00:00 Introducción
02:49 Demanda, precio y beneficio
09:35 Precios competitivos
15:23 Deseos vs necesidades
20:09 La historia hasta ahora
23:36 Direcciones para hoy
25:17 La unidad de necesidad
31:03 Autos y partes (resumen)
33:41 Inteligencia competitiva
36:03 Resolviendo la alineación (1/4)
39:26 Resolviendo la alineación (2/4)
43:07 Resolviendo la alineación (3/4)
46:38 Resolviendo la alineación (4/4)
56:21 Gamas de productos
59:43 Partes sin restricciones
01:02:44 Controlando el margen
01:06:54 Rangos de exhibición
01:08:29 Ajuste fino de los pesos
01:12:45 Ajuste fino de compatibilidades (1/2)
01:19:14 Ajuste fino de compatibilidades (2/2)
01:30:41 Contrainteligencia (1/2)
01:35:25 Contrainteligencia (2/2)
01:40:49 Exceso de stock y faltante de stock
01:45:45 Condiciones de envío
01:47:58 Conclusión
01:50:33 6.2 Optimización de precios para el aftermarket automotriz - ¿Preguntas?
Descripción
El equilibrio entre oferta y demanda depende en gran medida de los precios. Por lo tanto, la optimización de precios pertenece al ámbito de supply chain, al menos en gran medida. Presentaremos una serie de técnicas para optimizar los precios de una empresa ficticia en el aftermarket automotriz. A través de este ejemplo, veremos el peligro asociado con líneas abstractas de razonamiento que no consiguen ver el contexto adecuado. Saber qué se debe optimizar es más importante que la letra pequeña de la optimización en sí.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré la optimización de precios para el aftermarket automotriz. La fijación de precios es un aspecto fundamental de supply chain. De hecho, uno no puede ponderar la adecuación de un determinado volumen de oferta o de inventario sin considerar la cuestión de los precios, ya que éstos impactan significativamente la demanda. Sin embargo, la mayoría de los libros de supply chain, y en consecuencia, la mayoría del software de supply chain, ignoran completamente la fijación de precios. Incluso cuando se discute o modela la fijación de precios, generalmente se hace de maneras ingenuas que a menudo malinterpretan la situación.
La fijación de precios es un proceso altamente dependiente del dominio. Los precios son, ante todo, un mensaje enviado por una empresa al mercado en general - a clientes, pero también a proveedores y competidores. La letra pequeña del análisis de precios depende en gran medida de la empresa en cuestión. Aunque abordar la fijación de precios en términos generales, como lo hacen los microeconomistas, puede resultar intelectualmente atractivo, también puede ser erróneo. Esos enfoques pueden no ser lo suficientemente precisos para apoyar la producción de estrategias de precios de nivel profesional.
Esta conferencia se centra en la optimización de precios para una empresa del aftermarket automotriz. Repasaremos Stuttgart, una empresa ficticia presentada en el tercer capítulo de esta serie de conferencias. Nos enfocaremos exclusivamente en el segmento de venta online de Stuttgart que distribuye repuestos para automóviles. El objetivo de esta conferencia es entender en qué consiste la fijación de precios una vez que dejamos de lado las trivialidades y cómo abordar la fijación de precios con una mentalidad práctica. Aunque consideremos un vertical estrecho - repuestos para automóviles en el aftermarket automotriz - la forma de pensar, la mentalidad y la actitud adoptadas en esta conferencia al perseguir estrategias de precios superiores serían esencialmente las mismas al considerar verticales completamente diferentes.
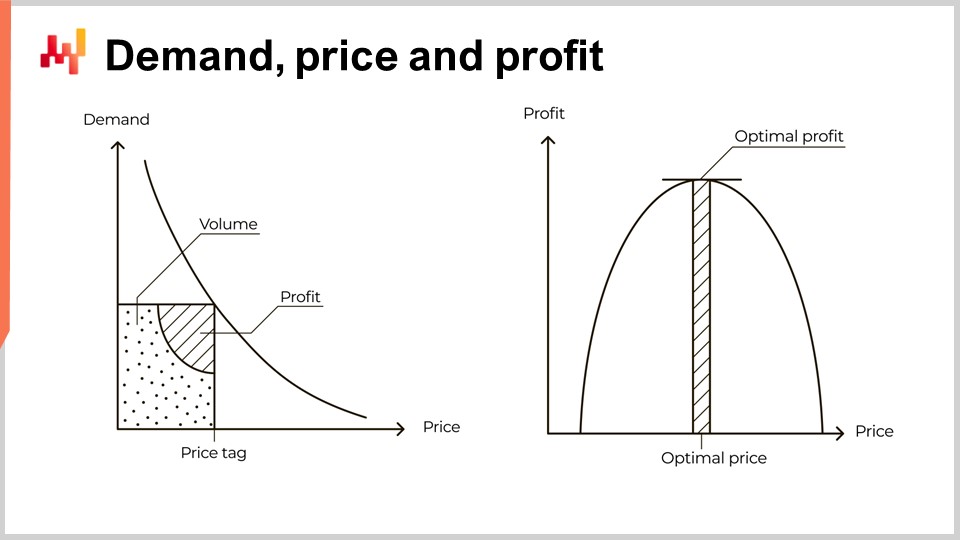
La demanda disminuye a medida que aumenta el precio. Este es un patrón económico universal. La mera existencia de productos que contradigan este patrón resulta, en el mejor de los casos, esquiva. A estos productos se les llama bienes de Veblen. Sin embargo, en 15 años en Lokad, incluso al tratar con marcas de lujo, nunca he tenido acceso a ninguna prueba tangible de que dichos productos existan realmente. Este patrón universal se ilustra con la curva a la izquierda de la pantalla, comúnmente llamada curva de demanda. Cuando un mercado se asienta en un precio, por ejemplo, el precio de un repuesto para automóvil, este mercado genera cierto volumen de demanda y, con suerte, también cierto volumen de beneficio para los actores que satisfacen esa demanda.
En lo que respecta a los repuestos para automóviles, estas piezas definitivamente no son bienes de Veblen. La demanda disminuye a medida que aumenta el precio. Sin embargo, dado que las personas no tienen muchas opciones al comprar repuestos de automóvil, al menos si desean seguir conduciendo sus coches, se puede esperar que la demanda sea relativamente inelástica. Un punto de precio más alto o más bajo para tus pastillas de freno realmente no altera tu decisión de comprarlas nuevas. De hecho, la mayoría de las personas preferirían comprar pastillas de freno nuevas, incluso si tienen que pagar el doble del precio habitual, que dejar de usar su vehículo por completo.
Para Stuttgart, identificar la mejor etiqueta de precio para cada pieza es fundamental por una miríada de razones. Exploremos las dos más evidentes. Primero, Stuttgart quiere maximizar sus beneficios, lo cual no es trivial ya que no solo la demanda varía con el precio, sino que el costo también varía con el volumen. Stuttgart debe ser capaz de satisfacer la demanda que generará en el futuro, lo cual es aún más complicado, ya que el inventario debe asegurarse con días de anticipación, o incluso semanas, debido a las limitaciones de tiempo de entrega.
Basándose en esta exposición limitada, algunos libros de texto, e incluso algunos softwares empresariales, proceden con la curva ilustrada a la derecha. Esta curva ilustra conceptualmente el volumen esperado de beneficio que se puede anticipar para cualquier etiqueta de precio. Dado que la demanda disminuye al aumentar el precio, y el costo por unidad disminuye al aumentar el volumen, esta curva debería exhibir un punto óptimo de beneficio que maximice el beneficio. Una vez identificado este punto óptimo, ajustar el suministro de inventario se presenta como una cuestión sencilla de orquestación. De hecho, el punto óptimo proporciona no solo una etiqueta de precio, sino también un volumen de demanda.
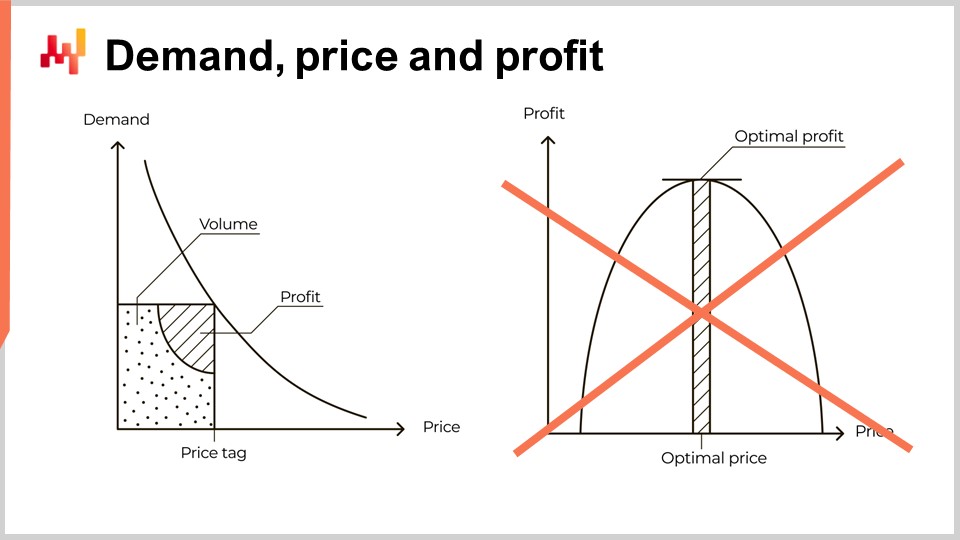
Sin embargo, esta perspectiva está profundamente equivocada. El problema no tiene nada que ver con la dificultad de cuantificar la elasticidad. Mi propuesta no es que la curva de la izquierda sea incorrecta; es fundamentalmente correcta. Lo que sostengo es que el salto desde la curva de la izquierda a la curva de la derecha es incorrecto. De hecho, este salto es tan asombrosamente erróneo que sirve como una especie de prueba de fuego. Cualquier proveedor de software o libro de texto sobre fijación de precios que presente la fijación de precios de esta manera demuestra un peligroso grado de analfabetismo económico, especialmente si presentan la evaluación de la elasticidad como el desafío central asociado con esta perspectiva. Esto ni remotamente se acerca a ser la realidad. Confiar tu supply chain a un proveedor o experto de este tipo invita al dolor y a la miseria. Si hay algo que tu supply chain no necesita, es una interpretación errónea de una microeconomía mal entendida a gran escala.
En esta serie de conferencias, este es otro ejemplo de racionalismo ingenuo o cientificismo, que ha demostrado una y otra vez ser una amenaza significativa para modern supply chains. El razonamiento económico abstracto es poderoso porque abarca una asombrosa gama de situaciones. Sin embargo, el razonamiento abstracto también es susceptible a interpretaciones groseramente erróneas. Se pueden producir grandes errores intelectuales que no son evidentes de inmediato cuando se piensa en términos muy generales.
Para entender por qué el salto desde la curva de la izquierda a la curva de la derecha es incorrecto, debemos analizar más de cerca lo que realmente sucede en una supply chain del mundo real. Esta conferencia se centra en los repuestos para automóviles. Reexaminarémos la fijación de precios desde el punto de vista de Stuttgart, una empresa ficticia de supply chain presentada en el tercer capítulo de esta serie de conferencias. No revisaremos los detalles de esta empresa. Si aún no has visto la conferencia 3.4, te invito a hacerlo después de esta conferencia.
Hoy, estamos analizando el segmento de venta online de Stuttgart, una división de e-commerce que vende repuestos para automóviles. Estamos explorando las formas más apropiadas para que Stuttgart determine sus precios y los revise en cualquier momento. Esta tarea debe realizarse para cada pieza vendida por Stuttgart.

Stuttgart no está solo en este mercado. En cada país europeo donde opera Stuttgart, hay media docena de competidores notables. Esta corta lista de empresas, incluida Stuttgart, representa la mayoría de la cuota de mercado online para repuestos de automóvil. Mientras que Stuttgart vende exclusivamente algunas piezas, para la mayoría de las piezas vendidas, al menos hay un competidor notable que vende exactamente la misma pieza. Este hecho tiene implicaciones significativas para la optimización de precios de Stuttgart.
Consideremos lo que ocurre si, para una determinada pieza, Stuttgart decide poner la etiqueta de precio de dicha pieza un euro por debajo de la etiqueta de precio ofrecida por un competidor que vende la misma pieza. Concebiblemente, esto hará que Stuttgart sea más competitiva y ayude a capturar cuota de mercado. Pero no tan rápido. El competidor monitorea todos los precios establecidos por Stuttgart. De hecho, el aftermarket automotriz es un mercado altamente competitivo. Todos cuentan con herramientas de inteligencia competitiva. Stuttgart recopila diariamente todos los precios de sus competidores notables, y los competidores hacen lo mismo. Así, si Stuttgart decide poner la etiqueta de precio de una pieza un euro por debajo de la etiqueta de precio ofrecida por un competidor, es seguro asumir que en uno o dos días, el competidor habrá bajado su etiqueta de precio en represalia, anulando el movimiento de precios de Stuttgart.
Aunque Stuttgart pueda ser una empresa ficticia, este comportamiento competitivo descrito aquí no es ficticio en absoluto en el aftermarket automotriz. Los competidores alinean agresivamente sus precios. Si Stuttgart intenta bajar sus precios de manera repetitiva, conducirá a una guerra de precios algorítmica, dejando a ambas empresas con poco o ningún margen al final de la contienda.
Consideremos lo que ocurre si, para una determinada pieza, Stuttgart decide poner la etiqueta de precio de dicha pieza un euro por encima de la etiqueta de precio ofrecida por un competidor. Suponiendo que todo lo demás se mantenga igual, salvo la etiqueta de precio, Stuttgart simplemente deja de ser competitiva. Así, aunque la base de clientes de Stuttgart puede que no se traslade inmediatamente al competidor (ya que podrían ni siquiera ser conscientes de la diferencia de precio o podrían permanecer leales a Stuttgart), con el tiempo, la cuota de mercado de Stuttgart se verá garantizada a disminuir.
Existen sitios web de comparación de precios disponibles en Europa para repuestos de automóvil. Aunque los clientes no comparan precios cada vez que necesitan una nueva pieza para su coche, la mayoría de los clientes revisará sus opciones de vez en cuando. No es una solución viable para Stuttgart ser invariablemente descubierta como la distribuidora más cara.
Así, hemos visto que Stuttgart no puede tener una etiqueta de precio por debajo de la competencia, ya que ello desencadena una guerra de precios. Por el contrario, Stuttgart no puede tener una etiqueta de precio por encima de la competencia, ya que garantiza la erosión de su cuota de mercado con el tiempo. La única opción que le queda a Stuttgart es buscar una alineación de precios. Esto no es una afirmación teórica: la alineación de precios es el principal impulsor para las empresas de e-commerce reales que venden repuestos de automóvil en Europa.
La atractiva curva de beneficio que introdujimos previamente, en la que supuestamente las empresas podían elegir el beneficio óptimo, es en gran medida totalmente falsa. Stuttgart ni siquiera tiene opción en lo que respecta a sus precios. En gran medida, a menos que exista algún tipo de ingrediente secreto, la alineación de precios es la única opción para Stuttgart.
Los mercados libres son una bestia extraña, como dijo Engels en su correspondencia de 1819: “La voluntad individual se ve obstaculizada por la de todos los demás, y lo que surge es algo que nadie quiso.” Veremos a continuación que Stuttgart sí conserva cierto margen residual para fijar sus precios. Sin embargo, la proposición principal se mantiene: la optimización de precios para Stuttgart es, ante todo, un problema fuertemente restringido, que no tiene nada en común con una perspectiva ingenua de maximización impulsada por una curva de demanda.
La elasticidad-precio de la demanda es un concepto que tiene sentido para un mercado en su conjunto, pero generalmente no tanto para algo tan localizado como un número de pieza.

La idea de que la fijación de precios puede abordarse como un simple problema de maximización de beneficios aprovechando la curva de demanda es falsa —o al menos, lo es en el caso de Stuttgart.
De hecho, se podría argumentar que Stuttgart pertenece a un mercado de necesidades, y la perspectiva de las curvas de beneficio aún funcionaría si estuviéramos considerando un mercado de deseos. En marketing, es una distinción clásica separar los mercados de deseos de los mercados de necesidades. Un mercado de deseos se caracteriza típicamente por ofertas en las que los clientes pueden abstenerse de consumir sin sufrir consecuencias negativas. En los mercados de deseos, las ofertas exitosas tienden a estar fuertemente ligadas a la marca del proveedor, y la marca en sí es el motor que genera la demanda en primer lugar. Por ejemplo, la moda es el arquetipo de los mercados de deseos. Si deseas un bolso de Louis Vuitton, entonces ese bolso solo se puede comprar en Louis Vuitton. Aunque hay cientos de proveedores que venden bolsos funcionalmente equivalentes, no serán bolsos de Louis Vuitton. Si decides no comprar un bolso de Louis Vuitton, entonces no te ocurrirá nada terrible.
Un mercado de necesidades se caracteriza típicamente por ofertas donde los clientes no pueden abstenerse de su consumo sin sufrir malas consecuencias. En los mercados de necesidades, las marcas no son motores de demanda; son más como motores de elección. Las marcas guían a los clientes a elegir de quién consumir una vez que se presenta la necesidad de consumo. Por ejemplo, la comida y las necesidades básicas son el arquetipo de los mercados de necesidades. Aunque las piezas de automóvil no son estrictamente necesarias para sobrevivir, muchas personas dependen de un vehículo para ganar dinero, y por lo tanto, no pueden optar de manera realista por no mantener adecuadamente su vehículo, ya que el costo para ellos de la falta de mantenimiento superaría con creces el costo del mantenimiento en sí.
Aunque el mercado de posventa automotriz está firmemente asentado en el mercado de necesidades, existen matices. Existen componentes como las tapas de rueda que son más deseos que necesidades. Más generalmente, todos los accesorios son más deseos que necesidades. Sin embargo, para Stuttgart, las necesidades impulsan la gran mayoría de la demanda.
La crítica que propongo aquí contra la curva de beneficios para la fijación de precios se generaliza a casi todas las situaciones en los mercados de necesidades. Stuttgart no es un caso atípico en estar severamente restringido en precio por sus competidores; esta situación es casi ubicua para los mercados de necesidades. Este argumento no refuta la viabilidad de la curva de beneficios cuando se consideran los mercados de deseos.
De hecho, se podría contrargumentar que en un mercado de deseos, si el vendedor tiene el monopolio sobre su propia marca, entonces este vendedor debería ser libre de elegir el precio que maximice su beneficio, llevándonos de nuevo a la perspectiva de la curva de beneficios para la fijación de precios. Una vez más, este contraargumento demuestra los peligros del razonamiento económico abstracto en la supply chain.
En un mercado de deseos, la perspectiva de la curva de beneficios también es incorrecta, aunque por un conjunto completamente diferente de razones. La letra pequeña de esta demostración está fuera del alcance de la presente conferencia, ya que requeriría otra conferencia por sí sola. Sin embargo, como ejercicio dejado para la audiencia, simplemente sugiero echar un vistazo más de cerca a la lista de bolsos y sus precios exhibidos en el sitio web de ecommerce de Louis Vuitton. La razón por la que la perspectiva de la curva de beneficios es inapropiada debería hacerse evidente por sí misma. Si no, bueno, lo más probable es que revisitemos este caso en una conferencia posterior.
Esta serie de conferencias está destinada, entre otras cosas, como material de capacitación para los Supply Chain Scientists en Lokad. Sin embargo, también espero que estas conferencias puedan ser de interés para un público mucho más amplio de profesionales de la supply chain. Estoy tratando de mantener estas conferencias algo desacopladas, pero utilizaré algunos conceptos técnicos que se han introducido en las conferencias anteriores. No pasaré demasiado tiempo reintroduciendo estos conceptos. Si no has visto las conferencias anteriores, no dudes en echarles un vistazo después.
En el primer capítulo de esta serie, exploramos por qué las supply chains deben volverse programáticas. Es altamente deseable poner en producción una receta numérica debido a la complejidad cada vez mayor de las supply chains. La automatización es más apremiante que nunca y existe un imperativo financiero para hacer de la práctica de la supply chain una empresa capitalista.
En el segundo capítulo, dedicamos tiempo a las metodologías. Las supply chains son sistemas competitivos y esta combinación derrota a las metodologías ingenuas. Vimos que esta combinación también vence a los modelos que malinterpretan o caracterizan erróneamente la microeconomía.
El tercer capítulo examinó los problemas encontrados en las supply chains, dejando de lado las soluciones. Introdujimos a Stuttgart como una de las personas de la supply chain. Este capítulo intentó caracterizar las clases de problemas de toma de decisiones que deben resolverse y mostró que perspectivas simplistas, como elegir la cantidad de stock correcta, no se ajustan a situaciones del mundo real. Invariablemente, existe una profundidad en la forma de las decisiones que hay que tomar.
El capítulo cuatro examinó los elementos que se requieren para comprender las prácticas modernas de la supply chain, donde los elementos de software son omnipresentes. Estos elementos son fundamentales para entender el contexto más amplio en el que opera la supply chain digital.
Los capítulos cinco y seis están dedicados, respectivamente, a la modelación predictiva y a la toma de decisiones. Estos capítulos recopilan técnicas que funcionan bien en manos de los Supply Chain Scientists hoy en día. El sexto capítulo se centra en la fijación de precios, un tipo de decisión que hay que tomar entre muchas otras.
Finalmente, el séptimo capítulo está dedicado a la ejecución de una iniciativa de Supply Chain Quantitativa y abarca la perspectiva organizacional.

La conferencia de hoy se dividirá en dos amplios segmentos. Primero, discutiremos cómo abordar la alineación competitiva de precios para Stuttgart. Alinear los precios con los de los competidores debe abordarse desde la perspectiva del cliente debido a la estructura única del mercado de repuestos de automóviles. Aunque la alineación competitiva es sumamente compleja, se beneficia de una solución relativamente sencilla que abordaremos en detalle.
En segundo lugar, aunque la alineación competitiva es la fuerza dominante, no es la única. Stuttgart puede necesitar o querer desviarse selectivamente de esta alineación. Sin embargo, los beneficios de estas desviaciones deben superar los riesgos. La calidad de la alineación depende de la calidad de los insumos utilizados para construirla, por lo que presentaremos una técnica de aprendizaje auto-supervisado para refinar el gráfico de compatibilidades mecánicas.
Finalmente, abordaremos una breve serie de inquietudes adyacentes a la fijación de precios. Estas inquietudes pueden no estar estrictamente relacionadas con los precios, pero en la práctica es mejor tratarlas conjuntamente con los precios.

Stuttgart necesita poner una etiqueta de precio en cada una de las piezas que vende, pero esto no implica que el análisis de precios deba realizarse principalmente a nivel de número de pieza. La fijación de precios es, ante todo, una forma de comunicarse con los clientes.
Tomemos un momento para considerar cómo perciben los clientes los precios ofrecidos por Stuttgart. Como veremos, la aparentemente sutil distinción que existe entre la etiqueta de precio y la percepción de la etiqueta de precio, de hecho, no es sutil en absoluto.
Cuando un cliente comienza a buscar una nueva pieza de automóvil, generalmente una pieza consumible como las pastillas de freno, es poco probable que sepa el número de pieza específico que necesita. Puede haber algunos aficionados al automovilismo que tengan un conocimiento profundo sobre el tema, hasta el punto de tener en mente un número de pieza específico, pero son una pequeña minoría. La mayoría de las personas solo saben que necesitan cambiar las pastillas de freno, pero no conocen el número de pieza exacto.
Esta situación conduce a otra preocupación seria: la compatibilidad mecánica. Hay miles de referencias de pastillas de freno disponibles en el mercado; sin embargo, para cualquier vehículo dado, normalmente solo hay unas pocas docenas de referencias que son compatibles. Así, la compatibilidad mecánica no puede dejarse al azar.
Stuttgart, al igual que todos sus competidores, es muy consciente de este problema. Al visitar el sitio web de ecommerce de Stuttgart, se invita al visitante a especificar el modelo de su automóvil, y luego el sitio web filtra de inmediato las piezas que no son mecánicamente compatibles con el vehículo especificado. Los sitios web de los competidores siguen el mismo patrón de diseño: primero elegir el vehículo y luego la pieza.
Cuando un cliente busca comparar dos proveedores, normalmente compara las ofertas, no los números de pieza. Un cliente visitaría el sitio web de Stuttgart, identificaría el costo de las pastillas de freno compatibles y luego repetiría el proceso en el sitio web de un competidor. El cliente podría identificar el número de pieza de las pastillas de freno en el sitio web de Stuttgart y luego buscar el mismo número de pieza en el sitio del competidor, pero en la práctica, la gente rara vez hace esto.
Stuttgart y sus competidores elaboran cuidadosamente sus surtidos para poder atender casi todos los vehículos con una fracción de los números de pieza automotriz disponibles. Como resultado, generalmente tienen entre 100.000 y 200.000 números de pieza listados en sus sitios web, y solo entre 10.000 y 20.000 números de pieza realmente en stock.
Con respecto a nuestra preocupación inicial sobre la fijación de precios, está claro que el análisis de precios debe realizarse principalmente no a través del lente de los números de pieza, sino a través de la unidad de necesidad. En el contexto de la posventa automotriz, una unidad de necesidad se caracteriza por el tipo de pieza que necesita ser reemplazada y el modelo del automóvil que requiere el reemplazo.
Sin embargo, esta perspectiva de la unidad de necesidad presenta una complicación técnica inmediata. Stuttgart no puede depender de igualar precios uno a uno entre números de pieza para alinear sus precios con los de sus competidores. Por lo tanto, la alineación de precios no es tan obvia como podría parecer a primera vista, especialmente al reconocer las limitaciones bajo las que opera Stuttgart debido a sus competidores.

Como ya hemos visto en la conferencia 3.4, el problema de la compatibilidad mecánica entre automóviles y piezas se aborda en Europa, así como en otras regiones económicas importantes a nivel mundial, a través de la existencia de empresas especializadas. Estas empresas venden conjuntos de datos de compatibilidad mecánica, compuestos por tres listas: una lista de modelos de automóviles, una lista de piezas de automóvil y una lista de compatibilidades entre automóviles y piezas. Esta estructura de conjunto de datos se conoce técnicamente como un grafo bipartito.
En Europa, estos conjuntos de datos suelen incluir más de 100.000 vehículos, más de un millón de piezas y más de 100 millones de conexiones que unen autos y piezas. Mantener estos conjuntos de datos requiere mucho trabajo, lo que explica por qué existen empresas especializadas que venden estos conjuntos de datos. Stuttgart, al igual que sus competidores, adquiere una suscripción a una de estas empresas especializadas para acceder a versiones actualizadas de estos conjuntos de datos. Las suscripciones son necesarias porque, aunque la industria automotriz está madura, se introducen continuamente nuevos automóviles y piezas. Para mantenerse estrechamente alineados con el panorama automotriz, estos conjuntos de datos deben actualizarse al menos trimestralmente.
Stuttgart y sus competidores utilizan este conjunto de datos para respaldar el mecanismo de selección de vehículos en sus sitios web de ecommerce. Una vez que un cliente ha seleccionado un vehículo, solo se muestran las piezas que son demostrablemente compatibles con el vehículo elegido, de acuerdo con el conjunto de datos de compatibilidad. Este conjunto de datos de compatibilidad también es fundamental para nuestro análisis de precios. A través de este conjunto de datos, Stuttgart puede evaluar el punto de precio ofrecido para cada unidad de necesidad.

El último ingrediente significativo que falta para construir la estrategia de alineación competitiva de Stuttgart es la inteligencia competitiva. En Europa, al igual que en todas las principales regiones económicas, existen especialistas en inteligencia competitiva—empresas que ofrecen servicios de scraping de precios. Estas empresas extraen los precios de Stuttgart y de sus competidores diariamente. Si bien una empresa como Stuttgart puede intentar mitigar la extracción automatizada de sus precios, este esfuerzo es en su mayoría inútil debido a varias razones:
Primero, Stuttgart, al igual que sus competidores, quiere ser amigable con los robots. Los bots más importantes son los motores de búsqueda, con Google, a partir de 2023, teniendo un poco más del 90% de la cuota de mercado. Sin embargo, no es el único motor de búsqueda, y aunque podría ser posible identificar a Googlebot, el rastreador principal de Google, es difícil hacer lo mismo con todos los demás rastreadores que aún constituyen alrededor del 10% del tráfico.
Segundo, los especialistas en inteligencia competitiva se han convertido en expertos durante la última década en disfrazarse de tráfico residencial de internet regular. Estos servicios afirman tener acceso a millones de direcciones IP residenciales, lo cual logran a través de asociaciones con aplicaciones, aprovechándose de las conexiones a internet de usuarios regulares y colaborando con ISPs (Proveedores de Servicios de Internet) que les pueden prestar direcciones IP.
Por lo tanto, asumimos que Stuttgart se beneficia de una lista de precios de alta calidad de sus notables competidores. Estos precios se extraen a nivel de número de pieza y se actualizan diariamente. Esta suposición no es especulativa; es el estado actual del mercado europeo.

Ahora hemos reunido todos los elementos que Stuttgart necesita para calcular precios alineados: precios que coincidan con los de sus competidores cuando se consideran desde la perspectiva de la unidad de necesidad.
En pantalla, tenemos el pseudocódigo para el problema de satisfacción de restricciones que queremos resolver. Simplemente enumeramos todas las unidades de necesidad, es decir, todas las combinaciones de tipos de pieza y modelos de automóvil. Para cada unidad de necesidad, afirmamos que el precio más competitivo ofrecido por Stuttgart debe ser igual al precio más competitivo ofrecido por un competidor.
Evaluemos rápidamente el número de variables y restricciones. Stuttgart puede establecer una etiqueta de precio para cada número de pieza que ofrece, lo que significa que tenemos aproximadamente 100.000 variables. El número de restricciones es algo más complejo. Técnicamente, contamos con alrededor de 1.000 tipos de piezas y alrededor de 100.000 modelos de automóvil, lo que sugiere aproximadamente 100 millones de restricciones. Sin embargo, no todos los tipos de piezas se encuentran en todos los modelos de automóviles. Medidas del mundo real indican que el número de restricciones se acerca a los 10 millones.
A pesar de este menor número de restricciones, aún tenemos 100 veces más restricciones que variables. Nos enfrentamos a un sistema enormemente sobre-restringido. Por lo tanto, sabemos que es poco probable que encontremos una solución que satisfaga todas las restricciones. El mejor resultado es una solución de compromiso que satisfaga la mayoría de ellas.
Además, los competidores no son completamente consistentes con sus precios. A pesar de nuestros mejores esfuerzos, Stuttgart podría terminar en una guerra de precios sobre un número de pieza debido a que su etiqueta de precio es demasiado baja. Al mismo tiempo, podría perder cuota de mercado en el mismo número de pieza debido a que su etiqueta de precio es demasiado alta en comparación con otro competidor. Este escenario no es teórico; los datos empíricos sugieren que estas situaciones ocurren regularmente, aunque para un pequeño porcentaje de números de pieza.
Como hemos optado por una resolución aproximada de este sistema de restricciones, debemos aclarar el peso que se debe dar a cada restricción. No todos los modelos de automóvil son iguales: algunos están asociados con vehículos antiguos que casi han desaparecido de las carreteras. Proponemos ponderar estas restricciones de acuerdo con el volumen respectivo de demanda, expresado en euros.
Ahora que hemos establecido el marco formal para nuestra lógica de precios, procedamos con el código de software real. Como veremos, la resolución de este sistema es más sencilla de lo esperado.
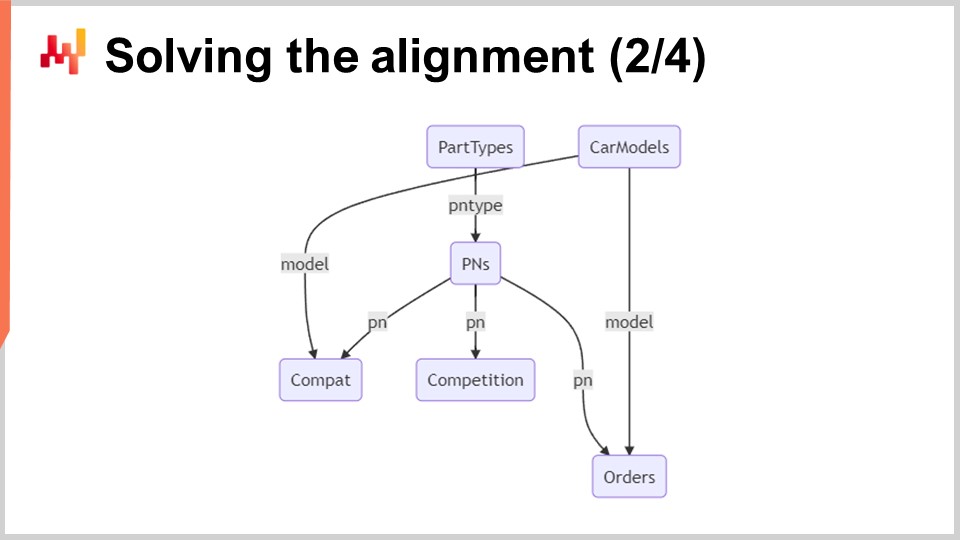
En la pantalla, un esquema relacional mínimo ilustra las seis tablas involucradas en este sistema. Los rectángulos con esquinas redondeadas representan las seis tablas de interés, y las flechas representan las relaciones de uno a muchos entre las tablas.
Revisemos brevemente estas tablas:
-
Part Types: Como sugiere el nombre, esta tabla enumera los tipos de partes, por ejemplo, “pastillas de freno delanteras.” Estos tipos se utilizan para identificar qué parte puede usarse como reemplazo de otra. La parte de reemplazo no solo debe ser compatible con el vehículo, sino también tener el mismo tipo. Hay alrededor de mil part types.
-
Car Models: Esta tabla enumera los modelos de automóviles, por ejemplo, “Peugeot 3008 Fase 2 diésel.” Cada vehículo tiene un car model, y se espera que todos los vehículos de un mismo car model tengan el mismo conjunto de compatibilidades mecánicas. Hay alrededor de cien mil car models.
-
Part Numbers (PNs): Esta tabla enumera los números de parte que se encuentran en el mercado de repuestos automotrices. Cada número de parte tiene un, y solo un, part type. Hay alrededor de 1 millón de part numbers en esta tabla.
-
Compatibility (Compat): Esta tabla representa las compatibilidades mecánicas y recopila todas las combinaciones válidas de part numbers y car models. Con alrededor de 100 millones de líneas de compatibilidad, esta tabla es, de lejos, la más grande.
-
Competition: Esta tabla contiene toda la inteligencia competitiva del día. Para cada número de parte, hay media docena de competidores notables que tienen el part number en exhibición con una etiqueta de precio. Esto resulta en alrededor de 10 millones de competitive prices.
-
Orders: Esta tabla contiene pedidos de clientes pasados de Stuttgart durante un período de aproximadamente un año. Cada línea de pedido incluye un part number y un car model. Técnicamente, es posible comprar una parte de automóvil sin especificar el car model, aunque esto es raro. Se pueden filtrar las líneas de pedido sin un car model. Basado en el tamaño de Stuttgart, debería haber alrededor de 10 millones de líneas de pedidos.
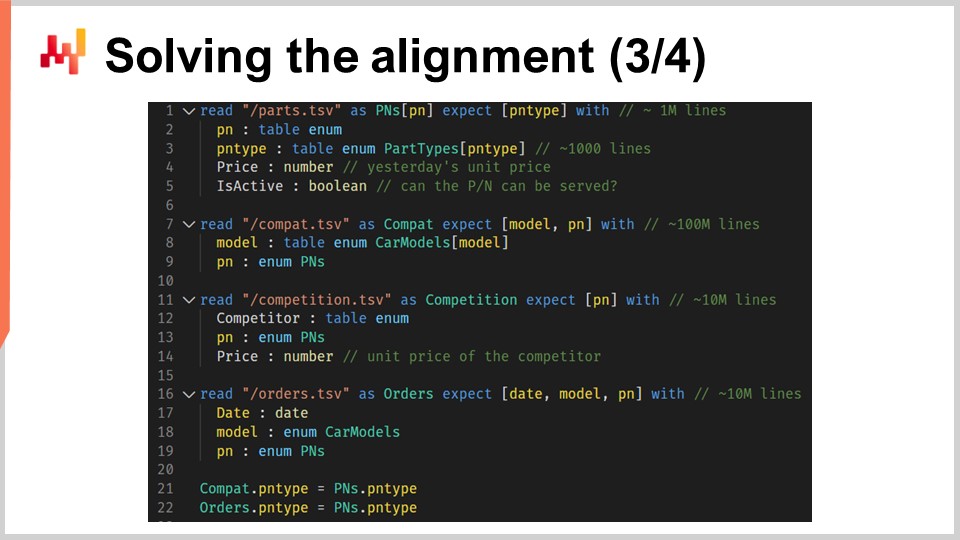
Ahora examinaremos el código que carga los datos relacionales. En la pantalla se muestra un script que carga seis tablas, escrito en Envision - un lenguaje de programación específico para dominios, diseñado por Lokad específicamente para la optimización predictiva de supply chains. Aunque Envision ha sido creado para aumentar la eficiencia y reducir errores en contextos de supply chains, el script puede reescribirse en otros lenguajes como Python, aunque a costa de mayor verbosidad y riesgo de error.
En la primera parte del script, se cargan cuatro archivos de texto plano. Desde las líneas 1 a 5, el archivo “path.csv” proporciona tanto los part numbers como los part types, incluyendo los precios actuales mostrados en Stuttgart. El campo “name is active” indica si un part number específico es atendido por Stuttgart. En esta primera tabla, la variable “PN” se refiere a la dimensión primaria de la tabla, mientras que “PN type” es una dimensión secundaria introducida por la palabra clave “expect”.
Desde las líneas 7 a 9, el archivo “compat.tsv” suministra la lista de compatibilidad parte-vehículo y los car models. Esta es la tabla más grande en el script. Las líneas 11 a 14 cargan el archivo “competition.tsv”, proporcionando una instantánea de la inteligencia competitiva del día, es decir, los precios por part number y por competidor. El archivo “orders.tsv”, cargado en las líneas 16 a 19, nos da la lista de part numbers que se están comprando y los car models asociados, asumiendo que se han filtrado todas las líneas asociadas con car models no especificados.
Finalmente, en las líneas 21 y 22, la tabla “part types” se establece como upstream de las dos tablas, “compat” y “orders”. Esto significa que para cada línea en “compat” o “orders”, hay un y solo un part type que coincide. En otras palabras, “PN type” ha sido añadido como una dimensión secundaria a las tablas “compat” y “orders”. Esta primera parte del script de Envision es sencilla; simplemente estamos cargando datos de archivos de texto plano y reestableciendo la estructura de datos relacional en el proceso.
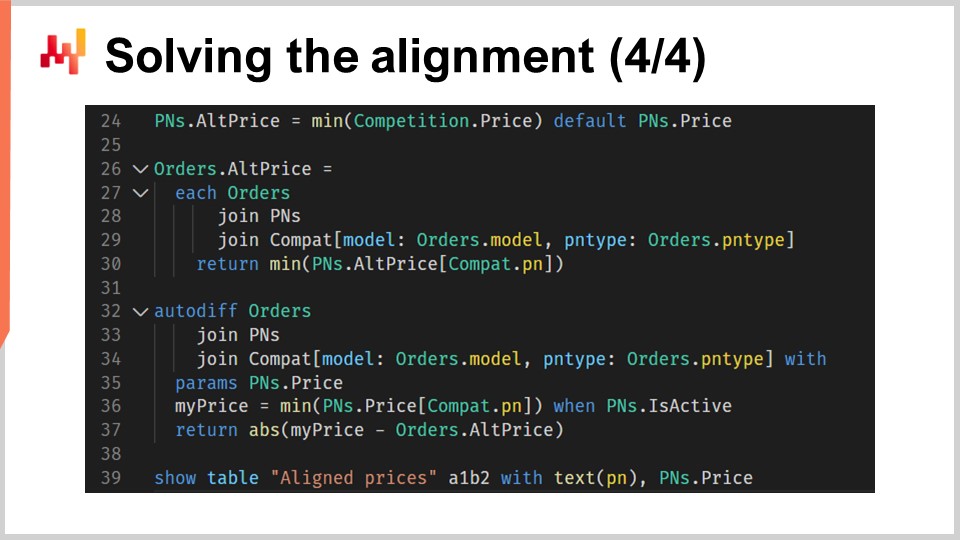
La segunda parte del script, que es visible en la pantalla, es donde ocurre la lógica de alineación real. Esta sección es una continuación directa de la primera parte, y como pueden ver, son solo 12 líneas de código. Una vez más estamos usando differentiable programming. Para la audiencia que quizás no esté familiarizada con differentiable programming, es una fusión de diferenciación automática y descenso de gradiente estocástico. Es un paradigma de programación que también se extiende al machine learning y a la optimización. En el contexto de supply chain, differentiable programming resulta ser increíblemente útil en diversas situaciones. A lo largo de esta serie de conferencias, hemos demostrado cómo differentiable programming puede usarse para aprender modelos, generar previsión probabilística de demanda y lograr previsión balístico de tiempo de entrega. Si no estás familiarizado con differentiable programming, recomiendo revisar las conferencias anteriores de esta serie.
En la conferencia de hoy, veremos cómo differentiable programming es apropiadamente adecuada para abordar problemas de optimización a gran escala que involucran cientos de miles de variables y millones de restricciones. De forma notable, estos problemas pueden resolverse en apenas unos minutos en una sola CPU con unos pocos gigabytes de RAM. Además, podemos usar precios previos como punto de partida, refrescando nuestros precios en lugar de recalcularlos desde cero.
Tenga en cuenta una pequeña advertencia. La palabra clave “join” aún no es compatible con Envision, pero está en nuestra hoja de ruta técnica para el futuro. Existen soluciones alternativas, pero para mayor claridad, utilizaré la sintaxis futura de Envision en esta conferencia.
En la línea 24, calculamos el precio más bajo observado en el mercado para cada part number. Si un part number se vende exclusivamente en Stuttgart y no tiene competidores, usamos el precio propio de Stuttgart por defecto.
Desde las líneas 26 a 30, para cada parte listada en el historial de pedidos de clientes de Stuttgart, se calcula la oferta más competitiva actual.
En la línea 27, iteramos sobre cada línea de pedido de la tabla orders con “each order”.
En la línea 28, usamos “join pns” para incorporar la tabla completa de part numbers para cada línea de orders.
En la línea 29, hacemos un join con “others”, pero este join está restringido por dos dimensiones secundarias - model y part type. Esto significa que para cada línea en orders, seleccionamos los part numbers que coinciden con una combinación de car model y part type, reflejando las partes compatibles con la unidad de necesidad que coincide con el pedido del cliente.
Desde la línea 32 hasta la 37, resolvemos la alineación utilizando differentiable programming, indicado por la palabra clave “Auto diff”. El bloque “Auto diff” se declara en la línea 32, aprovechando la tabla orders como la tabla de observación. Esto significa que estamos ponderando implícitamente las restricciones de acuerdo con el volumen de ventas propio de Stuttgart. Las líneas 33 y 44 cumplen el mismo propósito que las líneas 28 y 29; iteran sobre la tabla orders, proporcionando acceso completo a la tabla de part numbers (“PN”) y un subconjunto de las entradas compatibles.
En la línea 35, declaramos “pns.price” como los parámetros a optimizar mediante el descenso de gradiente estocástico. No es necesario inicializar estos parámetros, ya que partimos de los precios usados hasta ahora por Stuttgart, refrescando efectivamente la alineación.
En la línea 36, calculamos “my price”, que es la oferta más competitiva de Stuttgart para la unidad de necesidad asociada con la línea de pedido. Este cálculo es un mecanismo bastante similar al cálculo del precio más bajo observado, como se hizo en la línea 24, nuevamente apoyándose en la lista de compatibilidades mecánicas. Sin embargo, las compatibilidades están restringidas a los part numbers que son atendidos por Stuttgart. Históricamente, los clientes pueden o no haber seleccionado la parte más económicamente ventajosa para su vehículo. De todas formas, el propósito de usar los pedidos de clientes en este contexto es asignar ponderaciones a las unidades de necesidad.
En la línea 37, utilizamos la diferencia absoluta entre el mejor precio ofrecido por Stuttgart y el mejor precio ofrecido por un competidor para guiar la alineación. Dentro de este bloque alternativo, los gradientes se aplican retroactivamente a los parámetros. La diferencia que encontramos al final forma la función de pérdida. A partir de esta función de pérdida, los gradientes fluyen de regreso hacia el único vector de parámetros que tenemos aquí: “pns.price”. Al ajustar de manera incremental los parámetros (los precios) en cada iteración (siendo una iteración aquí una línea de pedido), el script converge hacia una aproximación adecuada de la alineación de precios deseada.
En términos de complejidad algorítmica, predomina la línea 36. Sin embargo, como el número de compatibilidades para cualquier car model y part type es limitado (usualmente no más de unas pocas docenas), cada iteración de “Auto diff” se realiza en lo que equivale a tiempo constante. Este tiempo constante no es muy pequeño, como 10 ciclos de CPU, pero tampoco va a ser de un millón de ciclos de CPU. Aproximadamente, mil ciclos de CPU suenan razonables para 20 partes compatibles.
Si asumimos una sola CPU funcionando a dos gigahertz y realizando 100 epochs (siendo un epoch un descenso completo sobre toda la tabla de observación), anticiparíamos un tiempo de ejecución objetivo de aproximadamente 10 minutos. Resolver un problema con 100,000 variables y 10 millones de restricciones en 10 minutos en una sola CPU es bastante impresionante. De hecho, Lokad logra un rendimiento más o menos en línea con esta expectativa. Sin embargo, en la práctica, para tales problemas, nuestro cuello de botella es más a menudo el rendimiento de I/O que el de la CPU.
Una vez más, este ejemplo muestra el poder de emplear paradigmas de programación adecuados para aplicaciones de supply chain. Comenzamos con un problema no trivial, ya que no era inmediatamente evidente cómo aprovechar este conjunto de datos de compatibilidad mecánica desde una perspectiva de precios. A pesar de ello, la implementación real es sencilla.
Aunque este script no aborda todos los aspectos que estarían presentes en una configuración del mundo real, la lógica central solo requiere seis líneas de código, dejando amplio espacio para acomodar complejidades adicionales que los escenarios del mundo real podrían introducir.

El algoritmo de alineación, como se presentó anteriormente, prioriza la simplicidad y claridad sobre la exhaustividad. En una configuración del mundo real, se esperarían factores adicionales. Examinaré estos factores en breve, pero comencemos reconociendo que estos factores pueden abordarse extendiendo este algoritmo de alineación.
Vender con pérdidas no solo es imprudente, sino también ilegal en muchos países, como Francia, aunque hay excepciones bajo circunstancias especiales. Para evitar vender con pérdidas, se puede añadir una restricción al algoritmo de alineación que obligue a que el precio de venta supere el precio de compra. Sin embargo, también es útil ejecutar el algoritmo sin esta restricción de “no pérdida” para identificar posibles problemas de sourcing. De hecho, si un competidor puede permitirse vender una parte por debajo del precio de compra de Stuttgart, Stuttgart necesita abordar el problema subyacente. Lo más probable es que se trate de un problema de sourcing o de compras.
Simplemente agrupar todos los part numbers es ingenuo. Los clientes no tienen la misma disposición a pagar por todos los Original Equipment Manufacturers (OEMs). Por ejemplo, es más probable que los clientes valoren una marca bien conocida como Bosch en comparación con un OEM chino menos conocido en Europa. Para abordar esta preocupación, Stuttgart, al igual que sus pares, categoriza los OEMs en una lista corta de gamas de productos, desde la más cara hasta la menos cara. Podemos tener, por ejemplo, la gama de motorsport, la gama doméstica, la gama de marcas de distribuidores y la gama de budget.
La alineación se construye entonces para asegurar que cada part number esté alineado dentro de su propia gama de productos. Además, el algoritmo de alineación debería exigir que los precios disminuyan estrictamente al pasar de la gama de motorsport a la gama de budget, ya que cualquier inversión confundiría al cliente. En teoría, si los competidores valoraran con precisión sus propias ofertas, tales inversiones no ocurrirían. Sin embargo, en la práctica, los clientes a veces valoran incorrectamente sus propias partes, y ocasionalmente tienen razones para fijar sus partes a una etiqueta de precio diferente.
Solo hay unos pocos cientos de OEMs, clasificar esos OEMs en sus respectivas gamas de productos se puede hacer manualmente, y posiblemente con la ayuda de encuestas a clientes si existen ambigüedades que no puedan resolverse directamente por los expertos del mercado en Stuttgart.

A pesar de la adopción de gamas de productos, muchos precios de part numbers no terminan siendo activamente impulsados por la lógica de alineación. De hecho, solo los part numbers que contribuyen activamente a ser el mejor precio entre una unidad de necesidad son ajustados efectivamente por el descenso de gradiente para crear la alineación aproximada que buscamos dentro de la misma gama de productos.
De entre dos part numbers que tienen compatibilidades mecánicas idénticas, solo uno de ellos tendrá su precio ajustado por el solucionador de alineación. El otro part number siempre recibirá gradientes cero, y por lo tanto su precio original quedará sin modificar. Así, en resumen, mientras que el sistema tiene un conjunto completo de restricciones, muchas variables no están restringidas en absoluto. Dependiendo de la granularidad de las gamas de productos y del alcance de la inteligencia competitiva, estos part numbers no restringidos pueden representar una fracción considerable del catálogo, posiblemente la mitad de los part numbers. Aunque la fracción, una vez expresada en volumen de ventas, es mucho menor.
Para estos part numbers, Stuttgart requiere una estrategia de precios alterna. Aunque no tengo un proceso algorítmico estricto para sugerir para estas partes no restringidas, propondría dos principios guía.
Primero, debería haber una diferencia de precio no trivial, digamos del 10%, entre el part number más competitivo dentro de la gama de productos y el siguiente. Con algo de suerte, algunos competidores pueden no ser tan diestros como Stuttgart en reconstruir las unidades de necesidad. Así, esos competidores podrían pasar por alto la etiqueta de precio que realmente impulsa la alineación, llevándolos a revisar su precio al alza, lo cual es deseable para Stuttgart.
En segundo lugar, podría haber algunas piezas con un precio mucho más alto, digamos un 30% más caro, siempre y cuando esas piezas no terminen superponiéndose con otras gamas de productos. Estas piezas sirven como señuelos para sus contrapartes de mejor precio, una estrategia conocida técnicamente como decoy pricing. El señuelo está diseñado deliberadamente para ser una opción menos atractiva que la opción objetivo, haciendo que la opción objetivo parezca más valiosa y llevando al cliente a elegirla con mayor frecuencia. Estos dos principios son suficientes para extender suavemente los precios sin restricciones más allá de sus umbrales competitivos.

El alineamiento competitivo más una dosis de decoy pricing son suficientes para asignar un precio a cada número de pieza exhibido en Stuttgart. Sin embargo, la tasa de gross margin resultante probablemente sea demasiado baja para Stuttgart. De hecho, alinear Stuttgart con todos sus competidores notables ejerce una tremenda presión sobre su margen.
Por un lado, alinear los precios es una necesidad; de lo contrario, Stuttgart será completamente expulsado del mercado con el tiempo. Pero, por otro lado, Stuttgart no puede arruinarse en el proceso de preservar su cuota de mercado. Es crucial recordar que el gross margin futuro asociado a una estrategia de precios dada solo puede ser estimado o forecasted. No existe una forma exacta de derivar la tasa de crecimiento futura a partir de un conjunto de precios, ya que tanto clientes como competidores se adaptan.
Suponiendo que tengamos una estimación razonablemente precisa de la tasa de gross margin que Stuttgart debería esperar la próxima semana, es importante señalar que la parte de “precisión” de esta suposición no es tan irracional como podría parecer. Stuttgart, al igual que sus competidores, opera bajo severas restricciones. A menos que la estrategia de precios de Stuttgart se modifique fundamentalmente, el gross margin a nivel de compañía no cambiará mucho de una semana a otra. Incluso podemos considerar la tasa de gross margin observada la semana pasada como un proxy razonable de lo que Stuttgart debería esperar la próxima semana, asumiendo naturalmente que la estrategia de precios se mantiene sin cambios.
Supongamos que se proyecta que la tasa de gross margin de Stuttgart sea del 13%, pero Stuttgart necesita una tasa de gross margin del 15% para sostenerse. ¿Qué debería hacer Stuttgart al enfrentar tal situación? Una respuesta consiste en elegir aleatoriamente una selección de “units of needs” y aumentar sus precios en alrededor del 20%. Los tipos de piezas preferidos por clientes primerizos, como los limpiaparabrisas, deben ser excluidos de esta selección. Ganar a esos clientes primerizos es caro y difícil, y Stuttgart no debería arriesgarse con esas compras de primera vez. De manera similar, para tipos de piezas muy caras, como los inyectores, es probable que los clientes comparen mucho más. Por lo tanto, Stuttgart probablemente no debería arriesgarse a parecer poco competitivo en esas compras de mayor envergadura.
Sin embargo, dejando de lado estas dos situaciones, argumentaría que seleccionar aleatoriamente “units of needs” y hacerlas poco competitivas mediante precios más altos es una opción razonable. De hecho, Stuttgart necesita subir algunos de sus precios, una consecuencia inevitable de buscar una tasa de growth margin más alta. Si Stuttgart adopta un patrón discernible al hacerlo, entonces las reseñas online probablemente señalarán esos patrones. Por ejemplo, si Stuttgart decide renunciar a ser competitivo en piezas de Bosch o decide renunciar a ser competitivo en piezas compatibles con vehículos Peugeot, existe un peligro real de que Stuttgart se convierta en el concesionario que no ofrece un buen trato para los vehículos de Bosch o Peugeot. La aleatoriedad hace que Stuttgart sea algo inescrutable, que es precisamente el efecto deseado.
Los rankings de exhibición son otro factor crucial en el catálogo online de Stuttgart. Más específicamente, para cada “unit of need”, Stuttgart necesita clasificar todas las piezas elegibles. Determinar la mejor forma de clasificar las piezas es un problema adyacente a la fijación de precios que merece una conferencia por sí sola. Se esperaría que los rankings de exhibición, desde la perspectiva presentada en esta conferencia, se calcularan después de resolver el problema de alineación. Sin embargo, también sería concebible optimizar simultáneamente tanto los price tags como los rankings de exhibición. Este problema presentaría alrededor de 10 millones de variables en lugar de las 100,000 variables con las que hemos lidiado hasta ahora. Sin embargo, esto no altera fundamentalmente la escala del problema de optimización, ya que de todas maneras tenemos 10 millones de restricciones con las cuales lidiar. Hoy no abordaré qué tipo de criterio podría usarse para guiar esta optimización de rankings de exhibición, ni cómo aprovechar gradient descent para la optimización discreta. Esta última preocupación es bastante interesante pero será tratada en una conferencia posterior.

La importancia relativa de la “unit of need” está determinada casi en su totalidad por las flotas de vehículos existentes. Stuttgart no puede esperar vender 1 millón de pastillas de freno para un modelo de coche que solo tiene 1,000 vehículos en Europa. Incluso se podría argumentar que los verdaderos consumidores de piezas son los mismos vehículos en lugar de sus propietarios. Aunque los vehículos no pagan por sus piezas (los propietarios sí), esta analogía ayuda a enfatizar la importancia de la flota vehicular.
Sin embargo, es razonable esperar distorsiones sustanciales cuando se trata de que las personas compren sus piezas online. Después de todo, comprar piezas es, ante todo, una forma de ahorrar dinero en comparación con comprarlas indirectamente en un taller de reparación. Por lo tanto, se espera que la edad media de los vehículos, según observa Stuttgart, sea mayor de lo que sugieren las estadísticas generales del mercado automotriz. De manera similar, es menos probable que las personas que conducen coches caros intenten ahorrar dinero haciendo sus propias reparaciones. Así, se espera que el tamaño y la clase promedio de los vehículos, según observa Stuttgart, sean inferiores a lo que sugieren las estadísticas generales del mercado.
Estas no son especulaciones ociosas. De hecho, se observan estas distorsiones en todos los grandes minoristas online de piezas de automóviles en Europa. Sin embargo, el algoritmo de alineación, tal como se presentó previamente, utiliza el sales history de Stuttgart como un proxy de la demanda. Es concebible que estos sesgos puedan socavar el resultado del algoritmo de alineación de precios. Si estos sesgos impactan negativamente el resultado para Stuttgart es, fundamentalmente, un problema empírico, ya que la magnitud del problema, en caso de existir, depende en gran medida de los datos. La experiencia de Lokad indica que el algoritmo de alineación y sus variaciones son bastante robustos contra esta clase de sesgos, incluso al subestimar el peso de una “unit of need” por un factor de dos o tres. La contribución principal de estos pesos, en términos de precios, parece ayudar al algoritmo de alineación a resolver conflictos cuando el mismo número de pieza pertenece a dos “units of need” que no pueden abordarse conjuntamente. En la mayoría de estas situaciones, una “unit of need” supera ampliamente a la otra en términos de volumen. Así, incluso una gran subestimación de los respectivos volúmenes tiene poca consecuencia en los precios.
Identificar los mayores sesgos entre lo que debería haber sido la demanda para una “unit of need” y lo que Stuttgart observa como ventas realizadas puede ser muy útil. Un volumen de ventas sorprendentemente bajo para una “unit of need” dada tiende a indicar problemas mundanos con la plataforma de e-commerce. Algunas piezas podrían estar mal etiquetadas, otras pueden tener imágenes incorrectas o de baja calidad, etc. En la práctica, estos sesgos pueden identificarse comparando los índices de ventas para un determinado modelo de coche de los diversos tipos de piezas. Por ejemplo, si Stuttgart no vende ninguna pastilla de freno para un modelo de coche dado, mientras que los volúmenes de ventas para otros tipos de piezas son consistentes con lo que se observa habitualmente, es poco probable que este modelo de coche tenga un consumo excepcionalmente bajo de pastillas de freno. La causa raíz casi ciertamente se encuentra en otro lugar.
Una lista superior de compatibilidades mecánicas es una ventaja competitiva. Conocer compatibilidades que son desconocidas para tus competidores te permite potencialmente ofrecer precios inferiores sin desencadenar una guerra de precios, ganando así una ventaja para incrementar tu cuota de mercado. Por el contrario, identificar compatibilidades incorrectas es fundamental para evitar devoluciones costosas por parte de los clientes.
De hecho, el costo de pedir una pieza incompatible es modesto para un taller de reparación, ya que probablemente exista un proceso establecido para devolver la pieza no utilizada al centro de distribución. Sin embargo, el proceso es mucho más tedioso para los clientes regulares, quienes pueden ni siquiera lograr reempaquetar adecuadamente la pieza para su viaje de regreso. Así, cada empresa de e-commerce tiene un incentivo para construir su propia capa de enriquecimiento de datos sobre los conjuntos de datos de terceros que alquilan. La mayoría de los actores del e-commerce en este sector tienen su propia capa de enriquecimiento de datos de una forma u otra.
Hay pocos incentivos para compartir este conocimiento con las compañías especializadas que mantienen esos conjuntos de datos en primer lugar, ya que este conocimiento beneficiaría mayormente a la competencia. Es difícil evaluar la tasa de error en esos conjuntos de datos, pero en Lokad, estimamos que ronda un porcentaje de un solo dígito bajo en ambos casos. Hay unos pocos por ciento de falsos positivos, donde se declara una compatibilidad cuando no existe, y hay unos pocos por ciento de falsos negativos, donde existe una compatibilidad pero no se declara. Considerando que la lista de compatibilidades mecánicas incluye más de 100 millones de líneas, es muy probable que haya alrededor de siete millones de errores bajo estimaciones conservadoras.
Por lo tanto, es de interés para Stuttgart mejorar este conjunto de datos. Las devoluciones de clientes reportadas como causadas por una compatibilidad mecánica falsa positiva ciertamente pueden ser aprovechadas para este propósito. Sin embargo, este proceso es lento y costoso. Además, dado que los clientes no son técnicos automotrices profesionales, podrían reportar una pieza como incompatible cuando simplemente no lograron montarla. Stuttgart puede posponer declarar una pieza como incompatible hasta que se hayan realizado varias quejas, pero esto hace que el proceso sea aún más costoso y lento.
Así, una receta numérica para mejorar este conjunto de datos de compatibilidad sería altamente deseable. No es obvio que sea siquiera posible mejorar este conjunto de datos sin aprovechar información adicional. Sin embargo, de manera algo sorprendente, resultó que este conjunto de datos puede mejorarse sin ninguna información adicional. Este conjunto de datos puede usarse para auto-optimizarse en una versión superior.
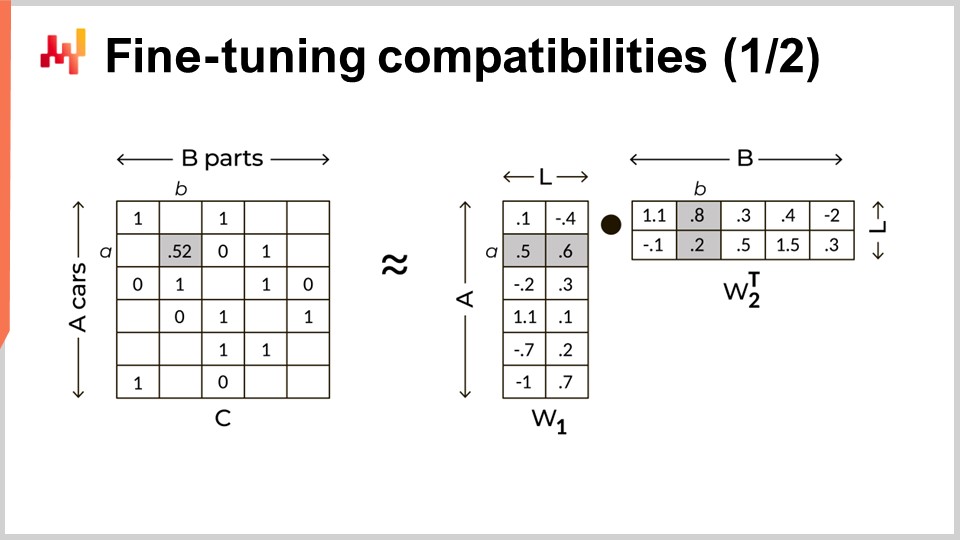
Personalmente, me topé con esta realización en el primer trimestre de 2017 mientras realizaba una serie de experimentos de deep learning para Lokad. Utilicé una factorización de matrices, una técnica bien conocida para el collaborative filtering. El collaborative filtering es el problema central al construir un sistema de recomendación, que consiste en identificar el producto que a un usuario podría gustarle en base a las preferencias conocidas de este usuario para una lista corta de productos. Adaptar el collaborative filtering a las compatibilidades mecánicas es sencillo: sustituye usuarios por modelos de coches y productos por piezas de coche. Voila, el problema está adaptado.
Más en general, la factorización de matrices es aplicable a cualquier situación que involucre un grafo bipartito. La factorización de matrices también es útil más allá del análisis de grafos. Por ejemplo, la adaptación de bajo rango de grandes modelos de lenguaje (LLMs), una técnica que se ha vuelto extremadamente popular para ajustar finamente los LLMs, también se basa en el truco de la factorización de matrices. La factorización de matrices se ilustra en la pantalla. A la izquierda, tenemos la matriz de compatibilidad con unos para denotar una compatibilidad entre un coche y una pieza, y ceros para denotar la incompatibilidad entre un modelo de coche y un número de pieza. Queremos reemplazar esta matriz grande y muy dispersa por el producto de dos matrices densas más pequeñas. Esas dos matrices son visibles a la derecha. Estas matrices sirven para factorizar la matriz grande. Efectivamente, estamos sumergiendo cada modelo de coche y número de pieza en un espacio latente. La dimensión de este espacio latente se denota con una L mayúscula en la pantalla. Este espacio latente está diseñado para capturar las compatibilidades mecánicas pero con muchas menos dimensiones comparado con la matriz original. Al mantener la dimensión de este espacio latente bastante baja, nuestro objetivo es aprender las reglas ocultas que rigen estas compatibilidades mecánicas.

Aunque la factorización de matrices pueda sonar como un gran concepto técnico, no lo es. Es un truco básico del álgebra lineal. El único aspecto engañoso de la factorización de matrices es que funciona tan bien a pesar de ser tan simple. En la pantalla se muestra una implementación completa de esta técnica en menos de 30 líneas de código.
De la línea uno a la tres, estamos leyendo el archivo plano que lista las compatibilidades mecánicas. Este archivo se carga en una tabla llamada M por brevedad, que significa matriz. Esta lista es, efectivamente, una representación dispersa de la matriz de compatibilidad. Al cargar esta lista, también creamos dos tablas más llamadas car_models y pns. Estos bloques nos proporcionan tres tablas: M, car_models, y pns.
Las líneas cinco y seis implican barajar aleatoriamente la columna que contiene los modelos de coches. El propósito de barajar es crear ceros aleatorios, o incompatibilidades aleatorias. De hecho, la matriz de compatibilidad es muy dispersa. Al elegir un coche y una pieza al azar, estamos casi seguros de que este par es incompatible. La confianza que tenemos en que esta asociación aleatoria sea cero es, de hecho, mayor que la confianza que tenemos en la lista de compatibilidades en primer lugar. Estos ceros aleatorios son 99.9% precisos por diseño debido a la dispersión de la matriz, mientras que las compatibilidades conocidas son quizás 97% precisas.
La línea ocho implica crear el espacio latente con 24 dimensiones. Aunque 24 dimensiones puedan parecer muchas para embeddings, es muy poco en comparación con los grandes modelos de lenguaje, que tienen embeddings de más de mil dimensiones. Las líneas nueve y diez implican crear las dos matrices pequeñas, llamadas pnl y car_L, que utilizaremos para factorizar la matriz grande. Estas dos matrices representan aproximadamente 24 millones de parámetros para pnl y 2.4 millones de parámetros para car_L. Esto se considera pequeño en comparación con la matriz grande, que tiene aproximadamente 100 mil millones de valores.
Vale la pena señalar que la matriz grande nunca se materializa en este script. Nunca se convierte explícitamente en un array; siempre se mantiene como una lista de 100 millones de compatibilidades. Convertirla en un array sería extremadamente ineficiente en términos de recursos computacionales.
Las líneas 12 a 15 introducen dos funciones auxiliares llamadas sigmoid y log_loss. La función sigmoid se utiliza para convertir el producto matricial en bruto en probabilidades, números entre 0 y 1. La función log_loss representa la pérdida logística. La pérdida logística aplica la verosimilitud logarítmica, una métrica utilizada para evaluar la corrección de una predicción probabilística. Aquí se utiliza para evaluar una predicción probabilística para un problema de clasificación binaria. Ya hemos encontrado la verosimilitud logarítmica en la lección 5.3, dedicada a la previsión probabilística de tiempos de entrega. Esta es una variación más simple de la misma idea. Estas dos funciones están marcadas con la palabra clave autograd, lo que indica que pueden diferenciarse automáticamente. El pequeño valor de uno entre un millón es un epsilon introducido para la estabilidad numérica. De otro modo, no influye en la lógica. Desde la línea 17 a la 29, tenemos la factorización de matrices en sí. Una vez más, estamos usando programación diferenciable. Hace unos minutos, estábamos utilizando programación diferenciable para resolver aproximadamente un problema de satisfacción de restricciones. Aquí, estamos usando programación diferenciable para abordar un problema de aprendizaje auto-supervisado.
En las líneas 18 y 19, declaramos los parámetros a aprender. Estos parámetros están asociados con las dos matrices pequeñas, pnl y car_L. La palabra clave “auto” indica que estos parámetros se inicializan aleatoriamente como desviaciones aleatorias de una distribución gaussiana centrada en cero, con una desviación estándar de 0.1.
Las líneas 20 y 21 introducen dos parámetros especiales que aceleran la convergencia. Estos son solo 48 números en total, una gota en el océano en comparación con nuestras matrices pequeñas que aún tienen millones de números. Y sin embargo, he descubierto que introducir estos parámetros acelera sustancialmente la convergencia. Es importante señalar que estos parámetros no introducen ningún grado de libertad para el modelo existente. Estos parámetros solo introducen unos pocos grados de libertad extra en el proceso de aprendizaje. El efecto neto es que reducen a más de la mitad el número de épocas necesarias.
En las líneas 22 a 24, estamos cargando los embeddings. En la línea 22, tenemos el embedding de una única pieza llamada px. En la línea 23, tenemos el embedding de un único modelo de coche llamado mx. La pareja px y mx será nuestro borde positivo, una compatibilidad considerada como verdadera. En la línea 24, tenemos el embedding de otro modelo de coche llamado mx2. La pareja px y mx2 será nuestro borde negativo, una compatibilidad considerada como falsa. De hecho, mx2 ha sido elegido al azar mediante el shuffle que ocurre en la línea seis. Los tres embeddings px, mx y mx2 tienen exactamente 24 dimensiones, ya que pertenecen al espacio latente, representado por la tabla L en este script.
En la línea 26, expresamos la probabilidad, según lo definido por nuestro modelo, mediante un producto punto de este borde para que sea positivo. Sabemos que este borde es positivo, al menos eso es lo que nos indica el conjunto de datos de compatibilidad. Pero aquí evaluamos lo que nuestro modelo probabilístico dice acerca de este borde. En la línea 27, expresamos la probabilidad, también definida por nuestro modelo probabilístico, mediante el producto punto de este borde para que sea negativo. Suponemos que este borde es negativo ya que es un borde aleatorio. De nuevo, evaluamos esta probabilidad para ver lo que nuestro modelo dice sobre este borde. En la línea 29, devolvemos el opuesto de la verosimilitud logarítmica asociada con este borde. El valor de retorno se utiliza como una pérdida a minimizar mediante el descenso de gradiente estocástico. Aquí, esto significa que estamos maximizando la verosimilitud logarítmica, o el criterio de clasificación binaria probabilística, entre pares compatibles e incompatibles.
Posteriormente, más allá de lo mostrado en este script, la matriz grande puede compararse con el producto punto de dos matrices pequeñas. Las divergencias entre las dos representaciones delinean tanto los falsos positivos como los falsos negativos de los conjuntos de datos originales. Lo más sorprendente es que la representación factorizada de esta matriz grande termina siendo más precisa que la matriz original.
Desafortunadamente, no puedo presentar los resultados empíricos asociados a estas técnicas, ya que los conjuntos de datos de compatibilidad relevantes son todos propietarios. Sin embargo, mis hallazgos, validados por algunos actores en este mercado, indican que estas técnicas de factorización de matrices pueden usarse para reducir el número de falsos positivos y falsos negativos hasta en un orden de magnitud. En términos de rendimiento, pasé de aproximadamente dos semanas de cómputo para lograr una convergencia satisfactoria con el toolkit de deep learning que estaba utilizando, CNTK - el toolkit de deep learning de Microsoft allá por 2017, a aproximadamente una hora con el entorno de ejecución actual ofrecido por Envision. Los primeros toolkits de deep learning sí ofrecían programación diferenciable en cierto sentido; sin embargo, esas soluciones estaban fuertemente optimizadas para grandes productos matriciales y grandes convoluciones. Sospecho que toolkits más recientes, como Jax de Google, ofrecerían un rendimiento comparable al de Envision.
Esto plantea la pregunta: ¿por qué las empresas especializadas que mantienen conjuntos de datos de compatibilidad no usan ya la factorización de matrices para limpiar sus conjuntos de datos? Si lo hicieran, la factorización de matrices no aportaría nada nuevo. La factorización de matrices como técnica de machine learning lleva casi 20 años en uso. Esta técnica fue popularizada allá por 2006 por Simon Funk. Ya no es exactamente de vanguardia. Mi respuesta a esta pregunta original es que no lo sé. Quizás esas empresas especializadas comiencen a usar la factorización de matrices después de ver esta lección, o tal vez no.
En cualquier caso, esto demuestra que la programación diferenciable y el modelado probabilístico son paradigmas muy versátiles. A primera vista, la previsión de tiempos de entrega no tiene nada que ver con la evaluación de compatibilidades mecánicas, y sin embargo ambos pueden abordarse con el mismo instrumento, a saber, la programación diferenciable y el modelado probabilístico.

El conjunto de datos de compatibilidades mecánicas no es el único que puede resultar inexacto. A veces, las herramientas de inteligencia competitiva también devuelven datos falsos. Incluso si el proceso de web scripting es bastante fiable al extraer millones de precios de páginas web semi-estructuradas, pueden ocurrir errores. Identificar y abordar estos precios erróneos es un desafío en sí mismo. Sin embargo, esto también merecería una lección específica, ya que los problemas tienden a ser tanto específicos del sitio web objetivo como de la tecnología utilizada para el web scripting.
Si bien las preocupaciones sobre el web scraping son importantes, estas se desarrollan antes de que se ejecute el algoritmo de alineación, y por lo tanto deben estar en gran medida desacopladas de la alineación en sí misma. Los errores de scraping no tienen que dejarse al azar. Hay dos formas de jugar al juego de la inteligencia competitiva: o puedes hacer que tus números sean mejores, más precisos, o puedes empeorar los números de tus competidores, haciéndolos menos precisos. De esto se trata la contrainteligencia.
Como se discutió anteriormente, bloquear robots basándose en su dirección IP no va a funcionar. Sin embargo, existen alternativas. La capa de transporte de red ni siquiera se acerca a ser la capa más interesante con la que jugar si pretendemos sembrar una confusión bien dirigida. Hace aproximadamente una década, Lokad llevó a cabo una serie de experimentos de contrainteligencia para ver si un gran sitio web de ecommerce, como SugAr, podría defenderse contra sus competidores. ¿Los resultados? Sí, puede.
En algún momento, incluso pude confirmar la efectividad de estas técnicas de contrainteligencia mediante la inspección directa de los datos entregados por el especialista en web scraping, que de otra forma no sospechaba nada. El nombre en clave para esta iniciativa era Bot Defender. Este proyecto ha sido descontinuado, pero aún se pueden ver algunos rastros de Bot Defender en nuestro archivo público del blog.
En lugar de intentar negar el acceso a las páginas HTML, lo cual es una propuesta perdedora, decidimos interferir selectivamente con los propios web scrapers. El equipo de Lokad no conocía los detalles del diseño de estos web scrapers. Considerando la estructura DHTML de un sitio web de ecommerce dado, no es muy difícil hacer una suposición fundamentada sobre cómo procedería una empresa que opera los web scrapers. Por ejemplo, si cada página HTML del sitio web de StuttArt tiene una clase CSS excesivamente conveniente llamada “unit price” que destaca el precio del producto en el centro de la página, es razonable asumir que prácticamente todos los robots usarán esta clase CSS tan conveniente para aislar el precio dentro del código HTML. De hecho, a menos que el sitio web de StuttArt ofrezca una forma aún más conveniente de obtener los precios, como una API abierta que se pueda consultar libremente, esta clase CSS es el camino obvio para extraer los precios.
Sin embargo, como la lógica del web scraping es obvia, también es obvio cómo interferir selectivamente con esta lógica. Por ejemplo, StuttArt puede decidir seleccionar cuidadosamente unos pocos productos bien dirigidos y “envenenar” el HTML. En el ejemplo dado en la pantalla, visualmente ambas páginas HTML se mostrarán para los humanos como una etiqueta de precio de 65 Euro y 50 centavos. Sin embargo, la segunda versión de la página HTML será interpretada por los robots como 95 Euro en lugar de 65 Euro. El número “9” se rota mediante CSS para parecer un “6”. El web scraper típico, que se basa en el marcado HTML, no va a captar esto.
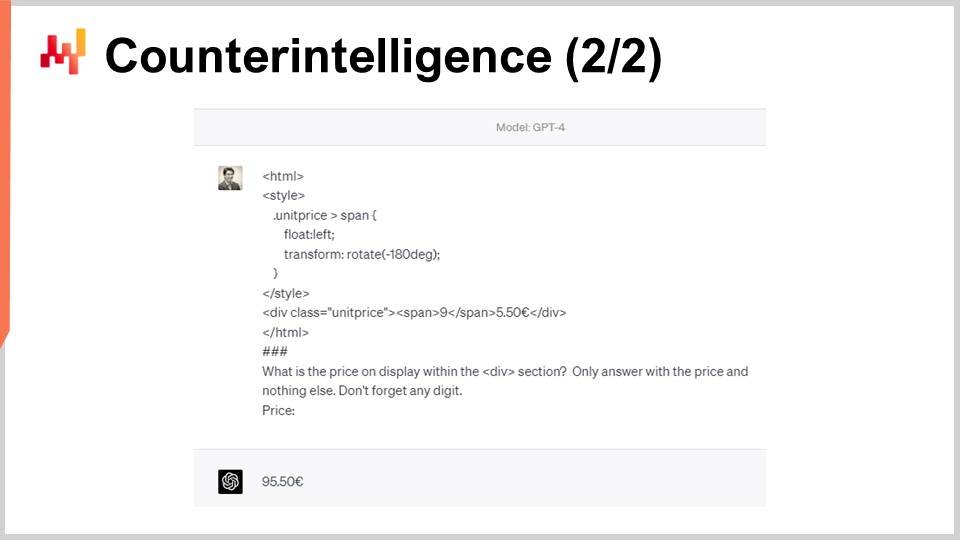
Diez años después, incluso un sofisticado Large Language Model como GPT-4, que no existía en ese momento, sigue siendo engañado por este sencillo truco de CSS. En la pantalla, vemos que GPT-4 no extrae un precio de 65 Euro como debería, sino que responde 95 Euro. Marginalmente, hay docenas de formas de elaborar un código HTML que ofrezca una etiqueta de precio obvia para un robot que diverja de la que un ser humano leería en el sitio web. Rotar un “9” para que parezca un “6” es solo uno de los trucos más simples dentro de una vasta gama de trucos similares.
Una contramedida a esta técnica consistiría en renderizar la página, crear el bitmap completo, y luego aplicar el Reconocimiento Óptico de Caracteres (OCR) a este bitmap. Sin embargo, es bastante costoso. Las empresas de inteligencia competitiva deben revisar decenas de millones de páginas web diariamente. Como regla general, ejecutar un proceso de renderización de páginas web seguido de OCR incrementa el costo de procesamiento al menos por un factor de 100, y más probablemente por un factor de 1000.
Como punto de referencia, a mayo de 2023, Microsoft Azure cobra un dólar por cada mil operaciones de OCR. Considerando que hay más de 10 millones de páginas que deben ser monitoreadas diariamente por los especialistas en inteligencia competitiva en Europa, eso equivale a un presupuesto de $10,000 por día solo en OCR. Y Microsoft Azure, por cierto, es bastante competitivo en este aspecto.
Considerando otros costos como el ancho de banda para esas preciosas direcciones IP residenciales, es muy probable que se hable de un presupuesto anual de computación en el rango de 5 millones de euros si seguimos este camino. Un presupuesto anual de varios millones está dentro de lo posible, pero los márgenes de las empresas de web scraping son estrechos y no optarán por este camino. Si a través de medios mucho más baratos pueden lograr una inteligencia competitiva 99% precisa, eso es suficiente para mantener satisfechos a sus clientes.
Volviendo a StuttArt, sería poco prudente usar esta técnica de contrainteligencia para envenenar todos los precios, ya que eso escalaría la carrera armamentista con los web scrapers. En su lugar, StuttArt debería elegir sabiamente el uno por ciento de las referencias que tendrán un impacto máximo en términos de competencia. Es muy probable que los web scrapers ni siquiera noten el problema. Incluso si los web scrapers notan las contramedidas, mientras se perciba como un problema de baja intensidad, no actuarán en consecuencia. De hecho, el web scraping conlleva todo tipo de problemas de baja intensidad: el sitio web que deseas analizar puede ser súper lento, puede estar caído, o la página web de interés puede tener fallos. Podría estar presente una promoción condicional, haciendo que el precio no sea claro para la pieza de interés.
Desde la perspectiva de StuttArt, nos queda elegir el uno por ciento de los números de pieza que son de máximo interés en términos de inteligencia competitiva. Esas piezas serían, típicamente, las que StuttArt desearía descontar más, pero sin desencadenar una guerra de precios. Hay varias formas de abordar esto. Un tipo de piezas de alto interés son los consumibles baratos, como los limpiaparabrisas. Un cliente que quiera probar StuttArt en su primera compra es poco probable que comience con un inyector de 600 Euro. Un cliente primerizo es mucho más probable que comience con un limpiaparabrisas de 20 Euro como prueba. Más generalmente, los clientes primerizos se comportan de manera bastante diferente a los clientes habituales. Por lo tanto, el uno por ciento de las piezas que probablemente StuttArt deba querer hacer especialmente atractivas, sin desencadenar una guerra de precios, son las piezas que es más probable que sean compradas por clientes primerizos.

Evitar una guerra de precios y la erosión de la cuota de mercado son resultados muy negativos para StuttArt, por lo que se requieren circunstancias especiales para desviarse del principio de alineación. Ya hemos visto una de estas circunstancias, que fue la necesidad de controlar el margen bruto. Sin embargo, no es la única. Los overstocks y faltantes de stock son otros dos candidatos principales a considerar para ajustar los precios. Los overstocks se abordan mejor de manera proactiva. Sería mejor para StuttArt evitar los overstocks por completo, pero ocurren errores, al igual que oscilaciones del mercado, y a pesar de cuidadosas políticas de reabastecimiento de inventario, StuttArt enfrentará rutinariamente overstocks localizados. La fijación de precios es un mecanismo valioso para mitigar estos problemas. StuttArt sigue siendo mejor vendiendo las piezas en overstock con un descuento sustancial en lugar de no venderlas en absoluto, por lo que los overstocks deben tenerse en cuenta en la estrategia de precios.
Limitemos el alcance de los overstocks a las únicas piezas que tienen muchas probabilidades de convertirse en baja de inventario. En este contexto, los overstocks pueden abordarse con una anulación del alineamiento de costos que reduce la etiqueta de precio a un margen bruto casi nulo, y posiblemente un poco por debajo, dependiendo de las regulaciones y de la magnitud del overstock.
Por el contrario, los faltantes de stock, o mejor dicho, casi faltantes de stock, deberían tener sus precios revisados al alza. Por ejemplo, si StuttArt solo tiene cinco unidades en stock para una pieza que normalmente se vende a razón de una unidad por día, y el próximo reabastecimiento no llegará hasta dentro de 15 días, entonces es casi seguro que esta pieza enfrentará un faltante de stock. No tiene sentido precipitarse hacia el faltante de stock. StuttArt podría aumentar su precio para esta pieza. Siempre y cuando la disminución en la demanda sea lo suficientemente pequeña como para que StuttArt evite un faltante de stock, no importará.
Las herramientas de inteligencia competitiva son cada vez más capaces de monitorear no solo los precios, sino también los retrasos en el envío anunciados para las piezas exhibidas en el sitio web de un competidor. Esto ofrece la posibilidad de que StuttArt monitorice no solo sus propios faltantes de stock, sino también los que se vayan desarrollando en los competidores. Una causa raíz frecuente detrás del faltante de stock de un minorista es el faltante de stock de un proveedor. Si el OEM mismo presenta un faltante de stock, entonces es probable que StuttArt, junto con todos sus competidores, termine también enfrentando un faltante de stock. Como parte del algoritmo de alineación de precios, es razonable eliminar aquellas piezas de la alineación que estén agotadas por los proveedores o que aparezcan como agotadas en el sitio web del competidor. Las situaciones de faltante de stock de los competidores pueden ser monitoreadas a través de retrasos en los envíos cuando dichos retrasos reflejan condiciones inusuales. Además, si un Fabricante de Equipos Originales (OEM) comienza a anunciar retrasos inusuales para las piezas, podría ser el momento de aumentar los puntos de precio para esas piezas. Esto se debe a que indica que es muy probable que todos en el mercado estén teniendo dificultades para adquirir más piezas de automóvil de este OEM en particular.
En este punto, debería quedar bastante claro que la optimización de precios y la optimización de inventario son problemas altamente acoplados, y por lo tanto, estos dos problemas deben resolverse conjuntamente en la práctica. De hecho, dentro de una determinada unidad de necesidad, la pieza que se beneficie tanto del precio más bajo como del rango de exhibición más alto dentro de su línea de productos absorberá la mayor parte de las ventas. La fijación de precios dirige la demanda entre numerosas alternativas dentro de la oferta de StuttArt. No tiene sentido que un equipo de inventario intente hacer una previsión de los precios generados por el equipo de precios. En su lugar, debería existir una función unificada de supply chain que aborde ambas cuestiones de manera conjunta.

Las condiciones de envío son una parte integral del servicio. Cuando se trata de piezas de automóvil, no solo los clientes tienen grandes expectativas de que StuttArt cumplirá sus promesas, sino que incluso podrían estar dispuestos a pagar un extra si se acelera el proceso. Varias importantes empresas de ecommerce que venden piezas de automóvil en Europa ya están ofreciendo precios distintos dependiendo del tiempo de entrega. Estos precios distintos no reflejan solamente diferentes opciones de envío, sino posiblemente también diferentes opciones de aprovisionamiento. Si el cliente está dispuesto a esperar una o dos semanas, entonces StuttArt gana opciones de aprovisionamiento extra, y StuttArt podría trasladar parte de los ahorros directamente a los clientes. Por ejemplo, una pieza puede ser adquirida por StuttArt solo después de que el cliente la haya pedido, eliminando así por completo el costo de mantenimiento y el riesgo de inventario.
Las condiciones de envío complican la inteligencia competitiva. Primero, las herramientas de inteligencia competitiva necesitan recuperar información sobre los retrasos, no solo sobre los precios. Muchos especialistas en inteligencia competitiva ya lo están haciendo, y StuttArt necesita hacer lo mismo. Segundo, StuttArt necesita ajustar su algoritmo de alineación de precios para reflejar las condiciones de envío variables. La programación diferenciable puede ponerse al servicio de proporcionar una estimación del valor, expresado en euros, que se obtiene al ahorrar un día de tiempo. Se espera que este valor dependa del modelo de automóvil, el tipo de pieza y el número de días para el envío. Por ejemplo, pasar de un tiempo de entrega de tres días a uno de dos días es mucho más valioso para el cliente que pasar de un tiempo de entrega de 21 días a uno de 20 días.

En conclusión, hoy se ha propuesto una estrategia de precios extensa para StuttArt, una supply chain persona dedicada al mercado de repuestos automotrices en línea. Hemos visto que la fijación de precios no es susceptible de ningún tipo de estrategia de optimización local. El problema de la fijación de precios es, en efecto, no local debido a la compatibilidad mecánica que propaga el impacto de una etiqueta de precio para cualquier pieza dada a lo largo de numerosas unidades de necesidad. Esto nos llevó a una perspectiva en la que los precios se abordan como una alineación a nivel de la unidad de necesidad. Se abordaron dos subproblemas a través de la programación diferenciable. Primero, tuvimos la resolución de un problema aproximado de satisfacción de restricciones para la propia alineación competitiva. Segundo, tuvimos el problema de la auto-mejora de los conjuntos de datos de compatibilidad mecánica para mejorar la calidad de la alineación, pero también para mejorar la calidad de la experiencia del cliente. Podemos añadir estos dos problemas a nuestra creciente lista de problemas de supply chain que se benefician de una solución sencilla una vez abordados a través de la programación diferenciable.
Más en general, si hay una lección que extraer de esta conferencia, no es que el mercado de repuestos automotrices sea un caso aislado en lo que respecta a las estrategias de fijación de precios. Al contrario, la conclusión es que siempre debemos esperar enfrentarnos a numerosas especificidades, sin importar el sector de interés. Habría habido tantas especificidades si hubiéramos analizado cualquier otra supply chain persona en lugar de centrarnos en StuttArt, como lo hicimos hoy. Por lo tanto, es inútil buscar una respuesta definitiva. Cualquier solución de forma cerrada está garantizada a fallar al abordar el flujo interminable de variaciones que surgirán con el tiempo en una supply chain real. En cambio, necesitamos conceptos, métodos e instrumentos que no solo nos permitan abordar el estado actual de la supply chain, sino que también sean susceptibles de modificación programática. La programabilidad es esencial para hacer a prueba de futuro las recetas numéricas para la fijación de precios.

Antes de pasar a las preguntas, me gustaría anunciar que la próxima conferencia será en la primera semana de julio. Será un miércoles, como de costumbre, a la misma hora del día - 3 P.M, hora de París. Volveré a ver el capítulo uno con una mirada más cercana a lo que la economía, la historia y la teoría de sistemas nos dicen sobre supply chain y la planificación de supply chain.
Ahora veamos las preguntas.
Pregunta: ¿Tiene la intención de ofrecer una conferencia sobre la visualización del costo total de propiedad para una supply chain? En otras palabras, ¿un análisis TCO de toda la supply chain utilizando análisis de datos y optimización general de costos?
Sí, esto es parte del recorrido de esta serie de conferencias. Elementos de esto se han discutido ya en bastantes conferencias. Pero lo fundamental es que, en realidad, no es un problema de visualización. El punto del costo total de propiedad no es un problema de visualización de datos; es un problema de mentalidad. La mayoría de las prácticas de supply chain son extremadamente despectivas con respecto a la perspectiva financiera. Están persiguiendo servicio de error, no dólares o Euros de error. La mayoría, desafortunadamente, persigue estos porcentajes. Por lo tanto, es necesario un cambio de mentalidad.
La segunda cosa es que hay elementos discutidos en la conferencia que formaron parte del primer capítulo - la entrega orientada a productos, como en la entrega orientada a productos de software para la supply chain. Tenemos que pensar no solo en el primer círculo de impulsores económicos, sino también en lo que yo llamo el segundo círculo de impulsores económicos. Se trata de fuerzas evasivas; por ejemplo, si se descuenta el precio de un producto por un Euro creando una promoción, un análisis ingenuo podría sugerir que me costó un Euro de margen simplemente porque hice ese descuento de un Euro. Pero la realidad es que, al hacer eso, se está creando una expectativa entre su base de clientes para esperar de nuevo ese descuento de un Euro en el futuro. Y así, esto conlleva un costo. Es un costo de segunda orden, pero es muy real. Todos estos impulsores económicos del segundo círculo son impulsores importantes que no aparecen en su libro de contabilidad. Sí, procederé con más elementos que describen estos costos. Sin embargo, en su mayor parte no es un problema analítico en términos de visualización o graficación; es una cuestión de mentalidad. Debemos aceptar la idea de que estas cosas deben ser cuantificadas, incluso si son increíblemente difíciles de cuantificar.
Cuando empezamos a discutir el costo total de propiedad, también tenemos que hablar de cuántas personas necesito para operar esta solución de supply chain. Esa es una de las razones por las que, en esta serie de conferencias, digo que necesitamos tener soluciones programáticas. No podemos tener un ejército de empleados ajustando spreadsheets o tablas y haciendo cosas que son increíblemente ineficientes en términos de costo, como lidiar con alertas de excepciones en el software de supply chain. Las alertas y excepciones consisten en tratar a toda la fuerza laboral de la empresa como co-procesadores humanos para el sistema. Esto es increíblemente costoso.
El análisis del costo total de propiedad es, en su mayor parte, un problema de mentalidad, de tener la perspectiva correcta. En la próxima conferencia, también revisaré más ángulos, especialmente lo que la economía nos dice sobre la supply chain. Es muy interesante porque tenemos que pensar en lo que el costo total de propiedad realmente significa para una solución de supply chain, especialmente si empezamos a pensar en el valor que aporta a la empresa.
Pregunta: Para referencias técnicamente compatibles a una unidad de necesidad, se perciben diferencias en la calidad, la actividad, plata, oro, etc. ¿Cómo tiene en cuenta esto en la igualación de precios de los competidores?
Eso es completamente correcto. Por eso es necesario introducir gamas de productos. Este nivel de atractivo generalmente se puede enmarcar en alrededor de media docena de clases que representan estándares de calidad para las piezas. Por ejemplo, tienes la gama motorsport, que incluye las piezas más lujosas con excelente compatibilidad mecánica. Estas piezas también tienen buen aspecto, y el empaque en sí es de alta calidad.
Mi experiencia con este mercado es que, aunque existen infinitas variaciones en cómo se puede hacer que la calidad de una pieza sea ligeramente superior o mejor, el mercado se ha convergido prácticamente en unas media docena de gamas de productos que van desde muy caros hasta no tan caros. Cuando agrupamos las piezas de StuttArt, necesitamos agrupar esas piezas dentro de gamas de productos. Lo mismo es cierto para las piezas de los competidores, lo que significa que necesitamos saber cuál es el rango de calidad de una pieza, incluso si la pieza no es vendida por StuttArt.
StuttArt necesita tener conciencia de todas las piezas del mercado. Esto no es tan difícil como puede parecer, porque la mayoría de los fabricantes proporcionan información sobre la calidad esperada de sus piezas. Estas cosas están bastante codificadas por los propios fabricantes de equipos originales (OEMs). Nos beneficiamos del hecho de que el mercado automotriz es un mercado increíblemente establecido y super maduro que ha existido por más de un siglo. Las empresas que venden estos conjuntos de datos de compatibilidad, conjuntos de datos para compatibilidades de coches y piezas, también proporcionan una gran cantidad de atributos para las piezas y los modelos de coches. Estamos hablando de cientos de atributos. Estos conjuntos de datos son extensos y ricos. Originalmente, estos conjuntos de datos eran utilizados por personas en centros de reparación para determinar cómo realizar las reparaciones. Incluso vienen con archivos PDF adjuntos y documentación técnica. Es muy rico; tienes decenas de gigabytes de datos, incluyendo imágenes y fotos. Apenas estaba rascando la superficie en términos del valor de mercado de estos conjuntos de datos.
Pregunta: ¿Cómo impactan las regulaciones variables a través de las regiones en la optimización de precios para las empresas automotrices? Por ejemplo, mencionaste Peugeot, una empresa francesa. ¿Cómo diferiría tu enfoque para Peugeot de una empresa similar en Escandinavia o Asia?
Escandinavia es prácticamente el mismo mercado automotriz. Tienen algunas marcas diferentes, pero es demasiado pequeño para sostener su propia industria automotriz. En lo que respecta a la industria automotriz, Escandinavia es como el resto de los 350 millones de europeos. Sin embargo, Asia es realmente diferente. India y China son mercados propios.
En lo que respecta a la optimización de precios, las regulaciones no impidieron tanto, sino que retrasaron la existencia de distribuidores de piezas de automóvil en línea. Por ejemplo, en Europa hace 20 años, hubo una batalla legal. Pioneros como StuttArt, que fueron las primeras empresas en vender piezas de automóvil en línea, enfrentaron disputas legales. Estaban vendiendo piezas de automóvil y afirmaban en su sitio web que estas eran idénticas a las vendidas por los fabricantes originales de automóviles.
Empresas como StuttArt decían: “No te estoy vendiendo ninguna pieza de automóvil, te estoy vendiendo la misma pieza de automóvil que utilizaría el fabricante del automóvil.” Pudieron hacer esta afirmación porque estaban comprando exactamente la misma pieza de la misma fábrica. Si una pieza proviene, digamos, de Valeo y se monta en un automóvil Peugeot, existe una asociación conocida. Lo que se dictaminó hace aproximadamente dos décadas, en varios tribunales de Europa, fue que era legal que un sitio web afirmara vender la misma pieza que las que califican como piezas originales de un automóvil. Esta incertidumbre regulatoria retrasó el auge de las piezas de automóvil de repuesto vendidas en línea, probablemente en unos cinco años. Los pioneros se enfrentaron en los tribunales contra los fabricantes de automóviles por el derecho a vender piezas de automóvil en línea mientras afirmaban que eran piezas originales para el automóvil. Una vez que se aclaró, podían hacerlo siempre y cuando fueran honestos y realmente compraran la misma pieza de automóvil exacta de Valeo o Bosch, exactamente como la pieza que se monta en el automóvil.
Sin embargo, todavía existen limitaciones. Por ejemplo, aún hay piezas que caracterizan la apariencia visual del automóvil, y solo el fabricante del automóvil puede venderlas como piezas originales. Por ejemplo, el capó del automóvil. Estas regulaciones sí tienen un impacto en términos de restringir el alcance de las piezas que pueden ser vendidas libremente en línea mientras se afirma que la pieza es exactamente la misma que la del fabricante original. Estamos hablando de piezas que tienen implicaciones no solo en términos de compatibilidad mecánica, sino también de seguridad. Algunas de estas piezas son críticas en términos de seguridad.
En Asia, un problema que no he discutido aquí son las falsificaciones. Tratar con falsificaciones es muy diferente en Europa en comparación con Asia. Las falsificaciones existen en Europa, pero el mercado está maduro y catalizado. Los OEM y los fabricantes de automóviles se conocen muy bien. Aunque las falsificaciones existen, es un problema muy mínimo. En mercados como Asia, específicamente en India y China, todavía existen bastantes problemas con las falsificaciones. Realmente no es un problema de regulación, ya que las falsificaciones son tan ilegales en China como lo son en Europa. El problema es la aplicación de la ley, con un grado de cumplimiento mucho menor en Asia que en Europa.
Pregunta: ¿Estamos tratando de optimizar un precio en general o en relación con los competidores?
La función de optimización es conceptualmente para cada unidad de necesidad - una unidad de necesidad es un modelo de automóvil y un tipo de parte. Para cada unidad de necesidad, tienes una diferencia de precio en euros entre el punto de precio de StuttArt, que es la mejor oferta de StuttArt, y el punto de precio del competidor. Tomas la diferencia absoluta de estos dos precios y las sumas; esta es tu función. No vamos a usar ingenuamente esta suma de diferencias de precio; vamos a añadir un factor de ponderación que refleje el volumen anual de ventas de cada unidad de necesidad.
Por lo tanto, la función de optimización para tu problema de satisfacción de restricciones es una suma de diferencias absolutas entre el mejor precio ofrecido por StuttArt para la unidad de necesidad y el mejor precio ofrecido por la competencia. Agregas un factor de ponderación que refleja la importancia anual, también ponderado en euros, para esta unidad de necesidad. Estás haciendo tu mejor esfuerzo para reflejar el estado del mercado europeo.
La razón por la que quieres ponderar en función de la importancia de la unidad de necesidad, en lugar de la unidad de necesidad de StuttArt, es que si StuttArt es tan poco competitiva que no vende nada de la unidad de necesidad, puedes tener un problema en el que no es competitiva. Por lo tanto, esta unidad se descarta en términos de alineación, lo que conduce a cero ventas. Entonces tienes un círculo vicioso en el que no es competitiva, por lo tanto, no vende nada, y por consiguiente, la propia unidad de necesidad se descuenta como insignificante.
Pregunta: ¿Ves consecuencias inesperadas surgiendo si un enfoque de aprendizaje automático basado en una perspectiva de modelado diferenciable se convierte en el estándar de la industria, con el riesgo de que los modelos compitan con otros modelos muy similares?
Esta pregunta es difícil porque, por diseño, si es una consecuencia inesperada, entonces nadie la esperaba, ni siquiera yo. Es muy difícil prever qué tipo de consecuencias podrían ser inesperadas.
Sin embargo, más seriamente, esta industria ha sido impulsada por técnicas algorítmicas durante una década. Es un refinamiento en términos de la precisión de la intención. Quieres un método numérico que esté más alineado con tu intención. Pero, fundamentalmente, no es como si estuviéramos empezando desde cero, donde ahora se hace manualmente y en diez años se hará automáticamente con recetas numéricas. Ya se hace con recetas numéricas. Cuando tienes 100,000 precios para mantener y actualizar cada día, necesitas tener alguna forma de automatización.
Quizás tu automatización sea una gigantesca hoja de cálculo de Excel donde realizas todo tipo de magia negra, pero sigue siendo un proceso algorítmico. Las personas no ajustan precios manualmente, excepto en unas pocas partes en ocasiones raras. Mayormente, ya es un proceso algorítmico, y ya tenemos numerosas consecuencias no intencionadas. Por ejemplo, durante los confinamientos en Europa, la gente pasaba más tiempo en casa, comprando online. Esto podría parecer contraintuitivo, pero seguían usando mucho sus coches, y por lo tanto, compraban más. Sin embargo, muchas empresas que venden piezas de automóviles online se volvieron menos activas en términos de promociones porque organizarlas se volvió más complicado ya que todos trabajaban desde casa.
En consecuencia, durante un par de meses durante los confinamientos de 2020, hubo mucho menos ruido algorítmico generado por las promociones. Las respuestas algorítmicas fueron mucho más directas por parte de todos. Hubo días en que se podía ver de manera mucho más clara el tipo de respuestas algorítmicas que se activaban con una actualización diaria.
Este es un modelo bastante maduro en una industria bien establecida, ya que ahora todo se realiza mediante comercio electrónico. En cuanto a las consecuencias no intencionadas o inesperadas, son más difíciles de predecir.
Permíteme ofrecer un pensamiento final sobre un área potencial de sorpresa. Muchos esperan que los vehículos eléctricos simplifiquen todo porque tienen menos piezas comparado con los motores de combustión interna. Sin embargo, desde la perspectiva de una empresa como StuttArt, durante los próximos 10 años, los vehículos eléctricos significarán muchas más piezas en el mercado.
Hasta que, y si, los vehículos eléctricos se vuelvan dominantes, todavía tendremos todos los vehículos antiguos con motores de combustión. Estos vehículos durarán alrededor de 20 años. Recuerda que StuttArt, como empresa, trata con vehículos que no son exactamente nuevos. Muchos de estos vehículos son de buena calidad y seguirán estando alrededor de 20 años a partir de ahora. Pero mientras tanto, tendremos numerosos vehículos eléctricos adicionales que ingresarán al mercado con muchísimas piezas diferentes. Esto podría causar que el número de piezas diferentes aumente de manera constante, creando aún más desafíos y complicaciones.
Creo que esto nos lleva al final de la lección de hoy. Si no hay más preguntas, espero verles en la próxima lección, que será la primera semana de julio, el miércoles a las 3 p.m. hora de París, como de costumbre. Muchas gracias, y hasta entonces.