00:00:00 Introducción a la charla sobre volcando en disco
00:00:34 Procesamiento de datos de minoristas y limitaciones de memoria
00:02:13 Solución de almacenamiento persistente y comparación de costos
00:04:07 Comparación de velocidad entre disco y memoria
00:05:10 Limitaciones de las técnicas de particionado y streaming
00:06:16 Importancia de los datos ordenados y del tamaño óptimo de lectura
00:07:40 Peor escenario para la lectura de datos
00:08:57 Impacto de la memoria de la máquina en la ejecución del programa
00:10:49 Técnicas de volcado en disco y uso de memoria
00:12:59 Explicación de la sección de código e implementación en .NET
00:15:06 Control sobre la asignación de memoria y sus consecuencias
00:16:18 Página mapeada en memoria y archivos mapeados en memoria
00:18:24 Mapas de memoria de lectura-escritura y herramientas de rendimiento del sistema
00:20:04 Uso de memoria virtual y páginas mapeadas en memoria
00:22:08 Manejo de archivos grandes y punteros de 64 bits
00:24:00 Uso de span para cargar desde memoria mapeada
00:26:03 Copia de datos y uso de estructuras para leer enteros
00:28:06 Creación de un span a partir de un puntero y un gestor de memoria
00:30:27 Creación de una instancia del gestor de memoria
00:31:05 Implementación del programa de volcado en disco y mapeo de memoria
00:33:34 Versión mapeada en memoria preferible por rendimiento
00:35:22 Estrategia de almacenamiento en búfer de FileStream y limitaciones
00:37:03 Estrategia de mapear un archivo grande
00:39:30 Dividir la memoria entre varios archivos grandes
00:40:21 Conclusión e invitación a preguntas
Resumen
Para procesar más datos de los que caben en la memoria, los programas pueden volcar parte de esos datos a un almacenamiento más lento pero de mayor capacidad, como los discos NVMe. Mediante una combinación de dos características bastante oscuras de .NET (archivos mapeados en memoria y gestores de memoria), esto se puede realizar desde C# con casi ninguna sobrecarga de rendimiento. Esta charla, presentada en Warsaw IT Days 2023, profundiza en los detalles de cómo funciona esto y discute cómo el paquete NuGet de código abierto Lokad.ScratchSpace oculta la mayoría de esos detalles a los desarrolladores.
Resumen Extendido
En una conferencia completa, Victor Nicolet, el CTO de Lokad, profundiza en las complejidades del volcado en disco en .NET, una técnica que permite procesar conjuntos de datos grandes que exceden la capacidad de memoria de un ordenador típico. Nicolet se basa en su amplia experiencia en el manejo de conjuntos de datos complejos en el campo de la Supply Chain Quantitativa en Lokad, proporcionando un ejemplo práctico de un minorista con cien mil productos en 100 ubicaciones. Esto resulta en un conjunto de datos de 10 mil millones de entradas al considerar puntos de datos diarios durante tres años, lo que requeriría 37 gigabytes de memoria para almacenar un valor de punto flotante por cada entrada, superando ampliamente la capacidad de un ordenador de escritorio típico.
Nicolet sugiere el uso de almacenamiento persistente, como el almacenamiento NVMe SSD, como una alternativa rentable a la memoria. Compara el costo de la memoria y el almacenamiento SSD, señalando que por el costo de 18 gigabytes de memoria, se podría comprar un terabyte de almacenamiento SSD. También discute la compensación en el rendimiento, indicando que la lectura desde el disco es seis veces más lenta que la lectura desde la memoria.
Introduce el particionado y el streaming como técnicas para utilizar el espacio en disco como alternativa a la memoria. El particionado permite procesar conjuntos de datos en partes más pequeñas que caben en la memoria, pero no permite la comunicación entre particiones. El streaming, por otro lado, permite mantener cierto estado entre el procesamiento de las diferentes partes, pero requiere que los datos en disco estén ordenados o alineados adecuadamente para un rendimiento óptimo.
Luego, Nicolet introduce técnicas de volcado en disco como solución a las limitaciones del enfoque de ajustarse a la memoria. Estas técnicas distribuyen los datos entre la memoria y el almacenamiento persistente de forma dinámica, utilizando más memoria cuando está disponible para funcionar más rápido, y ralentizando para usar menos memoria cuando hay menos disponible. Explica que las técnicas de volcado en disco usan tanta memoria como sea posible y solo comienzan a volcar datos en el disco cuando se agota la memoria. Esto las hace mejores para reaccionar a tener más o menos memoria de lo inicialmente esperado.
Explica además que las técnicas de volcado en disco dividen el conjunto de datos en dos secciones: la sección caliente, que siempre está en la memoria, y la sección fría, que puede volcar partes de su contenido al almacenamiento persistente en cualquier momento. El programa utiliza transferencias caliente-fría, que usualmente implican grandes lotes para maximizar el uso del ancho de banda del NVMe. La sección fría permite a estos algoritmos usar tanta memoria como sea posible.
Nicolet luego explica cómo implementar esto en .NET. Para la sección caliente se usan objetos .NET normales, mientras que para la sección fría se utiliza una clase de referencia. Esta clase mantiene una referencia al valor que se está almacenando en frío y dicho valor puede establecerse a null cuando ya no está en la memoria. Un sistema central en el programa lleva un seguimiento de todas las referencias frías, y cada vez que se crea una nueva referencia fría, determina si causa un desbordamiento de memoria e invoca la función de volcado de una o más de las referencias frías ya presentes en el sistema para mantener el presupuesto de memoria disponible para el almacenamiento en frío.
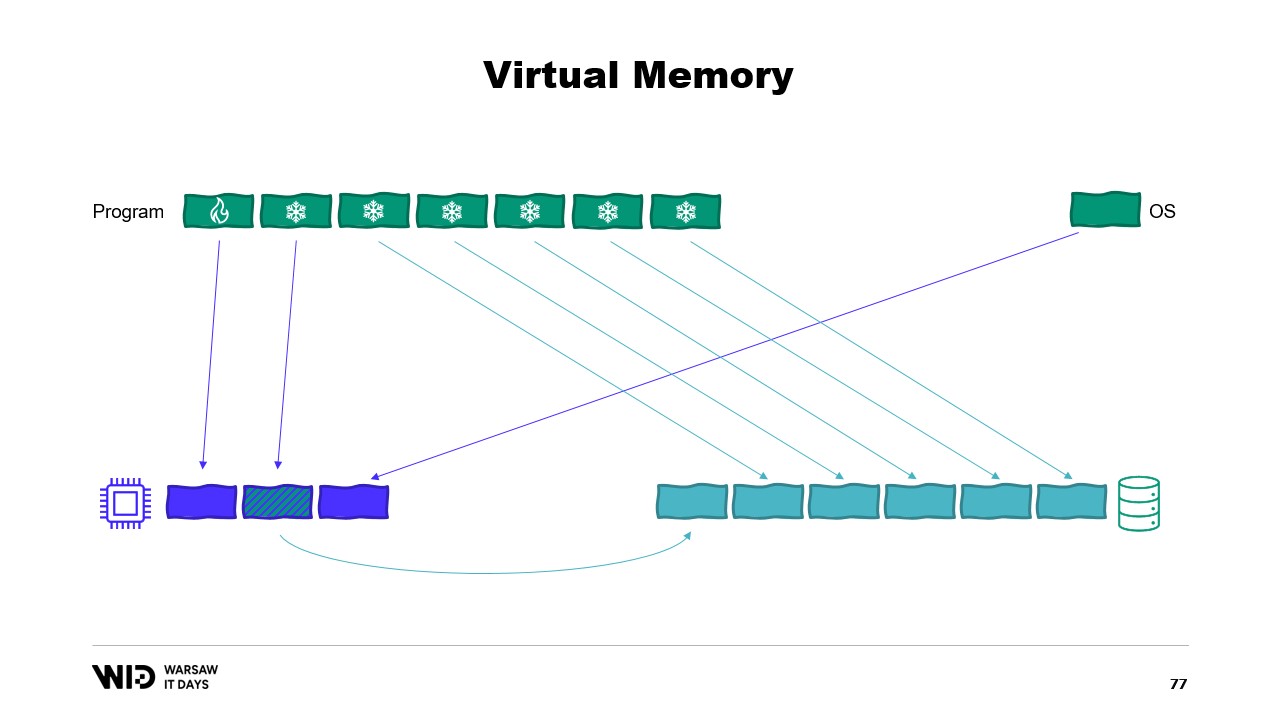
Luego, introduce el concepto de memoria virtual, donde el programa no tiene acceso directo a las páginas de memoria física, sino que accede a páginas de memoria virtual. Es posible crear una página mapeada en memoria, que es una forma común de implementar la comunicación entre programas y archivos mapeados en memoria. El objetivo principal del mapeo de memoria es evitar que cada programa tenga su propia copia de la DLL en la memoria, ya que todas esas copias son idénticas.
Nicolet luego analiza la Herramienta de Rendimiento del Sistema, que muestra el uso actual de la memoria física. En verde se encuentra la memoria que ha sido asignada directamente a un proceso, en azul está la caché de páginas, y las páginas modificadas en el medio son aquellas que deberían ser una copia exacta del disco, pero contienen cambios en memoria.
Luego, discute el segundo intento usando memoria virtual, donde la sección fría estará compuesta completamente de páginas mapeadas en memoria. Si el sistema operativo necesita repentinamente algo de memoria, sabe cuáles páginas están mapeadas y pueden ser descartadas de manera segura.
Nicolet luego explica los pasos básicos para crear un archivo mapeado en memoria en .NET, que son primero crear un archivo mapeado en memoria a partir de un archivo en disco y luego crear un view accessor. Ambos se mantienen separados porque .NET necesita manejar el caso de un proceso de 32 bits. En el caso de un proceso de 64 bits, se puede crear un view accessor que cargue el archivo completo.
Nicolet luego discute la introducción de memory y span hace cinco años, que son tipos utilizados para representar un rango de memoria de una manera más segura que solo punteros. La idea general detrás de span y memory es que, dado un puntero y un número de bytes, se puede crear un nuevo span que represente ese rango de memoria. Una vez creado un span, se puede leer de forma segura en cualquier parte de él, sabiendo que si se intenta leer más allá de los límites, el tiempo de ejecución lo detectará y se lanzará una excepción en lugar de simplemente finalizar el proceso.
Nicolet luego explica cómo usar span para cargar desde memoria mapeada en memoria gestionada de .NET. Por ejemplo, si hay una cadena que necesita ser leída, se pueden utilizar muchas APIs centradas en spans. Nicolet explica el uso de APIs centradas en spans, como MemoryMarshal.Read, que puede leer un entero desde el inicio del span. También menciona la función Encoding.GetString, que puede cargar desde un span de bytes a una cadena.
Explica además que estas operaciones se realizan en spans, que representan una sección de datos que podría estar en el disco en lugar de en la memoria. El sistema operativo se encarga de cargar los datos en memoria cuando se acceden por primera vez. Nicolet proporciona un ejemplo de una secuencia de valores de punto flotante que deben cargarse en un arreglo de flotantes. Explica el uso de MemoryMarshal.Read para leer el tamaño, la asignación de un arreglo de valores de punto flotante de ese tamaño, y el uso de MemoryMarshal.Cast para convertir el span de bytes en un span de valores de punto flotante.
También discute el uso de la función CopyTo de los spans, que realiza una copia de alto rendimiento de los datos desde el archivo mapeado en memoria al arreglo. Señala que este proceso puede ser algo derrochador, ya que implica crear una copia completamente nueva. Nicolet sugiere crear una estructura que represente el encabezado con dos valores enteros en su interior, la cual puede ser leída por MemoryMarshal. También discute el uso de una biblioteca de compresión para descomprimir los datos.
Nicolet discute el uso de un tipo diferente, Memory, para representar un rango de datos de mayor duración. Menciona la falta de documentación sobre cómo crear una Memory partiendo de un puntero y recomienda un gist en GitHub como el mejor recurso disponible. Explica la necesidad de crear un MemoryManager, que se utiliza internamente por una Memory cada vez que necesita hacer algo más complejo que simplemente apuntar a una sección de un arreglo.
Nicolet discute el uso del mapeo de memoria versus FileStream, señalando que FileStream es la elección obvia al acceder a datos que están en disco y que su uso está bien documentado. Señala que el enfoque FileStream no es seguro para hilos y requiere un bloqueo alrededor de la operación, impidiendo la lectura desde varias ubicaciones en paralelo. Nicolet también menciona que el enfoque FileStream introduce cierta sobrecarga que no está presente con la versión mapeada en memoria.
Explica que se debe usar la versión mapeada en memoria, ya que es capaz de usar tanta memoria como sea posible y, al agotarse la memoria, volcará partes de los conjuntos de datos de vuelta al disco. Nicolet plantea la pregunta de cuántos archivos asignar, cuán grandes deben ser, y cómo ciclar a través de esos archivos a medida que se asigna y libera memoria.
Sugiere dividir la memoria entre varios archivos grandes, nunca escribir dos veces en la misma memoria, y eliminar los archivos lo antes posible. Nicolet concluye compartiendo que, en producción en Lokad, utilizan Lokad scratch space con configuraciones específicas: cada archivo tiene 16 gigabytes, hay 100 archivos en cada disco, y cada L32VM tiene cuatro discos, lo que representa un poco más de 6 terabytes de espacio de volcado para cada VM.
Transcripción Completa

Victor Nicolet: Hola y bienvenidos a esta charla sobre volcado en disco en .NET.
El volcado en disco es una técnica para procesar conjuntos de datos que no caben en la memoria, manteniendo en su lugar partes del conjunto de datos que no están en uso en un almacenamiento persistente.
Esta charla se basa en mi experiencia trabajando para Lokad. Hacemos optimización de supply chain.
La parte cuantitativa significa que trabajamos con conjuntos de datos grandes y la parte de supply chain, bueno, es parte del mundo real, por lo que son desordenados, sorprendentes y llenos de casos extremos dentro de casos extremos.
Así que, realizamos un procesamiento bastante complejo.
Veamos un ejemplo típico. Un minorista tendría del orden de cien mil productos.
Estos productos están presentes en hasta 100 ubicaciones. Estas pueden ser tiendas, pueden ser almacenes, o incluso secciones de almacenes que están dedicadas al ecommerce.
Y si queremos realizar algún análisis real sobre esto, necesitamos observar el comportamiento pasado, lo que sucede con esos productos y esas ubicaciones.
Asumiendo que guardamos solo un punto de datos por día y consideramos solo tres años en el pasado, esto significa alrededor de 1000 días. Multiplicando todo esto, nuestro conjunto de datos tendrá 10 mil millones de entradas.
Si guardamos solo un valor de punto flotante por cada entrada, el conjunto de datos ya ocupa 37 gigabytes de memoria. Esto supera lo que tendría un ordenador de escritorio típico.

Y un valor de punto flotante no es ni de lejos suficiente para realizar cualquier tipo de análisis.
Un número mejor sería 20, y aun así estamos haciendo esfuerzos considerables para mantener la huella pequeña. Aún así, hablamos de aproximadamente 745 gigabytes de uso de memoria.
Esto cabe en máquinas en la nube si son lo suficientemente grandes, alrededor de siete mil dólares al mes. Así que, es algo asequible, pero también un poco derrochador.

Como habrán adivinado por el título de esta charla, la solución es usar almacenamiento persistente, que es más lento pero más barato que la memoria.
Hoy en día, se puede comprar almacenamiento NVMe SSD por alrededor de 5 centavos por gigabyte. Un NVMe SSD es aproximadamente el tipo de almacenamiento persistente más rápido que se puede obtener fácilmente hoy en día.
En comparación, un gigabyte de RAM cuesta 275 dólares. Esto representa una diferencia de aproximadamente 55 veces.

Otra forma de verlo es que, con el presupuesto necesario para comprar 18 gigabytes de memoria, tendrías suficiente para pagar por un terabyte de almacenamiento SSD.

¿Qué hay de las ofertas de computación en la nube? Bueno, tomando como ejemplo la nube de Microsoft, a la izquierda se encuentran los L32s, parte de una serie de máquinas virtuales optimizadas para almacenamiento.
Por alrededor de dos mil dólares al mes, obtienes casi 8 terabytes de almacenamiento persistente.
A la derecha están los M32ms, parte de una serie optimizada para la memoria y por más de dos veces y media el costo, obtienes solo 875 gigabytes de RAM.
Si mi programa se ejecuta en la máquina de la izquierda y tarda el doble en completarse, sigo ganando en términos de costo.

¿Y el rendimiento? Bueno, la lectura desde la memoria se ejecuta a aproximadamente 21 gigabytes por segundo. La lectura desde un NVMe SSD se ejecuta a aproximadamente 3.5 gigabytes por segundo.
Esto no es una prueba de referencia real. Simplemente creé una máquina virtual y ejecuté esos dos comandos, y hay muchas formas tanto de aumentar como de disminuir estos números.
La parte importante aquí es simplemente el orden de magnitud de la diferencia entre los dos. La lectura desde disco es seis veces más lenta que la lectura desde la memoria.
Entonces, el disco es decepcionantemente lento, no querrás estar leyendo desde él todo el tiempo con patrones de acceso aleatorio. Pero, por otro lado, también es sorprendentemente rápido. Si tu procesamiento está mayormente limitado por la CPU, es posible que ni siquiera notes que estás leyendo desde disco en lugar de la memoria.

Una técnica bastante conocida para usar el espacio en disco como alternativa a la memoria es la partición.
La idea detrás de la partición es seleccionar una de las dimensiones del conjunto de datos y dividirlo en piezas más pequeñas. Cada pieza debe ser lo suficientemente pequeña como para caber en la memoria.
Luego, el procesamiento carga cada pieza por separado, realiza su procesamiento y guarda esa pieza de nuevo en el disco antes de cargar la siguiente pieza.
En nuestro ejemplo, si dividiéramos los conjuntos de datos por ubicaciones y procesáramos cada ubicación una a la vez, entonces cada ubicación requeriría solo 7.5 gigabytes de memoria. Esto está dentro del rango de lo que una computadora de escritorio puede hacer.

Sin embargo, con la partición, no hay comunicación entre las particiones. Por lo tanto, si necesitamos procesar datos a través de ubicaciones, ya no podemos usar esta técnica.
Otra técnica es el streaming. El streaming es bastante similar a la partición en el sentido de que solo cargamos pequeñas porciones de datos en la memoria en un momento dado.
A diferencia de la partición, se nos permite mantener algún estado entre el procesamiento de diferentes partes. Entonces, mientras procesamos la primera ubicación, estableceríamos el estado inicial, y luego, al procesar la segunda ubicación, se nos permite utilizar lo que estuviera presente en el estado en ese momento para crear un nuevo estado al final del procesamiento de la segunda ubicación.
A diferencia de la partición, el streaming no se presta a la ejecución en paralelo. Pero sí resuelve el problema de calcular algo a través de todos los datos del conjunto en lugar de estar aislado en cada pieza por separado.
Sin embargo, el streaming tiene su propia limitación. Para que sea de alto rendimiento, los datos en disco deben estar ordenados o alineados correctamente.
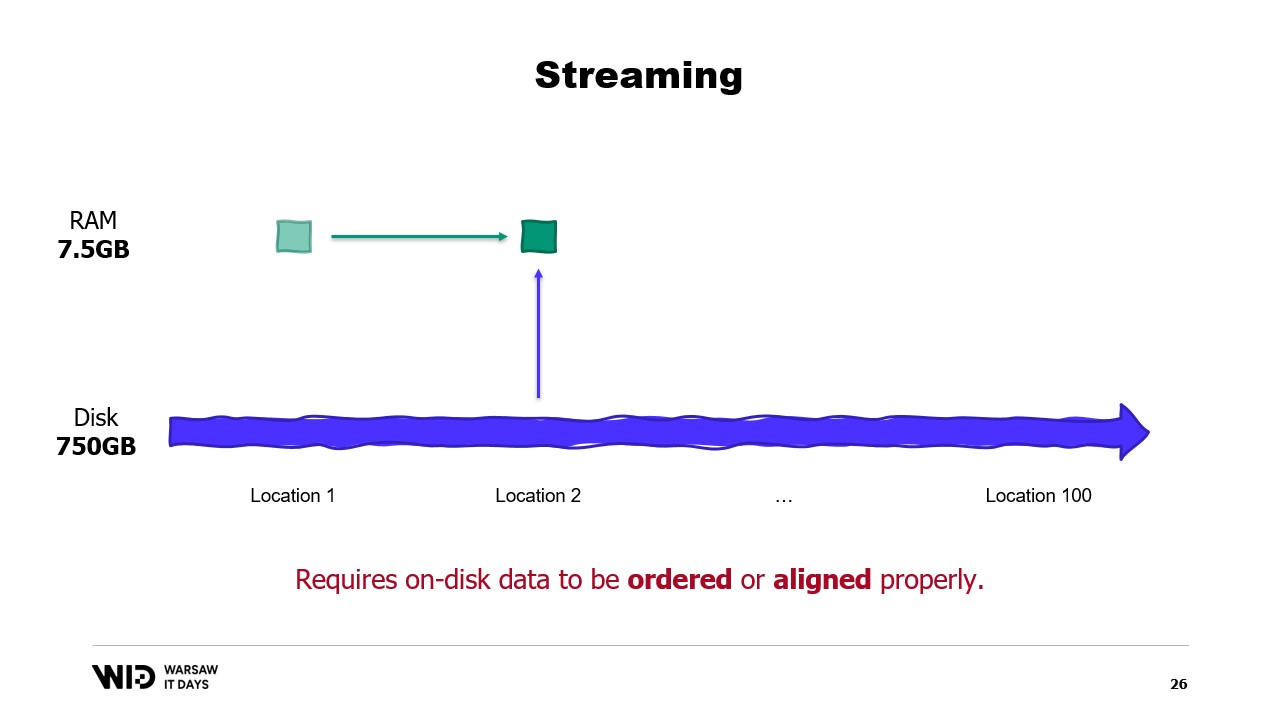
Para entender esos requisitos, es necesario saber que NVMe lee y escribe datos en sectores de medio kilobyte y los valores de rendimiento anteriores, como 3.5 gigabytes por segundo, asumen que los sectores se leen y utilizan en su totalidad.
Si solo usamos una parte del sector pero se tiene que leer el sector completo, entonces estamos desperdiciando ancho de banda y dividiendo nuestro rendimiento por un factor grande.

Y así, es óptimo cuando los datos que leemos son un múltiplo de medio kilobyte y están alineados en los límites de los sectores.
Ya no estamos usando discos giratorios, por lo que omitir y no leer el sector se hace sin ningún costo.

Sin embargo, si no es posible alinear los datos en los límites de los sectores, otra forma es cargarlos en orden secuencial.
Esto se debe a que, una vez que se ha cargado un sector en la memoria, leer la segunda parte del sector no requiere otra carga desde el disco. En su lugar, el sistema operativo simplemente podrá proporcionarte los bytes restantes que aún no se han utilizado.
Y así, si los datos se cargan de manera consecutiva, no se desperdicia ancho de banda y aún obtienes el rendimiento completo.

El peor caso es cuando solo lees uno o unos pocos bytes de cada sector. Por ejemplo, si lees un valor de punto flotante de cada sector, divides tu rendimiento por 128.

Lo que es peor es que hay otra unidad de agrupación de datos por encima de los sectores, que es la página del sistema operativo, y el sistema operativo generalmente carga páginas completas de aproximadamente 4 kilobytes en su totalidad.
Así que ahora, si lees un valor de punto flotante de cada página, habrás dividido tu rendimiento por 1024.
Por esta razón, es realmente importante asegurarse de que las lecturas de datos del almacenamiento persistente se realicen en grandes lotes consecutivos.

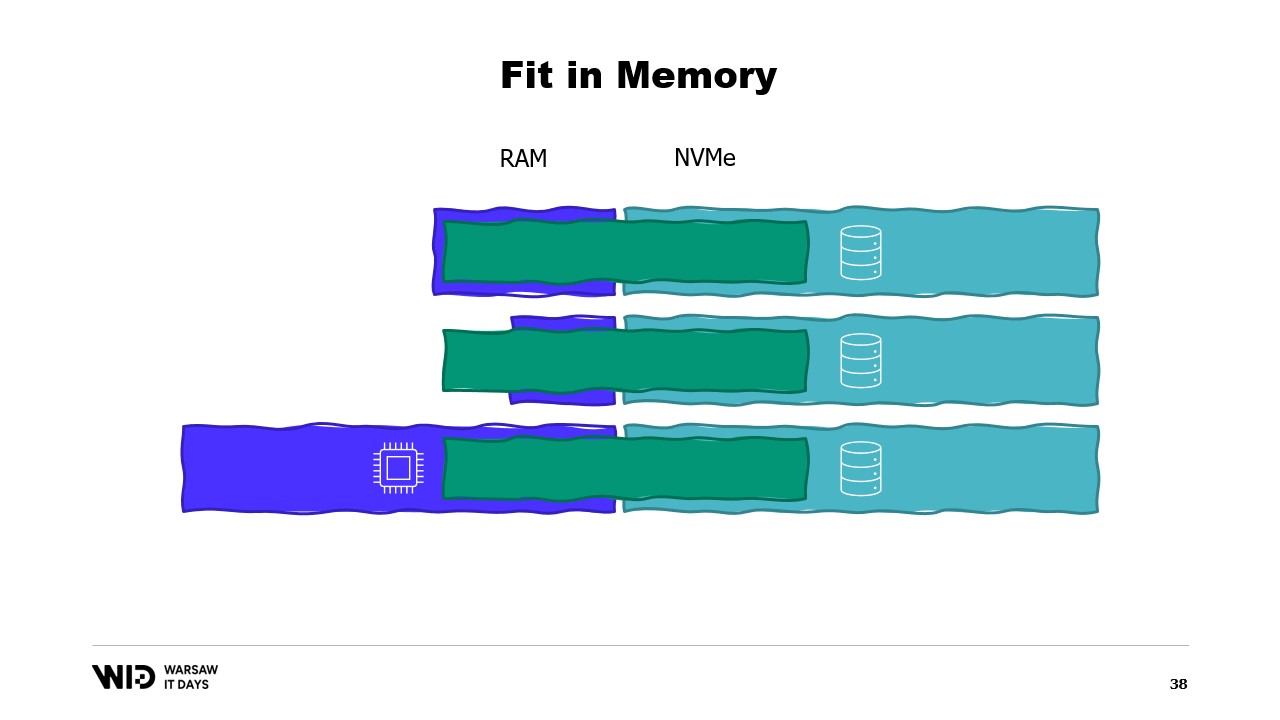
Utilizando esas técnicas, es posible hacer que el programa se ajuste a una menor cantidad de memoria. Ahora, esas técnicas tratarán a la memoria y al disco como dos espacios de almacenamiento separados e independientes entre sí.
Y así, la distribución del conjunto de datos entre la memoria y el disco está determinada enteramente por lo que es el algoritmo y la estructura del conjunto de datos.
Entonces, si ejecutamos el programa en una máquina que tenga exactamente la cantidad adecuada de memoria, el programa se ajustará perfectamente y podrá ejecutarse.
Si proporcionamos una máquina que tenga menos memoria de la requerida, el programa no podrá ajustarse en memoria y no podrá ejecutarse.
Finalmente, si proporcionamos una máquina que tenga más de la cantidad necesaria de memoria, el programa hará lo que suelen hacer los programas: no utilizará la memoria adicional y aún así se ejecutará a la misma velocidad.
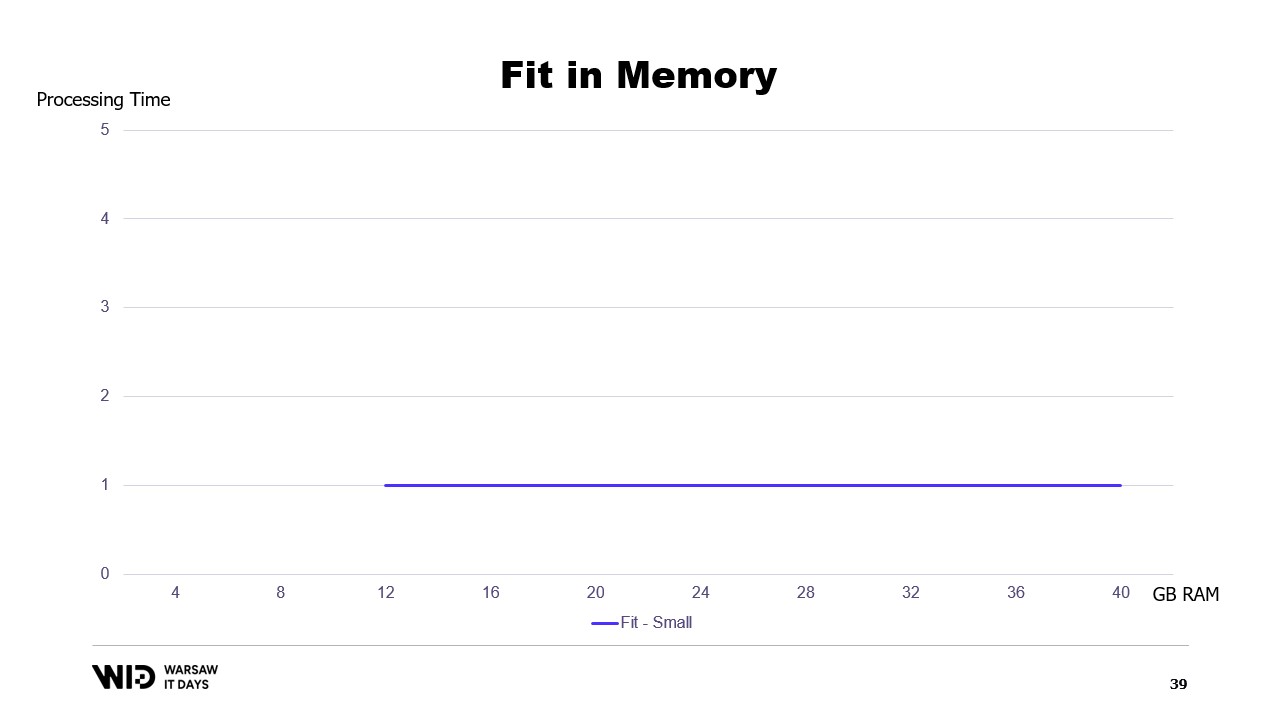
Si trazáramos un gráfico del tiempo de ejecución basado en la memoria disponible, se vería así. Por debajo de la huella de memoria, no hay ejecución, por lo que no hay tiempo de procesamiento. Por encima de la huella, el tiempo de procesamiento es constante porque el programa no puede usar la memoria adicional para ejecutar más rápido.
Y además, ¿qué pasa si el conjunto de datos crece? Bueno, dependiendo de la dimensión, si el conjunto de datos crece de una manera que aumenta el número de particiones, la huella de memoria se mantendrá igual, solo que habrá más particiones.
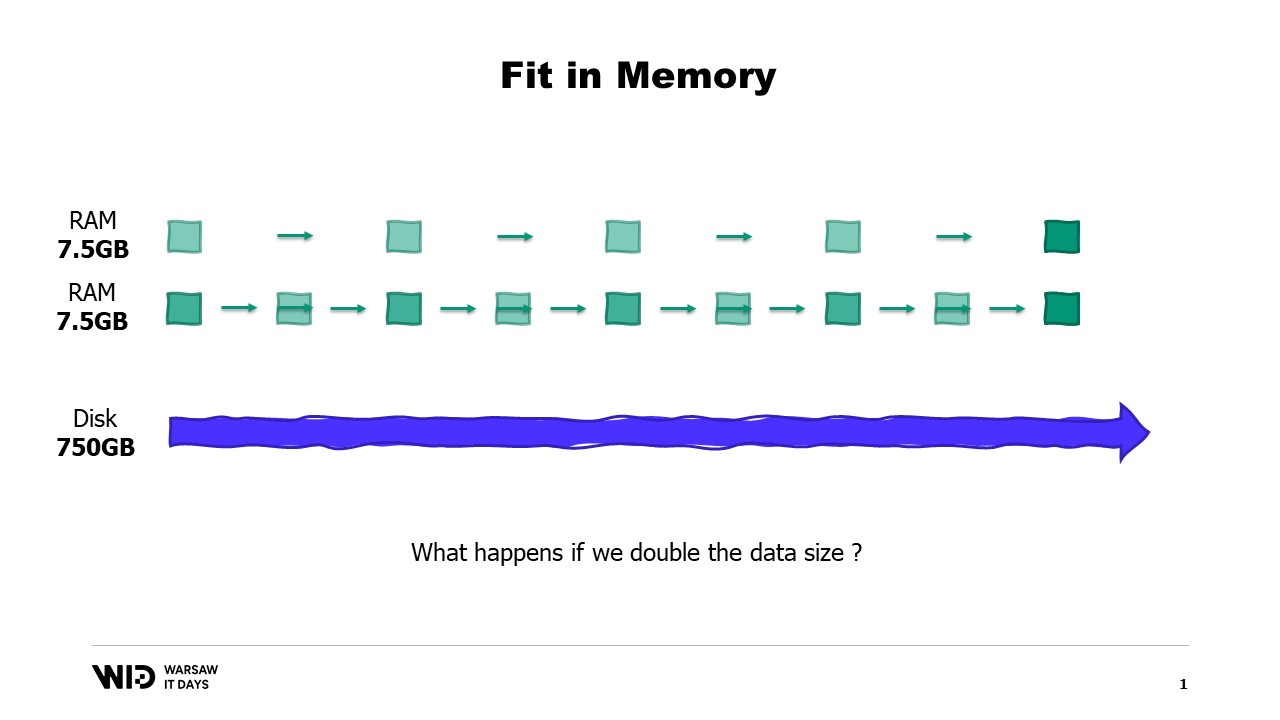
Por otro lado, si las particiones individuales crecen, entonces la huella de memoria también crecerá, lo que aumentará la cantidad mínima de memoria que el programa necesita para ejecutarse.
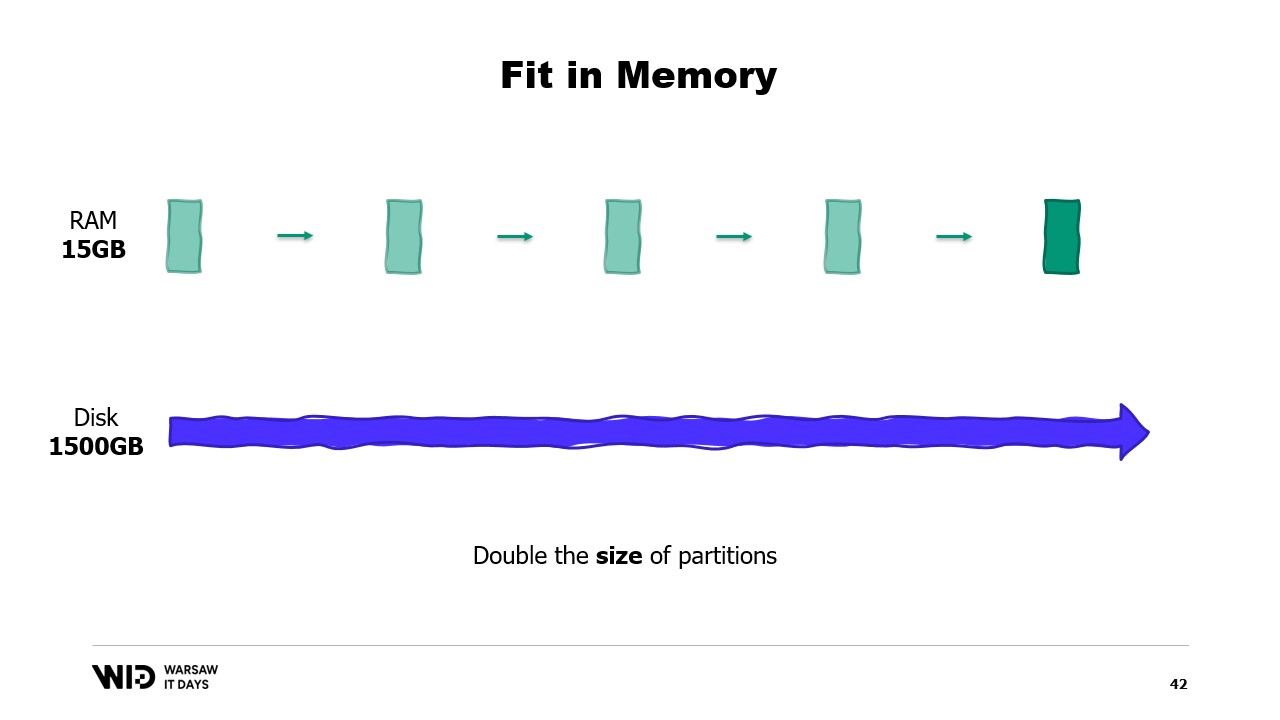
En otras palabras, si tengo un conjunto de datos más grande que necesito procesar, no solo tomará más tiempo, sino que también tendrá una huella mayor.
Esto crea una situación complicada en la que necesitaré agregar más memoria para poder ajustarse a conjuntos de datos grandes cuando aparezcan, pero agregar más memoria no mejora nada en lo que respecta a los conjuntos de datos más pequeños.
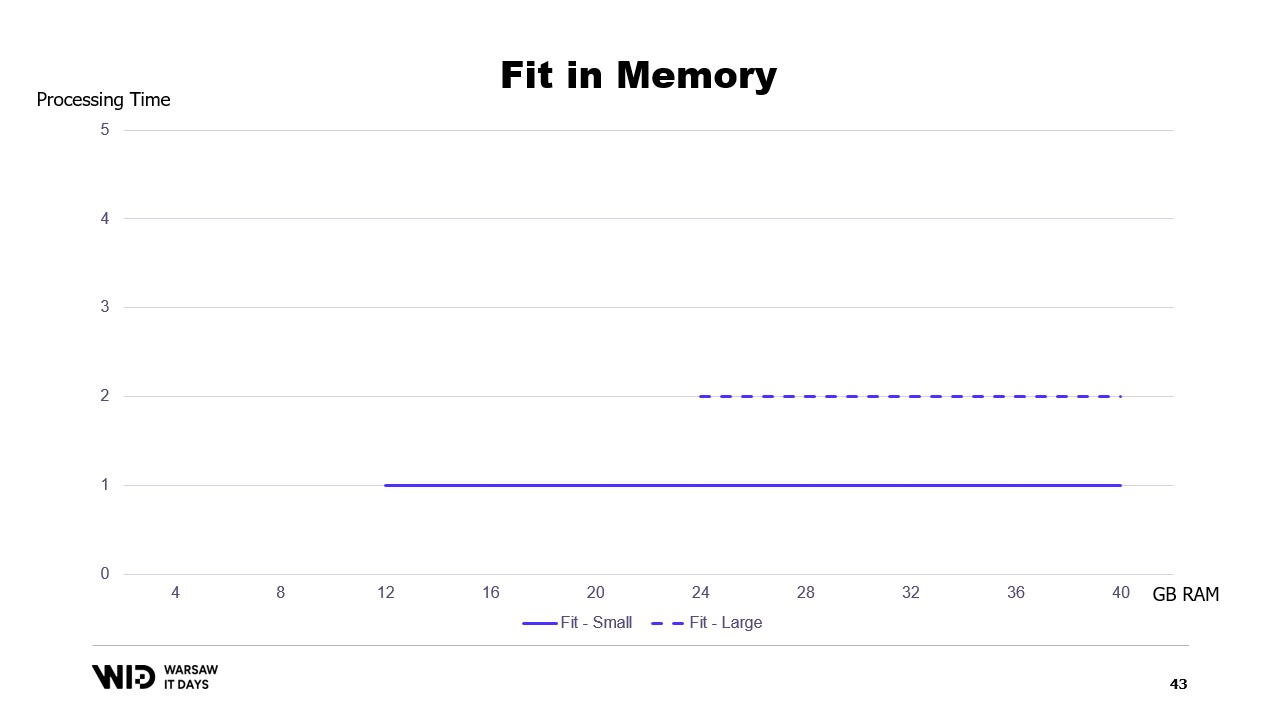
Esta es una limitación del enfoque de ajuste en memoria, donde la distribución del conjunto de datos entre la memoria y el almacenamiento persistente está determinada enteramente por la estructura del conjunto de datos y el propio algoritmo.
No toma en cuenta la cantidad real de memoria disponible. Lo que hacen las técnicas de volcado a disco es distribuir de forma dinámica. Entonces, si hay más memoria disponible, utilizarán más memoria para ejecutar más rápido.
Y por el contrario, si hay menos memoria disponible, hasta cierto punto, podrán ralentizarse para usar menos memoria. Las curvas se ven mucho mejor en ese caso. La huella mínima es más pequeña y es la misma para ambos conjuntos de datos.
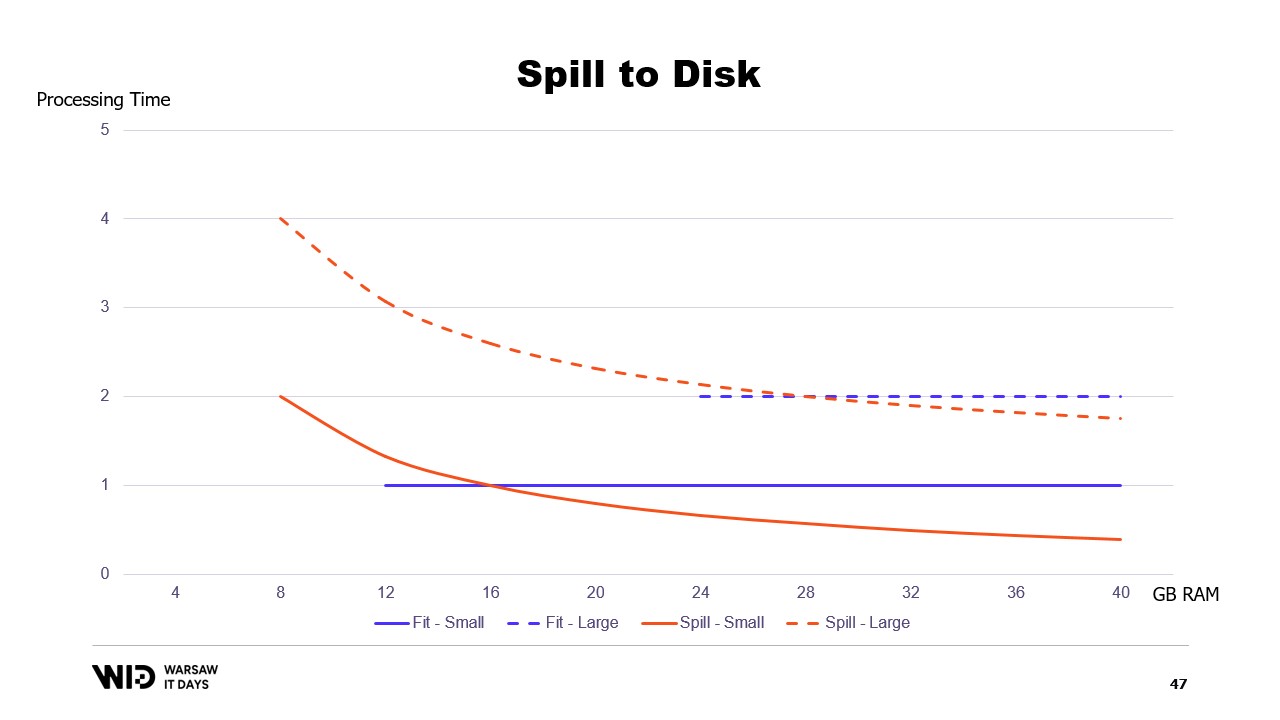
El rendimiento aumenta a medida que se agrega más memoria en todos los casos. Las técnicas de ajuste en memoria volcarán preventivamente algunos datos al disco para reducir la huella de memoria. Por el contrario, las técnicas de volcado a disco utilizarán tanta memoria como sea posible y solo cuando se queden sin memoria comenzarán a volcar algunos datos en el disco para liberar espacio.
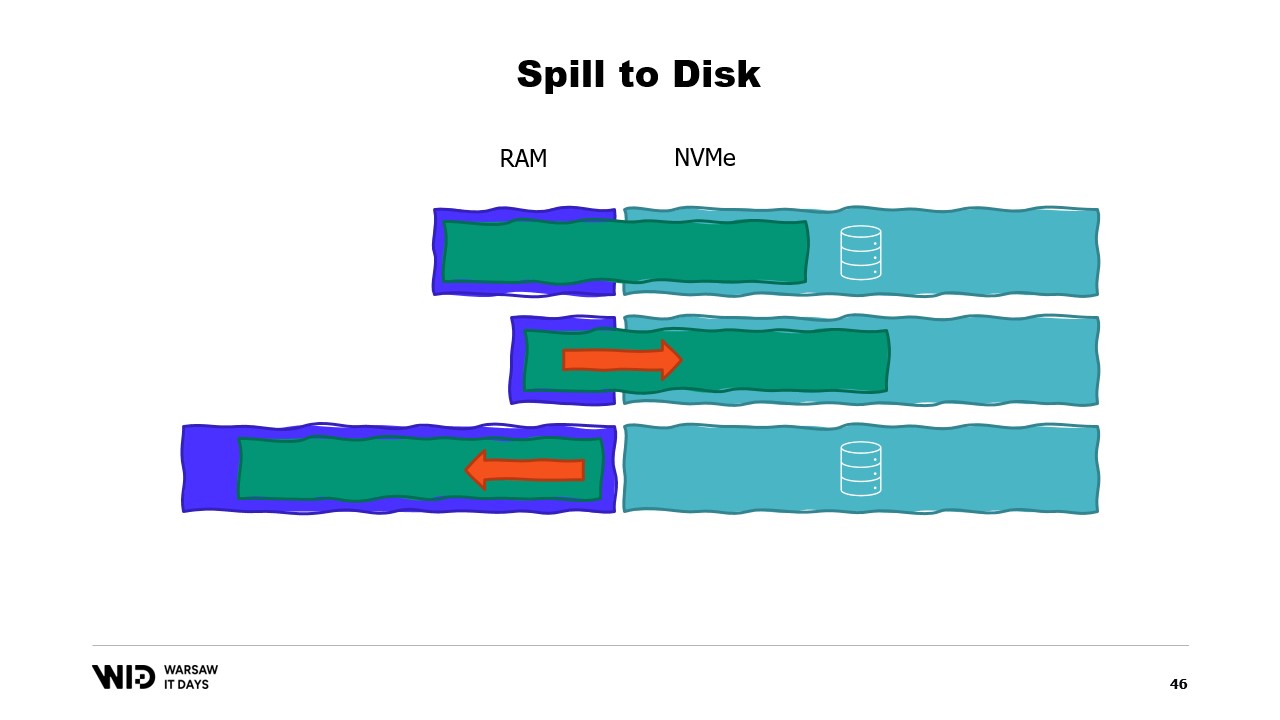
Esto los hace mucho mejores para reaccionar ante tener más o menos memoria de la inicialmente esperada. Las técnicas de volcado a disco dividirán el conjunto de datos en dos secciones. Se asume que la sección caliente siempre está en la memoria y, por lo tanto, es siempre segura en términos de rendimiento acceder a ella con patrones de acceso aleatorio. Por supuesto, tendrá un presupuesto máximo, tal vez algo como 8 gigabytes por CPU en una máquina típica de computación en la nube.
Por otro lado, a la sección fría se le permite, en cualquier momento, volcar partes de su contenido al almacenamiento persistente. No hay un presupuesto máximo, excepto la memoria disponible. Y, por supuesto, no es posible, en términos de rendimiento, leer de la sección fría de manera segura.
Entonces, el programa utilizará transferencias de caliente-frío. Estas usualmente implicarán grandes lotes para maximizar el uso del ancho de banda del NVMe. Y dado que los lotes son bastante grandes, también se realizarán a una frecuencia bastante baja. Y así, es la sección fría la que permite a esos algoritmos utilizar tanta memoria como sea posible.

Debido a que la sección fría llenará tanta RAM como esté disponible y luego volcará el resto al almacenamiento persistente. Entonces, ¿cómo podemos hacer que esto funcione en .NET? Dado que llamo a esto el primer intento, puedes adivinar que no funcionará. Así que intenta averiguar de antemano cuál será el problema.
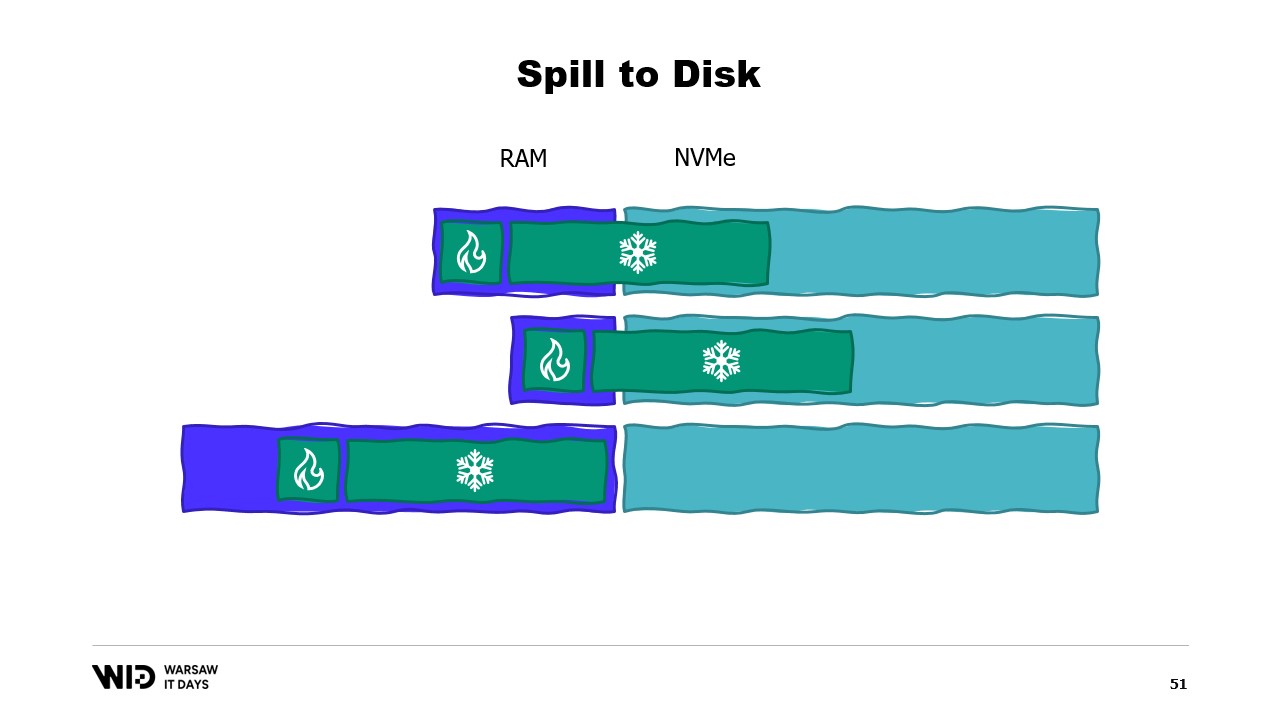
Para la sección caliente, utilizaré objetos .NET normales y el problema que veremos será un programa .NET normal. Para la sección fría, utilizaré lo que se llama una clase de referencia. Esta clase mantiene una referencia al valor que se está colocando en almacenamiento frío y ese valor puede ponerse a null cuando ya no está en la memoria. Tiene una función spill que toma el valor de la memoria y lo escribe en el almacenamiento, y luego anula la referencia, lo que permitirá que el recolector de basura de .NET recupere esa memoria cuando sienta presión.
Y finalmente, tiene una propiedad value. Esta propiedad, cuando se accede, devolverá el valor de la memoria si está presente y, si no, cargará de nuevo desde el disco a la memoria antes de devolverlo. Ahora, si configuro un sistema central en mi programa que lleve el registro de todas las referencias frías, entonces, cada vez que se cree una nueva referencia fría, puedo determinar si causa un desbordamiento de memoria e invocar la función spill de una o más de las referencias frías ya existentes en el sistema, solo para mantenerse dentro del presupuesto de memoria disponible para el almacenamiento frío.

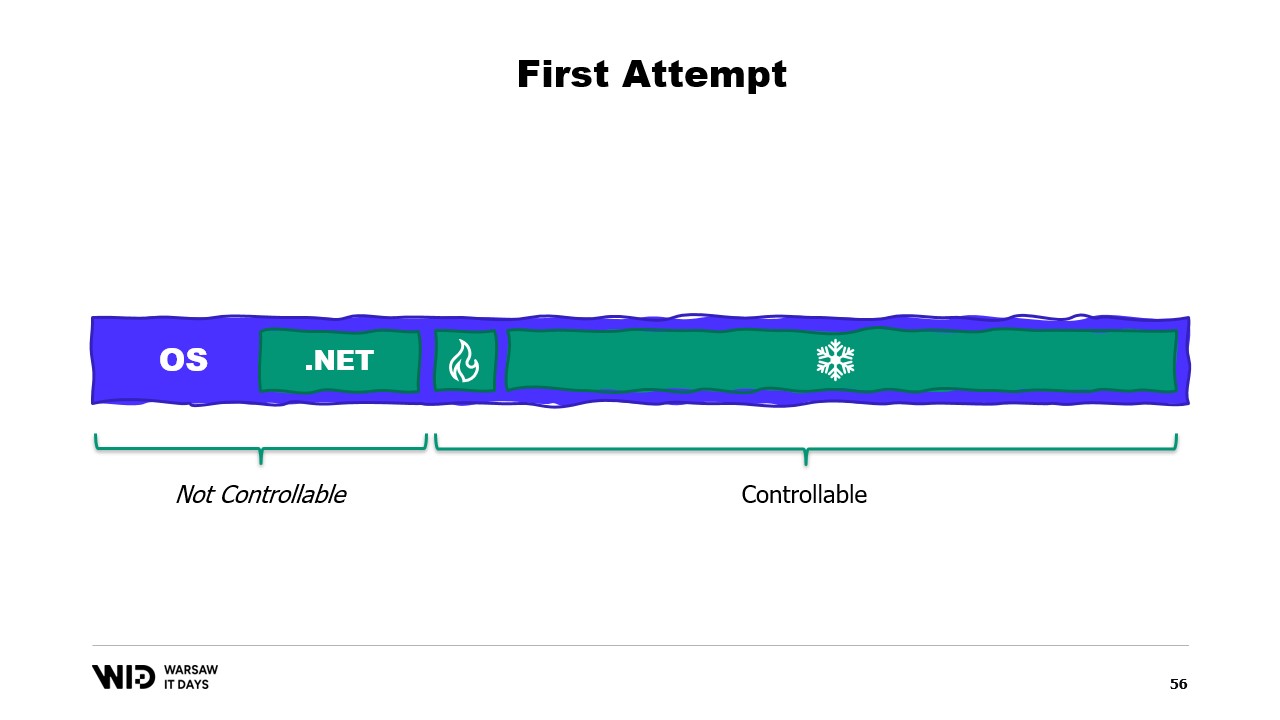
Entonces, ¿cuál va a ser el problema? Bueno, si miro el contenido de la memoria de una máquina que ejecuta nuestro programa, en el caso ideal, se verá así. Primero, a la izquierda, está la memoria del sistema operativo, que utiliza para sus propios fines. Luego está la memoria interna utilizada por .NET para cosas como ensamblados cargados o la sobrecarga del recolector de basura, y así sucesivamente. Luego está la memoria de la sección caliente y, finalmente, ocupando todo lo demás, la memoria asignada a la sección fría.
Con cierto esfuerzo, somos capaces de controlar todo lo que está a la derecha, porque eso es lo que asignamos y elegimos liberar para que el recolector de basura lo recoja. Sin embargo, lo que está a la izquierda está fuera de nuestro control. ¿Y qué sucede si, de repente, el sistema operativo necesita memoria adicional y se da cuenta de que todo está siendo ocupado por lo que ha creado el proceso .NET?
Bueno, la reacción típica, digamos, del kernel de Linux en ese caso, será matar el programa que use más memoria, y no hay forma de reaccionar lo suficientemente rápido para liberar algo de memoria de vuelta al kernel, de modo que no nos mate. Entonces, ¿cuál es la solución?

Los sistemas operativos modernos tienen el concepto de memoria virtual. El programa no tiene acceso directo a las páginas de memoria física. En su lugar, tiene acceso a las páginas de memoria virtual y existe una asignación entre esas páginas y las páginas reales de la memoria física. Sin embargo, si otro programa se está ejecutando en la misma computadora, no podrá acceder por sí mismo a las páginas del primer programa. Existen formas de compartir, sin embargo.
Es posible crear una página mapeada en memoria. En ese caso, cualquier cosa que el primer programa escriba en la página compartida será inmediatamente visible para la otra parte. Esta es una forma común de implementar la comunicación entre programas, pero su propósito principal es el mapeo de archivos en memoria. Aquí, el sistema operativo sabrá que esta página es una copia exacta de una página en el almacenamiento persistente, usualmente partes de un archivo de biblioteca compartida.
El propósito principal aquí es evitar que cada programa tenga su propia copia del DLL en memoria, ya que todas esas copias son idénticas, por lo que no hay razón para desperdiciar memoria almacenándolas. Aquí, por ejemplo, tenemos dos programas que suman cuatro páginas de memoria, cuando la memoria física solo tiene espacio para tres. Ahora, ¿qué sucede si queremos asignar una página más en el primer programa? No hay espacio disponible, pero el sistema operativo del kernel sabe que la página mapeada en memoria puede ser descartada temporalmente y, cuando sea necesario, podrá recargarse desde el almacenamiento persistente de manera idéntica.
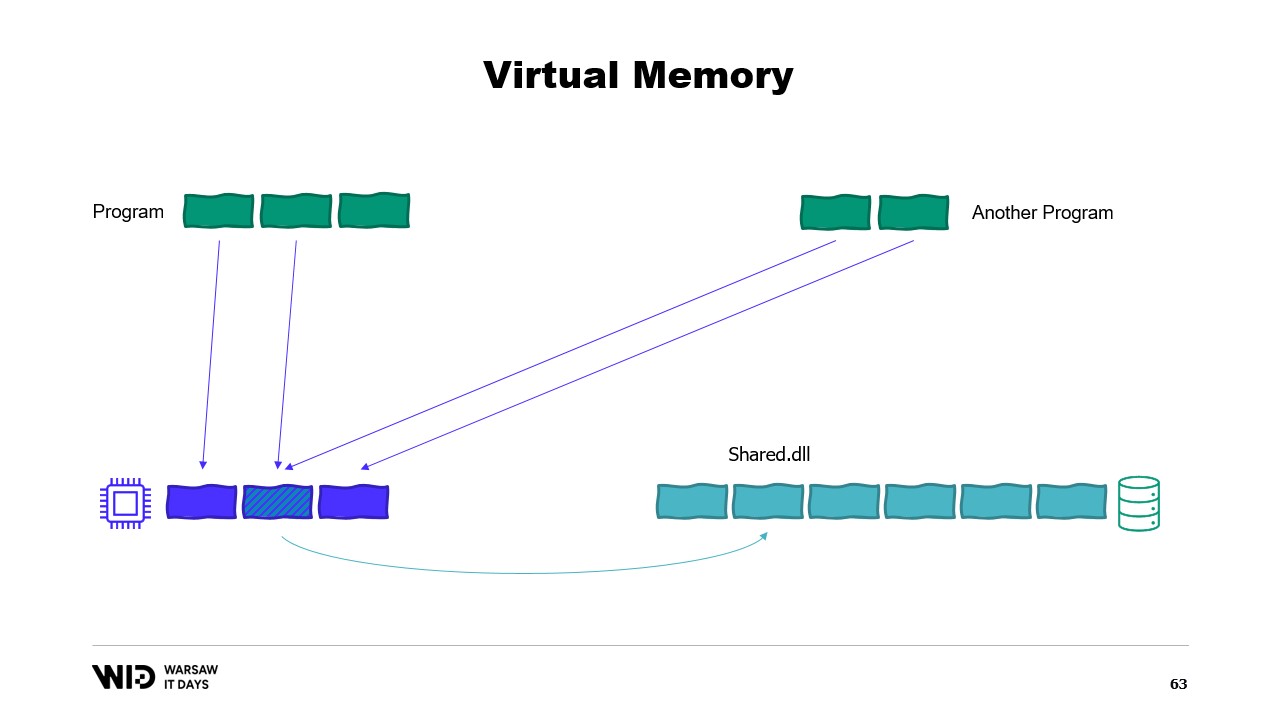
Entonces, hará exactamente eso. Las dos páginas compartidas apuntarán ahora al disco en lugar de a la memoria. La memoria se borra, se establece a cero por el sistema operativo, y luego se le da al primer programa para que la use en su tercera página lógica. Ahora, la memoria está completamente llena y si cualquiera de los programas intenta acceder a la página compartida, no habrá espacio para que se vuelva a cargar en la memoria porque las páginas asignadas a los programas no pueden ser reclamadas por el sistema operativo.
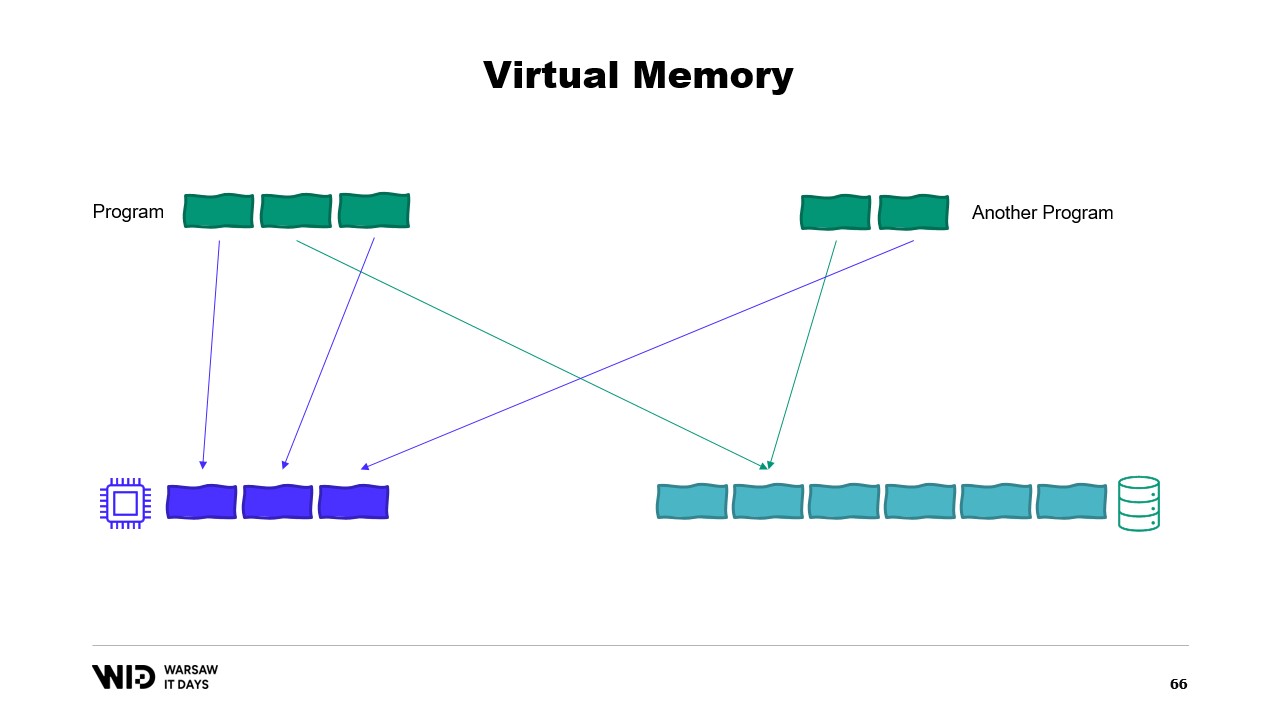
Entonces, lo que sucederá aquí es un error de falta de memoria. Uno de los programas morirá, se liberará memoria y luego se reutilizará para volver a cargar el archivo mapeado en memoria. Además, aunque la mayoría de los mapas de memoria son de solo lectura, también es posible crear algunos que sean de lectura-escritura.
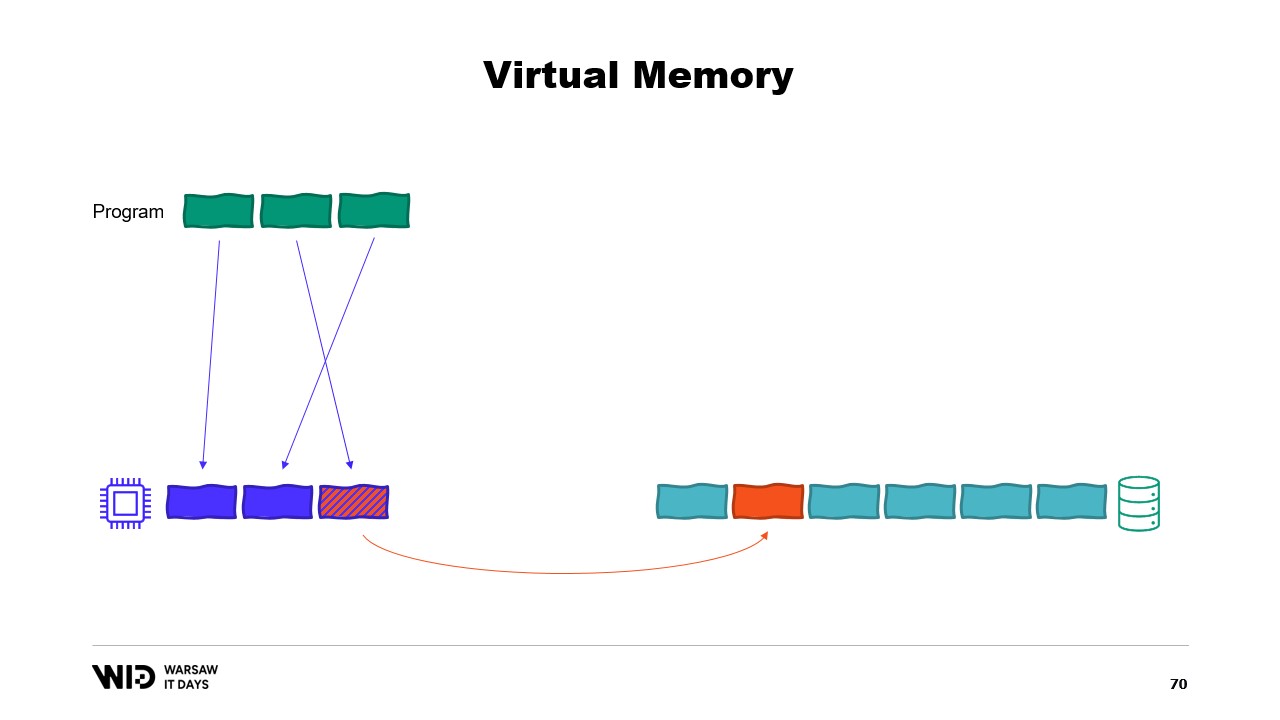
Un programa realiza un cambio en la memoria de la página mapeada, luego el sistema operativo, en algún momento en el futuro, guardará el contenido de esa página de vuelta en el disco. Y, por supuesto, es posible solicitar que esto suceda en un momento específico utilizando funciones como flush en Windows. La herramienta de Performance Tool del sistema tiene esta ventana agradable que muestra el uso actual de la memoria física.
En verde está la memoria que ha sido asignada directamente a un proceso. No se puede recuperar sin matar el proceso. En azul se encuentra la caché de páginas. Esas son páginas que se sabe que son copias idénticas de una página en el disco, por lo que siempre que un proceso necesita leer del disco una página que ya está en la caché, no se realizará una lectura desde el disco y el valor se devolverá directamente desde la memoria.
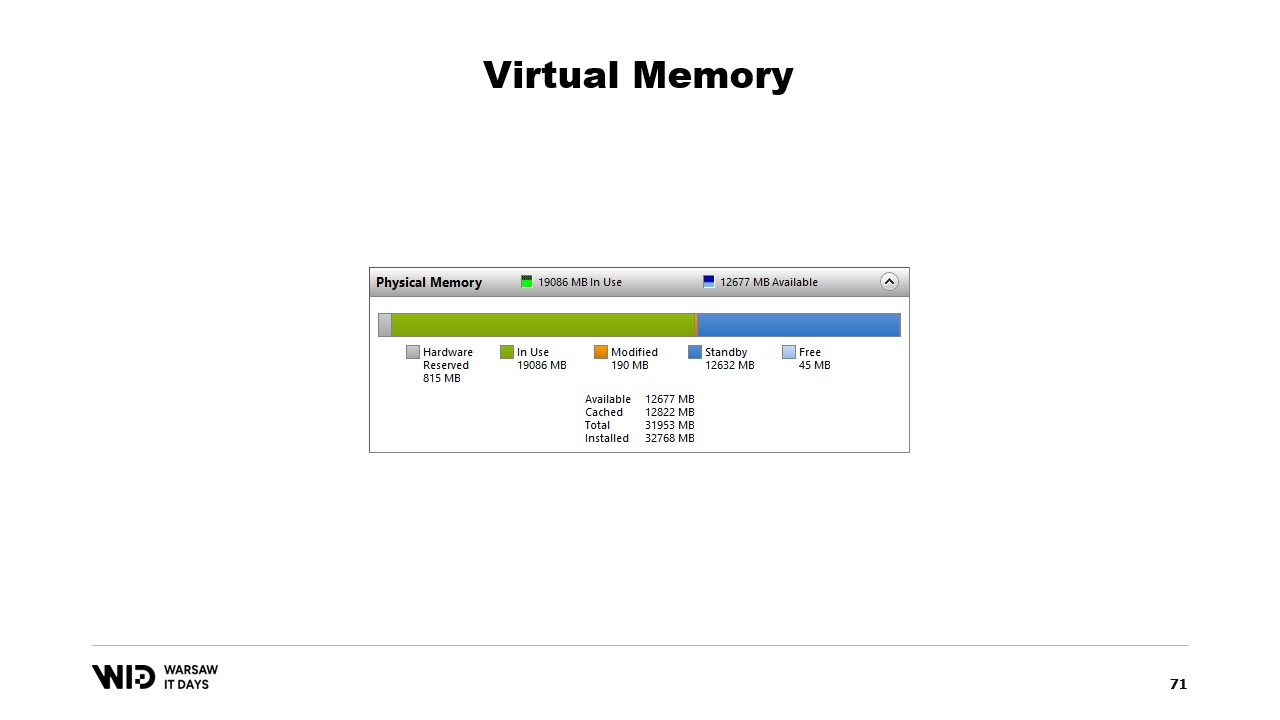
Finalmente, las páginas modificadas en el medio son aquellas que deberían ser una copia exacta del disco pero contienen cambios en la memoria. Esos cambios aún no se han aplicado de vuelta al disco, pero lo harán en un tiempo bastante corto. En Linux, la herramienta h-stop muestra un gráfico similar. A la izquierda están las páginas que han sido asignadas directamente a los procesos y no se pueden recuperar sin matarlos, y a la derecha, en amarillo, se encuentra la caché de páginas.

Si te interesa, existe un excelente recurso de Vyacheslav Biryukov sobre lo que ocurre en la caché de páginas de Linux. Usando memoria virtual, hagamos nuestro segundo intento. ¿Funcionará esta vez? Ahora, decidimos que la sección fría estará compuesta enteramente por páginas mapeadas en memoria. Así que se espera que todas ellas estén presentes en el disco primero.
El programa ya no tiene control sobre qué páginas estarán en la memoria y cuáles solo estarán presentes en el disco. El sistema operativo lo hace de forma transparente. Entonces, si el programa intenta acceder, digamos, a la tercera página en la sección fría, el sistema operativo detectará que no está en la memoria, descargará una de las páginas existentes, digamos la segunda, y luego cargará la tercera página en la memoria.
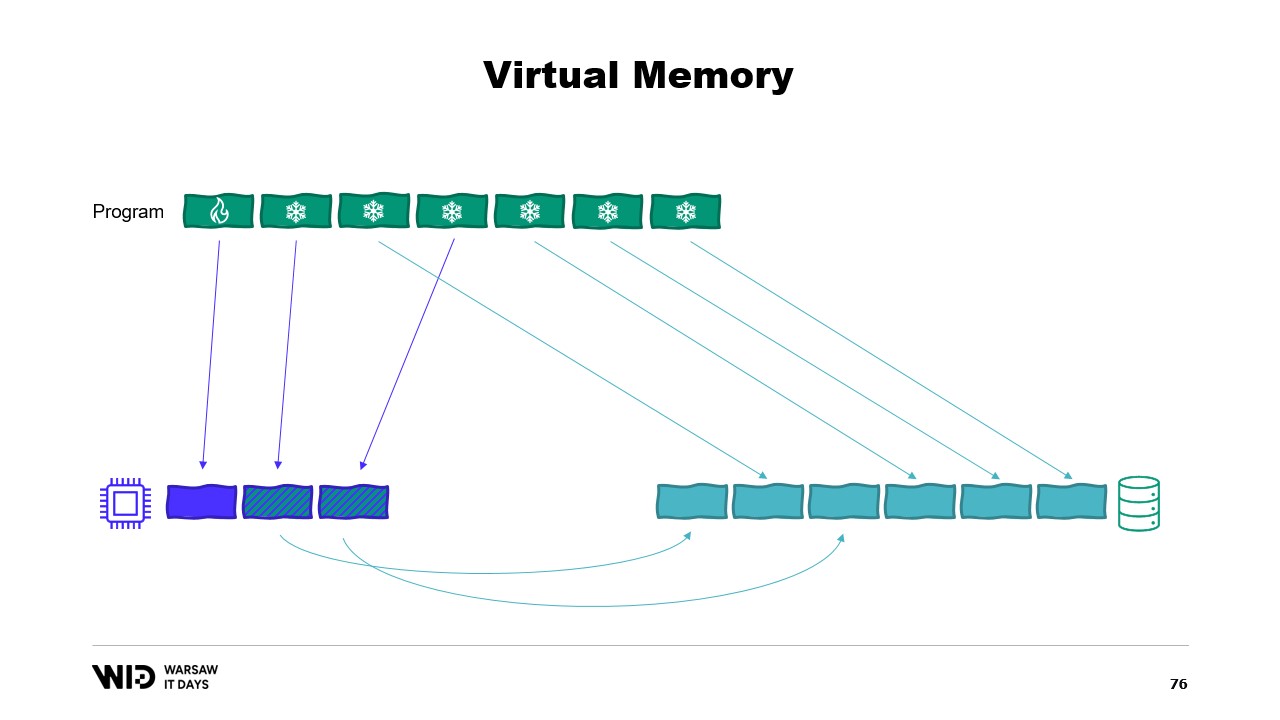
Desde el punto de vista del propio proceso, fue completamente transparente. La espera para leer desde la memoria fue solo un poco más larga de lo habitual. ¿Y qué pasa si el sistema operativo de repente necesita algo de memoria para hacer lo suyo? Bueno, sabe qué páginas están mapeadas en memoria y pueden descartarse de forma segura. Entonces, simplemente descartará una de las páginas, la usará para sus propios fines y luego la liberará cuando haya terminado.
Todas estas técnicas se aplican a .NET y están presentes en el proyecto de código abierto Lokad Scratch Space. Y la mayor parte del código que sigue se basa en cómo este paquete NuGet realiza las cosas.

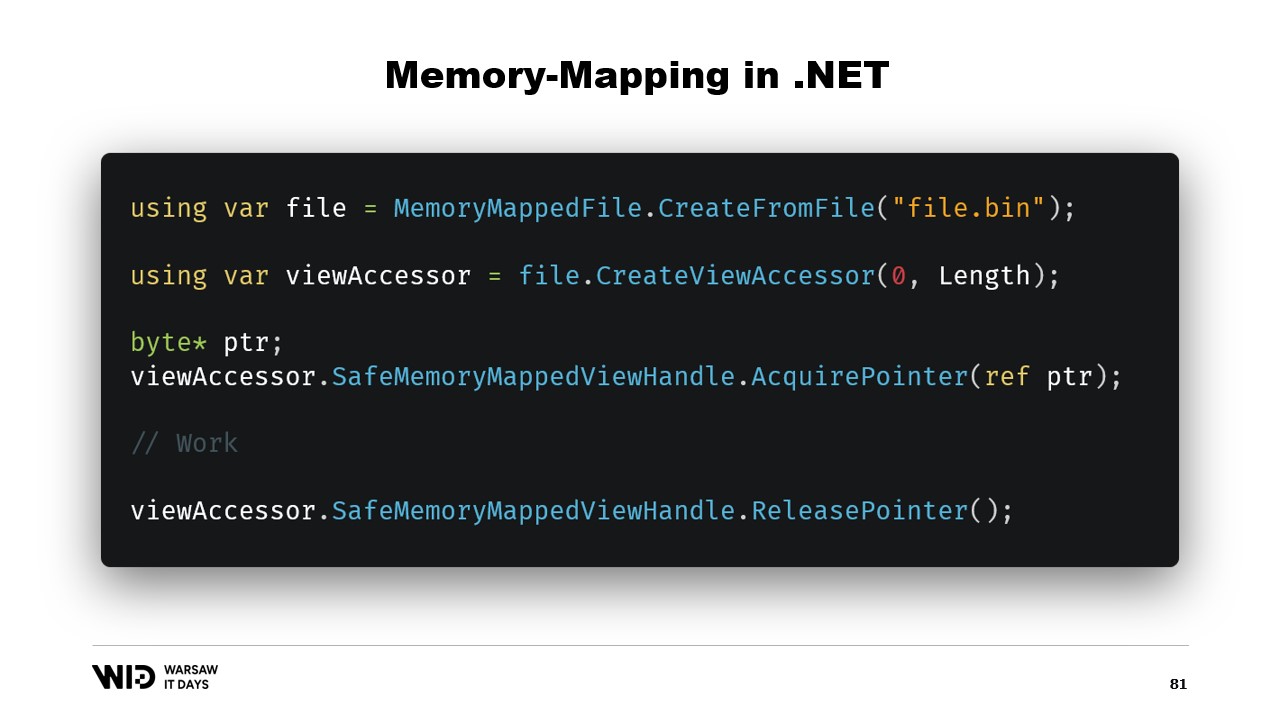
Primero, ¿cómo crearíamos un archivo mapeado en memoria en .NET? El mapeo de memoria ha existido desde .NET Framework 4, hace aproximadamente 13 años. Está bastante bien documentado en internet y el código fuente está completamente disponible en GitHub.

Los pasos básicos son, primero, crear un archivo mapeado en memoria a partir de un archivo en el disco y luego crear un acceso de vista. Esos dos tipos se mantienen separados porque tienen significados distintos. El archivo mapeado en memoria simplemente indica al sistema operativo que, a partir de este archivo, algunas secciones se mapearán a la memoria del proceso. El acceso de vista en sí representa esos mapeos.
Se mantienen separados porque .NET necesita lidiar con el caso de un proceso de 32 bits. Un archivo muy grande, uno que sea mayor a cuatro gigabytes, no puede ser mapeado al espacio de memoria de un proceso de 32 bits. Es demasiado grande. Ahora, el puntero no es lo suficientemente grande para representarlo. Entonces, en su lugar, es posible mapear solo pequeñas secciones del archivo una a la vez de manera que encajen.
En nuestro caso, trabajaremos con punteros de 64 bits. Entonces, podemos simplemente crear un acceso de vista que cargue el archivo completo. Y ahora, uso AcquirePointer para obtener el puntero a los primeros bytes de este rango de memoria mapeada. Cuando termine de trabajar con el puntero, simplemente lo libero. Trabajar con punteros en .NET es inseguro. Requiere agregar la palabra clave unsafe en todas partes y puede fallar si intentas acceder a la memoria más allá de los límites permitidos.
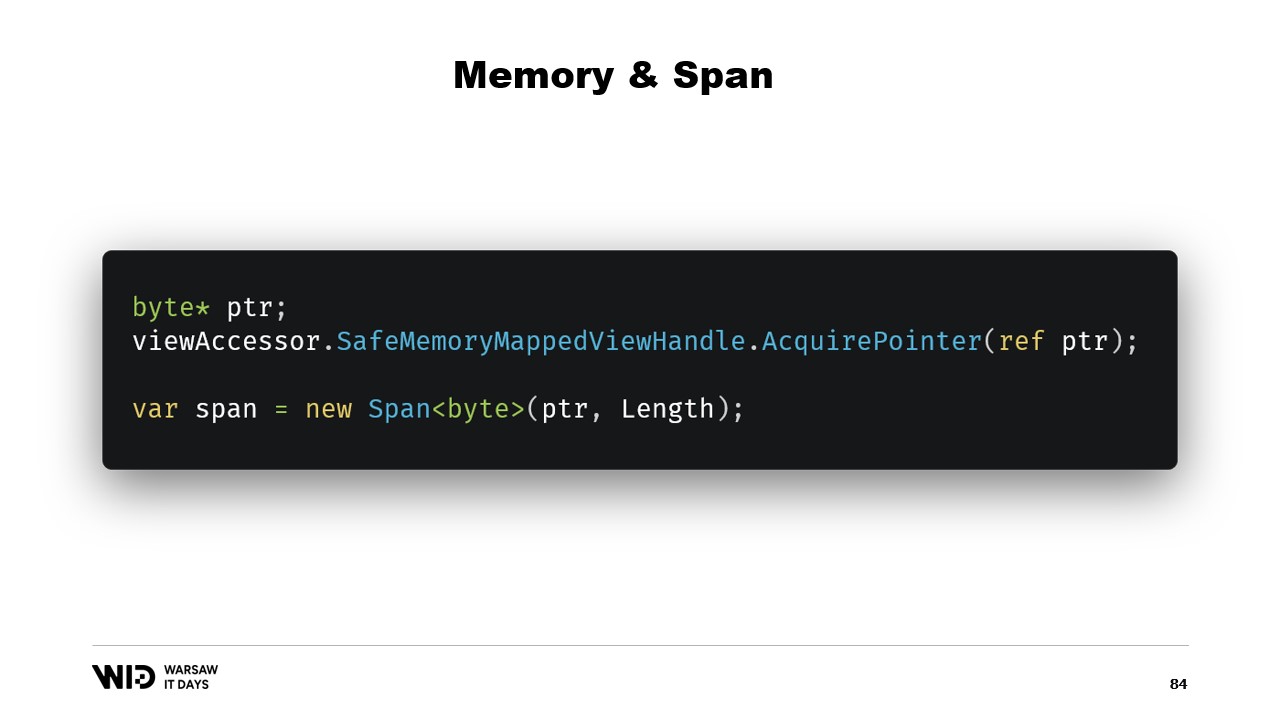
Afortunadamente, existe una forma de solucionar eso. Hace cinco años, .NET introdujo memory y span. Estos son tipos utilizados para representar un rango de memoria de una manera que es más segura que simplemente usar punteros. Está bastante bien documentado y la mayor parte del código se puede encontrar en esta ubicación en GitHub.

La idea general detrás de span y memory es que, dado un puntero y un número de bytes, puedes crear un nuevo span que represente ese rango de memoria.
Una vez que tienes este span, puedes leer de forma segura en cualquier parte dentro de él, sabiendo que si intentas leer fuera de los límites, el runtime lo detectará y obtendrás una excepción en lugar de que el proceso termine.
Veamos cómo podemos usar span para cargar desde la memoria mapeada a la memoria administrada de .NET. Recuerda, no queremos acceder directamente a la sección fría por razones de rendimiento. En cambio, queremos hacer transferencias de frío a caliente que carguen mucha información al mismo tiempo.
Por ejemplo, supongamos que tenemos una cadena que queremos leer. Se dispondrá en el archivo mapeado en memoria como un tamaño seguido de una carga útil codificada en UTF-8, y queremos cargar una cadena de .NET a partir de ello.
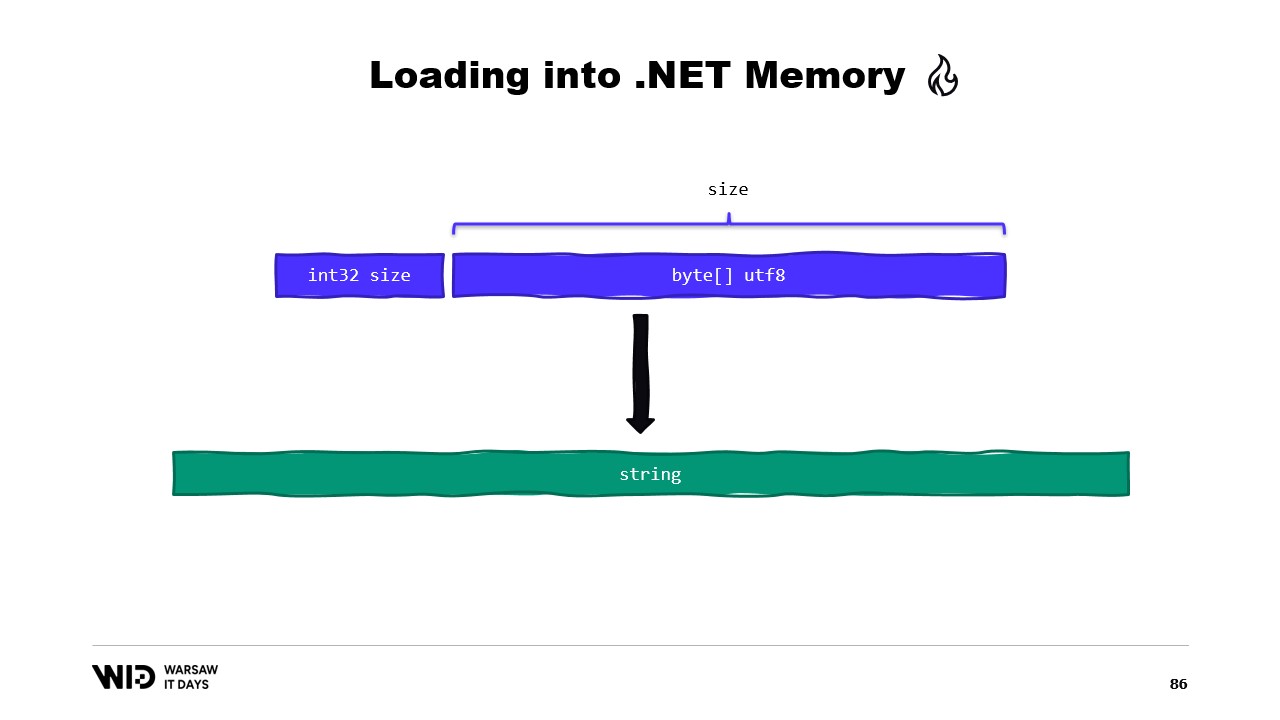
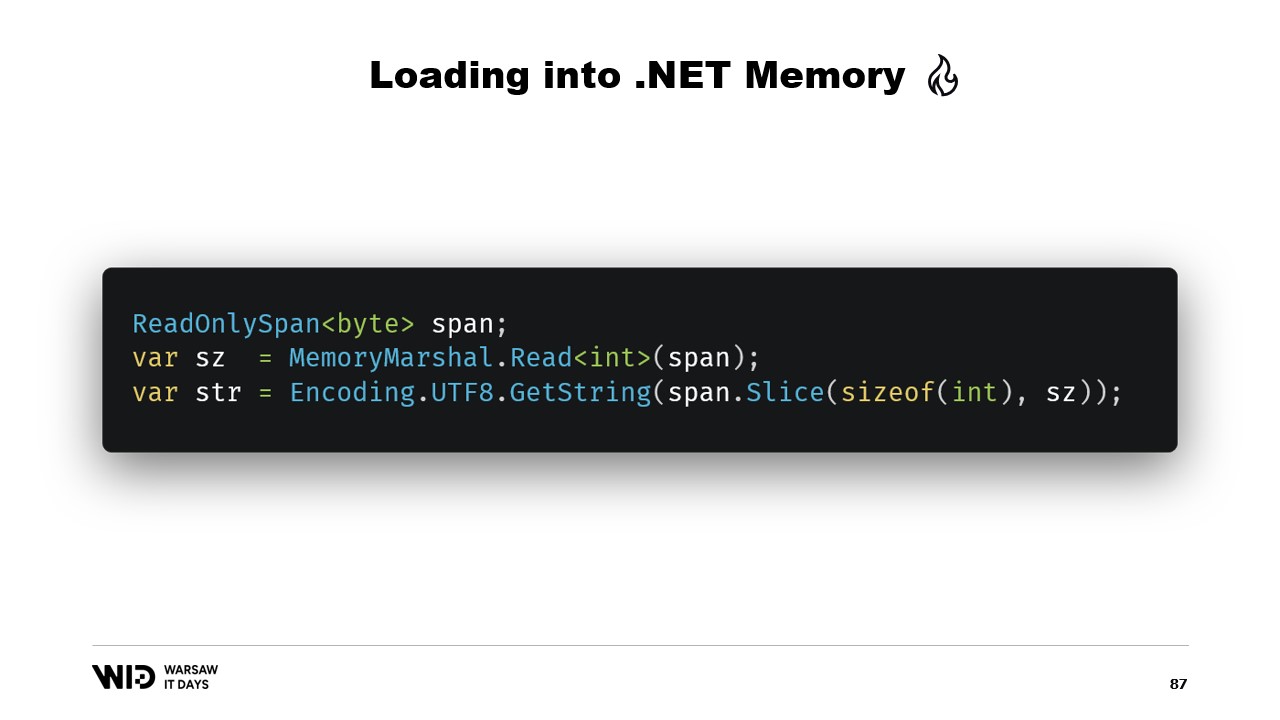
Bueno, hay muchas APIs centradas en spans que podemos utilizar. Por ejemplo, MemoryMarshal.Read puede leer un entero desde el inicio del span. Luego, usando este tamaño, puedo pedirle a la función Encoding.GetString que cargue de un span de bytes a una cadena.
Todas estas operan sobre spans y, aunque el span representa una sección de datos que posiblemente esté en el disco en lugar de en la memoria, el sistema operativo se encarga de cargarlos en la memoria de forma transparente cuando se accede a ellos por primera vez.
Otro ejemplo sería una secuencia de valores de punto flotante que queremos cargar en un arreglo de flotantes.
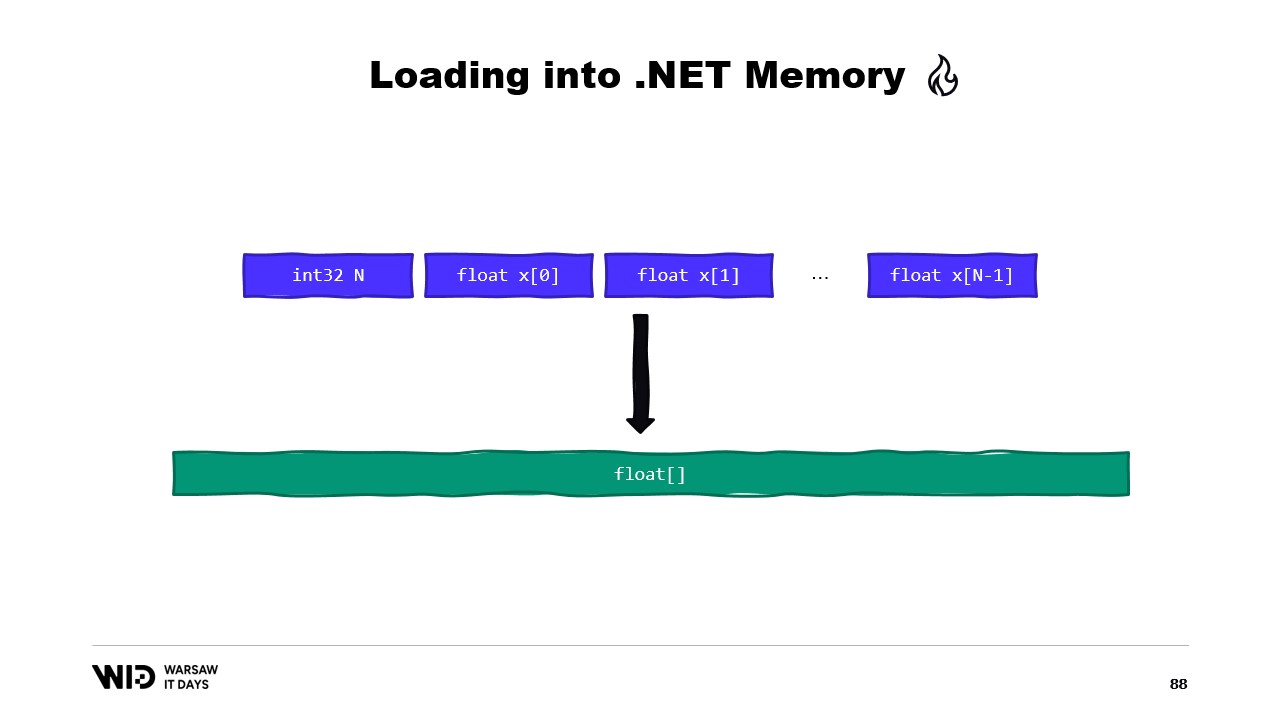
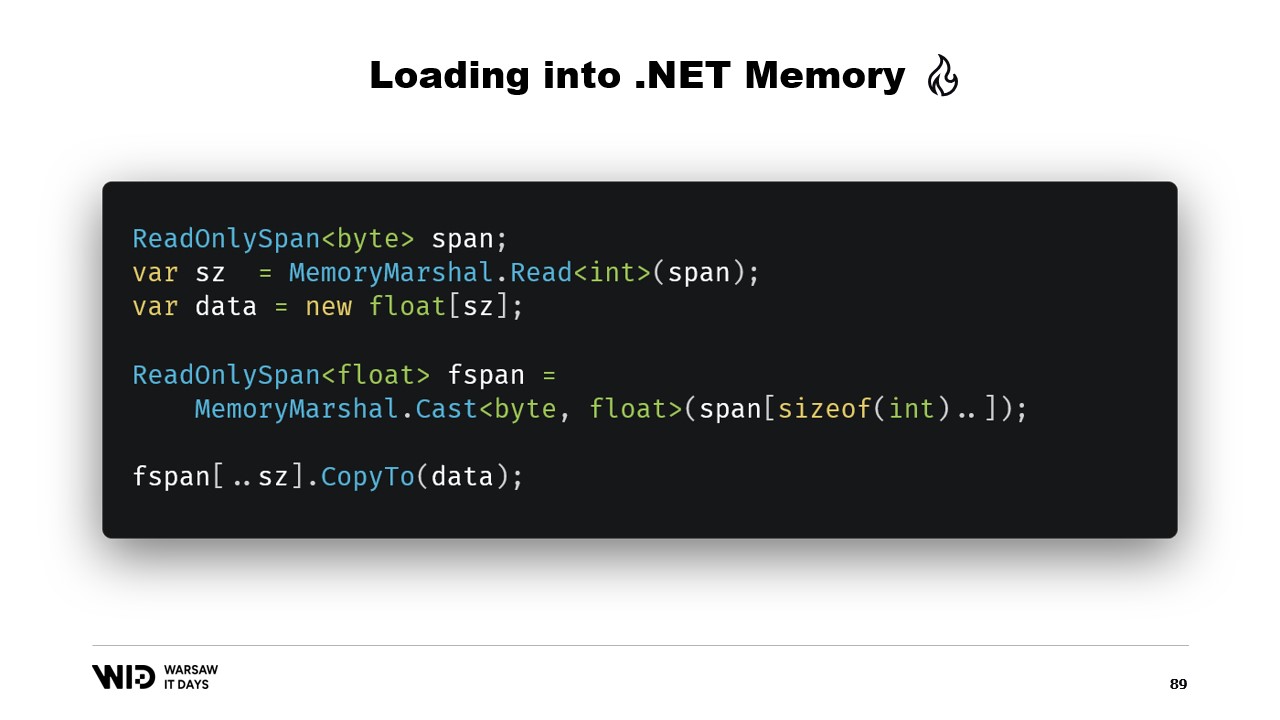
Nuevamente, usamos MemoryMarshal.Read para leer el tamaño. Asignamos un arreglo de valores de punto flotante de ese tamaño y luego usamos MemoryMarshal.Cast para convertir el span de bytes en un span de valores de punto flotante. Esto realmente solo reinterpreta los datos presentes en el span como valores de punto flotante en lugar de bytes.
Finalmente, usamos la función CopyTo de spans, que realizará una copia de alto rendimiento de los datos desde el archivo mapeado en memoria hacia el propio arreglo. Esto es, de cierta manera, un poco derrochador, ya que se está realizando una copia completamente nueva.
Quizás podríamos evitar eso. Bueno, normalmente lo que almacenaremos en el disco no serán los valores de punto flotante sin procesar. En cambio, guardaremos alguna versión comprimida de ellos. Aquí almacenamos el tamaño comprimido, que nos indica cuántos bytes necesitamos leer. Almacenamos el tamaño de destino o el tamaño descomprimido. Esto nos dice cuántos valores de punto flotante debemos asignar en la memoria administrada. Y finalmente, almacenamos la carga útil comprimida.
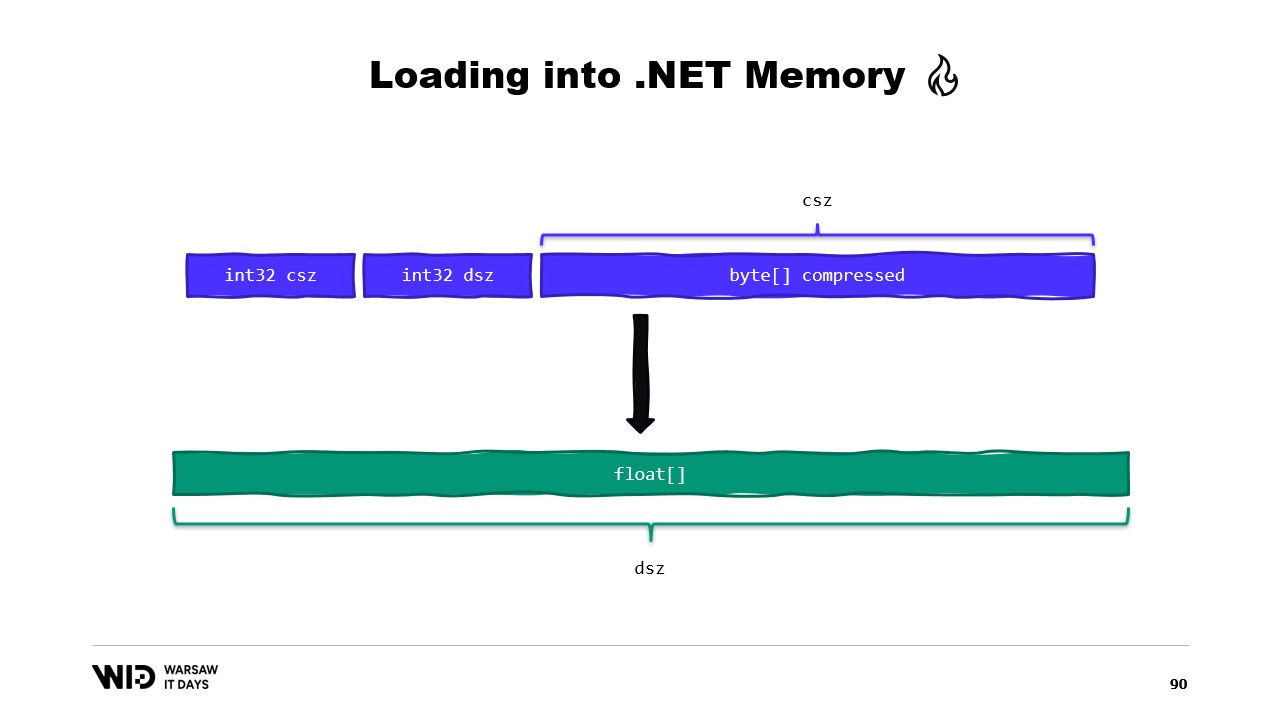
Para cargar esto, será mejor si, en lugar de leer dos enteros, creamos una estructura que represente ese encabezado con dos valores enteros en su interior.

MemoryMarshal podrá leer una instancia de esa estructura, cargando ambos campos al mismo tiempo. Asignamos un arreglo de valores de punto flotante y luego, casi con seguridad, nuestra biblioteca de compresión tiene alguna variante de una función de descompresión que toma un span de bytes de solo lectura como entrada y un span de bytes como salida. Podemos usar nuevamente MemoryMarshal.Cast, esta vez convirtiendo el arreglo de valores de punto flotante en un span de bytes para usarlo como destino.
Ahora, no se realiza ninguna copia. En su lugar, el algoritmo de compresión lee directamente desde el disco, usualmente a través de la caché de páginas, hacia el arreglo de floats de destino.

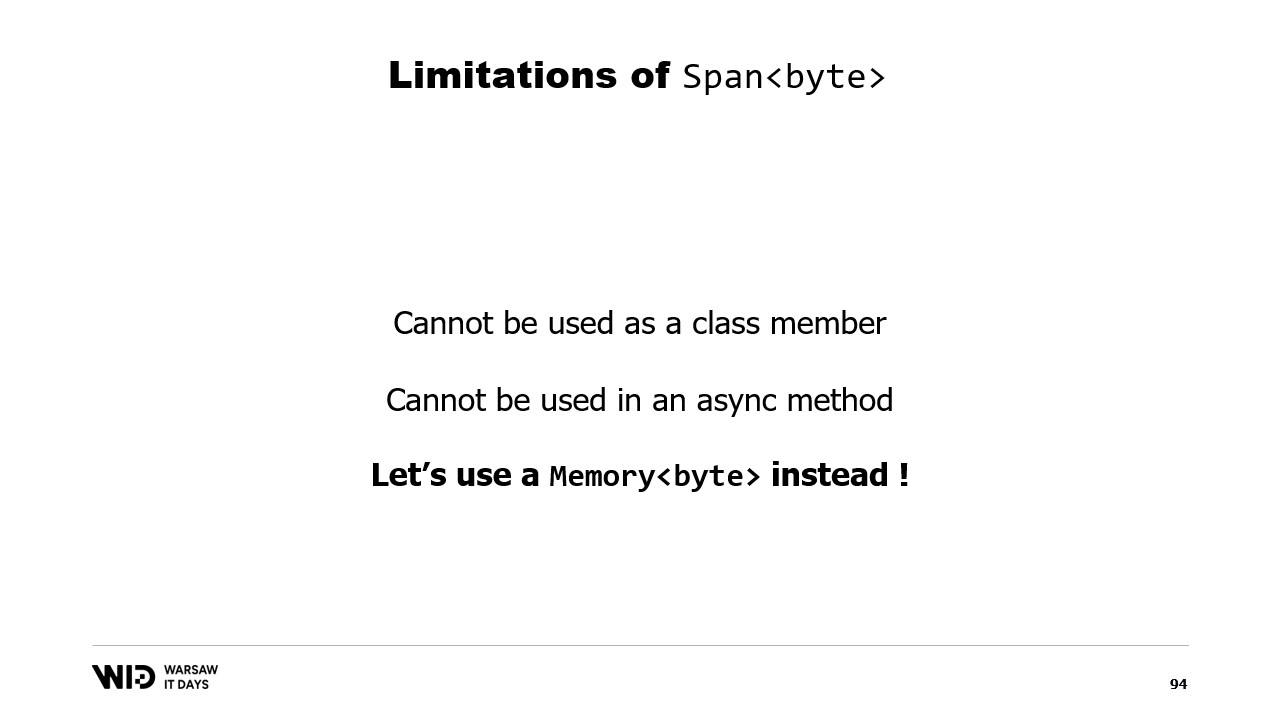
Span sí tiene una limitación importante, y es que no se puede usar como miembro de una clase y, por extensión, tampoco puede emplearse como variable local en un método async.
Afortunadamente, existe un tipo diferente, Memory, que debe usarse para representar un rango de datos de mayor duración.
Lamentablemente, hay escasa documentación sobre cómo hacer esto. Crear un span a partir de un puntero es fácil, pero crear una Memory a partir de un puntero no está documentado hasta el punto de que la mejor documentación disponible es un gist en GitHub, el cual realmente te recomiendo leer.
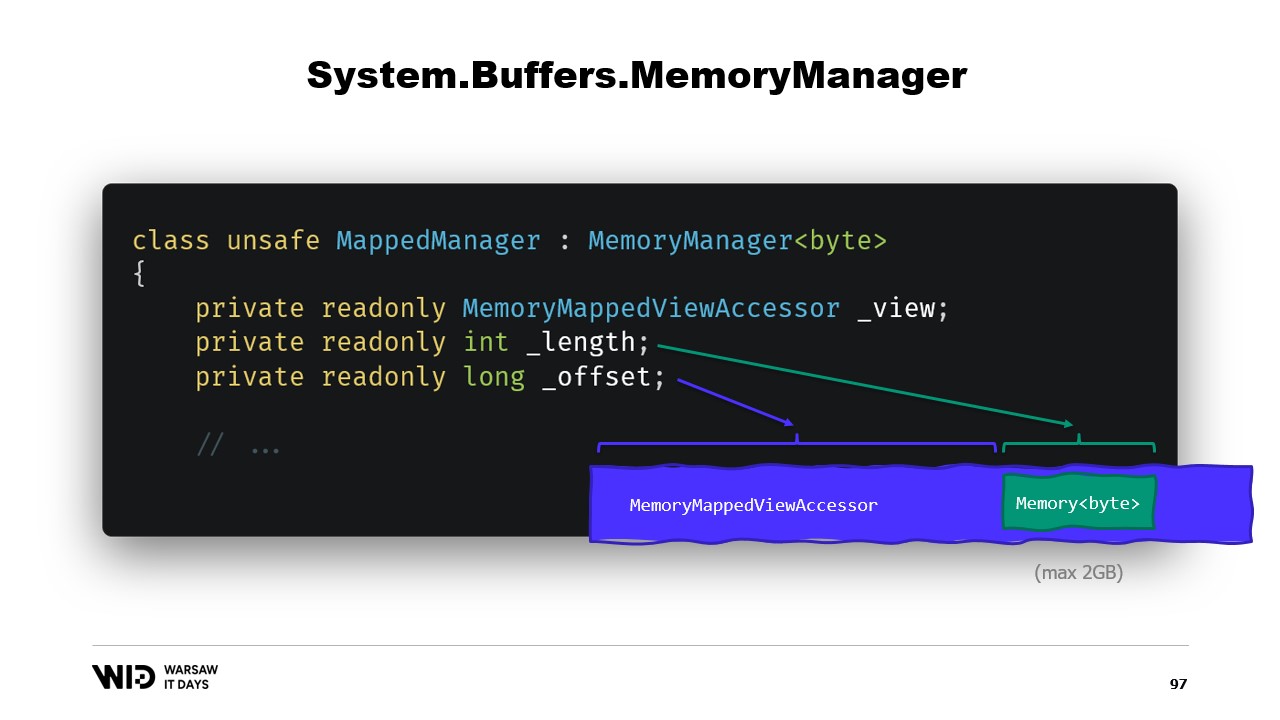
En resumen, lo que necesitamos hacer es crear un MemoryManager. El MemoryManager se utiliza internamente por una Memory siempre que necesita hacer algo más complejo que simplemente apuntar a una sección de un arreglo.
En nuestro caso, necesitamos referenciar el accesador de vista mapeado en memoria al que estamos accediendo. Necesitamos conocer la longitud que se nos permite ver y, finalmente, necesitaremos un offset. Esto se debe a que una Memory de bytes puede representar no más de dos gigabytes por diseño, y el archivo en sí probablemente sea más largo que dos gigabytes. Entonces, el offset nos indica la ubicación donde comienza la memoria dentro del accesador de vista más amplio.
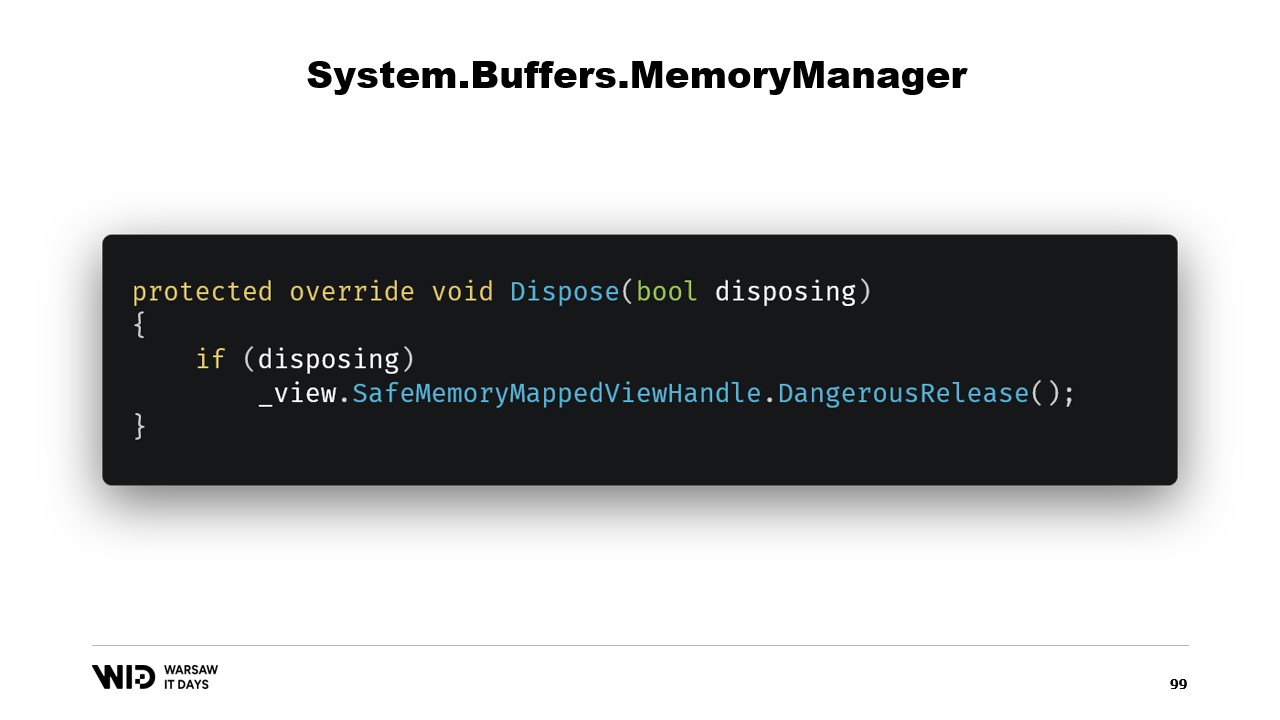
El constructor de la clase es bastante sencillo.

Solo necesitamos agregar una referencia al safe handle que representa la región de memoria y esta referencia se liberará en la función dispose.
A continuación, tenemos una propiedad address que no es nada extraordinaria, simplemente es algo que nos resulta útil. Usamos DangerousGetHandle para obtener un puntero y le sumamos el offset para que la dirección apunte a los primeros bytes de la región que queremos que nuestra Memory represente.
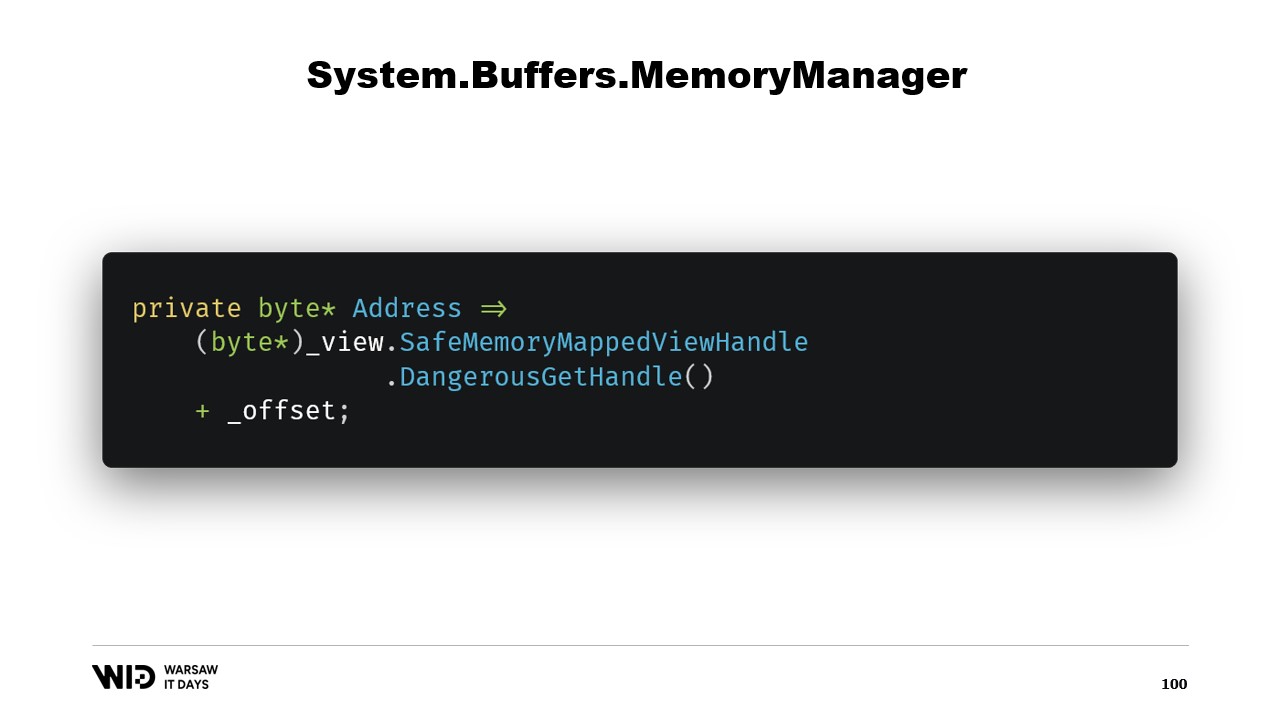
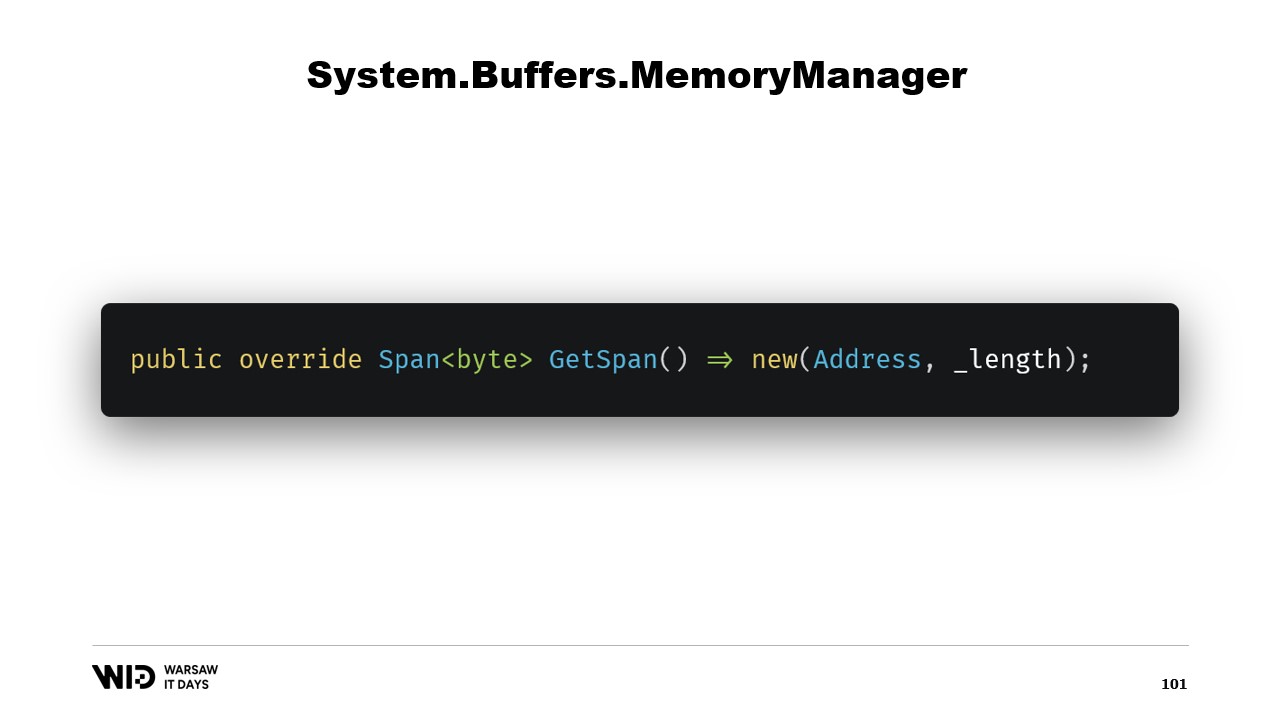
Sobrescribimos la función GetSpan que hace toda la magia. Simplemente crea un span utilizando la address y la longitud.
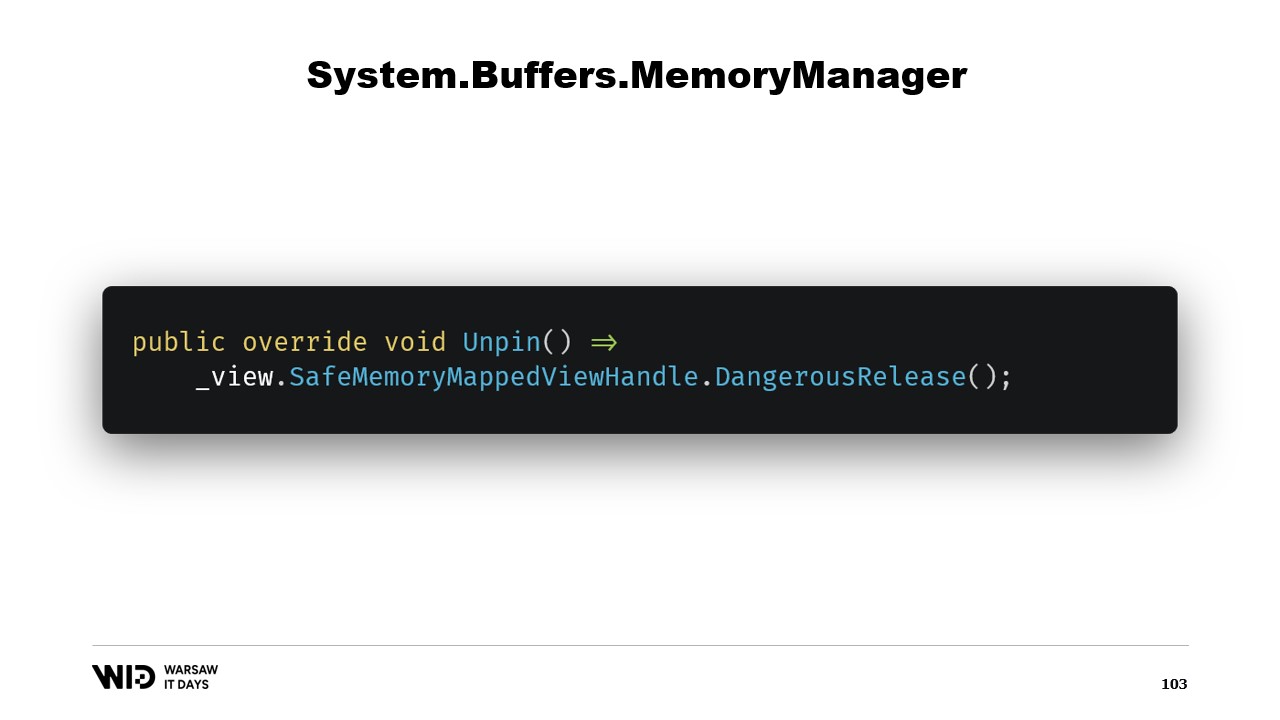
Hay otros dos métodos que deben implementarse en el MemoryManager. Uno de ellos es Pin. Es utilizado por el runtime en casos donde la memoria debe mantenerse en la misma ubicación por una corta duración. Agregamos una referencia y devolvemos un MemoryHandle que apunta a la ubicación correcta y que también referencia al objeto actual como el pinnable.

Esto permitirá al runtime saber que, cuando la memoria sea desprendida, llamará al método Unpin de este objeto, lo que provocará la liberación del safe handle nuevamente.
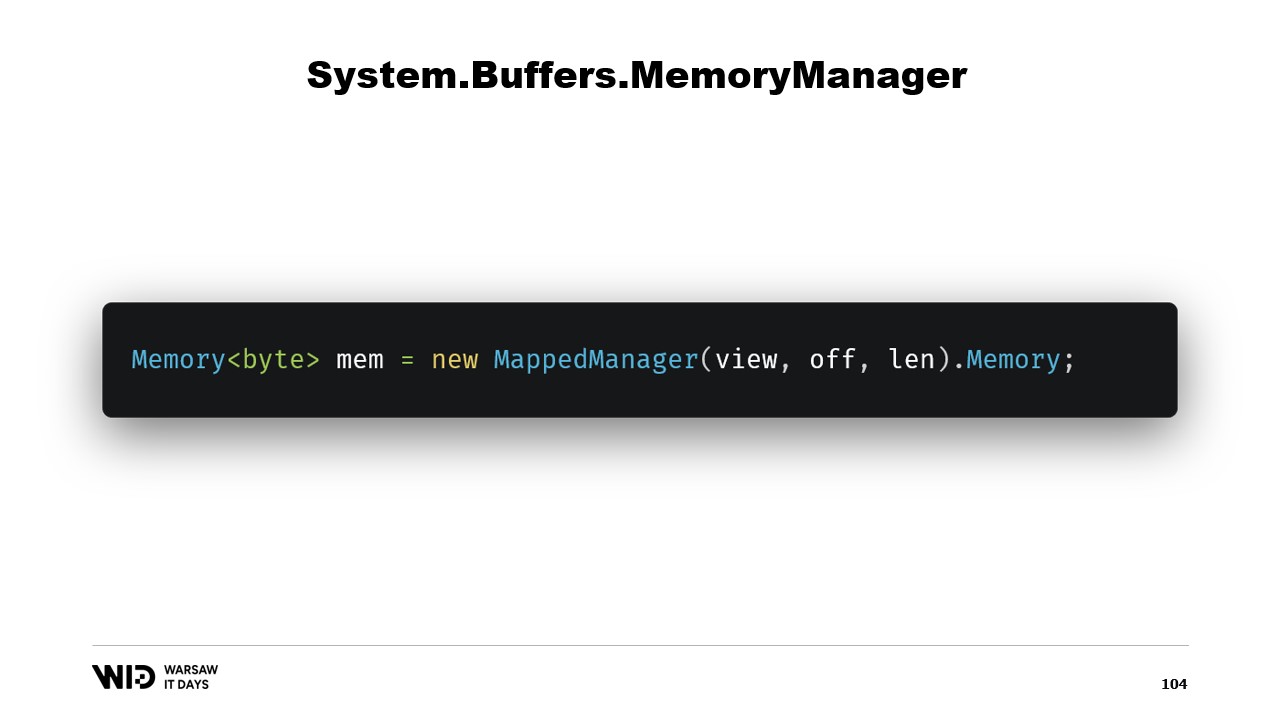
Una vez que se ha creado esta clase, basta con crear una instancia de la misma y acceder a su propiedad Memory, la cual devolverá una Memory de bytes que internamente referencia al MemoryManager que acabamos de crear. Y ahí lo tienes, ahora tienes un trozo de memoria. Cuando escribas en ella, se descargará automáticamente al disco cuando sea necesario espacio y, al acceder, se cargará de forma transparente desde el disco cada vez que la necesites.
Entonces, eso es suficiente para implementar nuestro programa de volcado a disco. Surge otra pregunta: ¿por qué usar mapeo de memoria cuando podríamos usar FileStream en su lugar? Después de todo, FileStream es la opción obvia para acceder a datos que están en el disco y su uso está bastante bien documentado. Para leer un arreglo de valores de punto flotante, por ejemplo, necesitas un FileStream y un BinaryReader envuelto alrededor del FileStream. Estableces la posición al offset donde se encuentran los datos, lees un Int32 con el reader, asignas el arreglo de valores de punto flotante y luego usas MemoryMarshal.Cast para convertirlo en un span de bytes.
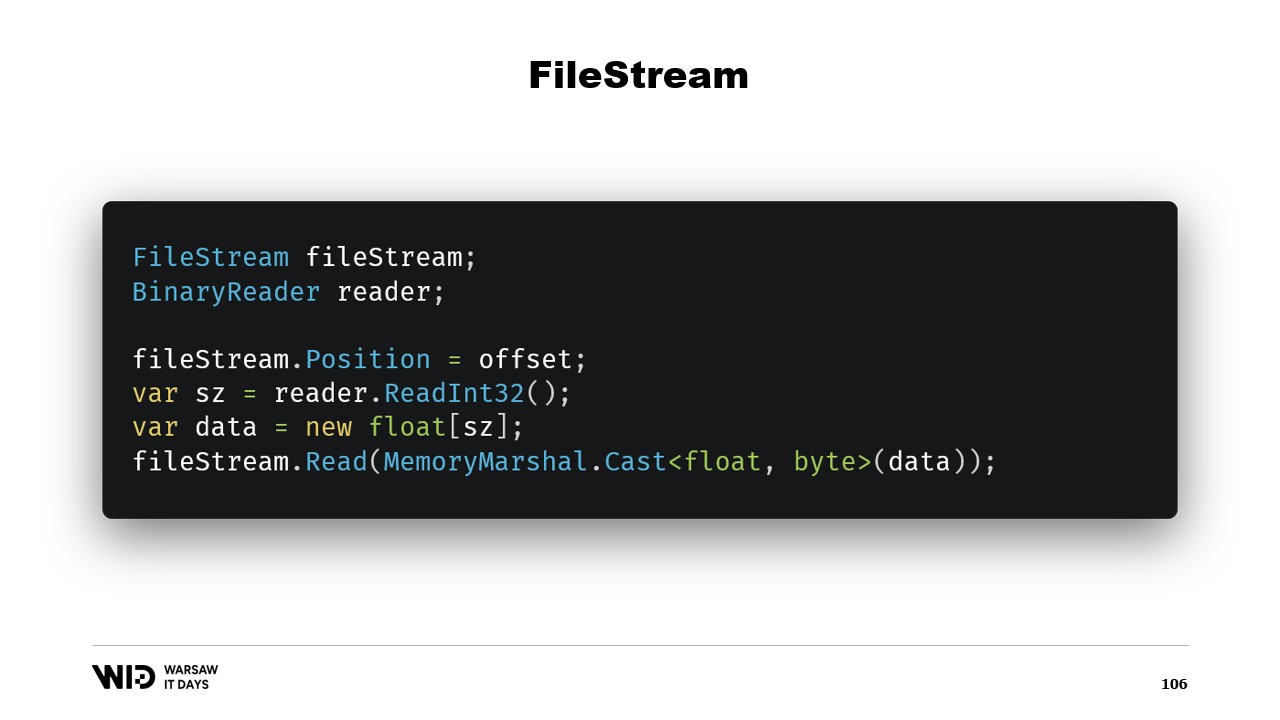
FileStream.Read ahora tiene una sobrecarga que acepta un span de bytes como destino. Esto, en realidad, también utiliza la caché de páginas. En lugar de mapear esas páginas al espacio de direcciones de tu proceso, el sistema operativo simplemente las mantiene y, para leer los valores, carga desde el disco en la memoria y luego copia de esa página al span de destino que proporcionaste. Así, esto es equivalente en términos de rendimiento y comportamiento a lo que sucedió en la versión de mapeo de memoria.
Sin embargo, hay dos diferencias importantes. Primero, esto no es thread safe. Estableces la posición en una línea y luego, en otra instrucción, dependes de que esa posición siga siendo la misma. Esto significa que necesitas un lock alrededor de esta operación y, por lo tanto, no puedes leer desde varias ubicaciones en paralelo, aunque eso sea posible con archivos mapeados en memoria.
Otra cuestión es que, dependiendo de la estrategia utilizada por FileStream, se realizan dos lecturas, una para el Int32 y otra para la lectura al span. Una posibilidad es que cada una de ellas realice una llamada al sistema. Esto invoca al sistema operativo y éste copia algunos datos de su propia memoria a la memoria del proceso. Eso implica cierto overhead. La otra posibilidad es que el stream esté en buffer. En ese caso, leer cuatro bytes inicialmente creará una copia de una página, probablemente. Y esta copia se efectúa encima de la copia real que hace la función de lectura más adelante. Por lo tanto, introduce un overhead que simplemente no está presente en la versión de mapeo de memoria.
Por esta razón, usar la versión de mapeo de memoria es preferible en términos de rendimiento. Después de todo, FileStream es la opción obvia para acceder a datos que están en el disco y su uso está muy bien documentado. Por ejemplo, para leer un arreglo de valores de punto flotante, necesitas un FileStream y un BinaryReader. Estableces la posición del FileStream al offset donde se encuentran los datos en el archivo, lees un Int32 para obtener el tamaño, asignas el arreglo de valores de punto flotante, lo conviertes en un span de bytes usando MemoryMarshal.Cast y se lo pasas a la sobrecarga de FileStream.Read que requiere un span de bytes como destino para la lectura. Y esto también utiliza la caché de páginas. En lugar de que las páginas estén asociadas con el proceso, son mantenidas por el propio sistema operativo y éste simplemente cargará desde el disco en la caché de páginas y copiará desde la caché de páginas a la memoria del proceso, tal como hicimos con la versión de mapeo de memoria.
Sin embargo, el enfoque FileStream tiene dos inconvenientes principales. El primero es que este código no es seguro para el uso en múltiples hilos. Después de todo, la posición se establece en una sentencia y luego se utiliza en las sentencias siguientes. Por lo tanto, necesitamos un lock alrededor de esas operaciones de lectura. La versión mapeada en memoria no necesita locks y, de hecho, es capaz de cargar desde varias ubicaciones en el disco en paralelo. Para los SSDs, esto aumenta la profundidad de la cola que incrementa el rendimiento y, por ende, suele ser deseable. El otro problema es que el FileStream necesita realizar dos lecturas.
Dependiendo de la estrategia utilizada internamente por el stream, esto puede resultar en dos llamadas al sistema que necesitan despertar al sistema operativo. Copiará algunos datos de su propia memoria a la memoria del proceso y luego tiene que borrar todo y devolver el control al proceso. Esto conlleva cierto overhead. La otra estrategia posible es que el FileStream esté en buffer. En ese caso, solo se realizaría una llamada al sistema, pero ello implicará una copia desde la memoria del sistema operativo al búfer interno del FileStream y luego la sentencia de lectura tendrá que copiar nuevamente desde el búfer interno del FileStream al array de punto flotante. Así, se crea una copia desperdiciada que no se presenta con la versión mapeada en memoria.
El file stream, aunque un poco más fácil de usar, tiene algunas limitaciones. En su lugar, se debería utilizar la versión mapeada en memoria. Así, ahora hemos terminado con un sistema que es capaz de usar tanta memoria como sea posible y, al agotarse la memoria, volcará partes de los conjuntos de datos de nuevo al disco. Este proceso es completamente transparente y coopera con el sistema operativo. Funciona al máximo rendimiento porque las partes del conjunto de datos que se acceden con frecuencia siempre se mantienen en memoria.
Sin embargo, hay una última pregunta que necesitamos responder. Después de todo, cuando mapeas cosas en memoria, no mapeas el disco, mapeas archivos en el disco. Ahora, la pregunta es, ¿cuántos archivos vamos a asignar? ¿Qué tan grandes serán? ¿Y cómo vamos a ciclar a través de esos archivos a medida que asignamos y liberamos memoria?
La elección obvia es simplemente mapear un archivo grande, hacerlo al inicio del programa y seguir utilizándolo. Cuando alguna parte ya no se use, simplemente sobrescribirla. Esto es obvio y, por lo tanto, está mal.

El primer problema con este enfoque es que sobrescribir una página de memoria requiere un algoritmo discreto.
El algoritmo es el siguiente: primero, cargas inmediatamente la página en memoria. Luego, cambias el contenido de la página en memoria. El sistema operativo no tiene forma de saber que, en el segundo paso, vas a borrar todo y reemplazarlo, por lo que aún necesita cargar la página para que las partes que no cambies permanezcan igual. Finalmente, programas que la página se escriba de nuevo en el disco en algún momento en el futuro.
Ahora, la primera vez que escribes en una página determinada en un archivo completamente nuevo, no hay datos que cargar. El sistema operativo sabe que todas las páginas son cero, por lo que la carga es gratuita. Simplemente toma una página cero y la utiliza. Pero cuando la página ya ha sido modificada y ya no está en memoria, el sistema operativo debe recargarla desde el disco.

Un segundo problema es que las páginas de la caché de páginas son expulsadas según el criterio de menos recientemente usadas, y el sistema operativo no es consciente de que una sección inactiva de tu memoria, que no se volverá a usar, debe ser descartada. Así, podría terminar manteniendo en memoria algunas porciones del conjunto de datos que no son necesarias y expulsar algunas porciones que sí lo son. No hay manera de indicarle al sistema operativo que simplemente ignore las secciones inactivas.
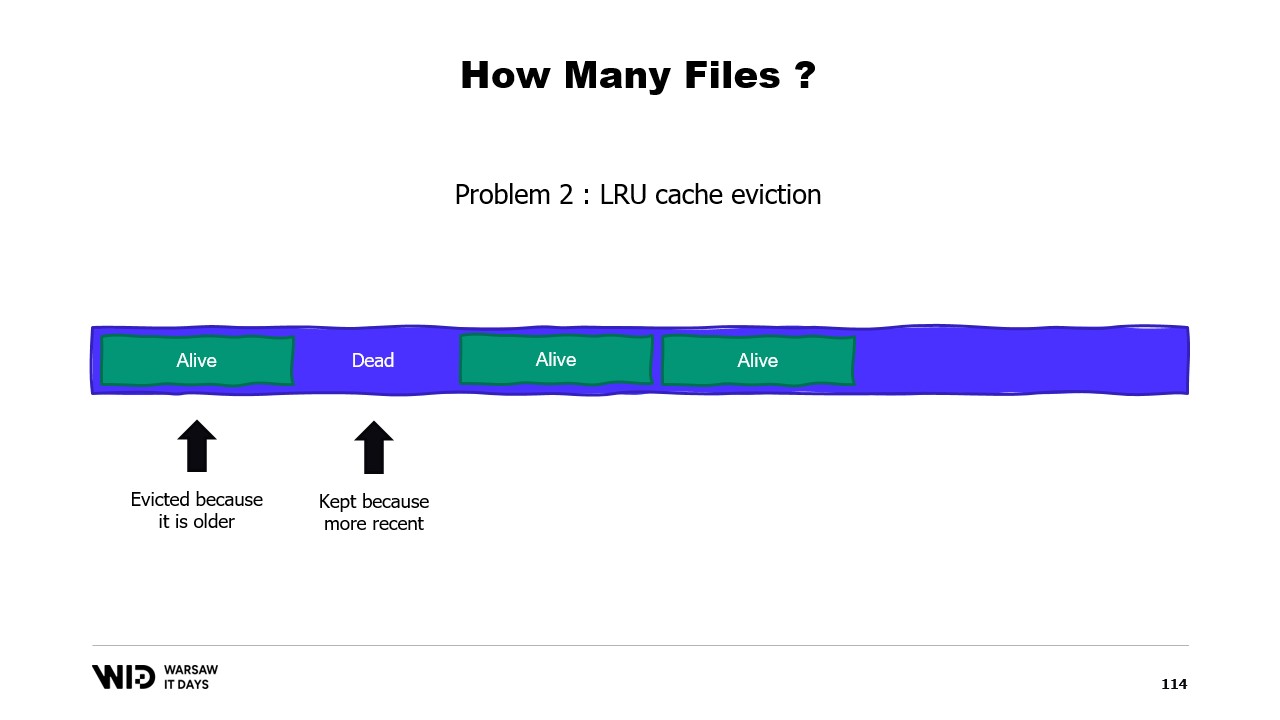
Un tercer problema también está relacionado, y es que la escritura de los datos en el disco siempre se retrasa respecto a la escritura de los datos en la memoria. Y si sabes que una página ya no es necesaria y aún no se ha escrito en el disco, pues, el sistema operativo no lo sabe. Entonces, aún emplea tiempo en escribir esos bytes que nunca se volverán a usar en el disco, ralentizando todo.
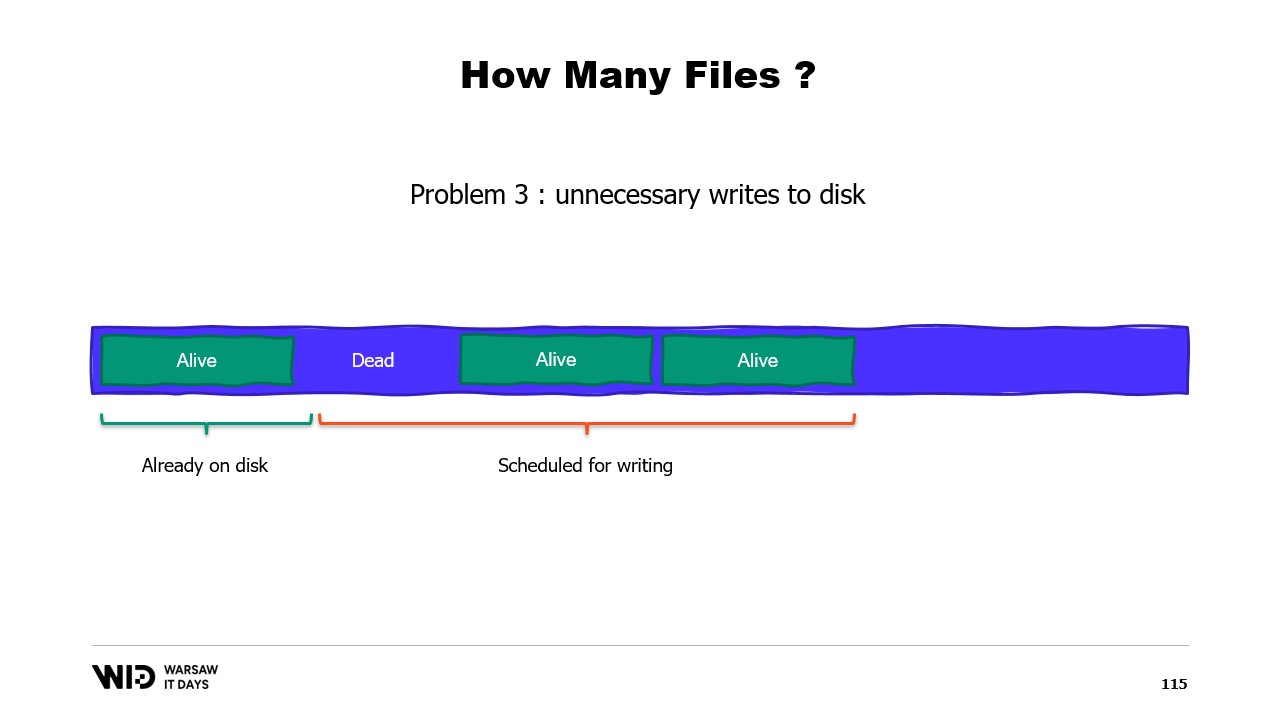
En cambio, deberíamos dividir la memoria entre varios archivos grandes. Nunca escribimos en la misma memoria dos veces. Esto asegura que cada escritura afecte a una página que el sistema operativo sabe que es completamente cero y no involucra cargar desde el disco. Y borramos los archivos tan pronto como es posible. Esto le indica al sistema operativo que esto ya no es necesario, que puede ser eliminado de la caché de páginas, y que no necesita ser escrito en el disco si aún no lo ha sido.

En producción en Lokad, en una VM de producción típica, utilizamos el espacio de trabajo Lokad con la siguiente configuración: cada archivo tiene 16 gigabytes, hay 100 archivos en cada disco, y cada L32VM tiene cuatro discos. En total, esto representa poco más de 6 terabytes de espacio de spill para cada VM.

Eso es todo por hoy. Por favor, contacta si tienes alguna pregunta o comentario, y gracias por ver.


