Geschäftsintelligenz (BI)
BI (Business Intelligence) bezieht sich auf eine Klasse von Enterprise-Software – gewidmet der Erstellung analytischer Berichte, die hauptsächlich auf den Transaktionsdaten basieren, die durch die verschiedenen Geschäftssysteme, die das Unternehmen für seinen Betrieb nutzt, gesammelt werden. BI soll den Nutzern, die keine IT-Spezialisten sind, Self-Service-Berichtsfähigkeiten bieten. Diese reichen von der Anpassung von Parametern bestehender Berichte bis hin zur Erstellung völlig neuer Berichte. Die meisten großen Unternehmen betreiben mindestens ein BI-System zusätzlich zu ihren Transaktionssystemen, welches häufig ein ERP umfasst.
Ursprung und Motivation
Der moderne analytische Bericht entstand mit den ersten Wirtschaftsvorhersagern1 2, überwiegend in den USA, zu Beginn des 20. Jahrhunderts. Diese frühe Version erwies sich als außerordentlich populär, erhielt mediale Aufmerksamkeit und weitreichende Verbreitung. Diese Popularität zeigte, dass ein ausgeprägtes Interesse an quantitativ dichten Berichten bestand. In den 1980er Jahren begannen viele große Unternehmen, ihre Geschäftsvorgänge als elektronische Aufzeichnungen zu speichern, in Transaktionsdatenbanken abgelegt, typischerweise unter Verwendung erster ERP-Lösungen. Diese ERP Lösungen waren primär dazu gedacht, bestehende Prozesse zu optimieren, um Produktivität und Zuverlässigkeit zu verbessern. Viele erkannten jedoch das enorme ungenutzte Potenzial dieser Aufzeichnungen, und 1983 führte SAP die ABAP3 Programmiersprache ein, die der Erstellung von Berichten auf Basis der im ERP selbst erfassten Daten gewidmet ist.
Allerdings wiesen relationale Datenbanksysteme, wie sie typischerweise in den 1980er Jahren verkauft wurden, zwei wesentliche Einschränkungen bei der Erstellung analytischer Berichte auf. Erstens musste das Design der Berichte von hochqualifizierten IT-Spezialisten durchgeführt werden. Dies machte den Prozess langsam und teuer und schränkte die Vielfalt der möglichen Berichte erheblich ein. Zweitens war die Erstellung der Berichte sehr belastend für die Rechnerhardware. In der Regel konnten Berichte nur nachts (und im Batch-Verfahren) erstellt werden, wenn der Geschäftsbetrieb eingestellt war. Dies spiegelte teilweise die Begrenzungen der damaligen Rechnerhardware wider, aber auch Software-Einschränkungen.
Anfang der 1990er Jahre ermöglichte der Fortschritt in der Rechnerhardware das Aufkommen einer anderen Klasse von Softwarelösungen4, nämlich Business Intelligence-Lösungen. Die Kosten für RAM (Random-Access Memory) waren stetig gesunken, während dessen Speicherkapazität kontinuierlich gestiegen war. Infolgedessen wurde das Speichern einer spezialisierten, kompakteren Version der Geschäftsdaten im Arbeitsspeicher (RAM) für den sofortigen Zugriff zu einer praktikablen Lösung – sowohl aus technologischer als auch aus wirtschaftlicher Sicht. Diese Entwicklungen adressierten die beiden wesentlichen Einschränkungen von Berichtssystemen, wie sie ein Jahrzehnt zuvor implementiert worden waren: Die neueren Software-Frontends waren für Nicht-Spezialisten viel zugänglicher; und die neueren Software-Backends – mit OLAP-Technologien (weiter unten erläutert) – beseitigten einige der größten IT-Beschränkungen. Dank dieser Fortschritte waren BI-Lösungen gegen Ende des Jahrzehnts in großen Unternehmen weit verbreitet.
Als sich die Rechnerhardware weiterentwickelte, entstand in den späten 2000er Jahren eine neue Generation von BI-Tools5. Die relationalen Datenbanksysteme der 1980er Jahre, die nicht in der Lage waren, Berichte komfortabel zu erstellen, wurden in den 2000er Jahren zunehmend fähig, die gesamte Transaktionshistorie eines Unternehmens im RAM zu speichern. Infolgedessen konnten komplexe analytische Abfragen innerhalb von Sekunden ohne dediziertes OLAP-Backend durchgeführt werden. Somit verlagerte sich der Fokus der BI-Lösungen auf das Frontend, wobei noch zugänglichere Web-Benutzeroberflächen – überwiegend SaaS (Software-as-a-Service) – bereitgestellt wurden und immer interaktivere Dashboards zum Einsatz kamen, die die Vielseitigkeit des relationalen Backends nutzten.
OLAP und mehrdimensionale Cubes
OLAP steht für Online Analytical Processing. OLAP wird mit dem Design des Backends einer BI-Lösung in Verbindung gebracht. Der Begriff, von Edgar Codd 1993 geprägt, vereint eine Reihe von Software-Design-Ideen6, von denen die meisten der 1990er Jahre vorausgehen, einige sogar bis in die 1960er Jahre zurückreichen. Diese Designideen waren maßgeblich an der Entstehung von BI als eigenständige Klasse von Softwareprodukten in den 1990er Jahren beteiligt. OLAP ging die Herausforderung an, frische analytische Berichte zeitnah zu erstellen, selbst wenn die bei der Berichtserstellung involvierte Datenmenge zu groß war, um sie zügig zu verarbeiten.
Die einfachste Methode, einen frischen analytischen Bericht zu erstellen, besteht darin, die Daten mindestens einmal zu lesen. Wenn jedoch der Datensatz so groß ist7, dass das vollständige Einlesen Stunden (wenn nicht Tage) dauert, erfordert auch die Erstellung eines frischen Berichts Stunden oder Tage. Um einen aktualisierten Bericht in Sekunden zu generieren, darf die Technik daher nicht beinhalten, den gesamten Datensatz jedes Mal erneut zu lesen, wenn ein Bericht aktualisiert wird.
OLAP schlägt vor, kleinere, kompaktere Datenstrukturen zu nutzen – die die interessanten Berichte widerspiegeln. Diese speziellen Datenstrukturen sollen inkrementell aktualisiert werden, sobald neue Daten verfügbar sind. Dadurch muss das BI-System bei Anforderung eines frischen Berichts nicht den gesamten historischen Datensatz erneut einlesen, sondern lediglich die kompakte Datenstruktur, die alle zur Erstellung des Berichts benötigten Informationen enthält. Darüber hinaus kann, wenn die Datenstruktur klein genug ist, diese im Arbeitsspeicher (RAM) gehalten werden und somit schneller zugänglich sein als der für Transaktionsdaten verwendete permanente Speicher.
Betrachten Sie folgendes Beispiel: Stellen Sie sich ein Einzelhandelsnetz vor, das 100 Hypermarkets betreibt. Der CFO wünscht einen Bericht mit den gesamten Umsätzen in Euro pro Geschäft und Tag der letzten 3 Jahre. Die rohen historischen Verkaufsdaten der letzten 3 Jahre umfassen mehr als 1 Milliarde Datenzeilen (jeder Barcode, der in jedem Geschäft während dieses Zeitraums gescannt wurde) und mehr als 50GB im rohen tabellarischen Format. Eine Tabelle mit 100 Spalten (eine pro Hypermarket) und 1095 Zeilen (3 Jahre * 365 Tage) hat dagegen insgesamt weniger als 0,5MB (bei einem Wert von 4 Bytes pro Zahl). Außerdem können bei jeder Transaktion die entsprechenden Zellen in der Tabelle entsprechend aktualisiert werden. Das Erstellen und Pflegen einer solchen Tabelle veranschaulicht, wie ein OLAP-System im Hintergrund aussieht.
Die oben beschriebenen kompakten Datenstrukturen treten üblicherweise in Form eines OLAP-Würfels auf, der auch als multidimensionaler Würfel bezeichnet wird. Zellen existieren im Würfel an den Kreuzungspunkten der diskreten Dimensionen, die die Gesamtstruktur des Würfels definieren. Jede Zelle enthält ein Maß (oder einen Wert), der aus den ursprünglichen Transaktionsdaten extrahiert wurde und häufig als Fakten-Tabelle bezeichnet wird. Diese Datenstruktur ähnelt den mehrdimensionalen Arrays, die in den meisten gängigen Programmiersprachen zu finden sind. Der OLAP-Würfel eignet sich für effiziente Projektions- oder Aggregationsoperationen entlang der Dimensionen (wie Summierung und Mittelwertbildung), sofern der Würfel klein genug ist, um in den Speicher des Computers zu passen.
Interaktive Berichterstattung und Datenvisualisierung
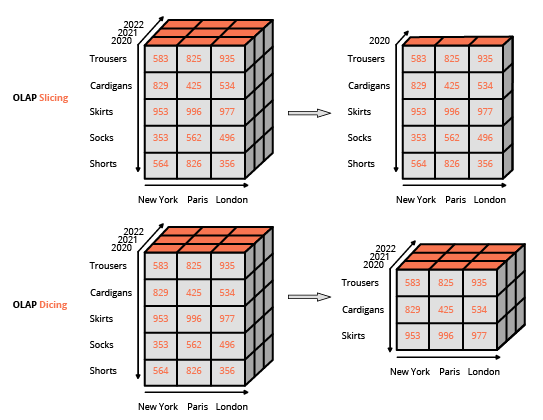
Die Zugänglichmachung von Berichtsfunktionen für Endanwender, die keine IT-Spezialisten sind, war ein wesentlicher Treiber für die Verbreitung von BI-Tools. Daher setzten diese auf ein WYSIWYG-Design (what-you-see-is-what-you-get), das auf reichhaltigen Benutzeroberflächen basiert. Dieser Ansatz unterscheidet sich von der üblichen Methode zur Interaktion mit einer relationalen Datenbank, bei der Abfragen mit einer spezialisierten Sprache (wie SQL) formuliert werden. Die übliche Schnittstelle zur Manipulation eines OLAP-Würfels ist eine Matrixoberfläche, wie z. B. Pivot-Tabellen in einem Tabellenkalkulationsprogramm, die es Benutzern ermöglicht, Filter anzuwenden (in der BI-Terminologie als slice and dice bezeichnet) und Aggregationen durchzuführen (Durchschnitt, Minimum, Maximum, Summe usw.).
Abgesehen von der Verarbeitung besonders großer Datensätze nahm der Bedarf an OLAP-Würfeln in den späten 2000er Jahren parallel zu den enormen Fortschritten in der Rechnerhardware ab. Neue, „dünne“ BI-Tools wurden mit einem ausschließlichen Fokus auf das Frontend eingeführt. Diese dünnen BI-Tools waren primär dafür konzipiert, mit relationalen Datenbanken zu interagieren, im Gegensatz zu ihren „dicken“ Vorgängern, die integrierte Backends mit OLAP-Würfeln nutzten. Diese Entwicklung war möglich, weil die Leistung relationaler Datenbanken zu jener Zeit in der Regel erlaubte, komplexe Abfragen über den gesamten Datensatz in Sekunden auszuführen – wiederum, solange der Datensatz unter einer bestimmten Größe blieb. Dünne BI-Tools können als einheitliche WYSIWYG-Editoren für die verschiedenen von ihnen unterstützten SQL-Dialekte betrachtet werden. (Tatsächlich generieren diese BI-Tools unter der Haube SQL-Abfragen.) Die Haupttechnische Herausforderung bestand in der Optimierung der generierten Abfragen, um die Antwortzeit der zugrunde liegenden relationalen Datenbank zu minimieren.
Die Datenvisualisierungs-Fähigkeiten von BI-Tools waren weitgehend eine Frage der Datenpräsentation auf der Client-Seite, entweder über eine Desktop- oder Web-App. Die Präsentationsmöglichkeiten entwickelten sich stetig weiter, bis in die 2000er Jahre, als die Hardware der Endanwender (z. B. Workstations und Notebooks) – rechnerisch betrachtet – die für Datenvisualisierungszwecke erforderlichen Kapazitäten bei weitem übertraf. Heutzutage sind selbst die aufwendigsten Datenvisualisierungen unaufwendige Prozesse, die im Vergleich zum Verbrauch an Rechnerressourcen, die für die Extraktion und Transformation der zugrunde liegenden Daten benötigt werden, unbedeutend erscheinen.
Die organisatorischen Auswirkungen von BI
Obwohl die Zugänglichkeit ein entscheidender Faktor für die Einführung der meisten BI-Tools war, gestaltet sich die Navigation durch die Datenlandschaft großer Unternehmen als schwierig – allein schon wegen der schieren Vielfalt an verfügbaren Daten. Darüber hinaus spiegelt die Berichtlogik, die Unternehmen über BI-Tools implementieren, oft die Komplexität des Geschäfts wider, sodass die Logik selbst wesentlich weniger zugänglich sein kann als das Tool, das ihre Ausführung unterstützt.
Infolgedessen führte die Einführung von BI-Tools – bei den meisten großen Unternehmen – zur Bildung dedizierter Analyseteams, die in der Regel als unterstützende Funktion neben der IT-Abteilung agieren. Wie das Parkinsonsche Gesetz vorhersagt, dehnt sich die Arbeit so aus, dass sie die für ihre Erledigung zur Verfügung stehende Zeit ausfüllt; diese Teams neigen dazu, im Laufe der Zeit mit der Anzahl der erstellten Berichte zu wachsen, unabhängig von den (wahrgenommenen oder tatsächlichen) Vorteilen, die dem Unternehmen durch den Zugang zu diesen Berichten entstehen.
Technische Grenzen von BI
Wie so oft gibt es einen Trade-off zwischen den Vorzügen bei BI-Tools, was bedeutet, dass eine höhere Zugänglichkeit zulasten der Ausdrucksfähigkeit geht; in diesem Fall sind die auf die Daten angewandten Transformationen auf eine relativ enge Klasse von Filtern und Aggregationen beschränkt. Dies ist die erste wesentliche Einschränkung, da viele – wenn nicht die meisten – Geschäftsfragen mit diesen Operatoren nicht beantwortet werden können (zum Beispiel: Wie hoch ist das Abwanderungsrisiko eines Kunden?). Natürlich ist es möglich, der BI-Benutzeroberfläche erweiterte Operatoren hinzuzufügen, jedoch unterlaufen solche „erweiterten“ Funktionen 8 den ursprünglichen Zweck, das Tool für nicht-technische Nutzer leicht zugänglich zu machen. Dementsprechend ist das Entwerfen fortgeschrittener Datenabfragen nicht anders als das Erstellen von Software – eine Aufgabe, die sich von Natur aus als schwierig erweist. Als anekdotischer Beleg bieten die meisten BI-Tools die Möglichkeit, „rohe“ Abfragen zu schreiben (typischerweise in SQL oder einem SQL-ähnlichen Dialekt) und greifen dabei auf den technischen Ansatz zurück, den das Tool eigentlich eliminieren sollte.
Die zweite wesentliche Einschränkung ist die Performance. Diese Einschränkung manifestiert sich in zwei unterschiedlichen Ausprägungen für dünne und dicke BI-Tools. Dünne BI-Tools enthalten in der Regel eine ausgefeilte Logik zur Optimierung der von ihnen generierten Datenbankabfragen. Diese Tools sind jedoch letztlich durch die Leistung der Datenbank begrenzt, die als Backend dient. Eine scheinbar einfache Abfrage kann sich als ineffizient in der Ausführung erweisen und zu langen Antwortzeiten führen. Ein Datenbankingenieur kann die Datenbank zweifellos modifizieren und verbessern, um dieses Problem zu beheben. Aber auch diese Lösung unterläuft erneut das ursprüngliche Ziel, das BI-Tool für nicht-technische Benutzer zugänglich zu halten.
Dicke BI-Tools sind in ihrer Performance durch das Design der OLAP-Würfel selbst begrenzt. Erstens steigt die für den Speicherbedarf eines mehrdimensionalen Würfels benötigte RAM-Menge rapide an, wenn die Dimensionen des Würfels zunehmen. Selbst eine moderate Anzahl von Dimensionen (z. B. 10) kann zu erheblichen Problemen im Zusammenhang mit dem Speicherbedarf des Würfels führen. Allgemeiner leiden In-Memory-Designs (wobei OLAP-Würfel am häufigsten auftreten) in der Regel unter speicherbezogenen Problemen.
Darüber hinaus ist der Würfel eine verlustbehaftete Darstellung der ursprünglichen Transaktionsdaten: Keine Analyse, die mit dem Würfel durchgeführt wird, kann Informationen wiederherstellen, die von Anfang an verloren gegangen sind. Erinnern Sie sich an das Beispiel des Hypermarkets. In einem solchen Szenario können Warenkörbe in einem Würfel nicht dargestellt werden. Somit gehen die Informationen zum gemeinsamen Kauf verloren. Das gesamte „Würfel“-Design von OLAP schränkt stark ein, welche Daten überhaupt dargestellt werden können; genau diese Einschränkung ermöglicht aber erst die „Online“-Eigenschaft.
Geschäftliche Grenzen von BI
Die Einführung von BI-Tools in einem Unternehmen ist weniger transformativ, als es erscheinen mag. Einfach ausgedrückt, das Erzeugen von Zahlen an sich hat für das Unternehmen keinen Wert, wenn keine Maßnahmen an diese Zahlen gekoppelt sind. Das Design der BI-Tools betont zwar eine „grenzenlose“ Produktion von Berichten, unterstützt jedoch keinen tatsächlichen Handlungsablauf. Tatsächlich erweist sich in den meisten Fällen die spärliche Ausdrucksfähigkeit der BI-Tools als zu einschränkend, wenn es darum geht, irgendetwas auf Basis der BI-Berichte zu automatisieren.
Außerdem neigt das BI-Tool dazu, die bürokratischen Tendenzen großer Unternehmen noch zu verstärken. Anekdotische Beweise, grobe Zahlen und solides Urteilsvermögen sind oft ausreichend, um Prioritäten für ein Unternehmen festzulegen. Die Existenz eines Self-Service-Analyse-Tools – wie BI – bietet jedoch reichlich Gelegenheit zum Aufschieben und zur Vernebelung der Sachlage durch einen endlosen Strom fragwürdiger und nicht umsetzbarer Kennzahlen.
BI-Tools sind anfällig für Design-by-Committee-Probleme, bei denen jedermanns Ideen in das Projekt einbezogen werden. Die selbstbedienende Natur des Tools betont einen äußerst inklusiven Ansatz, wenn es um die Einführung neuer Berichte geht. Infolgedessen neigt die Komplexität der Berichtslandschaft dazu, im Laufe der Zeit zu wachsen, unabhängig von der geschäftlichen Komplexität, die diese Berichte widerspiegeln sollen. Der Begriff Vanity Metrics hat sich weithin etabliert, um Metriken – in der Regel durch ein BI-Tool implementiert – wie diese zu bezeichnen, die nicht zum Geschäftsergebnis eines Unternehmens beitragen.
Lokads Sichtweise
Angesichts der Leistungsfähigkeit moderner Computerhardware ist es einfach, ein Berichtssystem zu verwenden, um 1 Million Zahlen pro Tag zu erzeugen; 10 Zahlen pro Tag, die es wert sind, gelesen zu werden, zu produzieren, ist jedoch schwierig. Während ein BI-Tool, das in kleinen Dosen verwendet wird, für die meisten Unternehmen von Vorteil ist, wird es in größeren Mengen zum Gift.
In der Praxis lassen sich aus BI nur begrenzt Erkenntnisse gewinnen. Die Einführung immer weiterer Berichte führt zu schnell schrumpfenden Erträgen in Bezug auf neue (oder verbesserte) Erkenntnisse, die mit jedem zusätzlichen Bericht gewonnen werden. Denken Sie daran, dass die Tiefe der Datenanalyse, die mit einem BI-Tool zugänglich ist, durch das Design begrenzt ist, da Abfragen über die Benutzeroberfläche für Nicht-Fachleute leicht zugänglich bleiben müssen.
Außerdem bedeutet der Gewinn einer neuen Erkenntnis aus den Daten nicht, dass das Unternehmen sie in etwas Umsetzbares verwandeln kann. BI ist im Kern eine Reporting-Technologie: Sie fordert das Unternehmen nicht zu einer Handlung auf. Das BI-Paradigma ist nicht darauf ausgerichtet, Geschäftsentscheidungen zu automatisieren (nicht einmal die alltäglichen).
Die Lokad-Plattformfunktionen bieten umfangreiche, maßgeschneiderte Reporting-Fähigkeiten, ähnlich wie BI. Im Gegensatz zu BI zielt Lokad jedoch auf die Optimierung von Geschäftsentscheidungen ab, und zwar insbesondere auf solche, die die supply chain betreffen. In der Praxis empfehlen wir, einen Supply Chain Scientist zu beauftragen, der für das Design und die spätere Pflege des numerischen Rezepts verantwortlich ist, das – über Lokad – die supply chain decisions von Interesse generiert.
Anmerkungen
-
Fortune Tellers: The Story of America’s First Economic Forecasters, by Walter Friedman (2013). ↩︎
-
A Selection of Early Prognose & Business Charts, by Walter Friedman (2014) (PDF) ↩︎
-
ABAP ist eine Programmiersprache, die 1983 von SAP veröffentlicht wurde und für Allgemeiner Berichts-Aufbereitungs-Prozessor steht, deutsch für “general report preparation processor”. Diese Sprache wurde als Vorläufer der BI-Systeme eingeführt, um das ERP (ebenfalls SAP genannt) um Reporting-Fähigkeiten zu ergänzen. Ziel von ABAP war es, den mit der Implementierung benutzerdefinierter Berichte verbundenen Entwicklungsaufwand zu verringern. In den 1990er Jahren wurde ABAP als Konfigurations- und Erweiterungssprache für das ERP selbst umfunktioniert. Die Sprache wurde zudem im Englischen in Advanced Business Application Programming umbenannt, um diesen Fokuswechsel widerzuspiegeln. ↩︎
-
BusinessObjects, 1990 gegründet und 2008 von SAP übernommen, ist der Archetyp der BI-Lösungen, die in den 1990er Jahren entstanden sind. ↩︎
-
Tableau, 2003 gegründet und 2019 von Salesforce übernommen, ist der Archetyp der BI-Lösungen, die in den 2000er Jahren entstanden sind. ↩︎
-
The origins of today’s OLAP products, Nigel Pendse, zuletzt aktualisiert im August 2007, ↩︎
-
Die Computerhardware hat sich seit den 1950er Jahren stetig weiterentwickelt. Allerdings wurde es jedes Mal, wenn es billiger wurde, mehr Daten zu verarbeiten, auch billiger, mehr Daten zu speichern. Infolgedessen wächst seit den 1970er Jahren die Menge an Geschäftsdaten fast so schnell wie die Leistungsfähigkeit der Computerhardware. Daher ist das Konzept von „zu vielen Daten“ weitgehend ein sich bewegendes Ziel. ↩︎
-
In den späten 1990er und frühen 2000er Jahren haben viele Softwareunternehmen versucht – und es nicht geschafft –, Programmiersprachen durch visuelle Werkzeuge zu ersetzen. Siehe auch, Lego Programming von Joel Spolsky, Dezember 2006 ↩︎