00:00 Introduzione
02:31 Cause radice del fallimento in condizioni reali
07:20 Risultato: una ricetta numerica 1/2
09:31 Risultato: una ricetta numerica 2/2
13:01 La storia finora
14:57 Portare a termine le cose oggi
15:59 Cronologia dell’iniziativa
21:48 Ambito: panorama applicativo 1/2
24:24 Ambito: panorama applicativo 2/2
27:12 Ambito: effetti di sistema 1/2
29:21 Ambito: effetti di sistema 2/2
32:12 Ruoli: 1/2
37:31 Ruoli: 2/2
41:50 Pipeline dei dati - Come
44:13 Una parola sui sistemi transazionali
49:13 Una parola sul data lake
52:59 Una parola sui sistemi analitici
57:56 Salute dei dati: livello basso
01:02:23 Salute dei dati: livello alto
01:06:24 Ispettori dei dati
01:08:53 Conclusione
01:10:32 Lezione in arrivo e domande del pubblico
Descrizione
Condurre una predictive optimization di successo di una supply chain è un insieme di problemi soft e hard. Sfortunatamente, non è possibile separare questi aspetti. Le sfaccettature soft e hard sono profondamente intrecciate. Di solito, questo intreccio si scontra frontalmente con la divisione del lavoro, come definita dall’organigramma dell’azienda. Osserviamo che, quando le iniziative di supply chain falliscono, le cause radice del fallimento sono solitamente errori commessi nelle fasi iniziali del progetto. Inoltre, gli errori iniziali tendono a plasmare l’intera iniziativa, rendendoli quasi impossibili da correggere ex post. Presentiamo le nostre conclusioni chiave per evitare tali errori.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel, e oggi presenterò “Iniziare con un’iniziativa di Quantitative Supply Chain”. La stragrande maggioranza delle iniziative di supply chain basate sull’analisi dei dati falliscono. Dal 1990, la maggior parte delle aziende che operano grandi supply chain ha lanciato importanti iniziative di predictive optimization ogni tre-cinque anni, con pochi o nessun risultato. Oggi, la maggior parte dei team nelle supply chain o data science, iniziando un nuovo ciclo di predictive optimization—tipicamente inquadrata come un progetto di previsione o di ottimizzazione dell’inventario—non si rende nemmeno conto che la loro azienda ha già sperimentato, fatto e fallito, possibilmente, mezza dozzina di volte.
Procedere con un ulteriore ciclo è talvolta dettato dalla convinzione che questa volta sarà diverso, ma frequentemente i team non sono nemmeno consapevoli dei numerosi tentativi falliti del passato. Un’evidenza aneddotica di questa situazione è che Microsoft Excel rimane lo strumento numero uno per guidare le decisioni di supply chain, mentre quelle iniziative dovevano sostituire i fogli di calcolo con strumenti migliori. Tuttavia, al giorno d’oggi, ci sono ancora pochissime supply chain che possono operare senza fogli di calcolo.
L’obiettivo di questa lezione è comprendere come dare una possibilità di successo a un’iniziativa di supply chain che intende fornire qualsiasi tipo di predictive optimization. Esamineremo una serie di ingredienti critici—ingredienti che sono semplici eppure molto frequentemente controintuitivi per la maggior parte delle organizzazioni. Al contrario, esamineremo una serie di anti-pattern che garantiscono quasi il fallimento di tale iniziativa.
Oggi, il mio focus è sull’esecuzione tattica dell’avvio di un’iniziativa di supply chain con una mentalità “get things done”. Non discuterò le grandi implicazioni strategiche per l’azienda. La strategia è molto importante, ma tratterò questo argomento in una lezione successiva.

La maggior parte delle iniziative di supply chain fallisce, e il problema viene a malapena menzionato pubblicamente. Il mondo accademico pubblica decine di migliaia di articoli all’anno vantandosi di ogni sorta di innovazioni nella supply chain, inclusi framework, algoritmi e modelli. Spesso, gli articoli affermano persino che l’innovazione è stata messa in produzione da qualche parte. Eppure, la mia osservazione informale del mondo della supply chain è che queste innovazioni non si vedono da nessuna parte. Allo stesso modo, i venditori di software promettono da tre decenni sostituti superiori ai fogli di calcolo, e ancora, la mia osservazione informale indica che i fogli di calcolo rimangono onnipresenti.
Rivisitiamo un punto già trattato nel secondo capitolo di questa serie di lezioni sulla supply chain. In poche parole, le persone non hanno alcun incentivo a pubblicizzare i fallimenti, e quindi non lo fanno. Inoltre, poiché le aziende che operano nelle supply chain tendono ad essere grandi, il problema si aggrava tipicamente per la naturale perdita di memoria istituzionale man mano che i dipendenti ruotano da una posizione all’altra. Ecco perché né il mondo accademico né i venditori riconoscono questa situazione piuttosto desolante.
Propongo di iniziare con un breve sondaggio delle cause radice più frequenti del fallimento da una prospettiva di esecuzione tattica. Infatti, queste cause radice si riscontrano tipicamente nelle fasi iniziali dell’iniziativa.
La prima causa di fallimento è il tentativo di risolvere i problemi sbagliati—problemi inesistenti, irrilevanti o che riflettono una sorta di incomprensione della supply chain stessa. Ottimizzare le percentuali di accuratezza delle previsioni è probabilmente l’archetipo di tale problema scorretto. Ridurre la percentuale di errore nelle previsioni non si traduce direttamente in euro o dollari di ritorno per l’azienda. La stessa situazione si verifica quando un’azienda mira a specifici livelli di servizio per il suo inventario. È molto raro ottenere un ritorno monetario in cambio.
La seconda causa radice del fallimento è l’uso di tecnologie software e di progetti software inadatti. Ad esempio, i fornitori di ERP cercano invariabilmente di utilizzare un database transazionale per supportare le iniziative di analisi dei dati, perché è su questo che si fonda l’ERP. Al contrario, i team di data science tendono a utilizzare l’avanguardia degli strumenti open-source di machine learning del momento, perché è una cosa figa da fare. Sfortunatamente, elementi tecnologici inadatti generano tipicamente un’enorme frizione e molta complessità accidentale.
La terza causa radice del fallimento è una divisione del lavoro e un’organizzazione errate. In un tentativo mal indirizzato di allocare specialisti a ogni fase del processo, le aziende tendono a frammentare l’iniziativa tra troppe persone. Ad esempio, la preparazione dei dati è molto frequentemente svolta da persone che non sono responsabili delle previsioni. Di conseguenza, si creano situazioni di garbage-in-garbage-out ovunque. Diluirsi marginalmente la responsabilità delle decisioni finali della supply chain è una ricetta per il fallimento.
Un aspetto che non ho incluso in questo breve elenco come causa radice è il cattivo dato. I dati sono molto frequentemente incolpati per i fallimenti delle iniziative di supply chain, il che è estremamente comodo, in quanto i dati non possono esattamente rispondere a tali accuse. Tuttavia, di solito i dati non sono colpevoli, almeno non nel senso di lottare contro dati scadenti. La supply chain delle grandi aziende si è digitalizzata decenni fa. Ogni articolo acquistato, trasportato, trasformato, prodotto o venduto ha dei record elettronici. Tali record potrebbero non essere perfetti, ma sono solitamente molto accurati. Se le persone non riescono a gestire correttamente i dati, non è davvero la transazione il vero colpevole.

Per far avere successo a un’iniziativa quantitativa, dobbiamo combattere la battaglia giusta. Che cosa stiamo cercando di fornire innanzitutto? Uno dei deliverable chiave per una quantitative supply chain è una ricetta numerica di base che calcola le decisioni finali della supply chain. Questo aspetto è stato già discusso nella Lezione 1.3 del primissimo capitolo, “Product-Oriented Delivery for Supply Chain.” Ripassiamo le due proprietà più critiche di questo deliverable.
Prima di tutto, l’output deve essere una decisione. Ad esempio, decidere quante unità riordinare oggi per un determinato SKU è una decisione. Al contrario, prevedere quante unità saranno richieste oggi per un determinato SKU è un artefatto numerico. Per generare una decisione che sia il risultato finale, sono necessari molti risultati intermedi, ovvero, molti artefatti numerici. Tuttavia, non dobbiamo confondere il mezzo con il fine.
La seconda proprietà di questo deliverable è che l’output, che è una decisione, deve essere completamente automatizzato come risultato di un processo software puramente automatizzato. La ricetta numerica stessa, la ricetta numerica di base, non deve prevedere alcuna operazione manuale. Naturalmente, il design della ricetta numerica è probabilmente fortemente dipendente da un esperto umano di scienza. Tuttavia, l’esecuzione non dovrebbe dipendere da un intervento umano diretto.
Avere una ricetta numerica come deliverable è essenziale per fare in modo che l’iniziativa di supply chain sia un’impresa capitalistica. La ricetta numerica diventa un asset produttivo che genera ritorni. La ricetta deve essere mantenuta, ma questo richiede una o due ordini di grandezza in meno di persone rispetto agli approcci che mantengono gli umani nel loop a livello di micro-decisione.

Tuttavia, molte iniziative di supply chain falliscono perché non inquadrano correttamente le decisioni di supply chain come il deliverable dell’iniziativa. Invece, queste iniziative si concentrano sul fornire artefatti numerici. Gli artefatti numerici sono intesi come ingredienti per arrivare alla risoluzione finale del problema, tipicamente a supporto delle decisioni stesse. Gli artefatti più comuni riscontrati nelle supply chain sono le previsioni, i safety stocks, gli EOQs, gli KPI. Mentre questi numeri possono essere di interesse, non sono reali. Questi numeri non hanno un corrispettivo fisico tangibile immediato nella supply chain, e riflettono prospettive di modellizzazione arbitrarie sulla supply chain.
Focalizzarsi sugli artefatti numerici porta al fallimento dell’iniziativa perché tali numeri mancano di un ingrediente critico: il feedback diretto dal mondo reale. Quando la decisione è errata, le conseguenze negative possono essere ricondotte alla decisione. Tuttavia, la situazione è molto più ambigua per quanto riguarda gli artefatti numerici. Infatti, la responsabilità si diluisce ovunque, poiché ci sono molti artefatti che contribuiscono a ogni singola decisione. Il problema è ancora peggiore quando vi è l’intervento umano nel mezzo.
Questa mancanza di feedback si rivela letale per gli artefatti numerici. Le supply chain moderne sono complesse. Scegli una qualsiasi formula arbitraria per calcolare un safety stock, una economic order quantity o un KPI; ci sono probabilità schiaccianti che tale formula sia errata in ogni sorta di modo. Il problema della correttezza della formula non è un problema matematico; è un problema di business. Si tratta di rispondere alla domanda, “Questa formula riflette veramente l’intento strategico che ho per la mia azienda?” La risposta varia da un’azienda all’altra e persino da un anno all’altro man mano che le aziende evolvono nel tempo.
Poiché gli artefatti numerici mancano di un feedback diretto dal mondo reale, manca il meccanismo per iterare da un’implementazione iniziale ingenua, semplicistica e molto probabilmente ampiamente errata, verso una versione approssimativamente corretta della formula che potrebbe essere considerata di livello produzione. Eppure, gli artefatti numerici sono molto allettanti perché danno l’illusione di avvicinarsi alla soluzione. Danno l’illusione di essere razionali, scientifici, persino intraprendenti. Abbiamo numeri, formule, algoritmi, modelli. È persino possibile fare benchmark e confrontare quei numeri con altri altrettanto inventati. Migliorare rispetto a un benchmark fittizio dà anch’esso l’illusione di progresso, ed è molto rassicurante. Ma alla fine della giornata, rimane un’illusione, una questione di prospettiva di modellizzazione.
Le aziende non fanno profitti pagando le persone per guardare gli KPI o eseguire benchmark. Fanno profitti prendendo decisioni una dopo l’altra e, si spera, migliorando nel prendere la decisione successiva ogni singola volta.
Questa lezione fa parte di una serie di lezioni sulla supply chain. Sto cercando di mantenere queste lezioni in certa misura indipendenti, ma siamo giunti a un punto in cui ha più senso guardarle in sequenza. Questa è la primissima lezione del settimo capitolo, dedicato all’esecuzione delle iniziative di supply chain. Con “iniziative di supply chain” intendo iniziative quantitative di supply chain – iniziative che intendono fornire qualcosa nel campo della predictive optimization per l’azienda.
Il primissimo capitolo è stato dedicato alle mie opinioni sulla supply chain sia come campo di studio sia come pratica. Nel secondo capitolo, ho presentato una serie di metodologie essenziali per la supply chain, poiché le metodologie naive vengono sconfitte a causa della natura avversa di molte situazioni di supply chain. Nel terzo capitolo, ho presentato una serie di personae della supply chain con un puro focus sui problemi; in altre parole, quale problema stiamo cercando di risolvere?
Nel quarto capitolo, ho presentato una serie di campi che, pur non essendo direttamente supply chain, ritengo siano essenziali per una pratica moderna della supply chain. Nel quinto e sesto capitolo, ho presentato gli elementi intelligenti di una ricetta numerica destinata a guidare le decisioni della supply chain, vale a dire l’ottimizzazione predittiva (la prospettiva generalizzata della previsione) e il decision making (essenzialmente l’ottimizzazione matematica applicata ai problemi della supply chain). In questo settimo capitolo, discutiamo come mettere insieme tali elementi in un’iniziativa reale di supply chain che intende portare questi metodi e tecnologie in produzione.

Oggi, esamineremo ciò che è considerata la pratica corretta per condurre un’iniziativa di supply chain. Ciò include inquadrare l’iniziativa con il deliverable adeguato, di cui abbiamo appena discusso, ma anche con la timeline appropriata, l’ambito adeguato e i ruoli idonei. Questi elementi rappresentano la prima parte della lezione di oggi.
La seconda parte della lezione sarà dedicata al data pipeline, un ingrediente critico per il successo di un’iniziativa così data-driven o data-dependent. Sebbene il data pipeline sia un argomento piuttosto tecnico, richiede una corretta divisione del lavoro e organizzazione tra IT e supply chain. In particolare, vedremo che i controlli di qualità dovrebbero essere principalmente affidati alla supply chain, con la progettazione di report sulla salute dei dati e data inspectors.
L’onboarding è la prima fase dell’iniziativa, in cui viene creata la ricetta numerica core, quella che genera la decisione insieme solo ad elementi di supporto. L’onboarding si conclude con un rollout progressivo in produzione, e durante questo rollout i processi precedenti vengono gradualmente automatizzati dalla stessa ricetta numerica.
Quando si considera la timeline appropriata per la prima iniziativa quantitativa di supply chain in un’azienda, si potrebbe pensare che dipenda dalla dimensione dell’azienda, dalla complessità, dal tipo di decisioni della supply chain e dal contesto generale. Sebbene ciò sia vero in una certa misura, l’esperienza che Lokad ha raccolto in oltre un decennio e in dozzine di tali iniziative indica che sei mesi sono quasi invariabilmente la timeline appropriata. Sorprendentemente, questa timeline di sei mesi ha poco a che fare con la tecnologia o addirittura con gli aspetti specifici della supply chain; ha molto più a che fare con le persone e le organizzazioni stesse e con il tempo necessario affinché si sentano a loro agio con quella che è tipicamente percepita come una maniera molto diversa di condurre la supply chain.
I primi due mesi sono dedicati all’installazione del data pipeline. Rivedremo questo punto tra pochi minuti, ma questo ritardo di due mesi è causato da due fattori. In primo luogo, dobbiamo rendere il data pipeline affidabile ed eliminare problemi poco frequenti che potrebbero impiegare settimane per manifestarsi. Il secondo fattore è che dobbiamo capire la semantica dei dati, ossia comprendere cosa significhino i dati dal supply chain perspective.
I mesi tre e quattro sono dedicati a rapide iterazioni sulla ricetta numerica stessa, che guiderà le decisioni della supply chain. Queste iterazioni sono necessarie perché generare decisioni finali effettive è solitamente l’unico modo per valutare se c’è qualcosa che non va con la ricetta sottostante o con tutte le assunzioni integrate nella ricetta. Questi due mesi sono anche tipicamente il tempo necessario affinché i supply chain practitioners si abituino alla prospettiva molto quantitativa e finanziaria che guida queste decisioni software-driven.
Infine, gli ultimi due mesi sono dedicati alla stabilizzazione della ricetta numerica dopo quello che solitamente è un periodo relativamente intenso di rapide iterazioni. Questo periodo rappresenta anche l’opportunità per far funzionare la ricetta in un ambiente simile alla produzione, ma senza ancora guidare la produzione. Questa fase è importante affinché i team della supply chain acquisiscano fiducia in questa soluzione emergente.
Anche se potrebbe essere auspicabile comprimere ulteriormente questa timeline, risulta essere tipicamente molto difficile. L’installazione del data pipeline può essere accelerata in una certa misura se l’infrastruttura IT adeguata è già presente, ma acquisire familiarità con i dati richiede tempo per comprendere cosa significhino i dati dal supply chain perspective. Nella seconda fase, se l’iterazione sulla ricetta numerica converge molto rapidamente, è probabile che i team della supply chain inizino a esplorare le sfumature della ricetta numerica, il che prolungherà il ritardo. Infine, gli ultimi due mesi sono tipicamente il tempo necessario per vedere esporsi la seasonality e acquisire fiducia nel software che guida decisioni importanti della supply chain in produzione.
In definitiva, ci vogliono circa sei mesi, e sebbene sarebbe auspicabile comprimerli ulteriormente, è una sfida farlo. Tuttavia, sei mesi rappresentano già un lasso di tempo considerevole. Se fin dal primo giorno, il periodo di onboarding, in cui la ricetta numerica non guida ancora le decisioni della supply chain, si prevede duri più di sei mesi, allora l’iniziativa è già a rischio. Se il ritardo extra è associato all’estrazione dei dati e all’installazione del data pipeline, allora c’è un problema IT. Se il ritardo extra è associato alla progettazione o configurazione della soluzione, eventualmente fornita da un vendor terzo, allora c’è un problema con la tecnologia stessa. Infine, se dopo due mesi di funzionamento stabilizzato in ambiente simile alla produzione il rollout in produzione non avviene, allora solitamente c’è un problema nella gestione dell’iniziativa.

Quando si cerca di introdurre una novità, un nuovo processo o una nuova tecnologia all’interno di un’organizzazione, il buon senso suggerisce di iniziare in piccolo, assicurarsi che funzioni e costruire sul successo iniziale per espandersi gradualmente. Purtroppo, la supply chain non è gentile con il buon senso, e questa prospettiva si accompagna a una particolarità riguardante la definizione dell’ambito della supply chain. In termini di ambito, ci sono due forze trainanti principali che definiscono in gran parte ciò che è o non è un ambito idoneo per un’iniziativa di supply chain.
Il panorama applicativo è la prima forza che impatta la definizione dell’ambito. Una supply chain nel suo insieme non può essere osservata direttamente; può essere osservata solo indirettamente attraverso le lenti del software enterprise. I dati saranno ottenuti tramite questi pezzi di software. La complessità dell’iniziativa dipende in larga misura dal numero e dalla diversità di questi software. Ogni app è una propria fonte di dati, e estrarre e analizzare i dati da una qualunque app aziendale tende a essere un’impresa significativa. Gestire più app di solito significa dover fronteggiare molteplici tecnologie di database, terminologie incoerenti, concetti inconsistenti e complicare notevolmente la situazione.
Pertanto, nel definire l’ambito dobbiamo riconoscere che le frontiere idonee sono solitamente determinate dalle stesse app aziendali e dalla struttura dei loro database. In questo contesto, iniziare in piccolo va inteso come mantenere l’impronta iniziale dell’integrazione dei dati il più ridotta possibile, preservando al contempo l’integrità dell’iniziativa di supply chain nel suo complesso. È meglio approfondire piuttosto che espandersi in larghezza in termini di integrazione delle app. Una volta che si dispone del sistema IT in grado di ottenere alcuni record da una tabella in una determinata app, di solito è semplice ottenere tutti i record da questa tabella e da un’altra tabella nella stessa app.

Un errore comune nella definizione dell’ambito consiste nel sampling. Il sampling viene solitamente realizzato selezionando una breve lista di categorie di prodotto, siti o fornitori. Il sampling è ben intenzionato, ma non rispetta i confini così come definiti dal panorama applicativo. Per implementare il sampling, devono essere applicati dei filtri durante l’estrazione dei dati, e questo processo crea una serie di problematiche che rischiano di compromettere l’iniziativa di supply chain.
In primo luogo, un’estrazione dei dati filtrata da un software enterprise richiede uno sforzo maggiore da parte del team IT rispetto a un’estrazione non filtrata. I filtri devono essere progettati in primo luogo, e il processo di filtraggio è intrinsecamente soggetto a errori. Il debugging di filtri errati è invariabilmente noioso perché richiede numerosi scambi con i team IT, il che rallenterà l’iniziativa e, di conseguenza, la metterà a rischio.
In secondo luogo, lasciare che l’iniziativa esegua il suo onboarding su un campione di dati è una ricetta per enormi problemi di performance del software man mano che l’iniziativa si espande in seguito verso l’ambito completo. La scarsa scalabilità, o l’incapacità di elaborare una grande quantità di dati mantenendo sotto controllo i costi computazionali, è un difetto molto frequente nel software. Consentendo all’iniziativa di operare su un campione, i problemi di scalabilità vengono mascherati ma ritorneranno con veemenza in una fase successiva.
Operare su un campione di dati rende le statistiche più difficili, non più facili. Infatti, avere accesso a più dati è probabilmente il modo più semplice per migliorare l’accuratezza e la stabilità di quasi tutti gli algoritmi di machine learning. Il sampling dei dati contrasta con questa intuizione. Pertanto, utilizzando un piccolo campione di dati, l’iniziativa potrebbe fallire a causa di comportamenti numerici erratici osservati sul campione. Questi comportamenti sarebbero stati in gran parte mitigati se fosse stato utilizzato l’intero set di dati.
Gli effetti di sistema sono la seconda forza che impatta la definizione dell’ambito. Una supply chain è un sistema, e tutte le sue parti sono collegate in una certa misura. La sfida con i sistemi, qualsiasi sistema, è che i tentativi di migliorare una parte del sistema tendono a spostare i problemi anziché risolverli. Ad esempio, consideriamo un problema di inventory allocation per una rete retail con un centro di distribuzione e molti negozi. Se scegliamo un singolo negozio come ambito iniziale per il nostro problema di inventory allocation, è banale assicurarsi che questo negozio riceva un servizio di altissima qualità dal centro di distribuzione riservandogli in anticipo l’inventario. Facendo ciò, possiamo garantire che il centro di distribuzione non rimanga mai out of stock mentre serve questo negozio. Tuttavia, questa riserva di stock verrebbe fatta a scapito della qualità del servizio per gli altri negozi della rete.
Pertanto, quando si considera un ambito per un’iniziativa di supply chain, dobbiamo tenere conto degli effetti di sistema. L’ambito dovrebbe essere progettato in modo da prevenire in larga misura un’ottimizzazione locale a scapito degli elementi che sono al di fuori dell’ambito. Questa parte dell’esercizio di definizione dell’ambito è difficile perché tutti gli ambiti presentano in una certa misura delle perdite. Ad esempio, tutte le parti della supply chain alla fine concorrono per la stessa quantità di liquidità disponibile a livello aziendale. Ogni dollaro allocato da qualche parte è un dollaro che non sarà disponibile per altri scopi. Tuttavia, alcuni ambiti sono molto più facilmente manipolabili di altri. È importante scegliere un ambito che tenda a mitigare gli effetti di sistema anziché amplificarli.

Pensare alla definizione dell’ambito di un’iniziativa di supply chain in termini di effetti di sistema potrebbe sembrare strano a molti supply chain practitioners. Quando si tratta di definire l’ambito, la maggior parte delle aziende è incline a proiettare la propria organizzazione interna sull’esercizio di definizione dell’ambito. Pertanto, i confini scelti per l’ambito tendono invariabilmente a mimare i confini della divisione del lavoro presenti all’interno dell’azienda. Questo schema è noto come Conway’s Law. Proposto da Melvin Conway mezzo secolo fa per i sistemi di comunicazione, la legge si è poi rivelata avere un’applicabilità molto più ampia, includendo una rilevanza fondamentale per il supply chain management.
I confini e i silos che dominano le supply chain odierne sono guidati da divisioni del lavoro che sono la conseguenza di processi piuttosto manuali in atto per gestire le decisioni della supply chain. Ad esempio, se un’azienda valuta che un supply and demand planner non possa gestire più di 1.000 SKU, e l’azienda ha complessivamente 50.000 SKU da gestire, l’azienda richiederà 50 supply and demand planners per farlo. Eppure, suddividere l’ottimizzazione della supply chain tra 50 coppie di mani è garantito introdurre molte inefficienze a livello aziendale.
Al contrario, un’iniziativa che automatizza queste decisioni non ha bisogno di adattarsi a quei confini che riflettono solo una divisione del lavoro obsoleta o destinata a diventare obsoleta. Una ricetta numerica può ottimizzare contemporaneamente quei 50.000 SKU ed eliminare le inefficienze derivanti dal fatto che dozzine di silos si contendano l’uno contro l’altro. Pertanto, è del tutto naturale che un’iniziativa che intende automatizzare in modo radicale queste decisioni si sovrapponga a molti confini preesistenti in azienda. L’azienda, o meglio il management dell’azienda, deve resistere all’impulso di imitare i confini organizzativi esistenti, soprattutto a livello di definizione dell’ambito, poiché questo tende a impostare il tono per ciò che segue.

Le supply chain sono complesse in termini di hardware, software e persone. Sebbene sia sfortunato, avviare un’iniziativa quantitativa di supply chain aumenta ulteriormente la complessità della supply chain, almeno inizialmente. A lungo termine, in realtà, può ridurre sostanzialmente la complessità della supply chain, ma probabilmente ne parleremo in una lezione successiva. Inoltre, più persone sono coinvolte nell’iniziativa, maggiore è la complessità dell’iniziativa stessa. Se questa complessità extra non viene immediatamente controllata, le probabilità sono molto alte che l’iniziativa collassi per la propria complessità.
Pertanto, quando si pensa ai ruoli dell’iniziativa, cioè a chi farà cosa, dobbiamo considerare il più piccolo insieme possibile di ruoli che renda l’iniziativa fattibile. Minimizzando il numero di ruoli, riduciamo la complessità dell’iniziativa, il che a sua volta migliora notevolmente le possibilità di successo. Questa prospettiva tende ad essere controintuitiva per le grandi aziende che amano operare con una divisione del lavoro estremamente frammentata. Le grandi aziende tendono a favorire specialisti estremi che fanno una sola cosa e niente più. Tuttavia, una supply chain è un sistema, e come tutti i sistemi, conta la prospettiva end-to-end.
Basandoci sull’esperienza acquisita in Lokad nel condurre questo tipo di iniziative, abbiamo identificato quattro ruoli che di solito rappresentano la divisione minima del lavoro necessaria per portare avanti l’iniziativa: un supply chain executive, un data officer, un Supply Chain Scientist, e un supply chain practitioner.
Il ruolo del supply chain executive è di supportare l’iniziativa affinché possa realizzarsi in primo luogo. Ottenere una ricetta numerica ben progettata a guidare le decisioni della supply chain in produzione rappresenta un notevole impulso sia in termini di redditività che di produttività. Tuttavia, si tratta anche di un cambiamento molto grande da assimilare. Occorre molta energia e supporto dal top management affinché tale cambiamento si realizzi in una grande organizzazione.
Il ruolo del responsabile dei dati è di impostare e mantenere il pipeline dei dati. La maggior parte del suo contributo è prevista nei primi due mesi dell’iniziativa. Se il pipeline dei dati è progettato correttamente, ci sarà pochissimo sforzo continuativo per il responsabile dei dati successivamente. Il responsabile dei dati di solito non è molto coinvolto nelle fasi successive dell’iniziativa.
Il ruolo del Supply Chain Scientist è quello di elaborare la ricetta numerica di base. Questo ruolo parte dai dati transazionali grezzi messi a disposizione dal responsabile dei dati. Non ci si aspetta che il responsabile dei dati prepari i dati, ma solo che li estragga. Il ruolo del Supply Chain Scientist si conclude con l’assunzione di responsabilità per la decisione della supply chain generata. Non è un pezzo di software a essere responsabile della decisione; è il Supply Chain Scientist. Per ogni decisione generata, il Supply Chain Scientist stesso deve essere in grado di giustificare perché tale decisione sia adeguata.
Infine, il ruolo del supply chain practitioner è quello di contestare le decisioni generate dalla ricetta numerica e fornire un feedback al Supply Chain Scientist. Al practitioner non è dato sperare di assumere la decisione. Questa persona è stata tipicamente responsabile di tali decisioni finora, almeno per un sottoscopo, e solitamente con l’aiuto di fogli di calcolo e sistemi esistenti. In una piccola azienda, è possibile avere una sola persona che svolga sia il ruolo del supply chain executive sia quello del supply chain practitioner. È anche possibile bypassare la necessità di un responsabile dei dati se i dati sono prontamente accessibili. Questo potrebbe accadere in aziende molto mature per quanto riguarda la loro infrastruttura dati. Al contrario, se l’azienda è molto grande, è possibile avere poche, ma davvero pochissime persone in ogni ruolo.
Il lancio con successo in produzione della ricetta numerica di base ha un notevole impatto sul mondo del supply chain practitioner. Infatti, in larga misura, lo scopo dell’iniziativa è automatizzare il lavoro precedente del supply chain practitioner. Tuttavia, ciò non implica che la strada migliore sia licenziare tali practitioner una volta che la ricetta numerica è in produzione. Riprenderemo questo aspetto specifico nella prossima lezione.

Essere organizzati non significa essere efficienti o efficaci. Esistono ruoli che, pur essendo benintenzionati, creano attriti nelle iniziative della supply chain, spesso al punto di farle fallire del tutto. Oggigiorno, il primo ruolo che maggiormente contribuisce al fallimento di tali iniziative tende a essere quello del data scientist, e ancor di più quando è coinvolto un intero team di data science. Tra l’altro, Lokad ha imparato a proprie spese questo fatto circa un decennio fa.
Nonostante la somiglianza nel nome tra data scientist e supply chain scientist, i due ruoli sono in realtà molto diversi. Il Supply Chain Scientist si preoccupa innanzitutto di fornire decisioni reali e di livello produttivo. Se questo può essere ottenuto con una ricetta numerica semi banale, ancora meglio; la manutenzione sarà semplice. Il Supply Chain Scientist si assume la piena responsabilità di occuparsi dei dettagli più minuziosi della supply chain. L’affidabilità e la resilienza al caos ambientale contano più della sofisticazione.
Al contrario, il data scientist si concentra sugli aspetti intelligenti della ricetta numerica, sui modelli e sugli algoritmi. Il data scientist, in termini generali, si percepisce come un esperto di machine learning e ottimizzazione matematica. In termini di tecnologie, un data scientist è disposto a imparare l’ultima toolkit numerico open-source all’avanguardia, ma questa persona di solito non è propensa a informarsi sull’ERP trentennale che gestisce l’azienda. Inoltre, il data scientist non è un Supply Chain Scientist, né solitamente disposto a diventarlo. Il data scientist cerca di fornire i migliori risultati secondo le metriche concordate. Il data scientist non ha alcuna ambizione di occuparsi dei dettagli più banali della supply chain; tali elementi dovrebbero essere gestiti da altre persone.
Coinvolgere i data scientist significa segnare il destino di queste iniziative perché, non appena vengono coinvolti, la supply chain non è più il fulcro – lo sono invece algoritmi e modelli. Mai sottovalutare il potere distrattivo che l’ultimo modello o algoritmo esercita su una persona intelligente e orientata alla tecnologia.
Il secondo ruolo che tende a creare attriti in un’iniziativa della supply chain è il team di business intelligence (BI). Quando il team BI fa parte dell’iniziativa, tende a rappresentare un ostacolo più che altro, sebbene in misura molto minore rispetto al team di data science. Il problema della BI è per lo più culturale. La BI fornisce report, non decisioni. Il team BI è solitamente disposto a produrre infiniti spazi di metriche, come richiesto da ogni divisione dell’azienda. Questo non è l’atteggiamento giusto per un’iniziativa quantitativa della supply chain.
Inoltre, la business intelligence in quanto software è una classe molto specifica di data analytics incentrata su cubi o OLAP cubes che ti consentono di sezionare e analizzare la maggior parte dei sistemi in-memory nei sistemi aziendali. Questo design solitamente non è affatto adatto a guidare le decisioni della supply chain.

Ora che abbiamo inquadrato l’iniziativa, diamo un’occhiata all’architettura IT di alto livello che essa richiede.
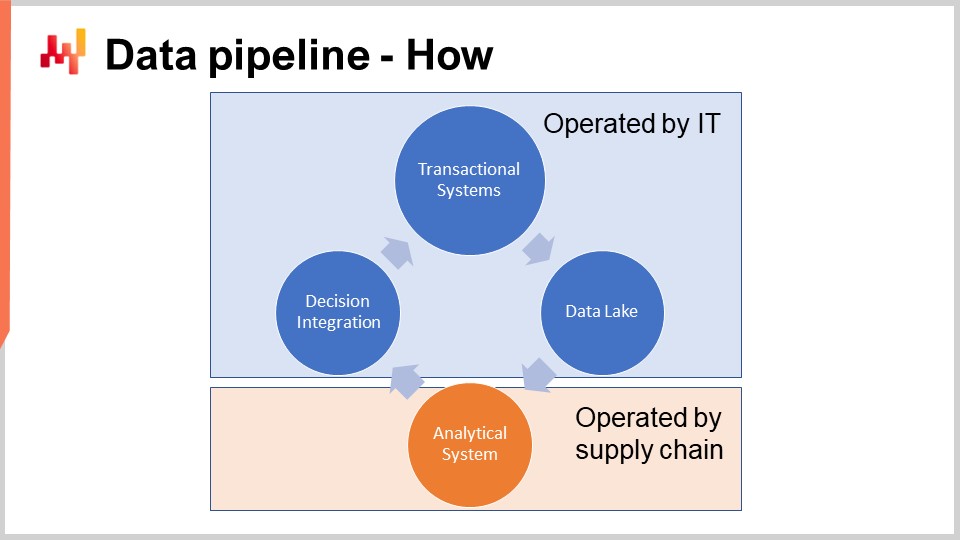
Lo schema sullo schermo illustra una tipica configurazione del pipeline dei dati per un’iniziativa quantitativa della supply chain. In questa lezione, sto discutendo di un pipeline dei dati che non supporta requisiti di bassa latenza. Vogliamo essere in grado di completare un ciclo completo in circa un’ora, non in un secondo. La maggior parte delle decisioni della supply chain, come gli ordini di acquisto, non richiede una configurazione a bassa latenza. Raggiungere una bassa latenza end-to-end richiede un tipo diverso di architettura, che esula dallo scopo della lezione di oggi.

I sistemi transazionali rappresentano la fonte primaria dei dati e il punto di partenza del pipeline dei dati. Questi sistemi includono l’ERP, il WMS e l’EDI. Gestiscono il flusso di merci come acquisti, trasporto, produzione e vendita. Questi sistemi contengono quasi tutti i dati richiesti dalla ricetta numerica di base. Per praticamente ogni azienda di dimensioni rilevanti, questi sistemi o i loro predecessori sono in uso da almeno due decenni.
Poiché questi sistemi contengono quasi tutti i dati di cui abbiamo bisogno, sarebbe allettante implementare la ricetta numerica direttamente in tali sistemi. Infatti, perché no? Integrando la ricetta numerica direttamente nell’ERP, elimineremmo la necessità di impostare l’intero pipeline dei dati. Purtroppo, ciò non funziona a causa del design stesso di questi sistemi transazionali.
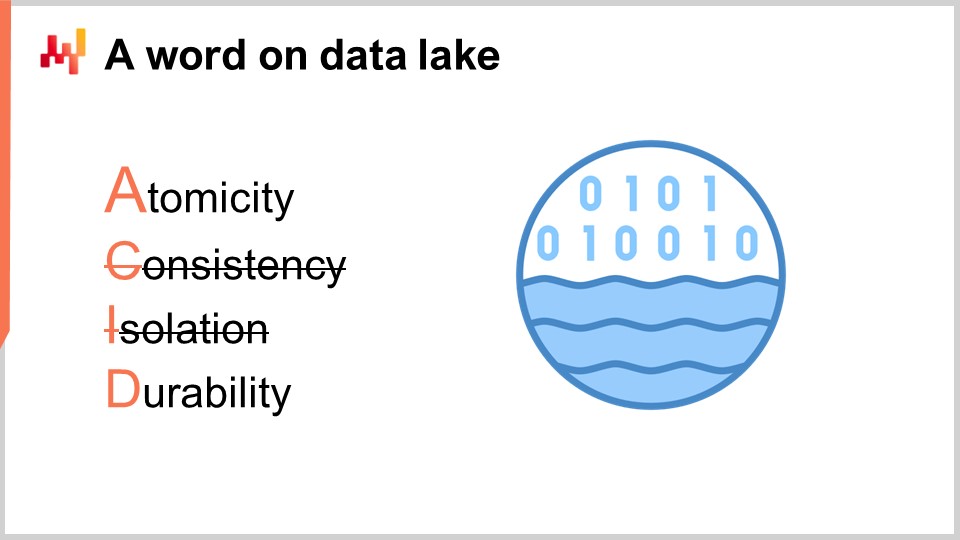
Questi sistemi transazionali sono invariabilmente costruiti con un database transazionale al loro interno. Questo approccio per la progettazione del software aziendale è stato estremamente stabile negli ultimi quattro decenni. Scegli qualsiasi azienda a caso, e probabilmente ogni singola applicazione aziendale in produzione è stata implementata su un database transazionale. I database transazionali offrono quattro proprietà chiave note con l’acronimo ACID, che sta per Atomicità, Coerenza, Isolamento e Durabilità. Non entrerò nei dettagli di queste proprietà, ma basta dire che tali proprietà rendono il database molto adatto a eseguire in modo sicuro e concorrente molte piccole operazioni di lettura e molte piccole operazioni di scrittura. Anche le rispettive quantità di operazioni di lettura e scrittura dovrebbero essere abbastanza bilanciate.
Tuttavia, il prezzo da pagare per queste proprietà ACID molto utili a livello più granulare è che il database transazionale è anche molto inefficiente quando si tratta di gestire grandi operazioni di lettura. Un’operazione di lettura che copre una parte consistente dell’intero database, in linea di massima, se i dati vengono gestiti tramite un database che si concentra su una fornitura molto granulare di tali proprietà ACID, può comportare un costo delle risorse informatiche aumentato di un fattore di 100 rispetto ad architetture che non puntano così tanto su queste proprietà ACID a livello così granulare. ACID è ottimo, ma ha un costo molto elevato.
Inoltre, quando qualcuno tenta di leggere una parte consistente dell’intero database, è probabile che il database diventi temporaneamente non rispondente mentre dedica la maggior parte delle sue risorse a gestire questa grande richiesta. Molte aziende si lamentano del fatto che l’intero sistema aziendale è lento e che tali sistemi spesso si bloccano per un secondo o più. Di solito, questa scarsa qualità del servizio può essere fatta risalire a query SQL pesanti che tentano di leggere troppe righe simultaneamente.
Pertanto, non si può permettere che la ricetta numerica di base operi nello stesso ambiente dei sistemi transazionali che supportano la produzione. Infatti, le ricette numeriche dovranno accedere alla maggior parte dei dati ogni volta che vengono eseguite. Di conseguenza, la ricetta numerica deve essere mantenuta rigorosamente isolata nel suo sottosistema, anche solo per evitare di degradare ulteriormente le prestazioni di quei sistemi transazionali.
Tra l’altro, sebbene sia noto da decenni che è una pessima idea avere un processo intensivo di dati che operi all’interno di un sistema transazionale, ciò non impedisce alla maggior parte dei fornitori di sistemi transazionali (ERP, MRP, WMS) di vendere moduli analitici integrati, per esempio, moduli di ottimizzazione dell’inventario. L’integrazione di tali moduli porta inevitabilmente a problemi di qualità del servizio pur offrendo capacità deludenti. Tutti questi problemi possono essere ricondotti a questo unico problema di design: il sistema transazionale e il sistema analitico devono essere mantenuti in rigorosa isolazione.
Il data lake è semplice. È una replica dei dati transazionali orientata verso operazioni di lettura molto ampie. Infatti, abbiamo visto che i sistemi transazionali sono ottimizzati per molte piccole operazioni di lettura, non per operazioni di lettura molto grandi. Pertanto, per preservare la qualità del servizio del sistema transazionale, il design corretto consiste nel replicare con attenzione i dati transazionali in un altro sistema, cioè il data lake. Questa replicazione deve essere implementata con cura, precisamente per preservare la qualità del servizio del sistema transazional, il che tipicamente significa leggere i dati in modalità molto incrementali ed evitare picchi di pressione sul sistema transazionale.
Una volta che i dati transazionali rilevanti sono replicati nel data lake, lo stesso data lake serve tutte le richieste di dati. Un ulteriore vantaggio del data lake è la sua capacità di servire più sistemi analitici. Mentre qui si discute della supply chain, se il marketing desidera la propria analisi, avrà bisogno degli stessi dati transazionali, e lo stesso vale per finanza, vendite, ecc. Pertanto, invece di avere ogni singolo dipartimento dell’azienda che implementa il proprio meccanismo di estrazione dei dati, ha senso consolidare tutte queste estrazioni in un unico data lake, in un unico sistema.
A livello tecnico, un data lake può essere implementato con un database relazionale, tipicamente ottimizzato per l’estrazione di big data, adottando un’archiviazione dei dati per colonne. I data lake possono anche essere implementati come un repository di file flat serviti tramite un file system distribuito. Rispetto a un sistema transazionale, un data lake rinuncia alle proprietà transazionali a grana fine. L’obiettivo è servire una grande quantità di dati nel modo più economico e affidabile possibile—niente di più, niente di meno.
Il data lake deve rispecchiare i dati transazionali originali, il che significa copiarli senza modificarli. È importante non preparare i dati nel data lake. Sfortunatamente, il team IT incaricato di impostare il data lake può essere tentato di semplificare le cose per altri team e quindi preparare un po’ i dati. Tuttavia, modificare i dati introduce inevitabilmente complicazioni che compromettono l’analisi in una fase successiva. Inoltre, aderire a una rigorosa politica di mirroring diminuisce notevolmente lo sforzo necessario al team IT per impostare e successivamente mantenere il data lake.
Nelle aziende in cui è già presente un team BI, può essere allettante utilizzare i sistemi BI come data lake. Tuttavia, sconsiglio fortemente di farlo e di non usare mai un setup BI come data lake. Infatti, i dati nei sistemi BI (business intelligence systems) sono invariabilmente già fortemente trasformati. Utilizzare i dati BI per guidare decisioni automatizzate della supply chain è una ricetta per problemi di garbage in, garbage out. Il data lake deve essere alimentato solo da fonti di dati primarie come l’ERP, non da fonti di dati secondarie come il sistema BI.
Il sistema analitico è quello che contiene la ricetta numerica di base. È anche il sistema che fornisce tutti i report necessari per strumentare le decisioni stesse. A livello tecnico, il sistema analitico contiene i “pezzi intelligenti”, come gli algoritmi di machine learning e gli algoritmi di ottimizzazione matematica. Sebbene, nella pratica, tali pezzi intelligenti non dominino la base di codice dei sistemi analitici. Di solito, la preparazione dei dati e la strumentazione dei dati richiedono almeno dieci volte più righe di codice rispetto alle parti relative all’apprendimento e all’ottimizzazione.
Il sistema analitico deve essere disaccoppiato dal data lake perché questi due sistemi sono completamente in contrasto in termini di prospettive tecnologiche. In quanto software, ci si aspetta che il data lake sia molto semplice, molto stabile ed estremamente affidabile. Al contrario, ci si aspetta che il sistema analitico sia sofisticato, in costante evoluzione ed estremamente performante in termini di supply chain performance. A differenza del data lake, che deve garantire un uptime quasi perfetto, il sistema analitico non deve necessariamente essere attivo la maggior parte del tempo. Per esempio, se si considerano le decisioni giornaliere di rifornimento dell’inventario, allora il sistema analitico deve eseguire e essere attivo solo una volta al giorno.
In linea di massima, è preferibile che il sistema analitico fallisca nel produrre decisioni piuttosto che generare decisioni errate e farle fluire in produzione. Ritardare le decisioni supply chain di qualche ora, come gli ordini di acquisto, è in genere molto meno grave rispetto a prendere decisioni sbagliate. Dato che il design del sistema analitico tende ad essere fortemente influenzato dai componenti intelligenti in esso contenuti, non c’è necessariamente molto da dire in generale sul design del sistema analitico. Tuttavia, esiste almeno una caratteristica chiave del design che deve essere applicata all’ecosistema: questo sistema deve essere stateless.
Il sistema analitico deve evitare di avere uno stato interno nella misura massima possibile. In altre parole, l’intero ecosistema deve partire dai dati così come presentati dal data lake e terminare con le decisioni supply chain generate, insieme ai report di supporto. Ciò che spesso accade è che, ogni volta che esiste un componente all’interno del sistema analitico che è troppo lento, come un algoritmo di machine learning, è tentante introdurre uno stato, ovvero persistere alcune informazioni dall’esecuzione precedente per accelerare quella successiva. Tuttavia, fare ciò, affidandosi a risultati precedentemente calcolati anziché ricalcolare tutto da zero ogni volta, è pericoloso.
Infatti, avere uno stato all’interno del sistema analitico mette a rischio la decisione. Mentre i problemi relativi ai dati inevitabilmente sorgono e vengono risolti a livello di data lake, il sistema analitico potrebbe comunque restituire decisioni che riflettono un problema già risolto. Ad esempio, se un modello di previsione della domanda viene addestrato su un dataset di vendite corrotto, allora il modello di previsione rimane corrotto fino a quando non viene riaddestrato su una versione fresca e corretta del dataset. L’unico modo per evitare che il sistema analitico subisca gli effetti di problemi di dati già risolti nel data lake è aggiornare tutto ogni volta. Questa è l’essenza di essere stateless.
In linea di massima, se una parte del sistema analitico risulta essere troppo lenta per essere sostituita quotidianamente, allora questa parte deve essere considerata affetta da un problema di prestazioni. Le supply chain sono caotiche, e arriverà un giorno in cui succederà qualcosa – un incendio, un lockdown, un cyber attack – che richiederà un intervento immediato. L’azienda deve essere in grado di aggiornare tutte le sue decisioni supply chain entro un’ora. L’azienda non deve aspettare e rimanere bloccata per 10 ore mentre si svolge la lenta fase di addestramento del machine learning.

Per operare in modo affidabile, il sistema analitico deve essere adeguatamente strumentato. Ed è di questo che trattano il report di data health e i data inspectors. A proposito, tutti questi elementi sono responsabilità della supply chain; non sono responsabilità dell’IT. Il monitoraggio della data health rappresenta la primissima fase di elaborazione dei dati, persino prima della preparazione dei dati in sé, e avviene all’interno del sistema analitico. La data health fa parte della strumentazione della ricetta numerica. Il report di data health indica se è accettabile o meno eseguire la ricetta numerica. Questo report individua anche l’origine del problema dei dati, se presente, per accelerare la sua risoluzione.
Il monitoraggio della data health è una pratica in Lokad. Negli ultimi dieci anni, questa pratica si è rivelata inestimabile per evitare situazioni di garbage in, garbage out che sembrano essere onnipresenti nel mondo del software aziendale. Infatti, quando un’iniziativa di elaborazione dei dati fallisce, spesso si incolpano i dati difettosi. Tuttavia, è importante notare che di solito non viene messo in campo quasi alcuno sforzo di ingegneria per garantire la qualità dei dati fin dall’inizio. La qualità dei dati non cade dal cielo; richiede sforzi di ingegneria.
La data pipeline finora presentata è piuttosto minimalista. Il data mirroring è semplice al massimo, il che è positivo per quanto riguarda la qualità del software. Tuttavia, nonostante questo minimalismo, ci sono ancora molte parti in movimento: molte tabelle, molti sistemi, molte persone. Di conseguenza, ci sono bug ovunque. Questo è software aziendale, e il contrario sarebbe piuttosto sorprendente. Il monitoraggio della data health è stato implementato per aiutare il sistema analitico a sopravvivere al caos ambientale.
La data health non deve essere confusa con il data cleaning. La data health riguarda solo l’assicurarsi che i dati messi a disposizione del sistema analitico siano una rappresentazione fedele dei dati transazionali esistenti nei sistemi transazionali. Non si tenta di correggere i dati; essi vengono analizzati così come sono.
In Lokad, distinguiamo tipicamente la data health di basso livello da quella di alto livello. La data health di basso livello è una dashboard che consolida tutte le anomalie strutturali e volumetriche dei dati, come problemi evidenti quali voci che non rappresentano nemmeno date o numeri ragionevoli, oppure identificativi orfani che mancano delle controparti attese. Tutti questi problemi possono essere individuati e sono in realtà quelli più semplici. Il problema difficile inizia con questioni che non possono essere rilevate perché i dati mancano fin dall’inizio. Ad esempio, se qualcosa va storto durante un’estrazione dei dati e i dati delle vendite estratti da ieri contengono solo la metà delle righe attese, ciò può mettere seriamente in pericolo la produzione. I dati incompleti sono particolarmente insidiosi perché di solito non impediscono alla ricetta numerica di generare decisioni, se non che queste decisioni saranno spazzatura, poiché i dati in ingresso sono incompleti.
Tecnicamente, in Lokad, cerchiamo di mantenere il monitoraggio della data health su un’unica dashboard, e questa dashboard è tipicamente destinata al team IT, poiché la maggior parte dei problemi rilevati dalla data health di basso livello tende ad essere correlata alla data pipeline stessa. Idealmente, il team IT dovrebbe essere in grado di capire a colpo d’occhio se tutto va bene o meno e se non è richiesto alcun ulteriore intervento.

Il monitoraggio della data health di alto livello considera tutte le anomalie a livello di business – elementi che appaiono errati quando osservati da una prospettiva aziendale. La data health di alto livello copre elementi come livelli di stock negativi o quantità minime d’ordine anormalmente elevate. Copre anche aspetti quali prezzi che non hanno senso perché l’azienda opererebbe in perdita o con margini ridicolmente alti. La data health di alto livello si propone di coprire tutti quegli elementi in cui un professionista della supply chain guarderebbe i dati e direbbe: “Non può essere giusto; abbiamo un problema.”
A differenza del report di data health di basso livello, il report di data health di alto livello è destinato principalmente al team della supply chain. Infatti, problemi come quantità minime d’ordine anomale saranno percepiti come tali solo da un professionista della supply chain che conosce adeguatamente l’ambiente aziendale. Lo scopo di questo report è poter dire a colpo d’occhio che tutto va bene e che non è necessario alcun ulteriore intervento.
In precedenza, ho detto che il sistema analitico doveva essere stateless. Ebbene, si scopre che la data health è l’eccezione che conferma la regola. Infatti, molti problemi possono essere identificati confrontando gli indicatori attuali con quelli raccolti nei giorni precedenti. Così, il monitoraggio della data health tipicamente persisterà una sorta di stato, che consiste fondamentalmente in indicatori chiave osservati nei giorni passati, in modo da poter identificare outlier nello stato attuale dei dati. Tuttavia, poiché la data health è una pura attività di monitoraggio, il peggiore che può accadere se c’è un problema a livello di data lake che viene risolto, e poi si hanno echi di problemi passati nello stato della data health, è una serie di falsi allarmi provenienti da quei report. La logica che genera le decisioni supply chain rimane completamente stateless; lo stato riguarda solo una piccola parte della strumentazione.
Il monitoraggio della data health, sia a livello basso che alto, è una questione di compromesso tra il rischio di fornire decisioni errate e il rischio di non fornire decisioni tempestive. Quando si osservano grandi supply chain, non è ragionevole aspettarsi che il 100 per cento dei dati sia corretto – possono verificarsi errori nelle voci transazionali, anche se rari. Pertanto, deve esserci un volume di problemi che sia ritenuto sufficientemente basso affinché la ricetta numerica operi. Il compromesso tra questi due rischi – essere eccessivamente sensibili ai piccoli errori dei dati o essere troppo tolleranti con i problemi dei dati – dipende fortemente dalla struttura economica della supply chain.
In Lokad, elaboriamo e perfezioniamo questi report su base cliente per cliente. Invece di inseguire ogni caso concepibile di corruzione dei dati, il Supply Chain Scientist, che è incaricato di implementare la data health di basso e alto livello e i data inspectors di cui parlerò tra un minuto, cerca di tarare il monitoraggio della data health in modo da essere sensibile ai tipi di problemi che sono realmente dannosi e si verificano effettivamente per la supply chain di interesse.
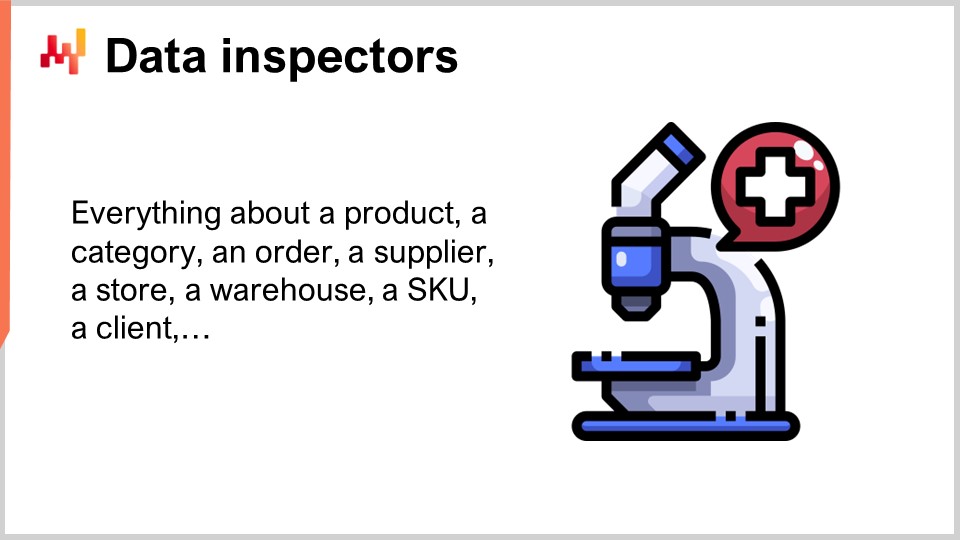
Nel gergo di Lokad, un data inspector, o semplicemente un inspector, è un report che consolida tutti i dati rilevanti riguardanti un oggetto di interesse. L’oggetto di interesse è inteso come uno dei cittadini di prima classe dal punto di vista della supply chain – un prodotto, un fornitore, un cliente, o un warehouse. Ad esempio, se consideriamo un data inspector per i prodotti, allora per ogni prodotto venduto dall’azienda dovremmo essere in grado di vedere, tramite l’inspector, su un’unica schermata tutti i dati ad esso collegati. Nel data inspector per i prodotti, ci sono in effetti tante viste quanti sono i prodotti, perché quando dico che vediamo tutti i dati, intendo tutti i dati collegati a un singolo barcode o numero di parte, non a tutti i prodotti in generale.
A differenza dei report di data health di basso e alto livello, che sono concepiti come due dashboard da ispezionare a colpo d’occhio, gli inspectors sono implementati per rispondere a domande e preoccupazioni che inevitabilmente sorgono durante la progettazione e l’operatività della ricetta numerica di base. Infatti, per prendere una decisione supply chain, non è raro dover consolidare dati provenienti da una dozzina di tabelle, possibilmente originarie di molteplici sistemi transazionali. Poiché i dati sono sparsi ovunque, quando una decisione appare sospetta è solitamente difficile individuare l’origine del problema. Può verificarsi una discrepanza tra i dati visti dal sistema analitico e quelli presenti nel sistema transazionale. Può esserci un algoritmo difettoso che non riesce a rilevare un pattern statistico nei dati. Può esserci una percezione errata, e la decisione ritenuta sospetta potrebbe, in realtà, essere corretta. In ogni caso, l’inspector è studiato per offrire la possibilità di approfondire l’oggetto di interesse.
Per essere utili, gli inspectors devono riflettere le specificità sia della supply chain che del panorama applicativo. Di conseguenza, realizzarli è quasi invariabilmente un’attività su misura. Tuttavia, una volta completato il lavoro, l’inspector rappresenta uno dei pilastri della strumentazione del sistema analitico stesso.
In conclusione, sebbene la maggior parte delle iniziative supply chain quantitative siano destinate a fallire già prima del loro avvio, non deve essere necessariamente così. Una scelta accurata di deliverable, tempistiche, ambito e regole è indispensabile per evitare problemi che inesorabilmente preannunciano il fallimento di tali iniziative. Purtroppo, queste scelte sono frequentemente alquanto controintuitive, come Lokad ha appreso a proprie spese in 14 anni di operatività.
Il principio stesso dell’iniziativa deve essere dedicato all’installazione di una data pipeline. Una data pipeline inaffidabile è uno dei modi più sicuri per garantire che qualsiasi iniziativa basata sui dati fallisca. La maggior parte delle aziende, persino la maggior parte dei dipartimenti IT, sottovaluta l’importanza di una data pipeline altamente affidabile che non richieda continue operazioni d’emergenza. Mentre la maggior parte dell’installazione della data pipeline spetta al dipartimento IT, la supply chain stessa deve essere responsabile della strumentazione del sistema analitico che opera. Non aspettatevi che l’IT lo faccia per voi; questo compito spetta al team della supply chain. Abbiamo osservato due differenti tipi di strumentazione, ossia i report di data health che adottano una prospettiva aziendale a tutto tondo e i data inspectors, che supportano diagnosi approfondite.

Oggi abbiamo discusso di come avviare un’iniziativa, ma la prossima volta vedremo come terminarla o, meglio, come portarla a compimento. Nella prossima lezione, che si terrà mercoledì 14 settembre, proseguiremo il nostro percorso e vedremo quale tipo di esecuzione è necessaria per realizzare una ricetta numerica di base e poi, gradualmente, portare le decisioni generate in produzione. Daremo anche uno sguardo più approfondito a cosa implichi questo nuovo modo di fare supply chain per l’operatività quotidiana dei professionisti della supply chain.
Adesso, diamo un’occhiata alle domande.
Domanda: Perché esattamente sei mesi come limite temporale dopo i quali un’implementazione non viene eseguita correttamente?
Direi che il problema non consiste davvero nell’avere sei mesi come limite temporale. È che, di solito, le iniziative sono destinate a fallire sin dall’inizio. Questo è il problema. Se la tua iniziativa di ottimizzazione predittiva parte con la prospettiva che i risultati saranno consegnati tra due anni, è quasi garantito che l’iniziativa si dissolverà a un certo punto e non riuscirà a produrre nulla in produzione. Se potessi, preferirei che l’iniziativa avesse successo in tre mesi. Tuttavia, sei mesi rappresentano, nella mia esperienza, il tempo minimo per portare una tale iniziativa in produzione. Qualsiasi ulteriore ritardo aumenta il rischio di fallimento dell’iniziativa. È molto difficile comprimere ulteriormente questa tempistica, perché una volta risolti tutti i problemi tecnici, i ritardi rimanenti riflettono il tempo necessario alle persone per mettersi in moto con l’iniziativa.
Domanda: I professionisti della supply chain potrebbero sentirsi frustrati da un’iniziativa che sostituisce la maggior parte del loro carico di lavoro, come il dipartimento acquisti, in contrasto con l’automazione delle decisioni. Come consiglieresti di gestire questa situazione?
Questa è una domanda molto importante, che sarà affrontata sperabilmente nella prossima lezione. Per oggi, ciò che posso dire è che credo che la maggior parte di ciò che gli operatori della supply chain stanno facendo nelle moderne supply chain non sia molto gratificante. Nella maggior parte delle aziende, le persone ricevono un insieme di SKU o codici di parte e poi li ciclicano senza sosta, prendendo tutte le decisioni necessarie. Ciò significa che il loro lavoro consiste essenzialmente nell’osservare un foglio di calcolo e ciclarlo una volta alla settimana o forse una volta al giorno. Questo non è un lavoro appagante.
La risposta breve è che l’approccio di Lokad affronta il problema automatizzando tutti gli aspetti monotoni del lavoro, così che le persone, dotate di una genuina competenza nella supply chain, possano iniziare a mettere in discussione i fondamenti della supply chain. Ciò permette loro di discutere di più con clienti e fornitori per rendere tutto più efficiente. Si tratta di raccogliere intuizioni in modo da poter migliorare la ricetta numerica. Eseguire la ricetta numerica è noioso, e saranno pochissime le persone a rimpiangere i vecchi tempi in cui dovevano ciclare i fogli di calcolo ogni giorno.
Domanda: Gli operatori della supply chain sono tenuti a lavorare con i report sulla salute dei dati per mettere in discussione le decisioni generate dai Supply Chain Scientist?
Gli operatori della supply chain sono tenuti a lavorare con i data inspectors, non con i report sulla salute dei dati. I report sulla salute dei dati sono come una valutazione a livello aziendale che risponde alla domanda se i dati in ingresso al sistema analitico siano validi a sufficienza affinché una ricetta numerica possa operare sul dataset. L’esito del report sulla salute dei dati è una decisione binaria: dare il via libera all’esecuzione della ricetta numerica oppure opporsi, affermando che c’è un problema da risolvere. I data inspectors, che saranno approfonditi nella prossima lezione, rappresentano il punto d’ingresso per gli operatori della supply chain per ottenere intuizioni riguardo a una decisione di supply chain proposta.
Domanda: È fattibile aggiornare un modello analitico, per esempio, impostando una politica di inventario su base giornaliera? Il sistema della supply chain non può rispondere ai cambiamenti quotidiani della politica, altrimenti non introdurrebbe solo rumore nel sistema?
Per rispondere alla prima parte della domanda, aggiornare un modello analitico quotidianamente è certamente fattibile. Per esempio, quando Lokad operava nel 2020 durante i lockdown in Europa, abbiamo assistito a paesi che chiudevano e riaprivano con sole 24 ore di preavviso. Ciò ha creato una situazione estremamente caotica che ha richiesto revisioni immediate e costanti su base giornaliera. Lokad ha operato sotto questa estrema pressione, gestendo lockdown che iniziavano o terminavano quotidianamente in tutta Europa per quasi 14 mesi.
Quindi, aggiornare un modello analitico quotidianamente è fattibile, ma non necessariamente auspicabile. È vero che i sistemi della supply chain hanno molta inerzia, e la prima cosa che una ricetta numerica appropriata deve riconoscere è l’effetto a cricchetto della maggior parte delle decisioni. Una volta ordinata la produzione e consumate le materie prime, non si può annullare la produzione. Bisogna tenere conto che molte decisioni sono già state prese al momento di prenderne di nuove. Tuttavia, quando ci si rende conto che la propria supply chain necessita di un cambiamento drastico nel suo corso d’azione, non ha senso ritardare questa correzione solo per il gusto di rimandare la decisione. Il momento migliore per attuare il cambiamento è proprio adesso.
Riguardo l’aspetto del rumore sollevato nella domanda, tutto dipende dal corretto design delle ricette numeriche. Esistono molti design errati che sono instabili, dove piccole variazioni nei dati generano grandi cambiamenti nelle decisioni, rappresentando l’esito della ricetta numerica. Una ricetta numerica non dovrebbe essere instabile ogni volta che c’è una piccola fluttuazione nella supply chain. Per questo motivo, Lokad ha adottato una prospettiva probabilistica nelle previsioni. Utilizzando una prospettiva probabilistica, i modelli possono essere progettati per essere molto più stabili rispetto a modelli che cercano di catturare la media e diventano instabili ogni volta che si verifica un outlier nella supply chain.
Domanda: Uno dei problemi che affrontiamo nella supply chain con aziende molto grandi è la loro dipendenza da diversi sistemi sorgente. Non è estremamente difficile portare tutti i dati da questi sistemi sorgente in un unico sistema unificato?
Concordo pienamente sul fatto che ottenere tutti i dati rappresenti una sfida significativa per molte aziende. Tuttavia, dobbiamo chiederci perché ciò costituisca una sfida sin dall’inizio. Come ho già accennato, il 99% delle applicazioni aziendali gestite oggi dalle grandi imprese si basa su database transazionali mainstream e ben progettati. Potrebbero ancora esistere alcune implementazioni super legacy in COBOL che operano su archivi binari arcani, ma ciò è raro. La stragrande maggioranza delle applicazioni aziendali, anche quelle implementate negli anni ‘90, si avvale di un database transazionale di produzione pulito come backend.
Una volta che si dispone di un backend transazionale, perché dovrebbe essere difficile copiare questi dati in un data lake? La maggior parte delle volte, il problema è che le aziende non cercano solo di copiare i dati – cercano di fare molto di più. Cercano di preparare e trasformare i dati, complicando spesso eccessivamente il processo. La maggior parte delle configurazioni dei database moderni dispone di funzionalità integrate di mirroring dei dati, che consentono di replicare tutte le modifiche da un database transazionale a un database secondario. Questa è una proprietà integrata in probabilmente i 20 sistemi transazionali più utilizzati sul mercato.
Le aziende tendono a faticare nel consolidare i dati perché cercano di fare troppo, e le loro iniziative collassano sotto il peso della loro stessa complessità. Una volta consolidati i dati, spesso le aziende commettono l’errore di pensare che mettere in collegamento i dati debba essere compito dei team IT, BI o di data science. Il concetto che intendo esprimere è che la supply chain deve essere responsabile delle proprie ricette numeriche, proprio come dovrebbe esserlo il marketing, le vendite e la finanza. Non dovrebbe trattarsi di una divisione di supporto trasversale che cerca di fare questo per l’azienda. Collegare dati provenienti da sistemi differenti richiede tipicamente una notevole quantità di intuizioni aziendali. Le grandi aziende spesso falliscono perché cercano di affidare questo compito a un esperto dei team IT, BI o di data science, quando invece dovrebbe essere realizzato all’interno della divisione interessata.
Grazie mille per il vostro tempo oggi, il vostro interesse e le vostre domande. Ci vediamo la prossima volta dopo l’estate, a settembre.