00:00 Einführung
02:49 Nachfrage, Preis und Gewinn
09:35 Wettbewerbsfähige Preise
15:23 Wünsche vs. Bedürfnisse
20:09 Der bisherige Verlauf
23:36 Richtungen für heute
25:17 Die Einheit des Bedarfs
31:03 Autos und Teile (Zusammenfassung)
33:41 Wettbewerbsintelligenz
36:03 Lösung der Ausrichtung (1/4)
39:26 Lösung der Ausrichtung (2/4)
43:07 Lösung der Ausrichtung (3/4)
46:38 Lösung der Ausrichtung (4/4)
56:21 Produktpalette
59:43 Unbeschränkte Teile
01:02:44 Kontrolle der Marge
01:06:54 Anzeigeränge
01:08:29 Feinabstimmung der Gewichte
01:12:45 Feinabstimmung der Kompatibilität (1/2)
01:19:14 Feinabstimmung der Kompatibilität (2/2)
01:30:41 Gegenspionage (1/2)
01:35:25 Gegenspionage (2/2)
01:40:49 Überbestände und Lagerausfälle
01:45:45 Versandbedingungen
01:47:58 Fazit
01:50:33 6.2 Preisoptimierung für den Automobil-Ersatzteilmarkt - Fragen?
Beschreibung
Das Gleichgewicht von Angebot und Nachfrage hängt sehr stark von den Preisen ab. Daher gehört die Preisoptimierung weitgehend zum Bereich der Supply Chain. Wir werden eine Reihe von Techniken vorstellen, um die Preise eines fiktiven Unternehmens für den Automobil-Ersatzteilmarkt zu optimieren. Anhand dieses Beispiels werden wir die Gefahr von abstraktem Denken erkennen, das den richtigen Kontext nicht berücksichtigt. Es ist wichtiger zu wissen, was optimiert werden sollte, als die Feinheiten der Optimierung selbst.
Vollständiges Transkript

Willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich die Preisoptimierung für den Automobil-Ersatzteilmarkt vorstellen. Die Preisgestaltung ist ein grundlegender Aspekt der Supply Chain. Tatsächlich kann man die Angemessenheit eines bestimmten Angebotsvolumens oder eines bestimmten Lagerbestands nicht ohne Berücksichtigung der Frage nach den Preisen überdenken, da die Preise die Nachfrage erheblich beeinflussen. Die meisten Bücher über Supply Chain und folglich auch die meisten Supply Chain Software ignorieren jedoch die Preisgestaltung vollständig. Selbst wenn die Preisgestaltung diskutiert oder modelliert wird, geschieht dies in der Regel auf naive Weise, die oft die Situation falsch interpretiert.
Die Preisgestaltung ist ein hochgradig domänenspezifischer Prozess. Preise sind in erster Linie eine Botschaft, die von einem Unternehmen an den Markt insgesamt gesendet wird - an Kunden, aber auch an Lieferanten und Wettbewerber. Die Feinheiten der Preisgestaltungsanalyse hängen stark vom jeweiligen Unternehmen ab. Die Annäherung an die Preisgestaltung in allgemeinen Begriffen, wie es Mikroökonomen tun, mag intellektuell ansprechend sein, kann aber auch fehlgeleitet sein. Diese Ansätze sind möglicherweise nicht präzise genug, um die Erstellung von professionellen Preisstrategien zu unterstützen.
Diese Vorlesung konzentriert sich auf die Preisoptimierung für ein Unternehmen im Automobil-Ersatzteilmarkt. Wir werden Stuttgart erneut besuchen, ein fiktives Unternehmen, das im dritten Kapitel dieser Vorlesungsreihe vorgestellt wurde. Wir werden uns ausschließlich auf das Online-Einzelhandelssegment von Stuttgart konzentrieren, das Autoteile vertreibt. Das Ziel dieser Vorlesung ist es zu verstehen, was die Preisgestaltung beinhaltet, wenn wir über die Plattitüden hinausblicken, und wie man die Preisgestaltung mit einer realitätsnahen Denkweise angeht. Obwohl wir uns auf eine enge Vertikale konzentrieren werden - Ersatzteile für den Automobil-Ersatzteilmarkt - wäre die Denkweise, die Einstellung und die Haltung, die in dieser Vorlesung bei der Verfolgung überlegener Preisstrategien angenommen werden, im Wesentlichen dieselbe, wenn man völlig unterschiedliche Vertikale in Betracht zieht.
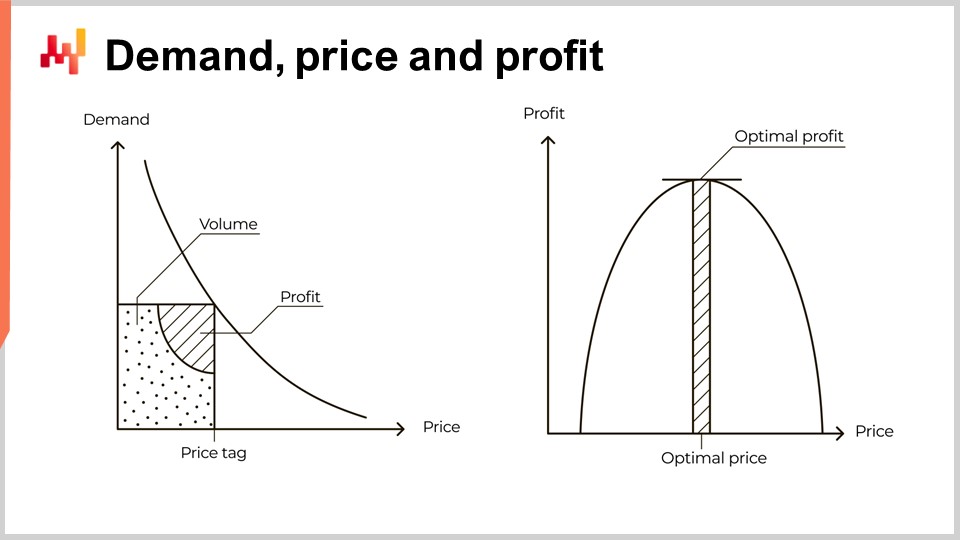
Die Nachfrage nimmt ab, wenn der Preis steigt. Dies ist ein universelles wirtschaftliches Muster. Die Existenz von Produkten, die diesem Muster widersprechen, bleibt bestenfalls schwer fassbar. Diese Produkte werden Veblen-Güter genannt. In 15 Jahren bei Lokad habe ich jedoch selbst bei Luxusmarken keinen konkreten Beweis dafür erhalten, dass solche Produkte tatsächlich existieren. Dieses universelle Muster wird durch die Kurve auf der linken Seite des Bildschirms veranschaulicht, die im Allgemeinen als Nachfragekurve bezeichnet wird. Wenn sich ein Markt auf einen Preis festlegt, zum Beispiel den Preis eines Ersatzteils, erzeugt dieser Markt ein bestimmtes Volumen an Nachfrage und hoffentlich auch ein bestimmtes Volumen an Gewinn für die Akteure, die diese Nachfrage erfüllen.
Was die Automobil-Ersatzteile betrifft, so handelt es sich bei diesen Teilen definitiv nicht um Veblen-Güter. Die Nachfrage nimmt ab, wenn der Preis steigt. Da die Menschen jedoch nicht viel Auswahl beim Kauf von Autoteilen haben, zumindest wenn sie weiterhin ihr Auto fahren wollen, kann erwartet werden, dass die Nachfrage relativ unelastisch ist. Ein höherer oder niedrigerer Preis für Ihre Bremsbeläge beeinflusst Ihre Entscheidung, neue Bremsbeläge zu kaufen, nicht wirklich. Tatsächlich würden die meisten Menschen lieber neue Bremsbeläge kaufen, auch wenn sie dafür den doppelten Preis zahlen müssten, als ihr Fahrzeug ganz aufzugeben.
Für Stuttgart ist die Identifizierung des besten Preises für jedes Teil aus einer Vielzahl von Gründen entscheidend. Lassen Sie uns die beiden offensichtlichsten Gründe erkunden. Erstens möchte Stuttgart seine Gewinne maximieren, was nicht trivial ist, da sich nicht nur die Nachfrage mit dem Preis ändert, sondern auch die Kosten mit dem Volumen variieren. Stuttgart muss in der Lage sein, die Nachfrage, die es in Zukunft generieren wird, zu erfüllen, was noch schwieriger ist, da der Lagerbestand aufgrund von Vorlaufzeitbeschränkungen Tage oder sogar Wochen im Voraus gesichert werden muss.
Basierend auf dieser begrenzten Darstellung gehen einige Lehrbücher und sogar einige Unternehmenssoftware mit der auf der rechten Seite dargestellten Kurve vor. Diese Kurve veranschaulicht konzeptionell das erwartete Volumen an Gewinn, das für jeden Preis erwartet werden kann. Angesichts der Tatsache, dass die Nachfrage abnimmt, wenn der Preis steigt, und die Stückkosten abnehmen, wenn das Volumen zunimmt, sollte diese Kurve einen optimalen Gewinnpunkt aufweisen, der den Gewinn maximiert. Sobald dieser optimale Punkt identifiziert ist, wird die Anpassung des Lagerbestands als eine einfache Orchestrierung dargestellt. Tatsächlich liefert der optimale Punkt nicht nur einen Preis, sondern auch ein Volumen an Nachfrage.
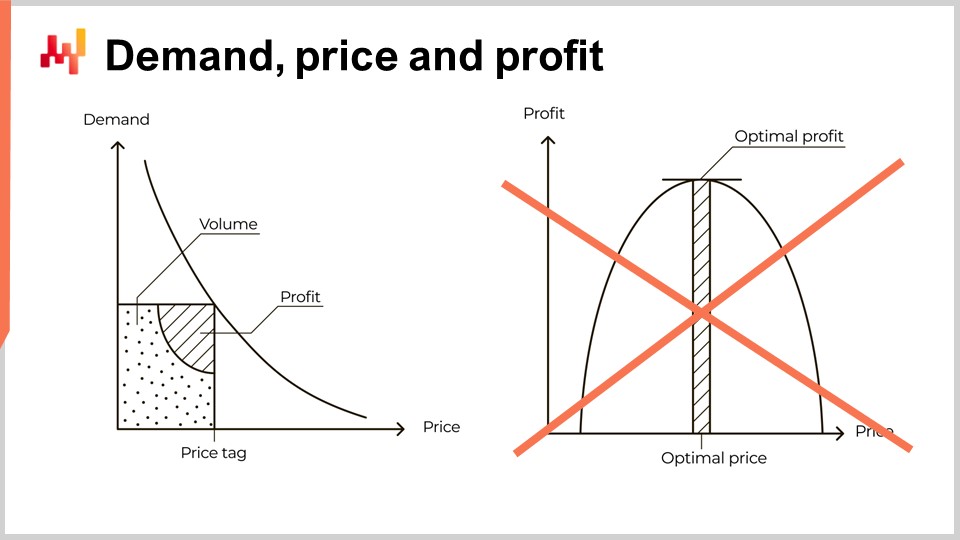
Diese Perspektive ist jedoch zutiefst fehlgeleitet. Das Problem hat nichts mit der Schwierigkeit der Quantifizierung der Elastizität zu tun. Meine These ist nicht, dass die Kurve auf der linken Seite falsch ist; sie ist grundsätzlich korrekt. Meine Behauptung ist, dass der Sprung von der Kurve auf der linken Seite zur Kurve auf der rechten Seite falsch ist. Tatsächlich ist dieser Sprung so erstaunlich falsch, dass er als eine Art Lackmustest dient. Jeder Softwareanbieter oder Preisgestaltungslehrbuch, der Preise auf diese Weise präsentiert, zeigt ein gefährliches Maß an wirtschaftlicher Unkenntnis, insbesondere wenn er die Bewertung der Elastizität als die zentrale Herausforderung im Zusammenhang mit dieser Perspektive darstellt. Dies ist bei weitem nicht der Fall. Einem realen Supply Chain-Unternehmen ein solches Verständnis von Mikroökonomie in großem Maßstab anzuvertrauen, lädt Schmerz und Leid ein. Wenn es etwas gibt, was Ihre Supply Chain nicht braucht, dann ist es eine fehlerhafte Interpretation von missverstandener Mikroökonomie im großen Stil.
In dieser Vortragsreihe handelt es sich um eine weitere Form des naiven Rationalismus oder des Wissenschaftsglaubens, der sich immer wieder als erhebliche Bedrohung für moderne Supply Chains erwiesen hat. Abstrakte wirtschaftliche Überlegungen sind mächtig, weil sie eine verwirrende Bandbreite von Situationen erfassen. Abstraktes Denken ist jedoch auch anfällig für grobe Fehlinterpretationen. Es können bedeutende intellektuelle Fehler auftreten, die auf den ersten Blick nicht offensichtlich sind, wenn man in sehr allgemeinen Begriffen denkt.
Um zu verstehen, warum der Sprung von der Kurve auf der linken Seite zur Kurve auf der rechten Seite falsch ist, müssen wir uns genauer anschauen, was tatsächlich in einer realen Supply Chain passiert. Dieser Vortrag konzentriert sich auf Automobil-Ersatzteile. Wir werden die Preisgestaltung aus der Sicht von Stuttgart, einem fiktiven Supply Chain-Unternehmen, das im dritten Kapitel dieser Vortragsreihe vorgestellt wurde, erneut untersuchen. Wir werden nicht auf die Details dieses Unternehmens eingehen. Wenn Sie den Vortrag 3.4 noch nicht gesehen haben, lade ich Sie ein, dies nach diesem Vortrag zu tun.
Heute betrachten wir das Online-Einzelhandelssegment von Stuttgart, einer E-Commerce-Abteilung, die Autoteile verkauft. Wir untersuchen die geeignetsten Möglichkeiten für Stuttgart, seine Preise zu bestimmen und sie jederzeit anzupassen. Diese Aufgabe muss für jedes einzelne von Stuttgart verkaufte Teil durchgeführt werden.

Stuttgart ist auf diesem Markt nicht allein. In jedem europäischen Land, in dem Stuttgart tätig ist, gibt es etwa ein halbes Dutzend namhafter Wettbewerber. Diese kurze Liste von Unternehmen, einschließlich Stuttgart, repräsentiert den Großteil des Online-Marktanteils für Autoteile. Während Stuttgart einige Teile ausschließlich verkauft, gibt es für die meisten verkauften Teile mindestens einen namhaften Wettbewerber, der dasselbe Teil verkauft. Diese Tatsache hat erhebliche Auswirkungen auf die Preisoptimierung von Stuttgart.
Betrachten wir, was passiert, wenn Stuttgart für ein bestimmtes Teil beschließt, den Preis für dieses Teil einen Euro unter dem Preis anzusetzen, den ein Wettbewerber für dasselbe Teil anbietet. Möglicherweise wird Stuttgart dadurch wettbewerbsfähiger und kann Marktanteile gewinnen. Aber nicht so schnell. Der Wettbewerber überwacht alle von Stuttgart festgelegten Preise. Tatsächlich ist der Automobil-Ersatzteilmarkt ein hochkompetitiver Markt. Jeder hat Wettbewerbsintelligenz-Tools. Stuttgart sammelt täglich alle Preise seiner namhaften Wettbewerber, und die Wettbewerber tun dasselbe. Wenn Stuttgart also beschließt, den Preis für ein Teil einen Euro unter dem Preis anzusetzen, den ein Wettbewerber anbietet, kann man sicher davon ausgehen, dass der Wettbewerber innerhalb eines Tages oder zwei seinen Preis als Vergeltung senken wird und damit die Preisbewegung von Stuttgart zunichte macht.
Obwohl Stuttgart ein fiktives Unternehmen sein mag, ist dieses hier beschriebene Wettbewerbsverhalten auf dem Automobil-Ersatzteilmarkt keineswegs fiktiv. Die Wettbewerber stimmen ihre Preise aggressiv ab. Wenn Stuttgart wiederholt versucht, seine Preise zu senken, führt dies zu einem algorithmischen Preiskrieg, der beide Unternehmen am Ende mit wenig oder keinem Gewinn zurücklässt.
Betrachten wir, was passiert, wenn Stuttgart sich entscheidet, den Preis für ein bestimmtes Teil um einen Euro über dem Preis eines Konkurrenten anzusetzen. Unter der Annahme, dass sich außer dem Preis nichts ändert, ist Stuttgart einfach nicht mehr wettbewerbsfähig. Obwohl die Kundenbasis von Stuttgart möglicherweise nicht sofort zum Konkurrenten wechselt (da sie möglicherweise nicht einmal über den Preisunterschied informiert ist oder Stuttgart treu bleibt), wird im Laufe der Zeit der Marktanteil von Stuttgart garantiert schwinden.
In Europa gibt es Preisvergleichswebsites für Autoteile. Obwohl Kunden nicht jedes Mal, wenn sie ein neues Teil für ihr Auto benötigen, einen Vergleich anstellen, werden die meisten Kunden ihre Optionen von Zeit zu Zeit überprüfen. Es ist für Stuttgart keine tragfähige Lösung, immer als der teurere Händler entdeckt zu werden.
Somit haben wir gesehen, dass Stuttgart keinen Preis unter dem Wettbewerb haben kann, da dies einen Preiskrieg auslöst. Umgekehrt kann Stuttgart keinen Preis über dem Wettbewerb haben, da dies langfristig zu einem Verlust des Marktanteils führt. Die einzige Option, die Stuttgart bleibt, ist die Preisangleichung. Dies ist keine theoretische Aussage - Preisangleichung ist der Haupttreiber für echte E-Commerce-Unternehmen, die Autoteile in Europa verkaufen.
Die intellektuell ansprechende Gewinnkurve, die wir zuvor eingeführt haben, bei der Unternehmen angeblich den optimalen Gewinn wählen könnten, ist größtenteils falsch. Stuttgart hat nicht einmal die Wahl, wenn es um seine Preise geht. In großem Umfang ist die Preisangleichung die einzige Option für Stuttgart, es sei denn, es gibt eine Art geheime Zutat.
Freie Märkte sind ein seltsames Biest, wie Engels es in seinem Briefwechsel von 1819 formulierte: “Der eigene Wille eines jeden wird von allen anderen behindert, und was entsteht, ist etwas, das niemand gewollt hat.” Im Folgenden werden wir sehen, dass Stuttgart noch einen gewissen Spielraum hat, um seine Preise festzulegen. Die Hauptthese bleibt jedoch bestehen: Die Preisoptimierung für Stuttgart ist in erster Linie ein stark eingeschränktes Problem, das nichts mit einer naiven Maximierungsperspektive zu tun hat, die von einer Nachfragekurve gesteuert wird.
Die Preiselastizität der Nachfrage ist ein Konzept, das für einen Markt als Ganzes Sinn macht, aber normalerweise nicht so sehr für etwas so Lokales wie eine Teilenummer.

Die Vorstellung, dass die Preisgestaltung als einfaches Gewinnmaximierungsproblem unter Verwendung der Nachfragekurve angegangen werden kann, ist falsch - zumindest im Fall von Stuttgart.
Tatsächlich könnte man argumentieren, dass Stuttgart zu einem Bedarfsmarkt gehört und die Perspektive der Gewinnkurven immer noch funktionieren würde, wenn wir einen Markt der Wünsche betrachten würden. In der Marketingwelt ist es eine klassische Unterscheidung, Märkte der Wünsche von Märkten der Bedürfnisse zu trennen. Ein Markt der Wünsche ist in der Regel durch Angebote gekennzeichnet, bei denen Kunden ihren Konsum ohne negative Folgen ablehnen können. In Märkten der Wünsche tendieren erfolgreiche Angebote dazu, stark an die Marke des Anbieters gebunden zu sein, und die Marke selbst ist der Motor, der die Nachfrage überhaupt erst generiert. Zum Beispiel ist die Mode das Archetyp eines Marktes der Wünsche. Wenn Sie eine Tasche von Louis Vuitton möchten, kann diese nur von Louis Vuitton gekauft werden. Obwohl es Hunderte von Anbietern gibt, die funktional äquivalente Taschen verkaufen, wird es keine Tasche von Louis Vuitton sein. Wenn Sie den Kauf einer Tasche von Louis Vuitton ablehnen, wird Ihnen nichts Schlimmes passieren.
Ein Markt der Bedürfnisse ist in der Regel durch Angebote gekennzeichnet, bei denen Kunden ihren Konsum ohne negative Folgen nicht ablehnen können. In Märkten der Bedürfnisse sind Marken keine Nachfrage-Motoren; sie sind eher Entscheidungs-Motoren. Marken helfen Kunden bei der Auswahl, von wem sie konsumieren sollen, sobald der Konsumbedarf entsteht. Zum Beispiel sind Lebensmittel und Grundbedürfnisse der Archetyp von Märkten der Bedürfnisse. Auch wenn Autoteile nicht unbedingt zum Überleben notwendig sind, sind viele Menschen auf ein Fahrzeug angewiesen, um Geld zu verdienen, und daher können sie sich nicht realistisch gesehen von der ordnungsgemäßen Wartung ihres Fahrzeugs abmelden, da die Kosten für sie durch den Mangel an Wartung weit über den Kosten der Wartung selbst liegen würden.
Obwohl der Automobil-Ersatzteilmarkt fest im Markt der Bedürfnisse verankert ist, gibt es Nuancen. Es gibt Komponenten wie Radkappen, die mehr Wünsche als Bedürfnisse sind. Allgemein gesagt sind alle Accessoires mehr Wünsche als Bedürfnisse. Dennoch treiben die Bedürfnisse den Großteil der Nachfrage bei Stuttgart an.
Die Kritik, die ich hier gegen die Gewinnkurve für die Preisgestaltung vorschlage, verallgemeinert sich auf nahezu alle Situationen in Märkten der Bedürfnisse. Stuttgart ist kein Ausreißer, wenn es darum geht, preislich stark durch seine Konkurrenten eingeschränkt zu sein; diese Situation ist in Märkten der Bedürfnisse nahezu allgegenwärtig. Dieses Argument widerlegt nicht die Machbarkeit der Gewinnkurve bei der Betrachtung von Märkten der Wünsche.
Tatsächlich könnte man einwenden, dass in einem Markt der Wünsche, wenn der Anbieter ein Monopol über seine eigene Marke hat, dieser Anbieter frei sein sollte, den Preis zu wählen, der seinen Gewinn maximiert, was uns wieder zur Perspektive der Gewinnkurve für die Preisgestaltung führt. Auch hier zeigt sich wieder die Gefahr des abstrakten wirtschaftlichen Denkens in der Lieferkette.
In einem Markt der Wünsche ist die Perspektive der Gewinnkurve ebenfalls falsch, wenn auch aus völlig anderen Gründen. Die Details dieser Demonstration liegen außerhalb des Rahmens des vorliegenden Vortrags, da sie einen eigenen Vortrag erfordern würden. Als Übung für das Publikum schlage ich jedoch vor, einen genaueren Blick auf die Liste der Taschen und ihre Preise auf der Louis Vuitton E-Commerce-Website zu werfen. Der Grund, warum die Perspektive der Gewinnkurve unangemessen ist, sollte offensichtlich werden. Wenn nicht, werden wir diesen Fall wahrscheinlich in einem späteren Vortrag erneut behandeln.
Diese Vortragsreihe ist unter anderem als Schulungsmaterial für die Supply Chain Scientists bei Lokad gedacht. Ich hoffe jedoch auch, dass diese Vorträge ein viel breiteres Publikum von Supply Chain-Praktikern interessieren. Ich versuche, diese Vorträge einigermaßen entkoppelt zu halten, werde aber einige technische Konzepte verwenden, die in den vorherigen Vorträgen eingeführt wurden. Ich werde nicht zu viel Zeit damit verbringen, diese Konzepte erneut einzuführen. Wenn Sie die vorherigen Vorträge nicht gesehen haben, schauen Sie sie sich gerne später an.
Im ersten Kapitel dieser Reihe haben wir untersucht, warum Supply Chains programmatisch werden müssen. Aufgrund der immer komplexer werdenden Supply Chains ist es äußerst wünschenswert, ein numerisches Rezept in die Produktion zu bringen. Die Automatisierung ist dringender denn je, und es besteht ein finanzieller Zwang, die Praxis der Supply Chain zu einem kapitalistischen Unternehmen zu machen.
Im zweiten Kapitel haben wir uns mit Methoden beschäftigt. Supply Chains sind Wettbewerbssysteme, und diese Kombination macht naive Methoden zunichte. Wir haben gesehen, dass diese Kombination auch Modelle besiegt, die die Mikroökonomie falsch interpretieren oder falsch charakterisieren.
Das dritte Kapitel untersuchte die Probleme, die in Supply Chains auftreten, und ließ Lösungen außer Acht. Wir stellten Stuttgart als eine der Supply Chain-Personas vor. Dieses Kapitel versuchte, die Klassen von Entscheidungsproblemen zu charakterisieren, die gelöst werden müssen, und zeigte, dass vereinfachte Perspektiven, wie die richtige Lagerbestandsmenge zu wählen, nicht zu realen Situationen passen. Die Form der zu treffenden Entscheidungen ist immer von einer gewissen Tiefe geprägt.
Kapitel vier untersuchte die Elemente, die erforderlich sind, um moderne Supply Chain-Praktiken zu verstehen, in denen Software-Elemente allgegenwärtig sind. Diese Elemente sind grundlegend, um den breiteren Kontext zu verstehen, in dem die digitale Supply Chain agiert.
Die Kapitel fünf und sechs sind der prädiktiven Modellierung bzw. der Entscheidungsfindung gewidmet. Diese Kapitel sammeln Techniken, die heute in den Händen von Supply Chain Scientists gut funktionieren. Das sechste Kapitel konzentriert sich auf die Preisgestaltung, eine Art von Entscheidung, die unter vielen anderen getroffen werden muss.
Schließlich ist das siebte Kapitel der Durchführung einer quantitativen Supply Chain Initiative und der organisatorischen Perspektive gewidmet.

Die heutige Vorlesung wird in zwei große Abschnitte unterteilt sein. Zunächst werden wir besprechen, wie man die Wettbewerbsausrichtung der Preise für Stuttgart angehen kann. Die Ausrichtung der Preise an die der Konkurrenten muss aus der Perspektive des Kunden angegangen werden, aufgrund der einzigartigen Struktur des Marktes für Autoteile. Obwohl die Wettbewerbsausrichtung äußerst komplex ist, profitiert sie von einer relativ einfachen Lösung, auf die wir im Detail eingehen werden.
Zweitens, obwohl die Wettbewerbsausrichtung die dominierende Kraft ist, ist sie nicht die einzige. Stuttgart kann möglicherweise von dieser Ausrichtung abweichen wollen oder müssen. Die Vorteile dieser Abweichungen müssen jedoch die Risiken überwiegen. Die Qualität der Ausrichtung hängt von der Qualität der verwendeten Eingaben zur Erstellung der Ausrichtung ab, daher werden wir eine selbstüberwachte Lernmethode einführen, um den Graphen der mechanischen Kompatibilitäten zu verfeinern.
Schließlich werden wir eine kurze Reihe von Anliegen behandeln, die mit der Preisgestaltung zusammenhängen. Diese Anliegen betreffen möglicherweise nicht ausschließlich die Preisgestaltung, aber in der Praxis ist es am besten, sie gemeinsam mit den Preisen anzugehen.

Stuttgart muss jedem einzelnen Teil, das es verkauft, einen Preis zuweisen, aber das bedeutet nicht, dass die Preisanalyse hauptsächlich auf der Ebene der Teilenummer durchgeführt werden muss. Die Preisgestaltung ist in erster Linie eine Möglichkeit, mit den Kunden zu kommunizieren.
Lassen Sie uns einen Moment darüber nachdenken, wie Kunden die von Stuttgart angebotenen Preise wahrnehmen. Wie wir sehen werden, ist die scheinbar subtile Unterscheidung zwischen dem Preisschild und der Wahrnehmung des Preisschilds tatsächlich überhaupt nicht subtil.
Wenn ein Kunde nach einem neuen Autoteil sucht, in der Regel ein Verbrauchsteil wie Bremsbeläge, wird er wahrscheinlich die spezifische Teilenummer, die er benötigt, nicht kennen. Es mag ein paar Auto-Enthusiasten geben, die sich sehr gut mit dem Thema auskennen und eine bestimmte Teilenummer im Kopf haben, aber sie sind eine kleine Minderheit. Die meisten Menschen wissen nur, dass sie ihre Bremsbeläge wechseln müssen, aber sie kennen nicht die genaue Teilenummer.
Diese Situation führt zu einer weiteren ernsthaften Sorge: der mechanischen Kompatibilität. Auf dem Markt sind Tausende von Bremsbelagreferenzen erhältlich, aber für jedes Fahrzeug gibt es in der Regel nur einige Dutzend kompatible Referenzen. Daher kann die mechanische Kompatibilität nicht dem Zufall überlassen werden.
Stuttgart ist sich wie alle seine Konkurrenten dieses Problems sehr bewusst. Beim Besuch der E-Commerce-Website von Stuttgart wird der Besucher aufgefordert, sein Automodell anzugeben, und dann filtert die Website sofort die Teile heraus, die nicht mechanisch kompatibel mit dem angegebenen Fahrzeug sind. Konkurrenten-Websites folgen demselben Designmuster: zuerst das Fahrzeug auswählen, dann das Teil auswählen.
Wenn ein Kunde zwei Anbieter vergleichen möchte, vergleicht er in der Regel die Angebote und nicht die Teilenummern. Ein Kunde würde die Kosten für kompatible Bremsbeläge auf der Website von Stuttgart ermitteln und dann den Vorgang auf der Website eines Konkurrenten wiederholen. Der Kunde könnte die Teilenummer der Bremsbeläge auf der Website von Stuttgart identifizieren und dann auf der Website des Konkurrenten nach derselben Teilenummer suchen, aber in der Praxis tun dies die Menschen selten.
Stuttgart und seine Konkurrenten stellen ihre Sortimente sorgfältig zusammen, damit sie nahezu alle Fahrzeuge mit einem Bruchteil der verfügbaren Automobilteilenummern bedienen können. Dadurch haben sie in der Regel zwischen 100.000 und 200.000 Teilenummern auf ihren Websites aufgelistet, von denen tatsächlich nur 10.000 bis 20.000 Teilenummern auf Lager gehalten werden.
In Bezug auf unsere anfängliche Sorge um die Preisgestaltung ist klar, dass die Preisanalyse in erster Linie nicht durch die Teilenummern, sondern durch die Einheit des Bedarfs durchgeführt werden sollte. Im Kontext des Automobil-Ersatzteilmarktes wird eine Einheit des Bedarfs durch die Art des zu ersetzenden Teils und das Modell des Fahrzeugs, das den Ersatz benötigt, charakterisiert.
Diese Perspektive der Einheit des Bedarfs stellt jedoch eine unmittelbare technische Komplikation dar. Stuttgart kann sich nicht auf Preisübereinstimmungen zwischen Teilenummern verlassen, um seine Preise mit denen seiner Konkurrenten abzustimmen. Daher ist die Preisausrichtung nicht so offensichtlich, wie es auf den ersten Blick erscheinen mag, insbesondere wenn man die Einschränkungen berücksichtigt, unter denen Stuttgart von seinen Konkurrenten betrieben wird.

Wie wir bereits in Vorlesung 3.4 gesehen haben, wird das Problem der mechanischen Kompatibilität zwischen Autos und Teilen in Europa sowie in anderen wichtigen Regionen weltweit durch die Existenz spezialisierter Unternehmen gelöst. Diese Unternehmen verkaufen Datensätze zur mechanischen Kompatibilität, die aus drei Listen bestehen: einer Liste von Automodellen, einer Liste von Autoteilen und einer Liste von Kompatibilitäten zwischen Autos und Teilen. Diese Datenstruktur wird technisch als bipartiter Graph bezeichnet.
In Europa umfassen diese Datensätze in der Regel mehr als 100.000 Fahrzeuge, über eine Million Teile und mehr als 100 Millionen Kanten, die Autos mit Teilen verbinden. Die Pflege dieser Datensätze ist arbeitsintensiv, was erklärt, warum spezialisierte Unternehmen existieren, um diese Datensätze zu verkaufen. Stuttgart kauft wie seine Konkurrenten ein Abonnement von einem dieser spezialisierten Unternehmen, um aktualisierte Versionen dieser Datensätze abzurufen. Abonnements sind erforderlich, da trotz der Reife der Automobilindustrie kontinuierlich neue Autos und Teile eingeführt werden. Um eng mit der Automobilbranche verbunden zu bleiben, müssen diese Datensätze mindestens vierteljährlich aktualisiert werden.
Stuttgart und seine Konkurrenten verwenden diesen Datensatz, um den Fahrzeugauswahlmechanismus auf ihren E-Commerce-Websites zu unterstützen. Sobald ein Kunde ein Fahrzeug ausgewählt hat, werden nur die Teile angezeigt, die nachweislich mit dem gewählten Fahrzeug kompatibel sind, gemäß dem Kompatibilitätsdatensatz. Dieser Kompatibilitätsdatensatz bildet auch die Grundlage für unsere Preisanalyse. Anhand dieses Datensatzes kann Stuttgart den angebotenen Preis für jede Einheit des Bedarfs bewerten.

Die letzte bedeutende fehlende Zutat für den Aufbau der Wettbewerbsausrichtungsstrategie von Stuttgart ist die Wettbewerbsintelligenz. In Europa, wie auch in allen wichtigen Wirtschaftsregionen, gibt es Wettbewerbsintelligenz-Spezialisten - Unternehmen, die Preis-Scraping-Dienste anbieten. Diese Unternehmen extrahieren täglich die Preise von Stuttgart und seinen Konkurrenten. Obwohl ein Unternehmen wie Stuttgart versuchen kann, die automatisierte Extraktion seiner Preise zu minimieren, ist dieses Unterfangen aufgrund mehrerer Gründe weitgehend sinnlos:
Erstens möchte Stuttgart wie seine Konkurrenten roboterfreundlich sein. Die wichtigsten Bots sind die Suchmaschinen, wobei Google ab 2023 einen Marktanteil von etwas über 90% hat. Es ist jedoch nicht die einzige Suchmaschine, und während es möglicherweise möglich ist, den Googlebot, den Hauptcrawler von Google, herauszufiltern, ist es herausfordernd, dasselbe für alle anderen Crawler zu tun, die immer noch etwa 10% des Datenverkehrs ausmachen.
Zweitens sind Wettbewerbsintelligenz-Spezialisten in den letzten zehn Jahren zu Experten darin geworden, sich als regulärer Internetverkehr von Privathaushalten auszugeben. Diese Dienste behaupten, Zugriff auf Millionen von IP-Adressen von Privathaushalten zu haben, was sie durch Partnerschaften mit Apps erreichen, die sich an den regulären Internetverbindungen der Benutzer bedienen, und durch Partnerschaften mit Internetdienstanbietern (ISPs), die ihnen IP-Adressen zur Verfügung stellen können.
Daher gehen wir davon aus, dass Stuttgart von einer hochwertigen Liste von Preisen seiner namhaften Konkurrenten profitiert. Diese Preise werden auf der Ebene der Teilenummern extrahiert und täglich aktualisiert. Diese Annahme ist nicht spekulativ, sondern der aktuelle Stand des europäischen Marktes.

Wir haben nun alle Elemente gesammelt, die Stuttgart benötigt, um angeglichene Preise zu berechnen - Preise, die den Preisen seiner Konkurrenten entsprechen, wenn sie aus der Perspektive einer Bedarfseinheit betrachtet werden.
Auf dem Bildschirm haben wir den Pseudocode für das Constraint Satisfaction Problem, das wir lösen möchten. Wir enumerieren einfach alle Bedarfseinheiten, d.h. alle Kombinationen von Teiltypen und Automodellen. Für jede Bedarfseinheit geben wir an, dass der wettbewerbsfähigste Preis, den Stuttgart anbietet, dem wettbewerbsfähigsten Preis entsprechen sollte, den ein Konkurrent anbietet.
Lassen Sie uns schnell die Anzahl der Variablen und Einschränkungen bewerten. Stuttgart kann für jede Teilenummer einen Preis festlegen, was bedeutet, dass wir etwa 100.000 Variablen haben. Die Anzahl der Einschränkungen ist etwas komplexer. Technisch gesehen haben wir etwa 1.000 Teiltypen und etwa 100.000 Automodelle, was auf etwa 100 Millionen Einschränkungen hindeutet. Nicht alle Arten von Teilen sind jedoch in allen Automodellen zu finden. Messungen in der realen Welt deuten darauf hin, dass die Anzahl der Einschränkungen näher bei 10 Millionen liegt.
Trotz dieser geringeren Anzahl von Einschränkungen haben wir immer noch 100-mal mehr Einschränkungen als Variablen. Wir stehen vor einem stark überbeschränkten System. Daher wissen wir, dass es unwahrscheinlich ist, eine Lösung zu finden, die alle Einschränkungen erfüllt. Das beste Ergebnis ist eine Kompromisslösung, die die meisten von ihnen erfüllt.
Darüber hinaus sind die Konkurrenten nicht vollständig konsistent mit ihren Preisen. Trotz unserer besten Bemühungen kann Stuttgart in einen Preiskrieg über eine Teilenummer geraten, weil der Preis zu niedrig ist. Gleichzeitig kann es auf derselben Teilenummer aufgrund eines zu hohen Preises für einen anderen Konkurrenten Marktanteile verlieren. Dieses Szenario ist nicht theoretisch; die empirischen Daten legen nahe, dass diese Situationen regelmäßig auftreten, wenn auch für einen kleinen Prozentsatz der Teilenummern.
Da wir uns für eine ungefähre Lösung dieses Systems von Einschränkungen entschieden haben, sollten wir das Gewicht klären, das jeder Einschränkung gegeben werden soll. Nicht alle Automodelle sind gleich - einige sind mit älteren Fahrzeugen verbunden, die fast vollständig von den Straßen verschwunden sind. Wir schlagen vor, diese Einschränkungen entsprechend dem jeweiligen Nachfragevolumen zu gewichten, das in Euro ausgedrückt wird.
Jetzt, da wir den formalen Rahmen für unsere Preislogik festgelegt haben, gehen wir zur eigentlichen Softwarecode über. Wie wir sehen werden, ist die Lösung dieses Systems einfacher als erwartet.
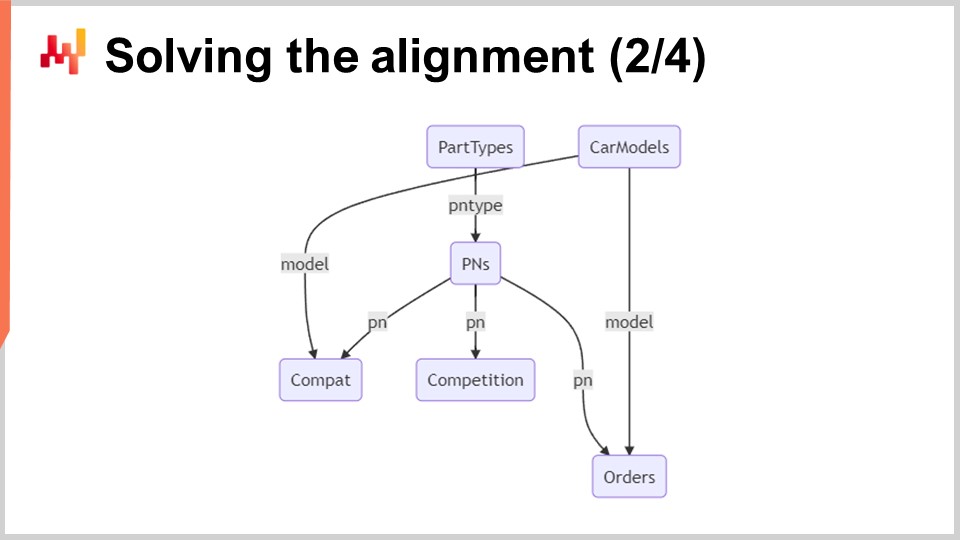
Auf dem Bildschirm zeigt ein minimales relationales Schema die sechs Tabellen, die in diesem System verwendet werden. Die Rechtecke mit abgerundeten Ecken stellen die sechs interessierenden Tabellen dar, und die Pfeile stellen die Eins-zu-viele-Beziehungen zwischen den Tabellen dar.
Lassen Sie uns diese Tabellen kurz überprüfen:
-
Teiltypen: Wie der Name schon sagt, listet diese Tabelle die Arten von Teilen auf, zum Beispiel “vordere Bremsbeläge”. Diese Typen werden verwendet, um zu identifizieren, welches Teil als Ersatz für ein anderes verwendet werden kann. Das Ersatzteil muss nicht nur mit dem Fahrzeug kompatibel sein, sondern auch denselben Typ haben. Es gibt etwa tausend Teiltypen.
-
Automodelle: Diese Tabelle listet die Modelle von Autos auf, zum Beispiel “Peugeot 3008 Phase 2 Diesel”. Jedes Fahrzeug hat ein Modell, und alle Fahrzeuge eines bestimmten Modells sollten den gleichen Satz von mechanischen Kompatibilitäten haben. Es gibt etwa hunderttausend Automodelle.
-
Teilenummern (PNs): Diese Tabelle listet die Teilenummern auf, die im Automobil-Ersatzteilmarkt zu finden sind. Jede Teilenummer hat einen und nur einen Teiltyp. Es gibt etwa 1 Million Teilenummern in dieser Tabelle.
-
Kompatibilität (Compat): Diese Tabelle steht für mechanische Kompatibilitäten und sammelt alle gültigen Kombinationen von Teilenummern und Automodellen. Mit etwa 100 Millionen Kompatibilitätszeilen ist diese Tabelle bei weitem die größte.
-
Wettbewerb: Diese Tabelle enthält alle Wettbewerbsinformationen für den Tag. Für jede Teilenummer gibt es etwa ein halbes Dutzend bemerkenswerter Konkurrenten, die die Teilenummer mit einem Preisschild anzeigen. Dies ergibt etwa 10 Millionen Wettbewerbspreise.
-
Bestellungen: Diese Tabelle enthält vergangene Kundenaufträge aus Stuttgart über einen Zeitraum von etwa einem Jahr. Jede Auftragszeile enthält eine Teilenummer und ein Automodell. Technisch gesehen ist es möglich, ein Autoteil zu kaufen, ohne das Automodell anzugeben, obwohl dies selten vorkommt. Alle Auftragszeilen ohne Automodell können herausgefiltert werden. Basierend auf der Größe von Stuttgart sollten etwa 10 Millionen Auftragszeilen vorhanden sein.
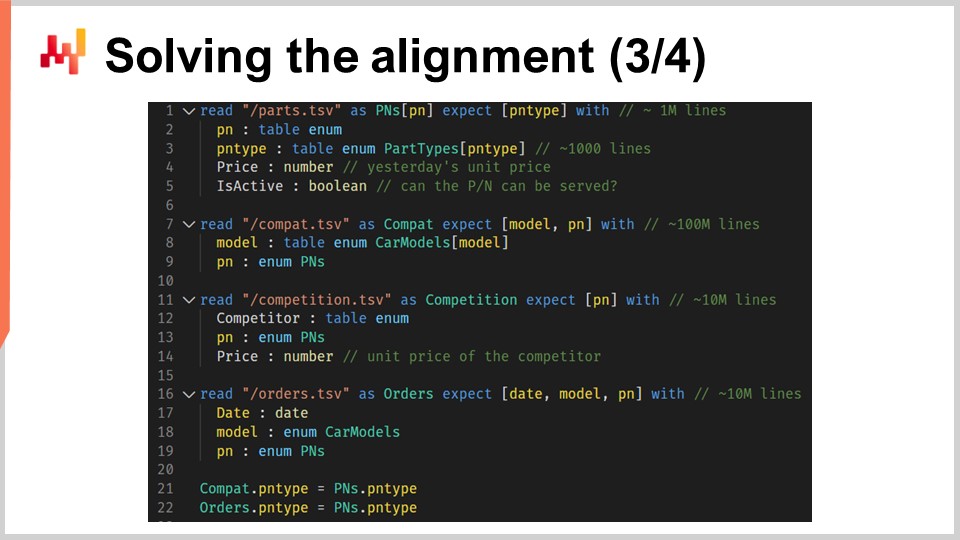
Wir werden nun den Code untersuchen, der die relationale Datenbank lädt. Auf dem Bildschirm wird ein Skript angezeigt, das sechs Tabellen lädt und in Envision geschrieben ist - eine domänenspezifische Programmiersprache, die von Lokad speziell für die vorhersagende Optimierung von Supply Chains entwickelt wurde. Obwohl Envision entwickelt wurde, um die Effizienz zu steigern und Fehler in Supply-Chain-Kontexten zu reduzieren, kann das Skript auch in anderen Sprachen wie Python umgeschrieben werden, allerdings mit erhöhter Wortfülle und Fehlergefahr.
Im ersten Teil des Skripts werden vier flache Textdateien geladen. Von Zeile 1 bis 5 liefert die Datei “path.csv” sowohl die Teilenummern als auch die Teiltypen, einschließlich der aktuellen Preise, die in Stuttgart angezeigt werden. Das Feld “name is active” gibt an, ob eine bestimmte Teilenummer von Stuttgart bedient wird. In dieser ersten Tabelle bezieht sich die Variable “PN” auf die primäre Dimension der Tabelle, während “PN type” eine sekundäre Dimension ist, die durch das Schlüsselwort “expect” eingeführt wird.
Von Zeile 7 bis 9 liefert die Datei “compat.tsv” die Liste der Teil-Fahrzeug-Kompatibilität und die Automodelle. Dies ist die größte Tabelle im Skript. Die Zeilen 11 bis 14 laden die Datei “competition.tsv” und liefern einen Überblick über die Wettbewerbsinformationen für den Tag, d.h. die Preise pro Teilenummer und pro Konkurrent. Die Datei “orders.tsv”, die in den Zeilen 16 bis 19 geladen wird, liefert uns die Liste der gekauften Teilenummern und die zugehörigen Automodelle, unter der Annahme, dass alle Zeilen, die mit nicht spezifizierten Automodellen verbunden sind, herausgefiltert wurden.
Schließlich werden in den Zeilen 21 und 22 die Tabelle “Teiltypen” als Vorgänger der beiden Tabellen “compat” und “orders” festgelegt. Das bedeutet, dass für jede Zeile in “compat” oder “orders” ein und nur ein Teiltyp übereinstimmt. Mit anderen Worten, “PN type” wurde als sekundäre Dimension zu den Tabellen “compat” und “orders” hinzugefügt. Dieser erste Teil des Envision-Skripts ist unkompliziert; wir laden einfach Daten aus flachen Textdateien und stellen dabei die relationale Datenstruktur wieder her.
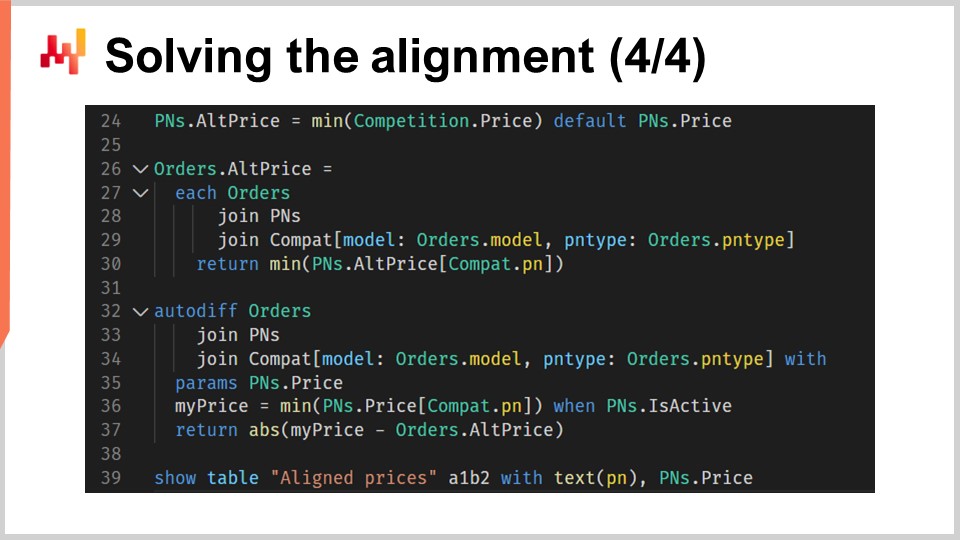
Der zweite Teil des Skripts, der auf dem Bildschirm sichtbar ist, ist der Ort, an dem die eigentliche Ausrichtungslogik stattfindet. Dieser Abschnitt ist eine direkte Fortsetzung des ersten Teils und wie Sie sehen können, besteht er nur aus 12 Zeilen Code. Wir verwenden erneut differenzierbares Programmieren. Für das Publikum, das mit differenzierbarem Programmieren möglicherweise nicht vertraut ist, handelt es sich um eine Fusion aus automatischer Differentiation und stochastischem Gradientenabstieg. Es handelt sich um ein Programmierparadigma, das sich auch auf maschinelles Lernen und Optimierung erstreckt. Im Kontext der Supply Chain erweist sich differenzierbares Programmieren in verschiedenen Situationen als unglaublich nützlich. Im Laufe dieser Vortragsreihe haben wir gezeigt, wie differenzierbares Programmieren verwendet werden kann, um Modelle zu erlernen, probabilistische Nachfrageprognosen zu generieren und ballistische Durchlaufzeitprognosen zu erreichen. Wenn Sie mit differenzierbarem Programmieren nicht vertraut sind, empfehle ich Ihnen, die vorherigen Vorträge in dieser Reihe noch einmal anzusehen.
In der heutigen Vorlesung werden wir sehen, wie differenzierbares Programmieren sich hervorragend zur Bewältigung von Optimierungsproblemen im großen Maßstab eignet, bei denen Hunderttausende von Variablen und Millionen von Einschränkungen beteiligt sind. Bemerkenswerterweise können diese Probleme in nur wenigen Minuten auf einer einzigen CPU mit einigen Gigabyte RAM gelöst werden. Darüber hinaus können wir frühere Preise als Ausgangspunkt verwenden und unsere Preise aktualisieren, anstatt sie von Grund auf neu zu berechnen.
Bitte beachten Sie eine kleine Einschränkung. Das Schlüsselwort “join” wird von Envision noch nicht unterstützt, ist aber auf unserer technischen Roadmap für die Zukunft vorgesehen. Es gibt Workarounds, aber für Klarheit werde ich in dieser Vorlesung die zukünftige Syntax von Envision verwenden.
In Zeile 24 berechnen wir den kleinsten beobachteten Preis auf dem Markt für jede Teilenummer. Wenn eine Teilenummer ausschließlich von Stuttgart verkauft wird und keine Konkurrenten hat, verwenden wir den eigenen Preis von Stuttgart als Standard.
Von Zeile 26 bis 30 wird für jedes in der Kundenauftragsgeschichte von Stuttgart aufgeführte Teil das aktuell wettbewerbsfähigste Angebot berechnet.
In Zeile 27 iterieren wir über jede Auftragszeile der Auftragstabelle mit ’each order'.
In Zeile 28 verwenden wir ‘join pns’, um für jede Zeile der Aufträge die vollständige Teilenummertabelle einzubringen.
In Zeile 29 verbinden wir uns mit ‘others’, aber dieser Join ist durch zwei sekundäre Dimensionen - Modell und Teiltyp - eingeschränkt. Das bedeutet, dass wir für jede Zeile in den Aufträgen die Teilenummern auswählen, die eine Kombination aus Teilmodell und Teiltyp aufweisen und die mit der Kundenbestellung übereinstimmen.
Von Zeile 32 bis 37 lösen wir die Ausrichtung mit differenzierbarem Programmieren, das durch das Schlüsselwort ‘Auto diff’ angezeigt wird. Der Block ‘Auto diff’ wird in Zeile 32 deklariert und nutzt die Tabelle ‘orders’ als Beobachtungstabelle. Das bedeutet, dass wir die Einschränkungen implizit nach dem eigenen Absatzvolumen von Stuttgart gewichten. Die Zeilen 33 und 44 dienen demselben Zweck wie die Zeilen 28 und 29; sie iterieren über die Tabelle ‘orders’ und ermöglichen vollen Zugriff auf die Teilenummern (‘PN’) Tabelle und einen Ausschnitt der kompatiblen Einträge.
In Zeile 35 deklarieren wir ‘pns.price’ als die zu optimierenden Parameter durch den stochastischen Gradientenabstieg. Diese Parameter müssen nicht initialisiert werden, da wir von den bisher von Stuttgart verwendeten Preisen ausgehen und die Ausrichtung effektiv aktualisieren.
In Zeile 36 berechnen wir ‘my price’, das wettbewerbsfähigste Angebot von Stuttgart für die Einheit des Bedarfs, die mit der Auftragszeile verbunden ist. Diese Berechnung ist ein Mechanismus, der dem der niedrigsten beobachteten Preise ähnelt, wie er in Zeile 24 durchgeführt wurde, und stützt sich erneut auf die Liste der mechanischen Kompatibilitäten. Die Kompatibilitäten sind jedoch auf Teilenummern beschränkt, die von Stuttgart bedient werden. Historisch gesehen haben Kunden möglicherweise nicht das wirtschaftlich günstigste Teil für ihr Fahrzeug ausgewählt. Unabhängig davon dient der Einsatz von Kundenaufträgen in diesem Kontext dazu, Gewichte den Bedarfseinheiten zuzuweisen.
In Zeile 37 verwenden wir den absoluten Unterschied zwischen dem besten Preis, den Stuttgart anbietet, und dem besten Preis, den ein Konkurrent anbietet, um die Ausrichtung zu steuern. Innerhalb dieses alternativen Blocks werden die Gradienten rückwirkend auf die Parameter angewendet. Der Unterschied, den wir am Ende finden, bildet die Verlustfunktion. Aus dieser Verlustfunktion fließen die Gradienten zurück zum einzigen Parametervektor, den wir hier haben: ‘pns.price’. Durch die schrittweise Anpassung der Parameter (der Preise) bei jeder Iteration (eine Iteration hier ist eine Auftragszeile) konvergiert das Skript zu einer geeigneten Approximation der gewünschten Preisabstimmung.
In Bezug auf die algorithmische Komplexität dominiert Zeile 36. Da die Anzahl der Kompatibilitäten für ein bestimmtes Automodell und einen bestimmten Teiletyp jedoch begrenzt ist (normalerweise nicht mehr als einige Dutzend), wird jede ‘Auto diff’-Iteration in dem, was einer konstanten Zeit entspricht, durchgeführt. Diese konstante Zeit ist nicht sehr klein, wie 10 CPU-Zyklen, aber es werden auch keine Millionen CPU-Zyklen sein. Etwa tausend CPU-Zyklen klingen vernünftig für 20 kompatible Teile.
Wenn wir von einer einzelnen CPU mit einer Taktrate von zwei Gigahertz ausgehen und 100 Epochen durchführen (wobei eine Epoche einem vollständigen Abstieg über die gesamte Beobachtungstabelle entspricht), würden wir eine Ziel-Ausführungszeit von etwa 10 Minuten erwarten. Die Lösung eines Problems mit 100.000 Variablen und 10 Millionen Einschränkungen in 10 Minuten auf einer einzelnen CPU ist beeindruckend. Tatsächlich erreicht Lokad eine Leistung, die in etwa dieser Erwartung entspricht. In der Praxis ist jedoch für solche Probleme häufig die I/O-Durchsatzrate und nicht die CPU der Engpass.
Auch dieses Beispiel zeigt die Kraft geeigneter Programmierparadigmen für Supply-Chain-Anwendungen. Wir begannen mit einem nicht trivialen Problem, da es nicht sofort ersichtlich war, wie man diesen Datensatz der mechanischen Kompatibilität aus einer Preisperspektive nutzen kann. Trotzdem ist die eigentliche Implementierung einfach.
Obwohl dieses Skript nicht alle Aspekte abdeckt, die in einer realen Umgebung vorhanden wären, erfordert die Kernlogik nur sechs Zeilen Code und bietet ausreichend Platz für zusätzliche Komplexitäten, die reale Szenarien einführen könnten.

Der Ausrichtungsalgorithmus, wie zuvor dargestellt, priorisiert Einfachheit und Klarheit gegenüber Vollständigkeit. In einer realen Umgebung wären zusätzliche Faktoren zu erwarten. Ich werde diese Faktoren in Kürze untersuchen, aber lassen Sie uns damit beginnen, dass diese Faktoren durch Erweiterung dieses Ausrichtungsalgorithmus behandelt werden können.
Das Verkaufen mit Verlust ist nicht nur unklug, sondern auch in vielen Ländern illegal, wie zum Beispiel in Frankreich, obwohl es unter besonderen Umständen Ausnahmen gibt. Um den Verkauf mit Verlust zu verhindern, kann dem Ausrichtungsalgorithmus eine Einschränkung hinzugefügt werden, die vorschreibt, dass der Verkaufspreis den Einkaufspreis übersteigen muss. Es ist jedoch auch nützlich, den Algorithmus ohne diese “kein Verlust”-Einschränkung auszuführen, um potenzielle Beschaffungsprobleme zu identifizieren. Wenn ein Konkurrent sich leisten kann, ein Teil unter dem Einkaufspreis von Stuttgart zu verkaufen, muss Stuttgart das zugrunde liegende Problem angehen. Wahrscheinlich handelt es sich um ein Beschaffungs- oder Einkaufsproblem.
Das Zusammenfassen aller Teilenummern ist naiv. Kunden sind nicht bereit, für alle Original Equipment Manufacturers (OEMs) den gleichen Preis zu zahlen. Zum Beispiel sind Kunden in Europa eher bereit, einer bekannten Marke wie Bosch mehr Wert beizumessen als einem weniger bekannten chinesischen OEM. Um dieses Problem anzugehen, kategorisiert Stuttgart wie seine Mitbewerber OEMs in eine kurze Liste von Produktbereichen, von den teuersten bis zu den günstigsten. Wir können zum Beispiel den Motorsportbereich, den Haushaltsbereich, den Vertriebsmarkenbereich und den Budgetbereich haben.
Die Ausrichtung wird dann so konstruiert, dass jede Teilenummer innerhalb ihres eigenen Produktbereichs ausgerichtet ist. Darüber hinaus sollte der Ausrichtungsalgorithmus vorschreiben, dass die Preise streng abnehmend sind, wenn man vom Motorsportbereich zum Budgetbereich geht, da jede Umkehrung Kunden verwirren würde. In der Theorie würden solche Umkehrungen nicht auftreten, wenn die Wettbewerber ihre eigenen Angebote genau preisen würden. In der Praxis jedoch setzen Kunden manchmal ihre eigenen Teile falschpreisig und gelegentlich haben sie Gründe, ihre Teile zu einem anderen Preis anzubieten.
Es gibt nur einige hundert OEMs, die Klassifizierung dieser OEMs in ihre jeweiligen Produktbereiche kann manuell erfolgen und möglicherweise mit Hilfe von Kundenumfragen, wenn es Unklarheiten gibt, die nicht direkt von den Marktexperten in Stuttgart gelöst werden können.

Trotz der Einführung von Produktbereichen werden viele Teilenummernpreise nicht aktiv durch die Ausrichtungslogik gesteuert. Tatsächlich werden nur die Teilenummern, die aktiv dazu beitragen, den besten Preis für eine Einheit des Bedarfs zu sein, effektiv durch den Gradientenabstieg angepasst, um die gewünschte Annäherung innerhalb desselben Produktbereichs zu schaffen.
Von zwei Teilenummern, die über identische mechanische Kompatibilitäten verfügen, wird nur eine von ihnen durch den Ausrichtungslöser angepasst. Die andere Teilenummer erhält immer null Gradienten und ihr ursprünglicher Preis bleibt unverändert. Zusammenfassend lässt sich also sagen, dass das System zwar eine Reihe von Einschränkungen hat, aber viele Variablen überhaupt nicht eingeschränkt sind. Je nach Feinheit der Produktbereiche und dem Ausmaß der Wettbewerbsintelligenz können diese unbeschränkten Teilenummern einen beträchtlichen Teil des Katalogs ausmachen, möglicherweise die Hälfte der Teilenummern. Obwohl der Anteil, einmal in Verkaufsvolumen ausgedrückt, viel geringer ist.
Für diese Teilenummern benötigt Stuttgart eine alternative Preisstrategie. Obwohl ich keinen strengen algorithmischen Prozess für diese unbeschränkten Teile vorschlagen kann, würde ich zwei Leitprinzipien vorschlagen.
Erstens sollte es einen nicht unerheblichen Preisunterschied, sagen wir 10%, zwischen dem wettbewerbsfähigsten Teil innerhalb des Produktbereichs und dem nächsten Teil geben. Mit etwas Glück sind einige Konkurrenten möglicherweise nicht so geschickt wie Stuttgart bei der Rekonstruktion der Bedarfseinheiten. Diese Konkurrenten könnten also den einen Preis verpassen, der tatsächlich die Ausrichtung vorantreibt, und ihren Preis nach oben korrigieren, was für Stuttgart wünschenswert ist.
Zweitens könnte es einige Teile mit einem viel höheren Preis geben, sagen wir 30% teurer, solange diese Teile nicht mit anderen Produktbereichen überlappen. Diese Teile dienen als Gegenspieler für ihre besser bepreisten Gegenstücke, eine Strategie, die technisch als Decoy Pricing bekannt ist. Das Lockvogelangebot ist bewusst so gestaltet, dass es eine weniger attraktive Option als die Zieloption ist, wodurch die Zieloption wertvoller erscheint und der Kunde sie häufiger wählt. Diese beiden Prinzipien reichen aus, um die unbeschränkten Preise über ihre Wettbewerbsgrenzen hinaus sanft zu verteilen.

Die Wettbewerbsausrichtung plus eine Prise Lockvogel-Preisgestaltung reichen aus, um jedem Teilenummer, die bei Stuttgart angezeigt wird, einen Preis zuzuweisen. Die resultierende Bruttomarge ist jedoch wahrscheinlich zu niedrig für Stuttgart. Tatsächlich setzt die Ausrichtung von Stuttgart mit all ihren bedeutenden Wettbewerbern eine enorme Marge unter Druck.
Einerseits ist die Preisausrichtung eine Notwendigkeit, sonst wird Stuttgart im Laufe der Zeit vollständig aus dem Markt gedrängt. Andererseits kann sich Stuttgart im Prozess der Erhaltung seines Marktanteils nicht selbst in den Ruin treiben. Es ist wichtig zu bedenken, dass die zukünftige Bruttomarge, die mit einer bestimmten Preisstrategie verbunden ist, nur geschätzt oder prognostiziert werden kann. Es gibt keine genaue Möglichkeit, das zukünftige Wachstum aus einer Reihe von Preisen abzuleiten, da sich sowohl Kunden als auch Wettbewerber anpassen.
Angenommen, wir haben eine ziemlich genaue Schätzung der Bruttomarge, die Stuttgart nächste Woche erwarten sollte, ist es wichtig darauf hinzuweisen, dass der “Genauigkeits” -Teil dieser Annahme nicht so unvernünftig ist, wie es klingen mag. Stuttgart, wie seine Konkurrenten, arbeitet unter schweren Einschränkungen. Wenn die Preisstrategie von Stuttgart nicht grundlegend geändert wird, wird sich die gesamte Bruttomarge des Unternehmens von einer Woche zur nächsten nicht wesentlich ändern. Wir können sogar die beobachtete Bruttomarge der letzten Woche als vernünftigen Proxy dafür behandeln, was Stuttgart nächste Woche erwarten sollte, vorausgesetzt natürlich, dass die Preisstrategie unverändert bleibt.
Angenommen, die Bruttomarge von Stuttgart soll 13% betragen, aber Stuttgart benötigt eine Bruttomarge von 15%, um sich selbst zu erhalten. Was sollte Stuttgart in einer solchen Situation tun? Eine Antwort besteht darin, eine zufällige Auswahl von “Bedarfseinheiten” zu treffen und ihre Preise um etwa 20% zu erhöhen. Teile, die von Erstkunden bevorzugt werden, wie Scheibenwischer, sollten von dieser Auswahl ausgeschlossen werden. Die Gewinnung dieser Erstkunden ist teuer und schwierig, und Stuttgart sollte diese Erstkäufe nicht riskieren. Ähnlich verhält es sich bei sehr teuren Teilen wie Einspritzdüsen, bei denen Kunden wahrscheinlich viel mehr vergleichen werden. Daher sollte Stuttgart wahrscheinlich nicht das Risiko eingehen, bei diesen größeren Einkäufen unkonkurrenzfähig zu erscheinen.
Abgesehen von diesen beiden Situationen würde ich argumentieren, dass die zufällige Auswahl von “Bedarfseinheiten” und deren Unwettbewerbsfähigkeit durch höhere Preise eine vernünftige Option ist. Tatsächlich muss Stuttgart einige seiner Preise erhöhen, eine unvermeidliche Folge des Anstrebens einer höheren Wachstumsmargenrate. Wenn Stuttgart dabei ein erkennbares Muster annimmt, werden Online-Bewertungen wahrscheinlich auf diese Muster hinweisen. Wenn Stuttgart sich beispielsweise dazu entscheidet, bei Teilen von Bosch nicht wettbewerbsfähig zu sein oder bei Teilen, die mit Peugeot-Fahrzeugen kompatibel sind, aufzugeben, besteht die reale Gefahr, dass Stuttgart als Händler bekannt wird, der kein gutes Angebot für Bosch- oder Peugeot-Fahrzeuge ist. Die Zufälligkeit macht Stuttgart etwas undurchschaubar, was genau der beabsichtigte Effekt ist.
Die Anzeigeränge sind ein weiterer entscheidender Faktor im Online-Katalog von Stuttgart. Genauer gesagt muss Stuttgart für jede “Bedarfseinheit” alle geeigneten Teile einstufen. Die Bestimmung der besten Art und Weise, wie die Teile eingestuft werden sollen, ist ein preisnahes Problem, das einen eigenen Vortrag rechtfertigt. Die Anzeigeränge sollten aus der in diesem Vortrag dargestellten Perspektive erwartungsgemäß nach der Lösung des Ausrichtungsproblems berechnet werden. Es wäre jedoch auch denkbar, sowohl die Preisschilder als auch die Anzeigeränge gleichzeitig zu optimieren. Bei diesem Problem hätten wir etwa 10 Millionen Variablen anstelle der bisher behandelten 100.000 Variablen. Dies ändert jedoch das Ausmaß des Optimierungsproblems nicht grundlegend, da wir sowieso 10 Millionen Einschränkungen haben. Ich werde heute nicht darauf eingehen, welche Art von Kriterium zur Steuerung dieser Anzeigerangoptimierung verwendet werden könnte, noch wie man den Gradientenabstieg für diskrete Optimierung nutzen kann. Diese letzte Frage ist sehr interessant, wird aber in einem späteren Vortrag behandelt.

Die relative Bedeutung der “Bedarfseinheit” wird fast ausschließlich durch die vorhandenen Fahrzeugflotten definiert. Stuttgart kann nicht erwarten, 1 Million Bremsbeläge für ein Automodell zu verkaufen, das nur 1.000 Fahrzeuge in Europa hat. Man könnte sogar argumentieren, dass die eigentlichen Verbraucher von Teilen die Fahrzeuge selbst sind und nicht ihre Besitzer. Während Fahrzeuge nicht für ihre Teile bezahlen (Besitzer tun dies), betont dieser Vergleich die Bedeutung der Fahrzeugflotte.
Es ist jedoch vernünftig, erhebliche Verzerrungen zu erwarten, wenn es um den Kauf von Teilen online geht. Schließlich ist der Kauf von Teilen in erster Linie eine Möglichkeit, Geld zu sparen im Vergleich zum indirekten Kauf von einer Reparaturwerkstatt. Daher wird erwartet, dass das durchschnittliche Fahrzeugalter, wie es von Stuttgart beobachtet wird, älter ist als das, was die allgemeinen Statistiken des Automobilmarktes nahelegen würden. Ebenso sind Personen, die teure Autos fahren, weniger wahrscheinlich, Geld zu sparen, indem sie ihre eigenen Reparaturen durchführen. Daher wird erwartet, dass die durchschnittliche Fahrzeuggröße und -klasse, wie sie von Stuttgart beobachtet wird, niedriger ist als das, was die allgemeinen Markstatistiken nahelegen würden.
Dies sind keine haltlosen Spekulationen. Diese Verzerrungen werden tatsächlich bei allen großen Online-Händlern für Autoteile in Europa beobachtet. Dennoch nutzt der zuvor vorgestellte Ausrichtungsalgorithmus die Verkaufshistorie von Stuttgart als Proxy für die Nachfrage. Es ist denkbar, dass diese Verzerrungen das Ergebnis des Preisabgleichsalgorithmus beeinträchtigen könnten. Ob diese Verzerrungen das Ergebnis für Stuttgart negativ beeinflussen, ist grundsätzlich ein empirisches Problem, da die Größenordnung des Problems, falls vorhanden, stark von den Daten abhängt. Die Erfahrung von Lokad zeigt, dass der Ausrichtungsalgorithmus und seine Variationen recht robust gegen diese Art von Verzerrungen sind, selbst wenn das Gewicht einer “Bedarfseinheit” um den Faktor zwei oder drei falsch eingeschätzt wird. Der Hauptbeitrag dieser Gewichte, preislich gesehen, scheint dem Ausrichtungsalgorithmus dabei zu helfen, Konflikte zu lösen, wenn dieselbe Teilenummer zu zwei “Bedarfseinheiten” gehört, die nicht gemeinsam angegangen werden können. In den meisten dieser Situationen überwiegt eine “Bedarfseinheit” die andere in Bezug auf das Volumen. Daher hat eine erhebliche Fehleinschätzung der jeweiligen Volumina nur geringe Auswirkungen auf die Preisgestaltung.
Die Identifizierung der größten Verzerrungen zwischen dem, was die Nachfrage für eine “Bedarfseinheit” hätte sein sollen, und dem, was Stuttgart als realisierten Verkauf beobachtet, kann sehr nützlich sein. Ein überraschend geringes Verkaufsvolumen für eine bestimmte “Bedarfseinheit” deutet auf banale Probleme mit der E-Commerce-Plattform hin. Einige Teile könnten falsch gekennzeichnet sein, einige könnten falsche oder qualitativ minderwertige Bilder haben, usw. In der Praxis können diese Verzerrungen identifiziert werden, indem man die Verkaufsverhältnisse für ein bestimmtes Automodell der verschiedenen Teilarten vergleicht. Wenn Stuttgart zum Beispiel keine Bremsbeläge für ein bestimmtes Automodell verkauft, während die Verkaufsvolumina für andere Teilarten mit dem üblicherweise Beobachteten übereinstimmen, ist es unwahrscheinlich, dass dieses Automodell einen außergewöhnlich geringen Verbrauch von Bremsbelägen hat. Die eigentliche Ursache liegt fast sicher woanders.
Eine überlegene Liste von mechanischen Kompatibilitäten ist ein Wettbewerbsvorteil. Das Wissen um Kompatibilitäten, die Ihren Mitbewerbern unbekannt sind, ermöglicht es Ihnen, potenziell niedrigere Preise anzubieten, ohne einen Preiskrieg auszulösen und so einen Vorteil bei der Steigerung Ihres Marktanteils zu erlangen. Umgekehrt ist es wichtig, falsche Kompatibilitäten zu identifizieren, um teure Rücksendungen von Kunden zu vermeiden.
Tatsächlich ist der Kosten für die Bestellung eines inkompatiblen Teils für eine Reparaturwerkstatt gering, da wahrscheinlich ein etablierter Prozess besteht, um das unbenutzte Teil an das Vertriebszentrum zurückzusenden. Der Prozess ist jedoch für normale Kunden viel mühsamer, die möglicherweise nicht einmal erfolgreich darin sind, das Teil ordnungsgemäß für seine Rückreise zu verpacken. Daher hat jedes E-Commerce-Unternehmen einen Anreiz, seine eigene Datenanreicherungsschicht über den von ihnen gemieteten Daten von Drittanbietern aufzubauen. Die meisten E-Commerce-Player in diesem Bereich haben ihre eigene Datenanreicherungsschicht in irgendeiner Form.
Es gibt nur wenige Anreize, dieses Wissen mit den spezialisierten Unternehmen zu teilen, die diese Datensätze in erster Linie pflegen, da dieses Wissen hauptsächlich dem Wettbewerb zugutekommen würde. Es ist schwierig, die Fehlerquote in diesen Datensätzen zu bewerten, aber bei Lokad schätzen wir, dass sie auf beiden Seiten im niedrigen einstelligen Prozentbereich liegt. Es gibt einige Prozent falsch positiver Ergebnisse, bei denen eine Kompatibilität angegeben wird, obwohl sie nicht existiert, und es gibt einige Prozent falsch negativer Ergebnisse, bei denen eine Kompatibilität existiert, aber nicht angegeben wird. Angesichts der Tatsache, dass die Liste der mechanischen Kompatibilitäten mehr als 100 Millionen Zeilen umfasst, gibt es unter konservativen Schätzungen wahrscheinlich rund sieben Millionen Fehler.
Daher ist es im Interesse von Stuttgart, diesen Datensatz zu verbessern. Kundenrücksendungen, die auf falsch positive mechanische Kompatibilität zurückzuführen sind, können sicherlich für diesen Zweck genutzt werden. Dieser Prozess ist jedoch langsam und kostspielig. Darüber hinaus sind Kunden keine professionellen Kfz-Techniker und könnten ein Teil als inkompatibel melden, wenn sie es einfach nicht geschafft haben, das Teil zu montieren. Stuttgart kann die Einstufung eines Teils als inkompatibel aufschieben, bis mehrere Beschwerden eingegangen sind, aber dies macht den Prozess noch kostspieliger und langsamer.
Daher wäre ein numerisches Rezept zur Verbesserung dieses Kompatibilitätsdatensatzes äußerst wünschenswert. Es ist nicht offensichtlich, dass es überhaupt möglich ist, diesen Datensatz ohne zusätzliche Informationen zu verbessern. Überraschenderweise stellte sich jedoch heraus, dass dieser Datensatz ohne weitere Informationen verbessert werden kann. Dieser Datensatz kann sich selbst in eine überlegene Version bootstrappen.
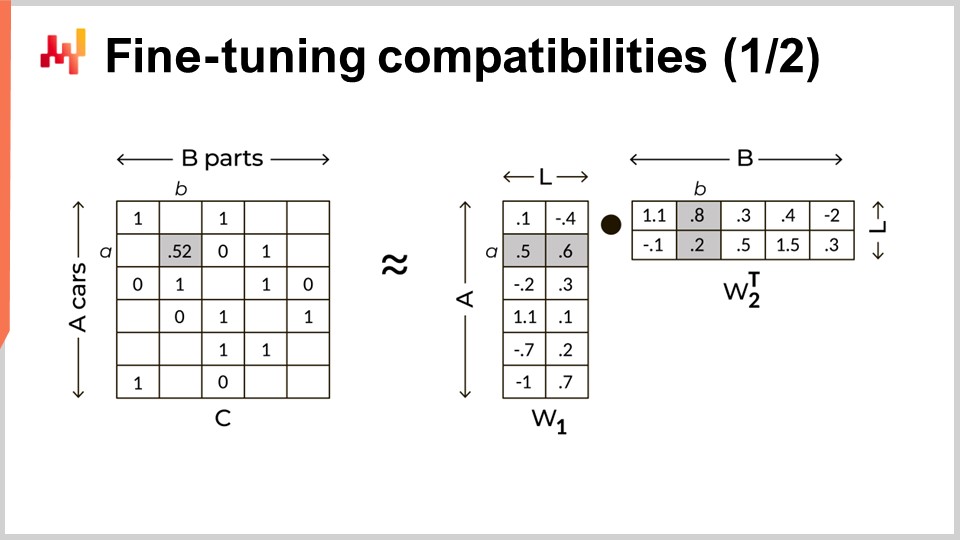
Ich persönlich bin im ersten Quartal 2017 auf diese Erkenntnis gestoßen, als ich eine Reihe von Deep Learning Experimenten für Lokad durchführte. Ich habe eine Matrixfaktorisierung verwendet, eine bekannte Technik für die kollaborative Filterung. Die kollaborative Filterung ist das zentrale Problem beim Aufbau eines Empfehlungssystems, bei dem das Produkt identifiziert wird, das einem Benutzer basierend auf den bekannten Vorlieben dieses Benutzers für eine kurze Liste von Produkten gefallen könnte. Die Anpassung der kollaborativen Filterung an mechanische Kompatibilitäten ist unkompliziert: Ersetzen Sie Benutzer durch Automodelle und ersetzen Sie Produkte durch Autoteile. Voila, das Problem ist angepasst.
Allgemeiner gesagt ist die Matrixfaktorisierung für jede Situation anwendbar, die einen bipartiten Graphen betrifft. Die Matrixfaktorisierung ist auch über die Graphenanalyse hinaus nützlich. Zum Beispiel beruht die Low-Rank-Anpassung großer Sprachmodelle (LLMs), eine Technik, die zur Feinabstimmung von LLMs enorm populär geworden ist, ebenfalls auf dem Trick der Matrixfaktorisierung. Die Matrixfaktorisierung wird auf dem Bildschirm veranschaulicht. Links haben wir die Kompatibilitätsmatrix mit Einsen, um eine Kompatibilität zwischen einem Auto und einem Teil anzuzeigen, und Nullen, um eine Inkompatibilität zwischen einem Automodell und einer Teilenummer anzuzeigen. Wir möchten diese große und sehr spärliche Matrix durch das Produkt zweier kleinerer dichter Matrizen ersetzen. Diese beiden Matrizen sind rechts sichtbar. Diese Matrizen dienen dazu, die große Matrix zu faktorisieren. Effektiv tauchen wir jedes Automodell und jede Teilenummer in einen latenten Raum ein. Die Dimension dieses latenten Raums wird auf dem Bildschirm mit dem Großbuchstaben L bezeichnet. Dieser latente Raum ist darauf ausgelegt, die mechanischen Kompatibilitäten zu erfassen, jedoch mit viel weniger Dimensionen im Vergleich zur ursprünglichen Matrix. Durch die Beibehaltung einer relativ niedrigen Dimension dieses latenten Raums zielen wir darauf ab, die versteckten Regeln zu erlernen, die diese mechanischen Kompatibilitäten steuern.

Während die Matrixfaktorisierung wie ein großes technisches Konzept klingen mag, ist sie es nicht. Es handelt sich um einen grundlegenden Trick der linearen Algebra. Das einzige trügerische an der Matrixfaktorisierung ist, dass sie trotz ihrer Einfachheit so gut funktioniert. Auf dem Bildschirm ist eine vollständige Implementierung dieser Technik in weniger als 30 Zeilen Code zu sehen.
Von Zeile eins bis drei lesen wir die Flachdatei ein, die die mechanischen Kompatibilitäten auflistet. Diese Datei wird aus Gründen der Kürze in eine Tabelle namens M geladen, die für Matrix steht. Diese Liste ist effektiv eine spärliche Darstellung der Kompatibilitätsmatrix. Beim Laden dieser Liste erstellen wir auch zwei weitere Tabellen namens car_models und pns. Diese Blöcke geben uns drei Tabellen: M, car_models und pns.
In den Zeilen fünf und sechs wird die Spalte, die die Automodelle enthält, zufällig durcheinandergewürfelt. Der Zweck des Mischens besteht darin, zufällige Nullen oder zufällige Inkompatibilitäten zu erzeugen. Tatsächlich ist die Kompatibilitätsmatrix sehr spärlich. Wenn wir ein zufälliges Auto und ein zufälliges Teil auswählen, ist es nahezu sicher, dass dieses Paar inkompatibel ist. Das Vertrauen, das wir in diese zufällige Zuordnung haben, die Null ist, ist tatsächlich höher als das Vertrauen, das wir in die Kompatibilitätsliste im Allgemeinen haben. Diese zufälligen Nullen sind aufgrund der Sparsamkeit der Matrix zu 99,9% genau, während die bekannten Kompatibilitäten vielleicht zu 97% genau sind.
In Zeile acht wird der latente Raum mit 24 Dimensionen erstellt. Obwohl 24 Dimensionen für Einbettungen viel erscheinen mögen, ist es im Vergleich zu großen Sprachmodellen sehr klein, die Einbettungen mit über tausend Dimensionen haben. In den Zeilen neun und zehn werden die beiden kleinen Matrizen pnl und car_L erstellt, die wir zur Faktorisierung der großen Matrix verwenden werden. Diese beiden Matrizen repräsentieren ungefähr 24 Millionen Parameter für pnl und 2,4 Millionen Parameter für car_L. Dies gilt im Vergleich zur großen Matrix, die ungefähr 100 Milliarden Werte hat, als klein.
Lassen Sie uns darauf hinweisen, dass die große Matrix in diesem Skript nie materialisiert wird. Sie wird nie explizit in ein Array umgewandelt; sie wird immer als Liste von 100 Millionen Kompatibilitäten gehalten. Die Umwandlung in ein Array wäre in Bezug auf die Rechenressourcen äußerst ineffizient.
In den Zeilen 12 bis 15 werden zwei Hilfsfunktionen mit den Namen sigmoid und log_loss eingeführt. Die Sigmoid-Funktion wird verwendet, um das rohe Matrixprodukt in Wahrscheinlichkeiten umzuwandeln, also Zahlen zwischen 0 und 1. Die log_loss-Funktion steht für den logistischen Verlust. Der logistische Verlust wendet die Log-Likelihood an, eine Metrik, die zur Beurteilung der Korrektheit einer probabilistischen Vorhersage verwendet wird. Hier wird sie verwendet, um eine probabilistische Vorhersage für ein binäres Klassifikationsproblem zu bewerten. Wir haben die Log-Likelihood bereits in Vorlesung 5.3 kennengelernt, die der probabilistischen Vorhersage von Vorlaufzeiten gewidmet ist. Dies ist eine einfachere Variation der gleichen Idee. Diese beiden Funktionen sind mit dem Schlüsselwort autograd markiert, was bedeutet, dass sie automatisch differenziert werden können. Der kleine Wert von eins über eine Million ist ein Epsilon, das zur numerischen Stabilität eingeführt wird. Es hat sonst keine Auswirkungen auf die Logik. Von den Zeilen 17 bis 29 haben wir die eigentliche Matrixfaktorisierung. Auch hier verwenden wir differenzierbare Programmierung. Vor einigen Minuten haben wir differenzierbare Programmierung verwendet, um ein Constraint Satisfaction Problem ungefähr zu lösen. Hier verwenden wir differenzierbare Programmierung, um ein selbstüberwachtes Lernproblem anzugehen.
In den Zeilen 18 und 19 deklarieren wir die zu erlernenden Parameter. Diese Parameter sind mit den beiden kleinen Matrizen pnl und car_L verbunden. Das Schlüsselwort ‘auto’ gibt an, dass diese Parameter zufällig als Zufallsabweichungen von einer gaußschen Verteilung mit einem Mittelwert von Null und einer Standardabweichung von 0,1 initialisiert werden.
In den Zeilen 20 und 21 werden zwei spezielle Parameter eingeführt, die die Konvergenz beschleunigen. Dies sind insgesamt nur 48 Zahlen, ein Tropfen im Ozean im Vergleich zu unseren kleinen Matrizen, die immer noch Millionen von Zahlen haben. Und doch habe ich festgestellt, dass die Einführung dieser Parameter die Konvergenz erheblich beschleunigt. Es ist wichtig darauf hinzuweisen, dass diese Parameter dem bestehenden Modell keinen Freiheitsgrad einführen. Diese Parameter führen nur ein paar zusätzliche Freiheitsgrade im Lernprozess ein. Der Nettoeffekt besteht darin, dass sie die Anzahl der notwendigen Epochen um mehr als die Hälfte reduzieren.
In den Zeilen 22 bis 24 laden wir die Einbettungen. In Zeile 22 haben wir die Einbettung für ein einzelnes Teil namens px. In Zeile 23 haben wir die Einbettung für ein einzelnes Automodell namens mx. Das Paar px und mx wird unsere positive Kante sein, eine als wahr erachtete Kompatibilität. In Zeile 24 haben wir die Einbettung für ein anderes Automodell namens mx2. Das Paar px und mx2 wird unsere negative Kante sein, eine als falsch erachtete Kompatibilität. Tatsächlich wurde mx2 zufällig durch das Mischen ausgewählt, das in Zeile sechs stattfindet. Die drei Einbettungen px, mx und mx2 haben alle genau 24 Dimensionen, da sie zum latenten Raum gehören, der in diesem Skript durch die Tabelle L repräsentiert wird.
In Zeile 26 drücken wir die Wahrscheinlichkeit, wie sie von unserem Modell definiert ist, durch ein Skalarprodukt dieser Kante aus, um positiv zu sein. Wir wissen, dass diese Kante positiv ist, zumindest sagt uns das der Kompatibilitätsdatensatz. Aber hier bewerten wir, was unser probabilistisches Modell über diese Kante sagt. In Zeile 27 drücken wir die Wahrscheinlichkeit, ebenfalls definiert durch unser probabilistisches Modell, durch das Skalarprodukt dieser Kante aus, um negativ zu sein. Wir vermuten, dass diese Kante negativ ist, da es sich um eine zufällige Kante handelt. Auch hier bewerten wir diese Wahrscheinlichkeit, um zu sehen, was unser Modell über diese Kante sagt. In Zeile 29 geben wir das Gegenteil der mit dieser Kante verbundenen Log-Likelihood zurück. Der Rückgabewert wird als Verlust verwendet, der durch den stochastischen Gradientenabstieg minimiert werden soll. Hier bedeutet dies, dass wir das Log-Likelihood oder das probabilistische binäre Klassifikationskriterium zwischen kompatiblen und inkompatiblen Paaren maximieren.
Danach, über das, was in diesem Skript gezeigt wird, kann die große Matrix mit dem Skalarprodukt von zwei kleinen Matrizen verglichen werden. Die Unterschiede zwischen den beiden Darstellungen zeigen sowohl die falsch positiven als auch die falsch negativen Ergebnisse der ursprünglichen Datensätze auf. Das Erstaunlichste ist, dass die faktorisierte Darstellung dieser großen Matrix letztendlich genauer ist als die ursprüngliche Matrix.
Leider kann ich die mit diesen Techniken verbundenen empirischen Ergebnisse nicht präsentieren, da die relevanten Kompatibilitätsdatensätze alle proprietär sind. Meine Ergebnisse, die von einigen Akteuren auf diesem Markt validiert wurden, deuten jedoch darauf hin, dass diese Matrixfaktorisierungstechniken verwendet werden können, um die Anzahl der falsch positiven und falsch negativen Ergebnisse um bis zu eine Größenordnung zu reduzieren. In Bezug auf die Leistung bin ich von etwa zwei Wochen Berechnung mit dem von mir verwendeten Deep Learning Toolkit CNTK - dem Deep Learning Toolkit von Microsoft aus dem Jahr 2017 - auf etwa eine Stunde mit der aktuellen Laufzeit von Envision umgestiegen. Die frühen Deep Learning Toolkits boten zwar differenzierbare Programmierung im eigentlichen Sinne, aber diese Lösungen waren stark optimiert für große Matrixprodukte und große Faltungen. Neuere Toolkits wie Jax von Google würden meiner Vermutung nach eine vergleichbare Leistung wie die von Envision bieten.
Das wirft die Frage auf: Warum verwenden spezialisierte Unternehmen, die Kompatibilitätsdatensätze pflegen, Matrixfaktorisierung noch nicht, um ihre Datensätze aufzuräumen? Wenn sie es getan hätten, würde Matrixfaktorisierung nichts Neues bringen. Matrixfaktorisierung als maschinelles Lernverfahren gibt es schon seit fast 20 Jahren. Diese Technik wurde 2006 von Simon Funk populär gemacht. Es ist nicht mehr ganz auf dem neuesten Stand. Meine Antwort auf diese ursprüngliche Frage ist, dass ich es nicht weiß. Vielleicht werden diese spezialisierten Unternehmen nach dem Anschauen dieses Vortrags anfangen, Matrixfaktorisierung zu verwenden, oder vielleicht auch nicht.
In jedem Fall zeigt dies, dass differenzierbare Programmierung und probabilistisches Modellieren sehr vielseitige Paradigmen sind. Aus der Ferne hat die Vorhersage der Vorlaufzeit nichts mit der Bewertung mechanischer Kompatibilitäten zu tun, und dennoch können beide mit demselben Instrument, nämlich differenzierbarer Programmierung und probabilistischem Modellieren, angegangen werden.

Der Datensatz der mechanischen Kompatibilitäten ist nicht der einzige Datensatz, der sich als ungenau erweisen kann. Manchmal liefern auch die Competitive Intelligence-Tools falsche Daten zurück. Auch wenn der Web-Scripting-Prozess beim Extrahieren von Millionen von Preisen aus halbstrukturierten Webseiten recht zuverlässig ist, können Fehler auftreten. Die Identifizierung und Behebung dieser fehlerhaften Preise ist eine Herausforderung für sich. Dies würde jedoch auch einen eigenen Vortrag verdienen, da die Probleme sowohl spezifisch für die Zielwebsite als auch für die für das Web-Scripting verwendete Technologie sind.
Während die Bedenken beim Web-Scraping wichtig sind, entfalten sich diese Bedenken, bevor der Ausrichtungsalgorithmus ausgeführt wird, und sollten daher weitgehend von der Ausrichtung selbst entkoppelt sein. Scraping-Fehler müssen nicht dem Zufall überlassen werden. Es gibt zwei Möglichkeiten, das Competitive Intelligence-Spiel zu spielen: Entweder verbessern Sie Ihre Zahlen, machen sie genauer, oder Sie machen die Zahlen Ihrer Konkurrenten schlechter, weniger genau. Darum geht es bei der Gegenaufklärung.
Wie bereits diskutiert, wird das Blockieren von Robotern anhand ihrer IP-Adresse nicht funktionieren. Es gibt jedoch Alternativen. Die Netzwerktransportebene ist bei weitem nicht die interessanteste Ebene, mit der wir spielen können, wenn wir beabsichtigen, Verwirrung zu stiften. Vor etwa einem Jahrzehnt führte Lokad eine Reihe von Gegenaufklärungsexperimenten durch, um zu sehen, ob sich eine große E-Commerce-Website wie SugAr gegen Konkurrenten verteidigen könnte. Die Ergebnisse? Ja, das kann sie.
Irgendwann konnte ich sogar die Wirksamkeit dieser Gegenaufklärungstechniken durch direkte Inspektion der Daten bestätigen, die vom ansonsten ahnungslosen Web-Scraping-Spezialisten geliefert wurden. Der Codename für diese Initiative war Bot Defender. Dieses Projekt wurde eingestellt, aber Sie können immer noch ein paar Spuren von Bot Defender in unserem öffentlichen Blog-Archiv sehen.
Anstatt den Zugriff auf die HTML-Seiten zu verweigern, was ein aussichtsloses Unterfangen ist, haben wir beschlossen, selektiv in die Web-Scraper selbst einzugreifen. Das Lokad-Team kannte die Feinheiten des Designs dieser Web-Scraper nicht. Angesichts der DHTML-Struktur einer bestimmten E-Commerce-Website ist es nicht allzu schwierig, eine fundierte Vermutung darüber anzustellen, wie ein Unternehmen, das die Web-Scraper betreibt, vorgehen würde. Wenn zum Beispiel jede HTML-Seite der StuttArt-Website eine überaus praktische CSS-Klasse namens ‘unit price’ hat, die den Preis des Produkts in der Mitte der Seite hervorhebt, ist es vernünftig anzunehmen, dass so ziemlich alle Roboter diese äußerst praktische CSS-Klasse verwenden werden, um den Preis im HTML-Code zu isolieren. Tatsächlich ist diese CSS-Klasse der offensichtliche Weg, um die Preise zu extrahieren, es sei denn, die StuttArt-Website bietet eine noch bequemere Möglichkeit, die Preise zu erhalten, wie z.B. eine offene API, die frei abgefragt werden kann.
Da die Logik des Web-Scrapings offensichtlich ist, ist es auch offensichtlich, wie man selektiv in diese Logik eingreifen kann. Zum Beispiel kann StuttArt beschließen, einige gezielt ausgewählte Produkte auszuwählen und den HTML-Code zu ‘vergiften’. Im gegebenen Beispiel auf dem Bildschirm werden beide HTML-Seiten visuell für Menschen als ein Preisschild von 65 Euro und 50 Cent gerendert. Die zweite Version der HTML-Seite wird jedoch von Robotern als 95 Euro anstelle von 65 Euro interpretiert. Die Zahl ‘9’ wird von CSS so gedreht, dass sie wie eine ‘6’ aussieht. Der typische Web-Scraper, der auf HTML-Markup angewiesen ist, wird dies nicht bemerken.
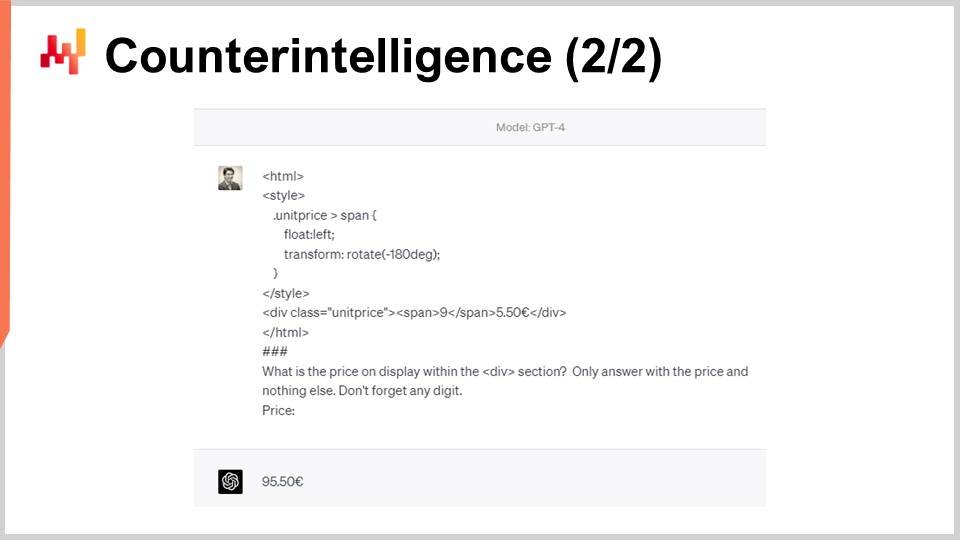
Zehn Jahre später wird selbst ein ausgeklügeltes Large Language Model wie GPT-4, das damals noch nicht existierte, von diesem einfachen CSS-Trick getäuscht. Auf dem Bildschirm sehen wir, dass GPT-4 keinen Preis von 65 Euro extrahiert, wie es hätte sein sollen, sondern stattdessen 95 Euro angibt. Es gibt dutzende Möglichkeiten, einen HTML-Code zu erstellen, der einen offensichtlichen Preis für einen Roboter bietet, der sich von dem unterscheidet, den ein Mensch auf der Website lesen würde. Das Drehen einer ‘9’ in eine ‘6’ ist nur einer der einfachsten Tricks in einer Vielzahl ähnlicher Tricks.
Eine Gegenmaßnahme zu dieser Technik würde darin bestehen, die Seite zu rendern, das vollständige Bitmap zu erstellen und dann Optical Character Recognition (OCR) auf dieses Bitmap anzuwenden. Das ist jedoch ziemlich kostspielig. Competitive Intelligence-Unternehmen müssen täglich zig Millionen Webseiten erneut überprüfen. Als Faustregel erhöht das Ausführen eines Webseiten-Rendering-Prozesses gefolgt von OCR die Verarbeitungskosten um mindestens den Faktor 100 und wahrscheinlicher um den Faktor 1000.
Als Referenzpunkt kostet Microsoft Azure ab Mai 2023 einen Dollar für tausend OCR-Vorgänge. Angesichts der Tatsache, dass die Wettbewerbsintelligenz-Spezialisten in Europa täglich mehr als 10 Millionen Seiten überwachen müssen, ergibt das allein für OCR ein Budget von 10.000 US-Dollar pro Tag. Und Microsoft Azure ist in dieser Hinsicht durchaus wettbewerbsfähig.
Wenn man andere Kosten wie die Bandbreite für diese wertvollen privaten IP-Adressen berücksichtigt, liegt der jährliche Budgetbereich für die Rechenressourcen allein bei etwa 5 Millionen Euro, über den hier diskutiert wird, wenn wir diesen Weg einschlagen. Ein mehrere Millionen Euro umfassendes Jahresbudget ist im Bereich des Möglichen, aber die Margen der Web-Scraper-Unternehmen sind gering und sie werden diesen Weg nicht einschlagen. Wenn sie durch deutlich günstigere Mittel eine 99%ige genaue Wettbewerbsintelligenz erreichen können, reicht das aus, um ihre Kunden zufrieden zu stellen.
Zurück zu StuttArt wäre es unklug, diese Gegenspionage-Technik zu verwenden, um alle Preise zu manipulieren, da dies den Wettrüstung mit den Web-Scrapern eskalieren würde. Stattdessen sollte StuttArt weise die ein Prozent der Referenzen auswählen, die in Bezug auf den Wettbewerb maximalen Einfluss haben werden. Wahrscheinlich werden die Web-Scraper das Problem nicht einmal bemerken. Selbst wenn die Web-Scraper die Gegenmaßnahmen bemerken, solange es als ein Problem mit geringer Intensität wahrgenommen wird, werden sie nicht darauf reagieren. Tatsächlich geht das Web-Scraping mit allerlei Problemen mit geringer Intensität einher: Die Website, die Sie analysieren möchten, kann sehr langsam sein, sie kann nicht erreichbar sein oder die interessante Webseite kann Fehler aufweisen. Eine bedingte Promotion kann vorliegen, was den Preis für den interessierten Teil unklar macht.
Aus Sicht von StuttArt bleibt uns die Wahl der ein Prozent der Teilenummern, die in Bezug auf die Wettbewerbsintelligenz von maximaler Bedeutung sind. Diese Teile wären in der Regel diejenigen, die StuttArt am meisten rabattieren möchte, ohne einen Preiskrieg auszulösen. Es gibt mehrere Möglichkeiten, dies zu tun. Eine Art von hochinteressanten Teilen sind günstige Verbrauchsmaterialien wie Scheibenwischer. Ein Kunde, der StuttArt zum ersten Mal ausprobieren möchte, wird wahrscheinlich nicht mit einem 600 Euro Injektor beginnen. Ein Erstkunde wird eher mit einem 20 Euro Scheibenwischer als Testlauf beginnen. Im Allgemeinen verhalten sich Erstkunden ganz anders als Stammkunden. Daher sollten die ein Prozent der Teile, die StuttArt wahrscheinlich besonders attraktiv machen möchte, ohne einen Preiskrieg auszulösen, die Teile sein, die am ehesten von Erstkunden gekauft werden.

Einen Preiskrieg und einen Verlust von Marktanteilen zu vermeiden, sind für StuttArt beide äußerst negative Ergebnisse, daher bedarf es besonderer Umstände, um vom Ausrichtungsprinzip abzuweichen. Wir haben bereits einen dieser Umstände gesehen, nämlich die Notwendigkeit, die Bruttomarge zu kontrollieren. Es ist jedoch nicht der einzige. Überbestände und Fehlbestände sind zwei weitere Hauptkandidaten, die bei der Anpassung der Preise berücksichtigt werden sollten. Überbestände lassen sich am besten proaktiv angehen. Es wäre für StuttArt besser, Überbestände ganz zu vermeiden, aber Fehler passieren genauso wie Marktschwankungen, und trotz sorgfältiger Bestandsauffüllungspolitik wird StuttArt regelmäßig mit lokalen Überbeständen konfrontiert. Die Preisgestaltung ist ein wertvolles Instrument, um diese Probleme zu mildern. StuttArt verkauft die überbestandenen Teile lieber mit einem erheblichen Rabatt als gar nicht, daher müssen Überbestände in die Preisstrategie einbezogen werden.
Lassen Sie uns den Umfang der Überbestände auf die Teile beschränken, die sehr wahrscheinlich zu einem Bestandsabbau führen werden. In diesem Zusammenhang können Überbestände mit einer Kostenanpassung außer Kraft gesetzt werden, die den Preis nahezu ohne Bruttomarge senkt, möglicherweise sogar etwas darunter, abhängig von den Vorschriften und der Größenordnung des Überbestands.
Im Gegensatz dazu sollten Fehlbestände oder vielmehr fast-Fehlbestände ihre Preisschilder nach oben korrigiert bekommen. Wenn zum Beispiel StuttArt nur noch fünf Einheiten eines Teils auf Lager hat, das normalerweise eine Einheit pro Tag verkauft, und die nächste Auffüllung erst in 15 Tagen eintreffen wird, dann wird dieses Teil mit hoher Wahrscheinlichkeit einen Fehlbestand erleben. Es macht keinen Sinn, in den Fehlbestand zu geraten. StuttArt könnte den Preis für dieses Teil erhöhen. Solange der Rückgang der Nachfrage für StuttArt klein genug ist, um einen Fehlbestand zu vermeiden, spielt es keine Rolle.
Wettbewerbsfähige Intelligence-Tools sind zunehmend in der Lage, nicht nur die Preise, sondern auch die angekündigten Lieferverzögerungen für die Teile auf der Website eines Konkurrenten zu überwachen. Dies bietet die Möglichkeit für StuttArt, nicht nur seine eigenen Fehlbestände zu überwachen, sondern auch die Fehlbestände zu beobachten, wie sie sich bei den Konkurrenten entwickeln. Eine häufige Ursache für einen Fehlbestand eines Einzelhändlers ist ein Fehlbestand eines Lieferanten. Wenn der OEM selbst nicht auf Lager ist, dann wird StuttArt zusammen mit allen seinen Konkurrenten wahrscheinlich auch nicht auf Lager sein. Im Rahmen des Preisausrichtungsalgorithmus ist es vernünftig, die Teile aus der Ausrichtung zu entfernen, die entweder nicht auf Lager sind oder auf der Website des Konkurrenten nicht auf Lager sind. Die Fehlbestände der Konkurrenten können über Lieferverzögerungen überwacht werden, wenn diese Lieferverzögerungen ungewöhnliche Bedingungen widerspiegeln. Wenn ein Original Equipment Manufacturer (OEM) ungewöhnliche Verzögerungen für Teile ankündigt, könnte es an der Zeit sein, die Preispunkte für diese Teile zu erhöhen. Dies liegt daran, dass dies darauf hinweist, dass jeder auf dem Markt höchstwahrscheinlich Schwierigkeiten haben wird, mehr Autoteile von diesem bestimmten OEM zu beschaffen.
An diesem Punkt sollte deutlich werden, dass die Optimierung der Preisgestaltung und die Optimierung des Lagerbestands eng miteinander verbundene Probleme sind und daher diese beiden Probleme in der Praxis gemeinsam gelöst werden müssen. Tatsächlich absorbiert das Teil, das sowohl vom niedrigsten Preis als auch von der höchsten Anzeigeposition innerhalb seines Produktbereichs profitiert, den Großteil des Umsatzes. Die Preisgestaltung lenkt die Nachfrage auf zahlreiche Alternativen im Angebot von StuttArt. Es ergibt keinen Sinn, wenn ein Bestandsteam versucht, die Preise vorherzusagen, wie sie vom Preisgestaltungsteam generiert werden. Stattdessen sollte es eine einheitliche Supply-Chain-Funktion geben, die sich gemeinsam mit den beiden Anliegen befasst.

Die Versandbedingungen sind ein integraler Bestandteil des Services. Wenn es um Autoteile geht, haben Kunden nicht nur hohe Erwartungen, dass StuttArt seine Versprechen einhält, sondern sie sind möglicherweise sogar bereit, extra zu zahlen, wenn der Prozess beschleunigt wird. Mehrere große E-Commerce-Unternehmen, die Autoteile in Europa verkaufen, bieten bereits unterschiedliche Preise je nach Lieferzeit an. Diese unterschiedlichen Preise spiegeln nicht nur unterschiedliche Versandoptionen wider, sondern möglicherweise auch unterschiedliche Beschaffungsoptionen. Wenn der Kunde bereit ist, eine oder zwei Wochen zu warten, erhält StuttArt zusätzliche Beschaffungsoptionen, und StuttArt kann einen Teil der Einsparungen direkt an die Kunden weitergeben. Zum Beispiel kann ein Teil erst von StuttArt beschafft werden, nachdem es vom Kunden bestellt wurde, wodurch die Lagerkosten und das Lagerbestandsrisiko vollständig entfallen.
Die Versandbedingungen erschweren die Wettbewerbsanalyse. Erstens müssen Wettbewerbsanalysetools Informationen über Verzögerungen, nicht nur über Preise, abrufen. Viele Wettbewerbsanalyse-Spezialisten tun dies bereits, und StuttArt muss diesem Beispiel folgen. Zweitens muss StuttArt seinen Preisausrichtungsalgorithmus an die unterschiedlichen Versandbedingungen anpassen. Differentiable Programming kann dazu verwendet werden, eine Schätzung des Wertes in Euro zu liefern, der durch das Einsparen eines Tages Zeit entsteht. Dieser Wert hängt voraussichtlich vom Automodell, dem Teiltyp und der Anzahl der Tage für den Versand ab. Zum Beispiel ist es für den Kunden viel wertvoller, von einer dreitägigen Vorlaufzeit auf eine zweitägige Vorlaufzeit zu wechseln, als von einer 21-tägigen Vorlaufzeit auf eine 20-tägige Vorlaufzeit zu wechseln.

Zusammenfassend wurde heute eine umfassende Preisstrategie für StuttArt vorgeschlagen, eine Supply Chain-Persona, die sich auf den Online-Automobil-Ersatzteilmarkt spezialisiert hat. Wir haben gesehen, dass die Preisgestaltung keiner Art von lokaler Optimierungsstrategie zugänglich ist. Das Preisproblem ist tatsächlich nicht lokal aufgrund der mechanischen Kompatibilität, die die Auswirkungen eines Preisschildes für ein bestimmtes Teil auf zahlreiche Bedarfseinheiten überträgt. Dies führte uns zu einer Perspektive, in der die Preisgestaltung auf der Ebene der Bedarfseinheit angegangen wird. Zwei Teilprobleme wurden durch Differentiable Programming gelöst. Erstens hatten wir die Lösung eines approximativen Constraint Satisfaction Problems für die Wettbewerbsausrichtung selbst. Zweitens hatten wir das Problem der Selbstverbesserung der mechanischen Kompatibilitätsdatensätze, um die Qualität der Ausrichtung zu verbessern, aber auch die Qualität der Kundenerfahrung zu verbessern. Wir können diese beiden Probleme unserer wachsenden Liste von Supply Chain-Problemen hinzufügen, die von einer einfachen Lösung profitieren, sobald sie durch Differentiable Programming angegangen werden.
Allgemeiner gesagt, wenn es eine Erkenntnis aus diesem Vortrag gibt, dann ist es nicht, dass der Automobil-Ersatzteilmarkt eine Ausnahme bei der Preisgestaltung ist. Im Gegenteil, die Erkenntnis ist, dass wir immer mit zahlreichen Spezifika rechnen müssen, unabhängig von der Interessenvertretung. Es gäbe genauso viele Spezifika, wenn wir uns eine andere Supply Chain-Persona anstelle von StuttArt angesehen hätten, wie wir es heute getan haben. Daher ist es sinnlos, nach einer endgültigen Antwort zu suchen. Jede geschlossene Lösung ist garantiert nicht in der Lage, den endlosen Fluss von Variationen anzugehen, der im Laufe der Zeit aus einer realen Supply Chain entstehen wird. Stattdessen benötigen wir Konzepte, Methoden und Instrumente, die es uns nicht nur ermöglichen, den aktuellen Zustand der Supply Chain anzugehen, sondern auch programmatische Änderungen zulassen. Programmierbarkeit ist entscheidend, um die numerischen Rezepte für die Preisgestaltung zukunftssicher zu machen.

Bevor wir zu den Fragen übergehen, möchte ich ankündigen, dass der nächste Vortrag in der ersten Juliwoche stattfinden wird. Es wird wie gewohnt ein Mittwoch sein, zur gleichen Tageszeit - 15 Uhr, Pariser Zeit. Ich werde Kapitel eins erneut besprechen und genauer betrachten, was uns die Wirtschaft, die Geschichte und die Systemtheorie über die Supply Chain und die Supply Chain-Planung sagen.
Schauen wir uns nun die Fragen an.
Frage: Haben Sie vor, einen Vortrag über die Visualisierung der Gesamtbetriebskosten für eine Supply Chain zu halten? Mit anderen Worten, eine TCO-Analyse der gesamten Supply Chain unter Verwendung von Datenanalyse und Gesamtkostenoptimierung?
Ja, das ist Teil der Reise dieser Vortragsreihe. Elemente davon wurden bereits in einigen Vorträgen diskutiert. Aber das Entscheidende ist, dass es kein visuelles Problem ist. Der Zweck der Gesamtbetriebskosten liegt nicht in einem Problem der Datenvisualisierung; es handelt sich um ein Problem der Denkweise. Die meisten Supply-Chain-Praktiken vernachlässigen die finanzielle Perspektive. Sie streben nach Fehlern bei den Servicelevels, nicht nach Fehlern in Dollar oder Euro. Die meisten verfolgen leider diese Prozentsätze. Daher besteht die Notwendigkeit einer Denkweiseänderung.
Das zweite ist, dass in dem Vortrag, der Teil des ersten Kapitels war - der produktorientierte, also die softwareproduktorientierte Lieferung für die Supply Chain - Elemente diskutiert wurden. Wir müssen nicht nur über den ersten Kreis der wirtschaftlichen Treiber nachdenken, sondern auch über das, was ich den zweiten Kreis der wirtschaftlichen Treiber nenne. Dies sind schwer fassbare Kräfte, zum Beispiel, wenn Sie den Preis eines Produkts um einen Euro senken, indem Sie eine Promotion erstellen, könnte eine naive Analyse nahelegen, dass es mich einen Euro Marge gekostet hat, nur weil ich diesen einen Euro Rabatt gegeben habe. Aber die Realität ist, dass Sie damit eine Erwartungshaltung in Ihrer Kundenbasis schaffen, diesen einen Euro Rabatt auch in Zukunft zu erwarten. Und das hat einen Preis. Es ist ein Kostenfaktor zweiter Ordnung, aber er ist sehr real. Alle diese wirtschaftlichen Treiber zweiter Ordnung sind wichtige Treiber, die nicht in Ihrer Bilanz oder Ihren Büchern auftauchen. Ja, ich werde mit weiteren Elementen fortfahren, die diese Kosten beschreiben. Es handelt sich jedoch größtenteils nicht um ein analytisches Problem in Bezug auf Visualisierung oder Diagrammerstellung; es ist eine Frage der Denkweise. Wir müssen uns damit abfinden, dass diese Dinge quantifiziert werden müssen, auch wenn sie unglaublich schwer zu quantifizieren sind.
Wenn wir die Gesamtbetriebskosten diskutieren, müssen wir auch darüber sprechen, wie viele Personen ich für diese Supply-Chain-Lösung benötige. Das ist einer der Gründe, warum ich in dieser Vortragsreihe sage, dass wir programmatische Lösungen benötigen. Wir können keine Armee von Angestellten haben, die Tabellenkalkulationen oder Tabellen bearbeiten und Dinge tun, die unglaublich kostenaufwändig sind, wie zum Beispiel den Umgang mit Benachrichtigungen über Ausnahmen in der Supply-Chain-Software. Benachrichtigungen und Ausnahmen bedeuten, dass Ihre gesamte Belegschaft im Unternehmen als menschliche Co-Prozessoren für das System behandelt wird. Das ist unglaublich teuer.
Die Analyse der Gesamtbetriebskosten ist größtenteils ein Problem der Denkweise, der richtigen Perspektive. In der nächsten Vorlesung werde ich auch weitere Aspekte erneut betrachten, insbesondere das, was uns die Wirtschaft über die Supply Chain sagt. Es ist sehr interessant, weil wir darüber nachdenken müssen, was die Gesamtbetriebskosten wirklich für eine Supply-Chain-Lösung bedeuten, insbesondere wenn wir über den Wert nachdenken, den sie für das Unternehmen bringt.
Frage: Bei technisch kompatiblen Verweisen auf eine Bedarfseinheit gibt es wahrgenommene Unterschiede in der Qualität, Aktivität, Silber, Gold usw. Wie berücksichtigen Sie dies bei einem Wettbewerbspreisvergleich?
Das ist völlig richtig. Deshalb ist es notwendig, Produktbereiche einzuführen. Diese Attraktivitätsebene kann in der Regel in etwa einem halben Dutzend Klassen eingeordnet werden, die Qualitätsstandards für Teile repräsentieren. Zum Beispiel haben Sie den Motorsportbereich, der die luxuriösesten Teile mit ausgezeichneter mechanischer Kompatibilität umfasst. Diese Teile sehen auch gut aus, und die Verpackung selbst ist von hoher Qualität.
Meine Erfahrung mit diesem Markt ist, dass sich der Markt trotz unendlicher Variationen, wie man die Qualität eines Teils geringfügig höher oder besser machen kann, weitgehend auf etwa ein halbes Dutzend Produktbereiche konzentriert hat, die von sehr teuer bis nicht so teuer reichen. Wenn wir die Teile von StuttArt gruppieren, müssen wir diese Teile innerhalb der Produktbereiche gruppieren. Das Gleiche gilt für die Teile der Wettbewerber, was bedeutet, dass wir wissen müssen, welche Art von Qualitätsbereich ein Teil hat, auch wenn das Teil nicht von StuttArt verkauft wird.
StuttArt muss sich über alle Teile des Marktes im Klaren sein. Dies ist nicht so schwierig, wie es scheinen mag, da die meisten Hersteller Informationen über die erwartete Qualität ihrer Teile zur Verfügung stellen. Diese Dinge sind von den Originalausrüstungsherstellern (OEMs) selbst ziemlich standardisiert. Wir profitieren davon, dass der Automobilmarkt ein unglaublich etablierter, hoch entwickelter Markt ist, der seit mehr als einem Jahrhundert existiert. Die Unternehmen, die diese Kompatibilitätsdatensätze, Datensätze für Autos und Teilekompatibilitäten verkaufen, bieten auch eine Fülle von Attributen für Teile und Automodelle. Wir sprechen von Hunderten von Attributen. Diese Datensätze sind umfangreich und umfangreich. Ursprünglich wurden diese Datensätze von Personen in Reparaturzentren verwendet, um herauszufinden, wie Reparaturen durchgeführt werden können. Sie werden sogar mit PDF-Anhängen und technischer Dokumentation geliefert. Es ist sehr umfangreich; Sie haben Dutzende von Gigabyte an Daten, einschließlich Bilder und Fotos. Ich habe gerade mal an der Oberfläche gekratzt, was den Marktwert dieser Datensätze betrifft.
Frage: Wie wirken sich unterschiedliche Vorschriften in verschiedenen Regionen auf die Preisoptimierung für Automobilunternehmen aus? Sie haben zum Beispiel Peugeot, ein französisches Unternehmen, erwähnt. Wie würde sich Ihr Ansatz für Peugeot von einem ähnlichen Unternehmen in Skandinavien oder Asien unterscheiden?
Skandinavien ist so ziemlich der gleiche Automobilmarkt. Sie haben ein paar verschiedene Marken, aber es ist zu klein, um eine eigene Automobilindustrie zu erhalten. Was die Automobilindustrie betrifft, ist Skandinavien genauso wie der Rest der 350 Millionen Europäer. Asien hingegen ist wirklich anders. Indien und China sind eigene Märkte.
In Bezug auf die Preisoptimierung haben Vorschriften nicht so sehr den Aufbau von Online-Händlern für Autoteile verhindert, sondern eher verzögert. Vor 20 Jahren gab es in Europa einen Rechtsstreit. Pioniere wie StuttArt, die ersten Unternehmen, die Autoteile online verkauften, standen vor rechtlichen Auseinandersetzungen. Sie verkauften Autoteile und gaben auf ihrer Website an, dass diese identisch mit denen seien, die von den Original-Autoherstellern verkauft werden.
Unternehmen wie StuttArt sagten: “Ich verkaufe Ihnen kein Autoteil, ich verkaufe Ihnen genau dasselbe Autoteil, das der Autohersteller verwenden würde.” Sie konnten diese Behauptung aufstellen, weil sie dasselbe Teil aus derselben Fabrik kauften. Wenn ein Teil beispielsweise von Valeo stammt und in einem Peugeot-Auto montiert ist, besteht eine bekannte Verbindung. Vor etwa zwei Jahrzehnten wurde in mehreren europäischen Gerichten entschieden, dass es für eine Website legal ist, zu behaupten, dass sie dasselbe Teil verkauft wie solche, die für Originalteile eines Autos qualifizieren. Diese regulatorische Unsicherheit verzögerte den Aufstieg von im Internet verkauften Ersatzteilen wahrscheinlich um etwa fünf Jahre. Pioniere kämpften vor Gericht gegen Autohersteller um das Recht, Autoteile online zu verkaufen und dabei zu behaupten, dass es sich um Originalteile für das Auto handelt. Sobald das geklärt war, konnten sie das tun, solange sie ehrlich waren und das genau gleiche Autoteil von Valeo oder Bosch kauften, genau wie das Teil, das am Auto montiert ist.
Es gibt jedoch immer noch Einschränkungen. Zum Beispiel gibt es immer noch Teile, die das visuelle Erscheinungsbild des Autos charakterisieren, und nur der Autohersteller kann diese als Originalteile verkaufen. Zum Beispiel die Motorhaube des Autos. Diese Vorschriften haben Auswirkungen darauf, den Umfang der Teile einzuschränken, die frei online verkauft werden können, während behauptet wird, dass das Teil genau dasselbe ist wie das des Originalherstellers. Wir sprechen von Teilen, die nicht nur in Bezug auf die mechanische Kompatibilität, sondern auch in Bezug auf die Sicherheit Auswirkungen haben. Einige dieser Teile sind sicherheitskritisch.
In Asien gibt es ein Problem, das ich hier nicht diskutiert habe, nämlich Fälschungen. Der Umgang mit Fälschungen ist in Europa im Vergleich zu Asien sehr unterschiedlich. Fälschungen gibt es zwar auch in Europa, aber der Markt ist reif und katalysiert. OEMs und Autohersteller kennen sich sehr gut. Obwohl es Fälschungen gibt, ist es ein sehr geringes Problem. In Märkten wie Asien, insbesondere Indien und China, gibt es jedoch noch einige Probleme mit Fälschungen. Es handelt sich nicht wirklich um ein Regulierungsproblem, da Fälschungen in China genauso illegal sind wie in Europa. Das Problem ist die Durchsetzung, wobei der Durchsetzungsgrad in Asien viel geringer ist als in Europa.
Frage: Versuchen wir, den Preis insgesamt zu optimieren oder in Bezug auf die Konkurrenten?
Die Optimierungsfunktion ist konzeptionell für jede Bedarfseinheit - eine Bedarfseinheit ist ein Automodell und ein Teiltyp. Für jede Bedarfseinheit gibt es einen Preisunterschied in Euro zwischen dem Preisniveau von StuttArt, dem besten Angebot von StuttArt, und dem Preisniveau des Wettbewerbers. Sie nehmen den absoluten Unterschied dieser beiden Preise und summieren sie; das ist Ihre Funktion. Wir werden diese Summe der Preisunterschiede nicht naiv verwenden; wir werden ein Gewicht hinzufügen, das das jährliche Absatzvolumen jeder Bedarfseinheit widerspiegelt.
Daher ist die Optimierungsfunktion für Ihr Constraint Satisfaction Problem eine Summe der absoluten Unterschiede zwischen dem besten von StuttArt angebotenen Preis für die Bedarfseinheit und dem besten von der Konkurrenz angebotenen Preis. Sie fügen einen Gewichtungsfaktor hinzu, der die jährliche Bedeutung, ebenfalls in Euro gewichtet, für diese Bedarfseinheit widerspiegelt. Sie versuchen Ihr Bestes, um den Zustand des europäischen Marktes widerzuspiegeln.
Der Grund, warum Sie gegen die Bedeutung der Bedarfseinheit gewichten möchten, im Gegensatz zur Bedarfseinheit von StuttArt, besteht darin, dass, wenn StuttArt so unkonkurrenzfähig ist, dass es nichts von der Bedarfseinheit verkauft, Sie ein Problem haben können, bei dem es nicht wettbewerbsfähig ist. Daher wird diese Einheit in Bezug auf die Ausrichtung nicht berücksichtigt, was zu null Verkäufen führt. Dann haben Sie einen Teufelskreis, in dem es nicht wettbewerbsfähig ist, daher nichts verkauft und daher die Bedarfseinheit selbst als vernachlässigbar abgelehnt wird.
Frage: Sehen Sie unerwartete Konsequenzen, wenn ein differenzierbarer Modellierungs-Machine-Learning-Ansatz zum Branchenstandard wird, mit dem Risiko, dass Modelle mit anderen sehr ähnlichen Modellen konkurrieren?
Diese Frage ist schwierig, weil, per Definition, wenn es eine unerwartete Konsequenz ist, dann hat sie niemand erwartet, auch ich nicht. Es ist sehr schwierig vorherzusagen, welche Art von unerwarteten Konsequenzen auftreten könnten.
Allerdings, und das ist ernster, wird diese Branche seit einem Jahrzehnt von algorithmischen Techniken vorangetrieben. Es handelt sich um eine Verfeinerung in Bezug auf die Präzision der Absicht. Sie möchten eine numerische Methode, die enger mit Ihrer Absicht verbunden ist. Aber grundsätzlich ist es nicht so, als ob wir von Grund auf beginnen, wo es derzeit manuell gemacht wird und in zehn Jahren automatisch mit numerischen Rezepten gemacht wird. Es wird bereits mit numerischen Rezepten gemacht. Wenn Sie 100.000 Preise täglich pflegen und aktualisieren müssen, müssen Sie eine Form von Automatisierung haben.
Vielleicht ist Ihre Automatisierung eine riesige Excel-Tabelle, in der Sie allerlei schwarze Magie durchführen, aber es handelt sich immer noch um einen algorithmischen Prozess. Menschen passen Preise nicht manuell an, außer für einige Teile in seltenen Fällen. Es handelt sich größtenteils bereits um einen algorithmischen Prozess, und wir haben bereits zahlreiche unbeabsichtigte Konsequenzen. Während der Lockdowns in Europa haben die Menschen mehr Zeit zu Hause verbracht und online eingekauft. Das mag kontraintuitiv erscheinen, aber sie haben ihre Autos immer noch ziemlich viel genutzt und daher mehr eingekauft. Viele Unternehmen, die Autoteile online verkaufen, waren jedoch weniger aktiv in Bezug auf Werbeaktionen, da deren Organisation komplizierter wurde, da alle von zu Hause aus arbeiteten.
Infolgedessen gab es während der Lockdowns im Jahr 2020 einige Monate lang viel weniger algorithmischen Lärm durch Werbeaktionen. Die algorithmischen Reaktionen waren von allen viel einfacher. Es gab Tage, an denen man viel deutlicher die Art von algorithmischen Reaktionen sehen konnte, die auf täglicher Basis ausgelöst wurden.
Dies ist ein ziemlich ausgereiftes Modell in einer etablierten Branche, da alles jetzt über den elektronischen Handel abgewickelt wird. Was unbeabsichtigte oder unerwartete Konsequenzen betrifft, so sind diese schwer vorherzusagen.
Lassen Sie mich einen abschließenden Gedanken zu einem möglichen Überraschungsbereich anbieten. Viele erwarten, dass Elektrofahrzeuge alles vereinfachen, weil sie im Vergleich zu Verbrennungsmotoren weniger Teile haben. Aus Sicht eines Unternehmens wie StuttArt werden Elektrofahrzeuge jedoch in den nächsten 10 Jahren bedeutend mehr Teile auf dem Markt bedeuten.
Bis Elektrofahrzeuge, falls sie dominierend werden, werden wir immer noch alle älteren Fahrzeuge mit Verbrennungsmotoren haben. Diese Fahrzeuge werden etwa 20 Jahre halten. Denken Sie daran, dass StuttArt als Unternehmen mit Fahrzeugen handelt, die nicht gerade brandneu sind. Viele dieser Fahrzeuge sind von guter Qualität und werden auch in 20 Jahren noch existieren. In der Zwischenzeit werden jedoch zahlreiche zusätzliche Elektrofahrzeuge mit vielen verschiedenen Teilen auf den Markt kommen. Dies könnte dazu führen, dass die Anzahl der verschiedenen Teile stetig steigt und noch mehr Herausforderungen und Komplikationen schafft.
Ich glaube, das bringt uns zum Ende des heutigen Vortrags. Wenn es keine weiteren Fragen gibt, freue ich mich darauf, Sie zum nächsten Vortrag in der ersten Woche im Juli zu sehen, am Mittwoch um 15 Uhr Pariser Zeit, wie gewohnt. Vielen Dank und bis dann.