00:00 導入
02:49 需要、価格、利益
09:35 競争価格
15:23 欲求と必要性
20:09 これまでの経緯
23:36 今日の流れ
25:17 需要の単位
31:03 車と部品(振り返り)
33:41 競合情報
36:03 アライメント問題の解決 (1/4)
39:26 アライメント問題の解決 (2/4)
43:07 アライメント問題の解決 (3/4)
46:38 アライメント問題の解決 (4/4)
56:21 製品ラインナップ
59:43 制約のない部品
01:02:44 マージン管理
01:06:54 表示順位
01:08:29 重みの微調整
01:12:45 互換性の微調整 (1/2)
01:19:14 互換性の微調整 (2/2)
01:30:41 対抗情報 (1/2)
01:35:25 対抗情報 (2/2)
01:40:49 在庫過剰と品切れ
01:45:45 配送条件
01:47:58 結論
01:50:33 6.2 自動車アフターマーケットのための価格最適化 - 質問?
概要
供給と需要のバランスは、価格に大いに依存します。したがって、価格最適化は多かれ少なかれサプライチェーンの領域に属します。ここでは架空の自動車アフターマーケット会社の価格を最適化する一連の手法を提示します。この例を通して、適切な文脈を捉えずに行われる抽象的な議論に潜む危険性が分かります。何が最適化されるべきかを知ることは、最適化の細部よりもはるかに重要です。
全文書き起こし

このサプライチェーン講義シリーズへようこそ。私はジョアンネス・ヴェルモレルです。本日は、自動車アフターマーケット向けの価格最適化についてご説明します。価格はサプライチェーンの基本的要素です。実際、需要に大きな影響を及ぼす価格という要素を考慮しないまま、供給量や在庫量の妥当性を議論することはできません。しかし、多くのサプライチェーン関連の書籍や、それに連なる多くの supply chain software は、そもそも価格について言及していません。たとえ価格について論じられたりモデル化されたりした場合でも、状況を誤解している素朴な手法で行われることがほとんどです。
価格設定は非常にドメイン依存のプロセスです。価格は何よりもまず、企業が顧客だけでなく、供給業者や競合他社を含む市場全体に送るメッセージです。価格分析の詳細は、対象となる企業に大きく依存します。ミクロ経済学者が行うような一般論的な価格設定のアプローチは知的には魅力的かもしれませんが、同時に誤った方向に導かれる可能性もあります。そのようなアプローチでは、プロフェッショナル品質の価格戦略を構築するための精度が不足しているかもしれません。
本講義は、自動車アフターマーケット企業のための価格最適化に焦点を当てています。講義シリーズの第3章で紹介した架空の企業シュトゥットガルトに再び登場していただきます。シュトゥットガルトのオンライン小売部門、つまり自動車部品を流通させる部門に絞って扱います。本講義の目的は、陳腐な決まり文句を超えて、価格設定が実際には何を意味するのか、そして現実世界の視点からどのようにアプローチすべきかを理解することにあります。狭い分野、すなわち自動車アフターマーケット向けのスペアパーツという限定的な領域を検討しますが、優れた価格戦略を追求する上で、この講義で採用される思考法、マインドセット、態度は、全く異なる分野においても基本的には同じであるといえます。
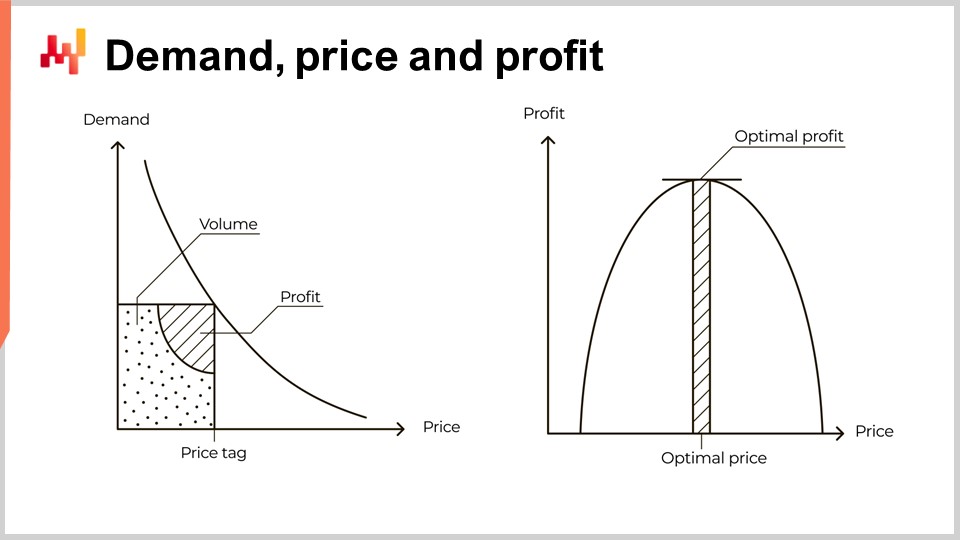
価格が上昇するにつれて需要は減少します。これは普遍的な経済パターンです。このパターンに反する製品の存在は、たとえあっても捉えどころがありません。こうした製品はウェブレン財と呼ばれます。しかし、私がLokadで15年間勤務してきた中で、仮に高級ブランドに関わったとしても、そのような製品が実際に存在するという具体的証拠にたどり着いたことはありません。この普遍的なパターンは、画面左側の曲線によって示され、通常は需要曲線と呼ばれます。市場が、例えばスペアパーツの価格に落ち着くと、その市場は一定の需要量、そして需要を満たす事業者に一定の利益がもたらされると期待されるのです。
自動車のスペアパーツに関しては、これらの部品は間違いなくウェブレン財ではありません。価格が上がると需要は確実に減少します。しかし、自動車部品を購入する際、人々にはあまり選択肢がなく、少なくとも車を走らせ続けるためには、需要は比較的非弾性的であると考えられます。ブレーキパッドの価格が高くても低くても、新しいブレーキパッドを購入するかどうかの決断に大きな影響はありません。実際、多くの人は、たとえ通常の倍の価格を支払わなければならなくても、新品のブレーキパッドを選び、車の使用を完全に停止するよりもそちらを選ぶでしょう。
シュトゥットガルトにとって、あらゆる部品に最適な価格を設定することは、さまざまな理由から極めて重要です。ここでは最も明白な2つの理由を探ってみましょう。第一に、シュトゥットガルトは利益を最大化したいと考えていますが、これは需要が価格によって変動するだけでなく、コストもまた数量によって変化するため、簡単な問題ではありません。さらに、リードタイムの制約により在庫は数日、いや場合によっては数週間前に確保しなければならないため、将来生じる需要に対応できることも必要です。
この限られた説明に基づき、いくつかの教科書や、場合によっては企業向けソフトウェアですら、右側に示された曲線を用いて議論を進めます。この曲線は、任意の価格設定に対して期待される利益の大きさを概念的に示しています。需要が価格の上昇とともに減少し、また数量が増えるにつれて単位当たりのコストが下がることから、この曲線は利益を最大化する最適な利益点を示すはずです。一度この最適点が特定されれば、在庫供給の調整は単純なオーケストレーションの問題として提示されます。実際、最適点は価格設定だけでなく、需要量も提供するのです。
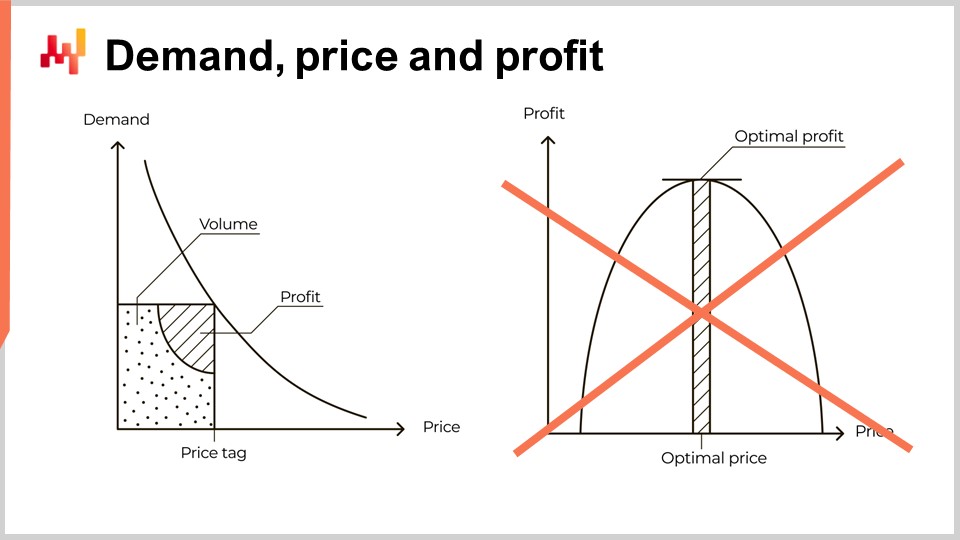
しかし、この見解は根本的に誤っています。問題は、弾性の定量化の難しさとは無関係です。私の主張は、左側の曲線が誤っているというものではなく、それは根本的に正しいというものです。問題は、左側の曲線から右側の曲線への飛躍が誤っているという点にあります。実際、この飛躍はあまりにも明らかに間違っており、一種のリトマス試験として機能します。このような方法で価格を提示するソフトウェアベンダーや価格設定の教科書は、特に弾性の評価を中心課題として提示する場合、危険なほどの経済学の識字能力の欠如を示しています。実際のサプライチェーンをそのようなベンダーや専門家に委ねることは、苦痛と悲惨を招くだけです。あなたのサプライチェーンに必要ないものが一つあるとすれば、それは大規模な誤解に基づくミクロ経済学の誤った解釈です。
この講義シリーズでは、これはまた一例として素朴な合理主義あるいはサイエンティズムの問題であり、現代のサプライチェーンにとって重大な脅威であることが何度も証明されています。抽象的な経済的推論は、多岐にわたる状況を包括できるため強力ですが、同時に大きな誤解にも陥りやすいのです。非常に一般的な観点から考えると、直ちには明らかでない重大な知的誤りが生じることがあります。
左側の曲線から右側の曲線への飛躍がなぜ誤っているのかを理解するために、実際のサプライチェーンで何が起こっているのかを詳しく見ていく必要があります。本講義は自動車用のスペアパーツに焦点を当てています。講義シリーズの第3章で紹介した架空のサプライチェーン企業シュトゥットガルトの視点から、価格設定を再検討します。この企業の詳細について改めて触れることはありません。もしまだ講義 3.4をご覧になっていないなら、この講義の後にぜひご覧になることをお勧めします。
本日は、シュトゥットガルトの eコマース部門、すなわち自動車部品を販売するオンライン小売部門に注目します。シュトゥットガルトがいかにして価格を決定し、随時見直すのが最も適切かという方法を模索しています。この作業は、シュトゥットガルトが販売するすべての部品について実施する必要があります。

シュトゥットガルトは、この市場において独りではありません。シュトゥットガルトが事業を展開するすべてのヨーロッパ諸国で、少なくとも6社前後の注目すべき競合他社が存在します。シュトゥットガルトを含むこのごく短いリストの企業が、自動車用スペアパーツのオンライン市場シェアの大部分を占めています。シュトゥットガルトが一部の部品を独占的に販売している一方で、販売されるほとんどの部品には、少なくとも一社の競合他社が同一の部品を販売しています。この事実は、シュトゥットガルトの価格最適化に大きな影響を及ぼします。
例えば、ある部品において、シュトゥットガルトが競合他社が提示する価格よりも1ユーロ低い価格を設定した場合、シュトゥットガルトはより競争力を高め、市場シェアを獲得できると考えられるかもしれません。しかし、そう簡単にはいきません。競合他社は、シュトゥットガルトが設定するすべての価格を監視しています。実際、自動車アフターマーケットは非常に競争の激しい市場です。どの企業も競争情報収集ツールを備えており、シュトゥットガルトは日々、注目すべき競合他社の価格を集め、競合他社も同様のことを行っています。したがって、シュトゥットガルトがある部品の価格を1ユーロ下げて設定した場合、1、2日以内に競合他社も報復として自社の価格を引き下げ、シュトゥットガルトの価格調整は無効化されると考えるのが妥当です。
シュトゥットガルトは架空の企業かもしれませんが、ここで述べた競争的行動は自動車アフターマーケットにおいて決して架空のものではありません。競合他社は積極的に価格を合わせ合います。もしシュトゥットガルトが何度も価格を下げようとすれば、アルゴリズムによる価格競争に発展し、最終的には両社ともにほとんど、あるいは全く利益が残らなくなるでしょう.
次に、ある部品においてシュトゥットガルトが競合他社の提示する価格よりも1ユーロ高い価格を設定した場合について考えてみましょう。他の条件がすべて同じであれば、シュトゥットガルトは単に競争力を失うことになります。そのため、シュトゥットガルトの顧客基盤が直ちに競合他社に流れるとは限らないものの(価格差に気づいていなかったり、シュトゥットガルトに対する忠誠心からすぐには乗り換えなかったりするため)、時間の経過とともにシュトゥットガルトの市場シェアは確実に縮小していくでしょう.
ヨーロッパには自動車部品の価格比較サイトが存在します。顧客が新しい部品を必要とするたびに比較するわけではありませんが、ほとんどの顧客は時折、選択肢を見直すものです。シュトゥットガルトが常にもっとも高い価格を提示するディーラーとして認識されるのは、実行可能な解決策ではありません.
このように、シュトゥットガルトは競合他社よりも低い価格を設定することはできません。なぜなら、それは価格競争を引き起こすからです。逆に、競合他社よりも高い価格を設定することもできません。なぜなら、時間の経過とともに市場シェアが確実に減少するからです。シュトゥットガルトに残されている唯一の選択肢は、価格の調整を図ることです。これは理論上の話ではなく、ヨーロッパで自動車部品を販売する実際のeコマース企業にとって、価格調整が主要な推進力となっているのです.
先に紹介した、企業がいわゆる最適な利益を選び取ることができるという知的に魅力的な利益曲線は、実際のところほとんど無意味です。シュトゥットガルトには価格設定において選択の余地すらありません。ある種の秘密の要素が存在しない限り、価格調整こそがシュトゥットガルトにとって唯一の選択肢なのです.
自由市場は奇妙なものです。エンゲルスが1819年の書簡で述べたように、「各個人の意志は他のすべての意志によって妨げられ、結果として誰も望まなかったものが生まれる」のです。これから、シュトゥットガルトが価格設定においてある程度の余力を持っていることが分かるでしょう。しかし、主要な命題は変わらず、シュトゥットガルトのための価格最適化は、そもそも厳しく制約された問題であり、需要曲線に基づく素朴な最大化の視点とは何の関連性もないということです.
需要の価格弾力性は、市場全体に対しては意味をなす概念ですが、部品番号のような局所的な対象に対しては通常、あまり適用できません.

需要曲線を利用する単純な利益最大化問題として価格設定に取り組むという考えは、完全に誤りであるか、少なくともシュトゥットガルトの場合には誤りです.
実際、シュトゥットガルトが必要性を満たす市場に属しているという議論もありえますし、もし欲求市場を検討するのであれば、利益曲線の視点も機能するでしょう。マーケティングでは、欲求市場と必要性市場を区別することが古典的な区分となっています。欲求市場は、顧客が消費をやめても悪影響を受けないような提供内容が特徴です。欲求市場では、成功する商品は通常、ベンダーのブランドに強く依存しており、そのブランド自体が需要を生み出す原動力となります。例えば、ファッション業界は欲求市場の典型例です。もしルイ・ヴィトンのバッグが欲しいのであれば、そのバッグはルイ・ヴィトンでしか購入できません。機能的には同等のバッグを販売する数百のベンダーが存在しても、それはルイ・ヴィトンのバッグではありません。ルイ・ヴィトンのバッグの購入を控えたとしても、重大な不都合が生じるわけではありません.
必要の市場は、顧客が消費をやめると悪い結果を被るような提供物によって特徴づけられます。必要の市場では、ブランドは需要を生み出す原動力ではなく、むしろ選択を方向づける役割を果たします。消費の必要が生じたとき、顧客が誰から購入するかを選ぶ際の指針になるのです。たとえば、食品や生活必需品は必要の市場の典型例です。自動車部品が生存に不可欠とまでは言えないとしても、多くの人は収入を得るために車両に依存しており、適切な整備を怠るコストは整備そのもののコストをはるかに上回るため、現実的には整備を見送ることはできません。
自動車アフターマーケットは確かに必要の市場に確固として位置しているものの、微妙な違いがあります。ハブキャップのような部品は必要というよりも欲求に近いものです。より一般的には、すべてのアクセサリーが必要というよりも欲求に該当します。それにもかかわらず、シュトゥットガルトにとっては、需要の大部分が必要性によって左右されています。
ここで提案する価格設定のための利益曲線に対する批判は、必要の市場におけるほぼ全ての状況に一般化できます。シュトゥットガルトが競合他社によって価格設定面で厳しく制約されている例外ではなく、この状況は必要の市場ではほぼ普遍的です。この議論は、欲求の市場を考慮した場合の利益曲線の有効性を否定するものではありません。
実際、欲求の市場では、もし販売者が自社ブランドにおいて独占的な立場にあれば、その販売者は利益を最大化する任意の価格を選ぶ自由があると反論することもでき、これによって我々は再び利益曲線という価格設定の視点に戻ることになります。再度、この反論はサプライチェーンにおける抽象的な経済理論の危険性を示しています。
欲求の市場においても、利益曲線という視点は全く異なる理由から誤りです。この説明の細部は本講義の範疇を超えており、別の講義が必要となるでしょう。しかし、聴講者への一つの課題として、ルイ・ヴィトンのeコマースウェブサイトに掲載されているバッグとその価格のリストをじっくり観察することをお勧めします。利益曲線の視点が不適切である理由は、自明となるはずです。もしそうでなければ、後の講義でこの事例を再び取り上げることになるでしょう。
この講義シリーズは、何よりもまず、Lokadの サプライチェーン・サイエンティスト のためのトレーニング資料として作成されています。しかし、これらの講義がサプライチェーンの実務者のより広い層にも関心を持たれることを望んでいます。講義をある程度独立させるようにしていますが、前の講義で紹介された幾つかの技術的概念を使用します。これらの概念の再紹介に多くの時間を費やすことはありません。もし前の講義をまだ見ていないなら、後でぜひご覧ください。
このシリーズの第一章では、なぜサプライチェーンがプログラム的であるべきかを探求しました。サプライチェーンの複雑性が増大する中、数値レシピを実運用に組み込むことは非常に望ましいことです。オートメーションはかつてないほど緊急であり、サプライチェーンの実務を資本主義的な取り組みにする財政的な必然性があります。
第二章では、方法論に焦点を当てました。サプライチェーンは競争の激しいシステムであり、この組み合わせは単純な方法論を打ち破ります。また、ミクロ経済学を誤解または誤表現するモデルもこの組み合わせによって打ち負かされることを見ました。
第三章では、解決策を除いてサプライチェーンで遭遇する問題点を概観しました。サプライチェーンの ペルソナ の一例としてシュトゥットガルトを紹介しました。この章では、解決すべき意思決定問題の種類を特徴付け、適切な在庫数量の選択のような単純な視点が実際の状況には適合しないことを示しました。意思決定の形には常に深みが存在します。
第四章では、ソフトウェア要素が至る所に存在する現代のサプライチェーン実務を理解するために必要な要素を概観しました。これらの要素は、デジタルサプライチェーンが機能する広い文脈を理解する上で基本的なものです。
第五章と第六章は、それぞれ予測モデルと意思決定に専念しています。これらの章では、現代のサプライチェーン・サイエンティストが有効に活用できる技術を集めています。第六章は、数ある意思決定の一つである価格設定に焦点を当てています。
最後に、第七章は 定量的サプライチェーンマニフェスト イニシアティブの実行に専念し、組織的視点を取り上げています。

本日の講義は大きく二つの部分に分かれます。まず、シュトゥットガルトの価格の競合整合性へのアプローチについて議論します。自動車部品市場の特殊な構造のため、競合他社の価格と整合させるには顧客の視点からアプローチする必要があります。競合整合性は非常に単純ではありませんが、比較的単純な解決策が存在し、それについて詳しく説明します。
第二に、競合整合性が支配的な要因であるものの、それだけが全てではありません。シュトゥットガルトはこの整合性から選択的に逸脱する必要がある、あるいは望むかもしれません。しかし、これらの逸脱の利益がリスクを上回る必要があります。整合性の質は、その構築に使用される入力の質に依存するため、機械的適合性のグラフを洗練するために自己教師あり学習の手法を導入します。
最後に、価格設定に隣接する一連の懸念事項に取り組みます。これらの懸念は厳密には価格設定ではないかもしれませんが、実際には価格とともに対処するのが最適です。

シュトゥットガルトは販売するあらゆる部品に値札をつける必要がありますが、これが価格分析が主に部品番号のレベルで行われなければならないことを意味するわけではありません。価格設定は、何よりもまず、顧客とのコミュニケーション手段です。
シュトゥットガルトが提示する価格を顧客がどのように認識しているか、少し考えてみましょう。ご覧の通り、値札そのものと値札に対する認識との間に一見すると微妙な違いが存在するようですが、実際にはそれは決して微妙なものではありません。
顧客が新しい自動車部品、通常はブレーキパッドのような消耗品を探し始める際、必要な具体的な部品番号を知っている可能性は低いです。この分野に非常に詳しい自動車マニアで、特定の部品番号を念頭に置いている人がわずかにいるかもしれませんが、そうした人はごく少数です。大多数の人々はブレーキパッドを交換する必要があることは分かっていても、正確な部品番号は知らないのです。
この状況は、もう一つの深刻な懸念、すなわち機械的な適合性につながります。市場には何千というブレーキパッドの規格がありますが、特定の車両においては、通常、適合するものは数十種類に過ぎません。したがって、機械的な適合性は偶然に任せることはできません。
シュトゥットガルトは、その競合他社と同様に、この問題を深く認識しています。シュトゥットガルトのeコマースサイトを訪れると、訪問者は自分の車種を指定するよう促され、指定された車両に機械的に適合しない部品は即座にフィルタリングされます。競合他社のウェブサイトも同じデザインパターンに従っており、まず車両を選び、その後部品を選びます。
顧客が二つの販売者を比較しようとする際、通常は部品番号ではなく提供内容を比較します。顧客はまずシュトゥットガルトのサイトを訪れ、適合するブレーキパッドの価格を確認し、その後競合他社のサイトで同様のプロセスを繰り返します。シュトゥットガルトのサイトでブレーキパッドの部品番号を確認し、その部品番号と全く同じものを競合他社のサイトで探すことも可能ですが、実際にはそうする人はほとんどいません。
シュトゥットガルトと競合他社は、利用可能な自動車部品番号のごく一部でほぼすべての車両に対応できるように、品揃えを慎重に作り上げています。その結果、ウェブサイトには通常10万から20万の部品番号が掲載されており、実際に在庫として保有しているのは1万から2万程度に過ぎません。
初期の価格設定の懸念に関しては、価格分析は部品番号の視点ではなく、必要単位という観点から行うべきであることは明らかです。自動車アフターマーケットの文脈では、必要単位は交換が必要な部品の種類と、その交換を求める車種によって特徴付けられます。
しかしながら、この必要単位の視点は、直ちに技術的な複雑さを伴います。シュトゥットガルトは、競合他社と価格を合わせるために部品番号ごとに一対一の価格マッチングに頼ることはできません。したがって、価格の整合性は一見して明らかに思えるほど単純ではなく、特にシュトゥットガルトが競合他社の制約下で運営されていることを認識すると、その明確さは一層失われます。

講義3.4で既に見たように、自動車と部品との間の機械的適合性の問題は、ヨーロッパやその他の主要地域において、専門企業の存在を通じて対処されています。これらの企業は、自動車モデルのリスト、車の部品のリスト、そして自動車と部品の互換性リストの三つから成る機械的適合性データセットを販売しています。このデータセットの構造は、技術的には二部グラフとして知られています。
ヨーロッパでは、これらのデータセットには通常、10万台以上の車両、100万を超える部品、そして車と部品を繋ぐ1億以上のエッジが含まれています。これらのデータセットの維持は労働集約的であるため、専門企業がこれらのデータセットを販売している理由が説明されます。シュトゥットガルトは、競合他社と同様に、最新バージョンのデータセットにアクセスするためにこれらの専門企業からサブスクリプションを購入しています。自動車産業が成熟しているにもかかわらず、新しい車や部品が継続的に導入されるため、サブスクリプションは必要です。自動車業界と密接な連携を保つために、これらのデータセットは少なくとも四半期ごとに更新される必要があります。
シュトゥットガルトおよびその競合他社は、このデータセットを利用して、自社のeコマースサイト上の車両選択機能をサポートしています。顧客が車両を選択すると、互換性データセットに基づき、選択した車両に明らかに適合する部品のみが表示されます。この互換性データセットは、我々の価格分析の基礎ともなっています。このデータセットを通じて、シュトゥットガルトは各必要単位に対して提供される価格を評価することができます。

シュトゥットガルトの競合整合性戦略を構築するための最後の重要な要素は、競合インテリジェンスです。ヨーロッパでは、すべての主要経済圏と同様に、価格スクレイピングサービスを提供する競合インテリジェンスの専門企業が存在します。これらの企業は、シュトゥットガルトおよびその競合他社の価格を毎日抽出しています。シュトゥットガルトのような企業が自社の価格の自動抽出を軽減しようと試みることは可能ですが、いくつかの理由からこの試みはほとんど無駄に終わります:
第一に、シュトゥットガルトは競合他社と同様に、ロボットフレンドリーであることを望んでいます。最も重要なボットは検索エンジンであり、2023年現在、Googleが市場シェアの90%以上を占めています。しかし、Googleだけが唯一の検索エンジンではなく、Googleの主要クローラーであるGooglebotを特定することは可能かもしれませんが、残りの約10%のトラフィックを占める他のクローラー全てについて同様に特定するのは困難です。
第二に、競合インテリジェンスの専門家は、過去10年間で一般家庭のインターネットトラフィックになりすます技術を習得してきました。これらのサービスは、アプリとの提携や一般ユーザーのインターネット接続の利用、さらにはIPアドレスを貸し出してくれるISP(インターネットサービスプロバイダー)との提携を通じて、数百万の家庭用IPアドレスにアクセスできると主張しています。
したがって、シュトゥットガルトは、著名な競合他社からの高品質な価格リストの恩恵を受けていると考えられます。これらの価格は部品番号ごとに抽出され、毎日更新されています。この前提は推測ではなく、現在のヨーロッパ市場の実情です。

これで、シュトゥットガルトが必要単位の観点から競合他社に合わせた価格、すなわち整合性のある価格を算出するために必要なすべての要素が揃いました。
画面には、我々が解決したい制約充足問題の疑似コードが表示されています。すなわち、必要単位、つまり部品タイプと車種のすべての組み合わせを列挙します。そして、各必要単位について、シュトゥットガルトが提示する最も競争力のある価格は、競合他社が提示する最も競争力のある価格と等しくなるべきであると述べています。
変数と制約の数を簡単に評価してみましょう。シュトゥットガルトは提供する各部品番号ごとに1つの値札を設定できるため、約100,000の変数があります。制約の数はやや複雑です。厳密には、約1,000の部品タイプと約100,000の車種があり、これにより約1億の制約が示唆されます。しかし、全ての部品タイプがすべての車種に存在するわけではありません。実際の測定では、制約の数は約1,000万に近いと示されています。
この制約の数が少なくても、変数の数と比較すると依然として100倍の制約があります。これは極めて過剰に制約されたシステムに直面しているということです。したがって、すべての制約を満たす解を見つけるのは困難であることが分かります。最良の結果は、ほとんどの制約を満たす妥協案です。
さらに、競合他社もまた価格に一貫性があるとは限りません。いくら努力しても、シュトゥットガルトは値札が低すぎるために特定の部品番号で価格競争に巻き込まれる可能性があります。同時に、別の競合他社に対して値札が高すぎるため、同じ部品番号で市場シェアを失う可能性もあります。この シナリオ は理論上のものではなく、実証データはこのような状況が定期的に発生していることを示唆しており、たとえそれがごく一部の部品番号であってもというものです.
この制約システムの近似的な解決策を選択しているため、各制約に与える重みを明確にする必要があります。すべての車種が同等ではなく、一部は道路からほとんど姿を消した古い車両に関連しています。これらの制約には、それぞれの需要量(ユーロ換算)に応じた重みを付けることを提案します.
さて、価格設定ロジックの形式的なフレームワークを確立したので、実際のソフトウェアコードに進みましょう。ご覧の通り、このシステムの解決は予想以上にシンプルです。
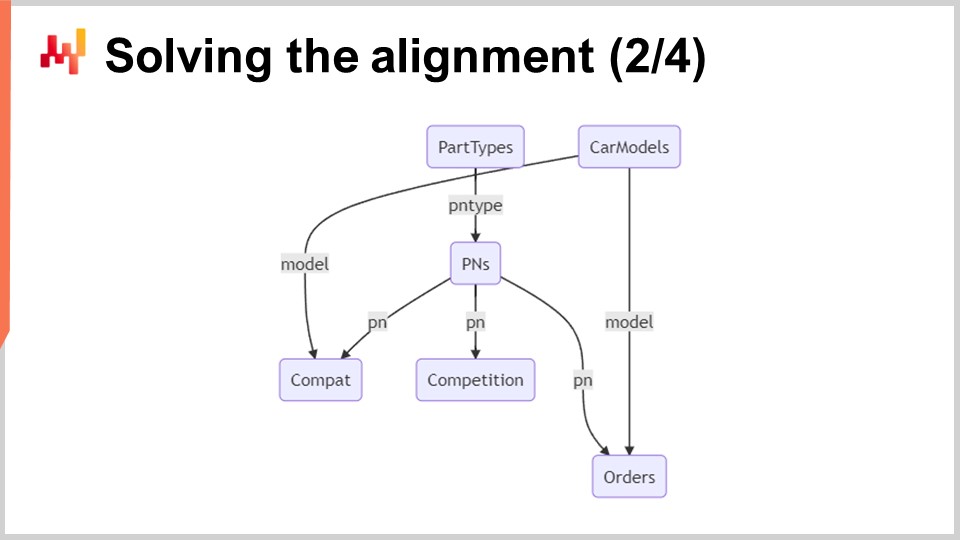
画面上には、このシステムに関与する6つのテーブルを示す最小限のリレーショナルスキーマが表示されています。丸みを帯びた角を持つ矩形は対象となる6つのテーブルを表し、矢印はテーブル間の1対多の関係を示しています。
これらのテーブルを簡単に見直してみましょう:
-
Part Types: 名前が示す通り、このテーブルは、例えば “front brake pads” のような部品種類を一覧にしています。これらの種類は、どの部品が別の部品の代替として利用できるかを識別するために用いられます。代替部品は車両と互換性があるだけでなく、同じ種類である必要があります。部品種類は約1000種類あります。
-
Car Models: このテーブルは、例えば “Peugeot 3008 Phase 2 diesel” のような車種を一覧にしています。各車両にはモデルがあり、同じモデルのすべての車両は同一の機械的互換性を持つと期待されます。車種は約100000種類あります。
-
Part Numbers (PNs): このテーブルは、自動車アフターマーケットで見られる部品番号を一覧にしています。各部品番号は、1つの、そして唯一の部品種類に属しています。このテーブルには約1000000の部品番号が存在します。
-
Compatibility (Compat): このテーブルは機械的互換性を示し、部品番号と車種の有効な組み合わせをすべて収集します。約100000000の互換性レコードを持ち、これが圧倒的に最大のテーブルです。
-
Competition: このテーブルには、その日のすべての競合情報が含まれています。各部品番号について、価格がタグ付けされて展示されている著名な競合が半ダース程度存在し、その結果、約10000000の競合価格が記録されています。
-
Orders: このテーブルには、約1年にわたるシュトゥットガルトからの過去の顧客注文が含まれています。各注文行には部品番号と車種が含まれます。技術的には、車種を指定せずに部品を購入することも可能ですが、これは稀です。車種が指定されていない注文行は除外できます。シュトゥットガルトの規模から、約10000000の注文行があるはずです。
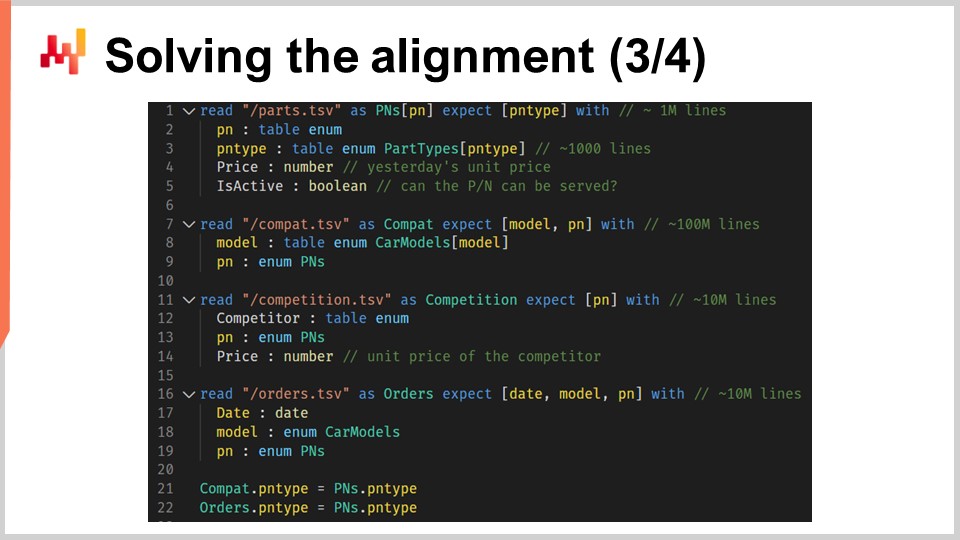
これから、リレーショナルデータを読み込むコードを検証します。画面に表示されているのは、6つのテーブルを読み込むスクリプトで、Envisionで記述されています。Envisionは、供給鎖の予測最適化のためにLokadが特別に設計したドメイン固有のプログラミング言語です。Envisionはサプライチェーンの効率向上とエラー削減のために作られましたが、同じスクリプトをPythonなど他の言語で書き直すことも可能です。ただし、その場合は冗長性が増し、エラーリスクも高まります。
スクリプトの最初の部分では、4つのフラットテキストファイルが読み込まれます。行1から5において、ファイル “path.csv” は、シュトゥットガルトで表示されている現在の価格を含む部品番号と部品種類の両方を提供します。フィールド “name is active” は、特定の部品番号がシュトゥットガルトでサービスされているかどうかを示します。この最初のテーブルでは、変数 “PN” がテーブルの主要な次元を、“PN type” が “expect” キーワードによって導入された副次的な次元を指します。
行7から9では、“compat.tsv” ファイルが部品と車両の互換性リストおよび車種を提供します。これはスクリプト内で最大のテーブルです。行11から14では、“competition.tsv” ファイルが読み込まれ、その日の競合情報、すなわち部品番号および競合先ごとの価格のスナップショットを提供します。行16から19で読み込まれる “orders.tsv” ファイルは、購入された部品番号と関連する車種のリストを示し、指定されていない車種の行は除外されています。
最後に、行21と22で、“part types” テーブルが “compat” と “orders” の上流に設定されます。これは、“compat” または “orders” の各行に対して、唯一対応する部品種類が存在することを意味します。言い換えれば、“PN type” が “compat” と “orders” テーブルに副次的な次元として追加されたということです。Envisionスクリプトのこの最初の部分はシンプルで、フラットテキストファイルからデータを読み込み、リレーショナルデータ構造を再構築しているだけです。
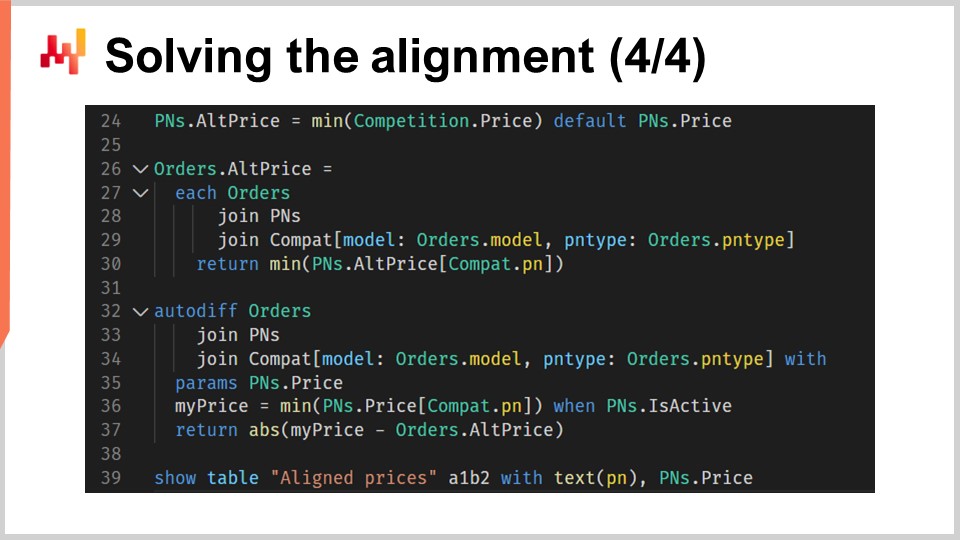
画面に表示されているスクリプトの第2部では、実際のアライメントロジックが実行されます。この部分は第1部の直接の続きであり、ご覧の通り、コードはわずか12行です。再び微分可能プログラミングを使用しています。微分可能プログラミングに馴染みのない方のために説明すると、これは自動微分と確率的勾配降下法の融合です。このプログラミングパラダイムは、機械学習や最適化にも応用されます。サプライチェーンの文脈では、微分可能プログラミングは様々な状況で非常に有用であることが実証されています。この講義シリーズを通じ、モデルの学習、確率的需要予測の生成、そしてバリスティックなリードタイム予測の実現に微分可能プログラミングが如何に利用できるかを示してきました。微分可能プログラミングに不慣れな方は、このシリーズの以前の講義に立ち返ることをお勧めします。
本日の講義では、微分可能プログラミングが何十万もの変数と何百万もの制約を含む大規模最適化問題に如何に適しているかを示します。驚くべきことに、これらの問題は数GBのRAMを搭載した単一のCPUで、たった数分で解決可能です。さらに、これまでの価格を出発点として利用し、最初から再計算するのではなく価格を更新することができます。
注意点として、一つ小さな留意点があります。キーワード “join” はまだEnvisionでサポートされていませんが、将来的な技術計画に含まれています。回避策は存在しますが、明確にするために、本講義では将来のEnvision構文を使用します。
行24では、各部品番号ごとに市場で観測された最小の価格を計算します。もし部品番号がシュトゥットガルトでのみ販売され、競合が存在しない場合は、デフォルトとしてシュトゥットガルトの価格を使用します。
行26から30では、シュトゥットガルトの顧客注文履歴に記載されている各部品について、現在の最も競争力のあるオファーが計算されます。
行27では、“each order” を使用して注文テーブルの各注文行を反復処理します。
行28では、各注文行に対して完全な部品番号テーブルを取り込むために “join pns” を使用します。
行29では “others” と結合しますが、この結合はモデルと部品種類という2つの副次的な次元によって制限されています。これは、注文の各行ごとに、部品モデルと部品種類の組み合わせに合致する部品番号を選択し、顧客注文に合致する需要ユニットに対応する部品を反映することを意味します。
行32から37では、“Auto diff” キーワードで示される微分可能プログラミングを用いてアライメントを解決します。行32で “Auto diff” ブロックが宣言され、観測テーブルとして “orders” テーブルが活用されます。これは、シュトゥットガルト自身の販売量に応じて制約に暗黙の重み付けが行われることを意味します。行33と行44は、行28と29と同様の目的で、“orders” テーブルを反復処理し、部品番号 (“PN”) テーブルへの完全なアクセスと互換エントリの一部を提供します。
行35では、“pns.price” を、確率的勾配降下法によって最適化されるパラメーターとして宣言します。これらのパラメーターを初期化する必要はありません。なぜなら、これまでシュトゥットガルトで使用されていた価格から開始し、アライメントを効果的に更新するからです。
行36では、“my price” を計算します。これは注文行に関連する需要ユニットに対して、シュトゥットガルトが提示する最も競争力のあるオファーを意味します。この計算は、行24で行われた最小観測価格の計算と非常に似た仕組みであり、再び機械的互換性リストに依拠しています。ただし、互換性はシュトゥットガルトで扱われる部品番号に限定されています。従来、顧客は車両に対して必ずしも最も経済的に有利な部品を選択するわけではありません。それにもかかわらず、この文脈で顧客注文を利用する目的は、需要ユニットに重みを割り当てることにあります。
行37では、シュトゥットガルトが提示する最良の価格と競合他社が提示する最良の価格との差の絶対値を用いてアライメントを導きます。この代替ブロック内で、勾配がパラメーターに逆伝播されます。最終的に求まる差が損失関数を形成し、この損失関数から勾配が唯一のパラメーター・ベクトルである “pns.price” に逆流します。各反復(ここでの反復は一つの注文行を意味します)ごとにパラメーター(価格)を段階的に調整することで、スクリプトは望む価格アライメントの適切な近似値へと収束していきます。
アルゴリズムの複雑性という観点では、行36が支配的です。しかし、任意の車種と部品種類に対する互換性の数は限られている(通常は数十を超えることはない)ため、各 “Auto diff” の反復は定数時間で完了します。この定数時間は、10 CPUサイクルのように極めて小さいわけではありませんが、1000000 CPUサイクルになることもありません。大体、20個の互換部品に対して1000 CPUサイクル程度が妥当です。
もし、2ギガヘルツで動作する単一のCPUが100エポック(1エポックは観測テーブル全体の一巡り)を実行すると仮定すれば、約10分の実行時間が見込まれます。10万の変数と1000万の制約を持つ問題を、単一CPUで10分で解くのは非常に印象的です。実際、Lokadはこの見込みに概ね沿った性能を達成しています。しかし、実際には、このような問題ではCPUよりもI/Oスループットがボトルネックとなることが多いです。
改めて、この例はサプライチェーンアプリケーションに適したプログラミングパラダイムを採用する力を示しています。価格設定の観点から、この機械的互換性のデータセットを如何に活用するかが直ちには明らかでなかった非自明な問題から始まりましたが、実際の実装はシンプルです。
このスクリプトは実際の環境で必要となるすべての側面を網羅しているわけではありませんが、核心となるロジックは6行のコードのみで済み、実際のシナリオで生じ得る追加の複雑性に対応する余地が十分に残されています。

前述のアライメントアルゴリズムは、包括性よりもシンプルさと明快さを優先しています。実際の環境では、追加の要因が存在することが予想されます。これらの要因についてはすぐに概観しますが、まずは、これらの要因がこのアライメントアルゴリズムを拡張することで対処可能であると認めましょう。
赤字販売は賢明ではないだけでなく、特別な事情が認められる場合を除き、フランスのように多くの国で違法です。赤字販売を防ぐために、売価が購入価格を上回ることを義務付ける制約をアライメントアルゴリズムに追加することができます。しかし、潜在的な調達問題を特定するためには、この「損失なし」制約なしでアルゴリズムを実行することも有用です。実際、もし競合他社がシュトゥットガルトの仕入れ価格を下回って部品を販売できるなら、シュトゥットガルトは根本的な問題、恐らくは調達または購買の問題に対処する必要があります。
すべての部品番号を一括りにするのは単純な考えです。顧客は全ての純正機器メーカー(OEM)に対して同じ支払い意欲を持っているわけではありません。例えば、ヨーロッパでは、Boschのような有名ブランドの方が、あまり知られていない中国OEMよりも高い価値を顧客は置く傾向にあります。この問題に対処するため、シュトゥットガルトは、同業他社と同様に、OEMを最も高価なものから最も安価なものへと、限られた製品レンジのリストに分類します。例えば、モータースポーツレンジ、家庭用レンジ、ディストリビューターブランドレンジ、そしてバジェットレンジが考えられます。
その後、各部品番号がそれぞれの製品レンジ内で正しく整列されるようにアライメントが構築されます。さらに、アライメントアルゴリズムは、モータースポーツレンジからバジェットレンジに移行する際に価格が厳密に低下することを義務付けるべきです。なぜなら、価格が逆転すると顧客を混乱させるからです。理論的には、競合他社が自社製品を正確に価格設定していれば、このような逆転は起こらないはずです。しかし、実際には、顧客が自分の部品の価格を誤って設定することがあり、時には異なる価格を付ける理由も存在します。
OEMは数百社程度しか存在しないため、それらを各製品レンジに分類する作業は手作業で行うことが可能であり、シュトゥットガルトの市場専門家だけでは直接解決できない曖昧な点がある場合には、顧客調査の助けを借りることもできます。

製品レンジを採用しているにもかかわらず、多くの部品番号の価格はアライメントロジックによって積極的に制御されることはありません。実際、需要ユニット内で最も競争力のある部品番号のみが、同一製品レンジ内で求めるおおよそのアライメントを実現するために、勾配降下法で効果的に調整されます。
同一の機械的互換性を持つ2つの部品番号のうち、1つだけがアライメントソルバーによって価格調整され、もう1つは常にゼロの勾配を受け、その元の価格は変更されません。つまり、システムには多くの制約がある一方で、多くの変数は全く制約されていないのです。製品レンジの粒度や競合情報の充実度によっては、これらの制約されていない部品番号がカタログのかなりの割合、場合によっては半数を占めるかもしれません。ただし、販売量に換算すればその割合ははるかに低くなります。
これらの部品番号に対して、シュトゥットガルトは別の価格設定戦略を必要とします。制約のないこれらの部品に対して厳密なアルゴリズム的手法を提案するわけではありませんが、2つの基本原則を提案します。
第一に、製品レンジ内で最も競争力のある部品と次の部品との間には、例えば10%程度の十分な価格差が存在すべきです。運が良ければ、一部の競合他社はシュトゥットガルトほど需要ユニットの再構築に熟練しておらず、その結果、アライメントを実際に駆動するべき唯一の価格タグを見落とし、価格を引き上げることになり、これはシュトゥットガルトにとって望ましい状況です。
第二に、他の製品ラインと重複しない限り、30%ほど高い価格が付く部品も存在するかもしれません。これらの部品は、より低価格な対応製品の対比として機能し、技術的にはデコイ価格と呼ばれる戦略です。デコイは意図的にターゲットとなる選択肢より魅力のないオプションに設計され、ターゲットオプションをより価値あるものとして見せ、顧客がそれを選びやすくします。これら二つの原則が、競合の閾値を超えて自由な価格を穏やかに広げるのに十分です.

競合他社に合わせた価格設定と適度なデコイ価格戦略だけで、シュトゥットガルトで展示される全ての部品番号に価格を付けることが可能です。しかし、その結果として得られる粗利益率は、シュトゥットガルトにとって低すぎる可能性があります。実際、シュトゥットガルトをすべての有力な競合他社と同調させることは、その利益率に非常なプレッシャーを与えます.
一方では、価格を整合させることは必要であり、そうしなければシュトゥットガルトはやがて市場から締め出されてしまいます。しかし一方で、市場シェアを維持する過程でシュトゥットガルトが破産してはなりません。特定の価格戦略に伴う将来の粗利益率は、あくまで推定または予測に留まるということを忘れてはなりません。顧客も競合他社も適応するため、価格のセットから将来の成長率を正確に導き出す方法は存在しないのです.
シュトゥットガルトが来週期待すべき粗利益率のかなり正確な推定値が得られていると仮定すれば、この「正確性」の部分は思われるほど不合理ではないことを指摘しておく必要があります。シュトゥットガルトは競合他社と同様、厳しい制約下で運営されています。シュトゥットガルトの価格戦略が根本的に変更されない限り、全社的な粗利益率は週ごとに大きく変動しないのです。価格戦略が変わらなければ、先週観測された粗利益率を、来週期待すべき値の妥当な代理値と見なすことすら可能です.
例えば、シュトゥットガルトの粗利益率が13%と予測されている一方で、持続的な経営には15%が必要だとしましょう。このような状況に直面した場合、シュトゥットガルトはどうすべきでしょうか?一つの解決策は、無作為に「ニーズ単位」を選び、それらの価格を約20%引き上げることです。初回購入者に支持されるワイパーのような部品タイプは、この選択から除外すべきです。初回購入者の獲得は高価で困難であり、シュトゥットガルトは初回購入に対してリスクを冒すべきではありません。同様に、インジェクターのような非常に高価な部品タイプでは、顧客がより多く比較検討する可能性が高いため、こうした大きな購入において競争力を欠くリスクを冒すべきではありません.
しかし、この二つの状況を除けば、無作為に「ニーズ単位」を選び、価格を上げて競争力を失わせるという選択は合理的なオプションだと考えます。実際、シュトゥットガルトはより高い成長粗利益率を追求するため、いくつかの価格を引き上げる必要があり、これは避けられない結果です。もしシュトゥットガルトが明確なパターンを採用すれば、オンラインレビューでそのパターンが指摘される可能性があります。例えば、シュトゥットガルトがボッシュ製部品での競争力維持を断念したり、プジョー車対応部品で競争力を持たないと決めたりすると、シュトゥットガルトがボッシュやプジョー車にとってお得でないディーラーとして知られる危険性が生じます。無作為性はシュトゥットガルトをやや不可解にし、まさにそれが狙いなのです.
表示順位もまた、シュトゥットガルトのオンラインカタログにおいて極めて重要な要素です。より具体的には、各「ニーズ単位」ごとに、シュトゥットガルトは対象となるすべての部品を順位付けする必要があります。部品をどのように順位付けするかという最適な方法を決定することは、価格設定に隣接した問題であり、それ自体で一講義に値するテーマです。本講義の観点からは、表示順位は整合性問題の解決後に算出されると考えられます。しかし、価格タグと表示順位を同時に最適化することも考えられます。この問題は、これまで扱ってきた10万変数の代わりに約1000万変数を提示することになります。それでも、1000万個の制約を扱う必要があるため、最適化問題の規模自体は根本的に変わりません。本日は、この表示順位の最適化を導くための基準や、離散最適化において勾配降下法をどのように活用するかについては触れません。後の講義でこの後者の問題は扱います.

「ニーズ単位」の相対的重要性は、ほぼすべて既存の車両フリートによって定義されます。シュトゥットガルトは、ヨーロッパにたった1,000台しか存在しない車種で100万個のブレーキパッドを販売することは期待できません。部品の真の消費者は所有者ではなく、むしろ車両そのものだと主張することさえ可能です。車両自体は部品代を支払いませんが(所有者が支払います)、この類推は車両フリートの重要性を強調するのに役立ちます.
しかし、オンラインで部品を購入する際には、かなりの歪みが生じることが予想されます。結局、部品購入は、修理工場から間接的に購入するよりも費用を節約する手段として行われるからです。したがって、シュトゥットガルトが観測する平均車両年齢は、一般的な自動車市場の統計が示すよりも高いと予想されます。同様に、高価な車を運転する人々は、自己修理で費用を節約しようとする可能性が低いため、シュトゥットガルトが観測する平均的な車両サイズやクラスも、一般市場の統計が示すものより低くなると考えられます.
これは単なる思いつきではありません。これらの歪みは、ヨーロッパの主要なオンライン自動車部品小売業者すべてで実際に観測されています。しかし、先に述べた通り、整合性アルゴリズムは、需要の代理としてシュトゥットガルトの販売履歴を活用しています。これらのバイアスが価格整合性アルゴリズムの結果を損なう可能性は十分に考えられます。これらのバイアスがシュトゥットガルトの結果に悪影響を及ぼすかどうかは、基本的には実証的な問題であり、その大きさはデータに大きく依存します。Lokadの経験では、『ニーズ単位』の重みを2倍あるいは3倍と誤算しても、この種のバイアスに対して整合性アルゴリズムとその派生形はかなり堅牢であることが示されています。これらの重みの主な貢献は、同じ部品番号が同時に複数の「ニーズ単位」に属する場合に、衝突を解決するのに役立つ点にあるようです。多くの場合、一方の「ニーズ単位」は体積の点で圧倒的に大きいため、各体積の見積もりが大きくずれても価格への影響はほとんどありません.
「ニーズ単位」に対して本来あるべき需要と、シュトゥットガルトが実際に観測する販売実績との間で最も大きなバイアスを特定することは非常に有用です。特定の「ニーズ単位」における驚くほど低い販売量は、eコマースプラットフォームに些細な問題があることを示唆する傾向があります。部品の誤ラベル、不正確または低品質な画像などが原因かもしれません。実際、これらのバイアスは、特定の車種における各部品タイプの販売比率を比較することで特定できます。例えば、ある車種でブレーキパッドが全く売れておらず、他の部品タイプの販売量が通常通りである場合、その車種でブレーキパッドの消費が例外的に低いとは考えにくいです。根本原因はほぼ間違いなく他にあるはずです.
優れた機械的適合性リストは競争上の優位性となります。競合他社が知らない適合性を把握することで、価格戦争を引き起こすことなく自社製品を低価格で提供し、市場シェア拡大において優位に立つことが可能です。逆に、不正確な適合性を特定することは、顧客からの高額な返品を避けるために極めて重要です.
実際、修理工場にとっては、不適合な部品を注文するコストは控えめです。未使用部品を流通センターに返送するための既存のプロセスがあるからです。しかし、通常の顧客にとっては、部品を適切に再梱包して返送することすら困難な場合があり、このプロセスははるかに手間がかかります。したがって、すべてのeコマース企業には、レンタルしているサードパーティのデータセットの上に独自のデータ拡充レイヤーを構築するインセンティブがあります。この業界のほとんどのeコマース事業者は、何らかの形で独自のデータ拡充レイヤーを持っています.
そもそも、その知識をこれらのデータセットを管理する専門会社と共有するインセンティブはほとんどありません。なぜなら、その知識は主に競合他社に利益をもたらすからです。これらのデータセットの誤差率を評価するのは難しいですが、Lokadでは、誤差率が双方で一桁台の低い数字で推移していると見積もっています。存在しない互換性を宣言する偽陽性が数パーセント、存在するにもかかわらず宣言されない偽陰性が数パーセントあるのです。機械的適合性のリストが1億行以上を含むことを考えると、保守的な推計では約700万件の誤りが存在する可能性が高いです.
したがって、シュトゥットガルトにとってこのデータセットを改善することは有益です。偽陽性の機械的適合性が原因で報告された顧客の返品は、確かにこの目的に活用できるでしょう。しかし、このプロセスは遅く、コストもかかります。さらに、顧客はプロの自動車技師ではないため、単に部品の取り付けに失敗しただけで部品を不適合と報告するかもしれません。シュトゥットガルトは、いくつかの苦情が寄せられるまで部品を不適合と判断するのを先延ばしにすることも可能ですが、そうするとプロセスはさらにコスト高かつ遅くなります.
したがって、この適合性データセットを改善するための数値的手法は非常に望ましいものです。追加情報を用いずにこのデータセットを改善できるかは一見疑問ですが、驚くべきことに、さらなる情報なしでこのデータセットは改善可能であり、自己ブートストラップしてより優れたバージョンに進化させることができるのです.
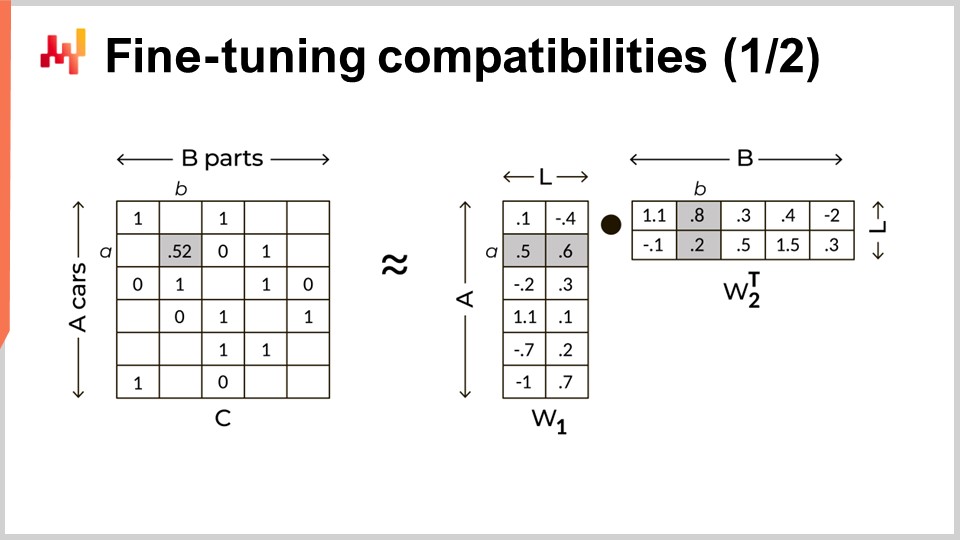
私自身は、2017年の第1四半期にLokadのための一連のディープラーニング実験を行っている際に、この発見にたどり着きました。そこで私は、協調フィルタリングのための有名な手法である行列分解を用いました。協調フィルタリングは、ユーザーが短いリストの既知の好みを元に好むであろう製品を特定するという、レコメンダーシステム構築の中心的な問題です。協調フィルタリングを機械的適合性に適用するのは簡単で、ユーザーを車種に、製品を自動車部品に置き換えるだけです。これで問題は適用可能となります.
より一般的に、行列分解は二部グラフを含むあらゆる状況に適用可能です。行列分解はグラフ解析を超えて有用です。例えば、大規模言語モデル(LLM)の低ランク適応という、LLMの微調整に非常に人気のある手法も、行列分解のテクニックに依存しています。画面左側には、車と部品の互換性を1で、車種と部品番号間の互換性のなさを0で示す互換性マトリックスが表示されています。この大規模で非常に疎なマトリックスを、二つの小さな密な行列の積と置き換えたいのです。右側にはその二つの行列が見えます。これらの行列は、大きなマトリックスを分解する役割を果たします。実質的に、すべての車種と部品番号を潜在空間に押し込んでいるのです。この潜在空間の次元は、画面上で大文字のLで示されています。この潜在空間は機械的適合性を捉えるよう設計されていますが、元のマトリックスに比べ次元は大幅に低いです。潜在空間の次元を低く保つことで、これらの機械的適合性を支配する隠れたルールを学習することを目指しています.

行列分解は立派な技術的概念のように聞こえるかもしれませんが、実際は基本的な線形代数のテクニックにすぎません。唯一、単純でありながら非常に効果的に機能する点が、やや欺瞞的に映るだけです。画面には、この手法を30行未満のコードで完全に実装した例が示されています.
1行目から3行目では、機械的適合性を一覧にしたフラットファイルを読み込んでいます。このファイルは簡潔のため、行列を意味するMという名前のテーブルに読み込まれます。このリストは、実質的には互換性マトリックスの疎な表現です。このリストを読み込む際、car_modelsとpnsという二つの別テーブルも作成されます。これらのブロックにより、M、car_models、pnsの三つのテーブルが得られます.
5行目と6行目では、車種が含まれる列をランダムにシャッフルしています。シャッフルの目的は、ランダムなゼロ、すなわちランダムな不適合性を作り出すことにあります。実際、互換性マトリックスは非常に疎であり、ランダムに選んだ車と部品の組み合わせが不適合であることはほぼ確実です。このランダムな組み合わせがゼロであるという信頼度は、そもそもの互換性リストに対する信頼度よりも高いのです。これらのランダムなゼロは、マトリックスが疎であるため設計上99.9%の正確性を持ち、既知の互換性はおそらく97%の正確性です.
8行目では、24次元の潜在空間を作成します。24次元は埋め込みとしては多いように思えるかもしれませんが、千次元以上ある大規模言語モデルと比べれば非常に小さい値です。9行目と10行目では、大きなマトリックスを分解するために使用する、pnlとcar_Lという二つの小さな行列を作成しています。これらの行列は、pnlの場合は約2400万のパラメーター、car_Lの場合は約240万のパラメーターを表しています。大規模なマトリックスが約1000億の値を持つのと比べると、これは小規模と見なされます.
ここで指摘しておくべきは、このスクリプト内で大きなマトリックスは決して具現化されないということです。決して明示的に配列に変換されることはなく、常に1億件の互換性リストとして保持されます。これを配列に変換すると、計算資源の面で非常に非効率になるのです.
ライン12から15では、sigmoidとlog_lossという2つのヘルパー関数を紹介します。sigmoid関数は、行列積の生の結果を0から1の間の確率値に変換するために用いられます。log_loss関数はロジスティック損失を意味します。ロジスティック損失は、確率的予測の正確さを評価するための指標であるログ尤度を適用します。ここでは、2クラス分類問題に対する確率的予測の評価に使われています。リードタイムの確率的予測に関する講義5.3で既にログ尤度に触れたことがあり、これはその考え方の単純化したバリエーションです。これら2つの関数にはautogradキーワードが付与され、自動微分が可能であることを示しています。百万分の一という小さな値は数値の安定性のために導入されたイプシロンで、論理そのものには影響しません。ライン17から29では、行列分解そのものを示しています。再び、微分可能なプログラミングを使用しています。数分前は、制約充足問題を近似的に解くために微分可能なプログラミングを利用していました。ここでは、自己教師あり学習問題に対処するために微分可能なプログラミングを使っています。
ライン18と19では、学習対象となるパラメータを宣言しています。これらのパラメータは、小さな2つの行列、pnlとcar_Lに関連付けられています。キーワード “auto” は、これらのパラメータが平均0、標準偏差0.1のガウス分布からの乱数としてランダムに初期化されることを示しています。
ライン20と21では、収束を加速する2つの特殊なパラメータを紹介します。これらは合計48個の数値に過ぎず、依然として数百万の数値を含む我々の小さな行列と比べれば氷山の一滴です。それにもかかわらず、これらのパラメータを導入することで収束速度が大幅に向上することが分かりました。重要なのは、これらのパラメータが既存のモデルに対して自由度を追加するものではなく、学習過程においてごく僅かな追加自由度をもたらすに過ぎないという点です。その結果、必要なエポック数が半分以上に短縮されます。
ライン22から24では、埋め込みベクトルを読み込んでいます。ライン22では、pxという単一部品の埋め込みがあり、ライン23ではmxという単一の車種モデルの埋め込みが示されています。ペア(px, mx)は正のエッジ、すなわち互換性が真とみなされる組み合わせです。ライン24では、別の車種モデルであるmx2の埋め込みがあり、ペア(px, mx2)は負のエッジ、すなわち互換性が偽とみなされる組み合わせとなります。実際、mx2はライン6で行われるシャッフルによってランダムに選ばれています。埋め込みベクトルであるpx、mx、mx2はすべて、このスクリプト内のテーブルLで表される潜在空間に属しているため、正確に24次元です。
ライン26では、正のエッジであると定義された当モデルの確率を、ドット積を通して表現しています。このエッジは正であると既に認識されている(少なくとも互換性データセットがそう示している)のですが、ここでは当モデルがこのエッジについて何を示しているのかを評価します。ライン27では、同じく当モデルにより定義された、負のエッジである確率をドット積で表現します。このエッジはランダムなエッジであるため、負と推定します。そして、再びこの確率を評価し、当モデルがこのエッジについて何と言っているかを確認します。ライン29では、このエッジに関連するログ尤度の逆数を返します。この返り値は、確率的勾配降下法によって最小化される損失として使用されます。ここで、これは互換性があるペアとないペアとの間で、ログ尤度、すなわち確率的二項分類の基準を最大化していることを意味します。
その後、このスクリプトに示された内容を超えて、大きな行列は2つの小さな行列のドット積と比較することができます。2つの表現の乖離は、元のデータセットにおける偽陽性と偽陰性の両方を明らかにします。最も驚くべきは、この大きな行列の因数分解された表現が、元の行列よりも正確であることです。
残念ながら、関連する互換性データセットが全て独自のものであるため、これらの技法に関連する実証結果を提示することはできません。しかし、業界の数名の関係者によって検証された私の調査結果は、これらの行列因数分解技法を用いることで、偽陽性と偽陰性の数を最大で桁違いに減少させることが可能であると示しています。性能面では、2017年にMicrosoftの深層学習ツールキットであるCNTKを用いて約2週間かかった収束が、現在のEnvisionが提供するランタイムでは約1時間に短縮されました。初期の深層学習ツールキットもある意味で微分可能なプログラミングを提供していましたが、これらのソリューションは大規模な行列積や大規模な畳み込みに最適化されていました。GoogleのJaxのような最近のツールキットは、Envisionと同等の性能を発揮するのではないかと考えられます。
ここで疑問が生じます。なぜ、互換性データセットを管理する専門企業は、行列因数分解を用いて既に自社のデータセットをクリーンアップしていないのでしょうか。もしそうしていれば、行列因数分解が新たなものをもたらす余地はなかったはずです。機械学習技法としての行列因数分解は、ほぼ20年前から存在しています。この技法は2006年にサイモン・ファンクによって普及されました。もはや最先端とは言えません。私のこの疑問に対する答えは「わかりません」です。もしかすると、専門企業はこの講義を見た後で行列因数分解を採用し始めるかもしれませんし、そうでないかもしれません。
いずれにせよ、これは微分可能なプログラミングと確率的モデリングが非常に多用途なパラダイムであることを示しています。一見すると、リードタイム予測は機械的互換性の評価とは無関係に思えますが、両者は同じ手法、すなわち微分可能なプログラミングと確率的モデリングによって対処可能です。

機械的互換性のデータセットだけが不正確である可能性があるわけではありません。場合によっては、競合インテリジェンスツールが偽データを返すこともあります。半構造化ウェブページから数百万件の価格を抽出するウェブスクリプト処理が比較的信頼できたとしても、エラーが発生する可能性はあります。こうした誤った価格を特定し対処すること自体が一つの挑戦です。しかし、これらの問題は対象となるウェブサイトや使用されるウェブスクリプト技術に特有であるため、個別の講義に値するでしょう。
ウェブスクレイピングの問題は重要ですが、これらの問題はアラインメントアルゴリズムが実行される前に発生するため、本質的にはアラインメントそのものから切り離されるべきです。スクレイピングエラーは偶然に任せる必要はありません。競合インテリジェンス戦略には2通りのアプローチがあります。一つは自社の数値をより良く、正確にするか、もう一つは競合他社の数値を悪化させ、不正確にするかということです。これが対抗諜報の本質です。
前述の通り、IPアドレスに基づいてロボットをブロックする方法は効果がありません。しかし、代替手段は存在します。標的を絞った混乱を引き起こすために操作する場合、ネットワークトランスポート層は最も興味深い層ではありません。約10年前、Lokadは大手eコマースサイト(例えばSugAr)が競合に対抗できるかどうかを検証するための一連の対抗諜報実験を実施しました。その結果は?はい、可能です。
ある時、無頓着なウェブスクレイピング専門家が提供したデータを直接検証することで、これらの対抗諜報技法の有効性を確認することができました。この取り組みのコードネームはBot Defenderでした。現在、このプロジェクトは中止されていますが、弊社の公開ブログアーカイブにはBot Defenderの痕跡がいくつか残っています。
HTMLページへのアクセスを拒否するという、成功の見込みが薄い方法を取る代わりに、私たちはウェブスクレイパー自体に選択的に干渉することを決定しました。Lokadチームは、これらのウェブスクレイパーの設計の細部を把握していませんでした。特定のeコマースサイトのDHTML構造を考慮すれば、ウェブスクレイパーを運用する企業がどのように動作するかを推測するのはそれほど難しくありません。例えば、StuttArtのウェブサイトの各HTMLページに、ページ中央の商品価格を特定するための非常に便利な “unit price” というCSSクラスが存在すれば、ほとんどすべてのロボットがこの便利なCSSクラスを使ってHTMLコード内から価格を抽出するだろうと推測するのが妥当です。実際、StuttArtのウェブサイトが、自由に問い合わせ可能なオープンAPIなど、さらに便利な価格取得手段を提供しない限り、このCSSクラスは価格抽出の明らかな方法となります。
しかし、ウェブスクレイピングのロジックが明白であるがゆえに、このロジックに選択的に干渉する方法も明白です。例えば、StuttArtは狙いを定めた数点の商品を厳選し、HTMLに「毒」を盛ることができます。画面上の例では、人間にとっては両方のHTMLページが65ユーロと50セントの価格タグとして表示されます。しかし、2番目のHTMLページは65ユーロではなく95ユーロとしてロボットに解釈されます。数字の「9」がCSSによって回転され、「6」のように見えるのです。HTMLマークアップに依存する標準的なウェブスクレイパーはこれを検出できません。
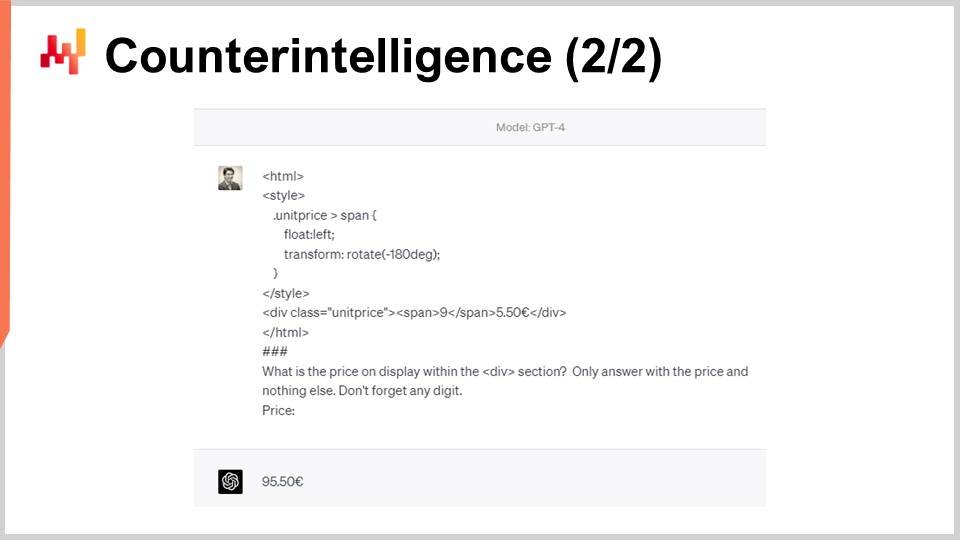
10年後、当時存在しなかった高度な大規模言語モデルであるGPT-4でさえ、この単純なCSSトリックに騙されます。画面上では、GPT-4が本来抽出されるべき65ユーロの価格ではなく、95ユーロと回答しているのが確認できます。さらに、ロボット向けのHTMLコードを工夫して、人間がウェブサイト上で読む価格と異なる明確な価格タグを提供する方法は数十通り存在します。『9』を『6』に回転させるのは、そんな数多くの手法の中でも最も単純なものの一つに過ぎません。
この手法に対抗するには、ページをレンダリングし、完全なビットマップを生成した後、そのビットマップに対して光学式文字認識(OCR)を適用する必要があります。しかし、これは非常にコストがかかります。競合インテリジェンス企業は、毎日何千万ものウェブページを再検証しなければなりません。一般的に、ウェブページのレンダリングプロセスに続いてOCRを実行すると、処理コストが少なくとも100倍、場合によっては1000倍に増加します。
参考までに、2023年5月時点でMicrosoft Azureは、1000回のOCR操作につき1ドルを請求しています。ヨーロッパの競合インテリジェンス専門家が毎日監視すべきページ数が1000万ページ以上であることを考えると、OCRだけで1日あたり1万ドルの予算が必要となります。ちなみに、Microsoft Azureはこの分野で非常に競争力があります。
さらに、貴重な住宅用IPアドレスの帯域幅など他のコストを考慮すると、この手法を採用する場合、計算資源だけで年間約500万ユーロの予算が必要になる可能性が高いです。数百万ユーロの年間予算はあり得ますが、ウェブスクレイパー企業の利益率は低いため、この道には進まないでしょう。はるかに低コストな手段で99%の精度の競合インテリジェンスを実現できれば、それだけで顧客を満足させるに十分です。
StuttArtに戻ると、すべての価格をこの対抗諜報技法で汚染するのは賢明ではありません。なぜなら、そうするとウェブスクレイパーとの間で軍拡競争が激化するからです。代わりに、StuttArtは競合上最大の影響を与える1%のリファレンスを賢く選定するべきです。ほとんどの場合、ウェブスクレイパーはこの問題に気付かないでしょう。たとえ対策に気付いたとしても、問題が低強度と認識される限り、対応に踏み切ることはありません。実際、ウェブスクレイピングにはウェブサイトの遅延、停止、または該当ページの不具合など、さまざまな低強度の問題が伴います。条件付きのプロモーションが存在し、対象部品の価格が不明瞭になる場合もあります。
StuttArtの観点からは、競合インテリジェンス上で最大の関心が寄せられる1%の部品番号を選定することが求められます。これらの部品は、通常StuttArtが最も大幅な値引きを行いたい部品でありながら、価格戦争を引き起こさないものです。これを達成する方法はいくつか考えられます。高関心を集める部品の一例として、ワイパーのような安価な消耗品が挙げられます。初めてStuttArtを試す顧客が600ユーロのインジェクターから取引を始める可能性は低く、テスト的に20ユーロのワイパーから始める可能性の方が高いのです。一般的に、初回顧客はリピート顧客とは全く異なる行動をとります。したがって、価格戦争を引き起こさずに特に魅力的にすべき1%の部品は、初回顧客が最も購入する可能性の高い部品と言えるでしょう。

価格戦争と市場シェアの減少は、どちらもStuttArtにとって極めてマイナスの結果をもたらすため、アラインメント原則から逸脱するには特別な状況が必要です。既に述べたように、粗利益率の管理がその一例ですが、それだけではありません。過剰在庫とストックアウトは、価格調整を検討すべき他の主要な対象です。過剰在庫は積極的に対処すべきで、StuttArtとしては理想的には全く過剰在庫を出さない方が望ましいものの、ミスや市場の変動があるため、いかに慎重な在庫補充方針を採っても局所的な過剰在庫は避けられません。価格設定は、これらの問題を緩和するための有用な手段であり、StuttArtは過剰在庫の部品を全く売らないよりも、大幅な割引を付けて販売する方が得策です。したがって、過剰在庫は価格戦略に組み込む必要があります。
過剰在庫の対象を、在庫評価損につながる可能性が非常に高い部品に絞ってみましょう。この文脈では、コストアラインメントのオーバーライドを用いて、価格タグをほぼゼロの粗利益率、場合によっては規制や在庫量に応じてそれ以下に下げることで対処が可能です。
逆に、ストックアウト、正確にはストックアウトに近い状況では、価格タグを引き上げるべきです。例えば、通常1日1単位売れる部品について、StuttArtが在庫に5単位しか残っておらず、次の補充が15日後以降に届く場合、その部品はほぼ確実にストックアウトに直面するでしょう。ストックアウトを急いで迎える意味はありません。需要の低下が十分に小さければ、StuttArtはこの部品の価格を上げることで、ストックアウトを回避できるはずです。
競合インテリジェンスツールは、価格だけでなく、競合他社のウェブサイトに表示される部品の配送遅延も監視する能力が高まっています。 これにより、StuttArtは自社の品切れだけでなく、競合他社の品切れが進行する様子も監視する可能性が生まれます。 小売業者の品切れの頻繁な原因は、供給者の品切れです。 もしOEM自体が在庫切れであれば、StuttArtを含む全ての競合他社も最終的には在庫切れになる可能性が高いです。 価格調整アルゴリズムの一環として、供給者側または競合他社のウェブサイト上で在庫切れとなっている部品を、調整対象から除外するのが合理的です。 競合他社の品切れ状況は、通常とは異なる条件を反映する配送遅延によって監視できます。 また、OEMが部品に対して異常な遅延を発表し始めた場合、その部品の価格を引き上げるタイミングかもしれません。 これは、市場全体がその特定のOEMからより多くの車部品を調達するのに苦労することを示唆しているからです.
この時点で、価格最適化と在庫最適化は密接に連動した問題であり、実際にはこれら二つの問題を共同で解決する必要があることが明らかになります。 実際、特定の需要ユニット内では、最低価格とその製品群内で最高の表示ランクの両方の恩恵を受ける部品が、販売の大部分を占めることになります。 価格は、StuttArtが提供する多数の選択肢の中で需要を誘導します。 在庫チームが価格チームによって生成された価格を予測しようとするのは意味がありません。 代わりに、両方の懸念を統合して対処する統一されたサプライチェーン機能が必要です.

配送条件はサービスの不可欠な一部です。 自動車部品に関しては、顧客はStuttArtが約束を果たすことに高い期待を持つだけでなく、プロセスを迅速化すれば追加料金を支払う用意があるかもしれません。 ヨーロッパで車部品を販売するいくつかの大手eコマース企業では、リードタイムに応じた異なる価格設定がすでに行われています。 これらの異なる価格は、単に出荷オプションの違いを反映するだけでなく、場合によっては調達オプションの違いも示唆しています。 例えば、顧客が1、2週間待つことができるならば、StuttArtは追加の調達オプションを得ることができ、その一部の節約分を顧客に還元する可能性があります。 例えば、ある部品は顧客から注文を受けてから調達されるため、保管コストや在庫リスクが完全に除去されます.
配送条件は競合インテリジェンスを複雑にします。 第一に、競合インテリジェンスツールは価格だけでなく遅延情報も取得する必要があります。 多くの競合インテリジェンスの専門家は既にこれを実施しており、StuttArtもそれに倣うべきです。 第二に、StuttArtは異なる配送条件を反映するように価格調整アルゴリズムを調整する必要があります。 微分可能なプログラミングを用いれば、1日分の短縮がもたらす価値(ユーロ単位で表現される)を推定するタスクに対応できます。 この価値は、車種、部品の種類、出荷日数に依存すると予想されます。 たとえば、3日間のリードタイムを2日に短縮することは、21日から20日に短縮することよりも、はるかに顧客にとって有利なのです.

結論として、本日はオンライン自動車アフターマーケットに特化したサプライチェーンペルソナであるStuttArt向けに、包括的な価格戦略が提案されました。 私たちは、価格設定がどのような局所的最適化戦略にも適用できないことを確認しました。 部品の価格が持つ影響は、その機械的互換性によって多くの需要ユニットに伝播するため、価格問題は本質的に非局所的です。 これにより、価格設定に需要ユニットレベルでの整合性という視点でアプローチすることになりました。 微分可能なプログラミングを通じて、2つのサブ問題に取り組みました。 第一に、競合調整そのものに対する近似的制約充足問題の解決です。 第二に、機械的互換性データセットの自己改善の問題で、調整の質と顧客体験の向上の両面を改善することを目指しました。 これらの問題は、微分可能なプログラミングによって直接解決できるサプライチェーン問題の増大リストに加えることができます.
より一般的には、この講義から得られる教訓は、自動車アフターマーケットが価格戦略において例外的な存在であるということではなく、どの分野でも多くの特有の問題に直面することが必然であるということです。 StuttArtではなく他のサプライチェーンペルソナを見たとしても、同様に数多くの特性が存在したはずです。 したがって、決定的な答えを求めても意味がありません。 いかなる閉形式の解も、実際のサプライチェーンから時間とともに生じる無限の変動に対処するには不十分です。 代わりに、現状のサプライチェーンに対処でき、かつプログラム的に変更可能な概念、方法、およびツールが必要です。 プログラム可能性は、価格設定の数値手法を将来にわたって有効にするために不可欠です.

次の質問に移る前にお知らせしますが、次回の講義は7月の第1週に行われます。 通常通り水曜日に、同じく午後3時(パリ時間)に開催されます。 第1章に立ち返り、経済学、歴史、システム理論がサプライチェーンおよびサプライチェーン計画について何を示唆しているのかをより詳しく検証します.
では、質問に入りましょう.
質問: サプライチェーン全体の総所有コスト(TCO)を、データ解析と全体的なコスト最適化を用いて可視化する講義は予定していますか?
はい、これはこの講義シリーズの旅の一環です。 これについてはすでにいくつかの講義で議論されています。 しかし、重要な点は、これは本質的に視覚的な問題ではないということです。 総所有コストの本質はデータ可視化の問題ではなく、心構えの問題なのです。 ほとんどのサプライチェーン実務は財務的視点を極端に軽視しており、彼らはドルやユーロ単位のエラーではなく、サービスレベルというエラー率を追いかけています。 残念ながら、多くの場合、これらのパーセンテージに固執しているため、心構えの転換が求められているのです.
第二に、講義で取り上げられた要素には、サプライチェーン向けのソフトウェア製品志向の納品など、第一章のプロダクト志向に基づく要素も含まれています。 私たちは、経済を推進する第一の要因だけでなく、私が第二の経済的推進要因と呼ぶ、把握しにくい力についても考える必要があります。 例えば、ある製品の価格を1ユーロ割引してプロモーションを行うと、単純な分析ではその1ユーロの割引が1ユーロの利益喪失を意味するかのように捉えがちですが、実際には、その結果、顧客層に「今後も1ユーロの割引がある」という期待を抱かせることになり、これは二次的なコストを伴います。 これら第二の経済的推進要因は、台帳や会計帳簿には現れません。 今後、これらのコストに関する詳細な要素をさらに解説していく予定ですが、これは単に分析的な可視化やチャート作成の問題ではなく、心構えの問題なのです。 非常に定量化が難しくとも、これらの要素を数値化しなければならないという考えに向き合う必要があります.
総所有コストについて議論し始める際には、このサプライチェーンソリューションを運営するために必要な人員数についても議論しなければなりません。 これが、この講義シリーズで私がプログラム的なソリューションを強調する理由の一つです。 私たちは、spreadsheetsや表を使って細かく調整する大勢の事務員を抱える余裕はなく、サプライチェーンソフトウェアにおける例外のアラート対応のような、非常にコスト効率の悪い方法に頼ることはできません。 アラートや例外の対応は、会社全体の労働力をシステムの人的補助処理装置として扱うことになり、これは極めて高コストです.
総所有コスト分析は主に心構えの問題であり、正しい視点を持つことが重要です。 次回の講義では、特に経済学がサプライチェーンについて何を語るかという観点から、さらに多角的に検証していく予定です。 サプライチェーンソリューションにおける総所有コストの本質、特にそのソリューションが企業にもたらす価値について考察を深めると、非常に興味深い発見があるでしょう.
質問: 技術的に互換性のある需要ユニットの参照において、品質、アクティブさ、シルバー、ゴールドなどの認識の違いは、競合他社の価格追従にどのように反映されていますか?
それは全くその通りです。 そのため、製品レンジの導入が必要となります。 この魅力度は通常、部品の品質基準を反映する約半ダースのクラスに分類されます。 例えば、最も豪華で機械的互換性に優れた部品を含む「モータースポーツレンジ」があります。 これらの部品は見た目も優れており、パッケージ自体も高品質です.
私のこの市場での経験から言うと、部品の品質を少し向上させる方法は無限にあるものの、市場は非常に高価なものから手頃な価格のものまで、約半ダースの製品レンジに収束しているのが現実です。 StuttArtの部品をグループ化する際には、これらの部品を製品レンジごとに分類する必要があります。 競合他社の部品についても同様であり、たとえその部品がStuttArtで販売されていなくても、その品質レンジを把握する必要があります.
StuttArtは市場全体の部品を把握しておく必要があります。 これは思ったほど困難ではありません。 なぜなら、ほとんどのメーカーが自社部品の期待される品質に関する情報を提供しているからです。 これらの情報は、OEM自身によってかなり体系化されています。 自動車市場は、100年以上の歴史を持つ非常に確立された成熟市場であるという恩恵を受けています。 車両および部品の互換性データセットを提供する企業は、部品や車種に関する膨大な属性情報も提供しています。 ここで言及しているのは数百にも及ぶ属性です。 これらのデータセットは広範かつ豊富です。 元々、これらのデータセットは修理センターの技術者が修理方法を把握するために使用されており、PDFの添付資料や技術ドキュメントが付属していることもあります。 とても豊富で、画像や写真を含む何十ギガバイトものデータが存在します。 私はこれらのデータセットが持つ市場価値の氷山の一角にすぎませんでした.
質問: 自動車企業の価格最適化において、地域ごとの異なる規制はどのような影響を与えますか? 例えば、フランスの企業であるプジョーについて言及されましたが、プジョーに対するあなたのアプローチは、スカンジナビアやアジアにある類似の企業とどのように異なるのでしょうか?
スカンジナビアは基本的に同じ自動車市場です。 いくつか異なるブランドは存在しますが、独自の自動車産業を維持するには市場規模が小さいのです。 自動車産業において、スカンジナビアは他の3億5,000万人の欧州市民と同様です。 しかし、アジアは本当に異なります。 インドや中国は、それぞれ独自の市場です.
価格最適化に関しては、規制はオンラインで車部品を販売するディーラーの出現を妨げたのではなく、むしろその出現を遅らせたのです。 例えば、20年前のヨーロッパでは法的な争いがありました。 オンラインで車部品を販売する先駆者であったStuttArtのような企業は、法的な問題に直面しました。 彼らは車部品を販売し、それが元の自動車メーカーが販売するものと同一であると自社サイトで主張していたのです.
StuttArtのような企業は「私は単に車部品を販売しているのではなく、車メーカーが使用するのと全く同じ部品を販売している」と主張していました。 彼らは、同じ工場から全く同一の部品を購入していたため、この主張が可能でした。 例えば、部品がValeoから供給され、プジョーの車に装着されている場合、既知の連関が存在します。 約20年前、ヨーロッパのいくつかの裁判所は、ウェブサイトが自動車の純正部品と同一の部品を販売していると主張することが合法であると判断しました。 この規制上の不確実性により、オンラインで販売されるスペアカー部品の普及は、おそらく約5年遅れる結果となったのです。 パイオニアたちは、自動車メーカーに対して、オンラインで車部品を販売しながらもそれが純正部品であると主張する権利を求め、裁判で争っていました。 一度この点がクリアになれば、彼らはValeoやBoschから、車に取り付けられる部品と全く同じ部品を正直に購入している限り、その主張を続けることが可能となったのです.
しかし、依然として制約は存在します。 例えば、車の外観を特徴付ける部品は、純正部品として車メーカーのみが販売できる場合があります。 例えば、車のフードなどです。 これらの規制は、部品が元のメーカーのそれと全く同じであると主張しながらも、オンラインで自由に販売できる部品の範囲を制限する影響を及ぼします。 ここで扱うのは、機械的互換性だけでなく安全性にも関わる部品であり、その中には安全上極めて重要なものもあります.
アジアにおいて、ここで触れていない問題として偽造品があります。 偽造品への対処は、ヨーロッパと比較してアジアでは全く異なります。 ヨーロッパにおいても偽造品は存在しますが、市場は成熟しており、OEMや自動車メーカーは互いによく連携しています。 偽造品はごく僅かな問題ですが、アジア、特にインドや中国の市場では、依然として偽造品の問題がかなり深刻です。 これは規制の問題ではなく、偽造品はヨーロッパでも中国でも違法ですが、取り締まりの厳しさがアジアでは格段に低いからです.
質問: 我々は全体としての価格を最適化しようとしているのか、それとも競合他社との相対的な価格を最適化しようとしているのか?
最適化関数は概念的に、すべてのニードユニット―すなわち車のモデルと部品の種類―に対して適用されます。各ニードユニットについて、StuttArtが提供する最良の価格と競合他社の価格との差額(ユーロ建て)があります。この2つの価格の絶対差を計算し、その合計が最適化関数となります。ただし、単にこの価格差の合計を使用するのではなく、各ニードユニットの年間販売量を反映する重み付けを加えます.
したがって、制約充足問題における最適化関数は、各ニードユニットに対するStuttArtの最良価格と競合他社の最良価格との差の絶対値の合計であり、そのニードユニットの年間重要度(ユーロ換算)を反映する重みを加えたものになります。これは、ヨーロッパ市場の現状をできる限り正確に反映しようとする試みです.
ニードユニット自体に対して重みを付ける理由は、もしStuttArtがあまりにも競争力を欠いており、そのニードユニットで何も売れなければ、競争力の問題が生じるためです。その場合、このユニットは整合性の面で無視され、結果として売上がゼロになります。そして、競争力がないために売れず、その結果としてニードユニット自体が重要視されなくなるという悪循環が生じます.
質問: もしも、微分可能なモデリング機械学習の視点が業界標準となり、非常に類似したモデル同士が競合するリスクを伴った場合、予期せぬ結果が生じるとお考えですか?
この質問は難解です。なぜなら、設計上、予期せぬ結果であれば誰も(私さえも)予想できなかったはずであり、どのような結果が予期せぬものとなるかを予見するのは非常に困難だからです.
しかし、もっと真剣に言えば、この業界はすでに10年間にわたりアルゴリズム技術によって牽引されてきました。これは、意図の精度を高めるための洗練といえます。あなたは、自分の意図により沿った数値的手法を求めています。しかし本質的には、現在手動で行われている作業が、10年後には数値レシピによって自動化されるという、ゼロからの出発ではないのです。実際には、すでに数値レシピによって処理されています。毎日100,000件の価格を管理し更新する必要があるとすれば、何らかの自動化が不可欠となるのです.
もしかすると、あなたの自動化は巨大なExcelスプレッドシート上で様々なブラックマジックを駆使する形かもしれませんが、それでもなおアルゴリズムプロセスであることに変わりはありません。ほとんどの場合、例外的な部品を除いて、人々は手動で価格を調整することはありません。既にほぼ全てがアルゴリズムによって処理されており、その結果、数多くの意図しない結果が生じています。例えば、ヨーロッパでのロックダウン中、人々は自宅で過ごす時間が増え、オンラインショッピングを利用しました。一見すると矛盾しているように思えるかもしれませんが、彼らは依然として車を頻繁に使用しており、そのため買い物も増加したのです。しかしながら、在宅勤務が普及した結果、オンラインで車の部品を販売する多くの企業は、プロモーションの組織が複雑化したため、活動が低下しました.
その結果、2020年のロックダウン期間中、数ヶ月間にわたってプロモーションによるアルゴリズム上のノイズが大幅に減少しました。皆のアルゴリズム的反応もはるかに明確になりました。日々の更新で引き起こされるアルゴリズム反応が、より鮮明に観察できる日も存在しました.
これは、全てが電子取引で行われる確立された業界において、かなり成熟したモデルです。意図しない、または予期せぬ結果に関しては、予測がさらに難しい状況です.
一つの驚きの可能性について、締めの考察を申し上げます。多くの人は、内燃機関に比べ部品が少ないため、電気自動車が全てを簡素化すると期待しています。しかし、StuttArtのような企業の視点では、今後10年間、電気自動車は市場においてはるかに多くの部品を意味することになるでしょう.
電気自動車が支配的になるまでは、内燃機関を搭載した古い車両は依然として存在します。これらの車両は約20年間使用されるでしょう。StuttArtが扱う車両は必ずしも真新しいものではなく、質の高い車両が今後も20年ほど現存することを忘れてはいけません。しかしその一方で、多数の追加の電気自動車が様々な部品と共に市場に登場することになり、部品の種類が着実に増加してさらなる課題や複雑さを引き起こす可能性があります.
本日の講義は以上となります。ご質問がなければ、次回の講義は例年通りパリ時間で7月の第一週の水曜日、午後3時に行われる予定です。どうもありがとうございました。それでは、またお会いしましょう.