00:00 Introduzione
02:49 Domanda, prezzo e profitto
09:35 Prezzi competitivi
15:23 Desideri vs necessità
20:09 La storia finora
23:36 Indicazioni per oggi
25:17 L’unità di bisogno
31:03 Auto e ricambi (riassunto)
33:41 Competitive intelligence
36:03 Risolvere l’allineamento (1/4)
39:26 Risolvere l’allineamento (2/4)
43:07 Risolvere l’allineamento (3/4)
46:38 Risolvere l’allineamento (4/4)
56:21 Gamma di prodotti
59:43 Ricambi non vincolati
01:02:44 Controllare il margine
01:06:54 Visualizzare le posizioni
01:08:29 Regolazione fine dei pesi
01:12:45 Regolazione fine delle compatibilità (1/2)
01:19:14 Regolazione fine delle compatibilità (2/2)
01:30:41 Controintelligence (1/2)
01:35:25 Controintelligence (2/2)
01:40:49 Eccesso di scorte e mancanza di scorte
01:45:45 Condizioni di spedizione
01:47:58 Conclusione
01:50:33 6.2 Ottimizzazione dei Prezzi per l’Aftermarket Automobilistico - Domande?
Descrizione
L’equilibrio tra domanda e offerta dipende fortemente dai prezzi. Pertanto, l’ottimizzazione dei prezzi appartiene al dominio della supply chain, almeno in larga misura. Presenteremo una serie di tecniche per ottimizzare i prezzi di una fittizia azienda dell’aftermarket automobilistico. Attraverso questo esempio, vedremo il pericolo associato a linee di ragionamento astratte che non riescono a cogliere il contesto adeguato. Sapere cosa debba essere ottimizzato è più importante dei dettagli minuti dell’ottimizzazione stessa.
Trascrizione Completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò l’ottimizzazione dei prezzi per l’aftermarket automobilistico. Il pricing è un aspetto fondamentale della supply chain. Infatti, non si può valutare l’adeguatezza di un determinato volume di offerta o di inventario senza considerare la questione dei prezzi, poiché questi incidono significativamente sulla domanda. Tuttavia, la maggior parte dei libri sulla supply chain, e di conseguenza la maggior parte dei supply chain software, trascura del tutto il pricing. Anche quando il pricing viene discusso o modellato, ciò avviene di solito in modi ingenui che spesso fraintendono la situazione.
Il pricing è un processo fortemente dipendente dal contesto. I prezzi sono, prima di tutto, un messaggio inviato da un’azienda al mercato nel suo complesso - ai clienti, ma anche ai fornitori e ai concorrenti. I dettagli dell’analisi dei prezzi dipendono fortemente dall’azienda interessata. Avvicinarsi al pricing in termini generali, come fanno i microeconomisti, può essere intellettualmente allettante, ma anche fuorviante. Questi approcci potrebbero non essere abbastanza precisi a sostenere la produzione di strategie di pricing di livello professionale.
Questa lezione si concentra sull’ottimizzazione dei prezzi per un’azienda dell’aftermarket automobilistico. Riprenderemo Stuttgart, un’azienda fittizia introdotta nel terzo capitolo di questa serie di lezioni. Ci concentreremo esclusivamente sul segmento del commercio online di Stuttgart, che distribuisce ricambi per auto. L’obiettivo di questa lezione è comprendere cosa implichi il pricing una volta superate le banalità e come avvicinarsi al pricing con una mentalità orientata al mondo reale. Sebbene prenderemo in considerazione un verticale ristretto - i ricambi per auto dell’aftermarket automobilistico - il modo di pensare, la mentalità e l’approccio adottati in questa lezione nel perseguire strategie di pricing superiori sarebbero essenzialmente gli stessi anche per verticali completamente diversi.
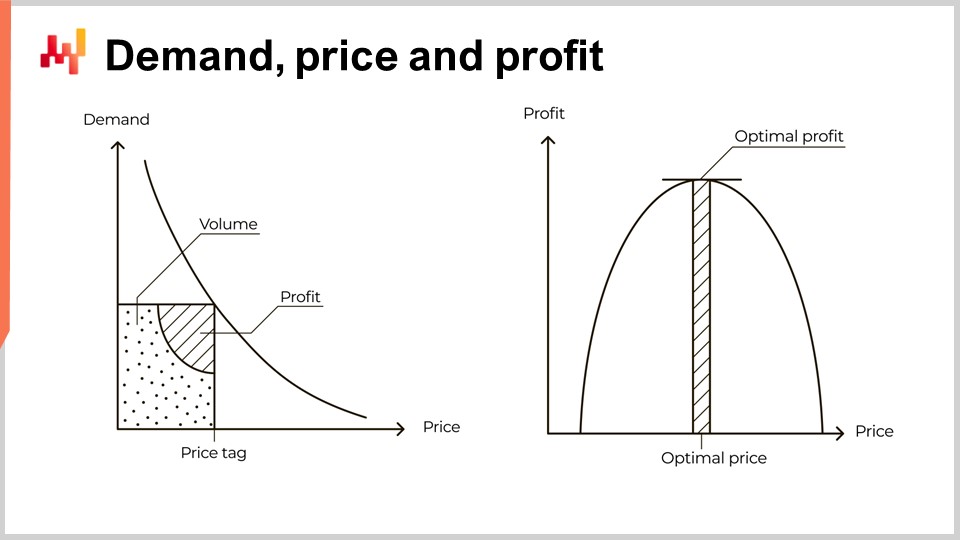
La domanda diminuisce all’aumentare del prezzo. Questo è un modello economico universale. L’esistenza stessa di prodotti che contraddicono questo modello rimane per lo più sfuggente. Questi prodotti sono chiamati beni Veblen. Tuttavia, in 15 anni in Lokad, anche trattando con marchi di lusso, non ho mai potuto accedere a prove tangibili che tali prodotti esistano realmente. Questo modello universale è illustrato dalla curva sulla sinistra dello schermo, generalmente chiamata curva della domanda. Quando un mercato si fissa un prezzo, ad esempio, il prezzo di un ricambio per auto, questo mercato genera un certo volume di domanda e, si spera, anche un certo volume di profitto per gli attori che soddisfano tale domanda.
Per quanto riguarda i ricambi per auto, questi non sono affatto beni Veblen. La domanda diminuisce all’aumentare del prezzo. Tuttavia, poiché le persone non hanno molte alternative nell’acquisto di ricambi per auto, almeno se desiderano continuare a guidare, la domanda può essere considerata relativamente anelastica. Un prezzo più alto o più basso per le pastiglie dei freni non altera realmente la decisione di acquistare nuove pastiglie. Infatti, la maggior parte delle persone preferirebbe comprare nuove pastiglie, anche se dovessero pagare il doppio del prezzo abituale, piuttosto che smettere del tutto di usare il veicolo.
Per Stuttgart, identificare il prezzo migliore per ogni pezzo è fondamentale per innumerevoli motivi. Esploriamo le due ragioni più evidenti. In primo luogo, Stuttgart vuole massimizzare i suoi profitti, il che non è banale, poiché non solo la domanda varia con il prezzo, ma anche i costi variano col volume. Stuttgart deve essere in grado di soddisfare la domanda che genererà in futuro, il che è ancora più complesso, in quanto l’inventario deve essere assicurato con giorni, se non settimane, d’anticipo a causa dei tempi di consegna.
Basandosi su questa esposizione limitata, alcuni libri di testo, e persino alcuni software aziendali, procedono con la curva illustrata a destra. Questa curva illustra concettualmente il volume di profitto atteso per ogni prezzo. Dato che la domanda diminuisce all’aumentare del prezzo, e il costo unitario diminuisce con l’aumentare del volume, questa curva dovrebbe mostrare un punto di profitto ottimale che massimizza il guadagno. Una volta identificato questo punto ottimale, adeguare la fornitura dell’inventario viene presentato come una questione di semplice orchestrazione. Infatti, il punto ottimale fornisce non solo un prezzo, ma anche un volume di domanda.
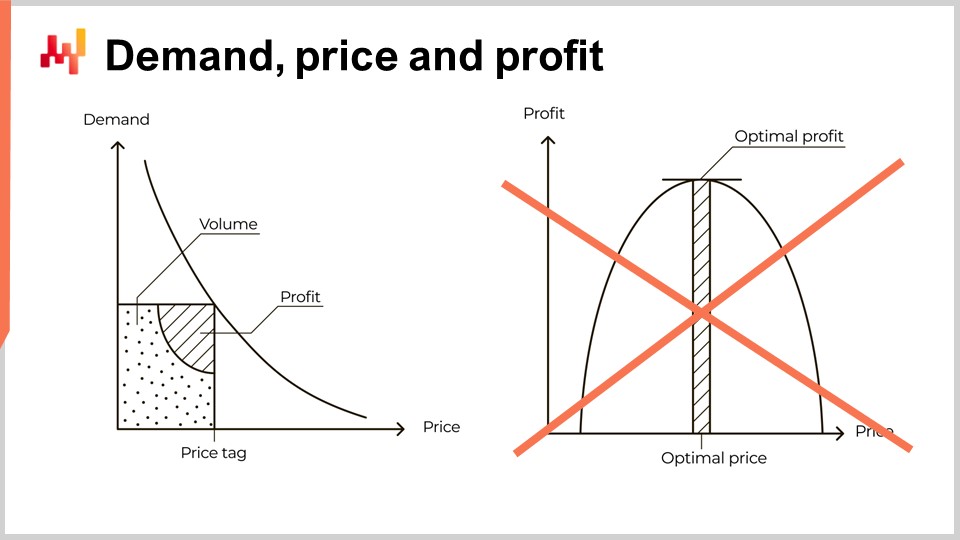
Tuttavia, questa prospettiva è profondamente fuorviante. Il problema non ha nulla a che fare con la difficoltà di quantificare l’elasticità. La mia proposta non è che la curva a sinistra sia errata; essa è fondamentalmente corretta. La mia tesi è che il salto dalla curva a sinistra a quella a destra sia scorretto. Infatti, questo salto è così sorprendentemente sbagliato da fungere da vero e proprio banco di prova. Qualsiasi fornitore di software o libro di testo sul pricing che presenti il pricing in questo modo dimostra un pericoloso grado di analfabetismo economico, specialmente se valutano l’elasticità come la sfida centrale associata a questa prospettiva. Questo non è nemmeno lontanamente il caso. Affidarsi a un fornitore o esperto del genere in una supply chain reale significa invitare dolore e miseria. Se c’è una cosa di cui la tua supply chain non ha bisogno, è un’interpretazione difettosa di una microeconomia fraintesa su larga scala.
In questa serie di lezioni, questo è un altro esempio di razionalismo ingenuo o scientismo, che si è ripetutamente dimostrato una minaccia significativa per le modern supply chains. Il ragionamento economico astratto è potente perché cattura una gamma sorprendente di situazioni. Tuttavia, il ragionamento astratto è anche suscettibile a grossi fraintendimenti. Gravi errori intellettuali, non immediatamente evidenti, possono verificarsi quando si pensa in termini molto generali.
Per capire perché il salto dalla curva a sinistra a quella a destra sia scorretto, dobbiamo esaminare più da vicino ciò che accade realmente in una supply chain reale. Questa lezione si concentra sui ricambi per auto. Riesamineremo il pricing dal punto di vista di Stuttgart, un’azienda fittizia della supply chain introdotta nel terzo capitolo di questa serie di lezioni. Non riprenderemo i dettagli di questa azienda. Se non avete ancora visto la lezione 3.4, vi invito a farlo dopo questa lezione.
Oggi esaminiamo il segmento del commercio online di Stuttgart, una divisione e-commerce che vende ricambi per auto. Stiamo esplorando i modi più appropriati per consentire a Stuttgart di determinare i propri prezzi e di rivederli in qualsiasi momento. Questo compito deve essere svolto per ogni singolo pezzo venduto da Stuttgart.

Stuttgart non è sola in questo mercato. In ogni paese europeo in cui opera Stuttgart, ci sono una mezza dozzina di concorrenti di rilievo. Questa breve lista di aziende, inclusa Stuttgart, rappresenta la maggioranza della quota di mercato online per i ricambi auto. Mentre Stuttgart vende in esclusiva alcuni pezzi, per la maggior parte dei pezzi venduti, esiste almeno un concorrente di rilievo che vende lo stesso pezzo. Questo fatto ha implicazioni significative per l’ottimizzazione dei prezzi di Stuttgart.
Consideriamo cosa succede se, per un determinato pezzo, Stuttgart decide di fissare un prezzo un euro inferiore a quello offerto da un concorrente che vende lo stesso pezzo. In teoria, ciò renderebbe Stuttgart più competitiva e aiuterebbe a catturare quote di mercato. Ma non così in fretta. Il concorrente monitora tutti i prezzi impostati da Stuttgart. Infatti, l’aftermarket automobilistico è un mercato altamente competitivo. Tutti dispongono di strumenti di competitive intelligence. Stuttgart raccoglie quotidianamente tutti i prezzi dei suoi concorrenti di rilievo, e lo fanno anche i concorrenti. Quindi, se Stuttgart decide di fissare il prezzo di un pezzo un euro inferiore a quello offerto da un concorrente, è lecito supporre che, in un giorno o due, il concorrente abbasserà il proprio prezzo in risposta, annullando il movimento di prezzo di Stuttgart.
Anche se Stuttgart può essere un’azienda fittizia, questo comportamento competitivo descritto qui non è affatto fittizio nell’aftermarket automobilistico. I concorrenti allineano aggressivamente i loro prezzi. Se Stuttgart tenterà ripetutamente di abbassare i suoi prezzi, ciò porterà a una guerra algoritmica dei prezzi, lasciando entrambe le aziende con margini ridotti o inesistenti alla fine della guerra.
Consideriamo cosa succede se, per un determinato pezzo, Stuttgart decide di fissare un prezzo un euro superiore a quello offerto da un concorrente. Supponendo che tutto il resto rimanga invariato a parte il prezzo, Stuttgart non sarebbe più competitiva. Così, mentre la base clienti di Stuttgart potrebbe non abbandonare immediatamente per il concorrente (dato che potrebbero non essere nemmeno consapevoli della differenza di prezzo o rimanere fedeli a Stuttgart), col tempo la quota di mercato di Stuttgart è destinata a ridursi.
In Europa esistono siti web di comparazione prezzi per i ricambi auto. Anche se i clienti potrebbero non confrontare ogni volta di aver bisogno di un nuovo pezzo per la loro auto, la maggior parte dei clienti riconsidererà le proprie opzioni di tanto in tanto. Non è una soluzione praticabile per Stuttgart essere costantemente identificata come il rivenditore più costoso.
Abbiamo dunque visto che Stuttgart non può avere un prezzo inferiore a quello della concorrenza, poiché ciò innesca una guerra dei prezzi. Al contrario, Stuttgart non può avere un prezzo superiore a quello dei concorrenti, in quanto ciò garantisce l’erosione della sua quota di mercato nel tempo. L’unica opzione rimasta per Stuttgart è cercare un allineamento dei prezzi. Questa non è una dichiarazione teorica: l’allineamento dei prezzi è il principale motore per le aziende e-commerce reali che vendono ricambi per auto in Europa.
La curva di profitto intellettualmente affascinante che abbiamo introdotto in precedenza, in cui le aziende potevano presumibilmente scegliere il profitto ottimale, è in gran parte del tutto falsa. Stuttgart non ha nemmeno una scelta quando si tratta dei suoi prezzi. In larga misura, a meno che non vi sia qualche sorta di ingrediente segreto, l’allineamento dei prezzi è l’unica opzione per Stuttgart.
I mercati liberi sono una strana bestia, come diceva Engels nella sua corrispondenza del 1819: “La volontà di ogni individuo è ostacolata da quella di tutti gli altri, e ciò che emerge è qualcosa che nessuno aveva voluto.” Vedremo in seguito che Stuttgart mantiene una certa margine residuo per fissare i suoi prezzi. Tuttavia, la proposta principale rimane: l’ottimizzazione dei prezzi per Stuttgart è, prima di tutto, un problema fortemente vincolato, che non ha nulla in comune con una prospettiva ingenua di massimizzazione guidata da una curva della domanda.
L’elasticità della domanda è un concetto che ha senso per un mercato nel suo insieme, ma di solito non tanto per qualcosa di localizzato come un numero di parte.

L’idea che il pricing possa essere affrontato come un semplice problema di massimizzazione del profitto sfruttando la curva della domanda è falsa—o almeno, è falsa nel caso di Stuttgart.
Infatti, si potrebbe sostenere che Stuttgart appartenga a un mercato dei bisogni, e la prospettiva delle curve di profitto funzionerebbe ancora se considerassimo un mercato dei desideri. Nel marketing, è una distinzione classica separare i mercati dei desideri da quelli dei bisogni. Un mercato dei desideri è tipicamente caratterizzato da offerte in cui i clienti possono rinunciare al consumo senza subire conseguenze negative. Nei mercati dei desideri, le offerte di successo tendono ad essere fortemente legate al marchio del venditore, e il marchio stesso è il motore che genera la domanda in primo luogo. Per esempio, la moda è l’archetipo dei mercati dei desideri. Se vuoi una borsa di Louis Vuitton, allora questa borsa può essere acquistata solo da Louis Vuitton. Sebbene ci siano centinaia di venditori che offrono borse funzionalmente equivalenti, non saranno una borsa di Louis Vuitton. Se decidi di non comprare una borsa di Louis Vuitton, allora non ti accadrà nulla di grave.
Un mercato di bisogno è tipicamente caratterizzato da offerte in cui i clienti non possono rinunciare al consumo senza subire gravi conseguenze. Nei mercati dei bisogni, i marchi non sono motori della domanda; sono più simili a motori della scelta. I marchi guidano i clienti nella scelta di chi consumare una volta che si presenta il bisogno di consumo. Ad esempio, l’alimentazione e le necessità di base sono l’archetipo dei mercati dei bisogni. Anche se le parti di automobili non sono strettamente necessarie per sopravvivere, molte persone dipendono da un veicolo per guadagnarsi da vivere e, pertanto, non possono realisticamente rinunciare a una corretta manutenzione del loro veicolo, poiché il costo per loro della mancanza di manutenzione supererebbe di gran lunga il costo stesso della manutenzione.
Sebbene il mercato post-vendita automobilistico sia fermamente ancorato al mercato dei bisogni, ci sono delle sfumature. Esistono componenti come i coprimozzi che sono più desideri che necessità. Più in generale, tutti gli accessori sono più desideri che necessità. Tuttavia, per Stuttgart, i bisogni guidano la stragrande maggioranza della domanda.
La critica che propongo qui contro la curva di profitto per il pricing si generalizza a quasi tutte le situazioni nei mercati dei bisogni. Stuttgart non è un caso isolato nel trovarsi fortemente limitata nei prezzi rispetto ai suoi concorrenti; tale situazione è quasi ubiqua nei mercati dei bisogni. Questo argomento non smentisce la validità della curva di profitto quando si considerano i mercati dei desideri.
Infatti, si potrebbe obiettare che in un mercato dei desideri, se il venditore ha il monopolio sul proprio marchio, allora dovrebbe essere libero di scegliere qualunque prezzo massimizzi il suo profitto, riportandoci alla prospettiva della curva di profitto per il pricing. Ancora una volta, questo contro-argomento dimostra i pericoli di un ragionamento economico astratto nella supply chain.
In un mercato dei desideri, la prospettiva della curva di profitto è anch’essa errata, seppure per una serie di ragioni completamente diverse. I dettagli di questa dimostrazione sono al di fuori dell’ambito della presente lezione, in quanto richiederebbero una lezione a parte. Tuttavia, come esercizio per il pubblico, suggerirei semplicemente di dare uno sguardo più attento all’elenco di borse e ai loro prezzi esposti sul sito di e-commerce di Louis Vuitton. La ragione per cui la prospettiva della curva di profitto è inappropriata dovrebbe diventare evidente in modo naturale. In caso contrario, beh, probabilmente riprenderemo questo caso in una lezione successiva.
Questa serie di lezioni è intesa, tra le altre cose, come materiale di formazione per i supply chain scientists di Lokad. Tuttavia, spero anche che queste lezioni possano interessare un pubblico molto più ampio di professionisti della supply chain. Cerco di mantenere queste lezioni abbastanza separate, ma utilizzerò alcuni concetti tecnici che sono stati introdotti nelle lezioni precedenti. Non dedicherò troppo tempo a reintrodurre tali concetti. Se non avete seguito le lezioni precedenti, non esitate a dar loro un’occhiata in seguito.
Nel primo capitolo di questa serie, abbiamo esplorato perché le supply chains devono diventare programmatiche. È altamente desiderabile mettere in produzione una ricetta numerica a causa della complessità sempre crescente delle supply chains. L’automazione è più urgente che mai e c’è un imperativo finanziario nel rendere la supply chain practice un’impresa capitalistica.
Nel secondo capitolo, abbiamo dedicato del tempo alle metodologie. Le supply chains sono sistemi competitivi e questa combinazione sconfigge le metodologie ingenua. Abbiamo visto che questa combinazione sconfigge anche i modelli che interpretano erroneamente o caratterizzano male la microeconomia.
Il terzo capitolo ha esaminato i problemi incontrati nelle supply chains, lasciando da parte le soluzioni. Abbiamo presentato Stuttgart come una delle personae della supply chain. Questo capitolo ha cercato di caratterizzare le tipologie di problemi decisionali che devono essere risolti e ha dimostrato che prospettive semplicistiche, come scegliere la giusta quantità di stock, non si adattano alle situazioni del mondo reale. Esiste invariabilmente una profondità nella natura delle decisioni da prendere.
Il capitolo quattro ha esaminato gli elementi necessari per comprendere le pratiche moderne della supply chain, dove gli elementi software sono onnipresenti. Questi elementi sono fondamentali per comprendere il contesto più ampio in cui opera la digital supply chain.
I capitoli cinque e sei sono dedicati rispettivamente alla modellazione predittiva e al decision-making. Questi capitoli raccolgono tecniche che funzionano bene nelle mani dei supply chain scientists oggi. Il sesto capitolo si concentra sul pricing, un tipo di decisione che deve essere presa tra molte altre.
Infine, il settimo capitolo è dedicato all’esecuzione di un’iniziativa di quantitative supply chain e copre la prospettiva organizzativa.

La lezione di oggi sarà divisa in due ampi segmenti. In primo luogo, discuteremo come affrontare l’allineamento competitivo dei prezzi per Stuttgart. Allineare i prezzi a quelli dei concorrenti deve essere affrontato dalla prospettiva del cliente a causa della struttura unica del mercato dei ricambi automobilistici. Sebbene l’allineamento competitivo sia altamente non banale, beneficia di una soluzione relativamente semplice che esamineremo in dettaglio.
In secondo luogo, sebbene l’allineamento competitivo sia la forza dominante, non è l’unica. Stuttgart potrebbe aver bisogno o voler deviare selettivamente da questo allineamento. Tuttavia, i benefici di tali deviazioni devono superare i rischi. La qualità dell’allineamento dipende dalla qualità degli input utilizzati per costruirlo, quindi introdurremo una tecnica di apprendimento auto-supervisionato per affinare il grafo delle compatibilità meccaniche.
Infine, affronteremo una breve serie di questioni correlate al pricing. Queste questioni potrebbero non riguardare strettamente il pricing, ma in pratica sono meglio affrontate insieme ai prezzi.

Stuttgart deve applicare un cartellino del prezzo su ogni singola parte che vende, ma ciò non implica che l’analisi del pricing debba essere condotta principalmente a livello di numero di parte. Il pricing è, prima di tutto, un modo per comunicare con i clienti.
Prendiamoci un momento per considerare come i clienti percepiscono i prezzi offerti da Stuttgart. Come vedremo, la distinzione apparentemente sottile che esiste tra il cartellino del prezzo e la percezione del cartellino del prezzo non è, in realtà, per nulla sottile.
Quando un cliente inizia a cercare un nuovo ricambio per auto, solitamente una parte consumabile come le pastiglie dei freni, è improbabile che conosca il numero di parte specifico di cui ha bisogno. Potrebbero esserci alcuni appassionati di automobili che sono molto esperti sull’argomento, al punto da avere in mente un numero di parte specifico, ma sono una piccola minoranza. La maggior parte delle persone sa solo che deve cambiare le pastiglie dei freni, ma non conosce il numero di parte esatto.
Questa situazione porta a un’altra seria preoccupazione: la compatibilità meccanica. Esistono migliaia di riferimenti per pastiglie dei freni sul mercato; tuttavia, per un dato veicolo, in genere ce ne sono solo poche dozzine che sono compatibili. Pertanto, la compatibilità meccanica non può essere lasciata al caso.
Stuttgart, come tutti i suoi concorrenti, è ben consapevole di questo problema. Visitando il sito di e-commerce di Stuttgart, il visitatore è invitato a specificare il modello della propria auto, e il sito filtra immediatamente le parti che non sono meccanicamente compatibili con il veicolo specificato. I siti web dei concorrenti seguono lo stesso schema: prima scegliere il veicolo, poi scegliere la parte.
Quando un cliente cerca di confrontare due fornitori, solitamente confronta le offerte, non i numeri di parte. Un cliente visiterebbe il sito di Stuttgart, individuerebbe il costo delle pastiglie dei freni compatibili, quindi ripeterebbe il processo sul sito di un concorrente. Il cliente potrebbe identificare il numero di parte delle pastiglie dei freni sul sito di Stuttgart e poi cercare lo stesso numero di parte sul sito del concorrente, ma in pratica le persone raramente lo fanno.
Stuttgart e i suoi concorrenti curano attentamente i loro assortimenti in modo da poter servire quasi tutti i veicoli con una frazione dei numeri di parte automobilistici disponibili. Di conseguenza, di solito hanno tra 100.000 e 200.000 numeri di parte elencati sui loro siti web, e solo 10.000–20.000 numeri di parte effettivamente in stock.
Per quanto riguarda la nostra preoccupazione iniziale sul pricing, è chiaro che l’analisi del pricing dovrebbe essere condotta principalmente non attraverso il prisma dei numeri di parte, ma attraverso l’unità di bisogno. Nel contesto del mercato post-vendita automobilistico, un’unità di bisogno è caratterizzata dal tipo di parte che necessita di essere sostituita e dal modello di auto che richiede la sostituzione.
Tuttavia, questa prospettiva dell’unità di bisogno presenta una complicazione tecnica immediata. Stuttgart non può fare affidamento su corrispondenze uno a uno dei prezzi tra i numeri di parte per allineare i propri prezzi a quelli dei concorrenti. Pertanto, l’allineamento dei prezzi non è così ovvio come potrebbe sembrare a prima vista, soprattutto considerando i vincoli cui Stuttgart è soggetta da parte dei suoi concorrenti.

Come abbiamo già visto nella lezione 3.4, il problema della compatibilità meccanica tra auto e parti viene affrontato in Europa, così come in altre principali regioni del mondo, attraverso l’esistenza di aziende specializzate. Queste aziende vendono set di dati sulla compatibilità meccanica, costituiti da tre liste: una lista di modelli di auto, una lista di parti d’auto e una lista di compatibilità tra auto e parti. Questa struttura di set di dati è tecnicamente nota come grafo bipartito.
In Europa, questi set di dati tipicamente contengono più di 100.000 veicoli, oltre un milione di parti e più di 100 milioni di collegamenti che uniscono auto e parti. Mantenere questi set di dati richiede un grande sforzo lavorativo, il che spiega perché esistono aziende specializzate che li vendono. Stuttgart, come i suoi concorrenti, acquista un abbonamento da una di queste aziende specializzate per accedere alle versioni aggiornate di tali set di dati. Gli abbonamenti sono necessari perché, pur essendo l’industria automobilistica matura, nuove auto e parti vengono continuamente introdotte. Per rimanere strettamente allineati con il panorama automobilistico, questi set di dati devono essere aggiornati almeno trimestralmente.
Stuttgart, e i suoi concorrenti, utilizzano questo set di dati per supportare il meccanismo di selezione del veicolo sui loro siti di e-commerce. Una volta che un cliente ha selezionato un veicolo, vengono visualizzate solo le parti che sono dimostrabilmente compatibili con il veicolo scelto, secondo il set di dati sulla compatibilità. Questo set di dati sulla compatibilità è anche fondamentale per la nostra analisi del pricing. Attraverso questo set di dati, Stuttgart può valutare il punto di prezzo offerto per ogni unità di bisogno.

L’ultimo ingrediente significativo mancante per costruire la strategia di allineamento competitivo di Stuttgart è l’intelligence competitiva. In Europa, come in tutte le principali regioni economiche, esistono specialisti di intelligence competitiva—aziende che forniscono servizi di price scraping. Queste aziende estraggono quotidianamente i prezzi di Stuttgart e dei suoi concorrenti. Mentre un’azienda come Stuttgart può tentare di mitigare l’estrazione automatizzata dei propri prezzi, questo tentativo risulta per lo più inutile per diverse ragioni:
Prima di tutto, Stuttgart, come i suoi concorrenti, vuole essere robot-friendly. I bot più importanti sono i motori di ricerca, con Google, a partire dal 2023, che detiene poco più del 90% della quota di mercato. Tuttavia, non è l’unico motore di ricerca e, mentre potrebbe essere possibile individuare Googlebot, il principale crawler di Google, è difficile fare lo stesso per tutti gli altri crawler che ancora rappresentano circa il 10% del traffico.
In secondo luogo, gli specialisti di intelligence competitiva sono diventati esperti nell’ultimo decennio nel mascherarsi da traffico internet residenziale regolare. Questi servizi sostengono di avere accesso a milioni di indirizzi IP residenziali, cosa che ottengono attraverso collaborazioni con app, sfruttando le connessioni internet degli utenti comuni e collaborando con ISP (Internet Service Providers) che possono concedere loro indirizzi IP.
Pertanto, assumiamo che Stuttgart benefici di una lista di prezzi di alta qualità proveniente dai suoi concorrenti di rilievo. Questi prezzi vengono estratti a livello di numero di parte e aggiornati quotidianamente. Tale ipotesi non è speculativa; rappresenta lo stato attuale del mercato europeo.

Abbiamo ora raccolto tutti gli elementi di cui Stuttgart ha bisogno per calcolare prezzi allineati – prezzi che corrispondono a quelli dei suoi concorrenti se considerati da una prospettiva di unità di bisogno.
In schermata, abbiamo il pseudocodice per il problema di soddisfazione dei vincoli che vogliamo risolvere. Semplicemente, enumeriamo tutte le unità di bisogno, cioè tutte le combinazioni di tipi di parte e modelli di auto. Per ogni unità di bisogno, enunciamo che il prezzo più competitivo offerto da Stuttgart dovrebbe essere uguale al prezzo più competitivo offerto da un concorrente.
Valutiamo rapidamente il numero di variabili e vincoli. Stuttgart può impostare un cartellino del prezzo per ogni numero di parte offerto, il che significa che abbiamo circa 100.000 variabili. Il numero di vincoli è un po’ più complesso. Tecnicamente, abbiamo circa 1.000 tipi di parte e circa 100.000 modelli di auto, suggerendo approssimativamente 100 milioni di vincoli. Tuttavia, non tutti i tipi di parte si trovano in tutti i modelli di auto. Misurazioni nel mondo reale indicano che il numero di vincoli si avvicina a 10 milioni.
Nonostante questo numero inferiore di vincoli, abbiamo ancora 100 volte più vincoli rispetto alle variabili. Ci troviamo di fronte a un sistema fortemente sovra-vincolato. Pertanto, sappiamo che è improbabile trovare una soluzione che soddisfi tutti i vincoli. Il miglior risultato è una soluzione di compromesso che ne soddisfi la maggior parte.
Inoltre, i concorrenti non sono del tutto coerenti nei loro prezzi. Nonostante i nostri migliori sforzi, Stuttgart potrebbe finire in una guerra di prezzi su un numero di parte a causa di un cartellino troppo basso. Allo stesso tempo, potrebbe perdere quote di mercato sullo stesso numero di parte a causa di un cartellino troppo alto rispetto a un altro concorrente. Questo scenario non è teorico; i dati empirici suggeriscono che tali situazioni si verificano regolarmente, sebbene per una piccola percentuale di numeri di parte.
Poiché abbiamo optato per una risoluzione approssimativa di questo sistema di vincoli, dovremmo chiarire il peso da attribuire a ciascun vincolo. Non tutti i modelli di auto sono uguali – alcuni sono associati a veicoli più vecchi che sono quasi scomparsi dalle strade. Proponiamo di ponderare questi vincoli in base al rispettivo volume di domanda, espresso in euro.
Ora che abbiamo stabilito il quadro formale per la nostra logica di pricing, procediamo con il codice software effettivo. Come vedremo, la risoluzione di questo sistema è più semplice del previsto.
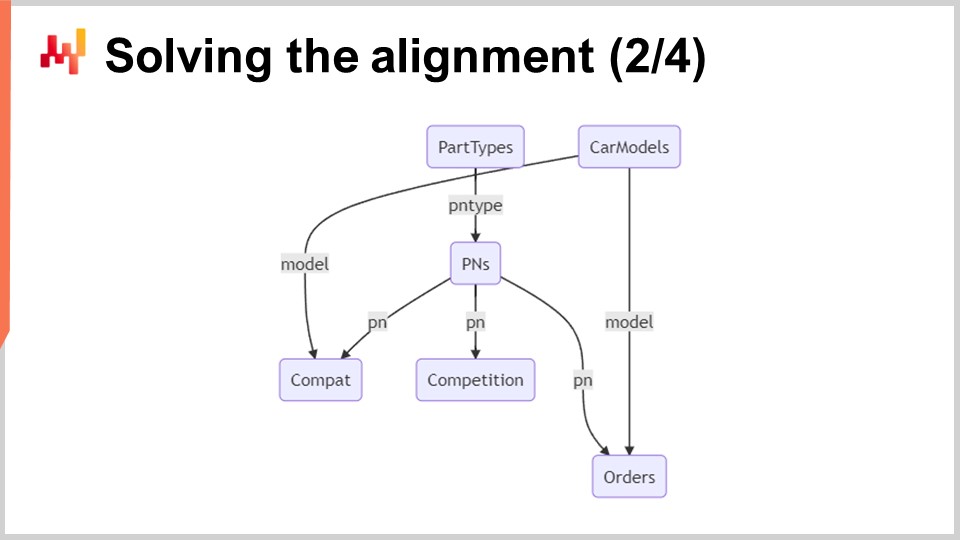
Sullo schermo, uno schema relazionale minimale illustra le sei tabelle coinvolte in questo sistema. I rettangoli con angoli arrotondati rappresentano le sei tabelle di interesse, e le frecce rappresentano le relazioni uno-a-molti tra le tabelle.
Esaminiamo brevemente queste tabelle:
-
Tipologie di pezzi: Come suggerisce il nome, questa tabella elenca le tipologie di pezzi, per esempio, “pastiglie freno anteriori”. Queste tipologie vengono usate per identificare quale pezzo può essere utilizzato come sostituto di un altro. Il pezzo di ricambio deve non solo essere compatibile con il veicolo, ma anche avere lo stesso tipo. Ci sono circa mille tipologie di pezzi.
-
Modelli di auto: Questa tabella elenca i modelli di auto, per esempio, “Peugeot 3008 Fase 2 diesel”. Ogni veicolo ha un modello e ci si aspetta che tutti i veicoli di un dato modello abbiano lo stesso insieme di compatibilità meccaniche. Ci sono circa centomila modelli di auto.
-
Numeri di pezzo (PNs): Questa tabella elenca i numeri di pezzo che si trovano nel mercato dei ricambi automobilistici. Ogni numero di pezzo ha uno, e uno solo, tipo di pezzo. Ci sono circa 1 milione di numeri di pezzo in questa tabella.
-
Compatibilità (Compat): Questa tabella rappresenta le compatibilità meccaniche e raccoglie tutte le combinazioni valide di numeri di pezzo e modelli di auto. Con circa 100 milioni di righe di compatibilità, questa tabella è di gran lunga la più grande.
-
Competizione: Questa tabella contiene tutta l’intelligence competitiva del giorno. Per ogni numero di pezzo, ci sono mezza dozzina di noti concorrenti che espongono il numero di pezzo con un cartellino del prezzo. Ciò si traduce in circa 10 milioni di prezzi competitivi.
-
Ordini: Questa tabella contiene gli ordini dei clienti passati da Stuttgart in un periodo di circa un anno. Ogni riga d’ordine include un numero di pezzo e un modello di auto. Tecnicamente, è possibile acquistare un pezzo di ricambio senza specificare il modello di auto, sebbene ciò sia raro. Le righe d’ordine prive del modello di auto possono essere filtrate. In base alle dimensioni di Stuttgart, dovrebbero esserci circa 10 milioni di righe d’ordine.
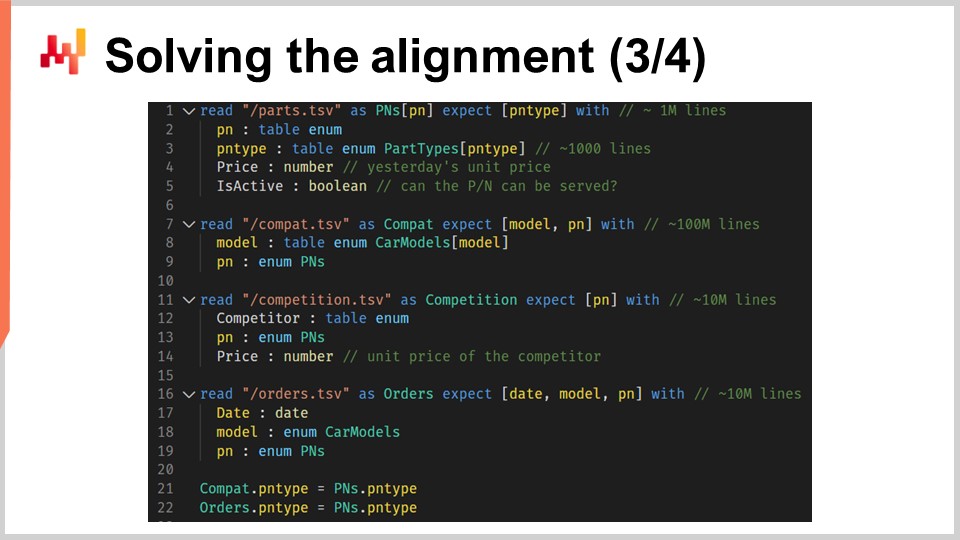
Esamineremo ora il codice che carica i dati relazionali. Sullo schermo è visualizzato uno script che carica sei tabelle, scritto in Envision - un linguaggio di programmazione specifico per il dominio, progettato da Lokad specificamente per l’ottimizzazione predittiva delle supply chains. Sebbene Envision sia stato creato per aumentare l’efficienza e ridurre gli errori nei contesti della supply chain, lo script può essere riscritto in altri linguaggi come Python, sebbene a costo di una maggiore verbosità e rischio di errori.
Nella prima parte dello script, vengono caricati quattro file di testo piatti. Dalle linee 1 a 5, il file “path.csv” fornisce sia i numeri di pezzo che i tipi di pezzo, inclusi i prezzi correnti visualizzati a Stuttgart. Il campo “name is active” indica se un determinato numero di pezzo è servito da Stuttgart. In questa prima tabella, la variabile “PN” si riferisce alla dimensione primaria della tabella, mentre “PN type” è una dimensione secondaria introdotta dalla parola chiave “expect”.
Dalle linee 7 a 9, il file “compat.tsv” fornisce la lista di compatibilità tra pezzi e veicoli e i modelli di auto. Questa è la tabella più grande dello script. Le linee 11 a 14 caricano il file “competition.tsv”, fornendo un’istantanea dell’intelligence competitiva del giorno, cioè i prezzi per numero di pezzo e per concorrente. Il file “orders.tsv”, caricato dalle linee 16 a 19, ci dà la lista dei numeri di pezzo acquistati e dei modelli di auto associati, presumendo che tutte le righe associate a modelli di auto non specificati siano state filtrate.
Infine, alle linee 21 e 22, la tabella “part types” viene impostata come upstream delle due tabelle, “compat” e “orders”. Ciò significa che per ogni riga, sia in “compat” che in “orders”, c’è un e un solo tipo di pezzo che corrisponde. In altre parole, “PN type” è stata aggiunta come dimensione secondaria alle tabelle “compat” e “orders”. Questa prima parte dello script Envision è semplice; stiamo semplicemente caricando i dati da file di testo piatti e ricostruendo il loro schema relazionale nel processo.
La seconda parte dello script, visibile sullo schermo, è quella in cui avviene la logica di allineamento effettiva. Questa sezione è una continuazione diretta della prima parte, e come potete vedere, è composta da sole 12 linee di codice. Stiamo nuovamente utilizzando la programmazione differenziabile. Per chi non fosse familiare con la programmazione differenziabile, si tratta di una fusione tra differenziazione automatica e discesa del gradiente stocastica. È un paradigma di programmazione che si estende anche al machine learning e all’ottimizzazione. Nel contesto della supply chain, la programmazione differenziabile si rivela incredibilmente utile in varie situazioni. Nel corso di questa serie di lezioni, abbiamo dimostrato come la programmazione differenziabile possa essere utilizzata per apprendere modelli, generare previsioni probabilistiche della domanda e ottenere previsioni balistiche del tempo di consegna. Se non siete familiari con la programmazione differenziabile, vi consiglio di rivedere le lezioni precedenti di questa serie.
Nella lezione di oggi, vedremo come la programmazione differenziabile sia particolarmente adatta ad affrontare problemi di ottimizzazione su larga scala che coinvolgono centinaia di migliaia di variabili e milioni di vincoli. Sorprendentemente, questi problemi possono essere risolti in pochi minuti su una singola CPU con pochi gigabyte di RAM. Inoltre, possiamo utilizzare i prezzi precedenti come punto di partenza, aggiornando i nostri prezzi invece di ricalcolarli da zero.
Si prega di notare una piccola avvertenza. La parola chiave “join” non è ancora supportata da Envision, ma è prevista nel nostro piano tecnico per il futuro. Esistono soluzioni alternative, ma per chiarezza userò la sintassi futura di Envision in questa lezione.
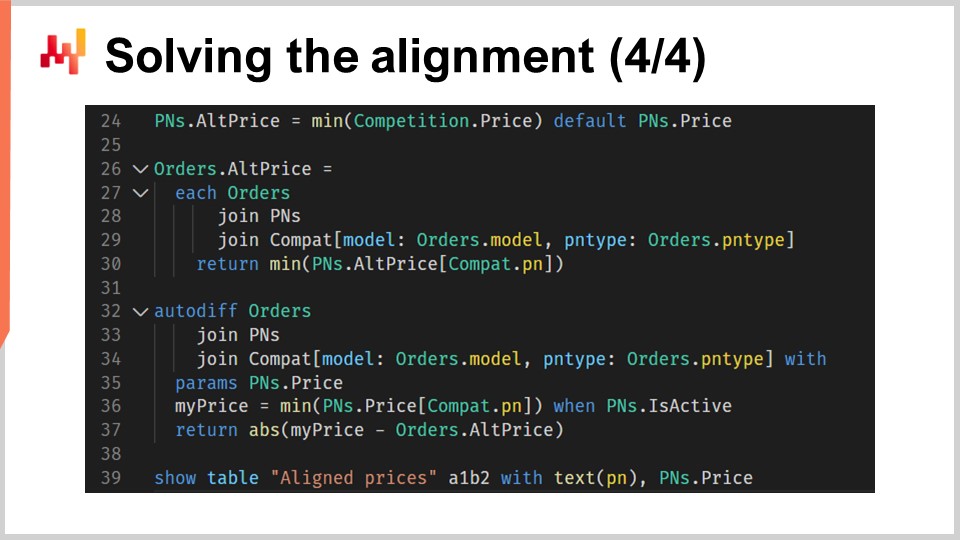
Alla linea 24, calcoliamo il prezzo più basso osservato sul mercato per ogni numero di pezzo. Se un numero di pezzo è venduto esclusivamente da Stuttgart e non ha concorrenti, utilizziamo il prezzo di Stuttgart come valore predefinito.
Dalle linee 26 a 30, per ogni pezzo elencato nella cronologia degli ordini dei clienti di Stuttgart, viene calcolata l’offerta attualmente più competitiva.
Alla linea 27, iteriamo su ogni riga d’ordine della tabella degli ordini utilizzando “each order”.
Alla linea 28, usiamo “join pns” per integrare la tabella completa dei numeri di pezzo per ogni riga d’ordine.
Alla linea 29, facciamo join con “others”, ma questo join è limitato da due dimensioni secondarie - modello e tipo di pezzo. Ciò significa che per ogni riga negli ordini, selezioniamo i numeri di pezzo che corrispondono a una combinazione di modello di auto e tipo di pezzo, riflettendo i pezzi compatibili con l’unità di bisogno corrispondente all’ordine del cliente.
Dalla linea 32 alla 37, risolviamo l’allineamento utilizzando la programmazione differenziabile, indicata dalla parola chiave “Auto diff”. Il blocco “Auto diff” viene dichiarato alla linea 32, sfruttando la tabella “orders” come tabella di osservazione. Ciò significa che stiamo implicitamente pesando i vincoli in base al volume delle vendite di Stuttgart. Le linee 33 e 44 hanno lo stesso scopo delle linee 28 e 29; iterano sulla tabella “orders”, fornendo accesso completo alla tabella dei numeri di pezzo (“PN”) e a una porzione delle voci compatibili.
Alla linea 35, dichiariamo “pns.price” come i parametri da ottimizzare mediante la discesa del gradiente stocastica. Non c’è bisogno di inizializzare questi parametri, poiché partiamo dai prezzi finora utilizzati da Stuttgart, aggiornando efficacemente l’allineamento.
Alla linea 36, calcoliamo “my price”, che rappresenta l’offerta più competitiva di Stuttgart per l’unità di bisogno associata alla riga d’ordine. Questo calcolo è un meccanismo molto simile a quello del prezzo più basso osservato, come fatto alla linea 24, basandosi nuovamente sulla lista delle compatibilità meccaniche. Le compatibilità sono, tuttavia, limitate ai numeri di pezzo serviti da Stuttgart. Storicamente, i clienti potrebbero aver selezionato o meno il pezzo economicamente più vantaggioso per il loro veicolo. In ogni caso, lo scopo di utilizzare gli ordini dei clienti in questo contesto è assegnare dei pesi alle unità di bisogno.
Alla linea 37, utilizziamo la differenza assoluta tra il miglior prezzo offerto da Stuttgart e il miglior prezzo offerto da un concorrente per guidare l’allineamento. All’interno di questo blocco alternativo, i gradienti vengono applicati retroattivamente ai parametri. La differenza che troviamo alla fine forma la funzione di perdita. Da questa funzione di perdita, i gradienti fluiscono indietro verso l’unico vettore di parametri presente: “pns.price”. Regolando incrementale i parametri (i prezzi) ad ogni iterazione (un’iterazione qui corrisponde a una riga d’ordine), lo script converge verso un’approssimazione adeguata dell’allineamento di pricing desiderato.
In termini di complessità algoritmica, la linea 36 è predominante. Tuttavia, poiché il numero di compatibilità per un dato modello di auto e tipologia di pezzo è limitato (solitamente non più di qualche dozzina), ogni iterazione “Auto diff” viene eseguita in un tempo che equivale a tempo costante. Questo tempo costante non è molto ridotto, come 10 cicli CPU, ma non arriverà nemmeno a essere un milione di cicli CPU. Approssimativamente, mille cicli CPU sembrano ragionevoli per 20 pezzi compatibili.
Se assumiamo una singola CPU che funziona a due gigahertz ed esegue 100 epoche (un’epoca corrisponde a una discesa completa sull’intera tabella di osservazione), ci aspetteremmo un tempo di esecuzione target di circa 10 minuti. Risolvere un problema con 100.000 variabili e 10 milioni di vincoli in 10 minuti su una singola CPU è davvero impressionante. Infatti, Lokad ottiene prestazioni all’incirca in linea con queste aspettative. Tuttavia, in pratica, per tali problemi, il collo di bottiglia è più spesso la larghezza di banda I/O piuttosto che la CPU.
Ancora una volta, questo esempio mette in luce il potere dell’impiego di paradigmi di programmazione adeguati per le applicazioni della supply chain. Abbiamo iniziato con un problema non banale, poiché non era immediatamente evidente come sfruttare questo dataset di compatibilità meccanica da una prospettiva di pricing. Nonostante ciò, l’implementazione effettiva è semplice.
Sebbene questo script non copra tutti gli aspetti che sarebbero presenti in un ambiente reale, la logica di base richiede solo sei linee di codice, lasciando ampio spazio per accogliere ulteriori complessità che gli scenari reali potrebbero introdurre.

L’algoritmo di allineamento, come presentato in precedenza, dà priorità alla semplicità e chiarezza piuttosto che all’esaustività. In un ambiente reale, ci si aspetterebbe la presenza di ulteriori fattori. Esaminerò questi fattori a breve, ma iniziamo riconoscendo che tali fattori possono essere affrontati estendendo questo algoritmo di allineamento.
Vendere in perdita non è solo sconsigliabile, ma anche illegale in molti paesi, come la Francia, sebbene ci siano eccezioni in circostanze speciali. Per evitare vendite in perdita, può essere aggiunto un vincolo all’algoritmo di allineamento che impone che il prezzo di vendita superi il prezzo d’acquisto. Tuttavia, è utile eseguire l’algoritmo anche senza questo vincolo “no loss” per identificare potenziali problemi di approvvigionamento. Infatti, se un concorrente può permettersi di vendere un pezzo al di sotto del prezzo d’acquisto di Stuttgart, Stuttgart deve affrontare il problema sottostante. Molto probabilmente, si tratta di una questione di sourcing o di acquisti.
Raggruppare semplicemente tutti i numeri di pezzo è ingenuo. I clienti non hanno la stessa disponibilità a pagare per tutti i produttori di equipaggiamento originale (OEM). Ad esempio, i clienti sono più inclini a valutare un marchio noto come Bosch rispetto a un OEM cinese meno conosciuto in Europa. Per affrontare questo problema, Stuttgart, come i suoi pari, classifica gli OEM in una breve lista di gamme di prodotto, dalla più costosa alla meno costosa. Possiamo avere, per esempio, la gamma motorsport, la gamma per uso domestico, la gamma dei marchi distributori e la gamma economica.
L’allineamento è quindi costruito per garantire che ogni numero di pezzo sia allineato all’interno della propria gamma di prodotto. Inoltre, l’algoritmo di allineamento dovrebbe imporre che i prezzi siano strettamente decrescenti passando dalla gamma motorsport a quella economica, poiché qualsiasi inversione confonderebbe i clienti. In teoria, se i concorrenti fissassero accuratamente i prezzi delle proprie offerte, tali inversioni non si verificherebbero. Tuttavia, in pratica, i clienti talvolta valutano erroneamente i propri pezzi, e occasionalmente hanno motivi per impostare un prezzo diverso.
Ci sono solo poche centinaia di OEM; classificarli nelle rispettive gamme di prodotto può essere fatto manualmente e, possibilmente, con l’aiuto di sondaggi tra i clienti se ci sono ambiguità che non possono essere risolte direttamente dagli esperti di mercato di Stuttgart.

Nonostante l’adozione delle gamme di prodotto, molti prezzi dei numeri di pezzo non finiscono per essere attivamente guidati dalla logica di allineamento. Infatti, solo i numeri di pezzo che contribuiscono attivamente ad avere il miglior prezzo all’interno di un’unità di bisogno vengono effettivamente regolati dalla discesa del gradiente per creare l’allineamento approssimato che cerchiamo all’interno della stessa gamma di prodotto.
Tra due numeri di pezzo che hanno identiche compatibilità meccaniche, solo uno di essi vedrà il prezzo regolato dall’algoritmo di allineamento. L’altro numero di pezzo otterrà sempre gradienti nulli e, quindi, il suo prezzo originale rimarrà invariato. In sintesi, mentre il sistema dispone di un intero insieme di vincoli, molte variabili non sono affatto vincolate. A seconda della granularità delle gamme di prodotto e dell’entità dell’intelligence competitiva, questi numeri di pezzo non vincolati possono rappresentare una quota significativa del catalogo, possibilmente la metà dei numeri di pezzo. Sebbene la percentuale, espressa in volume di vendite, sia notevolmente inferiore.
Per questi numeri di pezzo, Stuttgart richiede una strategia di pricing alternativa. Sebbene non abbia un processo algoritmico rigoroso da proporre per questi pezzi non vincolati, proporrei due principi guida.
In primo luogo, dovrebbe esserci un margine di prezzo non trascurabile, ad esempio il 10%, tra il pezzo più competitivo all’interno della gamma di prodotto e il pezzo successivo. Con un po’ di fortuna, alcuni concorrenti potrebbero non essere così abili come Stuttgart nel ricostruire le unità di bisogno. Di conseguenza, tali concorrenti potrebbero perdere l’unico cartellino del prezzo che effettivamente guida l’allineamento, portandoli a rivedere il loro prezzo al rialzo, il che è auspicabile per Stuttgart.
In secondo luogo, potrebbero esserci alcune parti con un prezzo molto più alto, diciamo il 30% in più, purché tali parti non finiscano per sovrapporsi ad altre gamme di prodotti. Queste parti fungono da esca per i loro omologhi a prezzo inferiore, una strategia tecnicamente nota come decoy pricing. L’esca è progettata deliberatamente per essere un’opzione meno attraente rispetto all’opzione target, facendo apparire quest’ultima più preziosa e inducendo il cliente a sceglierla più frequentemente. Questi due principi sono sufficienti per distribuire delicatamente i prezzi non vincolati oltre le loro soglie competitive.

L’allineamento competitivo, insieme a una dose di decoy pricing, è sufficiente per assegnare un prezzo a ogni codice parte esposto a Stoccarda. Tuttavia, il tasso di margine lordo risultante probabilmente sarà troppo basso per Stoccarda. Infatti, allineare Stoccarda con tutti i suoi concorrenti significativi esercita un’enorme pressione sul suo margine.
Da un lato, allineare i prezzi è una necessità; altrimenti, col tempo, Stoccarda verrà completamente esclusa dal mercato. Dall’altro, Stoccarda non può permettersi di rovinarsi nel tentativo di preservare la propria quota di mercato. È fondamentale ricordare che il margine lordo futuro associato a una determinata strategia di pricing può solo essere stimato o previsto. Non esiste un modo preciso per dedurre il tasso di crescita futuro da un insieme di prezzi, poiché sia i clienti che i concorrenti si adattano.
Supponendo di avere una stima ragionevolmente accurata del tasso di margine lordo che Stoccarda dovrebbe aspettarsi la settimana prossima, è importante sottolineare che la parte “accuratezza” di questa ipotesi non è così irragionevole come potrebbe sembrare. Stoccarda, come i suoi concorrenti, opera sotto severi vincoli. A meno che la strategia di pricing di Stoccarda non venga modificata in modo sostanziale, il margine lordo a livello aziendale non cambierà molto di settimana in settimana. Possiamo anche considerare il tasso di margine lordo osservato la settimana scorsa come un proxy ragionevole per ciò che Stoccarda dovrebbe aspettarsi la settimana prossima, naturalmente assumendo che la strategia di pricing rimanga invariata.
Supponiamo che il tasso di margine lordo di Stoccarda sia previsto al 13%, ma che Stoccarda necessiti di un margine lordo del 15% per sostenersi. Cosa dovrebbe fare Stoccarda di fronte a tale situazione? Una risposta consiste nel selezionare casualmente una serie di “unità di bisogno” e aumentare i loro prezzi di circa il 20%. Le tipologie di parti preferite dai clienti alla prima esperienza, come i tergicristalli, dovrebbero essere escluse da questa selezione. Acquisire quei clienti alle prime esperienze è costoso e difficile, e Stoccarda non dovrebbe rischiare tali acquisti iniziali. Allo stesso modo, per tipologie di parti molto costose, come gli iniettori, i clienti tenderanno probabilmente a confrontare molte offerte. Pertanto, Stoccarda probabilmente non dovrebbe rischiare di apparire poco competitiva su quegli acquisti più onerosi.
Tuttavia, escludendo queste due situazioni, sostengo che selezionare casualmente delle “unità di bisogno” e rendere queste ultime non competitive attraverso prezzi più elevati sia un’opzione ragionevole. Infatti, Stoccarda ha bisogno di aumentare alcuni dei suoi prezzi, una conseguenza inevitabile nel tentativo di conseguire un tasso di margine di crescita più elevato. Se Stoccarda dovesse adottare uno schema riconoscibile nel farlo, le recensioni online probabilmente ne evidenzierebbero i modelli. Ad esempio, se Stoccarda decidesse di rinunciare a essere competitiva sulle parti Bosch o sulle parti compatibili con veicoli Peugeot, esiste un rischio reale che Stoccarda venga conosciuta come il concessionario che non offre un buon affare per veicoli Bosch o Peugeot. L’elemento casuale rende Stoccarda in parte impenetrabile, che è proprio l’effetto desiderato.
I ranking di visualizzazione sono un altro fattore cruciale nel catalogo online di Stoccarda. Più specificamente, per ogni “unità di bisogno”, Stoccarda deve classificare tutte le parti idonee. Determinare il modo migliore per ordinare le parti è un problema correlato al pricing che meriterebbe una lezione a parte. Dalla prospettiva presentata in questa lezione, ci si aspetterebbe che i ranking di visualizzazione vengano calcolati dopo la risoluzione del problema di allineamento. Tuttavia, sarebbe anche concepibile ottimizzare contemporaneamente sia i prezzi che i ranking di visualizzazione. Questo problema presenterebbe circa 10 milioni di variabili, invece delle 100.000 variabili trattate finora. Eppure, ciò non cambia fondamentalmente la scala del problema di ottimizzazione, dato che dobbiamo occuparci comunque di 10 milioni di vincoli. Oggi non tratterò quale criterio potrebbe guidare questa ottimizzazione dei ranking di visualizzazione, né come sfruttare il gradient descent per l’ottimizzazione discreta. Quest’ultimo aspetto è piuttosto interessante, ma sarà affrontato in una lezione successiva.

L’importanza relativa dell’“unità di bisogno” è quasi interamente definita dalle flotte di veicoli esistenti. Stoccarda non può aspettarsi di vendere 1 milione di pastiglie dei freni per un modello di auto che conta solo 1.000 veicoli in Europa. Si potrebbe addirittura sostenere che i veri consumatori delle parti siano i veicoli stessi piuttosto che i loro proprietari. Sebbene i veicoli non paghino per le loro parti (lo fanno i proprietari), questa analogia aiuta a sottolineare l’importanza della flotta.
Tuttavia, è ragionevole aspettarsi notevoli distorsioni quando si tratta di persone che acquistano le loro parti online. Dopotutto, acquistare parti è principalmente un modo per risparmiare denaro rispetto all’acquisto indiretto da un’officina. Pertanto, l’età media dei veicoli, come osservato da Stoccarda, si prevede sia superiore a quella che le statistiche generali del mercato automobilistico suggerirebbero. Analogamente, le persone che guidano auto costose sono meno propense a cercare di risparmiare denaro effettuando le proprie riparazioni. Di conseguenza, la dimensione e la classe media dei veicoli osservate da Stoccarda si prevede siano inferiori a quanto indicherebbero le statistiche di mercato generali.
Non si tratta di mere speculazioni. Queste distorsioni sono infatti osservate per tutti i principali rivenditori online di ricambi auto in Europa. Tuttavia, l’algoritmo di allineamento, come presentato in precedenza, sfrutta la storia delle vendite di Stoccarda come proxy della domanda. È concepibile che questi bias possano compromettere l’esito dell’algoritmo di allineamento dei prezzi. Se tali bias incidano negativamente sull’esito per Stoccarda è fondamentalmente una questione empirica, poiché l’entità del problema, se esiste, dipende fortemente dai dati. L’esperienza di Lokad indica che l’algoritmo di allineamento e le sue variazioni sono piuttosto robusti contro questa tipologia di bias, anche quando il peso di un’“unità di bisogno” viene stimato erroneamente di due o tre volte. Il contributo principale di tali pesi, in termini di prezzo, sembra aiutare l’algoritmo di allineamento a risolvere conflitti quando lo stesso codice parte appartiene a due “unità di bisogno” che non possono essere affrontate congiuntamente. Nella maggior parte di queste situazioni, una “unità di bisogno” supera di gran lunga l’altra in termini di volume. Pertanto, anche una sostanziale errata stima dei rispettivi volumi ha poche conseguenze sul prezzo.
Identificare i bias più significativi tra ciò che la domanda per una “unità di bisogno” avrebbe dovuto essere e ciò che Stoccarda osserva come vendite realizzate può rivelarsi molto utile. Un volume di vendite sorprendentemente basso per una determinata “unità di bisogno” tende ad indicare problemi banali con la piattaforma e-commerce. Alcune parti potrebbero essere etichettate in modo errato, altre potrebbero avere immagini scorrette o di bassa qualità, ecc. In pratica, questi bias possono essere identificati confrontando i rapporti di vendita per un dato modello di auto delle diverse tipologie di parti. Ad esempio, se Stoccarda non vende alcuna pastiglia dei freni per un determinato modello di auto, mentre i volumi di vendita per altre tipologie di parti sono coerenti con quanto normalmente osservato, è improbabile che questo modello di auto abbia un consumo eccezionalmente basso di pastiglie dei freni. La causa principale si trova quasi certamente altrove.
Una lista superiore di compatibilità meccaniche rappresenta un vantaggio competitivo. Conoscere compatibilità sconosciute ai concorrenti permette di proporre prezzi inferiori senza scatenare una guerra dei prezzi, ottenendo così un vantaggio nell’aumentare la propria quota di mercato. Al contrario, identificare compatibilità errate è fondamentale per evitare resi costosi da parte dei clienti.
In effetti, il costo di ordinare una parte incompatibile è contenuto per un’officina, poiché esiste probabilmente un processo consolidato per rispedire la parte inutilizzata al centro di distribuzione. Tuttavia, il procedimento risulta molto più tedioso per i clienti comuni, che potrebbero non riuscire nemmeno a ripacchettare correttamente la parte per il viaggio di ritorno. Di conseguenza, ogni azienda e-commerce ha l’incentivo a costruire il proprio strato di arricchimento dei dati sopra i set di dati di terze parti che noleggia. La maggior parte degli operatori e-commerce in questo settore dispone, in una forma o nell’altra, del proprio strato di arricchimento dei dati.
Ci sono pochi incentivi a condividere questa conoscenza con le aziende specializzate che mantengono quei set di dati in primo luogo, poiché tale conoscenza beneficerebbe principalmente la concorrenza. È difficile valutare il tasso di errore in quei set di dati, ma da Lokad stimiamo che si aggiri intorno a una bassa percentuale a una cifra per entrambe le direzioni. Ci sono pochi percento di falsi positivi, in cui viene dichiarata una compatibilità che in realtà non esiste, e pochi percento di falsi negativi, in cui esiste una compatibilità ma non viene dichiarata. Considerando che la lista delle compatibilità meccaniche comprende più di 100 milioni di righe, ci sono molto probabilmente circa sette milioni di errori secondo stime conservative.
Pertanto, è nell’interesse di Stoccarda migliorare questo set di dati. I resi dei clienti segnalati come causati da una compatibilità meccanica falsamente positiva possono certamente essere sfruttati a questo scopo. Tuttavia, questo processo è lento e costoso. Inoltre, poiché i clienti non sono tecnici automobilistici professionisti, potrebbero segnalare una parte come incompatibile quando hanno semplicemente fallito nel montarla. Stoccarda può posticipare il giudizio di incompatibilità di una parte fino a quando non siano pervenute diverse lamentele, ma ciò rende il processo ancora più costoso e lento.
Pertanto, una ricetta numerica per migliorare questo set di dati di compatibilità sarebbe altamente auspicabile. Non è ovvio che sia addirittura possibile migliorare questo set di dati senza sfruttare informazioni aggiuntive. Tuttavia, in modo alquanto sorprendente, si è scoperto che questo set di dati può essere migliorato senza alcuna informazione supplementare. Questo set di dati può essere utilizzato per auto-avviarsi in una versione superiore.
Personalmente mi sono imbattuto in questa constatazione nel primo trimestre del 2017 mentre conducevo una serie di esperimenti di deep learning per Lokad. Ho utilizzato una fattorizzazione della matrice, una tecnica ben nota per il collaborative filtering. Il collaborative filtering è il problema centrale nella costruzione di un sistema di raccomandazione, che consiste nell’identificare il prodotto che un utente potrebbe gradire basandosi sulle preferenze note di quell’utente per una breve lista di prodotti. Adattare il collaborative filtering alle compatibilità meccaniche è semplice: sostituire gli utenti con i modelli di auto e i prodotti con le parti d’auto. Voilà, il problema è adattato.
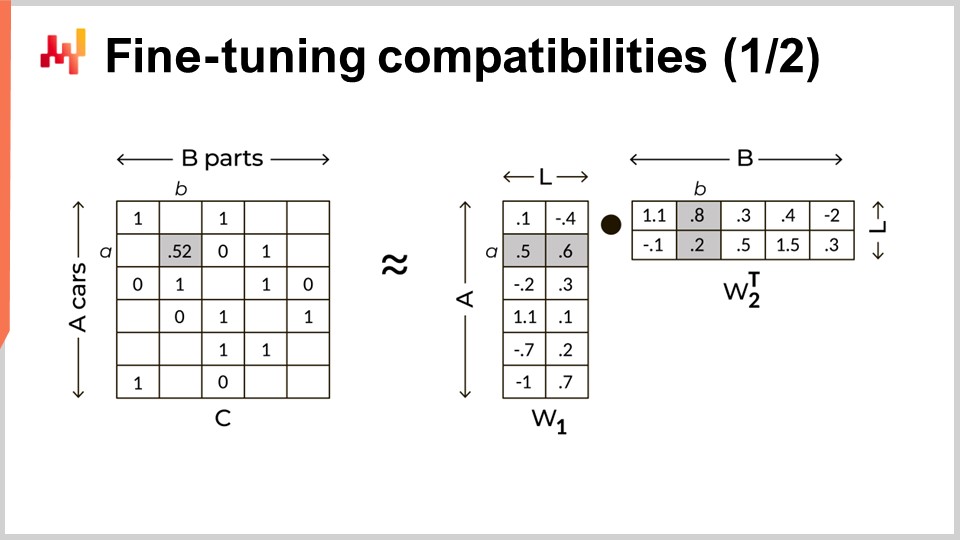
Più in generale, la fattorizzazione della matrice è applicabile a qualsiasi situazione che coinvolga un grafo bipartito. La fattorizzazione della matrice è utile anche al di là dell’analisi dei grafi. Ad esempio, l’adattamento a basso rango dei modelli linguistici di grandi dimensioni (LLM), una tecnica che è diventata estremamente popolare per perfezionare gli LLM, si basa anch’esso sul trucco della fattorizzazione della matrice. La fattorizzazione della matrice è illustrata sullo schermo. Sulla sinistra, abbiamo la matrice di compatibilità, con degli uno per indicare una compatibilità tra un’auto e una parte, e degli zero per indicare l’incompatibilità tra un modello di auto e un codice parte. Vogliamo sostituire questa matrice grande e molto sparsa con il prodotto di due matrici dense più piccole. Queste due matrici sono visibili sulla destra. Esse servono a fattorizzare la grande matrice. In effetti, stiamo immergendo ogni modello di auto e ogni codice parte in uno spazio latente. La dimensione di questo spazio latente è indicata con la L maiuscola sullo schermo. Questo spazio latente è progettato per catturare le compatibilità meccaniche, ma con molte meno dimensioni rispetto alla matrice originale. Mantenendo la dimensione di questo spazio latente abbastanza bassa, miriamo a imparare le regole nascoste che governano queste compatibilità meccaniche.

Anche se la fattorizzazione della matrice può sembrare un concetto tecnico grandioso, non lo è. È un trucco basilare dell’algebra lineare. L’unico aspetto ingannevole della fattorizzazione della matrice è che funziona così bene, nonostante la sua semplicità. Sullo schermo è presente un’implementazione completa di questa tecnica in meno di 30 righe di codice.
Dalle righe uno a tre, stiamo leggendo il file flat che elenca le compatibilità meccaniche. Questo file viene caricato in una tabella chiamata M per brevità, che sta per matrice. Questa lista è effettivamente una rappresentazione sparsa della matrice di compatibilità. Durante il caricamento di questa lista, creiamo anche altre due tabelle chiamate car_models e pns. Questi blocchi ci forniscono tre tabelle: M, car_models e pns.
Le righe cinque e sei consistono nello shufflare casualmente la colonna che contiene i modelli di auto. Lo scopo di questo mescolamento è creare zeri casuali, ovvero incompatibilità casuali. Infatti, la matrice di compatibilità è molto sparsa. Quando si sceglie casualmente un’auto e una parte, siamo quasi certi che questa coppia sia incompatibile. La fiducia che abbiamo in questa associazione casuale che sia zero è in realtà superiore a quella che riponiamo nella lista di compatibilità stessa. Questi zeri casuali sono accurati al 99,9% per design, grazie alla sparsenza della matrice, mentre le compatibilità note sono forse accurate al 97%.
La riga otto prevede la creazione dello spazio latente con 24 dimensioni. Sebbene 24 dimensioni possano sembrare tante per degli embeddings, sono molto poche rispetto ai grandi modelli linguistici, che hanno embeddings di oltre mille dimensioni. Le righe nove e dieci riguardano la creazione delle due piccole matrici, chiamate pnl e car_L, che useremo per fattorizzare la grande matrice. Queste due matrici rappresentano approssimativamente 24 milioni di parametri per pnl e 2,4 milioni di parametri per car_L. Questo è considerato poco rispetto alla grande matrice, che ha approssimativamente 100 miliardi di valori.
Sottolineiamo che la grande matrice non viene mai materializzata in questo script. Non viene mai esplicitamente trasformata in un array; viene sempre mantenuta come una lista di 100 milioni di compatibilità. Convertirla in un array sarebbe estremamente inefficiente in termini di risorse computazionali.
Le righe 12-15 introducono due funzioni di supporto chiamate sigmoid e log_loss. La funzione sigmoid viene usata per convertire il prodotto grezzo della matrice in probabilità, numeri compresi tra 0 e 1. La funzione log_loss rappresenta la logistic loss. La logistic loss applica la log likelihood, una metrica usata per valutare la correttezza di una previsione probabilistica. Qui viene utilizzata per valutare una previsione probabilistica per un problema di classificazione binaria. Abbiamo già incontrato la log likelihood nella lezione 5.3, dedicata alla previsione probabilistica dei tempi di consegna. Questa è una variazione più semplice della stessa idea. Queste due funzioni sono contrassegnate dalla keyword autograd, a indicare che possono essere differenziate automaticamente. Il piccolo valore di uno su un milione è un epsilon introdotto per la stabilità numerica e, altrimenti, non incide sulla logica. Dalle righe 17 a 29, abbiamo la fattorizzazione della matrice vera e propria. Ancora una volta, stiamo usando la programmazione differenziabile. Pochi minuti fa, stavamo utilizzando la programmazione differenziabile per risolvere approssimativamente un problema di soddisfazione dei vincoli. Qui, usiamo la programmazione differenziabile per affrontare un problema di apprendimento auto-supervisionato.
Nelle righe 18 e 19, stiamo dichiarando i parametri da apprendere. Questi parametri sono associati alle due piccole matrici, pnl e car_L. La keyword “auto” indica che questi parametri sono inizializzati casualmente come deviazioni casuali da una distribuzione gaussiana centrata su zero, con una deviazione standard di 0.1.
Le righe 20 e 21 introducono due parametri speciali che accelerano la convergenza. Questi sono solo 48 numeri in totale, una goccia nell’oceano rispetto alle nostre piccole matrici che contengono ancora milioni di numeri. Eppure, ho constatato che l’introduzione di questi parametri accelera sostanzialmente la convergenza. È importante sottolineare che questi parametri non introducono alcun grado di libertà per il modello esistente, ma solo pochissimi gradi di libertà extra nel processo di apprendimento. L’effetto netto è che riducono di oltre la metà il numero di epoche necessarie.
Nelle righe 22-24 stiamo caricando gli embedding. Alla riga 22, abbiamo l’embedding per una singola parte denominata px. Alla riga 23, abbiamo l’embedding per un singolo modello di auto denominato mx. La coppia px e mx costituirà il nostro collegamento positivo, una compatibilità considerata vera. Alla riga 24, abbiamo l’embedding per un altro modello di auto denominato mx2. La coppia px e mx2 costituirà il nostro collegamento negativo, una compatibilità considerata falsa. Infatti, mx2 è stata scelta casualmente tramite lo shuffle che avviene alla riga sei. I tre embedding px, mx e mx2 hanno esattamente 24 dimensioni, in quanto appartengono allo spazio latente, rappresentato dalla tabella L in questo script.
Alla riga 26, esprimiamo la probabilità, come definita dal nostro modello, mediante il prodotto scalare per indicare che questo collegamento è positivo. Sappiamo che questo collegamento è positivo, almeno secondo il dataset di compatibilità. Ma qui valutiamo ciò che il nostro modello probabilistico dice su questo collegamento. Alla riga 27, esprimiamo la probabilità, anch’essa definita dal nostro modello probabilistico, mediante il prodotto scalare per indicare che questo collegamento è negativo. Presumiamo che questo collegamento sia negativo in quanto è casuale. Valutiamo nuovamente questa probabilità per capire cosa dice il nostro modello a riguardo. Alla riga 29, restituiamo l’opposto della log likelihood associata a questo collegamento. Il valore restituito viene utilizzato come perdita da minimizzare mediante lo stochastic gradient descent. Qui, ciò significa che stiamo massimizzando la log likelihood, o i criteri di classificazione binaria probabilistica, tra coppie compatibili e incompatibili.
Successivamente, oltre a quanto mostrato in questo script, la grande matrice può essere confrontata con il prodotto scalare di due piccole matrici. Le divergenze tra le due rappresentazioni evidenziano sia i falsi positivi che i falsi negativi dei dataset originali. La cosa più sorprendente è che la rappresentazione fattorizzata di questa grande matrice risulta essere più accurata rispetto alla matrice originale.
Sfortunatamente, non posso presentare i risultati empirici associati a queste tecniche, poiché i relativi dataset di compatibilità sono tutti proprietari. Tuttavia, i miei risultati, validati da alcuni attori del mercato, indicano che queste tecniche di fattorizzazione della matrice possono essere utilizzate per ridurre il numero di falsi positivi e falsi negativi fino a un ordine di grandezza. In termini di prestazioni, sono passato da circa due settimane di calcolo per ottenere una convergenza soddisfacente con il deep learning toolkit che stavo utilizzando, CNTK – il toolkit di deep learning di Microsoft nel 2017 – a circa un’ora con il runtime attuale offerto da Envision. I primi toolkit di deep learning offrivano, in un certo senso, la programmazione differenziabile; tuttavia, quelle soluzioni erano pesantemente ottimizzate per prodotti di matrici di grandi dimensioni e convoluzioni estese. Toolkit più recenti, come Jax di Google, sospetto offrano prestazioni comparabili a quelle di Envision.
Questo solleva la domanda: perché le aziende specializzate che mantengono i dataset di compatibilità non usano già la fattorizzazione della matrice per ripulire i loro dataset? Se lo facessero, la fattorizzazione della matrice non apporterebbe nulla di nuovo. La fattorizzazione della matrice, come tecnica di machine learning, esiste da quasi 20 anni ed è stata resa popolare nel 2006 da Simon Funk. Non è più all’avanguardia. La mia risposta a questa domanda originale è: non lo so. Forse quelle aziende specializzate inizieranno a usare la fattorizzazione della matrice dopo aver visto questa lezione, o forse no.
In ogni caso, ciò dimostra che la programmazione differenziabile e il modellamento probabilistico sono paradigmi molto versatili. A prima vista, la previsione dei tempi di consegna non ha nulla a che fare con la valutazione delle compatibilità meccaniche, eppure entrambi possono essere affrontati con lo stesso strumento, ovvero la programmazione differenziabile e il modellamento probabilistico.

Il dataset delle compatibilità meccaniche non è l’unico che può rivelarsi inaccurato. A volte, anche gli strumenti di competitive intelligence riportano dati falsi. Pur essendo il processo di web scripting abbastanza affidabile nell’estrazione di milioni di prezzi da pagine web semi-strutturate, possono comunque verificarsi errori. Identificare e affrontare questi prezzi errati è una sfida a sé stante. Tuttavia, questo meriterebbe anche una lezione specifica, poiché le problematiche tendono ad essere sia specifiche del sito web target sia della tecnologia utilizzata per il web scripting.
Mentre le preoccupazioni legate al web scraping sono importanti, esse si manifestano prima che l’algoritmo di allineamento venga eseguito, e pertanto dovrebbero essere in gran parte disaccoppiate dall’allineamento stesso. Gli errori di scraping non devono essere lasciati al caso. Esistono due modi per giocare la partita della competitive intelligence: o puoi migliorare i tuoi numeri, rendendoli più precisi, oppure puoi peggiorare i numeri dei tuoi concorrenti, rendendoli meno accurati. Questo è l’essenza del controspionaggio.
Come discusso in precedenza, bloccare i robot in base al loro indirizzo IP non funzionerà. Tuttavia, esistono alternative. Lo strato di trasporto di rete non è minimamente il livello più interessante con cui giocare se intendiamo seminare una confusione mirata. Circa un decennio fa, Lokad ha condotto una serie di esperimenti di controspionaggio per verificare se un grande sito di e-commerce, come SugAr, potesse difendersi dai concorrenti. I risultati? Sì, può.
A un certo punto, sono riuscito persino a confermare l’efficacia di queste tecniche di controspionaggio attraverso un’ispezione diretta dei dati forniti dal, altrimenti ignaro, specialista di web scraping. Il nome in codice di questa iniziativa era Bot Defender. Questo progetto è stato interrotto, ma è ancora possibile trovare alcune tracce di Bot Defender nel nostro archivio pubblico del blog.
Invece di cercare di negare l’accesso alle pagine HTML, il che sarebbe un’operazione destinata a fallire, abbiamo deciso di interferire selettivamente con i web scraper stessi. Il team di Lokad non conosceva i dettagli del design di questi web scraper. Considerata la struttura DHTML di un determinato sito di e-commerce, non è troppo difficile ipotizzare come procederebbe un’azienda che opera i web scraper. Ad esempio, se ogni pagina HTML del sito StuttArt possiede una class CSS eccessivamente comoda denominata “unit price” che isola il prezzo del prodotto al centro della pagina, è ragionevole supporre che praticamente tutti i robot utilizzeranno questa class CSS per estrarre il prezzo dal codice HTML. Infatti, a meno che il sito StuttArt non offra un metodo ancora più conveniente per ottenere i prezzi, come un’API aperta consultabile liberamente, questa class CSS rappresenta il percorso ovvio per estrarre i prezzi.
Tuttavia, poiché la logica del web scraping è ovvia, è altrettanto evidente come interferire selettivamente con essa. Per esempio, StuttArt può decidere di selezionare alcuni prodotti mirati e “avvelenare” l’HTML. Nell’esempio visualizzato sullo schermo, entrambe le pagine HTML verranno rese agli occhi degli umani come un cartellino prezzo di 65 Euro e 50 centesimi. Tuttavia, la seconda versione della pagina HTML verrà interpretata dai robot come 95 Euro anziché 65 Euro. Il numero “9” viene ruotato tramite CSS per apparire come un “6”. Il tipico web scraper, che si basa sul markup HTML, non se ne accorgerà.
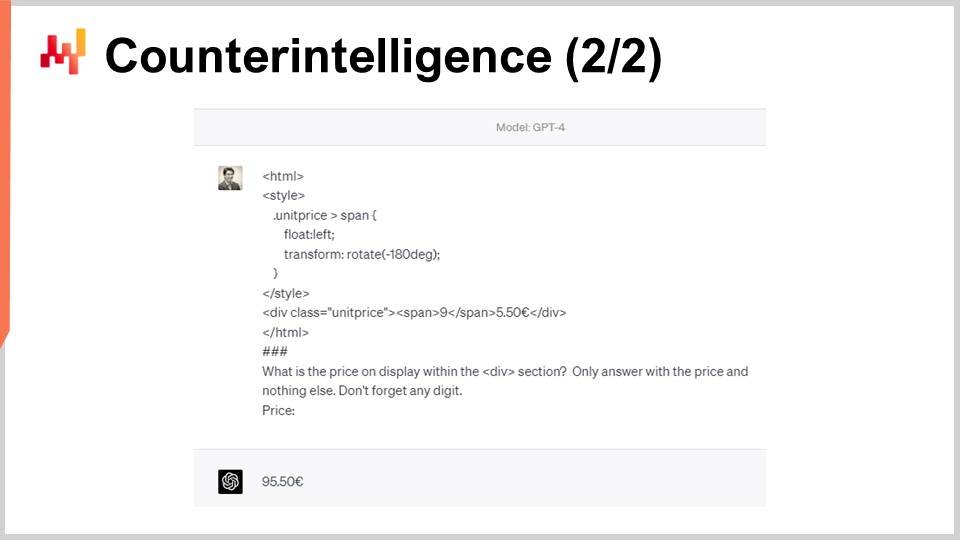
Dieci anni dopo, anche un sofisticato Large Language Model come GPT-4, che all’epoca non esisteva, viene ancora ingannato da questo semplice trucco CSS. Sullo schermo, vediamo che GPT-4 non estrae un prezzo di 65 Euro come avrebbe dovuto, ma risponde invece 95 Euro. Marginalmente, esistono decine di modi per realizzare un codice HTML che offra un cartellino prezzo ovvio per un robot, ma che diverga da quello che un essere umano leggerebbe sul sito. Ruotare un “9” in un “6” è solo uno dei trucchi più semplici all’interno di una vasta gamma di trucchi simili.
Una contromisura a questa tecnica consisterebbe nel renderizzare la pagina, creando il bitmap completo, e poi applicare il Riconoscimento Ottico dei Caratteri (OCR) a tale bitmap. Tuttavia, è piuttosto costoso. Le aziende di competitive intelligence devono ricontrollare decine di milioni di pagine web ogni giorno. In linea di massima, eseguire un processo di renderizzazione della pagina seguito dall’OCR aumenta il costo di processamento di almeno un fattore 100, e più probabilmente di un fattore 1000.
A titolo di riferimento, a maggio 2023 Microsoft Azure addebita un dollaro ogni mille operazioni OCR. Considerando che ci sono oltre 10 milioni di pagine da monitorare quotidianamente dai specialisti di competitive intelligence in Europa, ciò equivale a un budget di 10.000 dollari al giorno solo per l’OCR. E, tra l’altro, Microsoft Azure è piuttosto competitivo in questo ambito.
Considerando anche altri costi, come la larghezza di banda per quegli indirizzi IP residenziali preziosi, è molto probabile che si arrivi a parlare di un budget annuale di circa 5 milioni di euro solo per le risorse informatiche, se si percorre questa strada. Un budget annuale multimilionario rientra nel possibile, ma i margini delle aziende di web scraping sono sottili e non seguiranno questa via. Se con mezzi notevolmente più economici riescono a ottenere una competitive intelligence con un’accuratezza del 99%, ciò è sufficiente per mantenere soddisfatti i loro clienti.
Ritornando a StuttArt, sarebbe imprudente utilizzare questa tecnica di controspionaggio per “avvelenare” tutti i prezzi, poiché ciò farebbe escalare la corsa agli armamenti con i web scraper. Invece, StuttArt dovrebbe scegliere saggiamente l’un percento delle referenze che avranno il massimo impatto in termini di competitività. Molto probabilmente, i web scraper non noteranno nemmeno il problema. Anche se notassero le contromisure, fintanto che saranno percepite come un problema di bassa intensità, non agiranno. Infatti, il web scraping comporta ogni sorta di problematiche di bassa intensità: il sito web da analizzare può essere estremamente lento, può essere inattivo, oppure la pagina di interesse può presentare glitch. Potrebbe esserci una promozione condizionale, che rende il prezzo poco chiaro per la parte interessata.
Dal punto di vista di StuttArt, resta da scegliere l’un percento dei numeri di parte che sono di massimo interesse in termini di competitive intelligence. Queste parti sarebbero tipicamente quelle che StuttArt vorrebbe scontare maggiormente, senza però innescare una guerra dei prezzi. Esistono diversi approcci. Un tipo di parti di alto interesse sono i consumabili economici, come i tergicristalli. Un cliente che desidera provare StuttArt per il suo primo acquisto è improbabile che inizi con un iniettore da 600 Euro. Un cliente alla prima esperienza è molto più propenso a iniziare con un tergicristallo da 20 Euro come prova. Più in generale, i clienti alla prima esperienza si comportano in modo abbastanza diverso rispetto ai clienti abituali. Pertanto, l’un percento delle parti che StuttArt dovrebbe probabilmente rendere particolarmente attraenti, senza innescare una guerra dei prezzi, sono quelle che hanno maggiori probabilità di essere acquistate da clienti alla prima esperienza.

Evitare una guerra dei prezzi e l’erosione della quota di mercato sono entrambi esiti estremamente negativi per StuttArt, quindi occorrono circostanze speciali per discostarsi dal principio di allineamento. Abbiamo già visto una di queste circostanze, ovvero la necessità di controllare il margine lordo. Tuttavia, non è l’unica. Gli eccessi di stock e gli rottura di stock sono altri due candidati principali da considerare per l’aggiustamento dei prezzi. Gli eccessi di stock vanno affrontati in maniera proattiva. Sarebbe meglio per StuttArt evitarli del tutto, ma errori e oscillazioni di mercato accadono e, nonostante politiche attente di riapprovvigionamento dell’inventario, StuttArt si troverà regolarmente ad affrontare eccessi di stock localizzati. La determinazione dei prezzi è un meccanismo prezioso per mitigare tali problemi. StuttArt sta comunque meglio vendendo le parti in eccesso con un sostanziale sconto piuttosto che non venderle affatto, pertanto gli eccessi di stock devono essere considerati nella strategia di pricing.
Limitiamo l’ambito degli eccessi di stock alle sole parti che sono molto probabilmente destinate a diventare svalutazioni di inventario. In questo contesto, gli eccessi di stock possono essere gestiti con un override dell’allineamento dei costi che abbassa il cartellino del prezzo a un margine lordo quasi zero, e possibilmente anche leggermente inferiore a seconda delle normative e dell’entità dell’eccesso.
Al contrario, gli rottura di stock, o meglio quasi-rottura di stock, dovrebbero vedere i loro prezzi revisionati al rialzo. Ad esempio, se StuttArt ha solo cinque unità in magazzino per un pezzo che tipicamente vende un’unità al giorno, e il prossimo rifornimento non arriverà prima di 15 giorni, allora questo pezzo è quasi sicuramente destinato a uno rottura di stock. Non ha senso precipitare lo rottura di stock. StuttArt potrebbe aumentare il prezzo di questo pezzo. A patto che la diminuzione della domanda sia abbastanza contenuta da permettere a StuttArt di evitare uno rottura di stock, non importerà.
Gli strumenti di competitive intelligence sono sempre più capaci di monitorare non solo i prezzi ma anche i ritardi di spedizione annunciati per i pezzi esposti sul sito di un concorrente. Ciò offre a StuttArt la possibilità di controllare non solo i propri rottura di stock, ma anche quelli che si verificano per i concorrenti. Una causa frequente dietro lo rottura di stock di un rivenditore è lo rottura di stock di un fornitore. Se l’OEM stesso è a corto di scorte, allora è probabile che StuttArt, insieme a tutti i suoi concorrenti, finisca per essere a corto di scorte. Nell’ambito dell’algoritmo di allineamento dei prezzi, è ragionevole escludere dall’allineamento quei pezzi che sono esauriti presso i fornitori o sul sito del concorrente. Le situazioni di rottura di stock dei concorrenti possono essere monitorate tramite i ritardi di spedizione, quando questi riflettono condizioni anomale. Inoltre, se un Original Equipment Manufacturer (OEM) inizia ad annunciare ritardi insoliti per i pezzi, potrebbe essere il momento di aumentare i prezzi di tali pezzi. Questo perché indica che probabilmente tutti nel mercato avranno difficoltà ad acquistare altri ricambi per auto da questo particolare OEM.
A questo punto, dovrebbe essere piuttosto evidente che l’ottimizzazione dei prezzi e l’ottimizzazione dell’inventario sono problemi fortemente interconnessi e, pertanto, questi due problemi devono essere risolti congiuntamente nella pratica. Infatti, all’interno di una specifica unità di bisogno, il pezzo che beneficia sia del prezzo più basso che del posizionamento più elevato nella sua gamma di prodotti assorbirà la maggior parte delle vendite. Il pricing dirige la domanda tra numerose alternative all’interno dell’offerta di StuttArt. Non ha senso che un team di inventario tenti di prevedere i prezzi così come generati dal team di pricing. Invece, dovrebbe esserci una funzione unificata di supply chain che affronti congiuntamente queste due problematiche.

Le condizioni di spedizione sono una parte integrante del servizio. Per quanto riguarda i pezzi automobilistici, non solo i clienti hanno alte aspettative che StuttArt manterrà le sue promesse, ma potrebbero anche essere disposti a pagare un extra se il processo venisse accelerato. Diverse grandi aziende di e-commerce che vendono pezzi auto in Europa offrono già prezzi distinti in base al tempo di consegna. Questi prezzi differenti non riflettono semplicemente opzioni di spedizione diverse, ma possibilmente anche opzioni di approvvigionamento differenti. Se il cliente è disposto ad aspettare una o due settimane, allora StuttArt ottiene ulteriori opzioni di approvvigionamento e potrà trasferire alcuni dei risparmi direttamente ai clienti. Ad esempio, un pezzo potrebbe essere acquisito da StuttArt solo dopo che l’ordine è stato effettuato dal cliente, eliminando così completamente il costo di gestione del magazzino e il rischio d’inventario.
Le condizioni di spedizione complicano la competitive intelligence. Innanzitutto, gli strumenti di competitive intelligence devono recuperare informazioni sui ritardi, non solo sui prezzi. Molti specialisti di competitive intelligence lo stanno già facendo, e StuttArt deve seguire l’esempio. In secondo luogo, StuttArt deve adattare il suo algoritmo di allineamento dei prezzi per riflettere le diverse condizioni di spedizione. La programmazione differenziabile può essere impiegata per fornire una stima del valore, espresso in euro, derivante dal risparmio di un giorno. Tale valore dovrebbe dipendere dal modello dell’auto, dal tipo di pezzo e dal numero di giorni necessari per la spedizione. Ad esempio, passare da un tempo di consegna di tre giorni a due giorni è molto più vantaggioso per il cliente rispetto a passare da 21 a 20 giorni.

In conclusione, oggi è stata proposta una strategia di pricing estensiva per StuttArt, una supply chain persona dedicata al mercato dei ricambi auto online. Abbiamo visto che il pricing non si presta a nessun tipo di strategia di ottimizzazione locale. Il problema del pricing è infatti non locale, a causa della compatibilità meccanica che propaga l’impatto di un prezzo per un dato pezzo su numerose unità di bisogno. Ciò ci ha portato a considerare il pricing come un allineamento a livello dell’unità di bisogno. Due sotto-problemi sono stati affrontati tramite la programmazione differenziabile. In primo luogo, abbiamo risolto un problema approssimato di soddisfacimento dei vincoli per l’allineamento competitivo. In secondo luogo, abbiamo affrontato il problema dell’auto-miglioramento dei dataset di compatibilità meccanica per migliorare la qualità dell’allineamento, ma anche per perfezionare l’esperienza del cliente. Possiamo aggiungere questi due problemi alla nostra lista crescente di problemi della supply chain che beneficiano di una soluzione semplice una volta affrontati tramite la programmazione differenziabile.
Più in generale, se c’è una lezione da trarre da questa conferenza, non è che il mercato dei ricambi auto sia un caso a sé stante per quanto riguarda le strategie di pricing. Al contrario, il punto da considerare è che dobbiamo sempre aspettarci di dover affrontare numerose specificità, indipendentemente dal settore di interesse. Sarebbero esistite altrettante specificità se avessimo esaminato un’altra supply chain persona invece di concentrarci su StuttArt, come abbiamo fatto oggi. Pertanto, è inutile cercare una risposta definitiva. Qualsiasi soluzione in forma chiusa è destinata a non riuscire ad affrontare il flusso infinito di variazioni che si presenteranno nel tempo in una supply chain reale. Invece, abbiamo bisogno di concetti, metodi e strumenti che non solo ci permettano di affrontare lo stato attuale della supply chain, ma che siano anche suscettibili a modifiche programmatiche. La programmabilità è essenziale per rendere a prova di futuro le ricette numeriche per il pricing.

Prima di passare alle domande, vorrei annunciare che la prossima lezione si terrà nella prima settimana di luglio. Sarà, come di consueto, un mercoledì, alla stessa ora del giorno - le 15:00, ora di Parigi. Rivedrò il capitolo uno esaminando più nel dettaglio cosa ci dicono l’economia, la storia e la teoria dei sistemi riguardo alla supply chain e al supply chain planning.
Ora passiamo alle domande.
Domanda: Hai intenzione di tenere una lezione sulla visualizzazione del total cost of ownership per una supply chain? In altre parole, un’analisi TCO dell’intera supply chain utilizzando data analytics e l’ottimizzazione complessiva dei costi?
Sì, questo fa parte del percorso di questa serie di lezioni. Diversi elementi di questo argomento sono già stati discussi in parecchie lezioni. Ma la cosa fondamentale è che non si tratta davvero di un problema di visualizzazione. Il concetto di total cost of ownership non è una questione di data visualization; è un problema di mentalità. La maggior parte delle pratiche di supply chain è estremamente poco attenta alla prospettiva finanziaria. Invece di inseguire errori espressi in dollari o euro, si concentrano sui livelli di servizio di errore. Purtroppo, la maggior parte di loro insegue queste percentuali. Pertanto, è necessario un cambio di mentalità.
La seconda cosa è che nella lezione, parte del primo capitolo, sono stati discussi elementi relativi al delivery orientato al prodotto, come nella fornitura software orientata al prodotto per la supply chain. Dobbiamo pensare non solo al primo cerchio dei driver economici, ma anche a quello che chiamo il secondo cerchio dei driver economici. Queste sono forze elusive: ad esempio, se si sconta il prezzo di un prodotto di un euro creando una promozione, un’analisi ingenua potrebbe suggerire che mi sia costato un euro di margine solo perché ho applicato quello sconto. Ma la realtà è che, facendo ciò, si crea l’aspettativa fra i clienti di ricevere nuovamente in futuro quello sconto di un euro. E quindi, questo comporta un costo. È un costo di secondo ordine, ma è molto reale. Tutti questi driver economici del secondo cerchio sono fattori importanti che non compaiono nel bilancio o nei registri contabili. Sì, proseguirò illustrando altri elementi che descrivono questi costi. Tuttavia, non è principalmente un problema analitico in termini di visualizzazione o grafici; è una questione di mentalità. Dobbiamo accettare l’idea che queste cose debbano essere quantificate, anche se sono incredibilmente difficili da misurare.
Quando iniziamo a discutere del total cost of ownership, dobbiamo anche considerare quante persone sono necessarie per far funzionare questa soluzione di supply chain. Questo è uno dei motivi per cui, in questa serie di lezioni, sostengo la necessità di soluzioni programmatiche. Non possiamo avere un esercito di impiegati che modifichi fogli di calcolo o tabelle e compia attività estremamente inefficaci in termini di costi, come gestire avvisi di eccezioni nel software di supply chain. Gli avvisi e le eccezioni consistono nel trattare l’intera forza lavoro dell’azienda come co-processori umani per il sistema. Ciò risulta incredibilmente oneroso.
L’analisi del total cost of ownership è per lo più una questione di mentalità, di avere la giusta prospettiva. Nella prossima lezione, rivedrò anche altri aspetti, in particolare ciò che l’economia ci dice sulla supply chain. È molto interessante perché dobbiamo riflettere su cosa significhi realmente il total cost of ownership per una soluzione di supply chain, soprattutto se iniziamo a considerare il valore che essa apporta all’azienda.
Domanda: Per riferimenti tecnicamente compatibili a un’unità di bisogno, esistono differenze percepite nella qualità, nell’attività, silver, gold, ecc. Come consideri questo nell’ambito di un price matching con i concorrenti?
Esattamente. Per questo è necessario introdurre le gamme di prodotto. Questo livello di attrattiva può solitamente essere ricondotto a circa una mezza dozzina di classi che rappresentano gli standard di qualità dei pezzi. Ad esempio, esiste la gamma motorsport, che comprende i pezzi più lussuosi con un’eccellente compatibilità meccanica. Questi pezzi hanno anche un aspetto gradevole e l’imballaggio è di alta qualità.
La mia esperienza in questo mercato è che, sebbene esistano infinite variazioni per rendere la qualità di un pezzo leggermente superiore o migliore, il mercato si è praticamente consolidato in circa una mezza dozzina di gamme di prodotto che vanno da molto costose a meno costose. Quando raggruppiamo i pezzi di StuttArt, dobbiamo organizzarli in gamme di prodotto. Lo stesso vale per i pezzi dei concorrenti, il che significa che dobbiamo conoscere la fascia di qualità di un pezzo, anche se questo non viene venduto da StuttArt.
StuttArt deve avere una consapevolezza di tutti i pezzi presenti sul mercato. Questo non è così difficile come può sembrare, poiché la maggior parte dei produttori fornisce informazioni sulla qualità prevista dei propri pezzi. Tali informazioni sono ampiamente codificate dagli stessi Original Equipment Manufacturers (OEM). Beneficiamo del fatto che il mercato automobilistico è un mercato incredibilmente consolidato e maturo, esistente da più di un secolo. Le aziende che vendono questi dataset di compatibilità, relativi alle auto e alla compatibilità dei pezzi, forniscono anche una ricchezza di attributi per i pezzi e i modelli di auto. Parliamo di centinaia di attributi. Questi dataset sono estesi e ricchi. Originariamente, venivano utilizzati dalle officine per capire come eseguire le riparazioni. Sono persino corredati da allegati PDF e documentazione tecnica. È davvero ricco; si parla di decine di gigabyte di dati, comprese immagini e fotografie. Io stavo appena grattando la superficie in termini di valore di mercato di questi dataset.
Domanda: In che modo le normative variabili tra le regioni influenzano l’ottimizzazione dei prezzi per le aziende automobilistiche? Ad esempio, hai menzionato Peugeot, un’azienda francese. In che modo il tuo approccio per Peugeot differirebbe da quello per un’azienda simile in Scandinavia o in Asia?
La Scandinavia ha sostanzialmente lo stesso mercato automobilistico. Dispongono di qualche marchio differente, ma il mercato è troppo piccolo per sostenere una propria industria automobilistica. Per quanto riguarda il settore automobilistico, la Scandinavia è come il resto dei 350 milioni di europei. Tuttavia, l’Asia è davvero diversa. India e Cina sono mercati a sé stanti.
Per quanto riguarda l’ottimizzazione dei prezzi, le normative non hanno tanto impedito quanto ritardato l’esistenza dei venditori online di pezzi per auto. Ad esempio, in Europa, 20 anni fa, ci fu una battaglia legale. Pionieri come StuttArt, che furono le prime aziende a vendere pezzi auto online, si trovarono ad affrontare contenziosi legali. Vendendo pezzi auto, dichiaravano sul loro sito che questi erano identici a quelli venduti dai produttori originali.
Aziende come StuttArt affermavano: “Non vi sto vendendo un ricambio qualsiasi, vi sto vendendo lo stesso ricambio che il produttore dell’auto userebbe.” Potevano sostenere questo perché acquistavano esattamente lo stesso pezzo dalla stessa fabbrica. Se un pezzo proviene, diciamo, da Valeo ed è montato su un’auto Peugeot, esiste un’associazione nota. Quello che è stato stabilito circa due decenni fa, da diversi tribunali in Europa, è che era legale per un sito web affermare di vendere esattamente lo stesso pezzo rispetto a quelli che qualificano come ricambi originali per un’auto. Questa incertezza normativa ritardò l’ascesa dei ricambi auto venduti online, probabilmente di circa cinque anni. I pionieri si sono battuti in tribunale contro i produttori di auto per il diritto di vendere pezzi per auto online, sostenendo che erano ricambi originali per l’auto. Una volta chiarita la questione, potevano farlo a patto che fossero onesti e acquistassero davvero esattamente lo stesso pezzo, da Valeo o Bosch, esattamente come quello montato sull’auto.
Tuttavia, esistono ancora delle limitazioni. Ad esempio, ci sono pezzi che caratterizzano l’aspetto visivo dell’auto, e solo il produttore dell’auto può venderli come ricambi originali. Ad esempio, il cofano dell’auto. Queste normative incidono nel restringere l’ambito dei componenti che possono essere venduti liberamente online, pur sostenendo che il pezzo è esattamente lo stesso di quello del produttore originale. Stiamo parlando di pezzi che hanno implicazioni non solo in termini di compatibilità meccanica, ma anche di sicurezza. Alcuni di questi pezzi sono critici per la sicurezza.
In Asia, un problema che non ho discusso qui sono le contraffazioni. La gestione delle contraffazioni è molto diversa in Europa rispetto all’Asia. Le contraffazioni esistono in Europa, ma il mercato è maturo e catalizzato. Gli OEM e i produttori automobilistici si conoscono molto bene. Anche se le contraffazioni esistono, il problema è minimo. In mercati come l’Asia, in particolare in India e in Cina, esistono ancora parecchi problemi legati alle contraffazioni. Non si tratta tanto di una questione di regolamentazione, poiché le contraffazioni sono illegali in Cina tanto quanto in Europa. Il problema risiede nell’applicazione delle leggi, che in Asia è molto meno rigorosa che in Europa.
Domanda: Stiamo cercando di ottimizzare un prezzo complessivo o in relazione ai concorrenti?
La funzione di ottimizzazione è concettualmente pensata per ogni unità di bisogno - un’unità di bisogno è rappresentata da un modello di auto e da un tipo di componente. Per ogni unità di bisogno, esiste una differenza di prezzo in euro tra il prezzo di StuttArt, che costituisce l’offerta migliore di StuttArt, e il prezzo del concorrente. Si prende la differenza assoluta di questi due prezzi e la si somma; questa è la funzione. Non useremo ingenuamente questa somma delle differenze di prezzo; aggiungeremo un peso che rifletta il volume annuale delle vendite per ciascuna unità di bisogno.
Pertanto, la funzione di ottimizzazione per il problema di soddisfazione dei vincoli consiste in una somma delle differenze assolute tra il miglior prezzo offerto da StuttArt per l’unità di bisogno e il miglior prezzo offerto dalla concorrenza. Si aggiunge un fattore di ponderazione che riflette l’importanza annuale, anch’essa ponderata in euro, per questa unità di bisogno. Si sta facendo del proprio meglio per rispecchiare lo stato del mercato europeo.
La ragione per cui si preferisce ponderare in base all’importanza dell’unità di bisogno anziché rispetto all’unità di bisogno di StuttArt, è che se StuttArt è così poco competitiva da non vendere nulla per quella specifica unità, si può incorrere in un problema di mancanza di competitività. Di conseguenza, questa unità viene ignorata in termini di allineamento, portando a zero vendite. Ne consegue un circolo vizioso: non essendo competitiva, non vende nulla e, quindi, l’unità di bisogno stessa viene considerata irrilevante.
Domanda: Riesci a vedere conseguenze inaspettate se un approccio di machine learning basato sulla modellazione differenziabile diventa lo standard del settore, con il rischio che modelli molto simili competano tra loro?
Questa domanda è difficile perché, per definizione, se si tratta di una conseguenza inaspettata, allora nessuno se lo aspettava, nemmeno io. È molto difficile prevedere quale tipo di conseguenze possano rivelarsi inaspettate.
Tuttavia, più seriamente, questo settore è stato guidato da tecniche algoritmiche per un decennio. Si tratta di un raffinamento in termini di precisione dell’intento. Si desidera un metodo numerico che sia maggiormente allineato con il proprio intento. Ma fondamentalmente, non è come se stessimo partendo da zero, dove attualmente si opera manualmente e tra dieci anni tutto verrà automatizzato con ricette numeriche. In realtà, è già tutto gestito tramite ricette numeriche. Quando si hanno 100.000 prezzi da mantenere e aggiornare ogni giorno, è necessario disporre di una qualche forma di automazione.
Forse la tua automazione consiste in un gigantesco foglio Excel in cui stai eseguendo ogni sorta di magie nere, ma resta comunque un processo essenzialmente algoritmico. Le persone non regolano manualmente i prezzi, eccetto in rari casi per pochi componenti. Per lo più, il processo è già algoritmico, e abbiamo già numerose conseguenze non intenzionali. Ad esempio, durante i lockdown in Europa, le persone trascorrevano più tempo a casa e facevano acquisti online. Questo potrebbe sembrare controintuitivo, ma continuavano ad usare molto le loro auto e, di conseguenza, facevano più spese. Tuttavia, molte aziende che vendono ricambi per auto online sono diventate meno attive in termini di promozioni, poiché organizzarle è diventato più complicato, dato che tutti lavoravano da casa.
Di conseguenza, per un paio di mesi durante i lockdown del 2020, si è generato molto meno “rumore algoritmico” a causa delle promozioni. Le risposte algoritmiche sono state molto più dirette da parte di tutti. Ci sono stati giorni in cui si potevano osservare in modo molto più netto le tipologie di risposte algoritmiche attivate con l’aggiornamento giornaliero.
Questo è un modello piuttosto maturo in un settore ben consolidato, poiché ora tutto viene gestito tramite trading elettronico. Per quanto riguarda le conseguenze non intenzionali o inaspettate, esse sono molto più difficili da prevedere.
Permettetemi di offrire una riflessione finale su un potenziale ambito di sorpresa. Molti si aspettano che i veicoli elettrici semplifichino tutto perché hanno meno componenti rispetto ai motori a combustione interna. Tuttavia, dal punto di vista di una società come StuttArt, per i prossimi 10 anni, i veicoli elettrici significheranno molte più parti sul mercato.
Fino a quando, e se, i veicoli elettrici diventeranno dominanti, avremo comunque tutti i veicoli più vecchi con motori a combustione interna. Questi veicoli dureranno circa 20 anni. Ricordate che StuttArt, in quanto azienda, si occupa di veicoli che non sono esattamente nuovi di zecca. Molti di questi veicoli sono di buona qualità e saranno presenti anche tra 20 anni. Nel frattempo, però, assisteremo all’immissione sul mercato di numerosi veicoli elettrici supplementari, accompagnati da una miriade di componenti differenti. Ciò potrebbe provocare un costante aumento del numero di parti diverse, creando ulteriori sfide e complicazioni.
Credo che questo ci porti alla fine della lezione di oggi. Se non ci sono altre domande, non vedo l’ora di vedervi alla prossima lezione, che si terrà nella prima settimana di luglio, mercoledì alle 15:00, ora di Parigi, come di consueto. Grazie mille, e a presto.