00:02 Introduction
01:43 Mechanization
07:34 Beyond the paradox
12:14 The story so far
14:32 Today’s submodules
16:24 Requirements (mainstream 1/5)
20:12 Design (mainstream 2/5)
25:37 Construction (mainstream 3/5)
30:29 Testing (mainstream 4/5)
34:09 Maintenance (mainstream 5/5)
41:12 Identity (trenches 1/8)
46:35 Resume (trenches 2/8)
51:43 Practices (trenches 3/8)
56:47 Bastions (trenches 4/8)
01:02:00 Code writers (trenches 5/8)
01:06:23 Pain tolerance (trenches 6/8)
01:14:55 Productivity (trenches 7/8)
01:21:37 The Unknown (trenches 8/8)
01:27:00 Conclusion
01:29:55 4.6 Software engineering for supply chain - Questions?
Description
Taming complexity and chaos is the cornerstone of software engineering. Considering that supply chains are both complex and chaotic, it shouldn’t come as too much of a surprise that most of the enterprise software woes faced by supply chains boil down to bad software engineering. Numerical recipes used to optimize supply chains are software and, thus, subject to the exact same problem. These problems grow in intensity along with the sophistication of the numerical recipes themselves. Proper software engineering is for supply chains what asepsis is to hospitals: on its own it doesn’t do anything - like treating patients - but without it, everything falls apart.
Full transcript

Welcome to this series of supply chain lectures. I’m Joannes Vermorel, and today I will be presenting “Software Engineering for Supply Chain.” Software is the foundation of a modern supply chain practice, yet most supply chain textbooks vastly underemphasize the role of software in supply chain. Software for supply chain isn’t a mere requirement like access to means of transportation; it is much more than that. From the perspective of supply chain practitioners, most of the work is driven by software, driven by software bugs or the limitation of software, and driven by software-related concerns.
Software engineering is the discipline that comes with the ambition to help people conjure better software, to get more from software, to conjure this software faster, and to spend less to achieve more. The goal of this lecture is to understand what software engineering is about and to understand its prime relevance for supply chain. The goal of this lecture is also to understand what, as a supply chain practitioner, you can do to avoid crippling your supply chain either through action or inaction that, unfortunately, happened to antagonize your software undertakings.

The 20th century has been the century of the mechanization of the workforce. Large companies and large supply chains, as we know them, did emerge in the 20th century, and the progress delivered by the mechanization of the workforce has been incredible. During the course of the last century, for almost every labor-intensive task that is relevant for supply chain, such as production or distribution, productivity has increased a hundredfold.
On the contrary, I believe that the 21st century is and will be the century of the mechanization of intellectual work, and this transition is very difficult to apprehend. The sort of intuition that applies when we go from the mechanization of the physical workforce does not translate at all into the sort of intuition that applies when we go into the mechanization of intellectual work. I’m not saying that the transition is any less dramatic, but the reality is that at this point in time, the transition towards the elimination of the workforce that was dealing with very labor-intensive tasks is already behind us.
In 2020 in France, there were 27 million people with white-collar jobs – essentially office employees – while there were only less than a million people left who were factory workers. The ratio is 27 to 1. When we start to look at what the mechanization of intellectual work entails, it is very surprising and is also very related to a paradox known as the Moravec paradox.
Hans Moravec, a computer scientist, remarked in 1980 that concerning computing, the tasks that seemed the most difficult for the human mind, like becoming a chess grandmaster, were actually the types of tasks that were easiest to tackle with computers. On the contrary, if we look at tasks that seem extremely easy for humans, like standing upright on two legs, those tasks prove to be incredibly challenging for computers. That’s the essence of the Moravec paradox: our intuition about what is difficult to achieve in terms of intellectual tasks with computers is very deceptive.
One thing that complicates the problem further is that suddenly, when we are talking about the automation of white-collar employees, it is done by the white-collar employees themselves. This was not the case with blue-collar factory workers; they were not the ones to decide that the factory would be mechanized further and that their jobs would be eliminated. Yet, this is what is happening with white-collar jobs. Thus, we have a challenge where not only is the mechanization process deeply counterintuitive due to the Moravec paradox, but the management of the people who are in charge of implementing this mechanization, namely software engineers, is itself very counterintuitive. This is probably one of the biggest challenges for supply chain: the management of the people who will be in charge, one way or another, of dealing with this mechanization.
Here, I can’t help but remark that many supply chains and associated companies are still firmly anchored in a 20th-century mindset, where you approach the corporate world as if you had white-collar people doing the intellectual work, and then they come up with the solution or plan, which is handed over to blue-collar workers for execution. However, with a ratio of 27 people to one when it comes to office jobs versus factory jobs in France, and likely similar statistics in most developed countries, this is not the way it happens now. It is literally about automating your own work, and it means that in this world of the 21st century, the very best white-collar employees are the ones that constantly manage to automate themselves, make themselves obsolete, and then move on to something else. This is very challenging for many companies that are still very much rooted in the 20th-century mindset.

Opinions diverge widely about the very notion of software engineering. One of the strongest criticisms came from Edsger Dijkstra, one of the founding fathers of computer science. According to his view, software engineering is not even possible as a discipline or field of research, and he said that it boils down or devolves into “how to program if you cannot,” sort of recipe. The criticism of Dijkstra, which is very interesting, is that software engineering devolves into some kind of self-help fiction that cannot possibly succeed. Indeed, if we propose that the goal of software engineering is to ensure the success of creating useful, superior software, then software engineering is mostly doomed. Success in software is incredibly difficult; it is as difficult as success in science. It takes a spark of genius, quite a bit of luck, and there is no recipe for that. Moreover, every single success tends to consume the very opportunity that it took to achieve this success, and thus the whole thing becomes non-replicable.
However, I disagree with the vision that software engineering is doomed. I believe that the main problem is defining the ambition of software engineering. If we decide that the ambition of software engineering is success in creating software, then indeed it is doomed. However, if we decide to approach software engineering as a narrow sub-branch of experimental psychology, I believe that we can gather, through this angle, very valuable and actionable insights, and this is the perspective that I will be adopting today in this lecture. Thus, software engineering is about software engineers themselves and their interactions. Focusing on software engineers is a good starting point because human nature is stable over time, unlike software technology, which is constantly changing. The nature of the people who are struggling with this technology is not; human nature has been very stable for a very long time.
If we look at other fields, such as science, we can see that approaching a field through the lens of the inspection of what its practitioners are doing can be very fruitful. For example, in science, it is now widely established that a conflict of interest leads to bad science and a corruption of knowledge. This point was previously covered in the lecture titled “Adversarial Market Research for Enterprise Software.” From this perspective, we see that it is possible to gather insights of wide applicability and relevance if we focus on the practitioners themselves. Thus, software engineering is about the people who are dealing with software technology, their struggles, and their processes, and not so much about the technology itself.
Today is the sixth lecture of the four chapters. This chapter is dedicated to the auxiliary sciences of supply chain. These auxiliary sciences represent elements that I believe are of foundational importance for a modern supply chain practice, but they are not strictly speaking supply chain elements. They are more like supporting elements for your supply chain practice.
So far, in this fourth chapter, we started with the physics of computing, dealing with modern computers, and then we moved upward through a ladder of abstractions. We moved from computers to algorithms, which represent the tiniest, smallest bits of interest in software. Then we moved to mathematical optimization, which is of interest for supply chain but also for plenty of other relevant software undertakings, such as machine learning. We have seen that mathematical optimization is directly interesting for supply chain, but it is also directly interesting for machine learning, which, in turn, is also of interest for supply chain.
As far as mathematical optimization and machine learning are concerned, most of the interesting concepts and paradigms nowadays are of a programmatic nature. It’s not just simple algorithms; it is something incredibly expressive and needs to be addressed through the lens of programming languages. That’s why the last lecture was about languages and compilers.
Today, we are still moving up this ladder of abstraction, and we focus on the people instead of focusing on what they are doing. We are going to focus on the software engineers themselves, and that’s the whole point of this software engineering analysis.

Today, I will be specifically presenting two sets of views about software engineering. First, I will present the mainstream view, which I believe dominates the field. Unfortunately, this mainstream view has generated criticism, as mentioned earlier, with people presenting self-help approaches that some, including myself, have reasons to oppose because they do not present a realistic ambition for the discipline of software engineering. Nevertheless, I will survey this mainstream view, if only because some misguided insights are still incredibly popular. Being familiar with these misguided concepts is of prime importance, if only to root out incompetent people who may endanger your supply chain through their incompetence.
Then, I will move towards a view from the trenches, which is a collection of elements rooted in my personal experience as the CEO of a software company that happens to operate precisely in the field of enterprise supply chain software. As we will see, the insights are very much about the people and not really about the technology itself.

The mainstream view of software engineering states that a software initiative starts with gathering requirements for the software of interest. Most software initiatives in large companies adopt this perspective through a process that typically starts with a Request for Proposal (RFP), Request for Quote (RFQ), or Request for Information (RFI). This approach is inherited from 20th-century practices that have been very successful in mechanical engineering and construction works. However, I believe that as far as software is concerned, these approaches for gathering requirements are deeply misguided.
In software, you do not know what you want; you just don’t. Knowing what you want is invariably the hardest part of software. For example, if we consider a simple problem like inventory replenishment, the problem statement is incredibly straightforward: at any point in time, I want to know the quantity that I should be replenishing or reordering for every single SKU. The problem itself is simple, yet defining what a good quantity is becomes devilishly complex and difficult. As a rule of thumb, clarifying requirements is vastly more difficult than writing the piece of software itself.
It is only by confronting your intuition with the feedback given by the real world that you can gradually let the requirements emerge. The requirements don’t fall from the sky; they can only be obtained through a fairly experimental process, and you need to have this interaction with the real world. However, the only way to have this interaction is to have the software product, as gathering requirements is fundamentally a very empirical and emerging process. The problem is that by the time you are done with the requirements, having the requirements becomes moot because, if you have the requirements, it means that you already have the corresponding product that implements those requirements. So, by the time you do have access to the proper requirements, you already have the product in production, up and running, and the fact that you have those requirements is somewhat irrelevant.
Thus, the point is that starting the process through the lens of requirements is, I believe, a lunacy. Requirements should probably come last as a late-stage documentation, where you document all the core reasons that led you to implement the product the way you did, not the other way around.
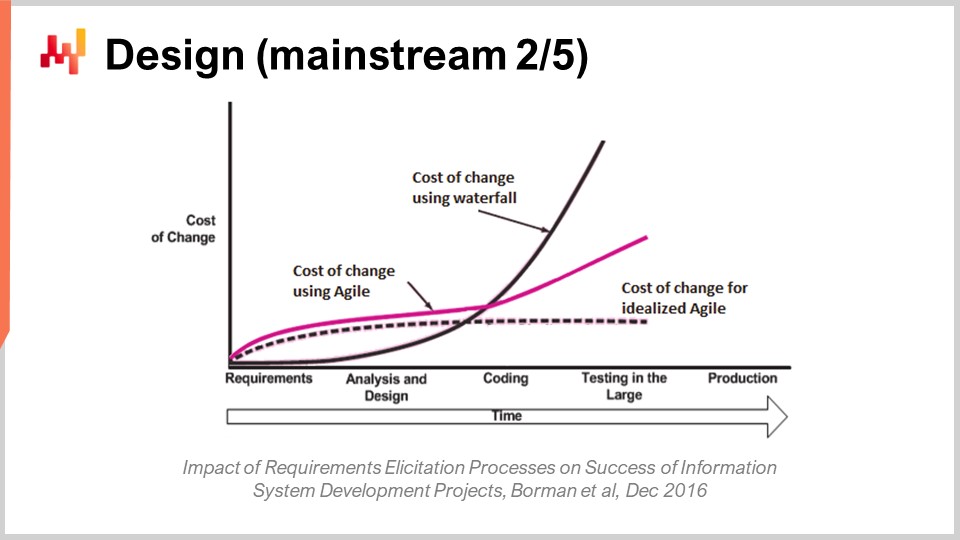
Once requirements are laid out, the classic approach states that one needs to proceed with the design phase. I agree that, at some point, some design may happen. However, the sort of thinking that goes into this design phase is frequently misguided. The problem boils down to getting the cost of change under control. The classic non-software perspective on the cost of change is that the cost increases exponentially over time. For example, if you change the design of a car very early when you’re only dealing with a blueprint, the cost of change is minimal. In contrast, if you wait until millions of those cars are on the roads, the cost of change is incredibly high because it implies a recall, which can be incredibly expensive.
However, unlike the physical realm, in the software realm, the cost of change is not naturally increasing exponentially. The cost increase cannot be entirely mitigated; however, to a large extent, the cost increase can be managed. Indeed, the cost of change does increase over time, mostly because codebases tend to grow over time. I’ve never seen a codebase of a piece of enterprise software significantly shrink from one year to the next; they tend to keep growing. Nevertheless, it is possible to manage the cost of change to a certain degree.
Nowadays, this aspect is becoming more widely recognized, even in software circles. By the way, this is the essence of the Agile methodology. You might have seen these terms floating around when people say, “Oh, we have this Agile software methodology.” One of the biggest intents of the Agile methodology is to put the cost of change under control. I won’t go into the fine print today about the Agile methodology, but suffice it to say that I believe this approach is slightly misguided when it comes to how exactly you bring this cost of change under control.
I observed that the cost of change mostly originates from the decisions that are being made about the software and, more specifically, the fact that it is very difficult to resist the urge of making decisions. Imagine you’re looking at a potential future software product, and there are plenty of decisions to be made. The early attempt would be to make those decisions just to clarify what you have in front of you. On the contrary, a very good design phase, rather than good design, is the ability to postpone all the decisions that are not absolutely required, where the product doesn’t require those decisions to be made now. Indeed, if you don’t make the decision, as long as the decision isn’t made, and you’ve not established that you need to take this specific design approach or technological approach, it’s still floating in the air, ready to be changed because nothing has been decided yet.
One of the aspects to keep the cost of change under control is to learn to postpone all the decisions to the greatest extent that is practically possible. From a supply chain perspective, this looks very strange because it means that for all the people in the software team and all the people observing the product and the software team, it appears as if they’re being kept in the dark. It’s even worse than that because they’re kept in the dark on purpose, which is very puzzling. Yet, it is precisely what needs to happen, and it has to be done on purpose. That’s why it’s disconcerting, to say the least.

Now, if premature design decisions are rooted in the sometimes misguided need for control, the problems associated with this need for control don’t stop there. Once the design phase is out of the way, the mainstream view on software engineering states that we should proceed with the construction of the software, also frequently called the implementation phase. The way it is typically done is to present some kind of waterfall projection, also called Gantt charts. This is what you can see on the screen. I believe that this approach, Gantt charts and waterfalls, is incredibly toxic, and the toxicity of this approach should not be underestimated as far as software is concerned. Approaching the problem like this is literally setting your supply chain to fail, at least as far as its software initiatives are concerned.
A much better way to understand the problem and approach the construction of the software is to think of it as a learning process. The construction of the software is about learning all it takes to get a good product. This is a learning process, and all those learned parts are a byproduct of letting the world interact with the software that is emerging from the construction process. The key problem with a waterfall prediction is that you are projecting what you are about to discover. This is just not possible by definition. What you’re about to discover was unknown until you discover those elements. You can’t project your discoveries. You can expect them, but you can’t plan the fine print of what you’re about to discover. You can have hunches, but that’s the best you can get. The idea that you can turn those vague intuitions into a precise waterfall prediction is, again, complete lunacy.
By the way, this small apparent paradox about the construction of software as a learning process also explains why sometimes replicating a piece of software can be either incredibly easy or incredibly difficult. If a team attempts to replicate a software product that is already in the market, and this team has access to the understanding or the lessons that led to the production of the software they’re trying to copy, then typically replicating the software product – re-implementing or recoding it – can be done with only a tiny fraction of the time and budget that was needed to create the software in the first place. On the contrary, if the team does not have access to these high-level insights, and for example, the only thing they have access to is the source code, the team will very frequently end up with a product of very low quality because essentially, all the learning parts or the knowledge tidbits have been lost. You’ve just replicated the surface appearance of the product.
From a supply chain perspective, the biggest challenge here is to willingly give up and tame your need for control. The waterfall process is an expression of a company that wants to control the process. For example, if I say, “let’s get this project under control,” that would be perceived as something very reasonable. Why would you do the opposite? Why would you state, for example, “let’s have this project completely out of control?” But the reality is that this degree of control is a complete delusion as far as software is concerned, and it completely hurts your capacity to deliver a high-quality product in the end. Taming your desire for control is, from a supply chain perspective, probably the biggest challenge when it comes to the construction of software.

Since the emergence of computer programs, they have been riddled with bugs and defects. In order to address those obvious problems, the mainstream view is that testing must take place. Testing takes many forms. Concerning the need for testing, I agree, although this is very vague at this point. Some tools emphasize that testing needs to be done after construction, some emphasize that testing must be done during construction, and others specify that testing must be done before construction. Some approaches state that testing must be done before, during, and after the construction of the software.
My general view on the problem is that you should do whatever it takes to keep the feedback loop as short as possible. We discussed this point in the previous lecture: keeping the feedback loop as short as possible is of critical importance to actually get something that works in the real world. Thus, I would typically recommend paying attention to whether what you’re doing in terms of testing is actually tightening this feedback loop or not. For example, for most situations, I would not naturally recommend test-driven development (a methodology that says testing comes first), just because for most situations, testing first will just delay the amount of time it takes to get feedback about your piece of software from the world at large.
However, my biggest concern about testing is an untold limitation, something that seems to be generally dismissed. Testing can ultimately only assess compliance toward the very rules that you’ve established yourself. The problem is that in software, there are no hard constraints. There is no chemical way to approach the adequacy of your product with regard to the problem that you are attempting to solve. This is very unlike the physical realm. For example, in mechanical engineering, there is a canonical criterion: the dimensional tolerance of a part. Whatever you happen to be engineering in terms of mechanical engineering, dimensional tolerance is going to be of primary importance. It is an obvious and natural candidate. However, there is no such thing as natural and obvious candidates in software.
The problem here becomes one of adequacy. If we want to take a supply chain example, such as safety stocks, it is completely straightforward to design an automated testing suite to validate safety stock calculations. It is very straightforward to implement this sort of testing logic. However, this cannot tell you that safety stocks are a bad idea in the first place. You’re only testing for what you know.
When we are dealing with a physical machine, we expect wear and tear, and thus we expect some sort of maintenance to keep the machine in working condition. However, why would software need any kind of maintenance to keep operating? Certainly, we need to replace computers as they break down over time occasionally. However, this aspect is very marginal, and in enterprise software, the physical breakdowns of machines do not even account for 10% of the actual maintenance costs. This exists, but the impact of this sort of maintenance is incredibly thin.
Yet, maintenance in enterprise software is of primary importance. The maintenance costs are massive. For many enterprise software vendors, maintenance is literally 80% or more of the engineering cost. It turns out that the factors that generate this need for maintenance have very little to do with physics. The first factor is the willingness to pay of the clients themselves. If a vendor can get away with an annual maintenance fee of 20% with regard to what was paid for the setup of the software during the first year, then the software vendor will charge that. Essentially, from the cost perspective, the cost of maintenance is driven by the willingness to pay of enterprise clients.
The second factor is the sort of maintenance that needs to happen just to keep the software operating. Indeed, for every single day that passes, the environment surrounding the product of interest diverges from the product. The operating system keeps evolving, the database system keeps evolving, and the same can be said for all the third-party libraries that are used by the software. No software product is an island. Every single software product depends on a myriad of other software products, and those other products are evolving on their own. The people who are developing those software products keep working on them, and as they work on those products, they keep changing them. Thus, there comes a point in time where the product you have just stops working because there is an incompatibility. You’ve not done anything except not keeping up with the rest of the market. The second factor is all the maintenance that needs to take place just to keep the software running and to keep the software compatible with the rest of the market.
The third factor is the amount of work it takes to keep the product useful. Indeed, the software was designed and engineered at a certain point in time, and every single day that passes, the world diverges from what was seen at the time when the product was engineered in the first place. Thus, even if nothing really breaks down in terms of hardware compatibility, it turns out that as the world changes, invariably the usefulness of the product decreases because the world is simply diverging from the sort of expectations that were built into the product. If you want to keep the software useful, you need to constantly maintain the software.
From a supply chain perspective, maintenance is a big challenge, and we touched on this aspect in the previous lecture, which was about product-oriented delivery for supply chain. The cost of maintenance significantly impacts the capitalistic benefits that you can have from your software undertaking. Ideally, you want your software undertaking to have a very high return on investment, but in order to do that, you need to make sure that you don’t end up with massive maintenance costs. These costs will completely undo the capitalistic profit and return that you can get from your software investment.
The biggest challenge here, again from a supply chain perspective, is that the simplest way to minimize maintenance cost is to focus on what does not change. As I mentioned earlier, most of the costs are related to the things that happen to be changing, either in the software ecosystem or in the world at large. However, if you focus on the things that do not change, then what you get is essentially the bulk of your software that will only decay slowly because, precisely, most of what your software tackles are the things that do not change.
The problem is that focusing on what does not change is easier said than done, because you have a very human force that antagonizes this intent: the fear of missing out. When you are looking at the press, the media, your colleagues, etc., there will be a constant stream of novelty, buzzwords, and every single buzzword has this urge, due to the fear of missing out, to just do the thing and not be left behind. For example, all those buzzwords would be AI, blockchain, IoT, and all those things that are very present. I believe that in supply chain, these buzzwords are really a distraction and they significantly contribute to maintenance problems because they are a distraction from what does not change. On the contrary, when you start looking at those buzzwords, you are riding a wave, and you’re riding exactly the sort of things that are very likely to be changing over time, thus inflating your maintenance cost over time.

Now that we are done with the mainstream view on software engineering, let’s delve into a series of personal nuggets that should hopefully prove useful to conduct software initiatives while keeping supply chain in mind. One of the most frequent problems when dealing with software people is a misconception about their own identity, and I’m stealing this idea from an entrepreneur named Paul Graham. An engineer will, for example, say, “I am a Python engineer.” While it may not be as extreme, it is very frequent that software engineers perceive their own identity through the sort of short series of technologies that they have mastered, which make up their skill set. This confusion between their identity and their current skill set tends to be reinforced by the hiring practices that are prevalent in the IT and software world at large. From a hiring viewpoint, there are many companies that state in their job advertisements, “I need a Python programmer.” So, there is someone on one side thinking, “I am a Python programmer,” and then there is a company that is going to post a job position where it’s basically written, “I need a Python programmer.” Thus, suddenly having the right identity is not just a matter of perception; there are financial rewards attached to having the right identity, the right label, the right tag that you can attach to yourself, making you more attractive in the market.
However, this identity-driven perception, where technologies become attached to oneself as a software engineer, leads to numerous issues that impact pretty much every single software project, and supply chain software projects in particular. When interacting with a person, typically a software engineer, who has their identity strongly attached to the tech that is in place in your company, the problem becomes that every criticism of the tech tends to be taken from a personal angle. If you say that I am a Python programmer and you critique my software, I take it personally. The problem is that as soon as people take criticism of the tech as personal criticism, it becomes very difficult to reason about those problems. These software engineers will, unfortunately, tend to deflect all the feedback, just because they partially see it as personal criticism.
Conversely, if the company happens to be using a technology that is not the technology perceived as core identity by the software engineer, for example, your company has some systems implemented in Java and you have a software engineer that says, “I am a Python programmer,” then all the problems will be perceived through the lens that this piece of technology is subpar. Again, that’s another problem where the criticism and feedback will be deflected as an attitude of “not my problem; this is just because of this very poor technology that happened to be used here and now in this company.” In both situations, whether the software engineer has an identity that is attached to the technology you’re using or has an identity attached to a technology you’re not using, it creates a whole series of problems, and the feedback gets deflected instead of being leveraged to improve the technology.
Now, from a supply chain perspective, we have to keep in mind that the supply chain environment is incredibly chaotic, and thus problems will happen all the time. Precisely due to this ambient chaos, it is very important to have teams of software engineers that can look straight into the eyes of these problems and do something about them, and not just deflect the feedback when it happens. It is crucial to assemble teams that do not foster drama on top of supply chain chaos due to their perception of their identity.

This idea extends to software engineers, who often choose technologies that fit their identity or the identity they want to acquire. They pick technology to acquire the skills, so they can add another keyword to their resume. However, this approach leads to choosing technologies for reasons unrelated to solving the problems faced by the company. This is the wrong perspective for deciding whether a technology is relevant or adequate for addressing the specific issues faced by the organization.
Building a resume can be a powerful motivator for software engineers, as there are real-world financial benefits associated with having a list of keywords on it. The very best software companies often look down on resumes with a long list of keywords. As the CEO of Lokad, if I see a resume with half a page of keywords, it is directly discarded. However, many companies, especially mediocre ones, actively seek people with many keywords, thinking that these individuals will be incredibly versatile and agile within the organization. From my experience, this is often the opposite.
Continuing with the topic of identity and resume building, it is vital to pay attention to the fact that software architects should not be too attached to any particular technology. It is already difficult to hire software engineers, so sometimes compromises have to be made. However, when it comes to software architects, compromising by selecting individuals with an emotional attachment to a certain technology can be disastrous. These individuals will have a large-scale impact on your company.
This problem of resume-building bias is not limited to software engineers or software professionals. It also occurs among IT personnel. For instance, I have met several IT directors in large companies who wanted to transition to SAP while their existing legacy ERP was perfectly fine. The massive costs associated with transitioning to SAP would never be offset by the expected benefits of a more modern ERP. In these cases, an irrational behavior was at play, where the personal interest of the IT director in deploying SAP on their resume was trumping the interest of the company itself.
From a supply chain perspective, it is essential to pay attention to these conflicts of interest. It doesn’t take much software skills or competence to detect conflicts of interest. In other fields, such as medical science, even physicians can prescribe the wrong drugs due to conflicts of interest, even when lives are at stake. This demonstrates that conflicts of interest are incredibly toxic. Just imagine how these issues play out in supply chain management, where there are no lives at stake and the main concern is money. There is even less reluctance to let conflicts of interest unfold in this context.

Unlike the physical realm, the software realm offers very few constraints on how to proceed with software initiatives and approach work. Human nature does not like a vacuum, and people can become unsettled by a lack of structure. As a result, numerous practices have appeared over the years and continue to emerge. With each practice comes a notion of orthodoxy. Some examples of these practices include extreme programming, domain-driven design, test-driven design, microservices, Scrum, and agile programming. There are many practices, and new ones emerge every year.
With every practice comes a notion of orthodoxy. As soon as people start following a practice, they may question whether they are adhering to the core principles. Software engineers are just people, and people love rituals and tribes. A practice provides a sense of belonging to a tribe with shared beliefs. This is why you will find meetups associated with these practices as well, fulfilling a very human need.
It can be difficult and even depressing to stare at a problem, unsure about everything, and having almost nobody to relate to when it comes to tackling the issue. The interesting thing is that while a practice can be questionable or slightly irrational, the benefits can be real. Advertising a practice inside and outside your company can boost morale and help hire prospective applicants.
In a job interview, when people ask about how you work, it is not exactly compelling to say that you improvise and have no rules. It is more efficient to inspire confidence by presenting a practice as if it will solve problems within the company. The key point is that, in the short term, these practices are not all bad, even if they are mostly irrational. Generating a sense of belonging can be beneficial. However, it becomes poisonous if practices are taken too seriously or for too long. A practice can be of interest just because it forces you to look at the problem from a different angle. But once you’ve looked at the problem from a different angle, you should try to find yet another angle. You should not stick with one angle for too long. From a supply chain perspective, this illustrates the radical oddity of the software realm.
On the factory floor, excellence means always doing exactly the same thing. In the software world, it’s the exact opposite. If you’re doing the same thing, then it’s a recipe for stagnation and failure over time.

Software is complex, and enterprise software even more so. Frequently, multiple engineers end up working on a given initiative, which leads to a natural tendency for specialization. When an engineer works on a certain portion of the codebase, there is a natural inclination to assign the same person when new tasks require touching that same portion of the codebase. The benefits are real, as this person is already familiar with the code and can be more productive.
The main issue with specialization is that it can lead to a sense of ownership over portions of the codebase, creating various problems. There are two classes of problems associated with this ownership: the “truck factor” and power games. The truck factor refers to the risk of losing an employee who possesses unique knowledge or skills. This could be due to the employee leaving for another company or being unable to work for any other reason. Power games can occur if an employee realizes their contribution is vital to the company and uses this leverage to demand a higher salary or other benefits.
In my experience, software engineers typically do not have a strong propensity for playing power games, but these problems can become increasingly frequent in larger companies. There are many software engineering practices that try to tackle this problem head-on, such as pair programming. However, the key insight is that too much of a good thing can be poisonous for the company. The best thing is to be aware of this class of problem, rather than just sticking to one particular practice that is supposed to address the problem. This is because such practices can create other problems, distract you, or restrict your capacity to pay attention to other things that you have not seen yet. From a software perspective, the key lesson here is that culture is the antidote to this class of problems, not process.
We face a situation where we have a very subtle trade-off between the productivity gains achieved by having people specialize in portions of the code and the risks associated with having those people owning those portions of the code. What you want is to cultivate a situation where there is always some degree of redundancy in terms of knowledge about the code base from the entire team, so that every single engineer has some kind of overlap of competency. This is a very subtle trade-off that you need to achieve if you want to maintain any degree of productivity. The only way to actually do that in the real world is through a well-understood culture about software engineering. There is no process that can guarantee people will be curious about the work of their colleagues. You can’t have a process about curiosity; it has to be part of the culture.

Assessing the skills and competence of software engineers is difficult, and this question is key because although software is clearly a team effort and the team is more than the sum of its members, the base level of the members of the team has a big impact on the performance of the team as a whole.
One aspect that I observed to be largely underestimated by people outside the software industry, and sometimes also by people inside the industry, is the importance of writing skills. If you are creating software, you are catering for two distinct audiences. On one side, you have the audience of the machine—your compiler. You write code, and your compiler will accept or reject it. This is the easy part. Your compiler is your indefatigable companion that will tell you if your code is correct or wrong. The compiler is completely predictable and has an infinite amount of patience.
On the other side, you have the audience of your colleagues, which will likely include yourself six months down the road. You write code and will eventually forget it. Six months later, you’ll look at the code you wrote, thinking that it was written by someone else because it seems so unfamiliar. When you write code for your colleagues, the benefit is that unlike compilers, your colleagues will try to understand what you’re trying to achieve. The compiler does not try to understand your intentions; it applies a set of rules mechanically.
Your colleagues will try to understand, but unfortunately, they are not like compilers. They don’t have an infinite amount of patience, and they can be easily confused and misguided by your code. That’s why, for example, picking memorable, insightful, and appropriate names is of primary importance. A good program is not just about having something that is correct; even choosing the names of variables, functions, and modules is of critical importance if you want to have code that will play well with your colleagues, and again, your colleagues include yourself six months down the road. From a supply chain perspective, the key takeaway is that writing skills are of primary importance, and I would go as far as to say that writing skills are frequently more important than raw technical skills. Good writing skills are the number one skill you will need to tame the complexity present in your supply chain. Taming the complexity of your applicative landscape is not a great technical challenge; it is a challenge of organizing ideas and elements, and having a consistent story across the board. These are very much writing skills, and we touched on this aspect in a previous lecture titled “Writing for Supply Chain.”

If writing skill is of primary importance to be a good software engineer, there is another skill that is of primary importance to be a software engineer at all: tolerance to pain. I believe this is the number one skill in the sense of what it takes to actually be a software engineer, not a great one, just to be one. More specifically, when I say pain, I mean the resistance to boredom and frustration that goes along with the process of engineering software when facing systems that are incredibly fragile, badly designed, and booby-trapped in all sorts of ways, sometimes by people who are not even there anymore. When you’re dealing with software, you have four decades of accumulated issues under your feet, and you’re struggling with that all the time. This can be an incredibly frustrating exercise at times.
Just to give you an illustration, as a software engineer, you will need to have the patience to spend four hours digging through random, semi-garbage conversations on a web forum that mention an error code similar to the one you’re facing. You will have to go through this kind of nonsense for hours to get to the bottom of it, and sometimes it takes weeks to resolve a seemingly trivial bug. Thus, the consequence of that is that we have a very intense adverse selection process at play in the entire software industry, which selects people who have a high tolerance for pain. This selection process has two major consequences.
First, people who remain software engineers tend to be incredibly tolerant to pain. When I say tolerant to pain, I mean resistance to frustration from the constant software problems faced. As you’re selecting for people with incredible tolerance to pain, they might not even recognize when their actions are making the situation worse. They may add extra quirks into the software products, increasing the pain level of interacting with the software for everyone, including themselves. However, if they happen to be incredibly tolerant to pain, they don’t pay attention. This adverse selection process leaves out regular people who would pay attention but did not become software engineers because they could not stand the pain. This problem is particularly intense for supply chain software because there are many parts that are not super exciting. Some aspects can be necessary but mundane, which means that people with high tolerance to pain operating in this field can make the situation worse due to the abundance of potentially boring tasks.
The second aspect of this adverse selection process is that when people can afford the luxury of going for a lower salary to avoid problems that generate intense pain, they do so. If someone is already well paid, they may decide to go for a job that is not as well paid but comes with the benefit of less intense pain. Most people would likely do this, and in practice, many people do. It means that the people who remain in this industry, where there is a very high intensity of ambient pain, are often those who cannot afford to not go for the opportunity of a higher salary. This explains, to a large degree, why there is a significant number of software engineers coming from India and North Africa. These countries have fairly good education systems that produce well-educated individuals, but the countries are still relatively poor. People in these positions don’t have the luxury of giving up on higher-paying software engineering jobs due to the high demand and higher salaries compared to their baseline salaries. They don’t have the luxury of going for something else, and thus they end up being very prevalent in the industry.
There is nothing wrong with these countries; it’s merely a mechanical application of market forces. This is not a judgment, just an observation. The thing is, tolerance to pain is not all it takes to be a great software engineer. It is just a condition, but if you don’t have that, then you’re not a software engineer at all. However, if tolerance to pain is the only thing that you have, it will make you a fairly poor software engineer. From a supply chain perspective, the lesson here is to pay close attention to the sort of teams that your company is gathering, either internally or through software vendors. Ensure that the engineers being gathered don’t have tolerance to pain as their only skill, because that means you’re going to have a very poor outcome in terms of software quality and added value from the software. Again, tolerance to pain is required, but it’s just not enough.

In 1975, Frederick Brooks was already pointing out that man-months were not representative of the value created by software and the value generated by software engineers at large. Almost five decades later, IT companies are among the largest employers in the world. In 2020, in the USA, there were 3 million employees in the IT industry, but less than 1 million people for the entire automotive industry. The IT industry now has at least three times more people than the automotive industry. Most of those IT companies, some being absolutely gigantic with several hundred or thousands of employees, do not charge by man-month anymore. This was the 70s. We now charge by kilo-days, which is basically a thousand days of manpower. The situation has arguably become much worse compared to the problem Frederick Brooks was outlining almost five decades ago, primarily due to the incredible increase in terms of scale and magnitude of the problem. However, most of the early lessons are still valid. “The Mythical Man-Month” remains a very interesting book about software engineering.
In software, productivity varies enormously. On one end of the spectrum, you don’t have people with low productivity; you have people with negative productivity. That means that when they start working on a software product, they just make it worse. You can’t even make a ratio anymore between the productivity of people. It is much worse than that; you have people who will actively degrade your product. That’s a massive problem. On the other end of the spectrum, you have the so-called 10x engineers, people who have ten times the productivity of your average engineer, who hopefully has positive productivity. These 10x engineers do exist, but this massive productivity is incredibly context-dependent. You can’t just transfer a 10x software engineer from one company to another or even from one position to another and expect that person to retain their incredible productivity. Usually, it’s a combination of unique skills and a specific situation that generates that productivity. Nevertheless, it is important to keep in mind that a tiny few people can drive the bulk of the value generated by a software product. Sometimes, it boils down to just one person who is creating the bulk of all the smart elements of the software and the true added value, with the rest dealing with things that have dubious added value at best. The key lesson here, identified five decades ago, is that when you’re running against a deadline in supply chain, the only reasonable option at your disposal is to reduce the scope of the software initiative. All the other options are worse.
Adding manpower makes things worse, as it is often said that adding manpower to a late software project makes it later. This statement by Brooks was valid five decades ago and is still valid nowadays. The other options do not work either. If you start having people doing overtime, it will backfire because people will be tired and make more bugs, delaying the product further. If you try to lower the quality, you will end up with something that does not work anymore. These things will spiral out of control and explode in your hands, so you cannot compromise on quality.
From a supply chain perspective, the key lesson here is that if you tackle any initiative that seems to require more than ten full-time software engineers, proceed with utmost caution. Usually, it’s a sign that it is a very badly framed problem. It takes incredible teamwork to have ten people working on the same product simultaneously while retaining productivity. In supply chain, I observe that people are often too ambitious in terms of scale and the number of people involved. I have seen ERP migration projects with 50, 100, or 200 people working on them simultaneously. This is absolutely nonsensical. Achieving any degree of cooperation requires incredibly capable team players to avoid losing everything through friction. If you’re struggling, keep your software initiative focused, short, and narrow.

My final observation is about a frequent misunderstanding regarding large companies. Most people would say that large companies are risk-averse, but that is not my experience. My experience is that large companies are averse to uncertainty, not risk, although from afar, the two can be confused. From afar, the rational explanation given is that large companies are averse to risk, but in reality, I have observed over and over that large companies, when faced with the opportunity to go for a certain failure versus an uncertain success, will invariably favor the certainty of failure over the uncertain success.
Large companies will invariably favor the certainty of failure over the uncertain success, over and over again. This may seem baffling and irrational on the surface, but it is not. Large companies are not a single entity; they are political beasts made up of many people. Politics and appearances are paramount, especially in very large structures.
Consider the perspective of whoever is in charge of a software initiative. On one hand, you have an initiative where the outcome is certain – it will fail. However, you are playing by the book, following the rules, and everyone knows that it will fail. Nobody will blame you for playing it safe and failing because that is what they expect. On the contrary, uncertain success looks weird. Pursuing this path means doing things that are unusual and potentially damaging career-wise, much more so than just playing it by the book.
From a supply chain perspective, the lesson here is that in the software world, it is critically important not to set yourself up for failure just for the sake of playing it by the book, especially when the book is completely bogus. For example, I have seen companies fail for decades using methods like ABC analysis and safety stocks, methods that can be provably incorrect and guarantee the failure of the corresponding initiatives. These methods are wrong for basic mathematical and statistical reasons, so it should not come as a surprise that they fail to deliver added value in supply chain. However, they were deemed preferable because they did not appear as crazy, being textbook material.
Beware of the comfort that can be gained by setting yourself up for failure just to eliminate uncertainty. Eliminating uncertainty is not the goal; the goal is to maximize the chance of success, not to reduce uncertainty.

In conclusion, software engineering is too important to be left only in the hands of software engineers. Software is all over the place in supply chain and is driving the mechanization of intellectual work. We are still at an early stage of the process, but it can already be said, without a doubt, that companies that do not remain extremely competitive on this front will be eliminated from the market altogether by regular market forces. For supply chain, the biggest challenge is a cultural one. This is not a technical problem, but a cultural problem. Software engineering challenges the very way we look at and approach problems. Most intuitive solutions tend to be wrong, spectacularly so.
In a way, software engineering in supply chain is about taming chaos, taming all the complexity and uncertainty that happens to be all over the place in supply chain. In order to tame this chaos, which will be the job of software engineers, if the process itself is too polished or ordered, if the process itself does not have an element of chaos at its core, then there is no room left for change, chance, or creativity. What is perceived as excellence quickly devolves into stagnation and then failure. For more traditional companies, the biggest challenge from this cultural approach, besides the culture shock, is to let go of the illusion of control. Your five-year ERP migration plan is a delusion; you have no control over such a massive project. Similarly, your business case that outlines the expected profits of your current initiative is also an illusion.
When tackling the mechanization of intellectual work, the biggest danger is not doing things that you cannot fully rationalize. The biggest danger is to do things that are completely irrational under the guise of rationality.

Let’s have a look at the question. The next lecture will happen on Wednesday, December 15th, same time, 3 p.m., time of Paris, and it will be about cybersecurity. Now, I will have a look at the question.
Question: How do you measure the capitalistic return on your software investments?
Mostly, you don’t. The measurement is the byproduct of the undertaking itself. It is something that is puzzling if you want to measure the return on investment. It assumes that you can come up with a measurement beforehand, which is typically implied with this sort of question. It assumes that you can come up with this measurement before building your business case with scenarios, and then you can make a decision and go through or not with your software investment. What I am saying is that it doesn’t work that way with software. It’s literally first, you do the thing, then you learn what has to be learned, and then along the way, you will even learn what sort of benefits there are. To guide your action, you need a high-level understanding. The lesson is not to do things randomly, but not to do things that are deeply irrational under the guise of rationality. High-level intuition, if you’re absolutely convinced about something and your gut tells you it’s the correct path, can be a much more rational argument compared to fancy calculations that only have the pretense of rationality but are based on garbage numbers. The reality is that as you progress through your software undertaking, the measurements will become clearer because you will start learning about what you’re trying to achieve, and then you will learn how to measure the adequacy of what you’re doing with what you should be doing. The measurement is something that will come as a byproduct if you do it well. However, as a consequence of this, it means that as far as software is concerned, it is much better to just try stuff and fail fast. You don’t want to engage yourself in some massive commitment; it’s better to do it in ways that are incredibly incremental, with fewer people and high productivity. You learn along the way how to proceed.
But then comes another problem: as soon as you start doing that, the management in companies needs to be able to juggle many initiatives at the same time. This is very disconcerting, especially for more traditional companies, because management does not expect to have so many initiatives all going in different directions. Yet, this is exactly what has already been happening in large software companies for decades now, and this is one of the essences of the takeaways from software engineering from a human perspective.
Question: Isn’t it a contradiction to say that those with many keywords don’t associate with a particular technology?
Well, I don’t say that having many keywords protects you from associating yourself with one particular technology. There are two different problems. One is the problem of having a person that has a strong association between their personal identity, their perceived identity, and their skillset. That’s problem number one. The problem number two is that building your resume comes with a very strong latent conflict of interest. My message is, on one side, beware of those identity politics; they are incredibly toxic. My second message is beware of conflicts of interest in all their forms; they are incredibly toxic as well.
Now, if you really super emphasize one technology in particular, you may remove some keywords for tech that you disapprove of on your resume. However, usually, the two problems are separate, and you can even have someone who says, “My identity is I am a Python programmer,” as I was showing in a slide, and then on your resume, put 20+ keywords. The two things are not exclusive; they can even happen simultaneously. Also, don’t underestimate the fact that sometimes the identity can be associated with something aspirational, something that you want to acquire. You may say, “So far, I’ve been programming Python, but I want to become a Rust programmer, so I’m going to consider myself as a Rust programmer, although so far I’ve mostly done Python.” All sorts of behaviors are possible.
Question: Software engineering is considered to be an auxiliary science for supply chain. What would be auxiliary sciences for software engineering?
Probably psychology, sociology, and ethnology are all relevant fields when it comes to software engineering. If you start approaching it as essentially the interaction of people, then these auxiliary sciences are crucial. To do serious work in software engineering, it is not solely about the software technology, although you need to understand the software context so that the interactions between people make sense. You don’t necessarily need to understand what goes into the code, but you need to understand concepts like a codebase or the tools that exist and the problems they are trying to solve. However, for the purpose of this series of supply chain lectures, I need to draw a line in the sand, deciding what I include and what I do not include, as I obviously cannot cover every single field of research.
Question: Ask ten clever people for a solution, and they will come up with more than ten ways. Agreeing on one of the top five and using it consistently is better. How do you balance those two conflicting approaches and benefits?
That’s a very broad question, but if I try to frame it in the specific case of software engineering, you can have many propositions, but not all should be considered with equal weight. There is such a skill as having a long-term view of software. When I say you should focus on what does not change, it turns out that some people are very good at this work, and some are not. Experience comes into play when you want to look at who has the skills for this long-term view and what does not change. In my humble experience, it typically takes someone at least 35 years old to start getting very good at that, and the very best people are over 60. It takes years of experience to see the motion and the patterns.
When you say that you have that many people, one illusion is that all of those solutions look good, but that’s just an appearance. You don’t know how much effort it will take to test out the waters. Can you just prototype or test it out? Among those ten people, are there some with unique skills at identifying solutions that will be poisonous in the long term? Remember that your maintenance costs are essentially driven by decisions you’ve made. Is there an important decision that can hurt you in the long run?
This is a tricky aspect, and by the way, someone who has the long view can explain why a certain option, in the long run, is going to generate all sorts of problems. It’s not just a hunch or intuition. They will tell you, “This sort of thing, been there, done that. I’ve seen that in some other products.” There is a saying: the smart man learns from his own mistakes, but the wise man learns from the mistakes of others. This is very applicable to this case.
Question: How do enterprises measure the increase in operational efficiency per dollar invested in implementing software for supply chains?
This is an incredibly difficult question. The problem is literally the incommensurability of paradigms. It comes from epistemology; the idea is that when you go from one way to operate to another, and those paradigms are radically different, most of the measures are just pointless. Let’s look at tele-sales versus e-commerce, for example. Mail-order companies had been around since the mid-19th century. If you start looking at e-commerce as an improvement over mail-order companies, you could try to measure the improvement, but the reality is that virtually every single mail-order company went bankrupt. The e-commerce companies that dominate nowadays are several orders of magnitude bigger than the biggest mail-order company ever was. Amazon is probably 100 times larger than the biggest historical mail-order company, and the comparison is very blurry.
The mechanization of intellectual work is so incredibly troubling and puzzling because it is not like the physical realm. With physical production, you can measure efficiency with canonical ways. However, when you start mechanizing your intellectual work, what does efficiency even mean? For a company like Amazon, their entire supply chain is completely driven by software. If people were just staying at home and not doing anything, I suspect the entire supply chain would run just fine, even if all those engineers were doing nothing for a day or two. So why is Amazon even keeping those engineers around? Well, because they invest in their improvements.
By the way, an interesting thing about Jeff Bezos is his management process called “disagree but commit.” He says that there are projects where his gut feeling as a CEO tells him it’s wrong, and he disagrees with the project. However, he commits to supporting the project budget-wise because he has hired and trusts the people working on it. It’s kind of a schizophrenic approach – as the CEO, he’s supposed to be the ultimate authority in the company, but he relinquishes this authority and says, “I disagree, but you can have the budget and proceed.”
The reason for this approach is that software undertakings are usually fairly cheap. If someone comes up with a seemingly crazy idea that’s not very expensive and won’t bankrupt the company, why not give it a try? If it works, it could be a brilliant idea. This represents a culture shock when transitioning from traditional supply chain companies, where management is supposed to have the vision and drive the teams. In the realm of software, leadership is mainly about sorting out problems that emerge among software engineers.
At Lokad, when investing in software, the primary concern isn’t the dollar returns. Instead, the focus is on whether the investment addresses a foundational aspect of supply chain management. If it’s core to a wide variety of supply chain situations, then it’s worth pursuing.
For example, in the automotive aftermarket, tackling the problem of mechanical compatibility is of primary importance. You’re not selling car parts to serve people; you’re selling parts to serve cars. A single part can be compatible with multiple vehicles, and some parts might have mechanical overlap. This problem must be addressed; it’s core to the business. If you don’t tackle it, someone else will, and you’ll eventually be pushed out of the market.
Regarding software investments, it’s important to take risks and embrace innovation, as long as they don’t threaten the company’s financial stability.
Question: It’s misleading to say that large project teams are ludicrous. In ERP systems, a 10-person team might be good for development, but larger projects require more people. A tower requires more people to build than a house. Could you clarify your comments?
I’m going to take a position that may antagonize a lot of people. The livelihoods of millions depend on incredibly large IT companies. In the USA in 2020, IT companies represented three million American employees. So when I say that there is absolutely no reason to have an ERP that requires so many people, obviously, all the people making a living either by selling large teams or being part of such a team will vehemently disagree with me.
My counterpoint is: does your disagreement come from core scientific reasons explaining why the work cannot be done with fewer people, or is it in your own financial interest to maintain the status quo and have an army of people to do the work? If we look at all the innovation that took place – the creative destruction outlined by the economist Schumpeter – every single time there was an important economic innovation, there was usually massive productivity improvement. But those behind the curve fought bitterly to prevent these innovations from taking place.
ERPs are nothing new; they’ve been around for essentially four decades. Most ERPs I see nowadays don’t add much value compared to the ones companies had one or two decades ago. I’ve seen plenty of older ERPs that are just fine, and new ERPs often aren’t substantially better, especially considering the millions poured into ERP migration projects. In these massive projects, I see abysmal productivity from the IT companies.
My counterpoint is to look at companies like JD.com, Amazon, or Rakuten. How many people do these companies need to accomplish similar tasks? Usually, you end up with insane ratios. For example, Zalando, a large European e-commerce company based in Berlin, Germany, built its own ERP with a team that is smaller than most teams I’ve seen for companies of a similar size that need to migrate their ERP. So you see, on one side, you have a company like Zalando, capable of engineering their own ERP, completely tailored to their needs. It does a very good job at being a suitable ERP for them, and the cost and number of people involved are only a fraction of what other companies of a similar size need to merely do a version upgrade. The cost is again only a fraction. I challenge whether it’s necessary to have so many people involved, and that’s the problem with white-collar work in the 21st century. To be a very good employee, it means you need to have the courage to automate yourself, to make yourself obsolete.
This is something very peculiar. When blue-collar workers were being made obsolete, it was done by others. But nowadays, there are almost no blue-collar workers left. It takes a different mindset, and that’s why there’s a struggle to adapt to this new paradigm, mostly coming from the software industry. It’s fine to make yourself obsolete because you’re not actually making yourself obsolete; there’s no limit to human ingenuity. You’re just automating some tasks, freeing yourself to tackle the next challenge, which is even more interesting than the previous one. Companies like Amazon don’t fire their software engineers as soon as they solve a problem. They reward them and promote them to tackle the next, more difficult problem.
In response to a question about supply chain practitioners being stuck in post-World War II analytical thinking, I agree that for many companies, not all, software engineering has moved on. It defines itself as a people process, or an interpretive process. I do agree. The software industry is not just about hard, core technologies. Although some positions require incredible quantitative technical skills, the bulk of the software industry perceives itself as having a people-minded approach, a shared culture.
To a large extent, I believe the dominance that the US and Silicon Valley have on software across the world is due to the difficulty in replicating their culture. Culture tends to be very intangible and difficult to document. When you document it, you tame the chaotic ingredient necessary for innovation. If you document the culture, organize, and process it, you suddenly lose that aspect of raw, chaotic emergence of ideas and innovations.
There are places like Silicon Valley where this culture is prevalent, and they are ahead of their time in this regard. To conclude on this topic, I would like to quote William Gibson, who said, “The future is already here; it’s just not evenly distributed.” I see this culture now being replicated on much smaller scales in many other places, and the process will continue and grow over time.
That’s all for today. See you next time. In our next session, we will be discussing a topic that can be fairly depressing but is very important: cybersecurity. See you next time!


