Las especies del forecast: clasificación vs. regresión
La palabra forecasting abarca un espectro muy amplio de procesos, tecnologías e incluso mercados. En el pasado, introdujimos los mundos del forecasting software, distinguiendo entre:
- Software de simulación determinista
- Software de agregación de expertos
- Software de Statistical forecasting
Lokad se encuentra en la última categoría, ya que nuestra tecnología es puramente estadística. Sin embargo, Lokad está lejos de cubrir todo el espectro estadístico por sí solo. Existen dos amplias categorías de forecast en statistical forecasting (*):
- Forecast de clasificación
- Forecast de regresión
(*) Estamos simplificando aquí por el bien de la claridad, ya que las sutilezas del statistical learning están muy por fuera del alcance de este modesto post del blog.
La clasificación intenta separar (o clasificar) objetos de acuerdo con sus propiedades. La ilustración a continuación de Tomasz Malisiewicz ilustra una tarea de clasificación que trata de separar imágenes que muestran una silla de imágenes que muestran una mesa.
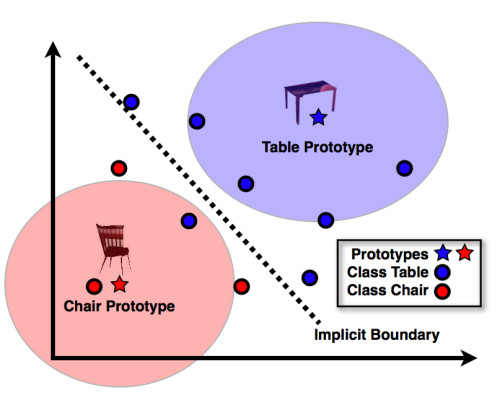
Ilustración del blog de tombone
La salida de una clasificación es binaria (o más bien discreta): los objetos se asignan a clases con mayor o menor confianza, es decir, con probabilidades más altas o más bajas.
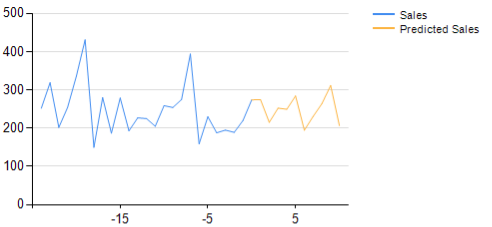
Por otro lado, las regresiones típicamente generan curvas. La ilustración a continuación considera una serie temporal que representa las ventas históricas y muestra el forecast correspondiente.
El forecast de regresión es una curva en lugar de configuraciones binarias (o una combinación de binarias). Las entradas se extienden hacia el futuro.
¿Cómo impacta esta distinción en el negocio?
Resulta que Lokad - tal como estaba a principios de 2010 - solo ofrece forecast de regresión. Por lo tanto, existen muchos problemas interesantes que Lokad no puede abordar porque se trata de problemas de clasificación:
- Segmentación de clientes: para cada cliente, nos gustaría evaluar la probabilidad de lograr un up-sale exitoso a través de una acción de marketing directo. Siguiendo la misma idea, también podríamos intentar predecir el churn.
- Detección de fraudes: para cada transacción, nos gustaría evaluar, en función del patrón de la transacción, la probabilidad de que la operación sea un intento de fraude.
- Priorización de ofertas: basándonos en las propiedades del prospecto (disponibilidad de presupuesto, industria, rango de contacto en la empresa, nivel de interés expresado, …), nos gustaría evaluar la probabilidad de obtener un acuerdo rentable de cada prospecto para priorizar los esfuerzos del equipo de ventas.
Frecuentemente, se nos pregunta si Lokad podría ofrecer también forecast de clasificación. Desafortunadamente, la respuesta será negativa por el momento. A pesar de estar basados en la misma teoría matemática, la clasificación y la regresión implican tecnologías muy diferentes; y Lokad está concentrando todos sus esfuerzos en problemas de regresión.
Aunque, no somos despectivos con respecto a los problemas de clasificación, realmente merecen atención y esfuerzos. Para 2010, nos estamos apegando a nuestra hoja de ruta, pero más adelante, la clasificación podría ser una extensión natural de nuestros servicios de forecasting.


