Echtzeit-Datenexploration mit Slices
Vor zwei Monaten haben wir ein bahnbrechendes neues Feature für Lokad eingeführt: unseren ersten Ansatz zur Echtzeit-Datenexploration. Dieses Feature trägt den Codenamen dashboard slicing und erforderte eine komplette Überarbeitung des Low-Level-Datenverarbeitungs-Back-Ends, das Envision antreibt, um es umzusetzen. Mit dashboard Slices wird jedes Dashboard zu einem umfassenden Nachschlagewerk von Dashboard-Ansichten, die in Echtzeit mit einer Suchleiste erkundet werden können.
Beispielsweise ist es möglich, in Echtzeit von einem Produkt zum nächsten zu wechseln, indem ein Dashboard, das als Produktinspektor gedacht ist und alle Informationen über ein Produkt – einschließlich probabilistischer Nachfrage- und Durchlaufzeitprognosen – an einem Ort zusammenführt, gesliced wird.
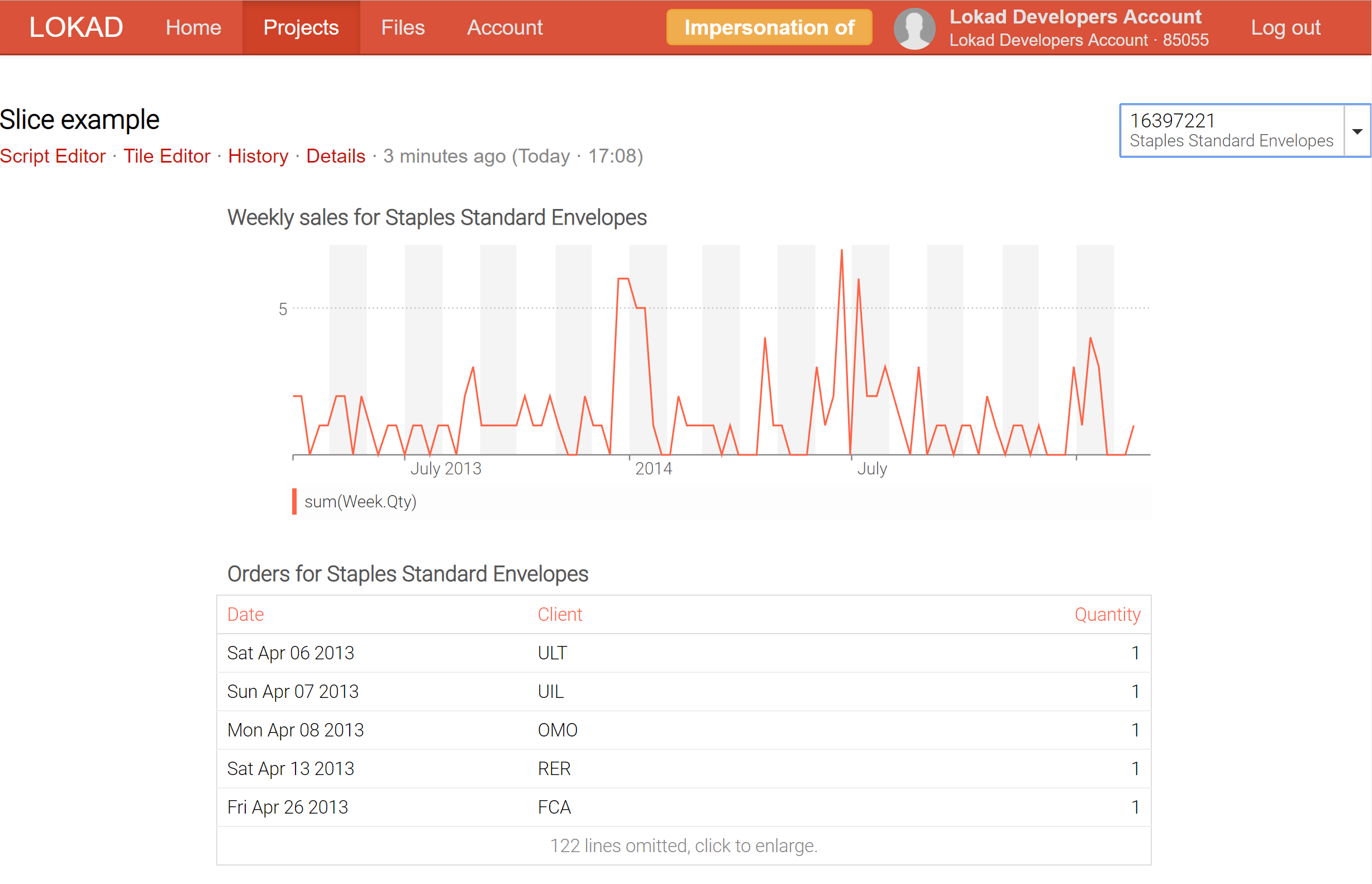
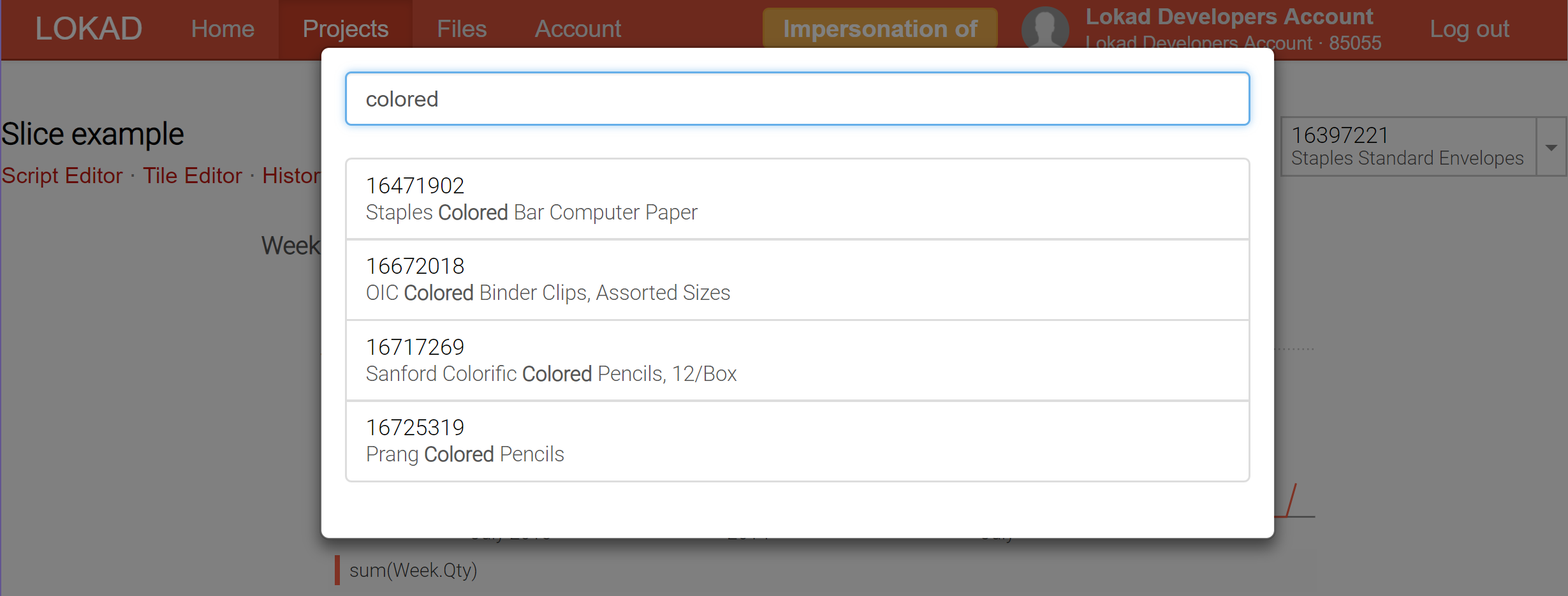
Derzeit unterstützt Lokad die Erstellung von bis zu 200,000 Slices (alias Dashboard-Ansichten) für ein einzelnes Dashboard; und diese Slices können in Echtzeit über den Selektor angezeigt werden, der über eine Echtzeitsuchfunktion verfügt, um die Datenexploration zu erleichtern. Im Gegensatz zu business intelligence (BI)-Tools können diese Slices hochkomplexe Berechnungen enthalten und nicht nur slice-and-dice über einen OLAP-Würfel ausführen.
Wenn es um die Datenverarbeitung und Berichterstattung geht, gibt es typischerweise zwei Lager: Online-Verarbeitung und Batch-Verarbeitung. Bei der Online-Verarbeitung wird ein kontinuierlicher Datenstrom verarbeitet, und es wird in der Regel erwartet, dass alles, was das System anzeigt, stets aktuell ist – das System liegt nicht mehr als wenige Minuten, manchmal gar nur wenige Sekunden, hinter der Realität zurück. OLAP-Würfel und die meisten der als business intelligence bezeichneten Tools fallen in diese Kategorie. Obwohl Echtzeit-Analysen 1 nicht nur aus unternehmerischer Sicht (aktuelle Daten sind besser als stagnierende Daten), sondern auch aus Endanwendersicht (Leistung ist ein Feature) sehr wünschenswert sind, gehen sie mit strengen Einschränkungen einher. Kurz gesagt, es ist überaus schwierig, intelligente Analysen2 in Echtzeit zu liefern. Infolgedessen unterliegen alle Online-Analyse-Systeme erheblichen Beschränkungen hinsichtlich der durchführbaren Analysen.
Andererseits wird Batch-Verarbeitung typischerweise nach einem festen Zeitplan (z.B. tägliche Durchläufe) ausgeführt, während alle historischen Daten (oder ein erheblicher Teil davon) eingespeist werden. Die Aktualität der Ergebnisse wird durch die Frequenz des Zeitplans begrenzt: Ein täglicher Batch liefert stets Ergebnisse, die den Zustand von gestern widerspiegeln, nicht den von heute. Da alle Daten von Beginn an verfügbar sind, ist Batch-Verarbeitung ideal, um alle möglichen Rechenoptimierungen durchzuführen, die die Gesamtleistung des Prozesses erheblich steigern können. Infolgedessen ermöglicht Batch-Verarbeitung die Durchführung ganzer Klassen komplexer Berechnungen, die bei der Betrachtung der Online-Verarbeitung unerreichbar bleiben. Zudem ist Batch-Verarbeitung aus IT-Sicht in der Regel sowohl in der Implementierung als auch im Betrieb 3 wesentlich einfacher. Der Hauptnachteil der Batch-Verarbeitung ist jedoch die durch die gepaarte Natur des Prozesses bedingte Verzögerung.
Als Softwareplattform befindet sich Lokad definitiv im Lager der Batch-Verarbeitung. Tatsächlich erfordert die Optimierung der die Quantitative Supply Chain ein hohes Maß an Reaktivität, jedoch gibt es viele Entscheidungen, die keine sofortige Reaktivität benötigen – wie zum Beispiel die Entscheidung, ob eine zusätzliche Palette von Produkten produziert werden soll oder ob es an der Zeit ist, den Preis zu senken, um einen Lagerbestand zu liquidieren. Bei diesen Entscheidungen steht an erster Stelle, die bestmögliche Entscheidung zu treffen, und wenn diese Entscheidung messbar verbessert werden kann, indem man eine weitere Rechenstunde investiert, ist es nahezu garantiert, dass diese zusätzliche Computerstunde eine lohnende Investition darstellt 4.
Daher ist Envision aus der Perspektive der Batch-Verarbeitung konzipiert. Wir haben etliche Tricks auf Lager, um Envision selbst beim Umgang mit Terabytes an Daten sehr schnell zu machen; allerdings sprechen wir in diesem Maßstab von Ergebnissen innerhalb von Minuten, nicht unter einer Sekunde. Tatsächlich ist es aufgrund der stark verteilten Natur des Envision-Berechnungsmodells für Lokad eine Herausforderung, die Ausführung irgendeines Envision-Skripts in weniger als etwa 5 Sekunden abzuschließen – selbst wenn nur wenige Megabytes an Daten verarbeitet werden. Je verteilter ein System ist, desto mehr interne Trägheit entsteht, um alle Teile zu synchronisieren. Mehr Skalierbarkeit ist der Feind niedriger Latenz.
Vor einigen Jahren haben wir in Envision das Konzept der Eingabeformulare eingeführt: ein Feature, das es ermöglicht, ein konfigurierbares Formular auf dem Dashboard hinzuzufügen, welches als Eingabe für das Envision-Skript dient. So war es beispielsweise unkompliziert, ein Dashboard als Produktinspektor zu entwerfen, das alle relevanten Informationen zu den angegebenen Produkten anzeigt. Leider musste das Envision-Skript neu ausgeführt werden, um das Dashboard an den neu eingegebenen Formularwert anzupassen, was zu mehreren Sekunden Verzögerung führte, bevor die aktualisierten Ergebnisse vorlagen – eine Dauer, die für die Datenexploration inakzeptabel war.
Die Dashboard-Slices (siehe unsere technische Dokumentation) stellen unseren Versuch dar, das Beste aus beiden Welten: Online- und Batch-Verarbeitung zu vereinen. Der Clou ist, dass Lokad nun in der Batch-Verarbeitung eine Vielzahl von Slices berechnen kann (jeder Slice kann ein Produkt, einen Standort, ein Szenario oder eine Kombination all dieser Elemente abbilden) und es Ihnen ermöglicht, in Echtzeit von einem Slice zum anderen zu wechseln, da alles vorkomputiert wurde. Natürlich ist das Vorkomputieren einer großen Anzahl von Slices rechenintensiver, aber nicht so sehr, wie man vielleicht denkt. In der Regel ist es für Lokad günstiger, 10,000 Slices auf einmal zu berechnen, als 100 unabhängige Durchläufe durchzuführen, wobei jeder Durchlauf einem einzelnen Slice gewidmet ist.
Durch Slices gewinnt Lokad Business-Intelligence-on-Steroid-Fähigkeiten: Es ist nicht nur möglich, viele verschiedene Ansichten (z.B. Produkte, Standorte, Zeiträume) in Echtzeit zu erkunden, sondern dies auch ohne die üblichen Einschränkungen von Online-Verarbeitungsarchitekturen.
-
In einem verteilten System gibt es so etwas wie „Echtzeit“ nicht. Selbst die Lichtgeschwindigkeit setzt harte Grenzen für den Grad der Synchronisation eines Systems, das sich über mehrere Kontinente erstreckt. Daher ist diese Terminologie etwas missbräuchlich. Dennoch, wenn die Gesamtlatenz unter etwa einer Sekunde liegt, ist es in der Regel akzeptabel, eine datenverarbeitende Anwendung als „Echtzeit“ zu bezeichnen. ↩︎
-
Selbst fortschrittliche Echtzeit-Datenverarbeitungssysteme, wie sie beispielsweise im autonomen Fahren verwendet werden, vermeiden im Echtzeitbetrieb sorgfältig jede lernende Operation. Alle Machine-Learning-Modelle sind vorkomputiert und statisch. ↩︎
-
Die typische Implementierung eines Batch-Prozesses besteht darin, dass einfache Dateien verschoben werden – eine grundlegende Funktion, die von nahezu jedem System heutzutage unterstützt wird. Aus betrieblicher Sicht löst in der Regel eine einfache Wiederholungsstrategie das Problem, wenn eine Komponente des Batch-Prozesses eine vorübergehende Ausfallzeit erleidet. Im Gegensatz dazu verhalten sich Online-Systeme oft sehr instabil, wenn eine Komponente ausfällt. ↩︎
-
Zum gegenwärtigen Zeitpunkt kostet eine Stunde Rechenleistung auf einer modernen CPU in der Regel weniger als $0.02, wenn man pay-as-you-go auf den dominierenden Cloud-Computing-Plattformen nutzt. Daher, solange die Vorteile, die durch eine einzelne bessere supply chain decision erzielt werden, weitaus mehr wert sind als $0.02, ist es sinnvoll, diese eine Stunde Rechenzeit zu investieren. ↩︎

