00:00:00 Введение в доклад о переливе данных на диск
00:00:34 Обработка данных ритейлера и ограничения памяти
00:02:13 Решение с постоянным хранилищем и сравнение затрат
00:04:07 Сравнение скорости диска и памяти
00:05:10 Ограничения методик разделения и потоковой передачи
00:06:16 Важность упорядоченных данных и оптимального размера чтения
00:07:40 Худший сценарий чтения данных
00:08:57 Влияние памяти машины на выполнение программы
00:10:49 Техники перелива на диск и использование памяти
00:12:59 Объяснение раздела кода и реализация в .NET
00:15:06 Контроль распределения памяти и последствия
00:16:18 Страница с отображением памяти и файлы отображения памяти
00:18:24 Чтение-запись отображения памяти и инструменты производительности системы
00:20:04 Использование виртуальной памяти и страниц отображения памяти
00:22:08 Работа с большими файлами и 64-битными указателями
00:24:00 Использование span для загрузки из памяти с отображением
00:26:03 Копирование данных и использование структуры для чтения целых чисел
00:28:06 Создание span из указателя и менеджера памяти
00:30:27 Создание экземпляра менеджера памяти
00:31:05 Реализация программы перелива на диск и отображение памяти
00:33:34 Отображенная в память версия предпочтительна для производительности
00:35:22 Стратегия буферизации файлового потока и ограничения
00:37:03 Стратегия отображения одного большого файла
00:39:30 Разделение памяти между несколькими большими файлами
00:40:21 Заключение и приглашение к вопросам
Резюме
Чтобы обрабатывать больше данных, чем помещается в памяти, программы могут выгружать часть этих данных на более медленное, но емкое хранилище, такое как NVMe-накопители. Сочетая две довольно малоизвестные функции .NET (отображение файлов в память и менеджеры памяти), это можно сделать в C# с минимальными потерями производительности. Этот доклад, представленный на Warsaw IT Days 2023, вдается в детали работы этой техники, и рассматривает, как пакет open source NuGet Lokad.ScratchSpace скрывает большинство этих деталей от разработчиков.
Расширенное резюме
В рамках подробной лекции Виктор Николе, технический директор Lokad, погружается в тонкости выгрузки данных на диск в .NET, техники, позволяющей обрабатывать большие наборы данных, превышающие возможности памяти обычного компьютера. Николе опирается на свой обширный опыт работы с комплексными наборами данных в области количественной оптимизации цепей поставок, приводя практический пример розничного продавца со ста тысячами товаров в 100 точках. Это приводит к набору данных размером в 10 миллиардов записей, если учитывать ежедневные данные за три года, для хранения одного значения с плавающей точкой на каждую запись потребуется 37 гигабайт памяти, что значительно превышает возможности обычного настольного компьютера.
Николе предлагает использовать постоянное хранилище, такое как NVMe SSD, в качестве экономически выгодной альтернативы оперативной памяти. Он сравнивает стоимость памяти и SSD, отмечая, что за цену 18 гигабайт памяти можно приобрести один терабайт SSD. Он также обсуждает компромисс в производительности, указывая, что чтение с диска в шесть раз медленнее, чем чтение из памяти.
Он представляет техники разделения и потоковой обработки как способы использования дискового пространства вместо памяти. Разделение позволяет обрабатывать наборы данных малыми частями, которые помещаются в памяти, но не допускает обмена данными между частями. Потоковая обработка, с другой стороны, позволяет сохранять некоторое состояние между обработкой различных частей, однако требует, чтобы данные на диске были упорядочены или правильно выровнены для оптимальной производительности.
Затем Николе представляет техники выгрузки данных на диск как решение ограничений подхода, основанного на укладывании всего в память. Эти техники динамически распределяют данные между оперативной памятью и постоянным хранилищем, используя больше памяти, когда она доступна, для ускорения работы, и снижая потребление, когда памяти меньше. Он объясняет, что техники выгрузки данных на диск используют максимально возможный объем памяти и начинают записывать данные на диск только при ее исчерпании. Это позволяет им лучше реагировать на наличие большего или меньшего объема памяти, чем предполагалось изначально.
Он также объясняет, что техники выгрузки данных на диск делят набор данных на две части: горячую секцию, которая всегда находится в памяти, и холодную секцию, которая может в любой момент выгружать часть своего содержимого в постоянное хранилище. Программа использует передачи между горячей и холодной частями, которые обычно осуществляются большими партиями для максимального использования пропускной способности NVMe. Холодная секция позволяет этим алгоритмам использовать максимально возможный объем памяти.
Николе далее обсуждает, как реализовать это в .NET. Для горячей секции используются обычные объекты .NET, в то время как для холодной секции применяется класс-ссылка. Этот класс хранит ссылку на значение, которое помещается в холодное хранилище, и это значение может быть установлено в null, когда оно больше не находится в памяти. Центральная система в программе отслеживает все холодные ссылки, и каждый раз, когда создается новая холодная ссылка, система определяет, не приводит ли это к переполнению памяти, и вызывает функцию выгрузки одной или нескольких уже существующих холодных ссылок, чтобы уложиться в выделенный бюджет памяти для холодного хранилища.
Затем он вводит понятие виртуальной памяти, где программа не имеет прямого доступа к физическим страницам памяти, а работает с виртуальными страницами. Можно создать страницу с отображением памяти, что является обычным способом реализации взаимодействия между программами и файлами с отображением памяти. Главная цель отображения памяти — предотвратить ситуацию, когда каждая программа имеет свою копию DLL в памяти, так как все эти копии идентичны.
Николе затем рассказывает о системном инструменте Performance Tool, который показывает текущее использование физической памяти. Зеленым цветом обозначена память, выделенная напрямую процессу, синим — кэш страниц, а измененные страницы посередине представляют собой точную копию данных с диска, но с изменениями в памяти.
Затем он обсуждает вторую попытку использования виртуальной памяти, при которой холодная секция полностью состоит из страниц с отображением памяти. Если операционной системе внезапно понадобится память, она знает, какие страницы отображены, и может безопасно их сбросить.
Николе далее объясняет основные шаги для создания файла с отображением памяти в .NET: сначала создается файл с отображением памяти на основе файла с диска, а затем создается средство доступа (view accessor). Они разделяются, так как .NET должен учитывать случай 32-разрядного процесса. В случае 64-разрядного процесса можно создать один view accessor, загружающий весь файл.
Затем Николе обсуждает введение типов memory и span пять лет назад, которые используются для представления диапазона памяти более безопасным способом, чем просто указатели. Основная идея span и memory заключается в том, что, имея указатель и количество байтов, можно создать новый span, представляющий этот диапазон памяти. После создания span его можно безопасно читать в пределах заданного диапазона, зная, что если будет попытка чтения за его пределы, среда выполнения перехватит это и сгенерирует исключение, вместо того чтобы просто завершить процесс.
Николе далее рассказывает, как использовать span для загрузки данных из памяти с отображением в управляемую память .NET. Например, если необходимо прочитать строку, можно использовать множество API, основанных на span. Николе объясняет использование таких API, как MemoryMarshal.Read, который может читать целое число с начала span. Он также упоминает функцию Encoding.GetString, которая может загружать строку из span байтов.
Он дополнительно объясняет, что эти операции выполняются на span, представляющем собой участок данных, который может находиться на диске вместо оперативной памяти. Операционная система занимается загрузкой данных в память при первом обращении к ним. Николе приводит пример последовательности значений с плавающей точкой, которые необходимо загрузить в массив float. Он объясняет использование MemoryMarshal.Read для чтения размера, выделение массива с плавающими значениями этого размера, а также применение MemoryMarshal.Cast для преобразования span байтов в span значений с плавающей точкой.
Он также обсуждает использование функции CopyTo для span, которая выполняет высокопроизводительное копирование данных из файла с отображением памяти в массив. Он отмечает, что этот процесс может быть несколько расточительным, поскольку включает создание абсолютно новой копии. Николе предлагает создать структуру, представляющую заголовок с двумя целочисленными значениями внутри, которую можно прочитать с помощью MemoryMarshal. Он также затрагивает использование библиотеки сжатия для декомпрессии данных.
Николе обсуждает использование другого типа, Memory, для представления данных, предназначенных для длительного хранения. Он упоминает недостаток документации по созданию объекта Memory из указателя и рекомендует gist на GitHub как лучший доступный ресурс. Он объясняет необходимость создания MemoryManager, который используется внутри объекта Memory всякий раз, когда требуется выполнить что-то более сложное, чем просто указывать на участок массива.
Николе обсуждает использование отображения памяти по сравнению с FileStream, отмечая, что FileStream является очевидным выбором при доступе к данным на диске и его использование хорошо задокументировано. Он указывает, что подход с FileStream не является потокобезопасным и требует блокировки во время операции, что препятствует одновременному чтению с нескольких мест. Николе также отмечает, что подход с FileStream вносит дополнительные накладные расходы, отсутствующие в версии с отображением памяти.
Он объясняет, что следует использовать версию с отображением памяти, так как она способна использовать максимально возможный объем памяти и, при исчерпании памяти, выгружать части наборов данных обратно на диск. Николе поднимает вопрос о том, сколько файлов выделить, какого они должны быть размера и как организовать их циклическое использование по мере распределения и освобождения памяти.
Он предлагает распределять память между несколькими большими файлами, никогда не записывать в одну и ту же область памяти дважды и удалять файлы как можно раньше. Николе завершает, поделившись, что в производственной среде в Lokad они используют Lokad scratch space с конкретными настройками: каждый файл имеет объем 16 гигабайт, на каждом диске хранится 100 файлов, и каждый L32VM имеет четыре диска, что представляет чуть более 6 терабайт пространства для выгрузки на диск для каждой виртуальной машины.
Полная стенограмма

Виктор Николе: Здравствуйте и добро пожаловать на этот доклад о выгрузке данных на диск в .NET.
Выгрузка данных на диск — это техника обработки наборов данных, которые не помещаются в памяти, путем хранения неиспользуемых частей набора данных в постоянном хранилище.
Этот доклад основан на моем опыте работы в Lokad. Мы занимаемся количественной оптимизацией цепей поставок.
Количественная часть означает, что мы работаем с большими наборами данных, а цепочка поставок — это часть реального мира, поэтому они хаотичны, полны сюрпризов и множества крайних случаев внутри крайних случаев.
Таким образом, мы выполняем достаточно сложную обработку.
Рассмотрим типичный пример. У розничного продавца может быть порядка ста тысяч товаров.
Эти товары представлены в до 100 точках. Это могут быть магазины, склады, а также даже секции складов, предназначенные для электронной коммерции.
И если мы хотим провести какой-либо реальный анализ, нам необходимо изучить прошлое поведение, что происходит с этими товарами и локациями.
Если предположить, что мы сохраняем только одну запись в день и рассматриваем данные за три года, это около 1000 дней. Умножив всё это, получаем набор данных в 10 миллиардов записей.
Если для каждой записи хранить одно значение с плавающей точкой, набор данных займет уже 37 гигабайт памяти. Это превышает объем памяти, доступной на обычном настольном компьютере.

И одного значения с плавающей точкой недостаточно для проведения какого-либо анализа.
Более реалистичное число — 20, и даже при этом мы предпринимаем серьезные усилия, чтобы снизить объем памяти. Даже тогда мы говорим примерно о 745 гигабайтах использования памяти.
Это укладывается в возможности облачных машин, если они достаточно мощны, примерно за семь тысяч долларов в месяц. То есть это относительно доступно, но одновременно расточительно.

Как вы могли догадаться из названия этого доклада, решение заключается в использовании постоянного хранилища, которое медленнее, но дешевле оперативной памяти.
В наши дни можно приобрести NVMe SSD за примерно 5 центов за гигабайт. NVMe SSD — это, пожалуй, самое быстрое постоянное хранилище, которое можно легко приобрести.
Для сравнения, один гигабайт оперативной памяти стоит 275 долларов. Это примерно в 55 раз дороже.

Другими словами, на сумму, необходимую для покупки 18 гигабайт памяти, можно приобрести один терабайт SSD.

А как насчет облачных предложений? Так, например, если взять облако Microsoft, то слева представлены L32s, часть серии виртуальных машин, оптимизированных для хранения данных.
За примерно две тысячи долларов в месяц вы получаете почти 8 терабайт постоянного хранилища.
Справа представлены M32ms, часть серии, оптимизированной для оперативной памяти, и за более чем в два с половиной раза большую стоимость вы получаете только 875 гигабайт ОЗУ.
Если моя программа работает на машине слева и требует в два раза больше времени на выполнение, я все равно выигрываю по стоимости.

Что насчет производительности? Ну, чтение из памяти происходит со скоростью около 21 гигабайта в секунду. Чтение с NVMe SSD – примерно 3.5 гигабайта в секунду.
Это не настоящий тест производительности. Я просто создал виртуальную машину и запустил эти две команды, и существует множество способов как увеличить, так и уменьшить эти показатели.
Важная часть здесь заключается в порядке величины разницы между ними. Чтение с диска в шесть раз медленнее, чем чтение из памяти.
Таким образом, диск не только разочаровывающе медленный – вам не захочется постоянно читать с диска при случайных схемах доступа. Но, с другой стороны, он также на удивление быстр. Если ваша обработка в основном ограничена CPU, вы, возможно, даже не заметите, что читаете с диска вместо чтения из памяти.

Известной техникой использования дискового пространства в качестве альтернативы памяти является разделение.
Идея разделения заключается в том, чтобы выбрать одно из измерений набора данных и разделить его на более мелкие части. Каждая часть должна быть достаточно маленькой, чтобы уместиться в памяти.
Затем процесс поочередно загружает каждую часть, обрабатывает её и сохраняет обратно на диск перед загрузкой следующей.
В нашем примере, если мы разделим набор данных по локациям и будем обрабатывать локации по одной, то каждая локация займет всего 7.5 гигабайта памяти. Это вполне соответствует возможностям настольного компьютера.

Однако при разделении отсутствует обмен данными между частями. Таким образом, если нам необходимо обработать данные, охватывающие несколько локаций, мы уже не сможем использовать этот метод.
Другой подход – потоковая обработка. Потоковая обработка довольно схожа с разделением, поскольку в любой момент в память загружается только небольшая часть данных.
В отличие от разделения, нам разрешено сохранять некоторое состояние между обработками различных частей. Таким образом, обрабатывая первую локацию, мы устанавливаем начальное состояние, а затем, при обработке второй локации, можем использовать имеющееся состояние для формирования нового состояния по окончании её обработки.
В отличие от разделения, потоковая обработка не подходит для параллельного выполнения. Но она решает задачу вычисления чего-либо по всему набору данных, а не разрозненно для каждой части.
Однако у потоковой обработки есть своё ограничение. Чтобы она была эффективной, данные на диске должны быть должным образом упорядочены или выровнены.
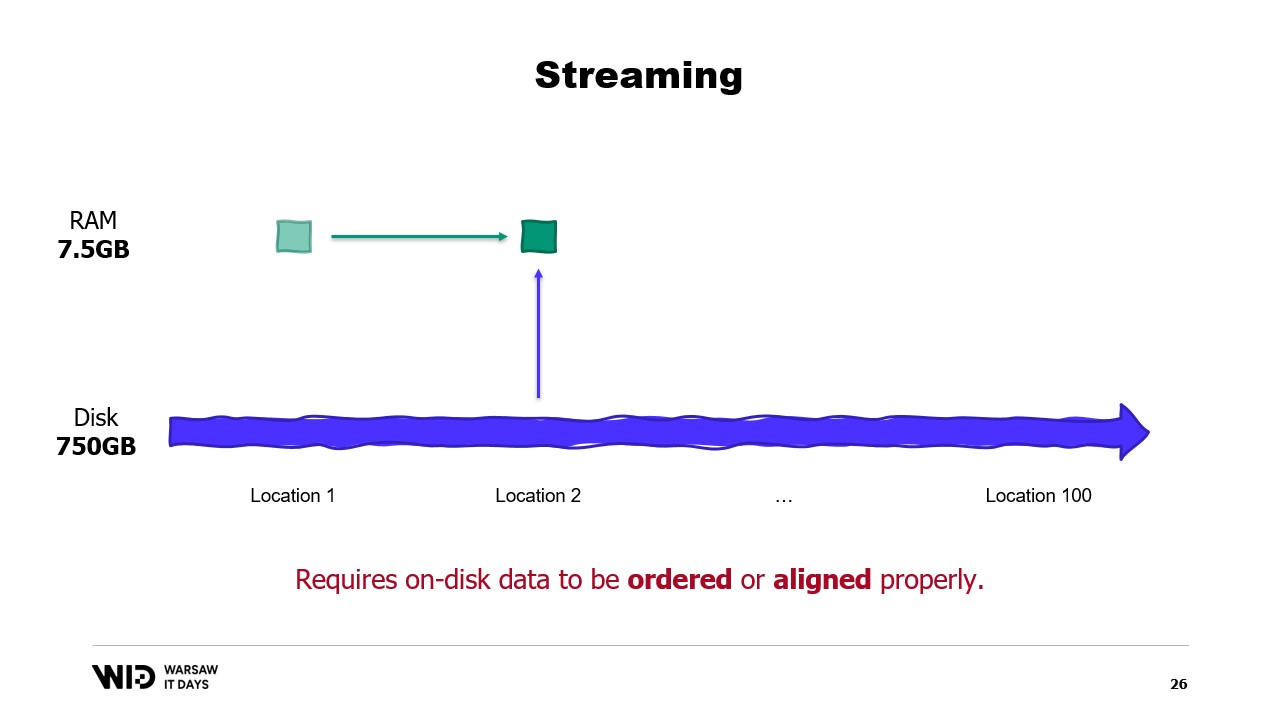
Чтобы понять эти требования, необходимо знать, что NVMe считывает и записывает данные секторами по полкилобайта, а ранее упомянутые показатели производительности, такие как 3.5 гигабайта в секунду, предполагают полное использование каждого сектора.
Если мы используем только часть сектора, но при этом считываем весь сектор, мы теряем пропускную способность, и наша производительность существенно падает.

Таким образом, оптимально, когда данные, которые мы читаем, являются кратными полкилобайта и выровнены по границам секторов.
Мы больше не используем вращающиеся диски, поэтому пропуск сектора теперь осуществляется без дополнительных затрат.

Если невозможно выровнять данные по границам секторов, другой подход – загрузка их в последовательном порядке.
Это объясняется тем, что как только сектор был загружен в память, считывание его второй части не требует повторной загрузки с диска. Вместо этого операционная система просто предоставляет оставшиеся байты, которые еще не были использованы.
Таким образом, если данные загружаются последовательно, не теряется пропускная способность, и вы всё равно получаете максимальную производительность.

Худший сценарий – когда вы считываете только один или несколько байт из каждого сектора. Например, если вы считываете число с плавающей запятой из каждого сектора, ваша производительность снижается в 128 раз.

Что еще хуже – существует еще одна единица группировки данных поверх секторов – это страница операционной системы, и обычно ОС загружает целиком страницы размером около 4 килобайт.
Таким образом, если вы считываете одно число с плавающей запятой с каждой страницы, вы делите свою производительность на 1024.
По этой причине крайне важно обеспечивать считывание данных из постоянного хранилища большими последовательными блоками.

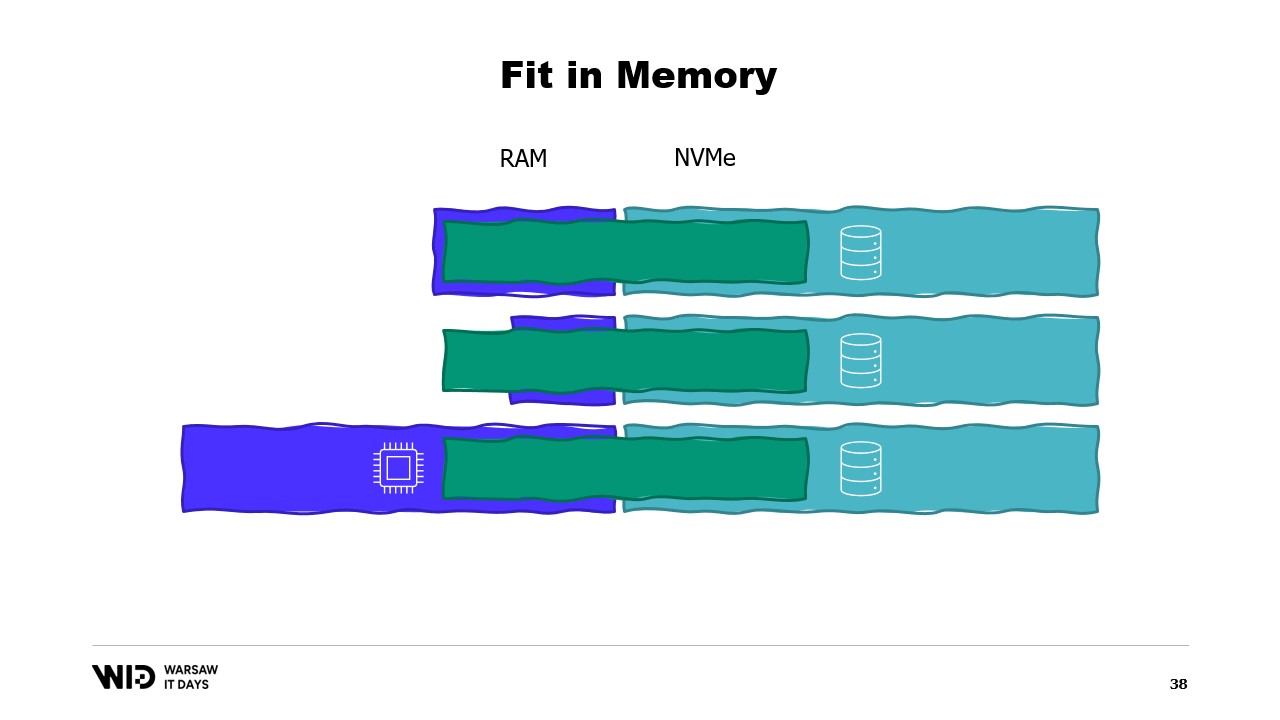
Используя эти методы, можно заставить программу работать с меньшим объемом памяти. При этом методы рассматривают память и диск как два отдельных хранилища, независимых друг от друга.
Таким образом, распределение набора данных между памятью и диском определяется исключительно алгоритмом и структурой набора данных.
То есть, если мы запустим программу на машине с точно необходимым объемом памяти, программа будет идеально помещаться и сможет работать.
Если же мы предоставим машину с меньшим, чем требуется, объемом памяти, программа не сможет уместиться в памяти и не запустится.
Наконец, если машина обладает избыточной памятью, программа поступит так, как обычно и будет работать с той же скоростью, не используя дополнительную память.
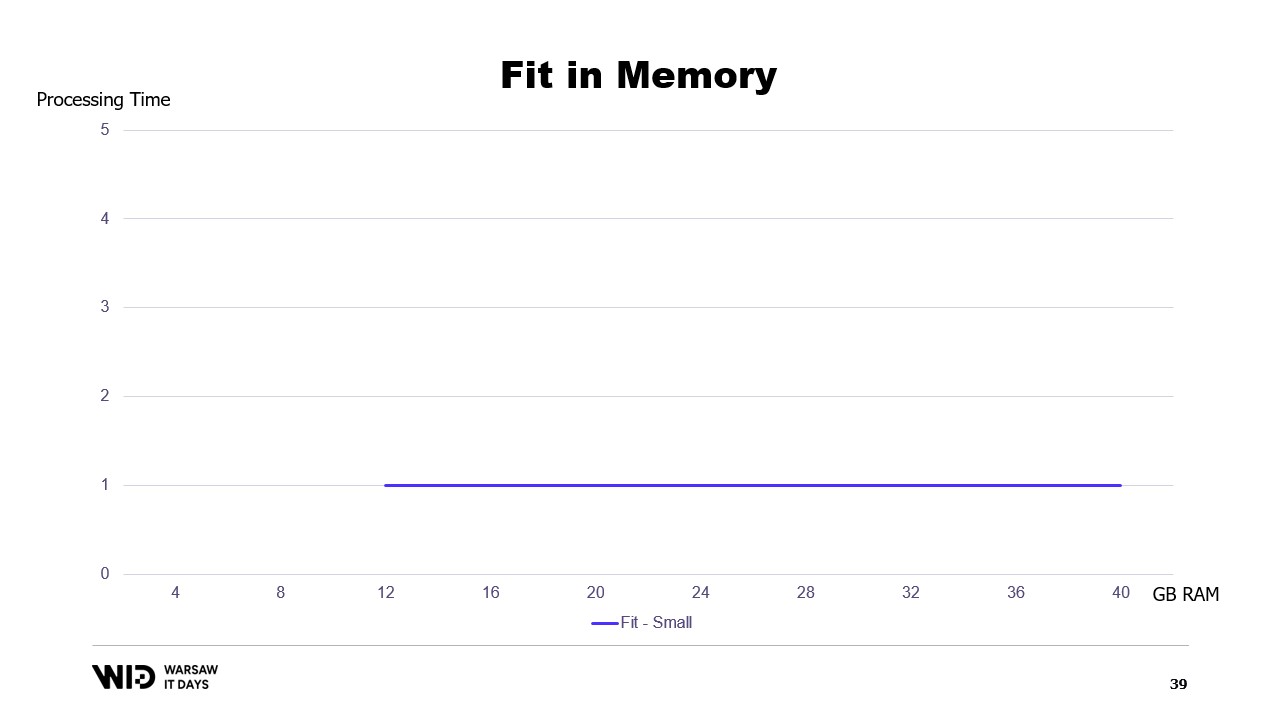
Если построить график времени выполнения в зависимости от доступной памяти, он будет выглядеть следующим образом. Ниже определенного порога памяти выполнение отсутствует, поэтому нет времени обработки. Выше этого порога время обработки является постоянным, поскольку программа не может использовать дополнительную память для ускорения работы.
А также, что происходит, если набор данных растет? Ну, в зависимости от направления роста: если набор данных увеличивается за счет увеличения количества разделов, то объем памяти остается неизменным – просто разделов становится больше.
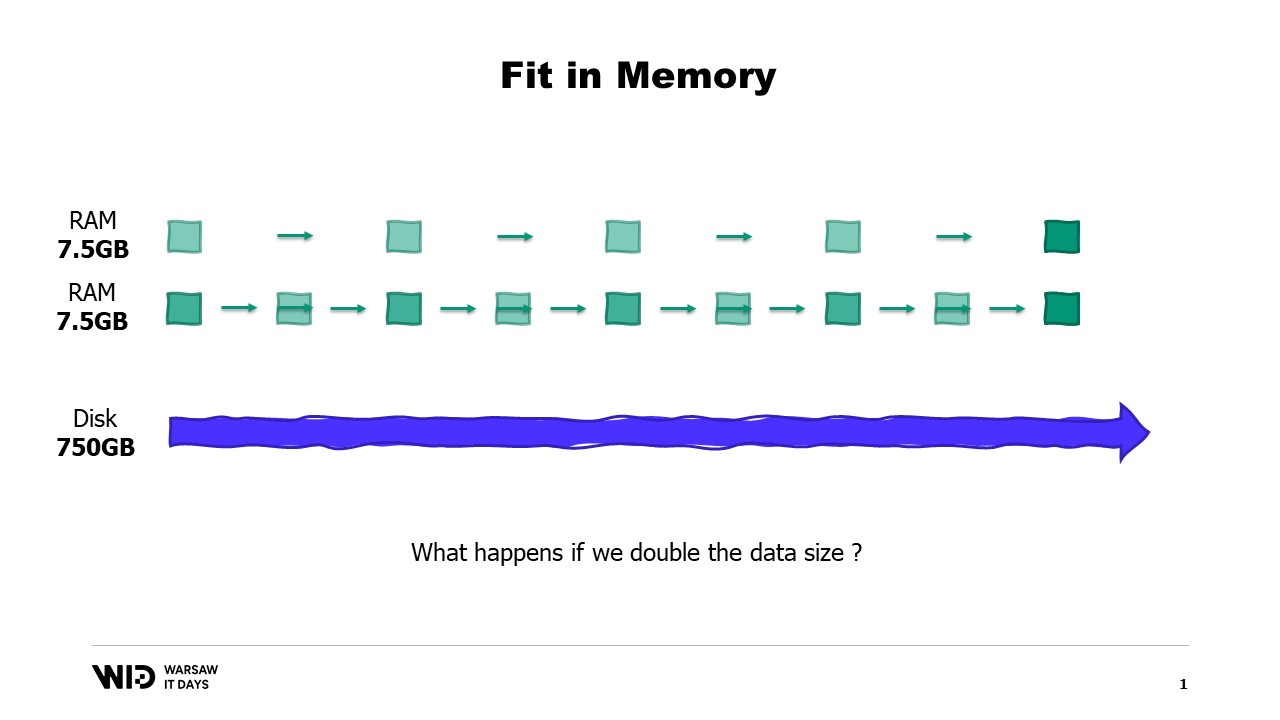
С другой стороны, если отдельные разделы растут, то объем памяти также увеличивается, что увеличивает минимальное количество памяти, необходимое для работы программы.
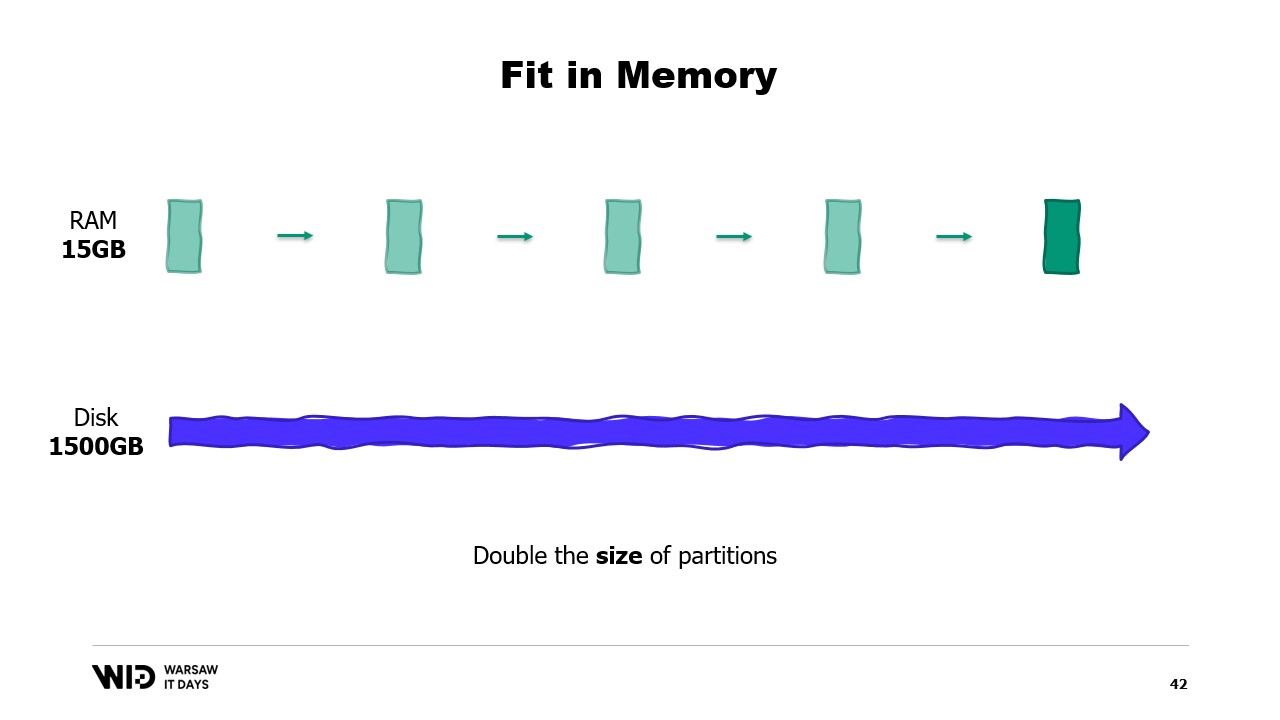
Другими словами, если у меня есть более крупный набор данных, который необходимо обработать, это не только займет больше времени, но и потребует большего объема памяти.
Это создает неприятную ситуацию, когда для обработки больших наборов данных необходимо добавлять больше памяти, в то время как добавление памяти не улучшает производительность для меньших наборов данных.
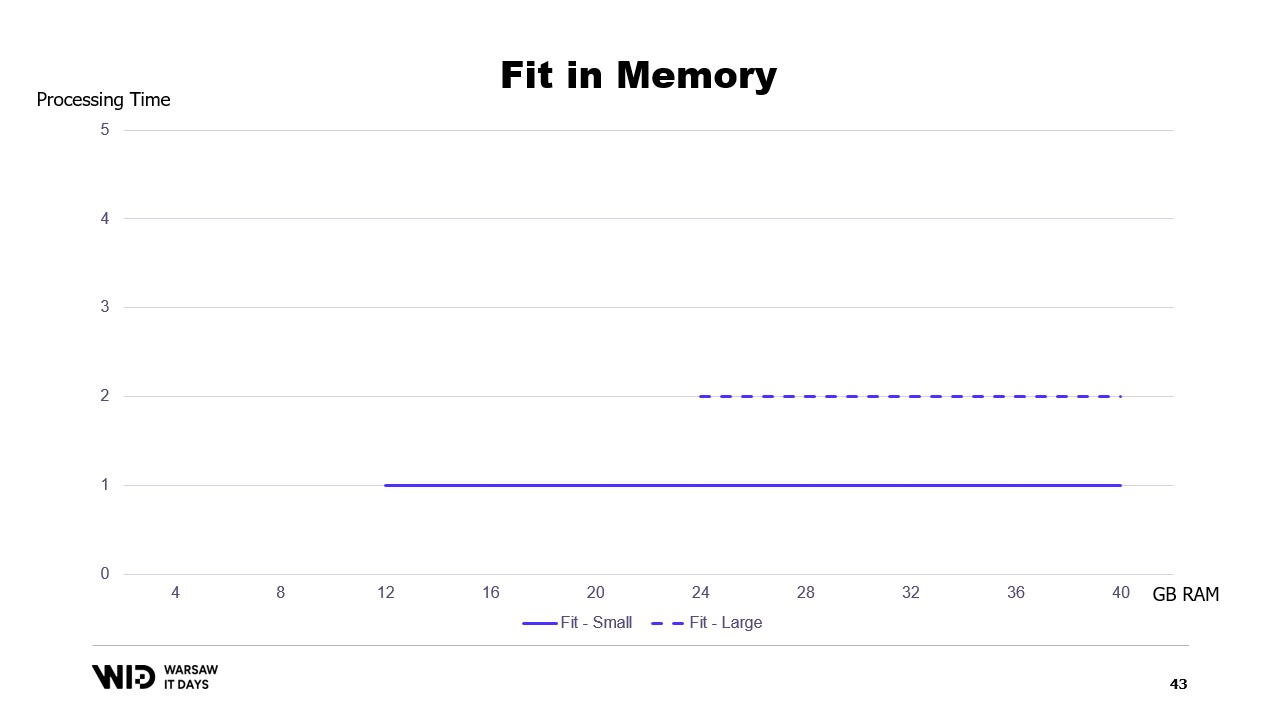
Это ограничение подхода, когда программа полностью помещается в памяти, при котором распределение набора данных между памятью и постоянным хранилищем определяется исключительно структурой набора данных и самим алгоритмом.
При этом фактический объем доступной памяти не принимается во внимание. Техники выгрузки на диск выполняют это распределение динамически. Таким образом, если доступно больше памяти, они будут использовать её для ускорения работы.
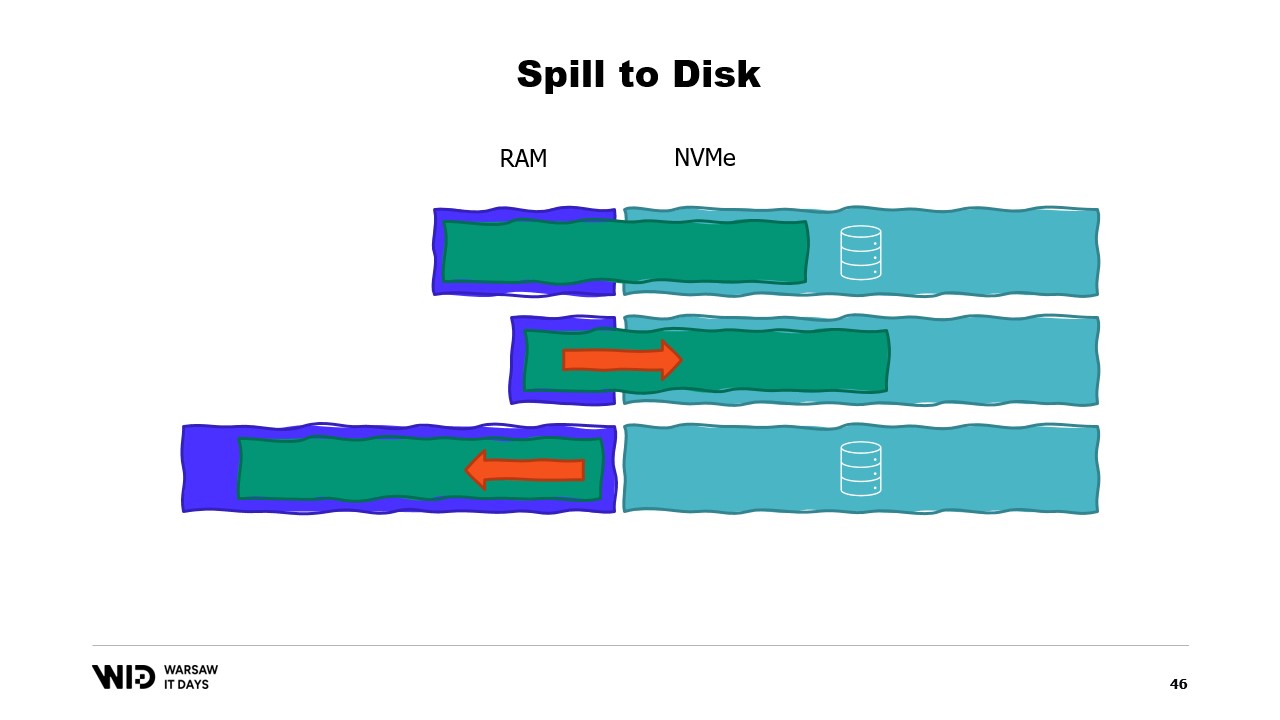
И наоборот, если доступно меньше памяти, то до определенного момента они смогут работать медленнее, чтобы использовать меньше памяти. Графики в этом случае выглядят значительно лучше. Минимальный объем памяти становится меньше и одинаков для обоих наборов данных.
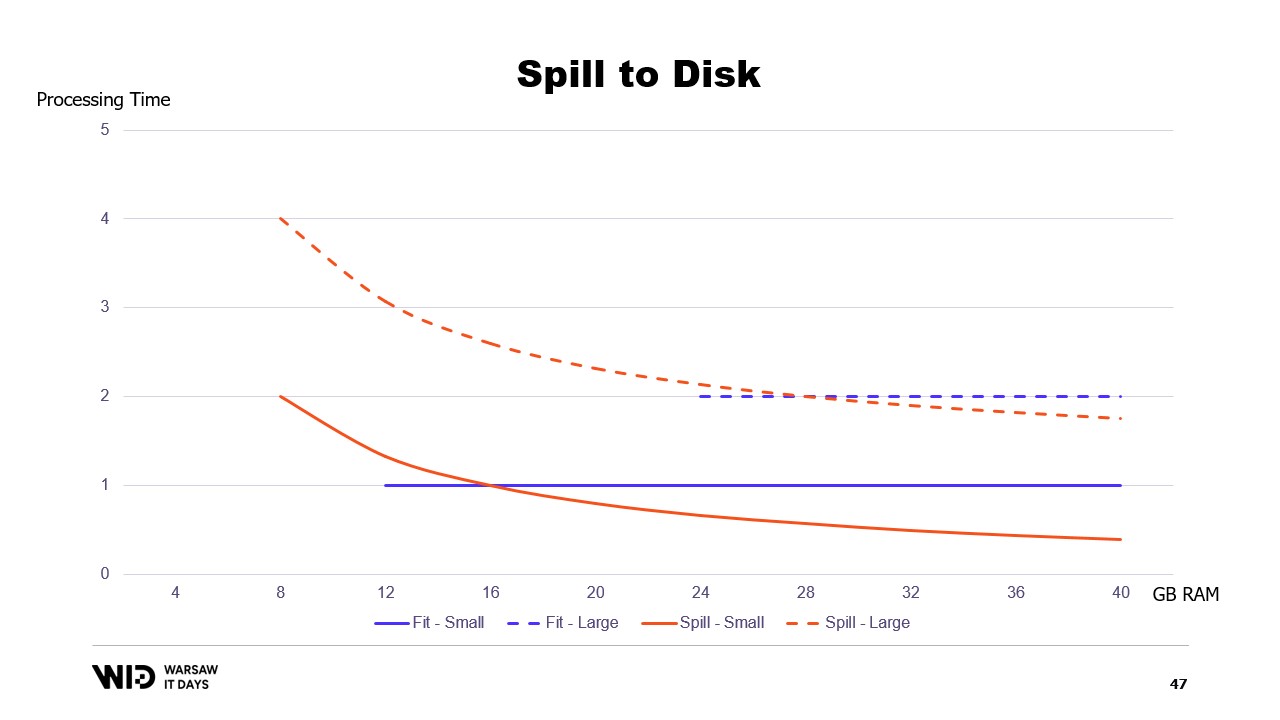
Производительность увеличивается с добавлением памяти во всех случаях. Подходы, предусматривающие помещение данных в память, предварительно сбрасывают часть данных на диск, чтобы уменьшить использование памяти. В отличие от них, техники выгрузки на диск используют как можно больше памяти и начинают сбрасывать данные на диск только когда память заканчивается, чтобы освободить место.
Это позволяет им гораздо лучше адаптироваться к тому, что доступно больше или меньше памяти, чем ожидалось изначально. Техники выгрузки на диск разделяют набор данных на две секции. Горячая секция предполагается всегда находиться в памяти, и к ней можно безопасно обращаться с произвольными схемами доступа. У неё, конечно, есть максимальный лимит, например, около 8 гигабайт на CPU для типичной облачной машины.
С другой стороны, холодной секции разрешается в любой момент выгружать части своего содержимого во внешнее хранилище. Максимального лимита нет, кроме объема доступной памяти. И, конечно, обращаться к холодной секции с точки зрения производительности небезопасно.
Таким образом, программа будет использовать горячее-холодное перемещение данных. Обычно это предполагает обработку больших блоков данных для максимального использования пропускной способности NVMe. И поскольку блоки достаточно большие, их выполнение происходит с довольно низкой частотой. Таким образом, именно холодная секция позволяет алгоритмам использовать максимально доступную память.

Поскольку холодная секция заполнит всю доступную оперативную память, а затем выгрузит остаток во внешнее хранилище, как же заставить это работать в .NET? Поскольку я называю это первой попыткой, можно догадаться, что это не сработает. Итак, попробуйте заранее определить, в чем будет проблема.
Для горячей секции я буду использовать обычные объекты .NET, и проблема будет рассмотрена на примере стандартной .NET программы. Для холодной секции я использую так называемый класс-ссылку. Этот класс хранит ссылку на значение, которое помещается в холодное хранилище, и это значение может быть установлено в null, когда оно больше не находится в памяти. Он имеет функцию выгрузки, которая забирает значение из памяти и записывает его в хранилище, а затем обнуляет ссылку, что позволяет сборщику мусора .NET освободить память при возникновении давления.
И, наконец, он имеет свойство value. Это свойство, при обращении к нему, возвращает значение из памяти, если оно есть, а если его нет – происходит загрузка с диска обратно в память перед возвратом. Теперь, если я настрою центральную систему в своей программе, которая будет отслеживать все холодные ссылки, то каждый раз, когда создается новая холодная ссылка, я смогу определить, приводит ли это к переполнению памяти, и вызвать функцию выгрузки для одной или нескольких уже существующих холодных ссылок, чтобы оставаться в пределах доступного лимита памяти для холодного хранилища.

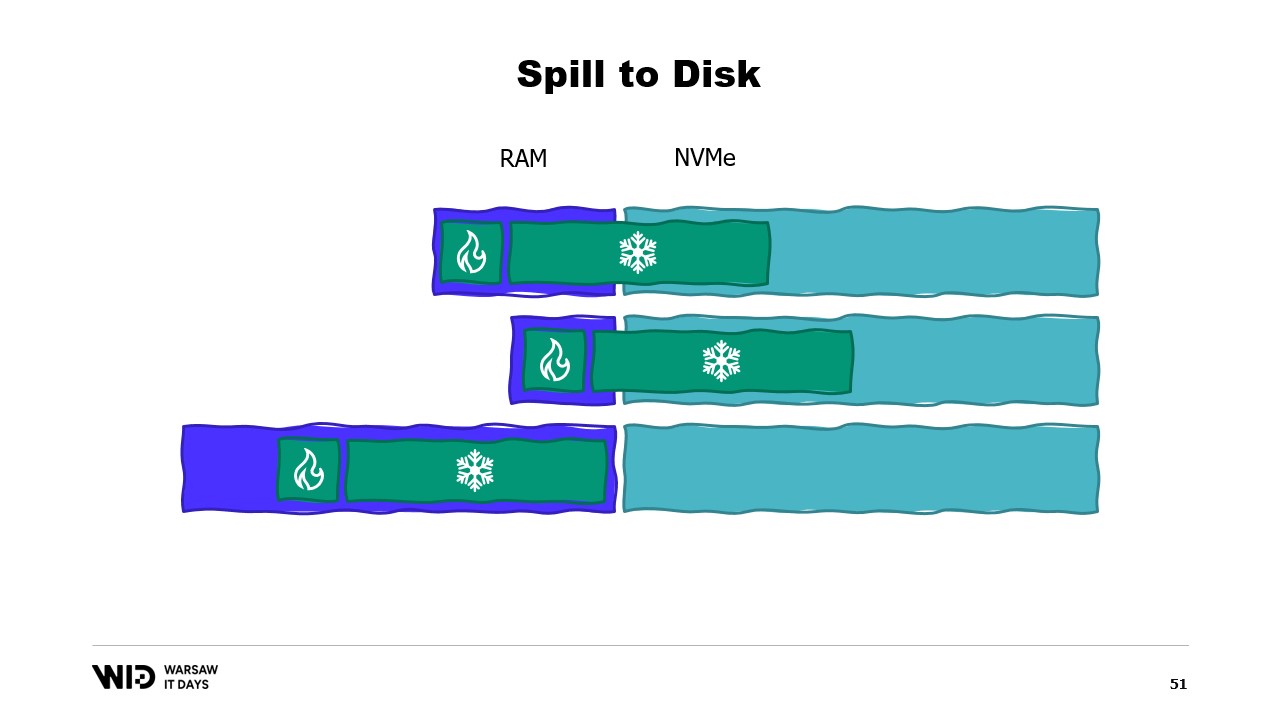
Итак, в чем же проблема? Если посмотреть на содержимое памяти машины, на которой запущена наша программа, в идеальном случае оно будет выглядеть следующим образом. Сначала, слева, находится память операционной системы, которая используется для её собственных нужд. Затем идёт внутренняя память .NET, используемая для таких вещей, как загруженные сборки или накладные расходы сборщика мусора и т.д. Затем – память горячей секции, а оставшаяся часть занимает память, выделенная для холодной секции.
При определенных усилиях мы можем контролировать всё, что находится справа, поскольку именно это мы выделяем и освобождаем для сбора мусора. Однако то, что находится слева, выходит из-под нашего контроля. И что произойдет, если операционной системе внезапно потребуется дополнительная память, а она обнаружит, что весь объем занят тем, что создал процесс .NET?
Типичной реакцией, например, ядра Linux в такой ситуации будет завершение работы программы, потребляющей наибольшее количество памяти, и нет возможности достаточно быстро освободить часть памяти, чтобы ядро не убило нас.

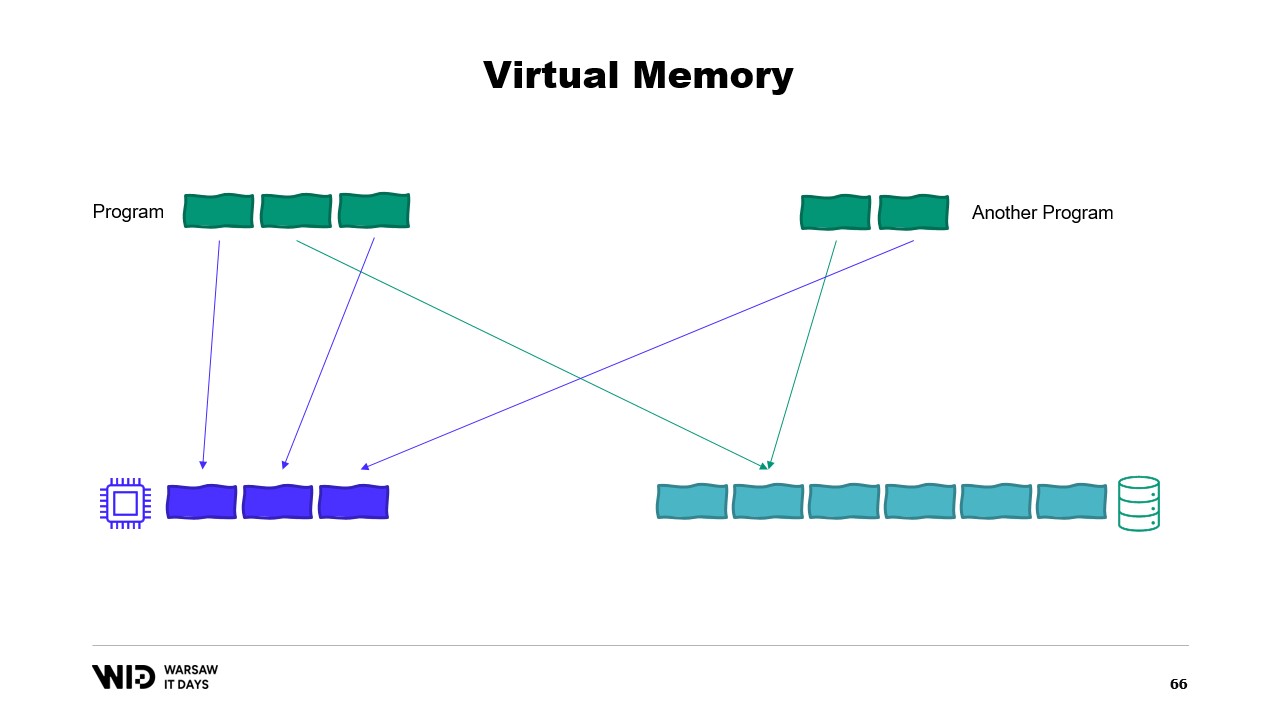
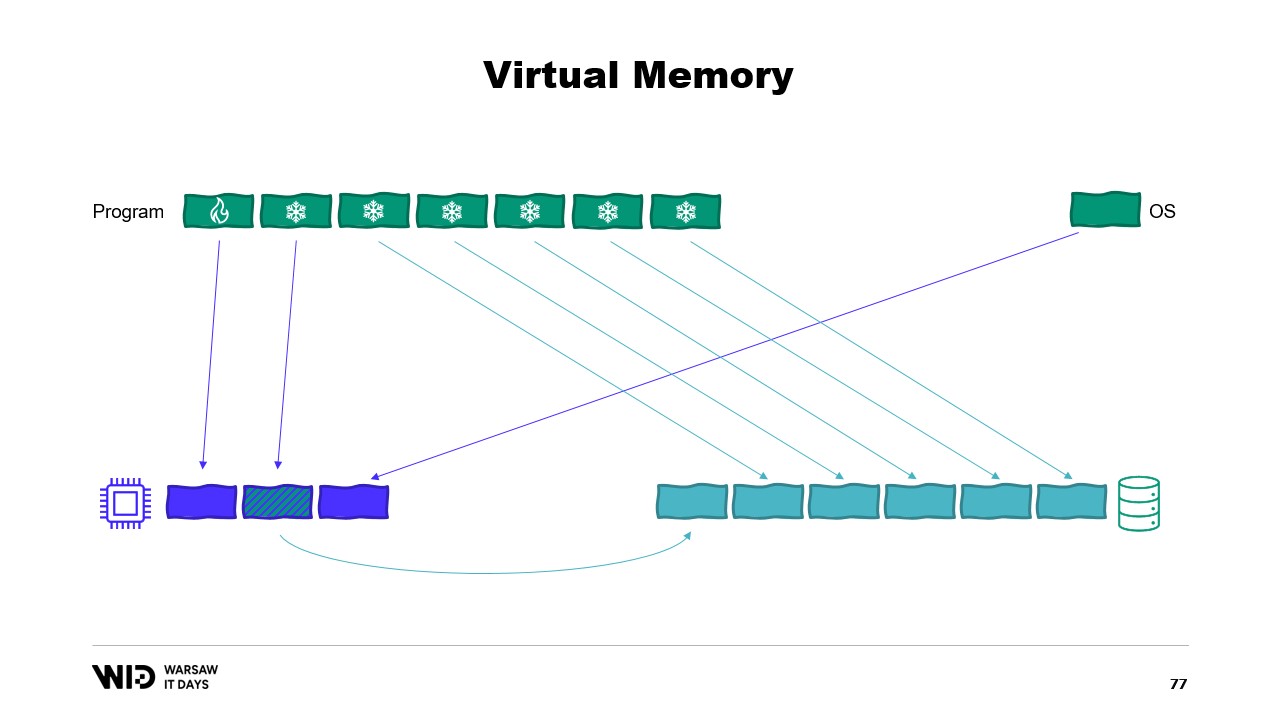
Современные операционные системы используют концепцию виртуальной памяти. Программа не имеет прямого доступа к физическим страницам памяти. Вместо этого она работает с виртуальными страницами памяти, между которыми существует отображение на реальные физические страницы. Если на том же компьютере запущена другая программа, она не сможет самостоятельно получить доступ к страницам первой программы. Существуют, однако, способы их совместного использования.
Возможно создание отображенной в память страницы (memory mapped page). В этом случае всё, что первая программа записывает в общую страницу, сразу же становится доступным для другой программы. Это обычный способ реализации взаимодействия между программами, но его основное назначение – отображение файлов в память. Здесь операционная система понимает, что эта страница является точной копией страницы на постоянном хранилище, обычно части файла общей библиотеки.
Основная цель здесь – предотвратить наличие у каждой программы отдельной копии DLL в памяти, поскольку все эти копии идентичны, и нет смысла тратить память на их хранение. Здесь, например, у нас две программы, в сумме занимающие четыре страницы памяти, в то время как физическая память может вместить только три. А что, если мы захотим выделить еще одну страницу в первой программе? Свободного места нет, но ядро операционной системы знает, что отображенная страница может быть временно отпущена, а при необходимости – снова загружена с диска.
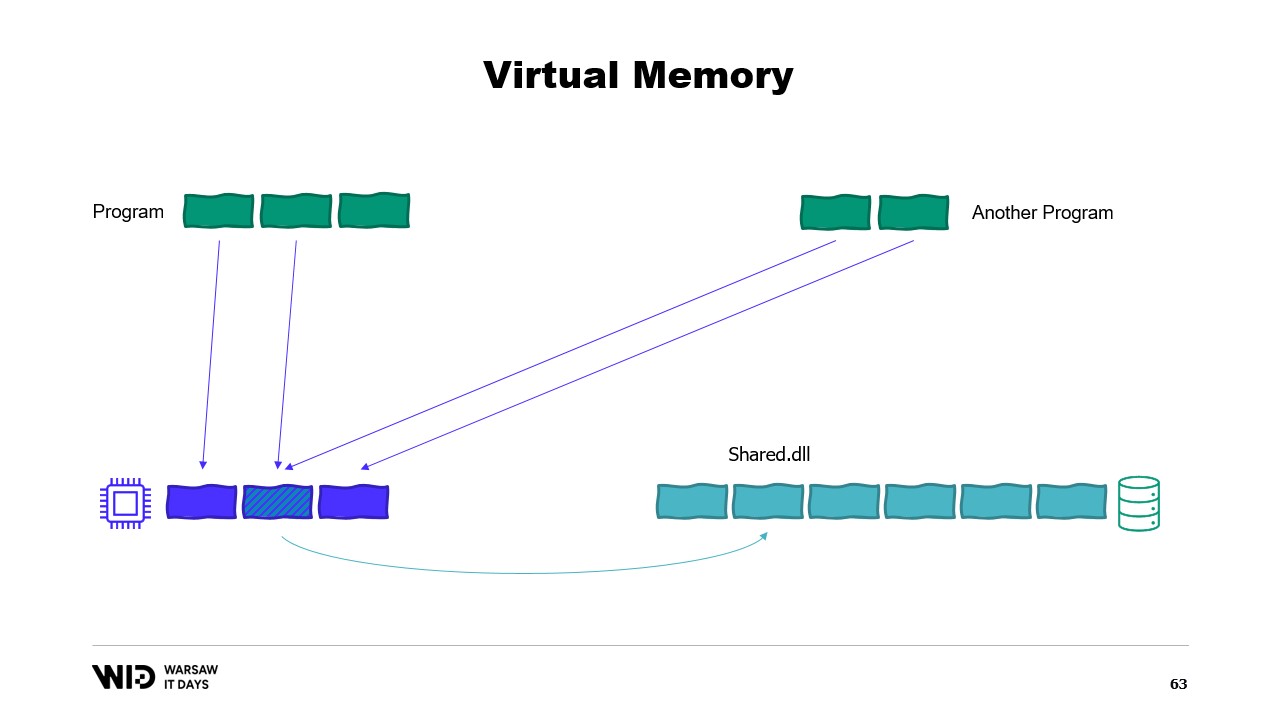
Таким образом, произойдет следующее. Две общие страницы теперь будут указывать на диск вместо памяти. Память будет очищена, обнулена операционной системой, и затем передана первой программе для использования в качестве её третьей логической страницы. Теперь память полностью заполнена, и если любая из программ попытается обратиться к общей странице, для её повторной загрузки в память не найдется свободного места, так как страницы, выделенные для программ, не могут быть возвращены операционной системой.
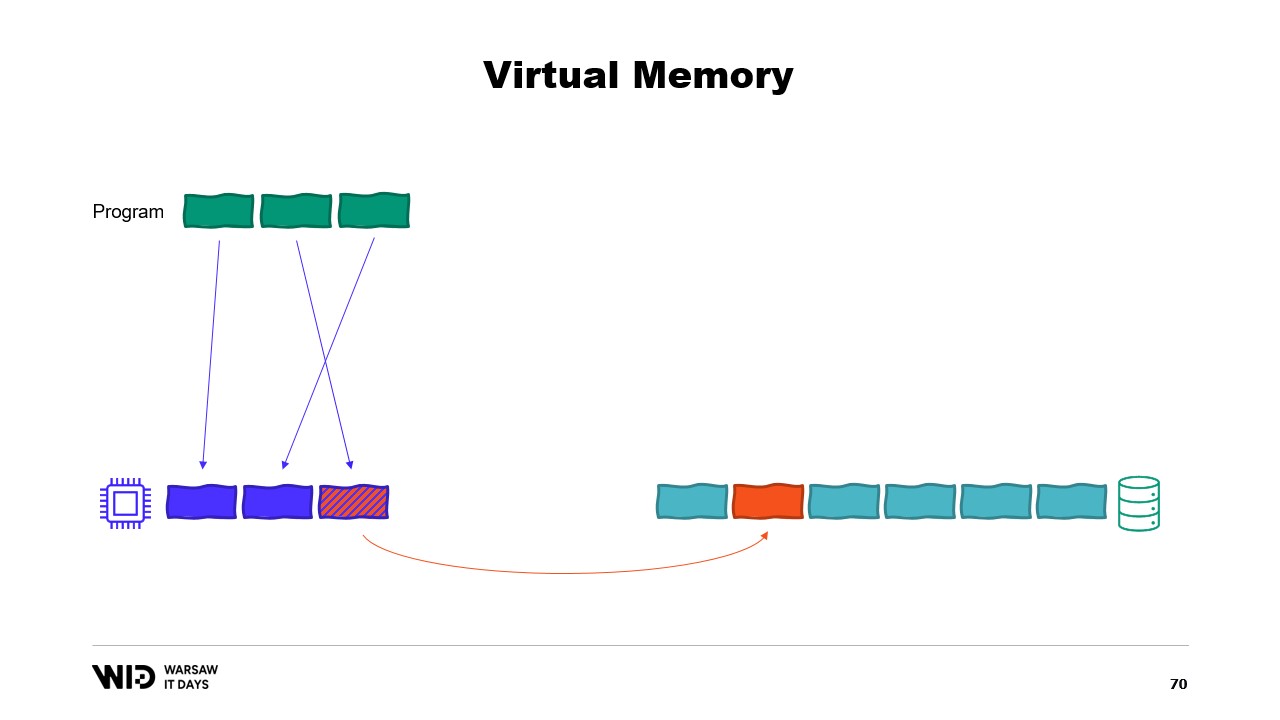
Таким образом, произойдет ошибка «недостаточно памяти». Одна из программ завершится, память освободится, и затем будет перераспределена для повторной загрузки отображаемого файла в память. Кроме того, хотя большинство отображений памяти являются только для чтения, возможно создание отображений с правами на запись.
Программа вносит изменения в память отображенной страницы, затем операционная система в какой-то момент в будущем сохраняет содержимое этой страницы обратно на диск. И, конечно, можно запросить такое сохранение в определенный момент, используя функции типа flush в Windows. Инструмент System Performance Tool имеет удобное окно, показывающее текущее использование физической памяти.
Зелёным цветом обозначена память, выделенная непосредственно для процесса. Её нельзя вернуть операционной системе без завершения процесса. Синим цветом обозначен кэш страниц. Это страницы, которые, как известно, являются идентичными копиями страниц на диске, поэтому всякий раз, когда процессу необходимо прочитать с диска страницу, которая уже находится в кэше, считывание с диска не происходит, и значение возвращается непосредственно из памяти.
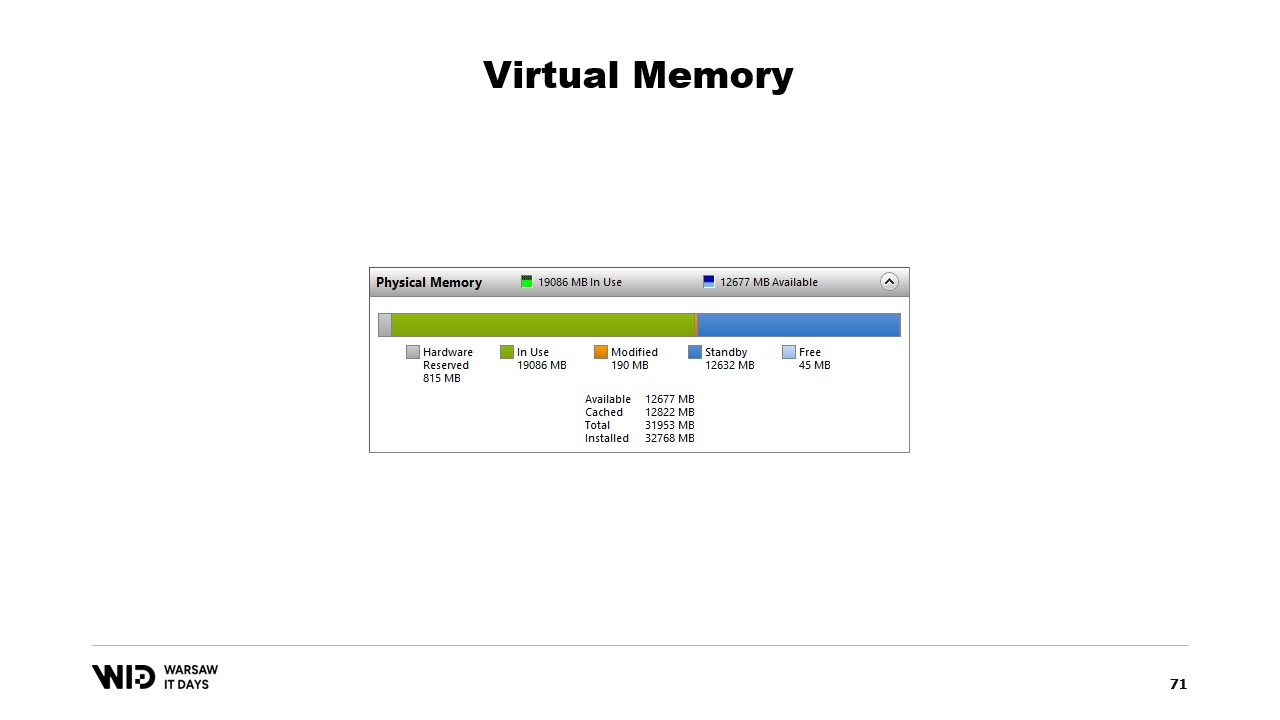
Наконец, изменённые страницы в центре — это те, которые должны быть точной копией данных на диске, но содержат изменения в памяти. Эти изменения ещё не записаны обратно на диск, но будут выполнены довольно скоро. В Linux инструмент h-stop отображает аналогичный график. Слева находятся страницы, которые были выделены непосредственно процессам и не могут быть возвращены системе без их завершения, а справа, жёлтым цветом, — кэш страниц.

Если вам интересно, существует отличный ресурс от Вячеслава Бирюкова о том, что происходит в кэше страниц Linux. Используя виртуальную память, давайте попробуем второй вариант. Сработает ли на этот раз? Теперь мы решаем, что холодная секция будет состоять полностью из страниц, отображённых в память. Таким образом, все они изначально должны присутствовать на диске.
Программа больше не контролирует, какие страницы находятся в памяти, а какие остаются только на диске. Операционная система делает это прозрачно. Так, если программа попытается обратиться, скажем, к третьей странице в холодной секции, операционная система обнаружит, что её нет в памяти, выгрузит одну из существующих страниц, скажем, вторую, и затем загрузит третью страницу в память.
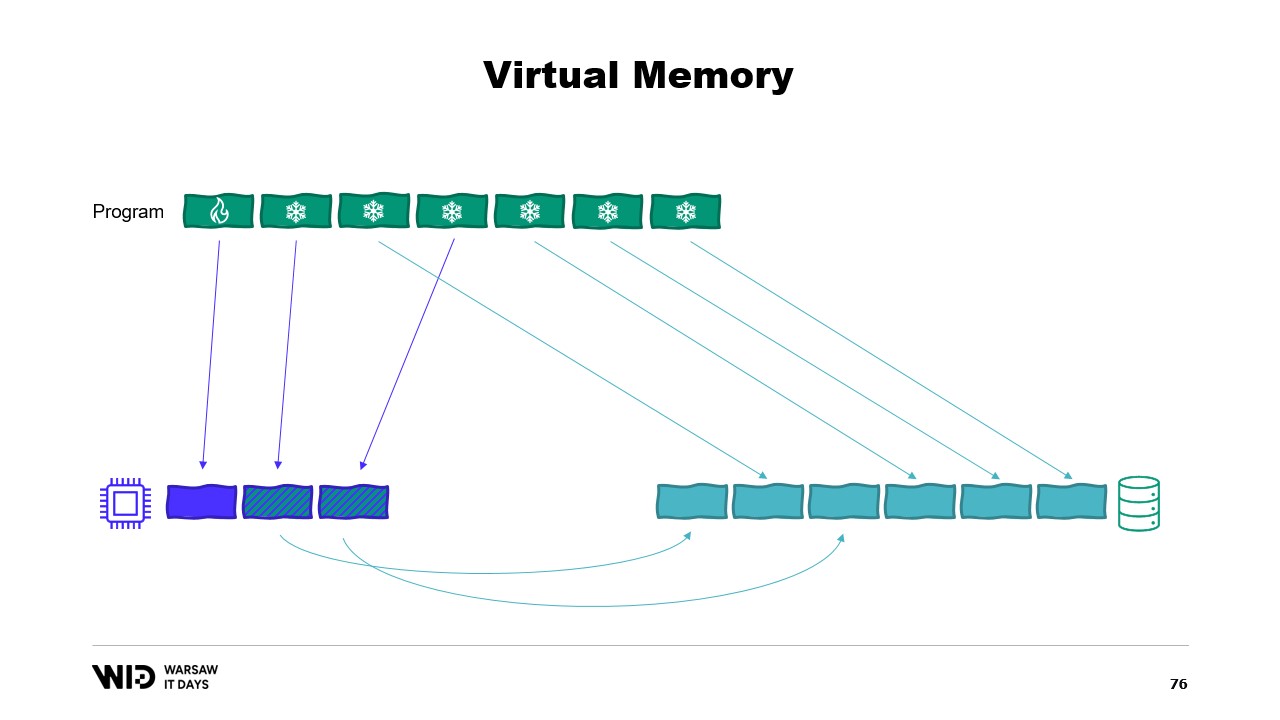
С точки зрения самого процесса всё происходило совершенно прозрачно. Ожидание чтения из памяти оказалось лишь немного длиннее обычного. А что происходит, если операционной системе вдруг потребуется дополнительная память для собственных нужд? Она знает, какие страницы отображены в память и могут быть безопасно сброшены. Таким образом, она просто сбрасывает одну из страниц, использует её для своих целей, а затем возвращает, когда заканчивает.
Все эти техники применимы в .NET и присутствуют в проекте с открытым исходным кодом Lokad Scratch Space. Большая часть следующего кода основана на том, как этот NuGet пакет реализует свои функции.

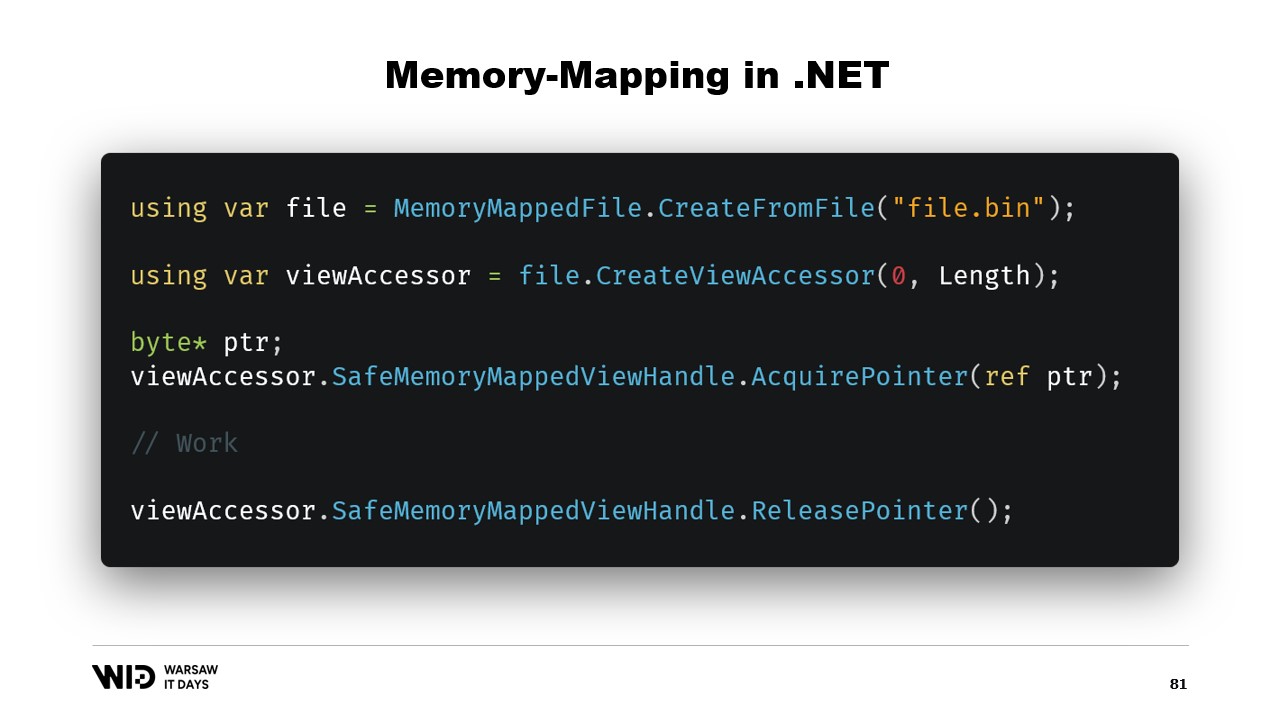
Во-первых, как создать файл с отображением в память в .NET? Отображение памяти существует с .NET Framework 4, примерно 13 лет назад. Тема достаточно хорошо задокументирована в интернете, и исходный код полностью доступен на GitHub.

Основные шаги заключаются сначала в создании файла с отображением в память из файла на диске, а затем в создании view accessor. Эти два типа разделены, поскольку они имеют разное назначение. Файл с отображением в память сообщает операционной системе, что некоторые его секции будут отображены в память процесса, а view accessor представляет эти отображения.
Они разделены, так как .NET должен учитывать случай 32-битного процесса. Очень большой файл, превышающий четыре гигабайта, не может быть отображён в адресное пространство 32-битного процесса, так как оно слишком маленькое. Поэтому можно отображать только небольшие участки файла по очереди, чтобы они помещались.
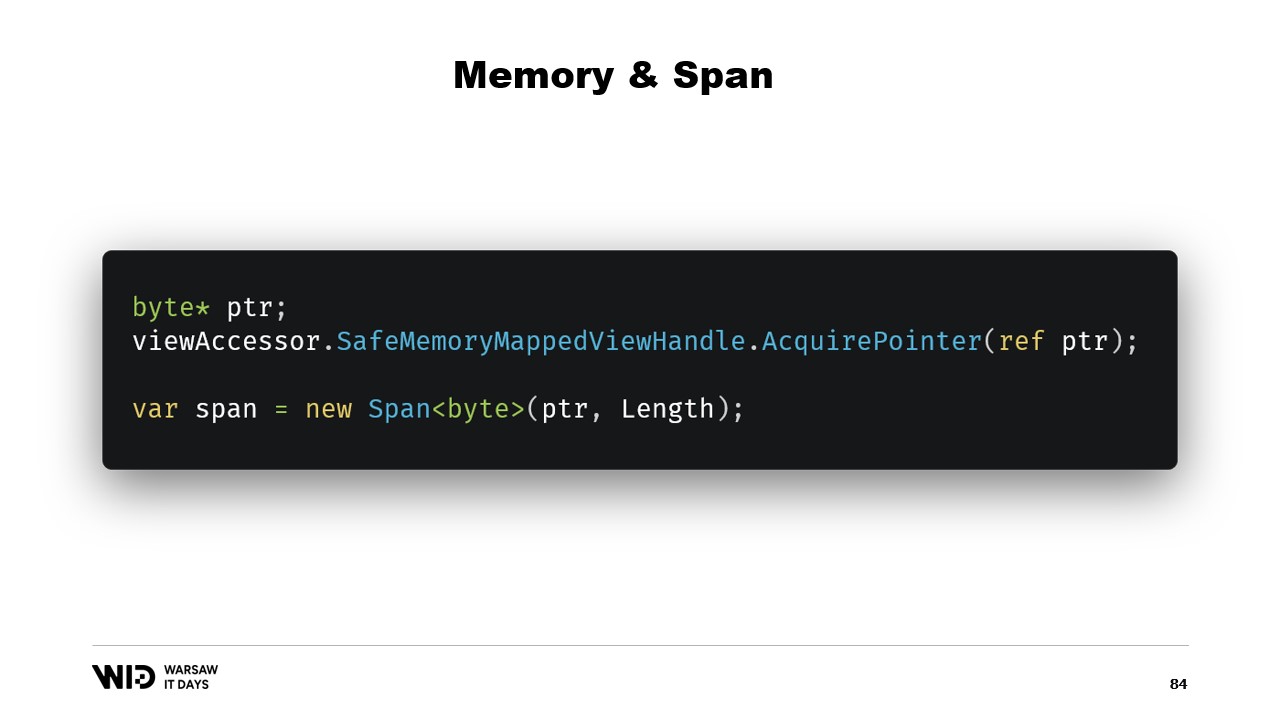
В нашем случае мы будем работать с 64-битными указателями. Таким образом, мы можем создать один view accessor, который загрузит весь файл. Затем я использую AcquirePointer, чтобы получить указатель на первые байты этого отображённого в память диапазона. Когда работа с указателем завершена, я просто его освобождаю. Работа с указателями в .NET небезопасна, требует повсеместного использования ключевого слова unsafe и может привести к аварийному завершению, если обратиться к памяти за пределами разрешённого диапазона.
К счастью, существует способ обойти эту проблему. Пять лет назад .NET представил типы Memory и span. Эти типы используются для представления диапазона памяти более безопасным способом, чем просто указатели. Тема достаточно хорошо задокументирована, и большинство кода можно найти в соответствующем репозитории на GitHub.

Основная идея span и Memory заключается в том, что, имея указатель и количество байтов, можно создать новый span, представляющий этот диапазон памяти.
Как только у вас есть этот span, вы можете безопасно читать из его любой части, зная, что при попытке чтения за его границы рантайм перехватит это и бросит исключение вместо того, чтобы просто завершить процесс.
Давайте посмотрим, как можно использовать span для загрузки данных из отображённой в память области в управляемую память .NET. Помните, мы не хотим напрямую обращаться к холодной секции по соображениям производительности. Вместо этого мы хотим выполнять передачу данных из холодного сегмента в горячий, загружая большое количество данных за один раз.
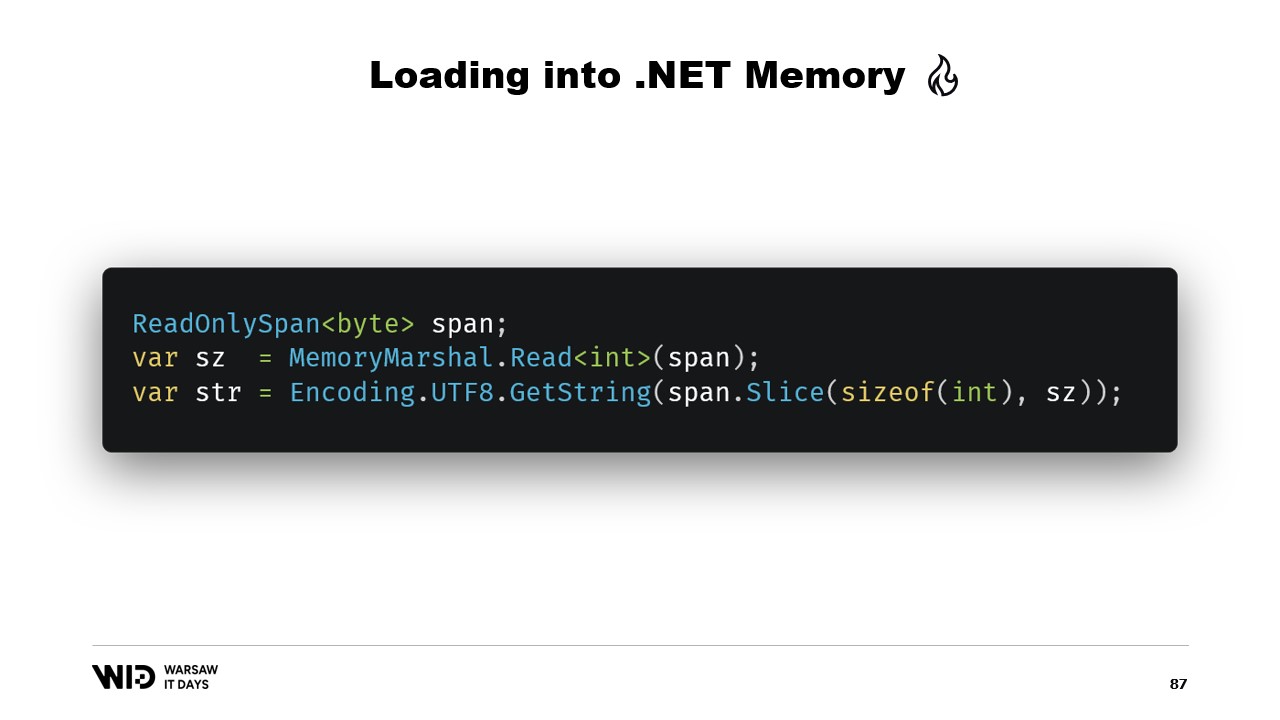
Например, предположим, что у нас есть строка, которую нужно прочитать. Она будет представлена в файле с отображением в память в виде размера, за которым следует полезная нагрузка, закодированная в UTF-8, и мы хотим получить из этого .NET-строку.
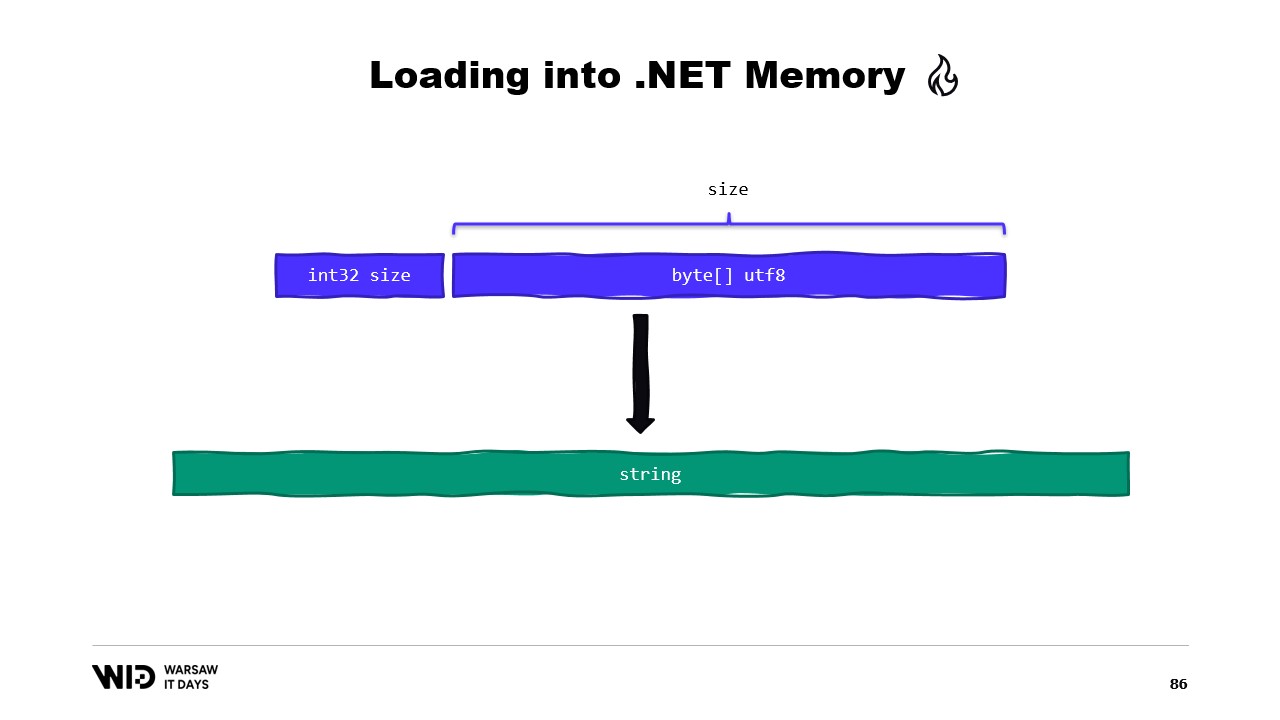
Существует множество API, ориентированных на работу со span, которые мы можем использовать. Например, MemoryMarshal.Read может прочитать целое число с начала span. Затем, используя этот размер, я могу вызвать функцию Encoding.GetString, чтобы загрузить строку из span байтов.
Все эти функции работают со span, и даже если span представляет собой участок данных, который возможно хранится на диске, а не в памяти, операционная система прозрачно загружает данные в память при первом обращении.
Другим примером может быть последовательность чисел с плавающей точкой, которую мы хотим сохранить в массиве float.
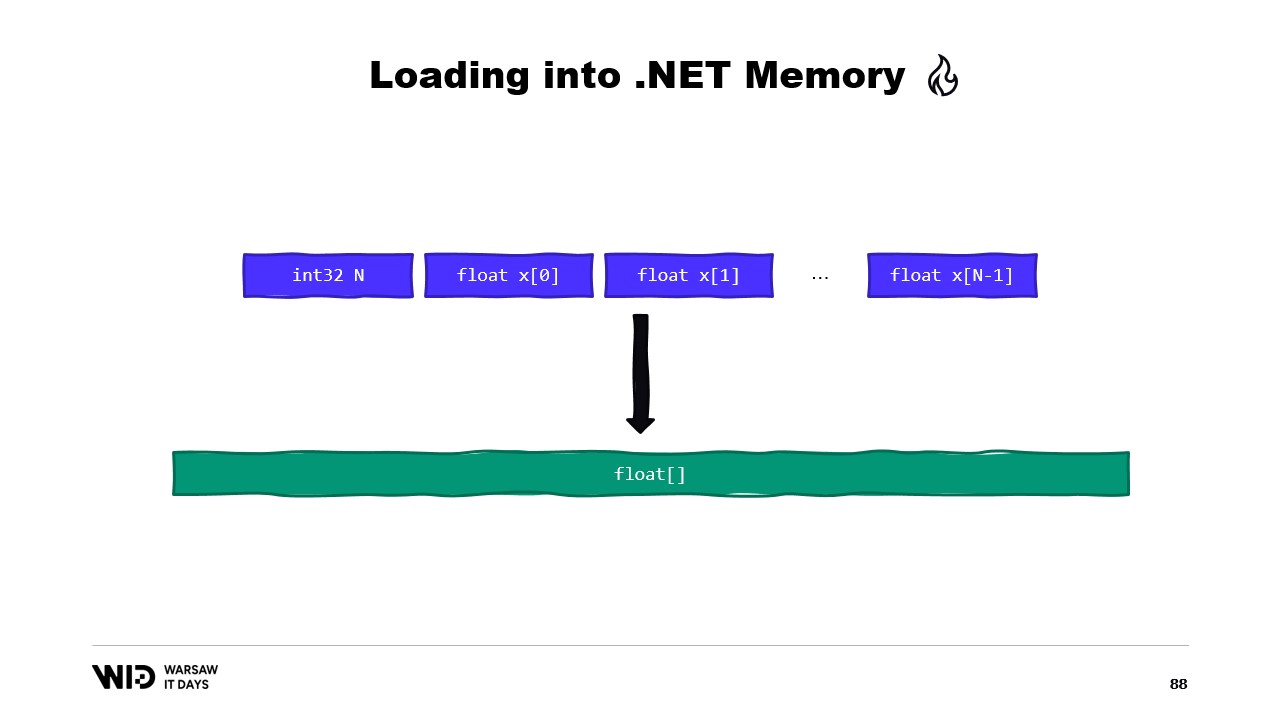
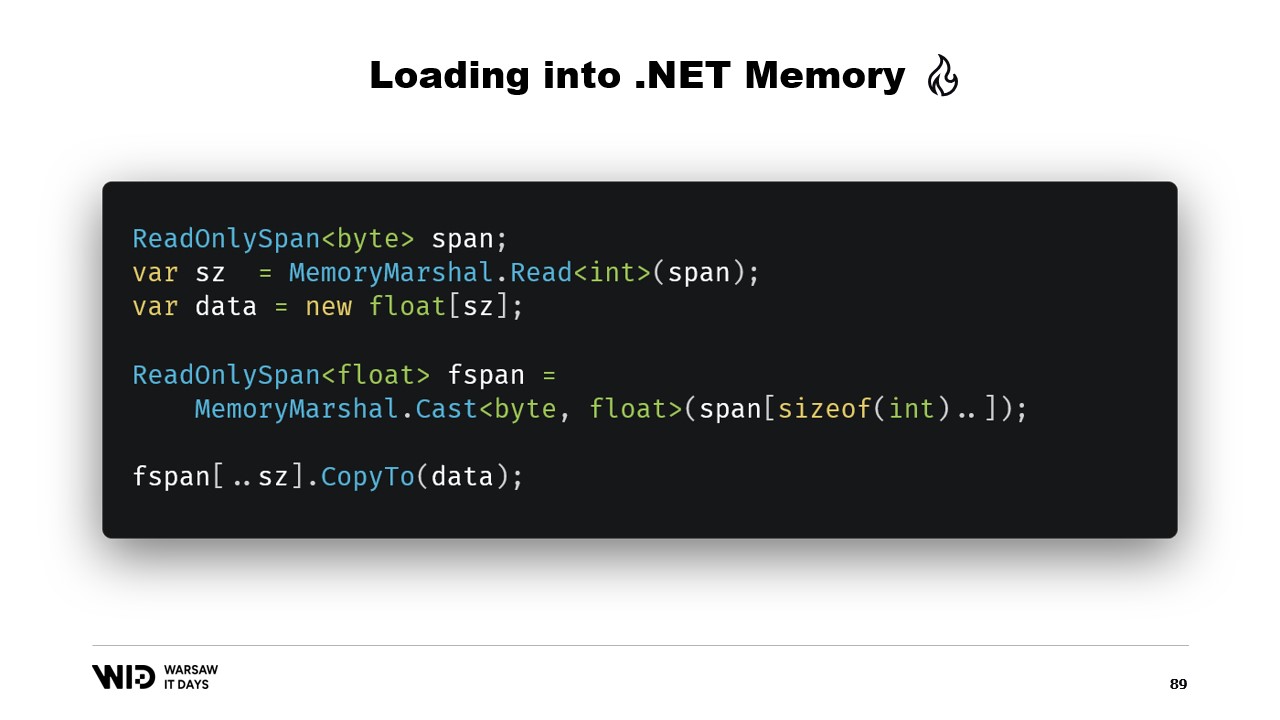
Снова мы используем MemoryMarshal.Read для чтения размера. Мы выделяем массив чисел с плавающей точкой нужного размера, а затем применяем MemoryMarshal.Cast, чтобы преобразовать span байтов в span чисел с плавающей точкой. Это, по сути, просто переинтерпретирует данные в span как числа с плавающей точкой, а не как обычные байты.
Наконец, мы используем функцию CopyTo для span, которая производит высокопроизводительное копирование данных из файла с отображением в память непосредственно в массив. Это, можно сказать, немного неэффективно, так как создаётся совершенно новая копия.
Возможно, это можно было бы избежать. Обычно на диске мы хранить не сырые числа с плавающей точкой, а их сжатую версию. Здесь мы сохраняем сжатый размер, который определяет, сколько байтов нужно прочитать. Также сохраняется размер назначения или несжатый размер, указывающий, сколько чисел с плавающей точкой нужно выделить в управляемой памяти. И, наконец, сохраняется сам сжатый полезный груз.
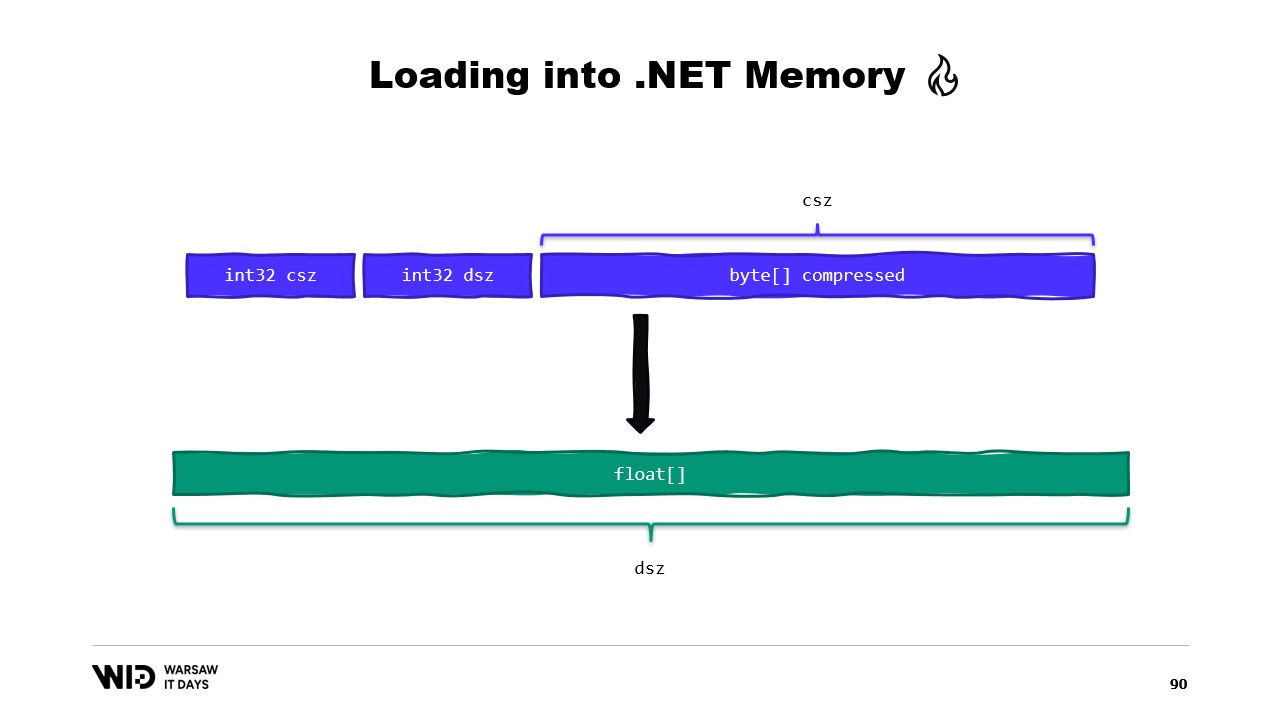
Чтобы загрузить это, лучше создать структуру, представляющую заголовок с двумя целочисленными значениями, вместо того чтобы читать два отдельных целых числа.

MemoryMarshal сможет прочитать экземпляр этой структуры, загрузив оба поля одновременно. Мы выделяем массив чисел с плавающей точкой, а затем наша библиотека сжатия почти наверняка содержит вариант функции декомпрессии, которая принимает только для чтения span байтов и возвращает span байтов в качестве результата. Мы можем снова использовать MemoryMarshal.Cast, на этот раз преобразуя массив чисел с плавающей точкой в span байтов для использования в качестве места назначения.
Теперь копирование не происходит. Вместо этого алгоритм сжатия напрямую считывает данные с диска, обычно через кэш страниц, в целевой массив чисел с плавающей точкой.

У span есть одно существенное ограничение: его нельзя использовать в качестве члена класса, а, следовательно, его также нельзя использовать как локальную переменную в асинхронном методе.
К счастью, существует другой тип — Memory, который предназначен для представления диапазона данных с более длительным временем жизни.
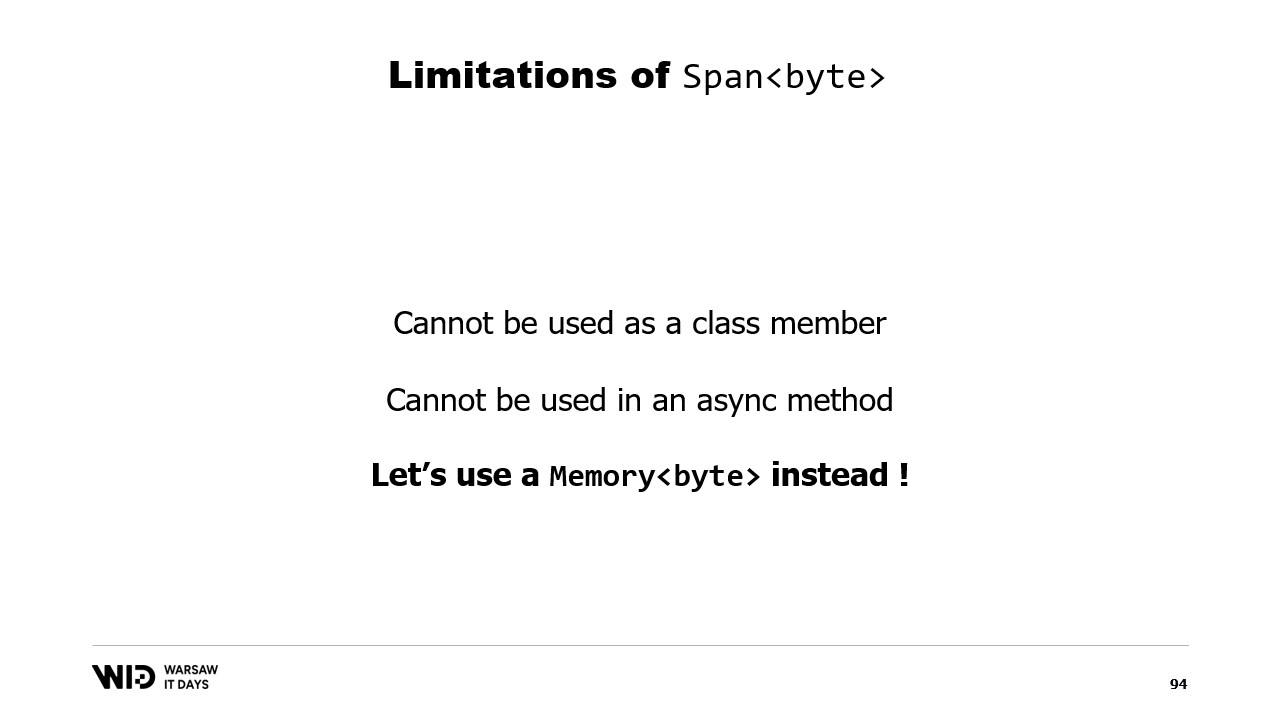
К сожалению, документации о том, как это реализовать, крайне мало. Создать span из указателя легко, а создание Memory из указателя описано настолько неполно, что лучшая доступная документация — это gist на GitHub, который я настоятельно рекомендую прочитать.
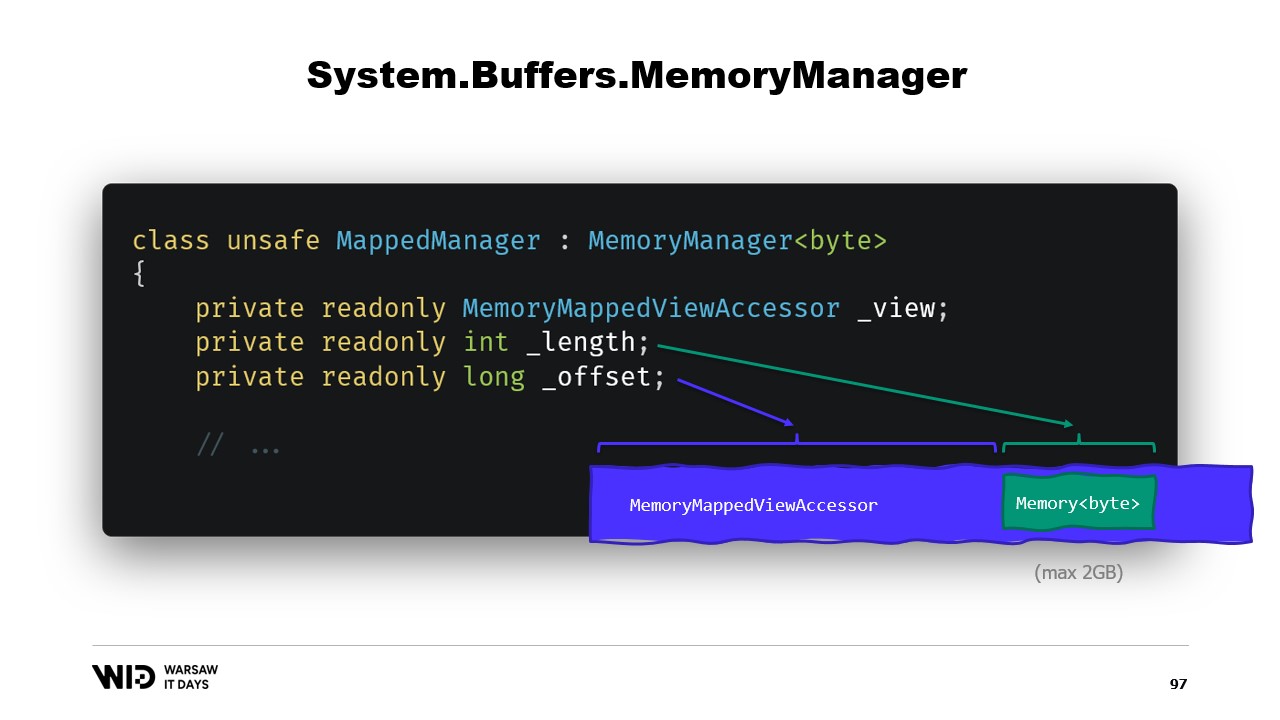
Короче говоря, нам нужно создать MemoryManager. MemoryManager используется внутри Memory всякий раз, когда требуется выполнить что-то более сложное, чем просто указание на участок массива.
В нашем случае нам нужно сослаться на view accessor, связанный с отображением в память, к которому мы обращаемся. Мы должны знать длину диапазона, который нам разрешено просматривать, и, наконец, потребуется смещение. Это связано с тем, что Memory байт по замыслу не может представлять более двух гигабайт, а сам файл, вероятно, будет больше двух гигабайт. Таким образом, смещение указывает, где начинается нужная нам память в рамках более широкого view accessor.
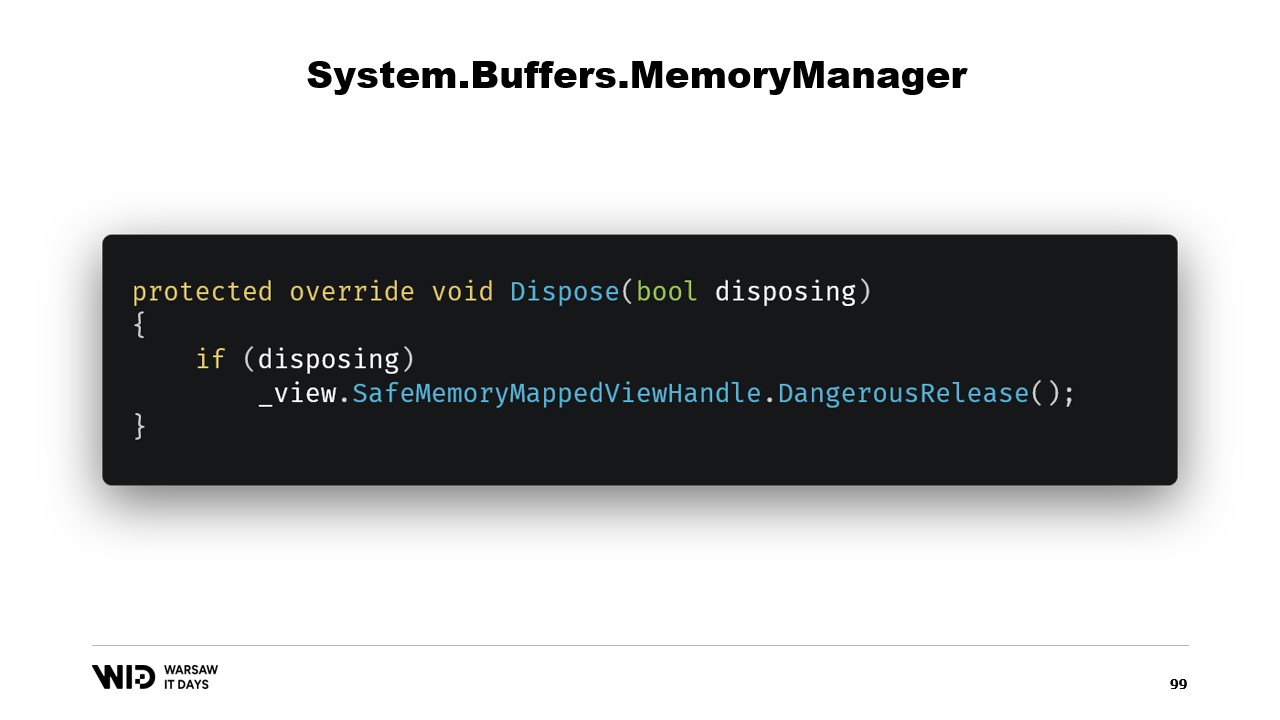
Конструктор класса достаточно прост.

Нам просто нужно добавить ссылку на безопасный дескриптор, представляющий область памяти, и эта ссылка будет освобождена в методе dispose.
Далее у нас есть свойство address, которое не является чем-то экстраординарным, а просто полезным. Мы используем DangerousGetHandle для получения указателя и добавляем смещение, чтобы адрес указывал на первые байты в области, которую мы хотим, чтобы представляла наша память.
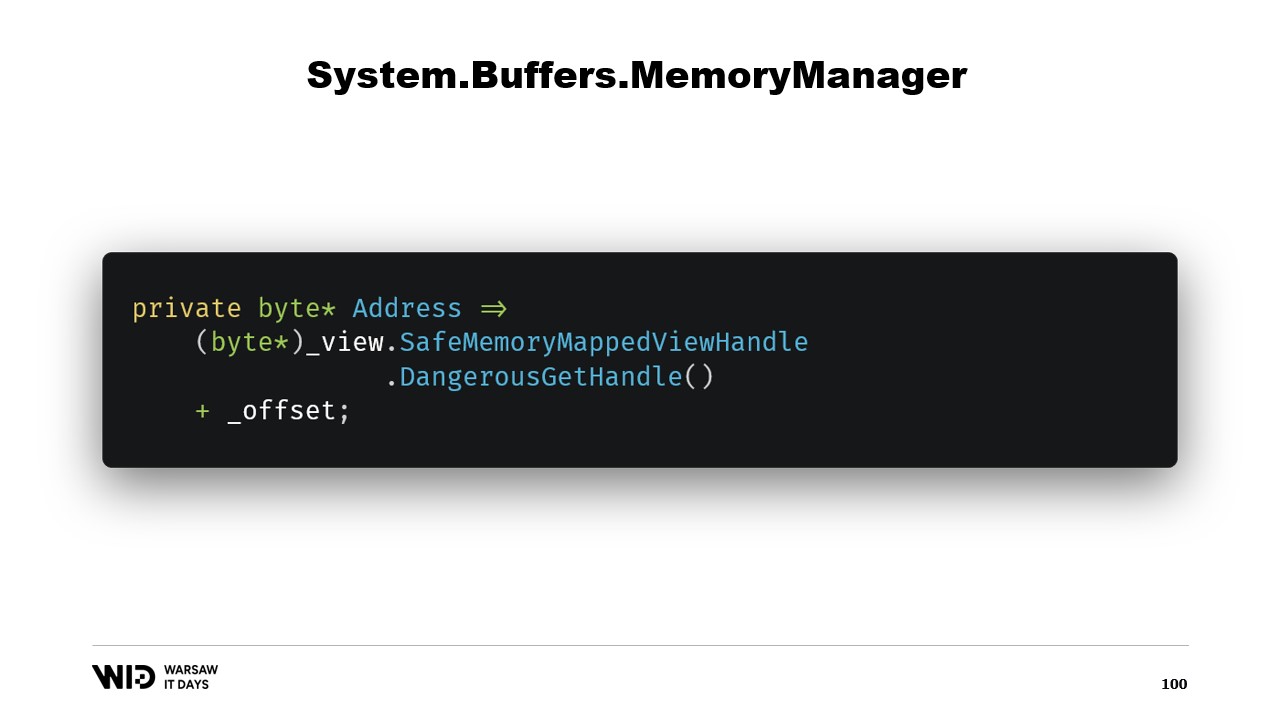
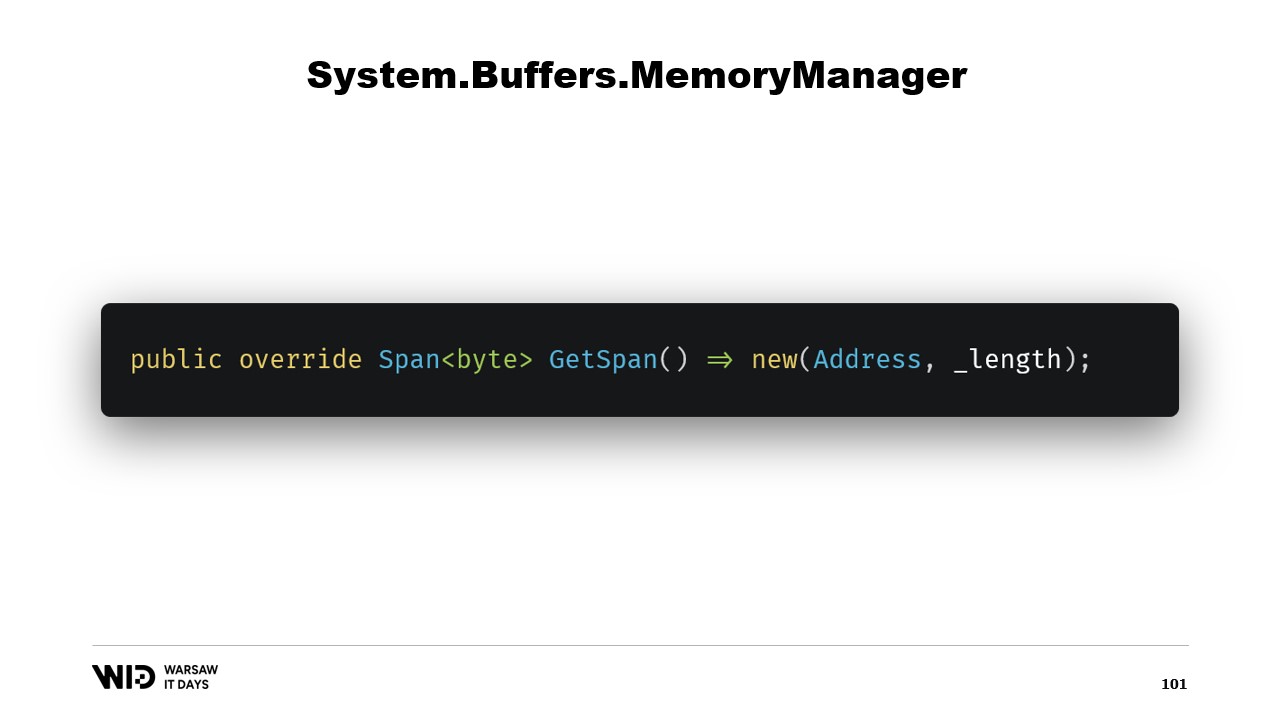
Мы переопределяем функцию GetSpan, которая и выполняет всю магию. Она просто создаёт span, используя адрес и длину.
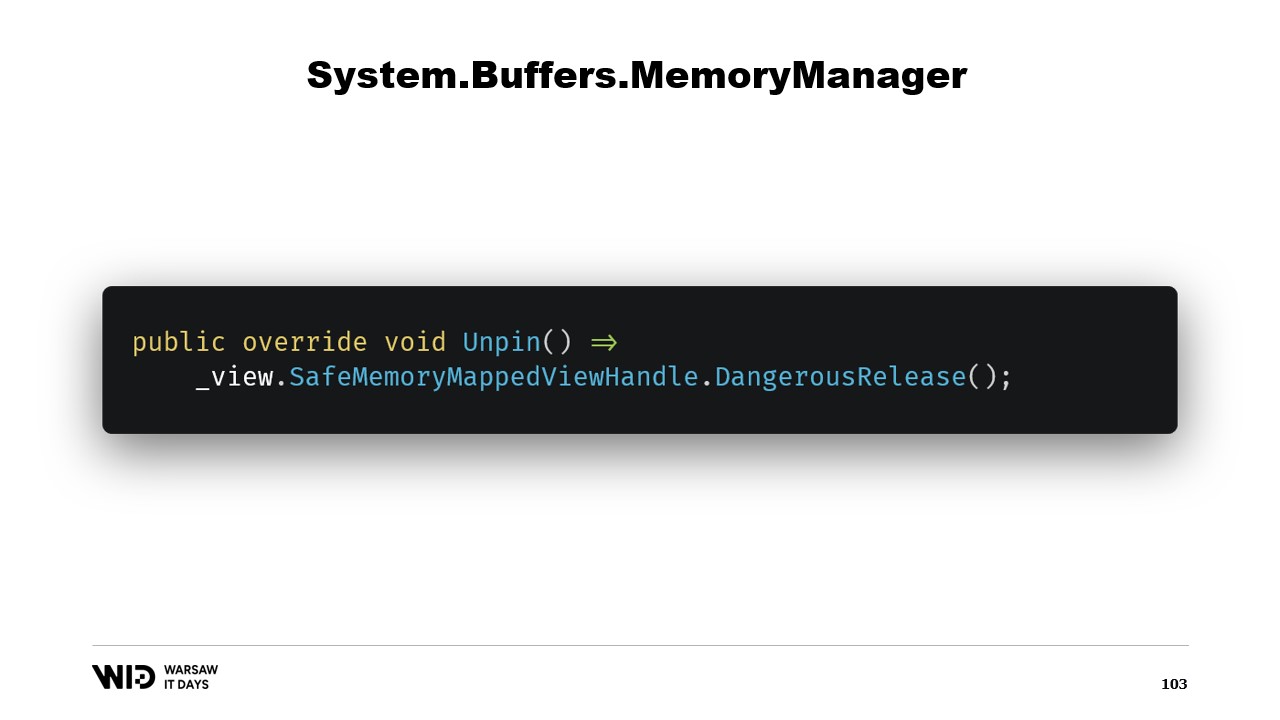
Существует ещё два метода, которые необходимо реализовать в MemoryManager. Один из них — Pin. Он используется рантаймом в ситуации, когда память должна оставаться в одном и том же месте в течение короткого времени. Мы добавляем ссылку и возвращаем MemoryHandle, который указывает на нужное место и также ссылается на текущий объект как на закрепляемый.

Это позволит рантайму узнать, что когда память будет откреплена, он вызовет метод Unpin этого объекта, который снова освободит безопасный дескриптор.
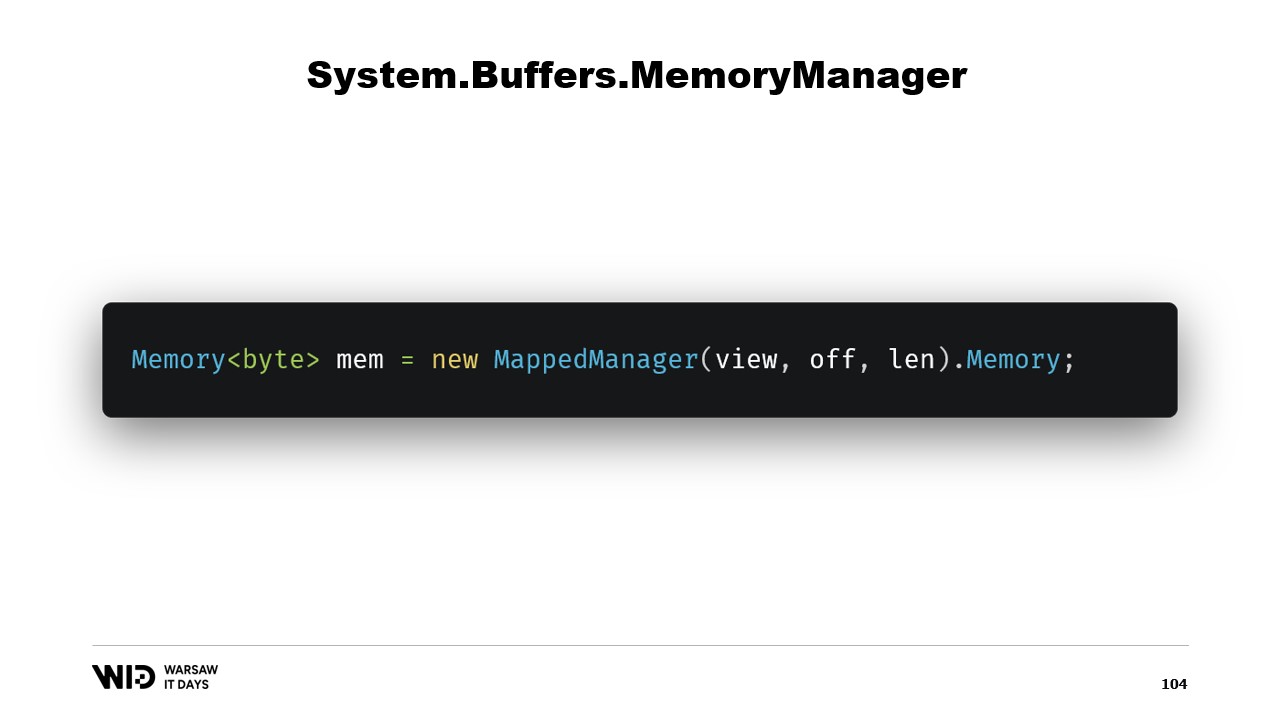
Как только этот класс будет создан, достаточно создать его экземпляр и обратиться к его свойству Memory, которое вернёт Memory байт, внутренне ссылающуюся на только что созданный MemoryManager. И вот, теперь у вас есть участок памяти. Когда вы записываете в него, он автоматически будет выгружен на диск, когда потребуется освободить место, а при обращении он прозрачно загрузится с диска.
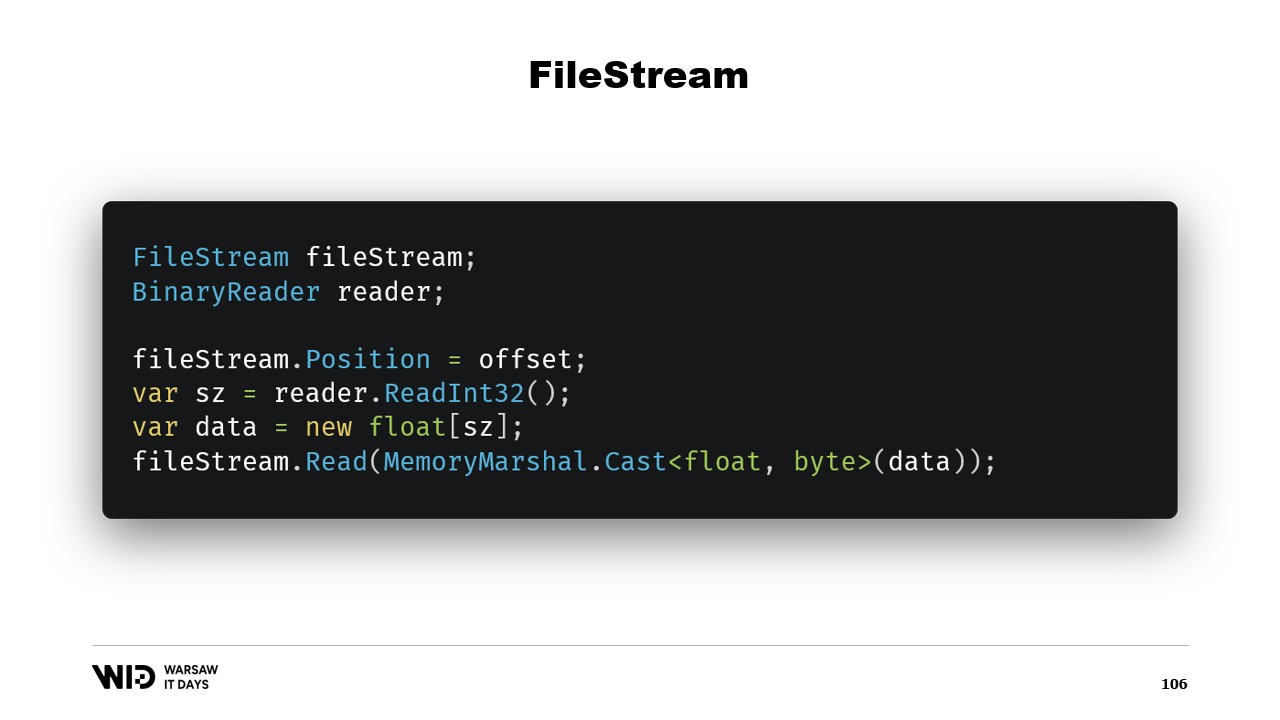
Таким образом, этого достаточно для реализации нашей программы выгрузки на диск. Возникает вопрос: зачем использовать отображение в память, когда можно использовать FileStream? В конце концов, FileStream — это очевидный выбор для доступа к данным на диске, и его использование хорошо задокументировано. Например, для чтения массива чисел с плавающей точкой вам понадобится FileStream и BinaryReader, обёрнутый вокруг FileStream. Вы устанавливаете позицию FileStream на смещение, где находятся данные, читаете Int32 с помощью ридера, выделяете массив чисел с плавающей точкой, а затем преобразуете его в span байтов с помощью MemoryMarshal.Cast.
FileStream.Read теперь имеет перегрузку, которая принимает span байтов в качестве места назначения. Это также использует кэш страниц. Вместо того чтобы отображать эти страницы в адресное пространство вашего процесса, операционная система просто хранит их, и чтобы прочитать данные, она загружает их с диска в память, а затем копирует с этой страницы в предоставленный вами span. Таким образом, по производительности и поведению это эквивалентно тому, что происходит в версии с отображением в память.
Однако есть два основных отличия. Во-первых, эта операция не является потокобезопасной. Вы устанавливаете позицию в одной строке, а затем в другой строке полагаетесь, что позиция не изменилась. Это означает, что для этой операции нужен блок, и поэтому вы не можете читать из нескольких мест параллельно, хотя с файлами с отображением в память это возможно.
Другая проблема заключается в том, что, в зависимости от используемой стратегии FileStream, может происходить два чтения: одно для Int32 и второе для чтения в span. Возможен вариант, когда каждое из них вызывает системный вызов, при котором операционная система копирует некоторую часть данных из своей памяти в память процесса, что создаёт накладные расходы. Либо поток буферизован, и первоначальное чтение четырёх байтов создаст копию одной страницы, поверх которой позже будет выполнено фактическое копирование функцией чтения. Это добавляет дополнительные накладные расходы, которых нет в версии с отображением в память.
По этой причине использование версии с отображением в память предпочтительнее с точки зрения производительности. В конце концов, FileStream — очевидный выбор для доступа к данным на диске, и его использование хорошо задокументировано. Например, чтобы прочитать массив чисел с плавающей точкой, вам нужны FileStream и BinaryReader. Вы устанавливаете позицию FileStream на смещение, где находятся данные, читаете Int32 для определения размера, выделяете массив чисел с плавающей точкой, преобразуете его в span байтов с помощью MemoryMarshal.Cast и передаёте его в перегрузку FileStream.Read, которая принимает span байтов в качестве места назначения для чтения. И это также использует кэш страниц. Вместо того чтобы страницы ассоциировались с процессом, они хранятся операционной системой, которая просто загружает их с диска в кэш страниц и копирует из кэша страниц в память процесса, как мы делали в версии с отображением в память.
The FileStream подход, однако, имеет два основных недостатка. Во-первых, этот код не является безопасным для использования в многопоточной среде. В конце концов, положение устанавливается в одной инструкции, а затем используется в последующих инструкциях. Поэтому нам нужна блокировка вокруг этих операций чтения. Версия с отображением памяти не требует блокировок и, фактически, способна загружать данные с нескольких участков на диске параллельно. Для SSD это увеличивает глубину очереди, что повышает производительность, и поэтому обычно считается желательным. Другой проблемой является то, что FileStream требует двух чтений.
В зависимости от стратегии, используемой внутри потока, это может привести к двум системным вызовам, которые требуют пробуждения операционной системы. Он скопирует некоторые данные из своей памяти в память процесса, а затем потребуется всё очистить и вернуть управление процессу. Это влечет за собой определенные накладные расходы. Другой возможной стратегией является буферизация FileStream. В этом случае будет выполнен только один системный вызов, но он потребует копирования из памяти операционной системы во внутренний буфер FileStream, а затем оператор чтения снова скопирует данные из внутреннего буфера FileStream в массив с плавающей точкой. Таким образом, создается лишнее копирование, которого не происходит в версии с отображением памяти.
Потоковый файл, хотя и несколько проще в использовании, имеет некоторые ограничения. Вместо него следует использовать версию с отображением памяти. Таким образом, мы получили систему, способную использовать максимально доступную память и, при её исчерпании, сбрасывать части наборов данных обратно на диск. Этот процесс является полностью прозрачным и взаимодействует с операционной системой. Он работает с максимальной производительностью, поскольку части набора данных, к которым осуществляется частый доступ, всегда остаются в памяти.
Однако, есть еще один вопрос, на который нам нужно ответить. В конце концов, когда вы отображаете память, вы не отображаете сам диск, вы отображаете файлы на диске. Теперь вопрос: сколько файлов мы собираемся выделить? Какого они будут размера? И как мы будем циклически использовать эти файлы при выделении и освобождении памяти?
Очевидный выбор — просто отобразить один большой файл, сделать это при запуске программы и постоянно использовать его. Когда какая-либо часть больше не используется, просто перезаписывать её. Это очевидно, а значит, и неверно.

Первая проблема этого подхода заключается в том, что перезапись страницы памяти требует отдельного алгоритма.
Алгоритм выглядит следующим образом: сначала вы сразу загружаете страницу в память. Затем вы изменяете содержимое страницы в памяти. Операционная система не может знать, что на втором шаге вы собираетесь стереть всё и заменить, поэтому ей все равно нужно загрузить страницу, чтобы части, которые вы не изменяете, остались неизменными. Наконец, вы планируете запись страницы обратно на диск в какой-то момент в будущем.
Теперь, в первый раз, когда вы записываете данные в определенную страницу нового файла, данных для загрузки нет. Операционная система знает, что все страницы заполнены нулями, поэтому загрузка не требует затрат. Она просто берет страницу, заполненную нулями, и использует её. Но когда страница уже была изменена и больше не находится в памяти, операционной системе необходимо загрузить её с диска.

Вторая проблема заключается в том, что страницы кэша выгружаются по принципу наименее недавно использованных, и операционная система не знает, что мертвая часть вашей памяти, которая никогда больше не будет использована, должна быть сброшена. Таким образом, она может в итоге оставить в памяти некоторые части набора данных, которые не нужны, и выгрузить те, которые необходимы. Нет способа сказать операционной системе, что ей следует просто игнорировать мертвые участки.
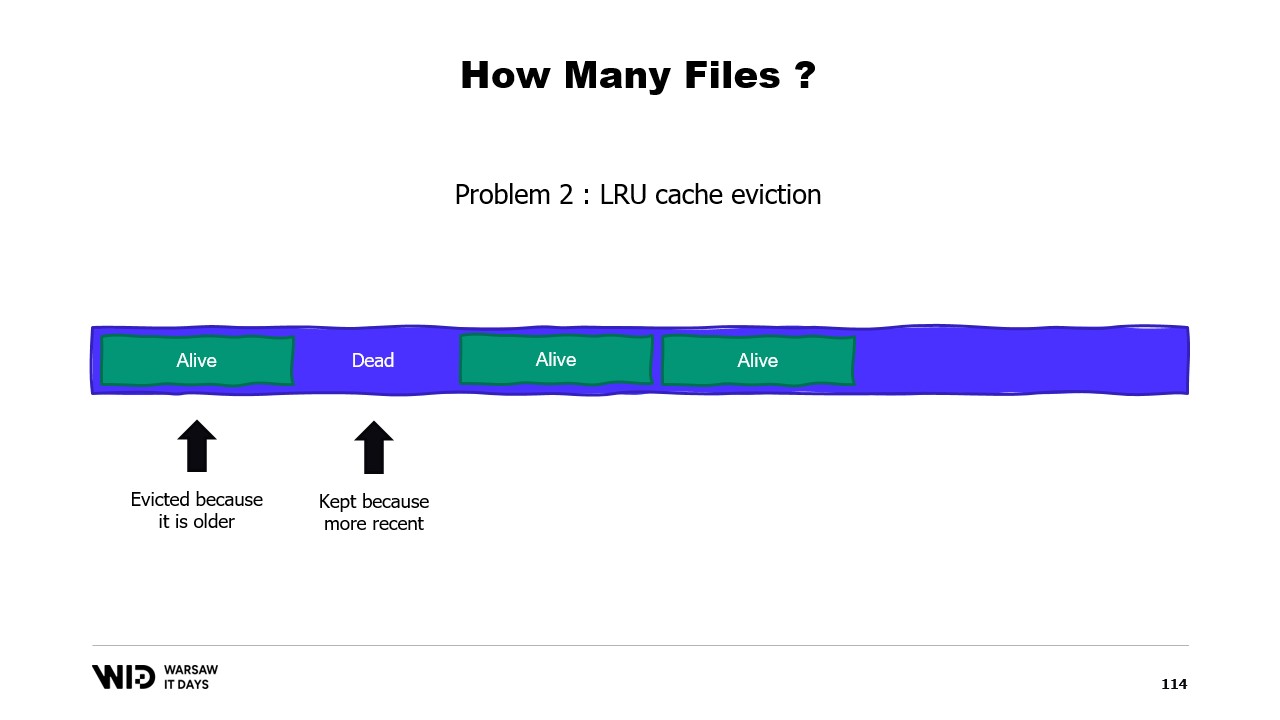
Третья проблема также связана с тем, что запись данных на диск всегда отстает от записи данных в память. И если вы знаете, что страница больше не нужна и еще не записана на диск, операционная система этого не знает. Поэтому она все равно тратит время на запись тех байтов, которые никогда больше не будут использованы, на диск, замедляя работу системы.
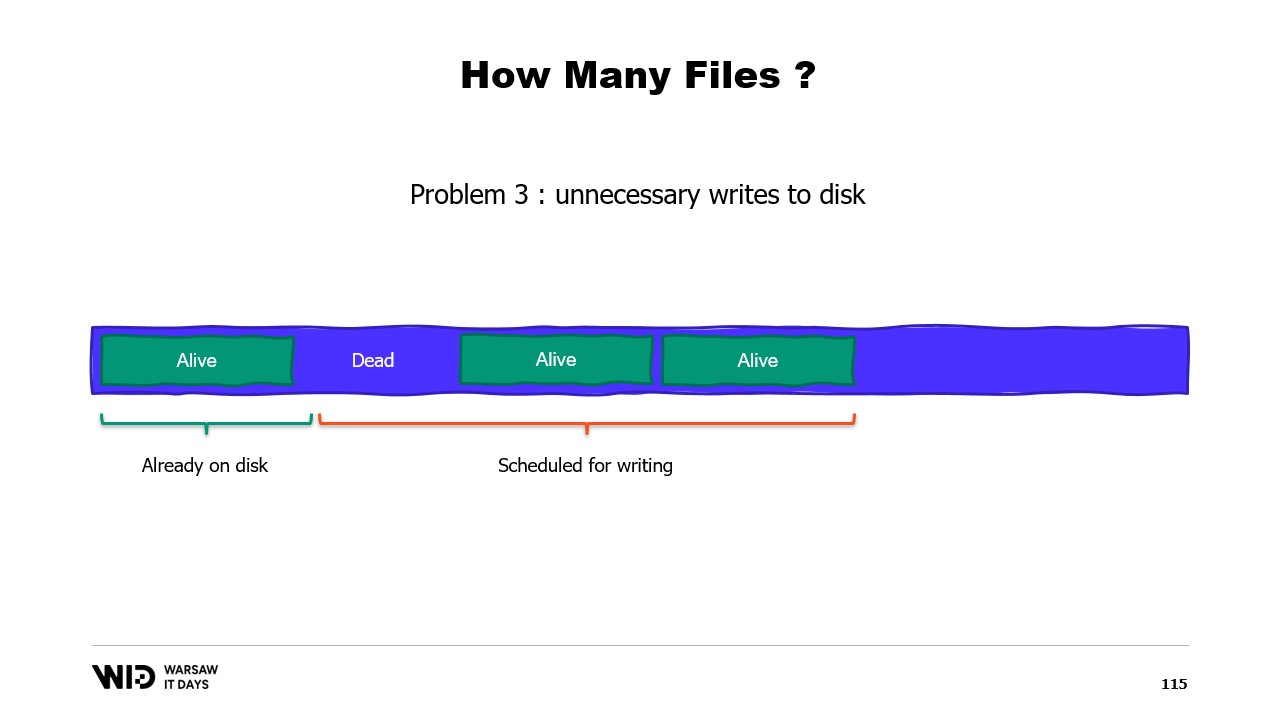
Вместо этого мы должны распределить память между несколькими крупными файлами. Мы никогда не записываем в одну и ту же область памяти дважды. Это гарантирует, что каждая запись выполняется на странице, которую операционная система знает как заполненную нулями, и не требует загрузки с диска. А также мы удаляем файлы как можно раньше. Это сообщает операционной системе, что данный файл больше не нужен, его можно выгрузить из кэша страниц, и его не нужно записывать на диск, если он еще не был записан.

В производственной среде в Lokad, на типичной производственной виртуальной машине, мы используем Lokad scratch space со следующими настройками: каждый файл имеет 16 гигабайт, на каждом диске находится 100 файлов, и каждая L32VM имеет четыре диска. В общей сложности это составляет чуть более 6 терабайт дополнительного пространства для каждой ВМ.

На сегодня всё. Пожалуйста, обращайтесь, если у вас возникнут вопросы или комментарии, и спасибо за просмотр.


