00:00:00 Introduction to the talk on spilling to disk
00:00:34 Retailer data processing and memory limitations
00:02:13 Persistent storage solution and cost comparison
00:04:07 Speed comparison of disk and memory
00:05:10 Partitioning and streaming techniques limitations
00:06:16 Importance of ordered data and optimal read size
00:07:40 Worst case scenario for data read
00:08:57 Impact of machine’s memory on program run
00:10:49 Spill to disk techniques and memory usage
00:12:59 Code section explanation and .NET implementation
00:15:06 Control over memory allocation and consequences
00:16:18 Memory mapped page and memory mapping files
00:18:24 Read-write memory maps and system performance tools
00:20:04 Using virtual memory and memory mapped pages
00:22:08 Dealing with large files and 64 bits pointers
00:24:00 Using span to load from memory mapped memory
00:26:03 Data copying and using structure to read integers
00:28:06 Creating a span from a pointer and memory manager
00:30:27 Creating an instance of memory manager
00:31:05 Implementing spill to disk program and memory mapping
00:33:34 Memory mapped version preferable for performance
00:35:22 File stream buffering strategy and limitations
00:37:03 Strategy of mapping one large file
00:39:30 Splitting memory over several large files
00:40:21 Conclusion and invitation for questions
Summary
In order to process more data than can fit in memory, programs can spill some of that data to a slower but larger storage, such as NVMe drives. Through a combination of two rather obscure .NET features (memory-mapped files and memory managers), this can be done from C# with little to no performance overhead. This talk given at Warsaw IT Days 2023 dives into the deep details how this works, and discusses how the open source NuGet package Lokad.ScratchSpace hides most of those details from developers.
Extended Summary
In a comprehensive lecture, Victor Nicolet, the CTO of Lokad, delves into the intricacies of spilling to disk in .NET, a technique that allows for the processing of large data sets that exceed the memory capacity of a typical computer. Nicolet draws from his extensive experience in dealing with complex data sets in the field of quantitative supply chain optimization at Lokad, providing a practical example of a retailer with a hundred thousand products across 100 locations. This results in a data set of 10 billion entries when considering daily data points over three years, which would require 37 gigabytes of memory to store one floating point value for each entry, far exceeding the capacity of a typical desktop computer.
Nicolet suggests the use of persistent storage, such as NVMe SSD storage, as a cost-effective alternative to memory. He compares the cost of memory and SSD storage, noting that for the cost of 18 gigabytes of memory, one could purchase one terabyte of SSD storage. He also discusses the performance trade-off, noting that reading from disk is six times slower than reading from memory.
He introduces partitioning and streaming as techniques to use disk space as an alternative to memory. Partitioning allows for processing data sets in smaller pieces that fit in memory, but it does not allow for communication between partitions. Streaming, on the other hand, allows for maintaining some state between the processing of different parts, but it requires the on-disk data to be ordered or aligned properly for optimal performance.
Nicolet then introduces spill to disk techniques as a solution to the limitations of the fits in memory approach. These techniques distribute data between memory and persistent storage dynamically, using more memory when available to run faster, and slowing down to use less memory when less is available. He explains that spill to disk techniques use as much memory as possible and only start dumping data on the disk when they run out of memory. This makes them better at reacting to having more or less memory than initially expected.
He further explains that spill to disk techniques divide the data set into two sections: the hot section, which is always in memory, and the cold section, which can spill parts of its contents to persistent storage at any point in time. The program uses hot-cold transfers, which usually involve large batches to maximize the usage of the NVMe bandwidth. The cold section allows these algorithms to use as much memory as possible.
Nicolet then discusses how to implement this in .NET. For the hot section, normal .NET objects are used, while for the cold section, a reference class is used. This class keeps a reference to the value that is being put into cold storage and this value can be set to null when it is no longer in memory. A central system in the program keeps track of all the cold references, and whenever a new cold reference is created, it determines if it causes the memory to overflow and will invoke the spill function of one or more of the cold references already in the system to keep within the memory budget available for the cold storage.
He then introduces the concept of virtual memory, where the program does not have direct access to physical memory pages, but instead has access to virtual memory pages. It is possible to create a memory mapped page, which is a common way to implement communication between programs and memory mapping files. The main purpose of memory mapping is to prevent each program from having its own copy of the DLL in memory because all those copies are identical.
Nicolet then discusses the system Performance Tool, which shows the current use of physical memory. In green is the memory that has been assigned directly to a process, in blue is the page cache, and the modified pages in the middle are those that should be an exact copy of the disk but contain changes in memory.
He then discusses the second attempt using virtual memory, where the cold section will be made up entirely of memory mapped pages. If the operating system suddenly needs some memory, it knows which pages are memory mapped and can be safely discarded.
Nicolet then explains the basic steps to create a memory mapped file in .NET, which are first to create a memory mapped file from a file on the disk and then to create a view accessor. The two are kept separate because .NET needs to deal with the case of a 32-bit process. In the case of a 64-bit process, one view accessor that loads the entire file can be created.
Nicolet then discusses the introduction of memory and span five years ago, which are types used to represent a range of memory in a way that is safer than just pointers. The general idea behind span and memory is that given a pointer and a number of bytes, a new span that represents that range of memory can be created. Once a span is created, it can be safely read anywhere within the span knowing that if an attempt is made to read past the boundaries, the runtime will catch it and an exception will be thrown instead of just the process done.
Nicolet then discusses how to use span to load from memory mapped memory into .NET managed memory. For example, if there is a string that needs to be read, many APIs centered around spans can be used. Nicolet explains the use of APIs centered around spans, such as MemoryMarshal.Read, which can read an integer from the start of the span. He also mentions the Encoding.GetString function, which can load from a span of bytes into a string.
He further explains that these operations are performed on spans, which represent a section of data that could be on the disk instead of in memory. The operating system handles the loading of the data into memory when it is first accessed. Nicolet provides an example of a sequence of floating point values that need to be loaded into a float array. He explains the use of MemoryMarshal.Read to read the size, the allocation of an array of floating point values of that size, and the use of MemoryMarshal.Cast to turn the span of bytes into a span of floating point values.
He also discusses the use of the CopyTo function of spans, which performs a high-performance copy of the data from the memory mapped file into the array. He notes that this process can be a bit wasteful as it involves creating an entirely new copy. Nicolet suggests creating a structure that represents the header with two integer values inside, which can be read by MemoryMarshal. He also discusses the use of a compression library to decompress the data.
Nicolet discusses the use of a different type, Memory, to represent a longer-lived range of data. He mentions the lack of documentation on how to create a memory from a pointer and recommends a gist on GitHub as the best available resource. He explains the need to create a MemoryManager, which is used internally by a Memory whenever it needs to do anything more complex than just pointing at a section of an array.
Nicolet discusses the use of memory mapping versus FileStream, noting that FileStream is the obvious choice when accessing data that is on the disk and its use is well documented. He notes that the FileStream approach is not thread safe and requires a lock around the operation, preventing reading from several locations in parallel. Nicolet also mentions that the FileStream approach introduces some overhead that is not present with the memory mapped version.
He explains that the memory-mapped version should be used instead, as it is able to use as much memory as possible and, when running out of memory, will spill parts of the data sets back to the disk. Nicolet raises the question of how many files to allocate, how large they should be, and how to cycle through those files as memory is allocated and deallocated.
He suggests splitting memory over several large files, never writing to the same memory twice, and deleting files as soon as possible. Nicolet concludes by sharing that in production at Lokad, they use Lokad scratch space with specific settings: the files each have 16 gigabytes, there are 100 files on each disk, and each L32VM has four disks, representing a little bit more than 6 terabytes of spill space for each VM.
Full Transcript

Victor Nicolet: Hello and welcome to this talk on spilling to disk in .NET.
Spilling to disk is a technique to process data sets that do not fit in memory by keeping parts of the data set that are not in use on persistent storage instead.
This talk is based on my experience working for Lokad. We do quantitative supply chain optimization.
The quantitative part means we work with large data sets and the supply chain part, well, it’s part of the real world so they are messy, surprising, and full of edge cases within edge cases.
So, we do a lot of rather complex processing.
Let’s look at a typical example. A retailer would have on the order of a hundred thousand products.
These products are present in up to 100 locations. These can be stores, they can be warehouses, they can even be sections of warehouses that are dedicated to e-commerce.
And if we want to do any kind of real analysis about this, we need to look at the past behavior, what happens to those products and those locations.
Assuming we keep only one data point for every day and we look only at three years in the past, this means about 1000 days. Multiply all these together and our data set will have 10 billion entries.
If we keep just one floating point value for each entry, the data set already takes 37 gigabytes of memory footprint. This is above what a typical desktop computer would have.

And one floating point value is not nearly enough to do any kind of analysis.
A better number would be 20 and even then we’re doing some very good efforts to keep the footprint small. Even then, we’re looking at about 745 gigabytes of memory usage.
This does fit in cloud machines if they are large enough, about seven thousand dollars per month. So, it is kind of affordable but it is also kind of wasteful.

As you might have guessed from the title of this talk, the solution is to use persistent storage instead, which is slower but cheaper than memory.
These days, you can purchase NVMe SSD storage for about 5 cents per gigabyte. An NVMe SSD is about the fastest kind of persistent storage you can get easily these days.
By comparison, one gigabyte of RAM costs 275 dollars. This is about a 55 times difference.

Another way to look at this is that for the budget it takes to buy 18 gigabytes of memory, you would have enough to pay for one terabyte of SSD storage.

What about Cloud offerings? Well, taking the Microsoft cloud as an example, on the left is the L32s, part of a series of virtual machines optimized for storage.
For about two thousand dollars per month, you get almost 8 terabytes of persistent storage.
On the right is the M32ms, part of a series optimized for memory and for more than two and a half times the cost, you get only 875 gigabytes of RAM.
If my program runs on the machine on the left and takes twice as long to complete, I am still winning on cost.

What about performance? Well, reading from memory runs at about 21 gigabytes per second. Reading from an NVMe SSD runs at about 3.5 gigabytes per second.
This is not an actual benchmark. I just created a virtual machine and ran those two commands and there are many ways to both increase and decrease these numbers.
The important part here is just the order of magnitude of the difference between the two. Reading from disk is six times slower than reading from memory.
So, the disk is both disappointingly slow, you don’t want to be reading from the disk all the time with random access patterns. But on the other hand, it’s also surprisingly fast. If your processing is mostly CPU bound, you might not even notice that you’re reading from disk instead of reading from memory.

A fairly well-known technique to use disk space as an alternative to memory is partitioning.
The idea behind partitioning is to select one of the dimensions of the data set and to cut the data set into smaller pieces. Each piece should be small enough to fit in memory.
The processing then loads each piece on its own, does its processing, and saves that piece back to the disk before loading the next piece.
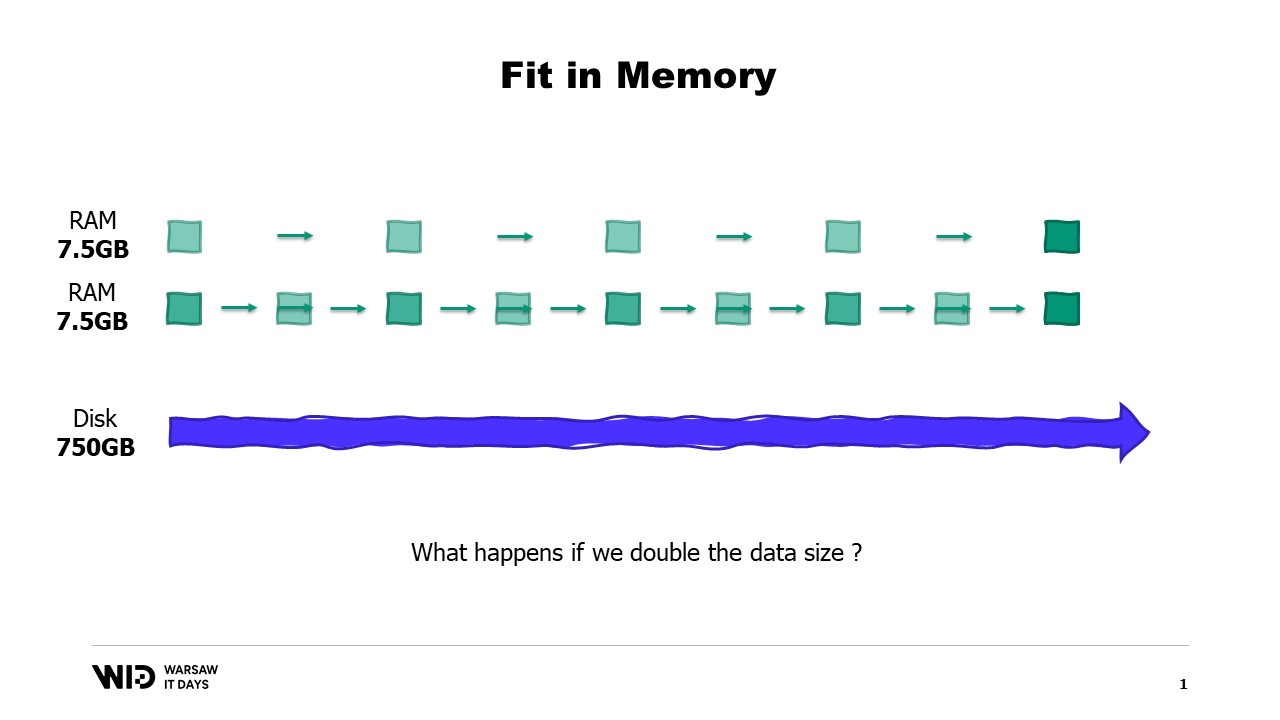
In our example, if we were to cut the data sets along locations and process locations one at a time, then each location would take only 7.5 gigabytes of memory. This is well within the range of what a desktop computer can do.

However, with partitioning, there is no communication between the partitions. So, if we need to process data across locations, we can no longer use this technique.
Another technique is streaming. Streaming is fairly similar to partitioning in that we only load small pieces of data into memory at any point in time.
Unlike partitioning, we are allowed to keep some state in between the processing of different parts. So, while processing the first location, we would set up the initial state, and then when processing the second location, we are allowed to use whatever was present in the state at that point in order to create a new state at the end of the processing of the second location.
Unlike partitioning, streaming does not lend itself to parallel execution. But it does solve the problem of computing something across all the data in the data set instead of being siloed into every piece separately.
Streaming does have its own limitation though. In order for it to be performance, the on-disk data should be ordered or aligned properly.
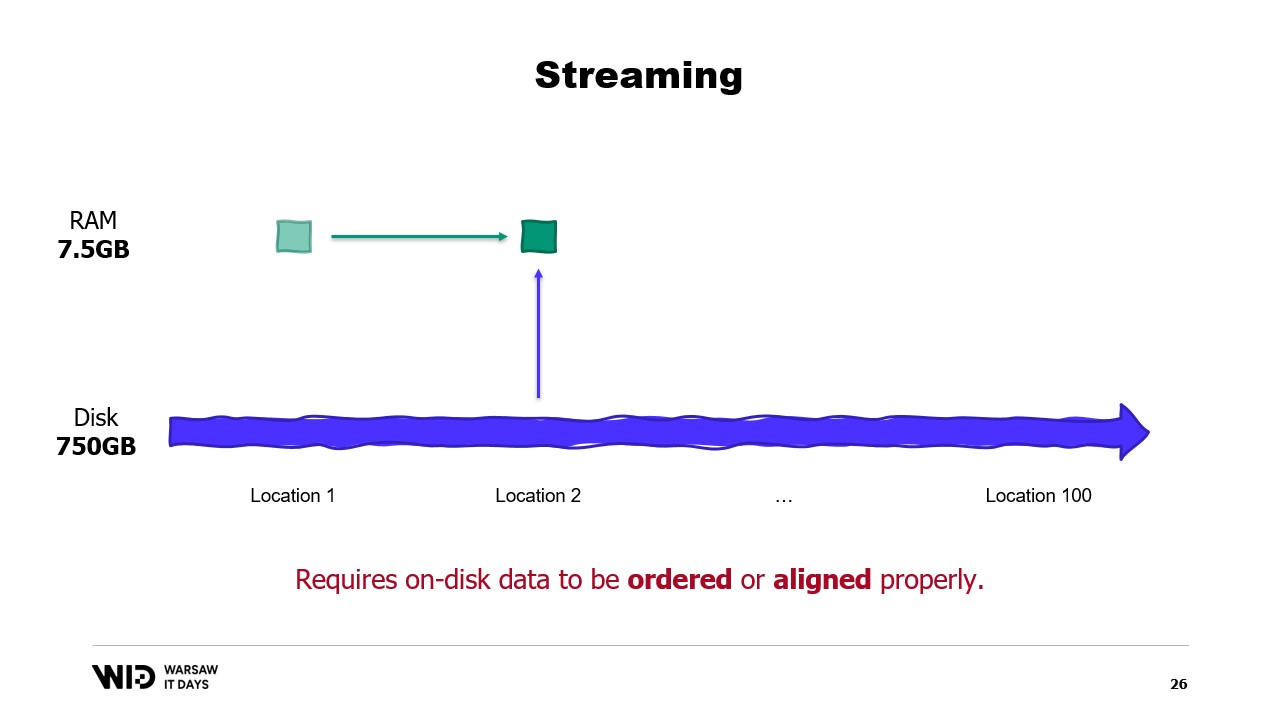
To understand those requirements, you need to know that NVMe reads and writes data in sectors of half a kilobyte and the earlier performance values, like 3.5 gigabytes per second, assume that sectors are being read and used in their entirety.
If we only use one portion of the sector but the entire sector has to be read, then we are wasting bandwidth and dividing our performance by a large factor.

And so, it is optimal when the data that we read is a multiple of half a kilobyte and is aligned on the boundaries of the sectors.
We are no longer using spinning disks now, so skipping ahead and not reading the sector is done at no cost.

If it is not possible to align the data on sector boundaries, however, another way is to load it in sequential order.
This is because once a sector has been loaded in memory, reading the second part of the sector does not require another load from the disk. Instead, the operating system will just be able to give you the remaining bytes that have not yet been used.
And so, if data is loaded consecutively, there is no wasted bandwidth and you still get the full performance.

The worst case is when you only read one or a few bytes from each sector. For example, if you read a floating point value from each sector, you divide your performance by 128.

What’s worse is that there is another unit of data grouping above the sectors, which is the operating system page, and the operating system usually loads entire pages of about 4 kilobytes in their entirety.
So now, if you read one floating point value from each page, you have divided your performance by 1024.
For this reason, it is really important to ensure that data reads from persistent storage are read in large consecutive batches.

Using those techniques, it is possible to make the program fit into a smaller amount of memory. Now, those techniques will treat memory and disk as two separate storage spaces, independent of one another.
And so, the distribution of the data set between memory and disk is entirely determined by what the algorithm is and what the structure of the data set is.
So, if we run the program on a machine that has exactly the right amount of memory, the program will fit tightly and it will be able to run.
If we provide a machine that has less than the required amount of memory, the program will not be able to fit in memory and it will not be able to run.
Finally, if we provide a machine that has more than the necessary amount of memory, the program will do what programs usually do, it will not use the additional memory and it will still run at the same speed.
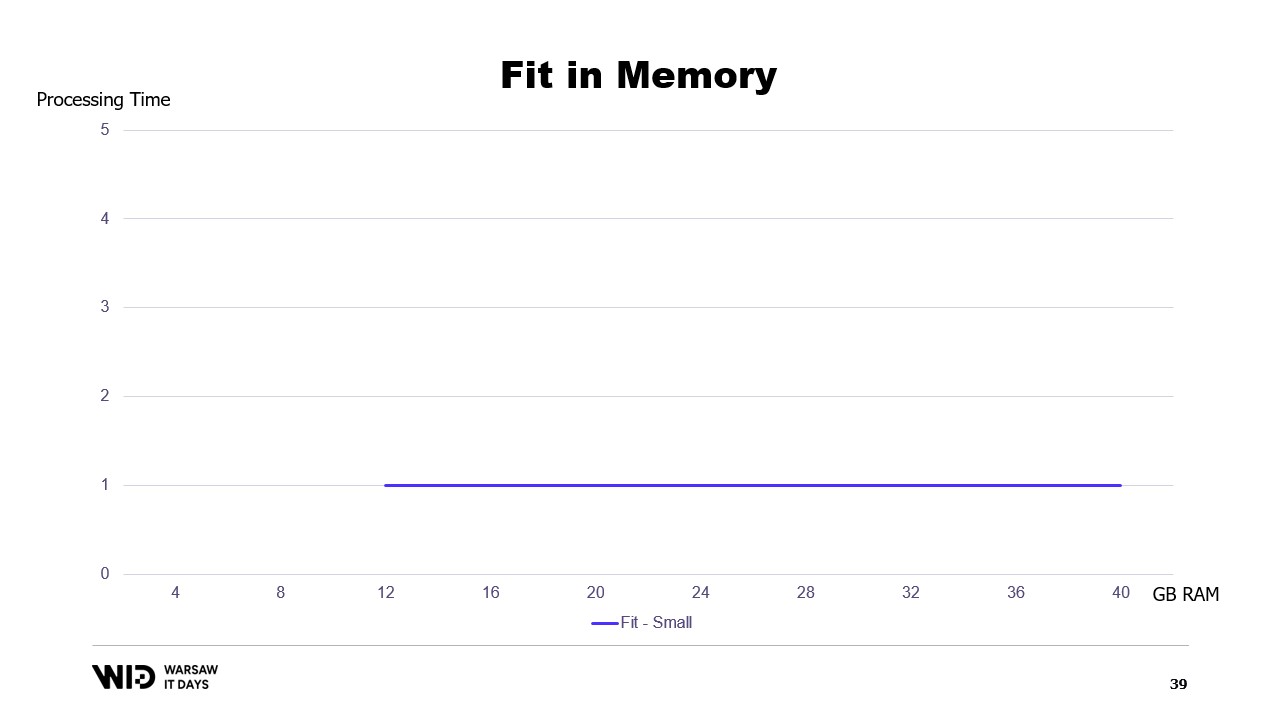
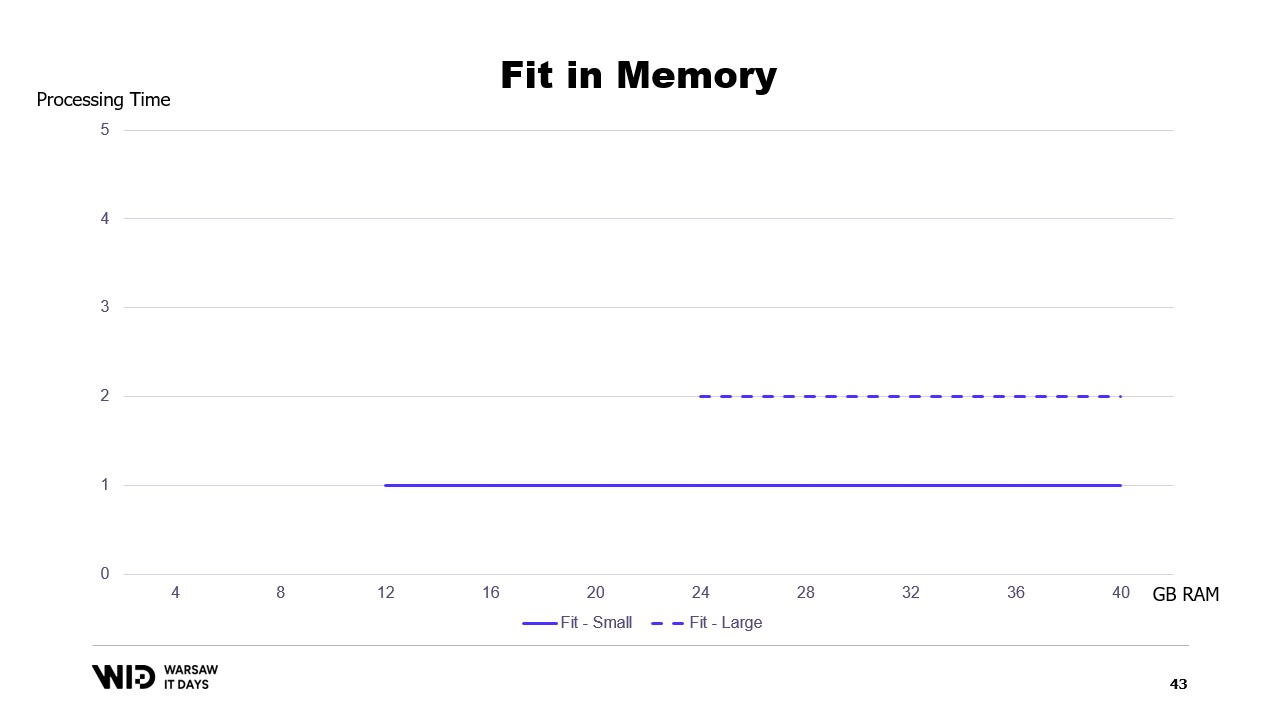
If we were to plot a graph of the execution time based on the memory available, it will look like this. Below the memory footprint, there is no execution, so there is no processing time. Above the footprint, the processing time is constant because the program is not able to use the additional memory to run faster.
And also, what happens if the data set grows? Well, depending on which dimension, if the data set grows in a way that increases the number of partitions, then the memory footprint will stay the same, there will just be more partitions.
On the other hand, if the individual partitions grow, then the memory footprint will grow as well, which will increase the minimum amount of memory that the program needs in order to run.
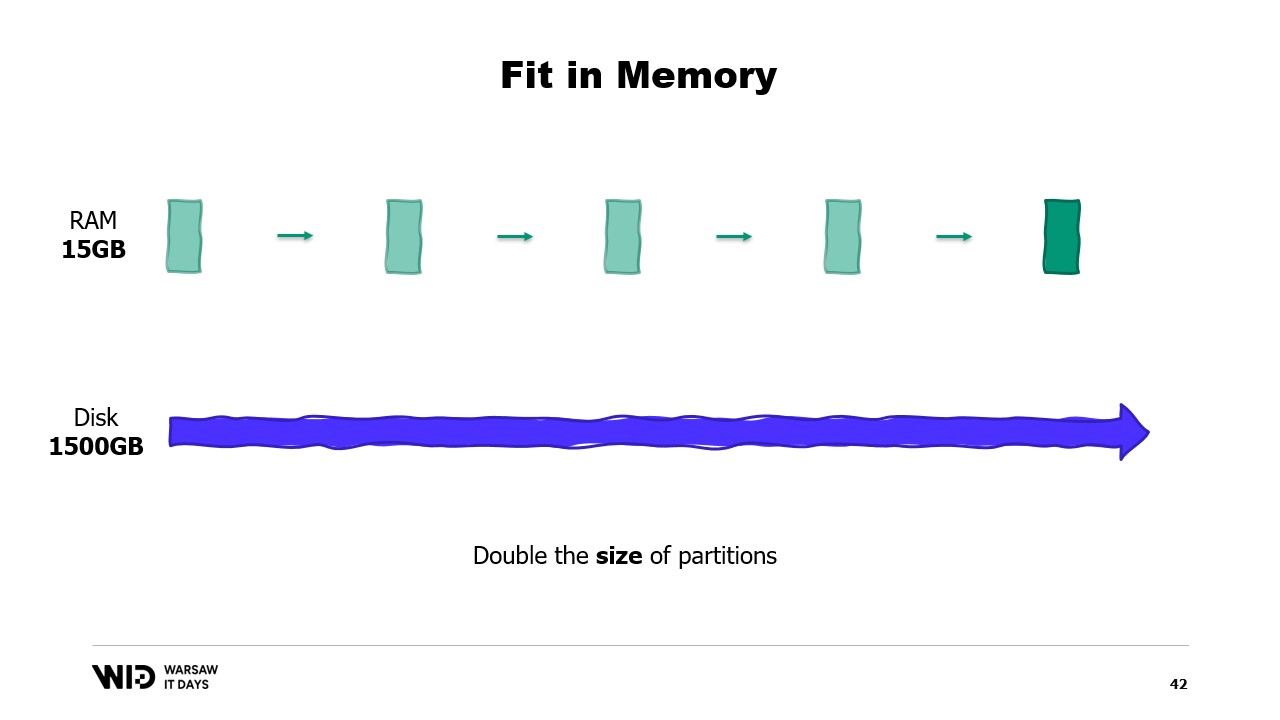
In other words, if I have a larger data set that I need to process, not only will it take longer, but it will also have a larger footprint.
This creates a nasty situation where I will need to add more memory in order to be able to fit large data sets when they appear, but adding more memory does not improve anything about the smaller data sets.
This is a limitation of the fits in memory approach where the distribution of the data set between memory and persistent storage is entirely determined by the structure of the data set and the algorithm itself.
It does not take into account the actual amount of available memory. What spill to disk techniques do is they do this distribution dynamically. So, if there is more memory available, they will use more memory in order to run faster.
And by contrast, if there is less memory available, then up to a point, they will be able to slow down in order to use less memory. The curves look a lot better in that case. The minimum footprint is smaller and is the same for both data sets.
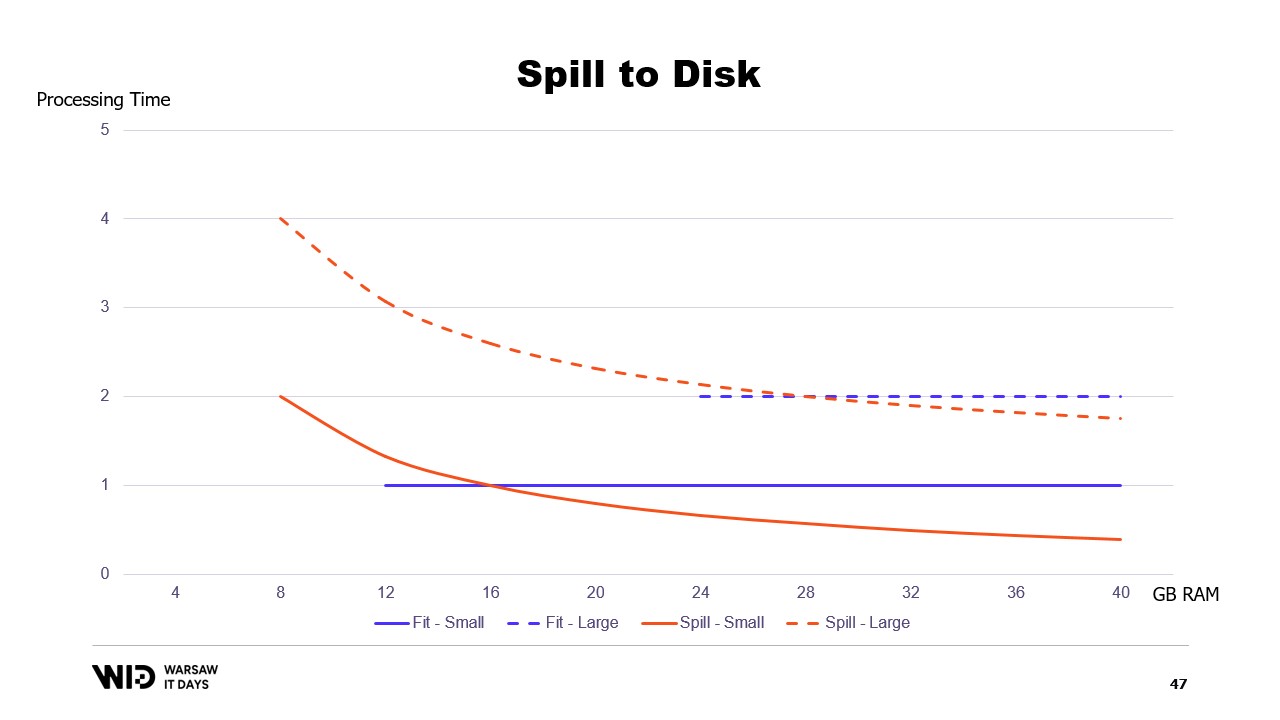
The performance increases as more memory is added in all cases. Fit to memory techniques will preemptively dump some data to the disk in order to reduce the memory footprint. By contrast, spill to disk techniques will use as much memory as possible and only when they run out of memory will they start dumping some data on the disk to make some room.
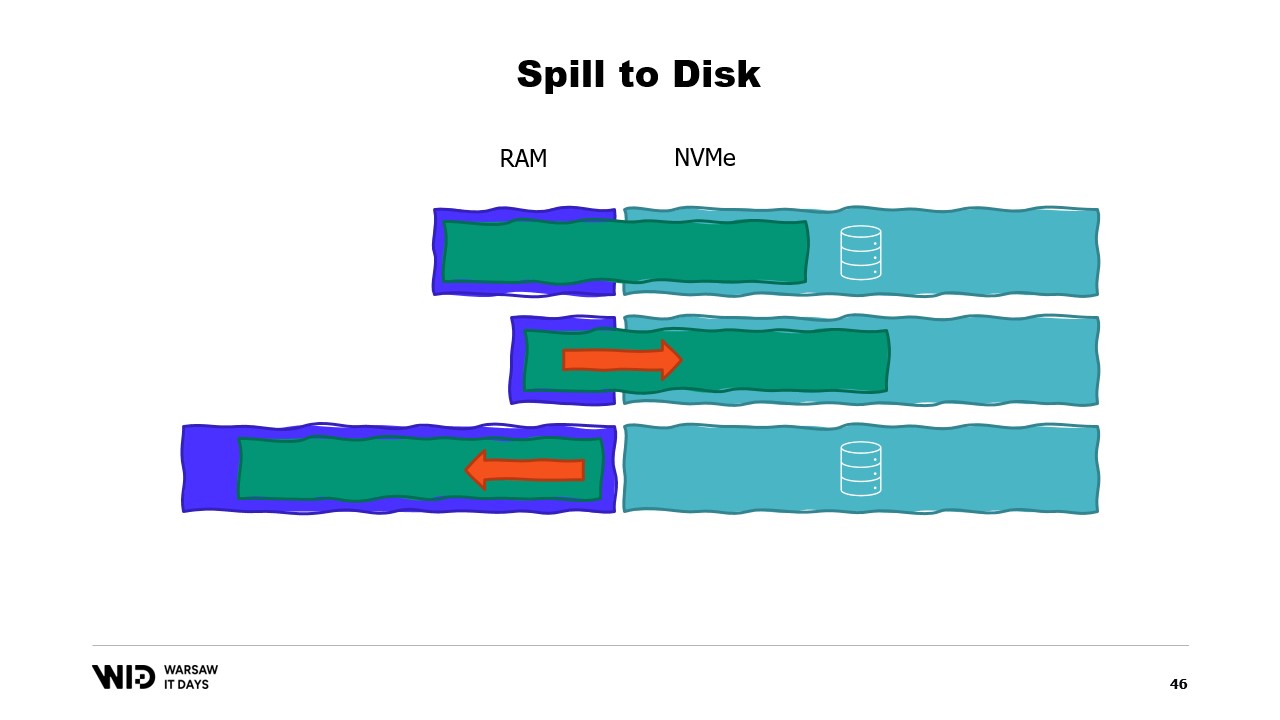
This makes them a lot better at reacting to having more or less memory than initially expected. Spill to disk techniques will cut the data set into two sections. The hot section is assumed to always be in memory and so it is always safe in terms of performance to access it with random access patterns. It will of course have a maximum budget, maybe something like 8 gigabytes per CPU on a typical Cloud machine.
On the other hand, the cold section is allowed at any point in time to spill parts of its contents to persistent storage. There is no maximum budget except what position is available. And of course, it is not safely possible in terms of performance to read from the cold section.
So, the program will use hot-cold transfers. These will usually involve large batches in order to maximize the usage of the NVMe bandwidth. And since the batches are fairly large, they will also be done at a fairly low frequency. And so, it is the cold section that allows those algorithms to use as much memory as possible.

Because the cold section will fill as much RAM as is available and then spill the rest to persistent storage. So, how can we make this work in .NET? Since I call this the first attempt, you can guess that it will not work. So, try and find out in advance what the problem will be.
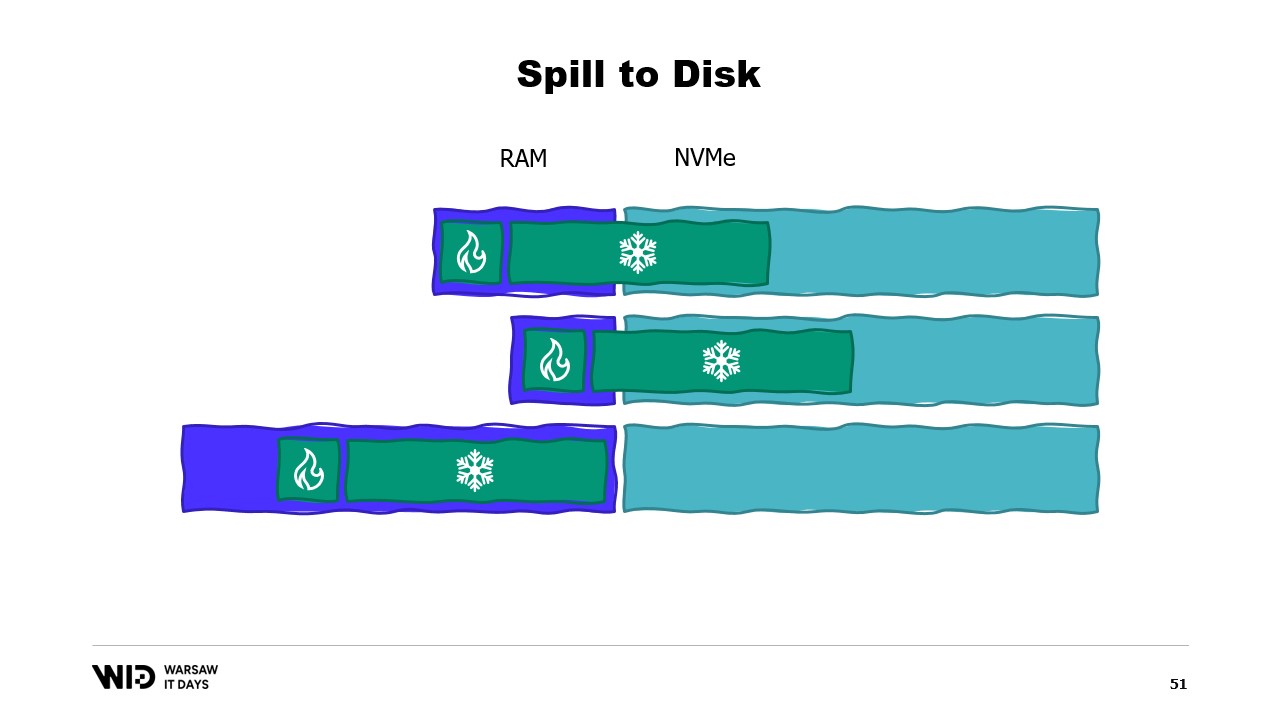
For the hot section, I will use normal .NET objects and the problem we will look at a normal .NET program. For the cold section, I will use this called reference class. This class keeps a reference to the value that is being put into cold storage and this value can be set to null when it is no longer in memory. It has a spill function which takes the value from memory and writes it to storage and then nulls out the reference which will let the .NET garbage collector reclaim that memory when it feels some pressure.
And finally, it has a value property. This property when accessed will return the value from memory if present and if not, we load back from disk into memory before returning it. Now, if I set up a central system in my program that keeps track of all the cold references, then whenever a new cold reference is created, I can determine if it causes the memory to overflow and will invoke the spill function of one or more of the cold references already in the system just to keep within the memory budget available for the cold storage.

So, what is going to be the problem? Well, if I look at the contents of the memory of a machine that runs our program, in the ideal case, it will look like this. First on the left is the operating system memory which it uses for its own purposes. Then there is the internal memory used by .NET for things like loaded assemblies or garbage collector overhead and so on. Then is the memory from the hot section and finally taking up everything else is the memory allocated to the cold section.
With some efforts, we are able to control everything that is on the right because that is what we allocate and choose to release for the garbage collector to collect. However, what is on the left is outside of our control. And what happens if suddenly the operating system needs some additional memory and finds out that everything is being occupied by what the .NET process has created?
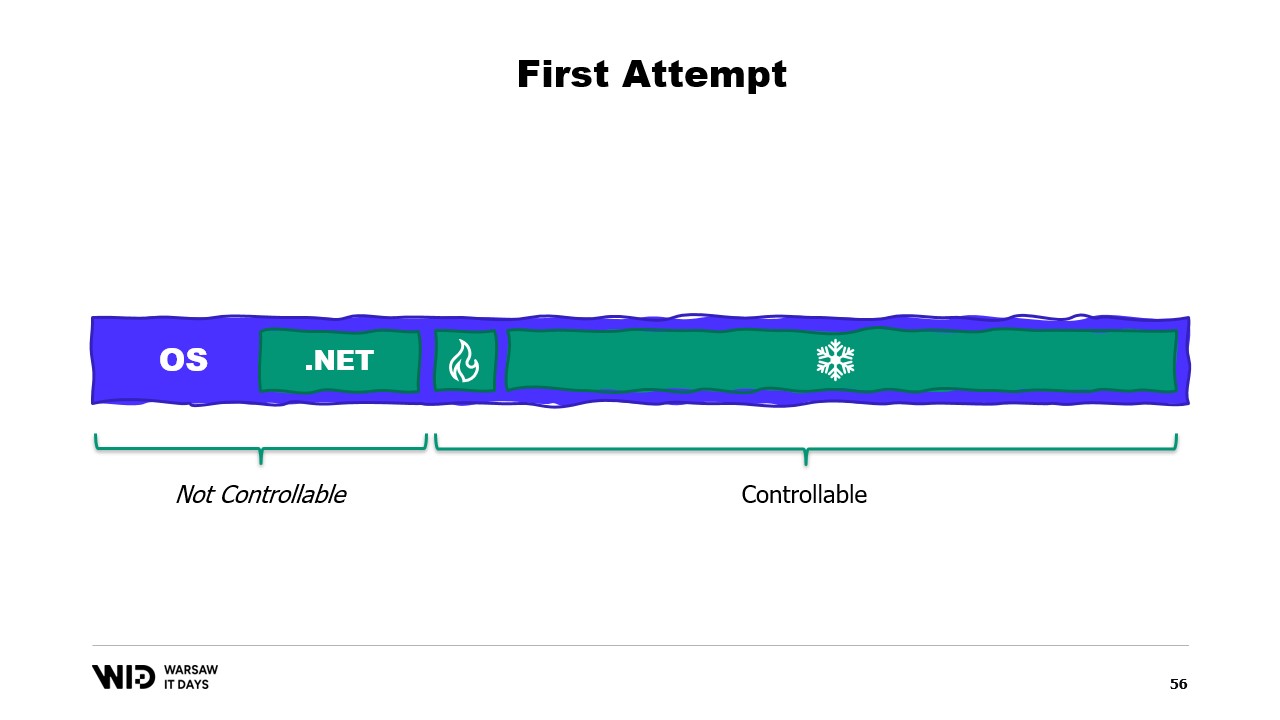
Well, the typical reaction of say the Linux kernel in that case will be to kill the program that uses the most memory and there is no way to react quickly enough to release some memory back to the kernel so that it will not kill us. So, what’s the solution?

Modern operating systems have the concept of virtual memory. The program does not have direct access to physical memory pages. Instead, it has access to virtual memory pages and there is a mapping between those pages and actual pages in physical memory. If another program is running on the same computer, it will not be able to access on its own the pages of the first program. There are ways to share, however.
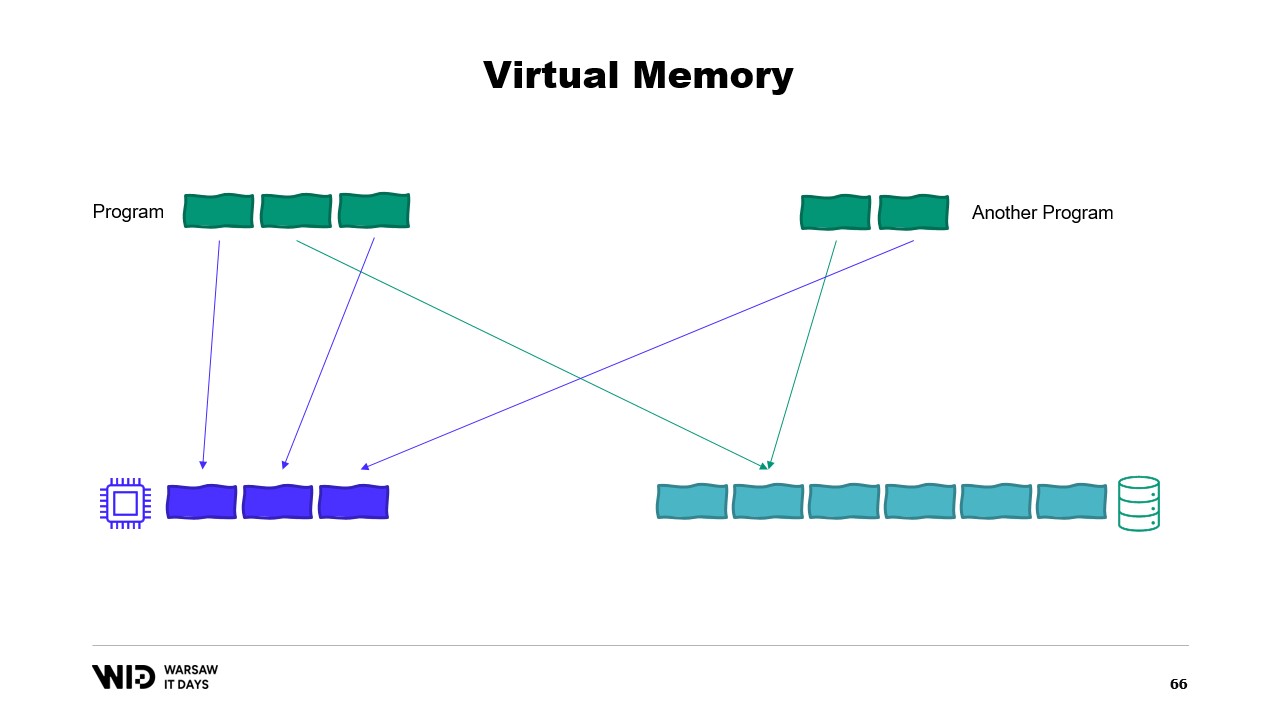
It is possible to create a memory mapped page. In that case, anything that the first program writes to the shared page will immediately be visible by the other part. This is a common way to implement communication between programs but its main purpose is memory mapping files. Here, the operating system will know that this page is an exact copy of a page on persistent storage, usually parts of a shared library file.
The main purpose here is to prevent each program from having its own copy of the DLL in memory because all those copies are identical so there is no reason to waste memory storing those copies. Here, for example, we have two programs totaling four pages of memory when physical memory only has room for three. Now, what happens if we want to allocate one more page in the first program? There is no room available but the kernel operating system knows that the memory mapped page can be dropped temporarily and when necessary, it will be able to be reloaded from persistent storage identically.
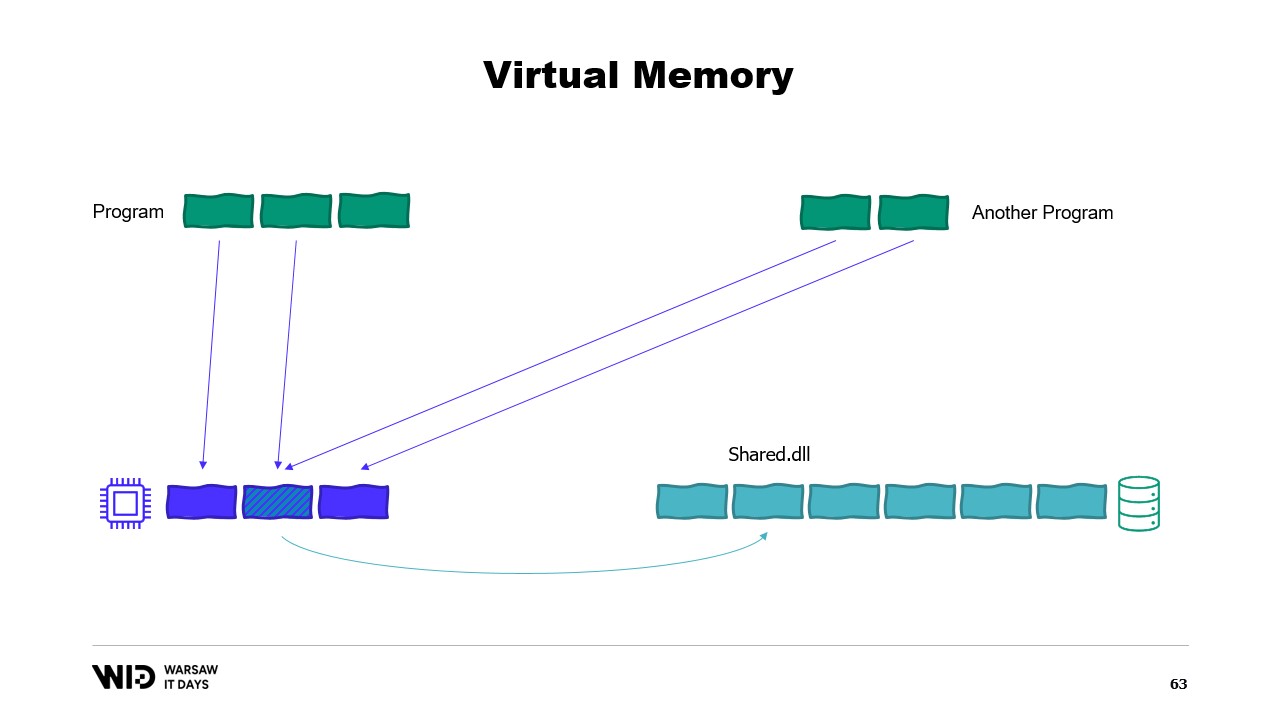
So, it will do just that. The two shared pages will point to the disk now instead of to memory. The memory is cleared, set to zero by the operating system, and then given to the first program to be used for its third logical page. Now, memory is completely full and if either program attempts to access the shared page, there will be no room for it to be loaded back into memory because pages that are given to programs cannot be reclaimed by the operating system.
So, what will happen here is an out of memory error. One of the programs will die, memory will be released, and it will be then repurposed to load the memory mapped file back into memory. Also, while most memory maps are read-only, it is also possible to create some that are read-write.
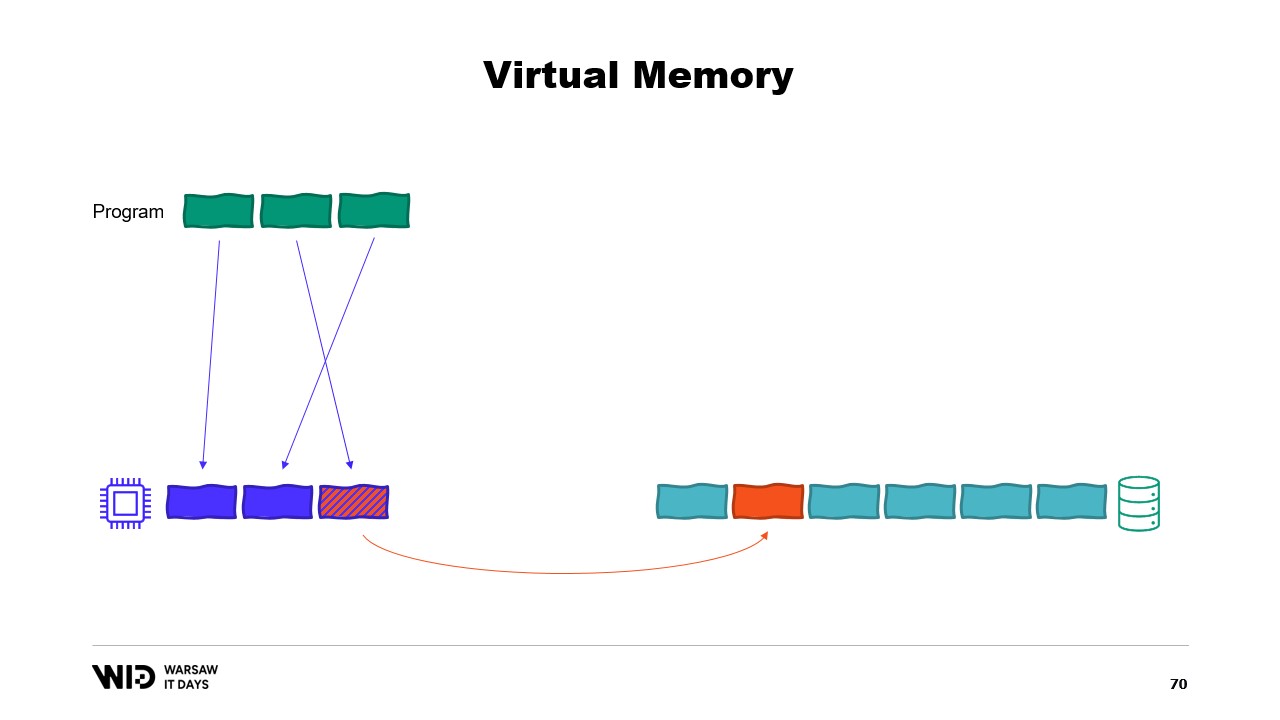
A program makes a change to the memory in the mapped page, then the operating system will at some point in the future save the contents of that page back to the disk. And of course, it is possible to ask for this to happen at a specific moment by using functions like flush on Windows. The system Performance Tool has this nice window that shows the current use of physical memory.
In green is the memory that has been assigned directly to a process. It cannot be reclaimed without killing the process. In blue is the page cache. Those are pages that are known to be identical copies of a page on the disk and so whenever a process needs to read from the disk a page that is already in the cache, then no disk read will happen and value will be returned directly from memory.
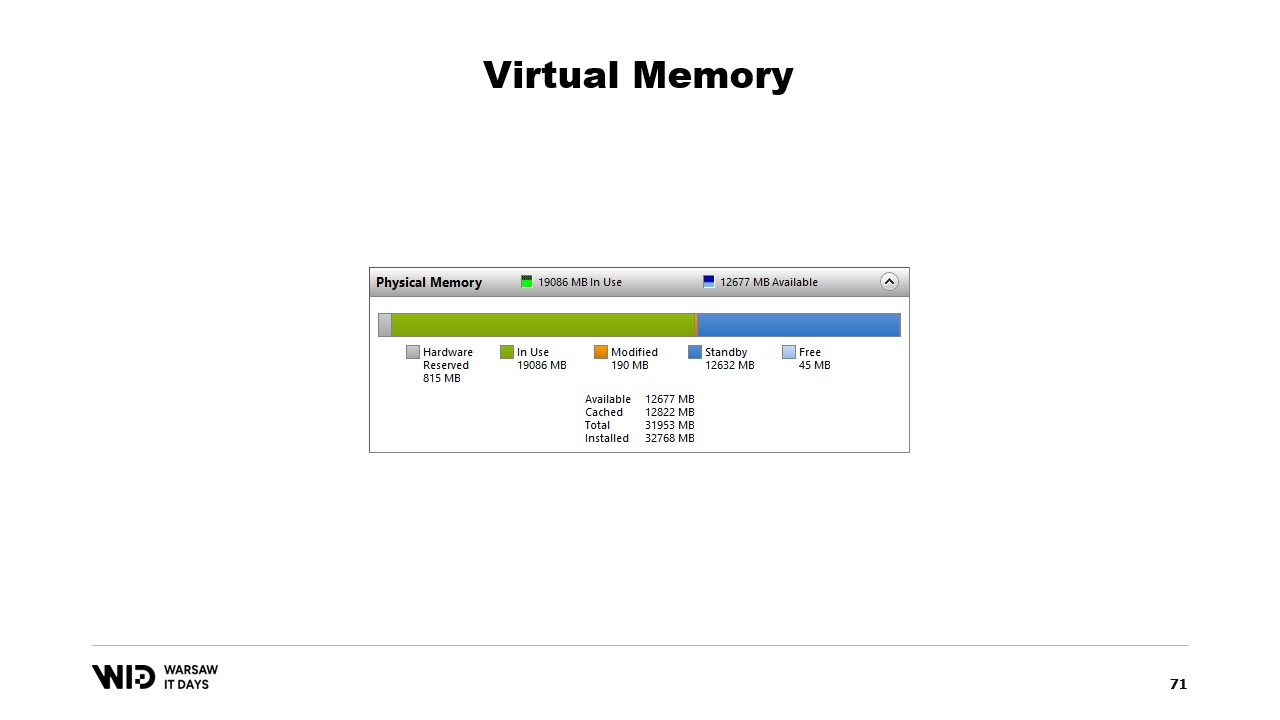
Finally, the modified pages in the middle are those that should be an exact copy of the disk but contain changes in memory. Those changes have not been applied yet back to disk but they will be in a fairly short time. On Linux, the h-stop tool displays a similar graph. On the left are the pages that have been assigned directly to processes and cannot be reclaimed without killing them and on the right in yellow is the page cache.

If you’re interested, there is an excellent resource by Vyacheslav Biryukov about what goes on in the Linux page cache. Using virtual memory, let’s make our second attempt. Will it work this time? Now, we decide that the cold section will be made up entirely of memory mapped pages. So all of them are expected to be present on the disk first.
The program no longer has any control over which pages will be in memory and which will only be present on the disk. The operating system does that transparently. So, if the program tries to access, let’s say, the third page in the cold section, the operating system will detect that it is not present in memory, will unload one of the existing pages, say the second one, and then it will load the third page into memory.
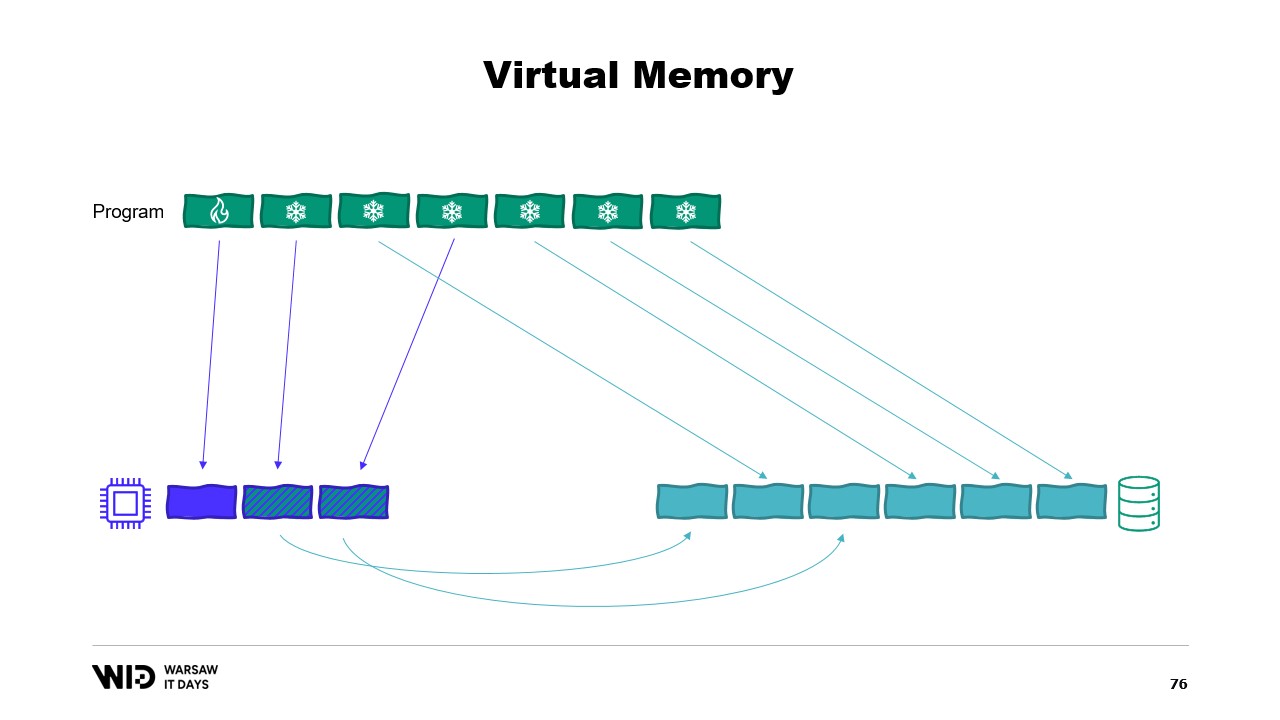
From the point of view of the process itself, it was completely transparent. The wait for reading from memory was just a little bit longer than usual. And what happens if the operating system suddenly needs some memory in order to do its own thing? Well, it knows which pages are memory mapped and can be safely discarded. So, it will just drop one of the pages, use it for its own purposes, and then release it back when it’s done.
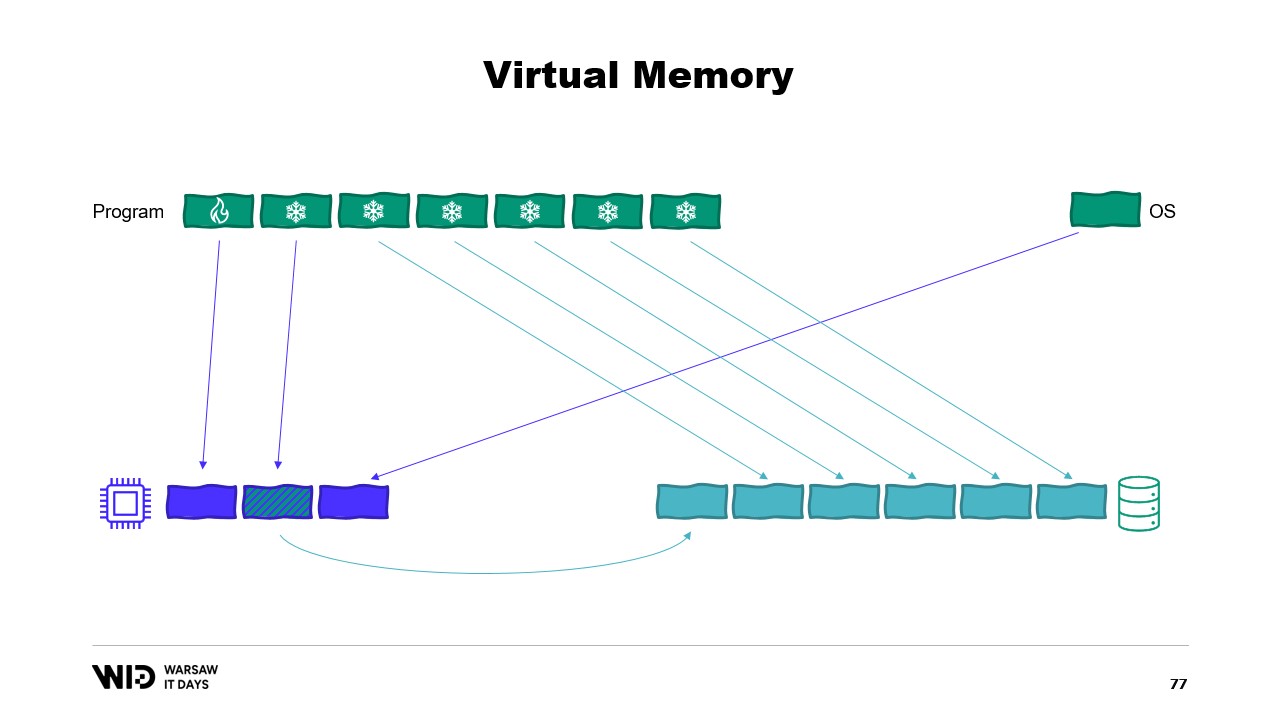
All of these techniques apply to .NET and are present in the Lokad Scratch Space open source project. And most of the code that follows is based on how this NuGet package does things.

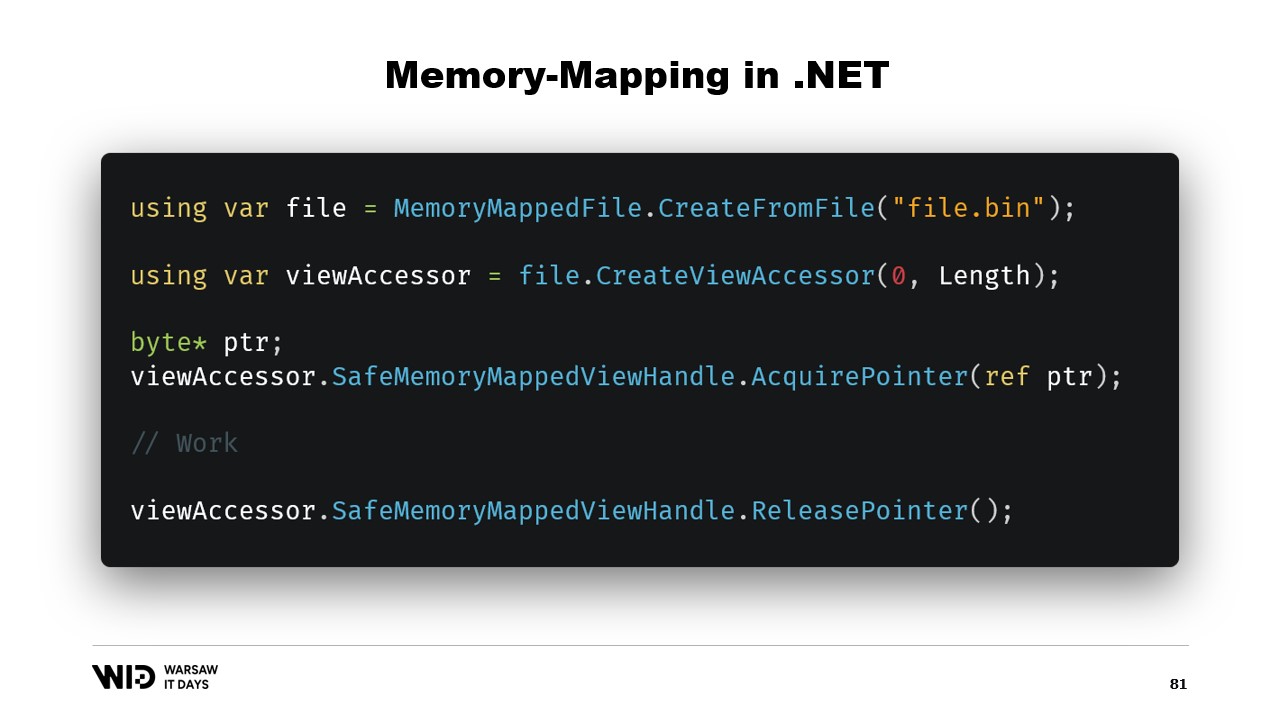
First, how would we create a memory mapped file in .NET? Memory mapping has existed since .NET Framework 4, about 13 years ago. It is fairly well documented on the internet and the source code is entirely available on GitHub.

The basic steps are first to create a memory mapped file from a file on the disk and then to create a view accessor. Those two types are kept separate because they have separate meanings. The memory mapped file just tells the operating system that from this file, some sections will be mapped to the memory of the process. The view accessor itself represents those mappings.
The two are kept separate because .NET needs to deal with the case of a 32-bit process. A very large file, one that is larger than four gigabytes, cannot be mapped to the memory space of a 32-bit process. It is too large. Now, the point is not large enough to represent it. So instead, it is possible to map only small sections of the file one at a time in a way that makes them fit.
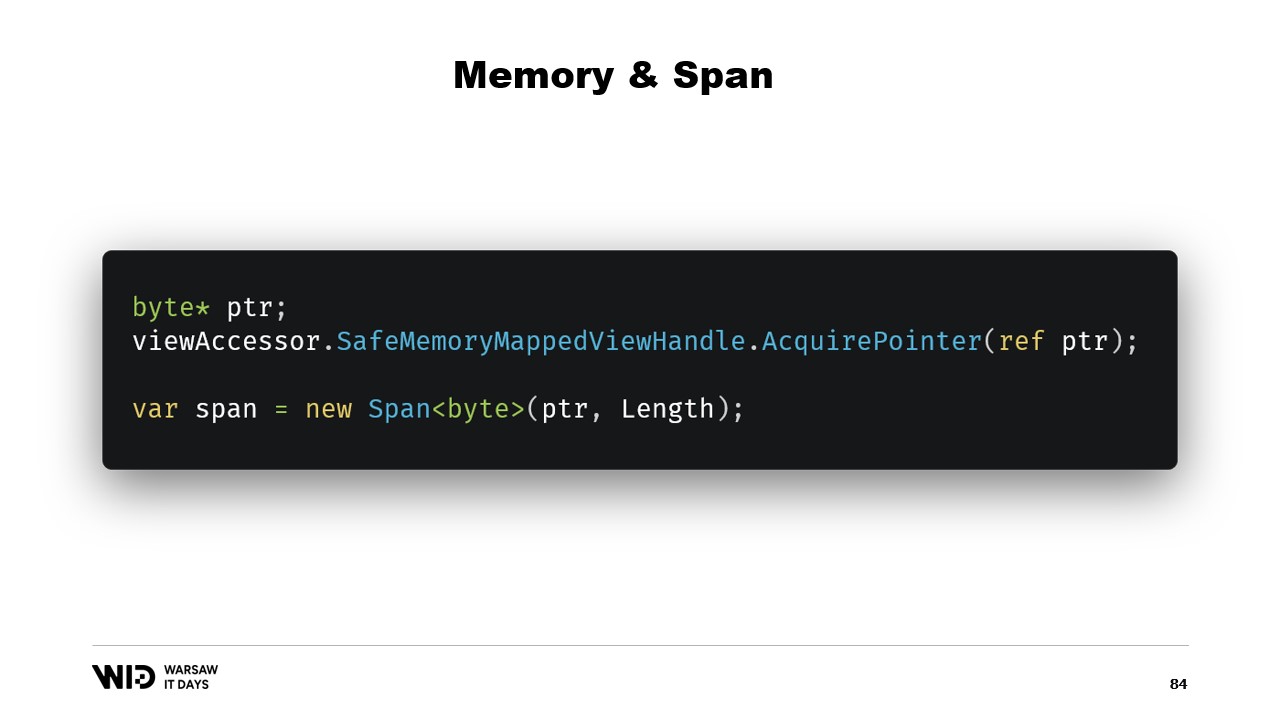
In our case, we will be working with 64-bit pointers. So, we can just create one view accessor that loads the entire file. And now, I use AcquirePointer to get the pointer to the first bytes of this memory mapped range of memory. When I’m done working with the pointer, I can just release it. Working with pointers in .NET is unsafe. It requires adding the unsafe keyword everywhere and it can blow up if you try to access memory beyond the ends of the allowed range.
Luckily, there is a way to work around that. Five years ago, .NET introduced memory and span. These are types used to represent a range of memory in a way that is safer than just pointers. It is fairly well documented and most of the code can be found in this location on GitHub.

The general idea behind span and memory is that given a pointer and a number of bytes, you can create a new span that represents that range of memory.
Once you have this span, you can safely read anywhere within the span knowing that if you try to read past the boundaries, the runtime will catch it for you and you will get an exception instead of just the process done.
Let’s see how we can use span to load from memory mapped memory into .NET managed memory. Remember, we do not want to directly access the cold section for performance reasons. Instead, we want to do cold to hot transfers which load a lot of data at the same time.
For example, let’s say we have a string that we want to read. It will be laid out in the memory mapped file as a size followed by a UTF-8 encoded payload of bytes, and we want to load a .NET string from that.
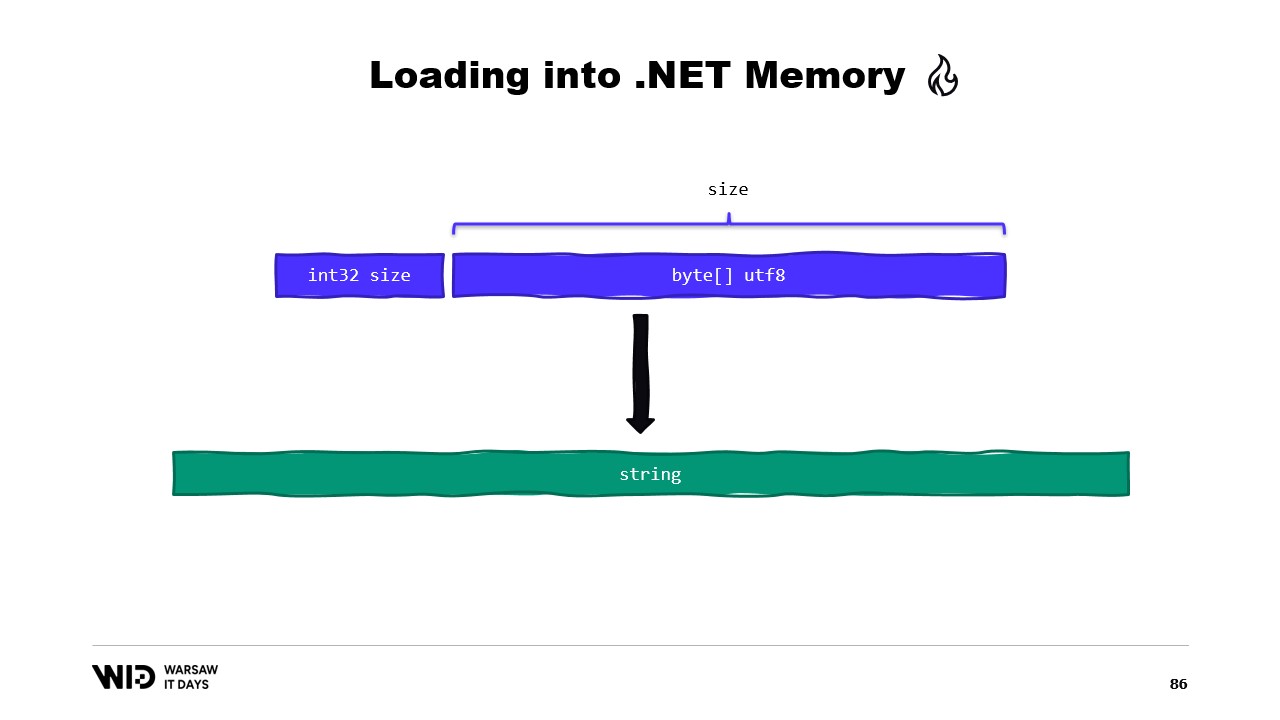
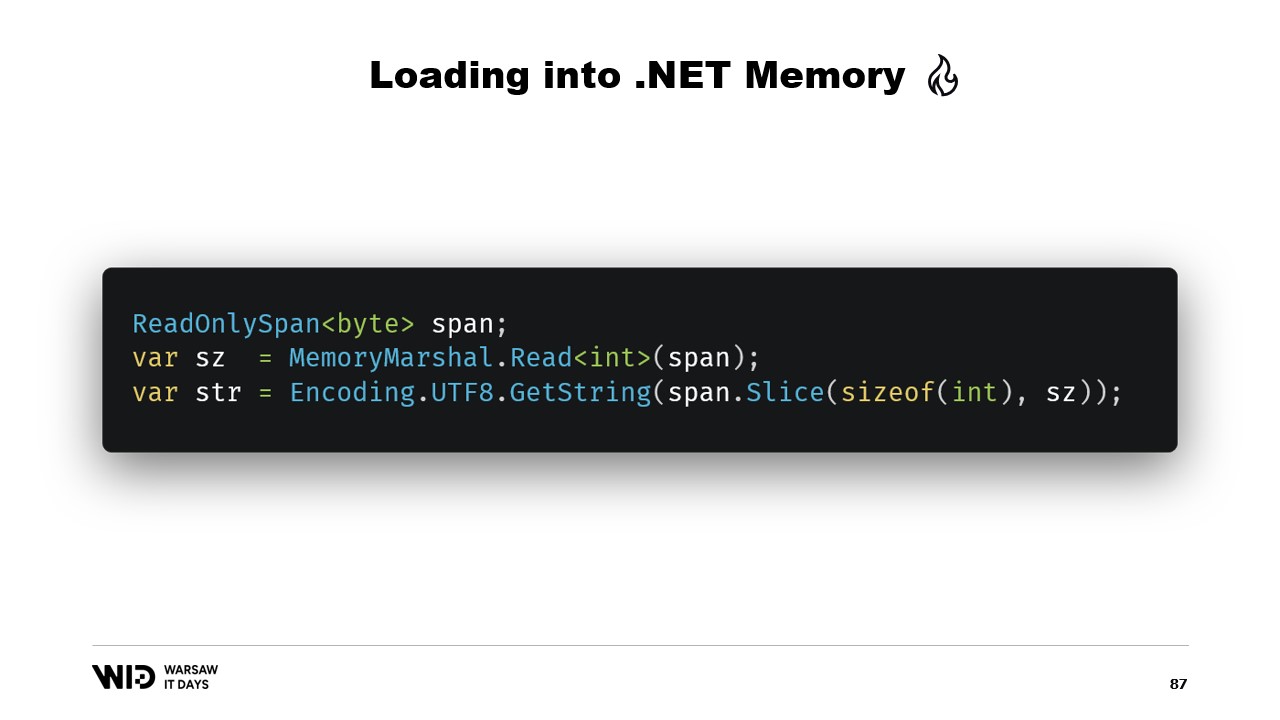
Well, there are many APIs that are centered around spans that we can use. For instance, MemoryMarshal.Read can read an integer from the start of the span. Then, using this size, I can ask the Encoding.GetString function to load from a span of bytes into a string.
All of these operate on spans and even though the span represents a section of data that is possibly present on the disk instead of in memory, the operating system takes care of transparently loading the data into memory when it is first accessed.
Another example would be a sequence of floating point values which we want to load into a float array.
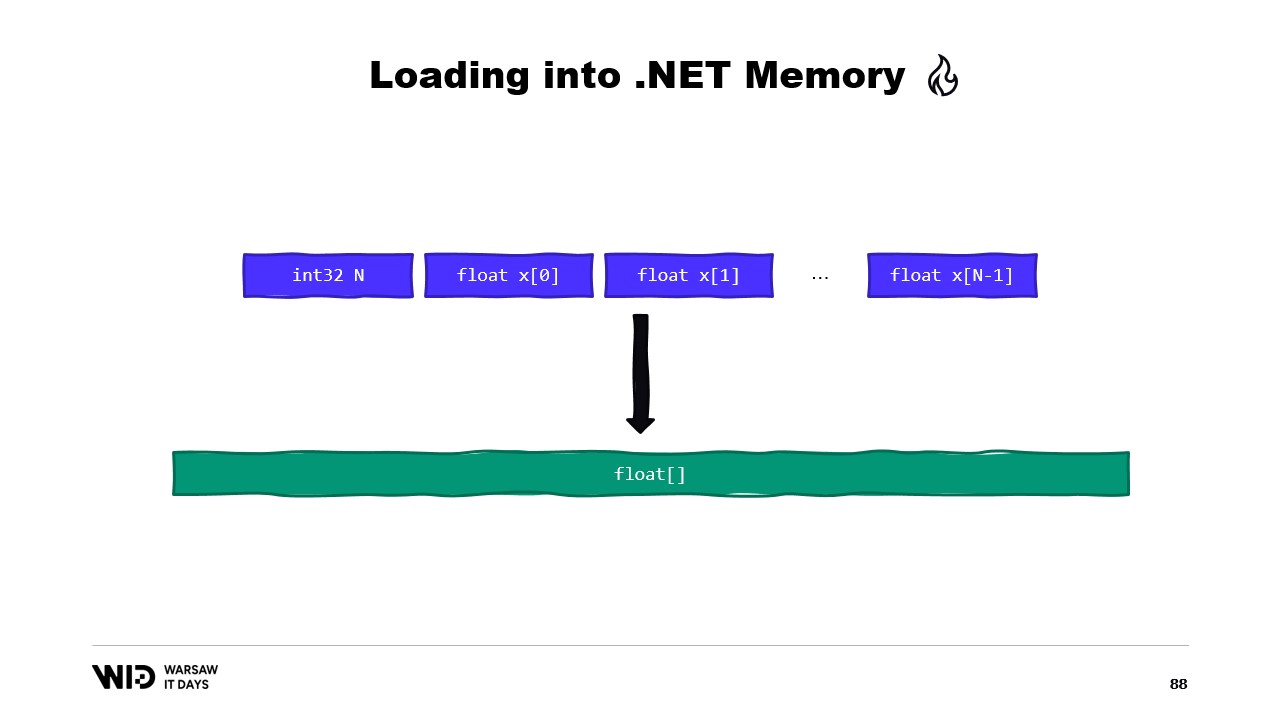
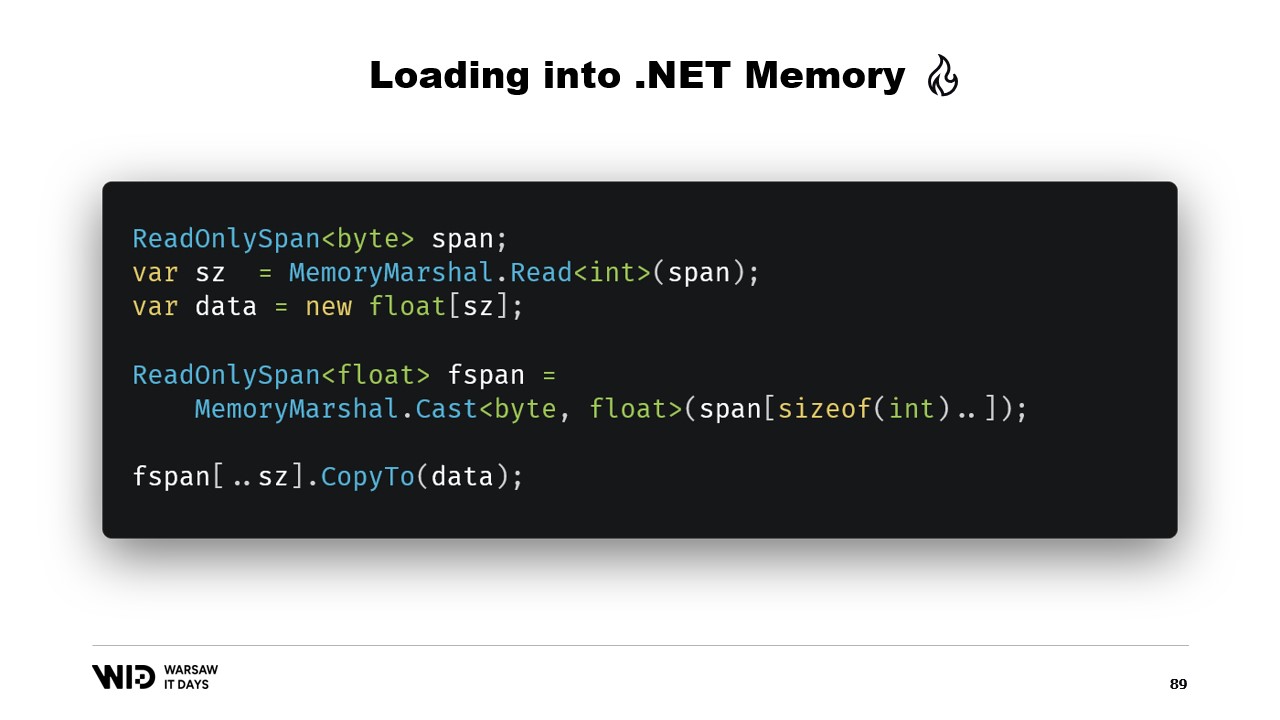
Again, we use MemoryMarshal.Read to read the size. We allocate an array of floating point values of that size and then we use MemoryMarshal.Cast to turn the span of bytes into a span of floating point values. This really just reinterprets the data present in the span as floating point values instead of just bytes.
Finally, we use the CopyTo function of spans which will do a high-performance copy of the data from the memory mapped file into the array itself. This is in a way a bit wasteful, we’re doing an entirely new copy.
Maybe we could avoid that. Well, usually what we will store on the disk will not be the raw floating point values. Instead, we will save some compressed version of them. Here we store the compressed size, which gives us how many bytes we need to read. We store the destination size or the decompressed size. This tells us how many floating point values we need to allocate in managed memory. And finally, we store the compressed payload itself.
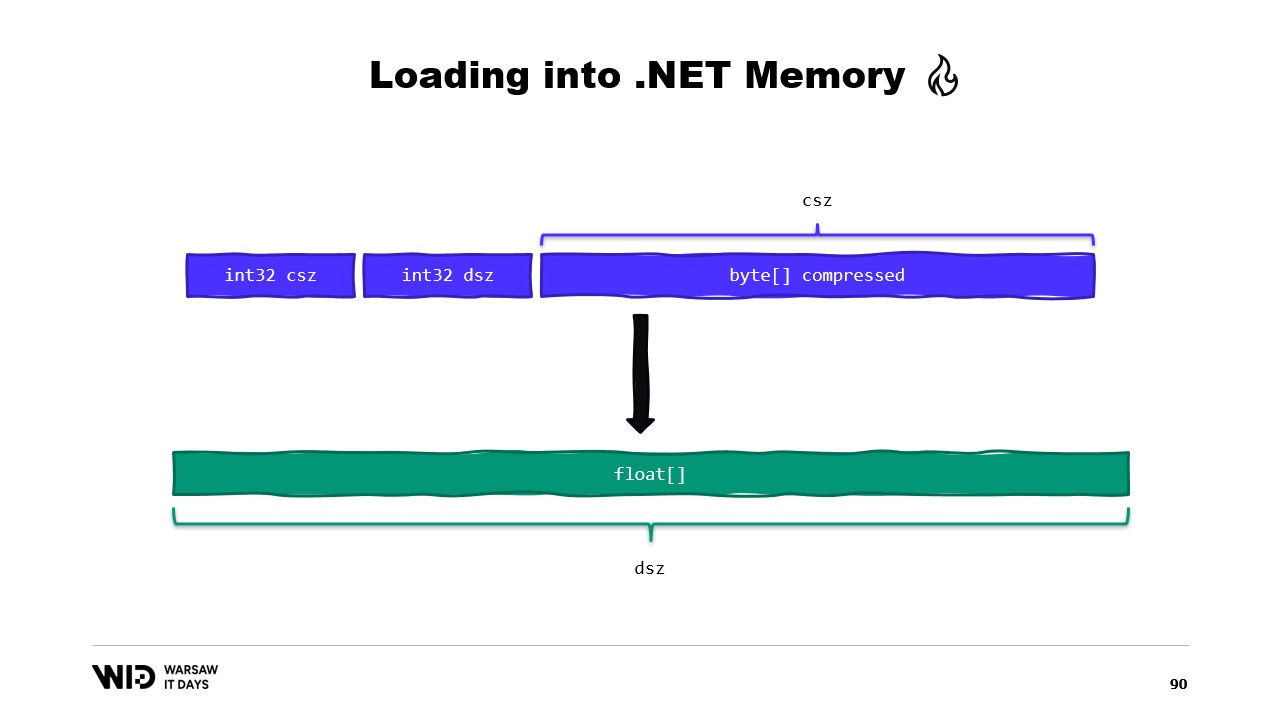
To load this, it will be better if instead of reading two integers, we create a structure that represents that header with two integer values inside.

MemoryMarshal will be able to read an instance of that structure, loading the two fields at the same time. We allocate an array of floating point values and then our compression library almost certainly has some flavor of a decompress function which takes a read-only span of bytes as input and takes a span of bytes as outputs. We can use again MemoryMarshal.Cast, this time turning the array of floating point values into a span of bytes to use as the destination.
Now, no copy is involved. Instead, the compression algorithm directly reads from the disk, usually through the page cache, into the destination array of floats.

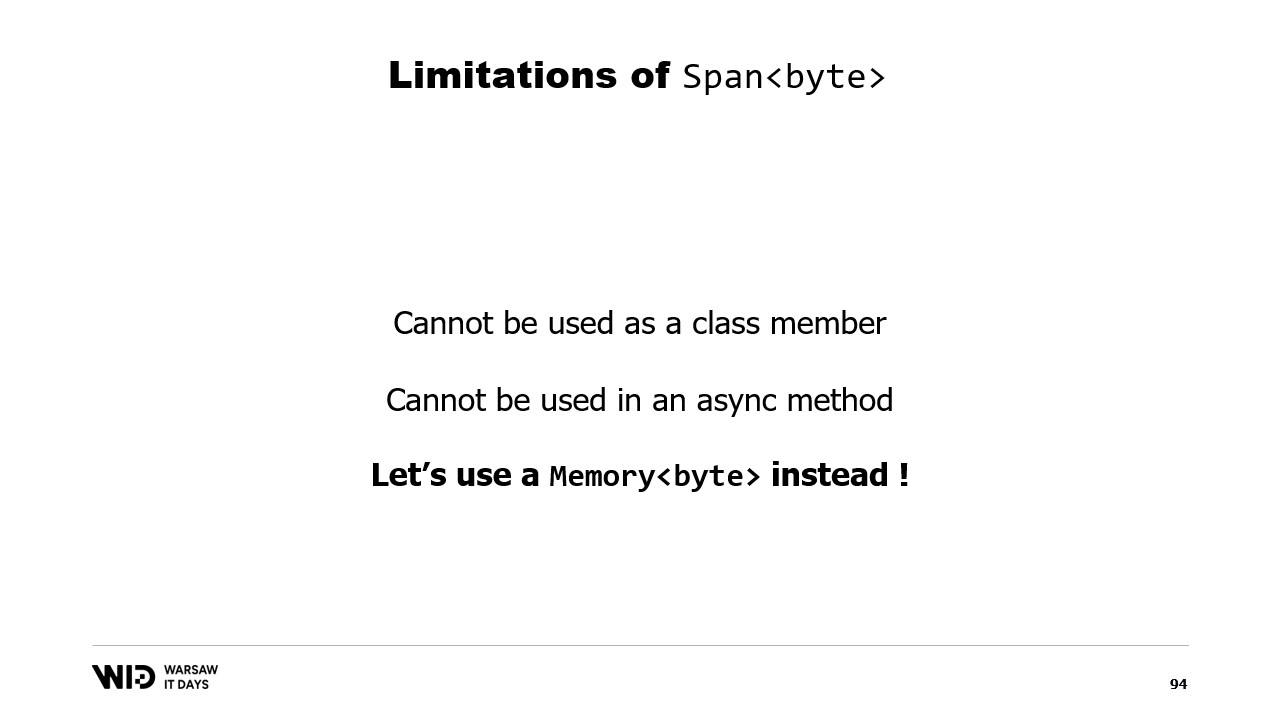
Span does have one major limitation, which is that it cannot be used as a class member and by extension, it also cannot be used as a local variable in an async method.
Luckily, there is a different type, Memory, which should be used to represent a longer-lived range of data.
Sadly, there is disappointingly little documentation about how to do this. Creating a span from a pointer is easy, creating a memory from a pointer is not documented to the point that the best available documentation is a gist on GitHub, which I really do recommend that you read.
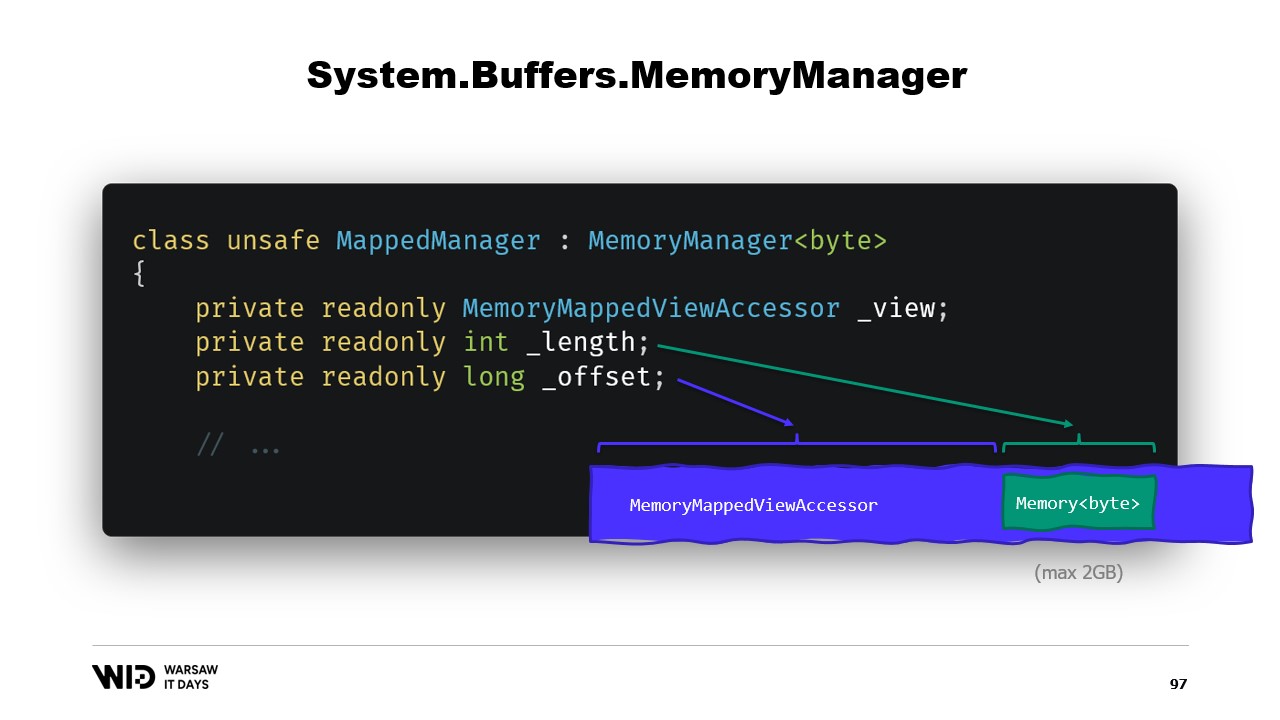
In short, what we need to do is to create a MemoryManager. The MemoryManager is used internally by a Memory whenever it needs to do anything more complex than just pointing at a section of an array.
In our case, we need to reference the memory mapped view accessor into which we are looking. We need to know the length that we are allowed to look at and finally, we will need an offset. This is because a Memory of bytes can represent no more than two gigabytes by design, and the file itself will likely be longer than two gigabytes. So the offset gives us the location where the memory starts within the wider view accessor.
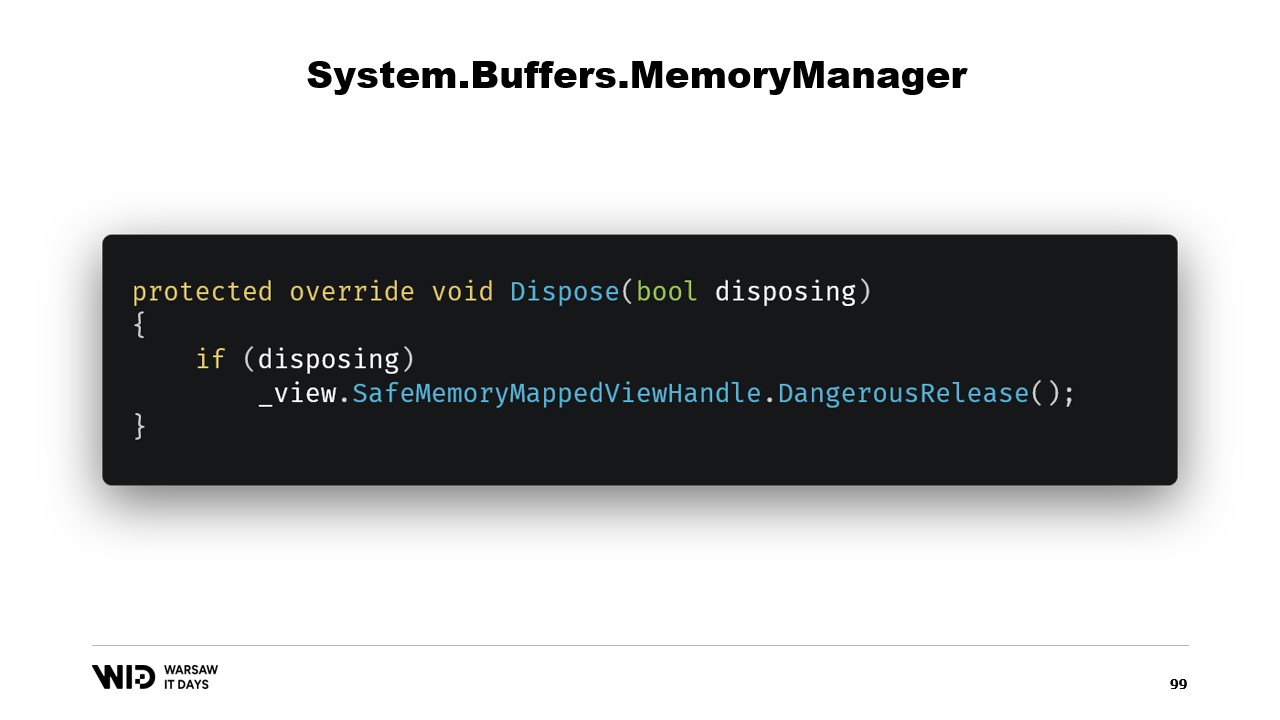
The constructor of the class is fairly straightforward.

We just need to add a reference to the safe handle that represents the memory region and this reference will be released in the dispose function.
Next, we have an address property which is not another ride, it’s just something that is useful for us to have. We use DangerousGetHandle to get a pointer and we add the offset so that the address points to the first bytes in the region that we want our memory to represent.
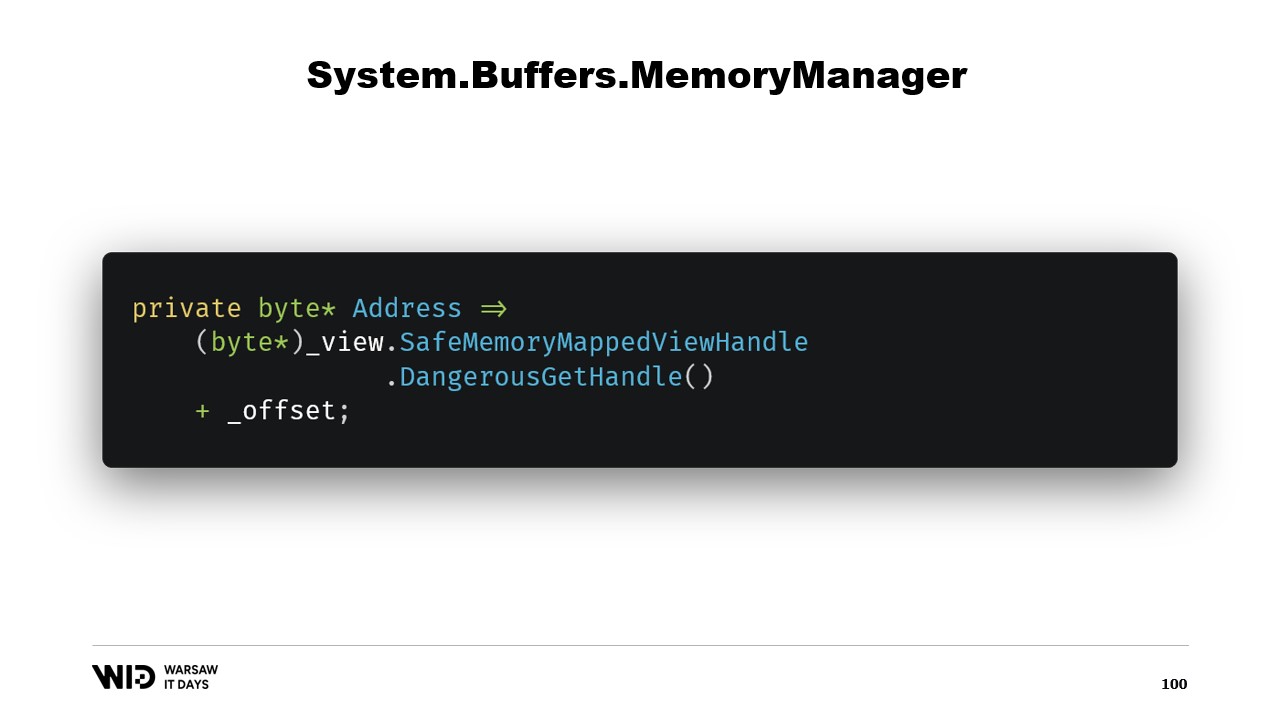
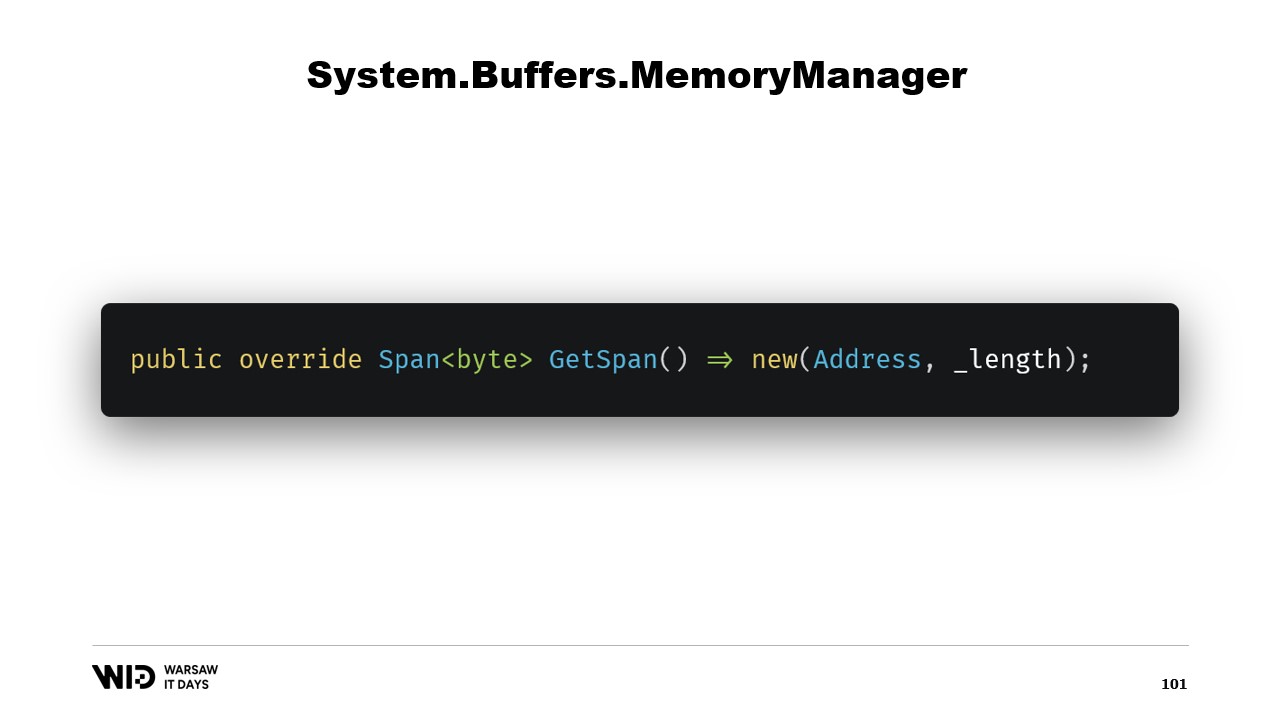
We override the GetSpan function which does all the magic. It just creates a span using the address and the length.
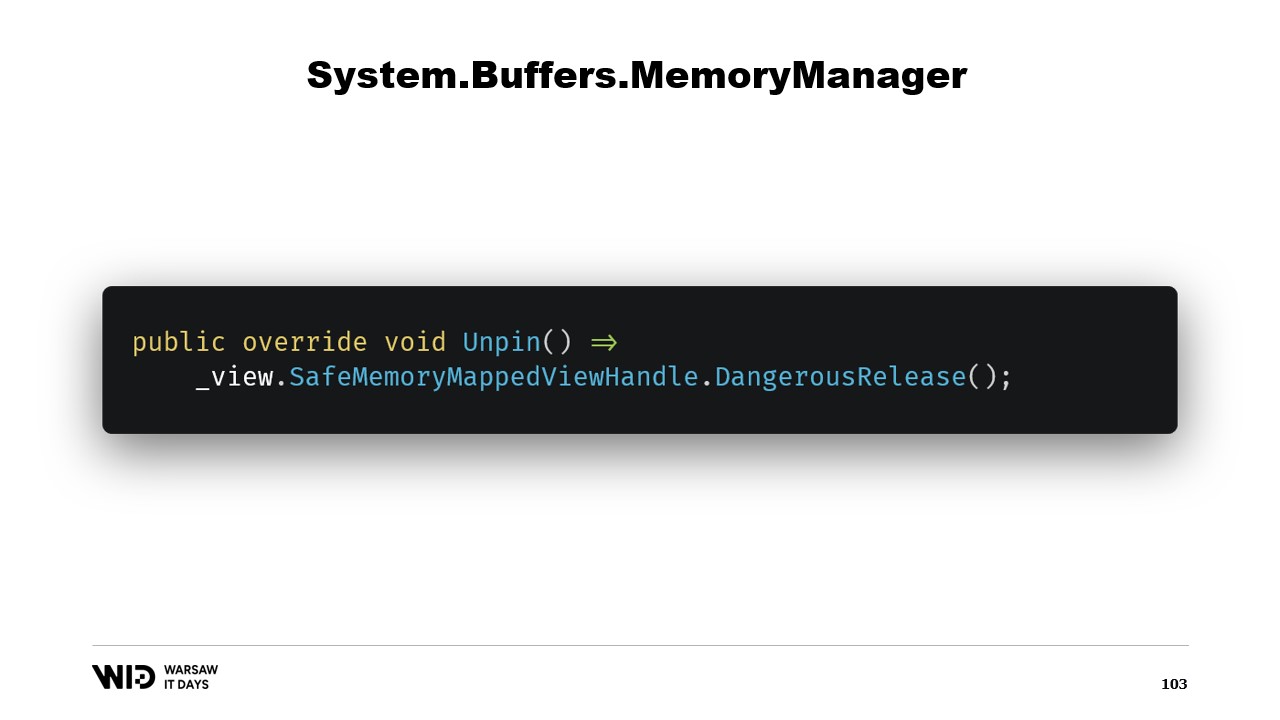
There are two other methods that need to be implemented on the MemoryManager. One of them is Pin. It is used by the runtime in a case where the memory must be kept in the same location for a short duration. We add a reference and we return a MemoryHandle that points to the correct location and also references the current object as the pinnable.

This will let the runtime know that when the memory will be unpinned, then it will call the Unpin method of this object, which causes the release of the safe handle again.
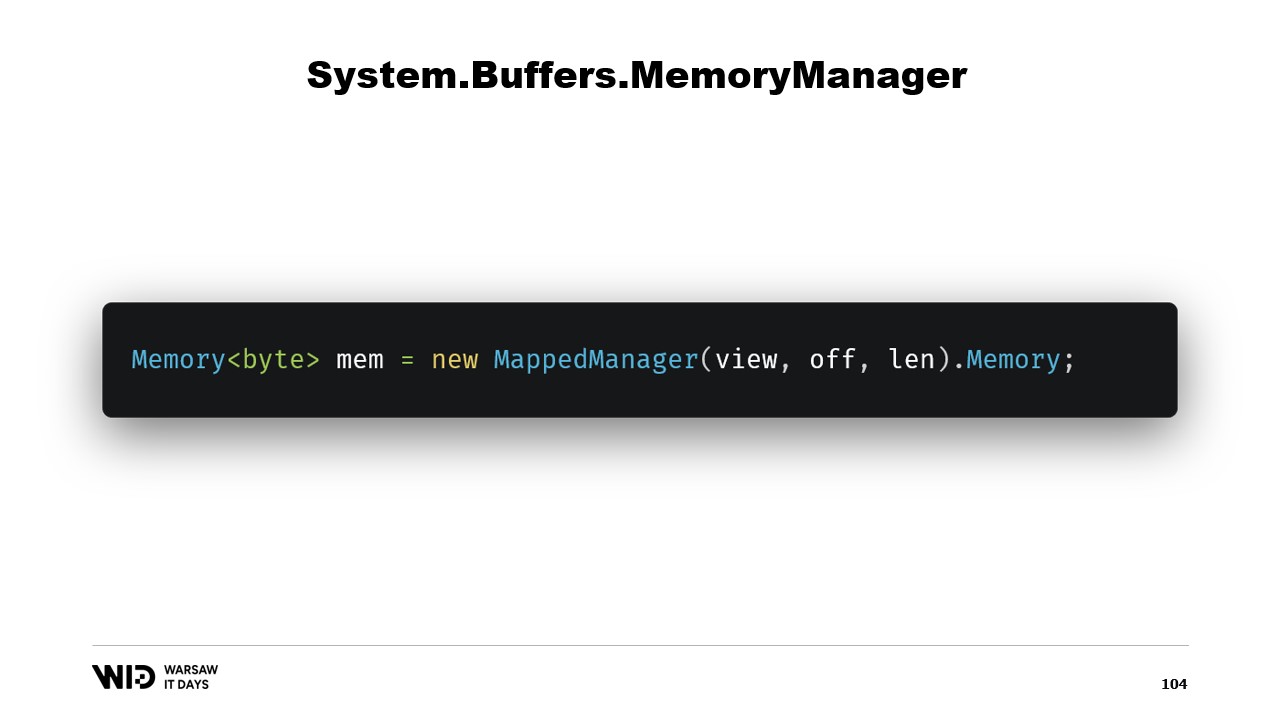
Once this class has been created, it is enough to create an instance of it and access its Memory property which will return a Memory of bytes that internally references the MemoryManager we just created. And there you go, now you have a piece of memory. When you write to it, it will automatically be unloaded to disk when space is necessary and when accessed, it will be transparently loaded back from disk whenever you need it.
So that is enough to implement our spill to disk program. There is another question, why use memory mapping when we could use FileStream instead? After all, FileStream is the obvious choice when accessing data that is on the disk and its use is fairly well documented. Reading an array of floating point values, for instance, you need a FileStream and a BinaryReader wrapped around the FileStream. You set the position to the offset where the data is present, you read an Int32 with the reader, allocate the floating point array and then MemoryMarshal.Cast it to a span of bytes.
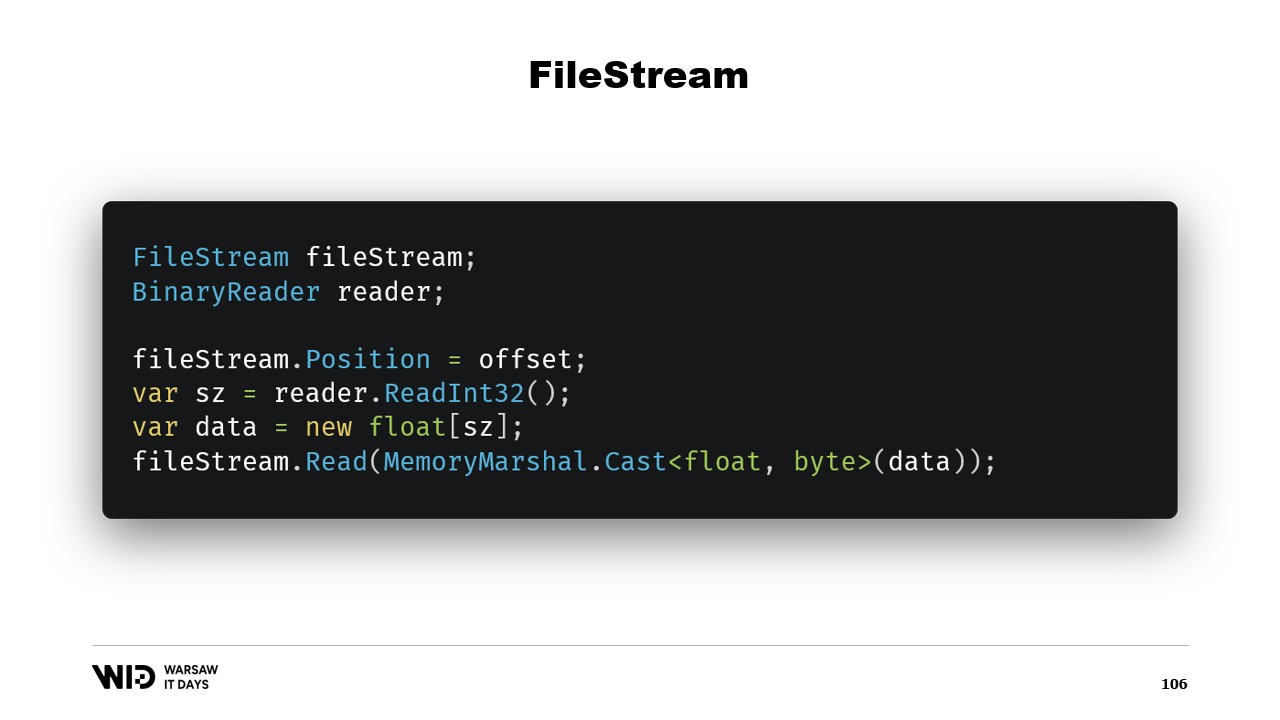
FileStream.Read now has an overload which takes a span of bytes as the destination. This actually uses the page cache as well. Instead of memory mapping those pages to your process address space, the operating system just keeps them around and in order to read the values, it will just load from the disk into memory and then copy from that page into the destination span that you provided. So this is equivalent in terms of performance and behavior to what happened in the memory mapped version.
There are however, two major differences. First, this is not thread safe. You set the position in one line and then in another statement, you rely on that position still being the same. This means you need a lock around this operation and so you cannot read from several locations in parallel, even though that is possible with memory map files.
Another issue is that, depending on the strategy used by the FileStream, you make two reads, one for the Int32 and one for the reading to the span. One possibility is that each of them will do one system call. It will call the operating system and the operating system will copy some data from its own memory into the process memory. That has some overhead. The other possibility is that the stream is buffered. In that case, reading four bytes initially will create a copy of one page, likely. And this copy happens on top of the actual copy that is done by the read function later. So it does introduce some overhead that is just not present with the memory mapped version.
For this reason, using the memory mapped version is preferable in terms of performance. After all, the FileStream is the obvious choice to access data that is present on the disk and its usage is very well documented. For example, to read an array of floating point values, you need a FileStream, a BinaryReader. You set the position of the FileStream to the offset where the data is present in the file, you read an Int32 to get the size, allocate the floating point array, turn it into a span of bytes using MemoryMarshal.Cast and pass it to the FileStream.Read overload which wants a span of bytes as its destination for reading. And this also uses the page cache. Instead of the pages being associated with the process, they are kept around by the operating system itself and it will just load from the disk into the page cache and copy from the page cache into the process memory, just as we did with the memory mapping version.
The FileStream approach however, has two major downsides. The first is that this code is not safe for multi-threaded use. After all, the position is set on one statement and then used in the following statements. So we need a lock around those read operations. The memory mapped version does not need locks and in fact is able to load from several locations on the disk in parallel. For SSDs, this increases the queue depth which increases performance and so is usually desirable. The other problem is that the FileStream needs to do two reads.
Depending on the strategy used internally by the stream, this may result in two system calls which need to wake up the operating system. It will copy some data from its own memory into the process memory and then it needs to clear everything and return control to the process. This has some overhead. The other possible strategy is for the FileStream to be buffered. In that case, only one system call would be done but it will involve a copy from the operating system memory to the internal buffer of the FileStream and then the read statement will have to copy again from the internal buffer of the FileStream into the floating point array. So that creates a wasteful copy which is not present with the memory mapped version.
The file stream, while a bit easier to use, has some limitations. The memory-mapped version should be used instead. So now, we have ended up with a system that is able to use as much memory as possible and, when running out of memory, will spill parts of the data sets back to the disk. This process is completely transparent and cooperates with the operating system. It runs at maximum performance because the pieces of the data set that are being accessed frequently are always kept in memory.
However, there is one final question that we need to answer. After all, when you memory map things, you do not memory map the disk, you memory map files on the disk. Now the question is, how many files are we going to allocate? How large are they going to be? And how are we going to cycle through those files as we allocate and deallocate memory?
The obvious choice is to just map one large file, do it at program start, and just keep running over it. When some part is no longer used, just write over it. This is obvious and therefore it is wrong.

The first problem with this approach is that writing over a page of memory requires a discrete algorithm.
The algorithm is as follows: first, you load the page into memory immediately. Then, you change the page contents in memory. The operating system has no way to know that in step two, you are going to erase everything and replace it, so it still needs to load the page so that the pieces that you do not change remain the same. Finally, you schedule the page to be written back to disk at some point in the future.
Now, the first time that you write to a given page in a brand new file, there is no data to be loaded. The operating system knows that all the pages are zero, so the load is free. It just takes a zero page and uses it. But when the page has already been modified and is no longer in memory, the operating system must reload it from the disk.

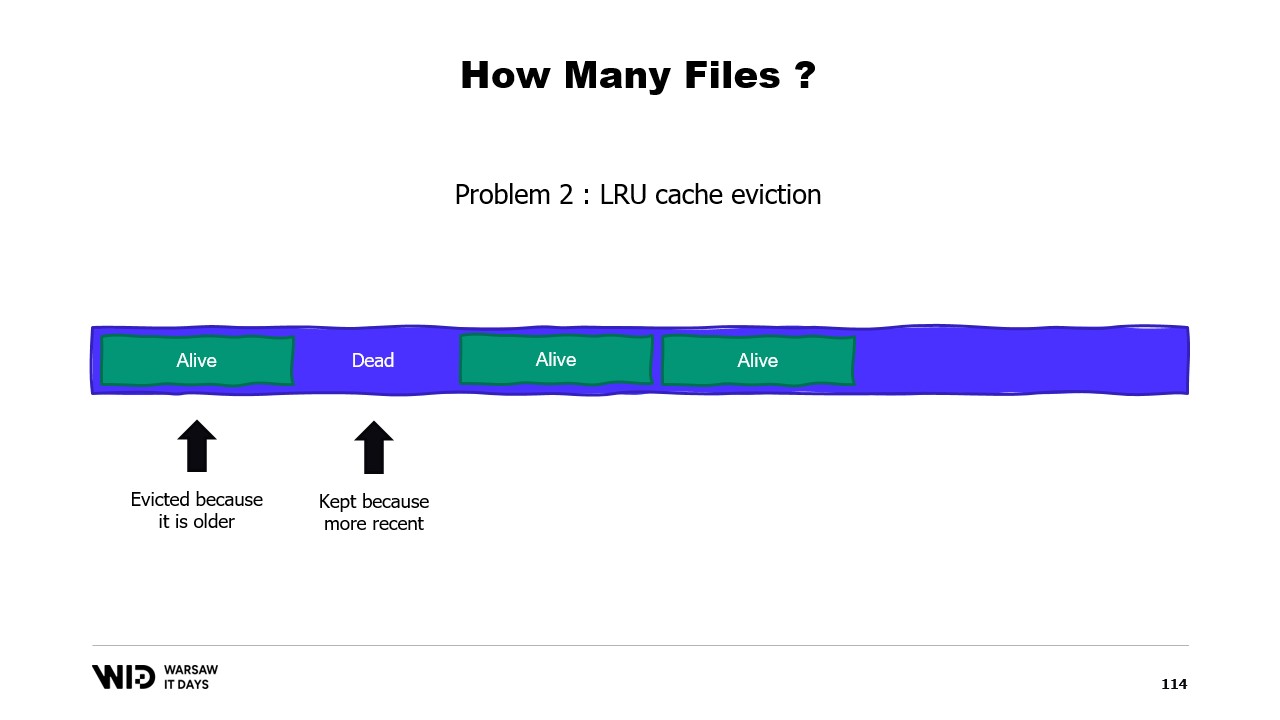
A second problem is that the pages from the page cache are evicted on a least recently used basis, and the operating system is not aware that a dead section of your memory, which will never be used again, needs to be dropped. So, it might end up keeping in memory some portions of the data set that are not needed and evict some portions that are needed. There’s no way to tell the operating system that it should just ignore the dead sections.
A third problem is also related, which is that the writing of the data to the disk always lags behind the writing of the data to the memory. And if you know that a page is no longer necessary and it has not yet been written to the disk, well, the operating system does not know that. So, it still spends the time to write those bytes that will never be used again to the disk, slowing everything down.
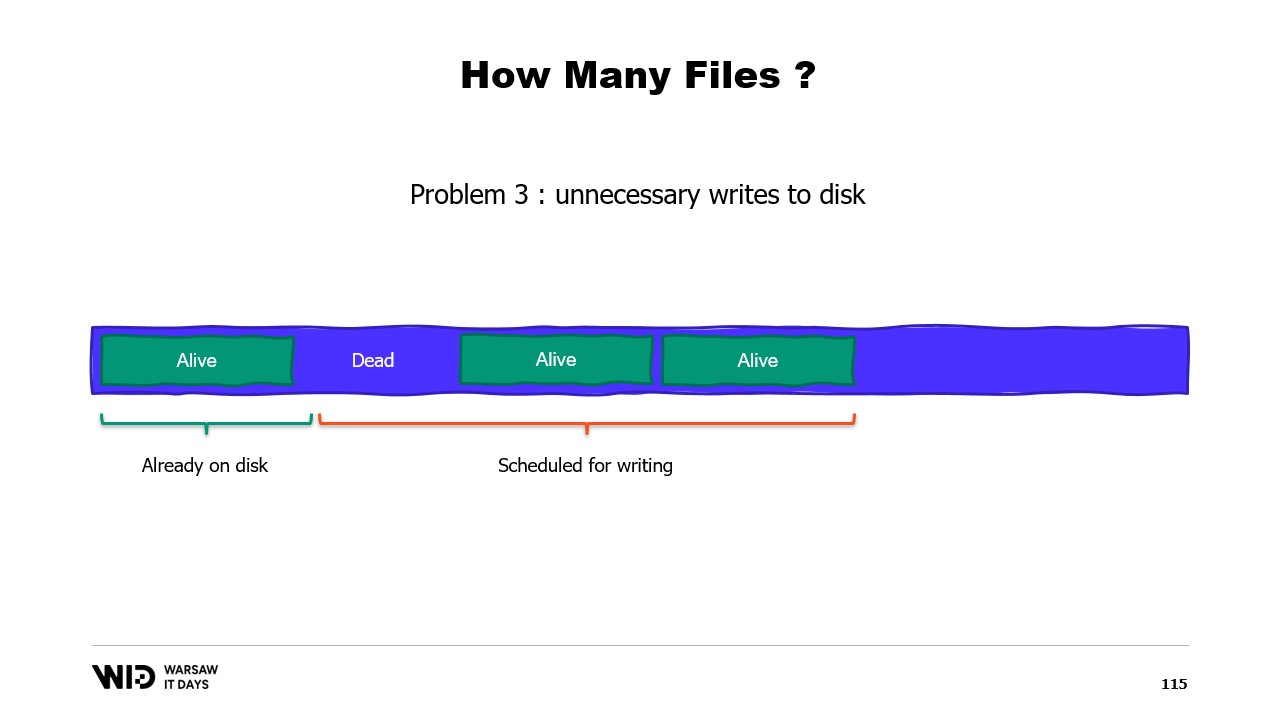
Instead, we should split memory over several large files. We never write to the same memory twice. This ensures that every write hits a page that is known by the operating system to be all zero and doesn’t involve loading from the disk. And we delete files as soon as possible. This tells the operating system that this is no longer needed, it can be dropped from the page cache, it doesn’t need to be written to disk if it hasn’t already.

In production at Lokad, on a typical production VM, we use Lokad scratch space with the following settings: the files each have 16 gigabytes, there are 100 files on each disk, and each L32VM has four disks. In total, this represents a little bit more than 6 terabytes of spill space for each VM.

That’s all for today. Please reach out if you have any questions or comments, and thank you for watching.


