternehmen zusammenarbeiten, das einen Umsatz von weniger als 20 Millionen US-Dollar hat und kein E-Commerce-Unternehmen ist, ist die IT-Abteilung in der Regel nicht vorhanden. Selbst wenn es eine winzige IT-Abteilung gibt, ist es in der Regel nur eine Person, die für die Einrichtung von Maschinen und Windows-Desktops für alle verantwortlich ist. Es handelt sich nicht um jemanden, der mit Datenbanken und fortgeschritteneren administrativen Aufgaben im Bereich IT-Setups vertraut ist.
Okay, ich denke, das ist es. Die nächste Sitzung wird in ein paar Wochen stattfinden. Sie wird am Mittwoch, dem 13. Oktober, stattfinden. Bis zum nächsten Mal!
Referenzen
- A theory of the learnable, L. G. Valiant, November 1984
- Support-vector networks, Corinna Cortes, Vladimir Vapnik, September 1995
- Random Forests, Leo Breiman, Oktober 2001
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, zuletzt überarbeitet im Dezember 2017
- Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, Dezember 2019
- Analyzing and Improving the Image Quality of StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, zuletzt überarbeitet im März 2020
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Juni 2014
- Unsupervised Machine Translation Using Monolingual Corpora Only, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, zuletzt überarbeitet im April 2018
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, zuletzt überarbeitet im Mai 2019
- A Gentle Introduction to Graph Neural Networks, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, September 2021


