00:21 Введение
01:53 От прогнозирования к обучению
05:32 Машинное обучение 101
09:51 История до сих пор
11:49 Мои сегодняшние прогнозы
13:54 Точность по данным, которых у нас нет 1/4
16:30 Точность по данным, которых у нас нет 2/4
20:03 Точность по данным, которых у нас нет 3/4
25:11 Точность по данным, которых у нас нет 4/4
31:49 Слава сопоставителю шаблонов
35:36 Глубина в обучении 1/4
39:11 Глубина в обучении 2/4
44:27 Глубина в обучении 3/4
47:29 Глубина в обучении 4/4
51:59 Рискуй по-крупному или иди домой
56:45 За пределами ошибки 1/2
01:00:17 За пределами ошибки 2/2
01:04:22 За пределами метки
01:10:24 За пределами наблюдения
01:14:43 Заключение
01:16:36 Предстоящая лекция и вопросы аудитории
Описание
Прогнозы в цепочке поставок являются неотъемлемыми, так как каждое решение (закупка, производство, хранение и т.д.) отражает предвидение будущих событий. Статистическое обучение и машинное обучение во многом вытеснили классическую область «прогнозирования», как с теоретической, так и с практической точек зрения. Мы попытаемся понять, что вообще означает предвидение будущего на основе данных с современной точки зрения «обучения».
Полная транскрипция

Добро пожаловать на серию лекций о цепочке поставок. Меня зовут Жоаннес Верморель, и сегодня я представлю «Машинное обучение для цепочки поставок». Мы не можем печатать товары на 3D-принтере в режиме реального времени, и мы не можем телепортировать их туда, куда они должны быть доставлены. На самом деле, почти все решения в области цепочки поставок необходимо принимать, заглядывая в будущее, предвидя будущий спрос или ценовые колебания, что подразумевает, как явно, так и неявно, некоторые ожидаемые рыночные условия как со стороны спроса, так и со стороны предложения. В результате прогнозирование является неотъемлемой и необходимой частью цепочки поставок. Мы никогда не можем быть уверены в будущем; мы можем только предполагать его с разной степенью вероятности. Цель этой лекции — понять, что машинное обучение привносит в вопрос захвата будущего.

Мы увидим на этой лекции, что предоставление более точных прогнозов является, в общей схеме вещей, относительно второстепенной задачей. На самом деле, в современной цепочке поставок прогнозирование означает прогнозирование с использованием временных рядов. Исторически прогнозы временных рядов стали популярны в начале 20-го века в США. Действительно, США стали первой страной, где миллионы представителей среднего класса владели акциями. Поскольку люди стремились быть искусными инвесторами, они хотели иметь представление о своих инвестициях, и оказалось, что временные ряды и прогнозы на их основе были интуитивно понятным и эффективным способом передачи этой информации. Можно было строить прогнозы временных рядов о будущих рыночных ценах, будущих дивидендах и будущих долях рынка.
В 80-х и 90-х годах, когда цепочки поставок фактически оцифровались, корпоративное программное обеспечение для цепочек поставок также начало использовать прогнозы временных рядов. На самом деле, прогнозы временных рядов стали повсеместными в подобных программных решениях. Однако, если вы посмотрите на эту картину, вы поймете, что прогнозы временных рядов — это на самом деле очень упрощенный и наивный способ взглянуть на будущее.
Видите ли, взглянув на эту картину, я уже могу сказать, что произойдет дальше: скорее всего, прибудет команда, которая уберет этот беспорядок, и, скорее всего, затем проведет осмотр погрузчиков в целях безопасности. Возможно, они даже проведут незначительный ремонт, и с высокой степенью уверенности можно сказать, что этот погрузчик вскоре будет снова работать. Просто взглянув на эту картину, мы также можем предположить, какие условия привели к этой ситуации. Ничто из этого не соответствует подходу временного ряда, однако все эти прогнозы весьма актуальны.
Эти прогнозы не о будущем как таковом, поскольку эта фотография была сделана некоторое время назад, и даже события, последовавшие за съемкой, теперь являются частью нашего прошлого. Но, тем не менее, это прогнозы в том смысле, что мы делаем утверждения о вещах, в отношении которых мы не можем быть абсолютно уверены. У нас нет прямых измерений. Поэтому основной вопрос заключается в том, как я вообще могу делать такие прогнозы и высказывать подобные утверждения?
Оказывается, как человек, я жил, наблюдал события и учился на них. Именно поэтому я могу делать такие утверждения. И оказывается, что машинное обучение — это именно то, о чем идет речь: это стремление воспроизвести способность к обучению на машинах, причем предпочтительными машинами в наши дни являются компьютеры. На этом этапе вы можете задаться вопросом, чем машинное обучение отличается от таких терминов, как искусственный интеллект, когнитивные технологии или статистическое обучение. Дело в том, что эти термины говорят гораздо больше о людях, которые их используют, чем о самой проблеме. В сущности, границы между всеми этими областями весьма расплывчаты.

Теперь давайте перейдем к обзору архетипа фреймворков машинного обучения, затрагивая короткую серию основных концепций машинного обучения. Большинство научных статей и программного обеспечения, созданных в данной области, в значительной степени опираются на этот фреймворк. Признаком является часть данных, предоставляемых для выполнения задачи прогнозирования. Идея заключается в том, что у вас есть задача прогнозирования, которую нужно выполнить, а признак (или несколько признаков) представляет собой то, что используется для выполнения этой задачи. В контексте прогнозов временных рядов признак представлял бы прошлую часть временного ряда, и вы бы имели вектор признаков, представляющий все предыдущие точки данных.
Метка представляет ответ на задачу прогнозирования. В случае прогноза временных рядов она обычно представляет ту часть временного ряда, которую вы не знаете, где кроется будущее. Если у вас есть набор признаков плюс метка, это называется наблюдением. Типичная установка машинного обучения предполагает, что у вас есть набор данных, содержащий как признаки, так и метки, который представляет ваш обучающий набор данных.
Цель заключается в том, чтобы создать программу, называемую моделью, которая принимает на вход признаки и вычисляет требуемую предсказанную метку. Эта модель обычно создается в процессе обучения, который проходит через весь обучающий набор данных и строит модель. Обучение в машинном обучении — это этап, на котором вы фактически создаете программу, осуществляющую прогнозирование.
Наконец, существует функция потерь. Функция потерь по сути представляет разницу между истинной меткой и предсказанной. Цель состоит в том, чтобы процесс обучения создал модель, делающую предсказания, максимально приближенные к истинным меткам. Вам нужна модель, которая сохраняет предсказанные метки как можно ближе к истинным меткам.
Машинное обучение можно рассматривать как обширное обобщение прогнозирования временных рядов. С точки зрения машинного обучения, признаки могут быть чем угодно, а не только прошлым фрагментом временного ряда. Метки также могут быть чем угодно, а не только будущим сегментом временного ряда. Модель может быть чем угодно, и даже функция потерь может быть практически чем угодно. Таким образом, у нас есть фреймворк, который является значительно более выразительным, чем прогнозы временных рядов. Однако, как мы увидим, большинство основных достижений машинного обучения как области исследований и практики проистекают из открытий элементов, которые заставляют нас пересмотреть и оспорить список концепций, которые я только что кратко представил.
Эта лекция является четвертой в серии лекций о цепочке поставок. Вспомогательные науки представляют собой элементы, которые не являются самим по себе цепочкой поставок, но имеют фундаментальное значение для нее. В первой главе я изложил свои взгляды на цепочку поставок как в теоретическом изучении, так и в практике. Во второй главе мы рассмотрели серию методологий, необходимых для решения такой области, как цепочка поставок, которая характеризуется множеством противоречивых аспектов и не может быть легко изолирована. Третья глава полностью посвящена персонам, что представляет собой способ сосредоточиться на проблемах, которые мы пытаемся решить.
В этой четвертой главе я постепенно поднимался по лестнице абстракции, начиная с компьютеров, затем алгоритмов и предыдущей лекции по математической оптимизации, которая может рассматриваться как базовый уровень современного машинного обучения. Сегодня мы отправляемся в область машинного обучения, которое является незаменимым для улавливания будущего, присутствующего во всех решениях в области цепочки поставок, которые нам приходится принимать каждый день.

Итак, каков план этой лекции? Машинное обучение — это обширная область исследований, и эта лекция будет построена вокруг короткой серии вопросов, связанных с концепциями и идеями, которые я представил ранее. Мы увидим, как ответы на эти вопросы вынуждают нас пересмотреть само понятие обучения и наш подход к данным. Одно из самых впечатляющих достижений машинного обучения заключается в том, что оно заставило нас осознать, что в деле задействовано гораздо больше факторов по сравнению с грандиозными первоначальными амбициями исследователей, которые полагали, что мы сможем воспроизвести человеческий интеллект в течение десятилетия.
В частности, мы рассмотрим глубокое обучение, которое, вероятно, является лучшим кандидатом на имитацию высшей степени интеллекта на данный момент. Хотя глубокое обучение возникло как невероятно эмпирическая практика, прогресс и достижения, достигнутые с его помощью, открывают новый взгляд на фундаментальную перспективу обучения на основе наблюдаемых явлений.
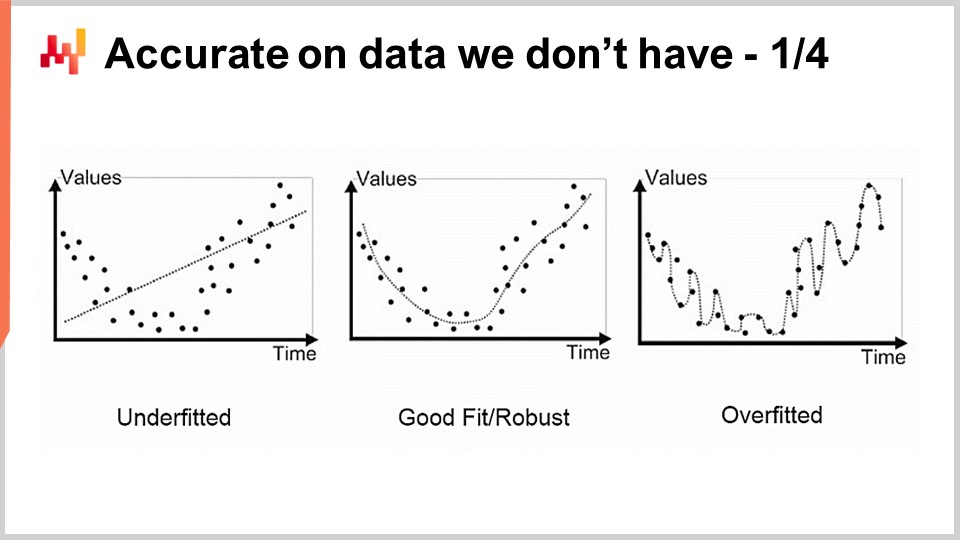
Первая проблема, с которой мы сталкиваемся при моделировании, статистическом или ином, — это точность данных, которых у нас нет. С точки зрения цепочки поставок это крайне важно, поскольку наш интерес заключается в способности улавливать будущее. По определению будущее представляет собой набор данных, которых у нас еще нет. Существуют методики, такие как ретроспективное тестирование или кросс-валидация, которые могут дать нам некоторые эмпирические оценки того, чего следует ожидать от точности данных, которых у нас нет. Однако то, почему эти методы вообще работают, является довольно интригующей и сложной задачей. Проблема не в том, чтобы построить модель, соответствующую имеющимся данным; создать модель, соответствующую данным, с помощью многочлена достаточной степени, легко. Однако такая модель не является удовлетворительной, поскольку она не улавливает то, что мы хотели бы уловить.
Классический подход к этой проблеме известен как компромисс смещения и дисперсии. Справа у нас модель с очень небольшим числом параметров, которая недообучается и, как мы говорим, имеет большое смещение. Слева у нас модель с избыточным числом параметров, которая переобучается и имеет слишком большую дисперсию. Посередине у нас модель, которая находит хороший баланс между смещением и дисперсией, которую мы называем хорошей подгонкой. До самого конца 20-го века было достаточно неясно, как подходить к этой проблеме помимо компромисса смещения и дисперсии.

Первое истинное понимание точности данных, которых у нас нет, было получено из теорий обучаемости, опубликованных Валянтом в 1984 году. Валянт представил теорию PAC — Достаточно Приблизительно Верную (Probably Approximately Correct). В этой теории часть «probably» относится к модели с определенной вероятностью предоставления достаточно хороших ответов. Часть «approximately» означает, что ответ не слишком далек от того, что считается хорошим или допустимым.
Валянт показал, что во многих ситуациях невозможно чему-либо научиться, или точнее, что для обучения нам потребовалось бы настолько чрезмерное количество образцов, что это было бы непрактично. Это уже было очень интересное наблюдение. Представленная формула исходит из теории PAC и является неравенством, которое говорит о том, что если вы хотите создать модель, которая является, вероятно, достаточно приближенной, вам необходимо иметь количество наблюдений n, превышающее определенное значение. Это значение зависит от двух факторов: эпсилон — уровня ошибки (часть «приблизительно верной») и эта — вероятности неудачи (1 минус эта — вероятность успеха).
Мы видим, что если мы хотим иметь меньшую вероятность неудачи или меньший эпсилон (допустимый уровень ошибки), нам потребуется больше образцов. Эта формула также зависит от мощности пространства гипотез. Идея заключается в том, что чем больше количество конкурентных гипотез, тем больше наблюдений необходимо для их различения. Это очень интересно, потому что, по сути, хотя теория PAC дает нам в основном отрицательные результаты, она говорит нам, что мы не можем сделать, а именно — построить доказуемо, вероятно, достаточно приближенную модель с меньшим количеством образцов. Теория на самом деле не подсказывает, как что-либо сделать; она не дает конкретных рекомендаций для улучшения решений задач прогнозирования. Тем не менее, это было знаковым событием, так как оно кристаллизовало идею о том, что можно подходить к проблеме точности и отсутствия данных гораздо более надежными способами, чем просто проводить эмпирические измерения с, скажем, кросс-валидацией или ретроспективным тестированием.
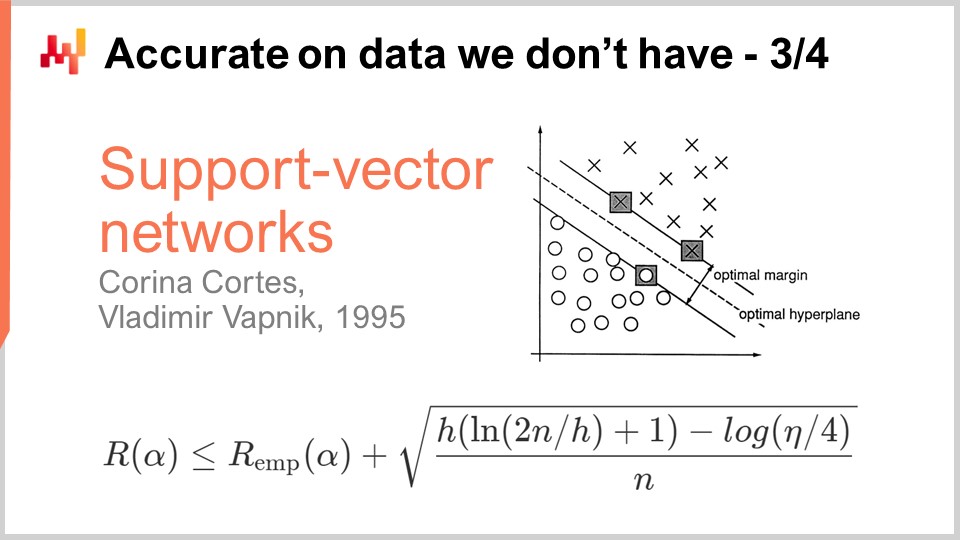
Десять лет спустя произошло первое практическое прорывное достижение, когда Вапник и несколько его коллег заложили основы того, что сегодня называется теорией Вапника-Червоненкиса (VC-теорией). Эта теория показывает, что можно уловить настоящие потери, называемые риском, то есть потери, которые вы увидите на данных, которых у вас не было. Математически было доказано, что существует возможность узнать что-либо о реальной ошибке, которую, по определению, нельзя измерить. Это весьма озадачивающий результат.
По сути, эта формула, непосредственно взятая из VC-теории, говорит нам, что настоящий риск ограничен сверху эмпирическим риском, то есть риском, который мы можем измерить на имеющихся данных, плюс еще один член, часто называемый структурным риском. У нас есть число наблюдений, n, и η, которое является вероятностью ошибки, как в теории PAC. Также имеется h, представляющее собой меру VC-размерности модели. VC-размерность отражает способность модели к обучению; чем больше способность модели к обучению, тем больше VC-размерность.
Эти результаты показывают, что для моделей, способных обучаться абсолютно всему, мы не можем сказать о них ничего определенного. Это весьма озадачивающе. Если ваша модель может обучаться чему угодно, то, по крайней мере математически, о ней нельзя ничего утверждать.
Прорыв в 1995 году произошел благодаря реализации со стороны Кортеса и Вапника того, что позже стало известно как машины опорных векторов (SVM). Эти SVM являются буквально прямой реализацией данной математической теории. Основная идея заключалась в том, что, обладая теорией, дающей это неравенство, мы можем реализовать модель, которая балансирует количество ошибок, которое мы совершаем на данных (эмпирический риск), и VC-размерность. Мы можем напрямую построить математическую модель, которая точно уравновешивает эти два фактора, делая неравенство настолько узким и настолько малым, насколько это возможно. Именно об этом и говорят машины опорных векторов (SVM). Эти результаты оказались настолько поразительными в практическом плане, что привели к очень хорошим результатам и оказали значительное влияние на сообщество машинного обучения. Впервые точность на данных, которых у нас не было, не была второстепенной задачей; она получалась непосредственно благодаря математическому дизайну самого метода. Это было настолько впечатляюще и мощно, что на десятилетие отвлекло всё сообщество машинного обучения на этот путь. Как мы увидим, этот путь оказался в основном тупиковым, но на то была веская причина: это был абсолютно поразительный результат.
С практической точки зрения, поскольку SVM в основном возникли из математической теории, им недоставало механической симпатии. Они не подходили для вычислительного оборудования, которое у нас есть. Более того, наивная реализация SVM обладает квадратичной зависимостью по расходу памяти относительно числа наблюдений. Это означает большие затраты, и, как следствие, SVM работают очень медленно. Позже появились улучшения с некоторыми онлайн-вариантами SVM, существенно снижавшими требования к памяти, но тем не менее, SVM никогда не считались действительно масштабируемым подходом для машинного обучения.

SVM проложили путь к другому, лучшему классу моделей, которые, вероятно, тоже не страдали переобучением. Переобучение, по сути, означает очень неточные предсказания на данных, которых у вас нет. Самыми заметными примерами, вероятно, являются случайные леса (Random Forests) и градиентно-усиленные деревья (Gradient Boosted Trees), которые являются их почти непосредственными потомками. В основе их лежит бустинг – метаалгоритм, превращающий слабые модели в более сильные. Бустинг возник из вопросов, поднятых в самом конце 80-х годов между Кернсом и Валиантом, о которых мы упоминали ранее в этой лекции.
Чтобы понять, как работает случайный лес, всё достаточно просто: возьмите обучающий набор данных, затем выберите из него случайную выборку. На этой выборке постройте дерево решений. Повторите этот процесс, создавая новую выборку из исходного обучающего набора и строя еще одно дерево решений. Повторяя этот процесс, в итоге вы получите множество деревьев решений. Деревья решений являются относительно слабыми моделями машинного обучения, поскольку они не способны уловить очень сложные закономерности. Однако, если объединить все эти деревья и усреднить результаты, вы получите лес, который называют случайным лесом (Random Forest), ведь каждое дерево построено на случайной подвыборке исходного набора данных. Случайный лес дает гораздо более сильную и качественную модель машинного обучения.
Градиентно-усиленные деревья представляют собой лишь незначительное отклонение от этой идеи. Главное отличие в том, что вместо того, чтобы случайным образом выбирать подвыборку из обучающего набора данных и строить независимое дерево, в градиентно-усиленных деревьях сначала строится лес, а затем следующее дерево создается с учётом ошибок (остатков) уже существующего леса. Идея состоит в том, что вы уже начали строить модель, состоящую из множества деревьев, и ваши предсказания расходятся с реальностью. Эти расхождения, или дельты, называются остатками – разницей между реальными и предсказанными значениями. Идея заключается в том, чтобы обучать следующее дерево не на исходном наборе данных, а на выборке остатков. Градиентно-усиленные деревья работают даже лучше, чем случайные леса. На практике случайные леса действительно склонны к переобучению, но только немного. Существуют доказательства, что при определённых условиях случайные леса не должны переобучаться.
Интересно, что градиентно-усиленные деревья уже полтора десятилетия доминируют на высоких местах практически во всех соревнованиях по машинному обучению. Если посмотреть на примерно 80–90% соревнований на Kaggle, то можно увидеть, что именно градиентно-усиленное дерево занимает первое место. Однако, несмотря на это невероятное доминирование в соревнованиях по машинному обучению, прорывов в применении градиентно-усиленных деревьев к задачам цепочек поставок в реальных условиях было очень мало. Основная причина в том, что градиентно-усиленные деревья обладают очень небольшой механической симпатией; их конструкция совсем не оптимизирована для вычислительного оборудования, которое у нас имеется.
Легко понять, почему так происходит: вы строите модель, состоящую из серии деревьев, и в итоге модель оказывается размером, сравнимым с долей вашего набора данных. Во многих случаях модель выходит даже больше по объему данных, чем исходный набор. Таким образом, если ваш набор данных уже очень велик, то ваша модель оказывается гигантской, что представляет собой серьезную проблему.
Что касается истории градиентно-усиленных деревьев, то было реализовано множество подходов, начиная с GBM (Gradient Boosted Machines) в 2007 году, который действительно популяризовал этот метод посредством R-пакета. С самого начала возникали проблемы с масштабируемостью. Люди быстро начали параллелизовать выполнение с помощью PGBRT (Parallel Gradient Boosted Regression Trees), однако это все равно было очень медленно. XGBoost стал поворотным моментом, так как обеспечил порядковый прирост масштабируемости. Ключевым моментом в XGBoost стало использование колонно-ориентированного представления данных для ускорения построения деревьев. Позже LightGBM перенял все идеи XGBoost, но изменил стратегию построения деревьев: XGBoost строил дерево по уровням, тогда как LightGBM решил расти дерево по листьям. В итоге LightGBM теперь в несколько раз быстрее, при условии использования того же вычислительного оборудования, чем когда-либо был GBM. Однако с практической точки зрения в цепочках поставок использование градиентно-усиленных деревьев зачастую оказывается непрактично медленным. Это не означает, что их невозможно использовать; просто преодолеть этот барьер обычно не стоит затраченных усилий.

Озадачивающим является то, что градиентно-усиленные деревья достаточно мощны, чтобы выигрывать почти все соревнования по машинному обучению, и тем не менее, на мой скромный взгляд, эти модели представляют собой технологический тупик. Машины опорных векторов, случайные леса и градиентно-усиленные деревья имеют общее: они представляют собой не более чем сопоставление с шаблоном. Они, безусловно, являются отличными инструментами для сопоставления с шаблоном, но ничем большим. То, что они делают исключительно хорошо, – это выбор переменных, и они в этом действительно преуспевают, но это практически всё, что в них есть. В частности, им не хватает выразительности, позволяющей преобразовывать входные данные во что-либо иное, кроме прямого выбора или фильтрации.
Если вернуться к изображению погрузчика, которое я показал в начале этой лекции, то нет никакой надежды, что какая-либо из этих моделей сможет делать такие утверждения, как я только что высказал, независимо от того, насколько велик набор изображений. Вы могли бы буквально снабдить все эти модели миллионами изображений со складов по всему миру, и они всё равно не смогли бы сделать вывод вроде: “О, я видел погрузчик в такой ситуации; скоро прибудет бригада для ремонта.” Совсем нет.
На практике мы видим, что тот факт, что эти модели выигрывают соревнования по машинному обучению, обманчив, поскольку в таких условиях есть факторы, играющие им на руку. Во-первых, реальные наборы данных чрезвычайно сложны, что отличается от соревнований по машинному обучению, где, в лучшем случае, используются игрушечные наборы данных, представляющие лишь малую часть сложности реальных условий. Во-вторых, чтобы выиграть соревнование по машинному обучению с использованием таких моделей, как градиентно-усиленные деревья, необходимо проводить обширное инженерное преобразование признаков. Поскольку эти модели являются прославленными сопоставлениями с шаблонами, вам нужны правильные признаки, чтобы простой выбор переменных приводил к отличной работе модели. Необходимо влить значительную дозу человеческого интеллекта в подготовку данных, чтобы модель работала. Это является серьезной проблемой, поскольку в реальном мире, пытаясь решить задачу для настоящих цепочек поставок, у вас ограничено количество инженерных часов, которые можно потратить на проблему. Вы не можете потратить шесть месяцев на крошечный, временный, игрушечный аспект вашей цепочки поставок.
Третья проблема заключается в том, что в цепочках поставок наборы данных постоянно меняются. Изменяются не только сами данные, но и сама задача постепенно эволюционирует. Это усугубляет проблемы, связанные с инженерной обработкой признаков. В конечном итоге мы остаемся с моделями, которые выигрывают соревнования по машинному обучению и прогнозированию, но если заглянуть в будущее на десятилетие, становится ясно, что эти модели не являются будущим машинного обучения, а представляют собой прошлое.

Глубокое обучение стало ответом на эти поверхностные сопоставления с шаблонами. Глубокое обучение часто представляют как потомка искусственных нейронных сетей, но на самом деле оно начало развиваться в тот момент, когда исследователи решили отказаться от биологических метафор и сосредоточиться на механической симпатии. И снова, механическая симпатия, то есть умение эффективно взаимодействовать с имеющимися у нас компьютерами, имеет решающее значение. Проблема с искусственными нейронными сетями заключалась в том, что мы пытались имитировать биологию, в то время как компьютеры, которыми мы располагаем, совершенно не похожи на биологические субстраты, поддерживающие наш мозг. Эта ситуация напоминает раннюю авиационную историю, когда многие изобретатели пытались создавать летающие машины, подражая птицам. Сегодня у нас есть летательные аппараты, которые летают во много раз быстрее самых быстрых птиц, но способ их полета практически не имеет ничего общего с полетом птиц.
Первое понимание глубинного обучения заключалось в необходимости иметь нечто глубокое и выразительное, способное применять любое преобразование к входным данным, позволяющее модели проявлять умное предсказательное поведение. Однако оно также должно было эффективно работать на том вычислительном оборудовании, которое у нас было. Идея состояла в том, что если у нас будут сложные модели, хорошо взаимодействующие с вычислительным оборудованием, мы, скорее всего, сможем обучать функции, которые в несколько порядков сложнее по сравнению с любым методом, не обладающим таким уровнем механической симпатии, при прочих равных условиях.
Дифференцируемое программирование, которое было представлено в предыдущей лекции, можно считать базовым уровнем глубокого обучения. Я не собираюсь углубляться в дифференцируемое программирование в этой лекции, но приглашаю аудиторию посмотреть предыдущую лекцию, если вы её не видели. Вы должны понять последующее, даже если не видели предыдущей лекции. Предыдущая лекция проясняет некоторые нюансы самого процесса обучения. Короче говоря, дифференцируемое программирование – это просто способ, при выборе определённой формы модели, определить наилучшие значения параметров, присутствующих в этой модели.
В то время как дифференцируемое программирование сосредоточено на определении оптимальных параметров, машинное обучение направлено на выявление превосходных форм моделей, обладающих наибольшей способностью к обучению на данных.

Итак, как же создать шаблон для произвольно сложной функции, способной отражать любое преобразование входных данных, каким бы сложным оно ни было? Начнем с цепи чисел с плавающей запятой. Почему числа с плавающей запятой? Потому что именно с ними можно применять градиентный спуск, который, как мы видели в предыдущей лекции, обладает высокой масштабируемостью. Так что используем числа с плавающей запятой. Мы будем иметь последовательность чисел с плавающей запятой, то есть на вход и выход будут подаваться числа с плавающей запятой.
Теперь, что же делать посередине? Давайте займемся линейной алгеброй, а точнее — умножением матриц. Почему именно умножение матриц? Ответ на этот вопрос был дан в самой первой лекции этой четвертой главы. Это связано со способом, которым сконструированы современные компьютеры; по сути, можно добиться значительного ускорения обработки, если придерживаться линейной алгебры. Итак, линейная алгебра — то, что нам нужно. А теперь, если я возьму входные данные и применю к ним линейное преобразование, которое представляет собой просто умножение на матрицу W (в этой матрице содержатся параметры, которые мы позже хотим изучить), как можно усложнить процесс? Можно добавить второе умножение матриц. Однако, если вспомнить курсы линейной алгебры, при умножении одной линейной функции на другую результат всё равно является линейной функцией. Таким образом, если просто композировать умножения матриц, мы все равно получим линейное преобразование.
Что мы собираемся сделать, так это чередовать нелинейности между линейными операциями. Именно это я и сделал на этом экране. Я чередовал функцию, обычно известную в литературе по глубокому обучению как Rectified Linear Unit (ReLU). Это название, которое выглядит фантастически сложным по сравнению с тем, что она делает, представляет собой очень простую функцию, которая говорит: если я беру число и если оно положительное, тогда я возвращаю то же самое число (то есть, функция идентичности), а если число отрицательное, я возвращаю 0. Вы также можете записать это как максимум вашего значения и нуля. Это очень тривиальная нелинейность.
Мы могли бы использовать гораздо более сложные нелинейные функции. Исторически, когда люди работали с нейронными сетями, они хотели применять сложные сигмовидные функции, поскольку предполагалось, что именно так работают наши нейроны. Но на самом деле, зачем тратить вычислительные ресурсы на что-то несущественное? Главное понимание заключается в том, что нам необходимо ввести какую-либо нелинейность, и не имеет значения, какую именно нелинейную функцию мы применим. Единственное, что имеет значение — это обеспечить её высокую скорость. Мы хотим, чтобы вся система работала максимально быстро.
То, что я строю здесь, называется плотными слоями. Плотный слой — это, по сути, матричное умножение с добавлением нелинейности (Rectified Linear Unit). Мы можем их укладывать один на другой. На экране вы видите сеть, обычно называемую многослойным перцептроном, состоящую из трёх слоёв. Мы могли бы продолжать их складывать, и их могло бы быть 20 или 2000 — это не имеет большого значения. Дело в том, что, как бы простовато это ни казалось, если взять такую сеть всего с несколькими слоями и применить её в вашем фреймворке дифференцируемого программирования, который предоставляет параметры, то дифференцируемое программирование как базовый слой сможет обучить эти параметры, изначально выбранные случайным образом. Если вы хотите произвести инициализацию, просто инициализируйте все параметры случайно. Вы получите довольно хорошие результаты для очень большого разнообразия задач.
Это очень интересно, потому что на данном этапе у вас уже присутствуют практически все фундаментальные компоненты глубокого обучения. Так что, для аудитории, поздравляю! Вы, вероятно, уже можете начинать добавлять в своё резюме «специалист по глубокому обучению», ведь это почти всё, что нужно. Ну, не совсем, но можно сказать, что это хороший старт.

Фактически, глубокое обучение требует совсем немного теории, помимо тензорной алгебры, которая, по сути, является компьютеризированной линейной алгеброй. Однако глубокое обучение включает в себя множество приемов. Например, нам нужно нормализовать входные данные и стабилизировать градиенты. Если мы начнём складывать множество таких операций, то градиенты могут расти экспоненциально при обратном распространении по сети, и в какой-то момент это превысит возможности представления этих чисел. Наши реальные компьютеры не способны представлять произвольно большие числа. В какой-то момент вы просто выйдете за пределы возможностей представления числа с 32-битным или 16-битным плавающим значением. Существует множество трюков для стабилизации градиентов. Например, обычно используется пакетная нормализация, но есть и другие методы.
Если у вас есть входные данные, обладающие геометрической структурой — например, одномерные данные, как временной ряд (исторические продажи, как мы видим в цепочке поставок), двухмерные (рассматривайте их как изображение), трёхмерные (это может быть фильм) или даже четырёхмерные и так далее — то существуют специальные слои, способные захватывать эту геометрическую структуру. Самые известные из них, вероятно, называются сверточными слоями.
Кроме того, существуют техники и приемы для работы с категориальными входными данными. В глубоком обучении все ваши входные данные представлены числами с плавающей запятой, так как же работать с категориальными переменными? Ответ — embeddings (встраивания). Также существуют заменяющие функции потерь, которые представляют собой альтернативные функции потерь с очень крутыми градиентами и способствуют процессу сходимости, в конечном итоге усиливая то, чему модель может научиться на данных. Существует множество приемов, и все эти хитрости обычно можно интегрировать в программу, которую вы разрабатываете, поскольку мы используем дифференцируемое программирование в качестве базового уровня.
Глубокое обучение на самом деле заключается в том, как мы составляем программу, которая, пройдя процесс обучения, предложенный дифференцируемым программированием, обладает очень высокой способностью к обучению. Большинство компонентов, которые я только что перечислил на экране, также являются программными, что очень удобно, учитывая, что у нас есть дифференцируемое программирование — парадигма, поддерживающая всё это.
На данном этапе должно стать понятнее, почему глубокое обучение отличается от классического машинного обучения. Глубокое обучение не сводится к моделям. На самом деле, большинство библиотек глубокого обучения с открытым исходным кодом даже не включают никаких моделей. В глубоком обучении действительно важны архитектуры моделей, которые можно рассматривать как шаблоны, требующие значительной настройки для конкретной ситуации. Однако если вы выберете правильную архитектуру, можно ожидать, что ваша настройка всё же сохранит суть способности модели к обучению. В глубоком обучении мы смещаем фокус с конечной модели, которая становится чем-то не очень интересным, на архитектуру, которая становится настоящим объектом исследований.
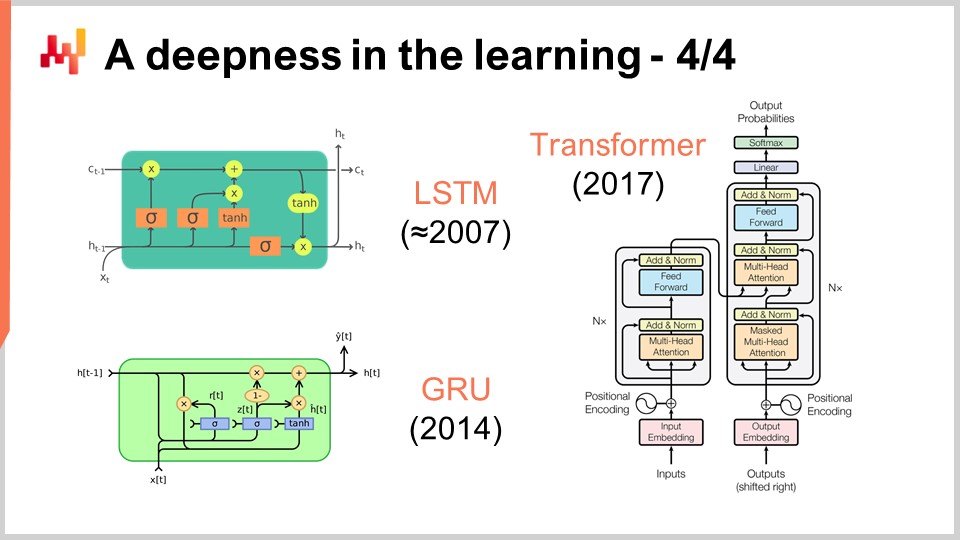
На экране вы видите ряд заметных примеров архитектур. Сначала — LSTM, что расшифровывается как Long Short-Term Memory (долгая краткосрочная память), начало работать примерно в 2007 году. История публикаций LSTM несколько запутана, но по сути она начала применяться в стиле глубокого обучения в 2007 году. Позже её заменили Gated Recurrent Units (GRU), которые по сути выполняют ту же функцию, что и LSTM, но являются проще и удобнее. В основном, большая часть сложности LSTM проистекает из биологических метафор. Оказывается, можно отказаться от биологических метафор, и в итоге получается нечто проще, что работает практически так же. Это и есть Gated Recurrent Units (GRU). Позже появились трансформеры, которые по сути сделали устаревшими как LSTM, так и GRU. Трансформеры стали прорывом, поскольку они намного быстрее, требуют меньше вычислительных ресурсов и обладают ещё большей способностью к обучению.
Большинство этих архитектур сопровождаются метафорами. У LSTM есть когнитивная метафора (долгая краткосрочная память), в то время как трансформеры сопровождаются метафорой поиска информации. Однако эти метафоры имеют незначительную прогностическую силу и, возможно, даже больше сбивают с толку и отвлекают от того, что действительно заставляет эти архитектуры работать, что пока не до конца понятно.
Трансформеры представляют большой интерес для цепочки поставок, поскольку они являются одними из самых универсальных архитектур. Сегодня их используют практически для всего: от автономного вождения до автоматизированного перевода и многих других сложных задач. Это свидетельствует о силе правильного выбора архитектуры, которую можно затем адаптировать к огромному разнообразию проблем. Что касается цепочки поставок, то одной из основных трудностей применения машинного обучения является невероятное разнообразие задач. Мы не можем позволить себе команду, которая тратит пять лет на исследования для каждой отдельной подзадачи, с которой мы сталкиваемся. Нам нужно что-то, что позволит двигаться быстро и не изобретать заново половину машинного обучения каждый раз, когда мы хотим решить новую задачу.
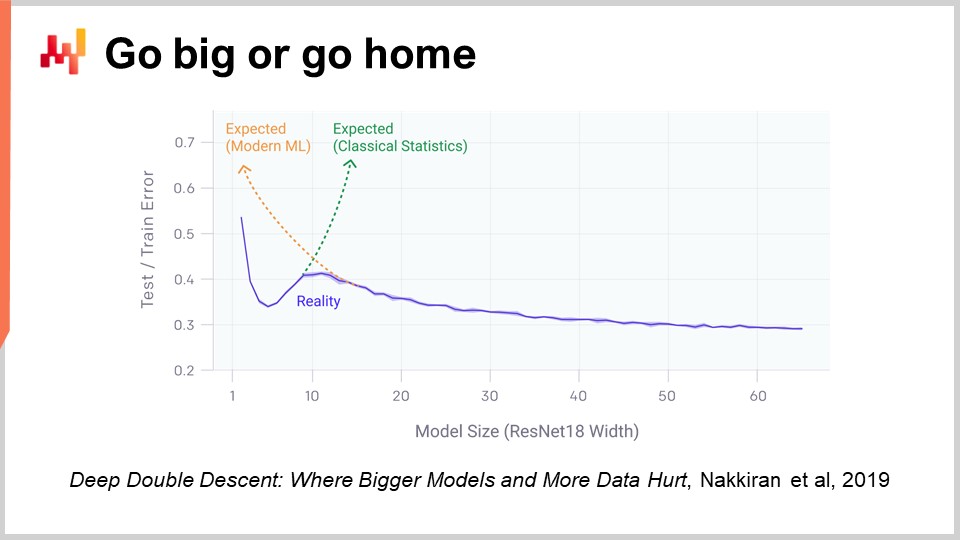
Один из аспектов глубокого обучения, который действительно шокирует при ближайшем рассмотрении, — это огромное количество параметров. В многослойном перцептроне, который я представил несколько минут назад, с плотными слоями, включающими матричные умножения, может быть очень много параметров в этих матрицах. На самом деле, несложно иметь столько же параметров, сколько у нас наблюдений или пунктов данных в тренировочных наборах. Как мы видели в самом начале лекции, если модель содержит такое количество параметров, она должна сильно страдать от переобучения.
Реальность глубокого обучения ещё более загадочна. Существует множество случаев, когда параметров значительно больше, чем наблюдений, и тем не менее мы не сталкиваемся с драматическими проблемами переобучения. Еще более удивительно, что модели глубокого обучения, как правило, полностью подгоняют тренировочный набор, так что ошибка на нём становится практически нулевой, и они всё равно сохраняют предсказательную способность для данных, которых в обучении не было.
Два года назад статья Deep Double Descent, опубликованная OpenAI, пролила очень интересный свет на эту ситуацию. Команда показала, что в области машинного обучения существует своего рода «зловещая долина». Идея заключается в том, что если вы берете модель с всего несколькими параметрами, у нее будет много смещения, и качество результатов на невиданных данных будет недостаточным. Это соответствует классическому видению машинного обучения и классической статистике. Если увеличить число параметров, качество модели улучшится, но в какой-то момент начнется переобучение. Именно это мы и наблюдали ранее при обсуждении недообучения и переобучения. Необходимо найти баланс.
Однако, как они показали, если продолжать увеличивать число параметров, происходит нечто очень странное: переобучение становится всё менее выраженным, что является полной противоположностью тому, что предсказывает классическая теория статистического обучения. Это поведение не случайно. Авторы доказали, что оно очень устойчивое и распространённое. Оно происходит практически всегда в самых разнообразных ситуациях. Пока не до конца понятно, почему так происходит, но уже хорошо известно, что эффект «глубокого двойного спада» является реальным и широко распространённым.
Это также помогает понять, почему глубокое обучение пришло в машинное обучение относительно поздно. Чтобы добиться успеха в глубоком обучении, нам сначала нужно было создать модели, способные обрабатывать десятки или даже сотни тысяч параметров, чтобы преодолеть эту «зловещую долину». В 80-х и 90-х годах прорыв в глубоком обучении был бы невозможен, просто потому что вычислительные мощности не позволяли перепрыгнуть через эту «зловещую долину».
К счастью, с современным вычислительным оборудованием можно без особых усилий обучать модели, содержащие миллионы или даже миллиарды параметров. Как мы отмечали в предыдущих лекциях, сейчас существуют компании, такие как Facebook, которые обучают модели с более чем триллионом параметров. Так что мы можем идти очень далеко.

До сих пор мы предполагали, что функция потерь известна. Однако почему это должно быть так? Действительно, давайте рассмотрим ситуацию модного магазина с точки зрения цепочки поставок. В модном магазине имеются уровни запасов для каждого SKU, и мы хотим спрогнозировать будущий спрос. Мы собираемся смоделировать один из возможных сценариев, который будет правдоподобен для будущего спроса в этом магазине. Что произойдет, так это то, что когда определенные SKU закончатся, мы должны будем наблюдать эффекты каннибализации и замещения. Когда для какого-либо SKU наступит дефицит-товара, спрос, как правило, частично переключится на похожие продукты.
Но если мы попытаемся подойти к этой задаче, используя классические метрики прогнозирования, такие как средний абсолютный процент ошибки (MAPE), средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (MSE) или другие метрики, работающие по SKU, день за днем или неделя за неделей, мы не сможем уловить ни один из этих эффектов. То, что нам действительно нужно, — это метрика, которая способна определить, насколько хорошо мы учитываем все эффекты каннибализации и замещения. Но как должна выглядеть эта функция потерь? Это очень неясно и, похоже, требует довольно сложного поведения. Один из ключевых прорывов глубокого обучения заключался именно в понимании, что функция потерь должна обучаться. Именно так было создано изображение на экране. Это полностью сгенерированное машиной изображение; ни один из этих людей не является настоящим. Они были сгенерированы, а задача заключалась в том, чтобы создать функцию потерь или метрику, которая определит, является ли изображение хорошим, фотореалистичным портретом человека или нет.
Реальность такова, что если начинать думать в терминах метрики, подобной среднеабсолютному процентному отклонению (MAPE), то получается метрика, действующая по пикселям. Проблема в том, что метрика, работающая на уровне пикселей, не дает информации о том, выглядит ли изображение в целом как человеческое лицо. У нас та же проблема в модном магазине с SKU и прогнозированием спроса. Очень просто разработать метрику на уровне SKU, но это не дает понимания общей картины магазина. Однако с точки зрения цепочки поставок нас не интересует точность на уровне отдельных SKU; нам важна точность для магазина в целом. Мы хотим знать, что уровни запасов являются адекватными для всего магазина, а не подходят ли они для одного SKU, а потом для другого. Так как же сообщество глубокого обучения решило эту проблему?
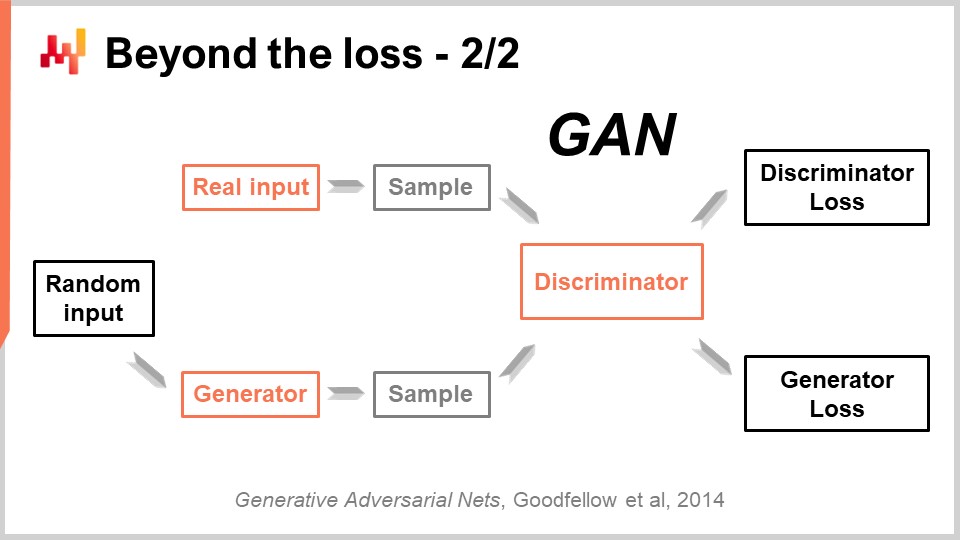
Это очень впечатляющее достижение было получено с помощью удивительно простой техники, называемой генеративно-состязательными сетями (GANs). В прессе вы могли слышать об этих техниках под названием deepfakes. Deepfakes — это изображения, созданные с использованием этой GAN-техники. Как это работает?
Итак, принцип работы таков: сначала вы начинаете с генератора. Генератор принимает на вход некоторый шум, то есть случайные значения, и в данном случае генерирует изображение. Если вернуться к случаю с цепочкой поставок, он мог бы генерировать траектории для всех точек спроса, наблюдаемых для каждого отдельного SKU, скажем, на следующие три месяца в этом модном магазине. Сам генератор является нейронной сетью глубокого обучения.
Теперь появляется дискриминатор. Дискриминатор тоже является нейронной сетью глубокого обучения, и его задача — научиться предсказывать, является ли сгенерированный объект реальным или синтетическим. Дискриминатор — это бинарный классификатор, которому достаточно определить, настоящий объект или нет. Если дискриминатор сумеет правильно определить, что образец поддельный, синтетический, мы проведем обратное распространение градиентов к генератору и позволим генератору учиться на этой информации.
В результате данной настройки генератор начинает учиться создавать образцы, которые действительно обманывают и сбивают с толку дискриминатор. При этом дискриминатор учится лучше отличать реальные образцы от синтетических. Если рассматривать этот процесс, он, надеюсь, сходится к состоянию, в котором у вас оказывается как генератор очень высокого качества, создающий невероятно реалистичные образцы, так и отличный дискриминатор, способный определить, является ли образец реальным или нет. Именно это и делается с помощью GAN для создания фотореалистичных картинок. Если вернуться к цепочке поставок, вы обнаружите, что эксперты в этой сфере утверждают, что для конкретной ситуации лучшая метрика — это MAPE, или взвешенный MAPE, или что-то подобное. Они предлагают рецепты, утверждая, что в определённых ситуациях нужно использовать ту или иную метрику. Реальность такова, что глубокое обучение показывает: метрика прогнозирования — концепция устаревшая. Если вы хотите добиться высокой размерной точности, а не просто точности по отдельным точкам, вам необходимо изучить саму метрику. Хотя на данный момент, как мне кажется, практически ни одна цепочка поставок не использует эти техники, в будущем они будут применяться. Станет нормой изучать прогнозную метрику с помощью генеративных состязательных сетей или их потомков, поскольку это позволяет уловить тонкое, высокоразмерное поведение, которое действительно имеет значение, а не просто добиться точности по отдельным точкам.

До сих пор каждое наблюдение сопровождалось меткой, и эта метка была выходом, который мы хотели предсказать. Однако существуют ситуации, которые нельзя оформить как задачи “ввод-вывод”. Меток просто нет. Если взять пример из цепочки поставок, то это будет гипермаркет. В гипермаркетах уровни запасов не являются абсолютно точными. Товары могут быть повреждены, украдены или просрочены, и существует множество причин, по которым электронные записи в вашей системе не отражают в точности то, что доступно на полке с точки зрения покупателей. Проведение инвентаризации слишком дорого, чтобы служить источником данных для точного учета запасов в режиме реального времени. Вы можете проводить инвентаризацию, но не сможете обходить весь гипермаркет каждый день. В итоге у вас оказывается огромный объем немного неточных запасов. Их у вас масса, но вы не можете по-настоящему сказать, какие из них точны, а какие — нет.
По сути, это именно тот случай, когда обучение без учителя имеет смысл. Мы хотим чему-то научиться; у нас есть данные, но у нас нет правильных ответов. Меток нет. Все, что у нас есть — это огромные объемы данных. Обучение без учителя на протяжении десятилетий считалось в сообществе машинного обучения священным граалем. Очень долгое время оно казалось будущим, но далеким будущим. Однако недавно в этой области произошли невероятные прорывы. Один из таких прорывов, например, был осуществлён командой Facebook, опубликовавшей статью под названием “Unsupervised Machine Translation Using Monolingual Corpora Only”.
То, что сделала команда Facebook в этой статье, заключалось в создании системы перевода, которая использовала только корпус английского текста и корпус французского текста. Эти два корпуса не имеют ничего общего; это даже не один и тот же текст. Это просто текст на английском и текст на французском. Затем, не предоставляя системе никаких фактических переводов, они обучили систему переводить с английского на французский. Это абсолютно поразительный результат. Кстати, способ, которым это было достигнуто, заключается в использовании техники, которая невероятно напоминает генеративные состязательные сети, которые я только что представил. Аналогично, команда Google опубликовала BERT (Bidirectional Encoder Representations from Transformers) два года назад. BERT — модель, которая обучается преимущественно без учителя. Речь снова идёт о тексте. Работа с BERT заключается в использовании огромных баз текстовых данных и случайном маскировании слов. Затем модель обучается предсказывать эти слова, и этот процесс повторяется для всего корпуса. Некоторые называют эту технику самообучением, но что особенно интересно в BERT и где он становится актуальным для цепочки поставок, так это то, что внезапно подход к вашим данным сводится к созданию машины, способной скрывать части данных, при этом успешно восстанавливая их.
Причина, по которой это имеет первостепенное значение для цепочки поставок, заключается в том, что то, что делается с помощью BERT в контексте обработки естественного языка, может быть расширено на многие другие области. Это своего рода универсальная машина для ответов на вопрос “что если”. Например, что если у меня был бы ещё один магазин? На такой вопрос можно ответить, просто изменив данные, добавив магазин и сделав запрос к модели машинного обучения, которую вы только что построили. Что если у меня был бы дополнительный продукт? Что если у меня был бы еще один клиент? Что если для этого продукта установлена другая цена? И так далее. Обучение без учителя имеет первостепенное значение, потому что вы начинаете рассматривать свои данные как целое, а не просто как список пар. В итоге у вас получается механизм, который является полностью универсальным и может делать прогнозы по любому аспекту, который присутствует в данных. Это очень мощно.
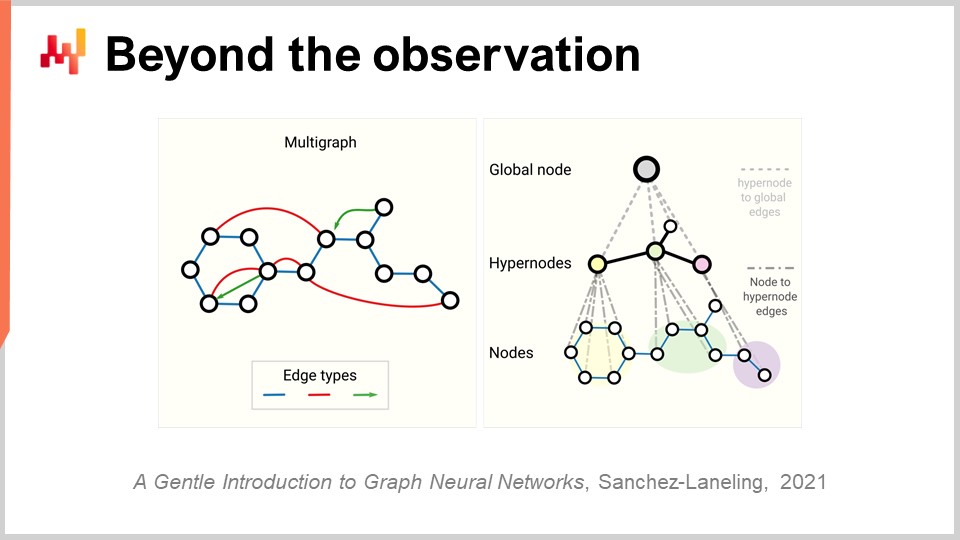
Теперь, наконец, нам нужно пересмотреть всю концепцию наблюдения. Изначально мы говорили, что наблюдение — это пара признаков плюс метка. Мы увидели, как можно убрать метку, но что насчёт самих признаков и самого наблюдения? Проблема цепочки поставок в том, что у нас на самом деле нет наблюдений. Даже неясно, можно ли разбить цепочку поставок на список независимых или однородных наблюдений. Как обсуждалось в предыдущей лекции, способ наблюдения цепочки поставок не заключается в каком-либо прямом научном наблюдении самой цепочки. Всё, что у нас есть, — это ряд компонентов корпоративного программного обеспечения, и единственный способ наблюдать за цепочкой поставок — это косвенно через записи, собранные в этих системах. Это может быть ERP, WMS, системы точек продаж и т.д. Но суть в том, что всё, что у нас есть, — это, по сути, электронные записи, транзакционной природы, поскольку все эти системы, как правило, реализованы поверх транзакционных баз данных. Таким образом, наблюдения не являются независимыми. Имеющиеся записи буквально взаимосвязаны, потому что они хранятся в реляционной базе данных. Когда я говорю, что у них есть связи, я имею в виду, что, если вы посмотрите на клиента с картой лояльности, например, он связан со всеми купленными им продуктами. Каждый продукт связан со всеми магазинами, где он является частью ассортимента. Каждый магазин связан со всеми складами, которые могут обслуживать данный магазин. Таким образом, у нас нет независимых наблюдений; у нас есть данные с множеством наложенных реляционных структур, и ни один из этих элементов не является по-настоящему независимым от остальных.
Ключевым прорывом в глубоких нейронных сетях для работы с такими взаимосвязанными данными является графовое обучение. Графовое обучение — это именно то, что нужно для анализа таких явлений, как замещение и каннибализация в модной индустрии. Лучший способ понять каннибализацию — представить, что все продукты конкурируют за одних и тех же клиентов, и анализируя данные, связывающие клиентов и продукты, можно изучить каннибализацию. Внимание: графовое обучение не имеет ничего общего с графовыми базами данных, которые представляют собой нечто совершенно иное. Графовые базы данных — это по сути просто базы данных для запросов по графам, без какого-либо обучения. Графовое обучение же направлено на изучение дополнительных свойств самих графов. Речь идёт об изучении взаимосвязей, которые могут быть или не могут быть наблюдаемыми, или не могут быть полностью наблюдаемыми, либо о дополнении существующих связей слоем практических знаний.
По моему мнению, учитывая, что по своей сути цепочка поставок — это система, в которой все части взаимосвязаны (это и есть проклятие цепочки поставок, когда нельзя просто оптимизировать что-либо локально, не создавая новых проблем), графовое обучение станет всё более распространённым подходом для решения таких задач в цепочке поставок и машинном обучении. По сути, графовые нейронные сети — это методы глубокого обучения, предназначенные для работы с графами.
В заключение, думать, что машинное обучение сводится к предоставлению более точных прогнозов — мягко говоря, наивно. Это всё равно, что утверждать, что главная цель автомобиля — это доступ к более быстрой лошади. Да, действительно, вполне вероятно, что благодаря машинному обучению мы сможем добиться более точных прогнозов. Однако это лишь малая часть очень большой картины, которая продолжает расширяться по мере появления прорывов в сообществе машинного обучения. Мы начинали с фреймворков машинного обучения, включающих ряд понятий: признак, метка, наблюдение, модель и функция потерь. Этот небольшой, элементарный фреймворк уже был значительно более универсальным, чем подход к прогнозированию временных рядов. С недавним развитием машинного обучения мы видим, что даже эти понятия медленно и постепенно утрачивают свою актуальность, поскольку мы находим способы их преодоления. Для цепочки поставок этот сдвиг парадигмы имеет решающее значение, поскольку означает, что мы должны применить аналогичный подход при прогнозировании. Машинное обучение заставляет нас полностью переосмыслить, как подходить к данным и что с ними можно делать. Машинное обучение открывает двери, которые до недавнего времени были плотно закрыты.

А теперь давайте рассмотрим несколько вопросов.
Вопрос: Разве случайные леса не используют бэггинг?
Моя точка зрения такова: да, они являются расширением этого метода, и в них заложено больше, чем просто бэггинг. Бэггинг — интересная техника, но каждый раз, когда вы сталкиваетесь с какой-либо техникой машинного обучения, вам следует спросить: поможет ли эта техника продвинуться в решении действительно сложных задач, таких как каннибализация или замещение? И будет ли эта техника хорошо работать с вашим вычислительным оборудованием? Это один из ключевых выводов, которые стоит вынести из этой лекции.
Вопрос: В условиях стремления компаний автоматизировать всё с помощью робототехники, каково будущее работников логистических складов? Заменят ли их роботы в ближайшем будущем?
Этот вопрос не совсем относится к машинному обучению, но он очень хороший. Заводы претерпели масштабные преобразования в сторону широкой роботизации, которая может, а может и не включать роботов. Производительность заводов возросла, и даже сейчас, например, в Китае, заводы в большинстве своем полностью автоматизированы. Складские комплексы опоздали с этим. Однако в наши дни я наблюдаю развитие складов, которые становятся всё более механизированными и автоматизированными. Я не стал бы утверждать, что речь идёт именно о роботах; существует множество конкурирующих технологий для создания склада с более высокой степенью автоматизации. Суть в том, что тенденция очевидна. Складские и логистические центры, в целом, претерпят такие же масштабные улучшения производительности, какие мы уже наблюдали в производстве.
Чтобы ответить на ваш вопрос, я не утверждаю, что люди будут заменены роботами; их заменит автоматизация. Автоматизация иногда принимает форму, подобную роботу, но может проявляться и в других формах. Некоторые из этих форм — это просто умные решения, которые значительно повышают производительность, не прибегая к технологиям, с которыми мы интуитивно ассоциируем роботов. Однако я считаю, что логистическая часть цепочки поставок в целом будет сокращаться. Единственное, что сейчас способствует её росту, — это факт, что с развитием электронной коммерции нам приходится заботиться о последней миле. Последняя миля всё больше занимает основную часть рабочей силы, занимающейся логистикой. Даже последняя миля будет автоматизирована в недалеком будущем. Автономные транспортные средства уже не за горами; их обещали в этом десятилетии, и, хотя они могут прийти с небольшим опозданием, они всё же появятся.
Вопрос: Считаете ли вы, что машинное обучение стоит изучать, чтобы работать в сфере цепочек поставок?
Абсолютно. На мой взгляд, машинное обучение является вспомогательной наукой для цепочки поставок. Подумайте о том, как врач относится к химии. Если вы современный врач, от вас не ожидают, что вы будете химиком. Однако если вы скажете пациенту, что абсолютно ничего не знаете о химии, люди подумают, что у вас нет качеств, необходимых для современного врача. К машинному обучению следует относиться так же, как к химии в медицине. Это не цель, а средство. Если вы хотите заниматься серьёзной работой в цепочке поставок, вам необходимо иметь прочную базу в машинном обучении.
Вопрос: Могли бы вы привести примеры применения машинного обучения? Стал ли инструмент работать в промышленном масштабе?
Говоря за себя, как Йоаннес Верморель, предприниматель и CEO компании Lokad, у нас сейчас более 100 компаний, использующих машинное обучение в производстве для различных задач. Эти задачи включают прогнозирование сроков поставки, создание вероятностных прогнозов спроса, предсказание возвратов, прогнозирование проблем с качеством, пересмотр оценок среднего времени между внеплановыми ремонтами и определение корректности конкурентных цен. Существует множество приложений, например, пересмотр матриц совместимости между автомобилями и запчастями на рынке автозапчастей. С помощью машинного обучения можно автоматически исправить большую часть ошибок в базах данных. В Lokad у нас работают не только эти 100 компаний, но они используют этот подход уже почти десятилетие. Будущее уже наступило; оно просто распределено неравномерно.
Вопрос: Какой лучший способ изучить машинное обучение в свободное время? Рекомендуете ли вы такие сайты, как Udemy, Coursera или что-то другое?
Мой совет состоит в том, чтобы сочетать Википедию с чтением научных статей. Как вы видели на этой лекции, важно понимать основы и быть в курсе последних разработок в этой области. Как вы видели на этих лекциях, я цитирую настоящие научные статьи. Не доверяйте информации из вторых рук — обращайтесь непосредственно к опубликованным материалам. Всё это доступно онлайн. В области машинного обучения есть статьи, которые плохо написаны и непонятны, но есть и такие, которые написаны блестяще и дают кристально ясное представление о происходящем. Мой совет — начать с Википедии, чтобы получить общее представление о предмете, а затем приступить к чтению статей. Сначала это может показаться непрозрачным, но со временем вы привыкнете. Можете воспользоваться платформами Udemy или Coursera, но лично я так никогда не делал. Моя цель, когда я читаю эти лекции, — дать вам несколько интуитивных идей, чтобы вы увидели общую картину. Если хотите углубиться в детали, просто перейдите к оригинальной статье, опубликованной годы или десятилетия назад. Обращайтесь к первоисточнику и доверьтесь своему разуму.
Глубокое обучение — это весьма эмпирическая область исследований. Большая часть работы не является математически сложной. Обычно это не требует знаний выше уровня окончания средней школы, поэтому оно достаточно доступно.
Вопрос: При росте популярности no-code инструментов, таких как CodeX и Co-Pilot от OpenAI, считаете ли вы, что специалисты по цепочке поставок когда-нибудь будут писать модели на простом английском?
Краткий ответ таков: нет, вовсе нет. Идея о том, что можно обойтись без программирования, существует уже давно. Например, Visual Basic от Microsoft задумывался как визуальный инструмент, чтобы людям больше не нужно было программировать; они могли бы просто визуально собирать всё как конструктор Лего. Но в наши дни этот подход оказался неэффективным, и следующая тенденция — выражать идеи устно.
Однако причина, по которой я использую математические формулы в этих лекциях, заключается в том, что существуют ситуации, когда применение математической формулы — единственный способ ясно передать то, что вы хотите сказать. Проблема английского языка, или любого естественного языка, в том, что он зачастую неточен и подвержен неправильной интерпретации. В отличие от него, математические формулы точны и ясны. Проблема простого языка в том, что он невероятно расплывчат, и, несмотря на свою полезность, формулы используются для придания однозначного смысла сказанному. Я стараюсь использовать формулы умеренно, но когда их включаю, это потому, что считаю, что это единственный способ чётко передать идею, превосходя устное объяснение по уровню ясности.
Что касается платформ с низким уровнем кода, я крайне скептически отношусь к ним, поскольку этот подход уже неоднократно пытались реализовать в прошлом, но без особого успеха. Лично я считаю, что мы должны сделать программирование более подходящим для управления цепочками поставок, выявив, почему программирование сложно, и устранив случайную сложность. Останется то программирование, которое выполнено правильно для цепочки поставок, а именно к этому стремится Lokad.
Вопрос: Делает ли машинное обучение прогнозирование спроса более точным для сезонных или регулярных данных о продажах?
Как я упоминал в этой презентации, машинное обучение лишает концепцию точности своего смысла. Если взглянуть на последний крупномасштабный конкурс по прогнозированию временных рядов — конкурс M5, то все топ-10 моделей в той или иной степени были моделями машинного обучения. Так делает ли машинное обучение прогнозы более точными? Фактически, исходя из данных конкурса, да. Но это лишь незначительное улучшение по сравнению с другими методами, и оно не является революционным.
Более того, не стоит рассматривать прогнозирование с односторонней точки зрения. Когда вы спрашиваете о точности для сезонности, вы рассматриваете один продукт за раз, но это не правильный подход. Истинная точность заключается в оценке того, как запуск нового продукта влияет на все остальные продукты, поскольку неизбежно возникает элемент каннибализации. Главное — оценить, насколько точно в вашей модели отражается этот эффект каннибализации. Внезапно задача становится многомерной. Как я показывал на лекции с генеративными сетями, метрика того, что на самом деле означает точность, должна быть обучена; её нельзя задать заранее. Математические формулы, такие как средняя абсолютная ошибка, средняя абсолютная процентная ошибка и средняя квадратическая ошибка, являются всего лишь математическими критериями. Это не те метрики, которые нам действительно нужны; они просто наивны.
Вопрос: Будет ли рутинная работа прогнозистов заменена автопрогнозированием?
Я бы сказал, что будущее уже наступило, но распределено оно неравномерно. В Lokad мы уже ежедневно прогнозируем десятки миллионов ТНВЕ, и у меня нет ни одного сотрудника, занимающегося настройкой прогнозов. Так что да, это уже практикуется, но это лишь малая часть картины. Если вам нужно, чтобы люди корректировали прогнозы или настраивали модели, это указывает на неэффективный подход. Вам следует рассматривать необходимость настройки прогнозов как ошибку и устранять её посредством автоматизации данного процесса.
Снова повторюсь, основываясь на опыте Lokad, эти процессы будут полностью исключены, потому что мы уже справились с этим. Мы не единственные, кто работает именно так, поэтому для нас это практически древняя история — ситуация, существующая уже почти десятилетие.
Вопрос: Насколько активно используется машинное обучение при принятии решений в области цепочек поставок?
Это зависит от компании. В Lokad оно применяется повсеместно, и, разумеется, когда я говорю «в Lokad», я имею в виду компании, обслуживаемые Lokad. Однако подавляющее большинство рынка всё ещё в основном использует Excel, без какого-либо машинного обучения. Lokad активно управляет запасами на миллиарды евро или долларов, так что это уже реальность и существует уже довольно давно. Но Lokad составляет даже не 0,1% рынка, так что мы по-прежнему остаёмся исключением. Мы быстро растём, как и многие наши конкуренты. Моё предположение, что это всё ещё нишевое решение на всём рынке цепочек поставок, но с двухзначным ростом. Никогда не стоит недооценивать силу экспоненциального роста в течение длительного времени. В конечном итоге всё станет очень большим, надеюсь, вместе с Lokad, но это уже другая история.
Вопрос: Какая стратегия может справляться с множеством неопределённостей в цепочке поставок, учитывая входные данные для модели?
Суть в том, что, да, существует масса неопределённостей, но выбор входных данных для вашей модели по сути ограничен. Всё сводится к тому, что имеется в ваших корпоративных системах, например, к тому, какие данные сохраняются в вашей ERP. Если в вашей ERP есть исторические данные по запасам, то вы можете использовать их в своей модели машинного обучения. Если же ERP хранит только текущие уровни запасов, тогда эти данные не доступны. Вы можете начать фиксировать уровни запасов, если захотите использовать их в качестве дополнительных входных данных, но основной вывод в том, что выбора минимален — это буквально то, что уже имеется в ваших системах.
Мой типичный подход заключается в том, что если вам нужно создавать новые источники данных, то процесс будет медленным и болезненным, и, скорее всего, это не станет отправной точкой для внедрения машинного обучения в цепочки поставок. Крупные компании оцифрованы уже десятилетиями, так что то, что находится в ваших транзакционных системах, таких как ERP и WMS, уже является отличной отправной точкой. Если со временем вы поймёте, что вам нужно больше, например, конкурентная разведка, авторизованные уровни запасов или прогнозируемые сроки поставок от ваших поставщиков, это будет достойным дополнением в качестве входных данных для ваших моделей. Обычно входные данные — это то, что, по вашей интуиции, коррелирует с тем, что вы пытаетесь предсказать, и общее представление зачастую оказывается достаточным. Здравый смысл, который трудно формализовать, зачастую более чем достаточен. Это не является узким местом в инженерном плане.
Вопрос: Как ценовые решения влияют на оценку будущего спроса, даже с точки зрения вероятностного подхода, и как с этим справляться с точки зрения машинного обучения?
Это очень хороший вопрос. Один из эпизодов на LokadTV был посвящён именно этой проблеме. Суть в том, что полученные знания превращаются в то, что обычно называют политикой — объект, который определяет, как вы реагируете на различные события. Ваш подход к прогнозированию заключается в создании своего рода ландшафта в стиле Монте-Карло. Вы будете генерировать траекторию, но ваш прогноз не будет состоять из статичных точек данных. Это будет гораздо более генеративный процесс, в котором на каждом этапе прогнозирования вам придётся генерировать наблюдаемый спрос, принимать решения и заново генерировать рыночную реакцию на свои действия.
Таким образом, становится очень сложно оценить точность процесса генерации отклика спроса, и именно поэтому необходимо обучать собственные метрики прогнозирования. Это очень сложно, но нельзя рассматривать метрики прогнозирования, или метрики точности, как одномерную проблему. Подытоживая, прогнозирование спроса превращается в генератор, то есть по своей сути динамичный, а не статичный. Это генеративный процесс. Этот генератор реагирует на агента, который реализуется в виде политики. И генератор, и система формирования политики должны быть обучены. Вам также придётся обучать функцию потерь. Многое нужно изучить, но, к счастью, глубокое обучение — это весьма модульный и программируемый подход, который прекрасно сочетается с композицией всех этих техник.
Вопрос: Трудно ли собирать данные, особенно от малых и средних предприятий (МСП)?
Да, это очень сложно. Причина в том, что если вы работаете с компанией с оборотом менее 10 миллионов, в ней отсутствует даже ИТ-отдел. Возможно, там внедрена небольшая ERP, но даже если инструменты хорошие, современные и достойные, в компании нет полноценной ИТ-команды. Когда вы запрашиваете данные, в клиентской компании нет никого, кто обладал бы компетенцией для выполнения SQL-запроса для извлечения данных.
Я не уверен, правильно ли я понял ваш вопрос, но проблема заключается не столько в сборе данных. Сбор данных осуществляется естественным образом через бухгалтерское программное обеспечение или ERP-систему, которая установлена, и в наши дни ERP доступны даже для довольно маленьких компаний. Проблема в извлечении данных из этих систем корпоративного ПО. Если вы работаете в компании с оборотом менее 20 миллионов долларов и она не является компанией электронной коммерции, то, скорее всего, ИТ-отдел отсутствует. Даже если существует крошечный ИТ-отдел, обычно там работает всего один человек, отвечающий за настройку оборудования и рабочих мест на Windows для всех. Это не тот человек, который хорошо знаком с базами данных и более сложными административными задачами в области ИТ.
Хорошо, думаю, на этом всё. Следующая сессия состоится через пару недель. Она пройдет в среду, 13 октября. До встречи!
Ссылки
- Теория обучаемости, L. G. Valiant, ноябрь 1984
- Сети опорных векторов, Corinna Cortes, Владимир Vapnik, сентябрь 1995
- Случайные леса, Leo Breiman, октябрь 2001
- LightGBM: Высокоэффективное дерево решений градиентного бустинга, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Внимание — вот всё, что вам нужно, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, последний пересмотр в декабре 2017
- Глубокий двойной спад: когда большие модели и больше данных вредят, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, декабрь 2019
- Анализ и улучшение качества изображений StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, последний пересмотр в марте 2020
- Генеративные состязательные сети, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, июнь 2014
- Машинный перевод без учителя с использованием только монолингвальных корпусов, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, последний пересмотр в апреле 2018
- BERT: Предобучение глубоких двунаправленных трансформеров для понимания языка, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, последний пересмотр в мае 2019
- Небольшое введение в графовые нейронные сети, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, сентябрь 2021


