00:28 Einführung
00:43 Robert A. Heinlein
03:03 Die bisherige Geschichte
06:52 Eine Auswahl von Paradigmen
08:20 Statische Analyse
18:26 Array-Programmierung
28:08 Hardware-Kompatibilität
35:38 Probabilistisches Programmieren
40:53 Differenzierbares Programmieren
55:12 Versionierung von Code+Daten
01:00:01 Sicheres Programmieren
01:05:37 Abschließend lässt sich sagen, dass auch im supply chain das richtige Tooling von Bedeutung ist
01:06:40 Anstehende Vorlesung und Fragen des Publikums
Beschreibung
Während sich die Mainstream supply chain Theorie in Unternehmen nicht durchsetzen kann, hat ein Werkzeug, nämlich Microsoft Excel, erheblichen operativen Erfolg erzielt. Die Neuimplementierung der numerischen Rezepte der Mainstream supply chain Theorie mittels Tabellenkalkulationen ist trivial; dennoch ist dies in der Praxis trotz Kenntnis der Theorie nicht erfolgt. Wir zeigen, dass Tabellenkalkulationen durch den Einsatz von Programmierparadigmen Vorteile gewonnen haben, die sich als überlegen erwiesen, um supply chain Ergebnisse zu erzielen.
Gesamtes Transkript

Hallo zusammen, willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute präsentiere ich meine vierte Vorlesung: Programmierparadigmen für Supply Chain.

Wenn man mich also fragt: “Herr Vermorel, welche Themen interessieren Sie im Bereich supply chain Wissen am meisten?”, dann gehören Programmierparadigmen in der Regel zu meinen wichtigsten Antworten. Und dann, nicht allzu häufig, aber doch oft genug, lautet die Reaktion meines Gesprächspartners: “Programmierparadigmen, Herr Vermorel? Wovon reden Sie da überhaupt? Was hat das überhaupt mit dem vorliegenden Problem zu tun?” Solche Reaktionen kommen zwar nicht allzu oft vor, erinnern mich aber stets an dieses absolut unglaubliche Zitat von Robert A. Heinlein, der als der Dekan der Science-Fiction-Autoren gilt.
Heinlein hat ein fantastisches Zitat über den kompetenten Menschen, das die Bedeutung von Kompetenz in verschiedenen Bereichen hervorhebt, insbesondere im supply chain, wo wir mit schwierigen Problemen konfrontiert sind. Diese Probleme sind fast ebenso herausfordernd wie das Leben selbst, und ich bin der Meinung, dass es sich wirklich lohnt, den Gedanken an Programmierparadigmen zu erforschen, da dies Ihrer supply chain großen Mehrwert bringen könnte.
Bislang haben wir in der ersten Vorlesung gesehen, dass supply chain Probleme äußerst komplex sind. Wer von optimalen Lösungen spricht, verfehlt den Kern der Sache; es gibt nichts, das auch nur annähernd optimal wäre. In der zweiten Vorlesung habe ich die Quantitative Supply Chain skizziert – eine Vision mit fünf zentralen Anforderungen für Exzellenz im supply chain management. Diese Anforderungen sind für sich allein nicht ausreichend, aber sie können nicht umgangen werden, wenn man Größe erreichen möchte.
In der dritten Vorlesung habe ich die Auslieferung von Softwareprodukten im Kontext der supply chain Optimierung thematisiert. Ich verteidigte die These, dass supply chain Optimierung die richtige Ansprache eines Softwareprodukts in kapitalistischer Manier erfordert, jedoch ein solches Produkt nicht im Handel zu finden ist. Es gibt zu viel Vielfalt, und die zu bewältigenden Herausforderungen gehen weit über die Technologien hinaus, die uns derzeit zur Verfügung stehen. Daher wird es zwangsläufig etwas völlig Maßgeschneidertes sein. Wenn es also ein Softwareprodukt sein soll, das speziell für das Unternehmen oder die jeweilige supply chain maßgeschneidert ist, stellt sich die Frage, welche Werkzeuge tatsächlich geeignet sind, um dieses Produkt bereitzustellen. Das führt mich zum heutigen Thema: Das richtige Werkzeug beginnt mit den passenden Programmierparadigmen, denn wir werden dieses Produkt mit der einen oder anderen Methode programmieren müssen.

Bisher benötigen wir programmgesteuerte Fähigkeiten, um uns mit der Optimierungsseite des Problems auseinanderzusetzen – was nicht mit der Management-Seite zu verwechseln ist. Wie ich in meiner vorherigen Vorlesung zeigte, war Microsoft Excel bislang der klare Favorit. Von sehr kleinen bis zu sehr großen Unternehmen ist es allgegenwärtig und wird überall eingesetzt. Selbst in Firmen, die Millionen Dollar in hocheffiziente Systeme investiert haben, dominiert Excel weiterhin – und warum? Weil es die richtigen Programmier-Eigenschaften besitzt. Es ist ausdrucksstark, agil, zugänglich und wartbar. Dennoch ist Excel nicht das Endziel. Ich bin fest davon überzeugt, dass wir weitaus mehr erreichen können, aber wir müssen die richtigen Werkzeuge, die richtige Denkweise, fundierte Einsichten und passende Programmierparadigmen besitzen.

Programmierparadigmen mögen dem Publikum überaus abstrakt erscheinen, doch es handelt sich um ein Studienfeld, das in den letzten fünf Jahrzehnten intensiv erforscht wurde. In diesem Bereich wurde eine enorme Menge an Arbeit geleistet. Es ist zwar einem breiteren Publikum wenig bekannt, doch existieren ganze Bibliotheken, die mit hochwertiger Arbeit zahlreicher Forscher gefüllt sind. Heute werde ich euch daher eine Reihe von sieben Paradigmen vorstellen, die Lokad übernommen hat. Wir haben keine dieser Ideen erfunden; wir haben sie von Personen übernommen, die sie vor uns entwickelt haben. All diese Paradigmen wurden in Lokads Softwareprodukt implementiert, und nach fast einem Jahrzehnt Produktionsbetrieb, in dem wir diese Paradigmen nutzten, bin ich überzeugt, dass sie entscheidend zu unserem bisherigen operativen Erfolg beigetragen haben.

Lasst uns diese Liste mithilfe statischer Analyse durchgehen. Das Problem hier ist Komplexität. Wie geht man in der supply chain mit Komplexität um? Man wird mit Unternehmenssystemen konfrontiert, die Hunderte von Tabellen mit jeweils Dutzenden von Feldern enthalten. Wenn man ein so simples Problem wie die Lager-Auffüllung in einem Lager betrachtet, gibt es unzählige Aspekte zu berücksichtigen. Man kann MOQs, Preisdifferenzierungen, Nachfrageprognosen, Prognosen von Durchlaufzeiten und allerlei Retouren haben. Es können Regallimitierungen, Empfangskapazitätsgrenzen und Verfallsdaten auftreten, die einige Ihrer Chargen obsolet machen. Somit ergeben sich zahllose Faktoren, die in Betracht gezogen werden müssen. In der supply chain ist die Devise “move fast and break things” schlichtweg fehl am Platz. Bestellt man versehentlich Waren im Wert von einer Million Dollar, die überhaupt nicht benötigt werden, ist das ein äußerst kostspieliger Fehler. Man kann nicht ein Stück Software haben, das die supply chain steuert, routinemäßige Entscheidungen trifft und bei einem Fehler Millionen kostet. Wir brauchen etwas, das von Grund auf korrekt konstruiert ist – Fehler sollen nicht erst in der Produktion entdeckt werden. Das unterscheidet sich grundlegend von durchschnittlicher Software, bei der ein Absturz kein kolossales Problem darstellt.
Wenn es um supply chain-Optimierung geht, ist dies nicht dein übliches Problem. Wenn du gerade eine massive, fehlerhafte Bestellung an einen Lieferanten übermittelt hättest, kannst du ihn nicht einfach eine Woche später anrufen und sagen: “Oh, mein Fehler, nein, vergiss das, wir haben das nie bestellt.” Diese Fehler werden eine Menge Geld kosten. Statische Analyse heißt so, weil es darum geht, ein Programm zu analysieren, ohne es auszuführen. Die Idee ist, dass du ein Programm hast, das mit Anweisungen, Schlüsselwörtern und allem geschrieben ist, und ohne es auch nur auszuführen, kannst du bereits feststellen, ob das Programm Probleme aufweist, die fast sicher deine Produktion, besonders deine supply chain-Produktion, negativ beeinflussen würden. Die Antwort lautet ja. Diese Techniken existieren, sie sind implementiert und außerordentlich wertvoll.
Um ein Beispiel zu geben, siehst du auf dem Bildschirm einen Envision-Screenshot. Envision ist eine domänenspezifische Programmiersprache, die von Lokad fast ein Jahrzehnt lang entwickelt wurde und sich der predictive optimization von supply chain widmet. Was du siehst, ist ein Screenshot des Code-Editors von Envision, einer Web-App, die du online zur Bearbeitung von Code nutzen kannst. Die Syntax ist stark von Python beeinflusst. In diesem winzigen Screenshot, der nur vier Zeilen umfasst, veranschauliche ich die Idee, dass, wenn du ein umfangreiches Logikstück für die Lagerbestandsauffüllung in einem Lager schreibst und dabei einige ökonomische Variablen, wie Preisstufen, einführst, eine logische Analyse des Programms zeigt, dass diese Preisstufen keinerlei Beziehung zu den Endergebnissen haben, die das Programm zurückliefert – nämlich den aufzubefüllenden Mengen. Hier liegt ein offensichtliches Problem vor. Du hast eine wichtige Variable, Preisstufen, eingeführt, und diese hat logischerweise keinen Einfluss auf die Endergebnisse. Somit haben wir hier ein Problem, das durch statische Analyse erkannt werden kann. Es ist ein offensichtliches Problem, denn wenn wir Variablen in den Code einführen, die keinerlei Einfluss auf die Ausgabe des Programms haben, erfüllen sie überhaupt keinen Zweck. In diesem Fall stehen uns zwei Möglichkeiten offen: Entweder handelt es sich tatsächlich um toten Code, und das Programm sollte nicht kompilieren (du solltest diesen toten Code einfach entfernen, um die Komplexität zu reduzieren und keine accidentelle Komplexität anzuhäufen), oder es war ein echter Fehler und es gibt eine wichtige ökonomische Variable, die in deine Berechnung hätte einfließen müssen, du hast aber aufgrund von Ablenkung oder aus einem anderen Grund den Ball fallen lassen.
Statische Analyse ist absolut grundlegend, um irgendeinen Grad an Korrektheit per Design zu erreichen. Es geht darum, Dinge schon zur Kompilierzeit zu beheben, wenn du den Code schreibst – noch bevor du die Daten berührst. Falls Probleme beim Ausführen auftreten, werden sie mit hoher Wahrscheinlichkeit in der Nacht geschehen, wenn der nächtliche Batch-Prozess die Lagerbestandsauffüllung steuert. Das Programm läuft vermutlich zu ungewöhnlichen Zeiten, wenn niemand es überwacht, und du möchtest nicht, dass etwas abstürzt, während niemand davor sitzt. Es sollte zu dem Zeitpunkt abstürzen, an dem tatsächlich am Code gearbeitet wird.
Statische Analyse hat viele Zwecke. Zum Beispiel verwenden wir bei Lokad statische Analyse für die WYSIWYG-Bearbeitung von dashboards. WYSIWYG steht für “what you see is what you get.” Stell dir vor, du erstellst ein Dashboard für Berichte mit Liniendiagrammen, Balkendiagrammen, Tabellen, Farben und verschiedenen Stileffekten. Du möchtest dies visuell gestalten können, anstatt den Stil deines Dashboards über Code anzupassen, was sehr umständlich wäre. Alle von dir implementierten Einstellungen werden anschließend wieder in den Code eingespielt – und das geschieht durch statische Analyse.
Ein weiterer Aspekt bei Lokad, der für die gesamte supply chain zwar womöglich nicht von größter Bedeutung ist, aber für die Durchführung des Projekts sicherlich entscheidend, war der Umgang mit einer Programmiersprache namens Envision, die wir entwickeln. Wir wussten von Anfang an, vor fast einem Jahrzehnt, dass Fehler gemacht werden würden. Wir hatten keine Kristallkugel, um von Beginn an die perfekte Vision zu haben. Die Frage war, wie wir sicherstellen können, dass wir diese Designfehler in der Programmiersprache selbst so bequem wie möglich korrigieren können. Hier war Python für mich eine mahnende Geschichte.
Python, das keine neue Sprache ist, wurde erstmals 1991 veröffentlicht – also vor fast 30 Jahren. Die Migration von Python 2 zu Python 3 dauerte der gesamten Community fast ein Jahrzehnt und war ein albtraumhafter Prozess, der für die beteiligten Unternehmen sehr schmerzhaft war. Meiner Auffassung nach besaß die Sprache selbst nicht genügend Konstrukte. Sie war nicht so konzipiert, dass man Programme von einer Version der Programmiersprache auf eine andere migrieren konnte. Es war tatsächlich außerordentlich schwierig, dies auf komplett automatisierte Weise zu bewerkstelligen – und das liegt daran, dass Python nicht mit Blick auf statische Analyse entwickelt wurde. Wenn du eine Programmiersprache für supply chain hast, möchtest du wirklich eine, die in Bezug auf statische Analyse exzellente Qualität besitzt, denn deine Programme werden langfristig eingesetzt. Supply chains haben nicht den Luxus zu sagen: “Wartet drei Monate; wir schreiben den Code einfach neu. Wartet auf uns; die Kavallerie kommt.” Es ist buchstäblich, als würdest du einen Zug reparieren, während er mit voller Geschwindigkeit auf den Schienen fährt, und du willst den Motor reparieren, während der Zug in Betrieb ist. So sieht es aus, wenn man supply chain-Sachen repariert, die tatsächlich in der Produktion sind. Du hast nicht den Luxus, das System einfach anzuhalten – es hält niemals an.

Das zweite Paradigma ist Array-Programmierung. Wir wollen die Komplexität unter Kontrolle halten, da dies ein großes wiederkehrendes Thema in supply chains ist. Wir streben eine Logik an, bei der bestimmte Klassen von Programmierfehlern nicht auftreten. Zum Beispiel setzt du dich, wenn du Schleifen oder Verzweigungen verwendest, die explizit von Programmierern geschrieben wurden, ganzen Klassen von sehr schwierigen Problemen aus. Es wird außerordentlich schwierig, wenn Menschen einfach beliebige Schleifen schreiben können, um Garantien über die Berechnungsdauer zu erhalten. Auch wenn es wie ein Nischenthema erscheinen mag, ist das im supply chain optimization keineswegs der Fall.
In der Praxis, nehmen wir an, dass du eine retail chain hast. Um Mitternacht werden alle Verkäufe aus dem gesamten Netzwerk vollständig konsolidiert, die Daten zusammengeführt und an ein System zur Optimierung übergeben. Dieses System hat genau ein 60-minütiges Zeitfenster, um für jeden einzelnen Laden des Netzwerks die Prognose, Lagerbestandsoptimierung und Umlagerungsentscheidungen durchzuführen. Sobald dies erledigt ist, werden die Ergebnisse an das Lagerverwaltungssystem übermittelt, damit dort mit der Vorbereitung aller Sendungen begonnen werden kann. Die Lastwagen werden beladen, vielleicht um 5:00 Uhr morgens, und bis 9:00 Uhr öffnen die Läden, da die Ware bereits empfangen und in die Regale gestellt wurde.
Allerdings haben Sie ein sehr strenges Timing, und wenn Ihre Berechnung über dieses 60-Minuten-Fenster hinausgeht, setzen Sie die gesamte supply chain execution aufs Spiel. Man möchte nicht in der Produktion erst herausfinden, wie lange Dinge dauern. Wenn Sie Schleifen haben, in denen Menschen entscheiden können, wie viele Iterationen sie durchführen, ist es sehr schwierig, einen Nachweis über die Dauer Ihrer Berechnung zu erbringen. Bedenken Sie, dass es hier um supply chain optimization geht. Sie haben nicht den Luxus, Peer-Review durchzuführen und alles doppelt zu prüfen. Manchmal, bedingt durch die Pandemie, werden einige Länder geschlossen, während andere sehr unregelmäßig wieder öffnen, meist mit einer 24-Stunden-Vorankündigung. Sie müssen unverzüglich reagieren.
Also, array programming ist die Idee, dass Sie direkt auf Arrays operieren können. Wenn wir uns den Codeausschnitt hier ansehen, so handelt es sich um Envision-Code, die DSL von Lokad. Um zu verstehen, was passiert, müssen Sie verstehen, dass wenn ich “orders.amounts” schreibe, dabei eine Variable entsteht und “orders” tatsächlich eine Tabelle im Sinne einer relationalen Tabelle ist, wie in einer Datenbanktabelle. Zum Beispiel wäre hier in der ersten Zeile “amounts” eine Spalte in der Tabelle. In Zeile eins sage ich buchstäblich: Für jede einzelne Zeile der orders-Tabelle nehme ich einfach die “quantity”, welche eine Spalte ist, multipliziere sie mit “price”, und erhalte so eine dritte Spalte, die dynamisch generiert wird und “amount” heißt.
Übrigens wird array programming heutzutage auch als data frame programming bezeichnet. Das Forschungsfeld ist ziemlich alt; es reicht drei oder vier Jahrzehnte, vielleicht sogar vier oder fünf zurück. Es wurde als array programming bezeichnet, auch wenn heutzutage die Leute normalerweise mit dem Konzept der data frames vertrauter sind. In Zeile zwei filtern wir, genau wie in SQL. Wir filtern die Daten, und zufälligerweise enthält die orders-Tabelle ein Datum. Es wird gefiltert, und ich sage “date that is greater than today minus 365”, also in Tagen. Wir behalten die Daten des letzten Jahres und schreiben dann “products.soldLastYear = SUM(orders.amount)”.
Nun, das Interessante ist, dass wir einen natural join zwischen products und orders haben. Warum? Weil jede Bestellzeile mit genau einem Produkt verknüpft ist, und ein Produkt mit null oder mehr Bestellzeilen assoziiert ist. In dieser Konfiguration können Sie direkt sagen: “Ich möchte etwas auf Produktebene berechnen, das einfach die Summe von allem ist, was auf orders-Ebene passiert”, und genau das wird in Zeile neun gemacht. Ihnen mag auffallen, dass die Syntax sehr schlicht ist; es gibt kaum Zufälligkeiten oder technische Feinheiten. Ich würde behaupten, dass dieser Code fast vollständig frei von zufälligen Komplikationen im Hinblick auf data frame programming ist. Dann, in den Zeilen 10, 11 und 12, zeigen wir einfach eine Tabelle auf unserem Dashboard an, was sehr bequem gemacht werden kann: “LIST(PRODUCTS)” und dann “TO(products)”.
Array programming bietet für supply chains viele Vorteile. Zunächst beseitigt es ganze Klassen von Problemen. In Ihren Arrays werden Sie keine Off-by-one-Fehler haben. Es wird viel einfacher sein, die Berechnungen zu parallelisieren und sogar zu verteilen. Das ist sehr interessant, denn es bedeutet, dass Sie ein Programm schreiben können, das nicht auf einer einzelnen lokalen Maschine, sondern direkt auf einer Flotte von Maschinen, die in der Cloud leben, ausgeführt wird – und übrigens genau das wird bei Lokad gemacht. Diese automatische Parallelisierung ist von enormem Interesse.
Sehen Sie, so funktioniert es: Wenn Sie supply chain optimization durchführen, sind Ihre typischen Verbrauchsmuster in Bezug auf die Computerhardware sehr intermittierend. Wenn ich auf das Beispiel zurückkomme, das ich bezüglich des 60-Minuten-Fensters für die Einzelhandelsnetze während der Lagerauffüllung genannt habe, bedeutet das, dass es pro Tag eine Stunde gibt, in der Sie Rechenleistung für all Ihre Berechnungen benötigen, während Sie die übrigen 23 Stunden nicht brauchen. Was Sie also wollen, ist ein Programm, das sich, wenn Sie es ausführen, auf viele Maschinen verteilt und, sobald es fertig ist, all diese Maschinen freigibt, sodass andere Berechnungen durchgeführt werden können. Die Alternative wäre, viele Maschinen zu mieten und den ganzen Tag dafür zu bezahlen, diese aber nur 5 % der Zeit zu nutzen, was sehr ineffizient ist.
Diese Idee, dass man sich schnell und vorhersehbar auf viele Maschinen verteilen und dann die Rechenleistung freigeben kann, erfordert die Cloud in einem Multi-Tenant-Setup und eine Reihe weiterer Aspekte, die Lokad umsetzt. Aber vor allem benötigt es die Kooperation der Programmiersprache selbst. Das ist mit einer generischen Programmiersprache wie Python schlichtweg nicht machbar, da die Sprache sich nicht für einen derart intelligenten und relevanten Ansatz eignet. Das ist mehr als nur ein Trick; es geht buchstäblich darum, Ihre IT-Hardwarekosten um den Faktor 20 zu senken, die Ausführung massiv zu beschleunigen und ganze Klassen potenzieller Fehler in Ihrer supply chain zu beseitigen. Das ist revolutionär.
Array programming existiert bereits in vielen Aspekten, zum Beispiel in NumPy und pandas in Python, die für das data scientist Segment des Publikums so populär sind. Aber meine Frage an Sie ist: Wenn es so wichtig und nützlich ist, warum sind diese Dinge dann nicht First-Class Citizens der Sprache selbst? Wenn alles über NumPy läuft, sollte NumPy ein First-Class Citizen sein. Ich würde sagen, man kann sogar noch besser als NumPy sein. NumPy bezieht sich lediglich auf array programming auf einer einzigen Maschine, aber warum nicht array programming auf einer Flotte von Maschinen durchführen? Es ist viel leistungsfähiger und viel angemessener, wenn Sie eine Cloud mit zugänglicher Hardwarekapazität haben.
Also, was wird der Flaschenhals bei der supply chain optimization sein? Es gibt ein Zitat von Goldratt, das besagt: “Jede Verbesserung, die neben dem Flaschenhals in einer supply chain erzielt wird, ist eine Illusion,” und dem stimme ich voll und ganz zu. Realistisch gesehen, wenn wir supply chain optimization betreiben wollen, wird der Flaschenhals die Menschen sein, und genauer gesagt, die Supply Chain Scientists, die – leider für Lokad und meine Kunden – nicht auf Bäumen wachsen.
Der Flaschenhals sind die Supply Chain Scientists, also die Menschen, die in der Lage sind, numerische Rezepte zu erstellen, welche alle Strategien des Unternehmens, das antagonistische Verhalten von Wettbewerbern berücksichtigen und all diese Intelligenz in etwas Mechanisches umwandeln, das in großem Maßstab ausgeführt werden kann. Die Tragödie der naiven Herangehensweise an data science, als ich mit meiner Promotion begann – die ich übrigens nie abgeschlossen habe – war, dass ich feststellen konnte, dass wirklich jeder im Labor buchstäblich data science betrieb. Die meisten schrieben Code für irgendein fortschrittliches Machine-Learning-Modell, drückten die Eingabetaste und warteten dann. Wenn Sie einen großen Datensatz haben, sagen wir 5–10 Gigabyte, wird es nicht in Echtzeit passieren. Das ganze Labor war also gefüllt mit Menschen, die ein paar Zeilen schrieben, Enter drückten und dann einen Kaffee holten oder etwas online lasen. Dadurch war die Produktivität extrem niedrig.
Als ich meine eigene Firma gründete, war mir klar, dass ich nicht am Ende eine Armee von hochintelligenten Menschen bezahlen wollte, die den größten Teil ihres Tages Coffee-Tassen schwenkend verbringen, während sie darauf warten, dass ihre Programme Ergebnisse liefern, um weitermachen zu können. Theoretisch könnten sie vieles parallelisieren und Experimente durchführen, aber in der Praxis habe ich das nie wirklich gesehen. Intellektuell, wenn man an einer Lösung für ein Problem arbeitet, möchte man seine Hypothese testen und benötigt das Ergebnis, um voranzukommen. Es ist sehr schwer, sich gleichzeitig auf hoch technische Themen zu konzentrieren und mehrere intellektuelle Aufgaben zu verfolgen.
Es gab jedoch einen Silberstreif am Horizont. Data Scientists und jetzt Supply Chain Scientists bei Lokad schreiben nicht tausend Zeilen Code und sagen dann “please run.” Sie fügen normalerweise zwei Zeilen zu einem Skript hinzu, das tausend Zeilen umfasst, und fordern dann den Lauf des Skripts an. Dieses Skript wird gegen exakt dieselben Daten ausgeführt, die paar Minuten zuvor gerade verarbeitet wurden. Es ist fast genau die gleiche Logik, abgesehen von diesen zwei Zeilen. Wie können Sie also Terabytes an Daten in Sekunden statt in mehreren Minuten verarbeiten? Die Antwort lautet: Wenn Sie bei der vorherigen Ausführung des Skripts alle Zwischenschritte der Berechnung aufgezeichnet und im Speicher abgelegt haben (typischerweise auf Solid-State-Drives oder SSDs), welche sehr günstig, schnell und praktisch sind.
Beim nächsten Ausführen Ihres Programms wird das System feststellen, dass es sich fast um dasselbe Skript handelt. Es wird einen Diff-Vergleich durchführen und erkennen, dass der Compute Graph nahezu identisch ist, abgesehen von ein paar Details. In Bezug auf die Daten ist er in der Regel zu 100 % identisch. Manchmal gibt es ein paar Änderungen, aber fast nichts. Das System wird automatisch diagnostizieren, dass nur wenige Dinge neu berechnet werden müssen, sodass Sie die Ergebnisse in Sekunden erhalten. Dies kann die Produktivität Ihres Supply Chain Scientist dramatisch steigern. Sie können von Personen, die Enter drücken und 20 Minuten auf das Ergebnis warten, zu denen übergehen, die Enter drücken und 5 oder 10 Sekunden später das Ergebnis haben und weitermachen.
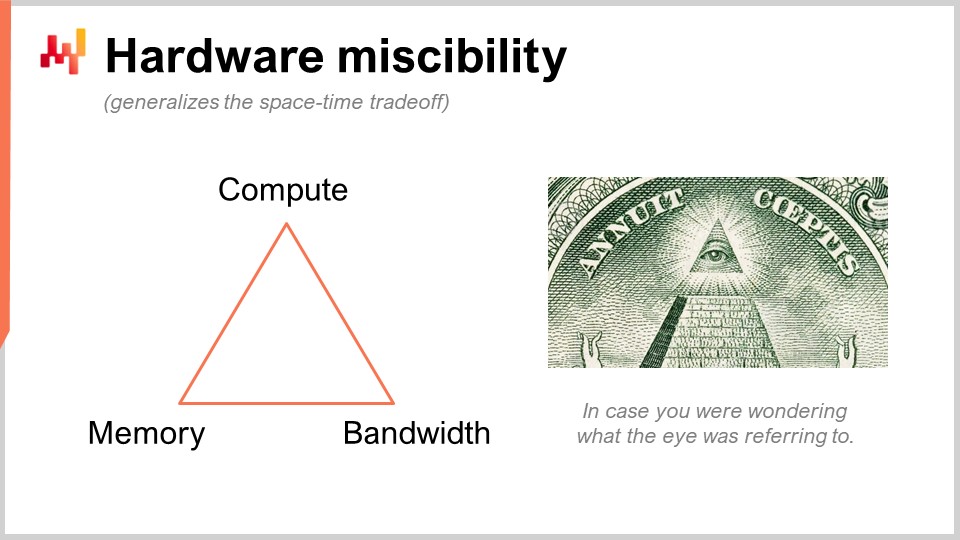
Ich spreche von etwas, das vielleicht sehr obskur erscheint, aber in der Praxis hat es einen 10-fachen Einfluss auf die Produktivität. Das ist enorm. Was wir hier tun, ist ein cleverer Trick, den Lokad nicht erfunden hat. Wir ersetzen eine rohe Rechenressource, nämlich compute, durch eine andere, nämlich Speicher und Storage. Wir haben die grundlegenden Rechenressourcen: compute, memory (entweder flüchtig oder persistent) und Bandbreite. Dies sind die grundlegenden Ressourcen, für die Sie bezahlen, wenn Sie Ressourcen auf einer Cloud-Computing-Plattform mieten. Sie können tatsächlich eine Ressource durch eine andere ersetzen, und das Ziel ist, das beste Preis-Leistungs-Verhältnis zu erzielen.
Wenn Leute sagen, dass man in-memory computing verwenden sollte, würde ich sagen, das ist Quatsch. Wenn Sie von in-memory computing sprechen, bedeutet das, dass Sie einen Design-Schwerpunkt auf eine Ressource im Vergleich zu allen anderen legen. Aber nein, es gibt Kompromisse, und das Interessante ist, dass Sie eine Programmiersprache und Umgebung haben können, die es einfacher macht, diese Kompromisse und Perspektiven umzusetzen. In einer üblichen Allzweck-Programmiersprache ist das zwar möglich, aber Sie müssen es manuell machen. Das bedeutet, dass die Person, die das durchführt, ein professioneller Softwareingenieur sein muss. Ein Supply Chain Scientist wird diese Low-Level-Operationen mit den grundlegenden Rechenressourcen Ihrer Plattform nicht selbst durchführen. Dies muss auf der Ebene der Programmiersprache selbst entwickelt sein.
Nun, sprechen wir über probabilistic programming. In der zweiten Vorlesung, in der ich die Vision für die quantitative supply chain vorstellte, war meine erste Anforderung, dass wir alle möglichen Zukünfte betrachten müssen. Die technische Antwort auf diese Anforderung ist probabilistische Prognoseing. Sie wollen mit Zukünften umgehen, bei denen Wahrscheinlichkeiten eine Rolle spielen. Alle Zukünfte sind möglich, aber sie sind nicht alle gleich wahrscheinlich. Sie benötigen eine Algebra, in der Sie Berechnungen mit Unsicherheit durchführen können. Eine meiner großen Kritiken an Excel ist, dass es außerordentlich schwierig ist, Unsicherheit in einer Tabellenkalkulation darzustellen, unabhängig davon, ob es sich um Excel oder eine modernere cloud-basierte Variante handelt. In einer Tabellenkalkulation ist es sehr schwierig, Unsicherheit darzustellen, weil man etwas Besseres als Zahlen benötigt.
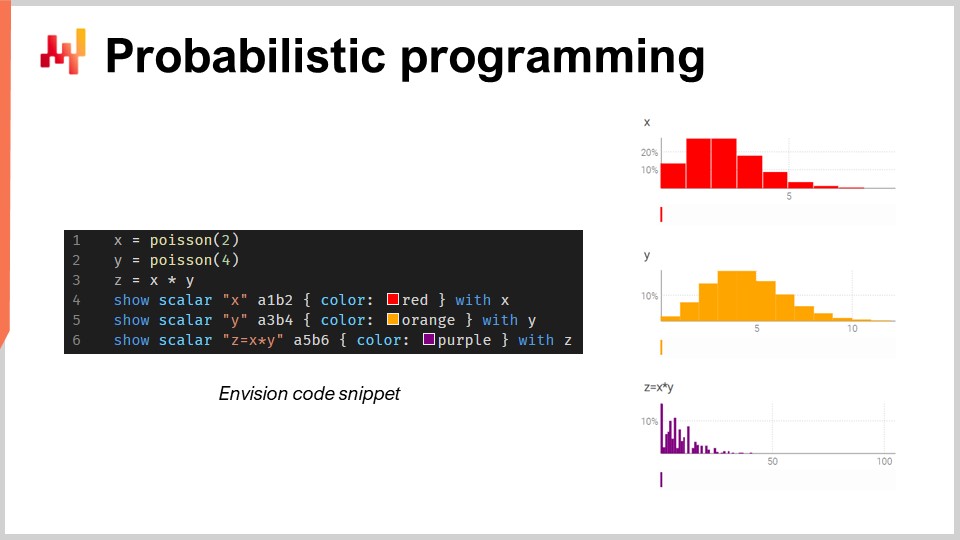
In diesem kleinen Ausschnitt illustriere ich die Algebra von Zufallsvariablen, die eine native Funktion von Envision ist. In Zeile eins erzeuge ich eine diskrete Poisson-Verteilung mit einem Mittelwert von 2 und speichere diese in der Variable X. Dann mache ich dasselbe für eine weitere Poisson-Verteilung, Y. Anschließend berechne ich Z als das Produkt von X mal Y. Dieser Vorgang, die Multiplikation von Zufallsvariablen, mag sehr bizarr erscheinen. Warum braucht man so etwas überhaupt aus der Perspektive der supply chain?
Angenommen, Sie sind im Automotive Aftermarket tätig und verkaufen Bremssättel. Die Leute kaufen Bremssättel nicht einzeln; sie kaufen entweder zwei oder vier. Die Frage ist also: Wenn Sie eine Prognose erstellen möchten, wollen Sie möglicherweise die Wahrscheinlichkeiten vorhersagen, mit denen Kunden tatsächlich erscheinen, um einen bestimmten Typ von Bremssätteln zu kaufen. Das wird Ihre erste Zufallsvariable sein, die Ihnen die Wahrscheinlichkeit liefert, dass null, ein, zwei, drei, vier etc. Einheiten an Nachfrage beobachtet werden. Anschließend haben Sie eine weitere Wahrscheinlichkeitsverteilung, die darstellt, ob Menschen zwei oder vier Bremssättel kaufen. Vielleicht ist es 50–50, oder vielleicht kaufen 10 Prozent zwei und 90 Prozent vier. Tatsache ist, dass Sie diese beiden Aspekte haben, und wenn Sie den tatsächlichen Gesamtverbrauch von Bremssätteln wissen wollen, müssen Sie die Wahrscheinlichkeit, dass ein Kunde für diesen Bremssättel erscheint, mit der Wahrscheinlichkeitsverteilung für den Kauf von entweder zwei oder vier multiplizieren. Somit benötigen Sie diese Multiplikation dieser beiden unsicheren Größen.
Hier gehe ich davon aus, dass die beiden Zufallsvariablen unabhängig sind. Übrigens wird diese Multiplikation von Zufallsvariablen in der Mathematik als diskrete Faltung bezeichnet. Auf dem Screenshot sehen Sie das Dashboard, das von Envision generiert wurde. In den ersten drei Zeilen führe ich diese zufällige Algebra-Berechnung durch, und in den Zeilen vier, fünf und sechs werden diese Ergebnisse auf der Webseite gezeigt, im durch das Skript generierten Dashboard. Ich stelle beispielsweise A1, B2 dar, ähnlich wie in einem Excel-Gitter. Die Lokad-Dashboards sind ähnlich wie Excel-Gitter organisiert, mit Positionen, die die Spalten B, C usw. und die Zeilen 1, 2, 3, 4, 5 haben.
Man sieht, dass die diskrete Faltung, Z, ein sehr bizarr wirkendes, super spitzes Muster aufweist, das in supply chains sehr häufig zu finden ist, wenn Leute Packs, Lose oder Mehrfachkäufe tätigen. In so einer Situation ist es meist besser, die Quellen der multiplikativen Ereignisse, die mit dem Los oder Pack verbunden sind, aufzuschlüsseln. Sie benötigen eine Programmiersprache, die diese Fähigkeiten als First-Class Citizens direkt zur Verfügung stellt. Genau darum geht es bei probabilistic programming, und genau so haben wir es in Envision implementiert.

Nun lasst uns über differenzierbares Programmieren sprechen. Ich muss hier einen Vorbehalt anbringen: Ich erwarte nicht, dass das Publikum wirklich versteht, was vor sich geht, und dafür entschuldige ich mich. Es liegt nicht daran, dass Ihre Intelligenz mangelhaft wäre; es ist nur so, dass dieses Thema eine ganze Vorlesungsreihe verdient. Tatsächlich gibt es, wenn man sich den Plan der kommenden Vorlesungen anschaut, eine ganze Reihe, die sich dem differenzierbaren Programmieren widmet. Ich werde sehr schnell vorgehen, und es wird ziemlich kryptisch, daher entschuldige ich mich im Voraus.
Kommen wir zum für diese Sitzung interessanten supply chain Problem, nämlich Kanibalisierung und Substitution. Diese Probleme sind sehr interessant, und vermutlich genau dort scheitert time series Prognose, das allgegenwärtig ist, auf die brutalste Weise. Warum? Denn häufig kommen Kunden oder Interessenten auf mich zu und fragen, ob wir beispielsweise 13-Wochen-Vorhersagen für bestimmte Artikel wie Rucksäcke erstellen können. Ich würde sagen, ja, das können wir, aber offensichtlich – wenn man einen Rucksack nimmt und die Nachfrage für dieses Produkt vorhersagen will – hängt dies massiv davon ab, was man mit den anderen Rucksäcken macht. Wenn Sie nur einen Rucksack haben, wird sich die gesamte Nachfrage für Rucksäcke vielleicht auf dieses eine Produkt konzentrieren. Führen Sie jedoch 10 verschiedene Varianten ein, wird es offensichtlich zu massiver Kanibalisierung kommen. Sie werden den Gesamtabsatz nicht einfach um den Faktor 10 erhöhen, nur weil Sie die Anzahl der Referenzen verzehnfachen. Offensichtlich finden hier Kanibalisierung und Substitution statt. Diese Phänomene sind in supply chains weit verbreitet.
Wie analysiert man Kanibalisierung oder Substitution? Der Weg, wie wir es bei Lokad machen – und ich behaupte nicht, dass es der einzige Weg ist, aber es funktioniert sicherlich – besteht in der Regel darin, sich das Diagramm anzusehen, das Kunden und Produkte verbindet. Warum ist das so? Denn Kanibalisierung tritt auf, wenn Produkte miteinander um dieselben Kunden konkurrieren. Kanibalisierung bedeutet buchstäblich, dass ein Kunde einen Bedarf hat, aber Präferenzen besitzt und sich aus dem vorhandenen Sortiment, das seinen Vorlieben entspricht, nur für ein Produkt entscheidet. Das ist das Wesentliche der Kanibalisierung.
Wenn Sie das analysieren möchten, müssen Sie nicht die Zeitreihen der Verkäufe untersuchen, da dort diese Informationen gar nicht erfasst werden. Stattdessen sollten Sie den Graphen analysieren, der die historischen Transaktionen zwischen Kunden und Produkten verbindet. Es stellt sich heraus, dass diese Daten in den meisten Unternehmen leicht verfügbar sind. Beim E-Commerce ist das selbstverständlich. Jede Einheit, die Sie verkaufen, ist einem Kunden zugeordnet. Im B2B ist es ähnlich. Sogar im B2C im Einzelhandel besitzen die meisten Handelsketten heutzutage loyalty Programme, bei denen ein zweistelliger Prozentsatz der Kunden, die mit ihrer Karte erscheinen, bekannt ist – so wissen Sie, wer was kauft. Nicht bei 100 % des Verkehrs, aber das reicht für diese Art der Analyse aus.
In diesem relativ kleinen Ausschnitt werde ich eine Affinitätsanalyse zwischen Kunden und Produkten detailliert erläutern. Das ist buchstäblich der grundlegende Schritt, den man gehen muss, um jegliche Art von Kanibalisierungsanalyse durchzuführen. Schauen wir uns an, was in diesem Code passiert.
Von Zeile 1 bis 5 ist alles sehr banal; ich lese einfach eine Flachdatei ein, die die Transaktionshistorie enthält. Ich lese eine CSV-Datei, die vier Spalten hat: Datum, Produkt, Kunde und Menge. Etwas sehr Grundlegendes. Zwar benutze ich nicht einmal alle diese Spalten, aber das soll das Beispiel greifbarer machen. In der Transaktionshistorie gehe ich davon aus, dass die Kunden für all diese Transaktionen bekannt sind. Es ist also ganz alltäglich; ich lese einfach Daten aus einer Tabelle.
In den Zeilen 7 und 8 erstelle ich dann lediglich die Tabelle für Produkte und die Tabelle für Kunden. In einer echten Produktionsumgebung würde ich diese Tabellen normalerweise nicht selbst erstellen, sondern sie aus anderen Flachdateien einlesen. Ich wollte das Beispiel super einfach halten, also extrahiere ich eine Produkttabelle aus den in der Transaktionshistorie beobachteten Produkten und mache dasselbe für die Kunden. Sehen Sie, es ist nur ein Trick, um es einfach zu halten.
Nun befassen sich die Zeilen 10, 11 und 12 mit sogenannten Latin Spaces, was etwas obskurer wird. Zuerst erstelle ich in Zeile 10 eine Tabelle mit 64 Zeilen. Die Tabelle enthält nichts; sie ist lediglich dadurch definiert, dass sie 64 Zeilen hat, und das war’s. Es ist also eine Art Platzhalter, eine triviale Tabelle mit vielen Zeilen und keinen Spalten, die so allein nicht sehr nützlich ist. Dann ist “P” im Grunde ein kartesisches Produkt, also eine mathematische Operation, die alle möglichen Paare bildet. Es ist eine Tabelle, in der Sie für jede Zeile in der Produkttabelle und jede Zeile in der Tabelle “L” eine Zeile haben. Diese Tabelle “P” hat also 64-mal so viele Zeilen wie die Produkttabelle, und ich mache dasselbe für die Kunden. Ich blase diese Tabellen einfach durch diese zusätzliche Dimension – die Tabelle “L” – auf.
Dies wird meine Grundlage für die Latin Spaces sein, die genau das sind, was ich lernen möchte. Was ich lernen möchte, ist, für jedes Produkt einen Latin Space zu haben, der ein Vektor von 64 Werten ist, und für jeden Kunden ebenfalls einen Latin Space von 64 Werten. Wenn ich die Affinität zwischen einem Kunden und einem Produkt bestimmen will, möchte ich einfach das Skalarprodukt der beiden berechnen. Das Skalarprodukt ist einfach die elementweise Multiplikation aller Werte der beiden Vektoren, gefolgt von einer Summierung. Es mag sehr technisch klingen, aber es ist einfach elementweise Multiplikation plus Summe – das ist das Skalarprodukt.
Diese Latin Spaces sind nur schicke Fachbegriffe dafür, einen Raum mit Parametern zu schaffen, die ein wenig erfunden sind, in dem ich einfach lernen möchte. Die gesamte Magie des differenzierbaren Programmierens passiert in nur fünf Zeilen, von Zeile 14 bis 18. Ich habe ein Schlüsselwort, “autodiff”, und “transactions”, was aussagt, dass es sich um eine interessante Tabelle, eine Beobachtungstabelle, handelt. Ich werde diese Tabelle zeilenweise verarbeiten, um meinen Lernprozess zu realisieren. In diesem Block deklariere ich eine Anzahl von Parametern. Die Parameter sind die Dinge, die Sie lernen möchten – wie Zahlen –, deren Werte Sie aber noch nicht kennen. Diese werden einfach zufällig initialisiert, mit Zufallszahlen.
Ich führe “X”, “X*” und “Y” ein. Ich werde nicht im Detail darauf eingehen, was “X*” genau bewirkt; vielleicht in den Fragen. Ich gebe einen Ausdruck zurück, der meine Verlustfunktion darstellt, und das ist die Summe. Die Idee des kollaborativen Filterings oder der Matrixzerlegung besteht einfach darin, Latin Spaces zu erlernen, die alle Verbindungen in Ihrem bipartiten Graphen abbilden. Ich weiß, es klingt ein wenig technisch, aber was wir tun, ist buchstäblich sehr simpel – supply chain-mäßig. Wir lernen die Affinität zwischen Produkten und Kunden.
Ich weiß, dass das Ganze wahrscheinlich super undurchsichtig erscheint, aber bleiben Sie dran, und es wird weitere Vorlesungen geben, in denen ich Ihnen eine fundiertere Einführung dazu gebe. Das Ganze geschieht in nur fünf Zeilen, was wirklich bemerkenswert ist. Wenn ich sage, “fünf Zeilen”, behaupte ich nicht, “Schauen Sie, es sind nur fünf Zeilen, aber ich rufe eigentlich eine Drittanbieter-Bibliothek von gigantischer Komplexität auf, in der ich all die Intelligenz verberge.” Nein, nein, nein. In diesem Beispiel gibt es buchstäblich keine magische Maschine im maschinellen Lernen abgesehen von den beiden Schlüsselwörtern “autodiff” und “params”. “Autodiff” wird verwendet, um einen Block zu definieren, in dem differenzierbares Programmieren stattfindet – und übrigens, in diesem Block kann ich beliebigen Code schreiben, sodass ich buchstäblich unser Programm einfügen kann. Dann deklariere ich mit “params” meine Problemparameter, und das war’s. Sehen Sie, es findet keine opake Magie statt; es gibt keine millionenzeilige Bibliothek im Hintergrund, die die ganze Arbeit übernimmt. Alles, was Sie wissen müssen, steht buchstäblich vor Ihnen – und das ist der Unterschied zwischen einem Programmierparadigma und einer Bibliothek. Das Paradigma ermöglicht Ihnen den Zugang zu scheinbar unglaublich anspruchsvollen Funktionen, wie etwa eine Kanibalisierungsanalyse mit nur wenigen Codezeilen durchzuführen, ohne auf massive Drittanbieter-Bibliotheken zurückgreifen zu müssen, die die Komplexität verbergen. Es hebt das Problem auf ein ganz anderes Level und macht es wesentlich einfacher, sodass etwas, das super kompliziert erscheint, in nur wenigen Zeilen gelöst wird.
Nun ein paar Worte dazu, wie differenzierbares Programmieren funktioniert. Es gibt zwei Erkenntnisse: Eine ist die automatische Differenzierung. Für diejenigen unter Ihnen, die das Glück hatten, eine Ingenieurausbildung zu erhalten, gibt es zwei Wege, Ableitungen zu berechnen. Es gibt die symbolische Ableitung – zum Beispiel, wenn Sie x² haben, berechnen Sie die Ableitung nach x, und es ergibt 2x. Das ist eine symbolische Ableitung. Dann haben Sie die numerische Ableitung: Wenn Sie eine Funktion f(x) haben, die Sie differenzieren möchten, dann gilt f’(x) ≈ (f(x + ε) - f(x)) / ε. Das ist die numerische Ableitung. Beide Methoden sind nicht geeignet für das, was wir hier vorhaben. Die symbolische Ableitung hat Probleme in Bezug auf die Komplexität, da Ihre Ableitung ein Programm sein könnte, das weitaus komplexer ist als das ursprüngliche Programm. Die numerische Ableitung ist numerisch instabil, sodass Sie zahlreiche Probleme mit der Stabilität haben werden.
Die automatische Differenzierung ist eine großartige Idee aus den 70er Jahren, die in den letzten Jahrzehnten von der breiten Masse wiederentdeckt wurde. Es ist die Idee, dass man die Ableitung eines beliebigen Computerprogramms berechnen kann – was unglaublich ist. Noch unglaublicher ist, dass das Programm, das die Ableitung berechnet, die gleiche Rechenkomplexität wie das ursprüngliche Programm besitzt, was beeindruckend ist. Differenzierbares Programmieren ist einfach eine Kombination aus automatischer Differenzierung und den Parametern, die Sie lernen möchten.
Wie lernen Sie also? Wenn Sie die Ableitung haben, können Sie Gradienten zurückführen, und mithilfe des stochastischen Gradientenabstiegs können Sie kleine Anpassungen an den Werten der Parameter vornehmen. Durch diese schrittweise Anpassung über viele Iterationen des stochastischen Gradientenabstiegs nähern Sie sich den Parametern, die sinnvoll sind und das erreichen, was Sie lernen oder optimieren möchten.
Differenzierbares Programmieren kann für Lernprobleme eingesetzt werden – wie das, was ich hier illustriere, bei dem ich die Affinität zwischen meinen Kunden und meinen Produkten erlernen möchte. Es eignet sich aber auch für numerische Optimierungsprobleme, wie die Optimierung unter Nebenbedingungen, und es ist als Paradigma sehr skalierbar. Wie Sie sehen, wurde dieser Aspekt in Envision zu einem erstklassigen Feature gemacht. Übrigens, es gibt noch einige Aspekte in der Envision-Syntax, die in Bearbeitung sind – erwarten Sie also noch nicht exakt diese Funktionen; wir verfeinern noch einige Details. Aber das Wesentliche steht fest. Ich werde nicht auf die Feinheiten der noch in Entwicklung befindlichen Elemente eingehen.

Kommen wir nun zu einem weiteren Problem, das für die Produktionsbereitschaft Ihres Setups relevant ist. Typischerweise begegnet man in der supply chain Optimierung Heisenbugs. Was ist ein Heisenbug? Es ist eine frustrierende Art von Fehler, bei der eine Optimierung durchgeführt wird und dabei unsinnige Ergebnisse produziert. Zum Beispiel hatten Sie eine Batchberechnung zur Bestandsauffüllung in der Nacht, und am Morgen stellen Sie fest, dass einige dieser Ergebnisse unsinnig waren und zu kostspieligen Fehlern führten. Sie möchten nicht, dass das Problem erneut auftritt, also führen Sie Ihren Prozess neu aus. Doch wenn Sie den Prozess neu ausführen, ist das Problem verschwunden. Sie können den Fehler nicht reproduzieren, und der Heisenbug tritt nicht wieder auf.
Es mag wie ein seltsamer Sonderfall klingen, aber in den ersten Jahren bei Lokad traten diese Probleme wiederholt auf. Ich habe viele supply chain Initiativen erlebt – vor allem aus dem Bereich Data Science – die aufgrund ungelöster Heisenbugs scheiterten. Fehler traten in der Produktion auf, man versuchte, die Probleme lokal zu reproduzieren, was jedoch nicht gelang, sodass die Probleme nie behoben wurden. Nach ein paar Monaten im Panikmodus wurde das gesamte Projekt in der Regel stillschweigend eingestellt, und die Leute kehrten zur Nutzung von Excel-Tabellen zurück.
Wenn Sie die vollständige Reproduzierbarkeit Ihrer Logik erreichen möchten, müssen Sie sowohl den Code als auch die Daten versionieren. Die meisten im Publikum, die Softwareingenieure oder Data Scientists sind, kennen vermutlich die Idee, Code zu versionieren. Sie müssen jedoch auch sämtliche Daten versionieren, sodass Sie genau wissen, welche Version von Code und Daten beim Ausführen Ihres Programms verwendet wird. Möglicherweise können Sie das Problem am nächsten Tag nicht reproduzieren, weil sich die Daten aufgrund neuer Transaktionen oder anderer Faktoren verändert haben – sodass die ursprünglichen Bedingungen, welche den Fehler ausgelöst haben, nicht mehr vorliegen.
Sie müssen sicherstellen, dass Ihre Programmierumgebung die Logik und Daten exakt so replizieren kann, wie sie zu einem bestimmten Zeitpunkt in der Produktion waren. Dies erfordert eine vollständige Versionierung von allem. Natürlich müssen dafür die Programmiersprache und der zugrundeliegende Stack zusammenarbeiten. Es ist möglich, dies zu bewerkstelligen, auch wenn das Programmierparadigma nicht als erstklassiger Bestandteil Ihres Stacks gilt – aber dann muss der Supply Chain Scientist äußerst sorgfältig bei allem vorgehen, was er tut und wie er programmiert. Andernfalls wird er seine Ergebnisse nicht reproduzieren können. Das setzt den Supply Chain Scientists enorm unter Druck, die ohnehin schon einem erheblichen Druck seitens der supply chain ausgesetzt sind. Man möchte nicht, dass diese Fachkräfte sich mit zufällig entstehender Komplexität auseinandersetzen müssen, wie zum Beispiel damit, dass sie ihre eigenen Ergebnisse nicht replizieren können. Bei Lokad nennen wir das eine “Zeitmaschine”, mit der Sie alles zu jedem beliebigen Zeitpunkt in der Vergangenheit nachbilden können.
Seien Sie gewarnt – es geht nicht nur darum, das zu replizieren, was letzte Nacht passiert ist. Manchmal entdeckt man einen Fehler erst lange später. Zum Beispiel, wenn Sie bei einem Lieferanten eine Bestellung aufgeben, die eine Vorlaufzeit von drei Monaten hat, stellen Sie möglicherweise erst drei Monate später fest, dass die Bestellung unsinnig war. Dann müssen Sie drei Monate in der Zeit zurückgehen, zu dem Zeitpunkt, an dem Sie diese fehlerhafte Bestellung generiert haben, um herauszufinden, wo das Problem lag. Es geht nicht nur darum, die letzten Stunden der Arbeit zu versionieren; es geht buchstäblich darum, eine vollständige Historie des letzten Jahres der Ausführung zu haben.

Ein weiteres Anliegen ist der Anstieg von Ransomware und Cyberangriffen auf supply chains. Diese Angriffe sind massiv störend und können sehr kostspielig sein. Bei der Implementierung softwaregesteuerter Lösungen müssen Sie berücksichtigen, ob Sie Ihr Unternehmen und Ihre supply chain dadurch anfälliger für Cyberangriffe und Risiken machen. Aus dieser Perspektive sind Excel und Python nicht ideal. Diese Komponenten sind programmierbar, was bedeutet, dass sie zahlreiche Sicherheitslücken mit sich bringen können.
Wenn Sie ein Team von Data Scientists oder Supply Chain Scientists haben, das sich mit supply chain Problemen beschäftigt, können sie sich nicht den sorgfältigen, iterativen Peer-Review-Prozess von Code leisten, der in der Softwarebranche üblich ist. Wenn sich ein Tarif über Nacht ändert oder ein Lager überflutet wird, brauchen Sie eine schnelle Reaktion. Sie können nicht wochenlang Code-Spezifikationen, Reviews und dergleichen erstellen. Das Problem ist, dass Sie Programmierfähigkeiten an Personen weitergeben, die per Definition das Potenzial haben, dem Unternehmen unbeabsichtigt Schaden zuzufügen. Es kann noch schlimmer werden, wenn es einen absichtlich abtrünnigen Mitarbeiter gibt, aber auch wenn man das beiseite lässt, bleibt das Problem, dass jemand versehentlich einen internen Teil der IT-Systeme exponiert. Denken Sie daran, dass supply chain Optimierungssysteme definitionsgemäß Zugriff auf eine große Menge an Daten im gesamten Unternehmen haben. Diese Daten sind nicht nur ein Vermögenswert, sondern auch eine Verbindlichkeit.
Was Sie wollen, ist ein Programmierparadigma, das sicheres Programmieren fördert. Sie möchten eine Programmiersprache, bei der es ganze Klassen von Dingen gibt, die Sie nicht tun können. Zum Beispiel: Warum sollten Sie eine Programmiersprache haben, die Systemaufrufe für supply chain Optimierungszwecke durchführen kann? Python kann Systemaufrufe durchführen, und Excel ebenso. Aber warum sollten Sie von vornherein ein programmierbares System mit solchen Fähigkeiten wünschen? Es ist, als würde man sich eine Waffe kaufen, um sich selbst in den Fuß zu schießen.
Sie wollen etwas, bei dem ganze Klassen oder Funktionen fehlen, weil Sie sie für die supply chain Optimierung nicht benötigen. Wenn diese Funktionen vorhanden sind, werden sie zu einer massiven Verbindlichkeit. Wenn Sie programmierbare Fähigkeiten einführen, ohne die Werkzeuge, die sicheres Programmieren by Design erzwingen, erhöhen Sie das Risiko von Cyberangriffen und Ransomware, was die Situation noch verschlimmert.
Natürlich ist es immer möglich, dies zu kompensieren, indem man die Größe des Cybersecurity-Teams verdoppelt, aber das ist sehr kostspielig und nicht ideal, wenn es zu dringenden supply chain Situationen kommt. Sie müssen schnell und sicher handeln, ohne die Zeit für die üblichen Prozesse, Reviews und Freigaben zu haben. Außerdem wollen Sie sicheres Programmieren, das banale Probleme wie Nullreferenzausnahmen, Out-of-Memory-Fehler, Off-by-One-Schleifen und Seiteneffekte eliminiert.

Zusammenfassend lässt sich sagen, dass die Werkzeuge eine wichtige Rolle spielen. Es gibt ein Sprichwort: “Bring kein Schwert zu einem Feuergefecht.” Sie benötigen die richtigen Werkzeuge und Programmierparadigmen – nicht nur die, die Sie an der Universität gelernt haben. Sie brauchen etwas Professionelles und Produktionsreifes, um den Anforderungen Ihrer supply chain gerecht zu werden. Zwar mag es mit minderwertigen Werkzeugen möglich sein, einige Ergebnisse zu erzielen, aber es wird nicht großartig sein. Ein fantastischer Musiker kann auch nur mit einem Löffel Musik machen, doch mit einem richtigen Instrument gelingt es wesentlich besser.

Nun gehen wir zu den Fragen über. Bitte beachten Sie, dass es eine Verzögerung von etwa 20 Sekunden gibt, sodass zwischen dem Video, das Sie sehen, und meinem Vorlesen Ihrer Fragen eine gewisse Latenz besteht.
Frage: Was ist mit Dynamic Programming im Hinblick auf Operations Research?
Dynamic Programming, trotz des Namens, ist kein Programmierparadigma. Es ist eher eine algorithmische Technik. Die Idee ist, dass wenn Sie eine algorithmische Aufgabe ausführen oder ein bestimmtes Problem lösen wollen, Sie dieselbe Unteroperation sehr häufig wiederholen. Dynamic Programming ist ein spezieller Fall des Raum-Zeit-Kompromisses, den ich zuvor erwähnt habe, bei dem Sie etwas mehr in den Speicher investieren, um Rechenzeit zu sparen. Es war eine der frühesten algorithmischen Techniken und lässt sich bis in die 60er und 70er Jahre zurückverfolgen. Es ist eine gute Methode, aber der Name ist etwas unglücklich, da daran nichts wirklich Dynamisches ist und es nicht wirklich ums Programmieren geht. Für mich qualifiziert es sich daher trotz des Namens nicht als Programmierparadigma; es handelt sich vielmehr um eine spezifische algorithmische Technik.
Frage: Johannes, würdest du bitte einige Referenzbücher nennen, die jeder gute supply chain Engineer haben sollte? Leider bin ich neu auf diesem Gebiet und mein aktueller Fokus liegt auf Data Science und System Engineering.
Ich habe eine sehr zwiespältige Meinung zur bestehenden Literatur. In meiner ersten Vorlesung habe ich zwei Bücher vorgestellt, die ich für den Höhepunkt der akademischen Studien im Bereich supply chain halte. Wenn Sie zwei Bücher lesen möchten, können Sie diese Bücher lesen. Allerdings habe ich konstante Probleme mit den Büchern, die ich bisher gelesen habe. Grundsätzlich gibt es Leute, die Sammlungen von kindlichen numerischen Rezepten für idealisierte supply chains präsentieren, und ich glaube, dass diese Bücher den supply chain nicht aus dem richtigen Blickwinkel betrachten und völlig verfehlen, dass es sich um ein bösartiges Problem handelt. Es gibt eine umfangreiche Literatur, die sehr technisch ist – mit Gleichungen, Algorithmen, Theoremen und Beweisen –, aber ich glaube, sie verfehlt den Kern völlig.
Dann gibt es noch einen anderen Stil von supply chain Management-Büchern, die eher im beraterischen Stil verfasst sind. Diese Bücher erkennt man leicht daran, dass sie auf jeder zweiten Seite Sportanalogien verwenden. Diese Bücher enthalten allerlei vereinfachte Diagramme, wie 2x2-Varianten von SWOT-(Strengths, Weaknesses, Opportunities, Threats)-Diagrammen, die ich als minderwertige Denkansätze betrachte. Das Problem mit diesen Büchern ist, dass sie tendenziell besser darin sind zu verstehen, dass supply chain ein bösartiges Unterfangen ist. Sie verstehen viel besser, dass es ein Spiel ist, das von Menschen gespielt wird, in dem alle möglichen bizarre Dinge passieren können, und dass man in seinen Ansatzweisen klug sein kann. Das muss ich ihnen lassen. Das Problem mit diesen Büchern, die typischerweise von Beratern oder Professoren von Managementschulen geschrieben werden, ist, dass sie nicht sehr umsetzbar sind. Die Botschaft reduziert sich auf “sei ein besserer Leader”, “sei klüger”, “habe mehr Energie” – und für mich ist das nicht umsetzbar. Es liefert Ihnen keine Elemente, die Sie in etwas höchst Wertvolles wie Software umwandeln können.
Also, ich komme zurück zur ersten Vorlesung: Lesen Sie die beiden Bücher, wenn Sie wollen, aber ich bin mir nicht sicher, ob die investierte Zeit es wert ist. Es ist gut zu wissen, was die Leute geschrieben haben. Auf der beraterischen Seite der Literatur ist mein Favorit wahrscheinlich die Arbeit von Katana, die ich in der ersten Vorlesung nicht erwähnt habe. Nicht alles ist schlecht; manche Leute haben mehr Talent, auch wenn sie eher beratungsnah sind. Sie können sich die Arbeit von Katana anschauen; er hat ein Buch über dynamic supply chains. Ich werde das Buch in den Referenzen aufführen.
Frage: Wie nutzen Sie Parallelisierung bei der Bewältigung von Kannibalisierung oder Sortimentsentscheidungen, bei denen das Problem nicht einfach parallelisierbar ist?
Warum ist es nicht einfach parallelisierbar? Stochastischer Gradientenabstieg ist relativ trivial zu parallelisieren. Es gibt stochastische Gradienten-Schritte, die in zufälliger Reihenfolge durchgeführt werden können, und Sie können mehrere Schritte gleichzeitig ausführen. Daher glaube ich, dass alles, was vom stochastischen Gradientenabstieg angetrieben wird, relativ einfach parallelisierbar ist.
Bei Kannibalisierung ist es schwieriger, mit einer anderen Art der Parallelisierung umzugehen, nämlich mit der Frage, was zuerst kommt. Wenn ich dieses Produkt zuerst einführe und dann eine Prognose erstelle, aber anschließend ein anderes Produkt hinzufüge, verändert das die Ausgangslage. Die Lösung besteht darin, das gesamte Szenario frontal anzugehen. Sie sagen nicht: “Zuerst führe ich dieses Produkt ein und erstelle die Prognose; dann füge ich ein anderes Produkt hinzu und erstelle die Prognose erneut, wobei ich die erste verändere.” Sie machen alles gleichzeitig, frontal, alle Elemente auf einmal. Dafür benötigt man weitere Programmierparadigmen. Die heute vorgestellten Programmierparadigmen können hierfür einen langen Weg gehen.
Bei Sortimentsentscheidungen stellen diese Probleme keine großen Schwierigkeiten bei der Parallelisierung dar. Dasselbe gilt, wenn Sie ein weltweites Retail-Netzwerk haben und das Sortiment für alle Ihre Filialen optimieren möchten. Sie können Berechnungen für alle Filialen parallel durchführen. Sie wollen es nicht sequenziell machen, indem Sie das Sortiment für eine Filiale optimieren und dann zur nächsten übergehen. Das ist der falsche Ansatz, aber Sie können das Netzwerk parallel optimieren, alle Informationen übertragen und dann wiederholen. Es gibt viele Techniken, und die Werkzeuge können Ihnen dabei erheblich helfen, dies auf wesentlich einfachere Weise zu realisieren.
Frage: Verwenden Sie einen Graphdatenbank-Ansatz?
Nein, nicht im technischen, kanonischen Sinne. Es gibt viele Graphdatenbanken auf dem Markt, die sehr interessant sind. Was wir intern bei Lokad verwenden, ist eine vollständige vertikale Integration durch einen einheitlichen, monolithischen Compiler-Stack, um alle traditionellen Elemente, die man in einem klassischen Stack finden würde, vollständig zu entfernen. So erreichen wir eine sehr gute Leistung in Bezug auf die Rechenleistung, ganz nah an der Hardware. Nicht, weil wir fantastisch kluge Programmierer sind, sondern einfach, weil wir nahezu alle Schichten eliminiert haben, die traditionell existieren. Lokad verwendet buchstäblich gar keine Datenbank. Wir haben einen Compiler, der sich um alles kümmert – bis hin zur Organisation der Datenstrukturen für die Persistenz. Es ist ein wenig seltsam, aber es ist viel effizienter, es auf diese Weise zu tun, und so arbeiten Sie auch viel besser damit, dass Sie ein Skript für eine Flotte von Maschinen in der Cloud kompilieren. Ihre Zielplattform, was die Hardware betrifft, ist nicht eine Maschine, sondern eine Flotte von Maschinen.
Frage: Was ist Ihre Meinung zu Power BI, das auch Python-Codes und verwandte Algorithmen wie Gradient Descent, Greedy usw. ausführt?
Das Problem, das ich mit allem im Bereich Business Intelligence habe – Power BI ist nur eines davon –, ist, dass es ein Paradigma besitzt, das ich für unzureichend in Bezug auf supply chain halte. Sie betrachten alle Probleme als einen Hyperwürfel, in dem es Dimensionen gibt, die Sie lediglich zerlegen und analysieren. Im Kern liegt ein Problem der Ausdruckskraft, das sehr einschränkend ist. Wenn Sie dann Power BI mit Python in der Mitte verwenden, benötigen Sie Python, weil die Ausdruckskraft des Hyperwürfels sehr gering ist. Um diese Ausdruckskraft wiederzuerlangen, fügen Sie Python hinzu. Denken Sie jedoch an das, was ich in der vorherigen Frage zu diesen Schichten gesagt habe: der Fluch moderner Enterprise Software besteht darin, dass es zu viele Schichten gibt. Jede einzelne Schicht, die Sie hinzufügen, wird Ineffizienzen und Fehler mit sich bringen. Wenn Sie Power BI plus Python verwenden, haben Sie viel zu viele Schichten. Sie haben Power BI, das auf anderen Systemen aufbaut – das heißt, Sie haben bereits mehrere Systeme vor Power BI. Dann kommt Power BI oben drauf, und über Power BI liegt Python. Aber wirkt Python eigenständig? Nein, es ist wahrscheinlich, dass Sie Python-Bibliotheken wie Pandas oder NumPy nutzen. So häufen sich die Schichten in Python, und am Ende haben Sie Dutzende von Schichten. In jeder dieser Schichten können Fehler auftreten, sodass die Situation ziemlich albtraumhaft wird.
Ich bin kein Anhänger jener Lösungen, bei denen man am Ende einfach eine massive Anzahl von Stacks hat. Es gibt den Scherz, dass man in C++ jedes Problem lösen kann, indem man eine weitere Indirectionsebene hinzufügt – selbst das Problem, zu viele Indirectionsebenen zu haben. Offensichtlich ist diese Aussage etwas unsinnig, aber ich lehne den Ansatz, bei dem Produkte mit einem unzureichenden Kerndesign ausgestattet werden und man dann, anstatt das Problem frontal anzugehen, einfach immer mehr Schichten obendrauf packt, während das Fundament wackelig ist, aufs Schärfste ab. Das ist nicht der richtige Weg, und letztlich führt das zu schlechter Produktivität, ständigen Kämpfen mit Fehlern, die nie gelöst werden, und hinsichtlich der Wartbarkeit ist es einfach ein Rezept für einen Albtraum.
Frage: Wie können die Ergebnisse einer Collaborative Filtering-Analyse in den Nachfragevorhersage-Algorithmus für jedes Produkt, beispielsweise Rucksäcke, eingebunden werden?
Es tut mir leid, aber dieses Thema werde ich in der nächsten Vorlesung behandeln. Kurz gesagt: Sie möchten dies nicht in einen bestehenden Vorhersage-Algorithmus einspeisen. Sie wollen etwas, das viel nativ integrierter ist. Sie tun dies nicht und kehren dann zu Ihren alten Vorgehensweisen bei der Prognose zurück; stattdessen verwerfen Sie die alte Methode der Prognose und machen etwas radikal Anderes, das darauf aufbaut. Aber ich werde das in einer späteren Vorlesung besprechen. Für heute wäre das zu viel.
Ich denke, das war’s für diese Vorlesung. Vielen Dank an alle, die teilgenommen haben. Die nächste Vorlesung findet am Mittwoch, den 6. Januar, zur gleichen Zeit und am gleichen Wochentag statt. Ich werde ein paar Weihnachtsferien machen, daher wünsche ich allen frohe Weihnachten und ein gutes neues Jahr. Unsere Vorlesungsreihe setzen wir im nächsten Jahr fort. Vielen Dank.


