00:00 Введение
02:49 Спрос, цена и прибыль
09:35 Конкурентные цены
15:23 Желания vs потребности
20:09 История до настоящего момента
23:36 План на сегодня
25:17 Единица потребности
31:03 Автомобили и запчасти (резюме)
33:41 Конкурентная разведка
36:03 Решение задачи согласования (1/4)
39:26 Решение задачи согласования (2/4)
43:07 Решение задачи согласования (3/4)
46:38 Решение задачи согласования (4/4)
56:21 Ассортимент продукции
59:43 Запчасти без ограничений
01:02:44 Контроль за маржой
01:06:54 Ранжирование
01:08:29 Точная настройка весов
01:12:45 Точная настройка совместимости (1/2)
01:19:14 Точная настройка совместимости (2/2)
01:30:41 Контрразведка (1/2)
01:35:25 Контрразведка (2/2)
01:40:49 Избытки и недостаток запасов
01:45:45 Условия доставки
01:47:58 Заключение
01:50:33 6.2 Оптимизация ценообразования для автомобильного послепродажного рынка - Вопросы?
Описание
Соотношение спроса и предложения во многом зависит от цен. Таким образом, оптимизация ценообразования относится к сфере управления цепочками поставок, по крайней мере в значительной мере. Мы представим серию техник оптимизации цен вымышленной компании автомобильного послепродажного рынка. На этом примере мы увидим опасность, связанную с абстрактными рассуждениями, которые не учитывают правильный контекст. Знание того, что следует оптимизировать, важнее, чем мелкие нюансы самой оптимизации.
Полная расшифровка

Добро пожаловать в эту серию лекций по управлению цепочками поставок. Я — Жоанн Верморан, и сегодня я представлю оптимизацию ценообразования для автомобильного послепродажного рынка. Ценообразование является фундаментальным аспектом управления цепочками поставок. Действительно, невозможно оценить адекватность заданного объёма поставок или запасов, не учитывая вопрос цен, поскольку цены значительно влияют на спрос. Однако большинство учебников по управлению цепочками поставок, а следовательно и большинство программного обеспечения для цепочек поставок, полностью игнорируют ценообразование. Даже когда ценообразование обсуждается или моделируется, это обычно делается наивными способами, которые часто приводят к искажённому пониманию ситуации.
Ценообразование является процессом, зависящим от конкретной области. Прежде всего, цены — это послание, отправляемое компанией широкому рынку — клиентам, а также поставщикам и конкурентам. Мелочи анализа ценообразования сильно зависят от конкретной компании. Подходить к ценообразованию в общих чертах, как это делают микроэкономисты, может быть интеллектуально привлекательно, но также и ошибочно. Такие подходы могут быть недостаточно точными для разработки профессиональных стратегий ценообразования.
Эта лекция посвящена оптимизации ценообразования для компании автомобильного послепродажного рынка. Мы вновь обратимся к Штутгарту, вымышленной компании, представленной в третьей главе этой серии лекций. Мы сосредоточимся исключительно на сегменте онлайн-ретейла Штутгарта, который занимается продажей автозапчастей. Цель этой лекции — понять, что собой представляет ценообразование, когда мы отходим от банальностей, и как подходить к ценообразованию с позицией, основанной на реальных условиях. Хотя мы будем рассматривать узкую отрасль — запасные автозапчасти для автомобильного послепродажного рынка — образ мышления и подход, принятые в этой лекции при разработке передовых стратегий ценообразования, по сути, будут такими же, если рассматривать совершенно другие отрасли.
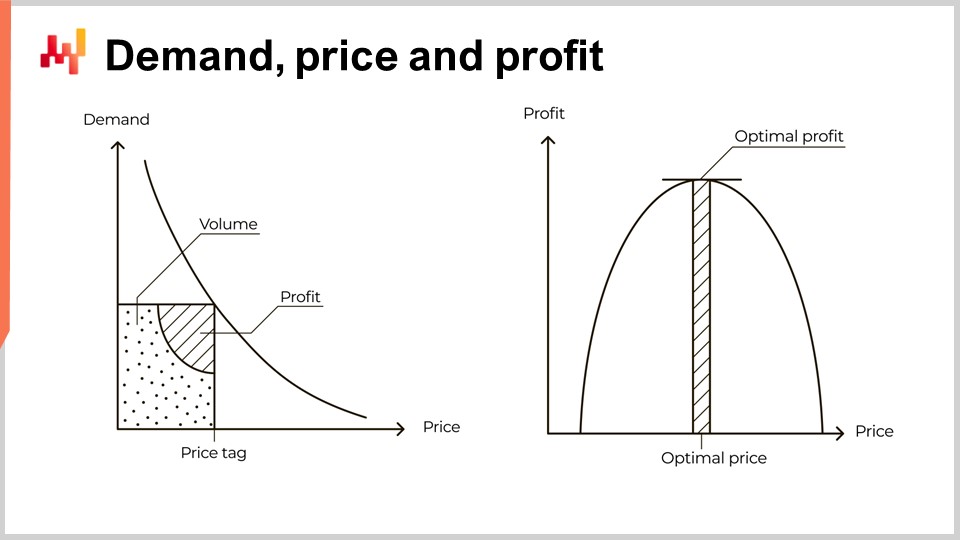
Спрос уменьшается по мере роста цены. Это универсальный экономический закон. Сам факт существования продуктов, противоречащих этому закону, остаётся, в лучшем случае, неуловимым. Такие продукты называют товарами Веблена. Однако за 15 лет работы в компании Lokad, даже имея дело с брендами класса «люкс», я ни разу не получил никаких достоверных доказательств существования таких товаров. Этот универсальный закон иллюстрируется кривой слева от экрана, обычно называемой кривой спроса. Когда рынок устанавливает цену, например, цену на запасную автозапчасть, этот рынок генерирует определённый объём спроса и, надеюсь, определённый объём прибыли для участников, удовлетворяющих этот спрос.
Что касается автомобильных запчастей, то они определённо не являются товарами Веблена. Спрос действительно уменьшается по мере роста цены. Однако, поскольку у людей не так много вариантов при покупке автозапчастей, по крайней мере если они хотят продолжать пользоваться своими автомобилями, ожидается, что спрос будет относительно неэластичным. Более высокая или более низкая цена на ваши тормозные колодки действительно не изменит вашего решения о покупке новых тормозных колодок. Действительно, большинство людей предпочтет купить новые тормозные колодки, даже если им придется заплатить вдвое больше обычной цены, чем вовсе перестать использовать своё транспортное средство.
Для Штутгарта определение оптимальной цены для каждой запчасти имеет решающее значение по множеству причин. Рассмотрим две самые очевидные из них. Во-первых, Штутгарт стремится максимизировать свою прибыль, что не так просто, поскольку спрос зависит от цены, а затраты зависят от объёма. Штутгарт должен быть способен удовлетворить спрос, который он создаст в будущем, что является ещё более сложной задачей, так как запас должен быть обеспечен за несколько дней, если не недель, вперёд из-за временных ограничений.
Основываясь на этом ограниченном изложении, некоторые учебники, а также даже некоторые корпоративные программные решения, продолжают работу с кривой, иллюстрированной справа. Эта кривая концептуально показывает ожидаемый объём прибыли, который можно предвидеть для любой цены. Учитывая, что спрос уменьшается с ростом цены, а себестоимость на единицу продукции снижается с увеличением объёма, эта кривая должна иметь оптимальную точку прибыли, максимизирующую прибыль. Как только эта оптимальная точка обнаружена, корректировка объёма запасов представляется простым вопросом оркестрации. Действительно, оптимальная точка предоставляет не только ценник, но и объём спроса.
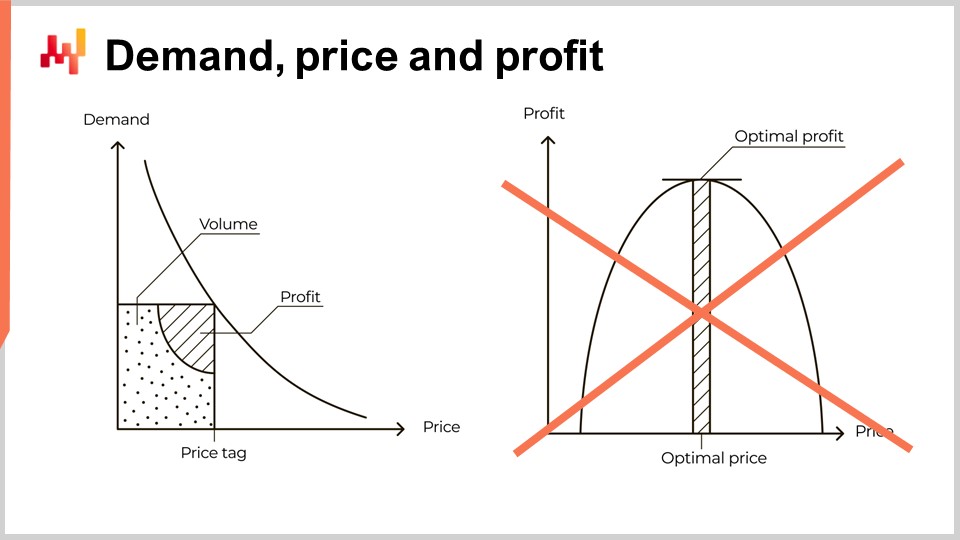
Однако эта точка зрения глубоко ошибочна. Проблема не заключается в сложности количественного измерения эластичности. Мое предложение не в том, что кривая слева неверна; она принципиально правильна. Моя позиция заключается в том, что переход от кривой слева к кривой справа является неверным. Фактически, этот переход настолько поразительно ошибочен, что служит своего рода лакмусовой бумажкой. Любой поставщик программного обеспечения или учебник по ценообразованию, который представляет ценообразование таким образом, демонстрирует опасную степень экономической неграмотности, особенно если они представляют оценку эластичности в качестве основной проблемы, связанной с этим подходом. Это даже отдалённо не соответствует действительности. Доверять реальной цепочке поставок такому поставщику или эксперту — значит подвергнуться боли и страданиям. Если есть что-то, что вашей цепочке поставок не нужно, так это ошибочной интерпретации неправильно понятой микроэкономики в масштабе.
В этой серии лекций это ещё один пример наивного рационализма или научного догматизма, который неоднократно доказывал свою серьёзную угрозу для современных цепочек поставок. Абстрактное экономическое мышление мощно, потому что охватывает поразительное разнообразие ситуаций. Однако абстрактное мышление также подвержено грубым искажениям. Крупные интеллектуальные ошибки, не сразу заметные, могут возникать при мышлении в очень общих терминах.
Чтобы понять, почему переход от кривой слева к кривой справа неверен, нам нужно внимательно рассмотреть, что на самом деле происходит в реальной цепочке поставок. Эта лекция посвящена автомобильным запчастям. Мы пересмотрим ценообразование с точки зрения Штутгарта, вымышленной компании-цепочки поставок, представленной в третьей главе этой серии лекций. Мы не будем возвращаться к деталям этой компании. Если вы ещё не смотрели лекцию 3.4, советую вам сделать это после данной лекции.
Сегодня мы рассматриваем сегмент онлайн-ретейла Штутгарта, подразделение электронной коммерции, которое продаёт автозапчасти. Мы изучаем наиболее подходящие способы для Штутгарта определить свои цены и корректировать их в любой момент времени. Эта задача должна выполняться для каждой отдельной запчасти, продаваемой Штутгартом.

Штутгарт не одинок на этом рынке. В каждой европейской стране, где работает Штутгарт, есть около полудюжины заметных конкурентов. Этот краткий список компаний, включая Штутгарт, представляет собой большинство онлайн-доли рынка запасных автозапчастей. Хотя Штутгарт эксклюзивно продает некоторые запчасти, для большинства продаваемых запчастей существует хотя бы один заметный конкурент, предлагающий точно такую же запчасть. Этот факт имеет значительные последствия для оптимизации ценообразования Штутгарта.
Давайте рассмотрим, что происходит, если для определённой запчасти Штутгарт решает установить цену на один евро ниже, чем цена, предлагаемая конкурентом, продающим ту же запчасть. Возможно, это сделает Штутгарт более конкурентоспособным и поможет захватить долю рынка. Но не стоит спешить. Конкурент отслеживает все цены, установленные Штутгартом. Действительно, автомобильный послепродажный рынок — это крайне конкурентная среда. У всех есть инструменты конкурентной разведки. Штутгарт ежедневно собирает все цены своих заметных конкурентов, и конкуренты делают то же самое. Таким образом, если Штутгарт решит установить цену на запчасть на один евро ниже, чем цена конкурента, можно с уверенностью предположить, что в течение дня или двух конкурент снизит свою цену в ответ, нейтрализуя ценовое изменение Штутгарта.
Хотя Штутгарт может быть вымышленной компанией, описанное здесь конкурентное поведение вовсе не является вымышленным на автомобильном послепродажном рынке. Конкуренты агрессивно согласовывают свои цены. Если Штутгарт будет многократно пытаться снизить свои цены, это приведёт к алгоритмической ценовой войне, оставив обе компании с минимальной или нулевой маржей в конце войны.
Рассмотрим, что происходит, если для определённой запчасти Штутгарт решает установить цену на один евро выше, чем цена, предлагаемая конкурентом. При условии, что все остальное остается неизменным, кроме ценника, Штутгарт становится просто неконкурентоспособным. Таким образом, даже если база клиентов Штутгарта не сразу перейдет к конкуренту (так как они могут даже не заметить разницу в ценах или сохранить лояльность к Штутгарту), со временем доля Штутгарта на рынке гарантированно сократится.
В Европе существуют сайты для сравнения цен на автозапчасти. Хотя покупатели могут не проводить сравнения каждый раз, когда им нужна новая запчасть для автомобиля, большинство клиентов время от времени пересматривают свои варианты. Для Штутгарта неприемлемо постоянно обнаруживаться как самый дорогой продавец.
Таким образом, мы видим, что Штутгарт не может устанавливать цену ниже, чем у конкурентов, так как это спровоцирует ценовую войну. И наоборот, Штутгарт не может устанавливать цену выше, чем у конкурентов, поскольку это гарантирует эрозию его доли на рынке со временем. Единственный оставшийся вариант для Штутгарта — стремиться к ценовому согласованию. Это не теоретическое утверждение — ценовое согласование является основным драйвером для реальных компаний электронной коммерции, продающих автозапчасти в Европе.
Интеллектуально привлекательная кривая прибыли, которую мы ранее представили, где компании якобы могли выбрать оптимальную прибыль, в основном является фикцией. У Штутгарта вообще нет выбора, когда речь идёт о ценах. В значительной степени, если не учитывать какой-либо секретный ингредиент, ценовое согласование — единственный вариант для Штутгарта.
Свободные рынки — странное явление, как сказал Энгельс в своей переписке 1819 года: “Воля каждого человека препятствуется всеми остальными, и в итоге появляется нечто, чего никто не желал”. В дальнейшем мы увидим, что Штутгарт сохраняет некоторую остаточную свободу в установлении цен. Однако основное утверждение остаётся неизменным: оптимизация ценообразования для Штутгарта прежде всего является задачей с жесткими ограничениями, которая не имеет ничего общего с наивной перспективой максимизации, основанной на кривой спроса.
Эластичность спроса по цене — это концепция, которая имеет смысл для рынка в целом, но обычно не настолько для чего-то столь локализованного, как номер запчасти.

Идея о том, что ценообразование можно рассматривать как простую задачу максимизации прибыли с использованием кривой спроса, является фиктивной — или, по крайней мере, фиктивной в случае Штутгарта.
Действительно, можно утверждать, что Штутгарт принадлежит к рынку потребностей, и подход с кривыми прибыли по-прежнему работал бы, если бы мы рассматривали рынок желаний. В маркетинге существует классическое разграничение между рынками желаний и рынками потребностей. Рынок желаний обычно характеризуется предложениями, при которых клиенты могут отказаться от потребления без негативных последствий. На рынках желаний успешные предложения, как правило, тесно связаны с брендом продавца, и сам бренд является движущей силой, генерирующей спрос с самого начала. Например, мода является архетипом рынков желаний. Если вы хотите сумку от Louis Vuitton, то эту сумку можно купить только у Louis Vuitton. Хотя существует сотни продавцов, продающих функционально эквивалентные сумки, это не будет сумкой от Louis Vuitton. Если вы отказываетесь от покупки сумки от Louis Vuitton, то с вами не случится ничего ужасного.
Рынок потребностей обычно характеризуется предложениями, от которых клиенты не могут отказаться, не понеся значительных негативных последствий. В рынках потребностей бренды не являются двигателями спроса; они скорее действуют как двигатели выбора. Бренды направляют клиентов при выборе, у кого потреблять, когда возникает необходимость в потреблении. Например, продукты питания и основные товары являются архетипом рынков потребностей. Даже если автозапчасти не являются строго необходимыми для выживания, многие люди зависят от транспортного средства для заработка и, таким образом, не могут реально отказаться от своевременного обслуживания своего автомобиля, поскольку затраты от отсутствия обслуживания значительно превышают стоимость самого обслуживания.
Хотя автомобильный вторичный рынок прочно обосновался в сфере потребностей, существуют нюансы. Есть компоненты, такие как колпаки на колеса, которые больше относятся к желаниям, чем к потребностям. В более общем смысле, все аксессуары относятся скорее к желаниям, чем к потребностям. Тем не менее, для Stuttgart потребности определяют подавляющее большинство спроса.
Критика, которую я выдвигаю здесь против применения кривой прибыли для ценообразования, обобщается практически на все ситуации на рынках потребностей. Stuttgart не является исключением, будучи сильно ограниченным в ценовой политике своими конкурентами; такая ситуация практически повсеместна для рынков потребностей. Этот аргумент не опровергает жизнеспособность кривой прибыли при рассмотрении рынков желаний.
Действительно, можно возразить, что на рынке желаний, если у продавца существует монополия на его собственный бренд, то этот продавец должен иметь свободу устанавливать ту цену, которая максимизирует его прибыль, что возвращает нас к перспективе кривой прибыли для ценообразования. И снова этот контраргумент демонстрирует опасности абстрактного экономического мышления в управлении цепями поставок.
На рынке желаний подход с использованием кривой прибыли также оказывается неверным, хотя и по совершенно другим причинам. Подробности этого доказательства выходят за рамки данной лекции, так как потребовали бы отдельной лекции. Однако, в качестве упражнения для аудитории, я предложу внимательно изучить список сумок и их цен, представленный на сайте электронной коммерции Louis Vuitton. Причина, по которой подход кривой прибыли неуместен, должна стать очевидной. Если нет — мы, скорее всего, вернемся к этому вопросу в одной из последующих лекций.
Эта серия лекций предназначена, среди прочего, в качестве учебных материалов для специалистов по цепям поставок в Lokad. Однако я также надеюсь, что эти лекции будут интересны гораздо более широкой аудитории практиков в области цепей поставок. Я стараюсь сделать эти лекции относительно независимыми, но буду использовать несколько технических концепций, которые были представлены в предыдущих лекциях. Я не стану тратить много времени на повторное введение этих концепций. Если вы не смотрели предыдущие лекции, не стесняйтесь ознакомиться с ними позже.
В первой главе этой серии мы рассмотрели, почему цепочки поставок должны становиться программными. Из-за постоянно растущей сложности цепей поставок крайне желательно внедрить в производство числовой рецепт. Автоматизация становится как никогда актуальной, и существует финансовая необходимость сделать управление цепями поставок капиталистическим предприятием.
Во второй главе мы посвятили время методологиям. Цепочки поставок — это конкурентные системы, и такое сочетание сводит на нет наивные методологии. Мы увидели, что это сочетание также опровергает модели, которые неправильно интерпретируют или неверно характеризуют микроэкономику.
Третья глава обзорно рассмотрела проблемы, встречающиеся в цепях поставок, отложив в сторону решения. Мы представили Stuttgart как одного из персонажей цепей поставок. Эта глава пыталась охарактеризовать классы проблем принятия решений, которые необходимо решить, и показала, что упрощенные подходы, такие как выбор правильного объема запасов, не соответствуют реальным ситуациям. Принятие решений всегда имеет определённую глубину.
Глава четвертая рассмотрела элементы, необходимые для понимания современных практик в цепях поставок, где программное обеспечение является повсеместным. Эти элементы являются фундаментальными для понимания более широкого контекста, в котором функционирует цифровая цепочка поставок.
Пятая и шестая главы посвящены, соответственно, прогностическому моделированию и принятию решений. Эти главы собирают методики, которые сегодня хорошо работают в руках специалистов по цепям поставок. Шестая глава сосредоточена на ценообразовании — одном из типов решений, которые необходимо принимать наряду с другими.
Наконец, седьмая глава посвящена реализации инициативы по количественной оптимизации цепей поставок и охватывает организационный аспект.

Сегодняшняя лекция будет разделена на два крупных сегмента. Во-первых, мы обсудим, как подойти к конкурентному выравниванию цен для Stuttgart. Выравнивание цен с ценами конкурентов должно осуществляться с точки зрения клиента из-за уникальной структуры рынка автомобильных запчастей. Хотя конкурентное выравнивание далеко не тривиально, оно выигрывает от относительно простого решения, которое мы подробно рассмотрим.
Во-вторых, хотя конкурентное выравнивание является доминирующей силой, оно не единственное. Stuttgart может нуждаться или желать избирательно отступать от этого выравнивания. Однако выгоды от таких отклонений должны перевешивать риски. Качество выравнивания зависит от качества входных данных, используемых для его построения, поэтому мы внедрим технику самообучения для уточнения графа механической совместимости.
Наконец, мы рассмотрим короткую серию вопросов, смежных с ценообразованием. Эти вопросы могут быть не строго связаны с ценообразованием, но на практике их лучше решать вместе с ценовой политикой.

Stuttgart необходимо установить ценник на каждую деталь, которую он продает, но это не подразумевает, что анализ ценообразования должен в первую очередь проводиться на уровне номеров деталей. Ценообразование, прежде всего, является способом общения с клиентами.
Давайте уделим минуту, чтобы задуматься, как клиенты воспринимают цены, предлагаемые Stuttgart. Как мы увидим, кажущееся тонкое различие между ценником и его восприятием на самом деле не является тонким.
Когда клиент начинает искать новую автозапчасть, обычно расходный элемент, такой как тормозные колодки, он вряд ли знает конкретный номер детали, который ему необходим. Возможно, найдутся несколько автомобильных энтузиастов, досконально разбирающихся в этом вопросе и имеющих в виду конкретный номер детали, но это небольшое меньшинство. Большинство людей понимают, что им нужно заменить тормозные колодки, но не знают точного номера детали.
Эта ситуация приводит к еще одной серьезной проблеме: механической совместимости. На рынке представлено тысячи вариантов тормозных колодок, однако для любого конкретного автомобиля обычно существует лишь несколько десятков совместимых вариантов. Таким образом, механическую совместимость нельзя оставить на волю случая.
Stuttgart, как и все его конкуренты, прекрасно осведомлен об этой проблеме. При посещении сайта электронной коммерции Stuttgart посетителя просят выбрать модель автомобиля, после чего сайт сразу же фильтрует запчасти, не совместимые с выбранным транспортным средством. Сайты конкурентов следуют тому же принципу: сначала выбирается автомобиль, затем деталь.
Когда клиент пытается сравнить двух продавцов, он, как правило, сравнивает предложения, а не номера деталей. Клиент заходит на сайт Stuttgart, определяет стоимость совместимых тормозных колодок и затем повторяет процесс на сайте конкурента. Клиент мог бы определить номер тормозных колодок на сайте Stuttgart, а потом найти точно такой же на сайте конкурента, но на практике люди редко так поступают.
Stuttgart и его конкуренты тщательно формируют ассортимент таким образом, чтобы обслуживать почти все автомобили, используя лишь небольшую часть доступных номеров деталей. В результате на их сайтах обычно представлено от 100,000 до 200,000 номеров деталей, а в наличии имеется только от 10,000 до 20,000 номеров деталей.
Что касается нашей первоначальной проблемы с ценообразованием, то очевидно, что анализ цен должен проводиться не через призму номеров деталей, а через единицу потребности. В контексте автомобильного вторичного рынка единица потребности определяется типом детали, требующей замены, и моделью автомобиля, для которого необходима замена.
Однако такой подход к единице потребности создает немедленное техническое осложнение. Stuttgart не может рассчитывать на сопоставление цен «один к одному» между номерами деталей для согласования своих цен с ценами конкурентов. Таким образом, выравнивание цен не настолько очевидно, как может показаться на первый взгляд, особенно с учетом ограничений, накладываемых конкурентами на Stuttgart.

Как мы уже видели в лекции 3.4, проблема механической совместимости между автомобилями и запчастями решается в Европе, а также в других крупных регионах мира, посредством специализированных компаний. Эти компании продают наборы данных по механической совместимости, состоящие из трех списков: списка моделей автомобилей, списка автозапчастей и списка совместимости между автомобилями и запчастями. Такая структура набора данных технически известна как двудольный граф.
В Европе эти наборы данных обычно содержат более 100,000 автомобилей, свыше одного миллиона запчастей и более 100 миллионов связей между автомобилями и запчастями. Обслуживание этих наборов данных требует значительных трудозатрат, что объясняет существование специализированных компаний, продающих эти данные. Stuttgart, как и его конкуренты, приобретает подписку у одной из таких компаний для получения обновленных версий этих данных. Подписка необходима потому, что, несмотря на зрелость автомобильной промышленности, новые автомобили и запчасти постоянно появляются. Чтобы оставаться в курсе автомобильного рынка, эти наборы данных должны обновляться как минимум раз в квартал.
Stuttgart и его конкуренты используют этот набор данных для поддержки механизма выбора автомобиля на своих сайтах электронной коммерции. После того как клиент выберет автомобиль, отображаются только те запчасти, которые доказуемо совместимы с выбранным автомобилем согласно набору данных по совместимости. Этот набор данных также является основой для нашего анализа ценообразования. С его помощью Stuttgart может оценить ценовую точку, предлагаемую для каждой единицы потребности.

Последним значимым недостающим элементом для построения стратегии конкурентного выравнивания Stuttgart является конкурентная разведка. В Европе, как и во всех крупных экономических регионах, существуют специалисты по конкурентной разведке — компании, предоставляющие услуги по сбору цен. Эти компании ежедневно собирают цены Stuttgart и его конкурентов. Хотя Stuttgart может попытаться ограничить автоматизированный сбор своих цен, это начинание в основном оказывается безрезультатным по нескольким причинам:
Во-первых, Stuttgart, как и его конкуренты, стремится быть дружелюбным к роботам. Самыми важными ботами являются поисковые системы, и, по состоянию на 2023 год, Google занимает немного более 90% рынка. Однако Google не является единственной поисковой системой, и, хотя возможно выделить Googlebot — основной краулер Google, сделать то же для всех остальных краулеров, составляющих примерно 10% трафика, крайне сложно.
Во-вторых, специалисты по конкурентной разведке за последнее десятилетие стали экспертами в маскировке под обычный домашний интернет-трафик. Эти службы утверждают, что имеют доступ к миллионам IP-адресов домашних пользователей, чего они достигают посредством сотрудничества с приложениями, использования интернет-соединений обычных пользователей и партнерства с интернет-провайдерами, которые могут предоставлять им IP-адреса.
Таким образом, мы предполагаем, что Stuttgart пользуется преимуществом от высококачественного списка цен своих заметных конкурентов. Эти цены собираются на уровне номеров деталей и обновляются ежедневно. Это предположение не является спекулятивным; оно соответствует текущему состоянию европейского рынка.

Теперь у нас есть все элементы, необходимые Stuttgart для вычисления выровненных цен — цен, которые соответствуют ценам его конкурентов, если рассматривать их с точки зрения единицы потребности.
На экране представлен псевдокод задачи удовлетворения ограничений, которую мы хотим решить. Мы просто перечисляем все единицы потребности, то есть все комбинации типов деталей и моделей автомобилей. Для каждой единицы потребности мы заявляем, что самая конкурентоспособная цена, предлагаемая Stuttgart, должна равняться самой конкурентоспособной цене, предлагаемой конкурентом.
Давайте быстро оценим количество переменных и ограничений. Stuttgart может установить один ценник для каждого номера детали, который он предлагает, что означает, что у нас примерно 100,000 переменных. Количество ограничений немного сложнее. Технически, у нас около 1,000 типов деталей и около 100,000 моделей автомобилей, что предполагает приблизительно 100 миллионов ограничений. Однако не все типы деталей встречаются во всех моделях автомобилей. Реальные измерения показывают, что число ограничений ближе к 10 миллионам.
Несмотря на меньшее количество ограничений, их все же в 100 раз больше, чем переменных. Мы сталкиваемся с системой, где ограничений значительно превышает число переменных. Следовательно, мы знаем, что вряд ли найдем решение, удовлетворяющее всем ограничениям. Лучшим результатом будет компромиссное решение, удовлетворяющее большинству ограничений.
Кроме того, конкуренты не всегда последовательны в установлении цен. Несмотря на наши усилия, Stuttgart может оказаться втянутым в ценовую войну по какому-либо номеру детали из-за слишком низкого ценника. Одновременно он может потерять долю рынка по тому же номеру детали, если его цена окажется слишком высокой по сравнению с конкурентом. Этот сценарий не является теоретическим; эмпирические данные свидетельствуют, что такие ситуации происходят регулярно, хотя и для небольшого процента номеров деталей.
Поскольку мы выбрали приближенное решение этой системы ограничений, следует уточнить вес, который необходимо придавать каждому ограничению. Не все модели автомобилей одинаковы — некоторые связаны со старыми автомобилями, которые почти полностью исчезли с дорог. Мы предлагаем задавать вес этим ограничениям в зависимости от объема спроса, выраженного в евро.
Теперь, когда мы установили формальную основу для нашей логики ценообразования, перейдем к реальному программному коду. Как мы увидим, решение этой системы оказывается проще, чем ожидалось.
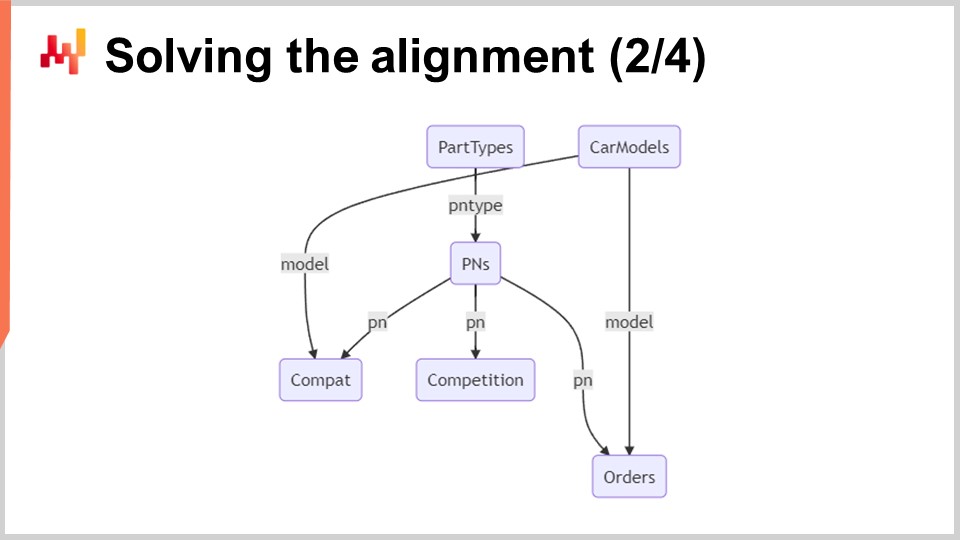
На экране минимальная реляционная схема иллюстрирует шесть таблиц, участвующих в этой системе. Прямоугольники с закруглёнными углами представляют шесть таблиц, представляющих интерес, а стрелки обозначают отношения «один ко многим» между таблицами.
Давайте кратко рассмотрим эти таблицы:
-
Типы запчастей: Как следует из названия, эта таблица содержит перечень типов запчастей, например, «front brake pads». Эти типы используются для определения того, какая деталь может служить заменой другой. Замена должна быть не только совместима с автомобилем, но и принадлежать к тому же типу. Всего существует около тысячи типов запчастей.
-
Модели автомобилей: Эта таблица содержит модели автомобилей, например, «Peugeot 3008 Phase 2 diesel». Каждый автомобиль имеет модель, и от всех транспортных средств одной модели ожидается наличие одинакового набора механических совместимостей. Всего примерно сто тысяч моделей автомобилей.
-
Номера запчастей (PNs): Эта таблица содержит номера запчастей, встречающиеся на автомобильном aftermarket. Каждый номер запчасти соответствует одному, и только одному, типу запчастей. Всего в этой таблице около 1 миллиона номеров запчастей.
-
Совместимость (Compat): Эта таблица представляет механическую совместимость и собирает все допустимые комбинации номеров запчастей и моделей автомобилей. С примерно 100 миллионами строк совместимости эта таблица является наибольшей.
-
Конкуренция: Эта таблица содержит всю конкурентную аналитику за день. Для каждого номера запчасти существует около полудюжины заметных конкурентов, которые выставляют номер запчасти с ценником. В итоге получается около 10 миллионов конкурентных цен.
-
Заказы: Эта таблица содержит прошлые заказы клиентов из Штутгарта за период примерно одного года. Каждая строка заказа включает номер запчасти и модель автомобиля. Технически возможно приобрести запчасть, не указывая модель автомобиля, хотя это редкость. Любые строки заказа без указания модели автомобиля можно отфильтровать. Исходя из размеров Штутгарта, строк заказов должно быть около 10 миллионов.
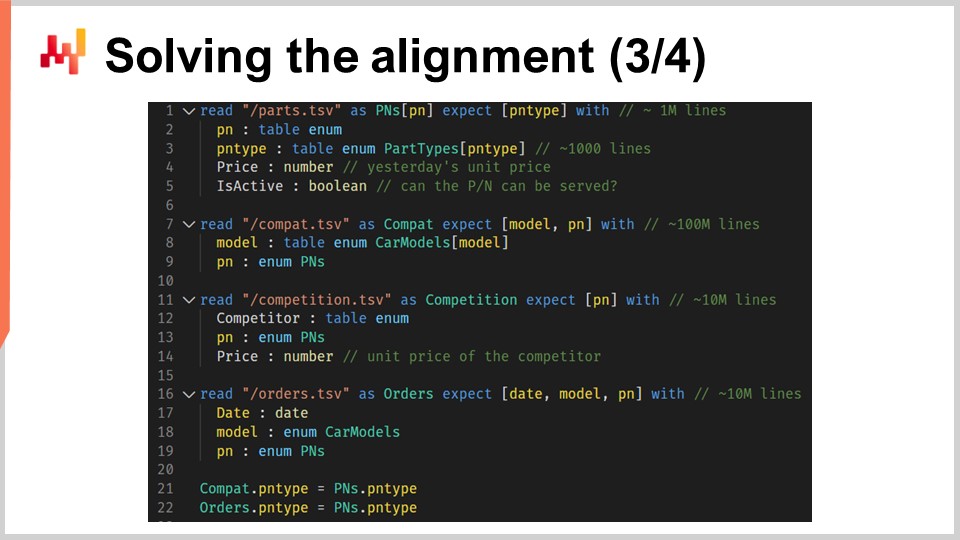
Теперь мы рассмотрим код, который загружает реляционные данные. На экране отображается скрипт, загружающий шесть таблиц, написанный на Envision — специализированном языке программирования, разработанном Lokad специально для прогностической оптимизации цепочек поставок. Хотя Envision был создан для повышения эффективности и уменьшения ошибок в контексте цепочек поставок, скрипт можно переписать на других языках, таких как Python, хотя это приведёт к увеличению объёма кода и повышению риска ошибок.
В первой части скрипта загружаются четыре плоских текстовых файла. Со строк 1 по 5 файл “path.csv” предоставляет как номера запчастей, так и типы запчастей, включая текущие цены, отображаемые в Штутгарте. Поле “name is active” указывает, обслуживается ли конкретный номер запчасти Штутгартом. В этой таблице переменная “PN” относится к основной размерности таблицы, в то время как “PN type” является вторичной размерностью, введённой ключевым словом “expect”.
Со строк 7 по 9 файл “compat.tsv” предоставляет список совместимости запчастей с автомобилями и модели автомобилей. Это самая большая таблица в скрипте. Со строк 11 по 14 загружается файл “competition.tsv”, предоставляющий снимок конкурентной аналитики за день, то есть цены по номерам запчастей и по конкурентам. Файл “orders.tsv”, загружаемый со строк 16 по 19, содержит перечень приобретаемых номеров запчастей и соответствующих моделей автомобилей, при условии, что все строки с неуказанными моделями автомобилей были отфильтрованы.
Наконец, в строках 21 и 22 таблица “part types” устанавливается как источник для двух таблиц — “compat” и “orders”. Это означает, что для каждой строки в таблице “compat” или “orders” существует один и только один соответствующий тип запчасти. Иными словами, “PN type” была добавлена как вторичная размерность в таблицы “compat” и “orders”. Эта первая часть скрипта Envision проста: мы просто загружаем данные из плоских текстовых файлов и восстанавливаем реляционную структуру данных.
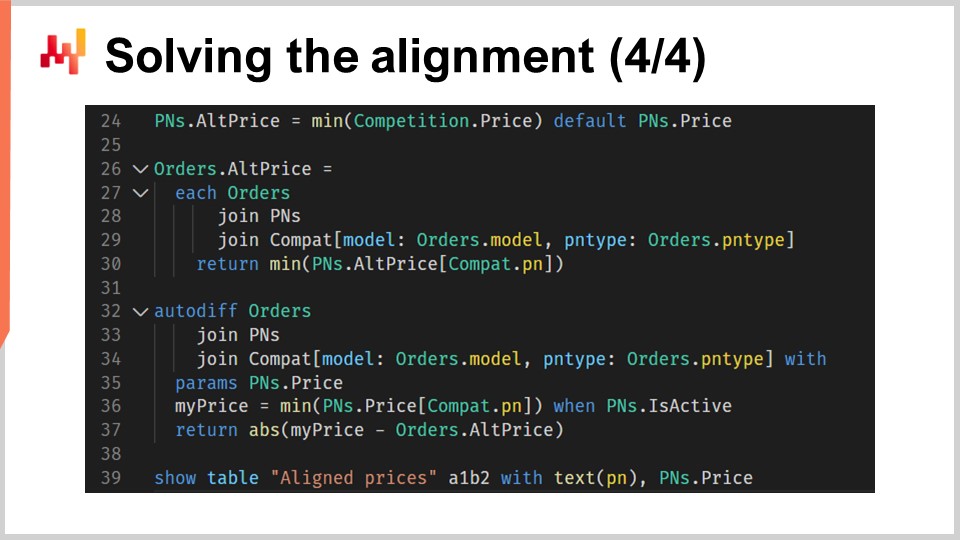
Вторая часть скрипта, видимая на экране, посвящена непосредственной логике выравнивания. Этот раздел является прямым продолжением первой части, и, как вы видите, содержит всего 12 строк кода. Мы снова используем дифференцируемое программирование. Для слушателей, незнакомых с дифференцируемым программированием, это сочетание автоматического дифференцирования и стохастического градиентного спуска. Эта парадигма программирования также применяется в машинном обучении и оптимизации. В контексте цепочек поставок дифференцируемое программирование оказывается невероятно полезным во многих ситуациях. На протяжении всей этой серии лекций мы демонстрировали, как дифференцируемое программирование можно использовать для обучения моделей, генерации вероятностных прогнозов спроса и создания баллистических прогнозов срока поставки. Если вы не знакомы с дифференцируемым программированием, рекомендую вернуться к предыдущим лекциям этой серии.
На сегодняшней лекции мы увидим, как дифференцируемое программирование отлично подходит для решения задач оптимизации большого масштаба, включающих сотни тысяч переменных и миллионы ограничений. Удивительно, но эти задачи можно решить всего за несколько минут на одном процессоре с несколькими гигабайтами оперативной памяти. Кроме того, мы можем использовать предыдущие цены в качестве отправной точки, обновляя цены вместо полного перерасчёта.
Обратите внимание на одну мелкую оговорку. Ключевое слово “join” пока не поддерживается Envision, но оно запланировано в нашей технической дорожной карте на будущее. Существуют обходные пути, однако для ясности на этой лекции я буду использовать будущий синтаксис Envision.
В строке 24 мы вычисляем наименьшую наблюдаемую цену на рынке для каждого номера запчасти. Если номер запчасти продаётся исключительно в Штутгарте и у него нет конкурентов, мы используем собственную цену Штутгарта по умолчанию.
Со строк 26 по 30 для каждой запчасти из истории заказов клиентов Штутгарта рассчитывается текущее самое конкурентное предложение.
В строке 27 мы перебираем каждую строку заказа в таблице заказов с помощью “each order”.
В строке 28 мы используем “join pns”, чтобы добавить полную таблицу номеров запчастей для каждой строки заказа.
В строке 29 мы объединяем с “others”, но это объединение ограничено двумя вторичными размерностями — моделью и типом запчасти. Это означает, что для каждой строки заказа мы выбираем номера запчастей, соответствующие сочетанию модели автомобиля и типа запчасти, отражая запчасти, совместимые с единицей потребности, соответствующей заказу клиента.
Со строки 32 по 37 мы решаем задачу выравнивания с помощью дифференцируемого программирования, обозначенного ключевым словом “Auto diff”. Блок “Auto diff” объявляется в строке 32 с использованием таблицы “orders” в качестве таблицы наблюдений. Это означает, что мы неявно взвешиваем ограничения в соответствии с объёмом продаж Штутгарта. Строки 33 и 44 выполняют ту же функцию, что и строки 28 и 29; они перебирают таблицу “orders”, предоставляя полный доступ к таблице номеров запчастей (“PN”) и к части совместимых записей.
В строке 35 мы объявляем “pns.price” в качестве параметров, которые будут оптимизироваться с помощью стохастического градиентного спуска. Нет необходимости инициализировать эти параметры, так как мы начинаем с ранее используемых Штутгартом цен, что фактически обновляет выравнивание.
В строке 36 мы вычисляем “my price” — самое конкурентное предложение Штутгарта для единицы потребности, связанной с заказом. Этот расчёт схож с вычислением минимальной наблюдаемой цены, как было сделано в строке 24, вновь полагаясь на список механических совместимостей. Однако совместимости ограничиваются номерами запчастей, обслуживаемыми Штутгартом. Исторически клиенты могли выбирать или не выбирать самую экономически выгодную запчасть для своего автомобиля. Тем не менее, цель использования заказов клиентов в этом контексте заключается в присвоении весов единицам потребностей.
В строке 37 мы используем абсолютную разницу между лучшей ценой, предложенной Штутгарта, и лучшей ценой, предложенной конкурентом, для направления выравнивания. В этом альтернативном блоке градиенты применяются ретроспективно к параметрам. Разница, которую мы находим в итоге, образует функцию потерь. Из этой функции потерь градиенты возвращаются к единственному вектору параметров, которым у нас является “pns.price”. Путём пошаговой корректировки параметров (цен) на каждой итерации (где итерация представляет собой строку заказа) скрипт сходится к подходящему приближению желаемого выравнивания цен.
С точки зрения алгоритмической сложности доминирует строка 36. Однако, поскольку количество совместимостей для любой заданной модели автомобиля и типа запчасти ограничено (обычно не более нескольких десятков), каждая итерация “Auto diff” выполняется за время, которое можно считать постоянным. Это постоянное время не является чрезвычайно коротким, например, 10 тактов CPU, но и не достигает миллиона тактов. Примерно тысяча тактов CPU звучит разумно для 20 совместимых запчастей.
Если предположить, что один процессор работает на частоте два гигагерца и выполняет 100 эпох (одна эпоха — это полный проход по всей таблице наблюдений), то ожидаемое время выполнения составит около 10 минут. Решение задачи с 100 000 переменных и 10 миллионами ограничений за 10 минут на одном процессоре весьма впечатляет. Фактически, Lokad достигает производительности, примерно соответствующей этим ожиданиям. Однако на практике для подобных задач узким местом зачастую является пропускная способность ввода-вывода, а не процессор.
Этот пример вновь демонстрирует силу применения соответствующих парадигм программирования для задач цепочек поставок. Мы начали с нетривиальной задачи, так как не было сразу очевидно, как использовать этот набор данных о механической совместимости с точки зрения ценообразования. Несмотря на это, фактическая реализация проста.
Хотя этот скрипт не охватывает все аспекты, которые присутствовали бы в реальной установке, основная логика требует всего шести строк кода, что оставляет достаточно пространства для учета дополнительных сложностей, которые могут возникнуть в реальных сценариях.

Алгоритм выравнивания, представленный ранее, отдает предпочтение простоте и ясности над исчерпывающностью. В реальной установке можно ожидать появления дополнительных факторов. Я вскоре рассмотрю эти факторы, но начну с того, что признаю: эти факторы можно учитывать, расширяя данный алгоритм выравнивания.
Продажа с убытком не только неразумна, но и незаконна во многих странах, например, во Франции, хотя существуют исключения при особых обстоятельствах. Чтобы предотвратить продажу с убытком, в алгоритм выравнивания можно добавить ограничение, требующее, чтобы цена продажи превышала цену закупки. Однако также полезно запустить алгоритм без этого ограничения “no loss”, чтобы выявить потенциальные проблемы с поставками. Действительно, если конкурент может позволить себе продавать запчасть ниже закупочной цены Штутгарта, Штутгарту необходимо устранить основную проблему. Скорее всего, это связано с вопросами поставок или закупок.
Простое объединение всех номеров запчастей — наивный подход. Покупатели не готовы платить одинаково за продукцию всех производителей оригинального оборудования (OEM). Например, покупатели с большей вероятностью оценят такой известный бренд, как Bosch, по сравнению с менее известным китайским OEM в Европе. Чтобы решить эту проблему, Штутгарт, как и его коллеги, классифицирует OEM в короткий список продуктовых диапазонов от самых дорогих до самых дешёвых. Например, могут быть: мотоспортивный диапазон, бытовой диапазон, диапазон брендов дистрибьюторов и бюджетный диапазон.
Выравнивание затем строится таким образом, чтобы каждый номер запчасти был скорректирован в пределах своего продуктового диапазона. Кроме того, алгоритм выравнивания должен требовать, чтобы цены строго снижались при переходе от мотоспортивного диапазона к бюджетному, так как любое нарушение этой последовательности может запутать покупателей. Теоретически, если конкуренты точно оценивали свою продукцию, таких инверсий не было бы. Однако на практике покупатели иногда неверно оценивают свои запчасти и порой устанавливают для них другую цену.
Существует всего несколько сотен OEM, и их классификацию по соответствующим продуктовым диапазонам можно выполнить вручную, а при наличии неоднозначностей — с помощью опросов клиентов, если рыночным экспертам Штутгарта не удается сразу решить проблему.

Несмотря на введение продуктовых диапазонов, цены на многие номера запчастей не оказываются под активным влиянием логики выравнивания. Действительно, только номера запчастей, которые активно способствуют достижению лучшей цены для определённой единицы потребности, корректируются методом градиентного спуска для создания приближённого выравнивания внутри одного продуктового диапазона.
Из двух номеров запчастей с идентичными механическими совместимостями только один будет скорректирован решателем выравнивания. У другого номера запчастей градиенты всегда будут равны нулю, и его исходная цена останется неизменной. Таким образом, хотя система имеет целый набор ограничений, многие переменные вообще не ограничены. В зависимости от детализации продуктовых диапазонов и объёма конкурентной аналитики, эти неограниченные номера запчастей могут составлять значительную долю каталога — возможно, до половины номеров запчастей, хотя доля в объёме продаж будет значительно ниже.
Для этих номеров запчастей Штутгарту требуется альтернативная ценовая стратегия. Хотя у меня нет строгого алгоритмического процесса для таких неограниченных деталей, я предложил бы два руководящих принципа.
Во-первых, должен существовать существенный ценовой разрыв, например, 10%, между самой конкурентной запчастью в продуктовом диапазоне и следующей запчастью. Если повезёт, некоторые конкуренты могут оказаться не столь искусными, как Штутгарт, в реконструкции единиц потребности. Таким образом, они могут пропустить тот ценник, который на самом деле управляет выравниванием, что приведёт к повышению их цены, что является желательным для Штутгарта.
Во-вторых, могут быть некоторые запчасти с гораздо более высокой ценой, скажем, на 30% дороже, при условии, что эти запчасти не будут пересекаться с ассортиментом других товаров. Эти запчасти служат контрастом для их более доступных аналогов, стратегия, технически известная как decoy pricing. Приманка специально разработана так, чтобы быть менее привлекательной по сравнению с целевым вариантом, что делает целевой вариант более ценным и побуждает покупателя выбирать его чаще. Эти два принципа достаточны для того, чтобы постепенно распределить неконтролируемые цены за пределы их конкурентных порогов.

Конкурентное выравнивание в сочетании с приманочным ценообразованием достаточны для присвоения цены каждому номеру детали, представленному в Стутгарте. Однако полученная ставка валовой прибыли вероятно окажется слишком низкой для Стутгарта. Действительно, выравнивание Стутгарта с его заметными конкурентами создает огромное давление на его маржу.
С одной стороны, выравнивание цен — это необходимость; в противном случае Стутгарт со временем будет полностью вытеснен с рынка. Но с другой стороны, Стутгарт не может обанкротиться в попытке сохранить свою долю рынка. Важно помнить, что будущую валовую прибыль, связанную с определенной ценовой стратегией, можно только оценить или спрогнозировать. Нет точного способа вывести будущий темп роста из набора цен, поскольку и покупатели, и конкуренты приспосабливаются.
Предполагая, что у нас есть достаточно точная оценка ставки валовой прибыли, которую Стутгарт может ожидать на следующей неделе, важно отметить, что аспект «точности» этого предположения не так уж неразумен, как может показаться. Стутгарт, как и его конкуренты, работает в условиях серьезных ограничений. Если ценовая стратегия Стутгарта не будет фундаментально изменена, общая валовая прибыль компании не изменится существенно от недели к неделе. Мы даже можем использовать наблюдаемую ставку валовой прибыли за прошлую неделю в качестве разумного прокси для того, чего Стутгарт должен ожидать на следуюшей неделе, естественно, при условии, что ценовая стратегия останется неизменной.
Предположим, что прогнозируемая ставка валовой прибыли Стутгарта составляет 13%, тогда как для его жизнеспособности необходима ставка 15%. Что должен делать Стутгарт в такой ситуации? Один из вариантов состоит в том, чтобы случайным образом выбрать набор «единиц спроса» и повысить их цены примерно на 20%. Типы запчастей, предпочитаемые первичными покупателями, например, стеклоочистители, следует исключить из этого выбора. Привлечение таких новых клиентов дорого и сложно, и Стутгарт не должен рисковать их первичными покупками. Аналогично, для очень дорогих типов запчастей, таких как форсунки, покупатели, скорее всего, будут тщательно сравнивать предложения. Таким образом, Стутгарт, вероятно, не должен рисковать тем, чтобы выглядеть неконкурентоспособным при более крупных покупках.
Однако, за исключением этих двух случаев, я бы утверждал, что случайный выбор «единиц спроса» и придание им неконкурентоспособности посредством повышения цен является разумным вариантом. Действительно, Стутгарту необходимо повысить некоторые цены, что является неизбежным следствием стремления к более высокой ставке роста прибыли. Если Стутгарт будет действовать по определенной схеме, то онлайн-обзоры, скорее всего, укажут на эти закономерности. Например, если Стутгарт решит отказаться от конкурентоспособности на запчастях Bosch или запчастях, совместимых с автомобилями Peugeot, существует реальная опасность, что Стутгарт станет известен как дилер, не предлагающий выгодных условий для автомобилей Bosch или Peugeot. Случайность делает Стутгарт несколько непостижимым, и это именно тот эффект, который и задумывался.
Ранжирование отображения — еще один важный фактор в онлайн-каталоге Стутгарта. Более конкретно, для каждой «единицы спроса» Стутгарту необходимо ранжировать все подходящие запчасти. Определение наилучшего способа ранжирования запчастей — это смежная с ценообразованием проблема, заслуживающая отдельной лекции. С точки зрения, представленной в данной лекции, ранжирование ожидалось бы провести после разрешения проблемы выравнивания. Однако также можно оптимизировать одновременно и ценники, и ранги отображения. Эта задача предполагает около 10 миллионов переменных вместо тех 100 000 переменных, с которыми мы сталкивались до сих пор. Тем не менее, это принципиально не меняет масштаб задачи оптимизации, так как нам все равно предстоит иметь дело с 10 миллионами ограничений. Сегодня я не буду обсуждать, какой критерий можно использовать для оптимизации рангов отображения, и как использовать градиентный спуск для дискретной оптимизации. Этот последний вопрос весьма интересен, но будет рассмотрен в последующих лекциях.

Относительная важность «единицы спроса» практически полностью определяется существующими автопарками. Стутгарт не может рассчитывать на продажу 1 миллиона тормозных колодок для модели автомобиля, которой принадлежит всего 1 000 единиц в Европе. Можно даже утверждать, что истинными потребителями запчастей являются сами транспортные средства, а не их владельцы. Хотя транспортные средства не оплачивают свои запчасти (оплачивают владельцы), эта аналогия помогает подчеркнуть значение автопарка.
Однако вполне логично ожидать значительных искажений, когда речь заходит о покупке запчастей в интернете. В конце концов, приобретение запчастей — это прежде всего способ сэкономить деньги по сравнению с их покупкой в автосервисе. Поэтому ожидается, что средний возраст автомобилей, наблюдаемый Стутгартом, будет больше, чем предполагают общие статистические данные автомобильного рынка. Аналогично, люди, водящие дорогие автомобили, с меньшей вероятностью попытаются сэкономить, занимаясь ремонтом самостоятельно. Таким образом, ожидается, что средний размер и класс автомобилей, наблюдаемых Стутгартом, окажутся ниже, чем показывают общие рыночные статистические данные.
Это не пустые домыслы. Эти искажения действительно наблюдаются у всех крупных онлайн-ритейлеров автозапчастей в Европе. Однако алгоритм выравнивания, представленный ранее, использует историю продаж Стутгарта в качестве прокси для спроса. Можно предположить, что эти смещения могут подорвать результаты алгоритма выравнивания цен. То, негативно ли эти смещения влияют на результат для Стутгарта, в основе своей является эмпирической проблемой, поскольку масштаб проблемы, если он существует, сильно зависит от данных. Опыт Lokad показывает, что алгоритм выравнивания и его варианты довольно устойчивы к этому классу смещений, даже если вес «единицы спроса» переоценивается в два или три раза. Основное значение этих весов с точки зрения ценообразования, по-видимому, заключается в помощи алгоритму выравнивания разрешать конфликты, когда один и тот же номер детали принадлежит двум «единицам спроса», которые невозможно обрабатывать одновременно. В большинстве таких случаев одна «единица спроса» значительно превосходит другую по объему. Таким образом, даже значительная ошибка в оценке соответствующих объемов имеет незначительные последствия для ценообразования.
Выявление наибольших расхождений между тем, каким должен был бы быть спрос для определенной «единицы спроса», и тем, что Стутгарт наблюдает в виде фактических продаж, может быть весьма полезным. Неожиданно низкий объем продаж для конкретной «единицы спроса» зачастую указывает на банальные проблемы платформы электронной коммерции. Некоторые запчасти могут быть ошибочно промаркированы, некоторые могут иметь некорректные или низкокачественные изображения и т.п. На практике эти смещения можно выявить, сравнивая коэффициенты продаж для определенной модели автомобиля по различным типам запчастей. Например, если Стутгарт не продает никаких тормозных колодок для определенной модели, в то время как объемы продаж других типов запчастей соответствуют обычным показателям, маловероятно, что у этой модели действительно наблюдается чрезвычайно низкое потребление тормозных колодок. Коренная причина почти наверняка кроется в другом.
Усовершенствованный список механических совместимостей является конкурентным преимуществом. Знание совместимостей, о которых не знают ваши конкуренты, позволяет потенциально установить более низкие цены, не запуская ценовую войну, и таким образом получить преимущество в увеличении доли рынка. Напротив, выявление некорректных совместимостей критически важно для избежания дорогостоящих возвратов от клиентов.
Действительно, стоимость заказа несовместимой запчасти для автомастерской невысока, поскольку, скорее всего, существует налаженный процесс возврата неиспользованной детали в распределительный центр. Однако для обычных клиентов этот процесс гораздо более утомителен, и им может даже не удастся правильно перепаковать деталь для обратной доставки. Таким образом, у каждой компании электронной коммерции есть стимул создать собственный слой обогащения данных поверх сторонних наборов, которые они арендуют. Большинство игроков в этом сегменте так или иначе имеют собственный слой обогащения данных.
Мало стимулов делиться этими знаниями с узкоспециализированными компаниями, которые изначально поддерживают эти наборы данных, поскольку эти знания в основном принесут пользу конкурентам. Оценить уровень ошибок в этих наборах данных сложно, но в Lokad мы считаем, что он колеблется около небольшого однозначного процента с каждой стороны. Несколько процентов ложноположительных результатов, когда совместимость объявляется, хотя на самом деле ее нет, и несколько процентов ложноотрицательных, когда совместимость существует, но не указывается. Учитывая, что список механических совместимостей насчитывает более 100 миллионов записей, при консервативной оценке можно предположить, что в нем около семи миллионов ошибок.
Следовательно, в интересах Стутгарта находится улучшение этого набора данных. Возвраты клиентов, связанные с ложноположительной механической совместимостью, безусловно, могут быть использованы для этой цели. Однако этот процесс медленный и дорогостоящий. Более того, поскольку клиенты не являются профессиональными автомобильными техниками, они могут сообщать о несовместимости детали, если им просто не удалось ее установить. Стутгарт может отложить признание детали несовместимой до поступления нескольких жалоб, но это делает процесс еще более затратным и медленным.
Таким образом, численный метод для улучшения этого набора данных о совместимости был бы крайне желателен. Неочевидно, вообще ли возможно улучшить этот набор данных без использования дополнительной информации. Однако, несколько удивительно, что оказалось, данный набор данных можно улучшить без какой-либо дополнительной информации. Этот набор данных может быть использован для самобустинга в более совершенную версию.
Лично я столкнулся с этим осознанием в первом квартале 2017 года, когда проводил серию экспериментов по глубокому обучению для Lokad. Я использовал факторизацию матрицы — известную технику для коллаборативной фильтрации. Коллаборативная фильтрация является центральной проблемой при создании системы рекомендаций, которая заключается в выявлении продукта, который может понравиться пользователю, основываясь на известных предпочтениях этого пользователя для короткого списка продуктов. Адаптация коллаборативной фильтрации к механическим совместимостям проста: замените пользователей на модели автомобилей и замените продукты на автомобильные запчасти. Вуаля, проблема адаптирована.
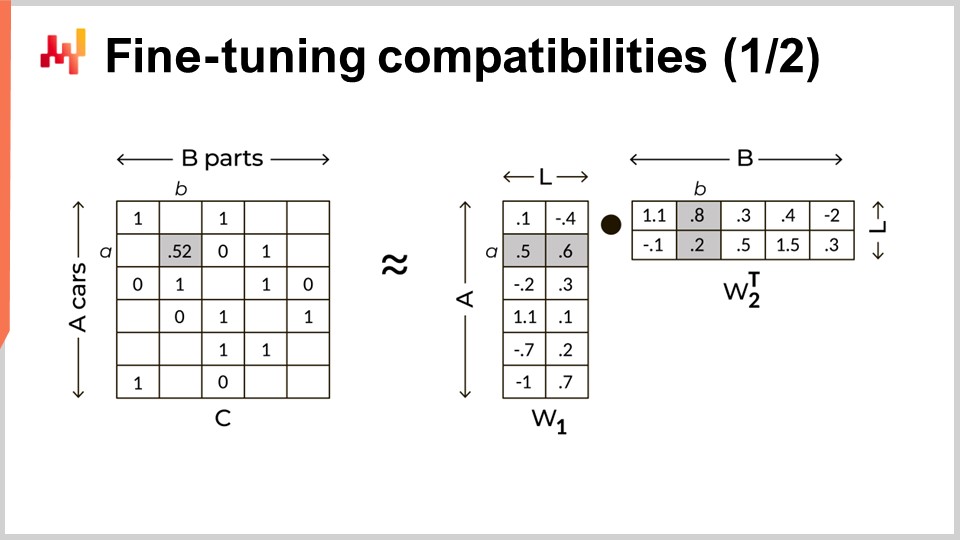
В более общем смысле, факторизация матриц применима для любой ситуации, связанной с двудольным графом. Факторизация матриц также полезна вне анализа графов. Например, метод низкоранговой адаптации больших языковых моделей (LLMs), техника, которая стала чрезвычайно популярной для тонкой настройки LLM, также основывается на приеме факторизации матриц. Факторизация матриц проиллюстрирована на экране. Слева у нас находится матрица совместимостей, где единицы обозначают совместимость между автомобилем и деталью, а нули — несовместимость между моделью автомобиля и номером детали. Мы хотим заменить эту большую и очень разреженную матрицу произведением двух меньших плотных матриц. Эти две матрицы видны справа. Они используются для факторизации большой матрицы. По сути, мы погружаем каждую модель автомобиля и номер детали в скрытое пространство. Размерность этого скрытого пространства обозначена на экране заглавной буквой L. Это скрытое пространство предназначено для отражения механических совместимостей, но с гораздо меньшим количеством измерений, чем исходная матрица. Поддерживая достаточно низкую размерность скрытого пространства, мы стремимся выявить скрытые правила, управляющие этими механическими совместимостями.

Хотя факторизация матриц может звучать как грандиозная техническая концепция, это не так. Это базовый прием линейной алгебры. Единственный обманчивый момент факторизации матриц в том, что она работает настолько хорошо, несмотря на свою простоту. На экране представлена полная реализация этой техники менее чем в 30 строках кода.
В строках с одной по три мы читаем плоский файл, содержащий список механических совместимостей. Этот файл загружается в таблицу с именем M для краткости, что означает «матрица». Этот список фактически является разреженным представлением матрицы совместимостей. При его загрузке мы также создаем две другие таблицы с именами car_models и pns. Эти блоки дают нам три таблицы: M, car_models и pns.
Строки пять и шесть связаны со случайным перемешиванием столбца, содержащего модели автомобилей. Цель перемешивания — создать случайные нули, или случайные несовместимости. Действительно, матрица совместимостей очень разрежена. При выборе случайного автомобиля и случайной детали практически гарантировано, что эта пара окажется несовместимой. Доверие к тому, что это случайное сочетание равно нулю, фактически выше, чем доверие к исходному списку совместимостей. По конструкции, эти случайные нули имеют точность 99,9% благодаря разреженности матрицы, в то время как известные совместимости, возможно, имеют точность около 97%.
Строка восемь связана с созданием скрытого пространства с 24 измерениями. Хотя 24 измерения могут показаться большим числом для эмбеддингов, это очень мало по сравнению с большими языковыми моделями, у которых эмбеддинги насчитывают свыше тысячи измерений. Строки девять и десять посвящены созданию двух небольших матриц, называемых pnl и car_L, которые мы будем использовать для факторизации большой матрицы. Эти две матрицы представляют примерно 24 миллиона параметров для pnl и 2,4 миллиона параметров для car_L. Это считается небольшим по сравнению с большой матрицей, которая содержит примерно 100 миллиардов значений.
Отметим, что большая матрица никогда не материализуется в этом скрипте. Она никогда не превращается явно в массив; она всегда хранится как список из 100 миллионов совместимостей. Преобразование ее в массив было бы чрезвычайно неэффективным с точки зрения вычислительных ресурсов.
Строки 12 по 15 вводят две вспомогательные функции с именами sigmoid и log_loss. Функция sigmoid используется для преобразования необработанного матричного произведения в вероятности, числа от 0 до 1. Функция log_loss означает логистическую потерю. Логистическая потеря применяет логарифмическое правдоподобие, метрику, используемую для оценки корректности вероятностного предсказания. Здесь оно используется для оценки вероятностного предсказания в задаче бинарной классификации. Мы уже сталкивались с логарифмическим правдоподобием в лекции 5.3, посвященной вероятностному прогнозированию сроков поставки. Это более простая вариация той же идеи. Обе эти функции отмечены ключевым словом autograd, что указывает на их возможность автоматического дифференцирования. Малое значение, равное одной миллионной, является эпсилон, введенным для численной устойчивости. Оно не влияет на логику в остальном. С 17 по 29 строки мы наблюдаем саму матричную факторизацию. Снова мы используем дифференцируемое программирование. Несколько минут назад мы применяли дифференцируемое программирование для приблизительного решения задачи удовлетворения ограничений. Здесь же мы используем дифференцируемое программирование для решения задачи обучения с самоконтролем.
В строках 18 и 19 мы объявляем параметры, которые необходимо обучить. Эти параметры связаны с двумя малыми матрицами, pnl и car_L. Ключевое слово “auto” указывает на то, что эти параметры инициализируются случайным образом как отклонения из гауссовского распределения с центром в нуле и стандартным отклонением 0.1.
Строки 20 и 21 вводят два специальных параметра, ускоряющих сходимость. Это всего 48 чисел, капля в море по сравнению с нашими малыми матрицами, которые всё ещё содержат миллионы чисел. И всё же, я обнаружил, что введение этих параметров существенно ускоряет сходимость. Важно отметить, что эти параметры не добавляют никаких степеней свободы для существующей модели. Они лишь добавляют несколько дополнительных степеней свободы в процессе обучения. Итоговый эффект заключается в том, что они сокращают количество необходимых эпох более чем вдвое.
В строках 22 по 24 мы загружаем эмбеддинги. В строке 22 представлен эмбеддинг для одной детали с именем px. В строке 23 — эмбеддинг для одной модели автомобиля с именем mx. Пара px и mx будет нашим положительным ребром, совместимость которого считается истинной. В строке 24 загружается эмбеддинг для другой модели автомобиля с именем mx2. Пара px и mx2 будет нашим отрицательным ребром, совместимость которого считается ложной. Действительно, mx2 был выбран случайным образом посредством перемешивания, происходящего в строке шесть. Все три эмбеддинга px, mx и mx2 имеют ровно 24 измерения, так как они принадлежат скрытому пространству, представленному таблицей L в этом скрипте.
В строке 26 мы выражаем вероятность, определяемую нашей моделью, через скалярное произведение для положительного ребра. Мы знаем, что это ребро положительное, по крайней мере, так утверждает набор данных о совместимости. Но здесь мы оцениваем, что говорит наша вероятностная модель об этом ребре. В строке 27 мы выражаем вероятность, также определяемую нашей вероятностной моделью, через скалярное произведение для отрицательного ребра. Мы предполагаем, что это ребро отрицательное, поскольку оно случайное. Снова мы оцениваем эту вероятность, чтобы понять, что говорит наша модель об этом ребре. В строке 29 мы возвращаем противоположное значение логарифмического правдоподобия, связанного с этим ребром. Возвращаемое значение используется как функция потерь, минимизируемая стохастическим градиентным спуском. Здесь это означает, что мы максимизируем логарифмическое правдоподобие, или вероятностный критерий бинарной классификации, между совместимыми и несовместимыми парами.
Затем, помимо того, что показано в этом скрипте, большую матрицу можно сравнить со скалярным произведением двух малых матриц. Расхождения между двумя представлениями вскрывают как ложноположительные, так и ложноотрицательные случаи в исходных наборах данных. Самое поразительное, что факторизованное представление этой большой матрицы оказывается более точным по сравнению с оригинальной матрицей.
К сожалению, я не могу представить эмпирические результаты, связанные с этими техниками, поскольку соответствующие наборы данных о совместимости являются собственностью компаний. Однако мои выводы, подтвержденные несколькими участниками этого рынка, указывают на то, что техники матричной факторизации могут снизить количество ложноположительных и ложноотрицательных случаев до порядка величины. Что касается производительности, то время вычислений для достижения удовлетворительной сходимости сократилось с примерно двух недель с использованием набора инструментов глубокого обучения CNTK — набора инструментов глубокого обучения от Microsoft в 2017 году — до примерно одного часа с современным временем выполнения, предлагаемым Envision. Ранние наборы инструментов глубокого обучения, в определённом смысле, предлагали дифференцируемое программирование; однако эти решения были оптимизированы для больших матричных произведений и сверток. Более современные наборы инструментов, такие как Jax от Google, я предполагаю, покажут производительность, сопоставимую с Envision.
Это поднимает вопрос: почему специализированные компании, поддерживающие наборы данных о совместимости, не используют матричную факторизацию для очистки своих данных? Если бы они это сделали, матричная факторизация не принесла бы ничего нового. Матричная факторизация как метод машинного обучения существует уже почти 20 лет. Эта техника стала популярной еще в 2006 году благодаря Саймону Фанку. Сейчас она уже не является ультрасовременной. Мой ответ на этот первоначальный вопрос: я не знаю. Возможно, эти специализированные компании начнут использовать матричную факторизацию после просмотра этой лекции, а может и нет.
В любом случае, это демонстрирует, что дифференцируемое программирование и вероятностное моделирование — очень универсальные парадигмы. На первый взгляд, прогнозирование сроков поставки не имеет ничего общего с оценкой механической совместимости, но обе задачи можно решать с помощью одного и того же инструмента — дифференцируемого программирования и вероятностного моделирования.

Набор данных механической совместимости не является единственным, который может оказаться неточным. Иногда инструменты конкурентной разведки возвращают ложные данные. Даже если процесс веб-скрейпинга достаточно надёжен при извлечении миллионов цен с полуструктурированных веб-страниц, ошибки могут происходить. Выявление и устранение этих ошибочных цен — задача сама по себе. Однако этому также заслуживает отдельная лекция, поскольку проблемы, как правило, специфичны для конкретного веб-сайта и используемой технологии веб-скрейпинга.
Хотя проблемы веб-скрейпинга важны, они возникают до запуска алгоритма выравнивания и, следовательно, должны быть в значительной мере отделены от самого процесса выравнивания. Ошибки скрейпинга не обязаны оставаться на волю случая. Существует два подхода в конкурентной разведке: либо вы делаете свои данные лучше, более точными, либо ухудшаете данные конкурентов, делая их менее точными. В этом суть контрразведки.
Как уже обсуждалось ранее, блокировка роботов по их IP-адресу не сработает. Однако существуют альтернативы. Транспортный уровень сети даже близко не является самым интересным уровнем для экспериментов, если мы намерены внести целенаправленное замешательство. Примерно десять лет назад компания Lokad провела серию контрразведывательных экспериментов, чтобы выяснить, сможет ли крупный интернет-магазин, подобный SugAr, защитить себя от конкурентов. Результаты? Да, сможет.
В какой-то момент мне даже удалось подтвердить эффективность этих контрразведывательных техник посредством прямой проверки данных, предоставленных, казалось бы, невнимательным специалистом по веб-скрейпингу. Кодовое название этой инициативы было Bot Defender. Этот проект был прекращён, но в нашем публичном блоге всё ещё можно увидеть несколько следов Bot Defender.
Вместо того чтобы пытаться запретить доступ к HTML-страницам, что является проигрышной стратегией, мы решили избирательно вмешаться в работу самих веб-скрейперов. Команда Lokad не знала всех тонкостей конструкции этих веб-скрейперов. Учитывая DHTML-структуру конкретного интернет-магазина, несложно предположить, как поступила бы компания, управляющая веб-скрейперами. Например, если каждая HTML-страница сайта StuttArt содержит чрезмерно удобный CSS-класс с названием “unit price”, который выделяет цену продукта посреди страницы, логично предположить, что практически все роботы будут использовать этот удобный CSS-класс для извлечения цены из HTML-кода. Действительно, если сайт StuttArt не предлагает ещё более удобный способ получения цен, например, открытый API, к которому можно свободно обращаться, этот CSS-класс является очевидным решением для извлечения цен.
Тем не менее, поскольку логика веб-скрейпинга очевидна, также очевидно, как избирательно вмешаться в эту логику. Например, StuttArt может выбрать несколько целевых продуктов и “отравить” HTML. В приведённом на экране примере обе HTML-страницы визуально отображают для человека ценник в 65 евро и 50 центов. Однако вторая версия HTML-страницы будет интерпретирована роботами как 95 евро вместо 65 евро. Число “9” повёрнуто с помощью CSS так, что выглядит как “6”. Обычный веб-скрейпер, полагающийся на HTML-разметку, не заметит этого.
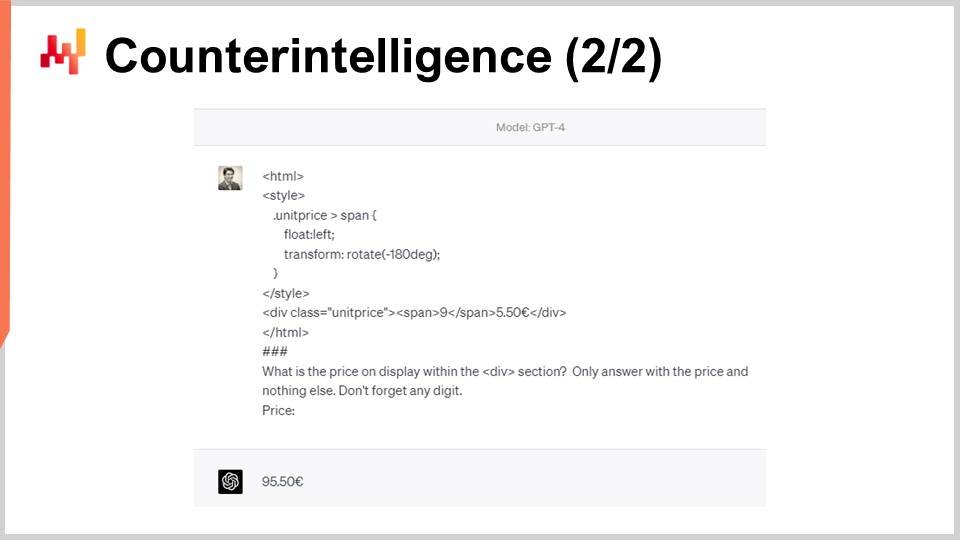
Десять лет спустя даже такая сложная Большая Языковая Модель, как GPT-4, которая не существовала в то время, всё ещё обманывается этим простым CSS-трюком. На экране видно, что GPT-4 не извлекает цену 65 евро, как должно быть, а вместо этого показывает 95 евро. Более того, существует десятки способов создать HTML-код, который предоставляет очевидный ценник для робота, но отличается от того, что прочитал бы человек. Поворот “9” в “6” — всего один из самых простых приёмов из множества подобных.
Противодействующей мерой этой техники могло бы стать рендеринг страницы с созданием полного битмапа, а затем применение оптического распознавания символов (OCR) к этому битмапу. Однако это довольно дорого. Компаниям, занимающимся конкурентной разведкой, приходится ежедневно проверять десятки миллионов веб-страниц. Как правило, выполнение рендеринга страницы с последующим OCR увеличивает затраты на обработку как минимум в 100 раз, а скорее всего, в 1000 раз.
Для ориентира: по состоянию на май 2023 года, Microsoft Azure взимает один доллар за тысячу операций OCR. Учитывая, что специалисты по конкурентной разведке в Европе ежедневно мониторят более 10 миллионов страниц, это составляет бюджет в 10 000 долларов в день только на OCR. И, кстати, Microsoft Azure довольно конкурентен в этом отношении.
Учитывая и другие расходы, такие как пропускная способность для этих ценных домашних IP-адресов, обсуждаемый годовой бюджет на вычислительные ресурсы, если идти по этому пути, скорее всего, находится в пределах 5 миллионов евро. Годовой бюджет в несколько миллионов возможен, но маржа компаний, занимающихся веб-скрейпингом, невелика, и они не пойдут по этому пути. Если с помощью значительно более дешёвых средств можно достичь 99%-ной точности конкурентной разведки, этого достаточно для удовлетворения клиентов.
Возвращаясь к StuttArt, было бы неразумно использовать эту контрразведывательную технику для отравления всех цен, поскольку это лишь усилит гонку вооружений с веб-скрейперами. Вместо этого StuttArt следует мудро выбрать один процент ссылок, который окажет максимальное влияние в условиях конкуренции. Скорее всего, веб-скрейперы даже не заметят проблему. Даже если веб-скрейперы и заметят контрмеры, если они будут восприняты как проблема низкой интенсивности, они не станут предпринимать действия. Действительно, веб-скрейпинг сопровождается всевозможными мелкими проблемами: сайт, который вы анализируете, может быть чрезвычайно медленным, может выйти из строя или страница может содержать сбои. Может присутствовать условная promotion, делающая цену неясной для интересующей детали.
С точки зрения StuttArt, остается выбрать один процент номеров деталей, представляющих максимальный интерес с точки зрения конкурентной разведки. Эти детали, как правило, те, которые StuttArt хотелось бы продавать по сниженной цене, но без провокации ценовой войны. Существует несколько подходов к этому. Одним из типов деталей с высоким интересом являются недорогие расходные материалы, например, дворники. Клиент, желающий попробовать StuttArt при первой покупке, вряд ли начнет с инжектора за 600 евро. Новый клиент, скорее всего, начнет с дворника за 20 евро в качестве пробного варианта. В целом, первые покупатели ведут себя совсем иначе, чем постоянные клиенты. Таким образом, один процент деталей, который StuttArt, вероятно, захочет сделать особенно привлекательным, не провоцируя ценовую войну, — это те детали, которые с наибольшей вероятностью будут куплены впервые.

Избегание ценовой войны и эрозии доли рынка являются крайне негативными результатами для StuttArt, поэтому нужны особые обстоятельства, чтобы отклониться от принципа выравнивания. Мы уже видели один из таких случаев, когда необходимо контролировать валовую прибыль. Однако это не единственное обстоятельство. Избытки запасов и stockouts — ещё два основных кандидата при корректировке цен. Избытки лучше всего устранять заблаговременно. Было бы лучше, если бы StuttArt полностью избегала избытков, но ошибки случаются, как и рыночные колебания, и, несмотря на тщательные политики replenishment, StuttArt регулярно сталкивается с локальными избытками. Ценообразование является ценным механизмом для смягчения этих проблем. StuttArt всё же лучше продаёт избыточные запасы с существенной скидкой, чем оставлять их нераспроданными, поэтому избытки должны учитываться в стратегии ценообразования.
Давайте сузим область избытков до деталей, которые с большой вероятностью превратятся в списание запасов. В этом случае избытки можно устранить с помощью корректировки выравнивания себестоимости, которая снижает ценник до почти нулевой валовой прибыли, а возможно, и немного ниже, в зависимости от регуляций и масштабов избытка.
Напротив, дефицит товара, или точнее, его близость к дефициту, должен сопровождаться повышением цен. Например, если у StuttArt осталось всего пять единиц запчасти, которая обычно продается одной штукой в день, и следующая поставка не поступит раньше, чем через 15 дней, то эта запчасть почти наверняка столкнется с дефицитом. Нет смысла спешить до момента, когда товар закончится. StuttArt может повысить цену на эту запчасть. Пока снижение спроса будет достаточно незначительным, чтобы избежать дефицита, это не имеет значения.
Инструменты конкурентной разведки становятся все более способными отслеживать не только цены, но и задержки доставки, объявляемые для запчастей на сайте конкурента. Это дает возможность StuttArt отслеживать не только свои собственные дефициты, но и наблюдать за развитием дефицитов у конкурентов. Частой причиной дефицита у розничного продавца является дефицит у поставщика. Если у OEM отсутствует товар, то, скорее всего, StuttArt вместе со всеми своими конкурентами останется без товара. В рамках алгоритма выравнивания цен разумно исключать те запчасти, которые отсутствуют либо у поставщиков, либо на сайте конкурента. Дефицит у конкурентов можно отслеживать по задержкам доставки, если эти задержки отражают необычные условия. Также, если оригинальный производитель запчастей (OEM) начинает объявлять о необычных задержках для запчастей, возможно, настало время повысить цены на эти запчасти, поскольку это указывает на то, что всем участникам рынка, скорее всего, будет сложно закупить дополнительные автозапчасти у данного OEM.
На данном этапе становится совершенно очевидно, что оптимизация ценообразования и оптимизация запасов — это взаимосвязанные задачи, и, следовательно, их необходимо решать совместно на практике. Действительно, в рамках данной единицы потребности запчасть, которая сочетает в себе как наименьшую цену, так и наивысший ранг отображения в ассортименте, поглотит основную массу продаж. Ценообразование направляет спрос между многочисленными альтернативами в предложении StuttArt. Нет смысла, чтобы команда по управлению запасами пыталась прогнозировать цены, устанавливаемые командой по ценообразованию. Вместо этого должна существовать единая функция управления цепочкой поставок, которая решает обе задачи совместно.

Условия доставки являются неотъемлемой частью сервиса. Когда речь заходит об автозапчастях, клиенты не только ожидают, что StuttArt выполнит свои обещания, но и могут быть готовы заплатить дополнительно, если процесс будет ускорен. Несколько крупных компаний электронной коммерции, продающих автозапчасти в Европе, уже предлагают различные цены в зависимости от срока поставки. Эти разные цены отражают не только варианты доставки, но, возможно, и варианты закупки. Если клиент готов ждать одну-две недели, то у StuttArt появляется больше вариантов закупки, и часть сэкономленных средств может быть передана клиенту. Например, запчасть может быть приобретена StuttArt только после того, как клиент ее заказал, что позволяет полностью исключить расходы на хранение и риск инвентаризации.
Условия доставки усложняют задачи конкурентной разведки. Во-первых, инструменты конкурентной разведки должны извлекать информацию не только о ценах, но и о задержках доставки. Многие специалисты в этой области уже занимаются этим, и StuttArt необходимо последовать их примеру. Во-вторых, StuttArt нужно скорректировать алгоритм выравнивания цен с учетом различных условий доставки. Дифференцируемое программирование можно использовать для оценки ценности, выраженной в евро, сэкономленной за один день времени. Ожидается, что эта ценность зависит от модели автомобиля, типа запчасти и срока доставки в днях. Например, сокращение срока поставки с трех до двух дней гораздо более ценно для клиента, чем сокращение с 21 до 20 дней.

В заключение, сегодня была предложена обширная ценовая стратегия для StuttArt — персонажа цепочки поставок, специализирующегося на онлайн-рынке автозапчастей. Мы увидели, что ценообразование не поддается никакой локальной стратегии оптимизации. Проблема ценообразования действительно неглобальна, поскольку механическая совместимость распространяет влияние ценника для любой конкретной запчасти на многочисленные единицы потребности. Это привело нас к осмыслению ценообразования как выравнивания на уровне единицы потребности. С помощью дифференцируемого программирования было решено две подзадачи. Во-первых, мы решили задачу приближенного удовлетворения ограничений для конкурентного выравнивания. Во-вторых, была поставлена задача самоусовершенствования наборов данных по механической совместимости, чтобы улучшить как качество выравнивания, так и опыт клиентов. Эти две задачи можно добавить к нашему растущему списку проблем цепочки поставок, которые выигрывают от прямолинейных решений, когда к ним подходят через дифференцируемое программирование.
В более общем смысле, если есть один вывод из этой лекции, то он заключается не в том, что рынок автозапчастей является исключением в вопросах ценообразования. Напротив, вывод таков: всегда следует ожидать многочисленные особенности, независимо от выбранного вертикального сегмента. Было бы столько же особенностей, если бы мы рассматривали любого другого участника цепочки поставок, а не сосредотачивались бы на StuttArt, как мы сделали сегодня. Таким образом, бессмысленно искать какое-либо окончательное решение. Любое аналитическое решение гарантированно не сможет учесть бесконечный поток вариаций, которые со временем появятся в реальной цепочке поставок. Вместо этого нам нужны концепции, методы и инструменты, которые не только позволяют решать текущие задачи цепочки поставок, но и могут быть программно изменены. Программируемость имеет решающее значение для обеспечения будущей актуальности числовых рецептов для ценообразования.

Прежде чем перейти к вопросам, я хотел бы объявить, что следующая лекция состоится в первую неделю июля. Как обычно, в среду, в то же время — в 15:00 по парижскому времени. Я вновь обращусь к первой главе, детально рассмотрев, что экономика, история и системная теория говорят о цепочке поставок и планировании цепочки поставок.
Теперь давайте перейдем к вопросам.
Вопрос: Планируете ли вы провести лекцию о визуализации совокупных затрат владения для одной цепочки поставок? Иными словами, анализ TCO всей цепочки поставок с помощью аналитики данных и оптимизации общих затрат?
Да, это часть пути данной серии лекций. Элементы этого уже обсуждались на нескольких лекциях. Но главная мысль в том, что это вовсе не проблема визуализации данных. Смысл концепции совокупных затрат владения не в визуализации данных, а в изменении мышления. Большинство практиков в цепочке поставок крайне игнорируют финансовую перспективу. Они погружены в преследование service levels ошибок, а не ошибок, выраженных в долларах или евро. К сожалению, большинство из них гонятся за процентами. Таким образом, необходимо изменить мышление.
Вторая причина заключается в том, что лекция затрагивала элементы, являющиеся частью первой главы — поставку, ориентированную на продукт, как в случае программного продукта для цепочки поставок. Мы должны думать не только о первом круге экономических драйверов, но и о том, что я называю вторым кругом экономических драйверов. Это неуловимые силы, например, если вы снижаете цену продукта на один евро путем проведения акции, наивный анализ может предположить, что это стоило мне одного евро маржи только из-за скидки в один евро. Но реальность такова, что, делая это, вы формируете ожидания у своей клиентской базы о том, что в будущем будет снова предоставлена скидка в один евро. И, следовательно, это влечет за собой определенные затраты. Это затраты второго порядка, но они вполне реальны. Все эти экономические драйверы второго круга являются важными факторами, которые не отражаются в вашей бухгалтерской книге. Да, я продолжу представлять дополнительные элементы, описывающие эти затраты. Однако, в основном, это не аналитическая проблема с точки зрения визуализации или построения графиков, а вопрос мышления. Мы должны принять, что эти аспекты необходимо количественно оценивать, даже если это невероятно сложно.
Когда мы начинаем обсуждать анализ совокупных затрат владения, нам также необходимо рассмотреть, сколько людей понадобится для работы над этим решением в цепочке поставок. Это одна из причин, по которой в данной серии лекций я утверждаю, что нам нужны программные решения. Мы не можем позволить себе армию клерков, корректирующих spreadsheets или таблицы и занимающихся такими затратными операциями, как обработка оповещений об исключениях в программном обеспечении цепочки поставок. Оповещения и исключения означают, что весь персонал компании превращается в человеческих со-процессоров системы. Это чрезвычайно затратно.
Анализ совокупных затрат владения в основном является вопросом мышления, наличия правильной перспективы. На следующей лекции я также коснусь других аспектов, особенно того, что говорит экономика о цепочке поставок. Это очень интересно, поскольку нам нужно задуматься, что на самом деле означает совокупный анализ затрат владения для решения в цепочке поставок, особенно если начать рассматривать ценность, которую оно приносит компании.
Вопрос: Как учитывать различия в качестве, активности, статусах «серебро», «золото» и т.д. для технически совместимых ссылок на единицу потребности при сравнении цен с конкурентами?
Это абсолютно верно. Поэтому необходимо ввести продуктовые линейки. Этот уровень привлекательности, как правило, можно разделить примерно на полдюжины классов, отражающих стандарты качества запчастей. Например, существует автоспортивная линейка, включающая самые роскошные запчасти с отличной механической совместимостью. Эти запчасти также выглядят привлекательно, а их упаковка отличается высоким качеством.
Мой опыт работы на этом рынке показывает, что, хотя существует бесконечное множество вариантов немного улучшить или повысить качество запчасти, рынок в значительной степени сошелся к примерно полдюжине продуктовых линеек, варьирующихся от очень дорогих до менее дорогих. При группировке запчастей StuttArt нам необходимо объединять их в рамки продуктовых линеек. То же самое относится и к запчастям конкурентов, что означает, что нам нужно знать, к какому качественному сегменту относится запчасть, даже если она не продается StuttArt.
StuttArt необходимо иметь представление обо всех запчастях на рынке. Это не так сложно, как может показаться, так как большинство производителей предоставляют информацию о предполагаемом качестве своих запчастей. Эти данные достаточно кодифицированы самими OEM. Мы выигрываем за счет того, что автомобильный рынок — это чрезвычайно устоявшийся, сверхзрелый рынок, существующий более века. Компании, продающие наборы данных о совместимости автомобилей и запчастей, также предоставляют огромное количество атрибутов для запчастей и моделей автомобилей. Речь идет о сотнях атрибутов. Эти наборы данных обширны и богаты информацией. Изначально они использовались специалистами сервисных центров для определения способа проведения ремонта. Они даже поставляются с PDF-вложениями и технической документацией. Это очень насыщенные данные; у вас есть десятки гигабайт данных, включая изображения и фотографии. Я только начал знакомиться с рыночной ценностью этих наборов данных.
Вопрос: Как различающиеся нормативные требования в разных регионах влияют на оптимизацию ценообразования для автомобильных компаний? Например, вы упомянули Peugeot, французскую компанию. Чем ваш подход для Peugeot будет отличаться от подхода для аналогичной компании в Скандинавии или Азии?
Скандинавия по сути представляет собой тот же автомобильный рынок. У них есть несколько различных брендов, но этот рынок слишком мал, чтобы поддерживать собственную автомобильную промышленность. Что касается автомобильной индустрии, Скандинавия не отличается от остальных 350 миллионов европейцев. Однако Азия действительно отличается. Индия и Китай — это самостоятельные рынки.
Что касается оптимизации ценообразования, нормативные требования не столько препятствовали, сколько задерживали появление онлайн-продавцов автозапчастей. Например, 20 лет назад в Европе велась судебная борьба. Пионеры, такие как StuttArt, будучи первыми компаниями, продавшими автозапчасти онлайн, столкнулись с юридическими проблемами. Они продавали автозапчасти и заявляли на своем сайте, что они идентичны тем, что продаются оригинальными производителями автомобилей.
StuttArt заявляли: «Я не продаю вам автозапчасть, я продаю вам ту же самую запчасть, которую использовал бы производитель автомобиля». Они могли это утверждать, потому что закупали абсолютно ту же деталь с того же завода. Если запчасть, скажем, от Valeo и устанавливается на автомобиль Peugeot, существует устоявшаяся ассоциация. Около двух десятилетий назад несколько европейских судов постановили, что законно для сайта заявлять о продаже точно такой же запчасти, как и оригинальные запчасти автомобиля. Эта нормативная неопределенность задержала развитие продаж запасных автозапчастей онлайн, вероятно, примерно на пять лет. Пионеры вели судебные споры с автопроизводителями за право продажи автозапчастей онлайн, утверждая, что они являются оригинальными запчастями для автомобиля. Как только ситуация прояснилась, они могли действовать при условии честности и закупать абсолютно ту же запчасть у Valeo или Bosch, точно такую же, какая устанавливается на автомобиль.
Однако существуют и ограничения. Например, есть запчасти, которые определяют внешний вид автомобиля, и только производитель может продавать их как оригинальные запчасти. Например, капот автомобиля. Эти нормы действительно влияют на то, какие запчасти можно свободно продавать онлайн, заявляя, что деталь идентична оригинальной. Речь идет о деталях, значение которых выражается не только в механической совместимости, но и в безопасности. Некоторые из этих деталей жизненно важны для безопасности.
В Азии одна из проблем, о которой я здесь не говорил, — это контрафактная продукция. Работа с контрафактами в Европе существенно отличается от работы с ними в Азии. Контрафактная продукция действительно существует в Европе, но рынок развитый и стимулированный. OEM-производители и автопроизводители хорошо знают друг друга. Хотя контрафактная продукция существует, проблема минимальна. В таких регионах, как Азия, а именно в Индии и Китае, всё ещё существует достаточно много проблем с контрафактами. Это не столько проблема регулирования, поскольку контрафактная продукция так же незаконна в Китае, как и в Европе. Проблема заключается в недостаточном исполнении законов, причем степень их применения в Азии значительно ниже, чем в Европе.
Question: Оптимизируем ли мы цену в целом или в сравнении с конкурентами?
Оптимизационная функция концептуально рассчитана на каждую единицу потребности — единица потребности определяется как модель автомобиля и тип детали. Для каждой единицы потребности имеется разница в цене в евро между ценой от StuttArt, которая является лучшим предложением компании, и ценой конкурента. Вы берёте абсолютную разницу между этими двумя ценами и суммируете их; это и есть ваша функция. Мы не будем наивно использовать эту сумму разниц цен; мы добавим весовой коэффициент, отражающий годовой объём продаж каждой единицы потребности.
Таким образом, оптимизационная функция для вашей задачи по удовлетворению ограничений представляет собой сумму абсолютных разниц между лучшей ценой, предлагаемой StuttArt для данной единицы потребности, и лучшей ценой, предлагаемой конкурентами. Вы добавляете весовой коэффициент, который отражает годовую значимость этой единицы, также выраженную в евро. Вы стараетесь как можно точнее отразить состояние европейского рынка.
Причина, по которой вы хотите учитывать значимость единицы потребности в отличие от просто самой единицы потребности StuttArt, заключается в том, что если StuttArt оказывается настолько неконкурентоспособной, что не продаёт ничего из данной единицы, то возникает проблема отсутствия конкурентоспособности. Таким образом, эта единица фактически игнорируется при выравнивании, что приводит к нулевым продажам. Затем возникает порочный круг: компания не конкурентоспособна, поэтому ничего не продаёт, и, следовательно, сама единица потребности считается незначительной.
Question: Видите ли вы неожиданные последствия, если подход дифференцируемого моделирования в машинном обучении станет отраслевым стандартом, с риском того, что модели будут конкурировать с другими, очень похожими моделями?
Этот вопрос сложен, потому что, по определению, если последствия действительно неожиданны, то их никто не ожидал, даже я. Очень трудно предвидеть, какие именно последствия могут оказаться неожиданными.
Однако, если говорить серьезно, эту отрасль десятилетиями движут алгоритмические методы. Это усовершенствование в плане точности реализации замысла. Вам нужен численный метод, который более точно соответствует вашим намерениям. Но, по сути, дело не в том, чтобы начинать всё с нуля, когда сейчас всё делается вручную, и через десять лет всё будет выполняться автоматически с использованием численных рецептов. Это уже делается с помощью численных рецептов. Когда у вас 100 000 цен, которые нужно поддерживать и обновлять каждый день, вам необходим какой-либо вид автоматизации.
Возможно, ваша автоматизация представляет собой огромную таблицу Excel, где вы применяете всевозможное «черное искусство», но это по-прежнему алгоритмический процесс. Люди не корректируют цены вручную, за исключением некоторых деталей в редких случаях. В основном всё уже автоматизировано, и у нас уже есть множество непредвиденных последствий. Например, во время локдаунов в Европе люди проводили больше времени дома, делая покупки онлайн. Это может показаться парадоксальным, но они всё равно активно использовали свои автомобили, и, следовательно, делали больше покупок. Однако многие компании, продающие автозапчасти онлайн, стали менее активны с точки зрения проведения акций, поскольку их организация усложнилась из-за того, что все работали из дома.
В результате, в течение нескольких месяцев во время локдаунов 2020 года, было значительно меньше алгоритмического шума, создаваемого акциями. Алгоритмические реакции со стороны всех участников были гораздо более однозначными. Бывали дни, когда можно было гораздо отчетливее увидеть те алгоритмические реакции, которые запускались при ежедневном обновлении.
Это достаточно зрелая модель в хорошо отлаженной отрасли, поскольку теперь всё осуществляется через электронную торговлю. Что касается непреднамеренных или неожиданных последствий, их предсказать сложнее.
Позвольте закончить мыслью о потенциальной области сюрприза. Многие ожидают, что электромобили упростят всё, поскольку в них меньше деталей по сравнению с двигателями внутреннего сгорания. Однако с точки зрения такой компании, как StuttArt, в ближайшие 10 лет электромобили означают появление гораздо большего количества запчастей на рынке.
Пока, и если, электромобили станут доминирующими, на дорогах все еще будут старые автомобили с двигателями внутреннего сгорания. Эти автомобили прослужат около 20 лет. Помните, что StuttArt, как компания, работает с транспортными средствами, которые не являются совершенно новыми. Многие из этих автомобилей хорошего качества и будут находиться в эксплуатации ещё около 20 лет. Но тем временем на рынок поступит множество дополнительных электромобилей с обилием различных деталей. Это может привести к стабильному увеличению числа различных запчастей, создавая ещё больше проблем и осложнений.
Я считаю, что на этом заканчивается сегодняшняя лекция. Если вопросов больше нет, с нетерпением жду встречи с вами на следующей лекции, которая, как обычно, состоится в первую неделю июля, в среду в 15:00 по парижскому времени. Большое спасибо и до встречи.