00:00:00 Introduzione alla conferenza sul versamento su disco
00:00:34 Elaborazione dei dati del rivenditore e limiti della memoria
00:02:13 Soluzione di storage persistente e confronto dei costi
00:04:07 Confronto della velocità tra disco e memoria
00:05:10 Limitazioni delle tecniche di partizionamento e streaming
00:06:16 Importanza dei dati ordinati e della dimensione ottimale di lettura
00:07:40 Scenario peggiore per la lettura dei dati
00:08:57 Impatto della memoria della macchina sull’esecuzione del programma
00:10:49 Tecniche di versamento su disco e uso della memoria
00:12:59 Spiegazione della sezione di codice e implementazione in .NET
00:15:06 Controllo sull’allocazione della memoria e conseguenze
00:16:18 Pagina mappata in memoria e file memory mapping
00:18:24 Mappe di memoria in lettura-scrittura e strumenti di performance del sistema
00:20:04 Utilizzo della memoria virtuale e delle pagine mappate in memoria
00:22:08 Gestione di file di grandi dimensioni e puntatori a 64 bit
00:24:00 Utilizzo di span per caricare dalla memoria mappata
00:26:03 Copia dei dati e utilizzo di strutture per leggere interi
00:28:06 Creazione di uno span da un puntatore e memory manager
00:30:27 Creazione di un’istanza di memory manager
00:31:05 Implementazione di un programma di versamento su disco e memory mapping
00:33:34 Versione mappata in memoria preferibile per le prestazioni
00:35:22 Strategia di buffering del file stream e limitazioni
00:37:03 Strategia di mappatura di un file di grandi dimensioni
00:39:30 Divisione della memoria su diversi file di grandi dimensioni
00:40:21 Conclusione e invito alle domande
Sommario
Per elaborare più dati di quanti ne possano stare in memoria, i programmi possono scaricare parte di tali dati su uno storage più lento ma più capiente, come le unità NVMe. Grazie a una combinazione di due funzionalità piuttosto oscure di .NET (file mappati in memoria e memory managers), ciò può essere fatto in C# con pochissimo o nessun overhead di prestazioni. Questa conferenza, presentata ai Warsaw IT Days 2023, approfondisce i dettagli su come funziona e spiega come il pacchetto NuGet open source Lokad.ScratchSpace nasconda la maggior parte di questi dettagli agli sviluppatori.
Sommario Esteso
In una lezione esaustiva, Victor Nicolet, CTO di Lokad, esplora le complessità del versamento su disco in .NET, una tecnica che permette di processare grandi insiemi di dati che superano la capacità di memoria di un computer tipico. Nicolet attinge dalla sua vasta esperienza nel trattare set di dati complessi nel campo dell’ottimizzazione quantitative supply chain a Lokad, fornendo un esempio pratico di un rivenditore con centomila prodotti distribuiti su 100 sedi. Ciò si traduce in un insieme di dati di 10 miliardi di voci, considerando punti dati giornalieri per tre anni, che richiederebbero 37 gigabyte di memoria per memorizzare un valore floating point per ogni voce, superando di gran lunga la capacità di un computer desktop tipico.
Nicolet suggerisce l’uso di storage persistente, come gli SSD NVMe, come alternativa economica alla memoria. Confronta il costo della memoria e dello storage SSD, osservando che al costo di 18 gigabyte di memoria, si potrebbe acquistare un terabyte di storage SSD. Discute inoltre il compromesso in termini di prestazioni, notando che la lettura dal disco è sei volte più lenta della lettura dalla memoria.
Introduce il partizionamento e lo streaming come tecniche per usare lo spazio su disco in alternativa alla memoria. Il partizionamento permette di elaborare insiemi di dati in blocchi più piccoli che si adattano in memoria, ma non consente la comunicazione tra le partizioni. Lo streaming, invece, permette di mantenere uno stato tra l’elaborazione delle diverse parti, ma richiede che i dati su disco siano ordinati o allineati correttamente per prestazioni ottimali.
Nicolet introduce quindi le tecniche di versamento su disco come soluzione ai limiti dell’approccio che si adatta in memoria. Queste tecniche distribuiscono i dati tra la memoria e lo storage persistente in modo dinamico, utilizzando più memoria quando disponibile per operare più velocemente, e rallentando per usare meno memoria quando questa è scarsa. Spiega che le tecniche di versamento su disco utilizzano quanta più memoria possibile e iniziano a scaricare i dati sul disco solo quando la memoria si esaurisce. Questo le rende più efficienti nel reagire a variazioni di disponibilità di memoria rispetto a quanto inizialmente previsto.
Spiega inoltre che le tecniche di versamento su disco dividono l’insieme di dati in due sezioni: la sezione “hot”, che rimane sempre in memoria, e la sezione “cold”, che può scaricare parti del suo contenuto su storage persistente in qualsiasi momento. Il programma utilizza trasferimenti hot-cold, che solitamente coinvolgono grandi batch per massimizzare l’uso della larghezza di banda NVMe. La sezione cold permette a questi algoritmi di utilizzare quanta più memoria possibile.
Nicolet poi discute come implementare questo in .NET. Per la sezione hot vengono usati oggetti .NET normali, mentre per la sezione cold si utilizza una classe di riferimento. Questa classe mantiene un riferimento al valore che viene depositato nello storage cold e tale valore può essere impostato a null quando non è più in memoria. Un sistema centrale nel programma tiene traccia di tutti i riferimenti cold e, ogni volta che viene creato un nuovo riferimento cold, verifica se causa un overflow della memoria e invocherà la funzione di spill di uno o più dei riferimenti cold già presenti nel sistema per rimanere entro il budget di memoria disponibile per lo storage cold.
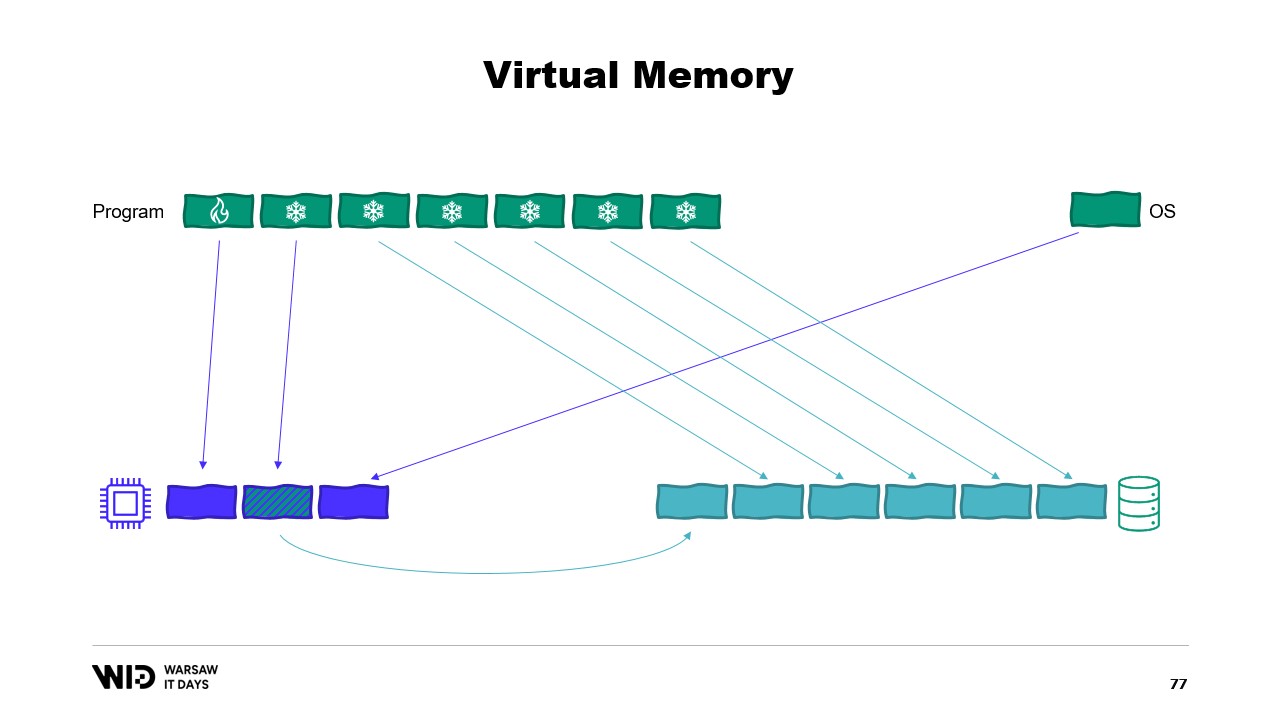
Introduce quindi il concetto di memoria virtuale, in cui il programma non ha accesso diretto alle pagine di memoria fisica, ma piuttosto a pagine di memoria virtuale. È possibile creare una pagina mappata in memoria, che è un modo comune per implementare la comunicazione tra programmi e file mappati in memoria. Lo scopo principale del memory mapping è evitare che ogni programma abbia la propria copia della DLL in memoria, dato che tutte quelle copie sono identiche.
Nicolet discute poi dello strumento Performance Tool del sistema, che mostra l’uso attuale della memoria fisica. In verde è mostrata la memoria assegnata direttamente a un processo, in blu è la cache delle pagine, e le pagine modificate al centro sono quelle che dovrebbero essere una copia esatta del disco ma contengono modifiche in memoria.
Discute poi del secondo tentativo utilizzando la memoria virtuale, in cui la sezione cold sarà composta interamente da pagine mappate in memoria. Se il sistema operativo avrà improvvisamente bisogno di memoria, saprà quali pagine sono mappate in memoria e potrà scaricarle in sicurezza.
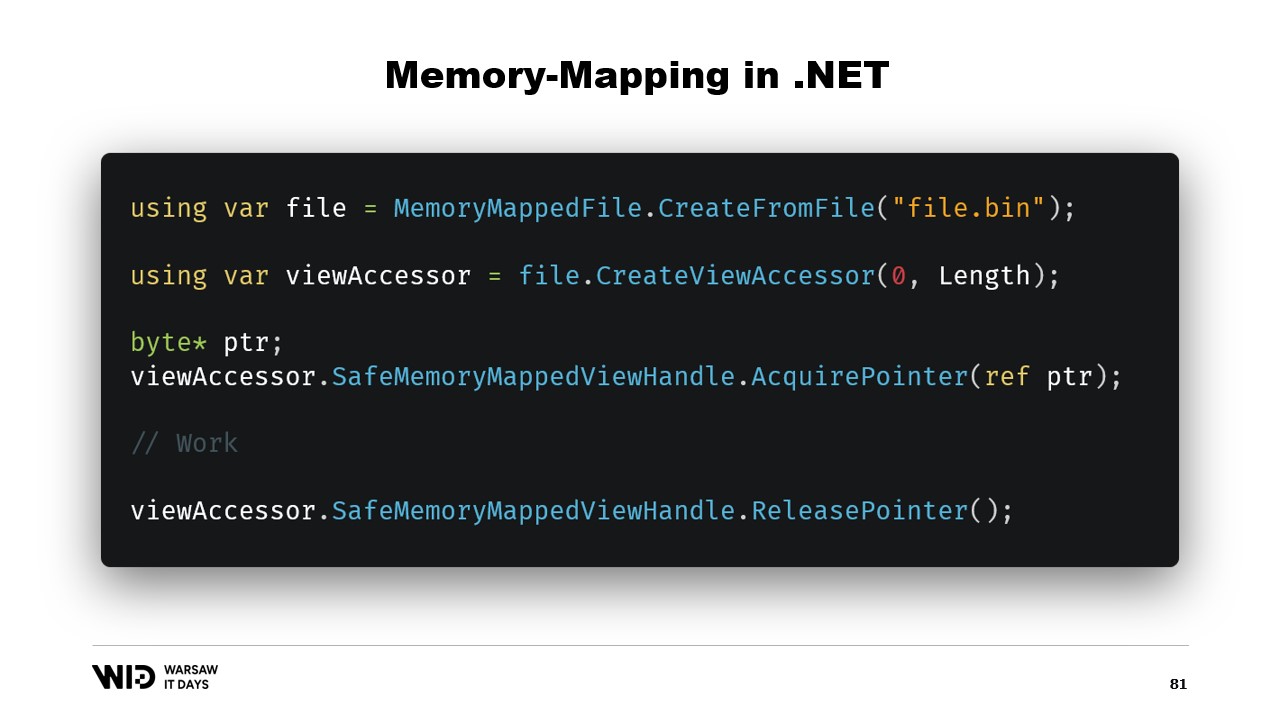
Nicolet poi spiega i passaggi fondamentali per creare un file mappato in memoria in .NET: prima creare un file mappato in memoria partendo da un file su disco e poi creare un view accessor. I due passaggi vengono mantenuti separati perché .NET deve gestire il caso di un processo a 32 bit. Nel caso di un processo a 64 bit, è possibile creare un view accessor che carica l’intero file.
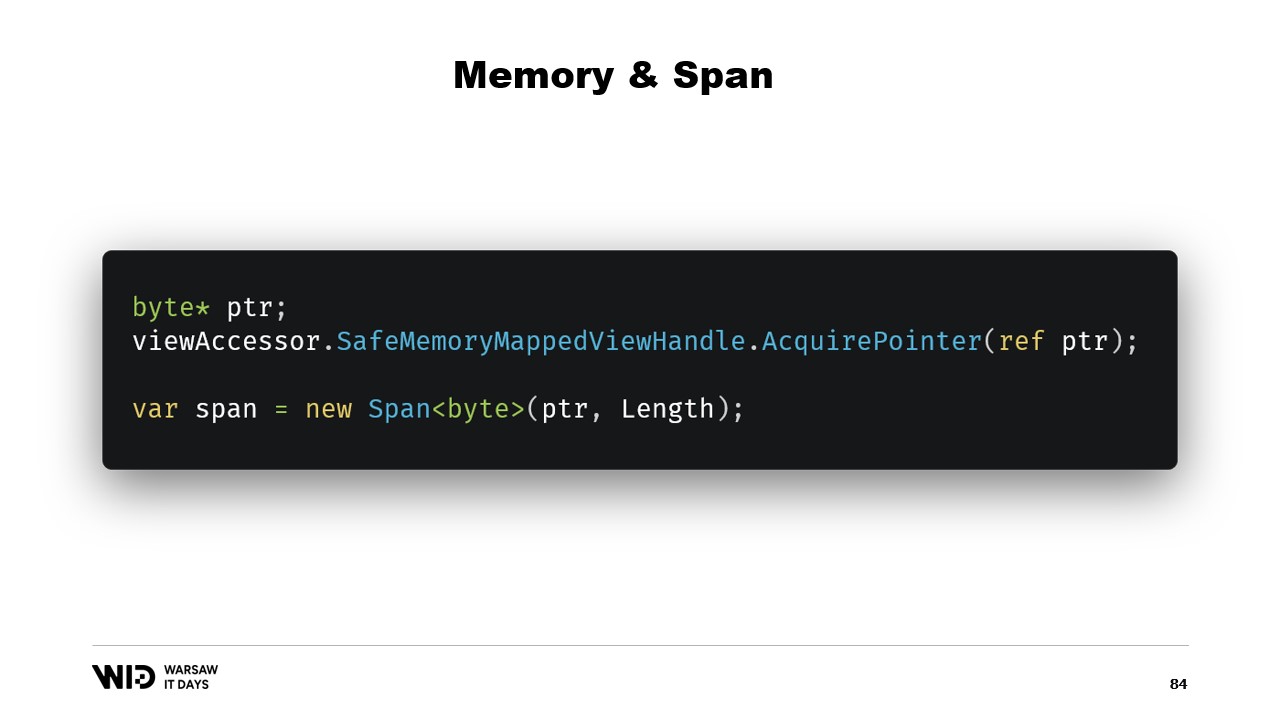
Nicolet poi discute dell’introduzione di memory e span cinque anni fa, che sono tipi utilizzati per rappresentare un intervallo di memoria in modo più sicuro rispetto ai semplici puntatori. L’idea generale alla base di span e memory è che, dato un puntatore e un numero di byte, può essere creato un nuovo span che rappresenta quell’intervallo di memoria. Una volta creato, lo span può essere letto in sicurezza ovunque al suo interno, sapendo che se si tenta di leggere oltre i limiti, il runtime lo intercetterà e verrà lanciata un’eccezione invece che terminare semplicemente il processo.
Nicolet poi discute di come utilizzare lo span per caricare dalla memoria mappata in memoria gestita da .NET. Ad esempio, se c’è una stringa da leggere, possono essere usate molte API basate sugli span. Nicolet spiega l’uso di API come MemoryMarshal.Read, che può leggere un intero dall’inizio dello span. Menziona inoltre la funzione Encoding.GetString, che può caricare da uno span di byte in una stringa.
Spiega inoltre che queste operazioni vengono eseguite sugli span, che rappresentano una sezione di dati che potrebbero trovarsi sul disco invece che in memoria. Il sistema operativo si occupa di caricare i dati in memoria quando vengono prima accessibili. Nicolet fornisce un esempio di una sequenza di valori floating point che devono essere caricati in un array di float. Spiega l’uso di MemoryMarshal.Read per leggere la dimensione, l’allocazione di un array di valori floating point di quella dimensione, e l’uso di MemoryMarshal.Cast per trasformare lo span di byte in uno span di valori floating point.
Discute anche l’uso della funzione CopyTo degli span, che esegue una copia dei dati ad alte prestazioni dal file mappato in memoria all’array. Nota che questo processo può essere un po’ inquinante in quanto comporta la creazione di una copia interamente nuova. Nicolet suggerisce di creare una struttura che rappresenti l’header contenente due valori interi, che può essere letta da MemoryMarshal. Discute inoltre l’uso di una libreria di compressione per decomprimere i dati.
Nicolet discute l’uso di un tipo diverso, Memory, per rappresentare un intervallo di dati di durata più lunga. Menziona la mancanza di documentazione su come creare una Memory a partire da un puntatore e raccomanda un gist su GitHub come migliore risorsa disponibile. Spiega la necessità di creare un MemoryManager, che viene utilizzato internamente da una Memory ogni volta che necessita di fare qualcosa di più complesso che non sia semplicemente puntare a una sezione di un array.
Nicolet discute l’uso del memory mapping rispetto a FileStream, osservando che FileStream è la scelta ovvia per accedere ai dati sul disco e il suo utilizzo è ben documentato. Nota che l’approccio FileStream non è thread-safe e richiede un lock intorno all’operazione, impedendo la lettura da più posizioni in parallelo. Nicolet menziona inoltre che l’approccio FileStream introduce un certo overhead che non è presente nella versione mappata in memoria.
Spiega che invece si dovrebbe utilizzare la versione mappata in memoria, in quanto è in grado di utilizzare quanta più memoria possibile e, quando si esaurisce la memoria, scaricherà parti degli insiemi di dati nuovamente su disco. Nicolet solleva la questione di quanti file allocare, di quanto debbano essere grandi e di come ciclare attraverso tali file durante l’allocazione e deallocazione della memoria.
Suggerisce di dividere la memoria su diversi file di grandi dimensioni, di non scrivere mai sulla stessa memoria due volte e di eliminare i file il prima possibile. Nicolet conclude condividendo che in produzione a Lokad, utilizzano Lokad scratch space con impostazioni specifiche: ogni file ha 16 gigabyte, ci sono 100 file per ogni disco e ogni L32VM dispone di quattro dischi, rappresentando poco più di 6 terabyte di spazio per lo spill per ciascuna VM.
Trascrizione Completa

Victor Nicolet: Ciao e benvenuti a questa conferenza sul versamento su disco in .NET.
Il versamento su disco è una tecnica per elaborare insiemi di dati che non entrano in memoria, mantenendo invece parti del set di dati non in uso su storage persistente.
Questa conferenza si basa sulla mia esperienza lavorando per Lokad. Ci occupiamo di ottimizzazione quantitativa supply chain.
La parte quantitativa significa che lavoriamo con insiemi di dati di grandi dimensioni e la parte supply chain, beh, fa parte del mondo reale, quindi sono disordinati, sorprendenti e pieni di casi limite all’interno di casi limite.
Quindi, eseguiamo elaborazioni abbastanza complesse.
Esaminiamo un esempio tipico. Un rivenditore avrebbe dell’ordine di centomila prodotti.
Questi prodotti sono presenti in fino a 100 sedi. Possono essere negozi, possono essere magazzini, o anche sezioni di magazzini dedicate all’e-commerce.
E se vogliamo eseguire qualsiasi tipo di analisi reale su questo, dobbiamo esaminare il comportamento passato, cosa succede a quei prodotti e a quelle sedi.
Assumendo di conservare un solo dato per ogni giorno e considerando solo gli ultimi tre anni, ciò significa circa 1000 giorni. Moltiplicando tutto ciò insieme, il nostro insieme di dati avrà 10 miliardi di voci.
Se conserviamo solo un valore floating point per ogni voce, il set di dati occupa già 37 gigabyte di memoria. Questo supera la capacità di un computer desktop tipico.

E un singolo valore floating point non è di certo sufficiente per eseguire qualsiasi tipo di analisi.
Un numero migliore sarebbe 20 e, anche in quel caso, stiamo facendo notevoli sforzi per mantenere ridotta l’impronta di memoria. Anche così, si parla di circa 745 gigabyte di utilizzo della memoria.
Questo può rientrare nelle macchine cloud, se sono sufficientemente potenti, a circa settemila dollari al mese. Quindi, è relativamente accessibile ma anche alquanto sprecone.

Come si può intuire dal titolo di questa conferenza, la soluzione è utilizzare lo storage persistente, che è più lento ma più economico rispetto alla memoria.
Oggigiorno, è possibile acquistare storage SSD NVMe a circa 5 centesimi al gigabyte. Un SSD NVMe è uno dei tipi di storage persistente più veloci che si possano ottenere facilmente oggi.
Per confronto, un gigabyte di RAM costa 275 dollari. Si tratta di una differenza di circa 55 volte.

Un altro modo di considerare la cosa è che, con il budget necessario per acquistare 18 gigabyte di memoria, si potrebbe permettere un terabyte di storage SSD.

Che dire delle soluzioni Cloud? Prendendo come esempio il cloud Microsoft, a sinistra troviamo gli L32s, parte di una serie di macchine virtuali ottimizzate per lo storage.
Per circa duemila dollari al mese, si ottengono quasi 8 terabyte di storage persistente.
A destra troviamo gli M32ms, parte di una serie ottimizzata per la memoria e, a più di due volte e mezzo il costo, si ottengono solo 875 gigabyte di RAM.
Se il mio programma gira sulla macchina a sinistra e impiega il doppio del tempo per completarsi, comunque risulta più conveniente in termini di costo.

E per quanto riguarda le prestazioni? Beh, la lettura dalla memoria funziona a circa 21 gigabyte al secondo. La lettura da un NVMe SSD funziona a circa 3,5 gigabyte al secondo.
Questo non è un benchmark reale. Ho semplicemente creato una macchina virtuale ed eseguito quei due comandi, e ci sono molti modi per aumentare o diminuire questi valori.
La parte importante qui è solo l’ordine di grandezza della differenza tra i due. La lettura da disco è sei volte più lenta della lettura dalla memoria.
Quindi, il disco è deludentemente lento, non vorresti leggere dal disco tutto il tempo con pattern di accesso casuali. Ma d’altra parte, è anche sorprendentemente veloce. Se il tuo processamento è principalmente limitato dalla CPU, potresti non notare nemmeno che stai leggendo dal disco anziché dalla memoria.

Una tecnica abbastanza nota per utilizzare lo spazio su disco come alternativa alla memoria è il partizionamento.
L’idea alla base del partizionamento è quella di selezionare una delle dimensioni del set di dati e di dividerlo in pezzi più piccoli. Ogni pezzo dovrebbe essere sufficientemente piccolo da poter essere caricato in memoria.
Il processamento carica quindi ogni pezzo singolarmente, lo elabora e lo salva nuovamente su disco prima di caricare il pezzo successivo.
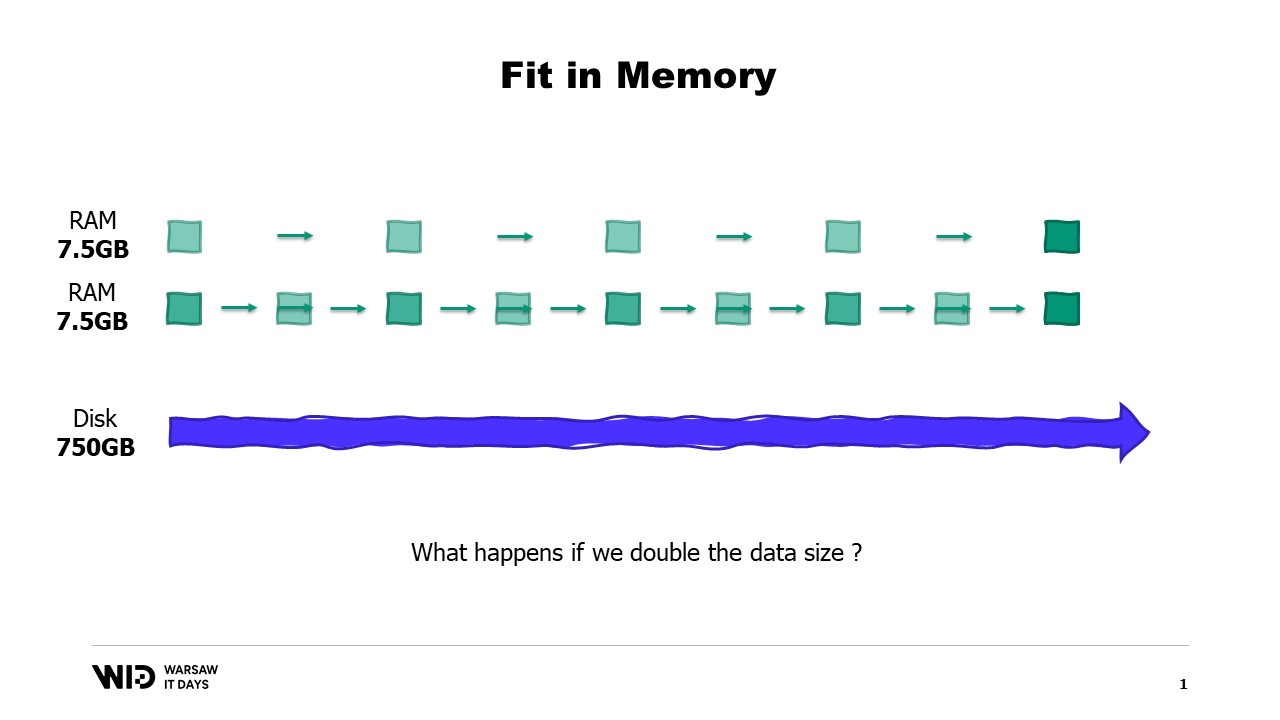
Nel nostro esempio, se dividessimo i set di dati per località ed elaborassimo una località alla volta, allora ogni località occuperebbe solo 7,5 gigabyte di memoria. Questo rientra comodamente nelle capacità di un computer desktop.

Tuttavia, con il partizionamento non c’è comunicazione tra le partizioni. Quindi, se dobbiamo elaborare dati che attraversano le località, non possiamo più utilizzare questa tecnica.
Un’altra tecnica è lo streaming. Lo streaming è abbastanza simile al partizionamento in quanto carichiamo piccoli pezzi di dati in memoria in qualsiasi momento.
A differenza del partizionamento, lo streaming permette di mantenere uno stato tra l’elaborazione di parti differenti. Quindi, mentre si elabora la prima località, si imposta lo stato iniziale, e poi, durante l’elaborazione della seconda località, è possibile utilizzare quanto presente nello stato in quel momento per creare un nuovo stato al termine dell’elaborazione della seconda località.
A differenza del partizionamento, lo streaming non si presta all’esecuzione parallela. Ma risolve il problema di computare qualcosa su tutti i dati del set, invece di essere confinato in pezzi separati.
Tuttavia, lo streaming ha una sua limitazione. Per garantire buone prestazioni, i dati su disco devono essere ordinati o allineati correttamente.
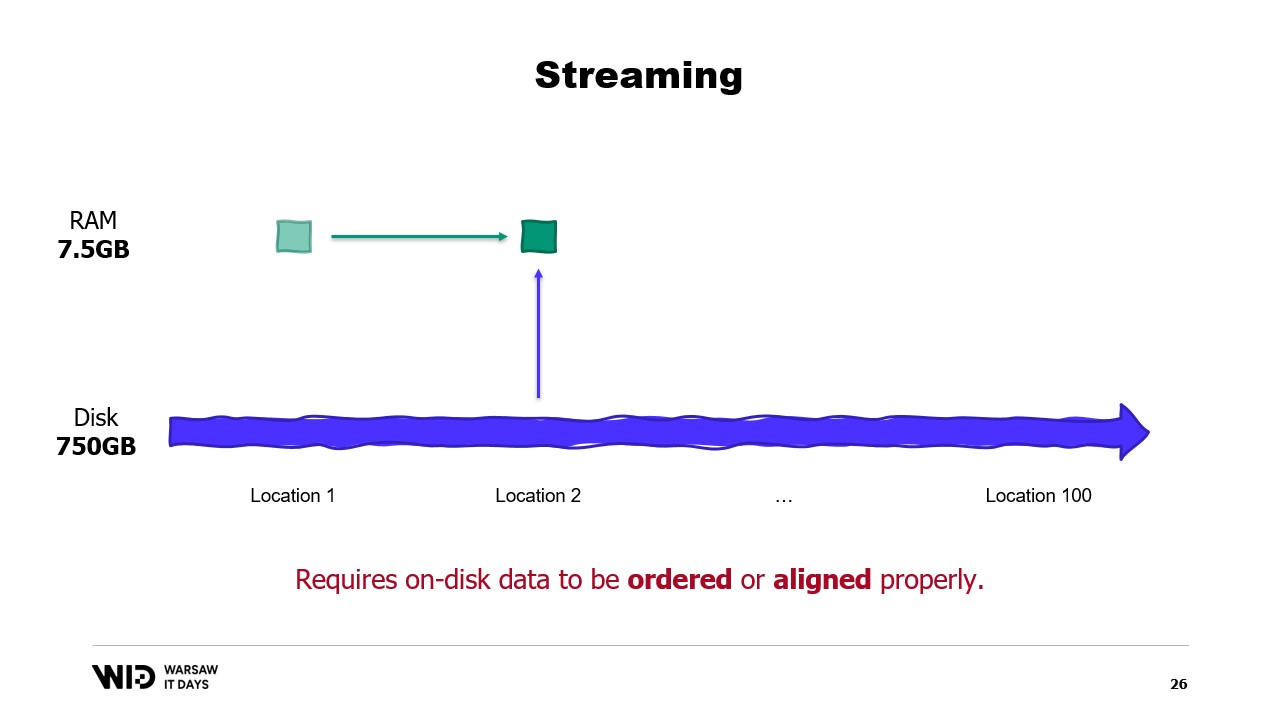
Per comprendere tali requisiti, è necessario sapere che NVMe legge e scrive dati in settori di mezzo kilobyte e i valori prestazionali precedenti, come 3,5 gigabyte al secondo, assumono che i settori vengano letti e utilizzati per intero.
Se utilizziamo solo una parte del settore, ma l’intero settore deve essere letto, si spreca banda e le prestazioni si riducono notevolmente.

Pertanto, è ottimale che i dati che leggiamo siano un multiplo di mezzo kilobyte e siano allineati sui confini dei settori.
Non utilizziamo più dischi rotanti, quindi saltare un settore e non leggerlo non comporta alcun costo.

Se non è possibile allineare i dati sui confini dei settori, tuttavia, un’altra soluzione è caricarli in ordine sequenziale.
Questo perché, una volta caricato un settore in memoria, leggere la seconda parte del settore non richiede un nuovo accesso al disco. Invece, il sistema operativo potrà semplicemente fornirti i byte rimanenti che non sono ancora stati utilizzati.
E dunque, se i dati sono caricati consecutivamente, non si spreca banda e si ottengono comunque le prestazioni complete.

Il caso peggiore è quando si legge solo uno o pochi byte da ciascun settore. Ad esempio, se si legge un valore in virgola mobile da ogni settore, si riducono le prestazioni di un fattore di 128.

Peggio ancora, esiste un’altra unità di raggruppamento dei dati sopra i settori, che è la pagina del sistema operativo, e quest’ultimo solitamente carica intere pagine di circa 4 kilobyte per intero.
Quindi ora, se leggi un valore in virgola mobile da ogni pagina, hai ridotto le prestazioni di un fattore di 1024.
Per questo motivo, è davvero importante assicurarsi che le letture dei dati dallo storage persistente vengano effettuate in grandi batch consecutivi.

Utilizzando queste tecniche, è possibile fare in modo che il programma si adatti a una quantità minore di memoria. Queste tecniche tratteranno la memoria e il disco come due spazi di storage separati, indipendenti l’uno dall’altro.
E quindi, la distribuzione del set di dati tra memoria e disco è determinata interamente dall’algoritmo e dalla struttura del set di dati.
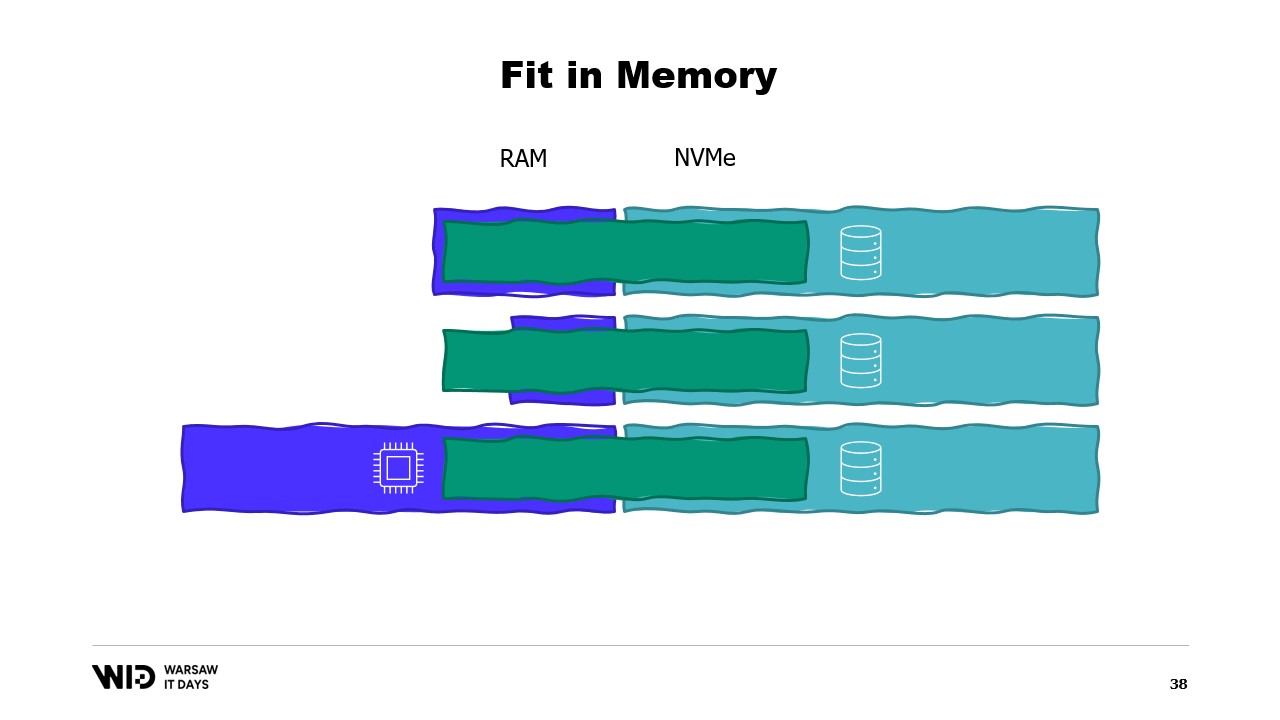
Quindi, se eseguiamo il programma su una macchina che possiede esattamente la quantità giusta di memoria, il programma si adatterà perfettamente e potrà essere eseguito.
Se utilizziamo una macchina che ha meno memoria di quella richiesta, il programma non riuscirà ad adattarsi in memoria e non potrà essere eseguito.
Infine, se utilizziamo una macchina che ha più memoria di quella necessaria, il programma farà ciò che i programmi solitamente fanno: non utilizzerà la memoria aggiuntiva e funzionerà comunque alla stessa velocità.
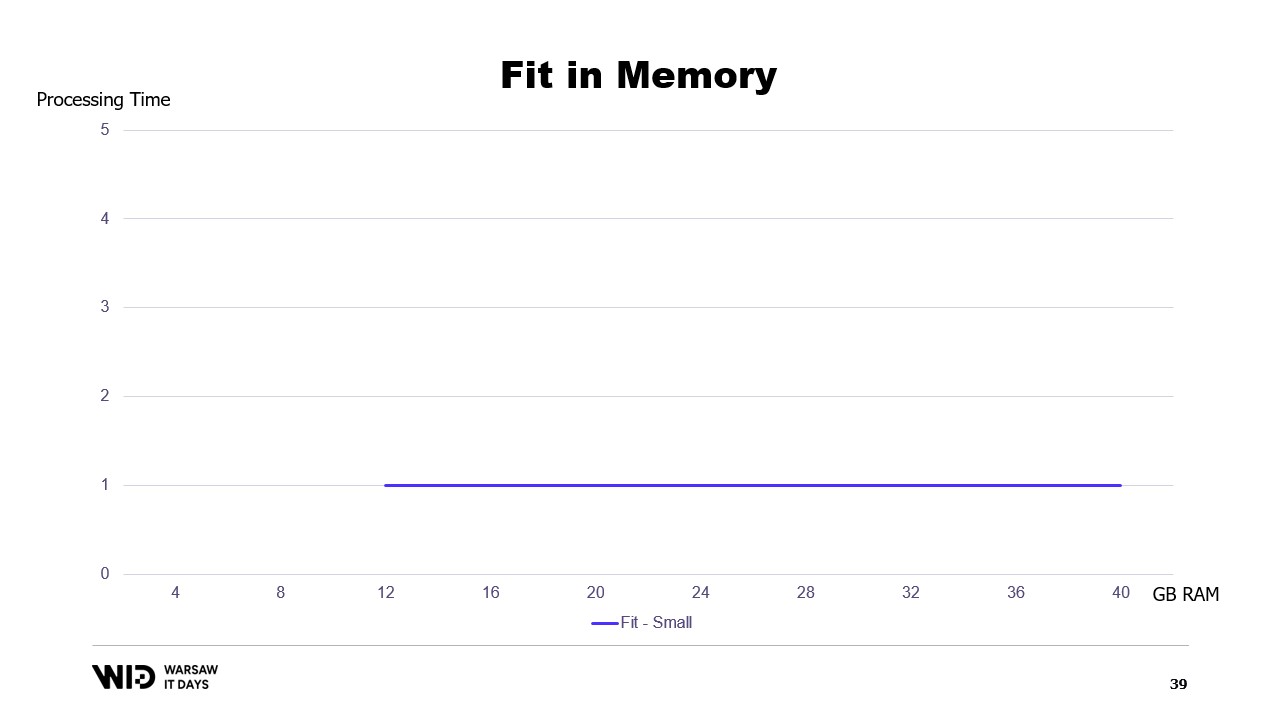
Se tracciassimo un grafico del tempo di esecuzione in base alla memoria disponibile, apparirebbe così. Al di sotto dell’impronta di memoria, non c’è esecuzione, quindi non c’è tempo di processamento. Al di sopra dell’impronta, il tempo di processamento è costante perché il programma non è in grado di utilizzare la memoria aggiuntiva per eseguire più velocemente.
E inoltre, cosa succede se il set di dati aumenta? Beh, a seconda della dimensione, se il set di dati cresce in modo da aumentare il numero di partizioni, allora l’impronta di memoria rimarrà la stessa, ci saranno solo più partizioni.
D’altra parte, se le singole partizioni crescono, l’impronta di memoria aumenterà, incrementando la quantità minima di memoria necessaria per far funzionare il programma.
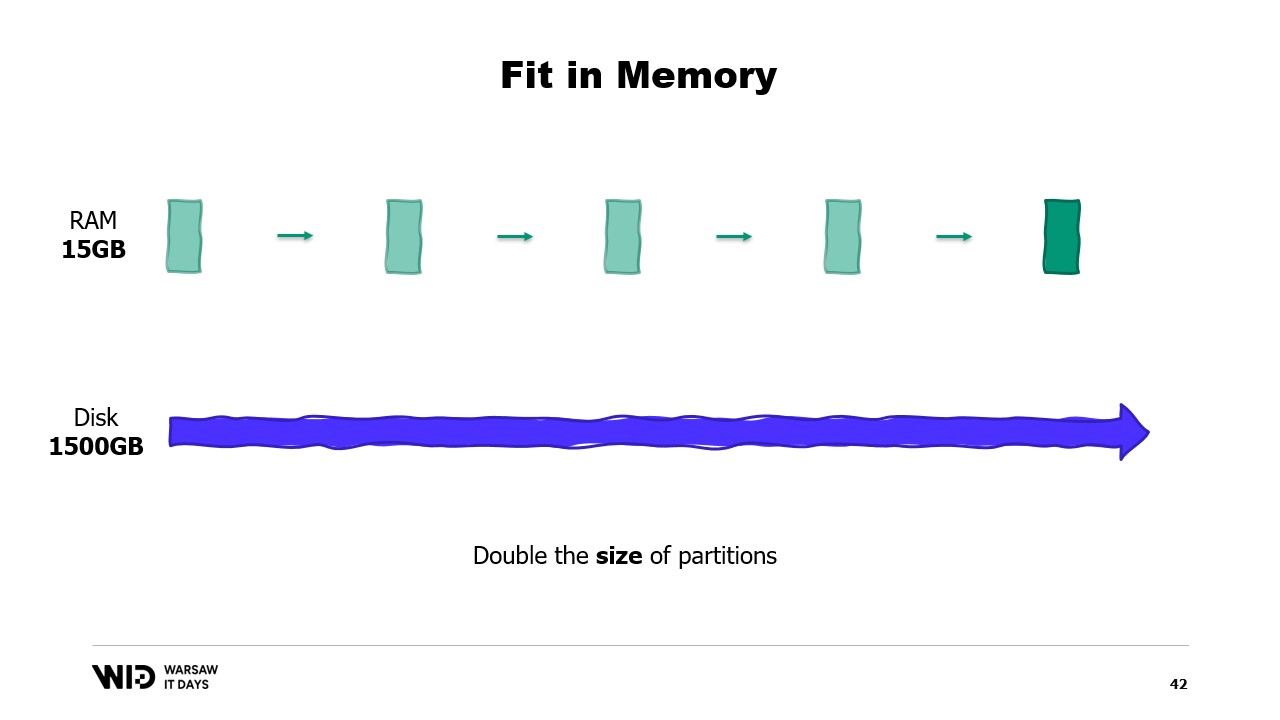
In altre parole, se ho un set di dati più grande da elaborare, non solo ci vorrà più tempo, ma avrà anche un’impronta più ampia.
Ciò crea una situazione spiacevole in cui sarà necessario aggiungere più memoria per poter gestire grandi set di dati quando si presentano, ma l’aggiunta di memoria non migliora nulla per i set di dati più piccoli.
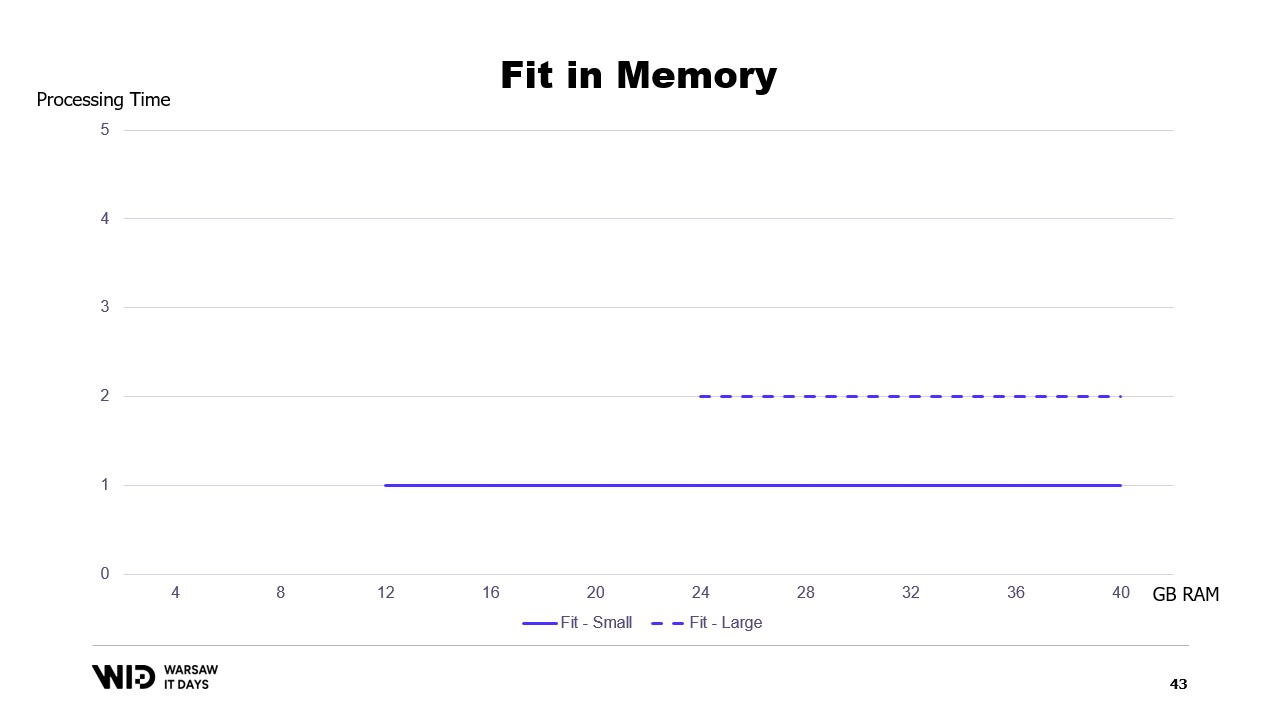
Questa è una limitazione dell’approccio basato sulla vestibilità in memoria, in cui la distribuzione del set di dati tra memoria e storage persistente è determinata interamente dalla struttura del set di dati e dall’algoritmo stesso.
Non tiene conto della quantità effettiva di memoria disponibile. Ciò che fanno le tecniche di spill to disk è distribuire dinamicamente i dati. Quindi, se c’è più memoria disponibile, utilizzeranno più memoria per eseguire più velocemente.
E al contrario, se c’è meno memoria disponibile, fino a un certo punto, saranno in grado di rallentare per utilizzare meno memoria. In quel caso, le curve sono molto migliori. L’impronta minima è più piccola ed è la stessa per entrambi i set di dati.
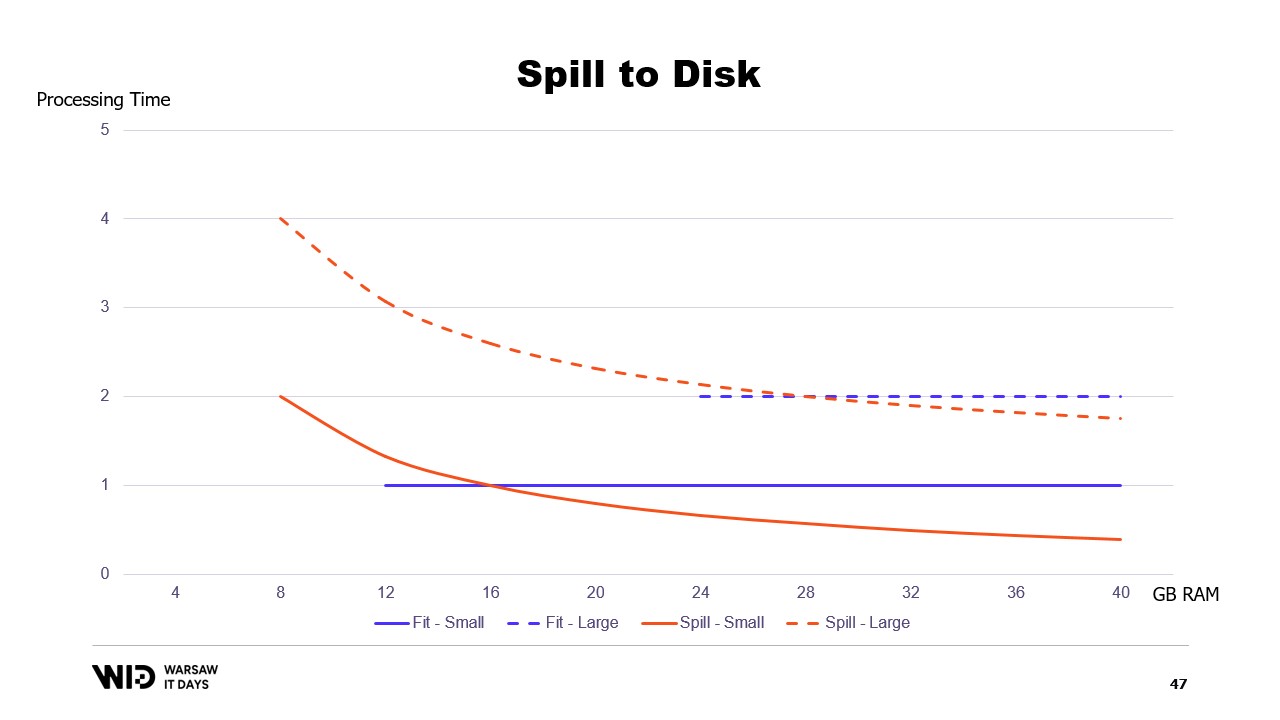
Le prestazioni aumentano man mano che viene aggiunta più memoria in tutti i casi. Le tecniche di fit to memory scaricheranno preventivamente alcuni dati sul disco per ridurre l’impronta di memoria. Al contrario, le tecniche di spill to disk utilizzeranno quanta più memoria possibile e solo quando la memoria si esaurirà inizieranno a scaricare alcuni dati sul disco per fare spazio.
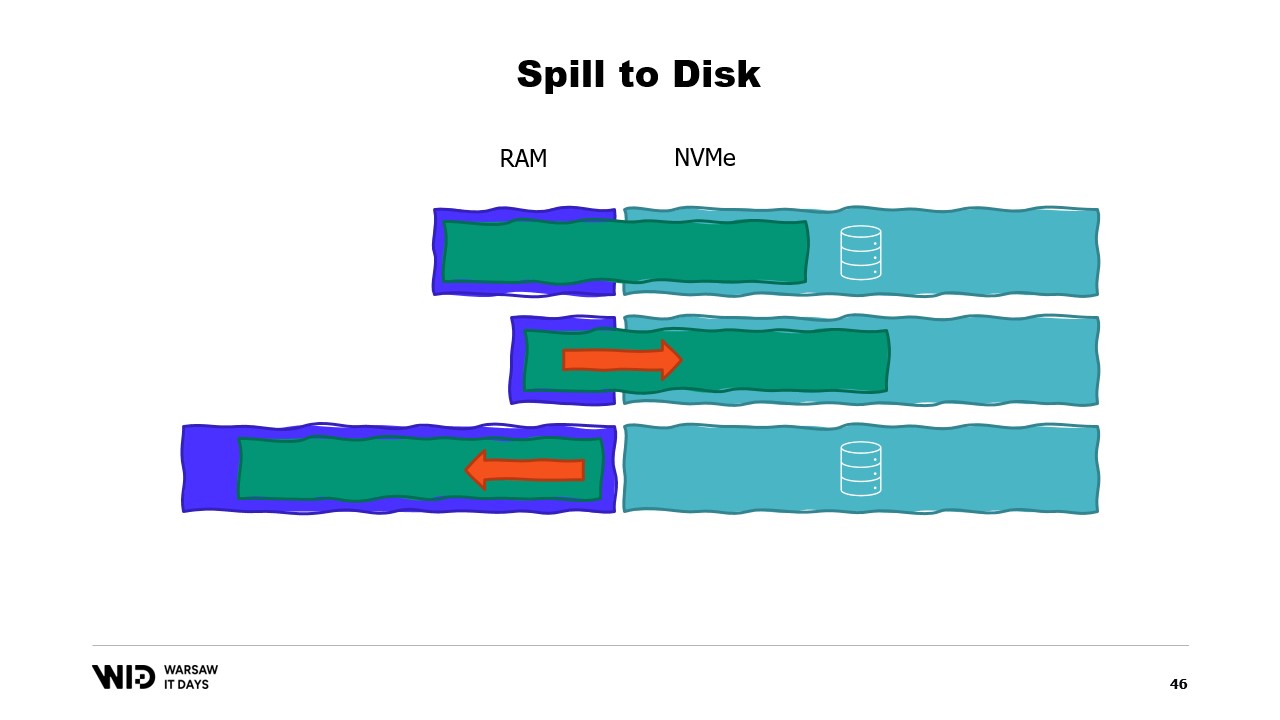
Questo le rende molto migliori nel reagire a situazioni in cui c’è più o meno memoria rispetto a quanto inizialmente previsto. Le tecniche di spill to disk divideranno il set di dati in due sezioni. Si assume che la sezione hot sia sempre in memoria e quindi sia sempre sicuro, in termini di prestazioni, accedervi con pattern di accesso casuale. Avrà ovviamente un budget massimo, forse qualcosa come 8 gigabyte per CPU su una tipica macchina Cloud.
D’altro canto, alla sezione cold è permesso, in qualsiasi momento, scaricare parti del suo contenuto sullo storage persistente. Non esiste un budget massimo, tranne quello disponibile. E ovviamente, in termini di prestazioni, non è sicuro leggere dalla sezione cold.
Quindi, il programma utilizzerà trasferimenti hot-cold. Questi di solito coinvolgono grandi batch per massimizzare l’utilizzo della larghezza di banda NVMe. E poiché i batch sono piuttosto grandi, verranno eseguiti anche a frequenza piuttosto bassa. E dunque, è la sezione cold che permette a quegli algoritmi di utilizzare quanta più memoria possibile.

Dato che la sezione cold riempirà tutta la RAM disponibile e poi scaricherà il resto sullo storage persistente. Allora, come possiamo far funzionare tutto ciò in .NET? Poiché chiamo questo il primo tentativo, puoi immaginare che non funzionerà. Quindi, prova a scoprire in anticipo qual sarà il problema.
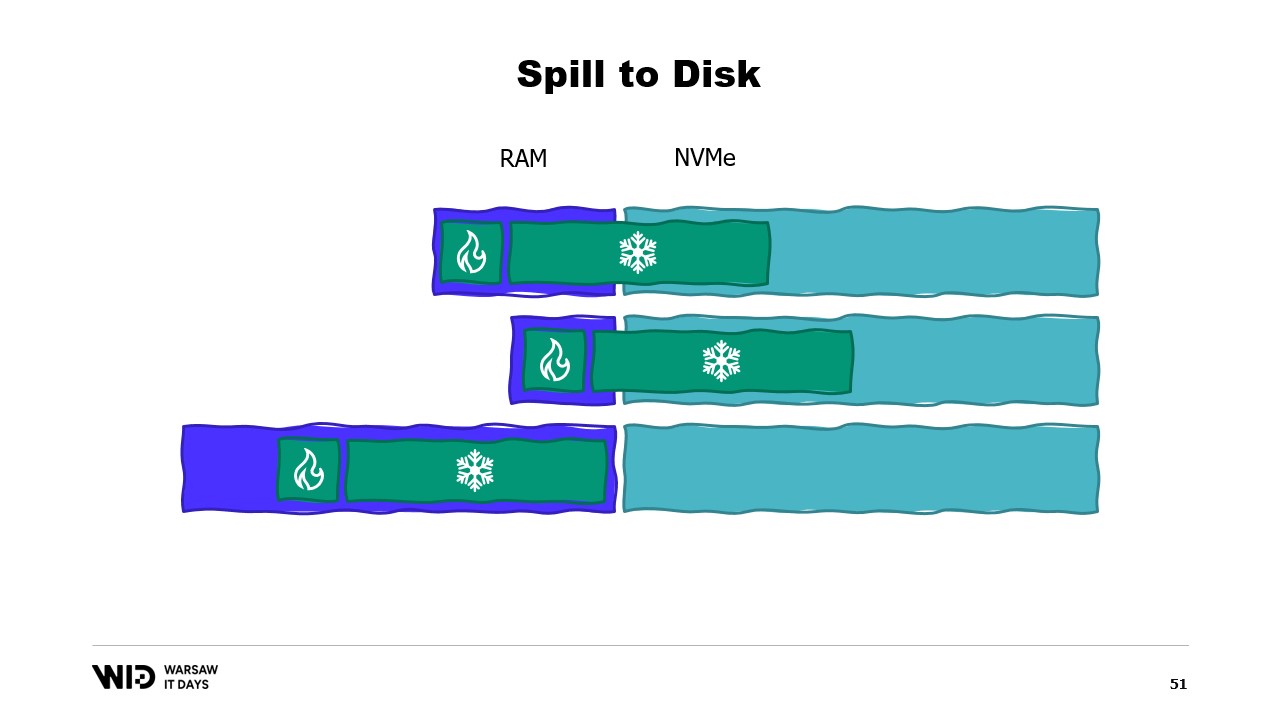
Per la sezione hot, utilizzerò normali oggetti .NET e il problema lo esamineremo in un programma .NET normale. Per la sezione cold, userò quella che chiamo classe reference. Questa classe mantiene un riferimento al valore che viene immagazzinato nel cold storage e questo valore può essere impostato a null quando non è più in memoria. Ha una funzione spill che prende il valore dalla memoria, lo scrive nello storage e poi nulifica il riferimento, permettendo al garbage collector di .NET di recuperare quella memoria quando si sente sotto pressione.
Infine, ha una proprietà value. Questa proprietà, quando viene accessa, restituisce il valore dalla memoria se presente e, in caso contrario, carica nuovamente da disco in memoria prima di restituirlo. Ora, se imposto un sistema centrale nel mio programma che tiene traccia di tutti i riferimenti cold, allora, ogni volta che viene creato un nuovo riferimento cold, posso determinare se provoca un overflow di memoria e invocare la funzione spill di uno o più dei riferimenti cold già presenti nel sistema, al fine di rimanere entro il budget di memoria disponibile per il cold storage.

Quindi, qual è il problema? Beh, se guardo il contenuto della memoria di una macchina che esegue il nostro programma, nel caso ideale apparirà così. Prima a sinistra c’è la memoria del sistema operativo, che utilizza per i propri scopi. Poi c’è la memoria interna usata da .NET per cose come assembly caricati o l’overhead del garbage collector e così via. Poi c’è la memoria della sezione hot e infine, a occupare tutto il resto, c’è la memoria allocata alla sezione cold.
Con alcuni sforzi, siamo in grado di controllare tutto ciò che si trova a destra, poiché è ciò che allochiamo e scegliamo di rilasciare affinché il garbage collector raccolga. Tuttavia, ciò che è a sinistra è fuori dal nostro controllo. E cosa succede se all’improvviso il sistema operativo ha bisogno di memoria addizionale e scopre che tutto è occupato da ciò che il processo .NET ha creato?
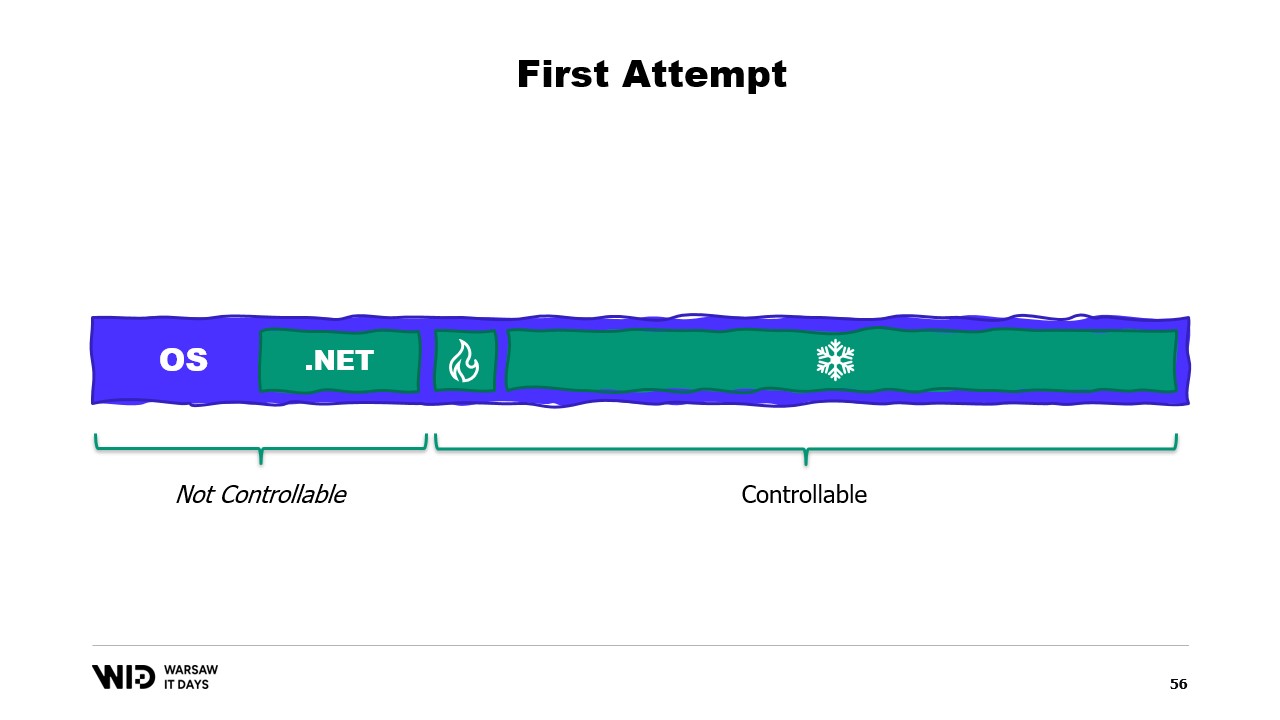
Beh, la reazione tipica, ad esempio, del kernel Linux in quel caso sarà di uccidere il programma che utilizza più memoria e non c’è modo di reagire abbastanza rapidamente per rilasciare un po’ di memoria al kernel, evitando così che ci termini. Allora, qual è la soluzione?

I sistemi operativi moderni hanno il concetto di memoria virtuale. Il programma non ha accesso diretto alle pagine di memoria fisica. Invece, ha accesso a pagine di memoria virtuale e vi è una mappatura tra quelle pagine e le pagine effettive nella memoria fisica. Se un altro programma è in esecuzione sullo stesso computer, non sarà in grado di accedere autonomamente alle pagine del primo programma. Esistono comunque modi per condividere.
È possibile creare una pagina mappata in memoria. In tal caso, tutto ciò che il primo programma scrive nella pagina condivisa sarà immediatamente visibile dall’altra parte. Questo è un modo comune per implementare la comunicazione tra programmi, ma il suo scopo principale è il memory mapping dei file. Qui, il sistema operativo saprà che questa pagina è una copia esatta di una pagina presente nello storage persistente, solitamente parti di un file di libreria condivisa.
Lo scopo principale qui è evitare che ogni programma abbia la propria copia della DLL in memoria, poiché tutte quelle copie sono identiche e non c’è motivo di sprecare memoria a conservarle. Qui, per esempio, abbiamo due programmi che in totale occupano quattro pagine di memoria, mentre la memoria fisica ha spazio solo per tre pagine. Ora, cosa succede se vogliamo allocare un’altra pagina nel primo programma? Non c’è spazio disponibile, ma il kernel sa che la pagina mappata in memoria può essere temporaneamente scaricata e, se necessario, ricaricata dallo storage persistente in modo identico.
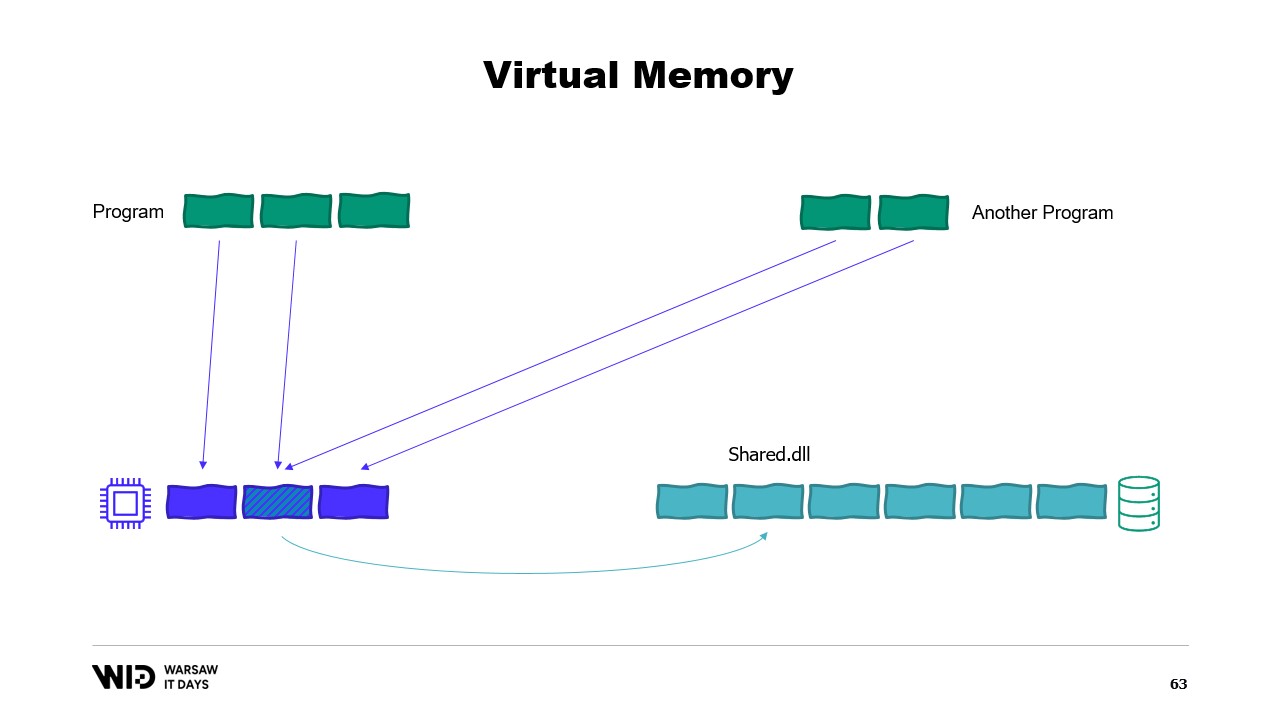
Quindi, farà proprio questo. Le due pagine condivise punteranno ora al disco anziché alla memoria. La memoria viene svuotata, impostata a zero dal sistema operativo, e poi assegnata al primo programma per essere utilizzata come terza pagina logica. Ora, la memoria è completamente piena e, se uno dei due programmi tenta di accedere alla pagina condivisa, non ci sarà spazio per ricaricarla in memoria, perché le pagine assegnate ai programmi non possono essere reclamate dal sistema operativo.
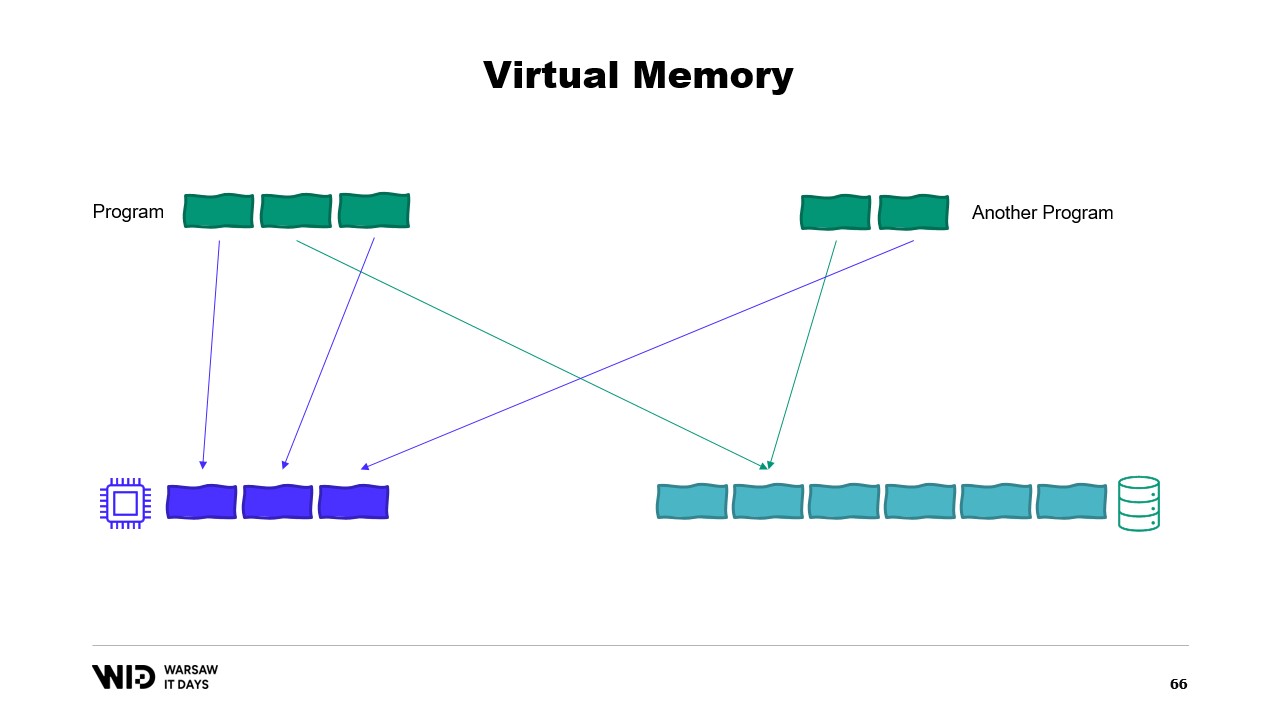
Quindi, ciò che succederà qui è un errore di memoria esaurita. Uno dei programmi morirà, la memoria verrà rilasciata e poi riutilizzata per ricaricare il file mappato in memoria. Inoltre, sebbene la maggior parte delle memory map siano in sola lettura, è anche possibile crearne di in lettura-scrittura.
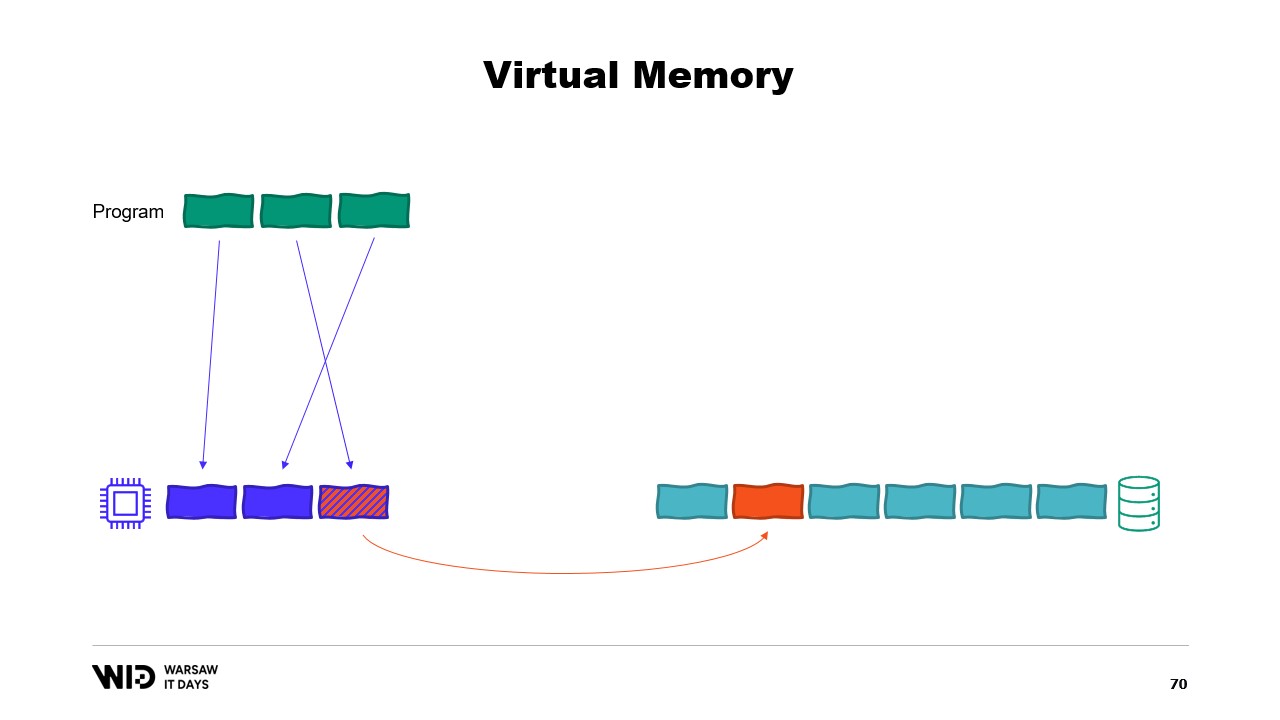
Un programma apporta una modifica alla memoria nella pagina mappata, poi, a un certo punto in futuro, il sistema operativo salverà il contenuto di quella pagina nuovamente sul disco. E naturalmente, è possibile richiedere che ciò avvenga in un momento specifico utilizzando funzioni come flush su Windows. Il System Performance Tool dispone di una bella finestra che mostra l’uso corrente della memoria fisica.
In verde è la memoria che è stata assegnata direttamente a un processo. Non può essere recuperata senza terminare il processo. In blu c’è la cache di pagine. Quelle sono pagine che si sa essere copie identiche di una pagina sul disco e quindi, ogni volta che un processo ha bisogno di leggere dal disco una pagina già presente nella cache, non verrà effettuata alcuna lettura da disco e il valore verrà restituito direttamente dalla memoria.
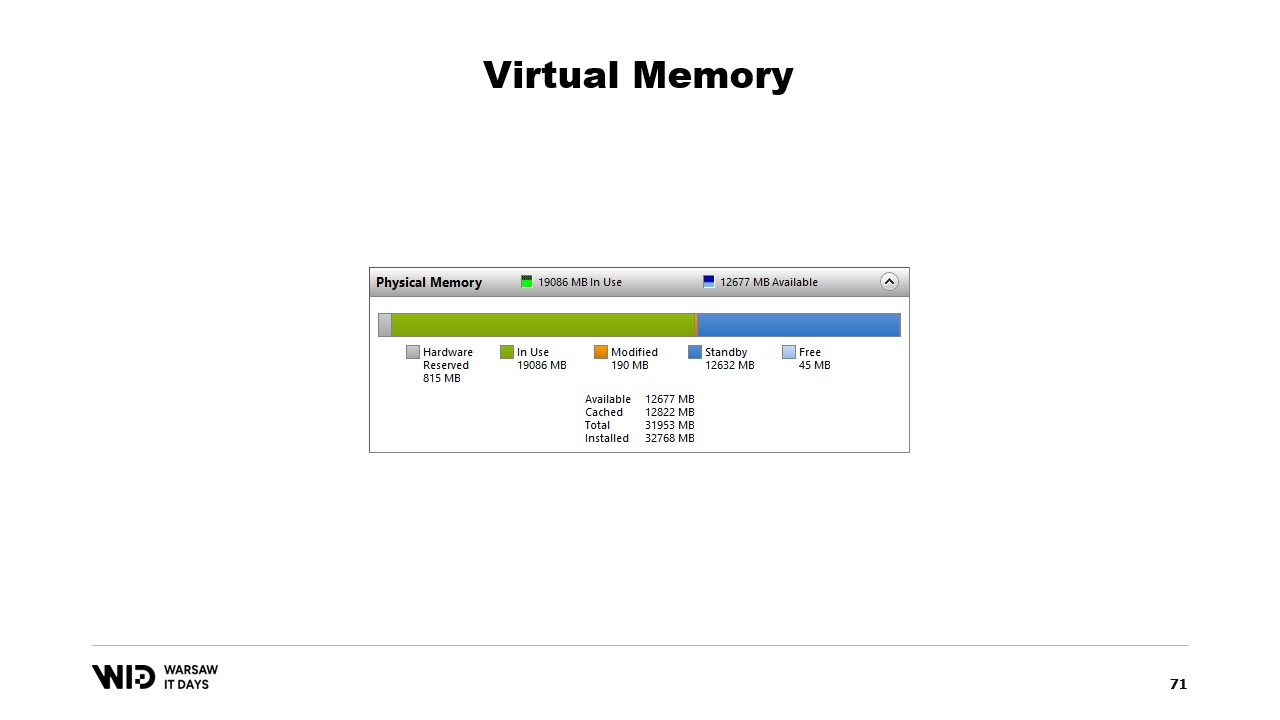
Infine, le pagine modificate al centro sono quelle che dovrebbero essere copie esatte del disco ma contengono modifiche in memoria. Tali modifiche non sono state ancora applicate al disco, ma lo saranno in breve. Su Linux, lo strumento h-stop visualizza un grafico simile. A sinistra ci sono le pagine che sono state assegnate direttamente ai processi e non possono essere recuperate senza terminarli, mentre a destra, in giallo, c’è la cache di pagine.

Se siete interessati, esiste una risorsa eccellente di Vyacheslav Biryukov su ciò che avviene nella cache di pagine di Linux. Utilizzando la memoria virtuale, proviamo il nostro secondo tentativo. Funzionerà questa volta? Ora decidiamo che la sezione fredda sarà composta interamente da pagine mappate in memoria. Quindi, ci si aspetta che tutte siano presenti sul disco in primo luogo.
Il programma non ha più alcun controllo su quali pagine saranno in memoria e quali saranno presenti solo sul disco. Il sistema operativo lo fa in maniera trasparente. Quindi, se il programma tenta di accedere, ad esempio, alla terza pagina nella sezione fredda, il sistema operativo rileverà che non è presente in memoria, scaricherà una delle pagine esistenti, ad esempio la seconda, e successivamente caricherà la terza pagina in memoria.
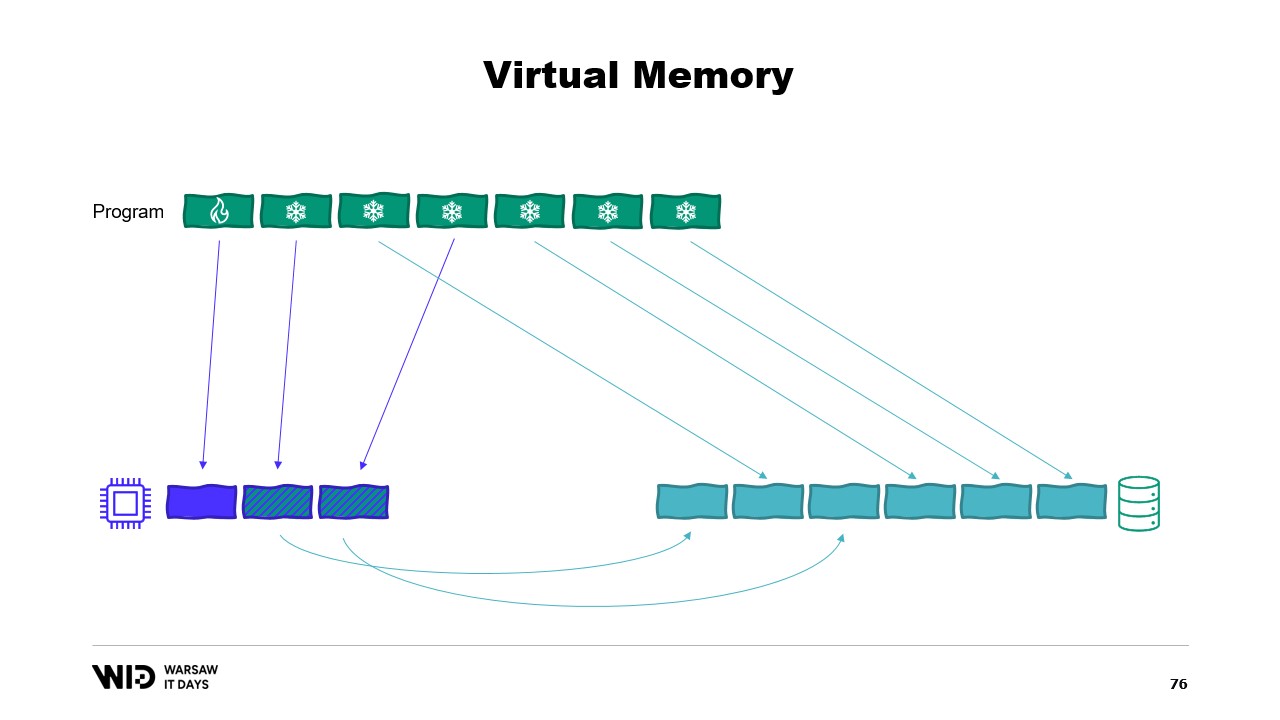
Dal punto di vista del processo stesso, tutto era completamente trasparente. L’attesa per la lettura dalla memoria era solo leggermente più lunga del solito. E cosa succede se il sistema operativo improvvisamente necessita di memoria per svolgere le proprie operazioni? Beh, sa quali pagine sono mappate in memoria e possono essere scartate in sicurezza. Quindi, semplicemente abbandonerà una delle pagine, la utilizzerà per i suoi scopi e poi la rilascerà una volta terminato.
Tutte queste tecniche si applicano a .NET e sono presenti nel progetto open source Lokad Scratch Space. E la maggior parte del codice che segue si basa su come questo pacchetto NuGet gestisce le operazioni.

Prima di tutto, come creeremmo un file mappato in memoria in .NET? Il memory mapping esiste dal .NET Framework 4, circa 13 anni fa. È abbastanza ben documentato su Internet e il codice sorgente è interamente disponibile su GitHub.

I passaggi fondamentali sono, prima di tutto, creare un file mappato in memoria a partire da un file sul disco e poi creare un view accessor. Questi due tipi vengono mantenuti separati perché hanno significati diversi. Il file mappato in memoria indica semplicemente al sistema operativo che da questo file, alcune sezioni saranno mappate nella memoria del processo. Il view accessor stesso rappresenta tali mappature.
I due sono mantenuti separati perché .NET deve gestire il caso di un processo a 32 bit. Un file molto grande, uno maggiore di quattro gigabyte, non può essere mappato nello spazio di memoria di un processo a 32 bit. È troppo grande. In altre parole, il puntatore non è abbastanza grande per rappresentarlo. Quindi, invece, è possibile mappare solo piccole sezioni del file una alla volta in modo da farle entrare.
Nel nostro caso, lavoreremo con puntatori a 64 bit. Quindi, possiamo semplicemente creare un view accessor che carica l’intero file. E ora, utilizzo AcquirePointer per ottenere il puntatore ai primi byte di questo intervallo di memoria mappata. Quando ho finito di lavorare con il puntatore, posso semplicemente rilasciarlo. Lavorare con i puntatori in .NET è non sicuro. Richiede di aggiungere la parola chiave unsafe ovunque e può comportare errori se si tenta di accedere a memoria al di fuori dei limiti consentiti.
Fortunatamente, esiste un modo per aggirare questo problema. Cinque anni fa, .NET ha introdotto Memory e Span. Questi sono tipi utilizzati per rappresentare un intervallo di memoria in modo più sicuro rispetto ai soli puntatori. È abbastanza ben documentato e la maggior parte del codice può essere trovata in questa posizione su GitHub.

L’idea generale alla base di Span e Memory è che, dati un puntatore e un numero di byte, è possibile creare un nuovo Span che rappresenta quell’intervallo di memoria.
Una volta ottenuto questo Span, puoi leggere in modo sicuro in qualsiasi punto al suo interno, sapendo che se provi a leggere oltre i limiti, il runtime lo intercetterà e otterrai un’eccezione anziché il semplice arresto del processo.
Vediamo come possiamo utilizzare Span per caricare dalla memoria mappata nella memoria gestita da .NET. Ricorda, non vogliamo accedere direttamente alla sezione fredda per motivi di prestazioni. Invece, vogliamo effettuare trasferimenti da “cold” a “hot” che caricano molti dati contemporaneamente.
Ad esempio, supponiamo di avere una stringa che vogliamo leggere. Essa sarà disposta nel file mappato in memoria come una dimensione seguita da un payload di byte codificato in UTF-8, e vogliamo caricare una stringa .NET a partire da ciò.
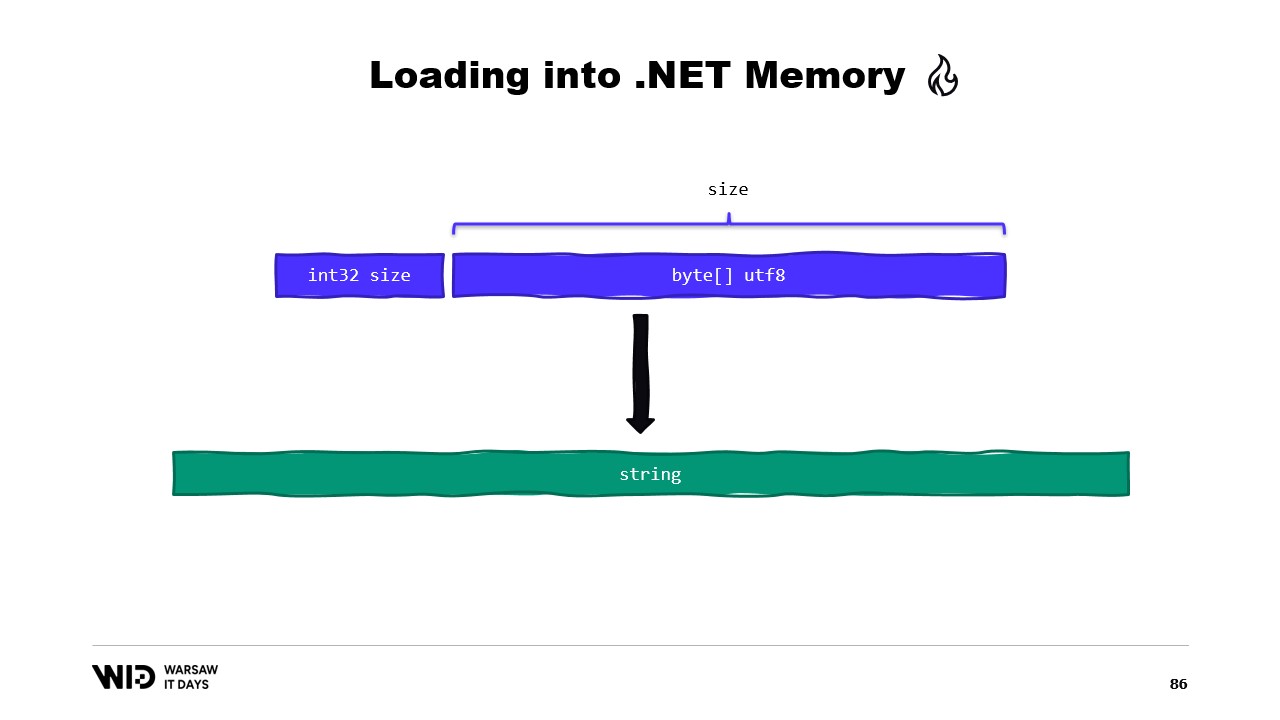
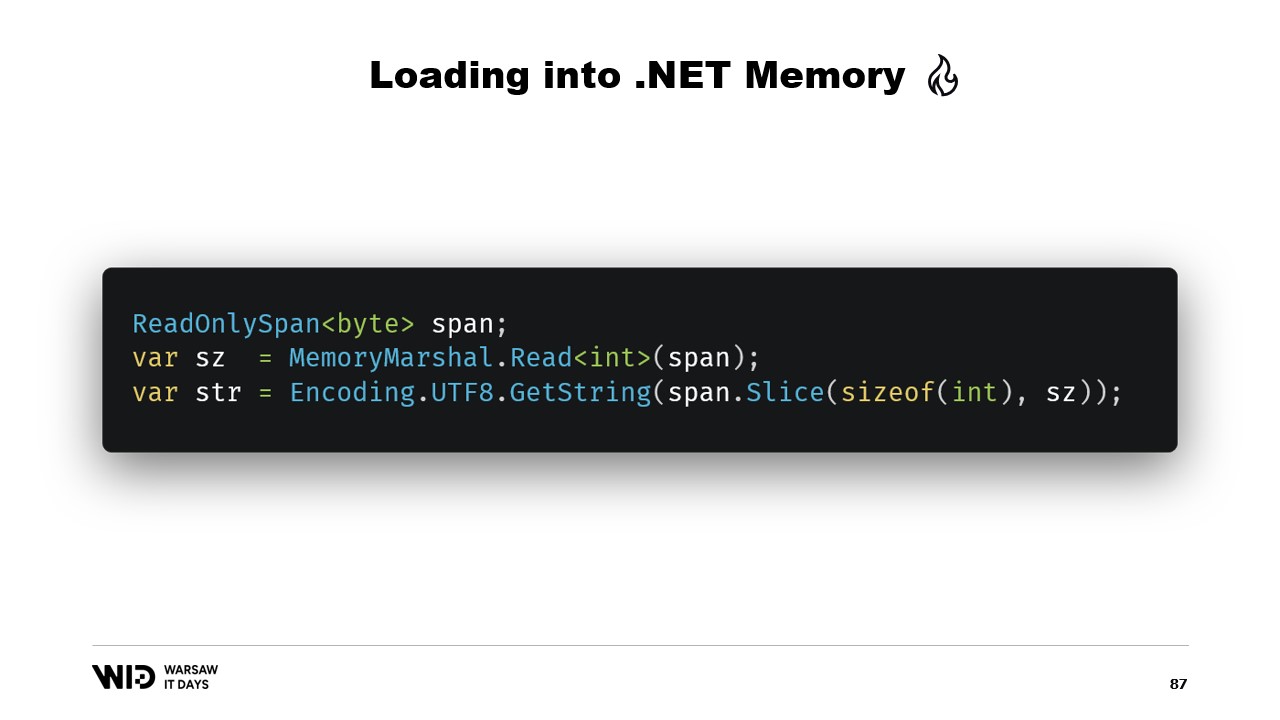
Bene, ci sono molte API incentrate sugli Span che possiamo utilizzare. Ad esempio, MemoryMarshal.Read può leggere un intero dall’inizio dello Span. Poi, utilizzando questa dimensione, posso chiedere alla funzione Encoding.GetString di caricare una stringa da uno Span di byte.
Tutte queste operazioni agiscono sugli Span e, anche se lo Span rappresenta una sezione di dati che è possibilmente presente sul disco anziché in memoria, il sistema operativo si occupa di caricare i dati in memoria in modo trasparente quando vengono per la prima volta accessati.
Un altro esempio potrebbe essere una sequenza di valori in virgola mobile che vogliamo caricare in un array di float.
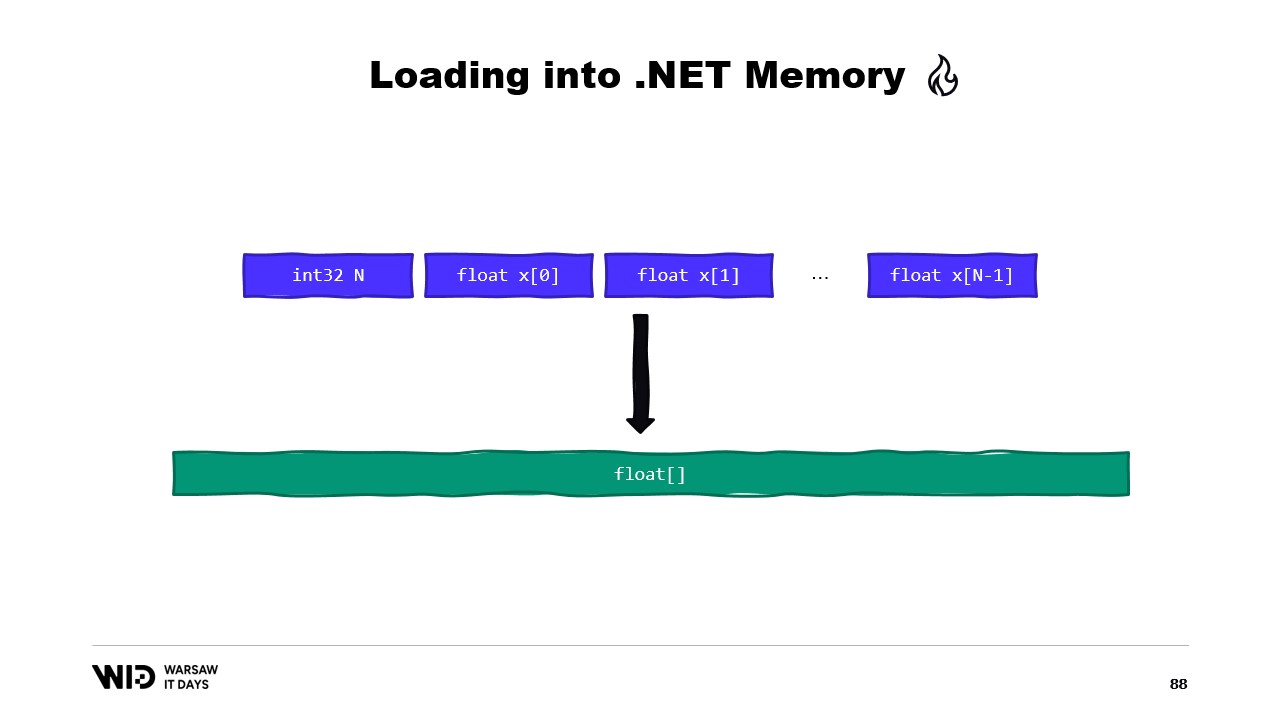
Ancora, utilizziamo MemoryMarshal.Read per leggere la dimensione. Allochiamo un array di valori in virgola mobile di quella dimensione e poi usiamo MemoryMarshal.Cast per convertire lo Span di byte in uno Span di valori in virgola mobile. Questo semplicemente reinterpreta i dati presenti nello Span come valori in virgola mobile invece che come semplici byte.
Infine, utilizziamo la funzione CopyTo degli Span che eseguirà una copia ad alte prestazioni dei dati dal file mappato in memoria nell’array stesso. In un certo senso, questo risulta un po’ sprecone, poiché stiamo effettuando una copia completamente nuova.
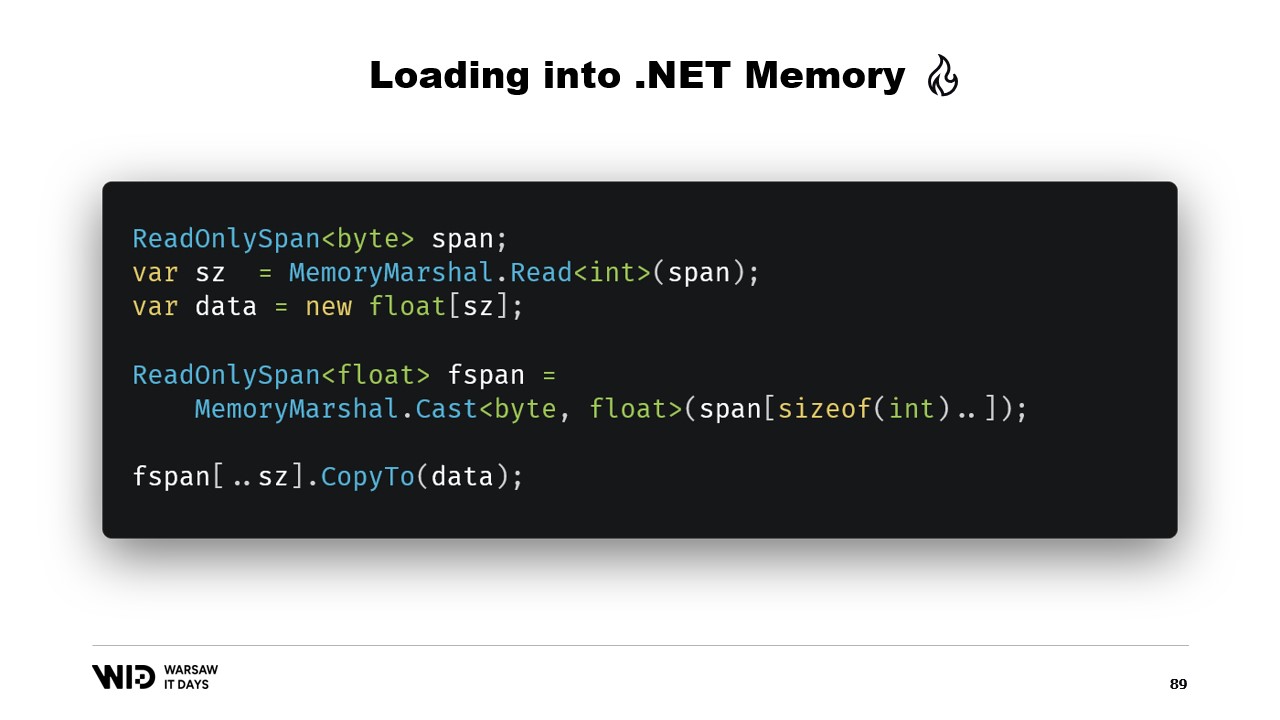
Forse potremmo evitarlo. In genere, quello che memorizzeremo sul disco non saranno i valori in virgola mobile grezzi. Invece, salveremo una versione compressa di essi. Qui memorizziamo la dimensione compressa, che ci indica quanti byte dobbiamo leggere. Memorizziamo la dimensione di destinazione o la dimensione decompressa, che ci dice quanti valori in virgola mobile dobbiamo allocare nella memoria gestita. E infine, salviamo il payload compresso stesso.
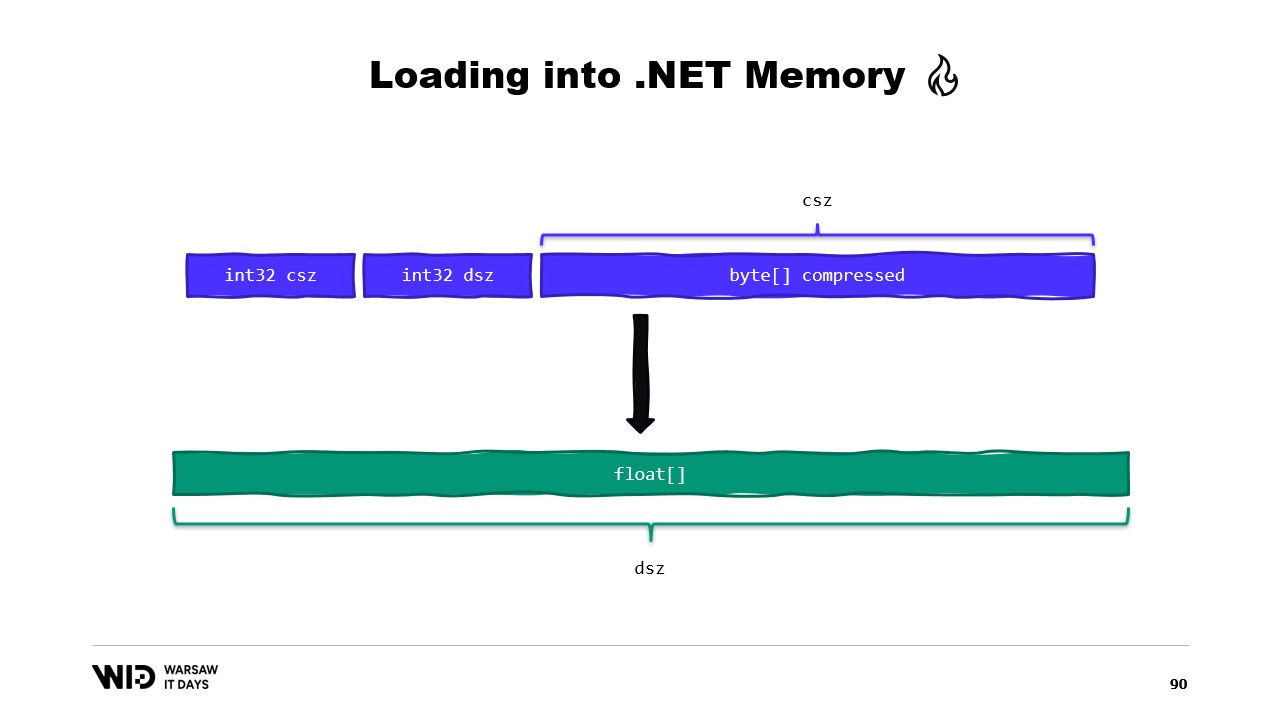
Per caricare ciò, sarà meglio se invece di leggere due interi, creiamo una struttura che rappresenta quell’header con due valori interi al suo interno.

MemoryMarshal sarà in grado di leggere un’istanza di quella struttura, caricando i due campi contemporaneamente. Allochiamo un array di valori in virgola mobile e poi la nostra libreria di compressione quasi certamente dispone di una funzione di decompressione che accetta come input uno Span di byte in sola lettura e come output uno Span di byte. Possiamo nuovamente utilizzare MemoryMarshal.Cast, questa volta convertendo l’array di valori in virgola mobile in uno Span di byte da utilizzare come destinazione.
Adesso, non è coinvolta alcuna copia. Invece, l’algoritmo di compressione legge direttamente dal disco, solitamente tramite la cache di pagine, nell’array di float di destinazione.

Span ha un’importante limitazione, ovvero che non può essere utilizzato come membro di una classe e, per estensione, non può essere usato come variabile locale in un metodo asincrono.
Fortunatamente, esiste un tipo diverso, Memory, che dovrebbe essere utilizzato per rappresentare un intervallo di dati a vita più lunga.
Purtroppo, esiste una documentazione sorprendentemente scarsa su come fare questo. Creare uno Span da un puntatore è facile, ma creare una Memory da un puntatore non è documentato al punto che la migliore documentazione disponibile è un gist su GitHub, che vi consiglio vivamente di leggere.
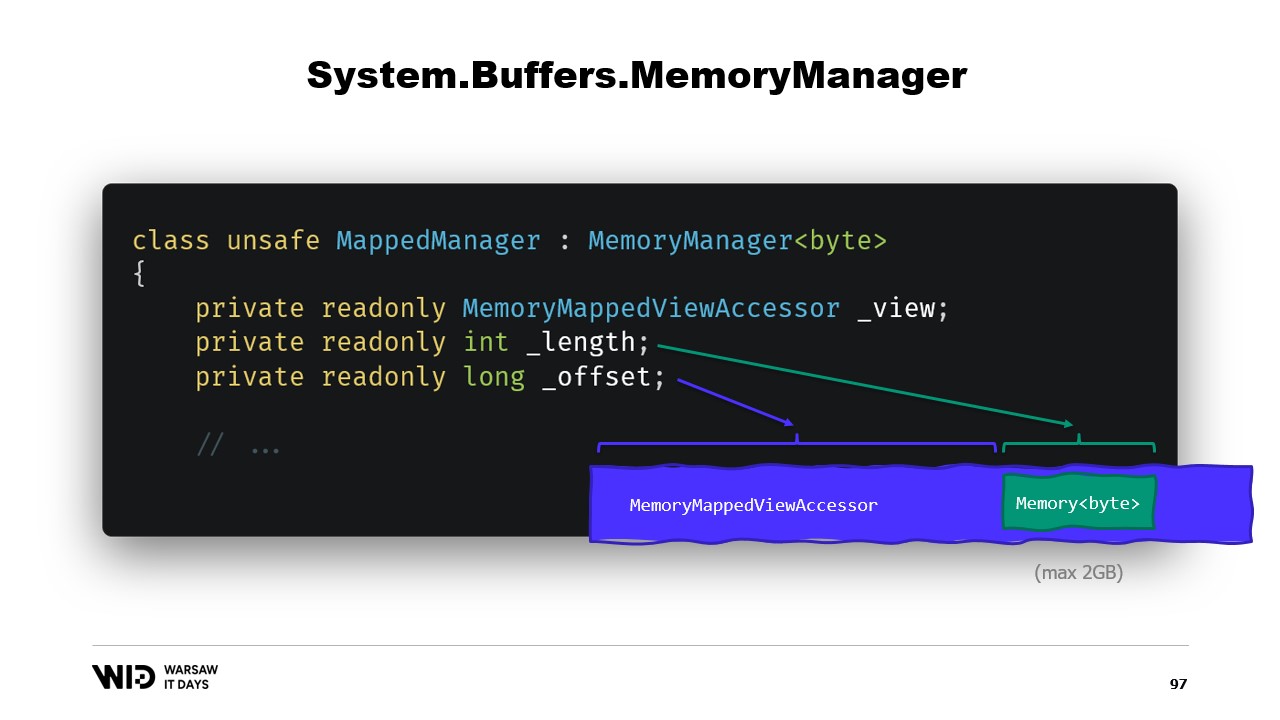
In breve, ciò che dobbiamo fare è creare un MemoryManager. Il MemoryManager viene utilizzato internamente da una Memory ogni volta che è necessario fare qualcosa di più complesso che semplicemente puntare a una sezione di un array.
Nel nostro caso, dobbiamo referenziare il view accessor mappato in memoria nel quale stiamo guardando. Dobbiamo conoscere la lunghezza che ci è consentito osservare e, infine, avremo bisogno di un offset. Questo perché una Memory di byte può rappresentare al massimo due gigabyte per design, e il file stesso probabilmente sarà più lungo di due gigabyte. Quindi, l’offset ci indica il punto in cui la memoria inizia all’interno del view accessor più ampio.
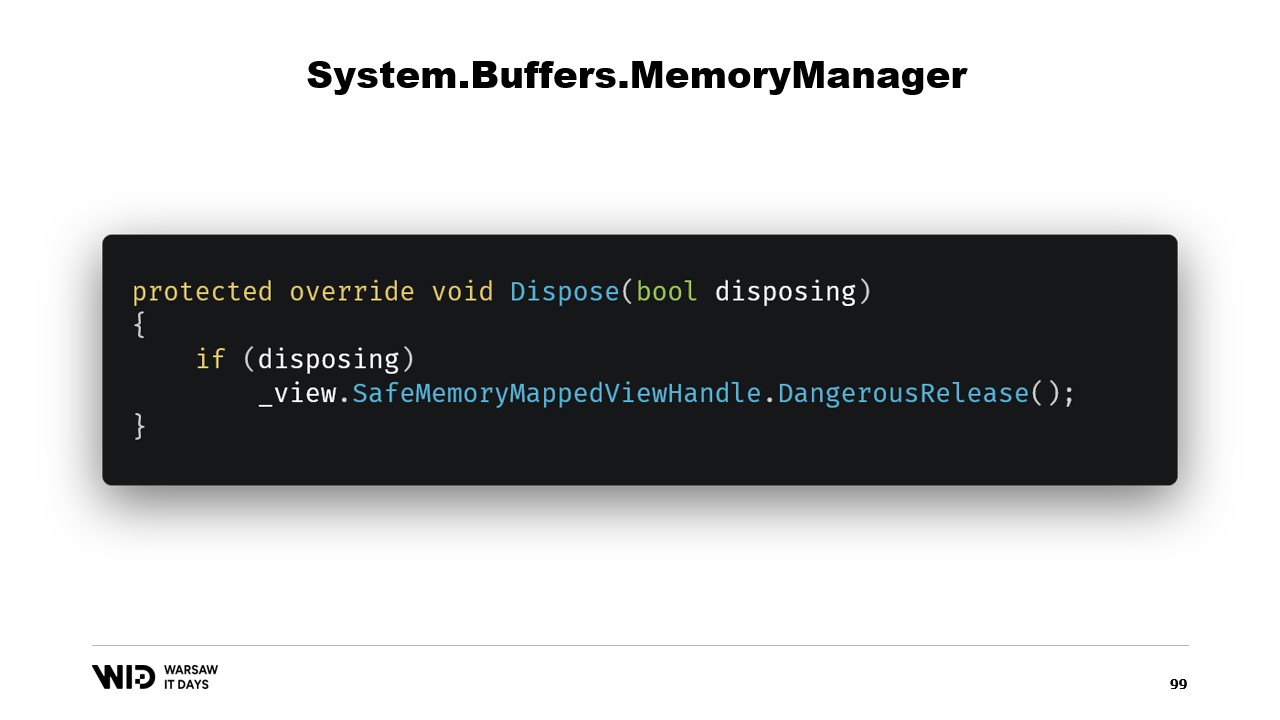
Il costruttore della classe è piuttosto semplice.

Dobbiamo semplicemente aggiungere un riferimento al safe handle che rappresenta la regione di memoria e questo riferimento verrà rilasciato nella funzione dispose.
Successivamente, abbiamo una proprietà address che non è altro che qualcosa di utile da avere. Usiamo DangerousGetHandle per ottenere un puntatore e aggiungiamo l’offset in modo che l’indirizzo punti ai primi byte nella regione che vogliamo che la nostra memoria rappresenti.
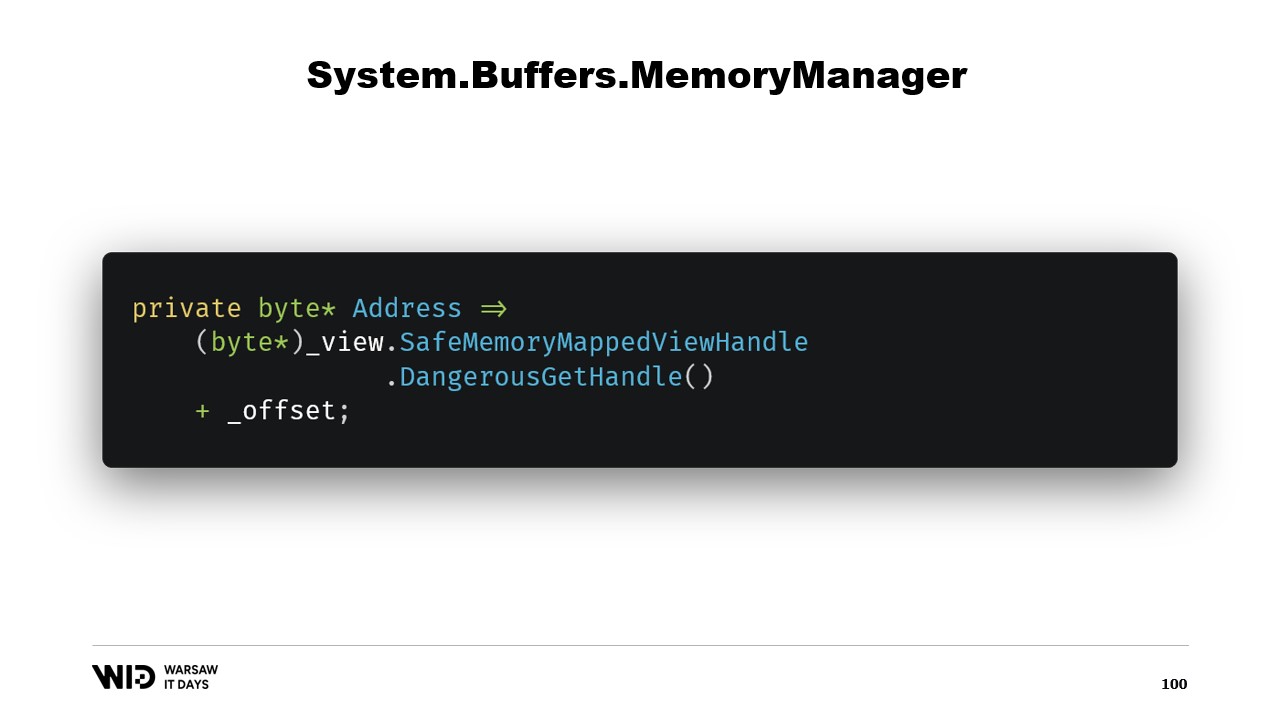
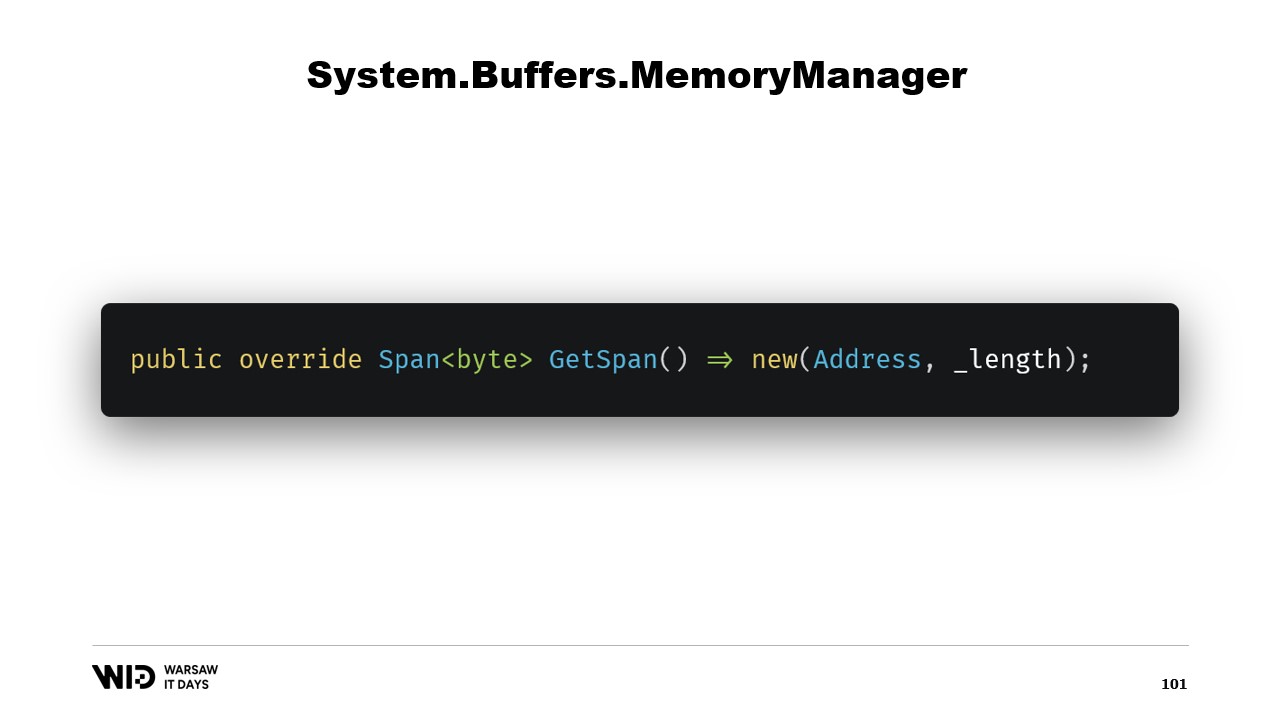
Sovrascriviamo la funzione GetSpan che fa tutta la magia. Essa crea semplicemente uno Span utilizzando l’indirizzo e la lunghezza.
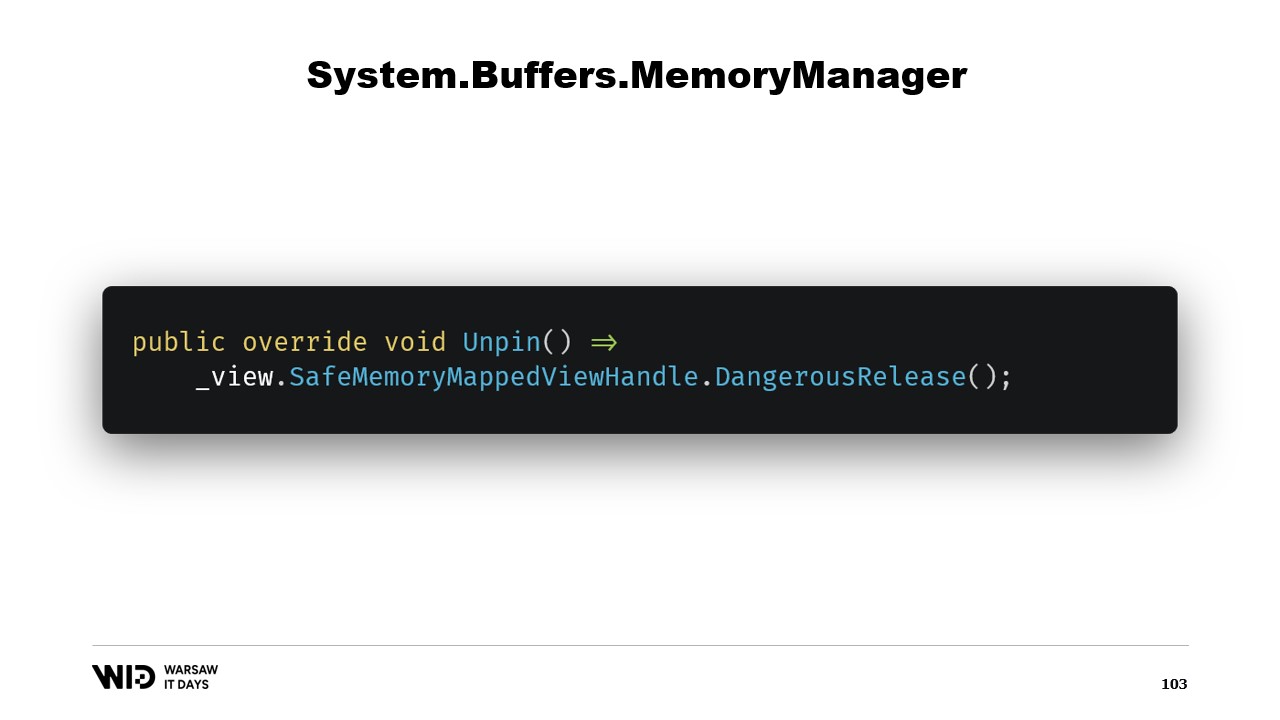
Ci sono altri due metodi che devono essere implementati nel MemoryManager. Uno di questi è Pin. Viene utilizzato dal runtime in situazioni in cui la memoria deve rimanere nella stessa posizione per una breve durata. Aggiungiamo un riferimento e restituiamo un MemoryHandle che punta alla posizione corretta e che tiene anche un riferimento all’oggetto corrente come pinnable.

Questo farà sapere al runtime che quando la memoria verrà depinnata, chiamerà il metodo Unpin di questo oggetto, il che comporterà il rilascio del safe handle nuovamente.
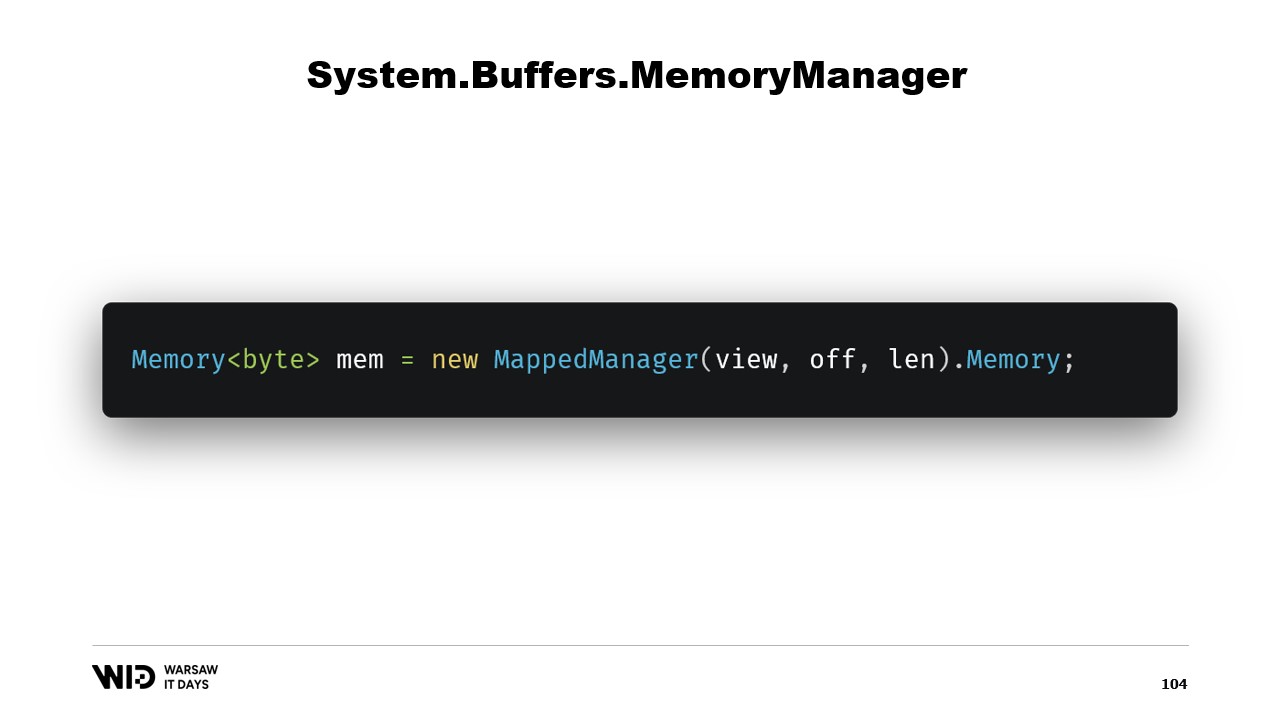
Una volta creata questa classe, è sufficiente crearne un’istanza e accedere alla sua proprietà Memory che restituirà una Memory di byte che fa riferimento internamente al MemoryManager che abbiamo appena creato. Ed ecco fatto, ora hai un pezzo di memoria. Quando ci scrivi sopra, verrà automaticamente scaricata su disco quando lo spazio sarà necessario e, al momento dell’accesso, verrà caricata nuovamente in memoria in modo trasparente ogni volta che ne hai bisogno.
Quindi, ciò è sufficiente per implementare il nostro programma di spill su disco. Sorge però un’altra domanda: perché usare il memory mapping quando potremmo utilizzare FileStream? Dopotutto, FileStream è la scelta ovvia per accedere ai dati presenti sul disco e il suo utilizzo è abbastanza ben documentato. Ad esempio, per leggere un array di valori in virgola mobile, hai bisogno di un FileStream e di un BinaryReader. Imposti la posizione del FileStream sull’offset in cui sono presenti i dati nel file, leggi un Int32 per ottenere la dimensione, allochi l’array di float e poi utilizzi MemoryMarshal.Cast per convertirlo in uno Span di byte.
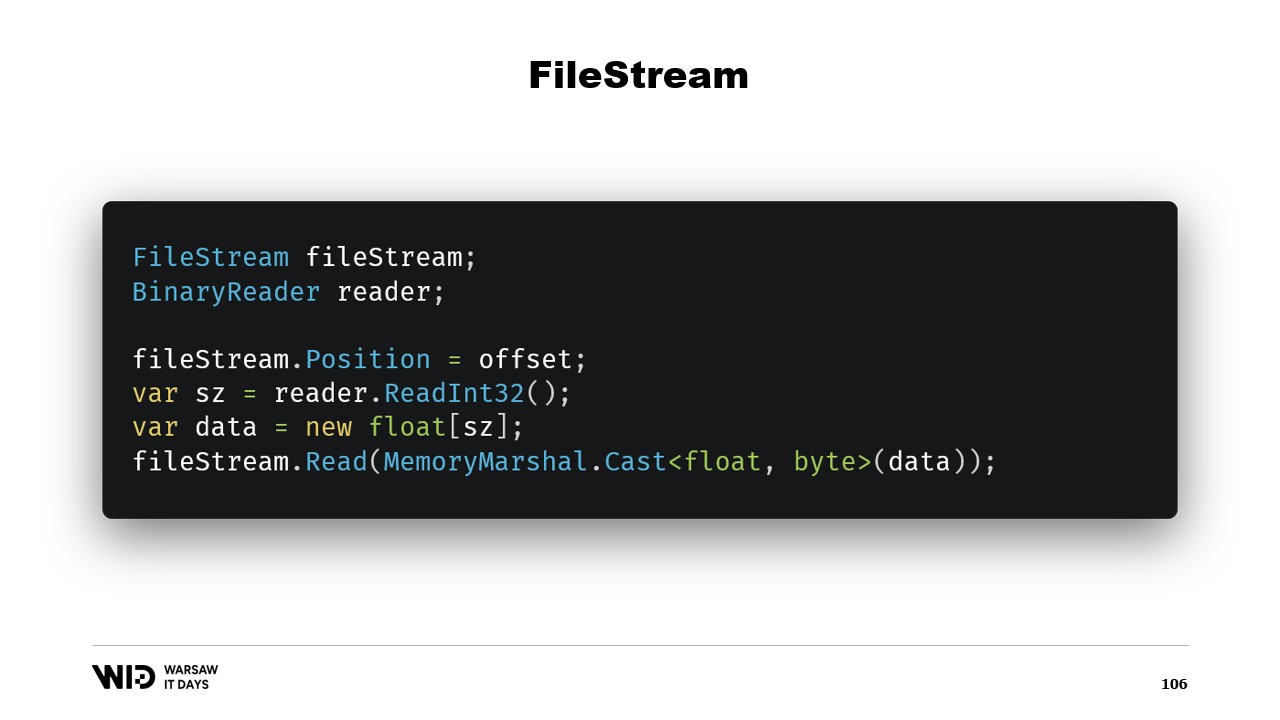
FileStream.Read ora dispone di un overload che accetta uno Span di byte come destinazione. Questo utilizza effettivamente anche la cache di pagine. Invece di mappare quelle pagine nello spazio di indirizzamento del tuo processo, il sistema operativo le mantiene intorno e, per leggere i valori, caricherà semplicemente dal disco in memoria e poi copierà da quella pagina nello Span di destinazione che hai fornito. Quindi, in termini di prestazioni e comportamento, ciò è equivalente a quanto avvenuto nella versione con memory mapping.
Ci sono tuttavia due differenze principali. Innanzitutto, questo non è thread-safe. Imposti la posizione in una riga e poi, in un’altra istruzione, ti basi sul fatto che quella posizione sia ancora la stessa. Ciò significa che è necessario un lock intorno a questa operazione e quindi non puoi leggere da diverse posizioni in parallelo, anche se ciò è possibile con i file mappati in memoria.
Un altro problema è che, a seconda della strategia utilizzata dal FileStream, vengono effettuate due letture, una per l’Int32 e una per la lettura nello Span. Una possibilità è che ciascuna di esse effettui una chiamata di sistema. Il sistema operativo copierà alcuni dati dalla propria memoria in quella del processo, comportando un certo overhead. L’altra possibilità è che lo stream sia bufferizzato. In tal caso, leggere inizialmente quattro byte creerà probabilmente una copia di una pagina, oltre alla copia effettivamente eseguita dalla funzione di lettura in seguito. Quindi, introduce un overhead che semplicemente non è presente nella versione con memory mapping.
Per questo motivo, l’utilizzo della versione con memory mapping è preferibile in termini di prestazioni. Dopotutto, FileStream è la scelta ovvia per accedere ai dati presenti sul disco e il suo utilizzo è ben documentato. Ad esempio, per leggere un array di valori in virgola mobile, hai bisogno di un FileStream, di un BinaryReader. Imposti la posizione del FileStream sull’offset in cui sono presenti i dati nel file, leggi un Int32 per ottenere la dimensione, allochi l’array di float, lo converti in uno Span di byte utilizzando MemoryMarshal.Cast e lo passi all’overload di FileStream.Read che richiede uno Span di byte come destinazione per la lettura. E questo utilizza anche la cache di pagine. Invece di associare le pagine al processo, esse vengono mantenute dal sistema operativo che semplicemente caricherà dal disco nella cache di pagine e copierà dalla cache di pagine nella memoria del processo, proprio come abbiamo fatto con la versione con memory mapping.
L’approccio FileStream, tuttavia, presenta due svantaggi principali. Il primo è che questo codice non è sicuro per l’uso multi-thread. Dopotutto, la posizione viene impostata in un’istruzione e poi utilizzata nelle istruzioni successive. Quindi abbiamo bisogno di un lock intorno a quelle operazioni di lettura. La versione a memoria mappata non necessita di lock e, infatti, è in grado di caricare da diverse posizioni sul disco in parallelo. Per gli SSD, questo aumenta la profondità della coda, che a sua volta aumenta le prestazioni, risultando quindi generalmente auspicabile. L’altro problema è che il FileStream deve effettuare due letture.
A seconda della strategia utilizzata internamente dallo stream, ciò potrebbe comportare due chiamate di sistema che devono risvegliare il sistema operativo. Copierà alcuni dati dalla propria memoria nella memoria del processo e poi dovrà cancellare tutto e restituire il controllo al processo. Ciò comporta un certo overhead. L’altra possibile strategia è che il FileStream sia buffered. In quel caso, verrebbe eseguita una sola chiamata di sistema, ma richiederebbe una copia dalla memoria del sistema operativo al buffer interno del FileStream e poi l’istruzione di lettura dovrebbe copiare nuovamente dal buffer interno del FileStream nell’array di numeri a virgola mobile. Questo crea quindi una copia inefficiente che non è presente con la versione a memoria mappata.
Il file stream, sebbene sia un po’ più facile da usare, presenta alcune limitazioni. Dovrebbe invece essere utilizzata la versione a memoria mappata. Così, ora ci troviamo con un sistema in grado di utilizzare quanta più memoria possibile e, in caso di esaurimento della memoria, scarica parti dei dataset sul disco. Questo processo è completamente trasparente e coopera con il sistema operativo. Funziona alla massima efficienza perché le parti del dataset a cui si accede frequentemente sono sempre mantenute in memoria.
Tuttavia, c’è un’ultima domanda a cui dobbiamo rispondere. Dopotutto, quando si utilizzano le memory map, non si mappa il disco, ma si mappano i file sul disco. Ora, la domanda è: quanti file allochiamo? Quanto saranno grandi? E come cicleremo attraverso questi file durante l’allocazione e la deallocazione della memoria?
La scelta ovvia è quella di mappare un unico file di grandi dimensioni, farlo all’avvio del programma e continuare a sovrascriverlo. Quando una parte non è più utilizzata, basta sovrascriverla. Questo è ovvio e quindi sbagliato.

Il primo problema con questo approccio è che la sovrascrittura di una pagina di memoria richiede un algoritmo discreto.
L’algoritmo è il seguente: prima, carichi immediatamente la pagina in memoria. Poi, modifichi il contenuto della pagina in memoria. Il sistema operativo non ha modo di sapere che nel secondo passaggio cancellerai tutto e lo sostituirai, quindi deve comunque caricare la pagina affinché le parti che non modifichi rimangano invariate. Infine, programmi la scrittura della pagina sul disco in un momento futuro.
Ora, la prima volta che scrivi su una determinata pagina in un file completamente nuovo, non ci sono dati da caricare. Il sistema operativo sa che tutte le pagine sono a zero, quindi il caricamento è gratuito. Prende semplicemente una pagina vuota e la utilizza. Ma quando la pagina è già stata modificata e non è più in memoria, il sistema operativo deve ricaricarla dal disco.

Un secondo problema è che le pagine dalla cache delle pagine vengono rimosse in base al criterio del meno recentemente usato, e il sistema operativo non è consapevole del fatto che una sezione inattiva della tua memoria, che non verrà mai più utilizzata, deve essere scartata. Quindi, potrebbe finire per mantenere in memoria alcune parti del dataset che non sono necessarie ed espellere alcune parti che invece lo sono. Non c’è modo di indicare al sistema operativo di ignorare semplicemente le sezioni inattive.
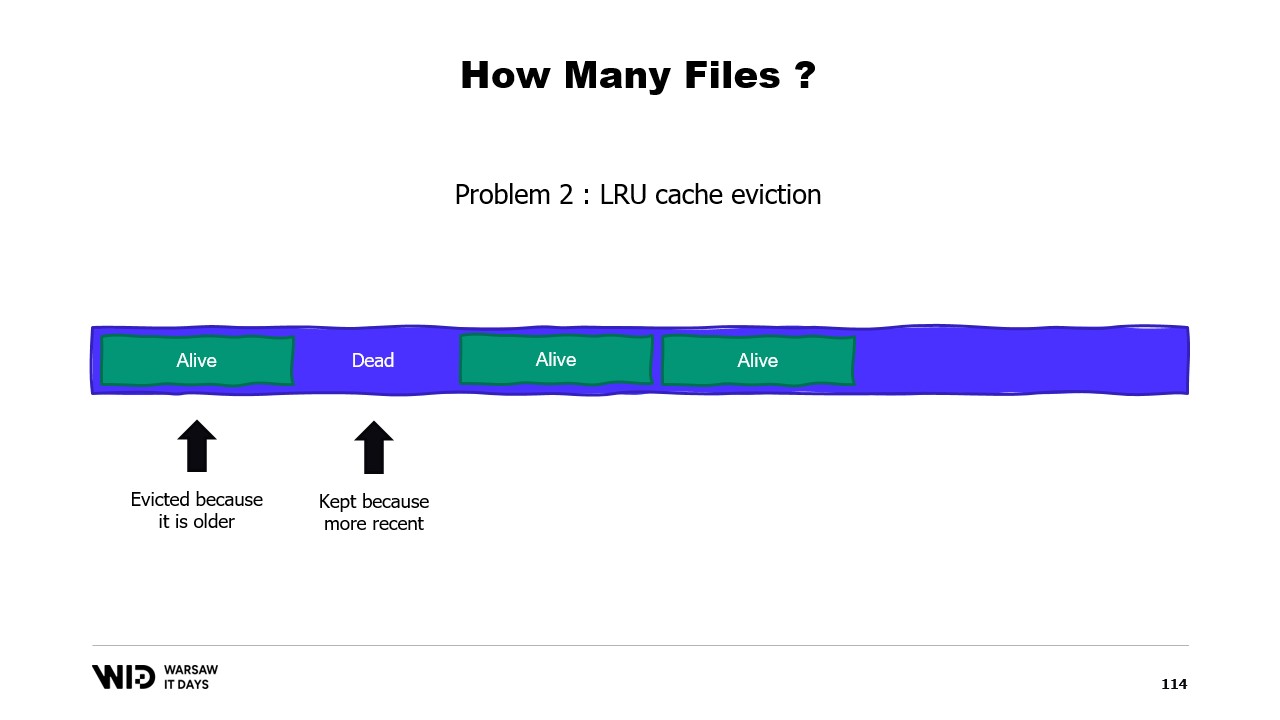
Un terzo problema è anch’esso correlato, ovvero che la scrittura dei dati sul disco è sempre in ritardo rispetto alla scrittura dei dati in memoria. E se sai che una pagina non è più necessaria e non è ancora stata scritta sul disco, beh, il sistema operativo non lo sa. Quindi, impiega comunque tempo per scrivere quei byte che non verranno mai più utilizzati sul disco, rallentando tutto.
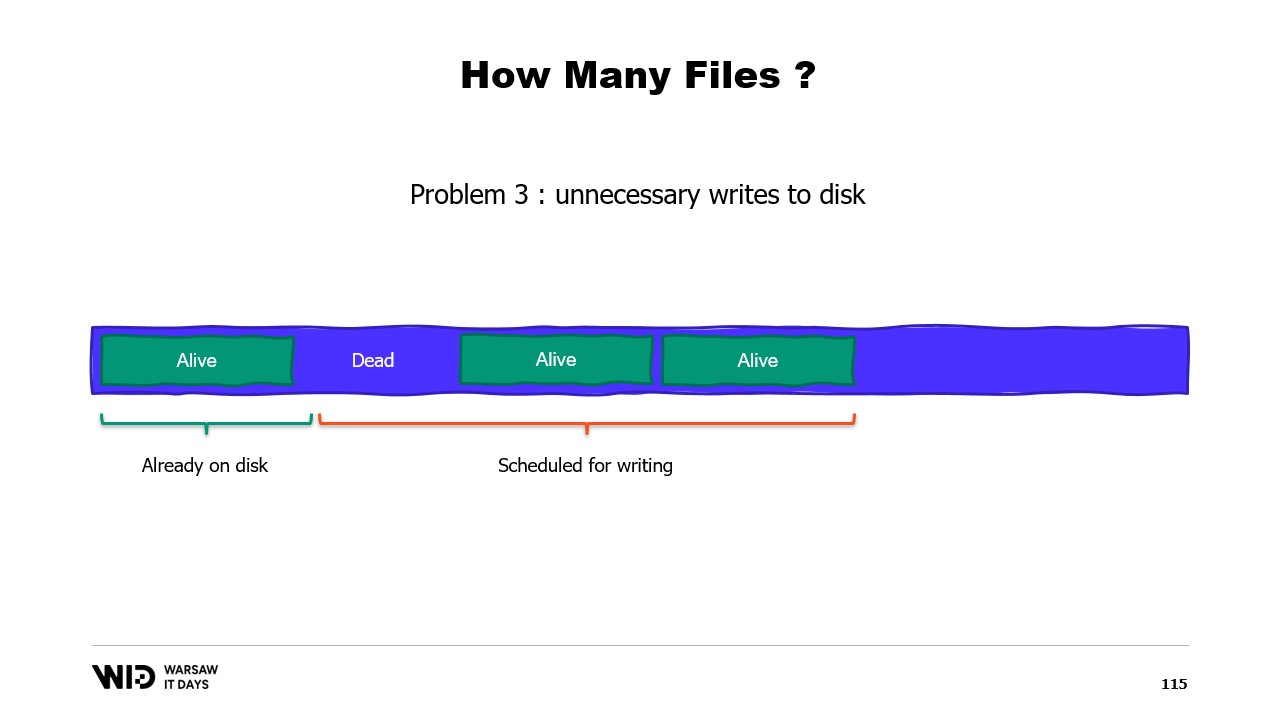
Invece, dovremmo suddividere la memoria in diversi file di grandi dimensioni. Non scriviamo mai due volte nella stessa area di memoria. Questo garantisce che ogni scrittura colpisca una pagina che il sistema operativo sa essere tutta a zero e non comporta un caricamento dal disco. Inoltre, eliminiamo i file il prima possibile. Questo informa il sistema operativo che non sono più necessari, possono essere eliminati dalla cache delle pagine e non necessitano di essere scritti sul disco se non lo sono già.

In produzione da Lokad, su una tipica VM di produzione, utilizziamo uno spazio di lavoro temporaneo Lokad con le seguenti impostazioni: i file hanno ciascuno 16 gigabyte, ci sono 100 file per ogni disco e ogni L32VM dispone di quattro dischi. In totale, questo rappresenta poco più di 6 terabyte di spazio di espansione per ogni VM.

Questo è tutto per oggi. Contattaci pure se hai domande o commenti, e grazie per averci seguito.


