00:00 Introduzione
02:55 Il caso dei tempi di consegna
09:25 Tempi di consegna reali (1/3)
12:13 Tempi di consegna reali (2/3)
13:44 Tempi di consegna reali (3/3)
16:12 La situazione finora
19:31 ETA: 1 ora da adesso
22:16 CPRS (riepilogo) (1/2)
23:44 CPRS (riepilogo) (2/2)
24:52 Validazione incrociata (1/2)
27:00 Validazione incrociata (2/2)
27:40 Smoothing dei tempi di consegna (1/2)
31:29 Smoothing dei tempi di consegna (2/2)
40:51 Composizione dei tempi di consegna (1/2)
44:19 Composizione dei tempi di consegna (2/2)
47:52 Tempi di consegna quasi stagionali
54:45 Modello di tempi di consegna log-logistico (1/4)
57:03 Modello di tempi di consegna log-logistico (2/4)
01:00:08 Modello di tempi di consegna log-logistico (3/4)
01:03:22 Modello di tempi di consegna log-logistico (4/4)
01:05:12 Modello di tempi di consegna incompleto (1/4)
01:08:04 Modello di tempi di consegna incompleto (2/4)
01:09:30 Modello di tempi di consegna incompleto (3/4)
01:11:38 Modello di tempi di consegna incompleto (4/4)
01:14:33 Domanda nel corso del tempo di consegna (1/3)
01:17:35 Domanda nel corso del tempo di consegna (2/3)
01:24:49 Domanda nel corso del tempo di consegna (3/3)
01:28:27 Modularità delle tecniche predittive
01:31:22 Conclusioni
01:32:52 Prossima lezione e domande del pubblico
Descrizione
I tempi di consegna sono un aspetto fondamentale della maggior parte delle situazioni della supply chain. I tempi di consegna possono e dovrebbero essere previsti proprio come la domanda. Possono essere utilizzati modelli di previsione probabilistica dedicati ai tempi di consegna. Vengono presentate una serie di tecniche per creare previsioni probabilistiche dei tempi di consegna per scopi legati alla supply chain. Comporre queste previsioni, tempi di consegna e domanda, è un pilastro della modellazione predittiva nella supply chain.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Previsione dei tempi di consegna”. I tempi di consegna, e più in generale tutti i ritardi applicabili, sono un aspetto fondamentale della supply chain quando si cerca di bilanciare l’offerta e la domanda. Bisogna considerare i ritardi coinvolti. Ad esempio, consideriamo la domanda di un giocattolo. La corretta anticipazione del picco stagionale della domanda prima di Natale non ha importanza se la merce viene ricevuta a gennaio. I tempi di consegna governano i dettagli della pianificazione tanto quanto la domanda stessa.
I tempi di consegna variano; variano molto. Questo è un fatto, e presenterò alcune prove tra un minuto. Tuttavia, a prima vista, questa proposizione è sorprendente. Non è chiaro perché i tempi di consegna dovrebbero variare così tanto in primo luogo. Abbiamo processi di produzione che possono operare con una tolleranza inferiore al micrometro. Inoltre, come parte del processo di produzione, possiamo controllare un effetto, ad esempio l’applicazione di una fonte di luce, fino a un microsecondo. Se possiamo controllare la trasformazione della materia fino al micrometro e al microsecondo, con sufficiente dedizione, dovremmo essere in grado di controllare il flusso delle richieste con un grado di precisione comparabile. O forse no.
Questa linea di pensiero potrebbe spiegare perché i tempi di consegna sembrano essere così poco apprezzati nella letteratura sulla supply chain. I libri sulla supply chain e, di conseguenza, i software per la supply chain riconoscono appena l’esistenza dei tempi di consegna oltre a introdurli come parametro di input per il loro modello di inventario. Per questa lezione, ci saranno tre obiettivi:
Vogliamo capire l’importanza e la natura dei tempi di consegna. Vogliamo capire come i tempi di consegna possono essere previsti, con un interesse specifico per i modelli probabilistici che ci permettono di abbracciare l’incertezza. Vogliamo combinare le previsioni dei tempi di consegna con le previsioni della domanda in modi che siano di interesse per la supply chain.

Secondo la letteratura mainstream sulla supply chain, i tempi di consegna valgono appena un paio di note a piè di pagina. Questa affermazione potrebbe sembrare un’esagerazione stravagante, ma temo che non lo sia. Secondo Google Scholar, un motore di ricerca specializzato nella letteratura scientifica, la query “previsione della domanda” per l’anno 2021 restituisce 10.500 articoli. Un’ispezione sommaria dei risultati indica che la maggior parte di quelle voci discute effettivamente della previsione della domanda in tutti i tipi di situazioni e mercati. La stessa query, sempre per l’anno 2021, su Google Scholar per “previsione dei tempi di consegna” restituisce 71 risultati. I risultati per la query di previsione dei tempi di consegna sono così limitati che bastano pochi minuti per esaminare un anno intero di ricerche.
Risulta che ci sono solo una dozzina di voci che discutono veramente della previsione dei tempi di consegna. Infatti, la maggior parte delle corrispondenze si trovano in espressioni come “previsione dei tempi di consegna lunghi” o “previsione dei tempi di consegna brevi” che si riferiscono a una previsione della domanda, e non a una previsione dei tempi di consegna. È possibile ripetere questo esercizio con “previsione della domanda” e “previsione dei tempi di consegna” e altre espressioni simili e altri anni. Queste variazioni producono risultati simili. Lascio questo come esercizio per il pubblico.
Quindi, come stima approssimativa, abbiamo circa mille volte più articoli sulla previsione della domanda rispetto alla previsione dei tempi di consegna. I libri sulla supply chain e il software sulla supply chain seguono la stessa linea, lasciando i tempi di consegna come cittadini di seconda classe e come una questione di poco conto. Tuttavia, il personale della supply chain che è stato presentato in questa serie di lezioni racconta una storia diversa. Questo personale potrebbe rappresentare aziende immaginarie, ma riflettono archetipi della supply chain. Ci parlano della situazione che dovrebbe essere considerata come tipica. Vediamo cosa ci dicono questo personale per quanto riguarda i tempi di consegna.
Parigi è un marchio di moda immaginario che gestisce la propria rete di vendita al dettaglio. Parigi ordina dai fornitori esteri, con tempi di consegna lunghi e talvolta superiori a sei mesi. Questi tempi di consegna sono solo imperfettamente conosciuti, eppure la nuova collezione deve arrivare in negozio al momento giusto come definito dall’operazione di marketing associata alla nuova collezione. I tempi di consegna dei fornitori richiedono una corretta anticipazione; in altre parole, richiedono una previsione.
Amsterdam è un’azienda immaginaria di beni di consumo di largo consumo (FMCG) specializzata nella produzione di formaggi, creme e burro. Il processo di maturazione del formaggio è noto e controllato, ma varia, con deviazioni di alcuni giorni. Eppure, alcuni giorni è precisamente la durata delle intense promozioni scatenate dalle catene di vendita al dettaglio che si rivelano il principale canale di vendita di Amsterdam. Questi tempi di produzione richiedono una previsione.
Miami è un’azienda immaginaria di manutenzione, riparazione e revisione (MRO) per l’aviazione. MRO sta per manutenzione, riparazione e revisione. Ogni aereo ha bisogno di migliaia di pezzi all’anno per continuare a volare. Un singolo pezzo mancante è probabile che metta a terra l’aereo. La durata della riparazione per un pezzo riparabile, anche chiamato TAT (turnaround time), definisce quando il pezzo rotabile diventa nuovamente utilizzabile. Tuttavia, il TAT varia da giorni a mesi, a seconda dell’entità delle riparazioni, che non sono note al momento in cui il pezzo viene rimosso dall’aereo. Questi TAT richiedono una previsione.
San Jose è un’azienda di e-commerce immaginaria che distribuisce una varietà di arredamento per la casa e accessori. Come parte del suo servizio, San Jose fornisce un impegno per una data di consegna per ogni transazione. Tuttavia, la consegna stessa dipende da aziende terze che sono ben lungi dall’essere perfettamente affidabili. Pertanto, San Jose richiede un’ipotesi informata sulla data di consegna che può essere promessa per ogni transazione. Questa ipotesi informata è implicitamente una previsione dei tempi di consegna.
Infine, Stoccarda è un’azienda immaginaria del settore dell’aftermarket automobilistico. Gestisce filiali che effettuano riparazioni auto. Il prezzo di acquisto più basso per i pezzi di ricambio può essere ottenuto dai grossisti che offrono tempi di consegna lunghi e piuttosto irregolari. Ci sono fornitori più affidabili che sono più costosi e più vicini. Scegliere il fornitore giusto per ogni pezzo richiede un’adeguata analisi comparativa dei rispettivi tempi di consegna associati ai vari fornitori.
Come possiamo vedere, ogni singolo membro del personale della supply chain presentato finora richiede l’anticipazione di almeno uno, e spesso diversi, tempi di consegna. Sebbene si possa sostenere che la previsione della domanda richieda più attenzione e sforzo rispetto alla previsione dei tempi di consegna, alla fine entrambi sono necessari per quasi tutte le situazioni della supply chain.
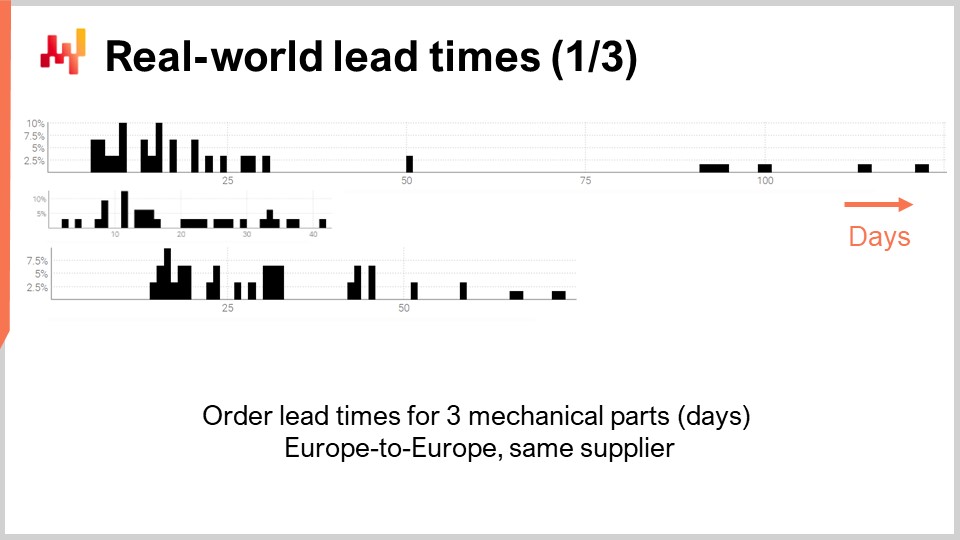
Quindi, diamo un’occhiata a alcuni tempi di consegna effettivi nel mondo reale. Sullo schermo ci sono tre istogrammi che sono stati tracciati compilando i tempi di consegna osservati associati a tre parti meccaniche. Queste parti vengono ordinate dallo stesso fornitore situato in Europa occidentale. Gli ordini provengono da un’azienda anch’essa situata in Europa occidentale. L’asse x indica la durata dei tempi di consegna osservati espressi in giorni, e l’asse y indica il numero di osservazioni espresse come percentuale. In seguito, tutti gli istogrammi adotteranno le stesse convenzioni, con l’asse x associato a durate espresse in giorni e l’asse y che riflette la frequenza. Da queste tre distribuzioni, possiamo già fare alcune osservazioni.
Innanzitutto, i dati sono sparsi. Abbiamo solo poche dozzine di punti dati, e queste osservazioni sono state raccolte nel corso di diversi anni. Questa situazione è tipica; se l’azienda ordina solo una volta al mese, ci vogliono quasi dieci anni per raccogliere oltre 100 osservazioni dei tempi di consegna. Quindi, qualunque cosa facciamo in termini di statistica, dovrebbe essere orientata verso numeri piccoli piuttosto che numeri grandi. Infatti, raramente avremo il lusso di occuparci di numeri grandi.
In secondo luogo, i tempi di consegna sono erratici. Abbiamo osservazioni che vanno da pochi giorni a un quarto. Sebbene sia sempre possibile calcolare un tempo di consegna medio, fare affidamento su qualsiasi tipo di valore medio per una di queste parti sarebbe imprudente. È anche chiaro che nessuna di queste distribuzioni è anche lontanamente normale.
In terzo luogo, abbiamo tre parti che sono in qualche modo confrontabili per dimensioni e prezzo, eppure i tempi di consegna variano molto. Sebbene possa essere tentante raggruppare insieme queste osservazioni per rendere i dati meno sparsi, è ovviamente imprudente farlo, poiché si mescolerebbero distribuzioni molto diverse. Queste distribuzioni non hanno la stessa media, mediana, né lo stesso minimo o massimo.
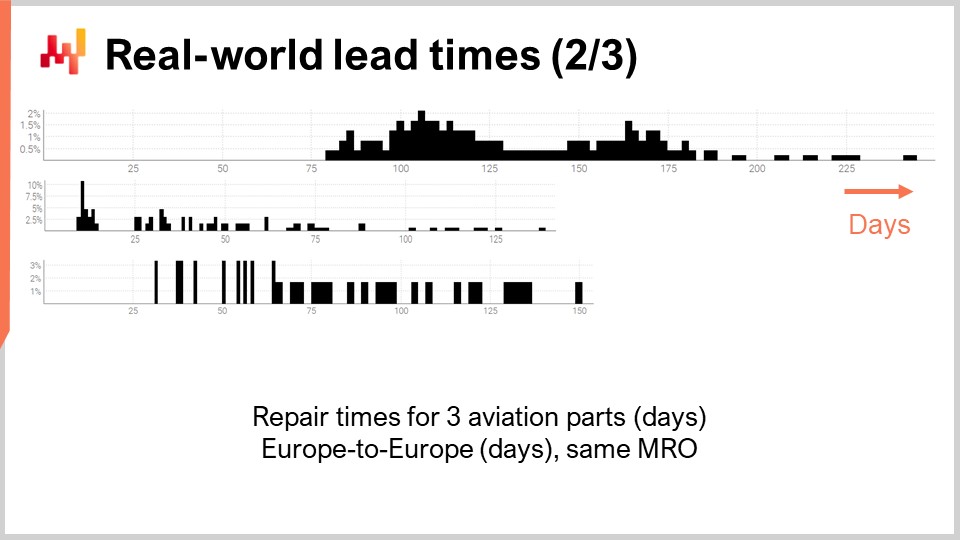
Diamo un’occhiata a un secondo gruppo di tempi di consegna. Queste durate riflettono il tempo necessario per riparare tre diverse parti di aeromobili. La prima distribuzione sembra avere due modalità più una coda. Quando una distribuzione presenta due modalità, di solito suggerisce l’esistenza di una variabile nascosta che spiega quelle due modalità. Ad esempio, potrebbero esserci due tipi distinti di operazioni di riparazione, ciascun tipo associato a un proprio tempo di consegna. La seconda distribuzione sembra avere una modalità più una coda. Questa modalità corrisponde a una durata relativamente breve, circa due settimane. Potrebbe riflettere un processo in cui la parte viene prima ispezionata e talvolta la parte viene considerata utilizzabile senza ulteriori interventi, quindi un tempo di consegna molto più breve. La terza distribuzione sembra essere completamente diffusa, senza una modalità o coda evidente. Potrebbero essere in gioco qui più processi di riparazione che vengono raggruppati insieme. La scarsità dei dati, con solo tre dozzine di osservazioni, rende difficile dire di più. Ritorneremo su questa terza distribuzione più avanti in questa lezione.
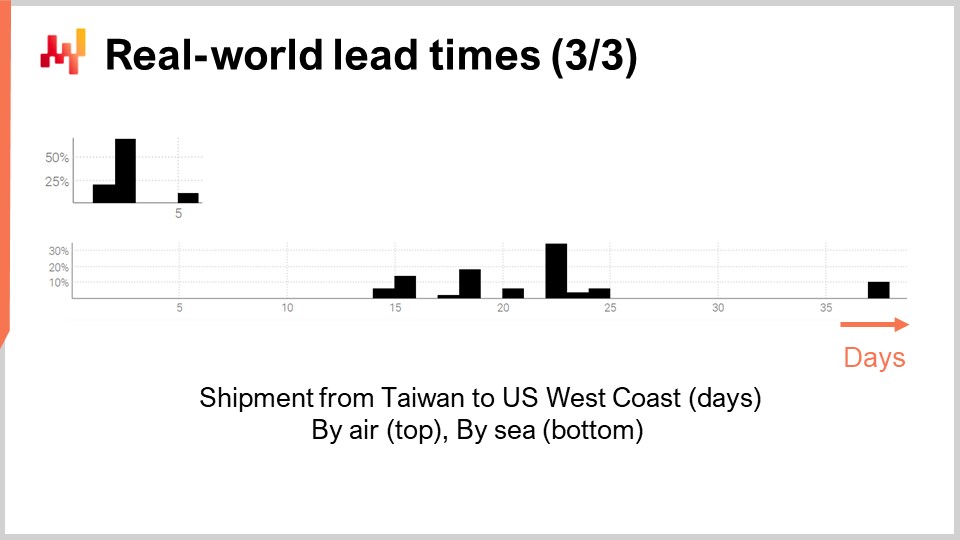
Infine, diamo un’occhiata a due tempi di consegna che riflettono i ritardi di spedizione da Taiwan alla costa occidentale degli Stati Uniti, sia via aerea che via mare. Non sorprende che gli aerei cargo siano più veloci delle navi cargo. La seconda distribuzione sembra suggerire che a volte una spedizione via mare potrebbe perdere la nave originale e quindi essere spedita con la nave successiva, quasi raddoppiando il ritardo. Lo stesso identico fenomeno potrebbe essere in gioco anche con la spedizione via aerea, anche se i dati sono così limitati che è solo un’ipotesi. Sottolineiamo che avere accesso a solo un paio di osservazioni non è fuori dal comune per quanto riguarda i tempi di consegna. Queste situazioni sono frequenti. È importante tenere presente che in questa lezione stiamo cercando strumenti e strumenti che ci permettano di lavorare con i dati dei tempi di consegna che abbiamo, fino a un pugno di osservazioni, non i dati dei tempi di consegna che vorremmo avere, come migliaia di osservazioni. Anche le brevi interruzioni in entrambe le distribuzioni suggeriscono un pattern ciclico giorno della settimana in atto, anche se la presente visualizzazione dell’istogramma non è appropriata per convalidare questa ipotesi.
Da questa breve panoramica dei tempi di consegna del mondo reale, possiamo già comprendere alcuni dei fenomeni sottostanti che sono in gioco. Infatti, i tempi di consegna sono altamente strutturati; i ritardi non accadono senza motivo e tali cause possono essere identificate, scomposte e quantificate. Tuttavia, i dettagli della scomposizione dei tempi di consegna spesso non vengono registrati nei sistemi informatici, almeno non ancora. Anche quando è disponibile una scomposizione estesa del tempo di consegna osservato, come potrebbe essere il caso in determinati settori come l’aviazione, ciò non implica che i tempi di consegna possano essere perfettamente anticipati. Sotto-segmenti o fasi all’interno del tempo di consegna sono probabilmente soggetti alla loro stessa incertezza irriducibile.
Questa serie di lezioni sulla supply chain presenta le mie opinioni e intuizioni sia sullo studio che sulla pratica della supply chain. Sto cercando di mantenere queste lezioni in qualche modo indipendenti, ma hanno più senso quando vengono seguite in sequenza. Il resto di questa lezione dipende dagli elementi che sono stati precedentemente introdotti in questa serie, anche se fornirò un ripasso tra un minuto.
Il primo capitolo è una introduzione generale al campo e allo studio della supply chain. Esso chiarisce la prospettiva che viene adottata in questa serie di lezioni. Come avrete già intuito, questa prospettiva si discosta notevolmente da quella che potrebbe essere considerata la prospettiva dominante sulla supply chain.
Il secondo capitolo introduce una serie di metodologie. Infatti, la supply chain sconfigge le metodologie naive. Le supply chain sono composte da persone che hanno le proprie agende; non esiste una parte neutrale nella supply chain. Questo capitolo affronta tali complicazioni, inclusi i miei stessi conflitti di interesse come CEO di Lokad, un’azienda di software aziendale specializzata nell’ottimizzazione predittiva della supply chain.
Il terzo capitolo presenta una serie di “personae” della supply chain. Queste personae sono aziende immaginarie che abbiamo brevemente esaminato oggi e sono destinate a rappresentare archetipi di situazioni di supply chain. Lo scopo di queste personae è concentrarsi esclusivamente sui problemi, rimandando la presentazione delle soluzioni.
Il quarto capitolo esamina le scienze ausiliarie della supply chain. Queste scienze non riguardano direttamente la supply chain, ma dovrebbero essere considerate essenziali per una pratica moderna della supply chain. Questo capitolo include una progressione attraverso i livelli di astrazione, a partire dall’hardware informatico fino alle preoccupazioni per la sicurezza informatica.
Il quinto e attuale capitolo è dedicato alla modellazione predittiva. La modellazione predittiva è una prospettiva più generale rispetto alla previsione; non riguarda solo la previsione della domanda. Si tratta della progettazione di modelli che possono essere utilizzati per stimare e quantificare i futuri fattori della supply chain di interesse. Oggi, ci addentriamo nei tempi di consegna, ma in generale nella supply chain, tutto ciò che non è noto con un grado di certezza ragionevole merita una previsione.
Il sesto capitolo spiega come prendere decisioni ottimizzate sfruttando modelli predittivi e, più specificamente, modelli probabilistici che sono stati introdotti nel quinto capitolo. Il settimo capitolo torna a una prospettiva in gran parte non tecnica per discutere l’effettiva esecuzione aziendale di un’iniziativa di supply chain quantitativa.

Oggi, ci concentriamo sui tempi di consegna. Abbiamo appena visto perché i tempi di consegna sono importanti e abbiamo appena esaminato una breve serie di tempi di consegna reali. Pertanto, procederemo con gli elementi della modellazione dei tempi di consegna. Poiché adotterò una prospettiva probabilistica, reintrodurrò brevemente il Continuous Rank Probability Score (CRPS), una metrica per valutare la bontà di una previsione probabilistica. Introdurrò anche la cross-validation e una variante della cross-validation adatta alla nostra prospettiva probabilistica. Con queste strumentazioni a disposizione, introdurremo e valuteremo il nostro primo modello probabilistico non ingenuo per i tempi di consegna. I dati dei tempi di consegna sono scarsi e il primo punto all’ordine del giorno è l’elaborazione di queste distribuzioni. I tempi di consegna possono essere decomposti in una serie di fasi intermedie. Pertanto, assumendo che siano disponibili alcuni dati dei tempi di consegna decomposti, abbiamo bisogno di qualcosa per ricomporre questi tempi di consegna preservando l’aspetto probabilistico.
Successivamente, reintrodurremo la programmazione differenziabile. La programmazione differenziabile è già stata utilizzata in questa serie di lezioni per prevedere la domanda, ma può essere utilizzata anche per prevedere i tempi di consegna. Lo faremo, partendo da un semplice esempio volto a catturare l’impatto del Capodanno cinese sui tempi di consegna, un tipico pattern osservato nell’importazione di merci dall’Asia.
Procederemo quindi con un modello probabilistico parametrico per i tempi di consegna, sfruttando la distribuzione log-logistica. Ancora una volta, la programmazione differenziabile sarà fondamentale per apprendere i parametri del modello. Estenderemo poi questo modello considerando osservazioni incomplete dei tempi di consegna. Infatti, anche gli ordini di acquisto non ancora completati ci forniscono informazioni sui tempi di consegna.
Infine, uniremo una previsione probabilistica dei tempi di consegna e una previsione probabilistica della domanda in una singola situazione di riapprovvigionamento dell’inventario. Questa sarà l’occasione per dimostrare perché la modularità è una preoccupazione essenziale quando si tratta di modellazione predittiva, più importante persino dei dettagli dei modelli stessi.

Nella Lezione 5.2 sulla previsione probabilistica, abbiamo già introdotto alcuni strumenti per valutare la qualità di una previsione probabilistica. Infatti, le usuali metriche di accuratezza come l’errore quadratico medio o l’errore assoluto medio si applicano solo alle previsioni puntuali, non alle previsioni probabilistiche. Tuttavia, non è perché le nostre previsioni diventano probabilistiche che l’accuratezza nel senso generale diventa irrilevante. Abbiamo solo bisogno di uno strumento statistico che si adatti alla prospettiva probabilistica.
Tra questi strumenti, c’è il Continuous Rank Probability Score (CRPS). La formula è riportata sullo schermo. Il CRPS è una generalizzazione della metrica L1, cioè l’errore assoluto, ma per le distribuzioni di probabilità. Il CRPS di solito confronta una distribuzione, chiamata F qui, con un’osservazione, chiamata X qui. Il valore ottenuto dalla funzione CRPS è omogeneo all’osservazione. Ad esempio, se X è un tempo di consegna espresso in giorni, anche il valore CRPS è espresso in giorni.

Il CRPS può essere generalizzato per il confronto di due distribuzioni. Questo è ciò che viene fatto sullo schermo. È solo una piccola variazione della formula precedente. L’essenza di questa metrica rimane invariata. Se F è la vera distribuzione dei tempi di consegna e F_hat è una stima della distribuzione dei tempi di consegna, allora il CRPS è espresso in giorni. Il CRPS riflette la quantità di differenza tra le due distribuzioni. Il CRPS può anche essere interpretato come la quantità minima di energia necessaria per trasportare tutta la massa dalla prima distribuzione in modo che assuma la forma esatta della seconda distribuzione.
Ora abbiamo uno strumento per confrontare due distribuzioni di probabilità unidimensionali. Questo diventerà interessante tra un minuto quando introdurremo il nostro primo modello probabilistico per i tempi di consegna.
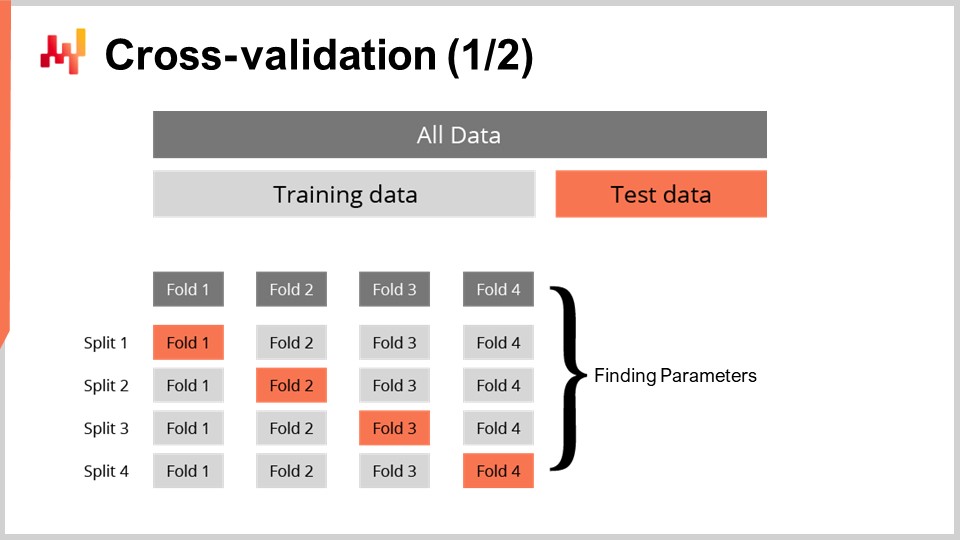
Avere una metrica per misurare la bontà di una previsione probabilistica non è sufficiente. La metrica misura la bontà sui dati che abbiamo; tuttavia, ciò che vogliamo veramente è essere in grado di valutare la bontà della nostra previsione sui dati che non abbiamo. Infatti, sono i tempi di consegna futuri che ci interessano, non i tempi di consegna che sono già stati osservati in passato. La nostra capacità di modellare affinché un modello si comporti bene sui dati che non abbiamo è chiamata generalizzazione. La cross-validazione è una tecnica generale di convalida del modello intesa appositamente per valutare la capacità di un modello di generalizzare bene.
Nella sua forma più semplice, la cross-validazione consiste nel suddividere le osservazioni in un piccolo numero di sottoinsiemi. Per ogni iterazione, un sottoinsieme viene messo da parte e chiamato sottoinsieme di test. Il modello viene quindi generato o addestrato in base agli altri sottoinsiemi di dati, chiamati sottoinsiemi di addestramento. Dopo l’addestramento, il modello viene convalidato rispetto al sottoinsieme di test. Questo processo viene ripetuto un certo numero di volte e la bontà media ottenuta su tutte le iterazioni rappresenta il risultato finale della cross-validazione.
La cross-validazione viene raramente utilizzata nel contesto della previsione delle serie temporali a causa della dipendenza temporale tra le osservazioni. Infatti, la cross-validazione, come appena presentata, assume che le osservazioni siano indipendenti. Quando sono coinvolte serie temporali, viene utilizzato il backtesting. Il backtesting può essere visto come una forma di cross-validazione che tiene conto della dipendenza temporale.
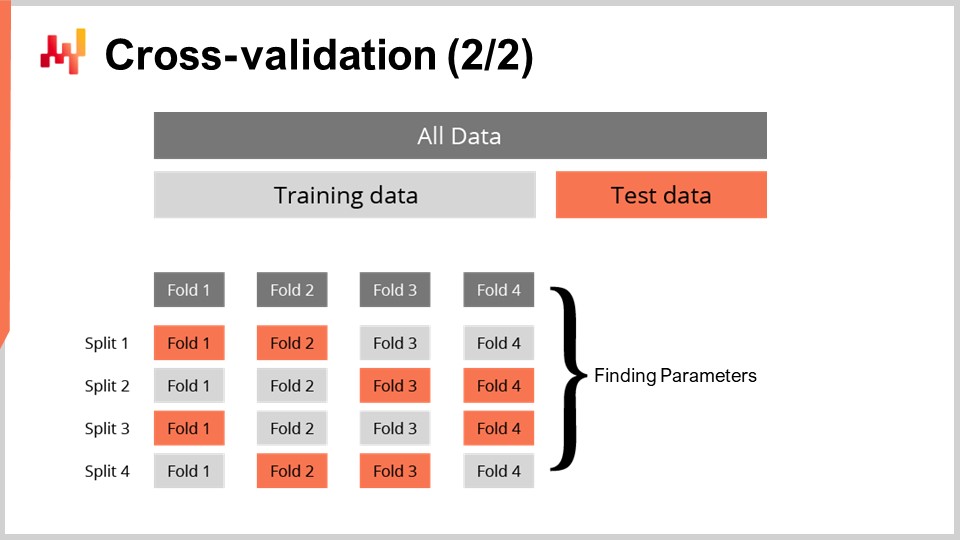
La tecnica della cross-validazione presenta numerose varianti che riflettono una vasta gamma di angolazioni potenziali che potrebbero dover essere affrontate. Non esamineremo queste varianti allo scopo di questa lezione. Userò una variante specifica in cui, ad ogni divisione, il sottoinsieme di addestramento e il sottoinsieme di test hanno approssimativamente la stessa dimensione. Questa variante è introdotta per affrontare la convalida di un modello probabilistico, come vedremo con del codice tra un minuto.
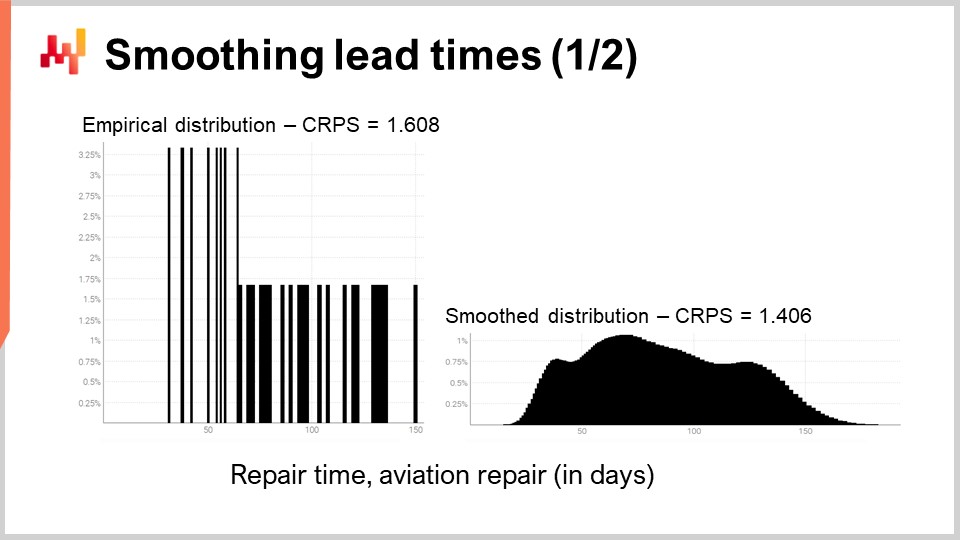
Rivisitiamo uno dei tempi di consegna del mondo reale che abbiamo visto in precedenza sullo schermo. A sinistra, l’istogramma è associato alle terze distribuzioni dei tempi di riparazione dell’aviazione. Queste sono le stesse osservazioni viste in precedenza e l’istogramma è stato semplicemente allungato verticalmente. In questo modo, i due istogrammi a sinistra e a destra condividono la stessa scala. Per l’istogramma di sinistra, abbiamo circa 30 osservazioni. Non è molto, ma è già più di quanto otterremo frequentemente.
L’istogramma a sinistra è definito come una distribuzione empirica. È letteralmente l’istogramma grezzo ottenuto dalle osservazioni. L’istogramma ha un bucket per ogni durata espressa in un numero intero di giorni. Per ogni bucket, contiamo il numero di tempi di consegna osservati. A causa della scarsità, la distribuzione empirica assomiglia a un codice a barre.
C’è un problema qui. Se abbiamo due tempi di consegna osservati esattamente di 50 giorni, ha senso dire che la probabilità di osservare 49 giorni o 51 giorni è esattamente zero? Non lo è. Chiaramente, c’è uno spettro di durate in corso; semplicemente non abbiamo abbastanza punti dati per osservare la vera distribuzione sottostante, che è molto probabilmente molto più regolare di questa distribuzione a forma di codice a barre.
Pertanto, quando si tratta di appianare questa distribuzione, esiste un numero indefinito di modi per eseguire questa operazione di appianamento. Alcuni metodi di appianamento potrebbero sembrare buoni ma non sono statisticamente validi. Come punto di partenza, vorremmo assicurarci che un modello liscio sia più accurato di quello empirico. Si scopre che abbiamo già introdotto due strumenti, il CRPS e la cross-validazione, che ci permetteranno di farlo.
Tra un minuto, i risultati saranno visualizzati. L’errore CRPS associato alla distribuzione a codice a barre è di 1,6 giorni, mentre l’errore CRPS associato alla distribuzione liscia è di 1,4 giorni. Queste due cifre sono state ottenute tramite la cross-validazione. L’errore inferiore indica che, nel senso del CRPS, la distribuzione a destra è quella più accurata delle due. La differenza di 0,2 tra 1,4 e 1,6 non è così grande; tuttavia, la proprietà chiave qui è che abbiamo una distribuzione liscia che non lascia in modo erratico alcune durate intermedie con una probabilità zero. Questo è ragionevole, poiché la nostra comprensione delle riparazioni ci dice che quelle durate molto probabilmente si verificheranno se le riparazioni vengono ripetute. Il CRPS non riflette la vera profondità del miglioramento che abbiamo appena apportato appianando la distribuzione. Tuttavia, almeno abbassando il CRPS, confermiamo che questa trasformazione è ragionevole da un punto di vista statistico.
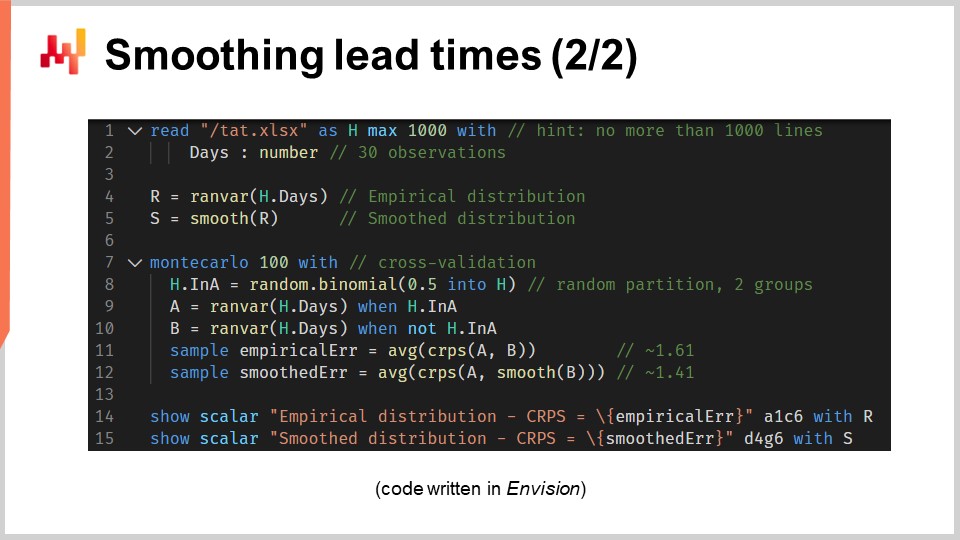
Ora diamo un’occhiata al codice sorgente che ha prodotto questi due modelli e ha mostrato questi due istogrammi. Tutto sommato, ciò viene realizzato in 12 righe di codice se escludiamo le righe vuote. Come al solito in questa serie di lezioni, il codice è scritto in Envision, il linguaggio di programmazione specifico del dominio di Lokad dedicato all’ottimizzazione predittiva delle supply chain. Tuttavia, non c’è magia; questa logica potrebbe essere stata scritta in Python. Ma per il tipo di problemi che stiamo considerando in questa lezione, Envision è più conciso e più autonomo.
Rivediamo queste 12 righe di codice. Alle righe 1 e 2, stiamo leggendo un foglio di calcolo Excel che ha una singola colonna di dati. Il foglio di calcolo contiene 30 osservazioni. Questi dati vengono raccolti all’interno di una tabella chiamata “H” che ha una singola colonna chiamata “days”. Alla riga 4, stiamo costruendo una distribuzione empirica. La variabile “R” ha il tipo di dati “ranvar” e sul lato destro dell’assegnazione, la funzione “ranvar” è un aggregatore che prende in input le osservazioni e restituisce l’istogramma rappresentato con un tipo di dati “ranvar”. Di conseguenza, il tipo di dati “ranvar” è dedicato alle distribuzioni unidimensionali di interi. Abbiamo introdotto il tipo di dati “ranvar” in una lezione precedente di questo capitolo. Questo tipo di dati garantisce una memoria costante e un tempo di calcolo costante per ogni operazione. Lo svantaggio del tipo di dati “ranvar” è che è coinvolta una compressione con perdita, anche se la perdita di dati causata dalla compressione è stata progettata per essere trascurabile per scopi di supply chain.
Alla riga 5, stiamo levigando la distribuzione con la funzione integrata chiamata “smooth”. Sotto il cofano, questa funzione sostituisce la distribuzione originale con una miscela di distribuzioni di Poisson. Ogni bucket dell’istogramma viene trasformato in una distribuzione di Poisson con una media uguale alla posizione intera del bucket e infine, la miscela assegna un peso a ciascuna distribuzione di Poisson proporzionale al peso del bucket stesso. Un altro modo per capire cosa fa questa funzione “smooth” è considerare che è equivalente a sostituire ogni singola osservazione con una distribuzione di Poisson con una media uguale all’osservazione stessa. Tutte queste distribuzioni di Poisson, una per osservazione, vengono quindi mescolate. Mescolare significa mediare i rispettivi valori dei bucket dell’istogramma. Le variabili “ranvar” “R” e “S” non verranno utilizzate nuovamente prima delle righe 14 e 15, dove vengono visualizzate.
Alla riga 7, iniziamo un blocco Monte Carlo. Questo blocco è una sorta di ciclo e verrà eseguito 100 volte, come specificato dai 100 valori che appaiono subito dopo la parola chiave Monte Carlo. Il blocco Monte Carlo è destinato a raccogliere osservazioni indipendenti che vengono generate secondo un processo che coinvolge un grado di casualità. Potresti chiederti perché c’è un costrutto Monte Carlo specifico in Envision invece di avere semplicemente un ciclo, come di solito accade con i linguaggi di programmazione mainstream. Si scopre che avere un costrutto dedicato offre notevoli vantaggi. In primo luogo, garantisce che le iterazioni siano veramente indipendenti, fino ai semi utilizzati per derivare la pseudocasualità. In secondo luogo, offre un obiettivo esplicito per la distribuzione automatizzata del carico di lavoro su diversi core della CPU o addirittura su diverse macchine.
Alla riga 8, creiamo un vettore casuale di valori booleani all’interno della tabella “H”. Con questa riga, stiamo creando valori casuali indipendenti, chiamati deviates (vero o falso), per ogni riga della tabella “H”. Come al solito con Envision, i cicli sono astratti attraverso la programmazione ad array. Con questi valori booleani, stiamo suddividendo la tabella “H” in due gruppi. Questa divisione casuale viene utilizzata per il processo di cross-validation.
Alle righe 9 e 10, stiamo creando due “ranvars” chiamati “A” e “B”, rispettivamente. Stiamo utilizzando nuovamente l’aggregatore “ranvar”, ma questa volta stiamo applicando un filtro con la parola chiave “when” subito dopo la chiamata all’aggregatore. “A” viene generato utilizzando solo le righe in cui il valore in “a” è vero; per “B”, è il contrario. “B” viene generato utilizzando solo le righe in cui il valore in “a” è falso.
Alle righe 11 e 12, raccogliamo le figure di interesse dal blocco Monte Carlo. In Envision, la parola chiave “sample” può essere inserita solo all’interno di un blocco Monte Carlo. Viene utilizzata per raccogliere le osservazioni effettuate durante l’iterazione molte volte attraverso il processo Monte Carlo. Alla riga 11, stiamo calcolando l’errore medio, espresso in termini di CRPS, tra due distribuzioni empiriche: un sottoinsieme dal set originale di tempi di lead. La parola chiave “sample” specifica che i valori vengono raccolti durante le iterazioni del processo Monte Carlo. L’aggregatore “AVG”, che sta per “average” sul lato destro dell’assegnazione, viene utilizzato per produrre una singola stima alla fine del blocco.
Alla riga 12, facciamo qualcosa di quasi identico a quanto accaduto alla riga 11. Questa volta, però, applichiamo la funzione “smooth” al “ranvar” “B”. Vogliamo valutare quanto sia vicina la variante liscia rispetto alla distribuzione empirica ingenua. Risulta che sia più vicina, almeno in termini di CRPS, rispetto alle sue controparti empiriche originali.
Alle righe 14 e 15, mettiamo in mostra gli istogrammi e i valori CRPS. Queste righe generano le figure che abbiamo visto nella diapositiva precedente. Questo script ci fornisce la nostra base per la qualità della distribuzione empirica del nostro modello. Infatti, mentre questo modello, quello “barcode”, è indubbiamente ingenuo, è comunque un modello, e un modello probabilistico. Pertanto, questo script ci fornisce anche un modello migliore, almeno dal punto di vista del CRPS, attraverso una variante liscia della distribuzione empirica originale.
Al momento, a seconda della vostra familiarità con i linguaggi di programmazione, potrebbe sembrare molto da digerire. Tuttavia, vorrei sottolineare quanto sia semplice produrre una distribuzione di probabilità ragionevole, anche quando non abbiamo più di qualche osservazione. Mentre abbiamo 12 righe di codice, solo le righe 4 e 5 rappresentano la vera parte di modellazione dell’esercizio. Se fossimo interessati solo alla variante liscia, allora il “ranvar” “S” potrebbe essere scritto con una sola riga di codice. Quindi, è letteralmente una riga di codice: prima, applicare un’aggregazione ranvar, e secondo, applicare un operatore liscio, e abbiamo finito. Il resto è solo strumentazione e visualizzazione. Con gli strumenti adeguati, la modellazione probabilistica, che si tratti di tempi di lead o altro, può essere resa estremamente semplice. Non ci sono grandi matematiche coinvolte, né grandi algoritmi, né grandi pezzi di software. È semplice e notevolmente così.

Come si fa ad avere una spedizione in ritardo di sei mesi? La risposta è ovvia: un giorno alla volta. Più seriamente, i tempi di lead possono di solito essere decomposti in una serie di ritardi. Ad esempio, un tempo di lead del fornitore può essere decomposto in un ritardo di attesa mentre l’ordine viene inserito in una coda di backlog, seguito da un ritardo di produzione mentre le merci vengono prodotte, e infine seguito da un ritardo di trasporto mentre le merci vengono spedite. Pertanto, se i tempi di lead possono essere decomposti, è anche interessante essere in grado di ricomporli.
Se vivessimo in un mondo altamente deterministico in cui il futuro potesse essere previsto con precisione, ricomporre i tempi di lead sarebbe solo una questione di somma. Tornando all’esempio appena menzionato, la composizione del tempo di lead dell’ordine sarebbe la somma del ritardo di attesa in giorni, del ritardo di produzione in giorni e del ritardo di trasporto in giorni. Tuttavia, non viviamo in un mondo in cui il futuro può essere previsto con precisione. Le distribuzioni dei tempi di lead del mondo reale che abbiamo presentato all’inizio di questa lezione supportano questa proposizione. I tempi di lead sono erratici e c’è poco motivo per credere che ciò cambierà fondamentalmente nei prossimi decenni.
Pertanto, i tempi di lead futuri dovrebbero essere affrontati come variabili casuali. Queste variabili casuali abbracciano e quantificano l’incertezza anziché respingerla. Più specificamente, ciò significa che ogni componente del tempo di lead dovrebbe essere modellata individualmente come una variabile casuale. Tornando al nostro esempio, il tempo di lead dell’ordine è una variabile casuale e viene ottenuto come somma di tre variabili casuali associate rispettivamente al ritardo di attesa in coda, al ritardo di produzione e al ritardo di trasporto.
La formula per la somma di due variabili casuali indipendenti, unidimensionali e a valori interi viene presentata sullo schermo. Questa formula afferma semplicemente che se otteniamo una durata totale di Z giorni e se abbiamo K giorni per la prima variabile casuale X, allora dobbiamo avere Z meno K giorni per la seconda variabile casuale Y. Questo tipo di somma è conosciuto, in generale, in matematica come convoluzione.
Sebbene sembri che ci sia un numero infinito di termini in questa convoluzione, nella pratica ci interessano solo un numero finito di termini. In primo luogo, tutte le durate negative hanno una probabilità zero; infatti, ritardi negativi significherebbero viaggiare indietro nel tempo. In secondo luogo, per ritardi elevati, le probabilità diventano così piccole che per scopi pratici della supply chain, possono essere affidabilmente approssimate a zero.
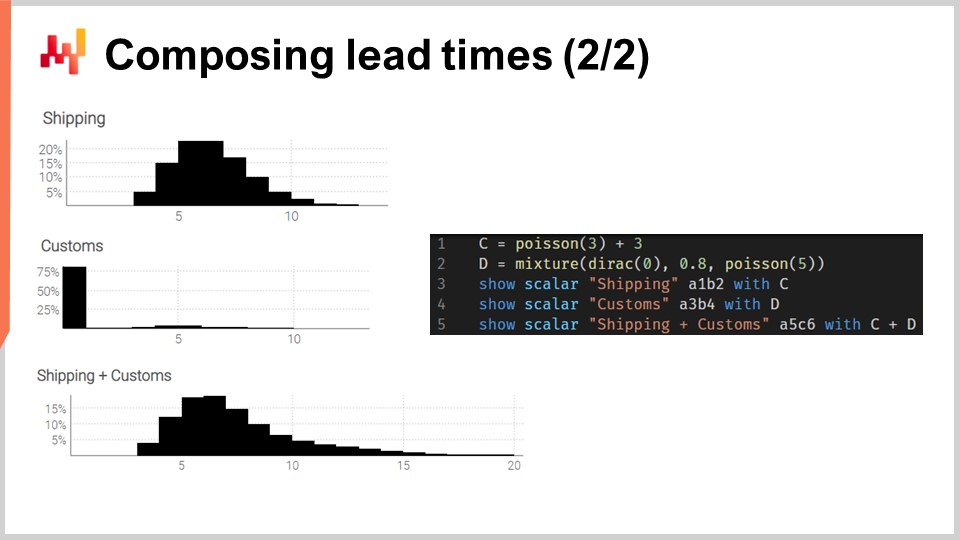
Mettiamo in pratica queste convoluzioni. Consideriamo un tempo di transito che può essere decomposto in due fasi: un ritardo di spedizione seguito da un ritardo di sdoganamento. Vogliamo modellare queste due fasi con due variabili casuali indipendenti e quindi ricomporre il tempo di transito aggiungendo queste due variabili casuali.
Sullo schermo, gli istogrammi a sinistra sono prodotti dallo script a destra. Alla riga 1, il ritardo di spedizione è modellato come una convoluzione di una distribuzione di Poisson più una costante. La funzione di Poisson restituisce un tipo di dato “ranvar”; l’aggiunta di tre ha l’effetto di spostare la distribuzione verso destra. Il “ranvar” risultante viene assegnato alla variabile “C”. Questo “ranvar” viene visualizzato alla riga 3. Può essere visto a sinistra come l’istogramma più in alto. Riconosciamo la forma di una distribuzione di Poisson che è stata spostata verso destra di alcune unità, tre unità in questo caso. Alla riga due, lo sdoganamento viene modellato come una miscela di una Dirac a zero e una Poisson a cinque. La Dirac a zero si verifica l’ottanta percento delle volte; questo è ciò che significa la costante 0.8. Riflette situazioni in cui nella maggior parte dei casi, le merci non vengono nemmeno ispezionate dalla dogana e passano senza alcun ritardo significativo. In alternativa, il venti percento delle volte, le merci vengono ispezionate in dogana e il ritardo viene modellato come una distribuzione di Poisson con una media di cinque. Il “ranvar” risultante viene assegnato a una variabile chiamata D. Questo “ranvar” viene visualizzato alla riga quattro e può essere visto a sinistra come l’istogramma centrale. Questo aspetto asimmetrico riflette che nella maggior parte dei casi, la dogana non aggiunge alcun ritardo.
Infine, alla riga cinque, calcoliamo C più D. Questa somma è una convoluzione, poiché sia C che D sono ranvars, non numeri. Questa è la seconda convoluzione in questo script, poiché una convoluzione è già avvenuta alla riga uno. Il “ranvar” risultante viene visualizzato ed è visibile a sinistra come il terzo e più basso istogramma. Questo terzo istogramma è simile al primo, tranne che la coda si estende molto più a destra. Ancora una volta, vediamo che con poche righe di codice, possiamo affrontare effetti del mondo reale non banali, come i ritardi di sdoganamento.
Tuttavia, si potrebbero fare due critiche a questo esempio. In primo luogo, non dice da dove provengono le costanti; nella pratica, vogliamo apprendere quelle costanti dai dati storici. In secondo luogo, sebbene la distribuzione di Poisson abbia il vantaggio della semplicità, potrebbe non essere una forma molto realistica per la modellazione dei tempi di lead, soprattutto considerando situazioni con code grasse. Pertanto, affronteremo questi due punti in ordine.
Per apprendere i parametri dai dati, rivedremo un paradigma di programmazione che abbiamo già introdotto in questa serie di lezioni, ovvero la programmazione differenziabile. Se non hai ancora guardato le lezioni precedenti di questo capitolo, ti invito a darci un’occhiata dopo la fine della presente lezione. La programmazione differenziabile è introdotta in maggior dettaglio in quelle lezioni.
La programmazione differenziabile è una combinazione di due tecniche: la discesa del gradiente stocastico e la differenziazione automatica. La discesa del gradiente stocastico è una tecnica di ottimizzazione che sposta i parametri un’osservazione alla volta nella direzione opposta dei gradienti. La differenziazione automatica è una tecnica di compilazione, come nel compilatore di un linguaggio di programmazione; calcola i gradienti per tutti i parametri che compaiono all’interno di un programma generale.
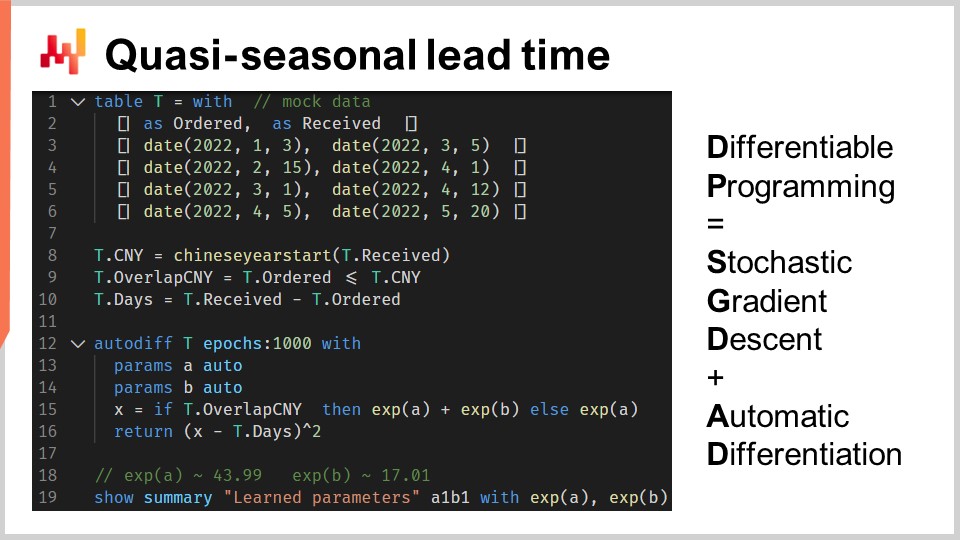
Illustreremo la programmazione differenziabile con un problema di tempi di lead. Questo servirà sia come ripasso che come introduzione, a seconda della tua familiarità con questo paradigma. Vogliamo modellare l’impatto del Capodanno cinese sui tempi di lead associati alle importazioni dalla Cina. Infatti, poiché le fabbriche chiudono per due o tre settimane per il Capodanno cinese, i tempi di lead si allungano. Il Capodanno cinese è ciclico; accade ogni anno. Tuttavia, non è strettamente stagionale, almeno non nel senso del calendario gregoriano.
Alle righe da uno a sei, stiamo introducendo alcuni ordini di acquisto di prova con quattro osservazioni, con sia una data di ordine che una data di ricezione. Nella pratica, questi dati non sarebbero codificati direttamente, ma caricheremmo questi dati storici dai sistemi dell’azienda. Alle righe otto e nove, calcoliamo se il tempo di lead si sovrappone al Capodanno cinese. La variabile “T.overlap_CNY” è un vettore booleano; indica se l’osservazione è influenzata dal Capodanno cinese o meno.
Alla riga 12, introduciamo un blocco “autodiff”. La tabella T viene utilizzata come tabella di osservazione e ci sono 1000 epoche. Ciò significa che ogni osservazione, quindi ogni riga nella tabella T, verrà visitata mille volte. Un passo della discesa del gradiente stocastico corrisponde a un’esecuzione della logica all’interno del blocco “autodiff”.
Alle righe 13 e 14, vengono dichiarati due parametri scalari. Il blocco “autodiff” imparerà questi parametri. Il parametro A riflette il tempo di lead di base senza l’effetto del Capodanno cinese, e il parametro B riflette il ritardo extra associato al Capodanno cinese. Alla riga 15, calcoliamo X, la previsione del tempo di lead del nostro modello. Questo è un modello deterministico, non probabilistico; X è una previsione del tempo di lead puntuale. Il lato destro dell’assegnazione è semplice: se l’osservazione si sovrappone al Capodanno cinese, restituiamo la base più il componente del Capodanno; altrimenti, restituiamo solo la base. Poiché il blocco “autodiff” prende in considerazione solo una singola osservazione alla volta, alla riga 15, la variabile T.overlap_CNY si riferisce a un valore scalare e non a un vettore. Questo valore corrisponde alla riga scelta come linea di osservazione all’interno della tabella T.
I parametri A e B sono avvolti nella funzione esponenziale “exp”, che è un piccolo trucco di programmazione differenziabile. Infatti, l’algoritmo che pilota la discesa del gradiente stocastico tende ad essere relativamente conservativo quando si tratta delle variazioni incrementali dei parametri. Pertanto, se vogliamo apprendere un parametro positivo che può crescere oltre, ad esempio, 10, avvolgere questo parametro in un processo esponenziale accelera la convergenza.
Alla riga 16, restituiamo un errore quadratico medio tra la nostra previsione X e la durata osservata, espressa in giorni (T.days). Di nuovo, all’interno di questo blocco “autodiff”, T.days è un valore scalare e non un vettore. Poiché la tabella T viene utilizzata come tabella di osservazione, il valore restituito viene trattato come la perdita che viene minimizzata attraverso la discesa del gradiente stocastico. La differenziazione automatica propaga i gradienti dalla perdita all’indietro ai parametri A e B. Infine, alla riga 19, visualizziamo i due valori che abbiamo appreso, rispettivamente, per A e B, che sono la linea di base e il componente dell’Anno Nuovo del nostro tempo di consegna.
Questo conclude la nostra reintroduzione della programmazione differenziabile come uno strumento versatile che apprende modelli statistici. Da qui, riprenderemo i blocchi “autodiff” con situazioni più elaborate. Tuttavia, sottolineiamo ancora una volta che anche se potrebbe sembrare un po’ schiacciante, qui non sta succedendo nulla di veramente complicato. Si potrebbe sostenere che il pezzo di codice più complicato in questo script sia l’implementazione sottostante della funzione “ChineseYearStart”, chiamata alla riga otto, che fa parte della libreria standard di Envision. In poche righe di codice, introduciamo un modello con due parametri e apprendiamo quei parametri. Ancora una volta, questa semplicità è notevole.
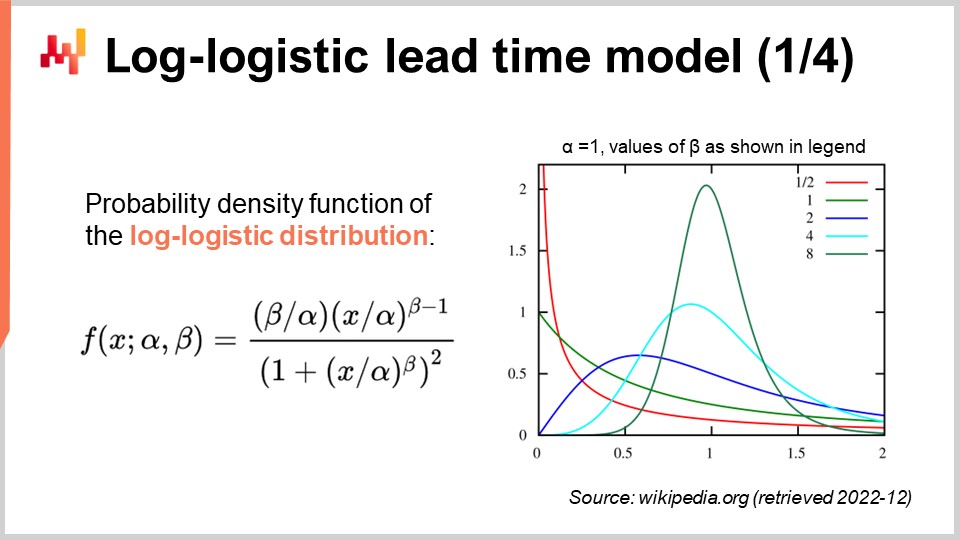
I tempi di consegna sono spesso a coda grassa; cioè, quando un tempo di consegna si discosta, si discosta molto. Pertanto, al fine di modellare il tempo di consegna, è interessante adottare distribuzioni che possono riprodurre questi comportamenti a coda grassa. La letteratura matematica presenta un elenco esteso di tali distribuzioni e molte di esse sarebbero adatte al nostro scopo. Tuttavia, limitarsi a esplorare il panorama matematico richiederebbe ore. Sottolineiamo solo che la distribuzione di Poisson non ha una coda grassa. Pertanto, oggi, sceglierò la distribuzione log-logistica, che si rivela essere una distribuzione a coda grassa. La giustificazione principale per questa scelta di distribuzione è che i team di Lokad stanno modellando i tempi di consegna attraverso distribuzioni log-logistiche per diversi clienti. Si sta rivelando efficace con un numero minimo di complicazioni. Tuttavia, teniamo presente che la distribuzione log-logistica non è affatto una soluzione miracolosa e ci sono numerose situazioni in cui Lokad modella i tempi di consegna in modo diverso.
Sullo schermo abbiamo la funzione di densità di probabilità della distribuzione log-logistica. Si tratta di una distribuzione parametrica che dipende da due parametri, alpha e beta. Il parametro alpha è la mediana della distribuzione e il parametro beta governa la forma della distribuzione. A destra, è possibile ottenere una breve serie di forme attraverso vari valori di beta. Sebbene questa formula di densità possa sembrare intimidatoria, è letteralmente materiale di testo, proprio come la formula per calcolare il volume di una sfera. Puoi cercare di decifrare e memorizzare questa formula, ma non è nemmeno necessario; devi solo sapere che esiste una formula analitica. Una volta che sai che la formula esiste, trovarla online richiede meno di un minuto.

Il nostro intento è sfruttare la distribuzione log-logistica per apprendere un modello di tempo di consegna probabilistico. Per fare ciò, andremo a minimizzare la log-verosimiglianza. Infatti, nella precedente lezione di questo quinto capitolo, abbiamo visto che ci sono diverse metriche appropriate dal punto di vista probabilistico. Poco fa, abbiamo ripreso il CRPS (Continuous Ranked Probability Score). Qui, riprendiamo la log-verosimiglianza, che adotta una prospettiva bayesiana.
In poche parole, dati due parametri, la distribuzione log-logistica ci dice la probabilità di osservare ogni osservazione come trovata nel dataset empirico. Vogliamo apprendere i parametri che massimizzano questa verosimiglianza. Il logaritmo, quindi la log-verosimiglianza anziché la semplice verosimiglianza, viene introdotto per evitare underflow numerici. Gli underflow numerici si verificano quando elaboriamo numeri molto piccoli, molto vicini a zero; quei numeri molto piccoli non si comportano bene con la rappresentazione in virgola mobile come comunemente si trova nell’hardware di calcolo moderno.
Pertanto, per calcolare la log-verosimiglianza della distribuzione log-logistica, applichiamo il logaritmo alla sua funzione di densità di probabilità. L’espressione analitica è riportata sullo schermo. Questa espressione può essere implementata, ed è esattamente ciò che viene fatto nelle tre righe di codice sottostanti.
Alla riga uno, viene introdotta la funzione “L4”. L4 sta per “log-verosimiglianza della log-logistica” - sì, ci sono molte L e molti log. Questa funzione prende tre argomenti: i due parametri alpha e beta, più l’osservazione x. Questa funzione restituisce il logaritmo della verosimiglianza. La funzione L4 è decorata con la parola chiave “autodiff”; la parola chiave indica che questa funzione è destinata a essere differenziata attraverso la differenziazione automatica. In altre parole, i gradienti possono fluire all’indietro dal valore di ritorno di questa funzione ai suoi argomenti, i parametri alpha e beta. Tecnicamente, il gradiente fluisce all’indietro anche attraverso l’osservazione x; tuttavia, poiché manterremo le osservazioni immutabili durante il processo di apprendimento, i gradienti non avranno alcun effetto sulle osservazioni. Alla riga tre, otteniamo la trascrizione letterale della formula matematica appena sopra lo script.
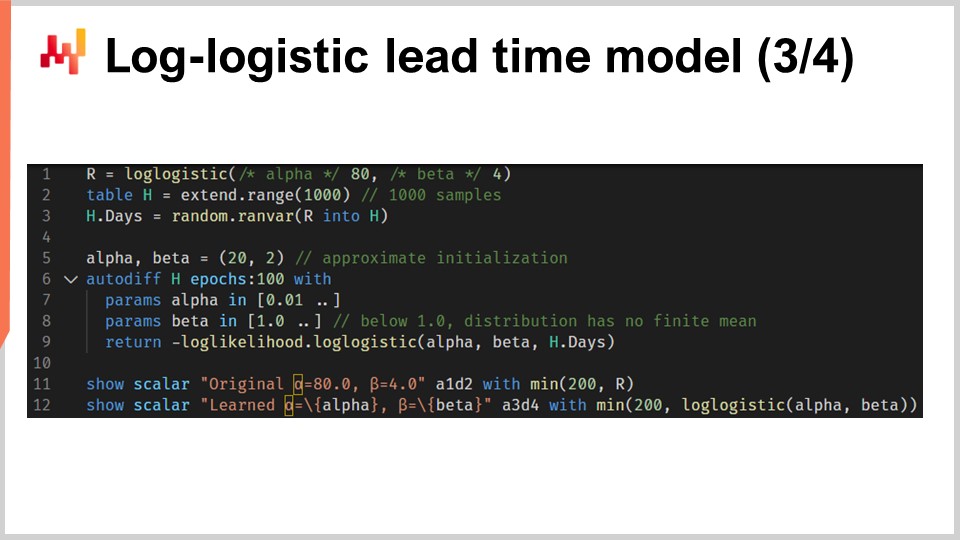
Mettiamo ora insieme le cose con uno script che apprende i parametri di un modello di tempo di consegna probabilistico basato sulla distribuzione log-logistica. Nelle righe uno e tre, generiamo il nostro dataset di addestramento fittizio. In contesti reali, useremmo dati storici invece di generare dati fittizi. Alla riga uno, creiamo un “ranvar” che rappresenta la distribuzione originale. Per esercizio, vogliamo apprendere nuovamente quei parametri, alpha e beta. La funzione log-logistica fa parte della libreria standard di Envision e restituisce un “ranvar”. Alla riga due, creiamo la tabella “H”, che contiene 1.000 voci. Alla riga tre, estraiamo 1.000 deviate che sono campionate casualmente dalla distribuzione originale “R”. Questo vettore “H.days” rappresenta il dataset di addestramento.
Alla riga sei, abbiamo un blocco “autodiff”; qui avviene l’apprendimento. Alle righe sette e otto, dichiariamo due parametri, alpha e beta, e al fine di evitare problemi numerici come la divisione per zero, vengono applicati dei limiti a quei parametri. Alpha deve rimanere maggiore di 0,01 e beta deve rimanere maggiore di 1,0. Alla riga nove, restituiamo la perdita, che è l’opposto della log-verosimiglianza. Infatti, per convenzione, i blocchi “autodiff” minimizzano la funzione di perdita, e quindi vogliamo massimizzare la verosimiglianza, da qui il segno meno. La funzione “log_likelihood.logistic” fa parte della libreria standard di Envision, ma sotto il cofano, è solo la funzione “L4” che abbiamo implementato nella slide precedente. Quindi, qui non c’è magia; è tutta differenziazione automatica che fa fluire il gradiente all’indietro dalla perdita ai parametri alpha e beta.
Alle righe 11 e 12, viene tracciata la distribuzione originale e la distribuzione appresa. Gli istogrammi sono limitati a 200; questo limite rende l’istogramma leggermente più leggibile. Torneremo su questo punto tra un attimo. Nel caso vi stiate chiedendo sulle prestazioni della parte “autodiff” di questo script, impiega meno di 80 millisecondi per eseguire su un singolo core della CPU. La programmazione differenziabile non è solo versatile; fa anche un buon uso delle risorse di calcolo fornite dall’hardware di calcolo moderno.
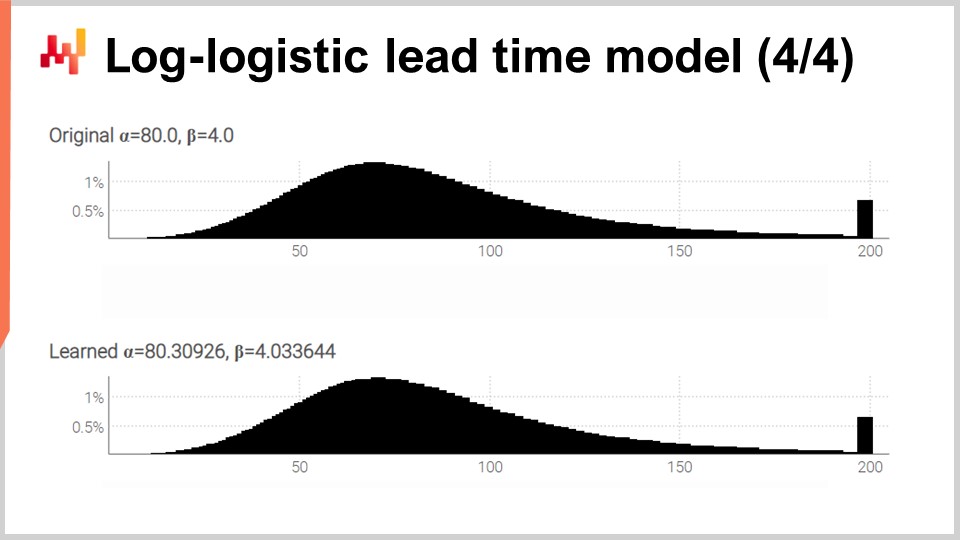
Sullo schermo abbiamo i due istogrammi prodotti dal nostro script che abbiamo appena esaminato. In alto, la distribuzione originale con i suoi due parametri originali, alpha e beta, rispettivamente a 80 e 4. In basso, la distribuzione appresa con due parametri appresi attraverso la programmazione differenziabile. Quei due picchi sulla destra sono associati alle code che abbiamo troncato, poiché quelle code si estendono abbastanza lontano. A proposito, anche se è raro, accade che certi beni vengano ricevuti più di un anno dopo essere stati ordinati. Questo non è il caso per ogni settore, certamente non per i latticini, ma per le parti meccaniche o l’elettronica, accade occasionalmente.
Sebbene il processo di apprendimento non sia esatto, otteniamo risultati entro l’uno percento dei valori dei parametri originali. Questo dimostra, almeno, che questa massimizzazione della log-verosimiglianza attraverso la programmazione differenziabile funziona nella pratica. La distribuzione log-logistica potrebbe essere appropriata o meno; dipende dalla forma della distribuzione dei tempi di consegna con cui ci si confronta. Tuttavia, possiamo praticamente scegliere qualsiasi altra distribuzione parametrica alternativa. Tutto ciò che serve è un’espressione analitica della funzione di densità di probabilità. Esiste una vasta gamma di tali distribuzioni. Una volta che si ha una formula di un libro di testo, una semplice implementazione attraverso la programmazione differenziabile di solito fa il resto.
I tempi di consegna non vengono osservati solo una volta che la transazione è conclusa. Mentre la transazione è ancora in corso, si sa già qualcosa; si ha già un’osservazione incompleta del tempo di consegna. Supponiamo che 100 giorni fa hai effettuato un ordine. Le merci non sono ancora state ricevute; tuttavia, si sa già che il tempo di consegna è di almeno 100 giorni. Questa durata di 100 giorni rappresenta il limite inferiore per un tempo di consegna che deve ancora essere osservato completamente. Questi tempi di consegna incompleti sono spesso molto importanti. Come ho detto all’inizio di questa lezione, i dataset dei tempi di consegna sono spesso sparsi. Non è raro avere un dataset che include solo mezza dozzina di osservazioni. In queste situazioni, è importante sfruttare al massimo ogni osservazione, comprese quelle ancora in corso.
Consideriamo il seguente esempio: abbiamo cinque ordini in totale. Tre ordini sono già stati consegnati con valori di tempo di consegna molto vicini a 30 giorni. Tuttavia, gli ultimi due ordini sono in sospeso da 40 giorni e 50 giorni, rispettivamente. Secondo le prime tre osservazioni, il tempo di consegna medio dovrebbe essere di circa 30 giorni. Tuttavia, gli ultimi due ordini che sono ancora incompleti smentiscono questa ipotesi. I due ordini in sospeso a 40 e 50 giorni fanno pensare a un tempo di consegna sostanzialmente più lungo. Pertanto, non dovremmo scartare gli ultimi ordini solo perché sono incompleti. Dovremmo sfruttare queste informazioni e aggiornare la nostra convinzione verso tempi di consegna più lunghi, magari 60 giorni.
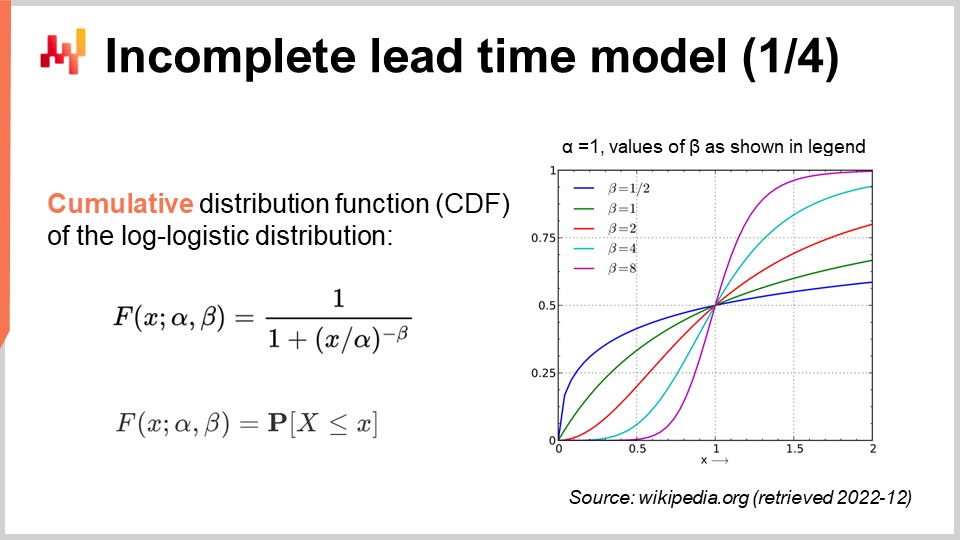
Riprendiamo il nostro modello di tempo di consegna probabilistico, ma questa volta teniamo conto delle osservazioni incomplete. In altre parole, vogliamo gestire osservazioni che a volte sono solo un limite inferiore per il tempo di consegna finale. Per fare ciò, possiamo utilizzare la funzione di distribuzione cumulativa (CDF) della distribuzione log-logistica. Questa formula è scritta sullo schermo; ancora una volta, si tratta di materiale di un libro di testo. La CDF della distribuzione log-logistica beneficia di una semplice espressione analitica. In seguito, farò riferimento a questa tecnica come “tecnica della probabilità condizionata” per gestire i dati censurati.

Basandoci su questa espressione analitica della CDF, possiamo riprendere la log-verosimiglianza della distribuzione log-logistica. Lo script sullo schermo fornisce un’implementazione rivista della nostra precedente implementazione alla riga 4. Alla riga uno, abbiamo praticamente la stessa dichiarazione di funzione. Questa funzione prende un quarto argomento extra, un valore booleano chiamato “is_incomplete” che indica, come suggerisce il nome, se l’osservazione è incompleta o no. Alle righe due e tre, se l’osservazione è completa, allora torniamo alla situazione precedente con la distribuzione log-logistica regolare. Quindi, chiamiamo la funzione di log-verosimiglianza che fa parte della libreria standard. Avrei potuto ripetere il codice della precedente implementazione alla riga 4, ma questa versione è più concisa. Alle righe quattro e cinque, esprimiamo la log-verosimiglianza di osservare alla fine un tempo di consegna maggiore dell’attuale osservazione incompleta, “X”. Questo viene ottenuto attraverso la CDF e, più precisamente, il logaritmo della CDF.
Possiamo ora ripetere la nostra configurazione con uno script che apprende i parametri della distribuzione log-logistica, ma questa volta in presenza di tempi di consegna incompleti. Lo script sullo schermo è quasi identico al precedente. Alle righe da uno a tre, generiamo i dati; queste righe non sono cambiate. Sottolineiamo che H.N è un vettore generato automaticamente che viene creato implicitamente alla riga due. Questo vettore numerizza le righe generate, a partire da uno. La versione precedente di questo script non utilizzava questo vettore generato automaticamente, ma attualmente, il vettore H.N appare alla fine della riga sei.
Le righe cinque e sei sono effettivamente quelle importanti. Qui, censuriamo i tempi di consegna. È come se facessimo un’osservazione del tempo di consegna al giorno e troncassimo le osservazioni troppo recenti per essere informate. Ciò significa, ad esempio, che un tempo di consegna di 20 giorni iniziato sette giorni fa appare come un tempo di consegna incompleto di sette giorni. Alla fine della riga sei, abbiamo generato un elenco di tempi di consegna in cui alcune delle osservazioni recenti (quelle che terminerebbero oltre la data attuale) sono incomplete. Il resto dello script è invariato, tranne alla riga 12, dove il vettore H.is_complete viene passato come quarto argomento della funzione di log-verosimiglianza. Quindi, stiamo chiamando, alla riga 12, la funzione di programmazione differenziabile che abbiamo appena introdotto un minuto fa.
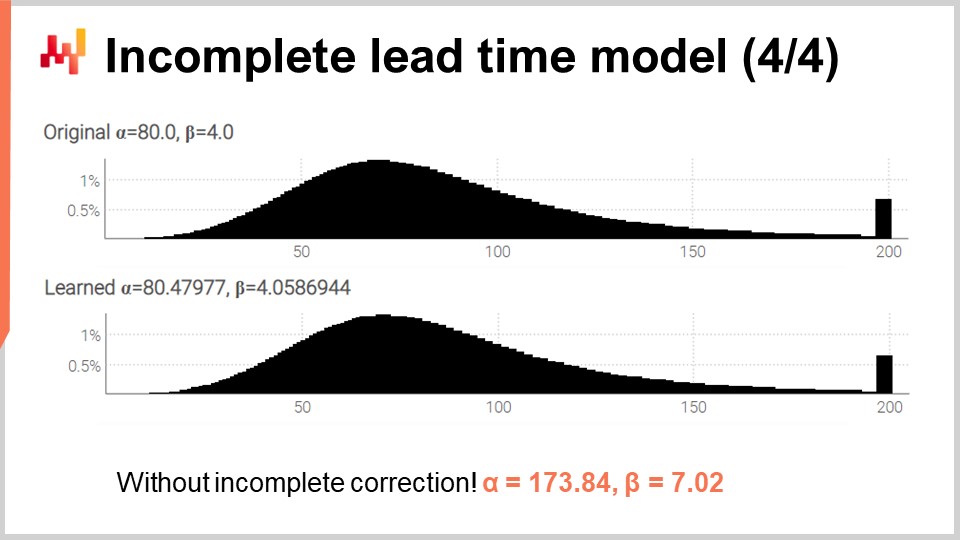
Infine, sullo schermo, i due istogrammi sono prodotti da questo script rivisto. I parametri sono ancora appresi con alta precisione, mentre ora siamo in presenza di numerosi tempi di consegna incompleti. Per convalidare che trattare con tempi incompleti non fosse una complicazione inutile, ho ri-eseguito lo script, ma questa volta con una variante modificata con il sovraccarico a tre argomenti della funzione di log-verosimiglianza (quella che abbiamo usato inizialmente e che assumeva che tutte le osservazioni fossero complete). Per alpha e beta, otteniamo i valori visualizzati in fondo allo schermo. Come previsto, quei valori non corrispondono affatto ai valori originali di alpha e beta.
In questa serie di lezioni, non è la prima volta che viene introdotta una tecnica per gestire dati censurati. Nella seconda lezione di questo capitolo, è stata introdotta la tecnica di mascheramento della perdita per gestire le rotture di stock. Infatti, di solito vogliamo prevedere la domanda futura, non le vendite future. Le rotture di stock introducono un bias verso il basso, poiché non riusciamo a osservare tutte le vendite che sarebbero avvenute se la rottura di stock non fosse avvenuta. La tecnica della probabilità condizionata può essere utilizzata per gestire la domanda censurata come avviene con le rotture di stock. La tecnica della probabilità condizionata è un po’ più complessa del mascheramento della perdita, quindi probabilmente non dovrebbe essere utilizzata se il mascheramento della perdita è sufficiente.
Nel caso dei tempi di consegna, la scarsità dei dati è la motivazione principale. Possiamo avere così pochi dati che può essere fondamentale sfruttare al massimo ogni singola osservazione, anche quelle incomplete. Infatti, la tecnica della probabilità condizionata è più potente del mascheramento della perdita nel senso che sfrutta le osservazioni incomplete anziché scartarle semplicemente. Ad esempio, se c’è un’unità in stock e se questa unità in stock viene venduta, alludendo a una rottura di stock, la tecnica della probabilità condizionata fa comunque uso dell’informazione che la domanda era maggiore o uguale a uno.
Qui otteniamo un beneficio sorprendente della modellazione probabilistica: ci offre un modo elegante per gestire la censura, un effetto che si verifica in numerose situazioni della supply chain. Attraverso la probabilità condizionata, possiamo eliminare intere classi di bias sistematici.
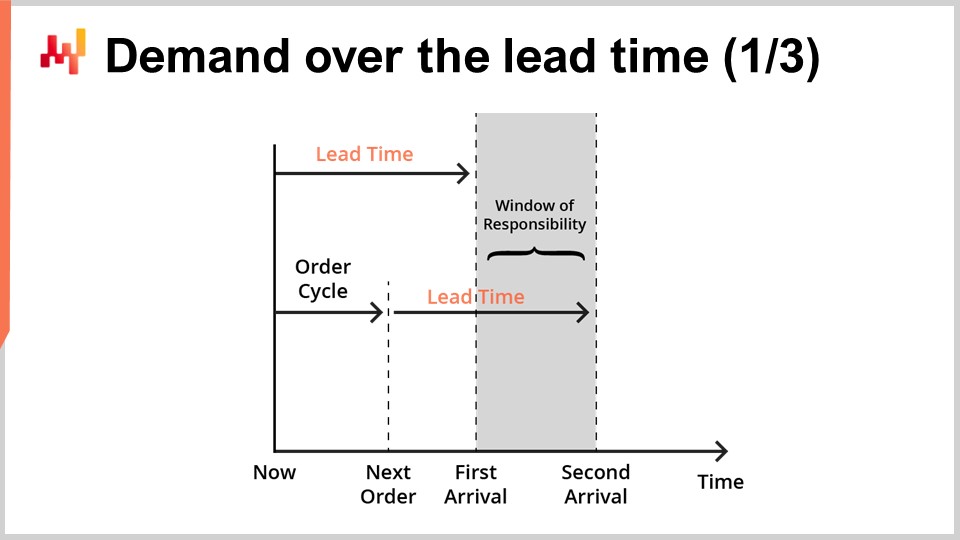
Le previsioni dei tempi di consegna sono tipicamente destinate ad essere combinate con le previsioni della domanda. Infatti, consideriamo ora una semplice situazione di riassortimento delle scorte, come illustrato sullo schermo.
Serviamo un singolo prodotto e le scorte possono essere rifornite riordinando da un singolo fornitore. Cerchiamo una previsione che supporti la nostra decisione di riordinare o meno dal fornitore. Possiamo riordinare ora e, se lo facciamo, la merce arriverà al punto nel tempo indicato come “primo arrivo”. In seguito, avremo un’altra opportunità di riordinare. Questa opportunità successiva avviene in un punto nel tempo indicato come “prossimo ordine” e, in questo caso, la merce arriverà al punto nel tempo indicato come “secondo arrivo”. Il periodo indicato come “finestra di responsabilità” è il periodo che conta per quanto riguarda la nostra decisione di riordino.
Infatti, qualunque cosa decidiamo di riordinare non arriverà prima del primo tempo di consegna. Quindi, abbiamo già perso il controllo sul servizio della domanda per tutto ciò che accade prima del primo arrivo. Poi, poiché avremo un’altra opportunità di riordinare, il servizio della domanda dopo il secondo arrivo non è più di nostra responsabilità; è responsabilità del prossimo riordino. Pertanto, il riordino con l’intenzione di servire la domanda oltre il secondo arrivo dovrebbe essere posticipato fino alla prossima opportunità di riordino.
Al fine di supportare la decisione di riordino, ci sono due fattori che dovrebbero essere previsti. Prima di tutto, dovremmo prevedere la quantità di stock prevista al momento del primo arrivo. Infatti, se al momento del primo arrivo c’è ancora abbondanza di stock, allora non c’è motivo di riordinare ora. In secondo luogo, dovremmo prevedere la domanda prevista per la durata della finestra di responsabilità. In una configurazione reale, dovremmo anche prevedere la domanda oltre la finestra di responsabilità al fine di valutare il costo di gestione delle scorte dei beni che stiamo ordinando ora, poiché potrebbero esserci avanzi che si riversano in periodi successivi. Tuttavia, per motivi di concisione e tempistica, oggi ci concentreremo sullo stock previsto e sulla domanda prevista per quanto riguarda la finestra di responsabilità.
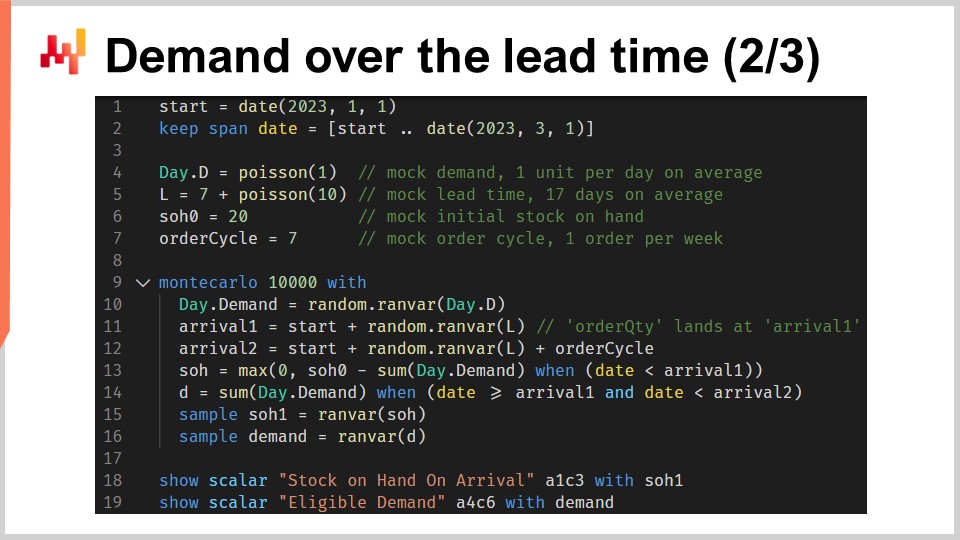
Questo script implementa i fattori o le previsioni della finestra di responsabilità che abbiamo appena discusso. Prende in input una previsione probabilistica dei tempi di consegna e una previsione probabilistica della domanda. Restituisce due distribuzioni di probabilità, ovvero lo stock disponibile al momento dell’arrivo e la domanda idonea come definita dalla finestra di responsabilità.
Alle righe uno e due, impostiamo le linee temporali, che iniziano il 1° gennaio e terminano il 1° marzo. In un setup di previsione, questa linea temporale non sarebbe codificata rigidamente. Alla riga quattro, viene introdotto un modello di domanda probabilistico semplicistico: una distribuzione di Poisson ripetuta giorno per giorno per l’intera durata di questa linea temporale. La domanda sarà di una unità al giorno in media. Sto utilizzando qui un modello semplicistico per la domanda per una questione di chiarezza. In un setup reale, ad esempio, potremmo utilizzare un ESSM (Ensemble State Space Model). I modelli di spazio di stato sono modelli probabilistici e sono stati introdotti nella prima lezione di questo capitolo.
Alla riga cinque, viene introdotto un altro modello probabilistico semplicistico. Questo secondo modello è destinato ai tempi di consegna. È una distribuzione di Poisson spostata di sette giorni verso destra. Lo spostamento viene effettuato attraverso una convoluzione. Alla riga sei, definiamo lo stock iniziale disponibile. Alla riga sette, definiamo il ciclo di ordine. Questo valore è espresso in giorni e caratterizza quando avverrà il prossimo riordino.
Dalla riga 9 alla 16, abbiamo un blocco Monte Carlo che rappresenta la logica principale dello script. In precedenza in questa lezione, abbiamo già introdotto un altro blocco Monte Carlo per supportare la nostra logica di convalida incrociata. Qui, stiamo utilizzando questa costruzione di nuovo, ma per un diverso scopo. Vogliamo calcolare due variabili casuali che riflettono, rispettivamente, lo stock disponibile al momento dell’arrivo e la domanda idonea. Tuttavia, l’algebra delle variabili casuali non è sufficientemente espressiva per effettuare questo calcolo. Pertanto, stiamo utilizzando un blocco Monte Carlo al suo posto.
Nella terza lezione di questo capitolo, ho sottolineato che c’è una dualità tra previsioni probabilistiche e simulazioni. Il blocco Monte Carlo illustra questa dualità. Partiamo da una previsione probabilistica, la trasformiamo in una simulazione e infine convertiamo i risultati della simulazione in un’altra previsione probabilistica.
Diamo un’occhiata ai dettagli. Alla riga 10, generiamo una traiettoria per la domanda. Alla riga 11, generiamo la data di arrivo per il primo ordine, assumendo che stiamo ordinando oggi. Alla riga 12, generiamo la data di arrivo per il secondo ordine, assumendo che stiamo ordinando un ciclo di ordine da adesso. Alla riga 13, calcoliamo ciò che rimane come stock disponibile alla prima data di arrivo. È lo stock iniziale disponibile meno la domanda osservata per la durata del primo tempo di consegna. Il max zero indica che lo stock non può diventare negativo. In altre parole, assumiamo che non ci sia alcun arretrato. Questa assunzione di nessun arretrato potrebbe essere modificata. Il caso dell’arretrato è lasciato come esercizio per il pubblico. Come suggerimento, la programmazione differenziabile può essere utilizzata per valutare la percentuale della domanda non soddisfatta che si converte con successo in arretrati, a seconda di quanti giorni mancano prima della disponibilità rinnovata dello stock.
Tornando allo script, alla riga 14 calcoliamo la domanda idonea, che è la domanda che si verifica durante la finestra di responsabilità. Alle righe 15 e 16, raccogliamo due variabili casuali di interesse attraverso la parola chiave “sample”. A differenza del primo script Envision di questa lezione, che si occupava della convalida incrociata, qui cerchiamo di raccogliere distribuzioni di probabilità da questo blocco Monte Carlo, non solo medie. Sia alla riga 15 che alla riga 16, la variabile casuale che appare sul lato destro dell’assegnazione è un aggregatore. Alla riga 15, otteniamo una variabile casuale per lo stock disponibile al momento dell’arrivo. Alla riga 16, otteniamo un’altra variabile casuale per la domanda che si verifica all’interno della finestra di responsabilità.
Alle righe 18 e 19, queste due variabili casuali vengono visualizzate. Ora, fermiamoci un attimo e ripensiamo a tutto questo script. Le righe da uno a sette sono dedicate esclusivamente alla configurazione dei dati di prova. Le righe 18 e 19 mostrano solo i risultati. L’unica logica effettiva avviene sulle otto righe tra le righe 9 e 16. Infatti, tutta la logica effettiva è situata, in un certo senso, alle righe 13 e 14.
Con poche righe di codice, meno di 10 a prescindere dal conteggio, combiniamo una previsione probabilistica del tempo di consegna con una previsione probabilistica della domanda al fine di comporre una sorta di previsione ibrida probabilistica della reale rilevanza della supply chain. Notiamo che qui non c’è nulla che dipenda realmente dalle specifiche della previsione del tempo di consegna o della previsione della domanda. Sono stati utilizzati modelli semplici, ma avrebbero potuto essere utilizzati modelli sofisticati al loro posto. Non avrebbe cambiato nulla. L’unico requisito è avere due modelli probabilistici in modo da poter generare quelle traiettorie.
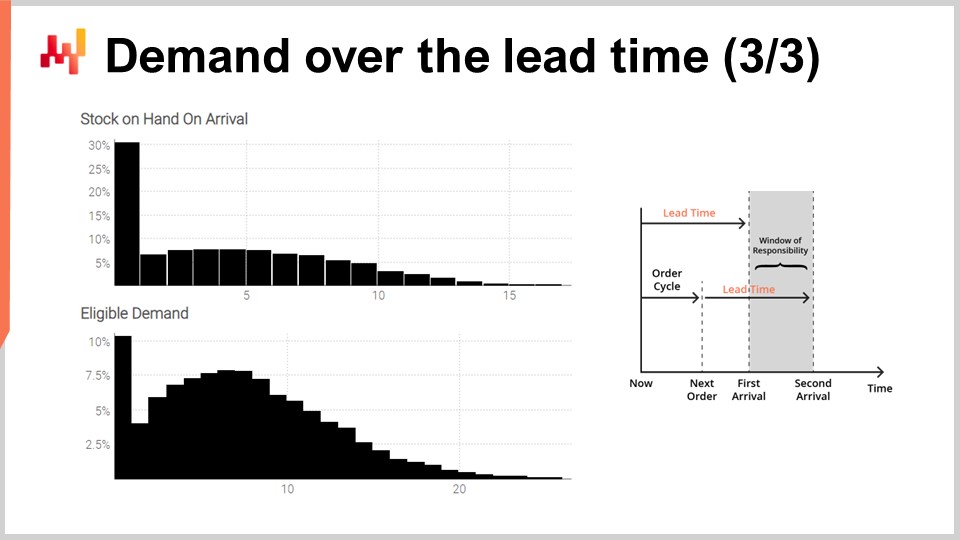
Infine, sullo schermo, gli istogrammi prodotti dallo script. L’istogramma superiore rappresenta lo stock disponibile al momento dell’arrivo. C’è circa il 30% di probabilità di trovarsi di fronte a uno stock iniziale pari a zero. In altre parole, c’è circa il 30% di probabilità che una carenza di stock possa essere avvenuta l’ultimo giorno appena prima della prima data di arrivo. Il valore medio dello stock potrebbe essere di circa cinque unità. Tuttavia, se dovessimo valutare questa situazione in base alla sua media, leggeremmo seriamente male la situazione. Una previsione probabilistica è essenziale per riflettere correttamente la situazione iniziale dello stock.
L’istogramma inferiore rappresenta la domanda associata alla finestra di responsabilità. Abbiamo circa il 10% di probabilità di affrontare una domanda pari a zero. Anche questo risultato potrebbe essere considerato sorprendente. Infatti, abbiamo iniziato questo esercizio con una domanda di Poisson stazionaria di una unità al giorno in media. Abbiamo sette giorni tra gli ordini. Se non fosse per il tempo di consegna variabile, ci sarebbe stata meno dello 0,1% di probabilità di ottenere una domanda pari a zero in sette giorni. Tuttavia, lo script dimostra che questa situazione è molto più frequente. Il motivo è che una piccola finestra di responsabilità può verificarsi se il primo tempo di consegna è più lungo del solito e se il secondo tempo di consegna è più breve del solito.
Affrontare una domanda pari a zero durante la finestra di responsabilità significa che lo stock disponibile è probabile che diventi piuttosto alto in un determinato momento. A seconda della situazione, ciò potrebbe essere o meno critico, ma potrebbe esserlo, ad esempio, se c’è un limite di capacità di stoccaggio o se lo stock è deperibile. Ancora una volta, la domanda media, probabilmente intorno a otto, non fornisce una visione affidabile di come appariva la domanda. Ricordiamo che abbiamo ottenuto questa distribuzione altamente asimmetrica da una domanda stazionaria iniziale, una unità al giorno in media. Questo è l’effetto del tempo di consegna variabile in azione.
Questa semplice configurazione dimostra l’importanza dei tempi di consegna quando si tratta di situazioni di rifornimento di inventario. Da una prospettiva della supply chain, isolare le previsioni dei tempi di consegna dalle previsioni della domanda è, nella migliore delle ipotesi, una astrazione pratica. La domanda giornaliera non è ciò che ci interessa veramente. Ciò che interessa veramente è la composizione della domanda con il tempo di consegna. Se altri fattori stocastici fossero presenti, come arretrati o resi, anche quei fattori sarebbero stati parte del modello.

Il presente capitolo di questa serie di lezioni è intitolato “Modellazione predittiva” invece di “Previsione della domanda”, come sarebbe tipicamente il caso nei manuali di supply chain mainstream. La ragione di questo titolo del capitolo dovrebbe essere diventata progressivamente evidente man mano che procediamo attraverso la presente lezione. Infatti, da una prospettiva della supply chain, vogliamo prevedere l’evoluzione del sistema della supply chain. La domanda è certamente un fattore importante, ma non è l’unico fattore. Altri fattori variabili come il tempo di consegna devono essere previsti. Ancora più importante, tutti questi fattori devono essere, alla fine, previsti insieme.
Infatti, dobbiamo unire questi componenti predittivi per supportare un processo decisionale. Quindi, ciò che conta non è cercare qualche sorta di modello di previsione della domanda finale. Questo compito è in gran parte una perdita di tempo, perché la maggiore precisione verrà ottenuta in modi che vanno contro gli interessi dell’azienda. Maggiore sofisticazione significa maggiore opacità, più bug, più risorse di calcolo. Come regola generale, più sofisticato è il modello, più difficile diventa comporlo con successo operativamente con un altro modello. Quello che conta è assemblare una collezione di tecniche predittive che possano essere composte a piacimento. Questo è ciò che la modularità rappresenta da una prospettiva di modellazione predittiva. In questa lezione, sono state presentate una mezza dozzina di tecniche. Queste tecniche sono utili perché affrontano angolazioni critiche del mondo reale come le osservazioni incomplete. Sono anche semplici; nessuno degli esempi di codice presentati oggi superava le 10 righe di logica effettiva. Ancora più importante, queste tecniche sono modulari, come i mattoncini Lego. Funzionano bene insieme e possono essere ricombinate all’infinito.
L’obiettivo finale della modellazione predittiva per la supply chain, come dovrebbe essere inteso, è l’identificazione di tali tecniche. Ogni tecnica dovrebbe essere, di per sé, un’opportunità per rivedere qualsiasi modello predittivo preesistente al fine di semplificare o migliorare questo modello.

In conclusione, nonostante il tempo di consegna sia in gran parte ignorato dalla comunità accademica, il tempo di consegna può e dovrebbe essere previsto. Attraverso la revisione di una breve serie di distribuzioni di tempi di consegna del mondo reale, abbiamo identificato due sfide: in primo luogo, i tempi di consegna variano; in secondo luogo, i tempi di consegna sono scarsi. Pertanto, abbiamo introdotto tecniche di modellazione adeguate per affrontare le osservazioni dei tempi di consegna che si rivelano sia scarse che erratiche.
Questi modelli di tempi di consegna sono probabilistici e sono, in larga misura, il proseguimento dei modelli che sono stati gradualmente introdotti in questo capitolo. Abbiamo anche visto che la prospettiva della probabilità fornisce una soluzione elegante al problema dell’osservazione incompleta, un aspetto quasi ubiquo nella supply chain. Questo problema si verifica ogni volta che ci sono esaurimenti di magazzino e ogni volta che ci sono ordini in sospeso. Infine, abbiamo visto come comporre una previsione probabilistica dei tempi di consegna con una previsione probabilistica della domanda al fine di creare il modello predittivo di cui abbiamo bisogno per supportare un successivo processo decisionale.

La prossima lezione sarà l'8 marzo. Sarà un mercoledì alla stessa ora, le 15:00 ora di Parigi. La lezione di oggi è stata tecnica, ma la prossima sarà in gran parte non tecnica e parlerò del caso dello “scienziato della supply chain”. Infatti, i manuali di supply chain mainstream affrontano la supply chain come se i modelli di previsione e i modelli di ottimizzazione emergessero e operassero dal nulla, ignorando completamente il loro componente “wetware”, ovvero le persone responsabili. Pertanto, daremo uno sguardo più da vicino ai ruoli e alle responsabilità dello scienziato della supply chain, una persona che si aspetta di guidare l’iniziativa quantitativa della supply chain.
Ora, procederò con le domande.
Domanda: Cosa succede se qualcuno vuole conservare le proprie scorte per ulteriori innovazioni o per motivi diversi dal just in time o da altri concetti?
Questa è davvero una domanda molto importante. Il concetto viene tipicamente affrontato attraverso la modellazione economica della supply chain, che chiamiamo tecnicamente “driver economici” in questa serie di lezioni. Quello che stai chiedendo è se è meglio non servire un cliente oggi perché, in un momento successivo, ci sarà l’opportunità di servire la stessa unità a un’altra persona che conta di più per qualsiasi motivo. In sostanza, stai dicendo che c’è più valore da catturare servendo un altro cliente in seguito, forse un cliente VIP, piuttosto che servire un cliente oggi.
Questo potrebbe essere il caso, ed effettivamente accade. Ad esempio, nell’industria dell’aviazione, diciamo che sei un fornitore di MRO (Manutenzione, Riparazione e Revisione). Hai i tuoi soliti clienti VIP, le compagnie aeree che servono abitualmente con contratti a lungo termine, e sono molto importanti. Quando succede questo, vuoi assicurarti di poter sempre servire quei clienti. Ma cosa succede se un’altra compagnia aerea ti chiama e chiede una unità? In questo caso, quello che succederà è che potresti servire questa persona, ma non hai un contratto a lungo termine con loro. Quindi, quello che farai è regolare il prezzo in modo che sia molto alto, garantendo di ottenere abbastanza valore per compensare la potenziale mancanza di scorte che potresti affrontare in un momento successivo. In conclusione per questa prima domanda, credo che non sia davvero una questione di previsione ma più una questione di modellazione adeguata dei driver economici. Se vuoi conservare le scorte, ciò che vuoi è generare un modello, un modello di ottimizzazione, in cui la risposta razionale non è servire il cliente che chiede una unità mentre hai ancora scorte in riserva.
A proposito, un’altra situazione tipica per questo è quando vendi kit. Un kit è un insieme di molte parti che vengono vendute insieme, e hai solo una parte rimasta che vale solo una piccola frazione del valore totale del kit. Il problema è che se vendi quest’ultima unità, non puoi più costruire il tuo kit e venderlo al suo prezzo pieno. Pertanto, potresti trovarti in una situazione in cui preferisci tenere l’unità in magazzino solo per poter vendere il kit in un momento successivo, potenzialmente con una certa incertezza. Ma ancora una volta, tutto si riduce ai driver economici, e questo sarebbe il modo in cui affronterei questa situazione.
Domanda: Negli ultimi anni, la maggior parte dei ritardi nella supply chain è stata causata da guerre o pandemie, che è molto difficile da prevedere perché non abbiamo mai avuto situazioni del genere in precedenza. Qual è la tua opinione in merito?
La mia opinione è che i tempi di consegna sono sempre stati variabili. Sono nel mondo della supply chain dal 2008 e i miei genitori lavoravano nella supply chain anche 30 anni prima di me. Per quanto possiamo ricordare, i tempi di consegna sono sempre stati erratici e variabili. C’è sempre qualcosa che succede, che si tratti di una protesta, di una guerra o di un cambiamento delle tariffe. Sì, gli ultimi due anni sono stati estremamente erratici, ma i tempi di consegna erano già molto variabili.
Sono d’accordo sul fatto che nessuno può pretendere di essere in grado di prevedere la prossima guerra o pandemia. Se fosse possibile prevedere questi eventi matematicamente, le persone non farebbero la guerra o investirebbero nella supply chain; giocherebbero semplicemente in borsa e diventerebbero ricche anticipando le mosse di mercato.
La cosa importante è che puoi pianificare l’imprevisto. Se non sei sicuro del futuro, puoi effettivamente aumentare le variazioni nelle tue previsioni. È il contrario di cercare di rendere la tua previsione più accurata: mantieni le tue aspettative medie, ma aumenti la coda in modo che le decisioni che prendi basate su quelle previsioni probabilistiche siano più resilienti alle variazioni. Hai progettato le tue variazioni previste in modo che siano più grandi di quelle attuali. La cosa importante è che l’idea che le cose siano facili o difficili da prevedere deriva da una prospettiva di previsione puntuale, in cui vorresti giocare come se fosse possibile avere un’anticipazione precisa del futuro. Questo non è il caso: non esiste una cosa del genere come un’anticipazione precisa del futuro. L’unica cosa che puoi fare è lavorare con distribuzioni di probabilità con una grande dispersione che manifesta e quantifica la tua ignoranza del futuro.
Invece di affinare le decisioni che dipendono criticamente dall’esecuzione minuziosa del piano esatto, stai considerando e pianificando un grado interessante di variazione, rendendo le tue decisioni più robuste contro quelle variazioni. Tuttavia, ciò si applica solo al tipo di variazione che non influisce sulla tua supply chain in modo troppo brutale. Ad esempio, puoi gestire tempi di consegna più lunghi da parte dei fornitori, ma se il tuo magazzino è stato bombardato, nessuna previsione ti salverà in quella situazione.
Domanda: Possiamo creare questi istogrammi e calcolare il CRPS in Microsoft Excel, ad esempio, utilizzando componenti aggiuntivi di Excel come itsastat o che ospita molte distribuzioni?
Sì, puoi farlo. Uno di noi di Lokad ha effettivamente prodotto un foglio di calcolo Excel che rappresenta un modello probabilistico per una situazione di riapprovvigionamento di inventario. Il nodo cruciale del problema è che Excel non ha un tipo di dati istogramma nativo, quindi tutto ciò che hai in Excel sono numeri: una cella, un numero. Sarebbe elegante e semplice avere un valore che è un istogramma, in cui hai un istogramma completo racchiuso in una sola cella. Tuttavia, per quanto ne so, questo non è possibile in Excel. Tuttavia, se sei disposto a dedicare circa 100 righe per rappresentare l’istogramma, anche se non sarà compatto e pratico, puoi implementare una distribuzione in Excel e fare qualche modellazione probabilistica. Pubblicheremo il link all’esempio nella sezione dei commenti.
Tieni presente che è un’operazione relativamente complessa perché Excel non è ideale per questo compito. Excel è un linguaggio di programmazione e puoi fare qualsiasi cosa con esso, quindi non hai bisogno nemmeno di un componente aggiuntivo per farlo. Tuttavia, sarà un po’ verboso, quindi non aspettarti qualcosa di super ordinato.
Domanda: Il tempo di consegna può essere suddiviso in componenti come tempo di ordinazione, tempo di produzione, tempo di trasporto, ecc. Se si desidera un controllo più dettagliato sui tempi di consegna, come cambierebbe questo approccio?
Prima di tutto, dobbiamo considerare cosa significa avere un controllo più dettagliato sui tempi di consegna. Vuoi ridurre il tempo di consegna medio o ridurre la variabilità del tempo di consegna? Curiosamente, ho visto molte aziende riuscire a ridurre il tempo di consegna medio, ma scambiando un po’ di variabilità aggiuntiva del tempo di consegna. In media, il tempo di consegna è più breve, ma ogni tanto è molto più lungo.
In questa lezione, stiamo facendo un esercizio di modellazione. Di per sé, non c’è azione; si tratta solo di osservare, analizzare e prevedere. Tuttavia, se riusciamo a scomporre il tempo di consegna e analizzare la distribuzione sottostante, possiamo utilizzare la modellazione probabilistica per valutare quali componenti variano di più e quali hanno il maggior impatto negativo sulla nostra supply chain. Possiamo esplorare scenari ipotetici con queste informazioni. Ad esempio, prendi una parte del tuo tempo di consegna e chiediti: “Cosa succederebbe se la coda di questo tempo di consegna fosse un po’ più corta, o se la media fosse un po’ più corta?” Puoi quindi ricomporre tutto, eseguire nuovamente il tuo modello predittivo per l’intera supply chain e iniziare a valutare l’impatto.
Questo approccio ti consente di ragionare per parti su determinati fenomeni, compresi quelli erratici. Non sarebbe tanto un cambiamento di approccio quanto una continuazione di ciò che abbiamo fatto, che porta al Capitolo 6, che tratta dell’ottimizzazione delle decisioni effettive basate su questi modelli probabilistici.
Domanda: Credo che ciò offra l’opportunità di ricalcolare i nostri tempi di consegna in SAP per fornire un periodo più realistico e aiutare a ridurre al minimo il nostro sistema di pull-in e pull-out. È possibile?
Avviso: SAP è un concorrente di Lokad nello spazio dell’ottimizzazione della supply chain. La mia risposta iniziale è no, SAP non può farlo. La realtà è che SAP ha quattro soluzioni distinte che si occupano dell’ottimizzazione della supply chain, e dipende da quale stack stai parlando. Tuttavia, tutti quei stack hanno in comune una visione incentrata sulle previsioni puntuali. Tutto in SAP è stato progettato sulla premessa che le previsioni saranno accurate.
Sì, SAP ha alcuni parametri da regolare, come la distribuzione normale di cui ho parlato all’inizio di questa lezione. Tuttavia, le distribuzioni dei tempi di consegna che abbiamo osservato non erano distribuite normalmente. A mia conoscenza, le configurazioni mainstream di SAP per l’ottimizzazione della supply chain adottano una distribuzione normale per i tempi di consegna. Il problema è che, nel nucleo, il software fa un’assunzione matematica ampiamente errata. Non puoi recuperare da un’assunzione matematica ampiamente errata che va direttamente al nucleo dell’architettura del tuo software regolando un parametro. Teoricamente, questo è possibile, ma nella pratica presenta così tanti problemi che la domanda è: perché vorresti davvero farlo?
Per adottare una prospettiva probabilistica, devi essere completamente coinvolto, il che significa che le tue previsioni sono probabilistiche e i tuoi modelli di ottimizzazione si basano anche su modelli probabilistici. Il problema qui è che anche se potessimo regolare la modellazione probabilistica per ottenere tempi di consegna leggermente migliori, il resto dello stack SAP tornerà alle previsioni puntuali. Qualunque cosa accada, ridurremo quelle distribuzioni a punti. L’idea che si possa approssimare questo con una media è preoccupante e semplicemente sbagliata. Quindi, tecnicamente, potresti regolare i tempi di consegna, ma dopo incontrerai così tanti problemi che potrebbe non valere la pena lo sforzo.
Domanda: Ci sono situazioni in cui si ordinano le stesse parti da fornitori diversi. Questa è un’informazione importante da elaborare nella previsione dei tempi di consegna. Fai previsioni dei tempi di consegna per articolo o ci sono situazioni in cui approfitti della raggruppamento degli articoli in famiglie?
Questa è una domanda notevolmente interessante. Abbiamo due fornitori per lo stesso articolo. La domanda sarà quanto simili siano gli articoli e i fornitori. Prima di tutto, dobbiamo guardare alla situazione. Se un fornitore si trova accanto e l’altro fornitore si trova dall’altra parte del mondo, è necessario considerare queste cose separatamente. Ma supponiamo la situazione interessante in cui i due fornitori sono abbastanza simili ed è lo stesso articolo. Dovresti raggruppare insieme quelle osservazioni o no?
La cosa interessante è che attraverso la programmazione differenziabile, è possibile comporre un modello che attribuisce un certo peso al fornitore e un certo peso all’articolo e lasciare che la magia dell’apprendimento faccia la sua magia. Si adatterà a se dovremmo dare più peso al componente dell’articolo del tempo di consegna o al componente del fornitore. Potrebbe essere che due fornitori che servono praticamente lo stesso tipo di prodotti potrebbero avere qualche pregiudizio in cui un fornitore è, in media, un po’ più veloce dell’altro. Ma ci sono articoli che richiedono sicuramente più tempo e quindi se selezioni gli articoli, non è molto chiaro che un fornitore sia più veloce dell’altro perché dipende davvero da quali articoli stai guardando. Probabilmente hai pochissimi dati se disaggregi tutto per ogni fornitore e ogni articolo. Quindi, la cosa interessante, e quello che consiglierei qui, sarebbe di ingegnerizzare attraverso la programmazione differenziabile. Potremmo effettivamente provare a riprendere questa situazione in una lezione successiva, una situazione in cui metti alcuni parametri a livello di parte e alcuni parametri a livello di fornitore. Quindi, hai un numero totale di parametri che non è il numero di parti per il numero di fornitori; sarebbe il numero di parti più il numero di fornitori, o forse più il numero di fornitori per categorie, o qualcosa di simile. Non fai esplodere il numero dei tuoi parametri; aggiungi solo un parametro, un elemento che ha un’affinità con il fornitore, e ti permette di fare una sorta di mix dinamico guidato dai tuoi dati storici.
Domanda: Credo che la quantità che viene ordinata e quali prodotti vengono ordinati insieme possano influire anche sul tempo di consegna alla fine. Potresti spiegare la complessità di includere tutte le variabili in questo tipo di problema?
Nell’ultimo esempio, avevamo due tipi di durata: il ciclo di ordine e il tempo di consegna stesso. Il ciclo di ordine è interessante perché è incerto solo nella misura in cui non abbiamo ancora preso la decisione. È fondamentalmente qualcosa che puoi decidere praticamente in qualsiasi momento, quindi il ciclo di ordinazione è completamente interno e di tua creazione. Questo non è l’unico elemento nella supply chain che è così; i prezzi sono gli stessi. Hai la domanda, osservi la domanda, ma puoi effettivamente scegliere il prezzo che vuoi. Alcuni prezzi sono ovviamente poco saggi, ma è la stessa cosa - è di tua creazione.
Il ciclo di ordine è di tua creazione. Ora, quello che stai dicendo è che c’è incertezza sul momento esatto per il prossimo tempo di consegna dell’ordine perché non sai esattamente quando effettuerai l’ordine. Infatti, hai completamente ragione. Quello che succede è che quando hai la capacità di implementare questa modellazione probabilistica, improvvisamente, come discusso nel sesto capitolo di questa serie di lezioni, non vuoi dire che il ciclo di ordine è di sette giorni. Invece, vuoi adottare una politica di riordino che massimizzi il ritorno sull’investimento per la tua azienda. Quindi, quello che puoi fare è pianificare il futuro in modo che se riordini ora, puoi prendere una decisione ora e poi applicare la tua politica giorno per giorno. Ad un certo punto in futuro, fai un riordino, e ora quello che hai è una sorta di situazione del “serpente che si morde la coda” perché la migliore decisione di ordinazione per oggi dipende dalla decisione della prossima decisione di ordinazione, quella che non hai ancora preso. Questo tipo di problema è noto come problema di politica ed è un problema di decisione sequenziale. In fondo, quello che vuoi veramente è creare una sorta di politica, un oggetto matematico che governa il tuo processo decisionale.
Il problema dell’ottimizzazione della politica è piuttosto complicato e ho intenzione di trattarlo nel sesto capitolo. Ma la cosa fondamentale è che abbiamo, se torniamo alla tua domanda, due componenti distinti. Abbiamo il componente che varia indipendentemente da ciò che fai, il tempo di consegna del fornitore, e poi hai il tempo di ordinazione, che è qualcosa che è realmente guidato internamente dal tuo processo e dovrebbe essere trattato come una questione di ottimizzazione.
Concludendo questo pensiero, vediamo una convergenza tra l’ottimizzazione e la modellazione predittiva. Alla fine, le due cose finiscono per essere praticamente la stessa cosa perché ci sono interazioni tra le decisioni che prendi e ciò che accade in futuro.
Per oggi è tutto. Non dimenticare, l'8 marzo, alla stessa ora, sarà mercoledì, alle 15:00. Grazie e arrivederci alla prossima volta.


