00:21 Introduction
01:53 De la prévision à l’apprentissage
05:32 Machine learning 101
09:51 L’histoire jusqu’à présent
11:49 Mes prévisions pour aujourd’hui
13:54 Précis sur des données que nous n’avons pas 1/4
16:30 Précis sur des données que nous n’avons pas 2/4
20:03 Précis sur des données que nous n’avons pas 3/4
25:11 Précis sur des données que nous n’avons pas 4/4
31:49 Gloire au template matcher
35:36 Une profondeur dans l’apprentissage 1/4
39:11 Une profondeur dans l’apprentissage 2/4
44:27 Une profondeur dans l’apprentissage 3/4
47:29 Une profondeur dans l’apprentissage 4/4
51:59 Donnez tout ou rentrez chez vous
56:45 Au-delà de la perte 1/2
01:00:17 Au-delà de la perte 2/2
01:04:22 Au-delà de l’étiquette
01:10:24 Au-delà de l’observation
01:14:43 Conclusion
01:16:36 Prochaine conférence et questions du public
Description
Les prévisions sont irréductibles dans la supply chain car chaque décision (achat, production, gestion des stocks, etc.) reflète une anticipation des événements futurs. L’apprentissage statistique et machine learning ont largement supplanté le domaine classique de la ‘prévision’, tant d’un point de vue théorique que pratique. Nous tenterons de comprendre ce que signifie réellement une anticipation du futur basée sur les données, dans une perspective moderne de l’apprentissage.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter « Machine Learning for Supply Chain ». Nous ne pouvons pas imprimer en 3D des biens en temps réel, et nous ne pouvons pas les téléporter à l’endroit où ils devraient être livrés. En réalité, presque toutes les décisions supply chain doivent être prises en anticipant, en prévoyant la demande future ou les mouvements de prix, reflétant implicitement ou explicitement des conditions de marché futures anticipées, que ce soit du côté de la demande ou de l’offre. En conséquence, la prévision constitue une partie intégrante et irréductible de la supply chain. Nous ne connaissons jamais l’avenir avec certitude ; nous ne pouvons qu’émettre des hypothèses sur le futur avec différents degrés de certitude. Le but de cette conférence est de comprendre ce que le machine learning apporte en matière de capture du futur.

Nous verrons dans cette conférence que fournir des prévisions précises est, dans l’ensemble, une préoccupation relativement secondaire. En fait, de nos jours dans la supply chain, la prévision signifie la prévision des séries temporelles. Historiquement, les prévisions basées sur les séries temporelles sont devenues populaires au début du XXe siècle aux États-Unis. En effet, les États-Unis furent le premier pays à avoir des millions d’employés de la classe moyenne qui possédaient également des stocks. Comme les gens voulaient être des investisseurs avisés, ils désiraient obtenir des éclairages sur leurs investissements, et il s’est avéré que les séries temporelles et leurs prévisions étaient un moyen intuitif et efficace de transmettre ces informations. Vous pouviez obtenir des prévisions des séries temporelles sur les prix futurs du marché, les dividendes futurs et les parts de marché futures.
Dans les années 80 et 90, lorsque la supply chain a été essentiellement digitalisée, les logiciels d’entreprise de la supply chain ont également commencé à bénéficier des prévisions des séries temporelles. En réalité, les prévisions des séries temporelles sont devenues omniprésentes dans ce type de logiciels d’entreprise. Cependant, si vous regardez cette image, vous pouvez constater que les prévisions des séries temporelles constituent en fait une manière très simpliste et naïve d’envisager l’avenir.
Vous voyez, rien qu’en regardant cette image, je peux déjà prédire ce qui se passera ensuite : très probablement une équipe va arriver, nettoyer ce désordre, et très probablement inspecter ensuite les chariots élévateurs pour des raisons de sécurité. Ils pourraient même effectuer quelques petites réparations, et avec un haut degré de confiance, je peux affirmer que ce chariot élévateur sera très probablement remis en service prochainement. Rien qu’en observant cette image, nous pouvons également prédire quelles conditions ont mené à cette situation. Rien de tout cela ne correspond à la perspective d’une prévision par séries temporelles, et pourtant, toutes ces prédictions sont très pertinentes.
Ces prédictions ne concernent pas l’avenir en soi, puisque cette image a été prise il y a un moment, et même les événements qui ont suivi la prise de cette image font désormais partie de notre passé. Néanmoins, ce sont des prédictions dans la mesure où nous formulons des affirmations sur des éléments que nous ne connaissons pas avec certitude. Nous n’avons pas de mesure directe. La question principale est donc de savoir comment je suis capable de produire ces prédictions et de formuler ces affirmations ?
Il s’avère qu’en tant qu’être humain, j’ai vécu, j’ai été témoin d’événements et j’en ai tiré des enseignements. C’est ainsi que je peux réellement formuler ces affirmations. Et il s’avère que le machine learning, c’est exactement cela : c’est l’ambition de pouvoir répliquer cette capacité d’apprentissage avec des machines, les ordinateurs étant de loin les machines privilégiées de nos jours. À ce stade, vous vous demandez peut-être comment le machine learning se différencie d’autres termes tels qu’intelligence artificielle, technologies cognitives ou apprentissage statistique. Eh bien, il s’avère que ces termes en disent beaucoup plus sur les personnes qui les utilisent que sur le problème lui-même. Du point de vue des problèmes, les frontières entre tous ces domaines sont très floues.

Approfondissons avec une revue de l’archétype des cadres de machine learning, couvrant une courte série de concepts centraux du machine learning. La plupart des articles scientifiques et des logiciels produits dans ce domaine utilisent largement ce cadre. La caractéristique représente une donnée mise à disposition pour accomplir la tâche de prédiction. L’idée est que vous avez une tâche de prédiction à réaliser, et une caractéristique (ou plusieurs) représente ce qui est fourni pour accomplir cette tâche. Dans le contexte des prévisions des séries temporelles, la caractéristique représenterait la partie passée de la série temporelle, et vous disposeriez d’un vecteur de caractéristiques représentant l’ensemble des points de données passés.
L’étiquette représente la réponse à la tâche de prédiction. Dans le cas d’une prévision des séries temporelles, elle représente généralement la portion de la série temporelle que vous ne connaissez pas, là où se trouve le futur. Si vous disposez d’un ensemble de caractéristiques et d’une étiquette, cela s’appelle une observation. Le cadre typique du machine learning suppose que vous avez un ensemble de données contenant à la fois des caractéristiques et des étiquettes, ce qui représente votre ensemble de données d’entraînement.
Le but est de créer un programme appelé le modèle qui prend les caractéristiques en entrée et calcule l’étiquette prédite souhaitée. Ce modèle est généralement conçu grâce à un processus d’apprentissage qui parcourt l’ensemble des données d’entraînement et construit le modèle. L’apprentissage dans le machine learning est la partie où vous construisez réellement le programme qui effectue les prédictions.
Enfin, il y a la perte. La perte est essentiellement la différence entre l’étiquette réelle et celle prédite. L’objectif est que le processus d’apprentissage génère un modèle dont les prédictions se rapprochent le plus possible des véritables étiquettes. Vous souhaitez un modèle qui maintienne les étiquettes prédites aussi proches que possible des étiquettes réelles.
Le machine learning peut être considéré comme une vaste généralisation de la prévision des séries temporelles. Du point de vue du machine learning, les caractéristiques peuvent être n’importe quoi, et pas seulement un segment passé d’une série temporelle. Les étiquettes peuvent également être n’importe quoi, et pas seulement le segment futur d’une série temporelle. Le modèle peut être n’importe quoi, et même la perte peut être pratiquement n’importe quoi. Ainsi, nous disposons d’un cadre beaucoup plus expressif que les prévisions des séries temporelles. Cependant, comme nous le verrons, la plupart des principales réalisations du machine learning en tant que domaine d’étude et de pratique découlent des découvertes d’éléments qui nous obligent à réexaminer et à remettre en question la liste des concepts que je viens de présenter brièvement.
Cette conférence est la quatrième de la série de conférences sur la supply chain. Les sciences auxiliaires représentent des éléments qui ne constituent pas la supply chain en soi mais revêtent une importance fondamentale pour celle-ci. Dans le premier chapitre, j’ai présenté mes points de vue sur la supply chain à la fois en tant qu’étude physique et en tant que pratique. Dans le deuxième chapitre, nous avons passé en revue une série de méthodologies nécessaires pour aborder un domaine comme la supply chain, qui présente de nombreux comportements antagonistes et ne peut pas être facilement isolé. Le troisième chapitre est entièrement dédié aux personae de la supply chain, qui est une manière de se concentrer sur les problèmes que nous cherchons à résoudre.
Dans ce quatrième chapitre, j’ai progressivement gravi l’échelle de l’abstraction, en commençant par les ordinateurs, puis les algorithmes, et la conférence précédente sur l’optimisation mathématique, que l’on peut considérer comme la couche de base du machine learning moderne. Aujourd’hui, nous nous aventurons dans le machine learning, qui est essentiel pour capturer le futur, omniprésent dans toutes les décisions supply chain que nous devons prendre chaque jour.

Alors, quel est le plan pour cette conférence ? Le machine learning est un domaine de recherche immense, et cette conférence sera guidée par une courte série de questions se rapportant aux concepts et idées que j’ai présentés précédemment. Nous verrons comment les réponses à ces questions nous obligent à revoir la notion même d’apprentissage et notre approche des données. L’une des réalisations les plus spectaculaires du machine learning est qu’il nous a forcés à réaliser qu’il y a bien plus en jeu comparé aux grandes ambitions initiales des chercheurs qui pensaient que nous serions capables de reproduire l’intelligence humaine en une décennie.
En particulier, nous allons jeter un coup d’œil au deep learning, qui est sans doute le meilleur candidat que nous ayons pour émuler un degré supérieur d’intelligence à l’heure actuelle. Bien que le deep learning soit apparu comme une pratique extrêmement empirique, les progrès et réalisations accomplis grâce à celui-ci apportent un nouvel éclairage sur la perspective fondamentale de l’apprentissage à partir de phénomènes observés.
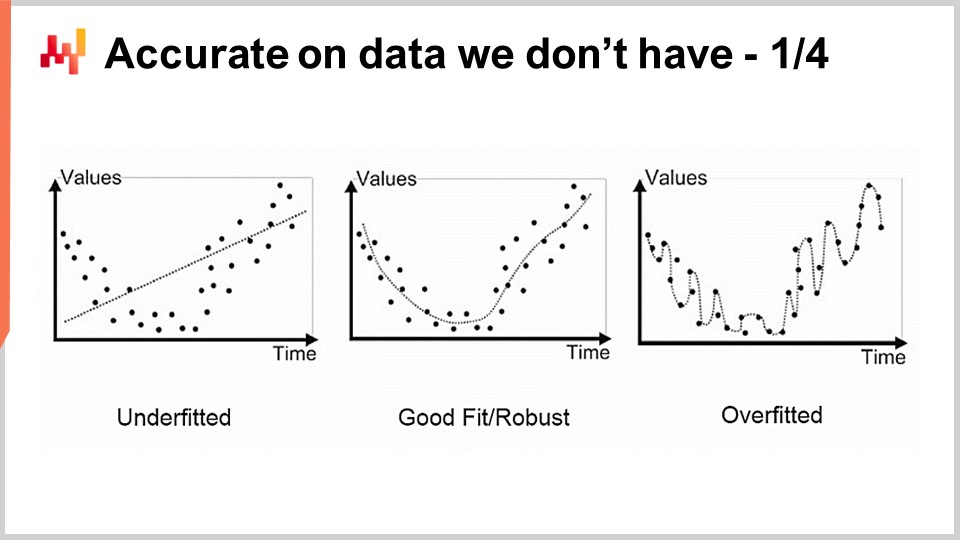
Le premier problème que nous rencontrons avec la modélisation, qu’elle soit statistique ou autre, est la précision des données que nous ne possédons pas. D’un point de vue supply chain, cela est essentiel car notre intérêt réside dans notre capacité à capturer le futur. Par définition, le futur représente un ensemble de données que nous n’avons pas encore. Il existe des techniques, telles que le backtesting ou la validation croisée, qui peuvent nous fournir des mesures empiriques sur ce à quoi nous devrions nous attendre en termes de précision des données manquantes. Cependant, le fait que ces méthodes fonctionnent du tout constitue un problème relativement intrigant et difficile. Le problème n’est pas d’avoir un modèle qui s’adapte aux données dont nous disposons ; il est facile de construire un modèle qui s’adapte aux données en utilisant un polynôme d’un degré suffisant. Pourtant, ce modèle n’est pas très satisfaisant car il ne capture pas ce que nous souhaiterions capturer.
L’approche classique de ce problème est connue sous le nom de compromis biais-variance. À droite, nous avons un modèle avec très peu de paramètres qui sous-ajuste le problème, ce que l’on dit être fortement biaisé. À gauche, nous avons un modèle avec trop de paramètres qui surajuste et présente une variance excessive. Au milieu, nous avons un modèle qui trouve un bon équilibre entre biais et variance, ce que nous appelons un bon ajustement. Jusqu’à la toute fin du 20e siècle, il était assez difficile d’aborder ce problème au-delà du compromis biais-variance.

La première véritable percée concernant la précision des données que nous ne possédons pas est venue des théories de l’apprenabilité publiées par Valiant en 1984. Valiant a introduit la théorie PAC - Probably Approximately Correct. Dans cette théorie PAC, la partie “probably” fait référence à un modèle ayant une probabilité donnée de fournir des réponses suffisamment bonnes. La partie “approximately” signifie que la réponse n’est pas trop éloignée de ce qui est considéré comme bon ou valide.
Valiant a montré que dans de nombreuses situations, il n’est tout simplement pas possible d’apprendre quoi que ce soit, ou plus précisément que, pour apprendre, nous aurions besoin d’un nombre d’échantillons si extraordinairement grand qu’il ne serait pas pratique. Ce fut déjà un résultat très intéressant. La formule présentée provient de la théorie PAC, et c’est une inégalité qui vous indique que si vous souhaitez produire un modèle qui est probably approximately correct, vous devez disposer d’un nombre d’observations, n, supérieur à une certaine quantité. Cette quantité dépend de deux facteurs : epsilon, le taux d’erreur (la partie approximately correct), et eta, la probabilité d’échec (un moins eta étant la probabilité de ne pas échouer).
Ce que nous constatons, c’est que si nous voulons réduire la probabilité d’échec ou diminuer epsilon (un intervalle acceptable), nous avons besoin de plus d’échantillons. Cette formule dépend également de la cardinalité de l’espace des hypothèses. L’idée est que plus il y a d’hypothèses concurrentes, plus il nous faut d’observations pour les distinguer. C’est très intéressant car, en substance, bien que la théorie PAC nous apporte principalement des résultats négatifs, elle nous indique ce que nous ne pouvons pas faire, à savoir construire un modèle provablement Probably Approximately Correct avec moins d’échantillons. La théorie ne nous dit pas vraiment comment faire quoi que ce soit ; elle n’est pas très prescriptive quant à la manière de s’améliorer dans la résolution de toute tâche de prédiction. Néanmoins, ce fut une étape marquante car elle a cristallisé l’idée qu’il était possible d’aborder ce problème de précision et de données manquantes de manière bien plus robuste que de simples mesures empiriques, par exemple à l’aide de la validation croisée ou du backtesting.
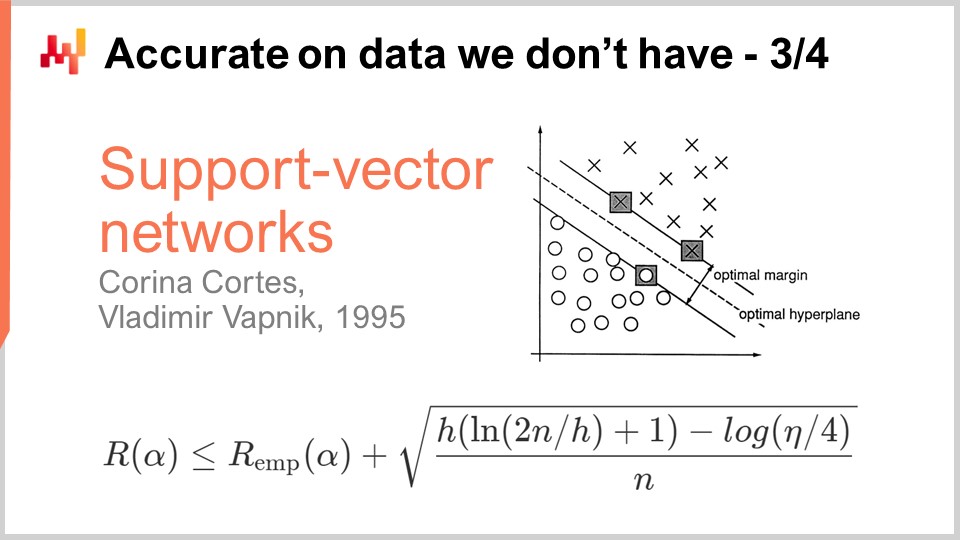
Une décennie plus tard, la première percée opérationnelle survint lorsque Vapnik et quelques autres établirent ce que l’on connaît aujourd’hui sous le nom de théorie Vapnik-Chervonenkis (VC). Cette théorie montre qu’il est possible de capturer la perte réelle, appelée le risque, c’est-à-dire la perte que vous observerez sur les données que vous ne possédez pas. Il fut possible de démontrer mathématiquement que vous aviez la capacité de connaître quoi que ce soit sur l’erreur réelle, qui, par définition, ne peut jamais être mesurée. C’est un résultat très déconcertant.
Essentiellement, cette formule, extraite directement de la théorie VC, nous indique que le risque réel est majoré par le risque empirique, qui est le risque que nous pouvons mesurer sur les données dont nous disposons, auquel s’ajoute un autre terme fréquemment appelé le risque structurel. Nous avons le nombre d’observations, n, et eta, qui est la probabilité d’échec, tout comme dans la théorie PAC. Nous avons également h, qui est une mesure de la dimension VC du modèle. La dimension VC reflète la capacité du modèle à apprendre ; plus la capacité d’apprentissage du modèle est grande, plus la dimension VC est élevée.
Avec ces résultats, nous constatons que pour des modèles ayant la capacité d’apprendre n’importe quoi, nous ne pouvons rien dire à leur sujet. C’est très déconcertant. Si votre modèle peut apprendre n’importe quoi, alors, du moins mathématiquement, vous ne pouvez rien dire à son sujet.
La percée de 1995 est venue d’une implémentation par Cortes et Vapnik de ce qui serait par la suite connu sous le nom de Support Vector Machines (SVM). Ces SVM sont littéralement l’implémentation directe de cette théorie mathématique. L’idée est que, parce que nous disposons d’une théorie qui nous fournit cette inégalité, nous pouvons mettre en œuvre un modèle qui équilibre la quantité d’erreur que nous commettons sur les données (le risque empirique) et la dimension VC. Nous pouvons construire directement un modèle mathématique qui équilibre exactement ces deux facteurs afin de rendre l’égalité aussi serrée et basse que possible. C’est précisément de cela qu’il s’agit avec les Support Vector Machines (SVM). Ces résultats étaient tellement stupéfiants, d’un point de vue opérationnel, qu’ils ont obtenu d’excellents résultats et ont eu un impact significatif sur la communauté du machine learning. Pour la première fois, la précision sur les données que nous ne possédons pas n’était pas une réflexion après coup ; elle était obtenue directement par la conception mathématique de la méthode elle-même. Cela fut si stupéfiant et puissant que toute la communauté du machine learning fut détournée pendant une décennie dans la poursuite de cette voie. Comme nous le verrons, cette voie s’est avérée être en grande partie une impasse, mais il y avait de bonnes raisons à cela : c’était un résultat absolument stupéfiant.
Opérationnellement, du fait que les SVM sont principalement issus d’une théorie mathématique, ils présentaient très peu de sympathie mécanique. Ils n’étaient pas adaptés au matériel informatique dont nous disposons. Plus précisément, l’implémentation naïve des SVM implique un coût quadratique en termes d’empreinte mémoire par rapport au nombre d’observations. C’est beaucoup, et par conséquent, cela rend les SVM très lents. Des améliorations ultérieures, avec certaines variantes en ligne des SVM, ont considérablement réduit les exigences en mémoire, mais néanmoins, les SVM n’ont jamais été vraiment considérés comme une approche véritablement scalable pour réaliser du machine learning.

Les SVM ont ouvert la voie à une autre classe de modèles, meilleurs, qui, probablement, ne souffraient pas de surapprentissage. Le surapprentissage consiste essentiellement à être très inexact sur les données que vous ne possédez pas. Les exemples les plus notables sont probablement les Random Forests et les Gradient Boosted Trees, qui se révèlent être leurs presque immédiats descendants. Au cœur de ces techniques se trouve le boosting, un méta-algorithme qui transforme des modèles faibles en modèles plus performants. Le boosting est apparu suite aux questions soulevées à la toute fin des années 80 entre Kearns et Valiant, que nous avons évoqués précédemment dans cette conférence.
Pour comprendre comment fonctionne une Random Forest, c’est relativement simple : prenez votre ensemble d’entraînement, puis prélevez-en un échantillon. Sur cet échantillon, construisez un arbre de décision. Répétez l’opération, en créant un nouvel échantillon à partir de l’ensemble d’entraînement initial et en construisant un autre arbre de décision. Réitérez ce processus, et à la fin, vous obtenez de nombreux arbres de décision. Les arbres de décision sont relativement faibles en tant que modèles de machine learning, car ils ne peuvent capturer des motifs très complexes. Cependant, si vous regroupez tous ces arbres et faites la moyenne des résultats, ce que vous obtenez est une forêt, appelée Random Forest, parce que chaque arbre a été construit sur un sous-échantillon aléatoire de l’ensemble d’entraînement initial. Ce que vous obtenez avec une Random Forest est un modèle de machine learning bien plus puissant et performant.
Les Gradient Boosted Trees ne sont qu’une variation mineure de cette idée. La principale différence est que, plutôt que de prélever un échantillon de votre ensemble d’entraînement et de construire un arbre de manière aléatoire, avec tous les arbres construits indépendamment, les Gradient Boosted Trees construisent d’abord la forêt, puis le prochain arbre est construit en se basant sur les résidus de la forêt que vous possédez déjà. L’idée est que vous avez commencé à constituer un modèle composé de nombreux arbres, et que vous effectuez des prédictions qui divergent de la réalité. Vous obtenez ces deltas, qui sont les différences entre les valeurs réelles et prédites, appelés résidus. L’idée est que vous allez entraîner le prochain arbre, non pas sur l’ensemble de données initial, mais sur un échantillon de résidus. Les Gradient Boosted Trees fonctionnent encore mieux que les Random Forests. En pratique, les Random Forests montrent un léger surapprentissage, mais très peu. Certaines démonstrations prouvent que, sous certaines conditions, les Random Forests ne devraient pas surapprendre.
Fait intéressant, les Gradient Boosted Trees dominent les meilleurs scores de presque toutes les compétitions de machine learning depuis une décennie et demie. Lorsque vous observez environ 80-90 % des compétitions sur Kaggle, vous constaterez qu’il s’agit essentiellement d’un Gradient Boosted Tree qui arrive en tête. Cependant, malgré cette incroyable domination dans les compétitions de machine learning, il y a eu très peu d’avancées quant à l’application des Gradient Boosted Trees aux problèmes de supply chain dans la pratique. La raison principale est que les Gradient Boosted Trees présentent très peu de sympathie mécanique ; leur conception n’est absolument pas adaptée au matériel informatique dont nous disposons.
Il est facile de comprendre pourquoi : vous construisez un modèle composé d’une série d’arbres, et le modèle finit par être aussi volumineux qu’une fraction de votre ensemble de données. Dans de nombreuses situations, vous vous retrouvez avec un modèle qui est, en termes de données, plus grand que l’ensemble de données de départ. Ainsi, si votre ensemble de données est déjà très grand, alors votre modèle devient gigantesque, et c’est un problème extrêmement problématique.
En ce qui concerne l’histoire des Gradient Boosted Trees, une série d’implémentations a vu le jour, à commencer par GBM (Gradient Boosted Machines) en 2007, qui a véritablement popularisé cette approche via un package R. Dès le départ, il existait des problèmes de scalabilité. On a rapidement commencé à paralléliser l’exécution avec PGBRT (Parallel Gradient Boosted Regression Trees), mais cela restait très lent. XGBoost a constitué une étape marquante car il a gagné un ordre de grandeur en scalabilité. L’astuce dans XGBoost a été d’adopter une conception en colonnes des données pour accélérer la construction des arbres. Par la suite, LightGBM a recyclé toutes les idées d’XGBoost mais en changeant la stratégie de construction des arbres. XGBoost faisait croître l’arbre niveau par niveau, tandis que LightGBM a opté pour une croissance de l’arbre feuille par feuille. Le résultat net est que LightGBM est désormais plusieurs ordres de grandeur plus rapide, compte tenu du même matériel informatique, que GBM ne l’a jamais été. Pourtant, d’un point de vue pratique pour la supply chain, l’utilisation des Gradient Boosted Trees est généralement d’une lenteur impraticable. Il n’est pas impossible de s’en servir ; c’est simplement un obstacle tel que cela ne vaut généralement pas le détour.

Ce qui est déconcertant, c’est que les Gradient Boosted Trees sont suffisamment puissants pour remporter presque toutes les compétitions de machine learning et, pourtant, à mon humble avis, ces modèles représentent une impasse technologique. Les Support Vector Machines, les Random Forests et les Gradient Boosted Trees ont en commun d’être rien de plus que des correspondances de modèles. Ce sont d’excellentes correspondances de modèles, certes, mais rien de plus. Ce qu’ils font remarquablement bien, c’est essentiellement la sélection de variables, et ils excellent dans ce domaine, mais il y a très peu d’autre. En particulier, ils ne possèdent aucune expressivité dans leur capacité à transformer l’entrée en autre chose qu’une simple sélection ou un filtrage direct de celle-ci.
Si nous revenons à l’image du chariot élévateur que j’ai présentée au tout début de cette conférence, il n’y a aucun espoir que l’un de ces modèles puisse formuler le même type d’énoncés que je viens de prononcer, peu importe la taille de l’ensemble d’images. Vous pourriez littéralement alimenter tous ces modèles avec des millions d’images prises dans des warehouses à travers le monde, et ils ne seraient toujours pas capables de formuler des affirmations telles que, “Oh, j’ai vu un chariot élévateur dans cette situation ; une équipe viendra effectuer des réparations.” Pas vraiment.
En pratique, ce que nous avons constaté, c’est que le fait que ces modèles remportent des compétitions de machine learning est trompeur, car certains facteurs jouent en leur faveur dans de telles situations. Premièrement, les ensembles de données du monde réel sont très complexes, ce qui diffère des compétitions de machine learning où, au mieux, vous disposez de petits ensembles de données ne représentant qu’une fraction des complexités rencontrées dans les environnements réels. Deuxièmement, pour gagner une compétition de machine learning en utilisant des modèles comme les Gradient Boosted Trees, il faut réaliser une ingénierie des features poussée. Du fait que ces modèles ne sont que des correspondances de modèles glorifiées, vous devez disposer des bonnes features pour que la simple sélection des variables rende le modèle performant. Il faut injecter une forte dose d’intelligence humaine dans la préparation des données pour que cela fonctionne. C’est un gros problème car, dans le monde réel, lorsqu’on tente de résoudre un problème pour de vraies supply chain, le nombre d’heures d’ingénierie que vous pouvez consacrer au problème est limité. Vous ne pouvez pas passer six mois sur un aspect minime et temporaire d’un problème de votre supply chain.
Le troisième problème est que, dans les supply chain, les ensembles de données évoluent constamment. Ce n’est pas seulement que les données changent, mais le problème lui-même change progressivement. Cela accentue les difficultés liées à l’ingénierie des features. Fondamentalement, nous nous retrouvons avec des modèles qui remportent des compétitions de machine learning et de prévision des séries temporelles, mais si nous regardons une décennie plus loin, nous constatons que ces modèles ne représentent pas l’avenir du machine learning ; ils appartiennent au passé.

Le deep learning fut la réponse à ces correspondances de modèles superficielles. Le deep learning est souvent présenté comme le descendant des réseaux de neurones artificiels, mais la réalité est que le deep learning n’a décollé que le jour où les chercheurs ont décidé de renoncer aux métaphores biologiques pour se concentrer plutôt sur la sympathie mécanique. Encore une fois, la sympathie mécanique, c’est-à-dire bien jouer avec les ordinateurs dont nous disposons, est essentielle. Le problème que nous avions avec les réseaux de neurones artificiels était que nous tentions d’imiter la biologie, alors que les ordinateurs que nous possédons sont complètement différents des supports biologiques qui sous-tendent nos cerveaux. Cette situation rappelle les débuts de l’aviation, où de nombreux inventeurs essayaient de construire des machines volantes en imitant les oiseaux. De nos jours, nous disposons de machines volantes qui volent plusieurs fois plus vite que les oiseaux les plus rapides, mais la manière dont ces machines volent n’a presque rien en commun avec la façon dont volent les oiseaux.
La première idée du deep learning fut la nécessité de quelque chose de profond et expressif, capable d’appliquer n’importe quelle transformation aux données d’entrée, permettant ainsi à un comportement prédictif intelligent d’émerger du modèle. Cependant, il devait également bien fonctionner avec le matériel informatique dont nous disposions. L’idée était que si nous possédions des modèles complexes qui interagissent très bien avec le matériel informatique, nous serions très probablement capables d’apprendre des fonctions plusieurs ordres de grandeur plus complexes, toutes choses égales par ailleurs, par rapport à toute méthode n’ayant pas le même degré de sympathie mécanique.
Le differentiable programming, qui a été présenté dans la conférence précédente, peut être considéré comme la couche de base du deep learning. Je ne vais pas revenir sur le differentiable programming dans cette conférence, mais j’invite le public à visionner la conférence précédente s’il ne l’a pas vue. Vous devriez être capables de comprendre ce qui suit même si vous n’avez pas vu la conférence précédente. La conférence précédente devrait clarifier certains détails techniques du processus d’apprentissage lui-même. En résumé, le differentiable programming est simplement un moyen de, en choisissant une forme spécifique de modèle, identifier les meilleures valeurs pour les paramètres qui existent au sein de ce modèle.
Tandis que le differentiable programming se concentre sur l’identification des meilleurs paramètres, le machine learning se focalise sur l’identification des formes de modèles supérieures ayant la plus grande capacité à apprendre à partir des données.

Alors, comment créer un modèle pour une fonction arbitrairement complexe capable de refléter n’importe quelle transformation complexe sur les données d’entrée ? Commençons par un circuit de valeurs à virgule flottante. Pourquoi des valeurs à virgule flottante ? Eh bien, c’est parce que c’est le type de données sur lequel nous pouvons appliquer la descente de gradient, qui, comme nous l’avons vu dans la conférence précédente, est très scalable. Donc, adoptons les nombres à virgule flottante. Nous allons disposer d’une séquence de nombres à virgule flottante, c’est-à-dire de nombres à virgule flottante en entrée et en sortie.
Maintenant, que faisons-nous au milieu ? Faisons de l’algèbre linéaire, et plus précisément, procédons à une multiplication matricielle. Pourquoi cela ? La réponse à cette question avait été donnée lors de la toute première conférence de ce quatrième chapitre. Cela est lié à la manière dont les ordinateurs modernes sont conçus ; en substance, il est possible d’obtenir un gain de vitesse relativement spectaculaire en termes de rapidité de traitement si l’on se limite à l’algèbre linéaire. Donc, optons pour l’algèbre linéaire. Maintenant, si je prends mes entrées et applique une transformation linéaire — qui consiste simplement en une multiplication matricielle avec une matrice nommée W (cette matrice contient les paramètres que nous souhaitons apprendre par la suite) — comment pouvons-nous complexifier cela ? Nous pouvons ajouter une deuxième multiplication matricielle. Cependant, si vous vous rappelez de vos cours d’algèbre linéaire, lorsque vous multipliez une fonction linéaire par une autre fonction linéaire, le résultat est une fonction linéaire. Ainsi, si nous nous contentons de composer les multiplications matricielles, nous obtenons toujours une multiplication matricielle, et cela reste complètement linéaire.
Ce que nous allons faire, c’est intercaler des non-linéarités entre les opérations linéaires. C’est exactement ce que j’ai fait sur cet écran. J’ai intercalé une fonction typiquement connue dans la littérature du deep learning sous le nom de Rectified Linear Unit (ReLU). Ce nom, qui est incroyablement compliqué par rapport à ce qu’il fait, est en réalité une fonction très simple qui dit que si je prends un nombre et que ce nombre est positif, alors je renvoie exactement le même nombre (donc c’est une fonction identité), mais si le nombre est négatif, je renvoie 0. On peut aussi l’exprimer comme le maximum entre votre valeur et zéro. C’est une non-linéarité très triviale.
Nous pourrions utiliser des fonctions non linéaires bien plus sophistiquées. Historiquement, lorsque les gens travaillaient sur les réseaux de neurones, ils souhaitaient utiliser des fonctions sigmoïdes sophistiquées car cela était supposé refléter le fonctionnement de nos neurones. Mais en réalité, pourquoi voudrions-nous gaspiller de la puissance de calcul pour effectuer des opérations sans importance ? L’idée clé est que nous devons introduire quelque chose de non linéaire, et peu importe vraiment quelle fonction non linéaire nous utilisons. La seule chose qui compte, c’est de la rendre très rapide. Nous voulons que l’ensemble soit aussi rapide que possible.
Ce que je construis ici s’appelle des couches denses. Une couche dense est essentiellement une multiplication de matrices suivie d’une non-linéarité (la Rectified Linear Unit). Nous pouvons les empiler. À l’écran, vous voyez un réseau, qui est typiquement appelé un perceptron multicouche, et nous avons trois couches. Nous pourrions continuer à les empiler et en avoir 20 ou 2 000 ; cela n’a guère d’importance. La réalité est que, aussi simpliste que cela puisse paraître, si vous prenez un tel réseau avec seulement quelques couches et que vous l’intégrez dans votre cadre de programmation différentiable, qui vous fournit les paramètres, la programmation différentiable en tant que couche de base sera capable d’entraîner ces paramètres, initialement choisis aléatoirement. Si vous souhaitez l’initialiser, il suffit d’initialiser tous les paramètres au hasard. Vous obtiendrez des résultats assez corrects pour une très grande variété de problèmes.
C’est très intéressant car, à ce stade, vous possédez quasiment tous les ingrédients fondamentaux du deep learning. Alors, pour le public, félicitations ! Vous pouvez probablement commencer à ajouter “deep learning specialist” à votre CV, car c’est presque tout ce qu’il y a. Enfin, pas vraiment, mais disons que c’est un bon point de départ.

La réalité est que le deep learning implique très peu de théorie à part l’algèbre tensorielle, qui est essentiellement de l’algèbre linéaire informatisée. Cependant, le deep learning recourt à une multitude d’astuces. Par exemple, nous devons normaliser les entrées et stabiliser les gradients. Si nous commençons à empiler de nombreuses opérations de ce type, les gradients peuvent croître de manière exponentielle lors de la rétropropagation dans le réseau, et à un moment donné, cela excédera la capacité de représentation de ces nombres. Nous disposons d’ordinateurs réels, qui ne peuvent pas représenter des nombres arbitrairement grands. À un certain moment, vous dépassez simplement la capacité à représenter le nombre avec une valeur en virgule flottante de 32 bits ou 16 bits. Il existe une multitude d’astuces pour stabiliser les gradients. Par exemple, l’astuce consiste typiquement en la normalisation par batch, mais il existe d’autres techniques à cet égard.
Si vous avez des entrées qui possèdent une structure géométrique, par exemple unidimensionnelles comme une série temporelle (ventes historiques, comme nous le voyons en supply chain), cela peut être bidimensionnel (considérez-le comme une image), tridimensionnel (cela pourrait être un film) ou quadrimensionnel, etc. Si les entrées présentent une structure géométrique, alors il existe des couches spéciales capables d’en capturer la structure. Les plus célèbres sont probablement appelées couches convolutionnelles.
Ensuite, vous disposez également de techniques et d’astuces pour traiter des entrées catégoriques. Dans le deep learning, toutes vos entrées sont des valeurs en virgule flottante, alors comment gérer les variables catégoriques ? La réponse réside dans les embeddings. Vous avez des pertes de substitution, qui sont des fonctions de coût alternatives présentant des gradients très raides et facilitant le processus de convergence, amplifiant en fin de compte ce que vous pouvez apprendre à partir des données. Il existe une multitude d’astuces, et toutes ces techniques peuvent généralement être intégrées dans le programme que vous composez, car nous opérons avec la programmation différentiable comme couche de base.
Le deep learning consiste en réalité à composer un programme qui, une fois soumis au processus d’entraînement offert par la programmation différentiable, possède une très grande capacité d’apprentissage. La plupart des éléments que je viens de présenter à l’écran sont également de nature programmatique, ce qui est très pratique étant donné que nous disposons de la programmation différentiable, un paradigme de programmation, pour supporter l’ensemble.
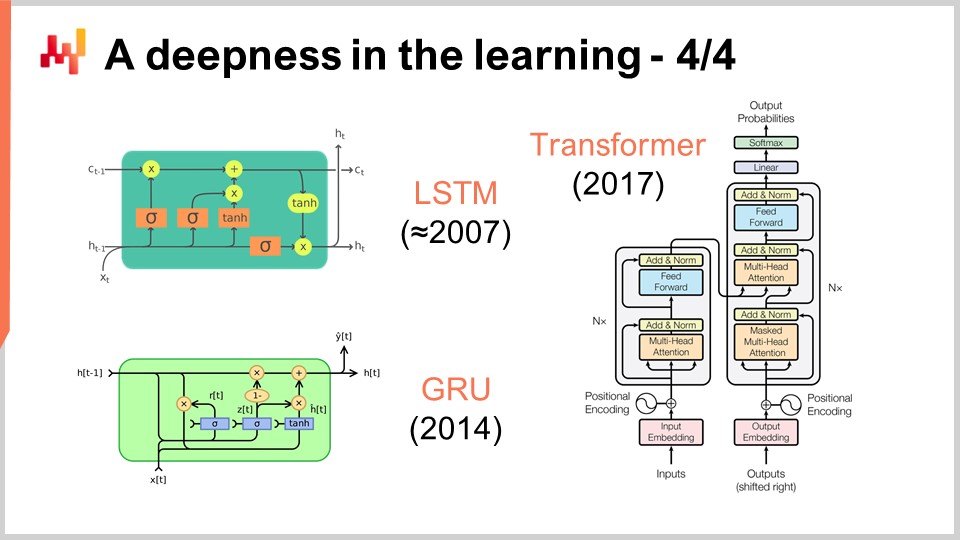
À ce stade, il devrait devenir plus clair pourquoi le deep learning est différent du machine learning classique. Le deep learning ne concerne pas les modèles. En fait, la plupart des bibliothèques open-source de deep learning n’incluent même pas de modèles. Avec le deep learning, ce qui importe vraiment, ce sont les architectures de modèles, que vous pouvez considérer comme des gabarits devant être fortement personnalisés lorsque vous souhaitez adapter une situation spécifique. Toutefois, si vous choisissez une architecture appropriée, vous pouvez anticiper que votre personnalisation préservera l’essence de la capacité de votre modèle à apprendre. Avec le deep learning, nous déplaçons l’intérêt du modèle final, qui devient quelque chose de peu intéressant, vers l’architecture, qui devient le véritable objet de recherche.
À l’écran, vous pouvez voir une série d’exemples d’architectures remarquables. D’abord, LSTM, qui signifie Long Short-Term Memory, a commencé à fonctionner vers 2007. L’historique des publications de LSTM est un peu plus compliqué, mais il a essentiellement débuté dans le style deep learning en 2007. Il a été supplanté par les Gated Recurrent Units (GRU), qui sont essentiellement la même chose que LSTM, mais simplement plus simples et plus agréables. En effet, une grande partie de la complexité de LSTM découle des métaphores biologiques. Il s’avère que vous pouvez abandonner ces métaphores, et ce que vous obtenez est quelque chose de plus simple qui fonctionne à peu près de la même manière. Ce sont les Gated Recurrent Units (GRU). Par la suite, les transformers sont apparus, rendant essentiellement obsolètes à la fois LSTM et GRU. Les transformers ont constitué une avancée majeure, car ils étaient bien plus rapides, plus légers en termes de ressources informatiques nécessaires et offraient une capacité d’apprentissage encore supérieure.
La plupart de ces architectures s’accompagnent de métaphores. LSTM possède une métaphore cognitive, la mémoire à court et long terme, tandis que les transformers s’accompagnent d’une métaphore de recherche d’information. Cependant, ces métaphores ont très peu de pouvoir prédictif et pourraient en réalité être davantage une source de confusion et de distraction par rapport à ce qui fait réellement fonctionner ces architectures, ce qui n’est pas encore entièrement compris à ce jour.
Les transformers présentent un grand intérêt pour la supply chain car ils constituent l’une des architectures les plus polyvalentes. Ils sont utilisés pour pratiquement tout de nos jours, de la conduite autonome à la traduction automatisée, en passant par de nombreux autres problèmes complexes. Cela témoigne de la puissance de choisir la bonne architecture, qui peut ensuite être utilisée pour s’adapter à une diversité énorme de problèmes. En ce qui concerne la supply chain, l’une des principales difficultés dans l’utilisation du machine learning est que nous avons une diversité incroyable de problèmes à traiter. Nous ne pouvons pas nous permettre d’avoir une équipe qui consacre cinq ans à des efforts de recherche pour chaque sous-problème rencontré. Nous avons besoin d’une solution qui nous permette d’avancer rapidement sans avoir à réinventer la moitié du machine learning à chaque nouveau problème à résoudre.
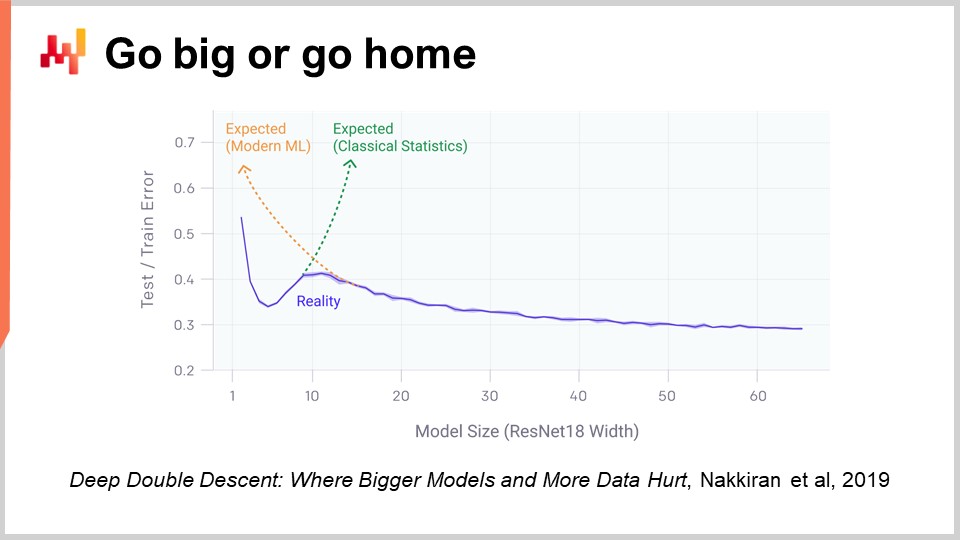
Un aspect du deep learning qui est vraiment choquant lorsqu’on y réfléchit, c’est le nombre massif de paramètres. Dans le perceptron multicouche que j’ai présenté il y a quelques minutes, avec des couches denses impliquant une multiplication de matrices, nous pouvons avoir énormément de paramètres dans ces matrices. En fait, il n’est pas très difficile d’avoir autant de paramètres que nous avons de points de données ou d’observations dans nos ensembles d’entraînement. Comme nous l’avons vu au tout début de notre cours, si vous disposez d’un modèle avec autant de paramètres, il devrait souffrir dramatiquement de surapprentissage.
La réalité avec le deep learning est encore plus déroutante. Il existe de nombreuses situations où nous possédons énormément plus de paramètres que d’observations, et pourtant nous ne rencontrons pas de problèmes de surapprentissage dramatiques. Encore plus étonnamment, les modèles de deep learning ont tendance à s’ajuster complètement à l’ensemble d’entraînement, de sorte que vous obtenez une erreur quasi nulle sur vos données d’entraînement, tout en conservant leur capacité prédictive sur des données que nous ne possédons pas.
Il y a deux ans, l’article Deep Double Descent publié par OpenAI a apporté un éclairage très intéressant sur cette situation. L’équipe a montré que nous avions essentiellement une vallée de l’étrange dans le domaine du machine learning. L’idée est que si vous prenez un modèle avec seulement quelques paramètres, vous avez beaucoup de biais, et la qualité de vos résultats sur des données non observées n’est pas très bonne. Cela correspond à la vision classique du machine learning ainsi qu’à celle de la statistique traditionnelle. Si vous augmentez le nombre de paramètres, vous allez améliorer la qualité de votre modèle, mais à un moment donné, vous commencerez à surapprendre. C’est exactement ce que nous avons constaté lors de la discussion précédente sur le sous-apprentissage et le surapprentissage. Il faut trouver un équilibre.
Cependant, ce qu’ils ont démontré, c’est que si vous continuez à augmenter le nombre de paramètres, quelque chose de très étrange se produit : vous allez surapprendre de moins en moins, ce qui est exactement l’inverse de ce que prédit la théorie classique de l’apprentissage statistique. Ce comportement n’est pas accidentel. Les auteurs ont montré que ce phénomène était très robuste et répandu. Il se produit pratiquement tout le temps dans une grande variété de situations. Nous ne comprenons pas encore très bien pourquoi, mais ce qui est désormais parfaitement établi, c’est que le deep double descent est bien réel et généralisé.
Cela aide également à comprendre pourquoi le deep learning est arrivé relativement tard dans le domaine du machine learning. Pour que le deep learning puisse réussir, nous avons d’abord dû parvenir à construire des modèles capables de traiter des dizaines de milliers, voire des centaines de milliers de paramètres, afin de dépasser cette vallée de l’étrange. Dans les années 80 et 90, il n’aurait pas été possible de réaliser une percée en deep learning, tout simplement parce que les ressources matérielles de calcul n’étaient pas en mesure de franchir cette vallée.
Heureusement, avec le matériel de calcul actuel, il est possible d’entraîner, sans trop d’effort, des modèles comptant des millions, voire des milliards de paramètres. Comme nous l’avons souligné dans les cours précédents, il existe désormais des entreprises comme Facebook qui entraînent des modèles comportant plus d’un trillion de paramètres. Nous pouvons donc aller très loin.

Jusqu’à présent, nous avons supposé que la fonction de perte était connue. Cependant, pourquoi en serait-il ainsi ? En effet, considérons la situation d’un magasin de mode d’un point de vue supply chain. Un magasin de mode dispose de niveaux de stocks pour chaque SKU, et nous souhaitons prévoir la demande future. Nous voulons projeter un scénario possible qui soit crédible pour la demande future de ce magasin. Ce qui se produira, c’est qu’à mesure que certains SKU seront en rupture de stock, nous devrions observer de la cannibalisation et de la substitution. Lorsqu’un SKU donné atteint une rupture de stock, normalement, la demande devrait, en partie, se rabattre sur des produits similaires.
Mais si nous essayons d’aborder ce type d’approche avec des métriques de prévision classiques telles que l’erreur en pourcentage absolu moyen (MAPE), l’erreur absolue moyenne (MAE), l’erreur quadratique moyenne (MSE) ou d’autres métriques qui opèrent SKU par SKU, jour par jour ou semaine par semaine, nous ne parviendrons pas à capturer ces comportements. Ce que nous souhaitons véritablement, c’est une métrique permettant de savoir si nous sommes très efficaces pour capturer tous ces effets de cannibalisation et de substitution. Mais à quoi devrait ressembler cette fonction de perte ? Ce n’est pas du tout clair, et cela semble nécessiter un comportement assez sophistiqué. L’une des percées majeures du deep learning a été essentiellement de concevoir l’idée que la fonction de perte devait être apprise. C’est exactement ainsi que l’image à l’écran a été produite. Il s’agit d’une image entièrement générée par machine ; aucune de ces personnes n’est réelle. Elles ont été générées, et le problème était le suivant : comment construire une fonction de perte ou une métrique qui indique si une image est un bon portrait photoréaliste d’un humain ou non ?
La réalité est que si vous commencez à penser en termes d’erreur en pourcentage absolu moyen (MAPE), vous obtenez une métrique qui opère pixel par pixel. Le problème est qu’une métrique opérant pixel par pixel ne vous indique rien quant à savoir si l’image dans son ensemble ressemble à un visage humain. Nous rencontrons le même problème dans le magasin de mode pour les SKU et la prévision de la demande. Il est très facile d’avoir une métrique au niveau du SKU, mais cela ne nous renseigne pas sur la vision d’ensemble du magasin. Pourtant, d’un point de vue supply chain, nous ne sommes pas intéressés par la précision au niveau du SKU ; nous sommes intéressés par la précision à l’échelle du magasin. Nous voulons savoir si les niveaux de stocks sont bons dans leur globalité pour le magasin, et non pas s’ils le sont pour un SKU puis un autre. Alors, comment la communauté deep learning a-t-elle abordé ce problème ?
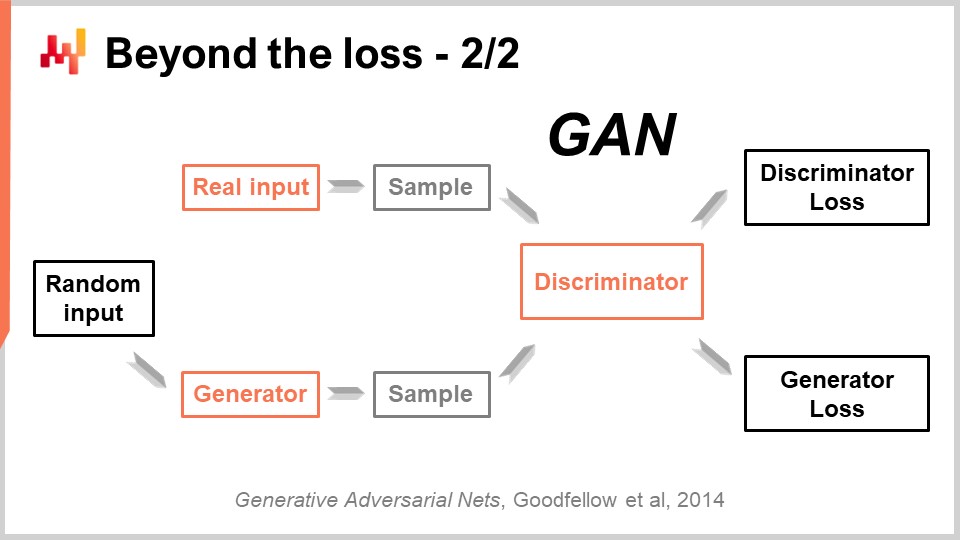
Cette réalisation très impressionnante a été obtenue grâce à une technique d’une simplicité remarquable appelée Generative Adversarial Networks (GANs). Dans la presse, vous avez peut-être entendu parler de ces techniques sous le nom de deepfakes. Les deepfakes sont des images qui ont été produites à l’aide de cette technique GAN. Comment cela fonctionne-t-il ?
Eh bien, le fonctionnement est le suivant : vous commencez d’abord par un générateur. Le générateur prend en entrée du bruit, c’est-à-dire des valeurs aléatoires, et il va produire une image dans le cas présent. Si nous revenons au cas de la supply chain, il produirait des trajectoires pour tous les points de demande observés pour chaque SKU, disons, pour les trois prochains mois dans ce magasin de mode. Ce générateur est lui-même un réseau de deep learning.
Ensuite, nous allons avoir un discriminateur. Un discriminateur est également un réseau de deep learning, et le but du discriminateur est d’apprendre à prédire si ce qui vient d’être généré est réel ou synthétique. Le discriminateur est un classificateur binaire qui doit simplement indiquer si c’est réel ou non. Si le discriminateur parvient à prédire correctement qu’un échantillon est faux, c’est-à-dire synthétique, nous allons rétropropager les gradients vers le générateur et laisser celui-ci en tirer des enseignements.
Ce qui se passe avec cette configuration, c’est que le générateur commence à apprendre comment créer des échantillons qui parviennent réellement à tromper et à désorienter le discriminateur. En même temps, le discriminateur apprend à mieux distinguer les échantillons réels des échantillons synthétiques. Si vous suivez ce processus, il converge, espérons-le, vers un état où vous obtenez à la fois un générateur de très haute qualité qui produit des échantillons incroyablement réalistes et un discriminateur très performant capable de vous indiquer si quelque chose est réel ou non. C’est exactement ce qui est réalisé avec les GANs pour générer ces images photoréalistes. Si nous revenons à la supply chain, vous rencontrerez des experts dans les cercles supply chain qui affirment que, pour une situation particulière, la meilleure métrique est le MAPE, ou le MAPE pondéré, ou autre. Ils proposeront des recettes indiquant que, dans certaines situations, il faut utiliser telle métrique ou telle autre. La réalité est que le deep learning montre qu’une métrique de prévision est un concept dépassé. Si vous souhaitez atteindre une précision en haute dimension – et pas seulement une précision point par point – il vous faut apprendre la métrique. Bien qu’actuellement, je soupçonne qu’il existe presque aucune supply chain qui exploite ces techniques, il viendra un moment où ce sera le cas. Il deviendra la norme d’apprendre la métrique de prévision en utilisant des réseaux antagonistes génératifs ou leurs descendants, car c’est un moyen de capturer le comportement subtil et en haute dimension qui est réellement intéressant, plutôt que de se contenter d’une simple précision point par point.

Jusqu’à présent, chaque observation était accompagnée d’une étiquette, et l’étiquette représentait la sortie que nous souhaitions prédire. Cependant, il existe des situations qui ne peuvent être formulées comme des problèmes d’entrée-sortie. Les étiquettes ne sont tout simplement pas disponibles. Si nous prenons un exemple supply chain, ce serait un hypermarché. Dans les hypermarchés, les niveaux de stocks ne sont pas parfaitement exacts. Les marchandises peuvent être endommagées, volées ou périmées, et il existe de nombreuses raisons pour lesquelles les données électroniques de votre système ne reflètent pas réellement ce qui est disponible sur les étagères tel que perçu par les clients. Inventorier est trop coûteux pour être une source de données en temps réel de stocks précis. Vous pouvez inventorier, mais vous ne pouvez pas parcourir l’intégralité de l’hypermarché chaque jour. Le résultat est une grande quantité de stocks légèrement inexacts. Vous en avez en masse, mais vous ne pouvez pas vraiment dire lesquels sont exacts ou non.
C’est essentiellement le genre de situation où l’apprentissage non supervisé prend tout son sens. Nous souhaitons apprendre quelque chose ; nous disposons de données, mais nous n’avons pas les bonnes réponses à disposition. Nous n’avons pas ces étiquettes. Ce que nous avons, ce sont tout simplement des tonnes de données. L’apprentissage non supervisé est considéré depuis des décennies par la communauté du machine learning comme le Saint Graal. Pendant très longtemps, il représentait l’avenir, mais un avenir lointain. Cependant, récemment, des avancées incroyables ont été réalisées dans ce domaine. L’une de ces avancées a été, par exemple, réalisée par une équipe de Facebook avec un article intitulé “Unsupervised Machine Translation Using Monolingual Corpora Only.”
Ce que l’équipe de Facebook a fait dans cet article, c’est construire un système de traduction qui n’utilisait qu’un corpus de texte en anglais et un corpus de texte en français. Ces deux corpus n’ont rien en commun ; il ne s’agit même pas des mêmes textes. Ce sont simplement des textes en anglais et des textes en français. Ensuite, sans fournir de traduction explicite au système, ils ont appris à construire un système qui traduit de l’anglais vers le français. C’est un résultat absolument stupéfiant. D’ailleurs, la manière dont cela est réalisé repose sur une technique qui rappelle fortement les réseaux antagonistes génératifs que je viens de présenter précédemment. De même, une équipe de Google a publié BERT (Bidirectional Encoder Representations from Transformers) il y a deux ans. BERT est un modèle qui est entraîné d’une manière largement non supervisée. Nous parlons à nouveau de texte. La méthode utilisée avec BERT consiste à prendre d’énormes bases de données de textes et à masquer aléatoirement des mots. Ensuite, on entraîne le modèle à prédire ces mots, et ainsi de suite pour l’ensemble du corpus. Certaines personnes qualifient cette technique d’auto-supervisée, mais ce qui est très intéressant avec BERT, et ce qui la rend pertinente pour la supply chain, c’est que soudainement, l’approche de vos données consiste à construire une machine dans laquelle vous pouvez masquer certaines parties, et cette machine est quand même capable de reconstituer les données.
La raison pour laquelle cela revêt une importance primordiale pour la supply chain, c’est qu’essentiellement, ce qui est réalisé avec BERT dans le contexte du traitement du langage naturel peut être étendu à bien d’autres domaines. C’est la machine ultime pour répondre au “what-if”. Par exemple, que se passerait-il si j’ouvrais un magasin de plus ? Ce “what-if” peut être traité, car il vous suffit de modifier vos données, d’ajouter le magasin, et d’interroger le modèle de machine learning que vous venez de construire. Que se passerait-il si j’avais un produit supplémentaire ? Et si j’avais un client en plus ? Ou si le prix de ce produit était différent ? Et ainsi de suite. L’apprentissage non supervisé est d’un intérêt majeur parce que vous commencez à traiter vos données dans leur ensemble, et non pas simplement comme une liste de paires. Vous obtenez un mécanisme complètement général capable de faire des prédictions sur n’importe quel aspect présent, même partiellement, dans les données. C’est très puissant.
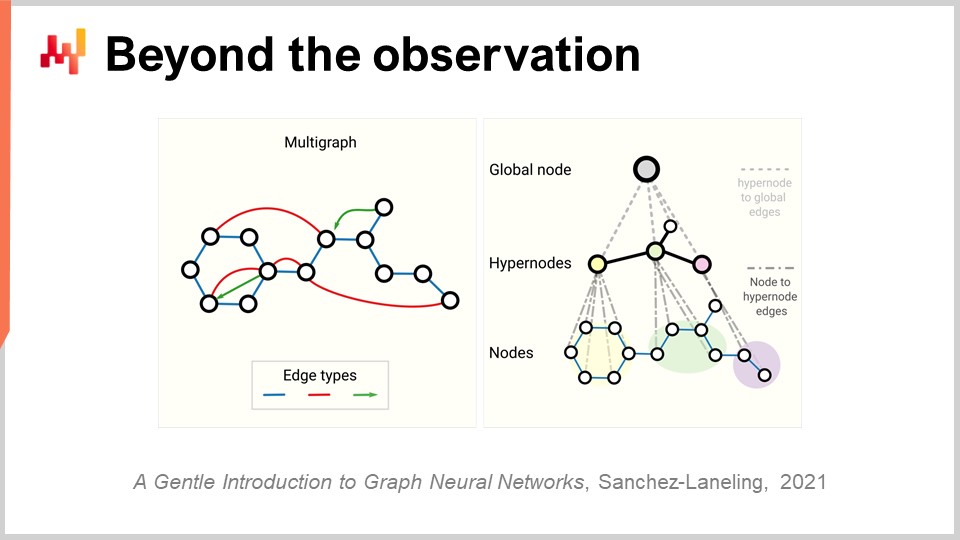
Enfin, nous devons revisiter le concept même d’observation. Au départ, nous disions qu’une observation était une paire de caractéristiques accompagnée d’une étiquette. Nous avons vu comment nous pouvions retirer l’étiquette, mais qu’en est-il des caractéristiques elles-mêmes et de l’observation ? Le problème avec la supply chain, c’est que nous n’avons pas vraiment d’observations. Il n’est même pas évident que l’on puisse décomposer une supply chain en une liste d’observations indépendantes ou homogènes. Comme évoqué dans une conférence précédente, pour observer une supply chain, il ne s’agit pas d’une observation scientifique directe de la supply chain elle-même. Ce que nous avons, ce sont une série d’outils logiciels d’entreprise, et la seule façon d’observer une supply chain est indirectement, à travers les enregistrements collectés dans ces outils. Cela peut être l’ERP, le WMS, le point de vente, etc. Mais en fin de compte, tout ce que nous avons, ce sont essentiellement des traces électroniques à caractère transactionnel, car tous ces systèmes sont généralement implémentés sur des bases de données transactionnelles. Ainsi, les observations ne sont pas indépendantes. Les enregistrements dont nous disposons sont relationnels, au sens propre du terme, car ils résident dans une base de données relationnelle. Quand je dis qu’ils sont liés, je veux dire que, par exemple, si vous voyez un client muni d’une carte de fidélité, il est relié à tous les produits qu’il a achetés. Chaque produit est lié à tous les magasins où il fait partie de l’assortiment. Chaque magasin est connecté à tous les entrepôts ayant la capacité de servir le magasin concerné. Ainsi, nous n’avons pas d’observations indépendantes ; nous disposons de données sur lesquelles se superpose une multitude de structures relationnelles, et aucun de ces éléments n’est véritablement indépendant des autres.
La percée pertinente du deep learning pour traiter ce type de données interconnectées est connue sous le nom de graph learning. Le graph learning est exactement ce qu’il vous faut pour aborder des comportements tels que la substitution et la cannibalisation dans la mode. La meilleure manière de visualiser la cannibalisation est de considérer que tous les produits se font concurrence pour les mêmes clients, et qu’en analysant les données qui relient clients et produits, vous pouvez étudier la cannibalisation. Attention, le graph learning n’a rien à voir avec les bases de données graphiques, qui sont une toute autre affaire. Les bases de données graphiques sont essentiellement de simples bases de données utilisées pour interroger des graphes, sans notion d’apprentissage. Le graph learning consiste à apprendre des propriétés supplémentaires propres aux graphes. Il s’agit d’apprendre des relations qui peuvent ou non être observées, qui ne peuvent pas être observées complètement, ou d’enrichir le type de relation que nous avons avec une couche de connaissances exploitables.
Mon point de vue est que, du fait que par conception la supply chain est un système où toutes les parties sont interconnectées – c’est la malédiction de la supply chain, où l’on ne peut optimiser localement quoi que ce soit sans déporter les problèmes – le graph learning deviendra de plus en plus répandu en tant qu’approche pour résoudre ces problèmes dans la supply chain et le machine learning. Essentiellement, les réseaux de neurones graphiques sont des techniques de deep learning conçues pour traiter les graphes.
En conclusion, penser que le machine learning consiste à fournir des prévisions plus précises est, pour le dire légèrement, plutôt naïf. C’est comme dire que l’objectif principal d’une automobile est d’avoir accès à un cheval plus rapide. Oui, il est vrai qu’il est fort probable que, grâce au machine learning, nous puissions obtenir des prévisions plus précises. Cependant, cela ne représente qu’une petite partie d’un ensemble bien plus vaste, un ensemble qui ne cesse de s’agrandir à mesure que des avancées sont réalisées par la communauté du machine learning. Nous avons commencé avec des cadres de machine learning incluant une série de concepts : caractéristique, étiquette, observation, modèle et perte. Ce petit cadre élémentaire était déjà bien plus général que la simple perspective de prévision des séries temporelles. Avec le développement récent du machine learning, nous observons que même ces concepts s’effacent lentement et progressivement pour devenir insignifiants, du fait que nous découvrons des moyens de les transcender. Pour la supply chain, ce changement de paradigme est d’une importance cruciale, car il signifie que nous devons adopter ce même changement de paradigme pour ce qui est des prévisions. Le machine learning nous oblige à repenser entièrement notre approche des données et ce que nous pouvons en faire. Le machine learning ouvre des portes qui étaient, jusqu’à très récemment, strictement fermées.

Examinons maintenant quelques questions.
Question: Les random forests n’utilisent-elles pas le bagging ?
Mon point de vue est que, oui, elles en sont une extension, et il y a plus en jeu que le simple bagging. Le bagging est une technique intéressante, mais chaque fois que vous examinez une technique de machine learning, vous devez vous demander : cette technique va-t-elle m’aider à progresser vers la résolution de problèmes vraiment difficiles comme la cannibalisation ou la substitution ? Et cette technique va-t-elle bien s’accorder avec le matériel informatique dont vous disposez ? C’est l’un des points clés à retenir de cette conférence.
Question: Avec la volonté des entreprises d’automatiser tout par la robotique, quel est l’avenir des employés des entrepôts logistiques ? Seront-ils remplacés par des robots dans un avenir proche ?
Cette question n’est pas directement liée au machine learning, mais c’est une très bonne question. Les usines ont connu une transformation massive vers une robotisation étendue, qui peut ou non impliquer des robots. La productivité des usines a augmenté, et même aujourd’hui en Chine, les usines sont largement automatisées dans l’ensemble. Les entrepôts ont tardé à suivre. Cependant, ce que je constate de nos jours, c’est le développement d’entrepôts de plus en plus mécaniques et automatisés. Je ne dirais pas qu’il s’agit nécessairement de robots ; il existe de nombreuses technologies concurrentes pour concevoir un entrepôt qui atteint un degré d’automatisation supérieur. En fin de compte, la tendance est claire. Les entrepôts et les centres logistiques, en général, vont connaître le même type d’amélioration massive de la productivité que nous avons déjà observé en production.
Pour répondre à votre question, je ne dis pas que les personnes seront remplacées par des robots ; elles seront remplacées par l’automatisation. L’automatisation prendra parfois la forme d’un robot, mais elle peut également revêtir bien d’autres aspects. Certaines de ces formes ne sont que des dispositifs ingénieux qui améliorent considérablement la productivité sans recourir à la technologie que nous associons intuitivement aux robots. Cependant, je pense que la partie logistique de la supply chain dans son ensemble va se réduire. La seule chose qui maintient actuellement sa croissance, c’est le fait qu’avec l’essor du le e-commerce, nous devons nous occuper du dernier kilomètre. Ce dernier kilomètre occupe de plus en plus la majeure partie de la main-d’œuvre chargée de la logistique. Même le dernier kilomètre sera automatisé dans un futur proche. Les véhicules autonomes ne sont plus très loin ; ils avaient été promis pour cette décennie, et bien qu’ils arrivent peut-être avec un peu de retard, ils sont en route.
Question: Pensez-vous que le machine learning vaut l’investissement de temps nécessaire pour l’apprendre afin de travailler dans la supply chain ?
Absolument. À mon avis, le machine learning est une science auxiliaire de la supply chain. Pensez à la relation qu’entretient un médecin avec la chimie. Si vous êtes un médecin moderne, personne n’attend de vous que vous soyez chimiste. Cependant, si vous dites à votre patient que vous ne savez absolument rien en chimie, les gens penseront que vous n’avez pas ce qu’il faut pour être un médecin moderne. Le machine learning doit être abordé de la même manière que les personnes qui étudient la médecine appréhendent la chimie. Ce n’est pas une fin en soi, mais un moyen. Si vous voulez réaliser un travail sérieux dans la supply chain, il vous faut des bases solides en machine learning.
Question: Pourriez-vous donner des exemples d’applications du machine learning ? L’outil est-il devenu opérationnel ?
Pour ma part, en tant que Joannes Vermorel, entrepreneur et CEO de Lokad, nous avons actuellement plus de 100 entreprises en production, toutes utilisant le machine learning pour diverses tâches. Ces tâches incluent la prévision des délais d’approvisionnement, la production de prévisions probabilistes de la demande, la prédiction des retours, la détection de problèmes de qualité, la révision des estimations du temps moyen entre les réparations non planifiées, et la vérification de la justesse des prix compétitifs. Il existe de nombreuses applications, comme la réévaluation des matrices de compatibilité entre voitures et pièces dans le marché de l’après-vente automobile. Grâce au machine learning, vous pouvez corriger automatiquement une grande partie des erreurs dans les bases de données. Chez Lokad, non seulement nous avons ces 100 entreprises en production, mais cela fait près d’une décennie que cela dure. Le futur est déjà là ; il n’est tout simplement pas réparti de manière homogène.
Question: Quelle est la meilleure façon d’apprendre le machine learning par soi-même ? Recommanderiez-vous des sites comme Udemy, Coursera ou autre chose ?
Ma suggestion serait une combinaison de Wikipedia et de la lecture d’articles scientifiques. Comme vous l’avez vu dans cette conférence, il est important de comprendre les fondamentaux et de rester à jour avec les derniers développements dans le domaine. Comme vous l’avez vu dans ces conférences, je cite des articles de recherche réels. Ne vous fiez pas aux informations de seconde main ; allez directement à ce qui a été publié. Toutes ces choses sont directement disponibles en ligne. Il existe des articles en machine learning qui sont mal rédigés et indéchiffrables, mais il y a aussi des articles qui sont brillamment rédigés et fournissent des éclaircissements limpides sur ce qui se passe. Ma suggestion est d’utiliser Wikipedia pour obtenir une vue d’ensemble d’un domaine, afin d’en saisir la globalité, puis de commencer à lire des articles. Au début, cela peut sembler obscur, mais au bout d’un moment, vous vous y habituerez. Vous pouvez opter pour Udemy ou Coursera, mais personnellement, je n’ai jamais fait cela. Mon objectif en faisant ces conférences est de vous donner quelques bribes d’intuition pour que vous ayez la vue d’ensemble. Si vous voulez entrer dans les détails les plus pointus, plongez directement dans l’article publié il y a des années ou des décennies. Optez pour l’information de première main et faites confiance à votre propre intelligence.
Le deep learning est un domaine de recherche très empirique. La plupart des travaux effectués ne sont pas extrêmement complexes, d’un point de vue mathématique. En général, cela ne dépasse pas ce que l’on apprend à la fin du lycée, donc c’est assez accessible.
Question: Avec l’essor des outils no-code tels que CodeX et Co-Pilot d’OpenAI, voyez-vous les praticiens de la supply chain rédiger des modèles en anglais simple à un moment donné ?
La réponse courte est : non, pas du tout. L’idée que l’on puisse contourner la programmation existe depuis longtemps. Par exemple, Visual Basic de Microsoft était destiné à être un outil visuel pour que les gens n’aient plus besoin de programmer ; ils pouvaient simplement composer visuellement des éléments comme des Legos. Mais de nos jours, cette approche s’est révélée inefficace, et la prochaine tendance est d’exprimer les choses verbalement.
Cependant, la raison pour laquelle j’utilise des formules mathématiques dans ces conférences est qu’il existe de nombreuses situations où l’emploi d’une formule mathématique est le seul moyen de transmettre clairement ce que vous essayez de dire. Le problème avec la langue anglaise, ou toute langue naturelle, est qu’elle est souvent imprécise et sujette à interprétation. En revanche, les formules mathématiques sont précises et claires. Le souci avec le langage ordinaire est qu’il est incroyablement flou, et bien qu’il ait ses usages, la raison pour laquelle nous utilisons des formules est de fournir une signification sans ambiguïté à ce qui est dit. J’essaie d’en limiter l’usage, mais lorsque j’en inclus une, c’est parce que je pense que c’est le seul moyen de transmettre clairement l’idée, avec un niveau de clarté surpassant ce que je peux exprimer verbalement.
En ce qui concerne les plateformes low-code, je suis très sceptique, car cette approche a été tentée à de nombreuses reprises dans le passé sans grand succès. Mon point de vue personnel est que nous devrions rendre la programmation plus adaptée à la gestion de la supply chain en identifiant pourquoi coder est difficile et en éliminant la complexité accidentelle. Ce qui reste, c’est une programmation effectuée correctement pour la supply chain, ce que Lokad vise à faire.
Question: Le machine learning rend-il la prévision de la demande plus précise pour des données historiques de ventes saisonnières ou régulières ?
Comme je l’ai mentionné dans cette présentation, le machine learning rend le concept de précision obsolète. Si vous regardez la dernière compétition de prévision des séries temporelles à grande échelle, la compétition M5, les 10 meilleurs modèles étaient tous, dans une certaine mesure, des modèles de machine learning. Alors, est-ce que le machine learning rend les prévisions plus précises ? Objectivement, d’après la compétition de prévision, oui. Mais c’est seulement marginalement plus précis par rapport à d’autres techniques, et ce n’est pas une précision révolutionnaire.
De plus, vous ne devriez pas envisager la prévision d’un point de vue unidimensionnel. Lorsque vous interrogez la précision pour la saisonnalité, vous considérez un produit à la fois, mais ce n’est pas la bonne approche. La véritable précision consiste à évaluer comment le lancement d’un nouveau produit affecte tous les autres produits, car il y aura un certain degré de cannibalisation. L’essentiel est d’évaluer si la manière dont vous intégrez cette cannibalisation dans votre modèle est exacte ou non. Soudainement, cela devient un problème multidimensionnel. Comme je l’ai présenté dans la conférence sur les réseaux génératifs, la métrique de ce que signifie réellement la précision doit être apprise ; elle ne peut pas être imposée. Les formules mathématiques, telles que l’erreur absolue moyenne, l’erreur absolue moyenne en pourcentage et l’erreur quadratique moyenne, ne sont que des critères mathématiques. Ce ne sont pas les types de métriques dont nous avons réellement besoin ; ce sont simplement des métriques très naïves.
Question: Le travail banal des prévisionnistes sera-t-il remplacé par une prévision en mode automatique ?
Je dirais que le futur est déjà là, mais il n’est pas réparti de manière homogène. Chez Lokad, nous prévoyons déjà des dizaines de millions de SKU par jour, et je n’ai personne de rémunéré pour ajuster les prévisions. Donc oui, c’est déjà fait, mais ce n’est qu’une petite partie du tableau. Si vous devez avoir des personnes qui ajustent les prévisions ou affinent les modèles de prévision, cela indique une approche dysfonctionnelle. Vous devriez considérer la nécessité d’ajuster les prévisions comme un défaut et y remédier en automatisant cette partie du processus.
Encore une fois, d’après l’expérience de Lokad, ces pratiques seront complètement éliminées car nous l’avons déjà fait. Nous ne sommes pas les seuls à procéder ainsi, donc pour nous, cela appartient presque à l’histoire ancienne, cela fait près d’une décennie.
Question: À quel point le machine learning est-il activement utilisé pour prendre des décisions supply chain ?
Cela dépend de l’entreprise. Chez Lokad, c’est utilisé partout, et évidemment, lorsque je dis “chez Lokad”, je fais référence aux entreprises servies par Lokad. Cependant, la grande majorité du marché utilise essentiellement Excel, sans aucun machine learning. Lokad gère activement des stocks valant des milliards d’euros ou de dollars, ce qui est déjà une réalité depuis un bon moment. Mais Lokad ne représente même pas 0,1 % du marché, donc nous restons un cas particulier. Nous connaissons une croissance rapide, tout comme plusieurs de nos concurrents. Je soupçonne que c’est encore une configuration marginale dans l’ensemble du marché de la supply chain, mais cela connaît une croissance à deux chiffres. Ne sous-estimez jamais le pouvoir d’une croissance exponentielle sur une longue période. En fin de compte, cela deviendra très important, espérons-le avec Lokad, mais c’est une autre histoire.
Question: Avec tant d’inconnues dans la supply chain, quelle est une stratégie qui permet de considérer les données d’entrée d’un modèle comme acquises ?
L’idée est que, oui, il y a une multitude d’inconnues, mais les données d’entrée de votre modèle ne dépendent pas de votre choix. Tout se résume à ce que vous avez dans vos systèmes d’entreprise, comme le type de données présent dans votre ERP. Si votre ERP dispose de niveaux de stocks historiques, alors vous pouvez les utiliser dans votre modèle de machine learning. Si votre ERP ne conserve que les niveaux de stocks actuels, alors ces données ne sont pas disponibles. Vous pouvez commencer à prendre des instantanés de vos niveaux de stocks si vous souhaitez les utiliser comme données d’entrée supplémentaires, mais le message principal est que vous avez très peu de choix concernant ce que vous pouvez utiliser comme données d’entrée ; c’est littéralement ce qui existe dans vos systèmes.
Mon approche typique est que, si vous devez créer de nouvelles sources de données, cela sera lent et pénible, et ce ne sera probablement pas votre point de départ pour utiliser le machine learning en supply chains. Les grandes entreprises sont digitalisées depuis des décennies, donc ce que vous avez dans vos systèmes transactionnels, comme votre ERP et votre WMS, constitue déjà un excellent point de départ. Par la suite, si vous réalisez que vous voulez en avoir davantage, comme l’intelligence concurrentielle, des niveaux de stocks autorisés ou des ETAs fournis par vos fournisseurs, ces éléments seront des ajouts pertinents à utiliser comme données d’entrée pour vos modèles. Habituellement, ce que vous utilisez comme données d’entrée est quelque chose pour lequel vous avez une bonne intuition quant à sa corrélation avec ce que vous essayez de prédire, et une intuition globale est généralement suffisante. Le bon sens, bien que difficile à définir, est largement suffisant. Ce n’est pas le goulot d’étranglement en termes d’ingénierie.
Question: Quel est l’impact des décisions de tarification sur l’estimation de la demande future, même d’un point de vue probabiliste, et comment y faire face d’un point de vue machine learning ?
C’est une très bonne question. Il y a eu un épisode sur LokadTV qui abordait précisément ce problème. L’idée est que ce que vous apprenez devient ce que l’on appelle typiquement une politique, un dispositif qui contrôle la manière dont vous réagissez à divers événements. La façon de prévoir consiste à produire une sorte de paysage, à la manière de Monte Carlo. Vous allez produire une trajectoire, mais votre prévision ne sera pas constituée de points de données statiques. Ce sera un processus beaucoup plus génératif, où à chaque étape du processus de prévision, vous devrez générer le type de demande que vous pouvez observer, générer les décisions que vous prenez et régénérer le type de réaction du marché face à ce que vous venez de faire.
Il devient très compliqué d’évaluer la précision de votre processus de génération de réponse à la demande, et c’est pourquoi vous devez réellement apprendre vos métriques de prévision. C’est très délicat, mais c’est la raison pour laquelle vous ne pouvez pas simplement envisager vos métriques de prévision, vos métriques de précision, comme un problème unidimensionnel. Pour résumer, la prévision de la demande devient un générateur, elle est donc fondamentalement dynamique, non statique. C’est quelque chose de génératif. Ce générateur réagit à un agent, un agent qui va être implémenté sous forme de politique. Tant le générateur que le système de prise de décision doivent être appris. Vous devez également apprendre la fonction de perte. Il y a beaucoup à apprendre, mais heureusement, le deep learning est une approche très modulaire et programmatique qui se prête bien à la composition de toutes ces techniques.
Question: Est-il difficile de collecter des données, notamment auprès des PME ?
Oui, c’est très difficile. La raison est que, si vous traitez avec une entreprise dont le chiffre d’affaires est inférieur à 10 millions, il n’existe pas de département informatique. Il peut y avoir un petit ERP en place, mais même si les outils sont bons, décents et modernes, vous ne disposez pas d’une équipe informatique. Lorsque vous demandez les données, il n’y a personne dans l’entreprise cliente qui ait la compétence pour exécuter une requête SQL afin d’extraire les données.
Je ne suis pas sûr de bien comprendre votre question, mais le problème n’est pas exactement la collecte des données. La collecte se fait naturellement via le logiciel de comptabilité ou l’ERP en place, et de nos jours, les ERP sont accessibles même aux entreprises relativement petites. Le problème réside dans l’extraction des données à partir de ces logiciels d’entreprise. Si vous êtes dans une entreprise dont le chiffre d’affaires est inférieur à 20 millions de dollars et qui n’est pas une entreprise de le e-commerce, il y a de fortes chances que le département informatique soit inexistant. Même lorsqu’il existe un petit département informatique, il s’agit généralement d’une seule personne chargée de configurer les machines et les postes Windows pour tout le monde. Ce n’est pas quelqu’un qui connaît les bases de données et les tâches administratives plus avancées en matière de configurations informatiques.
D’accord, je suppose que c’est tout. La prochaine session aura lieu dans quelques semaines. Ce sera le mercredi 13 octobre. À la prochaine !
Références
- Une théorie de ce qui peut être appris, L. G. Valiant, novembre 1984
- Réseaux à vecteurs de support, Corinna Cortes, Vladimir Vapnik, septembre 1995
- Random Forests, Leo Breiman, octobre 2001
- LightGBM : Un arbre de décision par gradient boosting hautement efficace, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, dernière révision en décembre 2017
- Deep Double Descent : quand des modèles plus grands et plus de données nuisent, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, décembre 2019
- Analyser et améliorer la qualité d’image de StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, dernière révision en mars 2020
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, juin 2014
- Traduction automatique non supervisée utilisant uniquement des corpus monolingues, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, dernière révision en avril 2018
- BERT : Pré-entraînement de transformers bidirectionnels profonds pour la compréhension du langage, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, dernière révision en mai 2019
- Une introduction en douceur aux graph neural networks, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, septembre 2021


